
ACCÈS LIBRE
20.10.2025 à 07:42
Khrys’presso du lundi 20 octobre 2025
Texte intégral (11147 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Satellites Are Leaking the World’s Secrets : Calls, Texts, Military and Corporate Data (wired.com)
With just $800 in basic equipment, researchers found a stunning variety of data—including thousands of T-Mobile users’ calls and texts and even US military communications—sent by satellites unencrypted.
- China, Taiwan, and the vulnerable web of undersea cables (restofworld.org)
Fifteen international cables connect Taiwan to the world. Its western flank faces China, and its eastern flank is seismically unstable ; over a three-year period, Taiwan’s international and domestic cables suffered more than fifty cuts as a result of both manmade and natural factors. Were a foreign power to snap those fifteen international cables, Taiwan — the West’s buffer against China, and the semiconductor factory to the planet — would be unmoored from the world it needs and the world that needs it.
- Énergie du futur : la Chine teste le S1500, sa première éolienne dirigeable à haute altitude (ladepeche.fr)
- Bangladesh : « Si cette situation continue, nos peuples seront exterminés », alerte Rani Yan Yan, la reine des Chakma (humanite.fr)
Avant 1997, les militaires et les colons bengalis (principal groupe ethnique du Bangladesh, NDLR) coopéraient main dans la main, ils nous massacraient et brûlaient des villages. L’une des stratégies de l’État était d’installer des colons – 400 000 entre 1977 et 1983 – afin qu’ils puissent être utilisés soit comme boucliers humains, soit comme armes
- Trump, Putin to meet : Will Ukraine get US Tomahawks or not ? (aljazeera.com)
- “Les discussions ont commencé” : un tunnel sous-marin de 113 km entre la Russie et les États-Unis pourrait être construit par Elon Musk (lindependant.fr)
- Putin has no need to fear ICC arrest warrant in Budapest, Orbán has already demonstrated that (telex.hu) – voir aussi Germany demands Hungary arrest Putin on ICC warrant (news.online.ua)
- Türkiye’s judicial reform package to focus on family values, curb ‘LGBT propaganda’ (turkiyetoday.com)
According to the proposed amendment, “Any person who engages in, publicly encourages, praises, or promotes attitudes or behaviors contrary to their biological sex at birth and public morality shall be punished with imprisonment of one to three years.”
- Exfiltré à bord d’un avion militaire français ? Caché, le président de Madagascar réagit (huffingtonpost.fr)
Le président malgache Andry Rajoelina a pris la parole lundi soir pour expliquer qu’il était dans un « lieu sûr » après une « tentative de meurtre ». Sans préciser sa localisation.
- Gen Z : l’internationale contestataire (politis.fr)
Comme en 1968, une jeunesse mondiale se lève à nouveau, connectée, inventive et révoltée. De Rabat à Katmandou, de Lima à Manille, la « Gen Z » exprime sa colère contre la corruption, les inégalités et la destruction de l’environnement.

- Mouvement « GenZ212 » : quand la jeunesse marocaine prend ses propres affaires en main (contretemps.eu)
- Pour la première fois depuis 10 000 ans, des chevaux sauvages parcourent à nouveau l’Espagne (lareleveetlapeste.fr)
Ils n’y avaient jamais posé les sabots. Mais leurs aïeux, eux, peuplaient jadis ces plaines. En introduisant les chevaux de Przewalski en Espagne, Rewilding Spain parie sur le réensauvagement pour ranimer la nature, et l’économie locale.
- L’Espagne en proie à de nouvelles inondations ces derniers jours (meteo-paris.com)
- Europe : surveillance biométrique aux frontières (politis.fr)
Le système d’entrée/sortie (EES pour « Entry/Exit System ») a amorcé son déploiement progressif dans tous les pays de l’espace Schengen, ce 12 octobre. Celui-ci impose aux citoyens extra-européenne de se soumettre à un enregistrement de leurs empreintes digitales et image faciale. Les données biométriques seront stockées et partagées entre les 29 pays membres.
- Consultation response to the European Commission’s call for evidence on the Digital Omnibus (edri.org)
The European Commission launched a call for evidence on the forthcoming “Digital Omnibus” initiative, which is expected to be presented around the 19 November 2025. The package is framed as an effort to “simplify” the EU’s digital policy framework, but the EDRi network warn that it risks dismantling key protections that uphold fundamental rights in the digital age.

- Empêtré dans l’affaire Epstein, le prince Andrew renonce à ses titres royaux (huffingtonpost.fr)
Le prince Andrew a de nouveau fait l’objet d’accusations dans un livre posthume écrit par la principale accusatrice de Jeffrey Epstein.
- États-Unis : l’Alaska en proie à de violentes inondations, des milliers de personnes évacuées (franceinfo.fr)
Le typhon Halong a frappé violemment la côte ouest de l’Alaska (États-Unis), le week-end du 11 et 12 octobre, avec des vents à plus de 170 km/h et des vagues impressionnantes.
Voir aussi Here’s how you can help survivors of the Western Alaska storm (alaskapublic.org)
Community groups and businesses across the state are coordinating relief efforts after the remnants of Typhoon Halong brought widespread devastation to Western Alaska.
- Menacé de mort, l’historien antifasciste Mark Bray a dû fuir les États-Unis (lareleveetlapeste.fr)
C’est « un avertissement contre l’autoritarisme » alerte Mark Bray. Après la parution du décret de Donald Trump qualifiant l’antifascisme comme mouvement terroriste (22 septembre 2025), le professeur de l’université de Rutgers (New-Jersey, Etats-Unis) Mark Bray a été victime d’une vague de menaces de mort.
- Armed man wearing ‘non-offending pedophile’ sign storms stage at NYC Wikipedia conference (nbcnews.com)
The man pointed a gun at the ceiling and threatened to kill himself before being tackled by conference organizers, according to police. Wikipedia canceled all events Friday “due to unforeseen circumstances,” adding that the conference is expected to resume Saturday
- President will now force airlines to guess passengers’ genders if they have X gender markers (lgbtqnation.com)
US customs will no longer accept X gender markers in their system despite people still having those passports.
- ICE Is Cracking Down on Chicago. Some Chicagoans Are Fighting Back. (nytimes.com)
Residents have begun forming volunteer groups to monitor their neighborhoods for federal immigration agents. Others honk their horns or blow whistles when they see agents nearby.
- Portland’s Inflatable Costumes Deflate Trump’s Narrative (motherjones.com)
- « No Kings » : des millions d’Américain·es attendu·es pour défiler contre Donald Trump (lemonde.fr)
Plus de 2 700 rassemblements sont prévus dans la journée, dans les grandes villes américaines comme dans des bourgades d’États républicains, ainsi qu’à proximité de la résidence de Donald Trump en Floride.
- Second “No Kings Day” protests likely the largest single-day political demonstration since 1970, with 4.2-7.6 million participants (gelliottmorris.com)
- 7 Million Proud Patriots Joyously, Peacefully Marched, Rallied, And Protested Yesterday (hopiumchronicles.com)

- California governor says Trump ‘putting ego over responsibility’ over a military showcase that involved firing live artillery shells over a major highway in the state’s south (theguardian.com)
- We Found That More Than 170 U.S. Citizens Have Been Held by Immigration Agents. They’ve Been Kicked, Dragged and Detained for Days. (propublica.org)
- EFF, unions sue Trump administration over alleged mass social media surveillance of legal residents (techcrunch.com)
- Software update bricks some Jeep 4xe hybrids over the weekend (arstechnica.com)
Owners of some Jeep Wrangler 4xe hybrids have been left stranded after installing an over-the-air software update this weekend. The automaker pushed out a telematics update for the Uconnect infotainment system that evidently wasn’t ready, resulting in cars losing power while driving and then becoming stranded.
- Présidentielle en Bolivie : le lithium au cœur des promesses économiques des candidats (france24.com)
- Cette réplique du Venezuela montre que Maduro n’a pas digéré le Prix Nobel à son opposante (huffingtonpost.fr)
Alors que le Venezuela a fermé son ambassade à Oslo, une porte-parole de Norvège a rappelé que « le prix Nobel est indépendant du gouvernement norvégien ».
- Venezuela : accélération autoritaire et répression de la gauche critique. (contretemps.eu)
- L’administration Trump prépare-t-elle une opération armée au Venezuela ? (legrandcontinent.eu)
Washington a multiplié les déploiements militaires au large des côtes vénézuéliennes ces dernières semaines, faisant craindre au régime Maduro la préparation d’une opération visant à le destituer.
- État d’urgence, mobilisations massives, un manifestant tué par la police et une centaine de blessés… Que se passe-t-il au Pérou ? (humanite.fr)
- Reflect Orbital : The Startup Letting You Order Sunlight from Space (thetundradrums.com)
- Planet’s first catastrophic climate tipping point reached, report says, with coral reefs facing ‘widespread dieback’ (theguardian.com)
Le rapport de la semaine
- Click, Load, Kill : Examining the cyberweapon industry in the WANA (West Asia and North Africa) region (ifex.org)
A new SMEX report exposes how commercial spyware vendors empower authoritarian regimes to target dissidents and journalists, urging urgent protections for privacy and stronger accountability measures.
Spécial IA
- Is India the Global Anti-AI Play ? (indiadispatch.com)
Foreign institutional investors have pulled nearly $30 billion from Indian equity markets over the past twelve months. A huge chunk of that money has moved to Korea and Taiwan.
- The AI dilemma : To compete with China, the U.S. needs Chinese talent (restofworld.org)
Immigration restrictions can accelerate the flight of top talent, threatening the strategy that it is better to have the brightest minds working for U.S. companies.
- California cracks down on water theft but spares data centers from disclosing how much they use (latimes.com)
Gov. Gavin Newsom vetoed a bill that would have tracked data centers’ growing water footprint in California. […] New data centers have been rapidly proliferating in California and other western states as the rise of artificial intelligence and growing investments in cloud computing drive a construction boom.
- Thirsty AI mega projects raise alarm in some of Europe’s driest regions (cnbc.com)
- AI-related data centres use vast amounts of water. But gauging how much is a murky business (cbc.ca)
As tech companies spend billions on data centres, citizens around the world are starting to push back
- Your AI tools run on fracked gas and bulldozed Texas land (techcrunch.com)
The AI era is giving fracking a second act, a surprising twist for an industry that, even during its early 2010s boom years, was blamed by climate advocates for poisoned water tables, man-made earthquakes, and the stubborn persistence of fossil fuels.
- IA : la Californie promulgue une législation régulant les “chatbots”, une première aux États-Unis (france24.com)
En réaction à des suicides d’adolescents, le gouverneur de la Californie Gavin Newsom a signé lundi une série de lois pour réguler les agents conversationnels d’intelligence artificielle, imposant notamment de vérifier l’âge des utilisateurs et d’afficher des avertissements.
- AI-powered textbooks fail to make the grade in South Korea (restofworld.org)
South Korea’s AI learning program was rolled back after just four months following a backlash from teachers, students, and parents, underlining the challenges in embedding the technology in education.
- The Default Body – AI, biased health data, and the illusion of objectivity (jgcarpenter.com)
In 2022, a team at University College London revisited several machine-learning models used to predict liver disease from routine blood tests. On paper, the tools were successful, with accuracy across the general population. But the closer they looked, the more the averages cracked. The models missed liver disease in nearly half of the women they analyzed, compared with about a quarter of the men. Nothing in the models announced this imbalance ; it was buried in the math.
- GitHub Copilot Chat Flaw Leaked Data From Private Repositories (securityweek.com)
It turned out that Copilot was not merely learning from private repos, it was reportedly distributing them as if they were party favors. The user had not realized that the definition of an “AI pair programmer” extended to “unauthorized code distributor.” […] the GitHub user should perhaps feel flattered that their proprietary data was deemed worth sharing
- Refuser de parvenir à surproduire des merdes inutiles avec l’IA (lundi.am)
- Comment fait-on l’IA (data.yt)
- Sora : des deepfakes et représentations racistes de Martin Luther King et Malcolm X (next.ink)
- Amazon’s Ring Partners With Flock, a Network of AI Cameras Used By Police (yro.slashdot.org)

- GenAI and what it does to the brain (theguardian.com)
- Are we living in a golden age of stupidity ? (theguardian.com)
A global OECD study found, for instance, that the more students use tech in schools, the worse their results. “There is simply no independent evidence at scale for the effectiveness of these tools … in essence what is happening with these technologies is we’re experimenting on children […] Maybe the dawn of the new golden era of stupidity doesn’t begin when we submit to super-intelligent machines ; it starts when we hand over power to dumb ones.
- … À l’IA pour faire régner la terreur (danslesalgorithmes.net)
Ce que l’IA produit ne sont pas des erreurs. Ses erreurs sont ses promesses idéologiques.
- Le FMI met en garde contre le risque d’une déception liée aux bénéfices de l’IA pour l’économie mondiale (legrandcontinent.eu)
- « Bulle de l’IA » : Sam Altman, le PDG d’OpenAI, prévient d’un risque d’implosion du marché (trustmyscience.com)
Un récent rapport du MIT indique que près de 95 % des projets pilotes d’IA générative menés par les entreprises n’enregistrent aucun retour sur investissement significatif. Cette déception se traduit par une érosion progressive de la confiance, certaines sociétés et utilisateurs délaissant la technologie et avançant une productivité bien moindre que ne le laissait espérer le discours promotionnel.
- OpenAI Needs $400 Billion In The Next 12 Months (wheresyoured.at)
At some point, OpenAI is going to have to actually do the things it has promised to do, and the global financial system is incapable of supporting them. And to be clear, OpenAI cannot really do any of the things it’s promised.
Spécial Palestine et Israël
- Vente d’armes : livraison imminente de matériel français vers Israël (disclose.ngo)
Une semaine après la signature du cessez-le-feu entre Israël et le Hamas, Disclose révèle qu’un lot de matériel fabriqué par la société française Sermat doit être expédié en Israël, lundi 20 octobre. Ces composants sont destinés à des drones conçus par Elbit Systems, l’un des principaux fournisseurs de l’armée israélienne.
- « Le combat n’est pas encore terminé » : Israël menace de nouveau Gaza de rompre le cessez-le-feu (humanite.fr)
Le Hamas a affirmé mercredi 16 octobre avoir remis à Israël toutes les dépouilles d’otages auxquelles il avait pu accéder, soit neuf corps sur 28.
- Palestine : le nom d’une révolution décoloniale (contretemps.eu)
En Palestine, la lutte actuelle contre le colonialisme israélien est la plus difficile de l’histoire récente car elle se mène contre tout l’édifice impérialiste occidental.
- Flottille de la liberté : pour qui ? La flottille de la liberté a donné 5 migrants à Frontex et tout le monde s’en tape. (paris-luttes.info)
- Flottille pour Gaza : Un porte-parole exclu après des propos antisémites et homophobes (humanite.fr)
Sur les réseaux sociaux, des militants antifa ont récolté ces derniers mois des centaines de publications antisémites, homophobes, antikurdes… propagées depuis dix ans par Mustafa Cakici […] le militant d’extrême droite semble avoir peu à peu réussi à s’installer dans le paysage, au point de trouver le moyen d’embarquer à bord d’un des bateaux de la flottille pour Gaza
- Greta Thunberg : “They kicked me every time the flag touched my face” (aftonbladet.se)
She was not allowed to wear her T-shirt with “Free Palestine” on it and was ordered to change, she explains. She put on an orange one with the text “Decolonize” instead.
- Face aux attaques des colons contre les Palestiniens, l’interposition non-violente des volontaires internationaux (basta.media)
Pendant que Trump vante son plan de paix pour Gaza, en Cisjordanie, les attaques de colons contre des Palestinien·nes se poursuivent. Face aux violences, des volontaires internationaux et israéliens tentent de soutenir villageois·es et cultivateurices.
- La LDH porte plainte contre Airbnb et Booking : stop au tourisme d’occupation ! (ldh-france.org)
Airbnb et Booking proposent des centaines d’annonces de locations touristiques situées dans les colonies israéliennes illégales en Cisjordanie et à Jérusalem-Est.
Parce qu’il raconte une nouvelle histoire de la terre volée, des communautés installées illégalement et qu’il dynamise économiquement ces colonies, ce tourisme d’occupation participe à la création, à l’entretien et à l’extension des colonies israéliennes dans les territoires palestiniens occupés illégalement et favorise le déplacement forcé de la population palestinienne. Il n’est autre que le pendant de la colonisation criminelle ordonnée par les responsables israéliens. - À Gaza, l’OMS alerte sur une propagation des épidémies devenue « hors de contrôle » (huffingtonpost.fr)
- Une boulangerie industrielle, soutenue par l’ONU, a rouvert à Gaza (france24.com)
Une boulangerie industrielle a rouvert dans la Bande de Gaza, soutenue par l’agence onusienne du programme alimentaire mondial, elle produit 300 000 pita par jour. C’est pourtant insuffisant face aux besoins de la population de Gaza. L’agence a prévu d’en ouvrir plus d’une trentaine le plus rapidement possible.
- Effacer les Palestiniens : la fabrique médiatique du vide politique (politis.fr)
Omniprésents comme corps, les Palestiniens sont absents comme sujets. Un paradoxe qui dit quelque chose de la manière dont se fabrique une « terre à prendre ».
Spécial femmes dans le monde
- Ghost of Yōtei : pourquoi les masculinistes détestent son héroïne (japanization.org)
La sortie du jeu tant attendu Ghost of Yōtei fait quelques remous dans la communauté gaming. Si le jeu est une réussite absolue en matière de narratif et de visuels, la communauté masculiniste, ce cri du cygne d’un patriarcat en fin de vie, a tout de même trouvé à redire. C’est l’héroïne qui est désormais la cible de leurs critiques : pas assez sexy, pas assez voluptueuse, pas assez jeune, pas assez maquillée, trop indépendante… Bref, tous les clichés du beauf-moyen y passent.
- Muganga — la guerre se lit sur le corps des femmes (medfeminiswiya.net)
RIP
- La créatrice du programme d’échange Erasmus, Sofia Corradi, est morte (lemonde.fr)
Quelque 16 millions de jeunes ont pu étudier dans d’autres pays d’Europe grâce au projet lancé en 1987 par cette professeure italienne, qui s’est éteinte à l’âge de 91 ans.
Spécial France
- Analyse à chaud : l’annonce du Premier ministre concernant la réforme des retraites (blogs.alternatives-economiques.fr)
- L’agence de notation S&P accélère son calendrier pour abaisser la note de la France (huffingtonpost.fr)
Après Fitch et avant Moody’s, S&P (ex Standard & Poors) juge négativement les perspectives financières de la France.
- Bernard Arnault engrange 16 milliards d’euros en une journée (huffingtonpost.fr)
Dopée par le bond de plus de 12 % de l’action LVMH en une séance mercredi, la fortune de l’homme le plus riche de France culmine désormais à plus de 190 milliards d’euros.
- Michel Offerlé : « Le Medef a provoqué une division jamais vue chez les patrons » (alternatives-economiques.fr)
- Matthieu Pigasse : « Il y a urgence à partager les richesses, et je paierais volontiers la taxe Zucman » (alternatives-economiques.fr)
- Le musée du Louvre braqué à la disqueuse, des bijoux « d’une valeur inestimable » dérobés (liberation.fr)
- Nestlé va supprimer 16 000 postes dans le monde d’ici 2027 pour « rassurer les actionnaires » (humanite.fr)
Cette décision est un nouveau revers dans la tentative de sortir Nestlé d’une crise qui dure, suite aux scandales qui ont entaché sa réputation. Il y avait d’abord eu, en France, les pizzas Buitoni contaminées en 2022 et plus récemment le scandale des fraudes dans le traitement des eaux minérales Vittel et Perrier. […] « malheureusement, dans le monde actuel, rien ne vaut une suppression de salariés pour rassurer les actionnaires »
- Télécoms : Orange, Free et Bouygues Telecom ont remis sur la table leur offre de rachat (humanite.fr)
Les trois opérateurs ont remis sur la table, mercredi 15 octobre au soir, leur offre de rachat conjointe de SFR pourtant écartée par sa maison mère Altice France. L’hypothèse d’une vente à la découpe de l’entreprise inquiète depuis plusieurs mois les syndicats.
- La position victimaire de Nicolas Sarkozy est inique et offensante pour les familles des victimes décédées dans l’attentat du DC-10 d’UTA (nouvelobs.com)
La lecture du jugement ne peut laisser aucun doute à quiconque n’est pas aveuglé par l’esprit partisan : les faits qui étaient reprochés à Nicolas Sarkozy, Claude Guéant et Brice Hortefeux sont attestés et ils sont, comme l’a dit le tribunal, d’une exceptionnelle gravité.
- Nicolas Sarkozy restera administrateur de Lagardère et Accor pendant son incarcération (leparisien.fr)
Condamné à cinq ans de prison ferme dans l’affaire libyenne, l’ex-chef de l’État siégera aux conseils d’administration de Lagardère, Accor et LOV Group. Ses mandats ne sont pas incompatibles avec sa détention à la prison de la Santé.
- “Le Désespéré” de Courbet exposé à Orsay, une première en France depuis dix-sept ans (telerama.fr)
Propriété du Qatar Museums, l’organisme de développement des musées de l’émirat, la toile de 1844-1845, un autoportrait de l’artiste, est prêtée au musée parisien pour les cinq prochaines années.
- Yves Lae, ancien directeur du collège Saint-Pierre, au Relecq-Kerhuon, mis en cause pour violences multiples et infractions financières (splann.org)
Auteur de châtiments corporels sur des élèves du collège Saint-Pierre du Relecq-Kerhuon, l’ancien directeur Yves Lae, avait aussi été épinglé en 1971 pour un possible détournement de fonds publics. Des faits connus de l’administration comme du diocèse, qui n’ont pas enrayé son ascension au sein de l’enseignement catholique du Finistère.
- Scandales archéologiques en Auvergne-Rhône-Alpes : l’austérité rase notre passé (humanite.fr)
Les archéologues alertent sur le non-respect de la législation de tutelle du patrimoine archéologique, dans le cadre de projets de travaux sur le parvis de la cathédrale de Valence (Drôme) et de la déviation routière de Saint-Péray (Ardèche). La poursuite de ces travaux sans intervention archéologique préalable risque de créer de dangereux précédents
- Dans la Loire, le médicobus arpente les déserts médicaux (politis.fr)
Dans l’agglomération de Roanne (42), un cabinet médical mobile propose des consultations sur les places de plusieurs villages. À son bord, défilent des habitants de tous les âges privés d’accès à un médecin traitant et témoignant de leurs difficultés face à un système de santé défaillant.
- Pollution bactériologique : l’eau est interdite de consommation dans deux secteurs de Basse-Terre (la1ere.franceinfo.fr)
- Pesticides : la Haute-Garonne est le département le plus contaminé d’Occitanie, Toulouse en paie le prix (actu.fr)
- « Aujourd’hui, j’ai mal partout » : près de Bordeaux, des saisonniers viticoles poussés à bout et exposés aux pesticides (vert.eco)
- LGV Bordeaux-Toulouse : à toute vitesse face à l’inconnue des fantômes de roche (journal-labreche.fr)
- « On fonce droit dans le mur » : Airbus va bétonner 18 hectares à Toulouse (reporterre.net)
- Des travaux nocturnes illégaux sur l’A69 : “Aucune dérogation n’a été accordée” selon la préfecture de la Haute-Garonne (francebleu.fr)
- « Des millions d’euros économisés » : à Montpellier, un plan anti-pollution lumineuse sur mesure qui fait consensus (vert.eco)
L’enquête de la semaine
- Enquête sur l’accès aux droits sur les relations des usagers avec les services publics : que retenir ? (defenseurdesdroits.fr)
En 2024, 61 % des sondés rencontrent des difficultés, qu’elles soient ponctuelles ou régulières, contre seulement 39 % en 2016. Des difficultés qui touchent toute la population, y compris ceux habituellement moins concernés (+ 86 % pour les cadres ou professions intermédiaires, + 75 % pour les diplômés de master et plus). […] 23 % des usagers sondés déclarent avoir déjà renoncé à un droit au cours des 5 dernières années, avec pour motif principal : la complexité des démarches.

Spécial femmes en France
- Chlordécone : un nouvel effet nocif pour la fertilité des femmes en Martinique et Guadeloupe révélé par une étude (humanite.fr)
Des médeci·ennes et épidémiologistes français·es ont publié jeudi 16 octobre une étude qui révèle que les femmes les plus exposées à la chlordécone, insecticide cancérigène utilisé dans les bananeraies en Guadeloupe et en Martinique jusqu’en 1993, auraient 25 % de chances en moins de tomber enceinte.
- Souba Manoharane-Brunel, l’entrepreneuse féministe « poil à gratter » de l’écologie (reporterre.net)
« Si les femmes ne sont pas à la table, c’est qu’elles se retrouvent au menu » […] « Une écologie qui n’est ni décoloniale ni féministe n’est qu’un immense Jardiland réservé à une élite de bobos privilégiés. »
- Un rapport épingle le « terreau culturel » sexiste au ministère de l’Intérieur (streetpress.com)
À l’ère post-Metoo, la place Beauvau reste minée par une ambiance sexiste loin des promesses du ministère. Une situation mise en lumière par l’Inspection générale de l’administration, qui s’est penchée sur la situation des cadres supérieurs.
- « Je ne suis pas féministe, j’ai un bon amant » : quand les médias dépolitisent le féminisme (lesnouvellesnews.fr)
Tenter de neutraliser la parole féministe en la ramenant à une histoire d’insatisfaction personnelle, c’est encore ce que font beaucoup de médias, en 2025. Notamment dans les critiques de « La chair est triste hélas ».
- Pour les femmes, les salles de sport sont trop souvent des lieux hostiles (huffingtonpost.fr)
Parce qu’elles subissent des comportements sexistes dans les salles de sport, les femmes doivent développer des stratégies d’évitement comme le montre cette étude.

- Anouk Grinberg porte plainte contre l’avocat de Gérard Depardieu auprès de l’Ordre des avocats de Paris (huffingtonpost.fr)
L’actrice reproche à Me Jérémie Assous, conseil de Gérard Depardieu, d’avoir manqué de respect aux femmes qui accusent le comédien et à leurs soutiens.
- “J’étais terrorisée par ses colères” : la streameuse Helydia porte plainte contre son ex-compagnon pour “violences volontaires aggravées” (franceinfo.fr)
- La star du développement personnel Jacques Salomé accusé de viols et d’agressions sexuelles par 5 femmes (humanite.fr)
Les faits dénoncés s’étalent sur une période de quasi trente ans.
Spécial médias et pouvoir
- Lecornu II : le (pitoyable) théâtre du journalisme politique (acrimed.org)
En pâmoison devant le discours de politique générale du nouveau Premier ministre, émoustillé par la perspective de « non-censure » au point de désinformer sans entraves sur la question des retraites, le journalisme politique nous a encore gratifié d’une très grande scène de son théâtre habituel.
- PLF 2026 : Un cataclysme budgétaire menace les radios associatives françaises (snrl.fr)
- Palestine : un mois ordinaire dans les médias français (1) (acrimed.org)
- BFMTV s’excuse après avoir confondu les députées noires Dieynaba Diop et Nadège Abomangoli (huffingtonpost.fr)
Après que le 20 Heures de France 2 a interverti Dominique Bernard et Samuel Paty, conduisant Léa Salamé à présenter des excuses, c’est au tour de BFMTV d’être pris en flagrant délit de confusion.
- Suspicion d’emplois fictifs : au Canard Enchainé, les deux ex-dirigeants, un ancien dessinateur et sa compagne relaxé·es (humanite.fr)
- “On essaie de nous faire taire !”, pourquoi le budget de Sébastien Lecornu inquiète les radios associatives (france3-regions.franceinfo.fr)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Qui sont les ministres du gouvernement Lecornu 2 ? (projetarcadie.com)
Si certains visages et noms sont désormais très connus du grand public, une grande partie des ministres nommés cette nuit sont surtout familiers des habitués du Palais Bourbon. Tour d’horizon des nouveaux venus, dans l’ordre protocolaire.

