06.10.2019 à 02:00
Apprendre à marcher
Lancé par Framasoft en 2014, le grand projet « Degooglisons Internet » a agit pour beaucoup comme un révélateur. Il devenait en effet possible d’utiliser des services en ligne sans accroître sa dépendance aux grands monopoles du web. L’objectif du projet de Framasoft était d’accompagner chaque service d’une rubrique d’aide et d’incitation à l’installation pour des besoins individuels ou collectifs. Après avoir fait goûter le plat, il fallait en donner la recette.
En tout cas c’est ainsi qu’il fut promu.
En réalité, les membres de Framasoft ont largement mûri leurs intentions au fur et à mesure que les services se multipliaient et le nombre d’utilisateurs croissait. Des questions existentielles se sont posées au sujet d’une réputation hégémonique de l’association, au sujet de la charge technique, de la charge de modération, et surtout sur le besoin de plus en plus pressant d’identifier en France et à travers le monde des groupes similaires susceptibles de proposer des solutions de « dégooglisation ». Un début de réponse à nos inquiétudes est devenue de plus en plus évident : nous savions bien sûr que tous les utilisateurs ne sont pas des fondus d’informatique et n’ont pas forcément envie ou les compétences d’installer des serveurs et des logiciels, mais nous avons aussi constaté à quel point il fallait pousser la vague de collectivisation et d’appropriation du Libre dans ce domaine. Rendre des collectifs libristes plus solidaires, mieux connus, et faire naître des initiatives sérieuses, tel fut l’objectif du projet CHATONS et, au-delà, de l’orientation plus générale (et plus mature ?) voulue par l’initiative Contributopia.
Selon le public concerné, le projet « Dégooglisons Internet » recèle des messages différents :
- Les services sont basés sur des logiciels libres. Ils sont autant de preuves qu’il est possible de construire une offre alternative aux GAFAM sur du code libre tout en y contribuant. Le cycle est vertueux.
- « Degooglisons Internet » permet d’évaluer ces logiciels, estimer leurs capacités de charge, les mettre à l’épreuve dans un contexte de production avec un nombre conséquent d’utilisateurs. Pour certains les essais sont concluants, d’autres non. D’autres encore ont finalement été mis de côté, non pas en raison d’un manque de connaissances techniques mais à cause des contraintes de gestion qu’ils impliquent (c’est le cas de la solution de courrier électronique).
- les services respectent les données des utilisateurs et nous n’en faisons aucun usage déloyal. En fait, le modèle économique qui se présente, qu’il soit associatif ou entrepreneurial, n’est tout simplement pas basé sur de l’offre marketing ou publicitaire. Il n’y a donc aucune pression quant à valoriser les données des utilisateurs. En revanche il faut développer à chaque fois des outils pour que l’utilisateur ne soit pas prisonnier du système en place (export des données en quelques clics, chiffrement, sécurité des comptes, règlement RGPD, etc.). Et certains de ces défis sont encore à relever.
- le projet « Degooglisons Internet » a montré assez exactement comment établir des relations de confiance dans les échanges entre un hébergeur et un utilisateur. La renommée d’une association comme Framasoft peut y être pour beaucoup, mais cela ne suffit clairement pas. C’est pourquoi le collectif CHATONS possède un manifeste et une charte assez contraignants.
Finalement, on constate à quel point la confiance et la solidarité entretiennent des relations étroites d’interdépendance. La confiance est l’élément décisif non seulement parce que depuis 2013-2014 les révélations Snowden ont largement entamé le capital confiance des GAFAM (et des États), mais surtout parce que nos dépendances aux dispositifs technologiques placent nos vies sous surveillance. Ces capteurs de données construisent nos doubles numériques dans lesquels nous n’avons aucune raison de nous reconnaître. Lorsque nous le faisons, nous agissons comme des consommateurs dont le comportement est conformé au marché, avec l’illusion de la liberté de choix, et les contraintes propres aux marchés bifaces qui conditionnent l’usage au pillage des données. Au contraire la confiance repose sur le choix éclairé et des engagements clairs de respect mutuel.
Nous le savions déjà.
Dans ce cas, pourquoi les utilisateurs ne sont donc pas plus nombreux à réclamer à cor et à cris la « dégafamisation » d’Internet ? Certains politiques commencent à entretenir des discours dans ce sens (même si cela relève bien souvent d’un autre abus de confiance). Plus crédibles, beaucoup d’initiatives collectives, plus ou moins militantes, comptent en leurs rangs de plus en plus de personnes sensibles à la question de l’invasion de nos vies privées, parce que leurs combats sont en réalité très proches d’une remise en question plus générale des dégâts environnementaux et sociaux du capitalisme. D’autres mouvements s’engagent sur d’autres fronts, en particulier l’éducation populaire, et là aussi sont extrêmement sensibilisés aux conditions de nos libertés.
Cela fait du monde, dans notre petit cercle de consommateurs de démocraties libérales. Pour d’autres pays c’est la question de la liberté d’expression et d’autres urgences sociales qui finiront par mettre en perspective le monopole des GAFAM. Et pour les dictatures, la question de la liberté de choix est de toute façon hors de propos.
Alors devant ces inégalités, devant ces aspirations à l’égalité et à la liberté, pourquoi tant d’utilisateurs demeurent encore dans la caverne des GAFAM, admirant les promesses malhonnêtes projetées sur la paroi ?
De manière non exhaustive, on peut diagnostiquer :
- Par désintérêt. C’est à nous de nous interroger alors à propos des bouleversements sociologiques et psychologiques de l’envahissement des dispositifs numériques dans nos quotidiens, et comprendre pourquoi les solutions alternatives peinent, dans leur complexité, à se faire entendre.
- Par ignorance. Les libristes ont longtemps cru qu’il suffisait de montrer pour faire adopter. Mais cette époque est révolue (même si certains discours persistent et en deviennent même culpabilisants). L’ignorance relève surtout de l’aveuglement des institutions : la solution réside dans l’éducation populaire.
- Par résignation. Oui, il faut du temps pour remettre en question des pratiques dont, par impératif d’immédiateté, les GAFAM et les États ont provoqué l’adoption à marche forcée. On en voit les stigmates, par exemple, dans les inégalités d’accès aux services publics « numérisés », alors que les plus éloignés de ces pratiques subissent la double peine de l’exclusion sociale et de l’exclusion numérique.
- Par stupidité. C’est le seul discours culpabilisant que je pourrai prononcer ici : oui, il faut être stupide lorsque, en connaissance de cause, on choisi de se complaire dans le profil du consommateur arrogant pour lequel la fiabilité matérielle est un autre mot pour dire « pouvoir d’achat ».
- Par naïveté. Certains choix collectifs sont de mauvaises décisions. Lorsque par exemple une entreprise ou une administration publique préfère s’en remettre aux produits des GAFAM en éludant volontairement que ces firmes américaines sont les support d’une autre hégémonie, politique et militaire (celle des États-Unis qui, en vertu du Cloud Act, assimile nos dispositions législatives, comme le RGPD, à des boucliers de papier). Et s’il ne s’agit pas de naïveté, on flirte dangereusement avec la trahison.
Malgré tout cela, et alors même qu’on pourrait penser que Framasoft a la prétention d’être comme un phare dans la nuit, l’association a récemment annoncé un plan de fermeture de plusieurs de ses services.
Abandon du navire ?
Il importe de se rappeler la première intention du projet « Degooglisons Internet » : proposer une démonstration de services basés sur du logiciel libre pour que d’autres puissent se les approprier. En effet, comme le font certains, prétendre que Framasoft aurait découvert aujourd’hui les contraintes liées à l’hébergement de services ou que le logiciel libre n’est pas à la hauteur, c’est nier 5 années de développement de support à l’installation, de contribution à ces logiciels et oublier aussi que, justement, le succès de ces services est en fait une consécration des logiciels en question.
Alors pourquoi ce plan de fermeture ?
D’abord tous les services ne fermeront pas leurs portes. Il suffit de lire attentivement les annonces pour comprendre que la fermeture des services sur un temps long est en soi un projet ! C’est le projet d’une émancipation. C’est bien ce mot qu’il faut entendre derrière « déframasoftisons internet ».
Framasoft a d’autres projets d’envergure. Ils seront annoncés en temps et en heure. En attendant, j’estime que chacun d’entre nous a le devoir de suivre un précepte : cesser d’attendre que des offres toutes cuites fassent leur apparition comme si la confiance que des bénévoles portent sur leurs épaules était après tout une offre comme une autre dans le paysage de la consommation de masse.
Vous êtes membre d’une association, d’un groupe de musique, d’une bande de copains, d’une équipe sportive… et vous n’êtes pas un manche avec un clavier et un écran ? Alors allez-y, prenez un peu de ce temps bénévole pour aider vos amis à s’émanciper dans de bonnes conditions en endossant vous-même la responsabilité de leurs données et donc leur confiance. Selon vos compétences, offrez-leur d’héberger des images avec Lutim, un dépôt de fichier avec Lufi ou carrément un service cloud avec Nextcloud, etc. Qui prétend que de telles solutions devraient réunir des milliers d’utilisateurs ? Si vous les utilisez pour vous, pourquoi ne pas en faire profiter vos amis ?
Vous n’y connaissez rien ? Prenez alors encore un peu de temps pour trouver un CHATONS et ramenez-y vos amis. Vous pourrez aussi leur apprendre quelques astuces d’usage.
L’argent ? oui, c’est le nerf de la guerre. Les modèles économiques des GAFAM ont trop longtemps fait croire aux utilisateurs qu’une adresse courriel, l’hébergement de données ou n’importe quel service devait être gratuit. C’est impossible. Nous devons réapprendre à estimer les coûts de nos besoins. Lorsqu’une association investit dans un serveur, il me semble normal que les utilisateurs contribuent à ces frais. Nous parlons de quelques euros par an. Et si vous décidez de vous lancer par exemple avec une solution Yunohost que vous dédiez à votre famille, un nom de domaine vous coûtera moins de 20 euros par an, et un serveur entre 5 et 10 euros par mois (d’expérience, pour héberger quelques fichiers, les contacts et les agendas de la famille, cela me revient à moins de 60 euros par an).
Oui, cent fois oui, tout le monde ne peut pas dépenser encore quelques dizaines d’euros pour une solution courriel payante ou un hébergement chez un CHATONS. L’abonnement internet et téléphonie portable coûte déjà bien assez d’argent comme cela. Cela reste toutefois, pour beaucoup d’autres personnes, une simple affaire de choix, entre cela et dépenser encore plusieurs centaines d’euros pour un téléphone portable qui fait le café. Ne généralisons pas mais restons lucides : derrière la gratuité des services des GAFAM le discours de l’égalité d’accès aux services est un vaste mensonge.
Cette gratuité s’est certes déclarée au détriment de nos vies privées, mais pas uniquement ! Elle est aussi la condition d’une dégradation des services : au détriment de la sécurité des données, au détriment des règles de chiffrement, au détriment de l’interopérabilité, au détriment de la liberté d’expression (notamment sur les médias sociaux), et surtout… surtout au détriment de nos savoirs.
Prenons le cas d’un usage assez simple comme configurer les options d’un clients de courriel (ses protocoles POP, IMAP, SMTP ou la sécurité SSL, TLS, les ports de connexion…). Tout cela, personne n’est tenu d’y comprendre goutte et d’ailleurs la plupart des bons logiciels client de courriel proposent d’automatiser les procédures. Mais il reste très important de savoir qu’en cas de besoin, on peut y avoir accès. Tout comme il est important de savoir qu’en cas de besoin et avec un peu de patience et de logique je peux changer seul la chambre à air de ma roue de vélo même si je vais chez un réparateur pour le faire. Au lieu de cela les services des GAFAM nous ont privé de ces savoirs : des savoirs censés être disponibles, pas forcément obligatoires mais présents.
La sortie de la caverne de Platon, ou le sapere aude d’E. Kant (dans « Qu’est-ce que les Lumières ? »), c’est exactement de cela dont il s’agit. Il est bien plus grave de ne pas pouvoir se servir de son entendement que de ne pas apprendre. L’éducation populaire dont se réclame Framasoft a au moins cette prétention : si les alternatives aux GAFAM doivent être des modèles d’équilibre entre les usages et la confiance, il doivent surtout rendre de nouveau accessibles les savoirs dont nous privent les GAFAM.
Après les avoir d’abord abêtis en les traitant comme des animaux domestiques, et avoir pris toutes leurs précautions pour que ces paisibles créatures ne puissent tenter un seul pas hors de la charrette où ils les tiennent enfermés, ils leur montrent ensuite le danger qui les menace, s’ils essayent de marcher seuls. – Emmanuel Kant, « Qu’est-ce que les Lumières ? » (1784), trad. fr. J. Barni, voir sur Wikisource.
22.08.2019 à 02:00
Ce que le capitalisme de surveillance dit de notre modernité
Cette partie de mon ouvrage (à paraître en automne 2019) intervient après une lecture critique du texte de J. B. Foster et R. W. McChesney (« Surveillance Capitalism. Monopoly-Finance Capital, the Military-Industrial Complex, and the Digital Age ») paru en 2014. Comme on le verra dans la suite de l’ouvrage, l’approche critique de Shoshana Zuboff est loin de satisfaire une lecture intégrée de l’histoire économique et politique du capitalisme de surveillance. À mon avis, c’est chez Anthony Giddens qu’on peut trouver assez de matière pour pouvoir mieux comprendre pour quelles raisons on ne peut pas décorréler l’histoire du capitalisme de surveillance de la modernité occidentale et donc des modèles organisationnels qui prévalent depuis un siècle au moins. Le post-modernisme (et avec lui on pourrait inclure les idéologies plus ou moins libertaires et californiennes des années 1980) nous a rendu en réalité bien démunis pour penser cet écrasement des sociétés par la surveillance, et en particulier à cause des conjonctures économico-politiques (et leur modèle américain).
Extrait (Archéologie du capitalisme de surveillance)
[…] Ce que soulève le texte de J. B. Foster et R. W. McChesney, c’est le besoin de redéfinir une certaine vision de la modernité. On la trouve chez Anthony Giddens qui synthétise cette modernité comme une description des organisations, des modes de vie, et leurs trajectoires historiques qui, depuis au moins le xviie siècle, ont configuré durablement la conjoncture mondiale1. C’est une modernité dont on pensait visiblement à tort que la conception unificatrice de l’histoire (c’est-à-dire les contraintes de notre temps comme le pouvoir des institutions sur les individus) avait été dépassée pour faire entrer l’homme dans ce que Jean-François Lyotard appelle, à la fin des années 1970, la condition post-moderne2 où les savoirs prétendument empiriques ne seraient finalement que des jeux de langages qui légitiment la vérité.
Or, c’est à la fois par un procédé narratif (l’histoire racontée par J. B. Foster et R. W. McChesney) et par un discours sur les institutions que nous nous retrouvons en proie à ces contraintes pour comprendre l’histoire qui nous est infligée, malgré nous, par un capitalisme de surveillance envisagé comme un processus qui transcende et traverse les histoires (de l’informatique, de la politique, de l’économie).
Le post-modernisme est une manière de penser l’individu selon son rapport à l’espace et au temps afin d’échapper au « désenchantement du monde », à la fin des utopies (la chute du Mur vue comme une fin de l’histoire sous un certain angle), ou aux failles épistémologiques (nous pensons par paradigmes, il n’y a pas de vérité éternelle). Le post-modernisme est un rempart à l’encontre des visions (trop) unificatrices. Et voilà qu’une dystopie, celle d’Orwell, nous rattrape. Elle nous montre à quel point sa modernité est radicale3, à l’heure où, grâce à Edward Snowden, l’organisation Wikileaks, et d’autres lanceurs d’alertes restés dans l’ombre, il apparaît aux yeux du monde que les États n’hésitent pas à investir des sommes colossales et beaucoup d’énergie pour espionner les populations à un degré inédit d’ampleur et de précision.
Nous sommes radicalement modernes. Du moins, à lire J. B. Foster et R. W. McChesney, nous n’échappons pas à la modernité tant les faits, à l’échelle mondiale, sont écrasants et conditionnent à ce point l’histoire sociale et politique.
Chez le sociologue Anthony Giddens, nous trouvons de quoi commenter en ces termes le capitalisme de surveillance. A. Giddens est célèbre surtout pour son approche critique (et exhaustive) des fondements de la sociologie contemporaine. Dans son livre Les conséquences de la modernité, il se livre à une approche critique de la vision post-moderne de notre rapport au monde. Il ne la considère cependant pas comme une erreur. Il en donne plutôt une nouvelle définition : un ensemble de transformations nécessaires, des améliorations rendues possibles par l’engagement politique, à l’encontre, justement, de la dispersion post-moderne qu’identifiait J.-F. Lyotard.
Pour A. Giddens, la post-modernité est comme un moment de réflexion qui ne prend pas en compte une approche plus intégrée de l’histoire. Selon lui, l’exemple le plus illustratif d’une modernité déconnectée et que le post-modernisme a assimilé comme un relativisme, c’est ce que K. Marx, M. Weber et E. Durkheim ont compris non comme une rupture mais comme autant d’opportunités de changement. Pour K. Marx la lutte des classes, aussi violente soit-elle, est un cheminement vers un nouvel ordre social. E. Durkheim concevait la division du travail comme une violence transitoire vers une harmonie possible entre l’industrie et la société. Seul M. Weber était assez pessimiste et assez critique vis-à-vis de la notion de progrès pour voir, dans la forme inéluctable de la bureaucratie et du contrôle, l’avenir des organisations soumises au pouvoir. A. Giddens en vient à affirmer4 :
Les penseurs de la sociologie, à la fin du dix-neuvième siècle et au début du vingtième, ne pouvaient prévoir l’invention de l’arme nucléaire. Mais le mécanisme liant innovation et organisation industrielles au pouvoir militaire remonte aux origines même de l’industrialisation moderne. Le fait que la sociologie ait amplement négligé cette réalité montre à quel point on était persuadé que l’ordre moderne en plein essor allait être pacifique, par opposition au militarisme typique des époques précédentes.
Si l’on suit A. Giddens, au lieu d’un dépassement de la modernité, l’histoire nous montre au contraire une radicalité des mécanismes qui la caractérisent. La modernité a changé de forme depuis l’arrivée de la société post-industrielle et des notions sont devenues centrales telles la globalisation, le choix de vie, l’identité personnelle, les relations familiales, le rôle de l’État-providence. Ces mécanismes sont aussi devenus universels, et même si cet universalisme chez A. Giddens a été souvent critiqué5, de même que ses positions politiques6, ce qui nous intéresse, c’est qu’il propose une approche de la formation des sociétés depuis les années 1960. Cette modernité qu’A. Giddens définit comme le mode de vie et les organisations européens qui se sont étendus dans le monde pendant près de trois siècles, sont entrés dans une phase critique fortement liée à la conjoncture du capitalisme et du consumérisme.
Nulle place pour un individualisme transcendant agissant d’aventure contre les contraintes du temps et de l’espace. On est loin de la toute-puissance du sujet dépassant les failles de la modernité, et la notion même de société, comme le promouvait Alain Touraine peu de temps avant la publication du livre d’A. Giddens7. Au contraire, A. Giddens donne des exemples on ne peut plus rationnels et s’efforce de penser une société embarquée dans l’histoire, parfois malgré elle et parfois par choix. Tel est l’exemple du complexe militaro-industriel : au regard de l’histoire du xxe siècle les sociétés ont été de plus en plus soumises à cette conjoncture. Cette dernière est aussi ressentie comme un manque de sécurité (un « environnement du risque » permanent hérité de l’époque pré-moderne) et, par conséquent, la société ressent un besoin croissant de sécurité qu’elle cherche par excès de confiance dans des dispositifs désincarnés, soit technocratiques, soit des mécanismes institutionnels en réseaux, ce qu’il nomme des « systèmes experts ». Face aux risques, que l’on souhaite mesurés, évalués, quantifiés, la société moderne s’est de plus en plus raccrochée à une foi envers ces systèmes sans toutefois se débarrasser de ses angoisses. Par conséquent, A. Giddens s’emploie à déterminer ce que sont les « institutions » de la modernité qui se sont radicalisées, à chaque fois source d’angoisses8 :
- le capitalisme (« L’accumulation de capital dans le contexte de marchés concurrentiels du travail et de la production »),
- l’industrialisme (« La transformation de la nature : développement de l’environnement créé »),
- Le militarisme (« La maîtrise des instruments de la violence dans le cadre de l’industrialisation de la guerre »),
- La surveillance (« Le contrôle de l’information et le monitoring social »).
Selon A. Giddens, il reste des possibilités pour dépasser ces régimes de la modernité et elles passent par les mouvements sociaux tels le syndicalisme, l’environnementalisme, le militantisme contre l’armement. Cependant on pourrait tout aussi bien lui reprocher de ne pas tenir compte des contre-mouvements, ceux qui ne provoquent que des contraintes supplémentaires à ces régimes, tels les populismes d’extrême droite, les fondamentalismes religieux et même certaines croyances libérales et autoritaires (dérégulation systématique des marchés, doctrine anti-interventionniste, etc.). Outre ce combat sans fin d’exemples et de contre-exemples, A. Giddens a fait de ces régimes organisationnels une définition globalisée de l’État moderne-contemporain : un système mondial d’États-Nations capitaliste qui ne repose pas uniquement sur des catégories marxistes mais intègre l’industrialisme (y compris militaire) et la surveillance comme les socles de sa permanence. En 1985, déjà, il affirmait ainsi, à propos de ces régimes organisationnels9 :
Ce sont des processus associés au système de l’État-nation, coordonnés par des réseaux mondiaux d’échange d’informations, l’économie capitaliste mondiale et l’ordre militaire mondial.
Toutefois, A. Giddens évacue les choix politiques trop radicaux, ou, du moins l’idée qu’une solution de dépassement puisse passer par un choix qui s’imposerait à la société, entre le capitalisme et le socialisme. Comme le précise un de ses commentateurs à propos des derniers chapitres de The Nation-State and Violence, A. Giddens « souligne qu’aucune théorie critique de la société moderne qui ne fait que poser le choix entre le capitalisme et le socialisme ne peut rendre justice aux complexités et aux problèmes de la modernité »10.
La raison à cela, c’est justement la surveillance. En 1981, alors même que la critique de la modernité n’était pas encore chez lui arrivée à un stade de maturité complète, il se livrait à une critique du matérialisme historique et démontrait combien la surveillance est un processus central qui appartient à nos sociétés et échappe cependant à toute tentative de dialectique marxiste. Pour A. Giddens, la surveillance est définie d’abord comme un processus d’accumulation d’informations par une organisation publique ou privée, de manière à accomplir un processus de contrôle11. On ne rassemble aucune information par quel procédé que ce soit si ce procédé n’est pas d’abord dessiné comme un outil de contrôle.
L’argument est double : premièrement, la surveillance est un instrument de pouvoir totalitaire et deuxièmement les technologies de l’information et en particulier l’informatique ne peuvent se penser indépendamment de la surveillance. Il affirme :
La théorie sociale classique n’a pas reconnu le potentiel de ce qui est devenu de nos jours une menace fondamentale pour les libertés humaines, un contrôle politique totalitaire maintenu par un système de surveillance à l’échelle de la société, lié à la « police » de la vie quotidienne. L’expansion de la surveillance dans les mains de l’État peut soutenir un totalitarisme de classe de la droite (fascisme) ; mais elle peut aussi produire un totalitarisme de gauche fortement développé (stalinisme).
En somme, ce qui est vrai pour le monde ouvrier contrôlé par les machines est tout aussi vrai du point de vue des institutions qui accumulent les informations à des fins de contrôle, et tout aussi vrai du point de vue de la consommation de masse que l’on contrôle et mesure en vue de maintenir ou optimiser les marchés (cette police de la vie quotidienne). Pour A. Giddens, en effet, c’est tout le processus d’informatisation de la société qui doit être pensé sous l’angle de la surveillance12 :
On pourrait supposer que l’arrivée de l’ordinateur, l’extension la plus extraordinaire de la capacité de stockage de l’esprit humain jamais imaginée, est le développement le plus récent et le plus important dans l’expansion de la surveillance comme contrôle de l’information. Même dans les années 1950, on trouvait rarement des ordinateurs à l’extérieur des universités et des établissements de recherche. Aujourd’hui, aux États-Unis, et de plus en plus dans les autres sociétés capitalistes avancées, de grands secteurs du contrôle de l’information sont informatisés tant au sein du gouvernement que de l’industrie. La « première génération » d’ordinateurs des années 1950 a déjà largement cédé la place à une deuxième (transistorisée) et une troisième (microprocesseur) génération d’ordinateurs, intégrés dans des systèmes de base de données. Mais l’ordinateur n’est pas aussi dissocié de l’histoire du capitalisme industriel que l’on pourrait l’imaginer ; et considérer l’informatisation seule comme un nouveau complément tout à fait distinct de la surveillance est trompeur.
D’aussi loin que nous pouvions croire qu’une société « post-industrielle » aurait succédé à la société industrielle d’un ancien monde, grâce à la montée du capitalisme en quelque sorte boosté par l’automatisation et les technologies de l’information, à défaut de rupture le lien est bel est bien continu. Il n’y a pas d’un côté une surveillance à la source du pouvoir à la manière du panoptique foucaltien et, de l’autre, une surveillance à visée productiviste aux fondements du capitalisme. Il n’y a pas d’un côté une société post-industrielle technologiquement avancée et, de l’autre, les archaïsmes du pouvoir politique dont les ressorts institutionnels et idéologiques seraient voués à la disparition. Au contraire, affirme A. Giddens, surveillance et État n’ont jamais été aussi fusionnels :
la « technocratisation » de l’État, au sujet de laquelle Habermas et d’autres ont écrit, tend de plus en plus à concilier les deux aspects de la surveillance de la même manière que dans l’entreprise. Le facteur technologie s’est avéré ici un facteur potentiellement obscurcissant, puisque la technologie a une forme matérielle visible, et peut être facilement considérée – comme l’ont supposé les partisans de la théorie de la société industrielle – comme ayant sa propre « logique » autonome. Mais la « logique » de la machine n’est pas différente par nature de la « logique » du contrôle technocratique de la politique (…)
Cette compréhension de la modernité a guidé la pensée d’A. Giddens à travers les années 1980 et 1990. Et même si les écoles de pensées sont très différentes, sur ces points elle fait aussi écho à la vision unificatrice de J. B. Foster et R. W. McChesney. L’intuition de départ est la même : alors que les idéologies libertariennes, plus ou moins formulées, pensent le « progrès » des technologies de l’information comme autant de solutions qui pallieraient les manquements des institutions, faciliteraient le développement social sur une base d’autonomie individuelle où tout un chacun pourrait s’épanouir grâce aux consumérisme numérique, J. B. Foster et W. Chesney tiennent le retour de l’État-Nation et de la surveillance comme l’instrument total de la soumission des sociétés mondiales à un ordre militaro-industriel.
À ceci près que, une fois regardé à travers les catégories de la critique de la modernité, le capitalisme de surveillance tel que le montre J. B. Foster et R. W. McChesney ressemble fort à une tautologie. Le capitalisme moderne suppose la surveillance : il n’a jamais échappé à une progression continue. Pour prendre l’exemple des États-Unis, il s’agit d’une application toujours plus sophistiquée de la doctrine impérialiste déjà fort ancienne, et d’une application toujours plus sophistiquée de la surveillance sublimée par les technologies. Or, nous sommes arrivés non pas à un point culminant mais à un point de rupture où toute critique de la surveillance est une critique du capitalisme. Ce que les révélations Snowden permettent de montrer, à ce moment de l’année 2013, c’est un instantané du contexte, un moment où la mondialisation du capitalisme de surveillance éclate non pas au grand jour mais dans une possibilité d’énonciation. C’est un moment où nous pouvons désormais construire un discours sur le capitalisme de surveillance en lui donnant un nom.
Nous sommes alors face à un nouveau choix. Soit nous considérons le capitalisme de surveillance comme une cage structurelle de notre société, un état de fait, soit nous cherchons à en déduire une dimension opératoire non plus pour comprendre « métaphysiquement » notre condition moderne mais pour comprendre les mécanismes concrets à l’échelle des société et des individus. Reformulé autrement : soit nous considérons que nous sommes condamnés et même soumis au capitalisme de surveillance et nous accordons, pour nous prémunir des abus, toute notre confiance aux institutions existantes (aux « systèmes experts » décrits par A. Giddens), soit nous tâchons de voir, empiriquement, comment ce capitalisme de surveillance opère et comment nous pourrions y réagir, par effet de mouvements voire de révolte.
-
Anthony Giddens, Les conséquences de la modernité, Paris, L’Harmattan, 1994. ↩︎
-
Jean-François Lyotard, La condition postmoderne, Paris, Les Éditions de Minuit, 1979. ↩︎
-
Auparavant dans le livre, j’effectue un commentaire poussé de l’interprétation dystopique des impacts sociaux de l’informatique dans l’histoire. ↩︎
-
Anthony Giddens, Les conséquences de la modernité, op. cit., p. 18. ↩︎
-
Jean Nizet, La sociologie d’Anthony Giddens, Paris, La Découverte, 2007, p. 87 sq. ↩︎
-
On retient A. Giddens comme le théoricien de la « troisième voie », qui a notamment inspiré le britannique Tony Blair. Très brièvement résumé, il s’agissait de poursuivre son analyse des transformations modernes en appelant à une refonte de la sociale-démocratie, pour opposer au néo-libéralisme une sorte de libéralisme de gauche libéré des carcans socialistes. Ses idées ont été bien trop caricaturées pour finir, notamment chez certains politiques français, comme un appel à un mouvement « ni droite ni gauche », ce que naturellement la pensée d’A. Giddens serait en peine de se satisfaire. Nous n’entrerons pas dans ce débat, d’autant plus que nous allons, dans la suite de cet ouvrage, utiliser des concepts qui nous éloignent assez radicalement du libéralisme. En revanche, nous mentionnons l’admirable travail d’A. Giddens en le situant aussi dans l’histoire du capitalisme de surveillance, et pour sa lecture socio-historique fort instructive. ↩︎
-
Alain Touraine, Critique de la modernité, Paris, Fayard, 1992. ↩︎
-
Anthony Giddens, The Consequences of Modernity, Cambridge, Polity Press, 1990, p. 59, nous traduisons. ↩︎
-
Anthony Giddens, The Nation-State and Violence, Cambridge, Polity Press, 1985, p. 135 et p. 290. ↩︎
-
Bob Jessop, « Capitalism, Nation-State and Surveillance », in Social Theory of Modern Societies. Anthony Giddens and his Critics, Cambridge, Cambridge University Press, 1989, p. 103‑128, p. 110. ↩︎
-
Anthony Giddens, A Contemporary Critic of Historical Materialism. Vol. 1 Power, Property and the State, Berkeley, University of California Press, 1981, p. 169. ↩︎
-
Ibid., p. 175. ↩︎
06.08.2019 à 02:00
Misère numérique
Les techniques ont toujours créé des formes de dépendances. C’est leur rôle, leur définition. Dans la lutte pour la survie dans un environnement hostile ou pour pallier les caprices du corps, la technologie a toujours été pour l’homme la source créative des supports cognitifs, mécaniques, biologiques. Mais par-dessus tout, fruits des apprentissages, elle suscite d’autres apprentissages encore : apprendre à utiliser des béquilles, apprendre à gérer ses doses d’insuline avec une pompe, apprendre à conduire une voiture, apprendre à utiliser un ordinateur, apprendre à utiliser Internet.
Les apprentissages fluctuent. Dans les années 1990, tous les utilisateurs ou presque de l’Internet grand public utilisaient le courrier électronique inventé 20 ans auparavant. « J’ai une adresse electronique », lançait-on à qui voulait l’entendre… et s’en fichait pas mal. L’époque a changé. Face aux grands chambardements de la « digitalization disruptive », des plateformes « ouine-ouine » et à la « start-up nation » qui prétend achever la grande transformation des services publics en services numériques (tout en inféodant le tout à des entreprises privées), le public ne retrouve plus ses billes.
Aujourd’hui, renforçant l’idée que le courrier électronique est d’abord un outil de travail, une pléthore d’utilisateurs ne connaissent d’Internet que les applications de médias sociaux et leurs messageries. Surtout chez les plus jeunes dont on nous faisait croire, pour mieux avaler la pilule, qu’ils savaient bien mieux se débrouiller dans un monde « digital » et qu’il ne fallait donc pas craindre pour leur avenir.
Quelle connerie, cette génération Y. Construction inique de marketeux malades soumis aux GAFAM. Le résultat : une dépendance de plus en plus grande vis-à-vis des monopoles, la centralisation de services, la concentration des capitaux et le pompage général des données. Même les plus grands scandales, des révélations de Snowden à Cambridge Analytica, ne semblent pas changer nos rapports quotidiens à ces plateformes.
Il faut l’intégrer, regarder la réalité en face : les usages et les pratiques d’Internet ne sont pas (et ne seront jamais) ce que les pouvoirs publics et le marketing nous en disent. Il faut lire l’étude de Dominique Pasquier, L’internet des familles modestes (2018) pour se faire une idée à peu près lucide des usages.
Zones rurales, quartiers pauvres, hyper centres urbains, les inégalités face aux usages des services numériques ne se résument pas aux inégalités d’accès aux réseaux. D’autres aspects doivent être pris en compte de manière prioritaire :
- compréhension des enjeux de la confidentialité et de la sécurité des données,
- apprentissage des protocoles de communication (et destination des usages) : courrier électronique, médias sociaux, messageries instantanées,
- rapports cognitifs aux contenus (savoir estimer la fiabilité d’un contenu, et donc la confiance à accorder et le degré d’attention qu’on peut lui prêter),
- etc.
Le modèle publicitaire des plateformes est un modèle de sectorisation et donc d’exclusion. Les bulles de filtres et autres usages qu’imposent Facebook, Twitter ou Google, par exemple, ne sont en fait qu’un aspect parmi d’autres où l’efficacité de l’usage des outils est conditionné par les choix permanents des utilisateurs. Ceux qui s’en sortent sont ceux qui ont les meilleures capacités à trier les contenus et gérer leur attention. Il se génère ainsi une charge mentale qui, avant cette numérisation généralisée des services, n’était pas nécessaire.
Faire croire une seconde que la connexion à un service public comme celui des impôts est indépendant de ces conditions cognitives et pratiques est un mensonge. Quels que soient les avantages qu’une partie de la population pourra trouver à pouvoir échanger à distance avec une institution publique, si on ne change pas d’urgence le modèle, les grandes inégalités qui existent déjà vont s’agraver.
Quel est ce modèle des services publics « numérisés » ? il se résume finalement à un principe simpliste : faire la même chose qu’avant mais par ordinateurs et applications interposés. Aucune remise en cause des organisations, des pratiques, du rapport au public.
Le couple ordinateur / Internet est à certaines administrations ce que l’hygiaphone était au guichet de La Poste il y a quarante ans. L’hygiaphone avait une fonction : instaurer plus de distance entre le préposé et l’usager. Au sommet : l’hygiaphone avec micro et haut-parleur, où même la voix humaine était devenue méconnaissable.
Désormais on a trouvé un moyen plus efficace de balancer une partie du travail administratif sur les usagers en rendant impossibles des demandes effectuées en présence. Invariablement, toute personne se rendant dans un centre des impôts ou une mairie en ressort avec une injonction : « rendez-vous sur internet pour faire votre démarche ». Et le pire, dans ces histoires, c’est que les préposés ne se posent jamais la question de savoir si la personne qu’ils renvoient ainsi dans les cordes numériques, sans ménagement, sont bel et bien en mesure de remplir les bonnes conditions d’usage du service numérique concerné. Corollaire : ces mêmes préposés scient aussi la branche de l’emploi dont ils dépendent.
Vous avez 80 ans avec une déclaration d’impôts un peu complexe ? Vous devez refaire votre carte d’identitié ? Un rendez-vous chez le médecin ? Remplissez des formulaires sur Internet, demandez des rendez-vous depuis une application… et si vous n’y parvenez pas, soit vous avez des enfants et des petits-enfants capables de vous aider, soit… rien.
Indiscutablement, les personnes âgées sont les premières victimes de cette misère numérique. C’était d’ailleurs l’objet du rapport des Petits Frères des Pauvres en 2018, intitulé « Exclusion numérique des peronnes âgées ». La misère numérique est sociale. Elle n’est plus seulement un clivage géographique entre zones rurales et zones urbaines, entre pays riches et pays pauvres.
La faute à la politique ? à l’économie ? On pourra invoquer toutes sorte de raisons pour lesquelles nos aînés aussi bien que les pauvres ou les jeunes précaires se trouvent tous doublement exclus. L’exclusion sociale et l’exclusion numérique vont de pair. On ne peut pas décorréler la question des usages numériques d’une lutte contre les inégalités sociales et économiques.
La transformation numérique des services publics s’est effectuée en excluant les utilisateurs. Tout changement technologique suppose une révision des organisations. Ici, il s’agit de l’ensemble de la société et pas seulement la réduction des effectifs des services. Imposer de tels changements dans les usages tout en conservant de vieux modèles de gestion est une mauvaise stratégie. Elle ne peut déboucher que sur l’exclusion.
Nos responsabilités individuelles ne sont pas pour autant exemptées. Renvoyer une personne âgée sur Internet lorsqu’elle vient effectuer une démarche administrative est un comportement inacceptable. Il est la preuve d’un service public mal rendu et le signe d’une indigence morale.
Quant à l’avenir, il se dessine déjà. D’aucuns pourraient penser que, habitués comme nous le sommes, nous n’aurons aucun mal à interagir avec ces services numériques lorsque nous aurons l’âge de nos aînés. C’est faire preuve de naïveté. D’abord, croire que la situation restera la même, avec les mêmes technologies et les mêmes usages. Ensuite, croire que nos capacités physiques et cognitives restent les mêmes qu’à vingt ans. Rien n’est plus faux. En entretenant ce genre de croyances nous construisons tous ensemble les cercueils numériques de nos vieux jours.
29.07.2019 à 02:00
Rocher de Mutzig-Schneeberg
Après plusieurs tournées du côté de ce massif fort connu des randonneurs (Rocher de Mutzig, Schneeberg), j’ai pu élaborer ce parcours réservé toutefois aux vététises confirmés. Il fera appel à un pilotage un peu engagé en cross-country (les descendeurs trouveront cela évidemment très facile). Les passages délicats seront signalés pour vous faire une idée précise. Des points de vue exceptionnels vous attendent et beaucoup de plaisir en descente.
La première remarque : ceux qui ont peur des dévers et n’aiment pas les longues montées monotones, passez votre chemin. Oui, le plaisir a un prix. Cependant, la distance totale est courte. Il ne s’agit que de 30 km avec un peu plus de 1100 m de dénivelé positif, du moins pour ce qui concerne la version « rapide » du parcours.
Une seconde remarque : sur la zone en question, notamment du côté de la commune de Wangenbourg-Egenthal, il existe tout un ensemble de circuits VTT fléchés (malheureusement la plupart du temps sur des grands chemins, cadre légal oblige), et nous en croiserons certains. Alors pourquoi un tel circuit supplémentaire ? Parce qu’il est conçu pour l’entraînement aussi : l’idée est de cumuler en peu de temps un maximum de dénivelé positif. Mais pour éviter les aspects pénibles d’un parcours uniquement dédié à cela, la zone offre une variété de terrain, ce qui romp la monotonie. Quant aux descentes, elles se feront de manière ludique.
Notez aussi que le Rocher de Mutzig est d’abord le royaume des randonneurs : soyez courtois et discret lorsque vous en croisez, en particulier sur les petits sentiers. Cela fait aussi partie des qualités de pilote que de rouler en sécurité.
Habituellement, sur le Rocher de Mutzig, la montée s’effectue via Lutzelhouse et descente du côté Porte de Pierre et col du Wildberg. Nous ferons tout l’inverse pour la première partie du parcours.
Le départ se fait depuis Oberhaslach. Garez-vous sur le parking de l’école, en tournant dans la petite rue au niveau de la mairie du village. Notez la présence de la fontaine, en façade, qui peut s’avérer utile en cas de terrain trop gras (mais ne faites pas ce circuit en temps de pluie).
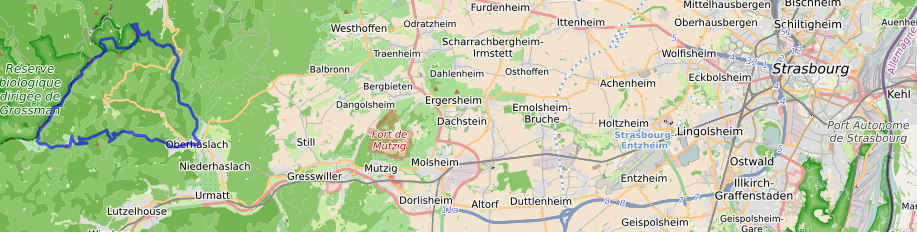
La carte du parcours ci-dessous montre le chemin le plus rapide du parcours. Je mentionne les variantes possibles.
La montée au Rocher de Mutzig
La montée sera longue. Dirigez-vous dans un premier temps (disques rouges) vers la maison forestière Weinbaechel. Dépassez cet endroit, puis suivez le chemin forestier. Tournez à gauche à l’intersection du GR532 et suivez le chemin forestier jusqu’au col du Wildberg. Variante : prenez les croix jaunes jusqu’au col du Wilberg avec un bon coup de mollet (80 m de dénivelé un peu raide) mais des récents travaux forestiers ont un peu gaché le chemin.
Au col du Wildberg, vous avez le choix :
- Suivez les croix bleues sur le chemin forestier puis les croix jaunes jusqu’à la Porte de Pierre. C’est à mon avis le plus simple. Une montée raide de 50 m vous attend une fois quittée le chemin forestier, et un seul portage juste en dessous de la Porte de Pierre.
- Ou bien suivez les croix jaunes d’emblée pour monter le Petit Katzenberg, mais il y aura plusieurs portages (au moins 3).
Juste après la Porte de Pierre et après avoir franchi quelques racines pénibles, vous pouvez monter sans problème jusqu’au Rocher de Mutzig. Le sentier est pierreux, il fera appel à votre sens de l’équilibre et à votre explosivité.
Du Rocher de Mutzig au Schneeberg
La descente du Rocher de Mutzig est très technique. Si vous ne le sentez pas, aucun problème, repartez sur vos pas et empruntez le chemin forestier jusqu’au Col du Narion. La descente technique, elle, se fait tranquillement une fois le terrain reconnu une ou deux fois auparavant. Si c’est la première fois que vous l’empruntez, ne présumez pas de vos réactions.
Attention aux randonneurs surtout ceux qui montent : s’ils ne sont pas vététistes, ils ne peuvent pas savoir où se placer pour vous laisser passer. Alors freinez, et laissez-les monter.
Depuis le Col du Narion, rejoignez le Altmatt via le large chemin forestier. Là encore vous avez le choix pour rejoindre le Elsassblick.
Le plus simple est de contourner le Grossmann par la Maison Forestière du Grossmann, prendre les croix bleues et le chemin forestier jusque Elsassblick.
Le plus amusant est d’emprunter la variante GR (rectangles blancs et rouges) qui est très jolie à cet endroit. Là vous aurez un festival de petits frissons. Certains passages avec un fort dévers (c’est carrément un ravin) vous laissent quelques 25 cm de chemin. Prudence. Un arbre a d’ailleurs été fourdroyé et a littéralement cassé le chemin : le portage peu être un peu délicat. Heureusement, il ne s’agit pas d’une descente : le chemin reste à niveau donc le risque est tout de même largement amoindri.
Surtout si vous passez à plusieurs, deux conseils : envisagez la présence des randonneurs (je me répète, je sais) et surtout restez attentifs, ne discutez pas, concentrez-vous sur ce que vous faites, pédale haute vers l’amont. Et tout se passera très bien.

Ensuite suivez toujours les rectangles blancs et rouges : prenez la route forestière sur quelques centaines de mètres et tournez vers le Eichkopf. Suivez toujours le GR mais méfiez-vous il faudra quitter le chemin large pour passer sous le Urstein (on loupe facilement cette bifurcation).
Ensuite, passez le col du Hoellenwasen, suivez toujours les rectangles blancs et rouges. Attention, un passage avec une descente très technique sur 40 m : je conseille même de descendre du vélo à cette occasion. Toujours sur le GR vous allez remonter, juste après cette descente, sur un chemin assez large. Vous quitterez ce chemin par les disques bleus pour rejoindre le GR 53 et monter au Schneeberg. Montez jusqu’au pied des rochers en franchissant les escaliers.
Descendre du Schneeberg
Une fois en haut des escaliers, il y a une petite place où vous pouvez faire une pause. Prenez ensuite un chemin non balisé qui serpente dans les myrtilles. C’est une descente un peu technique mais sans obstacle, traçée par d’autres vététistes, je suppose. Elle rejoint le GR en contrebas et le balisage des croix rouges.
Là encore vous avez le choix.
Soit vous prenez à gauche, en descente, jusqu’au croisement avec le chemin forestier des Pandours, que vous pouvez alors descendre tranquillement jusqu’au col du même nom. C’est du chemin large…
Soit vous prenez à droite et remontez un peu pour reprendre le sentier balisé croix rouges, passer l’abri du Schneeberg et rejoindre le chemin forestier des Pandours. La descente est encore une fois assez technique, et il y aura deux portages au moment de croiser d’autres chemins forestiers.
Col des Pandours
C’est la dernière étape après avoir traversé la route départementale 218. En empruntant le chemin forestier, vous suivrez les rectangles jaunes et blancs jusqu’au carrefour Anlagen puis les rectangles bleu (GR 531) jusqu’à Oberhaslach. Là c’est facile : c’est une très belle descente sur un sentier plutôt joueur. Une manière de terminer cette balade sur une note agréable.
Variante : du col des Pandours, poussez via les croix rouges vers le Carrefour du Brigadier Jérôme puis allez jusqu’au rocher du Pfaffenlap (très jolie vue). Ensuite, soit vous revenez sur le Carrefour Anlagen soit vous passez sur le Breitberg et, toujours en suivant les croix rouges, vous redescendez sur Oberhaslach via un sentier un peu moins joueur que l’autre (vous arrivez alors juste au-dessus de la Maison Forestière Ringenthal).
Dans les deux cas, reprenez les croix jaunes et rectangles bleus jusqu’au parking. Le tour est fini.
07.06.2019 à 02:00
Fuckapital
Il n’est pas toujours facile d’expliquer en quoi consiste le capitalisme de surveillance. C’est encore moins facile si l’approche que l’on choisit n’est pas tout à fait celle qui a le vent en poupe. Doit-on pour autant se contenter d’une critique édulcorée du capitalisme de surveillance ? Elle n’offre qu’une alternative molle entre un capitalisme immoral et un capitalisme supportable. Essayons de ne pas avoir à choisir entre la peste et le choléra.
Fuckapital. Dialogue à propos du capitalisme de surveillance
– Alors ça recommence, tu vas encore casser du sucre sur le dos de Madame Zuboff ?
– Maiiiis nooon. Que vas-tu imaginer ? Son travail sur le capitalisme de surveillance est exceptionnel. Et c’est justement pour cette raison qu’il est important d’un déceler les a priori et voir avec lesquels on peut ne pas être d’accord.
– Quoi par exemple ?
– La manière dont elle définit le capitalisme de surveillance.
– Oui, enfin… dans ce cas tu remets en cause tout son bouquin, The Age of Surveillance Capitalism.
– Non, non. J’ai déjà eu l'occasion d’en parler. Si elle ne cite pas les premiers chercheurs qui ont proposé cette notion (John Bellamy Foster et Robert W. McChesney), c’est parce que sa conception à elle est bien différente. Elle définit le capitalisme de surveillance à la manière d’un dictionnaire, avec une liste très bien faite détaillant sa polysémie. À lire cette définition, tout son livre est synthétisé (on salue au passage le talent). Mais ce n’est pas cela le problème. Je veux dire : le capitalisme de surveillance. C’est-à-dire la manière dont elle fait le lien entre les mécanismes du capitalisme et ceux du capitalisme de surveillance. En effet, pour elle, le capitalisme de surveillance est une évolution (néfaste) du capitalisme. Pour être plus exact, le capitalisme de surveillance est, selon elle, un exercice du capitalisme qui ne devrait pas fonctionner. Son livre est tout sauf une critique du capitalisme tel qu’il s’exerce aujourd’hui.
– Tu veux dire que, finalement, elle « détache » le capitalisme de surveillance du capitalisme tout court ? Comme si c’était une erreur de parcours ?
– Exactement. D’où la question : est-ce que le capitalisme de surveillance est une erreur de parcours du capitalisme ? Si oui, cela veut dire qu’il reste à le réglementer, comme on a (tenté de) réglementer les monopoles. Ce serait un peu comme on distingue le capitalisme « sauvage » et le capitalisme « apprivoisé », selon les orientations politiques d’un pays.
– Oui, je vois. Mais… C’est bien cela, non ? Regarde quelqu’un comme Hal Varian de chez Google, souvent cité par S. Zuboff. Ce type pense que pour améliorer notre « expérience utilisateur », il faut pomper toute notre vie privée, en réalité pour revendre ces données aux plus offrants et s’enrichir au passage. Ou bien ces allumés (doués) comme le germano-américain Peter Thiel, qui se disent libertariens. Si on les écoutait il n’y aurait presque plus d’État pour protéger nos libertés…
– Effectivement, Zuboff montre bien qu’il y a un grand danger dans ce laisser-faire. Cela va même beaucoup plus loin, puisque que grâce aux technologies dont ils ont le monopole, ces grands acteurs économiques que sont les GAFAM, sont capables non seulement de tout savoir de nous mais surtout d’influencer nos comportements de telle manière que le marché lui-même est modelé pour calibrer nos comportements, nos savoirs, et nos vies en général. Pour Zuboff, cela met en danger la démocratie libérale, c’est-à-dire cette démocratie basée sur les droits et les libertés civils. Mais justement, c’est-là tout le paradoxe qu’elle ne pointe pas : c’est bien grâce à ce libéralisme qu’il est possible de vivre dans une économie capitaliste. Dès lors, si le capitalisme de surveillance est un excès du capitalisme, et donc du libéralisme, le remettre en cause revient à questionner les raisons pour lesquelles, à un moment donné, la démocratie libérale a échoué. Cela revient à critiquer les politiques libérales des 10, 20, 30, 50 dernières années. Pour cette raison il faut non seulement en faire l’histoire mais aussi la critique et au moins tenter de proposer une porte de sortie. On a beau lire le livre de Zuboff, on reste carrément coincé.
– Je te vois venir : évidement tu arrives en grand sauveur… tu vas dévoiler la vérité. On connaît la chanson.
– Pas moi ! John Bellamy Foster et Robert W. McChesney ont déjà pointé la direction dans laquelle il faut absolument réfléchir : déconstruire les mécanismes du capitalisme de surveillance, c’est obligatoirement en faire une histoire pour comprendre comment le libéralisme a créé des bulles hégémoniques (à la fois politiques et économiques) à la source d’un modèle de domination dont les principaux instruments sont les technologies d’information et de la communication. Eux le font sur l’histoire politique. Moi, je compte proposer une approche plutôt axée sur l’histoire des technologies, mais pas uniquement.
– Mais attends une minute. J’ai vu une conférence de Zuboff donnée à Boston en janvier 2019 à la suite de la sortie de son livre. Je l’ai trouvée passionnante. Elle expliquait comment les pratiques du capitalisme de surveillance sont bien celles du capitalisme en général. Elle ne le détache pas de l’histoire.
– Vas-y, développe.
– Elle parlait de la tradition capitaliste. La manière dont évolue le capitalisme en s’accaparant des choses qui « vivent » en dehors du marché pour les introduire dans le marché, c’est-à-dire transformer en quelque chose qui peut être vendu et acheté.
– Heu.. si on réduit le capitalisme à un marché d’échange, dans ce cas, l’humanité à toujours vécu dans le capitalisme. C’est un peu léger. À moins que tu suggères par là que le capitalisme implique de tout transformer en biens marchands, y compris ce qui est censé y échapper comme les biens communs, les services publics, la santé, l’environnement, etc. Et dans ce cas, oui, c’est bien le cas, mais on enfonce des portes ouvertes.
– Certes. C’est même très orienté de penser les choses ainsi. Mais attends. Elle précise tout de même. Le capitalisme industriel procède de cette manière et accapare la nature pour la transformer en biens destinés à l’échange. De la même manière encore, notre force physique (un élément naturel) s’est trouvé valorisé sur le marché en tant que force de travail. Et encore de la même manière, ce qu’elle appelle notre expérience humaine privée se retrouve sur le marché du capitalisme de surveillance. Il y a ainsi un marché de nos données comportementales, avec des calculs prédictifs, des paris sur nos comportements futurs, bref, on marchande nos âmes, tu vois ce que je veux dire ?
– Mouais… Quoique… il faudrait encore savoir ce qu’on entend par capitalisme, dans ce cas. L’un des gros problèmes des libéraux, c’est qu’ils pensent que le capitalisme a toujours existé. Oups… non, ce n’est pas correct de ma part. Disons qu’il y a plusieurs acceptions du capitalisme et que leurs histoires sont relatives. Par exemple, la propriété des biens de production est un principe qui ne date pas uniquement du XIXe siècle ; la création de biens marchands est une activité qui date d’aussi loin que l’économie elle-même ; et pour ce qui concerne l’accumulation de capital, tout dépend de savoir si on se place dans un capitalisme modéré par l’État (dans ce cas, s’il y a une monarchie, n’importe qui ne peut pas accumuler le capital, n’est-ce pas) ou si on se place dans un régime libéral, auquel cas, soit c’est la fête du slip soit il y a tout de même des gardes-fous, voire des contradictions, selon les orientations politiques du moment.
– D’accord, mais quel rapport avec le capitalisme de surveillance d’aujourd’hui ?
– Attends, je n’ai pas fini là dessus. Il faut lire l’économiste Bruno Amable, par exemple, qui distingue géographiquement et culturellement différents modèles du capitalisme dans le monde (modèle européen, modèle asiatique, modèle méditerranéen, ou bien modèle socio-démocrate et modèle néolibéral). Et comme il y a plusieurs modèles du capitalisme, il y a aussi plusieurs manières d’envisager là où s’exerce le capitalisme selon les secteurs économiques. Par exemple le capitalisme financier, le capitalisme industriel ou bien… le capitalisme de surveillance, donc. Ce sont des formes du capitalisme.
– Tu veux dire que Zuboff dresse une filiation du capitalisme de surveillance avec un capitalisme fantasmé? qui n’existe pas en réalité ?
– Je veux dire que le capitalisme en général n’est pas ce qu’en dit Zuboff, mais ce n’est pas le plus important. Ce que fait Zuboff, c’est qu’elle sort le capitalisme de surveillance de l’histoire elle-même. Ses références historiques ne concernent que l’histoire fleuve du capitalisme dont elle imprime les mécanismes sur des pratiques (qu’on appelle la surveillance, la dataveillance, l’uberveillance, etc.) d’aujourd’hui alors que ces mêmes pratiques ont forcément une origine qui ne date pas d’hier. Elles ont elles aussi une histoire. Et dès lors qu’elles ont une histoire, le capitalisme auquel elles se rattachent n’est pas uniforme. Et attention, je n’oppose pas pour autant une approche matérialiste, mais c’est trop long pour t’expliquer maintenant.
– C’est pour cela que tu vas en faire une archéologie, parce que cette histoire nous est cachée ?
– En tout cas les vestiges ne sont pas directement visibles, il faut creuser. Par exemple, le capitalisme des années 1950-1960-1970 est un capitalisme qui a vu naître le consumérisme de masse, des technologies de marketing, et en même temps il se trouvait hyper-régulé par l’État, si bien que les pratiques de surveillance sont en réalité des pratiques qui naissent avec les institutions, l’économie institutionnelle : les secteurs bancaires, assurantiels, et les institutions publiques aussi. L’hégémonie des grosses entreprises monopolistiques est d’abord une hégémonie qui relève de l’économie politique, en particulier celle des États-Unis, mais pas uniquement. Par la suite, la libéralisation des secteurs a créé d’autres formes encore de ce capitalisme de surveillance. Et dans toutes ces histoires, il faut analyser quelles technologies sont à l’œuvre et quelles sont les tensions sociales qu’elles créent.
– Pfou… c’est nébuleux, tu peux donner un exemple ?
– Prenons l’exemple de la valorisation de l’information en capital. C’est un principe qui existe depuis fort longtemps. Si on prend plus exactement l’information personnelle qui relève de la vie privée ou ce que Zuboff appelle notre expérience humaine privée. Qu’est-ce que c’est ? jamais la même chose. Ce n’est pas une donnée naturelle dont le capitalisme se serait emparé pour la « mettre » sur le marché. D’abord ce qu’on appelle « vie privée » est une notion qui est définie dans le droit américain de manière très malléable depuis la fin du XIXe siècle, et cette notion n’a d’existence juridique en Europe dans un sens approchant celui d’aujourd’hui que depuis la seconde moitié du XXe siècle, de plus, selon les pays ce n’est pas du tout la même chose. Dans ce cas, quel est vraiment le statut des modèles mathématiques puis informatiques des analyses marketing, d’abord théorisés dans les années 1940 et 1950, puis informatisés dans la seconde moitié des années 1960 ? Par exemple, en 1966, DEMON (Decision Mapping via Optimum Go-No Networks), dédié à l’analyse prédictive concernant « la commercialisation de nouveaux biens de consommation avec un cycle d’achat court ». Ces systèmes utilisaient bien des informations personnelles pour modéliser des comportements d’achats et prédire les états du marché. Ils se sont largement améliorés avec l’émergence des systèmes de gestion de base de données dans les années 1980 puis du machine learning des années 2000 à aujourd’hui. Ces technologies ont une histoire, la vie privée a une histoire, le capitalisme de surveillance a une histoire. Les évolutions de chacune de ces parties sont concomitantes, et s’articulent différemment selon les périodes.
– Tout cela n’est manifestement pas né avec Google.
– Évidemment. Il n’y a pas des « capitalistes de la surveillance » qui se sont décidés un beau jour de s’accaparer des morceaux de vie privée des gens. C’est le résultat d’une dynamique. Si le capitalisme de surveillance s’est généralisé à ce point c’est que son existence est en réalité collective, sciemment voulue par nous tous. Il s’est développé à différents rythmes et ce n’est que maintenant que nous pouvons le nommer « capitalisme de surveillance ». C’est un peu comme nos économies polluantes dont nous avons théorisé les impacts climatiques qu’assez récemment, même si en avions conscience depuis longtemps : qui prétend jeter la première pierre et à qui exactement ? Est-ce que d’ailleurs cela résoudrait quelque chose ?
– Oui, mais à lire Zuboff, on a atteint un point culminant avec l’Intelligence artificielle, les monopoles comme Google / Alphabet et le courtage de données. Tout cela nous catégorise et nous rend économiquement malléables. C’est vraiment dangereux depuis peu de temps, finalement.
– À partir du moment où nous avons inventé le marketing, nous avons inventé le tri social dans le capitalisme consumériste. À la question « pourquoi existe-t-il un capitalisme de surveillance ? », la réponse est : « parce qu’il s’agit d’un moyen efficace de produire du capital à partir de l’information et du profilage des agents économiques afin d’assurer une hégémonie (des GAFAM, des États-Unis, ou autre) qui assurera une croissance toujours plus forte de ce capital ».
– Mais tu es bien d’accord avec l’idée que ce capitalisme est une menace pour la démocratie, ou du moins que le capitalisme de surveillance est une menace pour les libertés. Mais enfin, si tu prétends que cette histoire a plus de 50 ans, ne penses-tu pas que les régimes démocratiques auraient pu y mettre fin ?
– Dans les démocraties occidentales, les politiques libérales ont toujours encouragé les pratiques capitalistes depuis près de trois siècles, à des degrés divers. Elles se sont simplement radicalisées avec des formes plus agressives de libéralisme qui consistaient à augmenter les profits grâce aux reculs progressifs des régulations des institutions démocratiques et des protections sociales. Si d’un côté des lois ont été créés pour protéger la vie privée, de l’autre côté on a libéré les marchés des télécommunications. Tout est à l’avenant. Encore aujourd’hui par exemple, alors qu’on plaide pour rendre obligatoire l’interopérabilité des réseaux sociaux (pour que les utilisateurs soient moins captifs des monopoles), les politiques rétorquent qu’un tel principe serait « excessivement agressif pour le modèle économique des grandes plateformes ».
– Des luttes s’engagent alors ?
– Oui mais attention à ne pas noyer le poisson. Focaliser sur la lutte pour sauvegarder les libertés individuelles face aux GAFAM, c’est bien souvent focaliser sur la sauvegarde d’un « bon » libéralisme ou d’un « capitalisme distributif » plus ou moins imaginaire. C’est-à-dire vouloir conserver le modèle politique libéral qui justement a permis l’émergence du capitalisme de surveillance. Comme le montre ce billet, c’est exactement la brèche dans laquelle s’engouffrent certains politiques qui ont le beau jeu de prétendre défendre les libertés et donc la démocratie.
– C’est déjà pas mal, non ?
– Non. Parce que lutter contre le capitalisme de surveillance uniquement en prétendant défendre les libertés individuelles, c’est faire bien peu de cas des conditions sociales dans lesquelles s’exercent ces libertés. On ne peut pas mettre de côté les inégalités évidentes que créent ces monopoles et qui ne concernent pas uniquement le tri social du capitalisme de surveillance. Que dire de l’exploitation de la main d’œuvre de la part de ces multinationales (et pas que dans les pays les plus pauvres), sans compter les impacts environnementaux (terres rares, déchets, énergies). Si on veut lutter contre le capitalisme de surveillance, ce n’est pas en plaidant pour un capitalisme acceptable (aux yeux de qui ?) mais en proposant des alternatives crédibles, en créant des solutions qui reposent sur l’entraide et la coopération davantage que sur la concurrence et la croissance-accumulation sans fin de capital. Il ne faut pas lutter contre le capitalisme de surveillance, il faut le remplacer par des modèles économiques et des technologies qui permettent aux libertés de s’épanouir au lieu de s’exercer dans les seules limites de l’exploitation capitaliste. Fuck le néolibéralisme ! Fuck la surveillance !
– Bon, tu reprends une bière ?
28.05.2019 à 02:00
Rédiger et manipuler des documents avec Markdown
Rédiger des documents et élaborer un flux de production implique d’envisager clairement le résultat final. Formulé ainsi, cela pourra toujours sembler évident : que voulez-vous faire avec votre document ? À qui le destinez-vous ? Pour quels usages ? Après avoir livré quelques considérations générales relatives à la stratégie j’expliquerai comment j’envisage la rédaction de documents (souvent longs) avec Markdown vers ODT ou LaTeX.
Quelques considérations préalables
Rédiger un document avec LibreOffice, MSWord, LaTeX (ou d’autres logiciels de traitement de texte) c’est circonscrire le flux de production aux capacités de ces logiciels. Attention, c’est déjà beaucoup ! Les sorties offrent bien souvent un large choix de formats selon les besoins. Cela dit, une question peut se poser : ne serait-il pas plus logique de séparer radicalement le contenu du contenant ?
Après tout, lorsqu’on rédige un document avec un logiciel de traitement de texte, chercher à produire un format compatible consiste à produire un format qui sera non seulement lisible par d’autres logiciel et sur d’autres systèmes, mais aussi que sa mise en page soit la même ou quasi-similaire. Finalement, on veut deux choses : communiquer un format et une mise en page.
Voici quelques années que je fréquente différents logiciels dans le cadre de la rédaction et de l’édition de documents, à commencer par LibreOffice et LaTeX. Compte-tenu des pratiques actuelles de stockage dans les nuages et la sempiternelle question du partage de documents et de la collaboration en ligne, j’en suis arrivé à une conclusion : écrire, manipuler, partager, modifier un document déjà mis en forme par un logiciel de traitement de texte est une erreur. Les formats utilisés ne sont que très rarement faits pour cela (il y a bien sûr des exceptions, comme le XML, par exemple, mais nous parlons ici des pratiques les plus courantes).
Tous les formats propriétaires sont à bannir : leur manipulation est bien trop souvent source d’erreur, et suppose un enfermement non seulement de la chaîne de production mais aussi des utilisateurs dans un écosystème logiciel exclusif. Sitôt qu’un écart minime se forme dans cette chaîne, c’est fichu.
Les formats ouverts sont bien plus appropriés. Justement parce qu’ils sont ouverts, leur compatibilité pose d’autant moins de souci. Il subsiste néanmoins toujours des risques lorsque des logiciels propriétaire entrent dans la chaîne de production parce que tous les utilisateurs n’ont pas les mêmes outils.
La faiblesse ne concerne pas uniquement ces formats ou ces logiciels mais elle réside aussi dans leur manipulation. Même si on accepte de travailler (au prix de nos libertés et de notre confidentialité) avec des services comme ceux de Google ou Microsoft, et même si on utilise des solutions libres et ouvertes comme OnlyOffice ou LibreOffice Online, l’enjeu auquel nous faisons toujours face est le suivant : en ligne ou en local, choisir un logiciel de traitement de texte revient à restreindre d’emblée l’usage futur de la production en choisissant par avance son format final et sa mise en page.
Faire ce choix n’est pas interdit (et heureusement !). C’est d’ailleurs celui qui prévaut dans la plupart des situations. Il faut seulement l’assumer jusqu’au bout et manœuvrer de manière assez efficace pour ne pas se retrouver « coincé » par le format et la mise en page choisis. Là aussi, il faut réfléchir à une bonne stratégie de production et conformer toute la chaîne au choix de départ.
D’autres solutions peuvent être néanmoins adoptées. Au même titre que la règle « faites votre mise en page en dernier » doit prévaloir pour des logiciels wysiwyg, je pense qu’il faudrait ajouter un autre adage : « choisissez le format le plus basique en premier ». Cela permet en effet de produire du contenu très en amont de la phase finale de production et inclure dans cette dernière la production du format à la demande.
Quels choix ?
En d’autre termes, si votre éditeur, votre directeur de thèse, vos collègues ou vos amis, vous demandent un .odt, .doc, un PDF, un .epub, un .texou un .html, l’idéal serait que vous puissiez le produire à la demande et avec une mise en page (ou une mise en forme s’il s’agit d’un document .tex, par exemple) différente et néanmoins appropriée. Pour cela, il faut impérativement :
- connaître une méthode sûre pour convertir votre document,
- connaître les possibilités de mise en forme automatiques à configurer d’avance pour produire le document final.
Autrement dit, avant même de commencer à produire votre contenu (que vous allez détacher absolument de la forme finale), vous devez élaborer tout un ensemble de solutions de conversion et de mise en forme automatiques.
Rien de bien nouveau là-dedans. C’est exactement la même stratégie que l’on emprunte lorsqu’on rédige un contenu le formatant à l’aide d’un langage balisé comme le HTML ou (La)TeX. On ne fait alors que produire un document texte formaté et, parallèlement, on crée des modèles de mise en page (.css pour le HTML, ou des classes .cls pour LaTeX). La sortie finale emprunte alors les instructions et les modèles pour afficher un résultat.
L’idée est d’adopter cette démarche pour presque n’importe quel format. C’est-à-dire :
- créer du texte à l’aide d’un éditeur de texte et choisir un langage de balisage facile à l’utilisation et le plus léger possible : le Markdown est à ce jour le meilleur candidat ;
- convertir le document en fonction de la demande et pour cela il faut un convertisseur puissant et multi-formats : Pandoc ;
- créer des modèles de mise en page (pour les réutiliser régulièrement si possible).
Avantages
Les avantages de Markdown sont à la fois techniques et logistiques.
D’un point de vue technique, c’est sur la syntaxe que tout se joue. Comme il s’agit d’un balisage léger, le temps d’apprentissage de la syntaxe est très rapide. Mais aussi, alors qu’on pourrait considérer comme une faiblesse le fait que Markdown ne soit pas standardisé, il reste néanmoins possible d’adapter cette syntaxe en lui donnant un saveur particulière. C’est le cas de Multimarkdown, une variante de Markdown permettant des exports plus spécialisés. Ainsi, plusieurs fonctionnalités sont ouvertes lorsqu’on destine un document Markdown à la conversion avec Pandoc. On retient surtout les tables, les notes de bas de page et la gestion bibliographique ou d’index. Enfin, il est toujours possible d’inclure du code HTML ou même LaTeX dans le document source (parfois même les deux, en prévision d’une conversion multiple).
Pour ce qui concerne le travail Markdown + Pandoc + LaTeX, on peut se reporter à l’article que j’avais traduit sur ce blog : « un aperçu de Pandoc ».
Pour ce qui concerne la pérennité d’un fichier markdown, tout comme n’importe quel fichier texte, il sera toujours lisible et modifiable par un éditeur de texte, ce qui n’est pas le cas des formats plus complexes (exceptés les formats ouverts).
D’un point de vue logistique, la manipulation a plusieurs avantages, bien qu’ils ne soient pas réservés au seul format Markdown :
- les éditeurs de texte sont des logiciels très légers par rapport aux « gros » logiciels de traitement de texte, si bien que travailler sur un document Markdown ne nécessite que peu de ressources (et il y a un grand choix d’éditeurs de texte libres),
- on peut aisément travailler à plusieurs sur un document texte en utilisant des services en ligne légers comme des pads (par exemple sur framapad.org ou cryptpad),
- ce qui n’empêche pas l’utilisation de logiciels en ligne plus classiques, pourvu que l’export puisse se faire en texte ou dans un format qui permet la conversion « inverse » vers le Markdown (ou alors de simples copier/coller),
- on peut utiliser facilement un dépôt Git pour synchroniser ses fichiers et retrouver son travail où que l’on soit (ou collaborer avec d’autres utilisateurs),
- le fait de séparer le contenu de la forme permet de se concentrer sur le contenu sans être distrait par les questions de mise en page ou une interface trop chargée (c’est aussi un argument pour LateX, sauf que la syntaxe plus complexe contraint en fait le rédacteur à organiser son texte selon les critères « logiques » de la syntaxe, ce qui est aussi respectable).
Mon système à moi
J’en avais déjà parlé dans un autre billet sur Markdown, Pandoc HTML et LaTeX, aussi il y aura des répétitions…
J’utilise LibreOffice ou LaTeX ou la HTML en seconde instance. Dans la mesure du possible j’essaie de rédiger d’abord en Markdown, puis de convertir.
Je procède ainsi dans les cas de figure suivants (liste non exhaustive) :
- la rédaction d’un billet de blog (inutile de convertir car mon moteur de blog utilise le Markdown et converti tout seul en HTML),
- la rédaction de notes (pour une réunion ou un texte court) que je converti en PDF en vue d’une diffusion immédiate,
- la rédaction d’un document long que je produirai en PDF via LaTeX,
- la rédaction d’un document long que je produirai en HTML et/ou epub,
- la rédaction d’un document long que convertirai en ODT dans le cadre d’un projet éditorial,
- la rédaction d’un article que je destine à une diffusion en HTML et/ou epub.
Pour convertir avec Pandoc, la moulinette de base est la suivante (ici pour du .odt) :
pandoc fichier-de-depart.md -o fichier-de-sortie.html
Ensuite tout est une question d’ajout d’options / fonctions dans la ligne de commande.
Les difficultés sont les suivantes (je ne reviens pas sur le mode d’emploi de Pandoc, l’usage des templates, etc.).
Les styles
La gestion des styles dans la conversion en .odt dans LibreOffice n’est pas évidente. Le mieux est encore d’utiliser un modèle qui prenne en compte les styles que Pandoc produit lors de la conversion. En effet, la grande force de LibreOffice, ce sont les styles (voir cet ouvrage). Dès lors il est important que vous puissiez opérer dessus une fois votre document au format ODT.
Pour faire simple, il n’est pas utile de spécifier un modèle lors de la conversion avec Pandoc. Il faut la plupart du temps se contenter de produire le document en .odt puis appliquer les styles voulus. Pour aller vite, voici ce que je conseille de faire :
- rédigez une fois un document Markdown avec toutes les marques de formatage que vous voulez,
- convertissez-le en
.odt, - ouvrez le
.odtavec LibreOffice et modifiez les styles que Pandoc a créé, - sauvegardez ce document,
- puis à chaque fois que vous devrez produire un document similaire, effectuez un simple transfert de style en suivant la méthode expliquée pages 64-66 de cet ouvrage.
Pour gérer les styles en vue d’une production de document HTML/epub ou LaTeX/PDF, le mieux est encore de créer ses classes .css et/ou .cls et/ou .sty et d’y faire appel au moment de la conversion. On peut aussi intégrer l’appel à ces fichiers directement dans le template, mais faut dans ce cas donner leur nom, ce qui n’est pas pratique si l’on souhaite avoir plusieurs styles de mise en page à disposition et changer à la volée.
Par exemple, pour une sortie HTML :
pandoc --template=modele.html -H monstyle.css fichier-de-depart.md -o fichier-de-sortie.html
(notez que l’appel au fichier .css peut très bien être déjà inclus dans le modèle)
La bibliographie
J’ai indiqué dans cet article comment utiliser Pandoc avec une bibliographie. L’essentiel est de comprendre que, quel que soit le format de sortie choisi, il faut que votre bibliographie soit enregistrée dans le format de bibliographie par excellence, bibtex (.bib). Puis :
- si vous voulez sortir un fichier pour LaTeX, la bibliographie se gérera avec Biblatex (on ajoutera l’option
--biblatexdans la ligne de commande), - si vous voulez sortir des fichiers HTML, ou ODT, avec une mise en forme de la bibliographie, il faut aussi installer Citeproc, un jeu de programmes auxquels Pandoc fera appel pour appliquer des instructions de configuration en CSL Citation Style Language.
Concernant les styles de bibliographie obtenus en CSL, le mieux est encore d’utiliser le logiciel Zotero. Il peut vous servir à créer votre bibliographie (il est très pratique grâce à son extension pour Firefox) ou simplement ouvrir votre .bib obtenu par un autre logiciel, peu importe. Comme Zotero permet d’exporter des éléments bibliographiques formatés, il permet aussi de jouer avec les styles CSL disponibles sur ce dépôt. Si vous trouvez votre bonheur, conservez le fichier .csl de votre style ou bien utilisez l'éditeur en ligne pour en créer un de toutes pièces ou modifier un modèle existant.
Notez que la conversion vers le format .odt avec une bibliographie formatée avec un modèle .csl ne vous produira pas une bibliographie comme si vous l’aviez obtenu avec l’extension Zotero dans LibreOffice et des références dynamiques. Au contraire, selon la mise en forme choisie vous aurez vos éléments bibliographiques dans votre document (y compris avec une bibliographie à la fin) mais il faudra re-compiler si vous changez des éléments bibliographiques. N’oubliez pas que vous devez prendre en compte toute la chaîne depuis votre format de départ (c’est pareil avec LaTeX : il faut recompiler si on met la biblio ou l’index à jour).
Git : travailler dans l’cloude
Comme il m’arrive tous les jours d’utiliser au moins deux ordinateurs différents, j’ai choisi d’utiliser Git lorsque je dois rédiger des documents longs sur une longue période de temps. Là encore, l’avantage d’utiliser de simples fichiers texte, permet de jouer sur la rapidité et la flexibilité de Git. On peut aussi se payer le luxe (selon les programmes disponibles sur le serveur) de configurer des jobs qui permettent, une fois uploadé(s) le(s) fichier(s) Markdown, de créer automatiquement les sorties voulues. Si Pandoc est installé, vous pouvez une fois pour toute configurer votre dépôt pour créer l’artefact à chaque fois.
il est donc inutile de s’encombrer localement (et encombrer le dépôt avec) des fichiers de sortie à moins de les tracer avec Git LFS (cf. ci-dessous).
Concernant les fichiers binaires, trop volumineux, les illustrations, etc. , il faut utiliser GIT LFS qui permet de trier et tracer les fichiers qu’il est inutile de recopier en doublon à chaque fois sur le serveur.
Choisir un bon éditeur
Non, il ne s’agit pas de l’éditeur de la collection où vous allez publier votre livre. Il s’agit de l’éditeur de texte.
Pour ceux qui sont habitués à utiliser à chaque fois un logiciel de traitement de texte wysiwyg pour écrire, il pourrait à première vue sembler bien austère de choisir un logiciel avec une interface moins fournie (en apparence, en tout cas) pour écrire. Et pourtant, que de tranquillité ainsi gagnée !
Tout d’abord un bon éditeur est un éditeur avec coloration syntaxique. Avec cela, les éléments importants de la syntaxe Markdown, ainsi que les titres, les mots en italique, etc., apparaissent en évidence. Ensuite, un bon éditeur de texte est presque entièrement configurable : il vous sera très bénéfique de configurer selon vos goûts le thème de la coloration syntaxique et de l’interface, ainsi que la police. Cela vous assurera surtout un confort d’écriture.
Certains éditeurs sont spécialisés en Markdown, tel Ghostwriter. Mais vous pouvez toujours utiliser des éditeurs destinés à la programmation mais disposant de tout ce qu’il faut pour écrire en Markdown. Certains sont de véritable machines à tout faire (et intègrent souvent une extension pour gérer un dépôt Git), tel Atom ou Geany, d’autres sont des éditeurs de textes historiques du Libre, plus difficiles au premier abord, comme Vi ou Emacs (et avec un grand choix d’extensions). Et il y a ceux qui sont beaucoup plus simples (Gedit, Kate, Notepad++).
Inutile ici de s’étendre sur les centaines d’éditeurs de texte libres et disponibles pour tout un chacun. L’essentiel est de comprendre qu’un bon éditeur est d’abord celui qui conviendra à votre usage et qui vous permettra d’écrire confortablement (esthétique et ergonomie).
Quels outils de production ?
Pour terminer ce billet, voici les éléments pour créer mon flux de production (du moins celui auquel je me conforme le plus possible).
| Format | Outils | Fichiers | Résultats |
|---|---|---|---|
| Markdown | Pandoc + biblatex | .md, .bib, template .tex, .cls, .sty |
TeX (et PDF) |
| Markdown + .bibtex | Pandoc + CSL | .md, .bib, .csl, .css, template .html |
HTML |
| Markdown + .bibtex | Pandoc + CSL | .md, .bib, .csl |
ODT |
Logiciels utilisés :
- éditeurs : Gedit, Ghostwriter, Atom, Zettlr (cela dépend de mon humeur) ;
- Pour synchroniser et stocker en ligne : Git et Gitlab, ou bien une instance Nextcloud ;
- LaTeX (éditeur de texte classique ou Texmaker) ;
- LibreOffice pour un traitement de texte autre que LaTeX ;
- JabRef et Zotero pour la gestion bibliographique (parfois un simple éditeur de texte).
Concernant la rédaction d’un ouvrage à paraître bientôt, voici comment j’ai procédé tout au long du processus d’écriture :
- rédaction des parties (un fichier par partie) en Markdown avec Ghostwriter la plupart du temps (il dispose d’un outil de visualisation de table des matières fort pratique) ;
- Zotero ouvert sans interruption pour entrer les références bibliographiques au fur et à mesure et insérer leurs IDs dans le document en référence ;
- synchronisation à chaque fin de session de travail avec Git (une instance Gitlab), et une requête de récupération à chaque début de session ;
- pour donner à l’éditeur un « manuscrit » en ODT suivant ses prescriptions : conversion avec Pandoc et un fichier CSL pour la bibliographie : la collaboration avec l’éditeur se fera sur Libreoffice (mise en forme, suivi de corrections).
- à venir : récupération du travail fini en Markdown et export HTML/epub pour la postérité.
Ajoutons à cela que l’usage du Markdown tend à se prêter à bien d’autres situations. Ainsi ce blog est écrit entièrement en Markdown, mes courriels le sont parfois, le logiciel qui me permet de prendre des notes et de les synchroniser sur un serveur utilise le Markdown (j’utilise alternativement Joplin ou Notes de Nextcloud, et de temps à autre Firefox Notes). En somme, autant de situations qui me permettent d’écrire, synchroniser et exporter : le Markdown est omniprésent.
- Persos A à L
- Carmine
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- Lionel DRICOT (PLOUM)
- EDUC.POP.FR
- Marc ENDEWELD
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Christophe LEBOUCHER
- Michel LEPESANT
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Jean-Luc MÉLENCHON
- MONDE DIPLO (Blogs persos)
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Thomas PIKETTY
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- LePartisan.info
- Numérique
- Thomas BEAUFILS
- Blog Binaire
- Christophe DESCHAMPS
- Dans les Algorithmes
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Fake Tech (C. LEBOUCHER)
- Romain LECLAIRE
- Tristan NITOT
- Francis PISANI
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Scientifiques en Rebellion
- Bondy Blog
- Dérivation
- Économistes Atterrés
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- Rojava Info
- X-Alternative
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- Laura VAZQUEZ
- XKCD