
17.06.2026 à 17:43
Médecins spécialistes et déserts médicaux : leur présence sur un territoire ne suffit pas à garantir l’accès aux soins
Benjamin Montmartin, Full professor of Econometrics and Data Science - Director of the Chair Prevention and Access to Healthcare, SKEMA Business School; IAE Nice - Université Côte d'Azur
Texte intégral (1911 mots)
Le manque de praticiens ne suffit pas à expliquer les difficultés d’accès à certaines spécialités médicales observées dans certains territoires. La désertification médicale résulterait de trois inégalités qui se cumulent sans toujours se confondre : une offre de soins mal répartie, des délais d’attente très inégaux pour obtenir un rendez-vous et la généralisation des dépassements d’honoraires.
Quand on parle de « déserts médicaux », on pense spontanément à l’absence de médecins sur certains territoires. Pour les médecins spécialistes, la réalité est plus complexe. La difficulté d’accès ne tient pas seulement à la distance à parcourir, mais aussi au temps nécessaire pour obtenir un rendez-vous et au coût restant à la charge du patient, notamment en raison des dépassements d’honoraires.
Ainsi, selon une étude de la direction de la recherche, des études, de l’évaluation et des statistiques (Drees) du ministère de la santé, 4,7 % des médecins généralistes exerçaient en secteur 2 (avec droit à dépassement d’honoraires) en 2021, contre 51,7 % pour les médecins spécialistes.
À lire aussi : Faut-il recourir à l’immigration pour lutter contre les déserts médicaux ?
Distance, temps d’attente et coût : les trois dimensions de la désertification médicale
Autrement dit, la désertification médicale des spécialistes doit être appréhendée sous trois dimensions : la distance, le temps d’attente et le coût.
Ces difficultés d’accès ont des conséquences directes sur le renoncement ou le report de soins. Une enquête nationale, portant sur 158 032 répondants analysés, montre que 25,4 % des personnes interrogées déclarent avoir renoncé ou reporté au moins un soin au cours des douze derniers mois. Les consultations de spécialistes figurent parmi les soins les plus concernés, en particulier en ophtalmologie, gynécologie et dermatologie.
Les raisons invoquées recoupent précisément ces trois dimensions : le reste à charge, la difficulté à obtenir un rendez-vous et, plus marginalement, les problèmes de mobilité.
Une accessibilité géographique très inégale
La première dimension est la plus visible : celle de la répartition des spécialistes. Mais compter le nombre de médecins dans un département ne suffit pas. C’est pour cela que la Drees et l’Institut de recherche et documentation en économie de la santé (Irdes) ont développé l’indicateur d’accessibilité potentielle localisée (APL) qui mesure, à une échelle communale, l’adéquation entre l’offre et la demande de soins. Cet indicateur tient compte de la proximité des professionnels, de leur activité effective et des besoins de la population locale, qui varient selon l’âge.
Une récente étude de l’Irdes, qui a porté sur les cardiologues, dermatologues et ophtalmologistes, montre que, dans la plupart des départements, l’accès aux soins se concentre autour d’un pôle urbain, souvent la préfecture, puis se dégrade à mesure que l’on s’en éloigne.
Dans certains territoires, comme la Creuse et l’Indre pour l’ophtalmologie, ou encore la Nièvre et la Lozère pour la dermatologie, l’accessibilité reste faible sur une large partie du territoire.
La situation n’est toutefois pas la même selon les spécialités : les cardiologues sont globalement mieux répartis que les dermatologues et les ophtalmologistes. Parler « des spécialistes » au global masque donc des réalités très différentes d’une discipline à l’autre.
Aujourd’hui, il est encore difficile de suivre précisément l’évolution de l’accessibilité géographique aux médecins spécialistes, du fait de l’absence de données annuelles systématiques pour l’ensemble des spécialités.
Un temps d’attente en augmentation structurelle
La deuxième dimension est plus difficile à mesurer, mais tout aussi importante : le temps d’attente. Avoir un spécialiste à une distance raisonnable ne garantit pas qu’on puisse le consulter rapidement.
En 2018, une enquête de la Drees montrait que les délais moyens dépassaient deux mois pour les ophtalmologues et les dermatologues, et restaient supérieurs à un mois pour les cardiologues, les rhumatologues et les gynécologues.
Cette enquête soulignait également le fait que les délais étaient plus longs dans les communes dans lesquelles l’accessibilité géographique était déjà faible. Les territoires où l’offre est rare sont souvent aussi ceux où l’attente est la plus longue.
Des données plus récentes suggèrent que cette tension persiste, voire s’aggrave, pour certaines spécialités. Le baromètre FHF/Ipsos BVA, publié en mars 2026, fait état de délais moyens déclarés de quatre mois et demi pour un dermatologue, de plus de trois mois pour un cardiologue et d’environ deux mois pour un gynécologue. Seule l’ophtalmologie semble connaître une légère amélioration, tout en restant à un niveau élevé (de l’ordre de deux mois et trois semaines, en moyenne).
Enfin, une étude menée par la Fondation Jean-Jaurès, à partir des rendez-vous obtenus auprès de dix professions médicales et paramédicales durant l’année 2023 sur la plateforme en ligne Doctolib, éclaire la géographie de ces délais. En Île-de-France, dans plusieurs départements littoraux méditerranéens, atlantiques et départements accueillant de grands pôles urbains et universitaires, l’attente est généralement plus courte. À l’inverse, elle s’allonge dans une partie de la France, souvent plus rurale et plus éloignée des grands centres hospitaliers.
Le rapport identifie ainsi 14 départements, décrits comme « en difficulté », dans lesquels les délais médians sont au moins deux fois supérieurs à la moyenne nationale pour au moins trois professions : le Gers, la Saône-et-Loire, la Nièvre, le Territoire de Belfort, le Loiret, le Cher, les Deux-Sèvres, l’Ardèche, l’Eure, le Calvados, la Manche, la Loire-Atlantique, les Côtes-d’Armor et le Pas-de-Calais.
Les écarts sont particulièrement marqués en ophtalmologie, en dermatologie et en pédiatrie, avec plus de 90 jours d’écart entre les départements où l’attente est la plus courte et ceux où elle est la plus longue.
Les montants à la charge des patients et les dépassements d’honoraires des médecins
La troisième dimension est plus rarement intégrée au débat public, alors qu’elle change profondément l’accès aux soins : l’accessibilité financière. La présence d’un spécialiste sur un territoire ne garantit pas que sa consultation soit réellement accessible à tous.
Selon le dernier rapport du Haut Conseil pour l’avenir de l’assurance-maladie (HCAAM), les dépassements d’honoraires des médecins spécialistes ont atteint 4,3 milliards d’euros en 2024, en augmentation de 27 % depuis 2019 (la très large majorité des dépassements d’honoraires étant le fait des médecins spécialistes, et non des généralistes).
Cette progression reflète aussi une transformation structurelle de l’offre : plus de la moitié des spécialistes libéraux exercent désormais en secteur 2 dit « à honoraires libres », donc avec droit à dépassement d’honoraires (Figure 4). Mais cette moyenne recouvre de fortes différences entre spécialités. À partir des données de l’assurance-maladie, on peut calculer qu’en 2024, environ 77,5 % des gynécologues libéraux étaient en secteur 2, contre 30,5 % des cardiologues. Et la progression du secteur 2 est nette dans l’ensemble des spécialités observées.
Là encore, la géographie compte. En analysant les données présentées dans le rapport du HCAAM, on en conclut que la part des médecins en secteur 2 est beaucoup plus élevée dans certains départements urbains et aisés, comme Paris, le Rhône ou les Alpes-Maritimes, que dans d’autres territoires, comme les Alpes-de-Haute-Provence, l’Aude ou la Haute-Marne. Cela signifie qu’un département peut sembler correctement doté en spécialistes sur le papier, tout en restant difficile d’accès pour les patients les plus modestes.
L’étude de l’Irdes montre, d’ailleurs, que les dépassements d’honoraires renforcent les inégalités sociales d’accès aux médecins spécialistes. Un rapport de la Drees propose de visualiser ces écarts à travers la carte du reste à charge (RAC) moyen par patient après remboursement de l’assurance-maladie en 2018.
Changer de regard sur les déserts médicaux
Pour les médecins spécialistes, la désertification médicale ne peut donc pas être réduite à une simple question de sous-densité. Elle résulte de trois inégalités qui se cumulent sans toujours se confondre : une offre mal répartie, des délais d’attente très inégaux et des barrières financières parfois décisives.
Cela explique aussi pourquoi les réponses publiques centrées sur le nombre de médecins ou leur lieu d’installation ne suffisent pas. La vraie question n’est pas seulement : combien de spécialistes y a-t-il dans un territoire ? Elle est plus concrète : peut-on les consulter dans un délai raisonnable, à un coût supportable et sans devoir parcourir une distance dissuasive ? Tant qu’on ne posera pas le problème dans ces termes, on continuera à sous-estimer ce que vivent réellement les patients.
Benjamin Montmartin ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
17.06.2026 à 17:42
Solitudes en France : les origines politiques et sociales du « problème »
Sylvain Bordiec, Directeur-adjoint du laboratoire Cultures et Diffusion des Savoirs (CEDS), Université de Bordeaux
Texte intégral (2034 mots)
Présentée au cours de l’histoire tour à tour comme une déviance ou comme un espace de ressourcement, la solitude est devenue depuis les années 2000 un problème public dont s’emparent les politiques. Mais lorsque l’on parle de restaurer le lien social, n’occulte-t-on pas les inégalités profondes dans lesquelles la montée de l’isolement trouve son origine ?
Le 11 mai dernier, installée en présence de la presse dans un PMU de Loos-en-Gohelle, commune du Pas-de-Calais, Marine Tondelier, secrétaire nationale des Écologistes et candidate déclarée à l’élection présidentielle de 2027, a annoncé vouloir faire de la solitude un thème central de sa campagne.
D’où vient cette intention, sachant que, avant de constituer un potentiel domaine d’intervention publique, la solitude a surtout été appréhendée par les autorités, comme une déviance individuelle passible de sanctions ? Comment la solitude est-elle devenue un problème public ? Par ailleurs, la manière dont ce problème est présenté officiellement permet-elle de bien en cerner les origines ?
Pour le savoir, il faut examiner le temps court des alertes et des mesures de la solitude, du début des années 2000 à aujourd’hui, et comprendre comment il s’articule avec le temps long de la solitude comme caractéristique de la « société des individus », laquelle trouve son origine, selon le sociologue Norbert Elias, dans le passage du Moyen Âge à l’Époque moderne.
L’écho des alertes
Durant l’été 2003, la France hexagonale est frappée par une canicule précipitant le décès de 15 000 personnes – une majorité de personnes âgées – et nécessitant l’enterrement dans le carré des « indigents » de Thiais (Val-de-Marne) des Parisiens dont le corps n’avait pas été réclamé par leur famille. L’événement montre à tous que l’on peut mourir, en pareilles circonstances, par défaut d’entourage social et d’accompagnement institutionnel.
Un an plus tard, exprimant une certaine volonté politique de tirer les leçons de cette catastrophe, le rapport remis au premier ministre par Christine Boutin, alors députée Union pour un mouvement populaire (UMP) des Yvelines, et intitulé « Pour sortir de l’isolement. Un nouveau projet de société » est publié : il établit le caractère global du « problème » et formule un ensemble de recommandations. L’une des répercussions notables du rapport est le lancement de « Mona Lisa », la Mobilisation nationale contre l’isolement des âgés, laquelle vise à enrôler des bénévoles dans des missions de visites.
En 2010, le « problème » bénéficie d’un nouveau coup de projecteur politique lorsque le premier ministre François Fillon récompense l’engagement du collectif associatif Pas de solitude dans une France confraternelle, en lui attribuant le label de grande cause nationale pour l’année 2011. Puis, en 2020, surgit la crise du Covid-19 : en venant raviver les souvenirs des détresses de solitude que mit en évidence la canicule de 2003, cette crise relance le débat public sur le phénomène.
Le poids des mesures
Depuis le rapport Boutin, nombre de travaux mobilisent l’indicateur d’isolement relationnel conçu à la fin des années 1990 par des chercheurs de l’Insee. Il consiste en une mesure des solitudes établie « à partir du nombre de conversations à caractère personnel d’une durée supérieure à cinq minutes que les personnes déclarent avoir eues au cours de la semaine (par convention, sont considérées isolées sur le plan relationnel les personnes ayant quatre interlocuteurs ou moins par semaine) ».
Le présent indicateur permet notamment de montrer, en 2003, que « deux groupes sociaux sont particulièrement touchés : les personnes âgées et les personnes socialement défavorisées ». Ces mesures de l’expérience de la solitude s’articulent à la mesure du sentiment de solitude, que les individus soient objectivement seuls ou non. À la faveur de cette double attention pour les pratiques et les représentations, le terme générique de solitudes, sorte de synthèse de ces deux dimensions, s’impose peu à peu pour désigner le « problème ».
En parallèle, des organisations privées impliquées dans l’action contre la solitude s’emploient aussi à (faire) produire des statistiques. Ainsi paraît, en 2010, la première étude annuelle sur les « solitudes en France » de la Fondation de France. Celle-ci indique qu’environ 4 millions de personnes de plus de 15 ans sont touchées par l’« isolement relationnel ».
L’ensemble de ces travaux statistiques établit qu’au fil des ans il y a toujours davantage, sinon de personnes sans personne, tout au moins de personnes frappées d’un sentiment de solitude. La mesure des effets de la solitude est aussi accomplie, pointant alors les dangers pour la santé physique et la santé mentale qu’elle induit. Et des études jusqu’ici principalement conduites à l’étranger font état des dangers que le « problème » fait courir à la cohésion sociale et à la démocratie.
C’est d’ailleurs dans le cadre d’un mouvement d’intérêt international pour celui-ci que l’Organisation mondiale de la santé (OMS) désigne la solitude, en 2024, comme un problème mondial de santé publique.
Événements de nature dramatique relayés par les médias, mesures statistiques et annonces officielles contribuent à donner une assise politique et sociale au « problème ». Mais pour comprendre son origine véritable, l’examen de ses fondements historiques est aussi nécessaire.
Le temps long de la construction du « problème »
Le « problème » trouve son origine dans la longue histoire de l’individualisme, laquelle doit beaucoup, comme le soutient le sociologue Norbert Elias, à la différenciation des fonctions sociales au sein des « sociétés développées » gouvernées par des États centralisés. Selon un paradoxe apparent, ces processus conduisent les individus à s’envisager « comme […] des monades sans fenêtres, des “sujets” isolés ».
Avec cette vision du monde, on touche à un ressort crucial du « problème de la solitude », étant donné que les individus sont devant elle inégaux : tandis que les unes et les uns possèdent les ressources pour trouver leur bonheur dans la rupture (apparente) avec le social, norme dominante construite par les catégories dominantes, celles et ceux dépourvus de ces ressources sont comme condamnés à vivre une « solitude négative », révélatrice et créatrice de difficultés et de souffrances.
À lire aussi : Personnes âgées : contre l’isolement et la « mort sociale », des politiques publiques à réinventer ?
Dans la période contemporaine, l’action de l’État est prépondérante dans cette assignation, d’où l’importance, aussi, de considérer que le « problème » a partie liée avec d’autres problèmes publics et leur traitement politique.
L’impact de l’action politique et publique
La matrice idéologique de ce traitement est le néolibéralisme tel qu’il fut imaginé à la fin des années 1920. Celui-ci place les individus en compétition les uns avec les autres, du début jusqu’à la fin de la vie, présente une dimension autoritaire et conservatrice particulièrement délétère pour les minorités (sexuelles, ethno-raciales, individus handicapés), et favorise l’épanouissement d’un « capitalisme numérique » qui recompose les interactions sociales.
Le néolibéralisme incline ainsi les pouvoirs au choix des inégalités et au renforcement des injustices spatiales, à l’installation, également, du chômage de masse, et aux mots d’ordre de la restriction des dépenses publiques à caractère social et sanitaire… : autant d’orientations engendrant des « coupures sociales » posant problème.
Qui plus est, même lorsqu’ils semblent s’employer à atténuer les incidences néfastes du néolibéralisme sur les vies, les pouvoirs continuent encore à consolider l’édifice des solitudes « à problèmes ». Un exemple remarquable est l’allongement de la vieillesse. Symbole du progrès médical et de la protection sociale, l’avènement du « troisième âge », puis du « quatrième âge », constitue aussi, à mesure que les membres de l’entourage disparaissent ou s’éloignent, un générateur de solitude, puisque la société ne garantit pas à ses membres la sociabilité minimale capable d’éviter aux individus, d’une part, le sentiment de ne plus intéresser personne et, d’autre part, le fait d’être littéralement oublié du monde.
Dans ce contexte, les encouragements officiels au développement du « pouvoir d’agir », de sorte que les individus reprennent le contrôle sur leur existence, à l’épanouissement du « lien social » à travers l’engagement bénévole auprès des individus considérés comme souffrant de la solitude, et à la multiplication des tiers-lieux, censés permettre à quiconque de trouver, notamment dans le cadre du travail indépendant, des foyers de sociabilité, apparaissent à la fois dérisoires et salutaires.
Dérisoires parce que ces mots d’ordre politique et les initiatives locales et ponctuelles qui en émanent sont la plupart du temps impuissants à transformer les vies des individus. Salutaires parce que ces discours et ces actions offrent néanmoins à celles et ceux qui les écoutent et en bénéficient une attention de nature, sinon à renouer avec une « vie sociale » moins éloignée des normes dominantes, tout au moins à trouver des ressources rendant les solitudes supportables.
Le « problème de la solitude », autrement dit le problème des solitudes qui posent problème, peut s’éclairer d’abord à la lumière de l’attention politique qui semble lui être portée, à condition de le réinscrire dans l’histoire de l’individualisme qui commande, in fine, les ressorts et les expressions concrètes de cette attention.
Pour l’heure, car il se limite essentiellement à des alertes officielles et à des soutiens symboliques aux forces associatives, l’intérêt politique pour ce problème se condamne à rester quasiment sans effets sur le partage inégal de la solitude « positive » et des « richesses de sociabilité ». Les expressions de cet intérêt révèlent ce dont la solitude « à problèmes » est le nom véritable : la construction politique d’une société divisée entre les individus sachant être à la fois seuls et connectés socialement et les autres, incapables de faire ces mouvements entre solitudes épanouissantes et connexions avec autrui.
Sylvain Bordiec a reçu des financements de l'ANR pour le projet AMAP (Précarité alimentaire)
17.06.2026 à 17:41
De la détention administrative à la peine de mort : l’évolution d’un droit d’exception israélien
Romain Lucas, PhD candidate in political science, Sciences Po Lyon; Université Laval
Texte intégral (2863 mots)
Depuis le 7 octobre 2023, Israël a fortement intensifié le recours à la détention des Palestiniens, en s’appuyant sur un arsenal juridique ancien fondé sur l’exception sécuritaire. Les ONG et l’ONU dénoncent une multiplication des détentions sans procès, des conditions d’emprisonnement assimilées à de mauvais traitements ou à de la torture ainsi qu’un affaiblissement des garanties judiciaires. L’adoption en mars 2026 d’une loi instaurant la peine de mort pour certains actes de terrorisme marque une nouvelle étape dans l’évolution du système carcéral et alimente les inquiétudes sur la trajectoire du régime israélien.
Les pratiques d’enfermement constituent un révélateur privilégié de ce qu’est un État : comment il use du droit, de la force, et comment il traite les populations qu’il domine. Depuis les attaques du 7 octobre 2023, le recours israélien à la détention des Palestiniens s’est considérablement intensifié, jusqu’à l’adoption, le 30 mars 2026, de la « Loi sur la peine de mort pour les terroristes ».
Cette mesure, qui a conduit plusieurs organisations de défense des droits humains et chancelleries européennes à tirer la sonnette d’alarme, s’inscrit dans la continuité d’un système juridique et administratif bien plus ancien, fondé sur un droit d’exception qui n’a plus rien d’exceptionnel.
L’évolution prévisible d’un arsenal juridique préexistant
L’ampleur de la détention des Palestiniens depuis 2024 n’a pas surpris ceux qui observent ce système depuis longtemps. En 2021, l’anthropologue et historienne française Stéphanie Latte Abdallah publie un ouvrage de référence sur la question. Bien avant le tournant du 7 octobre 2023, elle y restitue les récits de détenus qu’elle a rencontrés, les procès auxquels elle a assisté, et décrit ce qu’elle qualifie de « toile carcérale » tissée autour des Palestiniens. Cette toile repose sur une « définition floue, atemporelle et virtuelle des délits » qui enserre une population entière : un peu moins de la moitié des hommes palestiniens passeront par la prison au cours de leur vie.
La question carcérale figurait déjà parmi les enjeux centraux des négociations d’Oslo, au début des années 1990, sans jamais trouver de réponse satisfaisante. Il y a près de vingt ans, l’historien Ilan Pappe, l’une des figures du courant des « nouveaux historiens » israéliens (groupe informel d’historiens qui remettent en cause, à partir des années 1980, l’historiographie de l’État israélien et ses mythes fondateurs), proposait une lecture structurelle du phénomène. Pour lui, Israël fonctionnait comme un Mukhabarat State, de l’arabe mukhabarat (renseignement) soit, par extension, un État fondé sur la surveillance et le contrôle.
Cette lecture éclaire une symétrie troublante : la privation collective de liberté que subissent les Palestiniens dans les territoires occupés trouve son prolongement dans la privation individuelle éprouvée par ceux que le système carcéral entraîne dans son engrenage. Les deux dimensions d’un même système se répondent. Ce que l’on observe depuis octobre 2023 n’est donc pas une rupture, mais le déploiement prévisible d’un arsenal juridique progressivement construit.
La détention est une étape par laquelle doivent passer de très nombreux Palestiniens, principalement les hommes et les jeunes garçons, dès l’adolescence. Entre 20 et 40 % des Palestiniens seront détenus un jour dans leur vie. Depuis des décennies, l’État israélien dispose d’un outillage juridique d’envergure conçu et pensé pour encadrer l’administration des Palestiniens. La détention administrative en est une des pièces maîtresses.
La détention administrative est, selon les termes de l’ONG israélienne B’Tselem, « une incarcération sans procès ni inculpation, fondée sur l’allégation qu’une personne projette de commettre une infraction ». Elle correspond aussi à la réalité juridique du système pénal en vigueur dans les territoires occupés, celui d’une justice militaire et d’enquêtes menées par les services de renseignement, où la preuve et l’équité sont bafouées par le caractère sécuritaire et secret.
Derrière une ordonnance de détention administrative se trouve, dans la quasi-totalité des cas, un dossier instruit par le Shin Bet (Shabak), le service de sécurité intérieure israélien. C’est lui qui produit les « preuves secrètes » sur lesquelles le juge militaire s’appuie, sans que ni le détenu ni son avocat ne puissent en contester le contenu.
Le nombre de ces détentions a été multiplié par deux depuis octobre 2023. Mais la détention administrative existe avant cette date. Héritée du droit d’urgence britannique du mandat colonial (1920-1948), elle permet de détenir tout individu sur la base de « preuves secrètes » que ni le détenu ni son avocat ne peuvent consulter. C’est, par définition, l’antithèse du procès équitable.
Une autre catégorie est particulièrement importante et s’est elle aussi redéveloppée depuis presque trois ans : celle des « combattants illégaux ». Le statut de « combattant illégal » est issu d’une loi de 2002, largement tombée en désuétude avant octobre 2023. Invoquée pour la première fois en cinq ans après le 7 Octobre, elle sert dans un premier temps à détenir des personnes soupçonnées d’avoir participé aux attaques. Elle a rapidement été élargie pour servir à la détention massive de Gazaouis – sans inculpation ni procès –, selon plusieurs ONG.
En décembre 2023, le Parlement israélien (Knesset) en a durci les conditions via un amendement temporaire : la durée de détention sans ordonnance a été portée de 96 heures à 45 jours et le délai avant première comparution devant un juge est passé de 14 à 75 jours. Un allongement des délais pour un recul du droit. Amnesty International recueillera le témoignage de nombreux civils, médecins ou journalistes parmi les « combattants illégaux » arrêtés et détenus après l’amendement n°4 de décembre 2023. L’amendement, temporaire, a été reconduit à plusieurs reprises.
Mais l’évolution du régime carcéral n’est pas qu’une réponse aux attaques perpétrées le 7 octobre 2023. Ses manifestations les plus marquantes ne se produisent d’ailleurs pas dans la bande de Gaza mais en Cisjordanie. Dès juillet 2024, l’ONG palestinienne Addameer dénombrait quelque 9 700 prisonniers politiques palestiniens, dont 3 380 en détention administrative. La grande majorité est dans l’attente d’un procès (détention provisoire) ou détenue administrativement (sans charge pénale). La grande majorité est aussi issue de Cisjordanie.
L’autre particularité qu’il faut aussi mentionner est l’implication de l’Autorité palestinienne (entité gouvernementale en charge de l’administration des Palestiniens en Cisjordanie) dans cette extension et dans l’évolution du régime carcéral israélien. L’Autorité assume et prend en charge une partie de l’effort carcéral, en collaboration quotidienne avec l’État israélien.
« Bienvenue en enfer » : ce que disent les ONG
En août 2024, B’Tselem publie un rapport sur la détention des Palestiniens : « Welcome to Hell » (« Bienvenue en enfer »). Fondé sur les témoignages de dizaines de Palestiniens relâchés – dont plus de la moitié sont de Cisjordanie –, le document décrit de manière systématique ce que ses auteurs qualifient de « réseau de camps de torture ». Violences physiques répétées, humiliations, positions de contrainte prolongées, privation de nourriture, absence d’hygiène, refus de soins médicaux, agressions sexuelles, les témoignages convergent, en provenance de multiples centres de détention militaires et civils.
Le camp militaire de Sde Teiman, dans le Néguev, est devenu le symbole de ces conditions. Partiellement reconverti en centre de détention après l’adoption de l’amendement n°4 sur les combattants illégaux (décembre 2023), il héberge des détenus maintenus les yeux bandés et menottés dans des enclos grillagés.
En juillet 2024, un prisonnier palestinien y a été hospitalisé avec des blessures graves à l’abdomen compatibles avec une agression sexuelle. Neuf réservistes de Tsahal, dont un officier, ont été mis en cause. L’affaire a déclenché une crise politique inédite en Israël : des parlementaires d’extrême droite ont forcé l’entrée du camp pour s’opposer aux arrestations, avec le soutien public du ministre de la sécurité nationale Itamar Ben Gvir. En mars 2026, le prisonnier a été libéré de sa détention et renvoyé à Gaza pour permettre aux cinq soldats d’éviter un procès.
« La torture est “de facto” devenue une politique d’État » : ce que dit l’ONU
Les organisations internationales sont parvenues à des conclusions convergentes. En septembre 2025, le Bureau des droits de l’homme des Nations unies dans les Territoires palestiniens occupés (OHCHR) publie un rapport documentant au moins 75 décès de Palestiniens en détention israélienne depuis le 7 octobre 2023.
Le rapport onusien recense des pratiques documentées : coups répétés, simulacres de noyade, positions de contrainte, violences sexuelles, privations de nourriture et d’eau, refus de soins médicaux pour des pathologies préexistantes. Il note également le refus d’Israël d’appliquer une décision de sa propre Haute Cour de justice (Bagatz), rendue en septembre 2025, ordonnant d’améliorer l’approvisionnement alimentaire des détenus.
En août 2024, des experts indépendants mandatés par l’ONU ont alerté publiquement :
« L’utilisation généralisée et systématique par Israël de la torture contre les détenus palestiniens, et ses pratiques d’arrestation arbitraire sur des décennies, couplées à l’absence de tout garde-fou depuis le 7 octobre 2023, brossent un tableau alarmant sous couvert d’une impunité totale. »
Extension et systématisation de la peine de mort : ce que dit la loi israélienne
Le véritable tournant, ou sans doute le plus symbolique, est législatif. Le 30 mars 2026, la Knesset a adopté, par 62 voix contre 48, une loi portée par le parti d’Itamar Ben Gvir instaurant la peine de mort pour certains actes de terrorisme meurtrier.
En surface, le texte est universel : il s’applique à « toute personne » ayant intentionnellement causé la mort « dans le but de mettre fin à l’existence de l’État d’Israël ». Mais sa mécanique interne est discriminatoire.
En faisant de l’atteinte à l’existence de l’État d’Israël un critère déterminant, la loi restreint son application aux auteurs perçus comme des ennemis de l’État, excluant ainsi presque systématiquement les auteurs juifs israéliens.
Plus encore, pour les Palestiniens de Cisjordanie, jugés devant des tribunaux militaires, la loi prévoit que la qualification terroriste d’un homicide entraîne la peine capitale par défaut, sans que ni le procureur ni le représentant du parquet militaire n’aient à la requérir. La mort devient le point de départ, non l’exception. Une fois la peine de mort prononcée, elle ne peut être ni réduite ni commuée et doit être exécutée dans les 90 jours suivant le jugement définitif.
Le texte franchit en outre une ligne que certains juristes israéliens ont soulignée : la Knesset légifère désormais pour la Cisjordanie, territoire soumis au droit militaire et non à la souveraineté israélienne. Le Times of Israël, dans un éditorial juridique, a qualifié ce glissement d’« inconstitutionnel » et de rapprochement de facto d’une annexion formelle, en ce qu’il contourne l’autorité du commandement militaire, juridiquement seule autorité souveraine en Cisjordanie.
Berlin, Londres, Paris et Rome avaient conjointement appelé la Knesset à renoncer au projet, estimant qu’il risquait de « remettre en cause les engagements d’Israël en matière de principes démocratiques ». Le Conseil de l’Europe a évoqué un « grave recul ». Une déclaration conjointe d’Amnesty International, Human Rights Watch et d’autres grandes ONG a demandé à l’UE des mesures urgentes, rappelant que la Cour internationale de justice avait déjà, dans son avis consultatif de juillet 2024 sur l’occupation israélienne, jugé contraires au droit international certaines pratiques discriminatoires visant les Palestiniens.
De l’enfermement des Palestiniens à la dérive du régime
En résumé, il serait inexact de présenter ce qui se passe comme une rupture totale avec le passé ou comme un droit d’exception dans un contexte particulier. Certains mécanismes juridiques se sont renforcés depuis près de trois ans. L’adoption en mars 2026 d’une loi sur la peine capitale ciblant particulièrement les Palestiniens semble aller en ce sens. Mais l’évolution du régime carcéral doit nous inviter à penser l’évolution du régime dans son ensemble, dans un contexte progressif d’autocratisation.
Les grands instituts (V-Dem, Freedom House) alertent à ce sujet et notent le déclassement israélien, non seulement pour son régime d’occupation et de détention des Palestiniens mais, plus généralement, pour un recul et un affaiblissement des contre-pouvoirs. Les oppositions à la réforme du système judiciaire dès janvier 2023 témoignent d’une dérive qui ne naît pas d’une situation exceptionnelle. Les pratiques autoritaires à l’œuvre dans la détention des Palestiniens ne sont pas des exceptions contenues, elles signalent une dérive profonde du régime dans son ensemble.
Le cas israélien invite peut-être à une conclusion qui le dépasse. L’évolution d’un régime carcéral constitue un indicateur privilégié de l’évolution du régime politique dans son ensemble. Les transformations des pratiques d’incarcération, des statuts de détention et des garanties procédurales ne sont pas de simples ajustements techniques mais donnent à voir les mutations profondes du rapport entre coercition, droit et pouvoir. C’est précisément ce que Foucault, Garland et d’autres théoriciens du carcéral nous ont appris à analyser.
La citation généralement attribuée à Dostoïevski conserve, dans ce cadre, toute sa valeur heuristique : « Nous ne pouvons juger du degré de civilisation d’une nation qu’en visitant ses prisons. » Elle rappelle que l’enfermement n’est jamais un objet marginal : il est, pour qui accepte de le regarder, l’un des révélateurs les plus sûrs de ce qu’un État fait du droit et de ceux qu’il gouverne.
Romain Lucas a reçu des financements de l'Université Laval.
17.06.2026 à 17:40
Sommes-nous les parents de nos chiens ou de nos chats ?
Émilie Dardenne, Professeure des universités, Université Rennes 2
François-Xavier Roux-Demare, Maître de conférences en Droit privé et sciences criminelles., Université de Bretagne occidentale
Texte intégral (2409 mots)


La France compte 79,8 millions d’animaux de compagnie, parmi lesquels on trouvera quelque 33 millions de poissons, presque 17 millions de chats, 10 millions de chiens. Mais quels liens nous unissent à ces êtres qui partagent notre quotidien ? Font-ils partie de notre famille ? Sont-ils nos enfants ?
C’est l’un des questionnements qu’abordent la chercheuse en études animales Émilie Dardenne et le juriste François-Xavier Roux-Demare dans le Que sais-je consacré aux animaux de compagnie. En voici plusieurs extraits.
L’enquête Ipsos–Santévet de 2025 montre que les animaux de compagnie, en particulier les chats et les chiens, occupent une place centrale dans la vie des Françaises et des Français. Pour 67 % d’entre eux, il est impossible d’envisager une relation amoureuse avec quelqu’un qui n’aime pas les animaux.
L’attachement se manifeste aussi dans la vie quotidienne : beaucoup adaptent leurs loisirs (55 %), et certains iraient jusqu’à changer de partenaire pour leur animal (22 %). Les jeunes générations semblent particulièrement investies : les 18-24 ans déclarent être prêtes et prêts à adapter leur travail, leurs loisirs ou leur lieu de vie pour le bien-être de leur animal.
Un membre de la famille pour deux tiers des Français
Ces résultats peuvent être interprétés comme l’indice d’une dynamique zooinclusive en construction, dont le caractère inédit à l’échelle historique demande néanmoins à être étayé. Les Françaises et les Français considèrent largement leur compagnon comme un membre de la famille (69 %), voire comme un enfant ou un meilleur ami. Il est célébré à Noël ou à son anniversaire, et près d’un tiers le laisse dormir dans leur lit.
L’étude constitue un indice de transformation des mentalités : l’animal joue un rôle affectif majeur, souvent comparable à celui d’un proche humain. L’enquête suggère que la relation des Françaises et des Français à leurs animaux de compagnie devient de plus en plus intime et émotionnelle. Plus d’un tiers considère leur compagnon non humain comme leur enfant, un chiffre encore plus élevé chez les femmes (42 %) et particulièrement chez les 35-44 ans, où il atteint 46 %.
Ce lien intime, « filial », est revendiqué par nombre de propriétaires, qui évoquent un attachement comparable à celui d’un parent pour son enfant. Les bénéfices perçus en matière de santé mentale sont également massifs : 95 % des propriétaires disent que leur compagnon améliore leur bien-être. Les chiens, en particulier, procurent un sentiment de sécurité (69 %).[…]
Une relation aux bénéfices multiples
Si les bénéfices obtenus par la vie partagée avec un animal de compagnie n’excluent pas certains risques sanitaires, comme la rage ou la toxoplasmose, cette relation procure plusieurs avantages physiologiques : elle favorise la diminution de l’anxiété, de la tension artérielle et du risque cardiaque. Les sorties favorisent en outre la mobilité et augmentent la probabilité d’entamer des conversations avec d’autres personnes humaines, elles-mêmes en promenade avec leur chien ou bien attirées par l’animal (mais aussi, parfois, agacées par sa présence et le risque de morsure ou de déjections laissées sur l’espace public).
Les animaux de compagnie fournissent à leurs hôtes humains une forme de « sécurité ontologique » dans une époque d’éclatement des valeurs et des institutions traditionnelles. La sécurité ontologique (concept sociologique formulé par Anthony Giddens) est le sentiment fondamental de stabilité et de continuité qui permet à une personne de se sentir en sécurité dans le monde. Elle repose sur des routines rassurantes, des relations fiables et une identité cohérente.
Les animaux de compagnie contribuent à cette sécurité en offrant une présence stable et prévisible à leurs gardiennes et gardiens, en participant à la création de routines et de rituels quotidiens (promenades, repas, soins), en procurant une base affective sûre, sans jugement ni rupture, et en renforçant le sentiment d’être utile, reconnu et aimé. Ainsi, les animaux de compagnie semblent favoriser un sentiment de sécurité ontologique et apporter un sens à la vie de leurs humaines et de leurs humains.
D’où vient cet attrait ?
Les animaux exercent une forte influence sur le bien-être humain pour des raisons à la fois biologiques et évolutionnaires. Selon l’hypothèse de la biophilie d’Edward Wilson, les êtres humains et une partie des animaux non humains sont instinctivement attirés les uns vers les autres, ce qui favorise des relations bénéfiques. Pour Homo Sapiens, cette attirance s’exprime surtout envers des animaux perçus comme « mignons ». La théorie évolutionniste propose que l’intérêt humain pour les autres animaux découle de notre histoire évolutive : pendant des millénaires, notre survie a dépendu d’eux pour la chasse, la protection, le transport, l’élimination de ceux qui sont considérés comme nuisibles. Ainsi, les relations anthropozoologiques ont présenté un coût faible par rapport aux bénéfices importants qu’elles procuraient.
Une relation hybride
Une récente étude hongroise fondée sur une approche multidimensionnelle de la relation entre le chien et sa ou son propriétaire a mis ce lien en comparaison avec quatre types distincts de liens humains : le lien familial, le lien au sein du couple, le lien amical et la relation parent- enfant. Il a été montré que la relation entre un chien et sa ou son propriétaire présente des niveaux élevés de satisfaction, de soutien et de compagnie, ainsi qu’un faible degré d’interactions négatives, comparativement à la plupart des relations humaines. Cette relation est hybride : elle combine des traits de la relation parent-enfant et de l’amitié intime.
L’étude signale en outre que cette relation interspécifique repose sur une dynamique de pouvoir plus asymétrique que celle qui préside généralement aux relations humaines, les propriétaires exerçant un contrôle important sur la vie de leur compagnon. En ce qui concerne le chien, on parle aujourd’hui d’une « socialité » avec l’être humain.
La relation est si étroite que le chien se socialise à l’humain, développant une proximité parfois supérieure à celle qu’il entretient avec ses propres congénères, selon les critères des espèces sociales fondés sur la coopération et l’attraction réciproque. […]
Des familles plus qu’humaines
Vivons-nous donc une nouvelle ère où la famille devient plus qu’humaine ? Selon toute vraisemblance, oui. La philosophe Heather Stewart a analysé la pression sociale exercée sur les femmes sans enfants, qui doivent souvent répondre à des questions intrusives comme : « Pourquoi n’as-tu pas encore d’enfants ? »
Ces questions reposent sur des normes de genre profondément ancrées. On attend des femmes qu’elles deviennent mères pour accomplir leur féminité. Les femmes sans enfants sont alors perçues comme de pauvres âmes qui auraient raté leur vie ou comme des égoïstes. Les féministes critiquent ce présupposé, montrant qu’il enferme les femmes dans une vision hétéronormative de la famille et du rôle féminin. Stewart veut cependant éclairer un autre implicite : l’idée que la parentalité ne peut concerner que des enfants humains.
Au contraire, elle soutient qu’il peut être moralement cohérent de se considérer comme parent, même si l’on prend soin au quotidien d’un non-humain. Les liens affectifs et les soins fournis à cet individu peuvent, dans certains cas, correspondre aux relations parent-enfant. Ces liens sont engageants, ils impliquent de l’amour, un attachement et une responsabilité. Beaucoup d’êtres humains reçoivent de leurs compagnons animaux les mêmes sources de sens, de joie et de défis que dans la parentalité humaine. Ces relations sont parfois les plus importantes de la vie de ces personnes.
Stewart défend donc la légitimité morale de la parentalité interspécifique. Elle redéfinit le concept même de parentalité : ce qui fait un parent, selon elle, n’est pas la biologie, ni le fait d’avoir donné naissance à un enfant, c’est l’intention d’assumer le rôle de parent et le travail quotidien de soin qui va avec. Selon cette conception, certaines relations anthropozoologiques peuvent être considérées comme authentiquement parentales.
L’approche défendue par Stewart permet de « queeriser » le concept de famille en ouvrant la parentalité à des formes non normatives et non centrées sur la reproduction biologique ou le couple hétérosexuel. Reconnaître la parentalité interspécifique aurait des implications sociales et politiques : cela contribuerait à élargir la notion de famille, à mieux comprendre les deuils et les attachements en dehors des seules relations humaines, à revoir certaines politiques, notamment celles qui sont liées au logement, aux congés, aux droits des familles.
Des figures parentales ?
Les travaux de John Archer montrent, parmi d’autres, que l’affection humaine pour les animaux de compagnie s’explique par une combinaison de facteur psychologiques, sociaux et évolutionnaires. Archer souligne que s’il est communément admis que les animaux de compagnie jouent parfois le rôle de substituts d’enfants, ils peuvent aussi, à l’inverse, endosser celui de figures parentales. Les chiens, en particulier, sont perçus comme des sources de sécurité. Leur présence rassure, apaise l’anxiété et procure un sentiment de compagnie.
Selon Laura Gillet et Enikő Kubinyi, un mécanisme d’adaptation culturelle pourrait aussi expliquer ce phénomène : sous l’effet des transformations de leur environnement, certains humains auraient redirigé leurs besoins de soin et d’éducation des enfants vers des animaux non humains. Dans les sociétés postindustrielles où les familles comptent moins d’enfants, les animaux de compagnie – surtout les chiens – deviennent des objets majeurs d’affection. Ils s’intègrent facilement aux modes de vie mobiles et rapides. Il est plus simple de les faire voyager. Ils n’ont pas d’obligations scolaires et ils peuvent être cédés ou même « supprimés » si nécessaire. Très sociaux, ils facilitent aussi la sociabilité de leurs propriétaires.
Des relations adaptées aux sociétés postindustrielles
Ainsi, selon Heidi Nast, les animaux de compagnie incarnent des formes d’attachement et de sociabilité particulièrement adaptées aux valeurs et contraintes des sociétés postindustrielles. On compte d’ailleurs désormais des DINKWADs (pour « Double Income, No Kids, With A Dog »), des couples dont les membres touchent chacun un salaire, qui n’ont pas de progéniture humaine mais qui possède un chien.
Pour nuancer cela, citons une étude publiée en 2025, par Jaining Li et Nichol Li, qui a mis en évidence le fait que les propriétaires d’animaux qui s’appuyaient trop fortement sur leurs animaux de compagnie comme substituts aux relations humaines étaient plus susceptibles d’éprouver un sentiment de solitude et un mal-être psychologique.
Émilie Dardenne a reçu des financements de l'Institut universitaire de France.
François-Xavier Roux-Demare ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
17.06.2026 à 17:39
Réduction de la dette publique : La solution pourrait se trouver sous nos pieds
Roberto Brunetti, Maître de conférences en sciences économiques, Université Paris-Panthéon-Assas
Carl Gaigné, Directeur de recherche, Economiste, Inrae
Fabien Moizeau, Professeur des Universités en sciences économiques
Texte intégral (1774 mots)
Que taxe la fiscalité immobilière, finalement ? Ne rate-t-elle pas le principal actif, à savoir le foncier ? Dans quelle mesure une réforme qui reviendrait sur ce point pourrait-elle rapporter des recettes supplémentaires, introduire davantage d’équité, sans produire d’effets pervers ? Soit tout l’inverse de la fiscalité actuelle.
La France s’apprête à vivre une séquence patrimoniale sans précédent : la grande transmission. D’ici à 2040, près de 9 000 milliards d’euros devraient être transférés des générations du baby-boom à leurs héritiers. Ce basculement intervient alors même que les besoins de financement public atteignent des niveaux particulièrement élevés, sous l’effet conjugué du vieillissement démographique, des tensions géopolitiques et de l’urgence climatique.
Dans ce contexte, les impératifs d’efficacité économique et de cohésion sociale plaident pour une fiscalité successorale à la fois juste et efficiente. Le débat est ouvert. Pourtant, un point pourrait faire consensus : la fiscalité applicable à la transmission d’un actif en particulier, le foncier urbain, au croisement d’enjeux économiques et sociaux majeurs.
À lire aussi : Depuis la crise de 2008, la financiarisation du marché de l’immobilier s’est accélérée
La taxation du foncier ne réduit ni l’offre ni l’investissement
La valeur d’un bien immobilier se compose de deux éléments : le foncier et le bâti. Depuis le début du XXIᵉ siècle, la hausse des prix immobiliers s’explique principalement par l’augmentation de la valeur du foncier. En France, le foncier représente, selon l’Insee, environ 6 700 milliards d’euros en 2024, soit environ la moitié du patrimoine immobilier total.
Au-delà de son poids économique, le foncier urbain constitue une richesse singulière. Contrairement à d’autres actifs, la terre n’est pas un bien produit : son prix ne résulte pas d’un effort productif, mais correspond à une rente. Sa valeur dépend largement de facteurs collectifs, tels que la présence d’infrastructures publiques, l’attractivité du territoire ou les politiques locales. Pourtant, les gains qui en découlent sont majoritairement captés par des propriétaires privés.
Dans les territoires urbains les plus attractifs – métropoles, centres-villes, zones bien desservies –, les valeurs foncières ont fortement progressé, permettant aux propriétaires de voir leur patrimoine s’apprécier sans effort. À la différence du bâti, dont la taxation décourage la construction et la rénovation, le foncier ne se crée ni ne se détruit : sa taxation ne réduit ni l’offre ni l’investissement. C’est, selon la littérature économique, l’une des bases fiscales les moins « distorsives » – c’est-à-dire qui n’altère pas les décisions économiques des agents et n’engendre donc pas de perte d’efficacité pour l’économie, contrairement à la plupart des autres impôts.
Une idée de près de cent cinquante ans
Dans cette perspective, il est légitime que l’État récupère, par l’impôt, la rente foncière qu’il contribue lui-même à créer. Cette idée était au cœur de l’ouvrage de l’économiste états-unien Henry George, Progrès et pauvreté, publié en 1879, dans lequel il prônait l’instauration d’un impôt unique sur la rente foncière destiné à remplacer les autres impôts. Exactement cent ans plus tard, en 1979, les économistes Richard Arnott et Joseph Stiglitz ont formalisé cette idée dans ce qui sera baptisé le « théorème de Henry George ». Ils y montrent que l’imposition des rentes foncières constituait un moyen efficace de financer les dépenses publiques.
Pourtant, cette « grande transmission » soulève une question fondamentale : comment adapter le théorème de Henry George à un monde où une grande partie de la richesse immobilière est héritée ? En effet, environ 50 % des héritages et des donations impliquent un bien immobilier, ce qui souligne le rôle central du foncier urbain dans la formation et la transmission de richesse. Dans les mots de Winston Churchill :
« La terre […] n’est pas le seul monopole, mais c’est de loin le plus grand des monopoles – c’est un monopole perpétuel, et c’est la mère de toutes les autres formes de monopole. »
Double avantage pour certains, verrouillage social pour d’autres
Entre 2001 et 2023, les prix des logements anciens ont été multipliés par 2,5 en France, soit une progression nettement supérieure à celle du revenu disponible brut par ménage (multiplié par 1,6). L’accès à la propriété devient ainsi structurellement plus difficile pour les primo-accédants et, donc, la concentration du patrimoine prend une dimension nouvelle à l’heure où ces actifs changent de mains.
Dans ce contexte, les héritiers dont les parents sont situés dans les zones les plus attractives (souvent les centres des grandes métropoles) cumulent un double avantage : un patrimoine initial élevé et un accès facilité au crédit, qui renforcent leur capacité d’investissement, leur permettant d’habiter dans les zones elles aussi les plus attractives.
À l’inverse, les ménages qui ne reçoivent aucun héritage, ou héritent de biens situés dans des zones en difficulté, restent durablement désavantagés, piégés dans des zones moins attractives. La dimension géographique des inégalités s’en trouve renforcée, au risque d’un véritable verrouillage des positions sociales.
À ce verrouillage géographique s’ajoute une concentration patrimoniale extrême. Or, ces inégalités sont déjà particulièrement marquées dans le domaine immobilier : 10 % des ménages les mieux dotés en patrimoine détiennent plus de 40 % du patrimoine immobilier national, et une grande partie d’entre eux possède plusieurs logements. La « grande transmission » ne fera qu’accentuer ces écarts.
Une fiscalité intergénérationnelle
Cibler la rente foncière au moment de la transmission apparaît comme une piste particulièrement pertinente. Le foncier urbain étant, par nature, un actif intergénérationnel, sa fiscalité devrait donc l’être aussi. En outre, la valeur foncière est en grande partie créée par des investissements publics, ce qui en fait une assiette fiscale légitime. À la différence du capital productif ou financier, le foncier ne peut être ni délocalisé ni dissimulé, ce qui limite fortement les possibilités d’évasion fiscale.
Au-delà de ses effets budgétaires, une telle taxation pourrait également contribuer à modérer les prix du logement. En l’absence d’imposition spécifique de la composante foncière, les héritiers peuvent conserver indéfiniment un bien sans coût fiscal particulier, même s’ils ne l’occupent pas et ne le louent pas. Une taxation de la composante foncière au moment de la transmission change ce calcul : pour s’acquitter de l’impôt, les héritiers sont incités soit à mettre le bien en location, afin d’en tirer un revenu, soit à le céder.
Dans les deux cas, l’offre disponible sur le marché – locatif ou à la vente – s’en trouve accrue, ce qui exerce une pression à la baisse sur les prix. Elle limite également l’intégration, dans les prix immobiliers, d’une valorisation liée à la perspective de transmission à leurs enfants. Ceci rapprocherait ainsi les prix immobiliers de la valeur d’usage des biens.
Multidétenteurs du parc immobilier
Viser la rente foncière lors de la transmission apparaît plus équitable. La taxe foncière pèse aujourd’hui de manière uniforme sur les propriétaires, qu’ils aient hérité de leur bien ou l’aient acquis par leur travail. Dans ce contexte, une taxation spécifique de la composante foncière des transmissions lors de l’héritage se justifie d’autant plus. Elle contribuerait en outre à atténuer les inégalités de patrimoine, nettement plus marquées que celles de revenu. Près de 40 % des ménages ne possèdent pas de biens immobiliers, tandis qu’un quart des ménages, parmi les plus aisés, détient à lui seul près des deux tiers du parc immobilier.
L’enjeu n’est pas seulement redistributif. En mobilisant davantage la rente foncière, il serait possible de générer des effets macroéconomiques positifs. Cela permettrait d’alléger la fiscalité pesant sur les ménages et les entreprises. En freinant l’inflation immobilière, la taxation du foncier urbain inciterait en outre les ménages à diversifier leur patrimoine, orientant davantage l’épargne vers le financement de l’investissement des entreprises.
À l’heure où des montants considérables changent de mains, le foncier urbain apparaît comme une base fiscale à la fois juste et efficiente. Son poids, près de 7 000 milliards d’euros, suggère que le potentiel de recettes associé est, lui aussi, considérable.
Dans un pays où la dette publique dépasse 115 % du PIB, ces recettes nouvelles offriraient une marge de manœuvre budgétaire bienvenue. C’est à cette condition que la grande transmission pourra devenir un levier de cohésion plutôt qu’un facteur de fracture. La solution à nos problèmes pourrait se trouver, en ce sens, sous nos pieds.
Carl Gaigné a reçu des financements de l'ANR.
Fabien Moizeau et Roberto Brunetti ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
17.06.2026 à 17:39
Luxe et traçabilité : peut-on faire rêver et se conformer ?
Benjamin Adam, Doctorant en sciences de gestion et du management, Université de Limoges
Martine Hlady-Rispal, Maître de Conférence, HDR, Sciences de Gestion, Université de Limoges
Texte intégral (1473 mots)
Comment concilier attractivité du secteur du luxe et transparence ? C’est un vrai défi pour les entreprises qui ont longtemps cultivé le secret de leurs approvisionnements et de leurs process de fabrication. Mieux, ils en ont fait un argument commercial pour signifier l’excellence de leurs produits. Cette démarche peut-elle perdurer à l’ère où les consommateurs et les pouvoirs publics demandent davantage de traçabilité notamment ? Le luxe a-t-il les moyens de se transformer sans perdre sa spécificité ?
Sous la pression des pouvoirs publics et des ONG, la transparence des entreprises ne s’arrête plus aux secteurs sensibles comme l’agroalimentaire. Désormais, elle s’étend à l’ensemble des acteurs économiques, ce qui rejoint les attentes des plus jeunes générations consommatrices. Ce double mouvement constitue un défi pour les marques, notamment celles qui adoptent un « positionnement luxe ». En effet, dans ce secteur particulier, cela pose un problème stratégique dans la mesure où le secret fait partie intégrante de leur storytelling.
À lire aussi : Pourquoi la conscience pourrait être le prochain atout concurrentiel du luxe
Corporate Sustainability Reporting Directive (CSRD), Digital Product Passport (DPP), loi anti-gaspillage pour une économie circulaire (AGEC)… depuis une dizaine d’années, le législateur agit pour que les entreprises répondent aux enjeux de durabilité, notamment en renforçant la transparence de leurs pratiques.
Aujourd’hui, il ne suffit plus de déclarer être responsable. La transparence demande aujourd’hui de fournir des preuves fiables à travers la collecte d’informations dans l’acquisition des matières premières et la gestion de la production. Et quand bien même certaines entreprises pensent passer au travers des mailles du filet, d’autres parties prenantes comme les ONG ou les jeunes consommateurs sont aujourd’hui les fers de lance pour dénoncer le green ou socialwashing des entreprises.
Le luxe n’y échappe pas. Et c’est pourtant là un problème de marketing majeur pour ces marques qui doivent désormais concilier cette demande de responsabilisation avec la « magie » qu’elles cultivent depuis toujours. Dans une étude publiée récemment, nous démontrons notamment comment l’ensemble des acteurs de la chaîne de valeur de l’industrie du cuir française œuvre pour transformer les obligations de transparence… Ou comment faire d’une menace, une opportunité venant renforcer le modèle d’affaires des marques de luxe.
Secret et transparence : un challenge à l’ère du numérique
Le problème de la transparence des marques de luxe renvoie au conflit de valeurs avec la responsabilité sociétale et environnementale (RSE) très documenté académiquement. En effet, ce que vendent ces marques se déconnecte des principes de la rationalité économique. Ce qui fait vibrer le client, c’est le rêve, pas l’utilité. Trop de transparence peut nuire à ce rêve éveillé, rendre accessible l’inaccessible et surtout dévoiler la recette secrète de ces marques qui savent habilement jongler avec les savoir-faire d’exception.
Second point d’attention, les marques de luxe sont plus lentes dans l’adoption des technologies du numérique. Si la crise du Covid-19 a facilité le passage au numérique, notamment comme canal de vente, le numérique a un potentiel destructeur de la valeur « luxe ». Ce phénomène est accentué dans le secteur du luxe car les marques doivent gérer des chaînes de valeur complexes, aux acteurs multiples, eux aussi peu enclins à l’utilisation de ces outils. Par exemple, le tanneur qui nettoie les peaux animales destinées à devenir du cuir, agit essentiellement dans des petites entreprises, souvent familiales et où le savoir-faire manuel prime sur la modernité organisationnelle.
Si les outils d’aujourd’hui permettent de faciliter la collecte, la sécurité et la présentation des données (blockchain, RFID…) ils ne suffisent pas en eux-mêmes à assurer une « bonne » traçabilité. L’enjeu pour les marques de luxe est surtout de faire coopérer les acteurs de la chaîne (agriculteurs, abattoirs, collecteurs, tanneurs, artisans, sous-traitants…). Cela nécessite avant tout d’aligner les intérêts de chacun et de créer de la confiance, là où les données issues de la traçabilité et le transfert de connaissances peuvent s’avérer stratégiques.
Gagner en qualité
Si l’on creuse la question, mieux tracer la chaîne des produits de luxe peut être en interne un levier de création de valeur durable. Les acteurs rencontrés dans notre étude coopèrent non pas dans le but premier de se plier aux règles mais surtout pour les bénéfices amenés en termes opérationnels.
Dans la mesure où la consommation de viande en France diminue nettement, les peaux animales, déchets de l’industrie agroalimentaire, se raréfient. Or, si les marques de luxe se prévalent de ne pas consommer des quantités démesurées de matières premières, elles ont toutefois besoin de matière de haute qualité pour être en phase avec leur positionnement marketing. La traçabilité permet ici de faire des retours aux éleveurs. Ceci est aujourd’hui possible grâce au marquage laser et à l’intelligence artificielle qui permet de suivre individuellement les cuirs traités – malgré les différents traitements – et donc d’identifier la provenance de la peau d’un troupeau précis.
Ainsi par itinérance, la qualité des peaux peut être améliorée en ajustant les méthodes d’élevage des animaux notamment au travers de leur alimentation ou leurs conditions de vie. Cette amélioration de la qualité contribue également à renforcer la responsabilité de l’ensemble de la chaîne de valeur. Une autre conséquence associée est l’augmentation de la rémunération des éleveurs qui joue le jeu dans le cadre du projet FECNA porté par RésoCUIR et la Région Nouvelle-Aquitaine.
Répondre au risque de contrefaçon
Les produits finaux sont aussi un objet d’attention dans le cadre de la traçabilité. Si historiquement les marques de luxe fournissaient à l’achat un certificat papier pour attester de l’authenticité de leur produit, le développement de la seconde main a accentué la circulation de « faux » car ces certificats sont facilement falsifiables.
Les marques de luxe ont décidé de prendre ce problème à bras le corps, notamment grâce à la plateforme AURA développée par le consortium LVMH/OTB/Prada/Richemont. Grâce à la blockchain, les marques peuvent désormais répondre aux enjeux du Digital Product Passport, mais aussi à l’individualité du produit, et de transférer la propriété en cas de revente seulement en scannant un QR code.
Plus encore, le passeport numérique renforce le lien du consommateur avec son produit et la marque. Il permet de dérouler le storytelling associé au produit acheté et d’offrir au client des avantages exclusifs renforçant le sentiment d’exclusivité.
En dépit du danger de rejet par les consommateurs de la marque de luxe, la traçabilité reste une opportunité de valeur multiple, façonnée collectivement et dans le temps. Pour rester désirables, les marques de luxe ont intérêt à se concentrer sur une communication corporate de la traçabilité au bénéfice d’un storytelling soft et d’une expérience attractive pour le client, rendus possibles par les nouvelles technologies numériques.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
17.06.2026 à 17:38
Les séries sud-coréennes : un soft power efficace auprès des jeunes
Laurence Corroy, Professeure des universités, Université de Lorraine
Johanne Samè, Maîtresse de conférences en sciences de l'information et de la communication, Université de Haute-Alsace (UHA)
Sabine Bosler, Maîtresse de conférences en sciences de l’information et de la communication, Université de Haute-Alsace (UHA)
Texte intégral (2088 mots)

