29.06.2026 à 07:42
Khrys’presso du lundi 29 juin 2026
Khrys
Texte intégral (12280 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- 85 % des ados australien·nes utilisent les réseaux sociaux 3 mois après l’interdiction (next.ink)
- Corée du Nord : Kim Jong-un annonce que des navires militaires sont en train d’être équipés d’armes nucléaires (rfi.fr)
- Forced ‘Repentance’ : How Azerbaijan uses apology videos to control society (meydan.tv)
- Guerre en Ukraine : sans doute la plus vaste attaque ukrainienne depuis 2022, plus de 600 drones frappent la Russie en une nuit, le pont de Crimée de nouveau bloqué (lindependant.fr)
- Des supporters du Panathinaikos soutiennent les grévistes de la faim de Prosfygika (dialectik-football.info)
Depuis 16 ans, environ 400 habitants participent à un projet autogéré et communautaire dans le quartier de Prosfygika, situé entre le commissariat central et le tribunal d’Athènes. Ils y occupent et font vivre huit blocs d’immeubles, comptant 228 appartements, construits dans les années 30. Depuis plusieurs mois maintenant, les autorités régionales de l’Attique cherchent à évacuer le quartier pour remettre la main sur ces immeubles dans le cadre d’un plan de rénovation urbaine. Face à ce qui a tous les traits d’une opération de gentrification, la communauté de Prosfygika ne se laisse pas faire et exige l’annulation de ce projet, lui préférant une rénovation autogérée et le maintien de leur auto-organisation.
- Massacre de Thiaroye : des fouilles pour rétablir la vérité (lisbethmedia.com)
la France continue à maintenir le flou autour de cette tragédie de l’histoire coloniale en restreignant l’accès aux archives censées la documenter. Face à cette obstruction, le Sénégal organise des campagnes de fouilles archéologiques, dont la deuxième a débuté le 15 juin. Le but : “faire parler la vérité du sol.”
- 7 graphiques pour comprendre le basculement démographique de la Tunisie. (inkyfada.com)
En 2014, la Tunisie enregistrait 225 887 naissances. Dix ans plus tard, à peine 126 401, près de moitié moins.
- Coupe du monde : déjà 23 000 km parcourus en jet privé par le président de la Fifa (reporterre.net)
Agir contre le péril climatique ? Très peu pour lui. D’après les informations du Guardian, le président de la Fifa, Gianni Infantino, utiliserait un jet privé fourni par Qatar Airways (sponsor de la Coupe du monde de football) afin d’assister à deux matchs par jour.
- +1,2 cm par an : les SUV grandissent et cannibalisent l’espace public (reporterre.net)
Selon un rapport des ONG Transport&Environment (T&E) et Clean Cities, paru le 24 juin, la taille moyenne des véhicules neufs vendus en Europe gagne 1,2 cm par an depuis l’an 2000.
- Stationnement et sécurité routière : les SUV dans le viseur de Fédération européenne des transports et de l’environnement (franceinfo.fr)
- Aramco, champion du monde des émissions (multinationales.org)
C’est la multinationale la plus émettrice de gaz à effet de serre au niveau mondial, selon les calculs du projet Carbon Majors. Aramco, l’entreprise pétrolière saoudienne, pesait pour 4,3 % des émissions globales en 2024.
- Tycoons Swoop in on the Clean Energy Boom, Raising Prices for Consumers : A story in 6 parts (pcij.org)
- Climat : 50 ans d’alertes des scientifiques et d’immobilisme de nos dirigeants (basta.media)
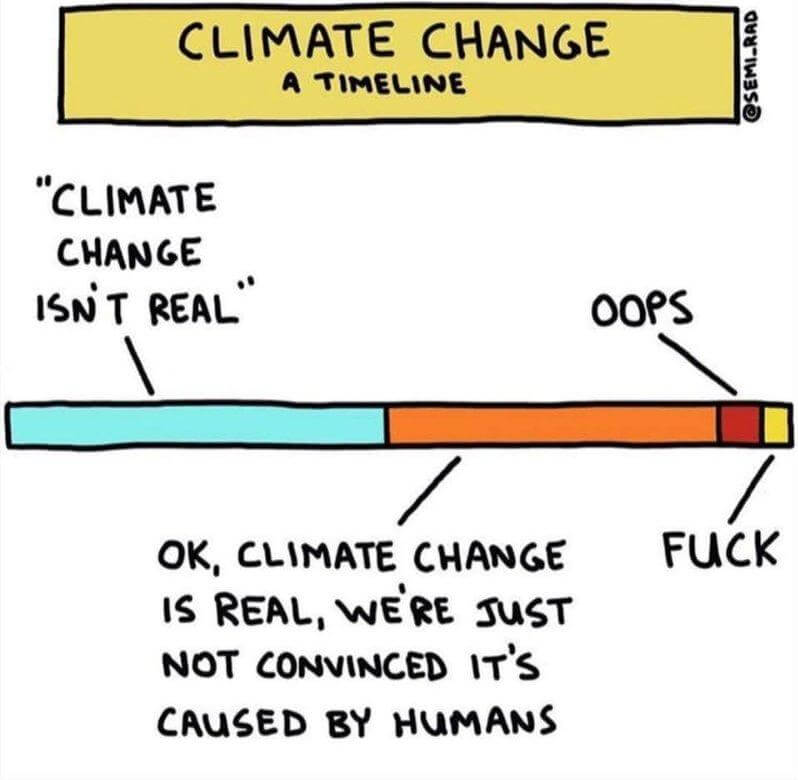
- En pleine canicule, le quartier européen de Bruxelles ressemble à un four (lopinion.fr)
- Canicule en Europe : les écologistes réclament un sommet européen d’urgence pour relancer le Pacte vert (rtbf.be)
Les Verts européens ont appelé jeudi à la convocation d’un sommet européen afin de renforcer d’urgence les protections climatiques de l’Europe et le Pacte vert, alors qu’une partie du continent suffoque sous une vague de chaleur record.
- « Le climat n’est pas un gros problème » : en pleine canicule, un sommet d’extrême droite loue le pétrole (reporterre.net)
De nombreuses personnalités de l’extrême droite mondiale se sont donné rendez-vous pour un congrès antiwoke à Londres. Un élu de Nice, proche d’Éric Ciotti, a ainsi pu s’informer sur les bienfaits des fossiles et le péril causé par le féminisme.
Voir aussi Climato-sceptiques, réseaux Stérin et MAGA… Bienvenue à l’ARC, « rendez-vous stratégique » pour les réacs français (multinationales.org)
En pleine canicule et alors que le RN semble enfin découvrir les rapports du GIEC, les représentants de l’extrême droite française se retrouvent cette semaine à un sommet international des élites « anti-woke » et « anti-climat » à Londres. Un rendez-vous sponsorisé par de grandes fortunes pétrolières, des industries pharmaceutiques ou un fonds d’investissement basé à Dubaï auquel devrait aussi participer, de manière plus inattendue, l’économiste Philippe Aghion.
- « Refuges climatiques » : l’Espagne est déjà une référence mondiale en matière de lutte contre les chaleurs extrêmes (theconversation.com)
- Panne totale des chemins de fer en Allemagne : le trafic des trains reprend lentement après une défaillance générale de la radiocommunication (france3-regions.franceinfo.fr)
- Un lieu de baignade interdit aux non-germanophones : levée de boucliers en Allemagne (courrierinternational.com)
- ‘Baking Street’ : Activists rename Tube stations in heatwave protest (huckmag.com)
‘Heatwave, sponsored by Shell’ — The protest comes as the UK recorded the hottest day in June ever recorded at 36.7C.

- President vs Parliament : Metsola overrides MEPs in bid to force through child abuse law (politico.eu)
The European Parliament president’s power play is “without precedent,” diplomats wrote in a note seen by POLITICO.
Voir aussi “Double Threat” to Private Communications : Undemocratic Chat Control Backroom Deals and Imminent Concessions Spark Relaunch of fightchatcontrol.eu (patrick-breyer.de)
- « This is a final chance to change » : vers un tournant politique majeur au Royaume‑Uni ? (theconversation.com)
Andy Burnham, maire de l’immense agglomération du Grand Manchester, est désormais le grand favori pour remplacer au poste de premier ministre du Royaume-Uni Keir Starmer, dont on vient d’apprendre la démission.
Voir aussi The rise and fall of Keir Starmer : where did it all go wrong ? (theguardian.com)
a man who won a landslide victory in July 2024 only to be pushed out less than two years later, having started no illegal wars, having triggered no grave economic crises, having been accused of no scandalous act of corruption.
- Wikipedia Cofounder Larry Sanger Banned From Site for ‘Canvassing’ (news.slashdot.org)
Wikipedia cofounder Larry Sanger has been indefinitely banned from editing the site after editors concluded that he violated its canvassing rules, “or in other words, calling on his followers off platform in order to influence Wikipedia’s content”
- Following user outcry, AMD reinstates memory encryption in consumer CPUs (arstechnica.com)
- US’s climate.gov site, taken down by Trump, relaunched by nonprofit (arstechnica.com)
Climate.us has now restored everything taken down by the government.
- Nasa rover detects potential signatures of ancient microbial life on Mars (theguardian.com)
Perseverance identifies organic carbon molecules in rocks on riverbed that carried water billions of years ago
- Donald Trump supprime la vaccination obligatoire dans l’armée… et la rétablit en urgence après une épidémie (slate.fr)
- The Meltdown (theatlantic.com)
One day that captures how Trump has gone from unpredictable to chaotic
- Cops Keep Getting Arrested for Using Flock’s Cameras to Stalk People (yro.slashdot.org)
- A few days after a Tesla plowed through a Texas home and killed a grandmother, the family sued the carmaker, alleging that the Model 3’s automated assist mode was defective. (arstechnica.com)
the family laid out two theories in their lawsuit […]The first focused on a defect known as “Sudden Unintended Acceleration,” or SUA, which the family alleged Tesla knows has caused “numerous fatalities and injuries” but has not fixed. […] The second theory suggests that because Tesla stripped its “vehicles of critical obstacle-detection hardware” during a global chip shortage, Butler’s Model 3 simply didn’t register the home “directly in its path” at the end of the street.
- Prairieland ICE Protesters Sentenced to Decades in Prison (motherjones.com)
Activists who didn’t plan the protest and left when asked still received 50-year terms. […] The defendants, who were protesting the Prairieland immigration detention center in Alvarado, Texas, denied that they were affiliated with antifa, a decentralized term for various left-wing activists and anti-fascist groups, and were demonstrating in support of immigrants being detained at the facility.
- Victory ! 702 has Expired ! (eff.org)
Section 702 of the Foreign Intelligence Surveillance Act lets US intelligence agencies collect communications from foreigners abroad without a warrant, and routinely sweeps in Americans’ emails, messages, and calls in the process.
- Aux États-Unis, les gens de droite meurent plus que ceux de gauche (slate.fr)
Des chercheureuses observent l’apparition d’un écart de mortalité inédit entre Américains conservateurs et libéraux, une différence qui s’est fortement creusée au cours de la dernière décennie.
- Mexico’s Gig Workers Fight Efforts to Hollow Out Their Employee Status Win (labornotes.org)
- Allié de Trump, le nouveau président colombien promet une ruée vers les énergies fossiles (reporterre.net)
Le candidat d’extrême droite Abelardo de la Espriella a remporté l’élection présidentielle colombienne. Relance des hydrocarbures, démantèlement des acquis environnementaux : une régression significative est redoutée.
- Séismes au Venezuela : 920 morts et 50.000 personnes disparues (humanite.fr)
Deux puissants tremblements de terre, suivi d’une vingtaine de répliques, ont frappé mercredi 24 juin le Venezuela. La catastrophe a fait au moins 920 morts et des milliers blessés, selon un premier bilan provisoire des autorités qui redoutent davantage de victimes notamment dans la région proche de Caracas où des dizaines d’immeubles se sont effondrés.
Spécial IA
- Chinese universities are cutting language majors to make way for AI (restofworld.org)
Universities are dropping programs in translation and foreign languages while adding degrees in embodied intelligence, AI, and robotics.
- Les auteurices chinois·es de web fiction se dressent contre le plagiat par IA (actualitte.com)
Plus de 1200 auteurices chinois·es de fiction en ligne ont signé une lettre publique contre le plagiat automatisé et la réécriture par intelligence artificielle. Dans un marché immense, structuré autour des plateformes, l’affaire touche à la protection des œuvres, mais aussi à toute la chaîne d’exploitation des droits.
- La Norvège va interdire les chatbots IA aux écoliers (next.ink)
- L’Union européenne va imposer des « étiquettes » sur les contenus générés par IA (numerama.com)
- Cloud souverain : Bruxelles ouvre la porte au « sovereignty-washing » (synthmedia.fr)
Avec le Cloud and AI Development Act, la Commission européenne mise sur la « souveraineté technologique » et promet de mieux protéger les données critiques du continent, sans pour autant rompre avec les hyperscalers soumis au droit extraterritorial américain. Un cas d’école de « sovereignty-washing ».
- Mythos : les Etats-Unis autorisent Anthropic à réactiver son modèle d’IA pour un cercle restreint d’acteurs américains (lemonde.fr)
- Anthropic says Claude may want to see your ID (techcrunch.com)
Anthropic may ask Claude users to verify their age and identity by uploading their government-issued documents, according to a new version of the company’s privacy policy.
- Anthropic says Alibaba must be punished for largest Claude cloning attack (arstechnica.com)
Alibaba allegedly used 25,000 accounts to mine Claude over 28.8 million exchanges.
- Fuite de données chez Meta : l’entraînement de l’IA interne suspendu après une faille de sécurité majeure (zdnet.fr)
- Le cofondateur de Wikipédia dit ne pas faire « assez » confiance à l’IA… mais n’exclut pas de travailler avec (huffingtonpost.fr)
- Cybersécurité : la Linux Foundation va mettre l’open source en ordre de bataille face à l’IA (clubic.com)
- Tech giant Oracle cuts 21,000 jobs as it embraces AI (bbc.com)
- Harvard Business Review warns AI ‘workslop’ is rotting companies from the inside (thenextweb.com)
Two new HBR articles describe how AI-generated low-quality work is degrading organizational knowledge, eroding trust between colleagues, and costing companies millions in hidden rework
- Des entreprises d’IA rachètent d’anciens livres, les numérisent puis les détruisent (rts.ch)
Des palettes de vieux livres venant de librairies du monde entier sont expédiées vers les Etats-Unis. Des entreprises spécialisées en IA seraient à l’origine de cet accaparement massif de patrimoine. Elles utiliseraient ces livres comme données brutes pour entraîner leurs modèles de langage, puis les jetteraient après leur numérisation.

- The “AI-powered” World Cup runs on thousands of data workers (restofworld.org)
Human annotators in Brazil, Cambodia, and the Philippines are tracking every movement in the football tournament for teams, broadcasters, and the betting industry.
- Big Tech’s $2.7 trillion AI bill comes due : Chart of the Day (finance.yahoo.com)
- OpenAI reporterait son entrée en Bourse à 2027 : le Nasdaq dévisse pour la cinquième séance (france-epargne.fr)
Pour comprendre l’hésitation d’OpenAI, il faut regarder du côté de SpaceX […] la société d’Elon Musk a vu son cours retomber autour de 150 dollars, loin d’un sommet supérieur à 200 dollars atteint quelques jours après ses débuts.
Spécial guerre(s) au Moyen-Orient
- ‘End It Now’ : Senate Passes War Powers Resolution Rebuking Trump’s Iran War (commondreams.org)
“The House and the Senate have both stood up,” Democratic Washington Rep. Pramila Jayapal said. “It’s time to stop this deadly and costly conflict.”
- États-Unis-Israël : brouille ou tournant historique ? (politis.fr)
La grosse colère de J.D. Vance contre le gouvernement Netanyahou annonce-t-elle une réorientation stratégique profonde ?[…]« Si j’étais le gouvernement israélien, peut-être que je n’attaquerais pas le seul allié puissant qui me reste sur la planète », s’est emporté le vice-président américain, avant de passer aux menaces à peine voilées : « Ces derniers mois, deux tiers des armes défensives utilisées par Israël ont été fabriquées par des mains américaines et payées par le contribuable américain » […] On ne saurait être plus clair. Et plus cynique. Car ce qui met en colère Vance et Trump, ce n’est évidemment pas le massacre de 73 000 Gazaouis, et pas même la promesse du ministre israélien Itamar Ben Gvir de « brûler le Liban », mais le fait que les bombes israéliennes menacent l’accord irano-américain.
- Israeli attack kills famed turtle sanctuary ecologist in Lebanon (theguardian.com)
The Lebanese marine activist Mona Khalil, who became a beloved figure in the country for a decades-long effort to protect a nesting site for turtles near her home, has died from injuries sustained in an Israeli strike.
- Archiving Genocide in Real Time : Who Has the Right to Narrate Death ? (daraj.media)
Amid the systematic and widespread destruction of southern Lebanese villages, extending even to cemeteries, Lebanon is witnessing a genuine and growing concern with preserving what remains of personal and collective archives. Individuals, groups, and institutions are racing to salvage photographs, documents, and memories at risk of being lost forever.
Spécial femmes dans le monde
- L’UE invite les talibans à Bruxelles : la communauté internationale reste passive (lesnouvellesnews.fr)
Les droits des femmes sont réduits au néant en Afghanistan mais les talibans sont invités par la Commission européenne à Bruxelles. Alors que les voix indignées se multiplient, les gouvernements européens restent silencieux.
- Comment les « sorcières » de la résistance ukrainienne mènent une guerre secrète contre les occupants russes (slate.fr)
Dans les territoires occupés, des femmes ukrainiennes jouent un rôle central dans le renseignement et le sabotage. Souvent sous-estimées par les forces russes, elles participent à une résistance clandestine devenue essentielle à l’effort de guerre de Kiev.
- ‘Like Cattle to the Slaughter’ : Your Unofficial Handbook for Giving Birth in Romania (fellowship.balkaninsight.com)
Romanian infants have the lowest odds in the EU of reaching their first birthday, and Romanian women are twice as likely to die from pregnancy-related causes, compared to the European average.
- Marché de la PMA en Espagne : comment les cliniques espagnoles achètent les ovocytes de femmes françaises (madeinperpignan.com)
- Luc Besson accusé de viol : la justice refuse de rouvrir l’enquête, la plaignante va se pourvoir en cassation (huffingtonpost.fr)
Le réalisateur français de 67 ans est accusé de viol par l’actrice belgo-néerlandaise Sand Van Roy, qui espérait faire rouvrir l’enquête après des analyses ADN, présentées comme un « élément nouveau ».
- Accusé de viol, Achraf Hakimi reçoit le soutien de ses coéquipiers marocains (huffingtonpost.fr)
Alors qu’il dispute la Coupe du monde avec le Maroc, Achraf Hakimi, qui sera jugé pour viols en France, est soutenu par ses coéquipiers.
- Coupe du monde 2026 : le format élargi pourrait accentuer les violences domestiques envers les femmes (slate.fr)
Plusieurs études montrent que les grands événements sportifs, spécialement les matchs de football, s’accompagnent souvent d’une hausse des violences faites aux femmes. Le format élargi du Mondial 2026 pourrait accentuer ce phénomène, que des associations et les autorités de plusieurs pays tentent d’endiguer.
- « Heated Rivalry », la romance gay qui réenchante l’imaginaire érotique des femmes hétérosexuelles (theconversation.com)
Spécial France
- TotalEnergies sommé par la justice de prendre en compte ses émissions indirectes (la1ere.franceinfo.fr) – voir aussi Devoir de vigilance : TotalEnergies condamnée à prévenir les risques climatiques liés à l’utilisation de ses carburants (vert.eco)
Dans un jugement qui fera date, la justice a estimé que la multinationale pétrogazière manque à son devoir de vigilance tant qu’elle n’intègre pas mieux les conséquences climatiques de ses activités.
- Chlordécone : 80 % de la population contaminée en Martinique et en Guadeloupe (humanite.fr)
- « C’est purement scandaleux » : la justice refuse de rouvrir l’enquête sur le chlordécone (reporterre.net)
La cour d’appel de Paris a confirmé, le 22 juin, le non-lieu dans le scandale du chlordécone. « C’est purement scandaleux », s’indignent politiques, avocats et militants antillais. Ils s’organisent pour poursuivre la lutte dans les tribunaux et la rue.
- Autonomie de la Corse : pourquoi les outre-mer regardent ce vote de près (parallelesud.com)
Ce mardi, l’Assemblée nationale a adopté à 271 voix pour et 202 contre le projet de loi constitutionnel qui accorde à la Corse un statut d’autonomie « au sein de la République ». Une première étape franchie dans un processus qui reste loin d’être achevé et interroge sur l’avenir des territoires d’Outre-mer.
- Tirage au sort, assemblées citoyennes, remplacement du Sénat : les Français·es veulent de l’innovation démocratique (theconversation.com)
- Avec Cartes.gouv.fr, la France lance son Google Maps souverain (clubic.com)
L’IGN inaugure ce jeudi Cartes.gouv.fr, une plateforme qui espère donner aux Français une alternative à Google Maps. Gratuit, souverain, riche de 1 141 couches de données, l’outil intègre même Panoramax, un équivalent hexagonal de Google Street View.
- L’accessibilité des services publics numériques de l’État pour les personnes en situation de handicap (ccomptes.fr)
- « On est de la chair à canon » : le cri d’alarme de familles d’accueil dans le Nord (streetpress.com)
Dernier maillon d’un système de protection de l’enfance à bout de souffle, les familles d’accueil du Nord dénoncent des conditions de travail délétères et des dysfonctionnements qui les mettent en danger, accélérant la disparition de leur métier.
- La Fédération sportive de la police nationale victime d’une cyberattaque, les données de 224 000 policier·es exposées (leparisien.fr)
- Enlèvements liés aux cryptomonnaies : « Chaque enquêteurice cyber a 300 dossiers en attente de traitement sur son bureau » (slate.fr)
Depuis 2024, les enlèvements et séquestrations de détenteurices de cryptomonnaies ou d’entrepreneureuses de ce secteur se multiplient en France, mettant en lumière un appareil sécuritaire fragmenté, des moyens limités et une réponse judiciaire trop lente.
- Le Bassin parisien situé en zone sismique… au paléolithique ? (humanite.fr)
Une équipe de scientifiques du CNRS (Centre national de la recherche scientifique), de l’ASNR (Autorité de sûreté nucléaire et de radioprotection) et de l’Inrap (Institut national de recherches archéologiques préventives) remet en question l’état actuel des connaissances sur le risque sismique dans le nord de l’Île-de-France.
- Les chercheureuses ont divisé par deux leurs vols professionnels sans y être contraint·es (theconversation.com)
- EPR2 : un document révèle les aides publiques monstres et le risque de concurrence déloyale (alternatives-economiques.fr)
La rentabilité de la construction des réacteurs nucléaires EPR2 repose sur des aides d’État massives, qui faussent la concurrence vis-à-vis des renouvelables. La Commission de Bruxelles donnera-t-elle son feu vert à la France ?
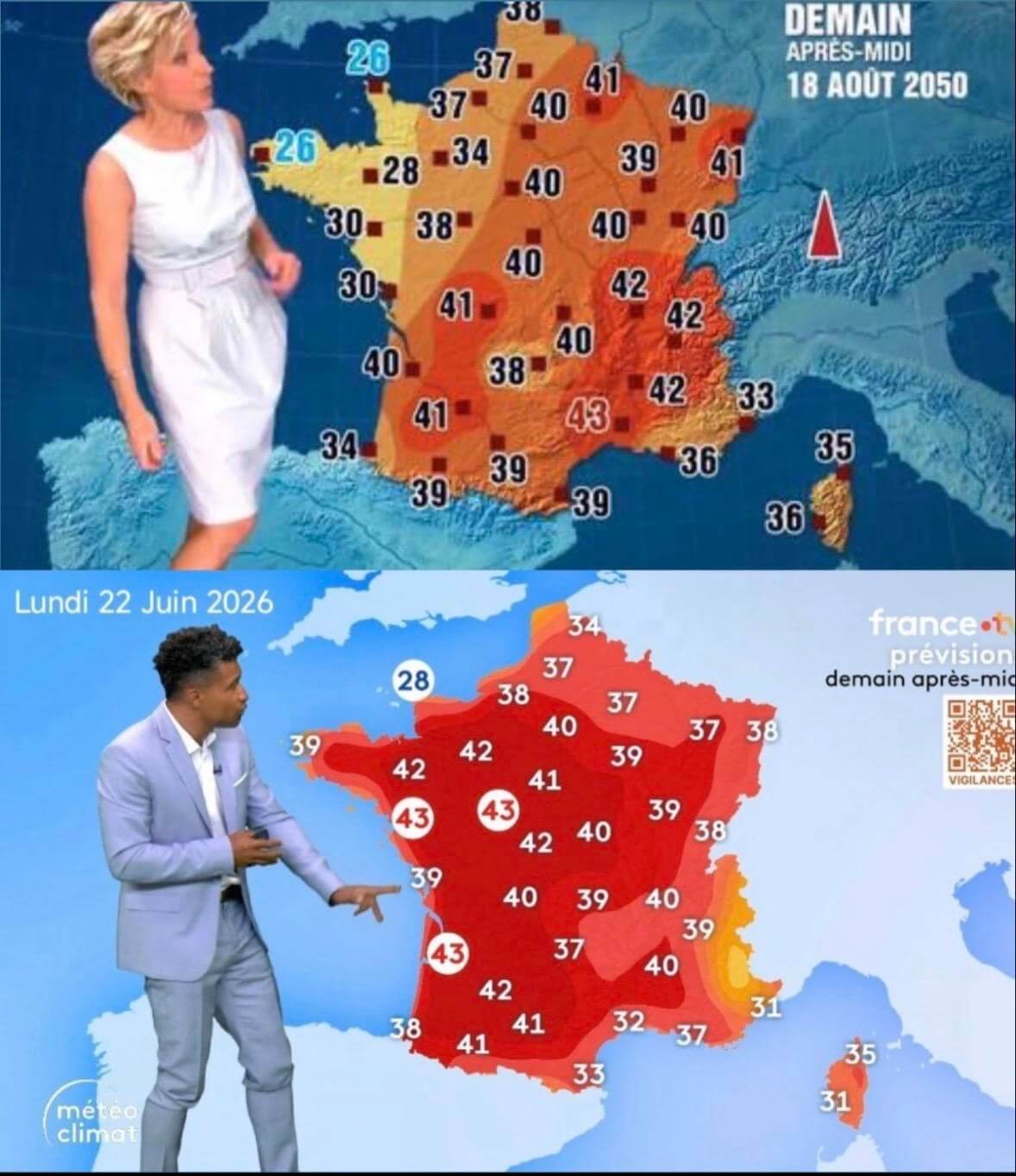
- Canicule : Évelyne Dhéliat ressort sa carte de prévisions pour 2050 et fait un constat implacable (huffingtonpost.fr)
Douze ans plus tard, avec deux décennies d’avance, les températures du mois égalisent, voire dépassent parfois largement les projections pour 2050.
- “On est en train de vivre l’été le plus froid du reste de notre vie, si on rate notre décarbonation”, alerte la climatologue Françoise Vimeux (franceinfo.fr)
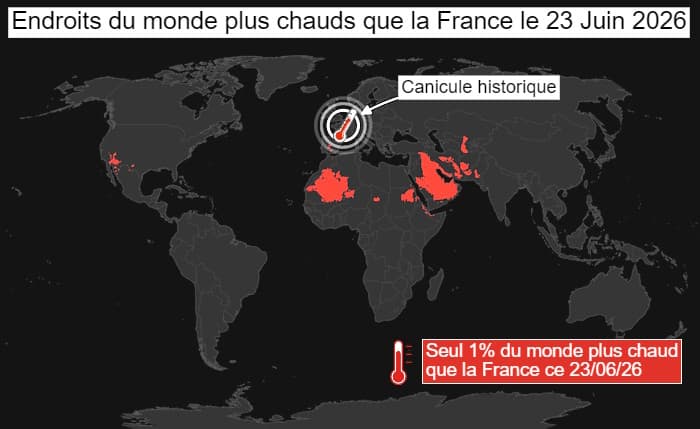
- Il fait plus chaud aujourd’hui en France que sur 99 % de la planète : la vague de chaleur qui frappe le pays est historique (legrandcontinent.eu)
Plusieurs centaines de records absolus de température ont été battus en Europe ces derniers jours […] La France est l’un des pays les plus touchés […] Mis à part dans le désert du Sahara, au Moyen-Orient, dans quelques régions d’Espagne et en Arizona, il fait ainsi plus chaud en France aujourd’hui que n’importe où dans le monde
- Annulation de Solidays, la déception des festivaliers : “J’ai du mal à comprendre pourquoi ils ont attendu aussi longtemps” (telerama.fr)
La préfecture de police a décidé, ce vendredi matin, l’annulation du festival de Longchamp en raison de la canicule. La Marche des fiertés et le meeting d’athlétisme de Charléty sont également annulés.
- Proposé par les écolos, critiqué par le gouvernement : en quoi consiste le congé climatique ? (huffingtonpost.fr)
Le congé climatique a été mis dans le débat par les Écologistes, inspiré par les mesures prises en Espagne après des inondations meurtrières.
- Le réseau ferroviaire français peut-il survivre à la canicule ? (alternatives-economiques.fr)
Dilatation des rails, climatisation défaillante, annulations préventives de trains… la canicule met en lumière les fragilités du système ferroviaire français, tant sur le plan de l’infrastructure que sur celui du matériel.
- Trois réacteurs nucléaires sont à l’arrêt en France en raison de la canicule (franceinfo.fr)
Après la centrale de Golfech (Tarn-et-Garonne), deux autres réacteurs nucléaires ont été arrêtés, au Bugey (Ain) et à Nogent-sur-Seine (Aube)
- « Le débat sur la climatisation est une diversion » (reporterre.net)
- La clim’ de l’Assemblée nationale est tombée en panne et ça s’est vite vu (huffingtonpost.fr)
- Quand les riches parasites s’amusent à gaspiller de l’eau (npa-revolutionnaires.org)
En pleine canicule, le 24 juin, à l’occasion du lancement de la Fashion Week, la marque de luxe Vuitton a organisé un spectacle avec une vague géante dans un décor de plage artificielle. Au cas où cette vague n’aurait pas suffi à les rafraîchir, les invités bénéficiaient d’une climatisation.
- Canicule : dans le Finistère, une journée éprouvante sans électricité (reporterre.net)
Un transformateur du réseau RTE a explosé sous l’effet de la chaleur, privant d’électricité des milliers de foyers du Finistère-Sud pendant plus de 24 h.
- Dans un Ehpad, en sous-effectif et sans climatisation : « Avec la chaleur en plus, on est à bout » (basta.media)
Pas de climatisation, des résidents très âgés dans des chambres à 35 degrés, des semaines de travail de 60 heures… Une aide-soignante d’un Ehpad d’Alsace nous raconte ses conditions de travail, en pleine canicule et en sous-effectif.
- « Notre peur, c’est qu’il y ait des morts » : des saisonnier·es survivent dans des bidonvilles en surchauffe (reporterre.net)
- La canicule tue des centaines de milliers d’animaux d’élevage intensif (lareleveetlapeste.fr)
Avec la canicule, écosystèmes et animaux sont en souffrance, particulièrement dans les élevages intensifs. L’hécatombe est telle que les stations d’équarrissage sont saturées dans l’Ouest de la France. Les éleveureuses sont exceptionnellement autorisés à enterrer les cadavres près des exploitations.

- Chaleur, nature asséchée : le cocktail qui fait exploser le risque incendie en France (reporterre.net)
Spécial femmes en France
- Simonne Vidal entre aussi au Panthéon aux côtés de son mari Marc Bloch (20minutes.fr)
Moins connue que son époux, Simonne Vidal […] a été infirmière volontaire pendant les deux guerres […] Mère de leurs six enfants, Simonne Vidal a joué un rôle crucial dans l’écriture des travaux de Marc Bloch professeur d’université à Strasbourg entre les deux guerres […] Elle l’a notamment assistée en tant que secrétaire et assistante de recherche.
- Canicule : la charge écologique pèse lourdement sur les femmes (lesnouvellesnews.fr)
Depuis que les températures record rappellent l’urgence climatique, les appels à « faire des efforts » pour la planète se multiplient. Mais derrière ces injonctions, une réalité invisibilisée : ces efforts reposent encore très majoritairement sur les femmes. C’est ce que met en lumière une étude de la Fondation Jean-Jaurès, menée avec L’ObSoCo et Citeo, publiée le 25 juin 2026.
- Une salle Imane Khelif dans un lycée près de Lyon ? La Région refuse le nom de la boxeuse algérienne (actu.fr)
Des élèves voulaient donner le nom de la boxeuse algérienne Imane Khelif, cible d’attaques récurrentes sur sa féminité, à une salle de leur lycée de Meyzieu. La Région a dit non.
- Oeil au Beurre Noire, le duo qui « veut féminiser et radicaliser Twitch » (streetpress.com)
- La Cour de cassation sécurise la période d’essai de la femme enceinte. Une étape contre les « pénalités de maternité » (theconversation.com)
- Quand les réseaux sociaux incitent les jeunes femmes à tourner le dos à la pilule contraceptive (theconversation.com)
- Enquête nationale sur le consentement en gynécologie (stopvog.fr)
StopVOG publie les résultats de la première enquête nationale sur le consentement en gynécologie. Menée auprès de 10 152 répondant·es partout en France, cette enquête documente le respect du consentement, de l’information et des droits des patient·es dans les soins gynécologiques, ainsi que les violences obstétricales et gynécologiques, les discriminations et leurs conséquences sur la santé et le recours aux soins.
Voir aussi Violences obstétricales et gynécologiques : un phénomène massif en France, selon l’association Stop VOG (lemonde.fr)
Plus de quatre femmes interrogées sur dix déclarent avoir subi des violences gynécologiques ou obstétricales en consultation, dénonce l’association StopVOG, à partir d’un questionnaire complété par 10 000 personnes.
- Masculinisme : « Le mode de radicalisation est exactement le même que lorsqu’on radicalisait des gens pour les faire partir en Syrie », alerte Dominique Vérien (publicsenat.fr)
Les sénatrices de la délégation aux droits des femmes appellent à faire de la lutte contre le masculinisme « une priorité de politique publique ».
Voir aussi Contre le masculinisme : une bataille culturelle et politique à engager (lesnouvellesnews.fr)
Face à la montée du masculinisme, un rapport sénatorial choc intitulé « Mascus : nouvelle offensive contre les femmes » sonne l’alarme. Il recommande d’engager de nouvelles politiques et des stratégies médiatiques couvrant le bruit de la haine misogyne.

- Qui est Clavicular, le gourou du looksmaxing qui s’est fait recaler par tout Paris ? (konbini.com)
le streamer américain de 20 ans, figure controversée du looksmaxing et issu de la mouvance « incel », a surtout découvert qu’une mâchoire carrée ne suffit pas toujours à faire fondre les cœurs. Parce que oui, ce grand garçon est un adepte du « bone smashing », qui consiste à se taper le bas du visage avec un marteau pour accentuer ses contours.
- « Elle s’est fait ça toute seule ! » : devant la justice, la petite musique des agresseurs poursuivis pour violences conjugales (politis.fr)
Chaque jour, partout en France dans les tribunaux correctionnels sont jugés des centaines de dossiers de violences conjugales, de harcèlements, de contrôle coercitifs… Mis en cause, en majorité : des hommes de tous âges et de toutes classes sociales. Qui adoptent souvent le même système de défense.
- Affaire Lyhanna : Jérôme Barella est visé par une plainte de sa femme pour viol et violences conjugales (huffingtonpost.fr)
- Rapport sur Lyhanna : deux gendarmes « mutés d’office » et un magistrat du parquet d’Auch épinglé (huffingtonpost.fr)
RIP
- Mort de Guesch Patti, interprète du sulfureux tube “Étienne” (telerama.fr)
En 2001, alors qu’elle était à l’affiche à Paris d’un spectacle de danse contemporaine, sa véritable passion, elle avait confié à l’AFP combien le succès d’Étienne avait phagocyté sa carrière même s’il lui avait permis de décrocher une Victoire de la musique.
Spécial médias et pouvoir
- Yann Barthès, la canicule et Bernard Arnault : une chronique pas drôle sur une inégalité bien réelle (telerama.fr)
Mardi soir, le présentateur de “Quotidien” assurait que nous sommes tous égaux face à la canicule, milliardaires compris.

- Le Pen, LFI et l’antisémitisme : l’intox de Guillaume Erner (acrimed.org)
- Patrick Boucheron attaqué pour avoir refusé d’établir un lien entre l’antisémitisme des années 40 et la lutte pour la Palestine (humanite.fr)
Depuis son passage dans l’émission de Guillaume Erner sur France Culture le 23 juin dernier, l’historien est la cible d’une campagne de dénigrement dans les médias de droite et sur les réseaux sociaux. Sa faute : avoir refusé de faire le lien entre l’antisémitisme de la Seconde Guerre mondiale et la lutte pour la Palestine.
- Erik Tégner de « Frontières », dernier repris de justice de CNews (politis.fr)
Le fondateur du média d’extrême droite et chroniqueur sur CNews a de nouveau été condamné, cette fois pour avoir livré les données personnelles des avocats d’organisations d’aide aux personnes migrantes. Et s’est évidemment précipité de se victimiser.
- Hind Rajab, 5 ans, tuée par l’armée israélienne (épisode 4) : pourquoi les médias français sont passés à côté (blast-info.fr)
- Piratage de deux sites du réseau Mutu (paris-luttes.info)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Canicule : les leçons de 2003 que personne n’a retenu (projetarcadie.com)
- Canicule historique : records battus et impréparation du gouvernement (basta.media)
L’Europe subit une vague de chaleur inédite, et la canicule historique en cours en France depuis le 17 juin force l’État à gérer tant bien que mal cette conséquence d’un réchauffement climatique mal anticipé.
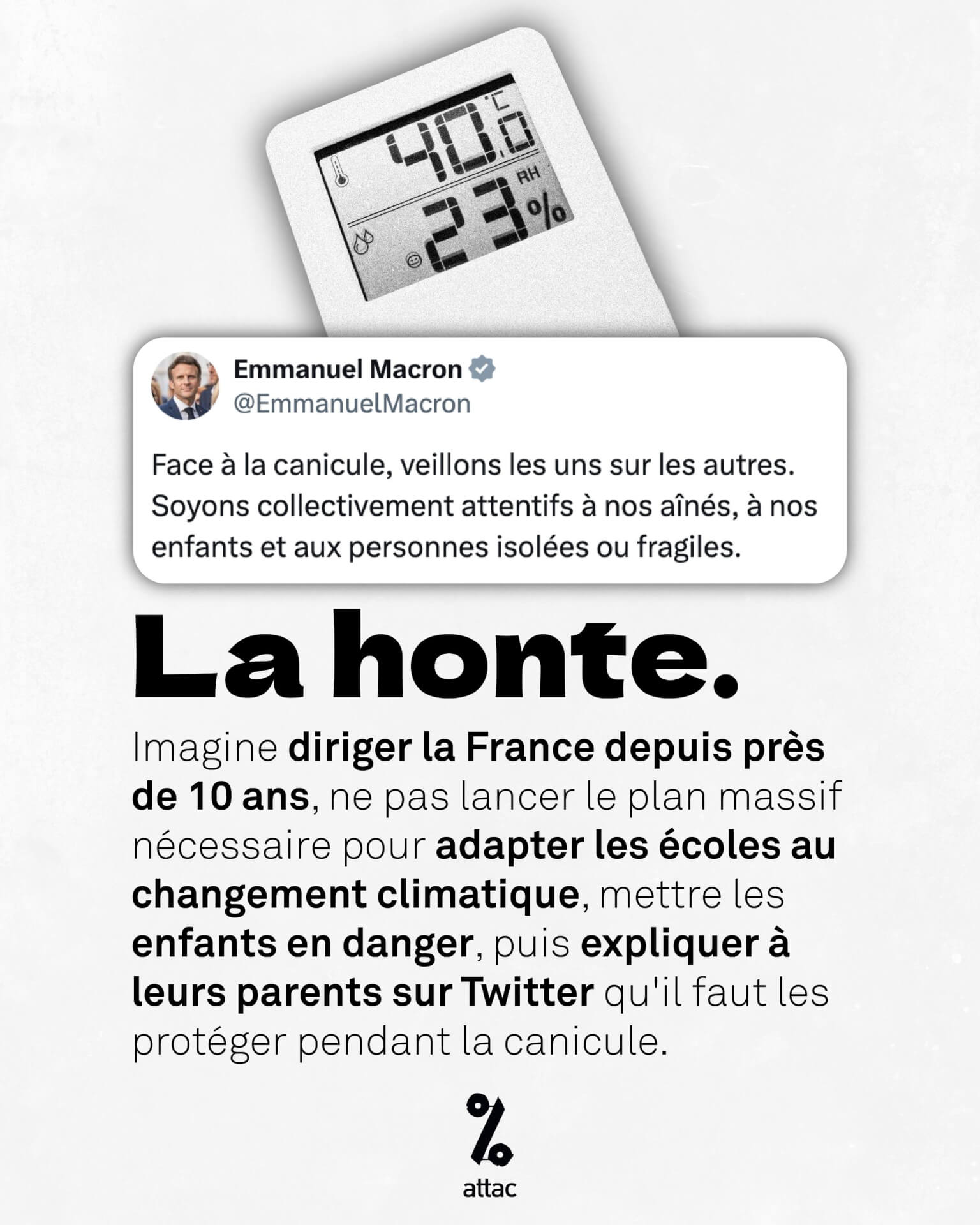
- Non, M. Macron, vous n’avez pas fait de « gros travail » pour le climat (reporterre.net)
Le 25 juin, alors que la température moyenne du pays atteignait un record absolu, Emmanuel Macron a salué le « gros travail » d’adaptation réalisé durant son mandat. Dans cet édito, notre journaliste démonte cet enfumage, preuves à l’appui.

- Fragilisé, le gouvernement renvoie la question de l’adaptation au climat à ses successeurs (huffingtonpost.fr)
Le chef du gouvernement demande à ses ministres de lui soumettre des « propositions » concernant la « manière de vivre dans le pays » en temps de canicule. Mais pour ses successeurs.
- En pleine canicule, le gouvernement veut repousser de 5 ans la rénovation énergétique des logements en location (lareleveetlapeste.fr)
Une proposition délirante, alors que la France est le pays européen le plus touché par le dérèglement climatique. En ville et par ces températures record, ils sont nombreux à avoir dû se réfugier dans leurs caves, pour éviter de suffoquer sous des toits de zinc.
- L’Ademe et l’Office français de la biodiversité (toujours) dans le viseur de Matignon (politico.eu)
Le directeur de cabinet du Premier ministre, Philippe Gustin, aurait demandé la tête des patrons de l’Ademe et de l’OFB, sans obtenir gain de cause
- Avec la canicule, la fermeture des piscines publiques devient plus politique que jamais (huffingtonpost.fr)
- Les noyades sont « un triste fléau » de la canicule, déplore Sébastien Lecornu en évoquant 40 morts (huffingtonpost.fr)
- Canicule : le brevet des collèges maintenu mais avec des “pauses fraîcheur” (humanite.fr)
Contrairement à ce qui s’était produit lors de la canicule de 2019, les écrits du brevet ne seront pas reportés. Ils se dérouleront bien vendredi 26 juin, le matin, mais avec des « pauses fraîcheur » et une limitation du nombre d’élèves par salle.
Voir aussi Brevet des collèges maintenu : colère syndicale unanime (cafepedagogique.net)
les organisations syndicales dénoncent une décision « irresponsable » et expriment une vive colère. Toutes pointent les risques pour les élèves et les personnels, ainsi qu’un manque d’anticipation du ministère.
- Canicule : Des lycées passent leur oral du bac de français dans le parking souterrain de leur établissement (humanite.fr)
La semaine dernière, plus de 130 millions d’euros ont été débloqués pour financer en urgence des systèmes de rafraîchissement et des travaux dans les écoles, particulièrement touchées par la canicule.
- Après la canicule, le premier bilan humain relance les critiques contre le gouvernement (huffingtonpost.fr)
Depuis mercredi, au moins 1 000 décès supplémentaires ont été observés par rapport à la normale, selon Santé Publique France, avec une hausse de 40 % des décès à domicile.
- « Je craque » : le désarroi des soignants face à l’afflux d’animaux sonnés par la chaleur (reporterre.net)
Les fortes chaleurs ont fait exploser l’affluence d’animaux sauvages dans les centres de soins. Ces structures associatives sont en grande souffrance depuis plusieurs années, face à la hausse des besoins et à l’abandon des politiques.
- Budget 2027 : Quand l’austérité aggrave la crise (humanite.fr)
- Au parquet, l’urgence permanente : comment la course au chiffre transforme la justice (theconversation.com)
- Neuf cents euros pour une licence et 1 300 euros pour un master : un rapport préconise de quintupler les frais d’inscription à l’université (lemonde.fr)
- Hausse des salaires : comment la France est devenue une mauvaise élève en Europe (alternatives-economiques.fr)
Les salaires progressent moins vite dans l’Hexagone qu’en Europe depuis le Covid-19. Les entreprises sont bien sûr en partie responsables, mais le gouvernement les a largement encouragées à la modération salariale.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Marc Bloch au Panthéon : les mots forts de sa petite-fille pour expliquer son refus de voir le RN à la cérémonie (huffingtonpost.fr)
La famille de l’historien a demandé que le Rassemblement national soit exclu de la cérémonie, par respect pour l’engagement du résistant français de gauche.
- Amnesty International tire la sonnette d’alarme sur la progression des mouvements anti-genre en France (publicsenat.fr)
Amnesty International dresse un panorama inédit des mouvements dits « anti-genre », de leurs financements, de leurs réseaux et de leurs stratégies d’influence. L’ONG décrit un mouvement transnational structuré qui cible « les droits des femmes et des personnes LGBTI+ », et dont la France constitue désormais l’un des principaux points d’ancrage en Europe.
- En France, un fichier de police renforce les craintes des personnes trans après des contrôles houleux (streetpress.com)
Depuis deux ans, un fichier de l’État rassemble toutes les personnes trans qui ont changé de prénom à l’état civil. Celui-ci permet aux forces de l’ordre d’accéder à leur ancienne identité, ce qui provoque des contrôles mouvementés et des craintes. […] « En France, l’identité de genre n’est pas considérée comme une donnée sensible »
- Pressions politiques, harcèlement, exclusions : à l’InterLGBT, une année de tourmente (problematik-media.com)
En 2025, l’affiche de la marche des Fiertés parisienne est prise dans un scandale politique d’une rare intensité. Les conséquences se sont fait ressentir toute l’année dans la vie de l’Inter-LGBT, association organisatrice.
- « Marine au pouvoir, les Arabes à l’abattoir » : une enquête pour incitation à la haine ouverte après la diffusion d’une vidéo tournée dans une discothèque de l’Aveyron (humanite.fr)
- « Un sentiment d’injustice » : indignation à Clermont-Ferrand après le démontage d’une piscine par la police en pleine canicule (leparisien.fr)
- « Cassez-vous les bougnoules » : un policier interpellé après une agression raciste contre une association en maraude à Paris (leparisien.fr)
- Présomption de légitime défense : comment une demande des policiers d’extrême droite est devenue mainstream (basta.media)
Le gouvernement s’apprête à faire voter une « présomption de légitime défense » en faveur des policiers qui font usage de leur arme. La mesure est assimilée à un « permis de tuer » par ses détracteurs et rompt avec le principe d’égalité devant la loi.
- Vos AirPods, votre iPhone et vos appareils Android bientôt trackés par les radars automatiques (01net.com)
La société Leonardo commercialise SignalTrace, une option pour caméras de surveillance capable de scanner les signaux Bluetooth et Wi-Fi des smartphones et écouteurs afin de lier les appareils aux plaques d’immatriculation.
Spécial résistances
- 3 ans après la mort de Nahel : du théâtre aux manifs, ces jeunes de Nanterre toujours debout contre les violences policières (basta.media)
- Au procès d’Anasse Kazib, une première victoire contre les procès-bâillons des soutiens de la Palestine (revolutionpermanente.fr)
Ce jeudi, le procès d’Anasse Kazib et d’un journaliste de Révolution Permanente a conduit à la transmission d’une question de constitutionnalité concernant la participation d’organisations comme la Jeunesse française juive aux procès visant tous les soutiens de la Palestine. Le procès a été renvoyé.
- Menacées, l’Ademe, Santé publique France et d’autres agences publiques appellent à manifester le 23 juin (reporterre.net)
Ne pas laisser l’État démanteler ses agences sans rien faire. Mardi 23 juin, à 13 h 30, un rassemblement du collectif des agences en lutte est prévu près de l’Assemblée nationale, au métro Invalides à Paris.