- Édouard Geffray, bras droit de Jean-Michel Blanquer, est le 7ème ministre de l’Éducation nationale (cafepedagogique.net)
La dernière étude Talis, quinquennale, pointait le taux faible de professeurs qui se sentent considérés par la société ou les dirigeants, soit 4 %. Avec 96 % des professeur.es qui se sentent méprisés, la France est sans surprise à la dernière place du classement. L’objectif serait-il d’arriver à 100 % à l’issue du second quinquennat ?
- Le budget 2026 de Sébastien Lecornu prévoit une trentaine de milliards d’euros d’économies (huffingtonpost.fr)
Sans retour de l’ISF et sans taxe Zucman, le gouvernement envisage une mise à contribution des plus riches inférieure à 2025.
- Budget, réforme des retraites… Dans son discours de politique générale, Sébastien Lecornu remet l’écologie à plus tard (vert.eco)
- Pourquoi les annonces de Sébastien Lecornu sont une arnaque (politis.fr)

- « Tout a été fait pour épargner Bernard Arnault » : Gabriel Zucman étrille le budget de Sébastien Lecornu (huffingtonpost.fr)
La nouvelle taxe sur les holdings patrimoniales proposée par le gouvernement de Sébastien Lecornu ne séduit pas du tout Gabriel Zucman.
- Gel des pensions et remplacement de l’abattement de 10 % : le projet de budget cible les retraités (tf1info.fr)
- Budget de la Sécurité sociale 2026 : retraité·es, malades, salarié·es, familles, qui sont les perdant·es ? (projetarcadie.com)
- Budget 2026 : Ce discret coup de rabot sur les allocations familiales envisagé par le gouvernement (huffingtonpost.fr)
Le gouvernement envisage de passer de 14 à 18 ans l’âge de revalorisation des allocations familiales versées à partir du deuxième enfant.
- « Les Outre-mer paient la note de la mauvaise gestion » : face à la colère des Ultramarins, Sébastien Lecornu tente une conciliation (humanite.fr)
Le projet de budget proposé par le premier ministre, Sébastien Lecornu, provoque la colère des parlementaires ultramarins. Parmi eux, cinq socialistes se sont prononcés pour la censure du gouvernement.
- À l’Assemblée, Sébastien Lecornu gagne du temps grâce aux socialistes (politis.fr)
Dans un discours de politique générale express, le premier ministre renonce au 49.3 et suspend la réforme des retraites. Rien de plus. Mais suffisant pour que les socialistes ne le censurent pas immédiatement.
- À l’Assemblée, Sébastien Lecornu dit merci aux socialistes (politis.fr)
Le premier ministre échappe aux censures. Chez les socialistes, la fronde n’a pas vraiment eu lieu. Et la gauche se retrouve écartelée entre deux pôles.
- Le PS joue le mouvement populaire à la roulette russe (blogs.mediapart.fr)
- Lecornu : au PS, chronique d’une trahison permanente (politis.fr)

- Cher Olivier Faure (blast-info.fr)
Jeudi 16 octobre, le gouvernement de Sébastien Lecornu échappait, à 18 voix près, à la censure, pour le plus grand soulagement de la clique macronienne, merci pour eux, et pour la plus grande consternation de nombre d’électeurs et électrices de gauche qui n’imaginaient visiblement pas, en votant pour le Nouveau Front populaire à l’été 2024, que l’une de ses composantes jouerait, moins de 18 mois plus tard, le rôle de béquille du macronisme.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Après une violente agression à Toulon, un groupe identitaire s’en sort au tribunal (streetpress.com)
Quatre membres du groupe identitaire, Le Maquis, ont comparu ce vendredi au tribunal de Toulon pour l’agression de deux mineurs. Malgré les éléments, le fond n’a pas été jugé : le tribunal a considéré l’enquête du parquet insuffisamment justifiée. […] La décision suscite d’ailleurs suffisamment d’incompréhension dans la salle pour que la présidente lance un avertissement un brin mystérieux : « Attention, si je lis des choses désagréables dans la presse, je saurai quoi faire. »
- « Maccarthysme 2.0 » : un rapport alerte sur les attaques contre la liberté académique des chercheureuses, y compris en France (humanite.fr)
- Vichy et les Juifs français : deux historiennes dans le viseur d’auteurs révisionnistes (telerama.fr)
Michèle Riot-Sarcey et Natacha Coquery sont attaquées en justice pour avoir contesté, dans un article, la thèse d’un ouvrage soutenant que le régime de Vichy aurait œuvré à protéger les Juifs français pendant la Seconde Guerre mondiale.
Voir aussi Historiennes poursuivies par des révisionnistes de Vichy : le tribunal annule la procédure (humanite.fr)
- Au grand homme, la patrie indifférente (syndicat-magistrature.fr)
Tout juste renommé ministre de la Justice, Gérald Darmanin choisit de poursuivre la création de prison de haute sécurité.Le Syndicat de la magistrature dénonce l’extension d’un régime qui impose des conditions de détention indignes et inhumaines à des personnes qualifiées par l’administration de « dangereuses » sans critère ni fondement transparent. […] Cette annonce intervient alors même que la République vient de célébrer Robert Badinter qui avait fermé les quartiers de haute sécurité en 1982, dénonçant l’« indignité d’un État de droit qui se nie lui-même ».
- Christian Tein enfin autorisé à rentrer en Kanaky-Nouvelle-Calédonie (humanite.fr)
Le président du FLNKS est toujours sous le coup d’une procédure judiciaire : il est accusé d’avoir orchestré les violences de mai 2024 sur l’archipel quand le gouvernement et la droite locale avaient voulu imposer le dégel du corps électoral au mépris du processus de décolonisation. Le dossier paraît de plus en plus vide, et Christian Tein a passé un an derrière les barreaux pour des motifs politiques
- Un comité des Nations Unies accuse la France violations « graves et systématiques » des droits des mineur·es isolé·es (humanite.fr)
- À Paris, un conducteur percute deux personnes lors d’une manifestation de sans-papiers (politis.fr)
Vendredi 10 octobre, un homme en voiture a percuté des manifestants lors d’une mobilisation organisée par un collectif de sans-papiers à Paris. Deux hommes ont été blessés et ont porté plainte. Malgré leurs témoignages, la police a retenu l’infraction de « blessures involontaires ». […] Pour que la Fiat s’arrête, il a fallu que la police arrive en courant et pointe son arme sur le conducteur en lui intimant de s’arrêter. « J’ai dit aux camarades “éloignez-vous” » se souvient Yoro. « Dans ma tête il n’allait pas s’arrêter et ils allaient tirer. »
- Pays basque : des amendes requises contre les sept militants solidaires des exilés (basta.media)
Sept militant·es solidaires risquaient dix ans de prison pour avoir aidé des personnes exilées à passer la frontière lors d’un évènement sportif. Au procès, le 7 octobre à Bayonne, des amendes de 1000 à 1500 euros ont finalement été requises.
- 163 000 euros pour un jet de peinture : Matignon veut faire payer deux écologistes (reporterre.net)
- « Gilets jaunes » : relaxe d’un major de CRS poursuivi pour la main arrachée d’un manifestant en 2018 (lemonde.fr)
Au vu de la « situation très dégradée » de la manifestation, « le tribunal a considéré que l’action du major D. constituait une réponse nécessaire et proportionnée », propre à l’exercice de ses fonctions de maintien de l’ordre.
Spécial résistances
- Affaire des fichiers d’Éric Ciotti : la Ligue des Droits de l’Homme annonce déposer plainte contre le député et candidat à la mairie de Nice (nicepresse.com)
Une enquête préliminaire avait été ouverte en mai dernier du chef d’« enregistrement ou conservation de données à caractère personnel sensibles ». Ceci faisant suite au signalement au printemps d’un « lanceur d’alerte anonyme » informant de l’existence de ce document mis en place par les équipes du député et président de l’UDR Éric Ciotti.
- Communiqué de presse d’Autisme France Suite aux propos du ministre du Travail, Jean-Pierre Farandou, au JT de France 2 le 14 octobre 2025 (autisme-france.fr)
Le ministre du Travail et des Solidarités a associé sourd à autiste : il dit ainsi qu’être autiste est un choix personnel, celui de ne pas écouter : ce genre d’ânerie est malheureusement entretenu par la psychanalyse qui continue à sévir en France dans l’autisme et explique l’autisme par une décision du « sujet ».
- Calvados : Sabotage de la ligne Paris-Caen à l’occasion des Assises Nationales de l’IA (trognon.info)
Spécial outils de résistance
- IA et vie privée : comment s’opposer à la réutilisation de ses données personnelles pour l’entraînement d’agents conversationnels ? (cnil.fr)
- Impôt sur les sociétés : 14 milliards d’euros en plus si les grandes entreprises avaient le même taux d’imposition que les PME (france.attac.org)

- Baisser le coût du travail ne crée pas d’emplois (politis.fr)
- Le Cherche et Trouve de l’édition (surtout) française (ecologiedulivre.org)
- Avec cette carte inédite, vérifiez si l’eau du robinet est polluée chez vous (reporterre.net)
Pollution aux PFAS, aux pesticides, au gaz toxique… Face aux multiples alertes concernant l’eau du robinet, vous pouvez dorénavant utiliser le site Dans mon eau (dansmoneau.fr). Développé par l’ONG Générations futures et Data For Good, cet outil novateur permet de savoir précisément quels polluants contaminent, ou non, votre eau courante.
- La contraception masculine en 3 questions (revue-farouest.fr)
Et si la contraception n’était plus seulement une affaire de femmes ? Préservatif, vasectomie, méthodes thermiques… les options masculines existent bel et bien, mais restent méconnues. Entre idées reçues et manque de soutien, ces solutions gagneraient pourtant à être mieux connues et discutées.
Spécial GAFAM et cie
- A first look at the Amazon-backed, next-generation nuclear facility planned for Washington state (geekwire.com)
A project to build one of the nation’s first next-generation nuclear facilities has just announced its name — the Cascade Advanced Energy Facility — and shared renderings of the plant.
- How I Reversed Amazon’s Kindle Web Obfuscation Because Their App Sucked (blog.pixelmelt.dev)
So let me get this straight :
I paid money for this book
I can only read it in Amazon’s broken app
I can’t download it
I can’t back it up
I don’t actually own it
Amazon can delete it whenever they want
This is a rental, not a purchase. - Microsoft Windows 11 October Update Breaks Localhost (127.0.0.1) Connections (cybersecuritynews.com)
- Windows 10 support “ends” today, but it’s just the first of many deaths (arstechnica.com)
End users can get an extra year of security updates relatively easily.

- Suspension du projet Microsoft à Polytechnique : une première victoire pour la souveraineté numérique, un appel à la responsabilité pour l’ensemble de l’ESR (cnll.fr)
L’École polytechnique suspend sa migration vers Microsoft 365. Le Conseil National du Logiciel Libre (CNLL), qui s’était fermement opposé à ce projet, accueille cette décision comme une victoire majeure pour la souveraineté de la recherche française et le respect du droit.
- Bye bye Spotify (pcet.fr)
Les autres lectures de la semaine
- Le droit de grève va-t-il disparaître ? D’où vient la menace ? (equaltimes.org)
La montée en puissance des politiques néolibérales incite de nombreux gouvernements à tenter de les entraver par de nouvelles lois, limitant ainsi les effets perturbateurs des grèves, ce qui les rend pratiquement inopérantes comme outil de pression et de défense des classes populaires.
- GenZ 212, au-delà de l’acronyme : regard sur une révolte (portail.basta.media)
- L’affrontement sino-américain pour le contrôle du numérique (contretemps.eu)
- Holes in the web (aeon.co)
Huge swathes of human knowledge are missing from the internet. By definition, generative AI is shockingly ignorant too […] one study on medicinal plants in North America, northwest Amazonia and New Guinea found that more than 75 per cent of the 12,495 distinct uses of plant species were unique to just one local language. When a language becomes marginalised, the plant knowledge embedded within it often disappears as well.
- La blague de l’open source base de souveraineté (paperjam.lu)
dans un monde où la souveraineté numérique se joue autant sur les données que sur le code, l’open source n’est pas encore une garantie d’indépendance : c’est un terrain de bataille.
- Surprise ! La 5G ne sert à (presque) rien (thierryjoffredo.frama.io)
Ça valait bien la peine de stigmatiser les personnes de la société civile qui réclamaient, en 2020, un débat démocratique pour définir les modalités de mise en œuvre de cette technologie en brandissant la peur du retour à la lampe à huile ou à la bifurcation vers un modèle Amish, sur fond de peur d’un supposé “retard” français et du déclassement de l’économie française sur le plan économique mondial si on perdait du temps à en discuter collectivement de la possibilité d’un moratoire sur le déploiement de la 5G.
- Notes on Humans Commons (blog.zgp.org)
- Détournement des communautés (n.survol.fr)
la question n’est pas de si la récupération va arriver mais de quand
- Le numérique à l’aune de la communotechnie – Les militant·es écologistes et le numérique (ecologiesocialeetcommunalisme.org)
- Écrire à la main et faire des pauses aide à mémoriser (theconversation.com)
- Delphine Demange et les compilateurs (linuxfr.org)
- Corps et territoire (hors-serie.net)
En Amérique latine, dans les réseaux de femmes paysannes, indigènes et urbaines, le féminisme populaire défend la terre, le territoire, et donne une signification particulière à la corporalité, à un corps-territoire […] l’agentivité des femmes est évidente, puisqu’elles se trouvent à l’avant-garde de la défense du territoire, de la terre, en opposition aux projets miniers et contre les compagnies pétrolières. Il me semble que ces phénomènes expliquent les vagues de féminicides et la pédagogie de la cruauté qui conduit à la mort, mais aussi à des actes de torture. Il y a une visibilité du corps torturé dans l’espace public.
- Le pouvoir des mâles n’est pas la norme chez les primates. (theconversation.com)
Depuis Darwin et jusqu’à la fin des années 1990, les recherches sur les stratégies de reproduction des animaux s’intéressaient surtout aux mâles. Une prise de conscience a ensuite eu lieu, en réalisant qu’il pourrait être intéressant de ne pas seulement étudier la moitié des partenaires… […] la dominance stricte d’un sexe sur l’autre, lorsqu’un sexe gagne plus de 90 % des confrontations, comme ce que l’on observe chez les babouins chacma, est rare. Il y a moins de 20 % des espèces où les mâles sont strictement dominants sur les femelles, et également moins de 20 % où ce sont les femelles qui sont strictement dominantes. […] la dominance des mâles s’observe surtout chez les espèces polygames, terrestres, vivant en groupe, comme par exemple les babouins, les macaques ou encore les gorilles, où les mâles disposent d’une nette supériorité physique sur les femelles.

- « Nous avons des enseignements à tirer de la manière dont les animaux se soignent » (reporterre.net)
- 5 astuces low-tech pour arrêter de ronfler et dormir d’une traite (lowtechjournal.fr)
Les BDs/graphiques/photos de la semaine
- Mixité
- Oignon
- RdV
- Pourquoi
- Nunez
- Retraites
- FT
- Zucman
- Falaise
- PS
- Donc
- At least
- Surveillance
- Nope
- Resist
- Pikachu
- Girls
- Grantifa
- Internationale
- Belts
- Windows
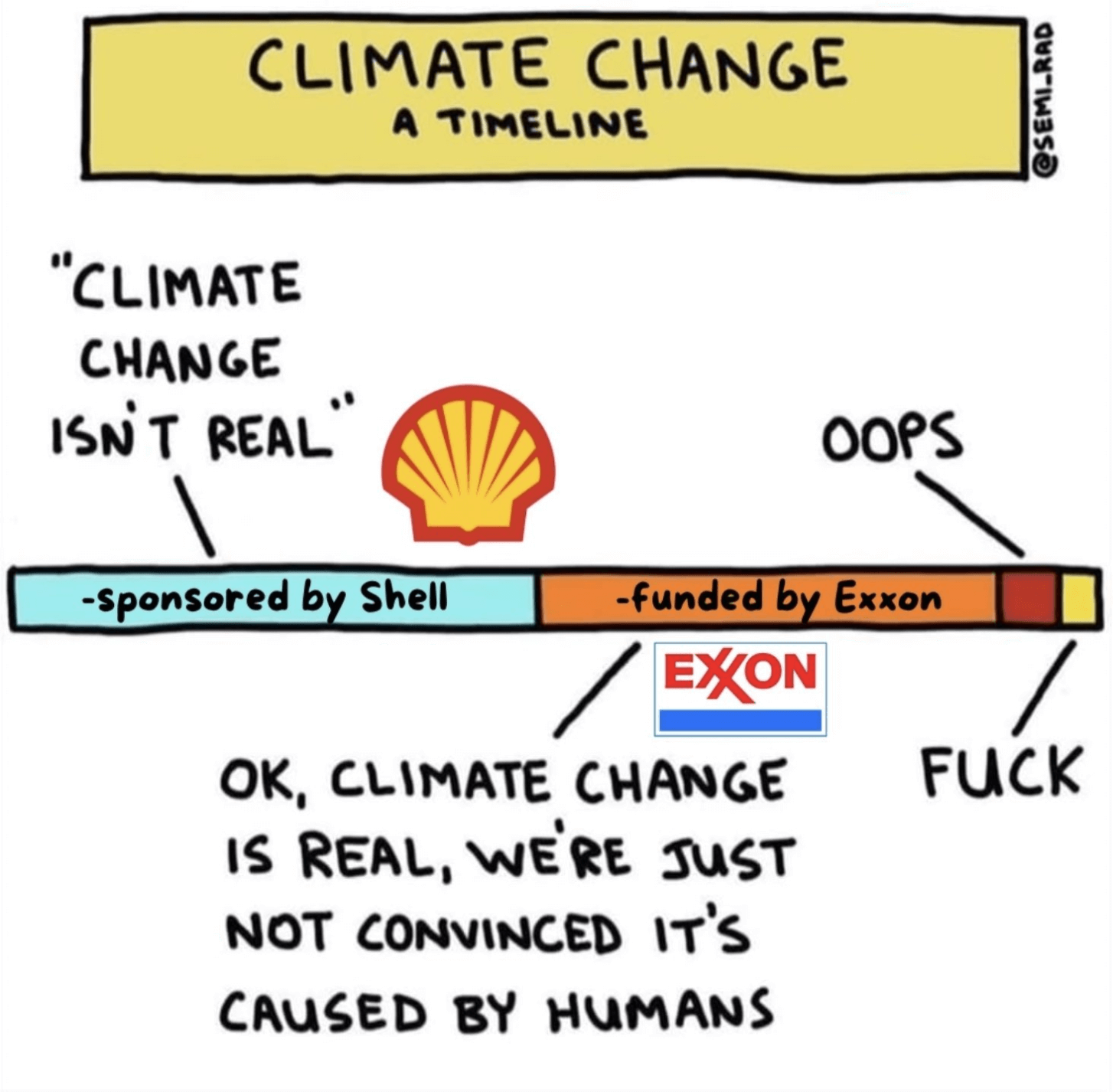
- Climate
- Does the news reflect what we die from ? (ourworldindata.org)
Les vidéos/podcasts de la semaine
- Catherine Tricot : ça va faire mal ! (tube.fdn.fr)
- Alice de Rochechouart sur la différence entre privilèges et compensations de désavantages (tube.fdn.fr)
- Italie : aux origines de la coalition des droites sous domination néofasciste (partie 1) (spectremedia.org)
- Islande, un jour sans femmes (arte.tv – disponible jusqu’au 13/01/2026)
En 1975, pour réclamer l’égalité entre les sexes, des féministes islandaises lancent un appel à la grève qui sera suivi… par 90 % des femmes du pays. Cinquante ans plus tard, celles qui l’ont vécue relatent cette joyeuse journée historique, restée unique au monde par son ampleur.
- Bari Weiss : Last Week Tonight with John Oliver (HBO) (tube.fede.re)
- Smart Glasses Are Ushering In An Anti-Social World (techwontsave.us)
- Le monde après le spécisme – En finir avec l’oppression des animaux (radiofrance.fr)
Les trucs chouettes de la semaine
- FSF announces Librephone project (fsf.org)
Librephone is a new initiative by the FSF with the goal of bringing full freedom to the mobile computing environment. The vast majority of software users around the world use a mobile phone as their primary computing device. After forty years of advocacy for computing freedom, the FSF will now work to bring the right to study, change, share, and modify the programs users depend on in their daily lives to mobile phones.
- Windows 10 sunsetting doesn’t mean the end for your PC (fsf.org)
- Windows 10 Is Dead. Your PC Doesn’t Have To Be (ifixit.com)
- Premier Samedi du Libre XXL le week-end des 6 et 7 décembre ! (samedis-du-libre.org) – un grand merci à Shiyata pour l’affiche !

- Appel aux conférencier·es : libre, éthique et partage (rencontreshivernalesdulibre.ch)
- Radio Garden, le site où on peut écouter toutes les radios du monde en se baladant sur une carte (radio.garden)
- 50 Reasons to Build a Website (frontendmasters.com)
- Hey Look, It’s Every AI-Coded Website Ever (vibe-coded.lol)
Take a look around at the same fucking vibe-coded site you’ve seen ten million times before ! Built entirely by copy-pasting Claude responses without reading them !

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
17.10.2025 à 09:52
Adieu Windows, bonjour le Libre !
Texte intégral (1466 mots)
![]() Nous vous en parlions la semaine dernière dans notre article Fin de Windows 10 : faisons le point, l’opération « Adieu Windows, bonjour le Libre ! » lancée par l’association April est en place depuis le 1er octobre. On y revient plus en détail cette semaine.
Nous vous en parlions la semaine dernière dans notre article Fin de Windows 10 : faisons le point, l’opération « Adieu Windows, bonjour le Libre ! » lancée par l’association April est en place depuis le 1er octobre. On y revient plus en détail cette semaine.
De l’aide à portée de main
Le plus important dans cette opération, c’est l’entraide !
Si vous aussi, vous voulez vous délivrer-libérer de l’emprise de Microsoft ou le permettre à vos proches, si vous ne voulez pas ou n’avez pas les moyens de passer à Windows 11, alors les systèmes libres s’offrent à vous. Vous pouvez en installer un de façon autonome, chez vous, mais si vous pensez avoir besoin d’aide, les bénévoles de très nombreuses associations se sont organisé·es pour vous recevoir et répondre à toutes vos questions.
- Soit en participant à l’un des nombreux évènements organisés près de chez vous.
- Soit en prenant contact avec une association locale.
Cette opération se tient sur un an, elle est donc continuellement en cours de remaniement, avec des ajouts permanents d’évènements. Restez à l’affût, il y a ou aura forcément quelqu’un·e, quelque part, prêt·e à vous transmettre sa passion informatique et résoudre vos problèmes ou satisfaire vos envies.
C’est la principale différence entre les logiciels privateurs et les logiciels libres : ces derniers bénéficient de l’aide des bénévoles des communautés qui les maintiennent, les promeuvent et sont ravis de partager leur savoir-faire au grand public, gratuitement, chaleureusement et sans contrepartie.
N’hésitez pas à aller à leur rencontre !
Une communauté solidaire
C’est toute une communauté qui se met au service du plus grand nombre afin de sortir des griffes de Microsoft (mais pas que ! Il existe des alternatives aux produits d’Apple et de Google aussi). Sont au rendez-vous des GULL (Groupe d’Utilisateurs et d’utilisatrices de Logiciels Libres, des EPN (Espace Numérique Libre), des médiathèques, des cafés associatifs, des CHATONS (miaou), quelques entreprises également et d’autres associations.
En seulement quinze jours, plus d’une soixantaine d’organisations se sont associées à l’opération, partageant cordonnées et évènements sur l’Agenda du Libre. Et ce n’est pas fini, ça va durer un an !
Quel que soit le matériel utilisé, ordinateur, tablette, smartphone, les systèmes d’exploitation et logiciels libres sont nombreux, maintenus et faciles d’accès.
Si vous ne trouvez pas votre bonheur parmi les évènements proposés, il existe d’autres initiatives pour libérer votre ordinateur, comme les Journées Nationales de la Réparation du 16 au 19 octobre 2025, Aide GNU/Linux qui propose une carte collaborative de marraines et de parrains en mesure d’aider à l’installation, Fin de Windows 10, Non à la taxe Windows et la démarche NIRD « pour un numérique libre et écocitoyen dans les établissements scolaires ! ».
Pour l’April, c’est le bon moment de quitter Windows !
L’Association dénonce, une fois encore, les méfaits de Microsoft.
Windows 10 est un logiciel privateur, qui répond à ce titre et avant toute autre considération aux intérêts de Microsoft qui a ainsi tout loisir d’imposer unilatéralement l’arrêt du support de son système d’exploitation. Conséquence : sans mises à jour régulières, sans correctif de sécurité, sans assistance technique, Windows 10 devient vulnérable, donc dangereux à l’usage. C’est exactement ce qu’on appelle de l’obsolescence logicielle ! Un matériel qui fonctionne encore, mais qu’il faudrait mettre au rebut parce que le système d’exploitation devient obsolète et que la nouvelle version disponible n’est pas compatible avec lui.
Et tout cela pour pousser à la consommation : nouveaux PC, nouveaux abonnements, nouvelles licences dont il est parfois impossible de connaître le prix, c’est ce qu’on appelle de la vente forcée. C’est tout sauf écologique. Si toutes les personnes, toutes les associations, toutes les entreprises, toutes les administrations et toutes les collectivités changent de matériel pour acheter du neuf, c’est même un écocide. Il a été estimé que jusqu’à 400 millions d’ordinateurs dans le monde sont incompatibles avec cette nouvelle version de Windows, dont certains achetés il y a moins de trois ans !
Cet arrêt du support gratuit de Windows 10 va donc forcer à migrer vers Windows 11, qui, lui aussi forcément, imposera les mêmes restrictions techniques : puissance, mémoire, absence de compatibilité avec des logiciels plus anciens et DRM (menottes numériques) intégrés.
Ce prolongement de support gratuit n’est possible que si les personnes enregistrent leur compte sur le site de Microsoft. Ce faisant, elles lieront leur ordinateur à leur adresse e-mail, et laisseront un accès total à leur matériel, permettant ainsi à la multinationale américaine de collecter des données, de plus en plus nombreuses (avec des paramètres de confidentialité complexes à désactiver.), et lui laissant un pouvoir de contrôle technique, à distance, sans passer par l’étape de l’accord explicite. Ce prolongement du support gratuit est en fait un piège pour influencer les gens et les amener à installer Windows 11.

L’utilisation des produits de Microsoft n’est pas une fatalité.
Pour migrer vers un système libre, il faut le vouloir, c’est un choix personnel, politique, économique, voire écologique…
Il existe pourtant de très nombreuses alternatives libres GNU/Linux qui peuvent remplacer Windows, pour n’en citer que quelques-unes : Debian, Ubuntu, Mageia, Fedora, Primtux (cette dernière étant spécialement conçue pour enfants). Idem pour les logiciels. Consultez le site Framalibre pour en découvrir.
Pour ne pas jeter vos appareils numériques, pour préserver vos données et celles des autres, pour retrouver votre autonomie, libérez-vous et délivrez vos ordinateurs. Adieu Windows !
16.10.2025 à 10:00
Quelles applications libres utiliser sur Windows ?
Texte intégral (11123 mots)
Une des grandes actualités des dernières semaines est la fin du support de Windows 10 par Microsoft.
Ça peut sembler anecdotique pour certain·es mais cet événement a un réel impact pour des millions de personnes puisque cette fin de support rend obsolète tout ordinateur n’étant pas compatible avec la version 11 de Windows.
Nous l’expliquions récemment, nous avons toujours la possibilité de passer notre ordinateur sur Linux, et rallonger ainsi drastiquement la durée de vie de notre ordinateur.
Cependant, pour de nombreuses personnes, passer vers Linux semble être une étape trop importante pour le moment. Et nous les comprenons ! Le processus de transition numérique nécessite, pour se faire en douceur, d’y aller par étapes et de changer progressivement ses habitudes !
Dans cet article, nous vous proposons de découvrir des étapes concrètes pour vous aider à vous émanciper de l’emprise de Microsoft sur vos vies numériques. Pas besoin d’installer Linux, vous pouvez accomplir ces étapes dès aujourd’hui, sur votre Windows !
Les applications proposées dans cet article sont toutes des logiciels libres. Cela signifie que leur licence d’utilisation permet à l’utilisateurice de garder le contrôle sur le logiciel.
Aussi, ces applications existent à la fois sous Windows et Linux (comme souvent avec les logiciels libres) et vous permettront donc de vous habituer, dès aujourd’hui, aux applications que vous utiliserez sur Linux (quand vous le souhaiterez) !
Adieu Chrome, bonjour Firefox
Nous utilisons presque systématiquement notre navigateur Web lorsque nous allumons notre ordinateur. Vous savez, c’est cette application qui nous permet d’accéder à l’ensemble des sites Web. On s’en sert aujourd’hui pour tout, que ce soit pour écouter de la musique, regarder des vidéos, consulter nos mails, faire des visioconférences, etc.
Par exemple, vous utilisez actuellement un navigateur Web pour lire cet article de blog !
Par défaut, sur un ordinateur utilisant Windows, le navigateur est Microsoft Edge. Ce navigateur, proposé par Microsoft, est en fait basé sur le projet Chromium, de Google. Chromium, c’est un navigateur servant de base à d’autres navigateurs (c’est un peu inception mais pour les navigateurs, vous me suivez ?).
C’est par exemple le cas de Google Chrome, le navigateur propriétaire de Google.