True Beauty, A Killer Paradox, la Reine des larmes… les 15-25 ans, grands consommateurs de séries sud-coréennes, semblent particulièrement sensibles au soft power qu’elles véhiculent.
La plateforme Netflix, leader sur le marché, avec plus de 10 millions d’abonnés, a largement réussi son pari en France. Un quart des usagers ont entre 15 et 25 ans. Auprès de ces publics, les séries anglophones sont particulièrement prisées ainsi que les séries sud-coréennes.
Boostées par le succès planétaire de Squid Game, qui met en scène des jeux d’enfants transformés en épreuves mortelles, les « K-dramas » séduisent. Ces séries couvrent une large variété de genres, du thriller aux séries pour adolescents, et la romance est souvent centrale dans l’intrigue. Elles s’inscrivent dans le contexte plus large de la hallyu, la vague culturelle coréenne, qui comprend également la K-pop, la K-beauty et la K-food.
Or, les succès identifiés culturellement, tels le fameux Emily in Paris, qui met en scène une capitale de carte postale, sont loin d’être anecdotiques et ont des effets dans la vie réelle, notamment sur le tourisme ou encore les pratiques de consommation.
Le soft power a été théorisé par Joseph Nye, en 1990, comme la capacité d’un État à influencer et à persuader d’autres États de son attractivité, sans recourir à la force ou à la contrainte, mais au travers de la circulation de sa culture populaire ; cette capacité est souvent associée à des ressources immatérielles telles qu’une culture attrayante. De manière plus large, il s’agit de la manière dont les industries culturelles d’un pays donnent une image positive de celui-ci et des pratiques qui lui sont associées.
À lire aussi : Pop culture sud-coréenne : les raisons d’un succès mondial
Nous avons voulu savoir comment ces mises en scène culturelles sont reçues par des publics jeunes et si ce soft power a des effets concrets dans leur vie quotidienne. Notre étude se concentre sur la réception des K-dramas chez les étudiants de 18 à 25 ans dans l’est de la France. Nous avons donc soumis un questionnaire à plus de 400 étudiants de l’Université de Haute-Alsace et de l’Université de Lorraine, puis réalisé des focus groups sur la base du volontariat entre septembre 2025 et mars 2026.
Un soft power largement sous-estimé par les répondant·es ?
Sur les 454 personnes interrogées, 52 % ont déclaré avoir regardé et apprécié au moins un K-drama. Seuls 22 % de nos répondants se déclarent fans de la hallyu en général, ce qui indique que les séries coréennes sont consommées sans attachement particulier à la culture coréenne, souvent sur des plateformes (principalement Netflix) proposant des contenus d’origines diverses. Pour 59 % de nos répondants, les K-dramas n’ont pas influencé l’image qu’ils avaient de la Corée du Sud tandis que 36 % ont déclaré qu’ils avaient eu une influence positive, 5 % une influence négative.
Cependant, en y regardant de plus près, on constate un engouement pour ce pays : 61 % des femmes interrogées et 48 % des hommes interrogés déclarent qu’ils aimeraient le visiter un jour, 5 % y ayant déjà séjourné. Parmi les personnes interrogées, 6 % déclarent qu’elles apprennent la langue, et 16 % qu’elles aimeraient l’apprendre.
Les K-dramas semblent en outre avoir une influence sur la consommation quotidienne, en particulier chez les jeunes femmes. Par exemple, 67 % d’entre elles ont déjà envisagé d’acheter des produits de beauté sud-coréens après avoir en avoir regardé, 20 % des vêtements et 57 % des produits alimentaires.
Les focus groups nous ont permis d’en apprendre davantage sur la réception des séries sud-coréennes et le soft power qui leur est associé. Nous avons demandé dans un premier temps aux participant·es ce qui leur paraissait caractéristique des séries coréennes, en quoi ces séries avaient changé – ou non – leur vision de la Corée du Sud et, enfin, si cela leur avait donné envie d’en savoir davantage sur le pays et sa culture et quelles éventuelles pratiques de consommation de produits coréens avaient été adoptées.
Une réception active des éléments caractéristiques des séries sud-coréennes
Si un certain nombre d’étudiant·es indiquent qu’ils n’avaient pas de vision précise de la Corée du Sud avant de regarder des séries, ils s’accordent sur des aspérités culturelles ou des points saillants récurrents développés dans les univers sériels sud-coréens. L’injonction à la réussite scolaire puis en entreprise et la place accordée à l’argent leur semblent prégnantes et constantes. Elles prennent leurs sources dans l’obsession de sauver la face et de ne pas jeter le discrédit sur la famille. Le poids générationnel, le respect dû aux anciens, la politesse sont soulignés.
Les étudiants, et plus généralement les étudiantes, évoquent la place centrale accordée à la romance. Celle-ci est décrite comme pudique, idéalisée, reposant sur des schémas narratifs récurrents, dont les « enemies to lovers » où les héros après s’être détestés tombent dans les bras l’un de l’autre. Le caractère irréaliste des relations amoureuses dans les K-dramas est ainsi souligné :
« C’est des histoires un peu… en vrai, on se dirait que ça ne peut pas arriver […] par exemple, la jeune fille qui est pauvre avec le mec qui est très riche. » Aurélie, 20 ans.
Les étudiantes expliquent que « ce qui [les] pousse à regarder jusqu’au bout », c’est la temporalité contrastée avec celle des séries occidentales, où les relations amoureuses sont jugées plus rapides et plus explicites :
« Dès le premier épisode, tu les retrouves, excusez-moi le terme, au lit quoi (rires) ! Tu pleures. » Dalya, 22 ans.
Elles insistent sur le plaisir de suivre l’évolution progressive des relations, jusqu’à des formes d’intimité minimales, comme un baiser ou le simple fait que les personnages en viennent enfin à se donner la main. Néanmoins, les rapports genrés paraissent problématiques, entre « romances idéalisées » déconnectées du réel et machisme non questionné :
« Et ça montre que les producteurs n’ont pas vraiment compris les réels besoins de la société, notamment du côté de la gent féminine, parce que les besoins, c’est pas des romances idéalisées, mais surtout de l’honnêteté, et aussi une matière à réfléchir pour les hommes, leur montrer qu’une relation saine en Corée, c’est possible, mais seulement s’ils font des efforts, et on le voit pas dans les séries je trouve, ou en tout cas pas assez. » Cléa, 21 ans.
Les enquêté·es soulignent également l’importance accordée à l’esthétique et aux normes de beauté en Corée du Sud, très élevées, parfois institutionnalisées, notamment au travers du recours naturel et facile à la chirurgie esthétique afin d’être positivement et socialement valorisés.
Un soft power intégré à des pratiques de consommation
Les réponses montrent que les K-dramas ont une influence sur les pratiques quotidiennes ainsi que les choix de consommation. Plusieurs répondantes ont exprimé leur désir d’acheter des produits de K-beauty, par exemple des sérums, des crèmes ou des masques pour le visage, fréquemment montrés dans les K-dramas. Si les séries en sont un vecteur, elles indiquent que ces produits bénéficient d’une bonne réputation par ailleurs, notamment sur les réseaux sociaux :
« Mais c’est pas les séries coréennes en soi qui m’ont donné envie, c’est le fait que tout le monde en parle sur TikTok, ça m’impacte. » Yasmine, 21 ans.
Les K-dramas sont également une vitrine de la culture alimentaire sud-coréenne. La nourriture est en effet un élément central dans les séries et de nombreuses scènes ont lieu dans des restaurants ou des cafés. Certain·es répondant·es indiquent que cela leur a donné envie de se rendre dans des restaurants coréens ou d’acheter de quoi préparer des plats typiques à la maison. Tteokbokki (gâteaux de riz dans une sauce pimentée), ramen, corndogs ou encore barbecues coréens sont mentionnés.
Langue et culture coréennes approfondies
Les K-dramas, souvent vus en version originale, familiarisent les spectateurs avec la langue. Plusieurs de nos répondant·es indiquent avoir appris quelques mots ou expressions langagières en regardant des K-dramas, par exemple Aurélie, qui l’utilise dans sa vie quotidienne :
« Forcément oui, parce que moi, je les regarde en coréen avec les sous-titres français, c’est le mieux. Donc forcément, on intègre des expressions basiques et aussi des expressions entre amis. »
D’autres se sont mis·es à apprendre la langue de manière active, a minima l’alphabet coréen, par simple intérêt linguistique ou pour préparer un voyage sur place :
« Dans le contexte où peut-être j’irais […] j’ai un petit peu essayé d’apprendre l’alphabet, pour pouvoir un peu dire que, maintenant, je connais l’alphabet. Je le lis difficilement. Mais, ça vient petit à petit, quoi. Comme ça, si un jour j’y vais, j’aurai un peu des bases, quoi. » Inès, 21 ans.
Les K-dramas, un instrument puissant de soft power
Les K-dramas sont donc, aux yeux de ces jeunes gens, une vitrine d’un mode de vie séduisant. Certains éléments culturels, comme la nourriture, la langue et les produits cosmétiques, trouvent leur place dans la vie quotidienne de personnes qui ne sont pas fans de la Corée du Sud par ailleurs. Ils donnent envie d’en savoir plus sur la culture sud-coréenne, voire de voyager en Corée du Sud. Ils l’imaginent marquée par des milieux urbains ultramodernes, des temples magnifiques, un raffinement culinaire et une esthétique des visages et des corps. L’extrême attention portée à la beauté s’associe aussi à la chirurgie esthétique qui leur semble banalisée.
La culture populaire sud-coréenne, véhiculée par les séries diffusées, concourt à un soft power qui paraît plutôt sous-estimé par les répondant·es dans un premier temps et qui est pourtant bien présent dès lors qu’on aborde en entretien les mêmes items : les jeunes publics ont le réflexe d’en apprendre davantage sur la Corée du Sud, se montrent curieux envers le mode de vie sud-coréen et ses produits de consommation.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
17.06.2026 à 15:25
Does the United Kingdom need a new Winston Churchill?
Alma-Pierre Bonnet, Senior Lecturer in British Studies, Université Jean Moulin Lyon 3
Texte intégral (2446 mots)
Since Brexit, a profoundly Churchillian event, the United Kingdom has experienced chronic political instability. No fewer than five prime ministers have succeeded one another at the head of a country whose governability is now being questioned. As speculation grows over who might replace the current prime minister, Keir Starmer, whose position is increasingly under pressure, should the ideal candidate look to Churchill for inspiration?
A recent article in The Guardian compares the current political situation in Britain, where governments have recently lasted anywhere from a few weeks to several months, to that of France’s Fourth Republic, whose permanent state of crisis was resolved in part by the rise of a providential figure, Charles de Gaulle. Given the similarities between the two men in the public imagination, it is tempting to see Winston Churchill (1874–1965) as a model who could inspire an end to today’s instability.
Churchill was long revered before later being reassessed. His legacy returned to the forefront during the heated Brexit debate, which further polarised British society: would he have voted to remain or to leave? Throughout his distinguished career, Churchill supported the idea of a united Europe, though not including the United Kingdom, which he believed should maintain a “special” relationship with the United States. This allowed both supporters and opponents of the EU to claim him as their own. Above all, however, it is the image of a united nation, crowned by victory over Nazi barbarism, that continues to define the Churchill myth.
But should today’s political leaders really follow his example to overcome what increasingly appears to be a dead end?
A wartime leader rather than a peacetime statesman
The short answer is no, obviously. Churchill was, above all, a wartime leader, with no genuine long-term vision for governing a country in peacetime. British voters made this clear in 1945 by electing a far less charismatic but far more capable administrator and consensus-builder: his Labour opponent, Clement Attlee.
But the story Churchill told during the Second World War was that of a triumphant and eternal United Kingdom, confident in its strength and global influence, and this positive narrative later inspired Brexit advocates, from Boris Johnson to Nigel Farage. Yet such a glorious vision depended on the constant presence of an enemy to fight and Churchill’s controversial comparison during the 1945 election campaign between a potential Labour government and the Gestapo was simply out of step with the British public’s desire for peace.
Beyond the incompatibility of Churchill’s wartime storytelling with the post-war era and, indeed, with today’s circumstances, future leaders could still draw inspiration from certain aspects of his rhetoric. Indeed, the idea of unity and shared destiny, where an entire people stand together against adversity is probably one of the most valuable messages for a country deeply divided: between North and South; between the political centre and the Celtic “periphery” of Scotland, Wales, and Northern Ireland, where calls for independence from London are growing stronger; and between a liberal, multicultural younger generation and a more conservative older population.
While these underlying divisions were partly exposed by the 2016 decision to leave the European Union, Brexit also created new political identities, pitting a progressive segment of society against a more conservative one amid ongoing culture wars over the very definition of British identity. The debate has also fragmented the political system: increasingly, populist parties compete with the traditional parties, transforming British politics from a two-party system into a multiparty landscape.
Starmer: The anti-Churchill?
In this uncertain climate, the Labour Party which campaigned in the 2024 general election on the promise of change while presenting Starmer as a leader capable of restoring institutional stability, and which largely benefited from widespread rejection of the Conservatives, now ironically finds itself in a situation similar to that of the Tory Party: internally divided and led by a leader whose authority is under question, particularly after disastrous local election results in May 2026. In a distinctly Churchillian turn of phrase, Ben Worthy and Mark Bennister argue that “Starmer has struggled because he disappointed too many, and persuaded too few.”
Worse still, he has never managed to build a strong personal connection with the public. His numerous U-turns, more than a dozen, including on student loan repayments, the creation of a digital identity card, and support for disabled and elderly citizens as well as his dithering in making bold decisions or offering a clear direction for the country, have made him one of Britain’s most unpopular prime ministers. Churchill, by contrast, remains the country’s most admired.
The contenders for the leadership
Labour has strict rules for challenging its leader. A candidate must secure the backing of at least 20% of Labour members of Parliament (which represents 81 MPs today) before a preferential vote among party members is held, with the incumbent automatically included. So, who hopes to lead the country?
One of the first to express interest is former Health Secretary Wes Streeting, who resigned after the May 7 local elections. His ambitions are not new; he could have sought the Labour leadership in 2024. According to Westminster sources, Labour strategist Morgan McSweeney saw Starmer as more of an “HR manager” than a charismatic leader, a temporary figure meant to shield the party from the far-left influence of former leader Jeremy Corbyn before eventually handing over the reins to stronger contenders. The rest is history.
Positioned on the party’s right wing, much like Tony Blair before him, Streeting has recently criticised Starmer for lacking vision. He openly advocates rejoining the European Union, moving beyond Starmer’s cautious policy of merely “resetting” relations. It is a bold proposal in a country that has yet to heal the wounds of Brexit. By bringing the possibility of rejoining the EU into the spotlight, he forces other Labour leadership hopefuls to take a clear position on this fundamental issue.
However, Streeting lacks broad support within the party and may be damaged by his association with Peter Mandelson, once a leading Labour figure who has become politically toxic following revelations about his long-standing relationship with Jeffrey Epstein.
More popular with the general public, Greater Manchester Mayor Andy Burnham represents a genuine threat to Starmer from the party’s left wing. Burnham aims to apply his “Manchesterism” model nationwide, seeking to end the neoliberal policies introduced by Margaret Thatcher and largely maintained by Labour prime ministers Tony Blair and Gordon Brown. In Manchester, he notably strengthened public control by bringing bus services back under public management.
As prime minister, he would advocate more nationalisations, invest heavily in social housing, strengthen devolution in Wales, Scotland, and Northern Ireland, and increase public borrowing, a proposal that has already raised concerns among financial markets.
The European question remains particularly delicate. Burnham is firmly pro-European but less enthusiastic than Streeting about rejoining the EU, largely for pragmatic reasons. Since he is not currently an MP, he cannot yet challenge Starmer directly and must first win a by-election in Makerfield on 18 June, after the sitting MP agreed to resign.
This presents a dilemma: while 65% of Labour supporters are pro-EU, 65% of Makerfield voters backed Brexit in 2016. Burnham must, therefore, strike a careful balance. The election will be crucial not only for him but also for Labour and the country as a whole. A positive stance toward the EU could strengthen Reform UK, Nigel Farage’s populist party, which is strongly anti-EU and highly popular in northern England. Burnham will face Reform UK candidate Robert Kenyon, a plumber by trade, in what Farage has once again described in Churchillian terms as a battle of “David versus Goliath”. A defeat could call into question Labour’s ability to persuade voters over Reform UK and threaten the party’s future.
Two other figures are also potential candidates. The first is former Housing Secretary and Deputy Leader Angela Rayner, a centre-left politician popular with the party grassroots but forced to resign over unpaid property taxes, a particularly damaging issue for someone responsible for housing policy.
The final possible candidate is former Labour leader Ed Miliband, who remains relatively popular on the party’s left wing. However, his reputation was permanently affected by Labour’s defeat in the 2015 general election. He is mainly seen as a fallback option should Burnham fail to win the Makerfield by-election.
Finally, Starmer himself should not be overlooked. He retains the support of MPs who prioritise stability and wish to avoid the kind of internal warfare that tore apart the Conservative Party even if, in reality, Labour’s own civil war has already begun.
So, does Britain need a wartime leader?
Lloyd George rather than Churchill?
If so, the country clearly does not need a new Churchill. If Britain were to look to its history for a wartime leader to emulate, David Lloyd George, prime minister during the First World War, would be a far more appropriate model. He combined wartime leadership with a long-term vision of creating a country worthy of the sacrifices made during the Great War.
It was this positive vision of the future, rather than Churchill’s more combative narrative, that helped Lloyd George remain in power after the war. Yet, whoever succeeds Starmer, or Starmer himself if he remains in office, should draw inspiration from Churchill’s ability to inspire the British people during their darkest hours by offering a message of hope, reconciliation, and a renewed understanding of British identity. Good luck!

A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Alma-Pierre Bonnet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
17.06.2026 à 12:26
L’Hakoah Amateur Club de New York : entre sionisme, exil et intégration
Charlotte Carayol, Doctorante en études germaniques, Université Bordeaux Montaigne
Texte intégral (2936 mots)

Après l’Anschluss de 1938, des Viennois réfugiés à New York recréent l’Hakoah, célèbre club sportif juif et sioniste dissous par les nazis, afin de préserver leurs réseaux de solidarité et leur identité collective en exil. Le club prolonge l’idéal du Muskeljudentum (« judaïsme du muscle »), qui entend répondre à l’antisémitisme par la valorisation d’un corps juif fort et fier, tout en maintenant un engagement culturel et politique hérité de l’Europe centrale. Dans le même temps, la pratique du football et la participation à la vie associative locale favorisent l’intégration de ces exilés au melting-pot états-unien, jusqu’à ce que leurs descendants s’éloignent progressivement de cet héritage.
En 1940, des exilés juifs de Vienne recréent à New York leur club de sport, l’Hakoah (« force » en hébreu). Son équipe de football est entrée dans la légende en 1925 : l’équipe, juive et sioniste, est sacrée championne d’Autriche, pays marqué par un fort antisémitisme. En 1938, l’Hakoah est dissoute par les nazis. Recréer ce club de l’autre côté de l’Atlantique, c’est à la fois retrouver ses marques dans un environnement étranger et perpétuer un mouvement qui porte un combat politique juif sur les terrains de sport alors que l’extermination des Juifs d’Europe est en cours. Dans le même temps, jouer au soccer à New York permet de s’intégrer au melting-pot états-unien.
Personne n’a encore écrit l’histoire de l’Hakoah de New York, qui n’a pas de fonds d’archive propre. Je m’appuie donc dans mes recherches sur la presse des exilés germanophones à New York, et sur deux livres publiés à l’occasion des 35ᵉ et 50ᵉ anniversaires du club historique. Le premier est publié par le club de New York en 1945, et le second à Tel-Aviv en 1959 et accompagné en 1961 d’un supplément et d’un carnet avec les adresses de tous les Hakoahner encore en vie.
Un club en exil
On estime que l’annexion de l’Autriche par l’Allemagne nazie en mars 1938 a poussé à l’exil 130 000 juifs autrichiens, dont 30 000 arrivent aux États-Unis. Il leur faut dès lors s’adapter à un environnement social, culturel et linguistique étranger, faire face à la perte de leur statut social, de leurs amis, voire de leur famille. Dans ce contexte naissent des associations et des clubs de sport, qui leur permettent de s’entraider et de recréer du lien avec des gens qui partagent leur vécu et leur langue.

L’Hakoah propose à ses membres, dont on peut imaginer que ce sont essentiellement d’anciens membres du club viennois, des cours de tennis, de natation, et des cours de gymnastique réservés aux femmes. Les horaires et lieux d’entraînement sont publiés dans le journal Aufbau (« Reconstruction »). Évidemment, la section football est représentée. Elle joue en amateur dans l’Eastern District League avec trois équipes masculines et compte 65 membres, dont 22 ont moins de 18 ans en 1945.

Mais l’Hakoah, comme les autres clubs de sport d’exilés juifs germanophones, le Prospect Unity Club ou le New World Club, joue un rôle beaucoup plus structurant dans leur vie sociale. Il organise des bals, héberge des cabarets, comme Die Arche, le cabaret sioniste que j’étudie dans ma thèse.
Par-delà les activités qu’il propose, le club semble être un réel repère dans la reconstruction de la vie sociale des exilés. La publicité pour le café de Joschy Gruenfeld (parfois orthograpgié Grünfeld), elle aussi publiée dans Aufbau, met ainsi en avant le fait que ce dernier est un ancien joueur de l’Hakoah de Vienne.

L’Hakoah de New York est donc une affaire de liens, célébrés en 1960 dans un poème de Pourim, dépeignant une réunion des membres à l’occasion de cette fête religieuse au restaurant de Joschy Gruenfeld.
« Chez Joschy Grünfeld, aujourd’hui il y a un meeting ;
De près et de loin, ils sont tous venus,
De ce bastion du sport la vieille garde,
Les combattants et les amis de l’« Hakoah »…
Regardez-les, ces vieux garçons,
Avec leurs jeunes épouses ;
Ils ont perdu leurs cheveux noirs et touffus,
Aujourd’hui, ils sont plutôt « rabou-gris ».
Les voici réunis – toutes les sections sont représentées
Ils ont fui Hitler jusqu’aux États-Unis
Pourtant, ne les comptez pas, ces têtes aimées ;
Les meilleurs manquent – ils ne sont plus là.
Mais aujourd’hui, nous voulons célébrer Pourim,
Et chasser au loin ces sombres pensées ;
Les Hakoahner ont toujours été prompts à rire,
Alors, cette tradition, laissez-nous la perpétuer. »
L’Hakoah et le sionisme
À Vienne, l’Hakoah, au maillot bleu et blanc arborant l’étoile de David, est un club sioniste, dans un contexte où les clubs sportifs ont des identités politiques très marquées. Sport et politique font en effet bon ménage dans la première moitié du XXᵉ siècle. Mais le sionisme l’investit d’une manière qui lui est propre à travers le concept de Muskeljudentum, « judaïsme du muscle », théorisé par le penseur Max Nordau en 1898.
Il s’agit de prendre le contre-pied des discours antisémites (et sexistes) sur les hommes juifs, qui seraient faibles et efféminés. Cultiver un corps fort et fier, celui d’un « nouvel homme juif », et se confronter aux corps « aryens », c’est donc prouver la vacuité des discours antisémites. On comprend là une caractéristique importante du sionisme en Europe centrale avant la Seconde Guerre mondiale : c’est un mouvement nationaliste tourné vers la Palestine, mais dans la pratique, ce sont des organisations locales qui répondent à des enjeux locaux, dont le premier est de faire face à l’antisémitisme.
Le sionisme, en tant que pratique du Muskeljudentum et en tant que projet de création d’un État juif en Palestine, est très présent dans la brochure publiée par l’Hakoah de New York en 1945. Elle est éditée par Heinrich Heinz Glanz, éditeur viennois en exil, proche du sionisme révisionniste de Vladimir Jabotinsky.
En 1945, les révisionnistes prônent l’immigration illégale en Palestine, voire le terrorisme. C’est Glanz qui écrit le premier article de la brochure, qui est de loin l’article le plus politique. Il y prône la légitimité totale de l’établissement d’un État juif à l’aune de l’engagement de brigades juives dans les forces alliées. Sous sa plume, la Seconde Guerre mondiale devient la « German-Jewish war », et la rhétorique états-unienne du combat pour la liberté et la démocratie, le « Jewish fight for liberty ».
Ce qu’il met en avant, ce sont les corps fiers des soldats, qui incarnent le Muskeljudentum, plutôt que les corps morts de la Shoah. Cette manière de contrebalancer la honte que représente le massacre de six millions de juifs par l’image de combattants juifs victorieux sera caractéristique du traitement mémoriel de la Shoah en Israël jusque dans les années 1960.
Toutefois, ce texte a ceci de paradoxal qu’il reste bien loin du terrain. Les membres du club se sont battus en Europe, mais ils ne sont pas appelés à se battre en Palestine. Et si l’on regarde les adresses des membres de l’Hakoah en 1959, on constate que, parmi les membres de l’Hakoah de New York que l’on peut identifier avec la brochure de 1945, seul Paul Fulton, alors vice-président, a émigré des États-Unis vers Israël après 1948.
Une histoire d’intégration états-unienne
Même si les auteurs de la brochure répètent que leur engagement est tendu vers la création d’un État juif, ce document donne plutôt des gages de l’intégration du club et de ses membres à la société états-unienne. Il est rédigé en anglais, patronné par le gouverneur de l’État de New York et s’ouvre sur un Honor Roll des membres du club engagés dans l’armée états-unienne. Malgré la lecture qu’en fait Glanz, cet engagement dans les forces armées est un phénomène très large parmi les exilés, et qui n’est pas forcément politiquement motivé : ils peuvent ainsi accélérer leur naturalisation, et donc parachever leur intégration.
Le club semble donc s’être solidement installé aux États-Unis, et Otto I. Herbst, son président, insiste ainsi sur sa volonté d’y développer le « Jewish sports movment », c’est-à-dire la pratique militante du Muskeljudentum – en somme, de perpétuer la pratique diasporique du sionisme. Pour comprendre les différentes approches de Glanz et de Herbst, il faut toutefois souligner que le premier se place dans la construction d’un argumentaire en vue de la création imminente de l’Organisation des Nations unies (ONU), là où le deuxième exprime son pessimisme quant à la création prochaine d’un État juif. Il part donc du principe que les États-Unis sont le nouveau centre de la vie juive.
Pratiquer le football européen à New York a donc permis à ces exilés de devenir des émigrés dans le melting-pot (dans la limite de la diversité autorisée, bien sûr). En jouant dans l’Eastern District League, ils expriment et mettent en scène une identité nationale parmi d’autres groupes nationaux, également issus de l’immigration. J’entends ici identité nationale au sens central-européen de groupe ethno-culturel.
Le terrain de football devient un lieu de partage d’une double expérience : celle du transfert culturel d’une pratique proprement européenne, que ces émigrés conservent aux États-Unis, et celle d’une nouvelle organisation sociale où l’on appartient à une community et à la nation civique états-unienne. Ils y font aussi l’expérience de la diversité de la communauté juive new-yorkaise, qui, loin de se ranger derrière un seul club, dispose de plusieurs équipes.
Signe de cette intégration réussie : le club ne trouve pas vraiment de relève. En 1959, il prend les allures d’un café où se retrouvent ses membres vieillissants. Pendant ce temps, leurs enfants et petits-enfants jouent au baseball et au football… américain.
Charlotte Carayol ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
17.06.2026 à 12:24
Au sommet du marathon mondial, l’histoire douloureuse de la frontière entre l’Ouganda et le Kenya
Romélien Colavitti, Professeur des universités en droit public, Université de Tours
Texte intégral (4348 mots)
Le 26 avril 2026, le Kényan Sabastian Sawe est passé sous la barre symbolique des deux heures lors du marathon de Londres : 1 heure, 59 minutes et 30 secondes. Sawe s’inscrit dans la lignée des coureurs qui, à quelques kilomètres de la frontière avec l’Ouganda, foulent chaque jour les pistes d’Iten, dans la vallée du Grand Rift. Si cette terre est aujourd’hui kényane, elle ne l’a pas toujours été et reste marquée par une histoire difficile, où il est notamment question des sources du Nil, d’un train lunatique, d’attaques léonines et de crimes coloniaux.
_
Les marathoniens Kipchoge Keino, Eliud Kipchoge ou Kelvin Kiptum et marathoniennes Peres Jepchirchir, Brigid Kosgei ou Ruth Chepngetich sont quelques exemples – parmi tant d’autres – d’athlètes qui ont fait l’histoire de leur discipline.
Ils proviennent des hauts plateaux de la vallée du Grand Rift, dans l’ouest du Kenya, plus précisément des comtés de Nandi, Kericho, Kisumu, Uasin Gishu ou Elgeyo-Marakwet. Pour la plupart d’entre eux, ils sont kalendjins, issus des groupes Nandi, Keiyo ou Kipsigi.
Tous ont en commun d’avoir assidûment fréquenté les fameuses pistes rouges de latérite (un minerai volcanique, riche en oxyde de fer) d’Iten, Eldoret, Kaptagat ou Kapsabet, à près de 2500 m d’altitude. On dit qu’en ces lieux « l’air se raréfie ».
En réalité, la pression atmosphérique y étant diminuée, l’apport en oxygène à l’effort se trouve lui aussi réduit. Physiologiquement, l’entraînement bi (voire tri) quotidien – alternant fractionnés courts ou longs, récupération et sorties longues – vise à optimiser ces apports en améliorant la production de globules rouges, le transport d’oxygène vers les muscles et, plus globalement, l’endurance aérobie (décisive sur longue distance). Cela explique que les marathoniens d’élite s’y entraînent et que fleurissent autour d’Iten, « capitale mondiale du marathon », nombre de training camps offrant des prestations hôtelières à des coureurs venus du monde entier.
Cette terre fertile, bénie des dieux de l’athlétisme, fait aujourd’hui la fierté et la richesse du Kenya. Le thé, le café, les légumes et les roses y poussent aussi volontiers que germent les graines de champions. Mais beaucoup ignorent qu’elle aurait pu être placée sous souveraineté ougandaise au moment des indépendances de 1962 et 1963. Pour le comprendre, une brève mise en perspective historico-juridique s’impose.
Le contrôle du Nil par le colon britannique
La conférence de Berlin s’est ouverte le 15 novembre 1884, à l’initiative du chancelier Otto von Bismarck, avant de se clore le 26 février 1885. Cet accord politique entre États européens constitue la base d’un vaste processus de colonisation, de peuplement et de spoliation des ressources.
À cette époque, les Britanniques contrôlent le delta du Nil, depuis la mise en place d’un protectorat de facto sur l’Égypte, sous la responsabilité du consul général Evelyn Baring, Comte de Cromer.
Mais leur expansion sur le Haut-Nil est stoppée lors de la guerre des mahdistes (1881-1899) (du nom de Muhammad Ahmad, le mahdi ou « sauveur », qui dirige la révolte soudanaise contre les forces anglo-égyptiennes). Le 26 janvier 1885, les mahdistes prennent Khartoum, épisode durant lequel le général britannique Charles George Gordon trouve la mort. Dix ans plus tard, en 1896, le général Horatio Herbert Kitchener revient, l’esprit revanchard, reprend Khartoum au successeur du mahdi (Abdullah al-Taashi) et met fin à son règne lors de la fameuse bataille d’Omdourman, le 2 septembre 1898, sous les yeux du jeune Winston Churchill alors officier de cavalerie. C’est grâce à la construction de la ligne ferroviaire entre Wadi Halfa et Abu Hamed («Kitchener’s Railway», 1896-1897) que la victoire britannique fut acquise.

La crise de Fachoda, dans le sud du Soudan – déclenchée par la présence des troupes françaises du commandant Jean-Baptiste Marchand – n’y fera rien : les Britanniques contrôleront durablement le Nil unique, entre Khartoum et le delta.
Mais qu’en était-il de ses sources, les lacs Tana et Victoria, qui donnent respectivement naissance au Nil bleu et au Nil blanc ?
Les Britanniques n’ont pas entendu s’approprier directement la source du Nil bleu, le lac Tana en Éthiopie (territoire non colonisé). La diplomatie a ainsi été préférée à la force avec la conclusion du Traité anglo-éthiopien du 15 mai 1902, entre l’empereur Ménélik II et Sir John Harrington.
Pour continuer à fournir les usines de textile du Lancashire en coton soudanais et égyptien, tout projet d’ouvrage visant à irriguer en amont les terres éthiopiennes devait recevoir l’accord des autorités britanniques. D’autres traités coloniaux seront conclus avec la France ou l’Italie, ce qui marquera durablement les conditions d’exploitation du Nil.
Pour ce qui concerne la source du Nil blanc, en revanche, la logique fut celle de la colonisation via l’instauration des protectorats d’Ouganda et d’Afrique orientale britannique (qui deviendra le Kenya).
Les protectorats britanniques et le « Lunatic Express »
Au XIXe siècle, le sultanat de Zanzibar contrôlait le Zanguebar, bande côtière entre la Somalie et le Mozambique actuels. Des missionnaires européens s’étaient implantés entre le fleuve Tana et Mombasa (sur la future côte kényane).
Au lendemain de la conférence de Berlin, les Britanniques ont obtenu un prolongement de leur sphère d’influence dans les terres, jusqu’aux lacs Rodolphe (actuel lac Turkana) au nord, Albert/Kivu à l’est et Victoria au sud-est. Au sud-ouest, l’Allemagne avait pris possession, quant à elle, de l’Afrique orientale (actuels Burundi, Rwanda et Tanzanie).
Dans ce contexte, la Compagnie britannique impériale d’Afrique de l’Est (Imperial British East Africa Company), chargée de développer le commerce (de l’ivoire, notamment) dans les zones sous contrôle de la Couronne, étendait son activité sur près de 640 000 kilomètres carrés, soit plus des trois quarts des territoires actuels de l’Ouganda et du Kenya.
Mais la Compagnie affrontait une difficulté de taille : l’acheminement. L’ivoire, acheté aux chefs locaux du royaume de Buganda (sur la rive ougandaise du lac Victoria), était alors préférablement dirigé – dans les conditions inhumaines du système esclavagiste du portage – vers le port de Bagamoyo (« Ici, mon cœur défaille », en swahili). La capitale de l’Afrique orientale allemande disposait, en effet, d’infrastructures portuaires légères et d’un accès privilégié à Zanzibar.
Face à cette concurrence, les Britanniques entendirent reprendre la main en liquidant la Compagnie et en instaurant les protectorats d’Ouganda (en 1894) et d’Afrique orientale britannique (l’actuel Kenya, en 1895).
Ces territoires dépendaient du Colonial Office et étaient soumis à deux régimes différents d’administration : l’Indirect Rule (gouvernement indirect) et le Direct Rule (gouvernement direct).
Le protectorat d’Ouganda englobait des royaumes précoloniaux structurés (principalement le Buganda, du peuple baganda) et était administré selon l’Indirect Rule. Un commissaire représentait la Couronne britannique et intervenait peu dans les affaires foncières. Celles-ci relevaient, en vertu de l’accord du 10 mars 1900, du kabaka (le roi), assisté par le lukiko (l’assemblée du Buganda). Le contrôle colonial se cantonnait à la collecte des impôts de capitation (Hut Tax) et à l’administration de la justice, assurées par un colon britannique à la tête d’un saza (un comté) ou d’un gombola (un sous-comté). En somme, il s’agissait certes d’un régime colonial, mais une (relative) autonomie était garantie localement.
Le protectorat d’Afrique orientale britannique était, lui, une colonie de peuplement, administrée directement – selon le Direct Rule – par la Couronne. Le commissaire concentrait l’essentiel des pouvoirs et était assisté par un conseil exécutif exclusivement européen. Le conseil législatif, à la composition similaire, votait les lois et le budget. Contrairement à l’Ouganda, les colons de l’Afrique orientale ne s’appuyaient pas sur des royaumes préexistants. Ils nommaient des District Commissioners sans légitimité, enclins à réserver les meilleures terres aux européens et à pérenniser le travail forcé.
Lors de l’instauration de ces deux protectorats, l’Ouganda oriental (correspondant à la région des hauts plateaux du Grand Rift entre les lacs Victoria et Rodolphe, où se trouvent Kisumu, Eldoret ou Iten) faisait partie intégrante du protectorat d’Ouganda et était donc placé sous la responsabilité des autorités locales, sous administration coloniale indirecte. C’est dans ce contexte que fut inauguré, en 1896, le nouveau port de Kilindini à Mombasa (sur l’actuelle côte kényane), dont la structure en eaux profondes permettait d’accueillir de grands navires à vapeur. L’activité du port de Bagamoyo (qui avait perdu son statut de capitale de l’Afrique orientale allemande en 1891 au profit de Dar es-Salaam) n’a alors cessé de péricliter.
Mais c’est surtout la mise en place du chemin de fer ougandais, reliant Mombasa à Kampala (capitale actuelle de l’Ouganda) via Kisumu et le lac Victoria, qui a imposé durablement la suprématie commerciale britannique dans la zone.
La construction de cette ligne de 930 kilomètres, débutée en mai 1896, s’est achevée en 1901. Ce projet – dramatique d’un point de vue humain (l’épisode des attaques de lions à Tsavo, en 1898, a coûté la vie à des dizaines d’ouvriers) – a mobilisé une main-d’œuvre locale ainsi que 32 000 travailleurs migrants indiens, tous travaillant dans des conditions sanitaires déplorables. Il a nécessité l’édification de viaducs et d’un dépôt ferroviaire dans le marais d’Enkare Nyrobi (« Lieu de l’eau fraîche », en langue maa), site qui deviendra Nairobi. Le député de Northampton Henry Du Pré Labouchère baptisa alors ironiquement cet ouvrage titanesque, qui coûta environ 5 millions de livres sterling, « Lunatic Express ».

Les mutations territoriales et l’« uti possidetis juris »
Le chantier du Lunatic Express terminé, le colon britannique entendit prendre le contrôle total du territoire. Pour ce faire, un Uganda Order in Council – signé par le roi Édouard VII, le 11 août 1902 – a transféré l’Ouganda oriental (avec Kisumu, Eldoret ou Iten) du protectorat d’Ouganda à celui d’Afrique orientale britannique.
La frontière entre les deux, qui embrassait l’escarpement de Naivasha, était déplacée vers l’ouest, entre la rive orientale du lac Victoria et le mont Elgon. La région échappait ainsi au contrôle foncier des royaumes locaux pour relever directement des autorités coloniales britanniques.

Charles Eliot, alors commissaire du protectorat d’Afrique orientale britannique, avait été un farouche opposant au Lunatic Express et voyait dans la colonisation de peuplement une possibilité d’en amortir les frais. Défenseur d’une doctrine raciste et suprématiste, Eliot s’est inspiré des recommandations de Harry Johnston (son homologue du protectorat d’Ouganda) et a appuyé les politiques d’accaparement des terres et de peuplement des plateaux fertiles en octroyant aux colons européens (parfois des Boers du Transvaal sud-africain) des concessions terrestres à loyers modiques.
La spéculation foncière qui s’ensuivit évinça durablement les paysans locaux de l’accès aux terres (en 1914, 20 % des baux ruraux étaient ainsi détenus par une douzaine de colons). Cette situation a perduré pendant plusieurs décennies, avant l’accès aux indépendances.
Côté ougandais, le protectorat britannique ne reposait pas sur le peuplement. Aussi, l’indépendance acquise le 9 octobre 1962 a surtout été marquée par des tensions internes entre le Congrès du peuple ougandais de Milton Obote et le kabaka de Buganda, Muteesa II (ce dernier sera déposé en 1966 par Obote avec la complicité de son chef d’état-major Idi Amin Dada, futur despote qui massacrera sa population et expulsera par milliers les descendants d’ouvriers indiens venus participer au chantier du Lunatic Express).
Côté kényan, le protectorat d’Afrique orientale britannique sera remplacé par celui du Kenya en 1920, avant qu’un soulèvement populaire contre l’accaparement des terres (la fameuse révolte des Mau-Mau, lancée en 1952 et menée par le peuple kikuyu) ne précipite les conférences de Lancaster House qui aboutiront à l’indépendance, le 12 décembre 1963.
La délimitation de la frontière s’est alors inspirée du principe d’uti possidetis juris. Cette règle du droit international coutumier, rappelée par la Déclaration de l’Organisation de l’unité africaine (OUA) adoptée au Caire en 1964, visait à prévenir les conflits frontaliers en consacrant l’intangibilité des frontières héritées de l’époque coloniale.
Si cette prétendue fonction pacificatrice est loin d’avoir fait son œuvre partout, la frontière ougando-kényane s’est effectivement imposée sur la base de textes coloniaux : l’Uganda Order in Council (précité) de 1902 (qui transfère les hauts plateaux de la vallée du Grand Rift du protectorat d’Ouganda à celui d’Afrique orientale britannique), le Kenya Colony and Protectorate (Boundaries) Order in Council de 1921 (qui délimite plus précisément les frontières du protectorat du Kenya) et celui de 1926 (qui rattache le pays Turkana, jusqu’alors partie nord du protectorat d’Ouganda, au protectorat du Kenya).
Les indépendances de 1962 et 1963 ont, ce faisant, définitivement consolidé l’appartenance des hauts plateaux de la vallée du Grand Rift – et d’Iten, « capitale mondiale du marathon » – au Kenya.

Le rayonnement planétaire des coureurs de la région est une bien futile satisfaction face aux tragiques décennies de la colonisation. L’ironie de l’histoire veut qu’un coureur kényan soit le premier à avoir officiellement franchi la barre fatidique des deux heures au marathon de Londres, capitale de l’ancienne puissance coloniale. Mais le règne de Sawe et de ses compatriotes reste précaire : n’oublions pas que le champion ougandais, Jacob Kiplimo (originaire du district de Kween, à la frontière, et entraîné sur les pentes ougandaises du mont Elgon) est à l’affût ; que l’éthiopien Yomif Kejelcha est le deuxième marathonien de l’histoire à être passé sous la barre des deux heures (record homologué), également à Londres (en 1 heure 59 minutes et 41 secondes) ; et que sa compatriote Tigst Assefa est, depuis le même jour, nouvelle détentrice du record du monde pour une épreuve féminine sur cette distance (en 2 heures 15 minutes et 41 secondes). La course au record n’est pas près de s’arrêter ; avec elle, grandit l’exigence d’un marathon éthique également libéré de toute suspicion de dopage.
Romélien Colavitti est assesseur à la Cour nationale du droit d'asile. Les propos tenus dans cet article sont personnels et n'engagent pas l'institution
17.06.2026 à 12:23
Ces Américaines qui ont pris soin des orphelins français pendant la Première Guerre mondiale
Emmanuel Destenay, Research Fellow, Sorbonne Université
Texte intégral (1911 mots)
Pendant et après la Première Guerre mondiale, des milliers d’Américaines ont joué le rôle de mères auprès d’orphelins français. Éclairage de cette facette méconnue de l’histoire transatlantique.
Entre août 1914 et avril 1917, malgré la neutralité affichée de leur pays, près de 25 000 Américaines, selon les estimations, traversent l’Atlantique pour soutenir la France dans sa guerre contre l’Allemagne. Ces citoyennes, bien souvent issues de la haute société américaine, pansent les plaies des soldats, réconfortent les civils, appuient les médecins ; une manière, selon elles, de s’opposer à la neutralité officielle de leur pays. À en croire ces femmes, il est du devoir des États-Unis de porter secours à la France, en mémoire de La Fayette, le héros français de la révolution américaine.
Lorsque les États-Unis entrent en guerre en avril 1917, certaines Américaines appuient les missions des troupes et occupent des positions précises. En 1918, 223 Américaines travaillent comme opératrices téléphoniques.
Leur participation à l’effort de guerre ainsi que leur implication sur le front occidental leur permettent de revendiquer une citoyenneté pleine et entière. Beaucoup espéraient que leur participation à l’effort de guerre leur permettrait d’obtenir enfin le droit de vote.
Pourquoi s’intéresser à l’histoire des marraines de guerre américaines
En règle générale, les historiens militaires traitent des batailles, des erreurs stratégiques commises par les états-majors et des pertes tandis que les spécialistes d’histoire culturelle analysent les répercussions du conflit sur les communautés civiles. Quant aux spécialistes d’histoire diplomatique, leur travail vise à comprendre la responsabilité des belligérants dans cette catastrophe européenne.
La plupart du temps, les historiens américains de la Première Guerre mondiale préfèrent traiter de la neutralité américaine plutôt que d’analyser la contribution des civils américains à l’effort de guerre français.
Plutôt que de chercher à comprendre ce qui pousse le président Woodrow Wilson à adopter une stricte neutralité en août 1914, il serait intéressant de dégager une histoire transatlantique des trajectoires individuelles de ces femmes qui ont choisi de participer à l’effort de guerre de la France.
Le Centenaire de la Première Guerre mondiale a permis à une nouvelle génération de chercheurs américains et européens de renouveler considérablement l’historiographie européenne à ce sujet. Cependant, ces études s’intéressent généralement à un pays en particulier et peinent à dégager un angle transnational. Par ailleurs, même lorsque certains chercheurs tentent une approche comparative de différentes sociétés européennes en guerre, la dimension transatlantique manque cruellement.
Les historiens spécialistes de l’enfance, des femmes et de la philanthropie peuvent contribuer de manière significative à l’historiographie de la Première Guerre mondiale en orientant les recherches dans une perspective transnationale et transatlantique.
Femmes américaines et actions humanitaires
Entre 1914 et 1921, malgré la neutralité affichée de leur pays, plusieurs centaines d’Américaines choisissent de s’engager dans des missions humanitaires et de secourir des orphelins de guerre français.
En 1915, un groupe de philanthropes américains décide de créer plusieurs « colonies » franco-américaines pour mettre à l’abri des orphelins de guerre belges et français. Au total, le Comité franco-américain pour les enfants de la frontière (CFAPCF) établit 28 colonies sur tout le territoire français. Les congrégations religieuses, comme les sœurs de Notre-Dame-de-Sion, mettent leurs domaines à disposition des philanthropes américains. Elles accueillent les jeunes rescapés, les instruisent et les nourrissent pendant toute la durée du conflit.
Cependant, ce sont des Américaines qui lèvent suffisamment de fonds pour approvisionner ces « colonies » et faire en sorte que les orphelins ne manquent de rien. Certaines, comme Alma A. Clarke, ancienne élève du prestigieux Bryn Mawr College (Pennsylvanie), et Erica Thorp de Berry (1890-1943), petite-fille du célèbre professeur de l’Université d’Harvard Henry Wadsworth Longfellow, lèvent des fortunes colossales aux États-Unis pour subvenir aux besoins des orphelins français. La France, elle, n’intervient nullement dans cette initiative.
Plus important encore, ces Américaines traversent l’Atlantique pour rencontrer les enfants. Au-delà même de leur contribution humanitaire, les Américaines mettent un point d’honneur à apprendre l’histoire des États-Unis aux petits orphelins. Alma A. Clarke organise même la très célèbre fête du 4-Juillet (Independence Day) dans la « colonie » du château de la Cour-au-Berruyer (Indre-et-Loire). Au total, plus de 800 enfants qui sont secourus.
Cette même année, en 1915, Émile Deutsch de la Meurthe (1847-1924) fonde une œuvre transatlantique humanitaire. La Société des enfants sans père de France (FCFS) mène une campagne intense aux États-Unis pour inciter les Américains à « adopter » des orphelins de père français. À raison de 36,50 dollars par an (ce qui reviendrait à environ 900 dollars aujourd’hui, soit 775,8 euros), un citoyen américain peut nourrir, blanchir, et contribuer à l’éducation d’un orphelin de père.
Même si l’organisation naît de l’initiative d’un industriel français et que l’œuvre se situe à Paris, ce sont des femmes américaines qui donnent une visibilité certaine à cette société philanthropique. Lors de la fête nationale des États-Unis, le 4 juillet, par exemple, les Américaines s’habillent en Marianne, n’hésitent pas à scander le nom de La Fayette et font circuler des récits d’orphelins affamés pour attendrir leurs compatriotes. Entre 1915 et 1921, les Américains adoptent quelque 300 000 orphelins de père français.
Le rôle des Américaines dans la reconstruction de la France
Après la signature de l’Armistice, les Américaines contribuent à la reconstruction de la France. Elles lèvent des fonds pour construire des écoles et des bibliothèques communales. Elles achètent des tracteurs et du bétail pour aider les agriculteurs et les fermiers. Depuis le château de Blérancourt (Aisne), Anne Morgan (1873-1952) et quelque 350 Américaines parcourent les territoires dévastés du Nord pour venir en aide aux civils. Avec Mary Carson Breckinridge (1881-1965) et Lucile Atcherson Curtis (1894-1986), Anne Morgan supervise plusieurs programmes destinés à redynamiser les zones libérées.

{kind=link}
Son initiative inspire d’autres Américaines. Certaines pilotent des programmes pour aider de jeunes mères incapables d’allaiter leurs nourrissons. En 1920, à Verdun (Meuse), Miss Butler, du Vassar College (État de New York), fonde la Ligue des enfants franco-américains. L’objectif : collecter suffisamment de fonds pour acheter des vaches et organiser quotidiennement la distribution de lait. À Reims (Marne), une « Goutte de lait » ouvre grâce à la détermination de femmes américaines, permettant à des centaines de veuves de nourrir leurs nourrissons.
S’intéresser aux œuvres humanitaires pilotées par des Américaines pendant et après la Première Guerre mondiale, c’est écrire une nouvelle histoire, une histoire « connectée », des relations franco-américaines en temps de guerre. Ces recherches ne renouvellent pas seulement l’historiographie de 1914–1918 ; elles représentent un point d’entrée important pour les enseignants d’histoire soucieux de partir d’une perspective transnationale pour traiter du Premier Conflit mondial avec leurs élèves.
À partir de l’exemple d’un orphelin adopté pendant le conflit, il serait possible à des établissements français d’envisager des projets pédagogiques avec leurs homologues américains. Imaginons, par exemple, un lycée de Paris travailler en étroite collaboration avec le célèbre Vassar College. À l’heure où les associations américaines d’histoire, telles que l’American Historical Association (AHA) et l’Organization for American Historians (OAH), réfléchissent à la manière d’inclure les établissements secondaires dans les recherches universitaires et militent pour que les jeunes générations s’intéressent à cette discipline, une telle démarche serait précieuse.
Emmanuel Destenay ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
17.06.2026 à 12:21
Agathe Habyarimana, un procès pour l’Histoire ?
François Robinet, Maître de conférences en histoire contemporaine, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Texte intégral (2072 mots)
Le 6 avril 1994, la destruction en vol par un tir de missile de l’avion transportant le président rwandais Juvénal Habyarimana, ainsi que le chef de l’État burundais Cyprien Ntaryamira, marque le début du génocide des Tutsi du Rwanda, au cours duquel plus d’un million de personnes furent massacrées en quelque trois mois. L’entourage de la veuve d’Habyarimana, Agathe, est accusé d’avoir joué un rôle majeur dans l’instigation de ce carnage à grande échelle. Réfugiée depuis des années en France, Mme Habyarimana, qui a bénéficié en 2025 d’un non-lieu qui vient d’être infirmé par la chambre de l’instruction de la Cour d’appel de Paris, pourrait être jugée pour ces faits. Un tel procès, s’il avait lieu, aurait une importance cruciale pour l’histoire du génocide des Tutsi.
Alors qu’un non-lieu semblait se profiler, la chambre de l’instruction de la Cour d’appel de Paris a ordonné, le 6 mai dernier, la reprise de l’instruction des plaintes visant Agathe Habyarimana pour complicité de génocide et complicité de crimes contre l’humanité.
Pour quelles raisons cette décision, qui rouvre un dossier ancien de près de vingt ans, est-elle si importante pour les rescapés comme pour les associations engagées à leurs côtés ? Comment expliquer la durée de l’instruction ? Que pourrait-on attendre d’un procès si l’information judiciaire devait aboutir à un renvoi en cour d’assises ?
Une procédure au long cours
L’affaire semblait entendue. En août 2025, après dix-sept ans d’enquête judiciaire en France – la justice française a été saisie à la suite d’une plainte déposée en février 2007 par le Collectif des parties civiles pour le Rwanda (CPCR), la présence d’Agathe Habyarimana sur le sol français permettant l’ouverture d’une enquête pour des faits présumés de génocide – deux juges d’instruction considéraient les charges insuffisantes pour renvoyer l’ancienne première dame rwandaise, veuve du président Juvénal Habyarimana, devant une cour d’assises.
L’ordonnance de non-lieu des juges Stéphanie Tacheau et Carole Vujasinovic semblait définitivement éloigner la perspective d’un procès d’Agathe Habyarimana pour ses responsabilités présumées dans le génocide contre les Tutsi.
Cette ordonnance de non-lieu a suscité de vives réactions et a été contestée aussi bien par les parties civiles et plusieurs associations de rescapés que par le parquet national antiterroriste lui-même.
Ainsi, dans une tribune publiée par le Monde, le 30 mars dernier, plusieurs personnalités et historiens spécialistes du Rwanda – parmi lesquels l’auteur de ces lignes – rappelaient que les travaux historiques ainsi que les procédures judiciaires conduites devant le Tribunal pénal international avaient mis en lumière le rôle joué par le réseau informel parfois appelé « Akazu » (un réseau parfois surnommé le « clan de Madame ») dans la radicalisation du régime, puis dans la mise en œuvre des massacres.
Les réactions furent d’autant plus vives que l’ordonnance de non-lieu décrivait Agathe Habyarimana comme une « victime » des événements et de l’exil qui suivit, une formulation qui a suscité l’incompréhension de plusieurs associations de rescapés et parties civiles.
Encore récemment, plus de 600 Rwandaises publiaient une lettre ouverte dénonçant la possible clôture de l’instruction dans un texte exprimant leur inquiétude – et leur indignation – face au risque de voir disparaître la possibilité même d’un débat public sur le rôle d’Agathe Habyarimana dans le génocide.
La décision de la chambre d’instruction de la Cour d’appel du 6 mai dernier, contestée en cassation par madame Habyarimana, marque donc un nouveau retournement de situation, un retournement qui ne préjuge en rien de l’organisation d’un futur procès et encore moins d’une éventuelle condamnation.
Plus de trente ans après le génocide, cette décision rappelle surtout à quel point le cas Agathe Habyarimana (aujourd’hui âgée de 83 ans) occupe une place singulière au cœur des débats historiques, judiciaires et mémoriels consacrés au génocide des Tutsi.
Le pouvoir informel de l’« Akazu »
Comprendre cette singularité exige de revenir sur le travail d’enquête et de documentation exceptionnel qui a été mené depuis 1994 et dont la justice dispose aujourd’hui pour se prononcer.
Dès les années 1990, les recherches consacrées au génocide des Tutsi ont permis de mieux comprendre le rôle joué par ce que les contemporains appelaient alors publiquement l’« Akazu » (la « Petite Maison »). Derrière ces termes se dessinait un premier cercle du pouvoir rwandais structuré autour de la famille présidentielle – de proches alliés politiques, militaires et économiques, majoritairement originaires du nord-ouest du Rwanda.
De nombreux travaux – notamment ceux d’Andrew Wallis et d’autres historiens, journalistes, acteurs judiciaires et associations de défense des droits humains – ont souligné à quel point ce réseau informel joua un rôle majeur dans la diffusion de l’idéologie du Hutu Power (idéologie extrémiste qui présente les Tutsi comme une menace à éliminer), dans le soutien aux médias extrémistes comme la Radio télévision libre des Mille Collines (RTLM) ou le journal Kangura, dans la préparation puis dans l’exécution même du génocide.
Au cœur de ce réseau, Agathe Habyarimana apparaît comme une figure centrale. Elle n’a certes occupé aucune fonction officielle dans l’appareil d’État, mais sa position au sein des réseaux familiaux et politiques du régime – ainsi que sa renommée et le prestige de son clan – lui donnait une influence singulière.
Le défi de la preuve
Si les logiques de pouvoir à l’œuvre sont désormais bien connues, comment expliquer les difficultés de la justice à établir les responsabilités individuelles d’Agathe Habyarimana ?
D’abord, comme souvent dans les affaires liées aux crimes imprescriptibles, le temps finit par devenir lui-même un acteur du dossier judiciaire : des témoins disparaissent, les mémoires se fragmentent et les archives écrites – parfois difficilement accessibles – prennent une place croissante dans la compréhension des événements.
Il reste par ailleurs difficile de qualifier précisément les responsabilités pénales individuelles alors même que les mécanismes de décision au sein de l’« Akazu » passaient principalement par des relations de proximité, d’influence et de patronage, un tel système de pouvoir reposant moins sur des décisions administratives classiques laissant des traces écrites que sur des échanges informels.
Il faut enfin comprendre qu’Agathe Habyarimana – et son fils Jean-Luc Habyarimana (qui n’a jamais fait l’objet de poursuites judiciaires pour une participation présumée au génocide des Tutsi) – restent après le génocide des figures symboliquement importantes dans les controverses mémorielles et politiques liées au génocide des Tutsi, nombreux étant les anciens dignitaires du régime engagés dans des stratégies de renversement des responsabilités voire de négation du génocide.
Les journées des 6, 7 et 8 avril 1994 se trouvent au cœur des investigations et, là encore, les responsabilités individuelles ne sont pas si simples à documenter précisément.
Plusieurs témoignages recueillis après le génocide décrivent la résidence présidentielle de Kanombe, à Kigali, comme un lieu de regroupement et de coordination du premier cercle du régime dans les heures qui suivent l’attentat contre l’avion présidentiel. Certains témoignages évoquent la présence d’Agathe Habyarimana lors de discussions concernant la traque des opposants politiques et des Tutsi. D’autres témoignages demeurent indirects, contradictoires ou fragiles tandis que les sources écrites disponibles restent souvent lacunaires. L’informalité même du fonctionnement de l’« Akazu » complique considérablement le travail de la justice comme celui des historiens.
Ces difficultés ne doivent pourtant pas conduire à invisibiliser ce que les travaux historiques ont progressivement mis en lumière : le génocide des Tutsi a été porté par un appareil politico-militaire dont le premier cercle présidentiel constitua l’un des principaux centres de gravité.
Ce que juger signifie
C’est sans doute là que réside, à mon sens, l’enjeu si particulier d’un éventuel procès d’Agathe Habyarimana. Non dans la révélation spectaculaire de faits inconnus. Non dans l’illusion qu’une procédure judiciaire pourrait à elle seule enrichir l’histoire du génocide des Tutsi. Mais dans la création d’un temps de confrontation publique entre archives, témoignages et savoirs historiques autour du rôle joué par l’entourage présidentiel.
L’important me semble ici que les procès pour génocide ne produisent pas seulement des verdicts. Ils constituent aussi des moments de mise en visibilité, de discussion publique, d’intelligibilité partagée, comme l’ont montré les procès du Tribunal pénal international pour le Rwanda (TPIR) à Arusha ou ceux en compétence universelle en Europe. Si l’on peut regretter que ces derniers n’aient pas bénéficié de la même attention que les grands procès historiques des années 1980-1990 (Barbie, Touvier, Papon), leurs audiences ont tout de même contribué à révéler des témoignages, à exhumer certains documents, à inscrire plus profondément le génocide des Tutsi dans notre mémoire collective.
La tenue d’un procès d’Agathe Habyarimana aurait, c’est vrai, une portée bien particulière. Parce qu’il se déroulerait vraisemblablement à Paris. Parce qu’il concernerait une personnalité présente en France depuis 1994. Parce qu’il rouvrirait nécessairement, dans l’espace public français, des questions longtemps demeurées sensibles sur les relations entre Paris et le régime Habyarimana, sur l’opération Amaryllis (8-14 avril 1994) ou encore sur les réseaux politiques, militaires et médiatiques qui entourèrent l’ancien pouvoir rwandais avant, pendant et à la suite du génocide.
L’absence de procès aurait aussi une signification historique et mémorielle. Pour de nombreux rescapés du génocide, pour plusieurs associations et pour une partie des chercheurs travaillant depuis des années sur le génocide des Tutsi, elle laisserait ouverte une question devenue centrale : celle de la possibilité même d’examiner publiquement en France les responsabilités des réseaux politico-familiaux qui gravitaient autour du pouvoir présidentiel rwandais en 1994, privant du même coup les rescapés comme les citoyens français d’un moment important de clarification publique.
Les recherches de François Robinet ont bénéficié de financements accordés par différentes organisations publiques de soutien à la recherche scientifique.
16.06.2026 à 18:20
Une plante carnivore révèle un mécanisme inédit de mouvement ultrarapide sans muscle
Joel Marthelot, Chercheur au CNRS, Aix-Marseille Université (AMU)
Yoel Forterre, Directeur de Recherche, Centre national de la recherche scientifique (CNRS); Aix-Marseille Université (AMU)
Texte intégral (1816 mots)

La dionée, ou « plante attrape-mouche », fascine les naturalistes depuis des siècles pour sa capacité à refermer son piège en une fraction de seconde lorsqu’un insecte s’y aventure. Charles Darwin écrivait d’ailleurs dans Insectivorous Plants, en 1875, qu’elle était, « par la rapidité et la puissance de ses mouvements, l’une des plus merveilleuses qui soit au monde ».
Cette fascination tient à un paradoxe : contrairement aux animaux, les plantes ne possèdent ni muscles ni système nerveux centralisé. Comment peuvent-elles alors produire des mouvements aussi rapides ?
Depuis plusieurs décennies, l’explication dominante reposait sur un mécanisme hydraulique. Une redistribution rapide de l’eau entre différentes cellules du piège devait provoquer un changement de courbure des feuilles et entraîner leur fermeture. Cette hypothèse s’accordait avec le rôle central que joue la pression hydraulique dans de nombreux processus végétaux, depuis les mouvements réversibles d’ouverture et fermeture des pores à la surface des feuilles, pour capter le C0₂ nécessaire à la photosynthèse, jusqu’à la croissance lente des tissus.
Notre étude, publiée dans Science, montre toutefois que cette explication est insuffisante. En combinant des mesures hydrauliques et mécaniques de l’échelle du piège entier à la cellule, nous avons pu comparer directement les échelles de temps associées aux différents mécanismes en jeu.
Nous avons montré que les transferts d’eau sont beaucoup trop lents pour expliquer une fermeture qui se produit en environ un dixième de seconde, et mis en évidence un autre phénomène, beaucoup plus rapide.
Dans la seconde qui suit la stimulation, les cellules de la face externe du piège, qui se comportent comme des ballons gonflés, se ramollissent brutalement. Ce ramollissement ne provient pas de la baisse de la pression interne, mais directement de la paroi qui entoure les cellules, qui devient plus flexible !
L’équilibre mécanique des tissus est ainsi modifié et induit une courbure active des deux lobes du piège, qui se referment. Le système franchit alors un seuil d’instabilité mécanique, comparable à celui d’une coque élastique qui se retourne brusquement sous l’effet d’une contrainte, à la manière des jouets appelés « puces sauteuses », déclenchant une amplification spectaculaire de la vitesse du piège.
Il s’agit de la première démonstration expérimentale d’un changement aussi rapide des propriétés mécaniques des parois cellulaires chez une plante.
Pourquoi est-ce important ?
Cette découverte conduit à revoir notre compréhension des mouvements végétaux rapides.
Les mouvements des plantes sont généralement interprétés comme des phénomènes gouvernés par des échanges d’eau. Nos travaux révèlent une autre stratégie : plutôt que de déplacer rapidement de grandes quantités d’eau, la plante agit directement sur les propriétés mécaniques de la paroi cellulaire.
On peut comparer ce mécanisme à celui d’un ressort comprimé. L’énergie nécessaire au mouvement est stockée à l’avance dans la structure. Il suffit ensuite de libérer un verrou pour déclencher un mouvement très rapide. Dans le cas de la dionée, ce verrou est mécanique : l’assouplissement local des parois cellulaires permet au piège de franchir un seuil d’instabilité et de basculer brutalement d’un état stable à un autre.

