
ACCÈS LIBRE UNE Politique International Environnement Technologies Culture
11.10.2025 à 08:26
Sommes-nous plus bêtes que nos parents ?
Vous avez peut-être entendu parler du déclin de l’intelligence ? C’est cette idée selon laquelle le quotient intellectuel moyen a tendance à diminuer dans le monde occidental. De quoi s’alarmer sur l’état du monde, les politiques publiques, l’éducation et l’avenir de la jeunesse ! Ce déclin existe-t-il vraiment ? Le déclin de l’intelligence est à la mode depuis quelques années. Le documentaire « Demain, tous crétins ? » diffusé par Arte en 2017 a diffusé cette polémique en France. La presse s'en est rapidement emparée à travers des titres alarmistes, comme « Le QI des Français en chute libre », « Et si l'humanité était en train de basculer dans l'imbécillité ? », ou même « Alerte ! Le QI des Asiatiques explose, le nôtre baisse ». On s’est inquiété, et comme dans toute panique morale, des coupables ont été désignés. Selon leurs orientations politiques, les commentateurs ont blâmé les pesticides et perturbateurs endocriniens, la désaffection pour la lecture, la réforme de l’orthographe, la construction européenne, ou bien sûr, l’exposition aux écrans. Avant de chercher pourquoi l’intelligence déclinerait, encore faut-il être sûrs qu’elle décline. Cette idée d’une diminution de l’intelligence est pour le moins surprenante, car l’intelligence moyenne a plutôt augmenté au cours du XXe siècle. Plusieurs centaines d’études impliquant des millions de participants dans plus de 70 pays montrent qu’en moyenne, chaque génération fait mieux que la précédente sur les tests d’intelligence. Si on préfère parler en termes de quotient intellectuel (QI : le score global à travers un ensemble d’épreuves d’intelligence – sa moyenne est fixée à 100, la plupart des gens se situent entre 85 et 115), le quotient intellectuel moyen a augmenté d’environ 3 points tous les dix ans depuis le début du XXe siècle. Cette augmentation de l’intelligence moyenne à chaque génération s’appelle l’effet Flynn. On connaît l’effet Flynn depuis les années 1930, et on l’attribue aux grandes améliorations du XXe siècle , telles que la baisse de la malnutrition et des maladies infantiles, ou le développement de la scolarisation. Aujourd’hui, il est ralenti dans les pays développés, mais continue à pleine vitesse dans les pays en voie de développement (les scores d’intelligence y augmentent deux fois plus vite, environ, que dans le monde occidental). Que notre effet Flynn ralentisse ou s’interrompe, rien d’étonnant : la scolarisation et les qualités de notre système sanitaire ne progressent plus à grande vitesse. Mais un déclin de l’intelligence ? De petites baisses sont bien retrouvées par une poignée d’études, mais elles sont sans commune mesure avec les gains du XXe siècle. L’exemple de la Norvège (Figure 1) est frappant : ces données de grande qualité (jusqu’au début du XXIe siècle, la Norvège a évalué l’intelligence de l’ensemble de sa population masculine dans le cadre du service militaire obligatoire) montrent bien une petite diminution dans les années 2000, mais elle tient plus de la fluctuation aléatoire. D’où vient, alors, l’idée que l’intelligence s’effondrerait en France ? La littérature ne contient qu’une unique étude d'Edward Dutton et Richard Lynn portant sur un échantillon de 79 personnes. C’est un très petit échantillon pour déclencher une panique morale, bien sûr : 79 personnes ne sont pas vraiment représentatives de la France dans son ensemble. Quand on crée un test d’intelligence, on l’étalonne plutôt sur un échantillon d’au moins 1000 personnes pour avoir une bonne estimation de la moyenne (c’est le cas de l’échelle d’intelligence pour adultes de Wechsler, la WAIS, la plus utilisée en France). Mais le problème de cette étude est surtout dans sa méthode et dans ses résultats. Notre petit groupe de 79 personnes a passé deux tests d’intelligence en 2009 : un ancien test d’intelligence (la WAIS-III, étalonnée en 1999), et un test plus récent (la WAIS-IV, étalonnée en 2009). En comparant les résultats de ce groupe de 79 personnes à la moyenne de l’échantillon de référence pour chacun de ces tests, Dutton et Lynn constatent que les résultats de ce groupe sont légèrement plus faibles que la moyenne sur l’ancien test d’intelligence, et légèrement plus élevés que la moyenne sur le nouveau test ; ils en déduisent qu’il était plus difficile d’obtenir un bon score sur le test de 1999… donc que l’intelligence moyenne a diminué entre 1999 et 2009. Sur le principe, le constat de Dutton et Lynn est correct : nous avons tendance à faire moins bien sur les anciens tests d’intelligence (nous avons répliqué ce résultat à un peu plus grande échelle). Mais le problème est qu’il y a d’autres raisons qu’un déclin de l’intelligence pour expliquer que les gens fassent moins bien en 2009 sur un test paru en 1999. Pour bien comprendre, il faut s’intéresser au contenu du test. Un test d’intelligence de type WAIS est composé d’un ensemble d’épreuves qui mesurent des choses différentes : le raisonnement logique abstrait (ce qu’on entend généralement par « intelligence » : compléter une série de figures géométriques, reproduire un dessin abstrait à l’aide de cubes…), mais aussi les connaissances (vocabulaire, culture générale…), la mémoire, ou encore la vitesse de traitement de l’information. Dans l’étude de Dutton et Lynn, les scores sont en fait rigoureusement stables dans le temps pour le raisonnement logique abstrait, la mémoire ou la vitesse de traitement, qui ne déclinent donc pas : les seuls scores qui sont plus faibles en 2009 qu’en 1999, ce sont les scores de connaissances. On retrouve exactement la même chose dans d’autres pays, comme la Norvège : le raisonnement logique abstrait est constant dans le temps tandis que les scores de connaissance deviennent plus faibles sur les anciens tests. L’intelligence générale ne décline donc pas, ni en France ni dans le monde occidental. Dans ce cas peut-on au moins se plaindre que les connaissances ont décliné : la culture se perd, les jeunes n’apprennent plus rien ? Même pas : si les gens font moins bien sur les anciennes versions des tests d’intelligence, c’est tout simplement parce que les questions deviennent obsolètes avec le temps. La WAIS-III demandait aux Français de calculer des prix en francs, de comparer les caractéristiques des douaniers et des instituteurs, de citer des auteurs célèbres du XXe siècle. Avec le temps, ces questions sont devenues plus difficiles. Les scores au test ont baissé, mais pas l’intelligence elle-même. Nous avons montré que cette obsolescence suffit à expliquer intégralement les résultats de Dutton et Lynn. Voici un petit exemple, tiré du tout premier test d’intelligence : il s’agit d’un texte à compléter, destiné à évaluer la présence d’une déficience chez de jeunes enfants. Pouvez-vous faire aussi bien qu’un enfant de 1905 en retrouvant les neuf mots manquants ? Il fait beau, le ciel est —1—. Le soleil a vite séché le linge que les blanchisseuses ont étendu sur la corde. La toile, d’un blanc de neige, brille à fatiguer les —2—. Les ouvrières ramassent les grands draps ; ils sont raides comme s’ils avaient été —3—. Elles les secouent en les tenant par les quatre —5— ; elles en frappent l’air qui claque avec —6—. Pendant ce temps, la maîtresse de ménage repasse le linge fin. Elle a des fers qu’elle prend et repose l’un après l’autre sur le —7—. La petite Marie, qui soigne sa poupée, aurait bien envie, elle aussi, de faire du —8—. Mais elle n’a pas reçu la permission de toucher aux —9—. Les mots « amidonnés » (3), « poêle » (7), et « fers » (9) vous ont probablement posé plus de problèmes qu’à un enfant de 1905 ; mais vous conviendrez sûrement que cette difficulté ne dit pas grand-chose de votre intelligence. Les scores d’intelligence sur ce test ont bien décliné, mais c’est plutôt l’évolution technologique du repassage qui rend le test obsolète. De la même façon, la probabilité qu’une personne dotée d’une intelligence moyenne (QI=100) réponde correctement à une question de la WAIS portant sur la pièce de théâtre Faust était de 27 % en 1999, elle est de 4 % en 2019. Ainsi, les scores aux tests de connaissance déclinent naturellement dans le temps, au fur et à mesure que la culture évolue. C’est même pour cette raison que de nouvelles versions des tests d’intelligence paraissent régulièrement : la WAIS est remise à jour tous les dix ans environ (et la WAIS-V devrait paraître en 2026). Confondre un déclin de l’intelligence avec l’obsolescence des questions du test, c’est tout de même une grosse erreur. Comment Dutton et Lynn ont-ils pu la commettre ? C’est que l’erreur n’est pas innocente, et que ces deux auteurs ne sont pas tout à fait neutres. La discipline d’Edward Dutton est la théologie, Richard Lynn est connu pour défendre l’idée qu’il existe des différences génétiques d’intelligence entre les sexes et les origines ethniques ; les deux ont été éditeurs en chef d’une célèbre revue suprémaciste blanche (Mankind Quarterly) et leurs travaux alimentent directement les mouvements d’extrême droite. Pour bien saisir l’agenda politique des auteurs, le mieux est peut-être de citer les explications qu’ils envisagent pour un déclin de l’intelligence. Deux extraits, issus des livres de Richard Lynn pour l’illustrer : « … un grand nombre de gouvernements occidentaux ont contribué au déclin de l’intelligence depuis les années 1960, à travers une politique d’état-providence encourageant les femmes d’intelligence basse, de mauvaise moralité et de faible éducation à avoir des bébés… ». « … l’immigration de masse de peuples non-européens en Europe de l’ouest, aux États-Unis et au Canada est un sérieux problème dysgénique… ils ont, en moyenne, une plus faible intelligence et une plus faible moralité… ils deviendront une majorité de la population en Europe de l’ouest… l’intelligence continuera à décliner… et la Chine deviendra une superpuissance mondiale » Les réformes envisagées par les auteurs pour limiter le déclin de l’intelligence en Europe occidentale sont cohérentes avec leur orientation politique : on y trouve, par exemple, « abolir la sécurité sociale », « se retirer de la convention des Nations unies de 1951 sur l’accueil des réfugiés », ou encore « introduire des politiques publiques pour accroître la fertilité de ces femmes (intelligentes) qui ont été éduquées au point de perdre leur fonction reproductive ». Aujourd’hui, nous avons la certitude qu’il n’y a pas réellement de déclin de l’intelligence en France, même si l’effet Flynn est bel et bien interrompu. Le déclin de l’intelligence dans le monde occidental n’est pas un sujet scientifique, mais plutôt un sujet politique – un argument idéal que les déclinistes utilisent pour faire peur, désigner des coupables, et promouvoir des réformes hostiles au changement. Si cette idée a autant de succès, c’est probablement qu’elle parle à nos tendances profondes : au second siècle de notre ère, Hésiode se plaignait déjà que les nouvelles générations laissent plus de place à l’oisiveté que les précédentes. Si nous bénéficions d’un droit inaliénable à critiquer les valeurs et les goûts musicaux de nos enfants, une chose est sûre : ils ne sont pas moins intelligents que nous. Cet article est publié dans le cadre de la Fête de la science (qui a lieu du 3 au 13 octobre 2025), dont The Conversation France est partenaire. Cette nouvelle édition porte sur la thématique « Intelligence(s) ». Retrouvez tous les événements de votre région sur le site Fetedelascience.fr. Corentin Gonthier ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche. Texte intégral 2689 mots
Une intelligence globale en hausse

Une étude pour le moins critiquable
Les tests doivent régulièrement être mis à jour
Une « erreur » qui sert un agenda politique
![]()
10.10.2025 à 11:37
La Fête de la science 2025 met toutes les intelligences à l’honneur
Il est entre parenthèses, mais il donne tout son sens au thème. En ajoutant un « s » à « intelligence », pour son édition 2025, la Fête de la science (dont « The Conversation » est cette année encore partenaire) nous propose d’explorer toutes les formes d’intelligence. Dans notre dossier spécial, vous trouverez donc aussi bien des articles sur l’IA, sur l’intelligence culturelle ou celle des animaux. Mais en vidéo, cette année, nous avons voulu mettre l’accent sur deux formes bien spécifiques d’intelligence. Tout d’abord celle qui permet de lutter contre la bêtise humaine. En poussant les portes de l’Inria, nous avons découvert les travaux de Célia Nouri, doctorante en intelligence artificielle, à la croisée du traitement automatique du langage et des sciences sociales. Elle développe des modèles de détection prenant en compte le contexte social et communautaire des propos haineux, modèle qui sert à mieux lutter contre le harcèlement en ligne. Le Cnes nous a également ouvert ses portes et avec elles, l’horizon de nos préoccupations. Jacques Arnould, théologien et spécialiste en éthique du Centre national d’études spatiales, il nous encourage à réfléchir aux intelligences extraterrestres. Si demain nous devions en rencontrer, comment arriverions-nous à leur faire reconnaître notre intelligence ? Des pistes de réponse dans cette vidéo. Lire 322 mots
![]()
09.10.2025 à 15:33
Décoloniser les pratiques scientifiques : le cas du désert d’Atacama au Chili
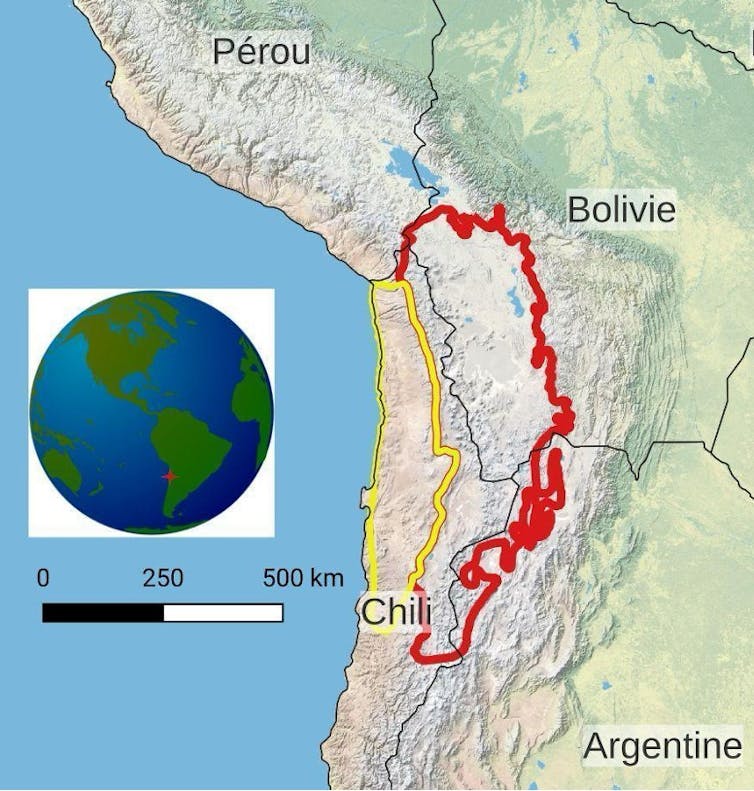
Est-il moral, éthique, voire tout simplement acceptable, que des projets de recherche soient menés dans des pays du « Sud global » sans qu’aucun scientifique local soit impliqué ? Une étude vient apporter une quantification de cette problématique dans la zone de la Puna sèche et du désert d’Atacama, en Amérique latine. Tout travail de recherche scientifique implique, initialement, une revue bibliographique. Le but de ce travail préliminaire est de parcourir la littérature afin de compiler les informations susceptibles d’étayer la question principale à laquelle une équipe scientifique souhaite répondre. C’est au cours de cette recherche bibliographique que notre équipe, travaillant sur la caractérisation environnementale de la Puna sèche et du désert d’Atacama, en Amérique du Sud, a eu l’impression que la plupart des travaux publiés jusqu’alors avaient été réalisés par des équipes étrangères, sans aucune implication de chercheurs appartenant à une institution locale. Pour ramener la situation à la France, serait-il possible et acceptable que les Puys d’Auvergne ou la Mer de Glace soient étudiés exclusivement par des équipes issues d’organismes de recherche argentins, chiliens, péruviens ou boliviens sans participation de chercheurs appartenant à des institutions françaises ? La Puna sèche et le désert d’Atacama sont des régions du globe à cheval sur quatre pays (Argentine, Bolivie, Chili et Pérou). Ces zones géographiques particulières ont pour caractéristique principale une aridité extrême qui façonne des paysages que beaucoup qualifierait spontanément de « lunaires » ou de « martiens ». Ces deux régions correspondent en effet à ce que l’on appelle, dans le jargon scientifique, des analogues planétaires : des lieux géographiques présents sur Terre mais qui peuvent s’apparenter à des environnements extraterrestres. La Puna sèche et le désert d’Atacama sont ainsi considérés comme de bons analogues terrestres de Mars et pourraient présenter, à l’heure actuelle, des conditions physico-chimiques proches de ce que la planète rouge aurait pu connaître au cours de son histoire géologique. Ce sont donc de formidables laboratoires naturels pour les domaines des sciences planétaires et de l’astrobiologie. Leur rareté suscite également l’intérêt des scientifiques du monde entier. Comment passer d’une vague impression à une certitude de la prépondérance de travaux étrangers sur la zone géographique concernée ? Notre équipe francochilienne composée de géologues, de géophysiciens, d’astrophysiciens et de biologistes a mis en place une méthode systématique de comparaison des articles basés, d’une manière ou d’une autre, sur les caractéristiques exceptionnelles de la Puna sèche et du désert d’Atacama, dans les domaines des sciences planétaires et de l’astrobiologie. Les résultats de cette étude ont été publiés en 2023 dans la revue Meteoritics and Planetary Science et notre impression a été confirmée : plus de 60 % des articles l’ont été sans impliquer un chercheur appartenant à une institution nationale d’un des pays abritant la Puna sèche et/ou le désert d’Atacama (5 369 articles analysés sur la sélection générale en sciences de la Terre, 161 pour les sciences planétaires et l’astrobiologie). Le déséquilibre mis en évidence est similaire à d’autres disciplines scientifiques et ne se limite pas à cette région. La valorisation scientifique du patrimoine naturel de certains pays, sans contribution majeure des chercheurs locaux, suscite de plus en plus d’inquiétudes dans une partie de la communauté scientifique. Au cours de ce travail, nous avons découvert les termes relativement récents (depuis les années 2000) de sciences hélicoptères, sciences parachutes, sciences safari ou sciences néocoloniales (terme privilégié dans la suite de cet article) qui permettent de mettre des noms sur ces pratiques caractérisées par la mise en œuvre de projets de recherches scientifiques menées par des équipes de pays développés (Nord global) dans des pays en développement ou sous-développés (Sud global) sans aucune implication des chercheurs locaux. Ces pratiques tendent à être considérées comme contraires à l’éthique et le sujet devient un thème de discussions et de publications au sein des sciences dures : le plus souvent sous forme de diagnostic général, mais aussi en termes de quantification. Certaines revues scientifiques, dont Geoderma (référence du domaine en science du sol) a été l’un des pionniers à partir de 2020, ont pris l’initiative d’un positionnement sans équivoque contre les pratiques de sciences néocoloniales ouvrant la voie à la modification des lignes éditoriales afin de prendre en compte la nécessité d’impliquer les chercheurs locaux dans les publications scientifiques. C’est le cas par exemple de l’ensemble des journaux PLOS qui exigent, depuis 2021, le remplissage d’un questionnaire d’inclusion de chercheurs locaux pour une recherche menée dans un pays tiers, exigence qui a depuis fait des émules au sein du monde de l’édition scientifique. L’exigence éthique vis-à-vis des recherches menées dans des pays étrangers devient donc un standard éditorial important mais pas encore majeur. D’autres leviers pourraient cependant être activés comme des cadres législatifs nationaux ou internationaux restrictifs imposant la participation de chercheurs locaux dans des travaux de terrain menés par des scientifiques étrangers. En France par exemple, la mise en place de programmes de recherche dans des territoires exceptionnels comme les îles Kerguelen (territoire subantarctique français de l’océan Indien) ou la terre Adélie en Antarctique nécessite que le projet soit porté par un scientifique, agent titulaire d’un organisme de recherche public français. Des modèles permettant d’éviter cette problématique d’appropriation culturelle d’un patrimoine naturel scientifique par des chercheurs appartenant à des institutions étrangères existent donc déjà et constituent autant de ressources sur lesquelles se fonder afin de limiter ces pratiques de sciences néocoloniales. Il nous semblerait cependant nécessaire que la communauté scientifique procède à une introspection de ces pratiques. C’est tout l’enjeu de l’étude que nous avons menée et des travaux similaires qui se généralisent depuis quelques années : rendre ces pratiques de sciences néocoloniales visibles, notamment en quantifiant le phénomène, afin que cette problématique soit débattue au sein de la communauté. Cela a notamment permis à notre équipe de se poser des questions fondamentales sur ses pratiques scientifiques et de (re)découvrir les apports conséquents menés, depuis plus de 60 ans, par les sociologues et les épistémologues sur les racines profondes et historiques pouvant lier colonialisme, impérialisme et science et plus généralement des relations entre centre et périphérie (par exemple les déséquilibres, au sein d’un même pays, entre institutions métropolitaines ou centrales vis-à-vis des institutions régionales). L’exemple des analogues terrestres de la Puna sèche et du désert d’Atacama illustre ainsi les écarts économique, scientifique et technologique creusés progressivement entre le Nord et le Sud global. Les sciences planétaires et l’astrobiologie, ont été historiquement liées au développement technologique de programmes spatiaux ambitieux et extrêmement coûteux dont souvent les principales ambitions n’étaient pas scientifiques. Les pays du Sud global n’ont ainsi pas eu l’opportunité de profiter de la conquête spatiale de la seconde moitié du XXe siècle pour développer une communauté scientifique locale en sciences planétaires et en astrobiologie. Des efforts sont actuellement menés au sein du continent sud-américain afin de pallier cette situation et ainsi faciliter l’identification d’interlocuteurs scientifiques locaux par des chercheurs d’institutions étrangères souhaitant mener des recherches en sciences planétaires ou en astrobiologie en Amérique du Sud. Des démarches vertueuses entre certains chercheurs sud-américains et leurs homologues du Nord global ont aussi été menées afin de développer ex nihilo des initiatives de recherche locales dans des domaines spécifiques des sciences planétaires et de l’astrobiologie (par exemple, vis-à-vis d’un cas que notre équipe connaît bien, la recherche sur les météorites au Chili). Dans le domaine de l’astronomie, à la marge donc des sciences planétaires et de l’astrobiologie, la mise en place des grands observatoires internationaux sur le sol chilien a permis la structuration d’une communauté locale d’astronomes et représente ainsi un bon exemple de début de coopération fructueuse entre le Nord et le Sud global. N’oublions pas de citer aussi le développement remarquable et exemplaire de l’astrobiologie au Mexique, dans les pas des scientifiques mexicains Antonio Lazcano et Rafael Navarro-González, qui démontre qu’une structuration locale indépendante reste possible et peut induire une dynamique positive pour l’ensemble du continent sud-américain. Toutes ces initiatives restent cependant trop rares ou encore trop déséquilibrées au profit d’un leadership du Nord global et ne peuvent, selon nous, se substituer à une introspection profonde des pratiques de recherche scientifique. Dans un contexte où la légitimité des sciences est contestée, cet effort d’autocritique émanant de la communauté scientifique ne nous semblerait pas superflu. Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche. Texte intégral 2358 mots

![]()