
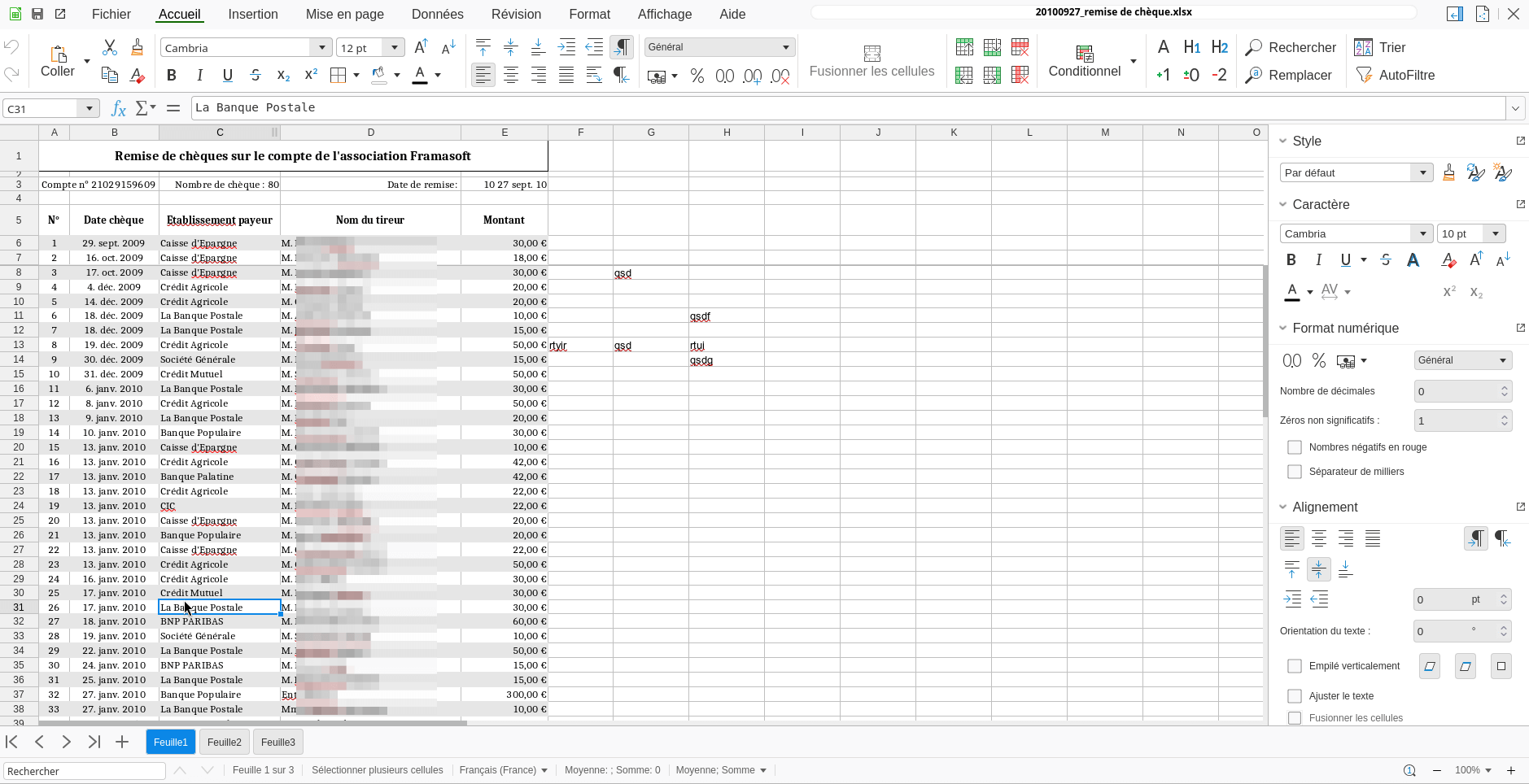
09.12.2025 à 09:00
PeerTube v8 : gérez vos vidéos en équipe !
Framasoft
Texte intégral (4340 mots)
Pour la première fois depuis le développement de PeerTube, nous avons réalisé un nouveau thème pour le lecteur vidéo !
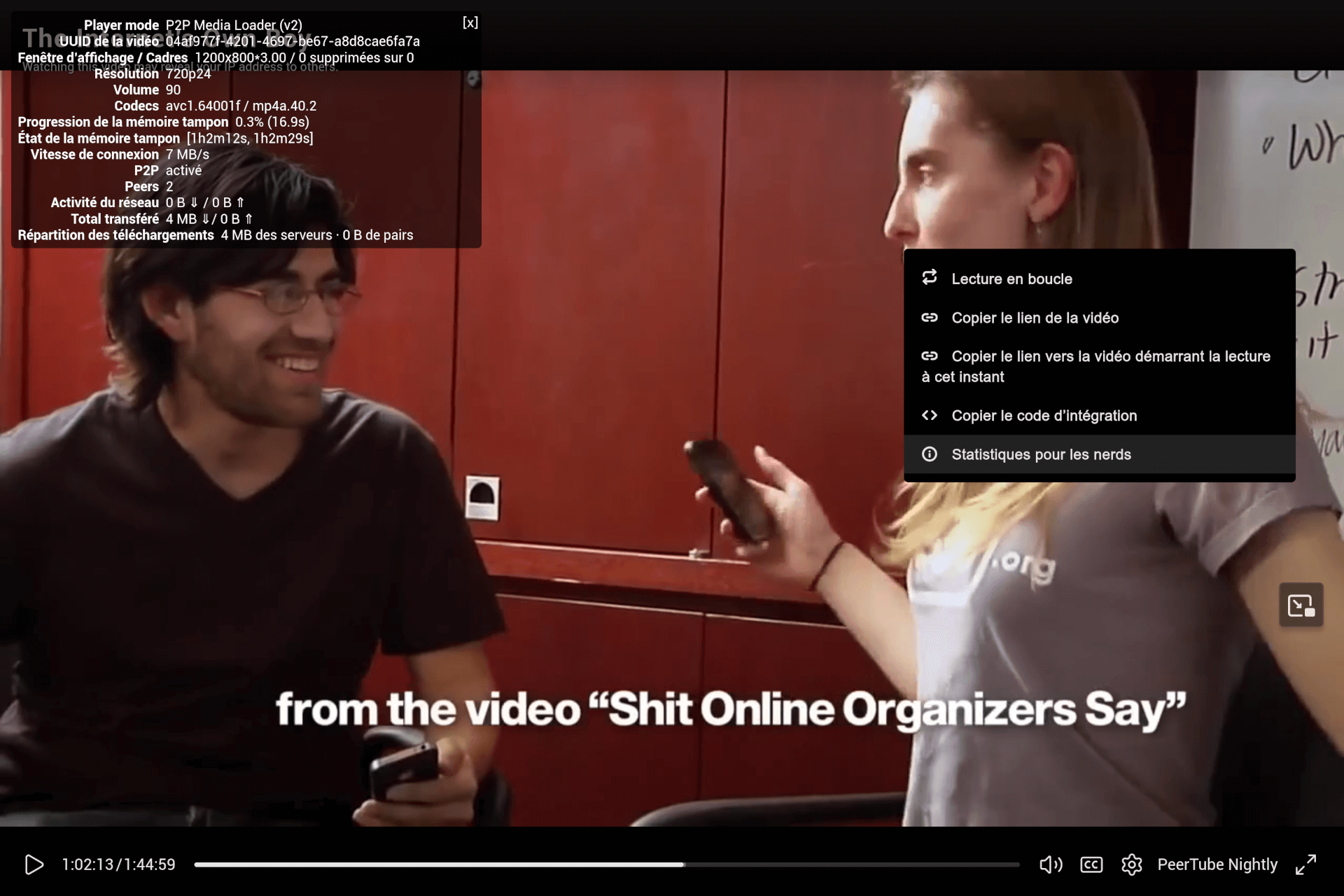
Affichage des « Statistiques pour les nerds ».
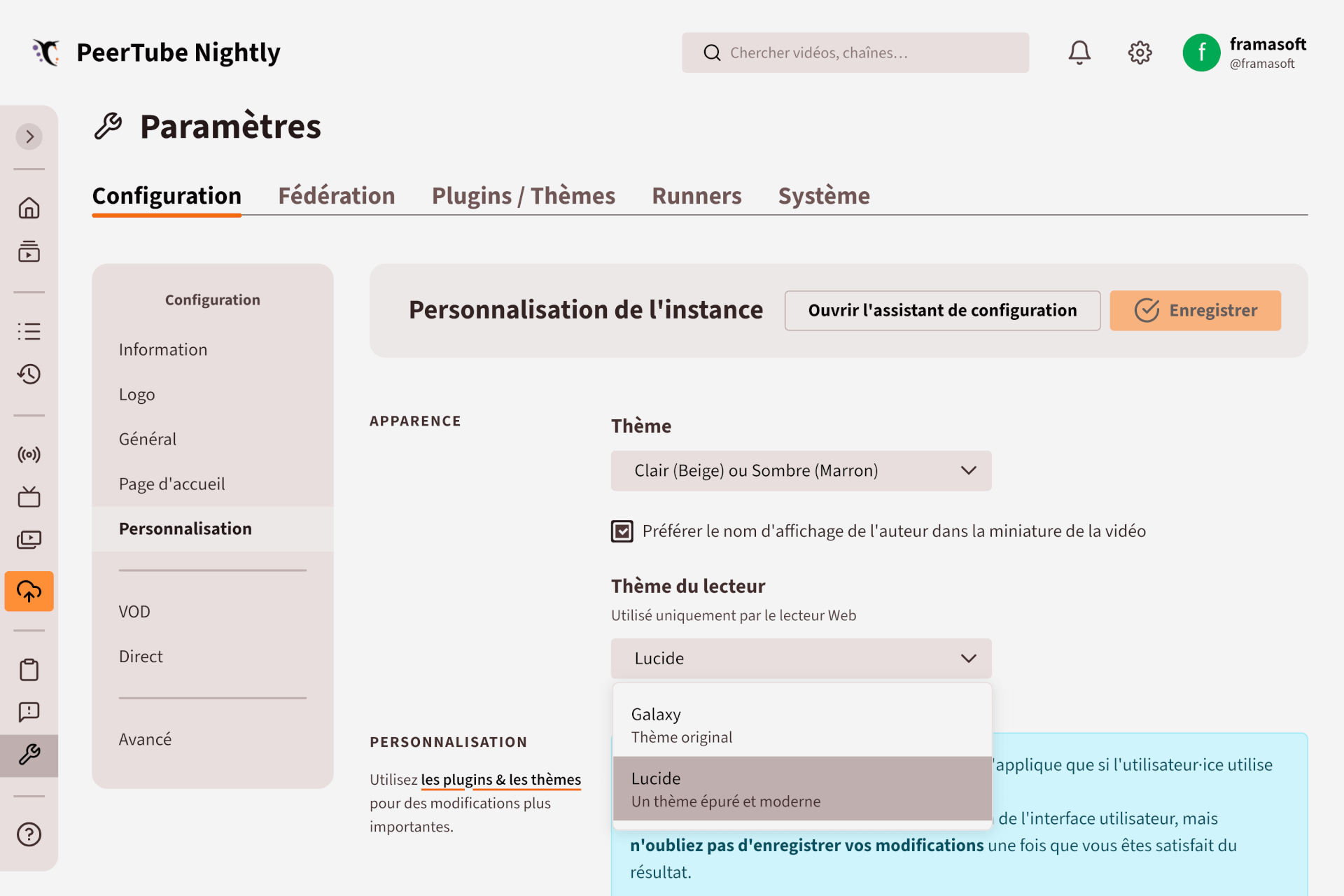
L’ancien thème du lecteur est nommé Galaxy.