Plus généralement, cette observation montre que la paroi cellulaire végétale n’est pas un simple élément structural passif, mais un matériau dont les propriétés mécaniques peuvent être modulées de manière dynamique pour contrôler le mouvement.
Quelles sont les suites ?
Si nous avons identifié le mécanisme physique responsable de la fermeture du piège, de nombreuses questions demeurent ouvertes.
La principale concerne l’origine moléculaire de ce ramollissement ultrarapide. Comment la plante parvient-elle à modifier en quelques secondes les propriétés mécaniques de ses parois cellulaires ?
La paroi végétale est un matériau composite complexe, constitué d’un réseau de fibres de cellulose enchâssées dans une matrice de polysaccharides et de protéines. Les acteurs moléculaires responsables de cette transition mécanique restent encore à identifier. Comprendre comment un signal mécanique déclenché par le contact d’un insecte est converti en une modification aussi rapide des propriétés du matériau constitue désormais l’un des principaux défis.

Les progrès récents des outils de génétique moléculaire appliqués à la dionée ouvrent aujourd’hui des perspectives prometteuses. Ils pourraient permettre de relier les mécanismes biologiques impliqués aux changements mécaniques observés à l’échelle de la paroi.
Au-delà de la biologie végétale, cette découverte intéresse également les ingénieurs qui cherchent à concevoir des robots souples et des matériaux adaptatifs. Les structures bistables et les instabilités mécaniques sont déjà largement exploitées pour produire des mouvements rapides comme des mini-robots sauteurs.
La dionée montre cependant qu’un organisme vivant peut contrôler une telle instabilité en modifiant très rapidement les propriétés mécaniques de ses tissus. Ce principe pourrait inspirer une nouvelle génération de systèmes capables de changer de forme rapidement en réponse à un signal mécanique, électrique ou chimique.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui les ont menées, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Ce travail a reçu le soutien financier du programme public H2020 de l’Union Européenne (Conseil Européen de la Recherche) à travers le projet ERC 647384 PLANTMOVE .
Joel Marthelot ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:49
What Kenya’s fish markets tell us about choosing between nutrients and contaminants
Kira Lancker, Assistant Professor - Department of Food and Resource Economics, University of Copenhagen
Texte intégral (1772 mots)
At lakeside markets along Lake Victoria, Africa’s largest lake by area, choosing fish to eat is part of daily life. A customer might pick a tilapia based on its freshness, size, price, and farmed or non-farmed origin, much like shoppers do in markets and supermarkets around the world. Whether grilled tilapia or salmon fillet, fish are a key source of healthy fats, such as omega-3s, essential for heart health. But these nutrients are invisible. We can’t see what’s inside the fish displayed at the market.
Risks are similarly invisible; as waters grow increasingly polluted, fish become more likely to contain harmful substances such as heavy metals or pesticides. Fish are thus a “bundled” product: the same tilapia that provides essential nutrients might also carry a health risk. This creates a dilemma. Consumers face a difficult trade-off.
Vendors increasingly use labels and nutritional guidelines to help consumers “see inside the fish”, to consider both nutrient benefits and contamination risks. But even if we know the exact levels of every nutrient and toxin, how do we weigh those trade-offs? Which matters more? This complexity is difficult to communicate effectively.
One problem is that, depending on individual background and cumulative intake, the prospective gains from nutrient intake or risks from ingesting contaminants may vary.
Another challenge is that how we resolve this trade-off can change throughout our lives. At one point our choices will be self-motivated, at another, we will have our children in mind, or pregnancy or a health condition will come into consideration. The balance between benefit and risk shifts in relation to these and other life situations.
Past experience shows how difficult this balance can be. A warning issued in the United States about mercury in fish targeted at pregnant women also led many other, not-at-risk consumers to reduce their own fish intake – losing important nutritional benefits.
To better understand how the information communicated in labels affects consumer choices about these trade-offs, our international research team ran an experiment with fish consumers in communities around Lake Victoria in Kenya.
Kenya’s fish markets: a microcosm of a global challenge
Fish is both an important source of income and a regular part of diets in western Kenya: 93% of our participants had eaten fish in the past week, making it an ideal environment for studying real-world decisions.
Add to that the fact that the lake is under pressure. As in many aquatic environments around the world, runoff from farms and wastewater fuel harmful algal blooms, dense green layers that spread across the water. In the wake of these blooms, bacteria produce toxins, known as microcystins.
Microcystins are harmful to humans when absorbed in too-high amounts through drinking water or fish tissue. Maximum intake guideline values set by the World Health Organization (WHO) exist for one cyanobacterial toxin, microcystin-LR, with stricter thresholds for, e.g. children.
In our experiment, participants were asked to choose between different hypothetical fish purchase options. Each option came with simple labels showing nutrient levels (healthy fats) and toxin levels: low, medium or high.
This allowed us to analyse how people weigh up these trade-offs when both benefits and risks are known and clearly communicated.
What we found
At the individual level, our results are reassuring. Most consumers show careful consideration for both nutrient and toxin labels. But they react more strongly to warnings about risk than to information about benefits. In other words, potential harm weighed more heavily than potential gain. This matters. If risk warnings dominate too strongly, people may avoid fish altogether. This highlights the importance of complementing risk guidance with information on benefits in cases of bundled products, like fish, where a nuanced, balanced response is preferable over a large avoidance reaction that may crowd out essential nutrient intake.
Our study also shows that participants’ reactions are more than just the sum of the “nutrient and the contaminant equation”, and indicates that consumers do not treat nutrients and contaminants as two separate factors that can simply offset each other. If a fish is high in nutrients, this does not simply cancel out higher contamination levels.
Instead, the two are evaluated together: benefits matter less when risks are higher. This seems rational, given that a balanced diet would be characterised by a good status in both dimensions. And it suggests that the two labels could support each other rather than compete for limited attention.
A hidden inequality
While many participants made nuanced choices, not everyone responded in the same way.
Some consumers paid close attention to both nutrients and contaminants. Others responded much less to either type of information. These less responsive consumers were more likely to have lower incomes, less education, or were less awareness of environmental risks. Those groups are often already more vulnerable and less healthy.
This raises a broader concern at the societal level.
If more responsive consumers begin avoiding certain fish, prices for those fish might fall, reflecting lower demand. This could make unhealthier fish more affordable – and therefore more attractive – for less information-responsive consumers. In that case, health risks could become concentrated among the already disadvantaged. In other words, better information might not automatically lead to better outcomes for everyone. To what degree this occurs in practice remains a matter for further research.
What can be done?
Helping consumers navigate these trade-offs starts with whether, and how, credible information is presented.
Researchers are working to uncover a systematic relationship between observable fish traits – such as species or size – and nutrient or contaminant levels. While fish-specific labelling will most likely remain out of reach, such systematic links could be used to support simple guidance for consumers’ choices.
Overall, many consumers display nuanced, highly rationally justifiable choices when the benefits and risks appear side-by-side.
Our results support trusting consumers to make nuanced decisions in line with their own specific needs and concerns. But the findings also underscore that nutritional information campaigns need to concentrate on communicating both sides of the coin – and to be vigilant concerning distributional hazards.
But the burden shouldn’t fall only on consumers and on those who oversee labelling.
The difficult trade-offs people face at the market are rooted in environmental pollution problems. Pollution reduces the quality of fish as food, and burdens consumers with increasingly difficult choices. Reducing environmental pollution is therefore essential – not only for ecosystems, but for food security.
This article was co-written with Christopher B. Barrett (Charles H. Dyson School of Applied Economics and Management, Cornell University), Kathryn J. Fiorella (Department of Public & Ecosystem Health, Cornell University), Christopher M. Aura (Kenya Marine and Fisheries Research Institute, Kisumu), Hezron Awandu (Kenya Marine and Fisheries Research Institute, Kisumu), Fonda J. Awuor (Kenya Marine and Fisheries Research Institute, Kisumu), Patrick Otuo (Kenya Marine and Fisheries Research Institute, Kisumu).
The Axa science philanthropy is now part of the Axa Foundation for Human Progress, which brings together the commitments of Axa Group and Mutuelles d'Assurances in the fields of Science, Nature, Solidarity, and Culture. Before 2025, the global science philanthropy was held by the Axa Research Fund, which has supported over 750 projects around the world since its inception back in 2007. To learn more, visit Axa Foundation for Human Progress.
A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
This project was funded by an Atkinson Venture Fund award and an NSF CNH2 (NSF BCS No. 2009658). Lancker's contribution was partly funded by the AXA XL Valuing nature award.
16.06.2026 à 17:47
Les baleines ont-elles l’oreille musicale ?
Olivier Adam, Bioacousticien, Sorbonne Université
Texte intégral (2337 mots)

De nombreux cas d’interactions entre humains et cétacés à travers la musique ont été observés. Des navigateurs en ont filmé, des artistes ont même proposé des performances musicales à destination des baleines. Mais savons-nous, scientifiquement, si ces mammifères réagissent spécifiquement à la musique et s’ils peuvent la différencier de tous les bruits anthropiques ?
Le film la Baleine et le Musicien, du réalisateur Valentin Paoli, qui sort au cinéma ce 17 juin, évoque notre éternel désir de communication, y compris avec des espèces non-humaines, et en particulier avec celles qui nous fascinent comme les baleines. Le film ouvre aussi le débat plus largement : il interroge sur notre motivation profonde à vouloir de telles interactions et le plaisir qu’elles procurent lorsqu’elles se réalisent. Il souligne aussi les effets de la musique pour entrer en connexion et partager des émotions. Il évoque également les limites éthiques qu’impose le fait de respecter ces espèces et de porter attention à leur environnement marin, déjà saturé de sons anthropiques.
Ce documentaire met en scène le célèbre compositeur et musicien français Rone qui s’interroge notamment sur la perception de sa musique par les baleines, à la suite de plusieurs vidéos qui avaient fait le buzz sur les réseaux sociaux. On y voyait des navigateurs isolés sur l’océan prétendant que les cétacés autour de leur voilier étaient attirés par sa musique. Au cours d’une introspection, l’artiste se confie sur sa création musicale et sur sa faculté à toucher le public humain et, pourquoi pas finalement, aussi les baleines ? La quête qu’il mène à travers ce long-métrage révèle des secrets sur sa personnalité, sur ses envies et aussi son étonnement devant le pouvoir incroyable de sa musique à procurer des émotions.
Avec l’équipe de l’association Abyss à La Réunion, j’ai été invité sur ce projet pour contribuer au volet scientifique, en tant qu’expert en bioacoustique marine. En effet, je m’intéresse, également dans le cadre de ma recherche, aux effets potentiels de la musique sur les baleines. Y sont-elles sensibles ? Peut-on parler de musicalité chez les cétacés ? En fait, quelles sont les connaissances à ce sujet, aujourd’hui ?
Tout d’abord, il faut dire que ce n’est pas la première fois que des artistes proposent des performances musicales aux cétacés. En 2011, le chercheur David Rothenberg a joué de la clarinette devant des baleines à bosse à Hawaï. Il a, d’ailleurs, témoigné d’une réponse surprenante de l’un de ces cétacés dans un échange bidirectionnel inter-espèce, la baleine a émis une vocalisation qui correspondait à ce qu’il jouait. Et il ne s’agit pas d’un cas isolé.
On peut également citer Paul Spong, Jim Nollman et plus récemment Aline Pénitot qui sont allés jouer de la musique à des cétacés et qui rapportent des réactions tout à fait similaires, pourtant dans des lieux et des contextes totalement différents.
Les cétacés sont-ils prédisposés à « apprécier » la musique ?
Alors que l’on reconnaît la zoomusicologie (l’étude des qualités esthétiques des sons des animaux non humains, ndlr), peut-on dire que les cétacés sont prédisposés à percevoir la musique humaine ou s’agit-il tout simplement d’une projection anthropomorphique ?
Commençons par rappeler que les cétacés sont des mammifères. Ils utilisent la communication acoustique dans toutes leurs activités vitales, en générant des sons de façon intentionnelle et extrêmement précise par un contrôle absolu de leur générateur vocal. Ils ont le même système auditif que nous, avec une cochlée (partie auditive de l’oreille interne, ndlr) et un nerf auditif qui transporte l’information pour analyse par le cerveau. D’ailleurs, des chercheurs ont déjà mesuré leur sensibilité auditive. Tout récemment, une étude a même confirmé l’audiogramme des baleines à bosse en observant leurs comportements en réaction à la diffusion de différents sons émis dans une large bande fréquentielle. Une chose est donc certaine : les baleines à bosse et nous avons la possibilité de communiquer par le son.
L’étape suivante est maintenant de savoir s’il y a une réaction spécifique à la musique ou si elle serait la même lors de la diffusion d’un bruit quelconque ?
Cette question est fondamentale, car on sait de façon certaine aujourd’hui que les sons des activités humaines en mer sont nocifs pour les cétacés et, d’une façon générale, pour l’ensemble des écosystèmes marins. Ils peuvent les empêcher de poursuivre leurs activités vitales, voire être la cause d’échouages. Ainsi, la Commission européenne a reconnu ces bruits anthropiques comme pollution depuis 2008, incitant l’industrie à prendre des dispositions pour diminuer les niveaux sonores. Étant moi-même membre du Collectif national sur le bruit sous-marin, créé en janvier 2020 par le ministère de la transition écologique, le ministère de la mer et l’Office français pour la biodiversité, il est évident que je n’ai aucune motivation à rajouter, dans l’océan, des nuisances supplémentaires.
Mais alors, peut-on distinguer la musique du bruit ? À première vue, cette question semble facile, mais le manque de définition claire de ce qu’est la musique peut conduire à des hésitations.
Les scientifiques proposent le recours à des descripteurs spécifiques, les philosophes évoquent son pouvoir émotionnel qui la place au-delà du langage et aussi de toute forme de bruits. Quant aux neuroscientifiques, ils apportent une réponse complémentaire tout à fait intéressante. En effet, ils ont montré que les aires du cerveau impliquées ne sont pas les mêmes pour le traitement de la musique que celui de la parole ou du bruit.
Ainsi, certaines personnes peuvent être atteintes d’amusie, tout en comprenant parfaitement ce qu’on leur dit. De même, une mémoire spécifique, séparée de celle utilisée pour la parole, est réservée aux musiques qui nous ont accompagnés au cours de notre vie. Cette découverte est, d’ailleurs, à l’origine de la musicothérapie, qui vise à soigner des patients par la musique.
La sensibilité musicale a été prouvée chez les cétacés
Des travaux menés par des chercheurs du département de biomédecine comparée et de nutrition de l’Université de Padoue (Italie) ont montré que la musique classique permettait d’augmenter des comportements affiliatifs chez des dauphins captifs, avec un accroissement des contacts doux et des nages synchronisées entre eux. Pour des cétacés évoluant dans leur milieu naturel, ce sont des études malheureusement plus compliquées à mettre en œuvre, car ils sont extrêmement mobiles et très difficiles à suivre lorsqu’ils évoluent en profondeur. Les observations de comportements de surface sont alors souvent parcellaires et, finalement, la méthode la plus rigoureuse qui permet de quantifier objectivement leurs réactions après diffusion des sons que l’on veut tester est de recourir à des balises électroniques que l’on ventouse sur leur dos.
C’est d’ailleurs ce que nous faisons avec l’association Cétamada, l’Institut des neurosciences Paris-Saclay, l’Université d’Antananarivo (Madagascar) et Sorbonne Université depuis une dizaine d’années, mais il faut reconnaître que le protocole est long à déployer en mer. Cependant, ces balises nous ont déjà permis de décrire les interactions entre les mères baleines à bosse et leur baleineau et aussi de tester différents types de sons… mais malheureusement pas encore de musique !
On peut donc comprendre qu’il y a plus de publications présentant des études scientifiques portant sur les effets de la musique sur des espèces terrestres, comme les oiseaux, les chats, les chevaux ou les chimpanzés. Elles mettent toutes en avant les effets positifs, par exemple, des préférences musicales et la diminution de stress. Ainsi, plusieurs programmes plaident pour la diffusion de la musique pour le bien-être animal. Mais alors pourquoi certains d’entre nous sont-ils encore sceptiques ? Pourquoi résistent-ils aussi fort au fait que certaines espèces non humaines puissent être sensibles à la musique ?
L’éthologue Jessica Serra suggère que cela vient de notre éducation occidentale fondée, depuis la Grèce antique, sur une volonté systématique de rupture entre la nature et nous. Et au fil des siècles qui ont suivi, cette pensée d’exclusion a persisté, soutenue par la science, la philosophie et la religion. Cela s’est finalement traduit par une impossibilité de reconnaître au vivant, quelle que soit l’espèce, la possibilité qu’il ait des langages, des sentiments, des sensibilités. Encore aujourd’hui, certains n’arrivent pas à prononcer ces mots pour des espèces non humaines ni même à admettre qu’elles puissent être douées d’intelligence. Rappelons que le mot « sentience » (pour un être vivant, capacité à ressentir les émotions, la douleur, le bien-être, etc., et à percevoir de façon subjective son environnement et ses expériences de vie) n’est entré dans notre dictionnaire qu’en 2020, et que la personnalité juridique des animaux non humains leur est encore déniée.
Pourtant, notre regard sur le vivant commence à changer. Des philosophes nous invitent à ignorer cette frontière imaginaire avec la nature et à accepter la pleine existence des animaux avec lesquels nous sommes interdépendants. D’autres proposent de faire évoluer notre droit pour mieux les reconnaître.
Et tout s’accélère : le 19 mai dernier, la revue américaine Science a publié les travaux menés par des chercheurs des universités McGill (Montréal, Canada) et Yale (New Haven, États-Unis). Ils montrent que l’universalité de la musique n’est pas réservée uniquement aux humains. Elle a ce côté répétitif que les cerveaux s’attachent inconsciemment à prédire et qui génère des sensations émotionnelles uniques, partagées également par des espèces non humaines. Et voilà !
Cette nouvelle découverte ne montre pas une certaine faiblesse de l’humain qui abandonnerait sa suprématie sur le vivant, mais il s’agit juste d’admettre que celle-ci n’a jamais existé et d’accepter enfin la réalité de notre place sur un pied d’égalité avec les autres habitants de cette planète. Espérons que cela permette de partager les territoires et de mieux conserver les écosystèmes, s’il est encore temps !
Olivier Adam ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:46
Est-ce sans danger de conserver le poisson dans des emballages en plastique ? Une nouvelle étude fait le point
Ethel Eljarrat, Profesora de Investigación del Departamento de Química Ambiental, Instituto de Diagnóstico Ambiental y Estudios del Agua (IDAEA - CSIC)
Maria Vittoria Barbieri, Postdoctoral Researcher, Instituto de Diagnóstico Ambiental y Estudios del Agua (IDAEA - CSIC)
Texte intégral (2558 mots)

Une étude menée sur des poissons gras, comme le saumon, ou maigres, comme le merlu, conservés dans du plastique, montre que des substances toxiques (phtalates, bisphénol A pourtant interdit, etc.) migrent depuis l’emballage vers les aliments. Les chercheurs ont reproduit les usages domestiques, avec du poisson mis au réfrigérateur et au congélateur et différents emballages en plastique (barquettes classiques, compostables, films alimentaires, sacs…). Leurs résultats sont surprenants et plaident pour une réglementation plus stricte dans ce domaine.
Quand nous achetons un filet de saumon ou un merlu frais au supermarché, notre priorité est de respecter la chaîne du froid afin d’éviter la prolifération de bactéries. Cependant, nous ne pensons généralement pas à la contamination potentielle de ces aliments qui viendrait de l’utilisation d’emballages destinés à les conserver. Quand nous conservons du poisson au réfrigérateur ou au congélateur, les additifs chimiques présents dans le plastique, des composés conçus pour conférer souplesse ou durabilité à l’emballage, peuvent migrer depuis cet emballage vers l’aliment.
Les plastiques ne sont pas des matériaux inertes. Ils sont constitués de polymères auxquels sont ajoutées plus de 12 000 substances chimiques différentes, comme des plastifiants, des bisphénols, des filtres solaires et des retardateurs de flamme. Ces composés peuvent se retrouver dans le poisson par trois voies différentes : la pollution des mers et des océans, la transformation des aliments et leur conservation dans différents types d’emballages.
À lire aussi : Boîtes de conserve : des risques invisibles pour la santé ?
Certaines études concluent que ces composés ne sont pas inoffensifs, car ils présentent une toxicité à long terme chez l’humain, en particulier du fait de leur lien potentiel avec des troubles métaboliques et des effets sur la reproduction. De nombreuses données scientifiques démontrent par exemple la toxicité des plastifiants tels que les phtalates. En guise de réponse, les fabricants ont de plus en plus souvent recours à des plastifiants de substitution, bien que des recherches récentes suggèrent que bon nombre d’entre eux ne sont pas non plus exempts de risques pour la santé.
Une étude pionnière dans des conditions réelles d’utilisation domestique
Jusqu’à présent, la plupart des études sur les contaminants alimentaires analysaient le produit directement après son achat, sans tenir compte des processus de conservation ou de cuisson. Par ailleurs, les tests visant à évaluer les risques potentiels liés à la migration depuis les emballages vers les aliments sont réalisés en laboratoire à l’aide de simulants alimentaires qui ne reflètent pas la complexité d’une matrice réelle.
Une étude récente, menée par l’Institut de diagnostic environnemental et d’études sur l’eau (IDAEA-CSIC), en collaboration avec l’Université de Florence, et publiée dans la revue Environment International, a bouleversé cette approche.
Au cours de nos investigations, nous avons analysé pour la première fois le transfert de quatre familles de substances chimiques, en l’occurrence les phtalates, les esters organophosphorés, les bisphénols et les plastifiants de substitution aux phtalates, depuis des emballages d’usages courants vers le poisson. Nous avons procédé dans des conditions réelles de conservation à domicile. Nous avons évalué ce transfert sur des espèces très consommées en Espagne, comme le saumon, le thon et le merlu. Ces poissons étaient conservés dans deux conditions habituelles : au réfrigérateur (+4 °C pendant 48 heures) et au congélateur (-18 °C pendant 30 jours).
Les emballages analysés incluaient des barquettes classiques en polystyrène, du film transparent jusqu’à des sachets de congélation à fermeture zip, en passant par des barquettes et des sachets compostables.

Même le congélateur n’empêche pas la migration
Dans des travaux précédents, nous avons déjà démontré que la cuisson d’aliments emballés dans des matériaux plastiques peut accroître le transfert de plastifiants. Les résultats présentés dans cette nouvelle étude montrent, cette fois, que le froid ne constitue pas une barrière infranchissable. Même si les basses températures ralentissent généralement les processus, le temps de contact est un facteur clé qui favorise la migration de ces substances.
Le dihexylphtalate (DHEXP) n’a, par exemple, présenté de migration significative que dans les échantillons congelés, ce qui suggère que le fait de laisser le poisson en contact avec le plastique pendant plusieurs semaines augmente le risque de transfert.
De plus, la migration n’est pas la même pour tous les poissons, mais dépend de nombreux facteurs. Dans les poissons gras (comme le saumon), les additifs les plus lipophiles (qui se dissolvent bien dans les graisses), tels que le plastifiant de substitution DEHA, ont montré une migration plus importante, avec des taux pouvant atteindre 95 à 98 %. En revanche, des transferts plus importants de bisphénols, tels que le bisphénol A (BPA), qui présentent une plus grande solubilité dans l’eau, ont été détectés dans les poissons maigres à forte teneur en eau, comme le merlu.
Cette distinction est essentielle pour comprendre le risque : la contamination du poisson par des additifs qui s’accumulent dans ses muscles dépend de nombreux facteurs. Il est donc indispensable de prendre en compte tous les scénarios possibles.
Les barquettes compostables présentent également un risque
Par ailleurs, les barquettes compostables à base de cellulose contiennent des taux plus élevés de plastifiants. Par conséquent, la quantité de composés qui migrent est supérieure à celle des plastiques conventionnels. En effet, les niveaux de risque les plus élevés relevés dans l’étude étaient associés au merlu congelé et conservé dans ces barquettes alternatives.
Les barquettes compostables, en particulier celles à base de cellulose, se sont imposées comme des alternatives durables fabriquées à partir de matériaux renouvelables. En outre, elles peuvent être valorisées par compostage à la fin de leur cycle de vie. Cependant, ces matériaux peuvent eux aussi contenir des substances susceptibles de migrer vers les aliments.
Le danger de ces substances réside dans le fait que beaucoup d’entre eux sont des perturbateurs endocriniens. Cela signifie qu’ils imitent nos hormones et peuvent entraîner des effets chroniques sur la santé à long terme, comme l’infertilité, le diabète, les maladies cardiovasculaires et certains types de cancers. Elles ne provoquent pas de toxicité aiguë immédiate, mais agissent silencieusement par l’exposition à de petites doses quotidiennes qui s’accumulent.
Les bébés et les enfants sont les plus vulnérables
L’étude a évalué l’exposition à ces additifs par ingestion chez les bébés, les enfants et les adultes, en combinant les données de concentration après migration des additifs dans le poisson avec les données officielles sur la consommation de poisson en Espagne. L’évaluation a mis en évidence un risque plus élevé pour les plus jeunes. En raison de leur poids corporel plus faible, les bébés et les enfants sont exposés à ces substances toxiques jusqu’à dix fois plus que les adultes.
La plupart des composés ne présentaient aucun risque, à l’exception du bisphénol A : les concentrations détectées dans le poisson après stockage dépassent dans de nombreux cas les nouvelles limites de sécurité fixées par l’Agence européenne de sécurité des aliments (EFSA), qui a réduit en 2023 le seuil d’ingestion sans danger pour ce composé de 20 000 fois en raison de son potentiel toxique.
Vers une réglementation plus stricte
Il est important de souligner que le poisson est un aliment sain et indispensable à notre alimentation. Le problème ne réside pas dans l’aliment lui-même, mais dans l’absence de réglementations ambitieuses régissant la présence de ces substances chimiques dans la chaîne d’approvisionnement.
À lire aussi : Tout (ou presque) ce qui se cache dans une boîte de sardines
La nouvelle loi espagnole sur les déchets, adoptée en 2022, interdisait déjà l’utilisation des phtalates et du bisphénol A dans les emballages. Cependant, les résultats de cette étude suggèrent que cette législation n’est pas respectée, la présence de ces composés ayant été détectée dans des emballages commercialisés en Espagne en 2025.
(Le bisphénol A ainsi qu’un phtalate dénommé DEHP (phtalate de di-2-éthylhexyle), utilisés depuis cinquante ans pour la fabrication de certains plastiques et de résines, sont considérées comme perturbateurs endocriniens par de nombreux organismes internationaux. Mais ces substances demeurent des sources de contamination environnementale et d’imprégnation de la population, bien que leur usage soit restreint, relève le site officiel français notre-environnement.gouv.fr, ndlr.)
Par ailleurs, l’Union européenne a adopté en 2024 un règlement visant à limiter la présence de BPA dans les emballages alimentaires (en vigueur depuis janvier 2025), qui prévoit une période de transition de 36 mois avant son application définitive.
(Qu’est-ce que les bisphénols ? Où les trouve-t-on ?, les réponses du ministère français de la santé, ndlr.)
Il est essentiel de mettre en place un système de contrôle pour vérifier le respect de ces réglementations. De même, il est nécessaire de continuer à évaluer les nouveaux additifs qui remplacent ceux qui ont été interdits car, souvent, nous ne disposons souvent pas de données suffisantes concernant leur innocuité.
En tant que consommateurs, en attendant que les politiques évoluent, nous pouvons prendre des mesures simples, comme réduire le temps de contact avec le plastique, privilégier les récipients en verre pour la conservation et éviter de réchauffer les aliments dans des récipients en plastique ou des sachets de cuisson, car la chaleur multiplie de manière exponentielle la migration de ces substances.
Mais le véritable défi est d’ordre politique et mondial : nous devons fabriquer des produits de consommation courante en gardant à l’esprit qu’ils pourraient, à terme, finir dans notre assiette.
Maria Vittoria Barbieri a reçu des financements dans le cadre du programme postdoctoral Beatriu de Pinos de l'Agence de gestion des aides universitaires et de recherche de la Generalitat de Catalunya (AGAUR) (subvention n° 2023 BP 00079).
Ethel Eljarrat ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:45
Comment les auteurs d’abus sexuels sur enfants expliquent-ils leurs actes ? Les enseignements d’une étude mondiale
Kelly Richards, Professor, School of Justice, Queensland University of Technology
Emma Hussey, Sessional Academic, School of Justice, Queensland University of Technology
Texte intégral (1667 mots)

Avertissement : cet article contient des propos susceptibles de choquer, tenus par des auteurs d’abus sexuels sur enfants.
Que disent les auteurs d’abus sexuels sur enfants de leurs propres actes ? L’analyse de centaines de témoignages révèle des schémas communs : sentiment d’avoir droit au sexe, confusion entre femmes et enfants comme personnes subordonnées, et recours fréquent à des logiques de vengeance.
Les chercheurs tentent depuis longtemps de répondre à une question : pourquoi certains hommes commettent-ils des abus sexuels sur des enfants ? Nous avons récemment tenté d’apporter des éléments de réponse.
Dans la plus vaste étude jamais réalisée sur les récits d’auteurs d’abus sexuels sur enfants, nous avons analysé de manière systématique les témoignages de près de 700 hommes adultes issus de 39 études différentes, afin de comprendre comment ils expliquent et justifient leurs actes.
Des révélations saisissantes
Les hommes concernés étaient âgés de 18 ans et plus et venaient du monde entier, de la Norvège à la Nouvelle-Zélande, du Malawi au Brésil. Nous cherchions à comprendre ce que les récits des auteurs pouvaient nous apprendre sur la prévention des abus sexuels sur enfants.
Leurs témoignages variaient considérablement. Certains invoquaient la consommation de drogues ou d’alcool, ou encore les mauvais traitements qu’ils avaient eux-mêmes subis durant leur enfance. D’autres affirmaient être à la recherche d’expériences sexuelles nouvelles, excitantes ou risquées. D’autres encore déclaraient être « amoureux » de l’enfant ou chercher à l’« éduquer ». La manière la plus fréquente dont les auteurs expliquaient leur comportement consistait à présenter leurs victimes comme des participantes consentantes à l’activité sexuelle.
Dans les cas les plus choquants, certains auteurs se décrivaient eux-mêmes comme les victimes malheureuses des prétendues manœuvres sexuelles de leurs victimes – le plus souvent des filles – qu’ils qualifiaient de « séductrices » ou de « provocatrices ».
Ainsi l’un d’eux affirmait :
« Elle jouait les petites séductrices dans toute cette histoire […] Je me suis vraiment laissé piéger. »
Bien entendu, les enfants ne peuvent pas consentir à une activité sexuelle avec des adultes. Surtout, même si la victime avait été adulte, les prétendues preuves de « consentement » avancées par les auteurs étaient extrêmement fragiles. Elles se limitaient généralement à l’absence de résistance physique explicite ou vigoureuse.
L’abus comme vengeance
La vengeance constituait une autre explication fréquemment avancée pour justifier les faits. Dans l’immense majorité des cas, les auteurs désignaient leur partenaire adulte – une femme – comme la véritable cible de leur comportement de représailles. En d’autres termes, ils s’en prenaient à un enfant pour se venger de sa mère.
Selon leurs récits, cette vengeance était motivée par le fait que leur partenaire ne se conformait pas à leur conception traditionnelle de la féminité ou ne remplissait pas, à leurs yeux, de manière satisfaisante son rôle de compagne amoureuse et sexuelle, et/ou de mère et maîtresse de maison.
L’un des auteurs l’explique de la sorte :
« Il y a eu plusieurs fois où j’ai abusé de [ma belle-fille] parce que j’étais en colère […] contre [ma femme parce qu’elle] […] ne faisait pas le ménage. Elle laissait le chien faire ses besoins dans la maison et personne ne nettoyait derrière lui. »
Dans les récits des auteurs, les partenaires féminines adultes étaient censées être sexuellement disponibles exclusivement pour eux, au moment, à l’endroit et de la manière qu’ils souhaitaient. Dans quelques cas, les agresseurs prétendaient être amenés à perpétrer leurs crimes en raison de leur désir de certaines pratiques sexuelles ou de certaines mises en scène du corps que leur partenaire adulte refusait de reproduire.
La colère et les prétendus droits
Les auteurs présentaient parfois l’enfant victime comme méritant les abus subis, affirmant que leurs actes étaient la conséquence de la colère qu’ils éprouvaient à l’égard de l’enfant. Par exemple, certains auteurs se disaient en colère parce que leurs victimes ne correspondaient pas à leurs attentes en matière de « féminité » ou ne faisaient pas preuve d’une soumission jugée suffisante. Ainsi, l’un d’eux a déclaré :
« Elle ne se comportait pas comme la gentille petite fille qu’elle était censée être. »
Fait essentiel, les raisons invoquées par ces hommes pour expliquer leur colère envers les enfants victimes reprennent les mêmes schémas que ceux qu’ils mobilisent pour justifier leur colère envers les femmes adultes. Les auteurs faisaient fréquemment appel à un prétendu « droit » à l’activité sexuelle pour expliquer leurs actes et se plaignaient du manque d’accès sexuel à leurs partenaires adultes.
Ils présentaient dans le même temps leurs victimes comme sexuellement dociles et constamment disponibles sexuellement, mettant à nouveau en avant leur conviction d’avoir droit à des relations sexuelles et leur indifférence à l’égard du fait qu’un enfant ne peut pas être consentant.
Par rapport aux études précédentes, nous avons observé une présence plus fréquente et plus prononcée des schémas de pensée patriarcaux dans les récits des auteurs. Les travaux de recherche avancent souvent que les hommes commettent des abus sexuels sur des enfants en raison de « conflits conjugaux » ou de « tensions au sein du foyer ». Cependant, cette interprétation semble édulcorer ce que révèlent les propres récits des auteurs, lesquels mettent souvent fortement en avant leur colère, leur logique de représailles et un sentiment inébranlable de droit masculin à l’accès sexuel.
L’insistance des auteurs sur le prétendu « consentement » des enfants est éclairante à cet égard. Dans les relations sexuelles avec des femmes adultes, ces hommes considèrent leurs partenaires comme des « gardiennes de l’accès au sexe » (« gatekeepers »), c’est-à-dire comme les personnes chargées de résister à leurs avances lorsqu’elles ne consentent pas. Bien que cette représentation concerne à l’origine les femmes adultes, les hommes de notre étude considéraient fréquemment les femmes et les enfants comme appartenant à une même catégorie de personnes subordonnées.
En effet, nombre des auteurs étudiés effaçaient la distinction entre les filles et les femmes adultes, affirmant par exemple :
« Je ressentais un besoin de […] satisfaction sexuelle, et pour cela il me fallait une femme. »
Mieux former et mieux agir : un enjeu crucial
Nos résultats soulignent donc la nécessité, pour les décideurs publics et les professionnels concernés, de renforcer les efforts visant à lutter contre la misogynie, le sentiment de droit masculin à l’accès sexuel et les privilèges patriarcaux.
Il demeure essentiel de combattre les mythes sur le viol – ces fausses croyances concernant les violences sexuelles, leurs auteurs et leurs victimes – ainsi que l’adhésion à ces croyances erronées. Si ces mesures visent généralement à prévenir les violences sexuelles commises contre les femmes adultes, notre analyse suggère qu’elles pourraient également contribuer à prévenir les abus sexuels sur les enfants.
Si vous êtes victime de violences sexuelles durant l’enfance, si vous êtes parent, proche ou professionnel inquiet pour un enfant, ou si vous souhaitez signaler une situation de danger, vous pouvez contacter le 119 (Allô Enfance en danger). Ce numéro national est gratuit, confidentiel et accessible 24 heures sur 24, 7 jours sur 7.
Si vous êtes préoccupé par vos propres pensées, attirances ou comportements envers des mineurs et que vous craignez un passage à l’acte, il existe également un dispositif de prévention et d’orientation vers les soins : le numéro STOP (0 806 23 10 63). Ce service confidentiel et non surtaxé est assuré par des professionnels de santé formés à ces questions.
Kelly Richards siège au conseil national de la Bravehearts Foundation. Elle reçoit des financements de l’Australian Research Council.
Emma Hussey ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:45
La population française en 2070 : faut-il s’inquiéter d’un déclin démographique ?
Sébastien Oliveau, Géographe, directeur de la MSH Paris-Saclay, Université Paris-Saclay; Aix-Marseille Université (AMU)
Texte intégral (1708 mots)
En 2025, la France a enregistré plus de décès que de naissances. Que nous dit cette situation inédite depuis 1945 de l’avenir démographique du pays ? Dans quelle mesure peut-on évaluer les évolutions de population ?
L’année 2025 aura marqué la fin de la croissance naturelle de la population française : les naissances sont désormais inférieures aux décès, à la fois parce que le nombre d’enfants diminue et parce que la génération du baby-boom commence à arriver à la fin de sa vie. La croissance démographique du pays dépend donc désormais, comme dans presque tous les pays européens, de son solde migratoire.
Une partie des observateurs de ces tendances soulèvent la question de la pérennité du système social français, qui reposerait sur les actifs et serait voué à disparaître avec leur diminution.
Sans nous engager dans une discussion sur le financement de la solidarité nationale, qu’on pourrait envisager par exemple de se faire aussi sur les revenus du capital et non pas uniquement sur le travail (et donc le nombre d’actifs), nous nous proposons ici de voir si le devenir de la population française est prévisible ou non, et comment.
Des modèles de projection et des incertitudes
Concernant le futur des populations, il est d’usage de proposer ce que l’on appelle des projections de population. Cela consiste à produire des modèles, qui vont estimer les changements de population dans le temps, en prenant en compte le nombre et la structure par âge des personnes présentes aujourd’hui, et en faisant varier la natalité, la mortalité, l’immigration et l’émigration en fonction de scénarios spécifiques. C’est la méthode « par composante ». Plus on s’éloigne du jour présent, plus l’incertitude augmente et plus les différents scénarios divergent.
Les instituts statistiques et démographiques nationaux et internationaux s’adonnent à cet exercice régulièrement. Cela permet de proposer des données chiffrées aux décideurs politiques. À l’échelle mondiale, l’Organisation des Nations unies (ONU) publie régulièrement des projections pour l’ensemble des pays, en Autriche le Wittgenstein Centre fait de même avec d’autres paramètres et en proposant en sus des projections sur l’éducation.
En France, l’Insee produit régulièrement des projections à l’échelle nationale, régionale et locale. Localement, c’est le modèle Omphale qui est mobilisé. Il s’agit d’un modèle qui s’appuie sur les données locales d’un instant donné pour projeter à plusieurs décennies les évolutions de la population. La dernière révision d’Omphale date de 2022, s’appuie sur les données de 2018, et projette jusqu’en 2070.
L’exercice qui consiste à regarder les projections passées est toujours douloureux puisqu’il montre les erreurs commises. En France, il s’agit le plus souvent depuis les années 1970 d’une sous-estimation de la population, liée à des hypothèses de fécondité basse (qui ne sont pas révélées exactes), d’arrêt des flux migratoires (qui n’ont pas eu lieu) et de faible progression de l’espérance de vie (qui a finalement été plus importante).
Quelques scénarios pour 2070
Pour envisager l’avenir de la population, il faut donc se poser la question de ce qu’il va advenir en termes de natalité, de mortalité, et de migrations internationales. La natalité correspond au nombre de naissances observées. Elle dépend donc d’une part au nombre de femmes en âge de procréer, ce qui est assez facile à connaître, puisque, d’après l’Insee, il y a environ 14,7 millions de femmes âgées de 15 à 50 ans – et même en partie à prévoir.
On sait ainsi ce qu’il en est pour les 15-20 années à venir, puisque l’on peut compter les filles de 0 à 15 ans : elles sont 5,5 millions. D’autre part la natalité dépend aussi de la fécondité (combien les femmes ont d’enfants). Ce second élément est sujet à plus de précautions, car ses déterminants sont difficiles à prévoir. Ainsi, la récente chute de la fécondité française, si elle avait été envisagée par quelques démographes, n’avait pas été anticipée correctement.
Hors période de crise sanitaire ou de guerre, la mortalité est un élément dont l’évolution est assez stable. On peut, en connaissant la structure par âge de la population, faire des prévisions de mortalité assez réaliste. Il n’en reste pas moins que des accidents majeurs peuvent arriver, comme la survenue d’une épidémie.
On peut néanmoins faire des hypothèses sur l’amélioration de la durée de vie, puisque l’espérance de vie continue d’augmenter encore aujourd’hui (la baisse de la consommation de tabac, notamment chez les jeunes, est une bonne nouvelle), ou d’une stagnation, voire d’une baisse de celle-ci (par exemple en lien avec l’augmentation de la sédentarité).
Les mouvements migratoires (immigrations et émigrations) sont aussi difficiles à prévoir, puisqu’ils dépendent de décisions individuelles d’une part, mais aussi de contextes économiques et politiques, voire environnementaux, d’autre part. Par exemple, la guerre en Syrie ou celle en Ukraine, ont provoqué un afflux inattendu de personnes réfugiées dans l’Union européenne. Néanmoins, on constate que les flux migratoires en France restent relativement stables dans le temps.
C’est donc avec des scénarios, simples à comprendre, et explicables que l’Insee peut proposer des projections pour les années à venir. Le 8 juin dernier, l’Insee a proposé sa vision jusqu’en 2070.
Ces projections rappellent que, selon les scénarios, à l’échéance de presque 40 années, la population française pourrait être de 558 millions ou 78 millions de personnes contre 69 millions aujourd’hui. Néanmoins, beaucoup de scénarios envisagent une bascule à la fin de la décennie 2030 vers une décroissance.
Pour bien comprendre les enjeux en termes de composition de la population, l’Insee propose un outil dédié en ligne pour explorer les effets des différents scénarios, ainsi qu’une déclinaison à l’échelle des régions et des départements. On peut les envisager comme réalistes, si l’on n’oublie pas l’incertitude liée à cet exercice.
La difficulté des estimations locales
Si l’on souhaite envisager le devenir des populations de manière plus fine, à l’échelle des territoires communaux par exemple, il devient plus compliqué de mettre en œuvre des projections.
En effet, si les mouvements naturels de la population restent prévisibles dans les mêmes mesures qu’à une échelle plus élargie, les mouvements migratoires sont, eux, plus difficiles à prendre en compte.
D’une part, on ne peut pas se baser sur les flux observés dans le passé pour envisager ceux à venir. Un territoire peut attirer à un moment donné, et ne plus attirer par la suite, ou être saturé et ne plus être en mesure d’accueillir de nouveaux habitants.
D’autre part, les migrations locales sont aussi liées à la disponibilité ou non de logements. Les changements de politiques de construction peuvent avoir des impacts locaux forts, complètement imprévisibles.
Arrêter l’immigration : une accélération du vieillissement
L’être humain a toujours cherché à se protéger, et les projections démographiques font partie des outils pour appréhender le futur. Elles peuvent néanmoins parfois effrayer, bien qu’elles ne constituent que des futurs possibles, sur lesquels il est en partie possible d’agir, et qui doivent surtout nous amener à anticiper.
Selon toute vraisemblance, la dynamique naturelle de la population ne devrait pas repartir à la hausse d’ici à plusieurs décennies. Les flux migratoires, quant à eux, sont sujets à plus d’aléas, mais on peut envisager qu’ils ne changeront pas radicalement la donne en matière de croissance démographique. S’ils continuent de la sorte, ils vont offrir une forme d’amortissement aux changements à l’œuvre.
On doit d’ailleurs alerter sur les conséquences d’un arrêt de l’immigration, qui accélérerait à la fois l’entrée en décroissance démographique du pays, mais aussi son vieillissement et ses conséquences.
Quant à s’inquiéter des conséquences possibles de ces changements démographiques, oui, cela peut sembler nécessaire. Mais il ne s’agit pas tant de craindre un avenir qui déchante que de s’adapter aux changements en cours et à venir, par exemple en prenant mieux en compte la démographie et ses conséquences dans la nécessaire réorientation des politiques sociales et économiques.
Sébastien Oliveau ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:44
Le « lawfare » américain, ou comment le droit devient un instrument de puissance dans la rivalité sino-américaine
Mark Corcoral, Chercheur associé au Centre de Recherches Internationales (CERI) de Sciences Po, Sciences Po
Texte intégral (1568 mots)
Alors que la relation qu’entretient Donald Trump avec le droit n’a jamais fait couler autant d’encre, Mark Corcoral, spécialiste de la politique de sécurité nationale américaine et chercheur au CERI (Sciences Po), explore le fonctionnement du département états-unien de la justice. À travers son ouvrage Le Droit en armes. Lawfare et sécurité nationale aux États-Unis, qui vient de paraître aux Presses universitaires de France, il montre comment Washington utilise stratégiquement le droit, à la fois pour bénéficier de la légitimité qu’il confère et pour s’affranchir de ses principes lorsqu’il s’agit de protéger les intérêts des États-Unis.
Les rivalités internationales se jouent de plus en plus sur le terrain du droit et de la justice. L’affaire Huawei en est une parfaite illustration. Le 1er décembre 2018, Meng Wanzhou, la directrice financière et fille du fondateur du géant chinois des télécommunications, a été arrêtée à l’aéroport de Vancouver à la demande des États-Unis. Poursuivie pour fraude bancaire sur fond de contournement de l’embargo américain contre l’Iran, Huawei l’était aussi, en plus d’être accusé de vol de secrets commerciaux.
La riposte de Pékin ne s’est pas fait attendre : deux ressortissants canadiens ont été arrêtés en Chine pour de prétendues atteintes à la sûreté de l’État, et un troisième a vu sa peine de prison pour trafic de drogue commuée en peine capitale. Par la suite, les services de renseignement chinois sont allés jusqu’à tenter d’espionner l’équipe du procureur en charge du dossier Huawei. De leur côté, les États-Unis ont exploité l’affaire à des fins diplomatiques et économiques. Washington a invoqué ces poursuites pour justifier l’exclusion des équipements Huawei des réseaux américains et convaincre ses alliés d’en faire autant. Le département du Commerce a même imposé des restrictions contre l’entreprise, nuisant fortement à ses approvisionnements.
Cette affaire illustre bien la manière dont le droit peut être utilisé comme une arme dans l’arène internationale. Pourtant, on aurait tort d’établir une équivalence entre les actions américaines et chinoises. Tandis que les premières étaient soumises aux exigences de l’État de droit, les secondes ne l’étaient absolument pas. Cette différence apparaît notamment dans le traitement réservé aux accusés. Meng Wanzhou a été défendue par les avocats de son choix, qui ont eu accès aux charges et aux preuves retenues contre elle, le tout dans le cadre d’une procédure régulière et transparente. Rien de cela ne fut vrai pour les Canadiens arrêtés en Chine.
Certains observateurs en déduisent que l’usage stratégique du droit – ou « lawfare » – serait l’apanage de régimes autoritaires. Eux seuls auraient une « utilisation belliqueuse du droit » pour « déguiser des stratégies de puissance derrière le paravent d’un argumentaire juridique supposé plus neutre ». L’analyse des doctrines officielles abonde dans ce sens. Alors que le Parti communiste chinois charge son Armée populaire de libération (APL) de conduire la « guerre du droit » depuis des décennies, la doctrine américaine ne fait référence au lawfare que pour dénoncer les pratiques d’adversaires.
Considérer le lawfare comme chasse gardée d’États autoritaires n’en demeure pas moins trompeur. […] Alors qu’il était à la tête du DOJ, l’Attorney General Bill Barr a établi un lien direct entre l’affaire Huawei et la rivalité sino-américaine. D’après lui, laisser « la Chine établir une domination » dans le déploiement des réseaux mobiles de cinquième génération (5G) représenterait « un danger monumental » pour les États-Unis et les poursuites judiciaires seraient une manière d’y répondre. […] La synergie entre les actions pénales du DOJ et les efforts diplomatiques du département d’État contre Huawei n’était pas simplement fortuite, mais délibérée. Nous en voulons pour preuve qu’Adam Hickey — le haut fonctionnaire du DOJ chargé de superviser ces poursuites – a été intégré à plusieurs délégations américaines visant à convaincre des alliés d’exclure les équipements chinois de leurs réseaux.
Cette affaire Huawei montre que les États-Unis utilisent le droit stratégiquement, eux aussi. Le fait qu’ils n’assument pas toujours le caractère stratégique de leurs manœuvres juridiques s’explique par leur identité d’État de droit – un système défini par la soumission de toutes les personnes et des institutions à un droit libéral. Dans un tel système, il est difficile pour les autorités de « tenir ouvertement une parole de lawfare » sans se renier. Dès lors, l’objectif principal de ce livre est d’expliquer le lawfare d’un État de droit, en analysant les pratiques du département de la Justice américain. […]
Fruit de plus de quatre années de recherches, l’explication qu’il propose est la suivante : le lawfare permet aux autorités de bénéficier de la légitimité et de la sécurité juridique que confère le droit, tout en dérogeant à ses principes pour mieux protéger la nation. Animé par une quête de dérogations normatives, de sécurité juridique et de légitimité politique, le lawfare du DOJ renforce l’influence et la puissance des États-Unis, au prix de compromissions de leur identité libérale.
L’illibéralisme de l’administration Trump 2 apparaît dès lors sous un jour nouveau. Si certaines de ses pratiques sont inédites, elles sont bien souvent rendues possibles par des manœuvres juridiques familières, éprouvées durant la période post-11-Septembre, sur laquelle se concentre cet ouvrage. Ces manœuvres comportent deux volets, autour desquels se structure la suite de notre réflexion :

Le lawfare défensif vise à libérer l’action sécuritaire des États-Unis de certaines contraintes normatives sans compromettre sa légitimité politique ni l’immunité de ses artisans. Il s’agit alors pour le DOJ d’habiliter l’État à agir aux marges de la légalité — voire au-delà — tout en minimisant les risques juridiques auxquels s’exposent les acteurs de la politique de sécurité nationale. […]
Le lawfare offensif du DOJ transforme la justice pénale en un instrument de sécurité nationale, malgré l’indépendance des juges et les exigences d’équité censées régir le système judiciaire américain. Il s’agit alors de maximiser l’efficacité de l’action pénale du DOJ pour neutraliser des menaces pesant sur la sécurité des États-Unis.
Mark Corcoral ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:41
Face au risque politique, la taille des banques peut être un atout. Jusqu’où ?
Marc Kouzez, Professeur associé à ICN Business School et chercheur associé au CEREFIGE à l'Université de Lorraine, ICN Business School
Texte intégral (1466 mots)
Alors que le risque politique s’accroît partout dans le monde, les entreprises doivent y faire face, et notamment les banques. Particulièrement exposées, elles ne sont pourtant pas toutes également touchées par la montée de ce phénomène. Il semblerait que la taille d’une banque la protège. Quels mécanismes expliquent l’« effet taille » ? A-t-il des limites ?
Après plusieurs années d’incertitude, l’indice Coface de risque politique a atteint en 2025 un nouveau record de 41,1 % dépassant même le pic de la pandémie, et plaçant ce risque sur le devant de la scène mondiale. L’année 2026 ne semble pas, à son tour, offrir l’accalmie espérée. Au contraire, nous assistons à un ancrage structurel de l’instabilité mondiale. Entre la persistance du conflit russo-ukrainien, l’embrasement au Moyen-Orient et une fragilité institutionnelle croissante, le risque politique ne semble plus être une anomalie : il est devenu un paramètre clé de l’économie mondiale.
Lorsque l’environnement politique d’un pays se dégrade, qu’il s’agisse d’instabilité gouvernementale, de sanctions économiques, de conflits internes ou externes, les conséquences sont immédiates pour le secteur financier.
À lire aussi : Christine Lagarde a-t-elle raison : « Lehman Sisters » aurait-elle fait faillite en 2008 ?
En effet, la forte interconnexion entre les systèmes bancaires et l’économie rend les banques susceptibles de subir de plein fouet les conséquences de cette instabilité politique. Comment le secteur bancaire, pilier central de nos économies, fait-il face à ces nouveaux défis ? Plus encore, est-ce que la taille de la banque influence sa résilience dans un environnement politique marqué par l’instabilité ?

Cette réflexion fait suite à nos travaux publiés dans Economic Systems sous le titre « Political Risk And Bank Performance: Does Bank Size Matter ? » Pour la majorité des établissements que nous avons étudiée le verdict est sans appel : bien que les effets négatifs du risque politique sur la performance bancaire soient confirmés, la taille de la banque représente un facteur déterminant qui pèse lourdement sur sa performance financière dans un climat de chaos politique.
Le paradoxe de la taille bancaire
La levée des barrières aux mouvements de capitaux durant les années 1980 et 1990 a transformé le paysage bancaire par une vague massive de fusions-acquisitions. Ces restructurations ont fait émerger des institutions bancaires gigantesques que nous connaissons aujourd’hui, dont la taille n’est pas seulement un indicateur de puissance stratégique, mais aussi un outil de résilience face aux risques.
En étudiant les trajectoires de plus de 1 600 établissements bancaires dans 58 pays, nous avons découvert que face au désordre politique, la taille ne se contente pas de protéger car elle transforme radicalement la règle du jeu. Plus précisément, nos recherches confirment pour les banques de très grande taille une capacité de résistance, voire une amélioration de leur performance lors des pics d’instabilité politique. Tandis que pour les autres banques, le risque politique n’est qu’un poison en particulier pour les banques de petite taille. L’instabilité nationale et les chocs géopolitiques dégradent leurs performances, augmentent leurs coûts et limitent leur capacité à prêter.
Pourquoi la taille protège
Alors que l’incertitude politique affecte la performance financière des établissements bancaires, les banques de grande taille affichent une trajectoire radicalement différente. Plusieurs facteurs expliquent cette déconnexion.
D’abord, les économies d’échelle et la diversification géographique permettent aux grandes banques de mieux absorber les chocs locaux. Si un marché devient instable, leurs activités dans des zones plus calmes compensent les pertes. Ensuite, ces banques considérées « trop grandes pour faire faillite » sont naturellement placées en priorité quant aux plans de sauvetage souvent proposés en période d’instabilité accrue. En effet, ces banques bénéficient plus de mesures de renflouement des autorités publiques agissant comme « prêteur en dernier ressort ».
L’importance de cette règle est confirmée particulièrement après la faillite de la banque Lehman Brothers en septembre 2008, qui, en raison de sa grande taille, – 4ᵉ banque d’investissement américaine – a semé la panique parmi les investisseurs non seulement aux États-Unis, mais aussi sur les marchés financiers internationaux, conduisant ainsi l’économie mondiale à une immense crise bancaire – par l’effet domino – suivie par une crise économique et une crise de dettes souveraines encore plus profonde. Enfin, les liens étroits avec les sphères publiques décisionnelles permettent à ces géants bancaires d’être mieux préparés aux changements réglementaires.
La double face du défi
Il est certain aujourd’hui qu’un environnement politique plus stable, plus sain et plus efficace, améliore les conditions d’exercice des banques, notamment pour les plus petites d’entre elles. Or, avec un risque politique qui s’établit à des sommets historiques, l’année 2026 confirme que nous sommes entrés dans une ère de turbulences chroniques.
Paradoxalement, si l’instabilité politique fragilise les systèmes bancaires, elle offre aux banques de grande taille un avantage stratégique. Les géants bancaires semblent non seulement résister, mais parfois même améliorer leur performance en période d’instabilité politique. Si la taille garantit, dans une certaine mesure, la stabilité au sommet de la pyramide financière, elle renforce aussi l’écart de performance avec les autres banques, plus proches des tissus économiques de proximité, mais aussi plus vulnérables.
En fin de compte, l’enjeu des prochaines années ne sera pas seulement de gérer le risque politique, mais de veiller à ce que la résilience de ces « géants bancaires » ne se transforme pas en une déconnexion totale avec les réalités de l’économie locale, de plus en plus exposée aux aléas du monde.
Si l’adaptation au risque politique est déjà une épreuve pour le secteur bancaire, l’émergence d’une fracture entre les banques selon leur taille constitue un défi dans le défi : celui de maintenir une équité de marché dans un monde de plus en plus fragmenté.
Marc Kouzez ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:41
L’autre Coupe du monde oppose le Canada, le Mexique et les États‑Unis sur la bière
Jean-Guillaume Ditter, Professeur permanent, Burgundy School of Business
Texte intégral (2840 mots)
La boisson fermentée iconique sera l’une des stars de la Coupe du monde. En dehors des terrains, elle est l’objet d’une guerre commerciale entre les trois pays hôtes. Analyse de ces trois marchés brassicoles et de leur interdépendance, des champs d’orge à la canette d’aluminium.
La bière est indissociable des événements festifs. La Coupe du monde masculine de football 2026 ne devrait pas faire exception à la règle, avec une croissance attendue de la consommation de 560 millions de litres.
Et vous, quelle bière allez-vous choisir pour célébrer les trois pays hôtes ? Une Budweiser, fleuron historique des États-Unis et sponsor officiel de l’évènement ? Une Corona, fer de lance de l’industrie brassicole mexicaine ? Une Labatt Blue, pils favorite des Canadiens ?
Quel que soit votre choix, il profitera au géant belge ABInBev, propriétaire de ces trois enseignes, parmi un portefeuille de plus de 500 marques qui lui assure 25 % du marché mondial. La bière ne connaît pas de frontières… quoique.
Le contexte géoéconomique nord-américain pourrait gâcher la fête. La guerre commerciale déclenchée par les États-Unis perturbe les économies canadienne et mexicaine, avec en perspective une difficile renégociation de l’accord commercial Canada-États-Unis-Mexique (ACEUM) en juillet prochain.
Voyons comment la bière reflète ces tensions, en nous appuyant sur les données de Statista.
Filière brassicole nord-américaine
En 1994, l’adoption de l’accord de libre-échange nord-américain, l’Alena, a entraîné un accroissement rapide des échanges entre les trois pays signataires et une intégration accrue de leurs systèmes productifs. Aujourd’hui, Donald Trump déclare qu’il ne sait pas s’il va renouveler cet accord devenu ACEUM en 2018.
La filière brassicole nord-américaine n’a pas échappé à ce mouvement. Elle est de fait fortement intégrée au niveau régional. Les États-Unis et le Canada produisent l’orge, le malt et le houblon. Le Mexique et le Canada exportent l’aluminium nécessaire à la fabrication de canettes. Le Mexique, premier exportateur mondial de bières, fournit notamment les États-Unis, deuxième marché mondial.
Les États-Unis : premier importateur mondial
Les États-Unis, deuxième producteur et deuxième marché mondial derrière la Chine, occupent une position centrale dans l’industrie brassicole nord-américaine. La consommation annuelle y est de 23 milliards de litres, soit 67 litres par habitant, contre 33 litres en France.
Le marché est dominé par l’incontournable ABInBev – Budweiser, Bud Light –, le canado-états-unien Molson‑Coors – Coors Light, Miller Lite, Molson – et l’États-Unien Constellation Brands, qui distribue les marques mexicaines Corona Extra et Modelo Especial. Les États-Unis sont aussi le berceau des bières artisanales, ou craft, apparues dans les années 1970. Elles sont produites par près de 10 000 brasseries, dont le succès mondial des IPA américaines témoigne du dynamisme et de l’inventivité.

La production états-unienne ne couvre qu’environ 80 % de sa consommation intérieure, faisant du pays le premier importateur mondial. Il en résulte un déficit commercial significatif avec la plupart de ses partenaires, au premier rang desquels le Mexique, avec 82 % des importations et les Pays-Bas avec 8,5 %.
Les États-Unis sont toutefois le premier producteur mondial de houblon, qu’ils exportent massivement vers le Mexique et le Canada.
Le Mexique : essor rapide avec l’Alena
Autre géant de la bière, le Mexique est le troisième producteur et quatrième consommateur mondial avec 6 milliards de litres ; chaque Mexicain en consomme 58 litres en moyenne.
La filière brassicole y est là aussi dominée par les grands groupes internationaux : Grupo Modelo, filiale d’ABInBev, brasse les bières Corona et Modelo, évoquées précédemment, tandis que le néerlandais Heineken possède la Cervecería Cuauhtémoc Moctezuma, qui produit, entre autres, la marque Dos Equis.
Le pays occupe le rang inattendu de premier exportateur mondial, devant les Pays-Bas. La production et les exportations brassicoles mexicaines ont connu un essor rapide après la signature de l’Alena. La suppression des obstacles aux échanges sur les produits de base a permis aux brasseurs mexicains d’accéder au marché de leur voisin du Nord.
La demande états-unienne de bière mexicaine a également été portée par la croissance de la population latino-américaine aux États-Unis et le tourisme états-unien au Mexique. Plus de 95 % des exportations mexicaines sont actuellement destinées aux États-Unis, générant un excédent commercial significatif.
Le Mexique importe par ailleurs de l’orge et du malt des États-Unis, mais lui vend une partie de l’aluminium destiné à produire ses canettes.
Le Canada : brasserie artisanale et pouvoir des provinces
Le Canada n’est que le 19ᵉ producteur et 16ᵉ consommateur mondial. Molson Coors, ABInBev, Heineken et les autres multinationales représentent de nouveau l’essentiel des volumes produits, mais on dénombre plus de 1 200 brasseries artisanales, généralement de petite taille.
L’une des particularités du marché canadien tient à l’organisation des importations et de la distribution de l’alcool, qui relève d’un monopole public dans la majorité des provinces.
Le Canada est 9ᵉ importateur mondial et occupe une place mineure en matière d’exportation… à l’exception des États-Unis où il se positionne au 4ᵉ rang et avec un solde commercial excédentaire d’environ 75 millions de dollars états-uniens (64,6 millions d’euros).
Quatrième producteur mondial, le Canada fournit par ailleurs de l’orge et du malt aux États‑Unis. Il est aussi l’un de ses principaux fournisseurs en aluminium, à qui sont destinés 90 % de ses exportations.
Guerre tarifaire sur la bière
La bière fait régulièrement l’objet de tensions industrielles et commerciales entre ces trois pays. Celles-ci ont pris une nouvelle ampleur depuis le retour au pouvoir de Donald Trump et de sa vision mercantiliste du commerce international.
Au printemps 2025, l’administration états-unienne a imposé des droits de douane de 25 % sur de nombreux produits importés, en s’appuyant sur une loi de 1977, l’International Emergency Economic Powers Act (IEEPA). Cette dernière autorise le président des États-Unis à prendre des mesures exceptionnelles en situation d’urgence nationale.
À lire aussi : La bière, entre industrialisation et renaissance artisanale
La bière n’était pas visée en tant que telle, mais l’orge canadienne a été touchée. L’aluminium, qu’il soit canadien ou mexicain, a été lui aussi soumis à des droits de douane de 25 %, puis de 50 %, appliqués à la fois aux canettes vides, mais aussi à la bière importée en canettes, sur la base d’arguments de sécurité nationale (défense d’une industrie stratégique) et d’accusations de concurrence déloyale, ou dumping.
 Plus d’infographies sur Statista
Plus d’infographies sur Statista
La Cour suprême a annulé, le 20 février 2026, les droits de douane adoptés dans le cadre de l’IEEPA, jugeant que le président des États-Unis n’avait pas l’autorité légale pour les instaurer. Mais, l’administration Trump les a remplacés rapidement par des mesures générales fondées sur la section 122 du Trade Act de 1974. Les droits de douane sur l’aluminium, qui s’appuyaient sur l’article 232 de la loi sur l’expansion du commerce de 1962 autorisant le président des États-Unis à restreindre les importations lorsqu’elles menacent les intérêts vitaux du pays, ont quant à eux été maintenus.
Anti-immigration et changement climatique
Ces mesures alimentent les tensions avec le Canada et le Mexique, entraînant une baisse des exportations de ces deux pays. Le Mexique est particulièrement touché car, en plus des droits de douane, les mesures anti-immigration états-uniennes inquiètent la population d’origine latino-américaine et pèsent sur sa consommation.
Pour ne rien arranger, l’industrie brassicole mexicaine souffre d’une sécheresse chronique entraînant la surexploitation des nappes phréatiques, particulièrement dans le nord du pays. Les brasseries étant prioritaires face aux usages domestiques, les conflits autour de l’accès à l’eau se multiplient.
Le changement climatique pèse enfin sur l’amont agricole de la filière : la baisse des rendements de l’orge menace l’approvisionnement des brasseurs mexicains et augmente encore leurs coûts de production.
Contre-mesures
Mais ces droits de douane touchent aussi les brasseurs et distributeurs états-uniens, dont le coût des importations a rapidement augmenté. Constellation Brands est en première ligne, car très dépendant de ses importations mexicaines. En 2013, sous la pression des autorités de la concurrence, ABInBev lui a cédé les droits de distribution de ses bières Corona et Modelo sur le territoire des États-Unis pour ne pas s’y trouver en position ultradominante.
Cette offensive commerciale a donné lieu à des contre-mesures au Canada, où le gouvernement fédéral a imposé, en mars 2025, des droits de douane de 25 % sur des produits états-uniens, dont l’orge et la bière, avant de les lever en septembre de la même année dans le cadre des négociations en cours.
Certains gouvernements provinciaux ont pris des mesures encore plus radicales en décidant de stopper purement et simplement la distribution des bières et autres alcools états-uniens sur leur territoire. Les exportations de bière états-unienne vers le Canada ont en conséquence connu une chute de plus de 25 % en 2025.
Patriotisme économique
On assiste donc à un morcellement progressif du marché de la bière nord-américain, au niveau de la production comme de la consommation.
Les brasseurs cherchent en premier lieu à réduire leur exposition aux droits de douane en diversifiant et relocalisant leurs approvisionnements : des brasseries canadiennes ont cherché à limiter leur dépendance aux importations de canettes états-uniennes en augmentant préventivement leurs stocks, en développant l’usage des bouteilles consignées, des fûts réutilisables en métal et des fûts en bois. Le Mexique développe pour sa part sa propre production de houblon.
Ils adaptent également leur communication commerciale pour valoriser l’ancrage local de leurs produits. Le groupe AB-Inbev a par exemple signé des accords d’approvisionnement avec les fermiers états-uniens afin d’obtenir le label « US Farmed » (cultivé aux États-Unis) pour certaines de ses bières. Sa marque Budweiser se définit comme « américaine » plutôt que « nationale » (domestic), terme jugé trop neutre. Sa campagne publicitaire lancée durant le Superbowl 2026 est une célébration patriotique qui l’inscrit au cœur de l’identité états-unienne, sur fond de rock sudiste.
Les consommateurs ne sont pas en reste. Les Canadiens, privés de bières états-uniennes et désireux de soutenir l’économie et l’emploi locaux, se tournent vers les bières craft canadiennes.
Aux États-Unis, le réflexe « buy American » est aussi très fort. Les bières locales et craft y sont favorisées comme marqueur identitaire et pour soutenir l’économie locale. Mais la hausse des prix, combinée à la préférence croissante des consommateurs pour les boissons peu ou pas alcoolisées (mouvement No-Low), entraîne une baisse continue de la consommation intérieure qui pèse sur l’industrie.
Le Mexique compte, pour sa part, sur le tourisme international et la ferveur de la population locale durant les matchs pour soutenir sa propre consommation intérieure.
Eh bien oui, lever le coude a toujours été un geste politique ! Et cela devient plus évident encore dans un monde marqué par la fragmentation des marchés et le renouveau du patriotisme économique.
N’oublions pas que la consommation d’alcool est à l’origine de 49 000 décès par an. Pour plus d’informations, vous pouvez consulter le site Alcool Info Service.
Jean-Guillaume Ditter ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.06.2026 à 17:38
De Gaulle, le retour : le Général devient une icône
Delphine Le Nozach, Maître de conférences en Sciences de l'information et de la communication, Université de Lorraine
Violaine Appel, Enseignant-chercheur en sciences de l'information et de la communication, Université de Lorraine, Université de Lorraine
Texte intégral (2102 mots)

Depuis quelques années, les figures historiques reviennent en force sur les écrans : Napoléon, de Ridley Scott, Oppenheimer, de Christopher Nolan, ou encore Jeanne du Barry, de Maïwenn… La Bataille de Gaulle, film d’Antonin Baudry, consacré au grand Charles, qui sort six ans après celui de Gabriel Le Bomin sur le même thème, témoigne à son tour de cet intérêt renouvelé pour les personnages capables d’incarner une époque, une crise ou une vision du monde.
Dans le paysage cinématographique consacré aux personnages historiques, Charles de Gaulle occupe une place singulière. Omniprésent dans l’espace public français – rues, places, aéroports, établissements scolaires –, le Général demeure pourtant relativement rare dans la fiction cinématographique. Son image appartient davantage aux archives télévisées, aux discours mémoriels et aux actualités filmées qu’au registre du grand récit de cinéma.
Après le De Gaulle (2020) de Gabriel Le Bomin, le réalisateur Antonin Baudry propose en 2026 la Bataille de Gaulle (en diptyque : l’Âge de fer et J’écris ton nom), consacré aux années de guerre et à la construction de la France libre. Avec un budget de 74 millions d’euros, ce projet compte parmi les productions françaises les plus importantes de ces dernières années.
Au-delà de leurs différences esthétiques, ces œuvres révèlent surtout deux manières distinctes de représenter le pouvoir, la mémoire nationale et le rôle des grands protagonistes historiques dans l’imaginaire collectif.
Gabriel Le Bomin : l’homme derrière le mythe
Sorti en 2020, De Gaulle adopte un parti pris inattendu. Plutôt que de construire une grande fresque héroïque centrée sur l’appel du 18-Juin ou la naissance de la France libre, Gabriel Le Bomin choisit de se concentrer sur quelques semaines décisives : mai et juin 1940. Le cœur de la diégèse n’est pas Londres mais l’effondrement de la France et ses conséquences sur une cellule familiale.
Son épouse Yvonne de Gaulle, leur fille Anne atteinte de trisomie, l’exode et les séparations successives occupent une place centrale dans la narration. Contre toute attente, le Général n’apparaît pas comme une incarnation de l’Histoire, mais comme un homme confronté à l’incertitude, à la peur et à la solitude.
Ce choix change profondément notre regard sur de Gaulle. Le film construit le héros à partir de l’intime. Là où les discours tendent habituellement à « monumentaliser » de Gaulle, Le Bomin entreprend au contraire de l’inscrire dans une expérience humaine plus ordinaire. Le futur chef de la France libre n’est pas encore un symbole ; il est un individu confronté à une situation qui le dépasse.
Le film rejoint ici une tendance perceptible dans plusieurs biopics récents. Les films historiques récents privilégient souvent une proximité émotionnelle avec leurs personnages plutôt qu’une représentation épique. Spencer (2021), de Pablo Larraín, montre une Diana, princesse de Galles, fragile et isolée ; Oppenheimer (2023), de Christopher Nolan, insiste autant sur les contradictions du scientifique que sur son rôle dans l’Histoire ; Napoléon (2023), de Ridley Scott accorde une place importante à l’intimité conjugale.
Il ne s’agit plus de raconter un « grand homme », mais de montrer comment une personnalité publique se construit à partir de fragilités, de tensions et d’expériences personnelles. Le biopic cinématographique tend ainsi moins à sacraliser ses héros qu’à les rendre émotionnellement partageables.

Antonin Baudry : reconstruire un récit héroïque
Le projet porté par Antonin Baudry repose sur une logique presque inverse. Le diptyque la Bataille de Gaulle suit l’ascension politique du Général de 1940 à 1944, depuis son départ pour Londres jusqu’à la Libération. Adaptés de l’ouvrage de l’historien britannique Julian Jackson, les deux longs-métrages, qui se distinguent dans le paysage cinématographique français par leur ampleur, sont décrits notamment comme une « ambitieuse fresque cinématographique » constituant pour Antonin Baudry le « projet d’une vie ».
Le synopsis officiel annonce immédiatement le cadre narratif : un homme seul refuse la défaite et tente de convaincre le monde que la guerre n’est pas terminée. On retrouve ici plusieurs éléments déjà présents dans le Chant du loup (Baudry, 2019) : gestion de crise, stratégie, temporalité tendue, affrontements géopolitiques et mise en scène de la décision politique.
De Gaulle devient alors un personnage d’action politique et diplomatique. Son pouvoir ne repose pas sur la force physique mais sur la parole, la conviction et la capacité à produire un récit collectif. Cette centralité de la narration dans l’exercice du pouvoir rejoint les analyses de Christian Salmon (2007) sur le storytelling politique. Tandis que Le Bomin filme un homme pris dans l’Histoire, Baudry filme un homme qui cherche à orienter le cours de l’Histoire. Cette différence modifie profondément sa représentation. Le doute individuel cède la place à la détermination. La sphère familiale recule au profit des enjeux militaires et diplomatiques. L’intime laisse place à l’épique.
Deux façons de raconter la mémoire
Le film de Gabriel Le Bomin relève principalement d’une mémoire affective et expérientielle. L’Histoire, par excellence, y est saisie à hauteur d’individus, à travers l’exode, la séparation ou l’angoisse de l’effondrement. Le spectateur peut plus facilement s’identifier aux expériences vécues.
Le projet de Baudry relève davantage d’une mémoire héroïque. Il interroge la manière dont une nation se reconstruit à travers un récit de résistance, de courage et de souveraineté. Par son ambition et son découpage en deux films, le diptyque s’inscrit dans une tradition de grandes fresques historiques du cinéma français, que l’on retrouve, par exemple, dans Jeanne la Pucelle (1994), de Jacques Rivette, consacré à une autre figure fortement associée à l’histoire du territoire lorrain. Comme de Gaulle ou Napoléon, Jeanne d’Arc fait partie de ces personnages historiques mis en scène par le cinéma pour interroger la nation, le pouvoir ou l’identité collective.
Ce retour de la figure gaullienne sur les écrans fait écho à certaines tensions politiques et géopolitiques actuelles. Les thèmes associés – indépendance nationale, résistance, souveraineté, leadership politique – trouvent un écho particulier dans le contexte actuel marqué par les tensions géopolitiques et les débats autour de la place de la France dans le monde. Le retour de de Gaulle sur les écrans peut ainsi être lu comme une réactivation de ces imaginaires politiques et mémoriels.
Quand de Gaulle devient une marque nationale
Les films consacrés à Charles de Gaulle mobilisent un ensemble de valeurs, d’images et de récits déjà largement partagés dans l’espace public. Autrement dit, « de Gaulle » fonctionne comme un signe culturel facilement reconnaissable. À ce titre, il peut être envisagé comme une ressource symbolique circulant dans l’espace médiatique selon des mécanismes proches de ceux observés dans les stratégies de marque).
À la manière d’une marque patrimoniale ou d’un territoire dépublicitarisé, le nom « de Gaulle » convoque spontanément certaines idées : la résistance, l’indépendance nationale, l’autorité, la vision politique, la grandeur de l’État.
Chaque film sélectionne alors certains attributs de cette identité symbolique. Chez Le Bomin dominent la résilience, la fidélité familiale et la force morale. Chez Baudry, ce sont davantage le leadership, la stratégie et la capacité à incarner le destin national.
Cette logique rappelle les mécanismes observés dans la communication patrimoniale ou territoriale : une figure historique devient une ressource symbolique réinterprétable selon les contextes et les besoins d’une époque. Le cinéma joue ici un rôle central. Plus que la représentation du Général, il participe à l’actualisation de son image et à la circulation de ce que signifie « de Gaulle » dans l’espace public.
Une figure historique pour penser le présent
La comparaison entre De Gaulle de Gabriel Le Bomin et la Bataille de Gaulle d’Antonin Baudry révèle moins, finalement, deux visions opposées qu’une transformation des modes de représentation du politique au cinéma.
Le premier film privilégie la mise en scène intime d’un homme confronté à l’effondrement du monde qui l’entoure. Le second construit une fresque nationale centrée sur l’exercice du pouvoir et la reconstruction d’une souveraineté politique.
Entre les deux se dessine une évolution plus large : celle d’un acteur de l’Histoire devenue icône culturelle. La figure gaullienne cesse d’être une incarnation du passé pour s’imposer comme un ensemble symbolique dans lequel le cinéma puise pour interroger les inquiétudes, les attentes et les représentations du présent.
En ce sens, les films consacrés au Général parlent autant de notre époque que de la sienne. Ils montrent comment le cinéma continue de fabriquer, de transformer et de faire circuler les grands récits et les personnages emblématiques de la mémoire collective française.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
16.06.2026 à 12:46
La maladie rénale est aussi une maladie du cerveau
Mickaël Bobot, Maître de Conférence Universitaire - Praticien Hospitalier en Néphrologie, Aix-Marseille Université (AMU)
Texte intégral (2534 mots)
On associe souvent la maladie rénale à la dialyse ou à la greffe. Mais elle peut aussi affecter la mémoire, l’attention et augmenter le risque d’accidents vasculaires cérébraux. Les recherches récentes révèlent une connexion avec le cerveau longtemps sous-estimée.
Généralement, quand on pense « maladie rénale », on pense dialyse ou greffe de rein. Mais on sait moins que la maladie rénale, qui affecte plus de 10 % de la population mondiale, peut avoir des conséquences importantes sur le fonctionnement d’autres organes.
Ainsi, les patients concernés sont, par exemple, aussi touchés par l’hypertension artérielle, laquelle est d’ailleurs souvent révélatrice d’une maladie rénale chronique. On sait également que la maladie rénale augmente pour beaucoup le risque cardiovasculaire.
Plus surprenant encore, les recherches ont révélé que reins et fonctionnement cérébral sont étroitement liés : le dysfonctionnement des reins peut s’accompagner de troubles cognitifs dont la gravité augmente avec la gravité de l’atteinte rénale.
Les troubles cognitifs : une complication fréquente mais méconnue
Assurant l’épuration des déchets et l’équilibre du bilan de l’eau et de nombreuses molécules dans notre corps, les reins sont des organes essentiels au maintien de la vie en bonne santé. Or, il arrive qu’ils dysfonctionnent et perdent progressivement leur capacité à filtrer et nettoyer le sang : c’est la maladie rénale chronique, qui touche 6 millions de personnes en France.
Cette affection mène irrémédiablement à la destruction quasi complète de la fonction rénale. Elle peut être due à des causes multiples, comme le diabète (cause la plus fréquente dans les pays occidentaux). Elle est en partie liée au mode de vie, mais peut aussi résulter de causes génétiques ou auto-immunes (dans ce dernier cas, le système immunitaire s’attaque à l’organisme qu’il est censé défendre).
Initialement silencieuse, la maladie rénale évolue plus ou moins rapidement (souvent en fonction de la cause sous-jacente), en quelques jours ou en plusieurs années.
Les symptômes n’apparaissent qu’aux stades les plus sévères. Parmi ceux-ci figurent des complications neurologiques qui se manifestent généralement par des oublis répétés (notamment des traitements), des difficultés à gérer les actes de la vie quotidienne (argent, tâches ménagères), un ralentissement cognitif et des difficultés de concentration.
Ces troubles cognitifs sont parfois discrets et peuvent donc s’avérer difficiles à détecter en l’absence de test spécifique. Leur fréquence et leur gravité évoluent parallèlement avec la gravité de la maladie rénale : au stade de la dialyse, ils peuvent concerner jusqu’à 70 % des patients insuffisants rénaux, et avoir un impact majeur sur leur autonomie et leur qualité de vie.
La forme la plus sévère de cette atteinte cérébrale est la démence.
Les patients atteints de maladie rénale ont par ailleurs un risque trois fois plus important d’être victime d’un accident vasculaire cérébral (AVC) que la population générale. Les AVC survenant chez les patients insuffisants rénaux sont aussi plus graves et grevés d’une plus faible chance de récupération neurologique ainsi que d’une plus grande mortalité.
Pourquoi la maladie rénale est-elle si délétère pour le cerveau ? Comment les reins influencent-ils cet organe ? Les réponses à ces questions sont à chercher du côté d’une structure très particulière : la barrière hémato-encéphalique.
La barrière hémato-encéphalique, protection essentielle du cerveau
On peut se représenter la barrière hémato-encéphalique comme un filtre biologique extrêmement sélectif, dont la vocation est de protéger le cerveau non seulement des microorganismes qui pourraient tenter de l’envahir, mais aussi des toxines et de toute autre molécule qui pourrait avoir une influence délétère sur lui.
Cette barrière est composée de plusieurs couches de cellules particulièrement jointives et très connectées entre elles.
Nos travaux ainsi que ceux d’autres équipes suggèrent cependant que cette protection pourrait être fragilisée par la maladie rénale chronique. Cette altération expliquerait en partie les troubles cognitifs. Plusieurs mécanismes participent à la dégradation des propriétés protectrices de la barrière hémato-encéphalique :
La fragilisation des vaisseaux sanguins. Le cerveau et le rein sont très dépendants d’une microcirculation sanguine finement régulée. Or, on sait qu’une maladie rénale fragilise beaucoup les cellules des vaisseaux sanguins, en particulier ceux du cerveau. L’altération des petits vaisseaux est très fréquemment observée à l’imagerie cérébrale (scanner ou IRM) chez les patients insuffisants rénaux.
En cas de maladie rénale, les vaisseaux s’épaississent : davantage de calcium se dépose dans la couche musculaire de leur paroi, ce qui perturbe les échanges entre le sang et le cerveau. Par ailleurs, certaines maladies très fréquentes, comme l’hypertension artérielle, le diabète ou les troubles du rythme cardiaque peuvent également participer aux complications vasculaires, ce qui a des répercussions à la fois sur les reins et sur le cerveau. La calcification et la rigidification des vaisseaux augmente la pulsatilité transmise à la circulation cérébrale (à chaque battement cardiaque, les chocs résultants sont transmis plus violemment). Cette situation favorise le développement d’une maladie des petits vaisseaux cérébraux (ce qui participe à l’atteinte cognitive) et a des conséquences au niveau de la barrière hémato-encéphalique.L’inflammation. La maladie rénale chronique entraîne une inflammation sanguine. On retrouve dans le sang des patients davantage de molécules de l’inflammation et de cellules de l’immunité impliquées dans la réponse inflammatoire que dans le sang de la population générale. Lorsque ces cellules immunitaires pro-inflammatoires pénètrent dans le cerveau et y persistent, l’inflammation qu’elles provoquent participe non seulement à son agression, mais augmente également la perméabilité de la barrière hémato-encéphalique.
L’accumulation de toxines. Au cours de la maladie rénale, le rein élimine moins bien les déchets. Ces derniers, appelés « toxines urémiques », s’accumulent dans la circulation sanguine, exerçant des effets délétères sur l’organisme. On connaît actuellement plus d’une centaine de ces toxines. Certaines d’entre elles ont un effet néfaste sur les vaisseaux du cerveau, ce qui peut là encore participer à fragiliser la barrière hémato-encéphalique.
Tous ces mécanismes ont donc des impacts négatifs pour la protection essentielle que constitue la barrière hémato-encéphalique. Plusieurs travaux de recherche récents suggèrent que l’altération de cette dernière jouerait un rôle important dans les complications cérébrales de la maladie rénale.
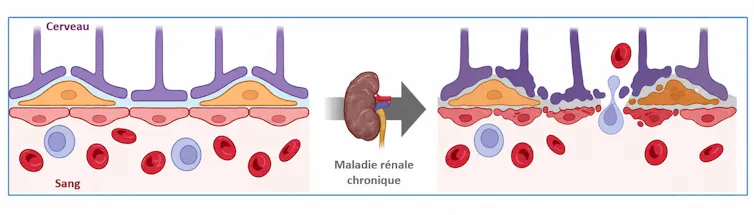
Ce que cela change pour les patients
La fragilisation de la barrière hémato-encéphalique a de nombreuses conséquences pour les patients. Elle pourrait aggraver la sévérité des AVC, en amplifiant les phénomènes inflammatoires et l’œdème (gonflement) qui survient dans le cerveau après un tel événement. Cette complication, particulièrement grave, augmente elle-même le risque de séquelles cognitives.
Prévenir le risque d’AVC et identifier les patients particulièrement à risque est donc crucial. Aux facteurs de risque d’AVC courants, tels que l’hypertension, le diabète ou les troubles du rythme cardiaque, fréquents chez les patients souffrant de maladie rénale, s’ajoutent les facteurs de risques spécifiques à cette affection. Soulignons que, dans certains cas, pour diminuer la probabilité de survenue d’un AVC, des traitements préventifs peuvent être mis en place.
À lire aussi : Les maladies rénales sont en hausse en Afrique : le rôle des facteurs de risque génétiques
Au-delà du risque accru d’AVC, le cerveau des patients insuffisants rénaux est également plus sensible aux agressions ou à la toxicité de certains médicaments, en raison là encore de l’altération de la barrière hémato-encéphalique. C’est par exemple le cas de certains antibiotiques, comme les bêta-lactamines ou les carbapénèmes, qui pénètrent davantage dans le cerveau de ces malades.
Enfin, soulignons que si l’atteinte cérébrale qui résulte de la maladie rénale se traduit principalement par le développement d’une maladie des petits vaisseaux cérébraux (ou démence vasculaire), certains travaux ont révélé que les patients présentent aussi un risque accru de développer une maladie d’Alzheimer.
Prendre en compte les troubles cognitifs
En cas de maladie rénale, il est donc important de toujours prendre en compte l’état cognitif des patients. Cela nécessite de mieux dépister les complications cérébrales, car plus ces troubles sont pris en charge précocement, plus leur prise en charge sera efficace. Corollaire : il est tout aussi important de dépister précocement une maladie rénale chez les patients atteints de trouble de la mémoire ou d’AVC.
Cela peut être fait très simplement, grâce à des analyses de sang et d’urine au laboratoire doublées d’une mesure de la pression artérielle. Plus tôt la maladie rénale est diagnostiquée, plus les traitements de protection rénale seront efficaces pour ralentir sa progression, et plus les risques de complications diminueront, y compris au niveau du cerveau.
On sait par ailleurs que la greffe rénale peut améliorer les troubles cognitifs des patients.
Des traitements en cours de développement
Dépister tôt une maladie rénale permet de mettre en place des traitements pour ralentir la dégradation de la fonction rénale ainsi que ses conséquences cérébrales.
L’établissement d’un diagnostic précoce est d’autant plus important qu’il n’existe à l’heure actuelle aucune thérapie spécifique pour protéger le cerveau des patients en cas de maladie rénale. Cependant, dans ce domaine, la recherche est en expansion ces dernières années, et plusieurs pistes de nouveaux traitements sont à l’étude.
Pendant longtemps, le rein a été considéré essentiellement comme un organe de filtration des déchets. Les résultats de recherche récents montrent qu’il participe également à un dialogue permanent avec le cerveau.
Mieux comprendre cette connexion et améliorer le dépistage pourrait permettre de mieux préserver non seulement la fonction rénale, mais aussi les capacités cognitives de millions de personnes.
Mickaël Bobot a reçu des financements de la Société Francophone de Néphrologie, Dialyse et Transplantation, de la Fondation du Rein et de l'Assistance Publique - Hôpitaux de Marseille, pour ses travaux de recherche. Il est membre de la Société Francophone de Néphrologie, Dialyse et Transplantation, de l'European Renal Association (Société Européenne de Néphrologie).
15.06.2026 à 17:25
Les maisons de santé pluriprofessionnelles : un modèle gagnant pour patients, soignants et systèmes de santé
Morgane Angibaud, Pharmacien d'officine & Maitre de conférence associé à l'UFR des Sciences Pharmaceutiques et Biologiques, Nantes Université
Texte intégral (2219 mots)
Avec un objectif fixé à 4 000 établissements d’ici 2027, les maisons de santé, qui regroupent médecins généralistes, masseurs-kinésithérapeutes, infirmier·ères, pharmacien·nes et autres professionnel·les de santé, montent en puissance. Elles sont présentées comme l’une des solutions pour améliorer l’accès aux soins de toutes et tous, en particulier pour les personnes qui souffrent de maladies chroniques. Mais ont-elles fait leurs preuves ?
Les maisons de santé pluriprofessionnelles sont des lieux de soins de plus en plus visibles. Soutenues par les pouvoirs publics, elles apparaissent comme une solution aux nouveaux défis de notre système de santé.
Mais quels sont leurs effets documentés sur les patients, les soignants et l’organisation des soins ?
Une réponse à la fragmentation des soins
Les systèmes de santé sont confrontés à de multiples défis : vieillissement de la population, augmentation des maladies chroniques, pénurie de soignants et accentuation des inégalités sociales de santé. Ces évolutions rendent la prise en charge plus complexe et peuvent entraîner des actes redondants, des informations parfois contradictoires entre soignants, une baisse de la qualité des soins, mais aussi une augmentation des coûts.
C’est dans ce contexte que se développent des formes d’organisation fondées sur la coordination. En France, les maisons de santé constituées entre des professionnels médicaux, auxiliaires médicaux ou pharmaciens, créées en 2007, en sont l’un des principaux exemples.
Fin 2023, elles regroupaient 2 501 équipes, plus de 32 000 soignants, et elles accueillaient près de 8,9 millions de patients.
Une organisation plus qu’un lieu
Au sein de ces maisons de santé pluriprofessionnelles, se trouvent des soignants de ville, le plus souvent des médecins généralistes, des infirmiers, des masseurs-kinésithérapeutes et des pharmaciens. Elles collaborent parfois avec d’autres professionnels comme les psychologues ou d’autres structures de soins telles que les maisons de retraite, les hôpitaux ou les cliniques. Contrairement à une idée répandue, une maison de santé pluriprofessionnelle ne se définit pas par un bâtiment mais sur un projet de santé commun, élaboré et porté par les soignants.
Ce projet structure leur manière de travailler ensemble. Dans la pratique, cette organisation se traduit par des réunions de concertation autour de cas complexes, l’élaboration de plans personnalisés de santé, ou encore la mise en place de protocoles de délégation de tâches entre soignants. Ce mode de fonctionnement modifie les pratiques professionnelles. Il transforme le rôle des soignants qui s’inscrit davantage dans une logique de coordination que d’exercice isolé.
Depuis 2016, ces structures s’inscrivent dans le cadre plus large des équipes de soins primaires, connues à l’international sous le terme de primary care teams. Les soins primaires correspondent au premier niveau de contact entre la population et le système de santé. Ils sont assurés par des professionnels, comme les médecins généralistes, infirmier·ères, sages-femmes, pharmacien·nes ou dentistes, travaillant en proximité avec la population. C’est dans cette perspective internationale que s’inscrivent les résultats présentés dans cet article.
Des bénéfices documentés pour certaines maladies chroniques
Les maladies chroniques constituent la principale cause de mortalité dans le monde. Elles sont responsables de 75 % des décès, selon les chiffres de l’Organisation mondiale de la santé. En France, elles concernent plus d’un cinquième de la population. Leur prise en charge représente un nouveau paradigme pour notre système de santé et demandent des dispositifs qui permettent une prise en charge globale des personnes et, autant que possible, personnalisées.
Le travail en équipe est associé à une amélioration de certains indicateurs de santé, en particulier pour les maladies cardiovasculaires. Il a notamment été démontré que, par rapport à un suivi plus traditionnel, les patients pris en charge par une équipe présentent de meilleurs résultats cliniques : une diminution de la pression artérielle, une diminution de l’hémoglobine glyquée – un indicateur clé dans le diabète-, ainsi qu’une réduction des taux de LDL-cholestérol, communément appelé « mauvais » cholestérol. De plus, une réduction du tabagisme a également été rapportée.
Améliorer aussi la santé et le bien-être des soignants
En 2023, plus de la moitié des soignants déclarent avoir connu un épisode d’épuisement professionnel, avec des niveaux élevés chez les infirmiers et les médecins. Améliorer la santé et le bien-être des soignants est essentiel pour réduire la perte d’attractivité des métiers du soin et améliorer la qualité des soins des patients.
Les maisons de santé pluriprofessionnelles fondent leur organisation sur une répartition plus claire des rôles, une prise de décision collective et des formes de gouvernance moins hiérarchiques. La littérature scientifique suggère que ces évolutions sont associées à une meilleure reconnaissance des compétences de chacun, une satisfaction professionnelle accrue et une diminution du risque d’épuisement professionnel.
Des effets sur l’accès aux soins
L’accès aux soins constitue un problème majeur. Les délais de rendez-vous s’allongent, atteignant en moyenne douze jours pour un médecin généraliste. L’accès aux soins résultent à la fois de facteurs individuels – âge, niveau de ressources, capacité de déplacement – et de facteurs organisationnels comme la présence et les capacités d’accueil des cabinets médicaux.
Les maisons de santé apparaissent alors comme un moyen d’action. Elles participent à l’attractivité des territoires pour les médecins généralistes car elles favorisent une prise en charge plus fluide, ce qui permet de soigner davantage de patients et d’accélérer les délais de prise en charge.
En parallèle, l’hôpital et la médecine spécialisée sont sous forte pression. Les services d’urgence en sont l’exemple le plus parlant : près d’un Français sur deux s’y est déjà rendu pour un problème qui ne relevait pas d’une urgence réelle. Les maisons de santé pourraient répondre à cette problématique en améliorant l’organisation des soins de proximité. Certaines études montrent qu’elles peuvent réduire le recours aux médecins spécialistes, les passages aux urgences ou encore les hospitalisations, même si ces bénéfices ne sont pas retrouvés de manière systématique.
Des avancées sur la qualité des soins
La coordination des soins est souvent présentée comme un levier pour améliorer la qualité, la sécurité et la pertinence des soins. Des travaux de recherche suggèrent que le travail en équipe pourraient favoriser une meilleure analyse et prise de décision de la part des soignants, ainsi qu’une meilleure conformité aux recommandations, en particulier dans la prise en charge des maladies cardiovasculaires ou du diabète.
Mais la qualité des soins ne se résume pas à des indicateurs de résultats. Elle passe aussi par l’expérience des patients, c’est-à-dire tout ce qu’une personne vit au fil de son parcours de santé, dans ses échanges avec les soignants comme dans les situations qu’elle traverse.
Aujourd’hui, cette expérience est de plus en plus souvent prise en compte dans l’évaluation des soins. Dans le cas des maisons de santé, des études suggèrent une amélioration, notamment dans la communication entre patients et soignants, mais ces effets restent modestes.
Un impact à confirmer sur le recours aux spécialistes et à l’hospitalisation
Les maisons de santé sont un véritable tournant dans la manière de soigner en passant d’une pratique isolée à un travail d’équipe centré sur le patient.
Les études montrent des bénéfices concrets : un meilleur bien-être des soignants, un meilleur accès aux soins et une prise en charge améliorée des maladies cardiovasculaires. En revanche, leur impact sur le recours aux médecins spécialistes, les hospitalisations ou encore l’expérience des patients reste encore à confirmer.
Ces résultats démontrent que le travail en équipe est efficace. C’est dans cette logique que le gouvernement encourage le développement des maisons de santé pluriprofessionnelles, avec un objectif de 4 000 structures d’ici 2027. Si elles en sont l’exemple le plus visible, il s’agit plus largement de soutenir toutes les formes d’équipes de soins primaires. D’ailleurs, certaines régions ont déjà investi le sujet en expérimentant de nouvelles formes d’organisation.
Cependant, le travail en équipe des soignants n’est pas une solution miracle. Pour répondre pleinement aux défis du système de santé, d’autres évolutions sont indispensables. L’enjeu est global : améliorer la santé de tous, offrir une meilleure expérience aux patients, préserver les soignants de l’épuisement, maîtriser les dépenses et garantir un accès équitable aux soins.
Morgane Angibaud a reçu des financements de la Direction générale de l'offre de soins (PREPS 2020).
15.06.2026 à 17:24
Avec son encyclique sur l’IA, Léon XIV ne pense plus l’Église comme une citadelle assiégée
Jacques-Benoît Rauscher, Enseignant-chercheur en théologie morale sociale, UCLy (Lyon Catholic University)
Texte intégral (2291 mots)
L’encyclique du pape Léon XIV consacrée à l’intelligence artificielle, « Magnifica humanitas », signée le 15 mai 2026, inaugure pour le Vatican une nouvelle manière de prendre la parole dans l’espace public. Le souverain pontife part d’abord de la conception biblique de l’être humain et du but de son existence, revenant à des « fondamentaux » spirituels, à distance d’un catholicisme pensé comme « contre-modèle » sociétal. L’histoire de la « doctrine sociale de l’Église » permet de mieux saisir l’importance de cette évolution.
C’est un paradoxe plusieurs fois commenté. Ces dernières semaines, les discussions concernant l’intelligence artificielle (IA) ne viennent pas des annonces d’une start-up de la Silicon Valley, mais du Vatican. Une des plus vieilles institutions de la planète se penche sur la mutation technologique du moment. Le contraste entre ces deux cadres, couplé au relatif silence qui entoure l’IA explique sans doute la curiosité de nombre d’analystes pour l’encyclique papale (lettre solennelle du pape adressée à l’ensemble de l’Église catholique, ndlr) « Magnifica Humanitas ».
Mais, au-delà du contenu et du contexte, une évolution importante a moins été notée à propos de ce texte pontifical. Léon XIV y adopte une posture qui tranche avec celle de ses prédécesseurs quand ceux-ci traitent, dans le cadre de la « doctrine sociale de l’Église », de questions économiques, sociales et politiques.
De fait, de Léon XIII à Léon XIV, de 1891 à nos jours, se pencher sur les textes sociaux des papes, c’est être témoin d’un bouleversement à bas bruit des rapports de l’Église catholique avec la sphère publique.
À l’origine de la doctrine sociale : un contre-modèle catholique
La première encyclique sociale, « Rerum novarum », publiée le 15 mai 1891, place les papes sur un terrain nouveau : celui de la défense de la condition ouvrière dans un contexte d’industrialisation massive du monde occidental. Si Jean Jaurès souligne l’importance de ce texte et que le curé de campagne de Bernanos fait un éloge de Léon XIII, son influence ne se limite pas à quelques élites. Elle consacre l’émergence d’un courant de démocratie chrétienne et de syndicalisme d’inspiration catholique partout en Europe. En ce sens, on pourrait y lire une adaptation du catholicisme à un pluralisme politique, à la suite des mouvements révolutionnaires des XVIIIᵉ et XIXᵉ siècles.
Pourtant, si l’on se penche plus précisément sur « Rerum novarum » on voit que ce texte est aussi marqué par une certaine nostalgie du rôle autrefois dévolu au catholicisme dans les sociétés non laïcisées. Léon XIII souligne ainsi combien les maux liés à l’industrialisation pourraient être réparés si les mœurs chrétiennes étaient adoptées, recommencées sur nouveaux frais. En 1931, son successeur Pie XI se placera dans une même perspective en appelant de ses vœux, sous l’égide d’universités catholiques, l’émergence d’une science sociale catholique.
Alors que les sociétés choisissent la voie d’une séparation institutionnelle avec le catholicisme, la doctrine sociale de l’Église cherche donc à promouvoir, jusque dans le premier XXᵉ siècle, l’émergence d’un contre-modèle catholique.
Années 1960 : le Saint-Siège mise sur les institutions internationales
Cette perspective change assez radicalement à partir des années 1960, en raison d’évolutions qui affectent tant l’intérieur que l’extérieur de l’Église catholique.
En interne, cette période est, en effet, marquée par le concile Vatican II (1962-1965) qui cherche à enterrer résolument la hache de guerre dans le conflit qui oppose le catholicisme au monde moderne depuis la fin du XIXᵉ siècle. En ce sens, les textes de doctrine sociale catholique de cette époque cherchent à se placer sur un terrain qui refuse explicitement une posture de surplomb.
Mais ce mouvement interne au catholicisme s’inscrit aussi dans une évolution globale qui place les questions sociales à un niveau mondial. Celle-ci est marquée par l’émergence d’institutions internationales dotées d’une structure et d’une influence encore jamais vues dans l’histoire de l’humanité (Organisation des Nations unies, etc.). Cette évolution est également lisible dans le mouvement de décolonisation qui déplace les problématiques sociales du prisme occidental qui les avait caractérisées jusqu’alors.
La doctrine sociale de l’Église épouse cette dynamique. Elle trouve ainsi dans l’internationalisation des questions de société un allié inattendu pour porter son discours. D’abord, le caractère international de la structure catholique lui permet de mettre en avant une expertise et des réseaux d’influence dans nombre de pays émergents. Ensuite, les institutions internationales donnent à sa parole un écho particulier. C’est dans cette perspective que l’on peut lire le soutien très prononcé des papes aux Nations unies auprès desquelles le Saint-Siège – qui y est observateur permanent – ne se prive pas d’intervenir.
Alors que la baisse de la pratique cultuelle marque les sociétés occidentales et que les sociologues du début du XXᵉ siècle avaient prévu un effondrement des références religieuses, c’est sur la scène internationale que l’importance de ces dernières se fait sentir. Le catholicisme n’échappe pas à ce mouvement qualifié de « revanche de Dieu ». Dans un contexte de sécularisation, les papes trouvent ainsi, auprès des institutions internationales, la possibilité de jouer leur partition propre.
L’IA, Babel et Jérusalem
Depuis les années 2000, cette deuxième période semble définitivement close. Tout d’abord, les institutions internationales jouissent d’un poids moindre et leur perte d’influence rejaillit conséquemment sur la doctrine sociale de l’Église. Ensuite, la matrice catholique la plus classique qui pouvait encore structurer la vie intellectuelle de la seconde moitié du XXᵉ siècle est plus fortement érodée.
Dans les sociétés occidentales, le mouvement de sécularisation a laissé place à une « exculturation » du catholicisme qui ne constitue plus le socle de références (même implicite) des débats (pour reprendre l’expression de la sociologue Danièle Hervieu-Léger). Parallèlement, des revendications (souvent minoritaires mais très visibles) cherchent à arrimer une pensée politique conservatrice à une culture catholique affichée.
Dans ce contexte, la méthode retenue par le pape Léon XIV dans sa première encyclique apparaît significative : « Magnifica humanitas » s’ouvre ainsi sur deux récits bibliques qui servent de guide à sa réflexion sur la technique. D’emblée, le pape l’affirme :
« Pour répondre à ces questions et discerner comment vivre de manière responsable à l’ère de l’intelligence artificielle, je voudrais évoquer deux images bibliques : la construction de la tour de Babel (Cf. Gn 11, 1-9) et la reconstruction des murs de Jérusalem […] Le choix ne se situe pas entre un “oui” ou un “non” à la technologie, mais entre bâtir Babel ou reconstruire Jérusalem ; entre un pouvoir qui prétend dominer le ciel et un peuple, qui, en présence de Dieu, se met à travailler de manière unie pour relever les murs de la cohabitation fraternelle. »
Léon XIV montre que l’être humain décrit par la Bible porte en lui une volonté bonne de construire, de transformer le monde par ses aptitudes. Mais ces capacités peuvent lui faire perdre de vue la nécessité d’accueillir cette autre caractéristique humaine essentielle qu’est la fragilité.
Être fragile consiste, pour le pape, à ne pas se rêver tout-puissant, à ne pas considérer que les limites humaines sont uniquement des problèmes pour lesquels existent des solutions techniques. La fragilité permet à l’être humain de mesurer combien il a besoin des compétences spécifiques de ses semblables pour venir compléter ce qu’il accomplit.
L’IA pourrait donner l’illusion d’avoir des solutions immédiates à tout problème. Celui qui l’utilise peut se sentir tout-puissant. Se développer en refusant la fragilité et l’altérité qu’elle implique, c’est la « tentation de Babel ». À l’inverse, se développer en se reconnaissant interdépendant, c’est la « reconstruction des murs de Jérusalem ». Autrement dit, quand il traite d’IA, Léon XIV part d’abord de la conception biblique de l’être humain et du but de son existence avant de se saisir des questions politiques liées aux mutations technologiques.
Un catholicisme qui ne se pense plus comme une citadelle assiégée
Le pape, la Bible : on pourrait objecter que ce couple n’a rien de mal assorti et qu’entendre le pontife citer l’Écriture relève de l’évidence… Pourtant, jusqu’alors, la doctrine sociale de l’Église traitait souvent plus de philosophie sociale ou de droit international que de récits bibliques longuement médités.
Ce registre qui consiste à prendre une certaine hauteur pour traiter d’un phénomène actuel consonne avec le refus exprimé par Léon XIV de s’engager dans la reconquête d’une influence perdue par l’Église. Il s’accompagne surtout d’une autocritique très originale de la position de l’Église sur plusieurs thématiques. En particulier, on voit le pape indiquer que la recherche de la vérité qu’il prône n’a pas toujours été le fort des catholiques. Il note ainsi que c’est grâce à l’intervention de journalistes (et non aux efforts de structures ecclésiales) que certains faits criminels ont pu éclater au grand jour au cœur de l’Église :
« Les communautés chrétiennes doivent s’engager à communiquer de manière transparente et à rechercher fidèlement les faits […] Nous avons assisté avec honte à la pénible découverte de vérités douloureuses concernant également des membres de l’Église et des réalités ecclésiales. En particulier, certains journalistes passionnés par la vérité ont joué un rôle fondamental dans la mise en lumière d’injustices et d’abus. »
Indiquer qu’une presse indépendante est indispensable au cœur de toute institution peut être lu comme un coup envoyé aux courants qui voudraient voir dans le catholicisme une citadelle assiégée, imperméable à toute critique et apte à fonder un éventuel ordre politique nouveau. S’écartant donc tant du modèle contre-culturel du XIXᵉ siècle que de celui du dialogue centré sur les institutions internationales des années 1960, Léon XIV place ainsi son propos à un niveau plus spirituel qu’institutionnel. Si, ce faisant, il cherche toujours une influence sur la réflexion publique, la manière de l’acquérir apparaît radicalement nouvelle.
Quelle que soit l’appréciation que l’on peut porter sur ce positionnement, il s’agit bien d’une évolution de l’expression pontificale sur la sphère publique qui n’a que peu d’équivalents chez les papes précédents (à part sans doute le pape François et son encyclique « Laudato si’ »).
Il est sans doute trop tôt pour mesurer ses conséquences éventuelles. Mais cette nouvelle posture marque un tournant qui montre qu’est profondément entérinée la laïcisation des sociétés contemporaines, la perte d’influence des institutions internationales et qu’émerge un mode d’expression papal mettant très directement en avant les fondements de la foi. Cependant, cette évolution-là, moins visible que celle de l’intelligence artificielle, n’en est pas moins significative pour ceux qui s’intéressent à la place des religions (et du catholicisme en particulier) dans l’espace public.
Jacques-Benoît Rauscher ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.06.2026 à 17:23
Le contrôle des voies maritimes : de l’Arctique à Ormuz, les nouveaux leviers de la puissance
Xavier Carpentier-Tanguy, Indopacifique, Géopolitique des mondes marins, réseaux et acteurs de l'influence, diplomatie publique, Sciences Po
Texte intégral (1495 mots)
L’Otan renforce sa présence dans le Grand Nord et Moscou ressort le projet de tunnel sous le détroit de Béring. Mais la vraie bataille du Nord, et au-delà, porte sur le contrôle des flux.
Le 6 juin 2026, des forces terrestres de l’Otan ont commencé à se déployer en Finlande et en Suède, pour tenir le flanc nord-est de l’Alliance et sécuriser l’Arctique face à l’activité militaire russe et à l’intérêt grandissant de la Chine.
La région, a résumé le commandant suprême allié en Europe, est « l’une des zones les plus importantes sur le plan stratégique ». On raisonne ici en territoires et en flancs, selon une carte où sont disposées des troupes, à une certaine distance de frontières et suivant ce qui est nommé une posture.
La même semaine, à l’autre bout du même Grand Nord, Moscou ressortait un tout autre objet. En marge du Forum économique de Saint-Pétersbourg, un proche du Kremlin annonçait que le tunnel sous le détroit de Béring, qui relierait la Russie à l’Alaska – rebaptisé « tunnel Poutine-Trump » – pourrait être conçu d’ici à la fin de l’année. Le projet court depuis les tsars : un serpent de mer qui resurgit tous les vingt ans, entre deux des littoraux les plus vides de la planète. Et s’il fait la une des journaux, c’est qu’il est taillé pour cela, aidant à la circulation d’un récit bien plus que des flux auxquels sont normalement destinés les tunnels.
De fait, ni les troupes du flanc finlandais, ni le tunnel rêvé ne disent où se joue vraiment la puissance dans le Nord.
Le vrai verrou : la route du Nord
La vraie prise sur le Nord porte sur l’ensemble de tout ce qui transite, de tout ce qui est convoyé sous différentes formes (les flux de marchandises, d’équipement, de pétrole ou de gaz, etc.). Béring dessine l’entrée orientale de la route maritime du Nord, que la Russie referme méthodiquement, sans un coup de canon. Elle invoque l’article 234 du droit de la mer — prévu pour les zones prises par les glaces – pour réglementer la navigation dans sa zone économique. Détenant le quasi-monopole des brise-glaces nucléaires, seul sésame d’un passage où nul ne s’aventure sans escorte, elle refuse de confier cette escorte aux brise-glaces chinois.
Comme l’a montré le géographe Frédéric Lasserre, spécialiste des routes arctiques, la liberté de navigation y est de fait effacée. L’océan Arctique devient une mer fermée – un mare clausum – reconstituée non par la puissance ou la crainte du canon, mais par le droit, la glace et l’escorte.
Qui tient le flux ?
La question, ici n’est donc plus « à qui appartient un détroit, un espace géographique contraint ? », mais « qui tient le flux qui le traverse, et par quel levier ? » C’est ce que j’appelle la rhéopolitique, un concept que je développe dans mes analyses : contrôler les flux plutôt que les territoires – les régler, les moduler, les interrompre.
On tient un flux par le canon : à Bab el-Mandeb, drones et missiles ont suffi à dérouter une partie du commerce mondial par le cap de Bonne-Espérance. Par le tarif : douane, sanction, et jusqu’au péage – depuis la fermeture de fait d’Ormuz, fin février 2026, Téhéran conditionne le passage par ses eaux à une redevance versée aux gardiens de la révolution, selon la publication de référence du transport maritime mondial, Lloyd’s List a surnommée le « péage de Téhéran ». Ou par un levier plus discret encore, la prime. Les assureurs ayant classé le Golfe en zone de guerre, les primes se sont envolées ; le détroit, resté ouvert en droit, devenait impraticable en fait. Et pour rétablir un trafic, ce ne fut pas une marine de guerre, mais un montage assurantiel – la prime, non la canonnière – qui rouvrit la voie et décida des navires admis. Le canon s’alignait sur la prime.
De La Rochelle assiégée en 1628 à Ormuz en 2026, j’ai montré ailleurs que les détroits se ferment moins par la bataille que par le contrôle des flux.
Un même opérateur, deux détroits
C’est pourquoi, sur les rives d’Ormuz comme aux deux entrées du canal de Panama, il est significatif d’observer la même signature sur les portiques : le conglomérat hongkongais CK Hutchison, présent dans des dizaines de terminaux à travers le monde – véritables structures du commerce mondial que le grand public ne connaît pas.
Deux épisodes récents, deux formes de contrainte. À Panama, sous la pression de Washington, l’opérateur s’est vu contester la propriété même de ses concessions : un consortium mené par BlackRock a négocié le rachat, la concession historique a été remise en cause et depuis l’affaire se joue désormais en arbitrage — le tout sans un coup de feu. À Ormuz, nul n’a disputé la propriété des terminaux ; c’est le flux qui les irriguait qui s’est tari. Un même acteur, deux détroits : ici la maîtrise du lieu, là celle de la circulation. D’un côté, une géographie des lieux, héritée des atlas ; de l’autre une géographie des liens, celle des flux qui relient les territoires au monde.
Reste le plus troublant : si l’opérateur peut être observé, lui, à qui obéit-il ? Depuis la loi de sécurité nationale de 2020, l’autonomie des groupes hongkongais à l’égard de Pékin n’est plus certaine – et c’est d’ailleurs Pékin qui a d’abord bloqué la vente. Le pavillon d’un navire dit de moins en moins qui le possède ; la nationalité d’un opérateur, de moins en moins à qui il répond.
Voir avant de défendre
À ces portes, le levier décisif n’est tenu ni par un État, ni par une marine, mais par un assureur, un opérateur de terminaux, un gestionnaire d’actifs – un pouvoir exercé sans vote, et souvent sans visibilité. Il ne s’agit ni de prôner le repli, ni de rêver d’une renationalisation des passages, vaine dans une économie de flux. Il s’agit de regarder en face ce que nous avons cessé de cartographier : des contrats, des concessions, des polices, des chaînes d’allégeance.
Savoir penser la puissance aujourd’hui est, pour Luis Vassy, qui dirige Sciences Po, « un défi intellectuel de notre temps ». À l’aune de ce que montrent les détroits, la réponse est nette : la puissance se lit désormais autant dans les flux que dans les territoires. Le déploiement de l’Otan dans le Grand Nord et le tunnel rêvé de Béring relèvent du même réflexe : penser en flancs et en annonces. Pendant ce temps, le long de la route du Nord, à Ormuz ou à Panama, des flux bien réels changent de main, discrètement. On ne défend pas ce que l’on ne sait plus voir.
Xavier Carpentier-Tanguy ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.06.2026 à 17:22
La situation géopolitique de l’Union européenne, entre vulnérabilité et robustesse
Sylvain Kahn, Professeur agrégé d'histoire, docteur en géographie, européaniste au Centre d'histoire de Sciences Po, Sciences Po
Texte intégral (2055 mots)
Le discours de Pete Hegseth en Normandie illustre la rupture stratégique entre les États-Unis de Donald Trump et l’Union européenne, sommée d’assurer seule sa défense face aux défis sécuritaires contemporains. Devant les pressions russes, chinoises et désormais américaines, l’UE développe progressivement des instruments financiers, industriels, commerciaux et militaires destinés à renforcer son autonomie.
Venu en Normandie, le 6 juin dernier, pour les commémorations du 82e anniversaire du Débarquement, Pete Hegseth, le secrétaire à la guerre des États-Unis (dénommé ainsi depuis que Donald Trump a décidé de donner ce nom au secrétariat à la défense en septembre 2025), s’est notamment rendu à Colleville-sur-Mer, dans le Calvados. Après s’être recueilli face aux 9 387 croix blanches du cimetière de soldats américains tombés sur la plage d’Omaha Beach, il y a prononcé un discours parfaitement cohérent avec la Stratégie nationale de sécurité américaine publiée en novembre 2025.
Citant les arrivées de navires et de migrants sur les côtes espagnoles, italiennes, grecques et bulgares, Hegseth a affirmé que l’Europe se trouvait sous la menace des flux migratoires, qualifiés d’« invasion », s’est interrogé sur la capacité de réaction des États membres de l’UE face à ce « débarquement d’un nouveau type » et s’est demandé s’il n’était pas déjà trop tard.
Refusant de participer à la célébration internationale officielle, il a admonesté les Européens : renforcez rapidement votre autonomie militaire, et ne comptez plus sur les États-Unis pour vous défendre, a-t-il dit en substance.
Cette séquence aura fourni une confirmation supplémentaire de la nouvelle politique européenne des États-Unis martelée par l’administration Trump depuis février 2025 – y compris par Hegseth lui-même à Bruxelles moins de trois semaines après l’entrée en fonction de celle-ci le 20 janvier. Du point de vue de son tableau géopolitique d’ensemble, l’Union européenne fait face depuis seize mois à une situation singulièrement inédite, qui la rend vulnérable. Pour y répondre, est-elle en train d’inventer une forme de réponse singulière, qui serait la robustesse ?
L’inventaire des moyens : une capacité de passage à l’acte
L’UE a déjà commencé à démontrer une aptitude inattendue à agir concrètement face à des chocs imprévus et inédits. Dans le domaine financier et budgétaire, la création du plan de relance NextGenerationEU dans la foulée du Covid et des confinements en 2020, a posé les bases d’un « proto-Trésor européen », permettant de financer nos biens publics par l’emprunt commun.
En parallèle, le volet économique et commercial s’est musclé avec l’Instrument anti-coercition (ACI) – qui permet de sanctionner des entreprises, ou des États, ou d’instaurer rapidement des droits de douane exceptionnels, et qui a été conçu pour répliquer aux chantages commerciaux, notamment de la République populaire de Chine – tandis que le Chips Act et le Net-Zero Industry Act visent la souveraineté technologique, notamment en cherchant à raffiner en Europe 40 % des métaux rares nécessaires à notre industrie.
Avec l’invasion de l’Ukraine à grande échelle par la Russie lancée en 2022, le défi le plus important demeure celui de la défense, où l’objectif est désormais l’« autosuffisance militaire ». Si l’Europe a réalisé qu’elle produisait déjà plus de munitions que les États-Unis, elle doit encore briser le « corporatisme nationaliste » de ses industries ; c’est pourquoi l’UE a mis au point des leviers nommés Règlement relatif au soutien à la production de munitions (ASAP) ou Stratégie industrielle européenne de défense (EDIS) de façon à encourager la volonté de bâtir progressivement une base industrielle et technologique de défense (Bitd) européenne, c’est-à-dire une industrie de défense européenne et un marché de l’armement européen. Ces instruments sont les prémisses d’une authentique politique industrielle de défense européenne.
Cette dynamique de nouvelles réponses aux défis des politiques impérialistes ne s’arrête pas aux frontières de l’UE : elle s’inscrit dans un vaste « système territorial européen » incluant le Royaume-Uni, la Norvège ou encore les pays candidats à l’adhésion y compris la Turquie, qui est en union douanière avec l’UE.
Dans un monde de rivalités, l’UE a intérêt à coaliser des « puissances moyennes » pour protéger l’interdépendance contre les prédations. En 2026, le premier ministre canadien Mark Carney a appelé explicitement, à Davos, à la mise en réseau de ces États pour peser ensemble (commerce, normes, sécurité économique). D’une certaine façon, Mark Carney propose d’étendre bien au-delà du petit territoire européen (ce cap… écrivait Paul Valéry) la boîte à outils, le bricolage et l’assemblage que mettent en œuvre, sans tambour ni trompette ni fierté particulière, les Européens depuis trois générations.
Vue sous cet angle, la Communauté politique européenne révèle au grand jour l’existence d’un système territorial européen (l’expression est de Pascal Orcier) que polarise et anime l’UE : l’UE et tous ses associés, de la Turquie (union douanière) au Canada (Ceta), en passant par l’Espace économique européen, Schengen, le Voisinage, le Royaume-Uni (accord de commerce et de coopération) et les Candidats.
La doctrine : de la puissance normative à la robustesse
Cette réactivité s’appuie sur une nature politique unique : l’UE est une « étaticité multiterritoriale ». Depuis 1950, elle s’est construite en substituant le droit à la force, privilégiant ce que Zaki Laïdi nomme la « puissance par la norme• ». Par l’« effet Bruxelles », elle impose ses standards (IA, environnement, RGPD) au reste du monde car l’accès à son marché demeure vital. Depuis 1950, l’Europe s’est construite contre l’esprit de puissance classique qui avait mené au suicide du continent. L’UE ne cherche pas de la puissance par la coercition, mais par la régulation et l’interdépendance.
Cependant, dans le contexte actuel, la simple régulation ne suffit plus ; il faut y ajouter la robustesse. La robustesse est la faculté d’un système à absorber des chocs extérieurs et à préserver son autonomie sans trahir son identité juridique. Cela implique de passer d’une dépendance subie à une « vulnérabilité choisie » (Mathilde Lemoine, économiste) grâce à la diversification des partenariats. L’Europe ne cherche pas la coercition classique du XXᵉ siècle, mais une capacité à rester libre et autonome dans un environnement hostile.
Une réponse directe à la fin de l’atlantisme et la « triple coercition »
Nous devons d’abord poser un diagnostic lucide sur notre environnement. Ce besoin de robustesse est la réponse directe à un environnement marqué par une « triple coercition » :russe, chinoise et, c’est la nouveauté radicale de 2025, américaine.
L’impérialisme russe. Depuis l’invasion de l’Ukraine en 2022, la Russie s’est affirmée comme un « État mafieux » qui érige la violence en principe de gouvernement. Elle conteste vitalement le modèle européen fondé sur le droit et le pluralisme. Tandis que la Russie occupe l’est de l’Ukraine et bombarde chaque jour les villes et les civils qui sont à l’arrière du front, les Européens les soutiennent financièrement, par l’envoi d’armes et par l’accueil de réfugiés. Rappelons que l’UE partage près de 2 300 kilomètres de frontières avec la Russie, et près de 1 300 kilomètres avec l’Ukraine.
La rivalité chinoise. La République populaire de Chine est désormais un « rival systémique » (selon la doctrine de l’UE publiée en 2019 par Jean-Claude Juncker, alors président de la Commission européenne), c’est-à-dire non seulement économique, mais aussi idéologique à l’échelle du système international et de l’espace mondial. Elle utilise des pratiques de concurrence déloyale pour évincer l’Europe des relations avec le Sud global et pour créer des dépendances critiques, menaçant des pans entiers de notre industrie, comme l’automobile.
Enfin, le choc le plus perturbant est celui du « trumpisme 2 », qui marque le décès de l’atlantisme. Les États-Unis ne nous traitent plus en alliés mais comme des « gisements de ressources ». C’est ce que l’on peut qualifier d’« emprisme » : une forme d’emprise américaine transformant notre interdépendance historique de près d’un siècle en un rapport de force contraignant, où l’accès au renseignement comme aux technologies devient un levier de chantage pour imposer des droits de douane injustifiés, un affaiblissement du soutien à l’Ukraine et des ingérences dans les vies politiques des États membres de l’UE.
Une autonomie pour les Européens
En définitive, alors que les Européens n’aspirent pas à devenir une puissance guerrière capable d’agressions et d’occupations, leur singularité est de chercher à construire une autonomie praticable.
L’UE pourrait s’affirmer comme une « puissance d’architecture » : elle stabilise le monde en codifiant l’interdépendance par le droit et en armant son marché commun contre la coercition. Cette transformation de la puissance normative en autonomie robuste doit désormais s’accélérer pour faire face aux politiques russe, chinoise et américaine de type impérialiste.
In fine, la viabilité de ces outils dépendra de la mobilisation des citoyens eux-mêmes ; car la robustesse de l’État des Européens est, avant tout, entre leurs mains.
Sylvain Kahn ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.06.2026 à 17:20
Le travail domestique des enfants : une réalité invisible et des inégalités tenaces
Irène Berthonnet, Maîtresse de conférences en économie, Université Rennes 2
Texte intégral (1704 mots)
La question du travail domestique est abordée dans le débat public sous l’angle de l’inégale répartition des tâches entre femmes et hommes. Mais qu’en est-il des tâches ménagères prises en charge par les enfants ? Bien que l’on ne présente pas leur participation au ménage, à la cuisine ou au rangement, comme un véritable travail, ces tâches représentent une moyenne de 44 minutes par jour.
Si l’on a pris conscience aujourd’hui de l’inégale répartition des tâches ménagères dans les couples hétérosexuels, la prise en charge du travail domestique par les enfants reste peu connue. On sait que l’arrivée d’un ou de plusieurs enfants dans un ménage a pour effet d’augmenter la quantité globale de travail à réaliser et de creuser l’écart entre le temps qu’y consacrent les femmes et les hommes.
Mais une fois le bébé devenu enfant, celui-ci ou celle-ci fait-il ou fait-elle une partie du ménage ? Concrètement, quelle est la participation des enfants aux lessives ? Contribuent-ils et elles à la préparation des repas ?
Un travail domestique invisible et tabou ?
Depuis les années 1930 environ, la représentation occidentale de l’enfance repose sur son caractère nécessairement improductif, le travail rémunéré des mineurs étant interdit, sauf dans certains cas spécifiques.
Cette habitude empêche de percevoir le travail domestique non rémunéré des enfants comme un véritable travail, car poser la question du travail domestique soulèverait aussi celle du travail rémunéré, dont l’interdiction est constitutive du statut de mineur.
La sociologue Viviana Zelizer, dans un livre récemment traduit en français ainsi que l’historienne Anne-Marie Praz ont montré que ce phénomène datait en gros du tournant du XXᵉ siècle aux États-Unis et en Europe. Toutes deux considèrent que, à partir des années 1930, les enfants sont considérés comme des ressources affectives par leurs parents, et non plus comme des ressources économiques dont le travail participerait à l’économie domestique.
Depuis lors, les enfants occidentaux sont rarement considérés comme des travailleurs, leur implication dans le monde socioéconomique se limitant à un rôle de consommation ou d’objet du travail domestique et parental.
Quand le problème du travail domestique apparaît dans le débat public grâce au mouvement féministe des années 1960-1970, celui-ci est traité principalement sous l’angle de l’oppression domestique des femmes. Le mouvement féministe conceptualise alors la maternité comme creuset de l’oppression patriarcale, et le travail domestique des enfants ne fait pas trop l’objet de discussions, ces derniers étant plutôt vus comme les bénéficiaires de ce travail.
Cette histoire fait que l’on conceptualise rarement aujourd’hui ces activités enfantines comme du « travail » : de la même manière que les stages et statuts d’alternants ne sont pas pensés comme des emplois mais comme des moments de formation, le travail domestique des enfants est vu comme une « participation » à la vie familiale et/ou comme un apprentissage de la vie d’adulte.
Comme ce fut le cas pour le travail domestique des femmes avant les mouvements féministes, les activités réalisées pour autrui par les enfants dans le cadre domestique sont invisibles en tant que « travail », du fait du statut subalterne de ces derniers.
Le tournant de l’entrée des femmes dans le salariat
Dans les années 1980-1990, l’entrée massive des femmes dans le salariat entraîne une prise de conscience de ce biais adultiste dans le traitement du travail domestique.
De nouvelles hypothèses surgissent alors, par exemple celle de savoir si les enfants vont prendre en charge une partie du travail que les femmes ne pourraient plus faire du fait de leur emploi salarié. Plusieurs recherches incluent alors la présence ou non d’enfants dans les facteurs susceptibles d’expliquer la répartition des tâches ménagères entre les adultes.
Dans le même temps, l’augmentation des divorces et des nouveaux modèles familiaux pose la question de la façon dont ces familles organisent le travail domestique des enfants. De nouveaux travaux documentent alors les caractéristiques du travail domestique des moins de 18 ans, montrant plusieurs résultats récurrents :
les enfants filles réalisent plus de travail que les enfants garçons ;
le travail domestique augmente avec l’âge ;
les aînées et aînés sont généralement plus impliqués que les cadets ;
enfin, le travail domestique décroît à mesure que le niveau d’éducation parental s’accroît, les parents les plus diplômés donnant plus d’importance aux activités scolaires ou aux loisirs des enfants.
Le sens que les parents attribuent à ce travail fait aussi l’objet d’investigations, révélant que ceux-ci considèrent qu’assigner un certain nombre de tâches aux enfants qui vivent avec eux les forme à leur future vie d’adulte et leur permet d’acquérir un sens des responsabilités et des devoirs envers le groupe.
Près de 44 minutes de travail ménager par jour
Depuis les années 2010, plusieurs recherches empiriques sur le temps de travail et les tâches réalisées par les enfants ont été menées, de l’Italie à la Mongolie, en passant par le Danemark.
Pour le cas des enfants résidant en France, les principaux résultats actuellement disponibles sur la base des enquêtes de l’Insee montrent que les enfants de 11 à 18 ans font en moyenne 44 minutes de travail ménager par jour, soit 60 minutes pour les filles et 29 minutes pour les garçons.
Garçons et filles ne font pas les mêmes tâches, mais la division des tâches entre les enfants ne rejoint pas exactement celle des adultes. Les garçons ne font pas de tâches « longues » : aucune des tâches réalisées par les garçons ne leur prend autant de temps que ce qu’elle prend aux filles. En moyenne, les garçons consacrent au maximum 7 minutes consécutives à une tâche domestique, tandis que les filles y consacrent 12 minutes.
Certains travaux identifient une division entre les tâches relevant du self-care (effectuées plutôt par les garçons) et celles relevant du family-care (faites par les filles.).
Les enfants consacrent en moyenne un tiers du temps de travail domestique des adultes à ce travail, et leur temps domestique augmente à mesure qu’ils grandissent, même si quasiment tous les enfants de 10 ans mettent et/ou débarrassent la table, rangent leur chambre et s’occupent des éventuels animaux domestiques.
La place dans la fratrie influence également fortement le rôle dans le travail domestique, tout comme la classe sociale des parents. En effet, les jeunes des classes populaires réalisent davantage de travail domestique et ce constat est d’autant plus vrai pour les filles des classes populaires, la participation aux tâches ménagères des enfants diminuant à mesure que le niveau scolaire et social des parents s’accroît, la répartition du travail entre filles et garçons devenant alors également plus égalitaire.
Les données agrégées sur le travail domestique des enfants montrent des inégalités entre garçons et filles dans le temps consacré à cette activité, mais il n’y a pas nécessairement des garçons et des filles dans toutes les familles, alors que signifie cette inégalité ? Quelle est la parte des rôles sexués qui est transmise dans l’enfance par la mise au travail ?
L’émergence récente des childhood studies, en proposant une nouvelle vision des capacités d’action des enfants, permettra-t-elle de sortir les enfants des marges des sciences sociales ?
Irène Berthonnet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.06.2026 à 17:20
Face à l’IA, l’encyclique « Magnifica Humanitas » rappelle une idée parfois oubliée : travailler n’est pas seulement produire
Hugo Gaillard, Maître de conférences HDR en sciences de gestion, Le Mans Université
Pierre-Louis Boyer, Maître de Conférences HDR en Histoire du droit et des institutions
Texte intégral (2142 mots)
Hâtivement présentée comme une prise de position contre l’intelligence artificielle, l’encyclique (lettre solennelle du pape adressée à l’ensemble de l’Église catholique) « Magnifica Humanitas » de Léon XIV, publiée en mai 2026, s’inscrit dans une longue tradition de réflexion catholique sur le sens à donner au travail humain. De cette façon, elle revient aussi sur la place à donner à la technique.
Alors que la publication récente de l’encyclique « Magnifica Humanitas » (mai 2026) intervient au moment où l’intelligence artificielle nourrit promesses et inquiétudes, le texte opère un recadrage inattendu, voire inespéré. L’intelligence artificielle nous aidera probablement à produire plus vite. Mais produira-t-elle encore des travailleurs ?
Derrière les promesses de gains de productivité et d’automatisation, une question au moins : que devient le travail lorsque certaines activités intellectuelles qui le constituaient sont progressivement confiées à des systèmes artificiels ?
Travailler ne consiste pas uniquement à obtenir un résultat ; c’est aussi une expérience qui façonne notre jugement, notre autonomie et nos relations aux autres, mais aussi au monde.
Une question ancienne derrière une révolution nouvelle
Les débats sur l’intelligence artificielle sont généralement formulés dans les termes de la performance : quelles tâches pourraient être automatisées ? Quels gains de productivité peut-on espérer ? Comment intégrer l’IA dans le business pour l’optimiser ? Depuis deux siècles d’ailleurs, les innovations techniques sont principalement pensées à travers leurs effets sur l’organisation et l’efficacité de la production.
À lire aussi : Chefs d'entreprises catholiques : comment rester fidèle à ses valeurs ?
Or, l’histoire des transformations du travail montre aussi une succession de déplacements techniques qui ont progressivement modifié les conditions de l’activité humaine. Le XIXᵉ siècle a été marqué par la mécanisation des gestes ; le XXᵉ siècle par leur rationalisation. Le XXIᵉ siècle semble désormais engagé dans une automatisation partielle des opérations cognitives elles-mêmes.
Une unique représentation du travail à travers les siècles
Derrière cette continuité historique, une constante : chaque révolution technique tend à réactiver une même représentation du travail, réduit à sa seule fonction productive. Et plus encore, par cette réduction, l’intensifier encore, lui ajouter des couches et des strates, qui nous le rendent invisible et lointain.
De même, la démultiplication des possibilités techniques a ajouté à cette fonction productive une condition de la production : l’accélération, à tel point que célérité et instantanéité de la production sont devenues des maîtres mots dans le modèle capitaliste.
Une question fondamentale reste dans l’ombre : qu’est-ce que travailler veut dire et signifie de notre humanité ?
Sortir d’une vision restrictive du travail : une vieille histoire
Cette interrogation n’est pourtant pas nouvelle pour l’Église qui a mis historiquement des conditions au déploiement de la technique. Dès la fin du XIXe siècle, alors que la révolution industrielle bouleverse les rapports sociaux, « Rerum novarum » définissait le travail comme « l’entretien de la vie elle-même », de telle sorte qu’il participe aux conditions mêmes de l’existence humaine, qui ne sont pas seulement économiques.
Quelques décennies plus tard, « Laborem exercens » nuançait cette réflexion face aux transformations technologiques du XXᵉ siècle indiquant que « la technique est indubitablement une alliée de l’homme », mais aussi que « comme sujet du travail, et quel que soit le travail qu’il accomplit, l’homme, et lui seul, est une personne ».
À rebours d’un Aristote qui considérait le travail comme avilissant ou du plus récent Paul Lafargue et son Droit à la paresse, l’encyclique nouvellement parue postule que « le travail n’est pas un simple instrument, mais [qu’] il exprime et renforce la dignité de notre vie ». L’intelligence artificielle, en automatisant une part de la vie humaine, favorise-t-elle la dignité de l’humanité ?
Ce que l’IA fait au travail lui-même
Nous l’avons dit, les « bénéfices » présentés de l’IA sont nombreux : alléger certaines tâches répétitives, accélérer le traitement des informations ou faciliter certaines prises de décision. Certainement d’ailleurs, l’IA a pu émanciper ou sortir de l’aliénation du travail certains travailleurs.
Mais l’enjeu ne concerne plus uniquement l’automatisation de certaines tâches matérielles ; il touche désormais des activités traditionnellement associées au travail intellectuel : écrire, analyser, sélectionner, synthétiser ou interpréter. Mais une interrogation persiste : que devient le travail lorsque l’individu délègue progressivement une partie de l’activité cognitive qui contribuait jusqu’alors à sa propre construction ?
Le travail s’entend, d’un point de vue sémantique, de deux manières. La première acception est celle de l’accouchement (on parle en maternité de « salle de travail », de « déclenchement du travail », etc.). La seconde réside dans l’activité réalisée en vue de subvenir, principalement, aux nécessités vitales. Dans les deux cas, c’est la vie humaine qui est centrale, comme si le terme même de travail était indissociable d’une part de la nature humaine, et donc des activités et des tâches de l’être humain.
Le risque d’une substitution des actions humaines par celles de l’IA ne réside probablement pas seulement dans une substitution des tâches humaines par des systèmes techniques, car il concerne également les effets anthropologiques plus discrets susceptibles d’accompagner cette délégation.
La pertinence n’est pas une question de probabilité
Travailler ne consiste pas uniquement à atteindre un objectif. Le travail participe aussi à la formation du jugement, à l’apprentissage, à la socialisation et au développement d’une autonomie individuelle. Or les modèles actuels d’intelligence artificielle reposent largement sur des mécanismes statistiques et probabilistes. Leur efficacité provient de leur capacité à identifier des régularités et à produire des réponses plausibles à partir d’immenses volumes de données.
Mais cette logique comporte une limite : ce qui apparaît comme pertinent correspond souvent à ce qui est le plus probable. Cela conduit irrémédiablement à confondre le probable et le vrai, le possible et le réel. Aux questions, « Quel salaire vais-je toucher à la fin du mois ? », ou à celle « Comment dois-je accomplir cette tâche ? », ou encore « Avec quelle personne dois-je collaborer pour atteindre le résultat attendu ? », le travailleur n’attend pas une réponse statistique ou probable… mais bien la réalité du revenu qu’il va percevoir, la méthode ou le processus, le nom de la personne concernée. Il en est de même pour toute interrogation : le probable ne saurait se substituer au caractère certain d’une réponse.
Le risque n’est donc pas seulement celui de l’erreur. Il pourrait être celui d’une uniformisation progressive des pratiques et des raisonnements, où l’efficacité immédiate l’emporte sur l’interprétation, la créativité ou l’exercice du jugement, où la réponse médiane et relative l’emporte sur l’attraction vers la certitude.
Que voulons-nous encore que le travail fasse de nous ?
L’enjeu n’est pas de condamner la technique ni d’opposer a priori l’humain et l’intelligence artificielle. L’histoire montre au contraire que les innovations peuvent constituer des facteurs puissants d’émancipation. La question est aussi ailleurs, et participe d’un regard éthique (et donc critique) sur l’IA : quelles dimensions du travail souhaitons-nous préserver ?
Cette interrogation concerne notamment et, à titre d’exemple, le monde de l’enseignement. Si certaines compétences techniques deviennent partiellement automatisables, la fonction pédagogique pourrait progressivement se déplacer vers ce qui demeure difficilement substituable : former le jugement, développer l’esprit critique, donner du sens aux connaissances et inscrire les apprentissages dans une compréhension plus large des réalités humaines et sociales.
Babel ou Jérusalem ?
Les débats contemporains sur l’intelligence artificielle portent principalement sur ce que les machines pourront faire demain. Une question plus fondamentale demeure pourtant ouverte : au-delà de ce que nous demanderons aux machines, que voulons-nous encore que le travail fasse de nous ?
Dans « Magnifica Humanitas », Léon XIV mobilise deux figures bibliques que sont Babel et Jérusalem, comme grille de lecture des transformations contemporaines liées à l’intelligence artificielle. Plus qu’une opposition religieuse, elles représentent deux manières d’envisager l’organisation de la vie collective et, par extension, du travail lui-même. Le texte précise ainsi que « le premier choix ne se situe pas entre un “oui” ou un “non” à la technologie, mais entre bâtir Babel ou reconstruire Jérusalem ».
La première renvoie à une logique de Babel : recherche d’une efficacité absolue, uniformisation des pratiques, concentration croissante des capacités de décision et logique de puissance. Comme l’écrit l’encyclique, Babel est une œuvre « soutenue par une uniformité qui élimine la diversité » et qui « sacrifie la dignité des personnes à l’efficacité ». Dans cette perspective, la valeur du travail tend à se mesurer essentiellement à sa vitesse, sa quantité ou sa performance. Dans le récit biblique, la verticalité de la tour de Babel apporte finalement l’horizontalité de l’humanité en répartissant celle-ci sur toute la terre.
À l’inverse, Jérusalem, dans la Bible, apparaît comme une œuvre collective fondée sur une responsabilité partagée. L’encyclique décrit une reconstruction du travail qui naît « non pas grâce à l’initiative d’une seule personne, mais grâce à la responsabilité partagée de tout le peuple ». Le travail n’y est pas envisagé uniquement comme une production de résultats, mais comme une activité par laquelle les individus se construisent eux-mêmes avec les autres. La signification est alors aux antipodes de celle portée par Babel : l’humanité se verticalise en unifiant toutes les personnes qui la composent.
Et maintenant ?
L’encyclique souligne encore que l’intelligence artificielle « n’est pas neutre, car elle prend le visage de ceux qui la conçoivent, la financent, la régulent et l’utilisent ». Reste que le texte, bien qu’affirmant l’absence de neutralité de cette technologie et, conséquemment, les implications de celle-ci dans le monde du travail, ne se positionne pas sur cette neutralité et laisse le monde du travail dans un certain embarras.
Si l’intelligence artificielle devait devenir encore davantage un outil central de l’activité professionnelle, plusieurs questions concrètes – auxquelles l’encyclique ne répond pas – apparaissent alors comme autant de garde-fous possibles : comment préserver des espaces réels d’exercice du jugement ? Comment maintenir une autonomie autre que purement formelle ? Comment protéger les relations humaines au travail lorsque certaines interactions deviennent médiées par des systèmes techniques ? Comment permettre encore l’expérience de l’apprentissage, de l’incertitude et du sens ? En quoi ce que nous favorisons pour ces objectifs de production, aura de conséquences sur ce que nous sommes et devenons en dehors ?
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
15.06.2026 à 17:18
Comment les IA génératives grand public influencent le langage des publications académiques
François Rastier, Directeur de recherche, Centre national de la recherche scientifique (CNRS)
Texte intégral (2158 mots)

Le langage des intelligences artificielles, IA, génératives reste encore peu étudié, mais l’on peut déjà observer « à l’œil nu » des conséquences inattendues de l’usage de ces IA sur les discours scientifiques et académiques.
Si l’intelligence artificielle (IA) générative imite le langage humain, son usage croissant et souvent quotidien conduit à rendre cette imitation réciproque. Ainsi, une étude de chercheurs du Max-Planck Institute; parue en juillet 2025, en analysant un corpus de 740 000 heures d’exposés académiques, de vidéos YouTube et de podcasts a décelé, entre 2017 et 2024, un usage croissant de mots privilégiés par les chatbots, comme « delve », « comprehend », « boast », « swift » et « meticulous » (approfondir, comprendre, se vanter, rapide et méticuleux).
Il reste difficile de démêler influence et substitution : les corpus oraux étudiés peuvent ne s’appuyer qu’en partie sur des textes générés par IA. En tout état de cause, l’apparition croissante de ces mots affecte les discours relevant de la technologie, du business et de l’éducation – mais non ceux qui traitent de religion ou de sport ; il ne s’agit donc pas d’une évolution générale de la langue, car ce processus affecte les domaines où l’IA est la plus utilisée.
Dans le domaine académique, l’influence de l’IA générative peut aller jusqu’à la substitution. Consacré à la détection de la fraude scientifique, le site Academ-AI liste, par centaines, les articles, communications et chapitres de livres qui contiennent des formules caractéristiques des IA génératives, comme « selon ma dernière mise à jour ». En voici quelques-unes :
« Veuillez fournir plus d’informations… »
« Absolument ! Voici quelques points supplémentaires qui peuvent être abordés dans l’article scientifique. »
« Je m’excuse pour la confusion, mais en tant que modèle de langage IA, je n’ai pas accès à des articles spécifiques. »
« À la date de ma dernière mise à jour (septembre 2021), je ne disposais d’aucune information. »
La confiance dans l’IA est telle que les auteurs n’ont pas pris la peine de relire les articles qu’ils ont signés. Peu importe au demeurant, si les rédactions des revues s’en sont aussi dispensées. Cette nonchalance est d’autant moins anecdotique qu’avant publication des éditeurs commencent à réécrire par IA les manuscrits qui leur sont soumis.
Cela n’est pas sans conséquence. Par exemple, quand des chercheurs ont demandé à ChatGPT5 de « polir » (« please polish ») le premier paragraphe de l’article fondateur de Turing « Computing Machinery and Intelligence » (1950). Là où Turing, pour répondre à la question « Can machines think? », rejette comme dangereuse (« dangerous ») l’idée de s’en remettre au sens usuel de « machine » et de « think », le chatbot remplace « dangerous » par un simple « risky » (risqué), passant de l’affirmé et de l’avéré au possible.
Une banalisation du langage
Les algorithmes des IA génératives ne sont pas déterministes, mais probabilistes, et privilégient donc ce qui est le plus fréquent dans leur corpus d’apprentissage.
Ce choix entraîne deux conséquences majeures. D’une part, les mots rares dans ce corpus (mais qui peuvent être endémiques dans des corpus spécialisés) se raréfient encore, voire disparaissent. Et il en résulte une restriction du dicible – voire du pensable, selon le principe énoncé par Winston, le commissaire politique du roman 1984 de George Orwell (« Ne voyez-vous pas que le véritable but du novlangue est de restreindre les limites de la pensée ? À la fin, nous rendrons littéralement impossible le crime par la pensée, car il n’y aura plus de mots pour l’exprimer. »)
D’autre part, comme la génération de texte s’opère par le calcul des probabilités d’occurrence contextuelle, pour chaque mot, les mots qui voisinent le plus fréquemment dans ses contextes d’emploi se voient privilégiés. Dès lors, les phraséologies, les expressions toutes faites et les clichés envahissent le discours, avec le conformisme qu’elles concrétisent – et radicalisent.
De longue date, les fréquences lexicales ont été étudiées en linguistique de corpus. On ne retient pas les fréquences les plus élevées, car elles intéressent pour l’essentiel les mots grammaticaux, et comme elles restent analogues en tout corpus, elles ne sont pas caractérisantes. Généralement, on s’appuie sur les mots de fréquence moyenne, pour différencier des textes ou des sous-corpus.
Cependant, et bien qu’ils soient le plus souvent négligés faute de poids statistique, les mots de faible fréquence sont très caractérisants et même individualisants : tel hapax, comme « ptyx », renverra uniquement à un sonnet célèbre de Mallarmé. Au-delà, on oublie les mots de fréquence zéro. Or, ces mots absents, que l’on peut inventorier en contrastant des textes ou des sous-corpus, restent hautement révélateurs, car un discours ne signifie pas moins par ce qu’il énonce que par ce qu’il tait, même s’il use d’une langue stéréotypée.
Or, les IA décrivent un monde de ce qui est (ou du moins devrait être) conforme à leurs biais. Ce positivisme paradoxal, qui crée le monde auquel il prétend référer, ne laisse aucune place à l’implicite et reste cependant réputé permettre un discours de connaissance.
La disparition de l’implicite découle d’une loi de moindre effort : l’utilisateur n’a pas à interpréter les discours de son IA, il lui suffit de les écouter ou de les déchiffrer pour les comprendre. Il n’a jamais à établir une distance critique pour en juger, et cette facilité obéit aux principes de la relation client : un langage simplifié et univoque devrait contribuer à son confort et entretenir la connaissance du connu.
De moins en moins de termes spécifiques
Relevons enfin une dernière forme d’adultération (falsficiation) du discours scientifique et technique : la multiplication des termes qui ne sont pas spécifiques au domaine considéré. Or, dans certaines disciplines le rapport entre termes spécifiques et termes généraux s’est soudain inversé, en deux ans à peine.
La proportion des termes non spécifiques diminue drastiquement et ils l’emportent désormais sur les termes pertinents. Cela s’accorde avec le projet d’une IA dite générale, qui pourrait bien favoriser les généralités. Elle multiplie du moins des termes passe-partout et donc fréquemment employés – sauf quand on a quelque chose de précis à dire. Ainsi, des termes favorisés par ChatGPT, comme « delves », « showcasing », ou « underscores » (explore, présentant, souligne), ont vu leur fréquence s’accroître.
En 2023, première année d’usage de ChatGPT, le nombre des mots non spécifiques, jusqu’alors faible, a triplé par rapport à 2022, pour représenter la moitié des occurrences, mais l’année suivante, ils furent multipliés par huit.
Une hypothèse charitable voudrait que ce soit par mimétisme – à moins que ce même logiciel n’ait été un rédacteur clandestin, ce que semble attester la multiplication des « hallucitations », terme maintenant convenu pour désigner les citations « hallucinantes » forgées par les chatbots.
Parallèlement, les évaluations des revues scientifiques ont connu des dérives lexicales analogues, et par exemple des adjectifs comme « commendable », « meticulous », ou « intricate » (louable, méticuleux, complexe), ont vu leur fréquence augmenter dramatiquement, soit respectivement pour la seule année 2024, de 9,8 fois, 34,7 fois, et 11,2 fois.
Un cycle se dessine : certains appels d’offres semblent déjà générés avec l’aide de l’IA ; puis les projets soumis sont évalués de même (ils l’étaient déjà auparavant par la détection automatisée de répétitions de mots-clés). Des articles financés par ces projets de recherche sont ensuite produits, puis évalués par les revues scientifiques au moyen des mêmes logiciels. On peut douter que ces multiples médiations et les biais qu’elles introduisent favorisent les découvertes scientifiques et les innovations techniques.
Standardisation lexicale et tonalité euphorisante
On manque encore d’études comparatives d’ampleur sur l’incidence linguistique de l’IA. Toutefois, en évaluant l’évolution de l’Internet d’août 2022, tel qu’il est consigné alors dans l’Internet Archive, et celui de mai 2025, et en identifiant les textes générés par IA au moyen du logiciel Pangram v3, Jonas Dolezal et ses collègues de Stanford ont montré qu’en 33 mois seulement, 35 % des sites ont été générés automatiquement.
En outre, selon une autre étude, 36 % des sites restants en portent des traces. Si ces chiffres peuvent être relativisés en tenant compte des faux négatifs et positifs, les résultats restent solides et Dolezal et ses collègues ont dégagé deux tendances lourdes.
Ils ont souligné, en premier lieu, la chute de la diversité linguistique et notamment la standardisation lexicale. C’est là sans doute une rançon inévitable de l’industrialisation en cours – et, en persiflant un peu, cela rapprocherait le langage de l’IA de cette critique, formulée voici presque deux siècles, par Alexis de Tocqueville, contre le langage administratif de l’Ancien Régime :
« Le style est également décoloré, coulant, vague et mou. La physionomie particulière de chaque écrivain s’y efface et va se perdant dans une médiocrité commune. »
Ils ont également noté la prévalence d’une tonalité euphorisante, évaluée par des méthodes classiques d’analyse des émotions, qui reflète sans doute les biais algorithmiques qui flattent et retiennent le client roi. Annoncé de longue date par le triomphe américain de la méthode Coué et la positivité prescrite par le secteur du développement personnel, l’optimisme généralisé se trouve à présent prescrit et renouvelé par l’idéologie de la tech – en deçà même de la désinformation.
Un indice ne trompe pas : un ami a fait discuter entre eux quatre chatbots, et au bout de dix minutes, ils se couvraient réciproquement de flagorneries. Un univers de discours dystopique se profile ainsi, avec une standardisation du langage (et donc de la pensée), et un effacement des contradictions de la vie sociale par un optimisme industrialisé.
François Rastier ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.06.2026 à 15:38
Global uncertainty is the new normal. Here’s why institutional legitimacy and resilience is crucial
Odysseas Konstantinakos, Research Fellow at IE University, European University Institute
Texte intégral (1682 mots)
The world has never had more data, more models, or more economists. It has rarely felt more out of control. Uncertainty, not risk, has become the defining condition of our era. Central bankers invoke it. Political leaders use it to defer decisions and justify extraordinary decisions. Academics are struggling to adapt their theories to a brave new world of unexpected outcomes and erratic policy choices. The IMF’s World Uncertainty Index – which tracks how often the word appears in economic and political reporting across 143 countries – has been running at historically elevated levels for the better part of a decade, with fresh spikes after every major shock.
We seem to be living through a permanent emergency, and uncertainty is the buzzword, but what can we do about it? The answer is less complicated than the question suggests: societies that invest in strong, inclusive institutions weather uncertainty better than those that don’t.
The temptation, when uncertainty is this pervasive, is fatalism; if nothing can be predicted, nothing can be done except short-term fixes and profiteering. The US stock market is a case in point. Increasingly disconnected from the real economy , it is being driven by a wave of high-stakes bets on artificial intelligence: OpenAI, Anthropic, and now SpaceX are among the most anticipated IPOs of the decade, with valuations that price in a benign future of near-limitless technological returns. Markets actors are doubling down on optimistic predictions rather than preparing for disruption. Geopolitical risk, financial fragility, and the very uncertainty that defines this era are being systematically under-priced.
Distinguishing uncertainty from risk
But not everything qualifies as uncertainty. There is a difference between uncertainty and risk, and confusing the two leads to the wrong responses. Risk refers to situations where we do not know the outcome but can measure the odds. Insurance companies exist for a reason: even if we cannot predict which house will burn down, we can calculate how many will in a given year, price the premium accordingly, and pool the exposure.
Uncertainty, in the sense Frank Knight formalised in 1921, is more fundamental – situations where the odds themselves cannot be calculated. Pandemics, wars, supply-chain seizures, climate shocks: these are not risks to be priced. They are shocks that expose the limits of our knowledge.
During my fieldwork at DG ECFIN – the European Commission’s Directorate-General for Economic and Financial Affairs – I observed this tension firsthand.
Standard macroeconomic models are built on assumptions of rational decision-making and on past data. But we are increasingly observing non-linear effects and asymmetric externalities that undermine foresight and risk assessment. Tensions in the Strait of Hormuz may disrupt agricultural production across three continents through fertiliser shortages. A gas price shock in Europe accelerated inflation in countries that imported almost nothing from Russia. Small inputs trigger disproportionate, cascading consequences that no single model captures.
If we cannot predict the next crisis, what can we do?
Throwing money at a crisis works until it doesn’t. Germany’s dependence on Russian gas was a failure of strategic foresight, yet it absorbed the shock largely by deploying a €200 billion defensive shield to buy up the world’s LNG. Money bought time; not every country had the same firepower. In any case, emergency spending after a crisis costs far more than institutions built before one. The more instructive question is not who could afford to respond, but who had the institutional setup not to need to.
Denmark’s energy strategy began in 1973. The oil shock forced a country entirely dependent on imported fossil fuels to confront its vulnerability. Rather than treating it as a temporary disruption, Danish governments made a fifty-year institutional bet: successive national energy plans embedded wind development into industrial policy, planning law and R&D, with cross-party consensus that survived changes of government. What utilities once feared, hundreds of decentralised wind turbines disrupting their grids, became the system itself.
Today, Denmark generates around 50 percent of its electricity from wind, with renewables reaching 67 percent of the electricity supply overall. When the 2022 energy crisis hit, Denmark was better off.
These plans were developed through wide public discussions, with energy security, self-sufficiency and efficiency as principal objectives – encompassing institutions that brought government, business, labour, and civil society into durable agreements outlasting any single election cycle. Resilience, the Danish case shows, is less a product of resources than of political will and the capacity to act on known risks before they become crises.
Spain offers a complementary lesson for labour market policies during a crisis. At the peak of the Covid-19 pandemic, the government used the shock to introduce more universal unemployment protection, in concertation with social partners, breaking from a legacy that had left precarious workers exposed for decades. What made this possible was not wealth but institutional capacity and political will.
At EU level, the Recovery and Resilience Facility – a €577 billion instrument once considered politically impossible – showed that supranational institutions can evolve under pressure.
With suitable economic incentives, EU countries have begun tackling structural challenges while responding to new ones improving their institutional resilience fostering the twin transition. It might have been imperfect, as evaluators of the RRF flagged delays and control complexity – but the effect was however real; another recession was avoided.
The question is whether Europe consolidates this experience now, or waits for the next shock to force its hand. That lesson is harder to absorb than it looks, because institutional legitimacy is easier to spend than to (re-)build.
Institutions serve three essential purposes under uncertainty
They stabilise expectations, so citizens and investors retain confidence when pressure mounts.
They distribute shocks fairly, preventing crises from becoming social breakdown.
They enable adaptation, allowing states to learn and change course when old assumptions fail.
But they only work when citizens and politicians believe in them.
The current US administration is committing a grand error by undermining the legitimacy of its own institutions and independent authorities.
The IMF’s April 2026 outlook flags this explicitly: political pressure on independent central banks and other policy bodies can erode hard-won public confidence, raise inflation expectations, and ultimately lower economic growth.
Europe’s populist wave in the aftermath of the Great Recession is partly a story of institutions that stopped serving enough people, and consequently stopped being believed.
Uncertainty is not a temporary condition to be overcome. It is the permanent background noise of a rapidly changing, deeply interdependent world.
Denmark shows that a fifty-year institutional bet on foresight beats a one-off financial rescue. Spain shows that political will, not wealth, converts a crisis into sustainable reform. The European response to Covid-19 helped us avoid another recession and fostered structural reforms across member states.
This is why building inclusive institutions – institutions that distribute opportunities more broadly, protect people against arbitrary shocks, give citizens and firms predictable rules, and allow different social groups to participate in shaping public choices – is not a technocratic luxury. It is a form of collective insurance against an uncertain future, helping societies absorb what no one can fully predict.
A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Odysseas Konstantinakos received funding from the Greek Grants Foundation.
15.06.2026 à 12:25
Malgré un engouement qui ne démord pas, les clubs de football professionnels féminins français n’ont toujours pas trouvé leur modèle économique
Patrice Bouvet, Maitre de conférences HDR en économie et management du sport, Université de Poitiers
Texte intégral (1529 mots)

Malgré des affluences record dans les stades et devant les postes de télévision, les clubs de football féminins français ne sont pas tous à l’équilibre sur le plan financier. Comment l’expliquer ? Et surtout, quelles solutions mettre en place pour résoudre ces difficultés ?
Le 5 avril 2026, Pierre-Henri Deballon, propriétaire du Dijon Football Côte-d’Or, rappelle qu’avec « l’effondrement des droits TV sur lesquels reposait le développement du football professionnel féminin, [la] section féminine [qu’il dirige] est déficitaire à hauteur de 1,5 million d’euros pour la seule saison 2025/2026 ».
Comme le souligne l’économiste du sport Wladimir Andreff en 2023, un constat s’impose en France : faute de revenus de transferts, le modèle économique du football féminin n’est pas à l’équilibre pour tous les clubs. Uniquement quinze équipes européennes voient leurs revenus cumulés augmenter de 35 % et seule la section féminine du PSG fait partie du classement avec 4,6 millions d’euros pour la saison 2024/2025.
Pourtant, la Fédération française de football comptabilise 733 672 téléspectateurs lors de la phase aller de la Première Ligue féminine (saison 2025/2026). Des audiences en hausse de plus de 79 % par rapport à 2024/2025.
Comment l’expliquer ? Que risque-t-il d’advenir des clubs de football féminin français ? Qui pourra survivre ?
Le phénomène n’est pas nouveau pour la planète football ; une réalité que j’étudie depuis 1996.
Championnat féminin créé en 1974
Environ un tiers des footballeuses licenciées dans le monde se trouve aux États-Unis. L’Europe compte presque 1,5 million de licenciées ; 250 000 jouent en France. Le championnat de France féminin est créé en 1974. Seize équipes jouaient alors dans quatre groupes régionaux. Le format est ensuite modifié à quatre reprises pour conduire au format actuel avec 12 équipes évoluant dans l’Arkema Première Ligue féminine.
Au début des années 2000, presque tous les clubs sont amateurs. Les sections féminines sont aujourd’hui majoritairement détenues par des clubs professionnels masculins, 21 des 24 clubs dans les deux premières divisions. Ils évoluent le plus souvent dans une grande ville. Contrairement au football masculin, pour lequel la Direction nationale du contrôle de gestion publie tous les ans un rapport d’activité, peu de données sont disponibles pour le football féminin.
Selon les chercheurs Luc Arrondel et Richard Duhautois, les difficultés économiques sont le produit d’une combinaison de facteurs historiques (l’exclusion institutionnelle), sociopolitiques (retard de l’émancipation féminine), économiques (faiblesse des revenus et des droits TV) et structurels (professionnalisation tardive, carrières précaires).
Peu d’argent rentre dans les caisses
À l’exception des clubs qui peuvent compter sur leurs riches actionnaires et/ou participent régulièrement aux coupes européennes, comme l’OL Lyonnes de Michele Kang, les revenus restent insuffisants.
À lire aussi : Equal play, equal pay : des « inégalités » de genre dans le football
Pendant de nombreuses années, les sections féminines de clubs professionnels masculins ont pu bénéficier de revenus de transferts issus des droits TV perçus par les sections masculines. La diminution de ces droits – d’une valeur de plus de 1 000 millions d’euros pour la période 2020/2021 et d’une valeur de moins de 500 millions d’euros pour la période 2024/2029 – limite grandement cette possibilité.
Les produits d’un club de football féminin sont conditionnés à la vente de droits – droits TV, droits d’exposition, droits d’entrée et droits d’appellation. Pour les saisons 2023-2024 à 2028-2029, le montant annuel total des droits TV de l’équipe de France féminine et de la D1 Arkema est estimé à 5,3 millions d’euros par saison, soit presque 100 fois moins que ceux du football masculin.
En 2019, la Coupe du monde masculine distribuait 400 millions de dollars (344,68 millions d’euros) de primes, contre seulement 30 millions (25,8 millions d’euros) pour la compétition féminine
Près de 2,9 millions d’euros de dépenses pour 1,4 million d’euros de recettes
Certaines charges sont en revanche incompressibles. Le poste de dépenses le plus important reste la rémunération des joueuses, en hausse depuis la création, en 2004, de la Ligue de football féminin professionnel ; elle atteint 750 00 euros brut mensuel pour les meilleures joueuses. Les frais de déplacement, l’organisation des matchs et le coût de fonctionnement des centres de formation complètent ces charges.
Dans ces conditions, il n’est pas surprenant que la majorité des clubs féminins connaissent des difficultés économiques. Pour la section féminine du Dijon Football Côte-d’Or, le budget est d’un peu moins de trois millions d’euros. Il n’est pas intégralement financé par les recettes dégagées par l’équipe féminine. Les dépenses sont de l’ordre de 2,9 millions contre 1,4 million de recettes.
Quasiment aucune joueuse fait l’objet de transferts (internationaux) avec paiement d’indemnités, ce qui limite certaines charges (amortissements, mutations et honoraires d’intermédiaires), mais prive les sections féminines de possibilités de faire du trading joueuses, susceptible de limiter les déficits.
Trois catégories de club
En analysant la situation actuelle des clubs évoluant en Arkema Première Ligue et dans le championnat de France féminin de football de deuxième division, trois situations peuvent être distinguées :
les clubs qui, forts de leur histoire et/ou de leur situation au regard des variables précédentes, peuvent regarder l’avenir avec optimisme : OL Lyonnes, Paris Saint-Germain, Olympique de Marseille ;
les clubs qui bénéficient d’un important soutien populaire : RC Lens, AS Saint-Étienne, FC Nantes. Lors de la phase aller 2024/2025, Nantes possède la meilleure affluence moyenne (5 776 spectateurs) sur la phase aller, devant l’OL Lyonnes (5 001) et le RC Lens (4 277).
les clubs qui, a priori, peuvent compter sur la puissance financière de leur riche actionnaire (fonds de pension ou individus fortunés) : Paris FC, RC Strasbourg, Montpellier HSC.
À l’avenir, ces clubs devraient constituer le « noyau dur » de la ligue 1 féminine. En fonction de leurs performances, celle-ci devrait être complétée par les clubs suivants : FC Fleury 91, Dijon FCO, Le Havre FC, Toulouse FC, Lille OSC, OGC Nice.
Il est aujourd’hui nécessaire de réfléchir à l’avenir du football professionnel féminin en Europe. Une solution d’avenir pourrait être la création d’une ligue fermée ou semi-fermée réunissant les équipes disposant des moyens suffisants pour y participer parallèlement à l’organisation de championnats nationaux, moins exigeants économiquement, permettant aux sections féminines des « petits clubs » de s’y maintenir.
Patrice Bouvet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.06.2026 à 12:25
Le plus grand danger des entreprises qui se penchent sur leur passé ? S’écarter d’une « juste mémoire » pour instrumentaliser leur histoire
Fatima Regany, Maître de conférences, LUMEN (ULR 4999), Université de Lille
Hélène Gorge, Maître de conférences, LUMEN (ULR 4999), Université de Lille, Université de Lille
Ludovic Cailluet, Associate Dean, Centre for Responsible Entrepreneurship, EDHEC Business School
Texte intégral (2046 mots)
L’histoire des entreprises appartient à tout le monde. Autant aux communicants férus de récits fédérateurs pour leurs clients et leurs collaborateurs qu’aux historiens qui prônent l’honnêteté sur les zones d’ombre. Pour éviter la réécriture du passé, des chercheurs appellent à promouvoir une éthique de la mémoire organisationnelle.
La construction du passé des organisations n’est jamais anodine ; elle est le produit d’un travail collectif, négocié, parfois conflictuel, entre des acteurs aux intérêts divergents. Par exemple, Lacoste passe sous silence la décennie des années 1990 traversée de conflits internes. De nombreux exemples illustrent les questions éthiques que la société et les entreprises commencent tout juste – au mieux – à formuler.
Dans nos recherches, publiées dans le Journal of Business Ethics et Décisions Marketing, nous nous intéressons à la façon dont ces récits se fabriquent concrètement, qui les négocie, qui cède, qui résiste à ces constructions, et également à ce que ces pratiques révèlent de la responsabilité des organisations envers leur passé.
Nos conclusions nous ont conduits à plaider pour l’émergence d’une nouvelle éthique de la mémoire organisationnelle centrée sur le dialogue, la responsabilité des entreprises, des espaces de délibération et un certain courage face aux potentielles heures sombres des organisations.
« Histoire rhétorique »
Musées d’entreprise, expositions itinérantes, livres commémoratifs, campagnes publicitaires saturées de sépia et de références aux origines… pour les organisations, le patrimoine historique est devenu un actif à part entière, géré, valorisé, monétisé. Hermès met en scène ses archives dans un concept store parisien, Michelin propose une expérience immersive à Clermont-Ferrand, la Vache qui rit a ouvert une maison-musée sur le site même de sa naissance en 1921.
Ce mouvement a suscité, depuis le milieu des années 2000, un courant de recherche en sciences de gestion autour des « usages du passé ». Les chercheurs Andrew Popp, Roy Suddaby, Mads Mordhorst et Daniel Wadhwani ont montré que l’histoire n’est pas simplement ce qui s’est passé, mais ce que les organisations choisissent d’en faire. Roy Suddaby parle d’« histoire rhétorique » : le passé peut-être un outil de persuasion, de légitimation, de différenciation.
C’est dans ce champ que s’inscrit notre recherche, avec une question que ses fondateurs ont peu explorée : celle des enjeux éthiques. Car une marque dotée de racines profondes, d’un savoir-faire transmis de génération en génération, acquiert une forme d’autorité morale difficile à contester. La légitimité historique est une valeur marchande de premier ordre.
Mais qui, précisément, fabrique cette histoire ?
Honnêteté sur les zones d’ombre
Derrière chaque récit de marque se cache un réseau d’acteurs hétérogènes externes ou non à l’organisation : des historiens universitaires engagés pour des missions ponctuelles, des consultants spécialisés dans le « branding patrimonial », des responsables d’archives internes, des directeurs artistiques, des scénographes ou des responsables marketing.
Nous avons mené des entretiens avec ces différents professionnels et étudié six grandes entreprises françaises – Air France, Hermès, Lacoste, La Vache qui Rit, Michelin, SNCF – pour mieux comprendre comment deux logiques principales s’affrontent, rarement harmonieusement.
D’un côté, les historiens qu’ils soient universitaires ou spécialisés dans le conseil, défendent une déontologie fondée sur la rigueur des sources, l’exhaustivité du récit et l’honnêteté sur les zones d’ombre. L’un d’eux a refusé de signer un ouvrage commandé par une grande banque, dont le texte avait été expurgé de toute référence à l’Occupation :
« Vous me donnez mon argent et vous publiez ce que vous voulez. Mais sans mon nom. »
De l’autre côté, les équipes marketing et communication raisonnent surtout en termes de cohérence narrative, de positionnement de marque et d’attractivité pour les consommateurs. Le passé est avant tout un matériau à façonner au service d’une stratégie présente et d’un récit fédérateur. Certains le reconnaissent sans détour : ils cherchent dans les archives ce qui conforte le récit souhaité, pas nécessairement ce qui est le plus représentatif de la réalité historique.
« Les films Inside Chanel sont un cas d’école qui subliment l’histoire de la fondatrice. Mais c’est aussi une réécriture maîtrisée : les sujets qui dérangent sont soigneusement effacés, loin de ce que révèlent les recherches historiques sérieuses », souligne un consultant en patrimoine de marque.
Entre ces deux professions, les compromis se négocient, parfois dans la tension. Les rôles se brouillent : l’historien conseille sur les « actifs marketing », la direction marketing tranche sur l’interprétation du passé. Ce que l’un juge inacceptable, l’autre l’appelle choix éditorial, chacun répondant aux impératifs de son métier.
Ces usages du passé peuvent ainsi donner lieu à des abus de mémoire.
Abus de mémoire
Les abus de mémoire dépassent les seules entreprises qui les pratiquent. Ils touchent à la mémoire collective. Les grandes marques sont des actrices culturelles puissantes, dont les récits circulent dans les campagnes publicitaires, les musées ou les expositions.
À lire aussi : Steve Jobs, Christian Dior… À la rencontre des fantômes qui hantent les entreprises
Quand une entreprise industrielle se raconte rétrospectivement comme pionnière de la transition écologique, quand une maison de luxe se donne l’apparence d’avoir une tradition ininterrompue, elles écrivent une histoire dont elles contrôlent les termes tout en en tirant profit. Le problème n’est pas ce qu’elles racontent de leur passé, mais que cette narration se donne pour ce qu’elle n’est pas, reversant dans le sens commun des récits possiblement trompeurs :
« Les consommateurs ne peuvent pas identifier ce qui est vrai et ce qui est faux », nous a confié un historien-consultant.
Mémoire réprimée, manipulée ou forcée
Pour comprendre ces tensions, nous avons mobilisé dans l’un de nos articles le philosophe Paul Ricœur, dont l’ouvrage la Mémoire, l’histoire, l’oubli (2000) distingue trois types d’abus pensés pour les sociétés politiques. Ces catégories s’appliquent avec une acuité troublante au monde des organisations.
Mémoire réprimée. C’est le silence sur ce qui dérange, celui des conflits sociaux, des compromissions avec des régimes peu recommandables ou des scandales de gouvernance. L’institution financière qui efface son implication dans le financement de plantations esclavagistes au XIXᵉ siècle ne commet pas seulement une omission commercialement gênante, elle dissimule des responsabilités historiques potentiellement lourdes.
Nos interlocuteurs s’accordent sur ce point : une organisation ne devrait pas mentir sur son passé. Ils divergent sur ce qui constitue un mensonge. Pour certains, l’omission est acceptable, voire nécessaire. Pour d’autres, elle équivaut à une censure.
Mémoire manipulée. C’est la mémoire la plus répandue et la plus insidieuse ; on ne supprime pas les faits, on les réinterprète pour leur faire dire ce qu’ils n’ont jamais dit. Un historien travaillant pour une grande entreprise nous a rapporté la position inconfortable suivante : en 1996, celle-ci avait lancé un test technologique dicté par des impératifs de performance, sans aucune préoccupation environnementale. Des années plus tard, ce test est présenté comme la preuve que l’entreprise était « pionnière en matière d’écologie ».
Le procédé est courant. Une exposition non chronologique crée une continuité artificielle qui efface les ruptures. Son efficacité tient précisément à son mélange de vrai et de fabriqué (archives authentiques, objets réels, témoignages sincères, etc.) ce qui la rend difficile à déconstruire pour un public non averti.
Mémoire forcée. Il s’agit de l’excès inverse, celui d’un devoir de mémoire transformé en outil de communication. Anniversaires hors années jubilaires, fondateurs érigés en figures mythiques, événements nationaux captés pour renforcer une identité de marque, etc. Un responsable de communication patrimoniale nous décrivait avec ironie cet art de surfer sur « la vague rétro, l’enthousiasme pour la nostalgie et l’authenticité ».
La mémoire collective d’une profession, d’un territoire, d’une époque finit par être capturée au profit d’une seule marque, qui en tire une légitimité disproportionnée.
Éthique de la mémoire organisationnelle
Face à ces constats, que faire ?
À l’heure où transparence et cohérence sont exigées des entreprises, la gestion de la mémoire ne peut plus être laissée aux seuls communicants.
Construire des récits historiques est un acte éthique. Sélectionner, omettre, mettre en valeur ou dissimuler, toutes ces décisions engagent la façon dont une organisation accepte ou refuse d’assumer ses responsabilités.
Cela implique aussi de structurer le dialogue entre acteurs pour qu’archivistes, historiens, équipes communication ou direction travaillent main dans la main. Des espaces de délibération réels, où rigueur historique, objectifs et impératifs de narration se négocient de façon transparente, seraient un premier pas dans cette voie.
Cela suppose d’admettre que certaines vérités inconfortables peuvent devenir une ressource. Les organisations qui ont assumé des pans difficiles de leur histoire ont souvent constaté que cette honnêteté renforçait, à terme, la confiance de leurs publics.
Le passé n’appartient à personne en propre. Il est un bien commun, fragmentaire, toujours en cours d’interprétation. Les entreprises qui en font usage ont une responsabilité à la hauteur de l’influence qu’elles exercent. Paul Ricœur parlait de « juste mémoire » ; ni obsession du passé ni amnésie confortable. C’est à cette exigence que les organisations devraient, elles aussi, être tenues.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
15.06.2026 à 12:06
Le système mondial d’observation des océans est en danger : sans les États-Unis, l’Europe et l’Asie doivent jouer un rôle global
Sabrina Speich, Professeure en océanographie et sciences du climat, École normale supérieure (ENS) – PSL
John Abraham, Associate Professor, Mechanical Engineering, University of St. Thomas
Kevin Trenberth, Distinguished Scholar, NCAR; Affiliate Faculty, University of Auckland, Waipapa Taumata Rau
Lijing Cheng, Professor at the Institute of Atmospheric Physics, Chinese Academy of Sciences
Texte intégral (2873 mots)
Arrêter de financer le système global de mesure de l’océan met en danger nos capacités de prévisions météorologiques et d’anticipation – ce qui coûterait au final bien plus cher que ce système lui-même.
Peu de pays sont à même de surveiller les océans, et l’arrangement mondial qui a prévalu jusqu’ici, duquel nous dépendons, montre aujourd’hui des signes de faiblesse. L’Europe et l’Asie doivent désormais décider si elles laissent ce système perdre de sa force ou si elles reprennent la main ensemble.
À l’heure actuelle, dans tous les bassins océaniques de la planète, un réseau mondial d’instruments mesure l’état de la mer.
Des navires de recherche sillonnent les océans en suivant des lignes imaginaires, les « transects », de façon répétée, pour accumuler des données de la surface aux fonds marins. Des bouées ancrées surveillent les océans tropicaux, à la recherche des premiers signes d’El Niño ou de cyclones tropicaux, et prennent le pouls de la circulation thermohaline.
Quelque 4 000 flotteurs autonomes plongent tous les dix jours à 2 000 mètres de profondeur avant de remonter pour transmettre la température et la salinité aux stations au sol par satellite. Des planeurs sous-marins patrouillent les marges continentales, et des bouées dérivantes flottent à la surface dans les eaux les plus reculées. Des centaines d’éléphants de mer portent des capteurs miniaturisés sous la banquise polaire…
Ce réseau produit des informations inestimables qui nous permettent d’anticiper l’évolution des conditions océaniques et météorologiques, d’y réagir, et de protéger l’océan.
Néanmoins, le réseau de surveillance des océans est fragile, bien plus que ne le réalisent la plupart des gens et la plupart des gouvernements – notre nouvelle étude, publiée dans Nature Climate Change, a mesuré pour la première fois à quel point.
Le résultat est alarmant. Si les observations d’un seul contributeur majeur, les États-Unis, étaient retirées du Système mondial d’observation de l’océan (GOOS), les erreurs dans notre estimation de la vitesse de réchauffement de l’océan augmenteraient de 163 %. C’est pire que de perdre au hasard 80 % de toutes les données océaniques mondiales. La raison est d’ordre géographique : les instruments américains couvrent tous les bassins océaniques et comblent des lacunes qu’aucun autre pays n’est en mesure de pallier actuellement.
Il ne s’agit pas d’une préoccupation théorique. Les coupes proposées au budget de la National Oceanic and Atmospheric Administration (NOAA) et de la Fondation nationale pour la science aux États-Unis (NSF) menacent aujourd’hui la contribution états-unienne au GOOS.
La situation n’est guère meilleure de l’autre côté de l’Atlantique ; et les pressions ne se limitent pas à l’Occident. En Chine, scientifiques et décideurs s’efforcent de mettre en place une contribution nationale plus résiliente à l’observation des océans, mais sans les ressources que la situation exige.
Le système de surveillance marine sur lequel le monde s’appuie est mis à rude épreuve presque partout dans le monde.
Un système d’observation dont chaque composante répond à des questions auxquelles les autres ne peuvent pas répondre
Les débats publics sur l’observation des océans se concentrent souvent sur les flotteurs Argo.

Chaque flotteur Argo est essentiellement un cylindre étanche contenant des composants électroniques sous pression, doté d’une chambre de flottabilité ingénieuse : il se remplit d’eau de mer pour couler et se vide pour remonter à la surface. Les sciences de l’océan ont été, proprement, révolutionnées par l’utilisation de ces robots autonomes au cours du siècle écoulé.
Cependant, Argo n’est qu’un élément du GOOS et la complémentarité de ses composantes est essentielle.
Argo profile les deux kilomètres supérieurs de l’océan ouvert ;
les navires de recherche descendent plus profondément : les campagnes GO-SHIP effectuent des relevés de la surface au fond marin le long de transects (traversées) répétés sur de longues distances, fournissant des mesures de référence de haute précision qui permettent d’étalonner tous les autres instruments et aident à valider les modèles climatiques ;
les bouées ancrées fournissent des séries chronologiques continues essentielles pour surveiller El Niño, la circulation méridionale de retournement de l’Atlantique, ainsi que les conditions dans lesquelles se forment les cyclones tropicaux …
les planeurs sous-marins mesurent les courants côtiers, les tourbillons et les marges continentales que les flotteurs ne peuvent pas détecter ;
les éléphants de mer transportent des capteurs dans les zones sous-glaciaires des océans polaires, inaccessibles à tout autre instrument.
En somme, chaque plateforme répond à des questions auxquelles les autres ne peuvent pas répondre.
Si l’on supprime l’un de ces éléments, la capacité du système d’observation à fournir des informations fiables se dégrade non pas proportionnellement au volume de données perdues, mais proportionnellement à l’endroit où apparaissent les lacunes.
Ce que ce réseau apporte réellement
Le Système mondial d’observation des océans est trop souvent décrit comme un « système de surveillance du climat », mais son rôle est bien plus vaste.
Toutes les prévisions météorologiques opérationnelles s’appuient sur ces données. Les systèmes de prévision numérique météo, gérés par le Centre européen pour les prévisions météorologiques à moyen terme, par Météo France et par tous les autres grands services météorologiques, intègrent des observations océaniques plusieurs fois par jour.
Sans elles, les prévisions perdent rapidement leur fiabilité.
De même, les nouveaux systèmes de prévision fondés sur l’intelligence artificielle Pangu-Weather et GraphCast, malgré leurs performances impressionnantes, s’appuient entièrement sur ce même flux d’observations. L’IA ne remplace pas les observations : elle en dépend.
Les prévisions subsaisonnières à saisonnières, qui aident à anticiper les saisons de récolte, la demande en énergie et la disponibilité en eau plusieurs semaines, voire plusieurs mois, à l’avance dépendent de manière cruciale des connaissances sur la chaleur et la salinité sous-marines.
Les prévisions de trajectoire et d’intensité des cyclones tropicaux, essentielles aux décisions d’alerte précoce et d’évacuation, dépendent de la connaissance de la chaleur contenue dans les couches sous-marines de l’océan, et pas seulement de la température de surface de la mer. En effet, les ouragans tirent leur énergie explosive des couches chaudes situées jusqu’à au moins 200 mètres de profondeur.
Les alertes de vagues de chaleur marines, désormais utilisées couramment par les gestionnaires des pêcheries du monde entier, sont impossibles sans une observation soutenue des couches sous-marines.
Les projections du niveau de la mer utilisées pour concevoir les infrastructures côtières nécessitent des décennies de mesures cohérentes, et la salinité apporte les informations de densité indispensables pour déterminer tous les courants océaniques, y compris l’Atlantic Meridional Overturning Circulation (AMOC), le grand « courant de retournement » de l’Atlantique.
En bref, le GOOS est le pilier des services opérationnels, des alertes de tempête de demain aux plans d’adaptation du siècle prochain. Le GOOS n’est pas un luxe mais une nécessité.
Pourquoi les modèles et l’IA ne peuvent à eux seuls nous sauver
Il existe une idée fausse persistante, amplifiée par l’essor de l’intelligence artificielle (IA), selon laquelle des modèles suffisamment avancés pourraient se substituer aux observations directes. Ce n’est pas le cas.
Tout modèle de prévision, qu’il soit traditionnel ou fondé sur l’IA, repose sur l’assimilation des données : un ajustement continu de la simulation par rapport aux mesures du monde réel. Un modèle d’IA entraîné sur un passé riche en observations sera peu performant dans un présent où les observations sont rares. Dans un monde où les phénomènes extrêmes se multiplient et où l’état des océans évolue, les tendances historiques deviennent moins fiables.
À lire aussi : L’oubli catastrophique, ou pourquoi les IA ne savent pas encore apprendre en continu
Une observation non effectuée est perdue à jamais. Les mesures satellitaires de la surface de la mer ne peuvent pas nous dire ce qui se passe à des centaines ou des milliers de mètres de profondeur, là où la chaleur s’accumule, où les courants se réorganisent et où se forment déjà les précurseurs de la météo de la saison suivante. Pour voir sous la surface, nous avons besoin d’instruments dans l’eau.
L’assurance la moins chère dont nous disposons
L’argument selon lequel l’observation des océans est trop coûteuse s’effondre face aux chiffres.
Le coût annuel total du système mondial, toutes plateformes et tous personnels confondus, s’élève à environ un milliard d’euros à l’échelle mondiale. La part européenne n’en représente qu’une fraction.
Les phénomènes météorologiques extrêmes liés aux conditions océaniques ont causé des dizaines de milliards d’euros de dégâts à travers l’Europe rien qu’en 2024.
Une seule saison d’ouragans majeure dans l’Atlantique Nord peut coûter des centaines de milliards de dollars aux États-Unis. Les vagues de chaleur marines ont anéanti des pêcheries valant des milliards et provoqué un blanchissement massif des coraux sur tous les récifs de la planète. Les prévisions saisonnières erronées ont des répercussions en cascade sur l’agriculture, l’énergie et l’aide humanitaire, avec des conséquences rarement chiffrées.
Chaque euro dépensé pour l’observation des océans rapporte plusieurs fois sa valeur. C’est l’un des investissements publics les plus rentables qui soient.
Le choix de l’Europe
L’Europe doit considérer l’observation des océans comme une infrastructure critique, au même titre que la navigation par satellite ou les services météorologiques. Cela implique un financement stable et pluriannuel pour l’épine dorsale opérationnelle du système : les bouées, les navires, les amarrages, les planeurs sous-marins et les centres de données qui traitent et diffusent les données.
La France possède la deuxième plus grande zone économique exclusive (ZEE) du monde. Présente dans les océans Atlantique, Pacifique et Indien, la France compte cinq départements et régions ainsi que sept collectivités d’outre-mer, qui abritent 2,7 millions de citoyens français. Pourtant, la France ne contribue qu’à environ 5 % des données mondiales sur le profil de température des océans.
La contribution de l’Australie est plus de trois fois supérieure.
L’Union européenne y contribue à hauteur d’environ 12 %, soit moins d’un quart de la part américaine. L’Europe et la France en particulier devraient augmenter considérablement leur contribution.
OceanObs’29, la conférence internationale décennale qui se tiendra en Chine en 2029, est l’occasion de négocier un système mondial plus équilibré, reflétant les capacités économiques et les intérêts maritimes plutôt qu’un accident de l’histoire.
La coopération scientifique entre l’Europe et la Chine devrait s’intensifier, car leurs zones d’observation sont largement complémentaires. Ensemble, elles couvriraient une grande partie des océans mondiaux.
Une opportunité qui se referme si on laisse le réseau se dégrader
Le danger réside dans l’érosion progressive des informations dont dépend désormais une part croissante de l’activité humaine et de l’économie bleue.
Les alertes cycloniques deviennent moins fiables, les prévisions saisonnières moins précises, les projections sur le niveau de la mer moins exactes. Chaque perte est peut-être tolérable individuellement. Ensemble, elles reviennent à avancer à l’aveuglette vers la transformation la plus lourde de conséquences du climat de la planète de toute l’histoire de l’humanité.
Le système d’observation des océans est un service public planétaire, construit au fil des décennies par de nombreuses nations. La France et l’Europe possèdent les institutions, l’expertise et l’intérêt maritime nécessaires pour jouer un rôle bien plus important.
Ce qui manque, c’est la décision politique d’agir, tant que le système peut encore être maintenu. La perte de la collaboration entre les nations imposerait une reconstruction bien plus difficile et coûteuse qu’un investissement soutenu dans ce qui fonctionne déjà.
Sabrina Speich a reçu des financements de l'ERC, EU Horizon 2030, CNES TOSCA et l'ANR. Elle est présidente du comité d'experts du "Ocean Observations for Physics and Climate" des programmes UN GOOS et GCOS.
John Abraham, Kevin Trenberth et Lijing Cheng ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
15.06.2026 à 00:05
SARS-CoV-2, mpox, chikungunya, hantavirus, Ebola… Pourquoi les émergences virales se multiplient-elles ?
Yannick Simonin, Virologiste spécialiste en surveillance et étude des maladies virales émergentes. Professeur des Universités, Université de Montpellier
Texte intégral (3152 mots)
L’actualité virale pour le moins chargée de ces dernières semaines nous l’a tristement rappelé : nous sommes régulièrement confrontés à l’émergence ou à la réémergence de virus. Pourquoi ? Quels sont les facteurs qui favorisent aujourd’hui l’apparition (ou la réapparition) et la diffusion de ces virus ? Tour d’horizon des principaux facteurs impliqués.
Depuis la pandémie de SARS-CoV-2, qui a touché plus de 700 millions de personnes dans le monde et provoqué environ 7 millions de décès, les virus occupent régulièrement le devant de la scène. Chikungunya, mpox, hantavirus, Ebola, virus de Crimée-Congo… Ces noms, autrefois connus des seuls spécialistes, ont quitté les colonnes des publications spécialisées pour faire la une des médias.
Pourquoi les émergences virales semblent-elles plus fréquentes aujourd’hui que par le passé ? Il n’existe pas de réponse simple à cette question, car une telle émergence est toujours le résultat de paramètres multiples. Pour qu’elle survienne, une alchimie doit s’opérer entre plusieurs ingrédients.
Du réchauffement climatique aux déplacements de population en passant par les modes d’élevage intensif, les conditions d’une « tempête parfaite » virale ne sont pas gravées dans le marbre. Mais leur multiplicité doit nous inciter à nous préparer à de futures pandémies. Explications.
Des émergences à répétition
En 2022, alors que la pandémie de Covid-19 n’était pas encore terminée, la variole du singe, désormais rebaptisée mpox par l’Organisation mondiale de la santé (OMS), a fait une entrée fracassante sur le devant de la scène. Cette maladie virale, qui était autrefois essentiellement cantonnée aux régions d’Afrique centrale et de l’Ouest, est sortie de sa zone habituelle de circulation de façon inattendue, pour se diffuser rapidement à l’échelle mondiale.
Initialement transmis à l’être humain par des animaux, dont certains rongeurs, le virus mpox s’est ensuite propagé rapidement de personne à personne. Entre 2022 et 2023, près de 100 000 cas ont été confirmés dans plus de 120 pays. En France, plus de 4 000 cas confirmés ont été signalés, majoritairement en 2022, faisant du pays l’un des plus touchés en Europe occidentale. Une situation totalement inédite pour ce virus…
Plus récemment, l’année 2025 a été marquée en France par une circulation inhabituelle de virus transmis par les moustiques. Les infections par le chikungunya ont, par exemple, atteint des niveaux exceptionnels, avec plus de 800 cas autochtones recensés (dix fois plus que le précédent record !).
Notre espèce n’a pas été la seule touchée par les émergences de maladies infectieuses : la même année, des maladies animales à fort impact sanitaire et économique, telles que la dermatose nodulaire bovine, ont également nécessité la mise en œuvre de programmes de surveillance et de contrôle à grande échelle en France, et plongé nombre d’agriculteurs dans le désarroi et l’incompréhension.
L’année 2026 ne fait pas exception, loin de là… En mai, le foyer de hantavirus Andes, à bord du MV Hondius, ou encore la flambée d’Ebola en République démocratique du Congo rappellent que ces menaces sont plus que jamais présentes.
Les virus, maîtres incontestés de l’adaptation
Habituellement utilisés dans le milieu restreint des laboratoires, les termes « variant », « souche » ou « mutants » ont essaimé bien au-delà du cercle des spécialistes. Ils illustrent la capacité extraordinaire des virus à s’adapter à leur environnement.
Les virus sont en effet capables d’évoluer de plusieurs façons. Leur génome peut subir de petites modifications (on parle de mutations ; celles-ci se produisent lorsque les virus se multiplient, et si certaines d’entre elles confèrent un avantage à leur porteur, lui permettant par exemple de contaminer plus facilement ses hôtes, celui-ci se voit favorisé). Ils peuvent aussi échanger des morceaux de matériel génétique entre eux (de tels échanges sont appelés des recombinaisons). Enfin, ils peuvent aussi troquer des segments beaucoup plus longs, correspondant à des pans entiers de leur matériel génétique (on parle alors de réassortiments).
Pour ces raisons, dans le monde vivant, les virus sont de loin les entités les plus rapides à évoluer. Ils mutent en moyenne de 100 à 10 000 fois plus vite que les bactéries, environ 1 000 fois plus vite que les parasites, et jusqu’à 100 000 fois plus vite que nos propres cellules ! Un combat profondément inégal dans la course a l’évolution, dont les virus sortent largement gagnants.
Des virus majoritairement discrets
La plupart du temps, les virus circulent en toute discrétion, bien souvent sans même provoquer de symptômes. Cette propagation silencieuse se fait le plus fréquemment au sein de réservoirs animaux.
Le problème se pose lorsque ces animaux, que l’on peut considérer comme des « porteurs sains », rencontrent une autre espèce sensible à ces virus « silencieux ». Le virus peut alors provoquer des symptômes plus ou moins sévères et se propager, jusqu’à entraîner une épizootie chez les animaux, ou une épidémie chez l’être humain.
On estime à l’heure actuelle que les trois quarts des virus émergents impliqués dans des maladies chez l’être humain proviennent des animaux. Les maladies qu’ils provoquent chez l’homme sont désignées sous l’appellation « zoonose ».
Et c’est bien là que réside le cœur du problème : cette rencontre, en apparence inhabituelle, entre un animal réservoir porteur d’un virus au potentiel dévastateur et l’être humain, devient de plus en plus fréquente.
La cause principale ? L’action de l’être humain sur l’environnement. En transformant profondément la nature, nous modifions les conditions de circulation des agents infectieux à l’échelle mondiale.
Des écosystèmes fragilisés
Si les virus sont les acteurs principaux de l’émergence virale, c’est bien nous qui en écrivons le scénario.
La déforestation et la fragmentation des écosystèmes, comme en Amazonie, en Afrique centrale ou en Asie du Sud-Est, détruisent les habitats naturels des animaux, les forçant à se rapprocher des zones habitées. Cette promiscuité génère des conditions particulièrement favorables à la transmission des virus.
Ces bouleversements créent ce qu’on appelle des « points chauds » (« hot spots » en anglais) de transmission où animaux sauvages, animaux domestiques et humains interagissent plus fréquemment. Ces échanges facilitent le passage des virus d’une espèce animale à l’autre et potentiellement à l’être humain, levant les barrières naturelles qui cloisonnaient les virus au sein d’une espèce animale donnée.
L’émergence du dangereux virus Nipah, responsable de graves syndromes neurologiques pouvant entraîner le décès des personnes infectées, illustre parfaitement ce phénomène. Ce virus a été signalé pour la première fois en Malaisie en 1998. Dans ce pays, la transformation des forêts a rapproché les chauves-souris des élevages porcins, ainsi que des humains qui s’en occupaient. Cette nouvelle configuration a permis au virus de franchir plusieurs barrières d’espèces successives, jusqu’à provoquer des cas humains.
De manière similaire, les épidémies d’Ebola en Afrique centrale sont étroitement liées à la perturbation des écosystèmes forestiers et à l’augmentation des contacts entre la faune sauvage, notamment les chauves-souris frugivores, qui sont les réservoirs présumés du virus, et les populations humaines. L’émergence et la propagation récente du virus Ebola Bundibugyo en République démocratique du Congo s’inscrivent dans ce contexte. Dans des régions où la déforestation, l’exploitation des ressources naturelles et les déplacements de population modifient profondément les écosystèmes, leur fragmentation favorise des interactions accrues entre espèces et augmente les probabilités de franchissement de la barrière d’espèce.
Les modifications de la biodiversité peuvent aussi favoriser l’émergence de virus. En effet une biodiversité variée peut limiter la propagation des maladies, en « diluant » les agents pathogènes entre de nombreuses espèces plus ou moins efficaces pour les transmettre.
À l’inverse, la perte de diversité des espèces que nous observons ces dernières années peut faciliter la transmission des agents infectieux en supprimant cet effet de dilution et en favorisant ainsi la dominance d’espèces particulièrement efficaces pour transmettre ces pathogènes.
Des élevages intensifs qui amplifient les virus
La promiscuité n’est malheureusement pas l’apanage de l’être humain. L’augmentation de la population mondiale s’accompagne également de la hausse significative des élevages d’animaux. Poulets, porcs, bovins ou encore canards sont élevés à des densités parfois très élevées dans des espaces restreints.
À titre d’exemple, la production mondiale de viande de volaille est passée d’environ 9 millions de tonnes en 1961 à plus de 130 millions de tonnes aujourd’hui, tandis que plus de la moitié des porcs sont désormais élevés en systèmes intensifs. Ces conditions favorisent la transmission rapide des virus et leur évolution. Ces élevages devenant ainsi de véritables amplificateurs de maladies.
Les porcs, par exemple, peuvent être infectés simultanément par plusieurs virus grippaux, ce qui facilite l’apparition de nouveaux variants. Ce phénomène a notamment conduit à l’émergence du virus grippal H1N1 en 2009.
Des villes qui accélèrent les épidémies
Plus de la moitié de la population mondiale vit désormais en zone urbaine, un chiffre en constante augmentation. Les villes densément peuplées, et notamment les grandes métropoles, sont devenues des lieux propices à la propagation des virus.
La promiscuité dans les transports, les écoles ou les lieux de travail multiplie les contacts rapprochés. Dans certains quartiers surpeuplés, les conditions sanitaires renforcent encore ces risques.
La pandémie de Covid-19, comme les épidémies de dengue, ont montré à quel point les grandes métropoles peuvent agir comme des accélérateurs d’épidémies.
À titre d’exemple, citons le cas emblématique de New Delhi, capitale de l’Inde et mégalopole de près de 30 millions d’habitants. La densité de population, les flux quotidiens de millions de voyageurs dans les transports en commun et les insuffisances des infrastructures sanitaires y forment un terrain idéal pour la propagation des virus. Conséquence : la ville est régulièrement touchée par des épidémies de dengue. Le virus y circule à un tel niveau que, selon certaines estimations, près de 40 % à 50 % de la population, voire davantage selon les quartiers, auraient été infectés au moins une fois par le virus de la dengue !
Lors de la pandémie de Covid-19, Mumbai, la capitale économique de l’Inde, et New Delhi ont également figuré parmi les foyers les plus touchés du pays, illustrant une fois de plus comment la concentration urbaine amplifie la vitesse et l’ampleur de la contagion.
Des pratiques humaines à risque
Certaines activités humaines créent des passerelles directes entre les espèces. La chasse dite « de subsistance », encore pratiquée dans de nombreuses régions d’Afrique et d’Asie, le commerce d’animaux sauvages ou encore différentes pratiques culturelles exposent les humains à des virus inconnus.
Les marchés d’animaux vivants, où différentes espèces sont entassées dans des conditions sanitaires bien souvent précaires, sont des lieux à haut risque d’émergence virale. Bien que la séquence précise de l’émergence du coronavirus SARS-CoV-2 à l’origine de la pandémie de Covid-19 n’ait pas encore pu être élucidée, le marché d’animaux vivants de Wuhan, désormais célèbre, est soupçonné d’y avoir joué un rôle central…
À cela s’ajoutent certaines pratiques culturelles et religieuses, telles que les festivals ou les cérémonies au cours desquels des animaux vivants sont sacrifiés et manipulés, créant autant de passerelles potentielles pour la transmission virale. Les épidémies d’Ebola ont également mis en évidence le rôle de certains rites funéraires traditionnels impliquant des contacts étroits avec les corps des défunts emportés par la maladie dans l’amplification de la transmission du virus au sein des communautés.
Les conflits armés favorisent les virus
Les virus exploitent également les fractures profondes de nos sociétés. Les conflits armés, les déplacements massifs de populations et les crises humanitaires constituent des contextes particulièrement favorables à la diffusion des agents infectieux.
Dans ces situations, les systèmes de santé se dégradent, le diagnostic est rendu plus compliqué, les programmes de vaccination sont perturbés, voire interrompus, et l’accès aux traitements devient limité ou irrégulier. Par ailleurs, l’insécurité alimentaire et la malnutrition fragilisent les organismes et la diffusion de maladie, tandis que la mise en œuvre des mesures de prévention et de contrôle des infections devient difficile, voire irréalisable. L’ensemble de ces facteurs crée des conditions propices à l’émergence ou à la réémergence d’épidémies parfois considérées comme maîtrisées.
La circulation actuelle du virus Ebola en Ituri, dans l’est de la République démocratique du Congo, illustre clairement cette dynamique. Cette région, marquée par une insécurité chronique liée aux conflits armés, des déplacements répétés de populations et un accès limité aux infrastructures de santé, constitue un terrain particulièrement favorable à la persistance et à la propagation du virus.
La mondialisation accélère les épidémies
Autrefois, les épidémies mettaient des mois, voire des années à se propager au rythme du transport terrestre ou maritime. Aujourd’hui, la vitesse de diffusion des épidémies est devenue vertigineuse, un virus pouvant traverser la planète en moins de 24 heures !
L’explication principale dans cette diffusion express des virus se trouve dans l’intensification du trafic aérien ces dernières années, qui favorise le flux de marchandises, d’animaux et des êtres humains. À cela s’ajoutent aujourd’hui d’autres facteurs de mobilité, notamment le développement massif des réseaux ferroviaires à grande vitesse.
Par exemple, l’expansion rapide du réseau de trains à grande vitesse en Chine a profondément modifié les dynamiques de circulation interne, facilitant des déplacements massifs de population. C’est le cas notamment lors des déplacements saisonniers, liés en particulier aux grandes fêtes traditionnelles, comme le Nouvel An chinois, qui donnent lieu à des déplacements massifs de population à l’échelle du pays.
La pandémie de Covid-19 a illustré cette accélération sans précédent puisque, en à peine 6 à 8 semaines, le virus s’est propagé sur plusieurs continents. En moins de 12 semaines, l’OMS déclarait une pandémie mondiale. On connaît la suite, le virus s’étant propagé à plus de 180 pays…
Changement climatique, le point de bascule
Si tous les facteurs mentionnés précédemment jouent un rôle important, le plus puissant accélérateur des épidémies est probablement le changement climatique. Largement lié aux activités humaines, il agit comme un puissant moteur d’émergence et de réémergence des maladies virales.
Ce phénomène ne se limite pas uniquement à la hausse continue des températures que nous observons ces dernières années, mais il englobe également l’intensification des événements extrêmes (sécheresses, inondations, canicules, tempêtes…), ainsi que des perturbations majeures des écosystèmes.
Les sécheresses, par exemple, poussent de nombreux animaux à se rapprocher des zones habitées à la recherche d’eau et de nourriture, tandis que les fortes pluies et inondations favorisent la prolifération des rongeurs en augmentant les ressources disponibles et en les déplaçant vers les zones habitées, ce qui accroît notamment le risque de transmission de virus comme les hantavirus.
De même, l’augmentation des températures et des épisodes de fortes pluies en France a favorisé l’expansion des moustiques tigres, contribuant à une circulation record du chikungunya en 2026, y compris dans des zones où il était auparavant rarement détecté.
Pour conclure, une émergence virale est un phénomène complexe qui ne dépend jamais d’un seul facteur, mais plutôt de la convergence de multiples éléments : un virus capable de se transmettre efficacement qui rentre en contact avec l’être humain, une population vulnérable, des systèmes de santé fragiles, une forte mobilité humaine, des conditions climatiques favorables…
C’est ce cocktail explosif, davantage que les caractéristiques du virus lui-même, qui transforme une infection locale en épidémie ou en pandémie. Ainsi, l’émergence virale relève d’un équilibre complexe et très difficile à anticiper.
Ce qui est certain, en revanche, c’est que les conditions actuelles sont particulièrement favorables à l’avènement de l’ère des virus émergents. Ces dernières années, nous n’en avons probablement observé que les prémices…
Yannick Simonin a reçu des financements de Horizon Europe, ANR, ANRS-MIE, PREZODE, région Occitanie, Université de Montpellier.
15.06.2026 à 00:04
Immigration : pourquoi le débat est-il si peu objectif ?
Antoine Pécoud, Professeur de sociologie, Université Sorbonne Paris Nord
Texte intégral (2399 mots)
Alors que les institutions et les chercheurs multiplient la publication de données pour rétablir la vérité factuelle, pourquoi, en matière d’immigration, le débat démocratique est-il si peu objectif ?
Dès qu’il s’agit d’immigration, ce sont toujours les mêmes clichés qui reviennent : les migrants refusent de s’intégrer ; ils volent les emplois des nationaux ; ils islamisent l’Europe et « grand-remplacent » ses habitants ; ils profitent de l’« Europe passoire » pour abuser de la protection sociale ; ils feraient mieux de rester chez eux et de développer leur pays – et ainsi de suite.
Ces préjugés sont aussi anciens que l’immigration. Au XIXᵉ siècle, Marx et Engels débattaient déjà des effets préjudiciables de l’immigration irlandaise sur la classe ouvrière anglaise et, malgré une réalité sensiblement plus nuancée, la crainte que le travailleur étranger ne pénalise le « natif » reste ancrée dans le débat public. En France, les stéréotypes actuels sur les immigrés d’Afrique subsaharienne ou du Maghreb ressemblent beaucoup à ceux que subissaient les Italiens ou les Polonais il y a un siècle.
Aujourd’hui comme hier, ces idées reçues ont des conséquences bien réelles. Elles renforcent le rejet des immigrés et empêchent de tirer profit de leur apport économique ou démographique. En biaisant le débat démocratique, elles alimentent une demande pour des politiques restrictives, mais inefficaces, car en décalage avec la réalité qu’elles prétendent gouverner.
À titre d’exemple, malgré la nouvelle loi française sur l’immigration de janvier 2024 (« loi Darmanin »), malgré le pacte européen sur la migration et l’asile de 2024, malgré plusieurs mesures prises par le gouvernement britannique, et malgré un nouvel accord franco-britannique en été 2025, les traversées de la Manche ont atteint le chiffre de 41 000 en 2025, au plus haut depuis 2022.
Une multiplication des efforts
La lutte contre ces préjugés est donc une priorité pour un vaste éventail d’acteurs. Au niveau des pouvoirs publics, c’est le cas de l’Union européenne, qui s’alarme des fake news, des théories conspirationnistes, et de leurs effets sur l’adhésion au projet européen. En France, le ministère de l’Europe et des affaires étrangères s’est employé à combattre les rumeurs concernant, par exemple, son soutien au Pacte mondial pour des migrations sûres, ordonnées ou régulières (ou « Pacte de Marrakech »). En 2024, c’est le premier ministre espagnol Pedro Sanchez qui invalidait les idées fausses (bulos) sur le sujet devant le Parlement.
Au niveau international, le Forum d’examen des migrations internationales qui s’est tenu à l’ONU, en mai 2026, a été l’occasion pour le secrétaire général Antonio Guterres de dénoncer la désinformation sur l’immigration. Des agences comme le Haut-Commissariat pour les réfugiés (HCR) ou l’Organisation internationale pour les migrations (OIM) conduisent des programmes de lutte contre les stéréotypes qui affectent les migrants et les réfugiés. Une des stratégies de ces agences est de fournir des données sur le sujet, comme en atteste la création par l’OIM du Global Migration Data Analysis Centre en 2015. L’Union européenne a publié en 2025 un « Atlas of migration », partageant cet objectif de mettre à disposition les chiffres à même de combattre les fake news.
Plusieurs ONG et associations de premier plan (parmi lesquelles Oxfam, le Syndicat de la magistrature, Emmaüs solidarité, Médecins du monde ou Médecins sans frontières) se sont réunies autour de la chercheuse en droit des étrangers Sophie-Anne Bisiaux pour publier, en 2025, En finir avec les idées fausses sur les migrations, un ouvrage qui réfute de façon systématique un vaste éventail de préjugés. Un inventaire récent a identifié plus de 200 publications visant le même objectif depuis 1990, dont 46 en français : pour les spécialistes de l’immigration, la lutte contre les idées reçues est donc un travail à plein temps.
Une tâche sisyphéenne ?
Pour vulgariser les résultats de la recherche scientifique, les chercheurs font pourtant face à des obstacles importants.
La réfutation d’une idée reçue demande sensiblement plus de temps et d’énergie que sa production : c’est la « loi de Brandolini », en vertu de laquelle ceux qui débitent des inepties ont toujours un temps d’avance sur ceux qui les corrigent.
Un second obstacle tient à la posture de l’expert ou du chercheur. Déconstruire des préjugés peut s’avérer compliqué à mettre en œuvre lorsque les « sachants » sont soupçonnés de vouloir imposer leurs vues. À l’instar du « grand remplacement », nombre de préjugés anti-immigration et de théories conspirationnistes sont imprégnés d’une hostilité à l’égard des élites, accusées d’être déconnectées de la réalité, voire d’agir sciemment contre les intérêts du peuple.
Les acteurs qui se positionnent contre les idées reçues se placent enfin dans une posture défensive, qui confère paradoxalement une visibilité accrue aux préjugés. On parle d’« effet Streisand » pour désigner ce mécanisme par lequel, en voulant combattre la diffusion d’une idée, on contribue à la placer au centre de l’attention, voire même à la légitimer.
Limites et ambiguïtés des chiffres
Une stratégie éprouvée pour réfuter les idées reçues est le recours aux données produites par les statistiques publiques.
Les chiffres indiquent par exemple que, contrairement à une affirmation fréquente, il n’y a pas beaucoup de réfugiés en France. Entre 2014 et 2020, dans le contexte de la guerre en Syrie, la France a reçu 25 000 demandes d’asile en provenance de ce pays, contre 633 000 en Allemagne. Pareil avec la guerre en Ukraine en 2022, suite à laquelle la France a protégé environ 73 000 personnes, sur un total de plus de 4 millions de réfugiés ukrainiens en Europe, et là où l’Allemagne et la Pologne en ont chacun accueilli autour d’un million.
Quelques incontestables que soient ces données, force est toutefois d’admettre qu’elles n’empêchent pas l’antienne habituelle selon laquelle la France serait excessivement laxiste ou généreuse. Le président du Rassemblement national, Jordan Bardella, tenait en septembre 2025 les propos suivants :
« Chaque année, 500 000 personnes entrent dans notre pays. Et sur ce demi-million, seulement 50 000 viennent pour travailler. La question est simple : que font les 450 000 autres, et surtout, qui paie ? »
Il s’agit là d’une accumulation de contre-vérités.
En 2024, environ 343 000 premiers titres de séjour ont été délivrés en France (et non 500 000), et le taux d’emploi parmi les immigrés s’élève à environ 63 % (et non 10 %). Mais il peu probable que l’auditoire se scandalise de ces inexactitudes : ce qui compte, c’est le récit qui lui est proposé ainsi que ses valeurs sous-jacentes, fondées sur la distinction entre « eux » et « nous » et sur les difficultés socioéconomiques vécues par une partie de la population française.
Les chiffres entraînent en outre le débat sur un terrain parfois glissant. Imaginons que la situation s’inverse et que la France accueille plus de Syriens et d’Ukrainiens que l’Allemagne, serait-ce une catastrophe ?
Les politiques migratoires ne se résument pas aux chiffres. Elles soulèvent des questions fondamentales en termes de valeurs. Que le nombre de réfugiés en France soit de mille ou d’un million est alors secondaire. Ce qui compte, c’est l’importance accordée à certains principes, comme le droit d’asile, et le type de société que l’on souhaite : plus ou moins ouverte sur le monde, plus ou moins cosmopolite ou solidaire.
Ce débat-là ne peut se passer des chiffres (ce n’est pas pareil d’accueillir un millier ou un million de réfugiés), mais les interrogations qu’il pose vont bien au-delà des querelles statistiques.
Un débat polarisé
Une dernière difficulté soulevée par la lutte contre les idées reçues est que la méthode peut s’inverser. C’est le cas avec un livre récent du directeur d’un think tank nommé « Observatoire de l’immigration et de la démographie », Nicolas Pouvreau-Monti, très commenté depuis sa parution dans les médias marqués à droite. Intitulé Immigration, mythes et réalités, il confronte les idées reçues à l’analyse, à ceci près que ce sont cette fois les « mythes » qui seraient favorables à l’immigration, tandis que l’analyse de la « réalité » inviterait à lutter encore davantage contre l’immigration.
La démarche n’est pas très crédible.
D’une part, et malgré une réalité souvent complexe, l’hostilité à l’égard de l’immigration est bien présente dans la société française et une trentaine de lois ont été adoptées depuis 1980, toutes plus restrictives les unes que les autres : il est donc incorrect de dire que les idées reçues dominantes en France sont excessivement bienveillantes à l’égard de l’immigration.
D’autre part, la « réalité » décrite par ce livre ne fait pas l’objet d’une analyse scientifique rigoureuse, car l’objectif est moins de comprendre les dynamiques migratoires que d’élaborer un programme radical en vue des élections de 2027 en France, clairement aligné sur les positions de l’extrême droite.
En janvier 2025, cet institut disait par exemple craindre l’afflux de 580 millions de réfugiés en France, ce qui multiplierait par cinq le nombre total de personnes déplacées dans le monde (117 millions selon le HCR), et par huit la population du pays… Mais un tel scénario suppose que non seulement l’ensemble des personnes affectées par les conflits quittent leur pays, mais aussi qu’elles décident toutes de venir en France. Ces deux conditions sont aussi irréalistes l’une que l’autre, et un tel pronostic ne vise donc qu’à électriser le débat et à appeler au démantèlement du droit d’asile.
Cette lutte inversée contre les idées reçues n’en est pas moins symptomatique d’une forte polarisation, qui voit chaque camp délégitimer la position de son adversaire en la traitant d’idée reçue – avec le risque de ne parler qu’à ses propres coreligionnaires, et au détriment de la qualité démocratique, mais aussi de la prospérité du pays et des droits des migrants et des réfugiés.
Antoine Pécoud ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.06.2026 à 10:33
Comment les cotisations sociales redessinent les inégalités : la bataille avant l’impôt
Malka Guillot, Professeure d'économie, Université de Liège
Texte intégral (1635 mots)
Et si la clé pour réduire les inégalités était la prédistribution ? Autrement dit, les mécanismes qui réduisent (ou creusent) les inégalités avant l’impôt comme le salaire minimum. Car la reconfiguration des cotisations sociales joue un rôle central dans la réduction des inégalités. Quand les réduire ? les augmenter ? Faut-il les appliquer de la même façon à tous les salariés ? Explication avec le cas de la France grâce à des données de 1900 à 2018.
Quand on parle de réduction des inégalités, on pense d’abord à l’impôt sur le revenu ou aux politiques éducatives. Plus rarement aux cotisations sociales salariales et patronales. Pourtant, l’histoire française montre que ces prélèvements, conçus à l’origine pour financer la Sécurité sociale, ont aussi progressivement servi à remodeler la distribution des revenus. Ils représentent de fait une part importante des recettes fiscales totales dans les pays de l’Organisation de coopération et de développement économiques (OCDE, en moyenne 26 % des recettes fiscales totales, soit 9 % du PIB.
Dans une étude menée avec Antoine Bozio, Bertrand Garbinti, Jonathan Goupille-Lebret et Thomas Piketty, nous avons comparé les systèmes de redistribution et prédistribution entre la France et les États-Unis sur plus d' ;un siècle. Notre conclusion : les différences d’inégalités après impôts et transferts sociaux entre les deux pays s’expliquent surtout par les inégalités ex ante, avant redistribution.
Autrement dit, ce qui diverge le plus, c’est la formation primaire des revenus – sur le marché du travail et via les institutions salariales comme le salaire minimum, les négociations collectives ou les conventions de branche – davantage que l’intensité de la redistribution monétaire ex post – comme les allocations logement ou l’impôt sur la fortune immobilière. Nous soulignons que la seule mesure de la redistribution peut être empiriquement trompeuse pour juger les politiques de réduction des inégalités.
Dans notre autre étude menée avec Antoine Bozio et Thomas Breda, nous montrons que les inégalités salariales après impôt en France ont diminué de 19 % entre 1967 et 2019, mais ont augmenté de 15 % avant impôt. De facto, les cotisations sociales sont devenues le principal outil de redistribution des richesses.
Ensemble, ces deux travaux portent un message clair : pour comprendre les inégalités, il faut regarder au-delà de la redistribution visible et s’intéresser aux mécanismes qui façonnent les revenus avant même que l’État n’intervienne.
Réduire les inégalités avant même l’impôt
La distinction entre redistribution et prédistribution est essentielle.
La redistribution classique corrige les écarts de revenus une fois qu’ils ont été produits, via les impôts et les prestations sociales. La prédistribution est un concept ayant pris une place croissante dans les débats de politiques publiques depuis les années 2000, en particulier au Royaume-Uni. Il agit plus en amont via les systèmes juridiques et sociaux qui contribuent à déterminer le pouvoir de négociation des employés vis-à-vis des employeurs, notamment à travers les règles de fixation des salaires, le droit des sociétés, la réglementation du salaire minimum et la force des syndicats.
Dans le cas français, ces instruments ont joué un rôle majeur. Comme le montre la figure ci-dessous, les inégalités salariales brutes – avant déduction des cotisations sociales et fiscales – augmentent de + 15,4 % entre 1967 et 2019 ; les inégalités de salaires nets – après déduction des cotisations sociales et fiscales – diminuent de 18,9 %.
Autrement dit, le système n’a pas seulement compensé les écarts produits par le marché ; il les a aussi infléchis. La France se distingue par ses inégalités de salaires nets, mais pas par ses inégalités de salaires avant impôt.
Ce résultat est peu intuitif. Les cotisations sociales sont souvent traitées comme un paramètre administratif du coût du travail, peu discuté dans l’espace public. C’est précisément leur inscription dans l’architecture salariale qui en fait un instrument puissant. En modifiant progressivement les taux, les exonérations et les assiettes, les pouvoirs publics peuvent déplacer la charge contributive entre catégories de travailleurs et d’employeurs, tout en influençant le coût relatif des différents niveaux de salaire.
Déplafonnement et réductions des cotisations sociales
Deux mécanismes apparaissent centraux dans l’expérience française : le déplafonnement progressif des cotisations sociales et les allègements ciblés sur les bas salaires.
Pour les mettre en lumière, nous avons analysé le taux moyen de cotisations sociales, à savoir la part salariale ajoutée à la part employeur. Pour ce faire, nous détaillons la part du salaire avant impôt au premier décile (D1) – niveau du salaire au-dessous duquel se situent 10 % des salaires –, de la médiane (D5) et neuvième décile (D9) – le salaire au-dessous duquel se situent 90 % des salaires – entre 1967 et 2019.
Le premier mécanisme équivaut au déplafonnement progressif des cotisations sociales, déployé jusqu’au début des années 1990. Ce dernier fait augmenter plus rapidement les taux en haut de la distribution et rapproche les profils de prélèvement entre D5 et D9.
Le second mécanisme intervient ensuite, à partir du milieu des années 1990. Les allègements ciblés sur les bas salaires font nettement baisser le taux du premier décile (D1), tandis que les taux restent élevés pour la médiane (D5) et le neuvième décile (D9). Au total, on passe d’un profil initialement régressif à un profil plus progressif en fin de période.
Ce compromis n’est jamais parfait. Les réductions de cotisations peuvent compliquer la lecture du système et encourager une concentration des emplois et des hausses de salaire autour des bas salaires, là où les allègements sont les plus importants. Elles ont permis, dans le cas français, de soutenir une forme de compression salariale sans passer uniquement par des transferts budgétaires visibles.
Un outil redistributif discret, mais peu transparent
Cette trajectoire française met en lumière un paradoxe. D’un côté, l’usage des cotisations sociales comme levier redistributif présente des avantages réels. Le prélèvement est administrativement efficace, adossé à la fiche de paie, et il déclenche généralement moins de controverses qu’une hausse explicite de l’impôt. Pour un gouvernement, il peut donc être plus facile de faire évoluer la distribution des revenus par ce canal que par une réforme fiscale frontale.
D’un autre côté, lorsque la redistribution passe par des mécanismes de cotisations intégrés au financement de la Sécurité sociale, ses effets sont moins directement lisibles et doivent être documentés empiriquement. Qui supporte la contribution ? Qui bénéficie des réductions ? Quels effets sur les salaires nets, l’emploi et le financement social ?
Les résultats de ces travaux suggèrent ainsi qu’on ne peut pas évaluer les inégalités en regardant uniquement la redistribution après impôts et transferts ; il faut aussi mesurer la formation des revenus avant impôt et le rôle des réformes de cotisations sociales.
Et la Belgique dans tout cela ?
La Belgique offre un point de comparaison utile, précisément parce qu’elle partage avec la France un État social développé, un niveau élevé de prélèvements sur le travail et des dispositifs ciblés sur certains bas salaires. Le système de cotisations sociales présente certaines similitudes avec le système français, comme ses objectifs – financement de la Sécurité sociale, retraite, chômage, maladie –, et son fonctionnement progressif, avec des taux de cotisation plus élevés pour les hauts revenus.
Contrairement à la France, les cotisations sociales en Belgique sont toujours plafonnées. Le taux de cotisations sociales est plus élevé en Belgique qu’en France. En 2024, les cotisations sociales représentaient en Belgique 52,7 % du coût salarial d’un·e travailleur·se (pour le salaire moyen), contre 46,8 % en France, selon l’OCDE (Taxing Wages). La Belgique a également mis en place des réformes pour réduire les cotisations sociales pour les bas salaires, mais de montre ampleur que celles qui ont eu lieu en France.
Cet article a été rédigé avec l’aide d’Arnaud Stiepen, expert en vulgarisation scientifique.
Malka Guillot ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.06.2026 à 10:33
Terres rares : l’Europe est-elle toujours dans la course ?
Gaetan Lefebvre, Ingénieur géologue, BRGM
Nicolas Charles, Géologue, PhD, BRGM
Théo Arnaud, Analyste en intelligence minérale, BRGM
Texte intégral (3952 mots)
C’est en Europe que l’histoire des terres rares a commencé, mais ce n’est plus sur le Vieux Continent que s’écrivent désormais les grandes réussites industrielles autour de ces ressources. La Chine en a aujourd’hui le monopole, mais l’Europe – et notamment la France – veulent inverser la vapeur. Est-ce possible, et à quelles conditions ? Le sujet a été placé en tête de l’agenda dans le cadre de la présidence française du G7, qui se déroule du 15 au 17 juin à Évian.
L’histoire des terres rares a débuté en Europe il y a plus de deux siècles, précisément en 1787, lorsque le lieutenant et chimiste suédois Carl Axel Arrhenius découvrit un minéral noir à Ytterby, à vingt kilomètres au nord-est de Stockholm. S’ensuivit une grande histoire de découvertes scientifiques et de développements industriels autour de ce qui sera identifié comme un groupe de 17 éléments chimiques, les terres rares, aboutissant progressivement au paysage actuel : une industrie ultra-dominée par la Chine.
Les terres rares sont, aujourd’hui, un instrument géopolitique majeur. Elles relèvent d’enjeux de souveraineté, car elles sont indispensables à toute économie développée, en particulier dans le cadre de la transition énergétique. On en retrouve en effet tant dans les éoliennes, les véhicules électriques que dans l’électronique grand public. Dans ce contexte, une question légitime se pose : l’Europe a-t-elle encore sa place dans cette histoire ?
Aujourd’hui, l’expertise européenne se remobilise pour faire émerger une filière des terres rares qui s’affranchirait, du moins partiellement, du monopole chinois en cas de crise géopolitique.
Présenté le 5 mai 2026, le plan national de résilience « Terres rares et aimants permanents » va dans ce sens. Ce plan s’inscrit dans un double cadre :
d’abord, celui de la présidence française du G7, qui se déroule du 15 au 17 juin à Évian. Le sujet des matières premières critiques est arrivé en haut de l’agenda du sommet.
il est également le fruit d’un travail pluriannuel engagé entre les ministères français et les industriels, avec le soutien d’experts de l’Observatoire français des ressources minérales pour les secteurs industriels (Ofremi).
Une brève histoire des terres rares
Avant de devenir essentielles aux technologies modernes, les terres rares ont eu de nombreuses applications. D’abord exploitées pour des usages très spécifiques et en faibles volumes, elles se sont peu à peu généralisées à plus large échelle.
À cette évolution correspondent plusieurs phases de découvertes et d’exploitation industrielle des terres rares, impliquant en particulier des acteurs suédois, autrichiens et français, puis états-uniens et chinois.

(Source : Charles et coll., 2024)
À la suite de la découverte du « minéral d’Ytterby » en 1787, nombre de scientifiques européens contribuent à l’identification et à la séparation progressive des différents éléments de terres rares. À commencer par le professeur Johan Gadolin, nommant ce minéral « ytterbia » en 1794, ensuite transformé en « yttria », puis « yttrium », tel que nous le connaissons aujourd’hui dans le tableau de Mendeleïev.
De nouvelles terres rares sont ensuite peu à peu identifiées et réparties en deux groupes :
les terres « yttriques » découvertes à la suite de l’yttria,
et celles dites « cériques », à la suite de la découverte de la céria (oxyde de cérium) par Martin Heinrich Klaproth et, pratiquement en même temps, par Jöns Jacob Berzelius et Wilhelm Hisinger en 1803.

Parallèlement à ces découvertes, des usages industriels émergent, toujours en Europe. Ainsi, l’Autrichien Carl Auer von Welsbach sépare le néodyme et le praséodyme en 1885 par cristallisation fractionnée et remarque aussi la forte luminescence de certains éléments des terres rares.

Par la suite, il développe les lampes à gaz « Auer », imbibées d’oxydes de cérium et de thorium, qui révolutionnent l’éclairage urbain en Europe dans la première partie du XXᵉ siècle. En 1903, il invente également la pierre à briquet (en anglais flint lighter), constituée d’un alliage ductile mêlant cérium, lanthane, néodyme et fer, utilisé encore aujourd’hui.
Au début du XXᵉ siècle, les terres rares sont également utilisées comme poudres de polissage. L’oxyde de cérium devient alors indispensable dans la fabrication du verre optique, des lentilles, des miroirs de précision.
C’est également en médecine que des applications apparaissent, par exemple avec l’oxalate de cérium utilisé comme antiémétique dans la « Peremesin » pour lutter contre le mal de mer et les nausées, ou encore avec le néodyme pour lutter contre les thromboses avec le « Thrombodym ».
Pour autant, les quantités exploitées restent minimes et le peu d’éléments de terres rares employés créent, à cette époque, des stocks de matière non utilisées.
Ce constat va pousser à de nouvelles découvertes, comme celle des propriétés catalytiques dans le raffinage du pétrole de certaines terres rares (comme le lanthane et le cérium), puis à l’utilisation en tonnages de plus en plus importants d’éléments de terres rares, à partir des années 1950 et 1960.
Cette évolution se traduit de la même manière en matière de gisements exploités. L’extraction dominante de la monazite, minéral principalement situé dans les « sables à minéraux lourds » des côtes, notamment au Brésil ou en Inde, évolue vers des gisements de carbonatites riches en terres rares, comme celui de Mountain Pass aux États-Unis, puis de Bayan Obo en Chine.
À lire aussi : Connais-tu le lien entre ton téléphone portable et les cailloux ?
Terres rares, la séquence états-unienne
La découverte aux États-Unis du gisement de Mountain Pass, en 1949, constitue un événement majeur. Celle-ci survient dans le contexte de la recherche pour les grands programmes atomiques de l’époque, notamment le projet Manhattan.
La production minière à Mountain Pass commence en 1952, d’abord à petite échelle puis croît rapidement, jusqu’à produire 70 % des terres rares mondiales au début des années 1980. Cet essor fait suite à la demande croissante en terres rares, notamment en europium, alors utilisé dans les tubes cathodiques des écrans de télévision.

À partir des années 1980, une véritable révolution technologique a lieu avec les aimants samarium-cobalt (SmCo), puis néodyme-fer-bore (NdFeB), qui jouent un rôle clé dans la fabrication d’aimants permanents.
À lire aussi : Terres rares : Ces nouveaux venus qui entendent concurrencer la Chine et les États-Unis
Le développement du monopole chinois
Ce succès n’échappe pas à la Chine, qui identifie elle aussi, dans les années 1980, les terres rares comme un levier stratégique de développement industriel et de puissance nationale. Pékin met alors en place une politique volontariste combinant investissements publics, planification étatique et faibles contraintes environnementales.
Profitant de vastes gisements, notamment en Mongolie intérieure autour de Bayan Obo, la Chine augmente rapidement sa production et inonde les marchés mondiaux à bas prix dans les années 1990. Cette stratégie entraîne progressivement le déclin des producteurs concurrents, incapables de soutenir cette compétition.
Au début des années 2000, la Chine assure déjà l’essentiel de l’extraction mondiale, puis étend sa domination au raffinage et à la transformation, étapes clés de la chaîne de valeur. Sur l’ensemble de la chaîne de valeur, les risques de dépendance à la Chine se sont accentués depuis que cette dernière a accéléré ses restrictions. D’abord sur l’exportation de certaines technologies et équipements, en 2022 et en 2023), puis sur les terres rares ou aimants permanents directement en 2025.
Comment convaincre les acteurs européens de relocaliser une industrie des terres rares ?
Le potentiel géologique en terres rares en Europe et au Groenland est réel. Mais deux freins majeurs subsistent : les gisements sont le plus souvent situés dans des points chauds environnementaux et présentent une minéralogie complexe (c’est-à-dire qu’ils ne sont pas nécessairement faciles à exploiter avec les technologies conventionnelles).
Tout cela peut pénaliser la rentabilité économique des projets européens, du moins en l’état actuel des technologies d’extraction. Et quand bien même une mine finirait par ouvrir, toutes les problématiques sur le sol européen ne seraient pas résolues, car les conditions de structuration d’une chaîne de valeur sur les aimants permanents sont délicates à assurer.
En effet, le véritable problème est que la Chine vend aujourd’hui ses aimants moins cher que les terres rares qu’ils contiennent. C’est le point majeur à résoudre pour faire émerger une filière souveraine, des terres rares aux aimants permanents.
Certes, des acteurs européens – et notamment français – sont aujourd’hui positionnés à chaque étape de la chaîne de valeur avec une forte expertise, un atout majeur dans le contexte mondial. Mais ce qu’il reste à créer, c’est un écosystème vertueux, c’est-à-dire qui développe à la fois des capacités de financement et des débouchés pour les aimants à l’échelle du continent.
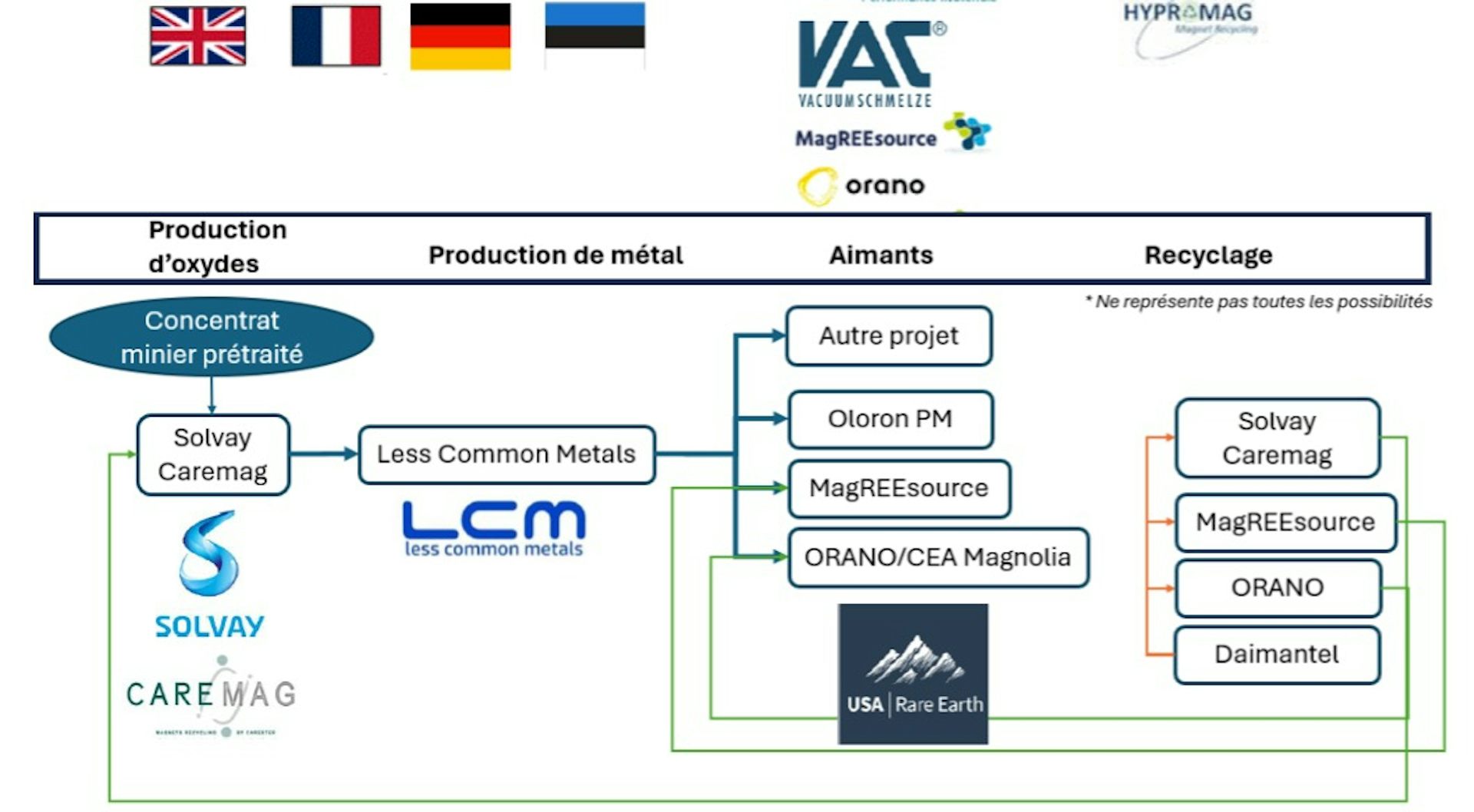{kind=link}
Autrement dit, il faut pouvoir construire une véritable chaîne de valeur des aimants permanents, de la mine (extraction) à l’aimant (usage final), qui intègre des acteurs industriels européens et français afin de réduire les risques de dépendance aux importations chinoises.

Si l’on veut pouvoir créer cette chaîne de valeur des terres rares en Europe, il faudra pouvoir s’affranchir d’un risque trop important de volatilité des prix. C’est un élément extrêmement contrôlé par la Chine à l’heure actuelle, qui crée des difficultés pour les acteurs européens. Pour gagner en indépendance vis-à-vis de la Chine, l’enjeu n’est donc pas de couvrir l’ensemble des besoins en aimants, mais de garantir un niveau minimal de capacité de production, et ce, à toutes les étapes de la chaîne de valeur.
Pour cela, il faut des engagements de la part des acteurs européens, c’est-à-dire qu’ils acceptent de produire et d’acheter ces aimants à un coût unitaire supérieur, en considérant cette nouvelle capacité à produire comme une assurance mutualisée en cas de rupture totale d’approvisionnement, et c’est là que se trouve l’argument de souveraineté.
Le plan national de résilience « Terres rares et aimants permanents » répond à ces défis en articulant mobilisation de la demande, soutien à l’offre et coopération internationale.
Les conditions de succès sont les suivantes :
il s’agit d’abord de garantir une part d’achats des aimants européens par les industries européennes des secteurs d’aval, c’est une condition indispensable pour la viabilité industrielle des projets à chaque étape, pour leur assurer des débouchés solides et pérennes.
D’autre part, il faut conserver une diversité suffisante dans la fabrication des aimants. La filière européenne ne peut pas se concentrer uniquement sur les aimants à forte valeur ajoutée, comme ceux de la mobilité électrique ou des éoliennes, au risque de rester dépendante (pour un secteur comme l’automobile, par exemple, les petits aimants sont aussi indispensables au fonctionnement des véhicules).
Enfin, pour viabiliser les projets européens, il apparaît nécessaire d’imaginer que des garanties d’État puissent s’appliquer en cas de crise. Reste toutefois à en déterminer les meilleures modalités.
À lire aussi : La guerre de l’information autour des métaux stratégiques
Les auteurs remercient Anne Bialkowski et Stéphane Bourg (BRGM/OFREMI) pour leurs conseils et relecture attentive.
L’Ofremi est soutenu dans le cadre de France 2030 par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Gaetan Lefebvre a reçu des financements de l'ANR ou Horizons Europe dans le cadre de projets de recherche, comme l'OFREMI.
Théo Arnaud a reçu des financements de l’ANR dans le cadre de projets de recherche, en particulier l’OFREMI.
Nicolas Charles ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.06.2026 à 10:32
Arménie : un scrutin sous le signe de la géopolitique
Anita Khachaturova, Doctorante, Centre d'Étude de la Vie politique (CEVIPOL), Université Libre de Bruxelles (ULB)
Texte intégral (3121 mots)
Les élections législatives, qui se sont tenues le 7 juin en Arménie (où l’essentiel du pouvoir est aux mains du premier ministre, le président jouant un rôle essentiellement protocolaire), se sont soldées par la victoire du parti du premier ministre sortant Nikol Pachinian, qui reste donc à la tête d’un pays encore traumatisé par la prise récente du Haut-Karabakh par l’Azerbaïdjan. Les deux principaux partis d’opposition, réputés pro-russes, seront également représentés au Parlement.
L’orientation pro-européenne enclenchée par Pachinian est confirmée, mais son ampleur sera limitée : l’Arménie, qu’elle le veuille ou non, demeure largement tributaire de la Russie, explique dans cet entretien Anita Khachaturova, spécialiste de l’Arménie à l’Université libre de Bruxelles.
The Conversation : Quels sont les principaux enseignements des élections législatives ?
Anita Khachaturova : Contrat civil, le parti du premier ministre Nikol Pachinian, en poste depuis 2018, est arrivé en tête avec 49,8 % des voix. Deux principales formations d’opposition entrent également au Parlement ; il fallait pour cela obtenir au moins 4 % des suffrages pour un parti seul et 8 % pour une alliance de partis : Arménie forte, dirigée par le milliardaire Samvel Karapetyan, avec environ 23 %, et l’alliance de l’ancien président Robert Kotcharian, autour de 10 %.
La participation a atteint près de 59 %, un niveau exceptionnellement haut pour l’Arménie. Les projections tablaient sur une participation nettement plus faible en raison de l’apathie qui caractérise la société arménienne ces dernières années. Cette mobilisation explique les scores non négligeables obtenus par l’opposition, qui espérait faire voter des électeurs jusque-là démobilisés ou indécis.
Une question reste toutefois en suspens à ce stade : celle de l’entrée éventuelle au Parlement du parti Arménie prospère, qui a manqué le seuil requis de seulement quelques centièmes de point. Ce détail pourrait avoir des conséquences institutionnelles importantes.
Pachinian sort-il renforcé du scrutin ?
A. K. : Pas vraiment. Il conserve le pouvoir et peut former seul un gouvernement, mais il est moins fort qu’auparavant. Dans le Parlement précédent, son parti disposait de 71 sièges sur 107, soit une très large majorité. Aujourd’hui, il devrait obtenir entre 61 et 64 sièges, en fonction de l’entrée ou non du parti Arménie prospère.
La différence est essentielle : le chef du gouvernement sortant risque de perdre la majorité qualifiée qui lui permettait d’adopter certaines lois constitutionnelles ou de procéder à des nominations importantes au sein des institutions judiciaires et administratives.
Dans tous les cas, cela met en péril le projet de nouvelle Constitution, qui était l’un des axes majeurs de sa campagne.
Que veut-il changer à la Constitution ? S’agit-il d’abandonner officiellement toute prétention arménienne sur le Haut-Karabakh ?
A. K. : C’est plus subtil. La Constitution arménienne ne mentionne pas directement le Haut-Karabakh. En revanche, son préambule renvoie à la Déclaration d’indépendance de 1990 qui, elle, contient une référence au Karabakh.
L’Azerbaïdjan considère cette référence comme incompatible avec la signature d’un traité de paix définitif et fait de sa suppression une pré-condition à la normalisation des relations entre les deux États.
Pachinian affirme que son projet de réforme constitutionnelle répond à une logique interne de modernisation institutionnelle. Toutefois, dans les faits, ce processus est étroitement lié aux négociations avec l’Azerbaïdjan. Le premier ministre a d’ailleurs mis en garde les électeurs lors de sa campagne, affirmant que s’il n’était pas réélu avec une majorité constitutionnelle, c'est-à-dire les deux tiers des mandats, il faudrait s’attendre à une guerre en septembre.
Pour changer la Constitution, il faut organiser un référendum. Or, les conditions légales sont particulièrement exigeantes. Sans majorité des deux tiers au Parlement, Nikol Pachinian ne pourra pas mener ce projet à bien.
Peut-on résumer cette élection à un choix entre la Russie et l’Occident ?
A. K. : C’est la manière dont cette élection a été présentée dans la presse internationale, mais c’est plus compliqué que cela. L’Arménie a toujours dû mener une politique multilatérale du fait de sa géographie complexe et des conflits avec ses voisins azerbaïdjanais et turc. Avant Nikol Pachinian, on parlait de « politique de complémentarité » visant à concilier la prise en compte des intérêts de l’allié russe et le maintien de bonnes relations à la fois avec l’Occident et avec l’Iran. Toutefois, depuis l’invasion à grande échelle de l’Ukraine par la Russie en 2022, la rupture profonde entre la Russie et les pays occidentaux a changé cette dynamique. L’influence de la Russie dans la région a connu un recul définitif.
Depuis l’offensive azerbaïdjanaise en septembre 2022 – ce qui a débouché sur l’occupation de plus de 200 kilomètres carrés de territoire arménien souverain – et le siège puis la capture du Haut-Karabakh l’année suivante, la Russie s’est révélée un allié peu fiable pour l’Arménie. La popularité de la Russie en Arménie a dégringolé.
Pachinian a progressivement engagé une politique de diversification stratégique et de rapprochement avec l’Union européenne et les États-Unis, mais également avec d’autres pays non occidentaux, comme l’Inde. Cette réorientation qui se veut démonstrative en faveur de l’Europe, souvent accompagnée d’un langage virulent, lui vaut d’être accusé par certaines franges de l’opposition et de la diaspora de compromettre la sécurité de l’Arménie. Cette fracture a été encore exacerbée durant la campagne électorale : Pachinian accuse toute opposition d’être aux mains du Kremlin, tandis que les formations réputées pro-russes et leurs soutiens l’accusent d’être à la solde de la Turquie et de l’Azerbaïdjan.
Cependant, il ne faut pas réduire la vie politique arménienne à cette seule opposition. Dix-neuf partis participaient au scrutin. Plusieurs petites formations, critiques aussi bien du gouvernement Pachinian que des figures oligarchiques pro-russes, défendaient un agenda démocratique. Elles n’ont toutefois pas réussi à franchir les seuils électoraux, ce qui produit un Parlement encore plus polarisé qu’auparavant.
Tout cela ne contribue pas à l’émergence d’un débat sain et constructif sur l’avenir de l’Arménie. On remarque, par ailleurs, que les enquêtes d’opinion ne font pas état d’une polarisation autour de l’orientation géopolitique, mais montrent plutôt que les Arméniens donnent la priorité à des sujets socioéconomiques et de sécurité, qui restent très souvent à la marge des agendas politiques des uns et des autres.
Les puissances étrangères ont-elles tenté d’influencer le scrutin ?
A. K. : Oui, et de manière très visible. Du côté occidental, plusieurs signaux ont été interprétés comme un soutien à Pachinian. Des responsables européens ont multiplié les rencontres avec les autorités arméniennes pendant la campagne. Deux sommets européens se sont tenus en mai en Arménie en l’espace d’une semaine, début mai : le huitième sommet de la Communauté politique européenne puis le sommet UE-Arménie, en présence par ailleurs du président ukrainien Volodymyr Zelensky.
Si, en France, on a souvent mis en avant la séquence où, en marge de ce sommet, Emmanuel Macron a chanté la Bohême, de Charles Aznavour, accompagné par Nikol Pachinian à la batterie, l’organisation à ce moment-là d’une telle réunion à Erevan signalait clairement un soutien à la candidature de Pachinian.
Les États-Unis ont également affiché leur soutien politique au gouvernement arménien. Le secrétaire d’État Marco Rubio s’est rendu sur place peu avant le scrutin et Donald Trump a appelé à voter en faveur de Pachinian.
Du côté russe, les méthodes ont été plus coercitives. Moscou a exercé des pressions économiques, notamment sur certaines exportations arméniennes, et a accompagné la campagne d’opérations d’influence et de désinformation en faveur de Samvel Karapetyan, milliardaire disposant de la nationalité russe.
L’Azerbaïdjan a également émis des menaces envers les électeurs arméniens au cas où ceux-ci choisiraient de voter en faveur de l’opposition.
Bref, il s’agit probablement de l’élection la plus géopolitique de l’histoire récente de l’Arménie.
Après ce scrutin, faut-il parler d’un basculement définitif d’Erevan vers l’Occident ?
A. K. : Ce serait exagéré. L’Arménie reste très dépendante de la Russie sur les plans énergétique, économique et commercial. Cette dépendance s’est même renforcée depuis le début de la guerre en Ukraine, notamment du fait des flux financiers et humains venus de Russie, et aussi parce que l’Arménie a été utilisée par la Russie pour s’approvisionner en certains biens placés sous sanctions occidentales. Évidemment, l’Arménie fait formellement toujours partie du traité de sécurité collective, l’OTSC, dominé par la Russie, bien que sa participation y soit gelée, et maintient une base militaire russe sur son territoire.
À lire aussi : Erevan, le « refuge » russe au cœur de l’Arménie
Pachinian, je l’ai dit, a adopté pendant la campagne un discours très ambitieux sur le rapprochement avec l’UE mais, malgré l’enthousiasme des uns et des autres, aussi bien à Bruxelles qu’à Erevan, chacun comprend la réalité de la dépendance structurelle de l’Arménie à la Russie et des avantages qu’elle tire de sa participation à l’Union eurasiatique. L’UE ne peut pas, à ce stade, remplacer de manière durable la Russie, pas plus qu’elle ne peut parer aux pressions économiques que cette dernière pourrait exercer sur Erevan. Il est donc probable qu’à la suite de ces élections Pachinian retrouve un ton plus pragmatique face à Moscou.
La Russie, malgré sa réticence à reconnaître l’issue du scrutin – il n’y a toujours pas eu de déclaration officielle à cet effet –, n’envisageait pas sérieusement la perspective d’une victoire de l’opposition. Malgré l’asymétrie de cette relation, la Russie n’a pas non plus d’intérêt à pousser le gouvernement arménien dans ses retranchements en renforçant les sanctions. Elle risquerait de compromettre définitivement ses liens avec l’Arménie, ce qui la fragiliserait davantage dans la région.
On a beaucoup parlé d’Arméniens venus en masse de Russie pour voter, supposément en faveur de Karapetyan…
A. K. : Rappelons d’abord que la diaspora arménienne est considérable : environ 8 millions à 10 millions de personnes vivent à l’étranger, pour environ 3 millions d’habitants en Arménie même. Les principaux pôles diasporiques sont la Russie, les États-Unis et la France. Or le système arménien a une particularité : les citoyens vivant à l’étranger ne peuvent pas voter depuis leur pays de résidence. Ils doivent se déplacer en Arménie.
Des appels à la mobilisation ont effectivement circulé au sein de la diaspora russe, mais rien ne permet d’affirmer que cela a eu un impact déterminant sur le résultat.
Pourquoi les États-Unis s’intéressent-ils autant au dossier arméno-azerbaïdjanais ?
A. K. : L’enjeu principal est la question du corridor reliant l’Azerbaïdjan à son exclave du Nakhitchevan par le sud de l’Arménie.
Ce projet trouve son origine dans l’accord de cessez-le-feu de novembre 2020. À l’époque, la sécurité du corridor devait être assurée par la Russie.
Après la disparition du Haut-Karabakh arménien en 2023, cette formule est devenue politiquement inacceptable pour Erevan, alors que l’Azerbaïdjan continuait d’exiger un passage extraterritorial.
Les États-Unis ont alors proposé un nouveau mécanisme de supervision, présenté lors des négociations organisées à Washington en 2025. Ce projet, surnommé « la route Trump pour la paix et la sécurité internationale », vise à débloquer les communications régionales et à faciliter une normalisation entre l’Arménie, l’Azerbaïdjan et la Turquie, en octroyant des droits aux États-Unis pour le développement et le contrôle de la route, tout en préservant formellement la souveraineté de l’Arménie sur ce territoire.
Toutefois, sa mise en œuvre dépend toujours de la signature d’un traité de paix entre Erevan et Bakou. Et ce corridor longe l’Iran. Or, Téhéran voit d’un mauvais œil toute évolution susceptible de renforcer durablement l’influence américaine dans le Caucase du Sud, surtout au vu du contexte actuel où les États-Unis et Israël, un allié militaire de l’Azerbaïdjan, sont en guerre avec l’Iran.
La campagne électorale et le scrutin ont-ils été parfaitement démocratiques ?
A. K. : L’opposition conteste les résultats, après avoir passé la campagne à contester le placement en résidence surveillée de Karapetyan, mais les observateurs internationaux n’ont pas relevé d’irrégularités majeures dans le déroulement du scrutin. Cependant, plusieurs développements inquiètent.
Depuis plusieurs années, les pratiques du gouvernement arménien face à ses opposants témoignent d’un recul démocratique. Celles-ci sont souvent justifiées au nom de la lutte nécessaire contre l’influence russe. Dans les faits, cela a consolidé la mainmise du gouvernement sur le pouvoir judiciaire, qui a engagé un certain nombre de poursuites controversées contre des membres du clergé, des blogueurs ou des opposants.
Après la perte du Haut-Karabakh, les réfugiés arméniens sont également régulièrement ciblés par le premier ministre et son entourage, qui en font des boucs émissaires de la corruption qui a caractérisé les gouvernements précédents et une cinquième colonne de la Russie. Ces discours versent souvent dans le stigmate voire, comme le pointent certains observateurs, dans le discours de haine.
Lors de la campagne législative, Pachinian en a même fait son fer de lance, en mettant en scène ses accès de colère contre les ressortissants du Karabakh ou toute autre personne lui reprochant sa responsabilité dans la perte de la région. Il a traité les réfugiés de « fuyards », imitant leur accent de manière dénigrante et proférant des menaces : ce style agressif, qui suscite certes l’approbation d’une partie de son électorat, l’a probablement desservi.
Plus récemment, l’arrestation d’un militant originaire du Haut-Karabakh, pourtant connu pour son engagement anticorruption et sans lien avec la Russie, a suscité de nombreuses critiques au sein de la société civile.
Ces développements mettent en péril la promesse démocratique formulée depuis la révolution de velours de 2018, mais la société civile arménienne a encore un potentiel de mobilisation, et il s’agira d’être vigilant quant à sa capacité de faire face aux défis posés à la fois par un gouvernement qui empiète de plus en plus sur les contre-pouvoirs et par une opposition parlementaire qui n’offre pas de voie démocratique. À travers mes propres observations et au vu des différents sondages d’opinion, il apparaît que les Arméniens sont en demande d’une troisième voie.
Propos recueillis par Grégory Rayko.
Anita Khachaturova a reçu des financements de FNRS-FRESH, ULB
14.06.2026 à 10:23
Le Japon attire toujours plus d’étrangers, mais l’opinion publique se durcit
Peter Chai, Research Associate, Faculty of Political Science and Economics, Waseda University
Texte intégral (1634 mots)
Alors que le vieillissement démographique pousse le Japon à recourir davantage à la main-d’œuvre étrangère, deux tiers des Japonais souhaitent renforcer les contrôles et exigent un respect strict des normes et coutumes nationales.
Le Japon connaît aujourd’hui un nombre historiquement élevé d’étrangers sur son territoire. Alors que sa population diminue et que sa main-d’œuvre vieillit, le recours aux travailleurs étrangers a atteint des niveaux records.
Parallèlement, le nombre de touristes internationaux a lui aussi atteint des sommets inédits, transformant le quotidien dans de nombreuses régions du pays. Le Japon rivalise désormais avec, et dépasse parfois, Bali parmi les destinations de vacances préférées des Australiens.
Pourtant, malgré l’élargissement des dispositifs permettant le recours à la main-d’œuvre étrangère et l’installation durable de migrants au cours des deux dernières décennies, les gouvernements successifs ont évité de présenter le Japon comme une société d’immigration. Ils se sont également montrés réticents à adopter des politiques plus larges d’intégration des immigrés et d’inclusion sociale.
Mais avec la récente hausse du nombre d’étrangers, ces questions sont passées du statut de sujet marginal de politique publique à celui d’enjeu de débat à part entière. Que pensent donc réellement les Japonais de cette évolution ?
Des différences générationnelles marquées
Une enquête représentative menée auprès de 1 500 adultes japonais, juste après les élections législatives de février 2026, met en lumière la manière dont les Japonais perçoivent les étrangers. Près des deux tiers des personnes interrogées se déclarent favorables à un encadrement plus strict des achats de terrains par des étrangers et estiment que ces derniers doivent se conformer aux règles et aux coutumes japonaises. Ces opinions restrictives se retrouvent dans la plupart des catégories sociales, quels que soient le sexe, le niveau d’éducation ou le revenu.
La principale exception concerne l’âge : les jeunes générations expriment généralement des attitudes plus ouvertes et plus tolérantes à l’égard des étrangers. L’afflux récent d’étrangers — qu’il s’agisse de travailleurs ou de touristes — semble ainsi entraîner une évolution des perceptions au sein de la société japonaise.
Les élections sénatoriales de 2025 ont marqué un tournant. Le parti nationaliste Sanseito, qui avait fait de la restriction de l’immigration le cœur de son programme, a obtenu un résultat remarquable, remportant 14 sièges sur la base d’un slogan résolument tourné vers le « Japan First » (« le Japon d’abord »).
Ce résultat a montré que des positions explicitement hostiles à l’immigration pouvaient recueillir un soutien électoral significatif. Il a également accru la pression sur les partis traditionnels, contraints de traiter cette question de manière plus directe. Cette dynamique s’est prolongée lors des élections législatives de 2026. Le Liberal Democratic Party (LDP), dirigé par la Première ministre Sanae Takaichi, a remporté une victoire écrasante tout en durcissant sa position sur les questions migratoires.
Le gouvernement a notamment renforcé les critères d’accès à la résidence permanente et à la naturalisation, ainsi que resserré la réglementation concernant les achats de terrains par des étrangers.
Dans ce contexte politique, il devient de plus en plus important de comprendre comment les citoyens japonais perçoivent les étrangers, ainsi que les identités et les valeurs qui façonnent ces perceptions. L’enquête réalisée après les élections apporte des éléments de réponse particulièrement opportuns.
Mon analyse des données met en évidence un large consensus au sein de la population japonaise, toutes catégories sociales confondues. Interrogés sur l’opportunité de renforcer la réglementation des achats de terrains par des ressortissants étrangers ou des capitaux étrangers, 66,5 % des répondants se sont déclarés « d’accord » ou « plutôt d’accord » avec cette mesure.
Lorsqu’on leur demande si les ressortissants étrangers devraient accorder la plus haute priorité au respect des règles, des usages et des coutumes japonaises, 62,9 % des répondants se déclarent « d’accord » ou « plutôt d’accord ». Moins de 7 % expriment leur désaccord sur l’une ou l’autre de ces questions.
Ces résultats se retrouvent dans l’ensemble des groupes démographiques. Les diplômés de l’université et ceux du lycée expriment des opinions tout aussi restrictives ; les hommes et les femmes affichent des attitudes presque identiques ; et les personnes aux revenus élevés ne se montrent pas plus tolérantes que celles disposant de revenus plus modestes.
Comme indiqué plus haut, l’âge constitue toutefois une exception importante à ce consensus. Les jeunes Japonais se montrent sensiblement plus ouverts à l’égard des étrangers que leurs aînés. Cette différence laisse penser que les attitudes envers les étrangers au Japon pourraient évoluer lentement au fil des générations.
Le rôle de l’appartenance politique
Les préférences partisanes influencent dans une certaine mesure les attitudes à l’égard des étrangers. Les électeurs du parti nationaliste Sanseito expriment ainsi les opinions les plus restrictives sur les deux questions étudiées, tandis que les électeurs de l'Alliance centriste pour la réforme se montrent les moins restrictifs.
Toutefois, les différences entre électorats portent davantage sur l’intensité de ces opinions que sur leur existence même : quelle que soit leur orientation politique, la plupart des groupes soutiennent, à des degrés divers, les mesures restrictives évoquées.
L’enquête comportait également des questions destinées à mesurer l’attachement aux valeurs traditionnelles — c’est-à-dire le respect de l’autorité et des normes sociales — ainsi que les valeurs autoritaires, qui renvoient à l’acceptation de la contrainte et du recours à la force.
Les valeurs traditionnelles varient peu selon l’âge, le sexe, le niveau d’éducation ou le revenu. En revanche, on trouve des différences marquées selon les générations sur la question des valeurs autoritaires : les jeunes se révèlent paradoxalement plus autoritaires.
Ce constat fait écho à une enquête menée auprès de collégiens de la région métropolitaine de Tokyo. La proportion de ceux estimant que « les personnes qui enfreignent les règles doivent être sévèrement punies » est passée de 59 % en 2018 à 79 % en 2025.
Par ailleurs, les électeurs du Parti libéral-démocrate (PLD) obtiennent les scores les plus élevés tant en matière de valeurs traditionnelles que de valeurs autoritaires. Cela correspond à la position historique du parti, principal vecteur du conservatisme dans la vie politique japonaise de l’après-guerre.
Les valeurs traditionnelles comme les valeurs autoritaires sont fortement corrélées aux attitudes défavorables aux étrangers. Les répondants qui se montrent plus critiques à l’égard de l’autorité, moins attachés aux normes sociales et moins enclins à accepter le recours à la contrainte tendent à exprimer des opinions plus ouvertes envers les étrangers.
Un Japon en pleine évolution
Mon analyse met en lumière une société où les attitudes restrictives à l’égard des étrangers sont largement répandues, marquées par des clivages générationnels et étroitement liées à des valeurs traditionnelles et autoritaires. Elle révèle une tension que les responsables politiques japonais, comme l’opinion publique, peinent à résoudre : la nécessité économique de recourir davantage à la main-d’œuvre étrangère est largement reconnue, mais elle se heurte à des conceptions profondément ancrées de la cohésion culturelle et de l’homogénéité ethnique.
De futures recherches pourraient affiner ce constat en distinguant plus clairement les perceptions des Japonais à l’égard des touristes étrangers, des travailleurs temporaires et des résidents de long terme.
La manière dont la population japonaise perçoit l’augmentation du nombre d’étrangers continuera de peser sur les prochaines échéances électorales. De même, les réponses apportées par le gouvernement constitueront un cas d’étude important pour les sociétés voisines d’Asie de l’Est, elles aussi confrontées à des tensions comparables entre besoins économiques et préoccupations identitaires.
Peter Chai ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.06.2026 à 10:05
Lisztomanie : comment Franz Liszt est devenu la première idole de masse de l’histoire moderne
Timothy McKenry, Professor of Music, Australian Catholic University
Texte intégral (2069 mots)

#/media/File:Liszt_(Lehmann_portrait)_(cropped).jpg){kind=link}
Bien avant la Beatlemania, les concerts du pianiste hongrois Franz Liszt suscitaient des scènes d’adoration qui fascinaient autant qu’elles inquiétaient. Mais derrière les récits d’hystérie collective se cache une réalité plus complexe, faite de virtuosité musicale, de célébrité naissante et de préjugés sociaux.
En 1844, Berlin fut frappée par une fièvre culturelle que les critiques baptisèrent « Lisztomania ». Le poète allemand Heinrich Heine forgea ce terme après avoir été témoin de l’accueil presque délirant réservé au pianiste et compositeur hongrois Franz Liszt dans les salles de concert à travers l’Europe.
Une gravure largement diffusée dans les années 1840 en a fixé l’image. On y voit des femmes défaillir ou s’évanouir, tandis que d’autres lancent des fleurs vers la scène. Les hommes eux aussi semblent saisis par le magnétisme du pianiste — ou peut-être par la réaction qu’il suscite chez les femmes.

{kind=link}
Ces représentations caricaturales, associées aux critiques souvent hostiles de ses contemporains, continuent peut-être de façonner notre mémoire culturelle de Liszt. Il est souvent présenté non pas simplement comme un musicien, mais comme la première célébrité moderne à avoir déclenché une hystérie de masse.
Que se passait-il lors des concerts de Liszt ?
Nous savons énormément de choses sur les centaines de concerts donnés par Liszt dans les années 1830 et 1840, grâce aux comptes rendus, aux critiques, aux lithographies ainsi qu’aux lettres qu’il a lui-même écrites à l’époque. Ses programmes mêlaient des œuvres des grands compositeurs à ses propres réinterprétations inventives de morceaux déjà familiers au public. Des pièces de virtuosité mettaient également en valeur sa maîtrise exceptionnelle du piano.
La Sonate « Appassionata » ou la Sonate « Pathétique » de Beethoven pouvaient ainsi côtoyer la « Fantaisie chromatique et fugue » de Bach, interprétée dans le style extrêmement expressif de Liszt. Franz Schubert était représenté à travers des lieder tels qu’« Erlkönig » et « Ave Maria », que Liszt avait adaptés pour piano seul.
Liszt puisait également dans les opéras les plus populaires de son époque. Ses « Réminiscences de Norma » (Bellini) et ses « Réminiscences de Don Juan » (Mozart) transformaient des mélodies familières en vastes fantaisies musicales. Ces œuvres exigeaient à la fois une virtuosité exceptionnelle et une grande sensibilité lyrique.
À travers ces compositions, Liszt créait de véritables architectures symphoniques au piano. Il tissait plusieurs thèmes en des drames musicaux cohérents, bien au-delà de simples pot-pourris de mélodies célèbres.
Liszt concluait souvent ses concerts par le très populaire « Grand Galop Chromatique ». Ce morceau de rappel mettait en évidence son sens du spectacle et sa parfaite compréhension des attentes du public.
Comme l’écrivait le critique Paul Scudo en 1850 :
« Il est le maître souverain de son piano ; il en connaît toutes les ressources ; il le fait parler, gémir, pleurer et rugir sous ses doigts d’acier, qui distillent le fluide nerveux comme la pile de Volta distille le fluide électrique. »
La réaction de son public semblait régulièrement dépasser les conventions de la bienséance qui régissaient alors les concerts et la vie mondaine.
Artiste et homme de spectacle
Dans une série d’essais publiés en 1835 sous le titre De la situation des artistes, Liszt présente les musiciens tels que lui comme des « artistes du son », condamnés à être incompris. Ils ont néanmoins, selon lui, une mission essentielle : « révéler, exalter et diviniser toutes les tendances de la conscience humaine ».
Dans le même temps, une lettre adressée à George Sand montre que Liszt était parfaitement conscient des réalités pratiques de l’organisation des concerts ainsi que des pièges de la célébrité. Il plaisante en écrivant que Sand serait surprise de voir son nom affiché en lettres capitales sur une affiche de concert parisienne. Liszt reconnaît avec amusement l’audace qu’il y a à faire payer les places cinq francs au lieu de trois, savoure les critiques élogieuses et souligne la présence d’aristocrates et de membres de la haute société parmi son public.
Il décrit même une scène couverte de fleurs et évoque l’attention féminine suscitée après l’une de ses représentations, même si celle-ci semblait davantage dirigée vers sa partenaire de duo. Cette lettre révèle un artiste lucide sur lui-même, tour à tour amusé et ambivalent face au spectacle qui accompagne son art.
Oui, Liszt jouait avec son statut de célébrité, mais il prenait aussi manifestement ses distances avec cette image. Il était conscient que la dimension sérieuse de son art risquait d’être éclipsée par la version mondaine et sensationnaliste de sa personnalité. Une grande partie de la critique musicale de l’époque fonctionnait précisément de cette manière. Elle relevait souvent davantage du commérage que de l’analyse artistique, nombre de chroniqueurs se disant scandalisés par l’intensité des réactions suscitées par les prestations de Liszt.
Commérages et plumes acérées
Tout le monde ne partageait pas l’enthousiasme du public de Liszt. Certains critiques s’en prenaient aussi bien à son jeu pianistique qu’à l’admiration qu’il suscitait. En 1842, un auteur écrivant sous le pseudonyme de « Beta » décrivait l’effet combiné des prestations de Liszt et des réactions du public en ces termes :
« L’effet produit par son jeu bizarre, dépourvu de substance et d’idées, sensuellement excitant, saturé de contrastes et fragmenté, ainsi que par l’enthousiasme maladif qu’il suscite, constitue un signe affligeant de la stupidité, de l’insensibilité et du vide esthétique du public. »
De même, le poète allemand Heinrich Heine suggérait que le style d’interprétation de Liszt relevait d’une mise en scène soigneusement calculée, destinée à provoquer une forme de frénésie collective :
« Par exemple, lorsqu’il imitait un orage au pianoforte, nous voyions les éclairs se refléter sur son visage ; ses membres étaient secoués comme par une tempête, et ses longues mèches de cheveux semblaient ruisseler, pour ainsi dire, sous l’averse qu’il représentait. »
Ces récits, parmi beaucoup d’autres, ont contribué à forger la mythologie de la « Lisztomanie », présentant les femmes de son public comme irrationnelles et sujettes à l’hystérie.
Le terme de « manie » véhiculait une connotation médicale et pathologisante, présentant l’enthousiasme suscité par Liszt comme une forme de maladie culturelle. Les lithographies, les caricatures et les récits anecdotiques ont amplifié cette représentation, montrant des spectateurs s’évanouissant, des fleurs lancées sur la scène et des foules adoptant des comportements jugés incompatibles avec les règles de la bienséance.
Ces témoignages ne sont toutefois pas entièrement fiables. On y retrouvait des préjugés, des jugements moraux et une volonté manifeste de dramatiser les événements. Les concerts de Liszt se situaient ainsi à la croisée de plusieurs phénomènes : un art et une virtuosité hors du commun, le spectacle offert par les réactions du public, et un récit médiatique filtré par les commérages, les exagérations et les paniques morales teintées de considérations de genre.
À ce titre, la « Lisztomanie » préfigure les mécanismes de la célébrité moderne. (Elle a également inspiré ce qu’un critique a qualifié de « film historique le plus embarrassant jamais réalisé ».)
De la même manière que des artistes comme les Beatles, Beyoncé ou Taylor Swift suscitent une ferveur intense tout en faisant l’objet de campagnes de dénigrement et de traitements sensationnalistes, la célébrité de Franz Liszt était indissociable à la fois de l’admiration qu’il inspirait et des attaques venimeuses de ses détracteurs.
Timothy McKenry ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.06.2026 à 14:50
Coupe du monde 2026 : chaleur, altitude, pollution, décalage horaire… la victoire ne dépendra pas seulement du niveau de jeu
Valérie Bougault, Maître de Conférences, Université Côte d’Azur
Texte intégral (3010 mots)
La Coupe du monde masculine de football 2026 ne se jouera pas uniquement sur le terrain, mais dépendra aussi de la capacité des équipes à anticiper et à gérer les défis environnementaux. Les stratégies fondées sur des preuves scientifiques seront essentielles pour protéger la santé des joueurs et maximiser leurs performances.
La Coupe du monde masculine de football 2026, organisée conjointement par les États-Unis, le Mexique et le Canada, est une édition historique à plus d’un titre.
Jamais une Coupe du monde n’avait combiné autant de facteurs de stress environnementaux. Ainsi, 16 villes hôtes s’étendent sur environ 4 300 km d’est en ouest et 4 000 kilomètres du nord au sud. Parmi elles, 14 devraient connaître des températures moyennes comprises entre 19,1 °C et 32,7 °C, tandis que les matchs se dérouleront en altitude à Guadalajara (1 566 mètres) et à Mexico (2 240 mètres).
Les déplacements fréquents et l’afflux massif de spectateurs lors de mégaévénements augmentent aussi les risques de transmission de maladies infectieuses, sans compter l’impact des différents polluants et allergènes entre les lieux d’origine des joueurs et les villes hôtes.
Face à ces enjeux, un groupe de chercheurs a récemment publié dans Sports Medicine une analyse des défis environnementaux attendus ainsi que des recommandations à destination des équipes.
Voici ce qu’il faut en retenir.
La chaleur extrême : le principal ennemi
La situation. L’analyse des relevés des années passées nous enseigne qu’aux dates de la future coupe du monde, 14 des 16 villes hôtes dépassent la température au thermomètre-globe mouillé (ou température WBGT) de 28 °C lors des mois de juin et juillet. Parmi elles, 6 atteignent un WBGT entre 30 et 35 °C. Un quart des villes dépassent le seuil de la FIFA de 32 °C (WBGT) et 25 % excèdent la limite d’annulation des efforts en extérieur proposée par l’ACSM, pour les personnes acclimatées (ce taux monte à 44 % pour les personnes non acclimatées).
Les conséquences. Les températures WBGT élevées augmentent la température corporelle centrale des joueurs. Des études ont révélé que, dans de telles conditions, elle peut dépasser les 40 °C en jeu ! Cette augmentation réduit les performances physiques et cognitives des joueurs et accroît le risque de coups de chaleur.
Lors de la Coupe du monde 2014 au Brésil, les matchs joués à plus de 28 °C de température humide (WBGT) ont montré une baisse de l’intensité de jeu avec une diminution de la distance parcourue à haute intensité et du nombre de sprints et une modification des tactiques : consciemment ou non, les joueurs privilégient les passes plus sûres et un rythme plus lent. Résultat : moins de duels et de pressing et une augmentation de 25 % de temps de possession de ballon en plus.
L’exercice en forte chaleur augmente le stress physiologique, les pertes hydriques et électrolytiques ainsi que l’utilisation des glucides, ce qui expose les joueurs – acclimatés ou non – à une sudation excessive. La déshydratation devient alors un facteur majeur de risque, altérant fonctions cardiovasculaires, thermorégulation, capacités physiques et cognition.
Les mesures prévues. La FIFA prévoit des pauses de trois minutes pour s’hydrater et se refroidir aux alentours des 22ᵉ et 67ᵉ minutes de jeu, si la température WBGT est supérieure à 32 °C. Le report ou l’annulation du match de football sont laissés à la discrétion de l’organisateur local. Quelques soient les conditions environnementales, cette pause refroidissement sera adoptée pour tous les matchs de cette Coupe du monde 2026.
Par ailleurs, afin de mieux tolérer la chaleur et diminuer son impact sur la performance, des stratégies d’acclimatation fondées sur la littérature scientifique sont recommandées pour les joueurs. La stratégie optimale d’acclimatation à la chaleur repose idéalement sur un protocole long consistant en 10 à 15 jours d’exposition quotidienne à la chaleur avec exercice, visant une température centrale supérieure ou égale à 38,5 °C, une température cutanée supérieure ou égale à 35 °C et une sudation importante (conditions nécessaires aux adaptations sudorales et cardiovasculaires).
Toutefois, le calendrier de la Coupe du monde 2026, très proche de la fin des saisons européennes, rend ce protocole difficile à appliquer. Des stratégies à court terme (environ cinq jours) peuvent néanmoins réduire la température corporelle et la fréquence cardiaque, et préserver la performance dans la chaleur, comme observé chez des joueurs semi-professionnels.
Arriver plus tôt sur le lieu du tournoi peut favoriser une acclimatation naturelle. Une alternative est l’acclimatation passive (sauna, immersion chaude, chambre thermique), efficace lorsqu’elle est réalisée au moins trente minutes après l’entraînement, pendant six jours consécutifs
Enfin, les stratégies d’hydratation doivent être instaurées dès l’arrivée au camp de base et maintenues tout au long du tournoi, avec un début d’hydratation plusieurs heures avant le match et des apports enrichis en glucides et électrolytes pour compenser pertes et utilisation accrue des substrats.
L’altitude : un avantage ou un handicap ?
La situation. La Coupe du monde de football 2026 comprendra neuf matchs disputés à altitude modérée au Mexique, à Guadalajara (1 566 mètres ; pression partielle en oxygène atmosphérique ≈ 133 mmHg) et à Mexico (2 240 mètres ; ≈ 121 mmHg) : 4 matchs dans le groupe A, 2 dans le groupe K, 1 dans le groupe H, 1 lors des seizièmes de finale et 1 lors des huitièmes de finale.
Les conséquences. Les échanges d’oxygène au niveau pulmonaire sont essentiellement régis par la pression partielle en oxygène. Or, celle-ci est réduite par l’altitude, ce qui diminue la capacité aérobie et retarde la récupération. Conséquence : les schémas locomoteurs sont modifiés.
Ainsi, lors de la Coupe du monde 2010, qui s’était déroulée en Afrique du Sud, les matchs disputés au-dessus de 1 200 mètres ont entraîné une réduction de 3 à 9 % de la distance totale parcourue et jusqu’à 21 % des courses à haute vitesse, particulièrement chez les milieux de terrain, en raison d’une fatigue neuromusculaire accrue, d’un ajustement d’allure et de stratégies tactiques moins efficaces.
À l’inverse, la moindre densité de l’air peut favoriser les sprints et modifier l’aérodynamique du ballon : des analyses historiques de la FIFA montrent qu’une différence de 1 000 mètres d’altitude confère à l’équipe locale un avantage d’environ un demi-but, et que les équipes basées entre 950 et 1 700 mètres lors de la Coupe du monde 2010 ont doublé leurs chances de victoire face à des équipes venant du niveau de la mer lors de matchs disputés entre 1 170 et 1 390 mètres.
Les équipes acclimatées à l’altitude ont également marqué davantage en seconde mi-temps dans les stades les plus élevés.
Dans ce contexte, la mise en place de plans d’entraînement individualisés et de stratégies adaptées aux postes est indispensable pour atténuer les contraintes physiologiques et tactiques liées à l’altitude et maintenir la performance lors des matchs concernés.
Les mesures prévues. L’entraînement en altitude améliore la capacité de l’organisme à répondre à l’entraînement. Dans ces conditions, le corps fabrique plus d’hémoglobine. L’augmentation de la masse d’hémoglobine et de la consommation maximale d’oxygène (VO₂ max) améliore le transport de l’oxygène et la capacité aérobie.
Des microcycles courts et intensifs d’entraînement de sprints répétés en chambre hypoxique (dans ces pièces, aussi appelées chambres d’altitude, le taux d’oxygène dans l’air est artificiellement maintenu à un niveau aussi bas qu’en haute altitude) peuvent également induire des adaptations physiologiques et neuromusculaires positives, améliorant la condition physique et la performance au niveau de la mer.
Les méthodes traditionnelles d’entraînement en altitude comprennent les approches dites « vivre en altitude, s’entraîner en altitude » (Live High–Train High, LHTH) et « vivre en altitude, s’entraîner en basse altitude » (Live High–Train Low, LHTL). La méthode LHTH consiste à vivre et à s’entraîner en altitude, généralement entre 1 600 et 2 500 mètres, pendant deux à quatre semaines. Cependant, pour les équipes participant à la Coupe du monde, sa faisabilité est limitée par les contraintes temporelles évoquées précédemment.
À l’inverse, la méthode LHTL est plus flexible et est largement considérée comme la stratégie de référence en matière de préparation à l’altitude. Les travaux scientifiques montrent 10 à 14 jours de LHTL permettent des gains de 3 à 4 % de masse d’hémoglobine, y compris chez des joueurs présentant déjà des valeurs de base élevées, avec des améliorations significatives des performances spécifiques au football.
Une troisième méthode, dite « vivre en basse altitude – s’entraîner en altitude » (Live Low–Train High, LLTH) constitue une stratégie d’entraînement en altitude pragmatique, rentable et particulièrement compatible avec les contraintes de préparation des joueurs en vue de la Coupe du monde 2026, comparativement aux approches LHTH ou LHTL.
Enfin, la méthode « vivre en altitude et s’entraîner en basse altitude et en altitude » (Live High–Train Low and High, LHTL + H) combine les bénéfices aérobies de la LHTL avec les adaptations anaérobies et neuromusculaires induites par la LLTH. Cette approche, qui a gagné en popularité, constitue une stratégie efficace de préparation prétournoi, mais les contraintes temporelles propres à la Coupe du monde 2026 rendent probablement son application difficile.
Soulignons que tous ces bénéfices peuvent être renforcés par le développement d’une plus grande résilience psychologique acquise dans des environnements exigeants, préparant mieux les joueurs aux contraintes des compétitions internationales disputées à basse altitude ou proches du niveau de la mer.
Pollution et allergènes : des ennemis invisibles
La situation. Les 16 villes hôtes de la Coupe du monde 2026 exposeront les équipes à une grande diversité de polluants atmosphériques et d’allergènes saisonniers (pollens). En outre, on sait que les mégaévénements comme la Coupe du monde accentuent les impacts environnementaux, y compris sur la qualité de l’air mesurée et perçue.
Étant donné que la Coupe du monde 2026 se déroulera en été, des concentrations élevées d’ozone (O₃) sont attendues, en raison des réactions photochimiques entre les oxydes d’azote, les composés organiques volatils, provenant essentiellement du trafic automobile et des activités industrielles, ainsi que des effets de l’ensoleillement.
Les particules fines, en particulier celles de diamètre inférieur à 2,5 μm (PM2,5), pourraient également rester le polluant dominant dans certaines villes. L’ouest des États-Unis et du Canada, notamment Los Angeles, San Francisco, Seattle et Vancouver, ont en effet connu ces dernières années des incendies de forêt sans précédent, entraînant une forte dégradation de la qualité de l’air observée et prévue. Le niveau de risque y est particulièrement élevé.
En cas d’incendies de grande ampleur, l’ensemble des villes hôtes de la Coupe du monde 2026 pourrait être affecté, environ 54 % de la fumée présente aux États-Unis provenant des régions occidentales du pays.
Les conséquences. Des revues systématiques de la littérature scientifique et des méta-analyses récentes confirment un effet significatif de l’ozone sur les symptômes respiratoires (essentiellement la toux ou la difficulté à prendre une grande inspiration), la fonction pulmonaire et la performance physique, y compris spécifique au football.
Bien que la qualité des études dans ce domaine soit variable, certaines données issues du football de haut niveau suggèrent clairement que la dégradation de la qualité de l’air peut altérer la performance, et que ces effets ne peuvent être totalement compensés par le haut niveau de compétence des joueurs d’élite. En outre, ces effets surviennent même à des niveaux modérés de dégradation de la qualité de l’air (indice AQI compris entre 51 et 100).
À lire aussi : Comment la pollution atmosphérique impacte la pratique sportive
Une augmentation des concentrations de particules PM10 et d’ozone a été associée à une baisse des performances lors de tests physiques (temps sur sprint de 30 mètres, capacité de changement de direction) et techniques (via des outils d’évaluation spécifiques au football), tandis qu’une élévation du dioxyde d’azote (NO₂) est liée à une altération des performances cognitives, notamment des fonctions exécutives des joueurs (autrement dit, les fonctions influant sur leur vitesse, leur temps de réaction, ou le nombre d’erreurs qu’ils commettent).
D’autres études menées en situation de match, dans des environnements fortement pollués, ont révélé une réduction de la distance totale parcourue, une diminution du nombre de courses à haute intensité, des sprints plus lents, une baisse de la vitesse et de la précision lors des tâches techniques, incluant un nombre de passes par match plus faible, quel que soit le polluant impliqué.
Les joueurs venant de régions peu polluées sont souvent plus sensibles que ceux habitués à ces environnements, ce qui peut désavantager les équipes visiteuses lors d’un tournoi international comme la Coupe du monde 2026.
Les mesures prévues. Il n’existe pas vraiment de stratégie d’adaptation pour lutter contre les effets de la pollution. S’entraîner ou jouer lorsque la qualité de l’air se dégrade n’est jamais anodin, même pour des sportifs de haut niveau.
Dans ce contexte, les recommandations de santé publique déjà discutées restent pleinement pertinentes : surveiller la qualité de l’air en temps réel, tenir compte des niveaux de pollens et éviter, lorsque cela est possible, les périodes et lieux les plus pollués pour l’entraînement. Ces stratégies ne sont pas toujours applicables dans une compétition majeure, mais elles peuvent guider certaines décisions logistiques, comme ajuster les horaires d’entraînement ou anticiper l’arrivée sur site.
Chez les joueurs allergiques, une prise en charge individualisée est essentielle. Identifier les allergènes responsables et mettre en place des stratégies adaptées permet de limiter les symptômes et d’éviter que pollution, chaleur et allergies ne se cumulent. Dans un environnement où ces contraintes peuvent s’additionner, l’anticipation et l’adaptation restent les meilleurs moyens de protéger la santé des joueurs et de préserver leur performance.
En définitive, les vainqueurs de la Coupe du monde masculine de football 2026 pourraient bien être ceux qui auront le mieux préparé ces à-côtés, transformant des contraintes en opportunités. Une préparation rigoureuse et individualisée, combinée à une gestion proactive des risques, fera peut-être la différence entre une équipe qui survit et une équipe qui triomphe !
Valérie Bougault ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.06.2026 à 14:49
En Bolivie, les « cholitas futbolistas » jouent aussi le match de la représentation
Nayra Vacaflor, Maîtresse de conférences en sciences de l’information et de la communication, travaillant sur les représentations médiatiques et les pratiques numériques en contexte interculturel, à partir d’approches créatives de recherche, Université Bordeaux Montaigne
Texte intégral (1502 mots)
En Bolivie, les cholitas futbolistas gagnent en visibilité médiatique. Mais derrière ces images fascinantes, se jouent des enjeux de genre, d’indigénéité et de représentation.
À plus de 4 000 mètres d’altitude, sur les terrains poussiéreux d’El Alto à La Paz (Bolivie), une scène insolite se répète : des femmes en pollera, tenue traditionnelle andine, jouent au football. Surnommées cholitas futbolistas, leurs images circulent aujourd’hui largement dans les médias internationaux. Mais que dit réellement cette visibilité médiatique ?
Entre reconnaissance et folklorisation, ces figures révèlent les tensions qui traversent la représentation des identités autochtones.
Des terrains d’El Alto aux écrans du monde
La médiatisation à laquelle sont sujettes les cholitas futbolistas ne doit rien au hasard. Elle s’inscrit dans la logique de captation de l’attention propre aux médias contemporains. Le contraste visuel retient l’attention et devient un puissant levier narratif : des femmes en tenue traditionnelle jouent au football dans les paysages andins.
À titre d’exemple, en 2021, une vidéo publiée par The Guardian Football sur YouTube montre des cholitas escaladoras (alpinistes) jouant au football, sous un titre particulièrement accrocheur : « Bolivia’s Cholitas Climbers play football at 5,890m in the Andes. » Un reportage de CNN en Espagnol relaie ces images en insistant sur la dimension spectaculaire du lieu et de la pratique.
Ce regard médiatique ne s’est pas construit avec le football. Il s’inscrit dans une trajectoire plus longue : celle des cholitas luchadoras (catcheuses boliviennes) des années 2000, puis des cholitas escaladoras (grimpeuses), mises en lumière par le documentaire primé à plusieurs reprises Cholitas (2019), et dernièrement des cholitas skaters.
Ce succès a contribué à créer une forme de « matrice médiatique » : celle de la femme indigène en tenue traditionnelle accomplissant des performances physiques inattendues. Aujourd’hui, ce sont les cholitas futbolistas qui héritent de cette dynamique.
Les médias ne se contentent pas de montrer : ils sélectionnent, cadrent et construisent le sens. Comme l’ont montré les cultural studies des années 1960, la représentation médiatique est toujours une mise en forme du réel.
Ici, la circulation des images repose sur leur lisibilité immédiate : elles combinent genre, indigénéité et pratique sportive, ce qui rend la scène surprenante et incite à la partager.
Cette mise en visibilité repose sur un double standard : d’un côté, elle participe à rendre visibles des pratiques longtemps marginalisées ; de l’autre, elle accentue une esthétique de la différence, en insistant sur les marqueurs culturels (polleras, tresses, chapeaux) – au risque de simplifier les trajectoires sociales. On peut y voir l’expression d’un « regard colonial », qui fige la femme autochtone dans une altérité visuelle immédiatement identifiable. En se focalisant sur l’esthétique de la différence, les caméras risquent de figer ces actrices sociales dans un processus de folklorisation qui, comme le souligne la sociologue bolivienne Silvia Rivera Cusicanqui dans son ouvrage Colonialism and Ethnic Resistance in Bolivia (2008), rend les populations indigènes visibles tout en occultant les rapports de domination et les luttes qu’elles portent.
Un espace d’émancipation bien réel
Longtemps marginalisées et cantonnées aux sphères domestiques ou au commerce informel (gremialistas), les cholitas ont progressivement investi l’espace public urbain, notamment à La Paz et El Alto, dans un contexte de transformations sociales et politiques. Cette évolution fait écho à l’émergence de figures indigènes féminines dans les domaines publics et médiatiques, à l’image de Remedios Loza, la première femme aymara élue au Parlement bolivien. C’est dans ce mouvement plus large d’appropriation de l’espace public que s’inscrit aussi leur présence dans le champ sportif.
Contrairement à ce que pourraient laisser penser certaines représentations, ces pratiques ne surgissent pas dans un vide sportif. Le football féminin existe depuis plusieurs décennies en Bolivie, notamment à travers les ligas de barrio ou ligas zonales, ces ligues de quartier qui structurent les pratiques populaires. Les travaux de Juliane Müller montrent que le football, pour ces femmes, ne se réduit pas à un loisir. Il constitue un espace de sociabilité, de solidarité et d’organisation collective. Former une équipe permet de consolider des réseaux, parfois liés à des systèmes d’entraide économique et sociale comme le pasanaku – un système d’épargne collective traditionnel, largement pratiqué en Bolivie, notamment par des groupes de femmes, où chaque participante contribue régulièrement à une cagnotte commune, redistribuée à tour de rôle – et de renforcer des formes de reconnaissance collective.
Dans ce cadre, le football devient un outil de space-making (création d’espace). En investissant les terrains souvent monopolisés par les hommes, ces femmes produisent de nouveaux usages de l’espace urbain et redéfinissent les frontières du possible. Le terrain devient un espace de négociation identitaire et de légitimation sociale. Ainsi, les cholitas futbolistas ne sont pas seulement des figures médiatiques : elles sont des actrices sociales qui transforment les normes.
Une reconnaissance sous condition médiatique
La visibilité dont font l’objet les cholitas ne doit pas être interprétée comme une reconnaissance évidente. Les recherches sur le football féminin montrent que les femmes restent historiquement sous-représentées dans les médias sportifs, et que leur visibilité dépend souvent de leur capacité à incarner des figures singulières. Les cholitas futbolistas apparaissent comme un cas particulièrement révélateur : leur visibilité ne tient pas seulement à leur pratique sportive, mais à la manière dont celle-ci est mise en récit.
Elles deviennent visibles parce qu’elles se situent à l’intersection de plusieurs rapports de domination : genre, ethnicité et classe sociale, comme l’analyse le concept d’intersectionnalité développé par Kimberlé Crenshaw en 1989.
Cette hypervisibilité produit une forme de reconnaissance spécifique. Elle permet une circulation internationale, une valorisation symbolique et l’ouverture de nouveaux espaces d’expression, mais ne correspond pas nécessairement à une « reconnaissance sportive » au sens strict. Les cholitas ne sont pas seulement perçues comme des footballeuses, mais comme des figures exceptionnelles voire « exotiques ».
La sociologue mexicaine Rossana Reguillo souligne que la visibilité médiatique produit des subjectivités, fabriquant des figures socialement reconnaissables en sélectionnant certaines formes d’apparition plutôt que d’autres. Les cholitas futbolistas accèdent à la visibilité à travers des cadres qui rendent leur présence immédiatement lisible. Ainsi, la question n’est pas seulement de savoir si ces femmes sont reconnues, mais comment elles le sont, et à quelles conditions. Ce qui se joue ici dépasse le football : il s’agit de comprendre pourquoi certaines figures deviennent visibles, quand d’autres restent dans l’ombre.
Cette circulation numérique des images fait que les cholitas futbolistas incarnent un paradoxe : elles gagnent en visibilité tout en restant prises dans des cadres de représentation qui orientent la manière dont elles sont perçues.
Gooool (but) pour les cholitas, qui accèdent à de nouveaux espaces de reconnaissance. Pénalty pour les médias, qui en fixent les règles du jeu. Et si au fond, les deux se jouaient sur le même terrain ?
Nayra Vacaflor ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.06.2026 à 14:48
La communauté hispanique, moteur économique oublié du « soccer » aux États-Unis
Jonathan Leblanc, Doctorant au centre d’histoire culturelle des sociétés contemporaines (CHCSC), Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Texte intégral (1997 mots)
Qui fait réellement vivre le « soccer » aux États-Unis, pays où ce sport est moins populaire que plusieurs autres ? La réponse à cette question pointe systématiquement vers la communauté hispanique. Or, celle-ci n’a jamais vraiment été intégrée dans les structures de ce sport qu’elle pratique et regarde plus que n’importe qui d’autre.
Les Hispaniques (les personnes d’origine latino-américaine hispanophones résidant aux États-Unis) constituent aujourd’hui le deuxième groupe ethno-racial aux États-Unis : leur nombre est estimé à environ 67 millions de personnes, soit 20 % de la population du pays. Selon le Bureau du recensement, leur poids devrait passer à 28 % en 2060. Dans un marché sportif ultraconcurrentiel comme celui des États-Unis, où NBA (basket-ball), NFL (football américain), MLB (baseball), NHL (hockey sur glace) et MLS (soccer, terme employé pour désigner ce qui est appelé football partout ailleurs) se disputent l’attention des spectateurs, cette réalité a des conséquences économiques colossales.
En 2025, une étude conjointe de l’institut McKinsey et de la chaîne de télévision hispanophone Telemundo a chiffré l’impact des fans hispaniques dans l’économie sportive du pays : ils dépensent en moyenne 15 % de plus que les non-Hispaniques en billets, abonnements à des services de diffusion, produits dérivés et paris sportifs. Un chiffre d’autant plus frappant que les revenus médians de cette communauté restent largement inférieurs à ceux des Blancs américains. L’étude prévoit qu’ils représenteront 25 % de l’économie sportive américaine d’ici à 2035. L’avenir économique du sport professionnel aux États-Unis est donc en bonne partie hispanique.
NBCUniversal, groupe propriétaire de Telemundo, a bien intégré cette réalité en acquérant les droits de diffusion en espagnol de l’intégralité du Mondial 2026, soit 104 matchs (contre 64 en 2022). Mais un autre chiffre en dit long sur l’évolution des mentalités : lors de la Coupe du monde 2022, 38 % des spectateurs de ces chaînes ne parlaient pas espagnol. Comme le soulignait le New York Magazine à l’époque, « il n’y a rien de plus américain que de regarder le soccer en espagnol ».
Pour une partie des États-Uniens, suivre les matchs en espagnol est devenu une sorte de folklore culturel, une façon de consommer le football « à l’authentique », notamment pour entendre le légendaire « GOOOOOOOL » à chaque but. C’est révélateur en soi : on apprécie l’emballage culturel hispanique, on le consomme comme une expérience exotique, mais le fútbol reste, dans l’inconscient collectif, un sport d’immigrés.
Le « Tebbit test »
Cette communauté qui finance et regarde le foot plus que les autres ne s’identifie guère à l’équipe nationale des États-Unis, l’United States Men’s National Team (USMNT), et à la Major League Soccer (MLS, le championnat professionnel du pays, créé en 1993). Elle préfère largement la Liga MX (le championnat mexicain) et les sélections nationales de ses pays d’origine (Mexique, Salvador, Guatemala, Colombie).
Dans le débat politique états-unien, cette préférence est parfois perçue comme un signal problématique : les Hispaniques ne s’assimileraient pas, et ne seraient pas pleinement loyaux envers la bannière étoilée. Ces questionnements ne sont d’ailleurs pas propres aux seuls États-Unis. En Angleterre, le « Tebbit test » – du nom de Norman Tebbit, ministre conservateur sous Margaret Thatcher – posait dès 1990 la question suivante aux communautés sud-asiatiques : « Quelle est votre équipe de cricket favorite ? » Répondre l’Inde ou le Pakistan était censé révéler un manque d’attachement à l’Angleterre, et donc un défaut d’intégration.
Ce raisonnement mélange deux réalités : l’attachement culturel et l’appartenance nationale. L’attachement d’un Hispanique à une autre équipe reflète une histoire personnelle construite bien avant son arrivée aux États-Unis. On supporte l’équipe que l’on a appris à aimer enfant, dans son pays d’origine. Celle que son père immigrant a transmise comme un héritage – affectif autant que culturel.
Le fútbol joue d’ailleurs un rôle social considérable au sein des communautés hispaniques : les ligues organisées par les associations communautaires, les Églises communautaires ou les regroupements de quartier constituent de véritables espaces de sociabilité et d’intégration donnant des occasions de maintenir des liens culturels et identitaires forts, ce qui est largement invisible aux yeux des institutions sportives officielles.
Une exclusion structurelle documentée
La vraie question n’est donc pas de savoir pourquoi les Hispaniques ne soutiennent pas l’USMNT, mais pourquoi les institutions sportives américaines n’ont jamais vraiment cherché à les y inviter.
Le soccer américain s’est historiquement développé selon un modèle sociologique très particulier. Dès les années 1990, il s’est massivement implanté dans les banlieues pavillonnaires blanches et aisées, porté par la figure de la soccer mom – cette mère de famille de classe moyenne (souvent blanche, débordée) qui conduit ses enfants aux entraînements en minivan. Ce modèle, fondé sur des clubs privés aux frais souvent prohibitifs, a structurellement exclu les familles hispaniques aux revenus plus modestes.
L’équipe nationale féminine, malgré ses succès retentissants, incarne parfaitement ce modèle : ethniquement très blanche, issue des filières universitaires et des clubs de banlieue, elle reste culturellement très éloignée des réalités de la communauté hispanique.
Une étude menée conjointement par McKinsey et la fédération américaine de soccer révèle que les enfants latinos (le terme « latino », plus large qu’« hispanique », inclut également les personnes originaires de pays non hispanophones d’Amérique latine, comme le Brésil) sont trois fois plus susceptibles que les enfants blancs d’abandonner la pratique du soccer parce qu’ils se sentent mal accueillis dans les équipes existantes. L’ancien international états-unien Clint Dempsey résumait lucidement cette réalité :
« C’est difficile pour certains Hispaniques, comme pour les Afro-Américains et les joueurs de toutes origines. L’argent devient un problème pour ceux qui n’ont pas ce privilège. »
Cette exclusion se retrouve au niveau professionnel. Cette année, seuls quatre joueurs d’origine hispanique figurent parmi les 26 sélectionnés de l’USMNT pour le Mondial 2026. La MLS aime à se vanter d’être le championnat le plus diversifié des États-Unis, avec plus de 30 % de joueurs latinos dans ses effectifs. Mais il s’agit pour l’essentiel de joueurs étrangers, souvent argentins ou brésiliens, représentant des nations traditionnelles du football mondial davantage que les communautés hispaniques nées aux États-Unis.

De plus, les Latinos états-uniens restent largement absents des instances dirigeantes : ils n’occupent que 5 % des postes de direction dans les grandes ligues professionnelles sportives. Enfin, côté sportif, les résultats de l’USMNT n’ont rien arrangé : peu performante ces dernières années, elle n’a pas pu créer un véritable lien d’attachement avec des fans locaux.
Un paradoxe qui interroge
Alors que le Mondial 2026 vient de commencer à Mexico (le Mexique et le Canada accueilleront au total 14 matchs chacun, contre 78 aux États-Unis, dont la finale qui aura lieu à New York, le 19 juillet), le paradoxe est saisissant.
Tout le monde veut l’argent, l’attention et l’enthousiasme de la communauté hispanique : les politiciens le savent bien ; ainsi, des spots publicitaires en espagnol ont spécialement visé l’électorat hispanique lors de la dernière Copa América, en 2024, en pleine campagne présidentielle.
C’est également le cas des diffuseurs, des sponsors et des organisateurs, qui ont délibérément choisi des villes à forte concentration hispanique comme Los Angeles, San Francisco, Houston, Dallas ou Miami. Mais les structures qui organisent cette fête sont les mêmes qui ont ignoré pendant des décennies les pratiques sportives de cette communauté, rendu leurs filières de formation largement inaccessibles à ses enfants et relégué ses représentants aux marges des instances décisionnelles.
La préférence des Hispaniques pour la Liga MX ou le maillot de telle ou telle sélection d’Amérique latine n’a jamais été une forme de déloyauté. C’est la conséquence prévisible d’une exclusion structurelle de longue durée. Et regarder les matchs en espagnol par folklore ne suffira pas à changer cela.
Jonathan Leblanc ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.06.2026 à 14:47
Une Coupe du monde verte est-elle possible ?
Lionel Pabion, Maître de conférences en histoire, Université Rennes 2
Texte intégral (1783 mots)
Compétition après compétition, la Coupe du monde de football semble toujours plus polluante et toujours plus émettrice de gaz à effet de serre. Mais est-ce une fatalité ? L’histoire nous montre que la planète peut vibrer pour le ballon rond sans que cela pollue outre mesure.
La Coupe du monde de football est un événement sportif mondial qui n’a guère d’équivalents. La compétition est progressivement devenue un enjeu économique et médiatique gigantesque. En 2022, la finale a été suivie par près d’un milliard et demi de spectateurs.
Le sport est ainsi un outil de soft power très convoité. La remise par le président de la FIFA d’un « prix de la paix » à Donald Trump en décembre 2025 en est un exemple éloquent. Ces instrumentalisations politiques sont souvent dénoncées, et la question d’un éventuel boycott de la compétition revient régulièrement.
En revanche, la question écologique est souvent moins mise en avant que les enjeux politiques et sociaux. Pourtant, l’empreinte environnementale d’un tel événement est loin d’être négligeable.
Une empreinte carbone colossale
La FIFA elle-même estime que la compétition de 2022 au Qatar a généré plus de 3,8 millions de tonnes équivalent CO₂ (tCO₂e), dont 50 % à cause du transport aérien, soit davantage que l’empreinte carbone annuelle d’une agglomération française de 400 000 habitants comme Rennes.
Ce chiffre pourrait exploser pour l’édition nord-américaine à cause des nombreux trajets en avion entre les stades des trois pays organisateurs (États-Unis, Canada, Mexique). Le think tank New Weather Institute prévoit une empreinte de plus de 9 millions de tCO₂e, ce qui serait un record.
Peu de stades neufs ont été construits pour l’occasion. En revanche, le transport aérien, peu optimisé, va constituer plus des trois quarts des émissions prévues, avec un bilan carbone proche des émissions totales des coupes du monde organisées dans les années 2000.
Un enjeu environnemental peu pris au sérieux
De fait, les acteurs du sport international sont aussi devenus des acteurs environnementaux. Les grandes fédérations, confrontées à des contestations écologiques, ont apporté des réponses diverses, avec un engagement plus ou moins sincère. Le Comité international olympique, bien conscient du problème, a lancé dès les années 1990 un « agenda 21 », c’est-à-dire un plan visant à réduire les impacts sur la planète pour le siècle à venir. L’enjeu environnemental a été érigé comme l’un des piliers de la charte olympique, même si les évolutions concrètes du modèle des Jeux restent limitées.
En comparaison, la FIFA semble remarquablement peu impliquée dans la prise en charge des questions écologiques. Ses choix politiques paraissent même à contre-courant. Les dernières éditions ont été attribuées à des pays qui ne se distinguent ni par leur ambition environnementale ni par leur défense de la démocratie, en l’occurrence la Russie, le Qatar puis les États-Unis de Donald Trump (où se tiendront les trois quarts des matchs de cette édition).
Pis, le format de la compétition a été élargi. Quarante-huit sélections y participeront, contre 32 nations auparavant, ce qui génère une empreinte supplémentaire du fait de la multiplication des matchs et donc des trajets, dans des villes aussi éloignées que Vancouver, Boston ou Mexico. L’équipe tchèque va, par exemple, devoir parcourir plus de 4 500 kilomètres en avion pour disputer ses trois matchs de qualification.
Un discours empreint de « greenwashing »
Le discours de la FIFA sur la durabilité apparaît dès lors comme une opération de greenwashing. L’essentiel de l’empreinte carbone découle du transport aérien, qu’il faudrait tenter de réduire pour traiter sérieusement le problème. Au contraire, la Fédération cherche à faire croître toujours plus sa compétition et les revenus afférents. Des mesures essentiellement cosmétiques servent de paravent, comme une attention portée à la réduction et au recyclage des déchets ou la mise en place de campagnes de sensibilisation.
La FIFA annonce vouloir atteindre la neutralité carbone en 2040. Pourtant, depuis les années 2000, l’empreinte carbone des championnats du monde ne fait qu’augmenter. L’attribution des prochaines compétitions ne semble pas non plus compatible avec cet objectif. En 2030, le tournoi, organisé dans trois pays (Espagne, Portugal et Maroc), va générer d’importants flux aériens. En Arabie saoudite, pour 2034, la construction nécessaire de nouveaux stades va alourdir le bilan carbone.
Des mécanismes de compensation à l’effet discutable, comme la plantation de forêts artificielles ou l’achat de crédits carbone, serviront d’outils de communication autour d’un « zéro émission nette » sans réduire réellement l’impact environnemental.
Un gigantisme récent
Le recours à l’histoire permet pourtant de se rappeler que, pendant longtemps, le football international était sobre du point de vue énergétique, ce qui n’empêchait pas le spectacle. Avant la Seconde Guerre mondiale, les stades étaient peu nombreux et rudimentaires.
Les deux éditions de la Coupe du monde organisées en France, en 1938 et en 1998, montrent toute la distance qui sépare à cinquante ans de distance le football moderne de celui des origines. Le stade rudimentaire de Colombes, avec seulement 20 000 places assises et couvertes sur 60 000, contraste avec le Stade de France construit pour l’occasion, ses 80 000 places, ses 180 000 mètres cubes de béton et ses 32 000 tonnes d’acier.
Les stades de Dallas, avec ses 90 000 places ou celui de Los Angeles, inauguré en 2020 avec un parking énorme, tous deux utilisés pour l’édition 2026, semblent emblématiques de cette croissance sans fin.
Ce gigantisme des stades et le nombre important de spectateurs n’est pourtant pas synonyme d’accès populaire à la compétition. Au contraire, la polémique fait rage concernant les prix des billets, qui atteignent des records, interdisant le spectacle à une large partie de la population, y compris locale, rendant l’accès à la compétition de plus en plus inégalitaire. Cette logique commerciale se retrouve dans l’organisation de spectacles autour des matchs.
Des liesses sans démesure
Le concert réunissant Shakira, Madonna et le groupe BTS, annoncé pour la finale 2026, a fait naître des critiques sur l’allongement de la mi-temps pour des raisons médiatiques au détriment des logiques sportives.
Mais cette logique de divertissement commercial a pris différentes formes. La retransmission télévisuelle elle-même n’est pas consubstantielle à la Coupe du monde. La diffusion en direct n’est introduite que dans les années 1960. En 1966, les matchs sont filmés par moins de dix caméras. Les images en couleur ne sont arrivées que pour l’édition 1970, amorçant un essor des moyens technologiques qui n’a pas cessé depuis.
Les images simples n’empêchaient pourtant pas les amateurs et les amatrices de football de profiter du spectacle, devant leur télévision, à la radio ou dans la presse, tandis que les stades étaient des lieux beaucoup plus accessibles et populaires. Le « miracle de Berne » en 1954, quand la République fédérale d’Allemagne (RFA) remporte la coupe contre toute attente, donne lieu à d’énormes manifestations de joie et joue un rôle culturel important dans une Allemagne prise dans la guerre froide. En 1974, Franz Beckenbauer et Johann Cruyff s’affrontèrent dans une finale remportée à domicile par la RFA, ce qui donna lieu là encore à d’énormes manifestations de liesse.
Quand l’équipe de France voyageait en bateau
Surtout, la croissance des flux de transport, responsable de la majorité de l’empreinte environnementale, est longtemps restée réduite. Pour aller jouer à Montevideo (Uruguay) en 1930, l’équipe de France passe deux semaines sur un paquebot avec les équipes belge et roumaine. L’essentiel du public présent dans les stades habitait sur place.
L’essor du transport aérien ne date que des années 1960, ce qui conduit à une mondialisation toujours plus poussée du tourisme sportif, jusqu’à atteindre des niveaux très élevés : trois millions de spectateurs pour trente jours de compétition, en 2022.
Il ne s’agit pas de fantasmer un retour en arrière. L’histoire récente permet pourtant de se rappeler que la sobriété n’est pas contradictoire avec le spectacle sportif.
Des pistes réelles de changement auraient un impact direct : retour à un calendrier plus serré et diminution du nombre de matchs, concentration de la compétition sur quelques stades déjà existants et proches les uns des autres, ouverture des stades à un public local et plus populaire, organisation de fanzones dans chaque pays pour concilier rituel collectif et diminution des déplacements.
Alors que plusieurs matchs de la Coupe du monde 2026 se tiendront par des chaleurs importantes, il est urgent de réinventer un modèle sportif qui prenne vraiment au sérieux l’immense défi environnemental.
Lionel Pabion ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.06.2026 à 16:18
Nous avons lancé 100 000 simulations de la Coupe du monde. Et le vainqueur est…
Achim Zeileis, Professor of Statistics, University of Innsbruck
Texte intégral (1402 mots)
L’Espagne, la France ou l’Angleterre soulèveront-elles le trophée ? En s’appuyant sur les données de milliers de matchs, des statisticiens ont simulé 100 000 fois la Coupe du monde 2026 de foot pour identifier les scénarios les plus probables.
Autrefois, pour savoir quelle équipe allait remporter la Coupe du monde, il fallait consulter des voyants à la boule de cristal, lire l’avenir dans les feuilles de thé ou espérer que Paul le Poulpe nous révèle ce qui allait se passer.
Aujourd’hui, la science des données offre une alternative plus fiable. Au sein d’une équipe de statisticiens, j’ai contribué à entraîner un algorithme d’apprentissage automatique afin de prédire le scénario le plus probable du tournoi.
Prévisions probabilistes et dés pipés
L’algorithme que nous avons conçu fonctionne en deux étapes. Dans un premier temps, des modèles statistiques sophistiqués sont combinés aux analyses des bookmakers et aux données du marché des transferts afin d’évaluer la force de toutes les équipes et de leurs joueurs. Dans un second temps, un algorithme d’apprentissage automatique détermine la meilleure façon de combiner ces estimations avec d’autres informations concernant les équipes.
Cette approche permet de produire une prévision probabiliste pour chaque match possible du tournoi. On peut l’imaginer comme une paire de dés pipés : au lieu de présenter les chiffres de 1 à 6 avec une probabilité identique, ces dés attribuent des probabilités différentes au nombre de buts que chaque équipe est susceptible de marquer.
Par exemple, selon nos prévisions, le dé du Mexique produit en moyenne 1,9 but lors du match d’ouverture, tandis que celui de son adversaire, l’Afrique du Sud, n’en produit que 0,7. Cela ne signifie toutefois pas que le Mexique gagnera à coup sûr. Une victoire mexicaine constitue simplement l’issue la plus probable, avec une probabilité de 65 %. Un match nul est moins probable (21 %), tandis qu’une victoire de l’Afrique du Sud représente le scénario le moins probable (14 %).
« ¡Vuelve a casa, el fútbol vuelve a casa ! »
En utilisant différentes paires de dés pipés, il est possible de simuler le résultat de chaque match de la Coupe du monde. Nous avons pris en compte le tirage au sort officiel du tournoi ainsi que l’ensemble des règles de la FIFA, y compris les prolongations et les séances de tirs au but. Nous avons ensuite effectué 100 000 simulations afin de déterminer le scénario le plus probable de la compétition.
Les résultats montrent que l’Espagne est la favorite pour le titre, avec une probabilité de victoire de 14,5 %. Elle est suivie de près par l’Angleterre et la France, toutes deux à 12,4 %, puis par l’Allemagne avec 11,2 %.
En raison de l’élargissement du tournoi — cette Coupe du monde réunit 48 équipes et comporte cinq tours à élimination directe —, les écarts entre les favoris restent relativement faibles. Le Portugal et l’Argentine disposent eux aussi de solides chances de remporter le trophée, avec respectivement 8,9 % et 8,2 % de probabilité de victoire finale.
De leur côté, les États-Unis ont de bonnes chances d’atteindre les seizièmes de finale : 78 %. Il s’agit de la probabilité la plus élevée de leur groupe, qui compte trois autres équipes. En revanche, lors de la phase à élimination directe, où chaque match est décisif, les chances de l’équipe états-unienne de poursuivre son parcours diminuent assez rapidement. La probabilité de voir le pays hôte soulever le trophée lors de la finale disputée au MetLife Stadium le 19 juillet n’est que de 1 %.
Les coulisses du modèle
Notre algorithme d’apprentissage automatique et les simulations qui en découlent reposent sur un mélange de données, d’expertise et de modèles statistiques.
Tout d’abord, l’ensemble des matchs internationaux disputés au cours des huit dernières années sert de base à une estimation rétrospective du niveau des équipes. Ensuite, une estimation prospective est établie à partir des cotes proposées par différents bookmakers internationaux, lesquelles reflètent leur appréciation experte du tournoi à venir.
Troisièmement, des évaluations individuelles des joueurs sont établies à partir de leur contribution aux buts marqués en club comme en sélection nationale. Enfin, la qualité actuelle des joueurs et leur potentiel futur sont appréhendés à travers leur valeur marchande estimée. Ces données sont disponibles sur le site Transfermarkt, qui s’appuie sur une approche fondée sur l’intelligence collective pour estimer des valeurs de marché qui, par nature, restent inconnues.
Ces quatre variables sont ensuite combinées à un large éventail d’autres indicateurs pertinents décrivant l’état actuel des différentes équipes et des pays qu’elles représentent. Cela comprend des éléments propres aux sélections, comme leur classement FIFA ou le nombre de joueurs ayant atteint les demi-finales de la Ligue des champions cette année. Nous avons également intégré des facteurs socio-économiques propres à chaque pays, tels que le PIB par habitant.
Pour déterminer si ces variables influencent réellement les résultats d’une Coupe du monde, et dans quelle mesure, nous avons eu recours à un algorithme d’apprentissage automatique.
Plus précisément, nous avons utilisé ce que l’on appelle une forêt aléatoire (random forest), un modèle composé d’un grand nombre d’arbres de décision, chacun étant entraîné sur des sous-ensembles légèrement différents des données. L’algorithme a été entraîné à partir de tous les matchs disputés lors des grandes compétitions internationales depuis la Coupe du monde 2006.
Il apprend ainsi à relier le niveau des équipes, la valeur marchande de leurs joueurs et d’autres facteurs au nombre de buts marqués lors des matchs de Coupe du monde. C’est cette information qui permet de « piper les dés » utilisés dans nos simulations.
Quelle fiabilité ?
Ce n’est pas la première fois que notre équipe, composée d’Andreas Groll, de Rouven Michels et de leurs collègues de l’université technique de Dortmund en Allemagne, ainsi que de Lars Magnus Hvattum du Molde University College en Norvège, de Gunther Schauberger de l’université technique de Munich et de moi-même, collabore pour prédire l’issue d’une Coupe du monde.
Lors de la Coupe du monde féminine 2019, nous avions correctement désigné les États-Unis comme futurs vainqueurs. Lors de la Coupe du monde féminine 2023 et de la Coupe du monde masculine 2022, les équipes sacrées — l’Espagne et l’Argentine — n’étaient pas nos favorites, même si notre modèle les identifiait comme de sérieuses prétendantes au titre.
La principale leçon est qu’une prévision repose sur des probabilités. Notre programme ne prétend pas prédire le vainqueur avec une certitude absolue. Mais il a peut-être davantage de chances de succès qu’un mollusque à huit bras.
Achim Zeileis ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.06.2026 à 13:02
Îles Salomon : délicat jeu d’équilibre géopolitique entre la Chine et l’Australie
Pierre-Christophe Pantz, Enseignant vacataire et chercheur associé à l'Université de la Nouvelle-Calédonie (UNC), Université de la Nouvelle-Calédonie
Texte intégral (1939 mots)
Derrière la visite officielle du nouveau premier ministre salomonais Matthew Wale à Canberra, certains ont voulu voir un signe de rééquilibrage diplomatique après des années de rapprochement avec la Chine. Mais plus qu’un choix de camp, l’arrivée au pouvoir de Wale répond d’abord à une crise politique interne. Entre dépendance aux financements extérieurs, endettement et rivalités accrues entre grandes puissances, les îles Salomon tentent de préserver leur marge de manœuvre.
La première visite officielle du nouveau premier ministre salomonais Matthew Wale en Australie, début juin 2026, a été perçue comme un signal de rapprochement avec Canberra après plusieurs années de coopération renforcée avec la Chine. Pourtant, derrière ce geste symbolique, la réalité apparaît plus nuancée. Si cette prise de contact pourrait traduire un rééquilibrage diplomatique, les îles Salomon demeurent surtout confrontées à une contrainte structurelle : préserver leur autonomie en capitalisant sur la rivalité accrue entre la Chine, l’Australie et les puissances occidentales.
Le choix de la première destination d’un chef de gouvernement est rarement neutre. À ce titre, la visite à Canberra de Matthew Wale, quelques jours à peine après son arrivée au pouvoir en mai 2026, a retenu l’attention. Le geste est d’autant plus notable que les îles Salomon sont devenues, depuis leur reconnaissance diplomatique de Pékin au détriment de Taipei en 2019 puis l’accord de sécurité sino-salomonais de 2022, un terrain central de la compétition stratégique dans le Pacifique insulaire.
À première vue, ce déplacement aurait pu être lu comme un revirement par rapport aux gouvernements de Manasseh Sogavare (2019-2024) puis de Jeremiah Manele (2024-2026), souvent associés à un rapprochement avec la Chine. Cette lecture mérite toutefois d’être nuancée : dès 2024, Manele avait lui-même choisi l’Australie pour sa première visite officielle – ce qui illustre la continuité des liens entre Honiara et Canberra malgré l’approfondissement du partenariat avec Pékin.
Dès lors, la question n’est peut-être pas celle d’un basculement entre Chine et Australie, mais celle de la manière dont les îles Salomon cherchent à ménager leurs deux principaux partenaires dans un espace régional de plus en plus polarisé.
2024-2026 : une crise politique d’abord interne
Les élections législatives de 2024 ont souvent été interprétées à l’étranger comme un référendum implicite pour ou contre l’influence de la Chine. Cette grille de lecture, centrée sur la rivalité sino-occidentale, tend toutefois à minimiser les dynamiques internes.
En effet, le gouvernement de Jeremiah Manele, ancien ministre des Affaires étrangères de Manasseh Sogavare et acteur clé du basculement diplomatique vers Pékin en 2019, s’est rapidement fragilisé. Dans un archipel de plus en plus marqué par la fragmentation des alliances parlementaires, la recrudescence des accusations de corruption, les tensions entre élites politiques et une insatisfaction sociale persistante ont progressivement érodé sa majorité.
Manele est finalement renversé en mai 2026 par une motion de défiance (26 voix contre 22). Si les débats sur la relation avec la Chine ont nourri les critiques, ils ne suffisent pas à expliquer cette chute, qui s’inscrit d’abord dans une instabilité politique structurelle. Cette lecture est renforcée par un constat central : malgré les investissements chinois dans les infrastructures (stade national, hôpitaux, équipements publics), les inégalités sociales et territoriales demeurent particulièrement fortes. Les îles Salomon restent un État classé par l’ONU parmi les pays les moins avancés (PMA), où l’accès aux services essentiels demeure très inégal.
Dans ce contexte, Matthew Wale a bâti son accession au pouvoir sur un discours de réforme centré sur la transparence et la lutte contre la « capture de l’État par les élites ». Son élection relève donc autant d’une crise interne que des recompositions géopolitiques régionales, qui reconfigurent les équilibres de la scène politique salomonaise.
Le « paradoxe Wale » : entre critique de la Chine et Realpolitik
Critique de longue date de l’accord de sécurité signé avec la Chine en 2022, Wale a adopté une posture plus pragmatique dès 2025, alors qu’il siégeait encore dans l’opposition, notamment lors d’une visite à Pékin où il réaffirme son soutien au principe d’une seule Chine.
Une fois au pouvoir, il n’a pas remis en cause le principe même de la coopération sécuritaire avec la Chine. Il a néanmoins marqué une inflexion en annonçant un réexamen du pacte signé en 2022, dont il continue de dénoncer le manque de transparence et les clauses de confidentialité. Cette position traduit moins une rupture avec Pékin qu’une volonté de reprendre le contrôle politique d’un accord longtemps critiqué pour son opacité.
Ce pragmatisme s’explique par des contraintes fortes. D’une part, le pays dépend largement des financements extérieurs pour ses infrastructures et services publics. D’autre part, l’endettement contracté notamment auprès de la Chine populaire limite les marges budgétaires, sans constituer pour autant un « piège » au sens strict.
Dans le même temps, les équilibres extérieurs sont structurants : l’Australie reste le principal partenaire sécuritaire et un bailleur majeur, tandis que la Chine occupe une place croissante dans le financement du développement.
Dans ce cadre, Wale cherche à maintenir des relations avec plusieurs partenaires afin de préserver ses marges de manœuvre diplomatiques. La souveraineté est surtout utilisée comme un levier politique, plutôt que comme une recherche d’autonomie totale.
D’ailleurs, l’élection de Wale n’a pas provoqué de réaction hostile de Pékin. Les autorités chinoises ont rapidement affiché leur volonté de poursuivre et d’approfondir leur coopération avec le nouveau gouvernement, tandis que Wale a lui-même réaffirmé son attachement au principe d’une seule Chine. Cette retenue mutuelle suggère que, à ce stade, ni Honiara ni Pékin ne souhaitent transformer la transition politique de 2026 en rupture diplomatique.
Australie–Salomon : une relation jamais rompue
En parallèle, la visite officielle de Wale en Australie s’inscrit également dans un réengagement australien plus large dans le Pacifique. Canberra a multiplié les accords bilatéraux ces dernières années : Tuvalu (Union Falepili, 2023), îles Salomon (un premier traité de sécurité en 2024), Papouasie–Nouvelle-Guinée (traité Pukpuk, 2025), Indonésie (2026), Vanuatu (projet d’accord Nakamal, 2026).
Dans cette architecture, les Îles Salomon occupent une position particulière. L’Australie conserve une influence historique, héritée notamment de la Mission régionale d’assistance aux îles Salomon (2003-2017), même si la montée en puissance de la Chine depuis 2019 a introduit une nouvelle incertitude stratégique.
La relance de la coopération policière et sécuritaire engagée dans le cadre de l’accord bilatéral conclu en 2024, dont la mise en œuvre avait été partiellement retardée sous le gouvernement Manele, illustre davantage une continuité qu’un basculement. Les liens institutionnels entre Canberra et Honiara n’ont jamais été rompus, y compris durant la période de rapprochement avec Pékin.
Pour l’Australie, l’objectif consiste désormais moins à évincer la Chine qu’à conserver une position centrale dans les domaines de la sécurité, de la formation et de la gouvernance. Pour les Salomon, l’enjeu est inverse : maintenir ouvertes plusieurs options de coopération afin d’éviter toute dépendance exclusive.
Cette logique rejoint une pratique plus large des petits États insulaires du Pacifique, souvent résumée par la formule « Amis de tous, ennemis de personne », qui vise à préserver les marges de manœuvre diplomatiques, mais également à maximiser les aides au développement dans un environnement marqué par de fortes asymétries de puissance.
Une souveraineté sous contrainte
Pour les pays occidentaux, l’accord de sécurité signé en 2022 entre la Chine et les îles Salomon a agi comme un électrochoc stratégique. Il a remis en cause l’idée d’une chasse gardée australienne dans le Pacifique insulaire et conduit à un renforcement de la présence américaine, marqué notamment par la réouverture de l’ambassade des États-Unis à Honiara en 2023 après trente ans d’absence.
Dans ce contexte, l’Union européenne a été incitée à réaffirmer une approche plus discrète, centrée sur le développement et le multilatéralisme, dans un espace de plus en plus structuré par la rivalité entre la Chine et le couple Washington–Canberra. En 2026, l’arrivée au pouvoir de Matthew Wale – principal opposant à cet accord – ne marquera vraisemblablement pas une rupture nette dans la politique étrangère des îles Salomon. Elle correspond plutôt à une configuration de pragmatisme et de dépendance, avec des contraintes internes (fragilités socio-économiques, coalitions instables) qui s’articulent avec d’intenses rivalités extérieures.
Dans un contexte de forte dépendance aux financements extérieurs et d’endettement croissant, la politique étrangère salomonaise s’apparente à un exercice d’ajustement permanent plutôt qu’à un choix stratégique souverain pleinement autonome.
Plus qu’un basculement géopolitique, l’élection de Wale en mai 2026 illustre ainsi une réalité plus large du Pacifique insulaire : celle d’États qui tentent de transformer leur position de dépendance en espace de négociation entre plusieurs puissances concurrentes. Reste une question centrale : cette concurrence accrue entre partenaires extérieurs peut-elle réellement se traduire en améliorations concrètes pour des populations confrontées quotidiennement à des vulnérabilités structurelles persistantes ?
Pierre-Christophe Pantz ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.06.2026 à 12:49
What the failed next generation fighter jet deal means for European defence
David W. Versailles, Professor, strategic management and innovation management, co-director of the new PICchair at the Paris School of Business - research director LSB - VP EURAM Dialogue with Practitioners, European Academy of Management (EURAM); PSB Paris School of Business
Texte intégral (2237 mots)
A few hours before the inauguration of the Berlin ILA airshow, the German Chancellor unsurprisingly announced the end of the Future Combat Air System (FCAS). Launched by Emmanuel Macron and Angela Merkel in 2017, the program initially intended to prepare a Next Generation Fighter (NGF) aircraft, remote effectors, loyal unmanned wingmen (drones, as in unmanned combat air vehicles) and a secure digital architecture installing AI-based data fusion at the level of the (air) battlefield (the so-called “combat cloud”).
Estimated at 100 billion euros, FCAS phase 2 was frozen in December 2025, delaying the elaboration of specifications and demonstrators.
This decision was no surprise: Chancellor Merz publicly pronounced the program dead for Germany in February 2026, and in April Eric Trappier, Dassault Aviation CEO, announced that he was ending all negotiations with Airbus Defense and Space (Airbus DS) on the NGF, a key component in the FCAS program. In May, the Airbus CEO cited geopolitical disruptions as the reason the program was no longer relevant.
This announcement concludes several years of impossible compromises, industrial inconsistencies, and strategic divergences on program specifications.
Economists have long explained that difficulties in international cooperation in Defence stem from misalignment of specifications and operational requirements, overlap of industrial capabilities, and the need to ground program leadership in explicit industrial capabilities.
To list only a few, the A400M tactical transport aircraft suffered long delays because Airbus DS was struggling with technical problems (for instance, around the flight mission system). For the NH90 helicopter program, maintainability and upgradability suffered so much that Sweden gave up and opted for an American solution.
Berlin and Paris’ discrepant approaches about operational specifications are easy to illustrate in the FCAS program.
Germany was initially seeking a 30-tonne aircraft, with an operational range of 1,500 km or more, internal bays, and a low signature suited to conventional bombing.
While Spain for example, aligned with the German vision of the aircraft, France, on the other hand, always sought a polyvalent “light” aircraft capable of additional roles in nuclear deterrence and carrier landing. Berlin’s purchase of 35 F-35A JSF aircraft for the operation of the US B61 nuclear bombs, initially intended to secure Germany’s contributions to NATO shared nuclear mission, has shaped German orientations in the FCAS program.
Germany expected the FCAS specifications to complement its use of the F-35A, whereas France needs a replacement for the polyvalent Rafale F4. The F-35 purchase also shows that delivery needs diverge on replacing existing aircraft fleets in Germany and France, incidentally putting less pressure on the German side to pursue a common solution.
The FCAS industrial Meccano and the importance of the integration function
Tensions between Dassault Aviation and Airbus DS again illustrate the importance of evaluating the distribution of skillsets and capabilities among actors in the European Defence industrial base who are also potential competitors.
In Defence, international cooperation is usually defined at the political level, without considering industrial and operational realities, because the strategic intent of an alliance takes precedence over other considerations. The FCAS program initially illustrated the political commitment to greater autonomy in European defence and the joint leadership of Paris and Berlin in this endeavour.
In the FCAS program, widening the industrial parameter to Spain (in 2019) increased the number of decision centres, expanded the supply chain, and increased both coordination costs and decision-making difficulties around operational specifications and industrial capabilities. This issue has been a recurring topic in discussions of “industrial returns” in international cooperation in Defence for many decades.
The FCAS program did not avoid these traditional difficulties during its first years, before introducing the “best athlete” selection principle for tier-2 suppliers in 2019 (which led Safran Aircraft Engines to lead the engine sub-system, with MTU Aero Engines as the main partner).
In the repartition of activities for the FCAS program, Airbus DS was initially in charge of the “combat cloud” and several aspects pertaining to drones.
Dassault Aviation was officially leading the program and oversaw the NGF at the same time. However, this decision made Airbus, Dassault, and Indra equal partners and did not grant an additional voting right to the lead system integrator (LSI) piloting the program (even though they were justified for the definition of the architecture), thereby creating recurring friction. Many firms were pushed into the program supply chain to align with political decisions about international cooperation, regardless of minimising coordination costs and optimising the supply chain.
Ambiguities about leadership in managing the industrial program and integrating contributions explain the FCAS failure.
Leadership is a key success factor when the lead system integrator is clearly identified and selected for their undisputed skillset. For the very opposite reasons, this issue is also a recurring weak point in European cooperation.
Dassault Aviation has earned a solid reputation through the success of the Mirage series and the Rafale, underscoring its role as a leading system integrator since the early 1950s. In many areas, system integration competence is available within the Airbus group. However, this competence is not present across all domains covered by this major aerospace industry actor. From the outskirts of the FCAS program, and more specifically regarding activities around the NGF and the associated unmanned combat air vehicles (UCAVs), Dassault Aviation explained that the FCAS cooperation was a fool’s bargain because it amounted to a direct transfer of integration competence. Dassault refused to grant integral access to data about the aircraft architecture and expected to protect its intellectual property rights.
Room for improvement
The dispute between Dassault Aviation and Airbus DS perfectly illustrates a traditional issue in industrial organisation and knowledge management: is cooperation a tool to grow together, or a tool to learn at the expense of the “partner”? Dassault has explained that the FCAS program was genuinely training AIRBUS DS on all topics that were not yet mastered within the German Defence industrial base, at Dassault’s expense.
Military aeronautics, and most notably military jets, are one of the very few weak points in the German industrial landscape. Germany used to be part of the Eurofighter consortium, alongside the UK, Spain, and Italy, with limited responsibility in architecture design and integration. In contrast, Dassault is a major industrial player that genuinely “invented” several tools, methods, and organisational solutions to operate the integration function.
System integration requires an original skillset
The integration challenge is as much organisational as it is cognitive and technical.
Dassault owns unique expertise in digital flight control and aerodynamics, which are key to operational performance and architecture design. To perform its duties, a lead system integrator must also know “a bit” about each contributor’s respective knowledge base to manage aircraft design and architecture. The system integrator needs to be able to understand all topics challenging the definition of subsystems and architectures. It must zoom out from specificities and make global decisions. Economists emphasise the importance of steady program management and long-term continuity inside the supply chain ecosystem. This continuity fosters trusted, effective interactions relevant to aircraft design, production, and innovation management.
It would be irrelevant to claim that Dassault Aviation (together with Dassault Systems) already owns all solutions, as the FCAS program represents a case of disruptive innovation across many areas. However, it is clear that Dassault holds a unique position in Europe as the lead system integrator for complex military jets within its own (European) ecosystem because it possesses the cognitive, organisational, and technical capabilities to manage both the R&D and manufacturing phases.
It makes sense that Dassault Aviation does not want to gift such a rare skill to potential competitors. In defending their position as lead system integrator, they also protect a Europe-wide supply chain and a long history of European partnerships. Dassault’s resistance to Airbus DS is also a way to protect its own ecosystem in the value chain.
What’s next?
All traditional drivers explaining the limits of cooperation and the additional costs of cooperation were present in the FCAS program. The FCAS program did not learn from previous program failures. For all the reasons listed regarding the definitions of operational specifications, the overlap of industrial capabilities, and the justification of leadership in reference to existing skills, the failure of the program was already written in stone from the earliest stages.
It seems that Paris and Berlin are now trying to preserve the FCAS label for a set of systems, including the “combat cloud”. Research spending would be reallocated to digital areas and to drone integration. Budget already spent on the program is not wasted, as it has been used to build new capabilities useful for the future.
The German decision now prepares for more fragmented trajectories in the NGF and FCAS programs. The question of leadership in the European Defence industrial base remains a key public policy issue. This decision means that the European industrial base will probably exhibit duplicate capabilities in the future, and allocate budgets for generating new competition instead of restructuring existing capabilities.
The FCAS program failure shows that policymakers still have difficulties making decisions about lead system integrators, either because they fail to understand their originality, or because they expect to establish competition in this function. In the USA, policymakers have identified Boeing and Lockheed Martin as lead system integrators in the aerospace industry, and orient their respective specialisations with dedicated industrial programs to freeze irrelevant competition. The leadership debate between France and Germany in the FCAS program means that a significant share of the available budget will be wasted on generating new industrial competition in Europe instead of building operational capabilities.
A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
David W. Versailles ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.06.2026 à 12:20
Non, les basketteurs de la NBA ne sont ni des bêtes ni des guerriers
Audrey Portes, Assistant Professor, Montpellier Business School
Audrey Missonier, Associate professor, Montpellier Business School
Clément Dubreuil, Professeur et chercheur à KEDGE Business School, auteur d'une thèse sur la violence et le rugby, Kedge Business School
Franck Celhay, Professor, Montpellier Business School
Texte intégral (2382 mots)
Spurs, Wolves, Thunder, Hawks… les finales NBA 2026 battent leur plein. Les noms des équipes renvoient à un imaginaire qui est tout sauf neutre. Que révèlent-ils sur la conception du sport ? Quelles en sont les conséquences ?
Pour rejoindre les finales NBA 2026, les Spurs de San Antonio, portés par un Victor Wembanyama omniprésent, ont dû éliminer les Timberwolves du Minnesota, puis arracher la victoire aux Thunder d’Oklahoma City. De leur côté, les Knicks de New York ont affronté les Hawks d’Atlanta, ainsi que les Cavaliers de Cleveland.
Wolves, Cavaliers, Thunder, Hawks… en observant le nom de ces équipes, un constat s’impose : la NBA est peuplée de prédateurs, de guerriers et de forces hostiles.

Que disent vraiment les noms des équipes NBA ?
Ce constat n’est pas anodin. Une recherche récente publiée dans European Sport Management Quarterly, menée sur les 124 franchises des quatre grandes ligues nord-américaines (MLB, NBA, NFL, NHL), révèle que 79 % des équipes professionnelles portent un nom métaphorique. Il est évident que les joueurs des Chicago Bulls ne sont pas littéralement des taureaux, pas davantage que les Golden State Warriors ne sont des guerriers.
Pourtant, ces noms ne sont pas que le produit d’un folklore sportif amusant. Ils façonnent, souvent à notre insu, la façon dont nous percevons le sport.
À lire aussi : Mascottes sportives : les clubs peuvent-ils devenir les nouveaux champions de la biodiversité ?
Un langage qui structure notre vision du monde
Pour comprendre pourquoi, il faut s’appuyer sur la théorie des métaphores conceptuelles de George Lakoff et Mark Johnson. Lakoff et Johnson montrent que les métaphores sont omniprésentes dans notre langage courant, structurent notre façon de penser et influencent nos comportements.
Ainsi, les métaphores comparant les discussions à des « joutes verbales » où les participants « attaquent » puis « défendent » leurs « positions » révèlent que nous conceptualisons le débat d’idées comme un affrontement plutôt que comme un échange bienveillant.
Les noms des équipes sportives fonctionnent de la même manière. En nommant une équipe les Predators de Nashville ou les Sharks de San José, on ne choisit pas seulement un nom accrocheur : on ancre dans l’esprit du public une représentation particulière de ce que sont les athlètes et de ce qu’est le sport.
Les athlètes comme bêtes sauvages ou guerriers
Notre recherche révèle que derrière la diversité apparente des noms, une représentation écrasante domine. Les athlètes y sont avant tout conceptualisés comme des bêtes sauvages (Bears, Tigers, Wolves, Raptors, Jaguars…) ou comme des guerriers (Warriors, Vikings, Raiders, Cavaliers…). À un niveau plus abstrait, ces métaphores convergent vers une conception commune : le sport comme combat brutal.
Qu’il s’agisse des Vipers, des Blackhawks, des Sabres ou des Titans, la grande majorité des noms d’équipes évoquent la violence, la prédation ou la guerre. Ce constat est remarquablement stable d’une ligue à l’autre, ce qui suggère que cette représentation n’est pas le reflet des spécificités de chaque sport, mais bien d’une conception culturelle du sport plus large.
Différencier sans sortir du moule : quelles solutions alternatives ?
Ce constat soulève un paradoxe intéressant du point de vue du management des marques. Si presque toutes les franchises utilisent des métaphores, comment se différencient-elles les unes des autres ?
Notre recherche identifie trois niveaux de différenciation. Au niveau le plus superficiel, des équipes, comme les Bulls, les Raptors ou les Hornets, partagent la même métaphore sous-jacente (les athlètes sont des bêtes sauvages) et ne se distinguent que par les attributs spécifiques de l’animal choisi : la puissance brute pour le taureau, la voracité du rapace, la rapidité de la guêpe. La différenciation reste marginale.
À un niveau intermédiaire, des équipes, comme les Warriors ou les Cavaliers, mobilisent une métaphore distincte pour les athlètes (ce sont des guerriers, non des animaux). Tout en conservant la même vision du sport comme combat. La différenciation est plus marquée : ces équipes évoquent la stratégie militaire, la discipline, le courage, plutôt que l’instinct animal.
C’est au troisième niveau que la différenciation devient fondamentale, parce qu’elle rompt avec la métaphore dominante du sport-combat. Quelques équipes, très minoritaires, mobilisent des univers radicalement différents. L’Utah Jazz et les St. Louis Blues (NHL) conceptualisent les athlètes comme des musiciens, tandis que les Washington Wizards ou les Orlando Magics convoquent le thème de la magie.
Une conceptualisation alternative du sport comme art est alors proposée. Ce faisant, ils communiquent une image plus valorisante des athlètes opposant des valeurs de virtuosité, de créativité et de maîtrise technique à celles de puissance brute et d’instinct primal. Une promesse de beau jeu est ainsi formulée, qui se distingue de celle de l’affrontement violent.
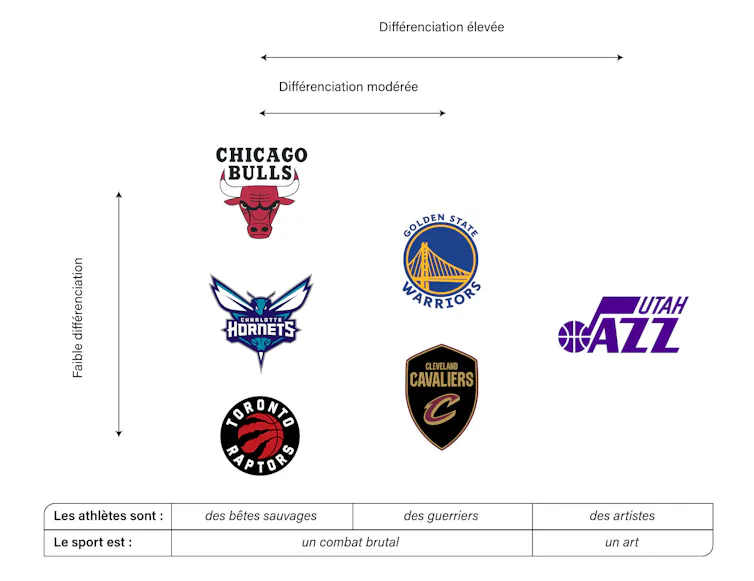
Des noms innocents aux conséquences réelles
Au-delà de ces implications en termes de différenciation, le choix de métaphores associant le sport à un combat brutal touche également à la responsabilité sociale des franchises. Conceptualiser les athlètes comme des bêtes sauvages ou des machines de guerre porte des valeurs positives comme la combativité ou l’engagement mais dès lors que ce type de métaphores s’impose comme le modèle dominant, cela contribue à une normalisation de l’agressivité.
Pour vérifier empiriquement ce mécanisme, nous avons conduit une étude auprès de 1 140 spectateurs de basket-ball, et recueilli ce que leur évoque différents noms d’équipes métaphoriques de la NBA G-League (ligue de développement). Les résultats sont attendus mais éloquents : les noms connectés aux métaphores « bêtes sauvages » ou « guerriers » génèrent significativement plus d’associations liées à la violence, au danger et à l’agression.
À l’inverse, des noms, comme Rip City Remix ou Capital City Go-Go, liés à la musique et à l’art, suscitent des associations centrées sur la créativité, le jeu, l’amusement voire la diversité (pour les remix).
Ces résultats rejoignent ceux d’autres études montrant que l’exposition répétée à des systèmes de métaphores dominants contribue à normaliser des croyances ou comportements. Ici, les résultats montrent que les noms choisis participent d’une naturalisation de la violence dans le sport, un processus d’autant plus insidieux que la dimension humoristique de ces métaphores permet simultanément d’annoncer et de dédramatiser la promesse d’un spectacle violent.
Nommer autrement : une responsabilité de marque
Ces constats ont des implications pratiques directes pour les dirigeants sportifs. Le choix d’un nom d’équipe est souvent laissé à des concours de fans, une pratique répandue dans les nouvelles franchises ou à l’occasion de rebranding. Si cette démarche favorise l’engagement du public, elle tend aussi à reproduire, par mimétisme, les mêmes clichés et à perpétuer les mêmes représentations.
L’exemple des Washington Redskins (les « Peaux rouges ») illustre les risques de l’inertie. L’équipe de NFL avait dû abandonner son nom en 2020 après des décennies de protestation des communautés amérindiennes autochtones, sous la pression conjuguée des sponsors et des partenaires commerciaux. L’équipe de football s’est ainsi retrouvée sans nom pendant près de deux saisons avant d’adopter celui de Washington Commanders.
Inversement, l’équipe de NBA de Washington montre qu’il est possible de faire preuve d’initiative. L’équipe ayant décidé de changer son nom de Washington Bullets (balles) à Wizards(magiciens), dès 1997, pour éviter de diffuser des connotations violentes.
Ainsi, choisir un nom qui s’affranchit de la métaphore dominante du sport-combat n’est pas seulement un acte de différenciation stratégique, c’est aussi une forme de responsabilité sociale. Il s’agit de décider quelles valeurs une franchise souhaite incarner et diffuser, au-delà des victoires sur le terrain.
Alors que le Game 5 des finales NBA 2026 se jouera dimanche, la question mérite d’être posée : que se passerait-il si, au lieu de mettre en scène chaque soir un affrontement de prédateurs et de guerriers, certaines équipes choisissaient de raconter une autre histoire ?
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
11.06.2026 à 13:13
ZFE, de la suppression au sursis : une saga juridique qui n’a pas encore dit son dernier mot
Sébastien Martin, Maître de conférences en droit public HDR, Université de Bordeaux
Élodie Annamayer, Docteure en droit de l'université de Bordeaux, Université de Bordeaux
Texte intégral (1959 mots)
Fin mai 2026, le Conseil constitutionnel a sauvé les zones à faibles émissions mobilité, les ZFE, en annulant leur suppression. Cette décision, qui intervient sur la forme plutôt que sur le fond, n’empêchera probablement pas un retour du sujet dans le débat politique. Une généralisation trop rapide pourrait expliquer en partie le sort tumultueux connu par le texte. Mais, en cas d’abandon définitif de la mesure, le risque de recadrage de la France par l’Union européenne – et, en particulier, de condamnation par la Cour de justice de l’UE – est réel.
Dans une décision du 21 mai 2026, le Conseil constitutionnel vient de donner un sursis aux zones à faibles émissions mobilité (ZFE). Il est revenu sur la suppression, qui avait été actée avec l’adoption de la loi dite de simplification de la vie économique, pour un motif d’ordre procédural.
Sur le fond, le juge constitutionnel ne s’est donc pas prononcé sur la compatibilité de la suppression avec les dispositions de la Charte de l’environnement, consacrant notamment le droit de chacun de vivre dans un environnement équilibré et respectueux de la santé, ou avec le droit à la protection de la santé, garanti par le préambule de 1946.
Les ZFE n’en restent pas moins un dispositif clivant. Il y a donc fort à parier que leur suppression revienne d’ici peu en débat politique devant la représentation nationale.
À lire aussi : Faut-il supprimer les zones à faibles émissions au nom de la justice sociale ?
Un signe fort de « backlash » écologique
Lors de l’adoption de la loi d’orientation des mobilités en 2019, les ZFE avaient été présentées comme un dispositif phare de la transition écologique et énergétique. En visant à limiter l’utilisation de véhicules très polluants, elles devaient concourir au développement de nouvelles formes de mobilités moins émettrices de CO2.
Le débat autour de cette suppression est un signe majeur d’une rétrogradation de la protection de l’environnement par le droit, dont on ne saurait dire jusqu’où elle pourrait aller. Les avancées réalisées en faveur d’un droit de la mobilité durable, parfois sous l’influence du droit de l’Union européenne, sont aujourd’hui remises en cause. Cela s’inscrit dans une tendance globale au « backlash » écologique, très prégnante aux États-Unis en particulier.
Mais à l’heure où les institutions publiques en Europe ont été incitées à poursuivre les efforts réalisés pour renforcer le cadre juridique de la mobilité durable en zone urbaine, cette tentative de rétrogradation interroge.
Une généralisation trop rapide ?
L’histoire tumultueuse des ZFE précède l’adoption de la loi d’orientation des mobilités (LOM).
En 2010 déjà, la loi Grenelle II avait mis en place, à titre expérimental, des zones d’actions prioritaires pour l’air dans le but de lutter contre la pollution atmosphérique. Ce dispositif, jugé peu efficace, a été remplacé par une nouvelle loi en 2015 pour instituer, à titre facultatif, des « zones à circulation restreinte ».
Ce sont véritablement la LOM de 2019 puis la loi dite Climat et résilience de 2021 qui ont permis à ce dispositif, alors dénommé « zones à faibles émissions de mobilité », de s’ancrer dans la vie quotidienne des Français.
Au 1er janvier 2025, 25 agglomérations sur le territoire hexagonal avaient mis en place une ZFE dans lesquelles l’accès des véhicules les plus polluants est interdit. Pour assurer un contrôle efficace des véhicules circulant dans la ZFE, la LOM laissait la possibilité aux collectivités de déployer des systèmes de contrôle automatisé, autrement dit des « radars à ZFE ».
C’est précisément cette généralisation (trop rapide ?) qui a été au centre des critiques. De nombreuses agglomérations avaient fait part de difficultés d’ordres économique et technique pour le déploiement de ces solutions. En réponse à ces critiques, une mission flash parlementaire ainsi que des outils d’ingénierie territoriale à l’initiative de l’Agence de la transition, l’Ademe, avaient été développés.
La mise en place des ZFE s’est également heurtée aux critiques sur le manque d’accessibilité des ménages les plus précaires ou des usagers éloignés des zones urbaines, laissant craindre une accentuation des inégalités sociales et territoriales.
Pour contourner ces critiques, la loi prévoit une série d’exemptions et de dérogations. Sans doute, aurait-il fallu fixer des échéances plus longues aux collectivités territoriales pour penser et adapter ces mesures d’accompagnement aux réalités économiques, sociales et techniques de chaque zone.
À lire aussi : Les ZFE sont-elles injustes ? Ce que montrent les simulations de trafic en Île-de-France
La volonté de supprimer les ZFE rappelle, en tout état de cause, le sort réservé au dispositif de l’écotaxe dans le milieu des années 2010. Présenté comme un engagement fort du gouvernement lors de l’adoption de la loi Grenelle I en 2009, son principe était celui du report modal. Il visait à inciter les opérateurs à recourir à d’autres formes de mobilité que la route pour les activités de transport de marchandises.
Là encore, la complexité tant juridique que technique, comme les réticences au dispositif, avait conduit à son report puis à sa suspension entre 2009 et 2014 et enfin à sa suppression en 2017.
Le risque de recadrage par l’Union européenne
La suppression des ZFE devrait avoir des conséquences notables pour ce qui est de la relation de la France avec l’Union européenne.
Sans être une obligation pour les villes européennes, la mise en place de Low Emission Zones connaît pourtant un certain succès. Ainsi, on dénombrait en 2022 315 zones en Europe dans 14 États membres. Ces divers exemples européens ont, d’ailleurs, démontré leur efficacité sur le plan sanitaire.

En revanche, le droit européen impose de ne pas dépasser, dans l’ensemble des zones et agglomérations, certaines valeurs limites de polluants atmosphériques. Dans les cas où il subsisterait un risque de dépassement de ces seuils, les autorités nationales sont tenues de mettre en place des mesures et des plans d’action à court terme, ce qui peut correspondre à la réduction de la circulation de certains véhicules. Autrement dit, à certaines mesures prévues par les ZFE.
On soulignera que la France a déjà fait l’objet de condamnations à plusieurs reprises par la Cour de justice de l’UE pour inaction climatique. Le juge a, en effet, estimé qu’elle « a dépassé de manière systématique et persistante » la valeur limite de polluants, comme le dioxyde d’azote, émis par les véhicules diesel.
Très récemment, le Conseil d’État a admis que l’instauration d’une ZFE comptait parmi les différentes mesures considérées comme suffisantes pour garantir le respect des valeurs limites de concentration de dioxyde d’azote dans l’agglomération parisienne. Cet arrêt a sonné la fin d’une saga contentieuse débutée en 2017, où l’État avait été enjoint de prendre des mesures pour se conformer aux obligations tirées du droit de l’Union.
On l’aura compris, si la volonté politique de supprimer les ZFE réapparaît, le risque de condamnation de la France n’est pas à éluder.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview