
11.08.2025 à 16:13
FramIActu – Le bilan après six mois de veille
Peut-être l’attendiez-vous impatiemment, et pourtant, la FramIActu de juillet n’a pas vu le jour. Différents termes techniques liés au champ de recherche de l’Intelligence Artificielle ont été utilisés dans cet article. Au cours des derniers mois, les entreprises et start-ups du domaine n’ont cessé d’améliorer les grands modèles de langage (LLMs) et autres systèmes d’IA, afin que ceux-ci puissent accomplir des tâches plus variées, être plus efficaces, et soient moins chers à produire et à déployer. L’institut sur l’intelligence artificielle centré sur l’humain de l’université de Standford a récemment publié un index analysant ces états et évolutions sous différents aspects. Autre amélioration : alors qu’en 2022 le plus petit modèle (PaLM) réalisait un score de 60 % à un un test comparatif spécifique (MMLU) avait besoin de 540 milliards de paramètres, le modèle Phi-3-mini de Microsoft accompli aujourd’hui les mêmes performances avec 3,8 milliards de paramètres. Il est donc aujourd’hui possible de construire des modèles qui nécessitent bien moins de ressources. Les améliorations des performances et des capacités des différents modèles d’IA génératives (IAg) sont particulièrement visibles pour les IAg spécialisées dans la génération d’images et de vidéo. Les IAg permettant de créer des vidéos sont d’autant plus impressionnantes (techniquement), notamment Veo 3, de Google, récemment sortie et permettant de créer des vidéos en tout genre avec une cohérence sans précédent. Il est désormais extrêmement difficile de discerner une vidéo générée par Veo 3 d’une vidéo filmée par des humain·es. Voici de nombreux exemples de vidéos générées par Veo 3. Mistral, de son côté, a publié un nouveau modèle de compréhension audio nommé Voxtral. Celui-ci aurait de meilleures performances que Whisper, le modèle d’OpenAI, jusqu’alors considéré comme le meilleur en terme de rapport qualité/prix. Toutes ces améliorations sont déjà utilisées par de nombreuses entités à travers le monde. Comme Netflix, qui a utilisé l’IAg pour créer une scène d’effondrement d’immeuble dans une de ses séries1, ou Disney, ayant utilisé ChatGPT pour écrire les paroles d’une des chansons de sa série indienne Save the Tigers2. Netflix, d’ailleurs, souhaite mettre en place des coupures publicitaires générées par IA pendant le visionnage des vidéos3. Les modèles d’IAg traditionnels sont basés sur un paradigme consistant à « entraîner » les IA à partir du plus grand nombre de données possible afin de créer les millions (voire les milliards) de paramètres qui composeront le modèle. Le coût de ce type de modèle est principalement concentré sur cette phase d’entraînement. Par exemple, le première modèle GPT d’OpenAI, GPT-1, sorti en juin 2018, contenait 117 millions de paramètres4. Un an plus tard, le modèle GPT-2 en comportait 1,5 milliards5. Quelques mois plus tard, GPT-3 en comportait 175 milliards6. Enfin, le modèle GPT-4.5, en comporterait, d’après les rumeurs7 (car nous n’avons pas de donnée officielle)… entre 5 et 10 billions (10 000 milliards) ! Ce paradigme, s’il fonctionnait très bien au cours des années précédentes, semble atteindre aujourd’hui un plafond de verre. Malgré l’augmentation massive du nombre de paramètres, les résultats obtenus ne sont pas aussi impressionnants que l’on pourrait s’y attendre, mais surtout, le coût pour exploiter de tels modèles devient difficile à assumer pour des entreprises comme OpenAI. L’entreprise a d’ailleurs rapidement retiré GPT-4.5 de son offre8, au profit d’un nouveau modèle nommé GPT-4.1, bien moins cher pour la compagnie. (On est d’accord, c’est un peu n’importe quoi les noms de modèle chez OpenAI !) Pour faire face aux limites qui semblent se dessiner, un nouveau paradigme a vu le jour : celui des modèles de raisonnement. L’idée est qu’au lieu de se concentrer principalement sur l’entraînement du modèle, les modèles de raisonnement sont conçus pour accomplir des étapes supplémentaires (par rapport aux modèles classiques) afin d’achever des résultats similaires voire meilleurs sans avoir à augmenter la taille du modèle. Contrairement à un modèle classique qui cherchera à donner directement une réponse lors de l’étape d’inférence, les modèles de raisonnement découpent cette étape en différents processus plus petits, cohérents les uns vis-à-vis des autres. Le nombre d’étapes qu’un modèle de raisonnement va effectuer est configurable, et peut aussi bien varier d’une étape unique à des dizaines ou des milliers. En revanche, plus le nombre d’étapes est conséquent, plus le coût (en temps, en énergie, en puissance de calcul) est élevé. Ce dernier point représente un changement majeur : les modèles de raisonnement peuvent potentiellement être bien plus coûteux en termes de ressources que les modèles classiques car le nombre d’étapes de raisonnement revient à multiplier — souvent de façon cachée à l’utilisateurice — la quantité de calculs nécessaires pour fournir une réponse. Or, face au succès de modèles comme Open-o1 ou DeepSeek-R1, les modèles de raisonnement ont le vent en poupe et sont souvent ceux privilégiés, aujourd’hui. Les IA agentiques sont des IA conçues pour être capables d’interagir avec leur environnement. Là où les IAg classiques s’appuient sur un jeu de données figé et apportent une réponse « simple » en fonction de la demande qu’on leur fournit, les IA agentiques ont pour objectif de pouvoir accéder à d’autres applications afin d’accomplir la tâche demandée en toute autonomie. De plus, l’IA agentique est capable d’exécuter une série de sous-tâches jusqu’à l’accomplissement de la demande. En théorie, vous pouvez demander à une IA agentique de créer votre site vitrine. Celle-ci va alors concevoir la structure du site, établir une charte graphique et l’appliquer. Elle le testera ensuite pour s’assurer qu’il fonctionne. Enfin, l’agent pourra très bien pousser le code sur une forge logiciel (comme Github, Gitlab, ou autre) et exécuter des actions sur la forge afin de créer un site accessible au public. Dans tout ce processus, votre seule action aurait été de demander à l’IA agentique de vous réaliser ce site. Dans la pratique, les IA agentiques sont encore largement peu efficaces, les plus performantes ne réussissent pour le moment que 30 % des tâches en totale autonomie9. Cependant, comme pour les IAg auparavant, on peut assez facilement imaginer, au regard de la vitesse d’évolution des techniques d’IA, que des progrès fulgurants arriveront d’ici un an ou deux. On peut d’ailleurs noter l’émergence d’un protocole nommé MCP, initié par Anthropic, pour standardiser la manière dont les IA se connectent à d’autres applications. À noter que’OpenAI vient de sortir ChatGPT Agent10 prétendant pouvoir presque tout réaliser et Google a annoncé différentes applications d’IA agentiques11. Il est probable que l’utilisation d’IA agentiques se démocratise à mesure que leurs capacités s’améliorent et que les géants comme Google les intègrent aux applications de notre quotidien. Nous l’avons vu, les IAg ne cessent de s’améliorer techniquement. Cependant, nombre des problèmes soulevés lors de l’apparition de ChatGPT n’ont pas été traités et de nouveaux apparaissent. Pour collecter les données nécessaires à l’entraînement des IA génératives, les acteurs de l’IA parcourent l’ensemble du Web pour en extraire le contenu. Aujourd’hui, de nombreux acteurs ont déployé leur propre robot pour y parvenir. Le problème est que ces robots mettent à mal l’ensemble de l’infrastructure faisant tourner le Web et ne respectent pas les sites précisant ne pas souhaiter être indexés par ces robots. Comme nous en parlions dans la FramIActu d’avril certains sites ont constaté que plus de 90 % de leur trafic proviennent désormais des robots d’IA. Pour Wikipédia, cela représente 50 % de trafic supplémentaire depuis 202412. Afin de palier ce pillage des ressources et garantir l’accès de leurs sites internet aux humain·es, des organisations comme l’ONU ont opté pour la mise en place d’un logiciel « barrière » à l’entrée de leurs site13. Nommé Anubis, ce logiciel permet d’empêcher les robots d’IA d’accéder au site web. Cependant, cette barrière n’est pas sans coût : les utilisateurices doivent parfois patienter quelques fractions de seconde (voire, parfois, quelques secondes) avant de pouvoir accéder à un site internet, le temps qu’Anubis s’assure que la demande d’accès provient bien d’un·e humain·e. À Framasoft, nous avons aussi été confronté à cette situation et certains de nos services sont désormais protégés par Anubis. D’autres acteurs se tournent vers Cloudflare puisque cette entreprise a mis en place un outil permettant de bloquer les robots d’IA par défaut14. Cloudflare est utilisé par environs 1/5 des sites web15. Cela signifie que l’entreprise se place dans une position privilégiée pour décider de qui a le droit d’accéder au contenu de ces sites web. À l’avenir, il est possible que les acteurs d’IA les plus riches doivent finir par payer Cloudflare pour accéder au contenu des sites protégés par l’entreprise. Si cela se produit, un des risques possibles est qu’au lieu d’empêcher l’essor de l’IA, la situation accentue plutôt l’écart entre les géants du numérique et les autres acteurs, plus modestes. Depuis l’arrivée de l’IA générative, un changement majeur dans l’histoire de l’humanité a eu lieu : il est désormais plus rapide de « créer » du contenu que d’en lire. Aussi, les IAg sont très fortes pour créer du contenu adapté aux règles de Google Search, permettant à des entités peu scrupuleuses de faire apparaître leur contenu en tête des résultats du moteur de recherche. Cette pratique, nommée IA Slop, représente un véritable fléau. Le contenu diffusé n’a pas besoin d’exprimer un propos en rapport avec le réel, il est généré et publié automatiquement à l’aide d’IAg afin d’attirer du public en espérant générer du trafic et des revenus publicitaires. De plus, le média Next publiait, il y a quelques mois, une enquête sur le millier de médias générés par IA mis en avant par Google Actualités, la principale plateforme d’accès aux médias16. L’IAg est aussi utilisée pour concevoir des articles et messages de médias sociaux promouvant des discours complotistes ou climato-sceptiques à une échelle presque industrielle17,18. À mesure que le Web se rempli de contre-vérités, celles-ci risquent de prendre de plus en plus de poids dans les réponses des futurs modèles d’IAg. On parle d’une forme d’autophagie, où les IAg se nourrissent d’éléments générés par d’autres IAg19. C’est à cause de ce phénomène d’autophagie que des entreprises comme Reddit (un média social très populaire dans le monde anglo-saxon) peuvent se permettre de revendre à prix d’or leurs données : du texte rédigé par des humain·es et facilement identifiable comme tel20,21. La pollution du Web ne s’arrête cependant pas aux contenus textuels… désormais, avec la facilité d’accès aux IAg d’images et de vidéos, des millions de contenus générés par l’IA pullulent sur internet. Certaines entreprises se spécialisent aussi dans la génération de DeepFake pornographiques. Ces outils permettent alors à des harceleurs de nuire à leurs ex petites-amies24 et à des adolescents de nuire leurs camarades25. Ces contenus générés par IA et la difficulté à les différencier des contenus « humains » participent à un sentiment d’abandon du réel. Il devient tellement difficile et exigeant de différencier le contenu généré par IA des autres que l’on peut être tenté·e de se dire « À quoi bon ? ». À la manière de ce que décrit Clément Viktorovitch vis-à-vis de la perception des discours politiques27, il est possible que nous entrons ici aussi dans une ère de post-vérité : qu’importe si le contenu est vrai ou faux, tant qu’il nous plaît. En construisant une encyclopédie collaborative, gérée comme un commun et disponible mondialement, Wikipédia a révolutionné l’accès au savoir. Wikipédia a permis de renverser un paradigme ancré depuis longtemps qui consistait à réserver la rédaction d’une encyclopédie aux experts du sujet. Grâce à quelques règles permettant d’assurer la qualité des contributions, l’encyclopédie en ligne permet un effort d’intelligence collective inédit dans l’histoire. Or, si Wikipédia est accessible librement dans la plupart des pays du monde, la majorité des personnes accèdent à son contenu… via le moteur de recherche Google. En effet, le réflexe commun pour accéder à Wikipédia est de chercher un terme sur son moteur de recherche préféré (Google pour l’immense majorité de la planète) et d’espérer que celui-ci nous présente un court résumé de la page Wikipédia correspondante et nous pointe vers celle-ci. Google sert donc aujourd’hui d’intermédiaire, de porte d’accès principale, entre une personne et la plus grande encyclopédie de l’humanité. Google possède un système éditorial complexe, « personnalisant » les résultats en fonction de l’identité d’un individu, sa culture, son pays28, et poussant les éditeurs des sites Web à se plier à la vision que l’entreprise a du Web. Ne pas respecter cette vision nuit à notre bon référencement sur le moteur de recherche et donc, fait encourir le risque de ne jamais être trouvé·e dans la masse des sites existants. Cette éditorialisation du contenu chez Google a encore évolué récemment avec la mise en place d’AI Overviews. Cette fonctionnalité (pas encore activée en France), s’appuyant sur l’IA de l’entreprise, résume automatiquement les contenus des différents sites Web. Certes, la fonctionnalité semble pratique, mais elle pourrait encourager une tendance à ne jamais réellement visiter les sites. À travers cette fonctionnalité, Google apporte d’autres briques pour transformer notre rapport au Web29 et asseoir sa position dominante dans l’accès au savoir. Cependant, Google n’est pas le seul acteur à transformer notre rapport au Web et à l’accès au savoir. Les IA conversationnelles prennent de plus en plus de place et récemment ChatGPT est même devenu plus utilisé que Wikipédia aux États-Unis30. Les acteurs de l’IA risquent donc de devenir les nouvelles portes principales pour accéder à l’encyclopédie. Nous pouvons imaginer différents risques à cela, semblables à ceux déjà existants avec Google, comme lorsque l’entreprise a volontairement dégradé la qualité des résultats des recherches pour que les utilisateurices consultent davantage de publicités31. Le rapport au savoir évolue aussi dans le monde de la recherche, où l’IA est aussi en train de bousculer des lignes, car de plus en plus de projets scientifiques s’appuient désormais sur ces outils32. Une étude estime que 13.5 % des recherches bio-médicales réalisées en 2024 étaient co-rédigé·es à l’aide d’une IAg33. Les auteurices de l’étude indiquent : Si les chercheurs peuvent remarquer et corriger les erreurs factuelles dans les résumés générés par IA de leurs propres travaux, il peut être plus difficile de trouver les erreurs de bibliographies ou de sections de discussions d’articles scientifiques générés par des LLM et ajoutent que les LLMs peuvent répliquer les biais et autres carences qui se trouvent dans leurs données d’entraînement « ou même carrément plagier ». De plus, l’IA n’est pas utilisée que pour la rédaction des papiers scientifiques. De plus en plus de chercheureuses basent leurs études sur des modélisations faites par IA34, entraînant parfois des résultats erronés et des difficultés à reproduire les résultats des études… voire même rendre la reproduction impossible. Il est difficile de mettre en lumière tous les impacts sociétaux de l’IA (et particulièrement l’IAg) dans un article de blog. Nous avons simplement sélectionné quelques points qui nous semblaient intéressants mais si vous souhaitez approfondir le sujet, le site FramamIA peut vous fournir des clés de compréhension sur l’IA et ses enjeux. Depuis le tsunami provoqué par l’arrivée de ChatGPT, nous entendons souvent que l’Intelligence Artificielle n’est qu’un « simple outil », sous-entendant que son impact sur nos vies et nos sociétés dépend avant tout de notre manière de l’utiliser. Ce discours s’appuie sur le postulat que l’outil — et la technique en général —, quel qu’il soit, est foncièrement neutre. Or, si on reconnaît l’ambivalence de la technique, c’est-à-dire qu’elle puisse avoir à la fois des effets positifs et négatifs, cela ne signifie pas pour autant que les conséquences de ces effets s’équilibrent les unes les autres et encore moins que la technique est neutre d’un point de vue idéologique, politique, social ou économique. Au contraire, tout outil porte forcément les intentions de ses créateurices et s’intègre dans un système économico-historico-social qui en fait un objet fondamentalement politique, éliminant toute possibilité de neutralité. De plus, les conditions d’existence d’un outil et son intégration dans nos sociétés l’intègrent de fait dans un système qui lui est propre, occultant ici l’idée de « simple outil ». Un outil est forcément plus complexe qu’il n’y paraît. Dans son blog, reprenant un billet d’Olivier Lefebvre paru sur Terrestre.org, Christophe Masutti écrivait récemment qu’« on peut aisément comprendre que comparer une IAg et un marteau pose au moins un problème d’échelle. Il s’agit de deux systèmes techniques dont les conditions d’existence n’ont rien de commun. Si on compare des systèmes techniques, il faut en déterminer les éléments matériels et humains qui forment chaque système. » Si le système technique du marteau du menuisier peut se réduire à des conditions matérielles et sociales relativement faciles à identifier dans un contexte restreint, il en va tout autre des IAg « dont l’envergure et les implications sociales sont gigantesques et à l’échelle mondiale ». On peut reprendre ainsi l’inventaire des conditions que dresse Olivier Lefebvre : … mais cela signifie pas que lorsque celle-ci éclatera, l’IA (et particulièrement les IA génératives) disparaîtra. Les changements apportés à la société semblent indiquer tout le contraire. L’IA a déjà commencé à transformer drastiquement notre société. Alors