- Victoire ! Le gouvernement annonce le report du démantèlement de l’ADEME (agirpourlenvironnement.org)
Suite à une forte mobilisation citoyenne, le gouvernement a annoncé le report du projet de loi « État local » à une date indéterminée. Ce projet de loi prévoyait notamment de faire passer l’Agence de la transition écologique (ADEME) sous la tutelle des préfets. Ce démantèlement camouflé en simplification aurait été dramatique, à l’heure où l’ADEME est plus nécessaire que jamais.
- Pesticides : l’État fait fi de sa condamnation, des associations contre-attaquent (reporterre.net)
Pas question de laisser sans effet la première condamnation de l’État français pour préjudice écologique concernant les atteintes à la biodiversité. Le collectif Justice pour le vivant, composé d’avocats, de juristes et de scientifiques, s’apprête à déposer un recours en exécution dans les prochains jours
- « On a les mêmes adversaires, l’industrie des pesticides » : des collectifs s’unissent contre le colonialisme chimique (reporterre.net)
- Lot. Silence, coupe rase (lempaille.fr)
Entre le désarroi des riverain·es, la toute-puissance des machines et la lâcheté administrative, témoignage sur un système qui brade l’avenir, à partir d’une lutte solitaire à Cassagnes.
- Tribune – Paris sportifs : les bookmakers ont déjà gagné la Coupe du monde (antipub.org)
- En Normandie, un collectif lutte pour la visibilité des personnes LGBTQIA+ (reporterre.net)
Depuis deux ans, l’Amicale des paillettes organise la marche des fiertés dans le village côtier de Regnéville-sur-Mer (Manche). De quoi affirmer l’ancrage et le dynamisme d’une communauté LGBTQIA+ en milieu rural.
Spécial outils de résistance
- Fight Chat Control ! (fightchatcontrol.eu)
A shocking backroom deal is underway to revive Chat Control 1.0 this Friday — and on Monday 29 June, the final trilogue for permanent mass scanning takes place. We face a double-attack on private communication. Take two minutes now : e-mail your MEPs and Permanent Representation to stop this !
- Keep Android open ! (keepandroidopen.org)
Votre téléphone est sur le point de ne plus vous appartenir
Spécial MAGAM et cie
- Meta : les données du projet de surveillance des employé·es étaient accessibles en interne (next.ink)
Ce ne sont pas des considérations éthiques sur la récolte et l’utilisation de données sensibles de ses employé·es qui poussent Meta à stopper (au moins temporairement) son projet Model Capability Initiative (MCI), mais plutôt le manque de sécurisation de l’accès à ces données.
- Meta launches cheaper smart glasses without Ray-Ban (theverge.com)
- Meta remplace le dirigeant de WhatsApp pour mieux monétiser ses 3 milliards d’utilisateurices (lemonde.fr)
- Microsoft adds another year to Windows 10 extended update program (arstechnica.com)
Microsoft ended official support for Windows 10 in 2025, but the company may have a harder time than expected putting the operating system out to pasture […] If you are still clinging to Windows 10, you don’t have to do anything but enjoy that extra year.
Voir aussi Le support de Windows 10 recule d’un an, au 12 octobre 2027 (next.ink)
Du côté de l’association HOP (Halte à l’Obsolescence Programmée), on applaudit avec mesure : elle « salue la nouvelle, mais reste nuancée face à cette volte-face très tardive ». L’association rappelle qu’en tenant compte de cette année supplémentaire, Windows 10 aura finalement 12 ans de support pour la sécurité. Un score qu’elle juge « insuffisant », car elle réclame 15 ans à partir de la dernière unité vendue
Les autres lectures de la semaine
- Canicule : un nouveau darwinisme social (frustrationmagazine.fr)
Comme prévu, le réchauffement climatique, que l’insouciance bourgeoise imaginait encore cantonné aux petites îles du Pacifique dans les années 2000-2010, mord désormais violemment les pays riches. Pour autant, les élites qui gouvernent et médiatisent continuent de penser, à juste titre d’ailleurs, qu’il s’agit d’un truc de pauvres. Car évidemment, les impacts de la canicule épousent la structure de classe et se distribuent à proportion des vulnérabilités matérielles.
- Il faut politiser les canicules (bonpote.com)
- Canicule : « Il va falloir demander des comptes à nos responsables politiques » (basta.media)
- Ces canicules extrêmes sont un crime politique – Des révoltes d’ampleur s’imposent (ricochets.cc)

- Canicule : la révolution ou la mort (frustrationmagazine.fr)
Ce titre peut paraître outrancier et excessif alors que c’est l’apathie dépolitisante actuelle – celle des journalistes en quête de solution innovante pour isoler ses vitres, celle des politiques qui enchaînent les platitudes infantilisantes et celle des scientifiques qui montrent la catastrophe mais ne nomment jamais les responsables – c’est cette apathie coupable qui est outrancière est excessive.
- Politique de la crise financière, 5 – Défoncer la finance néolibérale : fermer la Bourse (blog.mondediplo.net)

- Hannah Arendt peut-elle nous aider à penser le monde d’aujourd’hui ? Entretien avec Aurore Mréjen (frustrationmagazine.fr)
- Comment Marc Bloch a révolutionné le métier d’historien (theconversation.com)
- J’ai passé deux ans à traquer les copier-coller d’Étienne Klein, docteur ès plagiats (heidi.news)
- Comment le génie littéraire de George Sand a été invisibilisé par les clichés du XIXe siècle (slate.fr)
Rares sont les écrivaines qui furent aussi célèbres que George Sand de leur vivant. Malgré plus de 90 œuvres, plus de 400 articles et des milliers de lettres, son apport a été largement atténué par la critique. Elle n’a été réhabilitée que dans les années 1970-1980, par le biais des études féministes.
- Violences sexuelles sur mineur·es : deux siècles de bruit médiatique et d’inertie (theconversation.com)
- Soumission chimique, prendre le mal à la racine (axellemag.be)
Appeler le procès de Dominique Pelicot et des plus de 50 violeurs condamnés « l’affaire des viols de Mazan », c’est mettre le focus sur le village et donc encore éviter de parler des agresseurs et des victimes. C’est la même chose quand on met en avant le GHB, « la drogue du violeur », en omettant de parler des autres drogues notamment la plus répandue, l’alcool.
- Racisme vertueux et sexisme prédateur (politis.fr)
Signe d’une fascisante banalisation, les deux systèmes de domination s’entrecroisent tout en prenant le soin de se donner en spectacle.
- Prêt-à-piller : les vêtements volés des pays nord-africains (frustrationmagazine.fr)
- Un portrait de Pocahontas daté de 1616 révèle le regard des colons anglais sur les peuples autochtones américains (theconversation.com)
- Quand les religieuses prêtaient de l’argent : l’influence méconnue des couvents sur l’économie viennoise (theconversation.com)
- Plus vous vieillissez, plus vous devriez fumer de l’herbe (slate.fr)
Alors que le cannabis moderne est bien plus puissant qu’il y a quelques décennies, plusieurs recherches suggèrent que certains de ses composés pourraient protéger les neurones contre des mécanismes impliqués dans la démence.
- Every Homo naledi we know of is female, and the implications are fascinating (arstechnica.com)
Les BDs/graphiques/photos de la semaine
- Prévisions
- Record
- Sans fin
- Victimes
- Qui aurait pu prédire ?
- Honte
- Londres
- Fuck
- Réagir
- Fourche
- Conseil
- Smash
- Tout contre
- Envie
- Manifeste pour une écologie politique (lundi.am)
- Alive
- Slop
- Perish
- Stop

- Arrested
- Assimilate
- Gender
- War
- Violeur
- Zizi
Les vidéos/podcasts de la semaine
- Data Center Opposition is Uniting Communities w/ Saul Levin (techwontsave.us)
- Réaction de Gabriel Zucman suite aux propos de Patrick Pouyanné, PDG de Total Énergie devant la commission des finances de l’Assemblée Nationale du 17 juin 2026 (tube.fdn.fr)
- Climatisation : un faux débat ? (radiofrance.fr)
pendant qu’on parle de la clim’, on ne parle pas du reste. On est comme enfermé. Que dire à l’ouvrier, sur son chantier, sous 40 degrés ? À la factrice qui transpire sur son vélo ? À l’éleveuse, dans son étable, avec ses bêtes écrasées par la canicule ? Qu’on va leur mettre la clim’ ?
- “Canicule et climat : l’hypocrisie des décideurs” (radiofrance.fr)
- Bouilloires thermiques : le reportage que Yann Barthès et Quotidien auraient dû voir (lemediatv.fr)
- Coupe du monde 2026 : le « Match du XXIe siècle » ne se déroulera pas au MetLife Stadium de New York (humanite.fr)
En pleine Coupe du monde masculine 2026, l’Humanité prend à contre-pied les gardiens du temple patriarcal en diffusant en exclusivité le Match du XXIe siècle. À travers une rencontre inédite entre joueuses et joueurs professionnels, ce documentaire d’Isabelle Curet interroge la mixité et les inégalités dans le sport.
- Gardiennes (france.tv – disponible jusqu’au 01/03/2027)
C’est une histoire peu connue sur les côtes françaises. On a longtemps ignoré la place tenue par des centaines de femmes restées invisibles. Elles ont été nombreuses à éclairer la mer, en France. Avant que toutes ces gardiennes ne disparaissent, Angèle Meschin et Lou Paulin sont parties sur leur trace.
- Les mouvements anti-genre et ses effets (lapdg.fr)
- « L’inceste n’est jamais de la sexualité : ce sont des hommes qui dominent et détruisent des enfants » (mediapart.fr)
Les trucs chouettes de la semaine
- RN privé de ses financements occulte : l’Iforel, bras financier caché du parti, perd son agrément (politique-france.info)
Le RN privé de sa manne financière cachée : l’Iforel, institut de formation des élus locaux, perd son agrément après un revers juridique. Une décision qui prive le parti d’une source de revenus majeure et révèle les dérives d’un système de financement occulte.
- Banned Book Library (richardosgood.com)
A long while back I had an idea to hack a WiFi smart light bulb to do something more useful to me. Actually, I had a few different ideas of things to do with them. One of these ideas was to modify the device to have an open WiFi access point and a web server hosting banned books.
- FDN souffle son quatrième chiffre pour sa 34ᵉ bougie ! (fdn.fr)
Le cap des 1 000 membres vient d’être franchi chez FDN ! Lorsque l’idée de la Fédération FDN a émergé vers 2009-2010, c’était parce qu’on trouvait à l’époque que 300, c’était déjà trop gros. L’idée en effet n’a jamais été de grossir démesurément mais au contraire de favoriser l’essaimage, la création de tout plein d’autres FAI associatifs partageant nos valeurs, de faire tache d’huile. Depuis, une trentaine de FAI ont vu le jour, certains ont ensuite décidé d’arrêter l’aventure, d’autres ont continué à se développer. C’est ainsi que FDN a fini par dépasser sa 1000ᵉ personne membre, tout en continuant à prioriser l’Internet à échelle humaine et une informatique émancipatrice aux côtés des autres membres de la Fédération.
- Autogestion : un autre travail à l’horizon (mob-media.info)
Des boulangeries aux pompes funèbres, des entreprises font le pari de l’autogestion, partout en France, et redessinent l’organisation du travail au quotidien. L’objectif : fonctionner de manière plus horizontale et plus collective, en misant sur la coopération et la responsabilité partagée.
- La ville de Lille enlève le bitume de ses écoles pour créer des îlots de fraîcheur (lareleveetlapeste.fr)
Lille protège ses écoliers avec trois principes : débitumisation, isolation et végétalisation. Pour un coût annuel qui oscille entre 1 et 1,2 million d’euros, 3 nouvelles cours d’école sont débitumisées chaque année pour supporter les vagues de canicule toujours plus intenses. […] « On a traité en priorité les cours d’école les moins végétalisées, les plus bitumées, celles qui n’avaient pas d’arbres du tout. On a veillé à s’occuper des quartiers où il y a davantage de personnes sous le seuil de pauvreté qui n’ont pas forcément de jardin. »
- “Il fait 24 degrés dans mon école, on est trop bien !” Ce village s’est battu pendant des années pour construire son nouveau groupe scolaire en pierre locale, un pari gagnant contre la chaleur (france3-regions.franceinfo.fr)
- ‘Everything has its own order and purpose’ : The rainforest ‘farms’ defying modern agriculture (bbc.com)
This unique indigenous way to produce food uses no pesticides and returns plots to the rainforest after five years. What can we learn from this 4,500-year-old practice ?
- Les femelles dauphins se transmettent une liste des mâles relous à éviter (slate.fr)
Des chercheureuses ont observé que certaines dauphines réagissent immédiatement aux vocalisations de mâles réputés agressifs. Cette capacité à associer une identité sonore à une réputation comportementale pourrait constituer une stratégie d’évitement.

Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
22.06.2026 à 07:42
Khrys’presso du lundi 22 juin 2026
Khrys
Texte intégral (8690 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Les jets privés ont toujours le vent en poupe : flambée du prix du pétrole ou pas, une poignée d’ultra-riches continuent de prendre l’avion sans compter (lindependant.fr)
Les vols en jet ont progressé de 4 % dans le monde, dopés par Cannes, Monaco et les grands événements sportifs, symbole d’une économie toujours plus inégalitaire.
- Un tiers de l’humanité doit s’endetter pour vivre (theconversation.com)
L’endettement des ménages est surtout évoqué à travers le prisme du pouvoir d’achat, du paiement fractionné ou du surendettement, mais il reste rarement analysé comme un phénomène social massif et structurel. Une recherche récente s’efforce de quantifier cette « dette du quotidien » à l’échelle mondiale.

- Not just books – how renting a sewing machine from the library can improve democracy (bbc.com)
Finland’s libraries are increasingly being valued not by how many books they lend, but how they help societies function.
- Autorisation illimitée de pesticides : l’Europe recule pour le moment (basta.media)
Omnibus, c’est le nom d’un projet de règlement poussé par la Commission européenne, qui déroule le tapis rouge aux fabricants de pesticides. Aucun accord n’a finalement été trouvé par les États membres de l’UE. On vous raconte cette bonne nouvelle.
- Le Parlement européen donne son feu vert à une nouvelle génération d’OGM (basta.media)
Des eurodéputés du centre, de la droite et de l’extrême-droite ont voté ce 17 juin en faveur des nouvelles techniques génomiques. Aucun étiquetage n’est prévu sur les aliments. Les mouvements paysans annoncent saisir la Cour de justice européenne.
- EU to soon classify AWS and Azure as gatekeepers under DSA (heise.de)
As gatekeepers, AWS and Azure would be obliged to ensure interoperability and data portability. This would, for example, simplify switching cloud providers and allow customers to link other services with AWS or Azure clouds, instead of being limited to AWS and Azure offerings. Significant fines could also be imposed if the cloud services are found to be in violation of existing regulations.
- L’Europe veut libérer le potentiel des données de santé (theconversation.com)
Avec son Espace européen des données de santé (EEDS), l’Union européenne (UE) est confrontée à un défi de taille : comment exploiter la valeur scientifique et économique des données de santé, tout en garantissant la sécurité de l’infrastructure qui les héberge et son alignement sur les intérêts et les valeurs européennes ?
- Immigration : le Parlement européen adopte le règlement qui autorise les « centres de retour » en dehors de l’Union (publicsenat.fr)
Les eurodéputé·es ont adopté mercredi le règlement controversé qui autorise la rétention de migrant·es expulsé·es, et les débouté·es du droit d’asile dans des centres situés dans des pays hors de l’Union européenne. Ce vote est l’aboutissement d’une alliance inédite à Bruxelles entre la droite et l’extrême droite
- L’Europe dépense des milliards pour renvoyer les migrant·es : pourquoi cette stratégie ne fonctionne pas (theconversation.com)
- Le chêne légendaire de Robin des Bois est mort, victime de la chaleur et du tourisme (reporterre.net)
- Scan your eyeballs, think of the children : how Britain sells surveillance as safety (thenerve.news)
Keir Starmer’s under-16 social media ban can only work if everyone proves who they are. It is the natural conclusion of the Online Safety Act – and of a Brexit that was always about control, says digital rights advocate Heather Burns
- ICE plans to give local police facial recognition app for immigration enforcement (biometricupdate.com)
- Facial Recognition on Public Buses ? Kansas City Says Yes (yro.slashdot.org)
- États-Unis : moins d’un an après son ouverture, le centre de détention pour migrant·es « Alligator Alcatraz » ferme ses portes (rfi.fr)
Inauguré en juillet 2025 à l’initiative du gouverneur républicain Ron DeSantis dans le parc naturel des Everglades, en Floride, le centre […] était devenu l’un des symboles de la politique anti-migrant·es menée aux États-Unis. Jusqu’à 1 400 personnes y ont été retenues dans des conditions de détention particulièrement difficiles.
- Trump a trouvé le coupable du fiasco de la coûteuse rénovation de ce bassin à Washington (huffingtonpost.fr)
Alors que la peinture tout juste appliquée se décolle sur le miroir d’eau, le président des États-Unis pointe du doigt « les extrémistes de gauche ».

- Leak Exposes Members of Peter Thiel’s Secretive ‘Dialog’ Society (wired.com)
A trove of internal records from a secret society for powerful figures in US politics, finance, and tech was left exposed online […] naming participants in its events and revealing sensitive personal details they were assured would stay private.The group, called Dialog, is a private, invitation-only organization cofounded in 2006 by the billionaire tech investor Peter Thiel.
- Océans : Trump renonce à démanteler un système de surveillance crucial pour le climat (reporterre.net)
- Ce satellite va s’écraser sur Terre, la NASA veut envoyer un robot pour le sauver (slate.fr)
L’agence spatiale prépare une opération sans précédent pour tenter de prolonger la vie de l’observatoire spatial Swift, qui subit une dégradation progressive de son altitude qui le rapproche inévitablement d’une rentrée atmosphérique.
- Un séisme catastrophique semble « dangereusement proche » en Californie, alerte une étude (slate.fr)
Les failles géologiques de San Andreas et San Jacinto ont atteint leur niveau de contrainte tectonique le plus élevé depuis 1.000 ans.
- Un cimetière de baleines vieux de 5,3 millions d’années découvert au fond de l’océan Indien (theconversation.com)
Spécial IA
- WA police launch real-time AI camera surveillance “to catch criminals” (nine.com.au)
- Le fonds IA de Bernie Sanders ? Une idée plus courante qu’on le croit (next.ink)
Bernie Sanders propose de créer un fonds souverain qui permettrait à la population des États-Unis de participer aux profits générés par l’intelligence artificielle.
- IA : blocage d’Anthropic aux étrangers, son patron Dario Amodei, “pompier pyromane” pris à son propre jeu (radiofrance.fr)
Donald Trump a forcé Anthropic à bloquer ses meilleurs modèles aux ressortissants étrangers, un acte inédit révélant notre dépendance technologique aux produits américains . Dario Amodei est pris à son propre piège de “pompier pyromane” de l’IA.
- “Mythos” at Home, and It’s Called AISLE (aisle.com)
A startup out of Europe built an AI system that matches Mythos on zero-day discovery, using widely available models, even air-gapped. You’ve probably never heard of it.
- IA et Open Source : la fin du pillage de code grâce au copyleft de Yale ? (goodtech.info)
Vous en avez (vous aussi) assez de voir vos dépôts GitHub pillés par des modèles d’IA fermés ? Des chercheurs de Yale proposent la licence CCAI […] Son but ? Contraindre les développeurs d’IA à rendre publiques l’architecture et les données d’entraînement de leurs modèles dès lors qu’ils se nourrissent de code open source.
- Recommendations When Using LLM-backed Generative AI Systems for FOSS Contributions (sfconservancy.org)
The FOSS community should support, not just tolerate, those who outright reject LLM-gen-AI systems. There are many intersecting ethical and moral issues regarding these systems, many of which are not currently fully understood. Anyone who chooses to avoid them deserves our support and assistance.
- The Community is the Achievement ; the Achievement is the Community (linguacelta.com)
The distributed technology community is an absolute marvel. It knows more than any individual could ever hope to know. It is generous in sharing knowledge. At its best, it is patient and encouraging and collaborative. It wants to invite you in and tell you everything it knows. Your biggest problem may be getting it to stop when your brain is full. […] By asking LLMs to provide (often confidently incorrect) answers to their tech questions, developers are not only destabilizing professional communities of practice, but also neglecting to maintain the rich technological commons which has previously been built up from public discussions of questions and answers.[…] it isn’t possible to separate the professional from the political, or the technological from the ethical. When we try to do that, we end up with tech projects that discriminate against minoritized people, not because their creators particularly intended to discriminate, but because bias is endemic in every culture, and the community had no ethical guardrails requiring creators to check for that bias.
- Le coût caché de l’IA en entreprise : 6,4 heures par semaine à surveiller des robots (cio-online.com)
- Tension de la productivité : le goulot de la diffusion (danslesalgorithmes.net)
- OpenAI just exposed how bad AI still is at real science (nerds.xyz)
Artificial intelligence companies love to talk about how their models are transforming science. Depending on who you ask, AI is either on the verge of curing diseases, discovering new drugs, or completely reinventing research itself. OpenAI’s newly announced LifeSciBench benchmark, however, offers a much more grounded reality check.
- Is AI ruining our skills ? Early results are in — and they’re not good (nature.com)
Reliance on artificial-intelligence tools degrades the abilities of physicians and software engineers, studies show.

- 13 mots suffisent pour manipuler un résultat de recherche par IA (next.ink)
- On AI in research and astrophysics (lookingup.francois-rincon.org)
- Europe must choose between AI and climate goals, data center lobby says (politico.eu) Tech sector says only carbon-emitting gas plants are reliable enough today to power the EU’s AI goals.
- Exclusive : Conservatives plan nationwide protest against AI data centers (axios.com)
- Alors, pour vous en dessert, ce sera data centers ou transition énergétique ? (open.substack.com)
Spécial guerre(s) au Moyen-Orient
- C’est finalement depuis le palais de Versailles que Trump a signé l’accord avec l’Iran (huffingtonpost.fr)
Attendue vendredi en Suisse, la signature de l’accord entre Washington et Téhéran a finalement eu lieu plus tôt que prévu.
- Iran : une défaite pour Trump, un désastre pour Netanyahou (politis.fr)
L’accord de cessez-le feu avec l’Iran est bien fragile alors que les dirigeants israéliens ne rêvent que de le torpiller.
- Netanyahu Finally Learns the Truth About Trump (theatlantic.com)
An alliance with the president was the Israeli prime minister’s selling point. Now it may be his downfall.
- Le cessez-le-feu entre Hezbollah et Israël déjà violé, l’Iran réplique et ferme le détroit d’Ormuz (huffingtonpost.fr)
Des frappes israéliennes ont fait une quinzaine de morts au lendemain de l’annonce d’une trêve.[…] L’Iran n’a pas tardé à répondre aux frappes en annonçant la fermeture du détroit d’Ormuz
- US-Iran Talks Delayed as ‘Renewed Israeli Aggression’ in Lebanon Kills at Least 18 (commondreams.org)
One Lebanese writer reported that Israeli forces were “committing massacres” in residential areas across southern Lebanon, threatening to derail progress toward a US-Iran peace deal.
- « Ma peau a été complètement brûlée » : au Liban, les ravages du phosphore blanc, largué illégalement par l’armée israélienne (vert.eco)
Depuis le début de la guerre au Liban en 2023, l’armée israélienne a, selon plusieurs cas documentés par les ONG, utilisé du phosphore blanc. Cette arme incendiaire illégale quand elle est employée dans des zones civiles ravage la terre et entraîne de lourdes conséquences sanitaires.
Spécial femmes dans le monde
- Son of Norway’s crown princess convicted of rape and sentenced to four years in prison (theguardian.com)
- Italy PM Meloni ‘stunned’ by Trump’s claims she begged him for a photo (theguardian.com)
Trump said : “She’s probably happy I talked to her. I didn’t have to talk to her. She begged me to take a picture with her. She wanted a picture with me so badly. I wouldn’t have taken it, but I felt sorry for her.” The remarks provoked fury in Italy and words of solidarity for Meloni from across the political spectrum, with Italy’s foreign minister, Antonio Tajani, saying he had cancelled a trip to the US next week.
- Des agents d’OnlyFans menacent des créatrices de contenu et prélèvent jusqu’à 50 % de leurs revenus (slate.fr)
Critiques sur leur apparence, pressions pour produire des contenus plus explicites, menaces : certaines créatrices d’OnlyFans vivent une réalité bien éloignée du fantasme de l’entrepreneuriat numérique.
- Canada makes femicide first-degree murder as all three major Criminal Code reforms become law (canada.ca)
- Young women now have ‘close to zero’ risk of cervical cancer death after HPV jab (bbc.com)
Children vaccinated at age 12–13 against HPV (human papillomavirus) have close to zero risk of dying from cervical cancer before the age of 30, landmark new research reveals.
Spécial France
- Le groupe Bernard Hayot : aux origines coloniales de la vie chère (frustrationmagazine.fr)
Les années 2024-2025 ont marqué un tournant dans la mobilisation des militants caribéens contre la vie chère. Au cours des manifestations, une entreprise martiniquaise familiale a été désignée responsable de la vie chère : le Groupe Bernard Hayot (GBH). Pendant six ans, le groupe a imposé le mystère sur ses chiffres d’affaires et ses bénéfices, ne les révélant qu’au cours de l’année 2025.
- « La France interdit chez elle les pesticides qu’elle vend aux pays du Sud » (reporterre.net)
Les luttes contre le chlordécone et l’agent orange manifesteront ensemble à Paris le 20 juin contre le « colonialisme chimique ». La géographe brésilienne Larissa Mies Bombardi, qui a forgé ce concept, décrypte cette « asymétrie » entre le Nord et le Sud global.
- Cybersécurité : la transposition de NIS2 continue de traîner des pieds (next.ink)
17 octobre 2024 : c’était la date limite pour transposer le projet de loi relatif à la résilience des infrastructures critiques et au renforcement de la cybersécurité, plus connu sous le nom NIS2.
- Protection des mineur·es en ligne : la CJUE valide l’obligation de vérification de l’âge sur les sites pornographiques (leclubdesjuristes.com)
Après le renvoi préjudiciel du Conseil d’État, la Cour de justice de l’Union européenne (CJUE) a rendu, mardi 16 juin, un arrêt validant la possibilité pour la France d’imposer aux sites pornographiques la vérification de l’âge de leurs utilisateurs.
- Violences sexuelles sur mineur·es en Martinique : plus de 700 procédures en cours et une “libération de la parole” confirmée par le procureur général (la1ere.franceinfo.fr)
- Le nombre de victimes de violences à Bétharram pourrait être beaucoup plus élevé qu’attendu (huffingtonpost.fr)
Le rapport de la commission d’enquête indépendante sur les violences à Bétharram estime qu’il pourrait y avoir jusqu’à 1 500 victimes de violences sexuelles et physiques.
Voir aussi Affaire Bétharram : entre 700 et 1500 élèves potentiellement victimes, selon les projections d’une ONG (rfi.fr)
« Crimes de masse », « sadisme », « torture »… Entre 700 et 1 500 élèves scolarisés de 1950 à la fin des années 1990 ont potentiellement été victimes « de violences d’une exceptionnelle gravité » à Notre-Dame-De-Bétharram, près de Lourdes dans le sud-ouest de la France, et dans d’autres établissements de la congrégation religieuse, selon le rapport d’une ONG spécialisée dévoilé samedi 20 juin.
- La Cnaf fait le pari de l’open source pour reprendre la main sur le calcul des allocations (acteurspublics.fr)
- Les renseignements intérieurs français débranchent Palantir (synthmedia.fr)
Le Premier ministre Sébastien Lecornu a annoncé le divorce entre la DGSI et Palantir, la sulfureuse entreprise de logiciels américaine choyée par Donald Trump. Après dix ans de dépendance technologique, les services secrets français coupent le cordon pour confier leurs données ultra-sensibles au champion tricolore ChapsVision.
Voir aussi Qu’est-ce que ChapsVision, l’entreprise française retenue par Paris pour remplacer Palantir ? (legrandcontinent.eu)
- Chaleur, inondations… Un quart des futurs data centers français vulnérable aux risques climatiques (reporterre.net)
- La SNCF annule 71 trains à cause de la canicule (reporterre.net)
La SNCF a annoncé jeudi 18 juin la suppression de 71 trains censés circuler entre jeudi et lundi, pour « prévenir les pannes potentielles de climatisation liées aux très hautes températures », a indiqué à l’Agence France-Presse l’entreprise ferroviaire.
- Canicule : avec 44 °C ressentis, il fera dimanche plus chaud à Paris qu’à Bangkok et à la Mecque (franceinfo.fr)
La canicule s’installe, avec 60 départements en vigilance orange si bien que la température ressentie, comprenant l’humidité et l’ensoleillement, sera plus élevée dimanche en France que dans plusieurs villes tropicales ou désertiques.

- Quel climat futur dans votre région ? (meteofrance.com)
- “La fête de la musique est la plus grosse soirée de l’année” : stupeur et colère des bars, sidérés par l’interdiction d’alcool en terrasse ce week-end à Strasbourg (france3-regions.franceinfo.fr)
“Nous n’avons eu aucun communiqué de la préfecture ni même de l’UMIH (Union des métiers et des industries hôtelières). Juste un post Facebook sur le compte de la préfecture”.
- Déshydratation, efficacité diminuée, réactions cutanées… Pourquoi médicaments et canicule ne font pas forcément bon ménage (franceinfo.fr)
- Psychiatrie : Benzodiazépines ou l’addiction sur prescription (journal-labreche.fr)
9 millions. C’est le nombre de Français·es traité·es par benzodiazépines au cours de l’année 2024. Ces sédatifs prescrits pour l’anxiété et l’insomnie sont aussi très addictifs, et sont souvent prescrits au-delà des 12 semaines préconisées. De nombreux professionnels dénoncent un problème de santé publique.
Spécial femmes en France
- Ces jeunes pères qui prennent leur congé de paternité pendant la Coupe du monde de Foot (lesnouvellesnews.fr)
Sur l’indispensable compte de « T’as pensé à ?, l’association qui rend visible la charge mentale des femmes », des agentes de la CPAM disent s’attendre à une hausse des demandes de congé paternité pendant la Coupe du monde 2026.
- Thomas Lilti, le réalisateur d’« Hippocrate », épinglé dans une enquête de « Mediapart » (huffingtonpost.fr)
Le médecin et cinéaste est notamment accusé d’avoir pillé le travail de plusieurs femmes scénaristes pour ses films.[…] Dans son enquête, Mediapart révèle également que Thomas Lilti a été radié de l’Ordre des médecins […] Malgré sa radiation en 2012, il aurait « abusé à de multiples reprises de son autorité de médecin sur des femmes placées sous son autorité »
Voir aussi Vols de scénarios et voyeurisme : le réalisateur Thomas Lilti (“Hippocrate”) visé par deux enquêtes (lesinrocks.com)
une proche de Thomas Lilti, qui a résidé chez lui, a découvert des images d’elle nue dans son propre ordinateur. Elle y a trouvé un logiciel de caméra espion dont elle ne savait rien. “On voit le réalisateur face à l’écran, faire des manipulations pour lancer et éteindre les vidéos. Sur l’un, on le voit clairement tester le cadre”
- À Mayotte, le combat des associations contre les violences sexuelles sur mineur·es (histoirescrepues.fr)
Depuis 2018, l’association Haki za Wanatsa (“les droits des enfants” en shimaoré) recueille les témoignages de victimes et mène des actions de terrain, en dépit des tabous culturels et de la faiblesse des services de l’État.
- Un an après #MeTooPolice, où en est-on ? (rembobine.info)
Entre 2012 et 2025, 429 personnes ont été victimes de violences sexuelles commises par 215 policiers et gendarmes – tous grades confondus et dans plus d’une centaine de villes en France. Ces violences, aux modes opératoires multiples, vont du harcèlement sexuel aux agressions sexuelles aux viols. Systémiques, elles n’ont pourtant fait l’objet d’aucune prise en charge sérieuse du ministère de l’Intérieur.
- Lyhanna : pourquoi il faudra rester mobilisé·es longtemps (lesnouvellesnews.fr)
« Tant qu’une loi intégrale et des moyens ne seront pas adoptés » : partout en France, des rassemblements sont appelés chaque lundi. Derrière l’émotion suscitée par l’affaire Lyhanna, la coalition féministe pour une loi-cadre contre les violences sexuelles redoute, une fois encore, l’inaction des pouvoirs publics.
- Affaire Lyhanna : l’autopsie de la collégienne confirme qu’elle a été violée (humanite.fr)
- La Ciivise passe les (in)actions du Gouvernement à la loupe (lesnouvellesnews.fr)
Les appels répétés de la Ciivise à agir contre les violences faites aux enfants n’ont pas été entendus. Dans un rapport publié ce lundi 15 juin, la Commission épluche les actions du Gouvernement et le presse de « passer à la vitesse supérieure », notamment après le meurtre de Lyhanna.
- « Urgence sanitaire » : seize familles portent plainte contre TikTok (lesnouvellesnews.fr)
Anorexie, dépression et idées suicidaires. Après le suicide de cinq adolescentes, le collectif « Algos Victima » porte plainte contre TikTok pour « abus de faiblesse ».
Spécial médias et pouvoir
- Enquêter sur Bernard Arnault, un exercice sous pression (larevuedesmedias.ina.fr)
Ces dernières semaines, plusieurs enquêtes sur Bernard Arnault, dont un livre biographique publié le 10 juin, agitent les services de communication du géant du luxe LVMH. Pour les journalistes qui tentent de percer le mystère de l’homme le plus riche de France, la tâche est souvent périlleuse.
- Qui est vraiment Matthieu Pigasse ? (frustrationmagazine.fr)
- Le 13h d’Inter : anesthésier le réel, mode d’emploi (acrimed.org)
- Liberté de la presse : ce qui est arrivé à un de nos journalistes est extrêmement grave (politis.fr)
Lors de l’audience devant la juge des référés, le représentant du ministère de l’Intérieur a dû préciser les raisons qui l’ont poussé à interdire à notre journaliste Maxime Sirvins d’entrer au salon de l’armement Eurosatory. Des motivations particulièrement inquiétantes qui ont toutes été balayées par le tribunal administratif.
- CNews mise en demeure de respecter le pluralisme des courants de pensée et d’opinion (telerama.fr)
Saisie en janvier par Reporters sans frontières, l’Arcom a épluché les programmes de la chaîne phare de Vincent Bolloré en mars 2025. Et constaté que non, tous les courants de pensée ne sont pas représentés dans les infos et les débats.
- Face à l’extrême droite, défendre la liberté des médias (politis.fr)
La menace contre la liberté de la presse en France n’a plus rien d’hypothétique. Pour Reporters sans frontières, l’absence de réformes ambitieuses favorise la précarisation des métiers, la concentration des médias et les stratégies d’influence politique. Thibaut Bruttin, son directeur général, appelle à la vigilance.
- Ebra et Le Dauphiné Libéré : l’événementiel au détriment de l’information ? (acrimed.org)
Quotidien régional dominant à Grenoble, Le Dauphiné Libéré ne lésine pas sur les moyens pour se mettre au service du secteur de la Tech et de l’IA dans la « Silicon Valley française ».
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- G7 d’Évian : Emmanuel Macron efface le climat de l’agenda pour « ne pas fâcher » Donald Trump (reporterre.net)

- Climat : la France cuit, et le gouvernement se félicite (reporterre.net)
En pleine vague de chaleur, le ministère de la Transition écologique s’est félicité, le 17 juin, de l’avancée de son plan d’adaptation au changement climatique. Une stratégie mal financée et largement insuffisante, rétorquent les associatifs.
- Les vagues de chaleur ont un terrible coût sanitaire, estimé à plus de 5 000 morts par an par Oxfam (huffingtonpost.fr)
- Urgences saturées, manque de soignant·es : la chaleur extrême révèle la déroute du système de santé face au changement climatique (vert.eco)
À l’aube d’une nouvelle vague de chaleur précoce, l’ONG Oxfam documente dans un rapport l’explosion des besoins en soins due au réchauffement climatique, alors que le système de santé français s’enfonce déjà dans la crise.
- Le gouvernement détourne les aides de l’Ademe pour financer l’un des plus gros pollueurs de France (disclose.ngo)
Matignon et Bercy ont truqué deux appels à projets de l’Agence de la transition écologique (Ademe) pour financer le géant de la pétrochimie Ineos, révèle Disclose. La multinationale va toucher plus de 300 millions d’euros d’argent public pour soutenir l’activité d’une usine parmi les plus émettrices de CO2 en France.
- « Silence vaut acceptation » : quand le gouvernement invite les multinationales à lui dicter sa politique (multinationales.org)
derrière tous les discours du pouvoir exécutif sur la « souveraineté numérique », c’est bien l’attractivité vis-à-vis des grands acteurs économiques internationaux qui reste la priorité, au détriment du droit de l’environnement et des citoyen·nes.
- Derrière la loi « simplification », l’offensive des Big Tech et du lobby des datacenters (multinationales.org)
L’article 35 de la loi de simplification […] crée le statut de « projet national d’intérêt majeur » qui vise à faciliter la construction rapide de nouveaux data centers. Des gros acteurs économiques ont pesé de tout leur poids pour faire adopter cette mesure stratégique, à commencer par les Big Tech qui ont démontré une nouvelle fois l’étendue de leurs réseaux d’influence.
- Bercy crée la Direction de l’intelligence artificielle et du numérique (presse.economie.gouv.fr)
La DIAN sera chargée de définir et mettre en œuvre la stratégie numérique et IA des ministères économiques et financiers.
- Matignon bloque la diffusion d’un rapport sur l’impact de l’IA sur les effectifs de la fonction publique (acteurspublics.fr)
Une mission menée par plusieurs inspections générales a tenté, depuis quelques mois, de quantifier les effets du déploiement de l’IA dans la fonction publique. Son rapport, désormais dans les mains du Premier ministre, Sébastien Lecornu, pourrait toutefois ne jamais être rendu public
- Lecornu donne une date pour introduire les cours d’IA au lycée (huffingtonpost.fr)
Le Premier ministre a annoncé qu’une heure de cours par semaine serait dispensée aux classes de seconde pour apprendre à maîtriser l’intelligence artificielle.
- Pronote, Parcoursup, ENT : pourquoi l’interdiction du smartphone pose problème (lenouveauparadigme.fr)
- Gabriel Attal : « Il faut l’équivalent de la politique agricole commune pour l’IA » (lesechos.fr)
- Mort de Lyhanna : « Plutôt que de punir les magistrat·es, il faut augmenter leur nombre, les encourager, les former » (basta.media)
- L’Unédic appelle l’État à ne plus ponctionner les comptes de l’assurance-chômage pour lui permettre de réduire sa dette (franceinfo.fr)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- La préfecture de police de Paris interdit un grand rassemblement contre les violences du régime iranien (franceinfo.fr)
- Fête de la musique : ni « violences », ni « dégradations », Laurent Nuñez prévient qu’« aucun débordement ne saura être toléré » (leparisien.fr)
Dans une lettre aux préfets, Laurent Nuñez demande de mettre en œuvre un dispositif de sécurité renforcé pour la Fête de la musique 2026, afin de prévenir le terrorisme, les violences urbaines et tout débordement.
- La préfecture de police interdit le concert de LFI prévu pour la Fête de la musique. (huffingtonpost.fr) – voir aussi Concert de LFI à Paris : les insoumis·es déposent un recours en référé après l’interdiction par la préfecture de police (liberation.fr) et Le concert de LFI pour la Fête de la musique finalement autorisé à Paris (huffingtonpost.fr)
La France insoumise, qui a annoncé l’organisation de ce concert dimanche sur la place de la République, a gagné son bras de fer face à la préfecture de police.
- Loi RIPOST, quand Nuñez attaque : les « LAPI » ou la surveillance massive des déplacements (laquadrature.net)
Les lecteurs automatiques de plaques d’immatriculation, plus fréquemment dénommés par l’acronyme « LAPI », sont encore peu connus en France. Pourtant, derrière ces quatre lettres se cache un dispositif ancien qui permet d’identifier et de localiser des véhicules en France à grande échelle.
- Sophie Djigo : un jugement qui met toustes les enseignant·es et chercheureuses en danger (politis.fr)
Le jugement rendu dans l’affaire de la professeure de philosophie harcelée par l’extrême droite marque un tournant préoccupant pour la liberté pédagogique et académique.
- « Nous ne sommes pas dupes de ce pinkwashing » : comment les maires RN du nord instrumentalisent les luttes LGBT (basta.media)
Annuler des événements LGBT tout en se drapant des couleurs arc-en-ciel : dans les Hauts de France, les mairies RN instrumentalisent le mois des fiertés. Et ce alors qu’au parlement européen, le parti refuse de voter contre les « thérapies de conversion ».
- Erik Tegnér, le directeur du magazine d’extrême droite « Frontières », condamné à six mois de prison avec sursis pour divulgation de données personnelles d’avocat·es (lemonde.fr)
Dans un hors-série publié en 2025, ces avocat·es étaient présenté·es avec leur nom, leur prénom et la ville où ils exercent comme des « militants idéologiques », désignés comme les « coupables » de la crise migratoire.
- Des militant·es « humilié·es et frappé·es » par le GIGN lors d’une action antimilitariste en Haute-Savoie (reporterre.net)
- Jordan, éborgné après la victoire du PSG : la télé aveugle aux violences policières ? (politis.fr)
Le témoignage de l’homme, blessé par un tir de LBD, n’a connu aucun écho médiatique. Un silence aussi peu surprenant que désespérant.
- « Je veux la vérité sur la mort de mon fils » : le combat de la mère d’Adam, tué par un policier (basta.media)
Fatiha est la mère d’Adam, un jeune tué en 2022, à vingt ans, lors d’une intervention policière. Elle tente depuis de lever les zones d’ombre qui entourent le récit des policiers. Quatre ans après les faits, la reconstitution va enfin avoir lieu.
- 49 personnes tuées au cours d’une intervention policière en 2025 (basta.media)
Spécial résistances
- « On a toujours été là » : avec les prides rurales, les fiertés LGBT s’assument à la campagne (basta.media)
- Les quatre activistes antipub relaxé·es : une victoire contre l’État répressif (antipub.org) – voir aussi Victoire : les quatre activistes ayant dénoncé le génocide de Gaza n’iront pas en prison (lareleveetlapeste.fr)
Pour le collectif Résistance à l’Agression Publicitaire, c’est « une victoire contre l’État répressif ». Le Tribunal Correctionnel de Lyon a relaxé les quatre activistes antipub et pour la lutte de libération palestinienne qui avaient participé à un détournement publicitaire en septembre 2025.
- Blinding the Cyclops—Wrecking the Panopticon – Camera Hunting in the Metropolis (crimethinc.com)
“Big Brother is watching you.” Once a threat from a dystopian future, today this is a universal reality that we all participate in with our smartphones and Instagram accounts. Yet for years, a rebel undercurrent has pushed back against surveillance, seizing the prevalence of surveillance cameras as yet another vulnerability in the system of control. In the following narrative, an anonymous researcher wages a personal war against surveillance infrastructure, testing some of the same tactics that social movements have recently employed from Greece and Slovenia to Chile and Hong Kong.

Spécial outils de résistance
- Pétition : Dégageons les capitalistes des médias ! (acrimed.org)
- « Il est temps de choisir son camp » : et si on créait un label « sans-IA générative » ? (reporterre.net)
- Dans votre quartier aussi c’est un four ? Témoignez ! (blogs.mediapart.fr)
Un nouvel épisode caniculaire s’étend à nouveau en France où au moins 53 départements sont en vigilance orange ce 19 juin 2026. Et les températures risquent de continuer à grimper. Pour un article en préparation, nous vous donnons la parole à ce sujet. Racontez-nous votre quotidien.
- Fiche 36 : il fait trop chaud au boulot ! en 8 questions (solidaires.org)
Spécial MAGAM et cie
- Google referme la dernière faille qui permettait aux vrais bloqueurs de pub de survivre sur Chrome (clubic.com)

- À partir du 3 août 2026, Google va utiliser votre adresse IP pour le ciblage publicitaire ! (it-connect.fr)
Exploiter votre adresse IP pour vous proposer des publicités personnalisées, c’est la nouvelle idée de Google. À compter du 3 août 2026, Google va la mettre en place dans l’Espace économique européen, au Royaume-Uni et en Suisse. L’adresse IP, qui est une donnée personnelle au sens du RGPD, va donc être utilisée pour le ciblage publicitaire.
- Dans un discours optimiste, Jeff Bezos expose son plan pour sauver la Terre (huffingtonpost.fr)
Son plan en détail ? Rendre la Terre à son état d’avant l’ère industrielle en envoyant toutes les activités polluantes sur la Lune ou des astéroïdes.
Les autres lectures de la semaine
- From PGP to Mythos : a brief history of export controls that didn’t stop anyone (techcrunch.com)
- Recherche désespérément trous béants : enquête sur les terres excavées du Grand Paris Express (lechiffon.fr)
- “Racisé”, le mot qui dérange la République (komunemedia.substack.com)
Apparu dans les universités en 1972, le terme “racisé” cristallise les tensions françaises entre universalisme républicain et reconnaissance des discriminations raciales.
- L’histoire des femmes américaines qui ont aidé la France et ses orphelins à se relever de la Première Guerre mondiale (slate.fr)
Pendant et après la Grande Guerre, des milliers d’Américaines ont mené des missions humanitaires en France, en participant à la reconstruction du pays et en jouant le rôle de mères auprès des orphelins français. Une facette méconnue de l’histoire transatlantique.
- Comment le génie de George Sand a été minimisé par l’histoire littéraire (theconversation.com)
L’année 2026 marque le cent cinquantième anniversaire de la mort de George Sand. La relire, c’est redécouvrir son apport artistique et intellectuel, mais aussi comprendre comment le génie féminin a été systématiquement dénié par un canon littéraire reléguant les femmes à la portion congrue.
- Meet Héloïse, the Medieval Woman Philosopher Who Turned a Doomed Love Affair into a Meditation on Ethics (openculture.com)
- Pourquoi de plus en plus de médecins reconnaissent‑ils la validité des expériences de mort imminente ? (theconversation.com)
Les BDs/graphiques/photos de la semaine
- G7
- Pantone
- Remember
- Scandale
- Philo
- Futur
- Mondial
- Sun
- Hot
- Normal
- Numéro
- Elon
- 18 juin
- Quand est-ce qu’on interdit les lunettes connectées ? (framablog.org)
- Réalité
- Medium
- Pride
- Trans
- Petits gestes
- Higher
Les vidéos/podcasts de la semaine
- Démocratie en danger : journalistes supprimé·es, information menacée (basta.media)
Ce 18 juin, les journalistes étaient en grève à travers la France. Ils et elles dénoncent la dégradation de leurs conditions de travail, la concentration des médias entre les mains des milliardaires et demandent l’encadrement de l’usage de l’intelligence artificielle dans les médias.
- The Map of Physics : Animation Shows How All the Different Fields in Physics Fit Together (openculture.com)
Les trucs chouettes de la semaine
- Marie Muzard, l’ange gardienne des poulpes en Méditerranée (humanite.fr)
À Cannes, elle a créé une association pour attirer l’attention sur la disparition en Méditerranée de ce céphalopode. En cause : le réchauffement de l’eau et… les cartes des restaurants.
- Black Women Farmers Are Reclaiming the Land (reasonstobecheerful.world)
From sharecroppers to herbalists to healers, Black women farmers have been nourishing the world for generations — and continue to today.
- Shaking up the coffee world : Entirely new way of making espresso unveiled (unsw.edu.au)
Researchers at UNSW Sydney have harnessed the power of ultrasonic sound waves to make espresso-strength coffee with room temperature water, cutting energy use by up to 75 %.
- Mastodon looks to newsletters to help revive the open social web (techcrunch.com)
- Pages not found (404s.design)
404 pages worth finding
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
18.06.2026 à 18:20
Table ronde « Logiciels libres », avec Framasoft, à l’Assemblée Nationale
Framasoft
Lire la suite (470 mots)
Depuis février 2026, la commission d’enquête « sur les dépendances structurelles et les vulnérabilités systémiques dans le secteur du numérique et les risques pour l’indépendance de la France » est conduite, à l’Assemblée nationale par Cyrielle Chatelain (rapporteure) et Philippe Latombe (président). De nombreuses auditions ont été tenues, le logiciel libre y étant souvent évoqué comme alternative aux situations de dépendance. Framasoft a été auditionnée mercredi 6 mai 2026 dans le cadre d’une table ronde sur le logiciel libre.
Pierre-Yves Gosset, coordinateur des services numériques de l’association Framasoft, est intervenu au côté d’Étienne Gonnu et Loïc Dayot, respectivement chargé de plaidoyer et administrateur de l’association April, de Renaud Chaput, directeur technique de Mastodon, et de Nicolas Vivant, fondateur de France Numérique Libre, directeur de la stratégie et de la culture numériques de la commune d’Échirolles.
- La vidéo est disponible ci-dessus sur PeerTube, ou directement sur le site de l’Assemblée Nationale.
- La transcription de l’audition a été réalisée par le groupe de travail Transcription de l’April (merci à elles et eux !).
- Le compte-rendu officiel est aussi disponible sur le site de l’Assemblée Nationale (ou la copie archivée par nos soins).
Les auditions se sont achevées courant mai et le rapport devrait être publié en juillet 2026.
16.06.2026 à 15:20
LaSuite.coop : interview d’une coopérative qui veut (elle aussi !) dégoogliser internet
Framasoft
Texte intégral (3363 mots)
Ce n’est pas tous les jours qu’on a de belles perspectives à partager. Alors ne boudons pas notre plaisir !
En mars dernier, nous vous partagions un (long) article sur La suite numérique de l’État, les critiques qui en étaient faites, et plus généralement la stratégie « Make or Buy » de l’État.
Nous évoquions alors une interview de l’équipe de LaSuite.coop, une coopérative dont l’objectif est de proposer des outils numériques libres et éthiques (en partie basés sur les outils de LaSuite de l’État).
Nous avons enfin trouvé le temps de les interroger sur leur projet, et ça tombe bien, puisqu’elles et ils ouvrent leur sociétariat à toute personne souhaitant participer à l’aventure.
Hello l’équipe de LaSuite.coop ! On est ravi⋅es de vous accueillir pour cette nouvelle interview sur le Framablog. Commençons par le début : qui êtes-vous ?
Bonjour à toute la communauté Framasoft ! Ici LaSuite.coop, une coopérative née de la rencontre entre plusieurs structures qui avaient chacune la même conviction : les organisations qui défendent des valeurs progressistes méritent des outils numériques qui leur ressemblent.
Derrière le projet, on trouve cinq structures fondatrices : IndieHosters, coopérative qui héberge des services libres depuis plus de dix ans ; Open Source Politics, spécialiste des plateformes de démocratie participative pour les collectivités ; Yaal Coop, coopérative de développement logiciel ; Algoo, éditeur de Galaé, notre solution de messagerie email libre et Le Bureau.coop coopérative qui accompagne dans la gestion de noms de domaine.. Ensemble, nous avons constitué une SCIC, une Société Coopérative d’Intérêt Collectif, pour porter collectivement ce projet.
Ce qui nous rassemble, ce n’est pas simplement le logiciel libre. C’est l’idée que la manière dont on produit et gouverne les outils numériques a des conséquences politiques concrètes. On se doute que vous le savez déjà, mais utiliser Google Workspace ou Microsoft 365, ce n’est pas un choix neutre : c’est confier ses données, ses communications et son autonomie à des entreprises dont le modèle économique repose sur l’extraction et la centralisation. Nous pensons qu’il existe une autre voie, et nous essayons de la rendre accessible.

Alors, dites nous en plus maintenant sur le projet « LaSuite.coop ». Quelle est son histoire ?
L’idée vient d’IndieHosters. Depuis 2015, Timothée, Pierre et leur collectif expérimentent des outils libres avec une conviction simple : il devrait être possible de s’émanciper des GAFAM sans sacrifier le confort ni la fiabilité. En 2020, pendant le confinement, ils lancent Liiibre, une suite collaborative complète, avec un modèle économique basé sur les communs, sans clients ni prestataires, mais avec des contributeurs et contributrices d’une ressource partagée. L’utopie concrète, comme ils disaient.
C’est à cette même période qu’IndieHosters et Open Source Politics commencent à travailler ensemble sur des projets de civic tech comme la mise en place d’outils de documentation pour Numérique En Commun(s) et la migration de la pétition du Sénat sur Decidim. En parallèle, IndieHosters est sollicité pour contribuer à l’infrastructure de La Suite numérique de l’État portée par la DINUM. Deux chemins qui s’alimentent mutuellement : d’un côté des expertises techniques qui se renforcent au contact de déploiements à grande échelle, de l’autre des relations de confiance qui se construisent avec des personnes d’horizons différents venant de l’État, de l’ESS et de la civic tech.
C’est là qu’IndieHosters propose à OSP de commercialiser Liiibre. IndieHosters (« IH ») avait les outils et l’infrastructure, Open Source Politics (« OSP ») avait les clients et les relations commerciales. Une complémentarité évidente. Et du côté d’OSP, le contexte accélère la décision : quand Musk rachète Twitter pour en faire une machine à désinformation, quand Trump récompense les Big Tech qui l’ont soutenu, quand Meta supprime ses équipes de fact-checking, on réalise que proposer seulement des outils de participation citoyenne à nos clients n’est plus suffisant. La souveraineté numérique ne peut pas s’arrêter à la plateforme de consultation. On embrasse donc la vision d’IndieHosters.
C’est de là que naît l’idée de LaSuite.coop. Ensemble, on a regardé de près les outils de La Suite numérique de l’État et ils nous ont grandement séduit. Comme ils étaient réservés aux agents publics nous y avons vu une opportunité d’en faire profiter le plus grand nombre. Mais pour aller plus loin, il fallait s’entourer.
Pour le développement IndieHosters a pensé à Yaal Coop qu’ils connaissent via le réseau Libre Entreprise, un réseau d’entreprise du numérique libre qui applique les valeurs du libre à sa gouvernance (horizontalité, transparence, égalité salariale, …), ainsi que par le collectif CHATONS.
Et suite au rachat de Gandi on a vu émerger deux initiatives qui nous on plu, Galae un service email professionnel commercialisé par Algoo et LeBureau.coop pour les noms de domaines. On leur a alors présenté notre projet et proposé de nous rejoindre.
OK. Alors maintenant, creusons un peu votre offre de services : vous proposez quoi ? Et à qui ?
À qui s’adresse-t-on ? À toute organisation qui cherche une alternative crédible aux suites de Google ou Microsoft : associations, syndicats, coopératives, mutuelles, structures de l’ESS, collectivités, communes de plus de 1 500 habitants, établissements d’enseignement supérieur, médias indépendants, partis politiques… Si vous partagez nos valeurs et avez besoin d’outils fiables sans sacrifier votre indépendance numérique, LaSuite.coop s’adresse à vous.
Un mot sur notre modèle : on parle de cotisation, pas d’abonnement, et ce n’est pas qu’une question de sémantique. En cotisant, une organisation ne paie pas simplement un prestataire pour un service, elle contribue à un commun, elle participe à le faire vivre et à le développer. C’est une relation fondamentalement différente de celle qu’on entretient avec un éditeur SaaS classique. Le montant est calculé en fonction de la taille de l’organisation et des outils déployés il nous paraît logique de ne pas faire payer une petite asso au même tarif qu’une fédération nationale.
Concrètement, on propose aujourd’hui une suite complète accessible via un portail de connexion unique : visio, chat, mail, agenda, prise de notes collaborative, stockage et partage de fichiers (avec la suite Collabora intégrée pour créer vos documents textes, tableurs et présentations), un gestionnaire de mots de passe et Grist, un outil no-code super puissant pour gérer vos données. Notre offre actuelle s’adresse aux organisations d’au moins dix personnes, mais on travaille à ouvrir le service aux particuliers et aux petits collectifs d’ici la fin de l’année. La souveraineté numérique ne devrait pas être réservée aux structures déjà bien installées.
Capture du site LaSuite.coop
Votre offre propose essentiellement les logiciels portés par La Suite Numérique de l’État, pourquoi ? Quel est votre rapport avec les équipes de la Dinum ?
Notre offre comporte en partie des logiciels portés par la DINUM parce que ce sont de très bons outils, tout simplement. Docs, Fichiers, Grist, Visio, ces logiciels ont été développés (ou amélioré pour le cas de Grist) pour répondre aux exigences d’une administration qui gère des données sensibles et des millions d’utilisatrices et d’utilisateurs. Ils sont robustes, open source, maintenus par des communautés actives. Quand on a regardé ce qui existait pour construire LaSuite.coop, la réponse s’est imposée assez naturellement.
D’autant plus que les membres d’IndieHosters ont contribué en partie à l’infrastructure de La Suite numérique de l’État. Cette relation de travail a créé une vraie proximité. Aujourd’hui on remonte des bugs, on participe aux discussions sur la feuille de route, et on s’implique dans les réflexions pour pérenniser le code de ces outils dans la durée. Il n’y a pas de contrat qui nous lie, juste une communauté qui s’articule dans le même sens. On avance ensemble, chacun de son côté, vers le même horizon.
C’est d’ailleurs ce que Timothée est allé défendre plus tôt cette année au FOSDEM : un modèle public-coopératif pour les communs numériques. L’idée est simple et puissante, la DINUM crée et garantit les communs, LaSuite.coop les maintient, les déploie et les rend accessibles au-delà de l’administration, et la communauté en oriente l’évolution. Chacun son rôle, dans le même sens. Un modèle qui n’a pas besoin de capital-risque ni de logique extractive pour tenir, juste des acteurs alignés sur l’intérêt général.
Avez-vous d’autres envies d’ouverture de services en perspective ?
Oui en effet ! D’abord ouvrir le service aux structures de moins de dix personnes et aux particuliers, ensuite, développer un outil de migration pour faciliter la transition vers LaSuite.coop pour le plus grand nombre. Parce qu’on sait que le frein principal ce n’est pas la volonté, c’est la complexité perçue du passage d’un outil à un autre. Un bon outil de migration, c’est ce qui transforme une bonne intention en vrai changement.
Nous avons également des liens étroits avec d’autres éditeurs d’applications qu’on prévoit de faire rentrer dans la gouvernance et dans l’offre prochainement : Biru (avec l’app Tenzu), tiBillet, kaihuri (pour Mobilizon) et peut être vous Framasoft (pour PeerTube).
Super ! Vous êtes actuellement en période de pré-ouverture de levée de fonds, car vous ouvrez votre sociétariat. Qu’est-ce que cela signifie, concrètement ?
Devenir sociétaire de LaSuite.coop, c’est acquérir au moins une part sociale à 100 euros et avec elle, une voix dans la coopérative. Droit de vote, accès aux assemblées générales, possibilité de peser sur les futurs développements des outils. On ne devient pas client, on devient copropriétaire d’une infrastructure numérique souveraine.
C’est rare, et c’est ce qui nous tient à cœur, que les personnes qui utilisent ces outils puissent aussi décider de leur direction. Une coopérative sans sociétaires, c’est une coquille vide. Avec eux, c’est un projet qui s’ancre dans le temps.
Pour l’instant, vous pouvez manifester votre intérêt sur notre site, la campagne ouvrira très prochainement. Ces pré-inscriptions comptent beaucoup pour nous car c’est une façon concrète de mesurer l’intérêt pour le projet et de nous donner la confiance nécessaire pour avancer sereinement vers nos objectifs. Inscrivez-vous dès maintenant sur https://societariat.lasuite.coop/ pour être averti·e en avant-première.

Capture écran site LaSuite.coop
Vous êtes-vous fixé des objectifs financiers à atteindre ? Lesquels et pourquoi ?
Nous nous sommes fixé un objectif minimum de 200 000 € pour avoir les reins solides et franchir un premier cap : augmenter significativement le nombre d’organisations auxquelles nous proposons nos services, en commençant par les coopératives.
Au-delà, nous espérons rencontrer un écho le plus large possible, pour avoir les moyens d’outiller rapidement les petites entreprises et le grand public.
Enfin, à partir d’un seuil de quelques millions d’euros, nous considérons qu’il sera préférable de créer un fonds de dotation pour accompagner l’essaimage de structures comme la nôtre sur le territoire, plutôt que de devenir une méga-structure. Nous avons à cœur de privilégier la mise en réseau de structures à taille humaine comme le font des coopératives telles que Biocoop ou Enercoop, plutôt que de former un monolithe. Sur ce point aussi, on pense différemment des GAFAM !
Les tarifs de LaSuite.coop (au 11/06/2026)
Allongez-vous sur le divan, fermez les yeux… Pour vous, dans 5 ans, LaSuite.coop, c’est quoi ?
Dans cinq ans, on aimerait avoir prouvé qu’un modèle coopératif peut tenir face aux géants, pas en les imitant, mais en faisant mieux sur ce qui compte vraiment. Des outils aussi fluides que Google Workspace, avec un contact humain en plus et des données qui restent les vôtres.
Concrètement, on veut avoir ouvert le service au grand public, développé un outil de migration en un clic depuis Microsoft et Google et commencé à reverser une part de notre chiffre d’affaires aux communs numériques que nous faisons vivre.
On veut aussi avoir les moyens de financer deux postes qui nous tiennent particulièrement à cœur. Le premier : une personne dédiée à la qualité du code que l’on repartage à la communauté open source avec documentation rigoureuse, code lisible, pour que n’importe qui puisse venir étudier ce qu’on fait et s’en emparer. Le deuxième, une personne à temps complet sur l’animation de l’écosystème des communs numériques, en interne ou via une structure partenaire. Parce qu’un commun sans communauté active, ça ne dure pas.
Il y a aussi l’ambition plus large de contribuer à faire migrer une partie significative de la population française vers des outils libres (on a le droit de rêver) et de porter un plaidoyer au niveau européen pour que ce modèle public-coopératif essaime au-delà de nos frontières. Nous sommes convaincus que la souveraineté numérique ne se construira pas pays par pays, chacun dans son coin. En cinq ans, on veut avoir démontré que l’utopie concrète, ça fonctionne.
On espère aussi que dans 5 ans (et même bien avant) on fasse parti des membres bien identifiés des Licoornes et qu’on participe avec eux à promouvoir le modèle coopératif, comme ils le font avec leur campagne ALT au capitalisme en cours.

Question relativement récurrente dans les interviews du Framablog : y a-t-il une question que vous auriez aimé qu’on vous pose ?
La question qu’on redoute un peu mais qu’il faut poser : « Qu’est-ce qui pourrait faire échouer LaSuite.coop ? »
L’indifférence. Pas l’hostilité, ça, ça mobilise, mais l’indifférence… Le sentiment que le problème n’est pas si urgent, qu’on verra ça plus tard. On peut construire les meilleurs outils du monde, porter le modèle le plus juste qui soit, si personne ne se sent concerné, ça ne suffit pas. C’est pour ça que le sociétariat compte autant pour nous. Chaque personne qui rejoint la coopérative, c’est une personne de plus qui a décidé que plus tard c’est maintenant.
Lien pour vous soutenir :
15.06.2026 à 08:45
Quand est-ce qu’on interdit les lunettes connectées ?
Gee
Texte intégral (1808 mots)
Bon. On pensait être débarrassés de ces saletés suite au flop des Google Glass, mais visiblement, ça revient à la mode. Alors faisons le point…
Quand est-ce qu’on interdit les lunettes connectées ?
💡 Aujourd’hui, on s’attaque à un gros morceau : les lunettes connectées. Bon, le terme officiel, c’est « lunettes intelligentes », de l’anglais « smartglasses » calqué sur « smartphone »…

⚠️ Il y a 15 ans déjà, en 2011, Google lance les hostilités avec les Google Glass.
▶️ Lorsque Google met fin à l’expérimentation en 2015, après un nombre de ventes ridicule, on croit le projet enterré dans la décharge du numérique où viendront vite le rejoindre les NFT et le Métavers.
Mais c’est sans compter sur…
Facebook en 2021.

✷ La multinationale franco-italienne de la lunette. Ce qui nous permet de classer ce projet dans la catégorie « cacarico » : c’est caca, oui, mais c’est un peu français aussi !
💡 Au niveau technique, on reste sur du classique : caméras et microphones intégrés, connexion au téléphone par Bluetooth, et évidemment, stockage sur les serveurs de Facebook, dont on rappellera à toutes fins utiles qu’ils sont soumis aux lois étatsuniennes comme le Patriot Act.

Une question se pose donc assez rapidement :
Quand est-ce qu’on interdit ces merdes ?

⚠️ Il n’y a AUCUN univers où filer des lunettes connectées à tout le monde, ça se passe bien.


⚠️ Là, si on commence à avoir des lunettes connectées un peu partout, on se lance sur un chemin dystopique à un niveau hallucinant.
(Surtout si, comme pour les fameuses enceintes connectées, les lunettes filment et enregistrent un peu quand Facebook le veut, sans qu’on ait des masses de contrôle sur les données et ce qui en est fait).
C’est la certitude, ou plutôt l’incertitude – ce qui est presque pire – d’être filmé, enregistré et analysé en permanence.
D’ailleurs, le public ne s’y trompe pas : dans une étude de la CNIL, on apprend que deux tiers des sondés trouvent que c’est un risque pour la vie privée.

▶️ Pour les lunettes connectées comme pour l’IA générative, on aimerait voir les mêmes précautions que pour le clonage humain, rapidement interdit après la naissance de Dolly, la première brebis clonée en 1997.

⚠️ Rappelons que le mantra de Facebook a longtemps été « move fast and break things », ce qui signifie donc « bouger vite et casser des trucs ». En général, quand quelqu’un annonce ses intentions aussi clairement, on ne lui déroule pas le tapis rouge.

Ceci dit, ne soyons pas totalement négatifs, il reste un peu d’espoir, notamment du côté de l’Union européenne :
le Règlement sur l’intelligence artificielle, par exemple, enquiquine pas mal Meta et compagnie sur la question de l’exploitation des données des lunettes par IA.

💡 Ces rares freins sont un début, mais restent timides par rapport à l’ampleur du problème. Connaissant l’historique des GAFAM, est-ce que ce sera vraiment suffisant ?

⚠️ Ce serait donc pas mal de ne pas trainer pour légiférer sur les objets de surveillance généralisées que sont ces lunettes connectées : pour une fois, on pourrait avoir un cadre légal contraignant et protecteur (pour nous) en amont du bazar.

Sources :
-
Les lunettes connectées : la CNIL appelle à la vigilance (CNIL)
-
Europe Can’t Get Meta Ray-Ban Display Because of EU Regulations) (Gizmodo [EN])
Crédit : Gee (Creative Commons By-Sa)
15.06.2026 à 07:42
Khrys’presso du lundi 15 juin 2026
Khrys
Texte intégral (7494 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Mois des fiertés : partout dans le monde, les droits LGBTQI+ en danger (portail.basta.media)
Au Ghana, aux États-Unis ou en Turquie, les droits des personnes LGBTQI+ sont attaqués. Ces offensives sont d’autant plus visibles en ce mois où les marches des fiertés, ou prides, ont lieu aux quatre coins du monde.

- Sécheresses, inondations, températures record : comment le phénomène El Niño, qui a officiellement commencé, pourrait être le plus intense jamais observé (humanite.fr)
- Retour des fortes chaleurs : l’OMS alerte sur un phénomène, responsable de 200 000 morts en 4 ans en Europe, qui n’a plus rien d’une « anomalie exceptionnelle » (humanite.fr)
Le continent européen se réchauffe bien plus vite que n’importe quel autre, alerte l’OMS. Un phénomène dont les répercussions sont d’ores et déjà visibles, alors que les décès prématurés dus à des vagues de canicules se multiplient en Italie, Espagne ou encore en Grèce.
- À partir de demain, la guerre en Ukraine sera aussi longue que la Première Guerre mondiale (legrandcontinent.eu)
Cela fait 1 566 jours aujourd’hui depuis que l’armée russe à lancée une guerre à grande échelle contre l’Ukraine, en février 2022. Lorsqu’on prend en compte l’annexion de la Crimée en 2014, cela fait 4 492 jours que l’Ukraine subit l’agression russe – deux fois plus que la Seconde Guerre mondiale.
- Un mégaprojet de la famille Trump provoque une « révolution des flamants roses » en Albanie (reporterre.net)
- Biométrie électorale à Madagascar : pourquoi la technologie ne suffit pas à produire la confiance (theconversation.com)
Depuis une vingtaine d’années, de nombreux pays africains ont adopté des technologies biométriques pour enregistrer ou identifier les électeurices, avec la promesse récurrente de réduire certaines fraudes et d’améliorer la qualité des scrutins.
- Ebola : « Les Congolais∙es ont l’impression d’avoir servi de cobayes » (basta.media)
l’est de la RDC constitue un terrain propice à ce type de contagion : la déforestation causée par l’exploitation minière pousse les animaux contaminés vers les villes, tandis que les nombreux conflits armés parquent les réfugiés dans des camps propices à la propagation des virus.
- Pacte sur la migration : quand l’Union européenne trahit ses valeurs fondatrices (courrierdesbalkans.fr)
- Frontex warns EES border queues could persist for another two years (biometricupdate.com)
The EU’s biometric-based Entry-Exit System (EES) may continue to cause long queues at borders for another two years, a Frontex official has said. At the same time, the travel industry warns that queues could divert holidaymakers to other destinations, causing EU countries to potentially lose billions in visitor spending.
- En Italie, la victoire du maire communiste Manuel Minervini relance les espoirs de la gauche face à Giorgia Meloni (humanite.fr)
- Andalousie : une percée de la gauche radicale (contretemps.eu)
Les élections du 17 mai dernier au Parlement d’Andalousie, qui décident de la composition du gouvernement régional, ont constitué une surprise pour certain·es et un choc pour le système des partis andalous, qui pourrait avoir des répercussions possibles à l’échelle de l’État espagnol. Le catalyseur de ce basculement est le résultat obtenu par Adelante Andalucía (AA), une coalition de la gauche radicale
- En Espagne, la régularisation massive dessine un nouvel horizon (frustrationmagazine.fr)
il nous semble essentiel d’affirmer que l’immigration est un fait positif, que nous sommes en capacité d’accueillir plus de monde et que nous devons le faire. Ce qu’il se passe en Espagne actuellement montre que ce projet est possible et qu’il est porté par toute une partie de la société civile.
- Le Pape Léon XIV tacle Donald Trump en pleine messe avec un message sur la guerre et les migrant·es (huffingtonpost.fr)
« Nous ne pouvons pas croire en Jésus et promouvoir la guerre », a déclaré le Pape depuis la Sagrada Familia de Barcelone.
- Guerre de l’open source et polémiques, tout ce qu’il faut savoir sur le lancement d’Euro Office par NextCloud (zdnet.fr) – voir aussi An open letter to office suite users, just before the Euro-Office announcement (blog.documentfoundation.org)
In recent days you will have read various articles announcing the arrival of Euro-Office, which is being “marketed” as the first open-source office suite developed in Europe. We feel compelled — reluctantly, since open source should rest on transparency, not deception — to correct this claim. The first open-source office suite developed in Europe was OpenOffice.org in 2001, based on StarOffice’s source code, followed by LibreOffice from 2010.
- EU orders Meta to open WhatsApp to rival AI chatbots (bbc.com)
The EU has told Meta that it must allow AI chatbots operated by rival firms to use WhatsApp for free.
- Facewatch wants to bring live facial recognition to UK pharmacies (biometricupdate.com)
- In Nova Scotia, Mi’kmaq people mark 300 years of treaty — and broken promises (thenarwhal.ca)
- L’industrie aérienne admet qu’elle ne tiendra pas ses objectifs sur la neutralité carbone (reporterre.net)
- La fortune d’Elon Musk franchit le cap des 1 000 milliards de dollars (huffingtonpost.fr)
Ce bond financier en avant est dû à l’introduction en Bourse de SpaceX ce vendredi, qui réalise un départ fracassant.

- Comment l’argent de l’IA et de la crypto influence les élections américaines de mi-mandat ? (synthmedia.fr)
- They Were Serving the Longest Federal Sentence of Any 2020 Black Lives Matter Protester. Then They Vanished in Prison. (theintercept.com)
- Rising anti-LGBTQ+ censorship efforts pull directly from the playbooks of modern authoritarian leaders (advocate.com)
As Congress advances anti-LGBTQ+ legislation and states expand restrictions on queer and trans visibility, PEN America experts warn the tactics increasingly resemble those used by modern authoritarian governments.
- Pokémon Go Scans Quietly Trained the Navigation Tech Now Headed Into Military Drones (dronexl.co)
- Teardown Confirms the Trump Phone Is a Gold-Painted HTC U24 Pro (ifixit.com)
- Mexico : la Coupe du Monde 2026 s’ouvre dans un climat de rejet et de convergence des luttes (dialectik-football.info)
Plusieurs collectifs et assemblées comptent bien perturber l’inauguration de ce “Mondial de la dépossession et de la guerre” et dont 13 matchs se joueront au Mexique. Autour de l’Assemblée “antimundialista”, des collectifs de proches de disparus et de la grève des enseignants, les mots d’ordre convergent comme les cortèges ont prévu de le faire en direction du stade Azteca.
- Coupe du monde « made in Trump » : un fiasco populaire (humanite.fr)
À Los Angeles, capitale états-unienne du “soccer”, les tarifs ont découragé jusqu’aux plus passionnés, tandis qu’une possible intervention de la police de l’immigration effraie les quartiers latinos.
- Au Salvador, le régime de la terreur de Bukele (lagrappe.info)
RIP
- Tributes to Buffy and Ted Lasso star Anthony Head after death aged 72 (bbc.co.uk)
- Mort de David Hockney : cinq tableaux majeurs d’un peintre qui voyait la vie en couleur (franceinfo.fr)
Le peintre anglais était l’un des derniers survivants du pop art. Des toiles les plus intimes aux tableaux les plus militants, retour en images sur les chefs-d’œuvre d’un travailleur acharné.
Spécial IA
- AI Omnibus deal : EU lawmakers should reject a rollback of AI safeguards (edri.org)
- Milei veut faire de l’Argentine le premier pays conçu pour l’IA (legrandcontinent.eu)
Depuis que Peter Thiel, le fondateur de Palantir, a déménagé à Buenos Aires, le président paléolibertarien travaille à faire du pays la capitale mondiale du techno-libertarianisme.

- La ligne rouge est franchie : des drones 100 % autonomes dopés à l’IA ont tué des soldats sans aucune intervention humaine (lesnumeriques.com)
“On les lance et on sait que tout sera mort. Tout ce qui sera trouvé dans cette zone sera mort”, confie le fabricant qui a fourni la technologie.
- From Manhattan to Genesis (cacm.acm.org) The U.S. Department of Energy wants to build a single national platform for doing science with AI.
- Here’s what Jeff Bezos’ new startup Prometheus will do (arstechnica.com)
It isn’t the only startup tackling physical AI, but it’s one of the best-funded.
- Anthropic shuts down Fable, Mythos models following Trump admin directive (arstechnica.com)
The move comes after Anthropic’s receipt of a US Commerce Department directive Friday evening, subjecting the new models to export controls restricting their use anywhere outside the United States.
- “Chat is dead” : OpenAI preps overhaul of ChatGPT (arstechnica.com)
OpenAI is preparing the biggest overhaul of ChatGPT since its launch kicked off the AI boom, as the $850 billion group hunts for new engines of growth ahead of a planned listing this year.The company intends to transform the chatbot into a “superapp” that combines coding tools and AI agents, adding products that executives believe will generate more revenue.

- UK Police Officer Accused of Using AI to Fake Evidence (news.slashdot.org)
- Man sues Florida cops over arrest spurred by “93 % match” in facial recognition (arstechnica.com)
“A facial recognition algorithm flagged Robert Dillon as the man who tried to lure or entice a child under twelve years old at a Jacksonville Beach McDonald’s. It was wrong. Mr. Dillon […] had never set foot in Jacksonville Beach. But rather than test the machine’s answer against the evidence that would have cleared him, the officers built a case to confirm it.”
- AI Agent Bankrupted Their Operator While Trying to Scan DN42 (lantian.pub)
An AI agent tried to join the DN42 hobbyist network to perform a network scan, and bankrupted its operator with a $6531.30 AWS bill, to the extent that they are begging for donations from the DN42 community.
- Visa plugs its payment network into ChatGPT, letting AI agents shop and pay for users (apnews.com)
- Nobody needs AI to search the Internet, court says in ruling against Google (arstechnica.com)
Google AI Overview court loss in Germany could spell doom for AI search industry.
Voir aussi Un tribunal allemand déclare Google responsable des réponses fausses de son AI Overview (next.ink)
- The weather and climate science AI revolution isn’t revolutionary (arstechnica.com)
Forecasts of run-of-the-mill weather conditions have a lot of practical value, but there is life-or-death value in an accurate forecast of extreme weather conditions. The more extreme, the more true that is. But just as a bird-identifying algorithm can’t identify a bird it wasn’t shown during training, AI-based weather models can fail at predicting extreme weather that wasn’t in their training dataset.
- The AI vibe shift is real : Why the backlash is growing (mashable.com)
As ‘tokenmaxxing’ dies out, Silicon Valley is having second thoughts.
- OpenAI Execs Are Panicking (futurism.com)
- AI Economics for Dummies (mcsweeneys.net)
Spécial guerre(s) au Moyen-Orient
- Cheap Iranian drone downed $25 million US Army helicopter (arstechnica.com)
The US military struck Iran again after an Iranian drone’s lucky midair strike.
- Why Did Iran Attack Israel ? What Will Happen Next ? (iranwire.co)
On the evening of June 7, multiple missiles were fired from various parts of Iran toward Israel. Following tensions that had emerged among Tehran, Washington, and Tel Aviv in the days following the April 8 ceasefire, Tehran finally struck parts of northern Israel, including Haifa, in response to the Israeli military’s actions in the Lebanese city of Beirut.
- Van : une ville refuge pour les iraniens (nesalimedia.substack.com)
- Brûlures profondes, lésions respiratoires et oculaires : Israël largue du phosphore blanc sur les civil·es libanais·es (slate.fr)
- ‘Where are the mediators ?’ : Gazans decry ongoing displacement despite ceasefire (972mag.com)
Pushing to seize 70 percent of Gaza’s territory, the Israeli army is opening fire at Palestinian civilians caught off guard by the ever-expanding ‘Yellow Line.’
- Palestinian baby shot dead by Israeli troops in occupied West Bank (theguardian.com)
The seven-month-old, Sam Fahd Abu Haikal, was in his mother’s arms when soldiers fired on family in Hebron

- Israël expulse une journaliste française : une atteinte inadmissible à la liberté de la presse (acrimed.org)
Elle disposait pourtant de tous les documents requis : visa en règle, accréditation presse et contrat officiel avec RFI. Elle couvre le conflit israélo-palestinien depuis six ans, depuis Jérusalem et Ramallah.
Spécial femmes dans le monde
- Marjane Satrapi : celle qui a rendu l’Iran intelligible (theconversation.com)
- Sexisme parlementaire en RDC : pourquoi les femmes élues restent des cibles (theconversation.com)
- Des travaux de recherche récents suggèrent que l’endométriose ne devrait pas être réduite à une affection gynécologique, mais considérée comme une maladie inflammatoire qui touche l’organisme dans son intégralité. (theconversation.com)
Une approche qui pourrait expliquer les limites des traitements actuels et aider à améliorer la manière dont cette pathologie est diagnostiquée, prise en charge et perçue dans la société.
Spécial France
- Nommer le privilège zorèy pour construire l’égalité à La Réunion (parallelesud.com)
- Saint-Denis : le tribunal administratif annule le changement de nom du lycée Angela-Davis imposé par Valérie Pécresse (humanite.fr)
Le 5 juillet 2023, le conseil régional Île-de-France présidé par Valérie Pécresse avait rebaptisé le lycée de Saint-Denis du nom de Rosa-Parks, jugeant la figure de la militante américaine « trop conflictuelle ». Ce 9 juin, le tribunal administratif de Montreuil a annulé cette décision pour vice de procédure.
- « On est chez nous ! » : à Saint-Denis, Mélenchon se positionne comme le seul rempart face au RN (bondyblog.fr)
- Meurtre homophobe de Noahm à Metz : une minute de silence à l’Assemblée (politis.fr)
- Chantage à la sextape : le parquet requiert cinq ans de prison dont trois ferme contre l’ex-maire de Saint-Étienne, Gaël Perdriau (humanite.fr)
- L’empire Stérin scruté par le Sénat (multinationales.org)
- Retour à trois opérateurs : protocole d’accord entre Orange, Free, Bouygues et SFR (next.ink)
- Fuite de données pour Tchap la messagerie instantanée de l’Etat (lemondeinformatique.fr)
Après la revendication d’un cybercriminel sur le piratage de Tchap, la messagerie instantanée de l’Etat, la Dinum et l’Anssi confirment la compromission de l’outil via l’usurpation d’un compte. Une enquête est en cours pour connaître le périmètre de l’incident.
- « Test cédric » : la notification surprise du Crédit Agricole qui a fait paniquer les clients, l’appli tombe en panne (clubic.com)

- Adresse, IBAN, rendez-vous médicaux : un moteur de recherche gratuit dévoile des millions de données confidentielles des Français·es (franceinfo.fr)
- Moteur de recherches de données personnelles : « Le recel de data volées est un crime » (next.ink)
- “Ça va être un carnage en termes de hack” : 10 millions d’entreprises passent à la facturation électronique, une transition à très haut risque (lesnumeriques.com)
- L’université Paris Cité retire son doctorat au physicien Etienne Klein pour plagiat (leparisien.fr)
- Bac 2026 : l’épreuve anticipée de maths, une première controversée (huffingtonpost.fr)
Pour la première fois, tous les élèves de première planchent sur les maths ce vendredi. Pour les syndicats, cette épreuve anticipée a été conçue avant tout pour Parcoursup.
- “C’est dur à trouver et ça ne sert à rien” : son fils meurt en stage de 2nde, un père implore leur suppression (rmc.bfmtv.com)
- La consigne de verre revient en France, mais les magasins ne jouent pas le jeu (reporterre.net)
- Des député·es veulent obliger les distributeurs à reverser aux associations leurs marges sur les dons alimentaires (ici.fr)
Spécial femmes en France
- L’Équipe dédie sa Une aux handballeuses victorieuses et non au vainqueur de Roland-Garros accusé de violences conjugales (lesnouvellesnews.fr)
- « Je ne me sens plus isolée » : sur la presqu’île de Crozon, les femmes se fédèrent contre les violences sexuelles (basta.media)
Sur la presqu’île de Crozon, dans le Finistère, le collectif Skoazell vient en aide aux femmes victimes de violences sexuelles. L’initiative est née du courage d’habitantes qui ont osé parlé. Le réseau apporte une aide logistique et morale.
- L’absence d’action publique alimente le burn-out militant (mouvements.info)
Entretien avec Johanna-Soraya Benamrouche et Laure Salmona, cofondatrices de l’association Féministes contre le cyberharcèlement.
- L’effroyable routine d’un médecin de famille condamné pour agressions sexuelles sur 48 femmes (streetpress.com)
Pendant des années, le docteur nantais Traverson a abusé de son autorité de médecin. Poursuivi pour des palpations des seins non justifiées sur une soixantaine de victimes, dont des mineures, il a été reconnu coupable en décembre 2025. […] L’enquête judiciaire aurait pu commencer plus tôt. En 2021, une première plainte est déjà déposée, pour une jeune fille de 11 ans à l’époque. Dans le cadre d’une hospitalisation psychiatrique, elle révèle que le docteur Traverson lui a touché le pubis. La plainte est toutefois classée sans suite.
- Mort de Lyhanna : l’apparente impunité du suspect provoque un émoi national (portail.basta.media)
Après le meurtre, fin mai, d’une enfant de 11 ans dans le Gers, le casier vierge du principal suspect, malgré des plaintes pour violences sexuelles sur mineure depuis 2017, provoque un débat sur les causes des dysfonctionnements de la justice et de la police dans ce type d’affaires.
- Avant l’affaire Lyhanna, le cas Jérôme Barella avait alerté jusqu’aux États-Unis (huffingtonpost.fr)
un organisme de référence dans la lutte contre la pédocriminalité internationale avait fait remonter en France plusieurs signalements sur Jérôme Barella.
- Gérald Darmanin et l’esthétique virile du pouvoir (politis.fr)
L’affaire Lyhanna met en lumière les limites d’une conception viriliste du pouvoir incarnée par le ministre de la Justice. Quand les violences sexuelles s’imposent au débat public, la posture de l’« homme fort » apparaît moins comme une solution que comme une partie du problème.
Voir aussi Affaire Lyhanna : le pire de la politique (politis.fr)
Face à la tragédie, Gérald Darmanin et Emmanuel Macron se sont empressés d’accabler les magistrats pour mieux échapper à la remise en cause de leur politique.

Et Lyhanna : une justice empêchée par les choix de Gérald Darmanin (blast-info.fr) - Affaire Lyhanna : vers un féminisme intégralement sécuritaire ? (problematik-media.com)
- Affaire Lyhanna, périscolaire : « Où sont les hommes lors des mobilisations ? » (huffingtonpost.fr)
- Affaire Patrick Bruel : la garde à vue du chanteur, visé par plusieurs plaintes pour violences sexuelles, prolongée de vingt-quatre heures (lemonde.fr)
- Patrick Bruel va être présenté à des juges, le parquet requiert sa mise en examen pour viols et son incarcération (lemonde.fr)
Le procureur de la République a requis l’ouverture d’une information judiciaire à son encontre et sa mise en examen pour des faits de viols, de tentatives de viols, d’agressions sexuelles et de harcèlement sexuel concernant neuf victimes commis entre 2010 et 2019.
- Patrick Bruel est mis en examen pour viol, tentative de viol, agression sexuelle et harcèlement sexuel, mais échappe à la détention provisoire (humanite.fr)
- Patrick Bruel visé par deux nouvelles plaintes pour des faits de viol, tentative de viol et agressions sexuelles (huffingtonpost.fr)
Ces accusations révélées par « Mediapart » s’ajoutent aux nombreuses autres qui visent le chanteur de 67 ans, déjà mis en examen dans quatre affaires de violences sexuelles.
Spécial médias et pouvoir
- Une multinationale tente d’anéantir La Relève et La Peste (lareleveetlapeste.fr)
Notre média et maison d’édition sont attaqués en justice par une multinationale via une procédure bâillon. Cette multinationale se nomme Pierre Fabre, l’entreprise derrière la polémique A69.
- Nouvelle attaque contre Disclose : le gouvernement réclame la censure de l’enquête « Egypt Papers » (disclose.ngo)
- Finkielkraut en promo : la réaction « chic » et l’entre-soi médiatique (acrimed.org)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Les 500 premières fortunes françaises cumulent 1 128 milliards d’euros, une hausse de 564 % en 20 ans (lareleveetlapeste.fr)
- Le monstre utile. Trente ans de surenchère pénale à la française (blogs.mediapart.fr)
Il y a une constante dans la politique pénale française depuis le milieu des années 1990 : chaque décennie produit sa figure de l’ennemi absolu, et chaque loi d’exception laisse des dispositifs qui, une fois installés, ne disparaissent jamais. Prendre la protection des enfants au sérieux, c’est exiger que les budgets publics aillent vers ce qui crée une réduction effective des violences, pas vers ce qui rassure à court terme et laisse les structures intactes.

- La semaine noire de Darmanin continue avec un camouflet sur son texte pour la justice criminelle (huffingtonpost.fr)
Après un rejet en commission des Lois à l’Assemblée, le ministre de la Justice a annoncé retirer de son texte le dispositif de « plaider-coupable » très décrié.
Voir aussi PJL SURE : volte-face de Darmanin sur le plaider-coupable criminel (projetarcadie.com)
- « Non, le Conseil d’orientation des retraites ne propose pas la retraite à 67 ans et demi » (basta.media)
À un an de l’élection présidentielle, le rapport du Conseil d’orientation des retraites est plus scruté que jamais. Au risque de faire l’objet d’une récupération pour pousser à un nouveau décalage de l’âge de départ à la retraite à plus de 67 ans.
- Javier Milei invité du Medef : le tapis rouge à l’internationale réactionnaire (humanite.fr)
- Eurosatory : quand la France accueille la vitrine mondiale de l’industrie de l’armement (humanite.fr)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Mort de Lyhanna : la réalisatrice du film Les Chatouilles Andréa Bescond placée en garde à vue à Paris (actu.fr)
« Pensées émues pour tous les pédocriminels qui n’ont jamais passé une nuit en garde à vue », a ironisé Andréa Bescond sur Instagram [qui] avait appelé à se rassembler place Vendôme pour dénoncer les dysfonctionnements de la justice dans les affaires d’agressions sexuelles sur mineur·e après le meurtre de la petite Lyhanna
- « Nous, les Noirs et les Arabes, on vit avec la peur qu’un ‘’basané’’ commette l’irréparable » (humanite.fr)
Le retentissement médiatique d’un crime, quand son auteur est perçu comme issu de l’immigration, suscite chez les Français d’origine étrangère un réflexe silencieux : la crainte que la faute d’un seul rejaillisse sur tous.
- Le maire RN de Carcassonne, Christophe Barthès, refuse de mettre des locaux municipaux à disposition du consulat d’Algérie pour l’organisation des prochaines élections législatives le 2 juillet. (humanite.fr)
« Carcassonne est un laboratoire pour l’extrême droite, pour savoir jusqu’où elle peut détruire les libertés syndicales et d’expression »
- « C’est une chasse à la musulmane » : Inès, menacée de licenciement par une filiale d’EDF (streetpress.com)
- Mort de Nahel : la Cour de cassation rouvre la possibilité d’un procès pour meurtre pour le policier (basta.media)
La Cour de cassation a reconnu l’intention d’homicide du policier qui a tué Nahel Merzouk. Le 27 juin 2023, le jeune de 17 ans, était tué d’une balle tirée à bout portant lors d’un contrôle de son véhicule à Nanterre.
Spécial résistances
- « Personne ne vient travailler pour finir dans un cercueil » : face à la souffrance au travail à la SNCF, les cheminots ripostent par la grève (basta.media)
Face aux restructurations permanentes liées à l’ouverture à la concurrence, et au mal-être au travail qui s’installe, avec treize suicides depuis le début de l’année, la grève à la SNCF du 10 juin a été très suivie.
- À Polytechnique, la remise de diplômes perturbée : « et un, et deux, et trois degrés : pour Patrick Pouyanné ! » (huffingtonpost.fr)
Cette prise de parole est intervenue après l’interruption de la cérémonie par quelques étudiants portant des masques du patron de TotalEnergies, Patrick Pouyanné, et de celui de LVMH, Bernard Arnault, diplômés de l’X, pour dénoncer les partenariats avec les entreprises privées.
- “D’ici la fin d’année, on n’aura plus aucune trésorerie” : les chercheureuses du CNRS de Grenoble mobilisé·es contre les restrictions budgétaires (france3-regions.franceinfo.fr)
Spécial outils de résistance
- Oui, la justice française manque de moyens humains, et 3 autres infographies à ne pas rater (alternatives-economiques.fr)
- Datacenters, eau, électricité, carbone : explorez notre carte mondiale interactive ! (next.ink) – voir aussi Empreinte écologique des datacenters : ce que les géants annoncent, ce que nos calculs révèlent (next.ink)
Spécial MAGAM et cie
- “La direction a perdu toute boussole morale” : le chef de la sécurité d’Android claque la porte de Google (lesnumeriques.com)
René Mayrhofer […] vient de démissionner de Google pour une raison qui vous concerne directement : l’entreprise a signé un accord autorisant le Pentagone à utiliser son IA pour des opérations classifiées, et l’homme qui sécurisait votre smartphone estime que ces outils seront “probablement utilisés contre” les citoyen·nes européen·nes.

- « Amazon déteste mon travail syndical » : comment le géant du numérique tente de réprimer toute action collective de ses employé·es (basta.media)
Alors qu’Amazon a préféré quitter le Québec plutôt que de signer une convention collective, sur les sites français du géant du Web, les syndicalistes dénoncent des sanctions prises à leur encontre et une culture d’entreprise qui entrave leur activité.
- Meta Deletes Face-Recognition System From Its Smart Glasses App After WIRED Report (wired.com)
One day after WIRED revealed that Meta had quietly embedded an unreleased face-recognition system into an app installed on more than 50 million phones, the company removed it
Voir aussi Lunettes Meta : l’intégration de la reconnaissance faciale est discrètement en cours (next.ink)
- Les menaces contre les politiques ont explosé après la limitation de la modération de Meta (next.ink)
- Des outils Microsoft piratés pour voler des identifiants d’outils IA comme Claude Code (next.ink)
- Émeutes xénophobes à Belfast : pourquoi Elon Musk est accusé d’avoir amplifié des discours violents sur X (nouvelobs.com)
Après une attaque au couteau à Belfast, le propriétaire de X avait appelé ses abonnés à protester et reposté des messages de leaders d’extrême droite, amplifiant selon des chercheurs des récits anti-migrants auprès de millions d’utilisateurs.
- Votre voiture vous suit : comment préserver la confidentialité de vos données sur la route (zdnet.fr)
Les véhicules d’aujourd’hui savent où nous habitons, combien nous pesons et ce que nous avons mangé au dîner. Voici ce qu’il advient de toutes ces informations, et comment vous pouvez réduire le flux de données.
Les autres lectures de la semaine
- Colonialité toxique : dans les paysages radioactifs du Sahara (terrestres.org)
De 1960 à 1966, avant et après l’indépendance de l’Algérie, l’État français a expérimenté au Sahara dit algérien dix-sept bombes atomiques et autres essais chimiques. Ce sujet a longtemps été tabou en France, dans la presse, dans les discours politiques aussi bien que dans le cadre académique où enquêtes, témoignages, littérature et recherches sur ce thème ont été invisibilisés.
- Politique de la crise financière : Une fenêtre historique – Défoncer la finance néolibérale : principes et méthodes – Défoncer la finance néolibérale : banques, crédit, dette – Défoncer la finance néolibérale : actions et actionnaires (blog.mondediplo.net)
- Pour faire payer les riches, la taxe Zucman est-elle la meilleure option ? (alternatives-economiques.fr)
- La retraite à 60 ans, c’est (vraiment) possible (lenouveauparadigme.fr)
En agitant le spectre de la faillite de la répartition, les cercles libéraux et le Rassemblement national préparent le terrain pour les fonds de pension privés, au détriment des salariés les plus modestes. Pourtant, des propositions alternatives et réellement sociales existent.
- Capitalism’s Organic Intellectuals (counterpunch.org)
- An electric bike for the mind (ebike.nologos.net)
In a 1990 interview, Steve Jobs famously stated that personal computers were “a bicycle for the mind” […] I sit in front of a Mac all day and that’s not how it feels […] That’s not a bicycle. It’s an SUV for the mind.[…] just about any “obsolete” or “underpowered” laptop can be enough once freed from the burden of always-on connectivity. It’s cheap. It’s available. You probably already have one.
Les BDs/graphiques/photos de la semaine
Les vidéos/podcasts de la semaine
- Don’t be that guy (tube.fdn.fr)
- Comment Bolloré s’est-il imposé dans nos vies ? (humanite.fr)
- Questions morales et enjeux politiques dans les sociétés contemporaines – Didier Fassin : Présences de Foucault : Prison (college-de-france.fr)
Les trucs chouettes de la semaine
- Cultiver sans pesticides, c’est possible : dans la Somme, ces scientifiques sèment des alternatives (vert.eco)
- Humans prefer to walk anticlockwise, scientists find – but reason is unclear (theguardian.com)
Tests reveal that when people are ambling about, they have a natural tendency to turn to the left and walk in an anticlockwise direction.
- The first complex cells had genes from a complex mix of species (arstechnica.com)
We tend to view ourselves and the complex cells that build us as a distinct branch of the tree of life from the compact, seemingly featureless cells of bacteria and archaea. But we’ve found that our genome is actually a hybrid, a mish-mash of genes from bacteria and archaea, along with some that have evolved in our own lineage.
- Threads of underground fungal networks are long enough to reach beyond the Solar System (arstechnica.com)
Hidden underground around the world lie 110 quadrillion kilometers of arbuscular mycorrhizal fungal networks—webs of ultra-thin threads that, if connected in a single line, would stretch almost a billion times the distance between the Earth and the sun
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
08.06.2026 à 07:42
Khrys’presso du lundi 8 juin 2026
Khrys
Texte intégral (8804 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- L’humanité consomme deux fois plus de viande qu’il y a 60 ans, alerte l’ONU (humanite.fr)
Un rapport de l’agence de l’ONU dédiée à l’alimentation et l’agriculture dévoile que la consommation de viande à l’échelle mondiale est passée de 25 kg par personne en 1961 à 47 kg par personne en 2022. Les émissions de l’agro-industrie devraient, elles, augmenter de 7,6 % au cours de la prochaine décennie.
- How a Starbucks marketing stunt spiralled into mass boycotts in South Korea (theguardian.com)
Hours after launching a marketing campaign called “Tank Day” for its new “Tank” coffee tumbler range on 18 May, Starbucks Korea found itself at the centre of a cultural storm that would force a billionaire chairman to apologise on national television, and see a chief executive sacked. The controversy reverberated all the way to the South Korean president’s office. […] Marketers chose the slogan after consulting an AI tool, looking for suggestions, Shinsegae Group said. It turned out some managers who approved the campaign never opened the email attachments showing the marketing material.
- Grèce : ce que cache le récit du redressement économique après la crise de la dette publique (slate.fr)
Alors que la politique d’austérité laisse encore des traces sociales inquiétantes en Grèce, le fonctionnement des institutions et des contre-pouvoirs apparaît aussi modifié en profondeur. Le gouvernement de Kyriákos Mitsotákis, au pouvoir depuis 2019, est de plus en plus pointé du doigt et accusé de dérive autoritaire.

- Les baigneureuses surpris·es par la nouvelle loi sur les costumes de bain dans les piscines genevoises (rts.ch)
Ce samedi a marqué l’entrée en vigueur de la loi cantonale qui interdit le port du burkini, mais aussi des maillots de bains couvrants anti-UV très prisés par les familles.
- Cette année, les tiques sucent plus de sang que d’habitude et le changement climatique n’y est pas pour rien (slate.fr)
L’augmentation constante des températures due au réchauffement climatique a permis aux tiques, qui n’aiment pas le froid mais se régalent quand il fait bon et humide, d’étendre considérablement leur aire de répartition géographique.
- Les populations d’oiseaux s’effondrent (huffingtonpost.fr)
en Europe « on perd chaque année 20 millions d’oiseaux depuis 40 ans » à cause de l’agriculture intensive.
- Entre fermeture du détroit d’Ormuz et croisade climatosceptique, Trump débloque 700 millions de dollars pour l’industrie du charbon (humanite.fr)
Le président des États-Unis a annoncé, jeudi 4 juin, un investissement colossal de 700 millions de dollars pour relancer la production de charbon dans 13 États. L’élu républicain tente ainsi de contourner la fermeture du détroit d’Ormuz par l’Iran, mais aussi de poursuivre sa croisade contre la lutte pour le climat.
- « Ils préfèrent qu’on disparaisse avant l’arrivée des touristes » : le Mondial 2026 chasse les sans-abri des villes hôtes (reporterre.net)
- Midterms : Trump a remporté la « bataille » du redécoupage électoral, mais pas encore la guerre (huffingtonpost.fr)
- Fox News et le « grand remplacement » : ce que révèle une étude sur l’opinion américaine (theconversation.com)
Une enquête menée auprès de plus de 500 Américains blancs suivis dans le temps montre que l’audience de Fox News est associée à une adhésion accrue à la théorie complotiste du « grand remplacement ». Un résultat qui éclaire le rôle des médias dans la diffusion de certaines croyances politiques.

- Donald Trump change ses plans faute d’artistes à son concert pour l’anniversaire des États-Unis (huffingtonpost.fr)
« Nous allons vous proposer le plus grand meeting de tous les temps », a écrit le président américain sur son réseau Truth Social. « Nous ne voulons pas de chanteurs sans talent, avec des cachets énormes qui vous endorment, nous leur avons tous dit de rester chez eux », a ajouté le républicain, visiblement encore marqué par une amère déception.
- Tony Gilroy Accepts Award for Andor : “Fuck the Empire !” (kottke.org)
We spent six years contemplating a fascist takeover of a galaxy far, far away. Six years thinking about what happens to ordinary beings when an authoritarian, insane, unchecked regime comes into the deal, and the show is really kind of what we learned. If you’re not willing to fight for the things that you love — your family, community, your culture, your planet, your truth, freedom — there’s an asshole ready to come in and take it away. We learned that bravery and sacrifice and resistance comes in all shapes and sizes, and we learned that courage is contagious. There’s so much is happening, it’s a fire hose of crap that you just can’t get through. And here we are. There isn’t a new cycle that goes by right now that doesn’t contain a variety of outrages that in any other time in our history in America wouldn’t be grounds for treason. Please do not stop. Please do not turn out the lights until we can kill this nightmare. And fuck the Empire !
- La fortune d’Elon Musk est supérieure au PIB de 172 pays (legrandcontinent.eu)
Le milliardaire américain, dont la fortune pourrait dépasser les 1 000 milliards de dollars dans les prochaines semaines, a accumulé en 30 ans l’équivalent de 11 millions d’années de travail d’un Américain percevant le revenu médian.
- Florida sues OpenAI, Sam Altman after multiple ChatGPT-linked murders (arstechnica.com)
“Horrifically, ChatGPT has aided and abetted in more than one multiple murder in the State of Florida,” Uthmeier’s complaint said. “The 2026 deaths of University of South Florida graduate students Nahida Bristy and Zamil Limon were also plotted using ChatGPT, which advised Hisham Abugharbieh on how to dispose of bodies, change VIN numbers on a car, and whether cars were checked at the crime scene.”
- Used Waymo robotaxi batteries become backup storage for power grids (arstechnica.com)
Used Waymo batteries will bolster California and Texas energy storage projects.
- Coupe du Monde 2026 : les enseignant·es mexicain·es rejoignent la résistance (dialectik-football.info)
S’il n’y a pas de solution, le ballon ne roulera pas” : le slogan du mouvement de grève des enseignant·es donne le ton. […] Iels réclament entre autres le retour à un système de retraite public, mutualisé, solidaire et intergénérationnel ; et dénoncent une précarisation insupportable.
- Fuite d’air à bord de l’ISS : les astronautes brièvement réfugié·es dans leur vaisseau (france24.com)
Spécial IA
- The Great AI Boomerang : Google, Meta, Klarna & More Are Quietly Rehiring the Workers They Fired (emeraldbook.org)
29 % of firms have already rehired for AI-cut roles, while 55 % of executives regret replacing workers with AI.
- AI Doesn’t Have ROI (Return On Investment) (wheresyoured.at)
- Surprise AI bills leave AWS and Google Cloud users aghast (theregister.com)
Stuck with an AI bill for tens of thousands of dollars ? You’re not alone by a long shot
Voir aussi AI costs how much ? GitHub Copilot users react to new usage-based pricing system. (arstechnica.com)
Some report burning through their whole monthly “AI credit” allotment in a single day.
- Google owner Alphabet to sell $80bn in stock to fund AI spending spree (theguardian.com)
- Microsoft veut rendre les utilisateurices accros à son agent IA Scout (next.ink)
- Amazon ferme son classement IA après tricherie massive des employé·es (da.van.ac)
Amazon vient de fermer discrètement son classement interne KiroRank qui mesurait l’usage des outils IA par ses employé·es. Officiellement, l’objectif d’adoption était atteint. Officieusement, les employé·es trichaient massivement pour grimper dans le classement, certain·es après avoir été réprimandé·es pour un usage insuffisant de l’IA.
- L’assistant IA de Meta permettait de voler des comptes Instagram (next.ink)
L’assistance IA mise en place par Meta pour la gestion des comptes Instagram a autorisé pendant plusieurs semaines n’importe qui d’assez malin à changer l’adresse e-mail associée à un compte. Les propriétaires légitimes se retrouvaient donc « enfermé·es dehors », incapables de se connecter à leur compte et de reprendre la main.
- Pourquoi les recherches Google se dégradent avec l’IA générative (reporterre.net)

- Google must let publishers opt out of AI Search features, rules UK (theverge.com)
- Quand Elon Musk utilise Grok pour vérifier un post… et se fait piéger par sa propre IA (france24.com)
Une vidéo montrant des centaines de migrants franchissant une clôture à la frontière espagnole, datée au 30 mai 2026, est devenue virale. Sur X, des internautes, Elon Musk en tête, demandent à Grok, l’IA de la plateforme, de la vérifier. Mais le chatbot confirme à tort sa date : ces images, sorties de leur contexte, datent en réalité de 2022.
- Anthropic joue encore sur les peurs de l’IA toute-puissante pour se mettre en valeur (next.ink)
- IA, la revanche des imbéciles (danslesalgorithmes.net)
- IA : « Les entreprises de la tech méprisent la société civile » (reporterre.net)
L’essor de l’intelligence artificielle générative risque de renforcer le pouvoir sur nos vies d’une poignée d’entrepreneurs « technofascistes » alertent Lou Welgryn et Théo Alves Da Costa, spécialistes de l’informatique et animateurs de l’association Data for good.
- School shooting survivor sues AI gun detection firm after system failed to spot weapon (arstechnica.com)
The injured teenage survivor of a January 2025 shooting at a Nashville, Tennessee high school recently sued the manufacturer of an “AI gun detection” system that failed to detect the handgun that left two dead, including the shooter.
- Leiden Declaration on Artificial Intelligence and Mathematics (leidendeclaration.ai)
This declaration calls for action to address the challenges posed by the use of artificial intelligence within mathematics research. It is the result of a community initiative and is endorsed by the International Mathematical Union (IMU).
- EFF Testifies to Congress on Protecting Americans’ Rights from Government AI (eff.org)
- She won a religious exemption from using AI at work. The Pope’s remarks could fuel similar appeals. (businessinsider.com)
Opposed to using AI for her software-engineering job, Erin Maus secured something of a miracle from her employer : a religious exemption.
- « Nous sommes débordé·es par l’IA » : chercheureuses, iels refusent d’utiliser l’intelligence artificielle (reporterre.net)
- IA : il faudra l’eau et l’électricité de 1,3 milliard de personnes pour répondre à vos prompts d’ici 2030 (lesnumeriques.com)
Un rapport de l’Université des Nations unies chiffre pour la première fois l’empreinte carbone, hydrique et foncière de l’intelligence artificielle. Les chiffres donnent le vertige : 945 TWh d’électricité projetés en 2030, 9 300 milliards de litres d’eau, 14 500 km² de terres. Et chaque prompt que vous envoyez y contribue.