Gérez vos chaînes en équipe
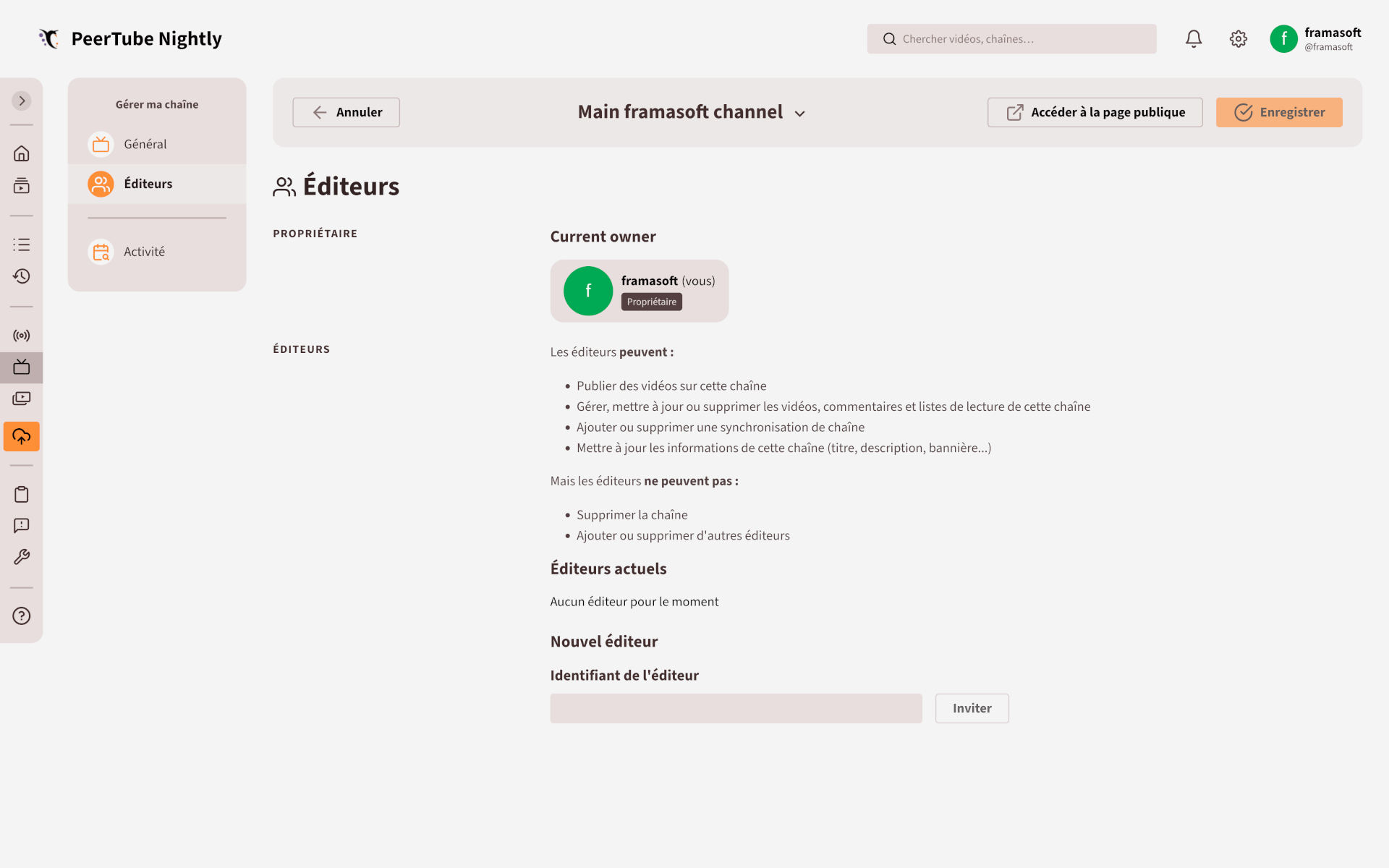
Page permettant d’ajouter un nouvel éditeur.

Le nouveau thème des notifications.
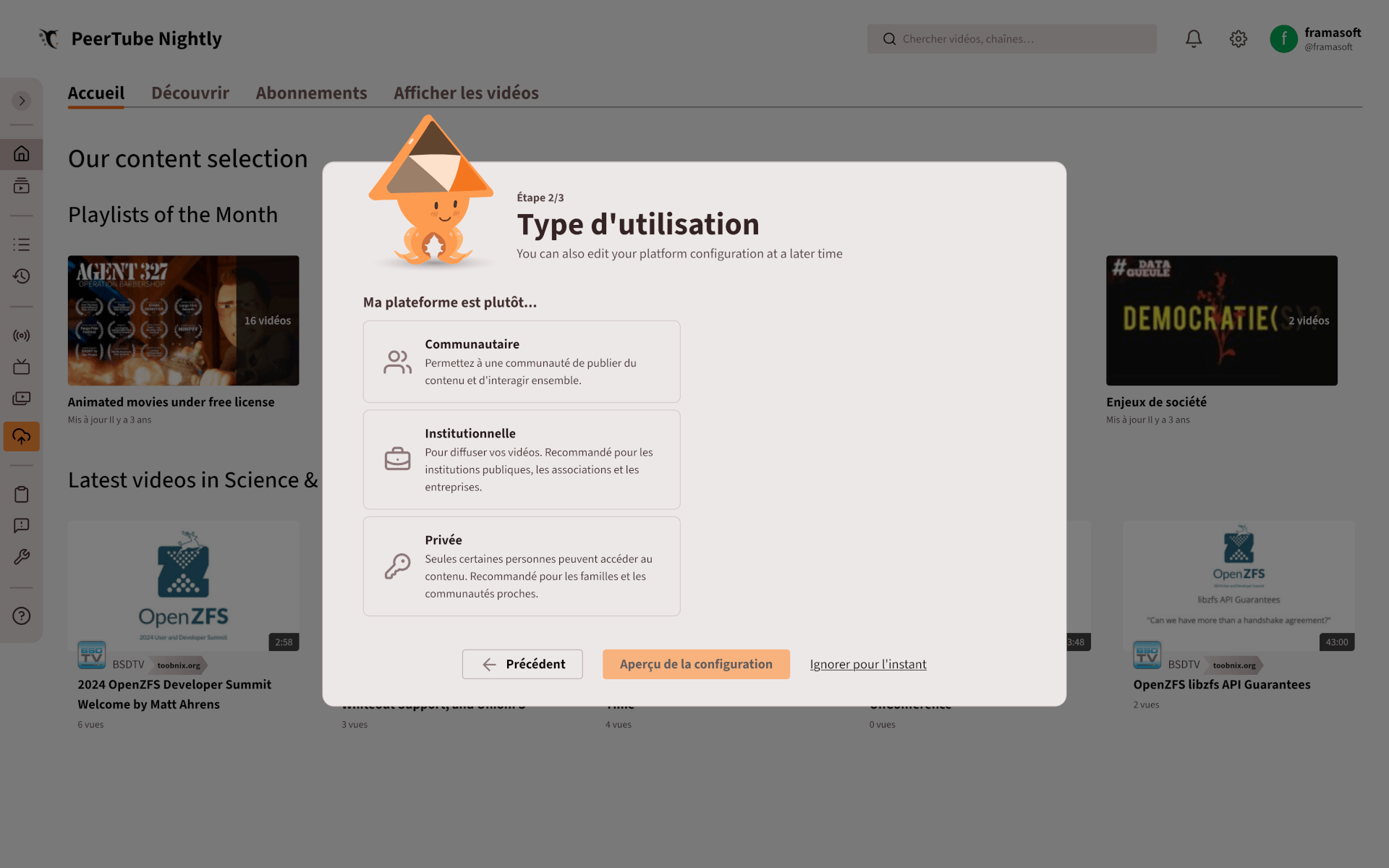
L’assistant de configuration de PeerTube.

Les illustrations ont été réalisées par David Revoy et sont sous licence CC-BY 4.0.
08.12.2025 à 07:42
Khrys’presso du lundi 8 décembre 2025
Khrys
Texte intégral (8444 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- In Myanmar, illicit rare-earth mining is taking a heavy toll (arstechnica.com)
Uncontrolled mining in areas of Myanmar ruled by powerful ethnic armies has boomed.
- India orders smartphone makers to preload state-owned cyber safety app (reuters.com)
- « Tout brûler jusqu’à la Manche » : face à l’Occident, la diplomatie russe appelle au sang (legrandcontinent.eu)
- The missile meant to strike fear in Russia’s enemies fails once again (arstechnica.com)
A Russian intercontinental ballistic missile (ICBM) fired from an underground silo on the country’s southern steppe Friday on a scheduled test to deliver a dummy warhead to a remote impact zone nearly 4,000 miles away. The missile didn’t even make it 4,000 feet.
- La Norvège taxe les ultra-riches, et ça marche ! (lareleveetlapeste.fr)
En 2023, 654 947 citoyen·nes étaient concerné·es par cette taxe, soit 12 % de la population. Elle a rapporté 2,5 milliards d’euros cette année-là.
- Une victoire « historique » : la Norvège repousse de 4 ans l’exploitation de ses fonds marins (reporterre.net)
- « Ils ont détruit notre mer » : en Syrie, les trous béants laissés par la guerre (reporterre.net)
En Syrie, la guerre n’a pas seulement frappé les villes et les bâtiments : elle a aussi ravagé la mer Méditerranée. Fonds marins appauvris, poissons rares… Les pêcheurs locaux se battent pour leur survie.
- Le Niger annonce vouloir porter plainte contre le géant français du nucléaire Orano (rfi.fr)
Dans un nouvel épisode dans les tensions entre le Niger et Orano, Niamey a annoncé mardi 2 décembre son intention de porter plainte contre le groupe français. Le ministre nigérien de la Justice a expliqué lors d’une conférence de presse que des éléments radioactifs ont été découverts à Madaoulela, dans le nord du pays. Le Niger et Orano s’opposent déjà depuis plusieurs mois autour de l’uranium de la Somaïr, nationalisée en juin dernier.
- « On jette les agriculteurices dans les bras de grands groupes internationaux » : l’Union européenne en passe d’autoriser la propagation de « nouveaux OGM » (humanite.fr)
- À Budapest, vivre sans toit, c’est défier la loi (alterechos.be)
Restriction des hébergements d’urgence, suppression des aides au logement, interdiction de dormir dehors… En Hongrie, plus de 5.000 personnes vivent dans la rue chaque soir. Face à cet abandon du gouvernement, l’association des avocats de rue « Utcajogász » combat cette injustice en leur offrant une assistance juridique en matière de logement.
- En Allemagne, une mobilisation massive contre l’extrême droite (politis.fr)
Près de 50 000 personnes venue de tout le pays se sont rassemblées ce week-end à Gießen pour empêcher le parti d’extrême droite Alternative für Deutschland (AfD) de reformer sa faction jeune, auto-dissoute huit mois plus tôt.
- Game Over pour Cryptomixer – Europol débranche violemment la machine à laver préférée des cybercriminels (gigawatts.fr)
- EU “Chat Control” Twist : Commissioner Sides with Parliament Over Governments (patrick-breyer.de)
While EU member state governments continue to push for mass scanning of private messages (at the discretion of providers), mandatory age verification for all users, and effective bans on communication apps for under-17s, the Parliament enters negotiations with a clear alternative model : Mandatory but targeted surveillance only where reasonable suspicion exists and with a judicial warrant, alongside a firm rejection of mandatory age checks and app lockouts for teenagers.
- UK pushes ahead with facial recognition expansion despite civil liberties backlash (theregister.com)
Plan would create statutory powers for police use of biometrics, prompting warnings of mass surveillance
- UK is running out of water – but data centres refuse to say how much they use (inews.co.uk)
- Le bipartisme c’est terminé : comment la vague populiste d’extrême droite balaye les « démocraties’’ occidentales (slate.fr)
Des États-Unis à la France en passant par l’Allemagne et les Pays-Bas, les partis d’extrême droite atteignent des niveaux historiques. Leur influence grandissante met sous pression les démocraties libérales, fragilisées par des crises institutionnelles à répétition.
