PIXEL DE TRACKING
Ancien de l'AdTech, passionné des médias et des nouvelles technologies, mais inquiet de l'extension du domaine de la surveillance, j'ai décidé d'ouvrir ce blog pour partager mes notes.
06.08.2023 à 22:57
Surveillance publicitaire : le meilleur de mes Tweets

Dissonance cognitive
Mieux qu'un Feedly, Twitter m'aura permis de connaître des gens passionnants, experts dans leur domaine, ayant un point de vue décalé ou incisif sur l'actualité. Il aura également été un excellent relais pour mes écrits sur l'adtech et le capitalisme de surveillance. Mais ses dérives, de plus en plus criantes depuis son rachat par Elon Musk, auront eu raison de moi.
2 articles résument très bien mon sentiment sur ce réseau social :
- "On Twitter, we look down", où l'auteur détaille sa schizophrénie concernant Twitter, pourquoi il est toujours dessus.
- "How to Blow Up a Timeline", où l'auteur raconte à quel point la magie du Twitter d'hier était exceptionnelle et fragile.
La goutte d'eau ayant déclenché la fermeture de mon compte ? Le renommage de Twitter en X, un détail dans le projet de vandalisme culturel d'Elon Musk. Vous pourrez maintenant me retrouver sur Mastodon, un réseau social fédéré, qui n'appartient à personne et ne peut donc pas être contrôlé par un milliardaire mégalomane fachiste.
Ayant beaucoup publié sur Twitter, parfois sur des sujets qui auraient mérité que j'écrive un article, je souhaitais néanmoins pouvoir republier mes tweets ailleurs. J'ai donc suivi ces 2 étapes :
- Le téléchargement de mes archives via le site Twitter.
- L'installation de tweetback (merci @aeris) sur mon blog, aidé par cet article.
Mes tweets sont donc disponibles ici, avec un moteur de recherche pour trouver des tweets sur une thématique précise, et ce billet pour référencer les tweets que je souhaite retrouver facilement.
À tout seigneur tout honneur, démarrons cette collection de tweets par le créateur du capitalisme de surveillance.
Le parrain de l'adtech
J'avais déjà écrit un article sur "la domination de Google sur les marché publicitaires", le caractère monopolistique de la brique adtech de Google et la surveillance publicitaire sont étroitement liés :
- Avec la Privacy Sandbox, Google ne permettra plus que vous soyez surveillé via un identifiant utilisateur ? Pas vraiment...
- Sur la possibilité d'utiliser des identifiants utilisateurs sur la stack adtech de Google, après disparition des cookies tiers de Chrome.
- Toujours le double-discours de Google sur les identifiants utilisateurs.
- À la différence d'iOS, il est encore très difficile de refuser le tracking publicitaire sur Android.
- La commission européenne dans son enquête sur l'adtech de Google met en balance vie privée et compétition, une mauvaise approche.
- L'Ad-Exchange Google, où le paradis des fraudeurs.
Google Chrome, agent des publicitaires
Les navigateurs sont généralement nommés "User Agents", ce n'est pas le cas de Chrome, le navigateur dominant de Google :
- Un guide sur la "confidentialité" dans Chrome.
- L'onboarding de Google Chrome, un cas d'école pour les #DarkPatterns.
- "First-Party Set", un dispositif de la Privacy Sandbox visant à continuer le tracking au sein des sites Google (YouTube, Maps...).
- "First-Party Set", un nouveau vecteur de tracking maintenant dans Chrome.
- Privacy Sandbox, ePrivacy s'applique (CNIL) et le consentement est donc obligatoire.
Vous pourrez approfondir le sujet Chrome avec 2 de mes articles :
- "L'entête HTTP problématique envoyé par Chrome à Google."
- "Fin des cookies tiers sur Chrome et Privacy Sandbox : une protection de la vie privée en trompe-l'oeil."
Google Analytics, le cheval de Troie publicitaire
En configuration minimum, Google Analytics devrait fonctionner sans surveillance publicitaire, mais ce n'est pas si simple :
- La création de compte Google, où l'art du #DarkPattern pour mieux vous surveiller.
- Le #PrivacyWashing de Google Analytics.
- Sur l'illégalité de Google Analytics, un debunk de l'article de @Devergranne.
- Un long thread sur l'illégalité de Google Analytics, suite aux décisions des CNILs autrichiennes puis françaises.
- Auchan utilise-t-il encore Google Analytics ? Il est permis d'en douter.
- La liste des plaintes de @NOYBeu à la CNIL, pour transfert de données personnelles vers les US (Google & Facebook).
Autres outils Google
L'adtech de Google, Chrome ou Google Analytics sont loin d'être les seules outils dédiés à mieux vous surveiller :
- Utilisation du Server-Side Tagging de Google Tag Manager.
- Google Fonts, un cheval de Troie pour vous surveiller ?
- Vos conversations avec Google Bard sont relues par des humains.
Approfondissez le sujet via la lecture de mon article "Google Tag Manager, la nouvelle arme anti adblock".
Alias Meta, le pire du capitalisme de surveillance, une source d'inspiration pour Google et pour toute l'adtech.
Une captation de données sans limites
Dans mon article "Avec les "signaux résilients" de Facebook, la surveillance publicitaire évolue", j'avais détaillé comment Facebook contournait les protections contre le tracking des navigateurs. Comme avec Google, abus de position dominante et violation de votre vie privée vont de pair, comme je l'avais d'ailleurs écrit dans l'article "Facebook et WhatsApp, où l'art de vous trahir". Facebook met tout en place pour capter toujours plus de données utilisateurs :
- Comment Facebook s'adapte aux protections navigateurs et autres adblockers.
- Les outils publicitaires de Facebook font du fingerprinting sur des applis tierces, exemple avec Duolingo.
- En particulier, Facebook récupère les données de l'accéléromètre de votre téléphone.
- Le partage de données entre WhatsApp et Facebook/Meta.
- La modération sur WhatsApp, vos messages ne sont pas toujours privés.
Des partenariats avec la terre entière
2 exemples intéressants, mais Facebook a interfacé son écosystème publicitaire avec tous les outils qui comptent :
- Un partenariat avec Criteo sur Facebook et Instagram.
- Shopify se lance dans la publicité ciblée (sur Facebook...), avec les données de ses clients.
Violer la loi, une spécialité
Facebook se moque des réglementations et de la CNIL :
- Bannières cookies (ePrivacy), Facebook se moque toujours de vous (et de la CNIL).
- Le parcours de la mort pour vous opposer à la publicité ciblée sur Facebook/Instagram.
- Sur WhatsApp, le parcours promet d'être aussi difficile.
- Le #PrivacyWashing de Facebook (et Google).
La surveillance des plateformes, via les "Pixels" & "Conversion APIs"
Pour contourner vos adblockers et autres protections navigateurs, Facebook a créé son "Pixel" et sa "Conversion API" (CAPI), il a inspiré les autres plateformes :
- Facebook.
- Google.
- TikTok.
- Snapchat.
- Pinterest.
- Un exemple de fuite sur Greenpeace.
- Un autre exemple avec Amnesty International.
- Un thread d'exemples de fuites.
- Une étude montrant l'ampleur de ces fuites.
- Lockr, un service pour cacher son e-mail... et continuer la surveillance publicitaire.
Je parle également de ces fuites de données dans l'article "Guerlain (LVMH) : luxe et surveillance".
Apple
Comme l'indique mon article "Apple vous protège-t-il vraiment de la surveillance publicitaire ?", Apple n'est pas parfait côté vie privée, mais c'est généralement un allié face à la surveillance de Google, de Facebook et de l'adtech.
Une définition particulière du "tracking"
Apple a mis en place des mécanismes assez efficaces pour vous protéger de la surveillance publicitaire, qui n'affectent pas son propre business, ce qui a le don d'énerver l'adtech :
- La désinformation de l'industrie publicitaire sur Apple.
- Sur le "tracking" d'Apple.
- Les arguments d'Apple concernant son "tracking" vs le tracking de l'industrie publicitaire.
- Les arguments des lobbyistes de l'adtech, anti Apple.
- Debung du lobbyiste Eric Seufert sur Apple ATT.
- Apple favoriserait la publicité ciblée sur ses propres Apps, plainte de France Digitale.
- La plainte du Geste contre Apple ATT.
- Arguments déployés par les apps pour vous pister (pop-ups ATT).
- Apple ne fait pas le ménage, certaines Apps continuent de vous pister, après opposition.
- Facebook note qu'il est toujours possible de surveiller les utilisateurs Safari via les paramètres de tracking (NB: en navigation privée, plus maintenant).
- Apple "privacy manifests", une initiative pour contrer le fingerprinting.
Apple aime vos données personnelles
Certaines pratiques d'Apple sont problématiques :
- Le parcours du combattant pour désactiver Siri #darkpattern.
- Apple ne respecte pas ePrivacy sur son propre site.
Adtech
Au côté de Google et de Facebook, des milliers d'entreprises "innovent", souvent pour mieux vous surveiller.
L'adtech, une énorme boite noire
Fonctionnement quasi incompréhensible, multiplication des intermédiaires, des fuites de données et des scandales, voici le merveilleux monde de l'adtech :
- Quand l'un des créateurs du "Real Time Bidding" ne comprend pas comment il a pu être re-ciblé, c'est mauvais signe pour cette industrie opaque.
- Un groupe de sénateurs américains se demande vers quels pays partent les données personnelles dans le cadre du "Real Time Bidding".
- Pas de scandales liés aux cookies publicitaires ? Pas vraiment, comme le montre cette longue liste.
- Les revendeurs publicitaires, porte grande ouverte aux fuites de données personnelles et à la fraude.
- À propos d'un mécanisme essentiel au "Real Time Bidding", la synchronisation des cookies.
- Illustration de la synchronisation des cookies avec ID5, une catastrophe pour l'expérience utilisateur et pour votre vie privée.
Vous identifier, pour mieux vous surveiller
L'adtech a du talent pour trouver de nouveaux mécanismes de tracking :
- Contourner les protections navigateurs et autres adblocks ? Certains, comme Tracedock, communiquent clairement là-dessus.
- Dans l'adtech aussi, on a des solutions pour contourner les protections navigateurs (e.g. Safari ITP).
- First.id, un identifiant qui contournerait les protections anti-tracking des navigateurs.
- Détail de la "promesse" de first.id, par rapport au navigateur d'Apple, Safari (et sa protection ITP).
- Tracking dans l'adtech toujours, avec la société ID5, spécialisée dans l'identification des utilisateurs.
- TrustId, où comment les opérateurs téléphoniques (Orange, Bouygues Telecom, SFR...) veulent permettre à l'industrie publicitaire de vous surveiller grâce à votre carte SIM.
- Le tracking sans cookies ni consentement, libre blanc de l'IAB.
- Plus fort que le Server-Side Tagging de Google Tag Manager pour contourner les protections navigateurs et autres adblocks ? Zaraz de Cloudflare.
- Taboola (les liens putaclics en bas des articles) a une techno "cookieless", votre e-mail (et les limites de Safari ITP ?).
- Déchiffrage d'une présentation de Liveramp, un des leaders sur la "data".
Tracking déguisé via les alias CNAME
Certains acteurs adtech mettent en danger la sécurité de vos comptes en ligne, en poussant à l'utilisation d'un alias de domaine appelé CNAME, juste pour contourner les protections des navigateurs. De nombreux sites français ne se posent pas la question et suivent ces préconisations. Quelques exemples :
- Criteo pousse la technique à tout ses clients.
- Eulerian aussi.
- Autre acteur français offrant cette option, Mediarithmics.
- Les acteurs américains ne sont pas en reste, avec Adobe.
La solution contre ce tracking ? Firefox avec uBlock Origin, et "NextDNS, mon nouveau bloqueur de traceurs et de publicités préféré".
Les bannières cookies, plaie du web
Plutôt que de changer de modèle économique, l'adtech préfère pourrir votre expérience utilisateur :
- Analyse de la dernière version du protocole de consentement publicitaire (bannières cookies), le TCF v2.2 de l'IAB.
- Le TCF jugé illégal ? Webinar réaction de Didomi, le leader des bannières cookies.
- Deux bannières cookies sur un même site !
- Bannière cookie de toute beauté, sur le site Ingeniance Tech Blog.
- Un #DarkPattern de toute beauté de TrustArc sur le site Starbucks, bannière cookie qui prend plus de 30 secondes pour valider votre refus de consentement.
- AT Internet, exemption de consentement et cookies tiers.
- Vous utilisez un adblock ? Pas d'accès à Rustica.
- Bannière cookies Gens de Confiance non conforme, corrigé rapidement !
- L'Équipe, champion de la surveillance.
Pour aller plus loin, lisez "De la légalité des bannières de consentement IAB", une analyse des bannières de consentement proposées par Sirdata.
Sirdata
Fournisseur de bannières cookies, de données comportementales et de solutions "consentless", Sirdata est une société intéressante :
- Consentement sur une myriade de sites avec Sirdata.
- Le recyblage sans consentement de Sirdata.
- Sirdata challenge la recommandation de proxification de Google Analytics de la CNIL.
- Avec quels arguments Sirdata prétend rendre Google Analytics conforme à la loi (via son produit, le Sirdata Helper) ?
- Sirdata Analytics Helper et Le Figaro.
- L'impunité de Sirdata, la CNIL est aux abonnés absents.
L'intérêt légitime, la plus grande arnaque de l'adtech
La plus grande arnaque de l'adtech ? Prétendre avoir un "intérêt légitime" (une des bases légales du RGPD) à vous surveiller :
- Vous surveiller grâce à votre adresse IP, sans consentement.
- Publicité ciblée basée sur l'intérêt légitime, avec le site web du Figaro.
- Même problématique sur l'App Le Figaro.
- Radio France, Didomi et l'intérêt légitime pour la publicité ciblée.
Les initiatives positives
Publicité et respect de la vie privée ne sont pas irréconciliables :
- Firefox et la publicité, des choix respectueux de la vie privée (dont IPA, une intéressante initiative avec... Facebook).
- Une proposition intéressante de NOYB pour remplacer les horribles bannières cookies.
Sites et Applications
Ce complexe de la surveillance publicitaire ne fonctionnerait pas si les sites web et applications refusaient de les utiliser. Mais la manne publicitaire est souvent trop tentante.
Conditions d'utilisation abusives
Beaucoup de sites jouent avec la réglementation, voire s'en affranchissent :
- Twitter n'a pas attendu Elon Musk pour cracher sur votre vie privée.
- Comment Microsoft vous force à donner votre numéro de téléphone.
- Decathlon, à fond la surveillance avec Valiuz.
- La coopérative de données personnelles Valiuz, présente sur tous les sites du groupe Mulliez.
- La pernicieuse mise à jour des conditions d'utilisation de Doctolib.
- Uber, la publicité ciblée par défaut.
- L'App Elyze, où comment constituer une base de données d'opinions politiques sans consentement.
Pour approfondir, vous pourrez lire "Decathlon, à fond la surveillance".
Fuites de données personnelles
Il n'y a pas que les conditions d'utilisations, celles-ci correspondent rarement à la réalité du terrain :
- Des éditeurs français tels que L'Équipe ou Le Bon Coin continuent de travailler avec Tapad, une société controversée ayant fermé en Europe.
- Appli SNCF Connect : vos données personnelles fuitent sans consentement.
- Cozy Cloud et la vie privée : promesses vs réalité.
- Un player vidéo sur le site des Echos (Digiteka) entraîne des fuites massives de données personnelles.
- La BBC ne respecte pas la directive ePrivacy (cookies).
- Inscription sur les listes électorales et fuites de données personnelles vers AT Internet.
- Prêt immobilier avec Pretto, surveillance publicitaire inclus.
- Les applis de météo et la fuite de votre géolocalisation, une histoire d'amour.
- Fuite de données personnelles avec l'application iOS LastPass.
- Groupama, cookies, #DarkPattern et CNAME.
Covid et fuites de données personnelles
Beaucoup de fantasmes en France sur la surveillance liée à TousAntiCovid (comparé au peu de relai médiatique sur la vidéosurveillance algorithmique par exemple, avec la France en pointe du domaine comme le dénonce La Quadrature du Net), mais j'ai néanmoins regardé l'appli TousAntiCovid :
L'hypocrisie du milieu
Dans la catégorie, on aime bien dénoncer Google et Facebook, mais on oublie de balayer à notre propre porte :
- L'hypocrisie d'Amnesty International, premier à dénoncer le capitalisme de surveillance mais aveugle sur son propre site.
- L'hypocrisie d'Amnesty International, suite.
- S'abonner pour soutenir la presse et éviter la surveillance de Google ? Une grande partie de la presse française permet à Google de gérer les abonnements (et vos données personnelles).
- Réaction du DG de Le Figaro après l'amende de la CNIL.
- Après l'amende de la CNIL, Le Figaro bafoue encore la loi.
La CNIL, un allié très frustrant
Pour vous défendre contre la surveillance publicitaire, la réglementation, incarnée en France par la CNIL. Elle est de bonne volonté, rend parfois des décisions importantes (contre Google ou Facebook), mais n'agit que trop rarement et très lentement. Manque de moyens ou complaisance avec l'adtech ? Probablement un peu des deux...
La CNIL et les cookies
La CNIL n'ayant pas envie d'appliquer la loi pour les sites d'information, les abus sont généralisés :
- Un thread de threads sur les différents types d'abus.
- Les bons élèves qui ont ensuite dégradé leur interface de consentement.
- "Continuer sans accepter", l'historique du #DarkPattern promu par la CNIL.
- "Continuer sans accepter", le #DakPattern de la CNIL généralisé sur le web.
- "Continuer sans accepter", le #DakPattern de la CNIL généralisé sur les Apps.
- "Continuer sans accepter", en bas du bandeau.
- "Continuer sans accepter", avec acceptation en haut à droite.
- Absence du bouton "Tout refuser", sur le web.
- Absence du bouton "Tout refuser", sur les Apps.
- Cookies non essentiels déposés avant acceptation, sur le web.
- Cookies non essentiels déposés avant acceptation, sur les Apps.
- Cookies non essentiels déposés après refus de consentement, sur les Apps.
- Cookie wall, sur le web.
- Cookie wall, sur les Apps.
- Dégradation de l'interface utilisateur si refus de consentement.
- Cookies et player vidéo sur l'Est Républicain.
Pour approfondir, lisez les articles suivants :
Les sanctions de la CNIL
La CNIL sanctionne donc parfois Google et Facebook, on peut regretter la lenteur des procédures et les montants pas si importants par rapport aux revenus de ces 2 sociétés, mais ces sanctions finissent par avoir de l'effet :
- Cookies publicitaires sans consentement chez Google et Facebook.
- Sur la faiblesse des sanctions de la CNIL envers Google et Facebook.
- Les sanctions du Luxembourg sont beaucoup plus conséquentes.
- La CNIL sanctionne Google sur l'absence du bouton "Tout refuser".
- Mais Google se moque toujours de la CNIL.
- Si vous cliquez sur "Tout refuser" sur la bannière Google, celui-ci vous surveille-t-il encore ? Mystère...
- L'avis (critique) de NOYB sur la CNIL.
Texte intégral (4830 mots)
Dissonance cognitive
Mieux qu'un Feedly, Twitter m'aura permis de connaître des gens passionnants, experts dans leur domaine, ayant un point de vue décalé ou incisif sur l'actualité. Il aura également été un excellent relais pour mes écrits sur l'adtech et le capitalisme de surveillance. Mais ses dérives, de plus en plus criantes depuis son rachat par Elon Musk, auront eu raison de moi.
2 articles résument très bien mon sentiment sur ce réseau social :
- "On Twitter, we look down", où l'auteur détaille sa schizophrénie concernant Twitter, pourquoi il est toujours dessus.
- "How to Blow Up a Timeline", où l'auteur raconte à quel point la magie du Twitter d'hier était exceptionnelle et fragile.
La goutte d'eau ayant déclenché la fermeture de mon compte ? Le renommage de Twitter en X, un détail dans le projet de vandalisme culturel d'Elon Musk. Vous pourrez maintenant me retrouver sur Mastodon, un réseau social fédéré, qui n'appartient à personne et ne peut donc pas être contrôlé par un milliardaire mégalomane fachiste.
Ayant beaucoup publié sur Twitter, parfois sur des sujets qui auraient mérité que j'écrive un article, je souhaitais néanmoins pouvoir republier mes tweets ailleurs. J'ai donc suivi ces 2 étapes :
- Le téléchargement de mes archives via le site Twitter.
- L'installation de tweetback (merci @aeris) sur mon blog, aidé par cet article.
Mes tweets sont donc disponibles ici, avec un moteur de recherche pour trouver des tweets sur une thématique précise, et ce billet pour référencer les tweets que je souhaite retrouver facilement.
À tout seigneur tout honneur, démarrons cette collection de tweets par le créateur du capitalisme de surveillance.
Le parrain de l'adtech
J'avais déjà écrit un article sur "la domination de Google sur les marché publicitaires", le caractère monopolistique de la brique adtech de Google et la surveillance publicitaire sont étroitement liés :
- Avec la Privacy Sandbox, Google ne permettra plus que vous soyez surveillé via un identifiant utilisateur ? Pas vraiment...
- Sur la possibilité d'utiliser des identifiants utilisateurs sur la stack adtech de Google, après disparition des cookies tiers de Chrome.
- Toujours le double-discours de Google sur les identifiants utilisateurs.
- À la différence d'iOS, il est encore très difficile de refuser le tracking publicitaire sur Android.
- La commission européenne dans son enquête sur l'adtech de Google met en balance vie privée et compétition, une mauvaise approche.
- L'Ad-Exchange Google, où le paradis des fraudeurs.
Google Chrome, agent des publicitaires
Les navigateurs sont généralement nommés "User Agents", ce n'est pas le cas de Chrome, le navigateur dominant de Google :
- Un guide sur la "confidentialité" dans Chrome.
- L'onboarding de Google Chrome, un cas d'école pour les #DarkPatterns.
- "First-Party Set", un dispositif de la Privacy Sandbox visant à continuer le tracking au sein des sites Google (YouTube, Maps...).
- "First-Party Set", un nouveau vecteur de tracking maintenant dans Chrome.
- Privacy Sandbox, ePrivacy s'applique (CNIL) et le consentement est donc obligatoire.
Vous pourrez approfondir le sujet Chrome avec 2 de mes articles :
- "L'entête HTTP problématique envoyé par Chrome à Google."
- "Fin des cookies tiers sur Chrome et Privacy Sandbox : une protection de la vie privée en trompe-l'oeil."
Google Analytics, le cheval de Troie publicitaire
En configuration minimum, Google Analytics devrait fonctionner sans surveillance publicitaire, mais ce n'est pas si simple :
- La création de compte Google, où l'art du #DarkPattern pour mieux vous surveiller.
- Le #PrivacyWashing de Google Analytics.
- Sur l'illégalité de Google Analytics, un debunk de l'article de @Devergranne.
- Un long thread sur l'illégalité de Google Analytics, suite aux décisions des CNILs autrichiennes puis françaises.
- Auchan utilise-t-il encore Google Analytics ? Il est permis d'en douter.
- La liste des plaintes de @NOYBeu à la CNIL, pour transfert de données personnelles vers les US (Google & Facebook).
Autres outils Google
L'adtech de Google, Chrome ou Google Analytics sont loin d'être les seules outils dédiés à mieux vous surveiller :
- Utilisation du Server-Side Tagging de Google Tag Manager.
- Google Fonts, un cheval de Troie pour vous surveiller ?
- Vos conversations avec Google Bard sont relues par des humains.
Approfondissez le sujet via la lecture de mon article "Google Tag Manager, la nouvelle arme anti adblock".
Alias Meta, le pire du capitalisme de surveillance, une source d'inspiration pour Google et pour toute l'adtech.
Une captation de données sans limites
Dans mon article "Avec les "signaux résilients" de Facebook, la surveillance publicitaire évolue", j'avais détaillé comment Facebook contournait les protections contre le tracking des navigateurs. Comme avec Google, abus de position dominante et violation de votre vie privée vont de pair, comme je l'avais d'ailleurs écrit dans l'article "Facebook et WhatsApp, où l'art de vous trahir". Facebook met tout en place pour capter toujours plus de données utilisateurs :
- Comment Facebook s'adapte aux protections navigateurs et autres adblockers.
- Les outils publicitaires de Facebook font du fingerprinting sur des applis tierces, exemple avec Duolingo.
- En particulier, Facebook récupère les données de l'accéléromètre de votre téléphone.
- Le partage de données entre WhatsApp et Facebook/Meta.
- La modération sur WhatsApp, vos messages ne sont pas toujours privés.
Des partenariats avec la terre entière
2 exemples intéressants, mais Facebook a interfacé son écosystème publicitaire avec tous les outils qui comptent :
- Un partenariat avec Criteo sur Facebook et Instagram.
- Shopify se lance dans la publicité ciblée (sur Facebook...), avec les données de ses clients.
Violer la loi, une spécialité
Facebook se moque des réglementations et de la CNIL :
- Bannières cookies (ePrivacy), Facebook se moque toujours de vous (et de la CNIL).
- Le parcours de la mort pour vous opposer à la publicité ciblée sur Facebook/Instagram.
- Sur WhatsApp, le parcours promet d'être aussi difficile.
- Le #PrivacyWashing de Facebook (et Google).
La surveillance des plateformes, via les "Pixels" & "Conversion APIs"
Pour contourner vos adblockers et autres protections navigateurs, Facebook a créé son "Pixel" et sa "Conversion API" (CAPI), il a inspiré les autres plateformes :
- Facebook.
- Google.
- TikTok.
- Snapchat.
- Pinterest.
- Un exemple de fuite sur Greenpeace.
- Un autre exemple avec Amnesty International.
- Un thread d'exemples de fuites.
- Une étude montrant l'ampleur de ces fuites.
- Lockr, un service pour cacher son e-mail... et continuer la surveillance publicitaire.
Je parle également de ces fuites de données dans l'article "Guerlain (LVMH) : luxe et surveillance".
Apple
Comme l'indique mon article "Apple vous protège-t-il vraiment de la surveillance publicitaire ?", Apple n'est pas parfait côté vie privée, mais c'est généralement un allié face à la surveillance de Google, de Facebook et de l'adtech.
Une définition particulière du "tracking"
Apple a mis en place des mécanismes assez efficaces pour vous protéger de la surveillance publicitaire, qui n'affectent pas son propre business, ce qui a le don d'énerver l'adtech :
- La désinformation de l'industrie publicitaire sur Apple.
- Sur le "tracking" d'Apple.
- Les arguments d'Apple concernant son "tracking" vs le tracking de l'industrie publicitaire.
- Les arguments des lobbyistes de l'adtech, anti Apple.
- Debung du lobbyiste Eric Seufert sur Apple ATT.
- Apple favoriserait la publicité ciblée sur ses propres Apps, plainte de France Digitale.
- La plainte du Geste contre Apple ATT.
- Arguments déployés par les apps pour vous pister (pop-ups ATT).
- Apple ne fait pas le ménage, certaines Apps continuent de vous pister, après opposition.
- Facebook note qu'il est toujours possible de surveiller les utilisateurs Safari via les paramètres de tracking (NB: en navigation privée, plus maintenant).
- Apple "privacy manifests", une initiative pour contrer le fingerprinting.
Apple aime vos données personnelles
Certaines pratiques d'Apple sont problématiques :
- Le parcours du combattant pour désactiver Siri #darkpattern.
- Apple ne respecte pas ePrivacy sur son propre site.
Adtech
Au côté de Google et de Facebook, des milliers d'entreprises "innovent", souvent pour mieux vous surveiller.
L'adtech, une énorme boite noire
Fonctionnement quasi incompréhensible, multiplication des intermédiaires, des fuites de données et des scandales, voici le merveilleux monde de l'adtech :
- Quand l'un des créateurs du "Real Time Bidding" ne comprend pas comment il a pu être re-ciblé, c'est mauvais signe pour cette industrie opaque.
- Un groupe de sénateurs américains se demande vers quels pays partent les données personnelles dans le cadre du "Real Time Bidding".
- Pas de scandales liés aux cookies publicitaires ? Pas vraiment, comme le montre cette longue liste.
- Les revendeurs publicitaires, porte grande ouverte aux fuites de données personnelles et à la fraude.
- À propos d'un mécanisme essentiel au "Real Time Bidding", la synchronisation des cookies.
- Illustration de la synchronisation des cookies avec ID5, une catastrophe pour l'expérience utilisateur et pour votre vie privée.
Vous identifier, pour mieux vous surveiller
L'adtech a du talent pour trouver de nouveaux mécanismes de tracking :
- Contourner les protections navigateurs et autres adblocks ? Certains, comme Tracedock, communiquent clairement là-dessus.
- Dans l'adtech aussi, on a des solutions pour contourner les protections navigateurs (e.g. Safari ITP).
- First.id, un identifiant qui contournerait les protections anti-tracking des navigateurs.
- Détail de la "promesse" de first.id, par rapport au navigateur d'Apple, Safari (et sa protection ITP).
- Tracking dans l'adtech toujours, avec la société ID5, spécialisée dans l'identification des utilisateurs.
- TrustId, où comment les opérateurs téléphoniques (Orange, Bouygues Telecom, SFR...) veulent permettre à l'industrie publicitaire de vous surveiller grâce à votre carte SIM.
- Le tracking sans cookies ni consentement, libre blanc de l'IAB.
- Plus fort que le Server-Side Tagging de Google Tag Manager pour contourner les protections navigateurs et autres adblocks ? Zaraz de Cloudflare.
- Taboola (les liens putaclics en bas des articles) a une techno "cookieless", votre e-mail (et les limites de Safari ITP ?).
- Déchiffrage d'une présentation de Liveramp, un des leaders sur la "data".
Tracking déguisé via les alias CNAME
Certains acteurs adtech mettent en danger la sécurité de vos comptes en ligne, en poussant à l'utilisation d'un alias de domaine appelé CNAME, juste pour contourner les protections des navigateurs. De nombreux sites français ne se posent pas la question et suivent ces préconisations. Quelques exemples :
- Criteo pousse la technique à tout ses clients.
- Eulerian aussi.
- Autre acteur français offrant cette option, Mediarithmics.
- Les acteurs américains ne sont pas en reste, avec Adobe.
La solution contre ce tracking ? Firefox avec uBlock Origin, et "NextDNS, mon nouveau bloqueur de traceurs et de publicités préféré".
Les bannières cookies, plaie du web
Plutôt que de changer de modèle économique, l'adtech préfère pourrir votre expérience utilisateur :
- Analyse de la dernière version du protocole de consentement publicitaire (bannières cookies), le TCF v2.2 de l'IAB.
- Le TCF jugé illégal ? Webinar réaction de Didomi, le leader des bannières cookies.
- Deux bannières cookies sur un même site !
- Bannière cookie de toute beauté, sur le site Ingeniance Tech Blog.
- Un #DarkPattern de toute beauté de TrustArc sur le site Starbucks, bannière cookie qui prend plus de 30 secondes pour valider votre refus de consentement.
- AT Internet, exemption de consentement et cookies tiers.
- Vous utilisez un adblock ? Pas d'accès à Rustica.
- Bannière cookies Gens de Confiance non conforme, corrigé rapidement !
- L'Équipe, champion de la surveillance.
Pour aller plus loin, lisez "De la légalité des bannières de consentement IAB", une analyse des bannières de consentement proposées par Sirdata.
Sirdata
Fournisseur de bannières cookies, de données comportementales et de solutions "consentless", Sirdata est une société intéressante :
- Consentement sur une myriade de sites avec Sirdata.
- Le recyblage sans consentement de Sirdata.
- Sirdata challenge la recommandation de proxification de Google Analytics de la CNIL.
- Avec quels arguments Sirdata prétend rendre Google Analytics conforme à la loi (via son produit, le Sirdata Helper) ?
- Sirdata Analytics Helper et Le Figaro.
- L'impunité de Sirdata, la CNIL est aux abonnés absents.
L'intérêt légitime, la plus grande arnaque de l'adtech
La plus grande arnaque de l'adtech ? Prétendre avoir un "intérêt légitime" (une des bases légales du RGPD) à vous surveiller :
- Vous surveiller grâce à votre adresse IP, sans consentement.
- Publicité ciblée basée sur l'intérêt légitime, avec le site web du Figaro.
- Même problématique sur l'App Le Figaro.
- Radio France, Didomi et l'intérêt légitime pour la publicité ciblée.
Les initiatives positives
Publicité et respect de la vie privée ne sont pas irréconciliables :
- Firefox et la publicité, des choix respectueux de la vie privée (dont IPA, une intéressante initiative avec... Facebook).
- Une proposition intéressante de NOYB pour remplacer les horribles bannières cookies.
Sites et Applications
Ce complexe de la surveillance publicitaire ne fonctionnerait pas si les sites web et applications refusaient de les utiliser. Mais la manne publicitaire est souvent trop tentante.
Conditions d'utilisation abusives
Beaucoup de sites jouent avec la réglementation, voire s'en affranchissent :
- Twitter n'a pas attendu Elon Musk pour cracher sur votre vie privée.
- Comment Microsoft vous force à donner votre numéro de téléphone.
- Decathlon, à fond la surveillance avec Valiuz.
- La coopérative de données personnelles Valiuz, présente sur tous les sites du groupe Mulliez.
- La pernicieuse mise à jour des conditions d'utilisation de Doctolib.
- Uber, la publicité ciblée par défaut.
- L'App Elyze, où comment constituer une base de données d'opinions politiques sans consentement.
Pour approfondir, vous pourrez lire "Decathlon, à fond la surveillance".
Fuites de données personnelles
Il n'y a pas que les conditions d'utilisations, celles-ci correspondent rarement à la réalité du terrain :
- Des éditeurs français tels que L'Équipe ou Le Bon Coin continuent de travailler avec Tapad, une société controversée ayant fermé en Europe.
- Appli SNCF Connect : vos données personnelles fuitent sans consentement.
- Cozy Cloud et la vie privée : promesses vs réalité.
- Un player vidéo sur le site des Echos (Digiteka) entraîne des fuites massives de données personnelles.
- La BBC ne respecte pas la directive ePrivacy (cookies).
- Inscription sur les listes électorales et fuites de données personnelles vers AT Internet.
- Prêt immobilier avec Pretto, surveillance publicitaire inclus.
- Les applis de météo et la fuite de votre géolocalisation, une histoire d'amour.
- Fuite de données personnelles avec l'application iOS LastPass.
- Groupama, cookies, #DarkPattern et CNAME.
Covid et fuites de données personnelles
Beaucoup de fantasmes en France sur la surveillance liée à TousAntiCovid (comparé au peu de relai médiatique sur la vidéosurveillance algorithmique par exemple, avec la France en pointe du domaine comme le dénonce La Quadrature du Net), mais j'ai néanmoins regardé l'appli TousAntiCovid :
L'hypocrisie du milieu
Dans la catégorie, on aime bien dénoncer Google et Facebook, mais on oublie de balayer à notre propre porte :
- L'hypocrisie d'Amnesty International, premier à dénoncer le capitalisme de surveillance mais aveugle sur son propre site.
- L'hypocrisie d'Amnesty International, suite.
- S'abonner pour soutenir la presse et éviter la surveillance de Google ? Une grande partie de la presse française permet à Google de gérer les abonnements (et vos données personnelles).
- Réaction du DG de Le Figaro après l'amende de la CNIL.
- Après l'amende de la CNIL, Le Figaro bafoue encore la loi.
La CNIL, un allié très frustrant
Pour vous défendre contre la surveillance publicitaire, la réglementation, incarnée en France par la CNIL. Elle est de bonne volonté, rend parfois des décisions importantes (contre Google ou Facebook), mais n'agit que trop rarement et très lentement. Manque de moyens ou complaisance avec l'adtech ? Probablement un peu des deux...
La CNIL et les cookies
La CNIL n'ayant pas envie d'appliquer la loi pour les sites d'information, les abus sont généralisés :
- Un thread de threads sur les différents types d'abus.
- Les bons élèves qui ont ensuite dégradé leur interface de consentement.
- "Continuer sans accepter", l'historique du #DarkPattern promu par la CNIL.
- "Continuer sans accepter", le #DakPattern de la CNIL généralisé sur le web.
- "Continuer sans accepter", le #DakPattern de la CNIL généralisé sur les Apps.
- "Continuer sans accepter", en bas du bandeau.
- "Continuer sans accepter", avec acceptation en haut à droite.
- Absence du bouton "Tout refuser", sur le web.
- Absence du bouton "Tout refuser", sur les Apps.
- Cookies non essentiels déposés avant acceptation, sur le web.
- Cookies non essentiels déposés avant acceptation, sur les Apps.
- Cookies non essentiels déposés après refus de consentement, sur les Apps.
- Cookie wall, sur le web.
- Cookie wall, sur les Apps.
- Dégradation de l'interface utilisateur si refus de consentement.
- Cookies et player vidéo sur l'Est Républicain.
Pour approfondir, lisez les articles suivants :
Les sanctions de la CNIL
La CNIL sanctionne donc parfois Google et Facebook, on peut regretter la lenteur des procédures et les montants pas si importants par rapport aux revenus de ces 2 sociétés, mais ces sanctions finissent par avoir de l'effet :
- Cookies publicitaires sans consentement chez Google et Facebook.
- Sur la faiblesse des sanctions de la CNIL envers Google et Facebook.
- Les sanctions du Luxembourg sont beaucoup plus conséquentes.
- La CNIL sanctionne Google sur l'absence du bouton "Tout refuser".
- Mais Google se moque toujours de la CNIL.
- Si vous cliquez sur "Tout refuser" sur la bannière Google, celui-ci vous surveille-t-il encore ? Mystère...
- L'avis (critique) de NOYB sur la CNIL.
16.01.2023 à 10:33
Decathlon, à fond la surveillance

Les règles du jeu
En août dernier, je tweetais sur le parcours de l'enfer pour refuser la surveillance de Decathlon. À ce jour, c'est le tweet qui m'a valu le plus de succès avec 1760 Retweets et plus d'1 million d'impressions. Manifestement, ce n'était pas suffisant pour avoir droit à une réponse de Yann, le CM de Decathlon. Quelques mois après cet épisode, quels ont été les changements ? Étudions cela en détail.
Dès votre arrivée sur le site Decathlon vous êtes accueilli par une bannière "Cookies : Les règles du jeu" :
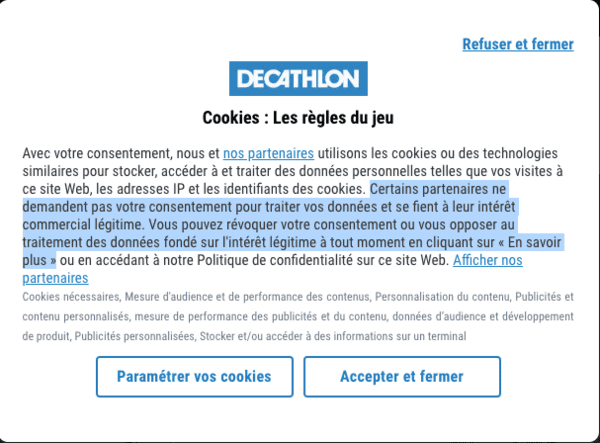
Les règles de Decathlon, celles de la loi ?
Vous êtes habitué à ces dark patterns et instinctivement, vous cliquez sur le bouton "Refuser et fermer" en haut à droite ? J'ai fait cela aussi... Lisez attentivement le texte :
Certains partenaires ne demandent pas votre consentement pour traiter vos données et se fient à leur intérêt commercial légitime. Vous pouvez révoquer votre consentement ou vous opposer au traitement des données fondé sur l'intérêt légitime à tout moment en cliquant sur « En savoir plus »
Qui sont ces partenaires ? Mystère... Comment s'opposer au traitement des données fondé sur l'intérêt légitime ? Le texte de Decathlon est incohérent car il n'y a pas de bouton « En savoir plus ». Essayons néanmoins en cliquant sur "Paramétrer vos cookies" :
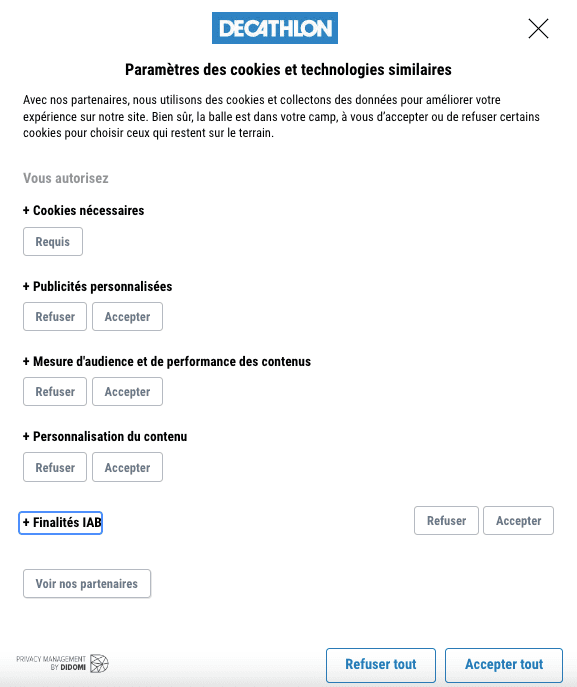
"Bien sûr, la balle est dans votre camp, à vous d'accepter ou de refuser certains cookies pour choisir ceux qui restent sur le terrain".
La bannière ne parle pas d'intérêt légitime, vous pouvez encore cliquer sur "Refuser tout". Continuons donc l'investigation en cliquant sur "Voir nos partenaires" :
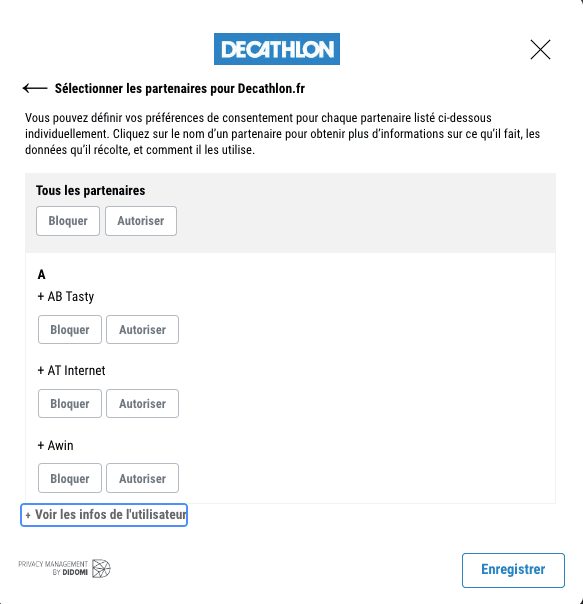
La longue liste des partenaires de Decathlon.
Decathlon aime partager vos données personnelles et travaille avec pas moins de 26 partenaires : AB Tasty, AT Internet, Awin, Bing (Microsoft), Content Square, Dynamics Yield, Easyence, Epsilon, Google, Hotjar, IAdvize, Idealo, Kelkoo, Lucky Orange, Meta (Facebook), Mobsuccess, Ogury, Pinterest, Rakuten advertising, RTB House, SpeedCurve, Target 2 Sell, Teads, Teester, Valiuz et Verizon Media.
Là aussi, vous pouvez cliquer sur "Bloquer" pour "Tous les partenaires", vous ne verrez aucune mention à l'intérêt légitime, ces partenaires se basent sur votre consentement. Le mystère demeure sur les "partenaires" se basant sur l'intérêt légitime, il semble à première vue qu'un simple clic sur "Refuser et fermer" en haut à droite de la bannière initiale soit suffisant.
Via le site Consent String Decoder, je vérifie néanmoins ma chaîne de consentement, une chaîne de caractère qui encode mes choix et qui doit être respecté par les partenaires de Decathlon :
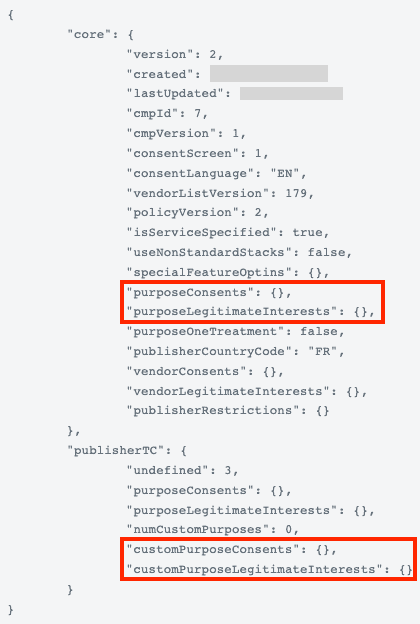
Les variables purposeConsents et purposeLegitimateInterests sont vides, aucun partenaire de Decathlon n'a de base légale pour traiter mes données personnelles.
Après refus, vous êtes quand même traqué par iAdvize
Après avoir cliqué sur "Refuser et fermer", je lance Charles Proxy pour observer les requêtes envoyées par mon navigateur :
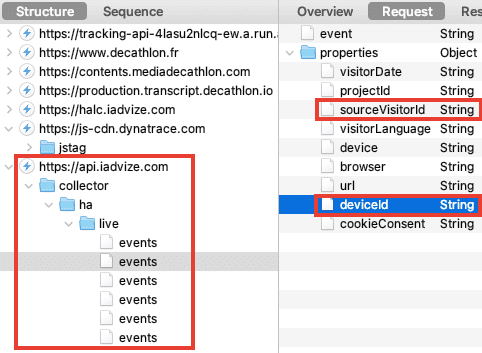
Surprise ! Decathlon n'est pas le seul destinataire de mes données personnelles.
iAdvize suit donc votre navigation, grâce aux paramètres url, sourceVisitorId et deviceId. Le paramètre cookieConsent interroge également, il est renseigné à unknown ! iAdvize c'est quoi ? Une fenêtre conversationnelle sur le site Decathlon, pour favoriser l'achat :
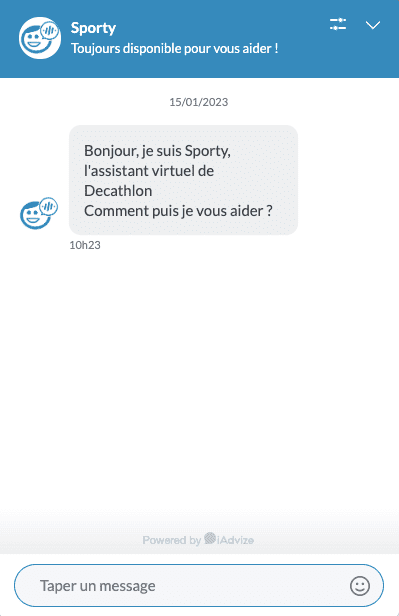
Sporty par iAdvize, toujours disponible pour observer votre comportement !
Si je reviens sur la bannière cookies pour vérifier mes choix, via "Gestion des cookies" (et non "Données personnelles") en pied de page :
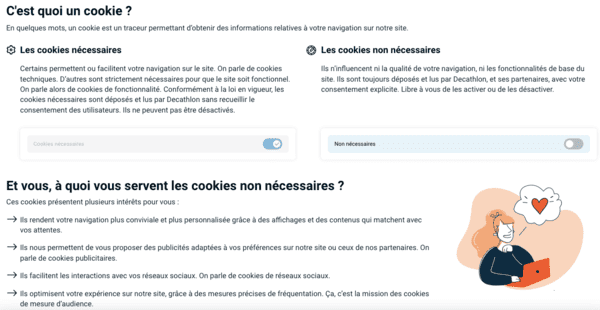
Beaucoup d'amour pour "les cookies non nécessaires".
Puis, si je clique sur "Gérer mes cookies" et que je cherche mon choix pour iAdvize :
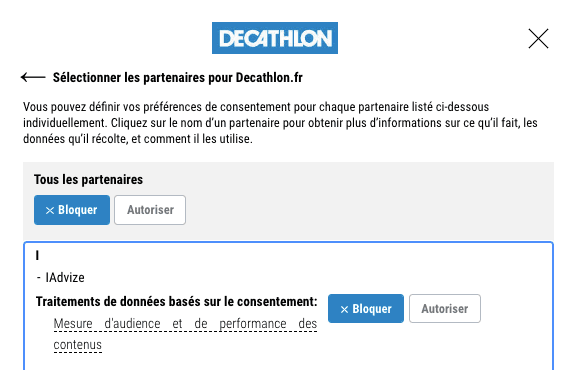
J'ai bien refusé la surveillance d'iAdvize, Decathlon ignore donc mon choix.
Notez que Decathlon et iAdvize pourraient arguer du fait qu'iAdvize ne dépose pas de cookies lorsque vous cliquez sur "Refuser et fermer". Sauf que ce dernier vous identifie via les identifiants sourceVisitorId et deviceId, un fingerprint est bien un identifiant utilisateur et votre consentement est nécessaire :

La CNIL est explicite sur l'application de la directive ePrivacy, le "fingerprinting" est concerné.
L'inscription, avec un partenaire mystérieux mais un engagement fort
Vous souhaitez maintenant commander chez Decathlon ? Vous allez devoir vous inscrire :
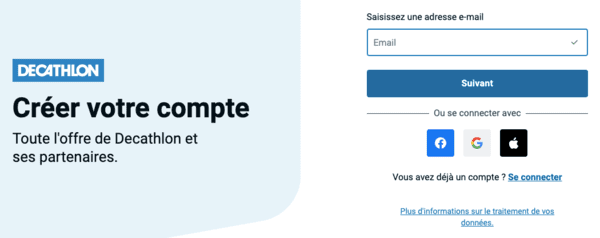
En équipe ! Decathlon vous propose son offre avec "ses partenaires".
Vous avez déjà refusé la surveillance de 26 partenaires, pourquoi Decathlon vous reparle-t-il de "partenaires" ? Il semble que la référence soit plutôt aux vendeurs de sa marketplace, mais on aurait aimé que Decathlon soit plus explicite. Renseignez une adresse e-mail, puis un mot de passe :
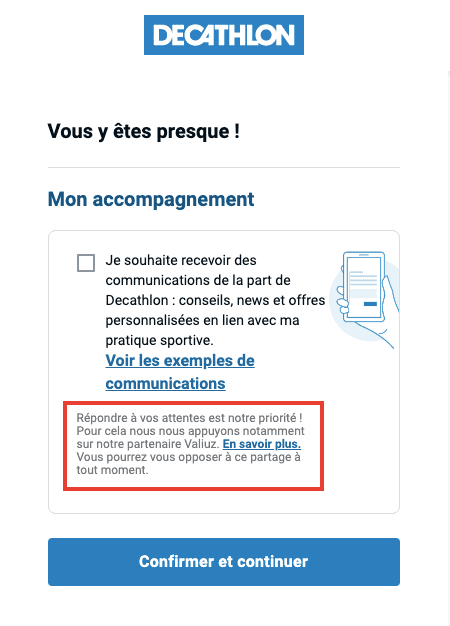
Un "partenaire" de plus, Valiuz (retenez ce nom pour la suite).
Vous n'avez pas forcément envie de recevoir des newsletters Decathlon, via le mystérieux partenaire "Valiuz", ne cochez donc pas la case et cliquez simplement sur "Confirmer et continuer" :
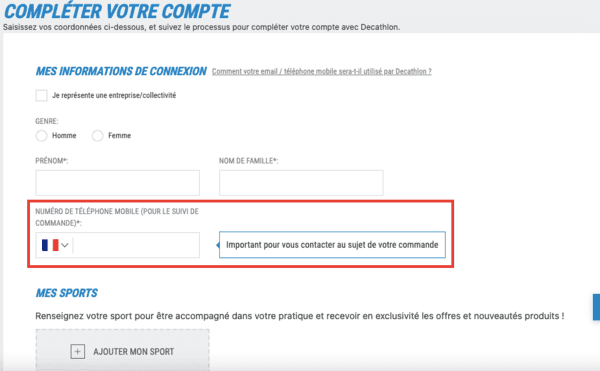
Le numéro de téléphone est obligatoire, et bien sûr, ce n'est que pour vous contacter au sujet de votre commande ;-)
Vous pouvez également renseigner vos sports favoris. Sur la même page, Decathlon communique sur la manière dont vos données sont utilisées, pour la création de compte tout d'abord :

Avec des mots forts :
Où vont vos données ? Chez nous, et c'est tout ! Il est rare que l'on apprécie que notre email soit vendu à d'autres enseignes. Rassurez-vous, ce n'est pas la politique de la maison. Vos données ne sont destinées qu'à Decathlon : notre service logistique, notre centre de relation clients, etc. Si nos sous-traitants traitent vos données, ils ne le font qu’à des fins statistiques, de dédoublonnement ou de correction, et sur instructions de DECATHLON.
Decathlon communique avec les mêmes mots sur la manière dont vos données sont utilisées pour une communication :

On note la confiance du sportif :
Enfin, si malgré l'intérêt que nous portons à la protection de vos données vous n'étiez pas satisfait, vous pouvez formuler une réclamation auprès de la CNIL.
Ces engagements concernent la création de compte et les communications de Decathlon. Mais comme on l'a vu précédemment, avec votre consentement (excepté pour iAdvize), Decathlon peux partager vos données personnelles avec pas moins de 26 partenaires pour diverses finalités : "Publicités personnalisées", "Mesure d'audience et de performance des contenus" et "Personnalisation du contenu".
Certaines de vos données personnelles ne sont donc pas destinées qu'à Decathlon...
À la recherche des paramètres de vie privée
Étant méfiant, je souhaite vérifier si Decathlon a correctement protégé mon compte, avec les options les plus protectrices côté vie privée. Pour cela, je me rends sur "Mon tableau de bord" :
L'accès le plus rapide vers les paramètres de vie privée ?!
Dans la section "Gérer mon compte Decathlon" du menu, caché dans "Préférences", je découvre 2 entrées intéressantes, "Historique de navigation" et "Données personnelles" :
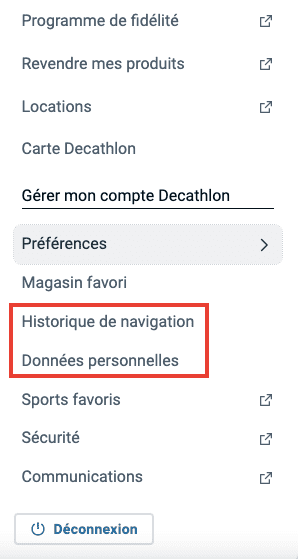
Victoire ?
Cliquons sur "Historique de navigation" :

Toujours "l'amélioration de l'expérience sur le site".
Lorsque vous décochez l'option, on vous explique que vous ne verrez plus les articles déjà consulté :

Cette option "Historique de navigation" est en effet bien cachée.
Si je clique maintenant sur "Données personnelles", je me retrouve sur la page "Vos données & Decathlon". Afin d'être sûr de ne pas louper d'options, je clique sur l'entrée "Sécurité" du menu de la page "Mon tableau de bord". Et là, surprise, un deuxième tableau de bord :
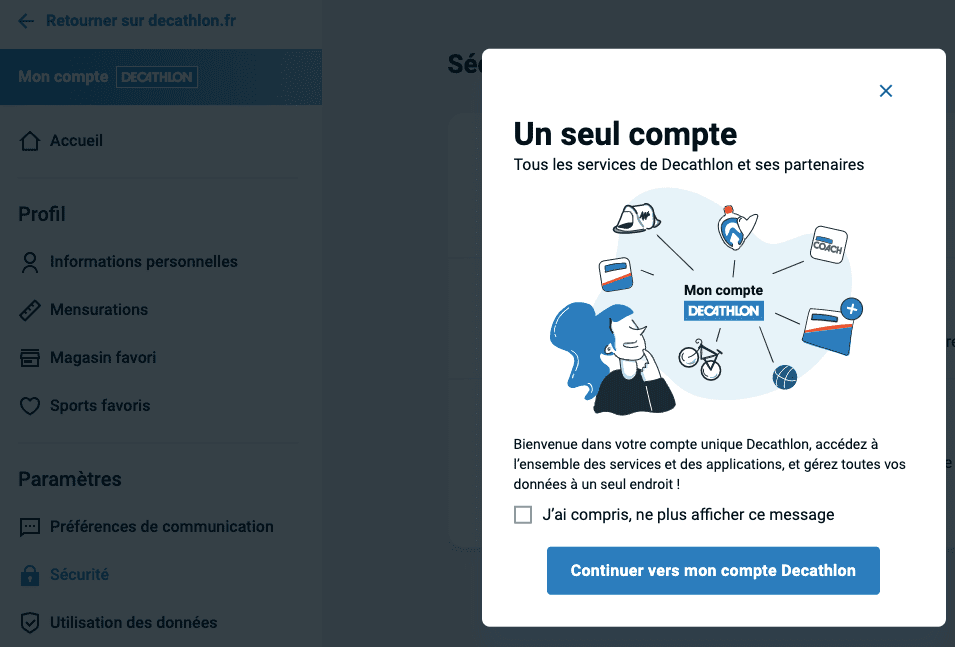
"Gérez toutes vos données à un seul endroit !" Si vous le trouvez ;-)
Là vous pourrez donner encore un peu plus d'informations à Decathlon, notamment vos mensurations :
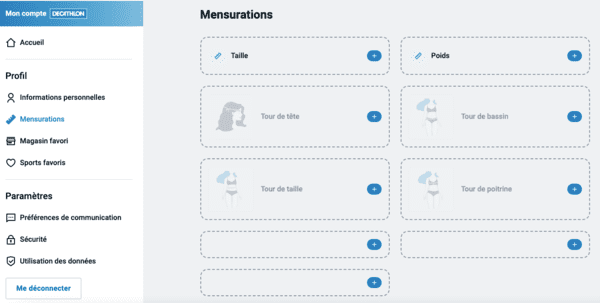
Le capitalisme de surveillance s'attaque à votre corps.
L'idée ? Vous proposer des produits et services adaptés à votre morphologie :
Decathlon vous accompagne dans votre discipline, ça fait envie non ?
Regardons ensuite les "Préférences de communication" :
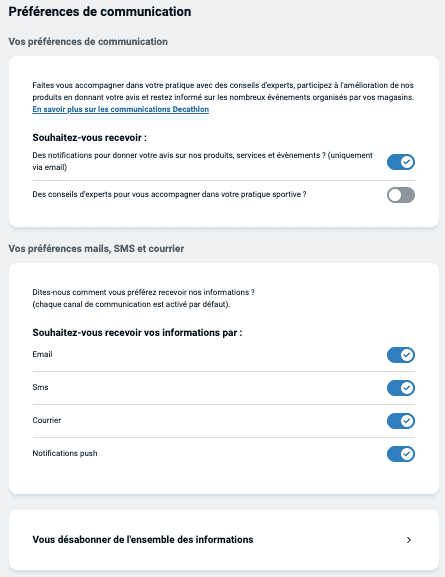
Évidemment, quasi toutes les communications sont pré-cochées.
Si vous cliquez sur "Vous désabonner de l'ensemble des informations", on vous demandera si vous êtes vraiment sûr :
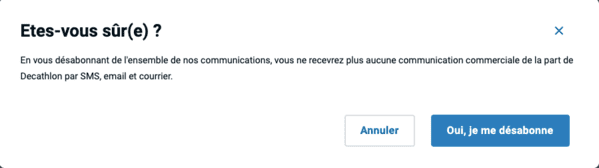
Après tous ces efforts, on se demande si vous souhaitez vraiment louper nos communications commerciales.
Finalement, allons sur l'entrée "Utilisation des données" du menu :
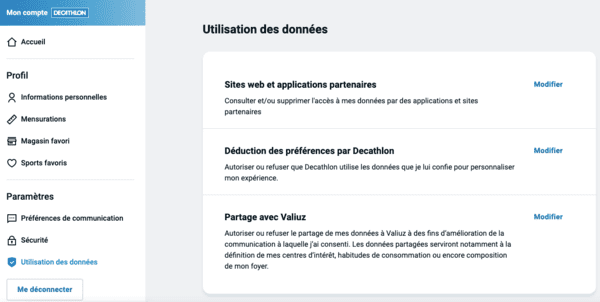
Une autre page pertinente concernant votre vie privée, bien cachée n'est-ce pas ?
Si vous cliquez sur "Modifier" pour "Sites web et applications partenaires", vous verrez une page plus ou moins vide, selon vos comptes :
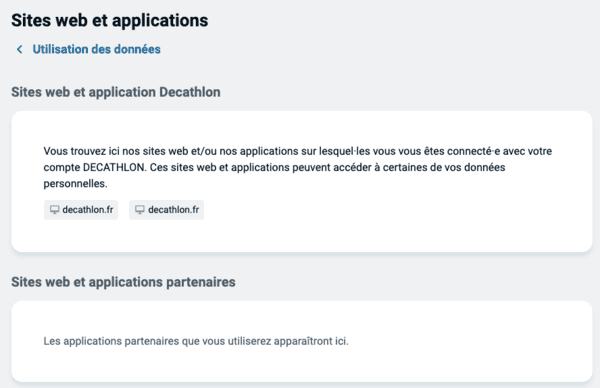
Toujours des partenaires, et pourtant "Vos données ne sont destinées qu'à Decathlon".
Je n'ai pas de "Sites web et applications partenaires", pas de partage supplémentaire de données personnelles. Si vous cliquez maintenant sur "Modifier" pour "Déduction des préférences par Decathlon" :
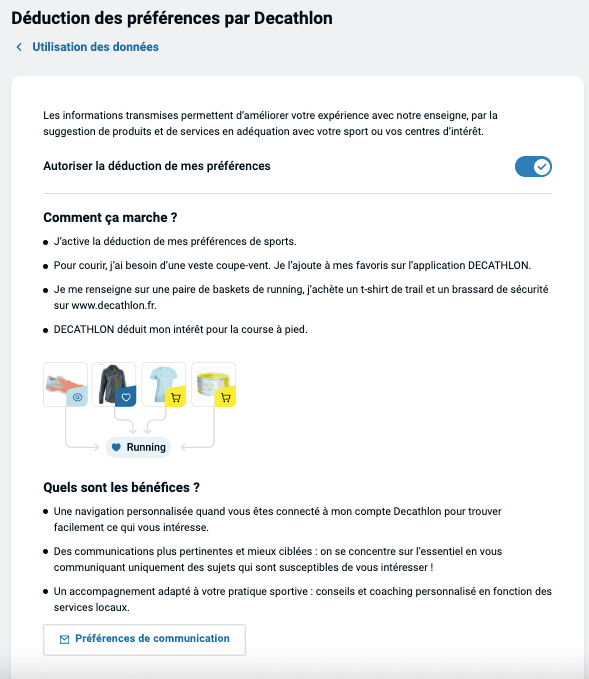
L'option est pré-cochée, un classique !
Si vous vous rappelez, j'ai déjà désactivé mon historique de navigation ainsi que toutes les communications, comment est-ce que Decathlon peut se permettre de continuer à "déduire" mes préférences ? Mystère... Cliquons maintenant sur "Modifier" pour "Partage avec Valiuz" :
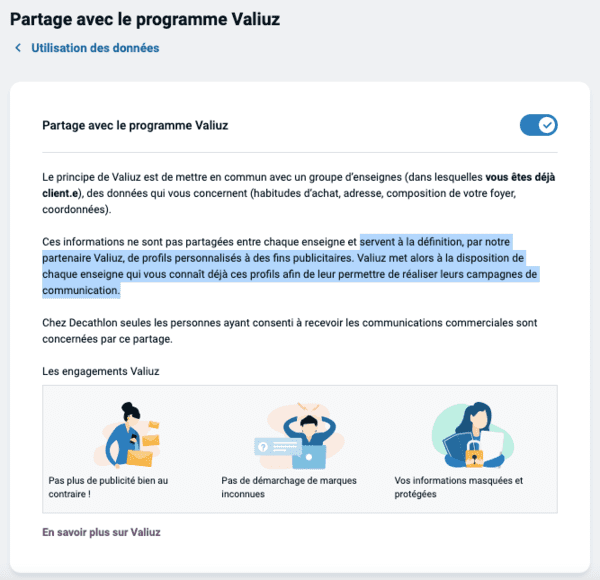
Nouvelle option pré-cochée, pour partager vos données avec "un groupe d'enseignes".
On rappelle l'engagement de Decathlon lors de votre inscription :
Où vont vos données ? Chez nous, et c'est tout ! Il est rare que l'on apprécie que notre email soit vendu à d'autres enseignes. Rassurez-vous, ce n'est pas la politique de la maison. Vos données ne sont destinées qu'à Decathlon : notre service logistique, notre centre de relation clients, etc. Si nos sous-traitants traitent vos données, ils ne le font qu’à des fins statistiques, de dédoublonnement ou de correction, et sur instructions de DECATHLON.
Donc ce n'est pas la politique de la maison, mais c'est quand même ce que fait Decathlon, pour vos données personnelles les plus intéressantes : habitudes d’achat, adresse, composition de votre foyer, coordonnées. Vous avez beau avoir tout refusé, ce partage est activé par défaut, partage avec un groupe d'enseignes mystérieux. Aussi, via @Eriatolc, vous apprendrez que Decathlon vous enrôle automatiquement dans son programme fidélité.
En parlant de Valiuz, c'est un partenaire que j'avais déjà bloqué :
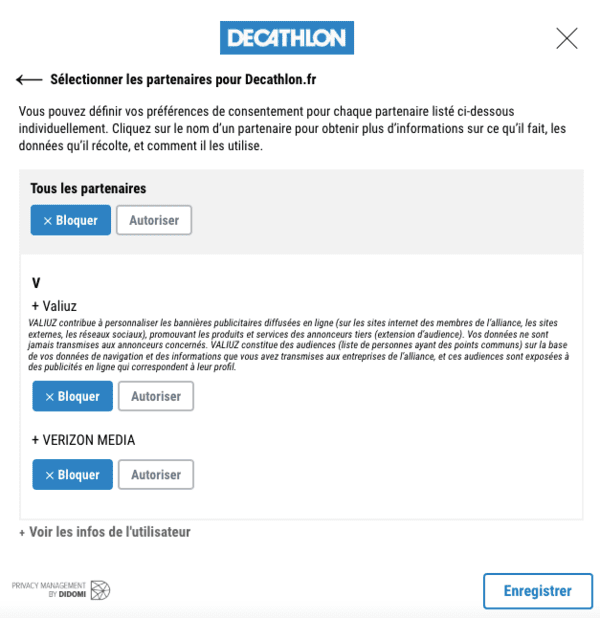
Un partenaire déjà bloqué, mais avec qui Decathlon partage quand même vos données personnelles.
Le texte de la bannière de consentement est intéressant d'ailleurs, Valiuz se permettant de faire beaucoup avec vos données personnelles :
VALIUZ contribue à personnaliser les bannières publicitaires diffusées en ligne (sur les sites internet des membres de l'alliance, les sites externes, les réseaux sociaux), promouvant les produits et services des annonceurs tiers (extension d'audience). Vos données ne sont jamais transmises aux annonceurs concernés. VALIUZ constitue des audiences (liste de personnes ayant des points communs) sur la base de vos données de navigation et des informations que vous avez transmises aux entreprises de l'alliance, et ces audiences sont exposées à des publicités en ligne qui correspondent à leur profil.
Sur la page "Vos données & Decathlon", section "NOS COMMUNICATIONS SONT ADAPTEES À VOTRE VIE SPORTIVE", vous pourrez en savoir un peu plus sur cette "extension d'audience" :

Valiuz vend des campagnes publicitaires basées sur votre profil, sur des sites web qui n'appartiennent pas à l'alliance ("extension d'audience"), un bien joli business !
En savoir plus sur Valiuz
Pour mieux comprendre ce que fait Valiuz, j'ai donc cliqué sur le lien "En savoir plus sur Valiuz" depuis la page "Partage avec le programme Valiuz" de Decathlon. Me voici sur le site Valiuz, et voici la liste des membres de l'alliance : Auchan, Boulanger, Kiabi, Leroy Merlin, Norauto, Flunch, 3 brasseurs, Alinea, Top Office, Saint Maclou, Tape à l'oeil, Jules, Electro Depot, Rouge-Gorge, Nhood, Chronodrive, Grain de Malice, Bizzbee, Decathlon, Oney, "et bien d'autres à venir !"
Sur la page "Comment ça fonctionne", Valiuz vous vend l'utilité de ses e-mails ciblés :

"Je suis une famille avec 2 enfants, qui a un intérêt marqué pour les produits frais & hi-tech pour la cuisine."
Valiuz vous vend aussi l'utilité de ses SMS et notifications ciblés :
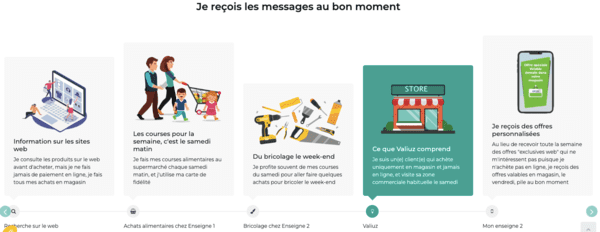
"Je suis un(e) client(e) qui achète uniquement en magasin et jamais en ligne, et visite sa zone commerciale habituelle le samedi."
Mais Valiuz cherche également à vous rassurer :
Vos données ne sont, et ne seront jamais, ni revendues, ni échangées entre les enseignes partenaires de Valiuz. Seule Valiuz a accès aux données qui lui sont transmises par ses partenaires.
Valiuz créé un pot commun de vos données personnelles sur les différentes enseignes partenaires, pour mieux les exploiter :

Valiuz permet à Decathlon et aux autres enseignes partenaires de mieux vous cibler.
Qu'en est-il de l'identifiant unique créé par Valiuz ? La page "Mes droits" donne un peu de détail :

J'espère que vous êtes rassuré, toutes vos données identifiantes (votre adresse e-mail, votre adresse postale ou encore votre numéro de téléphone) sont hachés avant d'être comparés entre enseignes. Pour les petits malins d'entre vous qui se serviraient d'un système d'alias e-mail type SimpleLogin, Valiuz vous retrouvera grâce à votre numéro de téléphone (obligatoire à l'inscription) et à votre adresse postale (recommandée si vous avez commandé).
Au passage, le hash de votre adresse e-mail est probablement déjà connu des grandes plateformes et de toute l'adtech. Est-ce "sécurisé" comme l'indique Valiuz ?

"Valiuz assure une sécurité maximale".
On peut en douter, allez faire un tour sur le site "Have I been pwned" et vérifiez votre adresse e-mail, il est probable qu'elle ait fuitée (tout comme votre numéro de téléphone). Si c'est le cas, une personne ayant accès à la fuite pourra remonter à votre adresse e-mail depuis son hash.
Toujours sur la page "Mes droits", vous pouvez vous opposer à l'utilisation de vos informations liées à vos achats (en magasin et en ligne) dans le cadre de Valiuz :
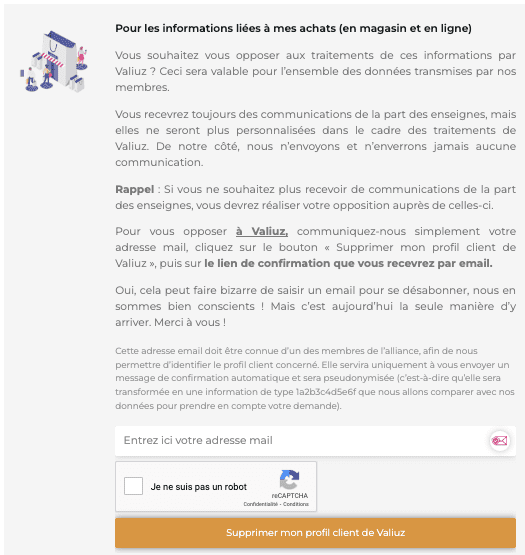
Renseignez votre e-mail pour ne pas être surveillé via votre e-mail.
Pourquoi donner son adresse e-mail ? Ce serait la seule manière de vous "désabonner" :
Cette adresse email doit être connue d’un des membres de l’alliance, afin de nous permettre d’identifier le profil client concerné. Elle servira uniquement à vous envoyer un message de confirmation automatique et sera pseudonymisée (c’est-à-dire qu’elle sera transformée en une information de type 1a2b3c4d5e6f que nous allons comparer avec nos données pour prendre en compte votre demande).
En vrai, vous pouvez aussi décocher l'option "Partage avec le programme Valiuz" sur votre compte Decathlon. Mais il faudra le faire avec toutes les autres enseignes de l'alliance Valiuz pour lesquelles vous avez un compte, si tant est qu'elles proposent l'option :

Opposition au partage de mes données Decathlon à Valiuz vs opposition au service Valiuz d'une manière globale.
Lors de mon test en août dernier, il était possible de s'opposer au traitement des informations de navigation, au prix d'un magnifique dark pattern :
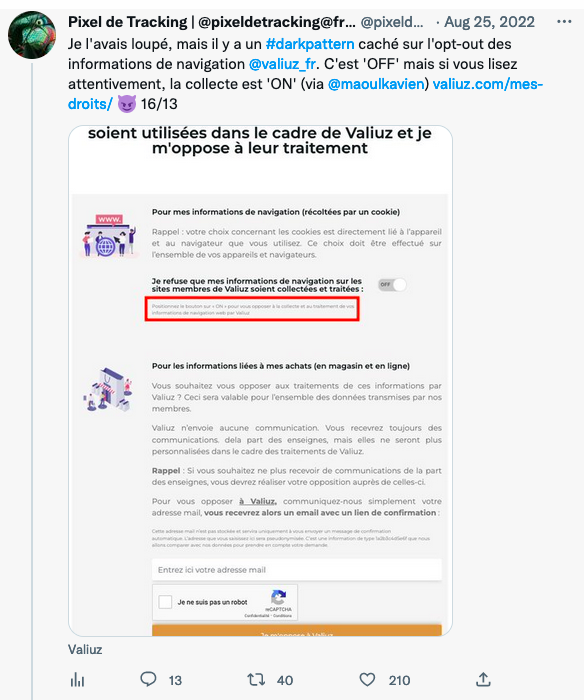
Quand c'est 'OFF', c'est 'ON'.
Alors comment faire pour bloquer le traitement des informations de votre navigation ? On en revient à la bannière de consentement initiale :

Le parcours du combattant.
pour refuser le cookie Valiuz, vous devez utiliser l’outil de gestion des cookies disponible sur le site internet de nos partenaires.
Ouf ! C'est donc déjà fait, dès le début de cet article. Il aurait néanmoins été intéressant de laisser l'utilisateur refuser cette surveillance directement depuis le site Valiuz, pour tous les sites de l'alliance. Vous devez maintenant cliquer sur "Tout refuser" sur la bannière de consentement de chacun des sites de l'alliance.
Et notez que lorsque Valiuz combine les informations liées à vos achats (en magasin et en ligne) avec les informations de votre navigation, cela fait beaucoup d'informations :

Pour mieux vous profiler, Valiuz récupère aussi "des données librement accessibles au public (open-data) ou issues de base de données fournies par des tiers (exemple: INSEE)."
Cadeau supplémentaire, les informations de votre navigation et le rapprochement avec les données détenues par les membres de l'alliance n'est pas opéré directement par Valiuz, il est effectué via l'adtech française Mediarithmics :

"Vos données ne sont destinées qu'à Decathlon", nouvel épisode.
Quelles bases légales pour les traitements de Valiuz ?
Question difficile, si l'on reprend les informations :
Valiuz se base sur le consentement (via la bannière cookies de Decathlon) pour :
- La personnalisation des bannières publicitaires diffusées en ligne (sur les sites internet des membres de l'alliance, les sites externes, les réseaux sociaux), promouvant les produits et services des annonceurs tiers (extension d'audience). VALIUZ constitue des audiences (liste de personnes ayant des points communs) sur la base de vos données de navigation et des informations que vous avez transmises aux entreprises de l'alliance, et ces audiences sont exposées à des publicités en ligne qui correspondent à leur profil.
Valiuz se base sur son intérêt légitime pour le reste, c'est à dire :
- Pour réaliser des analyses statistiques non individuelles permettant à ses entreprises partenaires de mieux comprendre les attentes de leur clientèle et d’y répondre en faisant évoluer leur activité.
- Pour améliorer la qualité des informations clients de ses entreprises partenaires et ainsi contribuer à leur mise à jour (exemple: identifier les personnes dont l’adresse postale est obsolète, pour arrêter de leur envoyer des communications).
- Pour segmenter les bases de données clients de ses entreprises partenaires et ainsi contribuer à améliorer la pertinence des communications qu’elles vous adressent.
On comprend mieux cette articulation dans la section "Quel est le service fourni par VALIUZ" sur la page "Politique données personnelles et cookies de l’Alliance" :

Intérêt légitime pour le profilage publicitaire, consentement pour les données de navigation et l'affichage de publicités ciblées.
Aussi, le message énigmatique de la bannière de consentement sur le site Decathlon fait maintenant sens :
Certains partenaires ne demandent pas votre consentement pour traiter vos données et se fient à leur intérêt commercial légitime. Vous pouvez révoquer votre consentement ou vous opposer au traitement des données fondé sur l'intérêt légitime à tout moment en cliquant sur « En savoir plus »
Sauf que l'opposition au traitement des données fondé sur l'intérêt légitime était un peu plus compliqué que de cliquer sur « En savoir plus », cette bannière est particulièrement malhonnête. Plus généralement, Decathlon semble avoir un problème avec la notion de consentement, comme en témoigne la page "Vos données & Decathlon", section "NOS COMMUNICATIONS SONT ADAPTEES À VOTRE VIE SPORTIVE" :

"[...] si et seulement si les personnes concernées ont consenti [...]", mais on se base quand même sur l'intérêt légitime.
Derrière Valiuz, le groupe Mulliez
Qui est derrière cette alliance "Valiuz" ? Si vous n'êtes pas un connaisseur du capitalisme à la française, vous ne devinerez pas forcément qu'Auchan, Decathlon ou Leroy Merlin appartiennent à la richissime famille Mulliez. L'article "Valiuz, le projet data aux 150 millions de cartes de fidélité du groupe Mulliez" (que vous pouvez lire grâce au mode "lecture" de votre navigateur), écrit en 2019, donne quelques informations :
- Valiuz touchait déjà 29 millions de foyers français.
- Il rassemblait donc plus de 150 millions de cartes de fidélité.
- Ce n'est pas la seule alliance, 3W.RelevanC (Casino) rassemblait 31 millions de consommateurs, l'article mentionne aussi RetailLink de Fnac-Darty.
- Mediarithmics renvoie les profils utilisateurs vers les Data Management Platforms (DMP) des différents membres de l'alliance, d'autres acteurs actech récupèrent donc vos données personnelles enrichies.
- Pour l'instant circonscrite à la galaxie Mulliez, l'initiative pourrait s'ouvrir à d'autres groupes dans les mois qui viennent. Notamment sur les verticales où les entités membres de l'AFM ne sont pas présentes, comme les télécoms, par exemple.
Si vous vous rappelez, Valiuz déclarait :
Vos données ne sont, et ne seront jamais, ni revendues, ni échangées entre les enseignes partenaires de Valiuz. Seule Valiuz a accès aux données qui lui sont transmises par ses partenaires.
Valiuz propose aussi une application de cashback, pour siphonner vos transactions bancaires
Valiuz récupère vos historiques d'achats sur le web et en magasin auprès des membres de l'alliance. Mais pourquoi ne pas récupérer toutes vos transactions bancaires ? Évidemment, si vous êtes un minimum concerné par votre vie privée, vous n'utiliserez pas ce genre d'applications, mais Valiuz propose une application de "cashback" appelé Naomi :
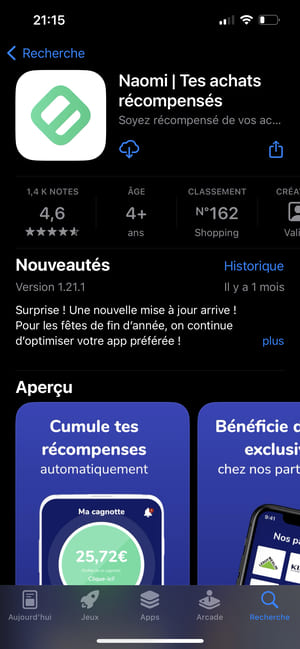
Cumuler des récompenses automatiquement, intéressant n'est-ce pas ?
À l'inscription, Naomi vous demande les accès à votre compte bancaire :

"Tes informations de connexion bancaire nous permettent simplement d'identifier tes achats pour verser tes gains."
Naomi n'a en effet pas accès aux identifiants bancaires, "seulement" à l'ensemble des transactions bancaires du client :

Confidentialité et sécurité, pourquoi s'inquiéter ?
La "politique de protection des données personnelles" de l'application Naomi est intéressante. On note que les études statistiques sur vos transactions bancaires se basent sur l'intérêt légitime de Naomi alias Valiuz :

Toujours la fameuse pseudonymisation, avec maintenant l'ensemble de vos transactions bancaires.
Vu la sensibilité des données récupérées, vous ne serez pas forcément rassuré de lire que Naomi passe par des sous-traitants pour de nombreuses actions :

"études statistiques, segmentation et profilage publicitaire à partir des données", effectué par des sous-traitants dont vous n'avez pas le nom.
Cerise sur le gâteau, Naomi travaille avec les rois du capitalisme de surveillance, Google et Facebook :
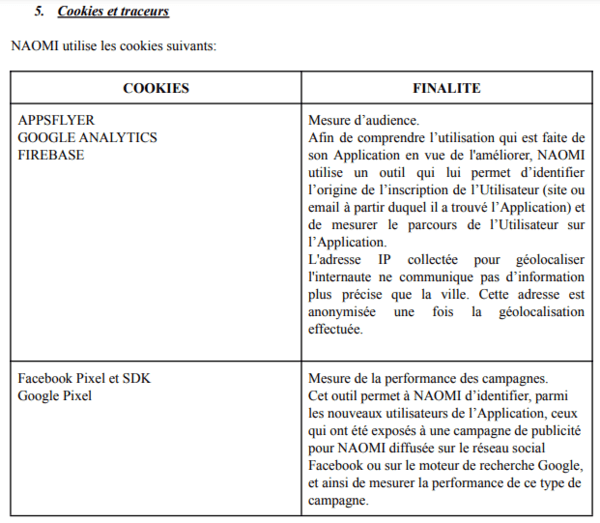
Les fameux "pixels", des vecteurs de tracking très efficaces.
Mais les transactions bancaires ne sont pas assez précises, Naomi veut savoir exactement ce que vous avez acheté, et vous propose donc de scanner les tickets de caisse :

Naomi récupère ainsi le détail des achats: nature du produit, magasins, date, montant.
Notez que, à la différence de Decathlon, la base légale du profilage pour l'alliance Valiuz est le consentement :

Vous avez de la chance, les achats ou paiements sensibles ou qui ne correspondent pas à un achat ne sont pas partagés par Naomi.
Comme le dit si joliment le compte Twitter de Valiuz :
Valiuz, mieux vous connaître pour mieux vous parler.
Le capitalisme de surveillance recrute
Convaincu par cet article élogieux, vous décidez d'aller sur la page Valiuz de Welcome to the Jungle et de lire les offres d'emplois. Si vous êtes dans l'opérationnel, vous pourriez être Account Manager Programmatique par exemple :

"Spécialisée dans la mise en place de modèles économiques autour de la data".
Si vous vous sentez l'âme d'un commercial, vous pourriez être Sales Manager - Retail Media :

"Valiuz Media, l’offre retail la plus puissante du marché : 18 enseignes complémentaires, 55 millions de clients encartés, 1,7 milliards de transactions omnicanales, 3 520 magasins en France."
Mais pourquoi travailler chez Valiuz me direz-vous ?

"[...] la plus large base data clients de France" ça fait rêver, non ?
Le mot de la fin, sur la page d'accueil de Valiuz, avec "Nos valeurs" :

"Nous ne commercialisons pas vos informations."
Texte intégral (5759 mots)
Les règles du jeu
En août dernier, je tweetais sur le parcours de l'enfer pour refuser la surveillance de Decathlon. À ce jour, c'est le tweet qui m'a valu le plus de succès avec 1760 Retweets et plus d'1 million d'impressions. Manifestement, ce n'était pas suffisant pour avoir droit à une réponse de Yann, le CM de Decathlon. Quelques mois après cet épisode, quels ont été les changements ? Étudions cela en détail.
Dès votre arrivée sur le site Decathlon vous êtes accueilli par une bannière "Cookies : Les règles du jeu" :
Les règles de Decathlon, celles de la loi ?
Vous êtes habitué à ces dark patterns et instinctivement, vous cliquez sur le bouton "Refuser et fermer" en haut à droite ? J'ai fait cela aussi... Lisez attentivement le texte :
Certains partenaires ne demandent pas votre consentement pour traiter vos données et se fient à leur intérêt commercial légitime. Vous pouvez révoquer votre consentement ou vous opposer au traitement des données fondé sur l'intérêt légitime à tout moment en cliquant sur « En savoir plus »
Qui sont ces partenaires ? Mystère... Comment s'opposer au traitement des données fondé sur l'intérêt légitime ? Le texte de Decathlon est incohérent car il n'y a pas de bouton « En savoir plus ». Essayons néanmoins en cliquant sur "Paramétrer vos cookies" :
"Bien sûr, la balle est dans votre camp, à vous d'accepter ou de refuser certains cookies pour choisir ceux qui restent sur le terrain".
La bannière ne parle pas d'intérêt légitime, vous pouvez encore cliquer sur "Refuser tout". Continuons donc l'investigation en cliquant sur "Voir nos partenaires" :
La longue liste des partenaires de Decathlon.
Decathlon aime partager vos données personnelles et travaille avec pas moins de 26 partenaires : AB Tasty, AT Internet, Awin, Bing (Microsoft), Content Square, Dynamics Yield, Easyence, Epsilon, Google, Hotjar, IAdvize, Idealo, Kelkoo, Lucky Orange, Meta (Facebook), Mobsuccess, Ogury, Pinterest, Rakuten advertising, RTB House, SpeedCurve, Target 2 Sell, Teads, Teester, Valiuz et Verizon Media.
Là aussi, vous pouvez cliquer sur "Bloquer" pour "Tous les partenaires", vous ne verrez aucune mention à l'intérêt légitime, ces partenaires se basent sur votre consentement. Le mystère demeure sur les "partenaires" se basant sur l'intérêt légitime, il semble à première vue qu'un simple clic sur "Refuser et fermer" en haut à droite de la bannière initiale soit suffisant.
Via le site Consent String Decoder, je vérifie néanmoins ma chaîne de consentement, une chaîne de caractère qui encode mes choix et qui doit être respecté par les partenaires de Decathlon :
Les variables purposeConsents et purposeLegitimateInterests sont vides, aucun partenaire de Decathlon n'a de base légale pour traiter mes données personnelles.
Après refus, vous êtes quand même traqué par iAdvize
Après avoir cliqué sur "Refuser et fermer", je lance Charles Proxy pour observer les requêtes envoyées par mon navigateur :
Surprise ! Decathlon n'est pas le seul destinataire de mes données personnelles.
iAdvize suit donc votre navigation, grâce aux paramètres url, sourceVisitorId et deviceId. Le paramètre cookieConsent interroge également, il est renseigné à unknown ! iAdvize c'est quoi ? Une fenêtre conversationnelle sur le site Decathlon, pour favoriser l'achat :
Sporty par iAdvize, toujours disponible pour observer votre comportement !
Si je reviens sur la bannière cookies pour vérifier mes choix, via "Gestion des cookies" (et non "Données personnelles") en pied de page :
Beaucoup d'amour pour "les cookies non nécessaires".
Puis, si je clique sur "Gérer mes cookies" et que je cherche mon choix pour iAdvize :
J'ai bien refusé la surveillance d'iAdvize, Decathlon ignore donc mon choix.
Notez que Decathlon et iAdvize pourraient arguer du fait qu'iAdvize ne dépose pas de cookies lorsque vous cliquez sur "Refuser et fermer". Sauf que ce dernier vous identifie via les identifiants sourceVisitorId et deviceId, un fingerprint est bien un identifiant utilisateur et votre consentement est nécessaire :
La CNIL est explicite sur l'application de la directive ePrivacy, le "fingerprinting" est concerné.
L'inscription, avec un partenaire mystérieux mais un engagement fort
Vous souhaitez maintenant commander chez Decathlon ? Vous allez devoir vous inscrire :
En équipe ! Decathlon vous propose son offre avec "ses partenaires".
Vous avez déjà refusé la surveillance de 26 partenaires, pourquoi Decathlon vous reparle-t-il de "partenaires" ? Il semble que la référence soit plutôt aux vendeurs de sa marketplace, mais on aurait aimé que Decathlon soit plus explicite. Renseignez une adresse e-mail, puis un mot de passe :
Un "partenaire" de plus, Valiuz (retenez ce nom pour la suite).
Vous n'avez pas forcément envie de recevoir des newsletters Decathlon, via le mystérieux partenaire "Valiuz", ne cochez donc pas la case et cliquez simplement sur "Confirmer et continuer" :
Le numéro de téléphone est obligatoire, et bien sûr, ce n'est que pour vous contacter au sujet de votre commande ;-)
Vous pouvez également renseigner vos sports favoris. Sur la même page, Decathlon communique sur la manière dont vos données sont utilisées, pour la création de compte tout d'abord :
Avec des mots forts :
Où vont vos données ? Chez nous, et c'est tout ! Il est rare que l'on apprécie que notre email soit vendu à d'autres enseignes. Rassurez-vous, ce n'est pas la politique de la maison. Vos données ne sont destinées qu'à Decathlon : notre service logistique, notre centre de relation clients, etc. Si nos sous-traitants traitent vos données, ils ne le font qu’à des fins statistiques, de dédoublonnement ou de correction, et sur instructions de DECATHLON.
Decathlon communique avec les mêmes mots sur la manière dont vos données sont utilisées pour une communication :
On note la confiance du sportif :
Enfin, si malgré l'intérêt que nous portons à la protection de vos données vous n'étiez pas satisfait, vous pouvez formuler une réclamation auprès de la CNIL.
Ces engagements concernent la création de compte et les communications de Decathlon. Mais comme on l'a vu précédemment, avec votre consentement (excepté pour iAdvize), Decathlon peux partager vos données personnelles avec pas moins de 26 partenaires pour diverses finalités : "Publicités personnalisées", "Mesure d'audience et de performance des contenus" et "Personnalisation du contenu".
Certaines de vos données personnelles ne sont donc pas destinées qu'à Decathlon...
À la recherche des paramètres de vie privée
Étant méfiant, je souhaite vérifier si Decathlon a correctement protégé mon compte, avec les options les plus protectrices côté vie privée. Pour cela, je me rends sur "Mon tableau de bord" :
L'accès le plus rapide vers les paramètres de vie privée ?!
Dans la section "Gérer mon compte Decathlon" du menu, caché dans "Préférences", je découvre 2 entrées intéressantes, "Historique de navigation" et "Données personnelles" :
Victoire ?
Cliquons sur "Historique de navigation" :
Toujours "l'amélioration de l'expérience sur le site".
Lorsque vous décochez l'option, on vous explique que vous ne verrez plus les articles déjà consulté :
Cette option "Historique de navigation" est en effet bien cachée.
Si je clique maintenant sur "Données personnelles", je me retrouve sur la page "Vos données & Decathlon". Afin d'être sûr de ne pas louper d'options, je clique sur l'entrée "Sécurité" du menu de la page "Mon tableau de bord". Et là, surprise, un deuxième tableau de bord :
"Gérez toutes vos données à un seul endroit !" Si vous le trouvez ;-)
Là vous pourrez donner encore un peu plus d'informations à Decathlon, notamment vos mensurations :
Le capitalisme de surveillance s'attaque à votre corps.
L'idée ? Vous proposer des produits et services adaptés à votre morphologie :
Decathlon vous accompagne dans votre discipline, ça fait envie non ?
Regardons ensuite les "Préférences de communication" :
Évidemment, quasi toutes les communications sont pré-cochées.
Si vous cliquez sur "Vous désabonner de l'ensemble des informations", on vous demandera si vous êtes vraiment sûr :
Après tous ces efforts, on se demande si vous souhaitez vraiment louper nos communications commerciales.
Finalement, allons sur l'entrée "Utilisation des données" du menu :
Une autre page pertinente concernant votre vie privée, bien cachée n'est-ce pas ?
Si vous cliquez sur "Modifier" pour "Sites web et applications partenaires", vous verrez une page plus ou moins vide, selon vos comptes :
Toujours des partenaires, et pourtant "Vos données ne sont destinées qu'à Decathlon".
Je n'ai pas de "Sites web et applications partenaires", pas de partage supplémentaire de données personnelles. Si vous cliquez maintenant sur "Modifier" pour "Déduction des préférences par Decathlon" :
L'option est pré-cochée, un classique !
Si vous vous rappelez, j'ai déjà désactivé mon historique de navigation ainsi que toutes les communications, comment est-ce que Decathlon peut se permettre de continuer à "déduire" mes préférences ? Mystère... Cliquons maintenant sur "Modifier" pour "Partage avec Valiuz" :
Nouvelle option pré-cochée, pour partager vos données avec "un groupe d'enseignes".
On rappelle l'engagement de Decathlon lors de votre inscription :
Où vont vos données ? Chez nous, et c'est tout ! Il est rare que l'on apprécie que notre email soit vendu à d'autres enseignes. Rassurez-vous, ce n'est pas la politique de la maison. Vos données ne sont destinées qu'à Decathlon : notre service logistique, notre centre de relation clients, etc. Si nos sous-traitants traitent vos données, ils ne le font qu’à des fins statistiques, de dédoublonnement ou de correction, et sur instructions de DECATHLON.
Donc ce n'est pas la politique de la maison, mais c'est quand même ce que fait Decathlon, pour vos données personnelles les plus intéressantes : habitudes d’achat, adresse, composition de votre foyer, coordonnées. Vous avez beau avoir tout refusé, ce partage est activé par défaut, partage avec un groupe d'enseignes mystérieux. Aussi, via @Eriatolc, vous apprendrez que Decathlon vous enrôle automatiquement dans son programme fidélité.
En parlant de Valiuz, c'est un partenaire que j'avais déjà bloqué :
Un partenaire déjà bloqué, mais avec qui Decathlon partage quand même vos données personnelles.
Le texte de la bannière de consentement est intéressant d'ailleurs, Valiuz se permettant de faire beaucoup avec vos données personnelles :
VALIUZ contribue à personnaliser les bannières publicitaires diffusées en ligne (sur les sites internet des membres de l'alliance, les sites externes, les réseaux sociaux), promouvant les produits et services des annonceurs tiers (extension d'audience). Vos données ne sont jamais transmises aux annonceurs concernés. VALIUZ constitue des audiences (liste de personnes ayant des points communs) sur la base de vos données de navigation et des informations que vous avez transmises aux entreprises de l'alliance, et ces audiences sont exposées à des publicités en ligne qui correspondent à leur profil.
Sur la page "Vos données & Decathlon", section "NOS COMMUNICATIONS SONT ADAPTEES À VOTRE VIE SPORTIVE", vous pourrez en savoir un peu plus sur cette "extension d'audience" :
Valiuz vend des campagnes publicitaires basées sur votre profil, sur des sites web qui n'appartiennent pas à l'alliance ("extension d'audience"), un bien joli business !
En savoir plus sur Valiuz
Pour mieux comprendre ce que fait Valiuz, j'ai donc cliqué sur le lien "En savoir plus sur Valiuz" depuis la page "Partage avec le programme Valiuz" de Decathlon. Me voici sur le site Valiuz, et voici la liste des membres de l'alliance : Auchan, Boulanger, Kiabi, Leroy Merlin, Norauto, Flunch, 3 brasseurs, Alinea, Top Office, Saint Maclou, Tape à l'oeil, Jules, Electro Depot, Rouge-Gorge, Nhood, Chronodrive, Grain de Malice, Bizzbee, Decathlon, Oney, "et bien d'autres à venir !"
Sur la page "Comment ça fonctionne", Valiuz vous vend l'utilité de ses e-mails ciblés :
"Je suis une famille avec 2 enfants, qui a un intérêt marqué pour les produits frais & hi-tech pour la cuisine."
Valiuz vous vend aussi l'utilité de ses SMS et notifications ciblés :
"Je suis un(e) client(e) qui achète uniquement en magasin et jamais en ligne, et visite sa zone commerciale habituelle le samedi."
Mais Valiuz cherche également à vous rassurer :
Vos données ne sont, et ne seront jamais, ni revendues, ni échangées entre les enseignes partenaires de Valiuz. Seule Valiuz a accès aux données qui lui sont transmises par ses partenaires.
Valiuz créé un pot commun de vos données personnelles sur les différentes enseignes partenaires, pour mieux les exploiter :
Valiuz permet à Decathlon et aux autres enseignes partenaires de mieux vous cibler.
Qu'en est-il de l'identifiant unique créé par Valiuz ? La page "Mes droits" donne un peu de détail :
J'espère que vous êtes rassuré, toutes vos données identifiantes (votre adresse e-mail, votre adresse postale ou encore votre numéro de téléphone) sont hachés avant d'être comparés entre enseignes. Pour les petits malins d'entre vous qui se serviraient d'un système d'alias e-mail type SimpleLogin, Valiuz vous retrouvera grâce à votre numéro de téléphone (obligatoire à l'inscription) et à votre adresse postale (recommandée si vous avez commandé).
Au passage, le hash de votre adresse e-mail est probablement déjà connu des grandes plateformes et de toute l'adtech. Est-ce "sécurisé" comme l'indique Valiuz ?
"Valiuz assure une sécurité maximale".
On peut en douter, allez faire un tour sur le site "Have I been pwned" et vérifiez votre adresse e-mail, il est probable qu'elle ait fuitée (tout comme votre numéro de téléphone). Si c'est le cas, une personne ayant accès à la fuite pourra remonter à votre adresse e-mail depuis son hash.
Toujours sur la page "Mes droits", vous pouvez vous opposer à l'utilisation de vos informations liées à vos achats (en magasin et en ligne) dans le cadre de Valiuz :
Renseignez votre e-mail pour ne pas être surveillé via votre e-mail.
Pourquoi donner son adresse e-mail ? Ce serait la seule manière de vous "désabonner" :
Cette adresse email doit être connue d’un des membres de l’alliance, afin de nous permettre d’identifier le profil client concerné. Elle servira uniquement à vous envoyer un message de confirmation automatique et sera pseudonymisée (c’est-à-dire qu’elle sera transformée en une information de type 1a2b3c4d5e6f que nous allons comparer avec nos données pour prendre en compte votre demande).
En vrai, vous pouvez aussi décocher l'option "Partage avec le programme Valiuz" sur votre compte Decathlon. Mais il faudra le faire avec toutes les autres enseignes de l'alliance Valiuz pour lesquelles vous avez un compte, si tant est qu'elles proposent l'option :
Opposition au partage de mes données Decathlon à Valiuz vs opposition au service Valiuz d'une manière globale.
Lors de mon test en août dernier, il était possible de s'opposer au traitement des informations de navigation, au prix d'un magnifique dark pattern :
Quand c'est 'OFF', c'est 'ON'.
Alors comment faire pour bloquer le traitement des informations de votre navigation ? On en revient à la bannière de consentement initiale :
Le parcours du combattant.
pour refuser le cookie Valiuz, vous devez utiliser l’outil de gestion des cookies disponible sur le site internet de nos partenaires.
Ouf ! C'est donc déjà fait, dès le début de cet article. Il aurait néanmoins été intéressant de laisser l'utilisateur refuser cette surveillance directement depuis le site Valiuz, pour tous les sites de l'alliance. Vous devez maintenant cliquer sur "Tout refuser" sur la bannière de consentement de chacun des sites de l'alliance.
Et notez que lorsque Valiuz combine les informations liées à vos achats (en magasin et en ligne) avec les informations de votre navigation, cela fait beaucoup d'informations :
Pour mieux vous profiler, Valiuz récupère aussi "des données librement accessibles au public (open-data) ou issues de base de données fournies par des tiers (exemple: INSEE)."
Cadeau supplémentaire, les informations de votre navigation et le rapprochement avec les données détenues par les membres de l'alliance n'est pas opéré directement par Valiuz, il est effectué via l'adtech française Mediarithmics :
"Vos données ne sont destinées qu'à Decathlon", nouvel épisode.
Quelles bases légales pour les traitements de Valiuz ?
Question difficile, si l'on reprend les informations :
Valiuz se base sur le consentement (via la bannière cookies de Decathlon) pour :
- La personnalisation des bannières publicitaires diffusées en ligne (sur les sites internet des membres de l'alliance, les sites externes, les réseaux sociaux), promouvant les produits et services des annonceurs tiers (extension d'audience). VALIUZ constitue des audiences (liste de personnes ayant des points communs) sur la base de vos données de navigation et des informations que vous avez transmises aux entreprises de l'alliance, et ces audiences sont exposées à des publicités en ligne qui correspondent à leur profil.
Valiuz se base sur son intérêt légitime pour le reste, c'est à dire :
- Pour réaliser des analyses statistiques non individuelles permettant à ses entreprises partenaires de mieux comprendre les attentes de leur clientèle et d’y répondre en faisant évoluer leur activité.
- Pour améliorer la qualité des informations clients de ses entreprises partenaires et ainsi contribuer à leur mise à jour (exemple: identifier les personnes dont l’adresse postale est obsolète, pour arrêter de leur envoyer des communications).
- Pour segmenter les bases de données clients de ses entreprises partenaires et ainsi contribuer à améliorer la pertinence des communications qu’elles vous adressent.
On comprend mieux cette articulation dans la section "Quel est le service fourni par VALIUZ" sur la page "Politique données personnelles et cookies de l’Alliance" :
Intérêt légitime pour le profilage publicitaire, consentement pour les données de navigation et l'affichage de publicités ciblées.
Aussi, le message énigmatique de la bannière de consentement sur le site Decathlon fait maintenant sens :
Certains partenaires ne demandent pas votre consentement pour traiter vos données et se fient à leur intérêt commercial légitime. Vous pouvez révoquer votre consentement ou vous opposer au traitement des données fondé sur l'intérêt légitime à tout moment en cliquant sur « En savoir plus »
Sauf que l'opposition au traitement des données fondé sur l'intérêt légitime était un peu plus compliqué que de cliquer sur « En savoir plus », cette bannière est particulièrement malhonnête. Plus généralement, Decathlon semble avoir un problème avec la notion de consentement, comme en témoigne la page "Vos données & Decathlon", section "NOS COMMUNICATIONS SONT ADAPTEES À VOTRE VIE SPORTIVE" :
"[...] si et seulement si les personnes concernées ont consenti [...]", mais on se base quand même sur l'intérêt légitime.
Derrière Valiuz, le groupe Mulliez
Qui est derrière cette alliance "Valiuz" ? Si vous n'êtes pas un connaisseur du capitalisme à la française, vous ne devinerez pas forcément qu'Auchan, Decathlon ou Leroy Merlin appartiennent à la richissime famille Mulliez. L'article "Valiuz, le projet data aux 150 millions de cartes de fidélité du groupe Mulliez" (que vous pouvez lire grâce au mode "lecture" de votre navigateur), écrit en 2019, donne quelques informations :
- Valiuz touchait déjà 29 millions de foyers français.
- Il rassemblait donc plus de 150 millions de cartes de fidélité.
- Ce n'est pas la seule alliance, 3W.RelevanC (Casino) rassemblait 31 millions de consommateurs, l'article mentionne aussi RetailLink de Fnac-Darty.
- Mediarithmics renvoie les profils utilisateurs vers les Data Management Platforms (DMP) des différents membres de l'alliance, d'autres acteurs actech récupèrent donc vos données personnelles enrichies.
- Pour l'instant circonscrite à la galaxie Mulliez, l'initiative pourrait s'ouvrir à d'autres groupes dans les mois qui viennent. Notamment sur les verticales où les entités membres de l'AFM ne sont pas présentes, comme les télécoms, par exemple.
Si vous vous rappelez, Valiuz déclarait :
Vos données ne sont, et ne seront jamais, ni revendues, ni échangées entre les enseignes partenaires de Valiuz. Seule Valiuz a accès aux données qui lui sont transmises par ses partenaires.
Valiuz propose aussi une application de cashback, pour siphonner vos transactions bancaires
Valiuz récupère vos historiques d'achats sur le web et en magasin auprès des membres de l'alliance. Mais pourquoi ne pas récupérer toutes vos transactions bancaires ? Évidemment, si vous êtes un minimum concerné par votre vie privée, vous n'utiliserez pas ce genre d'applications, mais Valiuz propose une application de "cashback" appelé Naomi :
Cumuler des récompenses automatiquement, intéressant n'est-ce pas ?
À l'inscription, Naomi vous demande les accès à votre compte bancaire :
"Tes informations de connexion bancaire nous permettent simplement d'identifier tes achats pour verser tes gains."
Naomi n'a en effet pas accès aux identifiants bancaires, "seulement" à l'ensemble des transactions bancaires du client :
Confidentialité et sécurité, pourquoi s'inquiéter ?
La "politique de protection des données personnelles" de l'application Naomi est intéressante. On note que les études statistiques sur vos transactions bancaires se basent sur l'intérêt légitime de Naomi alias Valiuz :
Toujours la fameuse pseudonymisation, avec maintenant l'ensemble de vos transactions bancaires.
Vu la sensibilité des données récupérées, vous ne serez pas forcément rassuré de lire que Naomi passe par des sous-traitants pour de nombreuses actions :
"études statistiques, segmentation et profilage publicitaire à partir des données", effectué par des sous-traitants dont vous n'avez pas le nom.
Cerise sur le gâteau, Naomi travaille avec les rois du capitalisme de surveillance, Google et Facebook :
Les fameux "pixels", des vecteurs de tracking très efficaces.
Mais les transactions bancaires ne sont pas assez précises, Naomi veut savoir exactement ce que vous avez acheté, et vous propose donc de scanner les tickets de caisse :
Naomi récupère ainsi le détail des achats: nature du produit, magasins, date, montant.
Notez que, à la différence de Decathlon, la base légale du profilage pour l'alliance Valiuz est le consentement :
Vous avez de la chance, les achats ou paiements sensibles ou qui ne correspondent pas à un achat ne sont pas partagés par Naomi.
Comme le dit si joliment le compte Twitter de Valiuz :
Valiuz, mieux vous connaître pour mieux vous parler.
Le capitalisme de surveillance recrute
Convaincu par cet article élogieux, vous décidez d'aller sur la page Valiuz de Welcome to the Jungle et de lire les offres d'emplois. Si vous êtes dans l'opérationnel, vous pourriez être Account Manager Programmatique par exemple :
"Spécialisée dans la mise en place de modèles économiques autour de la data".
Si vous vous sentez l'âme d'un commercial, vous pourriez être Sales Manager - Retail Media :
"Valiuz Media, l’offre retail la plus puissante du marché : 18 enseignes complémentaires, 55 millions de clients encartés, 1,7 milliards de transactions omnicanales, 3 520 magasins en France."
Mais pourquoi travailler chez Valiuz me direz-vous ?
"[...] la plus large base data clients de France" ça fait rêver, non ?
Le mot de la fin, sur la page d'accueil de Valiuz, avec "Nos valeurs" :
"Nous ne commercialisons pas vos informations."
27.11.2022 à 16:46
Guerlain (LVMH) : luxe et surveillance
Une surveillance publicitaire toujours plus intrusive
En dépit de la règlementation (RGPD, ePrivacy, CCPA), des protections navigateurs (Firefox, Safari ou Brave), des bloqueurs de publicité sur navigateur (uBlock Origin) ou via service DNS (NextDNS, Adguard ou Pi-hole), la surveillance publicitaire n'a pas diminuée. Elle a muté pour contourner vos protections.
L'accélérateur de cette évolution ? Facebook évidemment, avec ses "signaux résilients", lui permettant de siphonner une large part des données générées par vos activités en ligne et hors-ligne. Le cookie tiers comme vecteur de surveillance étant en voie de disparition (Google Chrome est l'exception), il fallait trouver de nouveaux vecteurs de surveillance, qui ne puissent être simplement réinitialisés par les internautes. Prenant pour inspiration des "champions" de l'adtech tels que Criteo, Facebook incite les annonceurs à lui transmettre votre e-mail, votre nom, votre numéro de téléphone ou votre adresse postale : des "signaux résilients".
Si de nombreux acteurs de l'adtech (Liveramp, Criteo) vous identifient depuis longtemps via votre e-mail, le phénomène est relativement nouveau chez les grandes plateformes publicitaires. L'étude "Leaky Forms: A Study of Email and Password Exfiltration Before Form Submission" illustrait l'étendue des fuites d'e-mail sur le web, vers des acteurs de l'adtech, mais aussi vers Facebook et TikTok.
Comment votre e-mail pourrait-il fuiter vers ces grandes plateformes ? C'est ce que nous allons découvrir avec Guerlain, un des fleurons du luxe à la française, et propriété du groupe LVMH.
Avant même la création de compte Guerlain, le hash de votre e-mail fuite déjà vers Pinterest
Pour ce test, naviguons sur le site Guerlain, avec l'outil Charles Proxy activé, et cliquons exceptionnellement sur "Accepter et fermer" à l'affichage de la bannière de consentement (au crédit de Guerlain, je n'ai pas noté de fuites de hash e-mail si refus) :
"Améliorer votre expérience et vous proposer des services et des communications adaptés à vos centres d’intérêts", message en apparence inoffensif.
Puis, naviguons sur la page de création de compte Guerlain, et commençons à renseigner le formulaire :

Ces données personnelles ne devraient concerner que Guerlain, n'est-ce pas ?
Regardons ce qui se passe sur Charles Proxy lorsque vous renseignez votre e-mail, avant même de confirmer l'e-mail :

Remarquez une étrange requête vers le réseau social Pinterest.
Le paramètre pd de la requête vers Pinterest contient un autre paramètre em, constitué d'une longue chaine de caractère en apparence indéchiffrable. La documentation de Pinterest pour les annonceurs donne la réponse :
pd: Partner data.
em: hashed email address value.
Guerlain fuite donc un hash de votre adresse e-mail à Pinterest avant même que vous n'ayiez confirmé la création de votre compte ! Ce service s'appelle en fait "Enhanced Match" (la signification de em), j'en avait parlé en mai dernier :

Pas de cookies tiers ? Pas de problème !
Mais ne vous inquiétez pas, Pinterest utilise un hash de votre adresse e-mail, et la connexion vers Pinterest est sécurisée, votre vie privée est protégée !
Permettre à des sites web de fuiter votre e-mail, et prétendre le faire pour protéger votre vie privée !
La réalité, c'est que la correspondance entre votre e-mail et son hash circule déjà probablement largement et que des sociétés se font de l'argent dessus.
Comment vérifier vous-même si Guerlain fuite un hash de votre e-mail à Pinterest ? Renseignez votre e-mail sur ce site, en sélectionnant la bonne fonction de hachage (souvent SHA256) :
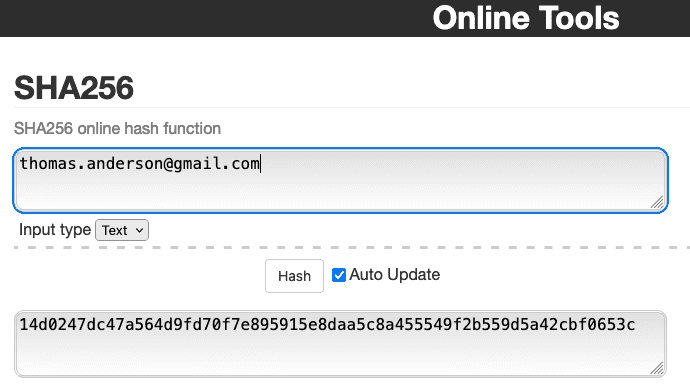
Bienvenue dans la matrice.
Bingo, la valeur chiffrée 14d0247dc47a564d9fd70f7e895915e8daa5c8a455549f2b559d5a42cbf0653c correspond au champs em envoyé à Pinterest.
Notez que lorsque l'annonceur envoie directement des données clients à Pinterest, celui-ci n'est pas si regardant sur l'e-mail :
email: We support both hashed (SHA256, SHA1, MD5) and cleartext customer data fields.
Confirmez la création du compte, et dites adieu à vos données personnelles
Je finis maintenant de remplir le formulaire, et je clique sur 'Confirmer'. Les fuites de données personnelles y sont massives :
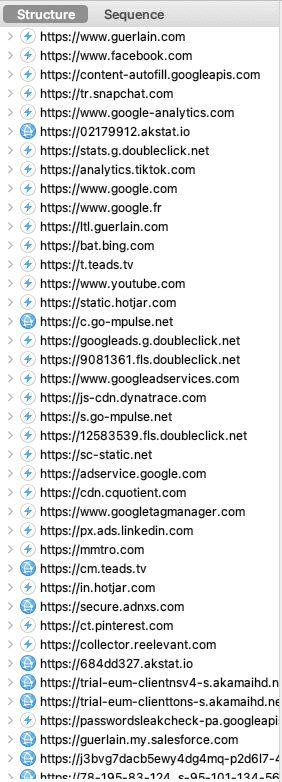
Notons déjà l'usage illicite de Google Analytics (si Guerlain souhaitait continuer à utiliser Google Analytics, il lui faudrait suivre ces recommandations de la CNIL).
En zoomant sur les paramètres envoyés à Google Analytics, on note le même hash de votre e-mail (SHA256), envoyé via le paramètre cd11 (une dimension 'custom', que Guerlain a donc pris la liberté de créer spécialement pour l'occasion). Il se trouve que la pratique est interdite par Google Analytics (si seulement Google appliquait son règlement) :
Pour protéger la confidentialité des utilisateurs, les règles Google interdisent l'envoi de données que nous pourrions utiliser comme des informations permettant d'identifier personnellement l'utilisateur ou considérer comme telles.
Vous pourriez argumenter : il s'agit d'un hash de mon e-mail, pas de mon e-mail en clair (comme si Google ne connaissait pas déjà votre e-mail et donc son hash). Sauf que Google a pris soin d'interdire également l'envoi de hash à Google Analytics :

Guerlain viole les règles de Google Analytics pour mieux vous surveiller, au calme.
Avec Guerlain, la surveillance est américaine mais elle est aussi chinoise puisque le même hash de votre e-mail fuite vers TikTok (la télécommande magique de Xi Jinping) :
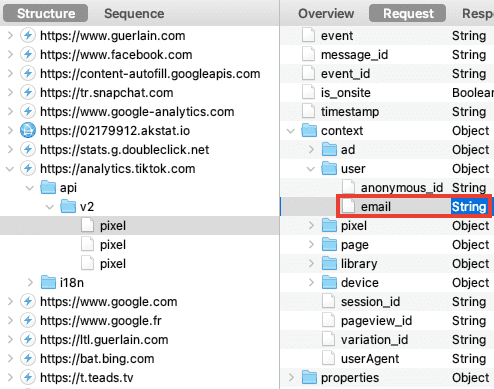
TikTok est plus transparent, la variable s'appelle email.
Cette fuite est permise grâce à la fonctionnalité "Advanced Matching" de TikTok :
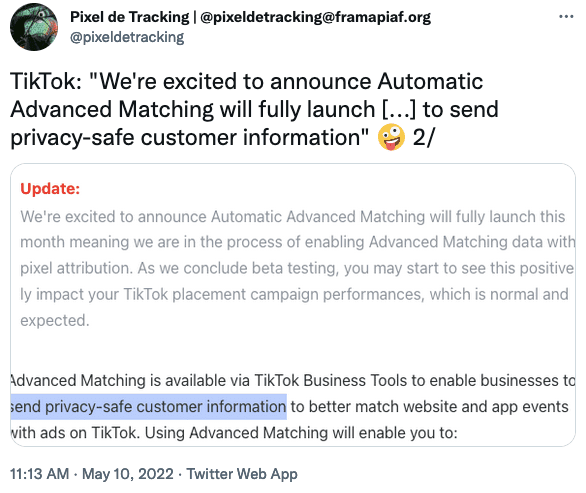
Bien sur, côté vie privée tout est étudié, fingerprinting si pas de match :

"Privacy Safe", par TikTok.
Le hachage SHA256, où la baguette magique de la protection de la vie privée :

TikTok n'est pas capable d'identifier les clients qui ne sont pas utilisateurs de TikTok, sauf que TikTok aspire les carnets d'adresses de ses utilisateurs...
Et pour les annonceurs feignants, TikTok propose l'option "Automatic Advanced Matching", ce qui lui permet de scanner tout seul les différents champs des formulaires, afin d'y récupérer par exemple votre e-mail et votre numéro de téléphone :

Réjouissez-vous les annonceurs, le spyware TikTok peut automatiquement récupérer les données personnelles de vos clients !
Notez que là encore, TikTok n'a rien inventé, il s'est contenté de copier Facebook.
Consultez une nouvelle page, votre e-mail fuite vers Facebook
Il était étonnant de ne pas voir Guerlain fuiter votre e-mail vers Facebook. Si vous consultez une page supplémentaire, vous verrez l'appel vers Facebook contenir une variable udff[em], celle-ci contenant le hash SHA256 de votre e-mail :
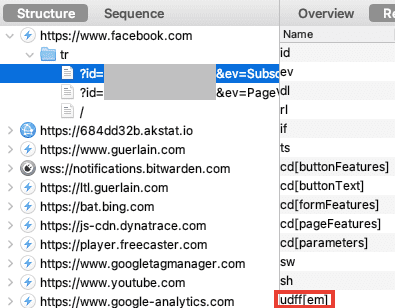
em, le petit mot pour votre e-mail.
La correspondance avancée permet aux annonceurs de fuiter une large palette de données personnelles :
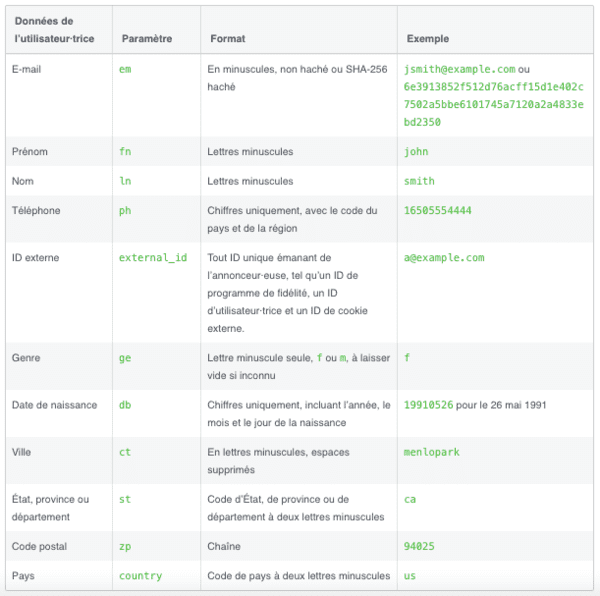
Ne vous inquiétez pas, Facebook saura vous retrouver.
Facebook Advanced Matching est loin d'être le seul outil Facebook mis à la disposition des annonceurs pour vous surveiller, vous en trouverez d'autres sur ce fil :

Pinterest, Google, TikTok et Facebook récupèrent l'intégralité de votre surf sur le site Guerlain, associé à un identifiant persistant (votre e-mail), mais celui-ci n'est pas une exception dans la galaxie LVMH, regardons par exemple Givenchy.
Création de compte Givenchy et fuites de données personnelles
Si vous créez un compte Givenchy, vous noterez également des fuites basées sur votre e-mail (hash SHA256 toujours), maintenant vers Snapchat via la variable u_hems :
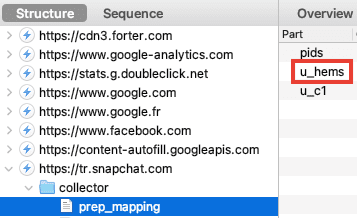
Un réseau social américain de plus, pourquoi se priver ?
Snapchat facilite aussi la vie des annonceurs, comme vous pourrez le lire sur ce thread :
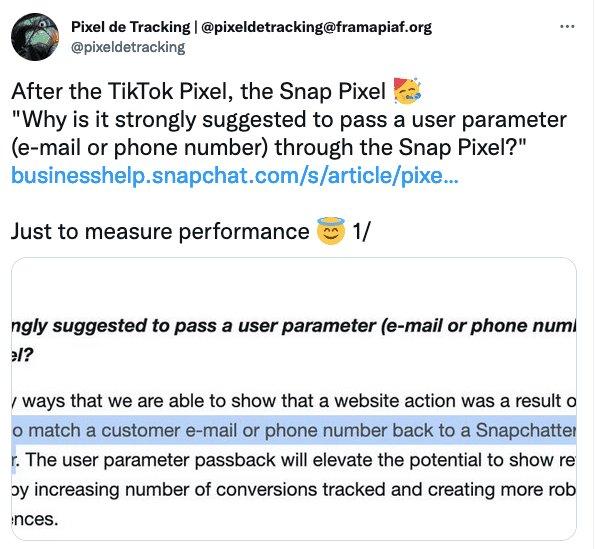
Création de compte Givenchy Beauty et fuites de données personnelles
À peine ai-je démarré la création de compte Givenchy Beauty (différent de Givenchy), que je vois des requêtes étranges passer via Charles Proxy :
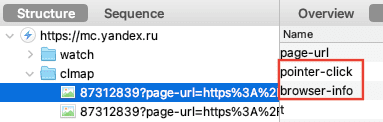
La variable browser-info est très détaillée, combinée à votre adresse IP, elle permet à Yandex d'avoir un fingerprinting d'une grande finesse. La variable pointer-click récupère la localisation en pixel de tous vos clicks. Alors, heureux de voir votre comportement fuiter vers la Russie ?
Mais ce n'est pas terminé, la société française ContentSquare semble récupérer beaucoup d'informations sur ce que vous tapez (keylogger ?!) :
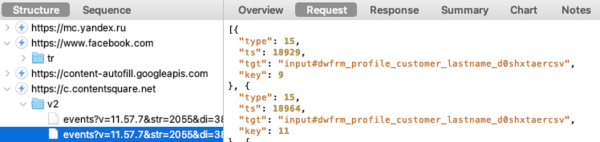
Every move you make, every step you take, I'll be watching you.
Après avoir renseigné prénom et nom, cliquez sur 'Continuer' :
Vérifiez sur Charles les requêtes envoyés, le hash de votre prénom (udff[fn]) et de votre nom (udff[ln]) fuitent déjà vers Facebook :
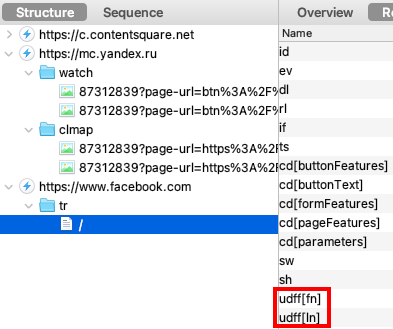
À l'étape suivante, lorsque vous renseignez votre e-mail, le hash celui-ci (udff[em]) fuite en direct vers Facebook (sans même cliquer sur 'Continuer') :
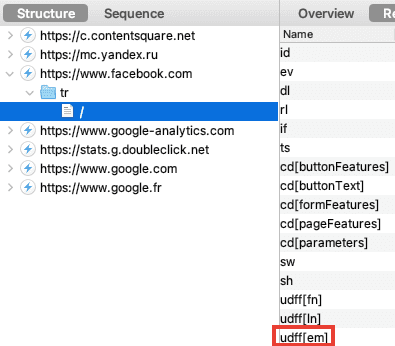
Notez les fuites vers Google Analytics et Doubleclick, tandis que ContentSquare continue de récupérer des informations pendant que vous créez votre mot de passe...
Notez que je n'ai testé que 3 sites du groupe LVMH, au hasard. Il est probable que cette surveillance des grandes plateformes publicitaires via des données persistantes telles que votre e-mail soit généralisée chez LVMH.
Toutes les grandes plateformes publicitaires ont un service de "Matching"
Nous avons pu constater l'utilisation du service de matching de Facebook, TikTok, Pinterest ou Snapchat par des sites du groupe LVMH. Évidemment, au delà de son service Google Analytics, Google n'est pas en reste :
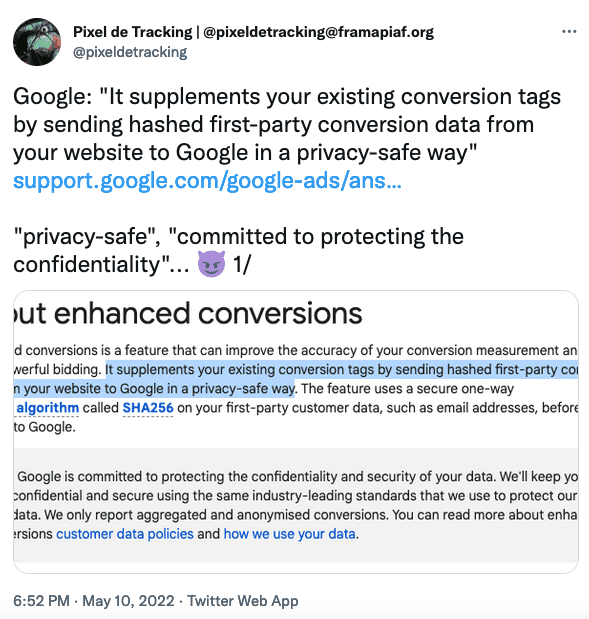
Le dernier jouet d'Elon Musk, Twitter, propose également son service de "matching" :