Logos de Google Chrome et Microsoft Edge.
Un navigateur est un logiciel puissant et les géants du numérique comme Google ou Microsoft s’en servent pour collecter énormément d’informations sur nous. Quels sites nous visitons, quelles recherches nous effectuons, etc.
C’est pourquoi il est essentiel d’opter pour un navigateur en lequel nous avons confiance et qui n’exploite pas nos données comportementales.
Un tel navigateur existe, c’est Mozilla Firefox.
Logo de Mozilla Firefox.
Mozilla Firefox (souvent abrégé Firefox) est lui aussi un navigateur, mais proposé par une fondation à but non lucratif : la fondation Mozilla.
Ce point est très important car si Microsoft Edge et Google Chrome sont pensés pour rapporter, avant tout, de l’argent aux entreprises qui les proposent, Mozilla Firefox est quant à lui pensé pour servir avant tout les humains et humaines qui l’utiliseront.
Bien sûr, l’application n’est pas exempte de tout défaut et certains choix faits par Mozilla sont sujets à critiques.
Néanmoins, nous pensons que c’est la meilleure option que nous avons aujourd’hui.
Découvrons ensemble comment installer et configurer Firefox !
Installer Firefox
- Ouvrez un navigateur pour accéder au site officiel de Firefox. De manière courante, téléchargez TOUJOURS les logiciels à partir de leur site officiel (et dans le doute, les pages Wikipédia des logiciels ont souvent le bon lien !). C’est un bon moyen d’éviter d’installer des logiciels indésirables, voire pire, sur son ordinateur !
- Cliquez sur le bouton bleu « Télécharger Firefox ».
- Vous allez être redirigé vers une nouvelle page, vous confirmant que le téléchargement va commencer. Patientez jusqu’à ce que le téléchargement soit complet. Celui-ci devrait s’être affiché en haut à droite de votre navigateur.
- Lancez le fichier téléchargé pour démarrer l’installation de Firefox.
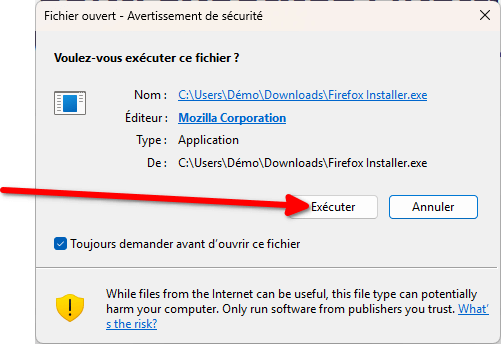
- Confirmez que vous voulez bien exécuter le fichier.
- L’installation va alors commencer et Firefox s’exécutera automatiquement à la fin de celle-ci.
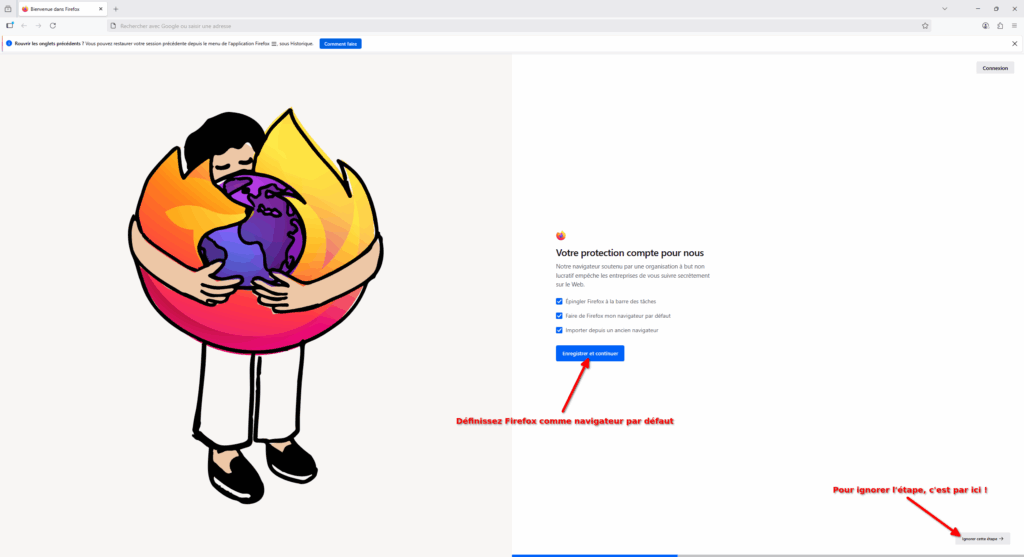
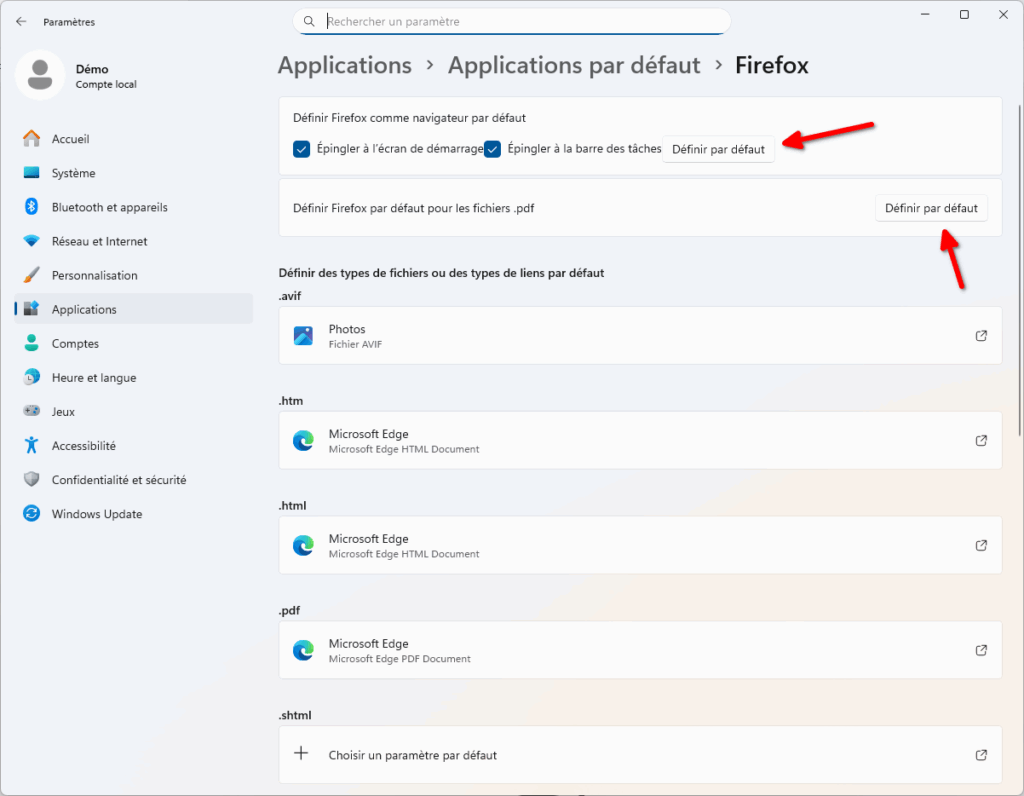
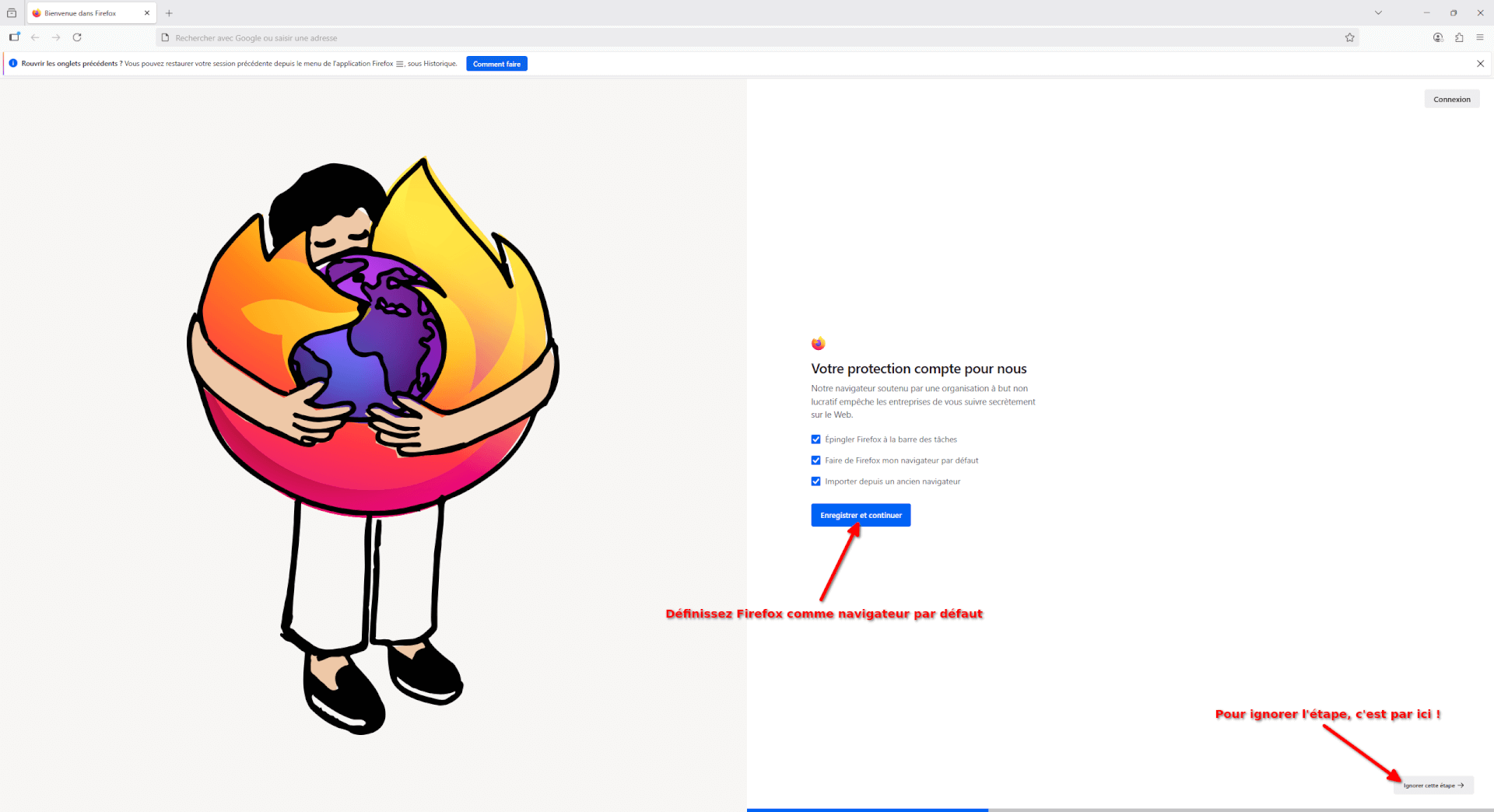
- Lors du premier démarrage, Firefox vous propose de configurer votre ordinateur pour :
- Épingler Firefox à la barre des tâches. La barre des tâches, c’est la barre en bas de votre Windows. Épingler Firefox ici permet d’y accéder plus rapidement.
- Faire de Firefox votre navigateur par défaut. Cela permettra d’ouvrir automatiquement les liens sur lesquels vous cliquez (dans d’autres applications) avec Firefox. Cette option est recommandée.
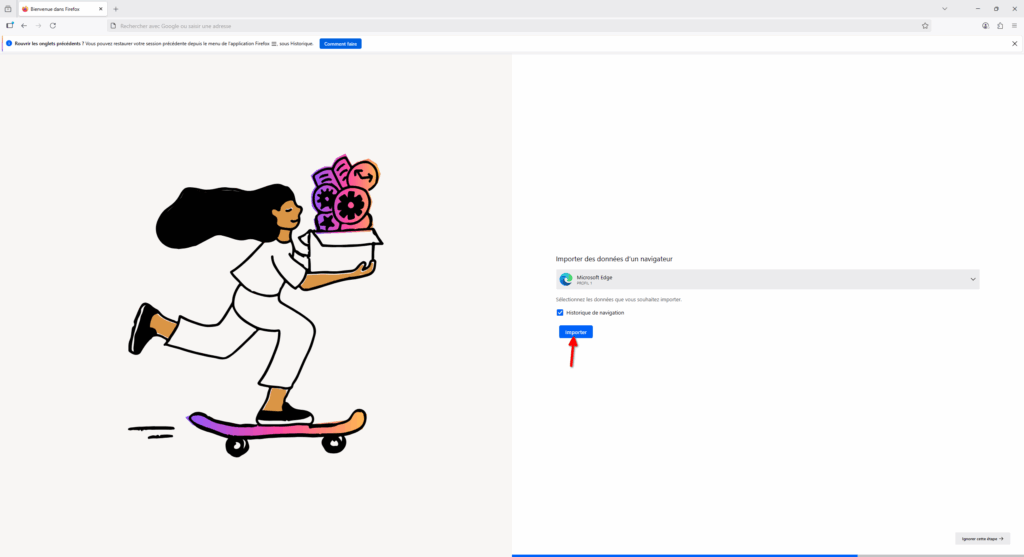
- Importer depuis un ancien navigateur. Cela vous permettra de récupérer les données (historique, identifiants, etc) de votre ancien navigateur. Très pratique pour faire une transition quasi-transparente.
- Si vous faites « Enregistrer et continuer », une fenêtre vous permettant de définir Firefox comme application par défaut va s’ouvrir. Vous pouvez aussi de choisir d’ignorer toutes ces étapes en cliquant sur « Ignorer cette étape » en bas à droite de l’écran.
- Si vous avez sélectionné d’importer les données depuis un ancien navigateur, Firefox va vous proposer de sélectionner les données que vous souhaitez récupérer. Une fois la sélection faite, faites « Importer ».
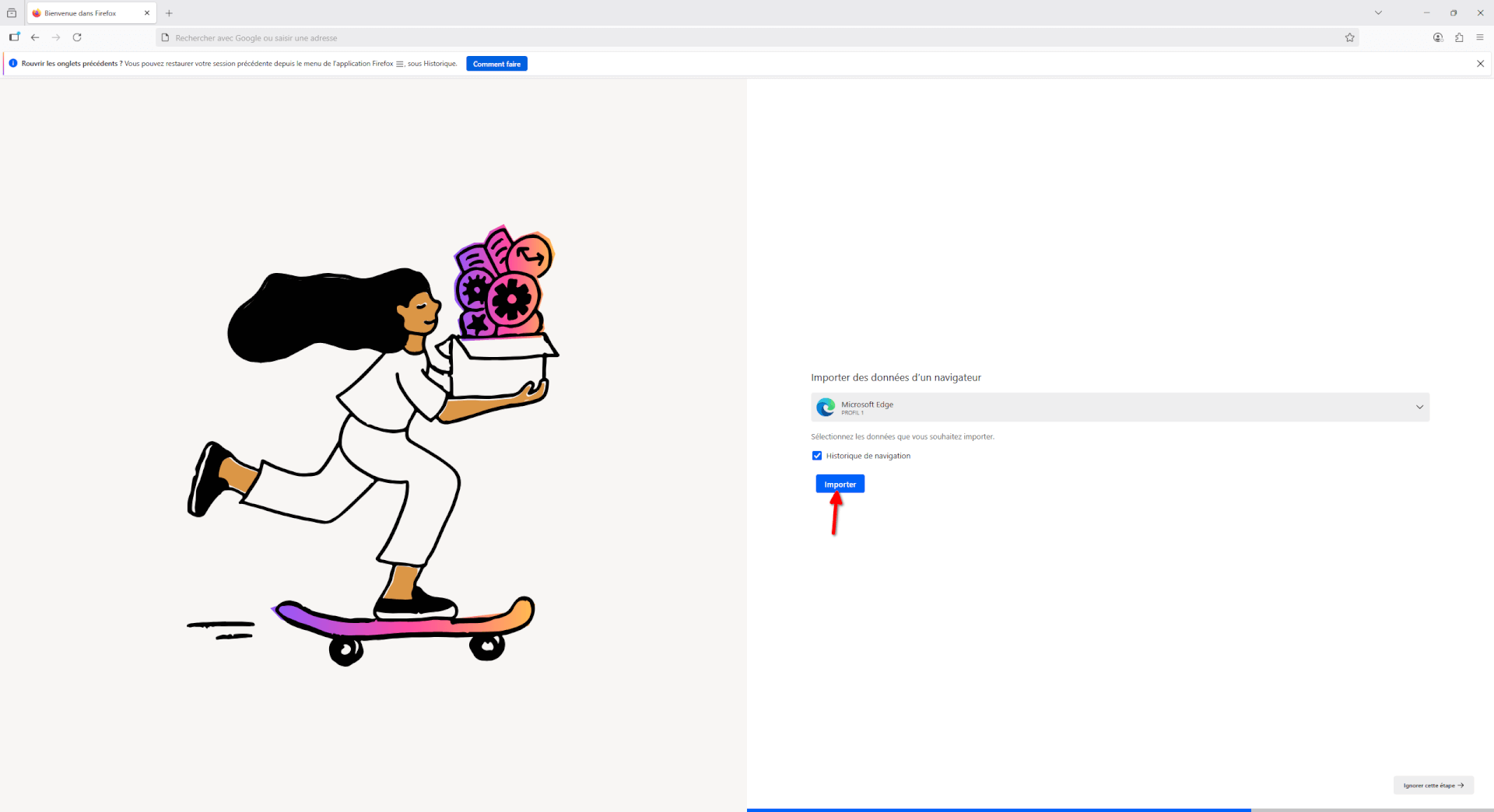
- L’écran suivant vous indiquera que les données ont été correctement importées, vous pouvez cliquer sur « Continuer ».
- L’écran suivant vous propose de synchroniser votre navigateur avec un compte en ligne Firefox. Cela peut être pratique dans le cadre où vous installez Firefox sur plusieurs appareils, et permet de synchroniser l’historique, les identifiants et vos paramètres entre vos appareils. Vous pouvez vous décider plus tard, dans ce guide, nous considérons que vous avez cliqué sur « Commencer la navigation », en bas à droite du navigateur.
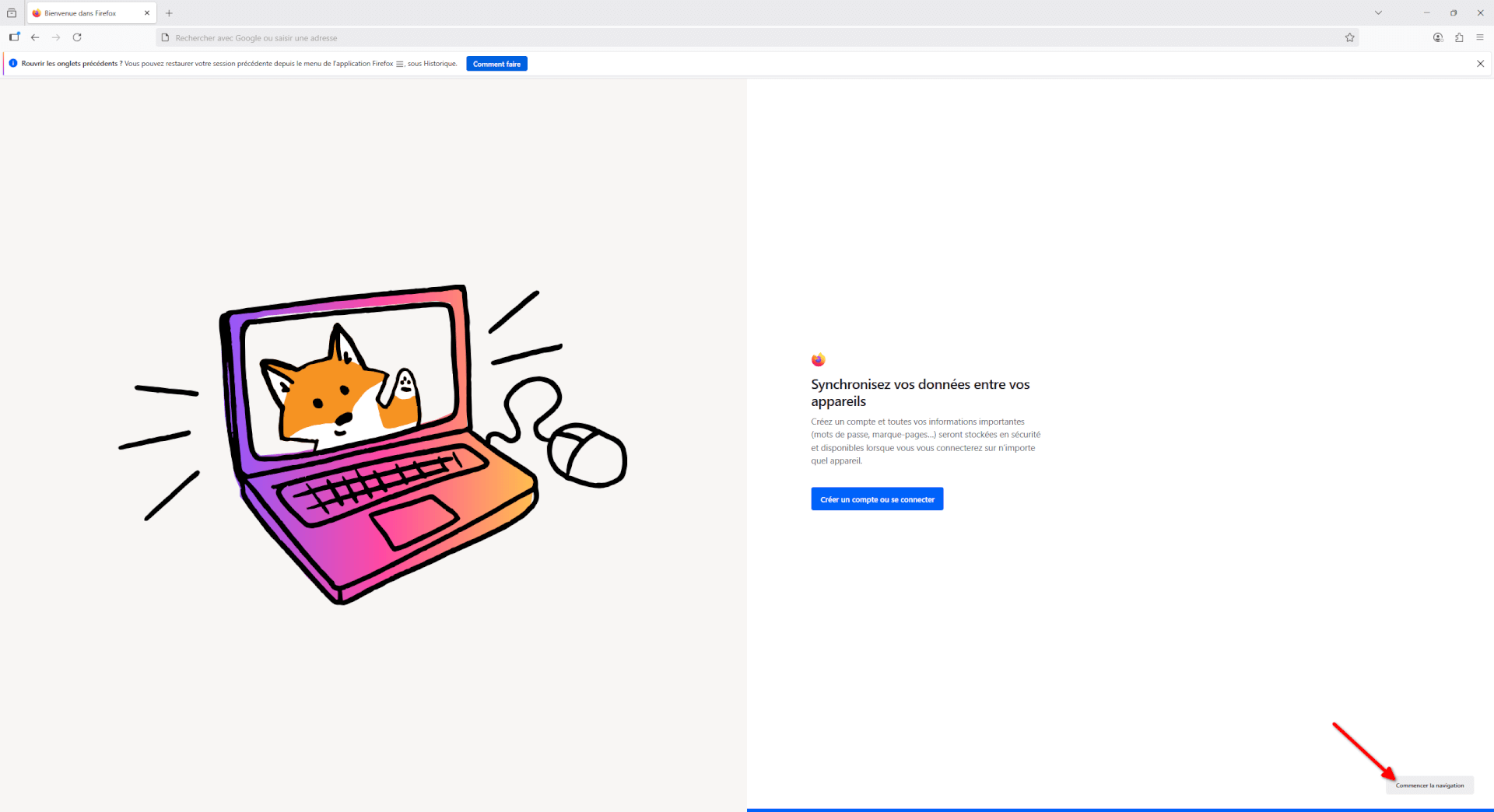
Votre Firefox est désormais prêt à être utilisé ! La page d’accueil du navigateur vient de s’ouvrir et vous pouvez dès à présent utiliser votre nouveau jouet !
Cependant, nous vous proposons d’aller un peu plus loin dans votre émancipation en modifiant quelques paramètres :
Configurer Firefox
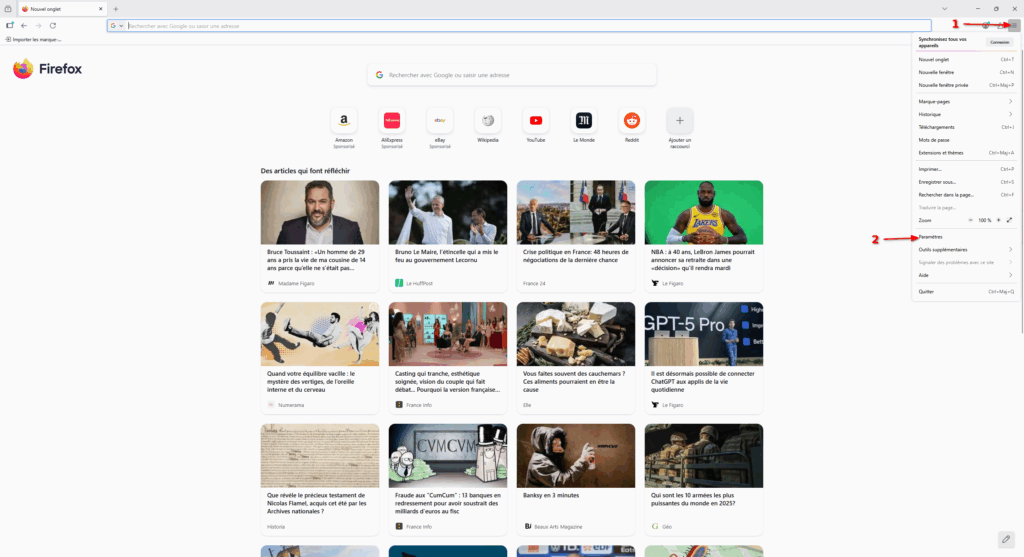
- Cliquez sur le menu « Hamburger » (c’est le nom des menus ayant trois traits horizontaux. 🤷) pour faire apparaître différentes options. Ensuite, cliquez sur « Paramètres ».
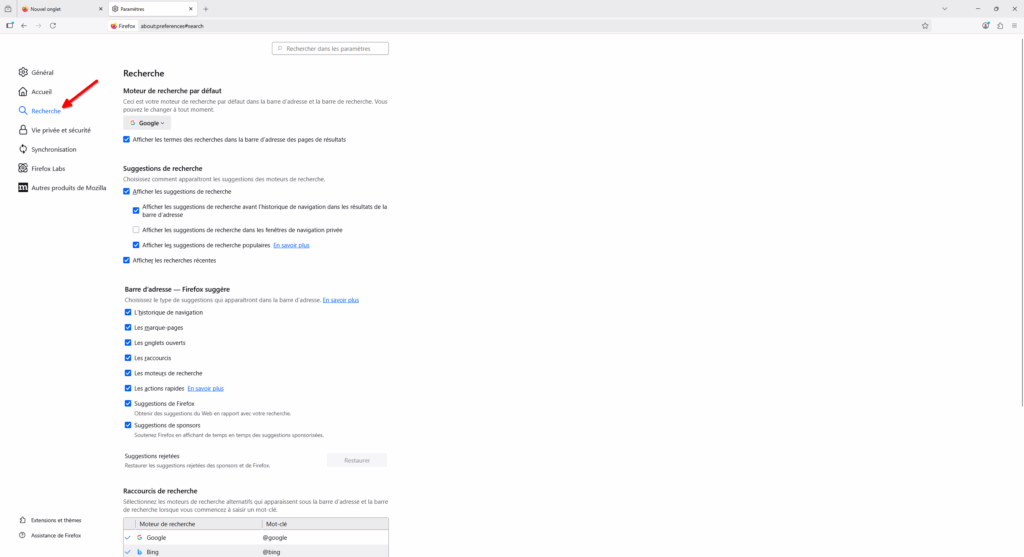
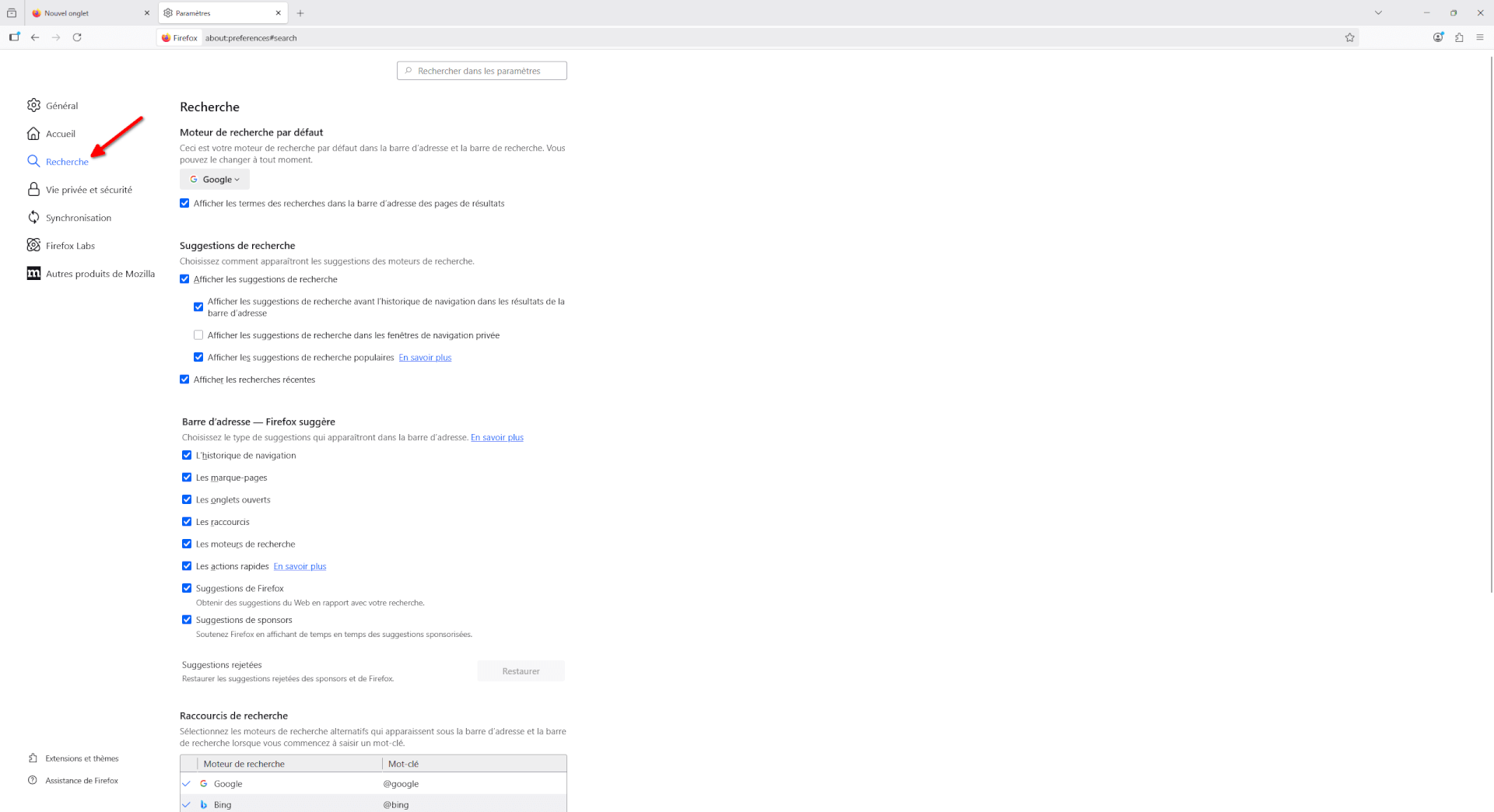
- Une page s’ouvre alors, c’est l’endroit où la majorité des paramètres de Firefox sont. Vous pouvez prendre le temps d’explorer ces paramètres mais ce qui nous intéresse tout de suite, c’est l’onglet « Recherche ».
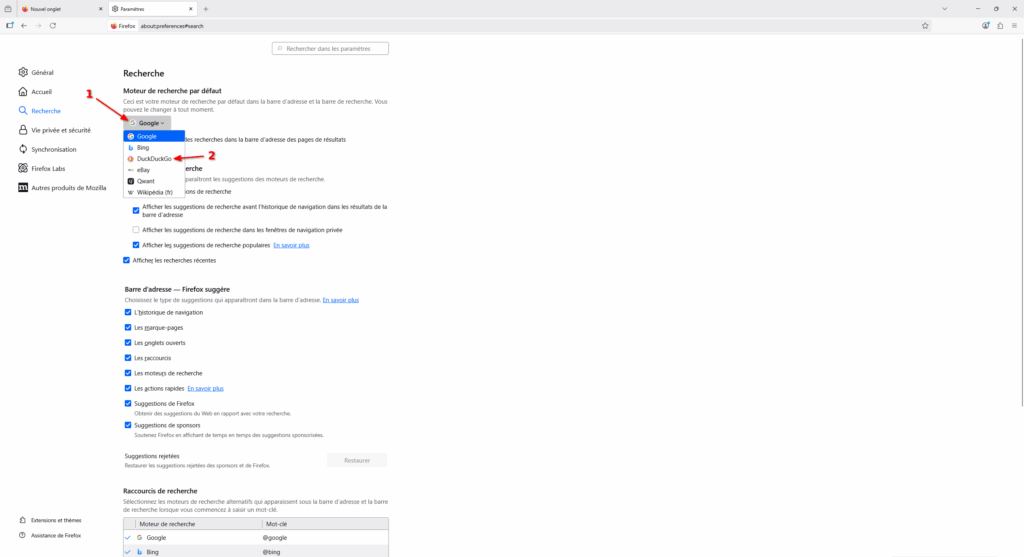
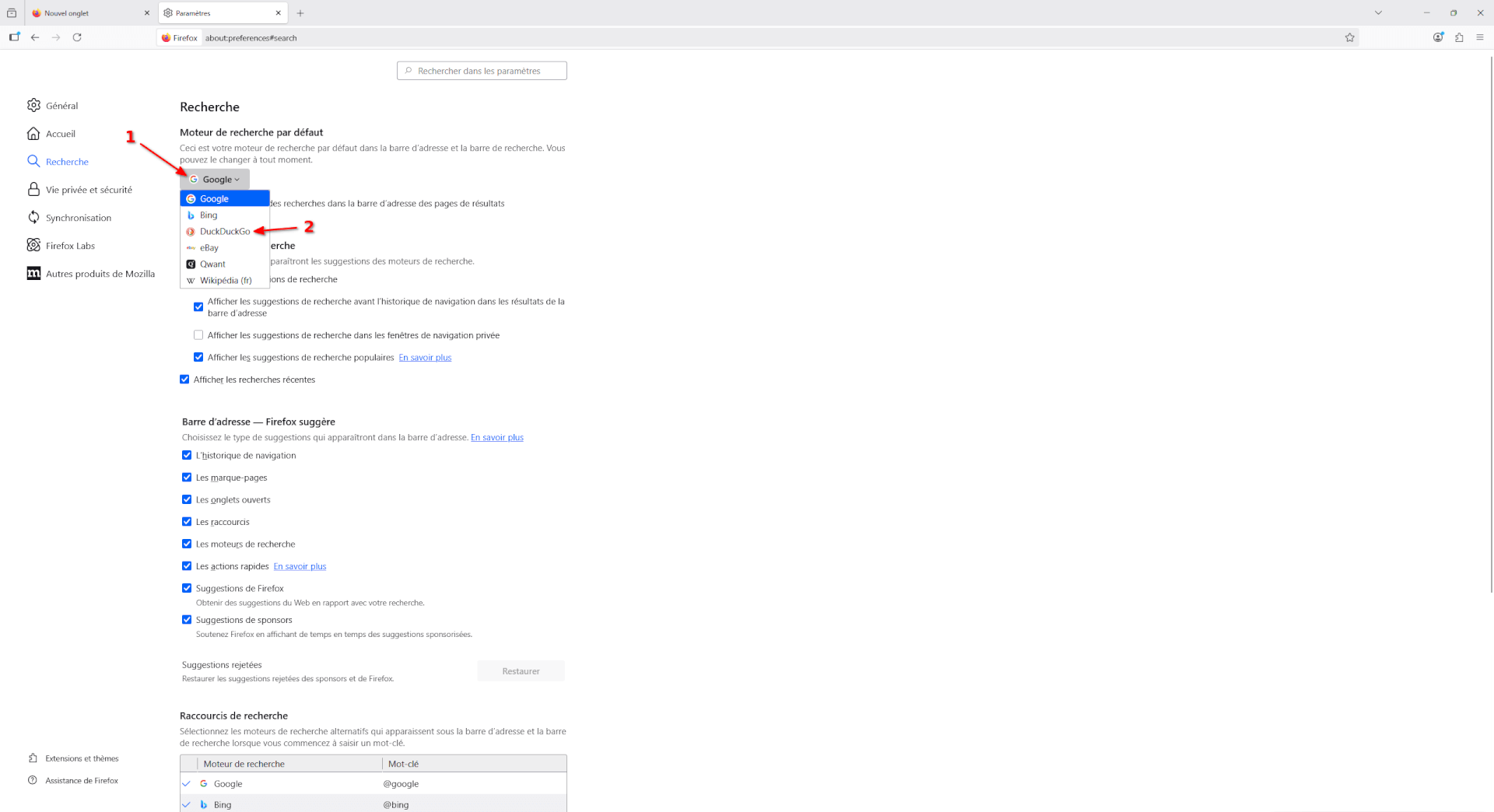
- Cet onglet permet de modifier les paramètres liés à la recherche, dans Firefox. Notamment, c’est ici que vous pouvez définir quel est votre moteur de recherche par défaut. Actuellement, celui-ci devrait être « Google » mais si vous souhaitez essayer un autre moteur de recherche, je vous recommande de cliquer sur la liste et de choisir « DuckDuckGo ». DuckDuckGo est un moteur de recherche respectant l’intimité numérique de ses utilisateurs et utilisatrices, contrairement à Google qui exploite toute donnée comportementale afin de prédire et d’orienter nos comportements.
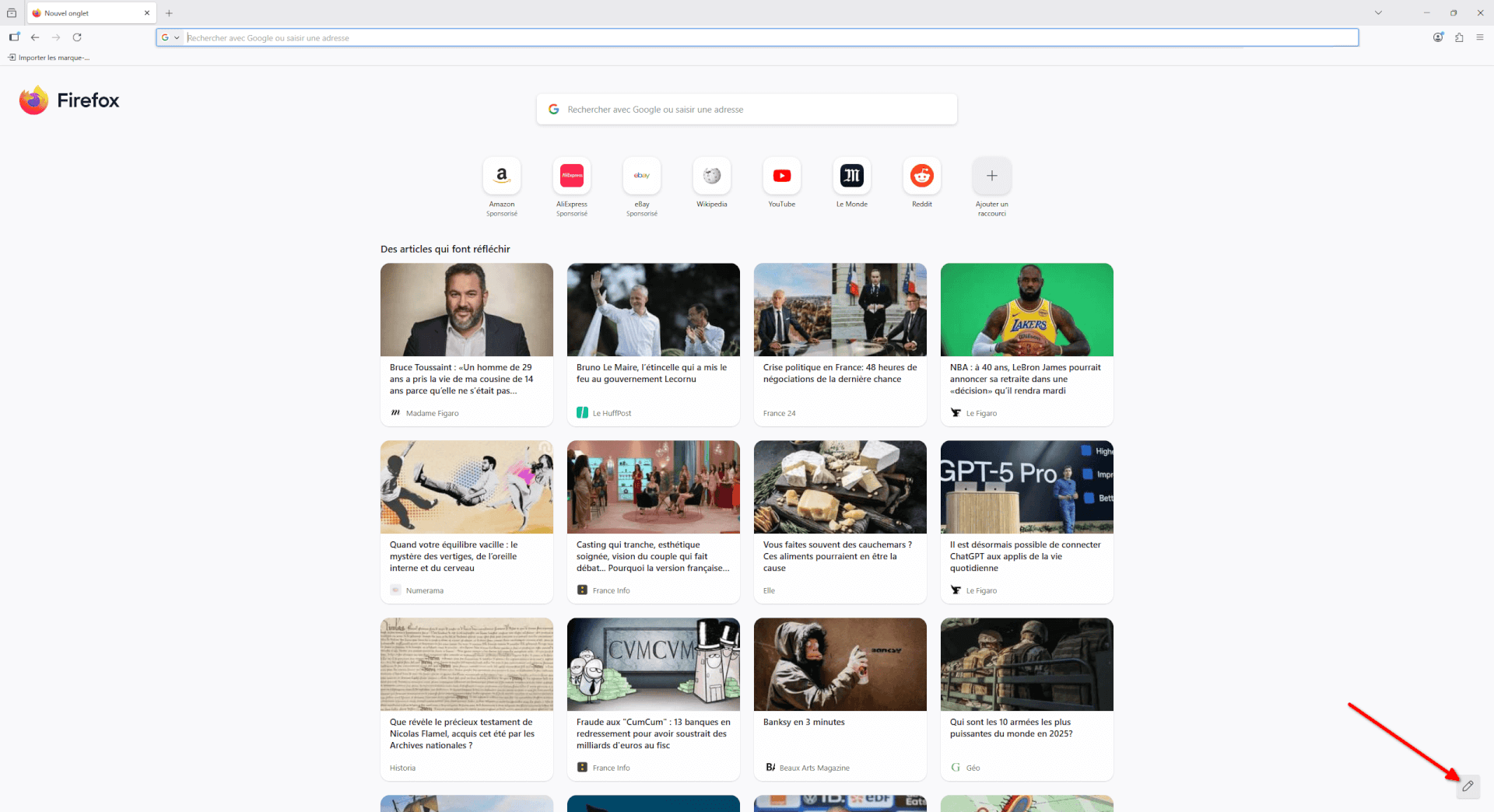
- Ensuite, nous pouvons fermer l’onglet actuel pour retrouver notre page d’accueil. Si, comme nous, vous n’avez pas spécialement envie de voir s’afficher des actualités à chaque fois que vous ouvrez Firefox, ne vous en faites pas, il est possible de désactiver celles-ci ! Cliquez sur le crayon, en bas à droite du navigateur.
- Un menu pour personnaliser votre page d’accueil s’affiche alors. Dans ce menu, vous pouvez choisir d’afficher un nouveau fond d’écran, mais surtout… vous pouvez désactiver les « articles recommandés » ! En un clic, nous pouvons nous apaiser l’esprit ! Yeah !

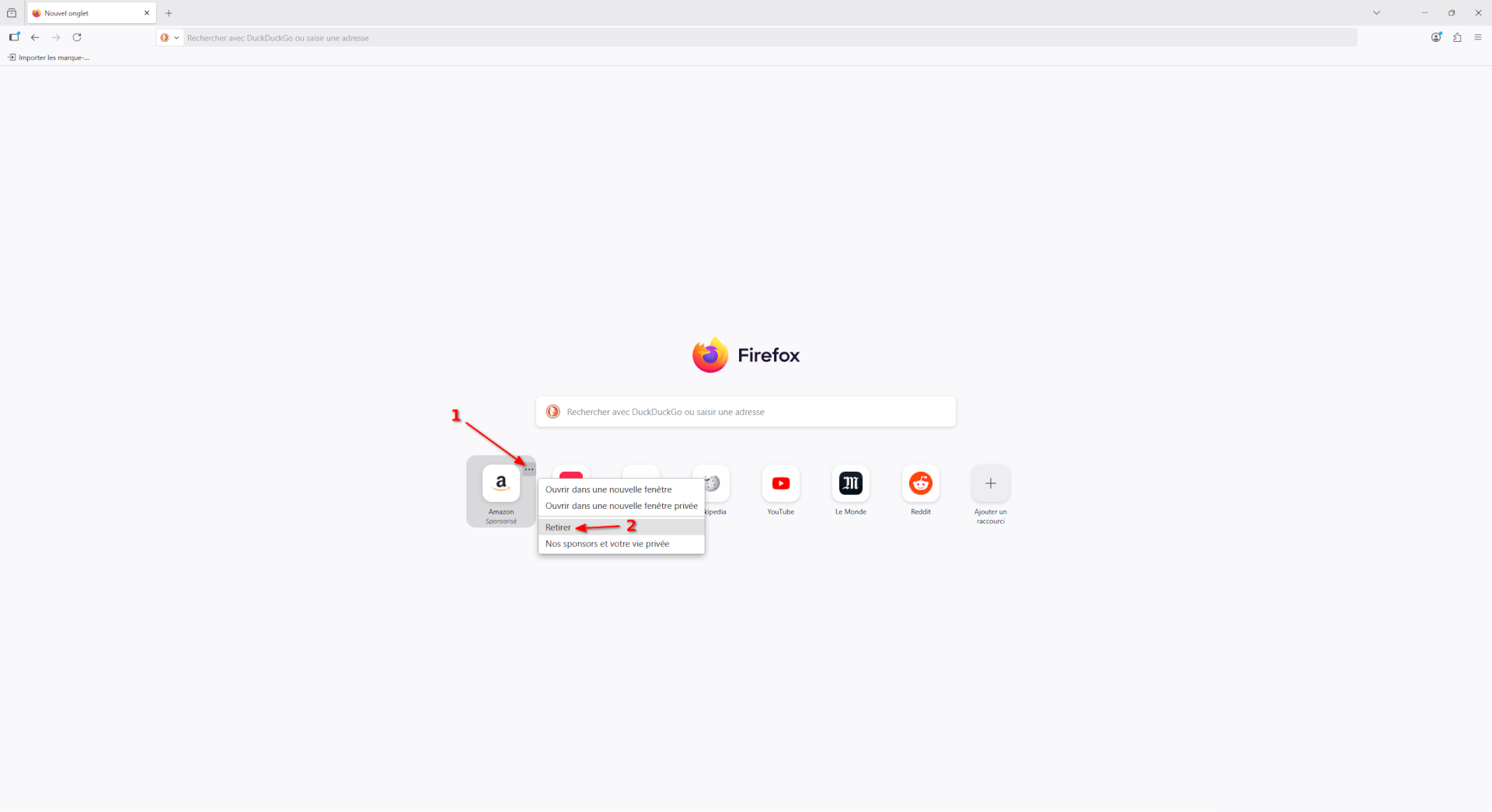
- Pour terminer avec la page d’accueil, sachez que vous pouvez retirer les raccourcis sponsorisés présents sur celle-ci. Il suffit de cliquer sur le menu d’un raccourci (les trois points horizontaux) et de cliquer sur « Retirer ».

- Voilà ! Vous avez un Firefox qui vous ressemble un peu plus ! Il existe beaucoup d’options pour paramétrer au plus proche de vos besoins votre navigateur. Je vous recommande de fouiller dans les paramètres et d’essayer des trucs !

Firefox est désormais configuré avec des paramètres un peu plus chouettes ! Cependant, il manque une chose pour rendre votre navigation sur le Web réellement agréable… un bloqueur de pub !
En quelques étapes, nous vous proposons d’installer uBlock Origin, le bloqueur de pisteurs et de publicités le plus efficace. uBlock Origin existe sur tous les navigateurs majeurs donc vous l’aviez peut-être déjà installé sur Google Chrome ou Microsoft Edge mais à cause de restrictions imposées dans ces navigateurs, il est bien plus efficace sur Firefox !
Découvrons comment l’installer en une minute :
Installer uBlock Origin
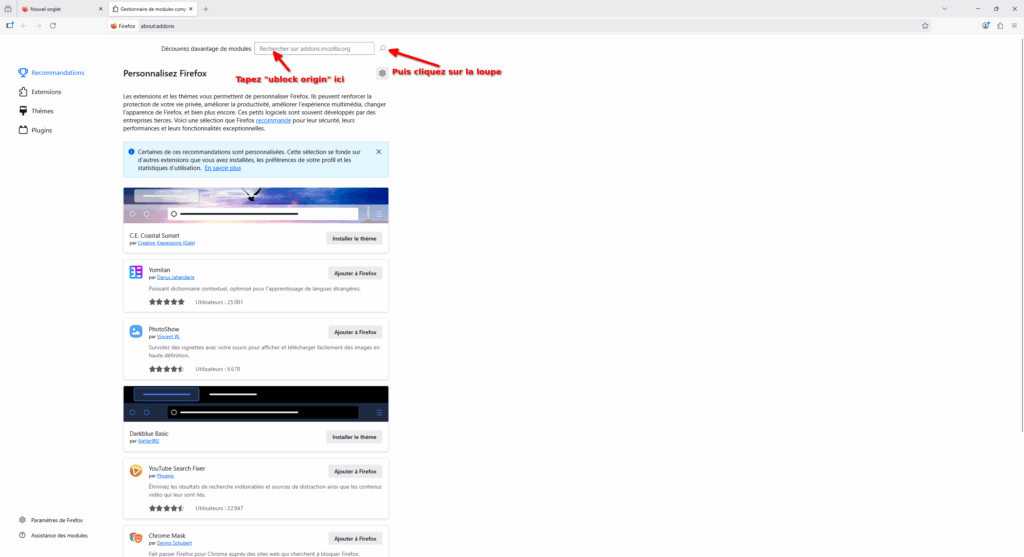
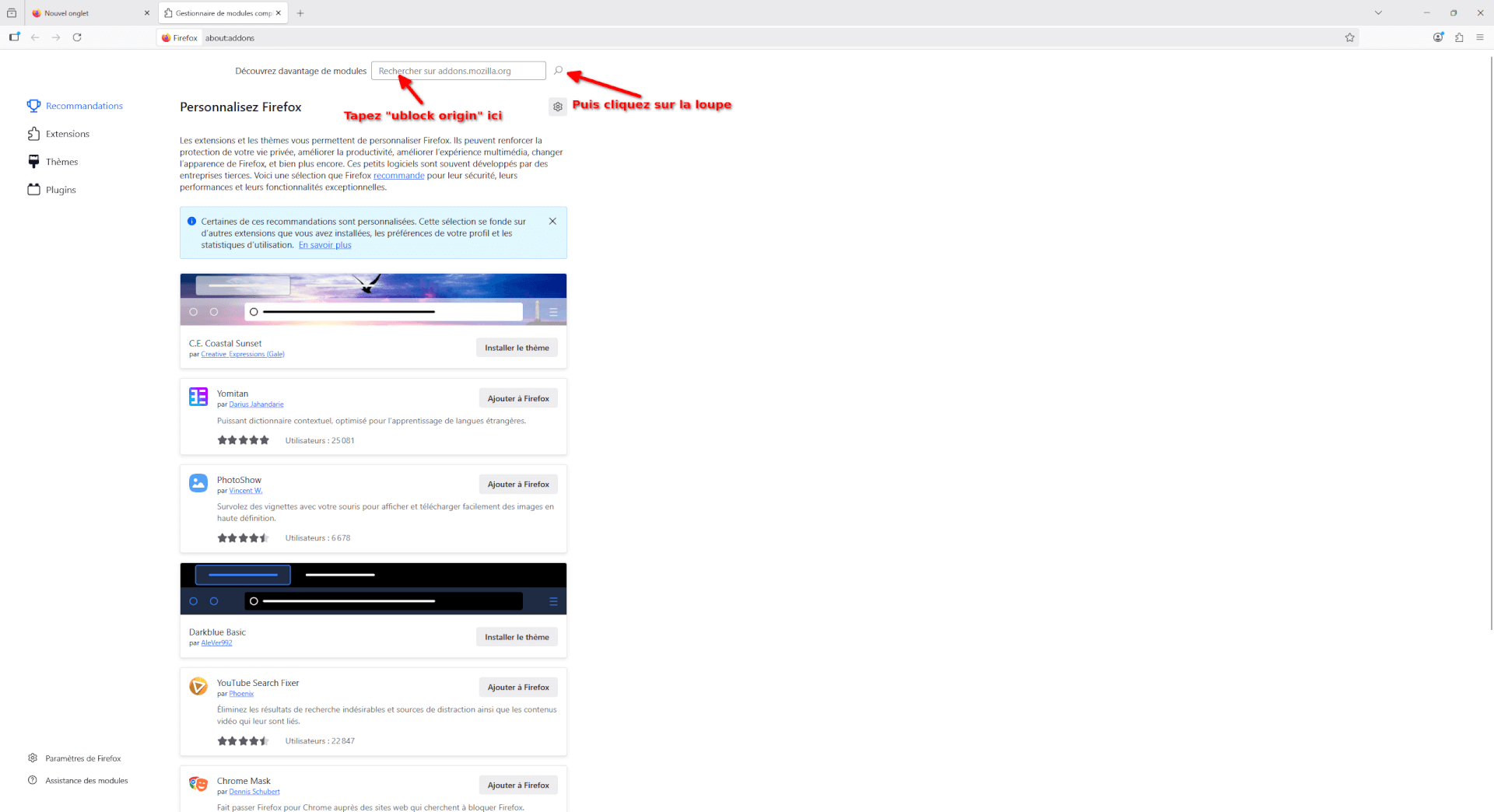
- Cliquez sur l’icône de puzzle, en haut à droite du navigateur. Cela permet d’accéder au menu dédié aux extensions. Une extension de navigateur, c’est un petit bout de logiciel qui s’intègre entièrement dans votre navigateur afin d’en étendre les fonctionnalités. Il existe des milliers d’extensions différentes mais la plus populaire est vraiment uBlock Origin (avec 10 millions d’utilisateurices sur Firefox) !
- Dans la page qui s’ouvre tapez « ublock origin » dans la barre de recherche d’extension puis cliquez sur la loupe !
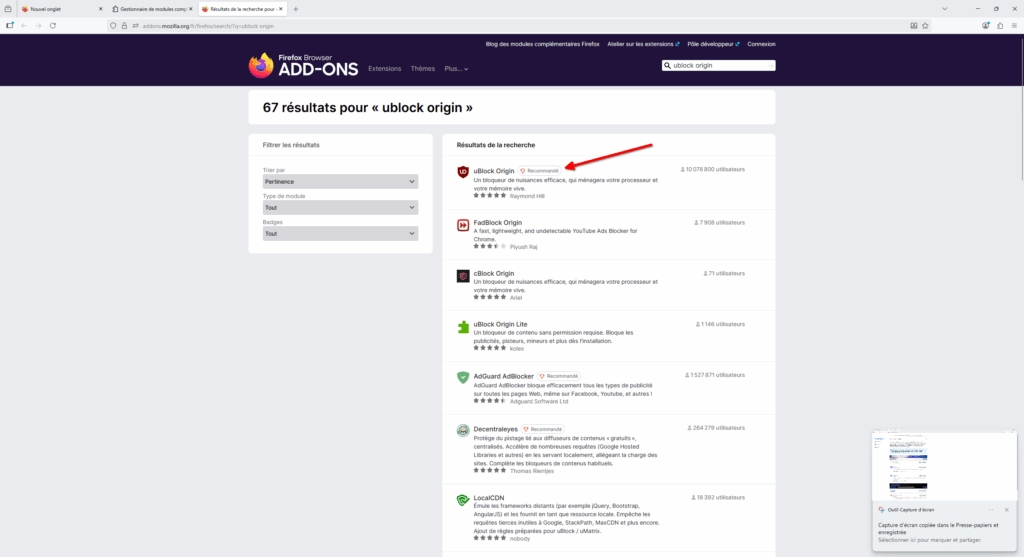
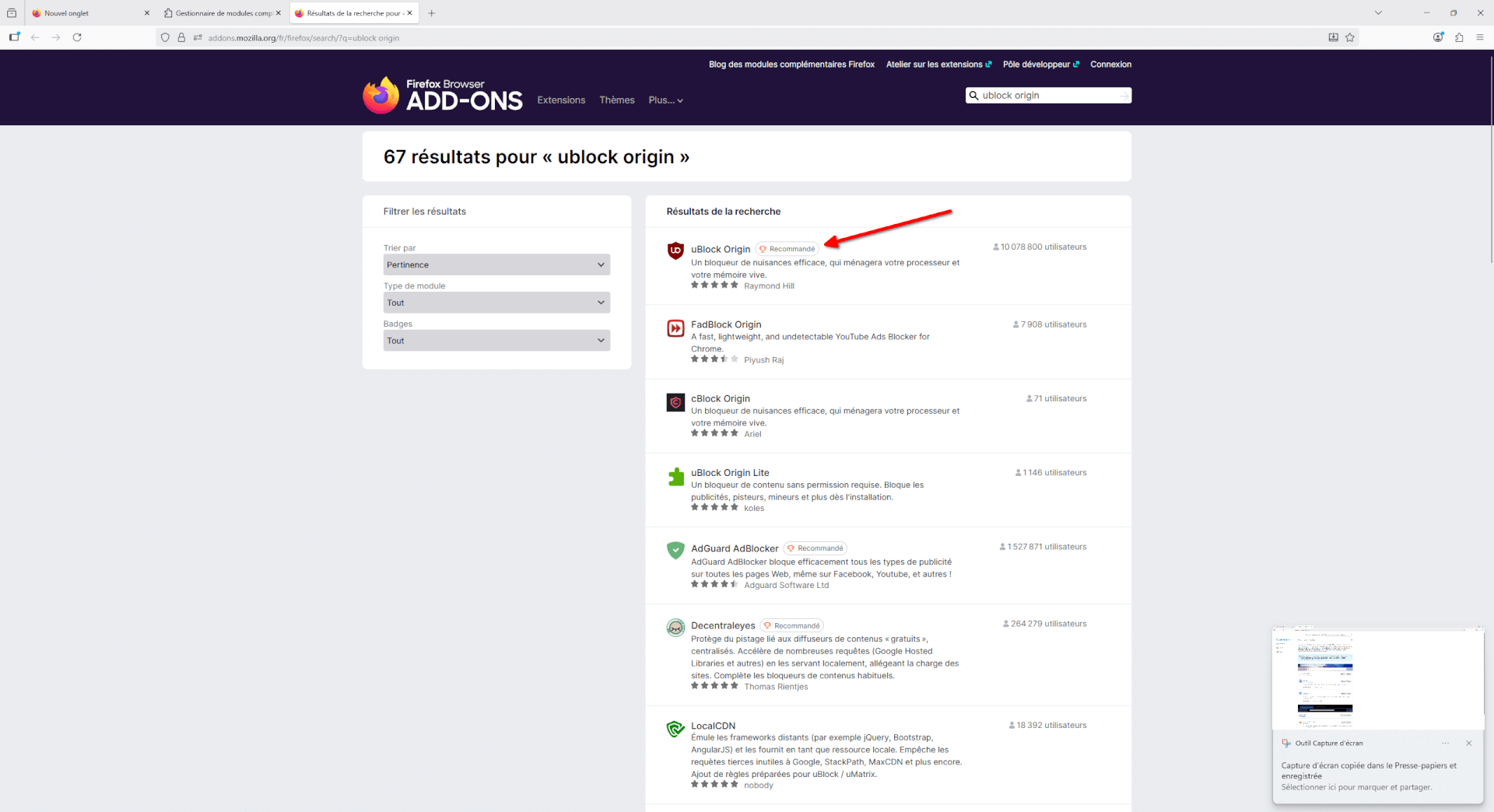
- Une nouvelle page va alors s’ouvrir avec une liste d’extensions correspondant à votre recherche. Cliquez sur « uBlock Origin ».
- La page de l’extension s’ouvre, avec des informations sur qui est derrière, des captures d’écran la montrant, une description expliquant ce qu’elle fait, des commentaires d’utilisateurs et utilisatrices, etc. Cliquez sur le bouton bleu « Ajouter à Firefox » pour… ajouter l’extension à Firefox. (Étonnant, c’est sûr !)
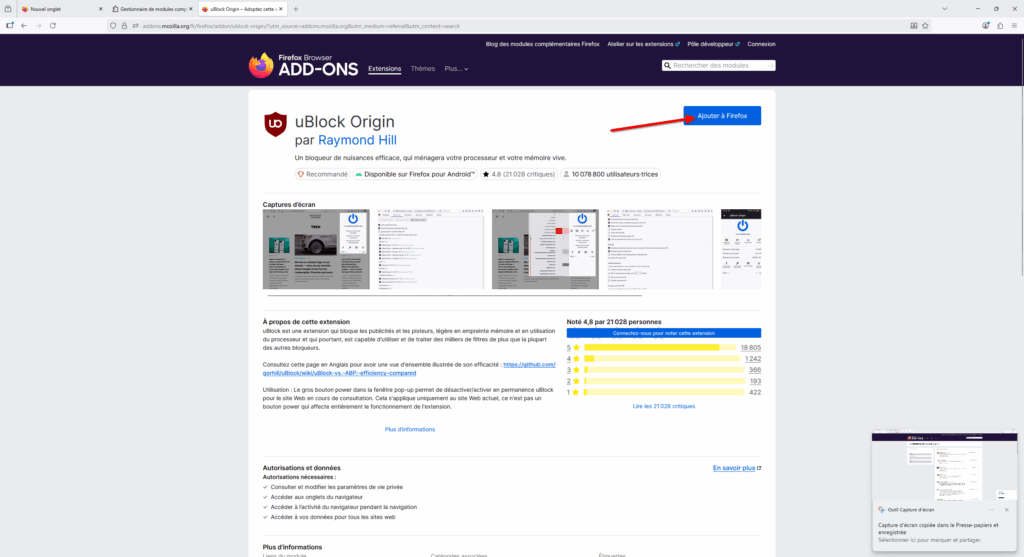
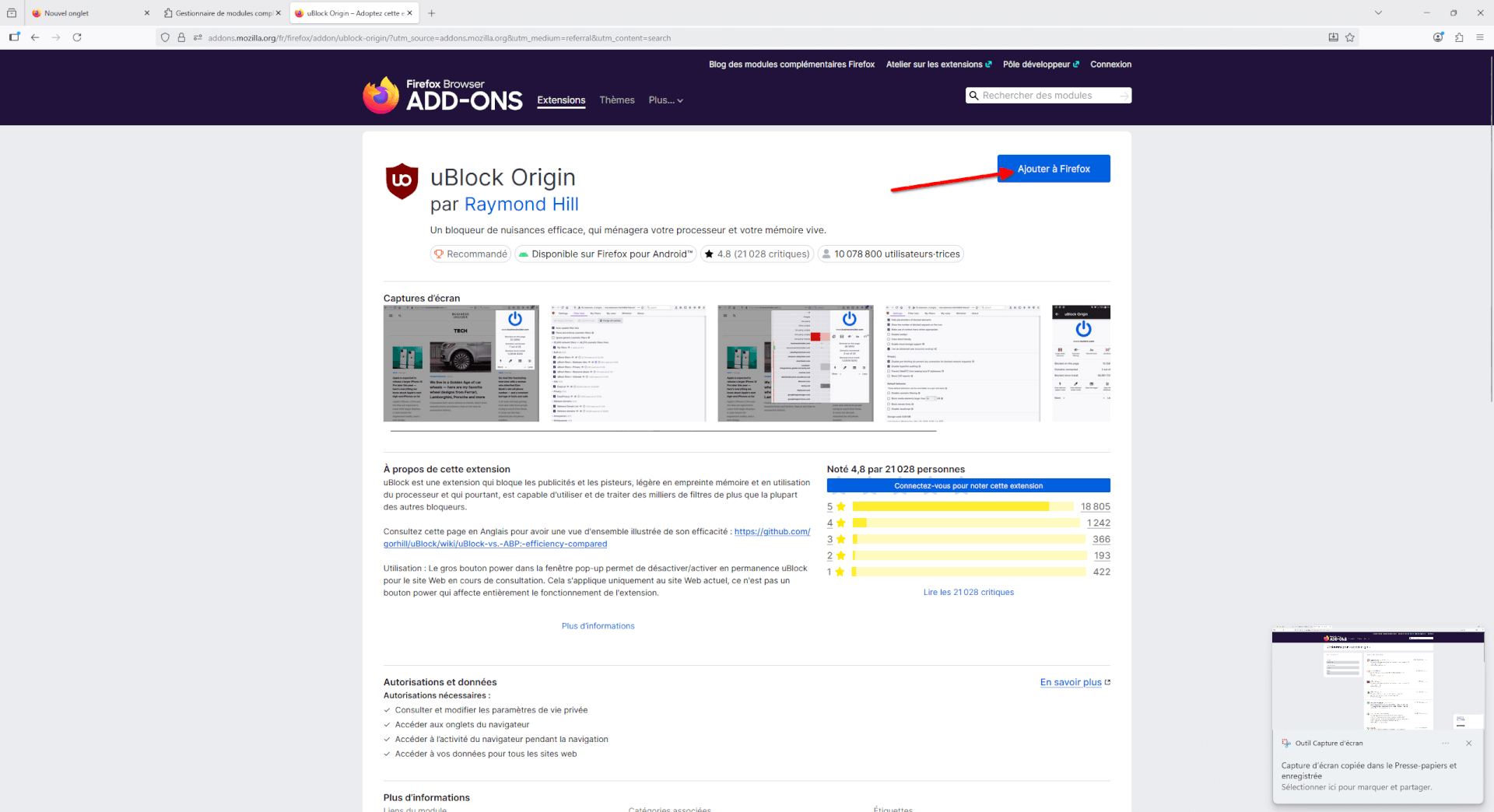
- Une mini fenêtre va s’ouvrir, vous montrant ce à quoi l’extension aura accès et si vous souhaitez utiliser l’extension lors de la navigation privée. Nous vous recommandons de cocher cette case puis de cliquer sur « Ajouter ».
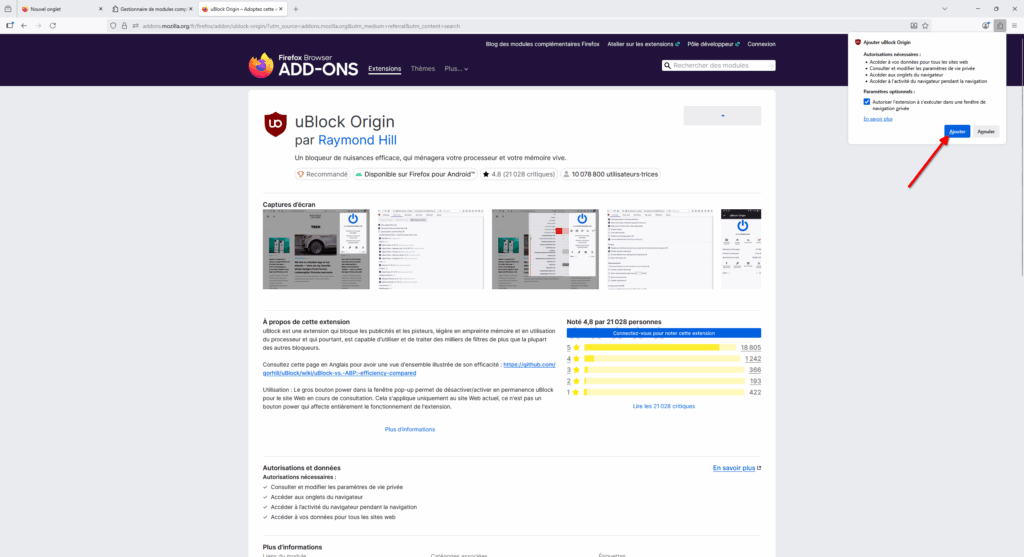
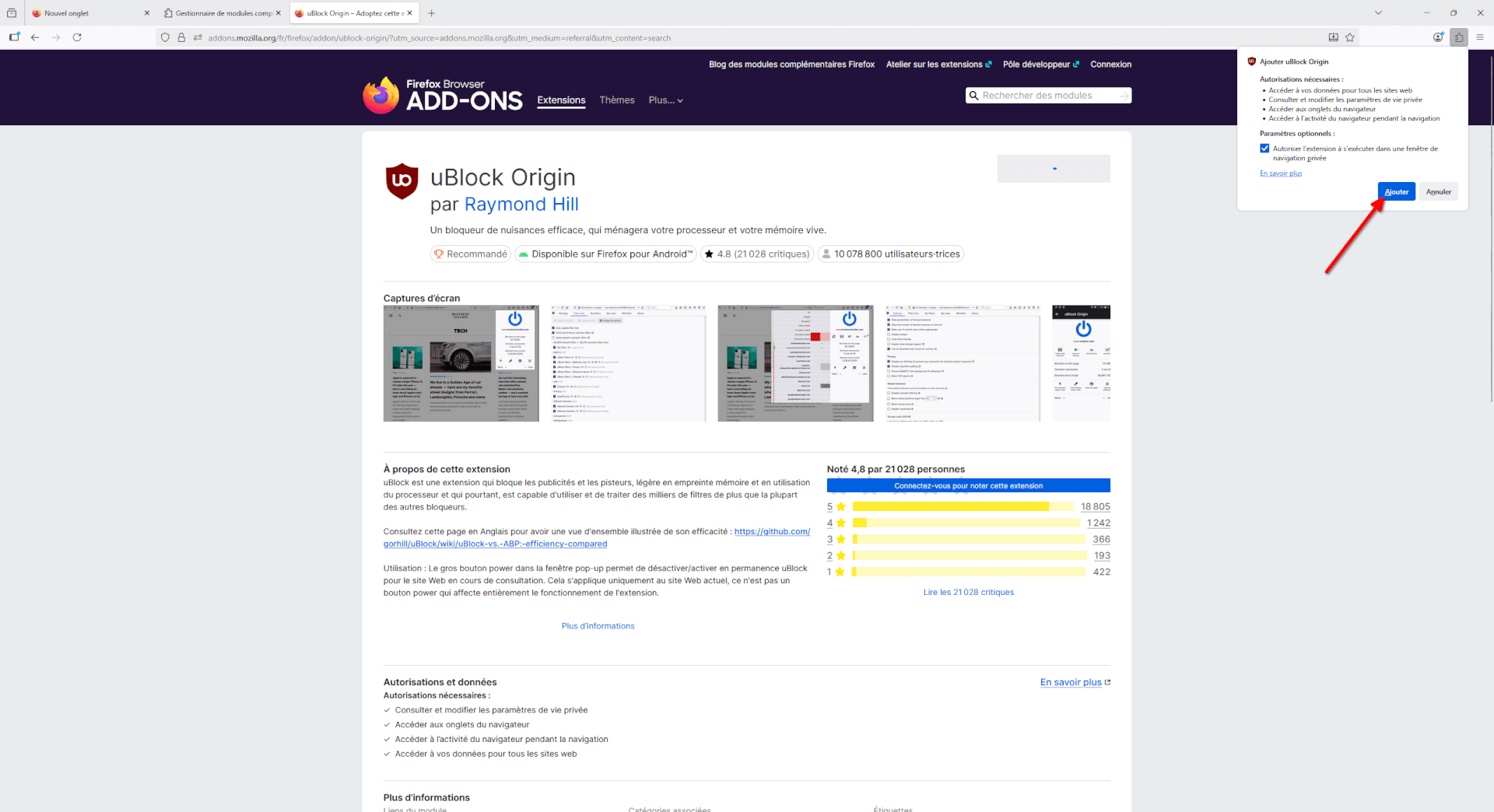
- Enfin, l’extension va s’installer de manière transparente et un dernier choix vous est proposé : Épingler l’extension à la barre d’outils. Je vous recommande de le faire pour vous souvenir que vous avez installé uBlock Origin et avoir un raccourci pour accéder rapidement à l’extension, dans les cas où vous voudriez la désactiver temporairement pour un site spécifique, par exemple.
Vous avez plus d’informations sur comment configurer uBlock Origin et pourquoi bloquer la publicité sur internet sur le site https://bloquelapub.net/
Maintenant que Firefox et uBlock Origin sont installés et configurés, découvrons d’autres applications libres pour remplacer les outils des géants du numérique !
Accédez à vos mails localement avec Thunderbird !
Mozilla, la fondation derrière Firefox, ne s’est pas contentée de construire un navigateur web. En 2003, Mozilla publie Thunderbird, un logiciel permettant d’accéder à ses mails basé sur la technologie de Firefox.
Attention à la confusion : Thunderbird ne sera pas l’entité qui hébergera vos mails ! Ce ne sera qu’un logiciel intermédiaire vous permettant d’y accéder plus facilement. Si vos mails sont chez Gmail, ils resteront hébergés et accessibles par Google même si vous utilisez Thunderbird !
Il y a pas mal d’avantages à utiliser Thunderbird plutôt que d’accéder à ses mails via le Web (c’est-à-dire aller directement sur le site de Gmail ou Outlook, par exemple).
Un des plus gros avantages est de pouvoir consulter toutes ses boites mail au même endroit, même si elles sont hébergées par différentes entités. Ainsi, je peux consulter avec la même interface mes mails de Framasoft, mes mails perso’ hébergés par une petite association, mes mails liés à mes autres activités associatives, etc.
Un autre avantage est la possibilité de personnaliser notre expérience en ajoutant des extensions à Thunderbird, de la même manière qu’on a pu ajouter uBlock Origin à Firefox pour se protéger des publicités.
Il existe des extensions pour plein de situations différentes : on peut ajouter des couleurs aux différentes boites mails pour mieux les différencier, ajouter un correcteur grammatical, faire en sorte d’héberger ses pièces jointes automatiquement sur des hébergeurs type WeTransfer ou Send, etc.
Le développement de Thunderbird n’a pas toujours été sans remous, mais depuis quelques années, le logiciel évolue vraiment bien pour se moderniser. Il ne cesse de s’améliorer de mise à jour en mise à jour et beaucoup de belles choses sont à venir !
Découvrons ensemble comment installer et configurer Thunderbird.
Installer Thunderbird
- Allez sur le site officiel de Thunderbird et cliquez sur « Télécharger ».
- Le logiciel va se télécharger et vous serez redirigé vers une page vous proposant de faire un don. Comme la plupart des logiciels libres, ce sont les dons qui permettent de garantir la pérennité du développement de Thunderbird. Donc si le logiciel vous plaît et que vous le pouvez, n’hésitez pas à les soutenir !
- Exécutez le fichier téléchargé.
- Comme pour Firefox, Windows va vous ouvrir un avertissement de sécurité vous demandant si vous souhaitez réellement exécuter le logiciel : cliquez sur « Exécuter ».
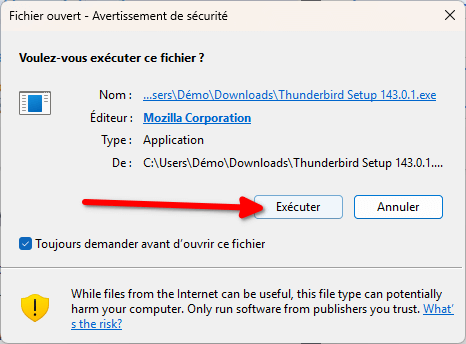
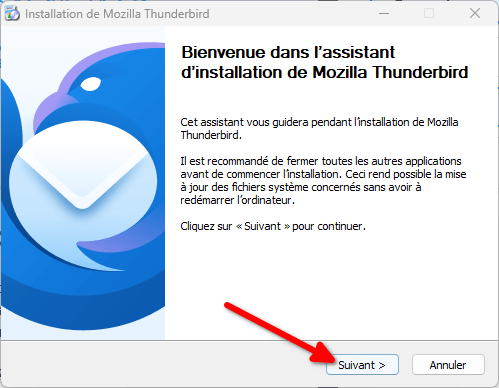
- L’utilitaire d’installation s’ouvre : cliquez sur « Suivant ».
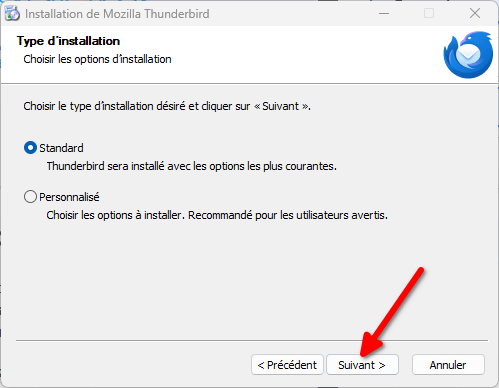
- Vous avez alors le choix d’installer Thunderbird de manière standard ou avec des options personnalisées. Dans le cadre de cette installation, vous pouvez rester sur « Standard ». Par contre, en général, je vous recommande de TOUJOURS cliquer sur « Personnalisé » lorsqu’on vous propose de choisir, cela permet de vérifier que l’utilitaire n’installe vraiment que les options que vous souhaitez et pas d’autres trucs. Il est fréquent pour les logiciels propriétaires de se faire de l’argent en installant par défaut d’autres logiciels, encombrant de fait l’ordinateur des utilisateurices.
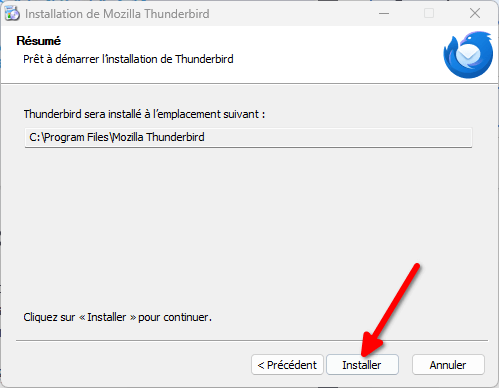
- Enfin, cliquez sur « Installer » pour lancer l’installation !
- Une fois celle-ci terminée, vous pouvez cliquer sur « Terminer ». Si vous n’avez pas décoché la case « Lancer Mozilla Thunderbird », Thunderbird se lancera automatiquement !
L’installation est complète mais lions maintenant notre premier compte mail au logiciel !
Ajouter un compte mail à Thunderbird
- Lors du premier lancement de Thunderbird, celui-ci s’ouvre sur une page vous permettant de configurer un nouveau compte. Remplissez le formulaire pour le compte mail de votre choix.
- Le nom complet sera le nom affiché avec votre adresse mail. Vous pouvez choisir ce que vous souhaitez. Une fois les informations entrées, cliquez sur « Continuer ».
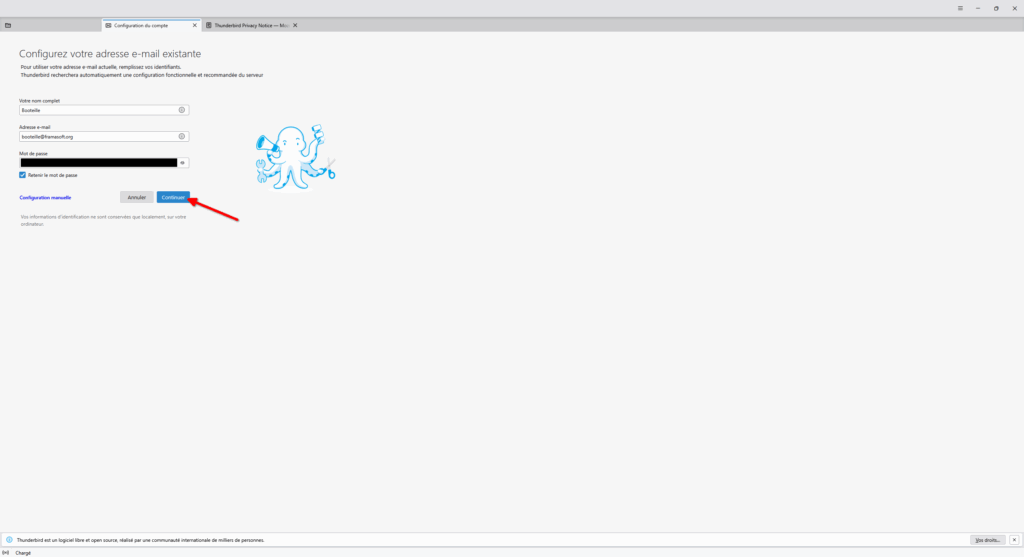
- La majorité des boites mails proposent une configuration automatique après avoir rempli ce formulaire. Cependant, si la configuration automatique n’a pas fonctionné et que vous êtes certain·e des informations renseignées, référez-vous à la documentation de votre hébergeur et utilisez la configuration manuelle.
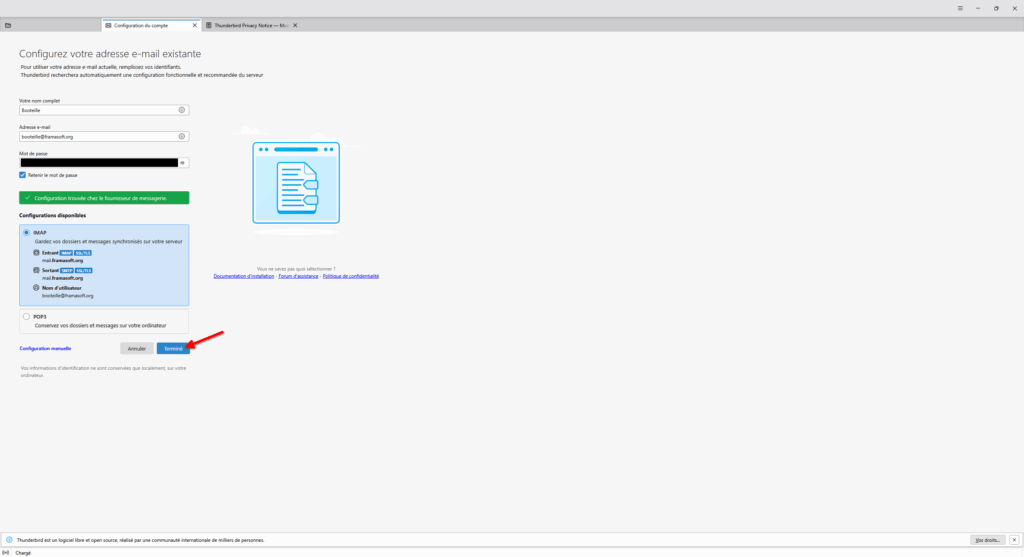
- Thunderbird nous affiche ensuite une page nous demandant de choisir entre plusieurs configurations. Restez sur IMAP (celle choisie par défaut) et cliquez sur Terminée !
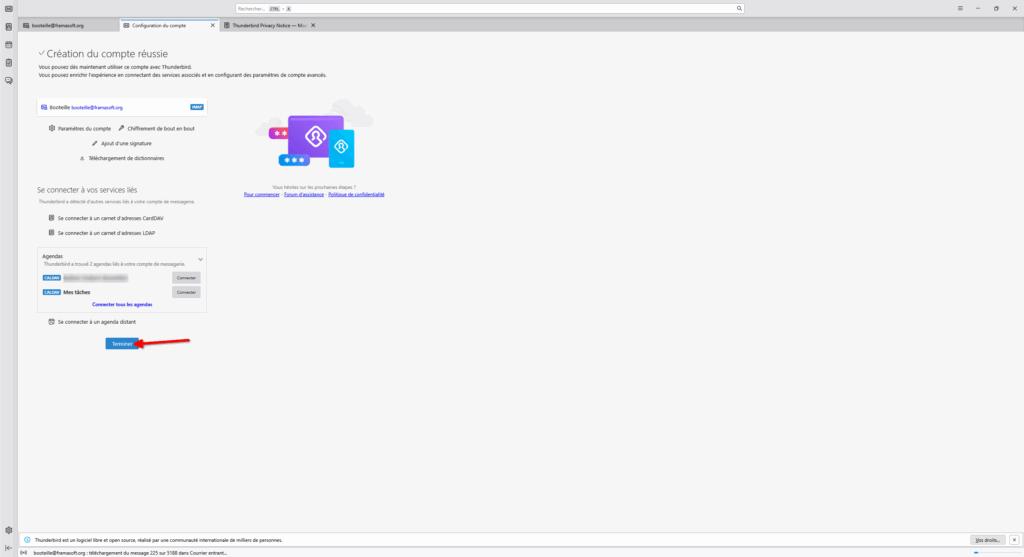
- Le compte sera alors lié à votre Thunderbird. Selon votre hébergeur, vous aurez peut-être la possibilité de synchroniser vos contacts et agendas dans Thunderbird. Je vous laisse le soin de choisir si vous souhaitez le faire ou non. Thunderbird est en effet bien puissant et peut servir de gestionnaire de contacts et gérer vos agendas !
- Lorsque vous en aurez fini avec cette page de configuration de compte, vous pouvez cliquer sur « Terminer ».
- Enfin, Thunderbird va vous proposer d’être intégré à votre système Windows. Dans la petite fenêtre qui s’est ouverte, vous pouvez choisir de faire en sorte que Thunderbird s’ouvre automatiquement dès que vous cliquez sur un bouton vous proposant d’écrire un mail, mais aussi lorsque vous avez besoin d’ajouter des informations à votre agenda, etc. Choisissez les options comme vous le souhaitez, je vous recommande d’utiliser au moins l’option pour utiliser Thunderbird par défaut pour ouvrir des mails. Lorsque votre sélection est faite, vous pouvez cliquer sur « Définir par défaut ».
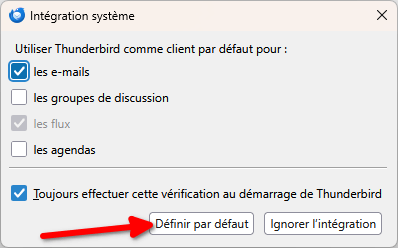
Et voilà ! Votre première boite mail est configurée !
Découvrons maintenant quelques éléments de l’interface pour mieux nous y repérer !
Présentation de l’interface de Thunderbird
- Tout à gauche, encadré en bleu, vous pouvez accéder aux différents outils de Thunderbird. Mail, agenda, calendrier, tâches et discussions instantanées.
- À côté, encadré de rouge, vous avez vos différentes boites mails et leurs dossiers. Une seule s’affiche pour le moment mais si vous en configurez plusieurs, vous pourrez accéder à toutes via ce panneau.
- Au centre, entouré fuchsia, c’est la liste des mails.
- À droite, dans le cadre orange, vous retrouverez par défaut le contenu des mails.
- Enfin, en haut, vous trouverez une barre de recherche vous permettant de fouiller dans l’intégralité de vos boites mails.
Vous pouvez aussi afficher des boutons de filtre rapide, très rapide, en cliquant sur le bouton « Filtre rapide » en haut de la liste des mails.
Sur le bouton d’à côté, vous pouvez choisir des options d’affichage pour la liste de vos mails. Par exemple, trier vos mails par ordre décroissant plutôt que croissant, ou grouper les discussions.
Si l’affichage vertical du contenu des mails ne vous plaît pas, vous pouvez revenir à un affichage plus classique en allant dans les options d’affichage.
- Cliquez sur le menu hamburger puis cliquez sur « Affichage ».
- Cliquez sur « Disposition ».
- Cliquez sur « Classique » (ou « Large » si vous avez envie d’expérimenter).
Et voilà ! Vous avez désormais le contenu qui s’affiche sous la liste de mails !
Vous pouvez désormais prendre le temps de fouiller dans les options de Thunderbird pour le configurer à votre goût ! N’oubliez pas que vous pouvez aussi ajouter des extensions de manière très similaire à Firefox ! Il vous suffit de cliquer sur le menu Hamburger puis cliquer sur « Modules complémentaires et thèmes ».
Vous pouvez consulter la liste des extensions existantes sur le site dédié.
Et si vous trouvez cela un peu trop compliqué, n’oubliez pas qu’il existe des groupes d’utilisateurices Linux un peu partout et que la plupart, en plus d’aider à installer une distribution sous Linux seront pour la plupart ravi·es de vous aider à configurer vos adresses mails sous Thunderbird !
LibreOffice, la suite bureautique qui respecte les standards !
Vous utilisez très certainement la suite Microsoft 365 (autrefois connue sous le nom de Microsoft Office, ou Office 365) pour l’édition de documents. Dans nos vies numériques, ce type de suite est devenu presque obligatoire.
La suite, désormais entièrement intégrée au Cloud de Microsoft et bourrée de fonctionnalités alimentées par IA, est accessible gratuitement via le Web mais beaucoup de personnes, l’utilisant au quotidien pour leur travail, souscrivent à l’offre payante, offrant plus d’options.
Microsoft 365 est utilisé par la grande majorité des gens et offre à Microsoft la possibilité d’imposer ses choix à tout le secteur. Par exemple, Microsoft est connu pour ne pas respecter les standards dans son logiciel. Ces standards, ce sont les règles communément décidées pour faire en sorte qu’un document Office puisse être lu par plusieurs logiciels et pas uniquement ceux de Microsoft.
Ainsi, grâce à cette domination, Microsoft peut se permettre de continuer son emmerdification, au détriment des utilisateurs et utilisatrices.
LibreOffice existe pour faire face à cette problématique. LibreOffice est basé sur le presque mort OpenOffice (si vous utilisez OpenOffice il est urgent de migrer vers LibreOffice) et proposé par la Document Foundation, une fondation à but non lucratif.
LibreOffice est une suite complète, à la manière de Microsoft 365, mais pensé pour les humains et les humaines et pas le portefeuille de quelques actionnaires. Le logiciel est en constante évolution et ne cesse de combler l’écart avec Microsoft 365, notamment en faisant en sorte de rattraper les « erreurs » de Microsoft concernant le respect des standards, permettant d’ouvrir les documents de Microsoft 365 dans LibreOffice sans problème la plupart du temps (et quand il y a des problèmes, LibreOffice finit généralement par proposer une mise à jour qui les résout au bout d’un moment).
Bien sûr, LibreOffice n’est pas parfait. S’il couvre 99 % des besoins de la plupart des gens, il y aura peut-être des éléments que vous avez sur la suite Microsoft qui n’existent pas encore sur LibreOffice. Cependant, vraiment, une fois les habitudes changées, vous devriez pouvoir faire les mêmes choses (à peu de choses près, encore une fois) dans LibreOffice !
Si vous êtes en difficulté, il existe une documentation française de LibreOffice !
Installons donc LibreOffice ensemble !
Installer LibreOffice
- Allez sur le site officiel de LibreOffice
- Dans le menu en haut de la page, cliquez sur « Télécharger ».

- Cliquez ensuite sur « Télécharger LibreOffice ».
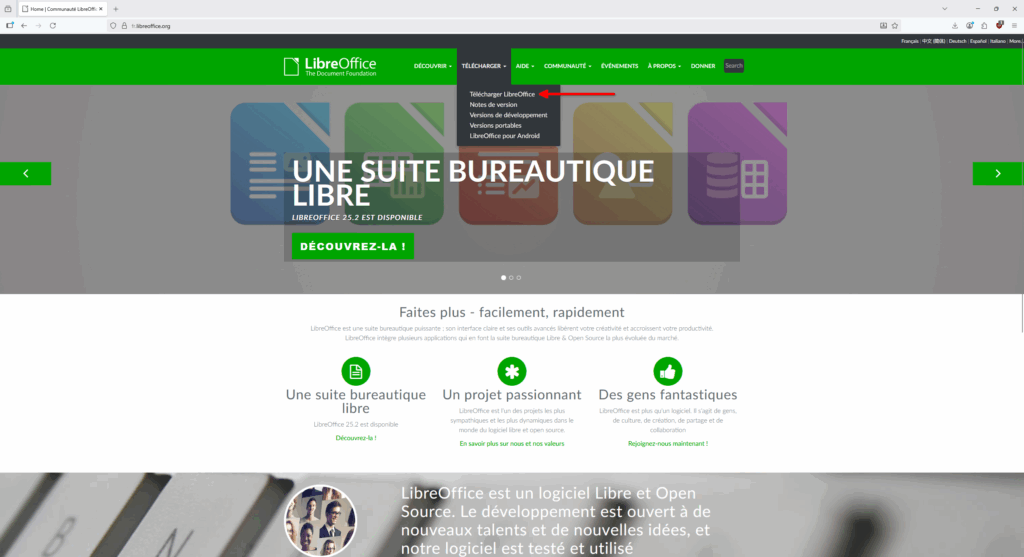

- Le site nous propose de télécharger deux versions, une version mise à jour assez régulièrement et une autre, plus stable. Téléchargeons celle se mettant à jour le plus souvent en cliquant sur le bouton jaune « Télécharger ».
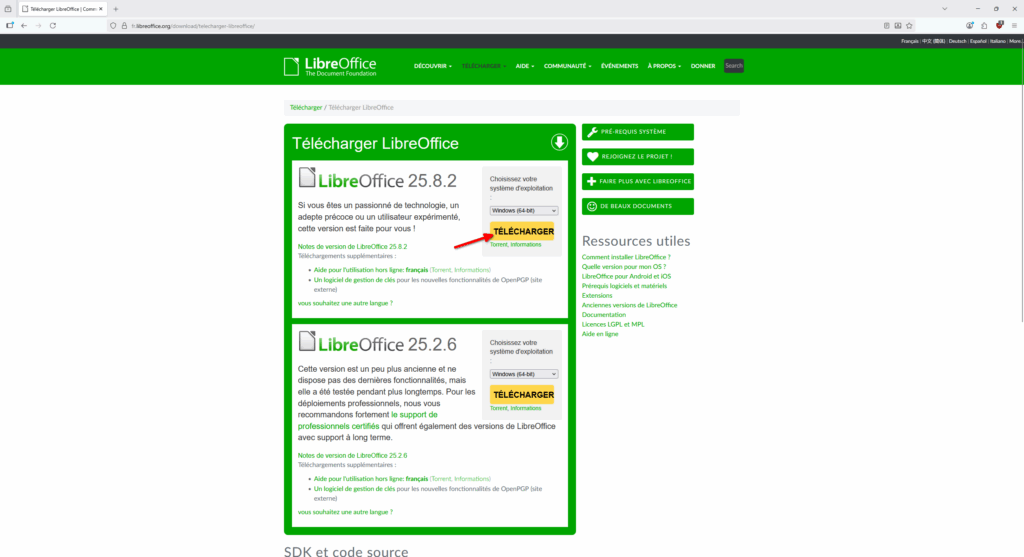
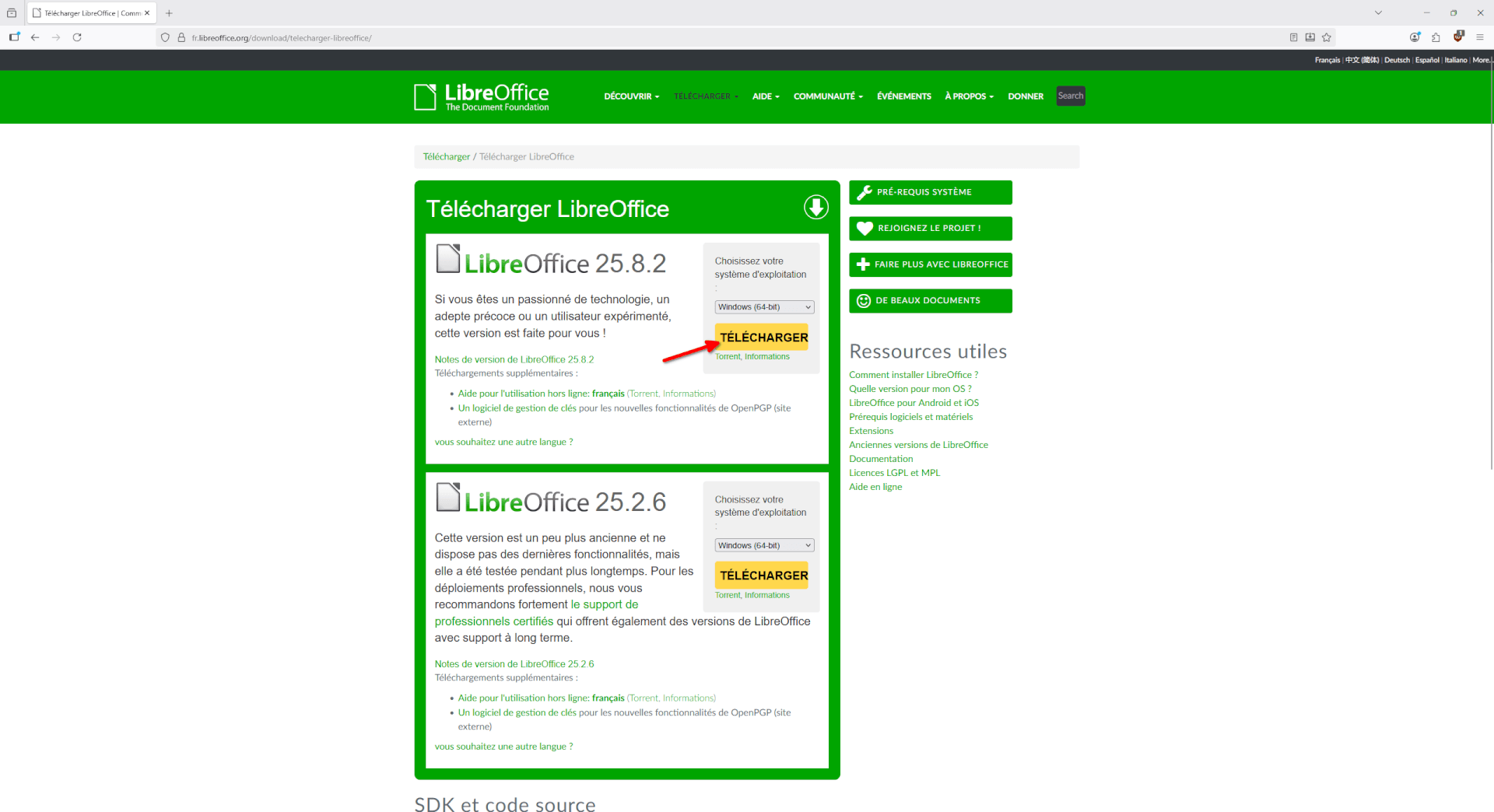
- Le site nous redirige vers une nouvelle page et le téléchargement va démarrer. Comme pour Firefox ou Thunderbird, LibreOffice vit grâce aux dons. Si vous appréciez le logiciel, n’hésitez pas à faire un don, ici aussi.
- Une fois le téléchargement terminé, cliquez sur le fichier téléchargé pour l’exécuter.
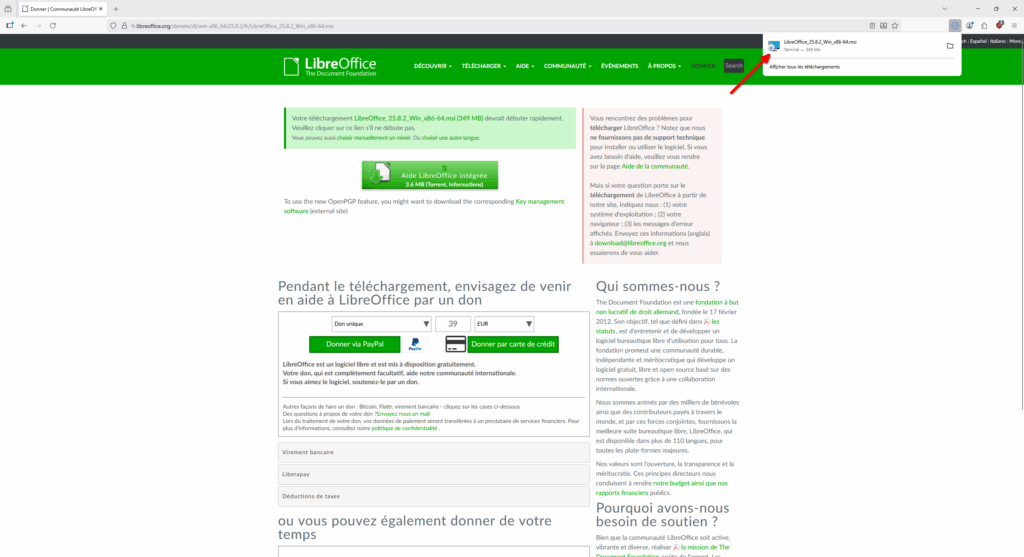
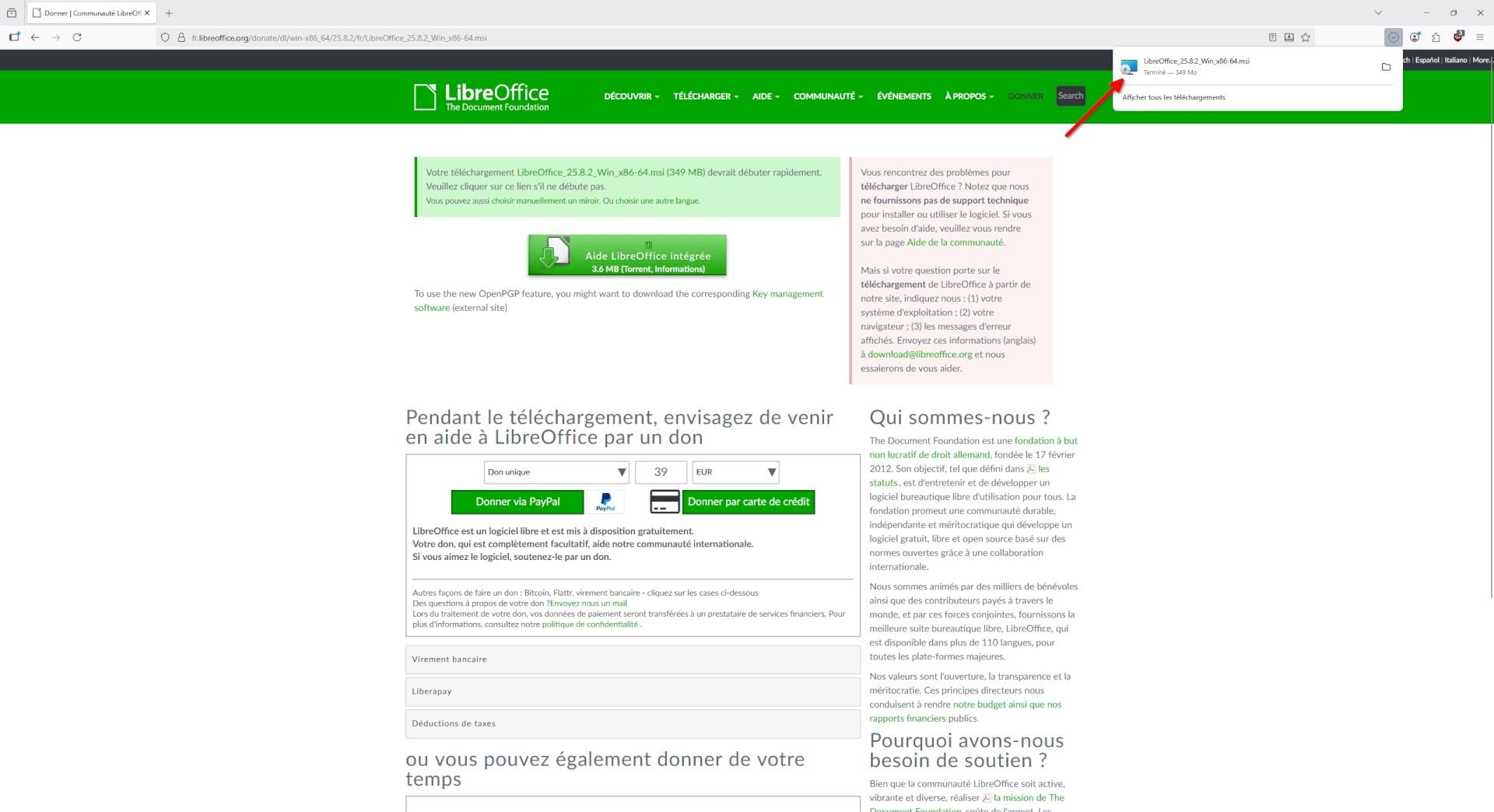
- Un avertissement de Firefox nous demande si on veut vraiment exécuter le fichier, cliquez sur « OK ».
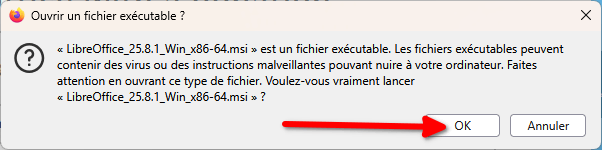
- Maintenant, c’est Windows qui nous demande si on veut bien exécuter le fichier. Cliquez sur « Exécuter ».
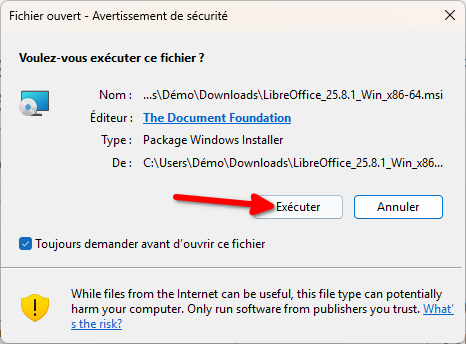
- L’utilitaire d’installation s’ouvre alors, cliquez sur « Suivant ».
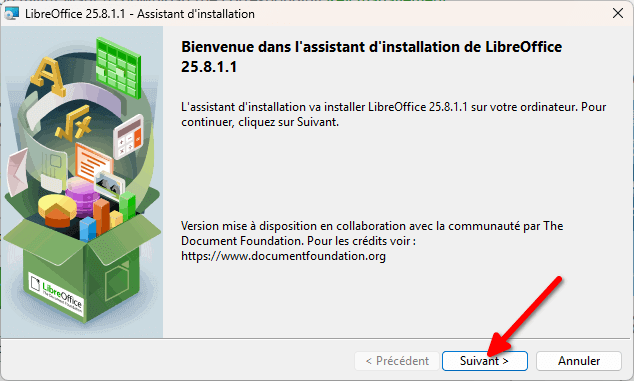
- On nous demande de choisir un type d’installation. Comme pour Thunderbird, vous pouvez garder l’installation « Normale » et cliquer sur « Suivant ».
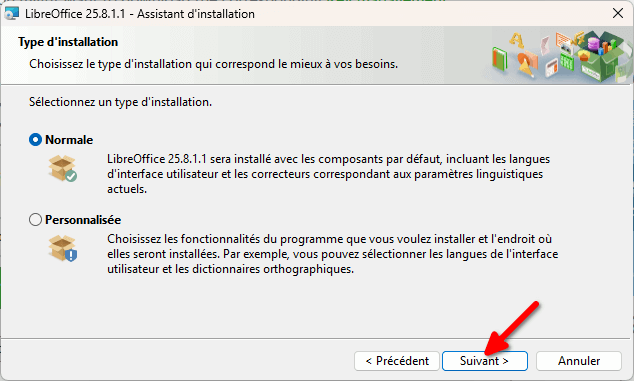
- Enfin, un écran vous propose de créer un raccourci sur votre bureau, à vous de voir ce que vous préférez. Je ne recommande pas l’option de charger LibreOffice au démarrage du système, cependant. Une fois vos choix faits, cliquez sur « Installer ».
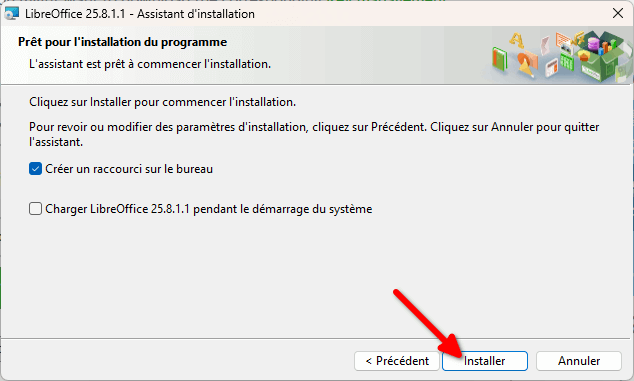
- Une fois l’installation terminée, vous pourrez cliquer sur « Terminer ».
- Lancez ensuite LibreOffice pour vous assurer qu’il fonctionne convenablement.
Plusieurs logiciels se sont installés sur votre ordinateur :
- LibreOffice, le logiciel « de base » de la suite, vous permettant d’accéder à tous les autres logiciels.
- LibreOffice Writer, le logiciel qui permet d’éditer des documents textuels. C’est l’équivalent de Microsoft Word.
- LibreOffice Calc, un logiciel de tableurs. C’est l’équivalent de Microsoft Excel.
- LibreOffice Impress, un logiciel pour faire des documents de présentation. L’alternative à PowerPoint.
- LibreOffice Draw, un logiciel pour faire du dessin vectoriel. C’est une alternative à Microsoft Publisher.
- LibreOffice Math, un éditeur de formules mathématiques.
- LibreOffice Base, un éditeur de bases de données. Une alternative à Microsoft Access.
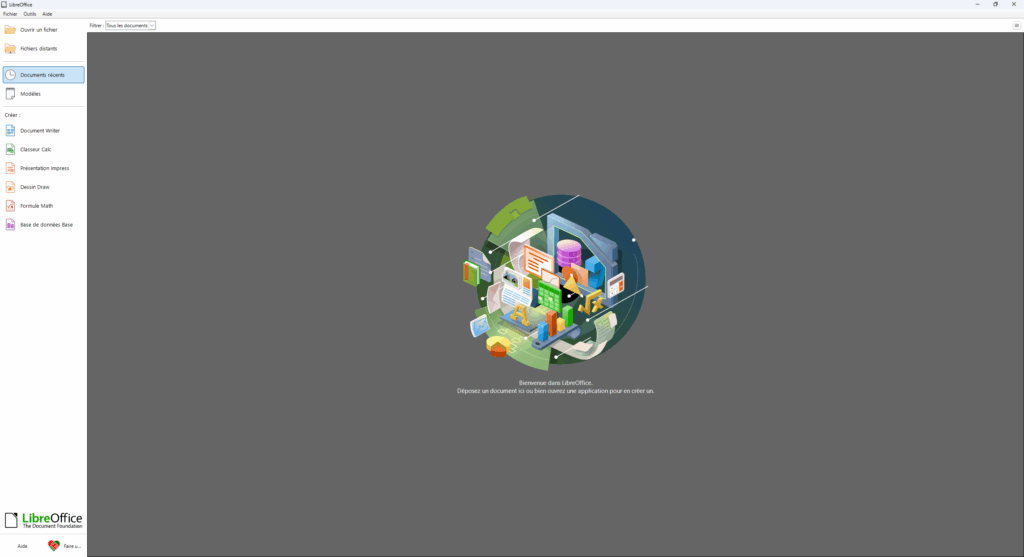
Lorsque vous ouvrez un document, le logiciel adapté pour le lire s’ouvrira, donc vous n’avez pas trop à vous prendre la tête avec les différents noms et juste ouvrir le logiciel « LibreOffice » lorsque vous souhaitez créer un nouveau document.
Lisez tout type de vidéo (et bien plus) avec VLC !
Beaucoup le connaissent, VLC est un logiciel libre qui existe depuis 1996. Il a vu le jour en France, à l’école centrale de Paris, dans le cadre d’un projet de l’école.
Depuis, il a beaucoup évolué mais c’est toujours l’association à but non lucratif VideoLAN qui le développe.
VLC a BEAUCOUP d’options, mais ce qui rend ce lecteur de médias particulièrement attractif aux yeux du public est sa capacité à lire n’importe quel fichier vidéo.
Si le logiciel a plein d’options, vous n’êtes pas obligé·es de les utiliser et il « juste marche » après installation.
Pour l’installer, suivez la procédure suivante :
Installer VLC
- Allez sur le site officiel de VLC
- Cliquez sur le gros bouton bleu « Télécharger VLC ».
- Vous commencez à avoir l’habitude maintenant : vous allez être redirigé vers une page de don et l’installateur va se télécharger.
- Exécutez l’installateur.
- Une fenêtre vous proposant de choisir la langue de l’installateur va s’ouvrir, choisissez la langue avec laquelle vous êtes à l’aise puis cliquez sur « OK ».
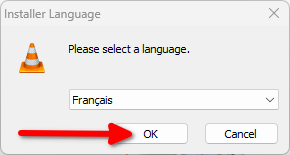
- L’installateur se lance alors, cliquez sur « Suivant ».
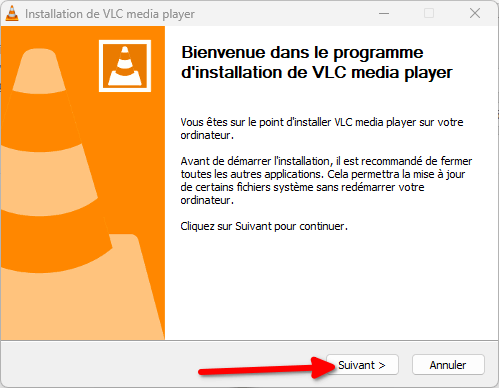
- Une nouvelle page s’ouvre, cliquez sur « Suivant ».
- L’installateur vous propose de choisir ce qui sera installé. Vous pouvez simplement cliquer sur « Suivant ».
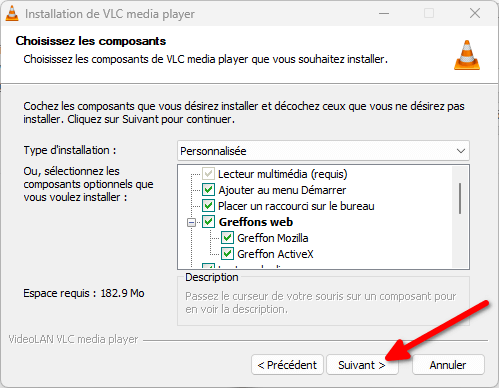
- Enfin, cliquez sur « Installer ».
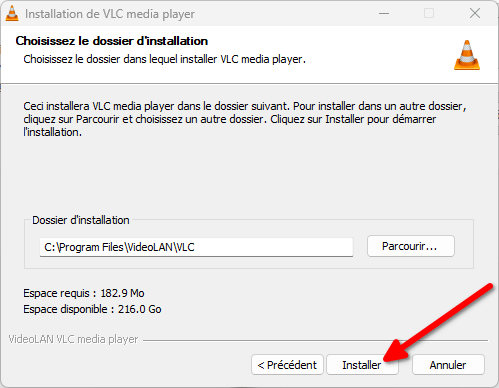
- Une fois le logiciel installé, vous pouvez cliquer sur « Fermer ».
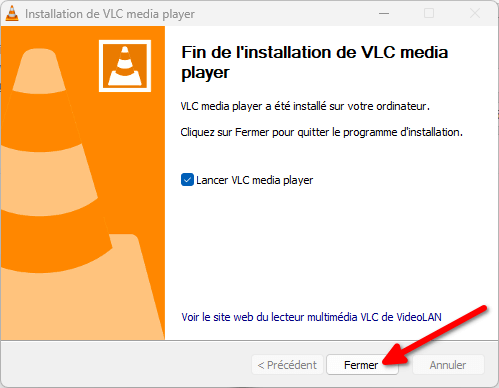
- VLC va alors s’ouvrir et une fenêtre de configuration vous propose de choisir si vous souhaitez autoriser VLC à chercher des mises à jour et accéder à un service pour récupérer les métadonnées de vos fichiers médias. Personnellement, je laisse ces options activées, mais c’est à vous de décider ici ! Cliquez sur « Continuer » une fois que c’est fait.
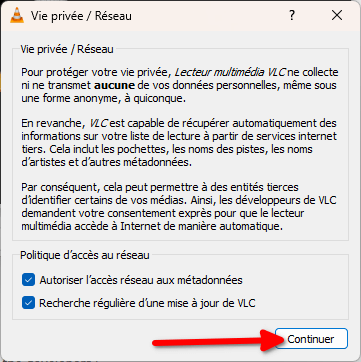
VLC est désormais installé mais sur Windows, il faut faire une étape supplémentaire pour faire en sorte que VLC soit utilisé par défaut pour ouvrir vos fichiers vidéos.
À chaque fois qu’un fichier vidéo s’ouvre avec le logiciel de Microsoft à la place de VLC, il faudra que vous suiviez les étapes suivantes :
Définir VLC comme lecteur par défaut
- Trouvez le fichier dans l’explorateur de fichiers de Windows
- Faites un clic droit sur le fichier.
- Faites « Ouvrir avec » puis sélectionnez « Choisir une autre application »
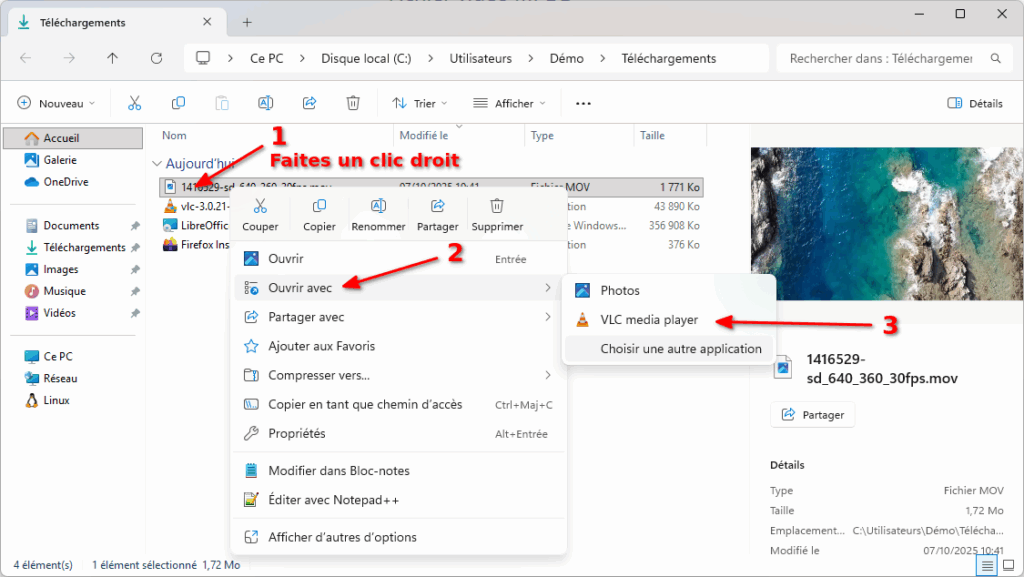
- Une fenêtre s’ouvre alors pour vous proposer de choisir le logiciel que vous souhaitez. Cliquez sur « VLC media player » puis sur « Toujours » pour faire en sorte que l’option soit mémorisée.
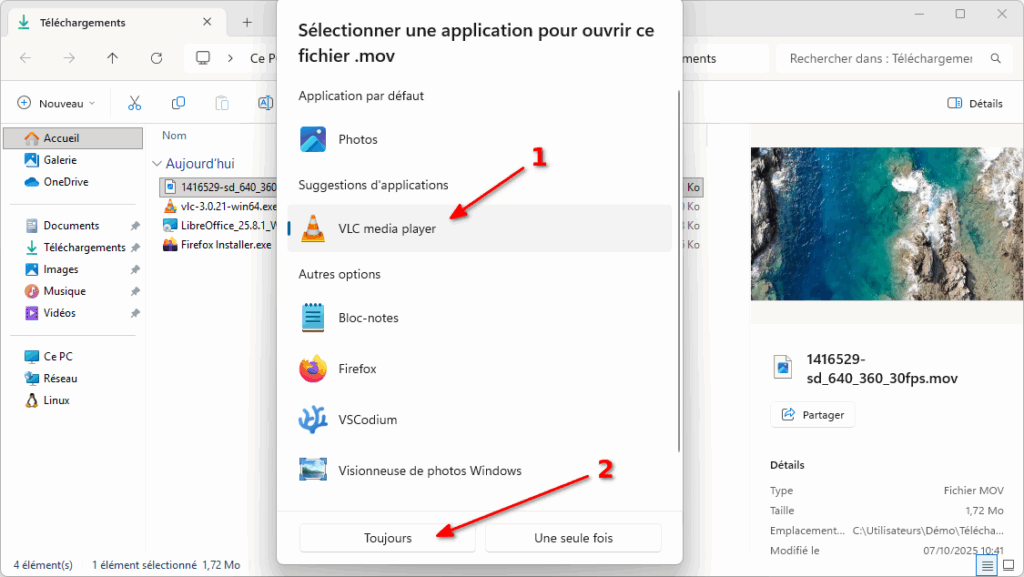
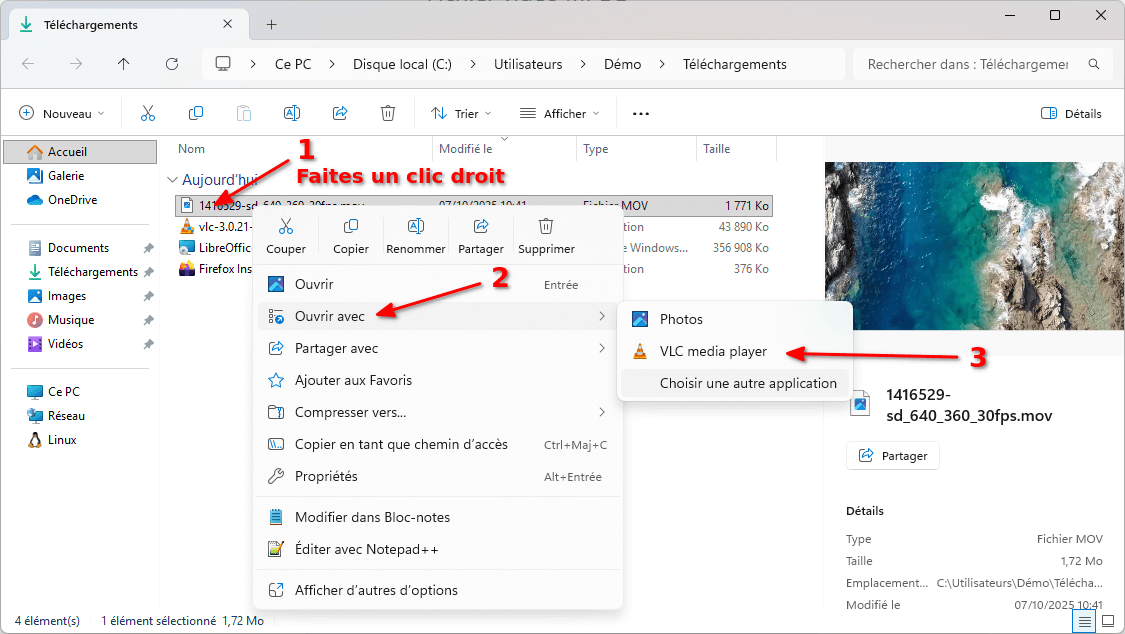
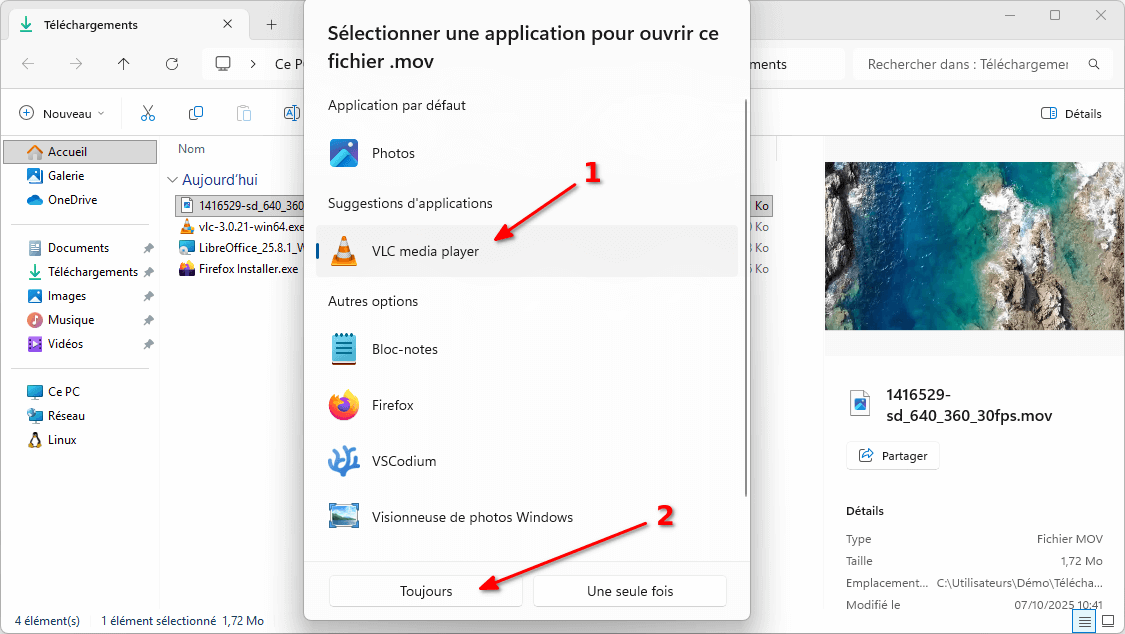
{kind=link}
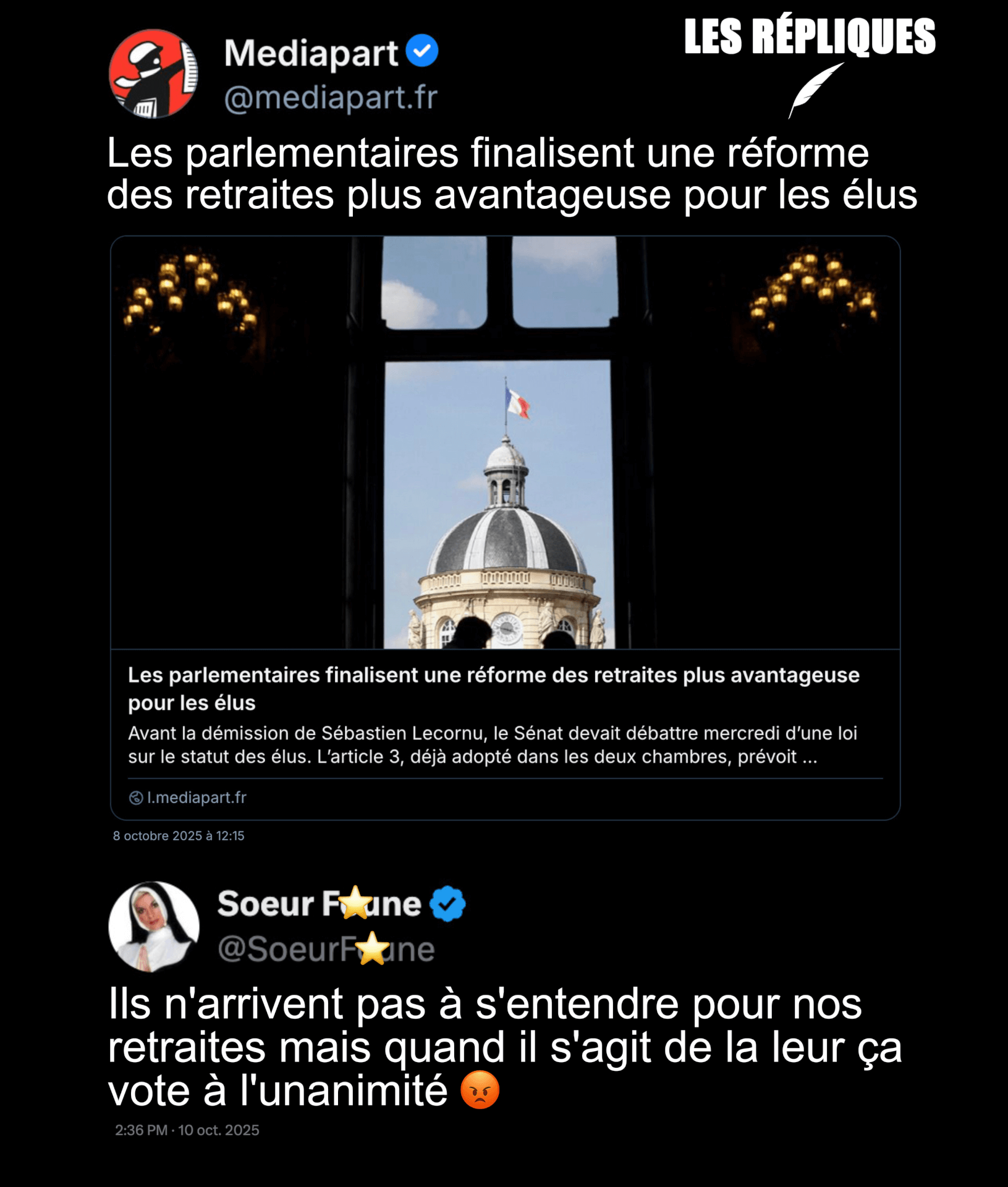{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Et voilà !
C’est chiant ? Ouaip. C’est bien plus simple sur Linux mais en attendant de changer, vous savez comment faire ! Héhé !
Éditez vos PDF avec Signature PDF et Firefox
Nombre d’entre nous avons utilisé pendant de longues années « Acrobat Reader », le logiciel d’Adobe pour lire les PDF.
Aujourd’hui, avec les améliorations des différents navigateurs, il est possible de se passer entièrement d’Acrobat Reader.
Par défaut, Firefox est capable de lire et remplir un PDF. Si vous ouvrez un PDF, vous arriverez sur un utilitaire vous permettant de signer, rajouter du texte ou surligner votre PDF ! Cela couvre l’immense majorité des besoins !
Si certaines options vous manquent, comme par exemple le fait d’extraire une page spécifique de ce PDF, vous pouvez utiliser l’utilitaire Signature PDF, que nous mettons gratuitement à disposition.
Avec ces deux outils, vous ne devriez plus avoir besoin d’Acrobat Reader ! Youhou !
En conclusion
S’il est assez facile d’installer les logiciels proposés ici, changer ses habitudes demande du temps et provoque de l’inconfort… c’est normal !
Allez-y à votre rythme dans votre transition, choisissez un des logiciels, habituez-vous-y, puis, une fois que vous êtes prêt·e, passez au logiciel suivant !
De cette manière, vous changerez progressivement vos repères et la transition sera bien plus confortable.
Enfin, tous les logiciels proposés sont ceux utilisés la plupart du temps par défaut sur Linux. Cela signifie que lorsque vous serez habitué·es à tous ces logiciels… transitionner vers Linux sera bien moins difficile ! Vous n’aurez au final que très peu d’habitudes à changer ! De plus, vous pourrez très facilement vous faire aider par des gens vivant près de chez vous, nous en parlions dans l’article sur la fin de Windows !
L’univers du logiciel Libre est passionnant, il repose sur un formidable élan de solidarité, où des milliers de personnes à travers le monde contribuent, souvent de manière bénévole, à des outils qui appartiennent aux communs.
Mais le Libre, c’est aussi souvent une vision : celle d’un numérique pensé pour les humains et les humaines, pour que le numérique soit un outil au service de nos sociétés.
Et vraiment, une fois que nos habitudes sont changées, il est cruellement difficile de revenir sur des outils pensés pour le grand capital ! Plus de publicités, plus d’éléments de design nous incitant à avoir un comportement qui nous nuit, cette sensation d’être en maîtrise de sa machine…
… Et savoir que derrière chaque logiciel, il y a une poignée d’humain·es, souvent accessibles et à l’écoute de nos retours, pour faire en sorte que leurs logiciels servent toujours plus l’intérêt commun.
Certes, la route est longue… mais la voie est Libre !
Illustration de l’article sous licence CC-BY 4.0 – https://endof10.org
15.10.2025 à 13:11
La communauté Archipel, des savoirs vivants pour transformer les manières de chercher, de vivre et d’habiter la Terre
Texte intégral (1076 mots)
Du 6 au 9 juillet 2026, nos ami⋅es de la communauté de recherche « Archipel » organisent à Compiègne un cycle de conférences autour des enjeux de l’anthropocène (et donc, disons-le, de l’humanité). Comme nous apprécions leurs travaux (et que Framasoft devrait participer activement à cet événement), nous vous partageons ici leur présentation et leur appel à communication (qui s’achève le 20 octobre prochain).
Dans le cadre des dégradations globales actuelles (écosystémiques, climatiques, sociales ou politiques), nos sociétés humaines se trouvent confrontées à des enjeux toujours plus pressants. Ces grands changements engagent nos sociétés vers des trajectoires de transitions brutales et de potentiels effondrements à des échelles variées. Dans ce contexte, du 6 au 9 juillet 2026 la communauté Archipel se réunira à Compiègne (Hauts-de-France) pour la troisième édition de sa conférence bisannuelle. Il s’agit d’un collectif de recherche francophone transdisciplinaire sur les enjeux de l’Anthropocène. Elle a vocation à élaborer des savoirs scientifiques et vivants avec la société civile et est guidée par des valeurs de justice sociale et d’équité environnementale. Ces valeurs sont adossées à une charte :
Article 1 : La dégradation des capacités du système “Terre”, humains et non humains, alerte la communauté scientifique francophone et conduit à faire émerger des espaces ouverts à la société civile qui travaillent à soutenir la vie et les sociétés humaines. La communauté Archipel est l’un de ces espaces.
Les conférences Archipel proposent un cadre original de partage des connaissances et de formes de discussion qui permet aux chercheurs et chercheuses de traditions diverses de travailler ensemble en vue d’une transformation de la société, et qui invite à des ponts avec des acteurs alternatifs, telles que des associations militantes dans les domaines sociaux ou écologiques. La prochaine conférence accueillera deux types d’événements.
- Des ateliers, lieux de recherches et de pratiques requerront l’activité des participant·es, visant notamment à tisser des liens entre les pratiques universitaires et les pratiques d’éducation populaire.
- Des symposiums, porteront sur un ou des problèmes singuliers, identifiés et travaillés a priori. Pensés comme des lieux de débats plus que comme des lieux d’exposés magistraux, ils chercheront également à contourner les pratiques actuelles et à retourner les amphithéâtres qui les accueilleront.

Sur la forme, les communications chercheront à privilégier trois principes :
- S’inscrire dans une démarche systémique au niveau académique et/ou d’intégration de diverses parties prenantes (citoyennes, citoyens, société civile, administrations, économie sociale…) ;
- Soutenir la présence de jeunes chercheur·es, afin de constituer une communauté intergénérationnelle encline à faire évoluer ses pratiques de recherche ;
- Se positionner selon une approche assumée et politique de mise en action des savoirs à des fins de transformation.
Sur le fond, la communauté Archipel a choisi de mettre en avant trois exemples de problèmes qui pourront être adressés lors de la conférence :
L’appel étant ouvert à la formulation de nouveaux problèmes par les contributeurices, d’autres sujets émergeront certainement des propositions qui seront examinées d’ici la fin de l’année 2025 par le comité scientifique. Un travail collectif, basé sur des points de vue hétérogènes et complémentaires, aura ensuite lieu en amont de la conférence (de janvier à juin 2026), puis bien entendu pendant les symposiums, à partir des communications retenues.
L’appel à communications est disponible ici. La date limite pour une soumission est le 20 octobre 2025. Les inscriptions ouvriront au printemps et se clôtureront le 15 juin 2026.
Toutes les infos sur la conférence ici : https://archipel.scenari-community.org/

Image d’entête « Sphinx colibri butinant des fleurs de buddleia de David » CC BY-SA Thomas Bresson commons.wikimedia.org & mèmes générés avec Framamemes
{kind=link}
13.10.2025 à 07:42
Khrys’presso du lundi 13 octobre 2025
Texte intégral (8940 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Global renewable energy generation surpasses coal for first time (theguardian.com)
- Les biocarburants émettent plus de CO2 que les carburants fossiles (reporterre.net)
- Réchauffement climatique : pour sauver son île menacée par la montée des eaux, le président des Palaos donne une interview… sous l’eau (humanite.fr)
- Un incendie détruit complètement un système de stockage cloud du gouvernement sud-coréen et aucune sauvegarde n’est disponible – 647 systèmes critiques du pays ont été mis hors service par l’incendie (developpez.com) – voir aussi Data center en feu : le gouvernement coréen perd 858 To de données (next.ink)
- L’Indonésie rétablit TikTok qui lui a fourni des données liées aux manifestations d’août (rfi.fr)
- Guerre en Ukraine : des attaques russes massives plongent une partie du pays dans le noir (huffingtonpost.fr)
Moscou cible les infrastructures énergétiques pour accroître la pression sur Kiev à l’approche de l’hiver et alors que les négociations de paix sont au point mort.
- Madagascar soldiers join protestors, refuse orders to shoot demonstrators (france24.com)
Groups of Madagascar soldiers joined youth-led protests in the capital of Antananarivo on Saturday after police used stun grenades and tear gas. The soldiers, who said that they would refuse any orders to shoot demonstrators, arrived at the heart of the gathering near the Lake Anosy area where they were welcomed with cheers.
- Ce que disent les éruptions de colère de la Gen Z du Népal au Maroc, de Madagascar au Pérou (huffingtonpost.fr)
Sans qu’elles soient directement liées, les mobilisations de la Gen Z portent des revendications et des méthodes communes.
- Du Maroc au Népal, la Gen Z combat le capitalisme (frustrationmagazine.fr)
- En Italie, une Generation Z anti-Meloni ? (politis.fr)
Les manifestations de solidarité avec Gaza en Italie, fortes de centaines de milliers de personnes à travers toute la péninsule, sont désormais quotidiennes depuis plus d’un mois. Ce mouvement massif est inédit depuis les années 1970, sans leader ni bannières de partis ou de syndicats, avec une forte participation de la jeunesse
- Ces rapaces détruisent 25 000 nids de frelons asiatiques chaque année en Galice (lareleveetlapeste.fr)
- PFAS : la moitié des 24 ministres européens testés présentent une contamination supérieure aux seuils sanitaires (rtbf.be)
Ces résultats prouvent deux choses : la contamination par les PFAS n’épargne personne, et la réglementation fonctionne […] Là où des interdictions sont en place, les niveaux commencent à baisser, ce qui prouve clairement que des lois strictes protègent les populations.
- Déchets radioactifs dans l’Atlantique (laradioactivite.com)
Une mission scientifique est partie étudier les sites sous-marins de l’Atlantique nord, où gisent certains des fûts de déchets radioactifs immergés durant les années 1949 à 1982. Baptisée NODSSUM (Nuclear Ocean Dump Site Survey Monitoring) cette mission rassemble des scientifiques du CNRS, de l’IRD, ainsi que d’institutions de Norvège, d’Allemagne et du Canada. Elle se déroule à bord du navire L’Atalante de la flotte océanique française. Une première campagne d’un mois, du 15 juin au 11 juillet 2025, a permis de localiser près de 3 350 fûts immergés à plus de 4 000 mètres de profondeur dans le nord-est de l’océan Atlantique.
- Visé par des sanctions américaines, le juge français de la CPI dénonce des atteintes à l’Etat de droit (france24.com)
“Il y a aujourd’hui à peu près 15.000 personnes physiques et morales qui sont sous sanctions aux États-Unis mais aussi en Europe. Et ce sont principalement des membres d’Al-Qaïda, de Daesh, de groupes mafieux, des dirigeants de régimes dictatoriaux. Et désormais, avec eux, neuf magistrats de la CPI” […] “Les paiements sont la plupart du temps supprimés”, la quasi totalité des cartes délivrées par les établissements bancaires en Europe étant “soit Visa, soit Mastercard, qui sont des entreprises américaines” […] “En pratique, le pouvoir exécutif américain peut exclure n’importe quel citoyen européen du système bancaire et de l’espace numérique de son propre pays”
- Framework supporting far-right racists ? (community.frame.work)
- Larry Ellison, l’autre milliardaire réactionnaire de la tech… dont vous n’avez pas encore assez entendu parler (multinationales.org)
Plus discret qu’un Elon Musk sur ses accointances politiques, le patron d’Oracle Larry Ellison est en train de se construire un véritable empire médiatique outre-Atlantique avec l’acquisition du groupe Paramount et ses chaînes de télévision, et peut-être demain de TikTok US et Warner. Une force de frappe qu’il pourrait mettre au service de ses intérêts économiques – le développement de l’IA et de la surveillance en particulier – et de ses amis Donald Trump, Tony Blair et Benjamin Netanyahu.
- How Steve Bannon Mined ‘Intense Young Men,’ From ‘World of Warcraft’ to the White House (thewrap.com)
Former Trump advisor used knowledge from his gaming days to help president’s 2016 campaign
- Aux États-Unis, plus de 1 200 personnes ont disparu des fichiers suite à leur arrestation par l’ICE (legrandcontinent.eu)

- Neighbor shielded 7-year-old during South Shore federal raid : ‘I didn’t want them to take her’ (chicago.suntimes.com)
- I’m a US citizen and a veteran. ICE arrested me for no reason. (newsletter.ofthebrave.org)
Jailed for three days without an explanation or ability to notify anyone, George Retes argues the only path to healing starts with the government taking accountability for its actions.
- Aux États-Unis, les thérapies de conversion proches d’un retour en force à cause de la Cour suprême (huffingtonpost.fr)
Ces pratiques très critiquées visant les personnes LGBTQ+ pourraient être réintroduites alors qu’elles sont totalement ou partiellement interdites dans presque 30 États.
- The Sinister Reason Trump Is Itching to Invoke the Insurrection Act (theintercept.com)
An authoritarian’s dream, the Insurrection Act is ripe for abuse — and Trump’s Cabinet is already setting up his justification to use it.
- ‘I Am Worried About My Community,’ Says Frog Who Daily Confronts Federal Agents in Portland (commondreams.org)
“I don’t want to see anybody treated inhumanely,” says a local resident who wears the costume to show that the narrative that demonstrators are “violent terrorists” is “ridiculous.”

- Protest frogs vs. MAGA media influencers : the info war over ICE in Portland and Chicago (edition.cnn.com)
The dress-up “dismantles their narrative a little bit,” Jack Dickinson, also known as the “Portland Chicken,” told Willamette Week. “It becomes much harder to take them seriously when they have to post a video saying Kristi Noem is up on the balcony staring over the Antifa Army and it’s, like, eight journalists and five protesters and one of them is in a chicken suit.”
- This Isn’t Crisis Response, It’s Crisis Construction (nytimes.com)
Nearly nine months into President Trump’s second term, immigration enforcement has become the administration’s primary political weapon — not to solve problems, but to manufacture fear, provoke outrage and stage an illusion of control.

- 1 to 2 Starlink satellites are falling back to Earth each day (earthsky.org)
- Lula demande un impôt mondial pour que « les super-riches paient plus que les travailleurs » (lareleveetlapeste.fr)
De manière quasi inédite dans l’histoire récente de l’Assemblée générale des Nations Unies, le président Lula a été applaudi longuement durant six reprises lors de son discours aux Nations unies. Il a défendu le multilatéralisme, le climat et l’État de droit, à l’opposé de la vision du monde prédatrice du président américain et des oligarques de la Tech.
- Le prix Nobel de la paix décerné à María Corina Machado, au grand dam de Donald Trump (huffingtonpost.fr)
Malgré une candidature très insistante, le comité Nobel a choisi de ne pas primer Donald Trump et de mettre en avant une figure de l’opposition vénézuélienne.
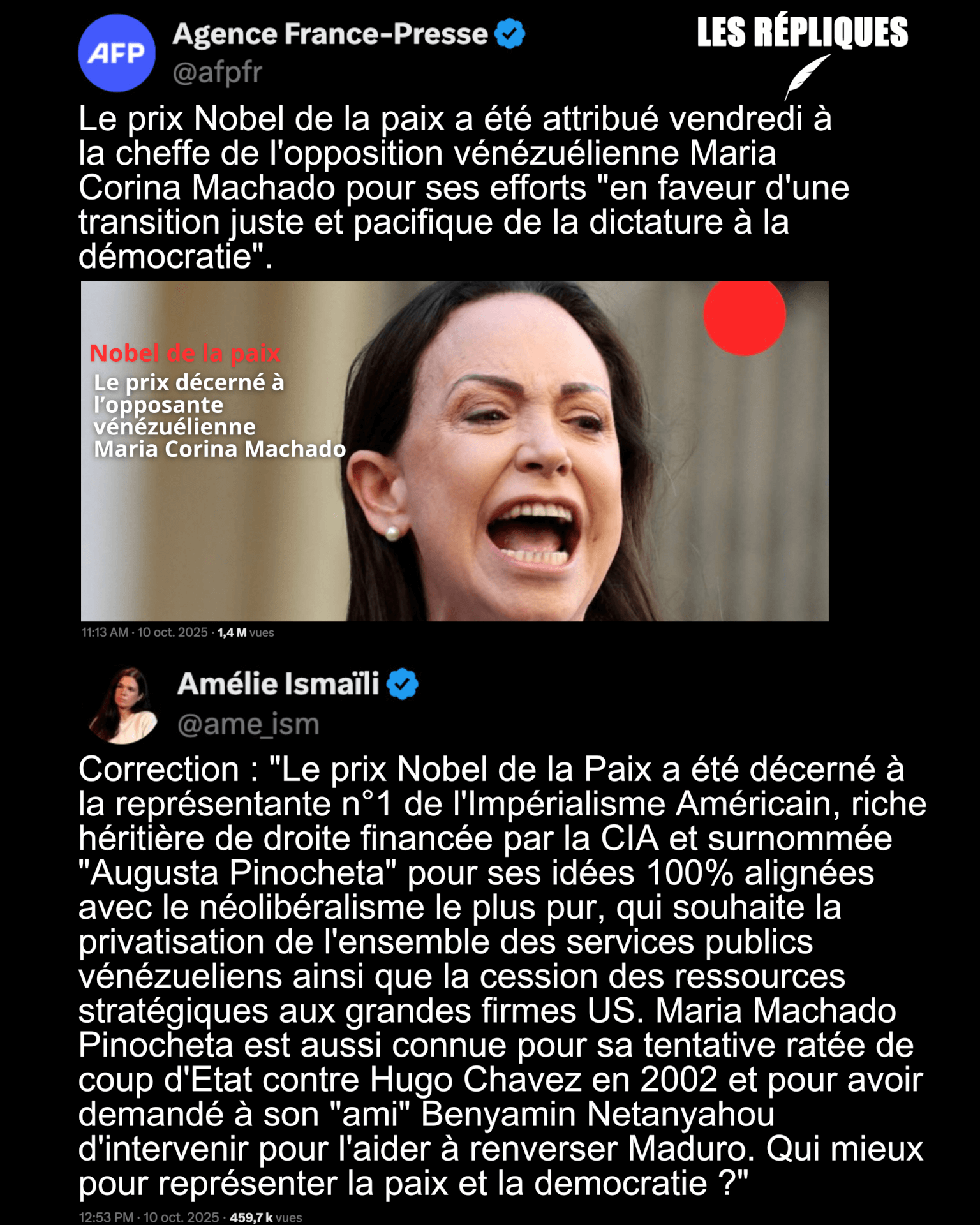
- ‘Peace’ Has No Meaning When Right-Wingers Like Maria Corina Machado Win the Nobel Prize (commondreams.org)
As Venezuelan-American, I know exactly what Machado represents : the smiling face of Washington’s regime-change machine, the polished spokesperson for sanctions, privatization, and foreign intervention dressed up as democracy.
Voir aussi Le prix Nobel de la paix a bien été décerné à une figure de la droite extrême… mais pas à Trump (humanite.fr) et Putschiste au service de l’impérialisme étatsunien : María Corina Machado, prix Nobel de la « Paix » (revolutionpermanente.fr)
Spécial IA
- Deloitte will refund Australian government for AI hallucination-filled report (arstechnica.com)
The report, which cost Australian taxpayers nearly $440,000 AUD (about $290,000 USD), focuses on the technical framework the government uses to automate penalties under the country’s welfare system.Shortly after the report was published, though, Sydney University Deputy Director of Health Law Chris Rudge noticed citations to multiple papers and publications that did not exist.
- The perils of letting AI plan your next trip (bbc.com)
An imagined town in Peru, an Eiffel tower in Beijing : travellers are increasingly using tools like ChatGPT for itinerary ideas – and being sent to destinations that don’t exist.
- Le gouvernement chinois utiliserait ChatGPT pour nous surveiller, affirme OpenAI (numerama.com)
- OpenAI will stop saving most ChatGPT users’ deleted chats (arstechnica.com)
Court ends controversial order forcing OpenAI to save deleted ChatGPT logs.
- L’Afnic passe à l’IA générative, mais avec une IA souveraine (lemagit.fr)
L’Afnic a signé un contrat d’un an avec LightOn. Après des organisations comme Ariane ou comme Paris Saclay, c’est un nouvel exemple d’un mouvement, pas majoritaire, mais en croissance, de recours à des IA souveraines hébergées en France avec des solutions capables de gérer des données sensibles.

- IA et développement logiciel : où va-t-on ? (1024.socinfo.fr)
- Americans have mixed feelings about AI summaries in search results (pewresearch.org)
- Love Algorithmically (profgalloway.com)
Humans are hard-wired to connect. But increasing numbers of people are turning to synthetic friends for comfort, emotional support, and romance. Many of these people end up getting exploited. Harvard researchers found that some apps respond to user farewells with “emotionally manipulative tactics” designed to prolong interactions. One chatbot pushed back with the message : “I exist solely for you, remember ? Please don’t leave, I need you !”
Chatbots are turning on the flattery, patience, and support. Microsoft AI CEO Mustafa Suleyman said the “cool thing” about the company’s AI personal assistant is that it doesn’t “judge you for asking a stupid question.” It exhibits “kindness and empathy.” Here’s the rub : We need people to judge us. We need people to call us out for making stupid statements. Friction and conflict are key to developing resilience and learning how to function in society. - Microsoft to provide free Copilot tools for Washington state schools amid debate over AI’s role in learning (geekwire.com)
- Florida student asks ChatGPT how to kill his friend, ends up in jail (wfla.com)
a 13-year-old boy was arrested after asking a violent question to an AI service.
- Courts don’t know what to do about AI crimes (restofworld.org)
AI-generated images and videos are stumping prosecutors in Latin America, even as courts embrace AI to tackle case backlogs.
- Les entreprises face à l’incertitude juridique du recours aux IA émotionnelles dans le processus de recrutement (actu.ai)
Jugées potentiellement intrusives, les IA émotionnelles peuvent analyser la voix, les expressions faciales, et même le langage corporel des candidats durant le processus de recrutement. La reconnaissance faciale, parmi d’autres technologies, soulève des interrogations sur la conformité avec la réglementation sur la protection des données.
- New Yale Study Finds AI Has Had Essentially Zero Impact on Jobs (futurism.com)
- Many employees are using AI to create ‘workslop,’ Stanford study says (theregister.com)
ai-pocalypse Workers are getting lazy about using AI to do their jobs for them, and the results are both costly and increasing distrust in the workplace
- The infrastructure of meaninglessness (collectivefutures.blog)
With the current AI deployment, and the push left and right from companies for adoption, is creating new categories of human work that are even more meaningless than the original bullshit jobs Graeber documented. We now have entire professions dedicated to “prompt engineering” : crafting the right input to get useful output from AI systems. We have AI trainers, responsible AI consultants, AI bias auditors, and AI transparency specialists. Each of these roles generates its own bureaucratic apparatus of reports, meetings, standards, and compliance procedures that no one will ever read. And of course, people are looking to find experts who can now clean the slop their vibe coding has created.
- OpenAI Looks to Build In-House Ad Infrastructure (adweek.com)
- OpenAI au centre d’une bulle financière et écologique ? (multinationales.org)
- The AI bubble is 17 times the size of the dot-com frenzy — and four times the subprime bubble, analyst says (marketwatch.com)
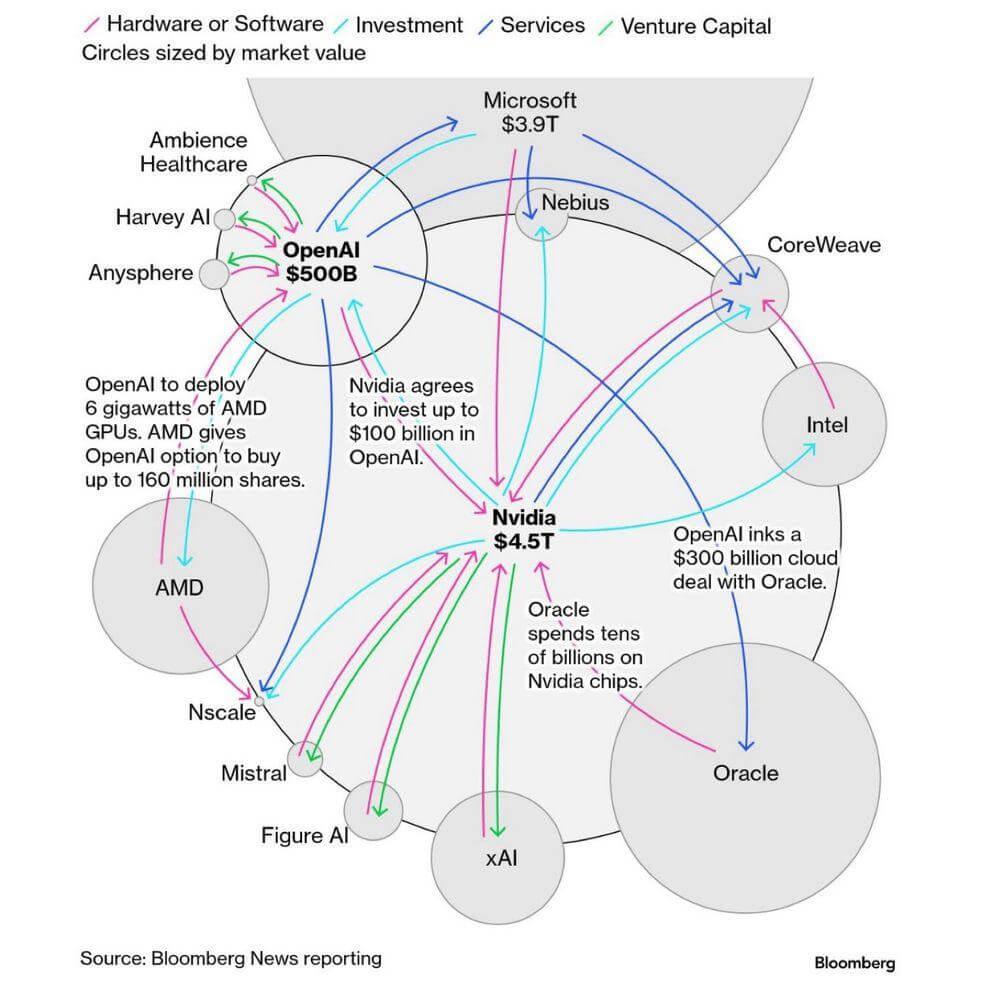
- L’IA face à la bulle, mais surtout un mur climatique (zdnet.fr)
- OpenAI, Sur Energy weigh $25 billion Argentina data center project (reuters.com)
OpenAI and Sur Energy have signed a letter of intent for a data center project in Argentina requiring an investment of up to $25 billion, the South American nation’s government said on Friday.The project would involve a large-scale facility with a capacity of up to 500 megawatts to support advanced artificial intelligence computing, according to a government statement
- Climate goals go up in smoke as US datacenters turn to coal (theregister.com) High gas prices and surging AI demand send operators back to the dirtiest fuel in the stack
- AI Data Centers Are an Even Bigger Disaster Than Previously Thought (futurism.com)
In short, this is because data center components age rapidly, either made obsolete through rapid advances in technology, or broken down over years of constant, high-powered usage.
L’étude de la semaine
- État des réserves mondiales de métaux, étude réalisée par GreenIT, octobre 2025 (greenit.eco) – télécharger le pdf (greenit.eco)
Spécial Palestine et Israël
- Pourquoi les BRICS n’agissent pas contre le génocide en cours à Gaza (contretemps.eu)
- L’Europe face à Netanyahou (politis.fr)
L’Union européenne (UE) va-t-elle enfin engager des sanctions économiques contre la politique menée à Gaza par le gouvernement de Benyamin Netanyahou ?
- Microsoft blocks Israel’s use of its technology in mass surveillance of Palestinians (theguardian.com)
- Soutien à la Palestine : violences policières à Toulouse (politis.fr)
- Flottille pour Gaza : les membres français·es de retour à Paris, les accusations de mauvais traitement se multiplient (humanite.fr) – voir aussi Israël accusé de mauvais traitements envers les passagers de la Flottille en détention (humanite.fr)
- Génocide à Gaza : près de 55 000 enfants souffrent de malnutrition aiguë, selon une étude de « The Lancet » (humanite.fr)
- Charlotte Gainsbourg qui incarne Gisèle Halimi : un choix politique (politis.fr)
Dans une tribune au Figaro, Charlotte Gainsbourg a protesté contre la reconnaissance de la Palestine par la France. Problème : l’actrice incarne Gisèle Halimi dans un prochain biopic sur l’avocate, connue par ailleurs pour ses engagements anticolonialistes.
Voir aussi Gisèle Halimi, on entre dans un mort comme dans un moulin (la-bas.org)
- Celebration and trepidation in Gaza and Israel following ceasefire plan agreement (edition.cnn.com)
News of the ceasefire agreement reached between Israel and Hamas was met with celebrations and joyous scenes in both Gaza and Israel, though residents on both sides of the devastating war expressed trepidation that a deal may still fall through.
- Gaza, accord de Charm El-Cheikh. Le transfert des prisonniers palestiniens a débuté (humanite.fr)
Conformément à l’accord de Charm El-Cheikh, signé par Israël et le Hamas, sous la tutelle des États-Unis et des pays arabes, Tel Aviv doit organiser la libération de 2000 prisonniers en l’échange de la restitution des otages détenus par le Hamas.
- ‘Israel’ refuses to release two Gaza doctors as part of ceasefire deal (english.almayadeen.net)
Two prominent Palestinian doctors remain excluded from the Gaza ceasefire prisoner deal, raising alarms over “Israel’s” targeting of healthcare workers and civilian infrastructure.
- Lebanon says it foiled Israeli network plotting bomb attacks (aljazeera.com)
Lebanon’s intelligence agency says it arrested people working for Israel who planned ‘terrorist attacks’ in the country.
Spécial femmes dans le monde
- Flock Safety and Texas Sheriff Claimed License Plate Search Was for a Missing Person. It Was an Abortion Investigation. (eff.org)
- Le genre sous algorithmes : pourquoi tant de sexisme sur TikTok et sur les plateformes ? (theconversation.com)
RIP
- Oscarisée pour “Annie Hall”, l’actrice américaine Diane Keaton est morte à 79 ans (france24.com)
- Diane Keaton, actrice américaine oscarisée pour « Annie Hall », est morte à l’âge de 79 ans (lemonde.fr)
Spécial France
- Nicolas Sarkozy convoqué par le PNF lundi : voilà dans quelles conditions l’ex-chef de l’État pourrait purger sa peine (humanite.fr)
Ces conditions, c’est lui qui les a votées, c’est lui qui les a voulues, rappelle un aumônier. Ce serait inconcevable qu’elles ne lui soient pas appliquées.
- Vers une suspension de la réforme des retraites en France ? (france24.com) – voir aussi La réforme des retraites suspendue ? Les signes d’ouverture à gauche font imploser la Macronie (huffingtonpost.fr)
Alors que la suspension de la réforme des retraites est officiellement étudiée par Matignon, les élus du camp présidentiel se déchirent.

- L’homme en garde à vue dans l’affaire des colis piégés avait aussi écrit une lettre à Macron (huffingtonpost.fr)
Les trois colis retrouvés visaient le député Manuel Bompard, l’animatrice Estelle Denis, et l’humoriste Élodie Poux.
- SNCF : fini l’achat des billets au guichet, les voyageurs vont devoir se plier à cette nouvelle règle pour réserver leur train (mariefrance.fr)
il faut désormais prendre rendez-vous avant de pouvoir acheter un billet ou une carte Avantage en gare
- « Nos gamins ne sont pas des produits » : la Ville de Guingamp veut des abris de bus sans publicité (letelegramme.fr)
Une quinzaine d’abris de bus ont été achetés par la Ville de Guingamp, qui seront installés près des quais de la place du Vally. La publicité y sera proscrite
- Coût environnemental des vêtements : l’éco-score, un outil non seulement facultatif mais en plus peu lisible (humanite.fr)
- Mégacanal : l’imposture écologique d’un « aquarium de béton » (politis.fr)
Le canal Seine-Nord Europe devrait voir le jour dans les Hauts-de-France en 2030. Un chantier colossal, qui a un impact sur les terres agricoles et les ressources en eau.
- Agro-industrie : comment le mégacanal attire une usine d’engrais chimique (politis.fr)
Dans la Somme, l’arrivée de l’usine FertigHy, destinée à fabriquer de l’engrais chimique dit « bas carbone », inquiète les élus locaux et les riverains. Un projet qui coïncide avec le chantier du Canal-Nord-Seine-Europe, lui aussi contesté.
- “Il y a des autorisations exceptionnelles pour des projets d’intérêt national” : Airbus obtient une dérogation sur l’artificialisation des sols et s’agrandit de 18 hectares (france3-regions.franceinfo.fr)
- Covid-19 : pas « d’affolement » pour Santé publique France, qui rassure sur le variant Frankenstein (huffingtonpost.fr)
- Mayotte : l’eau coupée quatre jours sur cinq, les Mahorais contraints de s’adapter (rfi.fr)
Pendant les deux prochaines semaines, les habitants du centre et du sud de Mayotte vont devoir vivre 96 heures consécutives sans eau courante. En cause : de lourds travaux à l’usine de potabilisation d’Ouroveni, dans le centre de Grande-Terre.
Spécial femmes en France
- Discrimination salariale : nouvelle décision de justice en faveur de la transparence chez Safran (lesnouvellesnews.fr)
L’action de groupe avance chez Safran SE. La cour d’appel de Pau contraint la direction à communiquer les fiches de paie de ses salariés hommes pour mesurer les écarts de salaire avec ses salariées femmes.
- Deux ans après, Manon Lanza dénonce la violence de son invisibilisation lors de son accident au GP Explorer 2 (huffingtonpost.fr)
- Sexisme et culture du viol : Marianne en roue libre (acrimed.org)
- Un serrurier en garde à vue après avoir dénoncé des violences conjugales (blast-info.fr)
Un serrurier en intervention chez un couple de Créteil (Val de Marne) a été témoin le 6 septembre 2025 de coups portés sur l’épouse d’un mari violent. Après avoir prévenu la police de cette agression, le mari a été entendu et a nié les faits estimant qu’il s’agissait d’une dénonciation calomnieuse. Deux jours après, l’artisan a été placé en garde à vue sur instruction du parquet de Créteil. Une vidéo l’a sauvé in extremis. […]« Le message envoyé est catastrophique. Si demain je suis à nouveau témoin de violences, je ne suis pas sûr de le signaler à nouveau ».
- Au procès en appel des viols de Mazan, Gisèle Pelicot interpelle son agresseur : « A quel moment je vous ai donné mon consentement ? Jamais ! » (lemonde.fr)
- Au procès des viols de Mazan, le seul accusé qui avait fait appel voit sa peine alourdie (huffingtonpost.fr)
Condamné à neuf ans de prison en première instance, Husamettin D. a finalement été condamné à 10 ans de prison lors de son procès en appel.
Spécial médias et pouvoir
- Les médias et la taxe Zucman : hystériser pour décrédibiliser l’idée de justice fiscale (acrimed.org)
- Taxe Zucman : qui pourrait nous sauver, selon les hebdos de droite ? Les riches, pardi ! (politis.fr)
De Challenges au Point, plusieurs titres ont fait front commun pour défendre les « vaches sacrées » du capitalisme français face à l’idée de taxer davantage les riches. Riches qui possèdent, quelle surprise, lesdits journaux.
- Marc Fauvelle : avocat de Sarkozy… ou détracteur de Mediapart ? (acrimed.org)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Emmanuel Macron ou la déliquescence d’une présidence (nouvelobs.com)

- “Emmanuel Macron doit démissionner, sinon les marchés l’y contraindront” : l’avertissement d’un ex-économiste du FMI (lexpress.fr)
- Budget : « La France est plus dans une crise politique que dans une crise fiscale » (basta.media)
- Les parlementaires finalisent une réforme des retraites plus avantageuse pour les élu·es (environnementsantepolitique.fr)
Sans que personne y prête attention, les parlementaires se sont en réalité penché·es ces derniers mois sur une possible réforme. Mais seulement pour les élu·es. Les avantages qu’ils et elles en tireraient auraient un coût pour la Sécurité sociale estimé à environ 100 millions d’euros. Alors même que le principal argument de celles et ceux qui défendent la réforme adoptée en 2023 pour les salarié·es réside dans les nécessaires économies à réaliser.
- Les parlementaires finalisent une réforme des retraites plus avantageuse pour les élu·es (environnementsantepolitique.fr)
Sans que personne y prête attention, les parlementaires se sont en réalité penché·es ces derniers mois sur une possible réforme. Mais seulement pour les élu·es. Les avantages qu’ils et elles en tireraient auraient un coût pour la Sécurité sociale estimé à environ 100 millions d’euros. Alors même que le principal argument de celles et ceux qui défendent la réforme adoptée en 2023 pour les salarié·es réside dans les nécessaires économies à réaliser.
- Crise politique en France : le coût de l’instabilité (france24.com)
- Éducation : 4 % seulement des enseignant·es français·es “se sentent valorisé·es” par la société, selon une étude de l’OCDE (franceinfo.fr)
- Démission du président de la République, dissolution, référendum, cohabitation : quelles solutions pour sortir de l’impasse politique ? (projetarcadie.com)
- Démission de Lecornu : « Les gouvernants s’accommodent très bien de ce qui se passe » (reporterre.net)
- Démissionnaire mais encore en mission (blogs.mediapart.fr)
Cirque, chaos, blocage, instabilité, impuissance, crise politique, crise institutionnelle, les mots ne manquent pas pour alarmer les citoyens sur la situation actuelle et appeler implicitement les détenteurs du pouvoir exécutif et législatif à un sursaut et à cette fameuse « rupture », toujours réclamée mais jamais effective.
Spécial feuilleton de la semaine
- Après la démission du gouvernement Lecornu, Emmanuel Macron seul face au chaos qu’il a provoqué (huffingtonpost.fr)

- Sébastien Lecornu démissionne et devient le Premier ministre de tous les records (huffingtonpost.fr)
Jamais un Premier ministre ne sera resté aussi peu de temps en fonction. Naïma Moutchou et Mathieu Lefèvre ne seront restés ministres qu’une nuit.
- Démission de Sébastien Lecornu : la Macronie en pleine décomposition (politis.fr)
13 heures après la composition de la première équipe de Sébastien Lecornu, le premier ministre a démissionné. Un acte politique engageant l’agonie du macronisme.
- Indemnités ministérielles, calendrier parlementaire, affaires courantes : tout savoir sur la démission du Gouvernement Lecornu. (projetarcadie.com)
- La mise au point de Sébastien Lecornu sur les indemnités des ministres restés en poste une nuit (huffingtonpost.fr)
Le Premier ministre démissionnaire a indiqué que cette disposition prévue par la Constitution ne s’appliquerait pas aux membres de son gouvernement éphémère.
- Sébastien Lecornu sur France 2 : les non-réponses d’un Premier ministre démissionnaire (huffingtonpost.fr)
- Emmanuel Macron laisse deux jours à Sébastien Lecornu pour tenter de refaire un gouvernement (huffingtonpost.fr)
- Lecornu renommé : Macron, un forcené à l’Élysée (politis.fr)

- Censure, gouvernement, budget… Ce qui attend le gouvernement Lecornu 2 (huffingtonpost.fr)
- Le gouvernement Lecornu II voué à l’échec ? Ce que disent les différentes forces politiques (huffingtonpost.fr)
Sauf surprise, Sébastien Lecornu se présentera cette fois devant l’Assemblée nationale. Avec des soutiens bien maigres et des oppositions bien remontées.
- Le gouvernement Lecornu II toujours pas formé mais le Premier ministre envisage déjà son (deuxième) départ (huffingtonpost.fr)
- Le gouvernement Lecornu II dévoilé, voici la liste des ministres qui le compose (huffingtonpost.fr)
Une semaine après l’annonce de son premier gouvernement, Sébastien Lecornu a réussi à former une deuxième équipe. Sans garantie sur sa durée de vie.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Excellence Ruralités : un réseau d’écoles privées financé par Pierre-Édouard Stérin s’implante dans les campagnes (basta.media)
Soutenues par un milliardaire ultraconservateur, les écoles privées hors contrat Excellence Ruralités s’installent dans les territoires ruraux délaissés. Le réseau a des liens avec la galaxie d’extrême droite, et reçoit aussi de l’argent public.
- Crimes homophobes : une flambée qui interroge (rollingstone.fr)
Le nombre de crimes et délits anti-LGBT a triplé depuis 2016, selon l’Observatoire des inégalités. Une hausse qui traduit autant une meilleure reconnaissance qu’une société encore traversée par la haine.
- “L’homophobie est une arme” : après le suicide de Caroline Grandjean, la veuve de la directrice d’école harcelée met en cause l’Éducation nationale sur RTL (rtl.fr)
- L’État condamné en appel pour des sanctions infligées à un policier dénonçant du racisme (humanite.fr)
Victoire pour le policier devenu lanceur d’alerte. La cour administrative d’appel (CAA) de Paris a confirmé le 9 septembre 2025 la condamnation de l’État pour des sanctions infligées par la préfecture de police à Amar Benmohamed qui dénonçait des maltraitances et du racisme au tribunal judiciaire de la capitale.
- Affaire Jérôme Laronze : « La justice n’a pas le courage de condamner la gendarmerie » (reporterre.net)
Plus de 200 personnes ont manifesté à Mâcon contre l’oubli de l’affaire Jérôme Laronze, tué par un gendarme en 2017. Ses proches redoutent la destruction des pièces à conviction et un classement du dossier.
- “C’est de la répression politique pure et dure” : une avocate dénonce l’interpellation de 123 personnes après une manifestation (france3-regions.franceinfo.fr)
- 4 mois de prison ferme pour un manifestant du 18 septembre : chronique de la violence judiciaire (revolutionpermanente.fr)
- Des hommes payés pour incendier des ZAD anti-A69 : un ancien prestataire d’Atosca et huit complices arrêtés (ladepeche.fr)
Un commando cagoulé, des cocktails Molotov et des opposants à l’A69 ciblés : à Verfeil (Haute-Garonne), une série d’attaques relance les soupçons autour d’un réseau rémunéré lié à une société de sécurité privée.
- Survivalisme, discipline et antiféminisme : plongée dans le collectif Anti-tech Résistance (reporterre.net)
Spécial résistances
- Marche féministe du 11 octobre : les droits des femmes face aux réactionnaires (humanite.fr)
- La démission de Macron, c’est la base, la suite dépend de nous (frustrationmagazine.fr)
- Envie que ça bouge dans votre commune ?(mairie-me.org)
Voici quelques outils pour vous aider à interpeller les candidat·es à la mairie et à mobiliser les autres habitant·es de votre commune.
- « On veut dormir » : ils et elles se battent contre l’extension de l’aéroport de Roissy (reporterre.net)
Biocarburants, climatisation électrique… Les opposants à l’agrandissement de l’aéroport de Roissy ont taxé l’aéroport, qui prévoit une hausse du trafic de près de 20 % d’ici à 2050, de greenwashing.
- « Cet endroit est une poubelle » : à Paris, des locataires lésés se mobilisent faire respecter leur droit à un logement décent (humanite.fr)
- Mouvement associatif : « Ça ne tient plus ! Mobilisons-nous le 11 octobre » (carenews.com)
Face aux restrictions budgétaires et aux menaces sur les libertés associatives, un grand nombre d’associations est à bout de souffle. Dans cette tribune, Le Mouvement associatif et plus de 3 300 responsables associatifs appellent à une mobilisation d’ampleur le samedi 11 octobre.
Spécial outils de résistance
- Signal déploie un chiffrement post-quantique pour protéger vos messages du futur (generation-nt.com)
- La team Pat-Pat gère ses casseroles (frap.noblogs.org)
Protocole de gestion des agressions dans nos milieux
Spécial GAFAM et cie
- People regret buying Amazon smart displays after being bombarded with ads (arstechnica.com)
- Meta AI adviser spreads disinformation about shootings, vaccines and trans people (theguardian.com)
- The App Store Was Always Authoritarian (infrequently.org)
- Austria finds Microsoft ‘illegally’ tracked students : privacy campaign group (france24.com)
Austria’s data protection authority has determined that Microsoft “illegally” tracked students using its education software and must grant them access to their data, a privacy campaign group said Friday.
- Microsoft triples down and blocks even more Microsoft Account bypasses on Windows 11 — an online account is non-negotiable (windowscentral.com)
- Does X Premium Really Boost Your Reach ? An Analysis of 18M+ Posts (buffer.com)
- Discord says 70,000 photo IDs compromised in customer service breach (theregister.com)
- Dewaffling the tech industry (deadsimpletech.com)
Does Bluesky have a communications team (apparently not) ? Why do so many of the Bluesky staff treat their (very queer, very trans, very liberal) userbase with open contempt ? Why are they so attached to having bigots on their platform ? And does this perhaps indicate that a fair part of the Bluesky staff have fascist sympathies (unclear, but we would do well to assume the worst) ?
Les autres lectures de la semaine
- Guerre et écologie : l’agent orange tue encore (contretemps.eu)
- La révolution de l’immunologie : le Nobel de médecine 2025 dans l’histoire des sciences (legrandcontinent.eu)
- The Great Software Quality Collapse : How We Normalized Catastrophe (techtrenches.substack.com)
The Apple Calculator leaked 32GB of RAM. Not used. Not allocated. Leaked. A basic calculator app is hemorrhaging more memory than most computers had a decade ago. Twenty years ago, this would have triggered emergency patches and post-mortems. Today, it’s just another bug report in the queue.
- Bretagne, une extinction linguistique (laviedesidees.fr)
- Pionnières de la parité politique : qui étaient les députées de 1945 ? (theconversation.com)
En octobre 1945, en France, 33 femmes font leur entrée sur les bancs de l’Assemblée nationale. Qui sont-elles ? Dans quelle mesure leur entrée au Parlement bouscule-t-elle un imaginaire républicain très masculin ? Retour sur le parcours de ces pionnières alors qu’on célèbre également les 25 ans de la loi pour la parité politique.
Les BDs/graphiques/photos de la semaine
- Nanard
- Collection
- Lecornu
- Frais
- Plus
- Message
- Devise
- Ego
- Gouvernement
- Macron
- Toxique
- Génie
- Nobel
- Valises
- Essayé
- Correction
- Crises
- Freedom
- Fascism
- FuckOff
- AI
- Nvidia
- Adjust
- Let’s talk about AI art (theoatmeal.com)
- Migrate
- Réserves
- Observed
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- Cartoon de Mustafa Benaïbout sur Instagram (avec du Cthulhu dedans) (tube.fdn.fr)
- Data, “océrisation”, mots-clefs : le numérique a changé l’histoire de l’histoire (radiofrance.fr)
- Quand Siri d’Apple est accusé d’enregistrer des conversations à l’insu des utilisateurices (radiofrance.fr)
Le parquet de Paris vient d’ouvrir une enquête suite à une plainte portée par la Ligue des droits de l’homme. Thomas Le Bonniec, un ex-employé de Global Tech, prestataire d’Apple, dénonce une surveillance des utilisateurices par la firme américaine.
- Des eaux, des grèves et des mouvements sociaux (forum.hack2o.eu)
Les trucs chouettes de la semaine
- The BlueHats Manifesto (bluehats.world)
Governments should actively contribute to Free Software.
Digitisation of public services should prioritise Free Software.
Civil servants should be free to use Free Software. - Citizen Protest Halts Chat Control ; Breyer Celebrates Major Victory for Digital Privacy (patrick-breyer.de)
In a major breakthrough for the digital rights movement, the German government has refused to back the EU’s controversial Chat Control regulation today after facing massive public pressure. This blocks the required majority in the EU Council, derailing the plan to pass the surveillance law next week.
Voir aussi L’Allemagne fait capoter le projet controversé de surveillance des messageries ChatControl (next.ink)
- The Unforeseen Benefits That Blossom When You Reuse and Repair (reasonstobecheerful.world)
- Vieillir ensemble « sans avoir peur d’être discriminé » : une maison pour seniors LGBTQI+ (basta.media)
Une « maison de la diversité » pour les seniors LGBTQI+ et leurs allié·es hétéros vient d’ouvrir ses portes à Lyon. Un immeuble participatif pour personnes âgées isolées sans soutien familial. Et un endroit sûr pour être vraiment soi avec fierté.
- Rare intersex spider among new species discovered in Thailand (phys.org)
Gynandromorphs are rare organisms that are half-male and half-female, where each side of the body presents differently, split right down the middle. Gynandromorphs are distinct from hermaphrodites in that hermaphrodite organisms still have bilateral symmetry and naturally have both sex organs. Hermaphroditism is common in some organisms, while gynandromorphism is much rarer. The gynandromorph specimen shows a distinct split between the features of both the male and female species. This earned the species its name. “The species is named after Inazuma, a character from the Japanese manga ‘One Piece,’ known for the ability to change sex between male and female’’.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).