que de nombreux pays du monde et d’entreprises s’étaient engagés à atteindre une neutralité carbone d’ici 2050, ces engagements semblent aujourd’hui ne plus intéresser personne. Google a augmenté de 65 % ses émissions de gaz à effet de serre en 5 ans47, Microsoft de 29 % en 4 ans48, Trump relance la filière charbon aux États-Unis49… Les conséquences du recul de ces engagements et l’amplification du réchauffement climatique liée aux effets directs (construction de nouveaux centre de données, de nouvelles sources d’énergie, etc.) et indirects (encouragement du climato-scepticisme, report des engagements climatiques, etc.) sont des effets dont les conséquences nous affectent déjà et qui s’accentueront très certainement à l’avenir. Cependant, les bouleversements climatiques ne sont pas les seuls sujets sur lesquels s’exerce l’influence de l’IAg dans notre société. L’IAg est aussi un système poussant à la prolétarisation des sociétés. Aujourd’hui, 93 % des 18-25 ans ont utilisé une IAg ces six derniers mois, et 42 % les utilisent au quotidien, soit deux fois plus que l’année dernière51. Il est probable que des milliers (voire des millions) d’étudiant·es ont déjà développé une dépendance à l’IAg dans le cadre de leurs études et ne peuvent aujourd’hui plus s’en passer pour accomplir les tâches que la société et ses institutions attendent d’elles et eux. Alors qu’un tiers des PME (Petites et Moyennes Entreprises) l’utilisent déjà, la France souhaite que 80 % des PME et ETI (Entreprises de Taille Intermédiaire) adoptent l’IA dans leurs pratiques de travail d’ici 203052. ChatGPT est aujourd’hui utilisé par 400 millions d’utilisateurices hebdomadaires53… et nous parlons uniquement de ChatGPT, pas de Gemini, Claude, ou autre concurrent. Dans leur excellente étude sur le « forcing de l’IA », le collectif Limites Numérique décortiquait la manière dont les géants du numérique imposent l’utilisation de l’IA à leurs utilisateurices en l’intégrant absolument partout. WhatsApp et ses 2,4 milliards d’utilisateurices ? Meta AI est intégré par défaut. En trois ans, l’IA générative s’est imposée absolument partout dans notre environnement numérique et même si de nombreuses start-ups tomberont lors de l’explosion de la bulle financière54, il est probable que les géants du secteur restent en place. Par contre, nos habitudes, nos pratiques de travail, notre rapport au monde et au savoir… eux, auront bel et bien changé. Nous l’avons dit en introduction de cet article, cela fait des années que nous observons et cherchons à comprendre ce que représente l’IA et ses enjeux. Pour être honnête, ce n’est clairement pas chose aisée. Comme nous avons essayé de le faire comprendre à travers le site FramamIA, l’IA est bien plus qu’un « simple outil ». C’est d’abord un champ de recherche mais aussi un système complexe, similaire au système numérique (dans lequel il s’intègre). Depuis ChatGPT, notre temps de veille pour suivre l’actualité du numérique, déjà conséquent à l’époque, a presque doublé. Nous avons passé littéralement des centaines d’heures à lire des articles, à réfléchir à leur propos, à en discuter en interne. À chercher à comprendre comment techniquement fonctionne une IA générative et ses différences avec une IA spécialisée ou un algorithme n’étant pas considéré comme une IA. À chercher à comprendre, aussi, si l’adoption de cette technique n’est qu’une simple mode ou si celle-ci est bel et bien en train de révolutionner notre environnement. Nous continuerons, à l’avenir, d’accomplir cette veille même si le rythme de publication de la FramIActu sera moins dense. Malgré tout, nous continuerons de partager notre veille sur notre site de curation dédié. Aussi, comme nous sommes une association « qui fait », nous explorons d’autres pistes pour accomplir notre objet associatif (l’éducation populaire aux enjeux du numérique) autour de ce sujet. Nous souhaitons aider la société à subir le moins possible les conséquences négatives de l’imposition de l’IA dans nos vies. Nous avons des pistes d’action, nous vous les partagerons quand nous seront prêt·es ! Belle fin d’été à toutes et tous ! À bientôt sur le Framablog ! 10422 mots
Nous l’annoncions à demi-mot en juin : nous ne publierons plus la FramIActu sur un rythme mensuel. Les raisons à cela sont multiples et c’est pourquoi nous vous proposons un article « bilan », qui fait le point sur des mois (voire des années) de veille sur l’intelligence artificielle.
Si certains termes vous échappent, nous vous invitons à consulter le site FramamIA où nous avons cherché à expliquer la plupart d’entre eux.Les évolutions techniques des derniers mois
De meilleures performances
Dans ce rapport, nous constatons une forte amélioration des performances des IA sur les tests de référence servant à évaluer leurs capacités.
L’écart de performances entre les différents modèles est d’ailleurs largement réduit en comparaison de l’année dernière.
En revanche, de nouveaux tests comparatifs, bien plus exigeants, ont été développés (comme le fameux « Dernier examen de l’humanité ») et les IA y réalisent, pour le moment, des scores très faibles.Vous avez dit six doigts ?
Si à leurs débuts les IAg comme Dall-E ou Midjourney étaient moquées par le public en raison des absurdités qu’elles généraient, leurs résultats sont aujourd’hui bien plus difficiles à différencier de la réalité. Finies les mains à six doigts !
Voxtral propose des performances similaires ou supérieures à ses concurrents pour un coût bien plus bas.L’arrivée d’un nouveau paradigme : les modèles de raisonnement
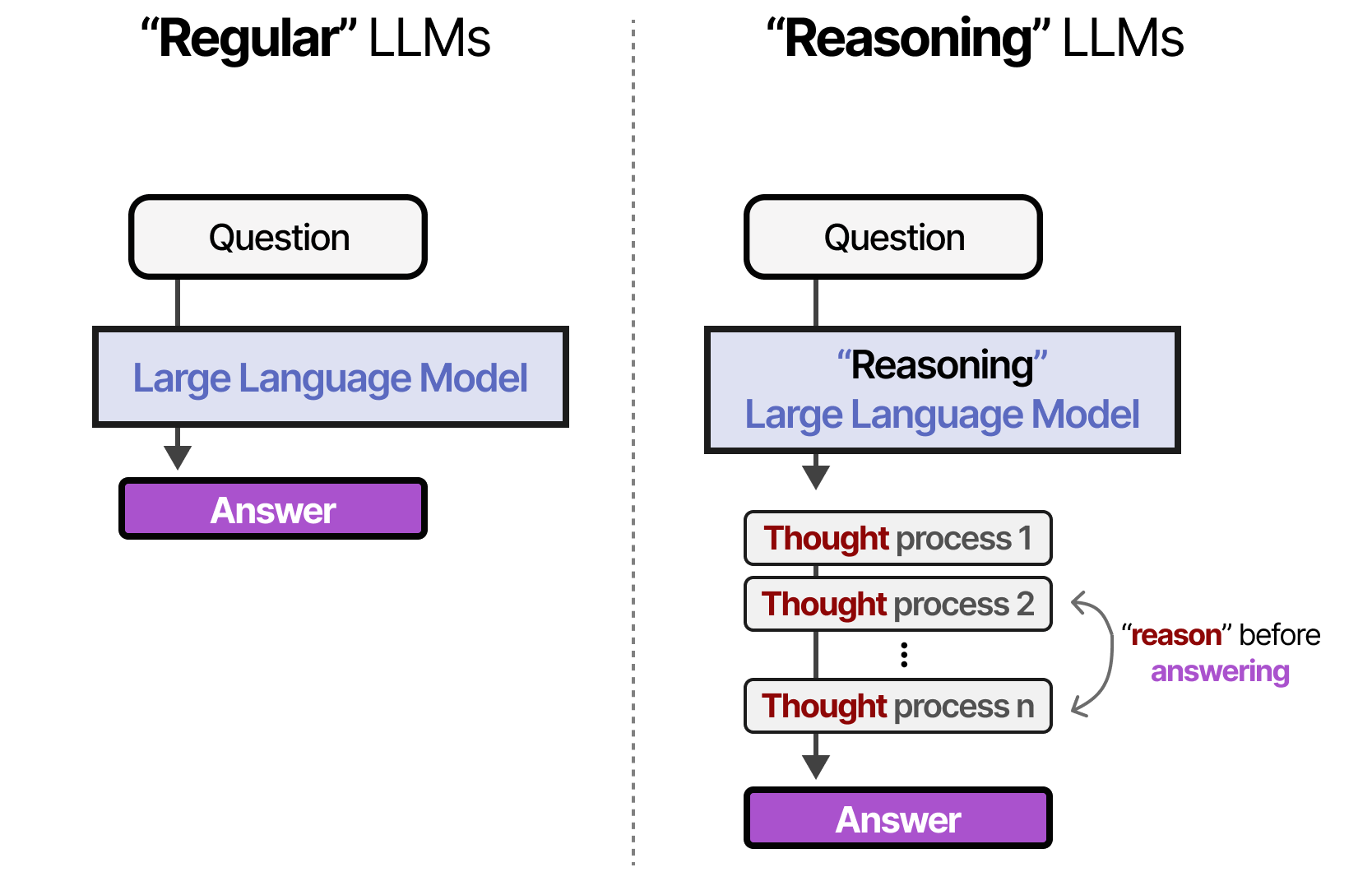
Source : Maarten Grootendorst – A visual guide to reasoning LLMsL’émergence des IA agentiques
Une accumulation de problèmes sociétaux
Les robots indexeurs d’IA attaquent le Web
Le Web est pollué
Ce simple fait semble totalement transfigurer notre rapport au Web puisque celui-ci se rempli à une vitesse vertigineuse de contenus générés par IA, dont une bonne partie se fait passer pour du contenu rédigé par des humain·es.
À ce sujet, nous republiions il y a quelques mois sur le Framablog un article passionnant d’Hubert Guillaud.
Les promoteurs de ces théories peuvent plus facilement que jamais trouver de nouvelles adhésions à leur discours. Cette facilité pour générer du contenu vraisemblable contribue fortement à l’accroissement des discours visant à désinformer.
À la sortie de Veo3, Tiktok s’est retrouvé noyé sous la quantité de vidéos généré par l’IAg, dont un certain nombre contenant des propos racistes22. Certain·es artistes ont même cherché à profiter de la tendance en prétendant que leurs vidéos étaient générée par l’IAg, alors que celles-ci étaient réalisées par des humain·es23.
Les principales victimes de ces DeepFakes sont des femmes26.Un rapport au savoir bouleversé
Non seulement la plus grande bibliothèque de l’histoire de l’humanité est à portée de clics, mais nous pouvons désormais participer aussi à son élaboration.
Le problème, c’est que Google est bien plus qu’un simple moteur de recherche.
Cette vision se confond avec le but lucratif de l’entreprise, dont le profit prévaut sur le reste. C’est pourquoi les liens sponsorisés prennent une place importante (principale, presque) dans l’interface du moteur. Il est ainsi nécessaire de payer Google pour s’assurer que notre site Web soit vu.
Avec l’AI Overviews, nous ne quittons plus de Google.
Sans que cela n’indique pour le moment une diminution dans l’usage de Wikipédia par les humain·es, il est possible que celui-ci se raréfie à mesure que la qualité des réponses des IAg s’améliorent ou recrachent directement le contenu de Wikipédia.
L’Intelligence Artificielle n’est pas un simple outil

L’Intelligence Artificielle est une bulle économique mais…
Au nom des sacro-saintes compétitions et productivités, les engagements climatiques reculent alors même que nous constatons qu’il est désormais impossible de limiter le réchauffement climatique à +1,5°C par rapport à l’ère pré-industrielle50.
Android et ses 3,3 milliards d’utilisateurices ? Gemini est désormais activé par défaut.
Google Search et ses 190 000 recherches par seconde ? Intégration d’AI Overviews pour 200 pays, permettant de résumer automatiquement les contenus des sites.Conclusion
11.08.2025 à 07:42
Khrys’presso du lundi 11 août 2025
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
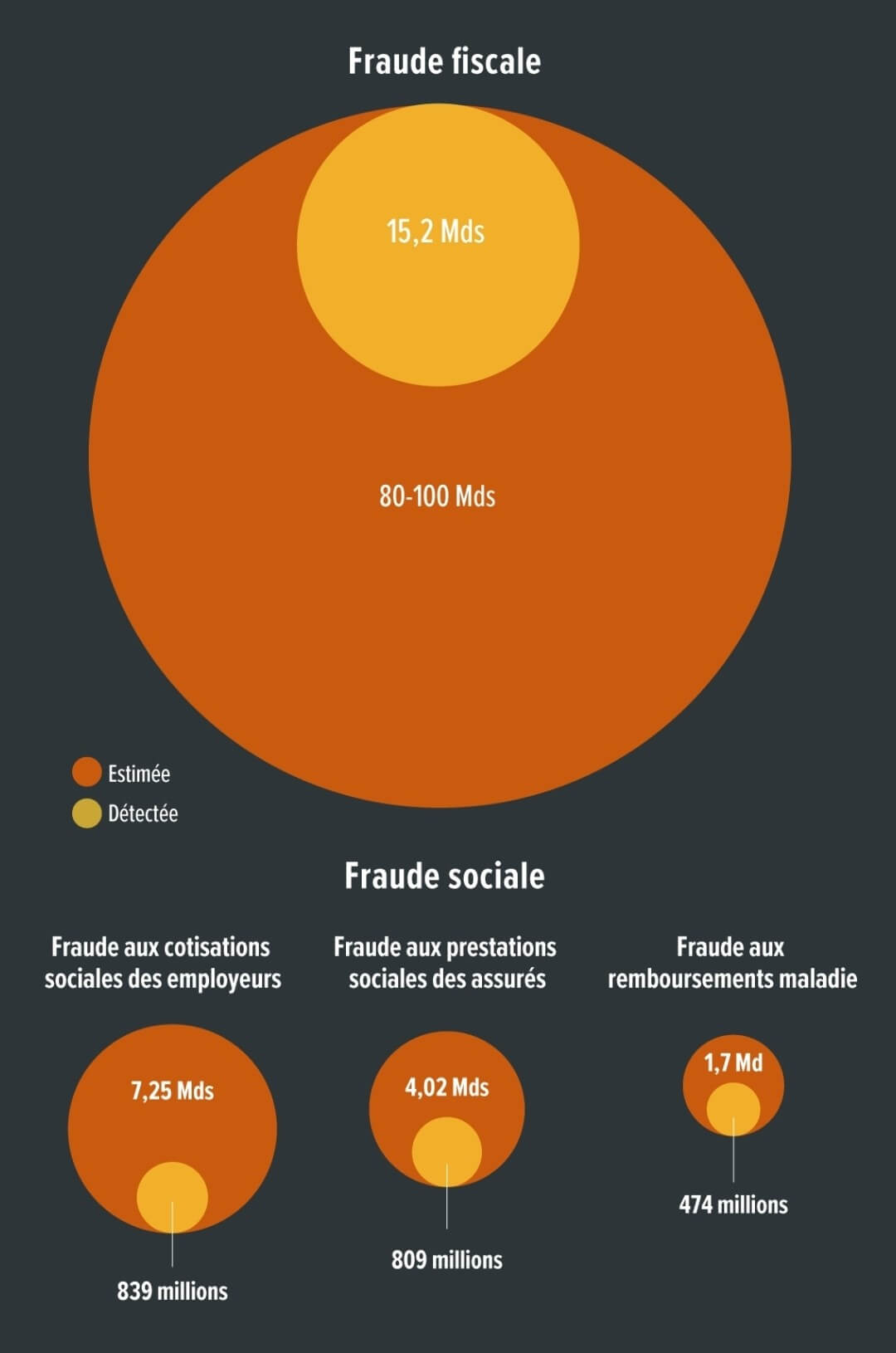
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-) Il y a cinq ans, 2 750 tonnes de nitrate d’ammonium ont explosé dans un entrepôt du port de Beyrouth, une boule de feu et un champignon de fumée violet-orange transperçant le ciel, avec une onde de choc répandant la mort à travers la ville. Voir aussi Cinq ans après l’explosion du port de Beyrouth, les proches de victimes réclament toujours justice (courrierinternational.com) Les familles des victimes de l’explosion meurtrière du port de Beyrouth ont réclamé justice lundi à l’occasion du 5e anniversaire du drame, à l’heure où le président libanais Joseph Aoun promettait de poursuivre les responsables. « Une mine dans cette zone causerait des dommages environnementaux graves et irréversibles, avec des conséquences considérables pour la faune, les communautés locales et, en particulier, pour l’élevage traditionnel de rennes » Un Britannique a écopé d’une amende de plus de 14 000 € de la part des services italiens de secours en montagne[…]Si vous venez d’un pays hors de l’UE et que vous n’avez pas d’assurance, vous devez payer plus » […] la note n’aurait été que de quelques centaines d’euros pour des randonneurs français ou italiens. Well, well, well. The “age assurance” part of the UK’s Online Safety Act has finally gone into effect, with its age checking requirements kicking in a week and a half ago. And what do you know ? It’s turned out to be exactly the privacy-invading, freedom-crushing, technically unworkable disaster that everyone with half a brain predicted it would be. Le président américain a annoncé ce mercredi des droits de douane supplémentaires de 25 % sur l’Inde. Sont notamment concernés les « ressortissant·es de pays identifiés comme ayant des taux élevés de dépassement de la durée de séjour autorisée ». All new funding on hold until Trump administration can cancel any previously funded grants. In the final merger deal, New Paramount has agreed to appoint a “bias monitor” who will report directly to Donald Trump, says the chairman of the Federal Communications Commission (FCC). This person will work with the company’s new president to review “any complaints of bias or other concerns.” In other words, Paramount is installing a censor at CBS News with a direct line to the president.[…] In addition to hiring a bias monitor, Paramount has promised that “news and entertainment programming embodies a diversity of viewpoints across the political and ideological spectrum,” while also eliminating all diversity, equity, and inclusion initiatives. Hard to do both, unless what you really mean is embodying only “conservative” (read : Trump’s) viewpoints. Le révisionnisme est en marche dans la capitale américaine : deux monuments à la gloire de personnalités pro-esclavage vont être remis en place. Effet direct d’un décret émis par Donald Trump en mars dernier. Ron Deibert, the director of Citizen Lab, one of the most prominent organizations investigating government spyware abuses, is sounding the alarm to the cybersecurity community and asking them to step up and join the fight against authoritarianism. C’est officiel. La Maison-Blanche veut mettre fin à deux missions spatiales de la NASA conçues pour mesurer avec une précision inédite le dioxyde de carbone. Leur disparition priverait la planète d’outils scientifiques uniques, tout en suscitant une tempête politique à Washington. Voir aussi Why a NASA satellite that scientists and farmers rely on may be destroyed on purpose (npr.org) The data the two missions collect is widely used, including by scientists, oil and gas companies and farmers who need detailed information about carbon dioxide and crop health. They are the only two federal satellite missions that were designed and built specifically to monitor planet-warming greenhouse gases. OceanGate avoided regulatory review and managed the submersible outside of standard protocols “by strategically creating and exploiting regulatory confusion and oversight challenges” More than 100 million ‘novel entity’ chemicals are in circulation, with health impact not widely recognised L’Argentine traverse l’une des crises économique, sociale et démocratique les plus graves de son histoire récente. Les élections législatives du 26 octobre prochain peuvent être une occasion de stopper le président d’extrême droite argentin. Security researchers found two techniques to crack at least eight brands of electronic safes—used to secure everything from guns to narcotics—that are sold with Securam Prologic locks. Multibillion-dollar partnerships show China’s rising influence in AI-driven pharmaceuticals. Nvidia said there are no backdoors or kill switches in its chips, denying an accusation from the Chinese government. The company also urged policymakers to reject proposals for backdoors and kill switches. The Gulf nation offers advanced software without fees or restrictions, positioning itself as a neutral tech power between the U.S. and China. Tech giants are pouring oil riches into Middle East data centers as water scarcity threatens digital ambitions. A statistical analysis found that the number of fake journal articles being churned out by “paper mills” is doubling every year and a half. The solution Wikipedians came up with is to allow the speedy deletion of clearly AI-generated articles that broadly meet two conditions. The first is if the article includes “communication intended for the user.” […] The other condition that would make an AI-generated article eligible for speedy deletion is if its citations are clearly wrong, another type of error LLMs are prone to. “A disastrous first impression.” So far, X has not commented on The Verge’s report. Instead, Musk has spent the day hyping Grok Imagine and encouraging users to share their “creations.” Google and Perplexity are offering free access to their AI-powered search in India, a key testing ground and source of training data for AI models. AI industry groups are urging an appeals court to block what they say is the largest copyright class action ever certified. They’ve warned that a single lawsuit raised by three authors over Anthropic’s AI training now threatens to “financially ruin” the entire AI industry if up to 7 million claimants end up joining the litigation and forcing a settlement. AI meeting transcription software is inadvertently sharing private conversations with all meeting participants through automated summaries. For likely the first time ever, security researchers have shown how AI can be hacked to create real-world havoc, allowing them to turn off lights, open smart shutters, and more. New tests reveal Microsoft Recall still screenshots sensitive data. Voir aussi Tested : Microsoft Recall can still capture credit cards and passwords, a treasure trove for crooks (theregister.com) Belgium’s detention of Israeli soldiers over alleged war crimes in Gaza has set a historic precedent for holding Israel to account for its war crimes. And it’s a sign that the tide is turning against Israel. Over 500 people are set to participate in a protest against the UK government’s ban on the direct action group Palestine Action, putting to the test a pledge by the Metropolitan Police to arrest anyone showing support for the proscribed organisation. Critiquée en interne pour son absence de prise de position politique face au “génocide en cours à Gaza”, l’institution a été contrainte de déprogrammer son spectacle, prévu à Tel-Aviv en 2026. Des ex-patrons du Mossad et du Shin Bet appellent le président américain à faire pression sur Benjamin Netanyahu pour mettre fin à la guerre à Gaza. Aux États-Unis, l’Université Columbia a dû accepter un accord de 200 millions de dollars et une surveillance fédérale pour avoir toléré des manifestations pro-palestiniennes. En Allemagne, des chercheureuses et artistes sont régulièrement mis sur liste noire ou déprogrammés pour avoir signé des pétitions en faveur d’un cessez-le-feu ou critiqué la politique israélienne. En Israël, des professeur·es ont été arrêté·es, des étudiant·es expulsé·es, et des responsables d’université contraint·es de sanctionner des enseignant·es et de réécrire les programmes selon les priorités de l’État. La décision du premier ministre israélien d’occuper totalement Gaza est largement condamnée de par le monde sauf par les États-Unis qui estiment qu’Israël fait ce qu’il veut. La France a tardé à condamner par la voix de son ministre des Affaires étrangères, Jean-Noël Barrot. Emmanuel Macron ne s’est toujours pas exprimé. Ce 5 août, l’interpellation est venue de l’ancien ambassadeur d’Israël en France Elie Barnavi et l’historien Vincent Lemire […] « Monsieur le Président, si des sanctions immédiates ne sont pas imposées à Israël, vous finirez par reconnaître un cimetière. Il faut agir maintenant pour que la nourriture et les soins puissent entrer massivement à Gaza » Dans une requête adressée au procureur de la Cour pénale internationale (CPI) par leur association « pour la justice au Proche Orient », 114 avocat·es français·es signent un document à charge très argumenté de 56 pages […] En ligne de mire, Emmanuel Macron, François Bayrou, le ministre des Affaires Étrangères Jean-Noël Barrot, le ministre des Armées Sébastien Lecornu, et les 19 députés de la commission des affaires européennes de l’Assemblée nationale. Tous accusés de complicité du génocide en cours à Gaza. Plusieurs pays, dont l’Allemagne et la Chine, ont fait part de leur vif désaccord quant aux intentions du Premier ministre israélien dans le territoire palestinien. « Le camion avait été contraint par l’armée israélienne d’emprunter des routes dangereuses, qui avaient auparavant été bombardées », a dénoncé le porte-parole de la Défense civile. Une maladie se propage rapidement dans la bande de Gaza, provoquant en quelques heures une paralysie des muscles respiratoires Deux photos publicitaires publiées sur le site Internet de la marque espagnole ont été retirées à cause de la « maigreur malsaine » des modèles. From August 2 to 8, 2025, more than 5,000 Indigenous women from across Brazil, the Amazon Basin, and beyond have converged in Brasília for a historic week of resistance, celebration, and collective action. Des sextoys ont été lancés sur les parquets de la WNBA, l’équivalent de la NBA pour les joueuses de basketball. Les lancers ont eu lieu pendant des matchs, alors même que les joueuses étaient sur le terrain. Un groupe voulant faire la promotion d’une nouvelle crypto-monnaie a revendiqué ces actions. Elle est considérée comme celle qui a inspiré le personnage de « M » (joué par Judi Dench), à la tête de l’agence MI6 dans les films James Bond.De 1992 à 1996, elle a été la première directrice générale du MI5 dont le nom a été publiquement annoncé par cette organisation. La reconnaissance d’une faute de l’État renforce la position de l’association et pourrait ouvrir la voie à des contentieux similaires pour d’autres structures. Le Conseil constitutionnel doit rendre jeudi 7 août sa décision concernant la controversée loi Duplomb sur l’agriculture. Les possibilités de censure, complète ou partielle, sont nombreuses, selon plusieurs juristes. De LR au RN en passant par le gouvernement, la décision du Conseil constitutionnel de censurer le retour de l’acétamipride, interdit en France depuis 2018, ne passe pas. Ils déplorent une manœuvre « antidémocratique ». « Les Sages » ont considéré qu’enfermer des étrangers condamnés pendant sept mois n’étaient pas constitutionnel. Un sérieux revers pour le ministre de l’Intérieur. Un « superhost » a réclamé 14 000 euros de réparation à une étudiante, en fournissant à Airbnb des photos falsifiées par IA de dégâts dans l’appartement. Les fermes de serveurs se multiplient dans la deuxième plus grosse ville de France, au point d’inquiéter les élus locaux et les riverains, qui craignent des conflits d’usage autour de l’électricité. La mairie de Paris a présenté jeudi son plan pluie, visant à transformer Paris en « ville éponge » de façon à rafraîchir l’air et cesser d’engorger les égouts. la préfecture de l’Aude a annoncé le 6 août au matin la mort d’une femme de 65 ans dans sa maison de Saint-Laurent-de-la-Cabrerisse, commune voisine de Ribaute. Le maire de la commune a précisé à RMC que la victime « a absolument voulu rester dans sa maison ». Voir aussi Incendie dans l’Aude : le feu ravageur a été fixé après avoir parcouru 17.000 hectares (huffingtonpost.fr) Il s’agit du pire incendie depuis au moins 50 ans sur le pourtour méditerranéen français, selon une base de données gouvernementale répertoriant les feux de forêt depuis 1973. Les trois espaces de baignade ouverts il y a un mois le 5 juillet dans la Seine ont pâti des pluies estivales mais ont accueilli plus de 35.000 personnes depuis leur ouverture. « Ce n’est pas tant leur venin qui présente un risque. Mais la douleur est tellement forte qu’elle peut provoquer panique, noyade ou choc cardiaque chez la victime »Reconnaissables à leur forme de croissant et leur couleur violacée, les physalies sont des invertébrés marins avec de longs tentacules, qui peuvent faire jusqu’à 30 mètres. L’élection de la femme de 39 ans, élue socialiste à Paris, homosexuelle et défenseuse du droit à l’avortement, avait suscité des remous dans l’Église et des attaques de la part de sites d’extrême droite. Voir aussi Victime d’homophobie et de sexisme, la présidente des Scouts et guides de France, Marine Rosset, contrainte de démissionner (humanite.fr) Lesbienne, mère d’un enfant et militante pour le droit à l’avortement, l’élue socialiste est devenue la cible des catholiques conservateurs et de l’extrême droite. Le gouvernement avait promis, en 2023, le remboursement des protections hygiéniques réutilisables pour les jeunes de moins de 26 ans. Le décret d’application se fait toujours attendre. Elia, entreprise française qui commercialise des culottes menstruelles, interpelle François Bayrou dans une lettre. L’actrice Sand Van Roy avait porté plainte contre le cinéaste pour viol en 2018, et elle a épuisé, en vain, tous les recours auprès de la justice : il n’y aura pas de procès. Mais la CEDH pourrait sanctionner l’État français. Au cœur de l’été, le Premier ministre a souhaité s’adresser plus directement aux citoyens français, et défendre son plan d’économies pour 2026. Bilan de sa première vidéo : hélas. Parmi les pistes d’économies présentées par François Bayrou lors de son discours sur le budget, le durcissement de la lutte contre la fraude sociale. Estimée à 13 milliards d’euros par an, celle-ci draine des idées reçues : la désignation des responsables, l’origine du déficit de la Sécurité sociale ou la manne financière qui échapperait aux caisses de l’État. Voir aussi À quoi se rapportent les 13 milliards de fraudes sociales évoqués par Catherine Vautrin ? (liberation.fr) la principale source de fraude sociale reste le travail dissimulé au sein des entreprises privées, et l’absence de cotisations sociales qui en découle. Avec plus de 7 milliards d’euros, cette catégorie représente 56 % de l’ensemble des 13 milliards de fraude. Avec près de 4,5 milliards d’euros, la fraude des assurés sociaux, s’élève, elle, à 34 % du total, dont 2,5 milliards pour le RSA. Les syndicats de pharmacien·nes annoncent une série de grèves en signe de protestation face à l’arrêté officialisant la réduction des remises sur les médicaments génériques. Ils dénoncent une menace directe pour l’accès aux soins de proximité. De son côté, Stéphane Babey n’a pas répondu à nos messages. Plusieurs de ses proches racontent qu’il s’est “volatilisé”. Il y a plusieurs mois, il a créé, sous un autre nom, une chaine YouTube dans laquelle il se présente comme un médium. Les Sages ont censuré un texte LR, très soutenu par le ministre, pour allonger la durée maximale de certains étrangers en centre de rétention administrative. plusieurs fêtes basques se sont retirées du label Plus belles fêtes de France, en raison de ses rapports avec l’extrême droite et notamment le milliardaire Pierre-Edouard Stérin Voir aussi Fêtes labellisées “Plus belles fêtes de France” par une association proche de l’extrême droite, Hendaye se retire (francebleu.fr) La préfecture s’est inspirée de vidéos virales mettant en scène des gorilles pour représenter des personnes noires et véhiculer des clichés racistes. Alertée, elle vient néanmoins d’en publier une seconde. Face à cette politique annoncée, la mobilisation de l’ensemble du monde du travail est une nécessité. Il est temps de leur faire comprendre qu’il ne peut y avoir d’économies sur nos vies et que sans nous, ils ne sont rien ! Nées dans les années 1970, les radios pirates ont porté les cris des usines, des immigrés et des luttes écologistes et féministes. Aujourd’hui, la résistance sonore ressurgit sous une forme nouvelle, des radios éphémères de lutte aux studios de podcasts indépendants. Google is the latest company to suffer a data breach in an ongoing wave of Salesforce CRM data theft attacks conducted by the ShinyHunters extortion group. A federal jury found on Friday that Meta violated the California Invasion of Privacy Act, the state’s wiretap law, by collecting data from a period-tracker app without user consent. The Israeli military undertook an ambitious project to store a giant trove of Palestinians’ phone calls on Microsoft’s servers in Europe some candidates are disproportionately impaired under stress, while others perform as usual or even slightly better. That’s why live coding is so unfair. All of these findings are no surprise to me. But here’s a surprising finding : not a single woman in the public setting passed, while every woman in the private setting did. So if your company wants to “support women in tech” but still do live coding interviews… congrats, you’re running a scientifically validated exclusion filter. Recently the CEO of Github wrote a blog post called Developers reinvented. It was reposted with various clickbait headings like GitHub CEO Thomas Dohmke Warns Developers : “Either Embrace AI or Get Out of This Career” (that one feels like an LLM generated summary of the actual post, which would be ironic if it wasn’t awful). To my great misfortune I read both of these. Even if we ignore whether AI is useful or not, the writings contain some of the absolute worst reasoning and stretched logical leaps I have seen in years, maybe decades. If you are ever in the need of finding out how not to write a “scientific” text on any given subject, this is the disaster area for you. Selon Godefroy Beauvallet, directeur général de Mines Paris PSL, et Benoît Thieulin, PDG de La WarRoom, cette taxe pourrait se chiffrer à près de 20 milliards d’euros par an. Aux avant-postes de l’empire algorithmique de Trump, Alex Karp et Peter Thiel, les fondateurs de la toute puissante Palantir, sont persuadés d’avoir déjà gagné : « les sceptiques sont désarmés, résignés à une forme de soumission ». When a great steak comes out of the microwave I get really excited. But more than half the steaks that come out of the microwave get sent back by the customer. To solve this problem I now run ten microwaves in parallel cooking ten steaks. One out of the ten steaks will most likely be good. The number of microwaves has required me to upgrade my restaurant’s electrical system and I now have a small nuclear reactor installed in the parking lot. There’s a common misconception that state-of-the-art technology has to be expensive, energy consumptive and hard to engineer. That’s because we have been persuaded to believe that innovative technology is whatever bombastic billionaires claim it is, whether that’s commercial spacecraft or the endless iterations of generative AI tools. La guerre s’achève mais laisse ses stigmates. Le gouvernement de Vichy a imprégné la société de sa révolution nationale, la République doit se reconstruire. La production est à l’arrêt. Les forces de la Libération, au premier rang desquelles le PCF, mène la bataille du relèvement national. Durant la nuit, la planète se pare de lumières vertes, certaines semblables aux aurores boréales ou australes se produisant sur Terre. Ces lueurs sont si intenses qu’elles pourraient être observées à l’œil nu par de futurs astronautes […] outre les aurores, les astronautes pourront également voir un autre phénomène lumineux nocturne appelé « nightglow », ce que l’on pourrait traduire par « lueur nocturne » Ten of 21 known cockatoo species exhibit dance behavior, and one bird executed 17 unique moves.[…]It’s still unclear why parrots in captivity love to dance so much, but encouraging such behavior could help birds like these thrive in an environment they often find challenging. Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog. Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys). Texte intégral 8564 mots
Brave New World

Spécial IA

Spécial Palestine et Israël

Spécial femmes dans le monde
RIP
Spécial France

Spécial femmes en France
Spécial médias et pouvoir
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)

Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
Spécial résistances
Spécial outils de résistance

Spécial GAFAM et cie
Les autres lectures de la semaine

Les BDs/graphiques/photos de la semaine
Les vidéos/podcasts de la semaine
Les trucs chouettes de la semaine

{kind=link}
{kind=link}
{kind=link}