Les sites du groupe LVMH sont loin d'être une exception comme le témoigne l'étude Leaky Forms. Un grand nombre d'annonceurs s'appuient déjà sur ces méthodes invasives, et avec la prochaine disparition des cookies tiers sur Chrome (si Google le veut bien), ce mode de tracking devient le standard.
Comment se protéger
À défaut de sanctionner ce genre de pratiques (bonjour la CNIL), vous devrez vous protéger individuellement. Les adblocks étant inefficaces (à moins de bloquer tous les appels vers Google et vers les réseaux sociaux), les protections navigateurs étant inefficaces (tracking basé sur une donnée persistante, pas sur des cookies), une option est de passer par un alias d'e-mail différent pour chaque service que vous utilisez. Je connais ces 4 services mais vous pourrez sans doute en trouver d'autres sur le net :
- SimpleLogin, racheté par ProtonMail récemment, ce qui augure d'une intégration intéressante.
- Firefox Relay, directement depuis votre navigateur préféré.
- DuckDuckGo Email Protection, avec l'extension DuckDuckGo, pour une bonne protection sur le web.
- Masquer mon adresse e-mail si vous êtes chez Apple, avec notamment une intégration Safari.
Notez qu'il y a des limites : les alias e-mail ne vous protégeront pas lorsque Facebook (ou autres) effectuera le "matching" via votre numéro de téléphone, votre prénom et votre nom, ou bien votre adresse postale.
Texte intégral (3056 mots)
Une surveillance publicitaire toujours plus intrusive
En dépit de la règlementation (RGPD, ePrivacy, CCPA), des protections navigateurs (Firefox, Safari ou Brave), des bloqueurs de publicité sur navigateur (uBlock Origin) ou via service DNS (NextDNS, Adguard ou Pi-hole), la surveillance publicitaire n'a pas diminuée. Elle a muté pour contourner vos protections.
L'accélérateur de cette évolution ? Facebook évidemment, avec ses "signaux résilients", lui permettant de siphonner une large part des données générées par vos activités en ligne et hors-ligne. Le cookie tiers comme vecteur de surveillance étant en voie de disparition (Google Chrome est l'exception), il fallait trouver de nouveaux vecteurs de surveillance, qui ne puissent être simplement réinitialisés par les internautes. Prenant pour inspiration des "champions" de l'adtech tels que Criteo, Facebook incite les annonceurs à lui transmettre votre e-mail, votre nom, votre numéro de téléphone ou votre adresse postale : des "signaux résilients".
Si de nombreux acteurs de l'adtech (Liveramp, Criteo) vous identifient depuis longtemps via votre e-mail, le phénomène est relativement nouveau chez les grandes plateformes publicitaires. L'étude "Leaky Forms: A Study of Email and Password Exfiltration Before Form Submission" illustrait l'étendue des fuites d'e-mail sur le web, vers des acteurs de l'adtech, mais aussi vers Facebook et TikTok.
Comment votre e-mail pourrait-il fuiter vers ces grandes plateformes ? C'est ce que nous allons découvrir avec Guerlain, un des fleurons du luxe à la française, et propriété du groupe LVMH.
Avant même la création de compte Guerlain, le hash de votre e-mail fuite déjà vers Pinterest
Pour ce test, naviguons sur le site Guerlain, avec l'outil Charles Proxy activé, et cliquons exceptionnellement sur "Accepter et fermer" à l'affichage de la bannière de consentement (au crédit de Guerlain, je n'ai pas noté de fuites de hash e-mail si refus) :
"Améliorer votre expérience et vous proposer des services et des communications adaptés à vos centres d’intérêts", message en apparence inoffensif.
Puis, naviguons sur la page de création de compte Guerlain, et commençons à renseigner le formulaire :
Ces données personnelles ne devraient concerner que Guerlain, n'est-ce pas ?
Regardons ce qui se passe sur Charles Proxy lorsque vous renseignez votre e-mail, avant même de confirmer l'e-mail :
Remarquez une étrange requête vers le réseau social Pinterest.
Le paramètre pd de la requête vers Pinterest contient un autre paramètre em, constitué d'une longue chaine de caractère en apparence indéchiffrable. La documentation de Pinterest pour les annonceurs donne la réponse :
pd: Partner data.
em: hashed email address value.
Guerlain fuite donc un hash de votre adresse e-mail à Pinterest avant même que vous n'ayiez confirmé la création de votre compte ! Ce service s'appelle en fait "Enhanced Match" (la signification de em), j'en avait parlé en mai dernier :
Pas de cookies tiers ? Pas de problème !
Mais ne vous inquiétez pas, Pinterest utilise un hash de votre adresse e-mail, et la connexion vers Pinterest est sécurisée, votre vie privée est protégée !
Permettre à des sites web de fuiter votre e-mail, et prétendre le faire pour protéger votre vie privée !
La réalité, c'est que la correspondance entre votre e-mail et son hash circule déjà probablement largement et que des sociétés se font de l'argent dessus.
Comment vérifier vous-même si Guerlain fuite un hash de votre e-mail à Pinterest ? Renseignez votre e-mail sur ce site, en sélectionnant la bonne fonction de hachage (souvent SHA256) :
Bienvenue dans la matrice.
Bingo, la valeur chiffrée 14d0247dc47a564d9fd70f7e895915e8daa5c8a455549f2b559d5a42cbf0653c correspond au champs em envoyé à Pinterest.
Notez que lorsque l'annonceur envoie directement des données clients à Pinterest, celui-ci n'est pas si regardant sur l'e-mail :
email: We support both hashed (SHA256, SHA1, MD5) and cleartext customer data fields.
Confirmez la création du compte, et dites adieu à vos données personnelles
Je finis maintenant de remplir le formulaire, et je clique sur 'Confirmer'. Les fuites de données personnelles y sont massives :
Notons déjà l'usage illicite de Google Analytics (si Guerlain souhaitait continuer à utiliser Google Analytics, il lui faudrait suivre ces recommandations de la CNIL).
En zoomant sur les paramètres envoyés à Google Analytics, on note le même hash de votre e-mail (SHA256), envoyé via le paramètre cd11 (une dimension 'custom', que Guerlain a donc pris la liberté de créer spécialement pour l'occasion). Il se trouve que la pratique est interdite par Google Analytics (si seulement Google appliquait son règlement) :
Pour protéger la confidentialité des utilisateurs, les règles Google interdisent l'envoi de données que nous pourrions utiliser comme des informations permettant d'identifier personnellement l'utilisateur ou considérer comme telles.
Vous pourriez argumenter : il s'agit d'un hash de mon e-mail, pas de mon e-mail en clair (comme si Google ne connaissait pas déjà votre e-mail et donc son hash). Sauf que Google a pris soin d'interdire également l'envoi de hash à Google Analytics :
Guerlain viole les règles de Google Analytics pour mieux vous surveiller, au calme.
Avec Guerlain, la surveillance est américaine mais elle est aussi chinoise puisque le même hash de votre e-mail fuite vers TikTok (la télécommande magique de Xi Jinping) :
TikTok est plus transparent, la variable s'appelle email.
Cette fuite est permise grâce à la fonctionnalité "Advanced Matching" de TikTok :
Bien sur, côté vie privée tout est étudié, fingerprinting si pas de match :
"Privacy Safe", par TikTok.
Le hachage SHA256, où la baguette magique de la protection de la vie privée :
TikTok n'est pas capable d'identifier les clients qui ne sont pas utilisateurs de TikTok, sauf que TikTok aspire les carnets d'adresses de ses utilisateurs...
Et pour les annonceurs feignants, TikTok propose l'option "Automatic Advanced Matching", ce qui lui permet de scanner tout seul les différents champs des formulaires, afin d'y récupérer par exemple votre e-mail et votre numéro de téléphone :
Réjouissez-vous les annonceurs, le spyware TikTok peut automatiquement récupérer les données personnelles de vos clients !
Notez que là encore, TikTok n'a rien inventé, il s'est contenté de copier Facebook.
Consultez une nouvelle page, votre e-mail fuite vers Facebook
Il était étonnant de ne pas voir Guerlain fuiter votre e-mail vers Facebook. Si vous consultez une page supplémentaire, vous verrez l'appel vers Facebook contenir une variable udff[em], celle-ci contenant le hash SHA256 de votre e-mail :
em, le petit mot pour votre e-mail.
La correspondance avancée permet aux annonceurs de fuiter une large palette de données personnelles :
Ne vous inquiétez pas, Facebook saura vous retrouver.
Facebook Advanced Matching est loin d'être le seul outil Facebook mis à la disposition des annonceurs pour vous surveiller, vous en trouverez d'autres sur ce fil :
Pinterest, Google, TikTok et Facebook récupèrent l'intégralité de votre surf sur le site Guerlain, associé à un identifiant persistant (votre e-mail), mais celui-ci n'est pas une exception dans la galaxie LVMH, regardons par exemple Givenchy.
Création de compte Givenchy et fuites de données personnelles
Si vous créez un compte Givenchy, vous noterez également des fuites basées sur votre e-mail (hash SHA256 toujours), maintenant vers Snapchat via la variable u_hems :
Un réseau social américain de plus, pourquoi se priver ?
Snapchat facilite aussi la vie des annonceurs, comme vous pourrez le lire sur ce thread :
Création de compte Givenchy Beauty et fuites de données personnelles
À peine ai-je démarré la création de compte Givenchy Beauty (différent de Givenchy), que je vois des requêtes étranges passer via Charles Proxy :
La variable browser-info est très détaillée, combinée à votre adresse IP, elle permet à Yandex d'avoir un fingerprinting d'une grande finesse. La variable pointer-click récupère la localisation en pixel de tous vos clicks. Alors, heureux de voir votre comportement fuiter vers la Russie ?
Mais ce n'est pas terminé, la société française ContentSquare semble récupérer beaucoup d'informations sur ce que vous tapez (keylogger ?!) :
Every move you make, every step you take, I'll be watching you.
Après avoir renseigné prénom et nom, cliquez sur 'Continuer' :
Vérifiez sur Charles les requêtes envoyés, le hash de votre prénom (udff[fn]) et de votre nom (udff[ln]) fuitent déjà vers Facebook :
À l'étape suivante, lorsque vous renseignez votre e-mail, le hash celui-ci (udff[em]) fuite en direct vers Facebook (sans même cliquer sur 'Continuer') :
Notez les fuites vers Google Analytics et Doubleclick, tandis que ContentSquare continue de récupérer des informations pendant que vous créez votre mot de passe...
Notez que je n'ai testé que 3 sites du groupe LVMH, au hasard. Il est probable que cette surveillance des grandes plateformes publicitaires via des données persistantes telles que votre e-mail soit généralisée chez LVMH.
Toutes les grandes plateformes publicitaires ont un service de "Matching"
Nous avons pu constater l'utilisation du service de matching de Facebook, TikTok, Pinterest ou Snapchat par des sites du groupe LVMH. Évidemment, au delà de son service Google Analytics, Google n'est pas en reste :
Le dernier jouet d'Elon Musk, Twitter, propose également son service de "matching" :
Les sites du groupe LVMH sont loin d'être une exception comme le témoigne l'étude Leaky Forms. Un grand nombre d'annonceurs s'appuient déjà sur ces méthodes invasives, et avec la prochaine disparition des cookies tiers sur Chrome (si Google le veut bien), ce mode de tracking devient le standard.
Comment se protéger
À défaut de sanctionner ce genre de pratiques (bonjour la CNIL), vous devrez vous protéger individuellement. Les adblocks étant inefficaces (à moins de bloquer tous les appels vers Google et vers les réseaux sociaux), les protections navigateurs étant inefficaces (tracking basé sur une donnée persistante, pas sur des cookies), une option est de passer par un alias d'e-mail différent pour chaque service que vous utilisez. Je connais ces 4 services mais vous pourrez sans doute en trouver d'autres sur le net :
- SimpleLogin, racheté par ProtonMail récemment, ce qui augure d'une intégration intéressante.
- Firefox Relay, directement depuis votre navigateur préféré.
- DuckDuckGo Email Protection, avec l'extension DuckDuckGo, pour une bonne protection sur le web.
- Masquer mon adresse e-mail si vous êtes chez Apple, avec notamment une intégration Safari.
Notez qu'il y a des limites : les alias e-mail ne vous protégeront pas lorsque Facebook (ou autres) effectuera le "matching" via votre numéro de téléphone, votre prénom et votre nom, ou bien votre adresse postale.
08.05.2022 à 15:44
De la légalité des bannières de consentement IAB

À l'origine de cet article
Début février, les CNILs Européennes, emmenées par l'APD (la CNIL Belge), ont jugé que les bannières de consentement estampillées IAB étaient illégales. Pour rappel, l'IAB (International Advertising Bureau) est le lobby de l'adtech, et 80% des sites web Européens utilisent le protocole proposé par l'IAB Europe (le "Transparency & Consent Framework" ou TCF) pour faire fonctionner ces fameuses bannières de consentement.
J'avais déjà pu écrire sur ces bannières de consentement et leurs simulacres de légalité :
- "Le recueil du consentement sur internet : un mensonge généralisé".
- "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- "La grande braderie de vos données personnelles sur Le Bon Coin".
- "Comment les éditeurs se moquent de la CNIL".
Même la directrice de la CNIL anglaise ne semble plus les supporter :
“I often hear people say they are tired of having to engage with so many cookie pop-ups. That fatigue is leading to people giving more personal data than they would like.
“The cookie mechanism is also far from ideal for businesses and other organisations running websites, as it is costly and it can lead to poor user experience. While I expect businesses to comply with current laws, my office is encouraging international collaboration to bring practical solutions in this area.
Pourtant, ces "bannières cookies" sont bien la création d'un lobbying intense de l'adtech, afin d'éviter la création un mécanisme de contrôle "Opt-In" au niveau du navigateur. La fatigue au consentement était prévue et voulue par l'adtech. Et la CNIL anglaise est complice de ce fiasco, comme le raconte Alexander Hanff dans l'article "The truth behind cookie banners".
Avec la décision de l'APD, est-ce la fin des bannières honnies ? Pas forcément, l'IAB Europe, ayant fait appel de la décision de l'APD. Pour rappel, voici un schéma représentant les différentes fuites de données personnelles :
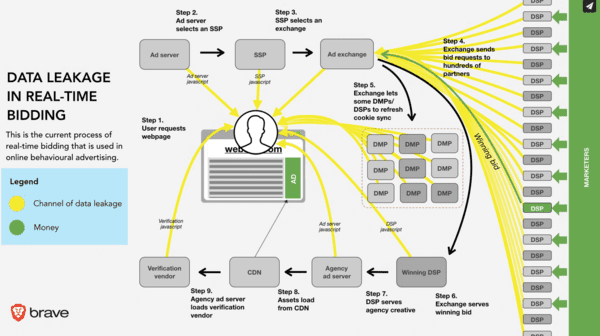
Via Johnny Ryan, du temps où il travaillait chez Brave. Rendre le RTB (et le TCF de l'IAB) compatible avec le RGPD, mission impossible ?
Aussi depuis l'été dernier, j'ai une longue correspondance par e-mail avec Benoit Oberlé, CEO et cofondateur de Sirdata, trésorier de l'IAB France et Vice-Président du comité de pilotage du "Transparency & Consent Framework". Sirdata est une société intéressante à plusieurs titres : elle propose une CMP (Consent Management Platform) aux éditeurs, en version gratuite ou payante. C'est aussi un fournisseur de données contextuelles et comportementales.
Les éditeurs qui acceptent de partager la donnée personnelle des internautes ne paient d'ailleurs pas la CMP Sirdata :

Une CMP pouvant être "financée par la donnée".
Si nous avons des désaccords, Benoit a toujours pris le temps de répondre à mes questions et d'expliciter les choix de Sirdata, et à ce titre, je le remercie vivement. De nos échanges, je souhaitais écrire un article pour illustrer les choix d'une CMP utilisant le protocole de l'IAB, et la CMP Sirdata était le parfait exemple.
Sirdata sur Psychologies.com
Pour étudier la CMP Sirdata, allons sur le site Psychologies.com avec le navigateur Chrome. Nous sommes accueillis par une bannière de consentement en apparence assez classique :
À votre avis, sur quel bouton l'internaute pressé va-t-il cliquer ?
Vous noterez la mise en valeur de l'option "Tout accepter et continuer", à la différence des options "Paramétrer vos choix" et surtout "continuer sans accepter". Il s'agit d'un "Dark Pattern" adopté par de nombreux sites web français, ayant reçu la bénédiction de la CNIL.
Si vous ne prenez pas le temps de lire le texte de la bannière de consentement, vous pourriez néanmoins rater 2 informations cruciales :
- Certaines sociétés de l'adtech ne se basent pas sur votre consentement mais sur l'intérêt légitime pour traiter vos données personnelles.
- Vos choix ne s'appliquent pas seulement sur Psychologies.com mais également sur quelques 4000 autres sites web.
L'intérêt légitime comme base légale de traitements
Voici un extrait de la bannière de consentement proposé par Sirdata :
Vous pouvez [...] faire un choix plus granulaire ou vous opposer aux traitements basés sur des intérêts légitimes via l'écran de paramétrage.
Traduction : Si vous cliquez simplement sur "Continuer sans accepter", certaines sociétés adtech continueront de se baser sur l'intérêt légitime pour traiter vos données personnelles. Pour vous opposer à ces traitements basés sur des intérêts légitimes, vous devrez aller sur l'écran de paramétrage (option "Paramétrer vos choix").
Revenez donc sur la bannière de consentement pour vérifier vos choix après avoir cliqué sur "Continuer sans accepter". Pour cela, il vous faut scroller jusqu'au pied de page du site Psychologies.com, ne pas cliquer sur "Données personnelles & Cookies" mais sur "Consentement" (le lien ne paraît pas cliquable, pourtant il l'est) :

Le lien caché, pourtant "il doit être aussi simple de retirer son consentement que de le donner".
Notez l'apparition du bouton "Tout refuser et continuer" :
Puis, afin de vérifier l'effet de votre choix précédent ("Continuer sans accepter"), cliquez sur "Paramétrez vos choix". Vous verrez que les différents traitements publicitaires ne sont pas décochés, comme si vous n'aviez pas déjà choisi :
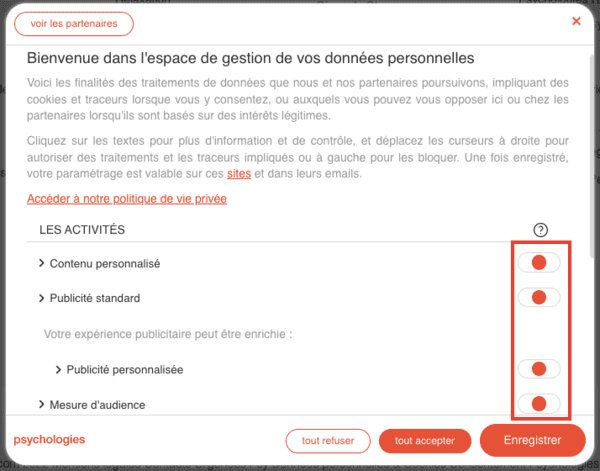
"Continuer sans accepter" ne veut donc pas dire "refuser", pourquoi ?
Suivez ensuite ces étapes :
- Développez l'option "Publicité personnalisée".
- Développez l'option "Créer un profil personnalisé de publicités".
- Notez que l'option "Pour cette activité, les partenaires suivants se reposent sur leur intérêt légitime", est pré-cochée. Développez l'option.
Vous verrez apparaître le partenaire "Sirdata Cookieless" :
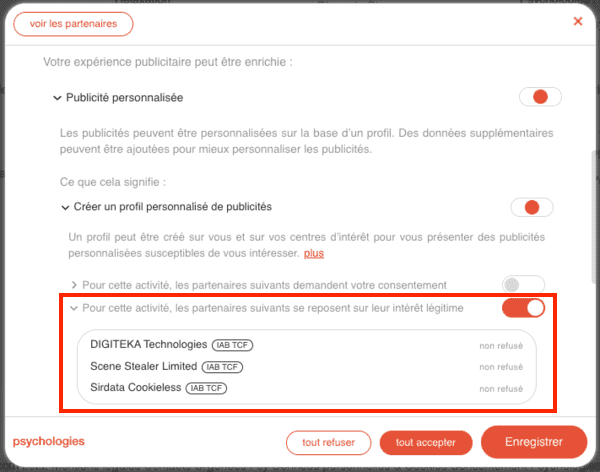
"Sirdata Cookieless" apparait comme "non refusé". Vous devez donc vous opposer à l'intérêt légitime pour refuser ce traitement.
Cette option accessible via la CMP Sirdata permet au fournisseur de données comportementales Sirdata de constituer des profils publicitaires même si l'internaute n'a pas donné son consentement.
D'ailleurs, si vous décidiez de développer l'option "Pour cette activité, les partenaires suivants demandent votre consentement", vous verriez apparaitre le partenaire "Sirdata" avec la mention "non accepté" :
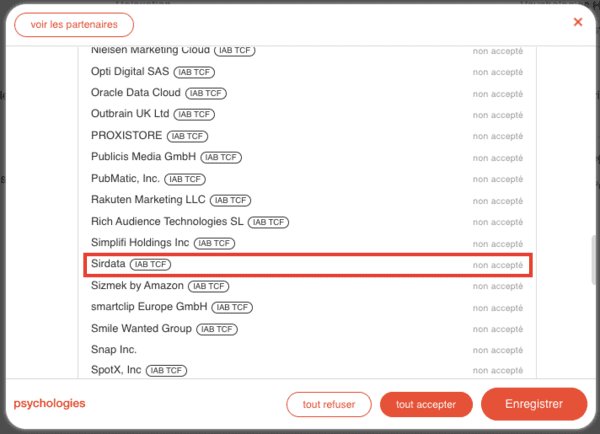
"Sirdata" apparait comme "non accepté". Sirdata ne peut pas se baser sur votre consentement pour créer un profil personnalisé de publicité.
Sirdata joue ainsi sur 2 tableaux pour ses traitements publicitaires (dont la création de profil personnalisé de publicité) :
- Le partenaire "Sirdata" se base sur votre consentement si vous cliquez sur "Tout accepter et continuer".
- Le partenaire "Sirdata Cookieless" se base sur son intérêt légitime si vous cliquez sur "Continuer sans accepter".
Avec consentement, Sirdata utilise des cookies et peut partager des identifiants et des segments d'audience avec les partenaires publicitaires. Sans consentement et sur la base d'un intérêt légitime, Sirdata se place en amont de la plateforme de vente (adserveur ou SSP) pour qu'elle puisse vendre des campagnes publicitaires ciblées avec de la donnée Sirdata lorsque l'utilisateur appartient au(x) bon(s) segment(s) d'audience.
Avec son offre "Cookieless", Sirdata continue de vous profiler et d'exploiter votre profil pour de la publicité personnalisée, mais le partage d'informations avec des tiers est plus limité. L'offre Sirdata est résumée ici :

Si vous cliquez sur "tout refuser", Sirdata propose de la publicité contextuelle. Au global, Sirdata juge son offre "respectueuse de la vie privée".
Afin de refuser la constitution d'un profil personnalisé de publicité Sirdata (et plus généralement, les différents traitements publicitaires des sociétés de l'adtech), il vous faudra donc lors de votre premier surf :
- Cliquez sur "Paramétrer vos choix" sur la bannière de consentement.
- Puis cliquez sur "tout refuser".
Notez qu'une option "Tout refuser et continuer" est disponible en premier niveau, mais seulement lorsque vous désirez revenir sur vos choix (si vous trouvez la fameuse option "Confidentialité" en pied de page de Psychologies.com) :
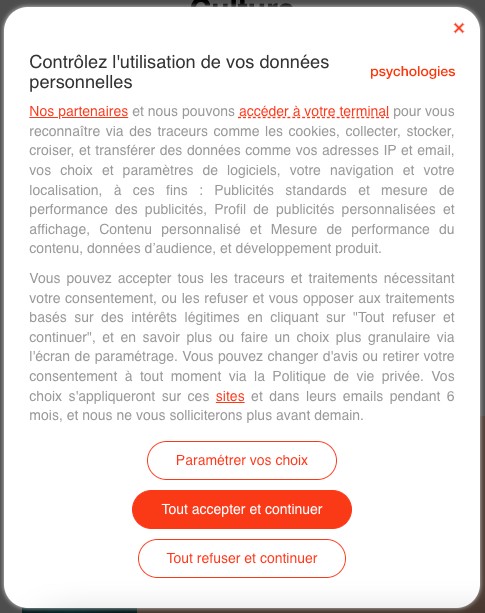
Une option que l'on aurait bien aimé voir sur la bannière de consentement initiale.
Ne refuser que la "Publicité personnalisée" n'est pas évident, un simple clic sur l'option vaudra consentement à la "Publicité personnalisée", mais aussi à la "Publicité standard" :
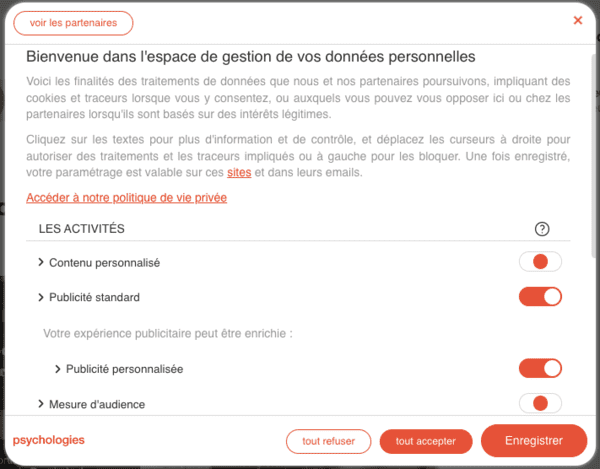
Un joli "Dark Pattern" repéré par @fourmeux, il vous faudra maintenant décocher les 2 options.
La publicité ciblée sans consentement basée sur l'adresse IP, une manière d'éviter la directive ePrivacy ?
Sirdata, le fournisseur de données comportementales, s'estime conforme aux réglementations européennes, ePrivacy (directive cookies) et RGPD. Quel argumentaire déploie-t-il ?
Tout d'abord, Sirdata estime que la directive ePrivacy ne s'applique pas à son offre "Cookieless" (ou "Consentless"). Son raisonnement : ePrivacy s'applique au stockage d'informations sur le terminal de l'utilisateur ou à l'accès à des informations déjà stockées sur celui-ci. Mais pour identifier les utilisateurs sans consentement, Sirdata se base uniquement sur l'adresse IP, et celle-ci n'est pas stockée sur le terminal de l'utilisateur.

Sirdata est peu explicite sur le fait que son offre "Cookieless" se sert de l'adresse IP de l'utilisateur. Mais il détaille les traitements supplémentaires effectués sur l'adresse IP sur sa page "Politique de protection des données personnelles et de la vie privée" rubrique "Lexique".
Sirdata considère qu'il applique un fingerprinting "passif" et non "actif". Le fingerprinting "passif" serait uniquement constitué de l'adresse IP, il n'implique pas d'accès au terminal. Le fingerprinting "actif" serait constitué des caractéristiques du terminal telles que le user-agent, les polices installées ou la taille écran.
Le ciblage via l'adresse IP, le dernier outil des publicitaires pour vous cibler sans consentement ?
Cette distinction entre fingerprinting "passif" (pour lequel ePrivacy ne s'appliquerait pas) et "actif" (pour lequel ePrivacy s'appliquerait) est discutable. Dans l'article 7.2 de l'Avis 9/2014 sur l’application de la directive 2002/58/CE à la capture d’empreintes numériques, du groupe de travail «Article 29» sur la protection des données, la nécessité du consentement pour de la publicité ciblée est clairement énoncée :
La capture d’empreintes numériques à des fins de publicité ciblée exige donc le consentement de l’utilisateur.
Sirdata maintient sa position : pas d'accès au terminal donc ePrivacy ne s'applique pas. Son offre ne rentre pas dans la définition de l'Avis 9/2014, qui n'est d'ailleurs pas une obligation légale.
Concernant le RGPD maintenant, comme Sirdata traite l'adresse IP de l'utilisateur, et que celle-ci est une donnée personnelle, il se doit d'avoir une base légale pour chacun de ses traitements publicitaires. Lorsque l'utilisateur n'a pas donné son consentement, il se base ainsi sur l'intérêt légitime.
À noter que Sirdata a confiance dans cet argumentaire, il le réutilise ainsi dans ses vidéos promotionnelles, exemple avec "le reciblage sans consentement" :

Sans consentement, la fête est plus folle pour l'adtech !
Sirdata propose également un produit pour rendre conforme les transferts vers Google Analytics aux USA, l'"Analytics Helper". Pour rappel, la CNIL Autrichienne et Française ont jugé les transferts de données vers Google Analytics aux USA illégaux.
Sirdata prend des précautions pour empêcher les services de renseignements US d'identifier un utilisateur via une demande à Google (anonymisation de l'IP avant envoi à Google, pseudonymisation du Client ID au niveau du proxy Sirdata). Intéressant dans le cadre de cet article, le "modèle légal de tracking" pour cet "Analytics Helper" est similaire au modèle de la CMP Sirdata :
- Si consentement, tracking habituel Google Analytics via cookies.
- Si absence de consentement, tracking Google Analytics via un fingerprint généré par Sirdata et "uniquement" basé sur votre adresse IP, avec pour base légale l'intérêt légitime.
- Si absence de consentement et opposition à l'intérêt légitime, pas de tracking Google Analytics.
Le Sirdata Helper est un produit ingénieux, mais sera-t-il suffisant pour rendre les transferts de données vers Google Analytics aux USA conformes ? La question reste ouverte comme je le détaille sur ce thread.
L'intérêt légitime pour de la publicité ciblée
Il paraît compliqué pour Sirdata fournisseur de données comportementales de se baser sur l'intérêt légitime pour de la publicité ciblée. Et notamment concernant le critère de mise en balance : la question est de savoir si les intérêts poursuivis par les fournisseurs adtech l'emportent sur les libertés et droits fondamentaux des personnes concernées.
L'APD mentionne notamment l'avis 03/2013 du Groupe de travail Article 29, l'ancien nom de l'EDPB (« European Data Protection Board »), pré-RGPD :
En outre, l'EDPB indique que l'intérêt légitime ne constitue pas une base juridique suffisante dans le contexte du marketing direct mettant en œuvre de la publicité comportementale [...] (460)
Groupe de travail Article 29 - Avis 03/2013 sur la limitation de la finalité (WP 203), 2 avril 2013 : « le consentement devrait être exigé, par exemple, pour le suivi et le profilage à des fins de marketing direct, de publicité comportementale, de courtage de données, de publicité basée sur la localisation ou d'études de marché numériques basées sur le suivi ».
Pour plus de détails, vous pourrez également lire la plainte de La Quadrature du Net contre Amazon pour violation du RGPD, à savoir pour l'absence de base légale concernant la publicité ciblée.
Après le consentement et le contrat, La Quadrature du Net étudie de manière impitoyable l'intérêt légitime comme base légale potentielle (points 36 à 50). Pour l'association de défense et de promotion des droits et libertés sur Internet, cette base légale ne peut fonctionner pour de la publicité ciblée (62). La CNIL Luxembourgeoise a validé son analyse, avec une amende record de 746 millions € contre Amazon.

La Quadrature du Net contre les GAFAM, malheureusement la CNIL est aux abonnés absents.
Quelques extraits de la plainte de La Quadrature :
C’est la voie que prend le G29 dans l’annexe II de son avis 03/2013, sur le Big Data et l’Open Data : « un consentement préalable libre, spécifique, informé et indubitable devrait presque toujours être requis » dès lors qu’une « organisation souhaite spécifiquement analyser ou prédire les préférences personnelles, le comportement et les attitudes de clients individuels, qui serviront ensuite à guider des “mesures ou décisions” prises à l’égard de ces clients ». (47)
Il donne comme exemple de telles « mesures et décisions » la diffusion « de réductions personnalisées, d’offres spéciales et de publicités ciblées à partir du profil du client ». (49)
Le G29 conclut clairement que le « consentement devrait surtout être requis, par exemple, pour le traçage et le profilage à des fins de prospection directe, de publicité comportementale, de courtage en informations, de publicités fondées sur la localisation ou d’étude de marché numérique fondée sur le traçage ». (50)
Avec Benoit, nous avons donc posé la question de l'intérêt légitime pour de la publicité ciblée à la CNIL l'été dernier (2021), sans réponse.
Vos choix s'appliquent sur une coopérative de 4000 sites
Voici un autre extrait de la bannière de consentement proposé par Sirdata (sur Chrome à minima, car sur Safari, du fait du blocage des cookies tiers, la coopérative de sites est désactivée) :
Vos choix s'appliqueront sur ces sites et dans leurs emails pendant 6 mois, et nous ne vous solliciterons plus avant demain.
Lorsque vous cliquez sur "sites", vous atterrissez sur une nouvelle page d'information, directement sur le site Sirdata. Il vous faut encore cliquer sur "Cliquez ici" en bas de page pour découvrir les sites de la coopérative Sirdata :

Vous retrouverez alors l'ensemble des sites de la coopérative Sirdata, 130 pages paginées, sans option d'export :
Ces sites ont fait le choix de participer à la coopérative de consentement Sirdata (qu'ils utilisent la CMP Sirdata en version gratuite ou payante d'ailleurs).
Alors, est-ce légal ? Selon Sirdata, oui car l'internaute reçoit de l'information en premier niveau. Libre à lui de creuser, et d'aller consulter la liste complète des sites web. Sirdata s'appuie aussi sur cette FAQ de la CNIL :

Il est néanmoins probable que la CNIL n'avait pas prévu ce cas-là, la question 21 faisant probablement référence aux responsables de traitement du site web consulté par l'utilisateur (les partenaires publicitaires), et non à d'autres sites web que l'utilisateur ne consulte pas. Sirdata argumente que ce choix est bénéfique à l'utilisateur en ce sens qu'il réduit la fatigue des bannières de consentement. Encore faut-il que ce choix soit éclairé.
Avec Benoit, nous avons également posé la question de la légalité de ce "choix groupé" à la CNIL l'été dernier (2021), sans réponse.
La coopérative Sirdata, une CMP sous contraintes
La participation d'un site web à la coopérative Sirdata impose certaines contraintes aux bannières de consentement :
- Pour les utilisateurs situés sur le territoire français, Sirdata impose le fameux "Dark Pattern" validé par la CNIL.
- Lorsque l'utilisateur revient sur ses choix, un bouton "Tout refuser et continuer" est disponible.
- L'option "Tout refuser" n'est par contre pas disponible sur la bannière de consentement initiale.
- Le nombre de partenaires publicitaires ne peut dépasser 200 (il y a plus de 1000 sociétés publicitaires dans le TCF, sans compter les partenaires publicitaires qui ne font pas partie de TCF et que Google décide d'intégrer via son "Mode Consentement supplémentaire").
S'il n'est pas sur Safari, les choix de l'utilisateur sont donc appliqués à l'ensemble des sites de la coopérative Sirdata. À noter qu'à la différence de certains de ses concurrents, afficher un mécanisme de "refus" au premier niveau ("Continuer sans accepter" ou "Tout refuser") est systématique si l'utilisateur est basé en France. Ceci est valable pour tous les clients Sirdata, payant ou non et adhérant ou non à la coopérative.
Sirdata évite ainsi les interfaces "non conformes", sans bouton "Refuser" ou "Continuer sans accepter".
Sirdata et l'illégalité du TCF
Dans sa communication, Sirdata indique que les éditeurs faisant partie de sa coopérative ne sont pas concernés par la décision de l'APD. Pour les éditeurs qui payent la CMP de Sirdata, il suffirait de ne pas activer l'ensemble des partenaires publicitaires pour ne pas être concerné par la décision. Voici le message de Sirdata à ses clients :
De manière générale, les éditeurs ayant suivi nos conseils ne sont pas en situation de risque en raison de ce jugement et n’ont pas de données à supprimer, pas plus que leurs partenaires, ni l’obligation de “poper” à nouveau pour recueillir un nouveau consentement.
Reprenons quelques éléments de la décision de l'APD. Tout d'abord, l'APD considère que la chaîne de caractères permettant le stockage et la transmission des préférences de l'utilisateur (TC String) est une donnée personnelle. Elle est en effet associée à l'adresse IP de l'utilisateur (à laquelle les CMP ont accès), cette chaîne de caractères détermine également les futurs traitements publicitaires de multiples sociétés adtech. Sirdata l'explique très bien :
L’APD confirme donc que le choix — la
TC String— en lui-même ne permet pas d'identifier directement des personnes ou des dispositifs mais que, dès lors que le choix est stocké sur le dispositif de l'utilisateur, une CMP a la possibilité d’attribuer un identifiant unique à cetteTC String, c'est-à-dire l'adresse IP du dispositif sur lequel il est stocké. La possibilité de combiner laTC Stringet l'adresse IP implique selon elle qu'il s'agit d'informations concernant un utilisateur identifiable.
L'APD distingue ainsi 2 types de traitements :
- La capture et la dissémination du signal de consentement et des objections à l'intérêt légitime des utilisateurs (via la chaîne de caractères
TC String). - La capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech.
En ce qui concerne la licéité et la loyauté du traitement, la Chambre Contentieuse distingue deux activités de traitement : d'une part, la saisie proprement dite du signal de consentement, des objections et des préférences des utilisateurs dans la
TC Stringpar les CMP (a), et, d'autre part, la collecte et la diffusion des données à caractère personnel des utilisateurs par les organisations participantes (b). (403)
Autre point important, l'APD considère que les CMP sont bien co-responsables de traitements, pour ces 2 types de traitements :
Cela amène la Chambre Contentieuse à conclure que la défenderesse ainsi que les CMP, les publishers et les fournisseurs adtech participants doivent être considérés comme des responsables conjoints du traitement pour ce qui concerne la collecte et la diffusion des préférences, des objections et du consentement des utilisateurs, ainsi que pour le traitement ultérieur de leurs données à caractère personnel. (402)
Sur la CMP Sirdata, quelle base légale pour la capture et la dissémination du signal TC String ?
Démarrons par une clarification de Benoit :
Quand Sirdata agit en tant que CMP, elle capture la
TC Stringet l'envoie vers sa base de données de stockage de la preuve du consentement et de sa validité. Elle ne l'envoie à personne d'autre, et seuls ces traitements s'appuient sur l'obligation légale. La CMP ne transmet pas la string à des Vendors Tiers : les Vendors peuvent y accéder de manière active via une API exposée sur la page mais la CMP de la "dissémine" pas.
S'il n'y a pas "dissémination" de la TC String par la CMP Sirdata, le fait d'exposer la chaîne de caractères via une API permet effectivement sa dissémination ultérieure.
Pour le premier type de traitement (capture et exposition du signal de consentement et des objections à l'intérêt légitime des utilisateurs), Sirdata en tant que CMP n'a pas indiqué sur quelle base légale il souhaitait s'appuyer. En effet, avant la décision de l'APD, l'IAB Europe considérait que la TC String n'était pas une donnée personnelle. Hors, nous avons vu que la TC String était bien une donnée personnelle, mais aussi que les CMP étaient co-responsables de traitement.
Ainsi les CMP doivent déclarer une base légale pour ce traitement de données personnelles. Si l'on étudie Sirdata :
- Le consentement n'est actuellement pas une base légale valable. Sirdata stocke la chaîne de consentement
TC Stringdans le local storage dès l'affichage de la bannière de consentement, et ne demande donc pas son avis à l'utilisateur. Après refus de consentement, laTC Stringest stockée dans le cookieeuconsent-v2. - L'intérêt légitime n'est actuellement pas valable non plus selon l'APD, car l'utilisateur n'a aucun moyen de s'opposer au stockage de cette donnée personnelle : "À cet égard, la Chambre Contentieuse trouve remarquable qu'aucune option ne soit offerte aux utilisateurs pour s'opposer complètement au traitement de leurs préférences dans le cadre du TCF. Quel que soit leur choix, la CMP générera une
TC Stringavant de la lier au User ID unique de l'utilisateur, par le biais d'un cookieeuconsent-v2placé sur l'appareil de la personne concernée." (421). L'APD note que ce traitement ne passerait pas le test de "mise en balance" au vu du nombre considérable de sociétés adtech récupérant cette donnée, et du peu de contrôle donné à l'utilisateur (423).
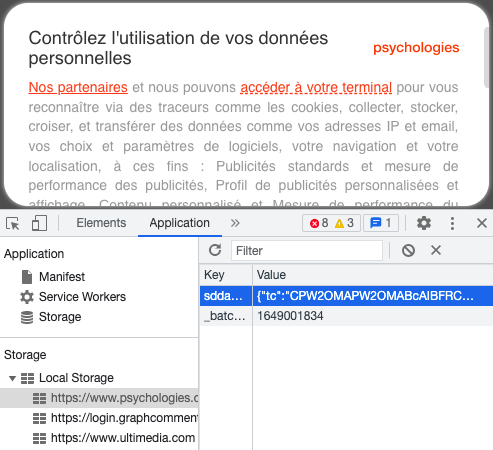
Avant toute interaction avec la bannière de consentement Sirdata, la chaîne TC String est stockée avec la clé sddan:cmp sur le local storage de mon navigateur.
D'après la décision de l'APD, la CMP Sirdata ne semble pas avoir de base légale pour la capture et l'exposition du signal de consentement et des objections à l'intérêt légitime des utilisateurs. Mais après discussions avec Benoit, je comprends que Sirdata s'appuie en fait sur une autre base légale pour la capture et l'exposition du signal TC String, l'obligation légale.
L'obligation légale comme base légale de traitement ?
L'information comme quoi la CMP Sirdata s'appuie sur l'obligation légale comme base de traitement pour la capture et l'exposition du signal TC String est absente de la bannière de consentement de Sirdata et elle n'est pas mentionnée dans l'article de Sirdata qui revient sur la décision de l'APD. Cependant, elle est indiqué dans les CGU de la CMP Sirdata :
9.5. The
TC stringand strictly necessary data, such as the date of the last prompt used to limit subsequent prompts, will be stored on the user's device, in local storage, in a cookie namedeuconsent-v2which can be used as a first party cookie or a third party cookie linked to the domain nameconsentframework.com. The Parties agree that, in accordance with CNIL Deliberation n°2020-092 of September 17, 2020 adopting a recommendation proposing practical modalities of compliance in the event of recourse to "cookies and other tracers" the storage of or access to this data in the terminal is not subject to prior consent, and if theTC Stringand the necessary data are considered personal data, the processing will be carried out by Sirdata as a data processor acting on behalf of You, data controller on the basis of the legal obligation under GDPR.
D'après l'APD, Sirdata n'est pas un simple sous-traitant mais bien co-responsable de traitement. Ceci-dit, cela n'impacte pas la base légale invoquée par Sirdata, l'obligation légale. L'argumentaire de Sirdata pour se baser sur l'obligation légale est le suivant : l’éditeur et ses partenaires doivent légalement faire la preuve d'un consentement, se souvenir d'un refus/retrait de consentement et mémoriser l'opposition pour ne pas "harceler" l'utilisateur.
Il est dommage que l'IAB Europe et l'APD n'ait pas discuté de cette base légale de traitement, il nous manque une décision juridique pour savoir si cette base légale tient vraiment.
Sirdata invoque la délibération n°2020-092 du 17 septembre 2020 de la CNIL (modalités pratiques de mise en conformité en cas de recours aux "cookies et autres traceurs"), mais celle-ci propose seulement un nommage du traceur permettant de stocker le choix des utilisateurs :
- Enfin, la Commission encourage les professionnels à nommer le traceur permettant de stocker le choix des utilisateurs
eu-consent, en attachant à chaque finalité une valeur booléenne « vrai » ou « faux » mémorisant les choix effectués.
La délibération n° 2020-091 du 17 septembre 2020 (lignes directrices "cookies et autres traceurs") porte sur l'exemption de consentement concernant le choix exprimé par les utilisateurs sur le dépôt des traceurs :
- En l’état des pratiques portées à sa connaissance, la Commission estime que les traceurs suivants peuvent, notamment, être regardés comme exemptés :
- les traceurs conservant le choix exprimé par les utilisateurs sur le dépôt de traceurs
- [...]
Mais la CNIL ne parle pas de base légale de traitement pour le RGPD, encore moins d'une quelconque obligation légale comme base légale. Une lecture attentive du texte de la CNIL sur l'obligation légale pose d'autres questions :
- L'obligation légale doit être prévue dans le cadre juridique national ou européen. Sur quel texte légal Sirdata peut-il alors s'appuyer ?
- Le responsable du traitement souhaitant se fonder sur cette base légale ne doit pas avoir le choix de se conformer ou non à l’obligation (nécessité).
- En particulier, l'organisme doit s'assurer qu'il n'existe pas de moyen moins intrusif d'atteindre cet objectif.
Hors, Sirdata pourrait très bien ajouter un paramètre opt-in aux appels vers sa CMP. Si appel à https://sirdata...?opt-in=0, alors pas de création de la TC String, et donc pas d'appel aux partenaires adtech. L'obligation légale ne semble donc pas nécessaire.
La CMP Sirdata pourrait s'appuyer sur l'intérêt légitime comme base légale de traitement de la TC String (via le paramètre opt-in, l'utilisateur pourrait s'opposer au stockage de la TC String). Encore faudrait-il passer le test de mise en balance au vu du nombre considérable de partenaires récupérant cette donnée (423). Ici, Sirdata argumentera qu'en limitant le nombre de partenaires dans sa coopérative à 200 maximum, le jugement de l'APD ne s'applique pas.
Pour le partenaire publicitaire Sirdata, quelle base légale pour la capture et la dissémination du signal TC String ?
Rappelez-vous, Sirdata opère en tant que CMP, mais il opère aussi en tant que fournisseur de données contextuelles et comportementales. Dans ce rôle, Sirdata capture et dissémine la TC String. Reprenons les explications de Benoit :
Quand Sirdata agit en tant que Vendor s'appuyant sur le consentement (Vendor "Sirdata"), nous pouvons capturer et transférer la
TC Stringet d'autres données personnelles sur la base du consentement et nous vérifions si l'entité à qui nous nous apprêtons à l'envoyer a le droit de la recevoir. Quand Sirdata agit en tant que Vendor s'appuyant sur l'intérêt légitime (Vendor "Sirdata cookieless"), nous pouvons capturer et transférer laTC Stringet d'autres données personnelles sur la base d'un intérêt légitime et nous ne transmettons pas cette donnée.Pour le futur, et précisément à cause de l'APD, nous allons changer la base légale du traitement de la
TC Stringen tant que Vendor, afin de pouvoir transmettre un retrait de consentement : nous nous appuierons bientôt uniquement sur l'intérêt légitime (mais uniquement pour laTC Stringutilisée dans ce cadre).
Le même commentaire semble ici s'appliquer : il faudra passer le test de mise en balance au vu du nombre considérable de partenaires récupérant cette donnée (423). Sirdata pourra probablement argumenter que lorsqu'il agit en tant que partenaire publicitaire ("Vendor"), il transmet la TC String à un nombre limité de partenaires.
Nous avons précédemment étudié les potentielles bases légales pour le premier type de traitements indiqué par l'APD : la capture et la dissémination du signal de consentement et des objections à l'intérêt légitime des utilisateurs (côté Sirdata CMP, mais aussi côté Sirdata "Vendor"). Passons maintenant au deuxième type de traitements : la capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech.
L'intérêt légitime comme base légale pour la capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech ?
Pour rappel, ici nous ne parlons plus de capture ou de dissémination de la TC String mais bien des différents traitements publicitaires effectués avec vos données personnelles :

Les finalités telles que définies dans la v2 du TCF, notez l'exception de la finalité "Stocker et/ou accéder aux informations d'un appareil", ne pouvant s'appuyer que sur votre consentement.
Étudions la décision de l'APD concernant l'intérêt légitime pour des traitements publicitaires dans le cadre du TCF. Ces traitements incluent donc la publicité ciblée, mais pas seulement. Le recours à l'intérêt légitime comme base légale de traitement est soumis à 3 conditions :
- Il doit être "légitime" : l'APD n'a pas d'opinion sur la question de savoir si l'intérêt économique d'un acteur de l'adtech à effectuer des traitements publicitaires est légitime. Mais cette condition n'est déjà pas remplie car l'APD considère que les traitements publicitaires ne sont pas assez spécifiquement décrits dans le cadre du TCF (452).
- Il doit satisfaire à la condition de "nécessité" : l'APD considère que cette condition n'est pas remplie car dans le cadre du RTB (Real-Time Bidding, enchères publicitaires en temps-réel), il n'y a aucune protection contre la dissémination d'informations personnelles (456).
- Il ne doit pas heurter les droits et intérêts des personnes dont les données sont traitées : selon l'APD, le nombre important d'acteurs publicitaires est problématique, ainsi que les nombreuses informations transmises dans le cadre d'une enchère publicitaire. L'APD cite également l'EDBP (le Comité européen de la protection des données) et l'ICO (la CNIL anglaise), jugeant tout deux que l'intérêt légitime n'est pas une base légale valide de traitement pour la publicité ciblée, notamment dans le cadre du RTB (460).
Lisons par exemple l'avis de l'EDBP :
Le consentement devrait être exigé, par exemple, pour le suivi et le profilage à des fins de marketing direct, de publicité comportementale, de courtage de données, de publicité basée sur la localisation ou d'études de marché numériques basées sur le suivi.
Et voici la décision de l'APD :
À la lumière des considérations susmentionnées, la Chambre Contentieuse estime que l'intérêt légitime des organisations participantes ne peut être considéré comme une base juridique adéquate pour les activités de traitement effectuées selon le protocole OpenRTB, conformément aux préférences et aux choix des utilisateurs saisis dans le cadre du TCF.
L'analyse de Sirdata maintenant : ce jugement ne s'applique pas au TCF dans sa globalité, mais seulement aux traitements liés au RTB. Par exemple, cela ne concerne pas le profilage effectué par Sirdata via son offre "Cookieless", qui a lieu en amont des échanges RTB, et n'entraîne pas de partage d'identifiants et de segments d'audience avec des partenaires publicitaires. Et donc la CMP Sirdata peut continuer à proposer à ses partenaires l'intérêt légitime comme base légale d'un traitement.
On pourra ici noter que sans même parler du RTB, l'intérêt légitime ne passe déjà pas le test de légitimité. Pour approfondir, vous pouvez lire le papier de Célestin Matte, Cristiana Santos et Nataliia Bielova, "Purposes in IAB Europe's TCF: which legal basis and how are they used by advertisers?". Celui-ci étudie chaque finalité, indépendamment des éventuels traitements liés au RTB, mais la conclusion reste la même pour l'intérêt légitime, cette base légale ne tient pas :
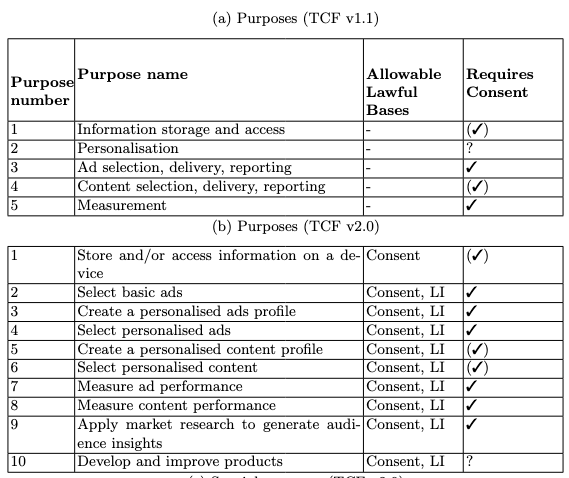
La nouvelle version du TCF détaille mieux les finalités, mais l'intérêt légitime ne serait toujours pas valide.
Même si ce papier est très solide, Sirdata pourra argumenter qu'il manque une décision légale sur la validité de l'intérêt légitime via le TCF, hors protocole OpenRTB. Le TCF est certes lié au protocole OpenRTB comme l'indique l'APD :
La Chambre Contentieuse constate que l'argument de la défenderesse ne peut être suivi, étant donné que la défenderesse indique à plusieurs reprises dans ses conclusions que la raison d'être du TCF est précisément de mettre les traitements de données à caractère personnel fondés sur le protocole OpenRTB, entre autres, en conformité avec la réglementation applicable, en ce compris le RGPD et la directive ePrivacy. Bien que la Chambre Contentieuse comprenne que le TCF puisse également être utilisé par les publishers pour d'autres applications, en collaboration ou non avec les CMP, il est également certain que le TCF n'a jamais été conçu pour être un écosystème autonome et indépendant. (368)
Mais le TCF est également utilisé hors OpenRTB, argument que pourra ressortir Sirdata pour maintenir la base légale "intérêt légitime" dans sa CMP. Avec donc son propre exemple : en l'absence de consentement, l'utilisation de l'intérêt légitime pour de la publicité ciblée basée sur l'adresse IP, techniquement hors RTB (en amont de celui-ci).
Le consentement comme base légale pour la capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech ?
Nous avons vu précédemment que l'intérêt légitime n'était pas une base légale valide pour les traitements de données personnelles dans l'OpenRTB telles que facilitées par le TCF, à fortiori pour les traitements relatifs à la publicité ciblée. L'APD détaille également pourquoi le consentement n'est pas une base légale valide pour les traitements de données personnelles.
L'argumentaire de Sirdata pour échapper à cette décision est alors le suivant (que ce soit pour l'intérêt légitime ou pour le consentement). Dans le cadre de sa coopérative, la CMP Sirdata va plus loin que le TCF lorsqu'il est implémenté à minima, avec notamment une meilleure hiérarchisation des données, une meilleure information et surtout une limitation du nombre de partenaires.
Sirdata est toutefois parfaitement consciente que le TCF n’a jamais eu vocation à garantir à lui tout seul une conformité au RGPD. Sirdata CMP implémente donc ce standard comme d’autres, et apporte en complément des mesures additionnelles et règles spécifiques permettant un respect des réglementations locales et régionales bien au-delà de ce que requiert le TCF.
Nous pourrions souligner que l'absence de base légale de traitement est loin d'être la seule violation du RGPD pointée par l'APD, et qu'il ne suffit pas de mieux adresser un des problèmes pour être conforme.
Ce à quoi Sirdata répondra qu'il n'est pas nécessairement conforme, mais qu'il faudrait une nouvelle analyse d'une Autorité de protection des données afin de déterminer la validité, qui s'apprécie au cas par cas. Il pourra notamment citer ce passage de la décision de l'APD :
Il convient également de noter que les CMP ont une grande marge d'appréciation en ce qui concerne l'interface qu'elles offrent aux utilisateurs. En effet, les TCF Policies n'imposent que des exigences d’interface minimales aux CMP participantes, avec pour conséquence qu'en pratique, les interfaces et le respect des principes d'équité et de transparence peuvent varier considérablement selon la CMP avec laquelle les publishers de sites web et d'applications collaborent. (381)
Ce passage de l'analyse de l'APD relevait la responsabilité conjointe des CMP concernant les finalités et les moyens du traitement des données personnelles. Étudions plutôt certaines des "mesures additionnelles" et "règles spécifiques" avancées par Sirdata.
Regrouper des finalités afin de ne pas être concerné par la décision de l'APD ?
Pour l'APD, le consentement n'est pas une base légale valide :
Le consentement n'est pas une base valide pour les opérations de traitement dans l'OpenRTB telles que facilitées par le TCF. (428) La Chambre Contentieuse estime que le consentement recueilli par les CMP et les publishers dans la version actuelle du TCF est insuffisamment libre, spécifique, éclairé et dénué d’ambiguïté. (432)
L'APD constate notamment que les finalités de traitement proposées ne sont pas décrites de manière suffisamment claire, et dans certains cas, sont même trompeuses :
À titre d'exemple, la Chambre Contentieuse constate que les finalités 8 (« Measure content performance ») et 9 (« Apply market research to generate audience insights ») fournissent peu ou pas d'indications sur la portée du traitement, la nature des données à caractère personnel traitées, ou encore la durée de conservation des données à caractère personnel collectées tant que l'utilisateur ne retire pas son consentement. (433)
Ce à quoi Sirdata indique avoir déjà répondu, via notamment le regroupement de ces 2 finalités sous le chapeau "Mesure d'audience" :

Sirdata précise sur son blog :
Pour permettre un consentement éclairé, en second niveau les “purposes” du TCF sont regroupées sous des finalités “chapeau” définies par la CNIL dans sa Recommandation Traceurs du 17 septembre 2021, telles que la “publicité ciblée” ou la “mesure d’audience”.
Sauf que ces finalités publicitaires sont en réalité très différentes de la mesure d'audience et de la fréquentation d'un site, telle que peut l'effectuer un outil tel que Google Analytics, AT Internet ou Matomo. En général, il s'agit plutôt de traitements effectués par des outils de panel et d'analyse de marché tels que des Nielsen ou autres Comscore. Ainsi par ce regroupement, Sirdata apporte de la confusion à des finalités déjà existantes.
Différents modes d'accès aux pages de vie privée des partenaires afin de ne pas être concerné par la décision de l'APD ?
Autre point sur lequel Sirdata déclare aller "plus loin que le TCF", et ainsi échapper à la décision de l'APD, l'accès à l'information sur les opérations de traitement spécifiques de chaque fournisseur adtech. Voici un passage de la décision de l'APD :
En outre, les informations que les CMP fournissent aux utilisateurs demeurent trop générales pour refléter les opérations de traitement spécifiques de chaque fournisseur adtech, ce qui empêche la nécessaire granularité du consentement. (436)
Que fait donc Sirdata ? Voici ce qu'il déclare :
L’information obligatoire dans le cadre du TCF est en effet un socle commun brut insuffisant : Sirdata et ses clients vont bien au-delà.
En plus de refléter les mentions obligatoires du TCF, l’UI de Sirdata CMP apporte un éclairage additionnel sur les données traitées et la finalité de ces traitements, et en hiérarchise l’information pour une compréhension et un contrôle utilisateur facilités.
Une partie de l’information est disponible en premier niveau, une autre, comme la liste des destinataires, l’est aisément en second niveau, et l’accès aux informations additionnelles comme les conditions d’exercice des droits est accessible via des liens vers les pages de Vie Privée.
En pratique, lorsque vous zoomez sur une finalité via la bannière de consentement, vous pouvez afficher la liste des partenaires. Si vous cliquez sur un des partenaires, vous aurez alors un lien vers sa page "vie privée" :
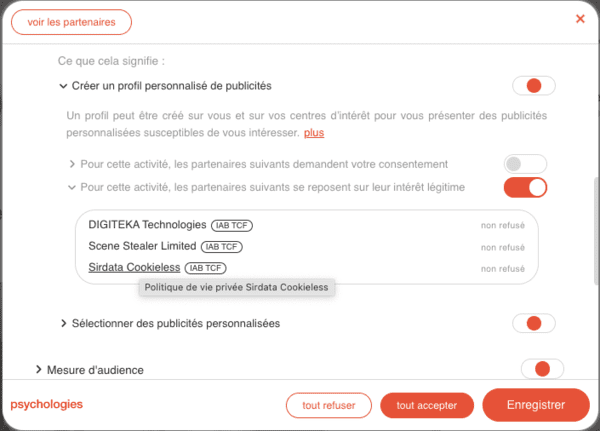
Le partenaire "Sirdata Cookieless", qui se base sur l'intérêt légitime pour créer un profil personnalisé de publicités.
On peut noter que ce lien vers la page "vie privée" est déjà imposé par le TCF de l'IAB :
When making use of a so-called layered approach, a secondary layer must be provided that allows the user to: review the list of named Vendors, their Purposes, Special Purposes, Features, Special Features, associated Legal Bases, and a link to each Vendor’s privacy policy.
Mais Sirdata indique aller plus loin que certaines CMP, qui n'imposent pas de pouvoir lister les partenaires à partir d'une finalité donnée. Nous pouvons voir la différence avec le site de L'Express, qui utilise la CMP de Didomi :
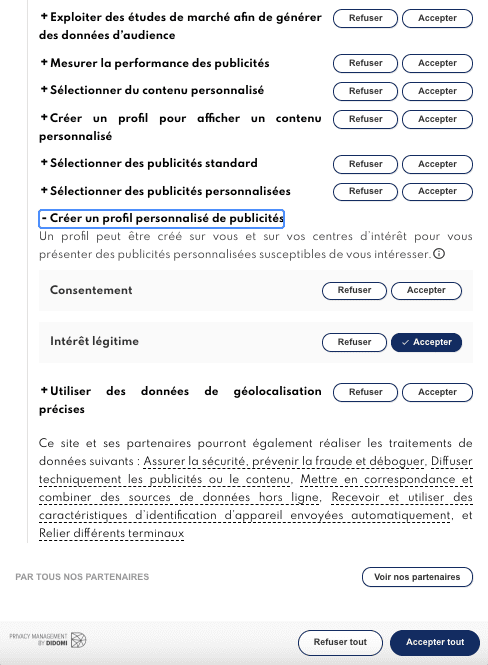
Je ne peux pas développer "Intérêt légitime", je ne peux voir que Sirdata s'appuie sur cette base légale pour "Créer un profil personnalisé de publicité".
Mais la vue "Partenaires" permet bien de lister les différents partenaires et de présenter un lien vers la page de vie privée de chaque partenaire :
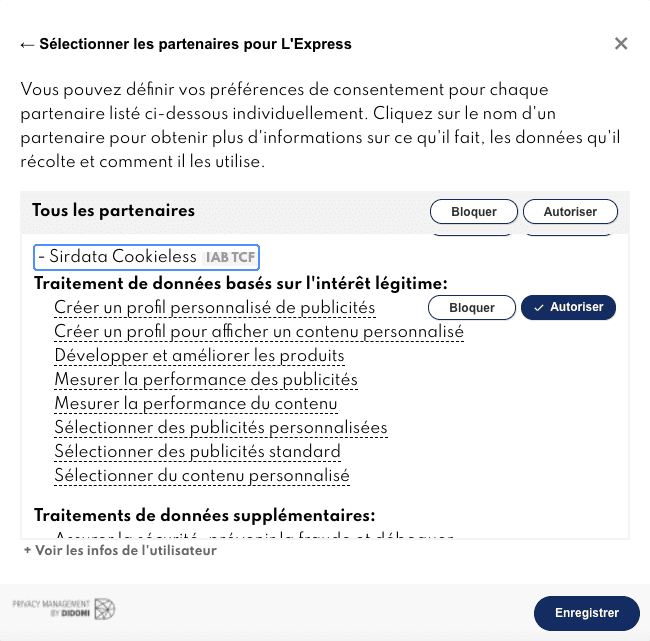
Pour "Créer un profil personnalisé de publicité" sur L'Express avec la CMP de Didomi, Sirdata s'appuie également sur l'intérêt légitime, via le fameux partenaire "Sirdata Cookieless".
Pour Sirdata, la "meilleure" hiérarchisation des informations de sa CMP ne la rend pas forcément licite, mais suppose une nouvelle décision de l'APD afin de juger de sa licéité.
Limiter le nombre de partenaires afin de ne pas être concerné par la décision de l'APD ?
Principal argument de Sirdata, la décision de l'APD ne s'appliquerait pas à Sirdata, car celui-ci impose un choix de partenaires à ses clients, avec une limite à 200 partenaires pour sa coopérative (hors coopérative, il n'y a pas de limite).
Dans le cadre de la coopérative de choix qu’elle gère, Sirdata va même jusqu’à imposer un plafond de 200 partenaires, très loin des 2000 partenaires potentiels du TCF et du réseau de consentement géré par Google en complément — “AC Mode” —.
De tels garde-fous permettent d’éviter les traitements à grande échelle des préférences des utilisateurs — collectées sous le TCF — dans le cadre du protocole open RTB : selon l’APD les intérêts des personnes concernées ne l’emportent sur l'intérêt légitime des organisations participant au TCF que lorsque ces dernières sont toutes sélectionnées.
Mais dans la décision de l'APD, nulle mention d'un intérêt légitime des organisations qui l'emporterait sur les intérêts des personnes concernées si ces dernières ne sont pas toutes sélectionnées... Sirdata déclare néanmoins s'appuyer sur cet extrait :
Bien que les TCF Policies interdisent aux CMP d'accorder une préférence à certains fournisseurs adtech de la Global Vendors List, et qu'ils sont donc en principe tenus de présenter aux utilisateurs tous les fournisseurs inscrits au TCF, sauf instruction contraire des publishers, quelques auteurs notent qu'un certain nombre de CMP ne respectent pas cette exigence. Soit parce que les CMP imposent aux publishers des fournisseurs présélectionnés, soit parce qu’elles leur refusent la possibilité de déroger à la liste complète des fournisseurs adtech, proposée par défaut. (380)
Ce passage est là pour expliquer pourquoi les CMP doivent être tenus pour co-responsables de traitement, et non pour indiquer une quelconque problématique d'un nombre trop grand de partenaires. Aussi, l'IAB Europe n'impose pas de présenter la liste complète, mais seulement de ne pas discriminer un partenaire en particulier :
In any interaction with the Framework, a CMP may not exclude, discriminate against, or give preferential treatment to a Vendor except pursuant to explicit instructions from the Publisher involved in that interaction and in accordance with the Specifications and the Policies.
Le raisonnement de Sirdata est le suivant :
- Dans le cadre du TCF, nous sommes tenus de présenter tous les fournisseurs par défaut (ce n'est pas une "obligation", comme le montre le document de l'IAB Europe).
- Cette présentation n'est pas valable selon l'APD (Sirdata interprète le "en principe" de l'APD comme une obligation).
- Nous ne respectons pas cette "obligation" du TCF, car nous imposons aux clients de choisir leurs partenaires (200 maximum sous peine de ne pouvoir faire partie de la coopérative, une trentaine par défaut).
- Et donc la décision de l'APD ne nous concerne pas.
Mais Sirdata suit bien les recommandations de l'IAB Europe car il ne discrimine pas de partenaire en particulier. On peut néanmoins retrouver un autre argument lié au nombre de partenaires dans la décision de l'APD :
En particulier, les destinataires pour lesquels le consentement est recueilli sont si nombreux que les utilisateurs auraient besoin d'un temps disproportionné pour lire ces informations, ce qui signifie que leur consentement peut rarement être suffisamment éclairé. (435)
Pour Sirdata, le fait d'imposer le choix des partenaires (avec plafond à 200 partenaires) ne rend pas nécessairement sa CMP licite, mais une autre évaluation d'une Autorité de régulation serait nécessaire.
L'illégalité des bannières de consentement de l'IAB ne concerne pas que la base légale de traitement
Via cet article, nous n'avons pu qu'effleurer les problèmes posées par les bannières de consentement de l'IAB. Sirdata indique que le fait d'aller "plus loin" que l'implémentation "à minima" du TCF permettrait à ses clients de continuer le "business as usual" avec sa CMP. Cependant, l'illégalité du TCF est systémique, continuer de s'appuyer dessus est légalement risqué. Aussi, faire évoluer le TCF pour le rendre licite ne sera pas facile, le mécanisme même du RTB paraissant irréconciliable avec le RGPD, notamment au regard de la sécurité des données personnelles.

Quelques adaptations pourraient rendre le TCF légal ?
Vous pourrez approfondir le sujet via la lecture de ces papiers :
- "An Unending Data Breach Immune to Audit? Can the TCF and RTB Be Reconciled with the GDPR?", de Johnny Ryan et Cristiana Santos.
- "Impossible Asks: Can the Transparency and Consent Framework Ever Authorise Real-Time Bidding After the Belgian DPA Decision?", de Michael Veale, Midas Nouwens et Cristiana Santos.
Et en regardant cette présentation de Robin Berjon, "Consent of the Governed".
Vers un internet sans surveillance imposée, et sans bannière de consentement
Charge aux CNILs Européennes de s'appuyer sur cette importante décision de l'APD pour correctement sanctionner les différents intervenants (CMP, éditeurs, partenaires publicitaires) et interdire la fuite massive de données personnelles via le RTB. Une interdiction de la publicité ciblée serait appréciée, et pas simplement pour les mineurs, comme le propose le DSA. À minima, la CNIL pourrait se prononcer plus clairement sur la publicité ciblée basée sur l'intérêt légitime.
Aussi, ces bannières de consentement ne devraient pas exister, l'utilisateur devrait être en mesure d'accepter ou de refuser le tracking de l'industrie publicitaire directement via les réglages de son navigateur (opt-in), sur le modèle de ce qu'Apple propose déjà via son système ATT. Et à ce titre, des initiatives comme le Global Privacy Control (GPC) ou le Advanced Data Protection Control (ADPC) méritent d'être développées et soutenues par la loi.
Texte intégral (10470 mots)
À l'origine de cet article
Début février, les CNILs Européennes, emmenées par l'APD (la CNIL Belge), ont jugé que les bannières de consentement estampillées IAB étaient illégales. Pour rappel, l'IAB (International Advertising Bureau) est le lobby de l'adtech, et 80% des sites web Européens utilisent le protocole proposé par l'IAB Europe (le "Transparency & Consent Framework" ou TCF) pour faire fonctionner ces fameuses bannières de consentement.
J'avais déjà pu écrire sur ces bannières de consentement et leurs simulacres de légalité :
- "Le recueil du consentement sur internet : un mensonge généralisé".
- "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- "La grande braderie de vos données personnelles sur Le Bon Coin".
- "Comment les éditeurs se moquent de la CNIL".
Même la directrice de la CNIL anglaise ne semble plus les supporter :
“I often hear people say they are tired of having to engage with so many cookie pop-ups. That fatigue is leading to people giving more personal data than they would like.
“The cookie mechanism is also far from ideal for businesses and other organisations running websites, as it is costly and it can lead to poor user experience. While I expect businesses to comply with current laws, my office is encouraging international collaboration to bring practical solutions in this area.
Pourtant, ces "bannières cookies" sont bien la création d'un lobbying intense de l'adtech, afin d'éviter la création un mécanisme de contrôle "Opt-In" au niveau du navigateur. La fatigue au consentement était prévue et voulue par l'adtech. Et la CNIL anglaise est complice de ce fiasco, comme le raconte Alexander Hanff dans l'article "The truth behind cookie banners".
Avec la décision de l'APD, est-ce la fin des bannières honnies ? Pas forcément, l'IAB Europe, ayant fait appel de la décision de l'APD. Pour rappel, voici un schéma représentant les différentes fuites de données personnelles :
Via Johnny Ryan, du temps où il travaillait chez Brave. Rendre le RTB (et le TCF de l'IAB) compatible avec le RGPD, mission impossible ?
Aussi depuis l'été dernier, j'ai une longue correspondance par e-mail avec Benoit Oberlé, CEO et cofondateur de Sirdata, trésorier de l'IAB France et Vice-Président du comité de pilotage du "Transparency & Consent Framework". Sirdata est une société intéressante à plusieurs titres : elle propose une CMP (Consent Management Platform) aux éditeurs, en version gratuite ou payante. C'est aussi un fournisseur de données contextuelles et comportementales.
Les éditeurs qui acceptent de partager la donnée personnelle des internautes ne paient d'ailleurs pas la CMP Sirdata :
Une CMP pouvant être "financée par la donnée".
Si nous avons des désaccords, Benoit a toujours pris le temps de répondre à mes questions et d'expliciter les choix de Sirdata, et à ce titre, je le remercie vivement. De nos échanges, je souhaitais écrire un article pour illustrer les choix d'une CMP utilisant le protocole de l'IAB, et la CMP Sirdata était le parfait exemple.
Sirdata sur Psychologies.com
Pour étudier la CMP Sirdata, allons sur le site Psychologies.com avec le navigateur Chrome. Nous sommes accueillis par une bannière de consentement en apparence assez classique :
À votre avis, sur quel bouton l'internaute pressé va-t-il cliquer ?
Vous noterez la mise en valeur de l'option "Tout accepter et continuer", à la différence des options "Paramétrer vos choix" et surtout "continuer sans accepter". Il s'agit d'un "Dark Pattern" adopté par de nombreux sites web français, ayant reçu la bénédiction de la CNIL.
Si vous ne prenez pas le temps de lire le texte de la bannière de consentement, vous pourriez néanmoins rater 2 informations cruciales :
- Certaines sociétés de l'adtech ne se basent pas sur votre consentement mais sur l'intérêt légitime pour traiter vos données personnelles.
- Vos choix ne s'appliquent pas seulement sur Psychologies.com mais également sur quelques 4000 autres sites web.
L'intérêt légitime comme base légale de traitements
Voici un extrait de la bannière de consentement proposé par Sirdata :
Vous pouvez [...] faire un choix plus granulaire ou vous opposer aux traitements basés sur des intérêts légitimes via l'écran de paramétrage.
Traduction : Si vous cliquez simplement sur "Continuer sans accepter", certaines sociétés adtech continueront de se baser sur l'intérêt légitime pour traiter vos données personnelles. Pour vous opposer à ces traitements basés sur des intérêts légitimes, vous devrez aller sur l'écran de paramétrage (option "Paramétrer vos choix").
Revenez donc sur la bannière de consentement pour vérifier vos choix après avoir cliqué sur "Continuer sans accepter". Pour cela, il vous faut scroller jusqu'au pied de page du site Psychologies.com, ne pas cliquer sur "Données personnelles & Cookies" mais sur "Consentement" (le lien ne paraît pas cliquable, pourtant il l'est) :
Le lien caché, pourtant "il doit être aussi simple de retirer son consentement que de le donner".
Notez l'apparition du bouton "Tout refuser et continuer" :
Puis, afin de vérifier l'effet de votre choix précédent ("Continuer sans accepter"), cliquez sur "Paramétrez vos choix". Vous verrez que les différents traitements publicitaires ne sont pas décochés, comme si vous n'aviez pas déjà choisi :
"Continuer sans accepter" ne veut donc pas dire "refuser", pourquoi ?
Suivez ensuite ces étapes :
- Développez l'option "Publicité personnalisée".
- Développez l'option "Créer un profil personnalisé de publicités".
- Notez que l'option "Pour cette activité, les partenaires suivants se reposent sur leur intérêt légitime", est pré-cochée. Développez l'option.
Vous verrez apparaître le partenaire "Sirdata Cookieless" :
"Sirdata Cookieless" apparait comme "non refusé". Vous devez donc vous opposer à l'intérêt légitime pour refuser ce traitement.
Cette option accessible via la CMP Sirdata permet au fournisseur de données comportementales Sirdata de constituer des profils publicitaires même si l'internaute n'a pas donné son consentement.
D'ailleurs, si vous décidiez de développer l'option "Pour cette activité, les partenaires suivants demandent votre consentement", vous verriez apparaitre le partenaire "Sirdata" avec la mention "non accepté" :
"Sirdata" apparait comme "non accepté". Sirdata ne peut pas se baser sur votre consentement pour créer un profil personnalisé de publicité.
Sirdata joue ainsi sur 2 tableaux pour ses traitements publicitaires (dont la création de profil personnalisé de publicité) :
- Le partenaire "Sirdata" se base sur votre consentement si vous cliquez sur "Tout accepter et continuer".
- Le partenaire "Sirdata Cookieless" se base sur son intérêt légitime si vous cliquez sur "Continuer sans accepter".
Avec consentement, Sirdata utilise des cookies et peut partager des identifiants et des segments d'audience avec les partenaires publicitaires. Sans consentement et sur la base d'un intérêt légitime, Sirdata se place en amont de la plateforme de vente (adserveur ou SSP) pour qu'elle puisse vendre des campagnes publicitaires ciblées avec de la donnée Sirdata lorsque l'utilisateur appartient au(x) bon(s) segment(s) d'audience.
Avec son offre "Cookieless", Sirdata continue de vous profiler et d'exploiter votre profil pour de la publicité personnalisée, mais le partage d'informations avec des tiers est plus limité. L'offre Sirdata est résumée ici :
Si vous cliquez sur "tout refuser", Sirdata propose de la publicité contextuelle. Au global, Sirdata juge son offre "respectueuse de la vie privée".
Afin de refuser la constitution d'un profil personnalisé de publicité Sirdata (et plus généralement, les différents traitements publicitaires des sociétés de l'adtech), il vous faudra donc lors de votre premier surf :
- Cliquez sur "Paramétrer vos choix" sur la bannière de consentement.
- Puis cliquez sur "tout refuser".
Notez qu'une option "Tout refuser et continuer" est disponible en premier niveau, mais seulement lorsque vous désirez revenir sur vos choix (si vous trouvez la fameuse option "Confidentialité" en pied de page de Psychologies.com) :
Une option que l'on aurait bien aimé voir sur la bannière de consentement initiale.
Ne refuser que la "Publicité personnalisée" n'est pas évident, un simple clic sur l'option vaudra consentement à la "Publicité personnalisée", mais aussi à la "Publicité standard" :
Un joli "Dark Pattern" repéré par @fourmeux, il vous faudra maintenant décocher les 2 options.
La publicité ciblée sans consentement basée sur l'adresse IP, une manière d'éviter la directive ePrivacy ?
Sirdata, le fournisseur de données comportementales, s'estime conforme aux réglementations européennes, ePrivacy (directive cookies) et RGPD. Quel argumentaire déploie-t-il ?
Tout d'abord, Sirdata estime que la directive ePrivacy ne s'applique pas à son offre "Cookieless" (ou "Consentless"). Son raisonnement : ePrivacy s'applique au stockage d'informations sur le terminal de l'utilisateur ou à l'accès à des informations déjà stockées sur celui-ci. Mais pour identifier les utilisateurs sans consentement, Sirdata se base uniquement sur l'adresse IP, et celle-ci n'est pas stockée sur le terminal de l'utilisateur.
Sirdata est peu explicite sur le fait que son offre "Cookieless" se sert de l'adresse IP de l'utilisateur. Mais il détaille les traitements supplémentaires effectués sur l'adresse IP sur sa page "Politique de protection des données personnelles et de la vie privée" rubrique "Lexique".
Sirdata considère qu'il applique un fingerprinting "passif" et non "actif". Le fingerprinting "passif" serait uniquement constitué de l'adresse IP, il n'implique pas d'accès au terminal. Le fingerprinting "actif" serait constitué des caractéristiques du terminal telles que le user-agent, les polices installées ou la taille écran.
Le ciblage via l'adresse IP, le dernier outil des publicitaires pour vous cibler sans consentement ?
Cette distinction entre fingerprinting "passif" (pour lequel ePrivacy ne s'appliquerait pas) et "actif" (pour lequel ePrivacy s'appliquerait) est discutable. Dans l'article 7.2 de l'Avis 9/2014 sur l’application de la directive 2002/58/CE à la capture d’empreintes numériques, du groupe de travail «Article 29» sur la protection des données, la nécessité du consentement pour de la publicité ciblée est clairement énoncée :
La capture d’empreintes numériques à des fins de publicité ciblée exige donc le consentement de l’utilisateur.
Sirdata maintient sa position : pas d'accès au terminal donc ePrivacy ne s'applique pas. Son offre ne rentre pas dans la définition de l'Avis 9/2014, qui n'est d'ailleurs pas une obligation légale.
Concernant le RGPD maintenant, comme Sirdata traite l'adresse IP de l'utilisateur, et que celle-ci est une donnée personnelle, il se doit d'avoir une base légale pour chacun de ses traitements publicitaires. Lorsque l'utilisateur n'a pas donné son consentement, il se base ainsi sur l'intérêt légitime.
À noter que Sirdata a confiance dans cet argumentaire, il le réutilise ainsi dans ses vidéos promotionnelles, exemple avec "le reciblage sans consentement" :
Sans consentement, la fête est plus folle pour l'adtech !
Sirdata propose également un produit pour rendre conforme les transferts vers Google Analytics aux USA, l'"Analytics Helper". Pour rappel, la CNIL Autrichienne et Française ont jugé les transferts de données vers Google Analytics aux USA illégaux.
Sirdata prend des précautions pour empêcher les services de renseignements US d'identifier un utilisateur via une demande à Google (anonymisation de l'IP avant envoi à Google, pseudonymisation du Client ID au niveau du proxy Sirdata). Intéressant dans le cadre de cet article, le "modèle légal de tracking" pour cet "Analytics Helper" est similaire au modèle de la CMP Sirdata :
- Si consentement, tracking habituel Google Analytics via cookies.
- Si absence de consentement, tracking Google Analytics via un fingerprint généré par Sirdata et "uniquement" basé sur votre adresse IP, avec pour base légale l'intérêt légitime.
- Si absence de consentement et opposition à l'intérêt légitime, pas de tracking Google Analytics.
Le Sirdata Helper est un produit ingénieux, mais sera-t-il suffisant pour rendre les transferts de données vers Google Analytics aux USA conformes ? La question reste ouverte comme je le détaille sur ce thread.
L'intérêt légitime pour de la publicité ciblée
Il paraît compliqué pour Sirdata fournisseur de données comportementales de se baser sur l'intérêt légitime pour de la publicité ciblée. Et notamment concernant le critère de mise en balance : la question est de savoir si les intérêts poursuivis par les fournisseurs adtech l'emportent sur les libertés et droits fondamentaux des personnes concernées.
L'APD mentionne notamment l'avis 03/2013 du Groupe de travail Article 29, l'ancien nom de l'EDPB (« European Data Protection Board »), pré-RGPD :
En outre, l'EDPB indique que l'intérêt légitime ne constitue pas une base juridique suffisante dans le contexte du marketing direct mettant en œuvre de la publicité comportementale [...] (460)
Groupe de travail Article 29 - Avis 03/2013 sur la limitation de la finalité (WP 203), 2 avril 2013 : « le consentement devrait être exigé, par exemple, pour le suivi et le profilage à des fins de marketing direct, de publicité comportementale, de courtage de données, de publicité basée sur la localisation ou d'études de marché numériques basées sur le suivi ».
Pour plus de détails, vous pourrez également lire la plainte de La Quadrature du Net contre Amazon pour violation du RGPD, à savoir pour l'absence de base légale concernant la publicité ciblée.
Après le consentement et le contrat, La Quadrature du Net étudie de manière impitoyable l'intérêt légitime comme base légale potentielle (points 36 à 50). Pour l'association de défense et de promotion des droits et libertés sur Internet, cette base légale ne peut fonctionner pour de la publicité ciblée (62). La CNIL Luxembourgeoise a validé son analyse, avec une amende record de 746 millions € contre Amazon.
La Quadrature du Net contre les GAFAM, malheureusement la CNIL est aux abonnés absents.
Quelques extraits de la plainte de La Quadrature :
C’est la voie que prend le G29 dans l’annexe II de son avis 03/2013, sur le Big Data et l’Open Data : « un consentement préalable libre, spécifique, informé et indubitable devrait presque toujours être requis » dès lors qu’une « organisation souhaite spécifiquement analyser ou prédire les préférences personnelles, le comportement et les attitudes de clients individuels, qui serviront ensuite à guider des “mesures ou décisions” prises à l’égard de ces clients ». (47)
Il donne comme exemple de telles « mesures et décisions » la diffusion « de réductions personnalisées, d’offres spéciales et de publicités ciblées à partir du profil du client ». (49)
Le G29 conclut clairement que le « consentement devrait surtout être requis, par exemple, pour le traçage et le profilage à des fins de prospection directe, de publicité comportementale, de courtage en informations, de publicités fondées sur la localisation ou d’étude de marché numérique fondée sur le traçage ». (50)
Avec Benoit, nous avons donc posé la question de l'intérêt légitime pour de la publicité ciblée à la CNIL l'été dernier (2021), sans réponse.
Vos choix s'appliquent sur une coopérative de 4000 sites
Voici un autre extrait de la bannière de consentement proposé par Sirdata (sur Chrome à minima, car sur Safari, du fait du blocage des cookies tiers, la coopérative de sites est désactivée) :
Vos choix s'appliqueront sur ces sites et dans leurs emails pendant 6 mois, et nous ne vous solliciterons plus avant demain.
Lorsque vous cliquez sur "sites", vous atterrissez sur une nouvelle page d'information, directement sur le site Sirdata. Il vous faut encore cliquer sur "Cliquez ici" en bas de page pour découvrir les sites de la coopérative Sirdata :
Vous retrouverez alors l'ensemble des sites de la coopérative Sirdata, 130 pages paginées, sans option d'export :
Ces sites ont fait le choix de participer à la coopérative de consentement Sirdata (qu'ils utilisent la CMP Sirdata en version gratuite ou payante d'ailleurs).
Alors, est-ce légal ? Selon Sirdata, oui car l'internaute reçoit de l'information en premier niveau. Libre à lui de creuser, et d'aller consulter la liste complète des sites web. Sirdata s'appuie aussi sur cette FAQ de la CNIL :
Il est néanmoins probable que la CNIL n'avait pas prévu ce cas-là, la question 21 faisant probablement référence aux responsables de traitement du site web consulté par l'utilisateur (les partenaires publicitaires), et non à d'autres sites web que l'utilisateur ne consulte pas. Sirdata argumente que ce choix est bénéfique à l'utilisateur en ce sens qu'il réduit la fatigue des bannières de consentement. Encore faut-il que ce choix soit éclairé.
Avec Benoit, nous avons également posé la question de la légalité de ce "choix groupé" à la CNIL l'été dernier (2021), sans réponse.
La coopérative Sirdata, une CMP sous contraintes
La participation d'un site web à la coopérative Sirdata impose certaines contraintes aux bannières de consentement :
- Pour les utilisateurs situés sur le territoire français, Sirdata impose le fameux "Dark Pattern" validé par la CNIL.
- Lorsque l'utilisateur revient sur ses choix, un bouton "Tout refuser et continuer" est disponible.
- L'option "Tout refuser" n'est par contre pas disponible sur la bannière de consentement initiale.
- Le nombre de partenaires publicitaires ne peut dépasser 200 (il y a plus de 1000 sociétés publicitaires dans le TCF, sans compter les partenaires publicitaires qui ne font pas partie de TCF et que Google décide d'intégrer via son "Mode Consentement supplémentaire").
S'il n'est pas sur Safari, les choix de l'utilisateur sont donc appliqués à l'ensemble des sites de la coopérative Sirdata. À noter qu'à la différence de certains de ses concurrents, afficher un mécanisme de "refus" au premier niveau ("Continuer sans accepter" ou "Tout refuser") est systématique si l'utilisateur est basé en France. Ceci est valable pour tous les clients Sirdata, payant ou non et adhérant ou non à la coopérative.
Sirdata évite ainsi les interfaces "non conformes", sans bouton "Refuser" ou "Continuer sans accepter".
Sirdata et l'illégalité du TCF
Dans sa communication, Sirdata indique que les éditeurs faisant partie de sa coopérative ne sont pas concernés par la décision de l'APD. Pour les éditeurs qui payent la CMP de Sirdata, il suffirait de ne pas activer l'ensemble des partenaires publicitaires pour ne pas être concerné par la décision. Voici le message de Sirdata à ses clients :
De manière générale, les éditeurs ayant suivi nos conseils ne sont pas en situation de risque en raison de ce jugement et n’ont pas de données à supprimer, pas plus que leurs partenaires, ni l’obligation de “poper” à nouveau pour recueillir un nouveau consentement.
Reprenons quelques éléments de la décision de l'APD. Tout d'abord, l'APD considère que la chaîne de caractères permettant le stockage et la transmission des préférences de l'utilisateur (TC String) est une donnée personnelle. Elle est en effet associée à l'adresse IP de l'utilisateur (à laquelle les CMP ont accès), cette chaîne de caractères détermine également les futurs traitements publicitaires de multiples sociétés adtech. Sirdata l'explique très bien :
L’APD confirme donc que le choix — la
TC String— en lui-même ne permet pas d'identifier directement des personnes ou des dispositifs mais que, dès lors que le choix est stocké sur le dispositif de l'utilisateur, une CMP a la possibilité d’attribuer un identifiant unique à cetteTC String, c'est-à-dire l'adresse IP du dispositif sur lequel il est stocké. La possibilité de combiner laTC Stringet l'adresse IP implique selon elle qu'il s'agit d'informations concernant un utilisateur identifiable.
L'APD distingue ainsi 2 types de traitements :
- La capture et la dissémination du signal de consentement et des objections à l'intérêt légitime des utilisateurs (via la chaîne de caractères
TC String). - La capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech.
En ce qui concerne la licéité et la loyauté du traitement, la Chambre Contentieuse distingue deux activités de traitement : d'une part, la saisie proprement dite du signal de consentement, des objections et des préférences des utilisateurs dans la
TC Stringpar les CMP (a), et, d'autre part, la collecte et la diffusion des données à caractère personnel des utilisateurs par les organisations participantes (b). (403)
Autre point important, l'APD considère que les CMP sont bien co-responsables de traitements, pour ces 2 types de traitements :
Cela amène la Chambre Contentieuse à conclure que la défenderesse ainsi que les CMP, les publishers et les fournisseurs adtech participants doivent être considérés comme des responsables conjoints du traitement pour ce qui concerne la collecte et la diffusion des préférences, des objections et du consentement des utilisateurs, ainsi que pour le traitement ultérieur de leurs données à caractère personnel. (402)
Sur la CMP Sirdata, quelle base légale pour la capture et la dissémination du signal TC String ?
Démarrons par une clarification de Benoit :
Quand Sirdata agit en tant que CMP, elle capture la
TC Stringet l'envoie vers sa base de données de stockage de la preuve du consentement et de sa validité. Elle ne l'envoie à personne d'autre, et seuls ces traitements s'appuient sur l'obligation légale. La CMP ne transmet pas la string à des Vendors Tiers : les Vendors peuvent y accéder de manière active via une API exposée sur la page mais la CMP de la "dissémine" pas.
S'il n'y a pas "dissémination" de la TC String par la CMP Sirdata, le fait d'exposer la chaîne de caractères via une API permet effectivement sa dissémination ultérieure.
Pour le premier type de traitement (capture et exposition du signal de consentement et des objections à l'intérêt légitime des utilisateurs), Sirdata en tant que CMP n'a pas indiqué sur quelle base légale il souhaitait s'appuyer. En effet, avant la décision de l'APD, l'IAB Europe considérait que la TC String n'était pas une donnée personnelle. Hors, nous avons vu que la TC String était bien une donnée personnelle, mais aussi que les CMP étaient co-responsables de traitement.
Ainsi les CMP doivent déclarer une base légale pour ce traitement de données personnelles. Si l'on étudie Sirdata :
- Le consentement n'est actuellement pas une base légale valable. Sirdata stocke la chaîne de consentement
TC Stringdans le local storage dès l'affichage de la bannière de consentement, et ne demande donc pas son avis à l'utilisateur. Après refus de consentement, laTC Stringest stockée dans le cookieeuconsent-v2. - L'intérêt légitime n'est actuellement pas valable non plus selon l'APD, car l'utilisateur n'a aucun moyen de s'opposer au stockage de cette donnée personnelle : "À cet égard, la Chambre Contentieuse trouve remarquable qu'aucune option ne soit offerte aux utilisateurs pour s'opposer complètement au traitement de leurs préférences dans le cadre du TCF. Quel que soit leur choix, la CMP générera une
TC Stringavant de la lier au User ID unique de l'utilisateur, par le biais d'un cookieeuconsent-v2placé sur l'appareil de la personne concernée." (421). L'APD note que ce traitement ne passerait pas le test de "mise en balance" au vu du nombre considérable de sociétés adtech récupérant cette donnée, et du peu de contrôle donné à l'utilisateur (423).
Avant toute interaction avec la bannière de consentement Sirdata, la chaîne TC String est stockée avec la clé sddan:cmp sur le local storage de mon navigateur.
D'après la décision de l'APD, la CMP Sirdata ne semble pas avoir de base légale pour la capture et l'exposition du signal de consentement et des objections à l'intérêt légitime des utilisateurs. Mais après discussions avec Benoit, je comprends que Sirdata s'appuie en fait sur une autre base légale pour la capture et l'exposition du signal TC String, l'obligation légale.
L'obligation légale comme base légale de traitement ?
L'information comme quoi la CMP Sirdata s'appuie sur l'obligation légale comme base de traitement pour la capture et l'exposition du signal TC String est absente de la bannière de consentement de Sirdata et elle n'est pas mentionnée dans l'article de Sirdata qui revient sur la décision de l'APD. Cependant, elle est indiqué dans les CGU de la CMP Sirdata :
9.5. The
TC stringand strictly necessary data, such as the date of the last prompt used to limit subsequent prompts, will be stored on the user's device, in local storage, in a cookie namedeuconsent-v2which can be used as a first party cookie or a third party cookie linked to the domain nameconsentframework.com. The Parties agree that, in accordance with CNIL Deliberation n°2020-092 of September 17, 2020 adopting a recommendation proposing practical modalities of compliance in the event of recourse to "cookies and other tracers" the storage of or access to this data in the terminal is not subject to prior consent, and if theTC Stringand the necessary data are considered personal data, the processing will be carried out by Sirdata as a data processor acting on behalf of You, data controller on the basis of the legal obligation under GDPR.
D'après l'APD, Sirdata n'est pas un simple sous-traitant mais bien co-responsable de traitement. Ceci-dit, cela n'impacte pas la base légale invoquée par Sirdata, l'obligation légale. L'argumentaire de Sirdata pour se baser sur l'obligation légale est le suivant : l’éditeur et ses partenaires doivent légalement faire la preuve d'un consentement, se souvenir d'un refus/retrait de consentement et mémoriser l'opposition pour ne pas "harceler" l'utilisateur.
Il est dommage que l'IAB Europe et l'APD n'ait pas discuté de cette base légale de traitement, il nous manque une décision juridique pour savoir si cette base légale tient vraiment.
Sirdata invoque la délibération n°2020-092 du 17 septembre 2020 de la CNIL (modalités pratiques de mise en conformité en cas de recours aux "cookies et autres traceurs"), mais celle-ci propose seulement un nommage du traceur permettant de stocker le choix des utilisateurs :
- Enfin, la Commission encourage les professionnels à nommer le traceur permettant de stocker le choix des utilisateurs
eu-consent, en attachant à chaque finalité une valeur booléenne « vrai » ou « faux » mémorisant les choix effectués.
La délibération n° 2020-091 du 17 septembre 2020 (lignes directrices "cookies et autres traceurs") porte sur l'exemption de consentement concernant le choix exprimé par les utilisateurs sur le dépôt des traceurs :
- En l’état des pratiques portées à sa connaissance, la Commission estime que les traceurs suivants peuvent, notamment, être regardés comme exemptés :
- les traceurs conservant le choix exprimé par les utilisateurs sur le dépôt de traceurs
- [...]
Mais la CNIL ne parle pas de base légale de traitement pour le RGPD, encore moins d'une quelconque obligation légale comme base légale. Une lecture attentive du texte de la CNIL sur l'obligation légale pose d'autres questions :
- L'obligation légale doit être prévue dans le cadre juridique national ou européen. Sur quel texte légal Sirdata peut-il alors s'appuyer ?
- Le responsable du traitement souhaitant se fonder sur cette base légale ne doit pas avoir le choix de se conformer ou non à l’obligation (nécessité).
- En particulier, l'organisme doit s'assurer qu'il n'existe pas de moyen moins intrusif d'atteindre cet objectif.
Hors, Sirdata pourrait très bien ajouter un paramètre opt-in aux appels vers sa CMP. Si appel à https://sirdata...?opt-in=0, alors pas de création de la TC String, et donc pas d'appel aux partenaires adtech. L'obligation légale ne semble donc pas nécessaire.
La CMP Sirdata pourrait s'appuyer sur l'intérêt légitime comme base légale de traitement de la TC String (via le paramètre opt-in, l'utilisateur pourrait s'opposer au stockage de la TC String). Encore faudrait-il passer le test de mise en balance au vu du nombre considérable de partenaires récupérant cette donnée (423). Ici, Sirdata argumentera qu'en limitant le nombre de partenaires dans sa coopérative à 200 maximum, le jugement de l'APD ne s'applique pas.
Pour le partenaire publicitaire Sirdata, quelle base légale pour la capture et la dissémination du signal TC String ?
Rappelez-vous, Sirdata opère en tant que CMP, mais il opère aussi en tant que fournisseur de données contextuelles et comportementales. Dans ce rôle, Sirdata capture et dissémine la TC String. Reprenons les explications de Benoit :
Quand Sirdata agit en tant que Vendor s'appuyant sur le consentement (Vendor "Sirdata"), nous pouvons capturer et transférer la
TC Stringet d'autres données personnelles sur la base du consentement et nous vérifions si l'entité à qui nous nous apprêtons à l'envoyer a le droit de la recevoir. Quand Sirdata agit en tant que Vendor s'appuyant sur l'intérêt légitime (Vendor "Sirdata cookieless"), nous pouvons capturer et transférer laTC Stringet d'autres données personnelles sur la base d'un intérêt légitime et nous ne transmettons pas cette donnée.Pour le futur, et précisément à cause de l'APD, nous allons changer la base légale du traitement de la
TC Stringen tant que Vendor, afin de pouvoir transmettre un retrait de consentement : nous nous appuierons bientôt uniquement sur l'intérêt légitime (mais uniquement pour laTC Stringutilisée dans ce cadre).
Le même commentaire semble ici s'appliquer : il faudra passer le test de mise en balance au vu du nombre considérable de partenaires récupérant cette donnée (423). Sirdata pourra probablement argumenter que lorsqu'il agit en tant que partenaire publicitaire ("Vendor"), il transmet la TC String à un nombre limité de partenaires.
Nous avons précédemment étudié les potentielles bases légales pour le premier type de traitements indiqué par l'APD : la capture et la dissémination du signal de consentement et des objections à l'intérêt légitime des utilisateurs (côté Sirdata CMP, mais aussi côté Sirdata "Vendor"). Passons maintenant au deuxième type de traitements : la capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech.
L'intérêt légitime comme base légale pour la capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech ?
Pour rappel, ici nous ne parlons plus de capture ou de dissémination de la TC String mais bien des différents traitements publicitaires effectués avec vos données personnelles :
Les finalités telles que définies dans la v2 du TCF, notez l'exception de la finalité "Stocker et/ou accéder aux informations d'un appareil", ne pouvant s'appuyer que sur votre consentement.
Étudions la décision de l'APD concernant l'intérêt légitime pour des traitements publicitaires dans le cadre du TCF. Ces traitements incluent donc la publicité ciblée, mais pas seulement. Le recours à l'intérêt légitime comme base légale de traitement est soumis à 3 conditions :
- Il doit être "légitime" : l'APD n'a pas d'opinion sur la question de savoir si l'intérêt économique d'un acteur de l'adtech à effectuer des traitements publicitaires est légitime. Mais cette condition n'est déjà pas remplie car l'APD considère que les traitements publicitaires ne sont pas assez spécifiquement décrits dans le cadre du TCF (452).
- Il doit satisfaire à la condition de "nécessité" : l'APD considère que cette condition n'est pas remplie car dans le cadre du RTB (Real-Time Bidding, enchères publicitaires en temps-réel), il n'y a aucune protection contre la dissémination d'informations personnelles (456).
- Il ne doit pas heurter les droits et intérêts des personnes dont les données sont traitées : selon l'APD, le nombre important d'acteurs publicitaires est problématique, ainsi que les nombreuses informations transmises dans le cadre d'une enchère publicitaire. L'APD cite également l'EDBP (le Comité européen de la protection des données) et l'ICO (la CNIL anglaise), jugeant tout deux que l'intérêt légitime n'est pas une base légale valide de traitement pour la publicité ciblée, notamment dans le cadre du RTB (460).
Lisons par exemple l'avis de l'EDBP :
Le consentement devrait être exigé, par exemple, pour le suivi et le profilage à des fins de marketing direct, de publicité comportementale, de courtage de données, de publicité basée sur la localisation ou d'études de marché numériques basées sur le suivi.
Et voici la décision de l'APD :
À la lumière des considérations susmentionnées, la Chambre Contentieuse estime que l'intérêt légitime des organisations participantes ne peut être considéré comme une base juridique adéquate pour les activités de traitement effectuées selon le protocole OpenRTB, conformément aux préférences et aux choix des utilisateurs saisis dans le cadre du TCF.
L'analyse de Sirdata maintenant : ce jugement ne s'applique pas au TCF dans sa globalité, mais seulement aux traitements liés au RTB. Par exemple, cela ne concerne pas le profilage effectué par Sirdata via son offre "Cookieless", qui a lieu en amont des échanges RTB, et n'entraîne pas de partage d'identifiants et de segments d'audience avec des partenaires publicitaires. Et donc la CMP Sirdata peut continuer à proposer à ses partenaires l'intérêt légitime comme base légale d'un traitement.
On pourra ici noter que sans même parler du RTB, l'intérêt légitime ne passe déjà pas le test de légitimité. Pour approfondir, vous pouvez lire le papier de Célestin Matte, Cristiana Santos et Nataliia Bielova, "Purposes in IAB Europe's TCF: which legal basis and how are they used by advertisers?". Celui-ci étudie chaque finalité, indépendamment des éventuels traitements liés au RTB, mais la conclusion reste la même pour l'intérêt légitime, cette base légale ne tient pas :
La nouvelle version du TCF détaille mieux les finalités, mais l'intérêt légitime ne serait toujours pas valide.
Même si ce papier est très solide, Sirdata pourra argumenter qu'il manque une décision légale sur la validité de l'intérêt légitime via le TCF, hors protocole OpenRTB. Le TCF est certes lié au protocole OpenRTB comme l'indique l'APD :
La Chambre Contentieuse constate que l'argument de la défenderesse ne peut être suivi, étant donné que la défenderesse indique à plusieurs reprises dans ses conclusions que la raison d'être du TCF est précisément de mettre les traitements de données à caractère personnel fondés sur le protocole OpenRTB, entre autres, en conformité avec la réglementation applicable, en ce compris le RGPD et la directive ePrivacy. Bien que la Chambre Contentieuse comprenne que le TCF puisse également être utilisé par les publishers pour d'autres applications, en collaboration ou non avec les CMP, il est également certain que le TCF n'a jamais été conçu pour être un écosystème autonome et indépendant. (368)
Mais le TCF est également utilisé hors OpenRTB, argument que pourra ressortir Sirdata pour maintenir la base légale "intérêt légitime" dans sa CMP. Avec donc son propre exemple : en l'absence de consentement, l'utilisation de l'intérêt légitime pour de la publicité ciblée basée sur l'adresse IP, techniquement hors RTB (en amont de celui-ci).
Le consentement comme base légale pour la capture, la dissémination et le traitement des données personnelles par les sociétés de l'adtech ?
Nous avons vu précédemment que l'intérêt légitime n'était pas une base légale valide pour les traitements de données personnelles dans l'OpenRTB telles que facilitées par le TCF, à fortiori pour les traitements relatifs à la publicité ciblée. L'APD détaille également pourquoi le consentement n'est pas une base légale valide pour les traitements de données personnelles.
L'argumentaire de Sirdata pour échapper à cette décision est alors le suivant (que ce soit pour l'intérêt légitime ou pour le consentement). Dans le cadre de sa coopérative, la CMP Sirdata va plus loin que le TCF lorsqu'il est implémenté à minima, avec notamment une meilleure hiérarchisation des données, une meilleure information et surtout une limitation du nombre de partenaires.
Sirdata est toutefois parfaitement consciente que le TCF n’a jamais eu vocation à garantir à lui tout seul une conformité au RGPD. Sirdata CMP implémente donc ce standard comme d’autres, et apporte en complément des mesures additionnelles et règles spécifiques permettant un respect des réglementations locales et régionales bien au-delà de ce que requiert le TCF.
Nous pourrions souligner que l'absence de base légale de traitement est loin d'être la seule violation du RGPD pointée par l'APD, et qu'il ne suffit pas de mieux adresser un des problèmes pour être conforme.
Ce à quoi Sirdata répondra qu'il n'est pas nécessairement conforme, mais qu'il faudrait une nouvelle analyse d'une Autorité de protection des données afin de déterminer la validité, qui s'apprécie au cas par cas. Il pourra notamment citer ce passage de la décision de l'APD :
Il convient également de noter que les CMP ont une grande marge d'appréciation en ce qui concerne l'interface qu'elles offrent aux utilisateurs. En effet, les TCF Policies n'imposent que des exigences d’interface minimales aux CMP participantes, avec pour conséquence qu'en pratique, les interfaces et le respect des principes d'équité et de transparence peuvent varier considérablement selon la CMP avec laquelle les publishers de sites web et d'applications collaborent. (381)
Ce passage de l'analyse de l'APD relevait la responsabilité conjointe des CMP concernant les finalités et les moyens du traitement des données personnelles. Étudions plutôt certaines des "mesures additionnelles" et "règles spécifiques" avancées par Sirdata.
Regrouper des finalités afin de ne pas être concerné par la décision de l'APD ?
Pour l'APD, le consentement n'est pas une base légale valide :
Le consentement n'est pas une base valide pour les opérations de traitement dans l'OpenRTB telles que facilitées par le TCF. (428) La Chambre Contentieuse estime que le consentement recueilli par les CMP et les publishers dans la version actuelle du TCF est insuffisamment libre, spécifique, éclairé et dénué d’ambiguïté. (432)
L'APD constate notamment que les finalités de traitement proposées ne sont pas décrites de manière suffisamment claire, et dans certains cas, sont même trompeuses :
À titre d'exemple, la Chambre Contentieuse constate que les finalités 8 (« Measure content performance ») et 9 (« Apply market research to generate audience insights ») fournissent peu ou pas d'indications sur la portée du traitement, la nature des données à caractère personnel traitées, ou encore la durée de conservation des données à caractère personnel collectées tant que l'utilisateur ne retire pas son consentement. (433)
Ce à quoi Sirdata indique avoir déjà répondu, via notamment le regroupement de ces 2 finalités sous le chapeau "Mesure d'audience" :
Sirdata précise sur son blog :
Pour permettre un consentement éclairé, en second niveau les “purposes” du TCF sont regroupées sous des finalités “chapeau” définies par la CNIL dans sa Recommandation Traceurs du 17 septembre 2021, telles que la “publicité ciblée” ou la “mesure d’audience”.
Sauf que ces finalités publicitaires sont en réalité très différentes de la mesure d'audience et de la fréquentation d'un site, telle que peut l'effectuer un outil tel que Google Analytics, AT Internet ou Matomo. En général, il s'agit plutôt de traitements effectués par des outils de panel et d'analyse de marché tels que des Nielsen ou autres Comscore. Ainsi par ce regroupement, Sirdata apporte de la confusion à des finalités déjà existantes.
Différents modes d'accès aux pages de vie privée des partenaires afin de ne pas être concerné par la décision de l'APD ?
Autre point sur lequel Sirdata déclare aller "plus loin que le TCF", et ainsi échapper à la décision de l'APD, l'accès à l'information sur les opérations de traitement spécifiques de chaque fournisseur adtech. Voici un passage de la décision de l'APD :
En outre, les informations que les CMP fournissent aux utilisateurs demeurent trop générales pour refléter les opérations de traitement spécifiques de chaque fournisseur adtech, ce qui empêche la nécessaire granularité du consentement. (436)
Que fait donc Sirdata ? Voici ce qu'il déclare :
L’information obligatoire dans le cadre du TCF est en effet un socle commun brut insuffisant : Sirdata et ses clients vont bien au-delà.
En plus de refléter les mentions obligatoires du TCF, l’UI de Sirdata CMP apporte un éclairage additionnel sur les données traitées et la finalité de ces traitements, et en hiérarchise l’information pour une compréhension et un contrôle utilisateur facilités.
Une partie de l’information est disponible en premier niveau, une autre, comme la liste des destinataires, l’est aisément en second niveau, et l’accès aux informations additionnelles comme les conditions d’exercice des droits est accessible via des liens vers les pages de Vie Privée.
En pratique, lorsque vous zoomez sur une finalité via la bannière de consentement, vous pouvez afficher la liste des partenaires. Si vous cliquez sur un des partenaires, vous aurez alors un lien vers sa page "vie privée" :
Le partenaire "Sirdata Cookieless", qui se base sur l'intérêt légitime pour créer un profil personnalisé de publicités.
On peut noter que ce lien vers la page "vie privée" est déjà imposé par le TCF de l'IAB :
When making use of a so-called layered approach, a secondary layer must be provided that allows the user to: review the list of named Vendors, their Purposes, Special Purposes, Features, Special Features, associated Legal Bases, and a link to each Vendor’s privacy policy.
Mais Sirdata indique aller plus loin que certaines CMP, qui n'imposent pas de pouvoir lister les partenaires à partir d'une finalité donnée. Nous pouvons voir la différence avec le site de L'Express, qui utilise la CMP de Didomi :
Je ne peux pas développer "Intérêt légitime", je ne peux voir que Sirdata s'appuie sur cette base légale pour "Créer un profil personnalisé de publicité".
Mais la vue "Partenaires" permet bien de lister les différents partenaires et de présenter un lien vers la page de vie privée de chaque partenaire :
Pour "Créer un profil personnalisé de publicité" sur L'Express avec la CMP de Didomi, Sirdata s'appuie également sur l'intérêt légitime, via le fameux partenaire "Sirdata Cookieless".
Pour Sirdata, la "meilleure" hiérarchisation des informations de sa CMP ne la rend pas forcément licite, mais suppose une nouvelle décision de l'APD afin de juger de sa licéité.
Limiter le nombre de partenaires afin de ne pas être concerné par la décision de l'APD ?
Principal argument de Sirdata, la décision de l'APD ne s'appliquerait pas à Sirdata, car celui-ci impose un choix de partenaires à ses clients, avec une limite à 200 partenaires pour sa coopérative (hors coopérative, il n'y a pas de limite).
Dans le cadre de la coopérative de choix qu’elle gère, Sirdata va même jusqu’à imposer un plafond de 200 partenaires, très loin des 2000 partenaires potentiels du TCF et du réseau de consentement géré par Google en complément — “AC Mode” —.
De tels garde-fous permettent d’éviter les traitements à grande échelle des préférences des utilisateurs — collectées sous le TCF — dans le cadre du protocole open RTB : selon l’APD les intérêts des personnes concernées ne l’emportent sur l'intérêt légitime des organisations participant au TCF que lorsque ces dernières sont toutes sélectionnées.
Mais dans la décision de l'APD, nulle mention d'un intérêt légitime des organisations qui l'emporterait sur les intérêts des personnes concernées si ces dernières ne sont pas toutes sélectionnées... Sirdata déclare néanmoins s'appuyer sur cet extrait :
Bien que les TCF Policies interdisent aux CMP d'accorder une préférence à certains fournisseurs adtech de la Global Vendors List, et qu'ils sont donc en principe tenus de présenter aux utilisateurs tous les fournisseurs inscrits au TCF, sauf instruction contraire des publishers, quelques auteurs notent qu'un certain nombre de CMP ne respectent pas cette exigence. Soit parce que les CMP imposent aux publishers des fournisseurs présélectionnés, soit parce qu’elles leur refusent la possibilité de déroger à la liste complète des fournisseurs adtech, proposée par défaut. (380)
Ce passage est là pour expliquer pourquoi les CMP doivent être tenus pour co-responsables de traitement, et non pour indiquer une quelconque problématique d'un nombre trop grand de partenaires. Aussi, l'IAB Europe n'impose pas de présenter la liste complète, mais seulement de ne pas discriminer un partenaire en particulier :
In any interaction with the Framework, a CMP may not exclude, discriminate against, or give preferential treatment to a Vendor except pursuant to explicit instructions from the Publisher involved in that interaction and in accordance with the Specifications and the Policies.
Le raisonnement de Sirdata est le suivant :
- Dans le cadre du TCF, nous sommes tenus de présenter tous les fournisseurs par défaut (ce n'est pas une "obligation", comme le montre le document de l'IAB Europe).
- Cette présentation n'est pas valable selon l'APD (Sirdata interprète le "en principe" de l'APD comme une obligation).
- Nous ne respectons pas cette "obligation" du TCF, car nous imposons aux clients de choisir leurs partenaires (200 maximum sous peine de ne pouvoir faire partie de la coopérative, une trentaine par défaut).
- Et donc la décision de l'APD ne nous concerne pas.
Mais Sirdata suit bien les recommandations de l'IAB Europe car il ne discrimine pas de partenaire en particulier. On peut néanmoins retrouver un autre argument lié au nombre de partenaires dans la décision de l'APD :
En particulier, les destinataires pour lesquels le consentement est recueilli sont si nombreux que les utilisateurs auraient besoin d'un temps disproportionné pour lire ces informations, ce qui signifie que leur consentement peut rarement être suffisamment éclairé. (435)
Pour Sirdata, le fait d'imposer le choix des partenaires (avec plafond à 200 partenaires) ne rend pas nécessairement sa CMP licite, mais une autre évaluation d'une Autorité de régulation serait nécessaire.
L'illégalité des bannières de consentement de l'IAB ne concerne pas que la base légale de traitement
Via cet article, nous n'avons pu qu'effleurer les problèmes posées par les bannières de consentement de l'IAB. Sirdata indique que le fait d'aller "plus loin" que l'implémentation "à minima" du TCF permettrait à ses clients de continuer le "business as usual" avec sa CMP. Cependant, l'illégalité du TCF est systémique, continuer de s'appuyer dessus est légalement risqué. Aussi, faire évoluer le TCF pour le rendre licite ne sera pas facile, le mécanisme même du RTB paraissant irréconciliable avec le RGPD, notamment au regard de la sécurité des données personnelles.
Quelques adaptations pourraient rendre le TCF légal ?
Vous pourrez approfondir le sujet via la lecture de ces papiers :
- "An Unending Data Breach Immune to Audit? Can the TCF and RTB Be Reconciled with the GDPR?", de Johnny Ryan et Cristiana Santos.
- "Impossible Asks: Can the Transparency and Consent Framework Ever Authorise Real-Time Bidding After the Belgian DPA Decision?", de Michael Veale, Midas Nouwens et Cristiana Santos.
Et en regardant cette présentation de Robin Berjon, "Consent of the Governed".
Vers un internet sans surveillance imposée, et sans bannière de consentement
Charge aux CNILs Européennes de s'appuyer sur cette importante décision de l'APD pour correctement sanctionner les différents intervenants (CMP, éditeurs, partenaires publicitaires) et interdire la fuite massive de données personnelles via le RTB. Une interdiction de la publicité ciblée serait appréciée, et pas simplement pour les mineurs, comme le propose le DSA. À minima, la CNIL pourrait se prononcer plus clairement sur la publicité ciblée basée sur l'intérêt légitime.
Aussi, ces bannières de consentement ne devraient pas exister, l'utilisateur devrait être en mesure d'accepter ou de refuser le tracking de l'industrie publicitaire directement via les réglages de son navigateur (opt-in), sur le modèle de ce qu'Apple propose déjà via son système ATT. Et à ce titre, des initiatives comme le Global Privacy Control (GPC) ou le Advanced Data Protection Control (ADPC) méritent d'être développées et soutenues par la loi.
03.08.2021 à 11:02
Avec les "signaux résilients" de Facebook, la surveillance publicitaire évolue

La publicité, le produit de Facebook
Les résultats financiers de Facebook sont limpides, plus de 98% de ses revenus proviennent de la publicité. Facebook dispose ici de 2 leviers de croissance :
- Augmenter l'offre : à savoir, proposer plus d'opportunités publicitaires aux annonceurs.
- Augmenter la demande : à savoir, convaincre les annonceurs existants d'augmenter leurs budgets publicitaires, et signer de nouveaux annonceurs.
Augmenter l'offre : votre temps de cerveau disponible
Le moyen le plus direct d'augmenter l'offre publicitaire est d'acquérir de nouveaux utilisateurs. Comme l'indique ce mémo interne, Facebook a appliqué cette stratégie de croissance à tout prix, à l'extrême :
That can be bad if they make it negative. Maybe it costs a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools.
[...] The ugly truth is that we believe in connecting people so deeply that anything that allows us to connect more people more often is de facto good. It is perhaps the only area where the metrics do tell the true story as far as we are concerned.
Autre levier, se diversifier via le rachat d'applications existantes. En 2012, Facebook a ainsi racheté Instagram, ses utilisateurs et son savoir-faire :

Zuckerberg sur le rachat d'Instagram : Facebook s'achète du temps, afin d'incorporer dans ses Apps les mécanismes de croissance d'Instagram (à l'époque en avance sur le mobile et sur les photos).
L'augmentation de l'offre publicitaire passe également par la monétisation de l'inventaire de tiers : Facebook propose aux Apps d'utiliser son ad-network, le "Facebook Audience Network", contre une commission. À noter que la monétisation de l'inventaire de tiers dépend de la capacité de lire les données Facebook de l'utilisateur, et c'est sans doute une des raisons qui ont poussé Facebook à fermer son ad-network sur le web mobile. Via Intelligent Tracking Prevention (ITP), les utilisateurs de Safari ont des protections contre le tracking de Facebook sur des sites tiers.
Avoir des milliards d'utilisateurs sur Facebook ou Instagram ne suffit pas, il faut les rendre dépendants, quel qu'en soit le coût. Voici un bon résumé de Robin Kelly, sénateur américain de l'Illinois :
The business model for your platforms is quite simple: keep users engaged. The more time people spend on social media, the more data harvested and targeted ads sold. To build that engagement, social media platforms amplify content that gets attention. That can be cat videos or vacation pictures, but too often it means content that’s incendiary, contains conspiracy theories or violence. Algorithms on the platforms can actively funnel users from the mainstream to the fringe, subjecting users to more extreme content, all to maintain user engagement.
Dernier levier, afficher toujours de publicités (en comparaison avec les publications de vos amis et des pages que vous suivez). Si vous êtes encore sur Instagram, vous avez pu noter l'invasion progressive des publicités dans votre fil et dans les stories. Instagram s'est mis au diapason de Facebook, et nous sommes probablement arrivés au point de saturation. Même si Facebook et Instagram n'ont pas vraiment de concurrents, la pression publicitaire est à son maximum.
Augmenter la demande : consumérisme et propagande
Proposer de nombreuses opportunités publicitaires ne suffit pas, encore faut-il convaincre les annonceurs de l'efficacité de la publicité sur les applis Facebook et sur son réseau de partenaires. Facebook a plusieurs points forts : sa capacité à cibler une grande partie de la population, à différents moments de la journée, ses critères de ciblages multiples ainsi que ses formats publicitaires "natifs". Mais le point clé est la rentabilité : Facebook doit prouver qu'il fait gagner de l'argent aux annonceurs, et non l'inverse.
Comment Facebook optimise-t-il une campagne publicitaire ? Voici un process standard :
- En démarrant la campagne publicitaire sans ciblage à priori : cela permet de toucher des utilisateurs et de tester les messages publicitaires.
- Puis en observant les conversions : afin de comprendre les caractéristiques des utilisateurs qui atteignent l'objectif de l'annonceur, les messages publicitaires les plus efficaces, le meilleur moment et le meilleur contexte pour diffuser la publicité, etc.
- Enfin en ciblant les utilisateurs similaires : les "lookalikes" ou "audiences similaires" dans le jargon de l'adtech.
Ainsi, l'efficacité des campagnes publicitaires de Facebook est étroitement liée aux informations qu'il détient sur ses utilisateurs ainsi qu'à sa capacité à mesurer correctement les conversions.
Par défaut, l'annonceur indique son but, son budget et son message, l'algorithme de Facebook gère le ciblage automatiquement.
Assez souvent, Facebook connaît à l'avance le type d'utilisateurs à cibler car l'annonceur lui a transmis une liste de clients appelée "audience personnalisée" et lui a demandé de cibler des utilisateurs similaires.
L'annonceur peut laisser Facebook trouver les bonnes audiences ou uploader une "audience personnalisée" ou renseigner manuellement des critères de ciblage. Il verra instantanément une estimation du nombre de personnes touchées.
Cela peut paraître presque innocent dit comme cela, mais le ciblage Facebook a contribué à la victoire de Trump en 2016. L'algorithme de Facebook ne se contente pas d'optimiser les campagnes publicitaires, il favorise également la diffusion de propagande à grande échelle et représente donc une menace sérieuse pour les démocraties.
Facebook vous espionne, partout
Sur ses applications
Le grand public connaît l'application Facebook. Mais celui-ci est également propriétaire des applications Instagram et WhatsApp, qui font partie des applications les plus utilisées au monde. Facebook a également un pied dans le futur avec Oculus, sa plateforme de réalité virtuelle, sur laquelle il aimerait d'ailleurs bien diffuser de la publicité. Chacune de vos interactions y est exploitée pour vous rendre dépendant et monétiser votre attention.
Ici , vous pouvez supprimer vos comptes Facebook et Instagram, faire migrer vos contacts de WhatsApp vers Signal, et ne pas acheter de casque Oculus. Un piège pour Facebook et Instagram, il ne vous faudra pas simplement désactiver vos comptes mais bien les supprimer.
Partout ailleurs
Ce que le grand public ignore, c'est que Facebook vous espionne aussi ailleurs. La liste des outils mis à la disposition de tiers est longue comme le bras, et ceux-ci sont fournis avec une contrepartie, permettre à Facebook de collecter toujours plus d'informations sur vous, pour son propre usage.
Voici quelques exemples, non exhaustifs :
- Les plugins sociaux dont le fameux bouton "Like", très apprécié des éditeurs.
- Le Facebook Audience Network, pour les développeurs d'applications qui veulent de la monétisation publicitaire via l'ad-network de Facebook.
- Le Facebook Pixel et le SDK, qui permettent aux annonceurs de faire remonter l'activité de leurs prospects et clients, depuis leurs sites web et leurs applications, vers Facebook.
- Facebook App Events, qui permet de faire remonter des évènements de toutes sortes (web, app, hors ligne) à Facebook.
- Le Facebook Login, qui permet de se connecter à une application via son compte Facebook.
La plupart des sites et applications utilisent au moins un des outils de Facebook. Et comme l'on vous demande rarement votre avis, Facebook est souvent au courant de ce que vous faites, ceci même si vous n'avez pas de compte Facebook ou Instagram. La publicité vidéo d'Apple pour l'App Tracking Transparency est une bonne illustration du côté invasif de Facebook.
Depuis début 2020 et en réaction à de multiples scandales, Facebook permet à ses utilisateurs de prendre conscience de l'activité "en dehors de Facebook" et de la dissocier de leurs comptes :

Ne vous laissez pas abuser par la propagande de Facebook, "parfois" signifie "en général".
Dissocier l'activité ne veut pas dire la supprimer des serveurs de Facebook... La firme conserve bien toutes vos interactions mais ne les associent plus à votre compte. À noter que Facebook ne vous facilitera pas la tâche : pour dissocier vos activités, il vous faudra :
Ce serait trop beau si c'était un peu plus visible et en une seule étape... Comme sur votre compte Google par exemple :
Google, l'autre big browser, vous facilite un peu plus la vie.
Bien évidemment, ni Facebook (ni Google) ne supprime votre activité, celle-ci a une trop grande valeur. Il s'agit simplement de ne plus l'associer à votre compte.
Et si vous n'avez pas de compte Facebook ni Instagram ? Facebook vous surveille quand même, il a vos coordonnées via les carnets d'adresses qu'il a pu aspirer chez vos amis, il conserve précieusement vos activités sur le web, dans les apps et hors ligne. Quel intérêt pour son modèle publicitaire ?
- Facebook mesure l'impact de ses publicités en comparant les taux de conversion entre les personnes exposées à la publicité et les personnes non exposées.
- Vous pourriez être exposé aux publicités du Facebook Audience Network sur des applis tierces.
- Plus généralement, votre comportement permet à l'algorithme de Facebook d'améliorer ses modèles prédictifs.
Une surveillance en danger
Les internautes étant de plus en plus sensibilisés à la protection de la vie privée, la surveillance hors applis Facebook devient plus difficile. Nous allons étudier comment Facebook s'adapte et communique auprès des annonceurs, via le livre blanc "Why you should leverage Facebook's resilient signals", co-écrit avec l'agence française Fifty-Five.
Pourquoi communiquer auprès des annonceurs ? Facebook a besoin de complices pour vous surveiller hors de son App, les annonceurs doivent correctement utiliser les outils mis à disposition par Facebook pour que vos données personnelles remontent correctement et de manière durable (les fameux "signaux résilients") vers l'ogre de Menlo Park.
Tout d'abord, pourquoi est-ce que la surveillance de Facebook hors de ses applis serait en danger ? Pour 3 raisons selon Facebook et Fifty-Five :
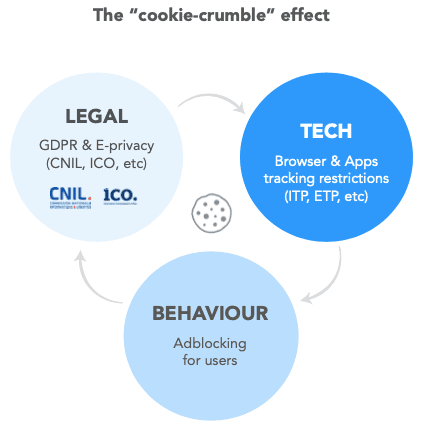
- Les nouvelles lois (RGPD, ePrivacy, CCPA, ...) imposent des restrictions légales à la surveillance généralisée telles qu'une base légale pour traiter des données personnelles, et un consentement préalable pour le stockage d'informations ou l'accès à des informations déjà stockées (hors cookies techniques).
- Les protections des navigateurs et systèmes d'exploitations (Apple App Tracking Transparency ou ATT, Webkit Intelligent Tracking Prevention ou ITP, Firefox Enhanced Tracking Protection ou ETP, ...) rendent le tracking plus difficile.
- Les adblockers (uBlock Origin, NextDNS, Adguard, Blokada...) permettent de bloquer les publicités et autres traceurs à la source.
Quel impact pour les campagnes publicitaires des annonceurs ?
Les traceurs actuels de Facebook, pixels et autres SDKs, des signaux peu résilients. On voit également l'opportunité pour Facebook d'étendre sa surveillance à ce que vous faites hors ligne.
Comme on peut le voir :
- Facebook peut continuer à mesurer ce que vous faites sur ses applis (Facebook, Instagram).
- Facebook a du mal à mesurer ce que vous faites sur les sites et applis des annonceurs : en raison des protections navigateurs et autres adblockers, les anciens traceurs Facebook sont de moins en moins efficaces.
- Facebook n'a qu'une vue très partielle de ce que vous faites hors ligne.
En quoi cette vision partielle est-elle problématique pour les annonceurs ? Ici Facebook et Fifty-Five doivent expliquer en quoi la surveillance généralisée serait nécessaire :
Ici, Facebook tente de vous rassurer avec des critères de ciblage très génériques. En réalité, votre profil publicitaire est incroyablement plus détaillé.
La mesure de la performance publicitaire est essentielle. Si Facebook a accès à moins de conversions (achats, inscriptions, installations...), son algorithme aura moins d'informations sur les critères qui fonctionnent (profils utilisateurs, message publicitaire, contexte publicitaire), ce qui diminuera l'efficacité de sa publicité. L'annonceur devra potentiellement payer plus cher pour un résultat moindre.
Comment faire peur aux annonceurs ? S'ils ne permettent pas à Facebook de vous surveiller suffisamment bien, leurs campagnes publicitaires ne fonctionneront plus correctement :

Des "trous" dans la mesure chez les annonceurs ? Une catastrophe selon Facebook...
Si l'annonceur ne comblent pas ces "trous" de mesure, voici les conséquences :
- Moins de conversions attribuées à Facebook : certaines conversions ne seront pas mesurées, le reporting montrera des campagnes publicitaires moins efficaces qu'elles ne le sont en réalité, avec un coût d'acquisition client plus important.
- Une campagne publicitaire réellement moins efficace : Facebook aura moins d'informations pour optimiser la campagne.
- Une information imparfaite : la conséquence, l'annonceur doutera du reporting d'éventuelles futures campagnes publicitaires.
Les "signaux résilients", où comment Facebook contourne vos protections
Comment Facebook permet-il aux annonceurs de combler ces "trous" ? Via ce qu'il appelle les "signaux résilients" :
Avec votre adblocker, vous pensiez être protégé de la surveillance invasive de Facebook ? Erreur...
Avec la complicité des annonceurs, voici comment Facebook contourne vos protections :
- Avec l'API Conversion (aussi appelée CAPI) : si un traceur Facebook peut être altéré ou bloqué par votre navigateur ou votre adblocker, l'idée est ici de fuiter vos données personnelles vers Facebook directement depuis un serveur contrôlé par l'annonceur, via l'utilisation de son API Conversion. L'annonceur peut dédupliquer les évènements déjà envoyés depuis votre surf sur son site web, il peut également fuiter d'autres informations qu'il a sur vous (vos achats "hors ligne", votre scoring dans son CRM, etc).
- Avec la correspondance avancée pour le web les applications : l'annonceur va pouvoir fuiter vos données personnelles d'identification (nom, prénom, adresse email, numéro de téléphone, etc) vers Facebook au moment où vous validez un formulaire. Notez que cette fuite peut même être configurée automatiquement (via le tag javascript Facebook pixel) ou de manière manuelle (via un pixel Facebook IMG).
- Avec les conversions hors ligne : Facebook s'assure de récupérer votre comportement "hors ligne" à savoir tous vos achats en magasin, vos réservations par téléphone, etc. L'annonceur peut fuiter ces informations à Facebook via l'API Offline Conversion, via son interface Facebook ou en s'appuyant sur l'un des nombreux partenaires de Facebook. Dans la liste des complices "hors ligne" : les terminaux de paiements des points de vente, les reçus numériques, les cartes de fidélité, les logiciels des centres d'appels, les logiciels marketing et CRM, les plateformes d'intégrations ainsi qu'une liste à rallonge de "partenaires Facebook Business".
Lorsqu'Apple l'y contraint, des publicités Facebook plus respectueuses de votre vie privée
L'outil de mesure agrégée des évènements (aussi appelé AEM) : permet à Facebook de mesurer l'efficacité des campagnes publicitaires de manière agrégée (256 campagnes publicitaires maximum, pas de suivi individuel) lorsque l'utilisateur a refusé le tracking Facebook ou Instagram sur iOS (via ATT). C'est un outil inspiré de la solution d'Apple, WebKit Private Click Measurement ou PCM, et c'est l'unique solution respectueuse de la vie privée proposée par Facebook.
Vous pourriez être surpris connaissant Facebook : pourquoi ne pas surveiller sur le web les utilisateurs d'iOS qui ont refusé le tracking sur les Apps Facebook ou Instagram ? Parce que dans ses directives pour les développeurs d'applications, Apple est très clair :
Tracking refers to the act of linking user or device data collected from your app with user or device data collected from other companies’ apps, websites, or offline properties for targeted advertising or advertising measurement purposes
Si Facebook violait cette règle, il prendrait le risque de se faire expulser de l'App Store. Vous pouvez approfondir le sujet avec l'article "Understanding Facebook’s updated iOS14 advertising guidance".
Et pourquoi n'avoir pas directement utilisé PCM ? Mystère, Facebook déclare seulement :
Notre solution est semblable à l’outil privé de mesure des clics d’Apple. Toutefois, elle répond à certains cas d’utilisation clés par les annonceurs non pris en compte par Apple.
Notez que si vous refusez le tracking Facebook ou Instagram via la fenêtre iOS ATT, Facebook déclare répercuter ce choix dans le traitement des évènements envoyés via l'API Conversion :
Les évènements envoyés à Facebook via l’API Conversions seront également traités conformément aux limites définies par l’outil de mesure agrégée des évènements.
Comment Facebook traite-t-il les évènements des autres "signaux résilients" (la correspondance avancée et les conversions hors ligne) ? Mystère...
À noter que Facebook peut également être source de propositions lorsqu'il s'agit de proposer des standards publicitaires qui respectent mieux la vie privée. Certaines discussions entre ingénieurs d'Apple et de Facebook (à savoir John Wilander et Ben Savage) permettent parfois de dépasser le conflit Apple vs Facebook, avec des propositions permettant de répondre à des cas d'usages publicitaires, tout en préservant la vie privée des internautes :
- Proposition pour mesurer l'impact d'une publicité : afin de savoir s'il y a une conversion même si l'utilisateur n'a pas cliqué sur une publicité au préalable, ce qui n'est actuellement pas possible avec WebKit PCM. Cette proposition permettrait de savoir si le groupe ayant été exposé à de la publicité a un meilleur taux de conversion que le groupe n'ayant pas été exposé.
- Proposition pour permettre à des plateformes de mesurer les campagnes publicitaires de leurs annonceurs : Ben Savage prend l'exemple d'Etsy, celui-ci permet à ses utilisateurs de diffuser des campagnes Facebook. Mais avec WebKit PCM, "l'annonceur Etsy" est limité à 256 campagnes publicitaires, et Facebook ne peut donc pas mesurer l'efficacité ni optimiser les campagnes des utilisateurs d'Etsy (il manque un niveau de granularité).
- Proposition pour redonner à l'utilisateur le contrôle sur ses centres d'intérêt : permet d'adresser certains problèmes de FLoC, la proposition très décriée de Google pour faire de la publicité comportementale sans cookies tiers.
Les évolutions des navigateurs afin de mieux protéger la vie privée sont discutées au sein du "Privacy Community Group" du W3C, l'organisme chargé de co-construire les standards du web. Facebook joue donc ici son rôle, tenter d'influer sur les évolutions des navigateurs afin de limiter l'impact sur son business publicitaire. Et pour cela, Facebook doit être crédible auprès des ingénieurs d'Apple, de Firefox ou de Brave. Ceux-ci ont pour premier principe le respect de la vie privée des internautes (les ingénieurs Chrome ont souvent le biais publicitaire de Google).
Sur le sujet du W3C et de cette guerre d'influence, lisez l'excellent article "Concern trolls and power grabs: Inside Big Tech’s angry, geeky, often petty war for your privacy".
Les contournements illustrés, exemples de campagnes publicitaires
Afin d'illustrer l'impact des "signaux résilients", Facebook et Fifty-Five donnent 2 exemples.
L'utilisateur voit une publicité mais ne clique pas
Premier cas, l'utilisateur voit une publicité sur Facebook, ne clique pas dessus, mais va ensuite sur le site de l'annonceur pour compléter un formulaire. Il sera rappelé par un centre d'appel, pour finalement s'inscrire.
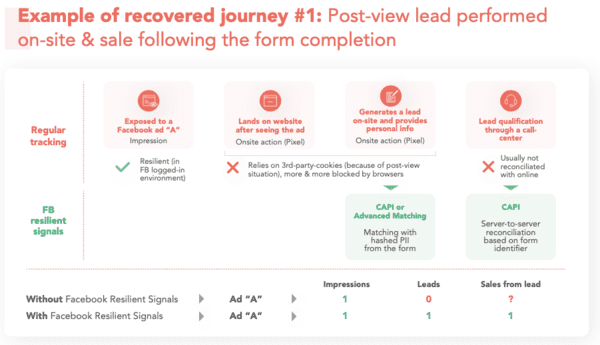
Vu que le navigateur (Safari ou Firefox par exemple) de cet utilisateur bloque les cookies tiers de Facebook, le traceur de Facebook (pixel) ne peut pas lire l'identifiant utilisateur Facebook sur le site de l'annonceur. Facebook n'est donc pas capable de faire le lien entre l'exposition publicitaire de l'utilisateur et son surf sur le site de l'annonceur.
Mais lorsque l'utilisateur remplit le formulaire, l'annonceur est capable d'appeler l'API Conversion ou la correspondance avancée pour le web. Il peut ainsi envoyer à Facebook les données personnelles d'identification du formulaire (nom, adresse email, numéro de téléphone, etc) et celui-ci peut ainsi faire le lien avec le compte de l'utilisateur. De même, après inscription de l'utilisateur via téléphone, l'annonceur utilisera l'API Conversion pour transmettre l'inscription à Facebook.
L'utilisateur clique sur une publicité
Deuxième cas, l'utilisateur est sur Safari, il clique sur une publicité Facebook, puis il consulte une page produit de l'annonceur 8 jours après pour enfin acheter hors ligne.
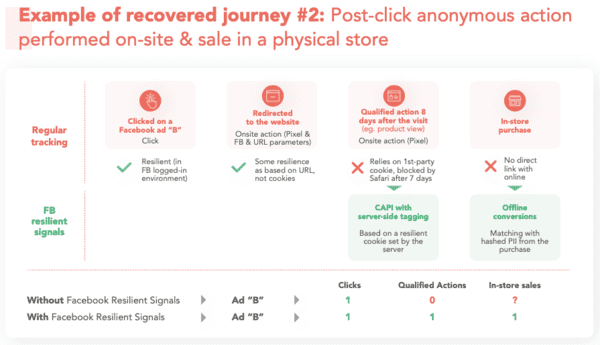
Lorsque l'utilisateur clique sur la publicité Facebook, celui-ci parvient à déposer un cookie first-party sur le site de l'annonceur. Le Facebook pixel installé sur le site de l'annonceur récupère en effet l'identifiant de clic fbclid contenu en paramètre d'URL, et le stocke dans le cookie first-party _fbc. Notons que Safari pourrait très bien supprimer ces paramètres de tracking, comme le fait déjà Brave depuis l'année dernière.
Depuis 2019 et la mise à jour ITP 2.1, Safari supprime les cookies créés côté client au bout de 7 jours (ici le cookie _fbc créé par le Facebook pixel). Lorsque l'utilisateur consulte la page produit de l'annonceur après 8 jours, Facebook ne peut plus faire le lien avec son clic initial, il ne reconnaît pas l'utilisateur.
Le contournement est indiqué par Facebook et Fifty-Five : le pré-requis est de passer par du serveur-side tagging comme celui de Google Tag Manager, ce qui permet de créer un cookie HTTP via le header HTTP Set-Cookie et ainsi de contourner la durée de vie à 7 jours des cookies clients.
L'étape suivante est de configurer l'API Conversions pour fonctionner avec Google Tag Manager, action déjà très bien documentée par Facebook et par Simo Ahava.
Ainsi lorsque l'utilisateur consulte la page produit, Google Tag Manager est appelé avec un cookie first-party permanent, le mapping avec l'identifiant de clic fbclic est bien enregistré et le containeur serveur de Google Tag Manager peut correctement appeler l'API Conversions de Facebook pour transmettre les informations. "Bénéfice" supplémentaire : le contournement des adblockers ! Ensuite, lorsque l'utilisateur achète en magasin, l'annonceur utilise l'outil de conversions hors ligne pour transmettre à Facebook les achats de l'utilisateur.
Les antisèches de la surveillance
Pour pousser les annonceurs à adopter ses "signaux résilients", Facebook a profité du remarquable travail de Fifty-Five. Le livre blanc contient ainsi des fiches récapitulatives de chaque "signal".

Un récapitulatif des différents "signaux résilients".
L'API Conversions
Voici l'antisèche pour l'équipe marketing :
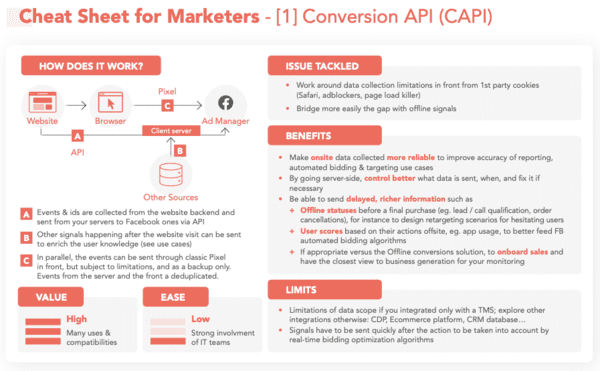
Facebook et Fifty-Five conseillent d'installer l'API Conversions en parallèle du pixel Facebook, et donc de collecter les évènements à la fois côté client et serveur.
L'API Conversion permet ainsi de contourner les protections de navigateurs tels que Safari (limite à 7 jours sur les cookies créés en javascript). Elle permet également de contourner les adblockers lorsqu'elle est utilisée conjointement avec du serveur-side tagging. Cette API permet finalement de transmettre des informations hors ligne, telles que le scoring utilisateur.
Voici l'antisèche pour l'équipe technique :

On note en particulier le conseil suivant : "CAPI is a way to secure data for sensitive sector (Bank, Insurance, ...)". Et oui, vos données bancaires ou d'assurance fuitent vers Facebook, mais ne vous inquiétez pas, la connexion est sécurisée ! Encore une fois, tout est fait pour faciliter la fuite de toutes vos interactions, notamment via les intégrations natives :
- Tag Managers pour vos interactions avec le site de l'annonceur
- Plateformes eCommerce, CRM et Customer Data Platforms pour vos achats et interactions hors-ligne.
Mise en avant d'une intégration native au Tag Manager de Google :
L'intégration de l'API Conversions avec le Server-Side Tagging de Google Tag Manager est mise en avant par Facebook, comme l'indique Simo Ahava.
La correspondance avancée
Voici l'antisèche pour l'équipe marketing :

Cette option permet de contourner le blocage des cookies tiers par les navigateurs, et de fuiter vos données personnelles même si vous n'avez jamais cliqué sur une publicité Facebook. En effet, l'annonceur envoie à Facebook vos données personnelles d'identification, ce qui permet à celui-ci de faire le lien avec votre compte Facebook.
On note dans les limitations :
- "Although cookie-less, it is key you collect consent from users" : Facebook et Fifty-Five considèrent-ils que votre consentement n'est pas nécessaire avec les autres "signaux résilients" ?
- "If you work in sensitive sectors such as Banking, a heavier setup is required" : il faut alors passer par la correspondance avancée manuelle et non automatique, à savoir configurer soi-même le pixel (IMG) permettant d'envoyer les données personnelles d'identification plutôt que de laisser le pixel Facebook (javascript) récupérer automatiquement les bons champs du formulaire.
Voici l'antisèche pour l'équipe technique :

Rien de nouveau, si ce n'est le rappel qu'il faut utiliser la correspondance avancée manuelle pour les secteurs "sensibles".
Les conversions hors-ligne
Voici l'antisèche pour l'équipe marketing :

Encore rien de nouveau, seulement le constat que la surveillance continue hors-ligne, elle s'appuie sur vos données personnelles d'identification (nom, email, numéro de téléphone, etc).
Voici l'antisèche pour l'équipe technique :
On peut de nouveau noter le fait qu'il est possible pour l'annonceur d'importer les conversions hors ligne par lui-même, ou de passer par un des nombreux partenaires de Facebook. Le capitalisme de surveillance de Facebook fonctionne grâce à un vaste écosystème.
L'outil de mesure agrégée des évènements (AEM)
Voici l'antisèche pour l'équipe marketing :

Ce paramétrage permet à l'annonceur et à Facebook de "limiter la casse" sur les utilisateurs iOS refusant le tracking. Facebook remonte des informations de performances agrégées, ce qui lui permet d'optimiser les campagnes publicitaires.
À noter que Facebook peut très bien apprendre des campagnes qui tournent sur Android et sur les utilisateurs iOS acceptant le tracking pour mieux comprendre ce qui marche, ce qui ne marche pas (profils utilisateurs et messages publicitaires), et ainsi optimiser les campagnes sur les utilisateurs iOS refusant le tracking.
Facebook et Google, les précurseurs de l'adtech
Comme nous avons pu le voir, Facebook a mis en place une série d'outils pour contourner vos protections et mieux vous surveiller, les "signaux résilients". Ces outils sont proposés aux annonceurs, clé en main, avec une documentation complète :
- Le livre blanc co-écrit avec Fifty-Five, "Why you should leverage Facebook's resilient signals".
- Le webinar de Fifty-Five, "How to leverage Facebook's resilient signals in a post-cookie world".
- Le "Signals Playbook" de Facebook, accompagné de son Webinar.
Le complexe de surveillance de Facebook est impressionnant, mais Google n'est pas en reste. L'API Conversions de Facebook peut s'appuyer sur l'infrastructure du Server-Side Tagging de Google Tag Manager pour contourner adblockers et protections navigateurs. Et Google fait évoluer sa propre surveillance sur le modèle de l'API Conversion avec son "suivi avancé des conversions".
Ces nouvelles pratiques seront malheureusement une source d'inspiration pour d'autres acteurs publicitaires, rendant la surveillance publicitaire encore plus omniprésente et difficile à éviter.
Que peut-on faire ? Cette course à l'armement (marketing de surveillance vs navigateurs et adblockers) ne suffit pas, elle ne protègera jamais les moins informés. Il nous faut donc bannir la publicité ciblée directement dans la loi :
- En faisant pression sur les législateurs, comme peut le faire la coalition internationale, "Ban Surveillance Advertising".
- En appuyant les propositions des régulateurs tels que l'EDPS (European Data Protection Supervisor, la CNIL de l'Union Européenne) : "EU’s top privacy regulator urges ban on surveillance-based ad targeting".
Texte intégral (6235 mots)
La publicité, le produit de Facebook
Les résultats financiers de Facebook sont limpides, plus de 98% de ses revenus proviennent de la publicité. Facebook dispose ici de 2 leviers de croissance :
- Augmenter l'offre : à savoir, proposer plus d'opportunités publicitaires aux annonceurs.
- Augmenter la demande : à savoir, convaincre les annonceurs existants d'augmenter leurs budgets publicitaires, et signer de nouveaux annonceurs.
Augmenter l'offre : votre temps de cerveau disponible
Le moyen le plus direct d'augmenter l'offre publicitaire est d'acquérir de nouveaux utilisateurs. Comme l'indique ce mémo interne, Facebook a appliqué cette stratégie de croissance à tout prix, à l'extrême :
That can be bad if they make it negative. Maybe it costs a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools.
[...] The ugly truth is that we believe in connecting people so deeply that anything that allows us to connect more people more often is de facto good. It is perhaps the only area where the metrics do tell the true story as far as we are concerned.
Autre levier, se diversifier via le rachat d'applications existantes. En 2012, Facebook a ainsi racheté Instagram, ses utilisateurs et son savoir-faire :
Zuckerberg sur le rachat d'Instagram : Facebook s'achète du temps, afin d'incorporer dans ses Apps les mécanismes de croissance d'Instagram (à l'époque en avance sur le mobile et sur les photos).
L'augmentation de l'offre publicitaire passe également par la monétisation de l'inventaire de tiers : Facebook propose aux Apps d'utiliser son ad-network, le "Facebook Audience Network", contre une commission. À noter que la monétisation de l'inventaire de tiers dépend de la capacité de lire les données Facebook de l'utilisateur, et c'est sans doute une des raisons qui ont poussé Facebook à fermer son ad-network sur le web mobile. Via Intelligent Tracking Prevention (ITP), les utilisateurs de Safari ont des protections contre le tracking de Facebook sur des sites tiers.
Avoir des milliards d'utilisateurs sur Facebook ou Instagram ne suffit pas, il faut les rendre dépendants, quel qu'en soit le coût. Voici un bon résumé de Robin Kelly, sénateur américain de l'Illinois :
The business model for your platforms is quite simple: keep users engaged. The more time people spend on social media, the more data harvested and targeted ads sold. To build that engagement, social media platforms amplify content that gets attention. That can be cat videos or vacation pictures, but too often it means content that’s incendiary, contains conspiracy theories or violence. Algorithms on the platforms can actively funnel users from the mainstream to the fringe, subjecting users to more extreme content, all to maintain user engagement.
Dernier levier, afficher toujours de publicités (en comparaison avec les publications de vos amis et des pages que vous suivez). Si vous êtes encore sur Instagram, vous avez pu noter l'invasion progressive des publicités dans votre fil et dans les stories. Instagram s'est mis au diapason de Facebook, et nous sommes probablement arrivés au point de saturation. Même si Facebook et Instagram n'ont pas vraiment de concurrents, la pression publicitaire est à son maximum.
Augmenter la demande : consumérisme et propagande
Proposer de nombreuses opportunités publicitaires ne suffit pas, encore faut-il convaincre les annonceurs de l'efficacité de la publicité sur les applis Facebook et sur son réseau de partenaires. Facebook a plusieurs points forts : sa capacité à cibler une grande partie de la population, à différents moments de la journée, ses critères de ciblages multiples ainsi que ses formats publicitaires "natifs". Mais le point clé est la rentabilité : Facebook doit prouver qu'il fait gagner de l'argent aux annonceurs, et non l'inverse.
Comment Facebook optimise-t-il une campagne publicitaire ? Voici un process standard :
- En démarrant la campagne publicitaire sans ciblage à priori : cela permet de toucher des utilisateurs et de tester les messages publicitaires.
- Puis en observant les conversions : afin de comprendre les caractéristiques des utilisateurs qui atteignent l'objectif de l'annonceur, les messages publicitaires les plus efficaces, le meilleur moment et le meilleur contexte pour diffuser la publicité, etc.
- Enfin en ciblant les utilisateurs similaires : les "lookalikes" ou "audiences similaires" dans le jargon de l'adtech.
Ainsi, l'efficacité des campagnes publicitaires de Facebook est étroitement liée aux informations qu'il détient sur ses utilisateurs ainsi qu'à sa capacité à mesurer correctement les conversions.
Par défaut, l'annonceur indique son but, son budget et son message, l'algorithme de Facebook gère le ciblage automatiquement.
Assez souvent, Facebook connaît à l'avance le type d'utilisateurs à cibler car l'annonceur lui a transmis une liste de clients appelée "audience personnalisée" et lui a demandé de cibler des utilisateurs similaires.
L'annonceur peut laisser Facebook trouver les bonnes audiences ou uploader une "audience personnalisée" ou renseigner manuellement des critères de ciblage. Il verra instantanément une estimation du nombre de personnes touchées.
Cela peut paraître presque innocent dit comme cela, mais le ciblage Facebook a contribué à la victoire de Trump en 2016. L'algorithme de Facebook ne se contente pas d'optimiser les campagnes publicitaires, il favorise également la diffusion de propagande à grande échelle et représente donc une menace sérieuse pour les démocraties.
Facebook vous espionne, partout
Sur ses applications
Le grand public connaît l'application Facebook. Mais celui-ci est également propriétaire des applications Instagram et WhatsApp, qui font partie des applications les plus utilisées au monde. Facebook a également un pied dans le futur avec Oculus, sa plateforme de réalité virtuelle, sur laquelle il aimerait d'ailleurs bien diffuser de la publicité. Chacune de vos interactions y est exploitée pour vous rendre dépendant et monétiser votre attention.
Ici , vous pouvez supprimer vos comptes Facebook et Instagram, faire migrer vos contacts de WhatsApp vers Signal, et ne pas acheter de casque Oculus. Un piège pour Facebook et Instagram, il ne vous faudra pas simplement désactiver vos comptes mais bien les supprimer.
Partout ailleurs
Ce que le grand public ignore, c'est que Facebook vous espionne aussi ailleurs. La liste des outils mis à la disposition de tiers est longue comme le bras, et ceux-ci sont fournis avec une contrepartie, permettre à Facebook de collecter toujours plus d'informations sur vous, pour son propre usage.
Voici quelques exemples, non exhaustifs :
- Les plugins sociaux dont le fameux bouton "Like", très apprécié des éditeurs.
- Le Facebook Audience Network, pour les développeurs d'applications qui veulent de la monétisation publicitaire via l'ad-network de Facebook.
- Le Facebook Pixel et le SDK, qui permettent aux annonceurs de faire remonter l'activité de leurs prospects et clients, depuis leurs sites web et leurs applications, vers Facebook.
- Facebook App Events, qui permet de faire remonter des évènements de toutes sortes (web, app, hors ligne) à Facebook.
- Le Facebook Login, qui permet de se connecter à une application via son compte Facebook.
La plupart des sites et applications utilisent au moins un des outils de Facebook. Et comme l'on vous demande rarement votre avis, Facebook est souvent au courant de ce que vous faites, ceci même si vous n'avez pas de compte Facebook ou Instagram. La publicité vidéo d'Apple pour l'App Tracking Transparency est une bonne illustration du côté invasif de Facebook.
Depuis début 2020 et en réaction à de multiples scandales, Facebook permet à ses utilisateurs de prendre conscience de l'activité "en dehors de Facebook" et de la dissocier de leurs comptes :
Ne vous laissez pas abuser par la propagande de Facebook, "parfois" signifie "en général".
Dissocier l'activité ne veut pas dire la supprimer des serveurs de Facebook... La firme conserve bien toutes vos interactions mais ne les associent plus à votre compte. À noter que Facebook ne vous facilitera pas la tâche : pour dissocier vos activités, il vous faudra :
Ce serait trop beau si c'était un peu plus visible et en une seule étape... Comme sur votre compte Google par exemple :
Google, l'autre big browser, vous facilite un peu plus la vie.
Bien évidemment, ni Facebook (ni Google) ne supprime votre activité, celle-ci a une trop grande valeur. Il s'agit simplement de ne plus l'associer à votre compte.
Et si vous n'avez pas de compte Facebook ni Instagram ? Facebook vous surveille quand même, il a vos coordonnées via les carnets d'adresses qu'il a pu aspirer chez vos amis, il conserve précieusement vos activités sur le web, dans les apps et hors ligne. Quel intérêt pour son modèle publicitaire ?
- Facebook mesure l'impact de ses publicités en comparant les taux de conversion entre les personnes exposées à la publicité et les personnes non exposées.
- Vous pourriez être exposé aux publicités du Facebook Audience Network sur des applis tierces.
- Plus généralement, votre comportement permet à l'algorithme de Facebook d'améliorer ses modèles prédictifs.
Une surveillance en danger
Les internautes étant de plus en plus sensibilisés à la protection de la vie privée, la surveillance hors applis Facebook devient plus difficile. Nous allons étudier comment Facebook s'adapte et communique auprès des annonceurs, via le livre blanc "Why you should leverage Facebook's resilient signals", co-écrit avec l'agence française Fifty-Five.
Pourquoi communiquer auprès des annonceurs ? Facebook a besoin de complices pour vous surveiller hors de son App, les annonceurs doivent correctement utiliser les outils mis à disposition par Facebook pour que vos données personnelles remontent correctement et de manière durable (les fameux "signaux résilients") vers l'ogre de Menlo Park.
Tout d'abord, pourquoi est-ce que la surveillance de Facebook hors de ses applis serait en danger ? Pour 3 raisons selon Facebook et Fifty-Five :
- Les nouvelles lois (RGPD, ePrivacy, CCPA, ...) imposent des restrictions légales à la surveillance généralisée telles qu'une base légale pour traiter des données personnelles, et un consentement préalable pour le stockage d'informations ou l'accès à des informations déjà stockées (hors cookies techniques).
- Les protections des navigateurs et systèmes d'exploitations (Apple App Tracking Transparency ou ATT, Webkit Intelligent Tracking Prevention ou ITP, Firefox Enhanced Tracking Protection ou ETP, ...) rendent le tracking plus difficile.
- Les adblockers (uBlock Origin, NextDNS, Adguard, Blokada...) permettent de bloquer les publicités et autres traceurs à la source.
Quel impact pour les campagnes publicitaires des annonceurs ?
Les traceurs actuels de Facebook, pixels et autres SDKs, des signaux peu résilients. On voit également l'opportunité pour Facebook d'étendre sa surveillance à ce que vous faites hors ligne.
Comme on peut le voir :
- Facebook peut continuer à mesurer ce que vous faites sur ses applis (Facebook, Instagram).
- Facebook a du mal à mesurer ce que vous faites sur les sites et applis des annonceurs : en raison des protections navigateurs et autres adblockers, les anciens traceurs Facebook sont de moins en moins efficaces.
- Facebook n'a qu'une vue très partielle de ce que vous faites hors ligne.
En quoi cette vision partielle est-elle problématique pour les annonceurs ? Ici Facebook et Fifty-Five doivent expliquer en quoi la surveillance généralisée serait nécessaire :
Ici, Facebook tente de vous rassurer avec des critères de ciblage très génériques. En réalité, votre profil publicitaire est incroyablement plus détaillé.
La mesure de la performance publicitaire est essentielle. Si Facebook a accès à moins de conversions (achats, inscriptions, installations...), son algorithme aura moins d'informations sur les critères qui fonctionnent (profils utilisateurs, message publicitaire, contexte publicitaire), ce qui diminuera l'efficacité de sa publicité. L'annonceur devra potentiellement payer plus cher pour un résultat moindre.
Comment faire peur aux annonceurs ? S'ils ne permettent pas à Facebook de vous surveiller suffisamment bien, leurs campagnes publicitaires ne fonctionneront plus correctement :
Des "trous" dans la mesure chez les annonceurs ? Une catastrophe selon Facebook...
Si l'annonceur ne comblent pas ces "trous" de mesure, voici les conséquences :
- Moins de conversions attribuées à Facebook : certaines conversions ne seront pas mesurées, le reporting montrera des campagnes publicitaires moins efficaces qu'elles ne le sont en réalité, avec un coût d'acquisition client plus important.
- Une campagne publicitaire réellement moins efficace : Facebook aura moins d'informations pour optimiser la campagne.
- Une information imparfaite : la conséquence, l'annonceur doutera du reporting d'éventuelles futures campagnes publicitaires.
Les "signaux résilients", où comment Facebook contourne vos protections
Comment Facebook permet-il aux annonceurs de combler ces "trous" ? Via ce qu'il appelle les "signaux résilients" :
Avec votre adblocker, vous pensiez être protégé de la surveillance invasive de Facebook ? Erreur...
Avec la complicité des annonceurs, voici comment Facebook contourne vos protections :
- Avec l'API Conversion (aussi appelée CAPI) : si un traceur Facebook peut être altéré ou bloqué par votre navigateur ou votre adblocker, l'idée est ici de fuiter vos données personnelles vers Facebook directement depuis un serveur contrôlé par l'annonceur, via l'utilisation de son API Conversion. L'annonceur peut dédupliquer les évènements déjà envoyés depuis votre surf sur son site web, il peut également fuiter d'autres informations qu'il a sur vous (vos achats "hors ligne", votre scoring dans son CRM, etc).
- Avec la correspondance avancée pour le web les applications : l'annonceur va pouvoir fuiter vos données personnelles d'identification (nom, prénom, adresse email, numéro de téléphone, etc) vers Facebook au moment où vous validez un formulaire. Notez que cette fuite peut même être configurée automatiquement (via le tag javascript Facebook pixel) ou de manière manuelle (via un pixel Facebook IMG).
- Avec les conversions hors ligne : Facebook s'assure de récupérer votre comportement "hors ligne" à savoir tous vos achats en magasin, vos réservations par téléphone, etc. L'annonceur peut fuiter ces informations à Facebook via l'API Offline Conversion, via son interface Facebook ou en s'appuyant sur l'un des nombreux partenaires de Facebook. Dans la liste des complices "hors ligne" : les terminaux de paiements des points de vente, les reçus numériques, les cartes de fidélité, les logiciels des centres d'appels, les logiciels marketing et CRM, les plateformes d'intégrations ainsi qu'une liste à rallonge de "partenaires Facebook Business".
Lorsqu'Apple l'y contraint, des publicités Facebook plus respectueuses de votre vie privée
L'outil de mesure agrégée des évènements (aussi appelé AEM) : permet à Facebook de mesurer l'efficacité des campagnes publicitaires de manière agrégée (256 campagnes publicitaires maximum, pas de suivi individuel) lorsque l'utilisateur a refusé le tracking Facebook ou Instagram sur iOS (via ATT). C'est un outil inspiré de la solution d'Apple, WebKit Private Click Measurement ou PCM, et c'est l'unique solution respectueuse de la vie privée proposée par Facebook.
Vous pourriez être surpris connaissant Facebook : pourquoi ne pas surveiller sur le web les utilisateurs d'iOS qui ont refusé le tracking sur les Apps Facebook ou Instagram ? Parce que dans ses directives pour les développeurs d'applications, Apple est très clair :
Tracking refers to the act of linking user or device data collected from your app with user or device data collected from other companies’ apps, websites, or offline properties for targeted advertising or advertising measurement purposes
Si Facebook violait cette règle, il prendrait le risque de se faire expulser de l'App Store. Vous pouvez approfondir le sujet avec l'article "Understanding Facebook’s updated iOS14 advertising guidance".
Et pourquoi n'avoir pas directement utilisé PCM ? Mystère, Facebook déclare seulement :
Notre solution est semblable à l’outil privé de mesure des clics d’Apple. Toutefois, elle répond à certains cas d’utilisation clés par les annonceurs non pris en compte par Apple.
Notez que si vous refusez le tracking Facebook ou Instagram via la fenêtre iOS ATT, Facebook déclare répercuter ce choix dans le traitement des évènements envoyés via l'API Conversion :
Les évènements envoyés à Facebook via l’API Conversions seront également traités conformément aux limites définies par l’outil de mesure agrégée des évènements.
Comment Facebook traite-t-il les évènements des autres "signaux résilients" (la correspondance avancée et les conversions hors ligne) ? Mystère...
À noter que Facebook peut également être source de propositions lorsqu'il s'agit de proposer des standards publicitaires qui respectent mieux la vie privée. Certaines discussions entre ingénieurs d'Apple et de Facebook (à savoir John Wilander et Ben Savage) permettent parfois de dépasser le conflit Apple vs Facebook, avec des propositions permettant de répondre à des cas d'usages publicitaires, tout en préservant la vie privée des internautes :
- Proposition pour mesurer l'impact d'une publicité : afin de savoir s'il y a une conversion même si l'utilisateur n'a pas cliqué sur une publicité au préalable, ce qui n'est actuellement pas possible avec WebKit PCM. Cette proposition permettrait de savoir si le groupe ayant été exposé à de la publicité a un meilleur taux de conversion que le groupe n'ayant pas été exposé.
- Proposition pour permettre à des plateformes de mesurer les campagnes publicitaires de leurs annonceurs : Ben Savage prend l'exemple d'Etsy, celui-ci permet à ses utilisateurs de diffuser des campagnes Facebook. Mais avec WebKit PCM, "l'annonceur Etsy" est limité à 256 campagnes publicitaires, et Facebook ne peut donc pas mesurer l'efficacité ni optimiser les campagnes des utilisateurs d'Etsy (il manque un niveau de granularité).
- Proposition pour redonner à l'utilisateur le contrôle sur ses centres d'intérêt : permet d'adresser certains problèmes de FLoC, la proposition très décriée de Google pour faire de la publicité comportementale sans cookies tiers.
Les évolutions des navigateurs afin de mieux protéger la vie privée sont discutées au sein du "Privacy Community Group" du W3C, l'organisme chargé de co-construire les standards du web. Facebook joue donc ici son rôle, tenter d'influer sur les évolutions des navigateurs afin de limiter l'impact sur son business publicitaire. Et pour cela, Facebook doit être crédible auprès des ingénieurs d'Apple, de Firefox ou de Brave. Ceux-ci ont pour premier principe le respect de la vie privée des internautes (les ingénieurs Chrome ont souvent le biais publicitaire de Google).
Sur le sujet du W3C et de cette guerre d'influence, lisez l'excellent article "Concern trolls and power grabs: Inside Big Tech’s angry, geeky, often petty war for your privacy".
Les contournements illustrés, exemples de campagnes publicitaires
Afin d'illustrer l'impact des "signaux résilients", Facebook et Fifty-Five donnent 2 exemples.
L'utilisateur voit une publicité mais ne clique pas
Premier cas, l'utilisateur voit une publicité sur Facebook, ne clique pas dessus, mais va ensuite sur le site de l'annonceur pour compléter un formulaire. Il sera rappelé par un centre d'appel, pour finalement s'inscrire.
Vu que le navigateur (Safari ou Firefox par exemple) de cet utilisateur bloque les cookies tiers de Facebook, le traceur de Facebook (pixel) ne peut pas lire l'identifiant utilisateur Facebook sur le site de l'annonceur. Facebook n'est donc pas capable de faire le lien entre l'exposition publicitaire de l'utilisateur et son surf sur le site de l'annonceur.
Mais lorsque l'utilisateur remplit le formulaire, l'annonceur est capable d'appeler l'API Conversion ou la correspondance avancée pour le web. Il peut ainsi envoyer à Facebook les données personnelles d'identification du formulaire (nom, adresse email, numéro de téléphone, etc) et celui-ci peut ainsi faire le lien avec le compte de l'utilisateur. De même, après inscription de l'utilisateur via téléphone, l'annonceur utilisera l'API Conversion pour transmettre l'inscription à Facebook.
L'utilisateur clique sur une publicité
Deuxième cas, l'utilisateur est sur Safari, il clique sur une publicité Facebook, puis il consulte une page produit de l'annonceur 8 jours après pour enfin acheter hors ligne.
Lorsque l'utilisateur clique sur la publicité Facebook, celui-ci parvient à déposer un cookie first-party sur le site de l'annonceur. Le Facebook pixel installé sur le site de l'annonceur récupère en effet l'identifiant de clic fbclid contenu en paramètre d'URL, et le stocke dans le cookie first-party _fbc. Notons que Safari pourrait très bien supprimer ces paramètres de tracking, comme le fait déjà Brave depuis l'année dernière.
Depuis 2019 et la mise à jour ITP 2.1, Safari supprime les cookies créés côté client au bout de 7 jours (ici le cookie _fbc créé par le Facebook pixel). Lorsque l'utilisateur consulte la page produit de l'annonceur après 8 jours, Facebook ne peut plus faire le lien avec son clic initial, il ne reconnaît pas l'utilisateur.
Le contournement est indiqué par Facebook et Fifty-Five : le pré-requis est de passer par du serveur-side tagging comme celui de Google Tag Manager, ce qui permet de créer un cookie HTTP via le header HTTP Set-Cookie et ainsi de contourner la durée de vie à 7 jours des cookies clients.
L'étape suivante est de configurer l'API Conversions pour fonctionner avec Google Tag Manager, action déjà très bien documentée par Facebook et par Simo Ahava.
Ainsi lorsque l'utilisateur consulte la page produit, Google Tag Manager est appelé avec un cookie first-party permanent, le mapping avec l'identifiant de clic fbclic est bien enregistré et le containeur serveur de Google Tag Manager peut correctement appeler l'API Conversions de Facebook pour transmettre les informations. "Bénéfice" supplémentaire : le contournement des adblockers ! Ensuite, lorsque l'utilisateur achète en magasin, l'annonceur utilise l'outil de conversions hors ligne pour transmettre à Facebook les achats de l'utilisateur.
Les antisèches de la surveillance
Pour pousser les annonceurs à adopter ses "signaux résilients", Facebook a profité du remarquable travail de Fifty-Five. Le livre blanc contient ainsi des fiches récapitulatives de chaque "signal".
Un récapitulatif des différents "signaux résilients".
L'API Conversions
Voici l'antisèche pour l'équipe marketing :
Facebook et Fifty-Five conseillent d'installer l'API Conversions en parallèle du pixel Facebook, et donc de collecter les évènements à la fois côté client et serveur.
L'API Conversion permet ainsi de contourner les protections de navigateurs tels que Safari (limite à 7 jours sur les cookies créés en javascript). Elle permet également de contourner les adblockers lorsqu'elle est utilisée conjointement avec du serveur-side tagging. Cette API permet finalement de transmettre des informations hors ligne, telles que le scoring utilisateur.
Voici l'antisèche pour l'équipe technique :
On note en particulier le conseil suivant : "CAPI is a way to secure data for sensitive sector (Bank, Insurance, ...)". Et oui, vos données bancaires ou d'assurance fuitent vers Facebook, mais ne vous inquiétez pas, la connexion est sécurisée ! Encore une fois, tout est fait pour faciliter la fuite de toutes vos interactions, notamment via les intégrations natives :
- Tag Managers pour vos interactions avec le site de l'annonceur
- Plateformes eCommerce, CRM et Customer Data Platforms pour vos achats et interactions hors-ligne.
Mise en avant d'une intégration native au Tag Manager de Google :
L'intégration de l'API Conversions avec le Server-Side Tagging de Google Tag Manager est mise en avant par Facebook, comme l'indique Simo Ahava.
La correspondance avancée
Voici l'antisèche pour l'équipe marketing :
Cette option permet de contourner le blocage des cookies tiers par les navigateurs, et de fuiter vos données personnelles même si vous n'avez jamais cliqué sur une publicité Facebook. En effet, l'annonceur envoie à Facebook vos données personnelles d'identification, ce qui permet à celui-ci de faire le lien avec votre compte Facebook.
On note dans les limitations :
- "Although cookie-less, it is key you collect consent from users" : Facebook et Fifty-Five considèrent-ils que votre consentement n'est pas nécessaire avec les autres "signaux résilients" ?
- "If you work in sensitive sectors such as Banking, a heavier setup is required" : il faut alors passer par la correspondance avancée manuelle et non automatique, à savoir configurer soi-même le pixel (IMG) permettant d'envoyer les données personnelles d'identification plutôt que de laisser le pixel Facebook (javascript) récupérer automatiquement les bons champs du formulaire.
Voici l'antisèche pour l'équipe technique :
Rien de nouveau, si ce n'est le rappel qu'il faut utiliser la correspondance avancée manuelle pour les secteurs "sensibles".
Les conversions hors-ligne
Voici l'antisèche pour l'équipe marketing :
Encore rien de nouveau, seulement le constat que la surveillance continue hors-ligne, elle s'appuie sur vos données personnelles d'identification (nom, email, numéro de téléphone, etc).
Voici l'antisèche pour l'équipe technique :
On peut de nouveau noter le fait qu'il est possible pour l'annonceur d'importer les conversions hors ligne par lui-même, ou de passer par un des nombreux partenaires de Facebook. Le capitalisme de surveillance de Facebook fonctionne grâce à un vaste écosystème.
L'outil de mesure agrégée des évènements (AEM)
Voici l'antisèche pour l'équipe marketing :
Ce paramétrage permet à l'annonceur et à Facebook de "limiter la casse" sur les utilisateurs iOS refusant le tracking. Facebook remonte des informations de performances agrégées, ce qui lui permet d'optimiser les campagnes publicitaires.
À noter que Facebook peut très bien apprendre des campagnes qui tournent sur Android et sur les utilisateurs iOS acceptant le tracking pour mieux comprendre ce qui marche, ce qui ne marche pas (profils utilisateurs et messages publicitaires), et ainsi optimiser les campagnes sur les utilisateurs iOS refusant le tracking.
Facebook et Google, les précurseurs de l'adtech
Comme nous avons pu le voir, Facebook a mis en place une série d'outils pour contourner vos protections et mieux vous surveiller, les "signaux résilients". Ces outils sont proposés aux annonceurs, clé en main, avec une documentation complète :
- Le livre blanc co-écrit avec Fifty-Five, "Why you should leverage Facebook's resilient signals".
- Le webinar de Fifty-Five, "How to leverage Facebook's resilient signals in a post-cookie world".
- Le "Signals Playbook" de Facebook, accompagné de son Webinar.
Le complexe de surveillance de Facebook est impressionnant, mais Google n'est pas en reste. L'API Conversions de Facebook peut s'appuyer sur l'infrastructure du Server-Side Tagging de Google Tag Manager pour contourner adblockers et protections navigateurs. Et Google fait évoluer sa propre surveillance sur le modèle de l'API Conversion avec son "suivi avancé des conversions".
Ces nouvelles pratiques seront malheureusement une source d'inspiration pour d'autres acteurs publicitaires, rendant la surveillance publicitaire encore plus omniprésente et difficile à éviter.
Que peut-on faire ? Cette course à l'armement (marketing de surveillance vs navigateurs et adblockers) ne suffit pas, elle ne protègera jamais les moins informés. Il nous faut donc bannir la publicité ciblée directement dans la loi :
- En faisant pression sur les législateurs, comme peut le faire la coalition internationale, "Ban Surveillance Advertising".
- En appuyant les propositions des régulateurs tels que l'EDPS (European Data Protection Supervisor, la CNIL de l'Union Européenne) : "EU’s top privacy regulator urges ban on surveillance-based ad targeting".
09.06.2021 à 18:48
Comment les éditeurs se moquent de la CNIL

3 ans pour se préparer
En application de la directive ePrivacy, les internautes doivent être informés et donner leur consentement préalablement au dépôt et à la lecture des traceurs "non essentiels". Depuis l'entrée en vigueur du RGPD il y a déjà 3 ans, les exigences en matière de validité du consentement ont été renforcées.
Le 1er octobre 2020, la CNIL a publié des lignes directrices modificatives et sa recommandation sur les cookies et autres traceurs. Elle a également accordé 6 mois aux éditeurs pour se conformer aux règles.
Comme nous avions pu le voir sur ce blog, les anciennes lignes directrices, pourtant laxistes, n'étaient déjà pas respectées. Voici quelques articles pour illustrer l'impunité :
- "Le recueil du consentement sur internet : un mensonge généralisé".
- "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- "La grande braderie de vos données personnelles sur Le Bon Coin".
Qu'en est-il des nouvelles lignes directrices ?
La CNIL recommande un "Dark pattern" pour "optimiser" le taux de consentement
En lisant la recommandation de la CNIL, on y découvre une première proposition de design de l'interface de consentement :
Page 9, Figure 4 : une interface claire, un choix aisé pour l'utilisateur.
Ainsi que des considérations générales sur l'interface (j'ai mis les passages clés en gras) :
- "Le responsable de traitement doit offrir aux utilisateurs tant la possibilité d’accepter que de refuser les opérations de lecture et/ou d’écriture avec le même degré de simplicité."
- "Ainsi, la Commission recommande fortement que le mécanisme permettant d’exprimer un refus de consentir aux opérations de lecture et/ou d’écriture soit accessible sur le même écran et avec la même facilité que le mécanisme permettant d’exprimer un consentement."
- "Par exemple, au stade du premier niveau d’information, les utilisateurs peuvent avoir le choix entre deux boutons présentés au même niveau et sur le même format, sur lesquels sont inscrits respectivement «tout accepter» et «tout refuser», «autoriser» et «interdire», ou «consentir» et «ne pas consentir», ou toute autre formulation équivalente et suffisamment claire."
Lorsque l'on continue la lecture du document, on voit une deuxième proposition de design :

Page 10, Figure 5 : recommandation de la CNIL ! Le "Continuer sans accepter" peut facilement être loupé.
Juste au-dessous de ce design trompeur, la CNIL se contredit :
- "Afin de ne pas induire en erreur les utilisateurs, la Commission recommande que les responsables de traitement s’assurent que les interfaces de recueil des choix n’intègrent pas de pratiques de design potentiellement trompeuses laissant penser aux utilisateurs que leur consentement est obligatoire ou qui mettent visuellement plus en valeur un choix plutôt qu’un autre."
- "Il est recommandé d’utiliser des boutons et une police d’écriture de même taille, offrant la même facilité de lecture, et mis en évidence de manière identique."
Ce "Dark pattern" a rapidement été "évangélisé" auprès des éditeurs :

Conseils de Converteo (agence conseil data et techno) aux éditeurs : suivez la "marge de manœuvre" proposée par la CNIL !
Le 1er avril 2021, c'est le grand jour, les sites et applications doivent enfin être en conformité comme le rappelle la CNIL :

Celle-ci n'a pas ménagé les efforts d'éducation, comme rappelé sur son site :
- Dix-huit webinaires pour les professionnels du secteur privé et public.
- De nombreux conseils pratiques et outils disponibles sur le site de la CNIL.
- Une campagne de sensibilisation des organismes publics et privés.
Pour quels résultats ? C'est ce que nous allons regarder via quelques threads Twitter (cliquez sur les liens pour dérouler les nombreux exemples).
L'interface de consentement, une calamité
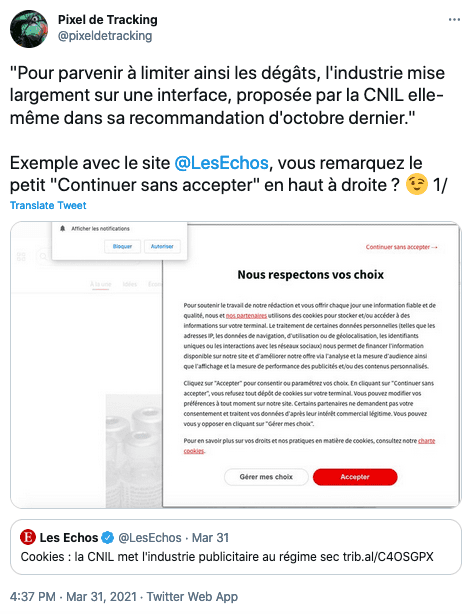
Le "Dark pattern" de la CNIL, interface standard sur les sites médias.
Vous en redemandez ? Voici le "Dark pattern" de la CNIL en version App :
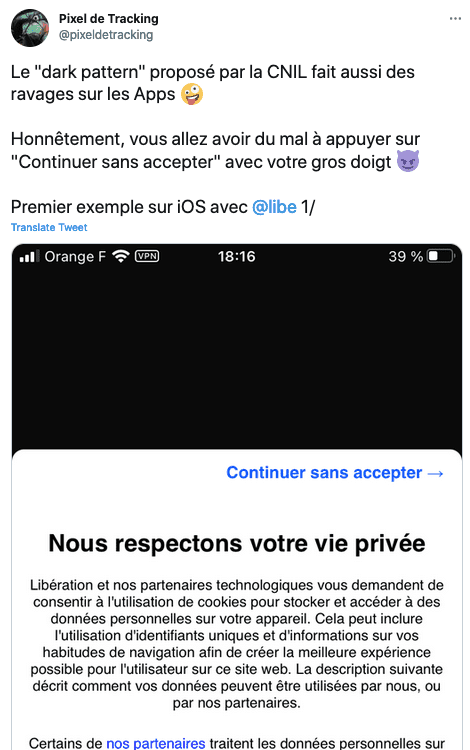
Gare aux gros doigts !
Autre option, assez largement adoptée, se moquer de la réglementation :
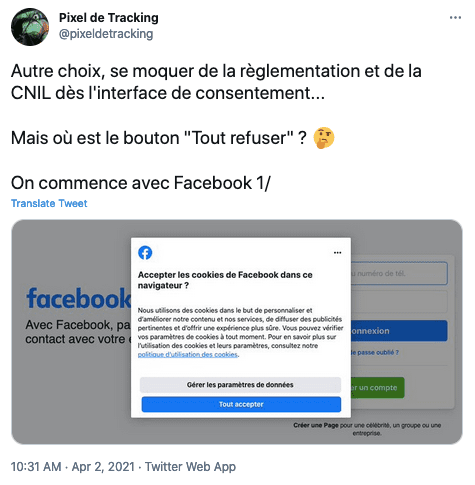
Facebook se fiche de la loi, mais il n'est pas seul.
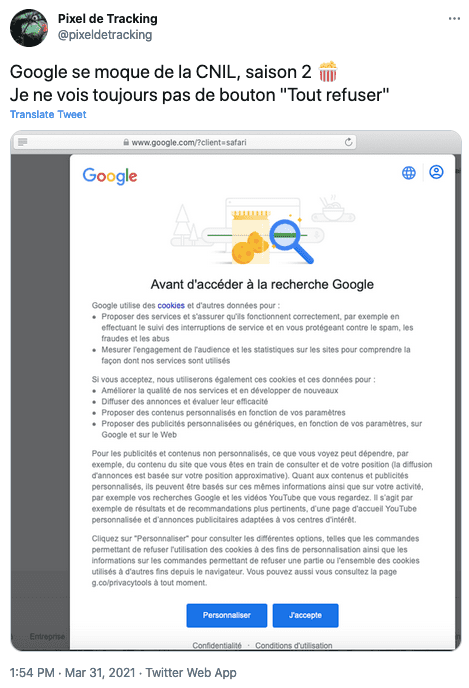
5 étapes pour refuser la surveillance, mais évidemment cela ne marche pas.
Sur les Apps, ce n'est pas mieux :
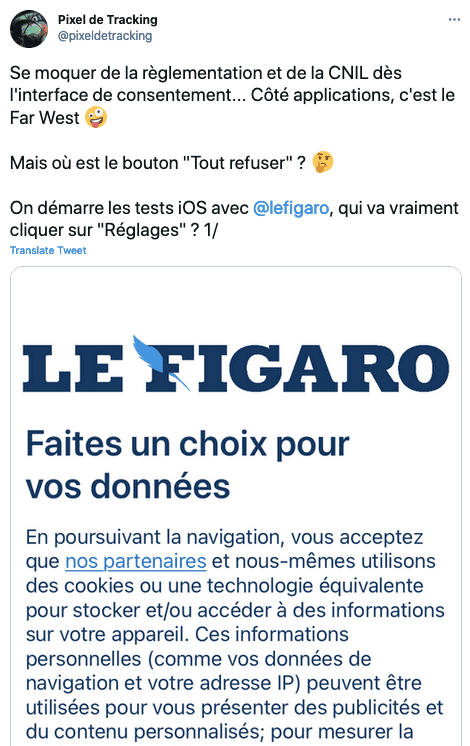
Un pari sur le fait que la CNIL n'audite pas les Apps ?
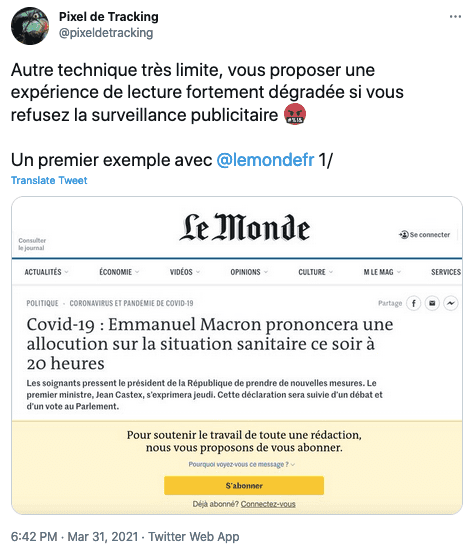
Nos éditeurs ont du talent.
Autre option pour vous surveiller, prétendre "l'intérêt légitime" :
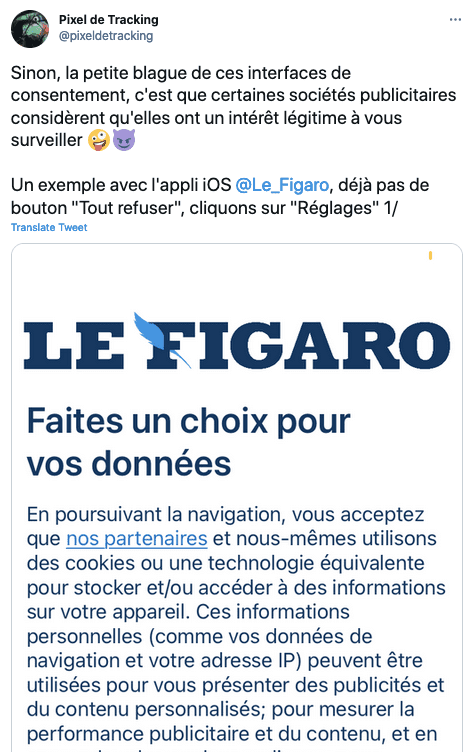
Bien sûr, la pratique est illégale.
Il faut le souligner, quelques éditeurs proposent une interface respectueuse :

Une interface propre, encore faut-il que vos choix soient respectés.
Quelques rares exceptions également sur les Apps :
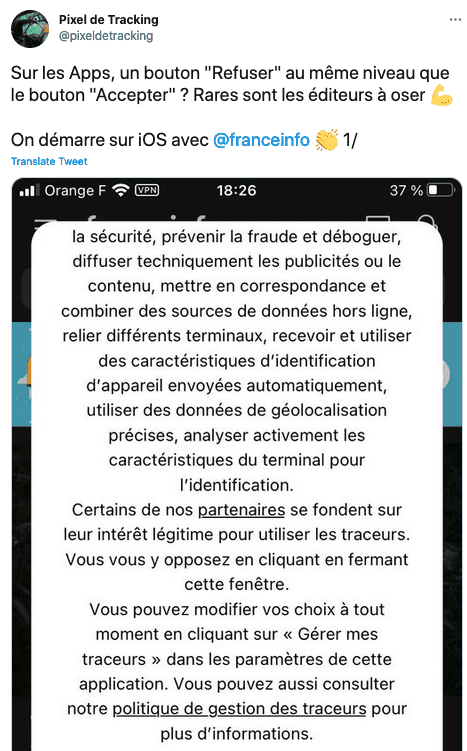
Message à rallonge, mais choix clair (passez sur Twitter pour la capture d'écran complète).
Les cookie walls, un chantage aux données personnelles
Adopté par certains éditeurs comme Webedia ou Prisma Media, le cookie wall en a énervé plus d'un :
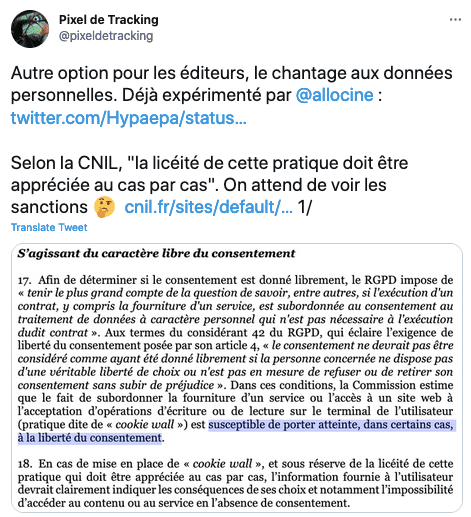
Chantage aux données personnelles, bonjour.
On retrouve également le cookie wall sur Apps :
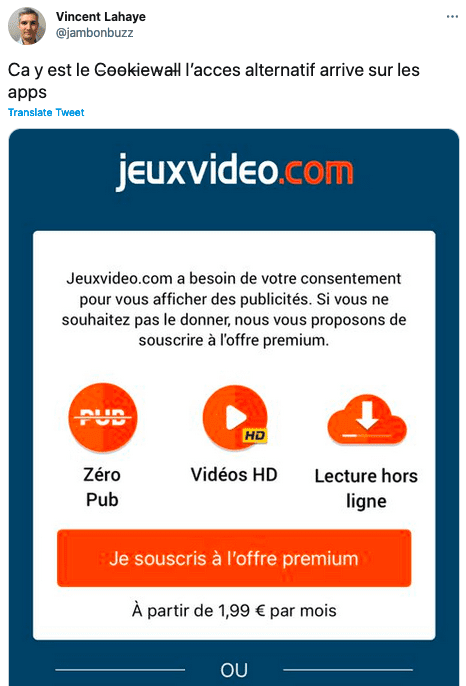
Chantage aux données personnelles, suite.
Le cookie wall est-il légal ? La CNIL a voulu l'interdire, sans succès :
Le « cookie wall » consiste à bloquer l'accès à un site web ou à une application mobile pour l’utilisateur qui ne donnerait pas son consentement. Dans certains cas, cette pratique, également appelée « pay wall », conditionne cet accès à une contrepartie financière, comme un abonnement.
Le Conseil d'État a estimé, le 19 juin 2020, que la CNIL ne pouvait pas interdire, par principe, cette pratique.
Dans l’attente d’une clarification pérenne sur cette question par le législateur européen, la CNIL appliquera les textes en vigueur, tels qu’éclairés par la jurisprudence, pour déterminer au cas par cas si le consentement des personnes est libre et si un cookie wall est licite ou non. Elle sera, dans ce cadre, très attentive à l’existence d’alternatives réelles et satisfaisantes, notamment fournies par le même éditeur, lorsque le refus des traceurs non nécessaires bloque l’accès au service proposé.
On attend donc impatiemment les premières décisions de la CNIL... D'ici là, vous pouvez lire ces excellents articles :
- "Cookie wall : quand vont-ils arrêter de nous prendre pour des abrutis ?" de Numendil.
- "Consent Wall et Cookie Wall" de Romain Bessuges-Meusy, le PDG de la CMP Axeptio.
- "Cookie walls et autres tracking walls : légal, pas légal ?" de Marc Rees.
Un consentement fictif
Vous pourriez vous dire : OK, ce n'est pas si facile de refuser la surveillance, mais j'ai maintenant le choix. Encore faut-il que les éditeurs respectent ce choix... Dans la vraie vie, c'est rarement le cas :
- Nombreux sont les éditeurs qui fuitent vos données personnelles avant même que vous ayez donné (ou refusé) votre consentement.
- Nombreux sont les éditeurs qui fuitent vos données personnelles alors que vous avez refusé de donner votre consentement.
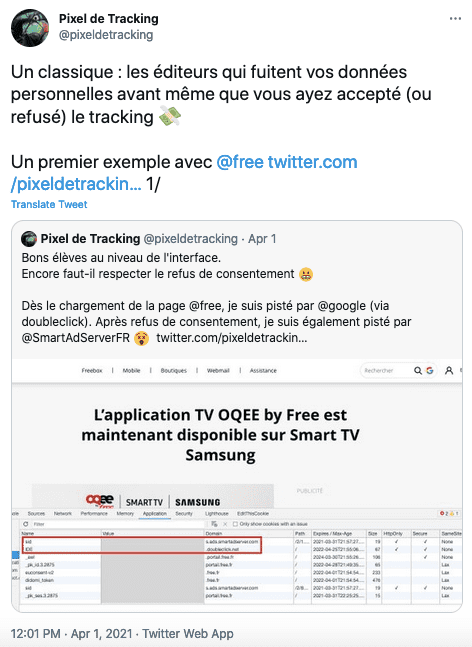
L'hypocrisie des éditeurs qui font semblant de respecter la loi.
Sur les Apps, ce n'est pas mieux :
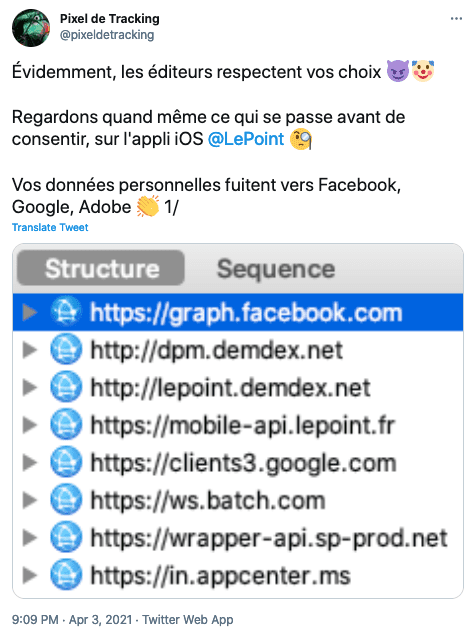
Sur les Apps, souvent le Far West.
Regardons les données personnelles qui fuitent :
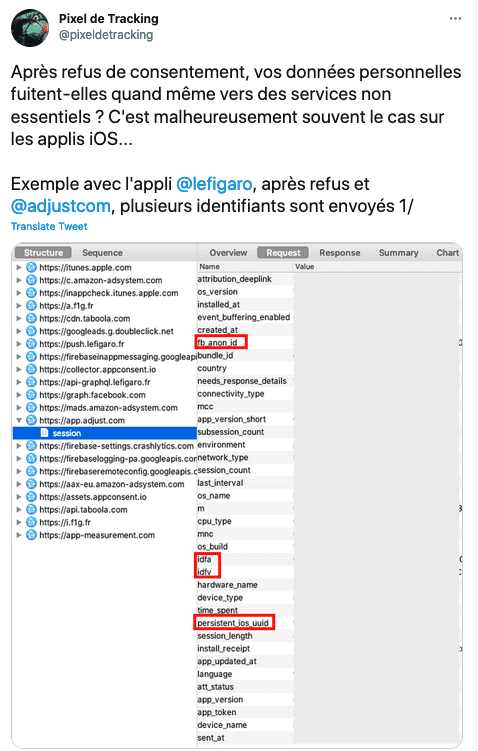
Via le logiciel Charles Proxy, il est possible d'observer toutes les requêtes.
À noter qu'Apple ATT n'empêche pas la fuite de données personnelles, seulement le tracking (la surveillance multi-Apps).
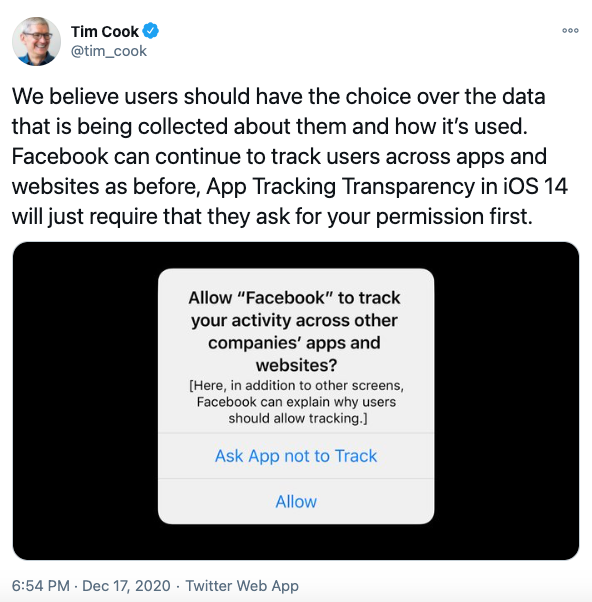
Apple vous protège bien mieux que Google contre la surveillance publicitaire, mais si vous voulez éviter toutes les fuites de données personnelles, il vous faudra passer par un bloqueur de traceurs tel que NextDNS.
Comment faire respecter la loi ?
La CNIL a récemment annoncé une vingtaine de mises en demeure :

Au vu de l'historique de l'organisme, je suis circonspect. Lisez par exemple le retour d'expérience de la Quadrature du Net : "Les GAFAM échappent au RGPD, la CNIL complice".
Noyb va néanmoins tenter l'aventure auprès des différentes CNIL européennes :
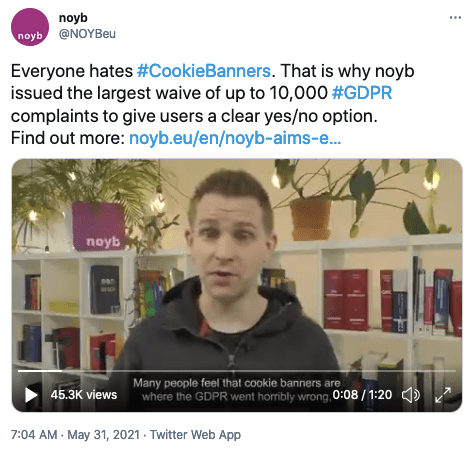
Pendant que la CNIL envoie péniblement une vingtaine de mises en demeure, Noyb prévoit d'envoyer 10.000 plaintes. On parle ici d'une petite association avec quelques bénévoles : preuve que la CNIL ne manque pas de moyens mais surtout de volonté politique.
Alors, aucun espoir ? Pas si sûr, les avancées les plus importantes pourraient venir des autorités de la concurrence, comme le décrit bien cet article. On croise les doigts et d'ici là, protégez-vous.
Texte intégral (2401 mots)
3 ans pour se préparer
En application de la directive ePrivacy, les internautes doivent être informés et donner leur consentement préalablement au dépôt et à la lecture des traceurs "non essentiels". Depuis l'entrée en vigueur du RGPD il y a déjà 3 ans, les exigences en matière de validité du consentement ont été renforcées.
Le 1er octobre 2020, la CNIL a publié des lignes directrices modificatives et sa recommandation sur les cookies et autres traceurs. Elle a également accordé 6 mois aux éditeurs pour se conformer aux règles.
Comme nous avions pu le voir sur ce blog, les anciennes lignes directrices, pourtant laxistes, n'étaient déjà pas respectées. Voici quelques articles pour illustrer l'impunité :
- "Le recueil du consentement sur internet : un mensonge généralisé".
- "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- "La grande braderie de vos données personnelles sur Le Bon Coin".
Qu'en est-il des nouvelles lignes directrices ?
La CNIL recommande un "Dark pattern" pour "optimiser" le taux de consentement
En lisant la recommandation de la CNIL, on y découvre une première proposition de design de l'interface de consentement :
Page 9, Figure 4 : une interface claire, un choix aisé pour l'utilisateur.
Ainsi que des considérations générales sur l'interface (j'ai mis les passages clés en gras) :
- "Le responsable de traitement doit offrir aux utilisateurs tant la possibilité d’accepter que de refuser les opérations de lecture et/ou d’écriture avec le même degré de simplicité."
- "Ainsi, la Commission recommande fortement que le mécanisme permettant d’exprimer un refus de consentir aux opérations de lecture et/ou d’écriture soit accessible sur le même écran et avec la même facilité que le mécanisme permettant d’exprimer un consentement."
- "Par exemple, au stade du premier niveau d’information, les utilisateurs peuvent avoir le choix entre deux boutons présentés au même niveau et sur le même format, sur lesquels sont inscrits respectivement «tout accepter» et «tout refuser», «autoriser» et «interdire», ou «consentir» et «ne pas consentir», ou toute autre formulation équivalente et suffisamment claire."
Lorsque l'on continue la lecture du document, on voit une deuxième proposition de design :
Page 10, Figure 5 : recommandation de la CNIL ! Le "Continuer sans accepter" peut facilement être loupé.
Juste au-dessous de ce design trompeur, la CNIL se contredit :
- "Afin de ne pas induire en erreur les utilisateurs, la Commission recommande que les responsables de traitement s’assurent que les interfaces de recueil des choix n’intègrent pas de pratiques de design potentiellement trompeuses laissant penser aux utilisateurs que leur consentement est obligatoire ou qui mettent visuellement plus en valeur un choix plutôt qu’un autre."
- "Il est recommandé d’utiliser des boutons et une police d’écriture de même taille, offrant la même facilité de lecture, et mis en évidence de manière identique."
Ce "Dark pattern" a rapidement été "évangélisé" auprès des éditeurs :
Conseils de Converteo (agence conseil data et techno) aux éditeurs : suivez la "marge de manœuvre" proposée par la CNIL !
Le 1er avril 2021, c'est le grand jour, les sites et applications doivent enfin être en conformité comme le rappelle la CNIL :
Celle-ci n'a pas ménagé les efforts d'éducation, comme rappelé sur son site :
- Dix-huit webinaires pour les professionnels du secteur privé et public.
- De nombreux conseils pratiques et outils disponibles sur le site de la CNIL.
- Une campagne de sensibilisation des organismes publics et privés.
Pour quels résultats ? C'est ce que nous allons regarder via quelques threads Twitter (cliquez sur les liens pour dérouler les nombreux exemples).
L'interface de consentement, une calamité
Le "Dark pattern" de la CNIL, interface standard sur les sites médias.
Vous en redemandez ? Voici le "Dark pattern" de la CNIL en version App :
Gare aux gros doigts !
Autre option, assez largement adoptée, se moquer de la réglementation :
Facebook se fiche de la loi, mais il n'est pas seul.
5 étapes pour refuser la surveillance, mais évidemment cela ne marche pas.
Sur les Apps, ce n'est pas mieux :
Un pari sur le fait que la CNIL n'audite pas les Apps ?
Nos éditeurs ont du talent.
Autre option pour vous surveiller, prétendre "l'intérêt légitime" :
Bien sûr, la pratique est illégale.
Il faut le souligner, quelques éditeurs proposent une interface respectueuse :
Une interface propre, encore faut-il que vos choix soient respectés.
Quelques rares exceptions également sur les Apps :
Message à rallonge, mais choix clair (passez sur Twitter pour la capture d'écran complète).
Les cookie walls, un chantage aux données personnelles
Adopté par certains éditeurs comme Webedia ou Prisma Media, le cookie wall en a énervé plus d'un :
Chantage aux données personnelles, bonjour.
On retrouve également le cookie wall sur Apps :
Chantage aux données personnelles, suite.
Le cookie wall est-il légal ? La CNIL a voulu l'interdire, sans succès :
Le « cookie wall » consiste à bloquer l'accès à un site web ou à une application mobile pour l’utilisateur qui ne donnerait pas son consentement. Dans certains cas, cette pratique, également appelée « pay wall », conditionne cet accès à une contrepartie financière, comme un abonnement.
Le Conseil d'État a estimé, le 19 juin 2020, que la CNIL ne pouvait pas interdire, par principe, cette pratique.
Dans l’attente d’une clarification pérenne sur cette question par le législateur européen, la CNIL appliquera les textes en vigueur, tels qu’éclairés par la jurisprudence, pour déterminer au cas par cas si le consentement des personnes est libre et si un cookie wall est licite ou non. Elle sera, dans ce cadre, très attentive à l’existence d’alternatives réelles et satisfaisantes, notamment fournies par le même éditeur, lorsque le refus des traceurs non nécessaires bloque l’accès au service proposé.
On attend donc impatiemment les premières décisions de la CNIL... D'ici là, vous pouvez lire ces excellents articles :
- "Cookie wall : quand vont-ils arrêter de nous prendre pour des abrutis ?" de Numendil.
- "Consent Wall et Cookie Wall" de Romain Bessuges-Meusy, le PDG de la CMP Axeptio.
- "Cookie walls et autres tracking walls : légal, pas légal ?" de Marc Rees.
Un consentement fictif
Vous pourriez vous dire : OK, ce n'est pas si facile de refuser la surveillance, mais j'ai maintenant le choix. Encore faut-il que les éditeurs respectent ce choix... Dans la vraie vie, c'est rarement le cas :
- Nombreux sont les éditeurs qui fuitent vos données personnelles avant même que vous ayez donné (ou refusé) votre consentement.
- Nombreux sont les éditeurs qui fuitent vos données personnelles alors que vous avez refusé de donner votre consentement.
L'hypocrisie des éditeurs qui font semblant de respecter la loi.
Sur les Apps, ce n'est pas mieux :
Sur les Apps, souvent le Far West.
Regardons les données personnelles qui fuitent :
Via le logiciel Charles Proxy, il est possible d'observer toutes les requêtes.
À noter qu'Apple ATT n'empêche pas la fuite de données personnelles, seulement le tracking (la surveillance multi-Apps).
Apple vous protège bien mieux que Google contre la surveillance publicitaire, mais si vous voulez éviter toutes les fuites de données personnelles, il vous faudra passer par un bloqueur de traceurs tel que NextDNS.
Comment faire respecter la loi ?
La CNIL a récemment annoncé une vingtaine de mises en demeure :
Au vu de l'historique de l'organisme, je suis circonspect. Lisez par exemple le retour d'expérience de la Quadrature du Net : "Les GAFAM échappent au RGPD, la CNIL complice".
Noyb va néanmoins tenter l'aventure auprès des différentes CNIL européennes :
Pendant que la CNIL envoie péniblement une vingtaine de mises en demeure, Noyb prévoit d'envoyer 10.000 plaintes. On parle ici d'une petite association avec quelques bénévoles : preuve que la CNIL ne manque pas de moyens mais surtout de volonté politique.
Alors, aucun espoir ? Pas si sûr, les avancées les plus importantes pourraient venir des autorités de la concurrence, comme le décrit bien cet article. On croise les doigts et d'ici là, protégez-vous.
19.04.2021 à 23:19
Apple vous protège-t-il vraiment de la surveillance publicitaire ?

La vie privée, un argument produit pour Apple
Face au capitalisme de surveillance développé par Google, Apple a un argument évident, la vie privée. Et il ne s'en prive pas, comme en témoigne cette campagne publicitaire :

Cet argument se retrouve aussi dans les paroles d'un Tim Cook, lors de la conférence "Computers, Privacy & Data Protection" de janvier 2021, un discours tout à fait remarquable.
Apple a toujours été très doué en marketing produit, mais s'agit-il seulement de belles paroles ? Une première réponse est apportée par cette page, une réponse plus détaillée est fournie ici : Apple prend en effet de nombreuses initiatives. On peut par exemple citer :
- Le chiffrement de bout en bout sur iMessage et FaceTime.
- La protection de la vie privée sur Apple Maps.
- Le Secure Element, qui permet à Apple Pay de fonctionner sans connaître votre numéro de carte bleue ni vos transactions.
- Le fait qu'Apple protège de mieux en mieux les accès aux fonctionnalités sensibles de vos appareils iOS tels que la géolocalisation, les photos, le micro ou la vidéo.
- L'initiative "Sign in with Apple", vous permettant de créer un compte sur un service tiers sans partager votre adresse e-mail.
La vie privée est une des valeurs fondamentales d'Apple :

Mais Apple pourrait aller beaucoup plus loin, et je serais prêt à payer pour que les services suivants soient chiffrés de bout en bout : Apple Photos, Calendriers, Contacts, iCloud Drive, Notes ou Messages sur iCloud. Après sa dispute avec le FBI lors de l'attaque terroriste de San Bernardino, durant laquelle il s'est battu courageusement contre l'introduction de portes dérobées sur iOS, Apple avait une opportunité pour étendre l'utilisation du chiffrement de bout en bout à tous ses services. Sous pression du FBI, il n'a malheureusement pas osé :
Apple dropped plans to let iPhone users fully encrypt backups of their devices in the company's iCloud service after the FBI complained that the move would harm investigations, six sources familiar with the matter told Reuters.
Pour le plus grand bonheur des gouvernements, services de polices et services secrets, Apple ne chiffre pas iCloud de bout en bout. Et pour mieux vendre ses produits en Chine, Apple accepte de stocker les clés de chiffrement iCloud de ses utilisateurs Chinois directement sur des serveurs situés en Chine. Autre compromission avec le régime Chinois, Apple censure des Apps en Chine.
Intéressons-nous maintenant aux initiatives d'Apple contre la surveillance publicitaire. Vont-elles assez loin ?
Safari ITP, une bonne protection contre le pistage
En 2017, Apple intègre la fonctionnalité "Intelligent Tracking Prevention" (ITP) à Safari, le but étant de combattre le pistage multi-sites. Depuis cette première sortie, Apple a fait évoluer ITP, avec par exemple le blocage complet des cookies tiers ou la limitation de la durée de vie des cookies déposés via CNAME, ce qui lui permet de vous offrir une bonne protection contre le pistage des sociétés de l'adtech.
Lorsque l'on parle vie privée, Apple a également une excellente influence sur l'écosystème du web.
Les actions d'Apple contre le pistage multi-sites inspirent sans doute d'autres navigateurs. En 2018, Firefox annonce changer sa politique concernant le pistage, souhaitant dorénavant proposer une protection contre le pistage par défaut. En 2019, Firefox passe à l'acte avec "Enhanced Tracking Protection" (ETP), l'équivalent d'ITP, fonctionnalité qu'il a également fait évoluer depuis.
En bonus, si vous utilisez un iPhone ou un iPad et que vous passez par un autre navigateur, les protections d'ITP s'appliquent également ! En effet, Apple verrouille les options des navigateurs tiers, qui se voient obliger d'utiliser WebKit, le moteur de rendu de Safari.
Apple contrebalance l'influence de Google au W3C
Au W3C, l'organisme chargé de construire et de faire évoluer les standards du web, Apple propose des alternatives à Google dans le domaine de la publicité. Si Google a fait beaucoup de bruits avec les propositions visant à remplacer les cookies tiers ("Privacy Sandbox"), notamment la proposition controversée FLoC, Apple propose des standards pour un meilleur respect de la vie privée :
- "Private Click Measurement (PCM)" : pour correctement attribuer des conversions aux campagnes publicitaires. Google a sa propre proposition appelée "Conversion Measurement API", mais celle-ci ne protège guère la vie privée car Google permet à l'annonceur d'attribuer un identifiant unique à chaque clic sur une publicité... Apple limite de son côté les options à 256 valeurs différentes, ce qui permet simplement de savoir quelle campagne publicitaire est efficace.
- "Storage Access API" : Si Apple empêche les tiers de pister l'utilisateur sans son consentement (via les restrictions sur les cookies, le local storage, etc), ceux-ci peuvent demander explicitement l'autorisation à l'utilisateur via cette API. Certains cas d'usages tels que des systèmes d'authentification pouvant justifier cette autorisation.
Toujours au W3C, si Apple n'est pas le seul à défendre la vie privée (Firefox et Brave sont également très actifs), son investissement n'est pas de trop lorsqu'il s'agit de contrebalancer les armées de développeurs Chrome. Ceux-ci vont souvent compromettre la vie privée des utilisateurs sous couvert d'ajouter de nouvelles fonctionnalités au web. Par exemple, voici une liste de 16 fonctionnalités que Safari n'implémente pas car les risques de sécurité et de fingerprint sont trop grands.
Safari pourrait-il aller plus loin ?
Safari pourrait décider de lutter plus radicalement contre la surveillance publicitaire en intégrant par défaut un bloqueur de traceurs et de publicités type uBlock Origin. Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, Google Analytics et Google Tag Manager ne sont pas bloqués par Safari.
- Les traceurs de tiers qui exploitent les vulnérabilités actuelles du web seraient également bloqués. Je pense par exemple à Criteo via son exploitation malsaine du CNAME cloaking, Safari se contentant de limiter la durée de vie des cookies déposés via CNAME à 7 jours.
En parlant de CNAME cloaking, la technique est d'ailleurs utilisé par Apple sur son site web, avec l'outil Adobe Analytics :
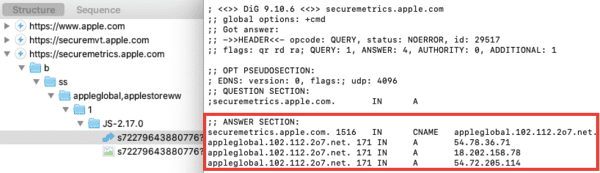
Aujourd'hui, Brave va beaucoup plus loin via sa fonctionnalité "Shields" : le but n'est pas d'empêcher le pistage multi-sites mais de bloquer l'exécution des traceurs. Un exemple pour illustrer la différence d'approche : les traceurs utilisant le CNAME cloaking sont bloqués par défaut.
De son côté, Firefox propose moins de protections par défaut mais son système d'extensions est très ouvert (Safari beaucoup moins, vous devez vous contenter d'un "Content Blocker" tels que Firefox Focus), ce qui permet par exemple à uBlock Origin d'être efficace contre le CNAME cloaking.
À noter que les outils marketing peuvent encore malheureusement échapper aux protections des navigateurs et autres bloqueurs de traceurs, parfois même via des solutions clé en main.
Une politique cohérente sur le web... à une exception près
Sur le web, Apple a donc une politique cohérente :
- Safari protège contre le pistage multi-sites.
- Le pistage au sein d'un même site est jugé légitime par Apple, il reste possible.
- Une publicité plus respectueuse de la vie privée est encouragée.
S'il est toujours possible de faire mieux, Safari est à des années-lumière de Google Chrome en ce qui concerne la protection de la vie privée.
Sauf que lorsque l'on parle d'argent, Apple pactise avec le diable : Google paye entre 8 et 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur Safari.
Sur les Apps, un rattrapage nécessaire
Avec iOS 14.5, Apple lance le système "App Tracking Transparency" (ATT), le tracking devient opt-in. Voici la définition du "tracking" selon Apple :
Tracking refers to the act of linking user or device data collected from your app with user or device data collected from other companies’ apps, websites, or offline properties for targeted advertising or advertising measurement purposes. Tracking also refers to sharing user or device data with data brokers.
Cette définition est classique, similaire à celle de Firefox :
Tracking is the collection of data regarding a particular user's activity across multiple websites or applications (i.e., first parties) that aren’t owned by the data collector, and the retention, use, or sharing of data derived from that activity with parties other than the first party on which it was collected.
Elle est également similaire à celle du W3C :
Tracking is the collection of data regarding a particular user's activity across multiple distinct contexts and the retention, use, or sharing of data derived from that activity outside the context in which it occurred. A context is a set of resources that are controlled by the same party or jointly controlled by a set of parties.
Apple est enfin cohérent avec la politique qu'il appliquait déjà sur le web :
- ATT protège contre le pistage multi-Apps.
- Le pistage au sein d'un même App ou sur plusieurs Apps d'une même société est jugé légitime par Apple, il reste possible.
Sur iOS, la surveillance publicitaire a historiquement été facilitée par Apple, via la mise à disposition d'un identifiant publicitaire unique appelé IDFA. Cet identifiant était activé par défaut, les utilisateurs iOS pouvaient le désactiver s'ils le souhaitaient :
 Dans Réglages > Confidentialité > Publicité, il était possible de cocher "Suivi publicitaire limité" (ce que j'avais fait, comme le montre la capture), mais l'option était décochée par défaut.
Dans Réglages > Confidentialité > Publicité, il était possible de cocher "Suivi publicitaire limité" (ce que j'avais fait, comme le montre la capture), mais l'option était décochée par défaut.
L'option par défaut a une importance capitale : peu de gens changent les paramètres de confidentialité (selon Adjust, seulement 20% des utilisateurs désactivaient l'identifiant).
Apple a donc ici une responsabilité historique : l'IDFA a permis à une multitude de sociétés de vous surveiller facilement, et ceci pendant des années. Pour rappel :
- Avec le lancement de l'iPhone (en 2007), Apple créé un identifiant unique, l'UDID (Unique Device Identifier), idéal pour vous surveiller.
- En 2008 avec la sortie de l'App Store, Apple met l'UDID à disposition des développeurs d'applications : le péché originel, qui ne sera ainsi corrigé que 13 ans plus tard.
- En 2011 et avec l'arrivée d'iOS 5, Apple rend l'UDID obsolète.
- Sauf qu'il faut attendre 2013 pour voir Apple refuser définitivement les Apps qui utilisent encore l'UDID.
- Entre temps (en 2012 avec iOS 6), Apple lance l'IDFA. Il choisit d'activer l'IDFA par défaut, l'utilisateur ne peut pas le désactiver mais seulement indiquer aux applications qu'il ne souhaite pas être pisté (un équivalent de "Do Not Track"), le réglage est bien caché dans "Publicité" (et non dans "Confidentialité").
- Jusqu'à la sortie d'iOS 10 (en 2016), si vous aviez activé "Suivi publicitaire limité", l'application pouvait continuer à utiliser cet identifiant pour le capping, la mesure de conversion, la mesure des visiteurs uniques, la sécurité, la détection de fraude et le debug ! Mais Apple n'avait aucun moyen de vérifier si les applications respectaient vraiment ces règles. Seule option pour l'utilisateur : réinitialiser l'iPhone ou l'iPad, afin de réinitialiser l'IDFA !
- Ce n'est qu'avec iOS 10 donc qu'Apple désactive l'IDFA lorsque l'utilisateur active le "Suivi publicitaire limité" ! L'IDFA est alors remplacé par une valeur non unique composée uniquement de zéros.
Voici la réaction d'un publicitaire à l'annonce du lancement de l'IDFA (en 2012 avec iOS 6), et du "dark pattern" associé à l'option "Suivi publicitaire limité" :
"It's a really pretty elegant, simple solution," says Mobile Theory CEO Scott Swanson. "The biggest thing we're excited about is that it's on by default, so we expect most people will leave it on."
Cette responsabilité historique a donc valu une plainte RGPD devant la CNIL, de la part de la Quadrature du Net :

Changement de paradigme donc avec iOS 14.5, les applications devront vous demander l'autorisation pour vous pister, comme le montre la nouvelle interface (visible dès iOS 14, même si la protection n'est pas encore effective) :
 Dans Réglages > Confidentialité > Suivi, "Autoriser les demandes de suivi des apps" est coché par défaut (au pire, les Apps vous demanderont si vous souhaitez être pisté), et vous pouvez décocher l'option.
Dans Réglages > Confidentialité > Suivi, "Autoriser les demandes de suivi des apps" est coché par défaut (au pire, les Apps vous demanderont si vous souhaitez être pisté), et vous pouvez décocher l'option.
Pour comparaison, l'équivalent Google Android de l'IDFA est l'Android Advertising ID. Mais les protections sont quasi inexistantes :
- Il est impossible de désactiver l'Android Advertising ID (il était possible de désactiver l'IDFA dès iOS 10).
- Il est seulement possible de le réinitialiser.
L'association noyb a lancé une plainte RGPD contre Google pour le suivi utilisateurs par le biais d'un "Android Advertising ID" sans base juridique valable. On peut noter qu'une plainte RGPD de noyb existe également contre Apple pour le suivi sans consentement via l'IDFA. Mais avec ce rattrapage, Apple risque beaucoup moins gros que Google (noyb signale aussi qu'après la mise à jour, Apple pourra toujours utiliser l'IDFA sans consentement, ce qui est faux).
Techniquement, les publicitaires n'auront plus accès à l'IDFA si vous n'avez pas explicitement donné votre autorisation. Mais les publicitaires ont d'autres armes en main pour vous surveiller (fingerprint, hash de l'adresse e-mail...). Apple va-t-il aussi lutter contre ces techniques ? L'avenir nous le dira, mais il semble bien que cela soit son intention :
- Apple a refusé des applications qui contenaient le SDK d'Adjust, une société marketing qui créait un fingerprinting afin d'identifier les utilisateurs.
- Apple a également déjà refusé des applications chinoises qui avaient créés un fingerprint commun (CAID).
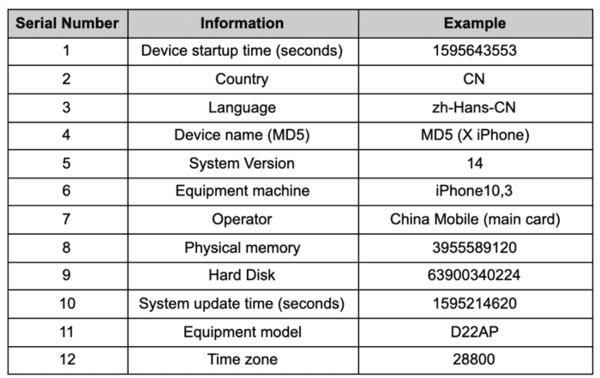
Les paramètres de votre appareil iOS permettant de générer le fingerprint CAID.
De la même manière que sur le web avec son "Private Click Measurement (PCM)", Apple ne laisse pas les publicitaires à l'abandon. La mesure de téléchargements d'applications à la suite d'une campagne publicitaire était effectuée via l'IDFA ou via un fingerprint (réalisé par des sociétés telles que Adjust). Apple met maintenant à disposition des développeurs l'API SKAdNetwork, pour effectuer la mesure tout en protégeant la vie privée des utilisateurs.
Apple contre Facebook
La promesse d'ATT est simple :
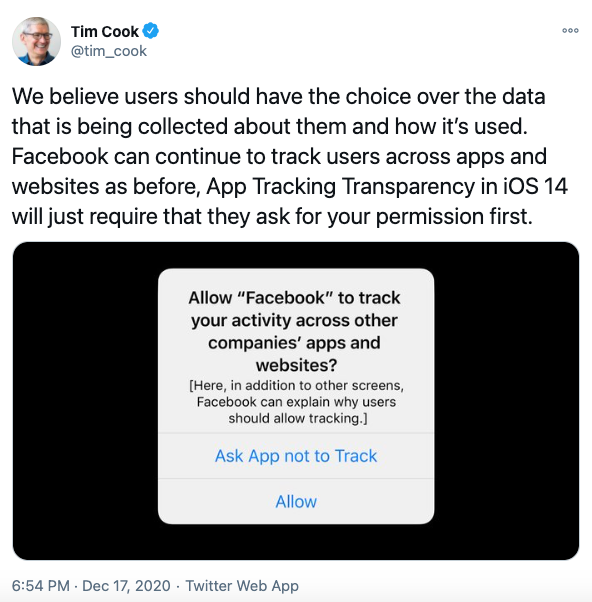
Merci Tim Cook.
L'importance de cette mise à jour peut se mesurer à la réaction épidermique de Facebook, qui voit sa capacité de surveillance sévèrement diminuée sur iOS (son SDK étant aujourd'hui omniprésent sur les Apps). Facebook justifie sa démarche par la défense des petits commerces, qui seraient dépendants de la publicité ciblée de Facebook pour trouver de nouveaux clients :
- Facebook a fait témoigner des petits commerces contre la mise à jour d'Apple.
- Même les propres employés de Facebook pointent l'hypocrisie de la démarche : “It feels like we are trying to justify doing a bad thing by hiding behind people with a sympathetic message,”
Facebook a aussi acheté des pages entières de publicité dans de grands journaux américains pour dénoncer la mise à jour d'Apple :
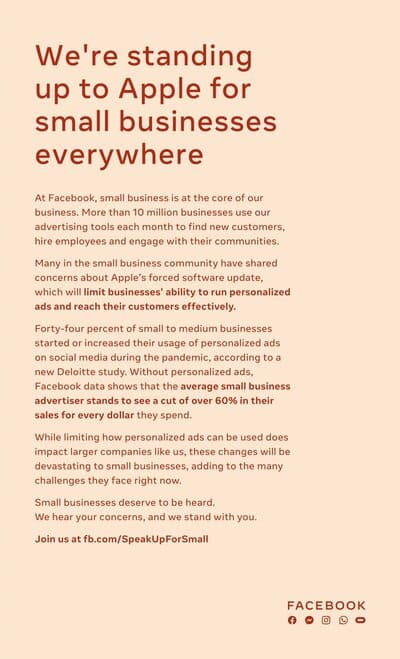

Apple contre les publicitaires français
Les publicitaires français sont à la pointe du combat contre Apple, et après une lettre publique envoyée à Tim Cook en juillet (spoiler : il n'a pas répondu), ils se décident à porter plainte auprès de l'autorité de la concurrence en octobre dernier. L'objet de leur plainte ? L’introduction obligatoire de la sollicitation ATT pour les applications sur iOS qui souhaiteraient faire un suivi de l’activité de l’utilisateur sur des sites tiers.
Première réponse de l'autorité de la concurrence le 17 mars et premier camouflet pour l'industrie publicitaire, sur le volet vie privée :
En l’état de l’instruction, l’Autorité a estimé que la décision d’Apple de mettre en place un dispositif de recueil du consentement complémentaire à celui mis en place par d’autres acteurs de la publicité en ligne, n’apparaissait pas comme une pratique abusive
L'instruction continue néanmoins :
Celle-ci devra notamment permettre de vérifier que la mise en place par Apple de la sollicitation ATT ne peut être regardée comme une forme de discrimination ou « self preferencing », ce qui pourrait notamment être le cas si Apple appliquait sans justification, des règles plus contraignantes aux opérateurs tiers que celles qu’elle s’applique à elle-même pour des opérations similaires.
Il est fort à parier que les publicitaires se fassent aussi débouter sur le volet anticoncurrentiel car Apple ne favorise pas ses propres applications : il ne pratique pas le tracking (et n'utilise donc pas l'IDFA). Apple propose des publicités ciblées sur ses Apps (Apple News, App Store, Bourse), en utilisant les données personnelles récoltées lui-même. Google, Facebook ou n'importe quelle autre App peut faire de même sur iOS, Apple ne s'oppose pas aux publicités personnalisées.
Autre plainte, cette fois-ci devant la CNIL par l'association France Digitale. L'attaque est plus subtile, Apple active par défaut les publicités personnalisés sur ses propres applications :
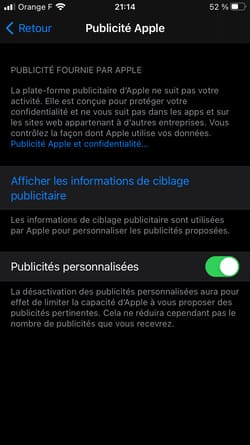
Si vous allez dans Réglages > Confidentialité > Publicité Apple, l'option publicités personnalisées est activée par défaut.
Clairement, Apple devrait demander votre consentement avant de pouvoir proposer de la publicité personnalisée, il ne respecte donc pas le RGPD. France Digital indique que cela porte un préjudice significatif :
- Aux utilisateurs (c'est vrai, encore que la publicité personnalisée sur Apple News, l'App Store et Bourse soit très loin du préjudice de la publicité personnalisée sur les applis Google ou Facebook).
- Aux startups françaises qui, je cite, "respectent scrupuleusement les règles posées par le RGPD". C'est osé ! La liste des entreprises faisant partie de l'association n'est pas publique, mais on peut noter que Frichti en fait partie, et l'appli qui bafoue le RGPD.
La plainte parle encore de distorsion de concurrence en insinuant qu'Apple proposerait de la publicité personnalisée avec ses "sociétés affiliées" :
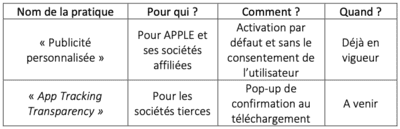
Tableau inclus dans la plainte de France Digitale, censé montrer une distorsion de concurrence.
Comme déjà vu, le pistage et la publicité personnalisé au sein d'une même App ou de plusieurs Apps d'une même société est jugé légitime par Apple, cette pratique n'est pas le simple fait d'Apple mais aussi de Google, Facebook, Twitter, etc. France Digitale parle donc des "sociétés affiliées", des partenaires d'Apple qui comploteraient ensemble pour vous traquer.
Les explications d'Apple sur son programme de publicité sont pourtant très clair, il n'y a ni transmission, ni partage de données personnelles avec des tiers :
Apple ne partage ni ne transmet les données pouvant vous identifier personnellement à des parties tierces.
Également, Apple ne récupère pas de données personnelles via des tiers :
La plateforme publicitaire d’Apple ne suit pas vos activités, c’est-à-dire qu’elle n’associe pas les données d’utilisateur ou d’appareil recueillies sur nos apps à des données d’utilisateur ou d’appareil recueillies auprès de tiers à des fins de ciblage ou de mesure publicitaires, et ne partage pas les données d’utilisateur ou d’appareil avec des courtiers en données.
Aucune mention de "sociétés affiliées" dans l'engagement de confidentialité d'Apple, cela ressemble à une invention de France Digitale.
Mais pourquoi un tel acharnement "d'entrepreneurs et investisseurs du numérique français" contre Apple ? Sans doute parce que l'adtech pèse très lourd en France, on peut voir par exemple l'implication de Criteo (le fameux géant du marketing de surveillance français) dès le lancement de France Digitale ici et là. Il faut dire que Criteo n'aime guère Apple, et cela depuis quelque temps déjà.
Apple contre les publicitaires américains
Chez les publicitaires américains, les attaques sont plus subtiles mais guère convaincantes. Vous pouvez lire Ben Thomson ou Eric Benjamin Seufert (chez Ben Thomson ou sur son site). Voici quelques arguments :
- En s'attaquant au tracking, on renforcerait les "Walled Gardens" (Google, Facebook, etc). Ce à quoi répond très bien Wolfie Christl dans ce thread Twitter :
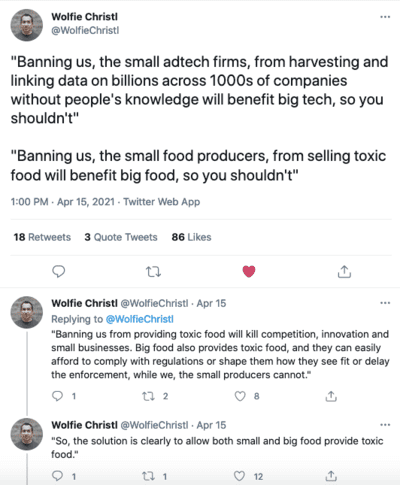
- Sur le renfort supposé aux "Walled Gardens", s'attaquer au tracking n'empêche d'ailleurs pas de s'attaquer aux géants publicitaires. Les 2 axes peuvent se compléter : lisez par exemple la plainte de Brave contre le RTB ("external" data free-for-all), ainsi que la plainte de Brave contre Google ("internal" data-free-for-all). Sans parler vie privée, il serait intéressant de s'attaquer aux abus de position dominante des géants publicitaires, Google et Facebook. Mais les lobbyistes publicitaires ignorent l'option.
- Apple ne chercherait pas à protéger votre vie privée sur les Apps (via ATT), mais plutôt à contrôler l'intégralité de votre expérience. Hors Facebook dérangerait Apple car la découverte de nouvelles Apps ne passeraient plus du tout par l'App Store mais par la publicité personnalisée sur Facebook ou Instagram. En s'attaquant au tracking, Apple chercherait donc à reprendre le contrôle sur la distribution des Apps. Mais quelle est la part réelle de la publicité dans la distribution des Apps ?
- Argument similaire sur le web (via ITP), où Apple chercherait plutôt à asphyxier les ressources publicitaires. En conséquence, les éditeurs devraient miser sur les abonnements via les Apps, sur lesquels Apple touche une commission. Mais pourquoi ne pas proposer de la publicité respectueuse de la vie privée ?
- Apple lutterait contre les acteurs publicitaires pour pousser son propre business publicitaire. Difficile à croire car le business publicitaire d'Apple (App Store, Apple News et Bourse) est dérisoire comparé à ses autres revenus (produits, services). Apple a également fermé iAd, son ad-network, en décembre 2016.
Si la volonté de contrôle d'Apple est évidente, et si le monopole de l'App Store est un énorme problème, les arguments des lobbyistes publicitaires manquent de pertinence. Apple a une raison évidente d'investir pour mieux protéger la vie privée : la demande de protection est forte (et les clients potentiels d'Apple ne sont pas les publicitaires, mais vous et moi).
Apple force la transparence chez les développeurs d'App
Depuis décembre 2020, Apple a rendu obligatoire les étiquettes de confidentialité sur les Apps. Ces étiquettes permettent de mettre en valeur les différences entre applications. Si l'on compare des navigateurs par exemple :
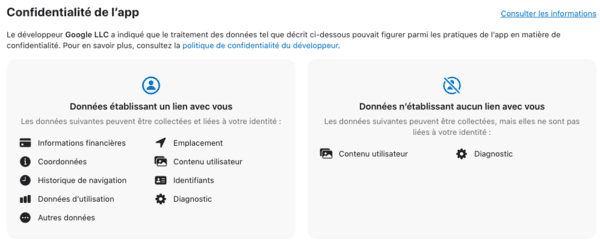
Le spyware Google Chrome.
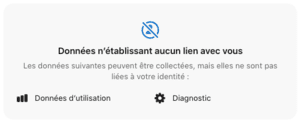
Le navigateur de DuckDuckGo, respectueux de votre vie privée.
Si l'on regarde maintenant les messageries :
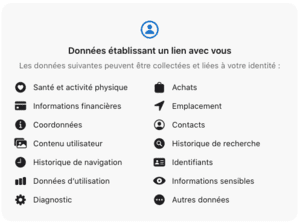
Messenger, le spyware de Facebook, encore pire que WhatsApp.

Signal, une App respectueuse de la vie privée.
Certes, ces étiquettes ont des limites :
- Elles sont basées sur de l'auto-déclaration. Apple va-t-il contrôler si le développeur dit la vérité ?
- Il n'y a pas d'informations sur les données personnelles qui peuvent fuiter vers des tiers. Il serait intéressant de voir qui récupère vos données personnelles et pourquoi.
Mais elles représentent déjà une belle avancée, et pousseront peut-être les développeurs d'Apps à limiter l'usage de données personnelles à celles qui sont strictement nécessaires.
Apple pourrait-il aller plus loin sur les Apps ?
Avec ATT, Apple s'est mis au niveau de Safari ITP (protection contre le tracking). S'il voulait aller plus loin, il pourrait décider de bloquer les publicités et les traceurs 1st-party (analytics, A/B testing, tag managers...). Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, les traceurs de Google Analytics, Segment, Mixpanel ou Amplitude ne sont pas bloqués.
Mais il se mettrait à dos certains développeurs, et ce ne serait pas cohérent avec sa politique actuelle sur le web via Safari ITP.
Malheureusement, cette publicité ne s'applique donc pas aux traceurs 1st-party, votre iPhone communique toujours avec de nombreux tiers, dont ceux de Google (même si les identifiants devraient maintenant être spécifiques à chaque App, car l'IDFA n'est plus disponible par défaut) :

Avec le support natif des DNS chiffrés via iOS 14, il a néanmoins permis à des bloqueurs de traceurs et de publicités de mieux faire leur travail (ces bloqueurs devaient créer un pseudo VPN local, ce qui était une catastrophe pour la batterie). J'utilise pour ma part NextDNS, ce qui me permet de bloquer tous les traceurs et autres publicités.
Oui, Apple vous protège contre la surveillance publicitaire, de mieux en mieux
Comme nous l'avons vu, les protections apportées par Apple contre la surveillance publicitaire sur iOS sont largement améliorables. Mais elles ont le mérite d'être cohérentes et de lutter assez efficacement contre le tracking, comme le prouve d'ailleurs l'énervement de Facebook et de l'adtech en général. Un utilisateur avancé pourra aller plus loin en passant par un bloqueur de traceurs et de publicités tel que NextDNS, AdGuard ou un Pi-Hole.
Même s'il est sain de critiquer une multinationale aussi dominante, et pour des raisons très valables (système fermé, verrouillé, réparabilité très limitée, monopole de l'App Store, "optimisation fiscale", obsolescence programmée, etc), l'alternative "Android by Google" n'est pas crédible si vous souhaitez protéger votre vie privée.
Si vous êtes allergique à Apple mais que vous souhaitez tout de même protéger votre vie privée sur votre smartphone, il vous faudra passer par des distributions qui auront supprimé la couche "Google" d'Android (/e/ par exemple, basé sur Lineage OS et microG), mais il vous faudra de bonnes compétences techniques.
Texte intégral (5859 mots)
La vie privée, un argument produit pour Apple
Face au capitalisme de surveillance développé par Google, Apple a un argument évident, la vie privée. Et il ne s'en prive pas, comme en témoigne cette campagne publicitaire :
Cet argument se retrouve aussi dans les paroles d'un Tim Cook, lors de la conférence "Computers, Privacy & Data Protection" de janvier 2021, un discours tout à fait remarquable.
Apple a toujours été très doué en marketing produit, mais s'agit-il seulement de belles paroles ? Une première réponse est apportée par cette page, une réponse plus détaillée est fournie ici : Apple prend en effet de nombreuses initiatives. On peut par exemple citer :
- Le chiffrement de bout en bout sur iMessage et FaceTime.
- La protection de la vie privée sur Apple Maps.
- Le Secure Element, qui permet à Apple Pay de fonctionner sans connaître votre numéro de carte bleue ni vos transactions.
- Le fait qu'Apple protège de mieux en mieux les accès aux fonctionnalités sensibles de vos appareils iOS tels que la géolocalisation, les photos, le micro ou la vidéo.
- L'initiative "Sign in with Apple", vous permettant de créer un compte sur un service tiers sans partager votre adresse e-mail.
La vie privée est une des valeurs fondamentales d'Apple :
Mais Apple pourrait aller beaucoup plus loin, et je serais prêt à payer pour que les services suivants soient chiffrés de bout en bout : Apple Photos, Calendriers, Contacts, iCloud Drive, Notes ou Messages sur iCloud. Après sa dispute avec le FBI lors de l'attaque terroriste de San Bernardino, durant laquelle il s'est battu courageusement contre l'introduction de portes dérobées sur iOS, Apple avait une opportunité pour étendre l'utilisation du chiffrement de bout en bout à tous ses services. Sous pression du FBI, il n'a malheureusement pas osé :
Apple dropped plans to let iPhone users fully encrypt backups of their devices in the company's iCloud service after the FBI complained that the move would harm investigations, six sources familiar with the matter told Reuters.
Pour le plus grand bonheur des gouvernements, services de polices et services secrets, Apple ne chiffre pas iCloud de bout en bout. Et pour mieux vendre ses produits en Chine, Apple accepte de stocker les clés de chiffrement iCloud de ses utilisateurs Chinois directement sur des serveurs situés en Chine. Autre compromission avec le régime Chinois, Apple censure des Apps en Chine.
Intéressons-nous maintenant aux initiatives d'Apple contre la surveillance publicitaire. Vont-elles assez loin ?
Safari ITP, une bonne protection contre le pistage
En 2017, Apple intègre la fonctionnalité "Intelligent Tracking Prevention" (ITP) à Safari, le but étant de combattre le pistage multi-sites. Depuis cette première sortie, Apple a fait évoluer ITP, avec par exemple le blocage complet des cookies tiers ou la limitation de la durée de vie des cookies déposés via CNAME, ce qui lui permet de vous offrir une bonne protection contre le pistage des sociétés de l'adtech.
Lorsque l'on parle vie privée, Apple a également une excellente influence sur l'écosystème du web.
Les actions d'Apple contre le pistage multi-sites inspirent sans doute d'autres navigateurs. En 2018, Firefox annonce changer sa politique concernant le pistage, souhaitant dorénavant proposer une protection contre le pistage par défaut. En 2019, Firefox passe à l'acte avec "Enhanced Tracking Protection" (ETP), l'équivalent d'ITP, fonctionnalité qu'il a également fait évoluer depuis.
En bonus, si vous utilisez un iPhone ou un iPad et que vous passez par un autre navigateur, les protections d'ITP s'appliquent également ! En effet, Apple verrouille les options des navigateurs tiers, qui se voient obliger d'utiliser WebKit, le moteur de rendu de Safari.
Apple contrebalance l'influence de Google au W3C
Au W3C, l'organisme chargé de construire et de faire évoluer les standards du web, Apple propose des alternatives à Google dans le domaine de la publicité. Si Google a fait beaucoup de bruits avec les propositions visant à remplacer les cookies tiers ("Privacy Sandbox"), notamment la proposition controversée FLoC, Apple propose des standards pour un meilleur respect de la vie privée :
- "Private Click Measurement (PCM)" : pour correctement attribuer des conversions aux campagnes publicitaires. Google a sa propre proposition appelée "Conversion Measurement API", mais celle-ci ne protège guère la vie privée car Google permet à l'annonceur d'attribuer un identifiant unique à chaque clic sur une publicité... Apple limite de son côté les options à 256 valeurs différentes, ce qui permet simplement de savoir quelle campagne publicitaire est efficace.
- "Storage Access API" : Si Apple empêche les tiers de pister l'utilisateur sans son consentement (via les restrictions sur les cookies, le local storage, etc), ceux-ci peuvent demander explicitement l'autorisation à l'utilisateur via cette API. Certains cas d'usages tels que des systèmes d'authentification pouvant justifier cette autorisation.
Toujours au W3C, si Apple n'est pas le seul à défendre la vie privée (Firefox et Brave sont également très actifs), son investissement n'est pas de trop lorsqu'il s'agit de contrebalancer les armées de développeurs Chrome. Ceux-ci vont souvent compromettre la vie privée des utilisateurs sous couvert d'ajouter de nouvelles fonctionnalités au web. Par exemple, voici une liste de 16 fonctionnalités que Safari n'implémente pas car les risques de sécurité et de fingerprint sont trop grands.
Safari pourrait-il aller plus loin ?
Safari pourrait décider de lutter plus radicalement contre la surveillance publicitaire en intégrant par défaut un bloqueur de traceurs et de publicités type uBlock Origin. Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, Google Analytics et Google Tag Manager ne sont pas bloqués par Safari.
- Les traceurs de tiers qui exploitent les vulnérabilités actuelles du web seraient également bloqués. Je pense par exemple à Criteo via son exploitation malsaine du CNAME cloaking, Safari se contentant de limiter la durée de vie des cookies déposés via CNAME à 7 jours.
En parlant de CNAME cloaking, la technique est d'ailleurs utilisé par Apple sur son site web, avec l'outil Adobe Analytics :
Aujourd'hui, Brave va beaucoup plus loin via sa fonctionnalité "Shields" : le but n'est pas d'empêcher le pistage multi-sites mais de bloquer l'exécution des traceurs. Un exemple pour illustrer la différence d'approche : les traceurs utilisant le CNAME cloaking sont bloqués par défaut.
De son côté, Firefox propose moins de protections par défaut mais son système d'extensions est très ouvert (Safari beaucoup moins, vous devez vous contenter d'un "Content Blocker" tels que Firefox Focus), ce qui permet par exemple à uBlock Origin d'être efficace contre le CNAME cloaking.
À noter que les outils marketing peuvent encore malheureusement échapper aux protections des navigateurs et autres bloqueurs de traceurs, parfois même via des solutions clé en main.
Une politique cohérente sur le web... à une exception près
Sur le web, Apple a donc une politique cohérente :
- Safari protège contre le pistage multi-sites.
- Le pistage au sein d'un même site est jugé légitime par Apple, il reste possible.
- Une publicité plus respectueuse de la vie privée est encouragée.
S'il est toujours possible de faire mieux, Safari est à des années-lumière de Google Chrome en ce qui concerne la protection de la vie privée.
Sauf que lorsque l'on parle d'argent, Apple pactise avec le diable : Google paye entre 8 et 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur Safari.
Sur les Apps, un rattrapage nécessaire
Avec iOS 14.5, Apple lance le système "App Tracking Transparency" (ATT), le tracking devient opt-in. Voici la définition du "tracking" selon Apple :
Tracking refers to the act of linking user or device data collected from your app with user or device data collected from other companies’ apps, websites, or offline properties for targeted advertising or advertising measurement purposes. Tracking also refers to sharing user or device data with data brokers.
Cette définition est classique, similaire à celle de Firefox :
Tracking is the collection of data regarding a particular user's activity across multiple websites or applications (i.e., first parties) that aren’t owned by the data collector, and the retention, use, or sharing of data derived from that activity with parties other than the first party on which it was collected.
Elle est également similaire à celle du W3C :
Tracking is the collection of data regarding a particular user's activity across multiple distinct contexts and the retention, use, or sharing of data derived from that activity outside the context in which it occurred. A context is a set of resources that are controlled by the same party or jointly controlled by a set of parties.
Apple est enfin cohérent avec la politique qu'il appliquait déjà sur le web :
- ATT protège contre le pistage multi-Apps.
- Le pistage au sein d'un même App ou sur plusieurs Apps d'une même société est jugé légitime par Apple, il reste possible.
Sur iOS, la surveillance publicitaire a historiquement été facilitée par Apple, via la mise à disposition d'un identifiant publicitaire unique appelé IDFA. Cet identifiant était activé par défaut, les utilisateurs iOS pouvaient le désactiver s'ils le souhaitaient :
Dans Réglages > Confidentialité > Publicité, il était possible de cocher "Suivi publicitaire limité" (ce que j'avais fait, comme le montre la capture), mais l'option était décochée par défaut.
L'option par défaut a une importance capitale : peu de gens changent les paramètres de confidentialité (selon Adjust, seulement 20% des utilisateurs désactivaient l'identifiant).
Apple a donc ici une responsabilité historique : l'IDFA a permis à une multitude de sociétés de vous surveiller facilement, et ceci pendant des années. Pour rappel :
- Avec le lancement de l'iPhone (en 2007), Apple créé un identifiant unique, l'UDID (Unique Device Identifier), idéal pour vous surveiller.
- En 2008 avec la sortie de l'App Store, Apple met l'UDID à disposition des développeurs d'applications : le péché originel, qui ne sera ainsi corrigé que 13 ans plus tard.
- En 2011 et avec l'arrivée d'iOS 5, Apple rend l'UDID obsolète.
- Sauf qu'il faut attendre 2013 pour voir Apple refuser définitivement les Apps qui utilisent encore l'UDID.
- Entre temps (en 2012 avec iOS 6), Apple lance l'IDFA. Il choisit d'activer l'IDFA par défaut, l'utilisateur ne peut pas le désactiver mais seulement indiquer aux applications qu'il ne souhaite pas être pisté (un équivalent de "Do Not Track"), le réglage est bien caché dans "Publicité" (et non dans "Confidentialité").
- Jusqu'à la sortie d'iOS 10 (en 2016), si vous aviez activé "Suivi publicitaire limité", l'application pouvait continuer à utiliser cet identifiant pour le capping, la mesure de conversion, la mesure des visiteurs uniques, la sécurité, la détection de fraude et le debug ! Mais Apple n'avait aucun moyen de vérifier si les applications respectaient vraiment ces règles. Seule option pour l'utilisateur : réinitialiser l'iPhone ou l'iPad, afin de réinitialiser l'IDFA !
- Ce n'est qu'avec iOS 10 donc qu'Apple désactive l'IDFA lorsque l'utilisateur active le "Suivi publicitaire limité" ! L'IDFA est alors remplacé par une valeur non unique composée uniquement de zéros.
Voici la réaction d'un publicitaire à l'annonce du lancement de l'IDFA (en 2012 avec iOS 6), et du "dark pattern" associé à l'option "Suivi publicitaire limité" :
"It's a really pretty elegant, simple solution," says Mobile Theory CEO Scott Swanson. "The biggest thing we're excited about is that it's on by default, so we expect most people will leave it on."
Cette responsabilité historique a donc valu une plainte RGPD devant la CNIL, de la part de la Quadrature du Net :
Changement de paradigme donc avec iOS 14.5, les applications devront vous demander l'autorisation pour vous pister, comme le montre la nouvelle interface (visible dès iOS 14, même si la protection n'est pas encore effective) :
Dans Réglages > Confidentialité > Suivi, "Autoriser les demandes de suivi des apps" est coché par défaut (au pire, les Apps vous demanderont si vous souhaitez être pisté), et vous pouvez décocher l'option.
Pour comparaison, l'équivalent Google Android de l'IDFA est l'Android Advertising ID. Mais les protections sont quasi inexistantes :
- Il est impossible de désactiver l'Android Advertising ID (il était possible de désactiver l'IDFA dès iOS 10).
- Il est seulement possible de le réinitialiser.
L'association noyb a lancé une plainte RGPD contre Google pour le suivi utilisateurs par le biais d'un "Android Advertising ID" sans base juridique valable. On peut noter qu'une plainte RGPD de noyb existe également contre Apple pour le suivi sans consentement via l'IDFA. Mais avec ce rattrapage, Apple risque beaucoup moins gros que Google (noyb signale aussi qu'après la mise à jour, Apple pourra toujours utiliser l'IDFA sans consentement, ce qui est faux).
Techniquement, les publicitaires n'auront plus accès à l'IDFA si vous n'avez pas explicitement donné votre autorisation. Mais les publicitaires ont d'autres armes en main pour vous surveiller (fingerprint, hash de l'adresse e-mail...). Apple va-t-il aussi lutter contre ces techniques ? L'avenir nous le dira, mais il semble bien que cela soit son intention :
- Apple a refusé des applications qui contenaient le SDK d'Adjust, une société marketing qui créait un fingerprinting afin d'identifier les utilisateurs.
- Apple a également déjà refusé des applications chinoises qui avaient créés un fingerprint commun (CAID).
Les paramètres de votre appareil iOS permettant de générer le fingerprint CAID.
De la même manière que sur le web avec son "Private Click Measurement (PCM)", Apple ne laisse pas les publicitaires à l'abandon. La mesure de téléchargements d'applications à la suite d'une campagne publicitaire était effectuée via l'IDFA ou via un fingerprint (réalisé par des sociétés telles que Adjust). Apple met maintenant à disposition des développeurs l'API SKAdNetwork, pour effectuer la mesure tout en protégeant la vie privée des utilisateurs.
Apple contre Facebook
La promesse d'ATT est simple :
Merci Tim Cook.
L'importance de cette mise à jour peut se mesurer à la réaction épidermique de Facebook, qui voit sa capacité de surveillance sévèrement diminuée sur iOS (son SDK étant aujourd'hui omniprésent sur les Apps). Facebook justifie sa démarche par la défense des petits commerces, qui seraient dépendants de la publicité ciblée de Facebook pour trouver de nouveaux clients :
- Facebook a fait témoigner des petits commerces contre la mise à jour d'Apple.
- Même les propres employés de Facebook pointent l'hypocrisie de la démarche : “It feels like we are trying to justify doing a bad thing by hiding behind people with a sympathetic message,”
Facebook a aussi acheté des pages entières de publicité dans de grands journaux américains pour dénoncer la mise à jour d'Apple :
Apple contre les publicitaires français
Les publicitaires français sont à la pointe du combat contre Apple, et après une lettre publique envoyée à Tim Cook en juillet (spoiler : il n'a pas répondu), ils se décident à porter plainte auprès de l'autorité de la concurrence en octobre dernier. L'objet de leur plainte ? L’introduction obligatoire de la sollicitation ATT pour les applications sur iOS qui souhaiteraient faire un suivi de l’activité de l’utilisateur sur des sites tiers.
Première réponse de l'autorité de la concurrence le 17 mars et premier camouflet pour l'industrie publicitaire, sur le volet vie privée :
En l’état de l’instruction, l’Autorité a estimé que la décision d’Apple de mettre en place un dispositif de recueil du consentement complémentaire à celui mis en place par d’autres acteurs de la publicité en ligne, n’apparaissait pas comme une pratique abusive
L'instruction continue néanmoins :
Celle-ci devra notamment permettre de vérifier que la mise en place par Apple de la sollicitation ATT ne peut être regardée comme une forme de discrimination ou « self preferencing », ce qui pourrait notamment être le cas si Apple appliquait sans justification, des règles plus contraignantes aux opérateurs tiers que celles qu’elle s’applique à elle-même pour des opérations similaires.
Il est fort à parier que les publicitaires se fassent aussi débouter sur le volet anticoncurrentiel car Apple ne favorise pas ses propres applications : il ne pratique pas le tracking (et n'utilise donc pas l'IDFA). Apple propose des publicités ciblées sur ses Apps (Apple News, App Store, Bourse), en utilisant les données personnelles récoltées lui-même. Google, Facebook ou n'importe quelle autre App peut faire de même sur iOS, Apple ne s'oppose pas aux publicités personnalisées.
Autre plainte, cette fois-ci devant la CNIL par l'association France Digitale. L'attaque est plus subtile, Apple active par défaut les publicités personnalisés sur ses propres applications :
Si vous allez dans Réglages > Confidentialité > Publicité Apple, l'option publicités personnalisées est activée par défaut.
Clairement, Apple devrait demander votre consentement avant de pouvoir proposer de la publicité personnalisée, il ne respecte donc pas le RGPD. France Digital indique que cela porte un préjudice significatif :
- Aux utilisateurs (c'est vrai, encore que la publicité personnalisée sur Apple News, l'App Store et Bourse soit très loin du préjudice de la publicité personnalisée sur les applis Google ou Facebook).
- Aux startups françaises qui, je cite, "respectent scrupuleusement les règles posées par le RGPD". C'est osé ! La liste des entreprises faisant partie de l'association n'est pas publique, mais on peut noter que Frichti en fait partie, et l'appli qui bafoue le RGPD.
La plainte parle encore de distorsion de concurrence en insinuant qu'Apple proposerait de la publicité personnalisée avec ses "sociétés affiliées" :
Tableau inclus dans la plainte de France Digitale, censé montrer une distorsion de concurrence.
Comme déjà vu, le pistage et la publicité personnalisé au sein d'une même App ou de plusieurs Apps d'une même société est jugé légitime par Apple, cette pratique n'est pas le simple fait d'Apple mais aussi de Google, Facebook, Twitter, etc. France Digitale parle donc des "sociétés affiliées", des partenaires d'Apple qui comploteraient ensemble pour vous traquer.
Les explications d'Apple sur son programme de publicité sont pourtant très clair, il n'y a ni transmission, ni partage de données personnelles avec des tiers :
Apple ne partage ni ne transmet les données pouvant vous identifier personnellement à des parties tierces.
Également, Apple ne récupère pas de données personnelles via des tiers :
La plateforme publicitaire d’Apple ne suit pas vos activités, c’est-à-dire qu’elle n’associe pas les données d’utilisateur ou d’appareil recueillies sur nos apps à des données d’utilisateur ou d’appareil recueillies auprès de tiers à des fins de ciblage ou de mesure publicitaires, et ne partage pas les données d’utilisateur ou d’appareil avec des courtiers en données.
Aucune mention de "sociétés affiliées" dans l'engagement de confidentialité d'Apple, cela ressemble à une invention de France Digitale.
Mais pourquoi un tel acharnement "d'entrepreneurs et investisseurs du numérique français" contre Apple ? Sans doute parce que l'adtech pèse très lourd en France, on peut voir par exemple l'implication de Criteo (le fameux géant du marketing de surveillance français) dès le lancement de France Digitale ici et là. Il faut dire que Criteo n'aime guère Apple, et cela depuis quelque temps déjà.
Apple contre les publicitaires américains
Chez les publicitaires américains, les attaques sont plus subtiles mais guère convaincantes. Vous pouvez lire Ben Thomson ou Eric Benjamin Seufert (chez Ben Thomson ou sur son site). Voici quelques arguments :
- En s'attaquant au tracking, on renforcerait les "Walled Gardens" (Google, Facebook, etc). Ce à quoi répond très bien Wolfie Christl dans ce thread Twitter :
- Sur le renfort supposé aux "Walled Gardens", s'attaquer au tracking n'empêche d'ailleurs pas de s'attaquer aux géants publicitaires. Les 2 axes peuvent se compléter : lisez par exemple la plainte de Brave contre le RTB ("external" data free-for-all), ainsi que la plainte de Brave contre Google ("internal" data-free-for-all). Sans parler vie privée, il serait intéressant de s'attaquer aux abus de position dominante des géants publicitaires, Google et Facebook. Mais les lobbyistes publicitaires ignorent l'option.
- Apple ne chercherait pas à protéger votre vie privée sur les Apps (via ATT), mais plutôt à contrôler l'intégralité de votre expérience. Hors Facebook dérangerait Apple car la découverte de nouvelles Apps ne passeraient plus du tout par l'App Store mais par la publicité personnalisée sur Facebook ou Instagram. En s'attaquant au tracking, Apple chercherait donc à reprendre le contrôle sur la distribution des Apps. Mais quelle est la part réelle de la publicité dans la distribution des Apps ?
- Argument similaire sur le web (via ITP), où Apple chercherait plutôt à asphyxier les ressources publicitaires. En conséquence, les éditeurs devraient miser sur les abonnements via les Apps, sur lesquels Apple touche une commission. Mais pourquoi ne pas proposer de la publicité respectueuse de la vie privée ?
- Apple lutterait contre les acteurs publicitaires pour pousser son propre business publicitaire. Difficile à croire car le business publicitaire d'Apple (App Store, Apple News et Bourse) est dérisoire comparé à ses autres revenus (produits, services). Apple a également fermé iAd, son ad-network, en décembre 2016.
Si la volonté de contrôle d'Apple est évidente, et si le monopole de l'App Store est un énorme problème, les arguments des lobbyistes publicitaires manquent de pertinence. Apple a une raison évidente d'investir pour mieux protéger la vie privée : la demande de protection est forte (et les clients potentiels d'Apple ne sont pas les publicitaires, mais vous et moi).
Apple force la transparence chez les développeurs d'App
Depuis décembre 2020, Apple a rendu obligatoire les étiquettes de confidentialité sur les Apps. Ces étiquettes permettent de mettre en valeur les différences entre applications. Si l'on compare des navigateurs par exemple :
Le spyware Google Chrome.
Le navigateur de DuckDuckGo, respectueux de votre vie privée.
Si l'on regarde maintenant les messageries :
Messenger, le spyware de Facebook, encore pire que WhatsApp.
Signal, une App respectueuse de la vie privée.
Certes, ces étiquettes ont des limites :
- Elles sont basées sur de l'auto-déclaration. Apple va-t-il contrôler si le développeur dit la vérité ?
- Il n'y a pas d'informations sur les données personnelles qui peuvent fuiter vers des tiers. Il serait intéressant de voir qui récupère vos données personnelles et pourquoi.
Mais elles représentent déjà une belle avancée, et pousseront peut-être les développeurs d'Apps à limiter l'usage de données personnelles à celles qui sont strictement nécessaires.
Apple pourrait-il aller plus loin sur les Apps ?
Avec ATT, Apple s'est mis au niveau de Safari ITP (protection contre le tracking). S'il voulait aller plus loin, il pourrait décider de bloquer les publicités et les traceurs 1st-party (analytics, A/B testing, tag managers...). Avantages pour l'utilisateur :
- Les publicités seraient bloquées.
- Les traceurs 1st-party (analytics, A/B testing, tag managers...) seraient également bloqués. Aujourd'hui par exemple, les traceurs de Google Analytics, Segment, Mixpanel ou Amplitude ne sont pas bloqués.
Mais il se mettrait à dos certains développeurs, et ce ne serait pas cohérent avec sa politique actuelle sur le web via Safari ITP.
Malheureusement, cette publicité ne s'applique donc pas aux traceurs 1st-party, votre iPhone communique toujours avec de nombreux tiers, dont ceux de Google (même si les identifiants devraient maintenant être spécifiques à chaque App, car l'IDFA n'est plus disponible par défaut) :
Avec le support natif des DNS chiffrés via iOS 14, il a néanmoins permis à des bloqueurs de traceurs et de publicités de mieux faire leur travail (ces bloqueurs devaient créer un pseudo VPN local, ce qui était une catastrophe pour la batterie). J'utilise pour ma part NextDNS, ce qui me permet de bloquer tous les traceurs et autres publicités.
Oui, Apple vous protège contre la surveillance publicitaire, de mieux en mieux
Comme nous l'avons vu, les protections apportées par Apple contre la surveillance publicitaire sur iOS sont largement améliorables. Mais elles ont le mérite d'être cohérentes et de lutter assez efficacement contre le tracking, comme le prouve d'ailleurs l'énervement de Facebook et de l'adtech en général. Un utilisateur avancé pourra aller plus loin en passant par un bloqueur de traceurs et de publicités tel que NextDNS, AdGuard ou un Pi-Hole.
Même s'il est sain de critiquer une multinationale aussi dominante, et pour des raisons très valables (système fermé, verrouillé, réparabilité très limitée, monopole de l'App Store, "optimisation fiscale", obsolescence programmée, etc), l'alternative "Android by Google" n'est pas crédible si vous souhaitez protéger votre vie privée.
Si vous êtes allergique à Apple mais que vous souhaitez tout de même protéger votre vie privée sur votre smartphone, il vous faudra passer par des distributions qui auront supprimé la couche "Google" d'Android (/e/ par exemple, basé sur Lineage OS et microG), mais il vous faudra de bonnes compétences techniques.
21.02.2021 à 19:09
Comment Google se moque de la CNIL

Google sanctionné pour manquement à la loi Informatique et Libertés
Le 7 décembre dernier, la CNIL sanctionne Google à hauteur de 100 millions d'euros pour avoir enfreint la législation française sur les cookies :
Sur le moteur de recherche de Google, la CNIL a relevé 3 violations à l'article 82 de la loi Informatique et Libertés (transposition de la directive « ePrivacy ») :
- Un dépôt de cookies sans recueil préalable du consentement de l’utilisateur : plusieurs cookies poursuivant une finalité publicitaire étaient automatiquement déposés lorsque l'utilisateur se rendait sur google.fr (cookies non essentiels au service).
- Un défaut d’information des utilisateurs du moteur de recherche google.fr : le bandeau d'information ne fournissait aucune information relative aux cookies.
- La défaillance partielle du mécanisme « d’opposition » : désactiver la personnalisation des annonces n'avait pas d'impact sur un des cookies publicitaires.
Le moteur de recherche, vache à lait de Google
Si Google propose une multitude de services, son moteur de recherche génère toujours la majorité de ses revenus :

