PIXEL DE TRACKING
Ancien de l'AdTech, passionné des médias et des nouvelles technologies, mais inquiet de l'extension du domaine de la surveillance, j'ai décidé d'ouvrir ce blog pour partager mes notes.
19.04.2021 à 23:19
Apple vous protège-t-il vraiment de la surveillance publicitaire ?

La vie privée, un argument produit pour Apple
Face au capitalisme de surveillance développé par Google, Apple a un argument évident, la vie privée. Et il ne s'en prive pas, comme en témoigne cette campagne publicitaire :

Cet argument se retrouve aussi dans les paroles d'un Tim Cook, lors de la conférence "Computers, Privacy & Data Protection" de janvier 2021, un discours tout à fait remarquable.
Apple a toujours été très doué en marketing produit, mais s'agit-il seulement de belles paroles ? Une première réponse est apportée par cette page, une réponse plus détaillée est fournie ici : Apple prend en effet de nombreuses initiatives. On peut par exemple citer :
- Le chiffrement de bout en bout sur iMessage et FaceTime.
- La protection de la vie privée sur Apple Maps.
- Le Secure Element, qui permet à Apple Pay de fonctionner sans connaître votre numéro de carte bleue ni vos transactions.
- Le fait qu'Apple protège de mieux en mieux les accès aux fonctionnalités sensibles de vos appareils iOS tels que la géolocalisation, les photos, le micro ou la vidéo.
- L'initiative "Sign in with Apple", vous permettant de créer un compte sur un service tiers sans partager votre adresse e-mail.
La vie privée est une des valeurs fondamentales d'Apple :

Mais Apple pourrait aller beaucoup plus loin, et je serais prêt à payer pour que les services suivants soient chiffrés de bout en bout : Apple Photos, Calendriers, Contacts, iCloud Drive, Notes ou Messages sur iCloud. Après sa dispute avec le FBI lors de l'attaque terroriste de San Bernardino, durant laquelle il s'est battu courageusement contre l'introduction de portes dérobées sur iOS, Apple avait une opportunité pour étendre l'utilisation du chiffrement de bout en bout à tous ses services. Sous pression du FBI, il n'a malheureusement pas osé :
Apple dropped plans to let iPhone users fully encrypt backups of their devices in the company's iCloud service after the FBI complained that the move would harm investigations, six sources familiar with the matter told Reuters.
Pour le plus grand bonheur des gouvernements, services de polices et services secrets, Apple ne chiffre pas iCloud de bout en bout. Et pour mieux vendre ses produits en Chine, Apple accepte de stocker les clés de chiffrement iCloud de ses utilisateurs Chinois directement sur des serveurs situés en Chine. Autre compromission avec le régime Chinois, Apple censure des Apps en Chine.
Intéressons-nous maintenant aux initiatives d'Apple contre la surveillance publicitaire. Vont-elles assez loin ?
Safari ITP, une bonne protection contre le pistage
En 2017, Apple intègre la fonctionnalité "Intelligent Tracking Prevention" (ITP) à Safari, le but étant de combattre le pistage multi-sites. Depuis cette première sortie, Apple a fait évoluer ITP, avec par exemple le blocage complet des cookies tiers ou la limitation de la durée de vie des cookies déposés via CNAME, ce qui lui permet de vous offrir une bonne protection contre le pistage des sociétés de l'adtech.
Lorsque l'on parle vie privée, Apple a également une excellente influence sur l'écosystème du web.
Les actions d'Apple contre le pistage multi-sites inspirent sans doute d'autres navigateurs. En 2018, Firefox annonce changer sa politique concernant le pistage, souhaitant dorénavant proposer une protection contre le pistage par défaut. En 2019, Firefox passe à l'acte avec "Enhanced Tracking Protection" (ETP), l'équivalent d'ITP, fonctionnalité qu'il a également fait évoluer depuis.
En bonus, si vous utilisez un iPhone ou un iPad et que vous passez par un autre navigateur, les protections d'ITP s'appliquent également ! En effet, Apple verrouille les options des navigateurs tiers, qui se voient obliger d'utiliser WebKit, le moteur de rendu de Safari.
Apple contrebalance l'influence de Google au W3C
Au W3C, l'organisme chargé de construire et de faire évoluer les standards du web, Apple propose des alternatives à Google dans le domaine de la publicité. Si Google a fait beaucoup de bruits avec les propositions visant à remplacer les cookies tiers ("Privacy Sandbox"), notamment la proposition controversée FLoC, Apple propose des standards pour un meilleur respect de la vie privée :
- "Private Click Measurement (PCM)" : pour correctement attribuer des conversions aux campagnes publicitaires. Google a sa propre proposition appelée "Conversion Measurement API", mais celle-ci ne protège guère la vie privée car Google permet à l'annonceur d'attribuer un identifiant unique à chaque clic sur une publicité... Apple limite de son côté les options à 256 valeurs différentes, ce qui permet simplement de savoir quelle campagne publicitaire est efficace.
- "Storage Access API" : Si Apple empêche les tiers de pister l'utilisateur sans son consentement (via les restrictions sur les cookies, le local storage, etc), ceux-ci peuvent demander explicitement l'autorisation à l'utilisateur via cette API. Certains cas d'usages tels que des systèmes d'authentification pouvant justifier cette autorisation.
Toujours au W3C, si Apple n'est pas le seul à défendre la vie privée (Firefox et Brave sont également très actifs), son investissement n'est pas de trop lorsqu'il s'agit de contrebalancer les armées de développeurs Chrome. Ceux-ci vont souvent compromettre la vie privée des utilisateurs sous couvert d'ajouter de nouvelles fonctionnalités au web. Par exemple, voici une liste de 16 fonctionnalités que Safari n'implémente pas car les risques de sécurité et de fingerprint sont trop grands.
Safari pourrait-il aller plus loin ?
Safari pourrait décider de lutter plus radicalement contre la surveillance publicitaire en intégrant par défaut un bloqueur de traceurs et de publicités type uBlock Origin. Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, Google Analytics et Google Tag Manager ne sont pas bloqués par Safari.
- Les traceurs de tiers qui exploitent les vulnérabilités actuelles du web seraient également bloqués. Je pense par exemple à Criteo via son exploitation malsaine du CNAME cloaking, Safari se contentant de limiter la durée de vie des cookies déposés via CNAME à 7 jours.
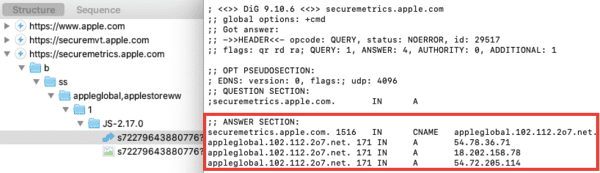
En parlant de CNAME cloaking, la technique est d'ailleurs utilisé par Apple sur son site web, avec l'outil Adobe Analytics :
Aujourd'hui, Brave va beaucoup plus loin via sa fonctionnalité "Shields" : le but n'est pas d'empêcher le pistage multi-sites mais de bloquer l'exécution des traceurs. Un exemple pour illustrer la différence d'approche : les traceurs utilisant le CNAME cloaking sont bloqués par défaut.
De son côté, Firefox propose moins de protections par défaut mais son système d'extensions est très ouvert (Safari beaucoup moins, vous devez vous contenter d'un "Content Blocker" tels que Firefox Focus), ce qui permet par exemple à uBlock Origin d'être efficace contre le CNAME cloaking.
À noter que les outils marketing peuvent encore malheureusement échapper aux protections des navigateurs et autres bloqueurs de traceurs, parfois même via des solutions clé en main.
Une politique cohérente sur le web... à une exception près
Sur le web, Apple a donc une politique cohérente :
- Safari protège contre le pistage multi-sites.
- Le pistage au sein d'un même site est jugé légitime par Apple, il reste possible.
- Une publicité plus respectueuse de la vie privée est encouragée.
S'il est toujours possible de faire mieux, Safari est à des années-lumière de Google Chrome en ce qui concerne la protection de la vie privée.
Sauf que lorsque l'on parle d'argent, Apple pactise avec le diable : Google paye entre 8 et 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur Safari.
Sur les Apps, un rattrapage nécessaire
Avec iOS 14.5, Apple lance le système "App Tracking Transparency" (ATT), le tracking devient opt-in. Voici la définition du "tracking" selon Apple :
Tracking refers to the act of linking user or device data collected from your app with user or device data collected from other companies’ apps, websites, or offline properties for targeted advertising or advertising measurement purposes. Tracking also refers to sharing user or device data with data brokers.
Cette définition est classique, similaire à celle de Firefox :
Tracking is the collection of data regarding a particular user's activity across multiple websites or applications (i.e., first parties) that aren’t owned by the data collector, and the retention, use, or sharing of data derived from that activity with parties other than the first party on which it was collected.
Elle est également similaire à celle du W3C :
Tracking is the collection of data regarding a particular user's activity across multiple distinct contexts and the retention, use, or sharing of data derived from that activity outside the context in which it occurred. A context is a set of resources that are controlled by the same party or jointly controlled by a set of parties.
Apple est enfin cohérent avec la politique qu'il appliquait déjà sur le web :
- ATT protège contre le pistage multi-Apps.
- Le pistage au sein d'un même App ou sur plusieurs Apps d'une même société est jugé légitime par Apple, il reste possible.
Sur iOS, la surveillance publicitaire a historiquement été facilitée par Apple, via la mise à disposition d'un identifiant publicitaire unique appelé IDFA. Cet identifiant était activé par défaut, les utilisateurs iOS pouvaient le désactiver s'ils le souhaitaient :
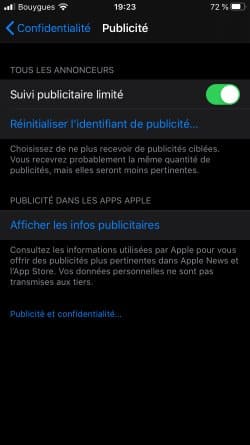 Dans Réglages > Confidentialité > Publicité, il était possible de cocher "Suivi publicitaire limité" (ce que j'avais fait, comme le montre la capture), mais l'option était décochée par défaut.
Dans Réglages > Confidentialité > Publicité, il était possible de cocher "Suivi publicitaire limité" (ce que j'avais fait, comme le montre la capture), mais l'option était décochée par défaut.
L'option par défaut a une importance capitale : peu de gens changent les paramètres de confidentialité (selon Adjust, seulement 20% des utilisateurs désactivaient l'identifiant).
Apple a donc ici une responsabilité historique : l'IDFA a permis à une multitude de sociétés de vous surveiller facilement, et ceci pendant des années. Pour rappel :
- Avec le lancement de l'iPhone (en 2007), Apple créé un identifiant unique, l'UDID (Unique Device Identifier), idéal pour vous surveiller.
- En 2008 avec la sortie de l'App Store, Apple met l'UDID à disposition des développeurs d'applications : le péché originel, qui ne sera ainsi corrigé que 13 ans plus tard.
- En 2011 et avec l'arrivée d'iOS 5, Apple rend l'UDID obsolète.
- Sauf qu'il faut attendre 2013 pour voir Apple refuser définitivement les Apps qui utilisent encore l'UDID.
- Entre temps (en 2012 avec iOS 6), Apple lance l'IDFA. Il choisit d'activer l'IDFA par défaut, l'utilisateur ne peut pas le désactiver mais seulement indiquer aux applications qu'il ne souhaite pas être pisté (un équivalent de "Do Not Track"), le réglage est bien caché dans "Publicité" (et non dans "Confidentialité").
- Jusqu'à la sortie d'iOS 10 (en 2016), si vous aviez activé "Suivi publicitaire limité", l'application pouvait continuer à utiliser cet identifiant pour le capping, la mesure de conversion, la mesure des visiteurs uniques, la sécurité, la détection de fraude et le debug ! Mais Apple n'avait aucun moyen de vérifier si les applications respectaient vraiment ces règles. Seule option pour l'utilisateur : réinitialiser l'iPhone ou l'iPad, afin de réinitialiser l'IDFA !
- Ce n'est qu'avec iOS 10 donc qu'Apple désactive l'IDFA lorsque l'utilisateur active le "Suivi publicitaire limité" ! L'IDFA est alors remplacé par une valeur non unique composée uniquement de zéros.
Voici la réaction d'un publicitaire à l'annonce du lancement de l'IDFA (en 2012 avec iOS 6), et du "dark pattern" associé à l'option "Suivi publicitaire limité" :
"It's a really pretty elegant, simple solution," says Mobile Theory CEO Scott Swanson. "The biggest thing we're excited about is that it's on by default, so we expect most people will leave it on."
Cette responsabilité historique a donc valu une plainte RGPD devant la CNIL, de la part de la Quadrature du Net :

Changement de paradigme donc avec iOS 14.5, les applications devront vous demander l'autorisation pour vous pister, comme le montre la nouvelle interface (visible dès iOS 14, même si la protection n'est pas encore effective) :
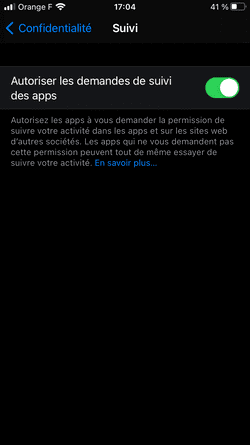 Dans Réglages > Confidentialité > Suivi, "Autoriser les demandes de suivi des apps" est coché par défaut (au pire, les Apps vous demanderont si vous souhaitez être pisté), et vous pouvez décocher l'option.
Dans Réglages > Confidentialité > Suivi, "Autoriser les demandes de suivi des apps" est coché par défaut (au pire, les Apps vous demanderont si vous souhaitez être pisté), et vous pouvez décocher l'option.
Pour comparaison, l'équivalent Google Android de l'IDFA est l'Android Advertising ID. Mais les protections sont quasi inexistantes :
- Il est impossible de désactiver l'Android Advertising ID (il était possible de désactiver l'IDFA dès iOS 10).
- Il est seulement possible de le réinitialiser.
L'association noyb a lancé une plainte RGPD contre Google pour le suivi utilisateurs par le biais d'un "Android Advertising ID" sans base juridique valable. On peut noter qu'une plainte RGPD de noyb existe également contre Apple pour le suivi sans consentement via l'IDFA. Mais avec ce rattrapage, Apple risque beaucoup moins gros que Google (noyb signale aussi qu'après la mise à jour, Apple pourra toujours utiliser l'IDFA sans consentement, ce qui est faux).
Techniquement, les publicitaires n'auront plus accès à l'IDFA si vous n'avez pas explicitement donné votre autorisation. Mais les publicitaires ont d'autres armes en main pour vous surveiller (fingerprint, hash de l'adresse e-mail...). Apple va-t-il aussi lutter contre ces techniques ? L'avenir nous le dira, mais il semble bien que cela soit son intention :
- Apple a refusé des applications qui contenaient le SDK d'Adjust, une société marketing qui créait un fingerprinting afin d'identifier les utilisateurs.
- Apple a également déjà refusé des applications chinoises qui avaient créés un fingerprint commun (CAID).
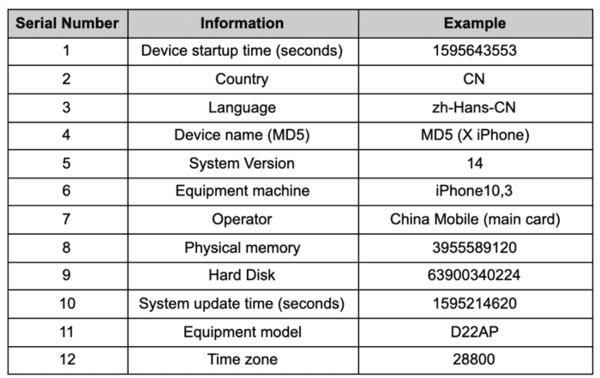
Les paramètres de votre appareil iOS permettant de générer le fingerprint CAID.
De la même manière que sur le web avec son "Private Click Measurement (PCM)", Apple ne laisse pas les publicitaires à l'abandon. La mesure de téléchargements d'applications à la suite d'une campagne publicitaire était effectuée via l'IDFA ou via un fingerprint (réalisé par des sociétés telles que Adjust). Apple met maintenant à disposition des développeurs l'API SKAdNetwork, pour effectuer la mesure tout en protégeant la vie privée des utilisateurs.
Apple contre Facebook
La promesse d'ATT est simple :
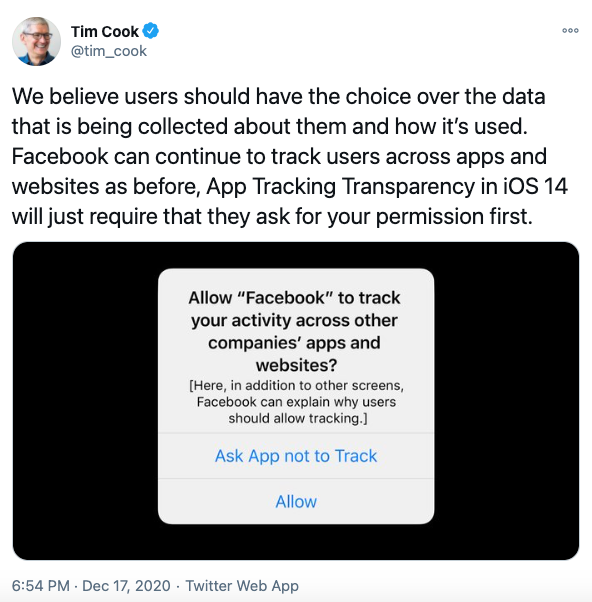
Merci Tim Cook.
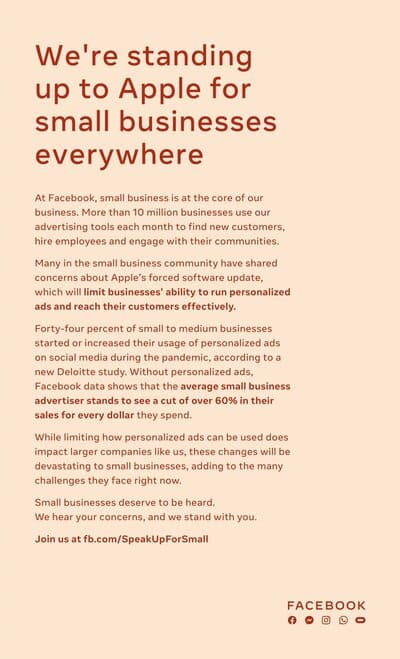
L'importance de cette mise à jour peut se mesurer à la réaction épidermique de Facebook, qui voit sa capacité de surveillance sévèrement diminuée sur iOS (son SDK étant aujourd'hui omniprésent sur les Apps). Facebook justifie sa démarche par la défense des petits commerces, qui seraient dépendants de la publicité ciblée de Facebook pour trouver de nouveaux clients :
- Facebook a fait témoigner des petits commerces contre la mise à jour d'Apple.
- Même les propres employés de Facebook pointent l'hypocrisie de la démarche : “It feels like we are trying to justify doing a bad thing by hiding behind people with a sympathetic message,”
Facebook a aussi acheté des pages entières de publicité dans de grands journaux américains pour dénoncer la mise à jour d'Apple :

Apple contre les publicitaires français
Les publicitaires français sont à la pointe du combat contre Apple, et après une lettre publique envoyée à Tim Cook en juillet (spoiler : il n'a pas répondu), ils se décident à porter plainte auprès de l'autorité de la concurrence en octobre dernier. L'objet de leur plainte ? L’introduction obligatoire de la sollicitation ATT pour les applications sur iOS qui souhaiteraient faire un suivi de l’activité de l’utilisateur sur des sites tiers.
Première réponse de l'autorité de la concurrence le 17 mars et premier camouflet pour l'industrie publicitaire, sur le volet vie privée :
En l’état de l’instruction, l’Autorité a estimé que la décision d’Apple de mettre en place un dispositif de recueil du consentement complémentaire à celui mis en place par d’autres acteurs de la publicité en ligne, n’apparaissait pas comme une pratique abusive
L'instruction continue néanmoins :
Celle-ci devra notamment permettre de vérifier que la mise en place par Apple de la sollicitation ATT ne peut être regardée comme une forme de discrimination ou « self preferencing », ce qui pourrait notamment être le cas si Apple appliquait sans justification, des règles plus contraignantes aux opérateurs tiers que celles qu’elle s’applique à elle-même pour des opérations similaires.
Il est fort à parier que les publicitaires se fassent aussi débouter sur le volet anticoncurrentiel car Apple ne favorise pas ses propres applications : il ne pratique pas le tracking (et n'utilise donc pas l'IDFA). Apple propose des publicités ciblées sur ses Apps (Apple News, App Store, Bourse), en utilisant les données personnelles récoltées lui-même. Google, Facebook ou n'importe quelle autre App peut faire de même sur iOS, Apple ne s'oppose pas aux publicités personnalisées.
Autre plainte, cette fois-ci devant la CNIL par l'association France Digitale. L'attaque est plus subtile, Apple active par défaut les publicités personnalisés sur ses propres applications :
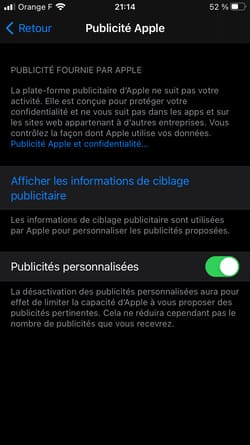
Si vous allez dans Réglages > Confidentialité > Publicité Apple, l'option publicités personnalisées est activée par défaut.
Clairement, Apple devrait demander votre consentement avant de pouvoir proposer de la publicité personnalisée, il ne respecte donc pas le RGPD. France Digital indique que cela porte un préjudice significatif :
- Aux utilisateurs (c'est vrai, encore que la publicité personnalisée sur Apple News, l'App Store et Bourse soit très loin du préjudice de la publicité personnalisée sur les applis Google ou Facebook).
- Aux startups françaises qui, je cite, "respectent scrupuleusement les règles posées par le RGPD". C'est osé ! La liste des entreprises faisant partie de l'association n'est pas publique, mais on peut noter que Frichti en fait partie, et l'appli qui bafoue le RGPD.
La plainte parle encore de distorsion de concurrence en insinuant qu'Apple proposerait de la publicité personnalisée avec ses "sociétés affiliées" :
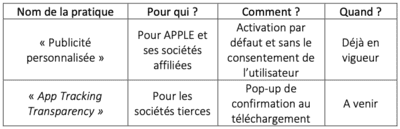
Tableau inclus dans la plainte de France Digitale, censé montrer une distorsion de concurrence.
Comme déjà vu, le pistage et la publicité personnalisé au sein d'une même App ou de plusieurs Apps d'une même société est jugé légitime par Apple, cette pratique n'est pas le simple fait d'Apple mais aussi de Google, Facebook, Twitter, etc. France Digitale parle donc des "sociétés affiliées", des partenaires d'Apple qui comploteraient ensemble pour vous traquer.
Les explications d'Apple sur son programme de publicité sont pourtant très clair, il n'y a ni transmission, ni partage de données personnelles avec des tiers :
Apple ne partage ni ne transmet les données pouvant vous identifier personnellement à des parties tierces.
Également, Apple ne récupère pas de données personnelles via des tiers :
La plateforme publicitaire d’Apple ne suit pas vos activités, c’est-à-dire qu’elle n’associe pas les données d’utilisateur ou d’appareil recueillies sur nos apps à des données d’utilisateur ou d’appareil recueillies auprès de tiers à des fins de ciblage ou de mesure publicitaires, et ne partage pas les données d’utilisateur ou d’appareil avec des courtiers en données.
Aucune mention de "sociétés affiliées" dans l'engagement de confidentialité d'Apple, cela ressemble à une invention de France Digitale.
Mais pourquoi un tel acharnement "d'entrepreneurs et investisseurs du numérique français" contre Apple ? Sans doute parce que l'adtech pèse très lourd en France, on peut voir par exemple l'implication de Criteo (le fameux géant du marketing de surveillance français) dès le lancement de France Digitale ici et là. Il faut dire que Criteo n'aime guère Apple, et cela depuis quelque temps déjà.
Apple contre les publicitaires américains
Chez les publicitaires américains, les attaques sont plus subtiles mais guère convaincantes. Vous pouvez lire Ben Thomson ou Eric Benjamin Seufert (chez Ben Thomson ou sur son site). Voici quelques arguments :
- En s'attaquant au tracking, on renforcerait les "Walled Gardens" (Google, Facebook, etc). Ce à quoi répond très bien Wolfie Christl dans ce thread Twitter :
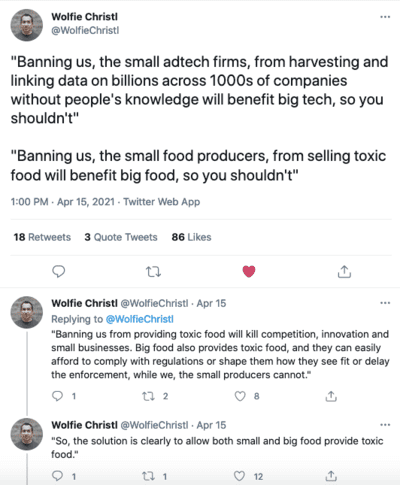
- Sur le renfort supposé aux "Walled Gardens", s'attaquer au tracking n'empêche d'ailleurs pas de s'attaquer aux géants publicitaires. Les 2 axes peuvent se compléter : lisez par exemple la plainte de Brave contre le RTB ("external" data free-for-all), ainsi que la plainte de Brave contre Google ("internal" data-free-for-all). Sans parler vie privée, il serait intéressant de s'attaquer aux abus de position dominante des géants publicitaires, Google et Facebook. Mais les lobbyistes publicitaires ignorent l'option.
- Apple ne chercherait pas à protéger votre vie privée sur les Apps (via ATT), mais plutôt à contrôler l'intégralité de votre expérience. Hors Facebook dérangerait Apple car la découverte de nouvelles Apps ne passeraient plus du tout par l'App Store mais par la publicité personnalisée sur Facebook ou Instagram. En s'attaquant au tracking, Apple chercherait donc à reprendre le contrôle sur la distribution des Apps. Mais quelle est la part réelle de la publicité dans la distribution des Apps ?
- Argument similaire sur le web (via ITP), où Apple chercherait plutôt à asphyxier les ressources publicitaires. En conséquence, les éditeurs devraient miser sur les abonnements via les Apps, sur lesquels Apple touche une commission. Mais pourquoi ne pas proposer de la publicité respectueuse de la vie privée ?
- Apple lutterait contre les acteurs publicitaires pour pousser son propre business publicitaire. Difficile à croire car le business publicitaire d'Apple (App Store, Apple News et Bourse) est dérisoire comparé à ses autres revenus (produits, services). Apple a également fermé iAd, son ad-network, en décembre 2016.
Si la volonté de contrôle d'Apple est évidente, et si le monopole de l'App Store est un énorme problème, les arguments des lobbyistes publicitaires manquent de pertinence. Apple a une raison évidente d'investir pour mieux protéger la vie privée : la demande de protection est forte (et les clients potentiels d'Apple ne sont pas les publicitaires, mais vous et moi).
Apple force la transparence chez les développeurs d'App
Depuis décembre 2020, Apple a rendu obligatoire les étiquettes de confidentialité sur les Apps. Ces étiquettes permettent de mettre en valeur les différences entre applications. Si l'on compare des navigateurs par exemple :
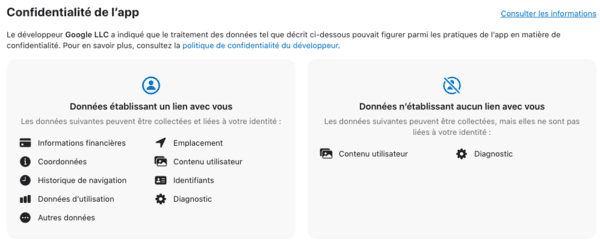
Le spyware Google Chrome.
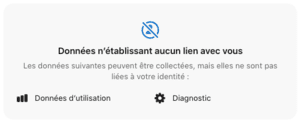
Le navigateur de DuckDuckGo, respectueux de votre vie privée.
Si l'on regarde maintenant les messageries :
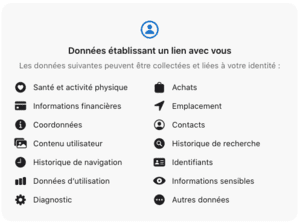
Messenger, le spyware de Facebook, encore pire que WhatsApp.

Signal, une App respectueuse de la vie privée.
Certes, ces étiquettes ont des limites :
- Elles sont basées sur de l'auto-déclaration. Apple va-t-il contrôler si le développeur dit la vérité ?
- Il n'y a pas d'informations sur les données personnelles qui peuvent fuiter vers des tiers. Il serait intéressant de voir qui récupère vos données personnelles et pourquoi.
Mais elles représentent déjà une belle avancée, et pousseront peut-être les développeurs d'Apps à limiter l'usage de données personnelles à celles qui sont strictement nécessaires.
Apple pourrait-il aller plus loin sur les Apps ?
Avec ATT, Apple s'est mis au niveau de Safari ITP (protection contre le tracking). S'il voulait aller plus loin, il pourrait décider de bloquer les publicités et les traceurs 1st-party (analytics, A/B testing, tag managers...). Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, les traceurs de Google Analytics, Segment, Mixpanel ou Amplitude ne sont pas bloqués.
Mais il se mettrait à dos certains développeurs, et ce ne serait pas cohérent avec sa politique actuelle sur le web via Safari ITP.
Malheureusement, cette publicité ne s'applique donc pas aux traceurs 1st-party, votre iPhone communique toujours avec de nombreux tiers, dont ceux de Google (même si les identifiants devraient maintenant être spécifiques à chaque App, car l'IDFA n'est plus disponible par défaut) :

Avec le support natif des DNS chiffrés via iOS 14, il a néanmoins permis à des bloqueurs de traceurs et de publicités de mieux faire leur travail (ces bloqueurs devaient créer un pseudo VPN local, ce qui était une catastrophe pour la batterie). J'utilise pour ma part NextDNS, ce qui me permet de bloquer tous les traceurs et autres publicités.
Oui, Apple vous protège contre la surveillance publicitaire, de mieux en mieux
Comme nous l'avons vu, les protections apportées par Apple contre la surveillance publicitaire sur iOS sont largement améliorables. Mais elles ont le mérite d'être cohérentes et de lutter assez efficacement contre le tracking, comme le prouve d'ailleurs l'énervement de Facebook et de l'adtech en général. Un utilisateur avancé pourra aller plus loin en passant par un bloqueur de traceurs et de publicités tel que NextDNS, AdGuard ou un Pi-Hole.
Même s'il est sain de critiquer une multinationale aussi dominante, et pour des raisons très valables (système fermé, verrouillé, réparabilité très limitée, monopole de l'App Store, "optimisation fiscale", obsolescence programmée, etc), l'alternative "Android by Google" n'est pas crédible si vous souhaitez protéger votre vie privée.
Si vous êtes allergique à Apple mais que vous souhaitez tout de même protéger votre vie privée sur votre smartphone, il vous faudra passer par des distributions qui auront supprimé la couche "Google" d'Android (/e/ par exemple, basé sur Lineage OS et microG), mais il vous faudra de bonnes compétences techniques.
Texte intégral (5859 mots)
La vie privée, un argument produit pour Apple
Face au capitalisme de surveillance développé par Google, Apple a un argument évident, la vie privée. Et il ne s'en prive pas, comme en témoigne cette campagne publicitaire :
Cet argument se retrouve aussi dans les paroles d'un Tim Cook, lors de la conférence "Computers, Privacy & Data Protection" de janvier 2021, un discours tout à fait remarquable.
Apple a toujours été très doué en marketing produit, mais s'agit-il seulement de belles paroles ? Une première réponse est apportée par cette page, une réponse plus détaillée est fournie ici : Apple prend en effet de nombreuses initiatives. On peut par exemple citer :
- Le chiffrement de bout en bout sur iMessage et FaceTime.
- La protection de la vie privée sur Apple Maps.
- Le Secure Element, qui permet à Apple Pay de fonctionner sans connaître votre numéro de carte bleue ni vos transactions.
- Le fait qu'Apple protège de mieux en mieux les accès aux fonctionnalités sensibles de vos appareils iOS tels que la géolocalisation, les photos, le micro ou la vidéo.
- L'initiative "Sign in with Apple", vous permettant de créer un compte sur un service tiers sans partager votre adresse e-mail.
La vie privée est une des valeurs fondamentales d'Apple :
Mais Apple pourrait aller beaucoup plus loin, et je serais prêt à payer pour que les services suivants soient chiffrés de bout en bout : Apple Photos, Calendriers, Contacts, iCloud Drive, Notes ou Messages sur iCloud. Après sa dispute avec le FBI lors de l'attaque terroriste de San Bernardino, durant laquelle il s'est battu courageusement contre l'introduction de portes dérobées sur iOS, Apple avait une opportunité pour étendre l'utilisation du chiffrement de bout en bout à tous ses services. Sous pression du FBI, il n'a malheureusement pas osé :
Apple dropped plans to let iPhone users fully encrypt backups of their devices in the company's iCloud service after the FBI complained that the move would harm investigations, six sources familiar with the matter told Reuters.
Pour le plus grand bonheur des gouvernements, services de polices et services secrets, Apple ne chiffre pas iCloud de bout en bout. Et pour mieux vendre ses produits en Chine, Apple accepte de stocker les clés de chiffrement iCloud de ses utilisateurs Chinois directement sur des serveurs situés en Chine. Autre compromission avec le régime Chinois, Apple censure des Apps en Chine.
Intéressons-nous maintenant aux initiatives d'Apple contre la surveillance publicitaire. Vont-elles assez loin ?
Safari ITP, une bonne protection contre le pistage
En 2017, Apple intègre la fonctionnalité "Intelligent Tracking Prevention" (ITP) à Safari, le but étant de combattre le pistage multi-sites. Depuis cette première sortie, Apple a fait évoluer ITP, avec par exemple le blocage complet des cookies tiers ou la limitation de la durée de vie des cookies déposés via CNAME, ce qui lui permet de vous offrir une bonne protection contre le pistage des sociétés de l'adtech.
Lorsque l'on parle vie privée, Apple a également une excellente influence sur l'écosystème du web.
Les actions d'Apple contre le pistage multi-sites inspirent sans doute d'autres navigateurs. En 2018, Firefox annonce changer sa politique concernant le pistage, souhaitant dorénavant proposer une protection contre le pistage par défaut. En 2019, Firefox passe à l'acte avec "Enhanced Tracking Protection" (ETP), l'équivalent d'ITP, fonctionnalité qu'il a également fait évoluer depuis.
En bonus, si vous utilisez un iPhone ou un iPad et que vous passez par un autre navigateur, les protections d'ITP s'appliquent également ! En effet, Apple verrouille les options des navigateurs tiers, qui se voient obliger d'utiliser WebKit, le moteur de rendu de Safari.
Apple contrebalance l'influence de Google au W3C
Au W3C, l'organisme chargé de construire et de faire évoluer les standards du web, Apple propose des alternatives à Google dans le domaine de la publicité. Si Google a fait beaucoup de bruits avec les propositions visant à remplacer les cookies tiers ("Privacy Sandbox"), notamment la proposition controversée FLoC, Apple propose des standards pour un meilleur respect de la vie privée :
- "Private Click Measurement (PCM)" : pour correctement attribuer des conversions aux campagnes publicitaires. Google a sa propre proposition appelée "Conversion Measurement API", mais celle-ci ne protège guère la vie privée car Google permet à l'annonceur d'attribuer un identifiant unique à chaque clic sur une publicité... Apple limite de son côté les options à 256 valeurs différentes, ce qui permet simplement de savoir quelle campagne publicitaire est efficace.
- "Storage Access API" : Si Apple empêche les tiers de pister l'utilisateur sans son consentement (via les restrictions sur les cookies, le local storage, etc), ceux-ci peuvent demander explicitement l'autorisation à l'utilisateur via cette API. Certains cas d'usages tels que des systèmes d'authentification pouvant justifier cette autorisation.
Toujours au W3C, si Apple n'est pas le seul à défendre la vie privée (Firefox et Brave sont également très actifs), son investissement n'est pas de trop lorsqu'il s'agit de contrebalancer les armées de développeurs Chrome. Ceux-ci vont souvent compromettre la vie privée des utilisateurs sous couvert d'ajouter de nouvelles fonctionnalités au web. Par exemple, voici une liste de 16 fonctionnalités que Safari n'implémente pas car les risques de sécurité et de fingerprint sont trop grands.
Safari pourrait-il aller plus loin ?
Safari pourrait décider de lutter plus radicalement contre la surveillance publicitaire en intégrant par défaut un bloqueur de traceurs et de publicités type uBlock Origin. Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, Google Analytics et Google Tag Manager ne sont pas bloqués par Safari.
- Les traceurs de tiers qui exploitent les vulnérabilités actuelles du web seraient également bloqués. Je pense par exemple à Criteo via son exploitation malsaine du CNAME cloaking, Safari se contentant de limiter la durée de vie des cookies déposés via CNAME à 7 jours.
En parlant de CNAME cloaking, la technique est d'ailleurs utilisé par Apple sur son site web, avec l'outil Adobe Analytics :
Aujourd'hui, Brave va beaucoup plus loin via sa fonctionnalité "Shields" : le but n'est pas d'empêcher le pistage multi-sites mais de bloquer l'exécution des traceurs. Un exemple pour illustrer la différence d'approche : les traceurs utilisant le CNAME cloaking sont bloqués par défaut.
De son côté, Firefox propose moins de protections par défaut mais son système d'extensions est très ouvert (Safari beaucoup moins, vous devez vous contenter d'un "Content Blocker" tels que Firefox Focus), ce qui permet par exemple à uBlock Origin d'être efficace contre le CNAME cloaking.
À noter que les outils marketing peuvent encore malheureusement échapper aux protections des navigateurs et autres bloqueurs de traceurs, parfois même via des solutions clé en main.
Une politique cohérente sur le web... à une exception près
Sur le web, Apple a donc une politique cohérente :
- Safari protège contre le pistage multi-sites.
- Le pistage au sein d'un même site est jugé légitime par Apple, il reste possible.
- Une publicité plus respectueuse de la vie privée est encouragée.
S'il est toujours possible de faire mieux, Safari est à des années-lumière de Google Chrome en ce qui concerne la protection de la vie privée.
Sauf que lorsque l'on parle d'argent, Apple pactise avec le diable : Google paye entre 8 et 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur Safari.
Sur les Apps, un rattrapage nécessaire
Avec iOS 14.5, Apple lance le système "App Tracking Transparency" (ATT), le tracking devient opt-in. Voici la définition du "tracking" selon Apple :
Tracking refers to the act of linking user or device data collected from your app with user or device data collected from other companies’ apps, websites, or offline properties for targeted advertising or advertising measurement purposes. Tracking also refers to sharing user or device data with data brokers.
Cette définition est classique, similaire à celle de Firefox :
Tracking is the collection of data regarding a particular user's activity across multiple websites or applications (i.e., first parties) that aren’t owned by the data collector, and the retention, use, or sharing of data derived from that activity with parties other than the first party on which it was collected.
Elle est également similaire à celle du W3C :
Tracking is the collection of data regarding a particular user's activity across multiple distinct contexts and the retention, use, or sharing of data derived from that activity outside the context in which it occurred. A context is a set of resources that are controlled by the same party or jointly controlled by a set of parties.
Apple est enfin cohérent avec la politique qu'il appliquait déjà sur le web :
- ATT protège contre le pistage multi-Apps.
- Le pistage au sein d'un même App ou sur plusieurs Apps d'une même société est jugé légitime par Apple, il reste possible.
Sur iOS, la surveillance publicitaire a historiquement été facilitée par Apple, via la mise à disposition d'un identifiant publicitaire unique appelé IDFA. Cet identifiant était activé par défaut, les utilisateurs iOS pouvaient le désactiver s'ils le souhaitaient :
Dans Réglages > Confidentialité > Publicité, il était possible de cocher "Suivi publicitaire limité" (ce que j'avais fait, comme le montre la capture), mais l'option était décochée par défaut.
L'option par défaut a une importance capitale : peu de gens changent les paramètres de confidentialité (selon Adjust, seulement 20% des utilisateurs désactivaient l'identifiant).
Apple a donc ici une responsabilité historique : l'IDFA a permis à une multitude de sociétés de vous surveiller facilement, et ceci pendant des années. Pour rappel :
- Avec le lancement de l'iPhone (en 2007), Apple créé un identifiant unique, l'UDID (Unique Device Identifier), idéal pour vous surveiller.
- En 2008 avec la sortie de l'App Store, Apple met l'UDID à disposition des développeurs d'applications : le péché originel, qui ne sera ainsi corrigé que 13 ans plus tard.
- En 2011 et avec l'arrivée d'iOS 5, Apple rend l'UDID obsolète.
- Sauf qu'il faut attendre 2013 pour voir Apple refuser définitivement les Apps qui utilisent encore l'UDID.
- Entre temps (en 2012 avec iOS 6), Apple lance l'IDFA. Il choisit d'activer l'IDFA par défaut, l'utilisateur ne peut pas le désactiver mais seulement indiquer aux applications qu'il ne souhaite pas être pisté (un équivalent de "Do Not Track"), le réglage est bien caché dans "Publicité" (et non dans "Confidentialité").
- Jusqu'à la sortie d'iOS 10 (en 2016), si vous aviez activé "Suivi publicitaire limité", l'application pouvait continuer à utiliser cet identifiant pour le capping, la mesure de conversion, la mesure des visiteurs uniques, la sécurité, la détection de fraude et le debug ! Mais Apple n'avait aucun moyen de vérifier si les applications respectaient vraiment ces règles. Seule option pour l'utilisateur : réinitialiser l'iPhone ou l'iPad, afin de réinitialiser l'IDFA !
- Ce n'est qu'avec iOS 10 donc qu'Apple désactive l'IDFA lorsque l'utilisateur active le "Suivi publicitaire limité" ! L'IDFA est alors remplacé par une valeur non unique composée uniquement de zéros.
Voici la réaction d'un publicitaire à l'annonce du lancement de l'IDFA (en 2012 avec iOS 6), et du "dark pattern" associé à l'option "Suivi publicitaire limité" :
"It's a really pretty elegant, simple solution," says Mobile Theory CEO Scott Swanson. "The biggest thing we're excited about is that it's on by default, so we expect most people will leave it on."
Cette responsabilité historique a donc valu une plainte RGPD devant la CNIL, de la part de la Quadrature du Net :
Changement de paradigme donc avec iOS 14.5, les applications devront vous demander l'autorisation pour vous pister, comme le montre la nouvelle interface (visible dès iOS 14, même si la protection n'est pas encore effective) :
Dans Réglages > Confidentialité > Suivi, "Autoriser les demandes de suivi des apps" est coché par défaut (au pire, les Apps vous demanderont si vous souhaitez être pisté), et vous pouvez décocher l'option.
Pour comparaison, l'équivalent Google Android de l'IDFA est l'Android Advertising ID. Mais les protections sont quasi inexistantes :
- Il est impossible de désactiver l'Android Advertising ID (il était possible de désactiver l'IDFA dès iOS 10).
- Il est seulement possible de le réinitialiser.
L'association noyb a lancé une plainte RGPD contre Google pour le suivi utilisateurs par le biais d'un "Android Advertising ID" sans base juridique valable. On peut noter qu'une plainte RGPD de noyb existe également contre Apple pour le suivi sans consentement via l'IDFA. Mais avec ce rattrapage, Apple risque beaucoup moins gros que Google (noyb signale aussi qu'après la mise à jour, Apple pourra toujours utiliser l'IDFA sans consentement, ce qui est faux).
Techniquement, les publicitaires n'auront plus accès à l'IDFA si vous n'avez pas explicitement donné votre autorisation. Mais les publicitaires ont d'autres armes en main pour vous surveiller (fingerprint, hash de l'adresse e-mail...). Apple va-t-il aussi lutter contre ces techniques ? L'avenir nous le dira, mais il semble bien que cela soit son intention :
- Apple a refusé des applications qui contenaient le SDK d'Adjust, une société marketing qui créait un fingerprinting afin d'identifier les utilisateurs.
- Apple a également déjà refusé des applications chinoises qui avaient créés un fingerprint commun (CAID).
Les paramètres de votre appareil iOS permettant de générer le fingerprint CAID.
De la même manière que sur le web avec son "Private Click Measurement (PCM)", Apple ne laisse pas les publicitaires à l'abandon. La mesure de téléchargements d'applications à la suite d'une campagne publicitaire était effectuée via l'IDFA ou via un fingerprint (réalisé par des sociétés telles que Adjust). Apple met maintenant à disposition des développeurs l'API SKAdNetwork, pour effectuer la mesure tout en protégeant la vie privée des utilisateurs.
Apple contre Facebook
La promesse d'ATT est simple :
Merci Tim Cook.
L'importance de cette mise à jour peut se mesurer à la réaction épidermique de Facebook, qui voit sa capacité de surveillance sévèrement diminuée sur iOS (son SDK étant aujourd'hui omniprésent sur les Apps). Facebook justifie sa démarche par la défense des petits commerces, qui seraient dépendants de la publicité ciblée de Facebook pour trouver de nouveaux clients :
- Facebook a fait témoigner des petits commerces contre la mise à jour d'Apple.
- Même les propres employés de Facebook pointent l'hypocrisie de la démarche : “It feels like we are trying to justify doing a bad thing by hiding behind people with a sympathetic message,”
Facebook a aussi acheté des pages entières de publicité dans de grands journaux américains pour dénoncer la mise à jour d'Apple :
Apple contre les publicitaires français
Les publicitaires français sont à la pointe du combat contre Apple, et après une lettre publique envoyée à Tim Cook en juillet (spoiler : il n'a pas répondu), ils se décident à porter plainte auprès de l'autorité de la concurrence en octobre dernier. L'objet de leur plainte ? L’introduction obligatoire de la sollicitation ATT pour les applications sur iOS qui souhaiteraient faire un suivi de l’activité de l’utilisateur sur des sites tiers.
Première réponse de l'autorité de la concurrence le 17 mars et premier camouflet pour l'industrie publicitaire, sur le volet vie privée :
En l’état de l’instruction, l’Autorité a estimé que la décision d’Apple de mettre en place un dispositif de recueil du consentement complémentaire à celui mis en place par d’autres acteurs de la publicité en ligne, n’apparaissait pas comme une pratique abusive
L'instruction continue néanmoins :
Celle-ci devra notamment permettre de vérifier que la mise en place par Apple de la sollicitation ATT ne peut être regardée comme une forme de discrimination ou « self preferencing », ce qui pourrait notamment être le cas si Apple appliquait sans justification, des règles plus contraignantes aux opérateurs tiers que celles qu’elle s’applique à elle-même pour des opérations similaires.
Il est fort à parier que les publicitaires se fassent aussi débouter sur le volet anticoncurrentiel car Apple ne favorise pas ses propres applications : il ne pratique pas le tracking (et n'utilise donc pas l'IDFA). Apple propose des publicités ciblées sur ses Apps (Apple News, App Store, Bourse), en utilisant les données personnelles récoltées lui-même. Google, Facebook ou n'importe quelle autre App peut faire de même sur iOS, Apple ne s'oppose pas aux publicités personnalisées.
Autre plainte, cette fois-ci devant la CNIL par l'association France Digitale. L'attaque est plus subtile, Apple active par défaut les publicités personnalisés sur ses propres applications :
Si vous allez dans Réglages > Confidentialité > Publicité Apple, l'option publicités personnalisées est activée par défaut.
Clairement, Apple devrait demander votre consentement avant de pouvoir proposer de la publicité personnalisée, il ne respecte donc pas le RGPD. France Digital indique que cela porte un préjudice significatif :
- Aux utilisateurs (c'est vrai, encore que la publicité personnalisée sur Apple News, l'App Store et Bourse soit très loin du préjudice de la publicité personnalisée sur les applis Google ou Facebook).
- Aux startups françaises qui, je cite, "respectent scrupuleusement les règles posées par le RGPD". C'est osé ! La liste des entreprises faisant partie de l'association n'est pas publique, mais on peut noter que Frichti en fait partie, et l'appli qui bafoue le RGPD.
La plainte parle encore de distorsion de concurrence en insinuant qu'Apple proposerait de la publicité personnalisée avec ses "sociétés affiliées" :
Tableau inclus dans la plainte de France Digitale, censé montrer une distorsion de concurrence.
Comme déjà vu, le pistage et la publicité personnalisé au sein d'une même App ou de plusieurs Apps d'une même société est jugé légitime par Apple, cette pratique n'est pas le simple fait d'Apple mais aussi de Google, Facebook, Twitter, etc. France Digitale parle donc des "sociétés affiliées", des partenaires d'Apple qui comploteraient ensemble pour vous traquer.
Les explications d'Apple sur son programme de publicité sont pourtant très clair, il n'y a ni transmission, ni partage de données personnelles avec des tiers :
Apple ne partage ni ne transmet les données pouvant vous identifier personnellement à des parties tierces.
Également, Apple ne récupère pas de données personnelles via des tiers :
La plateforme publicitaire d’Apple ne suit pas vos activités, c’est-à-dire qu’elle n’associe pas les données d’utilisateur ou d’appareil recueillies sur nos apps à des données d’utilisateur ou d’appareil recueillies auprès de tiers à des fins de ciblage ou de mesure publicitaires, et ne partage pas les données d’utilisateur ou d’appareil avec des courtiers en données.
Aucune mention de "sociétés affiliées" dans l'engagement de confidentialité d'Apple, cela ressemble à une invention de France Digitale.
Mais pourquoi un tel acharnement "d'entrepreneurs et investisseurs du numérique français" contre Apple ? Sans doute parce que l'adtech pèse très lourd en France, on peut voir par exemple l'implication de Criteo (le fameux géant du marketing de surveillance français) dès le lancement de France Digitale ici et là. Il faut dire que Criteo n'aime guère Apple, et cela depuis quelque temps déjà.
Apple contre les publicitaires américains
Chez les publicitaires américains, les attaques sont plus subtiles mais guère convaincantes. Vous pouvez lire Ben Thomson ou Eric Benjamin Seufert (chez Ben Thomson ou sur son site). Voici quelques arguments :
- En s'attaquant au tracking, on renforcerait les "Walled Gardens" (Google, Facebook, etc). Ce à quoi répond très bien Wolfie Christl dans ce thread Twitter :
- Sur le renfort supposé aux "Walled Gardens", s'attaquer au tracking n'empêche d'ailleurs pas de s'attaquer aux géants publicitaires. Les 2 axes peuvent se compléter : lisez par exemple la plainte de Brave contre le RTB ("external" data free-for-all), ainsi que la plainte de Brave contre Google ("internal" data-free-for-all). Sans parler vie privée, il serait intéressant de s'attaquer aux abus de position dominante des géants publicitaires, Google et Facebook. Mais les lobbyistes publicitaires ignorent l'option.
- Apple ne chercherait pas à protéger votre vie privée sur les Apps (via ATT), mais plutôt à contrôler l'intégralité de votre expérience. Hors Facebook dérangerait Apple car la découverte de nouvelles Apps ne passeraient plus du tout par l'App Store mais par la publicité personnalisée sur Facebook ou Instagram. En s'attaquant au tracking, Apple chercherait donc à reprendre le contrôle sur la distribution des Apps. Mais quelle est la part réelle de la publicité dans la distribution des Apps ?
- Argument similaire sur le web (via ITP), où Apple chercherait plutôt à asphyxier les ressources publicitaires. En conséquence, les éditeurs devraient miser sur les abonnements via les Apps, sur lesquels Apple touche une commission. Mais pourquoi ne pas proposer de la publicité respectueuse de la vie privée ?
- Apple lutterait contre les acteurs publicitaires pour pousser son propre business publicitaire. Difficile à croire car le business publicitaire d'Apple (App Store, Apple News et Bourse) est dérisoire comparé à ses autres revenus (produits, services). Apple a également fermé iAd, son ad-network, en décembre 2016.
Si la volonté de contrôle d'Apple est évidente, et si le monopole de l'App Store est un énorme problème, les arguments des lobbyistes publicitaires manquent de pertinence. Apple a une raison évidente d'investir pour mieux protéger la vie privée : la demande de protection est forte (et les clients potentiels d'Apple ne sont pas les publicitaires, mais vous et moi).
Apple force la transparence chez les développeurs d'App
Depuis décembre 2020, Apple a rendu obligatoire les étiquettes de confidentialité sur les Apps. Ces étiquettes permettent de mettre en valeur les différences entre applications. Si l'on compare des navigateurs par exemple :
Le spyware Google Chrome.
Le navigateur de DuckDuckGo, respectueux de votre vie privée.
Si l'on regarde maintenant les messageries :
Messenger, le spyware de Facebook, encore pire que WhatsApp.
Signal, une App respectueuse de la vie privée.
Certes, ces étiquettes ont des limites :
- Elles sont basées sur de l'auto-déclaration. Apple va-t-il contrôler si le développeur dit la vérité ?
- Il n'y a pas d'informations sur les données personnelles qui peuvent fuiter vers des tiers. Il serait intéressant de voir qui récupère vos données personnelles et pourquoi.
Mais elles représentent déjà une belle avancée, et pousseront peut-être les développeurs d'Apps à limiter l'usage de données personnelles à celles qui sont strictement nécessaires.
Apple pourrait-il aller plus loin sur les Apps ?
Avec ATT, Apple s'est mis au niveau de Safari ITP (protection contre le tracking). S'il voulait aller plus loin, il pourrait décider de bloquer les publicités et les traceurs 1st-party (analytics, A/B testing, tag managers...). Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, les traceurs de Google Analytics, Segment, Mixpanel ou Amplitude ne sont pas bloqués.
Mais il se mettrait à dos certains développeurs, et ce ne serait pas cohérent avec sa politique actuelle sur le web via Safari ITP.
Malheureusement, cette publicité ne s'applique donc pas aux traceurs 1st-party, votre iPhone communique toujours avec de nombreux tiers, dont ceux de Google (même si les identifiants devraient maintenant être spécifiques à chaque App, car l'IDFA n'est plus disponible par défaut) :
Avec le support natif des DNS chiffrés via iOS 14, il a néanmoins permis à des bloqueurs de traceurs et de publicités de mieux faire leur travail (ces bloqueurs devaient créer un pseudo VPN local, ce qui était une catastrophe pour la batterie). J'utilise pour ma part NextDNS, ce qui me permet de bloquer tous les traceurs et autres publicités.
Oui, Apple vous protège contre la surveillance publicitaire, de mieux en mieux
Comme nous l'avons vu, les protections apportées par Apple contre la surveillance publicitaire sur iOS sont largement améliorables. Mais elles ont le mérite d'être cohérentes et de lutter assez efficacement contre le tracking, comme le prouve d'ailleurs l'énervement de Facebook et de l'adtech en général. Un utilisateur avancé pourra aller plus loin en passant par un bloqueur de traceurs et de publicités tel que NextDNS, AdGuard ou un Pi-Hole.
Même s'il est sain de critiquer une multinationale aussi dominante, et pour des raisons très valables (système fermé, verrouillé, réparabilité très limitée, monopole de l'App Store, "optimisation fiscale", obsolescence programmée, etc), l'alternative "Android by Google" n'est pas crédible si vous souhaitez protéger votre vie privée.
Si vous êtes allergique à Apple mais que vous souhaitez tout de même protéger votre vie privée sur votre smartphone, il vous faudra passer par des distributions qui auront supprimé la couche "Google" d'Android (/e/ par exemple, basé sur Lineage OS et microG), mais il vous faudra de bonnes compétences techniques.
21.02.2021 à 19:09
Comment Google se moque de la CNIL

Google sanctionné pour manquement à la loi Informatique et Libertés
Le 7 décembre dernier, la CNIL sanctionne Google à hauteur de 100 millions d'euros pour avoir enfreint la législation française sur les cookies :
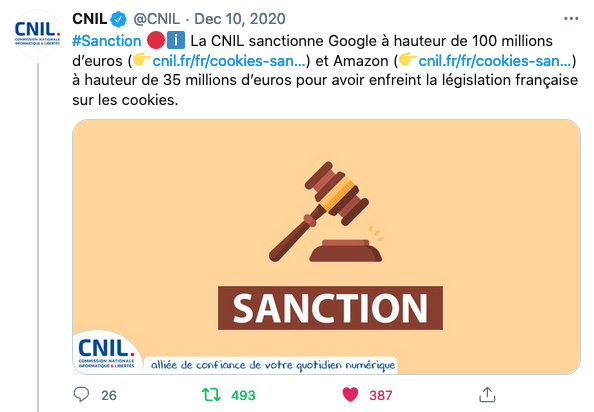
Sur le moteur de recherche de Google, la CNIL a relevé 3 violations à l'article 82 de la loi Informatique et Libertés (transposition de la directive « ePrivacy ») :
- Un dépôt de cookies sans recueil préalable du consentement de l’utilisateur : plusieurs cookies poursuivant une finalité publicitaire étaient automatiquement déposés lorsque l'utilisateur se rendait sur google.fr (cookies non essentiels au service).
- Un défaut d’information des utilisateurs du moteur de recherche google.fr : le bandeau d'information ne fournissait aucune information relative aux cookies.
- La défaillance partielle du mécanisme « d’opposition » : désactiver la personnalisation des annonces n'avait pas d'impact sur un des cookies publicitaires.
Le moteur de recherche, vache à lait de Google
Si Google propose une multitude de services, son moteur de recherche génère toujours la majorité de ses revenus :

Lors du 4ème trimestre 2020, la recherche Google générait 56% de ses revenus. Les sites partenaires, YouTube, Google Play ou Google Cloud représentent une part non négligeable des revenus, mais ils sont beaucoup moins rentables.
La recherche est stratégique pour Google, elle lui a permis d'imposer son capitalisme de surveillance à de multiples domaines :
- Dominer la recherche lui a permis de devenir dominant dans l'adtech, cf. "La domination des marchés publicitaires de Google".
- Cette domination est facilitée par l'exploitation de vos données personnelles, sans réel consentement cf. "Google associe vos données de surf à vos données personnelles, et il est difficile d'y échapper".
- Google permet également à des tiers de vous surveiller même lorsque vous prenez des précautions, cf. "Google Tag Manager, la nouvelle arme anti adblock".
- Les revenus générés par son moteur de recherche ont permis à Google d'être dominant dans de nombreux domaines, cf. "Les services Google qui captent vos données personnelles, et les alternatives".
Google face à la CNIL
Nous avons donc :
- D'un côté la loi, censée protéger la vie privée des internautes, matérialisée ici par une sanction de la CNIL.
- De l'autre côté, l'exploitation de vos données personnelles sur le service le plus stratégique de Google, son moteur de recherche.
Quel sera le vainqueur ?
Dans sa sanction, la CNIL relève 2 points :
- Depuis une mise à jour de septembre 2020, Google cesse de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
- Le nouveau bandeau d’information ne permet toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informe pas du fait qu’ils peuvent refuser ces cookies.
La CNIL indique que Google a 3 mois pour informer correctement les utilisateurs, sous peine du paiement d'une astreinte de 100.000 euros par jour de retard. Étudions maintenant ce qui se passe à la première visite sur google.fr.
Google continue le dépôt automatique de cookies publicitaires
Démarrons notre investigation sur google.fr :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur google.fr.
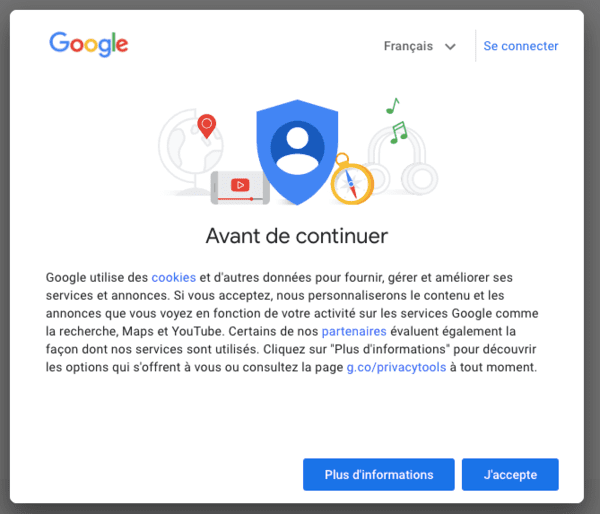
Comme vous pouvez le voir, le bandeau d'information fournit maintenant de l'information relative aux cookies, mais ne permet pas de refuser facilement le dépôt de cookies non essentiels.
Que dit la loi ? Si l'on cite la CNIL, le consentement n'est valide que si la personne exerce un choix réel. En particulier, "l'utilisateur doit pouvoir accepter ou refuser le dépôt et/ou la lecture des cookies avec le même degré de simplicité". Ce n'est clairement pas le cas ici.
Google cesse-t-il de déposer automatiquement des cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr comme le déclare la CNIL ? Regardons les requêtes via Charles Proxy :
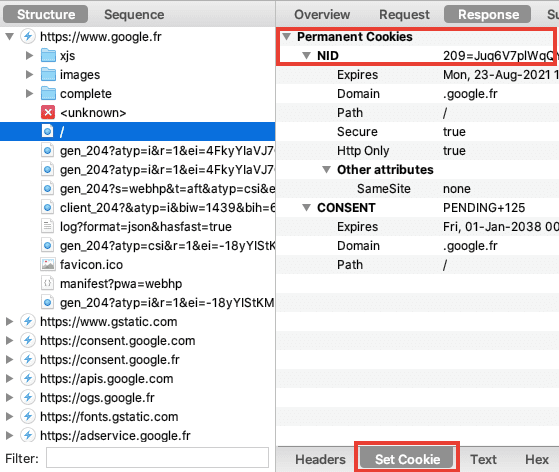
Comme on le voit, Google dépose le cookie NID dès l'arrivée sur google.fr. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
Google a également indiqué à la CNIL que le cookie NID poursuivait une finalité publicitaire (cf. la délibération, point 99) :
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Et pourtant, la CNIL souligne que Google a arrêté cette pratique (point 102) :
Elle souligne néanmoins que durant la procédure de sanction les sociétés ont apporté des modifications à la page google.fr, qui ont notamment amené, depuis le 10 septembre 2020, à l’arrêt du dépôt automatique de ces quatre cookies dès l’arrivée de l’utilisateur sur la page.
Le contrôle de la CNIL a-t-il été correctement effectué ? Toujours est-il que Google continue de violer la loi, cf. le site de la CNIL :
Le consentement doit être préalable au dépôt et/ou à la lecture de cookies. Tant que la personne n'a pas donné son consentement, les cookies ne peuvent pas être déposés ou lus sur son terminal.
Des pièges dans le parcours de consentement Google
Le bandeau d'information Google nous dit :
Si vous acceptez, nous personnaliserons le contenu et les annonces que vous voyez en fonction de votre activité sur les services Google comme la recherche, Maps et YouTube. [...] Cliquez sur "Plus d'informations" pour découvrir les options qui s'offrent à vous
Si je clique sur "Plus d'informations", je suis exposé à une nouvelle fenêtre d'information :
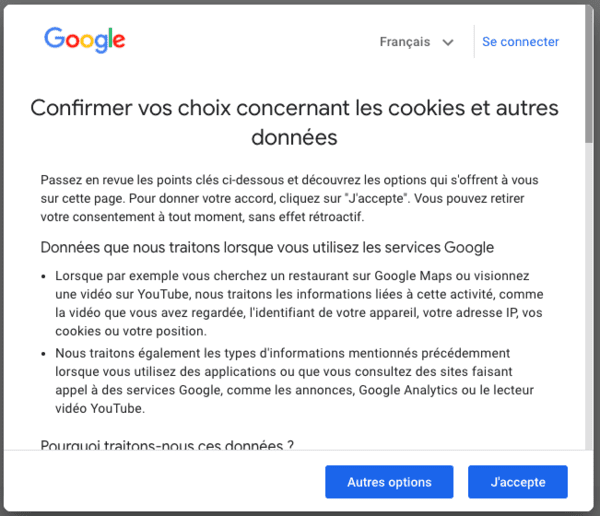
Google détaille ici les données personnelles traitées, les finalités, ainsi que les paramètres de confidentialité. Notez toujours les boutons "J'accepte" et "Autres options" : Google ne permet toujours pas de refuser le dépôt de cookies non essentiels.
Là, vous pourriez vous perdre dans le parcours de Google et cliquer sur "Autres options", en espérant tomber "rapidement" sur l'option pour refuser la surveillance publicitaire. Vous découvrirez cet écran :
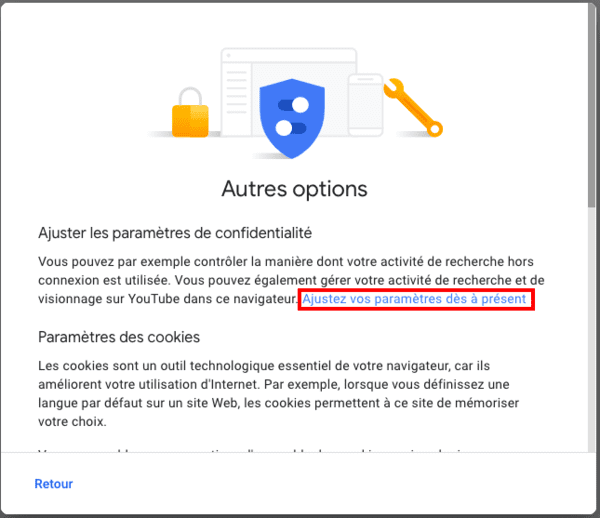
Là, Google présente plusieurs options :
- Ajuster les paramètres de confidentialité : c'est la bonne option ! Il vous faut cliquer sur "Ajustez vos paramètres dès à présent".
- Paramétrer les cookies dans le navigateur : option que Google ne recommande pas : "Vous pouvez bloquer une partie ou l'ensemble des cookies, mais cela risque d'empêcher l'exécution de certaines fonctionnalités sur le Web. Par exemple, de nombreux sites Web requièrent l'activation des cookies lorsque vous souhaitez vous y connecter.".
- Installer un module complémentaire pour désactiver le suivi de Google Analytics : Google Analytics est malheureusement loin d'être le seul outil dont Google se sert pour vous surveiller sur le web (Google vous surveille d'abord via la publicité). Inutile de dire qu'une personne soucieuse de sa vie privée préfèrera utiliser un adblocker.
- Vous connecter à votre compte Google : afin de ne plus voir ce rappel ! Google indique en effet : "Si vous effacez régulièrement les cookies de votre navigateur, vous continuerez à recevoir ce rappel de confidentialité, car nous n'avons aucun moyen de savoir que vous l'avez déjà vu". L'inconvénient de vous surveiller par défaut : sans cookies, Google part du principe qu'il a le droit de vous surveiller !
Que se passe-t-il si vous cliquez sur "Ajustez vos paramètres dès à présent" ? Vous revenez à l'étape précédente ! Mais vous n'étiez pas assez attentif, l'étape contient des liens vers la modification de paramètres :
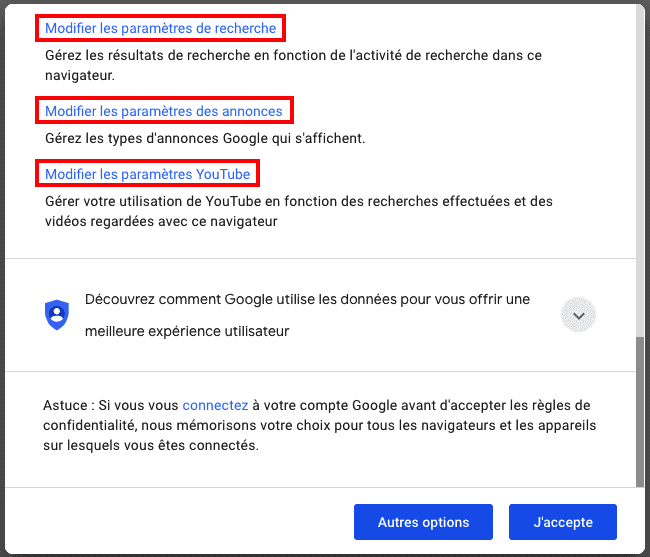
Le parcours du combattant n'est pas terminé.
16 clics supplémentaires pour refuser la surveillance
Cliquons donc sur "Modifier les paramètres de recherche" :
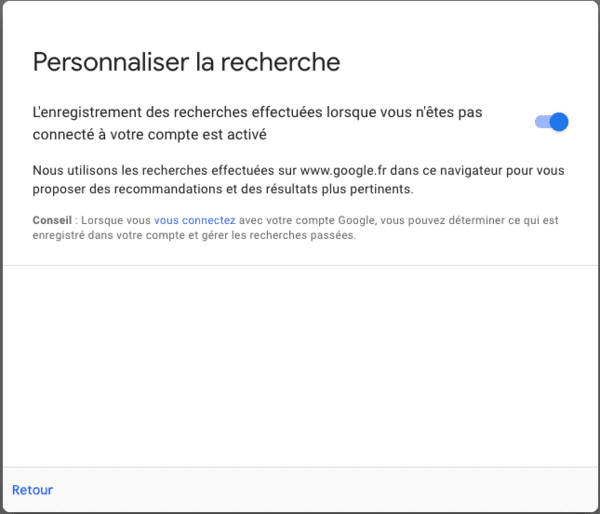
Décochons donc "L'enregistrement des recherches", puis cliquons sur "Retour" et enfin sur "Modifier les paramètres des annonces" :
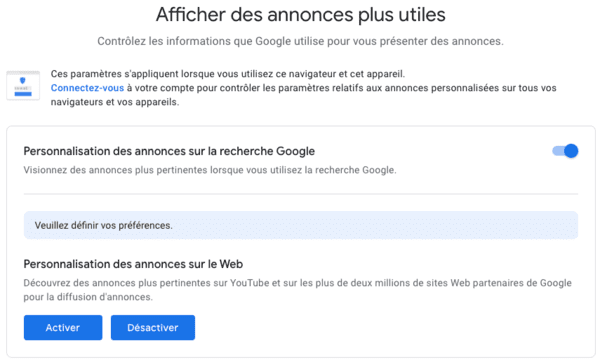
Ici, il vous faut décocher "Personnalisation des annonces sur la recherche Google" et "Personnalisation des annonces sur le Web". Avec ces paramètres cochés par défaut, Google se permet de vous surveiller sur les "plus de deux millions de sites Web partenaires de Google pour la diffusion d'annonces".
Lorsque vous décochez "Personnalisation des annonces sur la recherche Google", vous avez droit à une petite surprise supplémentaire :
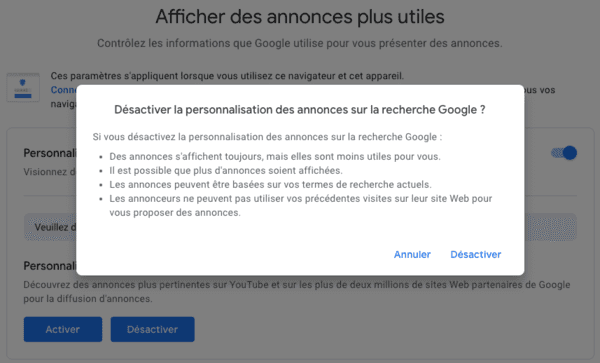
Êtes-vous vraiment sûr de vous ? Google vous rend la tâche encore un peu plus difficile : vos recherches en disent beaucoup sur vous...
Et lorsque vous cliquez sur "Désactiver", Google affiche un message de toute beauté :
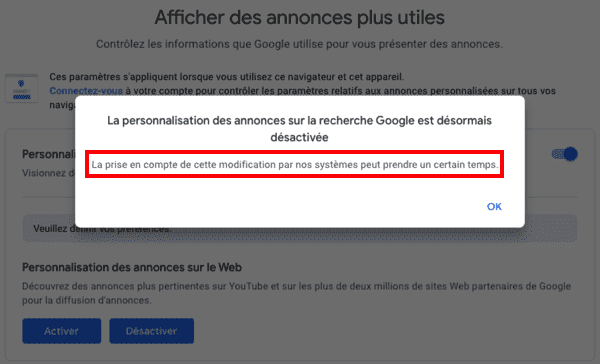
"La prise en compte de cette modification par nos systèmes peut prendre un certain temps."
Google ne doit pas s'attendre à ce que vous réussissiez le chemin d'obstacle ! Même punition si vous cliquez sur le bouton "Désactiver" pour la "Personnalisation des annonces sur le Web" :
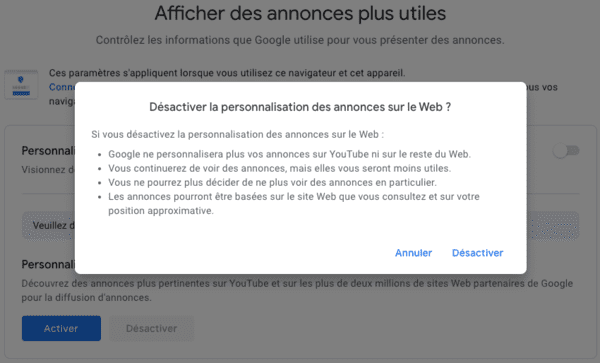
Là aussi, on voit que c'est compliqué pour Google :
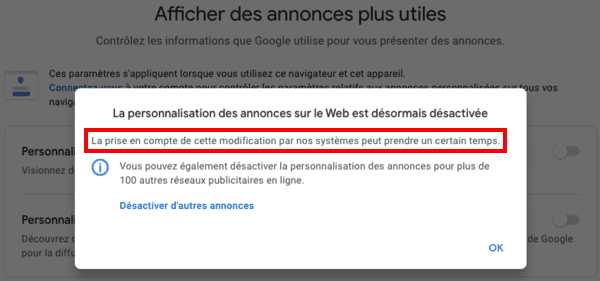
Si vous voulez installer d'autres cookies "Opt-out", qui ne désactivent que la personnalisation des publicités mais laissent les sociétés de l'adtech vous surveiller, Google vous redirige vers le site de l'industrie publicitaire :
Vous pouvez également désactiver la personnalisation des annonces pour plus de 100 autres réseaux publicitaires en ligne.
Revenez encore sur le bandeau d'information pour cliquer maintenant sur "Modifier les paramètres YouTube" :

Cette fois-ci, vous êtes dirigé vers le site YouTube, il vous faut encore décocher "Vidéos que vous regardez sur YouTube" et cliquer sur "Effacer l'historique des vidéos regardées":
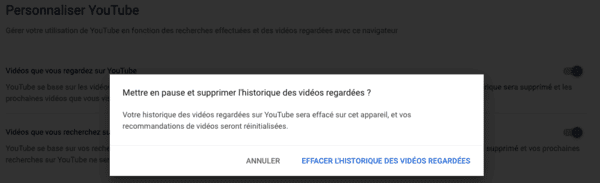
Puis il vous faut décocher "Vidéos que vous recherchez sur YouTube" et cliquer sur "Effacer l'historique des recherches" :
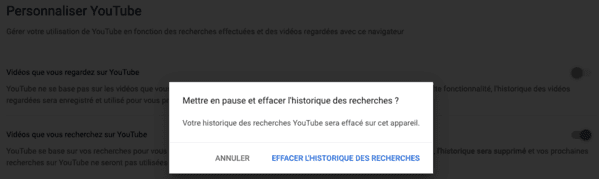
Et pour couronner ce beau parcours, lorsque vous revenez sur le bandeau d'information, il vous faut cliquer sur "J'accepte" (cela reste le seul moyen de supprimer ce bandeau d'information, même si vous venez de tout refuser) :
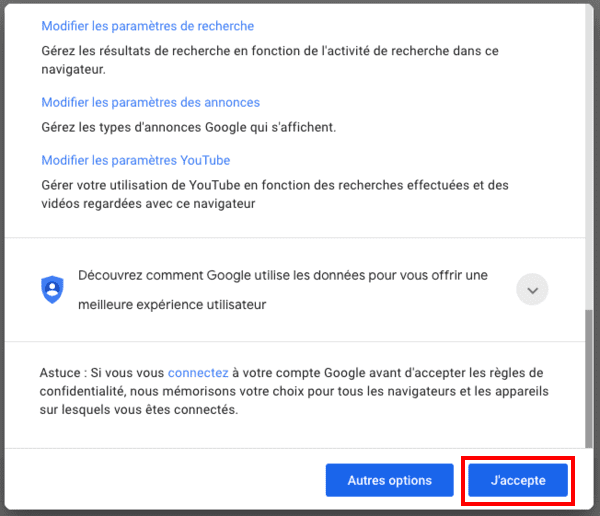
Au total, si vous prenez le chemin le plus rapide, il vous faut 17 clics !
Pendant le parcours de "non consentement", la surveillance continue
Que se passe-t-il pendant ce parcours de "non consentement" ? Si l'on observe les requêtes via Charles :
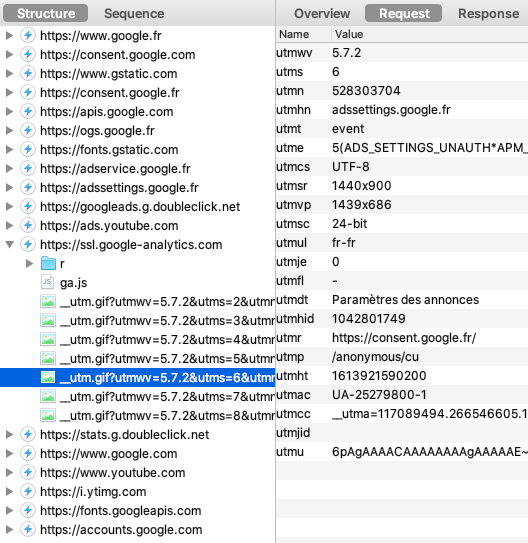
Google continue d'alimenter ses services publicitaires, dont Google Analytics et Doubleclick.
Malgré votre refus, vous continuez d'être surveillé par Google sur le web
Suite à ce parcours d'obstacles, consultons le site Lemonde.fr (dopé aux traceurs, cf. "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr") et filtrons les requêtes sur Google :
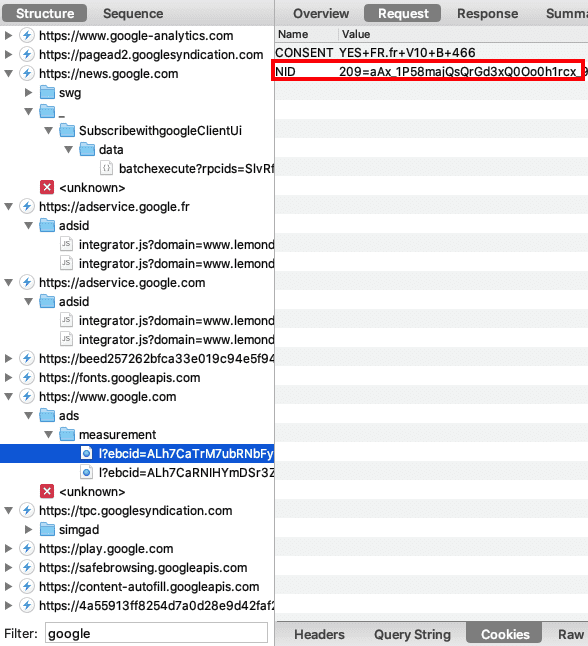
Comme vous le voyez, Lemonde.fr aime bien Google.
Manque de chance, Google n'a pas supprimé le cookie NID. En conséquence, de nombreuses requêtes sont envoyées depuis le site Lemonde.fr vers Google avec votre identifiant stocké dans le cookie NID (rappel, c'est un cookie publicitaire). Ainsi, la violation suivante est toujours valable :
Lorsqu’un utilisateur désactivait la personnalisation des annonces sur la recherche Google en recourant au mécanisme mis à sa disposition à partir du bouton « Consulter maintenant », un des cookies publicitaires demeurait stocké sur son ordinateur et continuait de lire des informations à destination du serveur auquel il est rattaché.
La formation restreinte a donc estimé que le mécanisme « d’opposition » mis en place par les sociétés était partiellement défaillant, en violation de l’article 82 de la loi Informatique et Libertés.
Google va-t-il proposer un vrai mécanisme de consentement ?
La CNIL a sanctionné Google sur des obligations qui préexistaient au RGPD (article 82 de la loi Informatique et Libertés, transposition de la directive « ePrivacy »).
Or depuis le 1er octobre 2020, la CNIL a publié ses lignes directrices modificatives ainsi qu’une recommandation portant sur l’usage de cookies et autres traceurs. La CNIL a demandé aux acteurs de se conformer aux règles ainsi clarifiées, en estimant que cette période d’adaptation ne devrait pas dépasser six mois.
Refuser les traceurs doit être aussi aisé que de les accepter. La CNIL recommande que l’interface de recueil du consentement ne comprenne pas seulement un bouton « tout accepter » mais aussi un bouton « tout refuser ».
Les utilisateurs devront être en mesure de retirer leur consentement, facilement, et à tout moment.
On attend donc avec impatience le 1er avril et la mise en conformité de Google afin de pouvoir refuser sa surveillance en 1 clic (et non en 17 clics)... En réalité, même les obligations antérieures au RGPD sont bafouées :
- Google a contesté son amende de 100 millions d'euros devant le Conseil d'État.
- Comme on l'a vu, Google vous surveille via le cookie
NID, avant même votre consentement mais aussi après votre refus de consentement. - Tenter de refuser la surveillance de Google est un parcours du combattant.
- Il est permis de douter du caractère dissuasif des sanctions de la CNIL, si tant est qu'elle arrive à se faire payer. 100 millions d'euros et 100.000 euros par jour (soit 36 millions d'euros par an), ce n'est pas si cher pour Google.
Google est l'exemple le plus frappant de ce mensonge au consentement, mais le web français est infesté de sites qui bafouent votre vie privée, exemples :
- "La grande braderie de vos données personnelles sur Le Bon Coin".
- "Le recueil du consentement sur internet : un mensonge généralisé".
Reste à voir si la CNIL prendra des sanctions dissuasives à partir du 1er avril.
Vos alternatives pour éviter la surveillance de Google
Si l'on se restreint au moteur de recherche Google (l'objet de cet article), vous avez d'autres options comme :
- DuckDuckGo : un moteur de recherche américain qui ne vous surveille pas. L'interface est épurée, le moteur de recherche est un des choix par défaut sur Safari, et le gros des résultats est basé sur Bing.
- Qwant : la version française, une interface moins épurée, le gros des résultats est aussi basé sur Bing.
- Ecosia : la version allemande, Ecosia reverse 80% de ses bénéfices à des associations à but non lucratif qui œuvrent au programme de reforestation présent essentiellement dans les pays du sud. Ecosia est aussi principalement basé sur Bing.
- Startpage : la version hollandaise, l'interface est épurée et les résultats sont ceux de Google. Du coup, c'est mon choix (les résultats de Google sont souvent bien plus pertinents que ceux de Bing). Startpage est devenu controversé depuis son rachat en 2019 par une société ayant des participations dans l'adtech (vous pouvez vous faire votre propre opinion en lisant cet article).
Il est intéressant de lire pourquoi Google fournit ses résultats de recherche à Startpage :
Why does Google let Startpage access their search results? Startpage.com has a contract with Google that allows us to use their official "Syndicated Web Search" feed, so we have to pay them to get those results.
À la différence de Bing qui fournit ses résultats à de nombreux méta-moteurs (DuckDuckGo, Qwant, Ecosia...), Google est avare de ses résultats de recherche. Startpage semble être le seul à y avoir accès, pour combien de temps ?
Texte intégral (3582 mots)
Google sanctionné pour manquement à la loi Informatique et Libertés
Le 7 décembre dernier, la CNIL sanctionne Google à hauteur de 100 millions d'euros pour avoir enfreint la législation française sur les cookies :
Sur le moteur de recherche de Google, la CNIL a relevé 3 violations à l'article 82 de la loi Informatique et Libertés (transposition de la directive « ePrivacy ») :
- Un dépôt de cookies sans recueil préalable du consentement de l’utilisateur : plusieurs cookies poursuivant une finalité publicitaire étaient automatiquement déposés lorsque l'utilisateur se rendait sur google.fr (cookies non essentiels au service).
- Un défaut d’information des utilisateurs du moteur de recherche google.fr : le bandeau d'information ne fournissait aucune information relative aux cookies.
- La défaillance partielle du mécanisme « d’opposition » : désactiver la personnalisation des annonces n'avait pas d'impact sur un des cookies publicitaires.
Le moteur de recherche, vache à lait de Google
Si Google propose une multitude de services, son moteur de recherche génère toujours la majorité de ses revenus :
Lors du 4ème trimestre 2020, la recherche Google générait 56% de ses revenus. Les sites partenaires, YouTube, Google Play ou Google Cloud représentent une part non négligeable des revenus, mais ils sont beaucoup moins rentables.
La recherche est stratégique pour Google, elle lui a permis d'imposer son capitalisme de surveillance à de multiples domaines :
- Dominer la recherche lui a permis de devenir dominant dans l'adtech, cf. "La domination des marchés publicitaires de Google".
- Cette domination est facilitée par l'exploitation de vos données personnelles, sans réel consentement cf. "Google associe vos données de surf à vos données personnelles, et il est difficile d'y échapper".
- Google permet également à des tiers de vous surveiller même lorsque vous prenez des précautions, cf. "Google Tag Manager, la nouvelle arme anti adblock".
- Les revenus générés par son moteur de recherche ont permis à Google d'être dominant dans de nombreux domaines, cf. "Les services Google qui captent vos données personnelles, et les alternatives".
Google face à la CNIL
Nous avons donc :
- D'un côté la loi, censée protéger la vie privée des internautes, matérialisée ici par une sanction de la CNIL.
- De l'autre côté, l'exploitation de vos données personnelles sur le service le plus stratégique de Google, son moteur de recherche.
Quel sera le vainqueur ?
Dans sa sanction, la CNIL relève 2 points :
- Depuis une mise à jour de septembre 2020, Google cesse de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
- Le nouveau bandeau d’information ne permet toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informe pas du fait qu’ils peuvent refuser ces cookies.
La CNIL indique que Google a 3 mois pour informer correctement les utilisateurs, sous peine du paiement d'une astreinte de 100.000 euros par jour de retard. Étudions maintenant ce qui se passe à la première visite sur google.fr.
Google continue le dépôt automatique de cookies publicitaires
Démarrons notre investigation sur google.fr :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur google.fr.
Comme vous pouvez le voir, le bandeau d'information fournit maintenant de l'information relative aux cookies, mais ne permet pas de refuser facilement le dépôt de cookies non essentiels.
Que dit la loi ? Si l'on cite la CNIL, le consentement n'est valide que si la personne exerce un choix réel. En particulier, "l'utilisateur doit pouvoir accepter ou refuser le dépôt et/ou la lecture des cookies avec le même degré de simplicité". Ce n'est clairement pas le cas ici.
Google cesse-t-il de déposer automatiquement des cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr comme le déclare la CNIL ? Regardons les requêtes via Charles Proxy :
Comme on le voit, Google dépose le cookie NID dès l'arrivée sur google.fr. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
Google a également indiqué à la CNIL que le cookie NID poursuivait une finalité publicitaire (cf. la délibération, point 99) :
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Et pourtant, la CNIL souligne que Google a arrêté cette pratique (point 102) :
Elle souligne néanmoins que durant la procédure de sanction les sociétés ont apporté des modifications à la page google.fr, qui ont notamment amené, depuis le 10 septembre 2020, à l’arrêt du dépôt automatique de ces quatre cookies dès l’arrivée de l’utilisateur sur la page.
Le contrôle de la CNIL a-t-il été correctement effectué ? Toujours est-il que Google continue de violer la loi, cf. le site de la CNIL :
Le consentement doit être préalable au dépôt et/ou à la lecture de cookies. Tant que la personne n'a pas donné son consentement, les cookies ne peuvent pas être déposés ou lus sur son terminal.
Des pièges dans le parcours de consentement Google
Le bandeau d'information Google nous dit :
Si vous acceptez, nous personnaliserons le contenu et les annonces que vous voyez en fonction de votre activité sur les services Google comme la recherche, Maps et YouTube. [...] Cliquez sur "Plus d'informations" pour découvrir les options qui s'offrent à vous
Si je clique sur "Plus d'informations", je suis exposé à une nouvelle fenêtre d'information :
Google détaille ici les données personnelles traitées, les finalités, ainsi que les paramètres de confidentialité. Notez toujours les boutons "J'accepte" et "Autres options" : Google ne permet toujours pas de refuser le dépôt de cookies non essentiels.
Là, vous pourriez vous perdre dans le parcours de Google et cliquer sur "Autres options", en espérant tomber "rapidement" sur l'option pour refuser la surveillance publicitaire. Vous découvrirez cet écran :
Là, Google présente plusieurs options :
- Ajuster les paramètres de confidentialité : c'est la bonne option ! Il vous faut cliquer sur "Ajustez vos paramètres dès à présent".
- Paramétrer les cookies dans le navigateur : option que Google ne recommande pas : "Vous pouvez bloquer une partie ou l'ensemble des cookies, mais cela risque d'empêcher l'exécution de certaines fonctionnalités sur le Web. Par exemple, de nombreux sites Web requièrent l'activation des cookies lorsque vous souhaitez vous y connecter.".
- Installer un module complémentaire pour désactiver le suivi de Google Analytics : Google Analytics est malheureusement loin d'être le seul outil dont Google se sert pour vous surveiller sur le web (Google vous surveille d'abord via la publicité). Inutile de dire qu'une personne soucieuse de sa vie privée préfèrera utiliser un adblocker.
- Vous connecter à votre compte Google : afin de ne plus voir ce rappel ! Google indique en effet : "Si vous effacez régulièrement les cookies de votre navigateur, vous continuerez à recevoir ce rappel de confidentialité, car nous n'avons aucun moyen de savoir que vous l'avez déjà vu". L'inconvénient de vous surveiller par défaut : sans cookies, Google part du principe qu'il a le droit de vous surveiller !
Que se passe-t-il si vous cliquez sur "Ajustez vos paramètres dès à présent" ? Vous revenez à l'étape précédente ! Mais vous n'étiez pas assez attentif, l'étape contient des liens vers la modification de paramètres :
Le parcours du combattant n'est pas terminé.
16 clics supplémentaires pour refuser la surveillance
Cliquons donc sur "Modifier les paramètres de recherche" :
Décochons donc "L'enregistrement des recherches", puis cliquons sur "Retour" et enfin sur "Modifier les paramètres des annonces" :
Ici, il vous faut décocher "Personnalisation des annonces sur la recherche Google" et "Personnalisation des annonces sur le Web". Avec ces paramètres cochés par défaut, Google se permet de vous surveiller sur les "plus de deux millions de sites Web partenaires de Google pour la diffusion d'annonces".
Lorsque vous décochez "Personnalisation des annonces sur la recherche Google", vous avez droit à une petite surprise supplémentaire :
Êtes-vous vraiment sûr de vous ? Google vous rend la tâche encore un peu plus difficile : vos recherches en disent beaucoup sur vous...
Et lorsque vous cliquez sur "Désactiver", Google affiche un message de toute beauté :
"La prise en compte de cette modification par nos systèmes peut prendre un certain temps."
Google ne doit pas s'attendre à ce que vous réussissiez le chemin d'obstacle ! Même punition si vous cliquez sur le bouton "Désactiver" pour la "Personnalisation des annonces sur le Web" :
Là aussi, on voit que c'est compliqué pour Google :
Si vous voulez installer d'autres cookies "Opt-out", qui ne désactivent que la personnalisation des publicités mais laissent les sociétés de l'adtech vous surveiller, Google vous redirige vers le site de l'industrie publicitaire :
Vous pouvez également désactiver la personnalisation des annonces pour plus de 100 autres réseaux publicitaires en ligne.
Revenez encore sur le bandeau d'information pour cliquer maintenant sur "Modifier les paramètres YouTube" :
Cette fois-ci, vous êtes dirigé vers le site YouTube, il vous faut encore décocher "Vidéos que vous regardez sur YouTube" et cliquer sur "Effacer l'historique des vidéos regardées":
Puis il vous faut décocher "Vidéos que vous recherchez sur YouTube" et cliquer sur "Effacer l'historique des recherches" :
Et pour couronner ce beau parcours, lorsque vous revenez sur le bandeau d'information, il vous faut cliquer sur "J'accepte" (cela reste le seul moyen de supprimer ce bandeau d'information, même si vous venez de tout refuser) :
Au total, si vous prenez le chemin le plus rapide, il vous faut 17 clics !
Pendant le parcours de "non consentement", la surveillance continue
Que se passe-t-il pendant ce parcours de "non consentement" ? Si l'on observe les requêtes via Charles :
Google continue d'alimenter ses services publicitaires, dont Google Analytics et Doubleclick.
Malgré votre refus, vous continuez d'être surveillé par Google sur le web
Suite à ce parcours d'obstacles, consultons le site Lemonde.fr (dopé aux traceurs, cf. "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr") et filtrons les requêtes sur Google :
Comme vous le voyez, Lemonde.fr aime bien Google.
Manque de chance, Google n'a pas supprimé le cookie NID. En conséquence, de nombreuses requêtes sont envoyées depuis le site Lemonde.fr vers Google avec votre identifiant stocké dans le cookie NID (rappel, c'est un cookie publicitaire). Ainsi, la violation suivante est toujours valable :
Lorsqu’un utilisateur désactivait la personnalisation des annonces sur la recherche Google en recourant au mécanisme mis à sa disposition à partir du bouton « Consulter maintenant », un des cookies publicitaires demeurait stocké sur son ordinateur et continuait de lire des informations à destination du serveur auquel il est rattaché.
La formation restreinte a donc estimé que le mécanisme « d’opposition » mis en place par les sociétés était partiellement défaillant, en violation de l’article 82 de la loi Informatique et Libertés.
Google va-t-il proposer un vrai mécanisme de consentement ?
La CNIL a sanctionné Google sur des obligations qui préexistaient au RGPD (article 82 de la loi Informatique et Libertés, transposition de la directive « ePrivacy »).
Or depuis le 1er octobre 2020, la CNIL a publié ses lignes directrices modificatives ainsi qu’une recommandation portant sur l’usage de cookies et autres traceurs. La CNIL a demandé aux acteurs de se conformer aux règles ainsi clarifiées, en estimant que cette période d’adaptation ne devrait pas dépasser six mois.
Refuser les traceurs doit être aussi aisé que de les accepter. La CNIL recommande que l’interface de recueil du consentement ne comprenne pas seulement un bouton « tout accepter » mais aussi un bouton « tout refuser ».
Les utilisateurs devront être en mesure de retirer leur consentement, facilement, et à tout moment.
On attend donc avec impatience le 1er avril et la mise en conformité de Google afin de pouvoir refuser sa surveillance en 1 clic (et non en 17 clics)... En réalité, même les obligations antérieures au RGPD sont bafouées :
- Google a contesté son amende de 100 millions d'euros devant le Conseil d'État.
- Comme on l'a vu, Google vous surveille via le cookie
NID, avant même votre consentement mais aussi après votre refus de consentement. - Tenter de refuser la surveillance de Google est un parcours du combattant.
- Il est permis de douter du caractère dissuasif des sanctions de la CNIL, si tant est qu'elle arrive à se faire payer. 100 millions d'euros et 100.000 euros par jour (soit 36 millions d'euros par an), ce n'est pas si cher pour Google.
Google est l'exemple le plus frappant de ce mensonge au consentement, mais le web français est infesté de sites qui bafouent votre vie privée, exemples :
- "La grande braderie de vos données personnelles sur Le Bon Coin".
- "Le recueil du consentement sur internet : un mensonge généralisé".
Reste à voir si la CNIL prendra des sanctions dissuasives à partir du 1er avril.
Vos alternatives pour éviter la surveillance de Google
Si l'on se restreint au moteur de recherche Google (l'objet de cet article), vous avez d'autres options comme :
- DuckDuckGo : un moteur de recherche américain qui ne vous surveille pas. L'interface est épurée, le moteur de recherche est un des choix par défaut sur Safari, et le gros des résultats est basé sur Bing.
- Qwant : la version française, une interface moins épurée, le gros des résultats est aussi basé sur Bing.
- Ecosia : la version allemande, Ecosia reverse 80% de ses bénéfices à des associations à but non lucratif qui œuvrent au programme de reforestation présent essentiellement dans les pays du sud. Ecosia est aussi principalement basé sur Bing.
- Startpage : la version hollandaise, l'interface est épurée et les résultats sont ceux de Google. Du coup, c'est mon choix (les résultats de Google sont souvent bien plus pertinents que ceux de Bing). Startpage est devenu controversé depuis son rachat en 2019 par une société ayant des participations dans l'adtech (vous pouvez vous faire votre propre opinion en lisant cet article).
Il est intéressant de lire pourquoi Google fournit ses résultats de recherche à Startpage :
Why does Google let Startpage access their search results? Startpage.com has a contract with Google that allows us to use their official "Syndicated Web Search" feed, so we have to pay them to get those results.
À la différence de Bing qui fournit ses résultats à de nombreux méta-moteurs (DuckDuckGo, Qwant, Ecosia...), Google est avare de ses résultats de recherche. Startpage semble être le seul à y avoir accès, pour combien de temps ?
03.02.2021 à 23:28
Facebook et WhatsApp, où l'art de vous trahir

Le pire du capitalisme de surveillance
Je n'avais encore jamais écrit sur Facebook, et pourtant cette société représente ce qui se fait de pire dans le domaine de la surveillance publicitaire. Les conséquences de sa domination sont graves :
- Addictions : Les équipes produit de Facebook ont pour objectif ultime de faire croître l'engagement. Plus vous passez de temps sur ses applications (Facebook, Instagram, Messenger, WhatsApp), mieux vous serez "monétisé".
- Radicalisation : Les contenus extrêmes font réagir, ils favorisent l'engagement sur la plateforme. En conséquence, les algorithmes de Facebook mettent en avant les contenus extrêmes et la désinformation. Facebook est une chance pour les complotistes, les fanatiques et l'extrême droite, ce qui met en danger la démocratie dans de nombreux pays.
- Censures : Facebook et Instagram sont quasi incontournables pour qui souhaite informer ou alerter. Mais les règles de modération sont arbitraires et les recours compliqués. Les modérateurs manquent dans certains pays, ne comprennent pas bien les subtilités culturelles. De nombreux membres de la société civile et activistes se voient censurés.
- Traumatismes pour les modérateurs : ceux-ci sont des contractuels, peu considérés et mal payés, confrontés à des horreurs au quotidien. Ils restent souvent traumatisés pour longtemps.
- Une société digne de 1984 : avec son compère Google, Facebook a un rôle fondateur dans l'installation de la surveillance généralisée dans nos sociétés, mettant à mal la démocratie.
Le très provocant mais honnête mémo 'The Ugly", écrit en 2016 par un des dirigeants de Facebook, résume bien la culture d'entreprise : "Growth at any cost". Voici un extrait :
So we connect more people That can be bad if they make it negative. Maybe it costs a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools. And still we connect people.
The ugly truth is that we believe in connecting people so deeply that anything that allows us to connect more people more often is de facto good. It is perhaps the only area where the metrics do tell the true story as far as we are concerned.
Et au cœur du modèle de Facebook, on retrouve l'exploitation abusive de vos données personnelles. Le mépris de Facebook pour la vie privée de ses utilisateurs est largement documenté sur le web aujourd'hui. Mais il est rare d'y trouver une histoire retraçant l'érosion de votre vie privée par Facebook, mise en parallèle avec l'état de la concurrence.
Dina Srinivasan est une chercheuse travaillant sur ces sujets, à l'intersection de l'"antitrust" et de la "privacy", j'avais déjà eu l'occasion de parler de son travail dans l'article "La domination des marchés publicitaires de Google". Je vais ici partir de sa thèse "The Antitrust Case Against Facebook" pour décrire comment Facebook a pu imposer sa surveillance publicitaire sur le web et les applications, en dépit d'une préférence marquée des utilisateurs pour un respect de leur vie privée.
Aux origines, le respect de la vie privée était une force de Facebook
Il est difficile de s'en souvenir aujourd'hui, mais initialement le marché des réseaux sociaux était très compétitif. En 2006, le réseau social le plus utilisé était MySpace. Mais Facebook se trouvait aussi face à de nombreux autres réseaux sociaux comme Bebo, Hi5, Friendster ou Orkut (propriété de Google). Comment se différencier dans un marché concurrentiel où le produit est "gratuit" ? Par la qualité, et le niveau de protection de la vie privée est rapidement devenu un point important de différenciation.
En 2006 donc, MySpace était le leader. Mais il était très décrié dans les médias, mis en accusation de favoriser les harcèlements sexuels, suicides ou meurtres (quelques articles de l'époque ici, là ou encore là). La raison ? L'ouverture trop grande de la communication sur MySpace, et le peu de considérations pour la vie privée de ses utilisateurs.
Facebook avait donc un boulevard pour se différencier, ce qu'il a fait :
- MySpace était ouvert à tout le monde, Facebook était initialement réservé aux étudiants, pouvant justifier d'une adresse e-mail universitaire (en ".edu").
- Par défaut, les profils utilisateurs de MySpace étaient ouverts à tout le monde. Aux débuts de Facebook, seuls les amis et les étudiants d'une même université pouvaient consulter leurs profils respectifs.
- Facebook a rapidement donné beaucoup de contrôle à ses utilisateurs, ce que ne permettait pas MySpace : choix de l'ouverture ou de la fermeture de son profil aux amis, amis d'amis, étudiants de la même université. Mais aussi la possibilité d'être visible ou non sur son moteur de recherche, ainsi que des contrôles granulaires sur les informations de contact comme le numéro de téléphone.
Aussi, Facebook a très rapidement embauché un responsable de la vie privée. Sa politique de confidentialité était courte et très claire, avec seulement 950 mots. On peut notamment y lire :
Use of Cookies
A cookie is a piece of data stored on the user's computer tied to information about the user. We use session ID cookies to confirm that users are logged in. These cookies terminate once the users close the browser. We do not and will not use cookies to collect private information from any user.
La logique de réseau privé, le contrôle donné aux utilisateurs ainsi que la courte politique de confidentialité ont été des éléments différenciants par rapport à d'autres réseaux sociaux tels que MySpace. Même si d'autres facteurs ont pu jouer (solide socle technique, élitisme initial, interface utilisateur plus épurée, etc), le meilleur respect de la vie privée a joué un rôle central dans le développement de Facebook.
Beacon, la première tentative (ratée) de surveillance du web
En 2007, Facebook devient le nouveau réseau social à la mode (et j'ouvre mon compte). En novembre, il lance Beacon, une initiative transparente de surveillance publicitaire en dehors de Facebook. Au lancement, le New York Times est l'un des partenaires. Si je lis un article du New York Times, Facebook me propose alors via une pop-up de partager ma lecture à mes amis. Facebook Beacon permet aussi de partager ses achats, la musique écoutée, les films regardés, etc :
Facebook Beacon vous surveille, mais vous êtes informé.
La présence de ces nouveaux traceurs de Facebook lui permet de surveiller le comportement des utilisateurs sur des sites tiers (via un cookie), même si ceux-ci déclinent le partage de leurs activités. Devant le tollé provoqué par Beacon, Facebook se défend pourtant de surveiller les utilisateurs lorsque ceux-ci refusent le partage. Voici un extrait de l'interview du vice président Marketing & Opérations de l'époque au New York Times :
Q. If I buy tickets on Fandango, and decline to publish the purchase to my friends on Facebook, does Facebook still receive the information about my purchase?
A. “Absolutely not. One of the things we are still trying to do is dispel a lot of misinformation that is being propagated unnecessarily.”
Déclaration évidemment démentie quelques heures plus tard par un chercheur. Avec les traceurs Beacon, Facebook surveille aussi les utilisateurs qui se sont déconnectés, ainsi que les personnes qui n'ont pas de compte Facebook. C'est une première violation de la vie privée pour Facebook, en contradiction avec sa politique de confidentialité qui indique alors uniquement utiliser les cookies "to confirm that users are logged in", et "these cookies terminate once the users close the browser".
Rapidement, Facebook est confronté à de nombreuses protestations, des pétitions et même des procès. Plusieurs participants au programme Beacon décident de se retirer. Les autres réseaux sociaux profitent également de ce scandale pour critiquer Facebook et améliorer la gestion de la vie privée sur leurs plateformes. Début décembre 2007, Mark Zuckerberg s'excuse (pour un historique des excuses de Zuckerberg, voici un bon article) et annonce une option d'Opt-out. L'option cachée dans les paramètres ne répondant toujours pas aux exigences des utilisateurs, Facebook fermera Beacon moins d'1 an après.
Ce retrait rapide est la preuve d'un marché encore compétitif. Facebook est sous pression de réseaux sociaux concurrents. Aussi, afin de restaurer une confiance déjà trahie, Facebook annonce en 2009 que tout changement à la politique de confidentialité sera désormais soumis à un vote.
Le bouton Like, un cheval de Troie idéal
Facebook a de la suite dans ses idées, il apprend de ses erreurs et en avril 2010, il introduit le bouton Like lors de sa conférence annuelle pour les développeurs. Pour les éditeurs, c'est une opportunité de profiter d'une distribution facile de leurs articles sur Facebook, et donc d'attirer de nouveaux lecteurs. Et rapidement c'est un succès : dès les premières semaines, plus de 50,000 sites installent le bouton like, dont des éditeurs célèbres tels que CNN, le New York Times, The Wall Street Journal ou Slate.
Mais comme avec Beacon, le bouton Like communique avec les serveurs de Facebook pour s'afficher sur votre écran. Facebook peut ainsi surveiller votre navigation, de nouveau en contradiction avec sa politique de confidentialité. CNET cite ainsi la FAQ de l'époque :
No data is shared about you when you see a social plug-in on an external website.
À la différence de Beacon, Facebook indique que ce produit ne sera pas utilisé dans un but de surveillance commerciale. 2 raisons :
- Facebook se souvient encore du scandale Beacon, et souhaite éviter un nouveau scandale.
- Il doit convaincre les éditeurs, des concurrents sur le marché publicitaire, d'installer ces boutons Like. Théoriquement, il pourrait ainsi revendre moins cher aux annonceurs l'audience du Wall Street Journal, directement sur Facebook.
Un chercheur a pu détailler la fuite des données personnelles via le bouton Like (Facebook Tracks and Traces Everyone: Like This!) dès novembre 2010. Via des cookies qu'il installe même si vous ne cliquez pas sur le bouton Like, le réseau social récupère votre identité, l'URL de la page consultée ainsi que le titre de l'article ou le nom du produit. Là également, la surveillance a lieu même si vous n'avez pas de compte Facebook. Mais à la différence de Beacon, pas de pop-up Facebook vous demandant de partager l'article que vous lisez ou l'achat que vous venez d'effectuer : la surveillance est maintenant invisible.
Comment Facebook réagit-il face à ces nouvelles révélations ? Le directeur technique de l'époque déclare que ces cookies ne sont pas utilisés par Facebook pour surveiller les utilisateurs mais pour protéger les comptes utilisateurs de cyber attaques. Concernant la surveillance des utilisateurs n'ayant pas de compte, il s'agirait là d'un bug qui aurait été corrigé depuis (faux). Le Wall Street Journal indique dans son enquête de mai 2011 que les boutons Like permettaient de vous surveiller sur plus d'un tiers des 1000 sites web les plus visités au monde, et sur plus d'un million de sites web. Devant de tels chiffres, on commence à prendre conscience de l'ampleur de la surveillance généralisée.
En septembre 2011, Facebook est accusé de continuer de surveiller les utilisateurs même après leur déconnexion. Facebook devrait supprimer les cookies lorsqu'un utilisateur se déconnecte et notamment l'identifiant utilisateur, il ne le fait pas, et tente de tromper son auditoire :
Facebook does not track users across the web. Instead, we use cookies on social plugins to personalize content (e.g. show you what your friends liked), to help maintain and improve what we do (e.g. measure click-through rate), or for safety and security (e.g. keeping underage kids from trying to sign up with a different age). No information we receive when you see a social plugin is used to target ads, we delete or anonymize this information within 90 days, and we never sell your information.
Specific to logged-out cookies, they are used for safety and protection, including identifying spammers and phishers, detecting when somebody unauthorized is trying to access your account, helping you get back into your account if you get hacked, disabling registration for underage people who try to re-register with a different birth date, powering account security features such as second factor login approvals and notification, and identifying shared computers to discourage the use of “Keep me logged in.”
Si l'on réfléchit à la meilleure manière pour Facebook d'imposer son capitalisme de surveillance, il lui faut d'abord parvenir à convaincre les éditeurs d'installer ses traceurs. La transparence n'ayant pas réussi (Beacon était présenté comme un outil commercial), Facebook a préféré opérer de manière déguisée (déclarer que le bouton Like ne serait pas utilisé pour de la surveillance publicitaire).
En décembre 2012, le Wall Street Journal revient sur son enquête pour indiquer que les boutons Like se retrouvent maintenant sur 2/3 des sites du top 1000, Facebook répond encore qu'il utilise les informations des boutons Like uniquement pour la sécurité et pour corriger les bugs. Mais la malhonnêteté est bien là. En février 2011, Facebook a déposé un brevet pour surveiller les utilisateurs en dehors de son propre site et proposer de la publicité ciblée basée sur ces profils :
The present disclosure relates generally to social network systems and other websites in which users can form connections with other users, and in particular, to tracking activities of users of social network systems on other domains to, for example, analyze, target, or gauge the effectiveness of advertisements (ads) rendered in conjunction with social network systems.
Avant d'utiliser la collecte de données des boutons Like pour la surveillance publicitaire, Facebook devait encore se débarrasser d'un dernier obstacle : le fait que tout changement de politique de confidentialité devait être soumis à un vote. Voici comment Facebook a procédé :
- Fin 2012, avec plus d'un milliard d'utilisateurs et une entrée en bourse réussie, Facebook propose un vote sur la suppression des futurs référendums concernant sa politique de confidentialité.
- 88% des utilisateurs ont voté contre, mais Facebook arguant du fait que seuls 589,000 personnes avaient voté (une clause indiquait qu'à minima, 30% des utilisateurs devaient voter), il pouvait s'asseoir sur la volonté des participants et abolir les référendums.
De nombreux utilisateurs se sont ensuite plaints de ne pas avoir été informés de ce vote, n'ayant reçu aucune notification ou aucun e-mail. Facebook ne voulait clairement pas que vous votiez.
En juin 2014, Facebook décide d'activer la surveillance publicitaire basée sur les boutons Like (et tous les autres plugins qu'il fournit aux éditeurs : Facebook Login, le pixel Facebook, le SDK pour les applications, etc). Le titre de l'article annonçant la mise à jour est un modèle de novlangue : Making Ads Better and Giving People More Control Over the Ads They See.
Après avoir passé 7 ans à promettre de ne pas exploiter les données collectées par ses plugins pour de la surveillance publicitaire, Facebook renie ses promesses. Pourquoi ? La concurrence a été écrasée (MySpace et Orkut ont fermés, Google+ s'est avéré être un échec) et même si la qualité de Facebook est grandement dégradée par cette atteinte massive à leur vie privée, les utilisateurs n'ont plus d'alternatives viables. Facebook peut maintenant sur-exploiter vos données personnelles pour son plus grand bénéfice.
En 2018, même le cofondateur de WhatsApp conseille de supprimer Facebook.
Avec WhatsApp, Facebook reproduit la même stratégie
WhatsApp est créé en 2009 et très vite, la protection de la vie privée est un axe fort de l'application :
So first of all, let's set the record straight. We have not, we do not and we will not ever sell your personal information to anyone. Period. End of story. Hopefully this clears things up.
En 2012, lorsque le co-fondateur de WhatsApp Jan Koum écrit le billet "Pourquoi nous ne vendons pas de pub", le discours sur la publicité est fort :
La publicité n'est pas seulement une gêne esthétique, une insulte à votre intelligence et une interruption de votre fil de pensées. Dans chaque entreprise vendant de la publicité, une importante partie de leur équipe d'ingénieurs passent leurs journées à affiner l'exploration de données, améliorer le code pour collecter toutes vos données personnelles, améliorer les serveurs qui contiennent toutes les données et s'assurer que tout est bien enregistré, rassemblé, découpé, emballé et envoyé... Au final, le résultat de tout cela est une bannière de publicité légèrement différente dans votre navigateur ou écran de téléphone mobile.
Voici un autre passage du même billet, traitant du recueil de données personnelles :
À WhatsApp, nos ingénieurs passent tout leur temps à réparer des bugs, ajouter de nouvelles fonctionnalités et passer le tout au peigne fin pour offrir une messagerie riche, abordable et fiable pour tous les téléphones dans le monde entier. C'est notre produit et notre passion. Vos données n'entrent même pas en jeu. Cela ne nous intéresse tout simplement pas.
À l'époque, WhatsApp avait une très bonne réputation. L'application était en effet appréciée pour sa simplicité, sa fiabilité, mais aussi pour son positionnement sur la publicité et les données personnelles. Comme avec Facebook à ses débuts, la protection de la vie privée est un avantage compétitif pour WhatsApp, qui lui permet de gagner des parts de marché (sur Facebook Messenger ou Google Hangouts par exemple).
Seulement voilà, en 2014 WhatsApp vend son application à Facebook pour 22 milliards de dollars. Vu l'historique de Facebook, on peut déjà craindre le pire. Jan Koum écrit pourtant sur le blog de WhatsApp :
Voici ce qui va changer pour vous, nos utilisateurs : rien.
WhatsApp restera autonome et fonctionnera indépendamment. Vous pouvez continuer à profiter du service à moindre coûts. Vous pouvez continuer à utiliser WhatsApp n'importe où dans le monde entier ou avec n'importe quel Smartphones que vous utilisez. Et vous pouvez toujours compter sur le fait qu'il n'y aura absolument aucune publicité pour venir interrompre votre communication. Il n'y aurait pas eu de partenariat entre nos deux sociétés si nous avions eu à faire des compromis sur nos principes fondamentaux qui font l'identité de notre entreprise, notre vision et notre produit.
Et en effet, WhatsApp revient ainsi sur sa parole et décide de partager vos données personnelles avec Facebook dès 2016 :
Mais en coordonnant davantage avec Facebook, nous pourrons faire des choses telles que suivre des mesures de base sur la fréquence d'utilisation de nos services des gens et améliorer la lutte contre les spams sur WhatsApp. Et en connectant votre numéro de téléphone avec les systèmes de Facebook, ce dernier peut vous offrir de meilleures suggestions d'amis et vous montrer des publicités plus pertinentes si vous avez un compte Facebook. Par exemple, vous pouvez voir une publicité d'une entreprise avec laquelle vous avez déjà travaillé au lieu de voir celle d'une entreprise dont vous n'avez jamais entendu parler.
Afin de mieux comprendre la portée de cette modification, il convient de s'extraire de la communication de WhatsApp. L'EFF détaille les données dorénavant partagées avec Facebook : numéro de téléphone, carnet d'adresses et données d'utilisation (quand vous utilisez WhatsApp, avec qui vous communiquez, sur quel appareil, votre adresse IP, etc). Ces métadonnées sont extrêmement précieuses pour Facebook, qui même s'il n'a pas accès au contenu de vos conversations WhatsApp (chiffrées de bout en bout), récolte les informations les plus importantes.
À l'époque, WhatsApp laisse un opt-out de seulement 30 jours aux utilisateurs existants (via ce "Dark Pattern"). Les nouveaux utilisateurs n'auront pas ce choix. Et encore, l'opt-out ne permet pas d'arrêter le partage d'informations, seulement d'empêcher Facebook d'utiliser vos informations WhatsApp pour de la publicité ciblée ou l'amélioration de ses produits (suggestion d'amis). Relisons l'EFF à ce propos :
Note that your WhatsApp information will still be passed to Facebook for other purposes such as “improving infrastructure and delivery systems, understanding how [Facebook and WhatsApp] services...are used, securing systems, and fighting spam, abuse, or infringement activities." Changing your settings does ensure, however, that Facebook will not use your WhatsApp data to suggest friends or serve ads.
En Europe, ce partage de données passe mal. L'Allemagne refuse le partage de données, puis les CNIL européennes demandent "instamment" d'arrêter le partage des données personnelles. La CNIL du Royaume-Uni demande ensuite la mise en pause de la synchronisation des données. Enfin la CNIL met en demeure WhatsApp de ne plus transmettre à Facebook les données de business intelligence de WhatsApp. Entre-temps, la Commission Européenne affirme que Facebook a fourni des informations trompeuses lors du rachat de WhatsApp et lui inflige une amende de 110 millions d'euros :
Facebook a indiqué à la Commission qu'elle ne serait pas en mesure d'associer automatiquement et de manière fiable les comptes d'utilisateur des deux sociétés
Ces épisodes sont très bien résumés dans le billet du blog de Killian Kemps, "WhatsApp transfère-t-elle des données à Facebook ?". Ce billet pose une question simple : WhatsApp a-t-il réellement stoppé le partage de vos données personnelles avec Facebook suite à ces plaintes dans l'Union Européenne ? Malheureusement non, même si la réponse n'est pas facile à trouver.
Voici ce que dit la politique de confidentialité de WhatsApp pour les résidents de l'Union Européenne (mise à jour en avril 2018) :
Comment nous travaillons avec d'autres entités Facebook
Nous faisons partie des entités Facebook. En tant que membre des entités Facebook, WhatsApp reçoit des informations des entités Facebook et leur transmet également des informations. Nous pouvons utiliser les informations qu’elles nous envoient, et elles peuvent utiliser celles que nous leur transmettons, afin de nous aider à exploiter, fournir, améliorer, comprendre, personnaliser, prendre en charge et commercialiser nos Services et leurs offres [...].
En approfondissant la question via l'article "Comment nous travaillons avec les entités Facebook", on comprend que les échanges de données personnelles entre WhatsApp et Facebook sont très nombreux. Un point cependant, sans l'action de la Commission Européenne, Facebook irait encore plus loin dans le traitement de vos données personnelles :
Nous ne partageons pas de données afin d'améliorer les produits Facebook sur la plateforme et d'offrir de meilleures expériences publicitaires sur Facebook.
Aujourd'hui, Facebook n'utilise pas les informations de votre compte WhatsApp pour améliorer votre expérience avec les produits Facebook ni pour vous proposer des publicités Facebook plus ciblées sur sa plateforme. Ceci est le résultat de discussions avec le commissaire irlandais chargé de la protection des données et d'autres autorités responsables de la protection des données en Europe. Nous cherchons constamment de nouvelles manières d'améliorer votre expérience avec WhatsApp et les Produits des entités Facebook que vous utilisez. Si, à l'avenir, nous décidons de partager de telles données avec les Entités Facebook à cette fin, nous conclurons d'abord un accord avec le commissaire irlandais chargé de la protection des données afin d'établir un mécanisme qui permette une telle utilisation. Nous vous informerons des nouvelles expériences mises à votre disposition et de nos pratiques concernant l'utilisation de vos données.
Et en effet, si vous n'êtes pas un résidant de l'Union Européenne, Facebook ne se prive de rien :
Facebook et les autres entités de la famille Facebook peuvent également utiliser des informations que nous avons fournies pour améliorer vos expériences au sein de leurs services, comme faire des suggestions de produit (par exemple d’amis, de connexions ou de contenus intéressants) et afficher des offres et des publicités pertinentes.
Depuis début janvier, la dernière mise à jour des conditions d'utilisation de WhatsApp passe mal. La date de mise en application des nouvelles conditions d'utilisation est repoussée : initialement prévue le 8 février, elle aura lieu le 15 mai, le temps pour WhatsApp d'affiner sa communication.
Si le partage de vos données personnelles avec Facebook était déjà effectif depuis presque 5 ans, cette mise à jour va permettre à Facebook d'aller plus loin :
- Partage de vos données transactionnelles WhatsApp avec les "Facebook Shops".
- Partage de vos communications avec les entreprises, via un service d'hébergement des communications proposé par Facebook.
Ce service d'hébergement est une première brèche du chiffrement de bout en bout car ces communications ne seront pas chiffrées chez l'hébergeur (un des 2 "bouts" du chiffrement). Voici comment WhatsApp noie le poisson :
WhatsApp considère les discussions avec les entreprises utilisant l’application WhatsApp Business ou gérant et stockant elles-mêmes les messages des clients comme chiffrées de bout en bout. Une fois le message reçu, il sera sujet aux propres pratiques de l’entreprise en matière de confidentialité. L’entreprise peut permettre à un certain nombre d’employés, voire d’autres prestataires, de traiter le message et y répondre.
Certaines entreprises pourront choisir de stocker les messages des clients et y répondre de façon sécurisée à travers la société mère de WhatsApp, Facebook. Vous pouvez toujours contacter les entreprises pour en savoir plus sur leurs pratiques en matière de confidentialité.
Par facilité, la grande majorité des sociétés choisira sans doute la solution d'hébergement de Facebook. Le contenu de vos discussions avec les entreprises sera donc visible de "l'hébergeur" Facebook et soumis à ses pratiques en matière de confidentialité.
Dernier argument en faveur de WhatsApp donc (notamment si l'on compare à Telegram), vos messages personnels restent protégés par le chiffrement de bout en bout, par défaut :
La confidentialité et la sécurité de vos messages et appels personnels ne changent pas. Ils sont protégés par le chiffrement de bout en bout et ni WhatsApp ni Facebook ne peuvent les lire ou les écouter. Nous n'affaiblirons jamais cette sécurité et nous faisons apparaître cette information dans chaque discussion afin que vous puissiez être au fait de notre engagement.
À noter que WhatsApp utilise le protocole open source de Signal pour le chiffrement des messages, un point fort :
Chaque message WhatsApp est protégé par le même protocole de chiffrement de Signal, sécurisant les messages avant qu’ils ne quittent votre appareil.
Mais pour le reste de vos données personnelles, c'est open bar. Comment WhatsApp a-t-il pu à ce point trahir ses utilisateurs ? Pour une histoire détaillée des compromissions (et résistances) de WhatsApp face à sa maison mère, lisez l'excellent article de Forbes "Exclusive: WhatsApp Cofounder Brian Acton Gives The Inside Story On #DeleteFacebook And Why He Left $850 Million Behind". Le co-fondateur de WhatsApp y déclare notamment :
I sold my users’ privacy to a larger benefit. I made a choice and a compromise. And I live with that every day.
Brian Acton a quitté WhatsApp en septembre 2017 (et son compère Jan Koum en avril 2018). Aujourd'hui, il est à la tête de la Signal Foundation, lancée en février 2018 avec un financement initial de 50 millions de dollars d'Acton. Il a également un rôle opérationnel important chez Signal.
Facebook a depuis dégouté les cofondateurs d'Instagram, Kevin Systrom et Mike Krieger, pour une histoire de jalousie (Instagram est à la mode, plus Facebook) et de croissance à tout prix (dégrader l'application Instagram pour mettre en avant l'application Facebook).
Une fin heureuse ?
On le voit donc, WhatsApp suit le modèle de sa maison mère : il s'est imposé en étant plus respectueux de la vie privée que ses concurrents. Racheté par Facebook et en position dominante, il trahit votre confiance en érodant progressivement votre vie privée.
Va-t-il s'en tirer à bon compte ? Cela dépendra de nos actions collectives. Pour ma part, la tâche est encore plus ardue qu'avec Facebook et Instagram (comptes que j'avais pu fermer il y a quelque temps déjà). J'ai pu migrer quelques conversations et groupes sur Signal, mais je vais devoir convaincre beaucoup de personnes avant d'espérer fermer mon compte WhatsApp.
Confidentialité de WhatsApp sur l'App Store.
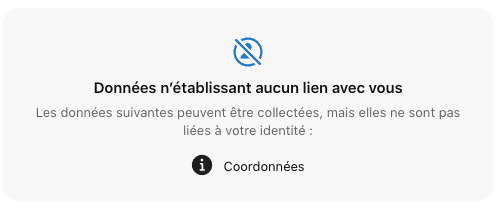
Confidentialité de Signal sur l'App Store.
Néanmoins, il est permis d'être optimiste sur le long terme. À la différence de Facebook ou d'Instagram qui n'ont aujourd'hui pas de vrais concurrents, les messageries Telegram et Signal vont donner du fil à retordre à WhatsApp. Et la vague d'installation actuelle de Signal fait plaisir à voir.
Un tweet d'Elon Musk ne peut jamais faire de mal.
On a connu pire comme sponsor.
Texte intégral (6033 mots)
Le pire du capitalisme de surveillance
Je n'avais encore jamais écrit sur Facebook, et pourtant cette société représente ce qui se fait de pire dans le domaine de la surveillance publicitaire. Les conséquences de sa domination sont graves :
- Addictions : Les équipes produit de Facebook ont pour objectif ultime de faire croître l'engagement. Plus vous passez de temps sur ses applications (Facebook, Instagram, Messenger, WhatsApp), mieux vous serez "monétisé".
- Radicalisation : Les contenus extrêmes font réagir, ils favorisent l'engagement sur la plateforme. En conséquence, les algorithmes de Facebook mettent en avant les contenus extrêmes et la désinformation. Facebook est une chance pour les complotistes, les fanatiques et l'extrême droite, ce qui met en danger la démocratie dans de nombreux pays.
- Censures : Facebook et Instagram sont quasi incontournables pour qui souhaite informer ou alerter. Mais les règles de modération sont arbitraires et les recours compliqués. Les modérateurs manquent dans certains pays, ne comprennent pas bien les subtilités culturelles. De nombreux membres de la société civile et activistes se voient censurés.
- Traumatismes pour les modérateurs : ceux-ci sont des contractuels, peu considérés et mal payés, confrontés à des horreurs au quotidien. Ils restent souvent traumatisés pour longtemps.
- Une société digne de 1984 : avec son compère Google, Facebook a un rôle fondateur dans l'installation de la surveillance généralisée dans nos sociétés, mettant à mal la démocratie.
Le très provocant mais honnête mémo 'The Ugly", écrit en 2016 par un des dirigeants de Facebook, résume bien la culture d'entreprise : "Growth at any cost". Voici un extrait :
So we connect more people That can be bad if they make it negative. Maybe it costs a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools. And still we connect people.
The ugly truth is that we believe in connecting people so deeply that anything that allows us to connect more people more often is de facto good. It is perhaps the only area where the metrics do tell the true story as far as we are concerned.
Et au cœur du modèle de Facebook, on retrouve l'exploitation abusive de vos données personnelles. Le mépris de Facebook pour la vie privée de ses utilisateurs est largement documenté sur le web aujourd'hui. Mais il est rare d'y trouver une histoire retraçant l'érosion de votre vie privée par Facebook, mise en parallèle avec l'état de la concurrence.
Dina Srinivasan est une chercheuse travaillant sur ces sujets, à l'intersection de l'"antitrust" et de la "privacy", j'avais déjà eu l'occasion de parler de son travail dans l'article "La domination des marchés publicitaires de Google". Je vais ici partir de sa thèse "The Antitrust Case Against Facebook" pour décrire comment Facebook a pu imposer sa surveillance publicitaire sur le web et les applications, en dépit d'une préférence marquée des utilisateurs pour un respect de leur vie privée.
Aux origines, le respect de la vie privée était une force de Facebook
Il est difficile de s'en souvenir aujourd'hui, mais initialement le marché des réseaux sociaux était très compétitif. En 2006, le réseau social le plus utilisé était MySpace. Mais Facebook se trouvait aussi face à de nombreux autres réseaux sociaux comme Bebo, Hi5, Friendster ou Orkut (propriété de Google). Comment se différencier dans un marché concurrentiel où le produit est "gratuit" ? Par la qualité, et le niveau de protection de la vie privée est rapidement devenu un point important de différenciation.
En 2006 donc, MySpace était le leader. Mais il était très décrié dans les médias, mis en accusation de favoriser les harcèlements sexuels, suicides ou meurtres (quelques articles de l'époque ici, là ou encore là). La raison ? L'ouverture trop grande de la communication sur MySpace, et le peu de considérations pour la vie privée de ses utilisateurs.
Facebook avait donc un boulevard pour se différencier, ce qu'il a fait :
- MySpace était ouvert à tout le monde, Facebook était initialement réservé aux étudiants, pouvant justifier d'une adresse e-mail universitaire (en ".edu").
- Par défaut, les profils utilisateurs de MySpace étaient ouverts à tout le monde. Aux débuts de Facebook, seuls les amis et les étudiants d'une même université pouvaient consulter leurs profils respectifs.
- Facebook a rapidement donné beaucoup de contrôle à ses utilisateurs, ce que ne permettait pas MySpace : choix de l'ouverture ou de la fermeture de son profil aux amis, amis d'amis, étudiants de la même université. Mais aussi la possibilité d'être visible ou non sur son moteur de recherche, ainsi que des contrôles granulaires sur les informations de contact comme le numéro de téléphone.
Aussi, Facebook a très rapidement embauché un responsable de la vie privée. Sa politique de confidentialité était courte et très claire, avec seulement 950 mots. On peut notamment y lire :
Use of Cookies
A cookie is a piece of data stored on the user's computer tied to information about the user. We use session ID cookies to confirm that users are logged in. These cookies terminate once the users close the browser. We do not and will not use cookies to collect private information from any user.
La logique de réseau privé, le contrôle donné aux utilisateurs ainsi que la courte politique de confidentialité ont été des éléments différenciants par rapport à d'autres réseaux sociaux tels que MySpace. Même si d'autres facteurs ont pu jouer (solide socle technique, élitisme initial, interface utilisateur plus épurée, etc), le meilleur respect de la vie privée a joué un rôle central dans le développement de Facebook.
Beacon, la première tentative (ratée) de surveillance du web
En 2007, Facebook devient le nouveau réseau social à la mode (et j'ouvre mon compte). En novembre, il lance Beacon, une initiative transparente de surveillance publicitaire en dehors de Facebook. Au lancement, le New York Times est l'un des partenaires. Si je lis un article du New York Times, Facebook me propose alors via une pop-up de partager ma lecture à mes amis. Facebook Beacon permet aussi de partager ses achats, la musique écoutée, les films regardés, etc :
Facebook Beacon vous surveille, mais vous êtes informé.
La présence de ces nouveaux traceurs de Facebook lui permet de surveiller le comportement des utilisateurs sur des sites tiers (via un cookie), même si ceux-ci déclinent le partage de leurs activités. Devant le tollé provoqué par Beacon, Facebook se défend pourtant de surveiller les utilisateurs lorsque ceux-ci refusent le partage. Voici un extrait de l'interview du vice président Marketing & Opérations de l'époque au New York Times :
Q. If I buy tickets on Fandango, and decline to publish the purchase to my friends on Facebook, does Facebook still receive the information about my purchase?
A. “Absolutely not. One of the things we are still trying to do is dispel a lot of misinformation that is being propagated unnecessarily.”
Déclaration évidemment démentie quelques heures plus tard par un chercheur. Avec les traceurs Beacon, Facebook surveille aussi les utilisateurs qui se sont déconnectés, ainsi que les personnes qui n'ont pas de compte Facebook. C'est une première violation de la vie privée pour Facebook, en contradiction avec sa politique de confidentialité qui indique alors uniquement utiliser les cookies "to confirm that users are logged in", et "these cookies terminate once the users close the browser".
Rapidement, Facebook est confronté à de nombreuses protestations, des pétitions et même des procès. Plusieurs participants au programme Beacon décident de se retirer. Les autres réseaux sociaux profitent également de ce scandale pour critiquer Facebook et améliorer la gestion de la vie privée sur leurs plateformes. Début décembre 2007, Mark Zuckerberg s'excuse (pour un historique des excuses de Zuckerberg, voici un bon article) et annonce une option d'Opt-out. L'option cachée dans les paramètres ne répondant toujours pas aux exigences des utilisateurs, Facebook fermera Beacon moins d'1 an après.
Ce retrait rapide est la preuve d'un marché encore compétitif. Facebook est sous pression de réseaux sociaux concurrents. Aussi, afin de restaurer une confiance déjà trahie, Facebook annonce en 2009 que tout changement à la politique de confidentialité sera désormais soumis à un vote.
Le bouton Like, un cheval de Troie idéal
Facebook a de la suite dans ses idées, il apprend de ses erreurs et en avril 2010, il introduit le bouton Like lors de sa conférence annuelle pour les développeurs. Pour les éditeurs, c'est une opportunité de profiter d'une distribution facile de leurs articles sur Facebook, et donc d'attirer de nouveaux lecteurs. Et rapidement c'est un succès : dès les premières semaines, plus de 50,000 sites installent le bouton like, dont des éditeurs célèbres tels que CNN, le New York Times, The Wall Street Journal ou Slate.
Mais comme avec Beacon, le bouton Like communique avec les serveurs de Facebook pour s'afficher sur votre écran. Facebook peut ainsi surveiller votre navigation, de nouveau en contradiction avec sa politique de confidentialité. CNET cite ainsi la FAQ de l'époque :
No data is shared about you when you see a social plug-in on an external website.
À la différence de Beacon, Facebook indique que ce produit ne sera pas utilisé dans un but de surveillance commerciale. 2 raisons :
- Facebook se souvient encore du scandale Beacon, et souhaite éviter un nouveau scandale.
- Il doit convaincre les éditeurs, des concurrents sur le marché publicitaire, d'installer ces boutons Like. Théoriquement, il pourrait ainsi revendre moins cher aux annonceurs l'audience du Wall Street Journal, directement sur Facebook.
Un chercheur a pu détailler la fuite des données personnelles via le bouton Like (Facebook Tracks and Traces Everyone: Like This!) dès novembre 2010. Via des cookies qu'il installe même si vous ne cliquez pas sur le bouton Like, le réseau social récupère votre identité, l'URL de la page consultée ainsi que le titre de l'article ou le nom du produit. Là également, la surveillance a lieu même si vous n'avez pas de compte Facebook. Mais à la différence de Beacon, pas de pop-up Facebook vous demandant de partager l'article que vous lisez ou l'achat que vous venez d'effectuer : la surveillance est maintenant invisible.
Comment Facebook réagit-il face à ces nouvelles révélations ? Le directeur technique de l'époque déclare que ces cookies ne sont pas utilisés par Facebook pour surveiller les utilisateurs mais pour protéger les comptes utilisateurs de cyber attaques. Concernant la surveillance des utilisateurs n'ayant pas de compte, il s'agirait là d'un bug qui aurait été corrigé depuis (faux). Le Wall Street Journal indique dans son enquête de mai 2011 que les boutons Like permettaient de vous surveiller sur plus d'un tiers des 1000 sites web les plus visités au monde, et sur plus d'un million de sites web. Devant de tels chiffres, on commence à prendre conscience de l'ampleur de la surveillance généralisée.
En septembre 2011, Facebook est accusé de continuer de surveiller les utilisateurs même après leur déconnexion. Facebook devrait supprimer les cookies lorsqu'un utilisateur se déconnecte et notamment l'identifiant utilisateur, il ne le fait pas, et tente de tromper son auditoire :
Facebook does not track users across the web. Instead, we use cookies on social plugins to personalize content (e.g. show you what your friends liked), to help maintain and improve what we do (e.g. measure click-through rate), or for safety and security (e.g. keeping underage kids from trying to sign up with a different age). No information we receive when you see a social plugin is used to target ads, we delete or anonymize this information within 90 days, and we never sell your information.
Specific to logged-out cookies, they are used for safety and protection, including identifying spammers and phishers, detecting when somebody unauthorized is trying to access your account, helping you get back into your account if you get hacked, disabling registration for underage people who try to re-register with a different birth date, powering account security features such as second factor login approvals and notification, and identifying shared computers to discourage the use of “Keep me logged in.”
Si l'on réfléchit à la meilleure manière pour Facebook d'imposer son capitalisme de surveillance, il lui faut d'abord parvenir à convaincre les éditeurs d'installer ses traceurs. La transparence n'ayant pas réussi (Beacon était présenté comme un outil commercial), Facebook a préféré opérer de manière déguisée (déclarer que le bouton Like ne serait pas utilisé pour de la surveillance publicitaire).
En décembre 2012, le Wall Street Journal revient sur son enquête pour indiquer que les boutons Like se retrouvent maintenant sur 2/3 des sites du top 1000, Facebook répond encore qu'il utilise les informations des boutons Like uniquement pour la sécurité et pour corriger les bugs. Mais la malhonnêteté est bien là. En février 2011, Facebook a déposé un brevet pour surveiller les utilisateurs en dehors de son propre site et proposer de la publicité ciblée basée sur ces profils :
The present disclosure relates generally to social network systems and other websites in which users can form connections with other users, and in particular, to tracking activities of users of social network systems on other domains to, for example, analyze, target, or gauge the effectiveness of advertisements (ads) rendered in conjunction with social network systems.
Avant d'utiliser la collecte de données des boutons Like pour la surveillance publicitaire, Facebook devait encore se débarrasser d'un dernier obstacle : le fait que tout changement de politique de confidentialité devait être soumis à un vote. Voici comment Facebook a procédé :
- Fin 2012, avec plus d'un milliard d'utilisateurs et une entrée en bourse réussie, Facebook propose un vote sur la suppression des futurs référendums concernant sa politique de confidentialité.
- 88% des utilisateurs ont voté contre, mais Facebook arguant du fait que seuls 589,000 personnes avaient voté (une clause indiquait qu'à minima, 30% des utilisateurs devaient voter), il pouvait s'asseoir sur la volonté des participants et abolir les référendums.
De nombreux utilisateurs se sont ensuite plaints de ne pas avoir été informés de ce vote, n'ayant reçu aucune notification ou aucun e-mail. Facebook ne voulait clairement pas que vous votiez.
En juin 2014, Facebook décide d'activer la surveillance publicitaire basée sur les boutons Like (et tous les autres plugins qu'il fournit aux éditeurs : Facebook Login, le pixel Facebook, le SDK pour les applications, etc). Le titre de l'article annonçant la mise à jour est un modèle de novlangue : Making Ads Better and Giving People More Control Over the Ads They See.
Après avoir passé 7 ans à promettre de ne pas exploiter les données collectées par ses plugins pour de la surveillance publicitaire, Facebook renie ses promesses. Pourquoi ? La concurrence a été écrasée (MySpace et Orkut ont fermés, Google+ s'est avéré être un échec) et même si la qualité de Facebook est grandement dégradée par cette atteinte massive à leur vie privée, les utilisateurs n'ont plus d'alternatives viables. Facebook peut maintenant sur-exploiter vos données personnelles pour son plus grand bénéfice.
En 2018, même le cofondateur de WhatsApp conseille de supprimer Facebook.
Avec WhatsApp, Facebook reproduit la même stratégie
WhatsApp est créé en 2009 et très vite, la protection de la vie privée est un axe fort de l'application :
So first of all, let's set the record straight. We have not, we do not and we will not ever sell your personal information to anyone. Period. End of story. Hopefully this clears things up.
En 2012, lorsque le co-fondateur de WhatsApp Jan Koum écrit le billet "Pourquoi nous ne vendons pas de pub", le discours sur la publicité est fort :
La publicité n'est pas seulement une gêne esthétique, une insulte à votre intelligence et une interruption de votre fil de pensées. Dans chaque entreprise vendant de la publicité, une importante partie de leur équipe d'ingénieurs passent leurs journées à affiner l'exploration de données, améliorer le code pour collecter toutes vos données personnelles, améliorer les serveurs qui contiennent toutes les données et s'assurer que tout est bien enregistré, rassemblé, découpé, emballé et envoyé... Au final, le résultat de tout cela est une bannière de publicité légèrement différente dans votre navigateur ou écran de téléphone mobile.
Voici un autre passage du même billet, traitant du recueil de données personnelles :
À WhatsApp, nos ingénieurs passent tout leur temps à réparer des bugs, ajouter de nouvelles fonctionnalités et passer le tout au peigne fin pour offrir une messagerie riche, abordable et fiable pour tous les téléphones dans le monde entier. C'est notre produit et notre passion. Vos données n'entrent même pas en jeu. Cela ne nous intéresse tout simplement pas.
À l'époque, WhatsApp avait une très bonne réputation. L'application était en effet appréciée pour sa simplicité, sa fiabilité, mais aussi pour son positionnement sur la publicité et les données personnelles. Comme avec Facebook à ses débuts, la protection de la vie privée est un avantage compétitif pour WhatsApp, qui lui permet de gagner des parts de marché (sur Facebook Messenger ou Google Hangouts par exemple).
Seulement voilà, en 2014 WhatsApp vend son application à Facebook pour 22 milliards de dollars. Vu l'historique de Facebook, on peut déjà craindre le pire. Jan Koum écrit pourtant sur le blog de WhatsApp :
Voici ce qui va changer pour vous, nos utilisateurs : rien.
WhatsApp restera autonome et fonctionnera indépendamment. Vous pouvez continuer à profiter du service à moindre coûts. Vous pouvez continuer à utiliser WhatsApp n'importe où dans le monde entier ou avec n'importe quel Smartphones que vous utilisez. Et vous pouvez toujours compter sur le fait qu'il n'y aura absolument aucune publicité pour venir interrompre votre communication. Il n'y aurait pas eu de partenariat entre nos deux sociétés si nous avions eu à faire des compromis sur nos principes fondamentaux qui font l'identité de notre entreprise, notre vision et notre produit.
Et en effet, WhatsApp revient ainsi sur sa parole et décide de partager vos données personnelles avec Facebook dès 2016 :
Mais en coordonnant davantage avec Facebook, nous pourrons faire des choses telles que suivre des mesures de base sur la fréquence d'utilisation de nos services des gens et améliorer la lutte contre les spams sur WhatsApp. Et en connectant votre numéro de téléphone avec les systèmes de Facebook, ce dernier peut vous offrir de meilleures suggestions d'amis et vous montrer des publicités plus pertinentes si vous avez un compte Facebook. Par exemple, vous pouvez voir une publicité d'une entreprise avec laquelle vous avez déjà travaillé au lieu de voir celle d'une entreprise dont vous n'avez jamais entendu parler.
Afin de mieux comprendre la portée de cette modification, il convient de s'extraire de la communication de WhatsApp. L'EFF détaille les données dorénavant partagées avec Facebook : numéro de téléphone, carnet d'adresses et données d'utilisation (quand vous utilisez WhatsApp, avec qui vous communiquez, sur quel appareil, votre adresse IP, etc). Ces métadonnées sont extrêmement précieuses pour Facebook, qui même s'il n'a pas accès au contenu de vos conversations WhatsApp (chiffrées de bout en bout), récolte les informations les plus importantes.
À l'époque, WhatsApp laisse un opt-out de seulement 30 jours aux utilisateurs existants (via ce "Dark Pattern"). Les nouveaux utilisateurs n'auront pas ce choix. Et encore, l'opt-out ne permet pas d'arrêter le partage d'informations, seulement d'empêcher Facebook d'utiliser vos informations WhatsApp pour de la publicité ciblée ou l'amélioration de ses produits (suggestion d'amis). Relisons l'EFF à ce propos :
Note that your WhatsApp information will still be passed to Facebook for other purposes such as “improving infrastructure and delivery systems, understanding how [Facebook and WhatsApp] services...are used, securing systems, and fighting spam, abuse, or infringement activities." Changing your settings does ensure, however, that Facebook will not use your WhatsApp data to suggest friends or serve ads.
En Europe, ce partage de données passe mal. L'Allemagne refuse le partage de données, puis les CNIL européennes demandent "instamment" d'arrêter le partage des données personnelles. La CNIL du Royaume-Uni demande ensuite la mise en pause de la synchronisation des données. Enfin la CNIL met en demeure WhatsApp de ne plus transmettre à Facebook les données de business intelligence de WhatsApp. Entre-temps, la Commission Européenne affirme que Facebook a fourni des informations trompeuses lors du rachat de WhatsApp et lui inflige une amende de 110 millions d'euros :
Facebook a indiqué à la Commission qu'elle ne serait pas en mesure d'associer automatiquement et de manière fiable les comptes d'utilisateur des deux sociétés
Ces épisodes sont très bien résumés dans le billet du blog de Killian Kemps, "WhatsApp transfère-t-elle des données à Facebook ?". Ce billet pose une question simple : WhatsApp a-t-il réellement stoppé le partage de vos données personnelles avec Facebook suite à ces plaintes dans l'Union Européenne ? Malheureusement non, même si la réponse n'est pas facile à trouver.
Voici ce que dit la politique de confidentialité de WhatsApp pour les résidents de l'Union Européenne (mise à jour en avril 2018) :
Comment nous travaillons avec d'autres entités Facebook
Nous faisons partie des entités Facebook. En tant que membre des entités Facebook, WhatsApp reçoit des informations des entités Facebook et leur transmet également des informations. Nous pouvons utiliser les informations qu’elles nous envoient, et elles peuvent utiliser celles que nous leur transmettons, afin de nous aider à exploiter, fournir, améliorer, comprendre, personnaliser, prendre en charge et commercialiser nos Services et leurs offres [...].
En approfondissant la question via l'article "Comment nous travaillons avec les entités Facebook", on comprend que les échanges de données personnelles entre WhatsApp et Facebook sont très nombreux. Un point cependant, sans l'action de la Commission Européenne, Facebook irait encore plus loin dans le traitement de vos données personnelles :
Nous ne partageons pas de données afin d'améliorer les produits Facebook sur la plateforme et d'offrir de meilleures expériences publicitaires sur Facebook.
Aujourd'hui, Facebook n'utilise pas les informations de votre compte WhatsApp pour améliorer votre expérience avec les produits Facebook ni pour vous proposer des publicités Facebook plus ciblées sur sa plateforme. Ceci est le résultat de discussions avec le commissaire irlandais chargé de la protection des données et d'autres autorités responsables de la protection des données en Europe. Nous cherchons constamment de nouvelles manières d'améliorer votre expérience avec WhatsApp et les Produits des entités Facebook que vous utilisez. Si, à l'avenir, nous décidons de partager de telles données avec les Entités Facebook à cette fin, nous conclurons d'abord un accord avec le commissaire irlandais chargé de la protection des données afin d'établir un mécanisme qui permette une telle utilisation. Nous vous informerons des nouvelles expériences mises à votre disposition et de nos pratiques concernant l'utilisation de vos données.
Et en effet, si vous n'êtes pas un résidant de l'Union Européenne, Facebook ne se prive de rien :
Facebook et les autres entités de la famille Facebook peuvent également utiliser des informations que nous avons fournies pour améliorer vos expériences au sein de leurs services, comme faire des suggestions de produit (par exemple d’amis, de connexions ou de contenus intéressants) et afficher des offres et des publicités pertinentes.
Depuis début janvier, la dernière mise à jour des conditions d'utilisation de WhatsApp passe mal. La date de mise en application des nouvelles conditions d'utilisation est repoussée : initialement prévue le 8 février, elle aura lieu le 15 mai, le temps pour WhatsApp d'affiner sa communication.
Si le partage de vos données personnelles avec Facebook était déjà effectif depuis presque 5 ans, cette mise à jour va permettre à Facebook d'aller plus loin :
- Partage de vos données transactionnelles WhatsApp avec les "Facebook Shops".
- Partage de vos communications avec les entreprises, via un service d'hébergement des communications proposé par Facebook.
Ce service d'hébergement est une première brèche du chiffrement de bout en bout car ces communications ne seront pas chiffrées chez l'hébergeur (un des 2 "bouts" du chiffrement). Voici comment WhatsApp noie le poisson :
WhatsApp considère les discussions avec les entreprises utilisant l’application WhatsApp Business ou gérant et stockant elles-mêmes les messages des clients comme chiffrées de bout en bout. Une fois le message reçu, il sera sujet aux propres pratiques de l’entreprise en matière de confidentialité. L’entreprise peut permettre à un certain nombre d’employés, voire d’autres prestataires, de traiter le message et y répondre.
Certaines entreprises pourront choisir de stocker les messages des clients et y répondre de façon sécurisée à travers la société mère de WhatsApp, Facebook. Vous pouvez toujours contacter les entreprises pour en savoir plus sur leurs pratiques en matière de confidentialité.
Par facilité, la grande majorité des sociétés choisira sans doute la solution d'hébergement de Facebook. Le contenu de vos discussions avec les entreprises sera donc visible de "l'hébergeur" Facebook et soumis à ses pratiques en matière de confidentialité.
Dernier argument en faveur de WhatsApp donc (notamment si l'on compare à Telegram), vos messages personnels restent protégés par le chiffrement de bout en bout, par défaut :
La confidentialité et la sécurité de vos messages et appels personnels ne changent pas. Ils sont protégés par le chiffrement de bout en bout et ni WhatsApp ni Facebook ne peuvent les lire ou les écouter. Nous n'affaiblirons jamais cette sécurité et nous faisons apparaître cette information dans chaque discussion afin que vous puissiez être au fait de notre engagement.
À noter que WhatsApp utilise le protocole open source de Signal pour le chiffrement des messages, un point fort :
Chaque message WhatsApp est protégé par le même protocole de chiffrement de Signal, sécurisant les messages avant qu’ils ne quittent votre appareil.
Mais pour le reste de vos données personnelles, c'est open bar. Comment WhatsApp a-t-il pu à ce point trahir ses utilisateurs ? Pour une histoire détaillée des compromissions (et résistances) de WhatsApp face à sa maison mère, lisez l'excellent article de Forbes "Exclusive: WhatsApp Cofounder Brian Acton Gives The Inside Story On #DeleteFacebook And Why He Left $850 Million Behind". Le co-fondateur de WhatsApp y déclare notamment :
I sold my users’ privacy to a larger benefit. I made a choice and a compromise. And I live with that every day.
Brian Acton a quitté WhatsApp en septembre 2017 (et son compère Jan Koum en avril 2018). Aujourd'hui, il est à la tête de la Signal Foundation, lancée en février 2018 avec un financement initial de 50 millions de dollars d'Acton. Il a également un rôle opérationnel important chez Signal.
Facebook a depuis dégouté les cofondateurs d'Instagram, Kevin Systrom et Mike Krieger, pour une histoire de jalousie (Instagram est à la mode, plus Facebook) et de croissance à tout prix (dégrader l'application Instagram pour mettre en avant l'application Facebook).
Une fin heureuse ?
On le voit donc, WhatsApp suit le modèle de sa maison mère : il s'est imposé en étant plus respectueux de la vie privée que ses concurrents. Racheté par Facebook et en position dominante, il trahit votre confiance en érodant progressivement votre vie privée.
Va-t-il s'en tirer à bon compte ? Cela dépendra de nos actions collectives. Pour ma part, la tâche est encore plus ardue qu'avec Facebook et Instagram (comptes que j'avais pu fermer il y a quelque temps déjà). J'ai pu migrer quelques conversations et groupes sur Signal, mais je vais devoir convaincre beaucoup de personnes avant d'espérer fermer mon compte WhatsApp.
Confidentialité de WhatsApp sur l'App Store.
Confidentialité de Signal sur l'App Store.
Néanmoins, il est permis d'être optimiste sur le long terme. À la différence de Facebook ou d'Instagram qui n'ont aujourd'hui pas de vrais concurrents, les messageries Telegram et Signal vont donner du fil à retordre à WhatsApp. Et la vague d'installation actuelle de Signal fait plaisir à voir.
Un tweet d'Elon Musk ne peut jamais faire de mal.
On a connu pire comme sponsor.
14.12.2020 à 14:14
Vie privée : le match des navigateurs iOS

Safari, l'inévitable navigateur iOS ?
Pour un navigateur tiers, il est difficile de concurrencer Apple Safari sur iOS :
- À la différence d'Android, iOS ne permet pas aux navigateurs tiers d'utiliser leur propre moteur de rendu. Si l'on lit les "guidelines" de l'App Store, section 2.5.6 : "Apps that browse the web must use the appropriate WebKit framework and WebKit Javascript".
- Apple a longtemps réservé l'usage de la dernière version de Webkit à Safari, les autres navigateurs étaient contraints d'utiliser une version périmée (basée sur la classe
UIWebView), lente et instable. - Toujours en raison de l'obligation d'utiliser WebKit, iOS ne permet pas aux navigateurs tiers de proposer leur propre bibliothèque d'extensions. Sur Android, je peux installer des extensions Firefox comme uBlock Origin.
- Les extensions de Safari telles que les bloqueurs de contenus ne sont pas accessibles aux autres navigateurs.
- Avant iOS 14, il n'était pas possible de changer le navigateur par défaut.
En conséquence, il n'était pas très intéressant d'utiliser un autre navigateur. Néanmoins, Apple évolue progressivement. Depuis iOS 8, les navigateurs tiers peuvent correctement utiliser le dernier moteur de rendu de WebKit. Et depuis iOS 14, Apple permet de changer le navigateur par défaut. Les navigateurs tiers peuvent ainsi mieux concurrencer Safari, notamment sur la protection de votre vie privée.
Quel que soit votre navigateur, vous bénéficiez déjà de la protection WebKit
Les navigateurs tiers ont obligation d'utiliser le moteur de rendu d'Apple, WebKit. Cela se traduit techniquement par l'utilisation de la classe WKWebView. Hors depuis iOS 14, celle-ci inclut par défaut Intelligent Tracking Prevention, le mécanisme de protection de la vie privée d'Apple (préalablement uniquement disponible sur Safari).
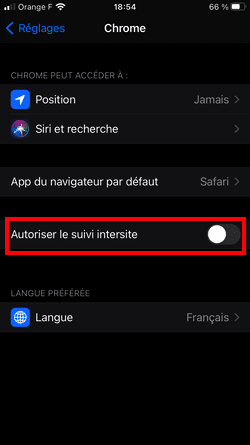
Oui, Chrome sur iOS vous protège contre le suivi intersite, par défaut ! L'obligation d'utiliser WebKit force Google à mieux protéger votre vie privée.
Intelligent Tracking Prevention (ITP) contient de nombreux mécanismes permettant de lutter contre le "suivi intersite", on peut notamment citer :
- Le blocage de tous les cookies tiers (prévu pour 2022 seulement sur Chrome).
- La limitation de la durée de vie des cookies créés via du javascript (cookies 1st party, mais pouvant être créés par des tiers) à 7 jours.
- La limitation de la durée de vie des cookies déposés via des domaines CNAME (là aussi, cookies 1st party, mais pouvant être déposés par des tiers) à 7 jours.
Les protections ITP ne se limitent pas aux cookies, pour une liste exhaustive lisez la page Cookie Status de Safari.
Si ces protections permettent de lutter contre le pire de la publicité (le suivi intersite), elles n'empêchent pas les sociétés marketing de mesurer chacune de vos interactions sur chaque site, ni de diffuser de la publicité. D'autres part, les sociétés marketing continuent de travailler à contourner les restrictions d'Apple (via du Server-Side Tagging, ou des identifiants de tiers déguisés en 1st party par exemple).
Si vous souhaitez être mieux protégé, quelles sont vos options ?
Le navigateur, un premier vecteur de surveillance
Avant même d'analyser les protections des navigateurs contre le pistage lors de votre surf, les navigateurs ont-ils mis en place leur propre système de surveillance ? Pour cela, je vais observer ce qu'il se passe lors du premier lancement du navigateur. À noter qu'une analyse similaire a déjà été effectuée par Brave récemment. Voici les étapes suivi :
- Téléchargement du navigateur à tester.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur, puis recherche dans la barre d'adresse (pas de navigation privée).
- Export de la session Charles sur mon ordinateur pour analyse.
Et voici un récapitulatif des différents navigateurs testés.
Safari, difficile à auditer de manière exhaustive
Safari est pré-installé donc je ne peux simuler un premier lancement. Il n'est pas impossible qu'Apple récupère des données de télémétrie de Safari si vous n'avez pas décoché les différents interrupteurs dans "Réglage" > "Confidentialité" > "Analyse et améliorations" :
J'ai décoché les différents interrupteurs dans "Analyse et améliorations", aussi je n'ai pas vu de traceurs Apple spécifiques à Safari.
Lorsque vous faites une recherche, le moteur de recherche par défaut est Google. Celui-ci verserait 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur tous les appareils Apple. Safari envoie ainsi à Google chaque caractère entré dans la barre de recherche (sans identifiant), pour faire marcher l'auto-complétion.

Côté vie privée, Apple prend de très bonnes initiatives. Mais il permet à Google et son capitalisme de surveillance de prospérer, pour beaucoup d'argent.
DuckDuckGo, le bon élève
Le moteur de recherche américain (en grande partie basé sur Bing) a fait de la vie privée son cheval de bataille, il fait d'ailleurs partie des moteurs de recherche recommandés par PrivacyTools. Il propose également un navigateur pour iOS, et voici les requêtes envoyées lors du premier lancement :

Lorsque l'on regarde dans le détail, c'est très propre : DuckDuckGo télécharge les bloqueurs de contenus. Lorsque vous tapez dans la barre d'adresse, il récupère les caractères pour de l'auto-complétion (avantage de fournir aussi un moteur de recherche), sans identifiant. La télémétrie est activée, mais là aussi sans identifiant.
Seule contrainte : le moteur de recherche par défaut (celui de la barre d'adresse) ne peut évidemment pas être changé. Mais si pour certaines requêtes vous n'êtes pas satisfait (rappel : derrière DuckDuckGo, c'est souvent Bing), vous pouvez utiliser les "bangs", des alias qui permettent de faire une recherche sur un autre moteur de recherche (Google évidemment, mais aussi YouTube, Wikipedia, Twitter, etc).
DuckDuckGo ne manque pas d'humour, voici le message dédié lors de votre première recherche Google (en préfixant votre recherche par !g).
Également très apprécié, la facilité à effacer les données :
Il vous suffit de cliquer sur la flamme pour effacer les données.
Brave vous protège... et fait tourner son business
Le navigateur Brave a été créé par Brendan Eich, ancien cofondateur de Firefox et créateur de Javascript. Brave a un discours fort contre les traceurs et autres publicités non respectueuses de la vie privée. Voici quelques points clés :
- Brave se base sur Chromium (et son moteur de rendu Blink), la partie Open-Source de Google Chrome. Mais sur iOS, il ne peut pas utiliser Chromium, et se voir forcé d'utiliser WebKit.
- Via Brave Shields, il bloque les traceurs et autres publicités qui vous pistent. Si vous l'acceptez, il diffuse des publicités respectueuses de la vie privée (servies en local, ce qui fait de Brave une régie publicitaire). Ce positionnement, en concurrence avec les éditeurs (Brave recrute les annonceurs), suscite des controverses.
- Brave Rewards vous permet de payer les sites que vous consultez de diverses manières : via un abonnement mensuel (par exemple, 10€ partagés avec les sites consultés, selon votre temps passé sur ces sites), via des pourboires (micro paiements) ou via la publicité servie en local par Brave (pour laquelle vous pouvez également être payé). Brave Rewards est basé sur la propre crypto monnaie de Brave : le BAT (ou Basic Attention Token).
UPDATE 15 décembre 2020 : Brave a d'autres controverses à son actif (merci @kinux), et notamment :
- Le financement via des liens d'affiliations vers des sites de crypto-monnaies, pratique arrêtée depuis que l'affaire a été révélée.
- L'inclusion de infogalactic, un Wikipédia d'extrême droite, dans les moteurs de recherche proposés par défaut. La pratique aurait cessé en décembre 2018 d'après ce site.
Brave vous permet au premier lancement de choisir votre moteur de recherche par défaut (et permet à des moteurs de recherche respectueux de la vie privée tels que Qwant, DuckDuckGo ou Startpage de trouver de nouveaux utilisateurs) :

Je sélectionne ici Startpage, un moteur de recherche basé sur Google, mais respectueux de la vie privée.
Vérifions les requêtes avant de cliquer sur "Enregistrer" :
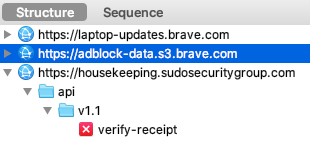
Certaines requêtes ne sont pas lisibles sur l'outil Charles et je n'ai donc pu vérifier si des identifiants fuitaient, néanmoins on peut noter l'appel à sudosecuritygroup.com. Il s'agit en fait de la société Guardian, qui s'est associé à Brave pour fournir un VPN qui bloque aussi les traceurs et les publicités. Vous pourrez activer le VPN dans Brave, mais il faudra payer.
Deuxième étape, Brave vous propose de bloquer les traceurs :
Évidemment j'accepte.
Troisième étape, Brave pense à sa propre régie publicitaire, et vous propose de visualiser des publicités "privées et anonymes" :
Je clique sur Ignorer, l'audit des publicités Brave sera pour une autre fois.
Quatrième étape, je lance une recherche. Brave me demande si je souhaite activer les suggestions de recherche :
Question appréciée, je refuse donc.
Regardons maintenant les requêtes envoyées (depuis le lancement de l'application) :
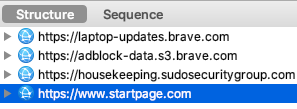
Si on regarde le détail, Brave n'a pas envoyé de requêtes supplémentaires depuis l'étape 1 excepté vers Startpage, appelé uniquement lorsque je valide ma requête de recherche.
Firefox, quelques mauvaises surprises
Firefox est mon navigateur sur Mac. À la différence d'un Brave, Firefox a son propre moteur de rendu, Gecko. Mais lui aussi se voit contraint d'utiliser WebKit. Je m'attendais à ce que Firefox pour iOS ait une attitude irréprochable sur la vie privée car Firefox ayant une belle réputation et communiquant avantageusement. J'ai été surpris :
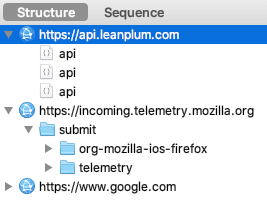
Dès la première ouverture, Firefox fuite mes données personnelles à Leanplum, une société marketing permettant d'afficher des messages ciblés. Leanplum est gourmand, il collecte notamment le deviceId, userId et uuid. Il récupère aussi mes principales interactions avec Firefox.
Firefox se permet également de collecter mes principales interactions (comme l'ouverture de l'application, sa fermeture, le clic sur la barre d'adresse) en direct (via incoming.telemetry.mozilla.org), avec l'identifiant clientId.
Pour les appels à Google, pas de surprise, il s'agit du moteur de recherche par défaut sur Firefox. Google représente la principale source de revenus pour Firefox, avec environ 450 millions de dollars par an. Chaque caractère entré dans la barre de recherche est envoyé à Google pour l'auto-complétion (sans identifiant).
Est-il possible de désactiver la fuite des données personnelles vers Leanplum ainsi que la télémétrie ? Oui, en décochant la bonne option dans les paramètres :
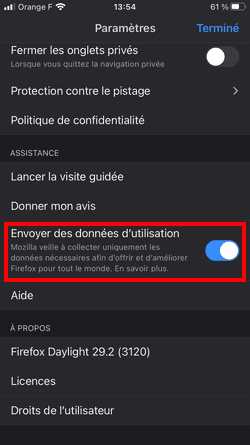
Je décoche "Envoyer des données d'utilisation"
On se serait attendu à de l'opt-in de la part de Firefox, et sans fuite de données personnelles vers une société marketing.
Chrome, le navigateur vorace de Google
Si vous utilisez Chrome pour iOS, vous n'avez à priori pas d'attente particulière concernant le respect de votre vie privée. Nous avions par exemple pu voir que Chrome envoie un en-tête HTTP unique à tous les domaines Google et Doubleclick, pratique pour vous pister. Lisez aussi "Why I'm done with Chrome", écrit il y a déjà 2 ans.
Dès l'ouverture de Chrome donc, Google vous informe que vous devez accepter les conditions d'utilisation. Premier problème, l'envoi de statistiques d'utilisation et des rapports d'erreur est coché par défaut :

Je décoche donc l'envoi de statistiques d'utilisation et des rapports d'erreur.
Si je regarde les requêtes passer avant le clic sur "Accepter et continuer", je vois que Chrome appelle déjà beaucoup de sites : pas d'inquiétude, il s'agit en fait de charger les images pour les signets par défaut (j'imagine les sites les plus consultés de France). Chrome récupère aussi des identifiants tels que le userid.
Deuxième étape, Chrome se montre ici très gourmand : il vous demande de synchroniser toute ma navigation avec mon compte Google. Une captation énorme de vos données personnelles donc, que Google enrobe en vous faisant miroiter de pouvoir synchroniser aussi vos mots de passe sur vos différents appareils "et plus encore".
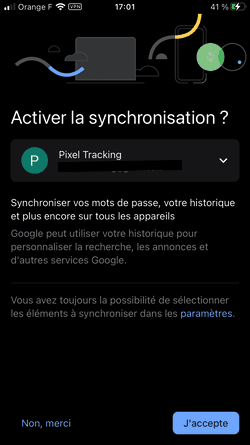
Je clique donc sur "Non, merci".
Si vous souhaitez sélectionner les éléments à synchroniser, le texte "paramètres" en bleu pourrait vous faire croire que vous avez déjà la main, mais il n'est pas cliquable. Notez encore le bouton bleu "J'accepte", très naturel. Comparé à "Non, merci" en noir : un bel exemple de "Dark Pattern".
Troisième étape, Chrome continue sur sa lancée et me demande d'accéder à ma position exacte (pour "Améliorer mon expérience") !
Je clique sur "Ne pas autoriser"
Notez qu'avec iOS, je ne peux maintenant autoriser les accès qu'une seule fois (Chrome devra alors me redemander au lancement suivant), je peux également désactiver "Position exacte". Ces options peuvent être utiles pour vous protéger de certaines applications.
Dernière étape, Chrome est déjà lancé mais je fais une recherche, sur Google évidemment, pour tomber sur un bandeau de consentement venant d'être retoquée par la CNIL :
Le nouveau bandeau d’information mis en œuvre par les sociétés lors de l’arrivée sur la page google.fr ne permettait toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informait pas du fait qu’ils pouvaient refuser ces cookies.
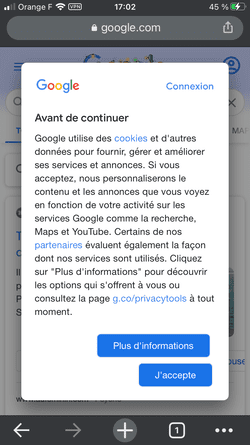
Et en effet, bon courage pour refuser les cookies, vous pouvez vous perdre dans les menus sans trouver l'option, ni même être sûr que l'option choisie permet bien de refuser les cookies (je ne détaille pas, cela mériterait un article dédié).
Ici vous pourriez vous dire : je n'ai pas encore cliqué sur "J'accepte", Google n'a pas dû déposer de cookies. D'autant que si on lit la dernière sanction de la CNIL à l'encontre de Google (daté du 10 décembre 2020), celui-ci se permettait de le faire mais il a corrigé le tir :
La formation restreinte a pris acte que, depuis une mise à jour de septembre 2020, les sociétés cessent de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
Regardons néanmoins les requêtes envoyées (depuis l'étape 2) :
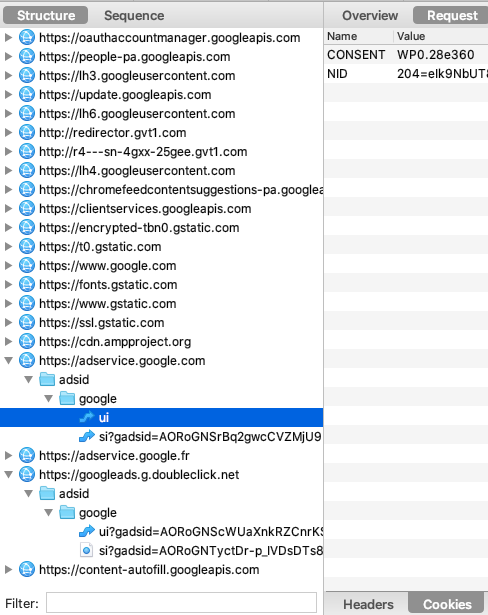
Parmi les nombreuses requêtes envoyées aux différents services de Google, on peut noter les requêtes à adservice.google.com et à doubleclick.net. La requête à adservice.google.com contient bien le cookie NID. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
La CNIL parle-t-elle du cookie NID dans sa délibération ?
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Ainsi, en contradiction avec la délibération de la CNIL, Google n'a pas arrêté de déposer automatiquement certains cookies publicitaires sur la page google.fr.
Edge fait encore pire que Chrome
La réputation des navigateurs Microsoft n'est plus à faire :
Via compte parodique Twitter @intrnetexp.
Seulement voilà, fini les moqueries sur le retard d'Internet Explorer, Microsoft se base maintenant sur Chromium et son moteur de rendu Blink pour son navigateur Edge (tout comme Brave, Opera ou Vivaldi), il investit pour le rendre compétitif. Pour Edge aussi, pas de Chromium sur iOS à cause des restrictions Apple, et donc l'utilisation forcée de WebKit. Qu'en est-il du respect de votre vie privée ?
Le premier lancement de Edge ressemble beaucoup à Chrome, ce qui n'est pas bon signe. Edge vous suggère de vous connecter pour activer la synchronisation : favoris, mots de passe et "bien plus encore".
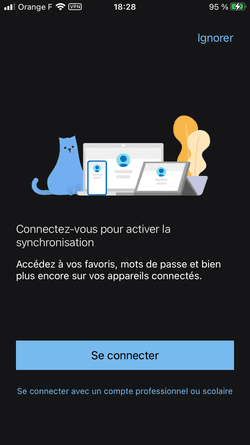
Je clique sur "Ignorer" (notez le Dark Pattern).
Si l'on regarde les requêtes envoyées avant clic sur "Ignorer", Edge est déjà gourmand :
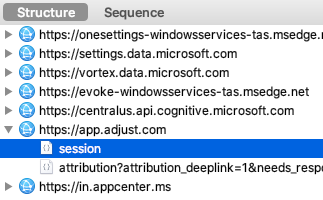
Via plusieurs requêtes, Edge récupère plusieurs identifiants tels que deviceId ou clientId. Notez notamment le domaine vortex.data.microsoft.com, si bien nommé. À chaque interaction avec Edge, celui-ci va collecter de la donnée, et cette fuite est impossible à désactiver.
Comme Firefox, Edge fuite aussi vos données personnelles vers un tiers, Adjust, société spécialisée dans la mesure mobile et l'attribution. Adjust récupère des identifiants tels que persistent_ios_uuid.
Deuxième étape, Edge est toujours aussi gourmand que Chrome, il cherche à enregistrer mon historique de navigation :

Je clique sur "Pas maintenant".
Troisième étape, on comprend pas tout à fait la différence avec l'étape précédente ("En savoir plus" redirige toujours vers la page "Historique d'activités Windows 10 et confidentialité"), Edge insiste en vous demandant des données sur "la façon dont vous utilisez le navigateur" :

Je clique encore sur "Pas maintenant".
Quatrième étape, je fais une recherche (sur Bing évidemment), notez le bandeau de consentement :
Vérifions les requêtes (je n'ai pas encore interagi avec le bandeau de consentement) :
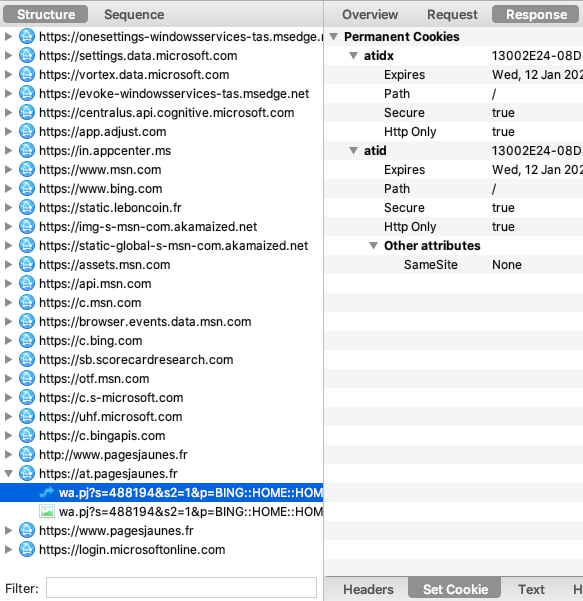
Les services Microsoft sont omniprésents, tous récupèrent vos données personnelles. Leboncoin est appelé mais simplement pour télécharger le logo. Edge ne fuite pas seulement vos données personnelles vers Adjust mais aussi vers Comscore (via scorecardresearch.com), géant du marketing qui peut ainsi mieux vous profiler.
Bonus : Bing fuite vos recherches au site Pages Jaunes
À cause de Bing (et non de Edge), j'ai été surpris (et alarmé) de voir que celui-ci fuite une donnée potentiellement sensible, ma requête, directement à Pages Jaunes (via pagesjaunes.fr) :
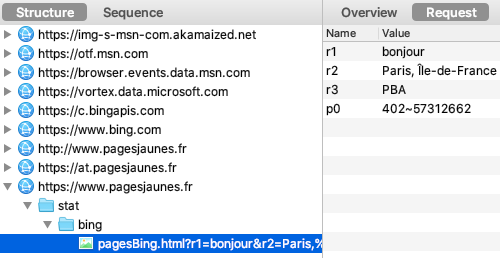
Heureusement ma recherche "bonjour" n'était pas sensible, mais Bing fuite l'intégralité de vos recherches au site Pages Jaunes (ainsi que votre ville), en temps réel, quelque soit l'appareil et le navigateur utilisé.
La régie publicitaire de Pages Jaunes s'appelle Solocal. Il s'agit d'un partenariat ancien, ayant surement été reconduit, sur le dos de votre vie privée (rappel, je n'ai toujours pas interagi avec le bandeau de consentement, ma recherche Bing a fuité vers le site Pages Jaunes).
Cadeau supplémentaire de Bing et Pages Jaunes, le domaine at.pagesjaunes.fr (qui dépose un cookie sans votre consentement) est un alias CNAME vers l'outils d'analytics français AT Internet :
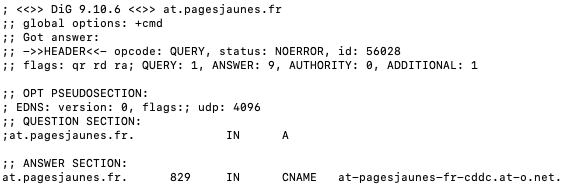
Comme on a déjà pu le voir avec Criteo, Boursorama ou Lemonde.fr, ces alias CNAME ont pour but de contourner les protections navigateurs et adblockers, ils sont également souvent à l'origine d'une faille de sécurité importante.
Cliquer sur "Plus d'options" pour ensuite désactiver les cookies "non essentiels" empêche-t-il de fuiter vos requêtes vers les pages jaunes et vos données de surf vers AT Internet ?
Le bandeau de consentement sans option de premier niveau pour tout refuser, un classique.
Malheureusement non, cela ne change strictement rien au comportement de Bing : celui-ci fuite toujours mes recherches au site Pages Jaunes.
Il manquait une information clé pour Microsoft : ma géolocalisation ! Et en effet, sans que je continue ma navigation, Edge me demande maintenant l'accès à ma position :
Conclusion : difficile à croire, mais via Edge et Bing, Microsoft réussit le tour de force d'être pire que Google sur le respect de votre vie privée.
Le navigateur comme protection contre la surveillance des sites
S'ils respectent eux-même plus ou moins bien votre vie privée, les navigateurs sont aussi censés vous protéger lorsque vous surfez sur le web. Regardons si c'est vraiment le cas, via une navigation sur deux sites connus pour fuiter massivement vos données personnelles :
- Le Bon Coin, cf. "La grande braderie de vos données personnelles sur Le Bon Coin".
- Le Monde, cf "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr".
Le protocole sera le même pour tous les navigateurs :
- Suppression des cookies et autres données navigateur.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur à tester, pas de navigation privée.
- Surf sur la page d'accueil de ces 2 sites, avec acceptation du pistage via la bannière de consentement.
Le comparatif ne peut être parfait car il ne s'agit que de 2 pages d'accueil, et d'un moment sur l'autre, les publicités servies peuvent être différentes. Mais le nombre de traceurs devrait nous donner une bonne idée de l'efficacité du navigateur.
Safari sans bloqueur de contenu, tout passe
Le cas nominal, j'ai désactivé mon bloqueur de contenu, Firefox Focus. Voici les résultats condensés :
- 94 hôtes contactés.
- 338 requêtes.
- 9,2 Mo de données téléchargées.
Inutile de dire que le nombre de traceurs est impressionnant, même si Intelligent Tracking Prevention limite la casse en stoppant le pistage intersite.
Safari avec bloqueur de contenu, des trous importants dans la raquette
Ici j'ai utilisé Firefox Focus (dont la liste de traceurs est fournie par Disconnect), vous pouvez aussi sélectionner d'autres bloqueurs de contenus comme Adguard. Les résultats sont-ils meilleurs ? Sensiblement :
- 45 hôtes contactés (ce qui signifie 49 traceurs en moins).
- 200 requêtes.
- 6.2 Mo de données téléchargées.
Est-ce à dire que le bloqueur de contenu vous a complètement protégé ? Lorsque l'on regarde dans le détail, de nombreux tiers continuent de vous pister, même si les traceurs les plus "évidents" ont disparu :
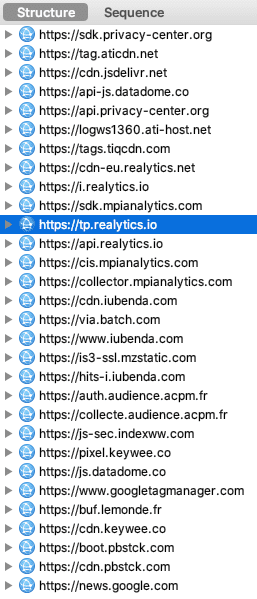
J'ai supprimé les requêtes 1st party pour y voir plus clair.
DuckDuckGo, une protection améliorée
DuckDuckGo utilise sa propre liste de traceurs, "Tracker Radar", généré par son propre crawl du web. Les informations de "Tracker Radar" sur les différents traceurs peuvent également être utilisés par des tiers (comme dans Safari, pour donner de l'information sur ces traceurs). Voici les résultats :
- 39 hôtes contactés.
- 226 requêtes.
- 6,3 Mo de données téléchargées.
Ces statistiques semblent proches de Safari avec bloqueur de contenus, si l'on regarde maintenant le détail :
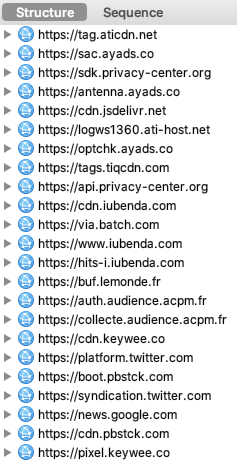
La liste des traceurs est moins longue, DuckDuckGo est un peu plus efficace que Safari combiné à Firefox Focus.
Brave, une protection forte
Brave Shields, le système de blocage des traceurs, permet d'être très souple :
- Les paramètres par défaut vous protègent bien.
- Vous pouvez changer les paramètres par défaut.
- Vous pouvez aussi changer les paramètres pour des sites spécifiques.
Voici donc les paramètres par défaut :
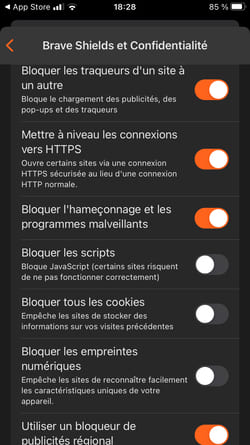
Vous pouvez décider de bloquer les scripts, tous les cookies et les empreintes numériques. Mais d'expérience, certains sites ne marcheront plus correctement. Voici donc les résultats avec les paramètres par défaut :
- 29 hôtes contactés.
- 168 requêtes.
- 5,4 Mo de données téléchargées.
Brave est donc le plus efficace. Si l'on regarde dans le détail :

C'est presque parfait (Brave protège par exemple contre le CNAME cloaking d'AT Internet sur le site lemonde.fr, via le domaine buf.lemonde.fr), mais Brave rate notamment Facebook et Twitter.
Firefox vous protège relativement mal par défaut
Si Firefox est une très bonne option sur mon Mac, il a une sévère limitation sur iOS : comme avec tous les autres navigateurs iOS, on ne peut pas installer d'extensions. Et Firefox sans extension vous protège malheureusement beaucoup moins bien. Voici les résultats avec les paramètres par défaut :
- 111 hôtes contactés.
- 454 requêtes.
- 11,9 Mo de données téléchargées.
Vous êtes donc largement pisté. Dans les faits, tout n'est pas noir, si vous allez dans les paramètres :
Cliquez dans la section "vie privée" sur "Protection contre le pistage"
Vous pouvez vous rendre compte que par défaut, Firefox applique la "Protection renforcée contre le pistage" (ETP pour "Enhanced Tracking Protection") en version "Standard" :
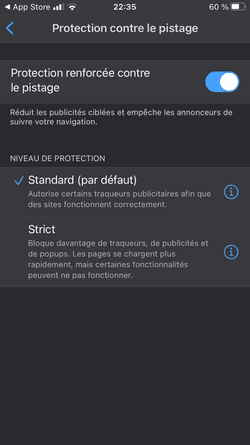
En cliquant sur le "i", vous pourrez apprendre que Firefox vous protège contre les traqueurs de réseaux sociaux (en effet, Facebook et Twitter ont été bloqués), contre les traqueurs intersites (rien de nouveau ici, vous l'êtes déjà via ITP), contre les mineurs de crypto monnaie et contre les détecteurs d'empreinte numérique (technique couramment appelée "fingerprinting").

Si vous activez la protection "Strict", Firefox vous protègera aussi contre le "Contenu utilisé pour le pistage" (protection qui nous intéresse tout particulièrement) :
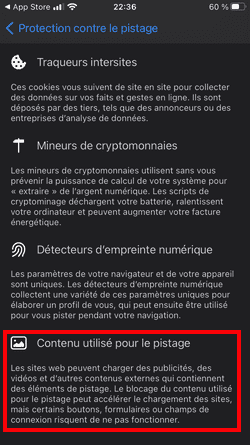
Êtes-vous mieux protégé ? Voici les nouveaux résultats :
- 42 hôtes contactés.
- 225 requêtes.
- 6,7 Mo de données téléchargées.
Les résultats sont donc bien meilleurs. Si l'on regarde le détail :

On retrouve les mêmes traceurs qu'avec l'option Safari et Firefox Focus : les 2 applications de Mozilla se servent d'une liste fournie par Disconnect pour bloquer certains traceurs.
Chrome, le navigateur sans protection
Avec Chrome c'est très simple, vous n'avez aucune protection par défaut, ni aucun réglage vous permettant de vous protéger. Chrome ne reste pas totalement inactif, les équipent travaillent sur le projet Privacy Sandbox, avec pour mission :
The Privacy Sandbox project’s mission is to “Create a thriving web ecosystem that is respectful of users and private by default.”
Dans le détail, "a thriving web ecosystem" signifie supporter les cas d'usages actuels de la publicité : mesure de conversion, publicité comportementale, retargeting, etc. "Private by default" signifie de ne plus permettre aux traceurs de pister individuellement les utilisateurs (Chrome bloquera les cookies tiers en 2022).
La mesure et le ciblage se feront via des "cohortes" d'utilisateurs (groupes suffisamment grands), via des décisions prises directement par le navigateur, via des mécanismes pour empêcher le croisement des données, etc.
Évidemment Google est moins concerné par les modifications de Chrome qu'un site web lambda : il continuera de pister la grande majorité des utilisateurs via leurs comptes Google.
Voici donc les résultats du surf sur Chrome :
- 100 hôtes contactés.
- 370 requêtes.
- 11,3 Mo de données téléchargées.
Pas de surprise donc, vous n'êtes pas du tout protégé.
Edge, des protections bien cachées
Edge était bon dernier lors du premier lancement du navigateur. Qu'en est-il des protections lors de votre surf ? Si l'on regarde les résultats avec la configuration par défaut :
- 96 hôtes contactés.
- 368 requêtes.
- 10,2 Mo de données téléchargées.
Edge est comparable à Chrome, ce qui n'est pas un compliment. Mais Edge dispose d'options cachées intéressantes. Si vous allez dans "Paramètres", à "Bloqueurs de contenus", vous pouvez découvrir une intégration "native" du bloqueur Adblock Plus :
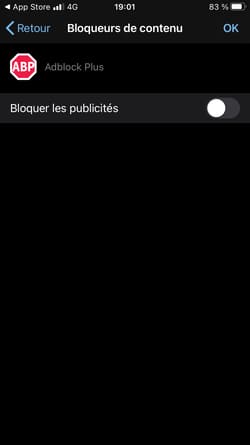
J'active donc "Bloquer les publicités"
Oui Edge a intégré Adblock Plus dans son navigateur. Seulement, Adblock Plus est aussi une société publicitaire, qui se fait payer de grosses sommes par des géants du marketing (dont Microsoft, mais aussi Google, Amazon, Criteo, Taboola ou Outbrain) pour laisser passer certaines publicités, une belle hypocrisie. Il vous faut donc aller plus loin pour bloquer toutes les publicités, à savoir aller dans les "Paramètres avancés" de "Bloqueurs de contenu" :
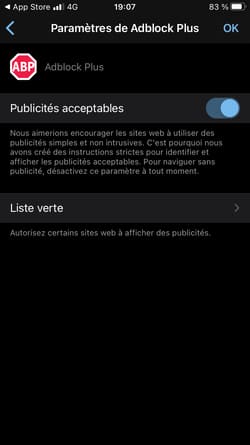
Je désactive "Publicités acceptables".
Mais vous n'êtes pas au bout de vos peines ! Une autre option est utile, elle se trouve dans "Paramètres", "Confidentialité et sécurité", et vous trouverez dans la section Sécurité (!), la rubrique "Prévention du suivi" (apparemment déjà "Activé") :
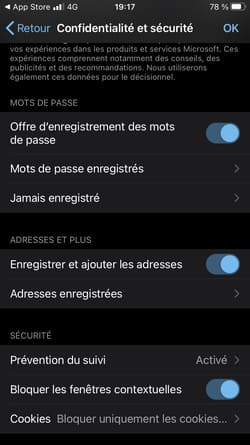
Ici il faut cliquer sur "Prévention du suivi".
Vous accédez alors à un nouvel écran :
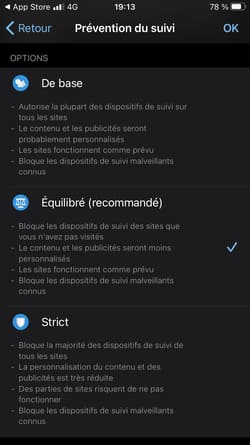
La version "Équilibré (recommandé)" est sélectionnée par défaut. Ainsi Edge bloquerait déjà "les dispositifs de suivi des sites que vous n'avez pas visités", ainsi que "les dispositifs de suivi malveillants connus". Dans les faits, on se demande ce que Edge bloque vraiment, tous les traceurs sont conviés à la fête (Criteo, Google, Doubleclick, Weborama, Facebook, Amazon, etc).
Microsoft indique se baser sur Disconnect pour bloquer les traceurs, dès la version "Équilibré" de "Tracking Prevention", il semble que cela soit un effet d'annonce (Firefox se base aussi sur Disconnect, mais bloque bien de nombreux traceurs).
Est-ce que le passage en "Prévention du suivi Strict", l'activation d'Adblock Plus et la désactivation des "Publicités acceptables" vous permet d'être protégé contre tous les traceurs ? Vu l'effort engagé, on aimerait bien. Voici les résultats :
- 41 hôtes contactés.
- 200 requêtes.
- 6,8 Mo de données téléchargées.
Edge se hisse au niveau d'un Safari avec Firefox Focus (ce qui est la moindre des choses avec Adblock Plus activé et Disconnect). Si on regarde maintenant dans le détail :
On voit bien que Edge a encore des progrès à faire.
NextDNS, en renfort du navigateur
Pour conclure, le choix du navigateur est personnel, mais certains navigateurs iOS apportent un bon premier niveau de protection : je pense notamment à DuckDuckGo. NextDNS pouvant être utilisé en complément.
J'ai l'habitude d'utiliser le combo Safari - Firefox Focus (bien que DuckDuckGo et Brave soient tentants), NextDNS permet de bloquer les traceurs qui sont passés à travers les mailles du filet. Voici le résultat sur le même test combiné LeBonCoin et Lemonde.fr :
Les traceurs qui n'ont pas pu être bloqués par le combo Safari - Firefox Focus ont été bloqués par NextDNS.
Bref, le choix de votre navigateur et d'éventuelles protections supplémentaires peut faire une grande difféence !
Texte intégral (7223 mots)
Safari, l'inévitable navigateur iOS ?
Pour un navigateur tiers, il est difficile de concurrencer Apple Safari sur iOS :
- À la différence d'Android, iOS ne permet pas aux navigateurs tiers d'utiliser leur propre moteur de rendu. Si l'on lit les "guidelines" de l'App Store, section 2.5.6 : "Apps that browse the web must use the appropriate WebKit framework and WebKit Javascript".
- Apple a longtemps réservé l'usage de la dernière version de Webkit à Safari, les autres navigateurs étaient contraints d'utiliser une version périmée (basée sur la classe
UIWebView), lente et instable. - Toujours en raison de l'obligation d'utiliser WebKit, iOS ne permet pas aux navigateurs tiers de proposer leur propre bibliothèque d'extensions. Sur Android, je peux installer des extensions Firefox comme uBlock Origin.
- Les extensions de Safari telles que les bloqueurs de contenus ne sont pas accessibles aux autres navigateurs.
- Avant iOS 14, il n'était pas possible de changer le navigateur par défaut.
En conséquence, il n'était pas très intéressant d'utiliser un autre navigateur. Néanmoins, Apple évolue progressivement. Depuis iOS 8, les navigateurs tiers peuvent correctement utiliser le dernier moteur de rendu de WebKit. Et depuis iOS 14, Apple permet de changer le navigateur par défaut. Les navigateurs tiers peuvent ainsi mieux concurrencer Safari, notamment sur la protection de votre vie privée.
Quel que soit votre navigateur, vous bénéficiez déjà de la protection WebKit
Les navigateurs tiers ont obligation d'utiliser le moteur de rendu d'Apple, WebKit. Cela se traduit techniquement par l'utilisation de la classe WKWebView. Hors depuis iOS 14, celle-ci inclut par défaut Intelligent Tracking Prevention, le mécanisme de protection de la vie privée d'Apple (préalablement uniquement disponible sur Safari).
Oui, Chrome sur iOS vous protège contre le suivi intersite, par défaut ! L'obligation d'utiliser WebKit force Google à mieux protéger votre vie privée.
Intelligent Tracking Prevention (ITP) contient de nombreux mécanismes permettant de lutter contre le "suivi intersite", on peut notamment citer :
- Le blocage de tous les cookies tiers (prévu pour 2022 seulement sur Chrome).
- La limitation de la durée de vie des cookies créés via du javascript (cookies 1st party, mais pouvant être créés par des tiers) à 7 jours.
- La limitation de la durée de vie des cookies déposés via des domaines CNAME (là aussi, cookies 1st party, mais pouvant être déposés par des tiers) à 7 jours.
Les protections ITP ne se limitent pas aux cookies, pour une liste exhaustive lisez la page Cookie Status de Safari.
Si ces protections permettent de lutter contre le pire de la publicité (le suivi intersite), elles n'empêchent pas les sociétés marketing de mesurer chacune de vos interactions sur chaque site, ni de diffuser de la publicité. D'autres part, les sociétés marketing continuent de travailler à contourner les restrictions d'Apple (via du Server-Side Tagging, ou des identifiants de tiers déguisés en 1st party par exemple).
Si vous souhaitez être mieux protégé, quelles sont vos options ?
Le navigateur, un premier vecteur de surveillance
Avant même d'analyser les protections des navigateurs contre le pistage lors de votre surf, les navigateurs ont-ils mis en place leur propre système de surveillance ? Pour cela, je vais observer ce qu'il se passe lors du premier lancement du navigateur. À noter qu'une analyse similaire a déjà été effectuée par Brave récemment. Voici les étapes suivi :
- Téléchargement du navigateur à tester.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur, puis recherche dans la barre d'adresse (pas de navigation privée).
- Export de la session Charles sur mon ordinateur pour analyse.
Et voici un récapitulatif des différents navigateurs testés.
Safari, difficile à auditer de manière exhaustive
Safari est pré-installé donc je ne peux simuler un premier lancement. Il n'est pas impossible qu'Apple récupère des données de télémétrie de Safari si vous n'avez pas décoché les différents interrupteurs dans "Réglage" > "Confidentialité" > "Analyse et améliorations" :
J'ai décoché les différents interrupteurs dans "Analyse et améliorations", aussi je n'ai pas vu de traceurs Apple spécifiques à Safari.
Lorsque vous faites une recherche, le moteur de recherche par défaut est Google. Celui-ci verserait 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur tous les appareils Apple. Safari envoie ainsi à Google chaque caractère entré dans la barre de recherche (sans identifiant), pour faire marcher l'auto-complétion.
Côté vie privée, Apple prend de très bonnes initiatives. Mais il permet à Google et son capitalisme de surveillance de prospérer, pour beaucoup d'argent.
DuckDuckGo, le bon élève
Le moteur de recherche américain (en grande partie basé sur Bing) a fait de la vie privée son cheval de bataille, il fait d'ailleurs partie des moteurs de recherche recommandés par PrivacyTools. Il propose également un navigateur pour iOS, et voici les requêtes envoyées lors du premier lancement :
Lorsque l'on regarde dans le détail, c'est très propre : DuckDuckGo télécharge les bloqueurs de contenus. Lorsque vous tapez dans la barre d'adresse, il récupère les caractères pour de l'auto-complétion (avantage de fournir aussi un moteur de recherche), sans identifiant. La télémétrie est activée, mais là aussi sans identifiant.
Seule contrainte : le moteur de recherche par défaut (celui de la barre d'adresse) ne peut évidemment pas être changé. Mais si pour certaines requêtes vous n'êtes pas satisfait (rappel : derrière DuckDuckGo, c'est souvent Bing), vous pouvez utiliser les "bangs", des alias qui permettent de faire une recherche sur un autre moteur de recherche (Google évidemment, mais aussi YouTube, Wikipedia, Twitter, etc).
DuckDuckGo ne manque pas d'humour, voici le message dédié lors de votre première recherche Google (en préfixant votre recherche par !g).
Également très apprécié, la facilité à effacer les données :
Il vous suffit de cliquer sur la flamme pour effacer les données.
Brave vous protège... et fait tourner son business
Le navigateur Brave a été créé par Brendan Eich, ancien cofondateur de Firefox et créateur de Javascript. Brave a un discours fort contre les traceurs et autres publicités non respectueuses de la vie privée. Voici quelques points clés :
- Brave se base sur Chromium (et son moteur de rendu Blink), la partie Open-Source de Google Chrome. Mais sur iOS, il ne peut pas utiliser Chromium, et se voir forcé d'utiliser WebKit.
- Via Brave Shields, il bloque les traceurs et autres publicités qui vous pistent. Si vous l'acceptez, il diffuse des publicités respectueuses de la vie privée (servies en local, ce qui fait de Brave une régie publicitaire). Ce positionnement, en concurrence avec les éditeurs (Brave recrute les annonceurs), suscite des controverses.
- Brave Rewards vous permet de payer les sites que vous consultez de diverses manières : via un abonnement mensuel (par exemple, 10€ partagés avec les sites consultés, selon votre temps passé sur ces sites), via des pourboires (micro paiements) ou via la publicité servie en local par Brave (pour laquelle vous pouvez également être payé). Brave Rewards est basé sur la propre crypto monnaie de Brave : le BAT (ou Basic Attention Token).
UPDATE 15 décembre 2020 : Brave a d'autres controverses à son actif (merci @kinux), et notamment :
- Le financement via des liens d'affiliations vers des sites de crypto-monnaies, pratique arrêtée depuis que l'affaire a été révélée.
- L'inclusion de infogalactic, un Wikipédia d'extrême droite, dans les moteurs de recherche proposés par défaut. La pratique aurait cessé en décembre 2018 d'après ce site.
Brave vous permet au premier lancement de choisir votre moteur de recherche par défaut (et permet à des moteurs de recherche respectueux de la vie privée tels que Qwant, DuckDuckGo ou Startpage de trouver de nouveaux utilisateurs) :
Je sélectionne ici Startpage, un moteur de recherche basé sur Google, mais respectueux de la vie privée.
Vérifions les requêtes avant de cliquer sur "Enregistrer" :
Certaines requêtes ne sont pas lisibles sur l'outil Charles et je n'ai donc pu vérifier si des identifiants fuitaient, néanmoins on peut noter l'appel à sudosecuritygroup.com. Il s'agit en fait de la société Guardian, qui s'est associé à Brave pour fournir un VPN qui bloque aussi les traceurs et les publicités. Vous pourrez activer le VPN dans Brave, mais il faudra payer.
Deuxième étape, Brave vous propose de bloquer les traceurs :
Évidemment j'accepte.
Troisième étape, Brave pense à sa propre régie publicitaire, et vous propose de visualiser des publicités "privées et anonymes" :
Je clique sur Ignorer, l'audit des publicités Brave sera pour une autre fois.
Quatrième étape, je lance une recherche. Brave me demande si je souhaite activer les suggestions de recherche :
Question appréciée, je refuse donc.
Regardons maintenant les requêtes envoyées (depuis le lancement de l'application) :
Si on regarde le détail, Brave n'a pas envoyé de requêtes supplémentaires depuis l'étape 1 excepté vers Startpage, appelé uniquement lorsque je valide ma requête de recherche.
Firefox, quelques mauvaises surprises
Firefox est mon navigateur sur Mac. À la différence d'un Brave, Firefox a son propre moteur de rendu, Gecko. Mais lui aussi se voit contraint d'utiliser WebKit. Je m'attendais à ce que Firefox pour iOS ait une attitude irréprochable sur la vie privée car Firefox ayant une belle réputation et communiquant avantageusement. J'ai été surpris :
Dès la première ouverture, Firefox fuite mes données personnelles à Leanplum, une société marketing permettant d'afficher des messages ciblés. Leanplum est gourmand, il collecte notamment le deviceId, userId et uuid. Il récupère aussi mes principales interactions avec Firefox.
Firefox se permet également de collecter mes principales interactions (comme l'ouverture de l'application, sa fermeture, le clic sur la barre d'adresse) en direct (via incoming.telemetry.mozilla.org), avec l'identifiant clientId.
Pour les appels à Google, pas de surprise, il s'agit du moteur de recherche par défaut sur Firefox. Google représente la principale source de revenus pour Firefox, avec environ 450 millions de dollars par an. Chaque caractère entré dans la barre de recherche est envoyé à Google pour l'auto-complétion (sans identifiant).
Est-il possible de désactiver la fuite des données personnelles vers Leanplum ainsi que la télémétrie ? Oui, en décochant la bonne option dans les paramètres :
Je décoche "Envoyer des données d'utilisation"
On se serait attendu à de l'opt-in de la part de Firefox, et sans fuite de données personnelles vers une société marketing.
Chrome, le navigateur vorace de Google
Si vous utilisez Chrome pour iOS, vous n'avez à priori pas d'attente particulière concernant le respect de votre vie privée. Nous avions par exemple pu voir que Chrome envoie un en-tête HTTP unique à tous les domaines Google et Doubleclick, pratique pour vous pister. Lisez aussi "Why I'm done with Chrome", écrit il y a déjà 2 ans.
Dès l'ouverture de Chrome donc, Google vous informe que vous devez accepter les conditions d'utilisation. Premier problème, l'envoi de statistiques d'utilisation et des rapports d'erreur est coché par défaut :
Je décoche donc l'envoi de statistiques d'utilisation et des rapports d'erreur.
Si je regarde les requêtes passer avant le clic sur "Accepter et continuer", je vois que Chrome appelle déjà beaucoup de sites : pas d'inquiétude, il s'agit en fait de charger les images pour les signets par défaut (j'imagine les sites les plus consultés de France). Chrome récupère aussi des identifiants tels que le userid.
Deuxième étape, Chrome se montre ici très gourmand : il vous demande de synchroniser toute ma navigation avec mon compte Google. Une captation énorme de vos données personnelles donc, que Google enrobe en vous faisant miroiter de pouvoir synchroniser aussi vos mots de passe sur vos différents appareils "et plus encore".
Je clique donc sur "Non, merci".
Si vous souhaitez sélectionner les éléments à synchroniser, le texte "paramètres" en bleu pourrait vous faire croire que vous avez déjà la main, mais il n'est pas cliquable. Notez encore le bouton bleu "J'accepte", très naturel. Comparé à "Non, merci" en noir : un bel exemple de "Dark Pattern".
Troisième étape, Chrome continue sur sa lancée et me demande d'accéder à ma position exacte (pour "Améliorer mon expérience") !
Je clique sur "Ne pas autoriser"
Notez qu'avec iOS, je ne peux maintenant autoriser les accès qu'une seule fois (Chrome devra alors me redemander au lancement suivant), je peux également désactiver "Position exacte". Ces options peuvent être utiles pour vous protéger de certaines applications.
Dernière étape, Chrome est déjà lancé mais je fais une recherche, sur Google évidemment, pour tomber sur un bandeau de consentement venant d'être retoquée par la CNIL :
Le nouveau bandeau d’information mis en œuvre par les sociétés lors de l’arrivée sur la page google.fr ne permettait toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informait pas du fait qu’ils pouvaient refuser ces cookies.
Et en effet, bon courage pour refuser les cookies, vous pouvez vous perdre dans les menus sans trouver l'option, ni même être sûr que l'option choisie permet bien de refuser les cookies (je ne détaille pas, cela mériterait un article dédié).
Ici vous pourriez vous dire : je n'ai pas encore cliqué sur "J'accepte", Google n'a pas dû déposer de cookies. D'autant que si on lit la dernière sanction de la CNIL à l'encontre de Google (daté du 10 décembre 2020), celui-ci se permettait de le faire mais il a corrigé le tir :
La formation restreinte a pris acte que, depuis une mise à jour de septembre 2020, les sociétés cessent de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
Regardons néanmoins les requêtes envoyées (depuis l'étape 2) :
Parmi les nombreuses requêtes envoyées aux différents services de Google, on peut noter les requêtes à adservice.google.com et à doubleclick.net. La requête à adservice.google.com contient bien le cookie NID. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
La CNIL parle-t-elle du cookie NID dans sa délibération ?
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Ainsi, en contradiction avec la délibération de la CNIL, Google n'a pas arrêté de déposer automatiquement certains cookies publicitaires sur la page google.fr.
Edge fait encore pire que Chrome
La réputation des navigateurs Microsoft n'est plus à faire :
Via compte parodique Twitter @intrnetexp.
Seulement voilà, fini les moqueries sur le retard d'Internet Explorer, Microsoft se base maintenant sur Chromium et son moteur de rendu Blink pour son navigateur Edge (tout comme Brave, Opera ou Vivaldi), il investit pour le rendre compétitif. Pour Edge aussi, pas de Chromium sur iOS à cause des restrictions Apple, et donc l'utilisation forcée de WebKit. Qu'en est-il du respect de votre vie privée ?
Le premier lancement de Edge ressemble beaucoup à Chrome, ce qui n'est pas bon signe. Edge vous suggère de vous connecter pour activer la synchronisation : favoris, mots de passe et "bien plus encore".
Je clique sur "Ignorer" (notez le Dark Pattern).
Si l'on regarde les requêtes envoyées avant clic sur "Ignorer", Edge est déjà gourmand :
Via plusieurs requêtes, Edge récupère plusieurs identifiants tels que deviceId ou clientId. Notez notamment le domaine vortex.data.microsoft.com, si bien nommé. À chaque interaction avec Edge, celui-ci va collecter de la donnée, et cette fuite est impossible à désactiver.
Comme Firefox, Edge fuite aussi vos données personnelles vers un tiers, Adjust, société spécialisée dans la mesure mobile et l'attribution. Adjust récupère des identifiants tels que persistent_ios_uuid.
Deuxième étape, Edge est toujours aussi gourmand que Chrome, il cherche à enregistrer mon historique de navigation :
Je clique sur "Pas maintenant".
Troisième étape, on comprend pas tout à fait la différence avec l'étape précédente ("En savoir plus" redirige toujours vers la page "Historique d'activités Windows 10 et confidentialité"), Edge insiste en vous demandant des données sur "la façon dont vous utilisez le navigateur" :
Je clique encore sur "Pas maintenant".
Quatrième étape, je fais une recherche (sur Bing évidemment), notez le bandeau de consentement :
Vérifions les requêtes (je n'ai pas encore interagi avec le bandeau de consentement) :
Les services Microsoft sont omniprésents, tous récupèrent vos données personnelles. Leboncoin est appelé mais simplement pour télécharger le logo. Edge ne fuite pas seulement vos données personnelles vers Adjust mais aussi vers Comscore (via scorecardresearch.com), géant du marketing qui peut ainsi mieux vous profiler.
Bonus : Bing fuite vos recherches au site Pages Jaunes
À cause de Bing (et non de Edge), j'ai été surpris (et alarmé) de voir que celui-ci fuite une donnée potentiellement sensible, ma requête, directement à Pages Jaunes (via pagesjaunes.fr) :
Heureusement ma recherche "bonjour" n'était pas sensible, mais Bing fuite l'intégralité de vos recherches au site Pages Jaunes (ainsi que votre ville), en temps réel, quelque soit l'appareil et le navigateur utilisé.
La régie publicitaire de Pages Jaunes s'appelle Solocal. Il s'agit d'un partenariat ancien, ayant surement été reconduit, sur le dos de votre vie privée (rappel, je n'ai toujours pas interagi avec le bandeau de consentement, ma recherche Bing a fuité vers le site Pages Jaunes).
Cadeau supplémentaire de Bing et Pages Jaunes, le domaine at.pagesjaunes.fr (qui dépose un cookie sans votre consentement) est un alias CNAME vers l'outils d'analytics français AT Internet :
Comme on a déjà pu le voir avec Criteo, Boursorama ou Lemonde.fr, ces alias CNAME ont pour but de contourner les protections navigateurs et adblockers, ils sont également souvent à l'origine d'une faille de sécurité importante.
Cliquer sur "Plus d'options" pour ensuite désactiver les cookies "non essentiels" empêche-t-il de fuiter vos requêtes vers les pages jaunes et vos données de surf vers AT Internet ?
Le bandeau de consentement sans option de premier niveau pour tout refuser, un classique.
Malheureusement non, cela ne change strictement rien au comportement de Bing : celui-ci fuite toujours mes recherches au site Pages Jaunes.
Il manquait une information clé pour Microsoft : ma géolocalisation ! Et en effet, sans que je continue ma navigation, Edge me demande maintenant l'accès à ma position :
Conclusion : difficile à croire, mais via Edge et Bing, Microsoft réussit le tour de force d'être pire que Google sur le respect de votre vie privée.
Le navigateur comme protection contre la surveillance des sites
S'ils respectent eux-même plus ou moins bien votre vie privée, les navigateurs sont aussi censés vous protéger lorsque vous surfez sur le web. Regardons si c'est vraiment le cas, via une navigation sur deux sites connus pour fuiter massivement vos données personnelles :
- Le Bon Coin, cf. "La grande braderie de vos données personnelles sur Le Bon Coin".
- Le Monde, cf "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr".
Le protocole sera le même pour tous les navigateurs :
- Suppression des cookies et autres données navigateur.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur à tester, pas de navigation privée.
- Surf sur la page d'accueil de ces 2 sites, avec acceptation du pistage via la bannière de consentement.
Le comparatif ne peut être parfait car il ne s'agit que de 2 pages d'accueil, et d'un moment sur l'autre, les publicités servies peuvent être différentes. Mais le nombre de traceurs devrait nous donner une bonne idée de l'efficacité du navigateur.
Safari sans bloqueur de contenu, tout passe
Le cas nominal, j'ai désactivé mon bloqueur de contenu, Firefox Focus. Voici les résultats condensés :
- 94 hôtes contactés.
- 338 requêtes.
- 9,2 Mo de données téléchargées.
Inutile de dire que le nombre de traceurs est impressionnant, même si Intelligent Tracking Prevention limite la casse en stoppant le pistage intersite.
Safari avec bloqueur de contenu, des trous importants dans la raquette
Ici j'ai utilisé Firefox Focus (dont la liste de traceurs est fournie par Disconnect), vous pouvez aussi sélectionner d'autres bloqueurs de contenus comme Adguard. Les résultats sont-ils meilleurs ? Sensiblement :
- 45 hôtes contactés (ce qui signifie 49 traceurs en moins).
- 200 requêtes.
- 6.2 Mo de données téléchargées.
Est-ce à dire que le bloqueur de contenu vous a complètement protégé ? Lorsque l'on regarde dans le détail, de nombreux tiers continuent de vous pister, même si les traceurs les plus "évidents" ont disparu :
J'ai supprimé les requêtes 1st party pour y voir plus clair.
DuckDuckGo, une protection améliorée
DuckDuckGo utilise sa propre liste de traceurs, "Tracker Radar", généré par son propre crawl du web. Les informations de "Tracker Radar" sur les différents traceurs peuvent également être utilisés par des tiers (comme dans Safari, pour donner de l'information sur ces traceurs). Voici les résultats :
- 39 hôtes contactés.
- 226 requêtes.
- 6,3 Mo de données téléchargées.
Ces statistiques semblent proches de Safari avec bloqueur de contenus, si l'on regarde maintenant le détail :
La liste des traceurs est moins longue, DuckDuckGo est un peu plus efficace que Safari combiné à Firefox Focus.
Brave, une protection forte
Brave Shields, le système de blocage des traceurs, permet d'être très souple :
- Les paramètres par défaut vous protègent bien.
- Vous pouvez changer les paramètres par défaut.
- Vous pouvez aussi changer les paramètres pour des sites spécifiques.
Voici donc les paramètres par défaut :
Vous pouvez décider de bloquer les scripts, tous les cookies et les empreintes numériques. Mais d'expérience, certains sites ne marcheront plus correctement. Voici donc les résultats avec les paramètres par défaut :
- 29 hôtes contactés.
- 168 requêtes.
- 5,4 Mo de données téléchargées.
Brave est donc le plus efficace. Si l'on regarde dans le détail :
C'est presque parfait (Brave protège par exemple contre le CNAME cloaking d'AT Internet sur le site lemonde.fr, via le domaine buf.lemonde.fr), mais Brave rate notamment Facebook et Twitter.
Firefox vous protège relativement mal par défaut
Si Firefox est une très bonne option sur mon Mac, il a une sévère limitation sur iOS : comme avec tous les autres navigateurs iOS, on ne peut pas installer d'extensions. Et Firefox sans extension vous protège malheureusement beaucoup moins bien. Voici les résultats avec les paramètres par défaut :
- 111 hôtes contactés.
- 454 requêtes.
- 11,9 Mo de données téléchargées.
Vous êtes donc largement pisté. Dans les faits, tout n'est pas noir, si vous allez dans les paramètres :
Cliquez dans la section "vie privée" sur "Protection contre le pistage"
Vous pouvez vous rendre compte que par défaut, Firefox applique la "Protection renforcée contre le pistage" (ETP pour "Enhanced Tracking Protection") en version "Standard" :
En cliquant sur le "i", vous pourrez apprendre que Firefox vous protège contre les traqueurs de réseaux sociaux (en effet, Facebook et Twitter ont été bloqués), contre les traqueurs intersites (rien de nouveau ici, vous l'êtes déjà via ITP), contre les mineurs de crypto monnaie et contre les détecteurs d'empreinte numérique (technique couramment appelée "fingerprinting").
Si vous activez la protection "Strict", Firefox vous protègera aussi contre le "Contenu utilisé pour le pistage" (protection qui nous intéresse tout particulièrement) :
Êtes-vous mieux protégé ? Voici les nouveaux résultats :
- 42 hôtes contactés.
- 225 requêtes.
- 6,7 Mo de données téléchargées.
Les résultats sont donc bien meilleurs. Si l'on regarde le détail :
On retrouve les mêmes traceurs qu'avec l'option Safari et Firefox Focus : les 2 applications de Mozilla se servent d'une liste fournie par Disconnect pour bloquer certains traceurs.
Chrome, le navigateur sans protection
Avec Chrome c'est très simple, vous n'avez aucune protection par défaut, ni aucun réglage vous permettant de vous protéger. Chrome ne reste pas totalement inactif, les équipent travaillent sur le projet Privacy Sandbox, avec pour mission :
The Privacy Sandbox project’s mission is to “Create a thriving web ecosystem that is respectful of users and private by default.”
Dans le détail, "a thriving web ecosystem" signifie supporter les cas d'usages actuels de la publicité : mesure de conversion, publicité comportementale, retargeting, etc. "Private by default" signifie de ne plus permettre aux traceurs de pister individuellement les utilisateurs (Chrome bloquera les cookies tiers en 2022).
La mesure et le ciblage se feront via des "cohortes" d'utilisateurs (groupes suffisamment grands), via des décisions prises directement par le navigateur, via des mécanismes pour empêcher le croisement des données, etc.
Évidemment Google est moins concerné par les modifications de Chrome qu'un site web lambda : il continuera de pister la grande majorité des utilisateurs via leurs comptes Google.
Voici donc les résultats du surf sur Chrome :
- 100 hôtes contactés.
- 370 requêtes.
- 11,3 Mo de données téléchargées.
Pas de surprise donc, vous n'êtes pas du tout protégé.
Edge, des protections bien cachées
Edge était bon dernier lors du premier lancement du navigateur. Qu'en est-il des protections lors de votre surf ? Si l'on regarde les résultats avec la configuration par défaut :
- 96 hôtes contactés.
- 368 requêtes.
- 10,2 Mo de données téléchargées.
Edge est comparable à Chrome, ce qui n'est pas un compliment. Mais Edge dispose d'options cachées intéressantes. Si vous allez dans "Paramètres", à "Bloqueurs de contenus", vous pouvez découvrir une intégration "native" du bloqueur Adblock Plus :
J'active donc "Bloquer les publicités"
Oui Edge a intégré Adblock Plus dans son navigateur. Seulement, Adblock Plus est aussi une société publicitaire, qui se fait payer de grosses sommes par des géants du marketing (dont Microsoft, mais aussi Google, Amazon, Criteo, Taboola ou Outbrain) pour laisser passer certaines publicités, une belle hypocrisie. Il vous faut donc aller plus loin pour bloquer toutes les publicités, à savoir aller dans les "Paramètres avancés" de "Bloqueurs de contenu" :
Je désactive "Publicités acceptables".
Mais vous n'êtes pas au bout de vos peines ! Une autre option est utile, elle se trouve dans "Paramètres", "Confidentialité et sécurité", et vous trouverez dans la section Sécurité (!), la rubrique "Prévention du suivi" (apparemment déjà "Activé") :
Ici il faut cliquer sur "Prévention du suivi".
Vous accédez alors à un nouvel écran :
La version "Équilibré (recommandé)" est sélectionnée par défaut. Ainsi Edge bloquerait déjà "les dispositifs de suivi des sites que vous n'avez pas visités", ainsi que "les dispositifs de suivi malveillants connus". Dans les faits, on se demande ce que Edge bloque vraiment, tous les traceurs sont conviés à la fête (Criteo, Google, Doubleclick, Weborama, Facebook, Amazon, etc).
Microsoft indique se baser sur Disconnect pour bloquer les traceurs, dès la version "Équilibré" de "Tracking Prevention", il semble que cela soit un effet d'annonce (Firefox se base aussi sur Disconnect, mais bloque bien de nombreux traceurs).
Est-ce que le passage en "Prévention du suivi Strict", l'activation d'Adblock Plus et la désactivation des "Publicités acceptables" vous permet d'être protégé contre tous les traceurs ? Vu l'effort engagé, on aimerait bien. Voici les résultats :
- 41 hôtes contactés.
- 200 requêtes.
- 6,8 Mo de données téléchargées.
Edge se hisse au niveau d'un Safari avec Firefox Focus (ce qui est la moindre des choses avec Adblock Plus activé et Disconnect). Si on regarde maintenant dans le détail :
On voit bien que Edge a encore des progrès à faire.
NextDNS, en renfort du navigateur
Pour conclure, le choix du navigateur est personnel, mais certains navigateurs iOS apportent un bon premier niveau de protection : je pense notamment à DuckDuckGo. NextDNS pouvant être utilisé en complément.
J'ai l'habitude d'utiliser le combo Safari - Firefox Focus (bien que DuckDuckGo et Brave soient tentants), NextDNS permet de bloquer les traceurs qui sont passés à travers les mailles du filet. Voici le résultat sur le même test combiné LeBonCoin et Lemonde.fr :
Les traceurs qui n'ont pas pu être bloqués par le combo Safari - Firefox Focus ont été bloqués par NextDNS.
Bref, le choix de votre navigateur et d'éventuelles protections supplémentaires peut faire une grande difféence !
15.11.2020 à 22:45
Google Tag Manager, la nouvelle arme anti adblock

EDIT 25 mai 2021 : le "Server-Side Tagging" de Google Tag Manager évolue, et contourner les adblockers devient de plus en plus simple. J'ai ajouté la section "Un temps d'avance sur les adblockers" à l'article.
Google Tag Manager, le cheval de Troie des équipes marketing
Google Tag Manager est un TMS (Tag Management System) : il permet aux équipes marketing d'ajouter des traceurs sur un site web ou une application, sans devoir passer par des développeurs. Via une interface web, ces équipes peuvent décider :
- Des traceurs à déclencher (analytics, A/B testing, attribution, etc).
- Des conditions de déclenchement (catégories de pages, caractéristiques utilisateur, etc).
- Des données à transmettre à ces outils tiers (caractéristiques utilisateur, données de navigation, variables présentes sur la page, etc).
Ce n'est pas le seul (on peut par exemple citer Segment, le français TagCommander ou Matomo Tag Manager) mais Google Tag Manager est ultra dominant :
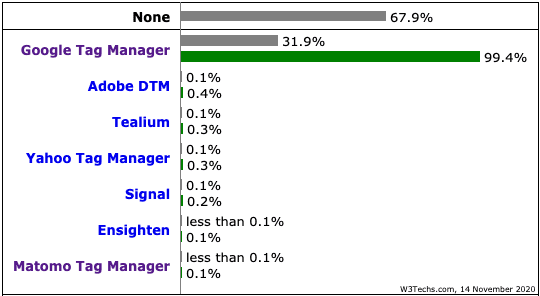
Google Tag Manager est présent sur 31,9% du top 10 millions des sites web Alexa, d'après W3Techs, mais surtout Google Tag Manager a une part de marché de 99,4% sur les TMS (!)
Comment Google a-t-il pu de nouveau s'imposer ? Tout comme avec Google Analytics, la version standard de Google Tag Manager est gratuite (les solutions du marché sont en général payantes), elle est très bien intégrée aux autres solutions Google et elle est bien faite.
Des traceurs qui ne sont plus appelés depuis votre navigateur
En août dernier, Google annonce une nouvelle version de Google Tag Manager, appelée Server-Side Tagging. Voici un schéma de Google pour expliquer comment fonctionne Google Tag Manager en version Client-Side Tagging (la version "historique") :
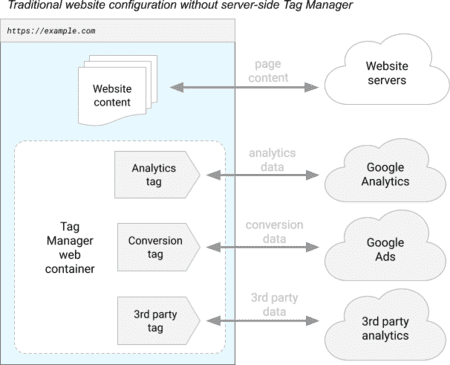
Google Tag Manager va permettre le déclenchement des différents traceurs tiers (sur le schéma : Google Analytics, Google Ads, et un outil d'analytics), directement sur votre navigateur.
Dans la nouvelle version Server-Side, les traceurs tiers ne sont plus exécutés depuis votre navigateur mais depuis un serveur "Proxy" appelé "Server container" sur le schéma ci-dessous (et hébergé chez Google) :
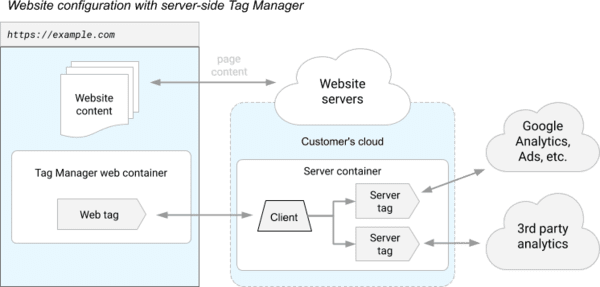
La librairie javascript (appelée sur le schéma "Tag Manager web container") s'exécute toujours sur votre navigateur afin de récolter vos interactions et vos données personnelles, mais l'exécution des différents traceurs tiers a lieu côté serveur.
Notez que cette nouvelle version s'applique aussi aux applications et à la collecte des données "offline" (pour transmettre les achats en magasin par exemple) :
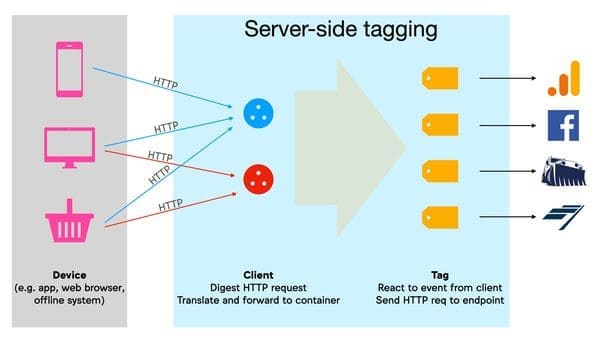
Schéma du blog de Simo Ahava : côté serveur, les "Clients" sont là pour traduire les requêtes HTTP reçues en "events", les "Tags" réagissent à ces évènements pour envoyer des "hits" aux sociétés de marketing tierces.
Cette logique de déclenchement des traceurs tiers côté serveur change la donne. Simo Ahava a détaillé les différents impacts dans un excellent article, je vais pour ma part résumer les avantages et m'attarder sur les problèmes pour votre vie privée (opérer côté serveur peut permettre de contourner vos choix et de fuiter vos données personnelles, sans être démasqué).
Une meilleure expérience utilisateur
Sur la plupart des sites web, le nombre de librairies javascript chargées par des tiers (pour de l'analytics, de la publicité, de l'A/B testing, etc) est impressionnant. Le chargement et l'exécution de ces librairies est souvent la cause principale d'une mauvaise expérience utilisateur : lenteur du site et manque d'interactivité.
Conséquences pour les sites web proposant une mauvaise expérience utilisateur : des internautes moins satisfaits, qui abandonneront directement la navigation ou ne reviendront pas.
Voici un exemple avec Le Bon Coin, celui-ci appelle un nombre incalculable de librairies javascript :
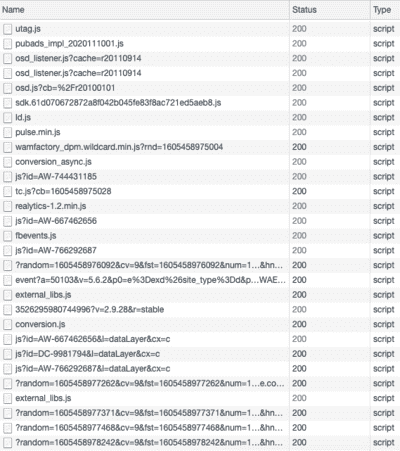
Une petite partie des scripts javascript appelés sur la page accueil de Le Bon Coin, celui-ci fuite vos données personnelles à de nombreux tiers.
Dans le meilleur des scénarios, le site web n'installera qu'une seule librairie javascript (les événements pouvant être très différents entre des outils n'ayant pas les mêmes buts, le site web utilisera parfois plus qu'une seule librairie). Celle-ci pourra être celle de Google Tag Manager mais pas obligatoirement : il est possible de créer sa propre librairie ou d'utiliser d'autres librairies du marché telles que Snowplow, Matomo, AT Internet, etc.
Charge ensuite à cette librairie d'envoyer les "hits" avec les paramètres requis lors des interactions clés. Puis le "client" du containeur serveur devra traduire ces "hits" en évènements, ceux-ci seront lus par les "Tags" qui enverront des "hits" aux sociétés marketing tierces. À noter que si la librairie javascript installée sur le site est fournie par Google, le "client" est déjà pré-configuré dans Google Tag Manager. Si le site web utilise une autre librairie, il lui faudra créer son propre "client" dans Google Tag Manager (exemple avec AT Internet), en attendant d'avoir des "clients" pré-configurés pour les principales librairies de tracking javascript.
Avantage donc : une seule librairie de tracking javascript est installée sur le site web et un seul "flux" de données en provenance du navigateur, l'utilisateur devrait voir la différence.
Un meilleur contrôle sur les données transmises aux tiers
Avoir un "proxy" côté serveur permet de contrôler les données transmises aux tiers (ce qui est beaucoup plus difficile lorsque les traceurs sont directement exécutés par le navigateur de l'utilisateur) :
- Par défaut et à la différence de la version "client-side", l'adresse IP et le User-Agent (nom du navigateur, version, système d'exploitation, langue, etc) de l'utilisateur ne fuitent pas (ce qui évite l'identification de l'utilisateur via "fingerprinting"). L'éditeur utilisant la version Server-Side Tagging de Google Tag Manager peut décider de transmettre ces informations aux tiers, mais ce n'est pas automatique.
- Il arrive souvent que des informations personnelles fuitent vers des tiers via des paramètres d'URLs (lisez par exemple l'article "Google Tag Manager Server-Side — How To Manage Custom Vendor Tags"), le Server-Side Tagging permet d'éviter cela.
- De manière générale, l'éditeur a la main sur les données personnelles et cookies envoyés par son "proxy" aux tiers (lisez la documentation technique de Google, notez par exemple les méthodes get_cookies et set_cookies). Il peut donc "nettoyer" les informations et n'envoyer aux tiers que le strict nécessaire.
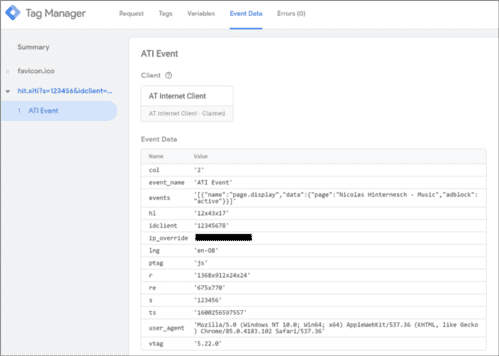
Exemple avec un hit AT Internet "vu" par le "proxy" serveur, le site web peut décider de ne pas transmettre l'adresse IP et le User-Agent de l'utilisateur à AT Internet.
Un site web mieux sécurisé
Mettre en place une Content-Security Policy (CSP) permet à un éditeur de mieux se prémunir contre différents types de menaces dont les attaques XSS (Cross-Site Scripting) et les injections de contenus. En ajoutant un en-tête aux réponses du serveur web, le site peut indiquer aux navigateurs quelles ressources (scripts, css, etc) sont autorisées.
Voici un exemple de CSP documenté par Google :
Content-Security-Policy: script-src 'self' https://apis.google.com.
Ce qui signifie : le navigateur n'a le droit d'exécuter que les scripts qui viennent directement du site consulté ('self') ou de apis.google.com. Et voici comment votre navigateur réagira si un script malicieux tente alors de s'exécuter à partir du site consulté :
Le script evil.js n'est pas hébergé sur le site consulté, ni sur apis.google.com : son exécution est bloquée par le navigateur.
En réduisant fortement les domaines tiers autorisés à exécuter du code javascript, la CSP devient plus robuste.
Si le Server-Side Tagging a des avantages pour les utilisateurs consentants à la surveillance marketing (rapidité, sécurité), il met en péril les protections des utilisateurs non consentants.
Un contournement des protections navigateurs
Le serveur "proxy" est hébergé dans le cloud de Google (instance App Engine) mais Google conseille de lier le domaine App Engine à un sous-domaine du site de ses clients (sans expliquer les raisons) :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
La liaison entre le domaine App Engine et le sous-domaine du client, documentée par Google.
Google ne conseille pas d'enregistrement DNS de type CNAME (alias), mais un enregistrement DNS de type A ou AAAA, directement lié aux adresses IPs de Google App Engine, qui fait office d'hébergeur. Le serveur "proxy" est donc bien considéré par les navigateurs comme 1st party, et les conséquences sont donc importantes.
En particulier, les cookies déposés par le serveur "proxy" ne sont pas des cookies tiers, ni des cookies créés via du javascript, ni des cookies déposés par un domaine CNAME. Ils sont donc autorisés, sans restriction :
- Safari via Intelligent Tracking Prevention (ITP) restreint la durée de vie des cookies créés en javascript à 7 jours (exemple : les cookies 1st-party créés par Google Analytics). Grâce au serveur "proxy", les traceurs tiers passent maintenant outre cette limitation.
- Toujours Safari via ITP restreint maintenant les cookies déposés via un domaine CNAME à 7 jours. Grâce au serveur "proxy", les traceurs tiers ne sont pas concernés par cette limitation.
- Brave de son côté bloque les requêtes CNAME vers des traceurs connus. Toujours grâce au serveur "proxy", les traceurs tiers évitent ce blocage.
Un contournement des adblockers
Votre adblocker (uBlock Origin sur Firefox par exemple), votre bloqueur de contenu (Firefox Focus ou Adguard sur iOS par exemple) ou votre bloqueur DNS (NextDNS par exemple) fonctionne sur votre appareil. Il peut ainsi détecter les traceurs tiers et les bloquer avant que vos données personnelles ne fuitent.
Rien de tout cela avec la version Server-Side Tagging de Google Tag Manager : les fuites de données personnelles se déroulent depuis le serveur proxy du client (hébergé dans le cloud Google) vers les tiers. Vous n'avez donc plus la main pour éviter ces fuites.
Vous pourriez vous dire : il suffit de bloquer le premier appel, celui de votre navigateur vers la librairie javascript en charge de récolter les données et de communiquer vers le serveur "proxy". Sauf que cette librairie javascript peut très bien être accessible sur le domaine du site web (et non sur un domaine Google par exemple). Aussi, Google conseille déjà à ses clients de changer leurs scripts gtag.js afin de renseigner le domaine du serveur proxy. Cette manipulation rend déjà le blocage via nom de domaine inopérant.
Toutes les librairies de tracking Google (gtag.js, analytics.js mais aussi gtm.js, la librairie "avancée" de Google, en charge de Google Tag Manager) peuvent être hébergées sur son propre domaine.
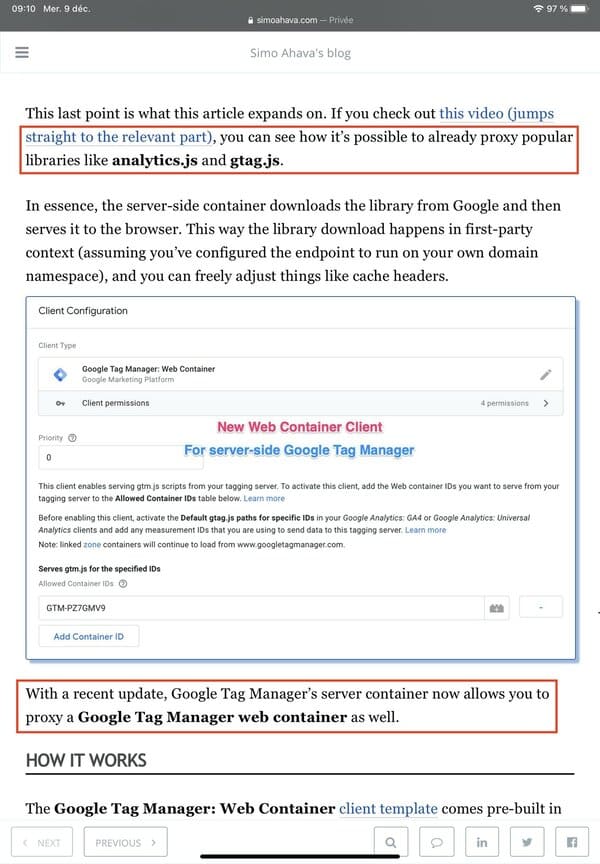
Si gtag.js ou gtm.js sont des librairies javascript dont les noms sont connus des principaux adblockers, ceux-ci devront trouver d'autres méthodes lorsque le nom de la librairie javascript aura été modifié ou que des sites auront créés leurs propres librairies.

uBlock Origin, efficace contre le CNAME cloaking sur Firefox, impuissant contre le Server-Side Tagging ?
Un temps d'avance sur les adblockers
La librairie javascript de Google Tag Manager s'appelle gtm.js, elle est appelée avec l'identifiant du containeur : GTM-.... Un adblocker peut donc facilement cibler ces noms et bloquer le chargement de cette librairie. Un site web pourrait décider de créer sa propre librairie javascript, mais ce n'est pas si facile.
Mais toujours grâce à Simo Ahava, il est maintenant facile de choisir un autre nom pour la librairie javascript gtm.js et de cacher l'identifiant du containeur (plus besoin de créer sa propre librairie javascript) :
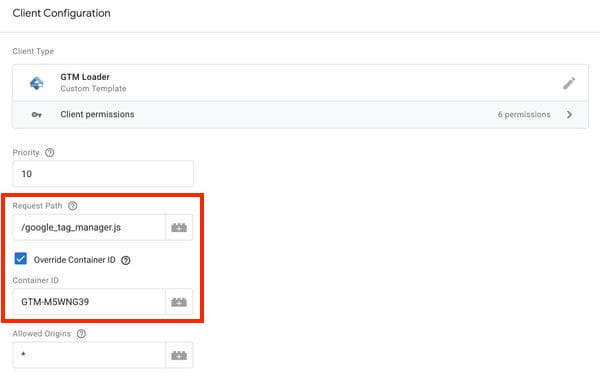
Via le blog de Simo Ahava : avec la template "GTM Loader" de Simo, le site web peut renommer la librairie javascript ("Request Path") et cacher l'identifiant du containeur ("Override Container ID" coché, "Container ID" vide).
Également, s'il était possible côté adblockers de cibler le proxy Google, un site web peut maintenant héberger le container serveur ailleurs (sur Amazon AWS, Microsoft Azure, OVH... ou sur sa propre infrastructure). Ce n'est pas si facile, mais Google fournit l'image Docker ainsi que les étapes à suivre.
Simo Ahava indique ainsi la marche à suivre pour déployer le containeur serveur sur Amazon AWS tandis que Mark Edmondson détaille comment déployer le containeur serveur sur Google Cloud Run (autre service de Google Cloud Platform, différent de Google App Engine).
Comment les adblockers peuvent-ils réagir ?
Le sujet n'est pas évident, voici des idées mais je ne suis pas certain qu'elles soient réalisables :
- Automatiquement détecter ces appels "1st party" au serveur "proxy" via les paramètres d'URLs envoyés. Sauf que ces paramètres d'URLs changeront d'un site à l'autre, en fonction de la librairie utilisée, de la page consultée, etc.
- Détecter la librairie javascript responsable des appels au serveur "proxy" pour bloquer son exécution. Comme nous avons pu le voir, cette méthode ne fonctionnera pas si le site web renomme la librairie de Google Tag Manager ou développe sa propre librairie javascript.
- Bloquer les proxy, au risque de bloquer des fonctionnalités essentielles de sites web ? Aussi, cette méthode ne fonctionne pas si le site web décide d'héberger le containeur serveur sur sa propre infrastructure.
- Ne jamais exécuter de javascript sur son navigateur, avec par exemple l'extension NoScript, paramétrée de manière radicale. Option efficace, sauf que de nombreux sites web ne fonctionneront plus.
Fuiter vos données personnelles dans l'opacité la plus totale
Si beaucoup de sites web fuitent aujourd'hui vos données personnelles, souvent sans votre consentement, il est néanmoins possible d'auditer les sites, de prouver la violation de consentement et de documenter les fuites. La CNIL pourrait par exemple faire son travail et sanctionner les fautes. Rien de tout cela avec le Server-Side Tagging, un site peut maintenant très facilement :
- Donner une apparence de consentement en vous laissant répondre à un bandeau de consentement.
- Tout en fuitant vos données personnelles à de multiples tiers, sans qu'un auditeur extérieur ne puisse s'en rendre compte (il verra simplement l'appel "1st-party" au serveur "proxy", sans savoir si les données personnelles sont utilisées, partagées ou revendues derrière).
Vos données sur le cloud de Google
Par défaut, le serveur "proxy" logue toutes les requêtes qu'il reçoit :
By default, App Engine logs information about every single request (e.g. request path, query parameters, etc) that it receives.
Mais les données personnelles contenues dans ces requêtes ne sont pas les seules informations qui fuitent vers Google. Tout comme pour le CNAME cloaking, les cookies associés au domaine du site consulté sont envoyés au sous-domaine du serveur "proxy". Ainsi, si vos cookies de session sont associés au domaine du site (et non à un sous-domaine distinct), ils seront bien envoyés au cloud de Google.
Celui-ci déclare que les données hébergées sur son cloud appartiennent au client, et non à Google. Il vous faut néanmoins faire confiance à Google.
Le Server-Side Tagging, probablement bientôt largement adopté
Si des solutions Server-Side existaient sur le marché depuis bien longtemps, et s'il était déjà possible de développer son propre "proxy", le lancement de la solution de Google aura probablement un impact énorme sur l'adoption du Server-Side Tagging :
- Google Tag Manager est présent sur un nombre considérable de sites web, il est ultra-dominant.
- Google présente cette version comme une évolution des outils TMS, améliorant la performance et la sécurité des sites web.
- Gros argument pour les marketeurs, fuiter vos données personnelles vers Facebook.
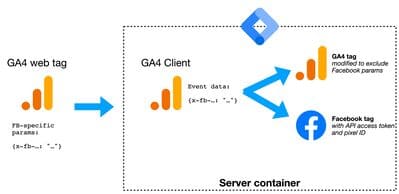
Un tag Google Analytics peut cacher la fuite de vos données personnelles vers Facebook, combo !
Même si un client Google Tag Manager peut continuer d'utiliser la version Client-Side, même si la version Server-Side a encore des limites (peu de librairies tierces, certaines solutions auront du mal à être supportés, etc), même si l'apprentissage de la solution est complexe et même si c'est souvent payant (facture Google App Engine du serveur "proxy"), on peut donc parier que les clients Google Tag Manager vont progressivement migrer vers cette version.
Contourner les adblockers et autres protections navigateurs, un argument de vente
Comme nous l'avons vu, Google n'explique pas le pourquoi de la création d'un sous-domaine du site web pour son serveur "proxy" :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
Il n'en a pas besoin, les contournements des protections navigateurs et adblockers ont déjà été listés comme "bénéfices" par de nombreuses publications :
- "Server-side Tagging In Google Tag Manager" de Simo Ahava, l'article indique comme bénéfice de pouvoir contourner les limitations de Safari concernant la durée de vie des cookies javascript. Tout à son honneur, l'auteur ne veut pas donner de détail sur le fait que le Server-Side Tagging permet de contourner les adblockers et indique que la collecte de données doit se faire après recueil du consentement.
- "GTM Server Side – L’évolution naturelle pour votre tagging ?" de Converteo. L'article liste en avantages le fait de pouvoir contourner les limitations navigateurs telles que celles de Safari et Firefox, ainsi que le contournement des adblockers.
- "Introduction to Google Tag Manager Server-side Tagging", du blog Analytics mania. Là aussi, les contournements des limitations navigateurs et adblockers sont listés en bénéfice.
- "Google introduit le tagging côté serveur, une bonne nouvelle ?" de Nicolas Jaimes sur le JDN. L'angle de l'article est la publicité, et donc le contournement des protections navigateurs est listé en bénéfice (même si pour l'instant, le manque de librairies tierces fait que le Server-Side Tagging reste complexe à implémenter).
Malheureusement, il y a fort à parier que beaucoup de sites seront également séduits par ces "bénéfices", en plus des gains de performance, de sécurité et de contrôle. L'impossibilité d'auditer les sites web sera également une grosse perte pour les défenseurs de la vie privée. En espérant que les navigateurs et adblockers trouvent des parades afin que les internautes soucieux de leur vie privée puissent continuer de se défendre.
Texte intégral (4157 mots)
EDIT 25 mai 2021 : le "Server-Side Tagging" de Google Tag Manager évolue, et contourner les adblockers devient de plus en plus simple. J'ai ajouté la section "Un temps d'avance sur les adblockers" à l'article.
Google Tag Manager, le cheval de Troie des équipes marketing
Google Tag Manager est un TMS (Tag Management System) : il permet aux équipes marketing d'ajouter des traceurs sur un site web ou une application, sans devoir passer par des développeurs. Via une interface web, ces équipes peuvent décider :
- Des traceurs à déclencher (analytics, A/B testing, attribution, etc).
- Des conditions de déclenchement (catégories de pages, caractéristiques utilisateur, etc).
- Des données à transmettre à ces outils tiers (caractéristiques utilisateur, données de navigation, variables présentes sur la page, etc).
Ce n'est pas le seul (on peut par exemple citer Segment, le français TagCommander ou Matomo Tag Manager) mais Google Tag Manager est ultra dominant :
Google Tag Manager est présent sur 31,9% du top 10 millions des sites web Alexa, d'après W3Techs, mais surtout Google Tag Manager a une part de marché de 99,4% sur les TMS (!)
Comment Google a-t-il pu de nouveau s'imposer ? Tout comme avec Google Analytics, la version standard de Google Tag Manager est gratuite (les solutions du marché sont en général payantes), elle est très bien intégrée aux autres solutions Google et elle est bien faite.
Des traceurs qui ne sont plus appelés depuis votre navigateur
En août dernier, Google annonce une nouvelle version de Google Tag Manager, appelée Server-Side Tagging. Voici un schéma de Google pour expliquer comment fonctionne Google Tag Manager en version Client-Side Tagging (la version "historique") :
Google Tag Manager va permettre le déclenchement des différents traceurs tiers (sur le schéma : Google Analytics, Google Ads, et un outil d'analytics), directement sur votre navigateur.
Dans la nouvelle version Server-Side, les traceurs tiers ne sont plus exécutés depuis votre navigateur mais depuis un serveur "Proxy" appelé "Server container" sur le schéma ci-dessous (et hébergé chez Google) :
La librairie javascript (appelée sur le schéma "Tag Manager web container") s'exécute toujours sur votre navigateur afin de récolter vos interactions et vos données personnelles, mais l'exécution des différents traceurs tiers a lieu côté serveur.
Notez que cette nouvelle version s'applique aussi aux applications et à la collecte des données "offline" (pour transmettre les achats en magasin par exemple) :
Schéma du blog de Simo Ahava : côté serveur, les "Clients" sont là pour traduire les requêtes HTTP reçues en "events", les "Tags" réagissent à ces évènements pour envoyer des "hits" aux sociétés de marketing tierces.
Cette logique de déclenchement des traceurs tiers côté serveur change la donne. Simo Ahava a détaillé les différents impacts dans un excellent article, je vais pour ma part résumer les avantages et m'attarder sur les problèmes pour votre vie privée (opérer côté serveur peut permettre de contourner vos choix et de fuiter vos données personnelles, sans être démasqué).
Une meilleure expérience utilisateur
Sur la plupart des sites web, le nombre de librairies javascript chargées par des tiers (pour de l'analytics, de la publicité, de l'A/B testing, etc) est impressionnant. Le chargement et l'exécution de ces librairies est souvent la cause principale d'une mauvaise expérience utilisateur : lenteur du site et manque d'interactivité.
Conséquences pour les sites web proposant une mauvaise expérience utilisateur : des internautes moins satisfaits, qui abandonneront directement la navigation ou ne reviendront pas.
Voici un exemple avec Le Bon Coin, celui-ci appelle un nombre incalculable de librairies javascript :
Une petite partie des scripts javascript appelés sur la page accueil de Le Bon Coin, celui-ci fuite vos données personnelles à de nombreux tiers.
Dans le meilleur des scénarios, le site web n'installera qu'une seule librairie javascript (les événements pouvant être très différents entre des outils n'ayant pas les mêmes buts, le site web utilisera parfois plus qu'une seule librairie). Celle-ci pourra être celle de Google Tag Manager mais pas obligatoirement : il est possible de créer sa propre librairie ou d'utiliser d'autres librairies du marché telles que Snowplow, Matomo, AT Internet, etc.
Charge ensuite à cette librairie d'envoyer les "hits" avec les paramètres requis lors des interactions clés. Puis le "client" du containeur serveur devra traduire ces "hits" en évènements, ceux-ci seront lus par les "Tags" qui enverront des "hits" aux sociétés marketing tierces. À noter que si la librairie javascript installée sur le site est fournie par Google, le "client" est déjà pré-configuré dans Google Tag Manager. Si le site web utilise une autre librairie, il lui faudra créer son propre "client" dans Google Tag Manager (exemple avec AT Internet), en attendant d'avoir des "clients" pré-configurés pour les principales librairies de tracking javascript.
Avantage donc : une seule librairie de tracking javascript est installée sur le site web et un seul "flux" de données en provenance du navigateur, l'utilisateur devrait voir la différence.
Un meilleur contrôle sur les données transmises aux tiers
Avoir un "proxy" côté serveur permet de contrôler les données transmises aux tiers (ce qui est beaucoup plus difficile lorsque les traceurs sont directement exécutés par le navigateur de l'utilisateur) :
- Par défaut et à la différence de la version "client-side", l'adresse IP et le User-Agent (nom du navigateur, version, système d'exploitation, langue, etc) de l'utilisateur ne fuitent pas (ce qui évite l'identification de l'utilisateur via "fingerprinting"). L'éditeur utilisant la version Server-Side Tagging de Google Tag Manager peut décider de transmettre ces informations aux tiers, mais ce n'est pas automatique.
- Il arrive souvent que des informations personnelles fuitent vers des tiers via des paramètres d'URLs (lisez par exemple l'article "Google Tag Manager Server-Side — How To Manage Custom Vendor Tags"), le Server-Side Tagging permet d'éviter cela.
- De manière générale, l'éditeur a la main sur les données personnelles et cookies envoyés par son "proxy" aux tiers (lisez la documentation technique de Google, notez par exemple les méthodes get_cookies et set_cookies). Il peut donc "nettoyer" les informations et n'envoyer aux tiers que le strict nécessaire.
Exemple avec un hit AT Internet "vu" par le "proxy" serveur, le site web peut décider de ne pas transmettre l'adresse IP et le User-Agent de l'utilisateur à AT Internet.
Un site web mieux sécurisé
Mettre en place une Content-Security Policy (CSP) permet à un éditeur de mieux se prémunir contre différents types de menaces dont les attaques XSS (Cross-Site Scripting) et les injections de contenus. En ajoutant un en-tête aux réponses du serveur web, le site peut indiquer aux navigateurs quelles ressources (scripts, css, etc) sont autorisées.
Voici un exemple de CSP documenté par Google :
Content-Security-Policy: script-src 'self' https://apis.google.com.
Ce qui signifie : le navigateur n'a le droit d'exécuter que les scripts qui viennent directement du site consulté ('self') ou de apis.google.com. Et voici comment votre navigateur réagira si un script malicieux tente alors de s'exécuter à partir du site consulté :
Le script evil.js n'est pas hébergé sur le site consulté, ni sur apis.google.com : son exécution est bloquée par le navigateur.
En réduisant fortement les domaines tiers autorisés à exécuter du code javascript, la CSP devient plus robuste.
Si le Server-Side Tagging a des avantages pour les utilisateurs consentants à la surveillance marketing (rapidité, sécurité), il met en péril les protections des utilisateurs non consentants.
Un contournement des protections navigateurs
Le serveur "proxy" est hébergé dans le cloud de Google (instance App Engine) mais Google conseille de lier le domaine App Engine à un sous-domaine du site de ses clients (sans expliquer les raisons) :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
La liaison entre le domaine App Engine et le sous-domaine du client, documentée par Google.
Google ne conseille pas d'enregistrement DNS de type CNAME (alias), mais un enregistrement DNS de type A ou AAAA, directement lié aux adresses IPs de Google App Engine, qui fait office d'hébergeur. Le serveur "proxy" est donc bien considéré par les navigateurs comme 1st party, et les conséquences sont donc importantes.
En particulier, les cookies déposés par le serveur "proxy" ne sont pas des cookies tiers, ni des cookies créés via du javascript, ni des cookies déposés par un domaine CNAME. Ils sont donc autorisés, sans restriction :
- Safari via Intelligent Tracking Prevention (ITP) restreint la durée de vie des cookies créés en javascript à 7 jours (exemple : les cookies 1st-party créés par Google Analytics). Grâce au serveur "proxy", les traceurs tiers passent maintenant outre cette limitation.
- Toujours Safari via ITP restreint maintenant les cookies déposés via un domaine CNAME à 7 jours. Grâce au serveur "proxy", les traceurs tiers ne sont pas concernés par cette limitation.
- Brave de son côté bloque les requêtes CNAME vers des traceurs connus. Toujours grâce au serveur "proxy", les traceurs tiers évitent ce blocage.
Un contournement des adblockers
Votre adblocker (uBlock Origin sur Firefox par exemple), votre bloqueur de contenu (Firefox Focus ou Adguard sur iOS par exemple) ou votre bloqueur DNS (NextDNS par exemple) fonctionne sur votre appareil. Il peut ainsi détecter les traceurs tiers et les bloquer avant que vos données personnelles ne fuitent.
Rien de tout cela avec la version Server-Side Tagging de Google Tag Manager : les fuites de données personnelles se déroulent depuis le serveur proxy du client (hébergé dans le cloud Google) vers les tiers. Vous n'avez donc plus la main pour éviter ces fuites.
Vous pourriez vous dire : il suffit de bloquer le premier appel, celui de votre navigateur vers la librairie javascript en charge de récolter les données et de communiquer vers le serveur "proxy". Sauf que cette librairie javascript peut très bien être accessible sur le domaine du site web (et non sur un domaine Google par exemple). Aussi, Google conseille déjà à ses clients de changer leurs scripts gtag.js afin de renseigner le domaine du serveur proxy. Cette manipulation rend déjà le blocage via nom de domaine inopérant.
Toutes les librairies de tracking Google (gtag.js, analytics.js mais aussi gtm.js, la librairie "avancée" de Google, en charge de Google Tag Manager) peuvent être hébergées sur son propre domaine.
Si gtag.js ou gtm.js sont des librairies javascript dont les noms sont connus des principaux adblockers, ceux-ci devront trouver d'autres méthodes lorsque le nom de la librairie javascript aura été modifié ou que des sites auront créés leurs propres librairies.
uBlock Origin, efficace contre le CNAME cloaking sur Firefox, impuissant contre le Server-Side Tagging ?
Un temps d'avance sur les adblockers
La librairie javascript de Google Tag Manager s'appelle gtm.js, elle est appelée avec l'identifiant du containeur : GTM-.... Un adblocker peut donc facilement cibler ces noms et bloquer le chargement de cette librairie. Un site web pourrait décider de créer sa propre librairie javascript, mais ce n'est pas si facile.
Mais toujours grâce à Simo Ahava, il est maintenant facile de choisir un autre nom pour la librairie javascript gtm.js et de cacher l'identifiant du containeur (plus besoin de créer sa propre librairie javascript) :
Via le blog de Simo Ahava : avec la template "GTM Loader" de Simo, le site web peut renommer la librairie javascript ("Request Path") et cacher l'identifiant du containeur ("Override Container ID" coché, "Container ID" vide).
Également, s'il était possible côté adblockers de cibler le proxy Google, un site web peut maintenant héberger le container serveur ailleurs (sur Amazon AWS, Microsoft Azure, OVH... ou sur sa propre infrastructure). Ce n'est pas si facile, mais Google fournit l'image Docker ainsi que les étapes à suivre.
Simo Ahava indique ainsi la marche à suivre pour déployer le containeur serveur sur Amazon AWS tandis que Mark Edmondson détaille comment déployer le containeur serveur sur Google Cloud Run (autre service de Google Cloud Platform, différent de Google App Engine).
Comment les adblockers peuvent-ils réagir ?
Le sujet n'est pas évident, voici des idées mais je ne suis pas certain qu'elles soient réalisables :
- Automatiquement détecter ces appels "1st party" au serveur "proxy" via les paramètres d'URLs envoyés. Sauf que ces paramètres d'URLs changeront d'un site à l'autre, en fonction de la librairie utilisée, de la page consultée, etc.
- Détecter la librairie javascript responsable des appels au serveur "proxy" pour bloquer son exécution. Comme nous avons pu le voir, cette méthode ne fonctionnera pas si le site web renomme la librairie de Google Tag Manager ou développe sa propre librairie javascript.
- Bloquer les proxy, au risque de bloquer des fonctionnalités essentielles de sites web ? Aussi, cette méthode ne fonctionne pas si le site web décide d'héberger le containeur serveur sur sa propre infrastructure.
- Ne jamais exécuter de javascript sur son navigateur, avec par exemple l'extension NoScript, paramétrée de manière radicale. Option efficace, sauf que de nombreux sites web ne fonctionneront plus.
Fuiter vos données personnelles dans l'opacité la plus totale
Si beaucoup de sites web fuitent aujourd'hui vos données personnelles, souvent sans votre consentement, il est néanmoins possible d'auditer les sites, de prouver la violation de consentement et de documenter les fuites. La CNIL pourrait par exemple faire son travail et sanctionner les fautes. Rien de tout cela avec le Server-Side Tagging, un site peut maintenant très facilement :
- Donner une apparence de consentement en vous laissant répondre à un bandeau de consentement.
- Tout en fuitant vos données personnelles à de multiples tiers, sans qu'un auditeur extérieur ne puisse s'en rendre compte (il verra simplement l'appel "1st-party" au serveur "proxy", sans savoir si les données personnelles sont utilisées, partagées ou revendues derrière).
Vos données sur le cloud de Google
Par défaut, le serveur "proxy" logue toutes les requêtes qu'il reçoit :
By default, App Engine logs information about every single request (e.g. request path, query parameters, etc) that it receives.
Mais les données personnelles contenues dans ces requêtes ne sont pas les seules informations qui fuitent vers Google. Tout comme pour le CNAME cloaking, les cookies associés au domaine du site consulté sont envoyés au sous-domaine du serveur "proxy". Ainsi, si vos cookies de session sont associés au domaine du site (et non à un sous-domaine distinct), ils seront bien envoyés au cloud de Google.
Celui-ci déclare que les données hébergées sur son cloud appartiennent au client, et non à Google. Il vous faut néanmoins faire confiance à Google.
Le Server-Side Tagging, probablement bientôt largement adopté
Si des solutions Server-Side existaient sur le marché depuis bien longtemps, et s'il était déjà possible de développer son propre "proxy", le lancement de la solution de Google aura probablement un impact énorme sur l'adoption du Server-Side Tagging :
- Google Tag Manager est présent sur un nombre considérable de sites web, il est ultra-dominant.
- Google présente cette version comme une évolution des outils TMS, améliorant la performance et la sécurité des sites web.
- Gros argument pour les marketeurs, fuiter vos données personnelles vers Facebook.
Un tag Google Analytics peut cacher la fuite de vos données personnelles vers Facebook, combo !
Même si un client Google Tag Manager peut continuer d'utiliser la version Client-Side, même si la version Server-Side a encore des limites (peu de librairies tierces, certaines solutions auront du mal à être supportés, etc), même si l'apprentissage de la solution est complexe et même si c'est souvent payant (facture Google App Engine du serveur "proxy"), on peut donc parier que les clients Google Tag Manager vont progressivement migrer vers cette version.
Contourner les adblockers et autres protections navigateurs, un argument de vente
Comme nous l'avons vu, Google n'explique pas le pourquoi de la création d'un sous-domaine du site web pour son serveur "proxy" :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
Il n'en a pas besoin, les contournements des protections navigateurs et adblockers ont déjà été listés comme "bénéfices" par de nombreuses publications :
- "Server-side Tagging In Google Tag Manager" de Simo Ahava, l'article indique comme bénéfice de pouvoir contourner les limitations de Safari concernant la durée de vie des cookies javascript. Tout à son honneur, l'auteur ne veut pas donner de détail sur le fait que le Server-Side Tagging permet de contourner les adblockers et indique que la collecte de données doit se faire après recueil du consentement.
- "GTM Server Side – L’évolution naturelle pour votre tagging ?" de Converteo. L'article liste en avantages le fait de pouvoir contourner les limitations navigateurs telles que celles de Safari et Firefox, ainsi que le contournement des adblockers.
- "Introduction to Google Tag Manager Server-side Tagging", du blog Analytics mania. Là aussi, les contournements des limitations navigateurs et adblockers sont listés en bénéfice.
- "Google introduit le tagging côté serveur, une bonne nouvelle ?" de Nicolas Jaimes sur le JDN. L'angle de l'article est la publicité, et donc le contournement des protections navigateurs est listé en bénéfice (même si pour l'instant, le manque de librairies tierces fait que le Server-Side Tagging reste complexe à implémenter).
Malheureusement, il y a fort à parier que beaucoup de sites seront également séduits par ces "bénéfices", en plus des gains de performance, de sécurité et de contrôle. L'impossibilité d'auditer les sites web sera également une grosse perte pour les défenseurs de la vie privée. En espérant que les navigateurs et adblockers trouvent des parades afin que les internautes soucieux de leur vie privée puissent continuer de se défendre.
31.10.2020 à 18:17
NextDNS, mon nouveau bloqueur de traceurs et de publicités préféré

Lors de mes analyses de sites et d'applications, la conclusion est souvent la même : faute de véritables sanctions contre les éditeurs, vous devez vous protéger contre la surveillance publicitaire via des moyens techniques. Cet article a pour but de partager ma configuration actuelle.
Les choix de bloqueurs de traceurs et de publicités sont évidemment très personnels : vous utilisez sans doute d'autres applications, d'autres extensions, vos choix sont peut-être plus efficaces. Aussi, je suis loin d'être le seul à écrire sur le sujet et je ne suis pas expert "Adblock", bref n'hésitez pas à partager votre expérience !
Selon les appareils, il est plus ou moins facile de bloquer les traceurs et publicités. Voici les différents scénarios auxquels je suis confronté.
Bloquer les traceurs et publicités sur un navigateur "Desktop" : des adblockers largement adoptés aujourd'hui
Sur mes MacBook (personnel, professionnel), lorsque je surfe sur le web, j'utilise Firefox avec l'extension uBlock Origin. Sur Firefox, cet adblocker détecte le "CNAME cloaking" et le bloque (ce qui n'est pas le cas sur Chrome). Le "CNAME cloaking" est une technique utilisée par certains acteurs du marketing de surveillance pour vous pister, même si vous avez pris vos précautions (cette technique pose aussi des problèmes de sécurité). Si vous souhaitez approfondir le sujet, lisez les explications de NextDNS (en anglais) et la présentation de la Quadrature du Net (en français).
Surtout, à la différence d'un Adblock Plus que je déconseille vivement, uBlock Origin n'offre aucun passe-droit aux publicitaires. La société Eyeo, éditrice d'Adblock Plus, est à l'origine du programme Acceptable Ads, et se fait payer de grosses sommes par des géants du marketing de surveillance tels que que Google, Microsoft, Amazon, Taboola, Outbrain et Criteo pour ne pas bloquer leurs publicités par défaut : une énorme hypocrisie !
Il m'est facile de conseiller Firefox et uBlock Origin à mes proches :
- Firefox est simple à installer et très rapide. C'est un logiciel développé par un acteur indépendant (Mozilla), open-source et respecteux de la vie privée de ses utilisateurs.
- uBlock Origin est également simple à installer, et très efficace.
Bloquer les traceurs et publicités sur le web, sur un iPhone : des bloqueurs de contenus moins démocratisés
Sur mon iPhone, lorsque je surfe sur le web, j'utilise Safari. Grâce à Intelligent Tracking Prevention (ITP), celui-ci me protège contre le pistage multi-sites par des tiers (notamment en bloquant les cookies tiers, mais pas que). À noter que depuis iOS 14, Intelligent Tracking Prevention s'applique aussi aux autres navigateurs : Chrome sur iOS vous protège aussi contre le pistage multi-sites par des tiers ! Seulement voilà, ITP ne répond pas à tous mes besoins :
- Il ne bloque pas les publicités.
- Il bloque le suivi multi-sites mais ne bloque pas l'envoi des traceurs (Safari continue d'envoyer les requêtes vers de multiples sociétés marketing).
- Il permet le suivi lorsqu'il est restreint à un seul site : l'outil analytics d'un éditeur (Google Analytics lorsque l'éditeur n'a pas activé les fonctionnalités publicitaires, AT Internet, Adobe Analytics...) continuera de fonctionner correctement et d'analyser votre parcours (même si l'analyse est restreinte au site consulté).
À la différence d'Android (exemple : Firefox pour Android), iOS ne permet pas à un navigateur d'installer des extensions (le navigateur doit nécessairement utiliser le moteur de rendu de Safari, Webkit) : impossible donc d'installer directement un adblocker.
Il est néanmoins possible d'installer un "bloqueur de contenu", celui-ci sera activé uniquement sur Safari (et non sur les autres navigateurs) et permettra de bloquer des listes de traceurs et de publicités. J'utilise donc le bloqueur de contenu Firefox Focus pour bloquer les publicités. AdGuard propose également un bloqueur de contenu pour Safari, mais lors de mon utilisation, il bloquait le chargement de certains sites, ce qui me forçait à le désactiver.
Il m'est également facile de conseiller cette option à mes proches qui sont sur iOS (pour Android, je recommande Firefox avec uBlock Origin) :
- Safari est le navigateur par défaut, rien à configurer.
- Firefox Focus demande un minimum de configuration, mais cela reste rapide.
Bloquer les traceurs et publicités sur les applications natives : le public est peu informé, NextDNS à la rescousse
Plus compliqué maintenant, sur les applications iPhone, il me manquait une bonne option pour bloquer les traceurs et publicités. Je payais pour ProtonVPN mais celui-ci ne peut être utilisé simultanément avec un bloqueur tel que NextDNS ou AdGuard.
Aussi, j'avais de gros problèmes de batteries avec les applications ProtonVPN, NextDNS et AdGuard et je pensais connaître la cause : ces applications étaient toutes basées sur un VPN (ces applications pouvaient parfois utiliser jusqu'à 50% de la batterie de mon vieil iPhone sur une journée). Avant la sortie de iOS 14, NextDNS et AdGuard devaient utiliser un VPN local pour chiffrer les requêtes DNS.
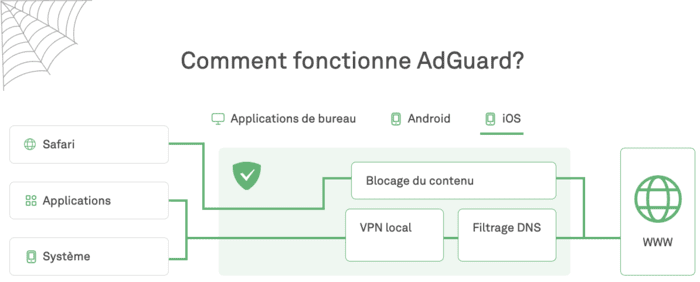
Adguard passe par un VPN local sous iOS
Mais avec iOS 14, Apple ajoute la possibilité de chiffrer les requêtes DNS nativement. Plus besoin de passer par le "hack" d'un VPN local, et donc plus d'impact sur ma batterie. NextDNS ayant implémenté cette option rapidement, j'ai décidé de l'utiliser systématiquement et je n'ai pas été déçu.
Avec NextDNS, je peux ainsi :
- Bloquer les traceurs et les publicités lorsque j'utilise des applications sur mon iPhone, via l'application iOS NextDNS donc.
- Bloquer les traceurs et les publicités sur mon Apple TV (tvOS permet également de chiffrer les requêtes DNS nativement), via le générateur de profils de configuration Apple.
- Bloquer les traceurs et publicités sur les applications lorsque j'utilise mon Mac. Un exemple : le player Mac Spotify est très bavard, il fuite vos données personnelles à Google et Comscore et uBlock Origin ne va pas aider. L'appli Mac de NextDNS permet de bloquer ces traceurs.
- Compléter le blocage des traceurs et publicités déjà effectué par uBlock Origin sur Firefox (Mac) et Firefox Focus sur Safari (iPhone) via une 2ème couche de blocage NextDNS. J'ai ainsi fait disparaitre de nombreuses bannières de consentement, rendant mon surf plus agréable.
- Configurer ma Freebox pour utiliser le DNS de NextDNS et ainsi bloquer les traceurs des objets connectés (mon thermostat en l'occurrence).
Je peux également facilement recommander cette solution à mes proches :
- NextDNS est rapide à installer et à configurer (à la différence d'un Pi-Hole, qui s'adresse principalement à des bidouilleurs).
- NextDNS fonctionne aussi en mobilité (toujours à la différence d'un Pi-Hole, qui ne fonctionnera que sur le WiFi personnel maison).
De l'utilité d'un annuaire DNS
NextDNS est un annuaire DNS (Domain Name System) parmi d'autres. Le DNS est un des services essentiels à l'internet : c'est un annuaire qui va permettre la correspondance entre un nom de domaine (exemple : google.fr) et une adresse IP (exemple : 216.58.204.99). Par défaut, vous utilisez le serveur DNS de votre fournisseur d'accès internet. Seulement voilà :
- Ces requêtes DNS ne sont pas chiffrées, un pirate peut donc les intercepter, apprendre quels sites vous consultez voire modifier ces requêtes à la volée pour vous faire télécharger un virus par exemple.
- Pour des raisons légales, les fournisseurs d'accès internet (FAI) bloquent également l'accès à certains sites web. Exemple : vous souhaitez télécharger des fichiers torrent (films, séries, musique) via le site The Pirate Bay, mais celui-ci risque d'être bloqué par votre fournisseur. Les FAI appliquent ce blocage via l'annuaire DNS qu'ils mettent à votre disposition.
Pour que vos requêtes DNS soient chiffrées et pour vous permettre d'accéder à certains sites web, vous pouvez changer de fournisseur DNS. Si vous ne souhaitez pas bloquer les traceurs et publicités, OpenDNS est un annuaire de confiance. Si vous souhaitez simplement utiliser un service rapide et que vous n'êtes pas inquiet de l'omniprésence de Google dans votre vie, vous pouvez utiliser le Google Public DNS. De même, si vous êtes peu concerné par la centralisation progressive du web mais simplement par la performance, vous pouvez utiliser le DNS de Cloudflare.
Mais ce serait dommage de s'arrêter en si bon chemin ! Dans le cas des traceurs et publicités, l'annuaire DNS peut retourner une réponse vide au lieu de renvoyer la bonne adresse IP. Exemple : si vous êtes en train de jouer à un jeu sur votre iPhone et que celui-ci souhaite délivrer une publicité, il va demander à votre annuaire DNS l'adresse de doubleclick.net (la régie publicitaire de Google). Si vous utilisez NextDNS et si vous avez activé les bloqueurs, celui-ci ne renverra pas de réponse : vous ne serez pas pisté et vous ne verrez pas de publicité !
NextDNS vous permet de choisir vos listes de blocage
Comme pour un adblocker "classique" tel que uBlock Origin, NextDNS vous permet de vous abonner à des listes de blocage :
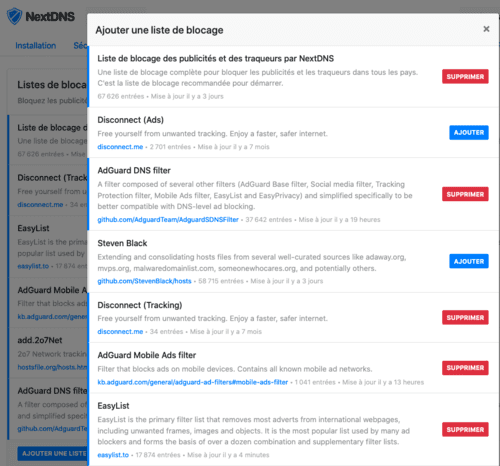
Mon choix parmi les listes les plus utilisés.
NextDNS vous propose également des listes de blocage pour se protéger contre le tracking "natif" :
Apple collecte des statistiques d'usage ? Je peux maintenant bloquer ces requêtes.
Le fonctionnement de NextDNS est transparent
Si vous décidez d'activer les logs de NextDNS, vous aurez une grande flexibilité :
- Sur la durée de rétention : de 1 heure à 2 ans. Si vous souhaitez vérifier que NextDNS fonctionne bien et affiner les domaines bloqués, 1 heure est suffisant.
- Sur la localisation du stockage : notamment dans l'Union Européenne ou mieux, en Suisse.
Vous pourrez alors "vérifier" le travail de NextDNS via une interface en ligne. Voici la vue lorsque je lance l'application L'Équipe sur mon iPhone :
Comme nous l'avons déjà vu, l'application L'Équipe fuite vos données personnelles. Mais NextDNS empêche bien ces fuites (vers ACPM et Weborama sur la capture écran), et vous ne verrez plus de publicité.
Si jamais vous observez des traceurs non bloqués, vous avez le choix de vous abonner à de nouvelles listes de blocage ou tout simplement d'ajouter ces traceurs à votre liste noire :
Quelques traceurs ajoutés manuellement
Si vos logs sont activés, vous aurez également accès à des statistiques agrégés :
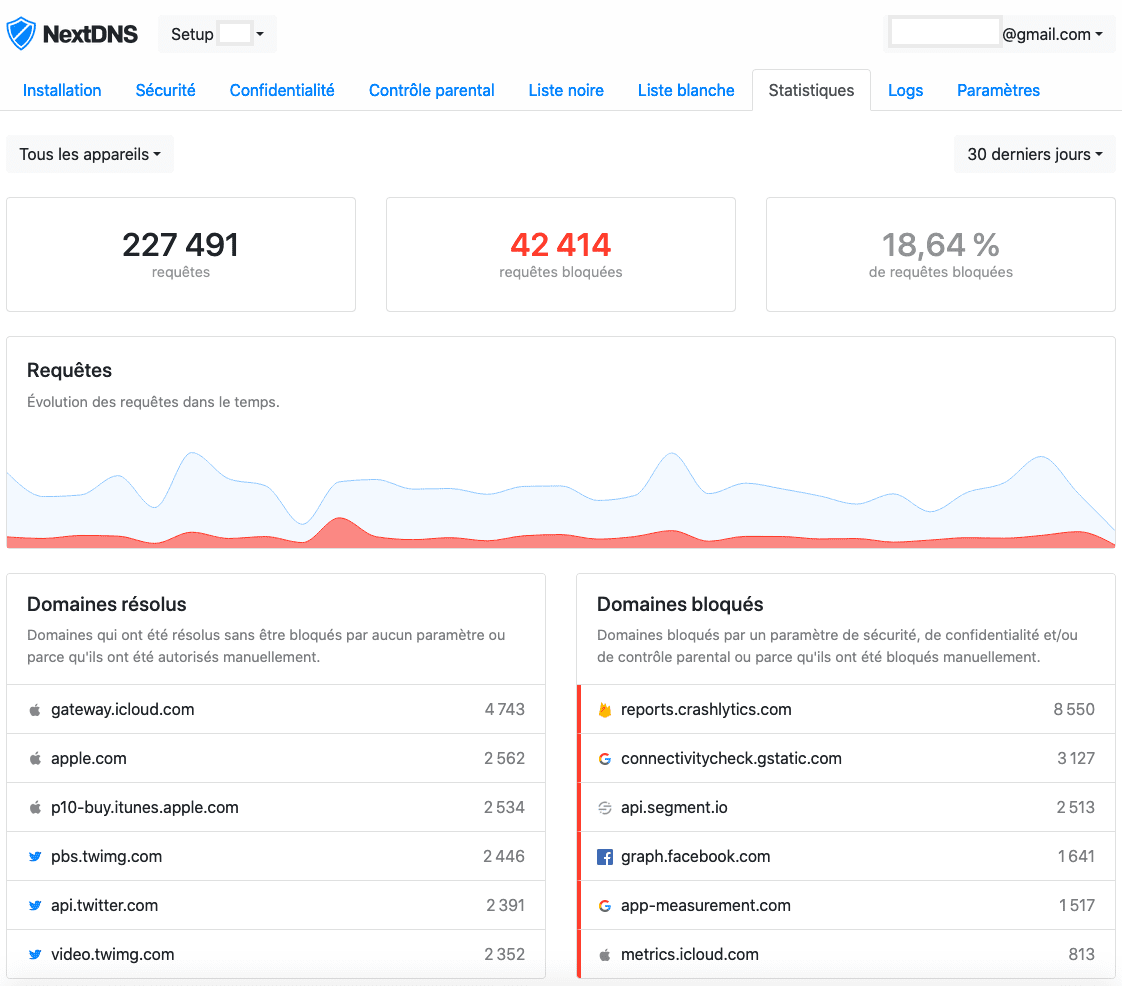
NextDNS bloque quasiment 20% de mes requêtes. Si je regarde la vue par appareil, NextDNS bloque jusqu'à 30% des requêtes sur mon iPhone et sur mon Apple TV (les applications n'y étant pas ciblées par d'autres adblockers). Au contraire, sur mes portables MacBook, NextDNS ne bloque que 3% des requêtes, uBlock Origin bloquant déjà les traceurs et autres publicités sur le web.
NextDNS bloque également le "CNAME cloaking"
Le "CNAME cloaking" est une manière insidieuse de vous surveiller, en passant outre les protections des navigateurs et autres adblockers. Son implémentation est souvent accompagnée d'une grave faille de sécurité la fuite de vos identifiants de connexion vers le tiers. Voici quelques exemples détaillés sur ce blog :
- LeBonCoin l'utilise en partenariat avec Criteo.
- Lemonde.fr l'utilise en partenariat avec AT Internet.
- Boursorama l'utilisait en partenariat avec AT Internet et Smart AdServer (le problème a depuis été corrigé).
- Criteo pousse cette technique agressivement à ses clients, plus de 10.000 éditeurs auraient déjà implémenté du "CNAME cloaking" avec Criteo.
Criteo en particulier est très vicieux dans son utilisation du "CNAME cloaking" : la "fonctionnalité" est activée uniquement si vous utilisez Safari (afin de contourner "Intelligent Tracking Prevention"). Ainsi vous pourriez croire qu'un site ne passe pas par du "CNAME cloaking" si vous observez les requêtes avec Firefox ou Chrome. Ainsi, lorsque vous utilisez Safari sur iPhone, vous n'êtes pas protégé contre cette technique de surveillance.
NextDNS a implémenté la protection contre le pistage via "CNAME cloaking" il y a déjà 1 an :

La protection est activée par défaut.
Quel modèle économique pour NextDNS ?
Avant d'utiliser un tel service, la première question est de bien comprendre le modèle économique. Un exemple : Google a pour modèle économique le marketing de surveillance. Si vous êtes inquiet de l'omniprésence de Google dans nos vies, vous éviterez surement Google Public DNS. NextDNS a un modèle "freemium" :
- Le service est gratuit jusqu'à 300.000 requêtes DNS par mois (note : pour mon premier mois d'utilisation, malgré un usage intensif, je n'ai pas atteint cette limite). Si vous atteignez la limite et ne payez pas, NextDNS se comportera comme un simple annuaire DNS pour les requêtes supplémentaires : ni filtre, ni logs.
- Si vous dépassez les quotas, le tarif est très raisonnable : $1.99/mois ou $19.90/an (à peu près l'équivalent en euros).
- NextDNS propose également des plans payant pour les entreprises et les écoles.
Pouvez-vous faire confiance à NextDNS ?
Si vous n'avez pas changé vos paramètres DNS, vous utilisez sans doute l'annuaire de votre fournisseur d'accès internet. Lorsque vous passez par NextDNS, vous devez faire confiance à un nouveau tiers, comment juger si ce tiers est digne de confiance ? À chacun de se faire son propre avis, voici les arguments qui m'ont convaincu.
La présentation des fondateurs, 2 français, explicite les principes de NextDNS :
NextDNS has been founded in May 2019 in Delaware, USA by two French founders Romain Cointepas and Olivier Poitrey. Olivier has been working on Internet infrastructures for the last 20 years. In 2005, he founded Dailymotion, the largest video sharing service after Youtube and the most popular European website in the world at the time. He is currently Director of Engineering at Netflix, working on Open Connect, Netflix's home CDN also known as the CDN moving about 30% of the total US Internet traffic. Romain and Olivier closely worked for years at Dailymotion on many different projects. Romain ended up leading the mobile & TV department.
We are true supporters of the net neutrality and Internet privacy. We believe that un-encrypted DNS resolvers operated by ISPs are detrimental to those two principles. Alternative solutions like Google DNS or Cloudflare DNS are great, but we think more actors need to step up and provide alternative services to avoid centralization of powers.
Je préfère utiliser les services d'une société ayant ces principes plutôt que ceux de mon fournisseur d'accès internet ou d'un Google. Notez également la compétence technique des 2 cofondateurs (Netflix et Dailymotion), qui se retrouve également dans la rapidité de NextDNS :
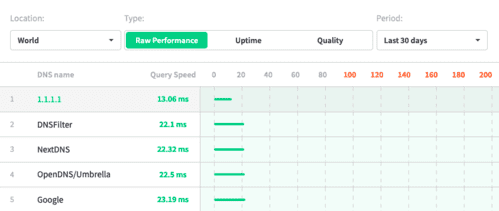
NextDNS est plus rapide que Google sur les 30 derniers jours.
La politique de confidentialité est également directe, concise et très claire :
- Les données récoltées ne seront jamais vendues ou partagées.
- Toute donnée ne devant pas être loguée (par choix utilisateur) est immédiatement supprimée.
- Si l'utilisateur ne demande pas explicitement à ce que ses données soient loguées, rien n'est logué. Si l'utilisateur le demande (pour voir ses logs, comme j'ai pu le faire), il a la main sur ses données et sur la durée de rétention.
- NextDNS vous protège (il n'expose pas votre adresse IP) lorsqu'il demande des informations à d'autres annuaires DNS.
NextDNS a également été choisi comme partenaire de Firefox afin de chiffrer les requêtes DNS de ses utilisateurs (pour l'instant, le programme est seulement disponible aux États-Unis). C'est un gage de sérieux (le seul autre partenaire est Cloudflare).
NextDNS vs Pi-Hole ?
Si vous souhaitez garder le contrôle et que vous êtes bidouilleur, le Pi-Hole est une excellente solution. Notez qu'il vous faudra quand même faire confiance au serveur DNS appelé par le Pi-Hole (upstream DNS), donc vous devrez toujours faire confiance à quelqu'un. NextDNS est une sorte de "Pi-Hole dans le cloud", cet article détaille les avantages et inconvénients des 2 options.
Si vous souhaitez creuser l'option NextDNS, je vous conseille cet article ainsi que la FAQ de NextDNS. Pour ma part, le choix est vite fait : par sa simplicité d'installation et par le fait qu'il fonctionne en mobilité, NextDNS répond parfaitement à mes besoins. Je peux également facilement l'installer chez des proches qui ne sont pas geeks.
Quelques soient vos préférences, je vous encourage à payer pour de l'information de qualité et à protéger vos proches en leur installant des bloqueurs de traceurs et de publicités sur leurs appareils.
Texte intégral (3555 mots)
Lors de mes analyses de sites et d'applications, la conclusion est souvent la même : faute de véritables sanctions contre les éditeurs, vous devez vous protéger contre la surveillance publicitaire via des moyens techniques. Cet article a pour but de partager ma configuration actuelle.
Les choix de bloqueurs de traceurs et de publicités sont évidemment très personnels : vous utilisez sans doute d'autres applications, d'autres extensions, vos choix sont peut-être plus efficaces. Aussi, je suis loin d'être le seul à écrire sur le sujet et je ne suis pas expert "Adblock", bref n'hésitez pas à partager votre expérience !
Selon les appareils, il est plus ou moins facile de bloquer les traceurs et publicités. Voici les différents scénarios auxquels je suis confronté.
Bloquer les traceurs et publicités sur un navigateur "Desktop" : des adblockers largement adoptés aujourd'hui
Sur mes MacBook (personnel, professionnel), lorsque je surfe sur le web, j'utilise Firefox avec l'extension uBlock Origin. Sur Firefox, cet adblocker détecte le "CNAME cloaking" et le bloque (ce qui n'est pas le cas sur Chrome). Le "CNAME cloaking" est une technique utilisée par certains acteurs du marketing de surveillance pour vous pister, même si vous avez pris vos précautions (cette technique pose aussi des problèmes de sécurité). Si vous souhaitez approfondir le sujet, lisez les explications de NextDNS (en anglais) et la présentation de la Quadrature du Net (en français).
Surtout, à la différence d'un Adblock Plus que je déconseille vivement, uBlock Origin n'offre aucun passe-droit aux publicitaires. La société Eyeo, éditrice d'Adblock Plus, est à l'origine du programme Acceptable Ads, et se fait payer de grosses sommes par des géants du marketing de surveillance tels que que Google, Microsoft, Amazon, Taboola, Outbrain et Criteo pour ne pas bloquer leurs publicités par défaut : une énorme hypocrisie !
Il m'est facile de conseiller Firefox et uBlock Origin à mes proches :
- Firefox est simple à installer et très rapide. C'est un logiciel développé par un acteur indépendant (Mozilla), open-source et respecteux de la vie privée de ses utilisateurs.
- uBlock Origin est également simple à installer, et très efficace.
Bloquer les traceurs et publicités sur le web, sur un iPhone : des bloqueurs de contenus moins démocratisés
Sur mon iPhone, lorsque je surfe sur le web, j'utilise Safari. Grâce à Intelligent Tracking Prevention (ITP), celui-ci me protège contre le pistage multi-sites par des tiers (notamment en bloquant les cookies tiers, mais pas que). À noter que depuis iOS 14, Intelligent Tracking Prevention s'applique aussi aux autres navigateurs : Chrome sur iOS vous protège aussi contre le pistage multi-sites par des tiers ! Seulement voilà, ITP ne répond pas à tous mes besoins :
- Il ne bloque pas les publicités.
- Il bloque le suivi multi-sites mais ne bloque pas l'envoi des traceurs (Safari continue d'envoyer les requêtes vers de multiples sociétés marketing).
- Il permet le suivi lorsqu'il est restreint à un seul site : l'outil analytics d'un éditeur (Google Analytics lorsque l'éditeur n'a pas activé les fonctionnalités publicitaires, AT Internet, Adobe Analytics...) continuera de fonctionner correctement et d'analyser votre parcours (même si l'analyse est restreinte au site consulté).
À la différence d'Android (exemple : Firefox pour Android), iOS ne permet pas à un navigateur d'installer des extensions (le navigateur doit nécessairement utiliser le moteur de rendu de Safari, Webkit) : impossible donc d'installer directement un adblocker.
Il est néanmoins possible d'installer un "bloqueur de contenu", celui-ci sera activé uniquement sur Safari (et non sur les autres navigateurs) et permettra de bloquer des listes de traceurs et de publicités. J'utilise donc le bloqueur de contenu Firefox Focus pour bloquer les publicités. AdGuard propose également un bloqueur de contenu pour Safari, mais lors de mon utilisation, il bloquait le chargement de certains sites, ce qui me forçait à le désactiver.
Il m'est également facile de conseiller cette option à mes proches qui sont sur iOS (pour Android, je recommande Firefox avec uBlock Origin) :
- Safari est le navigateur par défaut, rien à configurer.
- Firefox Focus demande un minimum de configuration, mais cela reste rapide.
Bloquer les traceurs et publicités sur les applications natives : le public est peu informé, NextDNS à la rescousse
Plus compliqué maintenant, sur les applications iPhone, il me manquait une bonne option pour bloquer les traceurs et publicités. Je payais pour ProtonVPN mais celui-ci ne peut être utilisé simultanément avec un bloqueur tel que NextDNS ou AdGuard.
Aussi, j'avais de gros problèmes de batteries avec les applications ProtonVPN, NextDNS et AdGuard et je pensais connaître la cause : ces applications étaient toutes basées sur un VPN (ces applications pouvaient parfois utiliser jusqu'à 50% de la batterie de mon vieil iPhone sur une journée). Avant la sortie de iOS 14, NextDNS et AdGuard devaient utiliser un VPN local pour chiffrer les requêtes DNS.
Adguard passe par un VPN local sous iOS
Mais avec iOS 14, Apple ajoute la possibilité de chiffrer les requêtes DNS nativement. Plus besoin de passer par le "hack" d'un VPN local, et donc plus d'impact sur ma batterie. NextDNS ayant implémenté cette option rapidement, j'ai décidé de l'utiliser systématiquement et je n'ai pas été déçu.
Avec NextDNS, je peux ainsi :
- Bloquer les traceurs et les publicités lorsque j'utilise des applications sur mon iPhone, via l'application iOS NextDNS donc.
- Bloquer les traceurs et les publicités sur mon Apple TV (tvOS permet également de chiffrer les requêtes DNS nativement), via le générateur de profils de configuration Apple.
- Bloquer les traceurs et publicités sur les applications lorsque j'utilise mon Mac. Un exemple : le player Mac Spotify est très bavard, il fuite vos données personnelles à Google et Comscore et uBlock Origin ne va pas aider. L'appli Mac de NextDNS permet de bloquer ces traceurs.
- Compléter le blocage des traceurs et publicités déjà effectué par uBlock Origin sur Firefox (Mac) et Firefox Focus sur Safari (iPhone) via une 2ème couche de blocage NextDNS. J'ai ainsi fait disparaitre de nombreuses bannières de consentement, rendant mon surf plus agréable.
- Configurer ma Freebox pour utiliser le DNS de NextDNS et ainsi bloquer les traceurs des objets connectés (mon thermostat en l'occurrence).
Je peux également facilement recommander cette solution à mes proches :
- NextDNS est rapide à installer et à configurer (à la différence d'un Pi-Hole, qui s'adresse principalement à des bidouilleurs).
- NextDNS fonctionne aussi en mobilité (toujours à la différence d'un Pi-Hole, qui ne fonctionnera que sur le WiFi personnel maison).
De l'utilité d'un annuaire DNS
NextDNS est un annuaire DNS (Domain Name System) parmi d'autres. Le DNS est un des services essentiels à l'internet : c'est un annuaire qui va permettre la correspondance entre un nom de domaine (exemple : google.fr) et une adresse IP (exemple : 216.58.204.99). Par défaut, vous utilisez le serveur DNS de votre fournisseur d'accès internet. Seulement voilà :
- Ces requêtes DNS ne sont pas chiffrées, un pirate peut donc les intercepter, apprendre quels sites vous consultez voire modifier ces requêtes à la volée pour vous faire télécharger un virus par exemple.
- Pour des raisons légales, les fournisseurs d'accès internet (FAI) bloquent également l'accès à certains sites web. Exemple : vous souhaitez télécharger des fichiers torrent (films, séries, musique) via le site The Pirate Bay, mais celui-ci risque d'être bloqué par votre fournisseur. Les FAI appliquent ce blocage via l'annuaire DNS qu'ils mettent à votre disposition.
Pour que vos requêtes DNS soient chiffrées et pour vous permettre d'accéder à certains sites web, vous pouvez changer de fournisseur DNS. Si vous ne souhaitez pas bloquer les traceurs et publicités, OpenDNS est un annuaire de confiance. Si vous souhaitez simplement utiliser un service rapide et que vous n'êtes pas inquiet de l'omniprésence de Google dans votre vie, vous pouvez utiliser le Google Public DNS. De même, si vous êtes peu concerné par la centralisation progressive du web mais simplement par la performance, vous pouvez utiliser le DNS de Cloudflare.
Mais ce serait dommage de s'arrêter en si bon chemin ! Dans le cas des traceurs et publicités, l'annuaire DNS peut retourner une réponse vide au lieu de renvoyer la bonne adresse IP. Exemple : si vous êtes en train de jouer à un jeu sur votre iPhone et que celui-ci souhaite délivrer une publicité, il va demander à votre annuaire DNS l'adresse de doubleclick.net (la régie publicitaire de Google). Si vous utilisez NextDNS et si vous avez activé les bloqueurs, celui-ci ne renverra pas de réponse : vous ne serez pas pisté et vous ne verrez pas de publicité !
NextDNS vous permet de choisir vos listes de blocage
Comme pour un adblocker "classique" tel que uBlock Origin, NextDNS vous permet de vous abonner à des listes de blocage :
Mon choix parmi les listes les plus utilisés.
NextDNS vous propose également des listes de blocage pour se protéger contre le tracking "natif" :
Apple collecte des statistiques d'usage ? Je peux maintenant bloquer ces requêtes.
Le fonctionnement de NextDNS est transparent
Si vous décidez d'activer les logs de NextDNS, vous aurez une grande flexibilité :
- Sur la durée de rétention : de 1 heure à 2 ans. Si vous souhaitez vérifier que NextDNS fonctionne bien et affiner les domaines bloqués, 1 heure est suffisant.
- Sur la localisation du stockage : notamment dans l'Union Européenne ou mieux, en Suisse.
Vous pourrez alors "vérifier" le travail de NextDNS via une interface en ligne. Voici la vue lorsque je lance l'application L'Équipe sur mon iPhone :
Comme nous l'avons déjà vu, l'application L'Équipe fuite vos données personnelles. Mais NextDNS empêche bien ces fuites (vers ACPM et Weborama sur la capture écran), et vous ne verrez plus de publicité.
Si jamais vous observez des traceurs non bloqués, vous avez le choix de vous abonner à de nouvelles listes de blocage ou tout simplement d'ajouter ces traceurs à votre liste noire :
Quelques traceurs ajoutés manuellement
Si vos logs sont activés, vous aurez également accès à des statistiques agrégés :
NextDNS bloque quasiment 20% de mes requêtes. Si je regarde la vue par appareil, NextDNS bloque jusqu'à 30% des requêtes sur mon iPhone et sur mon Apple TV (les applications n'y étant pas ciblées par d'autres adblockers). Au contraire, sur mes portables MacBook, NextDNS ne bloque que 3% des requêtes, uBlock Origin bloquant déjà les traceurs et autres publicités sur le web.
NextDNS bloque également le "CNAME cloaking"
Le "CNAME cloaking" est une manière insidieuse de vous surveiller, en passant outre les protections des navigateurs et autres adblockers. Son implémentation est souvent accompagnée d'une grave faille de sécurité la fuite de vos identifiants de connexion vers le tiers. Voici quelques exemples détaillés sur ce blog :
- LeBonCoin l'utilise en partenariat avec Criteo.
- Lemonde.fr l'utilise en partenariat avec AT Internet.
- Boursorama l'utilisait en partenariat avec AT Internet et Smart AdServer (le problème a depuis été corrigé).
- Criteo pousse cette technique agressivement à ses clients, plus de 10.000 éditeurs auraient déjà implémenté du "CNAME cloaking" avec Criteo.
Criteo en particulier est très vicieux dans son utilisation du "CNAME cloaking" : la "fonctionnalité" est activée uniquement si vous utilisez Safari (afin de contourner "Intelligent Tracking Prevention"). Ainsi vous pourriez croire qu'un site ne passe pas par du "CNAME cloaking" si vous observez les requêtes avec Firefox ou Chrome. Ainsi, lorsque vous utilisez Safari sur iPhone, vous n'êtes pas protégé contre cette technique de surveillance.
NextDNS a implémenté la protection contre le pistage via "CNAME cloaking" il y a déjà 1 an :
La protection est activée par défaut.
Quel modèle économique pour NextDNS ?
Avant d'utiliser un tel service, la première question est de bien comprendre le modèle économique. Un exemple : Google a pour modèle économique le marketing de surveillance. Si vous êtes inquiet de l'omniprésence de Google dans nos vies, vous éviterez surement Google Public DNS. NextDNS a un modèle "freemium" :
- Le service est gratuit jusqu'à 300.000 requêtes DNS par mois (note : pour mon premier mois d'utilisation, malgré un usage intensif, je n'ai pas atteint cette limite). Si vous atteignez la limite et ne payez pas, NextDNS se comportera comme un simple annuaire DNS pour les requêtes supplémentaires : ni filtre, ni logs.
- Si vous dépassez les quotas, le tarif est très raisonnable : $1.99/mois ou $19.90/an (à peu près l'équivalent en euros).
- NextDNS propose également des plans payant pour les entreprises et les écoles.
Pouvez-vous faire confiance à NextDNS ?
Si vous n'avez pas changé vos paramètres DNS, vous utilisez sans doute l'annuaire de votre fournisseur d'accès internet. Lorsque vous passez par NextDNS, vous devez faire confiance à un nouveau tiers, comment juger si ce tiers est digne de confiance ? À chacun de se faire son propre avis, voici les arguments qui m'ont convaincu.
La présentation des fondateurs, 2 français, explicite les principes de NextDNS :
NextDNS has been founded in May 2019 in Delaware, USA by two French founders Romain Cointepas and Olivier Poitrey. Olivier has been working on Internet infrastructures for the last 20 years. In 2005, he founded Dailymotion, the largest video sharing service after Youtube and the most popular European website in the world at the time. He is currently Director of Engineering at Netflix, working on Open Connect, Netflix's home CDN also known as the CDN moving about 30% of the total US Internet traffic. Romain and Olivier closely worked for years at Dailymotion on many different projects. Romain ended up leading the mobile & TV department.
We are true supporters of the net neutrality and Internet privacy. We believe that un-encrypted DNS resolvers operated by ISPs are detrimental to those two principles. Alternative solutions like Google DNS or Cloudflare DNS are great, but we think more actors need to step up and provide alternative services to avoid centralization of powers.
Je préfère utiliser les services d'une société ayant ces principes plutôt que ceux de mon fournisseur d'accès internet ou d'un Google. Notez également la compétence technique des 2 cofondateurs (Netflix et Dailymotion), qui se retrouve également dans la rapidité de NextDNS :
NextDNS est plus rapide que Google sur les 30 derniers jours.
La politique de confidentialité est également directe, concise et très claire :
- Les données récoltées ne seront jamais vendues ou partagées.
- Toute donnée ne devant pas être loguée (par choix utilisateur) est immédiatement supprimée.
- Si l'utilisateur ne demande pas explicitement à ce que ses données soient loguées, rien n'est logué. Si l'utilisateur le demande (pour voir ses logs, comme j'ai pu le faire), il a la main sur ses données et sur la durée de rétention.
- NextDNS vous protège (il n'expose pas votre adresse IP) lorsqu'il demande des informations à d'autres annuaires DNS.
NextDNS a également été choisi comme partenaire de Firefox afin de chiffrer les requêtes DNS de ses utilisateurs (pour l'instant, le programme est seulement disponible aux États-Unis). C'est un gage de sérieux (le seul autre partenaire est Cloudflare).
NextDNS vs Pi-Hole ?
Si vous souhaitez garder le contrôle et que vous êtes bidouilleur, le Pi-Hole est une excellente solution. Notez qu'il vous faudra quand même faire confiance au serveur DNS appelé par le Pi-Hole (upstream DNS), donc vous devrez toujours faire confiance à quelqu'un. NextDNS est une sorte de "Pi-Hole dans le cloud", cet article détaille les avantages et inconvénients des 2 options.
Si vous souhaitez creuser l'option NextDNS, je vous conseille cet article ainsi que la FAQ de NextDNS. Pour ma part, le choix est vite fait : par sa simplicité d'installation et par le fait qu'il fonctionne en mobilité, NextDNS répond parfaitement à mes besoins. Je peux également facilement l'installer chez des proches qui ne sont pas geeks.
Quelques soient vos préférences, je vous encourage à payer pour de l'information de qualité et à protéger vos proches en leur installant des bloqueurs de traceurs et de publicités sur leurs appareils.
- Persos A à L
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- EDUC.POP.FR
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Frédéric LORDON
- LePartisan.info
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Romain MIELCAREK
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Emmanuel PONT
- Nicos SMYRNAIOS
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- Numérique
- Binaire [Blogs Le Monde]
- Christophe DESCHAMPS
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Francis PISANI
- Pixel de Tracking
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Bondy Blog
- Dérivation
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- ROJAVA Info
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- XKCD