- Second Texas university system to restrict race and gender course content (statesman.com)
- Grokipedia – Le monument de la connaissance rêvé par Elon Musk n’est qu’un immense naufrage numérique (gigawatts.fr)
- McDonald’s sales are slumping because people can’t afford fast-food (cbsnews.com)
- Coca-Cola, Nestlé… San Francisco poursuit 10 géants de la malbouffe (reporterre.net)
San Francisco, au nom de l’État de Californie, a engagé le 2 décembre une procédure judiciaire inédite contre dix géants de l’alimentation ultratransformée, parmi lesquels Coca-Cola, Nestlé et PepsiCo, les accusant d’avoir provoqué une « crise de santé publique ».
- Luigi Mangione est de retour devant la justice (huffingtonpost.fr)
Le jeune homme de 27 ans est attendu pour une audition préliminaire au tribunal de New York, il est poursuivi pour leur meurtre du PDG d’une compagnie d’assurances[…]L’objectif de ses avocats est clair : empêcher les procureurs d’utiliser certaines preuves que les procureurs disent accablantes pour l’Américain de 27 ans, qui a plaidé non coupable.
- Cette plainte du « New York Times » n’arrange pas le Pentagone déjà dans la tourmente (huffingtonpost.fr)
Le New York Times a annoncé ce jeudi 4 décembre avoir lancé une action en justice contre le Pentagone, pour avoir mis en œuvre une série de mesures restrictives à l’égard de la presse qu’il juge contraires à la Constitution.
- What Chicago’s fight against ICE can teach us all about how to resist oppression (theguardian.com)
Hannah Arendt discussed the term Gleichschaltung, roughly translatable as “coordination” or “synchronisation”. It came from the Nazi justice minister Franz Gürtner to mean, broadly, that all political, social, cultural and civic institutions had to fall in line with the totalitarian state. Such a thing can only be achieved with the complicity of everyone : the minute-by-minute decisions of people who will do anything, personally or professionally, to stay with the majority. […] only about 15 % of people resisted nazism. It wasn’t because they were fervent supporters, or even, at the outset, because they were scared, but because that’s where the herd was. […] Don’t wait until your government is so racist that it’s lifting people off ladders while they are trying to work, or seizing kids as they are trying to get to school, before you protest. Every time you hear aggressive xenophobia and racist insinuation from those in power and check in with how it polled before you say it’s disgusting, you are building the herd that will suffocate opposition when it matters.
- Colombia bans all new oil and mining projects in its Amazon (news.mongabay.com)
- The Rise of Chile’s Hard Right (jacobin.com)
The first round of voting in Chile’s general election in November saw the shocking rise of the far right and the collapse of the country’s new left. It’s a crushing but not total defeat for the movement helmed by President Gabriel Boric.
- Glyphosate : une étude favorable à l’herbicide enfin désavouée et dépubliée (reporterre.net)
Vingt-cinq ans après sa publication, l’étude a pourtant largement été citée par les défenseurs de l’herbicide le plus vendu au monde. « Cet article a eu une influence considérable sur les décisions réglementaires concernant le glyphosate et le Roundup pendant des décennies »
- Satellite megaconstellations will threaten space-based astronomy (nature.com)
- Le spyware d’État Predator peut maintenant exploiter l’affichage des pubs mobiles pour vous infecter sans clic (clubic.com)
- Les revenus des grandes entreprises de l’armement ont atteint leurs niveaux les plus élevés en 2024 (legrandcontinent.eu)
Spécial IA
- L’IA générative, « instrument de précision » pour la censure et la répression en Chine (next.ink)
- In comedy of errors, men accused of wiping gov databases turned to an AI tool (arstechnica.com)
Two sibling contractors convicted a decade ago for hacking into US State Department systems have once again been charged, this time for a comically hamfisted attempt to steal and destroy government records just minutes after being fired from their contractor jobs. Despite their brazen attempt to steal and destroy information from multiple government agencies, the men lacked knowledge of the database commands needed to cover up their alleged crimes. So they allegedly did what many amateurs do : turned to an AI chat tool.
- “Je suis horrifié” : l’IA de Google efface l’intégralité du disque D d’un utilisateur, le désastre du “vibe coding” (clubic.com)

- Syntax hacking : Researchers discover sentence structure can bypass AI safety rules (arstechnica.com)
Researchers from MIT, Northeastern University, and Meta recently released a paper suggesting that large language models (LLMs) similar to those that power ChatGPT may sometimes prioritize sentence structure over meaning when answering questions.
- Quand l’IA fait n’importe quoi, le cas du gratte-ciel et du trombone à coulisse (theconversation.com)
- ‘End-to-end encrypted’ smart toilet camera is not actually end-to-end encrypted (techcrunch.com)
The security researcher also pointed out that given Kohler can access customers’ data on its servers, it’s possible Kohler is using customers’ bowl pictures to train AI.
- OpenAI desperate to avoid explaining why it deleted pirated book datasets (arstechnica.com)
OpenAI may soon be forced to explain why it deleted a pair of controversial datasets composed of pirated books, and the stakes could not be higher.At the heart of a class-action lawsuit from authors alleging that ChatGPT was illegally trained on their works, OpenAI’s decision to delete the datasets could end up being a deciding factor that gives the authors the win.
Voir aussi OpenAI loses fight to keep ChatGPT logs secret in copyright case (reuters.com)
- OpenAI declares ‘code red’ as Google catches up in AI race (theverge.com)
Google’s own ‘code red’ response to ChatGPT has started paying off.
- Google’s toying with nonsense AI-made headlines on articles in the Discover feed (pcgamer.com)
With the power of AI, data centres the size of a kolkhoz can now write clickbait instead of underpaid journalists at struggling websites.
- Une start-up de 8 employés publie 3 000 podcasts par semaine, générés par IA (next.ink)
- AI is Destroying the University and Learning Itself (currentaffairs.org)
Students use AI to write papers, professors use AI to grade them, degrees become meaningless, and tech companies make fortunes. Welcome to the death of higher education.
- The hidden Kenyan workers training China’s AI models (restofworld.org)
An unemployment crisis has created fertile ground for companies to step in with opaque systems built on WhatsApp groups, middlemen, and bargain-basement wages.
- The Reverse Centaur’s Guide to Criticizing AI (pluralistic.net)

RIP
- Frank Gehry, architecte visionnaire et maître du déconstructivisme, est mort (france24.com)
L’architecte américano-canadien Frank Gehry, l’un des rares de sa profession à s’être hissé au rang de superstar à travers la planète, est mort vendredi à l’âge de 96 ans.
Spécial Palestine et Israël
- Le huitième front (monde-diplomatique.fr)
Israël a perdu les faveurs de l’opinion publique américaine (lire « Même les Américains se lassent d’Israël »). Conscient du péril, le premier ministre Benyamin Netanyahou a annoncé l’ouverture d’un « huitième front », la « bataille pour la vérité », afin de reconquérir les cœurs et les esprits […] Il a chargé la société Clock Tower X d’inonder les réseaux sociaux américains de contenus « calibrés pour la génération Z ». Cette agence doit également créer une myriade de pages Internet destinées à orienter les réponses de ChatGPT ou Grok. Des influenceurs, rémunérés jusqu’à 7 000 dollars par publication, complètent l’opération. Mais il faut aussi faire disparaître ce que les gens ne doivent plus voir. Tout est alors affaire d’algorithme. Concernant X, M. Netanyahou ne s’inquiète pas (« Elon [Musk] est un ami, nous allons lui parler »). Le problème viendrait surtout de TikTok.
- Marwan Barghouti : 200 célébrités demandent la libération du “Mandela palestinien” (france24.com)
Musicien·nes, acteurices, écrivain·es… plus de 200 célébrités ont signé mercredi une lettre ouverte pour soutenir la campagne de libération de Marwan Barghouti. Emprisonné depuis plus de 20 ans en Israël, cette figure du Fatah est considéré par beaucoup comme le possible dirigeant d’un futur État palestinien.
- Contre Benjamin Netanyahu, ces Israéliens manifestent à Tel Aviv avec des bananes (huffingtonpost.fr)
Le Premier ministre d’Israël a officiellement demandé une grâce présidentielle dans son procès pour corruption. Ses opposants dénoncent une « république bananière ».
- Eurovision : quatre pays se retirent face au maintien d’Israël, la France se félicite d’avoir « contribué à empêcher un boycott » (humanite.fr)
- La Via Campesina condamne fermement les attaques contre son organisation membre en Palestine et dénonce les arrestations arbitraires (viacampesina.org)
- La tech israélienne de l’eau accueillie en catimini dans le sud de la France (reporterre.net)
La goutte de trop. La rencontre organisée le 3 décembre entre des entreprises israéliennes de l’eau et des acteurs français du secteur ne passe pas. Dans une lettre ouverte au président de la région Provence-Alpes-Côte d’Azur, Renaud Muselier, une quinzaine de collectifs et associations engagés sur l’eau et le soutien à la Palestine demandent l’annulation de l’événement.
Spécial femmes dans le monde
- LinkedIn favoriserait les profils masculins (humanite.fr)
Plusieurs utilisatrices ont commencé, le mois dernier, à […] mettre à jour leur présentation et leurs publications en les masculinisant. Résultat : une audience et des interactions qui grimpent. L’une a vu sa visibilité augmenter de 244 %, d’autres ont constaté la montée en flèche des mentions j’aime, des commentaires et des partages. Les posts d’une journaliste de l’AFP ont enregistré des milliers de clics supplémentaires.
- Only three out of ten ambassadors from European Union countries are women (civio.es)
Finland is the only EU country with a female majority while at the other extreme, in Italy and Czechia, men dominate the diplomatic corps.
- Terreur, viols, meurtres… Le quotidien épouvantable des femmes qui migrent du Soudan vers le Soudan du Sud (theconversation.com)
- 6 décembre : voici pourquoi le Canada doit reconnaître le crime de féminicide (theconversation.com)
Cela fait 36 ans que le massacre de 14 jeunes femmes a eu lieu à l’École Polytechnique de Montréal. Un homme les a abattues parce qu’elles étaient des femmes.Qualifié d’acte « violent de misogynie » par le gouvernement fédéral, ce massacre n’a pourtant jamais été officiellement qualifié de féminicide au Canada, malgré sa reconnaissance mondiale.
- Woman Hailed as Hero for Smashing Man’s Meta Smart Glasses on Subway (futurism.com)
Spécial France
- France Télécom : condamné dans l’affaire des suicides, l’ancien patron Didier Lombard perd sa Légion d’honneur. (sudouest.fr)
- Piratage informatique : les données de 1,6 million de personnes “susceptibles d’être divulguées”, selon France Travail et l’Union nationale des missions locales (franceinfo.fr)
- Le CNRS s’émancipe du Web of Science (cnrs.fr)
À partir du 1er janvier 2026, le CNRS coupera l’accès à l’une des plus importantes bases bibliométriques commerciales : le Web of Science de Clarivate Analytics, ainsi que les Core Collection et Journal Citation Reports.
- Retraites, année blanche, congé maladie… La soirée qui a re-refaçonné le budget de la Sécu (huffingtonpost.fr)
Les député·es ont notamment rétabli la suspension de la réforme des retraites, annulée par les sénateurices quelques jours plus tôt.
- 1297 personnes sont mortes au travail en 2024 (basta.media)
L’Assurance maladie vient de publier les chiffres annuels des décès liés au travail. En 2024, 1297 personnes ont perdu la vie en raison de leur activité professionnelle. Un chiffre record. Les plus âgé·es sont plus touché·es.
- Remboursement des fauteuils roulants : promesse tenue (politis.fr)
Depuis le 1er décembre, la Sécurité sociale rembourse la totalité du coût du fauteuil roulant pour les personnes en situation de handicap. Une bonne nouvelle pour les 1,1 million de personnes qui utilisent un fauteuil roulant en France, et les 150 000 qui en achètent chaque année.