Lors du 4ème trimestre 2020, la recherche Google générait 56% de ses revenus. Les sites partenaires, YouTube, Google Play ou Google Cloud représentent une part non négligeable des revenus, mais ils sont beaucoup moins rentables.
La recherche est stratégique pour Google, elle lui a permis d'imposer son capitalisme de surveillance à de multiples domaines :
- Dominer la recherche lui a permis de devenir dominant dans l'adtech, cf. "La domination des marchés publicitaires de Google".
- Cette domination est facilitée par l'exploitation de vos données personnelles, sans réel consentement cf. "Google associe vos données de surf à vos données personnelles, et il est difficile d'y échapper".
- Google permet également à des tiers de vous surveiller même lorsque vous prenez des précautions, cf. "Google Tag Manager, la nouvelle arme anti adblock".
- Les revenus générés par son moteur de recherche ont permis à Google d'être dominant dans de nombreux domaines, cf. "Les services Google qui captent vos données personnelles, et les alternatives".
Google face à la CNIL
Nous avons donc :
- D'un côté la loi, censée protéger la vie privée des internautes, matérialisée ici par une sanction de la CNIL.
- De l'autre côté, l'exploitation de vos données personnelles sur le service le plus stratégique de Google, son moteur de recherche.
Quel sera le vainqueur ?
Dans sa sanction, la CNIL relève 2 points :
- Depuis une mise à jour de septembre 2020, Google cesse de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
- Le nouveau bandeau d’information ne permet toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informe pas du fait qu’ils peuvent refuser ces cookies.
La CNIL indique que Google a 3 mois pour informer correctement les utilisateurs, sous peine du paiement d'une astreinte de 100.000 euros par jour de retard. Étudions maintenant ce qui se passe à la première visite sur google.fr.
Google continue le dépôt automatique de cookies publicitaires
Démarrons notre investigation sur google.fr :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur google.fr.
Comme vous pouvez le voir, le bandeau d'information fournit maintenant de l'information relative aux cookies, mais ne permet pas de refuser facilement le dépôt de cookies non essentiels.
Que dit la loi ? Si l'on cite la CNIL, le consentement n'est valide que si la personne exerce un choix réel. En particulier, "l'utilisateur doit pouvoir accepter ou refuser le dépôt et/ou la lecture des cookies avec le même degré de simplicité". Ce n'est clairement pas le cas ici.
Google cesse-t-il de déposer automatiquement des cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr comme le déclare la CNIL ? Regardons les requêtes via Charles Proxy :
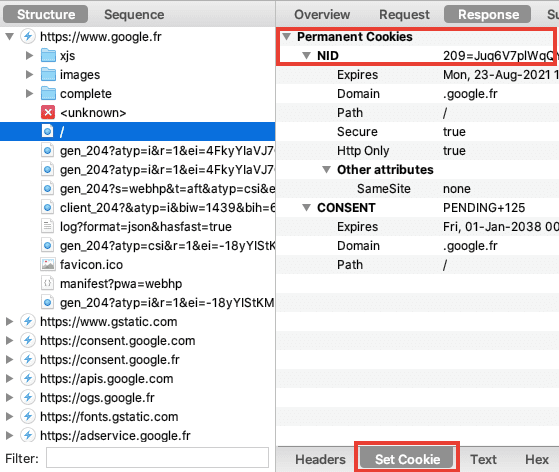
Comme on le voit, Google dépose le cookie NID dès l'arrivée sur google.fr. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
Google a également indiqué à la CNIL que le cookie NID poursuivait une finalité publicitaire (cf. la délibération, point 99) :
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Et pourtant, la CNIL souligne que Google a arrêté cette pratique (point 102) :
Elle souligne néanmoins que durant la procédure de sanction les sociétés ont apporté des modifications à la page google.fr, qui ont notamment amené, depuis le 10 septembre 2020, à l’arrêt du dépôt automatique de ces quatre cookies dès l’arrivée de l’utilisateur sur la page.
Le contrôle de la CNIL a-t-il été correctement effectué ? Toujours est-il que Google continue de violer la loi, cf. le site de la CNIL :
Le consentement doit être préalable au dépôt et/ou à la lecture de cookies. Tant que la personne n'a pas donné son consentement, les cookies ne peuvent pas être déposés ou lus sur son terminal.
Des pièges dans le parcours de consentement Google
Le bandeau d'information Google nous dit :
Si vous acceptez, nous personnaliserons le contenu et les annonces que vous voyez en fonction de votre activité sur les services Google comme la recherche, Maps et YouTube. [...] Cliquez sur "Plus d'informations" pour découvrir les options qui s'offrent à vous
Si je clique sur "Plus d'informations", je suis exposé à une nouvelle fenêtre d'information :
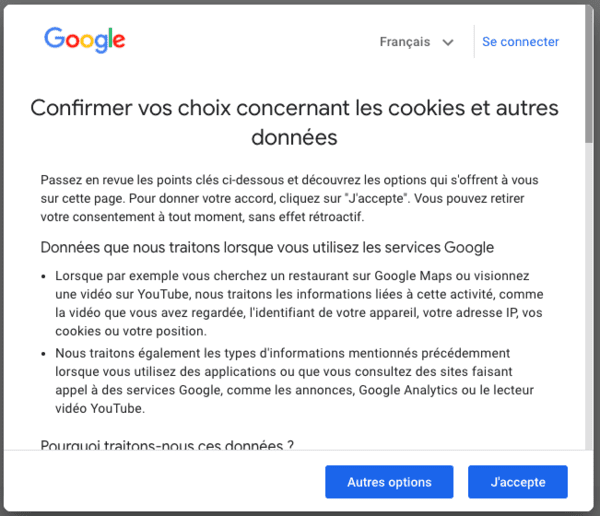
Google détaille ici les données personnelles traitées, les finalités, ainsi que les paramètres de confidentialité. Notez toujours les boutons "J'accepte" et "Autres options" : Google ne permet toujours pas de refuser le dépôt de cookies non essentiels.
Là, vous pourriez vous perdre dans le parcours de Google et cliquer sur "Autres options", en espérant tomber "rapidement" sur l'option pour refuser la surveillance publicitaire. Vous découvrirez cet écran :
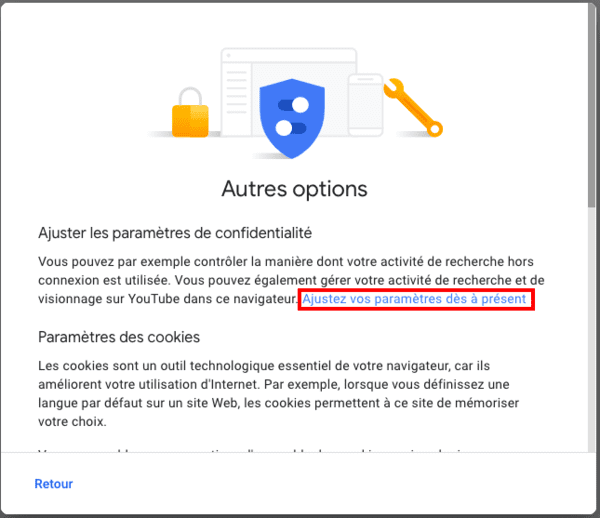
Là, Google présente plusieurs options :
- Ajuster les paramètres de confidentialité : c'est la bonne option ! Il vous faut cliquer sur "Ajustez vos paramètres dès à présent".
- Paramétrer les cookies dans le navigateur : option que Google ne recommande pas : "Vous pouvez bloquer une partie ou l'ensemble des cookies, mais cela risque d'empêcher l'exécution de certaines fonctionnalités sur le Web. Par exemple, de nombreux sites Web requièrent l'activation des cookies lorsque vous souhaitez vous y connecter.".
- Installer un module complémentaire pour désactiver le suivi de Google Analytics : Google Analytics est malheureusement loin d'être le seul outil dont Google se sert pour vous surveiller sur le web (Google vous surveille d'abord via la publicité). Inutile de dire qu'une personne soucieuse de sa vie privée préfèrera utiliser un adblocker.
- Vous connecter à votre compte Google : afin de ne plus voir ce rappel ! Google indique en effet : "Si vous effacez régulièrement les cookies de votre navigateur, vous continuerez à recevoir ce rappel de confidentialité, car nous n'avons aucun moyen de savoir que vous l'avez déjà vu". L'inconvénient de vous surveiller par défaut : sans cookies, Google part du principe qu'il a le droit de vous surveiller !
Que se passe-t-il si vous cliquez sur "Ajustez vos paramètres dès à présent" ? Vous revenez à l'étape précédente ! Mais vous n'étiez pas assez attentif, l'étape contient des liens vers la modification de paramètres :
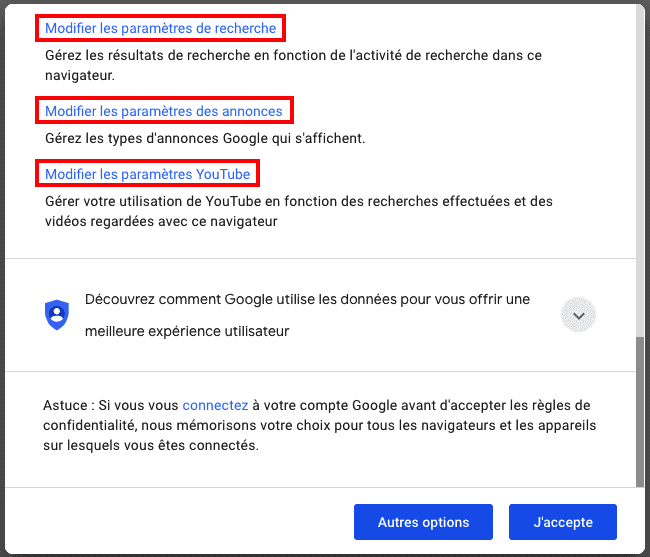
Le parcours du combattant n'est pas terminé.
16 clics supplémentaires pour refuser la surveillance
Cliquons donc sur "Modifier les paramètres de recherche" :
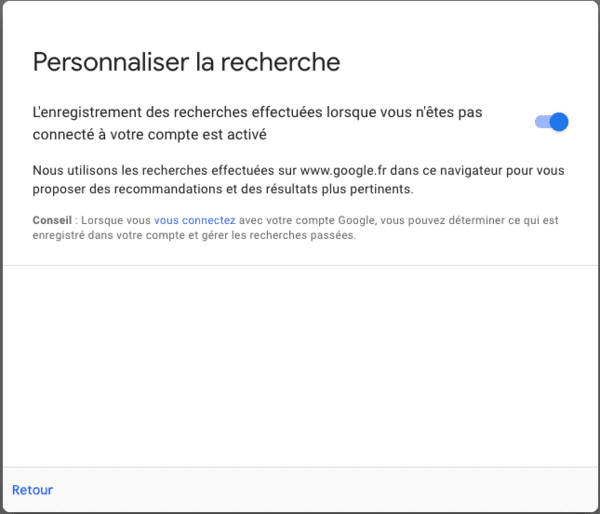
Décochons donc "L'enregistrement des recherches", puis cliquons sur "Retour" et enfin sur "Modifier les paramètres des annonces" :
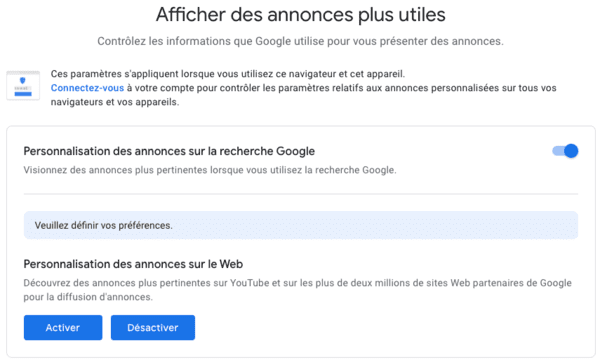
Ici, il vous faut décocher "Personnalisation des annonces sur la recherche Google" et "Personnalisation des annonces sur le Web". Avec ces paramètres cochés par défaut, Google se permet de vous surveiller sur les "plus de deux millions de sites Web partenaires de Google pour la diffusion d'annonces".
Lorsque vous décochez "Personnalisation des annonces sur la recherche Google", vous avez droit à une petite surprise supplémentaire :
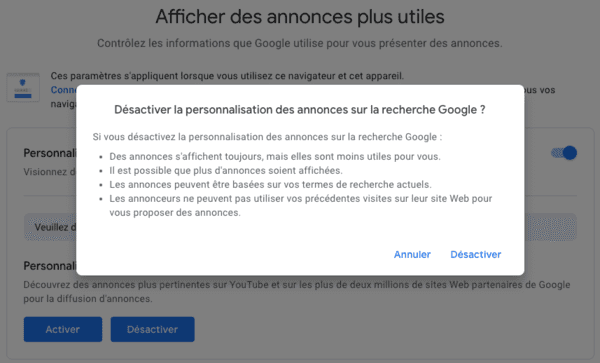
Êtes-vous vraiment sûr de vous ? Google vous rend la tâche encore un peu plus difficile : vos recherches en disent beaucoup sur vous...
Et lorsque vous cliquez sur "Désactiver", Google affiche un message de toute beauté :
"La prise en compte de cette modification par nos systèmes peut prendre un certain temps."
Google ne doit pas s'attendre à ce que vous réussissiez le chemin d'obstacle ! Même punition si vous cliquez sur le bouton "Désactiver" pour la "Personnalisation des annonces sur le Web" :
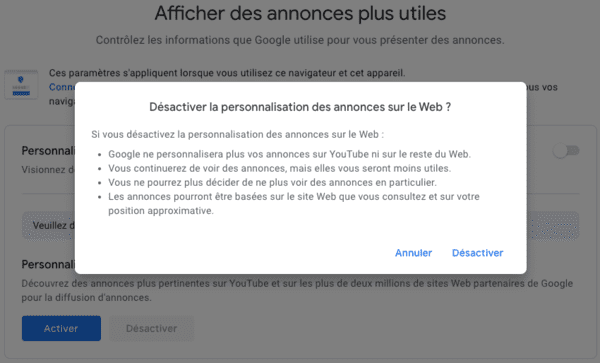
Là aussi, on voit que c'est compliqué pour Google :
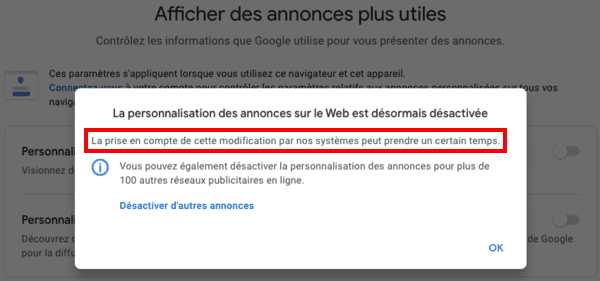
Si vous voulez installer d'autres cookies "Opt-out", qui ne désactivent que la personnalisation des publicités mais laissent les sociétés de l'adtech vous surveiller, Google vous redirige vers le site de l'industrie publicitaire :
Vous pouvez également désactiver la personnalisation des annonces pour plus de 100 autres réseaux publicitaires en ligne.
Revenez encore sur le bandeau d'information pour cliquer maintenant sur "Modifier les paramètres YouTube" :

Cette fois-ci, vous êtes dirigé vers le site YouTube, il vous faut encore décocher "Vidéos que vous regardez sur YouTube" et cliquer sur "Effacer l'historique des vidéos regardées":
Puis il vous faut décocher "Vidéos que vous recherchez sur YouTube" et cliquer sur "Effacer l'historique des recherches" :
Et pour couronner ce beau parcours, lorsque vous revenez sur le bandeau d'information, il vous faut cliquer sur "J'accepte" (cela reste le seul moyen de supprimer ce bandeau d'information, même si vous venez de tout refuser) :
Au total, si vous prenez le chemin le plus rapide, il vous faut 17 clics !
Pendant le parcours de "non consentement", la surveillance continue
Que se passe-t-il pendant ce parcours de "non consentement" ? Si l'on observe les requêtes via Charles :
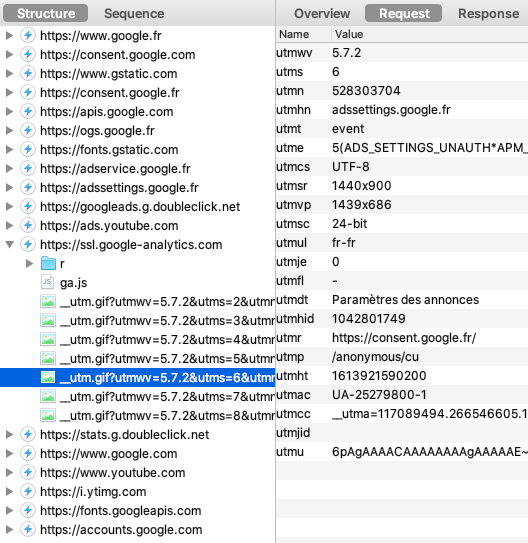
Google continue d'alimenter ses services publicitaires, dont Google Analytics et Doubleclick.
Malgré votre refus, vous continuez d'être surveillé par Google sur le web
Suite à ce parcours d'obstacles, consultons le site Lemonde.fr (dopé aux traceurs, cf. "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr") et filtrons les requêtes sur Google :
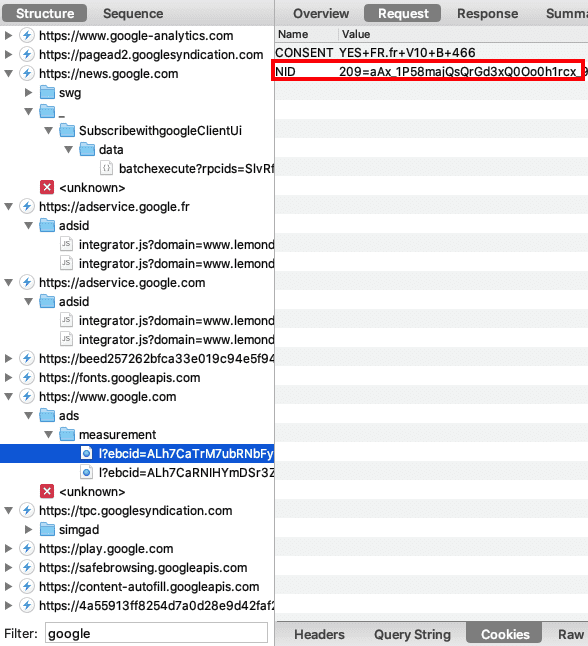
Comme vous le voyez, Lemonde.fr aime bien Google.
Manque de chance, Google n'a pas supprimé le cookie NID. En conséquence, de nombreuses requêtes sont envoyées depuis le site Lemonde.fr vers Google avec votre identifiant stocké dans le cookie NID (rappel, c'est un cookie publicitaire). Ainsi, la violation suivante est toujours valable :
Lorsqu’un utilisateur désactivait la personnalisation des annonces sur la recherche Google en recourant au mécanisme mis à sa disposition à partir du bouton « Consulter maintenant », un des cookies publicitaires demeurait stocké sur son ordinateur et continuait de lire des informations à destination du serveur auquel il est rattaché.
La formation restreinte a donc estimé que le mécanisme « d’opposition » mis en place par les sociétés était partiellement défaillant, en violation de l’article 82 de la loi Informatique et Libertés.
Google va-t-il proposer un vrai mécanisme de consentement ?
La CNIL a sanctionné Google sur des obligations qui préexistaient au RGPD (article 82 de la loi Informatique et Libertés, transposition de la directive « ePrivacy »).
Or depuis le 1er octobre 2020, la CNIL a publié ses lignes directrices modificatives ainsi qu’une recommandation portant sur l’usage de cookies et autres traceurs. La CNIL a demandé aux acteurs de se conformer aux règles ainsi clarifiées, en estimant que cette période d’adaptation ne devrait pas dépasser six mois.
Refuser les traceurs doit être aussi aisé que de les accepter. La CNIL recommande que l’interface de recueil du consentement ne comprenne pas seulement un bouton « tout accepter » mais aussi un bouton « tout refuser ».
Les utilisateurs devront être en mesure de retirer leur consentement, facilement, et à tout moment.
On attend donc avec impatience le 1er avril et la mise en conformité de Google afin de pouvoir refuser sa surveillance en 1 clic (et non en 17 clics)... En réalité, même les obligations antérieures au RGPD sont bafouées :
- Google a contesté son amende de 100 millions d'euros devant le Conseil d'État.
- Comme on l'a vu, Google vous surveille via le cookie
NID, avant même votre consentement mais aussi après votre refus de consentement. - Tenter de refuser la surveillance de Google est un parcours du combattant.
- Il est permis de douter du caractère dissuasif des sanctions de la CNIL, si tant est qu'elle arrive à se faire payer. 100 millions d'euros et 100.000 euros par jour (soit 36 millions d'euros par an), ce n'est pas si cher pour Google.
Google est l'exemple le plus frappant de ce mensonge au consentement, mais le web français est infesté de sites qui bafouent votre vie privée, exemples :
- "La grande braderie de vos données personnelles sur Le Bon Coin".
- "Le recueil du consentement sur internet : un mensonge généralisé".
Reste à voir si la CNIL prendra des sanctions dissuasives à partir du 1er avril.
Vos alternatives pour éviter la surveillance de Google
Si l'on se restreint au moteur de recherche Google (l'objet de cet article), vous avez d'autres options comme :
- DuckDuckGo : un moteur de recherche américain qui ne vous surveille pas. L'interface est épurée, le moteur de recherche est un des choix par défaut sur Safari, et le gros des résultats est basé sur Bing.
- Qwant : la version française, une interface moins épurée, le gros des résultats est aussi basé sur Bing.
- Ecosia : la version allemande, Ecosia reverse 80% de ses bénéfices à des associations à but non lucratif qui œuvrent au programme de reforestation présent essentiellement dans les pays du sud. Ecosia est aussi principalement basé sur Bing.
- Startpage : la version hollandaise, l'interface est épurée et les résultats sont ceux de Google. Du coup, c'est mon choix (les résultats de Google sont souvent bien plus pertinents que ceux de Bing). Startpage est devenu controversé depuis son rachat en 2019 par une société ayant des participations dans l'adtech (vous pouvez vous faire votre propre opinion en lisant cet article).
Il est intéressant de lire pourquoi Google fournit ses résultats de recherche à Startpage :
Why does Google let Startpage access their search results? Startpage.com has a contract with Google that allows us to use their official "Syndicated Web Search" feed, so we have to pay them to get those results.
À la différence de Bing qui fournit ses résultats à de nombreux méta-moteurs (DuckDuckGo, Qwant, Ecosia...), Google est avare de ses résultats de recherche. Startpage semble être le seul à y avoir accès, pour combien de temps ?
Texte intégral (3582 mots)
Google sanctionné pour manquement à la loi Informatique et Libertés
Le 7 décembre dernier, la CNIL sanctionne Google à hauteur de 100 millions d'euros pour avoir enfreint la législation française sur les cookies :
Sur le moteur de recherche de Google, la CNIL a relevé 3 violations à l'article 82 de la loi Informatique et Libertés (transposition de la directive « ePrivacy ») :
- Un dépôt de cookies sans recueil préalable du consentement de l’utilisateur : plusieurs cookies poursuivant une finalité publicitaire étaient automatiquement déposés lorsque l'utilisateur se rendait sur google.fr (cookies non essentiels au service).
- Un défaut d’information des utilisateurs du moteur de recherche google.fr : le bandeau d'information ne fournissait aucune information relative aux cookies.
- La défaillance partielle du mécanisme « d’opposition » : désactiver la personnalisation des annonces n'avait pas d'impact sur un des cookies publicitaires.
Le moteur de recherche, vache à lait de Google
Si Google propose une multitude de services, son moteur de recherche génère toujours la majorité de ses revenus :
Lors du 4ème trimestre 2020, la recherche Google générait 56% de ses revenus. Les sites partenaires, YouTube, Google Play ou Google Cloud représentent une part non négligeable des revenus, mais ils sont beaucoup moins rentables.
La recherche est stratégique pour Google, elle lui a permis d'imposer son capitalisme de surveillance à de multiples domaines :
- Dominer la recherche lui a permis de devenir dominant dans l'adtech, cf. "La domination des marchés publicitaires de Google".
- Cette domination est facilitée par l'exploitation de vos données personnelles, sans réel consentement cf. "Google associe vos données de surf à vos données personnelles, et il est difficile d'y échapper".
- Google permet également à des tiers de vous surveiller même lorsque vous prenez des précautions, cf. "Google Tag Manager, la nouvelle arme anti adblock".
- Les revenus générés par son moteur de recherche ont permis à Google d'être dominant dans de nombreux domaines, cf. "Les services Google qui captent vos données personnelles, et les alternatives".
Google face à la CNIL
Nous avons donc :
- D'un côté la loi, censée protéger la vie privée des internautes, matérialisée ici par une sanction de la CNIL.
- De l'autre côté, l'exploitation de vos données personnelles sur le service le plus stratégique de Google, son moteur de recherche.
Quel sera le vainqueur ?
Dans sa sanction, la CNIL relève 2 points :
- Depuis une mise à jour de septembre 2020, Google cesse de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
- Le nouveau bandeau d’information ne permet toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informe pas du fait qu’ils peuvent refuser ces cookies.
La CNIL indique que Google a 3 mois pour informer correctement les utilisateurs, sous peine du paiement d'une astreinte de 100.000 euros par jour de retard. Étudions maintenant ce qui se passe à la première visite sur google.fr.
Google continue le dépôt automatique de cookies publicitaires
Démarrons notre investigation sur google.fr :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur google.fr.
Comme vous pouvez le voir, le bandeau d'information fournit maintenant de l'information relative aux cookies, mais ne permet pas de refuser facilement le dépôt de cookies non essentiels.
Que dit la loi ? Si l'on cite la CNIL, le consentement n'est valide que si la personne exerce un choix réel. En particulier, "l'utilisateur doit pouvoir accepter ou refuser le dépôt et/ou la lecture des cookies avec le même degré de simplicité". Ce n'est clairement pas le cas ici.
Google cesse-t-il de déposer automatiquement des cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr comme le déclare la CNIL ? Regardons les requêtes via Charles Proxy :
Comme on le voit, Google dépose le cookie NID dès l'arrivée sur google.fr. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
Google a également indiqué à la CNIL que le cookie NID poursuivait une finalité publicitaire (cf. la délibération, point 99) :
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Et pourtant, la CNIL souligne que Google a arrêté cette pratique (point 102) :
Elle souligne néanmoins que durant la procédure de sanction les sociétés ont apporté des modifications à la page google.fr, qui ont notamment amené, depuis le 10 septembre 2020, à l’arrêt du dépôt automatique de ces quatre cookies dès l’arrivée de l’utilisateur sur la page.
Le contrôle de la CNIL a-t-il été correctement effectué ? Toujours est-il que Google continue de violer la loi, cf. le site de la CNIL :
Le consentement doit être préalable au dépôt et/ou à la lecture de cookies. Tant que la personne n'a pas donné son consentement, les cookies ne peuvent pas être déposés ou lus sur son terminal.
Des pièges dans le parcours de consentement Google
Le bandeau d'information Google nous dit :
Si vous acceptez, nous personnaliserons le contenu et les annonces que vous voyez en fonction de votre activité sur les services Google comme la recherche, Maps et YouTube. [...] Cliquez sur "Plus d'informations" pour découvrir les options qui s'offrent à vous
Si je clique sur "Plus d'informations", je suis exposé à une nouvelle fenêtre d'information :
Google détaille ici les données personnelles traitées, les finalités, ainsi que les paramètres de confidentialité. Notez toujours les boutons "J'accepte" et "Autres options" : Google ne permet toujours pas de refuser le dépôt de cookies non essentiels.
Là, vous pourriez vous perdre dans le parcours de Google et cliquer sur "Autres options", en espérant tomber "rapidement" sur l'option pour refuser la surveillance publicitaire. Vous découvrirez cet écran :
Là, Google présente plusieurs options :
- Ajuster les paramètres de confidentialité : c'est la bonne option ! Il vous faut cliquer sur "Ajustez vos paramètres dès à présent".
- Paramétrer les cookies dans le navigateur : option que Google ne recommande pas : "Vous pouvez bloquer une partie ou l'ensemble des cookies, mais cela risque d'empêcher l'exécution de certaines fonctionnalités sur le Web. Par exemple, de nombreux sites Web requièrent l'activation des cookies lorsque vous souhaitez vous y connecter.".
- Installer un module complémentaire pour désactiver le suivi de Google Analytics : Google Analytics est malheureusement loin d'être le seul outil dont Google se sert pour vous surveiller sur le web (Google vous surveille d'abord via la publicité). Inutile de dire qu'une personne soucieuse de sa vie privée préfèrera utiliser un adblocker.
- Vous connecter à votre compte Google : afin de ne plus voir ce rappel ! Google indique en effet : "Si vous effacez régulièrement les cookies de votre navigateur, vous continuerez à recevoir ce rappel de confidentialité, car nous n'avons aucun moyen de savoir que vous l'avez déjà vu". L'inconvénient de vous surveiller par défaut : sans cookies, Google part du principe qu'il a le droit de vous surveiller !
Que se passe-t-il si vous cliquez sur "Ajustez vos paramètres dès à présent" ? Vous revenez à l'étape précédente ! Mais vous n'étiez pas assez attentif, l'étape contient des liens vers la modification de paramètres :
Le parcours du combattant n'est pas terminé.
16 clics supplémentaires pour refuser la surveillance
Cliquons donc sur "Modifier les paramètres de recherche" :
Décochons donc "L'enregistrement des recherches", puis cliquons sur "Retour" et enfin sur "Modifier les paramètres des annonces" :
Ici, il vous faut décocher "Personnalisation des annonces sur la recherche Google" et "Personnalisation des annonces sur le Web". Avec ces paramètres cochés par défaut, Google se permet de vous surveiller sur les "plus de deux millions de sites Web partenaires de Google pour la diffusion d'annonces".
Lorsque vous décochez "Personnalisation des annonces sur la recherche Google", vous avez droit à une petite surprise supplémentaire :
Êtes-vous vraiment sûr de vous ? Google vous rend la tâche encore un peu plus difficile : vos recherches en disent beaucoup sur vous...
Et lorsque vous cliquez sur "Désactiver", Google affiche un message de toute beauté :
"La prise en compte de cette modification par nos systèmes peut prendre un certain temps."
Google ne doit pas s'attendre à ce que vous réussissiez le chemin d'obstacle ! Même punition si vous cliquez sur le bouton "Désactiver" pour la "Personnalisation des annonces sur le Web" :
Là aussi, on voit que c'est compliqué pour Google :
Si vous voulez installer d'autres cookies "Opt-out", qui ne désactivent que la personnalisation des publicités mais laissent les sociétés de l'adtech vous surveiller, Google vous redirige vers le site de l'industrie publicitaire :
Vous pouvez également désactiver la personnalisation des annonces pour plus de 100 autres réseaux publicitaires en ligne.
Revenez encore sur le bandeau d'information pour cliquer maintenant sur "Modifier les paramètres YouTube" :
Cette fois-ci, vous êtes dirigé vers le site YouTube, il vous faut encore décocher "Vidéos que vous regardez sur YouTube" et cliquer sur "Effacer l'historique des vidéos regardées":
Puis il vous faut décocher "Vidéos que vous recherchez sur YouTube" et cliquer sur "Effacer l'historique des recherches" :
Et pour couronner ce beau parcours, lorsque vous revenez sur le bandeau d'information, il vous faut cliquer sur "J'accepte" (cela reste le seul moyen de supprimer ce bandeau d'information, même si vous venez de tout refuser) :
Au total, si vous prenez le chemin le plus rapide, il vous faut 17 clics !
Pendant le parcours de "non consentement", la surveillance continue
Que se passe-t-il pendant ce parcours de "non consentement" ? Si l'on observe les requêtes via Charles :
Google continue d'alimenter ses services publicitaires, dont Google Analytics et Doubleclick.
Malgré votre refus, vous continuez d'être surveillé par Google sur le web
Suite à ce parcours d'obstacles, consultons le site Lemonde.fr (dopé aux traceurs, cf. "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr") et filtrons les requêtes sur Google :
Comme vous le voyez, Lemonde.fr aime bien Google.
Manque de chance, Google n'a pas supprimé le cookie NID. En conséquence, de nombreuses requêtes sont envoyées depuis le site Lemonde.fr vers Google avec votre identifiant stocké dans le cookie NID (rappel, c'est un cookie publicitaire). Ainsi, la violation suivante est toujours valable :
Lorsqu’un utilisateur désactivait la personnalisation des annonces sur la recherche Google en recourant au mécanisme mis à sa disposition à partir du bouton « Consulter maintenant », un des cookies publicitaires demeurait stocké sur son ordinateur et continuait de lire des informations à destination du serveur auquel il est rattaché.
La formation restreinte a donc estimé que le mécanisme « d’opposition » mis en place par les sociétés était partiellement défaillant, en violation de l’article 82 de la loi Informatique et Libertés.
Google va-t-il proposer un vrai mécanisme de consentement ?
La CNIL a sanctionné Google sur des obligations qui préexistaient au RGPD (article 82 de la loi Informatique et Libertés, transposition de la directive « ePrivacy »).
Or depuis le 1er octobre 2020, la CNIL a publié ses lignes directrices modificatives ainsi qu’une recommandation portant sur l’usage de cookies et autres traceurs. La CNIL a demandé aux acteurs de se conformer aux règles ainsi clarifiées, en estimant que cette période d’adaptation ne devrait pas dépasser six mois.
Refuser les traceurs doit être aussi aisé que de les accepter. La CNIL recommande que l’interface de recueil du consentement ne comprenne pas seulement un bouton « tout accepter » mais aussi un bouton « tout refuser ».
Les utilisateurs devront être en mesure de retirer leur consentement, facilement, et à tout moment.
On attend donc avec impatience le 1er avril et la mise en conformité de Google afin de pouvoir refuser sa surveillance en 1 clic (et non en 17 clics)... En réalité, même les obligations antérieures au RGPD sont bafouées :
- Google a contesté son amende de 100 millions d'euros devant le Conseil d'État.
- Comme on l'a vu, Google vous surveille via le cookie
NID, avant même votre consentement mais aussi après votre refus de consentement. - Tenter de refuser la surveillance de Google est un parcours du combattant.
- Il est permis de douter du caractère dissuasif des sanctions de la CNIL, si tant est qu'elle arrive à se faire payer. 100 millions d'euros et 100.000 euros par jour (soit 36 millions d'euros par an), ce n'est pas si cher pour Google.
Google est l'exemple le plus frappant de ce mensonge au consentement, mais le web français est infesté de sites qui bafouent votre vie privée, exemples :
- "La grande braderie de vos données personnelles sur Le Bon Coin".
- "Le recueil du consentement sur internet : un mensonge généralisé".
Reste à voir si la CNIL prendra des sanctions dissuasives à partir du 1er avril.
Vos alternatives pour éviter la surveillance de Google
Si l'on se restreint au moteur de recherche Google (l'objet de cet article), vous avez d'autres options comme :
- DuckDuckGo : un moteur de recherche américain qui ne vous surveille pas. L'interface est épurée, le moteur de recherche est un des choix par défaut sur Safari, et le gros des résultats est basé sur Bing.
- Qwant : la version française, une interface moins épurée, le gros des résultats est aussi basé sur Bing.
- Ecosia : la version allemande, Ecosia reverse 80% de ses bénéfices à des associations à but non lucratif qui œuvrent au programme de reforestation présent essentiellement dans les pays du sud. Ecosia est aussi principalement basé sur Bing.
- Startpage : la version hollandaise, l'interface est épurée et les résultats sont ceux de Google. Du coup, c'est mon choix (les résultats de Google sont souvent bien plus pertinents que ceux de Bing). Startpage est devenu controversé depuis son rachat en 2019 par une société ayant des participations dans l'adtech (vous pouvez vous faire votre propre opinion en lisant cet article).
Il est intéressant de lire pourquoi Google fournit ses résultats de recherche à Startpage :
Why does Google let Startpage access their search results? Startpage.com has a contract with Google that allows us to use their official "Syndicated Web Search" feed, so we have to pay them to get those results.
À la différence de Bing qui fournit ses résultats à de nombreux méta-moteurs (DuckDuckGo, Qwant, Ecosia...), Google est avare de ses résultats de recherche. Startpage semble être le seul à y avoir accès, pour combien de temps ?
03.02.2021 à 23:28
Facebook et WhatsApp, où l'art de vous trahir

Le pire du capitalisme de surveillance
Je n'avais encore jamais écrit sur Facebook, et pourtant cette société représente ce qui se fait de pire dans le domaine de la surveillance publicitaire. Les conséquences de sa domination sont graves :
- Addictions : Les équipes produit de Facebook ont pour objectif ultime de faire croître l'engagement. Plus vous passez de temps sur ses applications (Facebook, Instagram, Messenger, WhatsApp), mieux vous serez "monétisé".
- Radicalisation : Les contenus extrêmes font réagir, ils favorisent l'engagement sur la plateforme. En conséquence, les algorithmes de Facebook mettent en avant les contenus extrêmes et la désinformation. Facebook est une chance pour les complotistes, les fanatiques et l'extrême droite, ce qui met en danger la démocratie dans de nombreux pays.
- Censures : Facebook et Instagram sont quasi incontournables pour qui souhaite informer ou alerter. Mais les règles de modération sont arbitraires et les recours compliqués. Les modérateurs manquent dans certains pays, ne comprennent pas bien les subtilités culturelles. De nombreux membres de la société civile et activistes se voient censurés.
- Traumatismes pour les modérateurs : ceux-ci sont des contractuels, peu considérés et mal payés, confrontés à des horreurs au quotidien. Ils restent souvent traumatisés pour longtemps.
- Une société digne de 1984 : avec son compère Google, Facebook a un rôle fondateur dans l'installation de la surveillance généralisée dans nos sociétés, mettant à mal la démocratie.
Le très provocant mais honnête mémo 'The Ugly", écrit en 2016 par un des dirigeants de Facebook, résume bien la culture d'entreprise : "Growth at any cost". Voici un extrait :
So we connect more people That can be bad if they make it negative. Maybe it costs a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools. And still we connect people.
The ugly truth is that we believe in connecting people so deeply that anything that allows us to connect more people more often is de facto good. It is perhaps the only area where the metrics do tell the true story as far as we are concerned.
Et au cœur du modèle de Facebook, on retrouve l'exploitation abusive de vos données personnelles. Le mépris de Facebook pour la vie privée de ses utilisateurs est largement documenté sur le web aujourd'hui. Mais il est rare d'y trouver une histoire retraçant l'érosion de votre vie privée par Facebook, mise en parallèle avec l'état de la concurrence.
Dina Srinivasan est une chercheuse travaillant sur ces sujets, à l'intersection de l'"antitrust" et de la "privacy", j'avais déjà eu l'occasion de parler de son travail dans l'article "La domination des marchés publicitaires de Google". Je vais ici partir de sa thèse "The Antitrust Case Against Facebook" pour décrire comment Facebook a pu imposer sa surveillance publicitaire sur le web et les applications, en dépit d'une préférence marquée des utilisateurs pour un respect de leur vie privée.
Aux origines, le respect de la vie privée était une force de Facebook
Il est difficile de s'en souvenir aujourd'hui, mais initialement le marché des réseaux sociaux était très compétitif. En 2006, le réseau social le plus utilisé était MySpace. Mais Facebook se trouvait aussi face à de nombreux autres réseaux sociaux comme Bebo, Hi5, Friendster ou Orkut (propriété de Google). Comment se différencier dans un marché concurrentiel où le produit est "gratuit" ? Par la qualité, et le niveau de protection de la vie privée est rapidement devenu un point important de différenciation.
En 2006 donc, MySpace était le leader. Mais il était très décrié dans les médias, mis en accusation de favoriser les harcèlements sexuels, suicides ou meurtres (quelques articles de l'époque ici, là ou encore là). La raison ? L'ouverture trop grande de la communication sur MySpace, et le peu de considérations pour la vie privée de ses utilisateurs.
Facebook avait donc un boulevard pour se différencier, ce qu'il a fait :
- MySpace était ouvert à tout le monde, Facebook était initialement réservé aux étudiants, pouvant justifier d'une adresse e-mail universitaire (en ".edu").
- Par défaut, les profils utilisateurs de MySpace étaient ouverts à tout le monde. Aux débuts de Facebook, seuls les amis et les étudiants d'une même université pouvaient consulter leurs profils respectifs.
- Facebook a rapidement donné beaucoup de contrôle à ses utilisateurs, ce que ne permettait pas MySpace : choix de l'ouverture ou de la fermeture de son profil aux amis, amis d'amis, étudiants de la même université. Mais aussi la possibilité d'être visible ou non sur son moteur de recherche, ainsi que des contrôles granulaires sur les informations de contact comme le numéro de téléphone.
Aussi, Facebook a très rapidement embauché un responsable de la vie privée. Sa politique de confidentialité était courte et très claire, avec seulement 950 mots. On peut notamment y lire :
Use of Cookies
A cookie is a piece of data stored on the user's computer tied to information about the user. We use session ID cookies to confirm that users are logged in. These cookies terminate once the users close the browser. We do not and will not use cookies to collect private information from any user.
La logique de réseau privé, le contrôle donné aux utilisateurs ainsi que la courte politique de confidentialité ont été des éléments différenciants par rapport à d'autres réseaux sociaux tels que MySpace. Même si d'autres facteurs ont pu jouer (solide socle technique, élitisme initial, interface utilisateur plus épurée, etc), le meilleur respect de la vie privée a joué un rôle central dans le développement de Facebook.
Beacon, la première tentative (ratée) de surveillance du web
En 2007, Facebook devient le nouveau réseau social à la mode (et j'ouvre mon compte). En novembre, il lance Beacon, une initiative transparente de surveillance publicitaire en dehors de Facebook. Au lancement, le New York Times est l'un des partenaires. Si je lis un article du New York Times, Facebook me propose alors via une pop-up de partager ma lecture à mes amis. Facebook Beacon permet aussi de partager ses achats, la musique écoutée, les films regardés, etc :
Facebook Beacon vous surveille, mais vous êtes informé.
La présence de ces nouveaux traceurs de Facebook lui permet de surveiller le comportement des utilisateurs sur des sites tiers (via un cookie), même si ceux-ci déclinent le partage de leurs activités. Devant le tollé provoqué par Beacon, Facebook se défend pourtant de surveiller les utilisateurs lorsque ceux-ci refusent le partage. Voici un extrait de l'interview du vice président Marketing & Opérations de l'époque au New York Times :
Q. If I buy tickets on Fandango, and decline to publish the purchase to my friends on Facebook, does Facebook still receive the information about my purchase?
A. “Absolutely not. One of the things we are still trying to do is dispel a lot of misinformation that is being propagated unnecessarily.”
Déclaration évidemment démentie quelques heures plus tard par un chercheur. Avec les traceurs Beacon, Facebook surveille aussi les utilisateurs qui se sont déconnectés, ainsi que les personnes qui n'ont pas de compte Facebook. C'est une première violation de la vie privée pour Facebook, en contradiction avec sa politique de confidentialité qui indique alors uniquement utiliser les cookies "to confirm that users are logged in", et "these cookies terminate once the users close the browser".
Rapidement, Facebook est confronté à de nombreuses protestations, des pétitions et même des procès. Plusieurs participants au programme Beacon décident de se retirer. Les autres réseaux sociaux profitent également de ce scandale pour critiquer Facebook et améliorer la gestion de la vie privée sur leurs plateformes. Début décembre 2007, Mark Zuckerberg s'excuse (pour un historique des excuses de Zuckerberg, voici un bon article) et annonce une option d'Opt-out. L'option cachée dans les paramètres ne répondant toujours pas aux exigences des utilisateurs, Facebook fermera Beacon moins d'1 an après.
Ce retrait rapide est la preuve d'un marché encore compétitif. Facebook est sous pression de réseaux sociaux concurrents. Aussi, afin de restaurer une confiance déjà trahie, Facebook annonce en 2009 que tout changement à la politique de confidentialité sera désormais soumis à un vote.
Le bouton Like, un cheval de Troie idéal
Facebook a de la suite dans ses idées, il apprend de ses erreurs et en avril 2010, il introduit le bouton Like lors de sa conférence annuelle pour les développeurs. Pour les éditeurs, c'est une opportunité de profiter d'une distribution facile de leurs articles sur Facebook, et donc d'attirer de nouveaux lecteurs. Et rapidement c'est un succès : dès les premières semaines, plus de 50,000 sites installent le bouton like, dont des éditeurs célèbres tels que CNN, le New York Times, The Wall Street Journal ou Slate.
Mais comme avec Beacon, le bouton Like communique avec les serveurs de Facebook pour s'afficher sur votre écran. Facebook peut ainsi surveiller votre navigation, de nouveau en contradiction avec sa politique de confidentialité. CNET cite ainsi la FAQ de l'époque :
No data is shared about you when you see a social plug-in on an external website.
À la différence de Beacon, Facebook indique que ce produit ne sera pas utilisé dans un but de surveillance commerciale. 2 raisons :
- Facebook se souvient encore du scandale Beacon, et souhaite éviter un nouveau scandale.
- Il doit convaincre les éditeurs, des concurrents sur le marché publicitaire, d'installer ces boutons Like. Théoriquement, il pourrait ainsi revendre moins cher aux annonceurs l'audience du Wall Street Journal, directement sur Facebook.
Un chercheur a pu détailler la fuite des données personnelles via le bouton Like (Facebook Tracks and Traces Everyone: Like This!) dès novembre 2010. Via des cookies qu'il installe même si vous ne cliquez pas sur le bouton Like, le réseau social récupère votre identité, l'URL de la page consultée ainsi que le titre de l'article ou le nom du produit. Là également, la surveillance a lieu même si vous n'avez pas de compte Facebook. Mais à la différence de Beacon, pas de pop-up Facebook vous demandant de partager l'article que vous lisez ou l'achat que vous venez d'effectuer : la surveillance est maintenant invisible.
Comment Facebook réagit-il face à ces nouvelles révélations ? Le directeur technique de l'époque déclare que ces cookies ne sont pas utilisés par Facebook pour surveiller les utilisateurs mais pour protéger les comptes utilisateurs de cyber attaques. Concernant la surveillance des utilisateurs n'ayant pas de compte, il s'agirait là d'un bug qui aurait été corrigé depuis (faux). Le Wall Street Journal indique dans son enquête de mai 2011 que les boutons Like permettaient de vous surveiller sur plus d'un tiers des 1000 sites web les plus visités au monde, et sur plus d'un million de sites web. Devant de tels chiffres, on commence à prendre conscience de l'ampleur de la surveillance généralisée.
En septembre 2011, Facebook est accusé de continuer de surveiller les utilisateurs même après leur déconnexion. Facebook devrait supprimer les cookies lorsqu'un utilisateur se déconnecte et notamment l'identifiant utilisateur, il ne le fait pas, et tente de tromper son auditoire :
Facebook does not track users across the web. Instead, we use cookies on social plugins to personalize content (e.g. show you what your friends liked), to help maintain and improve what we do (e.g. measure click-through rate), or for safety and security (e.g. keeping underage kids from trying to sign up with a different age). No information we receive when you see a social plugin is used to target ads, we delete or anonymize this information within 90 days, and we never sell your information.
Specific to logged-out cookies, they are used for safety and protection, including identifying spammers and phishers, detecting when somebody unauthorized is trying to access your account, helping you get back into your account if you get hacked, disabling registration for underage people who try to re-register with a different birth date, powering account security features such as second factor login approvals and notification, and identifying shared computers to discourage the use of “Keep me logged in.”
Si l'on réfléchit à la meilleure manière pour Facebook d'imposer son capitalisme de surveillance, il lui faut d'abord parvenir à convaincre les éditeurs d'installer ses traceurs. La transparence n'ayant pas réussi (Beacon était présenté comme un outil commercial), Facebook a préféré opérer de manière déguisée (déclarer que le bouton Like ne serait pas utilisé pour de la surveillance publicitaire).
En décembre 2012, le Wall Street Journal revient sur son enquête pour indiquer que les boutons Like se retrouvent maintenant sur 2/3 des sites du top 1000, Facebook répond encore qu'il utilise les informations des boutons Like uniquement pour la sécurité et pour corriger les bugs. Mais la malhonnêteté est bien là. En février 2011, Facebook a déposé un brevet pour surveiller les utilisateurs en dehors de son propre site et proposer de la publicité ciblée basée sur ces profils :
The present disclosure relates generally to social network systems and other websites in which users can form connections with other users, and in particular, to tracking activities of users of social network systems on other domains to, for example, analyze, target, or gauge the effectiveness of advertisements (ads) rendered in conjunction with social network systems.
Avant d'utiliser la collecte de données des boutons Like pour la surveillance publicitaire, Facebook devait encore se débarrasser d'un dernier obstacle : le fait que tout changement de politique de confidentialité devait être soumis à un vote. Voici comment Facebook a procédé :
- Fin 2012, avec plus d'un milliard d'utilisateurs et une entrée en bourse réussie, Facebook propose un vote sur la suppression des futurs référendums concernant sa politique de confidentialité.
- 88% des utilisateurs ont voté contre, mais Facebook arguant du fait que seuls 589,000 personnes avaient voté (une clause indiquait qu'à minima, 30% des utilisateurs devaient voter), il pouvait s'asseoir sur la volonté des participants et abolir les référendums.
De nombreux utilisateurs se sont ensuite plaints de ne pas avoir été informés de ce vote, n'ayant reçu aucune notification ou aucun e-mail. Facebook ne voulait clairement pas que vous votiez.
En juin 2014, Facebook décide d'activer la surveillance publicitaire basée sur les boutons Like (et tous les autres plugins qu'il fournit aux éditeurs : Facebook Login, le pixel Facebook, le SDK pour les applications, etc). Le titre de l'article annonçant la mise à jour est un modèle de novlangue : Making Ads Better and Giving People More Control Over the Ads They See.
Après avoir passé 7 ans à promettre de ne pas exploiter les données collectées par ses plugins pour de la surveillance publicitaire, Facebook renie ses promesses. Pourquoi ? La concurrence a été écrasée (MySpace et Orkut ont fermés, Google+ s'est avéré être un échec) et même si la qualité de Facebook est grandement dégradée par cette atteinte massive à leur vie privée, les utilisateurs n'ont plus d'alternatives viables. Facebook peut maintenant sur-exploiter vos données personnelles pour son plus grand bénéfice.
En 2018, même le cofondateur de WhatsApp conseille de supprimer Facebook.
Avec WhatsApp, Facebook reproduit la même stratégie
WhatsApp est créé en 2009 et très vite, la protection de la vie privée est un axe fort de l'application :
So first of all, let's set the record straight. We have not, we do not and we will not ever sell your personal information to anyone. Period. End of story. Hopefully this clears things up.
En 2012, lorsque le co-fondateur de WhatsApp Jan Koum écrit le billet "Pourquoi nous ne vendons pas de pub", le discours sur la publicité est fort :
La publicité n'est pas seulement une gêne esthétique, une insulte à votre intelligence et une interruption de votre fil de pensées. Dans chaque entreprise vendant de la publicité, une importante partie de leur équipe d'ingénieurs passent leurs journées à affiner l'exploration de données, améliorer le code pour collecter toutes vos données personnelles, améliorer les serveurs qui contiennent toutes les données et s'assurer que tout est bien enregistré, rassemblé, découpé, emballé et envoyé... Au final, le résultat de tout cela est une bannière de publicité légèrement différente dans votre navigateur ou écran de téléphone mobile.
Voici un autre passage du même billet, traitant du recueil de données personnelles :
À WhatsApp, nos ingénieurs passent tout leur temps à réparer des bugs, ajouter de nouvelles fonctionnalités et passer le tout au peigne fin pour offrir une messagerie riche, abordable et fiable pour tous les téléphones dans le monde entier. C'est notre produit et notre passion. Vos données n'entrent même pas en jeu. Cela ne nous intéresse tout simplement pas.
À l'époque, WhatsApp avait une très bonne réputation. L'application était en effet appréciée pour sa simplicité, sa fiabilité, mais aussi pour son positionnement sur la publicité et les données personnelles. Comme avec Facebook à ses débuts, la protection de la vie privée est un avantage compétitif pour WhatsApp, qui lui permet de gagner des parts de marché (sur Facebook Messenger ou Google Hangouts par exemple).
Seulement voilà, en 2014 WhatsApp vend son application à Facebook pour 22 milliards de dollars. Vu l'historique de Facebook, on peut déjà craindre le pire. Jan Koum écrit pourtant sur le blog de WhatsApp :
Voici ce qui va changer pour vous, nos utilisateurs : rien.
WhatsApp restera autonome et fonctionnera indépendamment. Vous pouvez continuer à profiter du service à moindre coûts. Vous pouvez continuer à utiliser WhatsApp n'importe où dans le monde entier ou avec n'importe quel Smartphones que vous utilisez. Et vous pouvez toujours compter sur le fait qu'il n'y aura absolument aucune publicité pour venir interrompre votre communication. Il n'y aurait pas eu de partenariat entre nos deux sociétés si nous avions eu à faire des compromis sur nos principes fondamentaux qui font l'identité de notre entreprise, notre vision et notre produit.
Et en effet, WhatsApp revient ainsi sur sa parole et décide de partager vos données personnelles avec Facebook dès 2016 :
Mais en coordonnant davantage avec Facebook, nous pourrons faire des choses telles que suivre des mesures de base sur la fréquence d'utilisation de nos services des gens et améliorer la lutte contre les spams sur WhatsApp. Et en connectant votre numéro de téléphone avec les systèmes de Facebook, ce dernier peut vous offrir de meilleures suggestions d'amis et vous montrer des publicités plus pertinentes si vous avez un compte Facebook. Par exemple, vous pouvez voir une publicité d'une entreprise avec laquelle vous avez déjà travaillé au lieu de voir celle d'une entreprise dont vous n'avez jamais entendu parler.
Afin de mieux comprendre la portée de cette modification, il convient de s'extraire de la communication de WhatsApp. L'EFF détaille les données dorénavant partagées avec Facebook : numéro de téléphone, carnet d'adresses et données d'utilisation (quand vous utilisez WhatsApp, avec qui vous communiquez, sur quel appareil, votre adresse IP, etc). Ces métadonnées sont extrêmement précieuses pour Facebook, qui même s'il n'a pas accès au contenu de vos conversations WhatsApp (chiffrées de bout en bout), récolte les informations les plus importantes.
À l'époque, WhatsApp laisse un opt-out de seulement 30 jours aux utilisateurs existants (via ce "Dark Pattern"). Les nouveaux utilisateurs n'auront pas ce choix. Et encore, l'opt-out ne permet pas d'arrêter le partage d'informations, seulement d'empêcher Facebook d'utiliser vos informations WhatsApp pour de la publicité ciblée ou l'amélioration de ses produits (suggestion d'amis). Relisons l'EFF à ce propos :
Note that your WhatsApp information will still be passed to Facebook for other purposes such as “improving infrastructure and delivery systems, understanding how [Facebook and WhatsApp] services...are used, securing systems, and fighting spam, abuse, or infringement activities." Changing your settings does ensure, however, that Facebook will not use your WhatsApp data to suggest friends or serve ads.
En Europe, ce partage de données passe mal. L'Allemagne refuse le partage de données, puis les CNIL européennes demandent "instamment" d'arrêter le partage des données personnelles. La CNIL du Royaume-Uni demande ensuite la mise en pause de la synchronisation des données. Enfin la CNIL met en demeure WhatsApp de ne plus transmettre à Facebook les données de business intelligence de WhatsApp. Entre-temps, la Commission Européenne affirme que Facebook a fourni des informations trompeuses lors du rachat de WhatsApp et lui inflige une amende de 110 millions d'euros :
Facebook a indiqué à la Commission qu'elle ne serait pas en mesure d'associer automatiquement et de manière fiable les comptes d'utilisateur des deux sociétés
Ces épisodes sont très bien résumés dans le billet du blog de Killian Kemps, "WhatsApp transfère-t-elle des données à Facebook ?". Ce billet pose une question simple : WhatsApp a-t-il réellement stoppé le partage de vos données personnelles avec Facebook suite à ces plaintes dans l'Union Européenne ? Malheureusement non, même si la réponse n'est pas facile à trouver.
Voici ce que dit la politique de confidentialité de WhatsApp pour les résidents de l'Union Européenne (mise à jour en avril 2018) :
Comment nous travaillons avec d'autres entités Facebook
Nous faisons partie des entités Facebook. En tant que membre des entités Facebook, WhatsApp reçoit des informations des entités Facebook et leur transmet également des informations. Nous pouvons utiliser les informations qu’elles nous envoient, et elles peuvent utiliser celles que nous leur transmettons, afin de nous aider à exploiter, fournir, améliorer, comprendre, personnaliser, prendre en charge et commercialiser nos Services et leurs offres [...].
En approfondissant la question via l'article "Comment nous travaillons avec les entités Facebook", on comprend que les échanges de données personnelles entre WhatsApp et Facebook sont très nombreux. Un point cependant, sans l'action de la Commission Européenne, Facebook irait encore plus loin dans le traitement de vos données personnelles :
Nous ne partageons pas de données afin d'améliorer les produits Facebook sur la plateforme et d'offrir de meilleures expériences publicitaires sur Facebook.
Aujourd'hui, Facebook n'utilise pas les informations de votre compte WhatsApp pour améliorer votre expérience avec les produits Facebook ni pour vous proposer des publicités Facebook plus ciblées sur sa plateforme. Ceci est le résultat de discussions avec le commissaire irlandais chargé de la protection des données et d'autres autorités responsables de la protection des données en Europe. Nous cherchons constamment de nouvelles manières d'améliorer votre expérience avec WhatsApp et les Produits des entités Facebook que vous utilisez. Si, à l'avenir, nous décidons de partager de telles données avec les Entités Facebook à cette fin, nous conclurons d'abord un accord avec le commissaire irlandais chargé de la protection des données afin d'établir un mécanisme qui permette une telle utilisation. Nous vous informerons des nouvelles expériences mises à votre disposition et de nos pratiques concernant l'utilisation de vos données.
Et en effet, si vous n'êtes pas un résidant de l'Union Européenne, Facebook ne se prive de rien :
Facebook et les autres entités de la famille Facebook peuvent également utiliser des informations que nous avons fournies pour améliorer vos expériences au sein de leurs services, comme faire des suggestions de produit (par exemple d’amis, de connexions ou de contenus intéressants) et afficher des offres et des publicités pertinentes.
Depuis début janvier, la dernière mise à jour des conditions d'utilisation de WhatsApp passe mal. La date de mise en application des nouvelles conditions d'utilisation est repoussée : initialement prévue le 8 février, elle aura lieu le 15 mai, le temps pour WhatsApp d'affiner sa communication.
Si le partage de vos données personnelles avec Facebook était déjà effectif depuis presque 5 ans, cette mise à jour va permettre à Facebook d'aller plus loin :
- Partage de vos données transactionnelles WhatsApp avec les "Facebook Shops".
- Partage de vos communications avec les entreprises, via un service d'hébergement des communications proposé par Facebook.
Ce service d'hébergement est une première brèche du chiffrement de bout en bout car ces communications ne seront pas chiffrées chez l'hébergeur (un des 2 "bouts" du chiffrement). Voici comment WhatsApp noie le poisson :
WhatsApp considère les discussions avec les entreprises utilisant l’application WhatsApp Business ou gérant et stockant elles-mêmes les messages des clients comme chiffrées de bout en bout. Une fois le message reçu, il sera sujet aux propres pratiques de l’entreprise en matière de confidentialité. L’entreprise peut permettre à un certain nombre d’employés, voire d’autres prestataires, de traiter le message et y répondre.
Certaines entreprises pourront choisir de stocker les messages des clients et y répondre de façon sécurisée à travers la société mère de WhatsApp, Facebook. Vous pouvez toujours contacter les entreprises pour en savoir plus sur leurs pratiques en matière de confidentialité.
Par facilité, la grande majorité des sociétés choisira sans doute la solution d'hébergement de Facebook. Le contenu de vos discussions avec les entreprises sera donc visible de "l'hébergeur" Facebook et soumis à ses pratiques en matière de confidentialité.
Dernier argument en faveur de WhatsApp donc (notamment si l'on compare à Telegram), vos messages personnels restent protégés par le chiffrement de bout en bout, par défaut :
La confidentialité et la sécurité de vos messages et appels personnels ne changent pas. Ils sont protégés par le chiffrement de bout en bout et ni WhatsApp ni Facebook ne peuvent les lire ou les écouter. Nous n'affaiblirons jamais cette sécurité et nous faisons apparaître cette information dans chaque discussion afin que vous puissiez être au fait de notre engagement.
À noter que WhatsApp utilise le protocole open source de Signal pour le chiffrement des messages, un point fort :
Chaque message WhatsApp est protégé par le même protocole de chiffrement de Signal, sécurisant les messages avant qu’ils ne quittent votre appareil.
Mais pour le reste de vos données personnelles, c'est open bar. Comment WhatsApp a-t-il pu à ce point trahir ses utilisateurs ? Pour une histoire détaillée des compromissions (et résistances) de WhatsApp face à sa maison mère, lisez l'excellent article de Forbes "Exclusive: WhatsApp Cofounder Brian Acton Gives The Inside Story On #DeleteFacebook And Why He Left $850 Million Behind". Le co-fondateur de WhatsApp y déclare notamment :
I sold my users’ privacy to a larger benefit. I made a choice and a compromise. And I live with that every day.
Brian Acton a quitté WhatsApp en septembre 2017 (et son compère Jan Koum en avril 2018). Aujourd'hui, il est à la tête de la Signal Foundation, lancée en février 2018 avec un financement initial de 50 millions de dollars d'Acton. Il a également un rôle opérationnel important chez Signal.
Facebook a depuis dégouté les cofondateurs d'Instagram, Kevin Systrom et Mike Krieger, pour une histoire de jalousie (Instagram est à la mode, plus Facebook) et de croissance à tout prix (dégrader l'application Instagram pour mettre en avant l'application Facebook).
Une fin heureuse ?
On le voit donc, WhatsApp suit le modèle de sa maison mère : il s'est imposé en étant plus respectueux de la vie privée que ses concurrents. Racheté par Facebook et en position dominante, il trahit votre confiance en érodant progressivement votre vie privée.
Va-t-il s'en tirer à bon compte ? Cela dépendra de nos actions collectives. Pour ma part, la tâche est encore plus ardue qu'avec Facebook et Instagram (comptes que j'avais pu fermer il y a quelque temps déjà). J'ai pu migrer quelques conversations et groupes sur Signal, mais je vais devoir convaincre beaucoup de personnes avant d'espérer fermer mon compte WhatsApp.
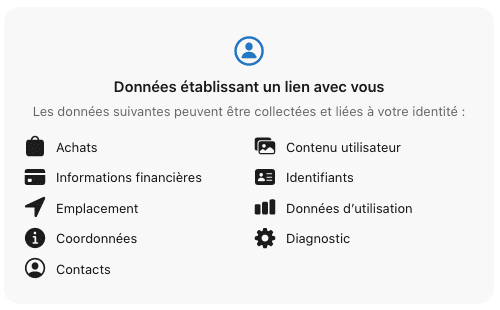
Confidentialité de WhatsApp sur l'App Store.
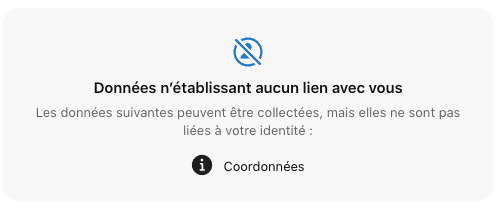
Confidentialité de Signal sur l'App Store.
Néanmoins, il est permis d'être optimiste sur le long terme. À la différence de Facebook ou d'Instagram qui n'ont aujourd'hui pas de vrais concurrents, les messageries Telegram et Signal vont donner du fil à retordre à WhatsApp. Et la vague d'installation actuelle de Signal fait plaisir à voir.
Un tweet d'Elon Musk ne peut jamais faire de mal.
On a connu pire comme sponsor.
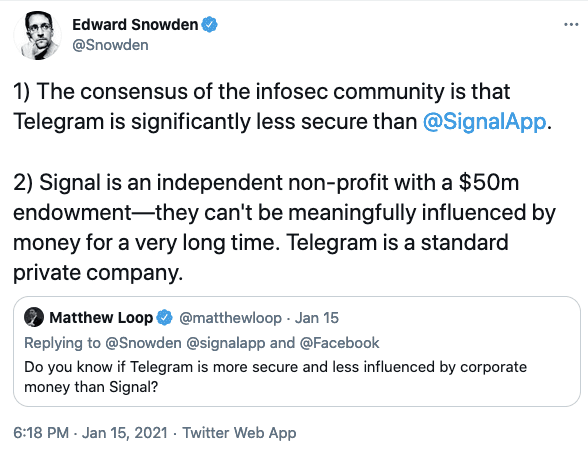
Texte intégral (6033 mots)
Le pire du capitalisme de surveillance
Je n'avais encore jamais écrit sur Facebook, et pourtant cette société représente ce qui se fait de pire dans le domaine de la surveillance publicitaire. Les conséquences de sa domination sont graves :
- Addictions : Les équipes produit de Facebook ont pour objectif ultime de faire croître l'engagement. Plus vous passez de temps sur ses applications (Facebook, Instagram, Messenger, WhatsApp), mieux vous serez "monétisé".
- Radicalisation : Les contenus extrêmes font réagir, ils favorisent l'engagement sur la plateforme. En conséquence, les algorithmes de Facebook mettent en avant les contenus extrêmes et la désinformation. Facebook est une chance pour les complotistes, les fanatiques et l'extrême droite, ce qui met en danger la démocratie dans de nombreux pays.
- Censures : Facebook et Instagram sont quasi incontournables pour qui souhaite informer ou alerter. Mais les règles de modération sont arbitraires et les recours compliqués. Les modérateurs manquent dans certains pays, ne comprennent pas bien les subtilités culturelles. De nombreux membres de la société civile et activistes se voient censurés.
- Traumatismes pour les modérateurs : ceux-ci sont des contractuels, peu considérés et mal payés, confrontés à des horreurs au quotidien. Ils restent souvent traumatisés pour longtemps.
- Une société digne de 1984 : avec son compère Google, Facebook a un rôle fondateur dans l'installation de la surveillance généralisée dans nos sociétés, mettant à mal la démocratie.
Le très provocant mais honnête mémo 'The Ugly", écrit en 2016 par un des dirigeants de Facebook, résume bien la culture d'entreprise : "Growth at any cost". Voici un extrait :
So we connect more people That can be bad if they make it negative. Maybe it costs a life by exposing someone to bullies. Maybe someone dies in a terrorist attack coordinated on our tools. And still we connect people.
The ugly truth is that we believe in connecting people so deeply that anything that allows us to connect more people more often is de facto good. It is perhaps the only area where the metrics do tell the true story as far as we are concerned.
Et au cœur du modèle de Facebook, on retrouve l'exploitation abusive de vos données personnelles. Le mépris de Facebook pour la vie privée de ses utilisateurs est largement documenté sur le web aujourd'hui. Mais il est rare d'y trouver une histoire retraçant l'érosion de votre vie privée par Facebook, mise en parallèle avec l'état de la concurrence.
Dina Srinivasan est une chercheuse travaillant sur ces sujets, à l'intersection de l'"antitrust" et de la "privacy", j'avais déjà eu l'occasion de parler de son travail dans l'article "La domination des marchés publicitaires de Google". Je vais ici partir de sa thèse "The Antitrust Case Against Facebook" pour décrire comment Facebook a pu imposer sa surveillance publicitaire sur le web et les applications, en dépit d'une préférence marquée des utilisateurs pour un respect de leur vie privée.
Aux origines, le respect de la vie privée était une force de Facebook
Il est difficile de s'en souvenir aujourd'hui, mais initialement le marché des réseaux sociaux était très compétitif. En 2006, le réseau social le plus utilisé était MySpace. Mais Facebook se trouvait aussi face à de nombreux autres réseaux sociaux comme Bebo, Hi5, Friendster ou Orkut (propriété de Google). Comment se différencier dans un marché concurrentiel où le produit est "gratuit" ? Par la qualité, et le niveau de protection de la vie privée est rapidement devenu un point important de différenciation.
En 2006 donc, MySpace était le leader. Mais il était très décrié dans les médias, mis en accusation de favoriser les harcèlements sexuels, suicides ou meurtres (quelques articles de l'époque ici, là ou encore là). La raison ? L'ouverture trop grande de la communication sur MySpace, et le peu de considérations pour la vie privée de ses utilisateurs.
Facebook avait donc un boulevard pour se différencier, ce qu'il a fait :
- MySpace était ouvert à tout le monde, Facebook était initialement réservé aux étudiants, pouvant justifier d'une adresse e-mail universitaire (en ".edu").
- Par défaut, les profils utilisateurs de MySpace étaient ouverts à tout le monde. Aux débuts de Facebook, seuls les amis et les étudiants d'une même université pouvaient consulter leurs profils respectifs.
- Facebook a rapidement donné beaucoup de contrôle à ses utilisateurs, ce que ne permettait pas MySpace : choix de l'ouverture ou de la fermeture de son profil aux amis, amis d'amis, étudiants de la même université. Mais aussi la possibilité d'être visible ou non sur son moteur de recherche, ainsi que des contrôles granulaires sur les informations de contact comme le numéro de téléphone.
Aussi, Facebook a très rapidement embauché un responsable de la vie privée. Sa politique de confidentialité était courte et très claire, avec seulement 950 mots. On peut notamment y lire :
Use of Cookies
A cookie is a piece of data stored on the user's computer tied to information about the user. We use session ID cookies to confirm that users are logged in. These cookies terminate once the users close the browser. We do not and will not use cookies to collect private information from any user.
La logique de réseau privé, le contrôle donné aux utilisateurs ainsi que la courte politique de confidentialité ont été des éléments différenciants par rapport à d'autres réseaux sociaux tels que MySpace. Même si d'autres facteurs ont pu jouer (solide socle technique, élitisme initial, interface utilisateur plus épurée, etc), le meilleur respect de la vie privée a joué un rôle central dans le développement de Facebook.
Beacon, la première tentative (ratée) de surveillance du web
En 2007, Facebook devient le nouveau réseau social à la mode (et j'ouvre mon compte). En novembre, il lance Beacon, une initiative transparente de surveillance publicitaire en dehors de Facebook. Au lancement, le New York Times est l'un des partenaires. Si je lis un article du New York Times, Facebook me propose alors via une pop-up de partager ma lecture à mes amis. Facebook Beacon permet aussi de partager ses achats, la musique écoutée, les films regardés, etc :
Facebook Beacon vous surveille, mais vous êtes informé.
La présence de ces nouveaux traceurs de Facebook lui permet de surveiller le comportement des utilisateurs sur des sites tiers (via un cookie), même si ceux-ci déclinent le partage de leurs activités. Devant le tollé provoqué par Beacon, Facebook se défend pourtant de surveiller les utilisateurs lorsque ceux-ci refusent le partage. Voici un extrait de l'interview du vice président Marketing & Opérations de l'époque au New York Times :
Q. If I buy tickets on Fandango, and decline to publish the purchase to my friends on Facebook, does Facebook still receive the information about my purchase?
A. “Absolutely not. One of the things we are still trying to do is dispel a lot of misinformation that is being propagated unnecessarily.”
Déclaration évidemment démentie quelques heures plus tard par un chercheur. Avec les traceurs Beacon, Facebook surveille aussi les utilisateurs qui se sont déconnectés, ainsi que les personnes qui n'ont pas de compte Facebook. C'est une première violation de la vie privée pour Facebook, en contradiction avec sa politique de confidentialité qui indique alors uniquement utiliser les cookies "to confirm that users are logged in", et "these cookies terminate once the users close the browser".
Rapidement, Facebook est confronté à de nombreuses protestations, des pétitions et même des procès. Plusieurs participants au programme Beacon décident de se retirer. Les autres réseaux sociaux profitent également de ce scandale pour critiquer Facebook et améliorer la gestion de la vie privée sur leurs plateformes. Début décembre 2007, Mark Zuckerberg s'excuse (pour un historique des excuses de Zuckerberg, voici un bon article) et annonce une option d'Opt-out. L'option cachée dans les paramètres ne répondant toujours pas aux exigences des utilisateurs, Facebook fermera Beacon moins d'1 an après.
Ce retrait rapide est la preuve d'un marché encore compétitif. Facebook est sous pression de réseaux sociaux concurrents. Aussi, afin de restaurer une confiance déjà trahie, Facebook annonce en 2009 que tout changement à la politique de confidentialité sera désormais soumis à un vote.
Le bouton Like, un cheval de Troie idéal
Facebook a de la suite dans ses idées, il apprend de ses erreurs et en avril 2010, il introduit le bouton Like lors de sa conférence annuelle pour les développeurs. Pour les éditeurs, c'est une opportunité de profiter d'une distribution facile de leurs articles sur Facebook, et donc d'attirer de nouveaux lecteurs. Et rapidement c'est un succès : dès les premières semaines, plus de 50,000 sites installent le bouton like, dont des éditeurs célèbres tels que CNN, le New York Times, The Wall Street Journal ou Slate.
Mais comme avec Beacon, le bouton Like communique avec les serveurs de Facebook pour s'afficher sur votre écran. Facebook peut ainsi surveiller votre navigation, de nouveau en contradiction avec sa politique de confidentialité. CNET cite ainsi la FAQ de l'époque :
No data is shared about you when you see a social plug-in on an external website.
À la différence de Beacon, Facebook indique que ce produit ne sera pas utilisé dans un but de surveillance commerciale. 2 raisons :
- Facebook se souvient encore du scandale Beacon, et souhaite éviter un nouveau scandale.
- Il doit convaincre les éditeurs, des concurrents sur le marché publicitaire, d'installer ces boutons Like. Théoriquement, il pourrait ainsi revendre moins cher aux annonceurs l'audience du Wall Street Journal, directement sur Facebook.
Un chercheur a pu détailler la fuite des données personnelles via le bouton Like (Facebook Tracks and Traces Everyone: Like This!) dès novembre 2010. Via des cookies qu'il installe même si vous ne cliquez pas sur le bouton Like, le réseau social récupère votre identité, l'URL de la page consultée ainsi que le titre de l'article ou le nom du produit. Là également, la surveillance a lieu même si vous n'avez pas de compte Facebook. Mais à la différence de Beacon, pas de pop-up Facebook vous demandant de partager l'article que vous lisez ou l'achat que vous venez d'effectuer : la surveillance est maintenant invisible.
Comment Facebook réagit-il face à ces nouvelles révélations ? Le directeur technique de l'époque déclare que ces cookies ne sont pas utilisés par Facebook pour surveiller les utilisateurs mais pour protéger les comptes utilisateurs de cyber attaques. Concernant la surveillance des utilisateurs n'ayant pas de compte, il s'agirait là d'un bug qui aurait été corrigé depuis (faux). Le Wall Street Journal indique dans son enquête de mai 2011 que les boutons Like permettaient de vous surveiller sur plus d'un tiers des 1000 sites web les plus visités au monde, et sur plus d'un million de sites web. Devant de tels chiffres, on commence à prendre conscience de l'ampleur de la surveillance généralisée.
En septembre 2011, Facebook est accusé de continuer de surveiller les utilisateurs même après leur déconnexion. Facebook devrait supprimer les cookies lorsqu'un utilisateur se déconnecte et notamment l'identifiant utilisateur, il ne le fait pas, et tente de tromper son auditoire :
Facebook does not track users across the web. Instead, we use cookies on social plugins to personalize content (e.g. show you what your friends liked), to help maintain and improve what we do (e.g. measure click-through rate), or for safety and security (e.g. keeping underage kids from trying to sign up with a different age). No information we receive when you see a social plugin is used to target ads, we delete or anonymize this information within 90 days, and we never sell your information.
Specific to logged-out cookies, they are used for safety and protection, including identifying spammers and phishers, detecting when somebody unauthorized is trying to access your account, helping you get back into your account if you get hacked, disabling registration for underage people who try to re-register with a different birth date, powering account security features such as second factor login approvals and notification, and identifying shared computers to discourage the use of “Keep me logged in.”
Si l'on réfléchit à la meilleure manière pour Facebook d'imposer son capitalisme de surveillance, il lui faut d'abord parvenir à convaincre les éditeurs d'installer ses traceurs. La transparence n'ayant pas réussi (Beacon était présenté comme un outil commercial), Facebook a préféré opérer de manière déguisée (déclarer que le bouton Like ne serait pas utilisé pour de la surveillance publicitaire).
En décembre 2012, le Wall Street Journal revient sur son enquête pour indiquer que les boutons Like se retrouvent maintenant sur 2/3 des sites du top 1000, Facebook répond encore qu'il utilise les informations des boutons Like uniquement pour la sécurité et pour corriger les bugs. Mais la malhonnêteté est bien là. En février 2011, Facebook a déposé un brevet pour surveiller les utilisateurs en dehors de son propre site et proposer de la publicité ciblée basée sur ces profils :
The present disclosure relates generally to social network systems and other websites in which users can form connections with other users, and in particular, to tracking activities of users of social network systems on other domains to, for example, analyze, target, or gauge the effectiveness of advertisements (ads) rendered in conjunction with social network systems.
Avant d'utiliser la collecte de données des boutons Like pour la surveillance publicitaire, Facebook devait encore se débarrasser d'un dernier obstacle : le fait que tout changement de politique de confidentialité devait être soumis à un vote. Voici comment Facebook a procédé :
- Fin 2012, avec plus d'un milliard d'utilisateurs et une entrée en bourse réussie, Facebook propose un vote sur la suppression des futurs référendums concernant sa politique de confidentialité.
- 88% des utilisateurs ont voté contre, mais Facebook arguant du fait que seuls 589,000 personnes avaient voté (une clause indiquait qu'à minima, 30% des utilisateurs devaient voter), il pouvait s'asseoir sur la volonté des participants et abolir les référendums.
De nombreux utilisateurs se sont ensuite plaints de ne pas avoir été informés de ce vote, n'ayant reçu aucune notification ou aucun e-mail. Facebook ne voulait clairement pas que vous votiez.
En juin 2014, Facebook décide d'activer la surveillance publicitaire basée sur les boutons Like (et tous les autres plugins qu'il fournit aux éditeurs : Facebook Login, le pixel Facebook, le SDK pour les applications, etc). Le titre de l'article annonçant la mise à jour est un modèle de novlangue : Making Ads Better and Giving People More Control Over the Ads They See.
Après avoir passé 7 ans à promettre de ne pas exploiter les données collectées par ses plugins pour de la surveillance publicitaire, Facebook renie ses promesses. Pourquoi ? La concurrence a été écrasée (MySpace et Orkut ont fermés, Google+ s'est avéré être un échec) et même si la qualité de Facebook est grandement dégradée par cette atteinte massive à leur vie privée, les utilisateurs n'ont plus d'alternatives viables. Facebook peut maintenant sur-exploiter vos données personnelles pour son plus grand bénéfice.
En 2018, même le cofondateur de WhatsApp conseille de supprimer Facebook.
Avec WhatsApp, Facebook reproduit la même stratégie
WhatsApp est créé en 2009 et très vite, la protection de la vie privée est un axe fort de l'application :
So first of all, let's set the record straight. We have not, we do not and we will not ever sell your personal information to anyone. Period. End of story. Hopefully this clears things up.
En 2012, lorsque le co-fondateur de WhatsApp Jan Koum écrit le billet "Pourquoi nous ne vendons pas de pub", le discours sur la publicité est fort :
La publicité n'est pas seulement une gêne esthétique, une insulte à votre intelligence et une interruption de votre fil de pensées. Dans chaque entreprise vendant de la publicité, une importante partie de leur équipe d'ingénieurs passent leurs journées à affiner l'exploration de données, améliorer le code pour collecter toutes vos données personnelles, améliorer les serveurs qui contiennent toutes les données et s'assurer que tout est bien enregistré, rassemblé, découpé, emballé et envoyé... Au final, le résultat de tout cela est une bannière de publicité légèrement différente dans votre navigateur ou écran de téléphone mobile.
Voici un autre passage du même billet, traitant du recueil de données personnelles :
À WhatsApp, nos ingénieurs passent tout leur temps à réparer des bugs, ajouter de nouvelles fonctionnalités et passer le tout au peigne fin pour offrir une messagerie riche, abordable et fiable pour tous les téléphones dans le monde entier. C'est notre produit et notre passion. Vos données n'entrent même pas en jeu. Cela ne nous intéresse tout simplement pas.
À l'époque, WhatsApp avait une très bonne réputation. L'application était en effet appréciée pour sa simplicité, sa fiabilité, mais aussi pour son positionnement sur la publicité et les données personnelles. Comme avec Facebook à ses débuts, la protection de la vie privée est un avantage compétitif pour WhatsApp, qui lui permet de gagner des parts de marché (sur Facebook Messenger ou Google Hangouts par exemple).
Seulement voilà, en 2014 WhatsApp vend son application à Facebook pour 22 milliards de dollars. Vu l'historique de Facebook, on peut déjà craindre le pire. Jan Koum écrit pourtant sur le blog de WhatsApp :
Voici ce qui va changer pour vous, nos utilisateurs : rien.
WhatsApp restera autonome et fonctionnera indépendamment. Vous pouvez continuer à profiter du service à moindre coûts. Vous pouvez continuer à utiliser WhatsApp n'importe où dans le monde entier ou avec n'importe quel Smartphones que vous utilisez. Et vous pouvez toujours compter sur le fait qu'il n'y aura absolument aucune publicité pour venir interrompre votre communication. Il n'y aurait pas eu de partenariat entre nos deux sociétés si nous avions eu à faire des compromis sur nos principes fondamentaux qui font l'identité de notre entreprise, notre vision et notre produit.
Et en effet, WhatsApp revient ainsi sur sa parole et décide de partager vos données personnelles avec Facebook dès 2016 :
Mais en coordonnant davantage avec Facebook, nous pourrons faire des choses telles que suivre des mesures de base sur la fréquence d'utilisation de nos services des gens et améliorer la lutte contre les spams sur WhatsApp. Et en connectant votre numéro de téléphone avec les systèmes de Facebook, ce dernier peut vous offrir de meilleures suggestions d'amis et vous montrer des publicités plus pertinentes si vous avez un compte Facebook. Par exemple, vous pouvez voir une publicité d'une entreprise avec laquelle vous avez déjà travaillé au lieu de voir celle d'une entreprise dont vous n'avez jamais entendu parler.
Afin de mieux comprendre la portée de cette modification, il convient de s'extraire de la communication de WhatsApp. L'EFF détaille les données dorénavant partagées avec Facebook : numéro de téléphone, carnet d'adresses et données d'utilisation (quand vous utilisez WhatsApp, avec qui vous communiquez, sur quel appareil, votre adresse IP, etc). Ces métadonnées sont extrêmement précieuses pour Facebook, qui même s'il n'a pas accès au contenu de vos conversations WhatsApp (chiffrées de bout en bout), récolte les informations les plus importantes.
À l'époque, WhatsApp laisse un opt-out de seulement 30 jours aux utilisateurs existants (via ce "Dark Pattern"). Les nouveaux utilisateurs n'auront pas ce choix. Et encore, l'opt-out ne permet pas d'arrêter le partage d'informations, seulement d'empêcher Facebook d'utiliser vos informations WhatsApp pour de la publicité ciblée ou l'amélioration de ses produits (suggestion d'amis). Relisons l'EFF à ce propos :
Note that your WhatsApp information will still be passed to Facebook for other purposes such as “improving infrastructure and delivery systems, understanding how [Facebook and WhatsApp] services...are used, securing systems, and fighting spam, abuse, or infringement activities." Changing your settings does ensure, however, that Facebook will not use your WhatsApp data to suggest friends or serve ads.
En Europe, ce partage de données passe mal. L'Allemagne refuse le partage de données, puis les CNIL européennes demandent "instamment" d'arrêter le partage des données personnelles. La CNIL du Royaume-Uni demande ensuite la mise en pause de la synchronisation des données. Enfin la CNIL met en demeure WhatsApp de ne plus transmettre à Facebook les données de business intelligence de WhatsApp. Entre-temps, la Commission Européenne affirme que Facebook a fourni des informations trompeuses lors du rachat de WhatsApp et lui inflige une amende de 110 millions d'euros :
Facebook a indiqué à la Commission qu'elle ne serait pas en mesure d'associer automatiquement et de manière fiable les comptes d'utilisateur des deux sociétés
Ces épisodes sont très bien résumés dans le billet du blog de Killian Kemps, "WhatsApp transfère-t-elle des données à Facebook ?". Ce billet pose une question simple : WhatsApp a-t-il réellement stoppé le partage de vos données personnelles avec Facebook suite à ces plaintes dans l'Union Européenne ? Malheureusement non, même si la réponse n'est pas facile à trouver.
Voici ce que dit la politique de confidentialité de WhatsApp pour les résidents de l'Union Européenne (mise à jour en avril 2018) :
Comment nous travaillons avec d'autres entités Facebook
Nous faisons partie des entités Facebook. En tant que membre des entités Facebook, WhatsApp reçoit des informations des entités Facebook et leur transmet également des informations. Nous pouvons utiliser les informations qu’elles nous envoient, et elles peuvent utiliser celles que nous leur transmettons, afin de nous aider à exploiter, fournir, améliorer, comprendre, personnaliser, prendre en charge et commercialiser nos Services et leurs offres [...].
En approfondissant la question via l'article "Comment nous travaillons avec les entités Facebook", on comprend que les échanges de données personnelles entre WhatsApp et Facebook sont très nombreux. Un point cependant, sans l'action de la Commission Européenne, Facebook irait encore plus loin dans le traitement de vos données personnelles :
Nous ne partageons pas de données afin d'améliorer les produits Facebook sur la plateforme et d'offrir de meilleures expériences publicitaires sur Facebook.
Aujourd'hui, Facebook n'utilise pas les informations de votre compte WhatsApp pour améliorer votre expérience avec les produits Facebook ni pour vous proposer des publicités Facebook plus ciblées sur sa plateforme. Ceci est le résultat de discussions avec le commissaire irlandais chargé de la protection des données et d'autres autorités responsables de la protection des données en Europe. Nous cherchons constamment de nouvelles manières d'améliorer votre expérience avec WhatsApp et les Produits des entités Facebook que vous utilisez. Si, à l'avenir, nous décidons de partager de telles données avec les Entités Facebook à cette fin, nous conclurons d'abord un accord avec le commissaire irlandais chargé de la protection des données afin d'établir un mécanisme qui permette une telle utilisation. Nous vous informerons des nouvelles expériences mises à votre disposition et de nos pratiques concernant l'utilisation de vos données.
Et en effet, si vous n'êtes pas un résidant de l'Union Européenne, Facebook ne se prive de rien :
Facebook et les autres entités de la famille Facebook peuvent également utiliser des informations que nous avons fournies pour améliorer vos expériences au sein de leurs services, comme faire des suggestions de produit (par exemple d’amis, de connexions ou de contenus intéressants) et afficher des offres et des publicités pertinentes.
Depuis début janvier, la dernière mise à jour des conditions d'utilisation de WhatsApp passe mal. La date de mise en application des nouvelles conditions d'utilisation est repoussée : initialement prévue le 8 février, elle aura lieu le 15 mai, le temps pour WhatsApp d'affiner sa communication.
Si le partage de vos données personnelles avec Facebook était déjà effectif depuis presque 5 ans, cette mise à jour va permettre à Facebook d'aller plus loin :
- Partage de vos données transactionnelles WhatsApp avec les "Facebook Shops".
- Partage de vos communications avec les entreprises, via un service d'hébergement des communications proposé par Facebook.
Ce service d'hébergement est une première brèche du chiffrement de bout en bout car ces communications ne seront pas chiffrées chez l'hébergeur (un des 2 "bouts" du chiffrement). Voici comment WhatsApp noie le poisson :
WhatsApp considère les discussions avec les entreprises utilisant l’application WhatsApp Business ou gérant et stockant elles-mêmes les messages des clients comme chiffrées de bout en bout. Une fois le message reçu, il sera sujet aux propres pratiques de l’entreprise en matière de confidentialité. L’entreprise peut permettre à un certain nombre d’employés, voire d’autres prestataires, de traiter le message et y répondre.
Certaines entreprises pourront choisir de stocker les messages des clients et y répondre de façon sécurisée à travers la société mère de WhatsApp, Facebook. Vous pouvez toujours contacter les entreprises pour en savoir plus sur leurs pratiques en matière de confidentialité.
Par facilité, la grande majorité des sociétés choisira sans doute la solution d'hébergement de Facebook. Le contenu de vos discussions avec les entreprises sera donc visible de "l'hébergeur" Facebook et soumis à ses pratiques en matière de confidentialité.
Dernier argument en faveur de WhatsApp donc (notamment si l'on compare à Telegram), vos messages personnels restent protégés par le chiffrement de bout en bout, par défaut :
La confidentialité et la sécurité de vos messages et appels personnels ne changent pas. Ils sont protégés par le chiffrement de bout en bout et ni WhatsApp ni Facebook ne peuvent les lire ou les écouter. Nous n'affaiblirons jamais cette sécurité et nous faisons apparaître cette information dans chaque discussion afin que vous puissiez être au fait de notre engagement.
À noter que WhatsApp utilise le protocole open source de Signal pour le chiffrement des messages, un point fort :
Chaque message WhatsApp est protégé par le même protocole de chiffrement de Signal, sécurisant les messages avant qu’ils ne quittent votre appareil.
Mais pour le reste de vos données personnelles, c'est open bar. Comment WhatsApp a-t-il pu à ce point trahir ses utilisateurs ? Pour une histoire détaillée des compromissions (et résistances) de WhatsApp face à sa maison mère, lisez l'excellent article de Forbes "Exclusive: WhatsApp Cofounder Brian Acton Gives The Inside Story On #DeleteFacebook And Why He Left $850 Million Behind". Le co-fondateur de WhatsApp y déclare notamment :
I sold my users’ privacy to a larger benefit. I made a choice and a compromise. And I live with that every day.
Brian Acton a quitté WhatsApp en septembre 2017 (et son compère Jan Koum en avril 2018). Aujourd'hui, il est à la tête de la Signal Foundation, lancée en février 2018 avec un financement initial de 50 millions de dollars d'Acton. Il a également un rôle opérationnel important chez Signal.
Facebook a depuis dégouté les cofondateurs d'Instagram, Kevin Systrom et Mike Krieger, pour une histoire de jalousie (Instagram est à la mode, plus Facebook) et de croissance à tout prix (dégrader l'application Instagram pour mettre en avant l'application Facebook).
Une fin heureuse ?
On le voit donc, WhatsApp suit le modèle de sa maison mère : il s'est imposé en étant plus respectueux de la vie privée que ses concurrents. Racheté par Facebook et en position dominante, il trahit votre confiance en érodant progressivement votre vie privée.
Va-t-il s'en tirer à bon compte ? Cela dépendra de nos actions collectives. Pour ma part, la tâche est encore plus ardue qu'avec Facebook et Instagram (comptes que j'avais pu fermer il y a quelque temps déjà). J'ai pu migrer quelques conversations et groupes sur Signal, mais je vais devoir convaincre beaucoup de personnes avant d'espérer fermer mon compte WhatsApp.
Confidentialité de WhatsApp sur l'App Store.
Confidentialité de Signal sur l'App Store.
Néanmoins, il est permis d'être optimiste sur le long terme. À la différence de Facebook ou d'Instagram qui n'ont aujourd'hui pas de vrais concurrents, les messageries Telegram et Signal vont donner du fil à retordre à WhatsApp. Et la vague d'installation actuelle de Signal fait plaisir à voir.
Un tweet d'Elon Musk ne peut jamais faire de mal.
On a connu pire comme sponsor.
14.12.2020 à 14:14
Vie privée : le match des navigateurs iOS

Safari, l'inévitable navigateur iOS ?
Pour un navigateur tiers, il est difficile de concurrencer Apple Safari sur iOS :
- À la différence d'Android, iOS ne permet pas aux navigateurs tiers d'utiliser leur propre moteur de rendu. Si l'on lit les "guidelines" de l'App Store, section 2.5.6 : "Apps that browse the web must use the appropriate WebKit framework and WebKit Javascript".
- Apple a longtemps réservé l'usage de la dernière version de Webkit à Safari, les autres navigateurs étaient contraints d'utiliser une version périmée (basée sur la classe
UIWebView), lente et instable. - Toujours en raison de l'obligation d'utiliser WebKit, iOS ne permet pas aux navigateurs tiers de proposer leur propre bibliothèque d'extensions. Sur Android, je peux installer des extensions Firefox comme uBlock Origin.
- Les extensions de Safari telles que les bloqueurs de contenus ne sont pas accessibles aux autres navigateurs.
- Avant iOS 14, il n'était pas possible de changer le navigateur par défaut.
En conséquence, il n'était pas très intéressant d'utiliser un autre navigateur. Néanmoins, Apple évolue progressivement. Depuis iOS 8, les navigateurs tiers peuvent correctement utiliser le dernier moteur de rendu de WebKit. Et depuis iOS 14, Apple permet de changer le navigateur par défaut. Les navigateurs tiers peuvent ainsi mieux concurrencer Safari, notamment sur la protection de votre vie privée.
Quel que soit votre navigateur, vous bénéficiez déjà de la protection WebKit
Les navigateurs tiers ont obligation d'utiliser le moteur de rendu d'Apple, WebKit. Cela se traduit techniquement par l'utilisation de la classe WKWebView. Hors depuis iOS 14, celle-ci inclut par défaut Intelligent Tracking Prevention, le mécanisme de protection de la vie privée d'Apple (préalablement uniquement disponible sur Safari).
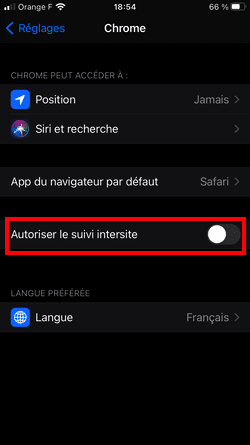
Oui, Chrome sur iOS vous protège contre le suivi intersite, par défaut ! L'obligation d'utiliser WebKit force Google à mieux protéger votre vie privée.
Intelligent Tracking Prevention (ITP) contient de nombreux mécanismes permettant de lutter contre le "suivi intersite", on peut notamment citer :
- Le blocage de tous les cookies tiers (prévu pour 2022 seulement sur Chrome).
- La limitation de la durée de vie des cookies créés via du javascript (cookies 1st party, mais pouvant être créés par des tiers) à 7 jours.
- La limitation de la durée de vie des cookies déposés via des domaines CNAME (là aussi, cookies 1st party, mais pouvant être déposés par des tiers) à 7 jours.
Les protections ITP ne se limitent pas aux cookies, pour une liste exhaustive lisez la page Cookie Status de Safari.
Si ces protections permettent de lutter contre le pire de la publicité (le suivi intersite), elles n'empêchent pas les sociétés marketing de mesurer chacune de vos interactions sur chaque site, ni de diffuser de la publicité. D'autres part, les sociétés marketing continuent de travailler à contourner les restrictions d'Apple (via du Server-Side Tagging, ou des identifiants de tiers déguisés en 1st party par exemple).
Si vous souhaitez être mieux protégé, quelles sont vos options ?
Le navigateur, un premier vecteur de surveillance
Avant même d'analyser les protections des navigateurs contre le pistage lors de votre surf, les navigateurs ont-ils mis en place leur propre système de surveillance ? Pour cela, je vais observer ce qu'il se passe lors du premier lancement du navigateur. À noter qu'une analyse similaire a déjà été effectuée par Brave récemment. Voici les étapes suivi :
- Téléchargement du navigateur à tester.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur, puis recherche dans la barre d'adresse (pas de navigation privée).
- Export de la session Charles sur mon ordinateur pour analyse.
Et voici un récapitulatif des différents navigateurs testés.
Safari, difficile à auditer de manière exhaustive
Safari est pré-installé donc je ne peux simuler un premier lancement. Il n'est pas impossible qu'Apple récupère des données de télémétrie de Safari si vous n'avez pas décoché les différents interrupteurs dans "Réglage" > "Confidentialité" > "Analyse et améliorations" :
J'ai décoché les différents interrupteurs dans "Analyse et améliorations", aussi je n'ai pas vu de traceurs Apple spécifiques à Safari.
Lorsque vous faites une recherche, le moteur de recherche par défaut est Google. Celui-ci verserait 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur tous les appareils Apple. Safari envoie ainsi à Google chaque caractère entré dans la barre de recherche (sans identifiant), pour faire marcher l'auto-complétion.

Côté vie privée, Apple prend de très bonnes initiatives. Mais il permet à Google et son capitalisme de surveillance de prospérer, pour beaucoup d'argent.
DuckDuckGo, le bon élève
Le moteur de recherche américain (en grande partie basé sur Bing) a fait de la vie privée son cheval de bataille, il fait d'ailleurs partie des moteurs de recherche recommandés par PrivacyTools. Il propose également un navigateur pour iOS, et voici les requêtes envoyées lors du premier lancement :

Lorsque l'on regarde dans le détail, c'est très propre : DuckDuckGo télécharge les bloqueurs de contenus. Lorsque vous tapez dans la barre d'adresse, il récupère les caractères pour de l'auto-complétion (avantage de fournir aussi un moteur de recherche), sans identifiant. La télémétrie est activée, mais là aussi sans identifiant.
Seule contrainte : le moteur de recherche par défaut (celui de la barre d'adresse) ne peut évidemment pas être changé. Mais si pour certaines requêtes vous n'êtes pas satisfait (rappel : derrière DuckDuckGo, c'est souvent Bing), vous pouvez utiliser les "bangs", des alias qui permettent de faire une recherche sur un autre moteur de recherche (Google évidemment, mais aussi YouTube, Wikipedia, Twitter, etc).
DuckDuckGo ne manque pas d'humour, voici le message dédié lors de votre première recherche Google (en préfixant votre recherche par !g).
Également très apprécié, la facilité à effacer les données :
Il vous suffit de cliquer sur la flamme pour effacer les données.
Brave vous protège... et fait tourner son business
Le navigateur Brave a été créé par Brendan Eich, ancien cofondateur de Firefox et créateur de Javascript. Brave a un discours fort contre les traceurs et autres publicités non respectueuses de la vie privée. Voici quelques points clés :
- Brave se base sur Chromium (et son moteur de rendu Blink), la partie Open-Source de Google Chrome. Mais sur iOS, il ne peut pas utiliser Chromium, et se voir forcé d'utiliser WebKit.
- Via Brave Shields, il bloque les traceurs et autres publicités qui vous pistent. Si vous l'acceptez, il diffuse des publicités respectueuses de la vie privée (servies en local, ce qui fait de Brave une régie publicitaire). Ce positionnement, en concurrence avec les éditeurs (Brave recrute les annonceurs), suscite des controverses.
- Brave Rewards vous permet de payer les sites que vous consultez de diverses manières : via un abonnement mensuel (par exemple, 10€ partagés avec les sites consultés, selon votre temps passé sur ces sites), via des pourboires (micro paiements) ou via la publicité servie en local par Brave (pour laquelle vous pouvez également être payé). Brave Rewards est basé sur la propre crypto monnaie de Brave : le BAT (ou Basic Attention Token).
UPDATE 15 décembre 2020 : Brave a d'autres controverses à son actif (merci @kinux), et notamment :
- Le financement via des liens d'affiliations vers des sites de crypto-monnaies, pratique arrêtée depuis que l'affaire a été révélée.
- L'inclusion de infogalactic, un Wikipédia d'extrême droite, dans les moteurs de recherche proposés par défaut. La pratique aurait cessé en décembre 2018 d'après ce site.
Brave vous permet au premier lancement de choisir votre moteur de recherche par défaut (et permet à des moteurs de recherche respectueux de la vie privée tels que Qwant, DuckDuckGo ou Startpage de trouver de nouveaux utilisateurs) :

Je sélectionne ici Startpage, un moteur de recherche basé sur Google, mais respectueux de la vie privée.
Vérifions les requêtes avant de cliquer sur "Enregistrer" :
Certaines requêtes ne sont pas lisibles sur l'outil Charles et je n'ai donc pu vérifier si des identifiants fuitaient, néanmoins on peut noter l'appel à sudosecuritygroup.com. Il s'agit en fait de la société Guardian, qui s'est associé à Brave pour fournir un VPN qui bloque aussi les traceurs et les publicités. Vous pourrez activer le VPN dans Brave, mais il faudra payer.
Deuxième étape, Brave vous propose de bloquer les traceurs :
Évidemment j'accepte.
Troisième étape, Brave pense à sa propre régie publicitaire, et vous propose de visualiser des publicités "privées et anonymes" :
Je clique sur Ignorer, l'audit des publicités Brave sera pour une autre fois.
Quatrième étape, je lance une recherche. Brave me demande si je souhaite activer les suggestions de recherche :
Question appréciée, je refuse donc.
Regardons maintenant les requêtes envoyées (depuis le lancement de l'application) :
Si on regarde le détail, Brave n'a pas envoyé de requêtes supplémentaires depuis l'étape 1 excepté vers Startpage, appelé uniquement lorsque je valide ma requête de recherche.
Firefox, quelques mauvaises surprises
Firefox est mon navigateur sur Mac. À la différence d'un Brave, Firefox a son propre moteur de rendu, Gecko. Mais lui aussi se voit contraint d'utiliser WebKit. Je m'attendais à ce que Firefox pour iOS ait une attitude irréprochable sur la vie privée car Firefox ayant une belle réputation et communiquant avantageusement. J'ai été surpris :
Dès la première ouverture, Firefox fuite mes données personnelles à Leanplum, une société marketing permettant d'afficher des messages ciblés. Leanplum est gourmand, il collecte notamment le deviceId, userId et uuid. Il récupère aussi mes principales interactions avec Firefox.
Firefox se permet également de collecter mes principales interactions (comme l'ouverture de l'application, sa fermeture, le clic sur la barre d'adresse) en direct (via incoming.telemetry.mozilla.org), avec l'identifiant clientId.
Pour les appels à Google, pas de surprise, il s'agit du moteur de recherche par défaut sur Firefox. Google représente la principale source de revenus pour Firefox, avec environ 450 millions de dollars par an. Chaque caractère entré dans la barre de recherche est envoyé à Google pour l'auto-complétion (sans identifiant).
Est-il possible de désactiver la fuite des données personnelles vers Leanplum ainsi que la télémétrie ? Oui, en décochant la bonne option dans les paramètres :
Je décoche "Envoyer des données d'utilisation"
On se serait attendu à de l'opt-in de la part de Firefox, et sans fuite de données personnelles vers une société marketing.
Chrome, le navigateur vorace de Google
Si vous utilisez Chrome pour iOS, vous n'avez à priori pas d'attente particulière concernant le respect de votre vie privée. Nous avions par exemple pu voir que Chrome envoie un en-tête HTTP unique à tous les domaines Google et Doubleclick, pratique pour vous pister. Lisez aussi "Why I'm done with Chrome", écrit il y a déjà 2 ans.
Dès l'ouverture de Chrome donc, Google vous informe que vous devez accepter les conditions d'utilisation. Premier problème, l'envoi de statistiques d'utilisation et des rapports d'erreur est coché par défaut :

Je décoche donc l'envoi de statistiques d'utilisation et des rapports d'erreur.
Si je regarde les requêtes passer avant le clic sur "Accepter et continuer", je vois que Chrome appelle déjà beaucoup de sites : pas d'inquiétude, il s'agit en fait de charger les images pour les signets par défaut (j'imagine les sites les plus consultés de France). Chrome récupère aussi des identifiants tels que le userid.
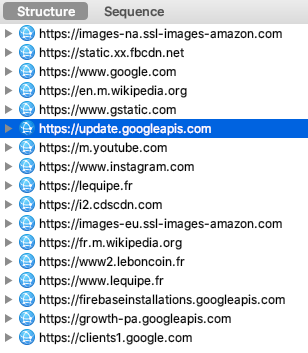
Deuxième étape, Chrome se montre ici très gourmand : il vous demande de synchroniser toute ma navigation avec mon compte Google. Une captation énorme de vos données personnelles donc, que Google enrobe en vous faisant miroiter de pouvoir synchroniser aussi vos mots de passe sur vos différents appareils "et plus encore".
Je clique donc sur "Non, merci".
Si vous souhaitez sélectionner les éléments à synchroniser, le texte "paramètres" en bleu pourrait vous faire croire que vous avez déjà la main, mais il n'est pas cliquable. Notez encore le bouton bleu "J'accepte", très naturel. Comparé à "Non, merci" en noir : un bel exemple de "Dark Pattern".
Troisième étape, Chrome continue sur sa lancée et me demande d'accéder à ma position exacte (pour "Améliorer mon expérience") !
Je clique sur "Ne pas autoriser"
Notez qu'avec iOS, je ne peux maintenant autoriser les accès qu'une seule fois (Chrome devra alors me redemander au lancement suivant), je peux également désactiver "Position exacte". Ces options peuvent être utiles pour vous protéger de certaines applications.
Dernière étape, Chrome est déjà lancé mais je fais une recherche, sur Google évidemment, pour tomber sur un bandeau de consentement venant d'être retoquée par la CNIL :
Le nouveau bandeau d’information mis en œuvre par les sociétés lors de l’arrivée sur la page google.fr ne permettait toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informait pas du fait qu’ils pouvaient refuser ces cookies.
Et en effet, bon courage pour refuser les cookies, vous pouvez vous perdre dans les menus sans trouver l'option, ni même être sûr que l'option choisie permet bien de refuser les cookies (je ne détaille pas, cela mériterait un article dédié).
Ici vous pourriez vous dire : je n'ai pas encore cliqué sur "J'accepte", Google n'a pas dû déposer de cookies. D'autant que si on lit la dernière sanction de la CNIL à l'encontre de Google (daté du 10 décembre 2020), celui-ci se permettait de le faire mais il a corrigé le tir :
La formation restreinte a pris acte que, depuis une mise à jour de septembre 2020, les sociétés cessent de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
Regardons néanmoins les requêtes envoyées (depuis l'étape 2) :
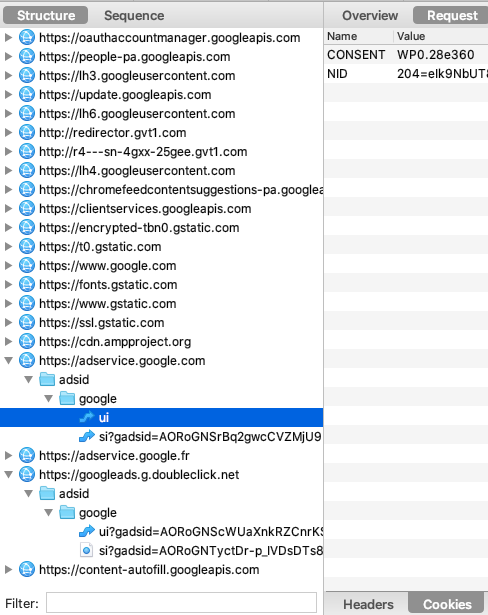
Parmi les nombreuses requêtes envoyées aux différents services de Google, on peut noter les requêtes à adservice.google.com et à doubleclick.net. La requête à adservice.google.com contient bien le cookie NID. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
La CNIL parle-t-elle du cookie NID dans sa délibération ?
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Ainsi, en contradiction avec la délibération de la CNIL, Google n'a pas arrêté de déposer automatiquement certains cookies publicitaires sur la page google.fr.
Edge fait encore pire que Chrome
La réputation des navigateurs Microsoft n'est plus à faire :
Via compte parodique Twitter @intrnetexp.
Seulement voilà, fini les moqueries sur le retard d'Internet Explorer, Microsoft se base maintenant sur Chromium et son moteur de rendu Blink pour son navigateur Edge (tout comme Brave, Opera ou Vivaldi), il investit pour le rendre compétitif. Pour Edge aussi, pas de Chromium sur iOS à cause des restrictions Apple, et donc l'utilisation forcée de WebKit. Qu'en est-il du respect de votre vie privée ?
Le premier lancement de Edge ressemble beaucoup à Chrome, ce qui n'est pas bon signe. Edge vous suggère de vous connecter pour activer la synchronisation : favoris, mots de passe et "bien plus encore".
Je clique sur "Ignorer" (notez le Dark Pattern).
Si l'on regarde les requêtes envoyées avant clic sur "Ignorer", Edge est déjà gourmand :
Via plusieurs requêtes, Edge récupère plusieurs identifiants tels que deviceId ou clientId. Notez notamment le domaine vortex.data.microsoft.com, si bien nommé. À chaque interaction avec Edge, celui-ci va collecter de la donnée, et cette fuite est impossible à désactiver.
Comme Firefox, Edge fuite aussi vos données personnelles vers un tiers, Adjust, société spécialisée dans la mesure mobile et l'attribution. Adjust récupère des identifiants tels que persistent_ios_uuid.
Deuxième étape, Edge est toujours aussi gourmand que Chrome, il cherche à enregistrer mon historique de navigation :

Je clique sur "Pas maintenant".
Troisième étape, on comprend pas tout à fait la différence avec l'étape précédente ("En savoir plus" redirige toujours vers la page "Historique d'activités Windows 10 et confidentialité"), Edge insiste en vous demandant des données sur "la façon dont vous utilisez le navigateur" :

Je clique encore sur "Pas maintenant".
Quatrième étape, je fais une recherche (sur Bing évidemment), notez le bandeau de consentement :
Vérifions les requêtes (je n'ai pas encore interagi avec le bandeau de consentement) :
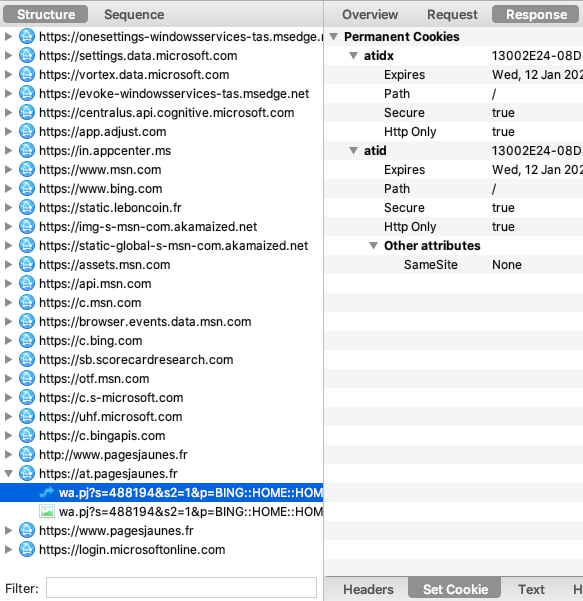
Les services Microsoft sont omniprésents, tous récupèrent vos données personnelles. Leboncoin est appelé mais simplement pour télécharger le logo. Edge ne fuite pas seulement vos données personnelles vers Adjust mais aussi vers Comscore (via scorecardresearch.com), géant du marketing qui peut ainsi mieux vous profiler.
Bonus : Bing fuite vos recherches au site Pages Jaunes
À cause de Bing (et non de Edge), j'ai été surpris (et alarmé) de voir que celui-ci fuite une donnée potentiellement sensible, ma requête, directement à Pages Jaunes (via pagesjaunes.fr) :
Heureusement ma recherche "bonjour" n'était pas sensible, mais Bing fuite l'intégralité de vos recherches au site Pages Jaunes (ainsi que votre ville), en temps réel, quelque soit l'appareil et le navigateur utilisé.
La régie publicitaire de Pages Jaunes s'appelle Solocal. Il s'agit d'un partenariat ancien, ayant surement été reconduit, sur le dos de votre vie privée (rappel, je n'ai toujours pas interagi avec le bandeau de consentement, ma recherche Bing a fuité vers le site Pages Jaunes).
Cadeau supplémentaire de Bing et Pages Jaunes, le domaine at.pagesjaunes.fr (qui dépose un cookie sans votre consentement) est un alias CNAME vers l'outils d'analytics français AT Internet :
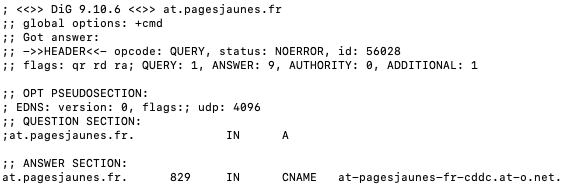
Comme on a déjà pu le voir avec Criteo, Boursorama ou Lemonde.fr, ces alias CNAME ont pour but de contourner les protections navigateurs et adblockers, ils sont également souvent à l'origine d'une faille de sécurité importante.
Cliquer sur "Plus d'options" pour ensuite désactiver les cookies "non essentiels" empêche-t-il de fuiter vos requêtes vers les pages jaunes et vos données de surf vers AT Internet ?
Le bandeau de consentement sans option de premier niveau pour tout refuser, un classique.
Malheureusement non, cela ne change strictement rien au comportement de Bing : celui-ci fuite toujours mes recherches au site Pages Jaunes.
Il manquait une information clé pour Microsoft : ma géolocalisation ! Et en effet, sans que je continue ma navigation, Edge me demande maintenant l'accès à ma position :
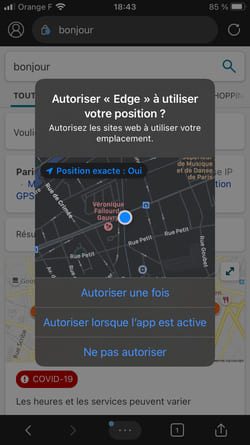
Conclusion : difficile à croire, mais via Edge et Bing, Microsoft réussit le tour de force d'être pire que Google sur le respect de votre vie privée.
Le navigateur comme protection contre la surveillance des sites
S'ils respectent eux-même plus ou moins bien votre vie privée, les navigateurs sont aussi censés vous protéger lorsque vous surfez sur le web. Regardons si c'est vraiment le cas, via une navigation sur deux sites connus pour fuiter massivement vos données personnelles :
- Le Bon Coin, cf. "La grande braderie de vos données personnelles sur Le Bon Coin".
- Le Monde, cf "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr".
Le protocole sera le même pour tous les navigateurs :
- Suppression des cookies et autres données navigateur.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur à tester, pas de navigation privée.
- Surf sur la page d'accueil de ces 2 sites, avec acceptation du pistage via la bannière de consentement.
Le comparatif ne peut être parfait car il ne s'agit que de 2 pages d'accueil, et d'un moment sur l'autre, les publicités servies peuvent être différentes. Mais le nombre de traceurs devrait nous donner une bonne idée de l'efficacité du navigateur.
Safari sans bloqueur de contenu, tout passe
Le cas nominal, j'ai désactivé mon bloqueur de contenu, Firefox Focus. Voici les résultats condensés :
- 94 hôtes contactés.
- 338 requêtes.
- 9,2 Mo de données téléchargées.
Inutile de dire que le nombre de traceurs est impressionnant, même si Intelligent Tracking Prevention limite la casse en stoppant le pistage intersite.
Safari avec bloqueur de contenu, des trous importants dans la raquette
Ici j'ai utilisé Firefox Focus (dont la liste de traceurs est fournie par Disconnect), vous pouvez aussi sélectionner d'autres bloqueurs de contenus comme Adguard. Les résultats sont-ils meilleurs ? Sensiblement :
- 45 hôtes contactés (ce qui signifie 49 traceurs en moins).
- 200 requêtes.
- 6.2 Mo de données téléchargées.
Est-ce à dire que le bloqueur de contenu vous a complètement protégé ? Lorsque l'on regarde dans le détail, de nombreux tiers continuent de vous pister, même si les traceurs les plus "évidents" ont disparu :
J'ai supprimé les requêtes 1st party pour y voir plus clair.
DuckDuckGo, une protection améliorée
DuckDuckGo utilise sa propre liste de traceurs, "Tracker Radar", généré par son propre crawl du web. Les informations de "Tracker Radar" sur les différents traceurs peuvent également être utilisés par des tiers (comme dans Safari, pour donner de l'information sur ces traceurs). Voici les résultats :
- 39 hôtes contactés.
- 226 requêtes.
- 6,3 Mo de données téléchargées.
Ces statistiques semblent proches de Safari avec bloqueur de contenus, si l'on regarde maintenant le détail :
La liste des traceurs est moins longue, DuckDuckGo est un peu plus efficace que Safari combiné à Firefox Focus.
Brave, une protection forte
Brave Shields, le système de blocage des traceurs, permet d'être très souple :
- Les paramètres par défaut vous protègent bien.
- Vous pouvez changer les paramètres par défaut.
- Vous pouvez aussi changer les paramètres pour des sites spécifiques.
Voici donc les paramètres par défaut :
Vous pouvez décider de bloquer les scripts, tous les cookies et les empreintes numériques. Mais d'expérience, certains sites ne marcheront plus correctement. Voici donc les résultats avec les paramètres par défaut :
- 29 hôtes contactés.
- 168 requêtes.
- 5,4 Mo de données téléchargées.
Brave est donc le plus efficace. Si l'on regarde dans le détail :

C'est presque parfait (Brave protège par exemple contre le CNAME cloaking d'AT Internet sur le site lemonde.fr, via le domaine buf.lemonde.fr), mais Brave rate notamment Facebook et Twitter.
Firefox vous protège relativement mal par défaut
Si Firefox est une très bonne option sur mon Mac, il a une sévère limitation sur iOS : comme avec tous les autres navigateurs iOS, on ne peut pas installer d'extensions. Et Firefox sans extension vous protège malheureusement beaucoup moins bien. Voici les résultats avec les paramètres par défaut :
- 111 hôtes contactés.
- 454 requêtes.
- 11,9 Mo de données téléchargées.
Vous êtes donc largement pisté. Dans les faits, tout n'est pas noir, si vous allez dans les paramètres :
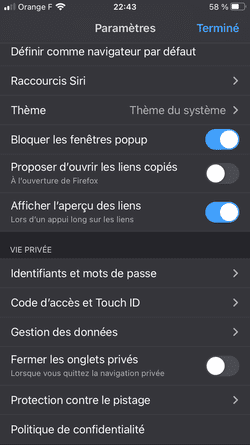
Cliquez dans la section "vie privée" sur "Protection contre le pistage"
Vous pouvez vous rendre compte que par défaut, Firefox applique la "Protection renforcée contre le pistage" (ETP pour "Enhanced Tracking Protection") en version "Standard" :
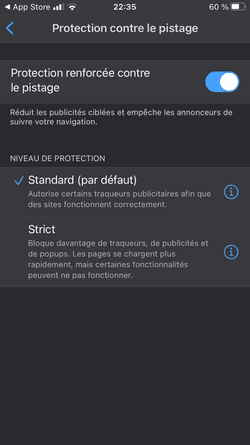
En cliquant sur le "i", vous pourrez apprendre que Firefox vous protège contre les traqueurs de réseaux sociaux (en effet, Facebook et Twitter ont été bloqués), contre les traqueurs intersites (rien de nouveau ici, vous l'êtes déjà via ITP), contre les mineurs de crypto monnaie et contre les détecteurs d'empreinte numérique (technique couramment appelée "fingerprinting").

Si vous activez la protection "Strict", Firefox vous protègera aussi contre le "Contenu utilisé pour le pistage" (protection qui nous intéresse tout particulièrement) :
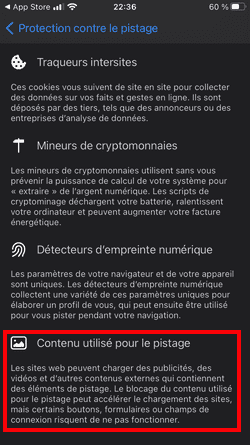
Êtes-vous mieux protégé ? Voici les nouveaux résultats :
- 42 hôtes contactés.
- 225 requêtes.
- 6,7 Mo de données téléchargées.
Les résultats sont donc bien meilleurs. Si l'on regarde le détail :

On retrouve les mêmes traceurs qu'avec l'option Safari et Firefox Focus : les 2 applications de Mozilla se servent d'une liste fournie par Disconnect pour bloquer certains traceurs.
Chrome, le navigateur sans protection
Avec Chrome c'est très simple, vous n'avez aucune protection par défaut, ni aucun réglage vous permettant de vous protéger. Chrome ne reste pas totalement inactif, les équipent travaillent sur le projet Privacy Sandbox, avec pour mission :
The Privacy Sandbox project’s mission is to “Create a thriving web ecosystem that is respectful of users and private by default.”
Dans le détail, "a thriving web ecosystem" signifie supporter les cas d'usages actuels de la publicité : mesure de conversion, publicité comportementale, retargeting, etc. "Private by default" signifie de ne plus permettre aux traceurs de pister individuellement les utilisateurs (Chrome bloquera les cookies tiers en 2022).
La mesure et le ciblage se feront via des "cohortes" d'utilisateurs (groupes suffisamment grands), via des décisions prises directement par le navigateur, via des mécanismes pour empêcher le croisement des données, etc.
Évidemment Google est moins concerné par les modifications de Chrome qu'un site web lambda : il continuera de pister la grande majorité des utilisateurs via leurs comptes Google.
Voici donc les résultats du surf sur Chrome :
- 100 hôtes contactés.
- 370 requêtes.
- 11,3 Mo de données téléchargées.
Pas de surprise donc, vous n'êtes pas du tout protégé.
Edge, des protections bien cachées
Edge était bon dernier lors du premier lancement du navigateur. Qu'en est-il des protections lors de votre surf ? Si l'on regarde les résultats avec la configuration par défaut :
- 96 hôtes contactés.
- 368 requêtes.
- 10,2 Mo de données téléchargées.
Edge est comparable à Chrome, ce qui n'est pas un compliment. Mais Edge dispose d'options cachées intéressantes. Si vous allez dans "Paramètres", à "Bloqueurs de contenus", vous pouvez découvrir une intégration "native" du bloqueur Adblock Plus :
J'active donc "Bloquer les publicités"
Oui Edge a intégré Adblock Plus dans son navigateur. Seulement, Adblock Plus est aussi une société publicitaire, qui se fait payer de grosses sommes par des géants du marketing (dont Microsoft, mais aussi Google, Amazon, Criteo, Taboola ou Outbrain) pour laisser passer certaines publicités, une belle hypocrisie. Il vous faut donc aller plus loin pour bloquer toutes les publicités, à savoir aller dans les "Paramètres avancés" de "Bloqueurs de contenu" :
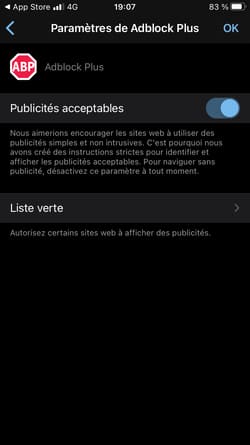
Je désactive "Publicités acceptables".
Mais vous n'êtes pas au bout de vos peines ! Une autre option est utile, elle se trouve dans "Paramètres", "Confidentialité et sécurité", et vous trouverez dans la section Sécurité (!), la rubrique "Prévention du suivi" (apparemment déjà "Activé") :
Ici il faut cliquer sur "Prévention du suivi".
Vous accédez alors à un nouvel écran :
La version "Équilibré (recommandé)" est sélectionnée par défaut. Ainsi Edge bloquerait déjà "les dispositifs de suivi des sites que vous n'avez pas visités", ainsi que "les dispositifs de suivi malveillants connus". Dans les faits, on se demande ce que Edge bloque vraiment, tous les traceurs sont conviés à la fête (Criteo, Google, Doubleclick, Weborama, Facebook, Amazon, etc).
Microsoft indique se baser sur Disconnect pour bloquer les traceurs, dès la version "Équilibré" de "Tracking Prevention", il semble que cela soit un effet d'annonce (Firefox se base aussi sur Disconnect, mais bloque bien de nombreux traceurs).
Est-ce que le passage en "Prévention du suivi Strict", l'activation d'Adblock Plus et la désactivation des "Publicités acceptables" vous permet d'être protégé contre tous les traceurs ? Vu l'effort engagé, on aimerait bien. Voici les résultats :
- 41 hôtes contactés.
- 200 requêtes.
- 6,8 Mo de données téléchargées.
Edge se hisse au niveau d'un Safari avec Firefox Focus (ce qui est la moindre des choses avec Adblock Plus activé et Disconnect). Si on regarde maintenant dans le détail :
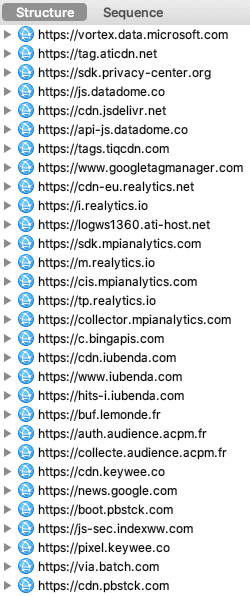
On voit bien que Edge a encore des progrès à faire.
NextDNS, en renfort du navigateur
Pour conclure, le choix du navigateur est personnel, mais certains navigateurs iOS apportent un bon premier niveau de protection : je pense notamment à DuckDuckGo. NextDNS pouvant être utilisé en complément.
J'ai l'habitude d'utiliser le combo Safari - Firefox Focus (bien que DuckDuckGo et Brave soient tentants), NextDNS permet de bloquer les traceurs qui sont passés à travers les mailles du filet. Voici le résultat sur le même test combiné LeBonCoin et Lemonde.fr :
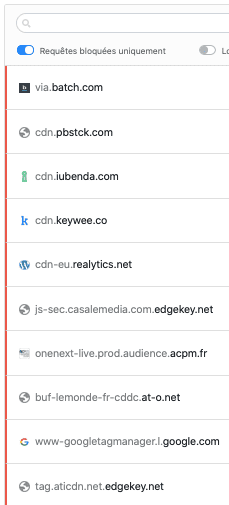
Les traceurs qui n'ont pas pu être bloqués par le combo Safari - Firefox Focus ont été bloqués par NextDNS.
Bref, le choix de votre navigateur et d'éventuelles protections supplémentaires peut faire une grande difféence !
Texte intégral (7223 mots)
Safari, l'inévitable navigateur iOS ?
Pour un navigateur tiers, il est difficile de concurrencer Apple Safari sur iOS :
- À la différence d'Android, iOS ne permet pas aux navigateurs tiers d'utiliser leur propre moteur de rendu. Si l'on lit les "guidelines" de l'App Store, section 2.5.6 : "Apps that browse the web must use the appropriate WebKit framework and WebKit Javascript".
- Apple a longtemps réservé l'usage de la dernière version de Webkit à Safari, les autres navigateurs étaient contraints d'utiliser une version périmée (basée sur la classe
UIWebView), lente et instable. - Toujours en raison de l'obligation d'utiliser WebKit, iOS ne permet pas aux navigateurs tiers de proposer leur propre bibliothèque d'extensions. Sur Android, je peux installer des extensions Firefox comme uBlock Origin.
- Les extensions de Safari telles que les bloqueurs de contenus ne sont pas accessibles aux autres navigateurs.
- Avant iOS 14, il n'était pas possible de changer le navigateur par défaut.
En conséquence, il n'était pas très intéressant d'utiliser un autre navigateur. Néanmoins, Apple évolue progressivement. Depuis iOS 8, les navigateurs tiers peuvent correctement utiliser le dernier moteur de rendu de WebKit. Et depuis iOS 14, Apple permet de changer le navigateur par défaut. Les navigateurs tiers peuvent ainsi mieux concurrencer Safari, notamment sur la protection de votre vie privée.
Quel que soit votre navigateur, vous bénéficiez déjà de la protection WebKit
Les navigateurs tiers ont obligation d'utiliser le moteur de rendu d'Apple, WebKit. Cela se traduit techniquement par l'utilisation de la classe WKWebView. Hors depuis iOS 14, celle-ci inclut par défaut Intelligent Tracking Prevention, le mécanisme de protection de la vie privée d'Apple (préalablement uniquement disponible sur Safari).
Oui, Chrome sur iOS vous protège contre le suivi intersite, par défaut ! L'obligation d'utiliser WebKit force Google à mieux protéger votre vie privée.
Intelligent Tracking Prevention (ITP) contient de nombreux mécanismes permettant de lutter contre le "suivi intersite", on peut notamment citer :
- Le blocage de tous les cookies tiers (prévu pour 2022 seulement sur Chrome).
- La limitation de la durée de vie des cookies créés via du javascript (cookies 1st party, mais pouvant être créés par des tiers) à 7 jours.
- La limitation de la durée de vie des cookies déposés via des domaines CNAME (là aussi, cookies 1st party, mais pouvant être déposés par des tiers) à 7 jours.
Les protections ITP ne se limitent pas aux cookies, pour une liste exhaustive lisez la page Cookie Status de Safari.
Si ces protections permettent de lutter contre le pire de la publicité (le suivi intersite), elles n'empêchent pas les sociétés marketing de mesurer chacune de vos interactions sur chaque site, ni de diffuser de la publicité. D'autres part, les sociétés marketing continuent de travailler à contourner les restrictions d'Apple (via du Server-Side Tagging, ou des identifiants de tiers déguisés en 1st party par exemple).
Si vous souhaitez être mieux protégé, quelles sont vos options ?
Le navigateur, un premier vecteur de surveillance
Avant même d'analyser les protections des navigateurs contre le pistage lors de votre surf, les navigateurs ont-ils mis en place leur propre système de surveillance ? Pour cela, je vais observer ce qu'il se passe lors du premier lancement du navigateur. À noter qu'une analyse similaire a déjà été effectuée par Brave récemment. Voici les étapes suivi :
- Téléchargement du navigateur à tester.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur, puis recherche dans la barre d'adresse (pas de navigation privée).
- Export de la session Charles sur mon ordinateur pour analyse.
Et voici un récapitulatif des différents navigateurs testés.
Safari, difficile à auditer de manière exhaustive
Safari est pré-installé donc je ne peux simuler un premier lancement. Il n'est pas impossible qu'Apple récupère des données de télémétrie de Safari si vous n'avez pas décoché les différents interrupteurs dans "Réglage" > "Confidentialité" > "Analyse et améliorations" :
J'ai décoché les différents interrupteurs dans "Analyse et améliorations", aussi je n'ai pas vu de traceurs Apple spécifiques à Safari.
Lorsque vous faites une recherche, le moteur de recherche par défaut est Google. Celui-ci verserait 12 milliards de dollars à Apple par an pour être le moteur de recherche par défaut sur tous les appareils Apple. Safari envoie ainsi à Google chaque caractère entré dans la barre de recherche (sans identifiant), pour faire marcher l'auto-complétion.
Côté vie privée, Apple prend de très bonnes initiatives. Mais il permet à Google et son capitalisme de surveillance de prospérer, pour beaucoup d'argent.
DuckDuckGo, le bon élève
Le moteur de recherche américain (en grande partie basé sur Bing) a fait de la vie privée son cheval de bataille, il fait d'ailleurs partie des moteurs de recherche recommandés par PrivacyTools. Il propose également un navigateur pour iOS, et voici les requêtes envoyées lors du premier lancement :
Lorsque l'on regarde dans le détail, c'est très propre : DuckDuckGo télécharge les bloqueurs de contenus. Lorsque vous tapez dans la barre d'adresse, il récupère les caractères pour de l'auto-complétion (avantage de fournir aussi un moteur de recherche), sans identifiant. La télémétrie est activée, mais là aussi sans identifiant.
Seule contrainte : le moteur de recherche par défaut (celui de la barre d'adresse) ne peut évidemment pas être changé. Mais si pour certaines requêtes vous n'êtes pas satisfait (rappel : derrière DuckDuckGo, c'est souvent Bing), vous pouvez utiliser les "bangs", des alias qui permettent de faire une recherche sur un autre moteur de recherche (Google évidemment, mais aussi YouTube, Wikipedia, Twitter, etc).
DuckDuckGo ne manque pas d'humour, voici le message dédié lors de votre première recherche Google (en préfixant votre recherche par !g).
Également très apprécié, la facilité à effacer les données :
Il vous suffit de cliquer sur la flamme pour effacer les données.
Brave vous protège... et fait tourner son business
Le navigateur Brave a été créé par Brendan Eich, ancien cofondateur de Firefox et créateur de Javascript. Brave a un discours fort contre les traceurs et autres publicités non respectueuses de la vie privée. Voici quelques points clés :
- Brave se base sur Chromium (et son moteur de rendu Blink), la partie Open-Source de Google Chrome. Mais sur iOS, il ne peut pas utiliser Chromium, et se voir forcé d'utiliser WebKit.
- Via Brave Shields, il bloque les traceurs et autres publicités qui vous pistent. Si vous l'acceptez, il diffuse des publicités respectueuses de la vie privée (servies en local, ce qui fait de Brave une régie publicitaire). Ce positionnement, en concurrence avec les éditeurs (Brave recrute les annonceurs), suscite des controverses.
- Brave Rewards vous permet de payer les sites que vous consultez de diverses manières : via un abonnement mensuel (par exemple, 10€ partagés avec les sites consultés, selon votre temps passé sur ces sites), via des pourboires (micro paiements) ou via la publicité servie en local par Brave (pour laquelle vous pouvez également être payé). Brave Rewards est basé sur la propre crypto monnaie de Brave : le BAT (ou Basic Attention Token).
UPDATE 15 décembre 2020 : Brave a d'autres controverses à son actif (merci @kinux), et notamment :
- Le financement via des liens d'affiliations vers des sites de crypto-monnaies, pratique arrêtée depuis que l'affaire a été révélée.
- L'inclusion de infogalactic, un Wikipédia d'extrême droite, dans les moteurs de recherche proposés par défaut. La pratique aurait cessé en décembre 2018 d'après ce site.
Brave vous permet au premier lancement de choisir votre moteur de recherche par défaut (et permet à des moteurs de recherche respectueux de la vie privée tels que Qwant, DuckDuckGo ou Startpage de trouver de nouveaux utilisateurs) :
Je sélectionne ici Startpage, un moteur de recherche basé sur Google, mais respectueux de la vie privée.
Vérifions les requêtes avant de cliquer sur "Enregistrer" :
Certaines requêtes ne sont pas lisibles sur l'outil Charles et je n'ai donc pu vérifier si des identifiants fuitaient, néanmoins on peut noter l'appel à sudosecuritygroup.com. Il s'agit en fait de la société Guardian, qui s'est associé à Brave pour fournir un VPN qui bloque aussi les traceurs et les publicités. Vous pourrez activer le VPN dans Brave, mais il faudra payer.
Deuxième étape, Brave vous propose de bloquer les traceurs :
Évidemment j'accepte.
Troisième étape, Brave pense à sa propre régie publicitaire, et vous propose de visualiser des publicités "privées et anonymes" :
Je clique sur Ignorer, l'audit des publicités Brave sera pour une autre fois.
Quatrième étape, je lance une recherche. Brave me demande si je souhaite activer les suggestions de recherche :
Question appréciée, je refuse donc.
Regardons maintenant les requêtes envoyées (depuis le lancement de l'application) :
Si on regarde le détail, Brave n'a pas envoyé de requêtes supplémentaires depuis l'étape 1 excepté vers Startpage, appelé uniquement lorsque je valide ma requête de recherche.
Firefox, quelques mauvaises surprises
Firefox est mon navigateur sur Mac. À la différence d'un Brave, Firefox a son propre moteur de rendu, Gecko. Mais lui aussi se voit contraint d'utiliser WebKit. Je m'attendais à ce que Firefox pour iOS ait une attitude irréprochable sur la vie privée car Firefox ayant une belle réputation et communiquant avantageusement. J'ai été surpris :
Dès la première ouverture, Firefox fuite mes données personnelles à Leanplum, une société marketing permettant d'afficher des messages ciblés. Leanplum est gourmand, il collecte notamment le deviceId, userId et uuid. Il récupère aussi mes principales interactions avec Firefox.
Firefox se permet également de collecter mes principales interactions (comme l'ouverture de l'application, sa fermeture, le clic sur la barre d'adresse) en direct (via incoming.telemetry.mozilla.org), avec l'identifiant clientId.
Pour les appels à Google, pas de surprise, il s'agit du moteur de recherche par défaut sur Firefox. Google représente la principale source de revenus pour Firefox, avec environ 450 millions de dollars par an. Chaque caractère entré dans la barre de recherche est envoyé à Google pour l'auto-complétion (sans identifiant).
Est-il possible de désactiver la fuite des données personnelles vers Leanplum ainsi que la télémétrie ? Oui, en décochant la bonne option dans les paramètres :
Je décoche "Envoyer des données d'utilisation"
On se serait attendu à de l'opt-in de la part de Firefox, et sans fuite de données personnelles vers une société marketing.
Chrome, le navigateur vorace de Google
Si vous utilisez Chrome pour iOS, vous n'avez à priori pas d'attente particulière concernant le respect de votre vie privée. Nous avions par exemple pu voir que Chrome envoie un en-tête HTTP unique à tous les domaines Google et Doubleclick, pratique pour vous pister. Lisez aussi "Why I'm done with Chrome", écrit il y a déjà 2 ans.
Dès l'ouverture de Chrome donc, Google vous informe que vous devez accepter les conditions d'utilisation. Premier problème, l'envoi de statistiques d'utilisation et des rapports d'erreur est coché par défaut :
Je décoche donc l'envoi de statistiques d'utilisation et des rapports d'erreur.
Si je regarde les requêtes passer avant le clic sur "Accepter et continuer", je vois que Chrome appelle déjà beaucoup de sites : pas d'inquiétude, il s'agit en fait de charger les images pour les signets par défaut (j'imagine les sites les plus consultés de France). Chrome récupère aussi des identifiants tels que le userid.
Deuxième étape, Chrome se montre ici très gourmand : il vous demande de synchroniser toute ma navigation avec mon compte Google. Une captation énorme de vos données personnelles donc, que Google enrobe en vous faisant miroiter de pouvoir synchroniser aussi vos mots de passe sur vos différents appareils "et plus encore".
Je clique donc sur "Non, merci".
Si vous souhaitez sélectionner les éléments à synchroniser, le texte "paramètres" en bleu pourrait vous faire croire que vous avez déjà la main, mais il n'est pas cliquable. Notez encore le bouton bleu "J'accepte", très naturel. Comparé à "Non, merci" en noir : un bel exemple de "Dark Pattern".
Troisième étape, Chrome continue sur sa lancée et me demande d'accéder à ma position exacte (pour "Améliorer mon expérience") !
Je clique sur "Ne pas autoriser"
Notez qu'avec iOS, je ne peux maintenant autoriser les accès qu'une seule fois (Chrome devra alors me redemander au lancement suivant), je peux également désactiver "Position exacte". Ces options peuvent être utiles pour vous protéger de certaines applications.
Dernière étape, Chrome est déjà lancé mais je fais une recherche, sur Google évidemment, pour tomber sur un bandeau de consentement venant d'être retoquée par la CNIL :
Le nouveau bandeau d’information mis en œuvre par les sociétés lors de l’arrivée sur la page google.fr ne permettait toujours pas aux utilisateurs résidant en France de comprendre les finalités pour lesquelles les cookies sont utilisés et ne les informait pas du fait qu’ils pouvaient refuser ces cookies.
Et en effet, bon courage pour refuser les cookies, vous pouvez vous perdre dans les menus sans trouver l'option, ni même être sûr que l'option choisie permet bien de refuser les cookies (je ne détaille pas, cela mériterait un article dédié).
Ici vous pourriez vous dire : je n'ai pas encore cliqué sur "J'accepte", Google n'a pas dû déposer de cookies. D'autant que si on lit la dernière sanction de la CNIL à l'encontre de Google (daté du 10 décembre 2020), celui-ci se permettait de le faire mais il a corrigé le tir :
La formation restreinte a pris acte que, depuis une mise à jour de septembre 2020, les sociétés cessent de déposer automatiquement les cookies publicitaires dès l’arrivée de l’utilisateur sur la page google.fr.
Regardons néanmoins les requêtes envoyées (depuis l'étape 2) :
Parmi les nombreuses requêtes envoyées aux différents services de Google, on peut noter les requêtes à adservice.google.com et à doubleclick.net. La requête à adservice.google.com contient bien le cookie NID. À quoi sert ce cookie ? Selon les propres mots de Google :
Nous utilisons des cookies, tels que "NID" et "SID", pour personnaliser les annonces sur les sites Google, tels que la recherche Google. Ils nous servent, par exemple, à mémoriser vos recherches les plus récentes, vos interactions précédentes avec les résultats de recherche ou les annonces d'un annonceur, ainsi que vos visites sur le site Web d'un annonceur. Cela nous permet de vous présenter des annonces personnalisées sur Google.
La CNIL parle-t-elle du cookie NID dans sa délibération ?
La formation restreinte relève que la société GIL a indiqué dans son courrier du 30 avril 2020 que quatre des sept cookies déposés, soit les cookies NID , IDE , ANID et 1P_JAR , poursuivent une finalité publicitaire.
Ainsi, en contradiction avec la délibération de la CNIL, Google n'a pas arrêté de déposer automatiquement certains cookies publicitaires sur la page google.fr.
Edge fait encore pire que Chrome
La réputation des navigateurs Microsoft n'est plus à faire :
Via compte parodique Twitter @intrnetexp.
Seulement voilà, fini les moqueries sur le retard d'Internet Explorer, Microsoft se base maintenant sur Chromium et son moteur de rendu Blink pour son navigateur Edge (tout comme Brave, Opera ou Vivaldi), il investit pour le rendre compétitif. Pour Edge aussi, pas de Chromium sur iOS à cause des restrictions Apple, et donc l'utilisation forcée de WebKit. Qu'en est-il du respect de votre vie privée ?
Le premier lancement de Edge ressemble beaucoup à Chrome, ce qui n'est pas bon signe. Edge vous suggère de vous connecter pour activer la synchronisation : favoris, mots de passe et "bien plus encore".
Je clique sur "Ignorer" (notez le Dark Pattern).
Si l'on regarde les requêtes envoyées avant clic sur "Ignorer", Edge est déjà gourmand :
Via plusieurs requêtes, Edge récupère plusieurs identifiants tels que deviceId ou clientId. Notez notamment le domaine vortex.data.microsoft.com, si bien nommé. À chaque interaction avec Edge, celui-ci va collecter de la donnée, et cette fuite est impossible à désactiver.
Comme Firefox, Edge fuite aussi vos données personnelles vers un tiers, Adjust, société spécialisée dans la mesure mobile et l'attribution. Adjust récupère des identifiants tels que persistent_ios_uuid.
Deuxième étape, Edge est toujours aussi gourmand que Chrome, il cherche à enregistrer mon historique de navigation :
Je clique sur "Pas maintenant".
Troisième étape, on comprend pas tout à fait la différence avec l'étape précédente ("En savoir plus" redirige toujours vers la page "Historique d'activités Windows 10 et confidentialité"), Edge insiste en vous demandant des données sur "la façon dont vous utilisez le navigateur" :
Je clique encore sur "Pas maintenant".
Quatrième étape, je fais une recherche (sur Bing évidemment), notez le bandeau de consentement :
Vérifions les requêtes (je n'ai pas encore interagi avec le bandeau de consentement) :
Les services Microsoft sont omniprésents, tous récupèrent vos données personnelles. Leboncoin est appelé mais simplement pour télécharger le logo. Edge ne fuite pas seulement vos données personnelles vers Adjust mais aussi vers Comscore (via scorecardresearch.com), géant du marketing qui peut ainsi mieux vous profiler.
Bonus : Bing fuite vos recherches au site Pages Jaunes
À cause de Bing (et non de Edge), j'ai été surpris (et alarmé) de voir que celui-ci fuite une donnée potentiellement sensible, ma requête, directement à Pages Jaunes (via pagesjaunes.fr) :
Heureusement ma recherche "bonjour" n'était pas sensible, mais Bing fuite l'intégralité de vos recherches au site Pages Jaunes (ainsi que votre ville), en temps réel, quelque soit l'appareil et le navigateur utilisé.
La régie publicitaire de Pages Jaunes s'appelle Solocal. Il s'agit d'un partenariat ancien, ayant surement été reconduit, sur le dos de votre vie privée (rappel, je n'ai toujours pas interagi avec le bandeau de consentement, ma recherche Bing a fuité vers le site Pages Jaunes).
Cadeau supplémentaire de Bing et Pages Jaunes, le domaine at.pagesjaunes.fr (qui dépose un cookie sans votre consentement) est un alias CNAME vers l'outils d'analytics français AT Internet :
Comme on a déjà pu le voir avec Criteo, Boursorama ou Lemonde.fr, ces alias CNAME ont pour but de contourner les protections navigateurs et adblockers, ils sont également souvent à l'origine d'une faille de sécurité importante.
Cliquer sur "Plus d'options" pour ensuite désactiver les cookies "non essentiels" empêche-t-il de fuiter vos requêtes vers les pages jaunes et vos données de surf vers AT Internet ?
Le bandeau de consentement sans option de premier niveau pour tout refuser, un classique.
Malheureusement non, cela ne change strictement rien au comportement de Bing : celui-ci fuite toujours mes recherches au site Pages Jaunes.
Il manquait une information clé pour Microsoft : ma géolocalisation ! Et en effet, sans que je continue ma navigation, Edge me demande maintenant l'accès à ma position :
Conclusion : difficile à croire, mais via Edge et Bing, Microsoft réussit le tour de force d'être pire que Google sur le respect de votre vie privée.
Le navigateur comme protection contre la surveillance des sites
S'ils respectent eux-même plus ou moins bien votre vie privée, les navigateurs sont aussi censés vous protéger lorsque vous surfez sur le web. Regardons si c'est vraiment le cas, via une navigation sur deux sites connus pour fuiter massivement vos données personnelles :
- Le Bon Coin, cf. "La grande braderie de vos données personnelles sur Le Bon Coin".
- Le Monde, cf "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr".
Le protocole sera le même pour tous les navigateurs :
- Suppression des cookies et autres données navigateur.
- Désactivation de NextDNS.
- Fermeture des différentes applications en cours.
- Lancement de Charles Proxy et activation du suivi.
- Lancement du navigateur à tester, pas de navigation privée.
- Surf sur la page d'accueil de ces 2 sites, avec acceptation du pistage via la bannière de consentement.
Le comparatif ne peut être parfait car il ne s'agit que de 2 pages d'accueil, et d'un moment sur l'autre, les publicités servies peuvent être différentes. Mais le nombre de traceurs devrait nous donner une bonne idée de l'efficacité du navigateur.
Safari sans bloqueur de contenu, tout passe
Le cas nominal, j'ai désactivé mon bloqueur de contenu, Firefox Focus. Voici les résultats condensés :
- 94 hôtes contactés.
- 338 requêtes.
- 9,2 Mo de données téléchargées.
Inutile de dire que le nombre de traceurs est impressionnant, même si Intelligent Tracking Prevention limite la casse en stoppant le pistage intersite.
Safari avec bloqueur de contenu, des trous importants dans la raquette
Ici j'ai utilisé Firefox Focus (dont la liste de traceurs est fournie par Disconnect), vous pouvez aussi sélectionner d'autres bloqueurs de contenus comme Adguard. Les résultats sont-ils meilleurs ? Sensiblement :
- 45 hôtes contactés (ce qui signifie 49 traceurs en moins).
- 200 requêtes.
- 6.2 Mo de données téléchargées.
Est-ce à dire que le bloqueur de contenu vous a complètement protégé ? Lorsque l'on regarde dans le détail, de nombreux tiers continuent de vous pister, même si les traceurs les plus "évidents" ont disparu :
J'ai supprimé les requêtes 1st party pour y voir plus clair.
DuckDuckGo, une protection améliorée
DuckDuckGo utilise sa propre liste de traceurs, "Tracker Radar", généré par son propre crawl du web. Les informations de "Tracker Radar" sur les différents traceurs peuvent également être utilisés par des tiers (comme dans Safari, pour donner de l'information sur ces traceurs). Voici les résultats :
- 39 hôtes contactés.
- 226 requêtes.
- 6,3 Mo de données téléchargées.
Ces statistiques semblent proches de Safari avec bloqueur de contenus, si l'on regarde maintenant le détail :
La liste des traceurs est moins longue, DuckDuckGo est un peu plus efficace que Safari combiné à Firefox Focus.
Brave, une protection forte
Brave Shields, le système de blocage des traceurs, permet d'être très souple :
- Les paramètres par défaut vous protègent bien.
- Vous pouvez changer les paramètres par défaut.
- Vous pouvez aussi changer les paramètres pour des sites spécifiques.
Voici donc les paramètres par défaut :
Vous pouvez décider de bloquer les scripts, tous les cookies et les empreintes numériques. Mais d'expérience, certains sites ne marcheront plus correctement. Voici donc les résultats avec les paramètres par défaut :
- 29 hôtes contactés.
- 168 requêtes.
- 5,4 Mo de données téléchargées.
Brave est donc le plus efficace. Si l'on regarde dans le détail :
C'est presque parfait (Brave protège par exemple contre le CNAME cloaking d'AT Internet sur le site lemonde.fr, via le domaine buf.lemonde.fr), mais Brave rate notamment Facebook et Twitter.
Firefox vous protège relativement mal par défaut
Si Firefox est une très bonne option sur mon Mac, il a une sévère limitation sur iOS : comme avec tous les autres navigateurs iOS, on ne peut pas installer d'extensions. Et Firefox sans extension vous protège malheureusement beaucoup moins bien. Voici les résultats avec les paramètres par défaut :
- 111 hôtes contactés.
- 454 requêtes.
- 11,9 Mo de données téléchargées.
Vous êtes donc largement pisté. Dans les faits, tout n'est pas noir, si vous allez dans les paramètres :
Cliquez dans la section "vie privée" sur "Protection contre le pistage"
Vous pouvez vous rendre compte que par défaut, Firefox applique la "Protection renforcée contre le pistage" (ETP pour "Enhanced Tracking Protection") en version "Standard" :
En cliquant sur le "i", vous pourrez apprendre que Firefox vous protège contre les traqueurs de réseaux sociaux (en effet, Facebook et Twitter ont été bloqués), contre les traqueurs intersites (rien de nouveau ici, vous l'êtes déjà via ITP), contre les mineurs de crypto monnaie et contre les détecteurs d'empreinte numérique (technique couramment appelée "fingerprinting").
Si vous activez la protection "Strict", Firefox vous protègera aussi contre le "Contenu utilisé pour le pistage" (protection qui nous intéresse tout particulièrement) :
Êtes-vous mieux protégé ? Voici les nouveaux résultats :
- 42 hôtes contactés.
- 225 requêtes.
- 6,7 Mo de données téléchargées.
Les résultats sont donc bien meilleurs. Si l'on regarde le détail :
On retrouve les mêmes traceurs qu'avec l'option Safari et Firefox Focus : les 2 applications de Mozilla se servent d'une liste fournie par Disconnect pour bloquer certains traceurs.
Chrome, le navigateur sans protection
Avec Chrome c'est très simple, vous n'avez aucune protection par défaut, ni aucun réglage vous permettant de vous protéger. Chrome ne reste pas totalement inactif, les équipent travaillent sur le projet Privacy Sandbox, avec pour mission :
The Privacy Sandbox project’s mission is to “Create a thriving web ecosystem that is respectful of users and private by default.”
Dans le détail, "a thriving web ecosystem" signifie supporter les cas d'usages actuels de la publicité : mesure de conversion, publicité comportementale, retargeting, etc. "Private by default" signifie de ne plus permettre aux traceurs de pister individuellement les utilisateurs (Chrome bloquera les cookies tiers en 2022).
La mesure et le ciblage se feront via des "cohortes" d'utilisateurs (groupes suffisamment grands), via des décisions prises directement par le navigateur, via des mécanismes pour empêcher le croisement des données, etc.
Évidemment Google est moins concerné par les modifications de Chrome qu'un site web lambda : il continuera de pister la grande majorité des utilisateurs via leurs comptes Google.
Voici donc les résultats du surf sur Chrome :
- 100 hôtes contactés.
- 370 requêtes.
- 11,3 Mo de données téléchargées.
Pas de surprise donc, vous n'êtes pas du tout protégé.
Edge, des protections bien cachées
Edge était bon dernier lors du premier lancement du navigateur. Qu'en est-il des protections lors de votre surf ? Si l'on regarde les résultats avec la configuration par défaut :
- 96 hôtes contactés.
- 368 requêtes.
- 10,2 Mo de données téléchargées.
Edge est comparable à Chrome, ce qui n'est pas un compliment. Mais Edge dispose d'options cachées intéressantes. Si vous allez dans "Paramètres", à "Bloqueurs de contenus", vous pouvez découvrir une intégration "native" du bloqueur Adblock Plus :
J'active donc "Bloquer les publicités"
Oui Edge a intégré Adblock Plus dans son navigateur. Seulement, Adblock Plus est aussi une société publicitaire, qui se fait payer de grosses sommes par des géants du marketing (dont Microsoft, mais aussi Google, Amazon, Criteo, Taboola ou Outbrain) pour laisser passer certaines publicités, une belle hypocrisie. Il vous faut donc aller plus loin pour bloquer toutes les publicités, à savoir aller dans les "Paramètres avancés" de "Bloqueurs de contenu" :
Je désactive "Publicités acceptables".
Mais vous n'êtes pas au bout de vos peines ! Une autre option est utile, elle se trouve dans "Paramètres", "Confidentialité et sécurité", et vous trouverez dans la section Sécurité (!), la rubrique "Prévention du suivi" (apparemment déjà "Activé") :
Ici il faut cliquer sur "Prévention du suivi".
Vous accédez alors à un nouvel écran :
La version "Équilibré (recommandé)" est sélectionnée par défaut. Ainsi Edge bloquerait déjà "les dispositifs de suivi des sites que vous n'avez pas visités", ainsi que "les dispositifs de suivi malveillants connus". Dans les faits, on se demande ce que Edge bloque vraiment, tous les traceurs sont conviés à la fête (Criteo, Google, Doubleclick, Weborama, Facebook, Amazon, etc).
Microsoft indique se baser sur Disconnect pour bloquer les traceurs, dès la version "Équilibré" de "Tracking Prevention", il semble que cela soit un effet d'annonce (Firefox se base aussi sur Disconnect, mais bloque bien de nombreux traceurs).
Est-ce que le passage en "Prévention du suivi Strict", l'activation d'Adblock Plus et la désactivation des "Publicités acceptables" vous permet d'être protégé contre tous les traceurs ? Vu l'effort engagé, on aimerait bien. Voici les résultats :
- 41 hôtes contactés.
- 200 requêtes.
- 6,8 Mo de données téléchargées.
Edge se hisse au niveau d'un Safari avec Firefox Focus (ce qui est la moindre des choses avec Adblock Plus activé et Disconnect). Si on regarde maintenant dans le détail :
On voit bien que Edge a encore des progrès à faire.
NextDNS, en renfort du navigateur
Pour conclure, le choix du navigateur est personnel, mais certains navigateurs iOS apportent un bon premier niveau de protection : je pense notamment à DuckDuckGo. NextDNS pouvant être utilisé en complément.
J'ai l'habitude d'utiliser le combo Safari - Firefox Focus (bien que DuckDuckGo et Brave soient tentants), NextDNS permet de bloquer les traceurs qui sont passés à travers les mailles du filet. Voici le résultat sur le même test combiné LeBonCoin et Lemonde.fr :
Les traceurs qui n'ont pas pu être bloqués par le combo Safari - Firefox Focus ont été bloqués par NextDNS.
Bref, le choix de votre navigateur et d'éventuelles protections supplémentaires peut faire une grande difféence !
15.11.2020 à 22:45
Google Tag Manager, la nouvelle arme anti adblock

EDIT 25 mai 2021 : le "Server-Side Tagging" de Google Tag Manager évolue, et contourner les adblockers devient de plus en plus simple. J'ai ajouté la section "Un temps d'avance sur les adblockers" à l'article.
Google Tag Manager, le cheval de Troie des équipes marketing
Google Tag Manager est un TMS (Tag Management System) : il permet aux équipes marketing d'ajouter des traceurs sur un site web ou une application, sans devoir passer par des développeurs. Via une interface web, ces équipes peuvent décider :
- Des traceurs à déclencher (analytics, A/B testing, attribution, etc).
- Des conditions de déclenchement (catégories de pages, caractéristiques utilisateur, etc).
- Des données à transmettre à ces outils tiers (caractéristiques utilisateur, données de navigation, variables présentes sur la page, etc).
Ce n'est pas le seul (on peut par exemple citer Segment, le français TagCommander ou Matomo Tag Manager) mais Google Tag Manager est ultra dominant :
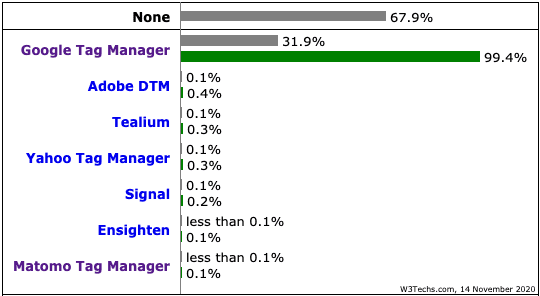
Google Tag Manager est présent sur 31,9% du top 10 millions des sites web Alexa, d'après W3Techs, mais surtout Google Tag Manager a une part de marché de 99,4% sur les TMS (!)
Comment Google a-t-il pu de nouveau s'imposer ? Tout comme avec Google Analytics, la version standard de Google Tag Manager est gratuite (les solutions du marché sont en général payantes), elle est très bien intégrée aux autres solutions Google et elle est bien faite.
Des traceurs qui ne sont plus appelés depuis votre navigateur
En août dernier, Google annonce une nouvelle version de Google Tag Manager, appelée Server-Side Tagging. Voici un schéma de Google pour expliquer comment fonctionne Google Tag Manager en version Client-Side Tagging (la version "historique") :
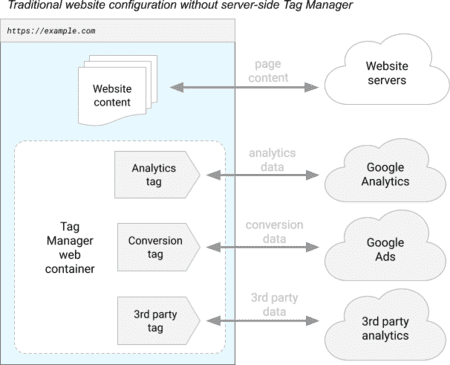
Google Tag Manager va permettre le déclenchement des différents traceurs tiers (sur le schéma : Google Analytics, Google Ads, et un outil d'analytics), directement sur votre navigateur.
Dans la nouvelle version Server-Side, les traceurs tiers ne sont plus exécutés depuis votre navigateur mais depuis un serveur "Proxy" appelé "Server container" sur le schéma ci-dessous (et hébergé chez Google) :
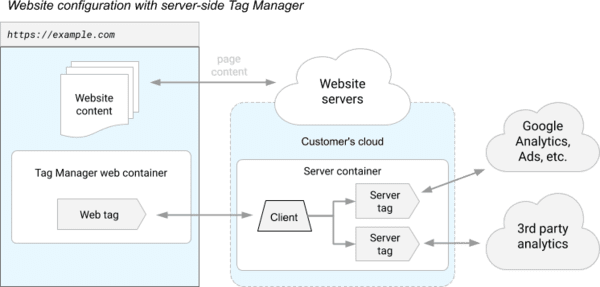
La librairie javascript (appelée sur le schéma "Tag Manager web container") s'exécute toujours sur votre navigateur afin de récolter vos interactions et vos données personnelles, mais l'exécution des différents traceurs tiers a lieu côté serveur.
Notez que cette nouvelle version s'applique aussi aux applications et à la collecte des données "offline" (pour transmettre les achats en magasin par exemple) :
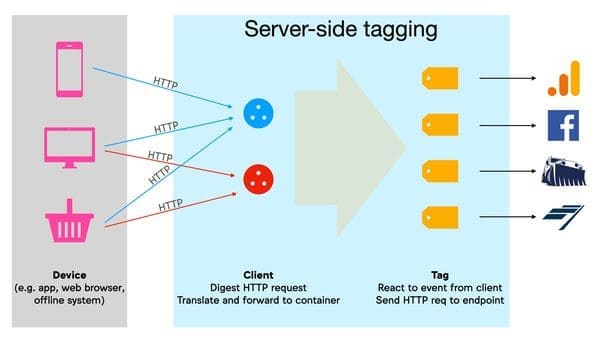
Schéma du blog de Simo Ahava : côté serveur, les "Clients" sont là pour traduire les requêtes HTTP reçues en "events", les "Tags" réagissent à ces évènements pour envoyer des "hits" aux sociétés de marketing tierces.
Cette logique de déclenchement des traceurs tiers côté serveur change la donne. Simo Ahava a détaillé les différents impacts dans un excellent article, je vais pour ma part résumer les avantages et m'attarder sur les problèmes pour votre vie privée (opérer côté serveur peut permettre de contourner vos choix et de fuiter vos données personnelles, sans être démasqué).
Une meilleure expérience utilisateur
Sur la plupart des sites web, le nombre de librairies javascript chargées par des tiers (pour de l'analytics, de la publicité, de l'A/B testing, etc) est impressionnant. Le chargement et l'exécution de ces librairies est souvent la cause principale d'une mauvaise expérience utilisateur : lenteur du site et manque d'interactivité.
Conséquences pour les sites web proposant une mauvaise expérience utilisateur : des internautes moins satisfaits, qui abandonneront directement la navigation ou ne reviendront pas.
Voici un exemple avec Le Bon Coin, celui-ci appelle un nombre incalculable de librairies javascript :
Une petite partie des scripts javascript appelés sur la page accueil de Le Bon Coin, celui-ci fuite vos données personnelles à de nombreux tiers.
Dans le meilleur des scénarios, le site web n'installera qu'une seule librairie javascript (les événements pouvant être très différents entre des outils n'ayant pas les mêmes buts, le site web utilisera parfois plus qu'une seule librairie). Celle-ci pourra être celle de Google Tag Manager mais pas obligatoirement : il est possible de créer sa propre librairie ou d'utiliser d'autres librairies du marché telles que Snowplow, Matomo, AT Internet, etc.
Charge ensuite à cette librairie d'envoyer les "hits" avec les paramètres requis lors des interactions clés. Puis le "client" du containeur serveur devra traduire ces "hits" en évènements, ceux-ci seront lus par les "Tags" qui enverront des "hits" aux sociétés marketing tierces. À noter que si la librairie javascript installée sur le site est fournie par Google, le "client" est déjà pré-configuré dans Google Tag Manager. Si le site web utilise une autre librairie, il lui faudra créer son propre "client" dans Google Tag Manager (exemple avec AT Internet), en attendant d'avoir des "clients" pré-configurés pour les principales librairies de tracking javascript.
Avantage donc : une seule librairie de tracking javascript est installée sur le site web et un seul "flux" de données en provenance du navigateur, l'utilisateur devrait voir la différence.
Un meilleur contrôle sur les données transmises aux tiers
Avoir un "proxy" côté serveur permet de contrôler les données transmises aux tiers (ce qui est beaucoup plus difficile lorsque les traceurs sont directement exécutés par le navigateur de l'utilisateur) :
- Par défaut et à la différence de la version "client-side", l'adresse IP et le User-Agent (nom du navigateur, version, système d'exploitation, langue, etc) de l'utilisateur ne fuitent pas (ce qui évite l'identification de l'utilisateur via "fingerprinting"). L'éditeur utilisant la version Server-Side Tagging de Google Tag Manager peut décider de transmettre ces informations aux tiers, mais ce n'est pas automatique.
- Il arrive souvent que des informations personnelles fuitent vers des tiers via des paramètres d'URLs (lisez par exemple l'article "Google Tag Manager Server-Side — How To Manage Custom Vendor Tags"), le Server-Side Tagging permet d'éviter cela.
- De manière générale, l'éditeur a la main sur les données personnelles et cookies envoyés par son "proxy" aux tiers (lisez la documentation technique de Google, notez par exemple les méthodes get_cookies et set_cookies). Il peut donc "nettoyer" les informations et n'envoyer aux tiers que le strict nécessaire.
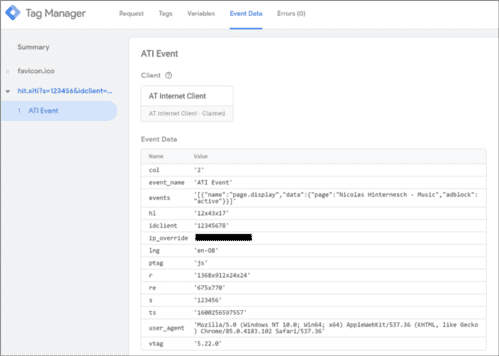
Exemple avec un hit AT Internet "vu" par le "proxy" serveur, le site web peut décider de ne pas transmettre l'adresse IP et le User-Agent de l'utilisateur à AT Internet.
Un site web mieux sécurisé
Mettre en place une Content-Security Policy (CSP) permet à un éditeur de mieux se prémunir contre différents types de menaces dont les attaques XSS (Cross-Site Scripting) et les injections de contenus. En ajoutant un en-tête aux réponses du serveur web, le site peut indiquer aux navigateurs quelles ressources (scripts, css, etc) sont autorisées.
Voici un exemple de CSP documenté par Google :
Content-Security-Policy: script-src 'self' https://apis.google.com.
Ce qui signifie : le navigateur n'a le droit d'exécuter que les scripts qui viennent directement du site consulté ('self') ou de apis.google.com. Et voici comment votre navigateur réagira si un script malicieux tente alors de s'exécuter à partir du site consulté :
Le script evil.js n'est pas hébergé sur le site consulté, ni sur apis.google.com : son exécution est bloquée par le navigateur.
En réduisant fortement les domaines tiers autorisés à exécuter du code javascript, la CSP devient plus robuste.
Si le Server-Side Tagging a des avantages pour les utilisateurs consentants à la surveillance marketing (rapidité, sécurité), il met en péril les protections des utilisateurs non consentants.
Un contournement des protections navigateurs
Le serveur "proxy" est hébergé dans le cloud de Google (instance App Engine) mais Google conseille de lier le domaine App Engine à un sous-domaine du site de ses clients (sans expliquer les raisons) :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
La liaison entre le domaine App Engine et le sous-domaine du client, documentée par Google.
Google ne conseille pas d'enregistrement DNS de type CNAME (alias), mais un enregistrement DNS de type A ou AAAA, directement lié aux adresses IPs de Google App Engine, qui fait office d'hébergeur. Le serveur "proxy" est donc bien considéré par les navigateurs comme 1st party, et les conséquences sont donc importantes.
En particulier, les cookies déposés par le serveur "proxy" ne sont pas des cookies tiers, ni des cookies créés via du javascript, ni des cookies déposés par un domaine CNAME. Ils sont donc autorisés, sans restriction :
- Safari via Intelligent Tracking Prevention (ITP) restreint la durée de vie des cookies créés en javascript à 7 jours (exemple : les cookies 1st-party créés par Google Analytics). Grâce au serveur "proxy", les traceurs tiers passent maintenant outre cette limitation.
- Toujours Safari via ITP restreint maintenant les cookies déposés via un domaine CNAME à 7 jours. Grâce au serveur "proxy", les traceurs tiers ne sont pas concernés par cette limitation.
- Brave de son côté bloque les requêtes CNAME vers des traceurs connus. Toujours grâce au serveur "proxy", les traceurs tiers évitent ce blocage.
Un contournement des adblockers
Votre adblocker (uBlock Origin sur Firefox par exemple), votre bloqueur de contenu (Firefox Focus ou Adguard sur iOS par exemple) ou votre bloqueur DNS (NextDNS par exemple) fonctionne sur votre appareil. Il peut ainsi détecter les traceurs tiers et les bloquer avant que vos données personnelles ne fuitent.
Rien de tout cela avec la version Server-Side Tagging de Google Tag Manager : les fuites de données personnelles se déroulent depuis le serveur proxy du client (hébergé dans le cloud Google) vers les tiers. Vous n'avez donc plus la main pour éviter ces fuites.
Vous pourriez vous dire : il suffit de bloquer le premier appel, celui de votre navigateur vers la librairie javascript en charge de récolter les données et de communiquer vers le serveur "proxy". Sauf que cette librairie javascript peut très bien être accessible sur le domaine du site web (et non sur un domaine Google par exemple). Aussi, Google conseille déjà à ses clients de changer leurs scripts gtag.js afin de renseigner le domaine du serveur proxy. Cette manipulation rend déjà le blocage via nom de domaine inopérant.
Toutes les librairies de tracking Google (gtag.js, analytics.js mais aussi gtm.js, la librairie "avancée" de Google, en charge de Google Tag Manager) peuvent être hébergées sur son propre domaine.
Si gtag.js ou gtm.js sont des librairies javascript dont les noms sont connus des principaux adblockers, ceux-ci devront trouver d'autres méthodes lorsque le nom de la librairie javascript aura été modifié ou que des sites auront créés leurs propres librairies.

uBlock Origin, efficace contre le CNAME cloaking sur Firefox, impuissant contre le Server-Side Tagging ?
Un temps d'avance sur les adblockers
La librairie javascript de Google Tag Manager s'appelle gtm.js, elle est appelée avec l'identifiant du containeur : GTM-.... Un adblocker peut donc facilement cibler ces noms et bloquer le chargement de cette librairie. Un site web pourrait décider de créer sa propre librairie javascript, mais ce n'est pas si facile.
Mais toujours grâce à Simo Ahava, il est maintenant facile de choisir un autre nom pour la librairie javascript gtm.js et de cacher l'identifiant du containeur (plus besoin de créer sa propre librairie javascript) :
Via le blog de Simo Ahava : avec la template "GTM Loader" de Simo, le site web peut renommer la librairie javascript ("Request Path") et cacher l'identifiant du containeur ("Override Container ID" coché, "Container ID" vide).
Également, s'il était possible côté adblockers de cibler le proxy Google, un site web peut maintenant héberger le container serveur ailleurs (sur Amazon AWS, Microsoft Azure, OVH... ou sur sa propre infrastructure). Ce n'est pas si facile, mais Google fournit l'image Docker ainsi que les étapes à suivre.
Simo Ahava indique ainsi la marche à suivre pour déployer le containeur serveur sur Amazon AWS tandis que Mark Edmondson détaille comment déployer le containeur serveur sur Google Cloud Run (autre service de Google Cloud Platform, différent de Google App Engine).
Comment les adblockers peuvent-ils réagir ?
Le sujet n'est pas évident, voici des idées mais je ne suis pas certain qu'elles soient réalisables :
- Automatiquement détecter ces appels "1st party" au serveur "proxy" via les paramètres d'URLs envoyés. Sauf que ces paramètres d'URLs changeront d'un site à l'autre, en fonction de la librairie utilisée, de la page consultée, etc.
- Détecter la librairie javascript responsable des appels au serveur "proxy" pour bloquer son exécution. Comme nous avons pu le voir, cette méthode ne fonctionnera pas si le site web renomme la librairie de Google Tag Manager ou développe sa propre librairie javascript.
- Bloquer les proxy, au risque de bloquer des fonctionnalités essentielles de sites web ? Aussi, cette méthode ne fonctionne pas si le site web décide d'héberger le containeur serveur sur sa propre infrastructure.
- Ne jamais exécuter de javascript sur son navigateur, avec par exemple l'extension NoScript, paramétrée de manière radicale. Option efficace, sauf que de nombreux sites web ne fonctionneront plus.
Fuiter vos données personnelles dans l'opacité la plus totale
Si beaucoup de sites web fuitent aujourd'hui vos données personnelles, souvent sans votre consentement, il est néanmoins possible d'auditer les sites, de prouver la violation de consentement et de documenter les fuites. La CNIL pourrait par exemple faire son travail et sanctionner les fautes. Rien de tout cela avec le Server-Side Tagging, un site peut maintenant très facilement :
- Donner une apparence de consentement en vous laissant répondre à un bandeau de consentement.
- Tout en fuitant vos données personnelles à de multiples tiers, sans qu'un auditeur extérieur ne puisse s'en rendre compte (il verra simplement l'appel "1st-party" au serveur "proxy", sans savoir si les données personnelles sont utilisées, partagées ou revendues derrière).
Vos données sur le cloud de Google
Par défaut, le serveur "proxy" logue toutes les requêtes qu'il reçoit :
By default, App Engine logs information about every single request (e.g. request path, query parameters, etc) that it receives.
Mais les données personnelles contenues dans ces requêtes ne sont pas les seules informations qui fuitent vers Google. Tout comme pour le CNAME cloaking, les cookies associés au domaine du site consulté sont envoyés au sous-domaine du serveur "proxy". Ainsi, si vos cookies de session sont associés au domaine du site (et non à un sous-domaine distinct), ils seront bien envoyés au cloud de Google.
Celui-ci déclare que les données hébergées sur son cloud appartiennent au client, et non à Google. Il vous faut néanmoins faire confiance à Google.
Le Server-Side Tagging, probablement bientôt largement adopté
Si des solutions Server-Side existaient sur le marché depuis bien longtemps, et s'il était déjà possible de développer son propre "proxy", le lancement de la solution de Google aura probablement un impact énorme sur l'adoption du Server-Side Tagging :
- Google Tag Manager est présent sur un nombre considérable de sites web, il est ultra-dominant.
- Google présente cette version comme une évolution des outils TMS, améliorant la performance et la sécurité des sites web.
- Gros argument pour les marketeurs, fuiter vos données personnelles vers Facebook.
Un tag Google Analytics peut cacher la fuite de vos données personnelles vers Facebook, combo !
Même si un client Google Tag Manager peut continuer d'utiliser la version Client-Side, même si la version Server-Side a encore des limites (peu de librairies tierces, certaines solutions auront du mal à être supportés, etc), même si l'apprentissage de la solution est complexe et même si c'est souvent payant (facture Google App Engine du serveur "proxy"), on peut donc parier que les clients Google Tag Manager vont progressivement migrer vers cette version.
Contourner les adblockers et autres protections navigateurs, un argument de vente
Comme nous l'avons vu, Google n'explique pas le pourquoi de la création d'un sous-domaine du site web pour son serveur "proxy" :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
Il n'en a pas besoin, les contournements des protections navigateurs et adblockers ont déjà été listés comme "bénéfices" par de nombreuses publications :
- "Server-side Tagging In Google Tag Manager" de Simo Ahava, l'article indique comme bénéfice de pouvoir contourner les limitations de Safari concernant la durée de vie des cookies javascript. Tout à son honneur, l'auteur ne veut pas donner de détail sur le fait que le Server-Side Tagging permet de contourner les adblockers et indique que la collecte de données doit se faire après recueil du consentement.
- "GTM Server Side – L’évolution naturelle pour votre tagging ?" de Converteo. L'article liste en avantages le fait de pouvoir contourner les limitations navigateurs telles que celles de Safari et Firefox, ainsi que le contournement des adblockers.
- "Introduction to Google Tag Manager Server-side Tagging", du blog Analytics mania. Là aussi, les contournements des limitations navigateurs et adblockers sont listés en bénéfice.
- "Google introduit le tagging côté serveur, une bonne nouvelle ?" de Nicolas Jaimes sur le JDN. L'angle de l'article est la publicité, et donc le contournement des protections navigateurs est listé en bénéfice (même si pour l'instant, le manque de librairies tierces fait que le Server-Side Tagging reste complexe à implémenter).
Malheureusement, il y a fort à parier que beaucoup de sites seront également séduits par ces "bénéfices", en plus des gains de performance, de sécurité et de contrôle. L'impossibilité d'auditer les sites web sera également une grosse perte pour les défenseurs de la vie privée. En espérant que les navigateurs et adblockers trouvent des parades afin que les internautes soucieux de leur vie privée puissent continuer de se défendre.
Texte intégral (4157 mots)
EDIT 25 mai 2021 : le "Server-Side Tagging" de Google Tag Manager évolue, et contourner les adblockers devient de plus en plus simple. J'ai ajouté la section "Un temps d'avance sur les adblockers" à l'article.
Google Tag Manager, le cheval de Troie des équipes marketing
Google Tag Manager est un TMS (Tag Management System) : il permet aux équipes marketing d'ajouter des traceurs sur un site web ou une application, sans devoir passer par des développeurs. Via une interface web, ces équipes peuvent décider :
- Des traceurs à déclencher (analytics, A/B testing, attribution, etc).
- Des conditions de déclenchement (catégories de pages, caractéristiques utilisateur, etc).
- Des données à transmettre à ces outils tiers (caractéristiques utilisateur, données de navigation, variables présentes sur la page, etc).
Ce n'est pas le seul (on peut par exemple citer Segment, le français TagCommander ou Matomo Tag Manager) mais Google Tag Manager est ultra dominant :
Google Tag Manager est présent sur 31,9% du top 10 millions des sites web Alexa, d'après W3Techs, mais surtout Google Tag Manager a une part de marché de 99,4% sur les TMS (!)
Comment Google a-t-il pu de nouveau s'imposer ? Tout comme avec Google Analytics, la version standard de Google Tag Manager est gratuite (les solutions du marché sont en général payantes), elle est très bien intégrée aux autres solutions Google et elle est bien faite.
Des traceurs qui ne sont plus appelés depuis votre navigateur
En août dernier, Google annonce une nouvelle version de Google Tag Manager, appelée Server-Side Tagging. Voici un schéma de Google pour expliquer comment fonctionne Google Tag Manager en version Client-Side Tagging (la version "historique") :
Google Tag Manager va permettre le déclenchement des différents traceurs tiers (sur le schéma : Google Analytics, Google Ads, et un outil d'analytics), directement sur votre navigateur.
Dans la nouvelle version Server-Side, les traceurs tiers ne sont plus exécutés depuis votre navigateur mais depuis un serveur "Proxy" appelé "Server container" sur le schéma ci-dessous (et hébergé chez Google) :
La librairie javascript (appelée sur le schéma "Tag Manager web container") s'exécute toujours sur votre navigateur afin de récolter vos interactions et vos données personnelles, mais l'exécution des différents traceurs tiers a lieu côté serveur.
Notez que cette nouvelle version s'applique aussi aux applications et à la collecte des données "offline" (pour transmettre les achats en magasin par exemple) :
Schéma du blog de Simo Ahava : côté serveur, les "Clients" sont là pour traduire les requêtes HTTP reçues en "events", les "Tags" réagissent à ces évènements pour envoyer des "hits" aux sociétés de marketing tierces.
Cette logique de déclenchement des traceurs tiers côté serveur change la donne. Simo Ahava a détaillé les différents impacts dans un excellent article, je vais pour ma part résumer les avantages et m'attarder sur les problèmes pour votre vie privée (opérer côté serveur peut permettre de contourner vos choix et de fuiter vos données personnelles, sans être démasqué).
Une meilleure expérience utilisateur
Sur la plupart des sites web, le nombre de librairies javascript chargées par des tiers (pour de l'analytics, de la publicité, de l'A/B testing, etc) est impressionnant. Le chargement et l'exécution de ces librairies est souvent la cause principale d'une mauvaise expérience utilisateur : lenteur du site et manque d'interactivité.
Conséquences pour les sites web proposant une mauvaise expérience utilisateur : des internautes moins satisfaits, qui abandonneront directement la navigation ou ne reviendront pas.
Voici un exemple avec Le Bon Coin, celui-ci appelle un nombre incalculable de librairies javascript :
Une petite partie des scripts javascript appelés sur la page accueil de Le Bon Coin, celui-ci fuite vos données personnelles à de nombreux tiers.
Dans le meilleur des scénarios, le site web n'installera qu'une seule librairie javascript (les événements pouvant être très différents entre des outils n'ayant pas les mêmes buts, le site web utilisera parfois plus qu'une seule librairie). Celle-ci pourra être celle de Google Tag Manager mais pas obligatoirement : il est possible de créer sa propre librairie ou d'utiliser d'autres librairies du marché telles que Snowplow, Matomo, AT Internet, etc.
Charge ensuite à cette librairie d'envoyer les "hits" avec les paramètres requis lors des interactions clés. Puis le "client" du containeur serveur devra traduire ces "hits" en évènements, ceux-ci seront lus par les "Tags" qui enverront des "hits" aux sociétés marketing tierces. À noter que si la librairie javascript installée sur le site est fournie par Google, le "client" est déjà pré-configuré dans Google Tag Manager. Si le site web utilise une autre librairie, il lui faudra créer son propre "client" dans Google Tag Manager (exemple avec AT Internet), en attendant d'avoir des "clients" pré-configurés pour les principales librairies de tracking javascript.
Avantage donc : une seule librairie de tracking javascript est installée sur le site web et un seul "flux" de données en provenance du navigateur, l'utilisateur devrait voir la différence.
Un meilleur contrôle sur les données transmises aux tiers
Avoir un "proxy" côté serveur permet de contrôler les données transmises aux tiers (ce qui est beaucoup plus difficile lorsque les traceurs sont directement exécutés par le navigateur de l'utilisateur) :
- Par défaut et à la différence de la version "client-side", l'adresse IP et le User-Agent (nom du navigateur, version, système d'exploitation, langue, etc) de l'utilisateur ne fuitent pas (ce qui évite l'identification de l'utilisateur via "fingerprinting"). L'éditeur utilisant la version Server-Side Tagging de Google Tag Manager peut décider de transmettre ces informations aux tiers, mais ce n'est pas automatique.
- Il arrive souvent que des informations personnelles fuitent vers des tiers via des paramètres d'URLs (lisez par exemple l'article "Google Tag Manager Server-Side — How To Manage Custom Vendor Tags"), le Server-Side Tagging permet d'éviter cela.
- De manière générale, l'éditeur a la main sur les données personnelles et cookies envoyés par son "proxy" aux tiers (lisez la documentation technique de Google, notez par exemple les méthodes get_cookies et set_cookies). Il peut donc "nettoyer" les informations et n'envoyer aux tiers que le strict nécessaire.
Exemple avec un hit AT Internet "vu" par le "proxy" serveur, le site web peut décider de ne pas transmettre l'adresse IP et le User-Agent de l'utilisateur à AT Internet.
Un site web mieux sécurisé
Mettre en place une Content-Security Policy (CSP) permet à un éditeur de mieux se prémunir contre différents types de menaces dont les attaques XSS (Cross-Site Scripting) et les injections de contenus. En ajoutant un en-tête aux réponses du serveur web, le site peut indiquer aux navigateurs quelles ressources (scripts, css, etc) sont autorisées.
Voici un exemple de CSP documenté par Google :
Content-Security-Policy: script-src 'self' https://apis.google.com.
Ce qui signifie : le navigateur n'a le droit d'exécuter que les scripts qui viennent directement du site consulté ('self') ou de apis.google.com. Et voici comment votre navigateur réagira si un script malicieux tente alors de s'exécuter à partir du site consulté :
Le script evil.js n'est pas hébergé sur le site consulté, ni sur apis.google.com : son exécution est bloquée par le navigateur.
En réduisant fortement les domaines tiers autorisés à exécuter du code javascript, la CSP devient plus robuste.
Si le Server-Side Tagging a des avantages pour les utilisateurs consentants à la surveillance marketing (rapidité, sécurité), il met en péril les protections des utilisateurs non consentants.
Un contournement des protections navigateurs
Le serveur "proxy" est hébergé dans le cloud de Google (instance App Engine) mais Google conseille de lier le domaine App Engine à un sous-domaine du site de ses clients (sans expliquer les raisons) :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
La liaison entre le domaine App Engine et le sous-domaine du client, documentée par Google.
Google ne conseille pas d'enregistrement DNS de type CNAME (alias), mais un enregistrement DNS de type A ou AAAA, directement lié aux adresses IPs de Google App Engine, qui fait office d'hébergeur. Le serveur "proxy" est donc bien considéré par les navigateurs comme 1st party, et les conséquences sont donc importantes.
En particulier, les cookies déposés par le serveur "proxy" ne sont pas des cookies tiers, ni des cookies créés via du javascript, ni des cookies déposés par un domaine CNAME. Ils sont donc autorisés, sans restriction :
- Safari via Intelligent Tracking Prevention (ITP) restreint la durée de vie des cookies créés en javascript à 7 jours (exemple : les cookies 1st-party créés par Google Analytics). Grâce au serveur "proxy", les traceurs tiers passent maintenant outre cette limitation.
- Toujours Safari via ITP restreint maintenant les cookies déposés via un domaine CNAME à 7 jours. Grâce au serveur "proxy", les traceurs tiers ne sont pas concernés par cette limitation.
- Brave de son côté bloque les requêtes CNAME vers des traceurs connus. Toujours grâce au serveur "proxy", les traceurs tiers évitent ce blocage.
Un contournement des adblockers
Votre adblocker (uBlock Origin sur Firefox par exemple), votre bloqueur de contenu (Firefox Focus ou Adguard sur iOS par exemple) ou votre bloqueur DNS (NextDNS par exemple) fonctionne sur votre appareil. Il peut ainsi détecter les traceurs tiers et les bloquer avant que vos données personnelles ne fuitent.
Rien de tout cela avec la version Server-Side Tagging de Google Tag Manager : les fuites de données personnelles se déroulent depuis le serveur proxy du client (hébergé dans le cloud Google) vers les tiers. Vous n'avez donc plus la main pour éviter ces fuites.
Vous pourriez vous dire : il suffit de bloquer le premier appel, celui de votre navigateur vers la librairie javascript en charge de récolter les données et de communiquer vers le serveur "proxy". Sauf que cette librairie javascript peut très bien être accessible sur le domaine du site web (et non sur un domaine Google par exemple). Aussi, Google conseille déjà à ses clients de changer leurs scripts gtag.js afin de renseigner le domaine du serveur proxy. Cette manipulation rend déjà le blocage via nom de domaine inopérant.
Toutes les librairies de tracking Google (gtag.js, analytics.js mais aussi gtm.js, la librairie "avancée" de Google, en charge de Google Tag Manager) peuvent être hébergées sur son propre domaine.
Si gtag.js ou gtm.js sont des librairies javascript dont les noms sont connus des principaux adblockers, ceux-ci devront trouver d'autres méthodes lorsque le nom de la librairie javascript aura été modifié ou que des sites auront créés leurs propres librairies.
uBlock Origin, efficace contre le CNAME cloaking sur Firefox, impuissant contre le Server-Side Tagging ?
Un temps d'avance sur les adblockers
La librairie javascript de Google Tag Manager s'appelle gtm.js, elle est appelée avec l'identifiant du containeur : GTM-.... Un adblocker peut donc facilement cibler ces noms et bloquer le chargement de cette librairie. Un site web pourrait décider de créer sa propre librairie javascript, mais ce n'est pas si facile.
Mais toujours grâce à Simo Ahava, il est maintenant facile de choisir un autre nom pour la librairie javascript gtm.js et de cacher l'identifiant du containeur (plus besoin de créer sa propre librairie javascript) :
Via le blog de Simo Ahava : avec la template "GTM Loader" de Simo, le site web peut renommer la librairie javascript ("Request Path") et cacher l'identifiant du containeur ("Override Container ID" coché, "Container ID" vide).
Également, s'il était possible côté adblockers de cibler le proxy Google, un site web peut maintenant héberger le container serveur ailleurs (sur Amazon AWS, Microsoft Azure, OVH... ou sur sa propre infrastructure). Ce n'est pas si facile, mais Google fournit l'image Docker ainsi que les étapes à suivre.
Simo Ahava indique ainsi la marche à suivre pour déployer le containeur serveur sur Amazon AWS tandis que Mark Edmondson détaille comment déployer le containeur serveur sur Google Cloud Run (autre service de Google Cloud Platform, différent de Google App Engine).
Comment les adblockers peuvent-ils réagir ?
Le sujet n'est pas évident, voici des idées mais je ne suis pas certain qu'elles soient réalisables :
- Automatiquement détecter ces appels "1st party" au serveur "proxy" via les paramètres d'URLs envoyés. Sauf que ces paramètres d'URLs changeront d'un site à l'autre, en fonction de la librairie utilisée, de la page consultée, etc.
- Détecter la librairie javascript responsable des appels au serveur "proxy" pour bloquer son exécution. Comme nous avons pu le voir, cette méthode ne fonctionnera pas si le site web renomme la librairie de Google Tag Manager ou développe sa propre librairie javascript.
- Bloquer les proxy, au risque de bloquer des fonctionnalités essentielles de sites web ? Aussi, cette méthode ne fonctionne pas si le site web décide d'héberger le containeur serveur sur sa propre infrastructure.
- Ne jamais exécuter de javascript sur son navigateur, avec par exemple l'extension NoScript, paramétrée de manière radicale. Option efficace, sauf que de nombreux sites web ne fonctionneront plus.
Fuiter vos données personnelles dans l'opacité la plus totale
Si beaucoup de sites web fuitent aujourd'hui vos données personnelles, souvent sans votre consentement, il est néanmoins possible d'auditer les sites, de prouver la violation de consentement et de documenter les fuites. La CNIL pourrait par exemple faire son travail et sanctionner les fautes. Rien de tout cela avec le Server-Side Tagging, un site peut maintenant très facilement :
- Donner une apparence de consentement en vous laissant répondre à un bandeau de consentement.
- Tout en fuitant vos données personnelles à de multiples tiers, sans qu'un auditeur extérieur ne puisse s'en rendre compte (il verra simplement l'appel "1st-party" au serveur "proxy", sans savoir si les données personnelles sont utilisées, partagées ou revendues derrière).
Vos données sur le cloud de Google
Par défaut, le serveur "proxy" logue toutes les requêtes qu'il reçoit :
By default, App Engine logs information about every single request (e.g. request path, query parameters, etc) that it receives.
Mais les données personnelles contenues dans ces requêtes ne sont pas les seules informations qui fuitent vers Google. Tout comme pour le CNAME cloaking, les cookies associés au domaine du site consulté sont envoyés au sous-domaine du serveur "proxy". Ainsi, si vos cookies de session sont associés au domaine du site (et non à un sous-domaine distinct), ils seront bien envoyés au cloud de Google.
Celui-ci déclare que les données hébergées sur son cloud appartiennent au client, et non à Google. Il vous faut néanmoins faire confiance à Google.
Le Server-Side Tagging, probablement bientôt largement adopté
Si des solutions Server-Side existaient sur le marché depuis bien longtemps, et s'il était déjà possible de développer son propre "proxy", le lancement de la solution de Google aura probablement un impact énorme sur l'adoption du Server-Side Tagging :
- Google Tag Manager est présent sur un nombre considérable de sites web, il est ultra-dominant.
- Google présente cette version comme une évolution des outils TMS, améliorant la performance et la sécurité des sites web.
- Gros argument pour les marketeurs, fuiter vos données personnelles vers Facebook.
Un tag Google Analytics peut cacher la fuite de vos données personnelles vers Facebook, combo !
Même si un client Google Tag Manager peut continuer d'utiliser la version Client-Side, même si la version Server-Side a encore des limites (peu de librairies tierces, certaines solutions auront du mal à être supportés, etc), même si l'apprentissage de la solution est complexe et même si c'est souvent payant (facture Google App Engine du serveur "proxy"), on peut donc parier que les clients Google Tag Manager vont progressivement migrer vers cette version.
Contourner les adblockers et autres protections navigateurs, un argument de vente
Comme nous l'avons vu, Google n'explique pas le pourquoi de la création d'un sous-domaine du site web pour son serveur "proxy" :
The default server-side tagging deployment is hosted on an App Engine domain. We recommend that you modify the deployment to use a subdomain of your website instead.
Il n'en a pas besoin, les contournements des protections navigateurs et adblockers ont déjà été listés comme "bénéfices" par de nombreuses publications :
- "Server-side Tagging In Google Tag Manager" de Simo Ahava, l'article indique comme bénéfice de pouvoir contourner les limitations de Safari concernant la durée de vie des cookies javascript. Tout à son honneur, l'auteur ne veut pas donner de détail sur le fait que le Server-Side Tagging permet de contourner les adblockers et indique que la collecte de données doit se faire après recueil du consentement.
- "GTM Server Side – L’évolution naturelle pour votre tagging ?" de Converteo. L'article liste en avantages le fait de pouvoir contourner les limitations navigateurs telles que celles de Safari et Firefox, ainsi que le contournement des adblockers.
- "Introduction to Google Tag Manager Server-side Tagging", du blog Analytics mania. Là aussi, les contournements des limitations navigateurs et adblockers sont listés en bénéfice.
- "Google introduit le tagging côté serveur, une bonne nouvelle ?" de Nicolas Jaimes sur le JDN. L'angle de l'article est la publicité, et donc le contournement des protections navigateurs est listé en bénéfice (même si pour l'instant, le manque de librairies tierces fait que le Server-Side Tagging reste complexe à implémenter).
Malheureusement, il y a fort à parier que beaucoup de sites seront également séduits par ces "bénéfices", en plus des gains de performance, de sécurité et de contrôle. L'impossibilité d'auditer les sites web sera également une grosse perte pour les défenseurs de la vie privée. En espérant que les navigateurs et adblockers trouvent des parades afin que les internautes soucieux de leur vie privée puissent continuer de se défendre.
31.10.2020 à 18:17
NextDNS, mon nouveau bloqueur de traceurs et de publicités préféré

Lors de mes analyses de sites et d'applications, la conclusion est souvent la même : faute de véritables sanctions contre les éditeurs, vous devez vous protéger contre la surveillance publicitaire via des moyens techniques. Cet article a pour but de partager ma configuration actuelle.
Les choix de bloqueurs de traceurs et de publicités sont évidemment très personnels : vous utilisez sans doute d'autres applications, d'autres extensions, vos choix sont peut-être plus efficaces. Aussi, je suis loin d'être le seul à écrire sur le sujet et je ne suis pas expert "Adblock", bref n'hésitez pas à partager votre expérience !
Selon les appareils, il est plus ou moins facile de bloquer les traceurs et publicités. Voici les différents scénarios auxquels je suis confronté.
Bloquer les traceurs et publicités sur un navigateur "Desktop" : des adblockers largement adoptés aujourd'hui
Sur mes MacBook (personnel, professionnel), lorsque je surfe sur le web, j'utilise Firefox avec l'extension uBlock Origin. Sur Firefox, cet adblocker détecte le "CNAME cloaking" et le bloque (ce qui n'est pas le cas sur Chrome). Le "CNAME cloaking" est une technique utilisée par certains acteurs du marketing de surveillance pour vous pister, même si vous avez pris vos précautions (cette technique pose aussi des problèmes de sécurité). Si vous souhaitez approfondir le sujet, lisez les explications de NextDNS (en anglais) et la présentation de la Quadrature du Net (en français).
Surtout, à la différence d'un Adblock Plus que je déconseille vivement, uBlock Origin n'offre aucun passe-droit aux publicitaires. La société Eyeo, éditrice d'Adblock Plus, est à l'origine du programme Acceptable Ads, et se fait payer de grosses sommes par des géants du marketing de surveillance tels que que Google, Microsoft, Amazon, Taboola, Outbrain et Criteo pour ne pas bloquer leurs publicités par défaut : une énorme hypocrisie !
Il m'est facile de conseiller Firefox et uBlock Origin à mes proches :
- Firefox est simple à installer et très rapide. C'est un logiciel développé par un acteur indépendant (Mozilla), open-source et respecteux de la vie privée de ses utilisateurs.
- uBlock Origin est également simple à installer, et très efficace.
Bloquer les traceurs et publicités sur le web, sur un iPhone : des bloqueurs de contenus moins démocratisés
Sur mon iPhone, lorsque je surfe sur le web, j'utilise Safari. Grâce à Intelligent Tracking Prevention (ITP), celui-ci me protège contre le pistage multi-sites par des tiers (notamment en bloquant les cookies tiers, mais pas que). À noter que depuis iOS 14, Intelligent Tracking Prevention s'applique aussi aux autres navigateurs : Chrome sur iOS vous protège aussi contre le pistage multi-sites par des tiers ! Seulement voilà, ITP ne répond pas à tous mes besoins :
- Il ne bloque pas les publicités.
- Il bloque le suivi multi-sites mais ne bloque pas l'envoi des traceurs (Safari continue d'envoyer les requêtes vers de multiples sociétés marketing).
- Il permet le suivi lorsqu'il est restreint à un seul site : l'outil analytics d'un éditeur (Google Analytics lorsque l'éditeur n'a pas activé les fonctionnalités publicitaires, AT Internet, Adobe Analytics...) continuera de fonctionner correctement et d'analyser votre parcours (même si l'analyse est restreinte au site consulté).
À la différence d'Android (exemple : Firefox pour Android), iOS ne permet pas à un navigateur d'installer des extensions (le navigateur doit nécessairement utiliser le moteur de rendu de Safari, Webkit) : impossible donc d'installer directement un adblocker.
Il est néanmoins possible d'installer un "bloqueur de contenu", celui-ci sera activé uniquement sur Safari (et non sur les autres navigateurs) et permettra de bloquer des listes de traceurs et de publicités. J'utilise donc le bloqueur de contenu Firefox Focus pour bloquer les publicités. AdGuard propose également un bloqueur de contenu pour Safari, mais lors de mon utilisation, il bloquait le chargement de certains sites, ce qui me forçait à le désactiver.
Il m'est également facile de conseiller cette option à mes proches qui sont sur iOS (pour Android, je recommande Firefox avec uBlock Origin) :
- Safari est le navigateur par défaut, rien à configurer.
- Firefox Focus demande un minimum de configuration, mais cela reste rapide.
Bloquer les traceurs et publicités sur les applications natives : le public est peu informé, NextDNS à la rescousse
Plus compliqué maintenant, sur les applications iPhone, il me manquait une bonne option pour bloquer les traceurs et publicités. Je payais pour ProtonVPN mais celui-ci ne peut être utilisé simultanément avec un bloqueur tel que NextDNS ou AdGuard.
Aussi, j'avais de gros problèmes de batteries avec les applications ProtonVPN, NextDNS et AdGuard et je pensais connaître la cause : ces applications étaient toutes basées sur un VPN (ces applications pouvaient parfois utiliser jusqu'à 50% de la batterie de mon vieil iPhone sur une journée). Avant la sortie de iOS 14, NextDNS et AdGuard devaient utiliser un VPN local pour chiffrer les requêtes DNS.
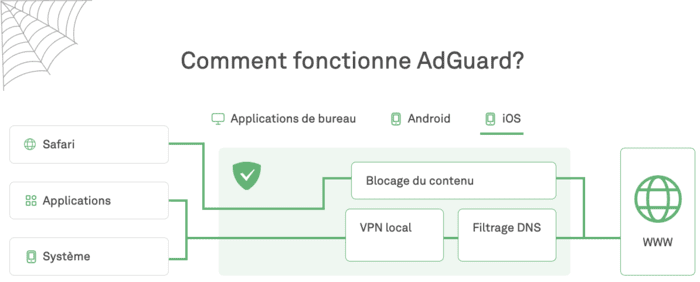
Adguard passe par un VPN local sous iOS
Mais avec iOS 14, Apple ajoute la possibilité de chiffrer les requêtes DNS nativement. Plus besoin de passer par le "hack" d'un VPN local, et donc plus d'impact sur ma batterie. NextDNS ayant implémenté cette option rapidement, j'ai décidé de l'utiliser systématiquement et je n'ai pas été déçu.
Avec NextDNS, je peux ainsi :
- Bloquer les traceurs et les publicités lorsque j'utilise des applications sur mon iPhone, via l'application iOS NextDNS donc.
- Bloquer les traceurs et les publicités sur mon Apple TV (tvOS permet également de chiffrer les requêtes DNS nativement), via le générateur de profils de configuration Apple.
- Bloquer les traceurs et publicités sur les applications lorsque j'utilise mon Mac. Un exemple : le player Mac Spotify est très bavard, il fuite vos données personnelles à Google et Comscore et uBlock Origin ne va pas aider. L'appli Mac de NextDNS permet de bloquer ces traceurs.
- Compléter le blocage des traceurs et publicités déjà effectué par uBlock Origin sur Firefox (Mac) et Firefox Focus sur Safari (iPhone) via une 2ème couche de blocage NextDNS. J'ai ainsi fait disparaitre de nombreuses bannières de consentement, rendant mon surf plus agréable.
- Configurer ma Freebox pour utiliser le DNS de NextDNS et ainsi bloquer les traceurs des objets connectés (mon thermostat en l'occurrence).
Je peux également facilement recommander cette solution à mes proches :
- NextDNS est rapide à installer et à configurer (à la différence d'un Pi-Hole, qui s'adresse principalement à des bidouilleurs).
- NextDNS fonctionne aussi en mobilité (toujours à la différence d'un Pi-Hole, qui ne fonctionnera que sur le WiFi personnel maison).
De l'utilité d'un annuaire DNS
NextDNS est un annuaire DNS (Domain Name System) parmi d'autres. Le DNS est un des services essentiels à l'internet : c'est un annuaire qui va permettre la correspondance entre un nom de domaine (exemple : google.fr) et une adresse IP (exemple : 216.58.204.99). Par défaut, vous utilisez le serveur DNS de votre fournisseur d'accès internet. Seulement voilà :
- Ces requêtes DNS ne sont pas chiffrées, un pirate peut donc les intercepter, apprendre quels sites vous consultez voire modifier ces requêtes à la volée pour vous faire télécharger un virus par exemple.
- Pour des raisons légales, les fournisseurs d'accès internet (FAI) bloquent également l'accès à certains sites web. Exemple : vous souhaitez télécharger des fichiers torrent (films, séries, musique) via le site The Pirate Bay, mais celui-ci risque d'être bloqué par votre fournisseur. Les FAI appliquent ce blocage via l'annuaire DNS qu'ils mettent à votre disposition.
Pour que vos requêtes DNS soient chiffrées et pour vous permettre d'accéder à certains sites web, vous pouvez changer de fournisseur DNS. Si vous ne souhaitez pas bloquer les traceurs et publicités, OpenDNS est un annuaire de confiance. Si vous souhaitez simplement utiliser un service rapide et que vous n'êtes pas inquiet de l'omniprésence de Google dans votre vie, vous pouvez utiliser le Google Public DNS. De même, si vous êtes peu concerné par la centralisation progressive du web mais simplement par la performance, vous pouvez utiliser le DNS de Cloudflare.
Mais ce serait dommage de s'arrêter en si bon chemin ! Dans le cas des traceurs et publicités, l'annuaire DNS peut retourner une réponse vide au lieu de renvoyer la bonne adresse IP. Exemple : si vous êtes en train de jouer à un jeu sur votre iPhone et que celui-ci souhaite délivrer une publicité, il va demander à votre annuaire DNS l'adresse de doubleclick.net (la régie publicitaire de Google). Si vous utilisez NextDNS et si vous avez activé les bloqueurs, celui-ci ne renverra pas de réponse : vous ne serez pas pisté et vous ne verrez pas de publicité !
NextDNS vous permet de choisir vos listes de blocage
Comme pour un adblocker "classique" tel que uBlock Origin, NextDNS vous permet de vous abonner à des listes de blocage :
Mon choix parmi les listes les plus utilisés.
NextDNS vous propose également des listes de blocage pour se protéger contre le tracking "natif" :
Apple collecte des statistiques d'usage ? Je peux maintenant bloquer ces requêtes.
Le fonctionnement de NextDNS est transparent
Si vous décidez d'activer les logs de NextDNS, vous aurez une grande flexibilité :
- Sur la durée de rétention : de 1 heure à 2 ans. Si vous souhaitez vérifier que NextDNS fonctionne bien et affiner les domaines bloqués, 1 heure est suffisant.
- Sur la localisation du stockage : notamment dans l'Union Européenne ou mieux, en Suisse.
Vous pourrez alors "vérifier" le travail de NextDNS via une interface en ligne. Voici la vue lorsque je lance l'application L'Équipe sur mon iPhone :
Comme nous l'avons déjà vu, l'application L'Équipe fuite vos données personnelles. Mais NextDNS empêche bien ces fuites (vers ACPM et Weborama sur la capture écran), et vous ne verrez plus de publicité.
Si jamais vous observez des traceurs non bloqués, vous avez le choix de vous abonner à de nouvelles listes de blocage ou tout simplement d'ajouter ces traceurs à votre liste noire :
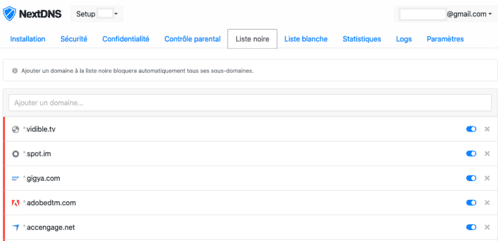
Quelques traceurs ajoutés manuellement
Si vos logs sont activés, vous aurez également accès à des statistiques agrégés :
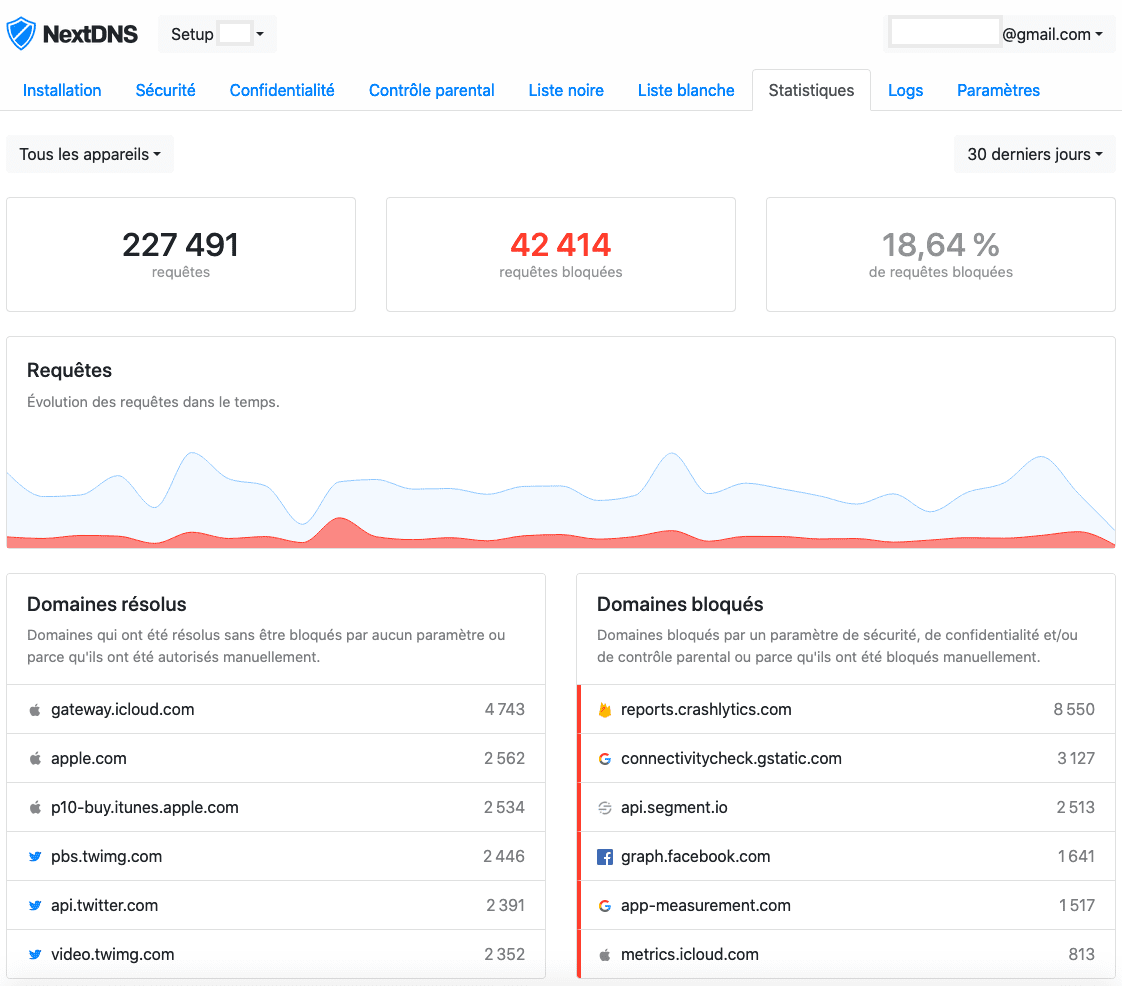
NextDNS bloque quasiment 20% de mes requêtes. Si je regarde la vue par appareil, NextDNS bloque jusqu'à 30% des requêtes sur mon iPhone et sur mon Apple TV (les applications n'y étant pas ciblées par d'autres adblockers). Au contraire, sur mes portables MacBook, NextDNS ne bloque que 3% des requêtes, uBlock Origin bloquant déjà les traceurs et autres publicités sur le web.
NextDNS bloque également le "CNAME cloaking"
Le "CNAME cloaking" est une manière insidieuse de vous surveiller, en passant outre les protections des navigateurs et autres adblockers. Son implémentation est souvent accompagnée d'une grave faille de sécurité la fuite de vos identifiants de connexion vers le tiers. Voici quelques exemples détaillés sur ce blog :
- LeBonCoin l'utilise en partenariat avec Criteo.
- Lemonde.fr l'utilise en partenariat avec AT Internet.
- Boursorama l'utilisait en partenariat avec AT Internet et Smart AdServer (le problème a depuis été corrigé).
- Criteo pousse cette technique agressivement à ses clients, plus de 10.000 éditeurs auraient déjà implémenté du "CNAME cloaking" avec Criteo.
Criteo en particulier est très vicieux dans son utilisation du "CNAME cloaking" : la "fonctionnalité" est activée uniquement si vous utilisez Safari (afin de contourner "Intelligent Tracking Prevention"). Ainsi vous pourriez croire qu'un site ne passe pas par du "CNAME cloaking" si vous observez les requêtes avec Firefox ou Chrome. Ainsi, lorsque vous utilisez Safari sur iPhone, vous n'êtes pas protégé contre cette technique de surveillance.
NextDNS a implémenté la protection contre le pistage via "CNAME cloaking" il y a déjà 1 an :

La protection est activée par défaut.
Quel modèle économique pour NextDNS ?
Avant d'utiliser un tel service, la première question est de bien comprendre le modèle économique. Un exemple : Google a pour modèle économique le marketing de surveillance. Si vous êtes inquiet de l'omniprésence de Google dans nos vies, vous éviterez surement Google Public DNS. NextDNS a un modèle "freemium" :
- Le service est gratuit jusqu'à 300.000 requêtes DNS par mois (note : pour mon premier mois d'utilisation, malgré un usage intensif, je n'ai pas atteint cette limite). Si vous atteignez la limite et ne payez pas, NextDNS se comportera comme un simple annuaire DNS pour les requêtes supplémentaires : ni filtre, ni logs.
- Si vous dépassez les quotas, le tarif est très raisonnable : $1.99/mois ou $19.90/an (à peu près l'équivalent en euros).
- NextDNS propose également des plans payant pour les entreprises et les écoles.
Pouvez-vous faire confiance à NextDNS ?
Si vous n'avez pas changé vos paramètres DNS, vous utilisez sans doute l'annuaire de votre fournisseur d'accès internet. Lorsque vous passez par NextDNS, vous devez faire confiance à un nouveau tiers, comment juger si ce tiers est digne de confiance ? À chacun de se faire son propre avis, voici les arguments qui m'ont convaincu.
La présentation des fondateurs, 2 français, explicite les principes de NextDNS :
NextDNS has been founded in May 2019 in Delaware, USA by two French founders Romain Cointepas and Olivier Poitrey. Olivier has been working on Internet infrastructures for the last 20 years. In 2005, he founded Dailymotion, the largest video sharing service after Youtube and the most popular European website in the world at the time. He is currently Director of Engineering at Netflix, working on Open Connect, Netflix's home CDN also known as the CDN moving about 30% of the total US Internet traffic. Romain and Olivier closely worked for years at Dailymotion on many different projects. Romain ended up leading the mobile & TV department.
We are true supporters of the net neutrality and Internet privacy. We believe that un-encrypted DNS resolvers operated by ISPs are detrimental to those two principles. Alternative solutions like Google DNS or Cloudflare DNS are great, but we think more actors need to step up and provide alternative services to avoid centralization of powers.
Je préfère utiliser les services d'une société ayant ces principes plutôt que ceux de mon fournisseur d'accès internet ou d'un Google. Notez également la compétence technique des 2 cofondateurs (Netflix et Dailymotion), qui se retrouve également dans la rapidité de NextDNS :
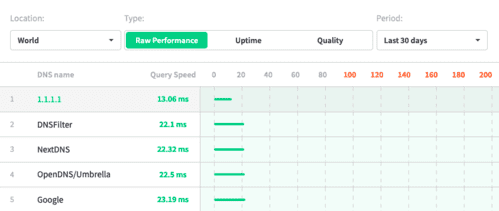
NextDNS est plus rapide que Google sur les 30 derniers jours.
La politique de confidentialité est également directe, concise et très claire :
- Les données récoltées ne seront jamais vendues ou partagées.
- Toute donnée ne devant pas être loguée (par choix utilisateur) est immédiatement supprimée.
- Si l'utilisateur ne demande pas explicitement à ce que ses données soient loguées, rien n'est logué. Si l'utilisateur le demande (pour voir ses logs, comme j'ai pu le faire), il a la main sur ses données et sur la durée de rétention.
- NextDNS vous protège (il n'expose pas votre adresse IP) lorsqu'il demande des informations à d'autres annuaires DNS.
NextDNS a également été choisi comme partenaire de Firefox afin de chiffrer les requêtes DNS de ses utilisateurs (pour l'instant, le programme est seulement disponible aux États-Unis). C'est un gage de sérieux (le seul autre partenaire est Cloudflare).
NextDNS vs Pi-Hole ?
Si vous souhaitez garder le contrôle et que vous êtes bidouilleur, le Pi-Hole est une excellente solution. Notez qu'il vous faudra quand même faire confiance au serveur DNS appelé par le Pi-Hole (upstream DNS), donc vous devrez toujours faire confiance à quelqu'un. NextDNS est une sorte de "Pi-Hole dans le cloud", cet article détaille les avantages et inconvénients des 2 options.
Si vous souhaitez creuser l'option NextDNS, je vous conseille cet article ainsi que la FAQ de NextDNS. Pour ma part, le choix est vite fait : par sa simplicité d'installation et par le fait qu'il fonctionne en mobilité, NextDNS répond parfaitement à mes besoins. Je peux également facilement l'installer chez des proches qui ne sont pas geeks.
Quelques soient vos préférences, je vous encourage à payer pour de l'information de qualité et à protéger vos proches en leur installant des bloqueurs de traceurs et de publicités sur leurs appareils.
Texte intégral (3555 mots)
Lors de mes analyses de sites et d'applications, la conclusion est souvent la même : faute de véritables sanctions contre les éditeurs, vous devez vous protéger contre la surveillance publicitaire via des moyens techniques. Cet article a pour but de partager ma configuration actuelle.
Les choix de bloqueurs de traceurs et de publicités sont évidemment très personnels : vous utilisez sans doute d'autres applications, d'autres extensions, vos choix sont peut-être plus efficaces. Aussi, je suis loin d'être le seul à écrire sur le sujet et je ne suis pas expert "Adblock", bref n'hésitez pas à partager votre expérience !
Selon les appareils, il est plus ou moins facile de bloquer les traceurs et publicités. Voici les différents scénarios auxquels je suis confronté.
Bloquer les traceurs et publicités sur un navigateur "Desktop" : des adblockers largement adoptés aujourd'hui
Sur mes MacBook (personnel, professionnel), lorsque je surfe sur le web, j'utilise Firefox avec l'extension uBlock Origin. Sur Firefox, cet adblocker détecte le "CNAME cloaking" et le bloque (ce qui n'est pas le cas sur Chrome). Le "CNAME cloaking" est une technique utilisée par certains acteurs du marketing de surveillance pour vous pister, même si vous avez pris vos précautions (cette technique pose aussi des problèmes de sécurité). Si vous souhaitez approfondir le sujet, lisez les explications de NextDNS (en anglais) et la présentation de la Quadrature du Net (en français).
Surtout, à la différence d'un Adblock Plus que je déconseille vivement, uBlock Origin n'offre aucun passe-droit aux publicitaires. La société Eyeo, éditrice d'Adblock Plus, est à l'origine du programme Acceptable Ads, et se fait payer de grosses sommes par des géants du marketing de surveillance tels que que Google, Microsoft, Amazon, Taboola, Outbrain et Criteo pour ne pas bloquer leurs publicités par défaut : une énorme hypocrisie !
Il m'est facile de conseiller Firefox et uBlock Origin à mes proches :
- Firefox est simple à installer et très rapide. C'est un logiciel développé par un acteur indépendant (Mozilla), open-source et respecteux de la vie privée de ses utilisateurs.
- uBlock Origin est également simple à installer, et très efficace.
Bloquer les traceurs et publicités sur le web, sur un iPhone : des bloqueurs de contenus moins démocratisés
Sur mon iPhone, lorsque je surfe sur le web, j'utilise Safari. Grâce à Intelligent Tracking Prevention (ITP), celui-ci me protège contre le pistage multi-sites par des tiers (notamment en bloquant les cookies tiers, mais pas que). À noter que depuis iOS 14, Intelligent Tracking Prevention s'applique aussi aux autres navigateurs : Chrome sur iOS vous protège aussi contre le pistage multi-sites par des tiers ! Seulement voilà, ITP ne répond pas à tous mes besoins :
- Il ne bloque pas les publicités.
- Il bloque le suivi multi-sites mais ne bloque pas l'envoi des traceurs (Safari continue d'envoyer les requêtes vers de multiples sociétés marketing).
- Il permet le suivi lorsqu'il est restreint à un seul site : l'outil analytics d'un éditeur (Google Analytics lorsque l'éditeur n'a pas activé les fonctionnalités publicitaires, AT Internet, Adobe Analytics...) continuera de fonctionner correctement et d'analyser votre parcours (même si l'analyse est restreinte au site consulté).
À la différence d'Android (exemple : Firefox pour Android), iOS ne permet pas à un navigateur d'installer des extensions (le navigateur doit nécessairement utiliser le moteur de rendu de Safari, Webkit) : impossible donc d'installer directement un adblocker.
Il est néanmoins possible d'installer un "bloqueur de contenu", celui-ci sera activé uniquement sur Safari (et non sur les autres navigateurs) et permettra de bloquer des listes de traceurs et de publicités. J'utilise donc le bloqueur de contenu Firefox Focus pour bloquer les publicités. AdGuard propose également un bloqueur de contenu pour Safari, mais lors de mon utilisation, il bloquait le chargement de certains sites, ce qui me forçait à le désactiver.
Il m'est également facile de conseiller cette option à mes proches qui sont sur iOS (pour Android, je recommande Firefox avec uBlock Origin) :
- Safari est le navigateur par défaut, rien à configurer.
- Firefox Focus demande un minimum de configuration, mais cela reste rapide.
Bloquer les traceurs et publicités sur les applications natives : le public est peu informé, NextDNS à la rescousse
Plus compliqué maintenant, sur les applications iPhone, il me manquait une bonne option pour bloquer les traceurs et publicités. Je payais pour ProtonVPN mais celui-ci ne peut être utilisé simultanément avec un bloqueur tel que NextDNS ou AdGuard.
Aussi, j'avais de gros problèmes de batteries avec les applications ProtonVPN, NextDNS et AdGuard et je pensais connaître la cause : ces applications étaient toutes basées sur un VPN (ces applications pouvaient parfois utiliser jusqu'à 50% de la batterie de mon vieil iPhone sur une journée). Avant la sortie de iOS 14, NextDNS et AdGuard devaient utiliser un VPN local pour chiffrer les requêtes DNS.
Adguard passe par un VPN local sous iOS
Mais avec iOS 14, Apple ajoute la possibilité de chiffrer les requêtes DNS nativement. Plus besoin de passer par le "hack" d'un VPN local, et donc plus d'impact sur ma batterie. NextDNS ayant implémenté cette option rapidement, j'ai décidé de l'utiliser systématiquement et je n'ai pas été déçu.
Avec NextDNS, je peux ainsi :
- Bloquer les traceurs et les publicités lorsque j'utilise des applications sur mon iPhone, via l'application iOS NextDNS donc.
- Bloquer les traceurs et les publicités sur mon Apple TV (tvOS permet également de chiffrer les requêtes DNS nativement), via le générateur de profils de configuration Apple.
- Bloquer les traceurs et publicités sur les applications lorsque j'utilise mon Mac. Un exemple : le player Mac Spotify est très bavard, il fuite vos données personnelles à Google et Comscore et uBlock Origin ne va pas aider. L'appli Mac de NextDNS permet de bloquer ces traceurs.
- Compléter le blocage des traceurs et publicités déjà effectué par uBlock Origin sur Firefox (Mac) et Firefox Focus sur Safari (iPhone) via une 2ème couche de blocage NextDNS. J'ai ainsi fait disparaitre de nombreuses bannières de consentement, rendant mon surf plus agréable.
- Configurer ma Freebox pour utiliser le DNS de NextDNS et ainsi bloquer les traceurs des objets connectés (mon thermostat en l'occurrence).
Je peux également facilement recommander cette solution à mes proches :
- NextDNS est rapide à installer et à configurer (à la différence d'un Pi-Hole, qui s'adresse principalement à des bidouilleurs).
- NextDNS fonctionne aussi en mobilité (toujours à la différence d'un Pi-Hole, qui ne fonctionnera que sur le WiFi personnel maison).
De l'utilité d'un annuaire DNS
NextDNS est un annuaire DNS (Domain Name System) parmi d'autres. Le DNS est un des services essentiels à l'internet : c'est un annuaire qui va permettre la correspondance entre un nom de domaine (exemple : google.fr) et une adresse IP (exemple : 216.58.204.99). Par défaut, vous utilisez le serveur DNS de votre fournisseur d'accès internet. Seulement voilà :
- Ces requêtes DNS ne sont pas chiffrées, un pirate peut donc les intercepter, apprendre quels sites vous consultez voire modifier ces requêtes à la volée pour vous faire télécharger un virus par exemple.
- Pour des raisons légales, les fournisseurs d'accès internet (FAI) bloquent également l'accès à certains sites web. Exemple : vous souhaitez télécharger des fichiers torrent (films, séries, musique) via le site The Pirate Bay, mais celui-ci risque d'être bloqué par votre fournisseur. Les FAI appliquent ce blocage via l'annuaire DNS qu'ils mettent à votre disposition.
Pour que vos requêtes DNS soient chiffrées et pour vous permettre d'accéder à certains sites web, vous pouvez changer de fournisseur DNS. Si vous ne souhaitez pas bloquer les traceurs et publicités, OpenDNS est un annuaire de confiance. Si vous souhaitez simplement utiliser un service rapide et que vous n'êtes pas inquiet de l'omniprésence de Google dans votre vie, vous pouvez utiliser le Google Public DNS. De même, si vous êtes peu concerné par la centralisation progressive du web mais simplement par la performance, vous pouvez utiliser le DNS de Cloudflare.
Mais ce serait dommage de s'arrêter en si bon chemin ! Dans le cas des traceurs et publicités, l'annuaire DNS peut retourner une réponse vide au lieu de renvoyer la bonne adresse IP. Exemple : si vous êtes en train de jouer à un jeu sur votre iPhone et que celui-ci souhaite délivrer une publicité, il va demander à votre annuaire DNS l'adresse de doubleclick.net (la régie publicitaire de Google). Si vous utilisez NextDNS et si vous avez activé les bloqueurs, celui-ci ne renverra pas de réponse : vous ne serez pas pisté et vous ne verrez pas de publicité !
NextDNS vous permet de choisir vos listes de blocage
Comme pour un adblocker "classique" tel que uBlock Origin, NextDNS vous permet de vous abonner à des listes de blocage :
Mon choix parmi les listes les plus utilisés.
NextDNS vous propose également des listes de blocage pour se protéger contre le tracking "natif" :
Apple collecte des statistiques d'usage ? Je peux maintenant bloquer ces requêtes.
Le fonctionnement de NextDNS est transparent
Si vous décidez d'activer les logs de NextDNS, vous aurez une grande flexibilité :
- Sur la durée de rétention : de 1 heure à 2 ans. Si vous souhaitez vérifier que NextDNS fonctionne bien et affiner les domaines bloqués, 1 heure est suffisant.
- Sur la localisation du stockage : notamment dans l'Union Européenne ou mieux, en Suisse.
Vous pourrez alors "vérifier" le travail de NextDNS via une interface en ligne. Voici la vue lorsque je lance l'application L'Équipe sur mon iPhone :
Comme nous l'avons déjà vu, l'application L'Équipe fuite vos données personnelles. Mais NextDNS empêche bien ces fuites (vers ACPM et Weborama sur la capture écran), et vous ne verrez plus de publicité.
Si jamais vous observez des traceurs non bloqués, vous avez le choix de vous abonner à de nouvelles listes de blocage ou tout simplement d'ajouter ces traceurs à votre liste noire :
Quelques traceurs ajoutés manuellement
Si vos logs sont activés, vous aurez également accès à des statistiques agrégés :
NextDNS bloque quasiment 20% de mes requêtes. Si je regarde la vue par appareil, NextDNS bloque jusqu'à 30% des requêtes sur mon iPhone et sur mon Apple TV (les applications n'y étant pas ciblées par d'autres adblockers). Au contraire, sur mes portables MacBook, NextDNS ne bloque que 3% des requêtes, uBlock Origin bloquant déjà les traceurs et autres publicités sur le web.
NextDNS bloque également le "CNAME cloaking"
Le "CNAME cloaking" est une manière insidieuse de vous surveiller, en passant outre les protections des navigateurs et autres adblockers. Son implémentation est souvent accompagnée d'une grave faille de sécurité la fuite de vos identifiants de connexion vers le tiers. Voici quelques exemples détaillés sur ce blog :
- LeBonCoin l'utilise en partenariat avec Criteo.
- Lemonde.fr l'utilise en partenariat avec AT Internet.
- Boursorama l'utilisait en partenariat avec AT Internet et Smart AdServer (le problème a depuis été corrigé).
- Criteo pousse cette technique agressivement à ses clients, plus de 10.000 éditeurs auraient déjà implémenté du "CNAME cloaking" avec Criteo.
Criteo en particulier est très vicieux dans son utilisation du "CNAME cloaking" : la "fonctionnalité" est activée uniquement si vous utilisez Safari (afin de contourner "Intelligent Tracking Prevention"). Ainsi vous pourriez croire qu'un site ne passe pas par du "CNAME cloaking" si vous observez les requêtes avec Firefox ou Chrome. Ainsi, lorsque vous utilisez Safari sur iPhone, vous n'êtes pas protégé contre cette technique de surveillance.
NextDNS a implémenté la protection contre le pistage via "CNAME cloaking" il y a déjà 1 an :
La protection est activée par défaut.
Quel modèle économique pour NextDNS ?
Avant d'utiliser un tel service, la première question est de bien comprendre le modèle économique. Un exemple : Google a pour modèle économique le marketing de surveillance. Si vous êtes inquiet de l'omniprésence de Google dans nos vies, vous éviterez surement Google Public DNS. NextDNS a un modèle "freemium" :
- Le service est gratuit jusqu'à 300.000 requêtes DNS par mois (note : pour mon premier mois d'utilisation, malgré un usage intensif, je n'ai pas atteint cette limite). Si vous atteignez la limite et ne payez pas, NextDNS se comportera comme un simple annuaire DNS pour les requêtes supplémentaires : ni filtre, ni logs.
- Si vous dépassez les quotas, le tarif est très raisonnable : $1.99/mois ou $19.90/an (à peu près l'équivalent en euros).
- NextDNS propose également des plans payant pour les entreprises et les écoles.
Pouvez-vous faire confiance à NextDNS ?
Si vous n'avez pas changé vos paramètres DNS, vous utilisez sans doute l'annuaire de votre fournisseur d'accès internet. Lorsque vous passez par NextDNS, vous devez faire confiance à un nouveau tiers, comment juger si ce tiers est digne de confiance ? À chacun de se faire son propre avis, voici les arguments qui m'ont convaincu.
La présentation des fondateurs, 2 français, explicite les principes de NextDNS :
NextDNS has been founded in May 2019 in Delaware, USA by two French founders Romain Cointepas and Olivier Poitrey. Olivier has been working on Internet infrastructures for the last 20 years. In 2005, he founded Dailymotion, the largest video sharing service after Youtube and the most popular European website in the world at the time. He is currently Director of Engineering at Netflix, working on Open Connect, Netflix's home CDN also known as the CDN moving about 30% of the total US Internet traffic. Romain and Olivier closely worked for years at Dailymotion on many different projects. Romain ended up leading the mobile & TV department.
We are true supporters of the net neutrality and Internet privacy. We believe that un-encrypted DNS resolvers operated by ISPs are detrimental to those two principles. Alternative solutions like Google DNS or Cloudflare DNS are great, but we think more actors need to step up and provide alternative services to avoid centralization of powers.
Je préfère utiliser les services d'une société ayant ces principes plutôt que ceux de mon fournisseur d'accès internet ou d'un Google. Notez également la compétence technique des 2 cofondateurs (Netflix et Dailymotion), qui se retrouve également dans la rapidité de NextDNS :
NextDNS est plus rapide que Google sur les 30 derniers jours.
La politique de confidentialité est également directe, concise et très claire :
- Les données récoltées ne seront jamais vendues ou partagées.
- Toute donnée ne devant pas être loguée (par choix utilisateur) est immédiatement supprimée.
- Si l'utilisateur ne demande pas explicitement à ce que ses données soient loguées, rien n'est logué. Si l'utilisateur le demande (pour voir ses logs, comme j'ai pu le faire), il a la main sur ses données et sur la durée de rétention.
- NextDNS vous protège (il n'expose pas votre adresse IP) lorsqu'il demande des informations à d'autres annuaires DNS.
NextDNS a également été choisi comme partenaire de Firefox afin de chiffrer les requêtes DNS de ses utilisateurs (pour l'instant, le programme est seulement disponible aux États-Unis). C'est un gage de sérieux (le seul autre partenaire est Cloudflare).
NextDNS vs Pi-Hole ?
Si vous souhaitez garder le contrôle et que vous êtes bidouilleur, le Pi-Hole est une excellente solution. Notez qu'il vous faudra quand même faire confiance au serveur DNS appelé par le Pi-Hole (upstream DNS), donc vous devrez toujours faire confiance à quelqu'un. NextDNS est une sorte de "Pi-Hole dans le cloud", cet article détaille les avantages et inconvénients des 2 options.
Si vous souhaitez creuser l'option NextDNS, je vous conseille cet article ainsi que la FAQ de NextDNS. Pour ma part, le choix est vite fait : par sa simplicité d'installation et par le fait qu'il fonctionne en mobilité, NextDNS répond parfaitement à mes besoins. Je peux également facilement l'installer chez des proches qui ne sont pas geeks.
Quelques soient vos préférences, je vous encourage à payer pour de l'information de qualité et à protéger vos proches en leur installant des bloqueurs de traceurs et de publicités sur leurs appareils.
25.10.2020 à 19:54
La domination des marchés publicitaires de Google

Google, acteur dominant de l'adtech
Le sujet de ce billet sera un peu différent des sujets traités habituellement sur ce blog. Au lieu d'observer les fuites de données personnelles sur les sites et applications, je vais tenter de documenter (de manière non exhaustive, les abus étant multiples) comment Google s'est imposé sur les marchés publicitaires. Si vous souhaitez en savoir plus, voici quelques études publiées récemment :
- L'étude de Dina Srinivasan : Why Google Dominates Advertising Markets.
- Les études de Damien Geradin et Dimitrios Katsifis : Google’s (Forgotten) Monopoly – Ad Technology Services on the Open Web, 'Trust me, I'm Fair': Analysing Google's Latest Practices in Ad Tech From the Perspective of EU Competition Law et Competition in Ad Tech: A Response to Google.
- L'étude de Fiona M. Scott Morton et David C. Dinielli : Roadmap for a Digital Advertising Monopolization Case Against Google.
- Les "notes de préparation du secrétariat de l'OCDE" : Competition in Digital Advertising Markets.
- L'étude de la "Competition and Markets Authority" (CMA) anglaise : Online platforms and digital advertising market study.
L'époque où les campagnes publicitaires étaient créées et gérées "manuellement" (contrats par fax, envoi des bannières publicitaires et éléments de tracking par e-mail, etc) entre agences et régies publicitaires est révolue :
- À l'instar des marchés financiers, cette gestion est maintenant automatisée (le "programmatique" ou "RTB" pour "Real-Time Bidding").
- La technologie permettant la réalisation de ces marchés publicitaires est appelé SSP (Supply-Side Platform) ou Ad Exchange.
- La réalisation de la vente d'espaces publicitaires se fait maintenant à l'unité : l'éditeur propose une opportunité publicitaire (l'affichage d'une publicité sur votre appareil), libre à l'annonceur de miser ou non sur cette opportunité.
- L'annonceur détient souvent des données personnelles sur vous lorsqu'il reçoit cette opportunité, ce qui lui permet de miser ce qu'il pense être le "juste prix".
- Il est en concurrence avec d'autres annonceurs, chacun passant par des robots acheteurs appelés DSPs (Demand-Side Platforms)
- L'enchère se réalise très rapidement, en souvent moins de 100 millisecondes.
- Beaucoup moins médiatisés, les accords préférentiels entre annonceurs et éditeurs (appelés "deals" dans le milieu de l'adtech) n'ont pas disparu, mais ils transitent également majoritairement dans les tuyaux du "programmatique").
Ces marchés publicitaires automatisés sont à l'origine d'une fuite massive de données personnelles, lisez par exemple la plainte pour violation du RGPD de Brave contre Google et l'IAB (le lobby de l'adtech) sur le RTB. Et ils sont dominés par Google, voici par exemple les chiffres pour l'Angleterre (les chiffres sont similaires sur les autres principaux marchés occidentaux) :
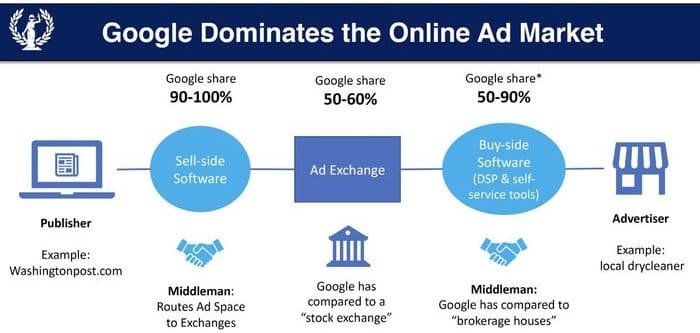
Online Platforms and Digital Advertising Market Study (CMA July 1st 2020)
À ce titre, le modèle économique choisi par Google (le capitalisme de surveillance) et ses décisions opérationnelles (support de la monétisation publicitaire du web via ces places de marchés automatisés, notion de consentement bafouée, etc) ont une influence démesurée sur les autres acteurs du web publicitaire, qui n'ont souvent d'autres choix que de rentrer eux aussi dans le jeu du capitalisme de surveillance.
Quel lien entre cette domination de Google et la bonne santé du web en général ? Si l'on reprend les bilans annuels de Google, on peut observer que celui-ci capte en propre (recherche Google, YouTube) une part de plus en plus importante des dépenses publicitaires effectuées via les outils d'achat proposés par Google (eux-même déjà dominants).
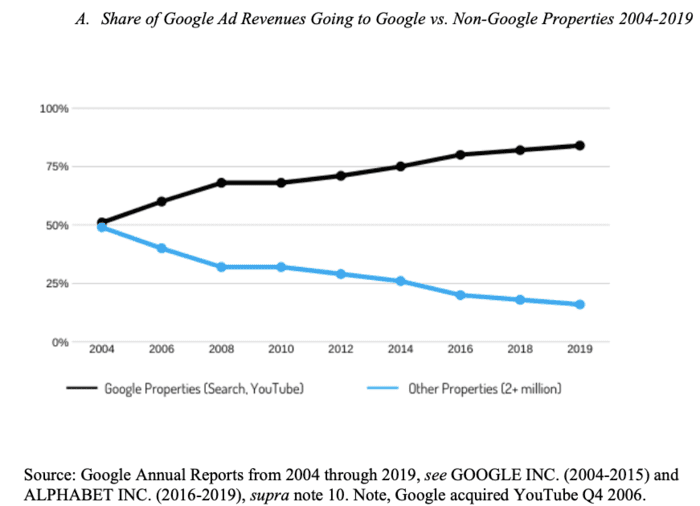
En 2007, Google captait en propre 64% de ses revenus publicitaires. Au premier trimestre de 2020, Google en capte 85%.
Conséquence : les éditeurs captent une part de plus en plus faible de ces financements (part sur laquelle Google prend sa taxe) et se retrouvent privés de financements importants. On peut citer la situation économique critique du secteur de l'information, entraînant :
- Une grande précarité chez beaucoup de journalistes.
- Un manque de moyens pour traiter des enquêtes de fond, si critiques pour nos démocraties.
- Une faible autonomie des médias face aux puissances de l'argent. Difficile de créer un grand média rentable aujourd'hui, les médias français sont pour la plupart détenus par quelques riches industriels, cf. la carte des Médias français réalisée par Acrimed et Le Monde diplomatique.
La thèse de Dina Srinivasan est que Google n'aurait jamais pu dominer à ce point les marchés publicitaires si ces marchés étaient régulés correctement. Elle dévoile que de nombreuses pratiques appliquées par Google pour favoriser son propre business ont été interdites sur ces marchés financiers. Et donc que Google a pu étendre sa toile grâce à l'inaction publique. Les études respectives de Damien Geradin et Dimitrios Katsifis, puis de Fiona M. Scott Morton et David C. Dinielli, détaillent également les multiples conflits d'intérêts et l'absence de transparence de Google.
Avant 2007, Google est déjà un géant publicitaire
En 2000, Google lance Google AdWords (aujourd'hui Google Ads) afin de mieux monétiser son moteur de recherche, très rapidement c'est un succès. Quelles en sont les raisons ?
- Tout d'abord, évidemment, son moteur de recherche très efficace, apprécié des utilisateurs (même si depuis 2000, Google a multiplié les abus de position dominante sur ce domaine, regardez l'évolution des résultats de recherche, c'est assez frappant).
- Un système en "self-service" où chaque annonceur (du petit artisan de quartier à la multinationale) peut créer sa campagne publicitaire rapidement à condition qu'il ait une carte bleue.
- Un paiement à la performance : l'annonceur achète les mots-clés qu'il souhaite et ne paye que lorsque l'utilisateur clique sur la publicité.
- Une publicité plus pertinente : afin de maximiser ses revenus, Google a intérêt à privilégier une publicité moins cher mais ayant un meilleur taux de clic.
En 2003, Google lance Google AdSense afin d'étendre sa régie publicitaire à des sites web tiers. Sur quels leviers s'appuie Google ?
- En premier, sur le fait qu'il ait déjà un marché captif unique : un nombre incalculable d'annonceurs déjà sur AdWords, petits et gros, avec leurs cartes bleues. Ailleurs sur le web, pour lancer une campagne publicitaire, vous devez payer une agence.
- En deuxième, sur le fait qu'il crawle déjà le web, il est donc capable de fournir des publicités contextuelles pertinentes : s'assurer que la publicité d'un annonceur opérant sur un secteur d'activité précis trouvera de quoi diffuser sur des sites en rapport avec son secteur d'activité (publicité contextuelle).
- En troisième, sur le fait que pour un "petit" site web qui n'a pas les moyens d'ouvrir de régie publicitaire pour démarcher les agences, il existait peu de concurrence.
Bref, c'est également un succès.
En 2007, le rachat de Doubleclick permet à Google d'obtenir une position clé chez les éditeurs
Mais les régies publicitaires des grands éditeurs n'utilisent pas que Google AdSense pour monétiser leurs inventaires publicitaires. Elle se méfient de la qualité des annonces diffusées par Google AdSense (la variété des annonceurs fait que l'on peut aussi tomber sur des annonces non souhaitées), et n'apprécient pas forcément le format des publicités (texte uniquement à l'origine, pas de bannières ni de vidéos). Elles travaillent aussi avec d'autres ad-networks et ont surtout des relations fortes avec les agences publicitaires, ce qui leur permet de vendre la plupart de leur inventaire publicitaire en direct, à des prix plus intéressants.
Pour gérer l'ensemble de leurs campagnes publicitaires (vente en directe, vente via des ad-networks tels que Google AdSense ou vente via les nouvelles places de marchés), elles passent par des outils spécialisés appelés adservers.
De même, les principales agences n'ont pas que les résultats de recherche Google pour diffuser les publicités de leurs clients annonceurs. Elles ont besoin d'un outil pour gérer et mesurer correctement l'ensemble de leurs campagnes publicitaires. Cet outil est également un adserver, à noter que ses fonctionnalités sont sensiblement différentes d'un adserveur éditeur, même s'ils partagent une base commune.
Afin de se rapprocher des gros éditeurs et annonceurs, Google achète Doubleclick pour 3,1 milliards de dollars. À l'époque Doubleclick a déjà une position très forte avec son adserver éditeur (DFP pour Doubleclick for Publishers) mais aussi avec son adserveur annonceur (DFA pour Doubleclick for Advertisers). Et surtout, la plupart des adserveurs concurrents ne se positionnent que d'un seul côté (éditeur ou annonceur).
En 2009, le lancement du Doubleclick Ad Exchange
En 2009, Google a automatisé depuis bien longtemps le marché du "Search" via ses liens sponsorisés. Il a étendu sa régie publicitaire AdWords à YouTube et à son réseau de partenaires Google AdSense, sa place de marché publicitaire à la performance est particulièrement efficace. De l'autre côté, les campagnes publicitaires "Display" (bannières publicitaires et vidéos sur le web) sont alors encore principalement gérées manuellement, "à l'ancienne" :
- Les agences et régies publicitaires vont se mettre d'accord sur des campagnes publicitaires (X impressions, période de diffusion, ciblage éventuel, prix).
- Les agences vont ensuite paramétrer les campagnes publicitaires dans leurs adserveurs (DFA ou autre), puis envoyer les tags de ces campagnes aux régies publicitaires.
- Celles-ci vont alors paramétrer dans leurs adserveurs (DFP ou autre) ces tags publicitaires.
Cette double programmation est très laborieuse, surtout lorsque l'on veut diffuser sa campagne publicitaire sur de nombreux sites. Comment la diffusion publicitaire fonctionne-t-elle ? Ce n'est déjà pas si simple :
Via Ad Ops Insider, How does adserving work?
Afin de pallier à ce manque, les intermédiaires appelés ad-network occupent déjà une place importante : ils proposent aux annonceurs de toucher de nombreux éditeurs sans avoir à les contacter un par un (Google AdSense est l'un d'eux). Les régies publicitaires paramètrent alors le tag de l'ad-network dans leurs adserveurs.
Mais gérer de multiples ad-networks reste complexe et inefficace : les ad-networks ne peuvent acheter en temps-réel car il n'y a pas encore de système d'enchères (la rémunération est fixée à l'avance, quelque soit l'utilisateur) et ils se réservent le droit de refuser d'acheter une opportunité publicitaire. Les régies publicitaires se retrouvent à devoir gérer les différents ad-networks dans un système appelé "Waterfall" : une cascade d'ad-networks, appelés les uns après les autres (ceux dont on suppose qu'ils seront les plus rentables en premiers), système ayant pour but de maximiser les revenus (tout en limitant la casse côté expérience utilisateur).
Via Ad Waterfalls explained, les "passbacks" sont du au fait que l'ad-network doit rappeler l'adserveur de l'éditeur s'il n'a rien à diffuser, pour que celui-ci rappelle ensuite l'ad-network suivant... L'expérience utilisateur est catastrophique.
S'inspirant du succès d'AdWords et s'appuyant sur son récent achat de Doubleclick, Google lance sa propre place de marché : le Doubleclick Ad Exchange (lisez l'interview de l'époque, en 2 parties). Quel est l'impact du programmatique sur le fonctionnement de la diffusion publicitaire ? Les mécanismes se complexifient :
Via Ad Ops Insider, How RTB adserving works
Google est en léger retard par rapport à d'autres acteurs tels que Right Media, AdECN, AdBrite et ADSDAQ. Mais le programmatique démarre à peine et la nouvelle place de marché coche toutes les bonnes cases :
- Enchères en temps-réel, pour laquelle l'acheteur peut utiliser les données personnelles qu'il détient sur l'utilisateur.
- Paiements sécurisés par Google (intermédiaire de confiance).
- Pour les acheteurs de la nouvelle place de marché, accès simplifié aux éditeurs AdSense mais aussi aux grands éditeurs qui utilisent déjà Doubleclick DFP et qui auront activé Doubleclick Ad Exchange.
- Pour les acheteurs Adwords, nouvel accès aux grands éditeurs DFP ayant activé Doubleclick Ad Exchange.
- Pour les grands éditeurs, accès simplifié aux annonceurs AdWords, mais aussi aux différents ad-networks qui ont déjà fait l'intégration avec la place de marché (dès le lancement, Google annonce avoir intégré la majeure partie des grands ad-networks américains).
- Pour les grands éditeurs toujours, l'allocation dynamique dans DFP entre leurs ventes en direct et les ventes via le Doubleclick Ad Exchange, leurs permettant de maximiser leurs revenus (compétition entre les campagnes vendues en direct et les enchères du Doubleclick Ad Exchange).
- Pour les éditeurs AdSense, demande additionnelle via les acheteurs du Doubleclick Ad Exchange.
Comment le programmatique fonctionne avec Google, grâce au rachat de Doubleclick et au lancement du Doubleclick Ad Exchange :
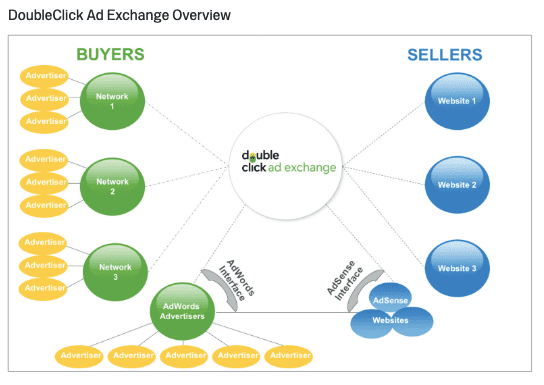
Vous voyez poindre les conflits d'intérêt ?
En 2010 et 2011, d'autres rachats permettent à Google d'étendre son poids sur le Display
En 2010, Google achète AdMob pour 750 millions de $. AdMob offrait des solutions de monétisation pour les sites et applications mobiles. Google était déjà très bien placé avec Google AdSense sur le web et décide de payer le prix fort pour ne pas laisser passer la vague de la publicité sur le mobile. Il réécrit le logiciel pour l'inscrire dans la suite Doubleclick en 2013.
En 2010 toujours, Google réalise un de ses meilleurs coups en achetant Invite Media pour 70 millions de $. Invite Media était un des principaux DSP sur le marché et une pièce manquante chez Google. Il permet à un annonceur ou à une agence d'acheter de l'inventaire publicitaire sur les Ad Exchanges. Google complète ainsi ses outils pour les annonceurs : de la même manière qu'il a pu ajouter la brique Doubleclick Ad Exchange à son adserveur éditeur DFP, il ajoute la brique d'achat Invite Media (renommé ensuite Doubleclick Bid Manager ou DBM lors de la réécriture du logiciel) à son adserveur annonceur DFA.
Ces achats d'outils côté annonceur lui permettent de proposer maintenant 2 plateformes d'achats :
- Google Ads : la plateforme d'achats permettant à tous les annonceurs, petits ou grands, d'acheter de la publicité sur les résultats de recherche Google. Elle permet également aux petits annonceurs de diffuser des campagnes publicitaires sur YouTube, sur AdSense et sur l'Ad Exchange de Google.
- Google Display & Video 360 ou DV 360 : la plateforme d'achats "Display & Video" à destination des grands annonceurs et agences, intégrant l'ancien DBM mais aussi DFA (renommé Doubleclick Campaign Manager ou DCM). Ceux-ci peuvent acheter l'inventaire sur YouTube, sur AdSense, sur l'exchange de Google mais aussi sur les principaux Ad Exchanges tiers.
En 2011, Google accroît sa domination côté éditeur en achetant AdMeld pour 400 millions de $. AdMeld était un concurrent de Doubleclick Ad Exchange, Google y gagne encore à plusieurs niveaux :
- AdMeld avait beaucoup d'éditeurs de qualité dans ses clients.
- Si la partie Ad Exchange était déjà bien gérée par Google, AdMeld vient compléter les capacités de DFP et de Doubleclick Ad Exchange via une meilleure gestion des ad-networks (le programmatique n'est pas encore dominant).
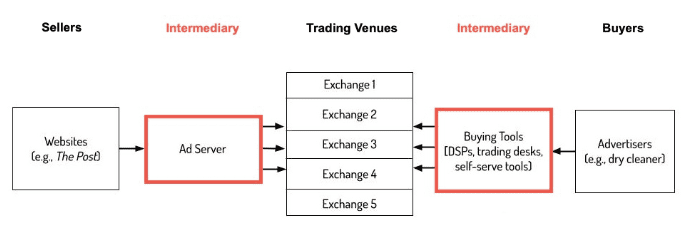
L'écosystème du programmatique, Google détient en 2011 avec Doubleclick le principal adserver éditeur (ainsi que le principal adserveur annonceur, absent de ce graphique), mais aussi un nouvel Exchange important (Doubleclick Ad Exchange, amélioré grâce à AdMeld) et une des principales plateformes d'achat (Invite Media). Google a d'autres pions qu'il intègre à sa "stack" : Admob sur le mobile, AdWords et AdSense, Google Analytics, Google Tag Manager, etc.
En 2013, l'exchange de Google (Doubleclick Ad Exchange, renommé AdX, et maintenant Authorized Buyers) devient la place de marché principale du programmatique. La plateforme d'achats de Google (DBM, maintenant DV 360) est elle-même maintenant majoritaire.
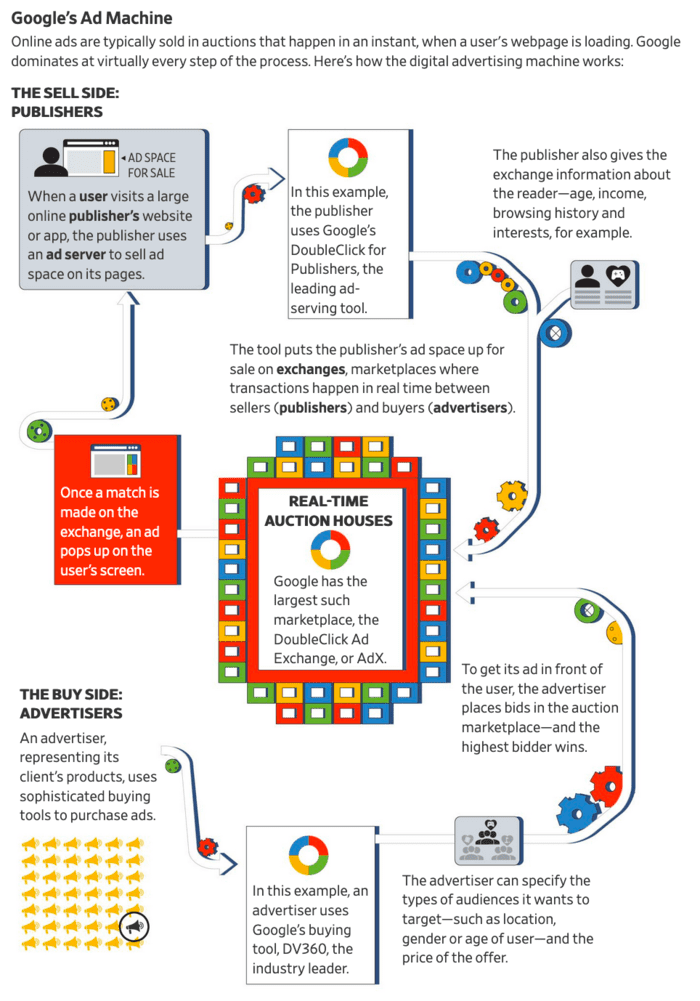
Mécanisme pour délivrer une publicité, intégralement dans l'écosystème de Google. Regardez l'excellente infographie du Wall Street Journal, How Google Edged Out Rivals and Built the World’s Dominant Ad Machine: A Visual Guide
Au-delà de la qualité des produits Google (qu'il ne faut pas sous-estimer), quels sont donc les points clés de cette ascension rapide ?
Google a un avantage d'information sur ses concurrents
Grâce à son rachat de Doubleclick en 2007, Google s'achète une empreinte énorme sur le web. De nombreux grands éditeurs utilisent Doubleclick en tant qu'adserveur (DFP), ce qui permet à Google de passer premier sur l'identification des utilisateurs sur le web et d'en reconnaître la plupart, via les cookies doubleclick. La plupart des grandes agences utilisant également Doubleclick en tant qu'adserveur (DFA), Google accroît encore son empreinte (même si un site n'utilise pas DFP, la plupart de ses campagnes publicitaires sera diffusé avec un tag annonceur DFA).
Là vous pourriez vous dire : Doubleclick est un outil acheté par les éditeurs et annonceurs, l'identité des utilisateurs sur l'outil (un identifiant numérique) n'est pas la propriété de Google mais la leur. Et en effet, c'est ce que Google déclare au congrès américain lors de l'enquête sur le rachat de Doubleclick : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it".
Sans accès à un identifiant utilisateur donc, il est beaucoup plus difficile de monétiser un utilisateur sur le marché du programmatique. Une étude de Google indique par exemple une chute de 52% des revenus sur les utilisateurs n'ayant pas de cookies tiers, nécessaires au stockage d'identifiants utilisateurs dans le cadre du programmatique sur le web. Ce chiffre se retrouve aussi dans d'autres études indépendantes.
Et Google utilise progressivement l'identifiant utilisateur Doubleclick pour ses propres intérêts :
- Dès 2009 pour sa plateforme d'achats Google Ads, il place des cookies doubleclick sur ses propres sites et chez ses partenaires AdSense : "Google uses the DoubleClick advertising cookie on AdSense partner sites and certain Google services to help advertisers and publishers serve and manage ads across the web".
- En 2009 toujours, Google utilise l'identifiant doubleclick sur son Exchange, le Doubleclick Ad Exchange, ce qui permet aux acheteurs Google Ads de reconnaître les utilisateurs qui surfent chez les nouveaux clients de l'Exchange. Par contre, les autres acheteurs (les ad-networks et autres DSPs, utilisés par les grands annonceurs) n'ont pas accès à cet identifiant : "For buyers, Google identifies users using a buyer-specific Google User ID consisting of an encrypted version of the doubleclick.net cookie, derived from but not equal to that cookie. Google passes the user ID to the buyer (raw cookies are never sent)."
- En 2009 encore, Google empêche ses clients adserveur éditeurs (ici : "The DoubleClick cookie ID associated with the user, encrypted.") et annonceurs (ici : "You will never be able to decrypt user IDs, and Google will not disclose the encryption method. No encryption keys will ever be provided to any Campaign Manager customer or any third-party partner.") d'accéder aux identifiants utilisateur doubleclick, en contradiction avec sa précédente déclaration : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it".
- En 2012, lorsque Google réécrit Invite Media pour lancer DBM, sa propre plateforme d'achats à destination des grands annonceurs, celle-ci a bien accès à l'identifiant doubleclick : "For itself, Google identifies users with cookies that belong to the doubleclick.net domain under which Google serves ads."
- En 2013, Google ne fournit plus qu'à ses éditeurs DFP des logs, sans l'identifiant doubleclick : "The DoubleClick cookie ID associated with the user, encrypted."
- En 2018, Google enlève l'identifiant doubleclick des logs de son adserveur DCM : "You will never be able to decrypt user IDs, and Google will not disclose the encryption method. No encryption keys will ever be provided to any Campaign Manager customer or any third-party partner". Rappel, Google avait déclaré lors du rachat de DoubleClick : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it".
Échec et mat ! Voici les conséquences :
- Annonceurs et éditeurs avaient l'habitude de travailler directement ensemble pour des campagnes publicitaires ciblées, via l'identifiant doubleclick. Ils doivent désormais passer par les outils Google, DBM et AdX (ou Google Ads et AdSense pour les petits annonceurs et petits éditeurs).
- DBM et Google Ads partent avec un avantage sur les autres plateformes d'achats : celles-ci doivent synchroniser leurs identifiants avec l'identifiant doubleclick (cf. Cookie Matching) avant de pouvoir reconnaître les utilisateurs lorsque Google leurs envoient les opportunitées publicitaires et ainsi mieux acheter. Au mieux, les plateformes d'achats peuvent espérer une non-reconnaissance des utilisateurs de l'ordre de 20%, au pire de plus de 50%.
- Les plateformes d'achats concurrentes n'ont pas la même empreinte sur le web tandis que le cookie doubleclick est omniprésent : chez les éditeurs AdSense et DFP, sur la recherche Google, sur Gmail, sur YouTube, etc.
Comment fonctionne la synchronisation d'identifiants ? Ici représentée entre un DSP et plusieurs SSPs, mais le mécanisme et le même lorsqu'un SSP doit synchroniser les identifiants avec plusieurs DSPs :
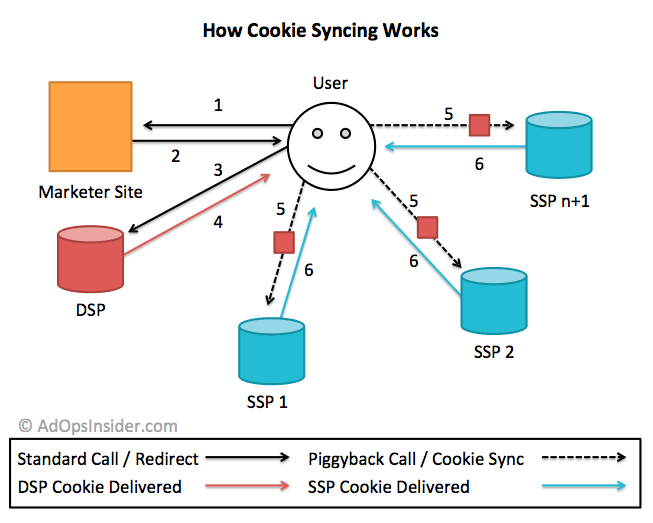
Via Ad Ops Insider, SSP to DSP Cookie Syncing Explained
Google explique d'ailleurs très bien les bénéfices d'une "lecture de cookies supérieure" à ses clients :
Google Ads et Display & Video 360 génèrent des performances optimales lors de l'achat d'inventaire sur Ad Exchange, car ces plates-formes d'achat partagent la même infrastructure que la place de marché. Cela signifie que la perte de lecture de cookies potentielle lorsque les utilisateurs de Google Ads et de Display & Video 360 achètent sur d'autres places de marché est réduite lors de l'achat sur Ad Exchange. Ainsi, lorsque des achats sont effectués via Google Ads et Display & Video 360 sur Ad Exchange, il est plus probable que ces solutions détectent des impressions répondant à leurs critères de ciblage, ce qui donne lieu à un accroissement de la pression au niveau des enchères et à une augmentation de la demande pour l'inventaire de l'éditeur.
Protéger votre vie privée ?! La belle hypocrisie de Google
Google ne détaille pas les raisons qui l'ont conduit à supprimer l'accès à l'identifiant doubleclick aux tiers. Simplement qu'il a agit pour des motifs de vie privée :
- Afin d'empêcher différents acteurs de combiner leurs informations (chaque acteur a sa propre version de l'identifiant doubleclick, et ne peut donc partager des informations utilisateur avec son voisin).
- Afin d'empêcher les acteurs de combiner des identifiants avec des informations nominatives.
Si l'objectif de protection de la vie privée est louable, Google ne l'applique pas à lui-même : il combine bien les informations qu'il a sur vous via ses différents services (Recherche, YouTube, Gmail, Maps, etc), via ses différents clients Doubleclick (annonceurs ou éditeurs), il combine aussi les informations DoubleClick avec les informations nominatives de votre compte Google si vous n'avez pas réglé correctement vos paramètres Google. Voici 2 décisions clés :
- En 2012, Google propose alors 70 différents services (et 70 politiques de confidentialités différentes), les données personnelles de ces différents services sont bien cloisonnées. Par exemple, YouTube ne connaît pas votre historique de recherche Google et ne peut donc vous cibler via des publicités en rapport avec cette historique. Google décide alors de ne proposer plus qu'une seule politique de confidentialité et de combiner vos données personnelles sur l'ensemble de ces services. Les réactions sont unanimement négatives et les enquêtes se multiplient mais rien n'y fait, Google ne recule pas.
- En 2016, Google modifie sa politique de confidentialité discrètement et y supprime l'interdiction de combiner les informations liées au cookie Doubleclick et les informations nominatives de votre compte Google si Google n'a pas votre opt-in explicite. L'association sera automatique pour les nouveaux utilisateurs. Pour les utilisateurs existants, Google maquille la dangereuse association en vous demandant si vous souhaitez accéder à des fonctionnalités supplémentaires, avec le titre : “Some new features for your Google account”.
Le jeu Googolopoly, créé en 2008 (depuis cette date, le nombre de sociétés rachetées par Google a explosé). La mission de Google est originellement d'organiser les informations à l'échelle mondiale. Aujourd'hui, il s'agit plutôt de s'accaparer des pans toujours plus larges de vos activités, pour mieux vous influencer.
Ces décisions s'accompagnent de nombreuses modifications insidieuses de produits Google. En 2018 par exemple, Chrome vous connecte automatiquement à votre compte Google lorsque vous vous connectez à un site Google (Gmail par exemple), sans vous demander votre avis. Il vous pousse également à envoyer tout votre historique de navigation à Google via un Dark Pattern, lisez à ce propos "Why I'm done with Chrome".
Si l'on s'intéresse aux données Doubleclick, rappelez vous la déclaration de Google en 2007 : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it". Aujourd'hui, Google récupère par exemple des données personnelles via ses clients éditeurs Google Ad Manager (exemple : les utilisateurs surfant sur un site d'informations financières), données personnelles qu'il peut ensuite utiliser pour son propre profit. Comment ? En vendant via Google Ads des campagnes publicitaires à des banques, ciblées sur les utilisateurs du premier site, mais sur d'autres sites web (ayant eux-mêmes intégrés Google AdSense ou Google AdX).
Si l'on regarde attentivement les règles de confidentialité de Google, cachées au dessous de la section "Protéger Google, nos utilisateurs et le public" (et non dans la section "Proposer des services personnalisés, notamment en matière de contenu et d'annonces"), on peut y lire :
Selon vos paramètres de compte, votre activité sur d'autres sites et dans d'autres applications peut être associée à vos informations personnelles dans le but d'améliorer les services Google et les annonces diffusées par Google.
Voilà comment discrètement, Google s'approprie les données de ses clients éditeurs et annonceurs, pour son propre profit. Mais attention, l'interdiction aux tiers d'accéder à l'identifiant doubleclick a été conçue pour protéger votre vie privée !
Google a un avantage de vitesse sur ses concurrents
Lorsqu'une place de marché (SSP ou Ad Exchange) propose une opportunité publicitaire à un robot acheteur (DSP), celui-ci a un temps limité pour répondre, généralement entre 100 ms et 200 ms. Aussi, s'il ne répond que rarement dans les temps, le SSP va réduire le nombre d'opportunités envoyées. Les plateformes d'achats de Google (Google Ads, DV 360) partent alors avec un avantage énorme, elles sont situées sur les mêmes serveurs que la place de marché de Google (AdX) :
L'avantage de vitesse de Google, une latence réduite.
Google met également cette "latence réduite" en avant dans sa documentation, les autres acteurs pouvant "perdre" jusqu'à 25% des demandes d'enchères :
Lorsque des achats sont effectués via Google Ads ou Display & Video 360 sur d'autres places de marché, les utilisateurs en question sont confrontés à la même latence du réseau que le reste des acheteurs. Nous avons constaté que, dans certains cas, les problèmes de latence peuvent empêcher les acheteurs de soumettre une enchère pour jusqu'à 25 % des demandes d'enchères, ce qui limite leur participation aux enchères ayant lieu sur d'autres places de marché.
Ce gain de temps permet aux plateformes d'achats de Google d'être plus "intelligentes" : de prendre le temps nécessaire pour récupérer les données utilisateurs et faire tourner les bons algorithmes afin de choisir la publicité qui aura le plus fort impact sur l'utilisateur, au prix optimal (et qui maximisera les profits de Google).
À noter que Google propose aux plateformes d'achats une option de colocation (via Google Cloud Platform), mais seul le SSP OpenX l'a choisit. Il est difficile de savoir si les autres plateformes d'achats refusent de passer par le Cloud Google pour des questions de coûts, pour des questions évidentes de conflits d'intérêt, ou tout simplement qu'elles jugent que cet avantage n'est pas si déterminant. Le chiffre des 25% des demandes d'enchères perdues à cause de problèmes de latence ne peut pas être audité car Google ne fournit pas à ses éditeurs l'information des enchères exclues car arrivées trop tard (cf. Bids data in Ad Manager Data Transfer).
Google impose ses propres plateformes d'achats
Pour pouvoir acheter de l'inventaire sur YouTube, un site incontournable, un annonceur est obligé de passer par les plateformes d'achats de Google car en 2015, Google a décidé de couper l'accès à l'inventaire YouTube aux plateformes d'achats tierces. Aussi, Google a été poursuivi par les autorités américaines en 2013 pour avoir limité les fonctionnalités des APIs Google Ads, compliquant l'achat de liens sponsorisés Google via des outils tiers.
Comme nous l'avons vu précédemment, utiliser Google DV 360 et une autre plateforme d'achats en parallèle fait prendre le risque de miser 2 fois pour le même utilisateur (car l'autre plateforme d'achats n'a pas accès aux cookies doubleclick et ne peut donc reconnaître qu'il s'agit du même utilisateur) et de faire ainsi monter artificiellement les prix.
Les plateformes d'achats de Google sont donc incontournables pour les annonceurs, seul Facebook pouvant rivaliser, mais celui-ci n'a plus d'empreinte sur le web depuis l'arrêt de son Audience Network (maintenant seulement disponible sur l'univers App) et ne peut ainsi "que" vendre sur le web l'accès à ses propres propriétés (Facebook, Instagram).
Google oriente les achats vers ses propres plateformes et sites
Lorsqu'un petit annonceur créé un compte sur Google Ads, il doit d'abord démarrer une campagne "Search" (sur les résultats de recherche Google) avant de pouvoir acheter de l'inventaire sur des sites tiers. Une première méthode pour diriger les achats vers ses propres sites.
Google peut également orienter les achats depuis ses plateformes d'achats vers les sites passant par ses solutions de monétisation :
- Jusqu'en 2016, Google n'orientait les achats de Google Ads que vers le Google Ad Exchange (cf. la présentation du Doubleclick Ad Exchange de l'époque : "Ad Exchange is the only exchange offering access to the full demand of Google AdWords"), empêchant les autres Ad Exchange de profiter de cette manne publicitaire potentielle. Cela a changé depuis, mais de manière limitée : seulement pour les campagnes de remarketing, cf. l'aide en ligne de Google Ads.
- S'il n'a pas bloqué l'accès aux autres Exchanges depuis sa plateforme d'achats à destination des grands annonceurs DBM (alias DV 360 maintenant), il est fréquemment accusé d'orienter les achats en priorité vers son propre Ad Exchange : "Most DBM buyers we talk to say more than half of their spend goes to AdX when they use DBM" déclarait alors le PDG d'AppNexus, un rival.
Google oriente les ventes vers sa propre place de marché
Côté éditeurs, l'adserveur dominant est Google DFP. Celui-ci a récemment été fusionné avec Google AdX pour être renommé Google Ad Manager. Suite au rachat de Doubleclick en 2007, Google a profité de la position dominante de DFP pour imposer AdX. Voici comment il a procédé :
- Directement dans DFP , l'éditeur peut paramétrer ses campagnes publicitaires à volume garanti (pré-vendues, pour lesquelles l'acheteur s'engage à acheter un certain volume d'opportunités publicitaires, sur des critères de diffusion précis) et ses campagnes publicitaires à volume non garanti (l'éditeur propose des opportunités publicitaires, l'acheteur potentiel n'a aucune obligation d'achat).
- Les campagnes publicitaires à volume non garanti peuvent provenir d'ad-networks ayant un accord direct avec l'éditeur. Mais comme évoqué précédemment, l'éditeur doit alors configurer un système d'appels aux ad-networks en cascade (les uns après les autres), entraînant pertes de revenus (prix fixe pour chaque ad-network, pas de concurrence directe) et mauvaise expérience utilisateur (lenteurs).
- Les campagnes publicitaires à volume non garanti peuvent également provenir de Google AdX, intégré "nativement" à DFP depuis 2010. Celui-ci permet une vraie mise en concurrence des acheteurs (enchère en temps-réel). Il est également connecté aux 2 plateformes d'achats de Google : DV 360 (ex DBM) et Google Ads (ex AdWords).
- Un système de mise en concurrence appelé "Allocation dynamique" arbitre entre les campagnes publicitaires à volume garanti et celles à volume non garanti. Son objectif est de maximiser les revenus de l'éditeur tout en s'assurant que les campagnes à volume garanti respecteront le contrat avec l'acheteur et diffuseront le bon volume d'impression, sur les bons critères (inventaire, ciblage, dates de diffusion). Comment ? En fixant dynamiquement un "prix fictif" pour les campagnes à volume garanti (assez fort pour leur permettre de diffuser) et en regardant si les campagnes à volume non garanti proposent un meilleur prix.
- Si AdX est intégré nativement à DFP, les autres places de marchés n'ont pas cette chance. Jusqu'en 2017 et l'annonce de l'Exchange Bidding, DFP obligeait les éditeurs à configurer les autres places de marchés comme de simples ad-networks (et donc à les appeler les uns après les autres, après AdX si celui-ci n'avait pas déjà "préempté" l'opportunité). Ils devaient également renseigner un prix de vente fixe pour chaque place de marché, hors le principe d'une enchère est de ne pas connaître le prix de vente.
Conséquence : fin 2014, les éditeurs désireux de travailler avec d'autres places de marchés, se retrouvent à "hacker" DFP via un système appelé "header bidding".
Le header bidding, un hack imparfait pour mettre en concurrence Google AdX
Le Header Bidding étape par étape, détaillé sur le site Ad Ops Insider :
De manière très résumée, comme DFP ne permet pas de vraie mise en concurrence entre AdX et les autres places de marchés, le header bidding permet une mise en concurrence des places de marchés (hors AdX) en dehors de l'adserver (via le header de la page), avant l'appel à DFP. Le vainqueur de l'enchère est alors mis en concurrence avec les autres campagnes de DFP, volume garanti ou non. L'éditeur est obligé de créer autant de "line items" (campagnes sur DFP) que de tranches de prix, pour chaque place de marché !
Via l'article Quelles sont les conséquences du header bidding sur l’achat programmatique ?, le header bidding permet une vraie compétition chez les places de marchés tierces.
Cette implémentation permet aux éditeurs de desserrer un peu l'étau de Google via une mise en concurrence avec d'autres places de marché, elle leur permet aussi de décider du temps de réponse maximum accordé aux différentes places de marchés, permettant ainsi de prendre en considération les enchères des acheteurs plus lents. La contrepartie : les tags des différentes places de marché, tous appelés directement via le header de la page, entraînent des lenteurs et dégradent l'expérience utilisateur.
Enfin une compétition équitable entre les différentes places de marchés ? Pas vraiment...
Le "last-look", où comment Google s'octroie un nouvel avantage sur ses concurrents
Le diable est dans les détails et les places de marchés tierces sont encore désavantagées par rapport à Google AdX, explications :
- Les enchères RTB fonctionnent alors quasiment exclusivement en mode "2nd price auction" : l'acheteur ne paye que le prix de la 2ème enchère. Exemple : Sur la place de marché AppNexus, A mise 5€, B mise 1€ ==> A gagne et devrait payer 1€.
- Ce prix de 1€ permet également à AppNexus de gagner la compétition header bidding (contre les autres places de marchés tierces).
- AppNexus soumet alors ce prix de 1€ à DFP. Via l'allocation dynamique, les acheteurs AdX savent qu'ils doivent miser plus pour espérer remporter la compétition.
- C mise 2€, D mise 0,5€, le plancher est à 1€ ==> C gagne et paye 1€.
Cet avantage que Google s'accorde à lui-même est appelé "last look" dans le milieu de l'adtech.
On le voit sur cet exemple, l'acheteur A était prêt à dépenser 5€, il n'a pas pu dépenser sa mise. La place de marché tierce avait un acheteur potentiel à 5€ contre un acheteur potentiel à 2€ sur Google AdX, elle a également perdu injustement la compétition. L'éditeur aurait pu gagner 5€ (moins les commissions), il gagne finalement 1€ (moins les commissions). Un seul gagnant : Google, qui aura ainsi pu satisfaire ses acheteurs et prendre sa commission via Google AdX.
Afin de maximiser leurs chances de gain dans la compétition avec Google AdX, les places de marchés tierces ont décidé progressivement (et tardivement, à partir de 2018) de basculer sur des enchères en mode "1st price auction" : l'acheteur paie alors le prix de son enchère. Une première partie du problème est résolu : dans l'exemple précédent, l'acheteur A gagne et paye 5€. Mais Google continue de transmettre ce prix plancher aux acheteurs de Google AdX (dont Google Ads).
Ceux-ci gardent donc un avantage d'information et peuvent décider de miser 1 centime de plus pour gagner l'enchère ("last look"). Les places de marchés tierces restent désavantagées.
Google Ads peut faire de l'arbitrage sans que personne ne s'en rende compte
Si un annonceur aura droit à une information transparente sur son DSP (prix de l'enchère et prix d'achat) lorsqu'il achète sur AdX, ce n'est pas le cas s'il utilise Google Ads : celui-ci ne fournit pas ce niveau de transparence dans ses rapports. Aussi, le mode d'achat sur Google Ads est au clic (CPC ou coût par clic), que la publicité soit diffusée sur les résultats de recherche Google ou sur Google AdX. Mais les ventes en programmatique se font à l'impression (CPM ou coût pour 1000 affichages), rendant les comparaisons plus difficiles.
Aussi, lorsqu'il mise sur Google AdX, Google Ads part avec un avantage d'information énorme :
- Il n'a pas besoin de synchroniser les identifiants utilisateurs.
- Il bénéficie de l'omniprésence des traqueurs Doubleclick (tous les clients éditeurs et annonceurs de Doubleclick, les clients Google Analytics ayant activés les fonctionnalités publicitaires, AdSense et YouTube), informations qu'il s'autorise à combiner à son propre profit (rappelez-vous, la fusion des politiques de confidentialité des 70 différents services de Google en 2012).
- Si l'utilisateur ne l'a pas refusé, les informations doubleclick sont également combinées avec les informations personnelles associées au compte Google de l'utilisateur (rappelez-vous, la modification des conditions d'utilisation de Google en 2016).
- Enfin, il représente un nombre considérable d'annonceurs, tous intéressés pour afficher leurs publicités sur les résultats de recherche Google.
Ces informations permettent à Google Ads de prédire avec une grande précision le taux de clics, et donc de miser au meilleur prix pour optimiser ses propres revenus (tout en garantissant une performance acceptable à l'annonceur). Un exemple ci-dessous, provenant du papier "‘Trust Me, I’m Fair’: Analysing Google’s Latest Practices in Ad Tech From the Perspective of EU Competition Law" :
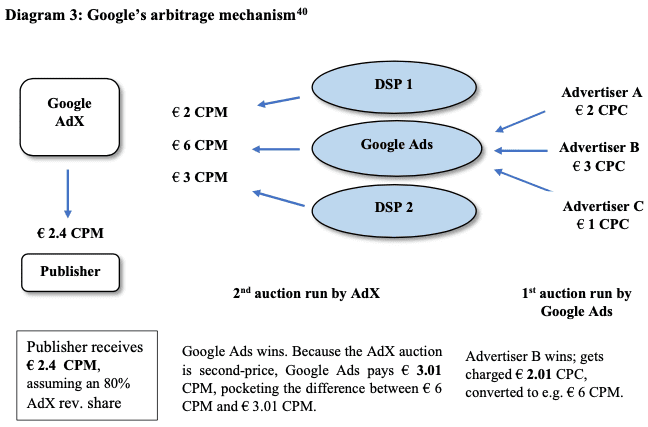
Ici, Google Ads reçoit 6€ mais paye seulement 3€ pour gagner l'enchère, il peut garder la différence
À noter que Google Ads tire parti de plusieurs facteurs pour faire de l'arbitrage :
- Tout comme les autres participants à l'enchère AdX, il ne paye que le prix du 2ème enchérisseur ("2nd price auction"). Mais comme il fonctionne en boîte noire, il peut se permettre d'encaisser la différence entre son enchère et le prix de vente effectif, sans aucun compte à rendre.
- Le mode d'achat au CPC rend la tâche d'audit encore plus compliqué : seul Google a l'info du taux de clics attendu.
- Même si l'enchère AdX passe en "1st price auction" (nous en reparlerons plus tard), le "last-look" lui permet de miser moins que ce qu'il pourrait, et d'encaisser la différence.
Open Bidding, la réponse de Google au header bidding
Le header bidding reste un hack qui ne plaît pas à Google :
- Il n'en est pas à l'origine et surtout, ne prend pas de commission sur les ventes qui passent par d'autres places de marchés.
- Conséquence, Google n'a aucun intérêt à faciliter l'opérationnel pour l'éditeur : paramétrer le header bidding dans DFP est complexe, le reporting est également très compliqué (de nouveaux acteurs adtech prennent le relais pour aider dans ces complexités).
- Google ne permet pas à Google AdX d'être intégré dans des solutions de header bidding. L'éditeur doit faire tourner une première enchère côté header bidding, puis une 2ème enchère dans DFP, dégradant l'expérience utilisateur. Multiplier les partenaires dans le header fait aussi prendre le risque de dégrader l'expérience utilisateur.
En 2017, Google propose de déplacer la compétition côté serveur (chez lui) :
Le "Server-Side Header Bidding", expliqué sur le blog Ad Ops Insider
La fonctionnalité est initialement appelée EBDA (Exchange Bidding in Dynamic Allocation), maintenant renommée Open Bidding. Google Ad Manager met directement en compétition les places de marchés qui auront bien voulu s'intégrer avec lui (ce qui n'est pas gagné, notez par exemple l'absence d'AppNexus, une des plus grandes places de marchés, et principal initiateur du header bidding) et Google AdX.
Les places de marchés y gagnent un accès facilité aux nombreux éditeurs qui utilisent Google Ad Manager. Google fournit également aux places de marchés (ainsi qu'aux autres acheteurs) le prix de vente effectif de chaque enchère, ce qu'il ne fait pas lors des intégrations en header bidding.
Les avantages pour l'éditeur ?
- S'il doit toujours signer un contrat avec les différentes places de marchés, le système est "plug & play", pas de galères opérationnelles.
- Le paiement est effectué directement par Google, ce qui facilite la comptabilité (et les éditeurs savent que Google paye rapidement, ce qui est moins vrai des SSPs plus petits, qui doivent se faire payer par les DSPs, eux-même devant se faire payer par les agences).
- L'éditeur n'a pas de limites sur le nombre de tiers avec qui travailler, car il n'y a pas d'impact côté expérience utilisateur (pas de tags additionnels sur site, les appels ont lieux côté serveur).
Mais voilà, rien n'est gratuit et Google prend une commission de 5% ou de 10% selon les publicités (standard, vidéo ou app). Une place de marché tierce est terriblement désavantagée :
- Elle doit d'abord prendre sa commission, puis soumettre l'enchère à Google qui prend également sa commission avant de comparer le prix diminué aux autres enchères, cf l'aide en ligne de Google : "L'enchère nette la plus élevée (qui tient compte de la part de revenus d'Ad Manager) remporte l'impression".
- Tout comme les plateformes d'achats tierces sur le Google Ad Exchange, elle n'a pas un accès direct à l'utilisateur (Google les appelle côté serveur) et doit donc synchroniser ses identifiants utilisateurs avec ceux de Google avant une enchère. Ceci entraîne un taux plus faible de reconnaissance des utilisateurs, et donc une moins bonne monétisation (sachant qu'elle doit aussi synchroniser ses identifiants utilisateurs avec ceux des plateformes d'achats).
- Elle est également désavantagée en terme de vitesse : elle doit répondre à Google en moins de 160 ms, sachant qu'elle doit elle-même conduire sa propre enchère. Comme on l'a vu précédemment avec les plateformes d'achats tierces achetant sur Google AdX, le fait d'être situé sur les mêmes serveurs (Google Ads et Google DV 360) permet aux acheteurs d'enchérir plus souvent et mieux. La logique s'applique ici entre Google AdX, avantagé car situé sur les mêmes serveurs que Google Ad Manager, et les autres places de marchés.
- Les acheteurs intelligents recherchent les opportunités les moins chers, et donc avec le moins d'intermédiaires. Ils privilégieront un achat direct via Google AdX plutôt qu'un partenaire Open Bidding. Ce mécanisme d'optimisation est appelé "Supply Path Optimization" ou SPO, il est appliqué par tous les DSPs dignes de ce nom. Si vous êtes intéressé par le sujet, vous pouvez lire cet article du co-fondateur d'AppNexus, Brian O'Kelley.
- Évidemment, l'éditeur peut désactiver une place de marché tierce mais il est impossible de désactiver Google AdX.
Google ne permet pas aux éditeurs de comprendre comment les enchères fonctionnent
Comprendre comment ces mécanismes d'enchères fonctionnent est crucial pour les éditeurs : quels acheteurs sont intéressés par mon inventaire ? Quel prix sont-ils prêts à payer ? Comment se comportent-ils si je modifie le prix plancher ? Ai-je intérêt à les contacter en direct s'ils achètent beaucoup d'inventaire, pour sécuriser des accords privilégiés ? La transparence est essentielle, à savoir accéder à toutes les informations sur ces enchères, seulement Google restreint l'information :
- L'accès à l'information est payant !
- Les données d'enchères (combien chaque acheteur est prêt à payer) et d'impressions (qui a gagné et quel est le prix de vente final) sont accessibles via 2 fichiers différents, un pour "données d'impressions" et un autre pour les "données d'enchères".
- Les données d'enchères contiennent le nom de l'acheteur, la valeur de l'enchère et si l'enchère est gagnante. Absents du fichier : les enchères des autres places de marché, ainsi que le prix d'achat effectif.
- Les données d'impressions contiennent le vainqueur, le prix d'achat effectif ainsi que les enchères des autres places de marchés.
- Les annonceurs Google Ads sont toujours cachés derrière l'acheteur Google Ads : impossible de les connaître, ni de savoir combien ils ont payé (la marge de Google est inconnue).
- Un éditeur pouvait faire le lien entre ces 2 fichiers mais depuis l'annonce de Google en septembre 2019, ce n'est désormais plus possible.
- Conséquences : impossible de vérifier l'impartialité de la tarification unifiée de Google, impossible de vérifier si Google ne fait pas de l'arbitrage, impossible de vérifier si Google ne fait pas tourner l'enchère AdX après avoir reçu les enchères des autres places de marchés, etc.
- Aussi, Google gagne de précieuses informations sur le comportement des places de marchés rivales. Il ne serait pas difficile d'utiliser ces informations pour prédire leurs enchères futures, et ainsi avantager Google AdX.
La fin du "last-look", vraiment ?!
Google décide en mars 2019 de suivre les autres places de marché et de basculer Google AdX en mode "1st price auction", il communique d'abord de manière vague sur la fin du "last-look" :
An advertising buyer’s bid will not be shared with another buyer before the auction or be able to set the price for another buyer
Son schéma explicatif est également très vague (aussi, impossible de savoir si le "1st price auction" s'applique lorsque Open Bidding n'est pas activé) :
En mai 2019, il donne un peu plus de précisions" :
Going forward, no price from any of a publisher’s non-guaranteed advertising sources, including non-guaranteed line item prices, will be shared with another buyer before they bid in the auction
Pourquoi ai-je mis "including non-guaranteed line item prices" en gras ? Parce que ces "line items" (éléments de campagnes renseignés sur Google Ad Manager) sont notamment utilisés par les places de marché tierces pour le header bidding. Et si l'on regarde l'historique de l'article de Google via la Wayback Machine, on se rend compte que ces "lines items" n'étaient pas incluses dans la version initiale de l'article, voici le passage complet de l'époque :
After the transition, Ad Manager will have a single auction that compares the prices from a publisher’s guaranteed campaigns with all of a publisher’s non-guaranteed advertising sources — including real-time bidding partners, such as Authorized Buyers and Exchange Bidding partners — and prices from non-guaranteed line items, like those from a publisher’s header bidding implementation. Going forward, no price from any of a publisher’s non-guaranteed advertising sources will be shared with another buyer before they bid in the auction. As has always been the case, all real-time bidding partners integrated with Ad Manager — including Google Ads and Display & Video 360 — will be notified of an auction at the same time.
Si l'on lit attentivement l'extrait initial, comme le remarquent judicieusement Damien Geradin et Dimitrios Katsifis, les auteurs de "'Trust me, I'm Fair': Analysing Google's Latest Practices in Ad Tech From the Perspective of EU Competition Law" en octobre 2019, Google ne mentionne pas les non-guaranteed line items lorsqu'il indique ne plus partager d'informations de prix avant l'enchère, seulement les non-guaranteed advertising sources, à savoir les acheteurs AdX (Authorized Buyers) et Exchange Bidding (Open Bidding).
Il se trouve que la presse spécialisée avait déjà annoncé la fin du "last-look" en 2017, qui semblait à l'époque ne concerner qu'Open Bidding (était-ce vraiment le cas, si Google communique seulement en 2019 ?). Même topo donc en mars 2019, la presse spécialisée s'empresse d'annoncer la fin du "last-look". Un argument avancé : le "last-look" serait incompatible avec les 1st price auctions. Il n'en est rien : Google Ads (ou un autre acheteur AdX) peut tout à fait décider de miser 1 centime de plus que le vainqueur de l'enchère header bidding s'il a l'info, ce qui permettra de donner beaucoup moins d'argent à l'éditeur et de potentiellement garder la marge pour lui.
Alors que s'est-il passé avec l'article ? D'après la Wayback machine toujours, les non-guaranteed line items ont été ajoutées à l'article entre le 15 novembre 2019 et le 15 août 2020. Est-ce suite au papier de Damien Geradin et Dimitrios Katsifis ? Est-ce que Google avait vraiment supprimé le "last-look" (se privant d'une option d'arbitrage via Google Ads) en mai 2019 ? L'a-t-il vraiment fait entre le 15 novembre 2019 et le 15 août 2020, et si oui, pourquoi n'a-t-il pas communiqué sur cette évolution ? Il est impossible de vérifier car Google ne fournit pas la transparence suffisante via les données d'enchères et d'impressions, il est donc permis d'en douter.
Le "1st price auction", une excuse pour verrouiller la monétisation de Google Ads
Avec le lancement en 2019 des enchères en 1st price auction, Google a bouleversé les règles de création de prix plancher pour les éditeurs. Auparavant, ils pouvaient décider de mettre des prix plancher plus haut pour certains acheteurs. Une règle fréquemment utilisée : augmenter le prix plancher de Google Ads (pour éviter que Google Ads se retrouve à payer beaucoup moins cher qu'il le pourrait, grâce au "2nd price auction" et au "last-look").
Aussi, ces règles de prix plancher ne s'appliquaient qu'aux acheteurs d'AdX. Les éditeurs pouvaient gérer les partenaires header bidding ou Open Bidding séparément, et leur appliquer un prix plancher plus bas s'ils le souhaitaient. Les nouvelles "règles unifiées" suppriment cette option, et évidemment, Google présente cela comme un avantage :
Our new unified pricing rules will help publishers more easily manage floor prices across all non-guaranteed partners. For example, instead of setting up the same floor prices in multiple places — in the auction in Ad Manager, and with their Exchange Bidding and other non-guaranteed advertising sources — which can take a lot of time and can lead to errors, a publisher can set up a single unified pricing rule to control pricing from one place.
Google interdit explicitement de créer des règles de prix plancher différent, selon les plateformes d'achats. Il présente cette manoeuvre abusive comme une mesure de justice :
To maintain a fair and transparent auction, these rules will be applied to all partners equally, and cannot be set for individual buying platforms.
Il s'agit surtout d'une perte de contrôle massive de l'éditeur sur la vente de son inventaire, et une opportunité en or pour accélérer l'arbitrage via Google Ads.
L'arme AMP pour supprimer le header bidding
Le format AMP est un format de pages web lancé par Google en 2016. Son objectif est d'accélérer le chargement des pages sur mobile, mais il est vu par beaucoup comme une menace pour le web ouvert : par sa position dominante sur la recherche en ligne, Google contraint les éditeurs à développer une version spécifique et très limitée de leur site, mise en cache sur les serveurs de Google. Sans version AMP de leur site, les éditeurs n'ont pas accès au carrousel. L'éclair représentant AMP dans les résultats de recherche incite aussi les utilisateurs à cliquer sur ces résultats.
Aussi, Google ne dit pas que AMP est un facteur de ranking (de meilleur classement dans les résultats de recherche), mais il appuie sur le fait que la vitesse de chargement est très important : "Même si le format AMP lui-même n'a pas d'impact direct sur votre position dans les résultats de recherche, la vitesse est un facteur de classement déterminant pour la recherche Google". En théorie les éditeurs ont le choix, dans les faits et s'ils ne veulent pas perdre leur ranking dans les résultats de recherche Google, ils sont contraints de fournir une version AMP de leurs pages.
Et pour la publicité me direz-vous ? AMP empêche les éditeurs d'utiliser du header bidding côté client (librairie javascript), ceux-ci sont donc encouragés à utiliser la solution Open Bidding s'ils veulent travailler avec des places de marchés tierces, ou tout simplement se contenter d'utiliser exclusivement la place de marché de Google. Les pages AMP étant mis en cache chez Google, toute la chaîne publicitaire peut s'exécuter sur les mêmes serveurs, encore l'avantage de vitesse (mais pour la monétisation, à part celle issue de la demande de Google, ce n'est pas gagné).
AMP étant très critiqué, la nouvelle stratégie de Google consiste à pousser les Core Web Vitals, de nouvelles métriques censées mieux représenter l'expérience utilisateur dans sa globalité. Ces métriques seront pris en compte l'année prochaine dans les rankings : "Today, we’re building on this work and providing an early look at an upcoming Search ranking change that incorporates these page experience metrics". Les éditeurs n'auront pas besoin d'avoir leurs pages en versions AMP pour être mis en avant dans le carrousel, mais plutôt d'avoir un bon score sur les Core Web Vitals.

Les Core Web Vitals, une mesure de l'expérience utilisateur sur différents axes. Aujourd'hui, Google mesure déjà ces indicateurs via les utilisateurs de Chrome ayant synchronisé leur historique de navigation et ayant l'envoi de statistiques activé (il met à disposition des statistiques agrégés via le Chrome User Experience Report).
Si cette initiative est louable, il est à craindre que AMP soit remplacée par une version encore plus problématique, les Web Bundles : un nouveau format permettant à un site de regrouper toutes les ressources d'une page web dans un même fichier, et potentiellement mis en cache chez des tiers tels que Google. Un point clé pour nous : ces Web Bundles vont grandement compliquer la tâche des adblockers. Lisez à ce propos l'article de Peter Snyder, WebBundles Harmful to Content Blocking, Security Tools, and the Open Web.
Le programmatique direct, une arme supplémentaire pour taxer l'écosystème publicitaire
Si la publicité "Display" passe maintenant essentiellement par les tuyaux du programmatique, les relations directes entre acheteurs et éditeurs n'ont pas disparu. En particulier :
- Les éditeurs ayant un inventaire de qualité et/ou une audience spécifique et/ou des formats publicitaires "innovants" peuvent toujours proposer des accords préférentiels aux acheteurs (les informer de ces opportunités particulières, voire même de leur donner la priorité par rapport à d'autres acheteurs). Évidemment, les acheteurs vont pousser pour avoir droit à ces accords préférentiels.
- Les acheteurs désirant sécuriser leurs achats vont toujours avoir besoin que les éditeurs garantissent un certains volume d'impression. Ce besoin est notamment important lorsque l'inventaire est rare : si je veux communiquer sur un nouveau film, je vais par exemple vouloir diffuser 10 millions d'impressions sur YouTube entre le 5 novembre et le 8 novembre.
Avant que le programmatique ne se démocratise, ces transactions passaient uniquement par les adserveurs annonceurs et éditeurs. En conséquence, ceux-ci ne payaient pas de taxe RTB (pas de commission sur le prix du média à payer côté DSP, pas de commission à payer côté SSP, seulement le coût de diffusion adserveur, qui est fixe et en conséquence bien moins cher). Google, de la même manière que ses concurrents DSP et SSP, y a vu un manque à gagner important : il a donc poussé l'écosystème publicitaire à faire entrer ces transactions dans les tuyaux du programmatique (via un système nommé "Deals") :
- D'abord avec les "Accords préférés" (alias "Preferred Deals") : accords entre 1 acheteur et un éditeur, à prix fixe, prioritaire sur les autres campagnes non garanties (AdX, Open Bidding, header bidding et ad-networks) mais à volume non garanti (l'acheteur ne s'engage pas à acheter, il peut choisir les opportunités).
- Puis avec le "Programmatique garanti" : accords où l'acheteur s'engage à acheter un volume garanti d'impressions.
Voici les arguments pouvant justifier le paiement d'un service sur ces transactions publicitaires :
- Dans le cas des "Accords préférés", l'acheteur choisit les opportunités (dans l'ancien monde, lorsqu'il est appelé, l'adserveur de l'annonceur n'a pas le choix).
- Le DSP gère toutes les campagnes de l'acheteur, ce qui permet à cet outil de proposer un reporting unifié.
- Les paiements aux éditeurs sont maintenant simplifiés et sécurisés, le SSP s'en occupe.
- Si le paramétrage des campagnes de gré à gré est complexe, Google permet aux acheteurs et éditeurs de négocier les accords directement dans leurs interfaces respectives (DV 360 et Google Ad Manager). Notez que cette option aurait pu être proposée sans les tuyaux du RTB mais que Google n'avait rien à y gagner.
Et si l'on compare la part des "Deals" aux enchères ouvertes, on se rend compte que ces relations de gré à gré représentent une part considérable des investissements publicitaires. Elles étaient moins visibles auparavant car les campagnes publicitaires ne transitaient pas par les tuyaux du programmatique :
Les chiffres et prévisions eMarketer pour le marché US, les "Deals" doivent dépasser les enchères ouvertes en 2020. La France suit en général la même tendance, avec 1 ou 2 ans de retard. Le potentiel pour les acteurs du programmatique est donc énorme.
Mais il est difficilement justifiable de continuer de prendre une commission sur les montants média dépensés (X% côté DSP, Y% côté SSP) : il s'agit ici d'un accord direct entre un acheteur et un éditeur, l'intermédiaire n'est pas un apporteur d'affaire. On s'attendrait plutôt à un CPM fixe, similaire aux prix d'un adserver. C'est pourtant le choix de Google, et sur lequel l'écosystème programmatique s'est aligné.
Le programmatique direct, un avantage supplémentaire pour AdX
Ces transactions de gré à gré sont un bon moyen de discriminer les autres places de marchés :
- Google propose une Marketplace dans DV 360 : cela permet aux acheteurs de découvrir les offres des éditeurs, mais aussi de négocier avec eux directement dans l'interface. Si la négociation aboutit, la création de la campagne est automatique, pour l'acheteur et l'éditeur. Problème : cette Marketplace est quasiment exclusive aux éditeurs AdX (excepté Rubicon).
- Le "programmatique garanti" suppose de pouvoir garantir un volume d'impressions. Seuls les adserveurs sont capables de gérer un volume d'impression. En conséquence, les places de marchés qui ne sont pas couplés avec un adserveur ne peuvent vendre du programmatique garanti (à Google DV 360 ou à une autre plateforme d'achats). Les éditeurs utilisant Google Ad Manager (DFP et AdX) sont bien entendu déjà équipés.
- Au sein de Google Ad Manager, les "accords préférés" sont seulement disponibles sur AdX : les partenaires Open Bidding et les places de marchés passant par du header bidding ne peuvent être priorisés par rapport aux autres campagnes non garanties.
Ainsi, si vous êtes une place de marché tierce, il est quasiment impossible de concurrencer AdX chez les éditeurs Google Ad Manager, seulement de récupérer les miettes.
Remplacer Google Ad Manager ? Mission (presque) impossible
Nous l'avons vu à de multiples reprises, le premier outil appelé sur la page de l'éditeur est stratégique : il s'agit de l'adserveur éditeur (DFP dans le cas de Google, qui a été dernièrement "fusionné" avec AdX pour être renommé Google Ad Manager). Google y favorise sa propre demande via de multiples procédés : "last-look", complexité à gérer le header bidding, taxe sur Open Bidding, boite noire sur les données d'enchères et d'impressions, bridages des règles de prix plancher, meilleure reconnaissance utilisateur, meilleure connexion avec ses propres plateformes d'achats, fusion de vos données personnelles doubleclick et Google, facilitation du programmatique direct, etc.
Que se passe-t-il si un éditeur décide de ne pas travailler avec Google sur la partie Adserveur ? Les difficultés sont très grandes :
- Ajouter une nouvelle place de marché sur Open Bidding est très facile, ajouter une nouvelle place de marché en header bidding est relativement facile, migrer d'adserveur est une tâche bien plus complexe opérationnellement, pouvant prendre plusieurs mois.
- Google AdX est la seule place de marché disposant de la totalité de la demande Google Ads (les autres places de marchés n'ont que les campagnes de remarketing). Hors Google Ads est le principal acheteur au monde. Mais Google refuse de proposer AdX en header bidding.
- Google refuse également d'intégrer AdX à des systèmes de header bidding server-side concurrents (tels que Prebid Server ou Amazon Transparent Ad Marketplace) ou à des places de marchés et autres adserveurs concurrents.
- Conséquence : si vous ne voulez pas vous couper de la principale source de demande (à savoir : mettre en compétition au même niveau les campagnes AdX et les campagnes des autres places de marchés), vous devez utiliser AdX, et donc vous êtes fortement incités à utiliser Google Ad Manager.
Pouvez-vous éviter Google Ad Manager et profiter d'AdX ? Oui mais seulement via un mécanisme incroyablement complexe, mis en place par Axel Springer (le plus gros groupe média européen) avec l'aide de son partenaire AppNexus (concurrent de Google Ad Manager, proposant adserveur et SSP) et permettant de mettre en compétition AdX avec les autres sources de demandes :
Si vous ne comprenez rien à ce schéma, c'est normal.
Une régulation nécessaire
Si Google a pu s'imposer si efficacement sur les marché publicitaires, ce n'est pas seulement parce que ses outils seraient "meilleurs" (l'argument ne doit pas être sous-estimé, Google propose de bons outils avec une excellente interface utilisateur), mais c'est surtout parce qu'il a pu profiter d'une absence absolue de régulation pour racheter de multiples sociétés et abuser de sa position dominante.
Les différentes pratiques documentées ne sont pas exclusives aux marchés publicitaires. Comme le documente si bien Dina Srinivasan, on peut retrouver ces pratiques sur d'autres marchés tels que les marché financiers, les ventes de billets en ligne, etc. Seulement voilà, les autres marchés sont régulés et les sanctions sont prises lorsqu'un acteur abuse d'un avantage. En conséquence, ces marchés fonctionnent mieux.
Comment Google a-t-il pu échapper à toute régulation sur ces marchés publicitaires ? Sans être expert juridique, un des éléments est sans doute la complexité et l'opacité de l'adtech, que vous avez pu constater si vous vous êtes accrochés pour lire cet article en entier... Les options offertes aux régulateurs sont nombreuses, en voici quelques-unes suggérés dans les récentes études :
- Séparer structurellement (vente, ou divisions indépendantes avec contrôles stricts) l'adserveur (DFP) de la place de marché (AdX).
- Séparer structurellement ses activités d'achat (Google Ads, DV 360) des activités de vente (AdX, AdSense, AdMob).
- Séparer structurellement Chrome.
- Activer la totalité de la demande Google Ads sur les autres places de marchés.
- Permettre aux adserveurs d'accéder simplement à la demande AdX.
- Permettre aux plateformes d'achats tierces d'acheter de l'inventaire YouTube.
- Faciliter l'achat de publicités sur les résultats de recherche de Google via des plateformes tierces.
- Obliger Google à une transparence complète sur les données d'enchères et d'impressions.
- Plus généralement, réguler et sanctionner l'ensemble de l'écosystème publicitaire : Google est la société qui abuse le plus, mais ce n'est pas la seule.
Plus fondamentalement, quel est l'utilité réelle de cet écosystème programmatique ultra complexe, à l'origine de fuites de données personnelles massive ? On voit bien les effets négatifs : expérience utilisateur catastrophique, surveillance banalisée et généralisée (merci Google), dépendance extrême des médias envers Google... Si l'on regarde son coût et son opacité, les résultats sont choquants :
Étude sur la transparence du programmatique : oui, l'éditeur ne touche que 51% du montant dépensé par l'annonceur, notez également que l'étude ne peut expliquer 15% de l'argent dépensé...
En tant qu'éditeur, si vous ne proposez pas d'abonnement, une vie en dehors de l'adtech est-elle possible ? Oui si l'on en croit l'expérience du "radio france hollandais", qui a vu ses revenus publicitaires augmenter, tout en abandonnant la publicité ciblée. Alors bien sûr, l'expérience est plus facile à mener lorsque l'on est un groupe public, mais le jeu en vaut la chandelle.
Texte intégral (12900 mots)
Google, acteur dominant de l'adtech
Le sujet de ce billet sera un peu différent des sujets traités habituellement sur ce blog. Au lieu d'observer les fuites de données personnelles sur les sites et applications, je vais tenter de documenter (de manière non exhaustive, les abus étant multiples) comment Google s'est imposé sur les marchés publicitaires. Si vous souhaitez en savoir plus, voici quelques études publiées récemment :
- L'étude de Dina Srinivasan : Why Google Dominates Advertising Markets.
- Les études de Damien Geradin et Dimitrios Katsifis : Google’s (Forgotten) Monopoly – Ad Technology Services on the Open Web, 'Trust me, I'm Fair': Analysing Google's Latest Practices in Ad Tech From the Perspective of EU Competition Law et Competition in Ad Tech: A Response to Google.
- L'étude de Fiona M. Scott Morton et David C. Dinielli : Roadmap for a Digital Advertising Monopolization Case Against Google.
- Les "notes de préparation du secrétariat de l'OCDE" : Competition in Digital Advertising Markets.
- L'étude de la "Competition and Markets Authority" (CMA) anglaise : Online platforms and digital advertising market study.
L'époque où les campagnes publicitaires étaient créées et gérées "manuellement" (contrats par fax, envoi des bannières publicitaires et éléments de tracking par e-mail, etc) entre agences et régies publicitaires est révolue :
- À l'instar des marchés financiers, cette gestion est maintenant automatisée (le "programmatique" ou "RTB" pour "Real-Time Bidding").
- La technologie permettant la réalisation de ces marchés publicitaires est appelé SSP (Supply-Side Platform) ou Ad Exchange.
- La réalisation de la vente d'espaces publicitaires se fait maintenant à l'unité : l'éditeur propose une opportunité publicitaire (l'affichage d'une publicité sur votre appareil), libre à l'annonceur de miser ou non sur cette opportunité.
- L'annonceur détient souvent des données personnelles sur vous lorsqu'il reçoit cette opportunité, ce qui lui permet de miser ce qu'il pense être le "juste prix".
- Il est en concurrence avec d'autres annonceurs, chacun passant par des robots acheteurs appelés DSPs (Demand-Side Platforms)
- L'enchère se réalise très rapidement, en souvent moins de 100 millisecondes.
- Beaucoup moins médiatisés, les accords préférentiels entre annonceurs et éditeurs (appelés "deals" dans le milieu de l'adtech) n'ont pas disparu, mais ils transitent également majoritairement dans les tuyaux du "programmatique").
Ces marchés publicitaires automatisés sont à l'origine d'une fuite massive de données personnelles, lisez par exemple la plainte pour violation du RGPD de Brave contre Google et l'IAB (le lobby de l'adtech) sur le RTB. Et ils sont dominés par Google, voici par exemple les chiffres pour l'Angleterre (les chiffres sont similaires sur les autres principaux marchés occidentaux) :
Online Platforms and Digital Advertising Market Study (CMA July 1st 2020)
À ce titre, le modèle économique choisi par Google (le capitalisme de surveillance) et ses décisions opérationnelles (support de la monétisation publicitaire du web via ces places de marchés automatisés, notion de consentement bafouée, etc) ont une influence démesurée sur les autres acteurs du web publicitaire, qui n'ont souvent d'autres choix que de rentrer eux aussi dans le jeu du capitalisme de surveillance.
Quel lien entre cette domination de Google et la bonne santé du web en général ? Si l'on reprend les bilans annuels de Google, on peut observer que celui-ci capte en propre (recherche Google, YouTube) une part de plus en plus importante des dépenses publicitaires effectuées via les outils d'achat proposés par Google (eux-même déjà dominants).
En 2007, Google captait en propre 64% de ses revenus publicitaires. Au premier trimestre de 2020, Google en capte 85%.
Conséquence : les éditeurs captent une part de plus en plus faible de ces financements (part sur laquelle Google prend sa taxe) et se retrouvent privés de financements importants. On peut citer la situation économique critique du secteur de l'information, entraînant :
- Une grande précarité chez beaucoup de journalistes.
- Un manque de moyens pour traiter des enquêtes de fond, si critiques pour nos démocraties.
- Une faible autonomie des médias face aux puissances de l'argent. Difficile de créer un grand média rentable aujourd'hui, les médias français sont pour la plupart détenus par quelques riches industriels, cf. la carte des Médias français réalisée par Acrimed et Le Monde diplomatique.
La thèse de Dina Srinivasan est que Google n'aurait jamais pu dominer à ce point les marchés publicitaires si ces marchés étaient régulés correctement. Elle dévoile que de nombreuses pratiques appliquées par Google pour favoriser son propre business ont été interdites sur ces marchés financiers. Et donc que Google a pu étendre sa toile grâce à l'inaction publique. Les études respectives de Damien Geradin et Dimitrios Katsifis, puis de Fiona M. Scott Morton et David C. Dinielli, détaillent également les multiples conflits d'intérêts et l'absence de transparence de Google.
Avant 2007, Google est déjà un géant publicitaire
En 2000, Google lance Google AdWords (aujourd'hui Google Ads) afin de mieux monétiser son moteur de recherche, très rapidement c'est un succès. Quelles en sont les raisons ?
- Tout d'abord, évidemment, son moteur de recherche très efficace, apprécié des utilisateurs (même si depuis 2000, Google a multiplié les abus de position dominante sur ce domaine, regardez l'évolution des résultats de recherche, c'est assez frappant).
- Un système en "self-service" où chaque annonceur (du petit artisan de quartier à la multinationale) peut créer sa campagne publicitaire rapidement à condition qu'il ait une carte bleue.
- Un paiement à la performance : l'annonceur achète les mots-clés qu'il souhaite et ne paye que lorsque l'utilisateur clique sur la publicité.
- Une publicité plus pertinente : afin de maximiser ses revenus, Google a intérêt à privilégier une publicité moins cher mais ayant un meilleur taux de clic.
En 2003, Google lance Google AdSense afin d'étendre sa régie publicitaire à des sites web tiers. Sur quels leviers s'appuie Google ?
- En premier, sur le fait qu'il ait déjà un marché captif unique : un nombre incalculable d'annonceurs déjà sur AdWords, petits et gros, avec leurs cartes bleues. Ailleurs sur le web, pour lancer une campagne publicitaire, vous devez payer une agence.
- En deuxième, sur le fait qu'il crawle déjà le web, il est donc capable de fournir des publicités contextuelles pertinentes : s'assurer que la publicité d'un annonceur opérant sur un secteur d'activité précis trouvera de quoi diffuser sur des sites en rapport avec son secteur d'activité (publicité contextuelle).
- En troisième, sur le fait que pour un "petit" site web qui n'a pas les moyens d'ouvrir de régie publicitaire pour démarcher les agences, il existait peu de concurrence.
Bref, c'est également un succès.
En 2007, le rachat de Doubleclick permet à Google d'obtenir une position clé chez les éditeurs
Mais les régies publicitaires des grands éditeurs n'utilisent pas que Google AdSense pour monétiser leurs inventaires publicitaires. Elle se méfient de la qualité des annonces diffusées par Google AdSense (la variété des annonceurs fait que l'on peut aussi tomber sur des annonces non souhaitées), et n'apprécient pas forcément le format des publicités (texte uniquement à l'origine, pas de bannières ni de vidéos). Elles travaillent aussi avec d'autres ad-networks et ont surtout des relations fortes avec les agences publicitaires, ce qui leur permet de vendre la plupart de leur inventaire publicitaire en direct, à des prix plus intéressants.
Pour gérer l'ensemble de leurs campagnes publicitaires (vente en directe, vente via des ad-networks tels que Google AdSense ou vente via les nouvelles places de marchés), elles passent par des outils spécialisés appelés adservers.
De même, les principales agences n'ont pas que les résultats de recherche Google pour diffuser les publicités de leurs clients annonceurs. Elles ont besoin d'un outil pour gérer et mesurer correctement l'ensemble de leurs campagnes publicitaires. Cet outil est également un adserver, à noter que ses fonctionnalités sont sensiblement différentes d'un adserveur éditeur, même s'ils partagent une base commune.
Afin de se rapprocher des gros éditeurs et annonceurs, Google achète Doubleclick pour 3,1 milliards de dollars. À l'époque Doubleclick a déjà une position très forte avec son adserver éditeur (DFP pour Doubleclick for Publishers) mais aussi avec son adserveur annonceur (DFA pour Doubleclick for Advertisers). Et surtout, la plupart des adserveurs concurrents ne se positionnent que d'un seul côté (éditeur ou annonceur).
En 2009, le lancement du Doubleclick Ad Exchange
En 2009, Google a automatisé depuis bien longtemps le marché du "Search" via ses liens sponsorisés. Il a étendu sa régie publicitaire AdWords à YouTube et à son réseau de partenaires Google AdSense, sa place de marché publicitaire à la performance est particulièrement efficace. De l'autre côté, les campagnes publicitaires "Display" (bannières publicitaires et vidéos sur le web) sont alors encore principalement gérées manuellement, "à l'ancienne" :
- Les agences et régies publicitaires vont se mettre d'accord sur des campagnes publicitaires (X impressions, période de diffusion, ciblage éventuel, prix).
- Les agences vont ensuite paramétrer les campagnes publicitaires dans leurs adserveurs (DFA ou autre), puis envoyer les tags de ces campagnes aux régies publicitaires.
- Celles-ci vont alors paramétrer dans leurs adserveurs (DFP ou autre) ces tags publicitaires.
Cette double programmation est très laborieuse, surtout lorsque l'on veut diffuser sa campagne publicitaire sur de nombreux sites. Comment la diffusion publicitaire fonctionne-t-elle ? Ce n'est déjà pas si simple :
Via Ad Ops Insider, How does adserving work?
Afin de pallier à ce manque, les intermédiaires appelés ad-network occupent déjà une place importante : ils proposent aux annonceurs de toucher de nombreux éditeurs sans avoir à les contacter un par un (Google AdSense est l'un d'eux). Les régies publicitaires paramètrent alors le tag de l'ad-network dans leurs adserveurs.
Mais gérer de multiples ad-networks reste complexe et inefficace : les ad-networks ne peuvent acheter en temps-réel car il n'y a pas encore de système d'enchères (la rémunération est fixée à l'avance, quelque soit l'utilisateur) et ils se réservent le droit de refuser d'acheter une opportunité publicitaire. Les régies publicitaires se retrouvent à devoir gérer les différents ad-networks dans un système appelé "Waterfall" : une cascade d'ad-networks, appelés les uns après les autres (ceux dont on suppose qu'ils seront les plus rentables en premiers), système ayant pour but de maximiser les revenus (tout en limitant la casse côté expérience utilisateur).
Via Ad Waterfalls explained, les "passbacks" sont du au fait que l'ad-network doit rappeler l'adserveur de l'éditeur s'il n'a rien à diffuser, pour que celui-ci rappelle ensuite l'ad-network suivant... L'expérience utilisateur est catastrophique.
S'inspirant du succès d'AdWords et s'appuyant sur son récent achat de Doubleclick, Google lance sa propre place de marché : le Doubleclick Ad Exchange (lisez l'interview de l'époque, en 2 parties). Quel est l'impact du programmatique sur le fonctionnement de la diffusion publicitaire ? Les mécanismes se complexifient :
Via Ad Ops Insider, How RTB adserving works
Google est en léger retard par rapport à d'autres acteurs tels que Right Media, AdECN, AdBrite et ADSDAQ. Mais le programmatique démarre à peine et la nouvelle place de marché coche toutes les bonnes cases :
- Enchères en temps-réel, pour laquelle l'acheteur peut utiliser les données personnelles qu'il détient sur l'utilisateur.
- Paiements sécurisés par Google (intermédiaire de confiance).
- Pour les acheteurs de la nouvelle place de marché, accès simplifié aux éditeurs AdSense mais aussi aux grands éditeurs qui utilisent déjà Doubleclick DFP et qui auront activé Doubleclick Ad Exchange.
- Pour les acheteurs Adwords, nouvel accès aux grands éditeurs DFP ayant activé Doubleclick Ad Exchange.
- Pour les grands éditeurs, accès simplifié aux annonceurs AdWords, mais aussi aux différents ad-networks qui ont déjà fait l'intégration avec la place de marché (dès le lancement, Google annonce avoir intégré la majeure partie des grands ad-networks américains).
- Pour les grands éditeurs toujours, l'allocation dynamique dans DFP entre leurs ventes en direct et les ventes via le Doubleclick Ad Exchange, leurs permettant de maximiser leurs revenus (compétition entre les campagnes vendues en direct et les enchères du Doubleclick Ad Exchange).
- Pour les éditeurs AdSense, demande additionnelle via les acheteurs du Doubleclick Ad Exchange.
Comment le programmatique fonctionne avec Google, grâce au rachat de Doubleclick et au lancement du Doubleclick Ad Exchange :
Vous voyez poindre les conflits d'intérêt ?
En 2010 et 2011, d'autres rachats permettent à Google d'étendre son poids sur le Display
En 2010, Google achète AdMob pour 750 millions de $. AdMob offrait des solutions de monétisation pour les sites et applications mobiles. Google était déjà très bien placé avec Google AdSense sur le web et décide de payer le prix fort pour ne pas laisser passer la vague de la publicité sur le mobile. Il réécrit le logiciel pour l'inscrire dans la suite Doubleclick en 2013.
En 2010 toujours, Google réalise un de ses meilleurs coups en achetant Invite Media pour 70 millions de $. Invite Media était un des principaux DSP sur le marché et une pièce manquante chez Google. Il permet à un annonceur ou à une agence d'acheter de l'inventaire publicitaire sur les Ad Exchanges. Google complète ainsi ses outils pour les annonceurs : de la même manière qu'il a pu ajouter la brique Doubleclick Ad Exchange à son adserveur éditeur DFP, il ajoute la brique d'achat Invite Media (renommé ensuite Doubleclick Bid Manager ou DBM lors de la réécriture du logiciel) à son adserveur annonceur DFA.
Ces achats d'outils côté annonceur lui permettent de proposer maintenant 2 plateformes d'achats :
- Google Ads : la plateforme d'achats permettant à tous les annonceurs, petits ou grands, d'acheter de la publicité sur les résultats de recherche Google. Elle permet également aux petits annonceurs de diffuser des campagnes publicitaires sur YouTube, sur AdSense et sur l'Ad Exchange de Google.
- Google Display & Video 360 ou DV 360 : la plateforme d'achats "Display & Video" à destination des grands annonceurs et agences, intégrant l'ancien DBM mais aussi DFA (renommé Doubleclick Campaign Manager ou DCM). Ceux-ci peuvent acheter l'inventaire sur YouTube, sur AdSense, sur l'exchange de Google mais aussi sur les principaux Ad Exchanges tiers.
En 2011, Google accroît sa domination côté éditeur en achetant AdMeld pour 400 millions de $. AdMeld était un concurrent de Doubleclick Ad Exchange, Google y gagne encore à plusieurs niveaux :
- AdMeld avait beaucoup d'éditeurs de qualité dans ses clients.
- Si la partie Ad Exchange était déjà bien gérée par Google, AdMeld vient compléter les capacités de DFP et de Doubleclick Ad Exchange via une meilleure gestion des ad-networks (le programmatique n'est pas encore dominant).
L'écosystème du programmatique, Google détient en 2011 avec Doubleclick le principal adserver éditeur (ainsi que le principal adserveur annonceur, absent de ce graphique), mais aussi un nouvel Exchange important (Doubleclick Ad Exchange, amélioré grâce à AdMeld) et une des principales plateformes d'achat (Invite Media). Google a d'autres pions qu'il intègre à sa "stack" : Admob sur le mobile, AdWords et AdSense, Google Analytics, Google Tag Manager, etc.
En 2013, l'exchange de Google (Doubleclick Ad Exchange, renommé AdX, et maintenant Authorized Buyers) devient la place de marché principale du programmatique. La plateforme d'achats de Google (DBM, maintenant DV 360) est elle-même maintenant majoritaire.
Mécanisme pour délivrer une publicité, intégralement dans l'écosystème de Google. Regardez l'excellente infographie du Wall Street Journal, How Google Edged Out Rivals and Built the World’s Dominant Ad Machine: A Visual Guide
Au-delà de la qualité des produits Google (qu'il ne faut pas sous-estimer), quels sont donc les points clés de cette ascension rapide ?
Google a un avantage d'information sur ses concurrents
Grâce à son rachat de Doubleclick en 2007, Google s'achète une empreinte énorme sur le web. De nombreux grands éditeurs utilisent Doubleclick en tant qu'adserveur (DFP), ce qui permet à Google de passer premier sur l'identification des utilisateurs sur le web et d'en reconnaître la plupart, via les cookies doubleclick. La plupart des grandes agences utilisant également Doubleclick en tant qu'adserveur (DFA), Google accroît encore son empreinte (même si un site n'utilise pas DFP, la plupart de ses campagnes publicitaires sera diffusé avec un tag annonceur DFA).
Là vous pourriez vous dire : Doubleclick est un outil acheté par les éditeurs et annonceurs, l'identité des utilisateurs sur l'outil (un identifiant numérique) n'est pas la propriété de Google mais la leur. Et en effet, c'est ce que Google déclare au congrès américain lors de l'enquête sur le rachat de Doubleclick : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it".
Sans accès à un identifiant utilisateur donc, il est beaucoup plus difficile de monétiser un utilisateur sur le marché du programmatique. Une étude de Google indique par exemple une chute de 52% des revenus sur les utilisateurs n'ayant pas de cookies tiers, nécessaires au stockage d'identifiants utilisateurs dans le cadre du programmatique sur le web. Ce chiffre se retrouve aussi dans d'autres études indépendantes.
Et Google utilise progressivement l'identifiant utilisateur Doubleclick pour ses propres intérêts :
- Dès 2009 pour sa plateforme d'achats Google Ads, il place des cookies doubleclick sur ses propres sites et chez ses partenaires AdSense : "Google uses the DoubleClick advertising cookie on AdSense partner sites and certain Google services to help advertisers and publishers serve and manage ads across the web".
- En 2009 toujours, Google utilise l'identifiant doubleclick sur son Exchange, le Doubleclick Ad Exchange, ce qui permet aux acheteurs Google Ads de reconnaître les utilisateurs qui surfent chez les nouveaux clients de l'Exchange. Par contre, les autres acheteurs (les ad-networks et autres DSPs, utilisés par les grands annonceurs) n'ont pas accès à cet identifiant : "For buyers, Google identifies users using a buyer-specific Google User ID consisting of an encrypted version of the doubleclick.net cookie, derived from but not equal to that cookie. Google passes the user ID to the buyer (raw cookies are never sent)."
- En 2009 encore, Google empêche ses clients adserveur éditeurs (ici : "The DoubleClick cookie ID associated with the user, encrypted.") et annonceurs (ici : "You will never be able to decrypt user IDs, and Google will not disclose the encryption method. No encryption keys will ever be provided to any Campaign Manager customer or any third-party partner.") d'accéder aux identifiants utilisateur doubleclick, en contradiction avec sa précédente déclaration : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it".
- En 2012, lorsque Google réécrit Invite Media pour lancer DBM, sa propre plateforme d'achats à destination des grands annonceurs, celle-ci a bien accès à l'identifiant doubleclick : "For itself, Google identifies users with cookies that belong to the doubleclick.net domain under which Google serves ads."
- En 2013, Google ne fournit plus qu'à ses éditeurs DFP des logs, sans l'identifiant doubleclick : "The DoubleClick cookie ID associated with the user, encrypted."
- En 2018, Google enlève l'identifiant doubleclick des logs de son adserveur DCM : "You will never be able to decrypt user IDs, and Google will not disclose the encryption method. No encryption keys will ever be provided to any Campaign Manager customer or any third-party partner". Rappel, Google avait déclaré lors du rachat de DoubleClick : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it".
Échec et mat ! Voici les conséquences :
- Annonceurs et éditeurs avaient l'habitude de travailler directement ensemble pour des campagnes publicitaires ciblées, via l'identifiant doubleclick. Ils doivent désormais passer par les outils Google, DBM et AdX (ou Google Ads et AdSense pour les petits annonceurs et petits éditeurs).
- DBM et Google Ads partent avec un avantage sur les autres plateformes d'achats : celles-ci doivent synchroniser leurs identifiants avec l'identifiant doubleclick (cf. Cookie Matching) avant de pouvoir reconnaître les utilisateurs lorsque Google leurs envoient les opportunitées publicitaires et ainsi mieux acheter. Au mieux, les plateformes d'achats peuvent espérer une non-reconnaissance des utilisateurs de l'ordre de 20%, au pire de plus de 50%.
- Les plateformes d'achats concurrentes n'ont pas la même empreinte sur le web tandis que le cookie doubleclick est omniprésent : chez les éditeurs AdSense et DFP, sur la recherche Google, sur Gmail, sur YouTube, etc.
Comment fonctionne la synchronisation d'identifiants ? Ici représentée entre un DSP et plusieurs SSPs, mais le mécanisme et le même lorsqu'un SSP doit synchroniser les identifiants avec plusieurs DSPs :
Via Ad Ops Insider, SSP to DSP Cookie Syncing Explained
Google explique d'ailleurs très bien les bénéfices d'une "lecture de cookies supérieure" à ses clients :
Google Ads et Display & Video 360 génèrent des performances optimales lors de l'achat d'inventaire sur Ad Exchange, car ces plates-formes d'achat partagent la même infrastructure que la place de marché. Cela signifie que la perte de lecture de cookies potentielle lorsque les utilisateurs de Google Ads et de Display & Video 360 achètent sur d'autres places de marché est réduite lors de l'achat sur Ad Exchange. Ainsi, lorsque des achats sont effectués via Google Ads et Display & Video 360 sur Ad Exchange, il est plus probable que ces solutions détectent des impressions répondant à leurs critères de ciblage, ce qui donne lieu à un accroissement de la pression au niveau des enchères et à une augmentation de la demande pour l'inventaire de l'éditeur.
Protéger votre vie privée ?! La belle hypocrisie de Google
Google ne détaille pas les raisons qui l'ont conduit à supprimer l'accès à l'identifiant doubleclick aux tiers. Simplement qu'il a agit pour des motifs de vie privée :
- Afin d'empêcher différents acteurs de combiner leurs informations (chaque acteur a sa propre version de l'identifiant doubleclick, et ne peut donc partager des informations utilisateur avec son voisin).
- Afin d'empêcher les acteurs de combiner des identifiants avec des informations nominatives.
Si l'objectif de protection de la vie privée est louable, Google ne l'applique pas à lui-même : il combine bien les informations qu'il a sur vous via ses différents services (Recherche, YouTube, Gmail, Maps, etc), via ses différents clients Doubleclick (annonceurs ou éditeurs), il combine aussi les informations DoubleClick avec les informations nominatives de votre compte Google si vous n'avez pas réglé correctement vos paramètres Google. Voici 2 décisions clés :
- En 2012, Google propose alors 70 différents services (et 70 politiques de confidentialités différentes), les données personnelles de ces différents services sont bien cloisonnées. Par exemple, YouTube ne connaît pas votre historique de recherche Google et ne peut donc vous cibler via des publicités en rapport avec cette historique. Google décide alors de ne proposer plus qu'une seule politique de confidentialité et de combiner vos données personnelles sur l'ensemble de ces services. Les réactions sont unanimement négatives et les enquêtes se multiplient mais rien n'y fait, Google ne recule pas.
- En 2016, Google modifie sa politique de confidentialité discrètement et y supprime l'interdiction de combiner les informations liées au cookie Doubleclick et les informations nominatives de votre compte Google si Google n'a pas votre opt-in explicite. L'association sera automatique pour les nouveaux utilisateurs. Pour les utilisateurs existants, Google maquille la dangereuse association en vous demandant si vous souhaitez accéder à des fonctionnalités supplémentaires, avec le titre : “Some new features for your Google account”.
Le jeu Googolopoly, créé en 2008 (depuis cette date, le nombre de sociétés rachetées par Google a explosé). La mission de Google est originellement d'organiser les informations à l'échelle mondiale. Aujourd'hui, il s'agit plutôt de s'accaparer des pans toujours plus larges de vos activités, pour mieux vous influencer.
Ces décisions s'accompagnent de nombreuses modifications insidieuses de produits Google. En 2018 par exemple, Chrome vous connecte automatiquement à votre compte Google lorsque vous vous connectez à un site Google (Gmail par exemple), sans vous demander votre avis. Il vous pousse également à envoyer tout votre historique de navigation à Google via un Dark Pattern, lisez à ce propos "Why I'm done with Chrome".
Si l'on s'intéresse aux données Doubleclick, rappelez vous la déclaration de Google en 2007 : "That data is owned by the customers, publishers and advertisers, and DoubleClick or Google cannot do anything with it". Aujourd'hui, Google récupère par exemple des données personnelles via ses clients éditeurs Google Ad Manager (exemple : les utilisateurs surfant sur un site d'informations financières), données personnelles qu'il peut ensuite utiliser pour son propre profit. Comment ? En vendant via Google Ads des campagnes publicitaires à des banques, ciblées sur les utilisateurs du premier site, mais sur d'autres sites web (ayant eux-mêmes intégrés Google AdSense ou Google AdX).
Si l'on regarde attentivement les règles de confidentialité de Google, cachées au dessous de la section "Protéger Google, nos utilisateurs et le public" (et non dans la section "Proposer des services personnalisés, notamment en matière de contenu et d'annonces"), on peut y lire :
Selon vos paramètres de compte, votre activité sur d'autres sites et dans d'autres applications peut être associée à vos informations personnelles dans le but d'améliorer les services Google et les annonces diffusées par Google.
Voilà comment discrètement, Google s'approprie les données de ses clients éditeurs et annonceurs, pour son propre profit. Mais attention, l'interdiction aux tiers d'accéder à l'identifiant doubleclick a été conçue pour protéger votre vie privée !
Google a un avantage de vitesse sur ses concurrents
Lorsqu'une place de marché (SSP ou Ad Exchange) propose une opportunité publicitaire à un robot acheteur (DSP), celui-ci a un temps limité pour répondre, généralement entre 100 ms et 200 ms. Aussi, s'il ne répond que rarement dans les temps, le SSP va réduire le nombre d'opportunités envoyées. Les plateformes d'achats de Google (Google Ads, DV 360) partent alors avec un avantage énorme, elles sont situées sur les mêmes serveurs que la place de marché de Google (AdX) :
L'avantage de vitesse de Google, une latence réduite.
Google met également cette "latence réduite" en avant dans sa documentation, les autres acteurs pouvant "perdre" jusqu'à 25% des demandes d'enchères :
Lorsque des achats sont effectués via Google Ads ou Display & Video 360 sur d'autres places de marché, les utilisateurs en question sont confrontés à la même latence du réseau que le reste des acheteurs. Nous avons constaté que, dans certains cas, les problèmes de latence peuvent empêcher les acheteurs de soumettre une enchère pour jusqu'à 25 % des demandes d'enchères, ce qui limite leur participation aux enchères ayant lieu sur d'autres places de marché.
Ce gain de temps permet aux plateformes d'achats de Google d'être plus "intelligentes" : de prendre le temps nécessaire pour récupérer les données utilisateurs et faire tourner les bons algorithmes afin de choisir la publicité qui aura le plus fort impact sur l'utilisateur, au prix optimal (et qui maximisera les profits de Google).
À noter que Google propose aux plateformes d'achats une option de colocation (via Google Cloud Platform), mais seul le SSP OpenX l'a choisit. Il est difficile de savoir si les autres plateformes d'achats refusent de passer par le Cloud Google pour des questions de coûts, pour des questions évidentes de conflits d'intérêt, ou tout simplement qu'elles jugent que cet avantage n'est pas si déterminant. Le chiffre des 25% des demandes d'enchères perdues à cause de problèmes de latence ne peut pas être audité car Google ne fournit pas à ses éditeurs l'information des enchères exclues car arrivées trop tard (cf. Bids data in Ad Manager Data Transfer).
Google impose ses propres plateformes d'achats
Pour pouvoir acheter de l'inventaire sur YouTube, un site incontournable, un annonceur est obligé de passer par les plateformes d'achats de Google car en 2015, Google a décidé de couper l'accès à l'inventaire YouTube aux plateformes d'achats tierces. Aussi, Google a été poursuivi par les autorités américaines en 2013 pour avoir limité les fonctionnalités des APIs Google Ads, compliquant l'achat de liens sponsorisés Google via des outils tiers.
Comme nous l'avons vu précédemment, utiliser Google DV 360 et une autre plateforme d'achats en parallèle fait prendre le risque de miser 2 fois pour le même utilisateur (car l'autre plateforme d'achats n'a pas accès aux cookies doubleclick et ne peut donc reconnaître qu'il s'agit du même utilisateur) et de faire ainsi monter artificiellement les prix.
Les plateformes d'achats de Google sont donc incontournables pour les annonceurs, seul Facebook pouvant rivaliser, mais celui-ci n'a plus d'empreinte sur le web depuis l'arrêt de son Audience Network (maintenant seulement disponible sur l'univers App) et ne peut ainsi "que" vendre sur le web l'accès à ses propres propriétés (Facebook, Instagram).
Google oriente les achats vers ses propres plateformes et sites
Lorsqu'un petit annonceur créé un compte sur Google Ads, il doit d'abord démarrer une campagne "Search" (sur les résultats de recherche Google) avant de pouvoir acheter de l'inventaire sur des sites tiers. Une première méthode pour diriger les achats vers ses propres sites.
Google peut également orienter les achats depuis ses plateformes d'achats vers les sites passant par ses solutions de monétisation :
- Jusqu'en 2016, Google n'orientait les achats de Google Ads que vers le Google Ad Exchange (cf. la présentation du Doubleclick Ad Exchange de l'époque : "Ad Exchange is the only exchange offering access to the full demand of Google AdWords"), empêchant les autres Ad Exchange de profiter de cette manne publicitaire potentielle. Cela a changé depuis, mais de manière limitée : seulement pour les campagnes de remarketing, cf. l'aide en ligne de Google Ads.
- S'il n'a pas bloqué l'accès aux autres Exchanges depuis sa plateforme d'achats à destination des grands annonceurs DBM (alias DV 360 maintenant), il est fréquemment accusé d'orienter les achats en priorité vers son propre Ad Exchange : "Most DBM buyers we talk to say more than half of their spend goes to AdX when they use DBM" déclarait alors le PDG d'AppNexus, un rival.
Google oriente les ventes vers sa propre place de marché
Côté éditeurs, l'adserveur dominant est Google DFP. Celui-ci a récemment été fusionné avec Google AdX pour être renommé Google Ad Manager. Suite au rachat de Doubleclick en 2007, Google a profité de la position dominante de DFP pour imposer AdX. Voici comment il a procédé :
- Directement dans DFP , l'éditeur peut paramétrer ses campagnes publicitaires à volume garanti (pré-vendues, pour lesquelles l'acheteur s'engage à acheter un certain volume d'opportunités publicitaires, sur des critères de diffusion précis) et ses campagnes publicitaires à volume non garanti (l'éditeur propose des opportunités publicitaires, l'acheteur potentiel n'a aucune obligation d'achat).
- Les campagnes publicitaires à volume non garanti peuvent provenir d'ad-networks ayant un accord direct avec l'éditeur. Mais comme évoqué précédemment, l'éditeur doit alors configurer un système d'appels aux ad-networks en cascade (les uns après les autres), entraînant pertes de revenus (prix fixe pour chaque ad-network, pas de concurrence directe) et mauvaise expérience utilisateur (lenteurs).
- Les campagnes publicitaires à volume non garanti peuvent également provenir de Google AdX, intégré "nativement" à DFP depuis 2010. Celui-ci permet une vraie mise en concurrence des acheteurs (enchère en temps-réel). Il est également connecté aux 2 plateformes d'achats de Google : DV 360 (ex DBM) et Google Ads (ex AdWords).
- Un système de mise en concurrence appelé "Allocation dynamique" arbitre entre les campagnes publicitaires à volume garanti et celles à volume non garanti. Son objectif est de maximiser les revenus de l'éditeur tout en s'assurant que les campagnes à volume garanti respecteront le contrat avec l'acheteur et diffuseront le bon volume d'impression, sur les bons critères (inventaire, ciblage, dates de diffusion). Comment ? En fixant dynamiquement un "prix fictif" pour les campagnes à volume garanti (assez fort pour leur permettre de diffuser) et en regardant si les campagnes à volume non garanti proposent un meilleur prix.
- Si AdX est intégré nativement à DFP, les autres places de marchés n'ont pas cette chance. Jusqu'en 2017 et l'annonce de l'Exchange Bidding, DFP obligeait les éditeurs à configurer les autres places de marchés comme de simples ad-networks (et donc à les appeler les uns après les autres, après AdX si celui-ci n'avait pas déjà "préempté" l'opportunité). Ils devaient également renseigner un prix de vente fixe pour chaque place de marché, hors le principe d'une enchère est de ne pas connaître le prix de vente.
Conséquence : fin 2014, les éditeurs désireux de travailler avec d'autres places de marchés, se retrouvent à "hacker" DFP via un système appelé "header bidding".
Le header bidding, un hack imparfait pour mettre en concurrence Google AdX
Le Header Bidding étape par étape, détaillé sur le site Ad Ops Insider :
De manière très résumée, comme DFP ne permet pas de vraie mise en concurrence entre AdX et les autres places de marchés, le header bidding permet une mise en concurrence des places de marchés (hors AdX) en dehors de l'adserver (via le header de la page), avant l'appel à DFP. Le vainqueur de l'enchère est alors mis en concurrence avec les autres campagnes de DFP, volume garanti ou non. L'éditeur est obligé de créer autant de "line items" (campagnes sur DFP) que de tranches de prix, pour chaque place de marché !
Via l'article Quelles sont les conséquences du header bidding sur l’achat programmatique ?, le header bidding permet une vraie compétition chez les places de marchés tierces.
Cette implémentation permet aux éditeurs de desserrer un peu l'étau de Google via une mise en concurrence avec d'autres places de marché, elle leur permet aussi de décider du temps de réponse maximum accordé aux différentes places de marchés, permettant ainsi de prendre en considération les enchères des acheteurs plus lents. La contrepartie : les tags des différentes places de marché, tous appelés directement via le header de la page, entraînent des lenteurs et dégradent l'expérience utilisateur.
Enfin une compétition équitable entre les différentes places de marchés ? Pas vraiment...
Le "last-look", où comment Google s'octroie un nouvel avantage sur ses concurrents
Le diable est dans les détails et les places de marchés tierces sont encore désavantagées par rapport à Google AdX, explications :
- Les enchères RTB fonctionnent alors quasiment exclusivement en mode "2nd price auction" : l'acheteur ne paye que le prix de la 2ème enchère. Exemple : Sur la place de marché AppNexus, A mise 5€, B mise 1€ ==> A gagne et devrait payer 1€.
- Ce prix de 1€ permet également à AppNexus de gagner la compétition header bidding (contre les autres places de marchés tierces).
- AppNexus soumet alors ce prix de 1€ à DFP. Via l'allocation dynamique, les acheteurs AdX savent qu'ils doivent miser plus pour espérer remporter la compétition.
- C mise 2€, D mise 0,5€, le plancher est à 1€ ==> C gagne et paye 1€.
Cet avantage que Google s'accorde à lui-même est appelé "last look" dans le milieu de l'adtech.
On le voit sur cet exemple, l'acheteur A était prêt à dépenser 5€, il n'a pas pu dépenser sa mise. La place de marché tierce avait un acheteur potentiel à 5€ contre un acheteur potentiel à 2€ sur Google AdX, elle a également perdu injustement la compétition. L'éditeur aurait pu gagner 5€ (moins les commissions), il gagne finalement 1€ (moins les commissions). Un seul gagnant : Google, qui aura ainsi pu satisfaire ses acheteurs et prendre sa commission via Google AdX.
Afin de maximiser leurs chances de gain dans la compétition avec Google AdX, les places de marchés tierces ont décidé progressivement (et tardivement, à partir de 2018) de basculer sur des enchères en mode "1st price auction" : l'acheteur paie alors le prix de son enchère. Une première partie du problème est résolu : dans l'exemple précédent, l'acheteur A gagne et paye 5€. Mais Google continue de transmettre ce prix plancher aux acheteurs de Google AdX (dont Google Ads).
Ceux-ci gardent donc un avantage d'information et peuvent décider de miser 1 centime de plus pour gagner l'enchère ("last look"). Les places de marchés tierces restent désavantagées.
Google Ads peut faire de l'arbitrage sans que personne ne s'en rende compte
Si un annonceur aura droit à une information transparente sur son DSP (prix de l'enchère et prix d'achat) lorsqu'il achète sur AdX, ce n'est pas le cas s'il utilise Google Ads : celui-ci ne fournit pas ce niveau de transparence dans ses rapports. Aussi, le mode d'achat sur Google Ads est au clic (CPC ou coût par clic), que la publicité soit diffusée sur les résultats de recherche Google ou sur Google AdX. Mais les ventes en programmatique se font à l'impression (CPM ou coût pour 1000 affichages), rendant les comparaisons plus difficiles.
Aussi, lorsqu'il mise sur Google AdX, Google Ads part avec un avantage d'information énorme :
- Il n'a pas besoin de synchroniser les identifiants utilisateurs.
- Il bénéficie de l'omniprésence des traqueurs Doubleclick (tous les clients éditeurs et annonceurs de Doubleclick, les clients Google Analytics ayant activés les fonctionnalités publicitaires, AdSense et YouTube), informations qu'il s'autorise à combiner à son propre profit (rappelez-vous, la fusion des politiques de confidentialité des 70 différents services de Google en 2012).
- Si l'utilisateur ne l'a pas refusé, les informations doubleclick sont également combinées avec les informations personnelles associées au compte Google de l'utilisateur (rappelez-vous, la modification des conditions d'utilisation de Google en 2016).
- Enfin, il représente un nombre considérable d'annonceurs, tous intéressés pour afficher leurs publicités sur les résultats de recherche Google.
Ces informations permettent à Google Ads de prédire avec une grande précision le taux de clics, et donc de miser au meilleur prix pour optimiser ses propres revenus (tout en garantissant une performance acceptable à l'annonceur). Un exemple ci-dessous, provenant du papier "‘Trust Me, I’m Fair’: Analysing Google’s Latest Practices in Ad Tech From the Perspective of EU Competition Law" :
Ici, Google Ads reçoit 6€ mais paye seulement 3€ pour gagner l'enchère, il peut garder la différence
À noter que Google Ads tire parti de plusieurs facteurs pour faire de l'arbitrage :
- Tout comme les autres participants à l'enchère AdX, il ne paye que le prix du 2ème enchérisseur ("2nd price auction"). Mais comme il fonctionne en boîte noire, il peut se permettre d'encaisser la différence entre son enchère et le prix de vente effectif, sans aucun compte à rendre.
- Le mode d'achat au CPC rend la tâche d'audit encore plus compliqué : seul Google a l'info du taux de clics attendu.
- Même si l'enchère AdX passe en "1st price auction" (nous en reparlerons plus tard), le "last-look" lui permet de miser moins que ce qu'il pourrait, et d'encaisser la différence.
Open Bidding, la réponse de Google au header bidding
Le header bidding reste un hack qui ne plaît pas à Google :
- Il n'en est pas à l'origine et surtout, ne prend pas de commission sur les ventes qui passent par d'autres places de marchés.
- Conséquence, Google n'a aucun intérêt à faciliter l'opérationnel pour l'éditeur : paramétrer le header bidding dans DFP est complexe, le reporting est également très compliqué (de nouveaux acteurs adtech prennent le relais pour aider dans ces complexités).
- Google ne permet pas à Google AdX d'être intégré dans des solutions de header bidding. L'éditeur doit faire tourner une première enchère côté header bidding, puis une 2ème enchère dans DFP, dégradant l'expérience utilisateur. Multiplier les partenaires dans le header fait aussi prendre le risque de dégrader l'expérience utilisateur.
En 2017, Google propose de déplacer la compétition côté serveur (chez lui) :
Le "Server-Side Header Bidding", expliqué sur le blog Ad Ops Insider
La fonctionnalité est initialement appelée EBDA (Exchange Bidding in Dynamic Allocation), maintenant renommée Open Bidding. Google Ad Manager met directement en compétition les places de marchés qui auront bien voulu s'intégrer avec lui (ce qui n'est pas gagné, notez par exemple l'absence d'AppNexus, une des plus grandes places de marchés, et principal initiateur du header bidding) et Google AdX.
Les places de marchés y gagnent un accès facilité aux nombreux éditeurs qui utilisent Google Ad Manager. Google fournit également aux places de marchés (ainsi qu'aux autres acheteurs) le prix de vente effectif de chaque enchère, ce qu'il ne fait pas lors des intégrations en header bidding.
Les avantages pour l'éditeur ?
- S'il doit toujours signer un contrat avec les différentes places de marchés, le système est "plug & play", pas de galères opérationnelles.
- Le paiement est effectué directement par Google, ce qui facilite la comptabilité (et les éditeurs savent que Google paye rapidement, ce qui est moins vrai des SSPs plus petits, qui doivent se faire payer par les DSPs, eux-même devant se faire payer par les agences).
- L'éditeur n'a pas de limites sur le nombre de tiers avec qui travailler, car il n'y a pas d'impact côté expérience utilisateur (pas de tags additionnels sur site, les appels ont lieux côté serveur).
Mais voilà, rien n'est gratuit et Google prend une commission de 5% ou de 10% selon les publicités (standard, vidéo ou app). Une place de marché tierce est terriblement désavantagée :
- Elle doit d'abord prendre sa commission, puis soumettre l'enchère à Google qui prend également sa commission avant de comparer le prix diminué aux autres enchères, cf l'aide en ligne de Google : "L'enchère nette la plus élevée (qui tient compte de la part de revenus d'Ad Manager) remporte l'impression".
- Tout comme les plateformes d'achats tierces sur le Google Ad Exchange, elle n'a pas un accès direct à l'utilisateur (Google les appelle côté serveur) et doit donc synchroniser ses identifiants utilisateurs avec ceux de Google avant une enchère. Ceci entraîne un taux plus faible de reconnaissance des utilisateurs, et donc une moins bonne monétisation (sachant qu'elle doit aussi synchroniser ses identifiants utilisateurs avec ceux des plateformes d'achats).
- Elle est également désavantagée en terme de vitesse : elle doit répondre à Google en moins de 160 ms, sachant qu'elle doit elle-même conduire sa propre enchère. Comme on l'a vu précédemment avec les plateformes d'achats tierces achetant sur Google AdX, le fait d'être situé sur les mêmes serveurs (Google Ads et Google DV 360) permet aux acheteurs d'enchérir plus souvent et mieux. La logique s'applique ici entre Google AdX, avantagé car situé sur les mêmes serveurs que Google Ad Manager, et les autres places de marchés.
- Les acheteurs intelligents recherchent les opportunités les moins chers, et donc avec le moins d'intermédiaires. Ils privilégieront un achat direct via Google AdX plutôt qu'un partenaire Open Bidding. Ce mécanisme d'optimisation est appelé "Supply Path Optimization" ou SPO, il est appliqué par tous les DSPs dignes de ce nom. Si vous êtes intéressé par le sujet, vous pouvez lire cet article du co-fondateur d'AppNexus, Brian O'Kelley.
- Évidemment, l'éditeur peut désactiver une place de marché tierce mais il est impossible de désactiver Google AdX.
Google ne permet pas aux éditeurs de comprendre comment les enchères fonctionnent
Comprendre comment ces mécanismes d'enchères fonctionnent est crucial pour les éditeurs : quels acheteurs sont intéressés par mon inventaire ? Quel prix sont-ils prêts à payer ? Comment se comportent-ils si je modifie le prix plancher ? Ai-je intérêt à les contacter en direct s'ils achètent beaucoup d'inventaire, pour sécuriser des accords privilégiés ? La transparence est essentielle, à savoir accéder à toutes les informations sur ces enchères, seulement Google restreint l'information :
- L'accès à l'information est payant !
- Les données d'enchères (combien chaque acheteur est prêt à payer) et d'impressions (qui a gagné et quel est le prix de vente final) sont accessibles via 2 fichiers différents, un pour "données d'impressions" et un autre pour les "données d'enchères".
- Les données d'enchères contiennent le nom de l'acheteur, la valeur de l'enchère et si l'enchère est gagnante. Absents du fichier : les enchères des autres places de marché, ainsi que le prix d'achat effectif.
- Les données d'impressions contiennent le vainqueur, le prix d'achat effectif ainsi que les enchères des autres places de marchés.
- Les annonceurs Google Ads sont toujours cachés derrière l'acheteur Google Ads : impossible de les connaître, ni de savoir combien ils ont payé (la marge de Google est inconnue).
- Un éditeur pouvait faire le lien entre ces 2 fichiers mais depuis l'annonce de Google en septembre 2019, ce n'est désormais plus possible.
- Conséquences : impossible de vérifier l'impartialité de la tarification unifiée de Google, impossible de vérifier si Google ne fait pas de l'arbitrage, impossible de vérifier si Google ne fait pas tourner l'enchère AdX après avoir reçu les enchères des autres places de marchés, etc.
- Aussi, Google gagne de précieuses informations sur le comportement des places de marchés rivales. Il ne serait pas difficile d'utiliser ces informations pour prédire leurs enchères futures, et ainsi avantager Google AdX.
La fin du "last-look", vraiment ?!
Google décide en mars 2019 de suivre les autres places de marché et de basculer Google AdX en mode "1st price auction", il communique d'abord de manière vague sur la fin du "last-look" :
An advertising buyer’s bid will not be shared with another buyer before the auction or be able to set the price for another buyer
Son schéma explicatif est également très vague (aussi, impossible de savoir si le "1st price auction" s'applique lorsque Open Bidding n'est pas activé) :
En mai 2019, il donne un peu plus de précisions" :
Going forward, no price from any of a publisher’s non-guaranteed advertising sources, including non-guaranteed line item prices, will be shared with another buyer before they bid in the auction
Pourquoi ai-je mis "including non-guaranteed line item prices" en gras ? Parce que ces "line items" (éléments de campagnes renseignés sur Google Ad Manager) sont notamment utilisés par les places de marché tierces pour le header bidding. Et si l'on regarde l'historique de l'article de Google via la Wayback Machine, on se rend compte que ces "lines items" n'étaient pas incluses dans la version initiale de l'article, voici le passage complet de l'époque :
After the transition, Ad Manager will have a single auction that compares the prices from a publisher’s guaranteed campaigns with all of a publisher’s non-guaranteed advertising sources — including real-time bidding partners, such as Authorized Buyers and Exchange Bidding partners — and prices from non-guaranteed line items, like those from a publisher’s header bidding implementation. Going forward, no price from any of a publisher’s non-guaranteed advertising sources will be shared with another buyer before they bid in the auction. As has always been the case, all real-time bidding partners integrated with Ad Manager — including Google Ads and Display & Video 360 — will be notified of an auction at the same time.
Si l'on lit attentivement l'extrait initial, comme le remarquent judicieusement Damien Geradin et Dimitrios Katsifis, les auteurs de "'Trust me, I'm Fair': Analysing Google's Latest Practices in Ad Tech From the Perspective of EU Competition Law" en octobre 2019, Google ne mentionne pas les non-guaranteed line items lorsqu'il indique ne plus partager d'informations de prix avant l'enchère, seulement les non-guaranteed advertising sources, à savoir les acheteurs AdX (Authorized Buyers) et Exchange Bidding (Open Bidding).
Il se trouve que la presse spécialisée avait déjà annoncé la fin du "last-look" en 2017, qui semblait à l'époque ne concerner qu'Open Bidding (était-ce vraiment le cas, si Google communique seulement en 2019 ?). Même topo donc en mars 2019, la presse spécialisée s'empresse d'annoncer la fin du "last-look". Un argument avancé : le "last-look" serait incompatible avec les 1st price auctions. Il n'en est rien : Google Ads (ou un autre acheteur AdX) peut tout à fait décider de miser 1 centime de plus que le vainqueur de l'enchère header bidding s'il a l'info, ce qui permettra de donner beaucoup moins d'argent à l'éditeur et de potentiellement garder la marge pour lui.
Alors que s'est-il passé avec l'article ? D'après la Wayback machine toujours, les non-guaranteed line items ont été ajoutées à l'article entre le 15 novembre 2019 et le 15 août 2020. Est-ce suite au papier de Damien Geradin et Dimitrios Katsifis ? Est-ce que Google avait vraiment supprimé le "last-look" (se privant d'une option d'arbitrage via Google Ads) en mai 2019 ? L'a-t-il vraiment fait entre le 15 novembre 2019 et le 15 août 2020, et si oui, pourquoi n'a-t-il pas communiqué sur cette évolution ? Il est impossible de vérifier car Google ne fournit pas la transparence suffisante via les données d'enchères et d'impressions, il est donc permis d'en douter.
Le "1st price auction", une excuse pour verrouiller la monétisation de Google Ads
Avec le lancement en 2019 des enchères en 1st price auction, Google a bouleversé les règles de création de prix plancher pour les éditeurs. Auparavant, ils pouvaient décider de mettre des prix plancher plus haut pour certains acheteurs. Une règle fréquemment utilisée : augmenter le prix plancher de Google Ads (pour éviter que Google Ads se retrouve à payer beaucoup moins cher qu'il le pourrait, grâce au "2nd price auction" et au "last-look").
Aussi, ces règles de prix plancher ne s'appliquaient qu'aux acheteurs d'AdX. Les éditeurs pouvaient gérer les partenaires header bidding ou Open Bidding séparément, et leur appliquer un prix plancher plus bas s'ils le souhaitaient. Les nouvelles "règles unifiées" suppriment cette option, et évidemment, Google présente cela comme un avantage :
Our new unified pricing rules will help publishers more easily manage floor prices across all non-guaranteed partners. For example, instead of setting up the same floor prices in multiple places — in the auction in Ad Manager, and with their Exchange Bidding and other non-guaranteed advertising sources — which can take a lot of time and can lead to errors, a publisher can set up a single unified pricing rule to control pricing from one place.
Google interdit explicitement de créer des règles de prix plancher différent, selon les plateformes d'achats. Il présente cette manoeuvre abusive comme une mesure de justice :
To maintain a fair and transparent auction, these rules will be applied to all partners equally, and cannot be set for individual buying platforms.
Il s'agit surtout d'une perte de contrôle massive de l'éditeur sur la vente de son inventaire, et une opportunité en or pour accélérer l'arbitrage via Google Ads.
L'arme AMP pour supprimer le header bidding
Le format AMP est un format de pages web lancé par Google en 2016. Son objectif est d'accélérer le chargement des pages sur mobile, mais il est vu par beaucoup comme une menace pour le web ouvert : par sa position dominante sur la recherche en ligne, Google contraint les éditeurs à développer une version spécifique et très limitée de leur site, mise en cache sur les serveurs de Google. Sans version AMP de leur site, les éditeurs n'ont pas accès au carrousel. L'éclair représentant AMP dans les résultats de recherche incite aussi les utilisateurs à cliquer sur ces résultats.
Aussi, Google ne dit pas que AMP est un facteur de ranking (de meilleur classement dans les résultats de recherche), mais il appuie sur le fait que la vitesse de chargement est très important : "Même si le format AMP lui-même n'a pas d'impact direct sur votre position dans les résultats de recherche, la vitesse est un facteur de classement déterminant pour la recherche Google". En théorie les éditeurs ont le choix, dans les faits et s'ils ne veulent pas perdre leur ranking dans les résultats de recherche Google, ils sont contraints de fournir une version AMP de leurs pages.
Et pour la publicité me direz-vous ? AMP empêche les éditeurs d'utiliser du header bidding côté client (librairie javascript), ceux-ci sont donc encouragés à utiliser la solution Open Bidding s'ils veulent travailler avec des places de marchés tierces, ou tout simplement se contenter d'utiliser exclusivement la place de marché de Google. Les pages AMP étant mis en cache chez Google, toute la chaîne publicitaire peut s'exécuter sur les mêmes serveurs, encore l'avantage de vitesse (mais pour la monétisation, à part celle issue de la demande de Google, ce n'est pas gagné).
AMP étant très critiqué, la nouvelle stratégie de Google consiste à pousser les Core Web Vitals, de nouvelles métriques censées mieux représenter l'expérience utilisateur dans sa globalité. Ces métriques seront pris en compte l'année prochaine dans les rankings : "Today, we’re building on this work and providing an early look at an upcoming Search ranking change that incorporates these page experience metrics". Les éditeurs n'auront pas besoin d'avoir leurs pages en versions AMP pour être mis en avant dans le carrousel, mais plutôt d'avoir un bon score sur les Core Web Vitals.
Les Core Web Vitals, une mesure de l'expérience utilisateur sur différents axes. Aujourd'hui, Google mesure déjà ces indicateurs via les utilisateurs de Chrome ayant synchronisé leur historique de navigation et ayant l'envoi de statistiques activé (il met à disposition des statistiques agrégés via le Chrome User Experience Report).
Si cette initiative est louable, il est à craindre que AMP soit remplacée par une version encore plus problématique, les Web Bundles : un nouveau format permettant à un site de regrouper toutes les ressources d'une page web dans un même fichier, et potentiellement mis en cache chez des tiers tels que Google. Un point clé pour nous : ces Web Bundles vont grandement compliquer la tâche des adblockers. Lisez à ce propos l'article de Peter Snyder, WebBundles Harmful to Content Blocking, Security Tools, and the Open Web.
Le programmatique direct, une arme supplémentaire pour taxer l'écosystème publicitaire
Si la publicité "Display" passe maintenant essentiellement par les tuyaux du programmatique, les relations directes entre acheteurs et éditeurs n'ont pas disparu. En particulier :
- Les éditeurs ayant un inventaire de qualité et/ou une audience spécifique et/ou des formats publicitaires "innovants" peuvent toujours proposer des accords préférentiels aux acheteurs (les informer de ces opportunités particulières, voire même de leur donner la priorité par rapport à d'autres acheteurs). Évidemment, les acheteurs vont pousser pour avoir droit à ces accords préférentiels.
- Les acheteurs désirant sécuriser leurs achats vont toujours avoir besoin que les éditeurs garantissent un certains volume d'impression. Ce besoin est notamment important lorsque l'inventaire est rare : si je veux communiquer sur un nouveau film, je vais par exemple vouloir diffuser 10 millions d'impressions sur YouTube entre le 5 novembre et le 8 novembre.
Avant que le programmatique ne se démocratise, ces transactions passaient uniquement par les adserveurs annonceurs et éditeurs. En conséquence, ceux-ci ne payaient pas de taxe RTB (pas de commission sur le prix du média à payer côté DSP, pas de commission à payer côté SSP, seulement le coût de diffusion adserveur, qui est fixe et en conséquence bien moins cher). Google, de la même manière que ses concurrents DSP et SSP, y a vu un manque à gagner important : il a donc poussé l'écosystème publicitaire à faire entrer ces transactions dans les tuyaux du programmatique (via un système nommé "Deals") :
- D'abord avec les "Accords préférés" (alias "Preferred Deals") : accords entre 1 acheteur et un éditeur, à prix fixe, prioritaire sur les autres campagnes non garanties (AdX, Open Bidding, header bidding et ad-networks) mais à volume non garanti (l'acheteur ne s'engage pas à acheter, il peut choisir les opportunités).
- Puis avec le "Programmatique garanti" : accords où l'acheteur s'engage à acheter un volume garanti d'impressions.
Voici les arguments pouvant justifier le paiement d'un service sur ces transactions publicitaires :
- Dans le cas des "Accords préférés", l'acheteur choisit les opportunités (dans l'ancien monde, lorsqu'il est appelé, l'adserveur de l'annonceur n'a pas le choix).
- Le DSP gère toutes les campagnes de l'acheteur, ce qui permet à cet outil de proposer un reporting unifié.
- Les paiements aux éditeurs sont maintenant simplifiés et sécurisés, le SSP s'en occupe.
- Si le paramétrage des campagnes de gré à gré est complexe, Google permet aux acheteurs et éditeurs de négocier les accords directement dans leurs interfaces respectives (DV 360 et Google Ad Manager). Notez que cette option aurait pu être proposée sans les tuyaux du RTB mais que Google n'avait rien à y gagner.
Et si l'on compare la part des "Deals" aux enchères ouvertes, on se rend compte que ces relations de gré à gré représentent une part considérable des investissements publicitaires. Elles étaient moins visibles auparavant car les campagnes publicitaires ne transitaient pas par les tuyaux du programmatique :
Les chiffres et prévisions eMarketer pour le marché US, les "Deals" doivent dépasser les enchères ouvertes en 2020. La France suit en général la même tendance, avec 1 ou 2 ans de retard. Le potentiel pour les acteurs du programmatique est donc énorme.
Mais il est difficilement justifiable de continuer de prendre une commission sur les montants média dépensés (X% côté DSP, Y% côté SSP) : il s'agit ici d'un accord direct entre un acheteur et un éditeur, l'intermédiaire n'est pas un apporteur d'affaire. On s'attendrait plutôt à un CPM fixe, similaire aux prix d'un adserver. C'est pourtant le choix de Google, et sur lequel l'écosystème programmatique s'est aligné.
Le programmatique direct, un avantage supplémentaire pour AdX
Ces transactions de gré à gré sont un bon moyen de discriminer les autres places de marchés :
- Google propose une Marketplace dans DV 360 : cela permet aux acheteurs de découvrir les offres des éditeurs, mais aussi de négocier avec eux directement dans l'interface. Si la négociation aboutit, la création de la campagne est automatique, pour l'acheteur et l'éditeur. Problème : cette Marketplace est quasiment exclusive aux éditeurs AdX (excepté Rubicon).
- Le "programmatique garanti" suppose de pouvoir garantir un volume d'impressions. Seuls les adserveurs sont capables de gérer un volume d'impression. En conséquence, les places de marchés qui ne sont pas couplés avec un adserveur ne peuvent vendre du programmatique garanti (à Google DV 360 ou à une autre plateforme d'achats). Les éditeurs utilisant Google Ad Manager (DFP et AdX) sont bien entendu déjà équipés.
- Au sein de Google Ad Manager, les "accords préférés" sont seulement disponibles sur AdX : les partenaires Open Bidding et les places de marchés passant par du header bidding ne peuvent être priorisés par rapport aux autres campagnes non garanties.
Ainsi, si vous êtes une place de marché tierce, il est quasiment impossible de concurrencer AdX chez les éditeurs Google Ad Manager, seulement de récupérer les miettes.
Remplacer Google Ad Manager ? Mission (presque) impossible
Nous l'avons vu à de multiples reprises, le premier outil appelé sur la page de l'éditeur est stratégique : il s'agit de l'adserveur éditeur (DFP dans le cas de Google, qui a été dernièrement "fusionné" avec AdX pour être renommé Google Ad Manager). Google y favorise sa propre demande via de multiples procédés : "last-look", complexité à gérer le header bidding, taxe sur Open Bidding, boite noire sur les données d'enchères et d'impressions, bridages des règles de prix plancher, meilleure reconnaissance utilisateur, meilleure connexion avec ses propres plateformes d'achats, fusion de vos données personnelles doubleclick et Google, facilitation du programmatique direct, etc.
Que se passe-t-il si un éditeur décide de ne pas travailler avec Google sur la partie Adserveur ? Les difficultés sont très grandes :
- Ajouter une nouvelle place de marché sur Open Bidding est très facile, ajouter une nouvelle place de marché en header bidding est relativement facile, migrer d'adserveur est une tâche bien plus complexe opérationnellement, pouvant prendre plusieurs mois.
- Google AdX est la seule place de marché disposant de la totalité de la demande Google Ads (les autres places de marchés n'ont que les campagnes de remarketing). Hors Google Ads est le principal acheteur au monde. Mais Google refuse de proposer AdX en header bidding.
- Google refuse également d'intégrer AdX à des systèmes de header bidding server-side concurrents (tels que Prebid Server ou Amazon Transparent Ad Marketplace) ou à des places de marchés et autres adserveurs concurrents.
- Conséquence : si vous ne voulez pas vous couper de la principale source de demande (à savoir : mettre en compétition au même niveau les campagnes AdX et les campagnes des autres places de marchés), vous devez utiliser AdX, et donc vous êtes fortement incités à utiliser Google Ad Manager.
Pouvez-vous éviter Google Ad Manager et profiter d'AdX ? Oui mais seulement via un mécanisme incroyablement complexe, mis en place par Axel Springer (le plus gros groupe média européen) avec l'aide de son partenaire AppNexus (concurrent de Google Ad Manager, proposant adserveur et SSP) et permettant de mettre en compétition AdX avec les autres sources de demandes :
Si vous ne comprenez rien à ce schéma, c'est normal.
Une régulation nécessaire
Si Google a pu s'imposer si efficacement sur les marché publicitaires, ce n'est pas seulement parce que ses outils seraient "meilleurs" (l'argument ne doit pas être sous-estimé, Google propose de bons outils avec une excellente interface utilisateur), mais c'est surtout parce qu'il a pu profiter d'une absence absolue de régulation pour racheter de multiples sociétés et abuser de sa position dominante.
Les différentes pratiques documentées ne sont pas exclusives aux marchés publicitaires. Comme le documente si bien Dina Srinivasan, on peut retrouver ces pratiques sur d'autres marchés tels que les marché financiers, les ventes de billets en ligne, etc. Seulement voilà, les autres marchés sont régulés et les sanctions sont prises lorsqu'un acteur abuse d'un avantage. En conséquence, ces marchés fonctionnent mieux.
Comment Google a-t-il pu échapper à toute régulation sur ces marchés publicitaires ? Sans être expert juridique, un des éléments est sans doute la complexité et l'opacité de l'adtech, que vous avez pu constater si vous vous êtes accrochés pour lire cet article en entier... Les options offertes aux régulateurs sont nombreuses, en voici quelques-unes suggérés dans les récentes études :
- Séparer structurellement (vente, ou divisions indépendantes avec contrôles stricts) l'adserveur (DFP) de la place de marché (AdX).
- Séparer structurellement ses activités d'achat (Google Ads, DV 360) des activités de vente (AdX, AdSense, AdMob).
- Séparer structurellement Chrome.
- Activer la totalité de la demande Google Ads sur les autres places de marchés.
- Permettre aux adserveurs d'accéder simplement à la demande AdX.
- Permettre aux plateformes d'achats tierces d'acheter de l'inventaire YouTube.
- Faciliter l'achat de publicités sur les résultats de recherche de Google via des plateformes tierces.
- Obliger Google à une transparence complète sur les données d'enchères et d'impressions.
- Plus généralement, réguler et sanctionner l'ensemble de l'écosystème publicitaire : Google est la société qui abuse le plus, mais ce n'est pas la seule.
Plus fondamentalement, quel est l'utilité réelle de cet écosystème programmatique ultra complexe, à l'origine de fuites de données personnelles massive ? On voit bien les effets négatifs : expérience utilisateur catastrophique, surveillance banalisée et généralisée (merci Google), dépendance extrême des médias envers Google... Si l'on regarde son coût et son opacité, les résultats sont choquants :
Étude sur la transparence du programmatique : oui, l'éditeur ne touche que 51% du montant dépensé par l'annonceur, notez également que l'étude ne peut expliquer 15% de l'argent dépensé...
En tant qu'éditeur, si vous ne proposez pas d'abonnement, une vie en dehors de l'adtech est-elle possible ? Oui si l'on en croit l'expérience du "radio france hollandais", qui a vu ses revenus publicitaires augmenter, tout en abandonnant la publicité ciblée. Alors bien sûr, l'expérience est plus facile à mener lorsque l'on est un groupe public, mais le jeu en vaut la chandelle.
30.09.2020 à 11:32
La grande braderie de vos données personnelles sur Le Bon Coin

Le Bon Coin fuite vos données personnelles dès votre arrivée sur son site web
Le Bon Coin est un énorme succès commercial en France, le site de petites annonces a su se rendre indispensable auprès de nombreux particuliers. Ayant assez régulièrement des biens à revendre, j'ai souhaité comprendre si Le Bon Coin était respectueux de ma vie privée. Démarrons avec le site web leboncoin.fr, voici les étapes à suivre si vous désirez reproduire l'expérience :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur la page d'accueil leboncoin.fr.
Première constatation : Le Bon Coin n'offre pas d'option directe pour refuser la surveillance marketing. Cette présentation n'est pas conforme au RGPD : l'option "J'ai compris" est mise en valeur par la couleur bleue et surtout elle oblige l'utilisateur à configurer ses choix via le bouton "Personnaliser", l'énorme majorité des utilisateurs ne feront pas l'effort.
Regardons maintenant les requêtes envoyées lors de votre arrivée sur le site, pour rappel vous n'avez pas encore fait le choix d'accepter ou de refuser d'être pisté :
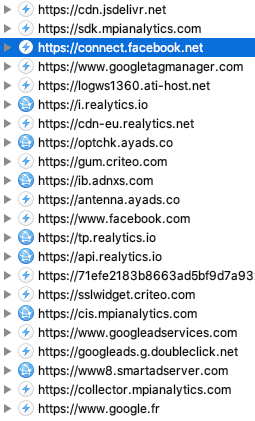
Surprise ! Vous n'avez effectué aucune action mais Le Bon Coin multiplie déjà les appels à des sociétés marketing, certaines de ces sociétés démarrent le pistage sans votre consentement. Voici une liste de traceurs utilisant un identifiant personnel (pseudonyme) :
- Datadome : solution de protection contre les bots.
- Sublime : via ayads.co, ad-network français spécialisé dans les habillages de page (anciennement Sublime Skinz).
- AT Internet : via ati-host.net, AT Internet est une société analytics française "historique", originellement appelée Xiti. Nous les avons déjà rencontré ailleurs, cf. "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr" et "Boursorama Banque fuite vos données de connexion".
- Facebook : Le Bon Coin utilise la boîte à outils marketing de Facebook, entre autres pour sa brique analytics.
- Google : via doubleclick.net. Le Bon Coin utilise également la solution de monétisation publicitaire "Google Ad Manager" de la firme de Mountain View.
Que se passe-t-il maintenant si vous cliquez sur le bouton "Personnaliser" ?
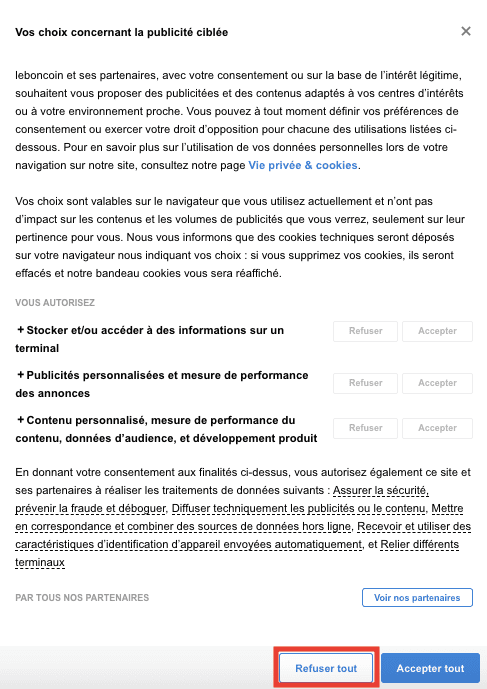
Bonne nouvelle, il y a bien un bouton "Refuser tout", cliquons dessus et observons les requêtes envoyées :

Vous venez de faire l'effort de refuser tout pistage, mais vous fuitez toujours vos données personnelles aux géants de la surveillance publicitaire :
- Facebook : la surveillance continue, Facebook suit toutes vos actions sur le site leboncoin.fr. Ironiquement, la firme de Menlo Park récupère ici spécifiquement l'information que vous avez cliqué sur le bouton "Refuser tout".
- Google : via sa plateforme de monétisation publicitaire Google Ad Manager (réunissant adserveur et SSP), Google récupère également votre surf.
Consultez quelques pages et constatez que les appels aux sociétés marketing représentent toujours la majorité des requêtes :
La plupart de ces acteurs semblent ici prendre en compte votre consentement (pas de cookies déposés, même s'ils pourraient théoriquement vous pister avec votre adresse IP et avec les caractéristiques de votre navigateur), mais on peut se demander pourquoi Le Bon Coin les appelle. Les traceurs déjà répertoriés précédemment continuent la surveillance (Google, Facebook, AT Internet, Sublime, Datadome), on peut aussi remarquer un petit nouveau, Index Exchange (via casalemedia.com), une autre plateforme de monétisation publicitaire.
Si maintenant vous continuez votre navigation sans faire attention à la bannière de consentement (comme la grande majorité des utilisateurs), c'est littéralement le carnage :
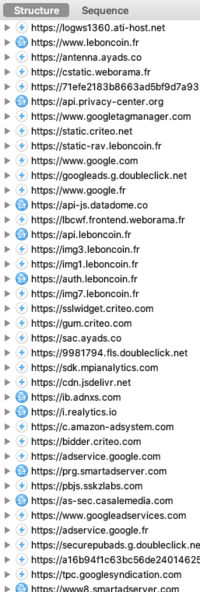
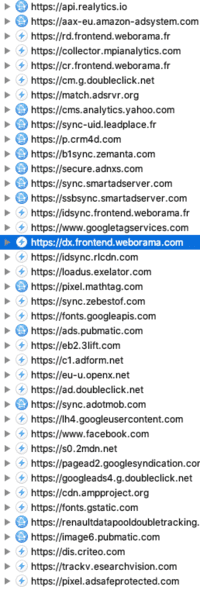
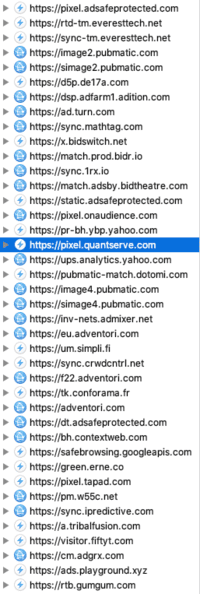
Ici pas de quartier, tout le monde vous traque, on peut ainsi repérer :
- Weborama : société de data marketing française, fuitant notamment vos données personnelles vers des sociétés Russes.
- Criteo : un géant du marketing de surveillance français spécialisé dans le "retargeting", aux pratiques peu éthiques.
- AppNexus : via adnxs.com, une plateforme de monétisation publicitaire (SSP) américaine, rachetée par le géant des télécoms AT&T et proposant également une plateforme d'achats d'espaces publicitaires (DSP).
- Realytics : une plateforme d'achats programmatique TV.
- Amazon : dans les GAFA, il n'y a pas que Google ou Facebook à fournir des solutions publicitaires, Amazon propose également ses solutions de monétisation aux éditeurs.
- Smart AdServer : une plateforme de monétisation publicitaire française.
- TheTradeDesk : via adsrvr.org, une plateforme d'achats d'espaces publicitaires américaine.
- Yahoo : oui Yahoo existe encore... Et propose des solutions publicitaires.
- Temelio : via leadplace.fr, solution française permettant de croiser vos données personnelles online et offline, vous n'y échapperez pas !
- Graphinium : via crm4d.com, autre solution française permettant de croiser vos données personnelles online et offline.
- Zemanta : racheté par Outbrain (leader mondial sur les liens putaclic en fin d'articles), Zemanta propose une plateforme d'achats de "publicité native" (publicité "déguisée", ayant le même visuel que le contenu, comme sur Facebook ou Twitter).
- Liveramp : via rlcdn.com, leader mondial du croisement de vos données personnelles online et offline (concurrent de Temelio et Graphinium).
- Nielsen : via exelator.com, le géant des études marketing s'est étendu sur le net via le rachat du fournisseur de données personnelles eXelate en 2015.
- ZBO Media : via zebestof.com, société du groupe Figaro - CCM Benchmark, se présentant comme "l’unique acteur programmatique à pouvoir exploiter toute la donnée du Groupe Figaro – CCM Benchmark". Pour rappel, lisez l'article "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- Pubmatic : plateforme de monétisation publicitaire américaine.
- TripleLift : via 3lift.com, ad-network spécialisé dans la publicité native.
- Adform : plateforme proposant une suite complète d'outils publicitaires, d'abord pour les annonceurs et agences (adserveur, DSP et DMP) mais aussi pour les éditeurs (adserver et SSP).
- OpenX : autre plateforme de monétisation publicitaire américaine.
- Adot : via adotmob.com, ad-network français.
- ESV Digital : via esearchvision.com, société française autrefois connu pour son outil de tracking de campagnes de liens sponsorisés sur Google.
- Integral Ad Science : via adsafeprotected.com, outil de détection de fraude, de mesure de visibilité (la publicité diffusée est-elle visible de l'utilisateur ou en bas de page ?), et de "brand safety" (la publicité diffuse-t-elle sur un site "de qualité" ?).
- Adobe : via everesttech.net, Adobe est connu pour Photoshop, mais la société américaine a fait de nombreuses acquisitions (Analytics, Tag Management, DMP, achats médias, etc) afin de fournir une suite marketing complète.
- Delta Projects : via de17a.com, société gérant l'achat d'espaces publicitaires.
- Adition : société allemande proposant des solutions publicitaires aux annonceurs et éditeurs.
- Turn : société proposant une plateforme d'achats d'espaces publicitaires et une "Data Management Platform", rachetée par Amobee en 2017.
- BidSwitch : acteur essentiel de la publicité programmatique, intermédiaire permettant de faire le pont entre les plateformes d'achats et les plateformes de monétisations qui ne sont pas directement connectées entre elles. C'est une filiale de la société Russe Iponweb.
- Beeswax : via bidr.io, propose une plateforme d'achats d'espaces publicitaires configurable, l'annonceur a ainsi une plus grande marge de manœuvre pour intégrer sa propre logique d'achat (comparé aux solutions "clé en main" telles que la plateforme d'achats de Google).
- Bid Theatre : plateforme d'achats d'espaces publicitaires.
- OnAudience : fournisseur de données personnelles.
- Quantcast : ad-network, proposant également un outil d'analytics (via lequel il va vous profiler) et une CMP (plateforme de recueil de consentement).
- Conversant : via dotomi.com, société de data marketing américaine.
- Admixer : société fournissant des outils publicitaires à destination des éditeurs et des annonceurs.
- Advendori : société spécialisée dans la personnalisation des bannières publicitaires.
- Simpli.fi : ad-network.
- Lotame : via crwdcntrl.net, fournisseur de données personnelles.
- Wizaly : via tk.conforama.fr, plateforme d'attribution. Permet à un annonceur de comprendre quelles sont les campagnes publicitaires efficaces. Apparemment donc, Conforama utilise Wizaly (qui passe par une délégation de domain ou CNAME) pour mesurer la diffusion de ses publicités sur Le Bon Coin.
- PulsePoint : via contextweb.com, acteur du programmatique spécialisé sur le domaine de la santé (!)
- CloudTechnologies : via erne.co, société polonaise se vantant d'analyser et de monétiser les données personnelles d'utilisateurs sur plus de 200 marchés.
- Tapad : société publicitaire américaine spécialisée dans la surveillance multi-appareils. Son pitch : vous retrouver quelque soit l'appareil que vous utilisez, puis vendre ces informations aux marques et aux autres sociétés de l'adtech.
- DataXu : via w55c.net, plateforme d'achats d'espaces publicitaires rachetée par Roku, le leader de la télévision connectée aux États-Unis (devant les autres ChromeCast, Android TV, Amazon Fire TV ou Apple TV).
- Adelphic : via ipredictive.com, plateforme d'achats d'espaces publicitaires, fait parti de la société marketing Viant.
- TribalFusion : ad-network à l'ancienne, on est ici sur du lourd, allez sur le site et vous verrez qu'il utilise encore Adobe Flash.
- Fifty : via fiftyt.com, société gérant les campagnes publicitaires des annonceurs (Trading Desk).
- Playground : société fournissant des outils pour créer des publicités et mesurer leur efficacité.
- Gumgum : ad-network.
Connectez-vous, et laissez Weborama vous traquer de manière permanente
Lorsque vous vous connectez à votre compte Le Bon Coin, Weborama ne se contente pas de vous suivre à la trace via un identifiant publicitaire que vous pourriez réinitialiser en supprimant vos cookies. Elle récupère un hash de votre adresse e-mail. Comment Weborama se présente-t-il ? Si on lit la page d'accueil :
Weborama offre des solutions avancées de connaissance du consommateur basées sur une technologie d’analyse sémantique unique, extrêmement précise et scalable pour permettre aux entreprises de générer de la croissance tout en rationalisant leurs coûts marketing. Conçue à partir de l’IA Sémantique, Weborama propose une combinaison de technologies, de data et d’expertises performantes et 100% conformes au RGPD.
Nous avions déjà pu rencontrer Weborama antérieurement :
- Weborama et Lemonde.fr, lenteur de site et fuite de vos données personnelles vers la Russie
- Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr
- L'Équipe, premier sur le sport et sur la surveillance
- La Fnac solde vos données personnelles
- Le Figaro, emblème du tracking publicitaire invasif des sites médias français
Weborama agit comme un cheval de troie sur le site leboncoin.fr : il "permet" la fuite de vos données personnelles vers tout un tas de nouvelles sociétés marketing, certaines situées en Russie :
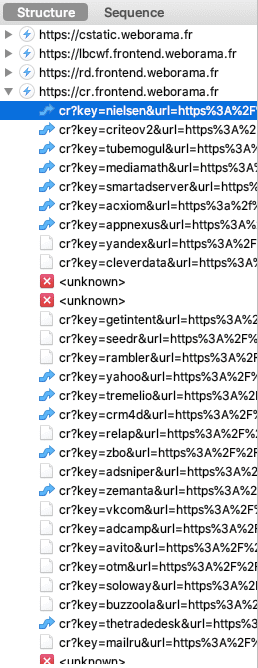
Liste non exhaustive des partenaires avec qui Weborama synchronise votre identifiant personnel sur le site Le Bon Coin. Des sociétés Françaises, Américaines ou bien Russes avec lesquelles Le Bon Coin n'a aucun rapport.
Mais Weborama récupère aussi le détail de votre surf sur Le Bon Coin, lié à une signature (la variable "_emailhashe") correspondant à votre e-mail. Voici les informations récoltées pour une simple consultation de table formica :
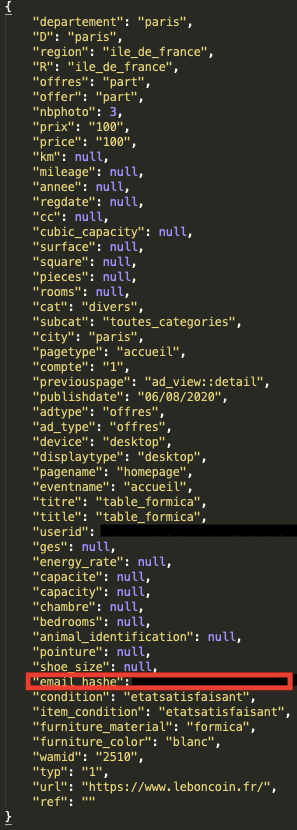
"100% conformes au RGPD", vraiment Weborama ?
Connectez vous sur Safari, et fuitez vos données de connexion à Criteo
Comme nous l'avons déjà vu avec l'article "Criteo, un géant du marketing de surveillance français", Criteo pousse ses clients à créer une faille de sécurité sur leurs sites afin de mieux pister les utilisateurs utilisant des adblockers ou des navigateurs respectueux de la vie privée tels que Safari. Afin de vérifier si Le Bon Coin est vulnérable, connectons-nous via Safari et regardons les requêtes passer :
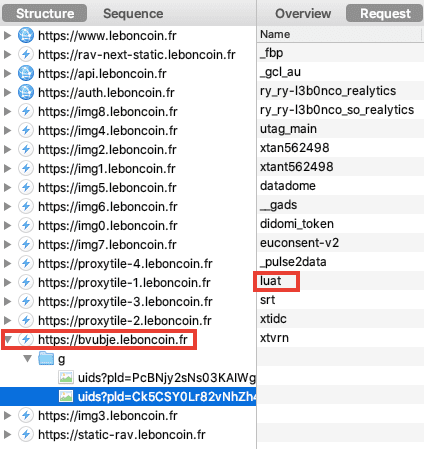
Banco ! Le Bon Coin fuite bien vos données de connexion à Criteo. L'étrange domaine bvubje.leboncoin.fr est une délégation de domaine (ou CNAME) vers dnsdelegation.io, qui lui même est une délégation de domaine vers gum.criteo.com. Quel intérêt pour Criteo de passer par un CNAME pour vous surveiller sur Safari ? Ce mécanisme a plusieurs objectifs :
- Éviter d'être bloqué par certains adblockers (utilisez uBlock Origin pour éviter ce pistage). Mais cet argument est valable pour tous les navigateurs.
- Passer outre le blocage des cookies tiers.
- Passer outre la limitation de durée sur les cookies créés en javascript (7 jours), le cookie étant maintenant créé côté serveur (pas de limitation de durée). NB : Safari va bientôt corriger ce point.
Mais le système de délégation de domaine permet l'envoi de tous les cookies associés au domaine leboncoin.fr à Criteo... Dont le cookie "luat" (cookie mémorisant le fait que vous êtes connecté), que je peux copier-coller dans Chrome via l'extension EditThisCookie pour être directement connecté. Un employé de Criteo peut ainsi se connecter à votre compte.
Sur l'appli iOS aussi, vous êtes traqué dès l'ouverture
Afin d'observer les requêtes envoyées par l'application Le Bon Coin sur iOS, j'utilise Charles Proxy. Ouvrons l'application Le Bon Coin :
Comme vous pouvez le voir et comme sur le web, vous pouvez vous débarrasser de l'ennuyeuse fenêtre de consentement en cliquant sur "Accepter et fermer" (choix mis en avant via la couleur bleue) ou dépenser de l'énergie à essayer d'éviter la surveillance en cliquant sur "En savoir plus". Encore une fois, un "Dark pattern" pour ne pas vous laisser choisir librement. Que se passe-t-il côté surveillance marketing ? Avant même de donner (ou pas) mon consentement, Le Bon Coin fuite mes données personnelles :
Certains de ces traceurs récupéraient déjà vos données personnelles sur le site web, mais nous observons également de nouveaux traceurs :
- Weborama : déjà présent sur le site web.
- Google : via Doubleclick (et la solution de monétisation publicitaire pour éditeur Google Ad Manager) et Firebase (la boîte à outils de Google pour les développeurs mobile), déjà présent sur le site web.
- Appsflyer : société de marketing mobile offrant notamment un produit d'attribution, ce qui permet à Le Bon Coin de savoir quelles campagnes publicitaires ont déclenchées l'installation de l'application.
- Accengage : outil de notifications push français, racheté en 2018 par la société du marketing mobile Airship.
- Datadome : déjà présent sur le site web.
- Amazon : via serving-sys.com, l'adserveur pour agence et annonceur Sizmek, anciennement Mediamind, à l'origine appelé Eyeblaster, a été racheté par le géant de l'e-Commerce américain en 2019.
Refusez la surveillance, Le Bon Coin fuite toujours vos données personnelles
Cliquons sur "En savoir plus" :
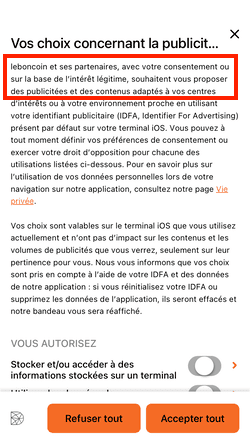
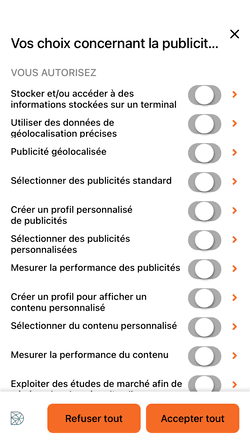
Ainsi certains partenaires souhaiteraient proposer des publicités ou contenus ciblés sur la base de l'intérêt légitime, ce qui est clairement en contradiction avec le RGPD. Cliquons sur "Refuser tout" et consultons quelques annonces :
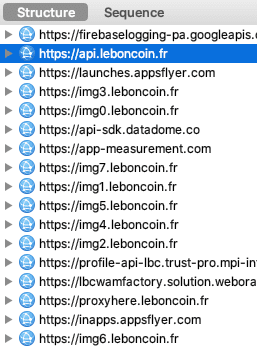
La surveillance ne s'arrête jamais : je suis toujours pisté par Google, Appsflyer, Datadome et Weborama.
Connectez-vous, Weborama vous retrouve
Lorsque vous vous connectez, les mêmes traceurs continuent de vous suivre. Mais un traceur va plus loin : Weborama reçoit le détail de chaque annonce consultée avec le hash de votre adresse e-mail. Oui, le même identifiant que sur le web, Weborama est ainsi capable de vous suivre quelque soit votre appareil, même si vous réinitialisez vos identifiants. Ce hash lui permet de vous suivre sur l'ensemble des sites web et des applications utilisant ses services, et donc de construire un profil très précis sur vous.
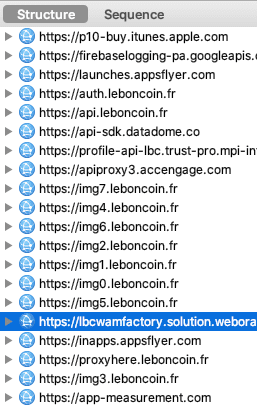
Dans les méandres de l'intérêt légitime
Vous vous dites peut-être, si je suis toujours pisté c'est que j'ai du rater une option. Tout en bas du formulaire "En savoir plus", vous pouvez cliquer sur "Voir nos partenaires" :
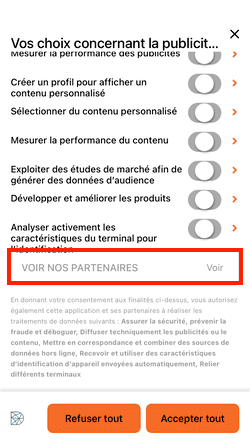
Là vous découvrez que certains partenaires sont pré-cochés, en contradiction avec le RGPD :
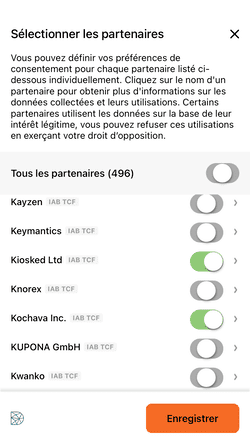
Regardons le partenaire Weborama :
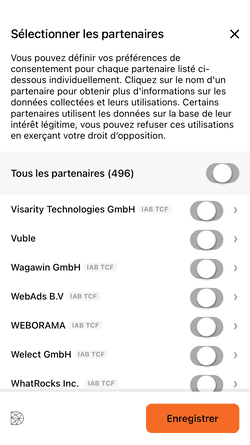

Ainsi l'intérêt légitime est pré-coché chez Weborama, et celui-ci considère qu'il peut utiliser cette base légale pour diverses finalités, dont la création de profil pour afficher un contenu personnalisé. Désactivons maintenant tous les partenaires :
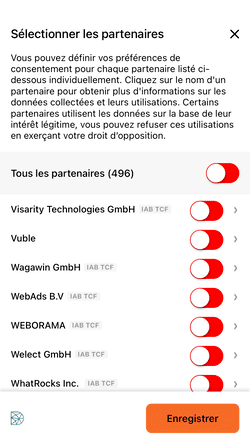
Rien ne change, Weborama est toujours là, on revoit également AT Internet :
Connectez-vous, Weborama récupère encore le hash de votre adresse e-mail. Pourtant vous avez bien indiqué refuser le pistage de l'ensemble des partenaires, en conséquence l'information de refus de consentement et de "opt-out" de l'intérêt légitime est bien envoyée à Weborama :
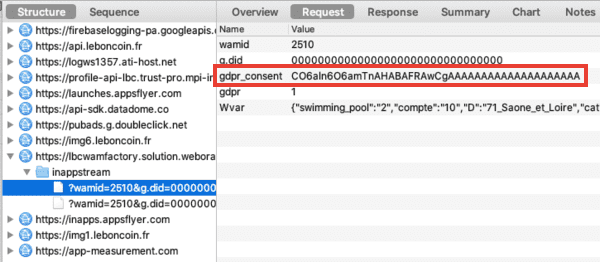
Ce signal a été codé en suivant le protocole du TCF v2 (protocole de collecte et de transmission des signaux de consentement entre acteurs publicitaires, mis en place par l'IAB Europe, le lobby des technologies publicitaires), décodons-le via ce site :
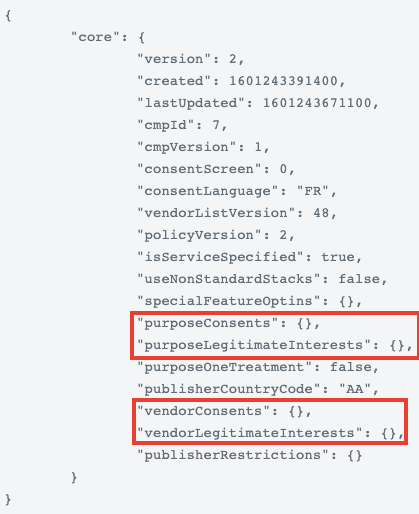
Comment Weborama peut-il alors me pister de manière aussi agressive (détail de toutes les annonces consultées, pistage permanent via l'utilisation d'un hash de mon adresse e-mail) alors qu'il reçoit l'information que j'ai refusé tout traitement sur base légale du consentement ou de l'intérêt légitime ?! Comment d'autres partenaires tels que Google peuvent-ils continuer de me pister ?
"Weborama, une combinaison de technologies, de data et d’expertises performantes et 100% conformes au RGPD" ?!
Le Bon Coin viole sa propre politique de confidentialité
Si l'on regarde attentivement la Politique de confidentialité du site Le Bon Coin, section "Utilisation de vos données", paragraphe "Utilisation de vos données avec votre consentement", on peux entre autres y lire :
- Nous sommes susceptibles, avec votre consentement : [...] de partager vos données à nos partenaires publicitaires, responsables de traitement, aux fins d’améliorer les performances des campagnes de nos partenaires sur notre site.
- Nous ne partageons pas vos données personnelles avec nos partenaires tiers sans votre consentement. Toutefois, si vous cliquez sur une publicité, son annonceur pourra savoir que vous avez consulté la page où vous avez cliqué.
Le Bon Coin viole ainsi sa propre politique de confidentalité.
Que faire ?
Comment Le Bon Coin et la CNIL peuvent-il permettre cela ? À défaut de sanctions dissuasives de la CNIL ou de réaction du site Le Bon Coin, vous pouvez vous protéger individuellement. Vous pouvez ainsi installer un adblocker tel que uBlock Origin sur le web ou des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
Texte intégral (4841 mots)
Le Bon Coin fuite vos données personnelles dès votre arrivée sur son site web
Le Bon Coin est un énorme succès commercial en France, le site de petites annonces a su se rendre indispensable auprès de nombreux particuliers. Ayant assez régulièrement des biens à revendre, j'ai souhaité comprendre si Le Bon Coin était respectueux de ma vie privée. Démarrons avec le site web leboncoin.fr, voici les étapes à suivre si vous désirez reproduire l'expérience :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur la page d'accueil leboncoin.fr.
Première constatation : Le Bon Coin n'offre pas d'option directe pour refuser la surveillance marketing. Cette présentation n'est pas conforme au RGPD : l'option "J'ai compris" est mise en valeur par la couleur bleue et surtout elle oblige l'utilisateur à configurer ses choix via le bouton "Personnaliser", l'énorme majorité des utilisateurs ne feront pas l'effort.
Regardons maintenant les requêtes envoyées lors de votre arrivée sur le site, pour rappel vous n'avez pas encore fait le choix d'accepter ou de refuser d'être pisté :
Surprise ! Vous n'avez effectué aucune action mais Le Bon Coin multiplie déjà les appels à des sociétés marketing, certaines de ces sociétés démarrent le pistage sans votre consentement. Voici une liste de traceurs utilisant un identifiant personnel (pseudonyme) :
- Datadome : solution de protection contre les bots.
- Sublime : via ayads.co, ad-network français spécialisé dans les habillages de page (anciennement Sublime Skinz).
- AT Internet : via ati-host.net, AT Internet est une société analytics française "historique", originellement appelée Xiti. Nous les avons déjà rencontré ailleurs, cf. "Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr" et "Boursorama Banque fuite vos données de connexion".
- Facebook : Le Bon Coin utilise la boîte à outils marketing de Facebook, entre autres pour sa brique analytics.
- Google : via doubleclick.net. Le Bon Coin utilise également la solution de monétisation publicitaire "Google Ad Manager" de la firme de Mountain View.
Que se passe-t-il maintenant si vous cliquez sur le bouton "Personnaliser" ?
Bonne nouvelle, il y a bien un bouton "Refuser tout", cliquons dessus et observons les requêtes envoyées :
Vous venez de faire l'effort de refuser tout pistage, mais vous fuitez toujours vos données personnelles aux géants de la surveillance publicitaire :
- Facebook : la surveillance continue, Facebook suit toutes vos actions sur le site leboncoin.fr. Ironiquement, la firme de Menlo Park récupère ici spécifiquement l'information que vous avez cliqué sur le bouton "Refuser tout".
- Google : via sa plateforme de monétisation publicitaire Google Ad Manager (réunissant adserveur et SSP), Google récupère également votre surf.
Consultez quelques pages et constatez que les appels aux sociétés marketing représentent toujours la majorité des requêtes :
La plupart de ces acteurs semblent ici prendre en compte votre consentement (pas de cookies déposés, même s'ils pourraient théoriquement vous pister avec votre adresse IP et avec les caractéristiques de votre navigateur), mais on peut se demander pourquoi Le Bon Coin les appelle. Les traceurs déjà répertoriés précédemment continuent la surveillance (Google, Facebook, AT Internet, Sublime, Datadome), on peut aussi remarquer un petit nouveau, Index Exchange (via casalemedia.com), une autre plateforme de monétisation publicitaire.
Si maintenant vous continuez votre navigation sans faire attention à la bannière de consentement (comme la grande majorité des utilisateurs), c'est littéralement le carnage :
Ici pas de quartier, tout le monde vous traque, on peut ainsi repérer :
- Weborama : société de data marketing française, fuitant notamment vos données personnelles vers des sociétés Russes.
- Criteo : un géant du marketing de surveillance français spécialisé dans le "retargeting", aux pratiques peu éthiques.
- AppNexus : via adnxs.com, une plateforme de monétisation publicitaire (SSP) américaine, rachetée par le géant des télécoms AT&T et proposant également une plateforme d'achats d'espaces publicitaires (DSP).
- Realytics : une plateforme d'achats programmatique TV.
- Amazon : dans les GAFA, il n'y a pas que Google ou Facebook à fournir des solutions publicitaires, Amazon propose également ses solutions de monétisation aux éditeurs.
- Smart AdServer : une plateforme de monétisation publicitaire française.
- TheTradeDesk : via adsrvr.org, une plateforme d'achats d'espaces publicitaires américaine.
- Yahoo : oui Yahoo existe encore... Et propose des solutions publicitaires.
- Temelio : via leadplace.fr, solution française permettant de croiser vos données personnelles online et offline, vous n'y échapperez pas !
- Graphinium : via crm4d.com, autre solution française permettant de croiser vos données personnelles online et offline.
- Zemanta : racheté par Outbrain (leader mondial sur les liens putaclic en fin d'articles), Zemanta propose une plateforme d'achats de "publicité native" (publicité "déguisée", ayant le même visuel que le contenu, comme sur Facebook ou Twitter).
- Liveramp : via rlcdn.com, leader mondial du croisement de vos données personnelles online et offline (concurrent de Temelio et Graphinium).
- Nielsen : via exelator.com, le géant des études marketing s'est étendu sur le net via le rachat du fournisseur de données personnelles eXelate en 2015.
- ZBO Media : via zebestof.com, société du groupe Figaro - CCM Benchmark, se présentant comme "l’unique acteur programmatique à pouvoir exploiter toute la donnée du Groupe Figaro – CCM Benchmark". Pour rappel, lisez l'article "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- Pubmatic : plateforme de monétisation publicitaire américaine.
- TripleLift : via 3lift.com, ad-network spécialisé dans la publicité native.
- Adform : plateforme proposant une suite complète d'outils publicitaires, d'abord pour les annonceurs et agences (adserveur, DSP et DMP) mais aussi pour les éditeurs (adserver et SSP).
- OpenX : autre plateforme de monétisation publicitaire américaine.
- Adot : via adotmob.com, ad-network français.
- ESV Digital : via esearchvision.com, société française autrefois connu pour son outil de tracking de campagnes de liens sponsorisés sur Google.
- Integral Ad Science : via adsafeprotected.com, outil de détection de fraude, de mesure de visibilité (la publicité diffusée est-elle visible de l'utilisateur ou en bas de page ?), et de "brand safety" (la publicité diffuse-t-elle sur un site "de qualité" ?).
- Adobe : via everesttech.net, Adobe est connu pour Photoshop, mais la société américaine a fait de nombreuses acquisitions (Analytics, Tag Management, DMP, achats médias, etc) afin de fournir une suite marketing complète.
- Delta Projects : via de17a.com, société gérant l'achat d'espaces publicitaires.
- Adition : société allemande proposant des solutions publicitaires aux annonceurs et éditeurs.
- Turn : société proposant une plateforme d'achats d'espaces publicitaires et une "Data Management Platform", rachetée par Amobee en 2017.
- BidSwitch : acteur essentiel de la publicité programmatique, intermédiaire permettant de faire le pont entre les plateformes d'achats et les plateformes de monétisations qui ne sont pas directement connectées entre elles. C'est une filiale de la société Russe Iponweb.
- Beeswax : via bidr.io, propose une plateforme d'achats d'espaces publicitaires configurable, l'annonceur a ainsi une plus grande marge de manœuvre pour intégrer sa propre logique d'achat (comparé aux solutions "clé en main" telles que la plateforme d'achats de Google).
- Bid Theatre : plateforme d'achats d'espaces publicitaires.
- OnAudience : fournisseur de données personnelles.
- Quantcast : ad-network, proposant également un outil d'analytics (via lequel il va vous profiler) et une CMP (plateforme de recueil de consentement).
- Conversant : via dotomi.com, société de data marketing américaine.
- Admixer : société fournissant des outils publicitaires à destination des éditeurs et des annonceurs.
- Advendori : société spécialisée dans la personnalisation des bannières publicitaires.
- Simpli.fi : ad-network.
- Lotame : via crwdcntrl.net, fournisseur de données personnelles.
- Wizaly : via tk.conforama.fr, plateforme d'attribution. Permet à un annonceur de comprendre quelles sont les campagnes publicitaires efficaces. Apparemment donc, Conforama utilise Wizaly (qui passe par une délégation de domain ou CNAME) pour mesurer la diffusion de ses publicités sur Le Bon Coin.
- PulsePoint : via contextweb.com, acteur du programmatique spécialisé sur le domaine de la santé (!)
- CloudTechnologies : via erne.co, société polonaise se vantant d'analyser et de monétiser les données personnelles d'utilisateurs sur plus de 200 marchés.
- Tapad : société publicitaire américaine spécialisée dans la surveillance multi-appareils. Son pitch : vous retrouver quelque soit l'appareil que vous utilisez, puis vendre ces informations aux marques et aux autres sociétés de l'adtech.
- DataXu : via w55c.net, plateforme d'achats d'espaces publicitaires rachetée par Roku, le leader de la télévision connectée aux États-Unis (devant les autres ChromeCast, Android TV, Amazon Fire TV ou Apple TV).
- Adelphic : via ipredictive.com, plateforme d'achats d'espaces publicitaires, fait parti de la société marketing Viant.
- TribalFusion : ad-network à l'ancienne, on est ici sur du lourd, allez sur le site et vous verrez qu'il utilise encore Adobe Flash.
- Fifty : via fiftyt.com, société gérant les campagnes publicitaires des annonceurs (Trading Desk).
- Playground : société fournissant des outils pour créer des publicités et mesurer leur efficacité.
- Gumgum : ad-network.
Connectez-vous, et laissez Weborama vous traquer de manière permanente
Lorsque vous vous connectez à votre compte Le Bon Coin, Weborama ne se contente pas de vous suivre à la trace via un identifiant publicitaire que vous pourriez réinitialiser en supprimant vos cookies. Elle récupère un hash de votre adresse e-mail. Comment Weborama se présente-t-il ? Si on lit la page d'accueil :
Weborama offre des solutions avancées de connaissance du consommateur basées sur une technologie d’analyse sémantique unique, extrêmement précise et scalable pour permettre aux entreprises de générer de la croissance tout en rationalisant leurs coûts marketing. Conçue à partir de l’IA Sémantique, Weborama propose une combinaison de technologies, de data et d’expertises performantes et 100% conformes au RGPD.
Nous avions déjà pu rencontrer Weborama antérieurement :
- Weborama et Lemonde.fr, lenteur de site et fuite de vos données personnelles vers la Russie
- Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr
- L'Équipe, premier sur le sport et sur la surveillance
- La Fnac solde vos données personnelles
- Le Figaro, emblème du tracking publicitaire invasif des sites médias français
Weborama agit comme un cheval de troie sur le site leboncoin.fr : il "permet" la fuite de vos données personnelles vers tout un tas de nouvelles sociétés marketing, certaines situées en Russie :
Liste non exhaustive des partenaires avec qui Weborama synchronise votre identifiant personnel sur le site Le Bon Coin. Des sociétés Françaises, Américaines ou bien Russes avec lesquelles Le Bon Coin n'a aucun rapport.
Mais Weborama récupère aussi le détail de votre surf sur Le Bon Coin, lié à une signature (la variable "_emailhashe") correspondant à votre e-mail. Voici les informations récoltées pour une simple consultation de table formica :
"100% conformes au RGPD", vraiment Weborama ?
Connectez vous sur Safari, et fuitez vos données de connexion à Criteo
Comme nous l'avons déjà vu avec l'article "Criteo, un géant du marketing de surveillance français", Criteo pousse ses clients à créer une faille de sécurité sur leurs sites afin de mieux pister les utilisateurs utilisant des adblockers ou des navigateurs respectueux de la vie privée tels que Safari. Afin de vérifier si Le Bon Coin est vulnérable, connectons-nous via Safari et regardons les requêtes passer :
Banco ! Le Bon Coin fuite bien vos données de connexion à Criteo. L'étrange domaine bvubje.leboncoin.fr est une délégation de domaine (ou CNAME) vers dnsdelegation.io, qui lui même est une délégation de domaine vers gum.criteo.com. Quel intérêt pour Criteo de passer par un CNAME pour vous surveiller sur Safari ? Ce mécanisme a plusieurs objectifs :
- Éviter d'être bloqué par certains adblockers (utilisez uBlock Origin pour éviter ce pistage). Mais cet argument est valable pour tous les navigateurs.
- Passer outre le blocage des cookies tiers.
- Passer outre la limitation de durée sur les cookies créés en javascript (7 jours), le cookie étant maintenant créé côté serveur (pas de limitation de durée). NB : Safari va bientôt corriger ce point.
Mais le système de délégation de domaine permet l'envoi de tous les cookies associés au domaine leboncoin.fr à Criteo... Dont le cookie "luat" (cookie mémorisant le fait que vous êtes connecté), que je peux copier-coller dans Chrome via l'extension EditThisCookie pour être directement connecté. Un employé de Criteo peut ainsi se connecter à votre compte.
Sur l'appli iOS aussi, vous êtes traqué dès l'ouverture
Afin d'observer les requêtes envoyées par l'application Le Bon Coin sur iOS, j'utilise Charles Proxy. Ouvrons l'application Le Bon Coin :
Comme vous pouvez le voir et comme sur le web, vous pouvez vous débarrasser de l'ennuyeuse fenêtre de consentement en cliquant sur "Accepter et fermer" (choix mis en avant via la couleur bleue) ou dépenser de l'énergie à essayer d'éviter la surveillance en cliquant sur "En savoir plus". Encore une fois, un "Dark pattern" pour ne pas vous laisser choisir librement. Que se passe-t-il côté surveillance marketing ? Avant même de donner (ou pas) mon consentement, Le Bon Coin fuite mes données personnelles :
Certains de ces traceurs récupéraient déjà vos données personnelles sur le site web, mais nous observons également de nouveaux traceurs :
- Weborama : déjà présent sur le site web.
- Google : via Doubleclick (et la solution de monétisation publicitaire pour éditeur Google Ad Manager) et Firebase (la boîte à outils de Google pour les développeurs mobile), déjà présent sur le site web.
- Appsflyer : société de marketing mobile offrant notamment un produit d'attribution, ce qui permet à Le Bon Coin de savoir quelles campagnes publicitaires ont déclenchées l'installation de l'application.
- Accengage : outil de notifications push français, racheté en 2018 par la société du marketing mobile Airship.
- Datadome : déjà présent sur le site web.
- Amazon : via serving-sys.com, l'adserveur pour agence et annonceur Sizmek, anciennement Mediamind, à l'origine appelé Eyeblaster, a été racheté par le géant de l'e-Commerce américain en 2019.
Refusez la surveillance, Le Bon Coin fuite toujours vos données personnelles
Cliquons sur "En savoir plus" :
Ainsi certains partenaires souhaiteraient proposer des publicités ou contenus ciblés sur la base de l'intérêt légitime, ce qui est clairement en contradiction avec le RGPD. Cliquons sur "Refuser tout" et consultons quelques annonces :
La surveillance ne s'arrête jamais : je suis toujours pisté par Google, Appsflyer, Datadome et Weborama.
Connectez-vous, Weborama vous retrouve
Lorsque vous vous connectez, les mêmes traceurs continuent de vous suivre. Mais un traceur va plus loin : Weborama reçoit le détail de chaque annonce consultée avec le hash de votre adresse e-mail. Oui, le même identifiant que sur le web, Weborama est ainsi capable de vous suivre quelque soit votre appareil, même si vous réinitialisez vos identifiants. Ce hash lui permet de vous suivre sur l'ensemble des sites web et des applications utilisant ses services, et donc de construire un profil très précis sur vous.
Dans les méandres de l'intérêt légitime
Vous vous dites peut-être, si je suis toujours pisté c'est que j'ai du rater une option. Tout en bas du formulaire "En savoir plus", vous pouvez cliquer sur "Voir nos partenaires" :
Là vous découvrez que certains partenaires sont pré-cochés, en contradiction avec le RGPD :
Regardons le partenaire Weborama :
Ainsi l'intérêt légitime est pré-coché chez Weborama, et celui-ci considère qu'il peut utiliser cette base légale pour diverses finalités, dont la création de profil pour afficher un contenu personnalisé. Désactivons maintenant tous les partenaires :
Rien ne change, Weborama est toujours là, on revoit également AT Internet :
Connectez-vous, Weborama récupère encore le hash de votre adresse e-mail. Pourtant vous avez bien indiqué refuser le pistage de l'ensemble des partenaires, en conséquence l'information de refus de consentement et de "opt-out" de l'intérêt légitime est bien envoyée à Weborama :
Ce signal a été codé en suivant le protocole du TCF v2 (protocole de collecte et de transmission des signaux de consentement entre acteurs publicitaires, mis en place par l'IAB Europe, le lobby des technologies publicitaires), décodons-le via ce site :
Comment Weborama peut-il alors me pister de manière aussi agressive (détail de toutes les annonces consultées, pistage permanent via l'utilisation d'un hash de mon adresse e-mail) alors qu'il reçoit l'information que j'ai refusé tout traitement sur base légale du consentement ou de l'intérêt légitime ?! Comment d'autres partenaires tels que Google peuvent-ils continuer de me pister ?
"Weborama, une combinaison de technologies, de data et d’expertises performantes et 100% conformes au RGPD" ?!
Le Bon Coin viole sa propre politique de confidentialité
Si l'on regarde attentivement la Politique de confidentialité du site Le Bon Coin, section "Utilisation de vos données", paragraphe "Utilisation de vos données avec votre consentement", on peux entre autres y lire :
- Nous sommes susceptibles, avec votre consentement : [...] de partager vos données à nos partenaires publicitaires, responsables de traitement, aux fins d’améliorer les performances des campagnes de nos partenaires sur notre site.
- Nous ne partageons pas vos données personnelles avec nos partenaires tiers sans votre consentement. Toutefois, si vous cliquez sur une publicité, son annonceur pourra savoir que vous avez consulté la page où vous avez cliqué.
Le Bon Coin viole ainsi sa propre politique de confidentalité.
Que faire ?
Comment Le Bon Coin et la CNIL peuvent-il permettre cela ? À défaut de sanctions dissuasives de la CNIL ou de réaction du site Le Bon Coin, vous pouvez vous protéger individuellement. Vous pouvez ainsi installer un adblocker tel que uBlock Origin sur le web ou des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
30.08.2020 à 22:31
Consentement : le pire de l'expérience utilisateur et de la surveillance avec Lemonde.fr

EDIT 6 juin 2021 : Lemonde.fr a fait quelques corrections supplémentaires :
- (+) Lemonde.fr déclenche toujours les traceurs d'AT Internet dès l'arrivée sur son site web. Mais AT Internet, sous réserve d'être configuré de manière adéquate et d’en faire un usage strictement nécessaire au fonctionnement et aux opérations d’administration courante du site web, rentre dans le périmètre de l'exemption de consentement défini par la CNIL.
- (+) Lorsque vous refusez de donner votre consentement, Lemonde.fr bloque le chargement du player vidéo Dailymotion, l'empêchant de fuiter vos données personnelles.
- (-) La plateforme de blogs est malheureusement toujours oubliée, elle fuite vos données personnelles vers Google Analytics avant consentement.
- (+) Si l'on ne tient pas compte d'AT Internet (exemption de consentement), de Batch (notifications) et de Google Firebase (technique), l'appli iOS ne vous piste pas au lancement, ni lorsque vous refusez de donner votre consentement.
EDIT 20 septembre 2020 : Via Twitter (ici et là), j'ai été informé que Lemonde.fr avait effectué des corrections. Après vérifications :
- (-) Lemonde.fr fuite toujours vos données personnelles vers AT Internet dès l'arrivée sur son site web.
- (-) Lemonde.fr n'offre toujours pas d'opt-out pour AT Internet.
- (-) Lemonde.fr fuite toujours vos données de connexion à AT Internet.
- (+) Votre scroll ne vaut plus consentement.
- (+) Si vous refusez d'être surveillé, Lemonde.fr respecte maintenant votre choix et ne multiplie pas les traceurs. En particulier, l'intérêt légitime n'est plus pré-coché lorsque vous avez refusé de donner votre consentement.
- (-) Mais Lemonde.fr a malheureusement oublié son player Dailymotion, intégré dès la page accueil. Celui-ci ne respecte pas vos choix et fuite vos données personnelles vers diverses sociétés (et présente un curieux timer, vous avez 10 secondes pour réagir).
- (-) Lemonde.fr a également oublié sa plateforme de blogs, dont les articles sont souvent mis en valeur via sa page accueil. Exemple avec cet article mis en avant le 20 septembre : vous avez beau avoir refusé les traceurs, vos données personnelles viennent enrichir de multiples sociétés de marketing.
- (-) Rien ne change sur l'appli iOS : Lemonde.fr vous traque dès le premier lancement et si vous refusez le pistage, la surveillance continue.
 Vous avez déjà refusé la surveillance publicitaire, mais ce n'est pas terminé : vous avez 10 secondes pour refuser la surveillance initié par le player vidéo Dailymotion. En fait, même si vous prenez la peine de cliquer sur Personnaliser et de "Tout refuser" sur la page "Vos paramètres de confidentialités" de Dailymotion, la surveillance continue.
Vous avez déjà refusé la surveillance publicitaire, mais ce n'est pas terminé : vous avez 10 secondes pour refuser la surveillance initié par le player vidéo Dailymotion. En fait, même si vous prenez la peine de cliquer sur Personnaliser et de "Tout refuser" sur la page "Vos paramètres de confidentialités" de Dailymotion, la surveillance continue.
EDIT 2 septembre 2020 : J'ai pu compléter les informations juridique (et corriger des coquilles) grâce aux explications de @Cellular_PP, merci !
Lemonde.fr fuite vos données personnelles vers AT Internet dès l'arrivée sur son site web
Depuis le 15 août, Google a intégré le nouveau "framework" de recueil de consentement de l'industrie publicitaire, le bien nommé "Transparency and Consent Framework (TCF) v2.0" et les éditeurs mettent à jour leurs bandeaux de consentement. Une amélioration de l'expérience utilisateur ? Pas forcément d'après mon fil Twitter français :
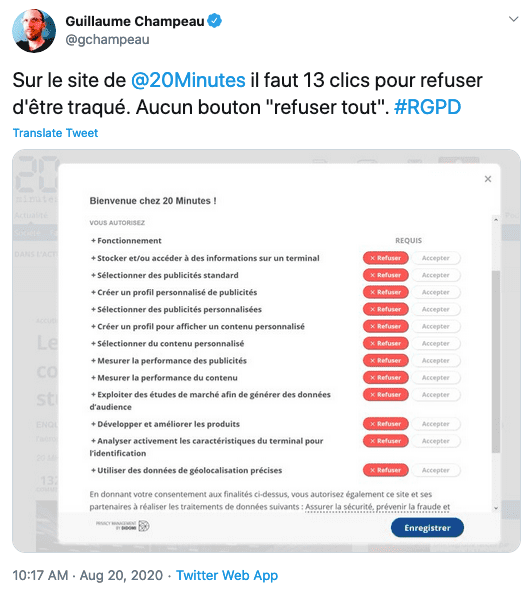
En Angleterre, ce n'est pas mieux :
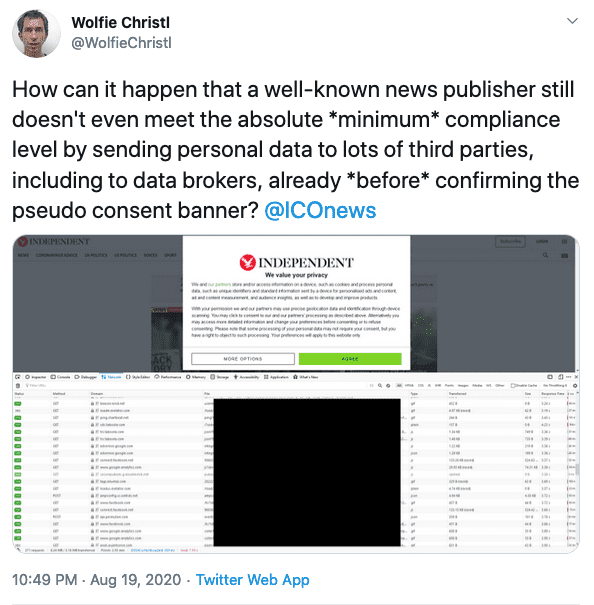
Afin de mieux comprendre ce qui a changé chez les sites médias, j'ai choisi de tester Lemonde.fr, le "journal de référence", dont je suis un lecteur occasionnel. Pour être honnête, je n'avais pas un très bon à priori :
- Lefigaro.fr, rival historique, traque extensivement ses lecteurs, cf "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- Avant leurs nouvelles versions, ces bandeaux de consentement trompaient déjà les internautes, cf "Le recueil du consentement sur internet : un mensonge généralisé".
- En décembre dernier, Lemonde.fr fuitait déjà vos données personnelles vers de nombreux tiers dont des sociétés Russes, cf "Weborama et Lemonde.fr, lenteur de site et fuite de vos données personnelles vers la Russie".
Mais vous êtes en droit d'exiger un meilleur respect de votre vie privée. Afin de vous rendre compte du tracking sur le site Lemonde.fr, suivez les étapes suivantes :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur la page d'accueil Lemonde.fr.

Première constatation : Le Monde ne permet pas de refuser le tracking directement, seulement de "Paramétrer les cookies". Ce choix est contraire à l'esprit du RGPD, même si la CNIL a beaucoup de retard sur sa mise en application. Lisons par exemple l'interview de la présidente de la CNIL dans le journal... Le Monde, en février 2020 :
Cela signifie que l’internaute n’aura plus un gros bouton vert proposant d’« Accepter » et un petit texte dans un coin pour refuser ?
Il faut qu’il y ait une symétrie entre les deux. Par ailleurs, les utilisateurs doivent pouvoir connaître les destinataires de leurs données collectées à des fins de profilage publicitaire. Il y a des textes en vigueur qui imposent le recueil d’un consentement libre et éclairé mais ces préconisations ne sont globalement pas mises en œuvre.
Rappel : Le RGPD est entrée en vigueur en mai 2016 et il est applicable depuis le 25 mai 2018 (cf. l'article 99 du RGPD). Les professionnels ont donc eu 4 ans pour se préparer, la CNIL ne devrait donc pas repousser l'applicabilité du texte au mépris des droits fondamentaux des personnes.
Mais Le Monde attend peut-être les nouvelles recommandations (voire les sanctions ?!) de la CNIL pour agir... Regardons maintenant les requêtes envoyées :
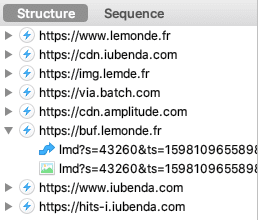
3 enseignements :
- Lemonde.fr appelle deux sociétés marketing pour télécharger leurs fichiers javascript, Batch et Amplitude, pas de hits de tracking ici.
- Iubenda est la CMP (Consent Management Platform) utilisée par Le Monde.
- Après recherches, le sous-domaine buf.lemonde.fr s'avère être un "cache sexe" pour la société d'analytics française AT Internet, Le Monde permet à celle-ci de vous pister avant même que vous ayez donné votre consentement.
Lemonde.fr n'offre pas d'opt-out pour AT Internet, en violation de la loi
Sur quoi Lemonde.fr peut-il s'appuyer pour fuiter vos données personnelles vers AT Internet avant même d'avoir reçu votre consentement ? Peut-être sur une vieille exonération de la CNIL, peu conforme à l'esprit du RGPD.
Sauf que cette exonération trouvait sa source à l'article 6 de la délibération CNIL de 2013, les conditions de placement de cookies sans consentement sont désormais précisées dans l'article 5 de la délibération CNIL de juillet 2019. Le fait que la CNIL laisse l'article en ligne pourrait amener un éditeur de site à indiquer que la CNIL l'a induit en erreur, que par conséquent il était de bonne foi en appliquant pas la délibération de 2019, aussi la CNIL devrait modifier son article.
Mais que l'on regarde la délibération de 2013 ou de 2019, une règle reste obligatoire : la mise en place de l'option "opt-out" : "elle doit disposer de la faculté de s'y opposer par l'intermédiaire d'un mécanisme d'opposition facilement utilisable sur l'ensemble des terminaux, des systèmes d'exploitation, des applications et des navigateurs web. Aucune opération de lecture ou d'écriture ne doit avoir lieu sur le terminal depuis lequel la personne s'est opposée".
Cliquons donc sur "Paramétrer les cookies" :
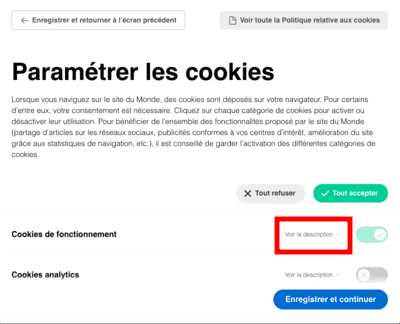
Curieux de connaître ce qui se cache derrière ces "Cookies de fonctionnement" ?
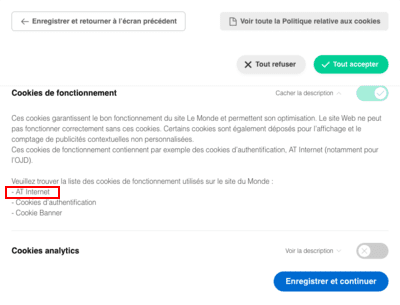
Surprise ! Au côté de cookies d'authentification, Lemonde.fr place les traceurs d'AT Internet dans la catégorie "Cookies de fonctionnement" (et non "Cookies analytics" comme l'on pourrait s'y attendre). L'excuse avancée ? L'OJD, maintenant nommée ACPM, un organisme de certification d'audience des médias, qui permet à Le Monde de se vanter régulièrement de ses bons chiffres d'audience.
Conséquence de ce classement d'AT Internet dans les "Cookies de fonctionnement", l'option "opt-out" n'a pas été mise en place, en violation des conditions de l'exemption.
Autre règle devant être respecté afin de bénéficier de l'exemption, l'information, qui doit avoir lieu avant le dépôt du cookie : "la personne doit être informée préalablement à leur mise en œuvre" (la délibération de 2013 indiquait seulement que la personne devait être informée). Là encore, Lemonde.fr viole les conditions de l'exemption de consentement
Via une faille de sécurité, Lemonde.fr fuite vos données de connexion à AT Internet
Continuons l'investigation sur ces appels à AT Internet, derrière le sous-domaine buf.lemonde.fr, se cache un obscure domaine :

Domaine qui appartient en fait à AT Internet :
Ce "cache-sexe" est effectué par un mécanisme appelée délégation de domaine ou CNAME. Lemonde.fr permet à AT Internet de gérer un sous-domaine en son nom, via un mécanisme d'alias. L'intérêt pour les sociétés marketing est de passer outre les protections navigateurs (comme Safari ITP ou Firefox Enhanced Tracking Protection) et autres adblockers (même si certains adblockers tels que uBlock Origin sur Firefox parviennent à bloquer ces traqueurs).
L'utilisation du CNAME est dangereuse, elle peut faire fuiter vos données de connexion : les cookies du domaine consulté (comme les cookies d'authentification de lemonde.fr) peuvent être envoyés au sous-domaine du traqueur (comme buf.lemonde.fr). Regardons donc les requêtes transmises à AT Internet lorsque je suis connecté au site Lemonde.fr :
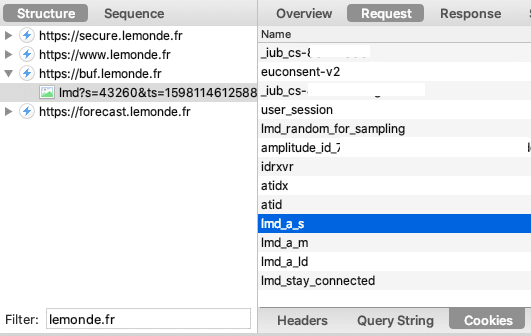
AT Internet récupère bien tous les cookies du domaine lemonde.fr. Afin de vérifier si ces cookies permettent d'accéder à mon compte client Lemonde.fr, je supprime mes cookies puis via l'extension Chrome Edit This Cookie, je renseigne les différents cookies récupérés par AT Internet. Rapidement, je me rends compte que le cookie "lmd_a_s" permet de se connecter à mon compte :
Magie ! Un employé AT Internet peut ainsi accéder à votre compte
J'ai déjà eu l'occasion de parler de cette faille de sécurité dans des articles précédents :
- Criteo pousse au crime en incitant de nombreux éditeurs à l'implémenter, cf "Criteo, un géant du marketing de surveillance français".
- Sur un site média, vous pourriez vous dire que ce n'est pas si grave, mais cette faille est parfois implémentée sur des sites web plus critiques tels que l'espace client de Boursorama Banque (faille corrigée depuis), cf. "Boursorama Banque fuite vos données de connexion".
Refusez d'être surveillé, Lemonde.fr multiplie les traceurs, notamment via Weborama
Continuons notre parcours sur le bandeau de consentement de Lemonde.fr :
![]()
À part les cookies de fonctionnement, tout est décoché par défaut, Lemonde.fr propose aussi un bouton "Tout refuser". De bonnes pratiques donc, cliquons maintenant sur "Enregistrer et continuer". Vous vous attendez maintenant à ne plus être surveillé ?
Oui vous ne rêvez pas, il s'agit de toutes les requêtes envoyées après avoir fait l'effort de refuser le tracking. Et ceci sans consulter un seul article ni même recharger la page. En détail, voici les traceurs qui déposent des cookies via header HTTP (certains traceurs créent également des cookies via du javascript, ou stockent des identifiants dans le local storage du navigateur), avec identifiant personnel (pseudonyme) :
- Outbrain : les articles putassiers en bas de page vous traquent aussi à travers le web, et sur le site lemonde.fr sans votre consentement.
- Weborama : société française de "data marketing" travaillant avec Lemonde.fr, vous profile sur le web et comme vous pouvez le lire ci-dessous, fuite vos données personnelles vers de nombreux autres tiers.
- Index Exchange : via casalemedia.com, plateforme de monétisation publicitaire (SSP) utilisé par Lemonde.fr via un système appelé "Header Bidding" (mise en concurrence de l'inventaire publicitaire sur plusieurs places de marchés.
- TheTradeDesk : via adsrvr.org, plateforme d'achat d'inventaires publicitaires, appelé par Index Exchange et Weborama.
- Criteo : leader mondial du retargeting et français, vous piste agressivement sur le web et dans les applis, Lemonde.fr a installé son "Direct bidder" (permet à Criteo d'acheter sans payer de commission à une plateforme de monétisation), Criteo est également appelé par Weborama.
- Nielsen : via exelator.com, la société eXelate rachetée par le géant des études de marché Nielsen en 2017 est également appelé par Weborama.
- Smart AdServer : plateforme de monétisation publicitaire française utilisé par Lemonde.fr via du "Header Bidding", aussi appelé par Weborama.
- Adobe : via everesttech.net, le géant américain propose aussi une suite marketing, il est aussi appelé par Weborama.
- MediaMath : via mathtag.com, plateforme d'achat d'inventaires publicitaires, appelé par Weborama.
- Temelio : via leadplace.fr, société française de data marketing, propose aux annonceurs de croiser vos données personnelles online et offline, toujours via Weborama.
- Graphinium : via crm4d.com, société française spécialisée dans la réconciliation des données personnelles online et offline, encore via Weborama.
- Yahoo : oui Yahoo existe encore, il est ressuscité par Weborama.
- ZBO Media : via zebestof.com, plateforme d'achat d'inventaires publicitaires française, appelé par Weborama.
- Sublime : via ayads.co, plateforme de monétisation publicitaire française, spécialisée dans les habillages de pages ("Sublime Skinz"), intégrée par Lemonde.fr via "Header Bidding".
- Pubstack ; via pbstck.com, solution de "Header Bidding" française.
Comme déjà vu en décembre dernier, Lemonde.fr permet à Weborama de fuiter vos données personnelles vers de nombreuses sociétés, pour le seul intérêt de Weborama. Ci-dessous, la liste complète des partenaires (dont plusieurs sociétés Russes) :
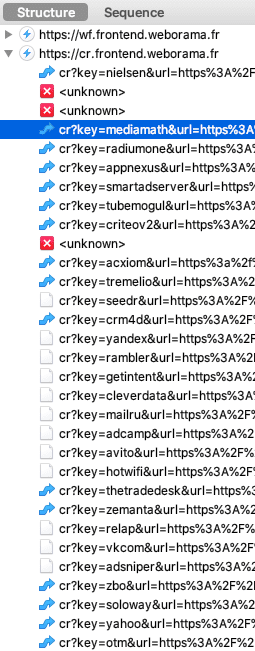
Les partenaires avec une petite flèche bleue devant ont été activés lors du chargement de la page accueil (redirection de Weborama vers le partenaire et donc fuite de mes données personnelles), les autres seront potentiellement activés lorsque de la lecture d'un article, joie !
À noter que certains acteurs publicitaires respectent votre choix et ne déposent pas de cookies : les plateformes de monétisation publicitaire AppNexus, Magnite (ex Rubicon) et surtout Google (qui a une position privilégiée chez Lemonde.fr, étant l'adserveur et la plateforme de monétisation publicitaire principale).
Bien cachée, l'information que vos données personnelles peuvent toujours être exploitées via une base légale douteuse, "l'intérêt légitime"
Que peuvent faire ces sociétés publicitaires de vos données personnelles ? Revenons sur le bandeau de consentement, et notamment sur les "Cookies de ciblage publicitaire" :

Pas d'erreur, vous les avez bien refusé. Cliquons néanmoins sur "Voir la description et personnaliser" :
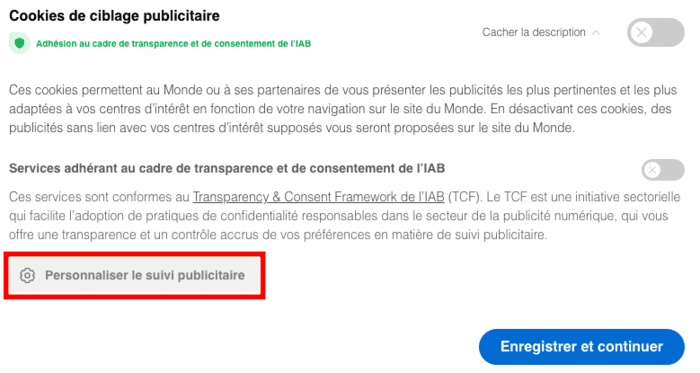
Toujours pas d'erreur, Lemonde.fr vous signale d'ailleurs qu'en désactivant ces cookies, des publicités sans lien avec vos centres d'intérêt supposés vous seront proposées. Cliquons maintenant sur "Personnaliser le suivi publicitaire", et là surprise ! De nombreuses finalités sont expliquées et le consentement est bien désactivé. Mais excepté pour la finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (celle permettant aux acteurs de déposer un cookie avec identifiant publicitaire), la case "Autoriser le traitement de vos données sur la base d’un intérêt légitime à cette fin" est cochée :
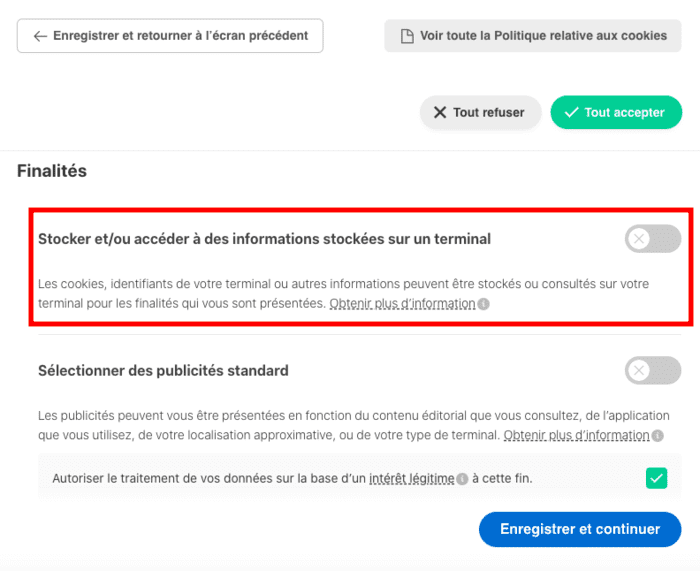 La finalité "Stocker et/ou accéder à des informations stockées sur un terminal" a besoin de votre consentement (pas d'intérêt légitime ici). Les différents acteurs publicitaires violent bien vos choix en déposant des cookies avec identifiants publicitaires.
La finalité "Stocker et/ou accéder à des informations stockées sur un terminal" a besoin de votre consentement (pas d'intérêt légitime ici). Les différents acteurs publicitaires violent bien vos choix en déposant des cookies avec identifiants publicitaires.
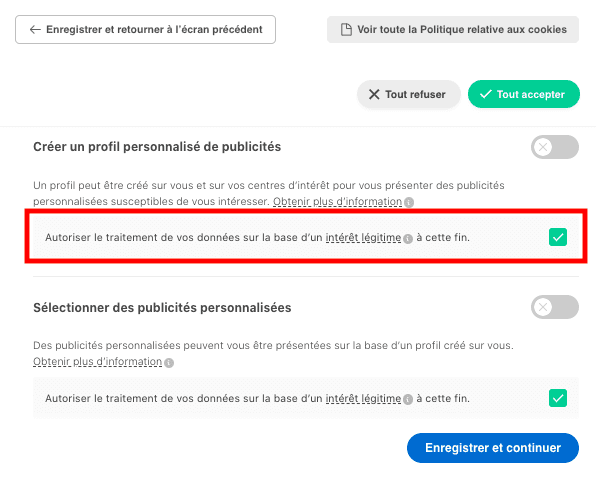 Le TCF v2 permet aux différentes sociétés publicitaires de déclarer l'intérêt légitime comme base légale pour différentes finalités. Mais ces acteurs ont souvent besoin d'un identifiant publicitaire pour réaliser ces finalités (pour lequel votre consentement est toujours requis)... C'est le serpent qui se mord la queue !
Le TCF v2 permet aux différentes sociétés publicitaires de déclarer l'intérêt légitime comme base légale pour différentes finalités. Mais ces acteurs ont souvent besoin d'un identifiant publicitaire pour réaliser ces finalités (pour lequel votre consentement est toujours requis)... C'est le serpent qui se mord la queue !
Ainsi les acteurs publicitaires qui vous surveillent se permettraient différents traitements non pas sur la base légale du consentement (rappel : vous avez déjà refusé) mais sur la base légale de l'intérêt légitime, prévue par le RGPD. Difficile de justifier de l'intérêt légitime lorsqu'il est question de finalités telles que :
- Créer un profil personnalisé de publicités (= vous profiler).
- Sélectionner des publicités personnalisées (= vous influencer selon votre profil).
Il est probable que l'intérêt légitime ne tienne pas pour la plupart des finalités présentées sur ce bandeau de consentement. La CNIL rappelle d'ailleurs que l’intérêt légitime ne peut être retenu que si le traitement satisfait à la condition de « nécessité », la surveillance et la publicité ciblée ne sont pas des "nécessités".
Décochez l'intérêt légitime sur les différentes finalités, rien ne change
Continuons notre marathon, pour refuser l'intérêt légitime sur les différentes finalités, le bouton "Tout refuser" ne marche pas ! Un nouveau "Dark Pattern" comme on les aime ! Il vous faut décocher l'intérêt légitime sur chacune des finalités individuellement, soit 9 clics ! Cliquez sur "Enregistrer et continuer" et observez le résultat :
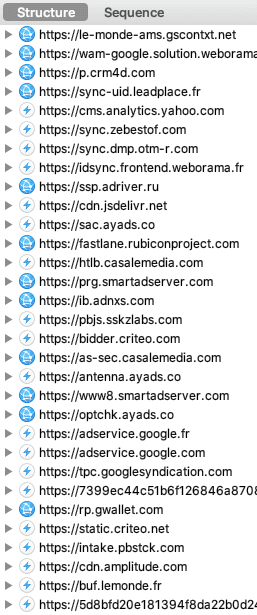
Caramba, rien ne change ! En observant le détail, la plupart de ces acteurs continuent de déposer un cookie, comme si de rien n'était.
Désactiver l'intérêt légitime pour chacune des sociétés individuellement ?
Tout espoir n'est pas perdu, reprenons notre bandeau de consentement, reproduisons les différents refus et cette fois-ci, scrollons tout en bas de la fenêtre "Personnaliser le suivi publicitaire" (faites vite car Lemonde.fr a un auto-refresh qui vous ramène à la page accueil et vous oblige à refaire toutes les étapes) :
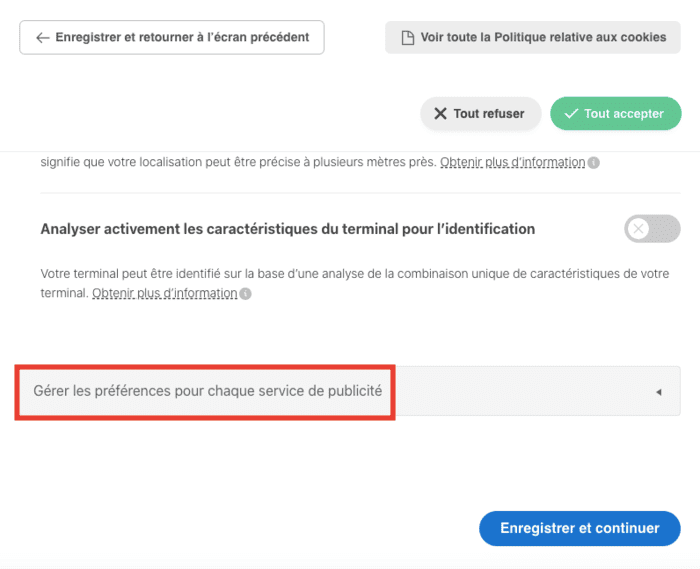
Vous arrivez sur une liste à rallonge de partenaires (plus de 500), dont certains s'appuient bien sur l'intérêt légitime pour des finalités déterminées. Et vous avez beau avoir décoché toutes les finalités d'intérêt légitime à l'étape précédente, ces partenaires ont encore la case intérêt légitime cochée ! Au hasard, Google :
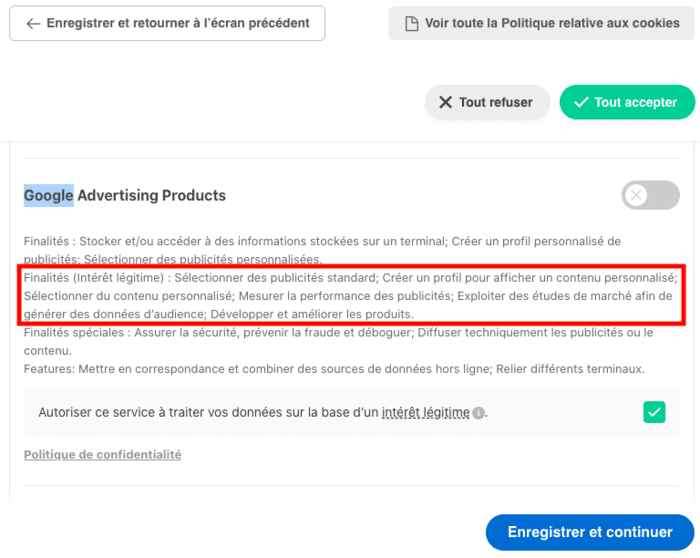
Google s'appuie sur le consentement pour la première finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (il n'a pas le choix, c'est la loi, et le TCF ne permet pas de faire autrement). Et en effet, Google n'a pas déposé d'identifiant publicitaire sur mon poste (pas de cookie doubleclick IDE). Google indique par contre s'appuyer sur l'intérêt légitime pour diverses finalités, ce qui est fort discutable :
Sélectionner des publicités standard; Créer un profil pour afficher un contenu personnalisé; Sélectionner du contenu personnalisé; Mesurer la performance des publicités; Exploiter des études de marché afin de générer des données d’audience; Développer et améliorer les produits.
Criteo fait partie des sociétés qui vous traquent toujours, même après refus de consentement. Quelles finalités déclare-t-il, et sur quelles bases légales ?

Criteo déclare donc s'appuyer sur le consentement pour la première finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (il n'a pas le choix, c'est la loi et le TCF ne permet pas de faire autrement), il ne s'appuie jamais sur l'intérêt légitime. Criteo viole la loi vu qu'il dépose un identifiant publicitaire sur mon poste sans mon consentement (via le cookie uid), ce qui n'est guère étonnant vu le passif de la société concernant les violations de votre vie privée.
Nous avions également constaté que Weborama, le "cheval de Troie" fuitant vos données personnelles à de multiples sociétés, ne respectait pas votre refus de consentement. Quelles finalités déclare-t-il, et sur quelles bases légales ?

Weborama déclare s'appuyer sur le consentement pour la première finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (il n'a pas le choix, c'est la loi et le TCF ne permet pas de faire autrement), mais sur l'intérêt légitime pour de nombreuses autres finalités. Weborama viole donc la loi en déposant un identifiant publicitaire sur mon poste sans mon consentement (via le cookie "AFFICHE_W"), et se permet de synchroniser cet identifiant publicitaire avec de nombreuses autres sociétés qui peuvent ainsi me surveiller. L'intérêt légitime dont il se targue pour diverses finalités lui permet ensuite de me profiler et d'exploiter mon surf.
À quel point les sociétés publicitaires de l'adtech abusent-elles de cette notion d'intérêt légitime ? Pour approfondir la question, vous pouvez lire la publication de Célestin Matte, Cristiana Santos et Nataliia Bielova, “Purposes in IAB Europe’s TCF: which legal basis and how are they used by advertisers?”. En mai 2020, seulement 325 sociétés de l'adtech étaient inscrites au TCF, mais l'intérêt légitime était abondamment utilisé :
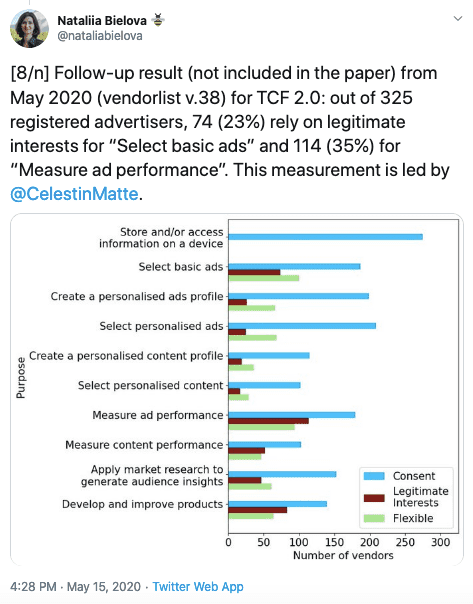
Évidemment, je ne peux pas refuser l'intérêt légitime pour toutes ces sociétés de surveillance (plus de 500 sociétés avec lesquelles Lemonde.fr pourrait théoriquement travailler). Notez que vous ne devriez pas avoir à refuser l'intérêt légitime pour chaque société publicitaire :
- Refuser le consentement en étape 1 doit vous permettre de refuser les "Cookies de ciblage publicitaire" : normalement c'est la fin de la partie pour l'industrie publicitaire.
- Si vous continuez votre navigation, la finalité "Stocker et/ou accéder à des informations stockées sur un terminal" ne peut se baser sur l'intérêt légitime, donc là encore, pas d'autres options que de se baser sur votre consentement pour déposer un cookie avec identifiant publicitaire.
- Lorsque vous décochez l'intérêt légitime sur les différentes finalités, cela s'applique à toutes les sociétés publicitaires. Vous ne devriez pas avoir besoin de décocher l'intérêt légitime pour une société spécifiquement.
Néanmoins, que se passe-t-il si je refuse l'intérêt légitime pour Weborama ("opt-out") ?
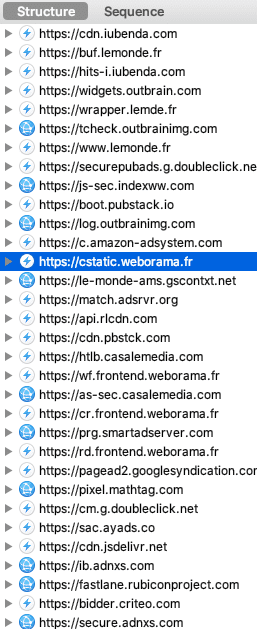
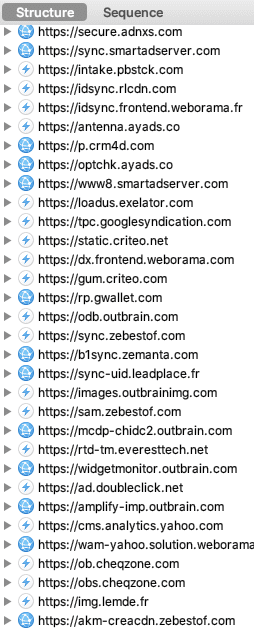
Comme vous pouvez le voir... c'est "business as usual". Vous êtes toujours traqué extensivement. En particulier, Weborama vous identifie toujours via un identifiant publicitaire et synchronise toujours cet identifiant avec le petit monde de la surveillance publicitaire en ligne.
Lemonde.fr, sa CMP Iubenda et les sociétés adtech, un trio infernal
Résumons le parcours du combattant d'un utilisateur désireux de ne pas être traqué, et qui suit le protocole mis en place par Lemonde.fr et son prestataire Iubenda (Consent Management Platform) :
- Lors de l'arrivée sur Lemonde.fr, ne pas scroller ni cliquer sur un article car via une faille introduite par la CNIL dans une délibération datant de 2013 2013, "la poursuite de sa navigation vaut accord au dépôt de Cookies sur son terminal". Et évidemment Lemonde.fr utilise cette faille, qui n'est d'ailleurs plus valable.
- En effet, cette délibération a été abrogée en juillet 2019, la nouvelle délibération indique : "Le renforcement des droits des personnes conduit la Commission à abroger sa délibération n° 2013-378 du 5 décembre 2013 portant adoption d'une recommandation relative aux cookies et aux autres traceurs visés par l'article 32-II de la loi du 6 janvier 1978 (ci-après « la recommandation cookies et autres traceurs ») pour la remplacer par les présentes lignes directrices. Ces lignes directrices seront complétées ultérieurement par des recommandations sectorielles ayant notamment vocation à préciser les modalités pratiques du recueil du consentement". Mais la valeur juridique des recommandations ne reporte cependant pas l'application ni d'ePrivacy, ni du RGPD, ni de la nouvelle délibération.
- Sur le scroll en particulier, la délibération de 2019 indique : "La Commission souligne que le consentement doit se manifester par le biais d'une action positive de la personne préalablement informée des conséquences de son choix et disposant des moyens de l'exercer. Le fait de continuer à naviguer sur un site web, d'utiliser une application mobile ou bien de faire défiler la page d'un site web ou d'une application mobile ne constituent pas des actions positives claires assimilables à un consentement valable".
- Malgré ces précautions, vous êtes déjà pisté par AT Internet, Lemonde.fr viole déjà la loi.
Continuons notre test du bandeau de consentement :
- Cliquer donc sur "Paramétrer les cookies", car il n'y a pas de choix de premier niveau pour refuser les cookies (à l'inverse du bouton "Accepter" au premier niveau).
- Se rendre compte que Lemonde.fr viole de nouveau la loi en ne permettant pas l'opt-out.
- Les "Cookies de ciblage publicitaire" sont bien décochés, mais la plupart des sociétés publicitaire continuent de vous surveiller (exception notable, Google). Cliquer sur "Voir la description et personnaliser" au bas de la fenêtre afin de comprendre si l'on peut éviter cette surveillance.
- Lire que les services publicitaires adhèrent au cadre de transparence et de consentement de l’IAB, et que celui-ci est bien décoché, mais quand même cliquer sur "Personnaliser le suivi publicitaire".
- S'apercevoir sur la page suivante que ces services publicitaires exploitent vos données personnelles pour diverses finalités (10 finalités et 2 finalités spéciales pour lesquelles vous n'avez aucun contrôle), et que si le consentement est bien décoché pour ces finalités, l'intérêt légitime est coché pour quasiment toutes les finalités sauf une ("Stocker et/ou accéder à des informations stockées sur un terminal" requiert votre consentement). Comme il n'y a pas de boutons pour décocher l'intérêt légitime pour ces différentes finalités en une fois, les décocher une par une (9 clics). Se rendre compte que cela n'a aucun effet sur les sociétés publicitaires qui continuent de vous surveiller.
- Tout en bas de cette longue fenêtre, cliquer sur "Gérer les préférences pour chaque service de publicité", se rendre compte qu'il y a plus de 500 partenaires qui peuvent théoriquement vous surveiller (Lemonde.fr pourrait d'ailleurs considérablement écrémer la liste, de nombreux acteurs sont trop petits ou absents du marché français). Se rendre également compte que vous avez beau avoir décoché l'intérêt légitime pour les différentes finalités à l'étape précédente, la case intérêt légitime est encore cochée chez une bonne partie de ces sociétés, pour diverses finalités.
- N'ayant pas d'option pour décocher d'un coup l'intérêt légitime pour chacune des sociétés, décocher Weborama, un "cheval de Troie" de la surveillance publicitaire, et se rendre compte que cela n'a aucun effet. Weborama continue de vous surveiller et de permettre à de nombreuses autres sociétés de vous surveiller.
Un parcours de la mort donc, grâce à Lemonde.fr, sa CMP Iubenda et des sociétés publicitaires qui se fichent de vos choix et de votre vie privée. Un dernier point sur Iubenda, le prestataire qui permet à Lemonde.fr de vous proposer cette bannière de recueil de consentement au parcours si pénible. Son travail est de recueillir et de transmettre vos choix aux différentes sociétés publicitaires, vérifions que le signal collecté puis transmis aux sociétés publicitaires est correct.
Voici le signal transmis lorsque vous vous contentez d'ignorer le bandeau publicitaire en scrollant sur la page accueil du site Lemonde.fr (ce qui vaut consentement grâce à la CNIL). Comment ai-je pu le récupérer ? Via Charles ou la console Chrome, récupérez le champs "gdpr_consent" d'une requête envoyée à un acteur publicitaire et décodez la chaîne de caractère via ce site (TCF v2) :

J'ai juste scollé mais évidemment c'est un "consentement libre, spécifique, éclairé et univoque". Regardons maintenant le signal envoyé lorsque vous avez refusé le consentement et l'intérêt légitime pour chacune des finalités proposées :
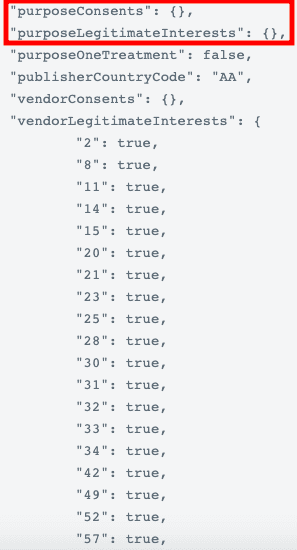
Iubenda ne renseigne pas la valeur des variables représentant les différentes finalités de consentement et d'intérêt légitime. Il s'avère que si l'on lit la spécification du TCF v2, c'est correct:

Si les variables purposeConsents et purposeLegitimateInterests ne sont pas définies, cela doit bien être interprété comme "Pas de consentement" (donc pas de cookies avec identifiants publicitaires) et "Intérêt légitime non établi".
Une bonne nouvelle, pas de surveillance Google... ni de publicité délivrée par Google
Si Lemonde.fr, sa CMP et le petit monde de la surveillance publicitaire s'arrangent pour violer vos choix et continuer de vous surveiller, on peut néanmoins noter que lorsque vous prenez la peine de cliquer sur "Personnaliser" sur le bandeau de consentement, puis de cliquer sur "Enregistrer et continuer", Google ne dépose plus de cookies, et le nombre de publicités chute fortement, vous permettant d'avoir une expérience de lecture un peu meilleure.
Pourquoi ? La première version du TCF (Transparency & Consent Framework), le protocole mis en place par l'IAB (l'industrie publicitaire) pour recueillir et propager les signaux de consentement à l'ensemble de la chaîne publicitaire, n'était pas supportée par Google.
Depuis le 15 août, Google supporte le TCF v2. Pour les clients de sa plateforme de monétisation Google Ad Manager (tels que Lemonde.fr), Google est tenu de respecter les choix utilisateurs. Voici comment il communique à propos de la première finalité, "Stocker des informations sur un appareil et/ou y accéder" :

Plusieurs informations intéressantes ici :
Google n'est pas capable de délivrer de publicité sans vous surveiller (a.k.a. sans déposer le cookie doubleclick IDE). Quelles raisons avance-t-il ? Google déclare en avoir besoin pour détecter la fraude et les abus, pour limiter le nombre d'expositions à une même publicité ("frequency capping") et pour fournir des rapports agrégés.
Google déclare avoir besoin de votre consentement pour déposer des cookies ou des identifiants mobiles, même pour des publicités non ciblées. Si on lit ses "Règles relatives au consentement de l'utilisateur dans l'Union européenne", mais aussi l'Aide concernant les règles relatives au consentement de l'utilisateur dans l'Union européenne", Google indique que cette obligation vient des "dispositions relatives aux cookies de la directive vie privée et communications électroniques de l'UE" (aussi appelée directive ePrivacy) :

Google a besoin d'identifiants utilisateurs pour mesurer la performance des publicités, donc de votre consentement :

Sans consentement pour la première finalité, les éditeurs ne doivent pas appeler Google (Lemonde.fr n'en tient pas compte et appelle Google). Si Google est appelé, il ne délivrera pas de publicité (et en effet, pas de publicité diffusée via Google).
Explications légales sur la nécessité du consentement pour le dépôt des cookies
Attention c'est technique, merci à @Cellular_PP pour ses explications détaillées. Partons de la Directive 2002/58/CE, article 5 paragraphe 3 (j'ai mis en gras le passage intéressant) :
Les États membres garantissent que l'utilisation des réseaux de communications électroniques en vue de stocker des informations ou d'accéder à des informations stockées dans l'équipement terminal d'un abonné ou d'un utilisateur ne soit permise qu'à condition que l'abonné ou l'utilisateur, soit muni, dans le respect de la directive 95/46/CE, d'une information claire et complète, entre autres sur les finalités du traitement, et que l'abonné ou l'utilisateur ait le droit de refuser un tel traitement par le responsable du traitement des données. Cette disposition ne fait pas obstacle à un stockage ou à un accès techniques visant exclusivement à effectuer ou à faciliter la transmission d'une communication par la voie d'un réseau de communications électroniques, ou strictement nécessaires à la fourniture d'un service de la société de l'information expressément demandé par l'abonné ou l'utilisateur.
La directive 2009/136/CE, applicable depuis 2012, modifie l'article 5 paragraphe 3 (en gras, observez l'introduction du consentement) :
Les États membres garantissent que le stockage d'informations, ou l’obtention de l’accès à des informations déjà stockées, dans l’équipement terminal d’un abonné ou d’un utilisateur n’est permis qu’à condition que l’abonné ou l’utilisateur ait donné son accord, après avoir reçu, dans le respect de la directive 95/46/CE, une information claire et complète, entre autres sur les finalités du traitement. Cette disposition ne fait pas obstacle à un stockage ou à un accès techniques visant exclusivement à effectuer la transmission d’une communication par la voie d’un réseau de communications électroniques, ou strictement nécessaires au fournisseur pour la fourniture d’un service de la société de l’information expressément demandé par l’abonné ou l’utilisateur.
La transposition française est dans l'article 82 de la loi informatique et liberté.
La notion de consentement est mentionnée dans l'article 2 de la même directive 2002/58/CE :
le "consentement" d'un utilisateur ou d'un abonné correspond au "consentement de la personne concernée" figurant dans la directive 95/46/CE
Voici donc la fameuse définition du consentement, dans l'article 2 de la directive 95/46/CE
«consentement de la personne concernée»: toute manifestation de volonté, libre, spécifique et informée par laquelle la personne concernée accepte que des données à caractère personnel la concernant fassent l'objet d'un traitement.
Quel lien entre ces directives "ePrivacy" et le RGPD sur cette obligation de consentement ? L'article 95 du RGPD indique ne pas imposer d'obligations supplémentaires :
Le présent règlement n'impose pas d'obligations supplémentaires aux personnes physiques ou morales quant au traitement dans le cadre de la fourniture de services de communications électroniques accessibles au public sur les réseaux publics de communications dans l'Union en ce qui concerne les aspects pour lesquels elles sont soumises à des obligations spécifiques ayant le même objectif énoncées dans la directive 2002/58/CE.
Un avis de l'@EU_EDPB vient clarifier la relation entre les deux textes.
Le point 28 de l'avis indique que l'article 5 paragraphe 3 s'applique aux cookies :
The overarching aim of the ePrivacy Directive is to ensure the protection of fundamental rights and freedoms of the public when they make use of electronic communication networks. In light of this aim, articles 5(3) and 13 of the ePrivacy Directive apply to providers of electronic communication services as well as website operators (e.g. for cookies) or other businesses (e.g. for direct marketing).
Le point 40 de l'avis indique que quand l'article 5 paragraphe 3 mentionne qu'il faut le consentement il n'est pas possible d'utiliser d'autres bases :
A similar situation occurs with regards article 5(3) of the ePrivacy Directive, insofar as the information stored in the end-user’s device constitutes personal data. Article 5(3) of the ePrivacy Directive provides that, as a rule, prior consent is required for the storing of information, or the gaining of access to information already stored, in the terminal equipment of a subscriber or user. To the extent that the adopted information stored in the end-users device constitutes personal data, article 5(3) of the ePrivacy Directive shall take precedence over article 6 of the GDPR with regards to the activity of storing or gaining access to this information. The outcome is similar in the interplay between article 6 of the GDPR and articles 9 and 13 of the ePrivacy Directive. Where these articles require consent for the specific actions they describe, the controller cannot rely on the full range of possible lawful grounds provided by article 6 of the GDPR.
Conclusion : il est bien illégal de prétexter l'intérêt légitime afin de déposer un cookie avec identifiant publicitaire.
Respecter votre vie privée, la grande peur de l'adtech
En lisant la presse, on peut suivre la pensée des régies publicitaires :
- Google ne délivre plus de publicité via Google Ad Manager si l'internaute ne donne pas son consentement. La majorité des sites d'informations français utilise justement Google Ad Manager comme outil de diffusion et de monétisation publicitaire.
- Les bannières de consentement actuelles dégoûtent la très grande majorité des internautes, mais la CNIL doit délivrer de nouvelles recommandations, pour enfin respecter l'esprit du RGPD.
Conséquence potentielle si la CNIL fait un jour son travail : un vrai mécanisme de consentement (comme placer les boutons "Accepter" et "Refuser" au même niveau, ou mieux, un choix simple au niveau du navigateur) avec de vraies sanctions en cas de violation de la loi. Voici une réaction représentative du secteur de l'adtech :
Dès lors que le refus de l'internaute n'a aucun impact sur son expérience de navigation, c'est dramatique de mettre cette option sur un même pied d'égalité que l'acceptation, s'insurge un patron d'adtech
Évidemment, le refus de consentement aurait un impact énorme sur l'expérience de navigation : vous ne seriez plus pisté (bonus, plus de publicité intrusive) et les temps de chargement de la page seraient grandement réduits.
Les régies publicitaires, elles, seraient bien inspirés de se poser les bonnes questions : la forte dégradation de l'expérience utilisateur et la surveillance généralisée sont-elles la solution à leurs problèmes économiques ? Pas vraiment si l'on regarde la mauvaise santé financière des sites d'informations, perfusés de publicités intrusives. À ce titre, vous pouvez lire ces 2 excellents articles :
- Sur Wired, "Can Killing Cookies Save Journalism?" : L'expérience de la radio publique néerlandaise (équivalent France Info), qui gagne maintenant plus d'argent via la publicité non ciblée qu'avant.
- Sur Forbes, "Marketers And Publishers Are Making More Money By Using Less Adtech" : des explications sur comment les intermédiaires de l'adtech s'accaparent la majorité de l'argent dépensé par les annonceurs, empêchant les éditeurs de vivre correctement.
De votre côté que faire ? Comme toujours, ne pas compter sur les sites web pour respecter vos choix, mais s'équiper d'un adblocker tel que uBlock Origin.
Sur son appli iOS, Le Monde vous traque dès le premier lancement
Sur Smartphone, vous n'êtes pas obligé de passer par le site web Lemonde.fr, vous pouvez également utiliser l'application. Est-elle plus respectueuse de votre vie privée ? Afin de tester l'appli iOS Le Monde, j'ai suivi la procédure suivante sur mon iPhone :
- Fermeture des différentes applications en arrière plan.
- Installation de l'application Le Monde.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Le Monde.
Comme sur son site web, Le Monde affiche bien son bandeau de consentement, sans offrir d'option de premier niveau pour refuser les traceurs. Regardons les traceurs envoyés via l'export des logs de ma session Charles Proxy vers mon ordinateur :
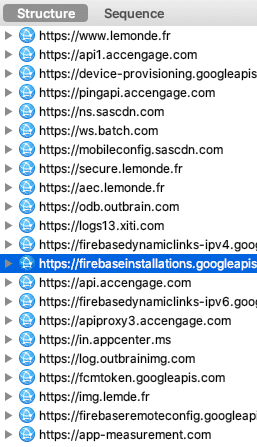
Avant même le paramétrage du bandeau de consentement, Le Monde a déjà fuité vos données personnelles à plusieurs sociétés :
- Accengage : outil de notifications push français, racheté en 2018 par la société du marketing mobile Airship.
- Google : Le Monde utilise Firebase, la boîte à outils des développeurs d'application.
- AT Internet : la société d'analytics française vous piste également sur l'appli Le Monde.
- Batch : solution de CRM mobile et de notifications push.
- Outbrain : les articles putassiers, aussi sur Appli.
- Microsoft : via appcenter.ms, Le Monde utilise Visual Studio App Center, pour gérer l'intégration continue et la livraison de son application.
Refusez le pistage, la surveillance continue
Revenez sur le bandeau de consentement et cliquez sur "Paramétrer les cookies" :
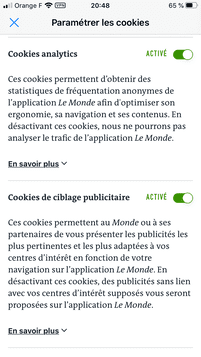
Première (mauvaise) surprise : toutes les finalités sont pré-cochées, ce n'est pas vraiment l'esprit du RGPD. Regardons le détail des "Cookies de fonctionnement" :
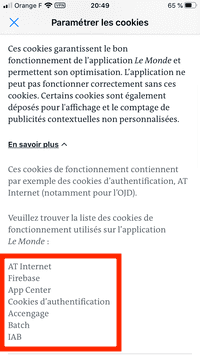
Ainsi de nouveau, Le Monde considère (à tort) que les traceurs d'AT Internet peuvent être classés dans les cookies de fonctionnement, sans vous offrir d'opt-out. Le classement d'Accengage, de Batch et de Google dans les cookies de fonctionnement est également discutable. Décochez maintenant les différentes finalités, consultez 3 articles et observez les traceurs :
La surveillance continue donc, avec les mêmes sociétés mais également un invité supplémentaire : Smart AdServer, un adserveur français, utilisé par Le Monde pour son application.
Comment vous protéger ? En attendant d'hypothétiques sanctions de la CNIL, vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
Texte intégral (9376 mots)
EDIT 6 juin 2021 : Lemonde.fr a fait quelques corrections supplémentaires :
- (+) Lemonde.fr déclenche toujours les traceurs d'AT Internet dès l'arrivée sur son site web. Mais AT Internet, sous réserve d'être configuré de manière adéquate et d’en faire un usage strictement nécessaire au fonctionnement et aux opérations d’administration courante du site web, rentre dans le périmètre de l'exemption de consentement défini par la CNIL.
- (+) Lorsque vous refusez de donner votre consentement, Lemonde.fr bloque le chargement du player vidéo Dailymotion, l'empêchant de fuiter vos données personnelles.
- (-) La plateforme de blogs est malheureusement toujours oubliée, elle fuite vos données personnelles vers Google Analytics avant consentement.
- (+) Si l'on ne tient pas compte d'AT Internet (exemption de consentement), de Batch (notifications) et de Google Firebase (technique), l'appli iOS ne vous piste pas au lancement, ni lorsque vous refusez de donner votre consentement.
EDIT 20 septembre 2020 : Via Twitter (ici et là), j'ai été informé que Lemonde.fr avait effectué des corrections. Après vérifications :
- (-) Lemonde.fr fuite toujours vos données personnelles vers AT Internet dès l'arrivée sur son site web.
- (-) Lemonde.fr n'offre toujours pas d'opt-out pour AT Internet.
- (-) Lemonde.fr fuite toujours vos données de connexion à AT Internet.
- (+) Votre scroll ne vaut plus consentement.
- (+) Si vous refusez d'être surveillé, Lemonde.fr respecte maintenant votre choix et ne multiplie pas les traceurs. En particulier, l'intérêt légitime n'est plus pré-coché lorsque vous avez refusé de donner votre consentement.
- (-) Mais Lemonde.fr a malheureusement oublié son player Dailymotion, intégré dès la page accueil. Celui-ci ne respecte pas vos choix et fuite vos données personnelles vers diverses sociétés (et présente un curieux timer, vous avez 10 secondes pour réagir).
- (-) Lemonde.fr a également oublié sa plateforme de blogs, dont les articles sont souvent mis en valeur via sa page accueil. Exemple avec cet article mis en avant le 20 septembre : vous avez beau avoir refusé les traceurs, vos données personnelles viennent enrichir de multiples sociétés de marketing.
- (-) Rien ne change sur l'appli iOS : Lemonde.fr vous traque dès le premier lancement et si vous refusez le pistage, la surveillance continue.
Vous avez déjà refusé la surveillance publicitaire, mais ce n'est pas terminé : vous avez 10 secondes pour refuser la surveillance initié par le player vidéo Dailymotion. En fait, même si vous prenez la peine de cliquer sur Personnaliser et de "Tout refuser" sur la page "Vos paramètres de confidentialités" de Dailymotion, la surveillance continue.
EDIT 2 septembre 2020 : J'ai pu compléter les informations juridique (et corriger des coquilles) grâce aux explications de @Cellular_PP, merci !
Lemonde.fr fuite vos données personnelles vers AT Internet dès l'arrivée sur son site web
Depuis le 15 août, Google a intégré le nouveau "framework" de recueil de consentement de l'industrie publicitaire, le bien nommé "Transparency and Consent Framework (TCF) v2.0" et les éditeurs mettent à jour leurs bandeaux de consentement. Une amélioration de l'expérience utilisateur ? Pas forcément d'après mon fil Twitter français :
En Angleterre, ce n'est pas mieux :
Afin de mieux comprendre ce qui a changé chez les sites médias, j'ai choisi de tester Lemonde.fr, le "journal de référence", dont je suis un lecteur occasionnel. Pour être honnête, je n'avais pas un très bon à priori :
- Lefigaro.fr, rival historique, traque extensivement ses lecteurs, cf "Le Figaro, emblème du tracking publicitaire invasif des sites médias français".
- Avant leurs nouvelles versions, ces bandeaux de consentement trompaient déjà les internautes, cf "Le recueil du consentement sur internet : un mensonge généralisé".
- En décembre dernier, Lemonde.fr fuitait déjà vos données personnelles vers de nombreux tiers dont des sociétés Russes, cf "Weborama et Lemonde.fr, lenteur de site et fuite de vos données personnelles vers la Russie".
Mais vous êtes en droit d'exiger un meilleur respect de votre vie privée. Afin de vous rendre compte du tracking sur le site Lemonde.fr, suivez les étapes suivantes :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation), ainsi vous êtes déconnecté de votre compte Google.
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur la page d'accueil Lemonde.fr.
Première constatation : Le Monde ne permet pas de refuser le tracking directement, seulement de "Paramétrer les cookies". Ce choix est contraire à l'esprit du RGPD, même si la CNIL a beaucoup de retard sur sa mise en application. Lisons par exemple l'interview de la présidente de la CNIL dans le journal... Le Monde, en février 2020 :
Cela signifie que l’internaute n’aura plus un gros bouton vert proposant d’« Accepter » et un petit texte dans un coin pour refuser ?
Il faut qu’il y ait une symétrie entre les deux. Par ailleurs, les utilisateurs doivent pouvoir connaître les destinataires de leurs données collectées à des fins de profilage publicitaire. Il y a des textes en vigueur qui imposent le recueil d’un consentement libre et éclairé mais ces préconisations ne sont globalement pas mises en œuvre.
Rappel : Le RGPD est entrée en vigueur en mai 2016 et il est applicable depuis le 25 mai 2018 (cf. l'article 99 du RGPD). Les professionnels ont donc eu 4 ans pour se préparer, la CNIL ne devrait donc pas repousser l'applicabilité du texte au mépris des droits fondamentaux des personnes.
Mais Le Monde attend peut-être les nouvelles recommandations (voire les sanctions ?!) de la CNIL pour agir... Regardons maintenant les requêtes envoyées :
3 enseignements :
- Lemonde.fr appelle deux sociétés marketing pour télécharger leurs fichiers javascript, Batch et Amplitude, pas de hits de tracking ici.
- Iubenda est la CMP (Consent Management Platform) utilisée par Le Monde.
- Après recherches, le sous-domaine buf.lemonde.fr s'avère être un "cache sexe" pour la société d'analytics française AT Internet, Le Monde permet à celle-ci de vous pister avant même que vous ayez donné votre consentement.
Lemonde.fr n'offre pas d'opt-out pour AT Internet, en violation de la loi
Sur quoi Lemonde.fr peut-il s'appuyer pour fuiter vos données personnelles vers AT Internet avant même d'avoir reçu votre consentement ? Peut-être sur une vieille exonération de la CNIL, peu conforme à l'esprit du RGPD.
Sauf que cette exonération trouvait sa source à l'article 6 de la délibération CNIL de 2013, les conditions de placement de cookies sans consentement sont désormais précisées dans l'article 5 de la délibération CNIL de juillet 2019. Le fait que la CNIL laisse l'article en ligne pourrait amener un éditeur de site à indiquer que la CNIL l'a induit en erreur, que par conséquent il était de bonne foi en appliquant pas la délibération de 2019, aussi la CNIL devrait modifier son article.
Mais que l'on regarde la délibération de 2013 ou de 2019, une règle reste obligatoire : la mise en place de l'option "opt-out" : "elle doit disposer de la faculté de s'y opposer par l'intermédiaire d'un mécanisme d'opposition facilement utilisable sur l'ensemble des terminaux, des systèmes d'exploitation, des applications et des navigateurs web. Aucune opération de lecture ou d'écriture ne doit avoir lieu sur le terminal depuis lequel la personne s'est opposée".
Cliquons donc sur "Paramétrer les cookies" :
Curieux de connaître ce qui se cache derrière ces "Cookies de fonctionnement" ?
Surprise ! Au côté de cookies d'authentification, Lemonde.fr place les traceurs d'AT Internet dans la catégorie "Cookies de fonctionnement" (et non "Cookies analytics" comme l'on pourrait s'y attendre). L'excuse avancée ? L'OJD, maintenant nommée ACPM, un organisme de certification d'audience des médias, qui permet à Le Monde de se vanter régulièrement de ses bons chiffres d'audience.
Conséquence de ce classement d'AT Internet dans les "Cookies de fonctionnement", l'option "opt-out" n'a pas été mise en place, en violation des conditions de l'exemption.
Autre règle devant être respecté afin de bénéficier de l'exemption, l'information, qui doit avoir lieu avant le dépôt du cookie : "la personne doit être informée préalablement à leur mise en œuvre" (la délibération de 2013 indiquait seulement que la personne devait être informée). Là encore, Lemonde.fr viole les conditions de l'exemption de consentement
Via une faille de sécurité, Lemonde.fr fuite vos données de connexion à AT Internet
Continuons l'investigation sur ces appels à AT Internet, derrière le sous-domaine buf.lemonde.fr, se cache un obscure domaine :
Domaine qui appartient en fait à AT Internet :
Ce "cache-sexe" est effectué par un mécanisme appelée délégation de domaine ou CNAME. Lemonde.fr permet à AT Internet de gérer un sous-domaine en son nom, via un mécanisme d'alias. L'intérêt pour les sociétés marketing est de passer outre les protections navigateurs (comme Safari ITP ou Firefox Enhanced Tracking Protection) et autres adblockers (même si certains adblockers tels que uBlock Origin sur Firefox parviennent à bloquer ces traqueurs).
L'utilisation du CNAME est dangereuse, elle peut faire fuiter vos données de connexion : les cookies du domaine consulté (comme les cookies d'authentification de lemonde.fr) peuvent être envoyés au sous-domaine du traqueur (comme buf.lemonde.fr). Regardons donc les requêtes transmises à AT Internet lorsque je suis connecté au site Lemonde.fr :
AT Internet récupère bien tous les cookies du domaine lemonde.fr. Afin de vérifier si ces cookies permettent d'accéder à mon compte client Lemonde.fr, je supprime mes cookies puis via l'extension Chrome Edit This Cookie, je renseigne les différents cookies récupérés par AT Internet. Rapidement, je me rends compte que le cookie "lmd_a_s" permet de se connecter à mon compte :
Magie ! Un employé AT Internet peut ainsi accéder à votre compte
J'ai déjà eu l'occasion de parler de cette faille de sécurité dans des articles précédents :
- Criteo pousse au crime en incitant de nombreux éditeurs à l'implémenter, cf "Criteo, un géant du marketing de surveillance français".
- Sur un site média, vous pourriez vous dire que ce n'est pas si grave, mais cette faille est parfois implémentée sur des sites web plus critiques tels que l'espace client de Boursorama Banque (faille corrigée depuis), cf. "Boursorama Banque fuite vos données de connexion".
Refusez d'être surveillé, Lemonde.fr multiplie les traceurs, notamment via Weborama
Continuons notre parcours sur le bandeau de consentement de Lemonde.fr :
![]()
À part les cookies de fonctionnement, tout est décoché par défaut, Lemonde.fr propose aussi un bouton "Tout refuser". De bonnes pratiques donc, cliquons maintenant sur "Enregistrer et continuer". Vous vous attendez maintenant à ne plus être surveillé ?
Oui vous ne rêvez pas, il s'agit de toutes les requêtes envoyées après avoir fait l'effort de refuser le tracking. Et ceci sans consulter un seul article ni même recharger la page. En détail, voici les traceurs qui déposent des cookies via header HTTP (certains traceurs créent également des cookies via du javascript, ou stockent des identifiants dans le local storage du navigateur), avec identifiant personnel (pseudonyme) :
- Outbrain : les articles putassiers en bas de page vous traquent aussi à travers le web, et sur le site lemonde.fr sans votre consentement.
- Weborama : société française de "data marketing" travaillant avec Lemonde.fr, vous profile sur le web et comme vous pouvez le lire ci-dessous, fuite vos données personnelles vers de nombreux autres tiers.
- Index Exchange : via casalemedia.com, plateforme de monétisation publicitaire (SSP) utilisé par Lemonde.fr via un système appelé "Header Bidding" (mise en concurrence de l'inventaire publicitaire sur plusieurs places de marchés.
- TheTradeDesk : via adsrvr.org, plateforme d'achat d'inventaires publicitaires, appelé par Index Exchange et Weborama.
- Criteo : leader mondial du retargeting et français, vous piste agressivement sur le web et dans les applis, Lemonde.fr a installé son "Direct bidder" (permet à Criteo d'acheter sans payer de commission à une plateforme de monétisation), Criteo est également appelé par Weborama.
- Nielsen : via exelator.com, la société eXelate rachetée par le géant des études de marché Nielsen en 2017 est également appelé par Weborama.
- Smart AdServer : plateforme de monétisation publicitaire française utilisé par Lemonde.fr via du "Header Bidding", aussi appelé par Weborama.
- Adobe : via everesttech.net, le géant américain propose aussi une suite marketing, il est aussi appelé par Weborama.
- MediaMath : via mathtag.com, plateforme d'achat d'inventaires publicitaires, appelé par Weborama.
- Temelio : via leadplace.fr, société française de data marketing, propose aux annonceurs de croiser vos données personnelles online et offline, toujours via Weborama.
- Graphinium : via crm4d.com, société française spécialisée dans la réconciliation des données personnelles online et offline, encore via Weborama.
- Yahoo : oui Yahoo existe encore, il est ressuscité par Weborama.
- ZBO Media : via zebestof.com, plateforme d'achat d'inventaires publicitaires française, appelé par Weborama.
- Sublime : via ayads.co, plateforme de monétisation publicitaire française, spécialisée dans les habillages de pages ("Sublime Skinz"), intégrée par Lemonde.fr via "Header Bidding".
- Pubstack ; via pbstck.com, solution de "Header Bidding" française.
Comme déjà vu en décembre dernier, Lemonde.fr permet à Weborama de fuiter vos données personnelles vers de nombreuses sociétés, pour le seul intérêt de Weborama. Ci-dessous, la liste complète des partenaires (dont plusieurs sociétés Russes) :
Les partenaires avec une petite flèche bleue devant ont été activés lors du chargement de la page accueil (redirection de Weborama vers le partenaire et donc fuite de mes données personnelles), les autres seront potentiellement activés lorsque de la lecture d'un article, joie !
À noter que certains acteurs publicitaires respectent votre choix et ne déposent pas de cookies : les plateformes de monétisation publicitaire AppNexus, Magnite (ex Rubicon) et surtout Google (qui a une position privilégiée chez Lemonde.fr, étant l'adserveur et la plateforme de monétisation publicitaire principale).
Bien cachée, l'information que vos données personnelles peuvent toujours être exploitées via une base légale douteuse, "l'intérêt légitime"
Que peuvent faire ces sociétés publicitaires de vos données personnelles ? Revenons sur le bandeau de consentement, et notamment sur les "Cookies de ciblage publicitaire" :
Pas d'erreur, vous les avez bien refusé. Cliquons néanmoins sur "Voir la description et personnaliser" :
Toujours pas d'erreur, Lemonde.fr vous signale d'ailleurs qu'en désactivant ces cookies, des publicités sans lien avec vos centres d'intérêt supposés vous seront proposées. Cliquons maintenant sur "Personnaliser le suivi publicitaire", et là surprise ! De nombreuses finalités sont expliquées et le consentement est bien désactivé. Mais excepté pour la finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (celle permettant aux acteurs de déposer un cookie avec identifiant publicitaire), la case "Autoriser le traitement de vos données sur la base d’un intérêt légitime à cette fin" est cochée :
La finalité "Stocker et/ou accéder à des informations stockées sur un terminal" a besoin de votre consentement (pas d'intérêt légitime ici). Les différents acteurs publicitaires violent bien vos choix en déposant des cookies avec identifiants publicitaires.
Le TCF v2 permet aux différentes sociétés publicitaires de déclarer l'intérêt légitime comme base légale pour différentes finalités. Mais ces acteurs ont souvent besoin d'un identifiant publicitaire pour réaliser ces finalités (pour lequel votre consentement est toujours requis)... C'est le serpent qui se mord la queue !
Ainsi les acteurs publicitaires qui vous surveillent se permettraient différents traitements non pas sur la base légale du consentement (rappel : vous avez déjà refusé) mais sur la base légale de l'intérêt légitime, prévue par le RGPD. Difficile de justifier de l'intérêt légitime lorsqu'il est question de finalités telles que :
- Créer un profil personnalisé de publicités (= vous profiler).
- Sélectionner des publicités personnalisées (= vous influencer selon votre profil).
Il est probable que l'intérêt légitime ne tienne pas pour la plupart des finalités présentées sur ce bandeau de consentement. La CNIL rappelle d'ailleurs que l’intérêt légitime ne peut être retenu que si le traitement satisfait à la condition de « nécessité », la surveillance et la publicité ciblée ne sont pas des "nécessités".
Décochez l'intérêt légitime sur les différentes finalités, rien ne change
Continuons notre marathon, pour refuser l'intérêt légitime sur les différentes finalités, le bouton "Tout refuser" ne marche pas ! Un nouveau "Dark Pattern" comme on les aime ! Il vous faut décocher l'intérêt légitime sur chacune des finalités individuellement, soit 9 clics ! Cliquez sur "Enregistrer et continuer" et observez le résultat :
Caramba, rien ne change ! En observant le détail, la plupart de ces acteurs continuent de déposer un cookie, comme si de rien n'était.
Désactiver l'intérêt légitime pour chacune des sociétés individuellement ?
Tout espoir n'est pas perdu, reprenons notre bandeau de consentement, reproduisons les différents refus et cette fois-ci, scrollons tout en bas de la fenêtre "Personnaliser le suivi publicitaire" (faites vite car Lemonde.fr a un auto-refresh qui vous ramène à la page accueil et vous oblige à refaire toutes les étapes) :
Vous arrivez sur une liste à rallonge de partenaires (plus de 500), dont certains s'appuient bien sur l'intérêt légitime pour des finalités déterminées. Et vous avez beau avoir décoché toutes les finalités d'intérêt légitime à l'étape précédente, ces partenaires ont encore la case intérêt légitime cochée ! Au hasard, Google :
Google s'appuie sur le consentement pour la première finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (il n'a pas le choix, c'est la loi, et le TCF ne permet pas de faire autrement). Et en effet, Google n'a pas déposé d'identifiant publicitaire sur mon poste (pas de cookie doubleclick IDE). Google indique par contre s'appuyer sur l'intérêt légitime pour diverses finalités, ce qui est fort discutable :
Sélectionner des publicités standard; Créer un profil pour afficher un contenu personnalisé; Sélectionner du contenu personnalisé; Mesurer la performance des publicités; Exploiter des études de marché afin de générer des données d’audience; Développer et améliorer les produits.
Criteo fait partie des sociétés qui vous traquent toujours, même après refus de consentement. Quelles finalités déclare-t-il, et sur quelles bases légales ?
Criteo déclare donc s'appuyer sur le consentement pour la première finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (il n'a pas le choix, c'est la loi et le TCF ne permet pas de faire autrement), il ne s'appuie jamais sur l'intérêt légitime. Criteo viole la loi vu qu'il dépose un identifiant publicitaire sur mon poste sans mon consentement (via le cookie uid), ce qui n'est guère étonnant vu le passif de la société concernant les violations de votre vie privée.
Nous avions également constaté que Weborama, le "cheval de Troie" fuitant vos données personnelles à de multiples sociétés, ne respectait pas votre refus de consentement. Quelles finalités déclare-t-il, et sur quelles bases légales ?
Weborama déclare s'appuyer sur le consentement pour la première finalité "Stocker et/ou accéder à des informations stockées sur un terminal" (il n'a pas le choix, c'est la loi et le TCF ne permet pas de faire autrement), mais sur l'intérêt légitime pour de nombreuses autres finalités. Weborama viole donc la loi en déposant un identifiant publicitaire sur mon poste sans mon consentement (via le cookie "AFFICHE_W"), et se permet de synchroniser cet identifiant publicitaire avec de nombreuses autres sociétés qui peuvent ainsi me surveiller. L'intérêt légitime dont il se targue pour diverses finalités lui permet ensuite de me profiler et d'exploiter mon surf.
À quel point les sociétés publicitaires de l'adtech abusent-elles de cette notion d'intérêt légitime ? Pour approfondir la question, vous pouvez lire la publication de Célestin Matte, Cristiana Santos et Nataliia Bielova, “Purposes in IAB Europe’s TCF: which legal basis and how are they used by advertisers?”. En mai 2020, seulement 325 sociétés de l'adtech étaient inscrites au TCF, mais l'intérêt légitime était abondamment utilisé :
Évidemment, je ne peux pas refuser l'intérêt légitime pour toutes ces sociétés de surveillance (plus de 500 sociétés avec lesquelles Lemonde.fr pourrait théoriquement travailler). Notez que vous ne devriez pas avoir à refuser l'intérêt légitime pour chaque société publicitaire :
- Refuser le consentement en étape 1 doit vous permettre de refuser les "Cookies de ciblage publicitaire" : normalement c'est la fin de la partie pour l'industrie publicitaire.
- Si vous continuez votre navigation, la finalité "Stocker et/ou accéder à des informations stockées sur un terminal" ne peut se baser sur l'intérêt légitime, donc là encore, pas d'autres options que de se baser sur votre consentement pour déposer un cookie avec identifiant publicitaire.
- Lorsque vous décochez l'intérêt légitime sur les différentes finalités, cela s'applique à toutes les sociétés publicitaires. Vous ne devriez pas avoir besoin de décocher l'intérêt légitime pour une société spécifiquement.
Néanmoins, que se passe-t-il si je refuse l'intérêt légitime pour Weborama ("opt-out") ?
Comme vous pouvez le voir... c'est "business as usual". Vous êtes toujours traqué extensivement. En particulier, Weborama vous identifie toujours via un identifiant publicitaire et synchronise toujours cet identifiant avec le petit monde de la surveillance publicitaire en ligne.
Lemonde.fr, sa CMP Iubenda et les sociétés adtech, un trio infernal
Résumons le parcours du combattant d'un utilisateur désireux de ne pas être traqué, et qui suit le protocole mis en place par Lemonde.fr et son prestataire Iubenda (Consent Management Platform) :
- Lors de l'arrivée sur Lemonde.fr, ne pas scroller ni cliquer sur un article car via une faille introduite par la CNIL dans une délibération datant de 2013 2013, "la poursuite de sa navigation vaut accord au dépôt de Cookies sur son terminal". Et évidemment Lemonde.fr utilise cette faille, qui n'est d'ailleurs plus valable.
- En effet, cette délibération a été abrogée en juillet 2019, la nouvelle délibération indique : "Le renforcement des droits des personnes conduit la Commission à abroger sa délibération n° 2013-378 du 5 décembre 2013 portant adoption d'une recommandation relative aux cookies et aux autres traceurs visés par l'article 32-II de la loi du 6 janvier 1978 (ci-après « la recommandation cookies et autres traceurs ») pour la remplacer par les présentes lignes directrices. Ces lignes directrices seront complétées ultérieurement par des recommandations sectorielles ayant notamment vocation à préciser les modalités pratiques du recueil du consentement". Mais la valeur juridique des recommandations ne reporte cependant pas l'application ni d'ePrivacy, ni du RGPD, ni de la nouvelle délibération.
- Sur le scroll en particulier, la délibération de 2019 indique : "La Commission souligne que le consentement doit se manifester par le biais d'une action positive de la personne préalablement informée des conséquences de son choix et disposant des moyens de l'exercer. Le fait de continuer à naviguer sur un site web, d'utiliser une application mobile ou bien de faire défiler la page d'un site web ou d'une application mobile ne constituent pas des actions positives claires assimilables à un consentement valable".
- Malgré ces précautions, vous êtes déjà pisté par AT Internet, Lemonde.fr viole déjà la loi.
Continuons notre test du bandeau de consentement :
- Cliquer donc sur "Paramétrer les cookies", car il n'y a pas de choix de premier niveau pour refuser les cookies (à l'inverse du bouton "Accepter" au premier niveau).
- Se rendre compte que Lemonde.fr viole de nouveau la loi en ne permettant pas l'opt-out.
- Les "Cookies de ciblage publicitaire" sont bien décochés, mais la plupart des sociétés publicitaire continuent de vous surveiller (exception notable, Google). Cliquer sur "Voir la description et personnaliser" au bas de la fenêtre afin de comprendre si l'on peut éviter cette surveillance.
- Lire que les services publicitaires adhèrent au cadre de transparence et de consentement de l’IAB, et que celui-ci est bien décoché, mais quand même cliquer sur "Personnaliser le suivi publicitaire".
- S'apercevoir sur la page suivante que ces services publicitaires exploitent vos données personnelles pour diverses finalités (10 finalités et 2 finalités spéciales pour lesquelles vous n'avez aucun contrôle), et que si le consentement est bien décoché pour ces finalités, l'intérêt légitime est coché pour quasiment toutes les finalités sauf une ("Stocker et/ou accéder à des informations stockées sur un terminal" requiert votre consentement). Comme il n'y a pas de boutons pour décocher l'intérêt légitime pour ces différentes finalités en une fois, les décocher une par une (9 clics). Se rendre compte que cela n'a aucun effet sur les sociétés publicitaires qui continuent de vous surveiller.
- Tout en bas de cette longue fenêtre, cliquer sur "Gérer les préférences pour chaque service de publicité", se rendre compte qu'il y a plus de 500 partenaires qui peuvent théoriquement vous surveiller (Lemonde.fr pourrait d'ailleurs considérablement écrémer la liste, de nombreux acteurs sont trop petits ou absents du marché français). Se rendre également compte que vous avez beau avoir décoché l'intérêt légitime pour les différentes finalités à l'étape précédente, la case intérêt légitime est encore cochée chez une bonne partie de ces sociétés, pour diverses finalités.
- N'ayant pas d'option pour décocher d'un coup l'intérêt légitime pour chacune des sociétés, décocher Weborama, un "cheval de Troie" de la surveillance publicitaire, et se rendre compte que cela n'a aucun effet. Weborama continue de vous surveiller et de permettre à de nombreuses autres sociétés de vous surveiller.
Un parcours de la mort donc, grâce à Lemonde.fr, sa CMP Iubenda et des sociétés publicitaires qui se fichent de vos choix et de votre vie privée. Un dernier point sur Iubenda, le prestataire qui permet à Lemonde.fr de vous proposer cette bannière de recueil de consentement au parcours si pénible. Son travail est de recueillir et de transmettre vos choix aux différentes sociétés publicitaires, vérifions que le signal collecté puis transmis aux sociétés publicitaires est correct.
Voici le signal transmis lorsque vous vous contentez d'ignorer le bandeau publicitaire en scrollant sur la page accueil du site Lemonde.fr (ce qui vaut consentement grâce à la CNIL). Comment ai-je pu le récupérer ? Via Charles ou la console Chrome, récupérez le champs "gdpr_consent" d'une requête envoyée à un acteur publicitaire et décodez la chaîne de caractère via ce site (TCF v2) :
J'ai juste scollé mais évidemment c'est un "consentement libre, spécifique, éclairé et univoque". Regardons maintenant le signal envoyé lorsque vous avez refusé le consentement et l'intérêt légitime pour chacune des finalités proposées :
Iubenda ne renseigne pas la valeur des variables représentant les différentes finalités de consentement et d'intérêt légitime. Il s'avère que si l'on lit la spécification du TCF v2, c'est correct:
Si les variables purposeConsents et purposeLegitimateInterests ne sont pas définies, cela doit bien être interprété comme "Pas de consentement" (donc pas de cookies avec identifiants publicitaires) et "Intérêt légitime non établi".
Une bonne nouvelle, pas de surveillance Google... ni de publicité délivrée par Google
Si Lemonde.fr, sa CMP et le petit monde de la surveillance publicitaire s'arrangent pour violer vos choix et continuer de vous surveiller, on peut néanmoins noter que lorsque vous prenez la peine de cliquer sur "Personnaliser" sur le bandeau de consentement, puis de cliquer sur "Enregistrer et continuer", Google ne dépose plus de cookies, et le nombre de publicités chute fortement, vous permettant d'avoir une expérience de lecture un peu meilleure.
Pourquoi ? La première version du TCF (Transparency & Consent Framework), le protocole mis en place par l'IAB (l'industrie publicitaire) pour recueillir et propager les signaux de consentement à l'ensemble de la chaîne publicitaire, n'était pas supportée par Google.
Depuis le 15 août, Google supporte le TCF v2. Pour les clients de sa plateforme de monétisation Google Ad Manager (tels que Lemonde.fr), Google est tenu de respecter les choix utilisateurs. Voici comment il communique à propos de la première finalité, "Stocker des informations sur un appareil et/ou y accéder" :
Plusieurs informations intéressantes ici :
Google n'est pas capable de délivrer de publicité sans vous surveiller (a.k.a. sans déposer le cookie doubleclick IDE). Quelles raisons avance-t-il ? Google déclare en avoir besoin pour détecter la fraude et les abus, pour limiter le nombre d'expositions à une même publicité ("frequency capping") et pour fournir des rapports agrégés.
Google déclare avoir besoin de votre consentement pour déposer des cookies ou des identifiants mobiles, même pour des publicités non ciblées. Si on lit ses "Règles relatives au consentement de l'utilisateur dans l'Union européenne", mais aussi l'Aide concernant les règles relatives au consentement de l'utilisateur dans l'Union européenne", Google indique que cette obligation vient des "dispositions relatives aux cookies de la directive vie privée et communications électroniques de l'UE" (aussi appelée directive ePrivacy) :
Google a besoin d'identifiants utilisateurs pour mesurer la performance des publicités, donc de votre consentement :
Sans consentement pour la première finalité, les éditeurs ne doivent pas appeler Google (Lemonde.fr n'en tient pas compte et appelle Google). Si Google est appelé, il ne délivrera pas de publicité (et en effet, pas de publicité diffusée via Google).
Explications légales sur la nécessité du consentement pour le dépôt des cookies
Attention c'est technique, merci à @Cellular_PP pour ses explications détaillées. Partons de la Directive 2002/58/CE, article 5 paragraphe 3 (j'ai mis en gras le passage intéressant) :
Les États membres garantissent que l'utilisation des réseaux de communications électroniques en vue de stocker des informations ou d'accéder à des informations stockées dans l'équipement terminal d'un abonné ou d'un utilisateur ne soit permise qu'à condition que l'abonné ou l'utilisateur, soit muni, dans le respect de la directive 95/46/CE, d'une information claire et complète, entre autres sur les finalités du traitement, et que l'abonné ou l'utilisateur ait le droit de refuser un tel traitement par le responsable du traitement des données. Cette disposition ne fait pas obstacle à un stockage ou à un accès techniques visant exclusivement à effectuer ou à faciliter la transmission d'une communication par la voie d'un réseau de communications électroniques, ou strictement nécessaires à la fourniture d'un service de la société de l'information expressément demandé par l'abonné ou l'utilisateur.
La directive 2009/136/CE, applicable depuis 2012, modifie l'article 5 paragraphe 3 (en gras, observez l'introduction du consentement) :
Les États membres garantissent que le stockage d'informations, ou l’obtention de l’accès à des informations déjà stockées, dans l’équipement terminal d’un abonné ou d’un utilisateur n’est permis qu’à condition que l’abonné ou l’utilisateur ait donné son accord, après avoir reçu, dans le respect de la directive 95/46/CE, une information claire et complète, entre autres sur les finalités du traitement. Cette disposition ne fait pas obstacle à un stockage ou à un accès techniques visant exclusivement à effectuer la transmission d’une communication par la voie d’un réseau de communications électroniques, ou strictement nécessaires au fournisseur pour la fourniture d’un service de la société de l’information expressément demandé par l’abonné ou l’utilisateur.
La transposition française est dans l'article 82 de la loi informatique et liberté.
La notion de consentement est mentionnée dans l'article 2 de la même directive 2002/58/CE :
le "consentement" d'un utilisateur ou d'un abonné correspond au "consentement de la personne concernée" figurant dans la directive 95/46/CE
Voici donc la fameuse définition du consentement, dans l'article 2 de la directive 95/46/CE
«consentement de la personne concernée»: toute manifestation de volonté, libre, spécifique et informée par laquelle la personne concernée accepte que des données à caractère personnel la concernant fassent l'objet d'un traitement.
Quel lien entre ces directives "ePrivacy" et le RGPD sur cette obligation de consentement ? L'article 95 du RGPD indique ne pas imposer d'obligations supplémentaires :
Le présent règlement n'impose pas d'obligations supplémentaires aux personnes physiques ou morales quant au traitement dans le cadre de la fourniture de services de communications électroniques accessibles au public sur les réseaux publics de communications dans l'Union en ce qui concerne les aspects pour lesquels elles sont soumises à des obligations spécifiques ayant le même objectif énoncées dans la directive 2002/58/CE.
Un avis de l'@EU_EDPB vient clarifier la relation entre les deux textes.
Le point 28 de l'avis indique que l'article 5 paragraphe 3 s'applique aux cookies :
The overarching aim of the ePrivacy Directive is to ensure the protection of fundamental rights and freedoms of the public when they make use of electronic communication networks. In light of this aim, articles 5(3) and 13 of the ePrivacy Directive apply to providers of electronic communication services as well as website operators (e.g. for cookies) or other businesses (e.g. for direct marketing).
Le point 40 de l'avis indique que quand l'article 5 paragraphe 3 mentionne qu'il faut le consentement il n'est pas possible d'utiliser d'autres bases :
A similar situation occurs with regards article 5(3) of the ePrivacy Directive, insofar as the information stored in the end-user’s device constitutes personal data. Article 5(3) of the ePrivacy Directive provides that, as a rule, prior consent is required for the storing of information, or the gaining of access to information already stored, in the terminal equipment of a subscriber or user. To the extent that the adopted information stored in the end-users device constitutes personal data, article 5(3) of the ePrivacy Directive shall take precedence over article 6 of the GDPR with regards to the activity of storing or gaining access to this information. The outcome is similar in the interplay between article 6 of the GDPR and articles 9 and 13 of the ePrivacy Directive. Where these articles require consent for the specific actions they describe, the controller cannot rely on the full range of possible lawful grounds provided by article 6 of the GDPR.
Conclusion : il est bien illégal de prétexter l'intérêt légitime afin de déposer un cookie avec identifiant publicitaire.
Respecter votre vie privée, la grande peur de l'adtech
En lisant la presse, on peut suivre la pensée des régies publicitaires :
- Google ne délivre plus de publicité via Google Ad Manager si l'internaute ne donne pas son consentement. La majorité des sites d'informations français utilise justement Google Ad Manager comme outil de diffusion et de monétisation publicitaire.
- Les bannières de consentement actuelles dégoûtent la très grande majorité des internautes, mais la CNIL doit délivrer de nouvelles recommandations, pour enfin respecter l'esprit du RGPD.
Conséquence potentielle si la CNIL fait un jour son travail : un vrai mécanisme de consentement (comme placer les boutons "Accepter" et "Refuser" au même niveau, ou mieux, un choix simple au niveau du navigateur) avec de vraies sanctions en cas de violation de la loi. Voici une réaction représentative du secteur de l'adtech :
Dès lors que le refus de l'internaute n'a aucun impact sur son expérience de navigation, c'est dramatique de mettre cette option sur un même pied d'égalité que l'acceptation, s'insurge un patron d'adtech
Évidemment, le refus de consentement aurait un impact énorme sur l'expérience de navigation : vous ne seriez plus pisté (bonus, plus de publicité intrusive) et les temps de chargement de la page seraient grandement réduits.
Les régies publicitaires, elles, seraient bien inspirés de se poser les bonnes questions : la forte dégradation de l'expérience utilisateur et la surveillance généralisée sont-elles la solution à leurs problèmes économiques ? Pas vraiment si l'on regarde la mauvaise santé financière des sites d'informations, perfusés de publicités intrusives. À ce titre, vous pouvez lire ces 2 excellents articles :
- Sur Wired, "Can Killing Cookies Save Journalism?" : L'expérience de la radio publique néerlandaise (équivalent France Info), qui gagne maintenant plus d'argent via la publicité non ciblée qu'avant.
- Sur Forbes, "Marketers And Publishers Are Making More Money By Using Less Adtech" : des explications sur comment les intermédiaires de l'adtech s'accaparent la majorité de l'argent dépensé par les annonceurs, empêchant les éditeurs de vivre correctement.
De votre côté que faire ? Comme toujours, ne pas compter sur les sites web pour respecter vos choix, mais s'équiper d'un adblocker tel que uBlock Origin.
Sur son appli iOS, Le Monde vous traque dès le premier lancement
Sur Smartphone, vous n'êtes pas obligé de passer par le site web Lemonde.fr, vous pouvez également utiliser l'application. Est-elle plus respectueuse de votre vie privée ? Afin de tester l'appli iOS Le Monde, j'ai suivi la procédure suivante sur mon iPhone :
- Fermeture des différentes applications en arrière plan.
- Installation de l'application Le Monde.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Le Monde.
Comme sur son site web, Le Monde affiche bien son bandeau de consentement, sans offrir d'option de premier niveau pour refuser les traceurs. Regardons les traceurs envoyés via l'export des logs de ma session Charles Proxy vers mon ordinateur :
Avant même le paramétrage du bandeau de consentement, Le Monde a déjà fuité vos données personnelles à plusieurs sociétés :
- Accengage : outil de notifications push français, racheté en 2018 par la société du marketing mobile Airship.
- Google : Le Monde utilise Firebase, la boîte à outils des développeurs d'application.
- AT Internet : la société d'analytics française vous piste également sur l'appli Le Monde.
- Batch : solution de CRM mobile et de notifications push.
- Outbrain : les articles putassiers, aussi sur Appli.
- Microsoft : via appcenter.ms, Le Monde utilise Visual Studio App Center, pour gérer l'intégration continue et la livraison de son application.
Refusez le pistage, la surveillance continue
Revenez sur le bandeau de consentement et cliquez sur "Paramétrer les cookies" :
Première (mauvaise) surprise : toutes les finalités sont pré-cochées, ce n'est pas vraiment l'esprit du RGPD. Regardons le détail des "Cookies de fonctionnement" :
Ainsi de nouveau, Le Monde considère (à tort) que les traceurs d'AT Internet peuvent être classés dans les cookies de fonctionnement, sans vous offrir d'opt-out. Le classement d'Accengage, de Batch et de Google dans les cookies de fonctionnement est également discutable. Décochez maintenant les différentes finalités, consultez 3 articles et observez les traceurs :
La surveillance continue donc, avec les mêmes sociétés mais également un invité supplémentaire : Smart AdServer, un adserveur français, utilisé par Le Monde pour son application.
Comment vous protéger ? En attendant d'hypothétiques sanctions de la CNIL, vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
26.07.2020 à 19:35
Boursorama Banque fuite vos données de connexion

EDIT 11 août 2020 : Boursorama ne fuite désormais plus vos données de connexion à AT Internet et Smart AdServer.
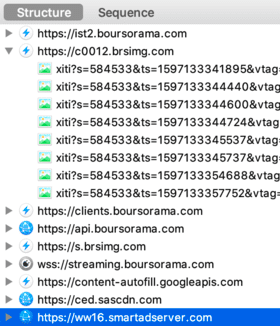
Les données envoyées à AT Internet passent désormais par le domaine c0012.brsimg.com, celles envoyées à Smart AdServer passent par plusieurs domaines dont ww16.smartadserver.com. Ainsi, AT Internet et Smart AdServer n'ont plus accès aux cookies d'authentifications de Boursorama (domaine boursorama.com).
La correction a eu lieu avant le 4 août, cf cette réponse de Boursorama. Notez également la transparence de Boursorama dans cette réponse tardive. Aussi, Boursorama respecte maintenant votre choix si vous refusez d'être pisté sur le web (excepté pour AT Internet qui dispose d'une exemption de la CNIL). Tout n'est pas parfait : Boursorama a toujours une attitude hostile envers les utilisateurs d'adblock, et ne vous permet pas de refuser le pistage sur son App iOS, mais c'est déjà un gros progrès. Les e-mails clients, articles et tweets (le problème du CNAME sur Boursorama était déjà connu en novembre 2019) auront sans doute aidé à faire bouger Boursorama.
Boursorama vous traque sur l'espace client de son site web
Boursorama a une activité de banque en ligne très populaire et efficace, Boursorama Banque. Celle-ci a dépassé les 2 millions de clients fin 2019. Étant client, j'ai voulu vérifier si le site web de Boursorama Banque fuitait mes données personnelles, vous pouvez faire de même en suivant ces étapes :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation).
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur la page de connexion à votre compte client Boursorama Banque et connectez-vous.
Surprise, Boursorama Banque vous traque bien sur l'espace client :
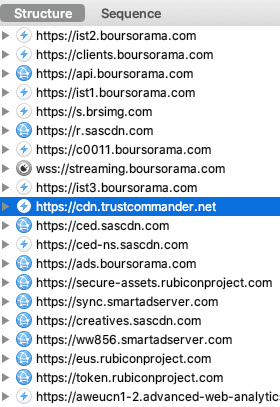
Voici les sociétés qui récupèrent vos données personnelles :
- AT Internet : via c0011.boursorama.com (nous reviendrons plus tard sur ce sous-domaine qui paraît anodin au premier abord), société historique d'analytics française, anciennement nommée Xiti, récupérant l'intégralité de votre navigation ainsi que les caractéristiques de votre appareil. L'outil d'analytics permet à Boursorama d'analyser les parcours utilisateurs et d'améliorer l'expérience de son site web.
- Smart AdServer : société française proposant un adserveur éditeur et une solution de monétisation d'inventaires publicitaires (SSP). Quel intérêt d'appeler une solution publicitaire dans un espace client sans publicité ?
- Rubicon : solution de monétisation d'inventaires publicitaires (SSP), a récemment fusionné avec Telaria pour former Magnite. Là encore, on ne comprend pas trop pourquoi Boursorama appelle une solution publicitaire.
- Commanders Act : via trustcommander.net, anciennement TagCommander, société française proposant plusieurs produits dont historiquement un "Tag Manager" (permet de déclencher des tags marketing sans devoir faire appel à des développeurs, un véritable "cheval de Troie" pour les équipes marketing), une "Customer Data Platform" (centralise vos données personnelles) et une "Consent Management Platform" (solution de recueil du consentement).
AT Internet et Smart AdServer peuvent se connecter à votre compte Boursorama Banque
L'intégration des traceurs AT Internet n'est pas directement visible dans les requêtes envoyées depuis votre poste. On observe des requêtes vers c0011.boursorama.com mais il faut creuser pour se rendre compte que ce sous-domaine n'est pas géré par Boursorama, il a été délégué par Boursorama à AT Internet. Comment ? Via l'enregistrement d'un CNAME (un alias) pointant vers un domaine géré par AT Internet. Vous pouvez vérifier l'enregistrement CNAME sur ce site par exemple :

Et vérifier ensuite le propriétaire du domaine at-o.net sur ce site :
AT Internet se dissimule donc chez Boursorama : un sous-domaine Boursorama qui n'attire pas l'attention (c0011.boursorama.com), mais qui pointe vers un obscure domaine (at-o.net). AT Internet se cache ensuite derrière des domaines AWS sur le régistre WHOIS (seul l'enregistrement CNAME permet de remonter à la source) :

Cette présence dissimulée d'AT Internet (ex Xiti) sur Boursorama Banque avait déjà été remarquée par l'excellent Aeris en novembre 2019 (Boursorama n'a donc toujours pas réagit) :

Pourquoi AT Internet propose-t-il cette option et pourquoi est-elle adoptée par Boursorama ? Si l'on lit la documentation d'AT Internet sur le "domaine personnalisé" (CNAME), le but est simple : contourner les protections des navigateurs et des adblockers :
Pour garantir une collecte de données dans les meilleures conditions, nous proposons l'envoi de hits à nos serveurs avec un CNAME depuis un de vos sous-domaines. En utilisant un domaine personnalisé, vous conservez vos hits, et en conservant vos SLAs, vous pouvez même bénéficier de la meilleure configuration cookie (ITP).
Par "vous conservez vos hits", il faut entendre que les adblockers ne seront pas forcément à jour et ne bloqueront probablement pas les requêtes (pas de chance pour Boursorama, uBlock Origin bloque bien c0011.boursorama.com).
Par "vous pouvez même bénéficier de la meilleure configuration cookie (ITP)", il faut comprendre que les cookies AT Internet étant associés au domaine du site (1st party), ils ne sont pas bloqués par des mécanismes de navigateurs permettant de protéger votre vie privée tels que Safari Intelligent Tracking Prevention (ITP). AT Internet revient sur cette caractéristique dans son article :
Les navigateurs comme Safari requièrent désormais que les cookies soient first party (déposés depuis le domaine courant), server-side (déposés par un serveur, non par JavaScript) et sécurisés (https). Pour répondre à ces attentes, nous fournissons une configuration qui évite les restrictions ou blocages potentiels à impact sur vos analyses.
AT Internet ne mentionne pas les risques de sécurité associés à l'utilisation de CNAME. Et pourtant, comme nous avions déjà pu le voir dans le cas de Criteo et comme l'avait expliqué Aeris auparavant, ils sont grands. Si le site partenaire n'a pas pris ses précautions, AT Internet peut lire tous les cookies déposés, et pas simplement les cookies créés par AT Internet. Regardons donc les cookies envoyés par votre navigateur à AT Internet via le domaine c0011.boursorama.com :
Ainsi AT Internet a accès à tous les cookies déposés sur le nom de domaine boursorama.com, dont les cookies qui vous permettent de rester connecté... Vérifions donc si un utilisateur récupérant la valeur de ces cookies peut usurper votre compte Boursorama Banque :
- Désactivez votre adblocker.
- Lancez Charles Proxy puis connectez-vous à votre compte client Boursorama Banque via Chrome.
- Récupérez les cookies envoyés à c0011.boursorama.com via Charles Proxy.
- Effacez toutes les données de navigation de Chrome.
- Rendez-vous sur https://clients.boursorama.com/, vous êtes bien déconnecté de Boursorama Banque.
- Utilisez l'extension Chrome EditThisCookie pour créer ou mettre à jour vos différents cookies Boursorama.
- Rafraichissez la page, vous êtes connecté !
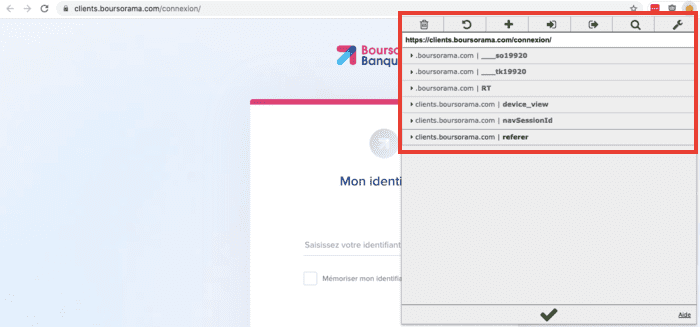 Vous devez ici paramétrer les différents cookies
Vous devez ici paramétrer les différents cookies
Votre session expire au bout d'un certain temps, AT Internet doit donc être rapide pour en profiter. Néanmoins, cela veut dire qu'un employé mal intentionné d'AT Internet peut se connecter au compte Boursorama Banque de n'importe qui. Menace théorique bien sur, cet employé devra avoir les compétences techniques et le bon niveau d'autorisation pour analyser les logs serveurs. Il n'en reste que les données bancaires de plus de 2 millions de français sont à risque.
La même faille de sécurité s'applique à Smart AdServer via le domaine ads.boursorama.com, déjà un peu plus "lisible" pour les adblockers :

Smart AdServer récupère donc également les cookies de boursorama.com, permettant à un employé mal intentionné de Smart AdServer de se connecter au compte Boursorama Banque de n'importe qui :
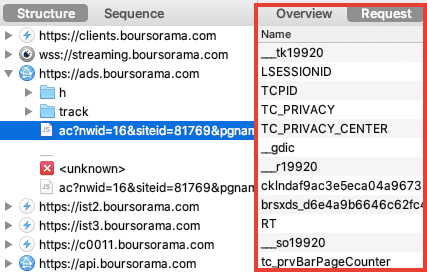
Regardons la politique de cookies de Boursorama, on peut y lire cette pépite :
Comme on vient de le voir, Boursorama a justement mis en place une technique permettant à des tiers (AT Internet et Smart AdServer) de lire les cookies de l'émetteur Boursorama.
Refusez le pistage, Boursorama n'en tient pas compte
Que se passe-t-il si vous prenez la peine de signifier à Boursorama que vous ne souhaitez pas être traqué ?
Boursorama considère que poursuivre votre navigation vaut consentement, comme le permet encore la CNIL dans sa trop grande faiblesse. Cliquons néanmoins sur "Paramétrez vos cookies" :

Oui, toutes les finalités sont cochées par défaut, encore une violation de la RGPD. Décochons donc les différentes finalités (publicité et statistiques). Si l'on lit attentivement celle liée aux statistiques par exemple :
La collecte d’informations relatives à votre utilisation du contenu et association desdites informations avec celles précédemment collectées afin d’évaluer, de comprendre et de rendre compte de la façon dont vous utilisez le service. Cela ne comprend pas la Personnalisation, la collecte d’informations relatives à votre utilisation de ce service afin de vous adresser ultérieurement du contenu et/ou des publicités personnalisés dans d’autres contextes, c’est-à-dire sur d’autres services, tels que des sites ou des applications
Notons que ce bandeau de consentement provient de la CMP (Consent Management Platform) de Commanders Act, la mal nommée TrustCommander. Si les sites vous rendent la vie aussi difficile avec ces insupportables bandeaux, supposant de cliquer une dizaine de fois pour refuser d'être traqué (et non un simple choix Oui/Non), c'est aussi parce que des éditeurs de logiciels le permettent.
On pourrait alors s'attendre à ne plus voir le tracking AT Internet n'est-ce pas ? Erreur, Boursorama ne prend pas en compte vos préférences, comme le montre Charles lorsque vous vous reconnectez à votre espace client :
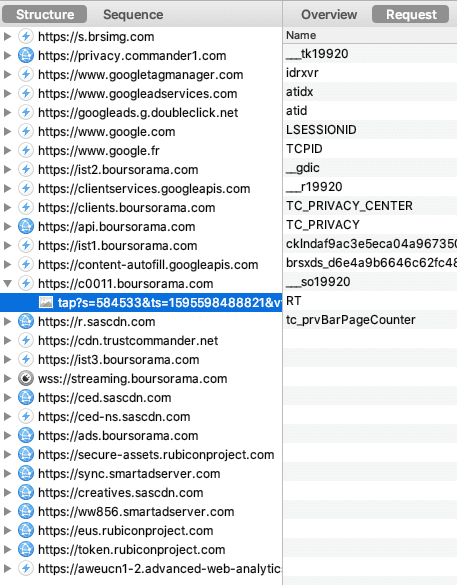
Boursorama fuite toujours vos données personnelles à Rubicon, AT Internet et Smart AdServer. Bonus : vous permettez toujours à AT Internet et Smart AdServer d'accéder à votre compte bancaire Boursorama via la fuite de l'ensemble des cookies associés au domaine boursorama.com.
Boursorama est hostile envers les utilisateurs d'adblockers
Vous pourriez alors vous dire : heureusement j'utilise un adblocker, celui-ci me protège contre le pistage généralisé ainsi que contre des failles de sécurité telles que celle-ci (et dans le cas de uBlock Origin c'est vrai, il bloque bien c0011.boursorama.com et ads.boursorama.com). Néanmoins, Boursorama ne veut pas que vous vous protégiez. Si vous activez votre adblocker, vous serez accueilli avec ce message :
Boursorama vous indique que l'utilisation d'un adblocker peut fortement perturber la bonne navigation au sein de l'espace client : c'est faux. Mais Boursorama va plus loin encore :
Boursorama vous recommande de désactiver votre adblocker pour une navigation et une consultation de vos comptes zéro risque !
Appréciez l'ironie, l'adblocker permet justement de vous protéger contre la faille de sécurité introduite par Boursorama ! Notez que Boursorama ne s'arrête pas là, ils ont également écrit un article expliquant comment désactiver Adblock dans l'aide en ligne de l'espace client, rubrique "Protéger mon espace client" !
Je vous conseille donc d'utiliser un adblocker tel que uBlock Origin combiné à Firefox sur le web (ou d'autres navigateurs respectueux de la vie privée tels que Brave et Safari).
Vous utilisez l'appli iPhone ? Boursorama Banque y fuite également vos données personnelles
Pour se rendre compte du pistage mis en place par Boursorama Banque sur son application iPhone, j'ai suivi la procédure suivante :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Boursorama Banque, puis navigation dans l'App.
- Export des logs de ma session Charles Proxy vers mon ordinateur.
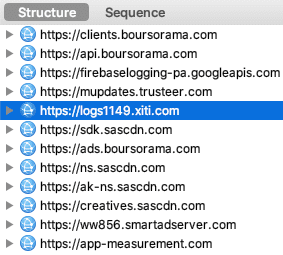
L'appli est tout aussi bavarde que le site web, elle fuite vos données personnelles aux sociétés suivantes :
- Google : via la boite à outil pour développeurs Firebase.
- AT Internet : via xiti.com (Xiti est l'ancien nom d'AT Internet), Boursorama fuite votre navigation mais cette fois ci, pas de fuite de cookies boursorama.com.
- Smart AdServer : pas de publicité dans l'application, on se demande donc encore pourquoi Boursorama appelle Smart AdServer.
"Heureusement" pas de fuite de données Boursorama vers Smart AdServer ici malgré l'utilisation du domaine ads.boursorama.com (seulement les cookies de Smart AdServer). Vos informations de session sur l'application iPhone ne sont pas stockées dans des cookies.
Comment vous protéger contre le pistage généralisé et les failles de sécurité sur les Apps ? Vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
Boursorama viole sa politique de protection des données clients
Si l'on lit la Politique de protection des données des clients de Boursorama Banque, l'engagement pour la sécurisation et la protection de vos données personnelles est ferme, le document commençant par :
Boursorama tient à construire avec ses clients une relation forte et durable, fondée sur la confiance et l’intérêt mutuel. En tant qu’établissement de crédit soumis au secret bancaire, Boursorama assure la sécurité et la confidentialité des informations qui lui sont confiées. Aussi, Boursorama est déterminée à protéger vos données personnelles et votre vie privée.
La confiance est évidemment rompue, Boursorama n'assure pas la sécurité et la confidentialité des informations qui lui sont confiées. Boursorama enchaîne ensuite avec ce paragraphe :

Boursorama permet à des tiers (AT Internet et Smart AdServer) d'accéder à mon compte client, contenant par exemple mes transactions bancaires. Dans la partie 3. Qui sont les destinataires des données personnelles, Boursorama informe qu'il peut communiquer vos données aux autorités publiques, à des organismes financiers et à ses prestataires techniques.
Aucune information sur AT Internet ou Smart AdServer, rentrent-ils dans la case "prestataires techniques" ? Si oui, voilà comment Boursorama communique sur les "prestataires techniques" :

Mes données de connexion ne font évidemment pas parti des informations strictement nécessaires à la mesure d'audience ou à la diffusion de publicités. Enfin, voici comment Boursorama communique sur la sécurisation de vos données :

Mes données de connexion sont interceptées par des tiers non autorisés : AT Internet et Smart AdServer.
Quels changements espérer ?
Si je ne m'attendais pas à une telle faille de sécurité chez une banque en ligne telle que Boursorama Banque, le problème est malheureusement généralisé :
- Criteo a réussi à convaincre plus de 10.000 sites d'installer un CNAME.
- Il est difficile d'avoir la liste complète, mais d'autres solutions analytics ou publicitaires proposent également l'installation d'un CNAME : AT Internet et Smart AdServer comme on l'a vu, mais également Eulerian, Keyade, Adobe, ContentSquare ou Commanders Act (oui, la société qui propose la solution de recueil de consentement "TrustCommander", utilisée par Boursorama et ayant pour moto "Créez de la confiance en jouant la carte de la transparence").
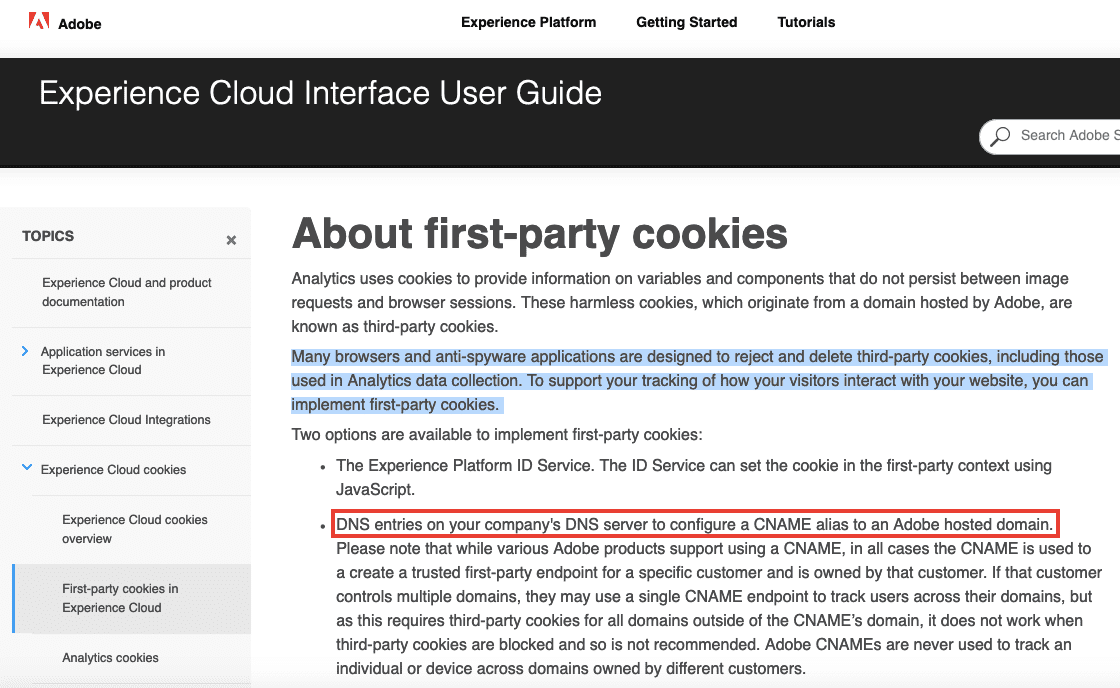 Vous pensiez que la technique du CNAME était "limitée" à d'obscures sociétés de marketing ? Erreur, Adobe la propose également.
Vous pensiez que la technique du CNAME était "limitée" à d'obscures sociétés de marketing ? Erreur, Adobe la propose également.
"Avantages" mis en avant par ces outils : contourner les adblockers et les protections des navigateurs pour toujours mieux vous pister, même si vous ne le souhaitez pas. Evidemment, ces outils devraient arrêter de proposer l'option du CNAME, ils portent une lourde responsabilité en tant que fournisseurs de technologie. Le sentiment d'impunité n'aide pas : sans sanctions de la CNIL, pourquoi changer ?
Mais les sites web portent également une forte responsabilité : dans leur volonté de toujours mieux vous surveiller et mieux monétiser vos informations, ils en oublient la sécurité de vos données personnelles. Là également, l'absence d'un vrai régulateur se fait sentir. Boursorama devrait ainsi :
- Supprimer les CNAMEs et utiliser les versions "standard" des traceurs AT Internet et Smart AdServer.
- Supprimer les traceurs publicitaires Smart AdServer et Rubicon de son espace client et de son application.
- Proposer un vrai mécanisme de recueil de consentement (opt-in) et le respecter.
- Stopper l'attitude hostile envers les utilisateurs d'adblockers.

À vous de jouer Boursorama, d'être réactifs et de mieux protéger les données bancaires de vos clients, c'est ainsi que vous gagnerez le droit d'être recommandé.
Texte intégral (3921 mots)
EDIT 11 août 2020 : Boursorama ne fuite désormais plus vos données de connexion à AT Internet et Smart AdServer.
Les données envoyées à AT Internet passent désormais par le domaine c0012.brsimg.com, celles envoyées à Smart AdServer passent par plusieurs domaines dont ww16.smartadserver.com. Ainsi, AT Internet et Smart AdServer n'ont plus accès aux cookies d'authentifications de Boursorama (domaine boursorama.com).
La correction a eu lieu avant le 4 août, cf cette réponse de Boursorama. Notez également la transparence de Boursorama dans cette réponse tardive. Aussi, Boursorama respecte maintenant votre choix si vous refusez d'être pisté sur le web (excepté pour AT Internet qui dispose d'une exemption de la CNIL). Tout n'est pas parfait : Boursorama a toujours une attitude hostile envers les utilisateurs d'adblock, et ne vous permet pas de refuser le pistage sur son App iOS, mais c'est déjà un gros progrès. Les e-mails clients, articles et tweets (le problème du CNAME sur Boursorama était déjà connu en novembre 2019) auront sans doute aidé à faire bouger Boursorama.
Boursorama vous traque sur l'espace client de son site web
Boursorama a une activité de banque en ligne très populaire et efficace, Boursorama Banque. Celle-ci a dépassé les 2 millions de clients fin 2019. Étant client, j'ai voulu vérifier si le site web de Boursorama Banque fuitait mes données personnelles, vous pouvez faire de même en suivant ces étapes :
- Désactivez votre adblocker.
- Supprimez les cookies sur Chrome (Paramètres > Paramètres avancés > Effacer les données de navigation).
- Ouvrez la console Chrome (⌘+Option+J sur Mac, Ctrl, Shift et J sur PC), onglet "Network" ou lancez Charles Proxy.
- Puis allez sur la page de connexion à votre compte client Boursorama Banque et connectez-vous.
Surprise, Boursorama Banque vous traque bien sur l'espace client :
Voici les sociétés qui récupèrent vos données personnelles :
- AT Internet : via c0011.boursorama.com (nous reviendrons plus tard sur ce sous-domaine qui paraît anodin au premier abord), société historique d'analytics française, anciennement nommée Xiti, récupérant l'intégralité de votre navigation ainsi que les caractéristiques de votre appareil. L'outil d'analytics permet à Boursorama d'analyser les parcours utilisateurs et d'améliorer l'expérience de son site web.
- Smart AdServer : société française proposant un adserveur éditeur et une solution de monétisation d'inventaires publicitaires (SSP). Quel intérêt d'appeler une solution publicitaire dans un espace client sans publicité ?
- Rubicon : solution de monétisation d'inventaires publicitaires (SSP), a récemment fusionné avec Telaria pour former Magnite. Là encore, on ne comprend pas trop pourquoi Boursorama appelle une solution publicitaire.
- Commanders Act : via trustcommander.net, anciennement TagCommander, société française proposant plusieurs produits dont historiquement un "Tag Manager" (permet de déclencher des tags marketing sans devoir faire appel à des développeurs, un véritable "cheval de Troie" pour les équipes marketing), une "Customer Data Platform" (centralise vos données personnelles) et une "Consent Management Platform" (solution de recueil du consentement).
AT Internet et Smart AdServer peuvent se connecter à votre compte Boursorama Banque
L'intégration des traceurs AT Internet n'est pas directement visible dans les requêtes envoyées depuis votre poste. On observe des requêtes vers c0011.boursorama.com mais il faut creuser pour se rendre compte que ce sous-domaine n'est pas géré par Boursorama, il a été délégué par Boursorama à AT Internet. Comment ? Via l'enregistrement d'un CNAME (un alias) pointant vers un domaine géré par AT Internet. Vous pouvez vérifier l'enregistrement CNAME sur ce site par exemple :
Et vérifier ensuite le propriétaire du domaine at-o.net sur ce site :
AT Internet se dissimule donc chez Boursorama : un sous-domaine Boursorama qui n'attire pas l'attention (c0011.boursorama.com), mais qui pointe vers un obscure domaine (at-o.net). AT Internet se cache ensuite derrière des domaines AWS sur le régistre WHOIS (seul l'enregistrement CNAME permet de remonter à la source) :
Cette présence dissimulée d'AT Internet (ex Xiti) sur Boursorama Banque avait déjà été remarquée par l'excellent Aeris en novembre 2019 (Boursorama n'a donc toujours pas réagit) :
Pourquoi AT Internet propose-t-il cette option et pourquoi est-elle adoptée par Boursorama ? Si l'on lit la documentation d'AT Internet sur le "domaine personnalisé" (CNAME), le but est simple : contourner les protections des navigateurs et des adblockers :
Pour garantir une collecte de données dans les meilleures conditions, nous proposons l'envoi de hits à nos serveurs avec un CNAME depuis un de vos sous-domaines. En utilisant un domaine personnalisé, vous conservez vos hits, et en conservant vos SLAs, vous pouvez même bénéficier de la meilleure configuration cookie (ITP).
Par "vous conservez vos hits", il faut entendre que les adblockers ne seront pas forcément à jour et ne bloqueront probablement pas les requêtes (pas de chance pour Boursorama, uBlock Origin bloque bien c0011.boursorama.com).
Par "vous pouvez même bénéficier de la meilleure configuration cookie (ITP)", il faut comprendre que les cookies AT Internet étant associés au domaine du site (1st party), ils ne sont pas bloqués par des mécanismes de navigateurs permettant de protéger votre vie privée tels que Safari Intelligent Tracking Prevention (ITP). AT Internet revient sur cette caractéristique dans son article :
Les navigateurs comme Safari requièrent désormais que les cookies soient first party (déposés depuis le domaine courant), server-side (déposés par un serveur, non par JavaScript) et sécurisés (https). Pour répondre à ces attentes, nous fournissons une configuration qui évite les restrictions ou blocages potentiels à impact sur vos analyses.
AT Internet ne mentionne pas les risques de sécurité associés à l'utilisation de CNAME. Et pourtant, comme nous avions déjà pu le voir dans le cas de Criteo et comme l'avait expliqué Aeris auparavant, ils sont grands. Si le site partenaire n'a pas pris ses précautions, AT Internet peut lire tous les cookies déposés, et pas simplement les cookies créés par AT Internet. Regardons donc les cookies envoyés par votre navigateur à AT Internet via le domaine c0011.boursorama.com :
Ainsi AT Internet a accès à tous les cookies déposés sur le nom de domaine boursorama.com, dont les cookies qui vous permettent de rester connecté... Vérifions donc si un utilisateur récupérant la valeur de ces cookies peut usurper votre compte Boursorama Banque :
- Désactivez votre adblocker.
- Lancez Charles Proxy puis connectez-vous à votre compte client Boursorama Banque via Chrome.
- Récupérez les cookies envoyés à c0011.boursorama.com via Charles Proxy.
- Effacez toutes les données de navigation de Chrome.
- Rendez-vous sur https://clients.boursorama.com/, vous êtes bien déconnecté de Boursorama Banque.
- Utilisez l'extension Chrome EditThisCookie pour créer ou mettre à jour vos différents cookies Boursorama.
- Rafraichissez la page, vous êtes connecté !
Vous devez ici paramétrer les différents cookies
Votre session expire au bout d'un certain temps, AT Internet doit donc être rapide pour en profiter. Néanmoins, cela veut dire qu'un employé mal intentionné d'AT Internet peut se connecter au compte Boursorama Banque de n'importe qui. Menace théorique bien sur, cet employé devra avoir les compétences techniques et le bon niveau d'autorisation pour analyser les logs serveurs. Il n'en reste que les données bancaires de plus de 2 millions de français sont à risque.
La même faille de sécurité s'applique à Smart AdServer via le domaine ads.boursorama.com, déjà un peu plus "lisible" pour les adblockers :
Smart AdServer récupère donc également les cookies de boursorama.com, permettant à un employé mal intentionné de Smart AdServer de se connecter au compte Boursorama Banque de n'importe qui :
Regardons la politique de cookies de Boursorama, on peut y lire cette pépite :
Comme on vient de le voir, Boursorama a justement mis en place une technique permettant à des tiers (AT Internet et Smart AdServer) de lire les cookies de l'émetteur Boursorama.
Refusez le pistage, Boursorama n'en tient pas compte
Que se passe-t-il si vous prenez la peine de signifier à Boursorama que vous ne souhaitez pas être traqué ?
Boursorama considère que poursuivre votre navigation vaut consentement, comme le permet encore la CNIL dans sa trop grande faiblesse. Cliquons néanmoins sur "Paramétrez vos cookies" :
Oui, toutes les finalités sont cochées par défaut, encore une violation de la RGPD. Décochons donc les différentes finalités (publicité et statistiques). Si l'on lit attentivement celle liée aux statistiques par exemple :
La collecte d’informations relatives à votre utilisation du contenu et association desdites informations avec celles précédemment collectées afin d’évaluer, de comprendre et de rendre compte de la façon dont vous utilisez le service. Cela ne comprend pas la Personnalisation, la collecte d’informations relatives à votre utilisation de ce service afin de vous adresser ultérieurement du contenu et/ou des publicités personnalisés dans d’autres contextes, c’est-à-dire sur d’autres services, tels que des sites ou des applications
Notons que ce bandeau de consentement provient de la CMP (Consent Management Platform) de Commanders Act, la mal nommée TrustCommander. Si les sites vous rendent la vie aussi difficile avec ces insupportables bandeaux, supposant de cliquer une dizaine de fois pour refuser d'être traqué (et non un simple choix Oui/Non), c'est aussi parce que des éditeurs de logiciels le permettent.
On pourrait alors s'attendre à ne plus voir le tracking AT Internet n'est-ce pas ? Erreur, Boursorama ne prend pas en compte vos préférences, comme le montre Charles lorsque vous vous reconnectez à votre espace client :
Boursorama fuite toujours vos données personnelles à Rubicon, AT Internet et Smart AdServer. Bonus : vous permettez toujours à AT Internet et Smart AdServer d'accéder à votre compte bancaire Boursorama via la fuite de l'ensemble des cookies associés au domaine boursorama.com.
Boursorama est hostile envers les utilisateurs d'adblockers
Vous pourriez alors vous dire : heureusement j'utilise un adblocker, celui-ci me protège contre le pistage généralisé ainsi que contre des failles de sécurité telles que celle-ci (et dans le cas de uBlock Origin c'est vrai, il bloque bien c0011.boursorama.com et ads.boursorama.com). Néanmoins, Boursorama ne veut pas que vous vous protégiez. Si vous activez votre adblocker, vous serez accueilli avec ce message :
Boursorama vous indique que l'utilisation d'un adblocker peut fortement perturber la bonne navigation au sein de l'espace client : c'est faux. Mais Boursorama va plus loin encore :
Boursorama vous recommande de désactiver votre adblocker pour une navigation et une consultation de vos comptes zéro risque !
Appréciez l'ironie, l'adblocker permet justement de vous protéger contre la faille de sécurité introduite par Boursorama ! Notez que Boursorama ne s'arrête pas là, ils ont également écrit un article expliquant comment désactiver Adblock dans l'aide en ligne de l'espace client, rubrique "Protéger mon espace client" !
Je vous conseille donc d'utiliser un adblocker tel que uBlock Origin combiné à Firefox sur le web (ou d'autres navigateurs respectueux de la vie privée tels que Brave et Safari).
Vous utilisez l'appli iPhone ? Boursorama Banque y fuite également vos données personnelles
Pour se rendre compte du pistage mis en place par Boursorama Banque sur son application iPhone, j'ai suivi la procédure suivante :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Boursorama Banque, puis navigation dans l'App.
- Export des logs de ma session Charles Proxy vers mon ordinateur.
L'appli est tout aussi bavarde que le site web, elle fuite vos données personnelles aux sociétés suivantes :
- Google : via la boite à outil pour développeurs Firebase.
- AT Internet : via xiti.com (Xiti est l'ancien nom d'AT Internet), Boursorama fuite votre navigation mais cette fois ci, pas de fuite de cookies boursorama.com.
- Smart AdServer : pas de publicité dans l'application, on se demande donc encore pourquoi Boursorama appelle Smart AdServer.
"Heureusement" pas de fuite de données Boursorama vers Smart AdServer ici malgré l'utilisation du domaine ads.boursorama.com (seulement les cookies de Smart AdServer). Vos informations de session sur l'application iPhone ne sont pas stockées dans des cookies.
Comment vous protéger contre le pistage généralisé et les failles de sécurité sur les Apps ? Vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
Boursorama viole sa politique de protection des données clients
Si l'on lit la Politique de protection des données des clients de Boursorama Banque, l'engagement pour la sécurisation et la protection de vos données personnelles est ferme, le document commençant par :
Boursorama tient à construire avec ses clients une relation forte et durable, fondée sur la confiance et l’intérêt mutuel. En tant qu’établissement de crédit soumis au secret bancaire, Boursorama assure la sécurité et la confidentialité des informations qui lui sont confiées. Aussi, Boursorama est déterminée à protéger vos données personnelles et votre vie privée.
La confiance est évidemment rompue, Boursorama n'assure pas la sécurité et la confidentialité des informations qui lui sont confiées. Boursorama enchaîne ensuite avec ce paragraphe :
Boursorama permet à des tiers (AT Internet et Smart AdServer) d'accéder à mon compte client, contenant par exemple mes transactions bancaires. Dans la partie 3. Qui sont les destinataires des données personnelles, Boursorama informe qu'il peut communiquer vos données aux autorités publiques, à des organismes financiers et à ses prestataires techniques.
Aucune information sur AT Internet ou Smart AdServer, rentrent-ils dans la case "prestataires techniques" ? Si oui, voilà comment Boursorama communique sur les "prestataires techniques" :
Mes données de connexion ne font évidemment pas parti des informations strictement nécessaires à la mesure d'audience ou à la diffusion de publicités. Enfin, voici comment Boursorama communique sur la sécurisation de vos données :
Mes données de connexion sont interceptées par des tiers non autorisés : AT Internet et Smart AdServer.
Quels changements espérer ?
Si je ne m'attendais pas à une telle faille de sécurité chez une banque en ligne telle que Boursorama Banque, le problème est malheureusement généralisé :
- Criteo a réussi à convaincre plus de 10.000 sites d'installer un CNAME.
- Il est difficile d'avoir la liste complète, mais d'autres solutions analytics ou publicitaires proposent également l'installation d'un CNAME : AT Internet et Smart AdServer comme on l'a vu, mais également Eulerian, Keyade, Adobe, ContentSquare ou Commanders Act (oui, la société qui propose la solution de recueil de consentement "TrustCommander", utilisée par Boursorama et ayant pour moto "Créez de la confiance en jouant la carte de la transparence").
Vous pensiez que la technique du CNAME était "limitée" à d'obscures sociétés de marketing ? Erreur, Adobe la propose également.
"Avantages" mis en avant par ces outils : contourner les adblockers et les protections des navigateurs pour toujours mieux vous pister, même si vous ne le souhaitez pas. Evidemment, ces outils devraient arrêter de proposer l'option du CNAME, ils portent une lourde responsabilité en tant que fournisseurs de technologie. Le sentiment d'impunité n'aide pas : sans sanctions de la CNIL, pourquoi changer ?
Mais les sites web portent également une forte responsabilité : dans leur volonté de toujours mieux vous surveiller et mieux monétiser vos informations, ils en oublient la sécurité de vos données personnelles. Là également, l'absence d'un vrai régulateur se fait sentir. Boursorama devrait ainsi :
- Supprimer les CNAMEs et utiliser les versions "standard" des traceurs AT Internet et Smart AdServer.
- Supprimer les traceurs publicitaires Smart AdServer et Rubicon de son espace client et de son application.
- Proposer un vrai mécanisme de recueil de consentement (opt-in) et le respecter.
- Stopper l'attitude hostile envers les utilisateurs d'adblockers.
À vous de jouer Boursorama, d'être réactifs et de mieux protéger les données bancaires de vos clients, c'est ainsi que vous gagnerez le droit d'être recommandé.
10.07.2020 à 09:16
Dépression sur vos données personnelles, Météo France fuite votre géolocalisation

Météo-France bafoue vos choix et fuite votre géolocalisation
Si vous souhaitez accéder à des prévisions météo fiables, Météo-France est un excellent choix. Les données météorologiques utilisées par l’app Apple Météo sur l'iPhone (application par défaut) proviennent de The Weather Channel, société américaine rachetée par IBM début 2016, et ses prévisions pour la France ne sont malheureusement pas très fiables. Météo-France étant un établissement public administratif, je m'attendais à ne pas être pisté sur son application iPhone. J'ai néanmoins souhaité le vérifier en suivant la procédure suivante :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Météo-France, après installation de celle-ci.
Au premier lancement, Météo-France vous demande d'utiliser votre position :
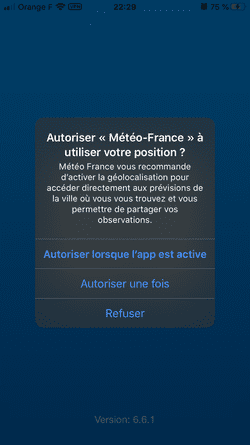
Difficile de se méfier : Météo-France a besoin de votre position pour afficher les prévisions météo de la ville où vous vous trouvez (sinon, vous devrez rentrer à la main la ville). J'autorise donc Météo-France à utiliser ma position, je me vois ensuite présenter la politique de confidentialité :

Météo-France vous demande clairement l'accès aux données de géolocalisation, dont la longitude et la latitude, pour des finalités publicitaires. Météo-France indique ainsi que si vous cliquez sur "Je refuse tout", vos données ne seront pas collectées. Scrollons sur l'écran afin de vérifier les différentes finalités et de cliquer sur "Je refuse tout" :
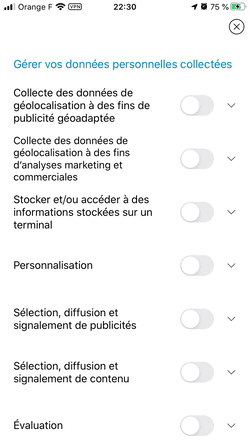
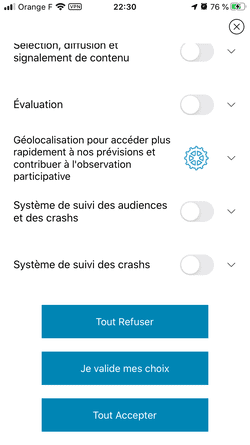
Comme vous pouvez le constater sur les captures écrans, l'approche est saine : les différentes finalités sont toutes décochées par défaut (système "opt-in'). Je vérifie quand même les données envoyées en stoppant l'enregistrement de ma session Charles Proxy et en envoyant les logs vers mon ordinateur pour analyse :
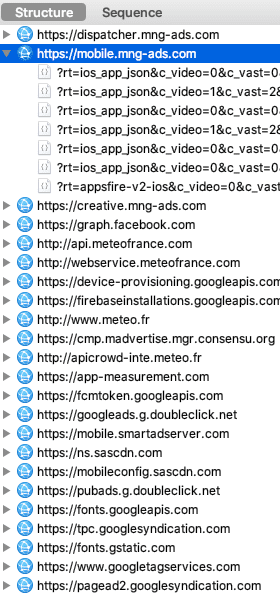
Surprise ! Je n'ai pas encore navigué sur l'App, ayant simplement refusé la surveillance publicitaire des partenaires de Météo France, mais je suis déjà pisté par de nombreuses sociétés :
- Facebook : Météo-France appelle la solution de monétisation publicitaire de Facebook pour les Apps, Facebook Audience Network. Et cette solution est particulièrement gourmande lorsqu'il s'agit de récupérer vos données, sans que l'on comprenne pourquoi Facebook récolte autant d'informations : Facebook récupère par exemple la mémoire totale ainsi que la mémoire libre de votre iPhone (en octets), le niveau de votre batterie, si votre batterie est en train de charger, ainsi que les paramètres de votre accéléromètre.
- Google : Météo-France appelle Firebase, la boîte à outils de Google pour les développeurs, ce qui lui permet de personnaliser son application sans faire de mise à jour. Météo-France appelle également la solution de monétisation publicitaire pour applications Google AdMob.
- Smart AdServer : solution de monétisation publicitaire française utilisée par Météo-France.
- Madvertise : via mng-ads.com, autre solution de monétisation publicitaire française, Madvertise est la régie exclusive de Météo-France. Madvertise est ainsi co-responsable (avec Météo-France) des appels publicitaires vers Google et Smart AdServer. Si l'on regarde le détail des données envoyées à mobile.mng-ads.com (rappel, j'ai refusé toute collecte de données personnelles, et je n'ai cliqué sur aucun écran), on voit 7 requêtes fuitant mes coordonnées GPS (longitude, latitude), permettant de connaître précisément mon domicile.
Ainsi Madvertise, la régie exclusive de Météo-France, s'approprie votre géolocalisation. Pourtant, j'ai bien refusé toute collecte de données personnelles. Quel est donc ce prestataire qui m'a laissé "choisir" de la collecte éventuelle de mes données personnelles par des partenaires ? Il s'agit encore de Madvertise (!) via le domaine cmp.madvertise.mgr.consensu.org. Récapitulons :
- Météo-France, via la Consent Management Platform (CMP) de Madvertise, demande à l'utilisateur son consentement pour la collecte de données personnelles par des partenaires (dont Madvertise fait parti).
- Je refuse toute collecte de données personnelles.
- Madvertise ne tient pas compte de mon choix et collecte notamment une donnée personnelle particulièrement sensible, ma géolocalisation.
Je continue la navigation, la surveillance s'intensifie
Que se passe-t-il lorsque je navigue sur l'application Météo-France ? Afin de voir si l'application cesse de fuiter mes données personnelles, je lance une nouvelle analyse via Charles Proxy et navigue pendant 2 minutes sur l'application :
On peut voir qu'en plus des précédents traceurs, toujours bien présents, de nouveaux traceurs apparaissent :
- Integral Ad Science : via adsafeprotected.com, cette société est spécialisée dans la mesure de visibilité (est-ce que la publicité délivrée est visible à l'écran ou cachée?), dans la détection de fraude (la publicité est-elle affichée à un humain ou à un bot?) et la "brand safety" (le site sur lequel s'affiche la publicité est-il en accord avec la marque? typiquement un site de streaming est rarement apprécié par les marques).
- AppNexus : via adnxs.com, racheté par le géant des télécoms américain AT&T en 2018, cette société propose une plateforme de monétisation publicitaire ainsi qu'une plateforme d'achat d'espaces publicitaires.
- Index Exchange : via casalemedia.com, plateforme de monétisation publicitaire.
- MobSuccess : plateforme d'achats d'espaces publicitaires (DSP) spécialisé sur l'univers applicatif.
- Teads : ad-network spécialisé sur le format InRead (les vidéos publicitaires en autoplay qui apparaissent au milieu des articles), a été acheté par Altice (notamment propriétaire de SFR) en 2017.
- OpenX : autre plateforme de monétisation publicitaire.
On peut également voir que Météo France fuite votre géolocalisation à Madvertise, en continu. J'ai coupé la capture écran mais il y avait le double de requêtes, en seulement 2 minutes de surf (et chacune des requêtes contient ma longitude et ma latitude) :
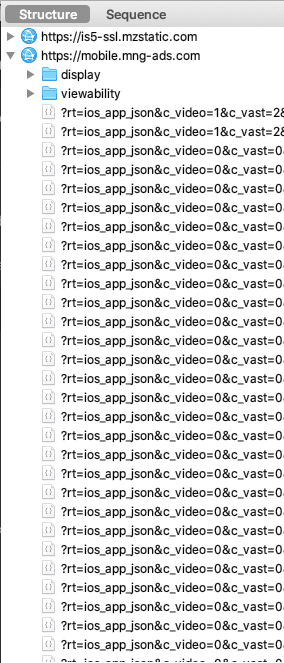
Un dernier point : si vous continuez à utiliser Météo France en relançant l'application (ou que vous la ré-installiez comme je l'ai fait pour ces tests), celle-ci vous demande d'utiliser votre position même si vous n'utilisez pas l'App (!)
Notez que la raison invoquée par Météo France est la même que lorsque l'app est active : accéder directement aux prévisions de la ville où vous vous trouvez et vous permettre de partager vos observations. Bref, aucun intérêt pour l'utilisateur, mais une autorisation qui permet à Madvertise d'être le parfait mouchard en vous suivant à la trace même lorsque vous ne lancez pas Météo France.
En attendant une meilleure protection côté iOS, protégez-vous
Voir un établissement public aussi réputé que Météo France violer la loi et permettre à un mouchard de vous suivre en continu est particulièrement choquant. Si malheureusement la CNIL reste impuissante face à ces violations répétées de la RGPD, il vous reste des options :
- Préférez l'application Météo proposé par Apple sur iOS (même si moins fiable) ou surfez sur le site web de Météo France avec un bloqueur de contenu.
- Utilisez une appli bloquant les traqueurs afin d'être mieux protégé contre la surveillance sur les applications telles que Météo France : DNSCloak, Adguard ou NextDNS sur iOS.
Et très bientôt, vous serez mieux protégé grâce à iOS 14, mise à jour qui vous permettra de ne fournir aux applications voulues qu'une localisation approximative (par zone de 25km2), ce qui est suffisant pour des applications telles que la météo.
Texte intégral (1806 mots)
Météo-France bafoue vos choix et fuite votre géolocalisation
Si vous souhaitez accéder à des prévisions météo fiables, Météo-France est un excellent choix. Les données météorologiques utilisées par l’app Apple Météo sur l'iPhone (application par défaut) proviennent de The Weather Channel, société américaine rachetée par IBM début 2016, et ses prévisions pour la France ne sont malheureusement pas très fiables. Météo-France étant un établissement public administratif, je m'attendais à ne pas être pisté sur son application iPhone. J'ai néanmoins souhaité le vérifier en suivant la procédure suivante :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Météo-France, après installation de celle-ci.
Au premier lancement, Météo-France vous demande d'utiliser votre position :
Difficile de se méfier : Météo-France a besoin de votre position pour afficher les prévisions météo de la ville où vous vous trouvez (sinon, vous devrez rentrer à la main la ville). J'autorise donc Météo-France à utiliser ma position, je me vois ensuite présenter la politique de confidentialité :
Météo-France vous demande clairement l'accès aux données de géolocalisation, dont la longitude et la latitude, pour des finalités publicitaires. Météo-France indique ainsi que si vous cliquez sur "Je refuse tout", vos données ne seront pas collectées. Scrollons sur l'écran afin de vérifier les différentes finalités et de cliquer sur "Je refuse tout" :
Comme vous pouvez le constater sur les captures écrans, l'approche est saine : les différentes finalités sont toutes décochées par défaut (système "opt-in'). Je vérifie quand même les données envoyées en stoppant l'enregistrement de ma session Charles Proxy et en envoyant les logs vers mon ordinateur pour analyse :
Surprise ! Je n'ai pas encore navigué sur l'App, ayant simplement refusé la surveillance publicitaire des partenaires de Météo France, mais je suis déjà pisté par de nombreuses sociétés :
- Facebook : Météo-France appelle la solution de monétisation publicitaire de Facebook pour les Apps, Facebook Audience Network. Et cette solution est particulièrement gourmande lorsqu'il s'agit de récupérer vos données, sans que l'on comprenne pourquoi Facebook récolte autant d'informations : Facebook récupère par exemple la mémoire totale ainsi que la mémoire libre de votre iPhone (en octets), le niveau de votre batterie, si votre batterie est en train de charger, ainsi que les paramètres de votre accéléromètre.
- Google : Météo-France appelle Firebase, la boîte à outils de Google pour les développeurs, ce qui lui permet de personnaliser son application sans faire de mise à jour. Météo-France appelle également la solution de monétisation publicitaire pour applications Google AdMob.
- Smart AdServer : solution de monétisation publicitaire française utilisée par Météo-France.
- Madvertise : via mng-ads.com, autre solution de monétisation publicitaire française, Madvertise est la régie exclusive de Météo-France. Madvertise est ainsi co-responsable (avec Météo-France) des appels publicitaires vers Google et Smart AdServer. Si l'on regarde le détail des données envoyées à mobile.mng-ads.com (rappel, j'ai refusé toute collecte de données personnelles, et je n'ai cliqué sur aucun écran), on voit 7 requêtes fuitant mes coordonnées GPS (longitude, latitude), permettant de connaître précisément mon domicile.
Ainsi Madvertise, la régie exclusive de Météo-France, s'approprie votre géolocalisation. Pourtant, j'ai bien refusé toute collecte de données personnelles. Quel est donc ce prestataire qui m'a laissé "choisir" de la collecte éventuelle de mes données personnelles par des partenaires ? Il s'agit encore de Madvertise (!) via le domaine cmp.madvertise.mgr.consensu.org. Récapitulons :
- Météo-France, via la Consent Management Platform (CMP) de Madvertise, demande à l'utilisateur son consentement pour la collecte de données personnelles par des partenaires (dont Madvertise fait parti).
- Je refuse toute collecte de données personnelles.
- Madvertise ne tient pas compte de mon choix et collecte notamment une donnée personnelle particulièrement sensible, ma géolocalisation.
Je continue la navigation, la surveillance s'intensifie
Que se passe-t-il lorsque je navigue sur l'application Météo-France ? Afin de voir si l'application cesse de fuiter mes données personnelles, je lance une nouvelle analyse via Charles Proxy et navigue pendant 2 minutes sur l'application :
On peut voir qu'en plus des précédents traceurs, toujours bien présents, de nouveaux traceurs apparaissent :
- Integral Ad Science : via adsafeprotected.com, cette société est spécialisée dans la mesure de visibilité (est-ce que la publicité délivrée est visible à l'écran ou cachée?), dans la détection de fraude (la publicité est-elle affichée à un humain ou à un bot?) et la "brand safety" (le site sur lequel s'affiche la publicité est-il en accord avec la marque? typiquement un site de streaming est rarement apprécié par les marques).
- AppNexus : via adnxs.com, racheté par le géant des télécoms américain AT&T en 2018, cette société propose une plateforme de monétisation publicitaire ainsi qu'une plateforme d'achat d'espaces publicitaires.
- Index Exchange : via casalemedia.com, plateforme de monétisation publicitaire.
- MobSuccess : plateforme d'achats d'espaces publicitaires (DSP) spécialisé sur l'univers applicatif.
- Teads : ad-network spécialisé sur le format InRead (les vidéos publicitaires en autoplay qui apparaissent au milieu des articles), a été acheté par Altice (notamment propriétaire de SFR) en 2017.
- OpenX : autre plateforme de monétisation publicitaire.
On peut également voir que Météo France fuite votre géolocalisation à Madvertise, en continu. J'ai coupé la capture écran mais il y avait le double de requêtes, en seulement 2 minutes de surf (et chacune des requêtes contient ma longitude et ma latitude) :
Un dernier point : si vous continuez à utiliser Météo France en relançant l'application (ou que vous la ré-installiez comme je l'ai fait pour ces tests), celle-ci vous demande d'utiliser votre position même si vous n'utilisez pas l'App (!)
Notez que la raison invoquée par Météo France est la même que lorsque l'app est active : accéder directement aux prévisions de la ville où vous vous trouvez et vous permettre de partager vos observations. Bref, aucun intérêt pour l'utilisateur, mais une autorisation qui permet à Madvertise d'être le parfait mouchard en vous suivant à la trace même lorsque vous ne lancez pas Météo France.
En attendant une meilleure protection côté iOS, protégez-vous
Voir un établissement public aussi réputé que Météo France violer la loi et permettre à un mouchard de vous suivre en continu est particulièrement choquant. Si malheureusement la CNIL reste impuissante face à ces violations répétées de la RGPD, il vous reste des options :
- Préférez l'application Météo proposé par Apple sur iOS (même si moins fiable) ou surfez sur le site web de Météo France avec un bloqueur de contenu.
- Utilisez une appli bloquant les traqueurs afin d'être mieux protégé contre la surveillance sur les applications telles que Météo France : DNSCloak, Adguard ou NextDNS sur iOS.
Et très bientôt, vous serez mieux protégé grâce à iOS 14, mise à jour qui vous permettra de ne fournir aux applications voulues qu'une localisation approximative (par zone de 25km2), ce qui est suffisant pour des applications telles que la météo.
31.05.2020 à 19:18
Vos données personnelles soldées avec Runkeeper d'Asics

Runkeeper multiplie les traceurs et fuite votre e-mail dans l'URL d'un outil tiers
Après avoir détaillé comment Runstatic fuite vos données personnelles sans base légale valide, je décide de regarder si son concurrent Runkeeper fait mieux. Tout comme Runstatic rachetée par Adidas en 2015, Runkeeper a suscité des convoitises et a été rachetée par Asics en 2016. Le leader des équipementiers sportifs Nike n'est pas en reste, il propose aussi son application, Nike Training Club.
Vos activités physiques et plus généralement vos données de santé sont en effet stratégiques. Si les équipementiers sportifs ont rapidement réagi, ils sont maintenant accompagnés des géants du numérique :
- Google propose depuis quelques années son application Google Fit. Il a également racheté Fitbit l'année dernière.
- Apple propose l'Apple Watch, la smartwatch la plus vendue au monde, et l'appli Apple Santé. À noter qu'Apple est plus respectueux de vos données personnelles car son objectif est différent (vendre des appareils haut de gamme et non capter vos données personnelles), ainsi les données de l'appli Santé sont chiffrées de bout en bout, ce qui veut dire qu'Apple ne peut les lire.
Runkeeper a déjà eu des problèmes de mauvaise gestion des données personnelles de ses utilisateurs. En 2016, l'application a été accusée par l'organisme public norvégien chargé de la protection des consommateurs de transmettre des données personnelles (dont la géolocalisation) à un tiers (Kiip.me), même lorsque l'application est inactive. Ses pratiques ont-elles changées ? Afin d'étudier les éventuels fuites de données personnelles de Runkeeper vers des sociétés tierces, j'ai suivi la procédure suivante sur mon iPhone :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Runkeeper, puis navigation dans l'App dont le lancement d'une activité.
- Export des logs de ma session Charles Proxy vers mon ordinateur.
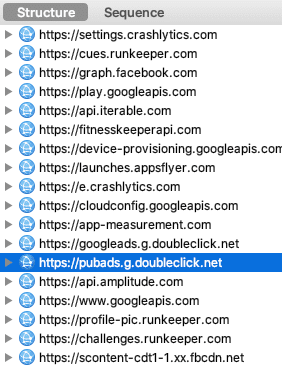
Runkeeper est très bavard, voici les sociétés qui vous pistent :
- Google : le géant de Mountain View est partout. Runkeeper utilise Firebase, la boîte à outil de Google, pour les Apps pour mesurer les crashs, via Crashlytics ainsi que pour personnaliser son application et faire de l'A/B testing via Remote Config. Runkeeper utilise également Google Ad Manager (l'adserveur éditeur) pour diffuser de la publicité.
- Facebook : le géant de Palo Alto est également partout. Runkeeper utilise la boite à outil de Facebook pour les Apps. Il est parfois difficile de savoir pourquoi une application utilise Facebook car sa boîte à outil inclut de nombreuses fonctionnalités comme de l'Analytics ou du reciblage publicitaire.
- Iterable : société de marketing mobile permettant à Runkeeper de vous segmenter pour ensuite mieux vous recibler via des notifications, des messages in-App, des SMS ou des e-mails personnalisés. Mauvaise surprise : Runkeeper fait fuiter à Iterable votre adresse e-mail en clair, dans l'URL. Voici l'URL fautive : https://api.iterable.com/api/inApp/getMessages?count=100&email=XXX&SDKVersion=6.2.2&packageName=RunKeeperPro&platform=iOS.
- Appsflyer : société de marketing mobile offrant notamment un produit d'attribution, ce qui permet à Runkeeper de savoir quelles campagnes publicitaires ont déclenchées l'installation de l'application.
- Amplitude : outil d'analytics, permet à Runkeeper d'analyser en détail votre comportement sur son application. Ici également, tout est tracé : chaque écran vu, le modèle de votre smartphone, votre opérateur mobile, votre identifiant de smartphone, mais également le type d'activité effectué, votre marque de chaussures, le nombre de pas, la distance parcourue, la durée de l'activité ou votre nombre d'amis sur l'application.
Si l'on regarde en détail les informations transmises à Google Ad Manager, l'outil de Google permettant à Runkeeper de diffuser de la publicité, on peut voir que Runkeeper fuite beaucoup d'informations via le champs '_custparams' de la requête https://pubads.g.doubleclick.net/gampad/ads (nous avions déjà vu cette fuite de données chez Spotify). Google collecte (liste non exhaustive) :
- Votre sexe.
- Votre tranche d'âge.
- Des informations sur votre course la plus longue (une fourchette de kilomètres et de durée).
- Des informations sur la moyenne de vos courses (une fourchette de kilomètres).
- Des informations sur le nombre de vos courses (une fourchette aussi).
- Si vous avez déjà fait du vélo ou non.
- Si vous avez déjà escaladé ou non.
- Si vous avez déjà marché ou non.
Ces informations sont envoyées délibérément par Runkeeper à Google Ad Manager afin de mieux vous cibler : Runkeeper peut ainsi diffuser une publicité pour du matériel d'alpinisme aux utilisateurs qui ont déjà fait de l'escalade.
Runkeeper n'a pas de politique de confidentialité dédiée !
Comment Runkeeper communique-t-il sur son usage de vos données personnelles ? Surprise, Asics ne s'embête pas à proposer une politique de confidentialité dédiée à l'application Runkeeper ! Ainsi vous serez redirigé vers la politique de confidentialité d'Asics, dont les marques regroupent Asics et Runkeeper notamment, mais aussi Onitsuka Tiger et Haglöfs.
Dans ces conditions, il est difficile d'analyser cette politique de confidentialité. Comme déjà constaté avec Runstatic, les données personnelles collectées par Asics sont massives, mais elles mélangent les 4 marques d'Asics. Si l'on regarde néanmoins la section "De quelle manière partageons-nous vos données ?", Asics indique :
Partenaires. ASICS vous propose parfois un service ou une application en partenariat avec ses partenaires. Nous pouvons également divulguer vos données personnelles à ces partenaires, mais uniquement lorsque vous avez donné votre consentement ou nous avez demandé de le faire.
Ceci est un mensonge car Runkeeper ne propose rien pour recueillir le consentement de l'utilisateur. Cela va même plus loin car comme nous l'avons vu précédemment, Runkeeper transmet vos données personnelles à Google, Facebook, Iterable (dont votre e-mail), Appsflyer et Amplitude. Vous n'êtes pas informé de cette fuite de données personnelles, vous n'avez pas de contrôle, et Runkeeper ne propose rien pour désactiver ce pistage.
Que pouvez-vous faire afin d'empêcher les fuites vers des outils tiers ? Comme pour Runstatic et pour de nombreuses Apps, en attendant une éventuelle sanction d'une autorité de régulation compétente, vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
Texte intégral (1462 mots)
Runkeeper multiplie les traceurs et fuite votre e-mail dans l'URL d'un outil tiers
Après avoir détaillé comment Runstatic fuite vos données personnelles sans base légale valide, je décide de regarder si son concurrent Runkeeper fait mieux. Tout comme Runstatic rachetée par Adidas en 2015, Runkeeper a suscité des convoitises et a été rachetée par Asics en 2016. Le leader des équipementiers sportifs Nike n'est pas en reste, il propose aussi son application, Nike Training Club.
Vos activités physiques et plus généralement vos données de santé sont en effet stratégiques. Si les équipementiers sportifs ont rapidement réagi, ils sont maintenant accompagnés des géants du numérique :
- Google propose depuis quelques années son application Google Fit. Il a également racheté Fitbit l'année dernière.
- Apple propose l'Apple Watch, la smartwatch la plus vendue au monde, et l'appli Apple Santé. À noter qu'Apple est plus respectueux de vos données personnelles car son objectif est différent (vendre des appareils haut de gamme et non capter vos données personnelles), ainsi les données de l'appli Santé sont chiffrées de bout en bout, ce qui veut dire qu'Apple ne peut les lire.
Runkeeper a déjà eu des problèmes de mauvaise gestion des données personnelles de ses utilisateurs. En 2016, l'application a été accusée par l'organisme public norvégien chargé de la protection des consommateurs de transmettre des données personnelles (dont la géolocalisation) à un tiers (Kiip.me), même lorsque l'application est inactive. Ses pratiques ont-elles changées ? Afin d'étudier les éventuels fuites de données personnelles de Runkeeper vers des sociétés tierces, j'ai suivi la procédure suivante sur mon iPhone :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Runkeeper, puis navigation dans l'App dont le lancement d'une activité.
- Export des logs de ma session Charles Proxy vers mon ordinateur.
Runkeeper est très bavard, voici les sociétés qui vous pistent :
- Google : le géant de Mountain View est partout. Runkeeper utilise Firebase, la boîte à outil de Google, pour les Apps pour mesurer les crashs, via Crashlytics ainsi que pour personnaliser son application et faire de l'A/B testing via Remote Config. Runkeeper utilise également Google Ad Manager (l'adserveur éditeur) pour diffuser de la publicité.
- Facebook : le géant de Palo Alto est également partout. Runkeeper utilise la boite à outil de Facebook pour les Apps. Il est parfois difficile de savoir pourquoi une application utilise Facebook car sa boîte à outil inclut de nombreuses fonctionnalités comme de l'Analytics ou du reciblage publicitaire.
- Iterable : société de marketing mobile permettant à Runkeeper de vous segmenter pour ensuite mieux vous recibler via des notifications, des messages in-App, des SMS ou des e-mails personnalisés. Mauvaise surprise : Runkeeper fait fuiter à Iterable votre adresse e-mail en clair, dans l'URL. Voici l'URL fautive : https://api.iterable.com/api/inApp/getMessages?count=100&email=XXX&SDKVersion=6.2.2&packageName=RunKeeperPro&platform=iOS.
- Appsflyer : société de marketing mobile offrant notamment un produit d'attribution, ce qui permet à Runkeeper de savoir quelles campagnes publicitaires ont déclenchées l'installation de l'application.
- Amplitude : outil d'analytics, permet à Runkeeper d'analyser en détail votre comportement sur son application. Ici également, tout est tracé : chaque écran vu, le modèle de votre smartphone, votre opérateur mobile, votre identifiant de smartphone, mais également le type d'activité effectué, votre marque de chaussures, le nombre de pas, la distance parcourue, la durée de l'activité ou votre nombre d'amis sur l'application.
Si l'on regarde en détail les informations transmises à Google Ad Manager, l'outil de Google permettant à Runkeeper de diffuser de la publicité, on peut voir que Runkeeper fuite beaucoup d'informations via le champs '_custparams' de la requête https://pubads.g.doubleclick.net/gampad/ads (nous avions déjà vu cette fuite de données chez Spotify). Google collecte (liste non exhaustive) :
- Votre sexe.
- Votre tranche d'âge.
- Des informations sur votre course la plus longue (une fourchette de kilomètres et de durée).
- Des informations sur la moyenne de vos courses (une fourchette de kilomètres).
- Des informations sur le nombre de vos courses (une fourchette aussi).
- Si vous avez déjà fait du vélo ou non.
- Si vous avez déjà escaladé ou non.
- Si vous avez déjà marché ou non.
Ces informations sont envoyées délibérément par Runkeeper à Google Ad Manager afin de mieux vous cibler : Runkeeper peut ainsi diffuser une publicité pour du matériel d'alpinisme aux utilisateurs qui ont déjà fait de l'escalade.
Runkeeper n'a pas de politique de confidentialité dédiée !
Comment Runkeeper communique-t-il sur son usage de vos données personnelles ? Surprise, Asics ne s'embête pas à proposer une politique de confidentialité dédiée à l'application Runkeeper ! Ainsi vous serez redirigé vers la politique de confidentialité d'Asics, dont les marques regroupent Asics et Runkeeper notamment, mais aussi Onitsuka Tiger et Haglöfs.
Dans ces conditions, il est difficile d'analyser cette politique de confidentialité. Comme déjà constaté avec Runstatic, les données personnelles collectées par Asics sont massives, mais elles mélangent les 4 marques d'Asics. Si l'on regarde néanmoins la section "De quelle manière partageons-nous vos données ?", Asics indique :
Partenaires. ASICS vous propose parfois un service ou une application en partenariat avec ses partenaires. Nous pouvons également divulguer vos données personnelles à ces partenaires, mais uniquement lorsque vous avez donné votre consentement ou nous avez demandé de le faire.
Ceci est un mensonge car Runkeeper ne propose rien pour recueillir le consentement de l'utilisateur. Cela va même plus loin car comme nous l'avons vu précédemment, Runkeeper transmet vos données personnelles à Google, Facebook, Iterable (dont votre e-mail), Appsflyer et Amplitude. Vous n'êtes pas informé de cette fuite de données personnelles, vous n'avez pas de contrôle, et Runkeeper ne propose rien pour désactiver ce pistage.
Que pouvez-vous faire afin d'empêcher les fuites vers des outils tiers ? Comme pour Runstatic et pour de nombreuses Apps, en attendant une éventuelle sanction d'une autorité de régulation compétente, vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
31.05.2020 à 15:22
Un jogging sous haute surveillance avec Runtastic d'Adidas

Runtastic multiplie les traceurs et fuite votre nom
Pratiquant le jogging régulièrement, j'ai souhaité en savoir plus sur les applications de "fitness", à commencer par Runtastic. Cette application a été rachetée en 2015 par Adidas et depuis renommée en "adidas Running par Runtastic". Si les applications de fitness sont excellentes pour se motiver et mesurer ses progrès, elles récupèrent des données personnelles assez sensibles comme :
- Votre activité physique : ces données peuvent par exemple intéresser des sociétés d'assurances car si vous êtes en meilleur forme, vous serez plus rentable (aux États-Unis, un assureur propose déjà de baisser ses prix si vous portez un bracelet de santé).
- Vos déplacements sportifs : notamment depuis votre domicile ou votre travail mais pas seulement, ces données intéressent notamment les publicitaires.
Google ne s'y est d'ailleurs pas trompé et a décidé d'acheter Fitbit l'année dernière, complétant encore la masse et la diversité des données personnelles qu'il détient sur une grande partie de la population mondiale.
Pour se rendre compte des outils de tracking installés par Runtastic, j'ai suivi la procédure suivante sur mon iPhone :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Runtastic, puis navigation dans l'App dont le lancement d'une activité.
- Export des logs de ma session Charles Proxy vers mon ordinateur.
Comme vous pouvez le voir, Runtastic appelle de nombreux tiers, regardons ceux qui vous pistent :
- Google : incontournable, Runtastic utilise Firebase, la boîte à outils de Google pour les Apps.
- Facebook : incontournable également, Runtastic utilise la boite à outil de Facebook pour les Apps, et notamment la brique analytics.
- Pushwoosh : boite à outils pour applications, fournit notamment des services de notification, d'e-mails et de messages in-App personnalisés. Mauvaise surprise : en plus d'envoyer un pseudonyme et vos différentes actions, Runtastic fuite votre prénom, votre nom, votre sexe et votre tranche d'âge.
- NewRelic : outil de mesure de la performance de l'application Runtastic, notamment utile pour les développeurs.
- Adjust : société de marketing mobile spécialisée dans l'attribution de campagnes publicitaires (savoir grâce à quelle pub vous avez installé Runtastic). Adjust collecte vos actions sur l'application Runtastic.
- Emarsys : société de data marketing permettant à Runtastic de vous profiler de manière extensive pour ensuite mieux vous recibler. Emarsys récupère ainsi le détail de vos activités : la distance parcourue, la durée de l'exercice, le nombre de calories brûlées, vos impressions à la fin de l'exercice, la météo, le type d'activité, la température extérieure, etc.
Une collecte de données personnelles massive, et une fuite vers des tiers sans fondement juridique valable
Au premier lancement de Runtastic, je n'ai malheureusement pas eu de choix : j'ai été obligé d'accepter les conditions d'utilisation pour me servir de l'application.

J'ai pu ensuite refuser de recevoir des publicités ciblées Runtastic sur des plateformes tierces telles que Google et Facebook (mais sans pouvoir interdire à ces tiers de collecter mes données personnelles) :

Notez le bouton "Accepter", clairement mis en avant comparé à "Je refuse", un exemple supplémentaire de Dark Pattern.
La politique de confidentialité de Runtastic liste dans le détail les différentes données personnelles collectées. Vous pouvez lire la section 3. "Données que nous collectons et traitons" afin de mieux saisir la variété et l'ampleur des données personnelles collectées (et ainsi mieux comprendre pourquoi Google a racheté Fitbit). Voici les différentes catégories de données personnelles :
- Informations d'identité.
- Coordonnées de contact.
- Informations de localisation.
- Informations sur les tailles et pointures.
- Informations concernant les achats.
- Informations de profil et comportementales.
- Informations communautaires.
- Informations des réseaux sociaux.
- Informations concernant l'appareil.
- Informations d'activité.
- Informations sur les préférences.
- Informations Creators Club.
- Inscription par le biais de Google ou Facebook.
- Liste d'ami(e)s Facebook.
- Informations concernant les activités d'entraînement importés à partir des Comptes connectés.
Pour chaque catégorie de destinataires, Runtastic informe des catégories de données personnelles transférées ici.
Runtastic explique ensuite de manière détaillée son usage de Firebase, Google Analytics, Adjust et Facebook Analytics. Plus bas dans la politique de confidentialité, Runtastic donne des informations succinctes sur les différents prestataires que nous avons vu précédemment :
Nous faisons appel à des sous-traitants tels que Adjust, Google, Facebook, Amazon Web Services, Inc., Emarsys eMarketing Systems AG, Pushwoosh, Inc., NewRelic, Inc., Apptimize, Inc. ou Zendesk, Inc.
Si ces explications sont louables, Runtastic indique se fonder sur l'intérêt légitime (lire la documentation de la CNIL sur cette base légale) pour fuiter vos données personnelles vers ces tiers : "Le fondement pour le traitement des Données est constitué par nos intérêts légitimes". Pourtant, cette interprétation du RGPD n'est pas valable. Pour les outils d'analytics, on peut notamment se référer à cette page de la CNIL :
Si le dispositif mis en œuvre par le responsable de traitement ne respecte pas strictement les critères des deux cas précédents, seul le consentement des personnes peut être retenu comme base légale du traitement (article 7 de la loi Informatique et libertés, article 6 du RGPD). Ce consentement peut être obtenu par tout moyen (par exemple, connexion à un réseau wifi spécifique, téléchargement d’une application spécifique, inscription via un site web dédié, « badgeage » du terminal auprès d’une borne NFC). Ce consentement doit être informé (les personnes doivent être informées conformément au point ci-dessous avant de consentir), libre (les personnes doivent pouvoir choisir librement de consentir ou non, et ne doivent pas souffrir de conséquences négatives si elles ne consentent pas) et spécifique (le consentement ne doit concerner que le traitement de suivi et ne peut être inclus dans l’acceptation de CGU par exemple).
Runtastic ne peut donc se fonder sur l'intérêt légitime et doit obtenir mon consentement pour fuiter mes données personnelles vers des tiers tels que Google, Facebook ou Adjust. En particulier, le fait d'avoir accepté les CGU ne veut pas dire que j'ai consenti à cette surveillance.
Pourtant, Runtastic persiste à s'appuyer sur la base légale de l'intérêt légitime, comme en témoigne aussi la section 8.1 de sa politique de confidentialité, "Fondements juridiques" :
La licéité du traitement des Données trouve sa source : [...] dans les intérêts légitimes de Runtastic ou d'un tiers, par exemple, notre recours aux cookies, aux plug-ins ou à la publicité ciblée.
Clairement, le recours aux cookies, aux plug-ins ou à la publicité ciblée ne peut s'appuyer sur l'intérêt légitime.
Il est surprenant de voir une célèbre multinationale Allemande (Adidas) collecter de manière aussi massive les données personnelles de millions d'utilisateurs, sans fondement juridique valable. Il est également surprenant de constater qu'Adidas ne se limite pas dans l'usage d'outils marketing fuitant vos données personnelles, toujours sans fondement juridique valable. Que pouvez-vous faire afin d'empêcher les fuites vers des outils tiers ? En attendant une éventuelle sanction d'une autorité de régulation compétente, vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
Texte intégral (1647 mots)
Runtastic multiplie les traceurs et fuite votre nom
Pratiquant le jogging régulièrement, j'ai souhaité en savoir plus sur les applications de "fitness", à commencer par Runtastic. Cette application a été rachetée en 2015 par Adidas et depuis renommée en "adidas Running par Runtastic". Si les applications de fitness sont excellentes pour se motiver et mesurer ses progrès, elles récupèrent des données personnelles assez sensibles comme :
- Votre activité physique : ces données peuvent par exemple intéresser des sociétés d'assurances car si vous êtes en meilleur forme, vous serez plus rentable (aux États-Unis, un assureur propose déjà de baisser ses prix si vous portez un bracelet de santé).
- Vos déplacements sportifs : notamment depuis votre domicile ou votre travail mais pas seulement, ces données intéressent notamment les publicitaires.
Google ne s'y est d'ailleurs pas trompé et a décidé d'acheter Fitbit l'année dernière, complétant encore la masse et la diversité des données personnelles qu'il détient sur une grande partie de la population mondiale.
Pour se rendre compte des outils de tracking installés par Runtastic, j'ai suivi la procédure suivante sur mon iPhone :
- Fermeture des différentes applications en arrière plan.
- Lancement de l'application Charles Proxy et activation du suivi.
- Lancement de l'application Runtastic, puis navigation dans l'App dont le lancement d'une activité.
- Export des logs de ma session Charles Proxy vers mon ordinateur.
Comme vous pouvez le voir, Runtastic appelle de nombreux tiers, regardons ceux qui vous pistent :
- Google : incontournable, Runtastic utilise Firebase, la boîte à outils de Google pour les Apps.
- Facebook : incontournable également, Runtastic utilise la boite à outil de Facebook pour les Apps, et notamment la brique analytics.
- Pushwoosh : boite à outils pour applications, fournit notamment des services de notification, d'e-mails et de messages in-App personnalisés. Mauvaise surprise : en plus d'envoyer un pseudonyme et vos différentes actions, Runtastic fuite votre prénom, votre nom, votre sexe et votre tranche d'âge.
- NewRelic : outil de mesure de la performance de l'application Runtastic, notamment utile pour les développeurs.
- Adjust : société de marketing mobile spécialisée dans l'attribution de campagnes publicitaires (savoir grâce à quelle pub vous avez installé Runtastic). Adjust collecte vos actions sur l'application Runtastic.
- Emarsys : société de data marketing permettant à Runtastic de vous profiler de manière extensive pour ensuite mieux vous recibler. Emarsys récupère ainsi le détail de vos activités : la distance parcourue, la durée de l'exercice, le nombre de calories brûlées, vos impressions à la fin de l'exercice, la météo, le type d'activité, la température extérieure, etc.
Une collecte de données personnelles massive, et une fuite vers des tiers sans fondement juridique valable
Au premier lancement de Runtastic, je n'ai malheureusement pas eu de choix : j'ai été obligé d'accepter les conditions d'utilisation pour me servir de l'application.
J'ai pu ensuite refuser de recevoir des publicités ciblées Runtastic sur des plateformes tierces telles que Google et Facebook (mais sans pouvoir interdire à ces tiers de collecter mes données personnelles) :
Notez le bouton "Accepter", clairement mis en avant comparé à "Je refuse", un exemple supplémentaire de Dark Pattern.
La politique de confidentialité de Runtastic liste dans le détail les différentes données personnelles collectées. Vous pouvez lire la section 3. "Données que nous collectons et traitons" afin de mieux saisir la variété et l'ampleur des données personnelles collectées (et ainsi mieux comprendre pourquoi Google a racheté Fitbit). Voici les différentes catégories de données personnelles :
- Informations d'identité.
- Coordonnées de contact.
- Informations de localisation.
- Informations sur les tailles et pointures.
- Informations concernant les achats.
- Informations de profil et comportementales.
- Informations communautaires.
- Informations des réseaux sociaux.
- Informations concernant l'appareil.
- Informations d'activité.
- Informations sur les préférences.
- Informations Creators Club.
- Inscription par le biais de Google ou Facebook.
- Liste d'ami(e)s Facebook.
- Informations concernant les activités d'entraînement importés à partir des Comptes connectés.
Pour chaque catégorie de destinataires, Runtastic informe des catégories de données personnelles transférées ici.
Runtastic explique ensuite de manière détaillée son usage de Firebase, Google Analytics, Adjust et Facebook Analytics. Plus bas dans la politique de confidentialité, Runtastic donne des informations succinctes sur les différents prestataires que nous avons vu précédemment :
Nous faisons appel à des sous-traitants tels que Adjust, Google, Facebook, Amazon Web Services, Inc., Emarsys eMarketing Systems AG, Pushwoosh, Inc., NewRelic, Inc., Apptimize, Inc. ou Zendesk, Inc.
Si ces explications sont louables, Runtastic indique se fonder sur l'intérêt légitime (lire la documentation de la CNIL sur cette base légale) pour fuiter vos données personnelles vers ces tiers : "Le fondement pour le traitement des Données est constitué par nos intérêts légitimes". Pourtant, cette interprétation du RGPD n'est pas valable. Pour les outils d'analytics, on peut notamment se référer à cette page de la CNIL :
Si le dispositif mis en œuvre par le responsable de traitement ne respecte pas strictement les critères des deux cas précédents, seul le consentement des personnes peut être retenu comme base légale du traitement (article 7 de la loi Informatique et libertés, article 6 du RGPD). Ce consentement peut être obtenu par tout moyen (par exemple, connexion à un réseau wifi spécifique, téléchargement d’une application spécifique, inscription via un site web dédié, « badgeage » du terminal auprès d’une borne NFC). Ce consentement doit être informé (les personnes doivent être informées conformément au point ci-dessous avant de consentir), libre (les personnes doivent pouvoir choisir librement de consentir ou non, et ne doivent pas souffrir de conséquences négatives si elles ne consentent pas) et spécifique (le consentement ne doit concerner que le traitement de suivi et ne peut être inclus dans l’acceptation de CGU par exemple).
Runtastic ne peut donc se fonder sur l'intérêt légitime et doit obtenir mon consentement pour fuiter mes données personnelles vers des tiers tels que Google, Facebook ou Adjust. En particulier, le fait d'avoir accepté les CGU ne veut pas dire que j'ai consenti à cette surveillance.
Pourtant, Runtastic persiste à s'appuyer sur la base légale de l'intérêt légitime, comme en témoigne aussi la section 8.1 de sa politique de confidentialité, "Fondements juridiques" :
La licéité du traitement des Données trouve sa source : [...] dans les intérêts légitimes de Runtastic ou d'un tiers, par exemple, notre recours aux cookies, aux plug-ins ou à la publicité ciblée.
Clairement, le recours aux cookies, aux plug-ins ou à la publicité ciblée ne peut s'appuyer sur l'intérêt légitime.
Il est surprenant de voir une célèbre multinationale Allemande (Adidas) collecter de manière aussi massive les données personnelles de millions d'utilisateurs, sans fondement juridique valable. Il est également surprenant de constater qu'Adidas ne se limite pas dans l'usage d'outils marketing fuitant vos données personnelles, toujours sans fondement juridique valable. Que pouvez-vous faire afin d'empêcher les fuites vers des outils tiers ? En attendant une éventuelle sanction d'une autorité de régulation compétente, vous pouvez passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS.
22.05.2020 à 17:44
Criteo, un géant du marketing de surveillance français

Criteo, un géant publicitaire dont le modèle économique est basé sur votre surveillance
Peu connu du grand public, Criteo est une success story française ayant réussi à devenir le leader mondial du retargeting. D'après LinkedIn, la société compte plus de 3000 employés, elle est également cotée au NASDAQ depuis octobre 2013.
Comment Criteo fonctionne-t-il ? Il suffit pour que je consulte un site d'e-Commerce partenaire (exemple : La Fnac), puis un site média (exemple: Lemonde.fr) pour être bombardé de publicités affichant les produits précédemment consultés ainsi que des suggestions :

Les publicités de retargeting telles que proposées par Criteo sont les plus intrusives du web, elles vous font réaliser que vos habitudes d'achat n'ont aucun secret pour les publicitaires. Et si l'on regarde la typologie des acteurs publicitaires, Criteo fait partie des acteurs les moins respectueux de votre vie privée :
- Criteo est un ad-network : plus il vous connaît, plus il gagne de l'argent.
- Les données récoltées par Criteo sont très personnelles : vos produits consultés et vos achats.
- À la différence d'un e-Commerçant tel qu'Amazon qui a pignon sur rue et une relation directe avec ses clients, Criteo opère de manière cachée. Vous ne savez pas que vous êtes traqué, vous ne l'avez pas choisi.
Des revenus mis en danger par les navigateurs web
Alors vous pourriez vous dire, Criteo est une société publicitaire à l'ancienne, qui s'est développée lorsque le mobile n'était pas encore dominant, lorsque le retargeting était uniquement basé sur les cookies tiers.
Si vous n'utilisez pas d'adblocker, il y a de fortes chances pour que votre navigateur bloque déjà le tracking de Criteo : Safari avec Intelligent Tracking Prevention, Firefox, Brave et même Edge ont récemment pris des mesures énergiques pour lutter contre les traceurs. Chrome est très en retard, mais il va interdire les cookies tiers dans moins de 2 ans. Et vous pouvez toujours décider de supprimer les cookies tiers via les paramètres de votre navigateur, afin de repartir à zéro vis à vis des sociétés de l'adtech.
Ces mesures des navigateurs vous protège contre le pistage invasif des sociétés de l'adtech, qui ne peuvent plus correctement vous identifier, comme l'explique Criteo à ses investisseurs (slide 7) :

Les protections mises en place par les navigateurs sont une excellente nouvelle pour les utilisateurs, elles représentent un danger vital pour Criteo, sa R&D investit donc sur des solutions de contournement.
Un historique de contournement des protections des navigateurs
Criteo ne l'indique pas dans sa présentation aux investisseurs, mais il a de l'expérience dans le contournement des protections des navigateurs. Si l'on revient à la première release de Safari Intelligent Tracking Prevention en septembre 2017, voici la communication de Criteo aux investisseurs en novembre 2017 :
Apples’ Intelligent Tracking Prevention feature, or ITP, was released on mobile on September 19, 2017. We believe our solution for Safari users currently allows us to mitigate about half of the potential impact from ITP. In the third quarter, ITP had a minimal net negative impact on our Revenue ex-TAC of less than $1 million. Given our expectations of the roll out of Apple’s iOS11 and our coverage of Safari users, we expect ITP to have a net negative impact on our Revenue ex-TAC in the fourth quarter of between 8% and 10% relative to our base case projections for the quarter. We will continue to improve and deploy our solution for Safari users over the coming quarters.
Criteo avait déjà mis en place une solution de contournement (expliqué sur cet article :
What we’ve developed is a privacy-friendly solution, which is reliant on a [non-cookie] identifier that allows the transfer of information between websites and our servers
Notez le "privacy-friendly" (!). Sauf qu'Apple a rapidement réagi pour introduire début décembre 2017 une mise à jour d'ITP, rendant le contournement de Criteo inopérant. Voici donc la nouvelle communication de Criteo aux investisseurs en décembre 2017 :
Earlier this month, Apple launched a new version of its mobile operating system, iOS 11.2, which disables the solution that some companies in the advertising ecosystem, including Criteo, currently use to reach Safari users. As a result, we believe the projected 9%-13% ITP net negative impact on Criteo’s 2018 Revenue ex-TAC relative to our pre-ITP base case projections, communicated on November 1, 2017, is no longer valid. We are focused on developing an alternative sustainable solution for the long term, built on our best-in-class user privacy standards, aligning the interests of Apple users, publishers and advertisers. This solution is still under development and its effectiveness cannot be assessed at this early stage. Should it not mitigate any ITP impact, we believe the ITP net negative impact on Criteo’s 2018 Revenue ex-TAC, relative to our pre-ITP base case projections, would become approximately 22%.
Il faut ici féliciter Apple de régulièrement améliorer sa solution ITP (le jeu du chat et de la souris ayant continué après 2017), ITP étant maintenant à la version 2.3. On peut néanmoins s'étonner que Criteo n'ait jamais été sanctionné pour ses contournements, et qu'il communique sans honte dessus.
Des réglementations pour mieux protéger la vie privée des internautes
Aussi, avec les réglementations évoluant pour mieux protéger la vie privée des internautes (RGPD, et ePrivacy en Europe, CCPA en Californie), Criteo se retrouve de plus en plus sous pression : une plainte de Privacy International a été déposée contre Criteo, Quantcast et Tapad en novembre 2018 pour violation du RGPD, la CNIL a démarré l'instruction de la plainte contre Criteo en mars 2020. Criteo note aussi ces réglementations dans son deck "Identification" pour les investisseurs (slide 8), sans s'appesantir sur les risques légaux :

La bourse ne s'y trompe pas : si Criteo est encore valorisé à 600 millions d'euros, sa côte a chuté fortement ces 5 dernières années :
Criteo a compris ces 2 tendances (technique via les navigateurs et règlementaire) : il se tourne maintenant vers une surveillance bien plus insidieuse et généralisée via le "Criteo Shopper Graph" et tient un double discours sur le respect de la vie privée.
Criteo Shopper Graph : la base de donnée massive des données personnelles fuitée vers Criteo
Toujours dans sa présentation "Identification" pour les investisseurs (slide 19), Criteo explique bien son but : vous identifier sans avoir besoin des cookies tiers. Aujourd'hui, 50% de son business serait toujours dépendant des cookies tiers :
Sur son site web, Criteo met en avant "Criteo Shopper Graph", sa base de données d'utilisateurs. Combien de personnes sont dans cette base de données ? Voici quelques chiffres avancés par Criteo pour présenter le "Criteo Shopper Graph" :
- 75% des acheteurs en ligne dans le monde.
- Plus de 1,9 milliards de consommateurs actifs par mois.
- Plus de 120 signaux d'achats différents.
- 35 milliards évènements de navigation ou d'achat traqués par jour.
- 800 milliards de dollars de ventes e-commerces annuelles.
- 1,5 milliards d'identifiants multi-appareils (Criteo vous reconnaît sur plusieurs de vos appareils).
- 4,5 milliards de produits.
Par défaut, Criteo ne mélange pas les données personnelles collectées chez un de ses clients avec ses autres clients. Mais si un client souhaite accéder au Shopper Graph, il doit accepter ce mélange. Exemple : La Fnac souhaite accéder au Shopper Graph pour améliorer la rentabilité de ses campagnes publicitaires, elle devra accepter que Criteo mélange vos données personnelles captées sur le site de la Fnac avec vos données personnelles captées chez d'autres clients Criteo qui ont souscrit au Shopper Graph.
Et la proposition fonctionne bien, Criteo indique que 75% de ses clients participent :
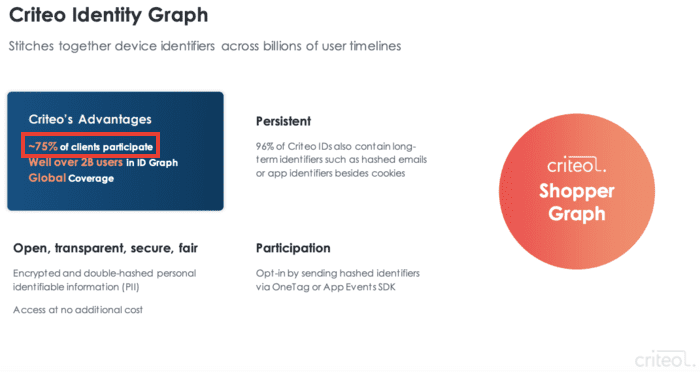
Comment Criteo construit-il cette base massive de données personnelles ? Criteo offre des explications sur son site, le Shopper Graph agrège 3 sources de données :
- L'identity Graph permet de vous reconnaître sur tous vos appareils.
- L'interest Map permet de connaitre vos différentes intentions d'achat.
- Le Measurement Data permet de collecter le détail de vos différents achats.
Étudions plus en détail l'identity Graph, le moteur de la surveillance de Criteo.
L'identity Graph, où comment Criteo vous reconnaît sur tous vos appareils
SI l'on repart du surf de l'utilisateur, la première étape est de vous identifier lors de votre surf sur des sites ou applis d'eCommerce. Criteo collecte les différents identifiants d'un même utilisateur selon l'appareil utilisé, il est alors capable de faire le lien entre eux pour déterminer qu'il s'agit d'un seule et même personne :
On voit ici que Criteo récupère plusieurs types d'identifiants et les associe au Criteo id pour mieux vous pister :
- Un identifiant cookie pour chacun de vos navigateurs web ou mobile.
- Un CRM id pour chacun des clients, lorsque vous êtes connecté chez le client.
- Un identifiant mobile (IDFA sur Apple, Android Advertising Id sur Android).
- Le hash de votre adresse e-mail (une empreinte unique, ne permettant pas à Criteo de retrouver l'adresse e-mail), lorsque le client ou le partenaire de Criteo fait passer l'information.
Cette surveillance est particulièrement invasive et irrespectueuse de votre vie privée car Criteo parvient à faire le lien entre vos différents identifiants ("Graph"), et il est difficile (identifiants mobile) voire quasiment impossible de réinitialiser certains de ces identifiants (CRM id, hash d'adresse e-mail). Un exemple parmi d'autres : l'application de La Fnac fuite le hash de votre adresse e-mail à Criteo, et ne fournit aucun moyen de refuser ce pistage.
Criteo vous a reconnu, la deuxième étape est de collecter toutes vos intentions d'achats (l'Interest Map) :
Quel que soit l'appareil ou le site e-Commerce que vous consultez, Criteo va ainsi récupérer :
- Les produits consultés.
- Les produits ajoutés au panier.
- Les produits achetés.
Les clients de Criteo peuvent également transmettre à Criteo leur propre liste de clients, via des adresses e-mails ou des identifiants utilisateurs tels que l'IDFA, l'Android Advertising ID ou le Criteo Id. Criteo indique alors le pourcentages des utilisateurs de la liste qui appartient déjà au Shopper Graph.
Ensuite, la 3ème étape est de vous reconnaître afin de vous cibler avec les fameuses publicités intrusives, lorsque vous surfez sur un site ou une appli media :
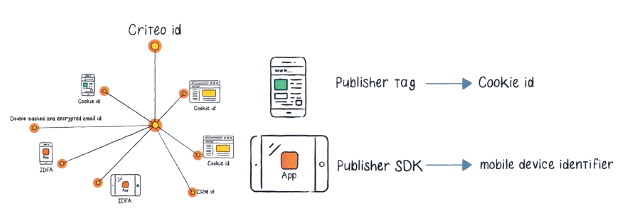
Ici on peut noter que Criteo a des partenariats privilégiés avec de nombreux médias, ce qui lui permet souvent d'accéder à l'inventaire publicitaire de manière préférentielle (voir notamment son Direct Bidder) et aussi de récupérer des identifiants permanents (adresses e-mails, logins). Pour les médias avec lesquels Criteo n'a pas de partenariat privilégié, Criteo achète en RTB (programmatique) mais doit payer une taxe aux SSPs (intermédiaires).
La 4ème étape est de mesurer si vous cliquez sur la publicité (Criteo paye les éditeurs à chaque affichage publicitaire, il est payé par l'annonceur non pas à l'achat mais au clic sur la publicité), puis de mesurer si vous achetez chez l'annonceur (les Measurement Data). Mais le pistage ne s'arrête pas à votre comportement "online", Criteo peut également récupérer vos achats "offline" si ses clients lui font passer l'information :
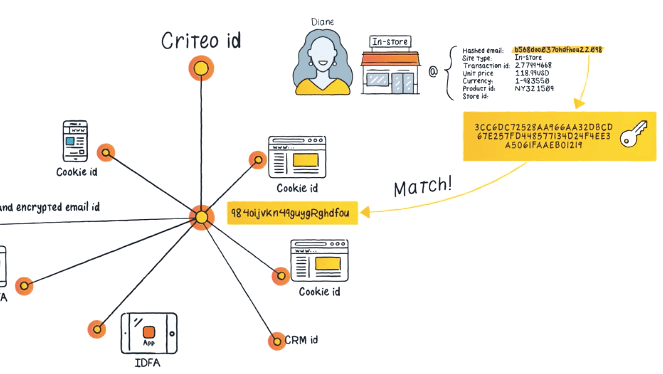
Criteo n'en parle pas dans sa présentation du Shopper Graph, mais sa présentation Identification pour les investisseurs nous apprend qu'il récupère également vos données personnelles via des partenariats (slide 27) :
Comme vous pouvez le voir, Criteo signale des partenariats avec Liveramp, Oracle ainsi que des éditeurs afin de récupérer des données d'identification. Vous pouvez en apprendre plus sur le partenariat avec Liveramp via cette vidéo commerciale. Si l'on regarde son site web, Criteo mentionne aussi d'autres partenariats lui permettant d'associer vos différents identifiants :

Criteo fuite les identifiants de son Shopper Graph à ses clients
Criteo ne se contente pas de pister 75% des acheteurs au monde, il propose gratuitement aux clients de son Shopper Graph (ceux qui acceptent de partager vos données personnelles) de récupérer les identifiants utilisateurs de ce graph (les Criteo Id) pour leurs propres comptes. Voici les options proposées par Criteo pour fuiter les données personnelles vers ses clients :
On résume :
- Depuis votre smartphone, vous avez vu une lampe sur le site web de l'e-Commerçant ABC.
- Vous retournez sur le site web de l'e-Commerçant ABC, mais cette fois-ci sur votre ordinateur portable.
Criteo vous reconnaît, même si vous ne vous êtes pas connecté au site web de l'e-Commerçant ABC car vous vous êtes déjà connecté sur d'autres sites partenaires de Criteo, sur votre smartphone et sur votre ordinateur portable.
Et Criteo permet à l'e-Commerçant ABC de vous reconnaître également.
Criteo contourne encore les protections de votre navigateur... et introduit une faille de sécurité
Excepté Chrome, les navigateurs prennent des mesures pour vous protéger contre les traceurs. Aussi, de nombreux internautes installent des adblockers. Nous avons déjà vu que Criteo a une longue expérience de contournement des mesures prises par les navigateurs et continue d'agir en ce sens pour continuer de vous tracer malgré vous.
Une de ses dernières initiatives ? Pousser ses clients annonceurs et éditeurs à déléguer un sous-domaine à Criteo via la mise en place d'un CNAME (lisez à ce propos l'article détaillé de Romain Cointepas, co-fondateur de NextDNS, appli qui lutte efficacement contre ce pistage). Le CNAME permet de spécifier qu'un sous-domaine est un alias vers un autre domaine.
C'est une vieille technique utilisé par certains outils d'analytics, elle connait actuellement un regain d'intérêt, notamment auprès de sociétés françaises telles que Eulerian, AT Internet et donc Criteo. Voici la documentation de Criteo permettant aux annonceurs et éditeurs de mettre en place un CNAME. Et voici des exemples de clients ayant mis en place cette délégation :
- Le nom de domaine xgctpf.allocine.fr est un alias vers dnsdelegation.io, qui pointe lui même vers gum.criteo.com
- Le nom de domaine ddhhbh.alfaromeo.fr est aussi un alias vers dnsdelegation.io qui pointe également vers gum.criteo.com
Notez les sous-domaines avec des chaînes de caractères aléatoires : Criteo peut ainsi vous tracer de manière caché, et il est difficile pour les adbloqueurs de mettre à jour les domaines à bloquer (l'éditeur pouvant décider facilement de changer le CNAME d'une semaine sur l'autre). Firefox permet aux extensions de faire de la résolution de CNAME, ce qui permet à uBlock Origin sur Firefox de correctement bloquer ces appels, mais les autres navigateurs ne permettent pas cela.
Criteo gagne ainsi un accès à la plupart des utilisateurs ayant un adblocker (le sujet CNAME anime les communautés travaillant sur les adblockers) ou un navigateur paramétré pour bloquer les cookies tiers, ce qui lui permet de :
- Pouvoir mesurer toutes les visites et conversions sur le site de l'annonceur.
- Pouvoir vous recibler sur l'un de vos autres appareils (si vous n'avez pas d'adblocker sur tous vos appareils et si l'annonceur envoie à Criteo un identifiant permanent tel que votre adresse e-mail).
- Pouvoir théoriquement vous identifier à travers différents sites via des techniques de fingerprinting : avec votre adresse IP voire avec des informations supplémentaires collectées sur votre navigateur. Je dis ici théoriquement car je n'ai pas de preuve que Criteo utilise des techniques de fingerprinting.
Un mot supplémentaire sur le fingerprinting, clairement Criteo s'intéresse au sujet comme l'indique cet article du blog R&D de Criteo, détaillant un article de recherche sur la surveillance basée sur l'adresse IP :
For the past few years, web browsers have increasingly limited the persistence of identifiers (cookies), making user tracking more difficult. A revealing example is Safari’s Intelligent Tracking Prevention. This paper presents a clever way to overcome the lack of persistent identifiers without infringing on user privacy, that is without using browser fingerprinting. It consists of using community detection in the Device Graph to detect stable cohorts (person or household level grouping). It is then possible to find the IP addresses that are associated with the cohort over time and thus defining a persistent ID based on these IP addresses. This technique is called Graph backfilling. This technique reaches its limits when many people use the same IP or in the case of dynamic IPs. This is why it works like a charm in the US, but is more difficult to apply in China.
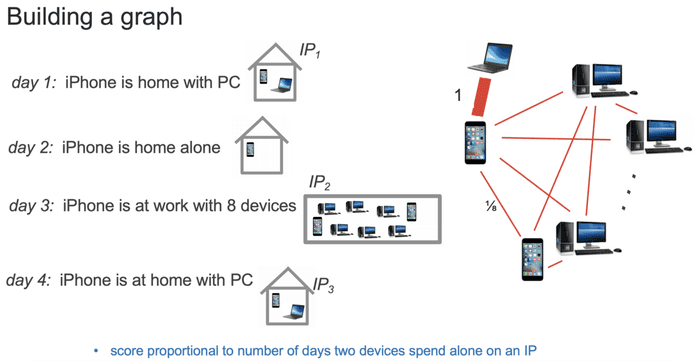
Le CNAME est une des techniques (avec les logins et e-mails) qui permettent à Criteo de se vanter auprès des investisseurs (slide 15) d'avoir un accès "1st party" aux sites web consultés par les internautes (il n'a pas ici besoin de cookies tiers pour collecter vos données personnelles) :
Voici l'e-mail envoyé par Criteo à ses clients et partenaires (via f_to_k) :
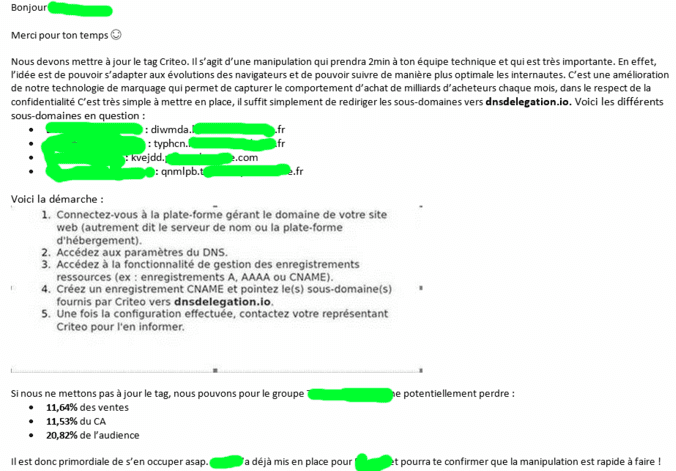
Cet e-mail parait anodin mais la technique du CNAME l'est beaucoup moins. Elle introduit une faille de sécurité si le site partenaire n'a pas pris ses précautions : Criteo peut alors y lire les cookies déposés sur le domaine du site partenaire. Étudions un exemple en surfant sur allocine.fr avec Safari et l'outil Charles Proxy :
Comme on le voit, xgctpf.allocine.fr (alias Criteo) récupère les cookies déposés sur allocine.fr (qui ne lui sont pas destinés) :
- Des cookies d'identifiants déposés par Google Analytics : _ga, _gat, _gid, _gads
- Un cookie d'identifiant Facebook : _fbp
- Des cookies stockant votre géolocalisation : geocode, geolevel1, geolevel2, geolevel3
- Vos cookies d'authentification à Allocine (j'étais connecté) : ACAUTH, ACCT, ACID, GraphToken
Via les différents identifiants "volés", Criteo peut enrichir son Shopper Graph, mais ce n'est pas le plus grave car via vos cookies d'authentification, Criteo peut se connecter à votre propre compte Allociné ! Voici les étapes pour le vérifier :
- Récupérez les cookies d'authentification à Allocine via Safari et Charles Proxy.
- Allez sur allocine.fr depuis Chrome, assurez-vous que vous êtes bien déconnecté.
- Utilisez l'extension Chrome EditThisCookie pour créer vos cookies d'authentification.
- Rafraichissez la page, vous êtes connecté !
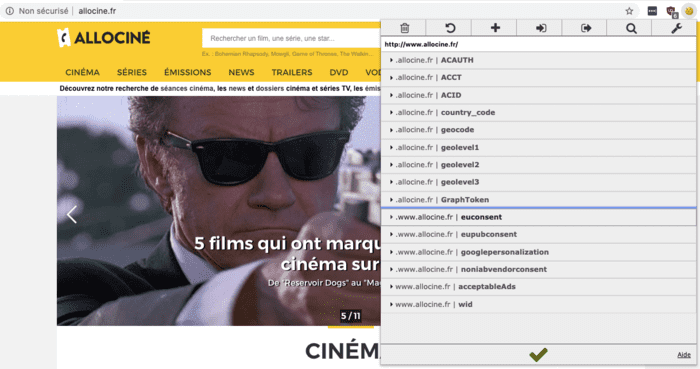 Cadeau : Allociné ne propose pas de version sécurisée de son site web, donc Criteo n'est pas le seul à pouvoir intercepter vos cookies d'authentifications. Votre FAI et les machines situées entre votre appareil et les serveurs d'Allociné peuvent aussi se connecter à votre place.
Cadeau : Allociné ne propose pas de version sécurisée de son site web, donc Criteo n'est pas le seul à pouvoir intercepter vos cookies d'authentifications. Votre FAI et les machines situées entre votre appareil et les serveurs d'Allociné peuvent aussi se connecter à votre place.
Cette importante faille de sécurité est probablement présente sur de nombreux sites partenaires car Criteo a déjà réussi à convaincre plus de 10.000 partenaires d'installer un CNAME (Allociné était un exemple bénin, la plupart des partenaires sont des sites d'e-Commerce qui peuvent détenir des informations bien plus sensibles comme votre carte bleue).
Lisez à ce propos cette conversation sur le channel Reddit r/adops, ajouter un CNAME est loin d'être anodin comme le laisse entendre l'e-mail de Criteo. Comment éviter cette fuite d'informations tout en utilisant le CNAME de Criteo ? En ne permettant pas aux sous-domaines de lire les cookies du domaine (lire par exemple la documentation de Mozilla, "Portée des cookies").
Néanmoins, Criteo évolue encore en toute impunité : la technique du CNAME a fait l'objet d'un article sur le journal du net dans lequel Criteo, ID5 et Prisma Media justifient la pratique du CNAME. Le responsable programmatique de Prisma Media accuse même les navigateurs d'outrepasser leurs rôles en voulant protéger la vie privée des internautes :
C'est franchement problématique qu'un navigateur décide de ce qui est juste ou non en prétextant protéger la vie privée des utilisateurs, alors que c'est le rôle de la gestion des consentements. Si la personne ne donne pas son consentement, bien sûr que nous ne déposons pas de cookie.
Pour Criteo aussi, le navigateur ne devrait pas "prendre des décisions" à la place de l'internaute, qui doit pouvoir consentir (ou non) à la surveillance publicitaire de lui-même. Mais comment se situe Criteo par rapport à la nécessité d'obtenir le consentement de l'utilisateur avant de le pister ?
Pour le recueil du consentement, Criteo se décharge sur les annonceurs et éditeurs partenaires
La page de Criteo expliquant l'utilisation des données personnelles donne une bonne idée de l'étendue des données personnelles collectées et de l'utilisation qui en est faite. La base légale avancée par Criteo pour justifier cet accaparement de vos données personnelles tout en respectant le RGPD est le consentement. Mais pour Criteo, l'obtention de celui-ci incombe uniquement à ses partenaires, annonceurs et éditeurs :
Les opérations de traitement de Criteo respectent les réglementations en vigueur, dans les pays exigeant le consentement des utilisateurs pour l’utilisation de cookies ou de toute autre technologie similaire. Ce consentement est recueilli sur les sites Web et les applications mobiles des Annonceurs et des Éditeurs.
Criteo appuie sur ce point dans sa politique de confidentialité :
Notez que l’utilisation des technologies Criteo est régie par les politiques de confidentialité publiées sur les sites web et les applications mobiles de nos partenaires. Ces derniers sont tenus de fournir des informations complètes et appropriées et, dans la mesure où la loi l’impose, d’obtenir votre consentement avant de communiquer toute donnée personnelle à votre sujet.
Criteo indique même exiger contractuellement de ses annonceurs et éditeurs partenaires qu'ils obtiennent le consentement des utilisateurs avant la mise en place de traceurs :
Criteo exige contractuellement que les Annonceurs et Éditeurs respectent sa Charte éditoriale générale et sa Charte dédiée aux partenaires, ainsi que les différentes réglementations en vigueur sur la protection des données personnelles, en particulier le RGPD. En utilisant les services Criteo, ils s’engagent, dans la mesure où la réglementation l’impose : [...] à obtenir le consentement des utilisateurs avant de mettre en place des cookies ou autres technologies similaires, dans le but de diffuser des annonces personnalisées.
Cependant, Criteo ne fait rien pour faire respecter ce contrat, comme on peut le voir avec l'exemple de La Fnac. Obtenir un vrai consentement de l'utilisateur avant de pouvoir l'identifier équivaudrait pour Criteo à mettre la clé sous la porte, d'où son double discours.
Criteo tord la définition du consentement
Criteo est un habitué du double discours. Ainsi d'un côté il va expliquer aux utilisateurs dans sa politique de confidentialité qu'il respecte la notion de consentement et demande contractuellement à ses partenaires de l'appliquer. D'un autre côté, il indique à ses partenaires qu'ils n'ont pas besoin de récolter un consentement explicite des utilisateurs.
Dans ses "Directives de confidentialité de Criteo pour les clients et partenaires éditeurs", Criteo conseille ses clients sur les clauses d'information à inclure dans leurs politiques de confidentialité. Aussi, Criteo indique de nouveau aux clients qu'ils ont l'obligation d'obtenir le consentement des utilisateurs au sein de l'UE. Mais que veux dire consentement pour Criteo ? La définition s'apparente plutôt à une simple obligation d'information :
En particulier, conformément aux lois de l’UE, la demande de consentement est considérée comme valide lorsque : Les utilisateurs sont informés sur l’utilisation des cookies et des technologies autres que les cookies par Criteo dans le but de proposer de la publicité ciblée au moment de donner leur consentement.
Criteo va même jusqu'à suggérer d'utiliser la faille introduite par la CNIL qui permet encore à la quasi totalité du web français de considérer que la poursuite de la navigation sur un site (simple scroll ou clic sur une nouvelle page) vaut consentement :
Suggestion d’avis de cookies pour les pays où le consentement est obligatoire En continuant à naviguer sur notre site, vous acceptez l’utilisation de cookies et de technologies autres que les cookies pour vous fournir des contenus et publicités personnalisés à travers les sites.
Comme l'indique le Comité Européen de la Protection des Données, organe européen indépendant dont les objectifs sont de garantir l’application cohérente du RGPD et de promouvoir la coopération entre les autorités de protection des données de l'UE, le consentement doit être clair, affirmatif et non ambigu. Les dernières lignes directrices ont été publiées le 4 mai, on peut par exemple y lire que scroller ne vaut pas consentement :

Dans un article intitulé "RGPD : Criteo est prêt à relever le défi", Criteo détaille sa vision du consentement, considérant qu'il n'a pas besoin d'obtenir un consentement explicite de l'utilisateur :
Le RGPD établit une distinction claire entre consentement non-ambigu et consentement explicite. Le consentement explicite implique un choix exprès de la part de l’utilisateur. Ceci s’applique par exemple pour la collecte de données sensibles telles que la race, la religion, l’orientation sexuelle, l’affiliation politique et la santé. En revanche, en tant que tels les dispositifs de suivi en ligne (par exemple, les cookies) sont catégorisés comme simple données personnelles. Aussi, selon le nouveau règlement, un opt-in exprès n’est pas requis en ce qui concerne les cookies de retargeting classique qui ne collectent pas de données sensibles.
Sauf que ce comportement est bien en violation du RGPD, qui requiert un consentement clair, affirmatif et non ambigu de l'utilisateur. La CNIL doit d'ailleurs avancer pour mettre sa doctrine en accord avec le RGPD : elle a démarré les démarches en juillet 2019, mais elle prétexte maintenant la crise du coronavirus pour mettre en pause cette nécessaire adaptation.
Criteo a même écrit un livre blanc sur le RGPD, détaillant ses arguments fallacieux, il n'en reste qu'un seul point : Criteo ne pourrait survivre s'il s'appuyait sur un consentement véritable de l'utilisateur. Il se sent donc obligé de tordre la définition du consentement.
Les mensonges de Criteo dans sa politique de confidentialité
Dans sa politique de confidentialité, Criteo indique ne pas recevoir de données à caractère personnel :
Aucune donnée à caractère personnel (nom, prénom, adresse postale, adresse e-mail non cryptée ou autres) ne nous est communiquée.
Ceci est faux, les clients de Criteo peuvent bien communiquer à Criteo votre adresse e-mail en clair comme l'indique cette page support pour "créer une audience" :
Un fichier CRM d'adresses e-mails contenant des adresses complètes, des adresses e-mails chiffrées par hachage MD5 ou SHA256 de MD5 (adresses complètes>MD5>SHA256).
Si le client envoie des adresses e-mails en clair, Criteo indique les chiffrer avant de les stocker, vous devez donc lui faire confiance.
Toujours dans sa politique de confidentialité, Criteo avoue que les données qui ne seraient pas à caractère personnel (les pseudonymes) sont bien considérées comme données personnelles dans l'Union Européenne et en Californie :
Ces informations sont toutefois considérées comme des données personnelles par le règlement général de l’UE sur la protection des données (RGPD) ainsi que par la loi californienne sur la protection de la vie privée des consommateurs (CCPA).
Autre mensonge, dans la section "Engagements de Criteo", on peut lire :
Les annonces Criteo n’impliquent en aucun cas de recueillir les données suivantes : [...] identifiants persistants, tels que les identifiants des appareils que vous utilisez (UDID, adresse MAC, etc.)
Sauf que le hash de votre adresse e-mail est bien un identifiant persistant. Aussi, cet "engagement" est en contradiction avec le deck "Online identification at Criteo" pour les investisseurs. Sur le slide 16, Criteo indique que 96% des "identités" (= utilisateurs) de son "Identity Graph" contient au moins un identifiant persistant :
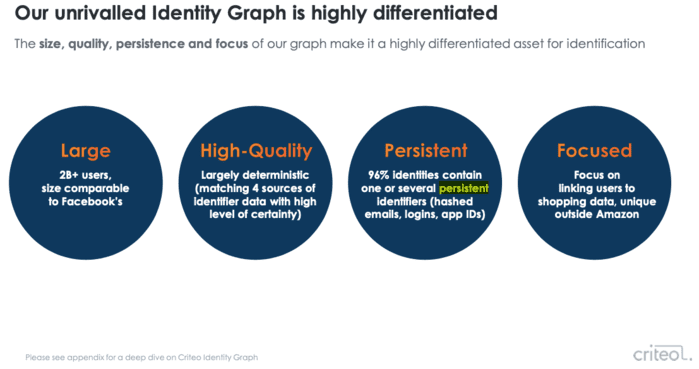
Sur le slide 22, Criteo indique aussi faire appel à des tiers pour obtenir d'avantages d'identifiants persistants, et ainsi ne plus être dépendant des cookies :

La duplicité de Criteo est flagrante : engagement auprès des internautes de ne recueillir "en aucun cas" des identifiants persistants d'un côté, mais facilitation de la collecte de ces identifiants persistants auprès des annonceurs et éditeurs partenaires (pour rappel, la page support indiquant comment envoyer à Criteo une liste d'e-mails), et communication sur ces identifiants persistants auprès des investisseurs de l'autre côté.
Désactiver les services Criteo sur les applications mobiles ne fonctionne pas
Comme vu avec l'exemple de La Fnac sur iOS, Criteo continue de collecter un hash de votre adresse e-mail, même lorsque vous avez désactivé le suivi publicitaire :
Pourtant sa page "Désactiver les services Criteo sur les applications mobiles" indique :
Nous retrouvons ici un double mensonge de Criteo : mon e-mail (ou même un hash de mon e-mail) est un identifiant persistant, pourtant Criteo le collecte bien (premier mensonge), même si je désactive le suivi publicitaire (deuxième mensonge).
Des abus répétés et documentés, mais toujours pas de sanction
Cela fait longtemps que les pratiques peu éthiques de Criteo sont détaillées et dénoncées, voici quelques éléments :
- La plainte de Privacy International contre Criteo, Quantcast et Tapad pour violation du RGPD date de novembre 2018, il aura fallu 16 mois à la CNIL pour réagir et démarrer l'instruction.
- La technique du CNAME n'est qu'un élément parmis d'autres mis au point par Criteo pour contourner les protections mis à en place par les navigateurs, l'EFF a documenté les précédentes tentatives de Criteo pour contourner ITP de Safari.
- Ces techniques ont été détaillés par Gotham City Research LLC dans un rapport dédié.
- Autre rapport de Gotham City Research LLC dénonçant la fraude généralisée sur l'inventaire géré par Criteo. À noter que les rapports n'étaient pas désintéressés car Gotham spéculait ouvertement à la baisse sur le cours de Criteo, il n'empêche que les pratiques dénoncées étaient avérées.
- Criteo fait partie du comité d'Acceptable Ads, une initiative créée par Adblock Plus, permettant à Criteo d'afficher des publicités même si vous avez installé Adblock Plus ou d'autres adblockers supportant l'initiative (ces publicités sont "adaptées" : elles prennent un peu moins de place que les publicités traditionnelles Criteo). Choquant car les publicités Criteo sont particulièrement intrusives, mais "Acceptable Ads" ne se base "que" sur la pollution visuelle.
Pourtant, rien ne se passe. Vu l'historique de la CNIL, il est permis de douter de l'hypothèse de réelles sanctions contre un champion du numérique français ayant un poids économique et politique important comme le démontre la visite de Bruno Le Maire pour les 1 ans du laboratoire d'intelligence artificielle de Criteo, en octobre dernier. Pour Bruno Le Maire, Criteo est "l'une des grandes réussites françaises de ces 15 dernières années" :
Que faire alors ? Malheureusement, en attendant une vraie ambition politique, les solutions restent individuelles et techniques : utiliser un adblocker tel que uBlock Origin combiné à Firefox sur le web (ou d'autres navigateurs respectueux de la vie privée tels que Brave et Safari), passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS, voire installer Pi-hole sur un Raspberry Pi si vous avez le goût de la technique.
Texte intégral (7165 mots)
Criteo, un géant publicitaire dont le modèle économique est basé sur votre surveillance
Peu connu du grand public, Criteo est une success story française ayant réussi à devenir le leader mondial du retargeting. D'après LinkedIn, la société compte plus de 3000 employés, elle est également cotée au NASDAQ depuis octobre 2013.
Comment Criteo fonctionne-t-il ? Il suffit pour que je consulte un site d'e-Commerce partenaire (exemple : La Fnac), puis un site média (exemple: Lemonde.fr) pour être bombardé de publicités affichant les produits précédemment consultés ainsi que des suggestions :
Les publicités de retargeting telles que proposées par Criteo sont les plus intrusives du web, elles vous font réaliser que vos habitudes d'achat n'ont aucun secret pour les publicitaires. Et si l'on regarde la typologie des acteurs publicitaires, Criteo fait partie des acteurs les moins respectueux de votre vie privée :
- Criteo est un ad-network : plus il vous connaît, plus il gagne de l'argent.
- Les données récoltées par Criteo sont très personnelles : vos produits consultés et vos achats.
- À la différence d'un e-Commerçant tel qu'Amazon qui a pignon sur rue et une relation directe avec ses clients, Criteo opère de manière cachée. Vous ne savez pas que vous êtes traqué, vous ne l'avez pas choisi.
Des revenus mis en danger par les navigateurs web
Alors vous pourriez vous dire, Criteo est une société publicitaire à l'ancienne, qui s'est développée lorsque le mobile n'était pas encore dominant, lorsque le retargeting était uniquement basé sur les cookies tiers.
Si vous n'utilisez pas d'adblocker, il y a de fortes chances pour que votre navigateur bloque déjà le tracking de Criteo : Safari avec Intelligent Tracking Prevention, Firefox, Brave et même Edge ont récemment pris des mesures énergiques pour lutter contre les traceurs. Chrome est très en retard, mais il va interdire les cookies tiers dans moins de 2 ans. Et vous pouvez toujours décider de supprimer les cookies tiers via les paramètres de votre navigateur, afin de repartir à zéro vis à vis des sociétés de l'adtech.
Ces mesures des navigateurs vous protège contre le pistage invasif des sociétés de l'adtech, qui ne peuvent plus correctement vous identifier, comme l'explique Criteo à ses investisseurs (slide 7) :
Les protections mises en place par les navigateurs sont une excellente nouvelle pour les utilisateurs, elles représentent un danger vital pour Criteo, sa R&D investit donc sur des solutions de contournement.
Un historique de contournement des protections des navigateurs
Criteo ne l'indique pas dans sa présentation aux investisseurs, mais il a de l'expérience dans le contournement des protections des navigateurs. Si l'on revient à la première release de Safari Intelligent Tracking Prevention en septembre 2017, voici la communication de Criteo aux investisseurs en novembre 2017 :
Apples’ Intelligent Tracking Prevention feature, or ITP, was released on mobile on September 19, 2017. We believe our solution for Safari users currently allows us to mitigate about half of the potential impact from ITP. In the third quarter, ITP had a minimal net negative impact on our Revenue ex-TAC of less than $1 million. Given our expectations of the roll out of Apple’s iOS11 and our coverage of Safari users, we expect ITP to have a net negative impact on our Revenue ex-TAC in the fourth quarter of between 8% and 10% relative to our base case projections for the quarter. We will continue to improve and deploy our solution for Safari users over the coming quarters.
Criteo avait déjà mis en place une solution de contournement (expliqué sur cet article :
What we’ve developed is a privacy-friendly solution, which is reliant on a [non-cookie] identifier that allows the transfer of information between websites and our servers
Notez le "privacy-friendly" (!). Sauf qu'Apple a rapidement réagi pour introduire début décembre 2017 une mise à jour d'ITP, rendant le contournement de Criteo inopérant. Voici donc la nouvelle communication de Criteo aux investisseurs en décembre 2017 :
Earlier this month, Apple launched a new version of its mobile operating system, iOS 11.2, which disables the solution that some companies in the advertising ecosystem, including Criteo, currently use to reach Safari users. As a result, we believe the projected 9%-13% ITP net negative impact on Criteo’s 2018 Revenue ex-TAC relative to our pre-ITP base case projections, communicated on November 1, 2017, is no longer valid. We are focused on developing an alternative sustainable solution for the long term, built on our best-in-class user privacy standards, aligning the interests of Apple users, publishers and advertisers. This solution is still under development and its effectiveness cannot be assessed at this early stage. Should it not mitigate any ITP impact, we believe the ITP net negative impact on Criteo’s 2018 Revenue ex-TAC, relative to our pre-ITP base case projections, would become approximately 22%.
Il faut ici féliciter Apple de régulièrement améliorer sa solution ITP (le jeu du chat et de la souris ayant continué après 2017), ITP étant maintenant à la version 2.3. On peut néanmoins s'étonner que Criteo n'ait jamais été sanctionné pour ses contournements, et qu'il communique sans honte dessus.
Des réglementations pour mieux protéger la vie privée des internautes
Aussi, avec les réglementations évoluant pour mieux protéger la vie privée des internautes (RGPD, et ePrivacy en Europe, CCPA en Californie), Criteo se retrouve de plus en plus sous pression : une plainte de Privacy International a été déposée contre Criteo, Quantcast et Tapad en novembre 2018 pour violation du RGPD, la CNIL a démarré l'instruction de la plainte contre Criteo en mars 2020. Criteo note aussi ces réglementations dans son deck "Identification" pour les investisseurs (slide 8), sans s'appesantir sur les risques légaux :
La bourse ne s'y trompe pas : si Criteo est encore valorisé à 600 millions d'euros, sa côte a chuté fortement ces 5 dernières années :
Criteo a compris ces 2 tendances (technique via les navigateurs et règlementaire) : il se tourne maintenant vers une surveillance bien plus insidieuse et généralisée via le "Criteo Shopper Graph" et tient un double discours sur le respect de la vie privée.
Criteo Shopper Graph : la base de donnée massive des données personnelles fuitée vers Criteo
Toujours dans sa présentation "Identification" pour les investisseurs (slide 19), Criteo explique bien son but : vous identifier sans avoir besoin des cookies tiers. Aujourd'hui, 50% de son business serait toujours dépendant des cookies tiers :
Sur son site web, Criteo met en avant "Criteo Shopper Graph", sa base de données d'utilisateurs. Combien de personnes sont dans cette base de données ? Voici quelques chiffres avancés par Criteo pour présenter le "Criteo Shopper Graph" :
- 75% des acheteurs en ligne dans le monde.
- Plus de 1,9 milliards de consommateurs actifs par mois.
- Plus de 120 signaux d'achats différents.
- 35 milliards évènements de navigation ou d'achat traqués par jour.
- 800 milliards de dollars de ventes e-commerces annuelles.
- 1,5 milliards d'identifiants multi-appareils (Criteo vous reconnaît sur plusieurs de vos appareils).
- 4,5 milliards de produits.
Par défaut, Criteo ne mélange pas les données personnelles collectées chez un de ses clients avec ses autres clients. Mais si un client souhaite accéder au Shopper Graph, il doit accepter ce mélange. Exemple : La Fnac souhaite accéder au Shopper Graph pour améliorer la rentabilité de ses campagnes publicitaires, elle devra accepter que Criteo mélange vos données personnelles captées sur le site de la Fnac avec vos données personnelles captées chez d'autres clients Criteo qui ont souscrit au Shopper Graph.
Et la proposition fonctionne bien, Criteo indique que 75% de ses clients participent :
Comment Criteo construit-il cette base massive de données personnelles ? Criteo offre des explications sur son site, le Shopper Graph agrège 3 sources de données :
- L'identity Graph permet de vous reconnaître sur tous vos appareils.
- L'interest Map permet de connaitre vos différentes intentions d'achat.
- Le Measurement Data permet de collecter le détail de vos différents achats.
Étudions plus en détail l'identity Graph, le moteur de la surveillance de Criteo.
L'identity Graph, où comment Criteo vous reconnaît sur tous vos appareils
SI l'on repart du surf de l'utilisateur, la première étape est de vous identifier lors de votre surf sur des sites ou applis d'eCommerce. Criteo collecte les différents identifiants d'un même utilisateur selon l'appareil utilisé, il est alors capable de faire le lien entre eux pour déterminer qu'il s'agit d'un seule et même personne :
On voit ici que Criteo récupère plusieurs types d'identifiants et les associe au Criteo id pour mieux vous pister :
- Un identifiant cookie pour chacun de vos navigateurs web ou mobile.
- Un CRM id pour chacun des clients, lorsque vous êtes connecté chez le client.
- Un identifiant mobile (IDFA sur Apple, Android Advertising Id sur Android).
- Le hash de votre adresse e-mail (une empreinte unique, ne permettant pas à Criteo de retrouver l'adresse e-mail), lorsque le client ou le partenaire de Criteo fait passer l'information.
Cette surveillance est particulièrement invasive et irrespectueuse de votre vie privée car Criteo parvient à faire le lien entre vos différents identifiants ("Graph"), et il est difficile (identifiants mobile) voire quasiment impossible de réinitialiser certains de ces identifiants (CRM id, hash d'adresse e-mail). Un exemple parmi d'autres : l'application de La Fnac fuite le hash de votre adresse e-mail à Criteo, et ne fournit aucun moyen de refuser ce pistage.
Criteo vous a reconnu, la deuxième étape est de collecter toutes vos intentions d'achats (l'Interest Map) :
Quel que soit l'appareil ou le site e-Commerce que vous consultez, Criteo va ainsi récupérer :
- Les produits consultés.
- Les produits ajoutés au panier.
- Les produits achetés.
Les clients de Criteo peuvent également transmettre à Criteo leur propre liste de clients, via des adresses e-mails ou des identifiants utilisateurs tels que l'IDFA, l'Android Advertising ID ou le Criteo Id. Criteo indique alors le pourcentages des utilisateurs de la liste qui appartient déjà au Shopper Graph.
Ensuite, la 3ème étape est de vous reconnaître afin de vous cibler avec les fameuses publicités intrusives, lorsque vous surfez sur un site ou une appli media :
Ici on peut noter que Criteo a des partenariats privilégiés avec de nombreux médias, ce qui lui permet souvent d'accéder à l'inventaire publicitaire de manière préférentielle (voir notamment son Direct Bidder) et aussi de récupérer des identifiants permanents (adresses e-mails, logins). Pour les médias avec lesquels Criteo n'a pas de partenariat privilégié, Criteo achète en RTB (programmatique) mais doit payer une taxe aux SSPs (intermédiaires).
La 4ème étape est de mesurer si vous cliquez sur la publicité (Criteo paye les éditeurs à chaque affichage publicitaire, il est payé par l'annonceur non pas à l'achat mais au clic sur la publicité), puis de mesurer si vous achetez chez l'annonceur (les Measurement Data). Mais le pistage ne s'arrête pas à votre comportement "online", Criteo peut également récupérer vos achats "offline" si ses clients lui font passer l'information :
Criteo n'en parle pas dans sa présentation du Shopper Graph, mais sa présentation Identification pour les investisseurs nous apprend qu'il récupère également vos données personnelles via des partenariats (slide 27) :
Comme vous pouvez le voir, Criteo signale des partenariats avec Liveramp, Oracle ainsi que des éditeurs afin de récupérer des données d'identification. Vous pouvez en apprendre plus sur le partenariat avec Liveramp via cette vidéo commerciale. Si l'on regarde son site web, Criteo mentionne aussi d'autres partenariats lui permettant d'associer vos différents identifiants :
Criteo fuite les identifiants de son Shopper Graph à ses clients
Criteo ne se contente pas de pister 75% des acheteurs au monde, il propose gratuitement aux clients de son Shopper Graph (ceux qui acceptent de partager vos données personnelles) de récupérer les identifiants utilisateurs de ce graph (les Criteo Id) pour leurs propres comptes. Voici les options proposées par Criteo pour fuiter les données personnelles vers ses clients :
On résume :
- Depuis votre smartphone, vous avez vu une lampe sur le site web de l'e-Commerçant ABC.
- Vous retournez sur le site web de l'e-Commerçant ABC, mais cette fois-ci sur votre ordinateur portable.
Criteo vous reconnaît, même si vous ne vous êtes pas connecté au site web de l'e-Commerçant ABC car vous vous êtes déjà connecté sur d'autres sites partenaires de Criteo, sur votre smartphone et sur votre ordinateur portable.
Et Criteo permet à l'e-Commerçant ABC de vous reconnaître également.
Criteo contourne encore les protections de votre navigateur... et introduit une faille de sécurité
Excepté Chrome, les navigateurs prennent des mesures pour vous protéger contre les traceurs. Aussi, de nombreux internautes installent des adblockers. Nous avons déjà vu que Criteo a une longue expérience de contournement des mesures prises par les navigateurs et continue d'agir en ce sens pour continuer de vous tracer malgré vous.
Une de ses dernières initiatives ? Pousser ses clients annonceurs et éditeurs à déléguer un sous-domaine à Criteo via la mise en place d'un CNAME (lisez à ce propos l'article détaillé de Romain Cointepas, co-fondateur de NextDNS, appli qui lutte efficacement contre ce pistage). Le CNAME permet de spécifier qu'un sous-domaine est un alias vers un autre domaine.
C'est une vieille technique utilisé par certains outils d'analytics, elle connait actuellement un regain d'intérêt, notamment auprès de sociétés françaises telles que Eulerian, AT Internet et donc Criteo. Voici la documentation de Criteo permettant aux annonceurs et éditeurs de mettre en place un CNAME. Et voici des exemples de clients ayant mis en place cette délégation :
- Le nom de domaine xgctpf.allocine.fr est un alias vers dnsdelegation.io, qui pointe lui même vers gum.criteo.com
- Le nom de domaine ddhhbh.alfaromeo.fr est aussi un alias vers dnsdelegation.io qui pointe également vers gum.criteo.com
Notez les sous-domaines avec des chaînes de caractères aléatoires : Criteo peut ainsi vous tracer de manière caché, et il est difficile pour les adbloqueurs de mettre à jour les domaines à bloquer (l'éditeur pouvant décider facilement de changer le CNAME d'une semaine sur l'autre). Firefox permet aux extensions de faire de la résolution de CNAME, ce qui permet à uBlock Origin sur Firefox de correctement bloquer ces appels, mais les autres navigateurs ne permettent pas cela.
Criteo gagne ainsi un accès à la plupart des utilisateurs ayant un adblocker (le sujet CNAME anime les communautés travaillant sur les adblockers) ou un navigateur paramétré pour bloquer les cookies tiers, ce qui lui permet de :
- Pouvoir mesurer toutes les visites et conversions sur le site de l'annonceur.
- Pouvoir vous recibler sur l'un de vos autres appareils (si vous n'avez pas d'adblocker sur tous vos appareils et si l'annonceur envoie à Criteo un identifiant permanent tel que votre adresse e-mail).
- Pouvoir théoriquement vous identifier à travers différents sites via des techniques de fingerprinting : avec votre adresse IP voire avec des informations supplémentaires collectées sur votre navigateur. Je dis ici théoriquement car je n'ai pas de preuve que Criteo utilise des techniques de fingerprinting.
Un mot supplémentaire sur le fingerprinting, clairement Criteo s'intéresse au sujet comme l'indique cet article du blog R&D de Criteo, détaillant un article de recherche sur la surveillance basée sur l'adresse IP :
For the past few years, web browsers have increasingly limited the persistence of identifiers (cookies), making user tracking more difficult. A revealing example is Safari’s Intelligent Tracking Prevention. This paper presents a clever way to overcome the lack of persistent identifiers without infringing on user privacy, that is without using browser fingerprinting. It consists of using community detection in the Device Graph to detect stable cohorts (person or household level grouping). It is then possible to find the IP addresses that are associated with the cohort over time and thus defining a persistent ID based on these IP addresses. This technique is called Graph backfilling. This technique reaches its limits when many people use the same IP or in the case of dynamic IPs. This is why it works like a charm in the US, but is more difficult to apply in China.
Le CNAME est une des techniques (avec les logins et e-mails) qui permettent à Criteo de se vanter auprès des investisseurs (slide 15) d'avoir un accès "1st party" aux sites web consultés par les internautes (il n'a pas ici besoin de cookies tiers pour collecter vos données personnelles) :
Voici l'e-mail envoyé par Criteo à ses clients et partenaires (via f_to_k) :
Cet e-mail parait anodin mais la technique du CNAME l'est beaucoup moins. Elle introduit une faille de sécurité si le site partenaire n'a pas pris ses précautions : Criteo peut alors y lire les cookies déposés sur le domaine du site partenaire. Étudions un exemple en surfant sur allocine.fr avec Safari et l'outil Charles Proxy :
Comme on le voit, xgctpf.allocine.fr (alias Criteo) récupère les cookies déposés sur allocine.fr (qui ne lui sont pas destinés) :
- Des cookies d'identifiants déposés par Google Analytics : _ga, _gat, _gid, _gads
- Un cookie d'identifiant Facebook : _fbp
- Des cookies stockant votre géolocalisation : geocode, geolevel1, geolevel2, geolevel3
- Vos cookies d'authentification à Allocine (j'étais connecté) : ACAUTH, ACCT, ACID, GraphToken
Via les différents identifiants "volés", Criteo peut enrichir son Shopper Graph, mais ce n'est pas le plus grave car via vos cookies d'authentification, Criteo peut se connecter à votre propre compte Allociné ! Voici les étapes pour le vérifier :
- Récupérez les cookies d'authentification à Allocine via Safari et Charles Proxy.
- Allez sur allocine.fr depuis Chrome, assurez-vous que vous êtes bien déconnecté.
- Utilisez l'extension Chrome EditThisCookie pour créer vos cookies d'authentification.
- Rafraichissez la page, vous êtes connecté !
Cadeau : Allociné ne propose pas de version sécurisée de son site web, donc Criteo n'est pas le seul à pouvoir intercepter vos cookies d'authentifications. Votre FAI et les machines situées entre votre appareil et les serveurs d'Allociné peuvent aussi se connecter à votre place.
Cette importante faille de sécurité est probablement présente sur de nombreux sites partenaires car Criteo a déjà réussi à convaincre plus de 10.000 partenaires d'installer un CNAME (Allociné était un exemple bénin, la plupart des partenaires sont des sites d'e-Commerce qui peuvent détenir des informations bien plus sensibles comme votre carte bleue).
Lisez à ce propos cette conversation sur le channel Reddit r/adops, ajouter un CNAME est loin d'être anodin comme le laisse entendre l'e-mail de Criteo. Comment éviter cette fuite d'informations tout en utilisant le CNAME de Criteo ? En ne permettant pas aux sous-domaines de lire les cookies du domaine (lire par exemple la documentation de Mozilla, "Portée des cookies").
Néanmoins, Criteo évolue encore en toute impunité : la technique du CNAME a fait l'objet d'un article sur le journal du net dans lequel Criteo, ID5 et Prisma Media justifient la pratique du CNAME. Le responsable programmatique de Prisma Media accuse même les navigateurs d'outrepasser leurs rôles en voulant protéger la vie privée des internautes :
C'est franchement problématique qu'un navigateur décide de ce qui est juste ou non en prétextant protéger la vie privée des utilisateurs, alors que c'est le rôle de la gestion des consentements. Si la personne ne donne pas son consentement, bien sûr que nous ne déposons pas de cookie.
Pour Criteo aussi, le navigateur ne devrait pas "prendre des décisions" à la place de l'internaute, qui doit pouvoir consentir (ou non) à la surveillance publicitaire de lui-même. Mais comment se situe Criteo par rapport à la nécessité d'obtenir le consentement de l'utilisateur avant de le pister ?
Pour le recueil du consentement, Criteo se décharge sur les annonceurs et éditeurs partenaires
La page de Criteo expliquant l'utilisation des données personnelles donne une bonne idée de l'étendue des données personnelles collectées et de l'utilisation qui en est faite. La base légale avancée par Criteo pour justifier cet accaparement de vos données personnelles tout en respectant le RGPD est le consentement. Mais pour Criteo, l'obtention de celui-ci incombe uniquement à ses partenaires, annonceurs et éditeurs :
Les opérations de traitement de Criteo respectent les réglementations en vigueur, dans les pays exigeant le consentement des utilisateurs pour l’utilisation de cookies ou de toute autre technologie similaire. Ce consentement est recueilli sur les sites Web et les applications mobiles des Annonceurs et des Éditeurs.
Criteo appuie sur ce point dans sa politique de confidentialité :
Notez que l’utilisation des technologies Criteo est régie par les politiques de confidentialité publiées sur les sites web et les applications mobiles de nos partenaires. Ces derniers sont tenus de fournir des informations complètes et appropriées et, dans la mesure où la loi l’impose, d’obtenir votre consentement avant de communiquer toute donnée personnelle à votre sujet.
Criteo indique même exiger contractuellement de ses annonceurs et éditeurs partenaires qu'ils obtiennent le consentement des utilisateurs avant la mise en place de traceurs :
Criteo exige contractuellement que les Annonceurs et Éditeurs respectent sa Charte éditoriale générale et sa Charte dédiée aux partenaires, ainsi que les différentes réglementations en vigueur sur la protection des données personnelles, en particulier le RGPD. En utilisant les services Criteo, ils s’engagent, dans la mesure où la réglementation l’impose : [...] à obtenir le consentement des utilisateurs avant de mettre en place des cookies ou autres technologies similaires, dans le but de diffuser des annonces personnalisées.
Cependant, Criteo ne fait rien pour faire respecter ce contrat, comme on peut le voir avec l'exemple de La Fnac. Obtenir un vrai consentement de l'utilisateur avant de pouvoir l'identifier équivaudrait pour Criteo à mettre la clé sous la porte, d'où son double discours.
Criteo tord la définition du consentement
Criteo est un habitué du double discours. Ainsi d'un côté il va expliquer aux utilisateurs dans sa politique de confidentialité qu'il respecte la notion de consentement et demande contractuellement à ses partenaires de l'appliquer. D'un autre côté, il indique à ses partenaires qu'ils n'ont pas besoin de récolter un consentement explicite des utilisateurs.
Dans ses "Directives de confidentialité de Criteo pour les clients et partenaires éditeurs", Criteo conseille ses clients sur les clauses d'information à inclure dans leurs politiques de confidentialité. Aussi, Criteo indique de nouveau aux clients qu'ils ont l'obligation d'obtenir le consentement des utilisateurs au sein de l'UE. Mais que veux dire consentement pour Criteo ? La définition s'apparente plutôt à une simple obligation d'information :
En particulier, conformément aux lois de l’UE, la demande de consentement est considérée comme valide lorsque : Les utilisateurs sont informés sur l’utilisation des cookies et des technologies autres que les cookies par Criteo dans le but de proposer de la publicité ciblée au moment de donner leur consentement.
Criteo va même jusqu'à suggérer d'utiliser la faille introduite par la CNIL qui permet encore à la quasi totalité du web français de considérer que la poursuite de la navigation sur un site (simple scroll ou clic sur une nouvelle page) vaut consentement :
Suggestion d’avis de cookies pour les pays où le consentement est obligatoire En continuant à naviguer sur notre site, vous acceptez l’utilisation de cookies et de technologies autres que les cookies pour vous fournir des contenus et publicités personnalisés à travers les sites.
Comme l'indique le Comité Européen de la Protection des Données, organe européen indépendant dont les objectifs sont de garantir l’application cohérente du RGPD et de promouvoir la coopération entre les autorités de protection des données de l'UE, le consentement doit être clair, affirmatif et non ambigu. Les dernières lignes directrices ont été publiées le 4 mai, on peut par exemple y lire que scroller ne vaut pas consentement :
Dans un article intitulé "RGPD : Criteo est prêt à relever le défi", Criteo détaille sa vision du consentement, considérant qu'il n'a pas besoin d'obtenir un consentement explicite de l'utilisateur :
Le RGPD établit une distinction claire entre consentement non-ambigu et consentement explicite. Le consentement explicite implique un choix exprès de la part de l’utilisateur. Ceci s’applique par exemple pour la collecte de données sensibles telles que la race, la religion, l’orientation sexuelle, l’affiliation politique et la santé. En revanche, en tant que tels les dispositifs de suivi en ligne (par exemple, les cookies) sont catégorisés comme simple données personnelles. Aussi, selon le nouveau règlement, un opt-in exprès n’est pas requis en ce qui concerne les cookies de retargeting classique qui ne collectent pas de données sensibles.
Sauf que ce comportement est bien en violation du RGPD, qui requiert un consentement clair, affirmatif et non ambigu de l'utilisateur. La CNIL doit d'ailleurs avancer pour mettre sa doctrine en accord avec le RGPD : elle a démarré les démarches en juillet 2019, mais elle prétexte maintenant la crise du coronavirus pour mettre en pause cette nécessaire adaptation.
Criteo a même écrit un livre blanc sur le RGPD, détaillant ses arguments fallacieux, il n'en reste qu'un seul point : Criteo ne pourrait survivre s'il s'appuyait sur un consentement véritable de l'utilisateur. Il se sent donc obligé de tordre la définition du consentement.
Les mensonges de Criteo dans sa politique de confidentialité
Dans sa politique de confidentialité, Criteo indique ne pas recevoir de données à caractère personnel :
Aucune donnée à caractère personnel (nom, prénom, adresse postale, adresse e-mail non cryptée ou autres) ne nous est communiquée.
Ceci est faux, les clients de Criteo peuvent bien communiquer à Criteo votre adresse e-mail en clair comme l'indique cette page support pour "créer une audience" :
Un fichier CRM d'adresses e-mails contenant des adresses complètes, des adresses e-mails chiffrées par hachage MD5 ou SHA256 de MD5 (adresses complètes>MD5>SHA256).
Si le client envoie des adresses e-mails en clair, Criteo indique les chiffrer avant de les stocker, vous devez donc lui faire confiance.
Toujours dans sa politique de confidentialité, Criteo avoue que les données qui ne seraient pas à caractère personnel (les pseudonymes) sont bien considérées comme données personnelles dans l'Union Européenne et en Californie :
Ces informations sont toutefois considérées comme des données personnelles par le règlement général de l’UE sur la protection des données (RGPD) ainsi que par la loi californienne sur la protection de la vie privée des consommateurs (CCPA).
Autre mensonge, dans la section "Engagements de Criteo", on peut lire :
Les annonces Criteo n’impliquent en aucun cas de recueillir les données suivantes : [...] identifiants persistants, tels que les identifiants des appareils que vous utilisez (UDID, adresse MAC, etc.)
Sauf que le hash de votre adresse e-mail est bien un identifiant persistant. Aussi, cet "engagement" est en contradiction avec le deck "Online identification at Criteo" pour les investisseurs. Sur le slide 16, Criteo indique que 96% des "identités" (= utilisateurs) de son "Identity Graph" contient au moins un identifiant persistant :
Sur le slide 22, Criteo indique aussi faire appel à des tiers pour obtenir d'avantages d'identifiants persistants, et ainsi ne plus être dépendant des cookies :
La duplicité de Criteo est flagrante : engagement auprès des internautes de ne recueillir "en aucun cas" des identifiants persistants d'un côté, mais facilitation de la collecte de ces identifiants persistants auprès des annonceurs et éditeurs partenaires (pour rappel, la page support indiquant comment envoyer à Criteo une liste d'e-mails), et communication sur ces identifiants persistants auprès des investisseurs de l'autre côté.
Désactiver les services Criteo sur les applications mobiles ne fonctionne pas
Comme vu avec l'exemple de La Fnac sur iOS, Criteo continue de collecter un hash de votre adresse e-mail, même lorsque vous avez désactivé le suivi publicitaire :
Pourtant sa page "Désactiver les services Criteo sur les applications mobiles" indique :
Nous retrouvons ici un double mensonge de Criteo : mon e-mail (ou même un hash de mon e-mail) est un identifiant persistant, pourtant Criteo le collecte bien (premier mensonge), même si je désactive le suivi publicitaire (deuxième mensonge).
Des abus répétés et documentés, mais toujours pas de sanction
Cela fait longtemps que les pratiques peu éthiques de Criteo sont détaillées et dénoncées, voici quelques éléments :
- La plainte de Privacy International contre Criteo, Quantcast et Tapad pour violation du RGPD date de novembre 2018, il aura fallu 16 mois à la CNIL pour réagir et démarrer l'instruction.
- La technique du CNAME n'est qu'un élément parmis d'autres mis au point par Criteo pour contourner les protections mis à en place par les navigateurs, l'EFF a documenté les précédentes tentatives de Criteo pour contourner ITP de Safari.
- Ces techniques ont été détaillés par Gotham City Research LLC dans un rapport dédié.
- Autre rapport de Gotham City Research LLC dénonçant la fraude généralisée sur l'inventaire géré par Criteo. À noter que les rapports n'étaient pas désintéressés car Gotham spéculait ouvertement à la baisse sur le cours de Criteo, il n'empêche que les pratiques dénoncées étaient avérées.
- Criteo fait partie du comité d'Acceptable Ads, une initiative créée par Adblock Plus, permettant à Criteo d'afficher des publicités même si vous avez installé Adblock Plus ou d'autres adblockers supportant l'initiative (ces publicités sont "adaptées" : elles prennent un peu moins de place que les publicités traditionnelles Criteo). Choquant car les publicités Criteo sont particulièrement intrusives, mais "Acceptable Ads" ne se base "que" sur la pollution visuelle.
Pourtant, rien ne se passe. Vu l'historique de la CNIL, il est permis de douter de l'hypothèse de réelles sanctions contre un champion du numérique français ayant un poids économique et politique important comme le démontre la visite de Bruno Le Maire pour les 1 ans du laboratoire d'intelligence artificielle de Criteo, en octobre dernier. Pour Bruno Le Maire, Criteo est "l'une des grandes réussites françaises de ces 15 dernières années" :
Que faire alors ? Malheureusement, en attendant une vraie ambition politique, les solutions restent individuelles et techniques : utiliser un adblocker tel que uBlock Origin combiné à Firefox sur le web (ou d'autres navigateurs respectueux de la vie privée tels que Brave et Safari), passer par des applis telles que DNSCloak, Adguard ou NextDNS sur iOS, voire installer Pi-hole sur un Raspberry Pi si vous avez le goût de la technique.
- Persos A à L
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- EDUC.POP.FR
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Frédéric LORDON
- LePartisan.info
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Romain MIELCAREK
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Emmanuel PONT
- Nicos SMYRNAIOS
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- Numérique
- Binaire [Blogs Le Monde]
- Christophe DESCHAMPS
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Francis PISANI
- Pixel de Tracking
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Bondy Blog
- Dérivation
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- ROJAVA Info
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- XKCD