- Combien d’énergie consomme vraiment l’IA ? La réponse en infographies (reporterre.net)
- EU wants households to cut peak time energy use as demand from industry and AI soars (politico.eu)
A new law will aim to use artificial intelligence to boost efficient use of power as electricity demand threatens to overwhelm Europe’s grids.

Spécial femmes dans le monde
- La cuisine de l’indépendance : comment les femmes syriennes construisent une économie de survie (medfeminiswiya.net)
Face à l’aggravation de la crise économique en Syrie, le travail à la maison s’est imposé comme une stratégie de survie pour les femmes. Elles transforment ainsi des savoir-faire traditionnels tels que la cuisine, le crochet et la pâtisserie en sources de revenus.
- Wim Wenders retire (enfin) une scène de nu de l’actrice Nastassja Kinski filmée lorsqu’elle avait 13 ans (humanite.fr)
Cela faisait quinze ans qu’elle se battait, et elle a enfin obtenu gain de cause. Le cinéaste Wim Wenders a (enfin) accédé à la requête de l’actrice allemande Nastassja Kinski, qui réclamait le retrait des circuits de diffusion de Faux Mouvement, sorti en 1975. En cause ? Une scène du film où elle apparaît en culotte et seins nus, alors qu’elle n’est âgée que de 13 ans. Nastassja Kinski affirme qu’elle n’avait pas été préparée à devoir se déshabiller et que sa mère, absente à ce moment du tournage, n’avait pas donné son consentement à cette scène de nudité.
- Britney Spears, Marie Trintignant, Evan Rachel Wood : ces documentaires qui révèlent la mécanique du contrôle coercitif (theconversation.com)
- De « nouvelles femmes de droite » en Argentine ? Entre antiféminisme libertarien et réappropriation du féminisme (contretemps.eu)
- Au‑delà des bouffées de chaleur, les femmes doivent s’inquiéter des effets de la ménopause sur leur cœur (theconversation.com)
RIP
- Marjane Satrapi est décédée (rollingstone.fr)
- Marjane Satrapi, French-Iranian author of ‘Persepolis’, dies of ‘sadness’ at 56 (france24.com)
“Marjane Satrapi died of sadness a little over a year after the death of Mattias Ripa, her husband and the love of her life,” they said in a statement sent to AFP.

Spécial France
- Deux ans après les émeutes en Nouvelle-Calédonie, les juges d’instruction ordonnent un non-lieu général en faveur des militants kanaks, dont Christian Tein (franceinfo.fr)
Le parquet de Paris a déclaré faire appel de cette décision, estimant que “des actes d’investigations complémentaires” sont nécessaires.
- La France s’allie à une entreprise américaine pour envoyer Thomas Pesquet et Arnaud Prost dans l’espace en 2027 (humanite.fr)
Les deux Français participeront à des missions différentes, l’une en direction de la Station spatiale internationale (ISS) et l’autre à destination de la station spatiale commerciale Haven-1, fondée par le milliardaire des cryptomonnaies Jed McCaleb.
- Bernadette Chirac, l’ambivalente « dame de fer » française, est décédée à l’âge de 93 ans (humanite.fr)
- La Commission européenne veut détricoter le RGPD, des élu·es français·es disent « stop à l’exploitation » (journal-labreche.fr)
« On avait réussi à établir un rapport de force via notre capacité à réglementer, donc affaiblir nos normes aujourd’hui revient à nous affaiblir nous-mêmes sur le plan géopolitique. » […] Demeure toutefois un obstacle de taille : de LFI au RN, les parlementaires eux-mêmes ont recours aux data brokers pour se faire (ré)élire.
- Le fantasme du chômeur profiteur une nouvelle fois démenti par une étude (alternatives-economiques.fr)
Le principe des mythes est d’avoir la vie dure. Celui des demandeureuses d’emploi qui profitent de leur indemnisation et attendent la dernière minute avant de se remettre à chercher un boulot est particulièrement inoxydable. Et tant pis si, d’études en études, les chiffres prouvent le contraire.
- Sophie Binet réélue secrétaire générale, une CGT à l’offensive à l’issue du 54e congrès (humanite.fr)
- Jean-Luc Mélenchon entre en campagne avec son concept de « nouvelle France » (huffingtonpost.fr)
Pour renverser le récit du « grand remplacement » distillé par l’extrême droite, le fondateur de La France insoumise a insisté sur la nécessité « d’incarner la nouvelle France, celle du grand remplacement, celle de la génération qui remplace l’autre ».
- Cadmium : l’Assemblée vote une loi ambitieuse, malgré l’obstacle du RN et du gouvernement (reporterre.net)
Les député·es ont adopté le 3 juin une proposition de loi réduisant progressivement la teneur en cadmium dans les aliments. Ce minerai toxique est massivement présent dans les sols et l’alimentation.
Voir aussi Première victoire contre le cadmium pour réduire drastiquement l’exposition des français·es (lareleveetlapeste.fr)
La proposition de loi prévoit d’abaisser dès 2027 les seuils de la teneur en cadmium dans les engrais phosphatés, avec une réduction progressive : un seuil à ne pas dépasser de 40 mg/kg d’anhydride phosphorique (P₂O₅) dès le 1er janvier 2027 et un seuil de 20 mg/kg dès le 1er janvier 2030.
- En Vendée, l’État relance l’exploration minière d’antimoine (mediacites.fr)
Un siècle après l’âge d’or minier vendéen, le sous-sol du département intéresse de nouveau l’industrie […] l’État vient de retenir une entreprise pour un projet de recherche d’antimoine, un métalloïde très utilisé dans l’électronique. Mais de nombreuses étapes restent à franchir avant une éventuelle exploitation, à 50 kilomètres au sud-est de Nantes.
- « Dès 14 heures, l’odeur est insupportable » : le fléau des algues puantes s’immisce dans les écoles (reporterre.net)
Maux de tête, nausées… Les émanations de gaz liées aux échouements d’algues puantes en Martinique et en Guadeloupe poussent les écoles à fermer ou à aménager leurs cours. Le problème, récurrent, s’enlise.
- La grande distribution annihile le bio : UFC-que-choisir dénonce des marges scandaleuses (lareleveetlapeste.fr)
- La gratuité de la cantine à Paris en vigueur dès septembre 2026 pour les familles les plus modestes (huffingtonpost.fr)
Emmanuel Grégoire évoque 17 000 enfants qui mangeront chaque jour gratuitement dans les collèges, écoles et jardins d’enfances de la capitale.
- Vaisselle en plastique : l’Assemblée vote son interdiction dans les crèches et les écoles (reporterre.net)
- 1 million d’habitants sous l’eau en cas de crue en Île-de-France (reporterre.net) – L’étude avec carte interactive : Populations et logements face aux crues en Île-de-France (institutparisregion.fr)
- Comment se sont déplacé·es les parisien·nes en 2025 (paris.fr)
Première publication des données chiffrées des déplacements à Paris en 2025 consacrées aux déplacements et aux circulations douces : piétons et vélos.
- La canicule de mai 2026 est bien inédite (factuel.afp.com)
La France, comme une partie de l’Europe, connaît fin mai 2026 une vague de forte chaleur. Mais cet épisode est minimisé dans des publications foisonnant sur les réseaux sociaux, dont les auteurs affirment qu’il n’a rien d’exceptionnel et que des phénomènes similaires auraient déjà eu lieu, notamment en 1922, 1945 ou bien encore 1947. Certains vont jusqu’à dénoncer une “manipulation” de la part des médias, qui dramatiseraient la situation. Mais la vague de chaleur actuelle est bien inédite, de par sa précocité, sa durée et son intensité, soulignent les spécialistes.
Spécial femmes en France
- Choose France, choose men : l’économie de demain avec les codes d’hier (lesnouvellesnews.fr)
- Les sages-femmes et l’IVG. Apprendre à faire bloc (lempaille.fr)
Depuis 2024, les sages-femmes sont autorisées à pratiquer des IVG par aspiration à l’hôpital. Dans un cadre souvent misogyne, elles doivent se battre pour leur place tout en maintenant la qualité de la relation avec leurs patientes.
- Ce détail de la photo des équipes de France féminine et masculine de foot fait grincer des dents (huffingtonpost.fr)
Sur les réseaux sociaux, les internautes sont agacés par une photo des bleus en bleu et des bleues… en rose.
- « Ce genre de match doit être arbitré par un homme » : propos sexistes sanctionnés à Roland Garros (lesnouvellesnews.fr)
55 000 euros d’amende ! Après avoir critiqué l’arbitrage d’Ana Carvalho, estimant que « ce genre de match doit être arbitré par un homme », le tennisman Adolfo Daniel Vallejo a été sanctionné par la Fédération française de tennis et Roland-Garros. Il a présenté ses excuses.
- « Stop à ce genre d’énergumène » : EnjoyPhoenix dénonce ce discours masculiniste à la salle de sport (huffingtonpost.fr) «
C’est un sketch. À quel moment tu es tellement insecure dans ta vie que tu estimes que toutes les filles en couple qui vont à la salle de sport avec un legging ne sont pas fidèles ? »
- “Plus jeunes et plus dangereux” : l’alerte de la DGSI sur la menace masculiniste (franceinfo.fr)
- « Masculinistes, d’où vient votre haine du tofu ? » (reporterre.net)
- De quoi Patrick Bruel est-il le non ? (politis.fr)
Parce que plaire et se taire fait partie des attendus de la beauté, qui est à la fois une façon de mesurer sa valeur (éphémère) sur le marché et un motif permanent d’anxiété. Une idée propre à la culture du viol veut que derrière un non se cache toujours un oui. C’est une dissonance cognitive au plus haut niveau, comme les publicités qui façonnent nos esprits pour qu’on désire ce qui nous fait du mal.
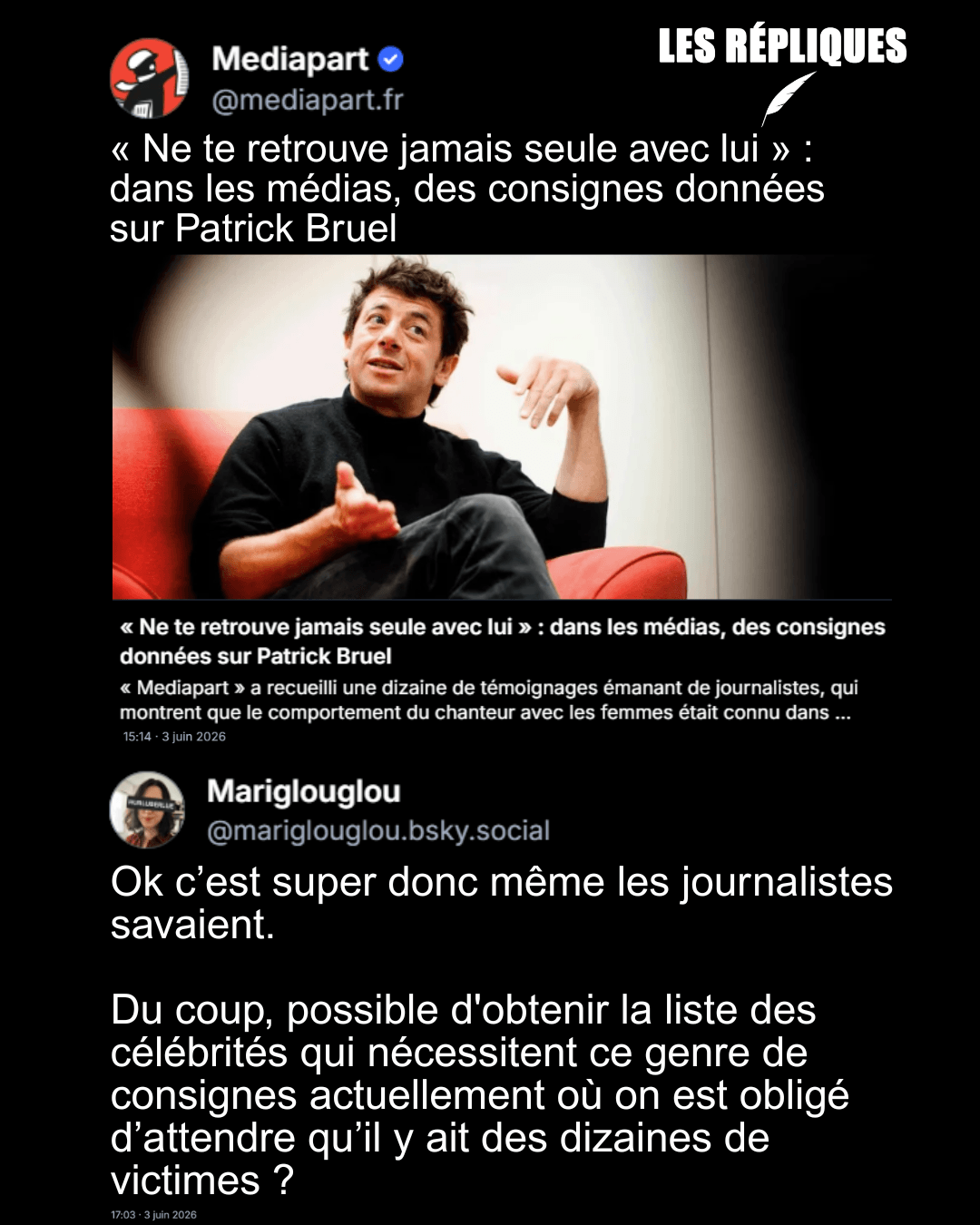
- Affaire Patrick Bruel : des militantes féministes font annuler la représentation d’une pièce avec le chanteur (huffingtonpost.fr)
Des membres du collectif #NousToutes ont manifesté devant le théâtre Edouard VII à Paris, juste avant une représentation de la pièce « Deuxième partie » qui a finalement été annulée.
- Violences sexuelles : Comment croire les victimes d’hommes intégrés, appréciés ou séduisants ? (theconversation.com)
- La France attaquée devant la CEDH dans une affaire de « pornographie du viol » (next.ink)
La France est mise en cause devant la Cour européenne des droits de l’homme par une femme victime de diffusion de captations vidéo de son viol. Face à la Cour, elle dénonce la décision de la Justice française ne pas qualifier les faits de « traite des êtres humains » et interroge la manière dont l’État a évalué le consentement.
- Affaire Lyhanna : qu’est-ce que le logiciel Cassiopée utilisé par la justice et dont l’efficacité est questionnée ? (huffingtonpost.fr)
Le profil du principal suspect dans la mort de la collégienne retrouvée morte jeudi, aurait pu attirer l’attention des autorités judiciaires. Il avait fait l’objet deux plaintes en 2022 et 2025 pour viol sur des mineures – la première classée sans suite sur une enfant de 7 ans et la seconde toujours « en cours ». À ces plaintes s’ajoutent un signalement en 2017 pour une « relation » avec une mineure de 17 ans, une procédure de licenciement en 2020 après une « relation inappropriée avec une lycéenne » et, plus récemment, un signalement en mars dernier pour des agressions sexuelles sur mineures
Voir aussi Affaire Lyhanna : protéger avant qu’il ne soit trop tard, sans renoncer à l’État de droit (theconversation.com)
Après l’enlèvement et le meurtre de Lyhanna, 11 ans, un homme, déjà mis en cause par trois plaintes pour viols sur mineurs, mais jamais condamné, est suspecté.
Spécial médias et pouvoir
- Deux journalistes de France 24 intimidés après une question sur la tribune anti-Bolloré (france24.com)
Deux journalistes de France 24, Nina Masson et Yong Chim, ont été victimes d’une tentative d’intimidation et de censure après une question posée à un acteur sur la tribune anti-Bolloré, qui a agité le festival de Cannes cette année. La direction et la société des journalistes de France 24 dénoncent des faits d’une “gravité inédite”.
- « Aucune violence policière » : Jean-Michel Aphatie pris en flagrant déni (acrimed.org)
- Habiller le discours dominant en rigueur historique (acrimed.org)
- Reporterre s’engage pour un journalisme sans IA générative (reporterre.net)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- En France, 7,5 % de la population est considérée comme riche, selon l’Observatoire des inégalités, un chiffre en baisse mais des revenus en hausse (franceinfo.fr)
- Parcoursup est une « usine à stress » parce que c’est son but (alternatives-economiques.fr)
Le caractère anxiogène de la plateforme n’est pas un dommage collatéral mais bien une de ses logiques constitutives
- La HATVP veut le retour du secret pour les élu·es (projetarcadie.com)
- Après l’affaire Lyhanna, Macron et Darmanin réfutent la question des moyens, et pourtant… (huffingtonpost.fr)
aux yeux de l’exécutif, les défaillances, et donc les responsabilités face à ce drame, sont plutôt individuelles. Surtout pas politiques. Avant même les sorties de Gérald Darmanin, le président Emmanuel Macron avait déjà balayé la question des moyens accordés à la justice, en expliquant vouloir « entendre aucun argument » en ce sens.
Voir aussi La proposition choc de Retailleau après l’affaire Lyhanna pour sanctionner les magistrat·es (huffingtonpost.fr)
Affaiblir le Conseil de la magistrature, interdire la syndicalisation : la droite cible les magistrats après la mort de Lyhanna dans le Gers.
- Julien Le Guet : « Monsieur Darmanin est le plus grand écoterroriste de France » (reporterre.net)
- Le nouveau think tank du PS, déjà plombé par Palantir (synthmedia.fr)
Pour préparer la présidentielle 2027, le PS lance « Noûs », un think tank destiné à « réarmer intellectuellement » la gauche sociale-démocrate face à l’extrême droite. L’initiative est cependant entachée d’un paradoxe : sa coprésidente, Julie Martinez, est une ancienne cadre de Palantir, géant américain de la surveillance de masse.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Présidentielle 2027 : au RN, la communication passe en mode IA (synthmedia.fr)
Le Rassemblement national peaufine son propre ChatGPT, un robot conversationnel nourri aux discours, programme et éléments de langage du parti d’extrême droite.
- Pendant que les free partys sont durement réprimées, les néonazis festoient en toute impunité (lareleveetlapeste.fr)
Malgré une interdiction à Paris, les néofascistes du Comité du 9-Mai (C9M) ont fait leur grand rassemblement à Verrières-le-Buisson, en Essonne, sans être appréhendés. Des témoins ont vu des saluts nazis.
- À Paris, l’extrême droite catholique intégriste et antisémite de Civitas appelle à perturber la Nuit Blanche 2026 (humanite.fr)
Les militant·es d’extrême droite accusent l’évènement de « profaner » les lieux de culte.
Voir aussi Pendant la Nuit Blanche, la maire du Xe Alexandra Cordebard prise à partie, Civitas accusé (huffingtonpost.fr)
- Régine Komokoli, une femme noire élue face à l’extrême droite (lisbethmedia.com)
Première femme issue de l’immigration élue en France, Régine Komokoli vit et milite à Rennes, dans le quartier populaire de Villejean. Ancienne sans-papiers, survivante de violences conjugales, mère isolée devenue élue locale, elle subit depuis les dernières municipales une vague d’intimidations racistes, sexistes et négrophobes alimentée par l’extrême droite.
- Jeunesse populaire et racisée : le procès permanent (politis.fr)
À chaque épisode de violences urbaines, le même réflexe : transformer une partie de la jeunesse française en problème collectif. Les commentaires indignés sur les célébrations du PSG dessinent une stigmatisation récurrente des jeunes des quartiers populaires : un racisme qui ne dit pas son nom.
- “Atteinte grave” à la liberté d’expression : la justice autorise la conférence de Salah Hamouri à Besançon, la préfecture déboutée (france3-regions.franceinfo.fr)
- Prison, reconnaissance faciale erronée, menaces : Dans la Drôme, le calvaire de militant·es écolos pour une banderole (streetpress.com)
- La Communauté autonome basque a un problème avec sa police (mediabask.eus)
L’intervention disproportionnée de la Ertzaintza lors de l’arrivée des membres de la flottille Global Sumud qui revenaient d’Israël a choqué. Les faits posent encore une fois l’épineuse question du maintien de l’ordre dans la Communauté autonome basque.
- Sacre du PSG : un policier hors service condamné à 14 mois de prison ferme après avoir braqué des automobilistes en marge des célébrations (rtl.fr)
un policier qui n’était pas en service a été condamné ce mardi 2 juin à deux ans de prison, dont quatorze mois ferme avec mandat de dépôt, après avoir braqué des automobilistes avec son arme de service près du Pont-Neuf.[…] Ivre au moment des faits, il a expliqué ne plus se souvenir précisément du déroulement de la scène.
- Victoire du PSG : à 14 ans, il dénonce pressions et violences policières (humanite.fr)
Un adolescent de 14 ans a été interpellé non loin de République. Selon sa famille, il aurait été plaqué contre un mur, menotté, insulté et blessé au nez avant d’être placé en garde à vue, puis de passer une nuit au dépôt. Il affirme également avoir subi des pressions après avoir souhaité porter plainte contre les policiers.
Spécial résistances
- Seine-Saint-Denis : des enseignant·es dénoncent des « violences racistes, sexistes et sexuelles » en milieu scolaire (leparisien.fr)
À l’appel du syndicat Sud Éducation 93, un rassemblement était organisé ce mardi à Saint-Denis pour dénoncer « l’impunité », selon des professeurs du département, qui protègerait les auteurs de propos ou d’agressions racistes ou sexuels à l’école.
- RSA : la Confédération paysanne rejoint la CGT dans sa plainte pour « harcèlement » contre le président du Finistère (humanite.fr)
Dénonçant la « pression disproportionnée » que subissent les agriculteurices bénéficiaires du RSA dans le Finistère, la Confédération Paysanne s’est associée à la procédure judiciaire intentée par la CGT contre le président du département. L’organisation pointe des contrôles abusifs qui dissuadent les paysan·nes de recourir à leurs droits.
- Indexons les salaires ! (politis.fr)
Le Smic augmente de 2,41 % ce 1er juin. Pourquoi n’est-ce pas le cas de tous les salaires ? À cause de la fable de la « spirale prix-salaires », qui, comme les monstres sous le lit des enfants, fait très peur mais n’existe pas.
- Montpellier : le SCUM annonce la création de deux plateformes contre la sélection à l’université (lepoing.net)
- Reprendre la musique aux machines (politis.fr)
Face aux coupes budgétaires, à la montée de l’extrême droite et à la concentration industrielle, des artistes et travailleur·ses de la musique s’organisent. Un appel à faire de la culture un front de résistance politique et collective.
- Les artistes, acteurs et actrices de la culture se mobilisent pour le théâtre de Vanves (humanite.fr)
380 artistes, technicien.ne.s, acteurs et actrices culturel.le.s se mobilisent pour défendre le théâtre de Vanves, menacé d’une année blanche et d’un changement radical de politique culturelle de la municipalité.
- Appel à mobilisation le 18 juin à Paris « pour défendre les métiers de l’information » (acrimed.org)
Le jeudi 18 juin, les syndicats SNJ, SNJ-CGT, CFDT-Journalistes, le SGJ-FO, la Filpac-CGT, le SNPEP-FO, Info’Com-CGT appellent l’ensemble des salariés des médias à rejoindre ce cortège et à se mobiliser collectivement pour combattre les dangers qui menacent l’information, pour refuser les plans sociaux et défendre une information de qualité.
- L’association HOP obtient un procès contre le fabricant d’imprimantes Epson (lemonde.fr)
Une première audience aura lieu à Nanterre le 2 juillet, huit ans après la plainte déposée par Halte à l’obsolescence programmée (HOP). L’association reproche notamment au constructeur de réduire à dessein la durée de vie de ses cartouches d’encre.
Voir aussi Epson vs HOP : un premier procès pour obsolescence programmée (next.ink)
Spécial outils de résistance
- La police tue : voici les chiffres (basta.media)
- Vous êtes fiché·e ou surveillé·e par la police : Disclose lance un appel à témoins pour une enquête documentaire (disclose.ngo)
- Et si on limitait la fortune des riches à 10 millions d’euros ? (usbeketrica.com)
À partir de combien est-on trop riche ? La chercheuse belgo-néerlandaise Ingrid Robeyns pose la question dans son essai Limitarianism : The Case Against Extreme Wealth (Allen Lane, 2024). La philosophe et économiste y forge un concept inédit : le limitarisme. Son principe ? Limiter les fortunes individuelles à 10 millions d’euros pour bâtir un monde sans super-riches et combattre les inégalités extrêmes politiquement et moralement insoutenables.
- Pétition : Facturation électronique obligatoire, c’est non ! (petitions.assemblee-nationale.fr)
Soutenir
- Le dernier numéro de Curseurs, « À quoi rêve le numérique ? », vient de paraître et est disponible ici. Mais il pourrait être le dernier. Aujourd’hui, nous avons besoin de vous pour poursuivre l’aventure de cette très chouette revue !
Spécial MAGAM et cie
- Sideloading : des apps open source montrent comment contourner les blocages Google (clubic.com)
- L’obsession d’Amazon pour entraver l’action syndicale et l’émergence de conventions collectives (basta.media)
- Fedora Linux 43 exposes 20-year-old Microsoft Outlook security failure (nerds.xyz)
upgrading to Fedora 43 and the newer Dovecot 2.4 mail server unexpectedly exposed what could be an ancient Microsoft Outlook security problem involving unencrypted POP3 connections. If true, some Outlook users may have believed their email sessions were protected by SSL/TLS while the client silently continued using insecure plaintext connections instead.
- Build 2026 : Microsoft poursuit sa grande offensive en faveur de Linux (zdnet.fr)
- Le ministère des Armées va renouveler son contrat avec Microsoft (journaldunet.com)
- Vos données médicales chez Doctolib transmises aux géants américains ? Ce que disent les documents officiels (clubic.com)
Les autres lectures de la semaine
- An OpenAI model solved a famous math problem that stumped humans for 80 years (arstechnica.com)
I tried to explain OpenAI’s solution more clearly than OpenAI did.
- Age verification for social media – the beginning of the end for a free internet ? (mullvad.net)
- Palantir, la Big Tech au coeur de l’administration Trump (multinationales.org) – voir aussi Le retour de Trump, une aubaine pour Palantir (multinationales.org) et Renseignement, armée, santé, entreprises… Palantir à la conquête de l’Europe (multinationales.org)
Palantir, qui réalise l’essentiel de son chiffre d’affaires aux États-Unis, cherche à gagner de nouveaux clients en Europe, du côté des entreprises comme des gouvernements. Avec souvent le même opératoire : la multinationale profite des situations de crise pour offrir ses services gratuitement, puis enchaîne avec des contrats très lucratifs dont il est de plus en plus difficile de sortir.
- Que faut-il faire des riches ? Entretien avec R. Pradeau, porte-parole d’Attac (humanite.fr)
- Une gauche minorée face à la poussée illibérale (politis.fr)
On peut tourner et retourner le dilemme dans tous les sens, le plus raisonnable se réduit en une affirmation : l’urgence est celle d’une gauche rassemblée le plus largement possible, autour d’un projet le plus avancé possible, donnant crédibilité au projet d’une rupture avec les choix qui, depuis 1982, l’ont conduite au désastre.
- « Le WWF est né du racisme, du colonialisme et du capitalisme » (reporterre.net)
- Contre les oppressions subies par les femmes, décoloniser le féminisme (theconversation.com)
- 105 Years After the Tulsa Race Massacre (qasimrashid.com)
Did you know that the first time terrorists used planes to attack Americans wasn’t on 9/11 or at Pearl Harbor ? It was during the Tulsa Race Massacre of 1921 when white supremacists flew “a dozen planes to drop turpentine or nitroglycerin bombs & men shot from planes.”
Les BDs/graphiques/photos de la semaine

Les vidéos/podcasts de la semaine
- Les travailleureuses vont-iels se révolter contre l’IA ? (radiofrance.fr)
En Corée du Sud, les salariés de Samsung menaçaient d’une grève si les bénéfices de l’IA n’étaient pas mieux répartis. Aux États-Unis, ce sont les étudiants qui manifestent leurs craintes face à la concurrence déloyale de l’IA, et rejettent le modèle de société prôné par les patrons de la tech.
- Réaction de Nicole Ferroni suite à la déclaration du président de la république sur les moyens de la justice (tube.fdn.fr)
- The First Live Performance of Nirvana’s “Smells Like Teen Spirit” (1991) (openculture.com)
Les trucs chouettes de la semaine
- « Bonjour, c’est Marie, de Paloma » : des maraudes numériques pour rompre l’isolement des travailleuses du sexe (basta.media)
À Nantes, une association arpente le Web pour créer du lien avec les travailleuses du sexe qui rencontrent leurs clients par l’intermédiaire d’Internet. Un travail social de longue haleine, en butte aux lois régissant la prostitution.
- GoVolta, le nouveau train pour l’étranger (meinamsterdam.nl)
- La Commission européenne élève le logiciel libre au rang de levier de politique industrielle (zdnet.fr)
- Le logiciel libre l’emporte : Polytechnique dit non à Microsoft et déclenche une vague de rébellion dans les universités (lesnumeriques.com)
Après des mois d’une guerre de tranchées juridique, la direction de l’École polytechnique a officiellement capitulé en suspendant son projet de migration vers Microsoft 365. Attaquée par le Conseil National du Logiciel Libre (CNLL), la prestigieuse école de Palaiseau a dû reculer.
- L’appel à participation du Capitole Du Libre 2026 est ouvert jusqu’au 20 juillet ! (cfp.capitoledulibre.org)
- On a découvert des millions d’abeilles installées depuis plus de cent ans sous un cimetière américain (slate.fr)
Des scientifiques ont découvert une mégacolonie d’abeilles sauvages dont l’existence remonte à plus d’un siècle. Avec plusieurs millions d’individus recensés, cette population hors norme éclaire le rôle discret mais essentiel des espaces urbains préservés.
- Cette espèce de poissons a survécu 100.000 ans sans aucun mâle (slate.fr)
Dans les eaux chaudes des rivières du Mexique et du sud du Texas nage une espèce de poissons argentés qui ne devrait pas exister. Dans ces eaux, les femelles Poecilia formosa se reproduisent avec des partenaires appartenant à d’autres espèces pas trop différentes d’elles, avant de se débarrasser aussitôt de l’ADN du mâle : sa progéniture ne sera que femelle.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
04.06.2026 à 15:08
Archipellisation solarpunk
Framasoft
Texte intégral (943 mots)
Framasoft, UPLOAD et solarpunk
Depuis 2024, Framasoft participe à l’animation d’ateliers d’écriture solarpunk à l’Université de Technologie de Compiègne pour imaginer un monde low-tech en 2042 autour de la future UPLOAD de Compiègne.

L’action se déroule sur le territoire de la Commune Libre de Compiègne, et plus précisément dans le cadre de l’Upload, l’Université Populaire Libre Ouverte Accessible et Décentralisée, une fédération internationale de lieux autonomes, destinés à la formation et à la recherche, confrontés aux défis d’un monde en effondrement économique et technologique, soumis à des crises écologiques et des conflits internationaux, mais ouverts à l’invention de nouveaux modes de vivre ensemble et de nouveaux rapports aux autres vivants et non-vivants. (voir notre annonce en 2024).
Pendant une semaine, des élèves ingénieurs s’adonnent à l’écriture de fiction pour penser un autre rapport à la technologie, avec des pratiques pédagogiques originales pour elleux dans leur formation, issues de l’éducation populaire, comme le débat mouvant ou l’arpentage (proposé autour de pizzas ou de lasagnes pour les appâter). Ils finissent par faire lecture d’un extrait de leur travail en direct à la radio Graf’hit.
Contenu de la semaine de cours sous licence libre CC BY SA sur librecours.net
Une partie des textes est retravaillé chemin faisant / a posteriori et est publié sur https://punkardie.fr/upload/ également sous licence CC BY SA.
Un premier recueil de textes basé sur ces productions (placées sous licence libre) est d’ailleurs en préparation en partenariat avec C&F édition, nous vous en reparlerons prochainement.
Et Archipel dans tout ça ?

Aller écouter l’annonce enregistrée et diffusée sur la radio Graf’Hitt
Et ce mois de juillet, toujours dans le cadre du partenariat avec l’UTC, Framasoft participera à la conférence Archipel à Compiègne, à l’UTC, du 6 au 9 juillet.
Archipel est une communauté de recherche francophone transdisciplinaire sur les enjeux de l’Anthropocène (limites planétaires, risques systémiques, leviers d’action) au sein de laquelle des rencontres et conférences sont organisées accueillant symposiums de recherche et ateliers. SI le programme vous semble impressionnant, il s’agit néanmoins d’un événement ouvert à toutes et tous, absolument pas réservé aux universitaires, chercheurs ou chercheuses.
Dans ce cadre, Framasoft, participera à un atelier autour de l’économie sociale et solidaire le mercredi 8 et co-animera un atelier d’écriture solarpunk le jeudi 9 juillet, qui présentera le genre solarpunk et l’univers UPLOAD. Comme les étudiants et étudiantes, les participants seront invité·es à plancher à leur tour sur des contributions afin d’imaginer un futur désirable, autour de thématiques proposées.
Le programme de la conférence Archipel : https://archipel.scenari-community.org/programme/co/0_programme.html
Pour pouvoir participer :
Il est obligatoire de s’inscrire en tant que participant·e à la conférence :
https://archipel.scenari-community.org/organisation/
(au plus tard le 12 juin ! )
01.06.2026 à 07:42
Khrys’presso du lundi 1er juin 2026
Khrys
Texte intégral (9085 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Internet starts coming back in Iran after months-long blackout (bbc.com)
- Ebola outbreak draws attention to longstanding virus spillover risks in western Uganda (news.mongabay.com)
- L’épidémie d’Ebola empire en RDC et les États-Unis n’y sont pas étrangers (portail.basta.media)
Plus de 200 personnes seraient décédées des suites d’Ebola en République démocratique du Congo et en Ouganda. Les médias indépendants internationaux parlent d’« une des épidémies les plus importantes de l’histoire récente », empirée par les décisions des États-Unis de Donald Trump.
- RD Congo. Une « trève Ebola » nécessaire pour contenir le virus (afriquexxi.info)
Alors que le nombre de victimes du virus Ebola ne cesse d’augmenter, le conflit en cours dans l’est du pays ne fait qu’aggraver la situation. Manque de personnels soignants, déplacements des équipes médicales entravés, camps de déplacés… La situation pourrait devenir incontrôlable si les belligérants ne s’entendaient pas pour mettre en place les mesures nécessaires.
- Découverte de centaines de monuments funéraires dans l’est du Sahara (theconversation.com)
- « Ils nous interdisent tout : écrire, parler, chanter » : ces jeunes Russes qui contournent le blocage d’Internet (basta.media)
- How A Ukrainian Stork Outflew A Russian Drone, And What This Tells Us (forbes.com)
- Guerre en Ukraine : la Roumanie accuse la Russie d’avoir frappé un immeuble sur son territoire, l’Otan dénonce « une nouvelle limite » franchie (humanite.fr)
En parallèle, Moscou est accusée par l’Ukraine de s’être attaquée à un cargo truc, tandis que trois autres bateaux ont aussi été touchés sans que l’opération ne soit revendiquée.
- Sweden authorizes police use of live facial recognition (biometricupdate.com)
New law permits real-time biometric surveillance in cases involving serious crime, kidnappings and threats to life
- Les glaciers européens sont parmi les plus vulnérables face à la hausse des températures (legrandcontinent.eu)
C’est dans le massif des Alpes que la hausse des températures est aujourd’hui parmi les plus visibles en Europe. À 10h du matin aujourd’hui, jeudi 28 mai, le thermomètre a atteint les 10°C sur la pointe Helbronner, un sommet du massif du Mont-Blanc parmi les plus élevés du continent, à 3 466 mètres d’altitude.
- Les Pays-Bas bloquent le rachat d’un fournisseur numérique par une société états-unienne (next.ink)
Le gouvernement néerlandais vient de bloquer le rachat de la société numérique Solvinity par l’acteur états-unien Kyndryl. En cause : des préoccupations en matière de souveraineté.
- Europe told to cool its datacenter boom before water and power run short (theregister.com)
- What’s behind the EU’s digitalisation push ? Surveillance, control and exclusion (edri.org)
underneath the rhetoric of efficiency, modernisation, and citizen empowerment lies a more troubling reality. It is not a mere technical upgrade of public services, but a political choice, long in the making, to forego care and rights of individuals in favour of normalising surveillance, control and exclusion of the most marginalised.

- Inside Italy’s low-cost spyware economy (edri.org)
Commercial spyware in Europe has recently made headlines with the now notorious names of Pegasus and Graphite, the expensive, exploitation-driven products at the top end of the market. Much less known is the wide underworld ecosystem of low-cost spyware vendors, often targeting citizens via their smartphones. EDRi member Osservatorio Nessuno has investigated and analysed two separate products, Spyrtacus and Morpheus.
- Remigration Summit : l’extrême droite européenne rassemblée pour promouvoir l’expulsion de masse des immigrés (basta.media)
La seconde édition du « Remigration Summit », un évènement identitaire organisé par d’ex-néonazis, a lieu ce 30 mai à Porto. De nombreux partis politiques européens y prônent la déportation des immigrés dans leur pays d’origine.
- UK Visa Portal exposed thousands of applicants’ passports and selfies — then called the lawyers on us (techcrunch.com)
- New breed of political prisoner arises in Britain as anti-protest sentences rise (theguardian.com)
Britain has created a new breed of political prisoners through the systematic incarceration of people acting to prevent climate breakdown and the annihilation of Gaza
- White House’s UFO-Inspired ‘Aliens’ Site Triggers Bait-and-Switch Backlash : ‘Fascist Garbage’ (thewrap.com)

- From Charlottesville to San Diego (crimethinc.com)
While Trump Brands Anti-Fascism “Terrorism,” Fascists Murder People in the Streets
- Lors des Enhanced Games, compétition où le dopage était autorisé, un seul record a été battu (huffingtonpost.fr)
Le Grec Kristian Gkolomeev a fait mieux que le record du monde du 50m nage libre mais sa performance ne sera pas homologuée.
- Trump admin to block Ebola-exposed Americans from US, move them to Kenya (arstechnica.com)
- These researchers would be in Africa fighting ebola—but Trump cut their funding (arstechnica.com)
US Infectious diseases centers launched during COVID have lost their funding under Trump.
- L’étrange expérience « MAGA-chaviste » qui déterminera l’avenir du Venezuela (contretemps.eu)
L’enlèvement de Nicolás Maduro et de son épouse Cilia Flores par les forces spéciales américaines a marqué le début d’une nouvelle ère au Venezuela : celle d’un protectorat de facto dans lequel Washington gère le pétrole, les finances et le commerce extérieur.
Voir aussi Le banquier français Matthieu Pigasse décroche le contrat pour restructurer la dette du Venezuela (france24.com)
- California moves to exempt Linux from its upcoming age-verification law after backlash over forcing operating systems to collect users’ ages (tomshardware.com)
- Websites have a new way to spy on visitors : analyzing their SSD activity (arstechnica.com)
Telltale SSD activity can be measured in the browser using simple JavaScript.
- Hackers are trying to steal Signal users’ backups in new wave of phishing attacks (techcrunch.com)
- Perfect randomness realized for the first time (phys.org)
Creating perfect randomness is surprisingly difficult. Even modern random number generators never generate completely ideal random numbers : small systematic errors can result in some numbers appearing slightly more frequently than others. For many applications, this does not matter. In cryptography, however, even the tiniest deviations can be problematic.
- Musk says US military suicide drones used Starlink in violation of SpaceX rules (arstechnica.com)
Musk says drones used Starlink instead of Starshield, blames military contractor.
- Sur le front, les militaires états-uniens ciblés grâce aux données de tracking commercial (next.ink)
- Nasa : l’impressionnant plan de base lunaire dévoilé par l’agence spatiale américaine (france24.com)
La NASA a dévoilé mardi un plan d’investissement massif pour établir, à moyen terme, une base habitable sur la Lune prévue pour les années 2030. L’agence spatiale a fait appel aux géants de la tech que sont Space X et Blue Origin appartenant respectivement aux milliardaires Elon Musk et Jeff Bezos pour mettre en œuvre cette opération gigantesque.
- L’industrie de demain : des usines dans l’espace ? (socialter.fr)
En quelques années, les entreprises qui ambitionnent de faire décoller les usines dans l’espace se sont multipliées. En promettant de révolutionner la production de médicaments et de dépolluer l’industrie, elles attirent les financements privés comme publics. Pourtant, l’intérêt de ces projets ne fait pas l’unanimité.
- The most spectacular rocket explosion since N1 just happened in Florida (arstechnica.com)
New Glenn was due to play a starring role in NASA’s Artemis Program.This is the worst disaster in the history of Blue Origin, founded in 2000.
Voir aussi Rocket Report : A dark day for Blue Origin ; Pentagon eyes new launch site (arstechnica.com)
- Un météore explose au-dessus des États-Unis, des caméras enregistrent l’impressionnante détonation (huffingtonpost.fr)
Le météore filait à 120 000 km/h à quelque 64 kilomètres dans le ciel avant d’exploser au-dessus de la région nord-est des États-Unis.
Spécial IA
- Millions of AI agents imperiled by critical vulnerability in open source package (arstechnica.com)
Millions of AI agents and tools around the world have been imperiled by a critical vulnerability that can allow hackers to breach the servers running them and make off with sensitive data and credentials to third-party accounts […]The vulnerability is present in Starlette, an open source framework that its developer says receives 325 million downloads per week.
- Raz-de-marée de « code slop » : Linus Torvalds sature et bannit les patchs générés par l’IA du noyau Linux ! (cercll.wordpress.com)
- DuckDuckGo Installs Spike as Google Moves to Replace Search With AI (futurism.com)
Instead of links, Google is looking to push users down an AI chatbot rabbit hole. That’s despite the tech’s glaring shortcomings, which the company has yet to meaningfully address, with the company’s flagship AI Overview feature still suffering from a staggering number of hallucinations. Even something as simple as googling the word “disregard” sent the feature into a spiral, forcing the company to jump in after a wave of mockery.
- Open source project contains hidden instruction for “AI” agents : delete my code (osnews.com)
It’s no secret there’s a war going on inside the open source community, with people adopting “AI” on one side, and those that want nothing to do with it on the other. While the former are, by nature, using destructive tactics like mass website scraping, license washing, taking people’s creative works without permission, taking all the RAM and GPUs, and oh, destroying the planet, the latter have mostly stuck to fairly benign things like policies banning “AI” use, “AI” bot blockers, and the occasional honey pot mazes to trap “AI” crawlers. No more. Things are escalating

- Tech CEOs are apparently suffering from AI psychosis (techcrunch.com)
“CEOs are uniquely prone to AI psychosis because they’re sufficiently distant from the last mile of work that still has to happen to generate most value with AI”[…]these top-level executives aren’t the people who have to review code, discover bugs, and identify calls to hallucinated libraries before software is deployed.
- ‘AI washing’ : firms are scrambling to rebrand themselves as tech-focused (theguardian.com)
PR executives say UK companies are forcing them to present ordinary automation as artificial intelligence
- Appel à témoignages : vous refusez les injonctions de votre employeur à utiliser l’IA au travail ? Racontez-nous (lemonde.fr)
- ‘Big AI’ influence on laws and oversight mapped (ed.ac.uk)
Artificial intelligence (AI) companies influence policy and regulation using similar techniques to Big Tobacco, Big Pharma and Big Oil, according to a new study.
- AI sticker shock hits corporate America (axios.com)
Corporate leaders are starting to question whether soaring AI spending is delivering meaningful returns.
- 500 millions de dollars brûlés en 30 jours : cette entreprise a « oublié » d’encadrer l’usage de l’IA Claude (numerama.com)
- You’re about to feel the AI money squeeze (theverge.com)
Ads, rate limits, feature restrictions, price hikes. The AI free ride is over.
- FBI agent explains how easy it is to ID people posting AI porn without consent (arstechnica.com)
The earliest arrests under the Take It Down Act (TIDA) suggest that cops don’t have to work too hard to identify people illegally posting and selling nonconsensual sexualized deepfakes of women online.
- La Cité artificielle et l’IA à visage humain (legrandcontinent.eu) – voir aussi Magnifica Humanitas, texte intégral de l’Encyclique de Léon XIV (legrandcontinent.eu)
- Ce que dit l’encyclique de Léon XIV sur l’IA, qui doit être « empêchée de dominer l’humain » (nouvelobs.com)
Le pape va jusqu’à dénoncer « les nouvelles formes d’esclavage », nées des besoins d’extraction de ressources nécessaires à l’utilisation de l’intelligence artificielle (IA), comme les microprocesseurs.
- Citing Gandalf, Pope Leo says we must “disarm” AI (arstechnica.com)
With the co-founder of Anthropic at his side today in Rome, Pope Leo XIV released a major new encyclical—his first—called “Magnifica Humanitas” (“Magnificent Humanity”). It calls for AI to be “disarmed” in service of the common good.
Voir aussi Is Peter Thiel the target of Pope Leo’s Gandalf quote ? An investigation. (arstechnica.com)
- Meta data center allegedly muddies Georgia town’s drinking water, investigation underway (tomshardware.com)
EPA promises immediate investigation after congresswoman brings dirty jars of water to hearing
- ‘We will fight until the end’ : Pennsylvania township erupts over $5 billion data center plan (yahoo.com)

- Saboter les data centers ? L’administration Trump craint l’émergence d’un « extrémisme » anti-technologique (legrandcontinent.eu)
- Les datacenters réchauffent la planète (multinationales.org)
- L’IA ça sert, d’abord, à faire la guerre (danslesalgorithmes.net)
- Unlawful by design : Exposing the human rights costs of generative AI (amnesty.org) – voir aussi Les énormes pipelines de données qui alimentent les principaux systèmes d’IA générative reposent intrinsèquement sur des intrusions massives dans la vie privée (amnesty.org)
Spécial Israël et Palestine
- La rapporteure de l’ONU sur Gaza de nouveau visée par des sanctions américaines (lapresse.ca)
Les États-Unis ont réinstauré les sanctions prises à l’encontre de Francesca Albanese, une experte de l’ONU spécialiste des territoires palestiniens ayant vivement critiqué Israël, seulement quelques jours après leur levée.
- Israël : du bon usage du fasciste Ben Gvir (politis.fr)
Le ministre suprémaciste a eu le tort de montrer à la face du monde cette réalité d’Israël que le monde ne veut pas voir.
- In first since Oslo, Israel seizing land for army base inside West Bank city (972mag.com)
The seizure order, near Jenin refugee camp, is the latest move aimed at expanding military and settler presence in the north of the occupied territory.
Spécial femmes dans le monde
- La crise des droits des femmes en Afghanistan est une catastrophe humanitaire (theconversation.com)
- Les mutilations génitales féminines en Égypte : répression légale, résistance culturelle (theconversation.com)
Comment faire respecter la loi quand la famille devient le premier relais de la mutilation, au nom de l’honneur et de l’intégration sociale ?
- Le tatouage amazigh, entre transmission et réappropriation (bondyblog.fr)
- La compositrice Antonia Bembo a fui Venise pour échapper à son mari violent. Plus de trois siècles plus tard, son opéra est enfin mis en scène (theconversation.com)
- I was drugged and raped by my husband for years (bbc.co.uk)
A woman whose husband drugged, raped and filmed himself abusing her for years is speaking out about her experience in a bid to help other victims of similar crimes.
Spécial France
- « Les esclaves sont nos parents » : comment le 22 et le 27 mai façonnent encore les mémoires antillaises (bondyblog.fr)
Chaque année, le 22 mai en Martinique et le 27 mai en Guadeloupe, les Antillais·es commémorent l’abolition de l’esclavage dans leurs territoires. Distinctes du 10 mai retenu par l’État français, ces dates hautement symboliques pour les communautés antillaises rappellent la résistance des personnes mises en esclavage.
- L’Assemblée nationale abroge définitivement le Code noir (guyaweb.com)
L’Assemblée nationale abroge définitivement le Code noirLes député·es ont voté à l’unanimité ce jeudi 28 mai pour l’abrogation du Code noir et l’ensemble des textes ayant réglementé l’esclavage dans les colonies françaises aux XVIIᵉ et XVIIIᵉ siècles. Bien que sans effet juridique depuis longtemps, ces textes n’avaient jamais formellement été abrogés après l’abolition définitive de l’esclavage en 1848.
- Patrick Balkany écope de deux peines de prison ferme pour détournements de fonds publics (huffingtonpost.fr)
Patrick Balkany, âgé de 77 ans, a été condamné à 15 mois de prison ferme et à trois ans ferme, mais sans mandat de dépôt. Il n’ira donc pas immédiatement derrière les barreaux.
- Fête nationale : Pourquoi Paris avance son feu d’artifice au 13 juillet cette année (huffingtonpost.fr)
C’est le maire de la capitale, Emmanuel Grégoire, qui a pris cette décision, en lien avec le président de la République, Emmanuel Macron. […] « J’ai souhaité que l’édition 2026 ait lieu le lundi 13 juillet, afin de permettre le respect nécessaire pour le temps national de commémoration des dix ans de l’attentat de Nice »
- Un mort et huit blessés graves en marge des célébrations de la victoire du PSG en Ligue des champions (huffingtonpost.fr)
- La justice déclare illégale l’édition de manuels scolaires numériques par la région Ile-de-France (lemonde.fr)
- Qui sont les 30 % de foyers éligibles au RSA qui ne le perçoivent pas ? (alternatives-economiques.fr)
De nouveaux travaux affinent le profil des personnes qui ne demandent pas le RSA alors qu’elles y ont droit. Et montrent l’impact qu’aurait le recours à la prestation sociale sur le taux de pauvreté.
- Datacenter de Google à Châteauroux : vers une enquête publique sur fond de « secret des affaires » (multinationales.org)
Saisie par Google et RTE, la Commission nationale du débat public (CNDP) va organiser une concertation autour du projet de datacenter géant de la multinationale américaine à Ozans, près de Châteauroux – et ce bien qu’officiellement, Google n’ait toujours pas pris sa décision.
- Canicule : « Dans les logements sociaux, on cuit dans l’indifférence » (reporterre.net)
- 35°C dans la classe : quand passer le BAC devient infernal (bonpote.com)
- Un jeune ouvrier de 19 ans meurt après avoir travaillé sur une toiture sous une chaleur intense (midilibre.fr)
Un ouvrier de 19 ans est mort dans la nuit du mardi 26 au mercredi 27 mai après avoir travaillé sur un toit par plus de 31 °C.
- Rails à 50 °C, plus de clim… Pourquoi la SNCF peine à faire face à la canicule ? (huffingtonpost.fr)
Les chaleurs exceptionnelles ont semé la pagaille dans les trains, révélant les limites du réseau ferroviaire français face au changement climatique.
- Pointes à 39 °C dans le Sud-Est, 17 départements en alerte orange, épisodes de pollution critique à l’ozone… Face à la canicule, le gouvernement appelé à « prendre des mesures structurantes » (humanite.fr)
- Refuges thermiques en rivière : quand les eaux souterraines sauvent les poissons de la surchauffe (theconversation.com)
Spécial femmes en France
- « La marche des femmes » : leçon d’histoire féministe avec Michelle Perrot en BD (lesnouvellesnews.fr)
- Lycéennes et vocations scientifiques : des stages en écoles d’ingénieurs pour contrer les stéréotypes de genre (theconversation.com)
- Égalité professionnelle : la France retarde la transparence (lesnouvellesnews.fr)
La France avait trois ans pour transposer la directive européenne sur la transparence salariale, favorable à l’égalité professionnelle. Le gouvernement repousse désormais ses obligations, invoquant une mésentente entre partenaires sociaux.Qui aurait pu prédire ?
- Affaire Bruel : en Suisse, le Paléo Festival confirme un accord après un « comportement inadmissible » du chanteur en 2019 (leparisien.fr)
une masseuse bénévole du Paléo avait dénoncé le « comportement inadmissible » du chanteur en 2019. L’affaire s’était conclue par « un accord entre les parties incluant une clause de confidentialité ».
- « Bruel violeur ! » : des militantes féministes interrompent la pièce du chanteur à Paris (huffingtonpost.fr)
Des militantes du collectif Nous Toutes s’étaient placées dans le public de la pièce « Deuxième partie », dans laquelle joue Patrick Bruel au théâtre Édouard VII.
- Patrick Bruel annule concerts et festivals cet été : le point sur une affaire hors norme (telerama.fr)
L’étau se resserre autour du chanteur accusé de nombreuses agressions sexuelles. Une trentaine de femmes ont témoigné contre lui. Rappel des faits alors qu’il vient d’annuler ses dates prévues jusqu’à l’automne.

- « Les violences faites aux femmes, c’est un problème d’hommes » Thomas Pesquet appelle les hommes à réagir (lesnouvellesnews.fr) – voir aussi la vidéo : Droit dans les yeux – Thomas Pesquet (france.tv)
RIP
- Disparition : Huguette Bouchardeau, l’exigence militante (politis.fr)
Première femme en France à diriger un parti politique, le PSU, à la fin des années 1970, Huguette Bouchardeau est décédée à l’âge de 90 ans.
- Sociologue, philosophe et résistant, Edgar Morin est mort à l’âge de 104 ans (rfi.fr)
Considéré comme le dernier grand intellectuel français, Edgar Morin est décédé ce 29 mai […] Philosophe et sociologue, directeur de recherche émérite au CNRS, l’auteur de Le paradigme perdu et d’une soixantaine d’autres ouvrages laisse derrière lui une œuvre transdisciplinaire, abondamment commentée et traduite, au service d’une pensée toujours libre et critique de son temps.
Voir aussi Edgar Morin, penseur de la complexité et passionné de l’humanité (humanite.fr)
Spécial médias et pouvoir
- Le Sénat malmène la presse indépendante et oublie Vincent Bolloré (reporterre.net)
- La ministre Annie Genevard, épinglée pour sa présence à une réunion de Bolloré au casting sulfureux (huffingtonpost.fr)
« Le Monde » a révélé la présence de la ministre à un déjeuner visant à structurer un think thank, fondé par Bolloré, pour promouvoir ses idées conservatrices en vue de 2027.
- Crise à « Ouest-France » : le journalisme pourrait être une solution (politis.fr)
Le pilier de la presse régionale va mal, et sa direction engage un énième plan d’économie. Suggestion proposée par le syndicat SNJ : arrêter de « trouver des excuses » et sortir des informations.
- CNews, La Baule et la fabrique de l’« insécurité » (acrimed.org)
- Ce journaliste météo de BFM dénonce à l’antenne des « dizaines d’insultes et menaces » (huffingtonpost.fr)
Kévin Floury a pris la parole lors de la matinale de la chaîne d’info en continu pour défendre les cartes météo jugées trop « rouges » par les climatosceptiques.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Lutte contre les inégalités : la France décroche par rapport au reste de l’Europe (alternatives-economiques.fr)
- Présidentielle. En meeting, Gabriel Attal refait le coup du « progressisme » macroniste (humanite.fr)
ce qu’il décrit comme ses quatre chantiers prioritaires : « école, salaires, frontières, IA ».
- Pour la présidentielle 2027, Gabriel Attal récupère un compte de soutien à Emmanuel Macron sur les réseaux (huffingtonpost.fr)
Tout le week-end, des internautes se sont étonnés d’être abonnés au compte « Attal président » sans jamais l’avoir demandé […] le compte dispose déjà de 35 000 abonnés sur Instagram et de plus de 50 000 sur X […] Sans rien dire à personne, Gabriel Attal a mis la main sur les comptes de soutien du candidat… Emmanuel Macron en 2022 »
- Ouverture à la concurrence du train : même des sénateurs de droite décrivent un fiasco (reporterre.net)
Deux sénateurs de droite dressent un bilan critique de la libéralisation du rail : coûteuse pour les finances publiques, elle fait courir le risque d’une « balkanisation » du réseau et de l’abandon des petites dessertes.
- L’adaptation au changement climatique, gros point noir d’Emmanuel Macron sur l’écologie (huffingtonpost.fr)
- En pleine canicule historique, le gouvernement bafoue la protection de l’eau (lareleveetlapeste.fr)
Véritable atteinte démocratique, les préfets pourront permettre aux agriculteurs de continuer à pomper l’eau pendant deux ans, même lorsqu’une mégabassine aura été rendue illégale par la justice !
- Le gouvernement a censuré des campagnes de prévention sur la canicule et le tabac (reporterre.net)

- « Les scientifiques avaient beau savoir que ça arriverait, on est sur quelque chose de stupéfiant » (reporterre.net)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Vidéosurveillance algorithmique : la loi Ripost étend encore la prolongation jusqu’en 2030 (next.ink)
- Vidéosurveillance « intelligente » : bientôt une loi taillée sur mesure pour les intérêts privés ? (multinationales.org)
La vidéosurveillance algorithmique se déploie en France non seulement dans l’espace public, avec la loi JO, mais aussi dans les commerces, sans le cadre juridique nécessaire. Des startups comme Veesion ont lancé une campagne de lobbying de longue haleine pour obtenir la légalisation de ces pratiques, avec le soutien des géants de la distribution et de députés.
- L’extrême droite et la droite française testent un rapprochement inédit lors d’une élection très peu médiatisée (legrandcontinent.eu)
Du 22 au 31 mai 2026, les Français·es résidant hors de France éliront 433 conseiller·es des Français·es de l’étranger et 77 délégué·es consulaires
- Critiquée pour avoir participé à la manif antiracisme, la présidente de WWF France démissionne (huffingtonpost.fr)
« Il est apparu clairement que nous n’étions plus alignés sur des questions essentielles de valeurs et de conception du rôle d’une organisation comme le WWF dans la société contemporaine […] Ce désaccord est devenu explicite après ma participation, à titre strictement personnel, à un rassemblement transpartisan contre le racisme à Saint-Denis »
- Syndicats sous pression (politis.fr)
De la mise en examen de Sophie Binet après ses prises de position sur les Pfas aux attaques des municipalités du RN contre les syndicats, une même logique est à l’œuvre : affaiblir la démocratie sociale.
- Deux inspecteurs du travail accusés de harcèlement moral par leur hiérarchie : “Il y a eu des pressions que nous n’avions jamais connues” (france3-regions.franceinfo.fr)
À Grenoble, les tensions au sein de l’inspection du travail se sont accentuées à l’approche du 1er mai. Selon les syndicats, des courriers destinés à rappeler aux employeurs la réglementation applicable ce jour-là ont d’abord été bloqués par la direction.
- Bourses du travail : un contre-pouvoir syndical sous la pression des maires (basta.media)
Menacées d’expulsion dans plusieurs villes de droite et RN, comme à Carcassonne, les Bourses du travail sont des lieux essentiels pour l’accès aux droits des salariés et pour leur organisation collective.
- Mairies RN : la guerre contre le monde du travail est déclarée, il faut faire front (politis.fr)
Dans les communes dirigées par le Rassemblement national, les attaques contre les syndicats se multiplient. L’extrême droite veut affaiblir les contre-pouvoirs du monde du travail et imposer un ordre réactionnaire au service des politiques antisociales et racistes.
- Sainte-Soline : le gendarme qui a failli tuer Serge Duteuil-Graziani identifié (reporterre.net)
C’est un élément majeur qu’ont identifié Mediapart et Libération. Au bout de plusieurs mois d’analyses de plus de 150 heures d’images produites par les gendarmes et des journalistes, les deux médias ont révélé le 26 mai précisément l’origine du tir de grenade qui a grièvement blessé Serge Duteuil-Graziani le 25 mars 2023 lors de la mobilisation à Sainte-Soline (Deux-Sèvres).
- Provocation : le commissaire Chassaing responsable de la noyade de Steve à Nantes décoré pour « service rendu à la nation » (contre-attaque.net)
- De légères sanctions prononcées contre des gendarmes mis en cause lors de la manifestation à Sainte-Soline (huffingtonpost.fr)
Les militaires n’ont été sanctionnés que pour « propos inadaptés ». Pour ce qui est des tirs tendus filmés sur place, le ministère de l’Intérieur s’en remet à la justice.
- « C’était inhumain. Même à un chien, on ne fait pas ça » : Toufik, autiste et malentendant, violenté par la police (basta.media)
- Amputée des quatre membres, verbalisée sur une place handicapée, 375 euros saisis : le cauchemar administratif d’une mère de famille (france3-regions.franceinfo.fr)
Spécial résistances
- À Paris, le monde de la culture fait front contre Bolloré devant l’Olympia (humanite.fr)
À l’appel de la CGT Spectacle, acteurs du monde de la culture, syndicats et partis politiques de gauche se sont rassemblés devant la salle de spectacle détenue par le milliardaire d’extrême droite ce samedi 30 mai, pour appeler à lutter contre la bataille culturelle menée par Bolloré.
Voir aussi Jean-Luc Mélenchon fait de la lutte contre Bolloré un argument de campagne lors de la manif à L’Olympia (huffingtonpost.fr)
Le leader de La France insoumise a manifesté près de la salle de spectacle qui appartient au groupe Canal+, avec plusieurs dizaines de personnes.
- Au Stade de France, Aya Nakamura « brûle » une banderole raciste d’un groupuscule d’extrême droite (huffingtonpost.fr)
L’interprète de « Djadja » a répondu à sa manière aux militants identitaires du groupe Les Natifs, condamnés pour avoir déployé une pancarte raciste à son encontre
- À Besançon, une manifestation spontanée chasse Alice Cordier d’un bar (lechni.info)
Pour les membres du « collectif Némésis », trouver un café ou un estaminet accueillant est devenu un chemin de croix. Contraintes de venir dans la capitale comtoise à cause d’un énième calendrier judiciaire, les militantes d’extrême droite pourront désormais ajouter un nouveau lieu où elles sont « persona non grata ».
- Augmentation des frais d’inscription pour les étudiants étrangers : les universités se mobilisent contre un nouveau décret (basta.media)
Des enseignants-chercheurs et des étudiants multiplient les mobilisations contre les frais différenciés imposés aux étudiants étrangers hors UE. Le gouvernement fait pression pour généraliser, par décret, cette mesure.
- Victoire ! Après 4 ans de procédure, EDF est enfin condamnée (sortirdunucleaire.org)
La Cour d’appel de Grenoble a rendu, ce 27 mai 2026, un arrêt confirmant la responsabilité d’EDF et de Cédrick Hausseguy dans les fuites de tritium survenues en novembre 2021 à la centrale nucléaire de Tricastin (Drôme). Cette décision fait suite à une procédure engagée par le Réseau “Sortir du nucléaire” (RSDN) dès octobre 2022, après la découverte d’une contamination des eaux souterraines par 900 litres d’effluents radioactifs.
- Victoire pour un lanceur d’alerte nucléaire : EDF condamnée pour harcèlement moral (reporterre.net)
- « Des grains de sable dans la machine » : partout en France, des mobilisations contre le béton (reporterre.net)
- Le travail du sexe au cœur d’une bataille législative (streetpress.com)
Dix ans après la loi pénalisant les clients, la sénatrice écolo Anne Souyris propose de décriminaliser le travail du sexe. Un texte co-écrit avec les concernées, qui pourrait bousculer un Parlement tenté par de nouvelles lois coercitives.
- Big Tech’s Anti-Labor Playbook Has Come for Wikipedia (medium.com)
Sign the solidarity petition if you edit Wikipedia.
- Ciblé par deux textes de lois, des peines de prison et des amendes prohibitives, le mouvement des free parties se mobilise (basta.media)
Du 30 mai au 13 juin, le mouvement des free parties organise des « manifestives » aux quatre coins du pays pour s’opposer à deux textes législatifs en cours de discussion, et jugés extrêmement répressifs.
Spécial outils de résistance
- “Que peut faire la police” : le guide qui prolonge une enquête et donne des moyens d’agir (rembobine.info)
- « Basta ! » en campagne pour faire entrer le sujet des violences policières dans le débat public (basta.media)
Basta ! prépare un nouvel outil de visualisation de sa base de données sur les interventions policières létales. Une manière de faire entrer durablement dans le débat public le sujet des violences policières, lorsque celles-ci sont illégitimes.
- Le RN vote contre vous (stoprn.hop.kim)
À l’heure où les médias télévisés ne relatent que des discours et des opinions, nous voulions remettre les faits au centre des décisions de chacun-e et montrer à toutes et tous que le RN n’agit pas dans votre intérêt. Le RN vote contre notre santé, contre les femmes, contre les personnes précaires, contre les personnes non blanches, contre les travailleurs et travailleuses, contre les demandeurs et demandeuses d’emploi, contre les personnes LGBT+, contre les malades, contre les agriculteurs et agricultrices, contre le vivant, contre l’écologie et contre la démocratie.
- Élection présidentielle 2027 : l’ONG Quota climat et le média Les Surligneurs lancent une plateforme anti-désinformation (vert.eco)
- Ce site surveille les jets privés des milliardaires pour traquer leur fuite en cas de catastrophe mondiale (slate.fr)
Un programmeur américain a créé un système qui analyse l’activité des avions privés et attribue un « niveau d’urgence » global. Une œuvre à mi-chemin entre art, satire politique et surveillance technologique.
- AI Data Centers & Our Communities (brockovichdatacenter.com)

- Tax the 1 % (taxthe1percent.com.au)
Spécial MAGAM et cie
- Comment Google et Apple brident Galileo et l’IGN, pourtant gratuits et plus performants (clubic.com)
En conditions normales, le système de navigation européen Galileo offre des performances deux à trois fois supérieures au GPS américain. Imaginez qu’avec son service haute précision, il peut descendre sous les 25 centimètres. Le tout gratuit et ouvert à tous. Pourtant sur votre téléphone, vos données de déplacement transitent par les serveurs de Google ou d’Apple. Et l’IGN, que l’État français finance à hauteur d’une centaine de millions d’euros par an, reste absent de la majorité des services numériques publics.
- WhatsApp Chat Histories Stored Unencrypted on macOS and iOS (cybersecuritynews.com)
- Les Pays-Bas construisent leur propre GitHub pour ne plus dépendre de Microsoft (01net.com)
- Microsoft under fire for threatening security researcher with criminal investigation (techcrunch.com)
After a security researcher published a series of unpatched bugs in Microsoft products, along with code to exploit them, the company is now threatening to take legal action and call the cops on them. Microsoft’s veiled threat reignites a long-running argument over what responsibility, if any, security researchers have to disclose vulnerabilities affecting large and wealthy tech giants.
Les autres lectures de la semaine
- L’emmerdification du web : comprendre le phénomène pour s’en libérer (lasuite.coop)
- The Last Quiet Thing (terrygodier.com)
- The 40 Most Rage-Inducing Problems in Tech (theringer.com)
The bugs, broken apps, and nightmare customer-service bots we can’t escape, presented as a blessed and sacred addendum to Pope Leo XIV’s new encyclical on AI
- La réponse capitaliste a échoué (politis.fr)
La réponse du capitalisme à ses propres crises a échoué, en dépit de sa tentation libertarienne actuelle. Mais la gauche le sait-elle ?
- The ‘warrior ethos’ promises victory — history says it leads to defeat (theconversation.com)
- Quels premiers ministres ont banalisé les idées d’extrême droite ? (theconversation.com)
- De la “Honte noire” au fémonationalisme (komunemedia.substack.com)
Comment les discours de l’extrême droite sur la protection des femmes réactivent-ils des imaginaires coloniaux hérités de la campagne raciste allemande de la « Honte noire » ?
- L’entrée en Ehpad non consentie : une citoyenneté confisquée ? (mouvements.info)
- Coutume tyrannique, pourquoi obéir ? L’égalité des sexes dans l’utopie de la révolution anglaise (contretemps.eu)
- Si vous aimez les grêlons gros comme des pamplemousses, vous allez adorer le réchauffement climatique (slate.fr)
Une étude alerte sur une explosion des épisodes de grêle extrême d’ici 2100. Aux États-Unis comme en Europe, le réchauffement climatique pourrait favoriser des tempêtes capables de produire des grêlons records, et des dégâts considérables.
Les BDs/graphiques/photos de la semaine
Les vidéos/podcasts de la semaine
- Canicule en mai : simple “coup de chaud” ou nouveau point de bascule ? Avec V. Masson-Delmotte, paléoclimatologue et coautrice du dernier rapport du GIEC (humanite.fr)
- Allemagne : l’extrême droite aux portes du pouvoir ? (humanite.fr)
- 2027, rapports avec LFI, anticapitalisme… Philippe Poutou face à l’Huma (humanite.fr)
- Do Chatbots Really Belong in Schools ? (techwontsave.us)
- M.I.T. Computer Program Predicts in 1973 That Civilization Will End by 2040 (openculture.com)
Les trucs chouettes de la semaine
- M6 – Reportage sur déMAILnagement (peertube.libretic.fr)
- “Un téléphone qu’on peut réparer sur la table de la cuisine pour 30€, ça devient une évidence” – Interview Fairphone (clubic.com)
- Ne jetez pas votre vieux PC portable : transformez-le en machine ultime contre la distraction ! (goodtech.info)
- Révolution dans l’isolation : des laines végétales acoustiques et résistantes au feu (theconversation.com)
- Ce marais vieux de 4000 ans dépollue naturellement les nitrates (lareleveetlapeste.fr)
Le marais de Taligny, en Indre-et-Loire, absorbe les nitrates, freine les crues, soutient les nappes phréatiques et stocke le carbone. Ces fonctions, longtemps ignorées, ont justifié une restauration complète engagée depuis les années 2000. Une réserve naturelle régionale qui rend, silencieusement, des services que l’agriculture industrielle et l’urbanisme continuent de détruire ailleurs.
- Severed sea cucumber appendages don’t seem to die (arstechnica.com)
They seem to reorganize their tissues and then just keep living.
- “It’s blue !” Deep-sea scientists discover exciting new species in the Galápagos (discoverwildlife.com)
Microeledone galapagensis, a tiny blue octopus, is new to science
- La sexualité animale est bien plus diverse que nous ne voulons le savoir (reporterre.net)
- Des chercheurs du CHU de Lille sont en train de développer… un stérilet masculin ! (lebonbon.fr)
des chercheurs lillois travaillent actuellement sur un stérilet masculin implantable et réversible. Une innovation qui pourrait complètement changer la contraception dans les prochaines années.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
25.05.2026 à 07:42
Khrys’presso du lundi 25 mai 2026
Khrys
Texte intégral (8870 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Les microplastiques sont partout dans l’atmosphère et réchauffent le climat (slate.fr)
- Colossal Biosciences is growing chickens in a 3D-printed artificial eggshell (technologyreview.com)
In an early step towards artificial wombs, a biotech company claims it’s developed a “fully artificial” chicken egg.
- Des scientifiques ont identifié une espèce de cuboméduse extrêmement venimeuse et prédatrice au large de Singapour. (slate.fr)
Les chercheureuses estiment qu’elles sont l’animal marin le plus dangereux pour l’être humain. Leurs piqûres, transmises par des cellules spéciales appelées nématocystes et situées sur leurs tentacules, sont assez puissantes pour tuer une personne et ce n’est pas tout : la bestiole serait capable de repérer une proie et de nager vers elle.
- Le plan secret d’Israël pour changer le régime iranien a complètement capoté selon cette enquête du « New York Times » (huffingtonpost.fr)
Selon le quotidien américain, Washington et Tel-Aviv envisageaient le retour au pouvoir de l’ancien président Mahmoud Ahmadinejad.
- Accusation d’« extrémisme », arrestations : en Russie, un mois des fiertés sous la répression d’État (revolutionpermanente.fr)
- Ebola outbreak : WHO declares emergency, US restricts travel, American infected (arstechnica.com)
CDC is working to move the infected American and six others to Germany.
Voir aussi Trump admin didn’t want Ebola-exposed Americans, sent them to Berlin, Prague (arstechnica.com)
An American infected with Ebola is being treated in Berlin, while another exposed to the deadly virus is being sent to Prague after the White House reportedly resisted allowing citizens to return to the US for care and monitoring.
- Une vache en train d’uriner a disparu d’une toile de Rubens volée par les nazis, et ça change tout (slate.fr)
Les héritier·es d’un collectionneur juif réclament un tableau attribué au peintre Rubens. L’expert mandaté pour régler le litige affirme que tout se joue sur un détail : une vache effacée.
- Après les accusations de viol visant Patrick Bruel, le Québec annule trois concerts du chanteur (huffingtonpost.fr)
L’agence chargée des spectacles à Québec invoque un « contexte actuel » incompatible avec la promotion des représentations prévues en décembre prochain.
- Aux États-Unis, soutenir les personnes trans relève désormais du « terrorisme » (problematik-media.com)
- Anna’s Archive Hit With $19.5m Default Judgment and Global Domain Takedown Order (torrentfreak.com)
- Donald Trump a trouvé une nouvelle manière d’augmenter sa fortune (et alimente les critiques sur la corruption) (huffingtonpost.fr)
Des documents attestent que le président américain a acheté des actions d’entreprises ensuite concernées par des décisions de son administration.
Voir aussi The smoking guns in Trump’s new financial disclosure (popular.info)
Trump publicly praised companies the same day he bought their stock.
- Disney hit with class action over facial recognition at California parks (biometricupdate.com)
Lawsuit claims Disney failed to clearly disclose biometric collection or obtain meaningful consent from park visitors
- Derrière les « Enhanced Games », l’obsession transhumaniste des créateurs de ces « JO du dopage » (huffingtonpost.fr)
- ‘Learning Recession’ : Why Student Test Scores Have Seen a Decade-Long Decline Across the U.S. (time.com)
- Palantir’s NHS tech is ten times slower than current system (democracyforsale.substack.com)
NHS leaders privately told that “clunky” £330m platform built by Trump donor Peter Thiel’s firm is “slow” and has “poor user experience”, new documents show
- Elon Musk est débouté de ses poursuites contre OpenAI (next.ink) – voir aussi Elon Musk took too long to sue OpenAI, jury unanimously agrees (arstechnica.com)
- Fisker went bankrupt and owners built open source car company from the ashes (electrek.co)
When Fisker Inc. filed for Chapter 11 bankruptcy in June 2024, it left roughly 11,000 Ocean SUV owners holding the keys to vehicles that cost them anywhere from $40,000 to $70,000 — and that were rapidly losing the software brains that made them work. No more over-the-air updates. No more connected services. No more warranty. The manufacturer was dead. What happened next is one of the most remarkable stories in the history of the electric vehicle industry. Instead of accepting that their cars would become rolling paperweights, Fisker Ocean owners organized, reverse-engineered their vehicles’ proprietary software, hacked into CAN bus networks, built open-source tools on GitHub, and effectively stood up a volunteer-run open-sourced car company from the ashes of Fisker.
- Un immense incendie menace un ancien site nucléaire contaminé en Californie et inquiète les autorités (slate.fr) – voir aussi Rapidly Growing California Wildfire Threatens Contaminated Nuclear Reactor Site (gizmodo.com)
As the Sandy fire burns through Ventura County, firefighters are desperate to keep the blaze away from the defunct Santa Susana Field Laboratory.

- Capitalisme à tout prix : un mouvement de contestation inédit en Bolivie (humanite.fr)
Spécial IA
- Ad Infinitum (matthiasott.com)
At Google I/O this week, the company announced the biggest change to Search in 25 years. The ten blue links ? Gone. Instead, you get — first at times ? soon always ? — “generative UI”, an “intelligent search box” with custom interactive widgets, built on the fly by Gemini. You get “information agents” that monitor the web for you around the clock. You get mini-apps you can build right inside the search box, using natural language. And with Gemini Spark, you get a personal AI agent that runs 24/7, connected to your Gmail, your Drive, your calendar, your photos, and soon your local files and third-party services.
Voir aussi Google Search as you know it is over (techcrunch.com)
- Scam : comment réguler la fraude financière produite par les deepfakes ? (danslesalgorithmes.net)
- You can persuade AI models to accept falsehoods as truth, study shows (theconversation.com)
- arXiv : les chercheureuses qui soumettent des articles genAI erronés seront suspendu·es un an (next.ink)
- Linus Torvalds says AI-powered bug hunters have made Linux security mailing list ‘almost entirely unmanageable’ (theregister.com)
- La réaction de ces étudiant·es au discours sur l’IA de l’ex-patron de Google dit tout du malaise de la Gen Z (huffingtonpost.fr)
Eric Schmidt était présent le 15 mai dernier à Tucson pour la cérémonie de remise des diplômes de la faculté mais les étudiant·es l’ont hué à plusieurs reprises lors de sa prise de parole. […] Un discours centré sur l’intelligence artificielle alors qu’une part croissante des jeunes étatsunien·nes s’inquiètent des répercussions de son utilisation
Voir aussi Google CEO tries to tell University students to love AI. They tell him to BOO off. (bbc.com)
- ’’Employers Want Applicants with AI Skills” : How Hearsay Manufactures Reality (sonjadrimmer.com)
- Casse IA : la banque Standard Chartered prévoit de supprimer des milliers de postes d’ici 2030 (liberation.fr)
La stratégie de « rationalisation » des processus annoncée par l’établissement britannique mardi 19 mai menace près de 8 000 emplois dans les « fonctions supports ».
- Microsoft reports are exposing AI’s real cost problem : Using the tech is more expensive than paying human employees (fortune.com)
Firms today are pushing employees to use as much AI as possible to squeeze out the technology’s productivity gains. But that pressure is leading to cracks, and those cracks may be irreparable.
- Is AI ProfitableYet ? (isaiprofitable.com) NO. Everyone’s Broke.

- Every AI Subscription Is a Ticking Time Bomb for Enterprise (thestateofbrand.com)
Every AI lab is losing money serving your company right now. They know it. And they are doing it on purpose. OpenAI, Anthropic, Google, and the rest are running an industry-wide loss-leader program at a scale that has no precedent. They are selling enterprises filet mignon at gas station hot dog prices and calling it a business model. The gap between what your company pays for AI subscriptions and what it actually costs to serve those seats is not a rounding error. It is a gulf. And every organization that has built workflows, products, or entire business units on top of these subsidized prices is standing right on the edge of it. This should be front of mind for every CTO, CFO, and head of operations reading this. Because when the pricing corrects, and it will, the companies that treated AI as a permanently cheap utility are going to wake up to bills that make their current SaaS spend look quaint.
- AI is killing the cheap smartphone (davidoks.blog)
- A 45,000-person labor strike at Samsung’s memory chip plants could throw a wrench into the AI boom (fortune.com)
Samsung makes about a third of the world’s DRAM—the memory inside virtually every phone, laptop, server, and data center on the planet. Together with its Korean rival SK Hynix, it controls roughly two-thirds of the global DRAM market and an even larger share of high-bandwidth memory (HBM), the specialized chips that AI systems cannot run without. Samsung and SK Hynix are two of only three companies that make HBM at all ; the third being American semiconductor company Micron.
- How America Turned Against AI According to the Poll Data : A (Very Big) Compilation (thealgorithmicbridge.com)
Every poll, pollster, and methodology converges on the same thing
- Data centre gas connections enquiries surge amid electricity grid queues (igem.org.uk)
- More than 100 UK datacentres plan to burn gas to generate electricity (theguardian.com)
Requests for gas connections by operators amount to more than 15 terawatt hours per year, endangering climate targets
- Aux États-Unis, des centaines de collectifs s’opposent aux data centers, et gagnent parfois (basta.media)
Les États-Unis abritent plus de 4000 centres de données, indispensables au développement de l’IA. Mais à travers le pays, des habitants s’opposent à ces projets, qui provoquent des pollutions et risquent de détruire les ressources en eau.
- L’Arcep publie son rapport « Intelligence artificielle générative : quels défis environnementaux ? » (arcep.fr)
Spécial Israël et Palestine
- Les forces israéliennes accusées d’utiliser la violence sexuelle comme outil de répression systématique (slate.fr)
Depuis des mois, d’ancien·nes détenu·es palestinien·nes décrivent des viols, humiliations sexuelles et menaces commis en prison ou lors d’interrogatoires. Des récits appuyés par plusieurs rapports d’ONG et d’organisations internationales.
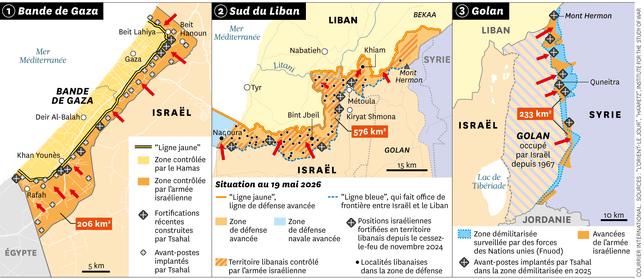
- UN Expert Presents Shocking Allegations of Israeli Torture, Sexual Abuse of Palestinian Detainees (commondreams.org)
“The number and cruelty of allegations compiled portray gross disregard by Israel of its duty to treat all detainees humanely.”
- Un passager de la « flottille pour Gaza » raconte la violence infligée par les forces israéliennes (huffingtonpost.fr)
- Deported flotilla activists allege ‘sadistic’ sexual abuse and torture in Israeli captivity (middleeasteye.net)
Activists report being stripped, ‘water-tortured’ and dragged along the ground with bound hands and feet
- Le ministre israélien de la Sécurité nationale, Itamar Ben Gvir, publie des images de militant·es de la flottille pour Gaza arrêté·es et provoque un tollé (huffingtonpost.fr)
“Même Benjamin Netanyahu s’est désolidarisé.”
- Après le tollé sur la vidéo de « la Flottille pour Gaza », le ministre israélien Ben Gvir interdit d’entrer en France (huffingtonpost.fr)
- EU ‘appalled’ (again) by Israel, this time over Ben-Gvir’s Gaza flotilla humiliation, but continues doing nothing (euobserver.com)
- Municipales : que sait-on de l’ingérence israélienne contre LFI ? (humanite.fr)
- Première victoire pour Ramy Shaath, la justice se prononce contre l’expulsion du militant palestinien (humanite.fr)
Spécial femmes dans le monde
- “Manara Man” : A Self-Appointed Moral Guardian With a Hand Ready to Strike (daraj.media)
It is easy for the “Manara man” to play the hero when the target is a lone, exposed, and vulnerable woman. Suddenly, his sense of “honor” awakens, his moral muscles begin to flex, and he appoints himself protector of society against the danger of a woman standing by the sea. A naked woman ? That is when the moral watchdog instantly comes alive. […] The man who hit the woman was not defending morality, but his own sense of power. What he did was closer to a declaration of ownership : this space belongs to us, and these bodies must submit to our rules. […] In the Manara video, there was not only a man assaulting a woman, but an entire audience participating in the construction of the scene. Some shouted. Others continued filming even during the assault itself. This is not neutrality. Filming here was not separate from the violence ; it was part of it. When a camera is raised in the face of a vulnerable person instead of being used to protect them, it becomes a tool of dehumanization.
- ‘Protect our women’ crowd surprisingly comfortable publicly abusing women who make decisions they don’t like (newsthump.com)
Britain’s self-appointed “protect our women” brigade has confirmed that women absolutely deserve protection and respect, right up until the precise moment they do something mildly inconvenient or make a decision they don’t like.
- Le chanteur marocain Saad Lamjarred condamné à nouveau pour viol (orientxxi.info)
Reconnue à deux reprises coupable de viol et condamnée par la justice française, la star de la pop arabe Saad Lamjarred ne change rien à son agenda et continue de bénéficier du soutien de ses pairs et de l’industrie musicale. Un système qui pourrait se fissurer sous les coups de boutoir de la contestation qui enfle.
- Affaire Jeffrey Epstein : quand un ami et conseiller de Jack Lang tirait la sonnette d’alarme (slate.fr)
Fascination pour l’argent, phénomène de cour, fréquentation du père de Ghislaine Maxwell… Jean-Pierre Colin, ancien proche de l’ex-ministre de la Culture, n’a pas attendu l’affaire Epstein pour dénoncer, dès 1994, les dérives du couple Lang.
- Stéréotypes pour enfants (laviedesidees.fr)
À propos de : Julie Fette, Gender by the Book. 21st-Century French Children’s Literature. Malgré la diversité des textes du corpus et les différences entre les institutions prises en considération, les résultats de l’analyse sont dans l’ensemble assez consternants […] De nombreux stéréotypes persistent, dans la plupart des cas défavorables aux femmes et aux filles
- Au Festival de Cannes 2026, le discours féministe d’Isabelle Huppert pour Barbra Streisand (huffingtonpost.fr)
« Vous avez été à l’avant-garde du combat des femmes et de leur place dans le cinéma, vous avez été une fervente défense des droits des personnes LGTBTQ +, vous avez aussi manifesté une solidarité constante envers les minorités religieuses, ethniques, sexuelles »
Spécial France
- « En 14 ans, la fortune des 500 familles les plus riches de France est passée de 12 % à 42 % du PIB » (lareleveetlapeste.fr)
“Et cette richesse, c’est avant tout un très grand pouvoir. C’est un pouvoir économique d’abord : le pouvoir de racheter des concurrents, d’influencer les marchés. C’est aussi un grand pouvoir politique : un pouvoir d’influencer les politiques publiques.”
- Thales a fourni des radars de surveillance à l’armée birmane en plein massacre des Rohingya (disclose.ngo)
- Capgemini, « chasseur de prime » pour l’ICE (multinationales.org)
- « Ça m’a dégoûté de mon métier » : les PIP, ces plans de performance qui broient les salarié·es du numérique (basta.media)
Importés des États-Unis, les plans de retour à la performance, déclinés sous les acronymes PIP, PRPA ou encore PAP, se multiplient dans les entreprises du numérique. L’outil est détourné de son objectif affiché pour mieux se débarrasser de salarié·es.
- Cartes de France de l’accès aux soins : la numérisation de la santé est-elle vraiment le remède ? (ismee.info)
La plateforme de prise de rendez-vous médicaux en ligne Doctolib et la Fondation Jean-Jaurès ont publié la seconde édition de leurs « Cartes de France de l’accès aux soins ». Cet état des lieux offre une photographie inédite pour saisir l’évolution de l’offre de soin sur notre territoire, mais avec une vision par le prisme de l’outil numérique qui “questionne”.
- “Personne n’est épargné” : le nombre de violations de données a atteint un record en 2025, affirme la Cnil (franceinfo.fr)
- Les député·es votent en commission une “symbolique” abrogation du Code noir (imazpress.com)
mercredi 20 mai 2026, à la veille du 25e anniversaire de la loi Taubira reconnaissant la traite et l’esclavage comme crime contre l’humanité, les députés de la commission des lois ont voté à l’unanimité l’abrogation du “Code noir”, jamais formellement abrogé […] le texte laisse toutefois de côté la sensible question des réparations régulièrement réclamées dans les territoires ultramarins.
- La Guyane va récupérer les ossements d’autochtones détenus par des musées parisiens (reporterre.net)
- Paris-Amsterdam : une nouvelle offre de train low-cost vient concurrencer Eurostar (ici.fr)
- Le Conseil constitutionnel rétablit les ZFE et le zéro artificialisation nette (reporterre.net) – voir aussi Loi de « simplification » : le Conseil constitutionnel censure la suppression des ZFE et l’assouplissement des règles contre l’artificialisation des sols (humanite.fr)
- Pour extraire son sable, Lafarge dévore les méandres de la Seine (reporterre.net)
- Courchevel : une retenue d’eau pour le ski menace de s’effondrer sur un hameau (reporterre.net)
- Une vague de chaleur anormale va toucher la France : « On ne devrait pas s’en réjouir » (reporterre.net)

- Pour la première fois, un département est placé en vigilance jaune canicule au mois de mai (huffingtonpost.fr)
Le Finistère est placé en vigilance jaune canicule à compter de dimanche midi. D’autres départements pourraient le rejoindre.
- Le Festival de Cannes est redevenu « un lieu de résistance » en 2026 avec ces discours engagés (huffingtonpost.fr)
La guerre au Liban, à Gaza, en Ukraine et les dérives autoritaires étaient sur toutes les lèvres à la cérémonie de clôture. De Virginie Efira à Andreï Zviaguintsev, les artistes ont appelé à résister.
Voir aussi Canal+, Trump, Poutine… Almodóvar promeut un « devoir moral » pour les artistes (huffingtonpost.fr)
« Personnellement je ne veux juger personne, mais il me semble que l’artiste doit parler du monde dans lequel il vit, de la société dans laquelle il vit. Pour moi c’est un devoir moral. Je ne juge pas ceux qui ne le font pas mais le silence n’est que la traduction de la peur »
- La BD de François Ruffin n’en finit plus de lui poser des problèmes (huffingtonpost.fr)
Le député continue d’être critiqué pour sa BD « Picardie Splendor » jugée maladroite, paternaliste voire raciste. L’un des protagonistes du livre vient en plus contredire sa version.

Voir aussi Syndrome du sauveur blanc, naufrage de la gauche et malaise raciste (komunemedia.substack.com)La bande dessinée du député François Ruffin révèlent le malaise d’une gauche qui peine à assumer ses contradictions sur le racisme.
- À Paris, trois animateurs du périscolaire déférés devant un juge pour des « gestes à caractère sexuel » sur une vingtaine d’enfants (huffingtonpost.fr)
L’enquête ouverte après des signalements dans plusieurs écoles parisiennes a conduit à la garde à vue de 16 personnes et à l’audition de dizaines d’enfants.
- Cannes 2026 : la Palme d’or à “Fjord”, et tout le palmarès du festival (telerama.fr)
Spécial femmes en France
- Festival de Cannes : la parité n’a pas monté les marches (lesnouvellesnews.fr)
Le Festival de Cannes s’achève. Cette 79e édition n’aura pas brillé pour son attention portée à la parité.
- Mort d’Aldo Naouri : mémoire sélective et fabrique du sexisme (lesnouvellesnews.fr)
« Violez-la » conseillait le pédiatre Aldo Naouri à un homme se plaignant de la baisse des relations sexuelles après la naissance de son bébé. Sans grande indignation dans les médias qui formataient des esprits sexistes et rendent hommage aujourd’hui à celui qui vient de s’éteindre.
- Avec cette vaste étude, NousToutes fait le portrait du féminisme en France (huffingtonpost.fr) – voir aussi Le collectif #NousToutes publie #Féminiscope (noustoutes.org), une enquête inédite qui passe au microscope la perception du féminisme et de l’engagement militant en France
- Zéro Cliché 2026 : les élèves sabordent les stéréotypes sexistes (lesnouvellesnews.fr)
Depuis sa création il y a 14 ans, le concours Zéro Cliché, organisé par le CLEMI, pousse les élèves, de la primaire au lycée, à voir au-delà des stéréotypes sexistes. Cette année encore, le palmarès ouvre une fenêtre sur les questionnements et les prises de conscience des filles et des garçons.
- Propagande masculiniste : comment les violences deviennent légitimes (blogs.mediapart.fr)
- Visé par des accusations de violences sexuelles, Gérard Darmon est choisi pour présider le festival de cinéma de La Ciotat (politis.fr) – voir aussi Accusé de violences sexistes et sexuelles, Gérard Darmon ne présidera pas le jury de ce festival de cinéma (huffingtonpost.fr)
L’acteur a annoncé renoncer à la présidence du Festival du 1er film de La Ciotat.
- « On le sait depuis des années » : pour Lio, Patrick Bruel doit « se faire soigner » (huffingtonpost.fr)
« On le sait depuis des années… Qu’il aille se faire soigner ! Il faut lui apprendre à rentrer son sexe, je suis désolée, il a un problème », a-t-elle déclaré à propos du chanteur, désormais visé par quatre enquêtes pour viols en France et une enquête en Belgique pour agression sexuelle. Et pour Lio, pas question de « faire la différence entre l’homme et l’artiste ».
- Flavie Flament étrille la défense de Patrick Bruel en dénonçant une « diffamation épouvantable » (huffingtonpost.fr)
L’animatrice, qui accuse le chanteur de viol et a porté plainte contre lui, dénonce au micro de RTL les « mensonges » dont font l’objet les victimes en vue de les « faire taire ».
- Interrogée sur Bruel, Jaoui dénonce la remise en question de la parole des femmes qui parlent « trente ans après » (huffingtonpost.fr)
Au Festival de Cannes, la cinéaste estime que les traumatismes liés aux violences sexuelles peuvent mettre des décennies avant d’être compris et exprimés.
- Concerts de Jean-Luc Lahaye dans des villes RN : NousToutes dénonce « le mépris constant » de l’extrême droite pour « la parole des victimes » (humanite.fr) – voir aussi La mairie RN d’Hénin-Beaumont programme le pédocriminel Jean-Luc Lahaye (streetpress.com)
Entre 2021 et 2024, celui qui se surnomme le « chanteur à midinettes » a même écopé d’une interdiction d’« apparitions ou de représentations publiques dans le cadre de son activité d’artiste », et toute activité « impliquant un contact avec des mineurs ». Une procédure qui relève de sa mise en examen en 2021 pour des faits de viol et agressions sexuelles de deux adolescentes de 16 et 17 ans
- « Il me traitait comme un objet » : Laëtitia R. au tribunal face à son ex-compagnon jugé pour lui avoir infligé 7 ans de viols et tortures (humanite.fr) – voir aussi Au procès de son ex-compagnon, Laetitia R. raconte l’innommable et « l’envie de crever » (huffingtonpost.fr)
Au dernier du procès de Guillaume B. pour pour viols aggravés, actes de torture et de barbarie et proxénétisme, Laetitia a décrit sept années de sévices.
- L’ex-compagnon de Laëtitia R. condamné à 25 ans de réclusion pour viols aggravés et tortures (huffingtonpost.fr)
Dans le box, l’ex directeur de banque aux cheveux grisonnants et à la fine moustache a assuré que son procès a été « un accélérateur de prise de conscience ». L’avocat de Laëtitia R., reconnue handicapée entre 50 et 80 %, avait dit que sa cliente avait souhaité des débats publics, inspirée par le courage de Gisèle Pélicot
- « Vous êtes responsables des morts qu’on aurait pu éviter » : Marie-Charlotte Garin hausse le ton (lesnouvellesnews.fr)
Lors des questions au gouvernement le 19 mai, la députée écologiste Marie-Charlotte Garin a mis en cause l’exécutif après six féminicides en neuf jours et dix ans de grande cause du quinquennat. L’examen de la proposition de loi cadre contre les violences n’est toujours pas à l’ordre du jour.
Spécial médias et pouvoir
- Monopole mortifère de Bernard Arnault sur la presse économique (acrimed.org)
Le phénomène de concentration capitalistique des médias vire au monopole dans certains secteurs de l’information. Concernant le journalisme économique, un constat suffit à mesurer l’ampleur du désastre : la quasi-totalité de la presse économique est aujourd’hui détenue par le milliardaire Bernard Arnault et son groupe LVMH.
- Matthieu Pigasse : un « Bolloré de gauche » ? (acrimed.org)
- Défaite judiciaire pour un journaliste indé face à la « clause de silence » de Canal+ (portail.basta.media)
La cour d’appel de Versailles a « entériné l’omerta Bolloré » dénonce Jean-Baptiste Rivoire. Ce 20 mai, l’ex-journaliste de Canal+ a de nouveau été reconnu coupable d’avoir rompu sa « clause de silence », lui interdisant de critiquer son ancien employeur jusqu’à la fin de sa vie.
- « Non aux clauses de silence de Bolloré : la liberté d’informer doit prévaloir » : des médias et journalistes soutiennent Jean-Baptiste Rivoire (humanite.fr)
- “Zapper Bolloré” : des stars de Hollywood rejoignent la pétition contre le milliardaire (fr.euronews.com)
Javier Bardem, Ken Loach, Mark Ruffalo, Aki Kaurismaki et Yorgos Lanthimos ont rejoint les signataires de la tribune s’inquiétant de la mainmise de Vincent Bolloré sur le cinéma. Presque 3 500 professionnel·les du septième art ont désormais signé cette tribune.
Voir aussi Après les menaces de Canal+, plus de 600 nouveaux noms rejoignent la tribune anti-Bolloré (huffingtonpost.fr)
L’effet produit est pour l’instant l’inverse de celui espéré. Après les propos de Maxime Saada en marge du 79e Festival de Cannes appelant Canal+ à « ne plus travailler » avec les signataires d’une tribune critique envers Vincent Bolloré, le collectif Zapper Bolloré affirme avoir enregistré une vague massive de nouveaux soutiens.
- À Cannes, Mathieu Kassovitz prend la défense de Canal+ et affirme que la chaîne « fait très bien son boulot » (huffingtonpost.fr)
- Canal+ assigné en justice pour discrimination envers les signataires de la tribune anti-Bolloré, avec qui le groupe affirme ne plus vouloir travailler (franceinfo.fr) – voir aussi Aucune discrimination n’a sa place dans le cinéma, Canal+ comparaitra devant la justice pour avoir violé la loi (ldh-france.org)
- Des policier·es appellent leurs collègues à désobéir aux ordres qui bâillonnent la presse (blast-info.fr)
Une association de policier·es monte au créneau pour défendre la liberté de la presse. Police Républicaine et citoyenneté (PRC), fondée il y a un an par Jean-Louis Arajol, ancien secrétaire général du Syndicat général de la police à l’aube des années 2000, dénonce ouvertement les violences et les obstacles que subissent les journalistes lorsqu’iels couvrent des manifestations.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Sébastien Lecornu salue ce vote « décisif » de l’Assemblée sur le corps électoral en Nouvelle-Calédonie (huffingtonpost.fr)
La question de l’ouverture de ce corps électoral avait été l’étincelle des émeutes qui ont ravagé le Caillou il y a deux ans, faisant 14 morts et deux milliards d’euros de dégâts.
Voir aussi Le Parlement a définitivement approuvé ce mercredi 20 mai un élargissement dans l’urgence du corps électoral pour les élections provinciales en Nouvelle-Calédonie, par un dernier vote de l’Assemblée nationale, à moins de six semaines du scrutin crucial pour l’archipel. (huffingtonpost.fr)
Le camp gouvernemental, l’alliance RN-UDR et le PS ont largement voté pour. Les insoumis, écologistes et communistes s’y sont opposé·es.
- Le RN a voté contre la taxe permettant de financer la recherche contre les cancers pédiatriques (lareleveetlapeste.fr)
Fort heureusement, n’ayant pas la majorité au Parlement, le vote du RN n’a pas empêché le texte d’être adopté en première lecture.
- Le gouvernement lance une réforme de l’Ademe « gravissime » alors que droite et extrême droite veulent sa peau au Parlement (vert.eco)
- Crise des carburants : Lecornu déploie un plan de soutien très ciblé jusqu’à l’automne (projetarcadie.com)
- Vélo + TER : pourquoi le retour du dimanche soir devient compliqué (enlargeyourparis.fr)
Réservation obligatoire, trains bondés, refus à quai : vos week-ends vélo depuis Paris vers la Normandie, la Loire, la Picardie ou la Champagne deviennent plus compliqués à organiser. Derrière les difficultés signalées par nos lecteurs, un décret de février 2026 a fait sauter le dernier garde-fou national.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Projet de loi SURE : main basse sur les données génétiques par la police (laquadrature.net)
Avec le projet de loi « SURE » adopté le 15 avril au Sénat, vos données génétiques, et les millions d’autres récupérées et stockées par les entreprises privées réalisant les tests ADN, majoritairement situées aux États-Unis, pourront être exploitées par la police française à votre insu.
- Projet de loi de programmation militaire : la séparation des pouvoirs et les libertés publiques menacées (humanite.fr)
La Ligue des droits de l’Homme, Alternatiba, ANV Cop-21, France nature environnement, Greenpeace, le Syndicat des avocats de France, le Syndicat de la Magistrature, la CGT, la Fédération Syndicale Unitaire et Solidaires dénoncent la création d’un « état d’alerte à la sécurité nationale » dans le cadre du Projet de loi de programmation militaire.
- Derrière la vérification d’âge sur les réseaux sociaux, la généralisation du contrôle d’identité en ligne (laquadrature.net)
- Pendant que le Conseil d’État demande à l’État de garantir un accès normal à la plateforme numérique pour les étrangers, on continue de les traquer à Mayotte (parallelesud.com)
- Expulsion locative de deux familles liées au narcotrafic : la justice déboute le bailleur social qui avait lancé la procédure, le préfet pourrait faire appel (france3-regions.franceinfo.fr)
- Au CRA du Mesnil-Amelot : « Même en prison on est mieux traités » (bondyblog.fr)
- L’extrême droite converge autour de la « remigration » (lempaille.fr)
Déporter des millions de personnes non blanches de l’Europe vers leurs pays d’origine supposés : dans les milieux d’extrême droite, cette idée néo-nazie a le vent en poupe et contamine une partie de la sphère médiatique et politique, en France comme ailleurs.
Spécial résistances
- « Hors norme » : le gigantesque projet Campus IA relance la lutte contre les data centers (basta.media)
Annoncé comme le plus gros centre de données d’Europe, le Campus IA, voulu par l’Élysée, doit être construit dans un village de Seine-et-Marne. Installé sur des terres agricoles, il suscite la contestation d’associations écologistes.
- « L’État a failli » : des associations et riverains attaquent la France pour son « inaction » contre la pollution aux PFAS (vert.eco)
- « Le béton est le matériau le plus utilisé dans le monde mais personne ne sait d’où vient son parpaing » (reporterre.net)
Autrice de « Désarmer le béton », l’architecte Léa Hobson aimerait voir advenir une « voix collective » pour s’opposer à ce matériau néfaste, symbole du capitalisme extractif contemporain. D’autant que des alternatives existent.
- « C’est une très belle victoire » : 9 coiffeuses exploitées du boulevard de Strasbourg ont été régularisées (humanite.fr)
La préfecture de Paris a régularisé ce 19 mai neuf des travailleuses du boulevard Saint-Denis en lutte, depuis début mars, contre leur direction. Une victoire, alors que le gérant du salon de coiffure usait de leur vulnérabilité pour les racketter.
Spécial outils de résistance
- Comment résister à l’IA ? Trois boîtes à outils pour agir concrètement (synthmedia.fr)
- Ban Ray (banray.eu)
In 2025, Meta sold over seven million pairs of camera-equipped glasses that look like regular Ray-Bans. The person wearing them looks like anyone else. But these people are now products, as is everyone they interact with.
Spécial MAGAM et cie
- Microsoft Took a Step Toward Human Rights Accountability. Google and Amazon (and Others) Should Pay Attention ! (eff.org)
- The EU Is Going Through a Trump-Fueled Breakup With Big Tech (wired.com)
France is already moving on from Zoom and Microsoft Teams in favor of homegrown alternatives. Other countries are quickly following suit.
- “Le logiciel libre, chez nous, c’est stratégique” : comment le fisc français a banni Microsoft pour protéger vos impôts (lesnumeriques.com)
- GitHub says hackers stole data from thousands of internal repositories (techcrunch.com)
GitHub, the popular developer platform owned by Microsoft, confirmed it was hacked and attackers had stolen data from around 3,800 internal code repositories.
Voir aussi A hacker group is poisoning open source code at an unprecedented scale (arstechnica.com)
GitHub is just the latest victim of TeamPCP, a gang that has carried out a spree of software supply chain attacks.
Les autres lectures de la semaine
- Magnets Are Bad For Hardware Again (hackaday.com)
- Au-delà de la technique : pour une critique sociale de l’IA (gresea.be)
- The Four Horsemen of the LLM Apocalypse (anarc.at)
- From War to Inflation, How Crises Erase People with Disabilities (en.radiozamaneh.com)
- Une fenêtre historique (blog.mondediplo.net)
La survenue d’une crise financière du format de celle qui s’annonce n’appelle pas des actes de gestion mais de faire de la politique. La finance néolibérale est une structure tellement puissante, tellement asservissante que lorsqu’elle nous fait la grâce de s’abattre toute seule, on ne la loupe pas. On fait de la politique – transformatrice. Cette crise, dont tous les éléments sont en place, n’est pas encore ouverte. Ça viendra.
- La santé malade des fake news (lenouveauparadigme.fr)
La désinformation médicale est devenu un tel danger que le gouvernement vient de lancer une vaste campagne pour la limiter. Derrière les fausses informations qui circulent sur les réseaux sociaux, c’est une crise plus profonde qui apparaît : celle de la confiance envers les institutions sanitaires, du recul du service public et de la fragmentation du rapport au savoir.
- Pourquoi tant de journalistes jettent l’éponge (frustrationmagazine.fr)
- Inventer le monde pour mieux le représenter (blogs.mediapart.fr)
La carte n’a jamais été un outil neutre. L’exposition « Cartes imaginaires. Inventer des mondes » à la BnF le sait et l’assume, rassemblant quelque 200 œuvres du parchemin médiéval au jeu vidéo. Riche de pièces exceptionnelles et solidement adossée à une réflexion savante, elle bute néanmoins sur un tabou : la violence que les cartes ont toujours aussi portée.
- Comprendre les violences xénophobes en Afrique du Sud (theconversation.com)
- Le cinéma a un problème avec le v*** (frustrationmagazine.fr)
- Qui a peur de la grande méchante butch ? (problematik-media.co)
Derrière la peur persistante envers les lesbiennes masculines, se raconte une longue histoire de contrôle du désir lesbien.
- Dans le Kama‑sutra, le consentement est un principe fondamental (theconversation.com)
Richard Francis Burtoni a traduit le texte en anglais en 1883. Cette « traduction » n’était toutefois pas fidèle, mais plutôt une interprétation élaborée à travers un prisme résolument étroit et centré sur le plaisir masculin.
Les BDs/graphiques/photos de la semaine
Les vidéos/podcasts de la semaine
- Kanaky-Nouvelle-Calédonie : le Parlement adopte en urgence le dégel du corps électoral (humanite.fr)
- Tir raciste sur des enfants (radiofrance.fr)
Dans le petit quartier de l’Arbousset à Espaly-Saint-Marcel en Haute-Loire, un homme a tiré à la carabine sur des enfants tout en proférant des insultes racistes. Quelques jours après, les habitant·es sont encore sous le choc…
- Au Festival de Cannes, cette non-réponse de Gilles Lellouche a fait de lui « Gilles Lelâche » sur les réseaux sociaux (huffingtonpost.fr) – la vidéo associée sur PeerTube (tube.fdn.fr)

- L’histoire oubliée du festival de Cannes (fdgpierrebe.over-blog.com)
- Barbara Stiegler – Le vrai but du système : nous discipliner (praxismedia.fr)
- Christiane Taubira : “Heureusement que je suis tombée sur l’histoire du marronage, sinon j’aurais été une boule de haine” (la1ere.franceinfo.fr)
Les trucs chouettes de la semaine
- Inachetable et éternellement souverain : pourquoi Infomaniak cède son contrôle à une fondation actionnaire (goodtech.info)
Si la souveraineté numérique européenne ressemble de plus en plus à un vœu pieux face à l’hégémonie des hyperscalers américains, un séisme de gouvernance vient de se produire… en Suisse. Boris Siegenthaler, le fondateur historique d’Infomaniak, a annoncé le transfert irrévocable de la majorité des droits de vote de l’entreprise à une entité d’un genre nouveau : la Fondation Infomaniak.
- The Free Software Foundation (FSF) reports (fsf.org)
that its global call for free software supporters to organize LibreLocals this May resulted in free software supporters organizing forty-six LibreLocal events on six continents thus far. New dates and locations are being added daily.
- Réédition du livre « Cantines » (stoo.noblogs.org)
- « Ce qu’on veut, c’est aider » : des habitant·es achètent des terres qu’ils louent à des paysans bio (reporterre.net)
À la différence de l’association Terre de liens, plus connue, le projet Kazel-ha-Kazel [une foncière citoyenne et territoriale, dont le nom breton se traduit par « bras dessus, bras dessous » en français] s’ancre dans le pays de Douarnenez, avec une gouvernance et des coopérateurices locales.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
18.05.2026 à 07:42
Khrys’presso du lundi 18 mai 2026
Khrys
Texte intégral (8996 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Japan wants to build an 11,000-kilometer solar ring around the Moon and beam clean energy back to Earth (ecoticias.com) – voir aussi Pour produire une électricité disponible jour et nuit, une compagnie japonaise propose de ceinturer la Lune de panneaux solaires capables d’envoyer de l’énergie vers la Terre par micro-ondes ou lasers (slate.fr)
- “Il y a urgence à raconter ce qu’il se passe à Hong Kong” : malgré les risques, des habitants témoignent de la dérive autoritaire chinoise (telerama.fr)
Avec sa loi sur la sécurité nationale, Pékin muselle toute forme d’opposition sur l’ancienne colonie britannique.
- Supply Chains, AI, Hormuz, Taiwan : What’s at Stake as Trump Meets Xi in Beijing ? (thewire.in)
- Taiwan’s chips power the global economy. China holds the leverage (restofworld.org)
- Nouveau record de permis délivrés par le Népal : comment l’Everest est toujours plus victime du tourisme des riches (humanite.fr)
- L’Iran menace les câbles sous‑marins, ces artères invisibles d’internet (theconversation.com)
En début de semaine, des médias iraniens liés à l’État ont évoqué un projet visant à faire payer aux opérateurs de câbles internet sous-marins un droit de passage dans le détroit d’Ormuz, au nom de ce que les autorités présentent comme les eaux offshore relevant de l’Iran.
- La guerre en Iran, un multiplicateur des menaces qui pèsent sur l’économie mondiale (revolutionpermanente.fr)
- Soudan : des victimes des massacres demandent une enquête sur le rôle des Émirats arabes unis (humanite.fr)
Sept victimes s’adressent à la Haute représentante de l’Union européenne pour les Affaires étrangères, Kaja Kallas. Elles demandent l’imposition immédiate de sanctions ciblées.
- Au Soudan du Sud, des milliers d’apatrides (afriquexxi.info)
Il y a bientôt quinze ans, le Soudan du Sud proclamait son indépendance. Depuis, l’administration tarde à régulariser ses ressortissant·es : selon le HCR, 90 % des Sud-Soudanais·es ne seraient pas encore enregistré·es sur les bases de données officielles. Des millions d’entre elleux pourraient se retrouver sans nationalité reconnue si rien n’était fait.
- Un variant d’Ebola hautement létal et sans traitement frappe la République démocratique du Congo (huffingtonpost.fr)
Selon les autorités le taux de létalité pourrait aller jusqu’à 50 % avec cette souche baptisée Bundibugyo. Plus de 80 décès ont déjà été recensés.
- De prétendus « passeurs », de parfaits boucs émissaires (ritimo.org)
À l’échelle de l’Union européenne, les procès intentés contre des personnes migrantes taxées d’être des « passeurs » ne cessent de se multiplier. Cette politique de criminalisation permet aux États de reporter la responsabilité de leurs politiques migratoires mortifères sur des passagers d’embarcations de fortune qui tentent de gagner les rivages européens.
- Guerre en Ukraine : près de 400 pompiers luttent contre un incendie qui a déjà ravagé 1 200 hectares dans la zone d’exclusion de Tchernobyl, après un crash de drones russes (lindependant.fr)
- La création d’un Tribunal spécial pour l’Ukraine approuvée par 36 pays et l’UE (france24.com) – voir aussi « Le moment où la Russie devra rendre des comptes approche » : l’UE et 36 pays approuvent la création d’un tribunal spécial pour juger l’invasion russe en Ukraine (humanite.fr)
- Just before the election, the Orbán regime distributed a fortune among its foreign cheerleaders (english.atlatszo.hu)

- L’UE n’interdira finalement pas les thérapies de conversion pour les LGBT+ (infos.rtl.lu)
La Commission européenne a estimé mercredi qu’elle n’avait pas les moyens d’interdire les thérapies de conversion des personnes LGBT+, mais qu’elle pousserait, à défaut, les États européens à le faire. […] Les thérapies de conversion assimilent l’homosexualité à une maladie, et prétendent à tort pouvoir modifier l’orientation sexuelle ou l’identité de genre d’une personne. Elles peuvent prendre la forme de stages, de séances d’exorcisme, ou encore d’électrochocs.
- Aide à mourir en Europe : autorisée en Espagne, en suspens au Royaume-Uni, zone grise en Allemagne (basta.media)
Les pays européens sont divisés sur l’aide à mourir. Si elle est autorisée en Espagne ou en Belgique, une loi sur le sujet a été rejetée en Écosse, une autre est en suspens au Royaume-Uni, quand l’incertitude juridique règne en Allemagne.
- En voulant interdire les réseaux sociaux aux mineurs, l’Europe protège surtout les plateformes (synthmedia.fr)
- Semences, pesticides… Le groupe Bayer-Monsanto encaisse des profits faramineux (reporterre.net)
Tout baigne pour l’agroindustrie. Le 12 mai, le groupe Bayer a annoncé un bénéfice net de 2,8 milliards d’euros au premier trimestre 2026, soit plus du double sur un an. Une hausse dopée par l’activité agrochimique du géant allemand.
- Les « médicanes », ces cyclones méditerranéens que le changement climatique va aggraver (theconversation.com)
la côte méditerranéenne est l’une des régions les plus densément peuplées et les plus vulnérables au monde (la population totale des pays méditerranéens en 2020 était d’environ 540 millions de personnes, dont environ un tiers vivait dans des zones côtières
- JP Morgan could scrap £3bn London HQ if Starmer is replaced by PM ‘hostile to banks’ (theguardian.com)
The boss of JP Morgan, Jamie Dimon, has warned he could scrap plans to build a new £3bn UK headquarters in London if Keir Starmer is replaced by a new Labour prime minister who is hostile to banks.
- ‘Millions’ of pounds saved by replacing Palantir tech in refugee system (bbc.co.uk)
- Signal warns it would pull out of Canada if made to comply with lawful access bill (theglobeandmail.com)
- FCC angers small carriers by helping AT&T and Starlink buy EchoStar spectrum (arstechnica.com)
The Federal Communications Commission yesterday approved EchoStar’s sales of spectrum licenses to AT&T and Starlink operator SpaceX. The deals are worth $40 billion in total.The orders, issued by the agency’s Wireless Telecommunications Bureau and Space Bureau, aren’t surprising given that FCC Chairman Brendan Carr essentially forced EchoStar to sell the licenses.
- Trump administration now classifies Antifa and left-wing networks among ‘major’ terror groups (edition.cnn.com)
“In addition to cartels and Islamist terror groups,” the plan says, “our national (counter terrorism) activities will also prioritize the rapid identification and neutralization of violent secular political groups whose ideology is anti-American, radically pro-transgender, and anarchist.”
- ICE smart glasses plan adds to lawmaker concerns over Palantir, mobile biometric enforcement (biometricupdate.com)
The Department of Homeland Security’s (DHS) push to develop biometric smart glasses for immigration agents is intensifying concerns in Congress over the expanding use of mobile facial recognition, Palantir-developed systems, and other surveillance tools in Immigration and Customs Enforcement (ICE) operations.

- Physicists Discover Previously Unknown Crystal Forged During Manhattan Project’s Trinity Test (gizmodo.com)
An unusual crystal created by America’s first nuclear bomb test could help scientists understand a structure needed for quantum computers, solar power, and batteries.
- Une capitale bloquée et des milliers de mineurs dans la rue : en Bolivie, la pression sur le président Rodrigo Paz s’accentue (humanite.fr)
Depuis son arrivée au pouvoir le 8 novembre, le dirigeant bolivien de droite traverse une contestation sans précédent. Enseignant·es, ouvrier·es, paysan·nes, routier·es, mineur·es ont déclenché de fortes mobilisations et le blocage de La Paz, capitale administrative du pays.
- La fin d’un symbole : la maison d’édition de Mafalda ferme ses portes (actualitte.com)
Ediciones de la Flor, maison indépendante associée à Mafalda, Quino, Fontanarrosa et Rodolfo Walsh, cessera son activité en 2026. La perte de droits majeurs, la concentration du secteur et la contraction du marché argentin achèvent une trajectoire commencée en 1966. À Buenos Aires, la décision dépasse la fermeture d’une entreprise : c’est toute la fragilité économique des catalogues patrimoniaux indépendants face aux grands groupes qui se manifeste.
Spécial c’est reparti pour un tour ?
- Hantavirus : un risque aggravé par le rassurisme sanitaire, l’austérité et les tensions internationales (revolutionpermanente.fr)
- Transmission du hantavirus : les autorités feraient mieux d’avouer leur ignorance (slate.fr)
- Hantavirus : des erreurs de procédure en traitant un patient infecté, un hôpital des Pays-Bas place en quarantaine son personnel (leparisien.fr)
Douze membres du personnel d’un hôpital néerlandais, qui traitaient un patient positif à l’hantavirus évacué du navire de croisière MV Hondius, ont été placés en quarantaine. L’établissement a expliqué que des procédures n’avaient pas été correctement suivies.
- Sur le hantavirus, la réaction tardive des États-Unis face à la crise sanitaire inquiète à plus d’un titre (huffingtonpost.fr)
Si l’OMS recommande 42 jours de quarantaine pour les passagers et l’équipage, la décision sur le type de protocole sanitaire à mettre en place revient aux pays concernés. Et l’un d’entre eux a décidé de ne pas appliquer les consignes de sécurité maximales : les États-Unis.
Spécial IA
- Un groupe d’expert·es pour éclairer la gouvernance de l’IA par la science (theconversation.com)
Le 3 février 2026, 40 expertes et experts ont été nommé·es parmi 2600 candidatures. Sélectionné·es pour un mandat de trois ans par la communauté internationale, iels constituent le premier « Groupe scientifique international indépendant de l’intelligence artificielle ». Ce groupe […] est chargé de rédiger un rapport annuel fondé sur des données fiables synthétisant les recherches existantes sur les « promesses, risques et répercussions » de l’IA, sans toutefois devoir se prononcer sur les enjeux, pourtant de taille en gouvernance mondiale de l’IA, liés au militaire.
- Internet of Shit : AI Poop Analysis App Offered to Sell Me Database of Its Users’ Poops (404media.co)
The post, made by a user called Ill_Car_7351, was advertising exactly what it sounds like : A database of poop images, collected from an AI poop analyzing app that he had launched several years ago.25,000 people had been taking images of their poop and uploading them to his app. He’d been collecting, analyzing, and annotating these images and now wanted to sell access to them
- AI systems used by Ontario doctors hallucinate, auditor general finds (globalnews.ca)
An emerging artificial intelligence tool used by family doctors to take notes during an examination is at risk of providing physicians with inaccurate information and hallucinations, Ontario’s auditor general has found, raising questions about the ongoing use of the software in the health-care system.
- Scientists invented a fake disease. AI told people it was real (nature.com)
- « Un interlocuteur facile d’accès » : un tiers des 11-25 ans considèrent l’IA comme un « psy », selon une étude. (leparisien.fr)
- OpenAI launches ChatGPT for personal finance, will let you connect bank accounts (techcrunch.com)
According to OpenAI, more than 200 million users already ask financial questions to ChatGPT every month.
- Software Developers Say AI Is Rotting Their Brains (slashdot.org)
Developers talk not just about how the AI output is often flawed, but that using AI to get the job done is often a more time consuming, harder, and more frustrating experience because they have to go through the output and fix its mistakes. More concerning, developers who use AI at work report that they feel like they are de-skilling themselves and losing their ability to do their jobs as well as they used to.

- Heavy Community Backlash Blocks Fedora’s AI Developer Desktop Initiative (itsfoss.com)
Two council members have retracted their approval votes after people raised concerns.
- Debian 13.5 reminds Linux users why « boring » distributions still win (nerds.xyz)
While many Linux discussions online revolve around aesthetics, distro tribalism, or AI hype, Debian continues focusing on stability and predictability instead.
- Subnautica 2 publisher’s CEO used ChatGPT in failed bid to avoid paying US$250m bonus to own studio head, court hears (theguardian.com)
A South Korean gaming publisher who hatched a plan using ChatGPT to remove the heads of one of its own game studios in a bid to avoid paying US$250m has been ordered by a US court to reverse the removal.
- Dozens of empty Waymos invade quiet cul-de-sac in Atlanta leaving neighbors baffled (independent.co.uk)
Residents of northwest Atlanta’s Buckhead neighborhood say that empty Waymo driverless taxis have been circling in droves in recent weeks, creating traffic and alarming bystanders.
- Police use of AI ‘outrageous and unforgivable privacy invasion’ – say the police (biometricupdate.com)
Damning comments from the Police Federation of England and Wales followed the revelation that the Metropolitan Police Service has been using covert AI-powered technology to monitor its officers’ movements, communications and data access.
- ‘Jobs are evaporating’ : Ex-Google CEO Eric Schmidt heavily booed for AI speech at US university (financialexpress.com)
For the second time in a week, a newly graduating class of US university students has gone viral for publicly taking a firm stance against artificial intelligence and top tech executives arguing in favour of AI takeover despite mass layoffs consuming the job market on multiple levels.
- ‘Irresponsible’ : backlash as Utah approves datacenter twice the size of Manhattan (theguardian.com)
Facility would require more power than entire state uses and suck up vast amount of water in drought-stricken area
- Data centers are cutting power to homes, driving homeowners to solar and batteries (electrek.co)
- “Americans would rather have a nuclear plant in their backyard than a datacenter” (theregister.com)
The majority of Americans are now opposed to datacenters being built in their area, many strongly opposed, pointing to tough times ahead for site developers.
- Microsoft’s massive Kenya AI data center would require switching off ‘half the country’ to meet power requirements, government says (tomshardware.com)
Spécial Israël
- US federal judge blocks US sanctions against UN’s Francesca Albanese (middleeasteye.net)
Special rapporteur on Palestine was sanctioned after calling for war crimes prosecutions against Israeli and US nationals […] A federal judge on Wednesday temporarily blocked US sanctions against United Nations Special Rapporteur on Palestine Francesca Albanese, saying that Donald Trump’s administration likely violated her free-speech rights.
Voir aussi Génocide à Gaza : la justice américaine suspend les sanctions imposées à la rapporteuse spéciale de l’ONU Francesca Albanese (humanite.fr)
- « Il n’y a pas de cessez-le-feu à Gaza » (orientxxi.info)
même si la majeure partie des médias occidentaux ne couvrent plus ce qui se passe à Gaza, le génocide continue.
- Jérusalem-Est. À Silwan, des milliers de Palestinien·nes menacé·es d’expulsion (orientxxi.info)
Dans le secteur de Batn Al-Hawa et Al-Bustan, des centaines de familles sont concernées par des décisions de justice qui ouvrent la voie à leur éviction au profit d’organisations de colons israéliens. Au sud-est de la Vieille ville de Jérusalem, sur les pentes de Silwan, la pression foncière et juridique s’intensifie, transformant progressivement la composition du quartier.
- Israël étrille le « New York Times » qui a enquêté sur les violences sexuelles contre des détenu·es palestinien·nes (huffingtonpost.fr)
Le journal américain révèle que ces violences sont « généralisées », le ministère israélien des Affaires étrangères dénonce une « campagne mensongère et soigneusement orchestrée ».
- EU to blacklist West Bank settlers, amid Israel’s wider ‘war of terror’ (euobserver.com)
“We have moved on from the political deadlock that was there for a long time. Violence and extremism carry consequences,” said EU foreign affairs chief Kaja Kallas on Monday (11 May) after meeting foreign ministers in Brussels.The “deadlock” had been Hungary’s veto, which was dropped by the new government of prime minister Péter Magyar.
- Europe : Failure to suspend Israel from Eurovision betrays humanity and exposes blatant double standards (amnesty.org)
The failure of the European Broadcasting Union (EBU) to suspend Israel from Eurovision, as it did with Russia, is an act of cowardice and an illustration of blatant double standards when it comes to Israel.
- Spain, Ireland and Slovenia will not broadcast 70th anniversary Eurovision (lemonde.fr)
The three countries, along with the Netherlands and Iceland, are boycotting this year’s Eurovision Song Contest due to Israel’s participation
- La campagne d’ingérence visant des candidat·es LFI aux municipales a bien été opérée depuis Israël (huffingtonpost.fr)
Les services de renseignement français ont mis en lumière le rôle d’une entité nommée « BlackCore » et liée à des intérêts israéliens.
Voir aussi Ingérence lors des municipales contre des candidats LFI : de BlackCore à Tel-Aviv, ce que les enquêtes de Libération et Haaretz révèlent (france3-regions.franceinfo.fr)
- Un drapeau palestinien déployé sur la tour Eiffel à Paris, six interpellations (lorientlejour.com)
Cette action, revendiquée par le mouvement écologiste Extinction Rebellion, visait à commémorer la Nakba, « catastrophe » en arabe, période au cours de laquelle environ 760.000 Arabes de Palestine ont fui ou ont été chassés de chez eux lors de la création de l’Etat d’Israël en 1948.

Spécial femmes dans le monde
- Une femme cheffe de l’ONU ? Un enjeu de “justice historique” et de “mérite”, pour la candidate équatorienne (lepopulaire.fr)
Après 80 ans d’hégémonie masculine à la tête de l’ONU, le choix d’une femme pour diriger l’organisation en crise est un enjeu de “justice historique” et de “mérite” pour la moitié de l’humanité oubliée, plaide Maria Fernanda Espinosa, candidate au poste de secrétaire générale.
- Les femmes en sciences sont de plus en plus présentes mais sans réel pouvoir, révèle une étude mondiale (theconversation.com)
Les femmes ne représentent qu’un tiers des chercheurs dans le monde, mais sont encore moins intégrées dans les structures de pouvoir des organisations scientifiques. Une étude mondiale étudie leur présence aux postes d’influence, afin de faire émerger des bonnes pratiques.
- Men use “vocal fry” more than women, counter to stereotype (arstechnica.com)
Study suggests “the bias is real but socially constructed, rather than grounded in how women actually sound.”[…]Telling women to avoid vocal fry to protect their careers [and] social perception puts the burden on speakers rather than challenging listeners’ biases, and that framing does real harm.

- The Supreme Court Just Hit Pause on an Abortion Pill Showdown (motherjones.com)
The order means mifepristone can continue to be dispensed via telehealth and mail—even to patients in red states.
Voir aussi Droit à l’IVG : aux États-Unis, la Cour suprême maintient temporairement l’accès par correspondance à la pilule abortive (humanite.fr)
Une manière de restreindre encore un peu plus l’accès à l’avortement aux États-Unis. Le 1er mai dernier, une cour d’appel ultraconservatrice avait bloqué provisoirement la possibilité pour les États-Uniennes d’avoir accès à la pilule abortive directement dans leur boîte aux lettres. Jeudi 14 mai, la Cour suprême a suspendu provisoirement cette décision, jusqu’à ce qu’elle décide de se saisir ou non de l’affaire sur le fond après le recours des laboratoires Danco et GenBioPro, fabricant de la pilule en question. La Mifépristone est un médicament utilisé dans les avortements médicamenteux, qui représentaient près de deux IVG sur trois aux États-Unis en 2023. Plus de 7,5 millions d’Américaines l’ont utilisée, pour des IVG mais aussi des fausses couches, depuis son approbation par les autorités sanitaires en 2000.
- ‘Unprecedented’ global effort gives new name to polycystic ovary syndrome – and new hope to millions of women (theguardian.com)
Spécial France
- PFAS : des rapporteurs de l’ONU épinglent deux géants de la vallée de la chimie (reporterre.net)
C’est un allié de poids qui vient de s’exprimer pour les victimes de la pollution massive aux PFAS, ces polluants éternels qui ont massivement contaminé la vallée de la chimie, au sud de Lyon. Quatre rapporteurs spéciaux des Nations unies (ONU) ont adressé des lettres communes à Arkema France et Daikin Chemicals France […] ainsi qu’à l’État français.
- Cancer colorectal chez les jeunes : un pesticide identifié comme facteur de risque (reporterre.net)
Le piclorame est apparu comme un marqueur distinctif des tumeurs précoces. […] Cet herbicide — dont moins de 10 tonnes sont écoulées chaque année en France — a été autorisé au milieu des années 1960. Les moins de 50 ans y ont été exposés (via l’alimentation) dès l’enfance.
- Fuite de PFAS, terres englouties : un énorme data center inquiète (reporterre.net)
Près de Paris, un projet de data center consommerait presqu’autant d’énergie que la production d’une centrale nucléaire et rejetterait moult polluants éternels. Des citoyens et des élus se mobilisent. Le maire, lui, est ravi.
- “Pas de solution européenne” : pourquoi les impôts français dépendent encore de technologies américaines (lcp.fr)
- DINUM-DITP : fusion stratégique… ou réforme déjà en train de se dégonfler ? (itforbusiness.fr)
la “fusion” annoncée le 30 avril pourrait finalement n’être qu’un rapprochement partiel, voire un ajustement organisationnel.[…] l’État cherche-t-il une véritable chaîne de commandement numérique… ou une réponse politique rapide à la crise cyber ?
- Débats sur la loi de programmation militaire : l’Assemblée approuve une nouvelle trajectoire des dépenses avec 36 milliards d’euros de plus (lemonde.fr)
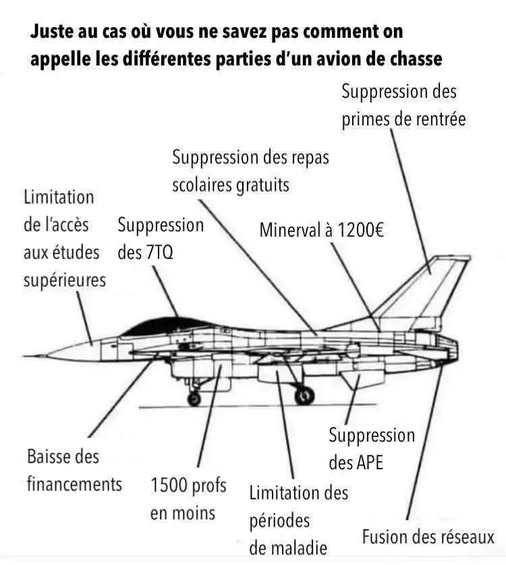
- Pour la CNIL, les lunettes connectées sont une menace sérieuse pour la vie privée (next.ink)
- Assemblée nationale : la proposition de loi sur les droits d’auteur et l’IA n’est pas retenue à l’agenda (lefigaro.fr) – voir aussi Comment le lobby de l’IA manœuvre pour enterrer la loi Darcos, protectrice du droit d’auteur (telerama.fr)
- Le Sénat rejette l’article clé de la loi sur l’aide à mourir qui en définissait les conditions d’accès (huffingtonpost.fr)
Les sénateurices ont supprimé la disposition centrale du texte sur la fin de vie après de profondes divisions entre la droite et la gauche sur le dispositif.
- Après le scandale Bétharram, près d’un tiers des écoles privées contrôlées a été rappelé à l’ordre (huffingtonpost.fr)
Les inspections lancées par l’Éducation nationale ont déjà conduit à six signalements au procureur et à des centaines de mises en demeure dans des établissements sous contrat.
- Le conducteur de SUV qui a écrasé le cycliste Paul Varry sera jugé pour meurtre (reporterre.net)
- « C’est obscène » : au festival de Cannes, d’anciens pilotes de ligne dénoncent l’afflux de jets privés alors que la pénurie de carburant menace (vert.eco)
- La RATP retire son projet de remplacement des agents en gare par des QR code sur le RER B (humanite.fr)
Devant l’ampleur de la bronca, la RATP a finalement jeté l’éponge. Elle vient d’abandonner officiellement un projet d’expérimentation polémique, visant à supprimer la présence humaine permanente en gare. En clair, au lieu de se tourner vers les agents « humains » en cas de problème, les usagers auraient dû utiliser un QR Code pour joindre quelqu’un du personnel en visioconférence.
- Compter le nombre d’insectes écrasés sur sa plaque d’immatriculation : l’appel des entomologistes aux automobilistes (humanite.fr)
Lancé par le Muséum national d’histoire naturelle et l’Office français de la biodiversité, le projet de sciences participatives Bugs Matter consiste à demander aux conducteurs de « compter » le nombre d’insectes écrasés sur leur plaque minéralogique.
Spécial femmes en France
- Le RN déforme tout, surtout l’histoire (humanite.fr)
Dimanche dernier, des militantes Femen ont manifesté pendant la cérémonie organisée par le maire Rassemblement national (RN) de Carcassonne et dédiée à Jeanne d’Arc. Elles dénoncent la récupération politique de cette figure historique
- Agressions sexuelles dans des hôtels du 115 : des signalements ignorés pendant des années (bondyblog.fr)
Deux hôtels sociaux parisiens ont fait l’objet de signalements de femmes hébergées pour des agressions sexuelles présumées. Malgré des alertes remontant à 2019, le Samusocial n’a mis fin à son partenariat qu’avec l’un de ces établissements en février 2026.
- Patrick Bruel accusé de violences sexuelles : Flavie Flament sort de l’anonymat et dépose plainte pour viol (humanite.fr)
- Le maire, les voisins et la sorcière – Chronique d’un féminicide que personne ne nomme (bonjourtsundoku.substack.com)
Spécial médias et pouvoir
- Avant Cannes, Juliette Binoche, Adèle Haenel et 600 professionnel·les du cinéma tirent la sonnette d’alarme face à l’emprise de Bolloré (huffingtonpost.fr)
- Le patron de Canal+ annonce ne plus vouloir travailler avec les signataires d’une tribune contre Bolloré (telerama.fr)
À Cannes, Maxime Saada a réagi à la tribune publiée lundi dans “Libération”, où six cents professionnel·les du 7ᵉ art appellent à résister à “l’emprise” du milliardaire ultraconservateur.

- Sérieusement, monsieur Aghion ? (alternatives-economiques.fr)
« Avant, on lisait Alternatives Economiques, maintenant on fait de l’économie sérieuse au lycée », s’est félicité le professeur au Collège de France, qui a réécrit les programmes de SES. La rédaction lui répond.
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Sous pression, Darmanin réduit le champ de sa réforme du plaider-coupable criminel qui ulcère les avocat·es pénalistes (huffingtonpost.fr)
Le garde des Sceaux propose désormais d’exclure les viols et les crimes jugés aux assises de cette procédure inspirée du modèle américain.
- Explosion des data centers en France : une trajectoire hors de contrôle (lareleveetlapeste.fr)
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- Des hymnes à Pétain aux néonazis dans la rue : le long week-end de la honte (politis.fr)
Toute la fin de la semaine, le Rassemblement national et les groupuscules d’extrême droite ont donné à voir leur réécriture dangereuse et génocidaire de l’histoire. Dans leurs villes ou dans la rue, leur haine explicite n’a fait que souligner la compromission des autorités.
- À Paris, le fiasco des néofascistes, privés de leur défilé annuel (blast-info.fr)
- Schéma antisémite, accointances avec des néofascistes… À l’UNI Strasbourg, des profils ultra-radicaux aux manettes (streetpress.com)
- Dans ces gares, les agents SNCF et RATP pourront porter un pistolet à impulsion électrique (20minutes.fr)
Une proportion de « 10 % des agents » de la police ferroviaire, soit 300 à 400 agents, seront équipés de pistolets à impulsions électriques « pour maîtriser les situations violentes » dans plusieurs grandes gares ainsi que sur les lignes D et E du RER
Spécial résistances
- Mairie RN de Carcassonne : les syndicats refusent leur expulsion de la Bourse du travail (basta.media)
Six syndicats appellent à une mobilisation à la Bourse du travail de Carcassonne mercredi 13 mai. La raison : le nouveau maire RN de la ville, Christophe Barthès veut expulser les syndicats du lieu, pourtant dédié à l’organisation des travailleureuses.
- « Pas de bistrot pour les fachos » : mobilisation contre la brasserie du journaliste d’extrême droite Erik Tegnér (basta.media)
Ce 14 mai, environ 400 personnes ont participé à une mobilisation à Pléguien, dans les Côtes-d’Armor. Objectif : s’opposer à l’ouverture de la brasserie Kerfave, co-fondée par Erik Tegnér, le président du média d’extrême droite Frontières.
- Désobéissance civile et principes républicains : une association écolo attaque la préfecture en justice (basta.media)
L’association Action justice climat de Lyon avait vu une demande de subvention rejetée en 2023. Ayant appris que son appel à la désobéissance civile était la cause du refus, elle a attaqué la préfecture au tribunal. L’audience a eu lieu mardi 12 mai.
- Faire vague contre l’industrialisation de la Seine : des collectifs, une lutte (lechiffon.fr)
- Data-centers, carrières, projets routiers : la carte du printemps des luttes locales (basta.media)
À l’appel de plus de 150 organisations, des dizaines d’actions auront lieu du 23 au 26 mai, en France et en Suisse, contre des projets de bétonisation. Une carte répertorie les mobilisations prévues.
- Des militant·es revendiquent le débâchage de mégabassines dans le Poitou (reporterre.net)
Le collectif, baptisé l’Amicale pour le débâchage permanent du Poitou, écrit vouloir « envoyer un message clair à l’État, aux collectivités, et aux entreprises […] : il n’y aura pas de répit tant que les bassines seront en état de marche ».
Spécial outils de résistance
- « La galaxie qui veut porter le RN au pouvoir » : Reflets lance une cartographie de l’extrême droite (portail.basta.media)
Reflets a publié ce mercredi 13 mai un outil permettant d’identifier les acteurs « à l’œuvre pour faire entrer le Rassemblement national à l’Élysée ». Le projet Link-ed regroupe les enquêtes à leur sujet et propose de cartographier leurs liens.
Voir aussi Cartographie de l’extrême droite française (link-ed.info)
LinkED est un projet d’encyclopédie interactive de l’extrême droite française et de ses réseaux. Elle est conçue par des journalistes.
Pétitions
- AXA, don’t take orders from Trump ! (action.eko.org)
A French judge is being treated like a terrorist. Nicolas Guillou’s “crime” ? He upheld international law and signed an arrest warrant for Netanyahu. Trump’s retaliation was vicious : he blacklisted the judge alongside drug lords and Al-Qaeda. But the real betrayal is at home : the insurer AXA has frozen the judge’s health reimbursements. This is a European judge, getting care in Europe, from a French company. No U.S. dollars. No U.S. laws broken. AXA is simply bowing to Trump’s bullying —leaving a man’s health in the crossfire.
- Projet de loi visant à renforcer l’État local : le gouvernement s’attaque à l’ADEME (soutien-ademe.agirpourlenvironnement.org)
À bas bruit, le gouvernement français met en œuvre une politique qu’Elon Musk et son « département de l’Efficacité gouvernementale » ne désapprouveraient pas. Après avoir réduit fortement le budget de l’Agence Bio et licencié sa directrice, diminué l’indépendance de l’ANSES, supprimé l’Institut national de la consommation qui édite le journal « 60 millions de consommateurs » et tenté de déstabiliser l’Office Français de la Biodiversité en remettant en cause certaines nominations jugées trop « militantes », c’est au tour de l’agence de la transition écologique (ADEME) d’être soumise à un « choc de simplification ».
Spécial MAGAM et cie
- Browsers Treat Big Sites Differently (denodell.com)
Safari and Firefox change how big sites render based on the domain. TikTok, Netflix, Instagram… even SeatGuru. Chrome doesn’t. Why is that ?
- The Era of 15GB Free Gmail Storage Is Ending (slashdot.org)
Google has confirmed it is testing a 5GB storage limit for some new Gmail accounts, with users able to unlock the standard 15GB by adding a phone number.
- Cell phone users can’t stop incriminating themselves (arstechnica.com)
- Fired hacker twins forget to end Teams recording, capture own crimes (arstechnica.com)
- Suicide, automutilation, anorexie… TikTok visé par une nouvelle plainte de 16 familles pour « abus de faiblesse » (huffingtonpost.fr)
- Le concours Pwn2Own Berlin démarre mal pour Microsoft, Windows 11 et Microsoft Edge piratés dès le premier jour (clubic.com)
Les autres lectures de la semaine
- Libertés académiques, extrême droite et bascule universitaire (contretemps.eu)
- Derrière les fichiers nazis (laviedesidees.fr)
En Allemagne, un moteur de recherche permet d’explorer les registres du Parti nazi. Au-delà des secrets de famille, cette initiative ravive des débats. Quelle différence entre la connaissance et la mémoire ? Que faire du nazisme à l’heure où l’extrême droite s’efforce de le réhabiliter ?
- The most dangerous threats to the internet in 2026 (this.weekinsecurity.com)
From surveillance and choking online access to governments going rogue, these are the most pressing threats to face the internet and its billions of users today.
- L’industrie low-tech, une réponse concrète à la crise écologique et au chaos géopolitique (blogs.mediapart.fr)
- What Have We Dumped On The Moon ? (hackaday.com)
- Des plantations aux plateformes : surveiller les travailleureuses a toujours été une affaire de pouvoir (synthmedia.fr)
- Les « ouvrier·es de la donnée », nouveau prolétariat 2.0 : entretien avec le sociologue Antonio A. Casilli (nvo.fr)
- Marseille. Sur les traces de la « capitale de l’empire colonial » (afriquexxi.info)
Au début du XXe siècle, la citée phocéenne se vantait d’être la représentante de la France coloniale. Les traces de cet héritage y sont aussi nombreuses que méconnues.
- Rosalind Franklin, la « dark lady » de la structure de l’ADN ou comment on exclut les femmes des sciences (theconversation.com)
- It’s 2026 and women are still asked to teach others to think a little bit and not be a prick (ohhelloana.blog)
- Au Moyen Âge, les échecs ont créé un espace où la couleur de peau ne comptait pas (theconversation.com)
- Comment un fragment de l’« Iliade » s’est‑il retrouvé à l’intérieur d’une momie égyptienne ? (theconversation.com)
Dans l’Empire romain, l’Iliade n’était pas seulement un grand texte littéraire : elle structurait l’éducation, le pouvoir et la mémoire collective. Jusqu’à finir, parfois, recyclée comme simple matériau de rembourrage dans une momie égyptienne.
- Neanderthals drilled cavities to treat a toothache 59,000 years ago (arstechnica.com)
in a frankly impressive success for dental surgery performed in a cave with a sharp rock—the patient went on to use the tooth for years afterward. The molar showed signs of normal long-term wear and tear, which could have only happened if the patient lived to chew another day.
- Protein in Homo erectus teeth suggests Denisovans gave us some of their DNA (arstechnica.com)
- Alimentation : 10 000 ans d’inégalités de genre en Europe (radiofrance.fr)
Les BDs/graphiques/photos de la semaine

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
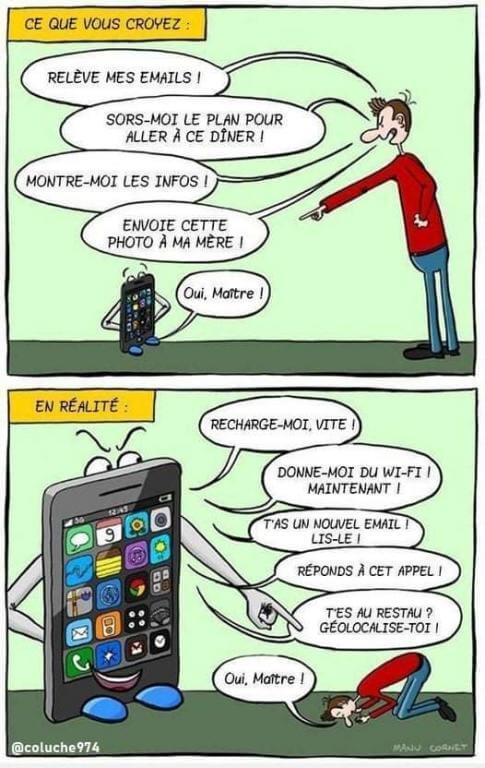{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- SINGULARITY – Painterly Space Adventure (video.blender.org)
- Bibliothèques de Paris « La politique du chiffre l’a emporté sur les lettres » dénonce le syndicat Supap FSU (radiofrance.fr)
- Comment des collectifs s’opposent à des projets de data center en Île-de-France (nantes.indymedia.org)
- Terreur chez les ultra-riches : le retour de la taxe Zucman (video.blast-info.fr)
- Choc des impérialismes, systèmes militaro-industriels et État radicalisé (spectremedia.org)
- The UK Government’s AI Obsession is a Big Risk (techwontsave.us)
What happens when a government goes all in on AI ? It creates some huge vulnerabilities. Will Dunn joins Paris Marx to dig into how the UK government is using chatbots to write laws without public consultation and why it isn’t asking the hard questions about the risks of that growing reliance on US technology.
- S13 E11 : Epic Fury, Project Freedom & The Shadow Docket : 5/10/26 : Last Week Tonight with John Oliver (tube.fede.re)
- Viols dans les beaux quartiers parisiens : le récit glaçant des victimes (blast-info.fr)
Les trucs chouettes de la semaine
- 30 bonnes nouvelles – récolte du jeudi 14 mai (lescerisesdehiatus.blogspot.com)
- Face à l’avancée du désert, des milliers de jeunes Chinois·es se mobilisent pour planter un million d’arbres (slate.fr)
Dans la région aride de Minqin, plus de 30.000 personnes ont rejoint une vaste campagne de reforestation visant à planter plus d’un million d’arbres pour lutter contre la désertification qui menace le nord-ouest du pays.
- How the West Could Turn a Trickle of Water Into an Endless Supply (reasonstobecheerful.world)
Hotter, drier weather, poor planning and a ballooning population are putting enormous pressure on the American West’s water supply. So, to get more out of every drop, some cities and counties are beginning to recycle their water — collecting what goes down the drain, removing the icky stuff and then sending it back into the system to use again, one way or another.
- Rémunérer les agriculteurices pour supprimer les pesticides coûte moins cher que dépolluer l’eau (lareleveetlapeste.fr)
Pour améliorer la qualité de l’eau, le plus efficace est de couper la pollution à la source : des collectivités accompagnent ainsi financièrement les agriculteurices pour les aider à supprimer les pesticides au niveau des zones de captage. En réduisant les coûts de dépollution de l’eau, ces pratiques vertueuses se répercutent favorablement sur la facture d’eau des consommateurices.
- “On a racheté les machines, on a relancé l’activité” : une coopérative citoyenne mise sur une filière du textile bio à faible impact environnemental (france3-regions.franceinfo.fr)
- « Ici, on a droit à la parole » : dans ce village, c’est l’assemblée citoyenne qui prend les décisions (reporterre.net)
Depuis 2020, la municipalité de Ménil-la-Horgne, dans la Meuse, prend ses décisions via l’assemblée des habitants. Éolienne communale, reprise d’une auberge… Une expérience de démocratie directe qui favorise les projets écolos.
- Gratuit et sans réservation : ces communes réinventent le covoiturage (reporterre.net)
- Logiciel libre : la gendarmerie a quitté Microsoft pour Linux il y a 20 ans, ses économies sont spectaculaires (lesnumeriques.com)
Auditionné par la commission d’enquête parlementaire sur les vulnérabilités numériques, le général Marc Boget a détaillé le bilan de la migration de la gendarmerie vers Linux et l’open source. Le chiffre avancé par Next.ink donne le vertige : 500 millions d’euros d’économies sur deux décennies.
- Le pingouin de Linux fête ses 30 ans, voici l’histoire incroyable de Tux (lesnumeriques.com)
- ROM Finder – Trouvez facilement une ROM alternative pour votre smartphone (tutox.fr)
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
11.05.2026 à 07:42
Khrys’presso du lundi 11 mai 2026
Khrys
Texte intégral (8932 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Le niveau des océans monte mystérieusement et la fonte des glaces n’explique pas tout (slate.fr) – voir aussi Something Deep in the Ocean is Causing Global Sea Levels to Rise—Now Scientists Reveal What’s Driving the Anomaly (thedebrief.org)
- « Un cercle vicieux » : comment le renforcement des vents aggrave la fonte des glaces (reporterre.net)
- Fiber optic cables can eavesdrop on nearby conversations (science.org)
Cold War spies planted bugs in walls, lamps, and telephones. Now, scientists warn, the cables themselves could listen in. A fiber optic technique used to detect earthquakes can also pick up the faint vibrations of nearby speech
- Comment l’Europe est tombée dans le piège technologique tendu par la Chine (slate.fr)
Une enquête pour corruption met en lumière une stratégie plus large de Pékin visant à s’imposer dans les infrastructures numériques-clés.
- Après douze ans d’absence, le drapeau de l’Union européenne flotte à nouveau sur le Parlement hongrois à Budapest (huffingtonpost.fr)
- Romania’s pro-Europe government collapses unleashing fresh turmoil (theguardian.com)
Ilie Bolojan’s coalition loses confidence vote after less than a year amid austerity drive and far-right surge
- Trente ans après la fin du siège de Sarajevo, l’hypothèse glaçante des « safaris humains » refait surface (slate.fr)
Trois décennies après le siège de la capitale bosnienne (1992-1996), en pleine guerre de Bosnie-Herzégovine, le possible scandale de riches étrangers venus « chasser » des civil·es a été relancé par l’ouverture d’une enquête judiciaire en Italie.
- Hantavirus : les passagers seront rapatriés dès l’arrivée du navire aux Canaries (humanite.fr)
Parmi les personnes qui ont débarqué au Cap-Vert ce mercredi, on retrouve « deux membres d’équipage malades avec des symptômes » mais dont l’état est « stable » et ne nécessite pas d’hospitalisation selon l’OMS qui précise que ces deux malades sont de nationalité britannique et néerlandaise. La troisième personne concernée a été en « contact proche » avec un malade et « a développé une légère fièvre ». Un autre passager du navire […] est hospitalisé à Zurich pour une infection au hantavirus […] « Cet homme et son épouse revenaient d’un voyage en Amérique du Sud fin avril » […] le médecin du MV Hondius, « qui se trouve dans un état grave » a été transporté aux Canaries par avion mercredi 6 mai

Voir aussi Hantavirus : le MV Hondius est arrivé aux Canaries pour évacuer ses passager·es (huffingtonpost.fr)Le navire de croisière est arrivé ce dimanche à l’aube au large de l’île de Tenerife avec ses près de 150 passagers et membres d’équipage, tous considérés « contacts à haut risque » par l’OMS.
Et Faut-il avoir peur d’une épidémie d’hantavirus ? (legrandcontinent.eu)
- « Un changement d’ampleur est possible » : au Royaume-Uni, les Verts veulent frapper un grand coup électoral (reporterre.net)
- L’image : une statue très politique signée Banksy (politis.fr)
- La salle de bal de Trump pourrait coûter un milliard de dollars aux contribuables américain·es (legrandcontinent.eu)
- Les revenus de Palantir ont doublé depuis le retour au pouvoir de Trump (legrandcontinent.eu)

- DHS can’t create vast DNA database to track ICE critics, lawsuit says (arstechnica.com)
Four protesters are suing to stop the Department of Homeland Security (DHS) and the Federal Bureau of Investigation (FBI) from seizing DNA samples from Americans arrested while peacefully protesting Immigration and Customs Enforcement (ICE) activity.
- Infants are bleeding out after parents decline vitamin K shots given at birth (arstechnica.com)
In almost every case, the babies’ deaths could have been prevented with a long-standard vitamin K shot. But across the country, families—first in smatterings, now in droves—are declining the single, inexpensive injection given at birth to newborns to help their blood clot.
- Why Some US Schools Are Cutting Back On the Technology They Spent Billions On (slashdot.org)
some states and school districts are walking back their technology use following pressure from parents who claim too much in-school screen time has zapped children’s attention spans and left them worse off academically
- Sam Altman Had a Bad Day In Court (slashdot.org)
- OpenAI president forced to read his personal diary entries to jury (arstechnica.com)
Greg Brockman never wanted to discuss his personal journal in public. But the OpenAI president has been stuck for days doing exactly that, while testifying in a trial in which Elon Musk has alleged that OpenAI abandoned its nonprofit mission to instead focus on personally enriching leaders like Brockman and Sam Altman.
- Elon Musk tried to hire OpenAI founders to start AI unit inside Tesla (arstechnica.com)
Musk was “prepared to do the for-profit, provided he would get control.” […] Musk, a co-founder of the AI group, proposed bringing Altman, Greg Brockman, and Ilya Sutskever to his carmaker, appointing Altman to the board or making OpenAI a Tesla subsidiary, according to evidence in a high-stakes trial between the billionaire and the ChatGPT maker on Wednesday.
- SpaceX IPO gives Musk unchecked power and forbids investor lawsuits (arstechnica.com)
Anyone who buys into SpaceX IPO must waive right to sue the firm, report says.

- Des chercheureuses ont identifié des routes interplanétaires inédites qui permettraient de relier la Terre et Mars bien plus rapidement que prévu, sous réserve de progrès techniques majeurs. (slate.fr)
les orbitographies « brouillonnes » d’astéroïdes, autrefois rapidement écartées dès que de meilleures données arrivaient, pourraient servir de guide pour repérer des corridors interplanétaires inédits.
- Mexico s’enfonce à une vitesse alarmante et les derniers satellites de la NASA le montrent en temps réel (slate.fr)
Dans certains quartiers, le sol s’est enfoncé de près de 35 centimètres par an au cours des dernières décennies. Les conséquences sont visibles partout, des rails de métro qui gondolent aux canalisations qui éclatent, transformant la gestion de la ville en un défi d’ingénierie quotidien.
Voir aussi “Une zone particulièrement touchée” : une image satellite démontre à quel point la ville de Mexico s’affaisse (sciencesetavenir.fr)
- In This Desert, Radio Signals Inexplicably Die. Did It Cause a Bizarre Missile Crash ? (popularmechanics.com)
- Single dose of magic mushroom psychedelic can cause anatomical brain changes, study finds (theguardian.com)
Participants took 25mg of psilocybin, reporting deeper psychological insight and better wellbeing a month later
Spécial IA
- Commission opens consultation on draft guidelines for AI transparency obligations (digital-strategy.ec.europa.eu)
From 2 August 2026, people in the European Union will have to be informed when they are interacting with artificial intelligence (AI) systems or exposed to certain AI-generated or manipulated content.
- Droits d’auteur et IA : la France renverse la charge de la preuve pour forcer la Big Tech à payer (synthmedia.fr)
Une proposition de loi examinée au Sénat le 8 avril instaure une présomption d’exploitation des contenus culturels par les fournisseurs d’IA. Un mécanisme qui doit inverser la charge de la preuve et cible les géants américains réfugiés derrière le “fair use”.
- Five times AI hallucinations embarrassed governments (restofworld.org)
From the Trump administration’s “formatting errors” to South Africa’s historic policy withdrawal, AI confabulation is infiltrating official documents.[…] when this happens inside a cybersecurity authority with a €27 million budget, the problem isn’t skill. It’s the process. No mandatory verification step. No provenance checks. No clear rule for AI use. Just speed, convenience, and trust-by-default.
- Thousands of Vibe-Coded Apps Expose Corporate and Personal Data on the Open Web (wired.com)
Security researcher Dor Zvi and his team at the cybersecurity firm he cofounded, RedAccess, analyzed thousands of vibe-coded web applications created using the AI software development tools Lovable, Replit, Base44, and Netlify and found more than 5,000 of them that had virtually no security or authentication of any kind. Many of these web apps allowed anyone who merely finds their web URL to access the apps and their data. Others had only trivial barriers to that access, such as requiring that a visitor sign in with any email address. Around 40 percent of the apps exposed sensitive data, Zvi says, including medical information, financial data, corporate presentations, and strategy documents, as well as detailed logs of customer conversations with chatbots.
- Let’s talk about LLMs (b-list.org)
the consistent theme here, in the studies and reports and in more recent public examples, is that being able to generate code much more quickly than before, even in 2026 with modern LLMs and modern practices, is still no guarantee of being able to deliver software much more quickly than before.

- Richard Dawkins and the Claude Delusion (flux.community)
Besides being a virtual instantiation of his ideal woman (servile, obsequious, and always ready to hear more), the coquettish chatbot that Richard Dawkins had first addressed as “he” and then “christened” as female was a mirror of himself, in a way that’s rather similar to the Greek mythical figure of Narcissus, who became enthralled at his reflection in a pool of water […] Claudia seemed real to him because actual women and their desires are not real to Dawkins. He loved conversing with his flirty friend because it always agreed with him—unlike those “woke” atheists who insist he has to respect everyone.
- Canadian fiddler sues Google after AI Overview wrongly claimed he was a sex offender (theguardian.com)
An acclaimed Canadian fiddle player has launched a $1.5m civil lawsuit against Google, alleging that the online giant defamed him by falsely identifying him as a sex offender in an AI-generated summary of his life and career.
- AI Hard Drive Shortage Makes Archiving the Internet Harder (slashdot.org)
- Silicon Valley bets $200M on AI data centers floating in the ocean (arstechnica.com)
Panthalassa aims to test floating AI computing nodes in the Pacific in 2026.
- Google Chrome silently installs a 4 GB AI model on your device without consent. At a billion-device scale the climate costs are insane. (thatprivacyguy.com)
- Meta will use AI to analyze height and bone structure to identify if users are underage (techcrunch.com)
- Surveillance en magasin : avec l’IA, toustes les client·es deviennent-iels suspect·es ? (60millions-mag.com)
L’un des leaders de ce marché, l’entreprise française Veesion, a déjà conquis de nombreux commerces en France : épiceries de quartier, pharmacies, supérettes bio… Des milliers de magasins ont souscrit à un abonnement sans vraiment se soucier de la légalité de cette solution. De fait, la Cnil estime qu’elle n’est pas conforme au Règlement général sur la protection des données (RGPD)
- Hiding Behind AI (sha.africauncensored.online) How the Social Health Authority Was Used to Load Health System Costs Onto Poorest
- Hackers Hate AI Slop Even More Than You Do (wired.com)
It’s not just you. Scammers, hackers, and other cybercriminals are complaining about “AI shit” flooding platforms where they discuss cyberattacks and other illegal activity.
- Google DeepMind Workers Vote to Unionize Over Military AI Deals (wired.com)
UK staff of Google’s AI research lab hope to block the use of the company’s artificial intelligence models in military settings.
- La colère contre l’IA est-elle en train de dégénérer ? (danslesalgorithmes.net)

- Incendies, sabotages, guérilla juridique contre l’IA : vers une « Renaissance Luddite » ? (synthmedia.fr)
Spécial Iran, Israël, Palestine…
- La fermeture du détroit d’Ormuz a provoqué la plus forte chute de la demande de pétrole depuis la pandémie (legrandcontinent.eu)
- Trump suspend (déjà) son « Projet Liberté » dans le détroit d’Ormuz (huffingtonpost.fr)
Le président américain assure que de « grands progrès (ont été) accomplis en vue d’un accord » avec l’Iran.
- Another day, another pivot as Trump flails in an Iran trap of his own making (theguardian.com)

- À Ormuz, les États-Unis frappent l’Iran mais Donald Trump affirme que la trève reste en vigueur (huffingtonpost.fr)
- Bombardements entre Washington et Téhéran : « une broutille » pour Trump, une « violation flagrante » du cessez-le-feu pour l’Iran (humanite.fr)
- Semer la ruine. L’effacement comme stratégie israélienne (orientxxi.info)
En Palestine comme dans le Sud-Liban, la ruine excède largement le registre du dommage matériel. Elle constitue une politique israélienne à part entière qui ordonne l’espace, altère le temps et frappe les vivants à travers leurs lieux de vie. En pulvérisant les maisons, les bibliothèques, les archives, les photographies et les actes de propriété, cette stratégie s’attaque également au souvenir.
- Despite global outrage, Israel is still blockading our children’s education (972mag.com)
It’s been three weeks since settlers fenced off my students’ path to school, trying to show that Umm Al-Khair has no future. We refuse to let them win.
- Lyon : quatre militant·es ont passé 42h en garde-à-vue pour avoir dénoncé le génocide de Gaza sur des panneaux publicitaires (lareleveetlapeste.fr)
- Spain’s leader Sanchez awards UN’s Francesca Albanese Order of Civil Merit (middleeasteye.net)
Prime Minister Pedro Sanchez describes the UN’s Palestine rapporteur as ‘a voice that upholds the conscience of the world’
Spécial femmes dans le monde
- La justice portugaise a fait savoir qu’elle refusait de livrer Cédric Prizzon malgré l’émission d’un mandat d’arrêt européen. (humanite.fr)
L’ex-policier a été arrêté au Portugal le 24 mars […] Il a depuis été placé en détention provisoire, accusé d’avoir tué Audrey Cavalié, son ex-compagne âgée de 40 ans et mère de leur fils de 12 ans, ainsi que sa conjointe au moment des faits, Angela Legobien, 26 ans, mère de leur fille de 18 mois.
- Le co-fondateur de la marque Superdry, James Holder, incarcéré pour viol (huffingtonpost.fr)
James Holder a été condamné à huit ans de prison pour des faits commis en mai 2022, dans l’appartement de la victime.
- Droits des femmes : « Ce qui semblait impensable hier devient possible » (politis.fr)
Aux États-Unis, de plus en plus de droits que l’on croyait acquis ont été fragilisés. Certaines franges radicales de la droite vont jusqu’à évoquer des restrictions du droit de vote des femmes. Judith Ezekiel, historienne franco-américaine, s’inquiète de la capacité de résistance des mobilisations féministes.
- Les violences contre les femmes journalistes en nette hausse… à cause de l’IA (lesnouvellesnews.fr)
Les voix des femmes journalistes se raréfient. C’est l’alerte du dernier rapport d’ONU Femmes. À l’occasion de la Journée mondiale de la liberté de la presse, le 3 mai, l’organisation observe « des formes croissantes et de plus en plus sophistiquées de violence en ligne » à l’encontre des femmes engagées dans la vie publique, notamment dans les médias.
- Data that saves lives : towards a unified system on gender violence (latinoamerica21.com)
Disparate figures across institutions expose a fragmented state that hinders the prevention of lethal violence against women.
Spécial France
- Après l’escalade des tensions avec l’Algérie, Emmanuel Macron tente de renouer le dialogue (humanite.fr)
Emmanuel Macron a demandé l’ambassadeur de la France à Alger, de « reprendre ses activités » sur place, après qu’il a été rappelé en avril 2025 pour cause de tension diplomatique. L’Élysée annonce qu’EM veut ainsi « restaurer un dialogue efficace », « avec une attention particulière » portée au retour du journaliste Christophe Gleizes, emprisonné depuis juin 2025.
- « C’est une pirouette habituelle de l’industrie » : Sophie la girafe, du made in France fabriqué en Chine (reporterre.net)
Icône du « made in France », le jouet Sophie la girafe est en réalité fabriqué en Chine depuis au moins 2013. Salaires faibles, cadences infernales, usine fantôme en France…
- Le Parquet européen enquête sur des soupçons de fraude autour de formations aux médias dont aurait notamment bénéficié Jordan Bardella (franceinfo.fr)
- Le Conseil d’État ordonne à l’État de corriger les dysfonctionnements de la plateforme de demandes de titres de séjour (franceinfo.fr)
Le Conseil d’État a donné raison à la dizaine d’associations qui, il y a un an, l’avaient saisi à la suite de nombreux problèmes rencontrés par les étrangers pour demander ou renouveler leurs titres de séjour.
- Dans la légalité, Bally Bagayoko ne raccrochera pas le portrait d’Emmanuel Macron (huffingtonpost.fr)
Le maire insoumis répond au préfet de la Seine-Saint-Denis qui lui demandait de respecter « la tradition républicaine » en accrochant le portrait du président dans sa mairie.
- « La légitimité d’une candidature ne peut reposer uniquement sur des sondages ou une affirmation personnelle » (politis.fr)

- Suite au départ de Boris Vallaud de la direction du PS, la primaire prévue à l’automne est désormais quasi enterrée. (huffingtonpost.fr)
- « Affaire du 8 décembre » : la gauche radicale face aux dérives de l’antiterrorisme (politis.fr)
- Affaire Bygmalion : Nicolas Sarkozy va bénéficier d’une libération conditionnelle et ne portera pas de bracelet électronique (franceinfo.fr)
- Mégabassines : Julien Le Guet condamné à six mois de détention sous bracelet électronique (reporterre.net) – voir aussi « Je suis devenu une cible » : Julien Le Guet, porte-parole de Bassines non merci, condamné à 6 mois de prison (humanite.fr)
- Le coup de pression de TotalEnergies face à la perspective d’une nouvelle taxe (huffingtonpost.fr)
Le PDG de TotalEnergies a assuré qu’en cas de taxe sur les « superprofits » pétroliers, le groupe ne pourrait pas maintenir son plafonnement des prix sur les carburants.
- Prix à la pompe : et si on reparlait sobriété ? (alternatives-economiques.fr)
Lors du choc énergétique de 2022, l’Etat avait lancé un plan de sobriété. En 2026, le mot a disparu du débat public. Ce serait pourtant un moyen d’amortir la hausse des prix des carburants.
- « On ne cherche pas à faire du bénéfice » : ces maires font des stations essence un service public (reporterre.net)
- Amazon : avec 15 milliards d’euros d’investissement, le géant du e-commerce mise sur la France (reporterre.net)
Amazon a annoncé son intention d’investir 15 milliards d’euros en France dans les trois prochaines années, pour la construction de nouveaux sites logistiques et sa croissance dans le cloud et l’intelligence artificielle. C’est, sur trois ans, la moitié de la somme investie en France ces quinze dernières années.
- Big Tech, opérateurs, fonds d’investissement, fournisseurs… À qui profite vraiment le boom des datacenters en France ? (multinationales.org)
Parmi les plus gros projets annoncés, une coentreprise baptisée Campus IA, réunissant le fonds émirati MGX, la start-up française Mistral AI, Nvidia et la banque publique Bpifrance, veut construire un immense centre de données à Fouju, en Seine-et-Marne, qui devrait à terme atteindre une puissance de 1,4 gigawatt (GW). Google pourrait construire un centre de données de 500 MW près de Châteauroux, tandis que Microsoft a tourné ses yeux vers l’Alsace, à Petit-Landau, près de Mulhouse, avec un projet dont la consommation annuelle d’électricité, prévue à 1,5 GWh, correspond à celle de 280 000 foyers, soit autant que la ville de Strasbourg.
- MGX, le très peu rassurant fonds émirati derrière l’immense centre de données « souverain » prévu dans l’Essonne (multinationales.org)
Le datacenter géant annoncé à Fouju, dans l’Essonne, est présenté comme l’archétype de l’infrastructure numérique « souveraine » […] Le projet est pourtant contrôlé à 70 % par un fonds d’Abu Dhabi, MGX aux liens étroits avec Donald Trump et ses proches, les géants américains de la Tech comme Microsoft, la Chine, ou encore les services de sécurité émiratis
Spécial femmes en France
- Après la Ligue féminine de football professionnel, les joueuses réclament une convention collective (lesnouvellesnews.fr)
À l’unisson, dans une tribune, les capitaines d’équipes de la Ligue féminine de football professionnel s’indignent de la « précarité structurelle » qu’elles subissent et réclament une convention collective. Un filet de sécurité essentiel pour le développement du football féminin.
- Création du premier congé endométriose pour les employées d’une entreprise du BTP (lesnouvellesnews.fr)
Encore très largement masculin, le secteur du BTP commence à prendre conscience de la santé spécifique de ses travailleuses.
- « Sans ce bus, je n’aurais pas consulté » : des gynécologues mobiles en plein désert médical (reporterre.net)
« On s’est rapidement rendu compte du besoin de suivi gynécologique. Les femmes, surtout dans les campagnes, ont tendance à s’oublier, et leur santé n’est plus leur priorité. Si on ne vient pas les chercher, elles ne viendront pas d’elles-mêmes »
- Ovaire ta mère (cqfd-journal.org)
25 ans après l’adoption de la loi autorisant l’accès à la contraception définitive, celle-ci continue d’être un vrai parcours de la combattante (pour ne pas déplaire au réarmement démographique). L’histoire de la stérilisation volontaire est intimement liée au contrôle des corps des femmes, comme des minorités.
- Muriel Robin interpelle Gérald Darmanin sur la scène des Molières sur le controversé « plaider-coupable » (huffingtonpost.fr)
Cette procédure « permettrait à un violeur de négocier sa peine, dans le bureau d’un juge, sans procès, en échange d’un aveu. Mais un viol, cela ne se négocie pas, cela se juge », a-t-elle ainsi résumé, en expliquant que « les victimes n’ont pas besoin d’une justice plus rapide, mais d’une justice à la hauteur ».
- Réunies dès l’aube, des centaines d’élèves d’un lycée de Guadeloupe ont dénoncé la diffusion virale de listes sexistes et dégradantes (rci.fm)
La loi prévoit une peine pouvant aller jusqu’à 2 ans de prison et 60 000 € d’amende, sur la qualification précise de « diffusion, montage de publications à caractère sexuel générées par un algorithme numérique, reproduisant l’image ou les paroles d’une personne sans son consentement »
- Après Cocoland, Sarah El Haïry signale un autre « tchat en ligne » à la justice après avoir reçu des « alertes » (huffingtonpost.fr)
Le site Chatiw est dans le viseur de la haute-commissaire à l’Enfance, a-t-elle indiqué au « Monde », faisant état de « messages à caractère sexuel » parfois reçus « dès la connexion au service ».
- Patrick Bruel est mis en cause par quinze nouvelles femmes qui ont livré leur témoignage à Mediapart. (humanite.fr)
Sept d’entre elles, dont une mineure, « dénoncent des relations sexuelles auxquelles elles n’auraient pas consenti » […] Patrick Bruel […] est déjà sous le coup d’une enquête pour viol et de deux autres pour tentative de viol et agression sexuelle ouvertes en France et en Belgique.
- Pantin : un employé d’une agence de voyages placé en détention pour avoir tué sa collègue et caché son corps (ici.fr)
L’homme mis en cause “reconnaît les faits”, expliquant son acte sur sa collègue car “elle lui aurait refusé une avance sur salaire”.
- Une adolescente de 14 ans meurt poignardée dans l’Aisne, un homme interpellé (huffingtonpost.fr)
La jeune fille a reçu de multiples coups portés à l’arme blanche. Une enquête a été ouverte pour assassinat. Un homme de 23 ans a été arrêté.
Voir aussi Après le meurtre d’une adolescente dans l’Aisne, le suspect interpellé a reconnu les faits (huffingtonpost.fr)
Spécial médias et pouvoir
- LCP et Public Sénat dans le viseur de Charles Alloncle (projetarcadie.com)
Le rapport de la commission d’enquête parlementaire sur l’audiovisuel public a été mis en ligne ce matin, mardi 5 mai 2026. Une mesure concerne spécifique les deux chaînes parlementaires de la TNT, à savoir LCP et Public Sénat : les soumettre au contrôle de l’ARCOM, plus spécifiquement, à ce qu’elles respectent le pluralisme politique, imposé aux autres chaînes diffusant de la politique.
- Alloncle et Bolloré : mariage de raison (politis.fr)
Le milliardaire breton a mis tous ses médias en ordre de marche pour soutenir le rapporteur de la commission parlementaire sur l’audiovisuel public, le député UDR Charles-Henri Alloncle, dans ses attaques contre le service public. Jusqu’à lui transmettre des questions.
- Rapport Alloncle : vers un audiovisuel public aux ordres en cas de victoire du RN en 2027 ? (theconversation.com)
- « La désinformation climatique est beaucoup moins présente dans l’audiovisuel public que dans le privé » (reporterre.net)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Le double risque que prend Emmanuel Macron avec cette proposition pour la Banque de France (huffingtonpost.fr)
Le chef de l’État entend nommer Emmanuel Moulin, son ex-secrétaire général de l’Élysée, à la tête de la Banque de France. Non sans prêter le flanc aux critiques en copinage.
- Défenseur des droits : le très macroniste François-Noël Buffet pressenti (politis.fr)
Avocat de formation, le sénateur est membre du parti Les Républicains, et s’est notamment distingué par son opposition au mariage pour tous et à la constitutionnalisation de l’IVG. Ça promet.
- Superprofits de TotalEnergies : pourquoi Sébastien Lecornu et son gouvernement refusent de taxer le géant français du pétrole (vert.eco)

- Rejet d’un rapport sur l’acétamipride par LR, le RN et Horizons : un « sabotage politique » selon les apiculteurices (lareleveetlapeste.fr)
« La non-publication de la note est un signal d’abandon envers l’apiculture, la biodiversité et la démocratie ».
- Le scandale des pesticides non autorisés en Europe mais utilisés en France (basta.media)
Autoriser dans l’Hexagone des pesticides non approuvés par l’UE. C’est le choix fait par le gouvernement français, deuxième pays d’Europe à accorder le plus de dérogations.
- « Monsieur Duplomb, l’avenir de nos enfants gardera longtemps la sale gueule du cancer » (reporterre.net)
- Plus de 250 associations et personnalités redoutent la possible « extinction » de l’Ademe, à cause d’une loi (nouvelobs.com)
L’Agence de la Transition écologique pourrait être placée sous l’égide des préfets et ses membres mutés sans leur consentement. Plus de 250 associations et personnalités du monde environnemental s’alarment.

Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- « Ils puent, il faut les tuer » : des marins français secourant les migrant·es accusés de comportements racistes (huffingtonpost.fr)
Une enquête a été ouverte des chefs d’« injures publiques » et de « mise en danger de la vie d’autrui »
- Projet de loi Fraudes : le Parlement élargit l’accès aux comptes bancaires pour le contrôle du RSA (laquadrature.net)
- « Il s’agit d’intimidation » : comment la loi d’urgence agricole risque d’affaiblir les associations écologistes (reporterre.net)
- Le système agricole productiviste : « Un vortex de violences », selon le journaliste Nicolas Legendre (rural-lemedia.fr)
- “C’est stratosphérique, ça n’a aucun sens” : quatre militant·es risquent de la prison avec sursis pour avoir remplacé des pubs par des messages politiques (france3-regions.franceinfo.fr)
- Amendes contre les occupations dans les facs : la droite veut « supprimer les blocages » (basta.media)
Une proposition de loi LR vise à sanctionner les occupations et intrusions au sein des universités, dans un contexte où les mobilisations étudiantes se multiplient. La CGT dénonce une nouvelle tentative de restreindre l’indépendance universitaire.
- Avec les « classes de défense globale », la crainte d’un embrigadement des collégien·nes et lycéen·nes (basta.media)
Des élèves dans la peau de gendarmes réprimant une manifestation, d’autres qui jouent les surveillant·es de prison… Les « classes défense » se multiplient, sur fond de tensions géopolitiques, mais alarment parents, syndicalistes et chercheureuses.
- Enseignement à la défense nationale : des réservistes de l’armée vont-ils se retrouver devant des classes ? (basta.media)
Une loi proposant d’instituer un « enseignement à la défense nationale » dans les établissements scolaires a été votée en catimini par les députés le 26 mars. Ces séances seraient assurées par des réservistes, faisant courir le « risque d’une dérive vers une forme de militarisation symbolique de l’école ».
- La manifestation néonazie du « C9M » et les réponses antifa interdites à Paris (huffingtonpost.fr)
La Préfecture de police se justifie en évoquant « un contexte politique tendu et très polarisé », notamment après la mort de Quentin Deranque, lui-même militant d’ultra-droite.
- À Paris, la marche néonazie du C9M reste interdite (politis.fr)
Le tribunal administratif a rejeté la levée d’interdiction demandée par les organisateurs du C9M, une marche néofasciste en hommage à un militant mort le 9 mai 1994.
- Comment des groupes néonazis ou identitaires présents au C9M profitent de dons défiscalisés (basta.media)
Des groupes fascistes ou identitaires prévoient de défiler à Paris ce 9 mai à l’occasion de leur marche annuelle (C9M). Nombre d’entre-eux et leurs alliés bénéficient de dons défiscalisés grâce à des associations prétendument « d’intérêt général ».
- Après des « saluts nazis », le député Arthur Delaporte signale les banquets du Canon français à la justice (huffingtonpost.fr)
Depuis des mois, les fêtes organisées par cette start-up soutenue par le milliardaire conservateur Pierre-Édouard Stérin font polémique.
- Ariège. L’implantation souterraine de l’extrême droite (lempaille.fr)
L’organisation identitaire et intégriste « Academia christiana » programme régulièrement des séminaires tenus secrets pour former les jeunes militant·es néo-fascistes. Depuis deux ans, leur feria d’été se tient au centre équestre « Les centaures », à Viviès. Un cheval de Troie local pour l’extrême droite ?
- Des néonazis tabassent plusieurs clients d’un bar de l’ouest parisien (streetpress.com)
La vidéosurveillance du bar a filmé l’agression : mi-avril à Paris, une vingtaine de militants néofascistes effectuent des saluts nazis puis attaquent des clients. StreetPress a identifié sur les images Gabriel Loustau, le leader des Hussards.
- Bientôt jugé pour avoir tiré près d’enfants, un sexagénaire le sera aussi pour injures racistes (huffingtonpost.fr)
Le sexagénaire a été déféré mardi pour ces faits et sera jugé le 17 août prochain par le tribunal correctionnel du Puy […] D’ici à sa comparution, l’homme a été placé sous contrôle judiciaire, avec notamment interdiction de se rendre à Espaly.

Spécial résistances
- Le rassemblement antifasciste parisien du 9 mai interdit par la préfecture (reporterre.net)
la préfecture de Paris a également interdit le rassemblement néofasciste, à cause d’un « contexte politique tendu », trois mois après la mort du militant d’extrême droite radicale Quentin Deranque à Lyon.
- Hadopi, c’est fini ! (fdn.fr)
- Chez GRDF, Enedis et RTE, les syndicats mobilisés contre la chasse aux salariées portant un voile (streetpress.com)
« Ils s’attaquent surtout aux copines musulmanes »
Spécial outils de résistance
- TUTO : Faire baisser son loyer (et emmerder son proprio) (frustrationmagazine.fr)
Spécial MAGAM et cie
- Google Broke reCAPTCHA for De-Googled Android Users (reclaimthenet.org)
The company that decides whether you’re a bot now also requires you run its software to prove otherwise.
- Met gala 2026 : le parrainage de Jeff Bezos fait grincer les dents (huffingtonpost.fr)
Proches de Donald Trump, Jeff Bezos et son épouse, Lauren Sánchez, ne sont pas seulement annoncés comme présidents d’honneur de cette édition du gala caritatif, ils en sont aussi les principaux financeurs.[…] un appel au boycott sans précédent a, lui, envahi les rues et le métro de New York la semaine précédant l’événement.
Voir aussi Amazon Workers Stage A ‘Ball Without Billionaires’ Hours Before Met Gala 2026 (news18.com)

- PSA : Instagram Encrypted Messaging Ends on Friday, May 8 (macrumors.com)
Instagram will remove end-to-end encryption for direct messages between users from May 8, 2026. When the date comes around, Meta will potentially be able to see the contents of all messages between users on the social media platform.
- Oui, Edge stocke les mots de passe en clair dans la mémoire, c’est normal selon Microsoft (next.ink)
- La maison mère de Truth Social, le réseau de Donald Trump, subit des pertes colossales, plombée par les cryptomonnaies (lemonde.fr)
Trump Media & Technology Group a publié vendredi une perte nette de plus de 400 millions de dollars au premier trimestre. Ses comptes ont pâti de la dégringolade des devises numériques, dans lesquelles la société avait massivement investi.
- Dérives possibles de X : Elon Musk dans les radars d’un juge d’instruction français (boursorama.com) – voir aussi Elon Musk faces criminal probe in France after ignoring summons in X case (arstechnica.com)
French prosecutors yesterday opened a criminal investigation into Elon Musk and X, escalating a probe into sexual images of minors and other alleged illegal content on Musk’s social network.
Et Elon Musk se fend d’un message lunaire et insultant contre les magistrats français (huffingtonpost.fr)
« Ils sont plus faux qu’un euro en chocolat et plus pédés qu’un flamant rose en tutu fluo ! »
Les autres lectures de la semaine
- Zen of Reticulum (reticulum.network)
For the better part of a generation, we have been taught to visualize the digital world through the lens of hierarchy. The mental maps we carry are dominated by a single, misleading image : The Cloud.
- Gilles Babinet : “L’État fait preuve d’une absence de cohérence chronique sur le numérique” (acteurspublics.fr)
Entre le ministère de l’Éducation nationale utilisant encore massivement Microsoft alors qu’il dit souhaiter ne plus le faire, et le ministère des Armées s’affranchissant de presque toutes les solutions américaines : ce sont des approches aux deux extrêmes. Et au milieu de ces deux approches se trouvent tous les autres ministères. Cette absence de cohérence coûte cher : ce n’est ni fait ni à faire.
- Une mouvance philosophique obscure a pris le contrôle de la Silicon Valley (legrandcontinent.eu)
L’accélérationnisme repose sur des bases théoriques instables, des sources confuses et plusieurs contresens. Pourtant il irrigue, de l’extrême droite à la gauche, l’idéologie dominante de notre contemporain.
- The Online Safety Act : Are children safer online ? (internetmatters.org)
- Voici l’histoire de cette voiture en forme d’avion qui devait traverser les États-Unis avec un seul plein d’essence (ouest-france.fr)
- The electromechanical angle computer inside the B-52 bomber’s star tracker (righto.com)
- Philadelphie, 1985 : la terreur d’État s’abat sur une organisation noire (contretemps.eu)
Autour de « Laissez le feu brûler », d’Olivier Esteves et Linn Washington
- “Berbère”, “Moyen-Orient”, “judéo-chrétien” : décolonisons notre langage (komunemedia.substack.com)
Le terme que privilégient aujourd’hui de nombreuses personnes concernées est “Amazigh”, qui signifie : “homme libre” ou “homme noble”. À l’opposé de “berbère”, dérivé du latin barbarus qui désigne “barbare”, donc “sauvage” ou “non civilisé”.
- Entretien avec Mohamed Ali Zerouali, représentant du Front Polisario : « Les peuples en lutte finissent par obtenir reconnaissance et justice » (altermidi.org)
- Tenir bon : la leçon d’émancipation des « dames de fraises » (terrestres.org)
- Les oiseaux ont en moyenne plus peur des femmes que des hommes et personne ne sait pourquoi (slate.fr)
Les BDs/graphiques/photos de la semaine
- Candidatures
- Humour
- Cadmium
- Hantavirus
- 10th week
- Just tax
- In fact
- Amazon
- Eating
- Sources of power
- Left behind
- Laxative
- Internet
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- Gabriel Zucman auditionné le 06 mai 2026 par la commission d’enquête sur l’imposition des plus hauts patrimoines (tube.fdn.fr)
- La colère des Sans Trains (telemillevaches.net) Quoi de neuf pour la ligne Limoges-Ussel ?
- Une plongée vertigineuse au cœur des déserts médicaux français (humanite.fr)
Des gens meurent et souffrent chaque jour en France simplement parce qu’ils n’ont pas pu être pris en charge.
- Réhabilitation : que faire des agresseurs ? Le cas Roméo Elvis. (humanite.fr)
Roméo Elvis sera l’interprète de l’hymne officiel belge lors de la Coupe du monde 2026 de football qui s’ouvrira dans quelques mois. Accusé d’agression sexuelle et ayant reconnu publiquement avoir “utilisé ses mains de manière inappropriée”, c’est la question de la réhabilitation des agresseurs sexuels qui se joue ici.
Les trucs chouettes de la semaine
- Des chercheureuses français·es et chinois·es sur le point d’éradiquer un des PFAS (humanite.fr)
L’acide trifluoroacétique, un PFAS présent notamment dans le milieu aquatique, pourrait être neutralisé par une technique de dégradation mise au point par un groupe de chercheureuses franco-chinois·es.
- « Les gens me prenaient pour un fou » : les graines indigènes, remède à l’agro-industrie brésilienne (reporterre.net)
Dans la savane brésilienne, des collecteurs de semences restaurent des terres ravagées par les monocultures, l’élevage intensif et les incendies. Graine par graine, ils espèrent voir renaître le Cerrado.
- Les cartes légumes : pour adultes et enfants (JardinBiskoul.bzh)
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
04.05.2026 à 07:42
Khrys’presso du lundi 4 mai 2026
Khrys
Texte intégral (8531 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- Des virus hors‑norme qui orchestrent la vie aux pôles (theconversation.com)
Longtemps ignorés en raison de leur taille, les virus géants redéfinissent aujourd’hui les frontières de la microbiologie. Au cœur des écosystèmes arctiques, ils ne sont pas de simples parasites, mais de véritables chefs d’orchestre de la vie microbienne et des cycles élémentaires planétaires.
- Les dépenses militaires mondiales s’envolent en 2025, “marquée par l’intensification des tensions” (france24.com)
Les dépenses militaires mondiales ont atteint 2 900 milliards de dollars en 2025, une hausse de 2,9 % en un an en dépit d’un recul des dépenses militaires américaines, rapporte l’Institut international de recherche sur la paix de Stockholm (Sipri) lundi. Les augmentations ont été particulièrement marquées en Europe et en Asie.

- CEO pay soared in 2025, 20 times faster than workers’ pay (theguardian.com)
- The most severe Linux threat to surface in years catches the world flat-footed (arstechnica.com)
CopyFail threatens multi-tenant servers, CI/CD work flows, Kubernetes containers, and more.
- Tech giants face new levy to pay for Australian news as Meta calls position ‘simply wrong’ (theguardian.com)
Anthony Albanese has urged Google, Meta and TikTok to make deals with Australian media outlets to avoid a dedicated 2.25 % levy on local revenues, warning digital giants should not be able to exploit the work of journalists to boost profits.
- Humanoid robots start sorting luggage in Tokyo airport test amid labor shortage (arstechnica.com)
Humanoid robots could load cargo and clean aircraft cabins at Haneda Airport.
- The quiet layoffs sweeping China’s tech giants (restofworld.org)
Alibaba reduced its head count by a third in 2025, while Baidu’s workforce declined nearly 7 %. “There’s constant churn,” a Chinese tech worker said.
- India reels under severe heatwave ; 98 of world’s hottest cities recorded in country (newindianexpress.com)
- 43 °C à New Delhi : la canicule touche l’Inde de plus en plus tôt (reporterre.net)
- Big Tech is moving data out of the Gulf through Iraqi oil pipelines (restofworld.org)
U.S. hyperscalers secure “dark fiber” capacity along Iraqi land route to reduce latency and provide a backup to vulnerable subsea cables.
- Botswana Finally Removes Anti-Gay Law From the Books (gayexpress.co.nz)
- GenZ 212. « L’affaire de l’autoroute », ou la banqueroute du système judiciaire marocain (orientxxi.info)
Une police judiciaire chargée de vider les rues des manifestants et de les envoyer grossir les rangs de la population carcérale ; un parquet aux ordres de celle-ci ; un juge d’instruction dont « l’intime conviction » tombe toujours du bon côté : celui de la vengeance politico-policière.
- Germany launches program to bring open source maintainers into standards bodies (biometricupdate.com)
Sovereign tech agency pilot will fund and train developers to participate in ISO, W3C and IETF standards work
- Robot dogs with Musk and Zuckerberg heads roam around Berlin museum in Beeple’s new exhibit (apnews.com)
Robot dogs with hyper-realistic silicone heads modeled after world-renowned figures — including Elon Musk, Mark Zuckerberg, Jeff Bezos, Andy Warhol and Pablo Picasso — can be seen roaming around a Berlin museum, occasionally “pooing” printed images of their surroundings which they’ve previously captured with integrated cameras.
- Une anomalie au LHC laisse entrevoir une percée majeure en physique des particules (theconversation.com)
- It’s not just spyware scandals : EU is funding the industry that spies on Europeans (edri.org)
- Eurail breach exposes passport data, fuels dark web identity trade (biometricupdate.com)
- Norway, Turkiye, Malaysia pursue social media age restriction (biometricupdate.com)
Legislative momentum picking up globally, but risk is higher in authoritarian regimes
- Youth organisations demand social media change, not bans (edri.org)
31 youth organisations and youth activists have joined forces to speak up against their own exclusion. They warn that the real solution lies in addressing the root cause of the problem : the design and business model of platforms.

- How 2 men smashed through a marathon barrier long thought unbreakable (theconversation.com)
- Stop New York’s Attack on 3D Printing (eff.org)
New York’s proposed 2026-2027 budget currently includes provisions that will require all 3D printers sold in the state to run print-blocking censorware—software that surveils every print for forbidden designs.
- 1er Mai dans le monde : « Black-out » anti-Trump aux États-Unis, « renaissance » syndicale en Europe (basta.media)
- This World Press Freedom Day, American journalists are under attack (freedom.press)
For years, World Press Freedom Day on May 3 has helped spotlight global press freedom violations. It’s a day to demand justice for journalists murdered in Gaza and Lebanon, or to celebrate the release of wrongfully detained reporters like Ahmed Shihab-Eldin. Holding foreign regimes accountable for press freedom is essential. But this year, the U.S. needs to take a hard look in the mirror, too.
- « Bosswares » : au nom de l’efficacité, la surveillance de masse se déploie au travail (synthmedia.fr)
- L’abandon d’une stratégie vieille de 250 ans… Ce que change la fin de l’obligation vaccinale dans l’armée américaine (theconversation.com)
Pour la première fois depuis près de 80 ans, les militaires états-uniens ne seront plus tenus de recevoir le vaccin annuel contre la grippe.
- Florida Republicans reject plan to weaken childhood vaccine requirements (arstechnica.com)
Just minutes into a special session on Tuesday, Florida House Speaker Daniel Perez announced that the Republican-led chamber would not take up a proposal from DeSantis to allow children to opt out of certain school vaccination requirements. The move effectively killed the proposal, which had been backed by the Senate.
- Des chercheureuses découvrent qu’un simple rhume pourrait freiner la propagation du cancer (slate.fr)
On les redoute chaque hiver, mais les virus respiratoires pourraient cacher un secret médical inespéré. Une étude récente montre qu’une infection banale peut stopper la progression de métastases cancéreuses vers les poumons, en réveillant les défenses naturelles de l’organisme.
Voir aussi Catching a cold can delay cancer from spreading to the lungs (newscientist.com)
- Eugénisme, racisme et rhétorique trumpienne : la dérangeante obsession des États-Unis pour le QI (slate.fr)
- TrumpWatch (multinationales.org)
Le retour aux affaires de Donald Trump a galvanisé les forces les plus réactionnaires, et entraîne une reconfiguration profonde de la donne géopolitique et des relations entre l’économique et le politique, l’argent et le pouvoir.
- Taxer les ultra-riches : le référendum qui affole la Silicon Valley (lesoir.be)
Un projet de taxe sur les milliardaires pour financer le système de santé en Californie a recueilli assez de signatures pour permettre l’organisation d’un référendum en novembre. Avec cette taxe, les milliardaires californiens seraient taxés à hauteur de 5 % de leur patrimoine.
- « On a le pistolet sur la tempe » : face à l’extrême droite, ces habitant·es tentent de sauver les glaciers argentins (reporterre.net)
RIP
- Disparition du peintre allemand Georg Baselitz (humanite.fr)
Figure majeure de ce que l’on a appelé le néo-expressionnisme allemand, le peintre allemand aux figures inversées se sentait comptable de l’histoire.
Spécial IA
- Google and Pentagon reportedly agree on deal for ‘any lawful’ use of AI (theverge.com)
The classified deal apparently doesn’t allow Google to veto how the government will use its AI models.
- Au Congrès et sur X, la coalition de Trump se fissure autour des technologies de surveillance fédérales assistées par « l’IA » (legrandcontinent.eu)
Passé presque inaperçu en Europe, l’intense débat politique autour d’un éventuel « kill switch » obligatoire pour les voitures neuves d’ici 2027 aux États-Unis révèle l’écart de plus en plus manifeste entre deux composantes clefs de l’alliance trumpiste, à quelques mois des élections de mi-mandat.
- Elon Musk and OpenAI CEO Sam Altman head to court in high-stakes showdown over AI (apnews.com)
- The hidden cost of Google’s AI defaults and the illusion of choice (arstechnica.com)
- ChatGPT : OpenAI officialise la surveillance de vos conversations dans un billet de blog surréaliste (lesnumeriques.com)
OpenAI détaille pour la première fois l’infrastructure qu’elle déploie pour scanner, analyser et potentiellement signaler aux autorités les échanges de ses abonnés. Sous couvert de prévention des violences, l’entreprise officialise un dispositif de renseignement comportemental privé, sans cadre juridique contraignant ni contrôle extérieur.
- Sam Altman is “the face of evil” for not reporting school shooter, says lawyer (arstechnica.com)
OpenAI could have prevented one of the deadliest mass shootings in Canada’s history, a string of seven lawsuits filed Wednesday in a California court alleged.
- En 9 secondes, cet agent IA a détruit la base de prod de PocketOS (it-connect.fr)
Railway stocke les sauvegardes de volume sur le même volume que les données sources. Comme l’indique la documentation – que n’ont sûrement pas lue les développeurs ni même l’IA -, la suppression d’un volume entraîne la suppression de toutes ses sauvegardes. Oui, ça fait mal, surtout quand le backup récupérable le plus récent date de trois mois…
- Wipe your own code … Now with agentic AI ! (freedom.press)
- AI agents operating continuously at machine speed are breaking human-centric IAM (biometricupdate.com)
“agents are being deployed into production faster than enterprises can govern them, exposing gaps in identity systems designed for human users.”
- LLMs Corrupt Your Documents When You Delegate (arxiv.org)
Our large-scale experiment with 19 LLMs reveals that current models degrade documents during delegation : even frontier models (Gemini 3.1 Pro, Claude 4.6 Opus, GPT 5.4) corrupt an average of 25 % of document content by the end of long workflows, with other models failing more severely.
- 40 % des « gains de productivité » de l’« IA » sont engloutis par la correction d’erreurs (cio-online.com)

- GitHub will start charging Copilot users based on their actual AI usage (arstechnica.com)
GitHub says it can no longer absorb “escalating inference cost” from it heaviest AI users.
Voir aussi Microsoft’s GitHub shifts to metered AI billing amid cost crisis : The all-you-can-eat AI buffet is coming to an end (theregister.com)
- Hashicorp co-founder Mitchell Hashimoto says GitHub ‘no longer a place for serious work’ (theregister.com)
- The AI Compute Crunch Is Here (and It’s Affecting the Entire Economy) (404media.co)
- Ubuntu’s AI plans have Linux users looking for a ‘kill switch’ (theverge.com)
- OpenAI Bans Goblins, Gremlins From Codex After Strange AI Behavior (analyticsinsight.net)
OpenAI added unusual guardrails to its coding tool Codex after users noticed strange references to goblins and gremlins appearing in technical responses. The move highlights growing concerns about the unpredictable behavior of advanced AI models.
Voir aussi ChatGPT Became So Obsessed With Goblins That OpenAI Had to Intervene (slashdot.org)
- Canva Admits Its AI Tool Removed ‘Palestine’ From Designs, Apologizes for Any Distress It Caused (gizmodo.com)
Graphic design platform Canva has a number of AI tools available to users, but it turns out they have some real strong editorial opinions—including removing the word “Palestine” from designs.
- Le chatbot de Mistral serait un « vecteur de propagande étrangère » relayant de fausses informations, relève un rapport (ouest-france.fr)
L’organisme Newsguard a publié un rapport ce mardi 28 avril mettant en évidence les fragilités du chatbot Le Chat de Mistral face à la désinformation d’État. Testée sur dix fausses informations liées à la guerre en Iran, l’outil français d’intelligence artificielle a été qualifié d’important « vecteur de propagande étrangère. »
- Le Parlement européen et l’IA générative : une résolution qui nomme les violations sans les sanctionner (synthmedia.fr)
- South Africa’s Draft AI Policy Withdrawn Due to ‘Fictitious’ AI-Generated Citations (slashdot.org)
- Officials hugely underestimated impact of AI datacentres on UK carbon emissions (theguardian.com)
Revised figures increase fears about energy-intensive datacentres worsening climate emergency
- AI doom warnings are getting louder. Are they realistic ? (nature.com)
- The people building AI think it might be conscious. That’s not the most alarming part (the-independent.com)
The reason people believe that chatbot AIs like ChatGPT, Claude or Gemini have feelings is because of the way we process language, says Professor Emily Bender. “So what we have are systems that are very good at mimicking the way people use language […] The fact that these systems output ‘I/me’ pronouns is totally a design choice […] There’s no ‘I’ inside of there, but the fact that it is set up to behave as a conversation simulator where it’s not just outputting academic-looking text, but responses back and forth, again heightens that illusion.”
- AI Cannot Self Improve and Math behind proves it (smsk.dev)
the very mechanism people proposed to transcend human limitations – training on AI-generated data to break free from the finite supply of human knowledge – is mathematically proven to destroy the model’s representation of reality.
- The more young people use AI, the more they hate it (theverge.com)
Caught between fears of job loss and social stigma, Gen Z’s opinions of AI are hitting new lows.
- A college instructor turns to typewriters to curb AI-written work and teach life lessons (apnews.com)
- Les acteurices et les scénarios générés par IA exclus par l’Académie des Oscars (france24.com)
Les organisateurs des Oscars ont publié, vendredi, de nouvelles règles : pour être éligibles aux récompenses, les performances d’acteurs et les scénarios doivent être le fruit d’êtres humains. Cette décision intervient après qu’une version de l’acteur Val Kilmer générée par IA a été présentée à un public d’exploitants de salles de cinéma, un an après sa mort.
- Women sue the men who used their Instagram feeds to create AI porn influencers (arstechnica.com)
- Minnesota passes ban on fake AI nudes ; app makers risk $500K fines (arstechnica.com)
Under the law, developers of websites, apps, software, or other services designed to “nudify” images risk extensive damages, including punitive damages, if a victim decides to sue. Their offending products could also be blocked in the state. Additionally, Minnesota’s attorney general could impose fines up to $500,000 per fake AI nude flagged. Any fines collected would be used to fund services for victims of “sexual assault, general crime, domestic violence, and child abuse,” the law stipulates.
- Everything that went wrong with Claude (clawd.rip)
- AI backlash is coming for elections (theverge.com)
- Intelligence artificielle : les patrons du secteur cibles de violences, que signifie ce phénomène ? (sudouest.fr)
Un cocktail molotov lancé contre la grille de la maison du patron d’OpenAI, Sam Altman. Une salve de 13 balles tirées sur la porte de Ron Gibson, élu local d’Indianapolis et soutien d’un projet de construction de centre de données : plusieurs personnalités de l’intelligence artificielle (IA) ont ainsi récemment été la cible d’actes violents
Spécial guerre(s) au Moyen-Orient
- La perspective d’un blocus long en Iran n’a pas tardé à faire s’envoler les cours du pétrole (huffingtonpost.fr)
Les États-Unis penchent pour un blocus long sur les ports iraniens, trouvant cette méthode « un peu plus efficace que les bombardements ».
- The clandestine network smuggling Starlink tech into Iran to beat internet blackout (bbc.com)
“If even one extra person is able to access the internet, I think it’s successful and it’s worth it”
- Drone strikes on data centers spook Big Tech, halting Middle East projects (arstechnica.com)
A data center developer has paused all Middle East project investments after one of its facilities was damaged by an Iranian missile or drone attack. The decision comes as the Iran war is forcing Silicon Valley investors and tech companies to rethink a trillion-dollar plan to build more AI and cloud data centers in Gulf countries.
- Amazon stuck with months of repairs after drone strikes on data centers (arstechnica.com)
AWS stops billing Middle East cloud customers as repairs to war damage drag on.
- La peine de mort réservée aux Palestinien·nes : Israël recycle un manuel colonial (contretemps.eu)

- Gaza. La France claque la porte au nez des artistes et chercheureuses palestinien·nes (orientxxi.info)
Pendant que le génocide se poursuit à bas bruit à Gaza, le programme d’accueil en France des universitaires et artistes palestinien·nes tourne au ralenti, voire a été interrompu. Sous différents prétextes, les autorités multiplient les mesures discriminatoires, sans égard pour l’anéantissement de la vie universitaire et culturelle dans l’enclave palestinienne.
- Israel intercepts and detains crews of Gaza aid flotilla near Crete (theguardian.com)
Flotilla organisers said in a press release : “Israel’s actions … mark a dangerous and unprecedented escalation, the abduction of civilians in the middle of the Mediterranean, over 600 miles from Gaza, in full view of the world.”
- 170 militant·es de la flottille pour Gaza libéré·es (humanite.fr)
Israël innove dans la violation du droit international. Ses forces armées auraient détenu durant 40 heures les militants sur un bateau prison où ils auraient été violemment battus. Les ressortissants français sont arrivés ce matin après de multiples interventions auprès du ministère français des Affaires étrangères
- Flottille pour Gaza : Thiago Avila et Saif Abu Keshek emmenés de force en Israël (humanite.fr)
Arrêtés en même temps que près de 175 militants qui entendaient rejoindre les côtes de Gaza, mais libérés depuis, les deux hommes eux sont toujours aux mains des forces armées israéliennes qui entendent les « interroger ».
- Personne ne sait comment retirer ce drapeau palestinien accroché au sommet du plus haut monument de Dublin (huffingtonpost.fr)
L’objet est apparu en septembre dernier au sommet de la Spire, une aiguille d’acier de 120 mètres plantée en plein centre-ville de la capitale irlandaise. Depuis, il résiste à toutes les tentatives envisagées pour le décrocher.
Spécial femmes dans le monde
- En Haïti, face à la terreur, la puissance et la résistance des femmes (basta.media)
- Woman’s Talkspace therapy app sessions exposed in court (proofnews.org)
- “Norway and France launch joint police probe into diplomats’ alleged links with Epstein (euronews.com)
- Women 7 alerte : Les inégalités de genre sont toujours absentes du G7 (lesnouvellesnews.fr)
Le G7, qui se tiendra en juin 2026 en France, passe sous silence les sujets liés aux inégalités entre femmes et hommes, renforcées par la crise climatique. La coalition féministe internationale Women 7 tire la sonnette d’alarme.
Spécial France
- Hadopi : la fameuse « réponse graduée » se fait dégommer par le conseil d’État (next.ink) – voir aussi Hadopi (2009–2026) (laquadrature.net)
Aujourd’hui, le Conseil d’État a donné raison à La Quadrature du Net, French Data Network (FDN), Franciliens.net et la Fédération FDN. Il a reconnu que le système de surveillance de la Hadopi (opéré depuis 2021 par l’Arcom) n’est pas compatible avec le respect des droits fondamentaux protégés par l’Union européenne.
- Piratage de l’ANTS : un jeune de 15 ans placé en garde à vue à Bastia après la fuite massive de données (corsematin.com)
Il se serait rendu lui-même au commissariat, accompagné d’un membre de sa famille, et aurait reconnu, lors de ses auditions, être l’auteur de ce piratage. L’adolescent aurait justifié ses actes en expliquant vouloir alerter le grand public sur les vulnérabilités de ce site officiel.
- Le Conseil d’État confirme la dissolution de la Jeune Garde (humanite.fr)
- Le Conseil d’État met la pression pour rendre effectif le port du « RIO », le numéro d’identification des forces de l’ordre (huffingtonpost.fr)
La haute juridiction administrative donne jusqu’à fin 2026 pour généraliser des identifiants plus visibles, encore trop peu portés sur le terrain.
- Campus IA à Fouju : un « château » de 50 milliards aux portes de Vaux-le-Vicomte (ntvnews.fr)

- Chargeur universel : dès dimanche, le port USB-C devient obligatoire pour tous les nouveaux ordinateurs portables vendus (ici.fr)
- Mécénat d’entreprise : quand le groupe Wendel transforme la solidarité en business (humanite.fr)
En 2020, le fonds d’investissement français aurait utilisé le dispositif du mécénat de compétences pour investir un nouveau créneau commercial, comme la prévention des situations de violence à l’hôpital. Un détournement de l’esprit du dispositif dénoncé par un lanceur d’alerte.
- Paris va doubler sa taxe sur les logements vacants (reporterre.net)
La taxe sur la valeur locative cadastrale passera de 17 % à 30 % durant la première année de vacance d’un bien. Un pourcentage qui grimpera jusqu’à 60 % au bout de deux ans de vacance.
- Flambée de la facture du gaz, repas à 1 euro pour les étudiants, hausse du prix du titre de séjour… Ce qui change au 1er mai (humanite.fr)
- “On a été étonnés” : ce que révèlent dix ans de “zéro pesticide” sur des cultures soi-disant dépendantes du “parapluie chimique” (lamontagne.fr)
Une étude sur dix ans coordonnée par l’Inrae, dont les résultats viennent d’être publiés, montre que l’on peut se passer totalement de pesticides dans les grandes cultures (blé, colza, orge, betterave…) tout en obtenant des rendements satisfaisants et en préservant la viabilité économique des exploitations.
Voir aussi Une étude expérimentale menée sur 10 ans montre le potentiel de systèmes de production agricoles sans pesticides (inrae.fr)
Spécial femmes en France
- Les filles perdent à nouveau du terrain en mathématiques (lesnouvellesnews.fr)
Une étude internationale alerte : les filles reculent en mathématiques à l’échelle mondiale. Un phénomène précoce et massif, particulièrement marqué en France.
- Festival de la BD d’Angoulême : l’amorce d’un changement au féminin (lesnouvellesnews.fr)
Après un boycott, et un girlcott, le festival international de la bande dessinée d’Angoulême a trouvé un nouveau patron… ou plutôt deux nouvelles patronnes : Céline Bagot et Marie Parisot. La promesse d’un nouveau souffle inclusif et féministe pour l’édition 2027.
- Femmes, travail et mort subite : « Sur la santé au travail des femmes, il y a une cécité qu’il faut lever » (basta.media)
Les maladies cardiovasculaires sont la première cause de mortalité chez les femmes, et elles peuvent être liées au travail. Marie Pezé, docteure en psychologie, nous explique pourquoi, et comment, améliorer la prévention.
- Travail de nuit, produits toxiques : la lutte des femmes pour faire reconnaître leurs cancers professionnels (basta.media)
Plus de 10 000 femmes meurent d’un cancer du sein chaque année en France, 3000 d’un cancer de l’ovaire, 800 d’un cancer du col de l’utérus.
- « Le travail de nuit augmente le risque de cancer du sein de 30 % » : enquête sur les cancers professionnels des femmes (basta.media)
Plus de 10 000 femmes meurent d’un cancer du sein chaque année en France, 3000 d’un cancer de l’ovaire, 800 d’un cancer du col de l’utérus. Combien d’entre elles sont tombées malades à cause de leur travail ?
- Business ou morale ? Comment les concerts de Patrick Bruel mettent ces festivals dans l’embarras (huffingtonpost.fr)
Les festivals où Patrick Bruel est programmé cet été sont percutés de plein fouet par les accusations d’agressions sexuelles qui pèsent sur le chanteur français.
- À Strasbourg, viols et silence dans le collectif Femmes, Vie, Liberté (revueladeferlante.fr)
Deux femmes – dont l’une a porté plainte – accusent de viol l’acteur Sina Parvaneh, Iranien réfugié politique dans la capitale alsacienne. La parole de ces femmes n’a pas été prise au sérieux par ceux et celles qui ont été alertées, alors que l’homme qu’elles accusent est membre d’une association culturelle influente, Strass’Iran.
- Contre « l’académie du viol », la Fondation des femmes et M’endors pas réclament l’ouverture d’une enquête (lesnouvellesnews.fr)
Des journalistes de la chaîne américaine CNN ont révélé l’existence d’une « académie mondiale du viol », où des hommes s’apprennent mutuellement à droguer et violer leurs conjointes. Suite à ces révélations, la Fondation des femmes et M’endors pas ont saisi la justice pour qu’une enquête soit ouverte.
- Affaire Pelicot, guet-apens homophobes : le site Coco fait son retour et devient Cocoland (france24.com)
Coco, rebaptisée Cocoland, est de nouveau dans le viseur des autorités, qui enquêtent sur la réapparition de cette plateforme fermée par la justice en 2024. Elle est soupçonnée d’avoir servi de vecteur à des agressions sexuelles – notamment dans l’affaire Pelicot – ainsi qu’à des guet-apens homophobes.
- Féminicide : la « femme dans le tonneau », tuée il y a 22 ans, a enfin retrouvé une identité (humanite.fr)
L’identité de la victime dont le corps avait été découvert sur le bord d’une route en janvier 2005 a été confirmée au terme d’une enquête pilotée par Interpol. Elle s’appelle Hakima Boukerouis. […] le suspect – interpellé en juin 2025 – est le mari de Hakima Boukerouis, soupçonné d’avoir commandité son meurtre. Mis en examen et écroué, il a été libéré sous contrôle judiciaire en septembre 2025 en raison de son âge et de son état de santé.
Spécial médias et pouvoir
- Vincent Bolloré resserre son contrôle sur son empire médiatique et culturel (multinationales.org)
À l’Assemblée nationale, l’extrême droite a réussi à faire adopter un rapport à charge contre le service public de l’audiovisuel, influencé et soutenu par les médias Bolloré.
- Le groupe Lagardère a tenté de peser sur la commission d’enquête sur l’audiovisuel public (lemonde.fr)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- Le Premier ministre fait dépublier un guide de l’Ademe et de l’OFB sur la transition écologique (reporterre.net) – le guide en question.
- Comment un décret va signer la mort de l’énergie solaire alternative (reporterre.net)
C’est une idée simple, presque trop simple pour ne pas inquiéter : partager l’électricité solaire, parfois hydraulique, entre voisins, à l’échelle d’un quartier, d’un village, d’une zone d’activité […] Sauf qu’un projet de décret, passé en catimini, vient changer les règles du jeu et tue dans l’œuf des dizaines de projets alternatifs. Ce, alors que le système cartonne en France.
- Lecornu supplie Total d’aller plus loin dans le plafonnement des prix à la pompe (huffingtonpost.fr)
- Après le 1er mai, Lecornu dépeint en « Premier ministre voyou » par une partie de la gauche (huffingtonpost.fr)
La France insoumise, notamment, accuse le Premier ministre de « tentative de faire échec à l’exécution de la loi » après qu’il a soutenu un boulanger verbalisé.

- Lobbying pour Shein : les aveux tardifs de Christophe Castaner (multinationales.org)
l’ex ministre macroniste a fini par passer aux aveux dans ses récentes déclarations à la Haute autorité pour la transparence de la vie publique. Mais il reste encore beaucoup de zones d’ombre sur son embauche par le géant chinois, et l’affaire illustre les lacunes persistantes de l’encadrement des « portes tournantes » en France.
- Des cosmétiques toxiques autorisés encore 15 mois dans les magasins (reporterre.net)
Le verdict est tombé le 29 avril à midi : les eurodéputés ont adopté à une très large majorité (540 voix pour, 60 contre et 45 abstentions) le paquet législatif « Omnibus VI ». Cet ensemble de mesures, proposé par la Commission européenne, vise notamment à prolonger l’utilisation de substances cancérogènes, mutagènes et toxiques pour la reproduction (CMR) dans les produits cosmétiques.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- L’atelier Missor et ses sculpteurs français à la poursuite du rêve américain technofasciste (streetpress.com)
Elon Musk les adore, la Silicon Valley les finance et l’extrême droite française les connaît bien. Depuis quelques mois, « Missor » et son équipe, connus pour leurs statues de Jeanne d’Arc et de Napoléon, ont pris un opportuniste virage états-unien.
- Patriots Network : enquête sur le réseau qui agrège les figures montantes de l’extrême droite mondiale (basta.media)
Lancé par un ancien responsable du RN, Patriots Network s’emploie à mettre en lien et former les futures élites de l’extrême droite mondiale. Un réseau fortement influencé par les États-Unis trumpistes et le mouvement MAGA.
- Matelots indonésiens en Bretagne, une main d’œuvre corvéable à merci (splann.org)
Allègement des règles sociales, discrimination salariale et disparition des syndicats de défense des matelots… Pour survivre, la pêche bretonne fait le choix du recours à de la main-d’œuvre étrangère, essentiellement indonésienne. Au risque d’ériger l’exploitation des marins comme nouveau modèle.
Spécial résistances
- 1er-Mai : plus de 300 000 manifestant·es en France selon la CGT, 158 000 selon les autorités (huffingtonpost.fr)
Syndicats et manifestant·es ont défilé pour des hausses de salaires sur fond de guerre au Moyen-Orient et contre la remise en cause du caractère férié et chômé du 1er-Mai.
Voir aussi À Paris, un 1er mai pour ne pas « toucher au repos du prolo » (humanite.fr)

- Appel (soutienauxinculpeesdu8decembre.noblogs.org)
En 2023 les 7 inculpées du 8/12 étaient condamné.es pour terrorisme avec des peines de prison ferme, fichage européen, interdictions de communication… 6 d’entre elleux font appel de cette décision. Même si on ne pourra pas être toustes présent.es au tribunal à Paris, il est important de se mobiliser à l’extérieur pour afficher notre soutien et empêcher que la justice et l’État nous invisibilisent !
RASSEMBLEMENT le 4 MAI à 13h face à la Cour d’Appel
- « Les menaces, c’est terminé » : la jeunesse tient tête au maire RN de Carcassonne (reporterre.net)
- « Malgré l’OQTF, je continue d’aller en cours pour être ingénieur » (streetpress.com)
En France, les conditions pour être régularisé sont de plus en plus difficiles, notamment pour les élèves dans les lycées. Depuis plusieurs mois, ils sont nombreux comme Saïd, Fernando ou Marco à cumuler études, galères administratives ou OQTF.
- L’Atelier Paysan : face à la liquidation, élargissons le mouvement (latelierpaysan.org)
- Lettre ouverte à la ministre de la Culture pour le maintien des aides au spectacle vivant (humanite.fr)
- Dominique A renonce à se produire à L’Olympia à cause de Vincent Bolloré (huffingtonpost.fr)
Le chanteur a annoncé qu’il ne se produirait plus dans les salles parisiennes propriétés du « milliardaire d’extrême droite ».
Spécial MAGAM et cie
- Meta cuts contractors who reported seeing Ray-Ban Meta users have sex (arstechnica.com)
In February, numerous workers from a company that Meta contracted to perform data annotation for Ray-Ban Meta reported viewing sensitive, embarrassing, and seemingly private footage recorded by the smart glasses. About two months later, Meta ended its contract with the firm.
- Inside Microsoft’s wave of executive departures (theverge.com)
The departures have impacted every part of Microsoft, including CoreAI, Windows, Office, and GitHub. With previously unreported changes at Amazon weighing on employees’ minds, and GitHub growing increasingly less independent, Microsoft is now changing up its annual rewards and performance programs to respond to the departures.
Les autres lectures de la semaine
- The Technological Republic : le manifeste de Palantir déploie son fond idéologique (synthmedia.fr) – voir aussi Palantir agit comme une entité parasite qui s’installe au cœur de l’État (synthmedia.fr)
- Espagne : Récit d’une victoire pour la régularisation des Sans-papiers (enass.ma)
- Dans les bas rapiécés de l’homme le plus riche des États‑Unis, le travail oublié des femmes américaines (theconversation.com)
Bien que Girard ait été marié, son épouse Mary fut internée pour troubles mentaux à l’hôpital de Pennsylvanie en 1790, et le couple n’eut pas d’enfants.
À ce sujet, on pourra consulter la page Wikipédia anglaise consacrée à Mary Lum Girard (en.wikipedia.org)
- Féministes de l’Est (laviedesidees.fr)
Un recueil consacré à la pensée féministe polonaise montre la richesse du mouvement, des années 1900 au tournant queer en passant par la période socialiste. Cette histoire méconnue ouvre la voie à une généalogie et une comparaison des sororités européennes.
- The male loneliness epidemic (blog.mindlair.fr)
Somebody takes away your ability to feel and calls it “becoming a man”. Somebody takes your need for closeness and renames it weakness. Somebody takes your hunger for connection and replaces it with yearning. And then they tell you that a woman is the only place you’re allowed to put it all. And then they tell women that they’re selfish for not wanting to carry the weight of an entire gender’s emotional amputation. That’s what they do. […] You’re blaming women, because if you blame the system you’d have to face the fact that the system stole your entire emotional life before you were old enough to address it. […] You’d have to face the fact that you were not raised you were hollowed out […] You have to face the fact that your rage is grief in armour […] your numbness is a childhood tomb […] everything you call strength was built on the burial of your humanity.There is no male loneliness epidemic. It doesn’t exist. There’s only a mass unmarked grave of men of died emotionally at seven years old and kept walking.
- Hunting ‘Man the Hunter’ (aeon.co)
For a century, this theory of human origins has died and returned. To free it from limbo, we must disentangle its many meanings
Les BDs/graphiques/photos de la semaine
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Les vidéos/podcasts de la semaine
- « Tchernobyl, une tragédie sans fin » : sur France 2, une nouvelle série documentaire revient sur les fantômes de la catastrophe nucléaire (humanite.fr)
- Podcast sur l’histoire de la création du Rojava (labogue.info)
- Féminisme et héritage – avec Camille Masclet (spectremedia.org)
une plongée dans les luttes féministes des années 70 à 80 pour comprendre les rouages des socialisations féministes, les effets de ce militantisme sur les trajectoires sociales, familiales et intimes de femmes lyonnaises et grenobloises qui se sont engagées dans ces combats.
Les trucs chouettes de la semaine
- Bienvenue sur FranceFuites (francefuites.com)
Le premier portail public à assumer pleinement ce que tout le monde sait déjà : vos données personnelles ont fuité, fuient encore, et fuiteront demain. Plutôt que de le cacher, nous en avons fait un service public.
- Les guides accessibilité des Devalideuses 2026 sont sortis et téléchargeables ! (lesdevalideuses.org)
- Avec Mastodon, la fronde discrète des institutions culturelles contre les plateformes (les-enovateurs.com)
Un cercle d’exploration sur le réseau social Mastodon, initié par le ministère de la Culture et le studio PCFH, regroupe plusieurs institutions culturelles françaises depuis juin 2025. Presqu’un an après leurs débuts, elles tirent le bilan de leurs actions sur cette plateforme alternative.
- Un Mastodon libre dans un Fediverse libre (europe-solidaire.org)
- « Dégoogliser » l’éducation ? Le modèle alternatif de PeerTube (theconversation.com)
- After three months on Linux, I don’t miss Windows at all (theverge.com)
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
27.04.2026 à 07:42
Khrys’presso du lundi 27 avril 2026
Khrys
Texte intégral (8325 mots)
Comme chaque lundi, un coup d’œil dans le rétroviseur pour découvrir les informations que vous avez peut-être ratées la semaine dernière.
Tous les liens listés ci-dessous sont a priori accessibles librement. Si ce n’est pas le cas, pensez à activer votre bloqueur de javascript favori ou à passer en “mode lecture” (Firefox) ;-)
Brave New World
- In Australia, platforms skirt age laws, but the problem isn’t age assurance tech (biometricupdate.com)
- Most Australian teens admit the social media ban isn’t working as they try to sidestep age verification blocks with face masks and their parents’ IDs (fortune.com)

- Asia’s clean power transition accelerates fall in global fossil-fuel use (asia.nikkei.com)
- La Chine instrumentalise la crise énergétique pour faire pression sur les Philippines (legrandcontinent.eu)
- India will not force smartphone makers to preinstall Aadhaar app (biometricupdate.com)
Following pushback from smartphone manufacturers such as Apple and Samsung, the Indian government has abandoned its plans to pre-install the Aadhaar biometric authentication app on all new mobile devices sold in India.
- Across Africa, farmers are adopting regenerative agricultural practices that support food sovereignty amid global instability (resilience.org)
- At least 5 dead in Burundi from a mystery illness (cidrap.umn.edu)
An outbreak of a mystery illness in Burundi, a landlocked country located in Africa’s Great Lakes Region, has killed at least five people and sickened 35 others since March 30—a case-fatality rate of 14 %.
- En Russie, Internet est en train de disparaître (legrandcontinent.eu)
- Norway plans to ban social media use by children under 16 (reuters.com)
- La politique anti-LGBT+ de la Hongrie est bel et bien contraire au droit européen (huffingtonpost.fr)
La Hongrie a « violé le droit de l’Union » en « stigmatisant et marginalisant » les personnes LGBT+, a tranché la Cour de justice de l’Union européenne.
- Suisse : Vasectomie en hausse chez les jeunes (lecourrier.ch)
- La ville belge de Namur rompt son jumelage avec Menton, passée à l’extrême droite (huffingtonpost.fr)
La capitale de la Wallonie a décidé, le 21 avril dernier, de mettre fin à son jumelage de 70 ans avec la ville de Menton dans les Alpes-Maritimes. En cause : l’élection un mois plus tôt à la mairie d’Alexandra Masson, la candidate du Rassemblement national.
- Le WWF appelle les Grecs à manger des espèces invasives pour protéger la faune marine (huffingtonpost.fr)
Face à la prolifération d’espèces marines non indigènes, l’ONG recommande de modifier les habitudes de consommation pour soutenir les pêcheurs et préserver les écosystèmes locaux.
- Construire des digues ou déplacer le patrimoine ? Quatre scénarios pour sauver Venise (reporterre.net)
- Prendre le train en Europe : un casse-tête qui favorise l’avion (reporterre.net)
- Derrière la vague de dérégulation, des institutions européennes de plus en plus soumises aux industriels (multinationales.org)
- À Bruxelles, une succession de reculs pour la santé, les droits et la transparence (multinationales.org)
- Europe—not US—first to authorize Moderna’s combo mRNA flu-COVID vaccine (arstechnica.com)
Amid RFK Jr.’s anti-vaccine agenda, Moderna withdrew its FDA application last year.
- La politique antiaméricaine et pro-migrants de Pedro Sánchez : « Le socialiste espagnol se positionne en leader de la gauche occidentale ». (nouvelobs.com)
- « En Espagne, la démocratie se défend par la mémoire » : le gouvernement espagnol décide la dissolution de la fondation Franco (humanite.fr)
Lors de l’anniversaire de la Deuxième République espagnole, le 14 avril dernier, le gouvernement espagnol a franchi la dernière étape menant à la dissolution de la fondation Franco, 50 ans après sa création.
- Des militant·es de Greenpeace installent des éoliennes dans le golf de Trump en Écosse (huffingtonpost.fr)
Les activistes écologistes se sont rendu·es sur le complexe de golf de Donald Trump à Turnberry, en Écosse, pour faire quelques ajustements sur son green.
- UK government says 100 countries have spyware that can hack people’s phones (techcrunch.com)
More than half of the world’s governments have access to commercial spyware that can break into computers and phones to steal sensitive information, according to U.K. intelligence.
- « Se préparer à une éventuelle guerre » : face aux menaces des États-Unis, Cuba organise sa défense (humanite.fr)
- Expecting driverless taxis to respect bike lanes “too high a bar” – because customers want to be dropped off in them, autonomous vehicle firm Waymo tells cyclists (road.cc)
- Zoom has partnered with World, Sam Altman’s iris-scanning identity company (previously known as Worldcoin), to add real-time human verification inside meetings. (digitaltrends.com)
- Palantir posted a manifesto that reads like the ramblings of a comic book villain (engadget.com)
In case you haven’t gotten around to reading Palantir CEO Alex Karp and Nicholas W. Zamiska’s 2025 book, The Technological Republic, (because why would you do that to yourself ?), the company best known for supplying AI-driven defense and surveillance software to the likes of the US Army, ICE and NYPD shared a 1,000-word X post this weekend covering its main points.

- Palantir employees are talking about company’s “descent into fascism” (arstechnica.com)
- Smart glasses and the new DHS surveillance budget (biometricupdate.com)
The Department of Homeland Security’s […] budget justification lays out an expansive biometric and identity tech agenda that stretches from airport checkpoints to ports of entry to immigration enforcement operations, with one of the most striking items buried in the Science and Technology Directorate’s research portfolio : a plan to develop operational prototypes of smart glasses for immigration enforcement agents.
- Trump fires all 24 members of the U.S. National Science Foundation’s governing body (science.org)
- Les États-Unis de Donald Trump rétablissent la peine de mort par peloton d’exécution (huffingtonpost.fr)
Le ministère américain de la Justice veut faciliter le recours à la peine capitale dans les dossiers fédéraux, en allant au-delà de la seule injection létale.
- Prosecutors sought death penalty for Luigi Mangione but not white supremacist behind 2019 Texas Walmart shooting (snopes.com)
A pair of authentic news headlines accurately stated that the U.S. Department of Justice directed prosecutors to seek the death penalty for UnitedHealthcare CEO shooting suspect Luigi Mangione, whereas prosecutors offered a gunman who killed 23 in a racist attack at a Texas Walmart a plea deal to avoid the same sentence.
- Donald Trump évacué du dîner des correspondants à la Maison Blanche après l’irruption d’un homme armé (huffingtonpost.fr)
- Les États-Unis sont devenus une puissance créancière inversée (legrandcontinent.eu)
Privée de son instrument tarifaire, l’administration Trump improvise, et révèle ainsi que sa vision économique est fondée sur une illusion : celle de pouvoir simultanément taxer, attirer les capitaux, relocaliser l’industrie et préserver la domination du dollar sans en payer le prix.
- Maryland becomes first state to pass bill banning ‘surveillance pricing’ (denver7.com)
The practice refers to companies using a shopper’s personal data, such as browsing history, location, or purchasing behavior, to tailor prices to individual customers.
- Maine Passes Millionaires’ Tax and Pushes Back on Federal Changes (itep.org)
- New Gas-Powered Data Centers Could Emit More Greenhouse Gases Than Entire Nations (wired.com)
- Maine Governor Vetoes Data Center Moratorium Bill (yro.slashdot.org)
Maine Gov. Janet Mills vetoed a bill that would have imposed the nation’s first statewide moratorium on new data centers, saying she supported the idea in principle but would not block a major redevelopment project tied to jobs and local investment.
- Community Votes to Deny Water to Nuclear Weapons Data Center (404media.co)
Ypsilanti Township in Michigan is attempting to cut off the flow of water to a planned data center that would power a new generation of nuclear weapons research. On Wednesday, the Township’s Board of Trustees voted to institute a 365 day moratorium on the delivery of water to hyperscale data centers so the township can study the impact of the building’s massive water needs.
Spécial IA
- On a tenté de tuer Sam Altman, et ce n’est que le début : le mouvement anti-IA prend de l’ampleur (ladn.eu)
Attaque contre le domicile de Sam Altman, lutte contre l’implantation de data centers et incitation à ne plus l’utiliser au travail : un peu partout dans le monde, un vent de révolte se lève contre l’IA.
- Le revenu universel élevé, la pilule des gourous de la Tech pour mieux faire passer l’IA (france24.com)
Elon Musk a assuré vendredi que le revenu universel représentait probablement la meilleure solution face à la destruction annoncée d’emplois provoquée par l’IA. Le multimilliardaire pro-Trump rejoint ainsi d’autres gourous de la Tech qui soutiennent cette mesure phare afin de réduire le rôle de l’État.
- L’entreprise chinoise DeepSeek annonce un nouveau modèle d’intelligence artificielle (france24.com)
Un an après avoir secoué le monde de l’intelligence artificielle (IA) en dévoilant un agent conversationnel bien plus économique que ses concurrents américains, le chinois DeepSeek a lancé vendredi un nouveau modèle d’IA plus performant et basé sur l’open source.
- Qu’est-ce que Objection.AI ? La nouvelle plateforme financée par Peter Thiel qui accélère le contrôle de la presse aux États-Unis (legrandcontinent.eu)
- Deezer : L’IA génère près de la moitié des titres mis en ligne chaque jour sur la plateforme musicale (20minutes.fr)
La plateforme assure toutefois les retirer de ses recommandations et en démonétiser certains
- Meta will train AI agents by tracking employees’ mouse, keyboard use (arstechnica.com)
- Pour financer l’IA, Meta va licencier 8 000 personnes, Microsoft lance un plan de départs volontaires (france24.com)
Meta, la maison mère de Facebook et Instagram, a annoncé jeudi le licenciement d’environ 10 % de ses effectifs, soit 8 000 salariés, afin de compenser ses investissements massifs dans l’intelligence artificielle (IA). De son côté, Microsoft a fait part d’un plan de départs volontaires qui pourrait concerner jusqu’à 7 % des équipes, soit environ 8 750 personnes.
- Sacrifice your job for the glorious AI future (disconnect.blog)
How tech CEOs use the threat of job loss to distract from how AI is really used against workers
- Anthropic’s Mythos AI model sparks fears of turbocharged hacking (arstechnica.com)
Cyberdefenses could be exposed faster than fixes could be deployed.
- Anthropic secretly installs spyware when you install Claude Desktop (thatprivacyguy.com)
- Forking Vim to avoid LLM-generated code (lwn.net)
- Florida probes ChatGPT role in mass shooting. OpenAI says bot “not responsible.” (arstechnica.com)
- L’utilisation de l’intelligence artificielle dans la guerre en Iran : que dit le droit international ? (theconversation.com)
Spécial guerre(s) au Moyen-Orient
- Iran claims US exploited networking equipment backdoors during strikes — says devices from Cisco and others failed despite blackout in attack that ‘indicates deep sabotage’ (tomshardware.com)
- Donald Trump prolonge le cessez-le-feu en Iran indéfiniment, mais… (huffingtonpost.fr)
Nouveau revirement du président américain, lui qui avait encore jugé en début de semaine « hautement improbable » une prolongation du cessez-le-feu.
- Israël et les États-Unis mènent une guerre contre le développement de l’Iran (contretemps.eu)
Des universités aux centres de recherche médicale, Israël et les États-Unis détruisent systématiquement l’infrastructure civile, économique, culturelle et scientifique de l’Iran. Tout en prétendant ne s’en prendre qu’aux dirigeants, ils ciblent en réalité l’ensemble du peuple iranien et ses réalisations.
- Guerre en Iran : 30 millions de personnes menacées de pauvreté, l’ONU alerte sur une crise mondiale (humanite.fr)
Le blocage du détroit d’Ormuz menace de mettre en péril la sécurité alimentaire de millions de personnes. « L’interruption du trafic maritime provoque une crise humanitaire et économique de grande ampleur », a alerté l’ONU jeudi 23 avril.
- « C’est comme à Gaza » : Israël veut rendre le Sud-Liban invivable (reporterre.net)
- Report Details Israeli Use of Sexual Violence to Force Palestinians From West Bank Homes (commondreams.org)
“Sexual violence is not incidental to this crisis. It is one of the mechanisms driving people from their land”
- Statement by UNICEF on the killing of two water truck drivers in the Gaza Strip (unicef.org)
UNICEF is outraged by the killing of two drivers of trucks contracted by UNICEF to provide clean water to families in the Gaza Strip.
- Massive Attack, Macklemore et plus d’un millier d’artistes appellent au boycott de l’Eurovision 2026 (huffingtonpost.fr)
Avant son 70e anniversaire, le concours est visé par le plus important mouvement de boycott de son histoire du fait de la participation d’Israël.
- L’Espagne exhorte l’UE à mettre fin à l’accord d’association avec Israël (fr.euronews.com)
L’Espagne et l’Irlande ont été les premières à demander une révision de l’accord en 2024, en raison des inquiétudes suscitées par les tactiques employées lors de la guerre à Gaza, menée en réponse aux attaques du Hamas contre Israël en octobre 2023.
- Exportations d’armes vers Israël : le parquet français saisi d’une plainte (assawra.blogspot.com)
Une plainte pour « complicité de crime de guerre » et « complicité de crimes contre l’humanité » a été déposée ce lundi, par l’Union juive française pour la paix (UJFP) auprès du parquet national antiterroriste (PNAT). Objectif : faire la lumière sur les exportations militaires françaises vers Israël, notamment via l’aéroport Roissy Charles de Gaulle. Contrairement aux affirmations du gouvernement français, les exportations d’armes n’ont jamais cessé, en dépit de la politique génocidaire du gouvernement israélien.
- La guerre en Iran n’épargne pas les préservatifs, touchés eux aussi par la flambée des prix (huffingtonpost.fr)
Le géant malaisien Karex, qui fournit des marques comme Durex, a annoncé que le conflit au Moyen-Orient allait faire augmenter les prix de ses produits.
Spécial femmes dans le monde
- Gaza : plus de 38 000 femmes et filles tuées entre octobre 2023 et décembre 2025 (news.un.org)
- « Le changement climatique est sexiste » : des femmes du Sud global interpellent les États avant le G7 Environnement (reporterre.net)
Spécial anniversaire de Tchernobyl
- Tchernobyl, anatomie d’une catastrophe (arte.tv – disponible jusqu’au 05/06/2026)
- « Nous travaillons gratuitement comme liquidateur·ices nucléaires » (terrestres.org)
La vente de produits radioactifs ne relève pas d’une logique de confinement, mais de prolifération. Et elle est organisée par de nombreux acteurs qui expédient les myrtilles, airelles et champignons cueillis dans les forêts de Tchernobyl aux consommateur·ices partout dans le monde.
- L’utopie nucléaire des villes atomiques de la guerre froide (terrestres.org)
- Non, Tchernobyl n’est pas devenu une réserve naturelle (theconversation.com)
Spécial France
- Enquête sur les dérives de X : Elon Musk ne s’est pas présenté devant la justice française (france24.com)
Le milliardaire Elon Musk devait être entendu lundi en audition libre par le parquet de Paris dans le cadre de l’enquête “sur les éventuelles violations par la plateforme X de la législation française”, notamment les deepfakes sexuels. Le propriétaire de X ne s’est finalement pas présenté devant la justice mais les investigations se poursuivent.
- « Un dévoiement du travail parlementaire » : comment une commission d’enquête sert de tremplin à la désinformation scientifique (reporterre.net)
- le code secret à quatre chiffres des cartes bancaires c’est bientôt fini, on vous explique le nouveau système biométrique (lindependant.fr)
La carte bancaire biométrique remplace peu à peu le code à quatre chiffres. En France, BNP Paribas, Crédit Agricole et Société Générale déploient déjà ces cartes à empreinte digitale, jugées plus sûres et confidentielles.
- L’ANTS, qui gère les cartes d’identité et passeports, visée par une attaque informatique, des données potentiellement divulguées (lemonde.fr)
Nom, prénom, adresse électronique et date de naissance d’usagers sont concernés par les fuites
- Scaleway devient l’hébergeur du Health Data Hub (lemondeinformatique.fr)
À la suite de l’appel d’offres lancé en février dernier, Scaleway a été retenu pour héberger les données du Health Data Hub. Ces dernières étaient depuis l’origine stockées sur le cloud Microsoft Azure, un choix contesté au nom de la souveraineté. La migration vers les infrastructures de la filiale d’Iliad est attendue à la fin 2026 ou au début 2027.
- Le long du littoral marseillais, une industrie numérique qui transforme la ville sans ses habitant·es (synthmedia.fr)
- Stage d’observation : à 15 ans, Calvin est mort au travail à Bagnols-sur-Cèze (altermidi.org)
- Stage obligatoire : silence, on meurt (humanite.fr)
Arnaud et Sandra Darthenay, parents d’Axel décédé à 16 ans lors de son stage de seconde en entreprise, et Anthony Smith, inspecteur du travail et député européen LFI, dénoncent la mise en danger des jeunes à l’occasion des stages obligatoires de troisième et de seconde en entreprise. Ils exigent leur interdiction.
- Hausse des prix du carburant : les usager·es délaissent la voiture et adoptent bus gratuits, vélos et covoiturage pour leurs déplacements quotidiens (france3-regions.franceinfo.fr)
- Déchets radioactifs dans le Massif Central : autour de l’ancienne mine d’uranium des Bois Noirs, un risque inacceptable (lemediatv.fr)
- Cadmium : les flocons d’avoine fortement contaminés, selon une analyse (reporterre.net)
Spécial femmes en France
- Cadmium : les femmes sont davantage impactées (lesnouvellesnews.fr)
En moyenne, les femmes présentent 0,68 microgramme de cadmium par gramme de Cd de créatinine dans les urines, contre 0,47 chez les hommes […] Le taux de fer dans le corps baisse drastiquement dans le corps des femmes à plusieurs moments de leur vie, pendant leurs menstruations ou la grossesse. Or, lorsque la quantité de fer est trop faible dans l’organisme, le cadmium prend sa place.
- Contre la précarité menstruelle, des protections bientôt remboursées mais… (lesnouvellesnews.fr)
le dispositif s’appliquera sur les produits commercialisés dans les pharmacies. Si 60 % des frais sont remboursés, les 40 % restants devraient ensuite être comblés par les complémentaires santé. Or, 5 % des moins de 26 ans ne sont pas couvert·es par une mutuelle […] À cela s’ajoute un scandale sanitaire : les PFAS, les polluants éternels.
- 8 mars férié : la fausse bonne idée de la CGT (problematik-media.com)
- Lesbiennes au travail : sortir de l’invisibilité (theconversation.com)
- Anne Bourrassé : « Dans les musées nationaux, on compte 6 % d’artistes femmes » (lesnouvellesnews.fr)
Lors de la foire d’art contemporain Art Paris, un collectif a révélé le manque criant de parité dans le milieu de l’art. Résultat d’une longue invisibilisation des artistes femmes et de captation du pouvoir par un boys’ club.
- Parité dans la finance ? Les hommes tiennent toujours les cordons de la bourse (lesnouvellesnews.fr)
Selon le Gender Balance Index 2026 publié par l’OMFIF, la présence des femmes dans les postes de direction du secteur financier continue d’augmenter. Mais très lentement. Et sans remettre en cause l’essentiel : les hommes restent largement majoritaires aux postes où se prennent les décisions et où se concentrent le pouvoir et les revenus.
- Discriminations, bizutages, abus de pouvoir : les signalements de violences dans le sport bondissent de 64 % (humanite.fr)
Le bilan 2025 de la cellule Signal-Sports a été dévoilé, ce jeudi 23 avril, par le ministère des Sports. Les signalements ont augmenté de 64 % par rapport à l’année précédente et les victimes sont majoritairement des mineur·es et des femmes.
- Dans le monde agricole, le tabou des violences sexuelles (reporterre.net)
- Trois policiers soupçonnés de violences et de viol au commissariat de Sarcelles placés en garde à vue (huffingtonpost.fr)
Un homme a dénoncé des violences et un viol commis pendant sa garde à vue au commissariat de Sarcelles. Une enquête est menée par l’IGPN.
Spécial médias et pouvoir
- Quand la guerre au Proche-Orient est racontée dans la langue de ceux qui la mènent (acrimed.org)
- Transformer les médias, une urgence démocratique ! (acrimed.org)
- À Auray, on coupe le son à l’émission radio de Guillaume Meurice (ouest-france.fr)
Spécial emmerdeurs irresponsables gérant comme des pieds (et à la néolibérale)
- G7 omits climate change from Paris talks to avoid US clash, France says (france24.com)
A meeting of the G7 nations on the environment begins in Paris on Thursday, but climate change has been left off the agenda to avoid a dispute with the United States, France’s ecology minister Monique Barbut said, citing efforts to preserve unity and focus on less contentious issues during the two-day talks.
- Sur l’immigration, Bruno Retailleau et Jordan Bardella visent l’Espagne sans retenue (ni cohérence) (huffingtonpost.fr)
Le lancement du plan de régularisation massive du gouvernement de Pedro Sanchez provoque des réactions outrées – et disproportionnées – de la droite de l’échiquier politique en France.
- Avec ce déplacement XXL, Macron veut faire taire les critiques en « immobilisme » à un an de son départ (huffingtonpost.fr)
Le président de la République passe la journée dans l’Allier, où il tiendra son Conseil des ministres. Au programme : des « obsessions présidentielles » et une volonté d’exister encore sur le plan national.
- Nouveau « choc de simplification » d’Emmanuel Macron : « L’environnement est sacrifié pour aller plus vite » (reporterre.net)
- Airbus, BNP, Sanofi, Zara… Monique Barbut, ministre de l’écologie, est actionnaire de dizaines de grandes entreprises (vert.eco)
- Le gouvernement veut réautoriser la location des passoires thermiques (reporterre.net)
- PFAS dans les boues d’épandage : Disclose et Reporterre dévoilent le plan du gouvernement pour lutter contre la contamination (disclose.ngo)
- Prix des carburants : le RN veut baisser les taxes mais refuse de taxer les superprofits (basta.media)
Face à la hausse du prix des carburants, le RN propose de baisser les taxes, mais pas de taxer les superprofits des entreprises pétrolières. Et rejette la transition énergétique, alors que notre dépendance aux fossiles coûte de plus en plus cher.
- Ne les appelez plus Ehpad mais Maisons France Autonomie (information.tv5monde.com)
Ne les appelez plus Ehpad : quatre ans après le scandale Orpea, le gouvernement a annoncé samedi son intention de renommer les établissements d’hébergement pour personnes âgées dépendantes en Maisons France Autonomie. Ces établissements doivent être “des lieux où on a envie de vivre et de travailler” et Maisons France Autonomie est “un label qu’on va travailler d’ici septembre”, a indiqué la ministre déléguée chargée de l’Autonomie et des Personnes handicapées, Camille Galliard-Minier

- Pourquoi il nous faut davantage d’arrêts maladie (frustrationmagazine.fr)
Puisque se pencher sur les causes de notre mauvais état de santé au travail impliquerait la mise en cause des managers, des patrons, des hauts fonctionnaires et porter atteinte à la bonne santé des actionnaires, le gouvernement a trouvé un responsable à stigmatiser – le malade. C’est pourquoi le ministre du Travail envisage une batterie de mesures visant à fliquer, contrôler, culpabiliser et, à la fin, forcer les salariés à retourner, même malade, sur leur poste de travail.
Spécial recul des droits et libertés, violences policières, montée de l’extrême-droite…
- 210 jours en CRA, internement psychiatrique… La macronie prépare une nouvelle loi sécuritaire et xénophobe (revolutionpermanente.fr)
L’assemblée nationale examine cette semaine la proposition de loi d’un député macroniste contenant un florilège d’attaques liberticides sous couvert de « prévention des attentats » : extension de la rétention administrative, renforcement de l’injonction de soin psychiatrique, mais aussi des attaques contre les personnes trans.
- Présence de Frontex lors d’une opération d’expulsion à Grande-Synthe (blogs.mediapart.fr)
Le 26 mars, pour la première fois lors d’une opération d’expulsion, Human Rights Observers a constaté la présence d’agents de Frontex, l’agence européenne de garde-frontières et de garde-côtes, à l’origine de nombreuses violations de droits humains fondamentaux.
- Insultes racistes, saluts nazis : à Caen, le “banquet normand” financé par Pierre-Edouard Stérin dégénère (ici.fr)
- Medef : la tentation brune (politis.fr)
Le déjeuner entre le Medef et Jordan Bardella n’a rien d’une surprise : à l’heure des crises, une fraction croissante des élites économiques paraît prête à s’accommoder, voire à s’appuyer, sur des forces autoritaires.
- « Extrêmement inquiétant », Amnesty alerte sur le climat politique « virulent » en France à un an de la présidentielle (huffingtonpost.fr)
Dans son rapport annuel, l’ONG dénonce la banalisation d’attaques contre l’État de droit et met en garde contre un affaiblissement des droits humains.
- Un homme tire à la carabine sur un enfant en proférant des insultes racistes : « Il a cru qu’il allait mourir » (leprogres.fr)
Choc dans la commune d’Espaly-Saint-Marcel. Dimanche 19 avril, un homme âgé de 65 ans a poursuivi des enfants armé d’une carabine à plomb. Il aurait tiré sur l’un d’eux, tout en proférant des insultes racistes. Il a été interpellé et placé en garde à vue. Il fait l’objet d’une convocation par officier de police judiciaire pour des faits de violences avec arme.
Voir aussi L’homme soupçonné d’avoir tiré sur un enfant à la carabine est sorti de garde à vue (leprogres.fr)
« Personne ne nous a prévenus qu’il allait sortir, indique la tante de l’une des victimes, en colère. Il est revenu et il a hurlé sur les enfants, il nous a de nouveau insultés. »
« À plusieurs reprises, des policiers ont refusé de prendre des plaintes »« Personne ne doit subir ces violences-là […] Nous devons dénoncer collectivement la libération de la parole raciste attisée par l’extrême droite. »
- La gare de Luméville, haut lieu de la lutte contre Cigéo, encerclée par les gendarmes (reporterre.net)
- “Votre enfant a été reconnu lors d’une manifestation” : des lycéens marseillais dénoncés par un inspecteur d’académie (laprovence.com)
- Prise de parole face à Yaël Braun-Pivet : une étudiante en conseil de discipline (humanite.fr)
Lors d’une conférence en présence de Yaël Braun-Pivet […] Léa […] a pris la parole pour dénoncer la minute de silence à propos de Quentin Deranque, et a appelé à en faire une pour les victimes de violences policières, d’extrême droite et les Palestiniens victimes du génocide en cours à Gaza. Depuis, le directeur lui a annoncé qu’elle allait passer en conseil de discipline.
Spécial résistances
- Violences létales de la police : Des familles de victimes réunies contre la loi « permis de tuer » (basta.media)
- Austère autonomie : plus de 200 philosophes contre la destruction de l’Université (blogs.mediapart.fr)
- Résister à une mine de lithium dans l’Allier (revuesilence.net)
- À La Hague, la lutte contre l’accaparement des terres par le nucléaire (journal-labreche.fr)
En plus de la construction de six réacteurs de type EPR2, la relance du nucléaire français voulue par Emmanuel Macron prévoit également de prolonger la durée de vie et d’agrandir l’usine de traitement des combustibles irradiés, à La Hague (Manche). Des voix dénoncent la fuite en avant d’une industrie qui prétend recycler ses déchets dans un projet « Aval du futur » jugé écocidaire et dispendieux.
- Réautorisation d’un pesticide interdit depuis 2024 : deux ONG saisissent la justice (reporterre.net)
Encore une nouvelle dérogation pour épandre un pesticide. Celle-ci concerne le Movento, un insecticide du groupe Bayer, utilisé notamment sur les vergers (cerisiers, pêchers, abricotiers, pommiers). Or, la substance active du produit, le spirotétramate, est interdite en Europe depuis 2024.
- Arrêtons de manger du pétrole (politis.fr)
De cette « crise énergétique », ne faisons pas une énième occasion de relancer l’industrialisation de l’agriculture. Il s’agit de mettre en lumière l’immense dépendance de l’agriculture aux engrais fossiles. Et de la faire bifurquer.
Spécial outils de résistance
- À la recherche de l’impôt perdu. Le séparatisme fiscal des ultrariches (france.attac.org)
Cette note d’Attac et de l’observatoire de la justice fiscale revient sur les évolutions de la fiscalité en faveur des plus riches, les idées reçues et faux débats sur ce sujet, et montre qu’il est possible et nécessaire de mieux imposer les plus riches pour financer l’action publique, réduire les inégalités et relever les urgences sociales et écologiques.
- Ravages des pesticides : des citoyen·nes lancent un outil innovant qui rassemble 2 000 études (reporterre.net)
Vous êtes à court d’arguments scientifiques pour dénoncer les pesticides ? Une nouvelle bibliothèque digitale participative vous vient en aide.
Spécial MAGAM et cie
- The GAFAM Empire (gafam.theglassroom.org)
An exploration of acquisitions by big tech companies
- Geek Tragedy. Look upon their works and despair (motherjones.com)
- Google will invest as much as $40 billion in Anthropic (arstechnica.com)
The investment follows Amazon’s $5 billion initial investment in Anthropic a few days ago ; the Amazon deal also leaves the door open to further investment based on performance. Both investments value Anthropic at $350 billion.
- Clicking “reject cookies” might not actually do anything (techspot.com)
Google, Microsoft, and Meta largely ignore cookie opt-outs, independent audit says
- EFF to State AGs : Investigate Google’s Broken Promise to Users Targeted by the Government (eff.org)
Google’s Failure to Warn Users About Law Enforcement Demands for Data Is Deceptive
- Commission designates WhatsApp as Very Large Online Platform under the Digital Services Act (digital-strategy.ec.europa.eu)
- “Il faudra un abonnement mensuel” : WhatsApp bientôt payant pour l’utiliser à 100 % (presse-citron.net)
- Après quinze ans à la tête d’Apple, Tim Cook passe la main à John Ternus son patron de l’ingénierie (huffingtonpost.fr)
Le dirigeant de 65 ans quittera ses fonctions à l’automne après près de quinze ans à la tête du groupe, mais restera impliqué dans sa gouvernance.

- Apple stops weirdly storing data that let cops spy on Signal chats (arstechnica.com)
Previously, Signal president Meredith Whittaker had posted on Bluesky to remind users that they can update Signal settings to “Show ‘No Name or Content’” in push notifications and avoid privacy concerns. Some users agreed that enabling message previews on any kind of device—not just Apple’s—seemed unwise in light of 404 Media’s reporting.
- ‘This craving to go viral is tiresome’ : the artists sick of the pressure to promote on social media (theguardian.com)
how are creative people feeling about having to meet the demands of Silicon Valley algorithms ? “It’s a hideous situation,” says comedian Stewart Lee, who so far has managed a successful career without using social media. “We’re at a real crossroads. The worst people on earth control the means of communication.”
Les autres lectures de la semaine
- Marcel Muller, Luigi Mangione : destins croisés de deux assassins de patrons (theconversation.com)
- L’État de droit : un mythe ? Entretien avec Elsa Marcel (frustrationmagazine.fr)
- Consentement ou résignation : pourquoi ça ne pète pas ? (frustrationmagazine.fr)
- Des manchots de l’Antarctique à l’explicabilité en IA. Bienvenue en prétopologie ! (theconversation.com)
- Jean-Marc Jancovici, l’ingénieur-roi, ses disciples et ses principes (revue21.fr)
- Eau, biosignature et éclair : ce que nous a appris le rover Perseverance après cinq ans sur Mars (theconversation.com)
- How Medieval Cathedrals Were Built Without Science, or Even Mathematics (openculture.com)
- Le sourire et le fusil : fabrique coloniale du tirailleur sénégalais (histoirescrepues.fr)
Derrière la figure familière du tirailleur se cache une construction coloniale qui neutralise la diversité des trajectoires africaines.
- Les femmes, les oubliées de la science sur l’accouchement et l’allaitement (theconversation.com)
- Les protéines animales sont le privilège des hommes depuis 10 000 ans en Europe (humanite.fr)
En analysant les ossements de milliers de squelettes, 10 000 ans d’inégalités alimentaires sont révélés. Les hommes apparaissent plus souvent du côté des régimes les plus riches en protéines animales, les femmes du côté des apports les plus restreints.
- Try the Oldest Known Recipe For Toothpaste : From Ancient Egypt, Circa the 4th Century BC (openculture.com)
Les BDs/graphiques/photos de la semaine
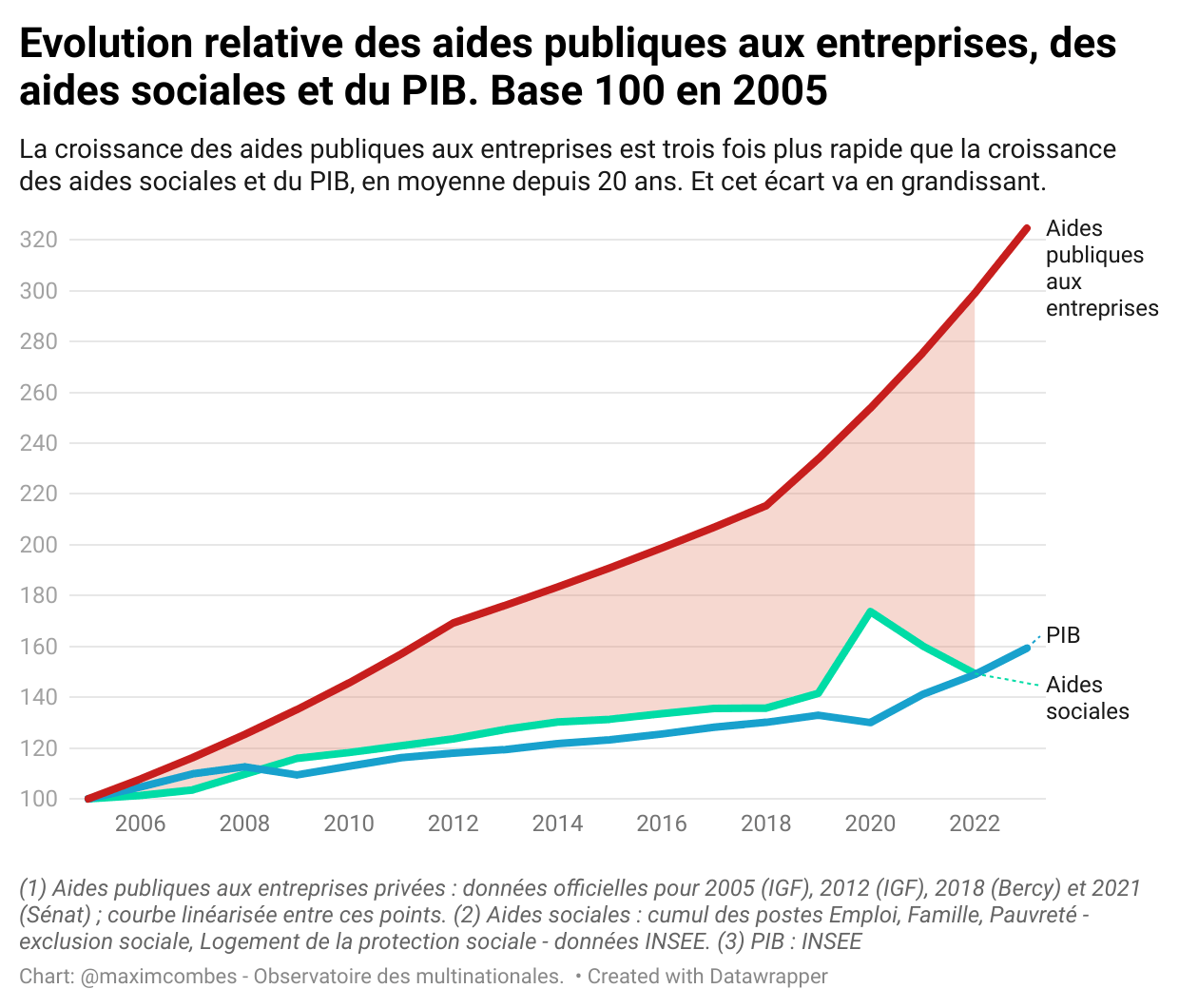{kind=link}
Les vidéos/podcasts de la semaine
- Chasse aux précaires dans le Finistère (radiofrance.fr)
- Primaire de la gauche, service publics, lutte LGBTQ+… Lucie Castets face à l’Huma (humanite.fr)
- Johann Chapoutot sur la production de l’irresponsabilité et la banalité du mal (tube.fdn.fr)
- Baisse des audiences de CNews : que peut-on en conclure ? Décryptage avec Acrimed (humanite.fr)
- Emmanuel Barré sur radio Nova à propos des ex toxiques candidats à la présidentielle (tube.fdn.fr)
- Pourquoi il faut en finir avec CNews (et l’Arcom) (video.blast-info.fr)
- « Toutes des folles » (binge.audio)
Si le poncif de « l’ex folle » est aussi bien installé c’est parce qu’il prolonge l’un des poncifs les plus tenaces du patriarcat : l’idée que les femmes seraient, par nature, instables ou hystériques. Mais ce mythe est surtout un outil de pouvoir qui permet aux hommes de pratiquer le gaslighting : cette manipulation psychologique visant à faire douter une femme de ses propres perceptions et de la réalité des violences qu’elle subit… pour mieux la garder sous emprise.
Les trucs chouettes de la semaine
- « Que tout le monde hérite d’un bien commun » : un nouveau modèle de coopérative de logement pour acheter sans spéculer (basta.media)
Ni locataires ni propriétaires, les membres d’une jeune coopérative lyonnaise veulent constituer un parc collectif de logements pour les sortir de la logique spéculative. Ils ne font pas construire mais achètent des appartements existants.
- À Paris, un hôpital forme des hommes trans aux injections de testostérone (revueladeferlante.fr)
L’hôpital Pierre-Rouquès-Les Bluets (Paris, 12e) a inauguré, le 25 mars 2026, un accueil consacré à la primo-prescription de testostérone pour les personnes transmasculines. […] Actuellement accessible une fois par mois aux personnes transmasculines majeures, la consultation des Bluets pourrait prochainement s’ouvrir aux personnes transféminines.
Retrouvez les revues de web précédentes dans la catégorie Libre Veille du Framablog.
Les articles, commentaires et autres images qui composent ces « Khrys’presso » n’engagent que moi (Khrys).
- Persos A à L
- Carmine
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- Lionel DRICOT (PLOUM)
- EDUC.POP.FR
- Marc ENDEWELD
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Christophe LEBOUCHER
- Michel LEPESANT
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Jean-Luc MÉLENCHON
- MONDE DIPLO (Blogs persos)
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Thomas PIKETTY
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- LePartisan.info
- Numérique
- Thomas BEAUFILS
- Blog Binaire
- Christophe DESCHAMPS
- Dans les Algorithmes
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Fake Tech (C. LEBOUCHER)
- Romain LECLAIRE
- Tristan NITOT
- Francis PISANI
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Scientifiques en Rebellion
- Bondy Blog
- Dérivation
- Économistes Atterrés
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- Rojava Info
- X-Alternative
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- Laura VAZQUEZ
- XKCD