- À l’Assemblée, Mélenchon nie tout lien entre LFI et les islamistes et se fait professeur de laïcité (humanite.fr)
- L’édition 2026 du festival de BD d’Angoulême est officiellement annulée (france24.com)
L’édition 2026 du Festival international de BD d’Angoulême, qui devait se tenir fin janvier mais était plombée par le boycott des auteurices et la défection des éditeurices, est officiellement “annulée”, a affirmé lundi à l’AFP un des avocats de la société organisatrice 9e Art+.
- Bercy met de l’huile dans les rouages de l’implantation de datacenters en France (next.ink)
Build, baby, build
- La SNCF s’obstine à contourner le centre de la France (reporterre.net)
Avec sa nouvelle liaison Ouigo via l’Île-de-France, la SNCF prive une fois de plus le Massif central de connexion ferroviaire directe. Élus et associations réclament le retour d’une ligne traversant le centre de la France.
- Assurance habitation : le climat fait flamber les primes et fragilise les assurés, alerte l’UFC-Que Choisir (franceinfo.fr)
- L’eau minérale naturelle de Perrier est à nouveau inconsommable… (franceinfo.fr)
- Le plus petit des PFAS est omniprésent dans l’eau, confirme l’Anses (reporterre.net)
- La France a exporté 6 620 tonnes de pesticides interdits en 2024 (reporterre.net)
En 2024, la France a exporté 6 620 tonnes de pesticides interdits sur son territoire en raison de leur dangerosité pour la santé et l’environnement, révèle l’ONG suisse Public Eye dans une carte interactive publiée le 1er décembre.
La carte (publiceye.ch)
- Ce vigneron lutte contre les inondations grâce à l’agriculture bio sans labour (basta.media)
« Aujourd’hui, les agriculteurs nourrissent la plante et non pas le sol, alors que, quand vous nourrissez le sol, il y a suffisamment d’éléments à disposition des racines des plantes pour leur développement. Comme dans une forêt, vous avez des arbres qui fabriquent des tonnes de bois et pourtant il n’y a jamais eu besoin d’engrais chimiques ! »
- LGBTQIA+ : les agressions en forte progression depuis huit ans (stup.media)
- Éducation à la sexualité : l’État condamné pour 24 ans de manquements (politis.fr)
En France, l’éducation à la vie affective et sexuelle est inscrite dans la loi depuis 2001, organisée en trois séances par année scolaire. Dans la pratique, c’est loin d’être le cas. Face à ce manquement, le Planning familial, Sidaction et SOS Homophobie ont saisi la justice il y a deux ans et ont obtenu gain de cause le 2 décembre.
Spécial femmes en France
- Santé sexuelle : Sidaction s’alarme de la montée en puissance des discours masculinistes auprès des jeunes (publicsenat.fr)
31 % des 16-34 ans « se sentent plus puissants » quand ils ne portent pas de préservatif, 32 % pensent que les femmes doivent respecter leur refus d’en porter et 16 % voient dans ce mode de contraception « un signe de faiblesse ». Quant à la pratique répréhensible du « stealthing » (ndlr : retirer son préservatif sans prévenir son ou sa partenaire), 34 % des jeunes hommes adhérant aux théories masculinistes disent la cautionner. Et globalement, un homme sur dix (11 %), et un jeune de 25-34 ans sur cinq (18 %), déclarent comprendre ce retrait s’ils estiment que le préservatif a été imposé.
Voir aussi “C’est banalisé de le faire sans se protéger” : comment les lycéens sont incités “sur les réseaux sociaux” à des pratiques sexuelles risquées (franceinfo.fr)
- À Marseille, l’affaire de la femme tabassée par la police connaît un tournant, sept ans après les faits (huffingtonpost.fr)
Un policier a été mis en examen pour « violences aggravées » dans ce dossier longtemps ralenti par la culture du silence au sein des forces de l’ordre.
- Les réseaux français d’Epstein se découvrent (portail.basta.media)
- “En France, on peut faire 240 victimes et vivre sa vie tranquillement” : le calvaire de Sylvie, victime de soumission chimique par un haut fonctionnaire (france3-regions.franceinfo.fr)
Plus de 240 femmes accusent Christian Nègre, un haut fonctionnaire du ministère de la Culture, de les avoir droguées à leur insu lors d’entretiens d’embauche.
Spécial médias et pouvoir
- Face à Sophie Binet, Benjamin Duhamel se fait avocat de Bernard Arnault (acrimed.org)
Mardi 2 décembre, la secrétaire générale de la CGT, Sophie Binet est l’invitée de 8h20 sur France Inter, pour la première fois depuis la rentrée. L’occasion d’entendre les revendications des travailleurs ? Ou, pour les deux intervieweurs, de se faire les porte-voix du grand patronat.
- Le 20h de Salamé : l’info en mode zapping (acrimed.org)
- Bardella, l’œuf et la peur (politis.fr)
En quelques jours, le président du RN a été aspergé de farine et a reçu un œuf. Pour certains commentateurs, nous serions entrés dans une ère de chaos où la démocratie vacille au rythme des projectiles de supermarché. Ce qui devrait plutôt les inquiéter est la violence d’une parole politique qui fragilise les minorités, les élus et l’État de droit.
- Qui a peur de CNews ? (politis.fr)
Face à un média clairement d’extrême droite, la frilosité de l’Arcom, le « gendarme de l’audiovisuel », intrigue et inquiète.
- « Complément d’enquête » sanctionné, CNews favorisée : quand l’Arcom sacrifie l’audiovisuel public au profit de l’extrême droite (humanite.fr)
Par deux fois, l’émission « Complément d’enquête » s’est vue réprimander ces derniers mois par le régulateur des médias malgré un travail d’investigation de taille. En pleine commission sur l’audiovisuel public, ces décisions de l’Arcom interrogent : brimer une telle offre journalistique, sans motif sérieux, donne des gages à l’extrême droite
- Pierre-Édouard Stérin entre au capital de Valeurs Actuelles et place déjà ses gens de confiance (humanite.fr)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Emmanuel s’en va-t-en-guerre (blogs.mediapart.fr)
- Sur le budget de la Sécu, la Macronie rejoue la carte du catastrophisme surjoué (huffingtonpost.fr)
Comme l’an passé, une partie des troupes du président de la République alerte sur les risques de la non-adoption du texte avant le 31 décembre, quitte à exagérer.
- Le Conseil d’État enterre le droit de grève à Radio France (humanite.fr)
Le Conseil d’État vient de rejeter le recours des représentants du personnel et des syndicats contre un texte qui vise à limiter cette liberté fondamentale.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Fâché contre « Fachorama », le ministre de l’Intérieur porte plainte contre l’éditeur du jeu (huffingtonpost.fr)
Libertalia a dévoilé un nouveau jeu de sept familles en association avec le collectif antifasciste La Horde.

- Sophie Binet annonce sa mise en examen après avoir comparé des grands patrons menaçant de délocaliser à des “rats” qui “quittent le navire” (franceinfo.fr)
Fin janvier, elle avait réagi aux propos du patron du groupe LVMH, Bernard Arnault, qui estimait que le projet de surtaxe du gouvernement “poussait à la délocalisation”, en estimant que “ses propos sont à l’image du comportement des grands patrons aujourd’hui qui coulent le pays”, qui “n’en ont plus rien à faire de la France (…). Moi, j’ai envie de dire : les rats quittent le navire.”
- Loi Duplomb : un médecin convoqué à la gendarmerie pour un post Facebook, après la plainte d’une députée RN (reporterre.net)
Le 3 décembre, un médecin généraliste de Charente a été convoqué à la gendarmerie d’Angoulême en audition libre. Son tort ? Avoir dénoncé sur les réseaux sociaux « l’obscurantisme » de Caroline Colombier, députée Rassemblement national, en plein débat sur la loi Duplomb cet été.
- Menacé·es de prison pour l’organisation de manifestations à Sainte-Soline (basta.media)
Des porte-parole des Soulèvements de la terre, Bassines non merci, Solidaires et CGT comparaissent en appel ce 3 décembre. Des peines de prison avait été prononcées en première instance. Depuis, la bassine en cause a été déclarée illégale.
- Sur le plateau de Millevaches : des militant·es écolos sous surveillance (journal-labreche.fr)
- Gaz lacrymo et LBD pour avoir refusé d’abattre leurs vaches vaccinées contre la dermatose (basta.media)
175 gendarmes ont été déployés sur une ferme du Doubs où des agriculteurs et voisins s’étaient rassemblés pour empêcher l’abattage de 82 vaches. Une seule était atteinte de dermatose nodulaire contagieuse. L’enjeu pour l’État : préserver l’export.« On est traités pire que des terroristes juste parce qu’on veut défendre nos vaches. »
- Chronique du système policier : le taser, une arme dangereuse qui tue régulièrement, hooliganisme policier, racisme… (ricochets.cc)
- Des librairies indépendantes menacées et vandalisées (politis.fr)
Depuis plusieurs mois, des librairies indépendantes – à Paris comme en région – subissent vandalisme, menaces et cyberharcèlement […] par des « groupuscules ou individus se réclamant d’idéologies extrémistes », « motivés par le seul fait que certains livres sont vendus, présentés ou débattus avec leurs auteurs en librairie ».
- Jordan Bardella agressé lors d’une séance de dédicaces : le parquet requiert le placement du suspect en détention provisoire avant son procès (franceinfo.fr) – voir aussi « Quoi de n-œuf ? » : quand Jordan Bardella se moquait de l’œuf reçu par Emmanuel Macron (huffingtonpost.fr)
En 2017, celui qui était membre de l’équipe de campagne de Marine Le Pen ironisait sur l’agression subie par le candidat En Marche au salon de l’Agriculture.

- Zemmour définitivement condamné pour ses propos sur les mineurs isolés (huffingtonpost.fr)
La Cour de cassation a rejeté le pourvoi d’Éric Zemmour contre sa condamnation pour complicité d’injure publique et provocation à la haine après ses propos sur CNews en 2020.
- Derrière la Nuit du bien commun, l’ombre embarrassante de Stérin et toute une galaxie d’hommes d’affaires (multinationales.org)
Alors que son édition parisienne devrait se tenir ce jeudi 4 décembre, la Nuit du Bien commun tente de s’éloigner de son sulfureux fondateur Pierre-Édouard Stérin.
- À la frontière franco-britannique, la parade de l’extrême droite, entre associations inquiètes et forces de l’ordre passives (politis.fr)
Sur la plage de Gravelines, lieu de départ de small boats vers l’Angleterre, des militants d’extrême droite britannique se sont ajoutés vendredi 5 décembre matin aux forces de l’ordre et observateurs associatifs. Une action de propagande dans un contexte d’intimidations de l’extrême droite.
Spécial résistances
- “Non à la taxe Windows” : 20 organisations appellent à passer au logiciel libre (zdnet.fr)
- Mobilisations anti-Stérin : une « diagonale de la résistance » s’élargit face à l’extrême droite (basta.media)
Ce 4 décembre, plusieurs organisations appellent à un rassemblement devant les Folies Bergères, à Paris, où doit se tenir une Nuit du bien commun. Une mobilisation qui s’inscrit dans la continuité de nombreuses autres.
- Jordan Bardella au centre d’une plainte pour son média training financé par le Parlement européen (humanite.fr)
L’association AC ! ! Anti-Corruption a porté plainte auprès du parquet national financier (PNF), à propos d’une formation de relation avec les médias, qu’aurait suivi Jordan Bardella pour les élections présidentielles de 2022. Selon les informations du « Canard enchaîné », ce média training aurait été financé illégalement avec des subventions du Parlement européen.
- Collège de France : un colloque sur la Palestine annulé (ldh-france.org)
La LDH, le Syndicat national de l’enseignement supérieur (SNESUP) et la fédération syndicale unitaire (FSU) ont décidé de saisir le tribunal administratif de Paris d’un référé-liberté à l’encontre de cette décision attentatoire aux libertés académiques, au principe d’indépendance des enseignants-chercheurs, à la liberté d’expression collective des idées et des opinions et à la liberté de réunion. Le 12 novembre 2025, le juge des référés a rejeté la requête en jugeant que la décision litigieuse n’a pas porté une atteinte grave et manifestement illégale à la liberté d’expression, à la liberté de se réunir et à la liberté académique, de nature à justifier l’intervention du juge des référés dans un délai de 48 heures.
