01.06.2026 à 02:00
Qucocoma Philippe Samyn ?
Ploum
Texte intégral (806 mots)
Qucocoma Philippe Samyn ?
J’apprends avec tristesse le décès de l’architecte Philippe Samyn, un esprit incroyable aux idées fulgurantes avec qui j’ai eu de longues et passionnantes discussions.
Car l’architecture était pour lui une porte d’entrée vers une compréhension plus globale du monde. Comme lorsqu’il m’a asséné :
— Le monde entier ne tourne qu’autour d’une seule et unique unité, qui est le cœur de tout.
— Euh, le dollar ?
— Tu me déçois Lionel ! C’est le joule bien entendu. Tout tourne autour du joule. Produire, stocker, échanger des joules. La monnaie internationale devrait être le joule ! Les puissants sont ceux qui exploitent la différence entre le dollar et le joule, les faibles ceux qui fournissent des joules pour rien ou si peu.
Ou cette discussion qui me revient régulièrement où il m’exposa que l’architecte devait construire des « ruines utiles ». Car un bâtiment ne va être utilisé que 50, 100 ou 300 ans. Mais ses ruines durent parfois 10 ou 100 fois plus longtemps. Certaines ruines dureront autant que la planète ! L’essentiel de la vie d’un bâtiment se fait à l’état de ruine et il faut le prévoir dès la conception.
Avant de le rencontrer, je n’avais jamais envisagé les choses sous cet angle. Ce qui m’a frappé en généralisant son discours, c’est à quel point le fait de tenter d’oublier l’étape des ruines est la maladie qui pourrit l’humanité tout entière à tous les niveaux.
Nous produisons, nous tentons de produire plus et plus rapidement sans jamais nous préoccuper de ce que nous allons faire de toute cette production. Nous en sommes au point d’automatiser la production d’images, d’écrits et de code informatique avec les chatbots sans nous poser la question des ruines que nous préparons.
Depuis plusieurs années, chaque fois que j’ai envie de me procurer un bien matériel, je me pose consciemment deux questions : « Où vais-je le ranger ? » et « Comment vais-je m’en débarrasser ? ». Penser consciemment à cette question au moment de l’achat rend l’achat en lui-même extrêmement anxiogène. Philippe Samyn avait lui poussé cette réflexion jusque dans la conception des bâtiments.
Mais l’ingénieur architecte était également un artiste attaché à son œuvre. Lorsque mon épouse et moi avons un jour critiqué « son » Aula Magna, bâtiment emblématique de Louvain-La-Neuve coincé entre un cinéma et un hôtel, il nous a déroulé, des larmes pleins les yeux, le plan de Louvain-la-Neuve tel qu’il l’avait imaginé et comment l’Aula Magna aurait du s’intégrer dans une superbe perspective bien plus vaste et cohérente. Une boule de colère et de tristesse dans la gorge, il nous a expliqué comment son projet avait été complètement dénaturé en n’en prenant qu’une partie et en l’encadrant d’autres immeubles qu’il trouvait hideux.
Philippe Samyn m’avait fait l’honneur de me compter parmi les bêta-lecteurs de l’œuvre de sa vie : un ouvrage exhaustif sur l’architecture et la société humaine, projet qu’il avait intitulé: « Qucocoma, Quoi Comment Construire Maintenant ».
Je lui avais prédit que cette œuvre risquait de ne jamais être achevée tant elle était ambitieuse, qu’il fallait absolument la publier par petite partie sous peine de laisser cette tâche à ses héritiers.
Je ne pensais pas avoir raison si tôt…
Philippe Samyn s’est éteint, mais le territoire reste à jamais marqué par ses idées.
À propos de l’auteur :
Je suis Ploum et je viens de publier Bikepunk, une fable écolo-cycliste entièrement tapée sur une machine à écrire mécanique. Pour me soutenir, achetez mes livres (si possible chez votre libraire) !
Recevez directement par mail mes écrits en français et en anglais. Votre adresse ne sera jamais partagée. Vous pouvez également utiliser mon flux RSS francophone ou le flux RSS complet.
10.04.2026 à 02:00
Ne rien avoir à penser
Ploum
Texte intégral (2238 mots)
Ne rien avoir à penser
Après le « Je n’ai rien à cacher », voici venu l’ère du « Je n’ai rien à penser »
Se faire prendre pour des crétins parce que ça fonctionne
Google l’annonce : il y a plus de personnes dans le monde avec un smartphone Android que de personnes qui ont accès à de l’eau propre et des égouts.
Cela implique, toujours selon Google, qu’il faut plus d’IA pour ces personnes.
Non, sérieusement, je ne déconne pas. C’est vraiment ce que les gens de Google vont raconter dans les universités dans des événements qui ressemblent un peu à ce que des vendeurs de cigarettes pourraient organiser dans des clubs de sport pour former la jeunesse à fumer en offrant un an de cigarettes gratuites.
Et ils enfoncent le clou: de toute façon, personne n’a le choix d’utiliser l’IA ou non. C’est comme ça. Exactement ce que disait Anthropic: « Que vous le vouliez ou non, préparez-vous pour ce monde stupide ! »
Mon exemple du vendeur de cigarettes semble exagéré, mais je viens d’être témoin, dans ma ville universitaire de Louvain-La-Neuve, d’une compétition qui consistait à faire le tour du lac en courant tout en buvant quatre bières de 33cl. La course était sponsorisée par… une marque de bière, bien entendu. L’université semble avoir donné sa bénédiction pour cet événement et beaucoup d’étudiants sont assez naïfs pour trouver ça cool…
Je suis moi-même un grand naïf. Je croyais que les personnes étaient majoritairement moralement « bonnes ». Elles produisent souvent un impact négatif lorsqu’elles travaillent à maximiser le profit d’une entreprise. C’est juste qu’elles ne s’en rendent pas compte.
Mais c’est faux. Nous savons aujourd’hui que des personnes comme Mark Zuckerberg sont tout simplement moralement inhumaines et que toutes les personnes impliquées savent très bien ce qu’elles font et pourquoi elles le font. Les produits Meta sont spécifiquement modifiés pour rendre les adolescents les plus addicts possibles, pour les perturber durant leur scolarité. Ce n’est pas une conséquence, c’est le but premier du produit. La distraction incessante n’est pas un effet insoupçonné, c’est littéralement ce que cherchent à faire les ingénieurs de Facebook.
Et dire que la plupart des profs sont en mode : « Il faut vivre avec, il faut apprendre à utiliser raisonnablement ».
Non. C’est faux et c’est complètement stupide. C’est comme donner aux adolescents des formations, sponsorisées par Philip Morris, où ils apprendraient à fumer « sans inhaler la fumée ». Ou leur dire que c’est cool de courir en buvant plus de bières que ton estomac ne peut en supporter.
La vérité c’est que la plupart des profs sont complètement addicts à leur smartphone et que c’est plus rassurant d’enseigner son addiction comme un truc positif que de se remettre en question.
La pub nous prend pour des crétins. Elle prend les politiciens pour des crétins. Et, expérimentalement parlant, elle a bien raison. Nous le sommes ! Ça fonctionne encore mieux que prévu parce que, du coup, nous allons leur donner raison et soutenir ceux qui se foutent de notre gueule !
Regardez le RGPD et les bannières de cookies qui ennuient tout le monde et pour lesquelles on accuse « l’Europe ».
Contrairement à une idée reçue, les ennuyeuses bannières de cookies sur les sites ne sont pas la faute du RGPD. D’ailleurs, dans l’immense majorité des cas, ces bannières sont illégales. Gee l’explique très bien en BD :
Mais il y a pire : si ces bannières sont ennuyeuses, c’est parce qu’elles ont été explicitement conçues pour ça. Et oui, pour faire baisser le degré d’adhésion du peuple envers le RGPD. C’est une pure manipulation politique volontaire et consciente de l’industrie publicitaire. Ils savent très bien ce qu’ils font : nous pourrir la vie pour décrédibiliser les institutions politiques afin de nous fourguer plus de pub.
La fin de l’intellectualisme
Un article important sur le retour à l’oralité et le déclin de la lecture. L’oralité, c’est l’émotion au lieu de l’information, c’est le charisme au lieu de la vérité, c’est la manipulation au lieu de la rationalité. C’est également la disparition de l’effort sur le long terme.
Cela semble alarmiste, mais, factuellement, lorsque les chercheurs scientifiques, censés représenter l’élite intellectuelle du monde, en sont réduits à générer des articles qui citent des articles qui n’existent pas, cela pose quand même des questions.
Oui, c’est la fin du monde, la fin d’un monde !
Mais ChatGPT n’est que la cerise sur le gâteau. La raison réelle, c’est que nous dévalorisons l’intellectualité depuis des décennies. Nous valorisons le CEO qui prend des décisions aléatoires en 5 minutes. Nous demandons à tout le monde de creuser des trous et de les reboucher pour « faire tourner l’économie ». Nous vivons dans un monde où Julius grimpe les échelons !
Bref, nous ne faisons que mener le monde vers sa destination la plus logique en regard des indicateurs que nous utilisons pour l’optimiser. C’est tout à fait normal. C’est tout à fait attendu. On ne réduira jamais les émissions de CO₂ tant qu’on tentera de maximiser le PIB d’un pays. Faire tourner l’économie implique de maximiser le travail et donc de consommer le plus de joules possible. Joules qu’il faut produire en émettant du CO₂. Les énergies dites « renouvelables » ne sont qu’une manière d’émettre « moins de CO₂ par joule ». Ce qui est une bonne chose en soi, mais ne résout pas le problème de base que nous cherchons justement à consommer le plus de joules possible. Le résultat du succès des énergies renouvelables est d’ailleurs évident : nous consommons plus de joules, tout simplement.
Nous sommes en train de connaître la fin de l’intellectualité comme nous avons traversé la fin de la vie privée. Non, ce n’est pas réellement la fin. C’est juste que l’intellectualité, tout comme la vie privée avant elle, a perdu son statut de valeur fondamentale pour devenir un truc underground, uniquement valorisée par quelques cercles de plus en plus considérés comme marginaux, y compris, surtout, au sein des plus prestigieuses institutions académiques.
« Je n’ai rien à cacher » s’est subtilement transformé en « Je n’ai rien à penser ».
Depuis les smartphones à ChatGPT en passant par les séries en streaming, les géants technologiques se sont ligués pour nous convaincre de ne plus penser, que penser est has been, que c’est fatigant, que ça ne sert à rien. Nul besoin d’avoir un doctorat en sciences politiques pour comprendre que ça arrange beaucoup de monde.
Ma défense : l’effet bibliothèque
Les chatbots ne font, au fond, qu’augmenter la disponibilité de l’information, y compris fausse. Cette disponibilité réduit l’engagement cognitif et donc le développement du cerveau. Cet effet était déjà visible et étudié en 2011 comme "l’effet Google". Si nous savons qu’une information est disponible en ligne, nous ne tentons plus de nous la rappeler, nous la cherchons (combien de fois avez-vous pris votre téléphone parce que vous ne vous souveniez plus du nom d’un acteur dans un film?)
Ce qui est amusant à constater c’est que, bien avant d’avoir lu ces études, j’ai instinctivement adopté la posture inverse depuis quelques années. Je me refuse de chercher immédiatement une info. Ma motivation était de ne pas interrompre une conversation en cours (je dissuade d’ailleurs mon interlocuteur de sortir son téléphone) ou ne pas interrompre mon travail en cours (je me connais, je sais que si je cherche l’info, je suis 30 minutes plus tard en train de lire la page Wikipédia consacrée à la biographie d’Henri IV ou à une espèce rare de méduse en Nouvelle-Calédonie).
On pourrait arguer qu’il en est de même avec une bibliothèque. Mais je vois des différences fondamentales.
Premièrement, il y a la composante physique : lorsque je cherche une information dans un livre, je me déplace, je cherche dans un rayon. Mon cerveau associe le mouvement avec la mémorisation. Ma bibliothèque a beau être fluide et mouvante, elle garde une structure. Avec le temps, se souvenir d’une information revient à se souvenir du déplacement à effectuer pour aller chercher le livre.
En second lieu, les informations dans les livres sont stables et figées. Elles peuvent être fausses, mais je sais qu’elles ne sont pas générées pour améliorer le SEO du livre ou obtenir des likes. Elles ne se transforment pas subitement en erreur 404.
Cette stabilité rassure mon cerveau. Celui-ci n’est pas dans la "perception", la tentative de comprendre un environnement changeant, ce qui est source de stress. Il est au contraire dans le familier et peut se permettre d’extrapoler, d’imaginer, de faire des liens imprévus.
Bref, je donne à mon cerveau la possibilité d’être créatif, je lui offre un espace stable où il peut expérimenter la mouvance et le changement dans ce qu’il crée : les mots, les histoires. Ce n’est pas un hasard si je n’écris que sur une machine à écrire ou depuis mon terminal dans un éditeur qui change très peu depuis 40 ans (Vim). Je veux libérer de l’espace mental pour créer et réfléchir.
Si vous avez déjà été dans une bibliothèque juste pour être au calme et réfléchir, vous voyez très bien ce que je veux dire.
Bref, je suis un technopunk ringard… Mais ça, vous le saviez déjà !
.jpg){kind=link}
À propos de l’auteur :
Je suis Ploum et je viens de publier Bikepunk, une fable écolo-cycliste entièrement tapée sur une machine à écrire mécanique. Pour me soutenir, achetez mes livres (si possible chez votre libraire) !
Recevez directement par mail mes écrits en français et en anglais. Votre adresse ne sera jamais partagée. Vous pouvez également utiliser mon flux RSS francophone ou le flux RSS complet.
03.04.2026 à 02:00
La première Madame Pipi de l’espace profond
Ploum
Texte intégral (892 mots)
La première Madame Pipi de l’espace profond
Outre la première victoire au Tour de France d’Eddy Merckx, 1969 fut une année qui marqua trois événements très importants.
1. Le premier homme sur la Lune
2. L’invention du système UNIX
3. La naissance de Linus Torvalds.
Deux de ces événements ont encore aujourd’hui un impact quotidien dans votre vie.
Adolescent, j’étais fasciné par les vidéos de Neil Armstrong descendant l’échelle du module lunaire et faisant quelques pas. Je tentais d’imaginer ce que j’aurais ressenti si j’avais vécu cet instant. J’espérais d’ailleurs aller un jour moi-même dans l’espace.
Il y a 20 ans, je suivais en quasi direct la découverte de Titan par la sonde Huygens.
Aujourd’hui, pour la première fois depuis 1972, quatre humains ont quitté l’orbite basse terrestre et sont en route vers la Lune. Cela devrait être un truc incroyablement excitant. Mais comme le dit très bien Kevin Boone, tout le monde semble s’en foutre.
Kevin donne plusieurs explications : la catastrophe climatique et les guerres nous rendent beaucoup moins enthousiastes envers la technologie. Mais, surtout, notre attention est trop fragmentée pour nous rendre compte de l’exploit, pour nous y intéresser.
Among the many crimes that can be attributed to Google and the other tech giants, perhaps the worst is that they've created a world in which a Moon landing is unexciting.
Il n’empêche que quatre humains vont tourner autour de la Lune pour la première fois de mon vivant. Trois hommes et une femme, Christina Koch, qui est donc d’ores et déjà la femme la plus éloignée de la Terre de l’histoire de l’humanité.
Et devinez quel est le rôle de Christina à bord du vaisseau sachant qu’elle est l’astronaute la plus expérimentée des quatre ?
Je vous le donne en mille !
Elle est responsable des toilettes !
Je n’invente rien, je l’ai lu sur Wikipédia dans la section « Spécialiste de Mission 1 ».
Christina Koch est donc la première Madame Pipi de l’espace profond !
Ça semble terriblement sexiste, mais, en réalité, les toilettes sont réellement critiques dans l’espace. Les astronautes des missions Apollo déféquaient dans des sacs en plastique à l’étanchéité douteuse et les étrons flottants n’étaient pas rares. Il me semble avoir lu qu’un cas de diarrhée faillit causer l’annulation d’une des missions, car il y en avait partout.
Dans « Stagiaire au spatioport Omega 3000 », j’ironisais sur le fait que les femmes astronautes n’étaient pas prêtes à laisser la responsabilité d’être Madame Pipi à un homme.
À voir si, comme mon héros Nathan Pasavan, Chrisina Koch recevra à l’atterrissage l’emblématique cache-poussière rose et l’assiette à piécette, insigne historique de cette fonction honorifique…
Bref, pendant qu’ils tournent là-haut, je vous invite à (re)lire cette nouvelle et toutes les autres qui peuplent le recueil, dont « Les filons chocolatifères de la Lune », qui se passe également sur notre satellite.
- Présentation de Stagiaire au spatioport Omega 3000 (ploum.net)
- Commander Stagiaire au spatioport Omega 3000 (pvh-editions.com)
À propos de l’auteur :
Je suis Ploum et je viens de publier Bikepunk, une fable écolo-cycliste entièrement tapée sur une machine à écrire mécanique. Pour me soutenir, achetez mes livres (si possible chez votre libraire) !
Recevez directement par mail mes écrits en français et en anglais. Votre adresse ne sera jamais partagée. Vous pouvez également utiliser mon flux RSS francophone ou le flux RSS complet.
26.03.2026 à 01:00
Le logiciel, un nouveau pétrole ?
Ploum
Lire la suite (301 mots)
Le logiciel, un nouveau pétrole ?
Extrait de mon journal du 24 septembre 2025
Nous sommes fiers de nous passer de pétrole grâce à des panneaux solaires contrôlés par des logiciels… appartenant aux producteurs de pétrole !
On a parfois dit que le logiciel était « le nouveau pétrole ». C’est faux. La seule chose qui compte, c’est de contrôler, d’étrangler le monde en ne le laissant survivre qu’avec un fin filet d’air. Le pétrole était une ressource qui a été utilisée pour établir une dépendance. Le logiciel, lui, se passe de cet intermédiaire lorsqu’il est propriétaire.
Le logiciel propriétaire est le contrôle total par essence ! Il est cette chaîne magique que l’esclave ne peut jamais briser. Il n’est pas le pétrole, il est le besoin de pétrole !
À propos de l’auteur :
Je suis Ploum et je viens de publier Bikepunk, une fable écolo-cycliste entièrement tapée sur une machine à écrire mécanique. Pour me soutenir, achetez mes livres (si possible chez votre libraire) !
Recevez directement par mail mes écrits en français et en anglais. Votre adresse ne sera jamais partagée. Vous pouvez également utiliser mon flux RSS francophone ou le flux RSS complet.
23.03.2026 à 01:00
Scène de salle d’attente
Ploum
Lire la suite (354 mots)
Scène de salle d’attente
Extrait de mon journal du 6 mars, dans la salle d’attente du docteur X.
Le couple entre, asphyxiant l’air de l’étroite salle d’attente avec leurs remugles de fumée de cigarette. Les deux s’asseyent à l’aveugle sans jamais quitter leur smartphone des yeux, sans que les pouces ne cessent de s’agiter.
Après quelques instants, elle tente de le regarder, elle lui sourit, elle lui adresse plusieurs fois la parole. Lui ne se retourne même pas, n’interrompt pas une fraction de seconde la sarabande de ses pouces.
Alors elle replonge sur son écran, le manipule, le triture avant de tendre le bras pour le mettre sous le nez de son homme.
Lui, forcé de s’interrompre, recule légèrement la nuque, regarde l’écran de sa compagne puis tourne enfin la tête pour la regarder elle. Il n’a pas un sourire, pas un seul trait de son visage renfrogné ne tressaille. Mais elle a pu établir un contact visuel, elle est satisfaite, elle sourit.
Ils replongent alors tous deux dans leur petit univers distinct, comme s’ils étaient deux étrangers.
À propos de l’auteur :
Je suis Ploum et je viens de publier Bikepunk, une fable écolo-cycliste entièrement tapée sur une machine à écrire mécanique. Pour me soutenir, achetez mes livres (si possible chez votre libraire) !
Recevez directement par mail mes écrits en français et en anglais. Votre adresse ne sera jamais partagée. Vous pouvez également utiliser mon flux RSS francophone ou le flux RSS complet.
20.03.2026 à 01:00
The Social Smolnet
Ploum
Texte intégral (969 mots)
The Social Smolnet
It might have been an email thread. Or a lobste.rs comment. It was a discussion about yet another attempt at a new decentralized social protocol. And we reached the conclusion that with blogs and email, we already had a decentralized social network. We only needed to use it.
This was the last push I needed to implement in Offpunk the social features I had imagined years ago. Share and Reply. Available since Offpunk 3.0.
Share
Are you reading something interesting in Offpunk and want to share it? Well, simply write it:
share
or
share myfriend@example.com
A new mail containing the URL to share will be opened in your email client of choice (as determined by xdg-open). The title will be the title of the page. You only need to add some text to explain why you want to share that page.
Reply
Ever read a blog post and wanted to send feedback or a simple thank you to the author? Simply write:
reply
Reply will try to find a mailto link by exploring the page, root pages and, since 3.1, potential "contact" pages. It sometimes works really well. Often, the mail address is obscured or hidden. That’s not a problem. You only need to find it once because Offpunk allows you to save it for the page or the whole online space.
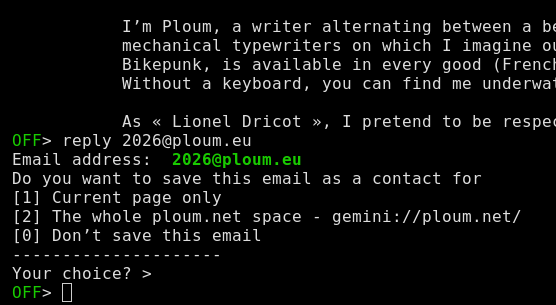
If you come across an email address that may be of use in the future but don’t want to react now, use "save":
reply save author@example.com
or, if you want to use autodetection:
reply save
Yes, it is enough
It looks like nothing. It looks like trivial. But for me, this really transformed Gemini/Gopher and the Small Web into a social network. As I use neomutt+neovim as my mail client, I don’t leave my terminal. I simply write "reply", neovim opens, I write "Thank you for this nice post", :wq, ,and voilà. The mail will be sent during my next synchronization.
Almost as easy as clicking a "like" button but way more personal. Even easier if, like me, you dislike touching a mouse or opening a browser!
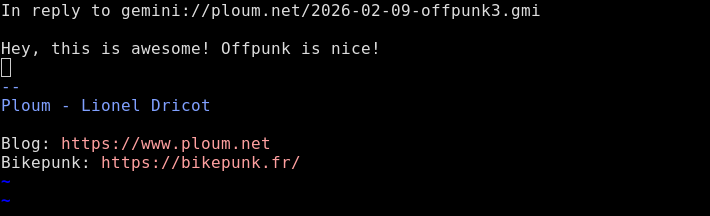
This is the Social SmolNet
In less than two months, I already used this feature to react to 40 different online spaces, not counting that I’ve used it multiple times with some people.

I even started using Offpunk as an address book for my blogger friends. Instead of laboriously autocompleting their email addresses, I go to their blog/gemini capsule/gopher hole and write "reply".
The biggest lesson I take is that "social networks" are not about protocols but about how we use the existing infrastructure. Microsoft and Google are working hard to make sure you hate email and hate building a website. But we don’t have to obey. We can enjoy writing lightweight HTML and sending quick emails to each other. We have the right to read, write, and have social fun without Javascript and centralized platforms. We have the duty to keep this torch lit.
In the meantime, if you receive from me very short emails reacting to some of your posts, now you know why.
But, of course, feel free not to reply!
About the author
I’m Ploum, a writer and an engineer. I like to explore how technology impacts society. You can subscribe by email or by rss. I value privacy and never share your adress.
I write science-fiction novels in French. For Bikepunk, my new post-apocalyptic-cyclist book, my publisher is looking for contacts in other countries to distribute it in languages other than French. If you can help, contact me!
- Persos A à L
- Carmine
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- Lionel DRICOT (PLOUM)
- EDUC.POP.FR
- Marc ENDEWELD
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Christophe LEBOUCHER
- Michel LEPESANT
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Jean-Luc MÉLENCHON
- MONDE DIPLO (Blogs persos)
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Thomas PIKETTY
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- LePartisan.info
- Numérique
- Thomas BEAUFILS
- Blog Binaire
- Christophe DESCHAMPS
- Dans les Algorithmes
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Fake Tech (C. LEBOUCHER)
- Romain LECLAIRE
- Tristan NITOT
- Francis PISANI
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Blogs Mediapart
- Bondy Blog
- Dérivation
- Économistes Atterrés
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- Rojava Info
- X-Alternative
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- Laura VAZQUEZ
- XKCD