
07.07.2026 à 11:30
Les applis de santé nous font-elles vraiment bouger plus… ou seulement cliquer davantage ? Exemple avec une appli pour compter ses pas
Claire Mollier, Assistant professor en économie comportementale et expérimentale , Université Paris Nanterre
Beatrice Braut, Professor, Università degli studi di Genova
Sarah Zaccagni, Assistant Professor in Economics, Aarhus University
Texte intégral (1800 mots)
L’essentiel
- La tendance est aux applications qui comptent vos pas et vous motivent à marcher avec des rappels fréquents envoyés sur votre smartphone.
- Une étude portant sur plus de 20 000 utilisateurs et utilisatrices d’une de ces applications montre que, si les notifications augmentent l’usage de l’appli, elles n’entraînent pas de pratique accrue de la marche, dans la plupart des cas.
- L’analyse des données suggère néanmoins que ces plateformes numériques pourraient présenter un intérêt pour les publics les plus éloignés de l’activité physique.
« Vous n’avez pas atteint votre objectif de pas aujourd’hui » est un message qui vous semble familier ? Chaque jour, des millions de personnes reçoivent ce type de notifications.
L’App Store d’Apple et les applications sous Android comptant respectivement près de 35 000 et 36 000 applications de santé en 2024, ces dernières cherchent toutes à se démarquer.
Certaines, par exemple Strava ou Runtastic, encouragent la comparaison sociale au moyen de challenges ou de posts qui permettent de partager ses activités avec la communauté. D’autres récompensent la pratique sportive, comme Carrot Rewards, éventuellement par des incitations financières, comme WeWard qui rémunère votre marche.
Une appli gratuite qui vous rémunère pour vous inciter à marcher
En effet, WeWard est une application gratuite qui vous permet de gagner un certain nombre de points à chaque fois que vous atteignez un objectif de pas accomplis dans la journée (1 500, 3 000, 6 500, 10 000, 15 000 ou 20 000 pas). Ces points peuvent ensuite être convertis en sommes d’argent et vous faire gagner jusqu’à 4 euros par mois environ.
Cette fonctionnalité est née lors du lancement de l’application, fin 2019, dans le contexte de la grève des transports. Elle visait à encourager et à récompenser les personnes qui choisissaient, ou étaient amenées, à se déplacer à pied.
Du point de vue de l’économie de la santé, cette incitation monétaire fait tout à fait sens puisque des études montrent qu’elle peut encourager la pratique d’une activité physique. De plus, dans le cadre de la marche (activité gratuite), les résultats ne devraient qu’en être décuplés puisque cette pratique ne nécessite aucun coût de maintenance (contrairement à une salle de sport, par exemple).
Pour rappeler à ses utilisateurs·ices de valider leurs pas, et d’ainsi collecter leurs points, WeWard envoie chaque jour des rappels. Mais ces messages vous encouragent-ils véritablement à marcher plus ?
Étudier les comportements de marche des utilisateurs·ices de l’appli
Pourquoi observer les comportements de marche ? Parce que la marche constitue l’une des formes d’activité physique les plus accessibles. Elle ne nécessite ni équipement particulier (donc pas de coût) ni lieu ou moment spécifique et peut donc être intégrée (plus ou moins facilement) dans sa routine.
Pour les économistes de la santé, la marche représente un levier intéressant puisqu’encourager les individus à marcher plus pourrait permettre de réaliser d’importantes économies de santé publique. C’est pourquoi, dans un article publié récemment, nous nous intéressons à cette pratique au travers d’une expérience.
Cependant, une des difficultés réside parfois dans la mesure de ces comportements. À partir de questionnaires, les individus déclarent-ils leur activité de manière fiable ? Savent-ils eux-mêmes combien de pas ils effectuent chaque jour ?
Grâce à une collaboration avec l’application de suivi de pas WeWard, nous avons pu observer les comportements réels de marche des personnes qui l’utilisent. Nous avons ainsi testé l’effet de différents rappels, envoyés directement sur leur téléphone par l’application.
Les rappels ont été conçus pour mettre en avant différents mécanismes que l’on peut retrouver sur l’application :
- Comparaison avec les autres :
« Aujourd’hui, les WeWarders ont marché en moyenne X pas. Et vous ? »
- Comparaison avec soi-même :
« La semaine dernière, vous avez marché en moyenne X pas. Combien en avez-vous fait aujourd’hui ? »
- Aspect monétaire :
« Vous avez déjà validé vos pas au cours de ces derniers jours, faites-le encore pour gagner plus de points. »
Nous avons récolté des données sur les comportements de marche de plus de 20 000 individus en France et étudié si leurs habitudes changeaient après l’introduction de ces nouveaux messages. Notre étude a également cherché à comprendre si des messages personnalisés, envoyés plus longtemps, sont plus efficaces que des messages envoyés sur une plus courte période.
Des clics, mais pas plus de marche
Le premier résultat de l’étude est clair : les nouveaux rappels parviennent bien à capter l’attention des utilisateurs·ices. Les messages fondés sur la comparaison avec les autres poussent à ouvrir davantage l’application. Cet effet est même plus marqué lorsque les rappels sont envoyés pendant trois semaines plutôt qu’une seule.
Cette observation est d’autant plus intéressante que notre expérience s’est déroulée pendant les fêtes de fin d’année, une période durant laquelle l’engagement envers les applications a tendance à diminuer naturellement. Les notifications ont ainsi permis de ralentir la baisse d’activité sur l’application. Cependant, cette hausse d’attention ne s’est pas traduite par davantage de marche.
Les différents indicateurs étudiés (activité quotidienne, moyenne hebdomadaire ou comportements des individus les plus actifs sur l’application) racontent la même histoire : les notifications augmentent l’usage de l’application sans entraîner davantage d’activité physique.
Quand capter l’attention devient un indicateur trompeur
L’un des principaux enseignements de notre étude est que l’attention portée à une application ne reflète pas forcément un changement concret des comportements. Dans le domaine du numérique, le succès d’une intervention est souvent mesuré à travers des statistiques d’usage : fréquence d’ouverture de l’application, temps passé sur la plateforme ou nombre d’interactions. Pourtant, ces indicateurs peuvent donner une image partielle, voire trompeuse, de leur effet réel sur la santé.
En effet, consulter une application est une action relativement simple. Modifier durablement ses habitudes quotidiennes l’est beaucoup moins. Marcher davantage implique de trouver du temps, de changer certaines routines et de faire face à des contraintes très concrètes, comme la fatigue, les obligations professionnelles ou encore les conditions météorologiques. Dans ce contexte, une simple notification a probablement une portée limitée.
Nos résultats rappellent ainsi qu’il existe une différence importante entre attirer l’attention des utilisateurs·ices et transformer réellement leurs comportements. Les plateformes numériques parviennent souvent très bien à capter notre attention ; cela ne signifie pas nécessairement qu’elles produisent des effets durables sur nos modes de vie.
Un potentiel surtout chez les personnes peu actives
Tous·tes les utilisateurs·ices ne réagissent pas de la même manière aux notifications. Chez les personnes qui marchaient le moins avant l’expérience, nous observons une légère progression du nombre de pas au cours du temps. Aucun type de notification ne semble expliquer à lui seul cette évolution, mais ce résultat suggère que les applications de santé pourraient être particulièrement utiles pour les publics les plus éloignés de l’activité physique.
Le simple fait de suivre ses pas au quotidien, de visualiser ses progrès ou de recevoir des rappels réguliers peut contribuer à rendre certains comportements plus concrets et plus visibles. D’un point de vue santé publique, ces populations représentent un enjeu central : ce sont aussi celles pour lesquelles une augmentation, même modeste, de l’activité physique pourrait produire les bénéfices les plus importants.
De l’importance de mesurer ce qui compte réellement
Notre étude met en évidence un défi important pour les plateformes numériques et les politiques publiques : mesurer ce qui compte réellement. Un fort engagement ne doit pas automatiquement être interprété comme un succès. Une application peut sembler très performante au regard de ses statistiques internes tout en produisant peu de changements concrets dans la vie quotidienne des utilisateurs·ices.
Nos résultats ne remettent pas en cause l’intérêt des applications de santé. Ils suggèrent plutôt que les outils numériques sont probablement plus efficaces lorsqu’ils s’inscrivent dans des dispositifs plus larges : être soutenu par son entourage, se fixer des objectifs ou construire des habitudes progressivement dans le temps.
De plus, augmenter son activité physique ne dépend pas seulement de la motivation, mais aussi des contraintes du quotidien ou de facteurs sociaux, comme le genre. En effet, nos résultats vont dans le même sens que les travaux existants : les femmes semblent moins actives que les hommes.
Les applications peuvent aider à rendre certains comportements plus visibles et encourager une prise de conscience. Transformer durablement les habitudes demande cependant davantage qu’une notification.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
06.07.2026 à 15:47
The public isn’t bored with economists, management scholars and sociologists but engaging people has conditions
Quentin Plantec, Professeur Stratégie & Management de l'Innovation, TBS Education; European Academy of Management (EURAM)
Cylien Gibert, Professeur Stratégie, Entrepreneuriat & Innovation, TBS Education
Julien Cloarec, Full Professor of Marketing, iaelyon School of Management – Université Jean Moulin Lyon 3
Marie-Alix Deval, Enseignante - chercheuse, ISTEC
Texte intégral (1565 mots)
For years, we’ve been told a familiar story: social scientists such as economists, management scholars, sociologists, talk and the public shrugs. The claim goes that people don’t find our work interesting, that our expertise is fuzzy compared with “hard” sciences, and that journalists and readers will always prefer the crisp authority of practitioners such as CEOs, consultants or politicians… Is that really true?
We put it to a real-world test in a large survey and found the opposite, with a twist: audiences do want to hear from economists, management scholars and sociologists, but they reward social scientists when we stay in our lane, and they pull back when we stray or act as quasi-practitioners.
In short: the public is listening, but it listens for fit.
Communication barriers around expertise, trust and a crowded stage
In public debate and in our research we reviewed three recurring “headwinds” that social scientists experience when trying to reach people through the media.
1) A perceived expertise gap: because questions related to social issues overlap with everyday experience and can feel like “common sense”, audiences may rate social sciences as less “scientific” than physics, biology or medicine. That proximity helps relevance, but it can also hide the value of specialised methods unless we make them explicit.
2) A trustworthiness barrier: In a polarised, “post-truth” environment, social science scholars are at times suspected of partisanship; reproducibility debates can also loom larger here than in many Science, Technology, Engineering and Mathematics (STEM) disciplines.
These are perceptions that circulate in the public arena, not judgements we endorse, yet they can raise the bar for social sciences scholars seeking legitimacy with broad audiences.
3) The channel problem: competition from practitioners. Media spaces are porous for social issues, and business leaders, consultants and politicians have frequent, sometimes privileged access to newsrooms. In that crowded arena, it is easy to assume that, for example, a CEO who “lives it every day” will sound more credible than a management scholar. This is why it is often predicted that practitioners will dominate attention and trust.
Why do these issues matter?
It follows on directly from those headwinds. If left unchallenged, they mute the very value social sciences create: ideas that frame problems, test claims and inform choices in policy, business and everyday life. Because our impact travels through interpretation more than through patents or products such as in “hard” science, broad, credible communication isn’t a nice-to-have, it’s one of the main routes by which social sciences scholars’ work reaches citizens, NGOs, firms and policymakers.
Mass media help on all three fronts: media outlets reach heterogeneous audiences, add editorial scrutiny that can bolster trust, and offer durable spaces (analysis, op-eds, explainers) where methods and evidence can be made visible.
Social sciences scholars already use these channels more than many “hard” science peers. But do those advantages actually let them break through the headwinds? Do audiences grant scholars trust and attention in this arena, and under what conditions? That is the question our study tests.
What we found: a scholar premium with guardrails
To move beyond assumptions, we built an experiment around a familiar media format: a paywalled newspaper op-ed on a current policy topic.
A representative French sample of 1,080 adults saw one version of the op-ed in which we randomly varied multiple elements. Participants then rated the author’s perceived trustworthiness, expertise and legitimacy, and told us whether they wanted to keep reading, a real behavioural proxy because the article was truncated behind a paywall.
We also ran partial replications in the UK and Spain to check generalisability. The stimuli and measures were built to mirror real op-eds and were validated for plausibility and fit.
Across countries, the pattern is clear. People trust social science scholars more than practitioners, but mainly when scholars talk about their own field. When an economist writes on the economy, a sociologist on social outcomes, or a management scholar on firms, trust and expertise turn into legitimacy and real engagement (measured through willingness to pay). Step outside that lane and the edge largely disappears.
The competition story then turns out to be subtler than the “practitioner always wins” intuition. Readers may reasonably expect a practitioner to sound practical, but in our data they still grant an initial trust edge to the academic label, and they reward it when the scholar writes within their field. Put differently: experience matters, but so does disinterested expertise, and audiences appear to use disciplinary fit to decide when the latter should lead.
One more finding concerns the “double hat”. When an author was introduced as both a scholar and a practitioner, credibility tended to drop. Readers seemed to treat the practitioner hat as trumping the scholar’s independence. Being a practitioner isn’t the issue; but in public-facing media, leading with the academic hat may keep the trust signal clearer.
What it means for universities, journalists and scholars
Universities should treat op-eds and news analysis as core dissemination work for the social sciences and resource it accordingly: training, editorial support and recognition in evaluation. But the incentive should be to communicate more within one’s field, not to opine on everything.
Our evidence indicates that credibility and engagement rise when scholars speak from inside their discipline; institutional nudges ought to reinforce that fit, not erode it.
For editors and reporters, the lesson is practical. The “right expert for the right story” is what readers use to grant trust. Make the disciplinary match explicit in intros and standfirsts; ask scholars to show what their evidence can and cannot claim; and double down on verification.
In a space where accusations of partisanship and “ivory tower” aloofness circulate, strong fact-checking and transparent sourcing provide the external stamp of quality that Social science commentary especially needs, and that our data links to higher engagement.
What about researchers?
Communicating well does not mean speaking about everything; it means speaking from your research. Make the fit obvious up front, keep a clear line between analysis and advocacy, and explain methods in plain language. If you also wear a practitioner hat, be transparent – but consider whether foregrounding that identity will distract from the scholarly message in mass-media contexts. In our data, it often did.
The claim that “the public doesn’t care about social sciences” doesn’t survive contact with data.
People will read social scientists – and credit them – when scholars speak from their evidence, within their discipline, and as scholars rather than stand-in practitioners. That is not a constraint; it is a charter for better public conversation. If universities and newsrooms organise themselves around those guardrails, social sciences won’t just be heard; they’ll be useful.
The European Academy of Management (EURAM) is a learned society founded in 2001. With over 2,000 members from 60 countries in Europe and beyond, EURAM aims at advancing the academic discipline of management in Europe.

A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
06.07.2026 à 15:47
La sécurité des drones militaires, ou comment protéger ce qui compte (et ce n’est pas toujours le drone lui-même)
Serge Chaumette, Professeur des Universités en Informatique, chercheur au LaBRI (Laboratoire Bordelais de Recherche en Informatique) et responsable des activités drones de ce laboratoire, Université de Bordeaux
Damien Sauveron, Professeur des Universités en Informatique à la Faculté des Sciences et Techniques, Université de Limoges
Texte intégral (2420 mots)
Sur les théâtres d’opération militaire, les drones évoluent dans un environnement hostile où ils doivent avant tout protéger les troupes qu’ils accompagnent. Pour mener à bien cette mission, ils déploient des stratégies qui leur offrent une certaine résilience, le but n’étant finalement pas de les protéger pour eux-mêmes, mais de leur permettre d’accomplir leur tâche coûte que coûte. Leur propre protection n’est qu’un enjeu secondaire : on les dit sacrifiables.
Face aux vulnérabilités de ces nouveaux acteurs des conflits militaires, on se trouve devant un jeu du gendarme et du voleur où le gendarme court après de nouvelles solutions pour se protéger du voleur alors que le voleur cherche de nouvelles failles lui permettant de mettre à mal les stratégies développées par le gendarme.
La guerre en Ukraine a suscité un regain d’intérêt des forces armées pour les drones, en particulier de taille petite et moyenne, qu’ils soient unitaires ou en essaim. On le constate quotidiennement, ils sont partout sur le champ de bataille et constituent un atout majeur pour les forces : ils portent le feu pour elles vers les lignes ennemies, mais surtout ils les renseignent, leur évitent une exposition inutile, les protègent.
Mais comment assurer leur propre protection afin de garantir leur disponibilité face aux attaques de l’ennemi et à la « guerre électronique », qui sert parfois de prélude aux opérations cyber (opérations visant à mettre à mal, voire à pirater, leurs composants matériels ou logiciels) ? Des technologies et des stratégies existent, qui se construisent dans les laboratoires de recherche académiques, dans les start-up et les entreprises spécialisées et, pour certaines, au jour le jour sur le front (ukrainien, en particulier).
Mais tout d’abord, précisons qu’un drone est rarement isolé. Les drones sont la plupart du temps pilotés par un opérateur distant, généralement au sol. Le pilote et les équipements informatiques nécessaires à l’analyse des données collectées et au suivi de la mission sont hébergés, selon la terminologie militaire, dans un C2 (Command and Control), souvent un camion ou un bâtiment où se trouvent les équipements et les personnels nécessaires.
Pour en assurer la sécurité, il faut donc envisager les drones comme des systèmes à plusieurs composantes, au-delà de l’aéronef lui-même.
La résilience, un enjeu civil et militaire
Quand on parle de protection du drone, on parle avant tout de sa résilience, c’est-à-dire de la capacité du système à conserver un fonctionnement aussi nominal que possible face à un environnement ou à des événements hostiles. Cette hostilité peut être le fait de l’action volontaire d’un ennemi, qui va tout faire pour perturber leur fonctionnement en intervention ; mais elle peut également être liée à la nature même de certaines missions, par exemple la surveillance de zones forestières pour la lutte contre les incendies de forêt, qui peuvent conduire le drone à s’approcher ou à survoler des « zones interdites de fréquences » (terrains militaires, aéroports, centrales nucléaires, etc.). Dans ces zones, il est impossible ou interdit de communiquer en utilisant des ondes radio. Il faut être capable de s’adapter à cette contrainte, d’être résilient face à elle.
Il est toutefois plus ou moins critique qu’un système de drone soit résilient, selon les cas : un appareil suffisamment petit, peu coûteux, et que l’on sait produire en masse, peut être perdu sans grande conséquence.
Le premier objectif de la résilience est d’assurer à un drone la capacité à mener à bien sa mission. Certains drones, par exemple, jouent le rôle d’éclaireurs : le succès de leur mission conditionne le bon déroulement des opérations qui s’ensuivent. C’est le cas également dans un cadre civil, par exemple pour le transport de matières biologiques ou d’organes nécessaires à des greffes.
Il faut parfois également respecter certaines contraintes, par exemple conserver la confidentialité des données transportées, qu’elles soient collectées pendant la mission ou nécessaires à la mission elle-même. Par exemple, le plan de vol (c’est-à-dire les différents points GPS que le drone doit atteindre successivement) peut être une information sensible, dont il est nécessaire d’assurer la confidentialité, la disponibilité et/ou le retour en fin de mission, même en cas de perte ou de dégradation de certains composants matériels ou logiciels du système.
Comme nous l’avons vu, les drones et leur environnement constituent un système complexe et donc fragile par définition. Ces fragilités se situent à tous les niveaux : interne, externe et au niveau des interconnexions entre les éléments du système (drone, opérateur, C2, etc.).
Les fragilités internes
Les fragilités internes concernent aussi bien l’électronique que le logiciel embarqué. Par exemple, l’électronique peut être victime d’attaques par des « fusils électromagnétiques », qui utilisent des micro-ondes pour détruire certains circuits. Des approches à base de laser se développent aussi. Ces attaques peuvent conduire à la perte totale d’un appareil et peuvent aussi provoquer des failles propices à une attaque cyber (qui peut être effectuée en vol, mais plus aisément au sol après capture de l’appareil) : modifier des données en mémoire grâce à un rayonnement peut aider à faire apparaître une faille logicielle qui sera exploitée par la suite.
Les drones, comme tout autre système, ne sont pas exempts de bugs logiciels ou de sécurités défaillantes par construction. Une conséquence qui peut s’avérer fatale est, par exemple, la survenue d’un flyaway : le drone part vers une destination non prévue. Ce type de bug peut aussi avoir une composante matérielle. De manière plus globale, la perte de contrôle d’un appareil représente 36 % des accidents, toutes causes confondues.
Les attaques externes, un enjeu majeur
Les attaques externes consistent pour un ennemi à cibler les interactions entre le système et le monde extérieur, par exemple le système de navigation par satellite (souvent dénommé abusivement GPS – Global Positioning System, qui est le système américain – au lieu de GNSS pour Global Navigation Satellite System) ou la radio (que le drone utilise pour communiquer avec une station au sol).
Le GPS peut être brouillé – auquel cas le signal reçu n’est plus exploitable : le drone n’est alors plus en mesure de connaître sa position effective. Il devient inutilisable : on parle d’environnement « GNSS denied », c’est-à-dire d’environnement dans lequel le GNSS ne peut pas être utilisé. Cela peut par exemple conduire à sa capture : les forces armées iraniennes, en 2011, ont capturé un drone américain RQ-170 Sentinel de cette façon. En Ukraine, nombreuses sont les zones dans lesquelles le signal GPS est soit inexistant, soit brouillé et devient donc inutilisable pour naviguer.
Ce phénomène a également été observé sur des événements de type show lumineux, à Shanghai par exemple, où des dizaines de drones sont allés se poser de manière inopinée sur des bateaux situés à proximité.
Les attaques d’interconnexion
Les attaques d’interconnexion portent sur l’interface du drone avec les autres éléments du système, typiquement sur ses échanges avec la station sol, et donc sur le lien radio.
Elles peuvent par exemple consister à envoyer des ordres contrefaits ou à transmettre des données erronées vers la station au sol. Le composant cible croit échanger avec un autre composant légitime alors qu’il échange avec un attaquant. Il devient ainsi possible d’exploiter les captations vidéo d’un drone pour déterminer la localisation de sa base de lancement, puis de la prendre pour cible.
Les solutions : un puzzle de stratégies
Tout d’abord, pour ce qui concerne les problématiques clés, il existe de nombreux travaux de recherche fondamentale.
Aujourd’hui, les spécialistes travaillent en particulier sur la capacité à poursuivre la navigation en environnement GNSS denied et sur la sécurisation des liens de communication drone sol-sol drone. En effet il est indispensable que les appareils disposent de solutions de repli en environnement GNSS denied. Des approches algorithmiques reposant sur une analyse fine et un filtrage des signaux reçus, des antennes spécifiques et même des approches de type IA permettent de traiter certaines attaques.
En cas d’échec de ces stratégies de remédiation, l’utilisation d’amers (terme de navigation faisant référence à des points de repère fixes) permet de se repérer en s’accrochant visuellement à des points au sol. C’est souvent une combinaison de plusieurs de ces techniques qui permet en cas de perte de la disponibilité de l’une d’entre elles d’assurer la résilience du système.
Pour ce qui est de la radio, qui en plus d’être inutilisable (neutralisée ou interdite), peut être exploitée pour localiser un C2, des stratégies sont étudiées ou déjà mises en œuvre. Par exemple, des fibres optiques reliant un télépilote à son appareil pour communiquer en lieu et place de la radio ont été expérimentées en Ukraine. À plus long terme, des approches quantiques permettront de sécuriser ces communications de manière efficace.
Pour d’autres problématiques, des stratégies existent déjà, et peuvent être exploitées. Leur coût en revanche peut ne pas être négligeable. Un compromis coût/capacité de résilience est donc à trouver.
De manière plus méthodologique, il existe des processus de certification permettant de valider la conformité à la réglementation en vigueur, laquelle intègre par nature une notion de résilience. Les enjeux sont différents dans le domaine militaire : ceux-ci n’échappent évidemment pas à toute réglementation, mais la résilience est plus focalisée sur le succès de la mission que sur la sécurité de l’environnement dans lequel elle se déroule, comme discuté dans cet article.
Il s’agit dans ce cas de développer des solutions au plus vite, de les tester, de les valider et de les déployer.
La première étape consiste à valider chaque sous-système et à mesurer son TRL (Technology Readiness Level – niveau de maturité de la technologie). On évalue ensuite la capacité de chaque sous-système à s’intégrer avec d’autres, son IRL (Intégration Readiness Level – niveau de maturité d’intégration) ; puis on intègre le système et on évalue son SRL (System Readiness Level – niveau de maturité du système global). Ces mesures sont loin d’apporter des garanties universelles, mais elles permettent déjà d’assurer une qualité significative du produit final.
Rappelons, enfin, que les drones de petite et moyenne taille, objets technologiques pourtant anciens, n’ont révélé tout leur potentiel militaire que récemment. Il faut donc garder en tête qu’il ne faudra pas ralentir les efforts de recherche et les expérimentations quand les conflits actuels seront derrière nous.
Il en va de la capacité de ces systèmes à réaliser leurs missions, qui visent, redisons-le, à nous protéger lors d’éventuels futurs conflits.
Serge Chaumette a reçu des financements de l'ANR, de BPI, de l'AID, de l'EDA, des ARL (Army Research Labs), de l'ORNL (Office of Naval Research). Il est Professeur et Chercheur à l'Université de Bordeaux et conseille et détient des parts dans la société IcarusSwamrs.ai dont il est Directeur Scientifique. Il est membre du Comité Stratégique Drones et Nouveaux Usages du Pôle de Compétitivité Mondial Aerospace Valley et co-animateur du groupe Drones et Systèmes Autonomes du GIS Albatros (Groupement d'Intérêt Scientifique entre Thales et l'Université de Bordeaux). Enfin, il collabore ou pilote de nombreux projets avec des partenaires académiques, industriels et institutionnels dans le monde du drone.
Damien Sauveron a reçu des financements de l'ANR (notamment pour le projet PANDRONE dédié à la sécurité des flottes de drones), du CNRS (PEPS TRUSTED), de la Région Nouvelle-Aquitaine et de la fédération de recherche MIRES. Dans le cadre de ses collaborations industrielles passées, ses travaux sur les flottes de drones ont également été soutenus par Thales (projet NetCod). Il est Professeur des Universités en Informatique à l'Université de Limoges et chercheur au laboratoire XLIM (UMR CNRS 7252), dont il est Doyen Honoraire de la Faculté des Sciences et Techniques. Ses recherches portent sur la cybersécurité, les systèmes embarqués et la souveraineté des architectures autonomes. Enfin, il intervient comme expert auprès de la Commission Européenne.
06.07.2026 à 15:46
Influenceur sur TikTok, président sur Facebook : la nouvelle stratégie de Jordan Bardella
Alma-Pierre Bonnet, Senior Lecturer in British Studies, Université Jean Moulin Lyon 3
Texte intégral (2590 mots)
Si Jordan Bardella est très actif sur les réseaux sociaux préférés de la génération Z, tels que TikTok, YouTube et Instagram, il investit aussi désormais beaucoup de temps sur Facebook. De janvier à mars 2026, les publications du président du Rassemblement national sur ce réseau social ont augmenté de 90 % par rapport à la même période en 2025. Sa stratégie y diffère sensiblement de ce qu’il déploie sur les autres plateformes.
Le président du Rassemblement national (RN) Jordan Bardella est aujourd’hui la personnalité politique la plus suivie sur TikTok, après Emmanuel Macron, grâce à une stratégie de communication fondée sur la personnalisation, la viralité et une apparente dépolitisation du contenu. Ses vidéos montrent des scènes de la vie quotidienne : il mange des bonbons, met de la mayonnaise sur un hot-dog, joue à des jeux vidéo, prend un verre, caresse un lapin, etc. Ces clips peuvent générer des millions de vues en quelques heures et s’inscrivent dans une logique de relations parasociales afin de répondre à la demande croissante de lien plus personnel avec les dirigeants politiques.
L’objectif principal sur TikTok semble être générationnel : les jeunes électeurs potentiels ont l’impression de « connaître » Bardella, indépendamment de son programme politique, lui garantissant un « capital politique » personnel, partiellement détaché des controverses historiques du parti. En somme, il adopte les codes de l’industrie des influenceurs pour construire et entretenir une communauté fidèle grâce à une stratégie en quatre volets : image d’authenticité, de proximité, d’accessibilité et de responsabilité (au sens « rendre des comptes » à ses followers).
Sur Facebook, nos recherches montrent que celui qui est aussi député européen du RN se détache de cette image d’influenceur pour tenter d’acquérir une stature présidentielle.
Influenceur sur TikTok, président sur Facebook ?
Facebook touche un public plus large (40 millions d’utilisateurs français sur Facebook en 2026 contre 25 millions pour TikTok), généralement plus âgé et socialement plus diversifié que TikTok.
L’architecture numérique de Facebook, construite autour de fonctionnalités, telles que les « amis » et les « j’aime », ainsi que le « filtrage algorithmique », qui hiérarchise la sélection, la séquence et la visibilité des publications, permettent de mettre en avant la personnalité de ses utilisateurs.
Cela rend Facebook particulièrement attrayant pour les partis d’extrême droite, qui sont généralement organisés selon des structures verticales et hiérarchiques, enclines à favoriser des organisations partisanes centrées autour d’un leader charismatique.
Notre analyse de 452 publications de Jordan Bardella sur Facebook depuis début 2026 révèle que cette plateforme lui permet de se façonner une stature présidentielle d’inspiration gaullienne.
La mise en scène de sa popularité
Une des caractéristiques principales de la communication de Jordan Bardella sur Facebook est le recours à une multitude de publications pour couvrir un seul et même événement (interviews télévisées, séances de dédicaces ou réunions politiques). Ces publications sont mises en ligne en temps réel, ou peu après, ce qui crée une longue succession de messages. Le découpage des extraits en courtes vidéos thématiques donne l’impression que Bardella est prêt à répondre à toutes les questions sur tous les sujets. Il se présente ainsi comme une figure avisée et proactive, contrairement, selon lui, à la classe politique actuelle qu’il accuse d’apathie et de manque d’intérêt pour les gens ordinaires.
Sur le plan terminologique, cette dynamique s’exprime à travers la récurrence du mot « alternance » (52 occurrences), qui suggère que ce changement politique est réalisable dans un cadre démocratique, par opposition à l’idée de « révolution » (aucune occurence), plus facilement associée à l’idée de violence.
S’inscrivant dans le processus de « dédiabolisation », l’image « rassurante » de Bardella s’exprime également dans les nombreuses vidéos de discours prononcés au Parlement européen. Il montre ainsi qu’il peut apporter le changement tout en restant dans un cadre démocratique, s’éloignant à la fois de la stratégie frontiste originelle, consistant à quitter purement et simplement l’Union européenne (UE), et de la rhétorique agressive d’autres leaders populistes, comme le Britannique Nigel Farage.
Ces vidéos de « bains de foule » cherchent à créer l’image d’une lame de fond populaire et d’une cohésion sociale autour de sa personne. Lors de telles occasions (notamment les séances de dédicaces), il s’habille de manière décontractée, ce qui établit un lien avec les gens ordinaires et renforce le fil conducteur de son storytelling : il est issu du peuple et bénéficie d’un soutien populaire important.
Facebook comme arène de la bataille culturelle contre la gauche
Dans 16 % des publications de Bardella sur Facebook (73 posts), la gauche est la cible d’attaques dans ce qui s’apparente à une croisade culturelle où la défense de la civilisation française et de ses valeurs serait en jeu. Le courroux de Bardella vise plus particulièrement l’extrême gauche. La France insoumise (LFI) est, en effet, décrite comme une menace existentielle pour la survie de l’« âme française », trope typique des dirigeants populistes.
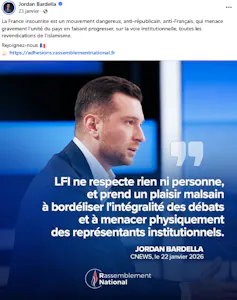
Au-delà de l’opposition idéologique traditionnelle, Bardella accuse le parti de Jean-Luc Mélenchon d’encourager la « bordélisation » de la politique française, un néologisme emprunté à Gérald Darmanin, alors ministre de l’intérieur, qui n’est pas sans rappeler la « chienlit » gaullienne, afin de se poser en défenseur du droit et de l’ordre.
Une attention forte portée aux relations internationales
Particulièrement actif sur les questions internationales, qui occupent 27 % de ses publications, Bardella se montre notamment très critique à l’égard de ce qu’il qualifie d’ingérence américaine et réclame une souveraineté totale de la France en matière de dépenses militaires et d’interventions à l’étranger.
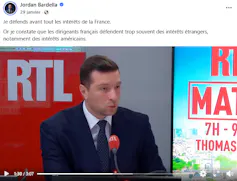
Le 29 janvier 2026, par exemple, un extrait d’interview montre Jordan Bardella interrogé sur le revirement de la ligne de son parti concernant Donald Trump. Le président du RN y affirme qu’il n’a de « fascination pour personne » et que si le second mandat de Trump est une bonne nouvelle pour les États-Unis, c’est une « très mauvaise nouvelle » pour la France, car il renforce le processus de « vassalisation » amorcé par le gouvernement Macron.
Le terme « vassalisation » évoque le refus de Charles de Gaulle de devenir un « vassal » des États-Unis après la Seconde Guerre mondiale. Cette référence intertextuelle permet à Bardella de s’éloigner des controverses du parti, dans une stratégie plus ouvertement présidentielle.
Une absence de Marine Le Pen qui en dit long
Enfin, dans l’ensemble des publications analysées, Marine Le Pen n’est évoquée qu’à 26 reprises (5,7 %) dont 20 fois au Salon de l’agriculture où elle partage la photo avec Jordan Bardella. En contraste, les publications assurant la promotion personnelle de Bardella (séances de dédicace, sondage de popularité) comptent pour près de 15 % des posts.
De même, 19 % des publications (86) expriment son soutien aux candidats RN, ce qui lui donne une stature d’autorité suprême au sein du parti lepéniste.
Le jeu du contre-récit
Le storytelling de Bardella sur Facebook met en scène un homme issu du peuple, un outsider politique providentiel, qui a identifié les différentes menaces pesant sur la nation française (perte de souveraineté, immigration, extrême gauche, etc.) et qui est prêt à y faire face, dans un cadre démocratique, consolidant ainsi la normalisation de son parti.
Cet imaginaire entre en contradiction avec le discours officiel du parti d’extrême droite, qui fait de Jordan Bardella un simple numéro deux du RN, alors que Marine Le Pen ignore, à ce stade, si la Cour d’appel de Paris l’autorisera à être candidate à l’élection présidentielle en 2027.