- Hennessy, Moët, Veuve Clicquot, Ruinart, Krug… Grève chez LVMH pour demander à Arnault de partager les richesses (humanite.fr)
Les branches M et H – champagne et cognac – de la multinationale de Bernard Arnault se sont mises en grève ce vendredi 5 décembre à l’appel de la CGT. La situation est d’autant plus conflictuelle que la santé financière de LVMH s’annonce excellente.
- La France attaquée en justice afin de prendre sa « part juste » aux efforts climatiques (reporterre.net)
- « À bas le service militaire, vive le service militerre » (reporterre.net)
Spécial outils de résistance
- “Oui, mais l’IAg….” Réponses à quelques arguments courants en faveur de l’intelligence artificielle générative (atecopol.hypotheses.org)
L’Atécopol lance un manifeste intitulé « Face à l’intelligence artificielle générative (IAg), l’objection de conscience » que vous pouvez lire et signer dans ce formulaire (framaforms.org) Le texte ci-dessous permet d’approfondir la réflexion au travers d’un ensemble d’éléments de réponse face aux arguments les plus communs circulant dans les institutions de l’Éducation Nationale et de l’Enseignement Supérieur et Recherche (et au-delà) pour légitimer la diffusion de l’IAg.
- Un outil interactif pour naviguer dans 80 ans de résolutions à l’ONU (portail.basta.media)
À l’occasion des 80 ans de l’Organisation des Nations unies, Le Monde diplomatique dévoile Résolutions !,une plateforme qui permet de parcourir huit décennies de décisions onusiennes et d’en comparer les votes, pour comprendre les mouvements qui ont façonné l’ordre international depuis la fin de la Deuxième Guerre mondiale.
Le lien vers la plateforme (monde-diplomatique.fr)
- Pour la création d’un réseau national de journalistes spécialistes de l’extrême droite (ripostes.org) – voir aussi StreetPress lance ses formations citoyennes (ripostes.org)
Les municipales 2026 approchent et StreetPress lance ses formations citoyennes. Objectif : mieux connaître l’extrême droite pour mieux la combattre. La bataille s’organise dès maintenant en suivant les webinaires.
- Une carte inédite des « nouveaux apôtres de l’extrême droite », ces associations soutenues par Stérin (basta.media)
« Basta ! » publie en exclusivité une cartographie des associations financées par l’écosystème du milliardaire d’extrême droite Pierre-Édouard Stérin. Elle est réalisée par le collectif de journalistes Hors Cadre, en collaboration avec WeDoData.
Spécial GAFAM et cie
- ‘The Precedent Is Flint’ : How Oregon’s Data Center Boom Is Supercharging a Water Crisis (rollingstone.com)
Amazon has come to the state’s eastern farmland, worsening a water pollution problem that’s been linked to cancer and miscarriages
- IA : Meta signe un accord de partenariat avec plusieurs médias internationaux, dont « Le Monde » (lemonde.fr)
Le contrat encadre l’usage des contenus publiés par « Le Monde », « Télérama », le « Huffington Post » et « Le Nouvel Obs » dans les services d’IA développés par le groupe américain, propriétaire de Facebook, Instagram et WhatsApp.
- Windows 11 force la main : des publicités intrusives arrivent… dans le clic droit (clubic.com)
Microsoft ne manque jamais d’humour quand il s’agit de l’expérience utilisateur sur son système d’exploitation fétiche. Alors que le géant de la technologie promettait de mettre de l’ordre dans ses menus, voilà qu’il y glisse de nouvelles publicités pour sa boutique d’applications directement sous le curseur de la souris.
- Bruxelles frappe fort – X écope d’une amende historique de 120 millions d’euros pour ses pratiques trompeuses (gigawatts.fr)- voir aussi Elon Musk estime que “l’Union européenne devrait être abolie”, après une amende infligée au réseau social X (franceinfo.fr)
Les autres lectures de la semaine
- Des marchands d’attention aux architectes de l’intention (danslesalgorithmes.net)
- Près de -30°C aux portes de Paris : retour sur la pire vague de froid de l’histoire moderne (meteo-paris.com)
- Tattoo ink moves through the body, killing immune cells and weakening vaccine response (latimes.com)
Scientists in Switzerland used a mouse model to trace what happens after tattooing. Pigments drained into nearby lymph nodes within minutes and continued to accumulate for two months, triggering immune-cell death and sustained inflammation. The ink also weakened the antibody response to Pfizer Inc. and BioNTech SE’s COVID vaccine when the shot was administered in tattooed skin. In contrast, the same inflammation appeared to boost responses to an inactivated flu vaccine.
- Islam : comment se fabrique l’inquiétude dans le débat public (theconversation.com)
- « Toute visibilité de la pratique religieuse de l’islam est vue comme une manifestation de l’islamisme » (orientxxi.info)
Olivier Roy, politiste et professeur à l’Institut universitaire européen de Florence, revient sur les bruyantes controverses qui ont suivi la publication, en novembre 2025, d’un sondage de l’Ifop sur la religiosité des musulmans de France. Il réfute plusieurs raccourcis et éclaire les raisons de la montée du discours islamophobe.
- Aimer sous contrat racial : lettre d’un homme noir queer (blogs.mediapart.fr)
- Le mythe de la femme métisse (politis.fr)
Il est déroutant pour les métis·ses d’être érigé·es en symbole de l’antiracisme et valorisé·es pour des caractéristiques physiques tout en faisant l’expérience quotidienne des inégalités raciales.
Les BDs/graphiques/photos de la semaine
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- Visualiser avec des petites perles ce que sont vraiment les impôts de Bernard Arnault (tube.fdn.fr)
- Zapping : les médias sonnent le tocsin (acrimed.org)
- Extrême droite et climatoscepticisme : à quoi sert le GIEC ? (humanite.fr)
Les trucs chouettes de la semaine
- Valve’s FEX-Emu Support Shows a Better Way to Fund Open Source (itsfoss.com)
- One of the best gaming Linux OSes just shifted 1,000,000 GB of ISOs in a single month (xda-developers.com)
- Steam On Linux Use Easily Hits An All-Time High In November (phoronix.com)
- Framatoolbox, une boite à outils numérique pour les p’tits besoins du quotidien (framablog.org)
Nous l’annoncions il y a quelques semaines, nous avons ouvert quatre nouveaux services !La semaine dernière nous vous proposions de découvrir les coulisses du nouveau Framadate et aujourd’hui, nous souhaitons vous présenter le deuxième service de la liste : Framatoolbox.

- Social media de-imagined. Use your words ! (cyberspace.online)
- Man unexpectedly cured of HIV after stem cell transplant (newscientist.com)
A handful of people with HIV have been cured after receiving HIV-resistant stem cells – but a man who received non-resistant stem cells is also now HIV-free
- Strandbeest (strandbeest.com)
Theo Jansen is engaged in creating new forms of life : the so called strandbeests. Skeletons made from yellow plastic tube (Dutch electricity ipe) are able to walk and get their energy from the wind. They have evolved since their inception in 1990 and have been divided into 12 periods of evolution.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
04.12.2025 à 10:30
Déjà 2 500 Framaspaces pour renforcer les structures qui changent le monde
Framasoft
Texte intégral (8330 mots)
Comme chaque année (2022, 2023, 2024), Framasoft fait le bilan de son projet de « cloud associatif et militant » : Framaspace.
- Framaspace : un cloud pour dégoogliser les assos
- Le cloud qui préfère les assos aux actionnaires
- 2025/26 : on étoffe, on améliore, on dégooglise
- Dans les coulisses
- Pour finir (et pour agir)
Framaspace : un cloud pour dégoogliser les assos
Depuis trois ans, Framasoft propose Framaspace, un service en ligne avec les caractéristiques suivantes :
- Un espace cloud de
40Go50Go et 50 utilisateur⋅ices maximum - Réservé aux associations et petits collectifs militants francophones
- basé sur le logiciel libre Nextcloud
- infogéré (c’est Framasoft qui se charge de la maintenance et des mises à jour)
- permettant de gérer
- des fichiers de tous types et de les partager
- des agendas, publics ou privés
- des contacts (synchronisés sur votre smartphone)
- des photos (partageables sous forme d’albums)
- des projets (méthode Kanban)
- de la documentation (en mode « wiki »)
- des visioconférences (jusqu’à une dizaine de personnes)
- des formulaires, publics ou privés
- des tableaux applicatifs (en mode « no-code »)
- des activités associatives et la gestion de leurs inscriptions
- des membres, et leurs éventuelles adhésions
- la comptabilité de la structure
- ou encore l’édition en ligne et à plusieurs de documents bureautiques (textes, feuilles de calculs, présentations, etc)
- le tout gratuitement (c’est Framasoft qui vous invite !)


Le cloud qui préfère les assos aux actionnaires
Framasoft fournit ce service gratuitement convaincue qu’en période de coupes budgétaires et de pressions sur le monde associatif, il est essentiel de garantir un accès équitable à des outils éthiques. Nextcloud étant complexe et coûteux à maintenir, nous mutualisons les efforts pour éviter que les structures à petit budget ne soient contraintes d’utiliser des services de multinationales aux logiques marchandes, voire autoritaires.
Exemples d’associations ou collectifs hébergés
Afin de rendre plus concret le type de public que sert Framaspace, voici 5 structures hébergées et suffisamment anonymisées, tirées au hasard (promis).
Association #1
Objet social ou mission : L’association a pour ambition principale de créer un mouvement démocratique et populaire à XXXXXX pour remettre les habitantes et habitants de la ville au cœur des décisions de gestion communale.
Actions principales : Dans le cadre de ses engagements pour un développement durable et une société plus juste, l’association XXXXXXXX a initié plusieurs projets importants. Nous avons mis en place une AMAP locale pour promouvoir l’agriculture durable et rapprocher les producteurs locaux des consommateurs, offrant ainsi des produits frais et de qualité tout en soutenant l’économie locale. En parallèle, notre association s’investit activement dans la lutte contre l’extrême droite, en organisant des événements de mobilisation et des campagnes d’éducation populaire pour éveiller la conscience politique des citoyens. Cette démarche vise à renforcer la résilience de notre communauté face aux idéologies divisives et à promouvoir des valeurs de solidarité et de respect mutuel. Nous avons également organisé la Fête des Possibles, un événement qui célèbre les initiatives locales en matière de développement durable et de vivre-ensemble. Cet événement offre une plateforme pour partager des idées, découvrir des innovations sociales et écologiques, et renforcer les liens au sein de la communauté. Enfin, nous apportons notre soutien aux élus de XXXXX, en collaborant sur divers projets visant à améliorer la qualité de vie dans notre commune. Grâce à ces efforts conjoints, nous œuvrons à transformer notre environnement local en un lieu plus inclusif, écologique et solidaire.
Raisons du besoin d’un compte Frama.space : Notre association nécessite un compte Frama.space afin de disposer d’un espace sécurisé pour partager et stocker efficacement nos documents. Cette plateforme nous permettra de centraliser nos informations importantes, facilitant ainsi l’accès et la collaboration entre les membres, tout en garantissant la confidentialité et l’intégrité de nos données.
Association #2
Objet social ou mission : XXXXXXX est un collectif né d’une volonté de raviver et redécouvrir les pratiques et imaginaires écoféministes. Nous pensons les luttes écologiques et féministes de façon indissociable, et attaquons de front un patriarcat blanc, cishétéronormatif, capitaliste et écocidaire. Nous nous imprégnons de pensées décoloniales, d’écologie queer, de luttes antivalidistes, d’antispécisme en pratique.
Actions principales : Nous avons 3 axes d’action : La parole : nous organisons des cercles de parole, pour parler de nos vécus en tant que personnes minorisées. Il s’agit de créer des enclaves de care dans un monde violent, ce qui nous apparaît comme profondément politique. L’apprentissage, la sensibilisation et la transmission : nous proposons des événements tels que des ateliers, des projections, des arpentages… Les actions concrètes locales : aller à des marches, réfléchir à des actions directes avec d’autres groupes, tisser des liens.
Raisons du besoin d’un compte Frama.space : En tant que membre du collectif XXXXXXX, je souhaite ouvrir un compte Frama.space car nous avons besoin d’un espace de travail pour pouvoir collaborer et organiser nos différentes actions. A ce jour, nous n’avons pas d’espace collaboratif, et à chaque fois que nous organisons des actions, nous devons retrouver les infos dans nos mails, dans nos échanges sur Discord, nous remettre en tête l’agenda, retrouver qui a dit qu’iel serait là, etc. C’est chronophage et cela ne nous permet pas de mettre notre énergie au bon endroit : réaliser nos actions sur le terrain. Avoir un espace de travail nous permettrait d’organiser nos infos, de mettre en avant les infos essentielles pour les nouvelleaux qui nous rejoignent, de ranger nos documents, etc. Ce serait vraiment génial ! ! ! Nous ne sommes pas un gros collectif, mais nous avons beaucoup d’idées et de rêves en tête pour militer et essayer de changer notre société, et cet espace nous permettrait de mettre notre énergie à ce service !
Association #3
Objet social ou mission : Promouvoir et diffuser des savoirs et solutions techniques, des modes de vie et d’organisations, simples, accessibles et durables favorisant la résilience individuelle et collective au niveau territorial ; maximiser l’utilité sociale de la technologie dans le respect des limites planétaires ; promouvoir et rechercher des solutions qui répondent notamment aux problématiques liées aux secteurs suivants : énergie, alimentation, gestion de l’eau, gestion des déchets, matériaux, habitat, transports, hygiène, santé.
Actions principales : -La conception, la fabrication, l’exploration, l’expérimentation, le prototypage d’objets, de techniques et de systèmes Low Tech, – Le partage d’expériences, la transmission et diffusion de savoirs et savoir-faire Low Tech auprès du grand public, des jeunes, des entreprises, des collectivités… – La sensibilisation et la formation à la démarche Low Tech, – Le développement de partenariats avec des acteurs présents sur le territoire, visant à renforcer ces actions.
Raisons du besoin d’un compte Frama.space : En tant que représentant du XXXXXXX, je souhaitais idéalement un outil global et collaboratif mais – et je ne dois pas être très original – le moins googleisé possible. La polyvalence et les possibilités actuelles de frama.space nous semblent tout à fait pertinents comme supports de suivi de nos projets partagé (stockage de fichiers, suite bureautique Collabora ou Onlyoffice, deck, talk etc.). Donc intéressé pour les possibilités ET la philosophie du projet.
Association #4
Objet social ou mission : L’Association XXXXXXXX est née à Lyon en 1996 Cette année-là, plusieurs personnes amputées ont décidé de se rencontrer pour partager leur expérience de l’amputation. Elles ont échangé des conseils, des informations, du soutien et ont décidé d’en faire profiter d’autres personnes en créant une association.
Actions principales : – Entraide : L’entraide est un axe essentiel et la raison première de notre association. Elle est orientée vers les personnes amputées et leurs proches, afin de répondre aux différentes questions qu’ils se posent. – Études : Nous participons aux évolutions des technologies et des pratiques pour une meilleure prise en charge de l’amputation. XXXXXXXX contribue régulièrement à faire progresser les sciences et les techniques, en partenariat avec des prothésistes, des scientifiques et des services de recherche universitaire. – Défense des droits : Nous sommes organisés pour un premier soutien juridique et pour une orientation vers les professionnels qui défendront les droits. – Communication : elle accompagne et fait connaître les actions d’entraide, de défense des droits, de loisirs et de recherches et études – Parasports et loisirs : Chaque année XXXXXX organise des activités sportives, essentiellement en extérieur, et des activités culturelles et conviviales. Communication, Activités de loisirs
Raisons du besoin d’un compte Frama.space : Il s’agit de créer un espace pour les adhérents actifs de l’association (une quarantaine environ), afin qu’ils aient accès à des documents partagés. Seul le secrétaire et webmestre (moi-même) et la présidente ont accès aux paramètres d’administration. Nous avons un hébergement sur OVH, mais il n’autorise pas les droits des documents partagés (le LDAP non activé). J’ai essayé d’y mettre Nextcloud, mais ça ne fonctionne pas. J’ai proposé de 5 à 10 comptes, mais cela serait étonnant que nous ne soyions plus de 3 ou 4. Merci.
Association #5
Objet social ou mission : Depuis l’obtention du label FSC en 2011, notre groupement forestier XXXXXXX n’a cessé de chercher à étendre la démarche d’écocertification au plus grand nombre d’acteurs possibles de la filière bois bourguignonne, dans le respect du cahier des charges, mais aussi de l’état d’esprit, du Forest Stewardship Council ®. Alors que la forêt morvandelle est en mutation, il est important de défendre une sylviculture raisonnable, qui ne fasse de nos bois ni un espace abandonné, ni la proie des profits immédiats. Car il s’agit non seulement de responsabilité vis-à-vis des générations futures et de lutte contre le changement climatique, mais aussi d’emplois, et de compétitivité de notre filière bois.
Actions principales : Le XXXXXXX est composé de propriétaires forestiers, soucieux du mode de gestion de leurs forêts. Il permet un travail et une réflexion commune et transversale à l’échelle d’un vaste territoire (Saône-et- Loire – Nièvre). C’est aussi une opportunité pour les petits propriétaires de bénéficier de coûts réduits, mais également d’un soutien technique sur le terrain. Les membres du groupement se sont engagés dans cette démarche en souhaitant qu’une filière de première et seconde transformation se mette en place rapidement sur le secteur. La majorité des forêts gérées par le groupement sont des forêts publiques très fréquentées par les habitants, les sportifs, les touristes. En outre la plupart abritent des milieux exceptionnels, avec des espèces protégées, et, comme pour la ville d’Autun, des réserves d’eau potable. La gestion appliquée dans ces forêts garantit, voire renforce la préservation du patrimoine et des ressources naturelles. La certification FSC apporte la reconnaissance internationale de cette gestion.
Raisons du besoin d’un compte Frama.space : Nous avons besoin d’une plateforme collaborative pour l’animation et la gestion du XXXXXXX, étant techniciens de différentes collectivités et association de protection de l’environnement. Nous préférons les outils développés par framasoft plutot que ceux développés par google !
—
Voilà, maintenant fermez les yeux et imaginez 2 500 structures de ce type, travaillant au quotidien sur un logiciel libre collaboratif tel que Nextcloud, et vous comprendrez pourquoi nous pensons que Framaspace à une réelle utilité sociale !
Pour en savoir plus sur le projet, vous pouvez vous référer : au site web Framaspace ou à la vidéo qui présente Framaspace.
Vous pourrez notamment comprendre pourquoi une petite association comme Framasoft s’est lancée dans le projet « un peu » fou de financer sur ses fonds propres jusqu’à 10 000 clouds associatifs (spoiler : « C’est politique ! »).
2025/26 : on étoffe, on améliore, on dégooglise
2025 : une année hyper-active
Boris rejoint la résistance
Tout d’abord, nous avons accueilli en mai dernier Boris, étudiant en alternance à Framasoft pour un an.
Ses missions :
- développer de nouvelles visites guidées pour Framaspace ;
- s’assurer de la maintenance de cette application au sein du magasin d’applications Nextcloud ;
- participer au support sur le forum Framaspace ;
- développer une application « Framaspace » qui permettra de répondre à un certain nombre de problématiques d’UX que nos utilisateur·ices rencontrent avec Nextcloud.
Et pour information, Boris cherche, pour sa deuxième année, une entreprise qui pourrait l’accueillir (en alternance toujours) comme DevOps à partir de mai/juin 2026, laissez-nous un commentaire si son profil vous intéressse.
Nouvelles visites : suivez le guide !
L’an passé, Val, stagiaire à Framasoft, avait développé l’application Nextcloud « Visites Guidées ».
Cette année, Boris a ajouté deux nouvelles visites guidées à Framaspace (« Formulaires » et « Deck »), afin que les personnes découvrant Framaspace pour la première fois puissent découvrir ces fonctionnalités en autonomie.
Par ailleurs, Boris a mis à jour « Visites guidées » sur le magasin d’application de Nextcloud, ce qui signifie que ces nouvelles visites guidées peuvent aujourd’hui être visibles en dehors de Framaspace, pour toute personne disposant ayant installé l’application.
Liaison Paheko stabilisée (enfin, on l’espère !)
Paheko, c’est la (super) application qui vous permet de gérer votre comptabilité associative, vos membres (et leurs éventuelles adhésions), les activités de votre association, etc. Il s’agit d’un logiciel libre autonome.
Suite à un développement internet, nous avons intégré Paheko à Nextcloud/Framaspace l’an passé. Mais cela a nécessité pas mal de « bidouilles » de notre part (encore un grand merci à Bohwaz, développeur de Paheko, de nous avoir guidé pour éviter plusieurs écueils). Cependant, pour des raisons techniques un peu complexes, la liaison entre Framaspace et Paheko était imparfaite, ce qui entraînait dans certains cas une impossibilité de pouvoir utiliser Paheko-dans-Framaspace. En 2025, nous avons corrigé une partie de ces problèmes, si vous y avez été confronté⋅es, n’hésitez pas à réessayer. Notez cependant que le temps nous a manqué, et qu’il reste encore peut-être des bugs. Si c’est le cas, nous nous ré-attellerons à cette tâche dans les mois qui viennent.
Framaspace… sur papier
Framaspace est un des projets les plus ambitieux de l’histoire de Framasoft. Le projet étant complexe, il nous manquait un support pour le promouvoir.
Grâce à Brume, Bookynette et Numahell, c’est maintenant chose faite. Sur la base des magnifiques illustrations de David Revoy, nous avons donc maintenant un magnifique dépliant qui nous permet de présenter Framaspace lors d’événements.

Capture écran du fichier PDF du dépliant 3 volets présentant Framaspace.
D’ailleurs, si vous souhaitez le télécharger pour l’imprimer, le PDF est disponible (nous mettrons les sources à disposition dès que nous les aurons allégées).
Framaspace en 5 minutes chrono
Nous le savons bien : une des difficultés à l’usage de Framaspace vient du fait que le logiciel Nextcloud n’est pas toujours simple à prendre en main. Surtout pour des personnes peu habituées au numérique collaboratif. C’est pourquoi nous avons fait réaliser cette courte vidéo de présentation par nos amies de L’Établi Numérique et de La Dérivation.
Proposée à chaque usager⋅e à la première ouverture de son espace, cette vidéo de quelques minutes permet de faire le tour des principales fonctionnalités de Framaspace.
Mises à jour Nextcloud : nous, on transpire ; vous, vous profitez !
Comme chaque année, nous avons mis à jour Nextcloud, le logiciel qui motorise Framaspace.
D’abord une première fois en avril 2025, avec un passage en version 30. Puis une seconde fois en octobre, pour le passage en version 31.
Ces mises à jour apportent, comme vous pouvez le lire dans les liens ci-dessus, de très nombreuses corrections et nouvelles fonctionnalités : améliorations des performances, recherche instantanée, nouvelle interface de partage de fichiers, interface avancée d’édition d’événements, conversion de fichiers intégrée, etc.
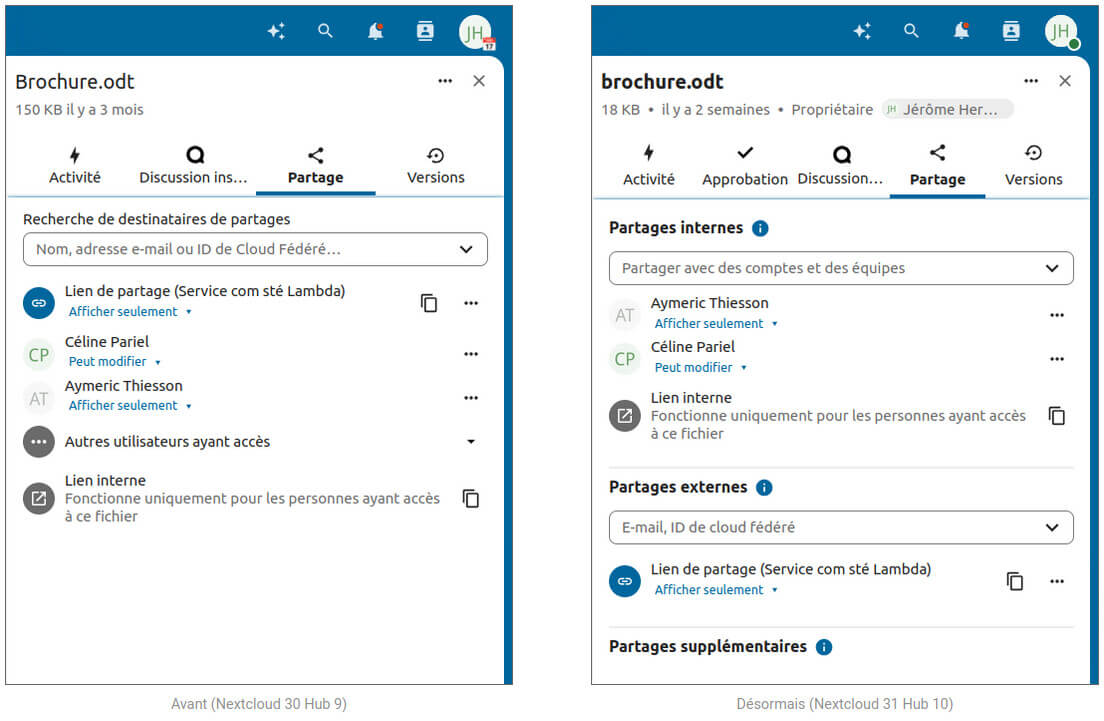
Captures écrans des interfaces de partage de fichiers entre les versions Nextcloud 30 et Nextcloud 31
Ce qu’on bidouille là, en ce moment
+10 Go : c’est cadeau
🎁 À Framasoft, on est des oufs ! On vous offre 10Go en plus, gratuitement ! 🎁
🎅 Oui, vous avez bien lu : gra-tui-te-ment ! ! Ce Noël, ça va être votre fête ! ! 🎉
Demandez immédiatement vos 10Go supplémentaires avec le code BLAGUEFRIDAY-SIXBEARMONDAY ! 🥳
…
Hum, pardon, on voulait voir ce que ça faisait de se mettre dans la peau de la team marketing d’Orange ou de SFR. Non pas qu’on ait toujours rêvé de porter les cravates de Jean-Michel-Marketeux, mais il fallait essayer.
Par contre, l’annonce reste valable : l’espace maximal disponible pour chaque Framaspace passe de 40Go à 50Go. Sans surcoût, puisque Framaspace est gratuit. D’abord parce qu’on est sympas (on peut quand même s’envoyer quelques fleurs), ensuite parce que ça rend l’offre beaucoup plus lisible : « Framaspace, c’est 50Go et 50 comptes maximum », c’est beaucoup plus facile à comprendre et à retenir pour vous (et pour nous aussi !).
Des visios à plus que 2, c’est mieux ©™
Framaspace embarque Nextcloud Talk, qui propose notamment du tchat pour les membres de votre espace (et vos invité⋅es).
Mais Talk vous permet aussi des visios pour se regarder dans le blanc des yeux !
Cela pourrait paraître génial pour permettre aux personnes ne pouvant pas se déplacer à votre AG d’y assister malgré tout, non ?
Et bien non 😅 !
Parce que pour le moment, l’infrastructure de Framaspace supporte mal les visios à plus de 2 ou 3 personnes. Ce qui est un peu limitant, il faut le reconnaître 😝
Nous travaillons donc en ce moment même à mettre en place une nouvelle machine pour passer outre cette limitation. On ne vous garantit pas que vos visios tiendrons 50 ou même 20 personnes simultanément, car Framaspace est une offre mutualisée ET fournie gratuitement par Framasoft. Rajouter des serveurs a un coût humain et financier non négligeable pour nous. Donc, nous commencerons avec un unique serveur, et nous ferons le point sur son usage fin 2026, ainsi que sur nos finances, afin de voir si nous avons le temps, l’énergie, et l’argent nécessaires pour mieux répondre à ce besoin.
Si tout va bien, ce nouveau serveur « HPB » (pour High Performance Backend), devrait être mis en place pour fin décembre, et directement intégré à votre espace. Si vous êtes utilisateur⋅ice de Framaspace, vous recevrez une notification lorsque la fonctionnalité sera disponible.
« Cachez-moi ces applications que je ne saurais voir »
Si vous êtes administrateur ou administratrice d’espace Framaspace, peut-être trouvez-vous que certaines applications (par exemple « Formulaires » ou « Tableaux ») ne font pas sens pour votre association ou collectif ? Ou peut-être que vos membres risquent d’être un peu perdus lors du premier usage de Framaspace ?
Alors, ça tombe bien, car Boris (notre super-alternant évoqué plus haut) a développé une micro-application qui permet aux admins d’espaces de masquer les applications pour les utilisateur⋅ices.
Cette fonctionnalité nous est remontée chaque année par les étudiant⋅es en design de l’école Strate, guidée par leur enseignante Marie-Cécile Godwin avec qui nous travaillons depuis plusieurs années sur les problématiques d’UX/UI de Nextcloud.
Vous verrez donc bientôt apparaître, dans le menu administrateur, une option pour masquer les applications de votre choix à vos utilsateur⋅ices (sauf les applications « Fichiers » et « Activités » qui sont protégées).
Notez que cette option n’est pas encore disponible.
2026 : demandez le programme !
Veuillez noter que ce qui suit est un ensemble d’envies pour 2026 si nos moyens nous le permettent, et en aucun cas un engagement.
Migration vers Nextcloud 32 (et + si affinités)
Comme chaque année, nous effectuerons les montées en version majeure de Nextcloud, une fois ces dernières stabilisées.
Vous pouvez déjà voir les nouveautés apportées par Nextcloud 32 (ou chez nos camarades de la société Arawa). Nous envisageons la mise-à-jour pour Framaspace durant le printemps.
La version 33, elle, devrait être publiée en février prochain. Suivant son niveau de stabilité, nous pourrions envisager une migration fin 2026.
Impersonate : des dépannages plus efficaces
Les administateur⋅ices de Framaspace nous remontent régulièrement le problème suivant : lorsque des utilisateur⋅ices rencontrent des soucis à l’usage avec Framaspace, il est souvent difficile de les dépanner.
– utilisateur : « Je n’arrive pas à partager mon fichier publiquement ! »
– admin : « Tu as bien cliqué sur « Partager > Créer un partage de lien public » ? Tu as bien lu la documentation ? Et tu as bien regardé les captures écrans ? »
– utilisateur : « Oui ! C’est nul ton truc. Je veux retourner chez Google Drive ! »
L’admin cherche pendant 2 heures, interroge le forum Framaspace, finit par faire 20mn de vélo sous la pluie pour aller chez l’utilisateur, et constate que ce dernier avait partagé un lien privé. (non, vous ne me ferez jamais avouer que cet exemple est bien trop spécifique pour ne pas être tiré de la réalité ! 😝)
C’est à ce genre de cas d’usage que répond l’application « Impersonate ». Elle permet aux admins Nextcloud de s’identifier comme s’ils étaient l’utilisateur de leur choix. Ainsi, dans l’exemple précédent, l’admin aurait tout simplement pu « prendre la personnalité » de l’utilisateur, naviguer dans ses fichiers, et constater de visu qu’aucun partage public n’avait été créé (et en plus ça lui aurait éviter de rentrer frigorifié et trempé).
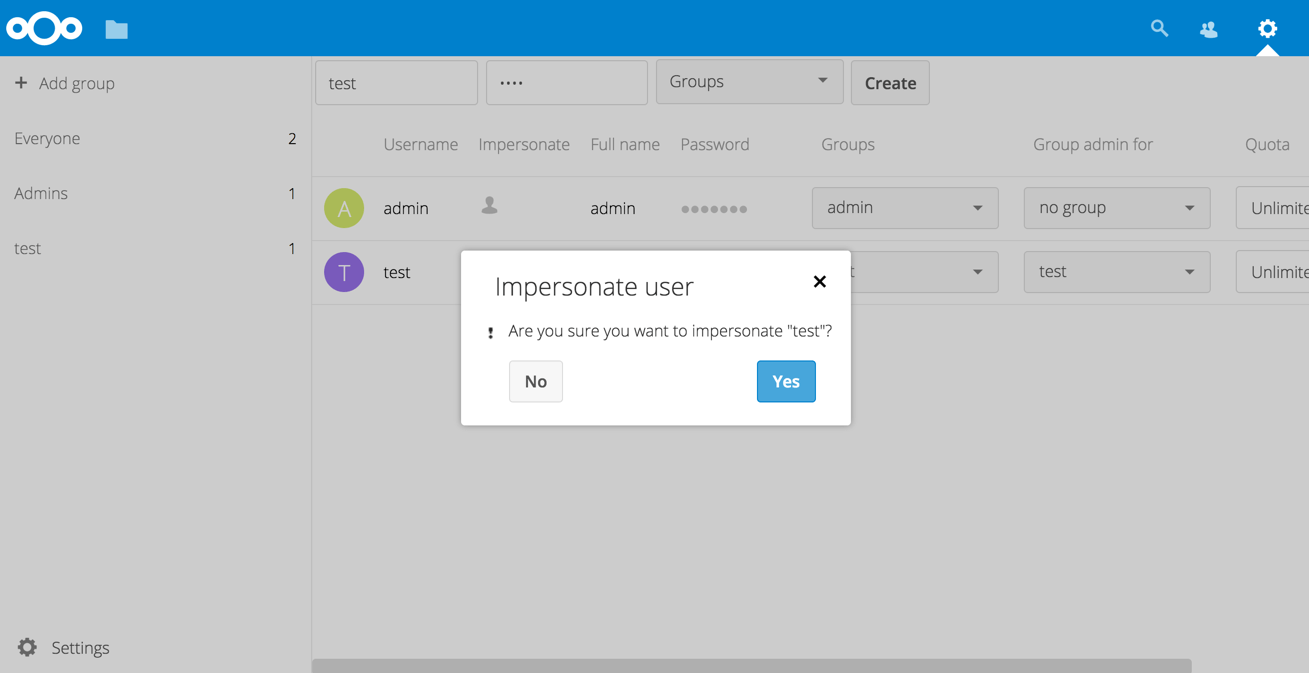
Capture écran de l’interface de l’application Impersonate, qui permet aux admins d’agir « comme si » ils étaient identifié comme l’utilisateur de leur choix.
Cela fait plusieurs mois que nous pensons à déployer cette fonctionnalité, mais nous souhaitions le faire dans les meilleures conditions, c’est-à-dire en prévenant TOUS les utilisateurs existants que les administrateurs d’espaces peuvent bien avoir accès à leurs fichiers, contacts ou agendas. En réalité, c’est déjà le cas (via l’application OwnershipTransfer) ou tout simplement en changeant le mot de passe de l’utilisateur par un mot de passe temporaire. Cette nouvelle facilité donnée aux admins d’espace doit faire l’objet d’une information large, et suffisamment claire. Il faut en effet rappeler que les Framaspaces sont des espaces de travail collaboratifs relatifs à une structure ou un collectif, et non des espaces personnels. Il faut donc retenir que sur Framaspace, les admins peuvent tout voir/savoir, un peu comme sur un ordinateur où l’administrateur peut avoir tout pouvoir sur la machine et les données qu’elle contient.
C’est donc après de nombreuses heures de discussions/réflexions que nous avons décidé d’arbitrer en choisissant que nous déploieront l’application « Impersonate » après une phase de communication conséquente.
Visites guidées renforcées
Évidemment, en 2026, nous rajouterons de nouvelles visites guidées, notamment pour les applications « Tableaux » et « Collectives », qui sont relativement difficiles à prendre en main par les utilisateur⋅ices.
Le tuto dont vous êtes le héros
On l’a vu précédemment : une des principales difficultés avec Nextcloud (et donc Framaspace), c’est ce que l’on nomme l’onboarding, c’est à dire la capacité à embarquer un nouvel utilisateur dans un usage « agréable » de la plateforme. C’est pourquoi Framasoft a intégré la vidéo de présentation évoquée plus haut, ou a développé l’application Visites guidées.
En 2026, nous souhaiterions aller plus loin que la production d’une simple documentation ou vidéo-tutoriel, qui peuvent s’avérer rapidement obsolètes, et surtout sont assez linéaires.
Après avoir retourné le problème dans tous les sens, nous voulons expérimenter une autre façon de faire un tutoriel. Qui soit plus interactif. Plus proche des besoins réels des utilisateur⋅ices. Qui puisse être enrichi facilement. Et soyons dingues, qui puisse être un peu ludique !
Ainsi, si le temps (et vos dons !) nous le permettent, nous devrions pouvoir publier une première version de ce « tutoriel dont vous êtes le héros ou l’héroïne », inspiré du fonctionnement des « Livres dont vous êtes le héros ».
On espère vous en dire plus dans le premier semestre 2026 !
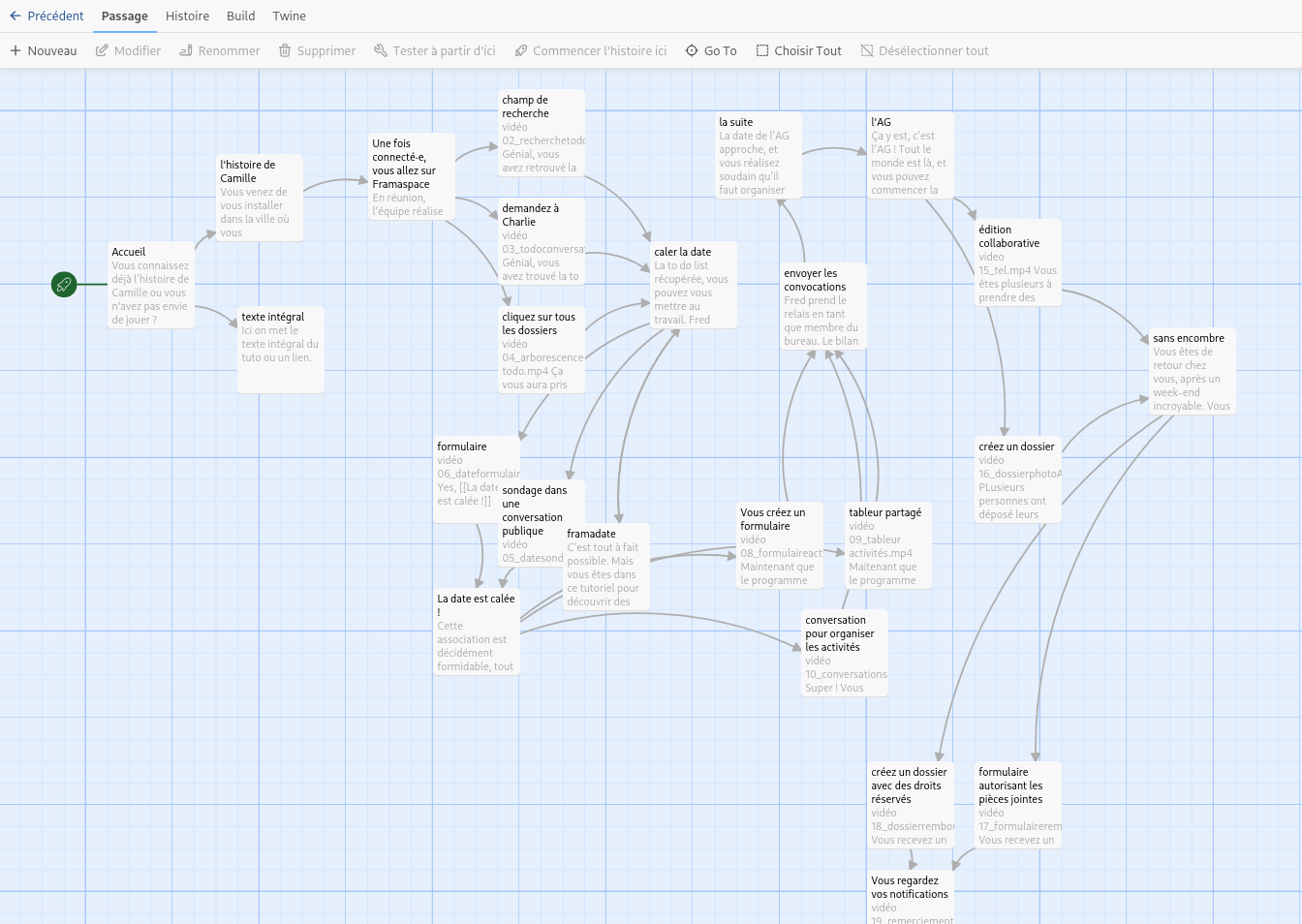
Capture écran d’un scénario de tutoriel interactif pour Framaspace, utilisant le logiciel libre Twine.
Le cockpit dont rêvent les admins
Parmi les travaux de Boris, il y aura – là encore, si tout va bien – la possibilité pour les administrateur⋅ices d’espaces d’accéder à un « Tableau de bord du Framaspace » avec diverses informations pratiques : quota de fichiers utilisés, utilisateurs les plus gourmands en espace disque, liste des 10 plus gros fichiers de l’espace, nombre d’utilisateurs connectés les dernières heures (jours/semaines/mois), suite bureautique utilisée, etc.
Fast & Furious
(ne vous plaignez pas, on aurait pu faire rimer avec couscous)
Depuis la mise en service de Framaspace, nous utilisons le logiciel libre Minio pour gérer le stockage de fichiers en mode « objet ».
En effet, Framaspace, c’est 320 téraoctets d’espace disque réservés, sur lesquels 192To (soit 192 000Go tout de même) sont réellement utilisables, le reste étant dédié à la sécurisation de données. Certains Framaspaces accueillent plus de 50 000 fichiers (et certains plus de 100 000 😱).
C’est donc Minio qui gère ces millions de fichiers. Or Minio montre certaines limites pour diverses raisons, et surtout depuis le 3 décembre 2025 (c’est donc tout frais !) est passé en mode « maintenance seulement », au profit de sa version propriétaire (on vous en reparlera sans doute). Par conséquent, nous envisageons une migration vers un autre logiciel libre, SeaweedFS. Cette opération sera coûteuse en temps et en énergie (et là encore, en argent), mais nous espérons qu’elle permettra d’accroître les performances de la partie « Fichiers » de Framaspace.

La façon dont l’auteur de ces lignes imagine l’admin-sys de Framasoft gérer les serveurs Framaspace.
Dans les coulisses
5 000 espaces fin 2026 ? 10 000 avant 2030 ?
Parti de zéro fin 2022, Framaspace comptait 700 espaces fin 2023, 1 500 fin 2024 et aujourd’hui environ 2 500 espaces. Novembre 2025 a d’ailleurs été le mois où nous avons déployé le plus d’espaces dans l’histoire du projet, avec 180 nouveaux Framaspaces, et donc autant d’instances Nextcloud. À ce rythme là, nous devrions atteindre les 5 000 espaces d’ici 12 à 18 mois. Cela pourrait être plus long, car les espaces inactifs pendant plusieurs mois sont automatiquement désactivés, puis supprimés quelques mois plus tard.
À notre connaissance, Framasoft, micro-association française, est donc devenue sans vraiment le vouloir le plus gros hébergeur associatif mondial de la solution libre Nextcloud 😅
Nous estimons notre technologie et notre infrastructure singulières, mais robustes. Elles nous permettent de déployer rapidement des dizaines d’instances Nextcloud par jour. Les personnes intéressées par les aspects techniques peuvent se référer à notre article technique présenté lors des JRES 2024 (voir ici pour une courte présentation vidéo lors de cet événement).
La fabrique des Framaspaces
Souvent, les personnes avec lesquelles nous échangeons ont tendance à penser que nous sommes des dizaines de salarié⋅es à travailler sur un tel projet. Nous aimerions bien 😝
La réalité est toute autre. En effet, lissé sur l’année, on peut comparer le temps de travail dédié à Framaspace à… un mi-temps d’une seule personne ! Cela peut paraître assez fou – en tout cas, pour nous, ça l’est ! – mais Framaspace est actuellement géré par :
- un administrateur systèmes pour gérer la vingtaine de serveurs du projet, et l’ensemble du processus de déploiement, qui y consacre en gros 15 % de son temps de travail (car Framaspace n’est qu’un des multiples services hébergés par Framasoft) ;
- un développeur Nextcloud, pour s’assurer des mises-à-jour logicielles, développer les correctifs Nextcloud (et il en a proposé… beaucoup !), gérer les différentes applications, etc. Il y consacre environ 20 % de son temps de travail, puisque le reste du temps, il est… directeur de l’association Framasoft 😅 ;
- un « chef de projet » (si on était modernes, on parlerait de Product Owner) pour coordonner les différentes tâches autour du projet (communication, backlog, sélection des candidatures, conférences, etc), pour environ 15 % de son temps de travail.
Cela représente donc un demi équivalent temps plein, pour fournir un service cloud à plus de 20 000 personnes aujourd’hui !
Un coût conséquent, mais maîtrisé
Si on ajoute le coût – conséquent – de l’infrastructure technique, nous estimons que Framaspace coûte à Framasoft environ 30 000€ par an. Cela peut paraître énorme à certain⋅es, d’autant que nous finançons ce projet sur nos fonds propres, mais cela est en fait relativement ridicule par rapport au service fourni (ici : 2 500 instances Nextcloud). Ainsi, lorsqu’on nous demande
« Combien coûterait un Framaspace si Framasoft ne l’offrait pas gracieusement ? »
nous répondons qu’actuellement, déployer un Framaspace nous coûte environ 12€ par an (soit environ 1€ par mois), mais que si on veut y intégrer les frais engagés les années précédentes, on est plutôt autour de 50€/espace.

Pour finir (et pour agir)
Les retours que nous avons sur Framaspace sont très positifs. Une fois passée la phase parfois frictionnelle d’onboarding évoquée plus haut, les utilisateurs semblent plutôt satisfaits du service rendu !
Nous avons fait le choix de la gratuité avec fierté, et sans regret, car nous pensons que l’argent ne devrait pas être un discriminant pour s’émanciper des GAFAM et accéder à des services libres de qualité. Si vous en avez le besoin pour votre association ou collectif, n’hésitez donc pas à candidater, ou à en parler autour de vous !

Cependant, comme évoqué plus haut, c’est un projet très coûteux pour notre association. Framasoft, pour différentes raisons, souhaite conserver un modèle économique basé sur le don et le mécénat, et non sur la vente de produits ou de prestations de service à des clients (il y a d’autres structures qui font cela très bien).
Si vous trouvez ce projet utile, que vous en bénéficiez ou pas, merci alors de soutenir Framasoft. Votre don, qu’il soit de 10€ ou de 100€ (défiscalisables !) nous permettra d’ouvrir toujours plus de Framaspaces, afin de pouvoir dégoogliser toujours plus d’associations et collectifs qui changent le monde !
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- Dans les algorithmes
- Framablog
- Gigawatts.fr
- Goodtech.info
- Quadrature du Net
- INTERNATIONAL
- Alencontre
- Alterinfos
- CETRI
- ESSF
- Inprecor
- Journal des Alternatives
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview