11.01.2026 à 14:30
Le réel, le vrai et la technorrhée. Comment la question du langage s’est déplacée.
Olivier Ertzscheid
Texte intégral (6796 mots)
Republication pour archivage et partage de l’article paru sur AOC.media le 20 Octobre 2025.
La question du langage s’est déplacée, et ce déplacement s’accélère de manière assez vertigineuse. Juin 2024 : mon livre « Les IA à l’assaut du cyberespace » revient sur les début tonitruants de ChatGPT et de ce que je nomme les « artefacts génératifs ». J’y pointe notamment les promesses encore maladroites de la génération de vidéos. Six mois plus tard, décembre 2024 : chacun reste bouche bée devant les prémisses des promesses de Sora d’OpenAI en termes de génération vidéo. Six mois plus tard encore, mai 2025, nous restons bouche bée devant cette fois Veo 3 de Google qui ajoute du son synchronisé à des vidéos toujours artificielles. Et en août 2025 c’est encore Google qui dévoile « Genie 3 », permettant de générer des mondes interactifs en temps réel à partir d’un simple prompt.
La question du langage s’est déplacée. C’est ce que depuis 25 ans et un peu plus, j’observe et documente à l’échelle de recherche qui est la mienne : celle de nos environnements numériques. Ces environnements avant-hier saturés de mots, puis hier encore d’images et de vidéos, et qui le sont désormais d’artefacts génératifs qui à leur tout sursaturent tant les mots que les images. Ad Libitum. Vertiges non d’une simple logorrhée mais d’une sorte de « technorrhée », l’emballement continu d’un capitalisme sémiotique ; une technorrhée pensée comme l’alliance chimiquement pure entre, d’une part, la merdification – « enshittification » – des médias sociaux en particulier et du web en général, et d’autre part, le « Brainrot » ou « abrutissement numérique » qui en est tout autant la cause que l’effet.
La question du langage s’est déplacée. Et dans ce déplacement, dans cette « différance » (Derrida), naissent et prennent place des mondes. Avec leurs images, leurs langages, leurs grammaires, et leurs vérités propres qui sont autant de singulières croyances. C’est dans cet écart par exemple que deviennent possibles, tristement et pathétiquement possibles, des images de Gaza transformée en Riviera, ou celles de soldats nazis défilant au milieu de résistants fêtant la fin de la guerre dans une vidéo mise en ligne par le pourtant très sérieux Service d’Information du Gouvernement (SIG). Dans ces déplacements du langage, dans ces « différances », et dans ces univers propres, cohabitent des représentations tenant aussi bien de délires, de fantasmes ou d’imaginaires que de saisissants réalismes.
Dans ce monde, dans ces mondes plus précisément qui sont aussi le nôtre, qui font en tout cas partie du nôtre, la frontière est extrêmement fine entre la capacité de ces technologies à nous laisser tout émerveillés et ahuris ou à nous transformer en autant d’abrutis totalement hébétés.
La question du langage s’est déplacée.
Et avec elle nos capacités à faire récit, à s’entendre et à s’écouter. Et avec elles, donc, notre capacité à faire société.
Longtemps cantonnées à la vallée de l’étrange, ces générations artificielles, ces vidéos notamment, n’ont aujourd’hui plus rien d’étrange dans leur rendu naturaliste. Fini les scènes animées où l’on détectait l’intervention de l’IA en regardant les mains et le nombre de doigts. Cela ne dispense pas ces générations d’erreurs factuelles ou contextuelles ou d’approximations, d’errances et d’hallucinations (nous y reviendrons) mais le photoréalisme est désormais totalement calculable. Certes le coût de ce calcul est vertigineux mais pour l’instant nous n’y prenons garde. Cette sortie de la vallée de l’étrange pour la plupart des contenus vidéos générés par IA (je parle ici de ceux qui ont vocation illustrative et non délirante ou seulement poético-ludique), nous fait entrer dans un monde … étrange. Une étrangeté qui ré-interroge notre capacité à dire le vrai, et surtout nos heuristiques de preuve, c’est à dire la manière dont collectivement nous pouvons attester que ceci s’est produit et s’inscrit dans une possibilité du monde que l’on appelle le réel.
On convoque souvent, à raison, l’argument selon lequel rien de tout cela ne serait vraiment nouveau. En effet l’invention de la peinture voit aussi l’invention des faussaires, l’invention de la photographie voit aussi celle de la retouche, avec l’invention du cinéma vient l’invention du truquage, et le développement de la radio et de la presse vont de pair avec celui des blagues, canulars, détournements, caricatures et fausses nouvelles. Mais les artefacts génératifs contemporains proposent une cinétique de représentations qui, à des échelles jamais atteintes d’usages massifiés et de circulations permanentes, cessent de nourrir nos imaginaires pour préférer les instancier, et ce faisant prive notre capacité individuelle et collective de recours à l’imaginaire d’une bonne part de sa puissance symbolique ; car tout est déjà là, car tout semble calculable et donc prévisible ; car tous les calculs ont été déjà faits ou le seront bientôt.
Pour bien saisir ce qui nous étreint et nous éreinte collectivement dans l’irruption de ces artefacts génératifs, il faut par exemple imaginer l’intérêt de l’écriture et le rôle d’un écrivain dans un monde où la bibliothèque infinie de Borges serait non seulement réelle mais dans laquelle chacun des ouvrages qu’elle contient serait surtout aisément accessible et consultable ; puisque tout est déjà là où peut l’être sur simple commande, alors la langue n’est plus un ouvroir de potentialités et d’imaginaires : elle semble n’être plus que la gangue de possibles concaténés, calculables et révélables.
Création, confiance et certification.
Sans refaire le débat du Phèdre de Platon et la condamnation de l’écriture, il est certain que quelque chose d’essentiel se joue aujourd’hui autour de la création, de la confiance et de la certification.
Création d’abord : qui peut encore être créateur/créatrice (dans le domaine des arts comme dans l’ensemble des métiers, tâches et fonctions de nos quotidiens) et de quelle manière l’être « avec », « à l’abri » ou « à l’écart » des artefacts génératifs ?
Confiance ensuite : comment avoir et faire confiance à celui ou celle qui crée dans l’originalité et l’intentionnalité de sa création ?
Certification enfin : comment certifier la part de cette création de la confiance qui peut ou doit lui être rattachée (et qui peut varier d’intensité et d’enjeu selon que ladite création concernera une oeuvre par exemple littéraire ou picturale, ou une décision médicale ou de justice) ? Des questions en triptyque que l’on ramène trop souvent à nos perceptions singulières alors qu’elles sont un bouleversement qui doit être pensé collectivement comme le suggérait Hervé Le Crosnier il y a … 30 ans de cela :
« La modification d’un document porteur de sens, de point de vue, d’expérience est problématique. Ce qui change dans le temps c’est la connaissance. Celle d’un environnement social et scientifique, celle d’un individu donné … Mais ce mouvement de la connaissance se construit à partir de référents stables que sont les documents publiés à un moment donné. Les peintres pratiquaient le « vernissage » des toiles afin de s’interdire toute retouche. Les imprimeurs apposaient « l’achevé d’imprimer ». Il convient d’élaborer de même un rite de publication sur le réseau afin que des points stables soient offerts à le lecture, à la critique, à la relecture … et parfois aussi à la réhabilitation. » Hervé Le Crosnier. « De l’(in)utilité de W3 : communication et information vont en bateau. » Présentation lors du congrès JRES’95, Chambéry, 22-24 Novembre 1995.
Ce que nous traversons avec l’IA dans sa dimension générative relève également d’un manque de ritualisation assumant la création de « points stables » qui fassent consensus ; mais apposer un label ou un filigrane « généré avec IA » ne suffira pas à construire ce repère car il ne s’agit plus ici de traiter seulement des questions de « modification » de documents porteurs de sens mais d’étendre ces points stables à des processus créatifs qui relèvent essentiellement de continuums complexes entremêlant des questions juridiques, économiques, techniques (informatiques) et éthiques.
Le temps des c(e)rises.
Nous sommes à ce moment de bascule où, pour l’instant, c’est comme si perdurait encore un effet Larsen dans l’esthétique de la réception de ces images et de ces vidéos ; comme si subsistait encore un bruit, une distorsion, un Larsen cognitif autant que collectif ; un Larsen qui ne s’éteint que lorsqu’enfin nous sommes à distance, à bonne distance, entre l’intention lisible de la génération et l’interprétation lucide de son effet sur nous ou sur le monde. Tant que cette distance n’est pas établie, ce bruit, ce doute, nécessaire, subsiste à l’horizon interprétatif : ce que nous voyons est-il réel malgré son photoréalisme ? Dès lors que cette distance est abolie – et tout est fait dans l’économie des plateformes pour y parvenir – alors ce bruit et ce doute s’éteignent, nous croyons ce que nous voyons. Or il n’est plus grand-chose de réel à voir dans ces enceintes.
Heuristique (et colégram).
C’est à chaque fois la même question qui revient et que je pointe (avec d’autres) depuis au moins 2011, parce que cette question est consubstancielle de chaque avancée technique qui touche à notre rapport au langage ou à l’image ou aux deux, c’est à dire à notre rapport au réel. Cette question c’est celle de savoir comme l’on bâtit de nouvelles heuristiques de preuve.
Il y a deux niveaux différents sur lesquels penser la complexification de nos anciennes heuristiques de preuve. D’abord la documentation récréative, ludique ou fictionnée du monde : l’enjeu est alors celui de la dissimulation ; il faut soit faire en sorte que le destinataire ne voit pas la simulation, soit qu’elle se dise pour ce qu’elle est (un « dit » de simulation) et qu’elle suscite l’étonnement sur sa nature. Et puis il y a la documentation rétrospective de tout ce qui fait histoire dans le temps long ainsi que celle qui concerne l’actualité. C’est alors l’exemple de la vidéo du SIG que j’évoquais plus haut, où le moindre casque à pointe nous fait basculer de l’ahurissement à l’abrutissement.
On croit souvent – et l’on s’abrite derrière cette croyance – que chaque simulation, chaque nouvelle production documentaire générée par intelligence artificielle, ajoute au réel. C’est totalement faux. Chaque nouvelle simulation enlève au réel. Parce que le réel historique n’est pas un réel extensible : il peut se nourrir de représentations historiques mouvantes au gré de l’historiographie et de l’émergence de preuves ou de témoignages, mais chaque nouvelle génération de ce réel historique potentiel va venir se sédimenter dans l’espace public mémoriel dont la part transmissible est extrêmement ténue et s’accommode mal d’effets de concurrences génératives. La question, dès lors, n’est pas tant de condamner les utilisations imbéciles ou négligentes de technologies d’IA pour illustrer un fait historique mais, par exemple, de savoir comment mieux rendre visible et faire pédagogie de la force incroyable d’authentiques images d’archives.
Nos imaginaires sont des réels en plus. Les effets de réel produits par les artefacts génératifs sont des imaginaires en moins.
Dans le domaine du langage les artefacts génératifs orientent bien plus qu’ils n’augmentent notre capacité à faire récit. Il se produit à peu de choses près ce que l’on avait déjà observé derrière la – fausse – promesse marketing initiale qui fut celle des grands réseaux sociaux généralistes : la promesse qu’en multipliant la diversité des profils, des origines, des croyances, des nationalités, des cultures auxquelles nous serions confrontés alors nous deviendrions plus ouverts, plus riches de liens sociaux, et plus empathiques. Or il se produisit essentiellement deux choses : d’abord cette exposition à une supposée diversité fut un feu de paille parce qu’elle allait contre la naturalité première de nos socialisations qui est de d’abord chercher celles et ceux qui nous sont semblables et que les plateformes, Facebook en tête s’aperçurent très vite que tout cela n’était pas bon pour le business (voir à ce sujet les travaux de danah boyd qui montra très tôt comment Facebook avait détruit l’expérience de la mixité sociale dans les universités de 1er cycle – « college » – aux états-unis). Ensuite les effets promis de proximité se transformèrent en effets subis de promiscuités effaçant toute forme d’empathie au profit de la dimension spéculative immédiatement virale et donc rentable de l’ensemble du spectre des discours de haine.
Il est en train de nous arriver exactement la même chose avec l’ensemble de l’actuelle panoplie des artefacts génératifs disponibles, de Genie 3 à ChatGPT5 : nous ne multiplions pas nos capacités collectives à faire récit (que ces récits soient imaginaires, réels ou réalistes et que leur support premier soit celui du texte, de l’image ou de la vidéo), nous les standardisons et nous nous enfonçons dans des dynamiques de reproduction qui se nourrissent de toutes les formes possibles de confusion ; une confusion entretenue par des formes complexes d’indiscernabilité qui tiennent à l’immensité non auditable des corpus sur lesquels ces IA et autres artefacts génératifs sont « entraînés » et ensuite calibrés.
Nous ne produisons pas davantage de nouveaux récits ou de nouveaux imaginaires mais, pour l’essentiel, nous reproduisons de manière industrielle toujours les mêmes, et après la phase de ce que l’on nomma des « hallucinations » vient aujourd’hui une autre phase, qui est celle de « l’effondrement » et qui désigne ce moment où les artefacts génératifs sont entraînés sur des contenus eux-mêmes artificiellement générés, des effondrements qui ruinent et minent les dynamiques d’interprétation et de représentation au fur et à mesure où celles-là mêmes sont érigées en modèles.
Au commencement était le mot-clé.
« En 2025 le web est donc un champ de ruine épistémique » écrit Thibault Prévost dans l’une de ses analyses à propos du phénomène de Slop AI, cette « technorrhée » symptôme de la merdification des plateformes et de notre expérience générale des environnement numériques. Je vous propose un (rapide) retour sur l’une des origines de cet effondrement qui fait qu’aujourd’hui et comme l’écrivait Balzac à propos d’une figure féminine de l’un de ses romans, la plupart de nos environnements numériques, dont le web, « n’ont plus que la beauté des villes sur lesquelles ont passé les laves d’un volcan. »
Au commencement donc était le mot-clé. Notre premier rapport au langage comme nouvelle agentivité opératoire sur une immensité de contenus non-ordonnés, c’est celui du mot-clé tel que les moteurs de recherche nous le proposèrent en prenant la suite des annuaires de recherche (lesquels catégorisaient en arborescence une série limitée de sites et pages choisies par des opérateurs humains). Ce mot-clé, longtemps utilisé seul, est de l’ordre de la formule incantatoire : écrivez « voyage » et vous trouverez les destinations et les prix et les conditions et les descriptions de vos destinations y compris celles non-choisies ; écrivez « voyage » et vous voyagerez. Nous ne donnons qu’un seul mot, qu’une seule clé, et nous attendons de recevoir un monde ordonné, accessible et surtout un monde soit « pertinent » (c’est à dire depuis le début aussi conforme que possible à notre propre désir), soit « populaire » (c’est à dire aussi conforme que possible au désir des autres, ce que René Girard appelle le désir mimétique). Un seul mot et en face, l’immensité ordonnée de pages choisies et triées dans l’économie libidinale où nous sommes passés du statut de déclamant à celui de simple variable statistique dans une chaîne de production qui ne vise que son propre maintient.
Puis de plus en plus, à la place des mots (clés), nous avons fait des phrases. Nous sommes partis à la conquête du langage naturel. Nous avons donc discouru avec des machines, avec des algorithmes. Qui en retour de notre déclamation naturelle, se mirent à nous répondre non plus sous forme de liste de sites, mais d’extraits choisis et signifiants.
Et puis lassés de leur écrire autant que par la simple possibilité offerte de le faire, nous leur avons parlé. Les interfaces vocales se sont proposées, souvent imposées. De cette vocalisation nouvelle sont nées en retour d’autres échos sonores : ceux des machines et de algorithmes nous répondant, prenant voix. Siri, Alexa, et les autres. World Wide Voice.
Il y a l’initiative de la parole, de la requête, de la question. Et l’espace de la réponse. Car durant tout ce temps, de nos premiers mots-clés balbutiés à nos dernières commandes vocales prononcées, s’est structuré un espace matériel du recueil de nos expressions, une géographie politique de nos espaces de parole, de nos espaces discursifs, singuliers et partagés.
Le passage du web aux plateformes, aux « jardins fermés » comme les appelle Tim Berners-Lee, ne fut pas simplement le passage d’un espace public à des espaces semi-privés. Il fut aussi celui où ces plateformes délimitèrent en nombre l’espace de nos énonciations possibles. On décrit souvent le numérique comme un espace de publication illimité, ce que fut et que demeure le web en effet, mais les plateformes, toutes les plateformes, ont installé des espaces discursifs bornés, limités, frustrants, dont rien ne peut ni ne doit dépasser tels de modernes Procuste, ce bandit qui dans la mythologie proposait aux gens de les héberger avant que de leur couper les membres qui dépassaient de son lit.
Procuste dans l’histoire des plateformes c’est 140 signes sur Twitter puis 280 sur X, 2200 signes sur Instagram, 3000 pour LinkedIn, 150 signes pour une vidéo TikTok et 5000 signes pour décrire une vidéo Youtube. Malgré l’extension du domaine de la statusphère, Et tout le reste de ces espaces tant limités que limitrophes d’une atrophie des possibles.
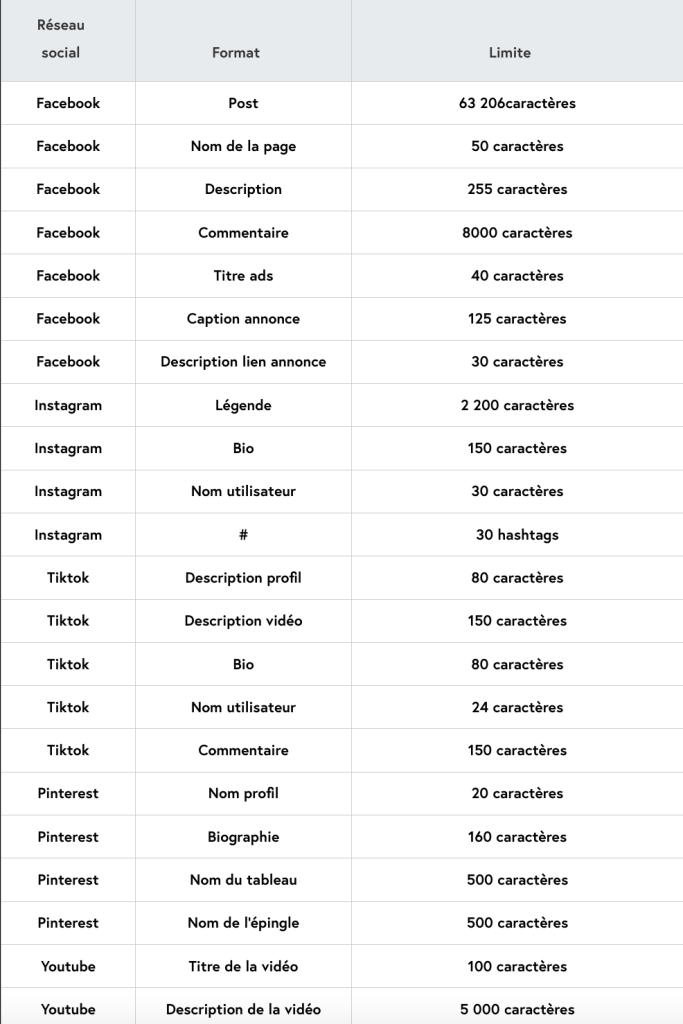
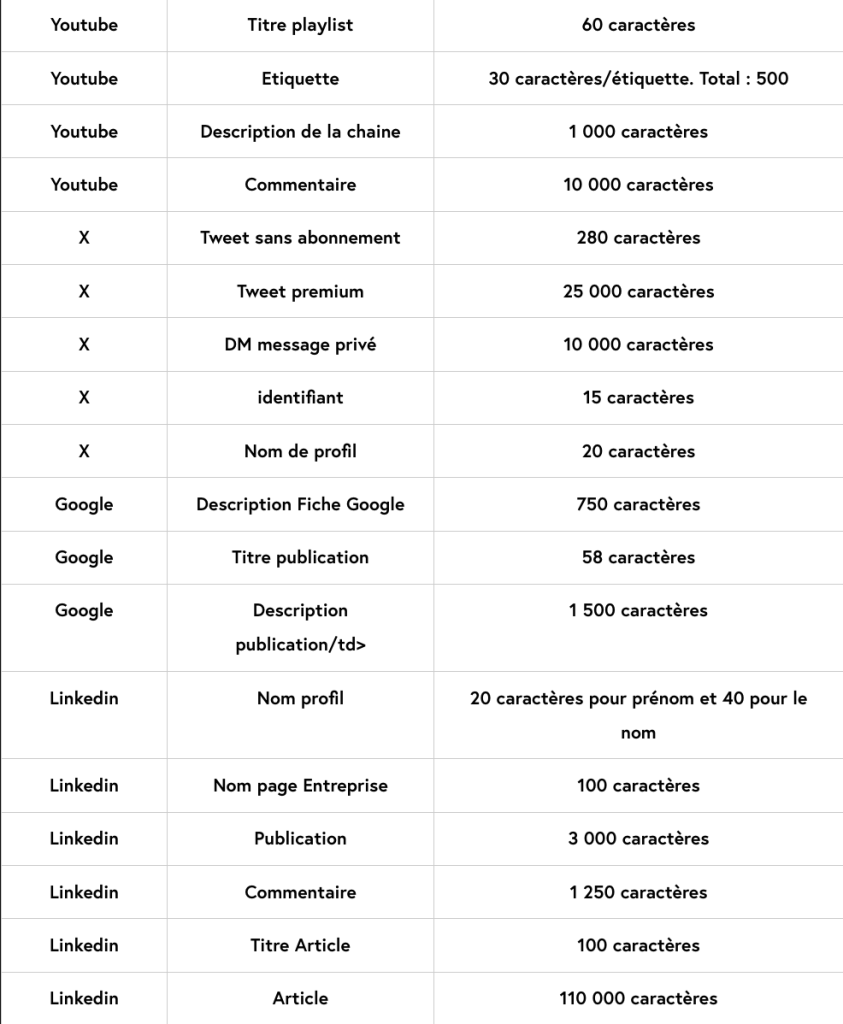
(source : Dailyfy.co)
Comme le montre ce tableau, chaque espace est catégorisé par sa nature « titre de publication », « nom de la page », « description », « commentaire », « description vidéo », « bio », « DM message privé », etc. Et à chaque catégorie un autre espace, une autre limite : 58 caractères pour un titre de publication, 80 caractères pour une bio Tiktok, 30 pour un nom de profil Instagram, 1250 pour un commentaire LinkedIn, et ainsi de suite. Tout est métrique. A coups de trique. Quelques grands espaces demeurent : 110 000 caractères l’article LinkedIn mais 3000 caractères la « publication » de la même plateforme ; 63206 caractères le le post Facebook mais 8000 seulement pour le commentaire. Le numérique des plateformes est tout sauf l’espace infini qui était celui de la publication web des années 2000, c’est un espace totalement sous contrainte et en permanence sous astreinte.
Aujourd’hui l’essentiel de nos espaces discursifs en ligne qui ont recours au langage indépendamment de l’image ou de la vidéo sont des espaces Procustéens (images et vidéos par ailleurs elles-mêmes soumises à des limitations de durée). Des espaces où l’énonciation, où l’accès à la capacité de dire, ne vaut que par l’acceptation de cet horizon court de la diction. Certes il est possible, et certains y parviennent, de sublimer ces limites en les esthétisant ou en les poétisant. Les formes courtes ont par ailleurs une existence culturelle et littéraire longue. Mais nous parlons ici des conditions de production de la langue et donc du réel à l’échelle d’une humanité toute entière, en tout cas de sa part connectée (près de 5,5 milliards d’êtres humains). La « merdification » (enshittification) des plateformes, de presque toutes les énonciations qui s’y déploient aujourd’hui, est aussi liée à cela. Ces espaces ne nous offrent pas tant la possibilité de dire qu’ils ne nous imposent la nécessité de rapidement nous taire. Il est d’ailleurs singulier de voir les plateformes parler de « liberté d’expression » dans des espaces aussi bornés et limités que ceux qu’elles nous offrent. Parlerait-on d’une « liberté de circulation » si celle-ci se limitait à un déplacement entre notre chambre et nos toilettes ?
D’un côté donc, il y eut, à l’échelle des plateformes numériques, la multiplication des espaces d’expression possibles. Mais en parallèle chaque nouvel espace énonciatif est apparu comme permettant de cadrer et de limiter « en nombre » toute expression singulière en ligne. Et désormais il y a la contamination de l’ensemble de ces espaces par des tiers énonciatifs logorrhéiques dopés à l’IA et aux artefacts génératifs. Voilà pour la parole « en émission ».
Quand à la parole « en réception », nous sommes aujourd’hui de plus en plus confrontés et exposés à ces dispositifs techno-logorrhéiques à proportion inverse de nos propres capacités à nourrir et à alimenter ces espaces expressifs et énonciatifs. Pour le dire plus trivialement : la part des bots et des contenus artificiellement générés explose et contamine l’ensemble des espaces numériques de l’ensemble des plateformes (c’est l’un des thèmes de mon livre « Les IA à l’assaut du cyberespace : vers un web synthétique » paru l’été dernier chez C&F Editions).
A l’échelle du numérique, si l’humanité se figeait à ce moment précis, et si nous l’observions à l’échelle macroscopique, nous serions alors forcés de constater que l’initiative de la parole, de la conversation, de la langue comme interaction et comme compréhension, que cette initiative revient davantage aux machines qu’à nous-mêmes. Et que notre réel s’y consomme d’abord, puis s’y épuise et s’y consume. Je le redis, chaque nouvelle simulation enlève au réel. Quand Trump annonce vouloir transformer Gaza en Riviera, des milliers d’images et de vidéos « génératives » viennent instantanément illustrer, montrer, filmer, documenter cet impossible, ce délire macabre autant que cynique. Ce qui était et aurait du rester impossible, y compris à formuler, devient sous le poids des générations illustratives un embranchement possible du futur qui nous est proposé comme instantanément disponible pour nos sens et nos imaginaires. C’est en cela qu’il enlève au réel, au seul réel possible qui est celui d’un arrêt des massacres en cours. Il ne s’agit pas uniquement d’élargir la fenêtre d’Overton mais bien de bâtir autour d’elle l’ensemble la totalité de la barre d’immeuble où elle ne sera plus qu’une fenêtre parmi d’autres, de faire exister la réalité qu’elle inaugure pour laisser au réel encore moins de chance de pouvoir la limiter ou la contraindre rapidement. C’est aussi cela que Trump a sinon compris, du moins intuitivement senti, et qui le fait tant à l’aise dans ces médias sociaux où prime l’expression courte et bouffonne : la parole politique, sa parole politique, se suffit au lit de Procuste tant que l’image y tient les dimensions voulues. Gaza en Riviera. Voilà ce qui seul doit tenir. Le reste s’abîme, s’épuise et s’effondre derrière ces dispositifs techno[-logo]rrhéiques pensés pour l’emballement viral et dont les IA et autres artefacts génératifs ne sont que la dernière – mais non ultime – instance contemporaine.
Les 3 chambres.
Depuis longtemps dans l’analyse des médias on utilise le concept de « chambre d’écho » pour désigner de manière métaphorique, le fait que « l’information, les idées, ou les croyances sont amplifiées ou renforcées par la communication et la répétition dans un système défini. »
Avec l’arrivée des médias sociaux, se fait jour chez Eli Pariser le concept de « bulle(s) de filtre« , cette idée que les algorithmes des moteurs de recherche comme des grands médias sociaux tendent à nous enfermer dans nos propres croyances et convictions.
Aujourd’hui, avec l’essor et la place que prennent les différents artefacts génératifs à l’identique de ChatGPT, des chercheurs (Jacob, Kerrigan, Bastos 2025) parlent d’un « Chat-Chamber effect ». Rien à voir avec les matous qui ont conquis l’internet, le « chat » doit être lu et compris comme le « Tchat », et caractérise l’un des biais de nos échanges conversationnels avec des artefacts génératifs, lequel biais désigne les informations incorrectes mais allant dans le sens du questionnement de l’utilisateur que les grands modèles de langage peuvent fournir ; des résultats et informations qui restent non contrôlées et non vérifiées par les mêmes utilisateurs mais auxquels ces mêmes utilisateurs font pourtant confiance. Le titre complet de leur article est ainsi : « L’effet ‘Chat-Chamber’ : faire confiance aux hallucinations de l’IA« .
Derrière ces 3 déclinaisons d’une même tendance à trois époques contemporaines successives, se jouent deux choses. D’abord des dynamiques médiatiques qui s’interpénètrent pour forger, favoriser et figer une certaine logique ou esthétique de réception des discours qui s’y tiennent. Ensuite une affordance informationnelle première qui est l’inverse du doute raisonnable : ces systèmes médiatiques ont pour affordance première leur capacité à nous faire croire qu’ils disent le vrai : les logiques virales de partage (« si c’est tant partagé c’est bien que ça doit être vrai« ), le dispositif de proximité (illusoire) avec l’énonciateur (« si c’est lui qui le dit alors cela doit être vrai« ), le biais de disponibilité (des informations délibérément erronées ou mensongères sont plus immédiatement accessibles et rendus visibles que d’autres plus sourcées) ne sont que quelques-uns des leviers de cette affordance de vérité supposée.
Depuis plus de 20 ans j’explique et documente le fait que les algorithmes sont des éditorialistes comme les autres, mais qui avancent essentiellement masqués et que les IA et autres artefacts génératifs installent dans une sorte de théâtre total, « gestes, sons, paroles, feus, cris« , dont plus personne n’est en capacité de comprendre les codes.
A.M.I. : Assemblage Machinique Informationnel.
L’arrivée des artefacts génératifs ajoute une dimension nouvelle et passablement problématique au tableau contemporain de la fabrication de nos croyances et adhésions. Jusqu’ici, moteurs de recherche et réseaux sociaux jouaient sur le levier déjà immensément puissant de leurs arbitraires d’indexation et de publication (le fait de choisir ce qu’ils allaient indexer et/ou publier) ainsi que sur celui, tout aussi puissant, de la hiérarchisation et de la circulation (viralisation) de ce qui pouvait être vu et donc en creux de ce qu’ils estimaient devoir l’être moins ou pas du tout.
Choisir quoi mettre à la « Une » et définir l’agenda médiatique selon le vieux précepte de « l’agenda setting » qui dit que les médias ne nous disent pas ce qu’il faut penser mais ce à quoi il faut penser. Ce principe premier de l’éditorialisation se double, avec les artefacts génératifs conversationnels à vocation de recherche, d’une capacité à produire des sortes d’assemblages machiniques informationnels, c’est à dire des contenus uniquement déterminés par ce que nous interprétons comme un « devenir machine** » en capacité de « phraser » les immenses bases de données textuelles sur lesquelles il repose. Des machines à communiquer mais en aucun cas, comme le souligne aussi Arthur Perret, en aucun cas des machines à informer.
** [ce « devenir-machine » est à lire dans le sens du « devenir-animal » chez Deleuze et Guattari : « le “devenir-animal” ne consiste pas à “imiter l’animal, mais d’entrer dans des rapports de composition, d’affect et d’intensité sensible” ».]
Ce concept d’assemblage machinique informationnel me semble intéressant à penser en miroir ou en leurre des agencements collectifs d’énonciation théorisés par Félix Guattari. D’abord parce qu’un assemblage n’est pas un agencement. Il n’en a justement pas l’agentivité. Il n’est mû par aucune intentionnalité, par aucun désir combinatoire, calculatoire, informationnel, communicationnel ou social. Ensuite parce que la dimension machinique est antithétique de la dimension collective, elle en est la matière noire : ChatGPT (et les autres artefacts génératifs) n’est rien sans la base de connaissance sur laquelle il repose et les immenses réservoirs de textes, d’images et de contenus divers qui ont été, pour le coup, assemblés, et sont l’oeuvre de singularités fondues dans un collectif qui n’a jamais été mobilisé ou sollicité en tant que tel. Enfin, l’information est ici un degré zéro de l’énonciation. L’énonciation c’est précisément ce qui va donner un corps social à ce qui étymologiquement, a donc déjà été « mis en forme » (in-formare) et se trouve prêt à être transmis, à trouver résonance. ChatGPT est l’ombre, le simulacre, le leurre d’une énonciation. Et cette duperie est aussi sa plus grande victoire.
La question du langage s’est déplacée. Un grand déplacement. Quelque chose qui n’est plus aligné entre le territoire du monde et la langue qui en est la carte.
Apostille(s).
Pendant que nos réels sont saturés et épuisés d’IA, en Israël, un spot de publicité pour une entreprise d’armement utilise pour la première fois des images réelles d’une attaque de drone à Gaza. C’est à la fois la plus cynique et la plus perverse des formes de publicitarisation. Pendant ce temps Youtube dévoile un système baptisé « Peak Points » qui utilise son IA « Gemini » pour insérer des publicités aux moments où l’attention des spectateurs est supposément la plus forte grâce à l’exploitation de données « émotionnelles » (ou qui sont en tout cas supposées rendre compte de notre état émotionnel).
Couplez maintenant ces deux informations et déterminez sans algorithme votre propre état émotionnel …
De manière plus anecdotique, on constate un jaunissement par contamination de nombreuses images générées artificiellement. Les animaux étaient malades de la peste, les IA le sont déjà de consanguinité. Pendant ce temps encore, Youtube fait des retouches de vidéos sans en avertir les créateurs, pour « rapprocher esthétiquement le rendu des vidéos de ce que l’IA générative peut proposer. » Standardiser la consanguinité des contenus générés.
Pendant ce temps, des images pédocriminelles générées par IA sèment autant le trouble que le doute et entravent les démarches déjà si complexes du travail de police et de justice. La volumétrie des faux-positifs est ici la première alliée des pédocriminels. Et une nouvelle fois la charge de la preuve s’inverse comme si souvent dans l’histoire du numérique : il ne s’agit plus de pouvoir détecter la marginalité de faux-positifs sur un volume de contenus donnés, il s’agit de la maximiser pour que les résultats « sincères » soient marginalisés.
En 1985, dans un entretien où elle était interrogée sur sa vision de l’an 2000, Marguerite Duras prophétisait avec une rare acuité « Il n’y aura plus que des réponses. Tous les textes seront des réponses. (…) » Nous sommes au moment où tout comme après l’avènement des moteurs de recherche au début des années 2000, il n’y a plus, aujourd’hui, que des réponses. De fausses réponses pourrait-on donc ajouter.
Marguerite Duras poursuivait : « Un jour un homme il lira. Et puis tout recommencera. » L’inflation des artefacts génératifs dans l’ensemble de nos écosystèmes informationnels et des sphères de nos savoirs sociaux (école, université, cercles politiques, etc.) pose autant la question de savoir ce qu’il restera encore à lire, que celle de savoir si nous serons en peine d’encore pouvoir écrire un destin commun. Christian Salmon le rappelait aussi dans sa récente analyse sur ce nouvel ordre narratif en train de s’imposer : « La prolifération de ces narrations non humaines interroge le devenir de l’humanité tout entière. »
La question du langage s’est déplacée, et notre technorrhée ressemble à s’y méprendre aux vers de Macbeth : un conte raconté par un idiot (ils sont en fait plusieurs), plein de bruit et de fureur, ne signifiant plus rien. (« It is a tale / Told by an idiot, full of sound and fury / Signifying nothing« ).
06.01.2026 à 18:25
La forme des réseaux. Ou pourquoi je suis devenu troll officiel de Christelle Morançais sur Linkedin.
Olivier Ertzscheid
Texte intégral (2848 mots)
L’affaire commence par une décision de nécropolitique prise par Christelle Morançais, la Trumpo-Thanato présidente de la région des Pays de la Loire et qui s’en va tronçonner avec jouissance et cynisme la presque totalité de tout ce qui fait lien et de tout ce qui sauve : culture, éducation, planning familial …
Décision brutale qui l’installe sur le trône des aspirant.e.s à une forme assumée de brutalisme en politique. Si Woody Allen l’avait connu il aurait probablement craint que l’écoute de Wagner ne lui donne envie d’envahir la Pologne.
Pour les avoir presque tous expérimentés, de manière constante et régulière (en « observation participante » dit-on dans le jargon des sciences), j’ai donc observé que chaque réseau social dispose de son espace propre, de sa topologie, de son rythme et de ses logiques de viralité qui sont à peu de choses près l’équivalent des rimes : ce qui se viralise est ce qui rappelle, ce qui fait écho, ce qui correspond et (se) répond, ce qui rend facile la mémorisation.
Mais cet espace, cet espace propre à chaque réseau, ce n’est pas seulement celui de ses codes de publication, pas seulement celui de ses logiques de viralité, pas seulement celui de la sociologie qui le compose (et de celles et ceux qui en sont exclus), pas uniquement de son identité structurelle fonctionnelle. Cet espace est également celui d’une affordance construite dans l’historicité de nos usages, et d’une métabolisation singulière de l’ensemble des interactions possibles, métabolisation dans laquelle le tout est bien plus que la somme de ses parties.
En plus de la question de l’affordance (capacité d’un objet à suggérer sa propre utilisation), on pourrait aussi rapprocher cela de la notion de « médiativité », un concept proposé par Philippe Marion et défini comme suit :
« la capacité propre de représenter […] qu’un média possède quasi ontologiquement », son « potentiel spécifique ». Selon Philippe Marion, chaque média possède « un ‘imaginaire spécifique’, sorte d’empreinte génétique qui influencerait plus ou moins les récits qu’il rencontre ou qu’il féconde ». L’auteur parle aussi de la « force d’inertie » propre à tout système d’expression, avec laquelle on ne peut faire autrement que de « négocier ». in Groensteen, Thierry. « Médiagénie et médiativité ». L’excellence de chaque art, Presses universitaires François-Rabelais, 2018, https://doi.org/10.4000/books.pufr.29530.
Un « imaginaire spécifique« , une « sorte d’empreinte génétique » influençant plus ou moins les récits rencontrés, portés, « fécondés » (sinon féconds). Chacune et chacun d’entre vous a certainement déjà fait cette expérience. Chaque réseau dispose de cette empreinte mais il en est où elle apparaît plus forte, plus prégnante, peut-être d’ailleurs en partie parce qu’elle nous est plus étrangère, moins familière, et qu’à ce titre nous la remarquons d’emblée et davantage. LinkedIn est (pour moi) de ceux-là.
Et le rapport avec Christelle Morançais ? J’y viens.
Les médias sociaux sont des espaces et des places politiques. Et, particulièrement depuis que les conservatismes les plus chimiquement purs s’y déploient, particulièrement aussi depuis que le militantisme de droite et d’extrême droite en a fait son terreau fertile, il est vital de continuer d’y faire exister des contre-discours, des contre-récits, des « narratifs » qui proposent d’autres chemins, d’autres imaginaires. Longtemps Facebook fut l’un des réseaux les plus riches en densité pour ces luttes et joutes politiques, pour la détermination d’un espace social politique à investir et à occuper, à une échelle macroscopique (les printemps arabes, les gilets jaunes, etc.) comme à une échelle microscopique (chaque élection municipale par exemple) et interpersonnelle. Mais Facebook a beaucoup perdu en réseau social (interactions entre pairs) ce qu’il a gagné en média social nourri de contenus essentiellement générés, automatisés, publicitarisés. Même perte d’équilibre (et donc d’intérêt) du côté de X qui à l’époque de Twitter était encore fécond dans la possibilité qu’il offrait de disposer de visibilités non-nécessairement dépendantes d’un alignement idéologique avec celui de la plateforme et qui désormais se réduit à une sociologie et à des interactions tristement monochromes (et très conservatrices tendance je lève la main très haut avec le bras bien tendu mais c’est pas forcément un salut Nazi hein)
Et dans cet espace vacant, LinkedIn (depuis son rachat par Microsoft et pour différentes raisons que je vous épargne) a pris une place qu’il n’occupait pas totalement jusqu’ici. L’idée qu’il ne s’agissait pas simplement de s’y pignoler le Casual Friday ou d’y jouer l’effeuillage malaisant de la doudoune sans manche du conseil en coaching adossée au vieux slip du récit de vie de l’entrepreneur qui doute mais qui en vrai, te conseille de ne jamais douter de tes doutes, soit la version Wish de Descartes en bad trip et en fin de soirée BDE.
Et c’est là où cela devient (un peu) amusant et (un peu aussi) scientifiquement intéressant. Le moment où l’on pose cette question : que se passe-t-il si on installe dans la « forme« , dans la « sorte d’empreinte génétique« , dans l’affordance de LinkedIn, des mots, des récits, des interactions qui n’y ont usuellement aucune place ?
C’est ce que j’ai fait dans un premier temps et sans trop y réfléchir, suite aux décisions de Christelle Mange tes Morançais qui affectèrent et continuent d’affecter tout un tas de gens que j’aime bien et avec qui je travaille et aussi et surtout tout un tas d’étudiantes et d’étudiants que je forme (et que j’aime bien aussi). Je suis allé sur son compte LinkedIn, sous chacun de ses posts et au milieu de ses habituels commenflatteurs (soit des commentateurs qui ne font que flatter) et circonstanciels thuriféraires, porter la contradiction, dire mon ire. Parfois en mode essentiellement factuel mais le plus souvent pas en mode LinkedIn c’est à dire consensuel et poli, mais plutôt en mode T & TT : Troll and Trash Talk. Et très vite, très très vite, j’ai observé avec une relative fascination et une grande délectation, observé et « ressenti » le changement de forme du réseau. Je vous explique.
Normalement, les commentaires sous un post LinkedIn classique (récit de vie, conseil en entreprenariat, et autres billevesées) empruntent une arborescence essentiellement verticale et aux embranchements binairement linéaires.
Le post LinkedIn
_____|_ 1er commentaire « wouah c’est trop bien moi aussi j’aime les doudounes sans manche »
__________I_ 1ère réponse au commentaire par l’auteur du post : « Wouah merci d’aimer les doudounes sans manche et bon casual friday »
_____|_ 2ème commentaire « wouah c’est trop bien moi aussi j’aime échouer pour réussir »
__________I_ 1ère réponse au commentaire par l’auteur du post : « Wouah merci d’aimer échouer pour réussir et bon casual friday »
_____|_ 3ème commentaire « wouah c’est trop bien moi aussi je kiffe d’upgrader mon potentiel »
__________I_ 1ère réponse au commentaire par l’auteur du post : « Wouah merci de kiffer upgrader ton potentiel et bon casual friday »
_____|_ énième commentaire …
__________I_ 1ère réponse au énième commentaire par l’auteur du post : « Wouah merci (…) et bon casual friday »
Du vertical poli (au sens de politesse) mais aussi poli (au sens de lisse à force de fatuité génuflexitarienne). Car vous l’aurez peut-être noté mais dans l’affordance de LinkedIn, comme on s’adresse à des « postes » et à des fonctions sociales avant que de s’adresser à des individus, les échelles habituelles de courtoisie ou de simple politesse sont totalement indexées à la différence de position sociale entre les gens qui se parlent. Du coup chaque fois que quelqu’un écrit « merci » on entend le plus souvent très distinctement « merci mon maître » (et on a donc logiquement envie de gifler tout le monde)
Mais quand on change le récit de ces espaces, quand on y récite par effraction, sans même l’intention d’effrayer mais tout au contraire de seulement frayer avec d’autres que nous et que nos récits, ou quand on y entre en force brute, « Troll & Trash Talk », alors la forme du réseau, oui, elle change. Déjà parce que le centre de gravité se déplace. On fait « ratio » 
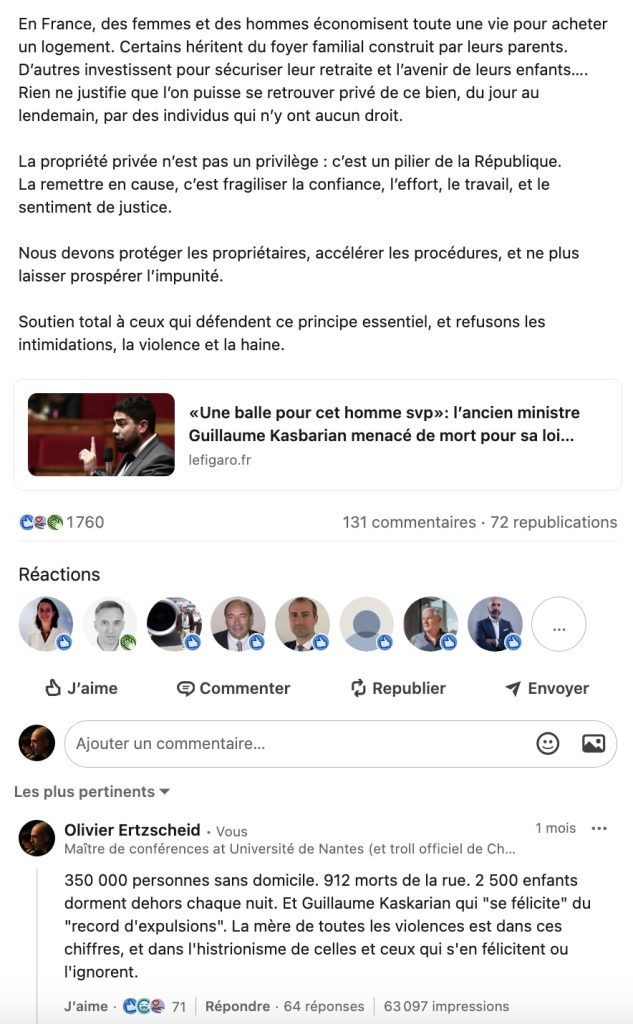
63 097 impressions pour mon commentaire et un taux d’engagement ma foi fort respectable.
J’ai ratio Christelle Morançais sur ce coup là
C’est autour de notre effraction douce que se centre l’attention et que les habituels commenflatteurs (les commentateurs qui flattent) se muent en commenthaters (des commentateurs qui nous détestent). Bien sûr plus vous montez en niveau de trolling et plus la forme du réseau change rapidement et ostensiblement. Vous êtes soudain l’immense Patrick Dewaere dans le film « Coup de tête », pendant la scène du dîner. « Prenez donc un petit alcool, j’vous l’offre« . Chef d’oeuvre sans avoir à passer par les hors-d’oeuvre. La capture d’écran ci-dessus illustre ma maîtrise de l’art du trolling puisque les 63 000 impressions se sont essentiellement distribuées autour de gens qui ont cru soit que je légitimais la violence, soit que je voulais abolir la propriété privée. Si vous n’avez que ça à faire, allez faire un tour dans les commentaires de mon commentaire, et si – ce que je vous souhaite – vous n’avez pas que ça à faire, bah croyez-moi sur parole y’a du croquignolet.
Me voilà donc désormais au titre de ma bio LinkedIn, troll officiel de Christelle Morançais. Tadaaam.
L’intérêt de tout cela (indépendamment de ma propre catharsis) ?
Pendant longtemps sur le web encore jeune de l’après Google, on pratiquait le Google Bombing, forme collaborative aboutie de détournement algorithmique coordonné. Le trolling LinkedIn est certes moins universel et plus singulier mais tout aussi réjouissant. Par-delà l’anecdote il montre aussi que chaque espace numérique indépendamment de ses codes, peut devenir un rassemblement, et qu’il n’est de forme figée qui ne puisse se transformer, même légèrement, même temporairement.
Alors bien sûr le réseau comme le roseau de la fable, souvent plie et ne rompt jamais ou que très rarement. Il reprend toujours sa forme initiale et son intérêt à rétablir des verticalités fortes qui protègent des aristocraties discursives, qui, notamment sur LinkedIn sont essentiellement de petites oligarchies, ou comme le dirait le philosophe Pierre-Emmanuel Barré, « une bien belle collection de cuves à pisse. »
L’exercice a par ailleurs ses limites. Déjà parce que ça prend du temps, ensuite parce que pour qu’il réussisse pleinement il faut que d’autres qui sont un peu les mêmes que nous, nous rejoignent pour participer à ce changement de forme du réseau. Et enfin parce que globalement dans la volumétrie des échanges, la prime revient presque toujours à celui ou celle qui parle davantage qu’aux commentateurs sauf dans de rares et réjouissants cas de « ratio ».
Ce dont il faut aujourd’hui s’inquiéter, c’est certes de la coloration très à droite et conservatrice de l’essentiel des réseaux sociaux encore un peu discursifs (je place à part des biotopes comme Twitch ou Youtube qu’il est difficile d’analyser avec la même grille de lecture). Mais ce dont il faut surtout s’inquiéter, se préoccuper et donc s’occuper, c’est de l’absence d’une agora numérique publique au sein de laquelle l’ensemble des points de vue avaient une chance disons, raisonnable, de bénéficier de dynamiques de visibilité indépendamment d’une souscription financière, d’un alignement idéologique avec la plateforme ou d’une manière de surjouer les codes établis de viralité.
Vous me direz : « bah si y’a … le web. » Et je vous répondrais : « Certes, mais le rêve du web il a pris un sacré coup de pompe dans la tronche quand même. » À l’image de ce qui se joue dans les médias plus classiques ou traditionnels, les espaces numériques de discours ne fonctionnent désormais qu’en silos de viralités, en verticalités d’appartenance, en carottages sociologiques aussi denses qu’homogènes. Et la presque totale disparition du « lien » (hypertexte) dans ces espaces au profit de logiques presse-bouton autochtones rend extrêmement complexe la construction de ponts et de chemins traversants pourtant aujourd’hui plus que jamais nécessaires (nota bene : la logique de disparition du lien dont je parle fut initiée en 2010 avec la lancement du bouton Like de Facebook, souvenez-vous de l’alerte que je lançais alors …)
Alors en plus de continuer de bâtir ici avec constance et depuis 20 ans et un peu plus de 3000 articles, ces ponts à grands coups de liens, je vais aussi continuer au moins un temps d’aller occuper l’espace promotionnel de Christelle Morançais sur son réseau préféré. Les tronçonneuses à la Javier Milei dont elle rêve de faire programme sont bien moins tranchantes et efficaces lorsqu’elles tapent dans le sable. Alors soyons autant de grains de sable 

Eat The Rich. Miam
05.01.2026 à 19:49
« Il neige. » Alors faites de vos culs des luges.
Olivier Ertzscheid
Texte intégral (1450 mots)
Il neige. Ou « il va neiger ». Mais surtout c’est certain demain ou cette nuit ou dans une heure à peine, il neige.
Le gars qui vous cause de ses 53 piges a grandi jusqu’à ses 17 ans dans un pays qu’on appelle les Pyrénées et où chaque hiver et plusieurs fois par semaine il fallait déblayer avec la pelle et le paternel (en vrai c’est surtout lui qui s’en chargeait) le chemin sous un mètre de neige qui menait à la départementale qui ensuite sur des routes et en lacets et en pente nous menait au collège puis au lycée. Il neigeait en hiver.
« Il neige. » Indépendamment de tout cela et de tout ce moi, la neige a toujours été un conversationnel ; un élément de nos conversations communes, parce que même à l’époque où elle n’était pas rare, même à l’époque où elle était attendue, elle advenait et survenait soudainement, nuitamment le plus souvent ou tôt le matin derrière les vitres de nos écoles et de nos yeux encore étourdis de sommeil. Elle arrivait et tout le paysage changeait. La neige est une mutation du paysage et de l’accroche de presque tous nos sens. L’une des rares mutations de la nature qu’il nous est donné d’observer en totalité. D’abord il n’y a pas de neige, et puis on voit la neige tomber, et puis la neige est tombée et tout le paysage est changé. Et l’enfant comme l’adulte n’est attentif qu’à ce changement, qu’à cette mutation en cours sous nos yeux, comme si l’on pouvait observer en accéléré la croissance d’un arbre. Ça y est, il a neigé. Et des jeux s’y agrégeaient dont on savourait chaque moment car on en savait aussi l’éphémère : après, très vite après, il n’y aurait plus de neige mais seulement de la boue. Après la neige, après le premier jour de la neige, il y aurait le 2ème jour, celui où les transports, où l’école, où le boulot, où la vie, où nos vies reprendraient leur cours. Entendez-bien cela : seul le premier jour de neige compte. Les premières heures même. Le reste ne vaut pas mieux qu’une vieille pluie sale. La neige est aujourd’hui encore et aujourd’hui bien plus qu’hier un conversationnel. Mais elle est aussi autre chose.
« Il neige. » La neige est un exceptionnel. Parce que le dérèglement climatique et la brutalisation de nos conditions d’existence et de vie qui l’accompagne. Parce qu’il ne neige ni aussi souvent ni aussi longtemps qu’avant. Et que cet exceptionnel complète et alimente le récit déjà ancien du conversationnel. « Il neige !!! »
« Il neige. » La neige est devenue un événementiel. Par seulement parce que le conversationnel s’est nourri d’exceptionnel et que donc à elle seule la neige « serait » un événement, mais pour au moins deux autres raisons.
La première raison c’est que l’éparpillement des canaux de diffusion de l’information (médias et réseaux sociaux en tête) ont décidé de « faire » événement de … cet événement. Ils ont événementialisé la neige et même mieux (ou pire …) ils ont réussi à événementialiser l’attente de la neige, à spectaculariser l’hypothèse de la neige, à médiatiser l’absence de neige, à faire conversation de la non-neige. Car depuis maintenant presque 8 heures que tous mes réseaux sociaux sont inondés de probabilités de neige, bah il ne neige pas. Imaginez alors ce qu’il adviendra quand il aura neigé. Quand la certitude de la neige sera devenue un paysage plus qu’un présage. Adviendra un nouveau cycle conversationnel faussement exceptionnel mais qui deviendra un événementiel nouveau. « Regardez, il a neigé. »
La seconde raison c’est que là où hier la seule mesure valable était celle de la hauteur de neige (en centimètres c’était l’amorce d’un décalage, d’un retard, alors qu’en mètres c’était la confirmation d’un blocage, d’une mise à l’arrêt), aujourd’hui les mesures ont été remplacées par des métriques d’alerte. Il y a tout une batterie de cartes et de régimes d’alertes, de vigilances, avec leurs codes couleurs, jaune, rouge, rouge vif, et le relai de ces métriques dans les matrices informationnelles qui à leur tour les conversationnalisent (« t’as vu ? on est en vigilance jaune« ), les exceptionnalisent (là où avant juste il neigeait là « t’as vu on est en vigilance jaune neige et verglas« ), qui les événementialisent (on sait comment sortir de la neige – on attend que ça fonde et on met des chaînes – mais personne ne sait vraiment quand la vigilance rouge deviendra vigilance jaune).
Que se raconte-t-il lorsque l’on ne dit plus autant ni plus simplement « il neige« ou « il va neiger » mais « nous sommes en vigilance orange neige et verglas » ? D’abord il y a de la vigilance, donc de l’inquiétude, là où il ne pourrait y avoir que … de la joie. Là où la neige n’appelle que l’observation contemplative, imaginative, ou la récréation active, il nous faudrait donc être en alerte, en vigilance. Il y a le code couleur. Orange, jaune ou rouge. Là où la neige est blanche. Il y a la qualification substantivée qui annule l’effet de la neige parce qu’elle oblige à la dissociation entre neige et verglas. Là où chacun vous dira que la neige et le verglas sont … des indissociables.
« Il va neiger. » Et l’attente est joyeuse. « Nous sommes en vigilance jaune neige et verglas. » Et l’angoisse est palpable. Une quiétude devient une inquiétude. Être en vigilance à chaque instant, à chaque présent, équivaut à une inattention au monde. On peut pas être chaque fois vigilant sans être contraint d’être inattentif à la construction de ce présent. La vigilance est une affaire et une responsabilité individuelle, qui ne nous est que « rappelée » ici, comme on rappelle à son devoir. La vigilance au présent n’est qu’une vigilance aux effets qui dépolitise la construction d’une attention aux causes.
En image ça donnerait un truc comme ça :

Nous quand on entend : « IL NEIGE. »

Nous quand on entend : « NOUS SOMMES EN VIGILANCE JAUNE ET VERGLAS. »
Demain il va neiger. Peut-être. Alors vous serez en retard au boulot. Alors vos réunions seront annulées ou basculées en visio. Alors vos cours et vos partiels seront décalés. Peut-être. Si demain il neige il n’y a qu’une chose à faire. Prenez des gants, et si vous n’en avez pas, n’en prenez pas. Ensuite balancez-vous des grandes boules de neige, si possible dans la figure, si possible pas trop tassées (c’est bien plus rigolo et efficace quand ça touche sa cible, ça explose bien mieux). Et puis trouvez un coin, un bout de champ, ou une rue en pente, et faites de vos culs vos luges.
Depuis ce matin
19.12.2025 à 08:55
20 ans et 3000 articles.
Olivier Ertzscheid
Texte intégral (2140 mots)
J’avoue que je ne l’avais même pas vu venir, c’est un signalement des ami.e.s de Framasoft qui a attiré mon attention sur le fait que mon dernier article était le … trois millième de ce blog. Blog ouvert en 2005, à l’occasion de mon premier poste de Maître de Conférences à l’université de Nantes, plus précisément à l’IUT de La Roche-sur-Yon.
Vingt ans et trois mille articles. Hé bé. Je crois que j’ai l’âge (53 piges) de me retourner un peu sur ces vingt ans.
Vingt ans et trois mille articles. Et avant cela une thèse avec une directrice formidable, Jo Link-Pezet, qui la première fit tomber tant de barrières, des représentations, et d’impossibles. Et qui la première posa sur moi le regard qui autorise, celui qui dit « c’est bon, tu peux y aller, cet espace est pour toi, va y porter tes idées et va y construire ta légitimité, et n’oublie pas tes combats ». Et qui en même temps m’apprit à n’être jamais dupe de tout ce qui pouvait s’y jouer de futile, de superficiel, d’artificiel et de toxique. Après cette thèse et pendant mon post-doc, la création d’un tout premier blog francophone collaboratif de veille scientifique avec les copains et copines du réseau des Urfist : « Urfist Info ». Blog depuis hébergé sur la plateforme d’OpenEdition.
Vingt ans et trois mille articles. Et 5 ou 6 livres avec, à une merveilleuse incartade près (chez Publie.net), l’autre merveilleuse chance et fidélité d’avoir eu un certain Hervé Le Crosnier qui le premier me convainquit que tout cela c’était très bien mais qu’il fallait aussi faire des livres.
Vingt ans et trois mille articles. Qui me virent toujours questionner les questions du numérique et l’écologie cognitive et informationnelle qu’il construit (ou détruit).
Vingt ans et trois mille articles. Avec quelques menaces de procès et tentatives d’intimidation (l’affaire Anne Franck notamment).
Vingt ans et trois mille articles. Et quelques renoncements, renoncement à publier dans des revues scientifiques (depuis déjà presque 10 ans), renoncement à trouver un laboratoire de recherche ailleurs qu’à quatre heures de route ou de train parce que Nantes Université a décidé (il y a déjà 10 ans) que les sciences de l’information et de la communication ne faisaient pas partie de sa « stratégie », et a laissé cela aux écoles privées qui s’en sont repues. Alors faire autrement, mais ne jamais cesser de faire. Et de la place qui est la mienne, dire, c’est faire. Alors dire.
Vingt ans et trois mille articles. Et l’octroi d’un ISSN qui est une petite fierté mal placée et essentiellement imbécile mais une petite fierté tout de même.
Vingt ans et trois mille articles. Avec très vite un éloignement des formes éditoriales historiques du « blogging », c’est à dire de simples et cours signalements de ressources vues ailleurs pour aller vers des formats plus longs. Souvent très très longs. Très.
Vingt ans et trois mille articles. Avec essentiellement des analyses, souvent denses et longues, et avec toujours le souci de d’abord organiser moi-même mon champ, mon horizon, mes lectures, ma veille, mes questionnements, et mon terrain de recherches. Et la surprise constante et renouvelée de voir l’intérêt suscité chez d’autres, universitaires, journalistes, ou d’autres rien de tout cela, d’autres, tout simplement. Avoir acquis en 20 ans et trois mille articles la certitude (et les preuves) que les textes, que mes textes, circulent et se sédimentent aussi ailleurs que sur ce blog.
Vingt ans et trois mille articles. Avec aussi des coups de gueule et des gros mots. De la colère et de l’indignation. Du trop plein. Souvent les articles les plus lus, les plus vus, les plus commentés, les plus repris mais qui représentent si peu sur les trois mille publiés, peut-être à peine une petite cinquantaine, et encore.
Vingt ans et trois mille articles. Et 5 ou 6 ministres d’état insulté.e.s mais qui, entre nous soit dit, le méritaient bien
Capture d’écran, autour de Novembre 2008 (via archive.org). Déjà énervé
Vingt ans et trois mille articles. À construire « quelque chose ». Je confesse vingt ans après ne toujours pas savoir quoi précisément, pas vraiment une « oeuvre », pas vraiment une « présence », mais quelque chose entre les deux, en tout cas un lieu, une (safe) place, une adresse. Le vieux rêve du web.
Vingt ans et trois mille articles. Depuis l’origine sous licence Creative Commons et dont vous pouvez donc faire ce que vous voulez tant que vous me mentionnez comme auteur et n’en faites pas d’usage commercial.
Vingt ans et trois mille articles. Et au moins 4 époques du numérique traversées. Première époque. Celle où tenir un blog en étant universitaire vous ramenait mépris et quolibets. Celle où des mandarins (et pas mal de mandarines aussi) vous expliquaient que prendre ainsi la parole en ligne c’était … un suicide scientifique et d’une absence totale d’intérêt (si si je l’ai entendu j’vous jure). Deuxième époque. Celle des egotrips et classements Technorati ou Wikio des meilleurs blogueurs influents (où je figurais souvent dans un improbable top 50), de Loïc Le Meur en figure totémique de la caricature de l’entrepreneur numérique, et des invitations (que je refusais) dans divers cénacles ministériels et élyséens. C’était une époque épique (et nous n’avions déjà plus rien d’épique). Troisième époque. Celle de la normalisation, des communautés, des liens, des fils RSS et des agrégateurs, des « trackbacks », d’un écosystème vivant d’échanges du tout début et des premiers temps des réseaux sociaux avant qu’ils ne deviennent entièrement des « médias sociaux » et que tout cela ne se reconfigure entièrement. Quatrième époque. Celle aujourd’hui où si peu « tiennent » encore des blogs mais où tant d’autres vont vivre la connaissance en ligne et rendent possible son partage, sur Youtube, Instagram, Twitch, en podcast et partout finalement, dans des formes renouvelées, fécondes, stimulantes mais en lutte et en résistance contre l’écrasement de l’invisibilité et de la difficulté à donner à cela toute sa place.
Vingt ans et trois mille articles. And counting. Et des visites, et des pages « lues ». Ou en tout cas « vues ». Et 1 million (de pages vues, circa 2012). Et 2 millions (circa 2016). Et 3 millions (circa 2021). Et après j’ai arrêté de compter.
Vingt ans et trois mille articles. Cela fait 150 articles par an en moyenne. Presque un tous les trois jours. Une bonne douzaine par mois. Un vrai mi-temps en plus de tous les autres.
Vingt ans et trois mille articles. Et un déménagement. Un seul. Le nom de domaine reste le même (affordance.info) mais en Septembre 2022, changement de plateforme, et passage d’un croulant et en déshérance Typepad à un flambant WordPress porté et supporté par les copains et copines de l’indispensable association Framasoft. Merci à elles et eux.
Vingt ans et trois mille articles. Et puis surtout des rencontres, des échanges, numériques et à distance essentiellement mais tellement féconds, tellement inattendus (pour moi en tout cas). J’ai pu grâce à ce travail croiser, échanger, cheminer avant tant de gens précieux que jamais je n’aurais imaginé croiser et dont, surtout, jamais je n’aurais cru ou pu imaginer qu’ils puissent s’intéresser et apprécier ce que j’écrivais. Je ne vais pas vous les nommer toutes et tous mais hommage aux morts, et aux premiers et premières qui furent de ces rencontres, alors je pense souvent encore à Jean Véronis et à Louise Merzeau.
Vingt ans et trois mille articles. Et des cycles. L’impression de revivre des histoires déjà chroniquées, étudiées, racontées. Depuis plus de 20 ans que j’écris sur le numérique et ses enjeux, j’observe de plus en plus de récurrences. Par exemple les débats qui reviennent tous les 5 ans sur « faut-il interdire » (wikipédia, les réseaux sociaux, les écrans, l’IA …). Par exemple sur le rapport entrer le code et la loi (et comment on légifère ou pas à l’échelle internationale). Par exemple sur la question de l’anonymat en ligne. Par exemple sur le très à la mode techno-fascisme (en 2018 je décrivais un système de néo-fascisme documentaire). Par exemple sur la question, j’ai même envie de dire sur … « LA » question de la responsabilité algorithmique et l’éditorialisation (rappel : ce n’est jamais la faute des algorithmes pour la simple et bonne raison que les algorithmes sont toujours la décision de quelqu’un d’autre). Par exemple sur tout ce qui se passe aujourd’hui autour des sociétés et outils d’IA qui se nourrissent en prédation d’immenses corpus de textes sans jamais se soucier du droit d’auteur et de ce que ça change et va changer à l’échelle des industries culturelles : figurez-vous que c’est presqu’exactement la même chose que ce qui s’est passé il y a 20 ans avec l’arrivée de la numérisation des livres et le positionnement de Google sur ce marché ; bon là pour le coup l’histoire se répète d’une manière tellement troublante que je vais publier bientôt un article sur ce sujet
Vingt ans et trois mille articles. C’est aussi un fichier texte (xml en fait) qui contient tout cela, et qui pèse son poids, un peu plus de 37 Mégas. Et qui est l’équivalent d’un livre de 13 047 pages. En 20 ans. Presque deux pages par jour. C’est beaucoup et si peu à la fois.
Vingt ans et trois mille articles. Une histoire commencée par ici : année 1, article 1.
Merci à toutes et tous pour l’intérêt porté. Merci surtout de vos lectures et de vos partages.
- Persos A à L
- Carmine
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- Lionel DRICOT (PLOUM)
- EDUC.POP.FR
- Marc ENDEWELD
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Christophe LEBOUCHER
- Michel LEPESANT
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Jean-Luc MÉLENCHON
- MONDE DIPLO (Blogs persos)
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Thomas PIKETTY
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- LePartisan.info
- Numérique
- Blog Binaire
- Christophe DESCHAMPS
- Dans les Algorithmes
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Fake Tech (C. LEBOUCHER)
- Romain LECLAIRE
- Tristan NITOT
- Francis PISANI
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Blogs Mediapart
- Bondy Blog
- Dérivation
- Économistes Atterrés
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- Rojava Info
- X-Alternative
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- Laura VAZQUEZ
- XKCD