Alma-Pierre Bonnet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
06.07.2026 à 15:45
Pourquoi l’Iran ne parviendra pas à instaurer un péage dans le détroit d’Ormuz
Jennifer Parker, Adjunct Professor, Defence and Security Institute, The University of Western Australia; UNSW Sydney
Texte intégral (1519 mots)
Téhéran envisage d’instaurer un péage dans le détroit d’Ormuz pour y asseoir son contrôle stratégique, mais son ambition se heurte à un écueil juridique et pratique : le droit international garantit le libre passage dans ces eaux, et cette voie large de près de 40 kilomètres n’a rien d’un canal de Suez étroit et verrouillé.
Au Moyen-Orient, la tension est récemment remontée d’un cran. Les États-Unis et l’Iran ont échangé de nouvelles frappes aux abords du détroit d’Ormuz, après qu’un drone iranien a visé un navire de fret en transit. Chaque camp dénonce une violation de l’accord de paix provisoire qui a été conclu pour soixante jours.
Depuis l’attaque conjointe menée par Washington et Tel-Aviv sur son territoire, la République islamique multiplie les déclarations sur son intention d’exercer un contrôle permanent sur le détroit. Ces déclarations ont suscité la crainte de voir Téhéran, une fois le conflit terminé, imposer des taxes de passage systématiques aux quelque 130 navires qui transitent quotidiennement par cette voie. Reste que les autres pays de la région ne l’accepteraient pas et, surtout, l’Iran ne pourrait sans doute pas y parvenir : le détroit d’Ormuz n’est pas un canal.
Aucune voie légale
Le monde a raison de s’inquiéter. Depuis le début des hostilités, l’Iran cherche à dissuader les navires de transiter par le détroit d’Ormuz, attaquant plus de 40 navires marchands neutres et tuant plusieurs marins civils. À cela s’ajoutent des attaques à la roquette et au drone ainsi que la pose de mines marines dans le détroit. Conséquence : le trafic maritime commercial est pratiquement au point mort depuis plus de trois mois, ce qui a des conséquences économiques considérables.
Les inquiétudes ont été encore attisées par la formulation du récent accord provisoire en 14 points, qui stipule que l’Iran fera « tout son possible » pour garantir le passage en toute sécurité des navires commerciaux « sans frais, pendant 60 jours seulement ».
Le plan prévoit que l’Iran discutera des dispositions futures avec Oman et d’autres États du Golfe, « conformément au droit international applicable et aux droits souverains des États côtiers du détroit d’Ormuz ».
En vertu de la Convention des Nations unies sur le droit de la mer, le détroit d’Ormuz est un détroit international où tous les navires jouissent d’un droit de passage en transit que les États côtiers ne peuvent suspendre.
Bien que certaines parties du détroit traversent les eaux territoriales iraniennes, le principal système de séparation du trafic se situe dans les eaux omanaises. Les systèmes de séparation du trafic sont des routes établies par l’Organisation maritime internationale pour gérer en toute sécurité le trafic dans les goulets d’étranglement très fréquentés. On peut les considérer comme des voies de circulation recommandées. Juridiquement, instaurer un péage serait irrecevable.
Mais il n’y a pas non plus de moyen pratique
La véritable question est toutefois de savoir si l’Iran pourrait, dans la pratique, imposer un péage, d’autant plus qu’il a effectivement bloqué la majeure partie du trafic maritime commercial dans le détroit d’Ormuz pendant plus de trois mois.
À première vue, il existe des précédents évidents. Les navires paient pour transiter par des canaux tels que ceux de Suez et de Panama. Mais ces voies navigables diffèrent fondamentalement du détroit d’Ormuz. Elles se trouvent sur le territoire d’un seul État et constituent des voies de transit étroites et contrôlées. Le chenal navigable du canal de Suez, par exemple, mesure sur toute sa longueur environ 200 mètres de large.
Le détroit d’Ormuz est un cas à part. À son point le plus étroit, il mesure environ 39 kilomètres de large, et comprend des zones relevant à la fois des eaux territoriales omanaises et iraniennes. L’étendue de cette voie navigable rend beaucoup plus difficile l’interception, l’inspection et le contrôle des navires qui refusent de s’acquitter d’un péage. Proclamer l’existence d’un péage est une chose ; le faire respecter auprès de navires récalcitrants en est une autre.
Les navires traversant le canal de Suez y pénètrent par Port-Saïd au nord ou par Suez au sud ; ensuite, des pilotes de l’Autorité du canal de Suez montent à bord des navires et ceux-ci rejoignent un système de convoi strictement contrôlé pour la traversée.
Du fait de la nature confinée et hautement réglementée du canal, il est pratiquement impossible pour un navire de transiter par celui-ci sans se conformer aux exigences de ses autorités et sans s’acquitter des droits de passage requis.
En ce qui concerne le détroit d’Ormuz, au-delà du droit international, il est peu probable que les compagnies maritimes et les États acceptent volontairement un péage permanent pour le transit à travers un détroit international. La question ne se résume pas simplement au coût, mais au précédent que cela créerait en matière de liberté de navigation et de gouvernance des détroits à travers le monde.
Levier de pression ou contrôle à long terme ?
L’Iran ne ferait pas payer les navires pour un service, comme c’est le cas dans les canaux de Suez ou de Panama. Il ferait payer les navires pour l’exercice d’un droit de transit préexistant à travers un détroit international. Oman et d’autres États du Golfe ont averti que la mise en place d’un système de péage porterait atteinte à la liberté de passage et créerait un dangereux précédent.
Il faudrait donc contraindre les entreprises à payer. Mais contrairement aux canaux de Suez ou de Panama, le détroit d’Ormuz est bien plus vaste et plus difficile à surveiller, ce qui rendrait l’application de ces mesures particulièrement difficile.
Au cours du conflit actuel, l’Iran, nous l’avons dit, a dissuadé la navigation par la force, tuant des marins innocents et en perturbant le commerce mondial.
Bien que la réaction internationale à ces agissements ait été relativement modérée, de telles actions ne constituent pas un moyen viable d’imposer un péage permanent en temps de paix. À moins que l’Iran ne soit disposé à continuer d’attaquer des navires marchands innocents après la fin du conflit – une approche qui susciterait une pression diplomatique considérable, des sanctions et des critiques, y compris de la part de pays tels que la Chine –, il est peu probable qu’il dispose de la motivation ou du mécanisme d’application nécessaires pour contraindre les navires à payer un péage contraire au droit international.
L’Iran utilise le fait qu’il parvient à perturber le trafic maritime dans le détroit d’Ormuz comme un moyen de pression dans les négociations. Mais exercer une pression et exercer un contrôle à long terme ne sont pas la même chose. Même si l’Iran est capable de perturber le trafic maritime, il est peu probable qu’il parvienne à bloquer définitivement le détroit d’Ormuz.
Jennifer Parker ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
06.07.2026 à 15:44
Qu’est-ce que « l’affichage parental d’images de mineurs » ?
Caroline Rouen-Mallet, Enseignant-chercheur en marketing, Université de Rouen Normandie
Texte intégral (839 mots)
Les enfants ont aussi une vie privée. Partager des photos d’eux sans leur consentement sur les réseaux sociaux va à l’encontre de leurs droits. Le nouveau terme d’« affichage parental d’images de mineurs » invite à interroger cette pratique de plus en plus courante dans un monde numérique.
Poster la photo du premier jour d’école de son enfant sur Instagram, ou la vidéo de ses premiers pas dans le groupe WhatsApp de la famille, c’est devenu un réflexe pour de nombreux parents. Cette pratique porte désormais un nom en français : « affichage parental d’images de mineurs ».
Dans une liste de termes publiée au Journal officiel, c’est en effet l’expression que la Commission d’enrichissement de la langue française a retenue pour traduire l’anglicisme « sharenting » : le fait, pour des parents, de publier en ligne, notamment sur les réseaux sociaux, des photos, des vidéos ou d’autres informations relatives à leurs enfants.
D’où vient ce mot ?
Sharenting est apparu vers 2010 dans la presse anglo-saxonne, sous la plume de journalistes qui observaient la multiplication des publications de parents sur les réseaux sociaux naissants. Le mot est une contraction de « share » (partager) et « parenting » (parentalité), suggérant un geste de partage entre proches, presque privé.
La traduction française fait un autre choix : « affichage » déplace le sens vers l’idée d’une exposition, d’un geste tourné vers un public plus large que le seul cercle familial. Ce choix de traduction n’est pas neutre : une fois en ligne, ces publications échappent largement au contrôle de celles et ceux qui les postent.
Un geste façonné par le design des plateformes
Les réseaux sociaux ne se contentent pas d’héberger les publications des parents : par leur conception même, à travers les « likes », commentaires, algorithmes de recommandation, ils transforment chaque photo en signal de validation sociale et chaque publication en donnée exploitable.
Documenter la vie d’un enfant devient alors une pratique qui répond aussi à une logique d’engagement : on choisit l’angle, le moment, le filtre qui généreront le plus de réactions. À l’instar d’un influenceur qui cherche à augmenter son audience, le parent rentre, sans forcément en être conscient, dans la logique d’un créateur de contenu. La fierté et le besoin de reconnaissance qui motivent ces publications sont exactement les ressorts psychologiques que ces plateformes savent activer.
L’enfant, qui ne peut pas encore consentir, devient malgré lui le sujet principal de ce contenu – mais il en est aussi le témoin : comme pour d’autres pratiques numériques, l’apprentissage se fait aussi par observation des habitudes parentales.
Ce que dit la loi
Le droit s’est saisi du phénomène avant que le terme français ne se stabilise. Depuis la loi du 19 février 2024, les parents doivent associer l’enfant, selon son âge et sa maturité, aux décisions concernant la diffusion de son image, ce droit s’exerçant conjointement par les deux titulaires de l’autorité parentale.
Selon l’Observatoire de la parentalité et de l’éducation numérique, plus d’un parent français sur deux a déjà partagé du contenu concernant son enfant sur les réseaux sociaux.
Nommer pour mieux comprendre les enjeux
Loin d’être un exercice purement linguistique, le fait de disposer d’un mot français pour désigner cette pratique permet de la rendre visible et discutable, plutôt que de la laisser filer comme une évidence technologique.
L’expression « affichage parental d’images de mineurs » invite chaque parent à se demander, avant de publier, s’il partage ou s’il expose. Il n’y a pas de bonne réponse universelle. Mais l’enfant, même très jeune, n’est pas seulement le sujet d’une image : il en est, ou en deviendra, le premier concerné.
La série « L’envers des mots » est réalisée avec le soutien de la délégation générale à la langue française et aux langues de France du ministère de la culture.
Caroline Rouen-Mallet a reçu des financements de l'Agence Nationale de Recherche - projet ALIMNUM : Alimentation et Numérique.
06.07.2026 à 15:44
Le changement climatique menace (aussi) notre patrimoine culturel
Anthony Schrapffer, PhD, EDHEC Climate Institute Scientific Director, EDHEC Business School
Camille Angué, Directrice de l'EDHEC Climate Institute, EDHEC Business School
Texte intégral (1520 mots)

Lorsque l’on parle du changement climatique, les débats portent le plus souvent sur l’énergie, la biodiversité, les émissions de carbone ou encore les coûts économiques de la transition. Mais une autre dimension du problème reste encore largement sous-estimée : l’impact du dérèglement climatique sur notre patrimoine culturel.
43 % des sites du patrimoine mondial de l’Unesco en Europe sont aujourd’hui fortement exposés aux risques climatiques extrême, inondations, et montée des eaux. Nos recherches arrivent à cette estimation en appliquant les méthodologies de quantification du risque climatique développées au sein de l’EDHEC Climate Institute aux actifs physiques compatibles provenant de la base de données spatiales de l’Unesco.
Cette vulnérabilité ne concerne pas uniquement quelques sites emblématiques, comme Venise, ou certains centres historiques méditerranéens. Elle touche l’ensemble des infrastructures culturelles européennes, y compris des œuvres moins visibles, souvent dispersées dans des églises, bibliothèques, collections locales ou petits musées.
Les risques sont déjà très concrets. Les œuvres d’art et les collections muséales sont directement exposées aux inondations, aux variations d’humidité, aux pics de chaleur et aux pannes affectant les systèmes de conservation. Une enquête menée auprès des musées d’art américains révèle que 35 % des directeurs déclarent avoir déjà subi des dommages liés au climat, tandis que 50 % indiquent avoir engagé une planification spécifique face à ces risques. En France, le musée du Louvre a d’ailleurs engagé le transfert d’environ 250 000 œuvres vers son Centre de conservation de Liévin, dans le Pas-de-Calais, afin de protéger les collections nationales contre le risque de crue.
Les principales menaces sont multiples :
- augmentation de l’humidité et développement des moisissures pour les peintures et fresques ;
- fragilisation des matériaux sous l’effet des variations thermiques ;
- intensification des pluies acides ;
- multiplication des incendies, submersions et glissements de terrain.
Même la musique est concernée
Le patrimoine musical lui-même n’échappe pas à cette fragilité climatique.
La fabrication des instruments dépend de ressources naturelles particulièrement sensibles au réchauffement climatique. Les épicéas de résonance du Val di Fiemme, dans les Dolomites (Italie), utilisés historiquement pour les violons de Stradivarius, sont aujourd’hui menacés par la hausse des températures et la prolifération de parasites.
Les bois utilisés pour les archets ou les instruments à cordes deviennent également plus rares sous l’effet du stress hydrique et de la déforestation.
Les salles de concert et opéras sont elles aussi directement exposés. À Venise, les projections climatiques suggèrent qu’à horizon 2100, la multiplication des épisodes d’« acqua alta » pourrait rendre impossible le maintien d’une activité normale à l’opéra de La Fenice.
D’autres infrastructures culturelles majeures situées en zones côtières pourraient être confrontées à des difficultés similaires : Royal Festival Hall (Londres, Royaume-Uni), Harpa (Reykjavik, Islande), Sydney Opera House (Sydney, Australia), la Philharmonie de l’Elbe (Hambourg, Allemagne), Muziekgebouw aan’t IJ (Amsterdam, Pays-Bas).
Un choc économique majeur
À cette fragilité culturelle s’ajoute une autre difficulté : la capacité économique à financer la protection de ces patrimoines.
Nos projections macroéconomiques montrent que certaines grandes régions culturelles européennes pourraient connaître des pertes économiques significatives d’ici la fin du siècle sous l’effet des risques physiques liés au climat. Les impacts sur le produit régional brut (équivalent du PIB local) local sont particulièrement marqués dans les villes méditerranéennes. À l’horizon 2100, les pertes pourraient atteindre 32 % à Madrid et jusqu’à 41 % à Rome, soit un niveau nettement supérieur à celui estimé à l’échelle nationale, où la baisse du PIB de l’Italie est évaluée à 19 %. D’autres grandes capitales européennes sont également fortement touchées, avec des pertes estimées à 13 % à Vienne et 18 % à Berlin.
Ce paradoxe est central : c’est précisément au moment où les besoins d’investissement pour protéger le patrimoine deviendront les plus importants que les capacités financières pourraient se trouver les plus contraintes.
Le climat comme enjeu culturel
Longtemps, le changement climatique a été pensé comme un problème de ressources naturelles ou d’équilibres énergétiques. Il apparaît désormais aussi comme une question culturelle et civilisationnelle.
Il interroge notre rapport à la transmission culturelle, à la mémoire collective et à la préservation de biens qui ne peuvent être ni reproduits ni remplacés.
La difficulté est qu’il ne s’agit pas seulement de protéger des objets ou des bâtiments, mais de préserver les conditions matérielles qui rendent possible la continuité d’une histoire, d’un héritage et d’une création artistique.
Des biens culturels non substituables
L’économie classique et néoclassique repose historiquement sur l’hypothèse de substituabilité des facteurs de production (voir David Ricardo, Jean-Baptiste Say et Robert Solow) : les ressources naturelles détruites, épuisées ou raréfiées pourraient être compensées par une accumulation accrue de capital, par l’investissement productif ou par le progrès technique. Bien que très critiquée, cette hypothèse de substituabilité constitue encore aujourd’hui l’un des fondements centraux d’une large partie des modèles macroéconomiques contemporains.
Cette approche rencontre une limite évidente lorsqu’il s’agit du patrimoine culturel. Une fresque détruite par l’humidité ne peut pas être remplacée. Une mosaïque antique dégradée par des stress thermiques ou des pluies acides ne peut pas être recréée à l’identique. Un site archéologique submergé est perdu de manière irréversible. C’est précisément cette notion d’irréversibilité qui distingue le patrimoine culturel d’autres catégories de biens économiques.
Cette contradiction entre expansion économique et limites environnementales ne conduit pas nécessairement à une impasse historique. L’approche économique possibiliste (héritée notamment de Paul Vidal de La Blache) rappelle que les sociétés humaines ne se développent jamais indépendamment de leur milieu. La nature fixe un ensemble de contraintes et de possibilités avec lesquelles les organisations économiques doivent composer. Cette perspective rompt avec l’idée d’une croissance potentiellement illimitée et réintroduit la matérialité des conditions écologiques dans l’analyse économique.
Dans une perspective plus dialectique, proche de la pensée hégélienne, les crises écologiques et énergétiques peuvent aussi être interprétées comme le moment d’une transformation profonde des sociétés industrielles. Les tensions actuelles ouvrent la possibilité d’un dépassement : réorientation des systèmes productifs, intégration des contraintes écologiques dans la rationalité économique, redéfinition des critères de prospérité et renouvellement des formes de progrès technique. Préserver notre héritage collectif est encore possible, mais la fenêtre d’action se referme.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
06.07.2026 à 15:43
Pourquoi les entreprises doivent parfois apprendre à « échouer vite »
Kumar Rakesh Ranjan, Professor of Marketing, EDHEC Business School
Scott Friend, Professor and Schaefer Endowed Chair in Marketing, University of Dayton
Texte intégral (2023 mots)
Comment réussir à échouer ? Rater n’est pas difficile, mais un échec réussi n’est pas si simple à atteindre. C’est une question de compétences disponibles et de préparation : bien échouer ne s’improvise pas. Mais aussi, et peut-être surtout, une question de timing.
Dans les entreprises, certaines idées, longtemps après avoir montré leurs limites, continuent d’absorber du temps, de l’argent et de l’attention. Les projets ne sont souvent arrêtés que lorsque les preuves de leur échec deviennent impossibles à ignorer. La stratégie de Meta dans le métavers en offre une illustration frappante. Après plusieurs années d’investissements massifs, les changements annoncés par le géant américain en mars 2026 peuvent être lus comme un net recul, voire un abandon, de ses ambitions dans le métavers.
Mais de nombreuses entreprises adoptent l’approche inverse, consistant à se détourner rapidement de l’échec plutôt que de s’entêter. Google, par exemple, a fermé son service de jeux en ligne Stadia lorsqu’il est devenu clair qu’il ne trouvait pas son marché, tout en réutilisant certaines technologies dans d’autres activités. En Formule 1, Mercedes a également renoncé à son concept de voiture sans pontons, lorsqu’il est apparu que cette solution l’enfermait dans une impasse concurrentielle. Et Slack est passé d’une application de jeu qui avait échoué à une plateforme de messagerie interne omniprésente.
À lire aussi : Pernod Ricard et le PSG : quand le territoire se rappelle à l’entreprise
Un apprentissage plus rapide
Ce qui a motivé toutes ces décisions, ce n’était pas une tolérance à l’échec. Elles traduisent plutôt une capacité à repérer tôt les signaux faibles, à regarder en face les fragilités d’un projet et à changer de cap avant que les pertes ne s’accumulent. En d’autres termes, les dirigeants et les équipes ont adopté la philosophie du « failure fast ».
Dans nos recherches, nous détaillons pourquoi ce concept est l’un des plus essentiels, mais aussi un des plus mal compris. Il ne s’agit ni de célébrer l’erreur, ni de revoir les ambitions à la baisse, ni d’autoriser les dirigeants à renoncer trop facilement.
Il s’agit plutôt de créer les conditions d’un apprentissage plus rapide. Cela suppose une discipline managériale précise : reconnaître qu’une opportunité a peu de chances d’aboutir, s’arrêter avant que les coûts irrécupérables ne s’alourdissent, puis réorienter les ressources disponibles vers des projets plus prometteurs. Cette stratégie peut fonctionner pour n’importe quelle entreprise, à n’importe quel niveau, quelle que soit l’importance des enjeux.
S’inspirer du cas Slack
Slack est aujourd’hui omniprésent. On oublie souvent que l’entreprise a été fondée en 2011 sous la forme d’un jeu en ligne multijoueurs appelé Glitch qui n’a pas réussi à percer. Slack, alors connue sous le nom de Tiny Speck, l’a arrêté en 2012, mais ce faisant, ses dirigeants ont identifié une valeur cachée dans un outil de communication interne qu’ils avaient développé simplement pour coordonner leur propre travail.
Ce simple outil interne s’est révélé adapté à un marché alors en plein essor, celui des logiciels de collaboration en équipe. L’entreprise a donc changé de cap en mobilisant son capital et ses talents disponibles pour lancer Slack en 2013. Depuis lors, Slack est devenue l’une des plateformes logicielles d’entreprise à la croissance la plus rapide de l’histoire, ce qui a finalement conduit à son acquisition pour un montant de 27,7 milliards de dollars (environ, 24,2 milliards d’euros) par la plateforme commerciale Salesforce en 2021.
Un abandon raisonné
De telles histoires sont souvent présentées comme des récits de persévérance, mais ce sont en réalité des exemples d’abandon raisonné. Parmi les cas similaires, on peut citer l’invention accidentelle des Post-it par 3M (initialement utilisés comme marque-pages de fortune pour des recueils de cantiques) ; le changement de cap de Shopify, qui est passé de la vente de snowboards à la mise en place d’une infrastructure de commerce électronique ; et la transformation d’Instagram, qui est passé d’une application de check-in encombrée à une plateforme de partage de photos ciblée.
Ces histoires rappellent que réussir ne consiste pas seulement à maintenir le cap. Il faut aussi savoir reconnaître le moment où ce cap ne mène plus nulle part, puis choisir une meilleure voie.
Savoir quand (et comment) passer son tour
Or, une grande partie du monde entrepreneurial continue de véhiculer un message simpliste selon lequel la ténacité est la clé du succès. Cette croyance peut pourtant conduire au piège des « coûts irrécupérables ». L’histoire des entreprises regorge d’exemples de ce piège.
Blockbuster n’a pas accepté une offre d’achat de Netflix et a préféré étendre son réseau de magasins physiques ; Kodak a inventé les appareils photo numériques, mais a choisi de donner la priorité à son activité dominante de pellicules photographiques ; et le financement en joint-venture de l’avion de ligne supersonique Concorde s’est poursuivi malgré des preuves solides que le projet ne serait pas viable commercialement. Ces entreprises ont finalement disparu après avoir dominé leur secteur respectif.
Ces coûts irrécupérables éclairent par contraste la notion d’échec rapide. Nos recherches montrent que les bénéfices de cette approche ne se limitent pas aux grands virages stratégiques très médiatisés. Ils concernent aussi des décisions plus ordinaires, prises au quotidien. Des études sur les ventes interentreprises, par exemple, montrent que se retirer rapidement des opportunités à faible potentiel peut améliorer la motivation et les performances.
Cela dit, il existe une condition importante : cette approche ne fonctionne que lorsque les dirigeants et les salariés en contact avec la clientèle ont une compréhension solide de ce que l’entreprise peut faire et de ce que les clients veulent – plutôt que de considérer l’abandon précoce comme un choix par défaut sous-optimal.
Une démarche en trois étapes
Ces cas variés font apparaître une logique commune. Échouer vite ne relève pas de l’improvisation : c’est une manière structurée de décider dans l’incertitude, en trois étapes. Là encore, l’histoire des débuts de Slack en est un bon exemple.
La première étape consiste à recueillir des informations permettant de déterminer si un projet donné a des chances de réussir. Ces signaux peuvent provenir d’une observation directe ou de données. L’objectif est de se forger rapidement une image factuelle permettant de savoir si une initiative prend de l’ampleur. Dans le cas de Slack, le PDG Stewart Butterfield et son équipe ont constaté, grâce à l’expérience directe des utilisateurs, que le jeu Glitch n’était tout simplement pas (suffisamment) amusant. Mais ils ont également détecté d’autres signaux indiquant des limites structurelles qui empêchaient toute voie viable vers le succès sur les appareils mobiles.
Délicate mise en œuvre
L’étape suivante consiste à interpréter les données collectées – en combinant expérience, connaissance du contexte et outils analytiques pour distinguer les idées qui méritent un investissement de celles qui n’en méritent pas. Des méthodes simples, comme comparer les résultats attendus à des références passées, aident à éviter les décisions fondées uniquement sur l’intuition. Dans le cas de Slack avec Glitch, S. Butterfield a synthétisé les premiers signaux et conclu que, malgré des coûts irrécupérables importants, le jeu ne justifiait pas l’allocation de ressources supplémentaires.
La dernière étape, et la plus difficile, est la mise en œuvre. Même lorsque les signaux indiquent qu’il faut arrêter, prendre cette décision reste difficile. Se retirer peut sembler contre-intuitif dans un environnement qui récompense la persévérance. C’est pourquoi les dirigeants doivent démontrer qu’il existe une manière plus judicieuse d’allouer le temps, le capital et l’attention. Chez Slack, le PDG a donné suite à ses convictions analytiques en fermant le jeu et en réorientant la technologie interne pour créer Slack – recadrant cet « échec » comme une réaffectation stratégique.
Une leçon pour toutes et tous
Ces enseignements dépassent largement le cadre de la vente, de la culture des start-up et des géants de la tech. Les dirigeants rencontrent les mêmes dilemmes lorsqu’ils développent un produit, nouent un partenariat ou recrutent. Dans ces situations, le véritable risque n’est pas toujours d’échouer, mais d’échouer trop tard.
Ainsi, les organisations solides savent comment échouer de manière calculée. Concrètement, cela signifie définir tôt les critères de réussite et d’échec, tester rapidement les hypothèses clés et limiter les pertes avant que l’engagement ne se transforme en gaspillage. Ces leçons valent pour de nombreux secteurs et à tous les niveaux de l’organisation.
Pour une analogie plus poétique, tournons-nous vers la mer. Aucun marin expérimenté ne tente de traverser toutes les étendues d’eau. Certaines mettront son endurance à l’épreuve, tandis que d’autres ouvriront de nouvelles routes. Les meilleurs marins savent lire les vents et changer de cap avant que la tempête n’éclate.
Les dirigeants d’entreprise font face au même arbitrage. La croissance ne vient ni de la persévérance à tout prix ni du renoncement instinctif. Elle dépend de la capacité à reconnaître le moment où l’effort ne crée plus de valeur.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
06.07.2026 à 15:43
Pourquoi est-ce si difficile d’estimer les bénéfices et les coûts du Brexit ?
Bernd Philipp, Docteur en sciences de gestion, enseignant chercheur en logistique et SCM, ESCE International Business School
Texte intégral (1702 mots)
Après le Brexit, en 2020, l’Union européenne a dû affronter la pandémie de Covid-19, le choc des prix de l’énergie des suites de la guerre en Ukraine et de la crise du détroit d’Ormuz. Alors, comment mesurer efficacement les conséquences du Brexit pour les entreprises ? Une étude propose de l’analyser comme un risque à l’aide des outils du « risk management ».
Le Royaume-Uni quittait officiellement le marché unique européen le 31 janvier 2020. Cette sortie mettait fin à la libre circulation des biens, des services, des capitaux et des personnes entre le Royaume-Uni et l’Union européenne.
Depuis, la Cour des comptes estime que « l’excédent français du solde des échanges de marchandises avec le Royaume-Uni s’est considérablement réduit de 12,7 milliards d’euros en 2019 à 5,6 milliards ».
Pour appréhender le Brexit sous une nouvelle approche, notre recherche s’intéresse à distinguer les effets directs du Brexit – exogènes – des stratégies – endogènes – mises en œuvre par les entreprises pour y faire face.
Pour ce faire, nous avons mobilisé le concept de la gestion des risques. Il permet d’étudier les différentes phases du processus de l’identification du risque à sa résolution, en passant par son évaluation et les enseignements à en tirer.
Dans cette perspective, le Brexit peut être considéré soit comme un événement de risque, soit comme un facteur générateur de risques, notamment pour les chaînes d’approvisionnement, ou supply chains. Ces dernières relient des entreprises, des fournisseurs, des prestataires logistiques et des clients, depuis l’extraction des matières premières jusqu’à la livraison du produit ou du service final.
C’est pourquoi nous appelons à utiliser les outils de la gestion des risques appliquée aux supply chains pour éclairer les décideurs économiques et politiques face aux impacts du Brexit.
Effet globalement défavorable sur l’économie
Qui sont les gagnants et les perdants du Brexit ? Il est encore difficile d’estimer le coût économique du Brexit.
Cet exercice est particulièrement complexe. L’année 2020 a marqué la sortie effective du Royaume-Uni de l’Union européenne ; elle a également été celle de la pandémie de Covid-19. Deux ans plus tard, la guerre en Ukraine et le choc des prix de l’énergie sont venus ajouter de nouvelles perturbations.
La France est l’un des pays européens qui ressent le plus fortement ses effets du Brexit. La Cour des comptes estime que le nombre d’entreprises françaises exportatrices vers le Royaume-Uni a chuté de 9 000 à 8 000 entre 2018 et 2021.
Lorsqu’on adopte une perspective britannique, les études concluent à un effet globalement défavorable sur l’économie du Royaume-Uni. Selon l’étude du National Bureau of Economic Research (NBER), fondée sur près de dix années de données depuis le référendum de 2016, l’investissement des entreprises britanniques aurait diminué de 12 % à 13 %, l’emploi de 3 % à 4 % et la productivité de 3 % à 4 %.
Dans le même temps, les données du Fonds monétaire international (FMI) montrent que l’économie britannique a progressé d’environ 5 % entre le début de l’année 2020 et aujourd’hui. Une croissance qui est supérieure à celle observée en France et comparable à celle de l’Italie.
L’analyse de la recherche académique
Il convient de nuancer les conséquences du Brexit selon la géographie (Royaume-Uni, Irlande, États-Unis ou Chine) et selon le secteur industriel (alimentaire, chimique ou automobile), tout en distinguant les impacts exogènes (augmentation des droits de douane) des réactions endogènes (reconfiguration des stratégies commerciales ou nouvelles routes logistiques).
À lire aussi : Le Royaume-Uni a-t-il besoin d’un nouveau Winston Churchill ?
Pour appréhender tous ces paramètres, nous nous sommes appuyés sur une revue de littérature académique consacrée au retrait du Royaume-Uni de l’Union européenne. À partir de mots-clés liés au Brexit et aux supply chains, une première recherche automatisée a identifié 122 articles, parmi lesquels 17 contributions étaient directement en lien avec notre problématique. Parmi celles-ci, seules huit identifiaient clairement des stratégies d’entreprise face au Brexit.
Ce nombre relativement faible constitue en lui-même un résultat intéressant : malgré l’importance économique et politique du Brexit, la recherche académique sur ses conséquences reste encore limitée.
Notre analyse s’est articulée autour :
de la répartition des publications dans le temps, en distinguant les études menées avant l’entrée en vigueur du Brexit (approche pré-Brexit) de celles réalisées après sa mise en œuvre (approche post-Brexit) ;
des approches méthodologiques complémentaires : études de cas, enquêtes, modélisations, rapports d’expertise, travaux théoriques ou revues de littérature ;
du degré d’utilisation des outils du risk management, appréhendés comme un ensemble de méthodes mobilisées tout au long du processus itératif de gestion des risques. Parmi ces méthodes, figure notamment la Failure Modes and Effects Analysis, ou FMEA, largement utilisée dans les systèmes de management de la qualité. Comme son nom l’indique, la FMEA sert à repérer les possibles défaillances d’un système et à analyser leurs conséquences.
Qui est touché par le Brexit… et comment ?
Quantifier précisément les coûts et les bénéfices semble quasiment impossible.
Cette démarche implique de prendre en compte à la fois les barrières commerciales, qu’elles soient tarifaires (droits de douane) ou non tarifaires (formalités administratives, contrôles, normes et procédures supplémentaires), les difficultés de recrutement et de disponibilité de la main-d’œuvre, ainsi que les coûts supplémentaires liés aux retards attendus dans les ports.
Par exemple, dans le secteur alimentaire, les coûts mêlent hausse du prix des denrées alimentaires, pénuries de main-d’œuvre liées au départ d’une partie des travailleurs européens, ainsi qu’une moindre efficacité du modèle logistique fondé sur le « juste-à-temps » (just-in-time).
Relocalisation, technologies et coopération
Dans notre étude, nous avons mis en lumière les différentes stratégies possibles pour une entreprise face aux impacts du Brexit, tirées d’études scientifiques :
la relocalisation des chaînes d’approvisionnement, qu’il s’agisse des sites de production, des activités de stockage ou du rapprochement des activités des marchés clients comme le soulignent Javier Bilbao-Ubillos et Vicente Camino-Beldarrain dans « Reconfiguring Global Value Chains in a Post-Brexit World: A Technological Interpretation » ;
saisir les opportunités des nouvelles technologies comme la blockchain et la traçabilité avec l’exemple de l’industrie alimentaire selon les chercheurs Christopher Brooks, Lesley Parr, Jordan M. Smith, Dominic Buchanan, Dominika Snioch et Essam Hebishy. L’utilité : mieux suivre les marchandises, sécuriser les échanges d’informations et gérer plus efficacement les nouvelles formalités administratives ;
adopter une démarche de coopération comme le soulignent Linda Caroline Hendry, Mark Stevenson, Jill MacBryde, Peter Ball, Maysara Sayed et Lingxuan Liu. Elle peut être verticale entre fournisseurs, fabricants et distributeurs ou horizontale entre les entreprises d’un même secteur. Elle permet de partager les informations, les ressources et les bonnes pratiques afin de mieux faire face aux perturbations.
Un nouveau cadre d’analyse
Notre principal résultat ne réside donc pas seulement dans le fait d’avoir dressé un « inventaire » des conséquences du Brexit, mais à donner un cadre d’analyse évaluant son importance pour les entreprises. La gestion des risques de la chaîne d’approvisionnement permet d’interpréter plus finement les impacts observés et d’identifier les stratégies adaptées aux différents contextes.
Elle offre également la possibilité de mobiliser des concepts encore peu exploités dans les recherches sur le Brexit, comme les stratégies d’atténuation des risques ou les capacités de résilience des chaînes d’approvisionnement. L’avenir implique d’étudier l’interaction entre ces deux concepts et le degré d’influence que l’organisation – typiquement la supply chain – exerce sur eux.
Bernd Philipp ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
06.07.2026 à 15:42
Sans eau, les forêts arrêtent de capter du CO₂
Nicolas Martin, Chercheur à INRAE, Inrae
Hervé Cochard, Directeur de recherche en écophysiologie, Inrae
Isabelle Maréchaux, Chercheuse, Inrae
Julien Lamour, Chercheur en écophysiologie végétale, spécialisé sur les espèces tropicales, Centre national de la recherche scientifique (CNRS)
Texte intégral (3678 mots)

Pour survivre en période de sécheresse, les arbres stoppent la photosynthèse, une activité très gourmande en eau au cours de laquelle s’échappent, pour chaque molécule de CO2 absorbée par une feuille d’arbre, environ 400 molécules d’eau en moyenne. Des forêts entières se retrouvent alors à émettre plus de CO2 qu’elles n’en capturent.
C’est une réalité révélée par les sécheresses récentes : les forêts peuvent émettre plus de CO2 qu’elles n’en capturent. Cet état de fait est alarmant quand on sait que les sécheresses sont de plus en plus fréquentes et que les forêts jouent un rôle clé dans les politiques d’atténuation du changement climatique. Même si la quantification du CO2 capté par les forêts mondiales reste un exercice difficile, on estime qu’elles captent environ un quart du CO2 émis par les activités humaines.
Mais face au manque d’eau, donc, les forêts peuvent cesser d’être des puits de carbone. Pour comprendre pourquoi, il faut regarder les feuilles des arbres.
À lire aussi : Comment une forêt peut-elle émettre plus de CO₂ qu’elle n’en capture ?
L’eau, monnaie d’échange du CO₂
Les feuilles des arbres constituent le point d’entrée principal du CO2 dans l’écosystème forestier. Elles agissent comme de véritables usines chimiques en captant l’énergie solaire pour convertir en sucre le CO2 présent dans l’air : c’est la photosynthèse. Ces sucres alimentent les besoins énergétiques de la plante. Ils permettent aussi aux arbres de grandir et, ainsi, de stocker davantage de CO2 émis par les activités humaines.
La surface des feuilles est en partie couverte de stomates, de minuscules fentes qui peuvent s’ouvrir et se fermer. C’est par ces pores que le CO2 pénètre dans l’arbre. Ce déplacement du CO2 ne nécessite pas d’énergie à l’arbre. Il se fait naturellement du milieu où le CO2 est plus abondant – l’atmosphère – vers le milieu où il l’est moins, ici l’intérieur de la feuille.
Mais l’ouverture des stomates ne permet pas seulement au CO2 d’entrer. Elle entraîne aussi une perte en eau pour l’arbre, car les cellules de l’intérieur des feuilles sont bien plus riches en vapeur d’eau que l’atmosphère, et ce, même dans les régions les plus humides. C’est ce qu’on appelle la transpiration des arbres. En moyenne, pour chaque molécule de CO2 absorbée par un stomate, environ 400 molécules d’eau s’échappent simultanément.
Cette transpiration est nécessaire à la croissance et au métabolisme des plantes. Elle peut représenter jusqu’à plusieurs centaines de litres d’eau – l’équivalent de plusieurs baignoires – par jour selon la taille de l’arbre en saison de croissance, et plusieurs dizaines de milliers de litres par jour pour un hectare de forêt. Ces grandes quantités d’eau sont puisées dans le sol par les racines de l’arbre.
Un fil d’eau fragile qui s’élève contre la gravité
Pour acheminer l’eau des racines jusqu’aux feuilles, les plantes ont besoin d’un système hydraulique performant. Le moteur de ce transport, à contre-courant de la gravité, est l’évaporation de l’eau au niveau des stomates. Celle-ci crée une tension qui « tire » les colonnes d’eau vers le haut, comme une paille géante, grâce à la forte cohésion des molécules d’eau entre elles.
Ce principe a été formulé à la fin du XIXᵉ siècle par le botaniste irlandais Henry Horatio Dixon, et a ainsi été appelé « tension-cohésion ». Il explique comment la transpiration est un mécanisme passif, sans coût énergétique pour l’arbre.
Pourtant, la tension nécessaire pour élever l’eau jusqu’à la cime des arbres est colossale. Imaginez que l’eau est aspirée comme à travers une paille de plusieurs dizaines de mètres, mais que cette paille est remplie d’obstacles : les parois des vaisseaux, les cellules… Résultat ? La force nécessaire pour faire monter l’eau jusqu’au sommet de l’arbre équivaut à celle qu’il faudrait pour pomper de l’eau d’un puits de plusieurs centaines de mètres de profondeur !
Dans ces conditions extrêmes, l’eau se trouve dans un état dit « métastable », c’est-à-dire qu’elle peut brusquement passer à l’état gazeux si la tension augmente encore : si c’est le cas, c’est la cavitation. Lorsque la cavitation survient, cela génère des bulles d’air dans ce réseau qu’on appelle le système hydraulique de l’arbre. Des embolies gazeuses empêchent alors la circulation de l’eau et le système hydraulique défaille. Les feuilles ainsi que les autres tissus de l’arbre se déshydratent progressivement, jusqu’à se dessécher de manière irréversible.

La cavitation est un phénomène irréversible qui intervient lors des sécheresses extrêmes, souvent liées au manque de pluie combiné aux vagues de chaleur. Dans ces situations, d’une part, l’eau du sol est de plus en plus difficile à extraire au fur et à mesure que celui-ci s’assèche, on parle de sécheresse du sol. D’autre part, lorsque l’atmosphère chauffe, l’air devient plus desséchant et le moteur de l’évaporation au niveau des feuilles s’emballe, ce qui augmente la tension dans la plante et accélère la vidange du sol. On parle de sécheresse atmosphérique.
Un dilemme entre la soif ou la faim
En période de sécheresse, les arbres font donc face à un dilemme : ouvrir les stomates pour favoriser la photosynthèse nécessaire au métabolisme et à la croissance de l’arbre ou fermer les stomates pour sauvegarder de l’eau et préserver leur système hydraulique de la rupture irréversible.
L’évolution des arbres au cours des temps géologiques a permis l’émergence d’un comportement qui résout ce dilemme. Les stomates s’ouvrent et se ferment dynamiquement, en quelques minutes, pour minimiser les pertes en eau quand les conditions sont défavorables à la photosynthèse, comme quand la lumière diminue. En situation de sécheresse, toutes les plantes vasculaires ferment leurs stomates.
Les forêts vont, pendant ce temps, continuer à émettre du CO2. D’abord du CO2 issu de la consommation des sucres produits par la photosynthèse et nécessaires à leur métabolisme. Ensuite, du CO2 émis par les arbres qui meurent face à la sécheresse et relarguent ainsi dans l’atmosphère le carbone qu’ils ont stocké de leur vivant. Ces deux réalités peuvent donc amener une forêt à ne plus être un puits mais une source de carbone, une inversion qui peut être amplifiée par certains types d’exploitation forestière, notamment ceux fondés sur un interventionnisme massif.
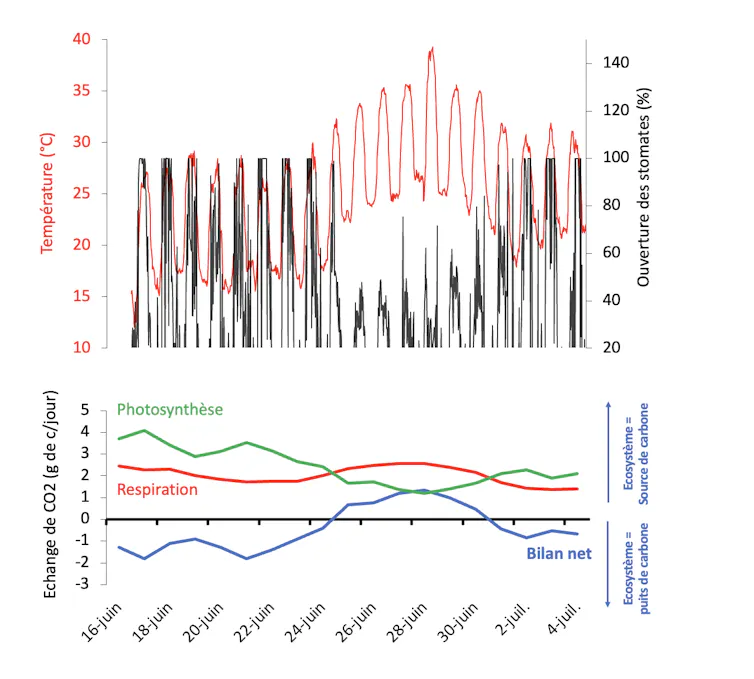
D’un arbre à l’autre, d’une espèce à l’autre, la résistance à la sécheresse peut toutefois beaucoup varier en fonction de la vulnérabilité de son système hydraulique à l’embolie. La fermeture des stomates a été sélectionnée pour exploiter au maximum l’eau disponible au regard des capacités à résister à l’embolie de l’espèce.
Un arbre avec un système hydraulique plus vulnérable, comme le bouleau, aura tendance à fermer ses stomates plus tôt qu’un arbre avec un système hydraulique plus résistant, comme le chêne vert. En fait, tous les arbres fonctionnent à la limite de l’embolie, même les plus résistants vivant dans des zones très arides. En conséquence, toutes les forêts du monde sont vulnérables à une augmentation des sécheresses causées par le changement climatique.
En effet, lorsque les sécheresses dépassent les conditions de référence auxquelles les arbres sont adaptés, les impacts physiologiques deviennent critiques, car, même après la fermeture des stomates, des pertes d’eau résiduelles se poursuivent à travers la cuticule des feuilles et des tiges. Ce phénomène peut entraîner la chute des feuilles, une embolie au sein du système hydraulique et le dessèchement des bourgeons, menant in fine à la mort de l’arbre.
L’eau contrôle le cycle du carbone et vice versa
Ainsi, pour comprendre et prédire la capacité des forêts à agir comme puits de carbone, il faut comprendre et prédire la variation de l’eau dans le temps et l’espace.
Il a parfois été mis en avant que le changement climatique et l’augmentation de la concentration en CO2 dans l’atmosphère auraient un effet fertilisant sur la végétation selon une logique en apparence implacable : qui dit plus de CO2, dit plus de photosynthèse, plus de croissance et plus gros puits de carbone. Mais, c’est oublier que le changement climatique est aussi synonyme de sécheresses plus intenses et plus fréquentes, qui privent les arbres de leur monnaie d’échange.

Et d’ailleurs, quand bien même les arbres auraient assez d’eau : le CO2 augmente la photosynthèse, mais réduit aussi l’ouverture des stomates, car plus il y a de CO2 dans l’air, plus celui-ci peut être capté avec une plus faible ouverture des stomates. Cela est bénéfique pour la plante qui sauvegarde de l’eau, mais, à large échelle, cela diminue la transpiration et donc le recyclage des eaux de pluie par les forêts. En effet, l’eau transpirée par les arbres est critique pour la stabilité des conditions climatiques sur les continents.
Par exemple, on estime que jusqu’à 50 % des précipitations à l’ouest de l’Amazonie proviennent de l’eau transpirée par la partie est du bassin amazonien et transportée par les alizés. La fermeture des stomates à l’est peut donc diminuer la pluie à l’ouest. Et ces effets en cascade pourraient mettre en péril la stabilité de ce fameux « poumon vert ».

Nicolas Martin bénéficie de financements de recherche de l’ANR et d’Horizon Europe. Cet article est le fruit de réflexions menées dans le cadre du réseau d’animation PsiHub (psihub.inrae.fr/past-workshops), financé par INRAE-ECODIV. Par ailleurs, il est membre du conseil d’administration de l’association Forêt Méditerranéenne.
Hervé Cochard a reçu des financements de l'Agence nationale de la recherche (ANR), du FAEDER, de fonds Européens H2020, et du Ministère de l'Agriculture et de la Souveraineté alimentaire.
Isabelle Maréchaux a reçu des financements du Labex CEBA (Centre d'étude de la Biodiversité Amazonienne, ANR-10-LABX-25-01) , de l'Agence Nationale de la Recherche (ANR) et du programme de recherche européen Biodiversa +. Cet article est le fruit de réflexions menées dans le cadre du réseau d’animation PsiHub (psihub.inrae.fr/past-workshops), financé par INRAE-ECODIV.
Julien Lamour a reçu des financements du projet "Next Generation Ecosystem Experiments - Tropics", programme de recherche du gouvernement américain qui vise à mieux comprendre le rôle des forêts tropicales sur le climat, et du projet de l'agence nationale de la recherche française "Paysages Amazoniens en transition".
06.07.2026 à 11:21
La formation ne suffit pas à garantir une reconversion des femmes sorties de l’emploi dans l’univers du numérique
Marion Lauwers, Enseignant-chercheur, Institut Catholique de Lille (ICL), Institut catholique de Lille (ICL)
Abir Karami, Enseignante-chercheuse en Informatique spécialité Intelligence Artificielle (IA), Institut catholique de Lille (ICL)
Mourad Ellouze, Docteur en informatique, ENS de Lyon
Texte intégral (1527 mots)
Les femmes restent très sous-représentées dans l’univers du numérique, malgré la multiplication de dispositifs de formation. Comment l’expliquer ? Comment lever les freins ?
L’inclusion des femmes et, notamment, des femmes sorties de l’emploi dans le secteur du numérique est cruciale pour développer des technologies plus justes et égalitaires. Elle est également critique pour la compétitivité européenne. Comme souligné par la Commission européenne, une augmentation de la part des femmes travaillant dans le numérique à hauteur de 45 % d’ici à 2027 permettrait d’améliorer le produit intérieur brut (PIB) de 260 milliards à 600 milliards d’euros.
Cependant, moins de 29 % de femmes travaillent aujourd’hui dans l’univers du numérique. Pis, ce taux semble stagner par rapport à 2025. Les femmes, en France, restent très sous-représentées dans les métiers du numérique.
De nombreux dispositifs de formation visant l’acquisition accélérée de compétences et l’insertion dans les métiers du numérique ont été créés ces dernières années. Certains programmes s’adressent spécifiquement aux femmes issues des milieux les plus défavorisés. Le gouvernement a même fait de la parité dans les métiers de la tech et du numérique une de ses priorités depuis 2023.
Alors, comment mieux accompagner les femmes sorties de l’emploi à se reconvertir dans l’univers du numérique ?
Notre étude, en parallèle de la publication de deux livres blancs sur les innovations pédagogiques pour une reconversion inclusive et sur les perspectives de parcours de e-learning inclusifs et personnalisés, montre que la formation, seule, ne suffit pas.
Monde complexe et inaccessible
Les entretiens que nous avons menés au sein d’une structure d’accompagnement des femmes, auprès d’accompagnatrices emploi, mettent en évidence l’importance de développer le regard des femmes sorties de l’emploi sur l’univers du numérique.
Nombreuses sont celles qui ne se sentent pas à la hauteur ; elles voient le secteur comme un monde complexe et inaccessible. De plus, ces métiers restent souvent méconnus ou mal connus.
« Ce qui répondait à leurs attentes, c’était vraiment de savoir de quoi on parle, de quel métier, quelle est la mission de chaque métier, qu’est-ce qu’on fait, à quoi ça sert, avec quels outils, type langage informatique ? C’est vraiment du concret », souligne Astrid, l’une des accompagnatrices d’emploi.
Outre les recommandations classiques – faire découvrir ce qu’est le numérique ou l’importance des rôles modèles ou des mentors –, nos entretiens mettent en lumière l’importance de donner de la visibilité aux formations :
« Avoir des ateliers qui leur permettent de découvrir la formation, c’est bien. Parce que ces personnes-là ne seraient jamais tombées sur les sites [de formation] », rappelle Sylvie, une autre accompagnatrice d’emploi.
Au-delà de la visibilité des formations existantes, il apparaît essentiel de travailler sur l’accessibilité du contenu proposé :
« On [leur] demande par exemple la définition d’un cloud. Pour des personnes qui sont très loin du numérique, ça ne leur parle pas du tout. Même si elles s’en servent tous les jours, elles ne réalisent pas et elles ne savent pas ce que c’est. Il faut le désacraliser », affirme Astrid.
Autocensure technologique
Les femmes concernées cumulent souvent une autocensure technologique, une rupture prolongée de l’emploi, des contraintes familiales et un réseau professionnel fragile. Trop souvent les solutions proposées peinent à lever les barrières des apprenantes.
La plupart des femmes accompagnées ont un accès au numérique réduit leur donnant l’impression qu’une reconversion dans ce secteur est tout simplement impossible.
« On a vraiment un public fragilisé, qui n’a pas obligatoirement les moyens et l’accès au numérique, ça reste encore quelque chose qui est rarissime. Sur le panel de femmes qu’on accompagne, je n’en ai aucune qui a un ordinateur à la maison », souligne Sarah, une autre accompagnatrice d’emploi.
Au-delà des freins matériels, les freins financiers et logistiques sont importants :
« C’est l’argent du coup [qui joue sur la motivation]. Nous, on travaille beaucoup sur des formations qui sont prises en charge par le Conseil régional et qui permettent [à ces personnes] de suivre une formation gratuitement. Les problématiques sont souvent liées au financement et au temps (…). Souvent, ce sont des femmes seules avec enfants ; il y a une réalité du quotidien. Elles ont vraiment besoin de travailler », rappelle Astrid.
Comme souligné par l’une des accompagnatrices :
« Travailler sur les freins qu’il y a en périphérie, autour de cette insertion professionnelle, aide aussi à développer des projets. (…) Nous, on est dans le faire faire. Et justement les ateliers sont là pour apporter cette indépendance », souligne Sarah.
En parallèle, des formations accessibles en version mobile, adaptables et personnalisées, sont nécessaires pour favoriser un apprentissage évolutif. Dans ce sens, un potentiel assez important se dessine autour des plateformes d’apprentissage renforcées par les intelligences artificielles (IA) génératives.
Parcours en étapes
Certaines formations sont fondées sur des effets de modes ou éloignées des opportunités locales, ce qui peut générer encore plus de précarité :
« J’en ai des femmes qui travaillent dans le numérique, qui ont participé à un parcours pendant trois ans et, aujourd’hui, elles ne trouvent pas de boulot de développeur. Elles ont appris une partie, une technologie. Ensuite, il y a eu l’arrivée de l’IA. Et là, du coup, elles ont été larguées », estime Astrid.
Il semble crucial de penser à long terme et d’orienter ces femmes dans des parcours en étapes, en adéquation avec leurs souhaits, leurs capacités et en adéquation avec les besoins réels du marché.
Renforcer les liens entre les Régions, France Travail et les acteurs locaux du marché de l’emploi, ainsi que ceux entre les femmes évoluant dans le numérique apparaît essentiel pour mieux accompagner leur retour à l’emploi. Ces coopérations amélioreraient les orientations vers des opportunités d’insertion professionnelle réelles.
Former oui, mais à quoi et pourquoi ?
De nombreux acteurs prônent la formation et l’accompagnement des femmes au numérique dès le lycée et même avant.
Cette stratégie ne comblera pas les besoins du marché actuels ni ne résoudra à courte échéance le manque de parité dans les métiers du numérique.
S’intéresser aux femmes sorties de l’emploi et/ou souhaitant se reconvertir reste un élément clé pour accélérer la mixité dans l’univers du numérique dès aujourd’hui. Encore faut-il comprendre leurs freins, les lever et s’assurer que l’offre de formation corresponde à leurs attentes et aux besoins du marché.
Cette recherche s'intègre dans un projet plus vaste: « Dispositifs France Formation Innovante NUMérique – Deffinum. Porté par un consortium représenté par l’Institut Catholique de Lille, la Fédération Nationale des Centres d'Information sur les Droits des Femmes et des Familles (FNCIDFF) et l’association Social Builder en qualité de chef de file. Une partie de ce projet a été financé par la Banque des Territoires
Abir Karami et Mourad Ellouze ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
06.07.2026 à 11:20
La gestion comme mise en dispositif
Franck Aggeri, Professeur de management, PSL Research University, Mines Paris - PSL
Sébastien Gand, Enseignant-chercheur en Sciences de gestion et des organisations, Sciences Po Grenoble - Université Grenoble Alpes; Université Grenoble Alpes (UGA)
Texte intégral (1369 mots)
La gestion ne peut pas être réduite à des chiffres. Il s’agit d’une matière vivante, qui crée des dispositifs. Pour mieux comprendre, l’œuvre du philosophe Michel Foucault est éclairante. Décryptage avec la mise en place d’outils dans le cadre de la transition bas carbone.
Cet article est publié dans le cadre d’un partenariat avec la Revue française de gestion, qui a fêté ses 50 ans en 2025.
La gestion n’est pas seulement cette activité, souvent caricaturée, de contrôle, de coordination et d’évaluation des performances. C’est également une activité plus exploratoire de conduite d’actions collectives inédites, comme organiser une transition écologique, numérique ou sanitaire.
Les objectifs, les moyens et les méthodes sont alors inventés chemin faisant. Dans de telles situations, le premier défi pour la recherche est de comprendre ce que gérer peut vouloir dire.
Pour cela, notre article paru dans la Revue française de gestion propose un cadre d’analyse, inspiré des travaux de Michel Foucault, que nous appelons « mise en dispositif ». Pourquoi cette formule et quels en sont les principes ? Pour y répondre, revenons d’abord sur le sens du mot « dispositif », puis sur l’usage qu’en a fait le philosophe, avant d’illustrer son intérêt sur l’exemple de la transition bas carbone.
Les deux sens du terme « dispositif »
Mot très usité dans la langue française, dispositif vient étymologiquement du latin dispositio qui désigne deux choses :
l’action de disposer des éléments en vue d’une finalité,
mais également l’une des dimensions de l’art rhétorique, agencer les arguments de façon à les rendre intelligibles.
À lire aussi : Une brève histoire des méthodes managériales
Ces deux dimensions se retrouvent dans l’usage courant de la notion : l’assemblage d’éléments formant un tout cohérent en vue de répondre à une fonction ou d’atteindre une finalité (par exemple, on parle de dispositif technique, pédagogique…) et les stratégies rhétoriques qui accompagnent la mise en place de tout dispositif public.
Le terme a depuis longtemps colonisé l’univers de la gestion dans une acception proche du sens commun. Ainsi, un dispositif de gestion est souvent décrit comme un agencement déjà constitué de règles, d’outils et d’acteurs formant un ensemble cohérent en vue d’une finalité, par exemple un dispositif de gestion des compétences.
L’héritage de Michel Foucault
Une telle conception courante est statique. Elle ne dit rien des modalités d’émergence du dispositif : comment et par qui a-t-il été conçu ? En vue de quelles finalités ?
La question de la formation des dispositifs a été précisément le cœur de la réflexion du philosophe Michel Foucault pour étudier la conduite de nouvelles formes d’action collective. Il souligne trois points essentiels de la formation d’un dispositif :
son caractère finalisé et situé, qui répond à une urgence stratégique dans un contexte précis ;
son hétérogénéité (il est composé d’éléments discursifs, spatiaux, instrumentaux, humains, légaux, moraux, etc.) ;
l’activité collective qui constitue le « dispositif » en agençant ces éléments hétérogènes pour leur donner un sens et une capacité à orienter la conduite des acteurs.
Dans notre article, nous mettons en évidence la fécondité du cadre de la « mise en dispositif » pour comprendre les processus d’émergence de nouvelles formes d’action collective. L’accent est particulièrement mis sur l’activité d’agencement d’éléments hétérogènes (discours, instruments, savoirs, rôles des acteurs, architecture…) en vue de finalités révisables.
Nous soulignons également que ce processus de mise en dispositif ne part jamais d’une page blanche. Les nouveaux dispositifs se superposent ou viennent compléter des dispositifs déjà existants pour les articuler et leur donner une nouvelle finalité et un nouveau sens pour les acteurs.
La transition bas carbone au concret
Illustrons la démarche en prenant l’exemple de la formation d’un dispositif carbone dans un grand groupe de la construction. La transition bas carbone est l’un des mantras contemporains des décideurs publics comme privés. Mais comment celle-ci peut-elle être mise en œuvre ?
Le point de départ de l’enquête est le suivant. Au milieu des années 2000, les dirigeants du groupe anticipent une évolution réglementaire en Europe : le bilan énergétique des bâtiments va être complété par un bilan carbone. La différence entre énergie et carbone ? L’enjeu n’est plus seulement d’améliorer l’isolation des bâtiments, mais de réduire l’empreinte carbone de leur fabrication, c’est-à-dire le choix des matériaux et des systèmes constructifs. Ceci implique un changement complet des méthodes de construction et des chaînes d’approvisionnement.
Or, à cette époque, le groupe n’a pas d’outils de calcul du carbone et n’a aucune solution à disposition. Plutôt que de décréter de grands objectifs, la direction choisit une voie plus modeste. Elle mandate un expert interne avec l’objectif de concevoir un bilan carbone simplifié, facilement appropriable par les opérationnels. Après une phase de test et de paramétrage, un outil de calcul est mis au point. Tous les chefs de projet ont alors l’obligation de chiffrer des variantes bas carbone, que le client le demande ou pas.
Un calcul qui ait du sens…
Pour que ce calcul ait du sens et produise des effets concrets s’engage un patient travail d’agencement de l’outil à toute une série d’éléments qui le complètent pour en faire un dispositif de gestion cohérent.
Des partenariats sur la conception de matériaux et solutions bas carbone sont lancés et testés sur des sites pilotes. Voici quelques exemples.
Un comité d’innovation bas carbone est créé. Un référentiel sectoriel de comptabilité carbone est construit en même temps qu’un label « bâtiments bas carbone », susceptible de préfigurer la réglementation. La conception de projets pilotes bas carbone permet de montrer la pertinence du concept.
Ce n’est qu’après un long processus de mise en dispositif qu’une feuille de route stratégique est enfin annoncée par le groupe. Elle sera régulièrement révisée au gré des événements et de l’élaboration d’autres dispositifs publics ou concurrents, alimentant, à leur tour, de nouveaux agencements.
La mise en dispositif, c’est cela, un processus multiforme, fruit d’initiatives locales et centrales dont le chercheur a pour mission de reconstituer minutieusement le processus, les effets attendus et inattendus, et les potentiels transformatifs.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
06.07.2026 à 11:19
Le syndrome du sauveur au travail : quand les héros de l’entreprise créent les crises qu’ils prétendent résoudre
Mohamad Fadl Harake, Docteur en Sciences de Gestion, Chercheur en Management Public Post-conflit, Université de Poitiers
George Kassar, Full-time Faculty, Research Associate, Ascencia Business School
Texte intégral (2210 mots)
La dynamique des organisations n’est pas toujours aisée à décrypter. La preuve avec ce profil particulier. En apprence, il est l’élément clé, la personne essentielle, toujours là pour trouver une solution quand un problème se pose. Et pourtant, dans certains contextes, ce collaborateur « sauveur » loin d’être la solution est surtout le symptôme d’un problème organisationnel majeur.
Dans certaines organisations, la personne qui sauve systématiquement la situation est parfois aussi celle qui a contribué, discrètement, à provoquer la crise. Ce paradoxe n’a rien d’anecdotique, mais correspond à un schéma bien identifié.
Souvent, il ne s’agit pas du dirigeant le plus haut placé, mais d’une personne devenue apparemment indispensable. Elle détient un savoir tacite difficile à formaliser ou à transmettre, ce qui renforce sa position.
Lorsque la situation se dégrade, souvent de manière récurrente, c’est cette même personne qui rétablit l’ordre, parfois de façon spectaculaire. On pourrait la qualifier d’« indispensable ».
Mais des questions restent rarement posées : pourquoi l’organisation a-t-elle si souvent besoin d’être sauvée ? Et pourquoi est-ce presque toujours par la même personne ?
À lire aussi : Les caïds, ces managers toxiques promoteurs d’univers de travail pathogènes
Un trio infernal
Le syndrome du sauveur renvoie à un schéma organisationnel récurrent. Il ne correspond pas aux formes les plus visibles du leadership toxique (ni supérieur autoritaire ni dirigeant colérique), mais à un profil plus discret, souvent plus coûteux pour l’organisation, celui d’un cadre expérimenté qui contribue à provoquer les crises dont il sera ensuite célébré comme le principal agent de la résolution.
Ce phénomène ne se maintient pas seul. Il s’inscrit dans une structure particulière impliquant trois autres acteurs. Au sommet se trouve souvent un dirigeant affaibli, désengagé, guidé par ses intérêts personnels ou simplement réticent à affronter les conflits. Il s’appuie alors sur le « sauveur » pour gérer les situations difficiles, en échange de sa protection, qui devient alors une ressource essentielle. La littérature décrit ce type de configuration à travers le concept de « triangle toxique », qui associe un leadership destructeur, des suiveurs vulnérables et un environnement propice.
Dans les configurations les plus problématiques, cette relation dépasse la simple dépendance fonctionnelle : le « sauveur » devient un allié stratégique de la direction générale, qui peut trouver dans cette alliance un moyen de préserver son pouvoir ou d’éviter toutes remises en cause du système existant.
Autour du « sauveur » gravite fréquemment un cercle de fidèles, des collaborateurs loyaux mais dépendants, dont l’avancement repose moins sur leurs compétences que sur leur proximité avec lui. Ce favoritisme nourrit une loyauté forte et peu critique. Cette dynamique correspond à ce que la littérature désigne comme du favoritisme relationnel, ou cronyism. Ensemble, ils brouillent les responsabilités, redirigent les décisions et compliquent discrètement le travail de toute personne susceptible de menacer cet équilibre.
Ce comportement ne relève pas seulement d’un défaut individuel. Il constitue aussi une conséquence prévisible de la relation qui peut se nouer entre des suiveurs fragilisés et un leader destructeur.
Un coût considérable pour l’entreprise
La victime est souvent le manager compétent. C’est fréquemment la personne la plus solide sur le plan professionnel, mais aussi celle dont le potentiel est perçu comme une menace. Progressivement associée à des échecs qu’elle n’a pas causés, rarement reconnue pour ses réussites, elle finit souvent par quitter l’organisation. Le coût pour l’entreprise est considérable : temps managérial gaspillé, ressources détournées, climat de travail fragilisé et affaiblissement durable de la performance collective.
Les mécanismes à l’œuvre sont particulièrement reconnaissables pour celles et ceux qui ont déjà été confrontés à ce type de dynamique organisationnelle. Le cycle débute rarement par un sabotage manifeste. Il s’installe à travers une succession d’actions discrètes et difficilement imputables.
Cela peut être une information essentielle retenue au moment opportun, une tâche sensible confiée à un collaborateur loyal mais insuffisamment préparé, ou encore l’abandon progressif d’un processus pourtant éprouvé. Pris isolément, aucun de ces éléments ne constitue une faute grave. Leur efficacité réside précisément dans leur banalité, car ils se confondent avec le bruit de fond d’une organisation déjà complexe ou sous tension.
La crise finit alors par émerger. Un projet échoue, un client exprime son mécontentement, une défaillance opérationnelle survient. C’est à ce moment que le « sauveur » adopte une posture contre-intuitive, puisqu’il choisit d’attendre. Il se retire suffisamment pour laisser la situation se dégrader, tandis que ses alliés orientent progressivement le récit des événements. Le manager compétent, devenu bouc émissaire, se retrouve alors à gérer la crise avec des moyens limités, souvent sans réel soutien.
Une résolution rapide
Puis, lorsque la situation devient critique, le « sauveur » intervient. La résolution est généralement rapide, précisément parce qu’il maîtrise déjà les leviers de sortie de crise. Cette logique rappelle le phénomène de Munchausen at work, où un individu provoque ou entretient un problème afin d’être ensuite reconnu pour sa capacité à le résoudre.
C’est cette répétition qui transforme l’épisode en cycle plutôt qu’en incident isolé. Le bouc émissaire s’affaiblit ou quitte l’organisation. Les fidèles du « sauveur » consolident leur position. Le dirigeant, convaincu de la valeur de la personne qu’il identifie comme un sauveur, va lui donner encore plus d’autonomie.
L’organisation retrouve alors un équilibre seulement apparent. Derrière un calme précaire restauré, se prépare souvent la crise suivante et, avec elle, la nécessité d’un nouveau sauvetage.
Pourquoi ce cycle se prolonge-t-il ?
On pourrait penser qu’un système aussi fragile finirait par s’effondrer sous le poids de ses contradictions. Pourtant, c’est rarement le cas. Cette résilience tient moins au hasard qu’à l’architecture même de l’organisation.
Le syndrome du sauveur est difficile à détecter précisément parce qu’il produit, en apparence, des résultats. Les crises sont résolues, les indicateurs de performance demeurent suffisamment acceptables pour éviter toute remise en question approfondie. Vue de l’extérieur, cette dynamique peut même être perçue comme une preuve de compétence. Cela aide à comprendre pourquoi certains profils narcissiques ou fortement centrés sur leur autopromotion accèdent plus facilement au pouvoir. En effet, ils excellent souvent davantage dans l’art d’être sélectionnés que dans l’exercice réel du leadership).
Les circuits de remontée d’information sont souvent compromis. Toute critique visant le « sauveur » remonte vers un dirigeant auprès duquel il est devenu indispensable. La sortie de ce cycle devient d’autant plus difficile lorsque les mécanismes de protection institutionnelle jouent en sa faveur.
Dès lors que la direction générale tire elle-même bénéfice du maintien de cet équilibre (par intérêt, faiblesse, corruption ou simple volonté de préserver le statu quo) les alertes sont neutralisées et toute tentative de changement devient structurellement coûteuse. Le partage des connaissances se dégrade lui aussi, puisque l’information est concentrée plutôt que diffusée, la rétention du savoir devenant parfois une véritable stratégie de pouvoir).
Impuissance apprise généralisée
Un effet plus discret s’installe également sur le plan psychologique. Les collaborateurs apprennent à ne plus résoudre les problèmes de manière autonome, car l’initiative devient risquée tandis que la déférence apparaît plus sûre. Une forme d’impuissance apprise peut alors émerger, avec des effets durables sur la performance.
Le coût réel apparaît souvent là où les indicateurs classiques regardent peu. Les équipes ne s’effondrent pas nécessairement (le « sauveur » veille précisément à l’éviter), mais elles cessent peu à peu d’exprimer leurs désaccords ou de signaler les erreurs. Lorsque les problèmes ne remontent plus, l’apprentissage collectif se dégrade et la performance finit par s’éroder.
Le stress chronique généré par cet environnement peut également conduire au burn out, marqué par l’épuisement, le cynisme et un sentiment croissant d’inefficacité. Ces signaux apparaissent rarement dans un tableau de bord ; ils deviennent surtout visibles dans les trajectoires professionnelles, de ceux qui restent, mais plus encore de ceux qui partent.
Il convient toutefois d’éviter toute généralisation excessive. Tous les leaders capables de résoudre des crises ne relèvent pas de cette logique. La différence essentielle se lit dans la trajectoire. Les leaders efficaces cherchent à réduire leur caractère indispensable. Ils documentent les processus, délèguent les responsabilités et développent les compétences de leurs équipes. Le « sauveur », à l’inverse, renforce la dépendance organisationnelle. Chaque crise résolue consolide son emprise et rend la suivante un peu plus probable, jusqu’à ce que l’organisation finisse par croire qu’aucune solution n’est possible sans lui.
Briser le cercle infernal
Quelques repères simples permettent pourtant d’identifier des signaux souvent visibles, mais rarement interprétés comme tels, et peuvent aider à enrayer cette dynamique.
Le premier consiste à examiner systématiquement l’origine des crises autant que leurs modalités de résolution. Lorsque les perturbations et les solutions convergent, de manière récurrente, vers une même personne, ce schéma mérite une attention particulière.
Le deuxième concerne la circulation des connaissances. Il est utile d’évaluer la capacité de transfert des savoirs au sein de l’organisation. Lorsqu’un individu résiste activement au partage de ses pratiques ou peine à expliquer pourquoi ses fonctions ne pourraient être assurées en son absence, il ne s’agit pas nécessairement d’expertise. Cela peut aussi révéler un pouvoir fondé sur la dépendance.
Le troisième signal réside dans l’analyse des départs. Les pertes de talents se concentrent souvent autour de certaines personnes plutôt qu’autour de services entiers. Ces départs sont rarement dépourvus de causes structurelles.
Au-delà de ces indicateurs, la création de véritables espaces de parole constitue sans doute le levier le plus efficace pour modifier durablement cette situation. Ces dispositifs doivent permettre aux collaborateurs de signaler des dysfonctionnements en dehors des circuits hiérarchiques habituels, dans des conditions de sécurité psychologique suffisantes pour s’exprimer sans crainte de représailles.
L’efficacité de ces mécanismes ne repose d’ailleurs pas uniquement sur leur usage effectif. Leur simple existence peut déjà produire un effet dissuasif, en limitant la capacité d’un acteur à monopoliser l’information ou à entretenir une dépendance organisationnelle. En définitive, la question la plus révélatrice n’est peut-être pas : « Que ferions-nous sans cette personne ? », mais plutôt : « Pourquoi personne d’autre ne peut-il accomplir cette fonction ? »
Lorsqu’aucune réponse convaincante n’émerge, il est possible que le cycle soit déjà installé. Lorsqu’il devient difficile d’imaginer la survie d’une organisation sans une figure héroïsée, ce sentiment mérite d’être interrogé. Il peut traduire une expertise réelle ou une admiration légitime. Mais il peut aussi révéler la forme la plus aboutie d’une dépendance soigneusement construite.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
05.07.2026 à 11:35
How do governance frameworks operate and what can major public projects gain from them?
Maude Brunet, Professeure agrégée, Gestion de projets, European Academy of Management (EURAM); HEC Montréal
Olivier Choinière, Professeur agrégé en gestion de projet, European Academy of Management (EURAM); Université du Québec à Rimouski (UQAR)
Vedran Zerjav, Professor, European Academy of Management (EURAM); Norwegian University of Science and Technology
Texte intégral (1848 mots)
Highways, rail networks, airports, national healthcare systems, defence and information technology… As governments around the world prepare to invest heavily in critical infrastructure, an important question remains: who ensures that the major projects to deliver it are well governed and how?
Global infrastructure investments are expected to exceed $150 trillion through 2050, with annual spending increase from US$4.4 trillion in 2024 to US$6.9 trillion in 2050.
Europe alone is preparing to account for a major share of these investments through increasingly ambitious policy instruments: from Jean-Claude Juncker’s €315 billion Investment Plan for Europe in 2014, to the €806 billion NextGeneration EU package in 2020, to Mario Draghi’s call in September 2024 for an additional €800 billion every year, close to 5% of EU GDP, in decarbonisation, digital and strategic technologies, and defence.
Why is governance the missing piece?
Each initiative has been larger and more ambitious than the last. Yet despite the visibility of these plans, the projects they fund are often poorly governed – running over budget and behind schedule. This issue is at the heart of our recent book on governance frameworks for major public projects which support the delivery of infrastructure, enabling and facilitating social and economic activities.

A governance framework refers to the systems, processes, and regulations government implement to improve the likelihood of projects being delivered according to plan and within an allocated timeframe and budget. These frameworks determine who makes decisions, how projects are evaluated, what information is required before funding is approved, and how lessons are retained after completion.
Our comparative study centred on ten national and provincial governments: Norway, the United Kingdom, the Netherlands, Ireland, Denmark, Sweden, the United States, Canada, the province of Quebec, and Australia – as well as supranational entities such as the European Union and the World Bank.
The book focuses on governance arrangements introduced at the topmost level of government for national infrastructure, with Quebec included as a province-level comparator.
For many countries in our sample, governance frameworks were introduced between 2000 and 2010 (with Canada as a notable exception, having introduced its first framework in 1978), providing an opportunity to assess their strengths and weaknesses.
Our analysis identifies the practices that distinguish governments with consistently better outcomes.
Norway stands out as an example of how a project governance framework can operate in a well-functioning institutional setup.
After the Norwegian Ministry of Finance introduced mandatory external quality assurance in 2000 for all public investments above NOK 1 billion (around €85 million), a 2015 study found that the share of large Norwegian road projects experiencing cost overruns fell from 72% before the framework to 27% afterwards.
A 2024 paper looking more broadly at 96 Norwegian government projects found just 25% had cost overruns, with the average project delivered 4.4% below budget. The framework is strictly managed – exemptions are not easily obtained – and independent quality assurance gives ministries a clear incentive to build internal expertise rather than rely on consultants.
Major projects delivered under this regime include the Ferry-free E39 coastal highway programme on Norway’s west coast and a multi-decade series of fjord crossings whose appraisal and quality assurance run through the State Project Model.
The Norwegian case also illustrates a broader pattern: well-governed delivery rests on clear ownership through the project lifecycle, capable public-sector project owners – the agencies that commission, build and operate national infrastructure, such as Norway’s Statens vegvesen – with their own in-house technical capacity, and learning systems that feed evaluations of completed projects back into the next decision.
Whether the frameworks work as intended may depend on transparency and development of skills, and whether the framework is mandatory. In line with that, our comparison points to several current challenges.
Accountability is not always accompanied by full transparency. It remains a central objective across the governments we studied, but is not pursued consistently.
In Canada, for example, “Cabinet Confidence” is frequently invoked to restrict access to information requested by journalists, researchers, and the public. While confidentiality serves a legitimate purpose, it also limits independent scrutiny of major public projects.
Another challenge is that large-scale projects are often announced with fanfare before a robust business case has been completed, as noted in the case of Australia.
Australia’s Snowy Hydro 2.0 – announced in 2017 at A$2 billion – was reset to A$12 billion in 2023 and is now undergoing a further reassessment. In June 2026, the Australian National Audit Office reported that the project’s final cost and completion date remain unknown. At the same time, independent review mechanisms often lack permission to cancel or terminate projects that present significant risks and concerns.
Across the governments we compared, governance frameworks for major public projects have already generated key benefits.
What differences did the frameworks make?
Overall, the experience from the cases suggests that the various frameworks have positively contributed to:
An improvement of the quality of decision-making
A streamlining of key processes
An improvement of cost control in some countries, but challenges remain
A disciplined effect on political decisions; however, the tension between politics and rational planning is a perennial issue.
Based on these findings, we recommend the following:
Governments should place emphasis on rigorous project appraisal before political commitment is made.
Independent quality assurance should play a crucial role: instead of relying solely on internal assessments, external experts should review business cases, cost estimates and rationales before projects can move forward.
Accountability should be clearly assigned throughout the project lifecycle. Governments should build in-house technical expertise and prioritise learning capabilities that feed lessons from completed projects into future investment decisions.
Governance frameworks should incorporate local stakeholders in management processes, encouraging different actors to collaborate in identifying solutions and addressing issues before conflicts escalate.
Taken together, these findings make the case for a sustained cross-country conversation – one that lets governments share experience and learn from one another.
Sharing experience through networks like the Concept Symposium at NTNU, the UK’s IPA/NISTA, and similar communities – engaging civil servants, practitioners and academics, conducting independent evaluations, and systematically reviewing completed projects – can help ensure that future investments deliver lasting public value rather than costly disappointments.
A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Olivier Choinière is an affiliated researcher at the University of Ottawa's Centre on Governance and a research fellow at the CDA Institute.
Vedran Zerjav is an associated member of the NTNU Concept Research Programme. The research was funded through the NTNU Concept Research Programme
Maude Brunet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:35
Sommes-nous prêts à faire confiance à l’IA pour organiser nos vacances ?
VO-THANH Tan, Full Professor, EMLV Business School, Pôle Léonard de Vinci, Pôle Léonard de Vinci
Texte intégral (1550 mots)
« Je vais passer une semaine à Rome en amoureux, trouve-moi cinq hôtels romantiques en centre-ville. » Faites-vous confiance aux IA génératives pour vous aider à organiser vos vacances ? Une nouvelle étude montre les points de résistance à l’utilisation de ces nouvelles technologies.
Les outils d’intelligence artificielle (IA) générative comme ChatGPT peuvent être considérés comme des compagnons de voyage et aident désormais les voyageurs à concevoir leurs itinéraires, à rechercher des destinations, à réserver des prestations touristiques et à résoudre leurs problèmes en temps réel.
Pourtant, malgré l’engouement, un nombre important de voyageurs reste profondément hésitants à les utiliser. Concrètement, une récente enquête de Longwoods International a révélé que seulement 33 % des voyageurs américains étaient disposés à utiliser ChatGPT pour planifier leurs voyages. Des hésitations similaires ont été constatées sur d’autres marchés comme la Corée du Sud, notamment là où la confiance numérique, les attentes culturelles et les pratiques de planification divergent des normes occidentales.
Alors que les défenseurs de la technologie se concentrent sur « l’adoption », notre étude récente explore l’envers du décor : pourquoi tant d’entre nous résistent-ils aux conseils de voyage générés par l’IA ? Cette étude utilise une approche qualitative pour explorer comment les voyageurs résistent aux conseils de voyage générés par l’IA. Elle permet de montrer comment les gens appréhendent, jugent et réagissent aux outils d’IA dans leurs contextes sociaux et culturels.
Une nouvelle étude menée en Iran
Elle a été menée en Iran, un pays en développement dont le tourisme représente une source de revenu important. Un échantillonnage raisonné (une méthode de sélection des participants dans laquelle le chercheur choisit délibérément les personnes les plus pertinentes pour répondre à la question de recherche, plutôt que de les sélectionner au hasard) a été utilisé pour recruter des voyageurs ayant effectué au moins quatre voyages internationaux au cours des trois dernières années. Ce critère garantissait que les participants étaient activement impliqués dans la planification de leurs voyages et avaient probablement déjà rencontré des recommandations générées par l’IA.
Les participants ont été recrutés via deux canaux : trois agences de voyages spécialisées dans les voyages à l’étranger permettant d’accéder à des clients réguliers, et des comptes Instagram publics présentant du contenu de voyage généré par les utilisateurs. Pour élargir l’échantillon, l’échantillonnage en boule de neige (une méthode de sélection des participants dans laquelle les premiers participants recrutés recommandent d’autres personnes qui répondent aux critères de l’étude) a également été utilisé.
Le guide d’entretien semi-structuré (une méthode de collecte de données, principalement utilisée dans les recherches qualitatives, où le chercheur suit un guide d’entretien composé de questions préparées à l’avance, tout en restant libre d’adapter l’ordre des questions et d’en poser de nouvelles selon les réponses du participant) a été élaboré à partir d’une analyse des recherches antérieures sur la résistance à la technologie, l’adoption de l’IA et le comportement des consommateurs dans le tourisme et d’autres domaines connexes. La collecte de données s’est poursuivie jusqu’à l’obtention de la saturation théorique (atteinte lorsque les nouvelles données ne permettent plus d’enrichir la théorie ou les catégories d’analyse que le chercheur développe) après 22 entretiens. Ce nombre est conforme aux normes de la recherche qualitative, qui privilégient le sens et la profondeur thématique plutôt que la couverture statistique.
Une résistance complexe
La résistance à l’utilisation de l’IA pour la planification de voyages n’est pas seulement une question d’être « en retard sur son temps ». Il s’agit plutôt d’une réaction complexe façonnée par des frustrations pratiques, des valeurs culturelles et même notre sentiment d’identité.
Plus qu’un simple problème technique, pour beaucoup, la résistance commence par des barrières fonctionnelles. Bien que l’IA puisse agréger des données rapidement, elle échoue souvent au « dernier kilomètre » de la planification de voyage.
On note différentes barrières :
la barrière d’usage : Les utilisateurs trouvent souvent les interfaces d’IA encombrantes ou déconnectées. Par exemple, si ChatGPT peut suggérer un vol, il ne peut pas le réserver, forçant les utilisateurs à basculer entre plusieurs plates-formes ;
la barrière de valeur : De nombreux voyageurs trouvent les suggestions de l’IA redondantes ou se limitant à des listes génériques de type « top 10 » qui n’offrent pas plus de valeur qu’une simple recherche Google ;
la barrière de risque : L’obstacle le plus important est sans doute celui des « hallucinations de l’IA » – où les systèmes fournissent avec assurance de fausses informations, comme fournir des informations imprécises sur les sites de visite ou suggérer des hôtels inexistants ou des règles de visa obsolètes. Un participant a partagé : « … Je l’ai testé en demandant les sites classés par l’Unesco à proximité, et il s’est trompé… Il a donné plusieurs mauvaises réponses, alors que ce sont des informations de base qu’on trouve facilement en ligne… S’il n’arrive pas à trouver ça, comment puis-je faire confiance à tout le reste qu’il suggère ? » Un autre participant a expliqué : « … Ses informations ne sont pas à jour, donc je ne m’y fie pas pour des informations importantes concernant les voyages, comme les règles relatives aux frontières ou aux visas. Ces règles changent souvent, et une erreur à ce sujet peut gâcher un voyage. »
Dans le monde à enjeux élevés des voyages internationaux, ces erreurs pourraient transformer des vacances de rêve en cauchemar.
La menace pour notre identité de voyageur
Au-delà des défauts techniques, il existe des barrières psychologiques plus profondes. Pour beaucoup, planifier un voyage n’est pas seulement une corvée à automatiser ; c’est un rituel précieux et une source de fierté personnelle. Certains voyageurs voient l’IA comme une menace pour leur autonomie. Utiliser une machine pour planifier un voyage donne l’impression de « déléguer » un processus créatif, rendant le voyage final moins personnel.
De plus, la tradition joue un rôle majeur. Dans la culture iranienne, les conseils de voyage reposent sur une confiance relationnelle – demander à un proche qui y est « réellement allé ». L’IA, en revanche, semble froide et impersonnelle, manquant de l’authenticité émotionnelle d’une recommandation humaine.
Notre recherche identifie finalement trois types distincts de « résistants » :
les opposants : ils considèrent la planification de voyage comme un acte personnel et relationnel et voient l’IA comme une menace pour leur autonomie ;
les temporisateurs : ce groupe n’est pas « anti-IA » mais attend que la technologie fasse ses preuves et nécessite des témoignages de réussite avant de s’engager ;
les leaders d’opinion : les résistants les plus actifs. Ils s’engagent de manière critique avec l’IA et expriment souvent leur opposition, considérant ces outils comme des systèmes « biaisés par l’Occident » ou culturellement déphasés qui ne comprennent pas les réalités locales.
Les développeurs devraient se concentrer sur des modèles hybrides qui soutiennent, plutôt que de supplanter, l’agence humaine. Le voyage est une expérience profondément humaine, ancrée dans l’interaction sociale. Tant que l’IA ne respectera pas ces nuances culturelles et émotionnelles, beaucoup préféreront encore discuter avec un ami plutôt que de rédiger une commande pour un robot.
VO-THANH Tan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:34
Percer les secrets de la stratosphère grâce à un ballon qui surfe sur différentes couches de vent
François Vacher, Chargé de projets "Ballons stratosphériques", Centre national d’études spatiales (CNES)
Laurent Tessariol, Chef de service Opérations Ballons et Chef de Centre Aire Sur l'Adour, Centre national d’études spatiales (CNES)
Texte intégral (3846 mots)

Et si les clés de notre climat se trouvaient à plusieurs dizaines de kilomètres au-dessus de nos têtes ? La stratosphère, parfois considérée comme une simple couche de l’atmosphère, a un impact décisif sur nos vies : elle nous protège des rayonnements ultraviolets, elle peut déclencher de grandes vagues de froid polaire et même bouleverser les saisons lorsqu’elle se charge d’aérosols. Il s’agit d’un véritable laboratoire naturel pour les chercheurs. Comprendre son fonctionnement, c’est mieux comprendre les mécanismes qui façonnent notre climat.
Pour percer les secrets de la stratosphère, les scientifiques disposeront bientôt d’un nouvel outil : le ballon manœuvrant. Véritable voilier des hautes couches de l’atmosphère, cet engin permet d’explorer cette région fascinante de manière inédite.
La stratosphère s’étend entre 18 et 50 kilomètres d’altitude. Située au-dessus de la troposphère, où se déroule l’essentiel de la météorologie, elle occupe une région singulière de l’atmosphère terrestre. À ces altitudes, l’air est trop raréfié pour permettre aux avions conventionnels de voler, mais demeure trop dense pour qu’un satellite puisse s’y maintenir en orbite. La stratosphère constitue ainsi une zone intermédiaire, longtemps restée difficile d’accès.
Cette inaccessibilité n’en fait pas moins un territoire d’un grand intérêt scientifique et stratégique. Les chercheurs y réalisent des mesures directes afin de mieux comprendre, par exemple, le climat. Dans le même temps, la très haute altitude suscite l’intérêt des acteurs de la défense, qui y voient un domaine propice au déploiement de plates-formes capables d’effectuer des missions de surveillance ou de communication tout en restant difficiles à détecter et à intercepter.

Une technologie aussi simple qu’ingénieuse permet pourtant d’accéder à la stratosphère : le ballon. Popularisé dès le XIXᵉ siècle par les récits de Jules Verne, ce moyen de transport aérien n’a cessé d’évoluer. Ainsi, les ballons modernes se distinguent désormais par leurs capacités de manœuvre : en modifiant leur altitude, ils exploitent les différentes couches de vent pour se déplacer et suivre des trajectoires choisies. Une élégante façon de naviguer dans les hautes couches de l’atmosphère, à la manière d’un voilier porté par les courants marins.
Léger comme un ballon
Parmi les différents engins capables de s’élever dans l’atmosphère – avions, hélicoptères ou fusées – les ballons occupent une place à part. Contrairement aux autres aéronefs, ils ne s’appuient ni sur la portance des ailes ni sur la poussée d’un moteur : ils utilisent la poussée d’Archimède pour se maintenir en altitude. Pour cela, leur enveloppe contient un gaz plus léger que l’air, généralement de l’hélium ou de l’hydrogène.
À mesure que l’on s’élève, l’air devient de moins en moins dense. Ainsi, à 18 kilomètres d’altitude, sa densité est divisée par dix par rapport à celle observée au niveau du sol. Cette diminution modifie directement la force d’Archimède, puisque celle-ci dépend de la masse d’air déplacée.
En ajustant soigneusement la quantité de gaz embarquée, le volume de l’enveloppe et la masse de la charge utile, il est possible d’atteindre une altitude d’équilibre dans la stratosphère. Le ballon peut alors demeurer pendant plusieurs semaines, voire plusieurs mois, à une altitude quasi constante.
Dans cette situation, deux forces s’équilibrent parfaitement : la poussée d’Archimède, dirigée vers le haut, et le poids du ballon, dû à la gravité terrestre, dirigé vers le bas. Le ballon « flotte » alors dans l’atmosphère, comme un navire à la surface de l’océan.
Histoire des ballons stratosphériques
Les ballons stratosphériques modernes sont fabriqués à partir de films de polyéthylène, un matériau léger, résistant et peu coûteux. Leur développement a véritablement pris son essor dans les années 1950, à mesure que la production industrielle de ces films plastiques se généralisait. Cette innovation a permis la réalisation de ballons de très grande taille, capables d’atteindre les hautes couches de l’atmosphère.
Dès 1960, les ballons stratosphériques suscitent l’intérêt des agences spatiales naissantes. En effet, ils offrent une plateforme idéale pour tester de nouvelles technologies et préparer les futures missions satellitaires. Plus simples à mettre en œuvre et beaucoup moins coûteux qu’un lancement orbital, ils permettent de valider des instruments dans un environnement proche de celui de l’espace.
Ainsi, dès sa création en 1961, le Centre national d’études spatiales (CNES) développe des programmes de ballons stratosphériques destinés à la recherche scientifique et à la préparation des technologies spatiales. Au fil des décennies, les progrès de l’électronique, des télécommunications et de l’informatique embarquée ont considérablement renforcé les capacités de ces plates-formes.

Les ballons stratosphériques ont ainsi contribué à l’étude de plusieurs enjeux scientifiques majeurs. Dans les années 1980 et 1990, ils ont participé à la compréhension de l’appauvrissement de la couche d’ozone au-dessus des régions polaires. Plus récemment, ils sont devenus des outils précieux pour l’observation du climat. Aujourd’hui, ils continuent de fournir des mesures uniques, indispensables à la compréhension de notre atmosphère et de son évolution.
Les ballons présentent également un atout remarquable : leur grande capacité à changer d’échelle. Il est possible de concevoir aussi bien des ballons d’une vingtaine de mètres de diamètre que des géants dépassant les 100 mètres. Les plus grands peuvent emporter près d’une tonne d’instruments scientifiques jusqu’à 40 kilomètres d’altitude.
Cette flexibilité est une des raisons du succès des ballons. Toutefois, ils sont confrontés à une limitation fondamentale. Contrairement à un avion ou à un satellite, un ballon ne dispose pas de moyen de propulsion lui permettant de modifier sa trajectoire. Une fois en vol, il est entraîné par les courants atmosphériques et dérive au gré des vents, ce qui limite fortement sa capacité à rejoindre ou à maintenir une position donnée.
Un voyage en ballon
Pour dépasser les limites des ballons traditionnels, les ingénieurs du CNES développent une nouvelle génération d’aéronefs stratosphériques : les ballons manœuvrants. Leur particularité réside dans leur capacité à modifier leur altitude en cours de vol. À l’image d’un voilier qui ajuste sa route en recherchant les vents les plus favorables, ces ballons exploitent les différentes couches de l’atmosphère pour se déplacer vers une destination choisie.
Cette capacité repose sur une architecture originale à double enveloppe. Le gaz porteur, généralement de l’hélium, est contenu dans une enveloppe interne. Autour de celle-ci se trouve une seconde enveloppe dans laquelle il est possible d’ajouter ou de retirer de l’air grâce à un dispositif spécialement conçu pour les conditions stratosphériques. En augmentant la quantité d’air embarquée, le ballon devient plus lourd et descend. À l’inverse, lorsque cet air est évacué, il retrouve de la flottabilité et remonte.

Le pilotage s’appuie ensuite sur les vents présents à différentes altitudes. Les ballons manœuvrants évoluent notamment autour de 20 kilomètres d’altitude, à la limite inférieure de la stratosphère, où les courants atmosphériques peuvent présenter des directions très différentes selon la hauteur. En choisissant soigneusement l’altitude la plus favorable, il devient possible d’orienter progressivement la trajectoire du ballon et de le guider vers sa zone d’observation.
Cette approche transforme le ballon en un véritable « voilier de la stratosphère », capable de parcourir de longues distances en utilisant uniquement l’énergie des vents, sans moteur ni consommation importante d’énergie.
Le concept de ballon manœuvrant n’est pas entièrement nouveau. Il a été développé à grande échelle au cours des années 2010 par l’entreprise états-unienne Google dans le cadre de son projet Loon. L’objectif était ambitieux : déployer une flotte de ballons stratosphériques capables d’apporter un accès à Internet dans les régions les plus isolées du globe, à l’image des constellations de satellites de télécommunication qui se développent aujourd’hui. Bien que le projet ait été arrêté en 2021 pour des raisons économiques, il a démontré la faisabilité et l’efficacité de la navigation stratosphérique par changement d’altitude.
Cette technologie a depuis trouvé de nouveaux débouchés. Aux États-Unis, l’entreprise Aerostar exploite des ballons manœuvrants capables de séjourner durablement dans la stratosphère. Ces plates-formes sont utilisées aussi bien pour des missions scientifiques que pour des applications liées à la surveillance et à la défense.
Consciente du potentiel stratégique et scientifique de ces véhicules, la France a engagé ses propres développements dans ce domaine. Depuis 2021, le CNES travaille à l’adaptation et à la maîtrise de cette technologie en partenariat avec Hemeria, acteur historique français du ballon stratosphérique.
L’objectif est de doter la France et l’Europe d’une capacité autonome de présence prolongée dans la stratosphère, au service de la recherche, de l’observation de l’environnement et des futures applications opérationnelles.
Des premiers tests de lâchers aux premiers tests en conditions réelles
Après plusieurs années de développement, le moment est venu de confronter notre ballon manœuvrant (Balman) à la réalité du terrain. Au printemps 2024, sur le site du CNES d’Aire-sur-l’Adour, dans les Landes, les équipes ont réalisé les premiers essais de lâcher de ce nouvel aéronef stratosphérique. Les opérations ont été menées à l’aube, quand les conditions météorologiques sont généralement plus calmes, limitant les rafales de vent susceptibles de compliquer les délicates opérations de décollage.

Mais réussir un lâcher de ballon ne constitue que la première étape. Pour valider pleinement le concept, il est indispensable de tester le véhicule dans son environnement opérationnel : la stratosphère. Ces essais doivent être réalisés en tenant compte de nombreuses contraintes, notamment l’insertion du ballon dans l’espace aérien et la maîtrise des risques liés au survol des populations. En effet, même si les vols sont soigneusement préparés, la retombée d’un équipement depuis plusieurs dizaines de kilomètres d’altitude nécessite des mesures de sécurité particulièrement rigoureuses.
Pour conduire ces essais dans les meilleures conditions, le CNES bénéficie d’un atout exceptionnel : le Centre spatial guyanais. Situé entre l’océan Atlantique et la forêt amazonienne, ce vaste territoire faiblement peuplé offre un environnement idéal pour les expérimentations aéronautiques et spatiales. C’est depuis cette base, mondialement connue pour les lancements d’Ariane-6, que les premiers vols du ballon manœuvrant ont été réalisés.
Ces campagnes d’essais ont permis de franchir plusieurs étapes majeures. Lors du premier vol, le ballon a démontré sa capacité à décoller, rejoindre la stratosphère puis revenir au sol en toute sécurité. Le second vol a marqué une avancée supplémentaire avec la première utilisation en conditions réelles du système de gestion d’air permettant de modifier l’altitude du ballon – une étape essentielle pour transformer ce simple ballon stratosphérique en véritable voilier capable de naviguer dans les vents de la haute atmosphère.
Le futur du Balman, le ballon manœuvrant
L’aventure Balman ne fait que commencer. Après les premiers vols d’essai, le programme poursuit sa qualification technologique. L’objectif est désormais d’accumuler de l’expérience en vol et d’enrichir progressivement le véhicule avec de nouvelles fonctionnalités. Parmi les prochaines évolutions figure notamment l’intégration d’un système de parachute, dont les premiers essais sont prévus à l’hiver 2026.
À mesure que sa maturité technologique augmentera, Balman ouvrira la voie à de nouvelles applications scientifiques. L’une des premières pourrait être sa contribution à la succession du projet Strateole-2, une future flotte de ballons longue durée développée conjointement par le CNES et le CNRS à l’horizon 2030. Grâce à leur capacité à séjourner plusieurs mois dans la stratosphère, ces ballons constitueront un outil unique pour observer et mieux comprendre les échanges entre les différentes couches de l’atmosphère.
L’étude du climat et de l’atmosphère repose aujourd’hui sur la complémentarité de plusieurs moyens d’observation. Les satellites offrent une vision globale de notre planète, tandis que les mesures réalisées directement dans l’atmosphère permettent d’analyser avec précision les phénomènes locaux et les mécanismes physiques à l’œuvre. En apportant sa capacité de manœuvre à ces futures missions, Balman permettra d’orienter les observations vers les zones les plus intéressantes et d’optimiser le déploiement des instruments scientifiques.
À plusieurs dizaines de kilomètres au-dessus de nos têtes, une nouvelle génération de ballons est ainsi en train d’émerger. Capables de naviguer dans les vents de la stratosphère comme des voiliers sur l’océan, ils pourraient bientôt devenir des outils essentiels pour mieux comprendre notre atmosphère et les changements qui l’affectent.
Francois VACHER ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d’une organisation qui pourrait tirer profit de cet article, et n’a déclaré aucune autre affiliation que son poste au CNES.
Laurent Tessariol ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:33
Mobiliser la justice face aux épidémies : en Italie, six ans après le covid, le succès d’une association de parents de victimes
Chiara Alfieri, Anthropologue de la santé, Institut de recherche pour le développement (IRD)
Alice Desclaux, Anthropologue de la santé, TransVIHMI, Institut de recherche pour le développement (IRD)
Marc Egrot, Anthropologue, médecin et chargé de recherche à l'IRD, Institut de recherche pour le développement (IRD)
Texte intégral (2696 mots)
L’essentiel
- En France notamment, dans les années 1990, les mobilisations associatives en contexte de pandémie de VIH ont eu pour effet le développement de la « démocratie sanitaire ».
- Six ans après le covid, une recherche en anthropologie auprès d’une association de parents de victimes du covid à Bergame en Italie, là où cette pandémie a débuté en Europe, montre qu’une mobilisation dans le domaine juridique peut avoir un impact majeur.
- La redéfinition du crime d’« épidémie coupable » par la Cour suprême de cassation italienne pourrait inspirer des changements de législations, ailleurs en Europe et dans le monde.
L’Organisation mondiale de la santé (0MS) recommande d’impliquer les populations dans la réponse aux épidémies, voire de co-construire les réponses avec elles. Cette approche est en phase avec la « démocratie sanitaire » inscrite dans la loi française et développée par un courant combinant éthique, droits humains et santé publique. Pour mémoire, la démocratie sanitaire est une démarche qui vise à associer usagers, professionnels et décideurs publics dans l’élaboration et la mise en œuvre des politiques de santé dans un esprit de dialogue et de concertation.
À lire aussi : La démocratie en santé fête ses 20 ans : le temps de la refondation ?
Mais la place qui lui est accordée reste variable d’un pays à l’autre et la concrétisation de cette notion est discutée lors de chaque nouvelle épidémie, comme actuellement avec l’épidémie d’Ebola en République démocratique du Congo.
À lire aussi : Ebola : Comment expliquer cette nouvelle flambée, malgré les vaccins qui ont amélioré la lutte contre les épidémies
En contexte covid, utiliser le droit pour faire appliquer la démocratie sanitaire
En Italie, le tissu associatif a été mobilisé pendant l’épidémie de covid-19 pour des interventions de secours et de soins, mais n’a pas été associé aux décisions de santé publique. À Bergame, l’association Sereni e sempre uniti (« Sereins et toujours unis ») a été créée par des familles de victimes pendant l’épidémie dans un objectif d’entraide et de plaidoyer.
Cette association a choisi un positionnement particulier du point de vue de la socioanthropologie des associations, qui lui confère un intérêt majeur sur le plan scientifique. Elle se différencie d’autres associations de professionnels et de familles, ou de personnes vivant avec le VIH, en ce qu’elle utilise le droit comme outil pour faire appliquer la démocratie sanitaire.
Notre recherche a débuté en 2020. Initialement centrée sur le vécu du covid et les rapports sociaux entre malades, familles et professionnels de santé autour de Bergame et dans la vallée Seriana, elle s’est progressivement focalisée sur les logiques d’action de l’association face à l’échec de la santé publique dans une province où 6000 décès ont été déplorés.
Les investigations ethnographiques (observation participante et méthodes classiques) ont été poursuivies jusqu’à ce jour pour parvenir à la documentation complète du processus.
En Italie, une gestion de crise défaillante
Premier foyer de la pandémie en Europe, l’Italie recense ses premiers cas dans la vallée Seriana, fortement industrialisée. La Lombardie possède un système de soins réputé mais caractérisé par une désertification progressive du dispositif sanitaire public imputée à des politiques de privatisation agressive. Dans cette situation, combinée aux choix politiques durant la crise, la première vague de covid-19 conduit en quelques semaines aux images qui ont circulé dans les médias internationaux d’une file de camions militaires évacuant des cercueils qui ne peuvent être gérés.
Une vive polémique éclate à propos de mesures qualifiées de « bricolées » et de négligences dans la mise en place des mesures. Les familles dénoncent les conditions de décès de leurs proches : saturation des établissements, encombrement des services d’urgences avec des files d’attente interminables, pénurie de ressources empêchant l’accès aux soins, entassement des cadavres dans les églises. De nombreuses personnes sont décédées chez elles par asphyxie alors que l’oxygène médical était introuvable.
Le combat d’une association devant les cours de justice
Des familles se regroupent alors pour créer un mouvement, Noi Denunceremo (en français : « Nous dénoncerons »), transformé assez vite en association, Sereni e sempre uniti (« Sereins et toujours unis »). L’association développe des actions de soutien aux membres et de diffusion de la mémoire des morts du covid-19, qui s’élargissent à des actions de plaidoyer (manifestations et déclarations publiques).
De plus, accompagnée par un groupe de juristes, avec comme chef de file l’avocate Consuelo Locati, l’association adopte la voie judiciaire pour obtenir des explications sur la pertinence et la légitimité des mesures adoptées pendant la pandémie. 700 plaintes font l’objet de deux procédures judiciaires contre le ministère de la santé, la présidence du Conseil des ministres et les administrateurs de la région Lombardie.
En avril 2020, le Parquet de Bergame ouvre une enquête qui durera trois ans et se terminera par la mise en examen des fonctionnaires et des politiciens qui ont géré la pandémie. Ces résultats constituent un point important pour l’action légale de Sereni, comme le souligne le Pr Andrea Crisanti dans son rapport de 2022 pour le parquet de Bergame (Crisanti A. 2022. Expertise technique du Pr Andrea Crisanti ordonnée par le Parquet de la République auprès du tribunal de Bergame. Rapport no 15749/2020/21 n°3).
Cette bataille légale, qui vise à établir vérité, justice et reconnaissance, tente de mettre fin à l’impunité des responsables sanitaires et, à travers cela, à restituer la dignité à laquelle les victimes n’ont pas eu droit jusque-là. Elle a aussi pour objectif que les populations soient à l’avenir moins démunies face aux erreurs des autorités et surtout plus impliquées dans l’élaboration et l’application des mesures de préparation et de réponse aux épidémies, une revendication en adéquation avec la démocratie sanitaire.
Pendant six ans, l’association Sereni, avec ses avocats à ses côtés, a mené un travail de documentation préalable basé sur le recueil, l’organisation, puis le dépôt auprès des tribunaux de milliers de pages de documents, une démarche essentielle dans les décisions de justice qui ont jalonné cette campagne.
Une victoire qui fera bouger les lignes
Un cap décisif de la bataille juridique a été franchi le 10 avril 2025, lorsque la Cour suprême de cassation italienne élargit la définition juridique du crime « d’épidémie coupable » en y incluant « l’omission, la négligence, l’inaction et le silence en contexte d’obligation d’informer ».
Cet arrêt pourrait permettre la réouverture des procédures pénales précédemment classées sans suite contre des hauts représentants des institutions politiques et sanitaires à l’époque des faits. Il pourrait aussi inspirer des changements de législations dans d’autres pays.
Cet évènement suscite d’autant plus d’espoir qu’il résonne avec deux autres succès à des étapes préalables. En 2024, la Cour européenne des Droits de l’homme (CEDH) accepte d’instruire le dossier présenté par Sereni, qui révèle des violations des droits humains dans la gestion de la pandémie, fait rare puisque seulement 5 % des plaintes soumises à cette cour sont acceptées. L’association attend les suites.
Puis le 24 mars 2026, les familles au sein de l’association sont reconnues victimes par le tribunal pénal de Rome. Lors de cette audition préliminaire impliquant des fonctionnaires du ministère de la Santé, il est formellement établi que le plan pandémique national qui aurait dû être mis à jour « ne l’a pas été, en partie par manque de moyens ». Une brèche est alors ouverte dans le mur d’omerta et l’immunité qui protège les autorités depuis six ans, à propos des défaillances dans la gestion de la crise.
Ces trois évènements montrent que l’association a obtenu des succès significatifs grâce à quatre éléments principaux : l’expertise de juristes engagés et eux-mêmes concernés par le décès de proches, un travail considérable de documentation pour la préparation des dossiers juridiques, une persévérance qui a permis de dépasser la temporalité des institutions, et le soutien de centaines de familles.
Une scène en témoigne :
Le 24 mars 2026, dans l’immense salle du Tribunal pénal de Rome, remplie d’éléments des forces de l’ordre, une centaine de membres de Sereni avaient fait le déplacement de plus de 600 kilomètres pour se tenir aux côtés de leurs avocats pendant l’audition. Un mur de solidarité et de soutien, une présence émotionnelle très forte, pour que la voix des citoyens soit entendue et ait un poids quand il s’agit de la santé de tous.
En Italie et ailleurs, la persévérance de Sereni ancre le pouvoir des associations face aux autorités
Dans un contexte national hostile dans lequel ni la politique, ni les responsables sanitaires chargés de la gestion de la crise n’ont été en mesure d’éclairer les raisons du désastre, cette association a trouvé dans la justice un moyen pour faire avancer ses revendications, celles des familles de victimes.
Les enjeux ne concernent pas seulement les familles éprouvées. Pour les populations, en Italie et ailleurs, la persévérance associative exemplaire de Sereni permet d’ancrer davantage le pouvoir des associations face aux autorités et ouvre la voie vers une forme de démocratie sanitaire. Le suivi des procédures initiées il y a six ans nécessitera encore quelques mois ou années de documentation anthropologique.
Aujourd’hui, l’enquête ethnographique auprès des familles des défunts et membres de l’association montre que son action militante a permis de redonner un sens aux épreuves qu’ils ont vécues, en surmontant des situations de deuils qualifiés de traumatiques, impossibles, ou absents, pour des morts ressenties comme injustes.
Encore des étapes à franchir et un final à écrire
La mobilisation citoyenne a aussi permis de requalifier la notion « d’épidémie coupable » avec une extension majeure de son champ d’application. Ainsi, « l’omission, la négligence, l’inaction et le silence en contexte d’obligation d’informer » deviennent passibles en Italie de peines de prison.
Au regard des positions des institutions de santé globale, le périmètre de cette requalification juridique mériterait d’être encore élargi pour y inclure la « préparation » aux épidémies, voire la « participation communautaire » à l’élaboration des stratégies.
Cette notion juridique aura-t-elle des effets incitatifs ? L’appel est lancé pour d’autres enquêtes afin de préciser si cette singularité italienne qu’est le « crime d’épidémie coupable par omission, négligence, inaction » permet désormais aux populations d’avoir un pouvoir concret face à l’État dans la définition et la mise en œuvre des politiques sanitaires.
La reconnaissance de cette notion dans d’autres pays pourrait aider à mettre les États devant leurs responsabilités à propos de la préparation de leur système de soin, un élément essentiel pour obtenir la confiance des populations et une réponse efficace aux épidémies.
Le projet COMESCOV pour « Confinement et mesures sanitaires visant à limiter la transmission du covid-19 : Expériences sociales en temps de pandémie en France, en Italie et aux USA » (ANR-20-COVI-0083-01) est soutenu par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Chiara Alfieri est membre de Associazione famigliari delle vittime del covid-19 Sereni e sempre uniti. Elle a reçu des financements de l’Agence nationale de la recherche pour le projet COMESCOV (« Confinement et mesures sanitaires visant à limiter la transmission du covid 19 : Expériences sociales en temps de pandémie en France, en Italie et aux USA », ANR-20-COVI-0083-01).
Marc Egrot a reçu des financements de l’Agence nationale de la recherche (ANR) pour le projet COMESCOV (« Confinement et mesures sanitaires visant à limiter la transmission du covid 19 : Expériences sociales en temps de pandémie en France, en Italie et aux USA », ANR-20-COVI-0083-01).
Alice Desclaux ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:33
Banalisation des pantouflages sous l’ère Macron : un risque démocratique ?
Antoine Vauchez, professeur, Université Paris 1 Panthéon-Sorbonne; Centre national de la recherche scientifique (CNRS)
Juliette Lelieur, Professeure de droit pénal, Université de Strasbourg
Lola Avril, Professeure junior en science politique, Université Paris 1 Panthéon-Sorbonne; Centre national de la recherche scientifique (CNRS)
Texte intégral (2459 mots)
La loi encadre le passage de fonctionnaires du secteur public vers le secteur privé, communément appelé « pantouflage ». Elle sanctionne la prise illégale d’intérêts d’un agent public lorsque ce dernier avantage une entreprise privée dans le but d’être recruté par elle. Or, la recherche montre que le pantouflage et le « rétro-pantouflage » (retour du fonctionnaire dans le public après un passage dans le privé) se sont développés sous la présidence d’Emmanuel Macron. Les contrôles et les sanctions, eux, sont très insuffisants.
En mars 2026, la Haute Autorité pour la transparence de la vie publique (HATVP) se prononçait sur un projet de reconversion singulier : l’ancien directeur de cabinet de la ministre Sophie Primas souhaitait rejoindre la Fédération nationale des syndicats d’exploitants agricoles (FNSEA), organisation qu’il avait servie précédemment comme lobbyiste, en qualité de directeur général délégué à la stratégie politique… Appelée à juger de la compatibilité de ce pantouflage sous l’angle du risque déontologique, la HATVP rendait un avis favorable. Les réserves qu’elle émet n’ont qu’une portée étroite : l’interdiction pour l’ancien agent de contacter la ministre et le premier ministre, ainsi que les membres de leurs cabinets.
Ce faisant, cet avis offrait un exemple particulièrement emblématique des trous et des flous du contrôle des mobilités public-privé aux sommets de l’État, et de la sous-estimation des risques démocratiques qui leur sont liés, et ce, à l’heure où les grandes entreprises consacrent des montants record au lobbying.
Il faut dire que les travaux de recherche, mais aussi diverses enquêtes journalistiques, montrent qu’il y a aujourd’hui une nouvelle donne du pantouflage en France, avec des risques qui vont bien au-delà de conflits d’intérêts ponctuels puisqu’il y va de l’indépendance de la puissance publique et de la confiance des citoyens dans celle-ci, c’est-à-dire dans sa capacité à effectivement les défendre et les protéger.
Dans un Livre blanc pour l’Observatoire de l’éthique publique, intitulé « Les portes tournantes de la République. Comment mieux protéger l’intérêt public face aux mobilités public-privé », nous pointons l’insuffisance des dispositifs de contrôle – préventif (HATVP) et répressif (délit pénal de prise illégale d’intérêt) – et proposons quatre chantiers de réforme pour une défense plus robuste de l’intérêt public.
Un phénomène banalisé, étendu et systémique
En deux décennies, les portes tournantes sont devenues une donnée structurelle de l’organisation du pouvoir en France, amplifiée par un ensemble de réformes successives des deux quinquennats d’Emmanuel Macron qui ont desserré les règles, voire incité à la mobilité public-privé des agents publics.
De fait, le pantouflage n’est plus un « bâton de maréchal » : il s’échelonne désormais tout au long de trajectoires professionnelles aux sommets et à la périphérie de l’État, et touche aujourd’hui des couches bien plus larges que les seuls grands corps puisque ministres, membres de cabinet ministériels et des états-majors de Matignon et de l’Élysée, ou encore régulateurs participent à ce mouvement brownien.
Le phénomène fonctionne désormais dans les deux sens : au pantouflage vers le privé s’ajoute un « rétro-pantouflage » croissant – des profils issus du privé prenant les rênes d’administrations publiques, mouvement facilité par la loi du 6 août 2019, même si ce flux inverse reste mal documenté. Et on peut dire qu’il est structurel, car il tient à la fois au rétrécissement des perspectives professionnelles pour les hauts fonctionnaires en milieu de carrière, à la dépendance croissante des grandes entreprises aux décisions des régulateurs nationaux ou européens et à l’émergence de générations d’élus qui conçoivent le passage en politique comme une séquence professionnelle parmi d’autres.
Dernier point essentiel de cette nouvelle donne : le fait que les flux se sont réorientés vers de nouveaux secteurs (numérique, santé, agroalimentaire), mais aussi vers les métiers du conseil – lobbying, affaires publiques, cabinets d’avocats, communication de crise –, structures qui se tiennent à la périphérie des institutions publiques et qui capitalisent sur le carnet d’adresses et la connaissance intime des institutions régulatrices.
Au-delà du seul conflit d’intérêts, un risque systémique
Nombreux sont ceux qui défendent les vertus de cette porosité et y voient une « pollinisation » croisée profitant à l’administration.
L’argument ne convainc pas : cette fertilisation ne fonctionne qu’à sens unique, les portes tournantes excluant de fait la société civile non marchande de leurs bénéfices. D’autres pointent l’effet désincitatif de l’accroissement des règles déontologiques sur l’attractivité des fonctions publiques, mais rien n’indique aujourd’hui une telle relation.
Mais ce point de vue tend surtout à sous-estimer les intérêts et les valeurs qui sont mis à mal par cette nouvelle donne des mobilités public-privé. Pour en prendre la mesure, il importe d’élargir la focale au-delà du conflit d’intérêts individuel.
Au-delà de ce niveau micro, les départs appauvrissent l’expertise publique et diffusent une « culture circulatoire » qui modifie la manière dont les administrations régulent l’économie et la société en se montrant tendanciellement moins sensibles aux intérêts les plus diffus portés par la société civile des organisations non gouvernementales, des syndicats et des associations (santé, travail, environnement, etc.) qu’aux intérêts et enjeux économiques privés constitués (compétitivité, attractivité économique, etc.).
Au niveau macro, c’est l’intégrité démocratique et la souveraineté qui sont en jeu lorsque la porosité ouvre des voies d’influence à des États étrangers ou à des multinationales (Cf. Lola Avril, Chloé Fauchon, Emilia Korkea-Aho, Juliette Lelieur, Antoine Vauchez, « Un an après le Qatargate, comment mieux protéger l’Union européenne contre les conflits d’intérêts et la corruption ? », Livre blanc pour l’Observatoire de l’éthique publique, 2023).
Au-delà, et de manière plus fondamentale encore, c’est la confiance des citoyens dans les institutions publiques et leur capacité à offrir des solutions aux grands défis et menaces de notre temps (bifurcation écologique, concentration économique dans les Big Tech, etc.) qui est en jeu (Cf. Antoine Vauchez, Public, Anamosa, 2022).
Quatre chantiers pour une meilleure protection de l’intérêt public
Pour y faire face, les dispositifs actuels de contrôle – qu’ils soient préventif ou répressif – se révèlent insuffisants. La Haute Autorité pour la transparence de la vie publique, chargée depuis 2019 de contrôler les mobilités d’environ 15 000 responsables publics, a adopté une doctrine d’accompagnement visant à dé-risquer les mobilités public-privé plutôt qu’à les interdire (Cf. Jana Vargovčíková et Antoine Vauchez, « Corps privés, intérêts publics Élites politico-administratives et formation d’une morale managériale d’État ») : les incompatibilités ne dépassent pas 4,5 % des cas, et elle n’a ni les moyens ni les pouvoirs d’enquête pour s’assurer du respect des « réserves » qui accompagnent ses avis de compatibilité des pantouflages ou rétro-pantouflages.
Quant au volet pénal, la loi du 2 février 2007 dite de modernisation de la fonction publique en a fortement réduit la portée : le délai de viduité pendant lequel l’agent public s’engage à ne pas travailler pour une entreprise qu’il aurait régulée dans ses fonctions est passé de cinq à trois ans, mais il est exigé désormais que l’agent ait directement supervisé l’entreprise qu’il rejoint – et non plus simplement qu’il ait été en charge du secteur, ce qui explique la rareté des condamnations, illustrée par l’affaire récente du conseiller d’État relaxé malgré son passage de TotalEnergies après l’avoir jugée au Palais-Royal. Un haut fonctionnaire ayant régulé un secteur peut ainsi légalement pantoufler vers toutes les entreprises qu’il n’a pas directement supervisées.
Il importe dès lors de réfléchir à un contrôle plus ambitieux et plus effectif pour mieux protéger l’intérêt public. Il ne s’agit pas de fermer hermétiquement les frontières entre public et privé, mais, quand les risques sont avérés, de doter la Haute Autorité et le juge pénal d’une capacité d’action beaucoup plus incisive.
Quatre chantiers sont envisageables qui sont présentés en détail dans le Livre blanc de l’Observatoire de l’éthique publique, publié le 14 juin.
1) Réduire les incitations structurelles au pantouflage
La réforme passe d’abord par un traitement des causes, qui tiennent aux réformes (voir notamment la loi du 5 septembre 2018 sur la liberté de choisir son avenir professionnel ; la loi du 6 août 2019 de transformation de la fonction publique ; et le décret du 5 décembre 2025 sur les conditions de disponibilité dans la fonction publique) des deux mandats d’Emmanuel Macron facilitant les circulations public-privé.
En réservant à nouveau les emplois de direction de l’État aux fonctionnaires, on valoriserait le professionnalisme spécifique des serviteurs de l’intérêt général. En contrepartie de ce monopole retrouvé qui apporte plus de garanties du point de vue de l’intégrité publique, le privilège statutaire de conserver son poste lors d’un départ dans le privé ne devrait plus valoir indéfiniment : tout départ serait considéré comme définitif au bout de cinq ans cumulés hors du public, contre dix aujourd’hui. Le passage dans le privé deviendrait ainsi un choix assumé, et non une parenthèse indéfiniment réversible aux frais de la collectivité.
2) Créer un Observatoire des mobilités public-privé au sein de la HATVP
Toute politique sérieuse de régulation suppose d’abord de savoir ce que l’on régule. Or, la connaissance des mobilités public-privé reste fragmentaire et discontinue. La construction d’un Observatoire de l’intégrité publique doit établir une cartographie des secteurs et des fonctions le plus exposés aux risques d’atteinte à la probité publique.
3) Interdire les pantouflages à risque
C’est la proposition centrale. Toutes les mobilités ne présentent pas le même niveau de risque, et il n’est pas raisonnable de soumettre à un simple régime de « réserves » des situations qui compromettent objectivement l’intérêt public ou la souveraineté nationale.
Pour les fonctions les plus exposées – ministres, régulateurs, hauts fonctionnaires de Bercy, conseillers de l’Élysée ou de Matignon ayant suivi un texte législatif – tout passage vers le secteur régulé serait interdit pendant trois ans, sous peine d’un délit expressément rebaptisé « pantouflage illégal » (art. 432-13 du Code pénal). Le droit doit également être modifié pour permettre de sanctionner les entreprises « débaucheuses » qui ne respecteraient pas cette interdiction.
4) Renforcer les moyens et refonder la doctrine de la HATVP
Quant aux mobilités ne relevant pas des fonctions les plus risquées, le Livre blanc propose un changement de doctrine de contrôle de la HATVP, fondé sur un recours plus fréquent aux décisions d’incompatibilité quand un risque est avéré et sur la création d’une infraction administrative de « mobilité public-privé contraire à l’intérêt public » qui donnerait à la HATVP les pouvoirs de sanction dont elle est aujourd’hui dépourvue, et ce, donc, sans passer par le juge pénal.
Ces quatre chantiers s’inspirent d’une même idée : doter la puissance publique des outils pour mesurer, contrôler et interdire des pratiques qui minent la confiance des citoyens dans la capacité de l’État à servir l’intérêt général. La campagne présidentielle à venir offre une occasion rare d’en débattre.
Une version longue de cet article a été publiée sur le blog d’Antoine Vauchez.
Juliette Lelieur a reçu un financement pour sa chaire de l'Institut thématique interdisciplinaire MAKErS (Université de Strasbourg) et elle est membre de l'Observatoire de l'éthique publique.
Lola Avril a reçu des financements du CNRS dans le cadre de la chaire REGANET. Elle est membre de l'Observatoire de l'éthique publique.
Antoine Vauchez ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:32
Coupe du monde 2026 : ce que nos débats sur le football révèlent de nos imaginaires politiques
Maxime Travert, Professeur des universités en STAPS, les jeunes, les sports, une approche sociologique, Aix-Marseille Université (AMU)
Texte intégral (1596 mots)
La Coupe du monde n’est pas seulement un événement sportif. En suscitant des débats sur la valeur de l’effort, l’appartenance nationale, les effets de la mondialisation, la marchandisation du sport et les inégalités de destin, elle révèle différentes manières de penser la société et la vie collective. À travers des conversations ordinaires, le football devient, le temps d’un tournoi, un véritable laboratoire des imaginaires politiques.
Depuis le début de la Coupe du monde, les matchs alimentent un vaste ensemble de conversations bien au-delà des stades. Au bureau, dans les cafés, dans une salle des professeurs, dans les transports ou autour d’un repas de famille, on commente une composition d’équipe, on juge une décision arbitrale, on s’indigne d’une défaite ou on célèbre un exploit.
Ces espaces ordinaires constituent autant de « tiers lieux », situés à mi-chemin entre l’intimité du foyer et les institutions, où se construisent discrètement des habitudes de sociabilité, d’échange et de délibération.
Dans des sociétés souvent décrites comme fragmentées, la Coupe du monde crée pendant quelques semaines un horizon commun. Elle oriente les regards vers les mêmes écrans, suscite des émotions partagées et fournit à chacun des sujets de conversation immédiatement accessibles. Elle agit ainsi comme une véritable caisse de résonance des sensibilités et des préoccupations de son époque.
Pourtant, regarder le même match ne signifie pas y voir la même chose.
Ce qui se déroule sur le terrain ne parle jamais de lui-même. Un but, une défaite ou une célébration ne se réduisent pas à leur signification sportive. Le football offre une sorte de « condensé de société », support d’interprétations multiples et de projections qui dépassent largement le cadre du jeu. La compétition agit, entre autres, alors comme un révélateur de nos imaginaires politiques. Chacun y projette une certaine manière de penser l’organisation de la société et la vie collective.
L’équipe comme métaphore de la société
Pour certains, la Coupe du monde raconte avant tout la force du collectif et les vertus de l’inclusion. Une équipe qui gagne n’est jamais la simple addition de talents individuels. Elle repose sur des complémentarités, des ajustements permanents et une confiance réciproque. On entend alors que « la diversité fait la richesse », que « personne ne gagne seul » ou encore que « chacun apporte quelque chose de différent ».
L’équipe deviendrait ainsi la démonstration qu’une société peut tenir ensemble sans exiger l’effacement des singularités. Se dessine ici une vision pluraliste et coopérative du vivre-ensemble, selon laquelle la cohésion naît moins de l’uniformité que de la capacité à faire coopérer des différences.
D’autres préfèrent y voir une école du mérite, de l’effort et de la transmission. Derrière la victoire, ils soulignent les heures d’entraînement, les sacrifices consentis, l’acceptation des règles communes et le respect de l’autorité. Les mêmes formules reviennent régulièrement : « on n’a rien sans rien », « le travail finit toujours par payer » ou « sans règles, chacun fait comme il veut ». Le terrain rappelle alors qu’une communauté politique ne peut durablement tenir sans responsabilité individuelle et sens des devoirs partagés. Affleure ici une conception républicaine de la vie collective attachée aux vertus civiques, à la culture de l’exigence et à la continuité des repères communs.
Une autre lecture met davantage l’accent sur l’appartenance collective. « Cela fait du bien d’être fiers de son pays », entend-on parfois. « Pendant quelques semaines, on est tous derrière la même équipe. » Dans des sociétés où les références communes paraissent parfois plus incertaines, la sélection nationale réactive le sentiment d’appartenir à une histoire partagée. Le maillot, l’hymne ou le drapeau rappellent qu’il existe encore un « nous » capable de transcender les différences ordinaires. Plus qu’un simple élan affectif, s’exprime ici une forme d’appartenance démocratique, de patriotisme civique nourri par des symboles, une mémoire commune et l’idée d’un destin partagé.
La compétition à l’épreuve de la critique
L’enthousiasme suscité par la compétition n’interdit pas les interrogations qu’elle soulève.
Pour certains, la Coupe du monde constitue aussi un révélateur des contradictions de la mondialisation contemporaine. Elle met au jour des intérêts économiques, diplomatiques et géopolitiques qui ravivent les débats sur les conditions de production de l’événement, ses coûts environnementaux ou les stratégies d’influence des États.
« Le football ne justifie pas tout », rappellent certains. « Il faut regarder l’envers du décor. » L’événement apparaît alors comme un révélateur des arbitrages qui traversent nos sociétés. Ce regard traduit une sensibilité attentive à la régulation collective et à la responsabilité publique, soucieuse de concilier prospérité, justice et préservation des ressources communes.
D’autres s’inquiètent de voir le jeu progressivement absorbé par les logiques du marché. Les transferts records, les droits télévisés, le prix des places ou la présence omniprésente des sponsors nourrissent l’impression que l’argent a pris le dessus. Beaucoup ont le sentiment que « le football est devenu un business », que « tout s’achète et tout se vend » ou que « les supporters passent après les intérêts financiers ». Cette vigilance exprime la crainte de voir une passion populaire progressivement absorbée par les logiques marchandes, jusqu’à ce que la valeur financière finisse par l’emporter sur ce qui faisait son sens collectif.
Enfin, l’histoire des grands champions nourrit elle aussi des lectures contrastées. Les parcours extraordinaires de quelques joueurs inspirent et entretiennent l’idée que le talent et la détermination peuvent changer une destinée. Mais ce récit rencontre parfois ses limites : « il n’y a pas les mêmes chances pour tout le monde », « tous les talents ne sont pas repérés » ou encore « pour un qui réussit, combien abandonnent en chemin ? »
Cette ambivalence renvoie à une tension profonde de nos démocraties entre la croyance dans la force émancipatrice du mérite et la reconnaissance du poids des héritages sociaux qui façonnent les trajectoires individuelles.
Des sensibilités politiques plus mouvantes qu’on ne le croit
Ces différentes interprétations ne renvoient pas toujours à des appartenances politiques clairement établies. Certaines traduisent des convictions relativement stabilisées ; d’autres se construisent davantage au gré des circonstances et des enjeux du moment.
Cette coexistence rappelle que les rapports contemporains au politique relèvent moins de fidélités durables qu’autrefois. Les sensibilités se composent, se déplacent et se réajustent selon les situations. Des convictions ancrées coexistent avec des prises de position plus contextuelles. Le même individu peut, selon les sujets, valoriser l’effort individuel, défendre des mécanismes de solidarité, dénoncer les excès du marché ou exprimer un attachement renouvelé à l’appartenance nationale.
À travers le football se donne ainsi à voir une politisation plus souple et plus circonstanciée, faite d’adhésions successives, de sensibilités plurielles et de positionnements parfois réversibles.
La Coupe du monde ne transforme évidemment pas les supporters en citoyens exemplaires. Les émotions partagées ne remplacent ni les institutions ni les formes plus durables de délibération démocratique. Elles rappellent toutefois qu’il existe encore des événements capables de retenir simultanément l’attention de millions d’individus et d’ouvrir des espaces de discussions sur ce qui nous relie, nous oppose ou nous oblige collectivement.
À ce titre, la Coupe du monde apparaît moins comme une simple parenthèse de divertissement que comme un observatoire privilégié des imaginaires politiques contemporains. Une forme de parlement ordinaire où, à travers les passions du jeu, une société continue de débattre d’elle-même.
Maxime Travert ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
05.07.2026 à 11:31
Au Liban, Israël se heurte aux limites de sa stratégie régionale
Lina Kennouche, Chercheuse associée au CREAT, Université de Lorraine
Texte intégral (2367 mots)
Les erreurs d’analyse de Tel-Aviv et de Washington sont patentes. Fin février dernier, Israël et les États-Unis pensaient pouvoir rapidement venir à bout de la République islamique d’Iran. Le gouvernement Nétanyahou a cru que cette perspective lui offrait une occasion rêvée d’en finir avec le Hezbollah libanais, déjà affaibli après les affrontements de 2024. Quatre mois plus tard, le régime iranien est toujours là, de même que l’organisation paramilitaire du Sud-Liban, et Donald Trump semble de plus en plus désireux de se dégager au plus vite de ce bourbier, au point d’exercer des pressions sans précédent sur son allié privilégié.
Après la guerre des soixante-six jours de 2024 au sud du Liban – durant laquelle Tel-Aviv a accumulé des succès tactiques et infligé des revers notables à l’« Axe de la résistance » –, s’est ancrée chez bon nombre d’observateurs et d’analystes la conviction qu’Israël était devenu la puissance hégémonique au Moyen-Orient. Une conviction encore renforcée par le fait que cette guerre a été suivie de l’effondrement du régime Assad en Syrie en décembre de la même année, ce qu’Israël a présenté comme la conséquence des coups de boutoir qu’il avait assénés aux alliés de Damas.
Cette vision des choses reste répandue aujourd’hui. Pourtant, dernièrement, le terrain libanais a révélé les limites de la puissance israélienne. La reprise des hostilités par Israël en mars 2026 n’a pas abouti à l’écrasement du Hezbollah qu’avait promis Benyamin Nétanyahou. Au contraire, la détermination du mouvement chiite libanais ne faiblit pas. Pour Tel-Aviv, les combats terrestres sont de plus en plus coûteux, tant sur le plan humain que matériel.
Dans le même temps, la relation entre Israël et les États-Unis est parcourue de tensions dans un contexte marqué par la signature, le 17 juin dernier, du protocole d’accord visant à mettre un terme à la guerre au Moyen-Orient : l’Iran exige dans ce cadre que les opérations militaires israéliennes au Liban prennent fin et qu’un agenda temporel pour un retrait israélien total du Sud-Liban soit élaboré.
L’agacement de la Maison-Blanche
Donald Trump, qui était toujours apparu comme un soutien systématique de Benyamin Nétanyahou, a récemment changé de ton, affirmant qu’« Israël se bat contre le Hezbollah depuis trop longtemps » et que « trop de gens ont été tués », avant d’ajouter : « Si Israël ne peut pas faire le boulot sans tuer tout le monde, le [président syrien] s’en occupera » – suggestion qu’Ahmed Al-Charaa s’est d’ailleurs empressé d’écarter.
Israël semble désormais dans l’impasse. Amos Harel, correspondant militaire du journal Haaretz estime à cet égard :
« Du point de vue d’Israël, c’est probablement le pire des scénarios : un bilan humain qui ne cesse de s’alourdir ; une réalité régionale dangereuse dans laquelle des accords problématiques lui sont imposés sur plusieurs fronts ; une crise politique interne ; et peut-être le problème le plus grave à long terme : une fracture grandissante avec l’administration américaine, pourtant amie. »
Israël qui, il y a quelques mois encore, ambitionnait d’imposer un nouveau rapport de force régional, de la Syrie à l’Iran en passant par le Liban, fondé sur sa suprématie militaire et le soutien inconditionnel de Washington, se retrouve en difficulté et peine à obtenir des résultats tangibles et pérennes sur le terrain libanais. L’explication tient avant tout au fait que Tel-Aviv a sous-estimé aussi bien la résilience du régime iranien que celle du Hezbollah.
Les paris perdus de l’offensive contre Téhéran
Lorsque le 28 février dernier, les États-Unis et Israël ont lancé leur offensive surprise contre l’Iran et éliminé plusieurs hauts responsables du régime, l’idée selon laquelle la République islamique se trouvait au bord de l’effondrement irriguait les déclarations et les analyses. Benyamin Nétanyahou avait alors réussi à convaincre Donald Trump que le moment était opportun en lui tenant le discours suivant :
« L’économie iranienne est en ruine. Le peuple est au bord de la révolte. Les gardiens de la révolution perdent le contrôle. »
Dès lors, l’ampleur de la démonstration de force devait contraindre l’Iran à capituler ou, au moins, à créer un contexte favorable à une dynamique interne de changement de régime. Comme le note l’universitaire américain Alfred McCoy, Washington a refusé d’effectuer un débarquement qui aurait provoqué de nombreuses pertes humaines au sein de son armée et a tenté de mobiliser les minorités ethniques iraniennes, qui représentent environ 40 % de la population du pays, le Pentagone étant « conscient que les forces terrestres américaines se heurteraient à une résistance redoutable : la milice bassidj, forte d’un million d’hommes, les 150 000 gardiens de la révolution (spécialisés dans la guérilla asymétrique) et les 350 000 soldats de l’armée régulière iranienne ».
Le plan consistant à s’appuyer sur des groupes armés kurdes pour déstabiliser le régime iranien s’est révélé hasardeux, Donald Trump ayant ouvertement accusé les combattants kurdes irakiens d’avoir conservé les armes envoyées par son administration au lieu de les utiliser pour s’attaquer à l’Iran.
L’offensive américano-israélienne, qui tablait sur la faiblesse du régime de Téhéran et sur un soulèvement de la population iranienne, n’a pas eu l’effet escompté. Au contraire : l’Iran a non seulement répondu par des frappes de missiles balistiques visant Israël, des bases américaines dans la région ainsi que plusieurs alliés de Washington, mais a aussi fait de la fermeture du détroit d’Ormuz une véritable arme de guerre.
Ces erreurs d’analyse sur l’Iran n’ont pas été sans incidence quant à l’appréhension de la situation libanaise. En effet, Israël semblait persuadé que ses coups d’éclat de l’année 2024 – explosion simultanée de bipeurs et de talkies-walkies de nombreux membres du Hezbollah ; assassinat du secrétaire général du parti Hassan Nasrallah ; désorganisation de la structure de commandement par l’élimination de plusieurs hauts responsables et la destruction d’une grande partie de son arsenal – avaient obéré les capacités de nuisance de l’organisation.
Dans un contexte où la République islamique d’Iran, parrain historique du Hezbollah, semblait sur le point de chuter, les Israéliens ont cru, début mars, que le moment était idéal pour neutraliser définitivement le mouvement chiite libanais.
Ces pronostics ont été déjoués. Le Hezbollah avait réorganisé et reconstruit son commandement en remplaçant sa structure pyramidale par une structure décentralisée, composée de petites unités ayant une connaissance limitée des opérations de leurs pairs afin de préserver le secret opérationnel. Tous les responsables identifiés par le Mossad dans le cadre de l’implication du Hezbollah dans la guerre en Syrie ont été remplacés.
Par ailleurs, l’organisation paramilitaire a démontré qu’elle disposait encore non seulement de combattants, mais aussi d’armements : les frappes d’artillerie, l’utilisation de missiles sophistiqués ou de drones à fibres optiques difficiles à intercepter ont illustré sa capacité de résistance et de nuisance.
Une stratégie sans cap sur le terrain libanais
La guerre sur le front libanais a donc essentiellement pris la forme d’une campagne aérienne de bombardements intensifs pour installer une zone tampon dont la frontière serait le fleuve Litani. En mars et en avril, 45 % des villages du Sud-Liban ont été endommagés et détruits, selon les données du Monde.
Depuis le 25 mai dernier, alors que Washington et Téhéran discutaient des termes d’un accord, Israël a élargi son offensive militaire contre le Hezbollah, et cherche à avancer au-delà de la « ligne jaune » (de défense avancée). Une stratégie qui semble dénuée de cap clair. Dans l’article déjà cité, Amos Harel constate que « beaucoup au sein de l’état-major général savent que les combats actuels n’ont aucun objectif stratégique utile ». « Dans cette guerre asymétrique, Israël ne peut pas éradiquer une force combattante qui est encore importante et bien armée », considère de son côté l’ancien diplomate français Denis Bauchard.
La situation est d’autant plus problématique que toute perspective d’accord final entre Washington et Téhéran reste conditionnée par l’exigence iranienne d’un arrêt de la guerre au Liban et d’un retrait israélien du sud du pays – exigence à laquelle le gouvernement israélien oppose une fin de non-recevoir, le ministre de la défense étant allé jusqu’à déclarer que l’armée israélienne resterait au Sud-Liban même si les États-Unis lui enjoignaient de s’en retirer.
Pour favoriser une désescalade, les États-Unis cherchent également à faire pression sur la partie libanaise. Ainsi, le gouvernement libanais a cédé aux injonctions américaines et signé un accord-cadre avec Israël qui, s’il venait à être appliqué, transformerait l’armée libanaise en force supplétive de l’armée israélienne. En effet, les termes de cet accord ne mentionnent jamais « le retrait » israélien, mais évoquent un « redéploiement » avec la création, à la lisière de la ligne jaune, de zones pilotes qui seraient confiées à l’armée libanaise et qui pourraient s’étendre à d’autres parties de la zone occupée par Israël ; si toutefois l’institution militaire libanaise venait à se montrer coopérative.
Cet accord suscite une opposition assez large au Liban : il est dénoncé par le Hezbollah et par le mouvement Amal (le plus grand parti chiite au Parlement), et vivement critiqué par Walid Joumblatt, leader politique de la communauté druze. Cette position a été suivie par le Courant patriotique libre, parti représentatif d’une partie du camp chrétien. L’opposition à cet accord transcende donc les clivages intercommunautaires.
Un échec pour Tel-Aviv… et pour Washington
Donald Trump a déjà exercé de fortes pressions sur son allié israélien pour l’empêcher de saboter le processus de négociation avec Téhéran. La tension culmine actuellement dans la relation bilatérale, sachant qu’un accord final avec l’Iran apparaît comme un développement indispensable pour le président américain : une fermeture prolongée du détroit d’Ormuz aurait des effets désastreux sur l’économie de son pays et, donc, sur les chances de son parti aux élections de mi-mandat de novembre prochain.
Aux États-Unis, de nombreuses voix s’élèvent aujourd’hui pour critiquer le mémorandum d’entente avec l’Iran. Robert Malley, principal négociateur de l’accord nucléaire iranien de 2015 puis émissaire spécial pour l’Iran sous Joe Biden, juge que Trump a accepté des conditions pires que celles qu’il aurait pu obtenir par la voie diplomatique. Son constat est sans appel :
« Aujourd’hui, les faucons qui avaient été exaltés par l’opération “Epic Fury” sont furieux contre M. Trump pour avoir mis fin au conflit. Les colombes ne lui pardonneront pas de l’avoir déclenché. Tout le monde est perdant, et personne n’est satisfait. »
Lina Kennouche ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
04.07.2026 à 23:55
Les tours Saint-Jacques, un prodige d’équilibre au cœur des Alpes
Patrick De Wever, Professeur, géologie, micropaléontologie, Muséum national d’histoire naturelle (MNHN)
Texte intégral (2985 mots)

Au-delà du sport, le Tour de France donne aussi l’occasion de (re)découvrir nos paysages et parfois leurs bizarreries géologiques. L’itinéraire de la 17ᵉ étape, le 23 juillet, entre Chambéry en Savoie et Voiron dans l’Isère, fait passer les coureurs par les tours Saint-Jacques, dans le massif des Bauges, en Haute-Savoie. Une curiosité géologique locale à la légende pour le moins insolite.
Pour leur 17ᵉ étape, le 23 juillet, les coureurs du Tour de France entreront dans le massif des Bauges (Haute-Savoie) par une trouée : la vallée du Chéran.
Les paysages de montagnes provoquent souvent une émotion par leur simple esthétique. Lorsque leur compréhension atteste en outre d’un phénomène rare et extraordinaire, l’émerveillement en est décuplé.

Les tours Saint-Jacques font partie de ces lieux : sur le flanc sud-ouest du massif du Semnoz dans les Bauges, dominant le village d’Allèves (Haute-Savoie), ces pitons rocheux baptisés d’après la chapelle d’un ancien prieuré attirent l’attention. Autrefois surnommés les « aiguilles de Racheroche », ces trois monolithes calcaires dont le plus grand mesure 70 mètres de hauteur et culmine à 991 mètres d’altitude, intriguent. De loin, ils évoquent les ruines d’anciennes tours.
Une histoire d’aigle, de loup et d’agneau
Comme beaucoup de lieux inhabituels, ces majestueuses aiguilles ont leur légende locale.

{kind=link}
Il est dit que, un jour, un aigle emporta un agneau menacé par un loup afin de lui éviter d’être dévoré. L’agnelet, un peu gros et un peu trop lourd pour être emmené au loin par le volatile aurait été déposé sur l’un des trois pitons, hors d’atteinte du loup. Des années plus tard, un alpiniste y aurait découvert un bélier. Les Aléviens, émerveillés par ce geste inattendu, y auraient vu un signe divin.
L’aigle et l’agneau sont alors devenus symboles de paix et de protection du bourg. Les tours ont ainsi offert, à partir de cette histoire, son identité à Allèves.
À lire aussi : Tour de France : marbre en serpentinite et traces d’un océan en haut des montagnes
Des sculptures naturelles

Le phénomène géologique de « paquet tassé », par lequel les roches glissent vers l’aval en ne perdant pas entièrement leur structure, est bien visible à travers les tours Saint-Jacques.
En réalité, de tels reliefs sont connus dans les Alpes en différents endroits et généralement appelés des « cheminées de fées ». Les « demoiselles coiffées » de Pontis, à l’est du lac de Serre-Ponçon (Alpes-de-Haute-Provence) sont les plus célèbres. Ces reliefs résultent d’une érosion différentielle qui décape des sédiments tendres (marnes, argiles sableuses, cendres…) sous un chapeau de roche plus résistante (bloc calcaire, bombe volcanique…)

{kind=link}
Les tours qui dominent Allèves sont le fruit d’un processus bien plus complexe. La pente d’où s’élèvent ces tours constitue le flanc sud du massif du Semnoz, dont le sommet est composé de calcaires d’âge crétacé (Valanginien, de -140 millions à -136 millions d’années), dits « calcaires de Fontanil » ou encore « marbre bâtard ». Ce massif forme une voûte (un anticlinal) dont la pente plonge vers le sud-ouest.
Cette épaisse couche de calcaires repose sur des marnes et des calcaires marneux un peu plus anciens (Berriasien, de -145 millions à -140 millions d’années). Les marnes, bien plus plastiques que le calcaire, peuvent former une sorte de couche « savon » sur laquelle des blocs détachés de la falaise du haut, tels des icebergs au front d’un glacier, peuvent glisser vers la rivière du Chéran.

Mais certaines inconnues demeurent.
Trois théories à l’épreuve
Trois propositions sont actuellement avancées pour expliquer la situation actuelle.

La première tiendrait à un simple phénomène érosif. Comme nous sommes sur la retombée d’un bombement, les couches sont inclinées vers le bas, vers la vallée. Elle sont parallèles – ou presque – à la pente. Soumises à l’érosion, des parties disparaissent, mais certains blocs résistent mieux et glissent plus bas. Elles constitueraient ainsi des buttes-témoins : les tours Saint-Jacques.
La deuxième postule un glissement de terrain en masse. Au front de la dalle calcaire, des blocs peuvent se détacher, un peu à l’image des icebergs qui se séparent de la banquise. Comme la dalle est inclinée, certains éléments reposant sur une couche plastique (les marnes du Berriasien) se mettent à glisser lentement tout en conservant leur position verticale.
La troisième explication fait appel à une logique plus complexe, associant séparation et glissement. La dalle calcaire du haut se serait fracturée en nombreux panneaux de tailles différentes. Ces éléments se seraient mis à glisser. Certains auraient basculé, d’autres se sont effondrés, auraient été érodés, en bref, certains seraient devenus invisibles dans la topographie au cours du temps. D’autres auraient résisté un peu mieux, se seraient fracturés en sous-blocs, continuant toutefois de glisser sans s’effondrer : les tours Saint-Jacques actuelles.
La deuxième théorie est, à l’heure actuelle, celle qui est privilégiée pour expliquer l’origine de ces structures. C’est aussi la mieux documentée. Les éléments n’auraient pas basculé en s’effondrant, mais en glissant tout doucement le long de la pente. Ils sont maintenant éloignés de plusieurs centaines de mètres de leur « port d’attache », de 700 mètres pour la plus haute et de 960 mètres pour la plus basse et la plus fine.
Et surtout, ils continuent à descendre, à une vitesse variable selon les éléments : de 2,1 cm/an pour la plus haute, de 1,8 cm/an pour le bloc du milieu et jusque 4,6 cm/an pour le plus fin, le plus bas, le plus rapide.
À lire aussi : Tour de France : entre Bourgogne et Quercy, grands crus et grenouilles momifiées
Patrick De Wever ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
04.07.2026 à 23:54
Fées, lutins et extraterrestres, comment le pic de Bugarach a donné vie aux mythes les plus fous
Patrick De Wever, Professeur, géologie, micropaléontologie, Muséum national d’histoire naturelle (MNHN)
Texte intégral (2455 mots)

Au-delà du sport, le Tour de France donne aussi l’occasion de (re)découvrir nos paysages et parfois leurs bizarreries géologiques. L’itinéraire de la quatrième étape, le 7 juillet, entre Carcassone et Foix, fait passer les coureurs par le pic de Bugarach, dans les Corbières. Un lieu dont la curieuse morphologie a, de longue date, suscité toutes sortes de mythes et de légendes – ainsi qu’une certaine fascination contemporaine pour les adeptes du New Age.
Le nom de cette montagne viendrait de l’occitan Pueg – dont est issu le mot puech, qui est parfois utilisé à la place de pic –, lui-même issu du latin podium, c’est-à-dire un site élevé. Le nom de Bugarach, quant à lui, proviendrait du latin bulgarus (boulgres ou bougres, c’est-à-dire hérétiques). C’est le nom que l’on donnait, à l’époque médiévale, aux ancêtres des cathares.
Ce paysage singulier a depuis toujours suscité l’imagination et inspiré de nombreux mythes et légendes. Certains curieux pensent y trouver, pêle-mêle : des trésors cachés, une prétendue base extraterrestre, voire un hangar à ovni, une porte galactique, un lieu d’inversion magnétique, l’entrée d’Agartha, supposé royaume souterrain légendaire, ou encore du sanctuaire de l’Arche d’alliance…
Toutes fantaisistes que soient ces croyances, qui empruntent beaucoup au New Age pour les plus contemporaines, il est instructif d’observer à quel point ce lieu, encore aujourd’hui, déchaîne les imaginaires.
Un promontoire pour protéger la plaine
Commençons par la plus ancienne – et célèbre – de ces légendes, qui renvoie à la mythologie romaine.
Elle raconte que l’Aude aurait autrefois été une plaine immense et fertile sur laquelle veillaient des fées et des lutins, tels Bug et Arach. Soumise aux aléas de Cers – un vent, fils d’Éole le père des vents et tempêtes –, elle obtenait pourtant de piètres récoltes. Les deux lutins auraient alors imploré Jupiter de les aider à calmer les outrances de Cers. En réponse, le dieu aurait dressé ce promontoire protecteur baptisé d’après les lutins, Bugarach, qui rendit à la plaine de Roussillon et au plateau des Corbières leur prospérité.
Plus tard, l’histoire cathare continuera d’alimenter les mythes et les imaginaires autour du pic de Bugarach. Il abriterait un trésor – celui des cathares ? Des Templiers ? Des Wisigoths ? Le Saint-Graal ? Certaines rumeurs vont jusqu’à imaginer qu’il s’agirait de l’Arche d’alliance, renfermant les tables de la loi.
À lire aussi : Tour de France 2025 : quand des réserves naturelles émergent sur des sites pollués
Les nouveaux mythes New Age, entre base extraterrestre et arche de Noé
Dans les années 1960, mystiques et hippies s’installent dans la région, font revivre les mythes et en alimentent de nouveaux. Certains assurent notamment qu’une base extraterrestre serait cachée dans ses nombreuses cavités, liées au réseau karstique développé depuis une dizaine de millions d’années dans le calcaire de la montagne.
À la clé, la croyance qu’il s’agirait d’un « haut lieu énergétique » qui réunirait « tous les ingrédients permettant de s’ouvrir à d’autres plans de conscience » (sic). Certains avancent même y avoir observé des « distorsions du temps » ou des « trous spatio-temporels ».
Ces croyances ont atteint leur paroxysme en 2012, lorsqu’un canular, attribuant la prédiction à Nostradamus, a annoncé la fin du monde pour le 21 décembre 2012. La prétendue base extraterrestre de Bugarach est alors vue par certains comme un refuge, l’espoir étant que ses occupants supposés puissent sauver quelques « élus » grâce à leur vaisseau, transformé pour l’occasion en nouvelle arche de Noé.
Cette rumeur, si forte, conduisit la préfecture de l’Aude à interdire l’accès au pic et à ses galeries souterraines, de même que le survol de la montagne entre le 19 et le 23 décembre 2012.
Dans les évocations de fin du monde annoncée pour le 21 décembre 2012, ce site était supposé être épargné en sa qualité de « montagne inversée ». En réalité, la montagne n’est pas vraiment inversée : les couches supérieures y sont plus anciennes que les couches inférieures.
Mais nul besoin de convoquer les extraterrestres pour en comprendre les raisons.
À lire aussi : Les ovnis, un mythe moderne façonné par Hollywood
La formation d’une drôle de montagne
Un peu de géologie permet de comprendre la naissance de cet étonnant sommet. Les Pyrénées se sont formées quand la péninsule Ibérique, à savoir l’Espagne et le Portugal, a commencé à se rapprocher de la France, il y a environ 50 millions d’années. Les terrains qui se sont rencontrés et affrontés ont constitué un bourrelet, un relief.
Certaines couches ont alors formé des plis qui se sont couchés. Les niveaux plus plastiques, tels le sel et le gypse déposés au Trias (il y a 250 millions d’années), ont permis que des couches glissent les unes sur les autres. Elles se sont délaminées, comme les pages d’un livre souple que l’on plie. Certains plis se sont étirés et ont chevauché les terrains voisins.
À lire aussi : Tour de France : marbre de Campan, talc de Luzenac et diamants de la Drôme
L’érosion a ensuite fait son œuvre : les éléments les plus hauts ont été les plus sévèrement attaqués, si bien qu’il ne reste parfois que la partie inverse du pli. Certaines parties du pli montrent des couches verticales, les parties dures résistent à l’érosion et forment des pics.

Le relief particulier est lié à la structure de l’ensemble, issue d’un plissement couché. Les couches supérieures sont ainsi plus anciennes (Jurassique, 135 millions d’années) que les couches inférieures (Crétacé, 80 millions d’années), ce qui lui a valu la réputation de « montagne inversée ».
Une géologie à part qui a nourri les mythes
Certains éléments de géologie liés ce phénomène, qui n’ont rien d’extraordinaire en soi mais donnent à ce mont isolé une allure bien particulière, ont contribué à la mythologie du lieu. La montagne a été supposée protectrice, car elle était susceptible de cacher des choses dans son réseau karstique.
L’origine des « couches inversées », au plan géologique, était un peu difficile à comprendre, ce qui a conduit à les interpréter comme « magiques ». Les imaginaires ont fait le reste.

Un autre fait scientifique insolite est associé à cette montagne. Le méridien 0 passe à 2 kilomètres du pic de Bugarach, et surtout, c’est sur cette montagne que Jean-Baptiste Delambre et Pierre Méchain, astronomes et mathématiciens, ont posé l’un des jalons fondateurs du système métrique universel à la fin du XVIIIᵉ siècle. Ils ont ainsi entrepris de mesurer un bout de l’arc terrestre (de Dunkerque à Barcelone, soit le quart d’un méridien). Ces travaux, poursuivis par Arago, ont permis de définir le « mètre étalon », qui correspond à la dix millionième part du quart de la longueur d’un méridien terrestre.
Patrick De Wever ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
04.07.2026 à 13:11
Comment une minuscule île des Caraïbes a rendu possible l'indépendance des États-Unis
R. Grant Gilmore III, Director, Historic Preservation and Community Planning Program, College of Charleston
Texte intégral (2551 mots)

{kind=link}
Au XVIIIᵉ siècle, Saint-Eustache était l'un des plus grands centres commerciaux de l'Atlantique. Son statut de port franc permit aux insurgés américains de contourner le blocus britannique et d'obtenir les ressources indispensables à leur indépendance.
La Révolution américaine est souvent racontée comme l'épopée héroïque de treize colonies se soulevant contre un puissant empire et remportant leur indépendance, avec l'aide de la France.
La réalité est toutefois plus complexe. À l'approche du 250ᵉ anniversaire de l'indépendance des États-Unis, il est utile de se rappeler que la victoire militaire n'a pas reposé uniquement sur le courage et les idéaux, mais aussi sur le commerce, le crédit, le transport maritime et l'accès aux approvisionnements militaires.
Le centre de ce commerce ne se trouvait pas dans les treize colonies, mais au sud de la Floride loyaliste, dans la grande Caraïbe. C'est là que s'est développé le cœur de l'économie atlantique, porté par l'appétit insatiable pour le sucre, qui s'était répandu dans toute l'Europe à la fin du XVIIIᵉ siècle. À elle seule, la Jamaïque produisait autant de richesses que l'ensemble des treize colonies.
Les économies caribéennes reposaient sur le travail des personnes réduites en esclavage, le commerce international et des approvisionnements venus du monde entier afin que le sucre continue d'affluer et que les recettes fiscales des puissances coloniales européennes soient maximisées. Une grande partie de ce soutien transitait par une petite île néerlandaise des Caraïbes orientales, aujourd'hui méconnue de la plupart des Américains : Saint-Eustache.
Une petite île au rôle immense
Je suis archéologue et, pendant huit ans au début de ma carrière, j'ai vécu à Saint-Eustache, où j'ai été archéologue de l'île et directeur fondateur du St. Eustatius Center for Archaeological Research.
À peine grande de 8 miles carrés (environ 21 kilomètres carrés), Saint-Eustache – ou Statia, comme l'appellent ses habitants – se situe au nord-ouest de Saint-Christophe-et-Niévès. Sans cette minuscule île, l'armée continentale américaine aurait peut-être manqué des armes, de la poudre à canon et des autres fournitures indispensables à sa survie.
L'importance de Statia tient d'abord à sa géographie. L'île surgit abruptement des eaux bleu profond de l'Atlantique et de la mer des Caraïbes. Son volcan endormi, appelé le Quill, domine toute la partie méridionale de l'île.
Contrairement à d'autres îles caribéennes plus élevées, Statia ne recevait pas suffisamment de précipitations pour être particulièrement propice à la culture intensive de la canne à sucre. Elle présentait donc moins d'intérêt pour les grandes puissances sucrières du XVIIIᵉ siècle, notamment la Grande-Bretagne et la France.
Si Statia n'avait guère d'atouts pour les plantations, elle excellait en revanche comme port de commerce. La baie d'Oranje, sur la côte ouest de l'île, offrait l'un des mouillages côtiers les plus profonds et les plus sûrs des Amériques. Les grands navires marchands pouvaient s'approcher du rivage, décharger leur cargaison puis repartir rapidement après avoir été rechargés.
Le long de la baie s'étendait un front de mer animé, bordé d'entrepôts, de boutiques et de maisons de commerce. Au milieu du XVIIIᵉ siècle, cette étroite bande littorale était devenue l'un des principaux centres commerciaux du monde atlantique.
Un impérialisme fondé sur le commerce
Les Néerlandais s'établirent à Saint-Eustache dans les années 1630, à peu près au moment où ils développaient la colonie de La Nouvelle-Amsterdam, l'actuelle ville de New York. Les marchands, familles et investisseurs néerlandais évoluaient au sein d'un vaste réseau atlantique reliant l'Europe, l'Afrique, les Caraïbes et l'Amérique du Nord. Ces liens commerciaux favorisaient la confiance, le crédit et les opportunités à travers de très longues distances.
Aux XVIIᵉ et XVIIIᵉ siècles, les empires européens cherchaient à contrôler le commerce colonial par le mercantilisme. Les colonies étaient censées enrichir la métropole en fournissant des matières premières et en achetant des produits manufacturés par des circuits commerciaux approuvés. Les taxes, droits de douane et restrictions commerciales profitaient aux gouvernements impériaux et aux négociants, mais renchérissaient le coût de la vie pour les colons, les commerçants et les planteurs.
Les colons britanniques d'Amérique du Nord supportaient mal ces restrictions, mais les négociants néerlandais étaient disposés à les aider à les contourner. Pendant des générations, les navires néerlandais ont transporté des marchandises à travers tout l'Atlantique, proposant souvent des produits à des prix inférieurs à ceux que les marchands britanniques pouvaient légalement pratiquer.
Les découvertes archéologiques réalisées sur des sites tels que la plantation de Pope’s Creek, en Virginie, demeure de la famille Washington, attestent de la présence de céramiques néerlandaises, de pipes en terre cuite et de briques jaunes. Bien avant la Révolution, le commerce néerlandais était déjà profondément intégré à la vie des colonies.
« L'entrepôt du monde »
En 1754, la Compagnie néerlandaise des Indes occidentales demanda au gouvernement des Provinces-Unies de faire d'Oranjestad, la capitale de Saint-Eustache, un port franc. Sa requête fut acceptée. Le résultat fut spectaculaire : les marchandises pouvaient transiter par l'île avec très peu de restrictions et sans les lourdes taxes en vigueur ailleurs. Les autorités tiraient leurs revenus de la location des terrains, des entrepôts et des habitations, plutôt que de taxer chaque cargaison.
Des marchands venus de tout le monde atlantique saisirent rapidement cette opportunité. Les navires arrivaient chargés de textiles, d'outils, de denrées alimentaires, d'armes, de produits de luxe et de matières premières. Ils transportaient aussi des Africains captifs, déportés de force dans le cadre de la traite transatlantique, puis vendus, détenus, contraints au travail et victimes de violences. Les personnes réduites en esclavage et leurs descendants étaient indispensables non seulement aux plantations de l'île, mais aussi aux foyers, aux quais, aux entrepôts et aux réseaux commerciaux qui faisaient fonctionner cette économie.
Saint-Eustache devint, selon une formule souvent associée à l'île, « l'entrepôt du monde ». En termes actuels, elle fonctionnait comme un centre logistique d'Amazon pour l'Atlantique du XVIIIᵉ siècle. Cette prospérité reposait toutefois en grande partie sur l'esclavage et sur les rapports de domination qui permettaient au commerce impérial de prospérer.
Cette réussite ne passa pas inaperçue d’Adam Smith, souvent considéré comme le père de l'économie, voire du capitalisme. Dans son ouvrage de 1776, La Richesse des nations, Smith contribua à faire de l'économie une discipline moderne. Bien qu'il ne se soit jamais rendu à Saint-Eustache, il y évoque l'île, qui constituait à ses yeux un exemple concret de ce qu'un commerce plus libre pouvait produire : prospérité, rapidité, diversité et dynamisme commercial.
Le même système qui fit la richesse de l'île en faisait aussi une menace pour les puissances impériales. La Grande-Bretagne et la France fondaient leur puissance sur un commerce colonial étroitement contrôlé, mais Saint-Eustache démontrait ce qu'il était possible d'accomplir lorsque les marchandises circulaient avec moins de contraintes. L'île montrait aussi que des marchands, des réseaux de crédit et des familles d'armateurs pouvaient ébranler les empires sans tirer un seul coup de feu.

{kind=link}
Lorsque les colonies américaines déclarèrent leur indépendance en 1776, elles avaient désespérément besoin de matériel militaire. Le Congrès continental savait que les idéaux ne suffiraient pas à vaincre la Grande-Bretagne. Les futurs États-Unis avaient besoin de mousquets, de canons, de munitions, d'uniformes, de tissus, de vivres et de crédit.
Saint-Eustache était idéalement placée pour leur fournir tout cela.
Les marchands de l'île entretenaient depuis longtemps des liens avec l'Amérique du Nord, et plusieurs des Pères fondateurs connaissaient bien ces réseaux. Alexander Hamilton, qui a grandi dans les Caraïbes, passa sa jeunesse dans l'univers du commerce maritime, de la comptabilité et du crédit. Sa famille entretenait des liens avec la région, et le commerce caribéen contribua à façonner sa compréhension de la finance et du pouvoir.
Saint-Eustache devint rapidement une véritable bouée de sauvetage pour la Révolution américaine. Les représentants américains s'y approvisionnaient en matériel avant de l'expédier vers les colonies. Les cargaisons arrivaient d'Europe à Statia, puis étaient réacheminées vers l'Amérique du Nord. Les armes et la poudre à canon, impossibles à obtenir par les circuits officiels, pouvaient être achetées dans ce port franc néerlandais.
Le premier salut
En novembre 1776, un événement modeste en apparence, mais historique, se produisit dans la baie d'Oranje. Le brick américain Andrew Doria arriva avec à son bord un exemplaire de la Déclaration d'indépendance et arborant les Continental Colors, l'ancêtre de la bannière étoilée. Conformément aux usages maritimes, le navire américain tira une salve d'honneur. Le fort Oranje lui répondit par une salve de ses canons.
Cet échange est entré dans l'histoire sous le nom de « premier salut ». De nombreux historiens y voient la première reconnaissance officielle de l'indépendance américaine par une puissance étrangère. Le geste fut bref, mais sa portée considérable : en répondant à cette salve, Saint-Eustache reconnaissait publiquement le pavillon et l'autorité des nouveaux États-Unis.
La Grande-Bretagne comprit immédiatement l'importance de cet acte. L'île n'était pas un simple comptoir commercial : elle contribuait à soutenir la rébellion. Au cours des années suivantes, une grande partie de la poudre à canon, des munitions, des étoffes et des autres fournitures qui permirent à l'effort de guerre américain de se poursuivre transita par les entrepôts et le port de Statia.
L'histoire de Saint-Eustache rappelle qu'une révolution ne se gagne pas uniquement par la force des idées. La Révolution américaine a certes reposé sur les agriculteurs, les soldats, les diplomates et les penseurs politiques, mais aussi sur les marchands, les marins, les entrepôts… et le crédit.
Sans Saint-Eustache, sans le commerce néerlandais et sans l'accès à un port franc dans les Caraïbes, les États-Unis n'auraient peut-être pas survécu assez longtemps pour célébrer le moindre anniversaire de leur indépendance. La Révolution américaine fut certes une lutte pour l'indépendance politique, mais aussi un combat pour le contrôle du commerce. Et dans cette bataille, une minuscule île contribua à changer le cours de l'histoire mondiale.
R. Grant Gilmore III ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
04.07.2026 à 12:42
L’énigme des nombres cachés au cœur de la Sagrada Familia
Sergi Muria Maldonado, Professor de Didàctica de les Matemàtiques, Universitat de Barcelona
Anton Aubanell Pou, Professor de l'Institut de Formació Continuada i professor jubilat de Didàctica de les Matemàtiques, Universitat de Barcelona
Jordi Font González, Professor de Didàctica de les Matemàtiques, Universitat de Barcelona
Texte intégral (2416 mots)

Les mathématiques jouent un rôle dans la beauté de la Sagrada Família. De ses proportions aux formes géométriques, l’édifice de Gaudí montre comment les nombres peuvent façonner une architecture à la fois stable, lumineuse et profondément symbolique.
L’année 2026 marque le centenaire de la mort d’Antoni Gaudí, l’architecte de la basilique de la Sagrada Família à Barcelone. Si la beauté de l’édifice est déjà exceptionnelle en elle-même, elle gagne encore en profondeur lorsque l’on découvre les formes mathématiques qui sous-tendent son architecture singulière.
En explorant les principes mathématiques qui structurent l’ensemble, l’harmonie visuelle du monument prend une nouvelle dimension, révélant une architecture où fonctionnalité, équilibre et cohérence se renforcent mutuellement.
Sans aucun doute, la personne qui a le plus profondément étudié les mathématiques de la Sagrada Família est Claudi Alsina i Català. Formé en mathématiques à l’université de Barcelone, il a également dirigé la thèse de doctorat de l’actuel architecte en chef du chantier, Jordi Faulí.
Dans ses mémoires, Alsina écrit :
« Tout le monde se demandait si la conception de la Sagrada Família reposait sur un module et un système de proportions guidant l’ensemble des relations métriques de l’édifice. […] Un samedi après-midi, assis à mon bureau, chez moi, avec tous les documents et toutes les données relatifs à ce mystérieux système de proportions – s’il existait vraiment… –, je l’ai découvert. Le module de 7,5 mètres et les rapports entre les diviseurs de 12 (1 :4, 1 :3, 1 :2, 3 :4, 2 :3, 1) semblaient expliquer une multitude de choses. »
Le nombre 12, un élément central
Il n’est pas surprenant que le nombre 12 occupe une place centrale dans la structure de l’édifice. Gaudí a conçu la Sagrada Família comme une synthèse entre architecture et symbolisme religieux, et le 12 est omniprésent dans la Bible : les douze fils de Jacob, les douze tribus d’Israël, les douze apôtres ou encore la couronne de douze étoiles du Livre de l’Apocalypse n’en sont que quelques exemples.
Mais son intérêt ne se limite pas à sa portée symbolique. D’un point de vue mathématique, le 12 est un nombre particulièrement propice à l’établissement de proportions, car il possède de nombreux diviseurs. Ce sont précisément les rapports entre ces diviseurs qui, selon Alsina, expliquent une grande partie du système de proportions de la basilique.
Au regard de ces fondements à la fois symboliques et mathématiques, le lien entre les éléments structurels et le nombre 12 n’a donc rien d’étonnant.
Le module de 7,5 mètres
En nous appuyant sur les travaux d’Alsina, nous vous proposons une brève visite de la Sagrada Família sous un angle mathématique. Les dimensions du temple sont étroitement liées au nombre 12 et à un module de 7,5 mètres. L’édifice mesure ainsi 90 mètres de long (7,5 × 12), 60 mètres de large (7,5 × 8), tandis que la nef principale atteint 45 mètres de largeur (7,5 × 6).
Les hauteurs obéissent au même principe : la voûte la plus élevée est celle de l’abside, avec 75 mètres (7,5 × 10), suivie de la voûte du transept, haute de 60 mètres (7,5 × 8). Viennent ensuite la voûte de la nef, à 45 mètres (7,5 × 6), celle des bas-côtés, à 30 mètres (7,5 × 4), et enfin le chœur, dont la hauteur est de 15 mètres (7,5 × 2).
En harmonie avec la colline de Montjuïc
La tour de Jésus est la tour centrale et la plus haute du temple. Avec ses 172,5 m (7,5 × 23), sa hauteur fait écho à celle de la colline de Montjuïc. Elle est surmontée d’une croix à quatre branches, haute de 17 mètres et large de 13,5 mètres. Autour d’elle s’élèvent les quatre tours des Évangélistes, qui culminent à 135 m (7,5 × 18).

Avec ses 138 mètres, la tour de Marie est la deuxième plus haute de la basilique. Elle est coiffée d’une étoile à douze branches reposant sur trois bras de soutien. D’un diamètre de 7,5 mètres, cette étoile est constituée d’un dodécaèdre régulier, dont chacune des faces est prolongée par une pointe pentagonale en forme de pyramide. Les reflets de la lumière du jour et son éclairage intérieur nocturne lui confèrent une beauté unique.
Des polyèdres au sommet des tours
Les polyèdres sont eux aussi omniprésents dans les tours de la Sagrada Família, comme l’explique cette étude. Les quatre tours de la façade de la Gloire sont coiffées de dodécaèdres, celles de la façade de la Nativité d’octaèdres irréguliers tronqués, et celles de la façade de la Passion de cubes tronqués.

Au sommet de chacune des douze tours s’élève un pinacle au-dessus des polyèdres. Les tours dédiées aux évangélistes sont couronnées d’icosaèdres réguliers (des solides composés de vingt faces) renfermant des projecteurs qui illuminent la grande croix dominant la tour de Jésus. Juste au-dessus de chaque icosaèdre se trouve une sculpture représentant symboliquement l’évangéliste correspondant. Le temple compte également de nombreux polyèdres étoilés, particulièrement sur la façade de la Nativité.
Ce ne sont pas des colonnes, c’est une forêt !
Les arcs en chaînette constituent l’un des principaux éléments structurels du temple. Cette forme est particulièrement efficace pour transmettre les charges vers le sol sans nécessiter d’autres éléments de soutien. On les retrouve dans le système de colonnes inclinées qui soutient les voûtes des nefs intérieures, dans les voûtes et les plafonds eux-mêmes, ainsi que sur la façade de la Nativité.
À l’intérieur de la Sagrada Família, on distingue quatre types de colonnes. Toutes sont des colonnes à torsion en double hélice. Leur base polygonale prend la forme d’une étoile aux contours arrondis et résulte de l’intersection de deux colonnes salomoniques opposées. Chacune se prolonge par un nœud d’où émergent plusieurs ramifications, semblables aux branches d’un arbre, qui soutiennent avec une remarquable efficacité les tours et la toiture du temple.
Les verrières du toit sont, elles aussi, des hyperboloïdes à une nappe.) Comme elles sont constituées de lignes droites, leur construction est plus simple tout en optimisant la captation et la diffusion de la lumière.
Le symbolisme de deux nombres : 7 et 33

D’autres nombres dissimulés dans le temple revêtent une forte portée symbolique. C’est le cas, par exemple, du baldaquin situé au-dessus du maître-autel, un heptagone régulier de 5 mètres de diamètre dont les sept côtés représentent les sept dons du Saint-Esprit.
Sur la façade de la Passion figure également un carré magique dont toutes les lignes, colonnes et diagonales totalisent 33, un nombre aux évidentes connotations religieuses. Il semble s’inspirer du carré magique représenté dans la gravure Melencolia I d’Albrecht Dürer.
Mettre au jour les mathématiques qui se cachent derrière la Sagrada Família ne fait qu’accroître la beauté de l’édifice et l’admiration que suscite le génie d’Antoni Gaudí.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview