
08.06.2026 à 17:25
Pouvait-on prédire les inondations espagnoles de 2024 ? Le problème de la dérive des données illustré par la climatologie
Rémi Vaucher, Enseignant-chercheur, EPITA
Texte intégral (2708 mots)

Le temps est l’ennemi des statisticiens. Même à l’ère des systèmes d’IA, un modèle météorologique qui serait uniquement fondé sur des données passées et des principes statistiques peut avoir des difficultés à prévoir correctement les quantités de pluie futures, dans le contexte du changement climatique – tout simplement parce que la situation évolue.
Nous avons toutes et tous vu passer les images terribles des inondations espagnoles d’octobre 2024. Avec plus de 200 morts, cet évènement est passé directement au statut d’incident le plus meurtrier survenu en Espagne depuis les inondations de 1962.
D’aucuns pourraient s’étonner du manque de préparation alors que les méthodes d’intelligence artificielle (IA) se répandent. À titre d’exemple, le modèle européen ECMFW, utilisé par Météo France, a récemment intégré un modèle d’IA (nommé AIFS) pour améliorer ses performances.
Avec toutes les méthodes récentes en météorologie et en climatologie, liées au déploiement de l’IA, pourquoi les inondations de Valence n’ont-elles pas pu être anticipées ?
Les statistiques au service de la climatologie
Avant d’entrer dans le vif du sujet, je voudrais clarifier un point crucial : je ne suis pas climatologue et ne me revendique pas tel. Je ne vais donc pas m’étendre en détail sur des phénomènes météorologiques que je ne maîtrise pas assez.
Par contre, je connais bien l’étude des données temporelles. Et la question de la prédictibilité de ce phénomène météorologique va me permettre de vous expliquer un problème de statistiques sur lequel la recherche travaille toujours : la dérive des données (en anglais, data drift).
Tout d’abord, il faut formaliser un peu cet évènement climatique.
Premièrement, ce n’est pas un événement qui arrive tous les quatre matins. Ce genre d’occurrence reste statistiquement rare : on utilisera donc l’appellation « événement rare » ou « événement extrême ».
Deuxièmement, les inondations espagnoles de 2024 sont un événement rare parmi des événements rares. Explication : les habitants des Cévennes connaissent bien ces fortes pluies sous le nom d’« épisodes cévenols ». Ces épisodes cévenols font partie de ce que l’on appelle les épisodes méditerranéens. La « DANA » espagnole de 2024 est un exemple typique d’épisode méditerranéen : c’est exactement le même phénomène que les épisodes cévenols, et donc aussi « rare », mais non localisé aux Cévennes.
Finalement, parlons un peu de ce que nous appelons la « distribution des données ». La distribution des données, tout du moins dans ce cas-ci, c’est la probabilité qu’un évènement (un épisode pluvieux en ce qui nous concerne) arrive, qu’il soit d’une intensité donnée, qu’il ait une durée donnée, etc. Par exemple :
Si nous sommes le 15 septembre, il est beaucoup plus probable que, demain, il pleuve à Brest (Finistère) qu’à Nice (Alpes-Maritimes) : la probabilité de l’événement « pluie » à Brest est bien plus élevée que celle du même événement à Nice.
Si toutefois il pleut demain à Brest, il est fort peu probable que cette pluie soit d’intensité très élevée. En parallèle, s’il pleut demain à Nice, la possibilité que ce soit un épisode méditerranéen est plus élevée qu’à Brest. Il est donc plus probable d’avoir de fortes pluies à Nice, « sachant qu’il pleuvra demain », qu’à Brest.
Il est impossible de connaître parfaitement cette distribution, c’est-à-dire la probabilité qu’il pleuve une quantité donnée à tel endroit donnée à tel instant précis. Par contre, les scientifiques disposent d’un certain nombre d’outils permettant d’apprendre à prédire les évènements.

Apprendre à prédire les évènements
Ces outils, ce sont majoritairement les statisticiens qui les inventent. Ils vont regarder les données passées et tenter d’en reproduire le comportement pour pouvoir prédire les données futures.
Par exemple, pour le sujet qui nous intéresse : les villes du pourtour méditerranéen ont besoin de pouvoir prédire les épisodes extrêmes et notamment la quantité d’eau (en millimètres) pour prévoir la mise en place de dispositifs exceptionnels (par exemple, des SMS alertant les habitants d’un risque de pluie ou d’inondation).
Pour cela, on va disposer de tous les relevés météorologiques (température, pression atmosphérique, vitesse du vent, orientation du vent, etc.) en plusieurs points géographiques autour de la zone concernée.
En apprenant à un algorithme à utiliser les données de la journée actuelle pour prédire la probabilité d’occurrence d’un épisode méditerranéen pour les deux ou trois jours à venir – et, si un épisode est envisagé, la quantité de précipitation prévue –, l’administration peut utiliser d’autres modèles (physique, statistique) pour prévoir les risques d’inondation dans telle ou telle zone de la localité.
Glissement de distribution et changement climatique
Malheureusement, avec le changement climatique, le climat change. Pour un statisticien, cette phrase signifie : « Un modèle entraîné sur le passé peut-il encore prévoir correctement la quantité de pluie de demain ? »
La figure ci-dessous nous montre mois par mois, depuis 2008, comment évolue le maximum de pluie dans une station météorologique proche de Valence (Espagne). Nous pouvons observer des valeurs maximales fluctuantes, mais dont les maximums restent sous 200 millimètres cumulés pendant deux jours.

Maintenant, admettons que nous entraînons un modèle à prédire les précipitations cumulées des deux prochains jours en utilisant ces données : nous lui donnons plein d’indicateurs au jour J, et nous souhaitons les précipitations cumulées des jours J+1 et J+2. Il est intuitif de penser que le modèle ne dépassera jamais la valeur de 200 millimètres, et cette intuition est réaliste : après tout, pourquoi le ferait-il ? Les modèles statistiques ne sont pas faits pour réfléchir à de nouvelles choses, ils sont faits pour reproduire un comportement appris, présent dans les données, qui aurait déjà pu (statistiquement) survenir dans le passé.
Analysons maintenant la suite des données.
Si nous avions utilisé notre modèle entraîné sur les données 2007-2023 pour prédire les précipitations des 16 et 17 octobre 2024, nous nous serions… certainement lamentablement plantés. Plus précisément, le modèle aurait sous-estimé la quantité de pluie (ce qui peut conduire des communes à avoir un faux sentiment de sécurité).
Ces dernières figures montrent bien que les inondations de Valence en 2024 étaient un évènement tellement extrême qu’il en devenait imprévisible. Pour mieux illustrer ce propos, la figure suivante montre, autour d’une ville où les épisodes cévenols sont plus fréquents, l’augmentation progressive de l’intensité de ces évènements. C’est ce que l’on appelle un « glissement de la distribution ».

Le temps : l’ennemi ancestral du statisticien
Ce phénomène de glissement dans le temps ne s’applique pas qu’en climatologie, mais il y est particulièrement crucial au vu des victimes causées ces dernières années. En santé, beaucoup de facteurs influencent les données. Sont susceptibles d’évoluer dans le temps par exemple : les sources de pollution, le nombre de personnes vaccinées, le nombre de fumeurs, etc. Dans le numérique, les systèmes de recommandations sur les plateformes de contenus doivent réussir à s’adapter aux phénomènes de mode.
Enfin, le glissement de distribution ne concerne pas que les évolutions temporelles. Par exemple, les résultats d’une étude neuroscientifique sur des étudiants aux États-Unis restent-ils valides lorsqu’on l’applique à des quadragénaires en Inde ?
En somme, l’évolution (temporelle) de certains facteurs, comme les populations ou le climat, représente de vrais défis pour les statisticiens. Pour ce qui est de la météorologie, il existe des systèmes dits « hybrides », c’est-à-dire qui combinent une compréhension de la physique du système et des statistiques sur les données passées. Cette hybridation améliore les performances de prévision, mais les modèles restent encore, pour l’instant, en difficulté sur les évènements climatiques extrêmes.
Rémi Vaucher ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
07.06.2026 à 18:32
Modéliser les territoires pour mieux décider ? Les promesses et les limites des jumeaux numériques pour l’environnement
Sébastien Dupraz, Coordinateur de programme, BRGM
Texte intégral (2299 mots)

Faut-il adapter les pratiques agricoles face à des ressources en eau de plus en plus incertaines ? Peut-on renforcer la résilience des territoires face aux risques d’inondation ou de pollution de l’air ? Comment anticiper les effets d’aménagements sur les sols, l’eau ou la biodiversité ?
Les réponses à ces questions reposent aujourd’hui sur des données fragmentaires et des arbitrages complexes entre acteurs du territoire. Mais une nouvelle approche émerge : l’usage de jumeaux numériques environnementaux, qui permet de représenter numériquement et automatiquement la réalité physique sur de longues périodes. Déjà utilisés dans l’industrie pour les véhicules ou les machines, ces formes de modélisation sont désormais appliquées à de nombreux autres objets : bâtiments, villes, organes humains, processus de fabrication… Elles assurent leur suivi de façon intégrée et continue, tout au long de leur cycle de vie, avec une promesse : mieux comprendre pour mieux décider.
Dans l’environnement au sens large (urbain, agricole, naturel, industriel) et dans un contexte de changement climatique où la gestion des ressources naturelles et énergétiques est devenue critique, ces approches suscitent un intérêt croissant auprès des acteurs publics et industriels.
En France, par exemple, l’État a annoncé mi-avril 2026 un investissement de 25 millions d’euros dans le cadre du plan France 2030 pour développer des jumeaux numériques des territoires, destinés à mieux anticiper leurs évolutions et éclairer les décisions des collectivités. Mais leur déploiement soulève encore plusieurs défis, techniques comme sociaux.
Décider au quotidien et sur le long terme
Une fois déployés sur un territoire, les jumeaux numériques permettent d’adapter les flux et les pratiques en fonction de la disponibilité des ressources et des risques.
Ils facilitent par exemple la détection de certains dysfonctionnements. Parmi ceux-ci, il y a la détection des fuites de réseaux d’eau, la gestion de zones problématiques comme les îlots de chaleurs pour lesquels des villes comme Enschede (Pays-Bas) ont développé des jumeaux thermiques dédiés, ou bien le suivi de pollutions locales notamment liées à la qualité de l’air. A contrario, ils peuvent également mettre en évidence des systèmes aux impacts positifs, comme des zones humides qui jouent un rôle clé dans le maintien de la biodiversité et favorisent la filtration et l’infiltration des eaux.
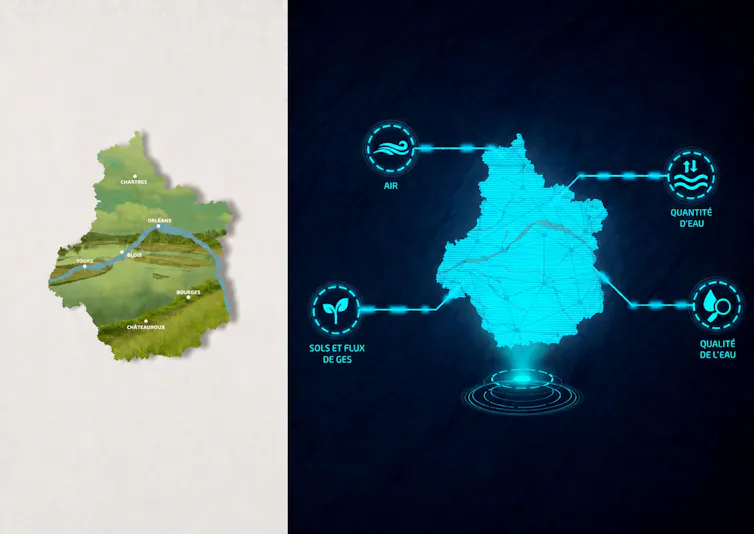
Mais leur intérêt ne se limite pas au suivi en temps réel. Les jumeaux numériques permettent aussi de tester différents scénarios et de planifier de futurs aménagements selon différentes problématiques. Les projets d’urbanisation, de paysagisme et de restauration environnementale peuvent ainsi se décliner afin d’estimer leurs impacts respectifs et de rationaliser les choix des collectivités.
Il devient par exemple possible de comparer l’impact de la création d’un bois ou d’une zone agricole, à l’aménagement d’une rive, à la création d’un parking, d’une autoroute ou bien d’un parc photovoltaïque. Quels seront leurs impacts respectifs par rapport aux émissions de CO₂, aux dépenses énergétiques, à la disponibilité de la ressource eau et à la qualité de l’air ? Ces impacts varient-ils selon les localisations ? Actuellement, plusieurs villes européennes et dans le monde construisent déjà leur plan d’urbanisme en fonction de ces paramètres grâce aux jumeaux numériques.
En objectivant ces effets, les jumeaux numériques contribuent à éclairer les décisions. Ils peuvent aider à apaiser des débats souvent sensibles entre acteurs du territoire, afin d’améliorer le dialogue social et le partage des ressources et des espaces communs. Mais si cette capacité à mieux comprendre et anticiper suscite un fort intérêt, elle se heurte encore à plusieurs obstacles.
Des outils encore difficiles à s’approprier
Le développement des jumeaux numériques repose en grande partie sur les progrès récents de l’intelligence artificielle (IA). Les techniques de machine learning permettent désormais de suivre et d’analyser en continu de grandes quantités de données et d’en tirer des capacités de prédiction inédites.
Cependant, pour de nombreux acteurs (personnels techniques, élus ou grand public), cette impulsion technologique constitue une rupture qui reste difficile à appréhender, tant dans sa mise en œuvre que dans l’interprétation des résultats. Peut-on se fier à un modèle pour orienter des décisions concrètes ? Comment comprendre les hypothèses et les calculs derrière les simulations ? L’enjeu ne se limite pas à un simple rejet : un manque de compréhension partagée peut conduire à des visions divergentes entre acteurs, et fragiliser des projets de jumeaux souvent longs et coûteux.
Dans ce contexte, l’accompagnement est essentiel. Retours d’expérience sur d’autres jumeaux numériques territoriaux, formations et démarches de médiation facilitent l’appropriation progressive de ces outils.
Gourmands en données
Les jumeaux numériques dépendent des données auxquelles ils ont accès. Pour représenter et suivre en temps réel des environnements complexes et étendus, ils ont besoin de volumes d’informations très importants et de dispositifs de mesure souvent onéreux. C’est le cas par exemple de certaines sondes de mesure sur la qualité des eaux, à la fois coûteuses à l’achat et à l’entretien, qui doit être régulier.
Certaines variables sont difficiles à mesurer de façon automatique, comme la biodiversité qui repose encore largement sur des observations de terrain. La fréquence et l’étendue des mesures sont limitées car elles doivent être réalisées par des spécialistes pour faire le décompte long et laborieux des différentes espèces présentes. De même, certains polluants émergents, comme les PFAS ou certains pesticides, ne sont toujours pas mesurables en dehors des laboratoires.
Pour pallier ces limites de métrologie, les jumeaux numériques s’appuient souvent sur des « proxys ». Il s’agit de variables plus faciles à mesurer, utilisées comme indicateurs indirects d’un phénomène car elles présentent une forte corrélation avec la variable cible. Par exemple, la hauteur d’eau mesurée par satellite (altimétrie ou images optiques) est utilisée comme proxy pour estimer le débit des rivières dans les zones non instrumentées, car les stations hydrométriques au sol sont rares et coûteuses.
D’autres proxys reposent sur des observations indirectes dans le temps. L’analyse d’images satellitaires permet ainsi d’identifier les périodes de développement des cultures (levées végétales), et donc de déduire la nature des semis. Cette information est essentielle pour estimer les besoins en eau, anticiper les périodes d’irrigation ou évaluer les pressions exercées sur la ressource.
Ces approches ont un potentiel important, mais elles ont aussi leurs limites. Les proxys peuvent encoder des approximations non validées, des biais de données, ou des relations non causales. Identifier les bons indicateurs et comprendre leurs limites constitue donc un enjeu majeur pour la fiabilité des jumeaux numériques.
Des jumeaux parfois redondants et peu coordonnés
Bien que ces technologies soient encore en développement à l’échelle des territoires, de nombreux projets émergent déjà, portés par des acteurs variés : collectivités, agences publiques, entreprises, bureaux d’études…
Or, ces initiatives sont souvent développées de manière indépendante. Il n’est pas rare que plusieurs jumeaux numériques mobilisent des flux de données similaires ou proposent des fonctionnalités proches, sans véritable mutualisation. Par exemple, un jumeau numérique régional simulant une crue centennale du Danube ne peut pas anticiper correctement les risques s’il est isolé : il nécessite les données du jumeau climatique global (précipitations en amont, fonte des neiges alpines) pour produire des simulations fiables. Sans cette interconnexion, les systèmes d’alerte des villes seraient basés sur des scénarios incomplets, sous-estimant potentiellement les risques. Le silotage des jumeaux territoriaux peut entraîner des redondances, des coûts supplémentaires et un usage moins efficient des ressources. Pour aller vers plus de frugalité, des initiatives telles que les projets LDT4SSC (Local Digital Twins for Smart and Sustainable Communities) visent à créer une fédération européenne de jumeaux numériques locaux interconnectés. L’un des enjeux majeurs consiste donc à rendre ces systèmes interopérables, c’est-à-dire capables de communiquer entre eux et de partager des données et des résultats.
Cette interopérabilité s’exerce à deux niveaux. D’une part, celui des données utilisées et générées : celles-ci doivent être accessibles, compréhensibles et réutilisables par différents acteurs. L’utilisation de principes comme les standards FAIR (Findable, Accessible, Interoperable, Reusable) permet de faciliter leur partage.
D’autre part, celui des méthodes et des outils. Aujourd’hui, les solutions sont encore largement hétérogènes. Le développement de standards communs (définir par exemple des procédures de communication ou protocoles d’échange, des architectures et des formats) qui permettraient de faciliter leur articulation et leur évolution est au cœur de nombreuses études. Une standardisation des jumeaux numériques pourrait rendre ces structures plus compatibles.
Les jumeaux numériques apparaissent désormais comme des outils de plus en plus omniprésents dans la gestion de nos territoires. Ils sont porteurs de solutions innovantes, mais supposent de nombreux défis qui devront être abordés collectivement.
Sébastien Dupraz a reçu des financements de la Région Centre-Val de Loire, de l'Etat Français et de l'Europe dans le cadre de ses activités liées aux Jumeaux Numériques Environnementaux.
06.06.2026 à 09:19
La poussière d’étoiles piégée dans la glace antarctique révèle des dizaines de milliers d’années de l’histoire du Système solaire
Dominik Koll, Honorary Lecturer, Nuclear Physics, Australian National University
Texte intégral (1810 mots)

Des atomes de fer 60, produits lors d’explosions stellaires, permettent de remonter le fil de l’histoire de notre environnement galactique. Leur présence dans la glace antarctique révèle une variation inattendue de la poussière interstellaire atteignant la Terre.
Quand vous pensez à l’espace, vous imaginez sans doute des étoiles, des planètes et des satellites. Pourtant, une grande partie de l’espace est remplie de nuages de gaz, de plasma et de poussières d’étoiles, appelés nuages interstellaires.
Rien que dans les régions proches de notre galaxie, on recense environ 15 nuages interstellaires distincts. Le Système solaire traverse actuellement l’un d’entre eux, baptisé de façon évocatrice le Nuage interstellaire local. On pense que l’origine et l’histoire de ces nuages sont étroitement liées à la naissance et à la mort des étoiles. Mais leurs traces sont également visibles ici même sur Terre, dans un endroit où l’on ne s’attendrait pas forcément à les trouver : la glace de l’Antarctique.
Mes collègues et moi étudions depuis plusieurs années la poussière d’étoiles piégée dans d’anciennes couches de neige et de glace antarctiques afin de retracer l’histoire de notre voisinage cosmique, y compris celle du Système solaire lui-même.
Dans une nouvelle étude publiée dans Physical Review Letters (https://doi.org/10.1103/nxjq-jwgp), nous avons mis en évidence un indice subtil qui révèle le déplacement de notre Système solaire à travers son environnement interstellaire local au cours des 80 000 dernières années.
Regarder le ciel en regardant vers le bas
L’astronomie consiste généralement à lever les yeux au ciel. Les télescopes collectent la lumière provenant d’étoiles et de galaxies lointaines, ce qui nous permet d’observer des événements sur d’immenses distances dans l’espace et le temps. À partir de ces observations, nous déduisons comment les étoiles naissent et meurent, comment les éléments chimiques se forment et comment l’Univers évolue.
Notre approche (https://theconversation.com/dust-from-exploding-stars-is-raining-down-on-earth-i-hunt-it-to-learn-how-the-elements-were-made-162242) renverse cette logique.
Au lieu d’étudier la lumière qui nous parvient, nous examinons les débris d’étoiles ayant explosé, directement ici sur Terre. Véritables fournaises cosmiques, les étoiles fabriquent dans leur cœur de nombreux éléments chimiques, du carbone et de l’oxygène jusqu’au calcium et au fer. Elles produisent également des isotopes rares (des variantes d’un même élément chimique), comme le fer 60.
Lorsque des étoiles massives explosent en supernovæ à la fin de leur existence, ces éléments sont projetés dans l’espace et deviennent de la poussière interstellaire.
De minuscules grains de cette poussière dérivent ensuite à travers la galaxie et finissent parfois par atteindre la surface de la Terre. Du fer 60 radioactif, véritable signature des explosions stellaires, est piégé à l’intérieur de ces grains. En recherchant ces atomes dans les archives géologiques terrestres (https://doi.org/10.1140/epja/s10050-025-01554-0), nous pouvons étudier des événements astrophysiques tels que les supernovæ, longtemps après que leur lumière s’est éteinte.
C’est ce qui rend l’Antarctique si précieux. Sa neige s’accumule lentement et reste en grande partie préservée des perturbations, formant une sorte d'enregistrement stratifié qui remonte sur des dizaines de milliers d’années. Chaque couche conserve une photographie du matériau présent dans notre voisinage cosmique à l’époque où elle s’est formée.
À la recherche de poussière d’étoiles dans la glace antarctique
Alors que nous étudions 500 kg de neige récente en Antarctique, nous avons découvert de manière inattendue cet isotope radioactif rare. D’où provenait-il ? Aucune supernova proche de la Terre ne s’était produite récemment.
Mais notre voisinage cosmique est rempli de 15 nuages interstellaires, et le Système solaire en traverse actuellement au moins un. La poussière d’étoiles serait-elle présente dans ces nuages avant d’être captée par la Terre ? Si c’est le cas, alors la quantité de poussière d’étoiles recueillie par notre planète devrait être liée à leur structure : plus ces nuages sont denses, plus ils contiennent de fer 60. C’était notre hypothèse en 2019 (https://doi.org/10.1103/PhysRevLett.123.072701).
Très vite, d’autres explications ont été avancées. Il y a plusieurs millions d’années, la Terre a reçu d’importantes pluies de fer 60 provenant de supernovæ massives (https://doi.org/10.1038/nature17196). Le fer 60 retrouvé dans la neige antarctique serait-il le dernier vestige, ou l’écho affaibli, de ce signal ancien ? Une pluie devenue simple bruine ?
Pour le vérifier, nous avons analysé une section de 300 kg de glace antarctique datant de 40 000 à 80 000 ans. Le processus est extrêmement minutieux. La glace doit être fondue puis traitée chimiquement afin d’isoler d’infimes quantités de fer, y compris le fer 60 contenu dans la poussière d’étoiles.
Nous avons ensuite utilisé la spectrométrie de masse par accélérateur, une technique extrêmement sensible permettant de compter les atomes individuellement, au sein du Heavy-Ion Accelerator Facility de l’Australian National University. Nos analyses ont consisté à dénombrer un à un les atomes de fer 60. Sur la base des mesures précédemment réalisées dans la neige de surface antarctique et dans des sédiments océaniques vieux de plusieurs milliers d’années, nous nous attendions à observer un niveau relativement stable de dépôt de fer 60.
Or, nous en avons trouvé moins. Pas zéro, mais une quantité nettement inférieure à celle que nous attendions.
Ce résultat suggère qu’une moindre quantité de poussière interstellaire atteignait la Terre à cette époque. Cette variation est remarquable, car elle s’est produite sur une période relativement courte à l’échelle de l’astrophysique. Elle ne correspond pas au scénario des dépôts de fer 60 issus des supernovæ qui ont atteint la Terre il y a plusieurs millions d’années, un phénomène qui s’inscrit, lui, sur des durées bien plus longues. Nous avons donc dû chercher une source plus modeste et plus locale pour expliquer la présence de cet isotope.

Une histoire qui tombe à point nommé
Naturellement, les astronomes s’intéressent aussi de près aux nuages qui entourent le Système solaire. L’an dernier, une étude reconstituant l’histoire de ces nuages a conclu qu’ils provenaient très probablement d’une explosion stellaire (https://iopscience.iop.org/article/10.3847/1538-4357/adc920). Les chercheurs ont également estimé que le Système solaire traverse le Nuage interstellaire local depuis une période comprise entre 40 000 et 124 000 ans (https://iopscience.iop.org/article/10.3847/1538-4357/adb033).
Si cette hypothèse est correcte, alors la quantité de fer 60 recueillie sur Terre aurait dû varier au cours de cette même période, c’est-à-dire entre 40 000 et 124 000 ans avant aujourd’hui.
C’est ce que montrent nos résultats obtenus en Antarctique.
L’histoire ne s’emboîte toutefois pas parfaitement. Si ces nuages provenaient directement d’une étoile ayant explosé, nous devrions observer dans la glace antarctique des quantités de fer 60 bien plus importantes que celles que nous mesurons réellement.
Malgré cela, la trace de ces nuages est bien inscrite dans les archives géologiques terrestres. En remontant plus loin dans le temps et en analysant des glaces encore plus anciennes, nous pourrions bientôt percer le mystère de ces nuages interstellaires locaux et reconstituer plus complètement leur histoire ainsi que leurs origines encore incertaines.
Dominik Koll a reçu des financements de l'Australian Institute of Nuclear Science and Engineering (AINSE).
05.06.2026 à 08:58
Pleut-il davantage en ville qu’à la campagne ? Oui, mais pas autant qu’on ne le croyait
Shankar Sharma, PhD student, Climate Change Research Centre, UNSW Sydney
Andy Pitman, Director of the ARC Centre of Excellence for Climate Extremes, UNSW Sydney
Jason Evans, Professor, Climate Change Research Centre, UNSW Sydney
Texte intégral (1660 mots)

Il pleut davantage en ville que dans la campagne environnante, mais peut-être pas autant qu’on le pensait. Des chercheurs montrent que les changements intervenus dans les réseaux de satellites influencent aussi les tendances observées.
Comme d'autres pays, l'Australie a été touchée, sur sa côte est par un épisode de mauvais temps, marqué par des orages, de fortes pluies et des crues soudaines à Sydney et dans certaines régions de la Nouvelle-Galles du Sud et en tant que chercheurs, nous nous sommes demandés si les villes influencent elles-mêmes les précipitations qui s’abattent sur elles.
La question est importante, car la majorité de la population vit désormais en milieu urbain. Si l’urbanisation modifie les précipitations, même légèrement, les conséquences peuvent toucher un grand nombre de personnes à travers les risques d’inondation, la conception des réseaux d’évacuation des eaux pluviales, l’approvisionnement en eau et la planification des infrastructures.
Les données satellitaires montrent de manière constante que de nombreuses villes connaissent davantage d’épisodes pluvieux que les zones rurales qui les entourent. L’explication la plus courante est que les villes elles-mêmes jouent un rôle : la chaleur urbaine, la rugosité accrue des surfaces, les aérosols et les modifications de l’occupation des sols peuvent tous influencer le développement des tempêtes et la répartition des précipitations.
Notre nouvelle étude, publiée dans la revue Environmental Research Letters, pose une question centrale : ces observations reflètent-elles de véritables modifications des précipitations ou dépendent-elles de la façon dont nous les mesurons ?
Pourquoi les satellites sont indispensables
Comprendre les précipitations au-dessus des villes est une tâche complexe.
Les pluviomètres mesurent avec précision la pluie en un point donné, mais leur répartition est irrégulière et ils ne permettent pas de rendre compte pleinement des variations des précipitations à l’échelle d’une grande agglomération. Les modèles climatiques peuvent simuler avec finesse la météo urbaine, mais effectuer des simulations à l’échelle du kilomètre pour de nombreuses villes et sur plusieurs décennies demeure extrêmement coûteux en puissance de calcul.
Les observations satellitaires permettent de combler cette lacune.
Le système Integrated Multi-satellite Retrievals for GPM, ou IMERG, développé par la NASA, fournit des estimations des précipitations à haute résolution sur la quasi-totalité du globe. Il est aujourd’hui largement utilisé pour étudier les pluies en milieu urbain.
Ce que révèlent les données satellitaires
Nous avons analysé les données de précipitations d’IMERG dans 15 des plus grandes villes du monde, dont Sydney et Melbourne. Ces villes couvrent une grande diversité de climats et de contextes géographiques, comprenant à la fois des régions côtières et des régions de l’intérieur des terres.
Un schéma clair s’est dégagé. Les épisodes pluvieux étaient plus fréquents au-dessus des zones urbaines que dans les zones rurales voisines. Le signal le plus marqué n’était pas que chaque tempête devenait plus intense, mais que les satellites comptabilisaient davantage d’heures de pluie au-dessus des villes. Les épisodes individuels sur les centres urbains déversaient souvent moins d’eau que ceux observés dans les zones environnantes.
Autrement dit, le principal signal urbain observé dans les données IMERG n’est pas une pluie plus abondante, mais une pluie plus fréquente.
Des capteurs différents, des récits différents
Les données satellitaires modernes sur les précipitations combinent des observations infrarouges et micro-ondes.
Les capteurs infrarouges estiment les précipitations de manière indirecte à partir de la température au sommet des nuages. Ils offrent une couverture étendue, mais peuvent passer à côté des pluies faibles, peu profondes ou associées à des nuages chauds, car celles-ci peuvent survenir même lorsque le sommet des nuages n’est pas particulièrement froid.
Les satellites équipés de capteurs micro-ondes évoluent sur des orbites basses et détectent des signaux plus directement liés aux gouttes de pluie et aux cristaux de glace présents dans les nuages. Ils sont donc particulièrement utiles pour déterminer si des précipitations sont réellement en cours.
Lorsque nous avons séparé les données IMERG selon le type d’observation utilisé, nous avons constaté que le signal urbain provenait principalement des observations micro-ondes, tandis que les estimations fondées sur l’infrarouge ne révélaient aucun schéma urbain particulier.
Cela ne signifie pas que le signal détecté par les micro-ondes est erroné, mais cela soulève un problème potentiel pour les études à long terme : les observations micro-ondes ont évolué au fil du temps. De nouveaux satellites ont été mis en service tandis que d’autres ont été retirés, et, dans les villes que nous avons étudiées, la fréquence d’échantillonnage par micro-ondes était presque deux fois plus élevée en 2023 qu’en 2001.
C’est un point important, car plus un capteur micro-onde survole fréquemment une zone, plus il a de chances de détecter des épisodes pluvieux. Une averse légère passée inaperçue en 2002 peut aujourd’hui être enregistrée par l’un des nombreux satellites susceptibles de survoler la région dans l’heure.
Évaluer l'impact des outils de mesure
Pour déterminer si cette évolution de l’échantillonnage influençait les tendances observées au niveau des précipitations, nous avons comparé les observations micro-ondes et non micro-ondes à leurs moyennes de long terme. Cette méthode nous a permis de distinguer ce qui relevait des changements dans l’échantillonnage satellitaire de ce qui résultait de véritables évolutions météorologiques.
Les variations de l’échantillonnage micro-onde expliquaient jusqu’à environ 20 % des tendances de long terme observées pour les précipitations dans les 15 villes étudiées. Concernant la fréquence des pluies, des villes comme Lagos, Londres, Melbourne, Pékin, Berlin, Mexico City et Paris présentaient des zones où plus de 40 % de la tendance apparente pouvait être attribuée à l’évolution du système d’observation lui-même.
Les satellites n’expliquent donc pas à eux seuls le schéma de précipitations observé au-dessus des villes. Après correction des effets liés à l’échantillonnage, ce signal subsiste, mais la tendance de long terme apparaît moins marquée. En d’autres termes, il semble bien qu’il pleuve plus souvent au-dessus des villes, mais probablement dans une moindre mesure que ce que les premières estimations laissaient penser.
Et maintenant ?
Pour Sydney, nous avons également comparé les données d’IMERG à celles de CMORPH, un autre dispositif satellitaire consacré aux précipitations, ainsi qu’aux mesures des pluviomètres du Bureau of Meteorology australien. CMORPH a mis en évidence un schéma urbain similaire, même si les deux jeux de données ne sont pas totalement indépendants puisqu’ils reposent en partie sur les mêmes observations micro-ondes.
Les pluviomètres constituent un moyen de vérification plus indépendant. Toutefois, à Sydney comme dans la plupart des villes, le nombre de stations situées en dehors du cœur urbain est trop limité pour confirmer avec certitude, à partir des seules observations au sol, l’ampleur réelle du phénomène.
Les données satellitaires sur les précipitations sont aujourd’hui utilisées dans de nombreux domaines : sciences du climat, évaluation des risques d’inondation, agriculture, assurance ou encore gestion des ressources en eau. Dans de nombreuses régions du monde, elles constituent même la seule source cohérente d’observations pluviométriques sur de vastes territoires. Nos résultats invitent toutefois à la prudence : une partie de tendance relevée peut provenir de l’évolution des systèmes d’observation plutôt que d’un changement réel du climat.
Quant aux raisons pour lesquelles les villes connaissent des pluies plus fréquentes, les explications les plus plausibles sont bien connues : la chaleur urbaine qui favorise l’ascension de l’air, les surfaces plus rugueuses qui dévient les vents vers le haut, ainsi que les aérosols qui modifient la formation des gouttelettes dans les nuages. Le phénomène est réel. Le défi consiste désormais à le mesurer correctement.
Shankar Sharma a reçu des financements de l'Australian Research Council.
Andy Pitman a reçu des financements de l'Australian Research Council.
Jason Evans a reçu des financements de l'Australian Research Council.
04.06.2026 à 16:13
La frontière entre éveil et sommeil est bien plus floue que l’on ne le pensait : on peut rêver en étant éveillé
Nicolas Decat, Doctorant, Sorbonne Université
Delphine Oudiette, Chercheure en neurosciences cognitives, Inserm
Texte intégral (1478 mots)
Ce soir, en fermant les yeux dans votre lit, il vous arrivera quelque chose d’étrange. Vous passerez d’une pensée ordinaire à un rêve. Vous ne sauriez dire quand exactement. On imagine que la frontière est nette : éveillé, on pense ; endormi, on rêve. Pourtant, dans notre étude, publiée dans Cell Reports, nous montrons que cette frontière n’existe pas vraiment. On peut rêver avant de s’endormir, et planifier sa journée de demain en plein sommeil.
Pensez à ce que signifie être éveillé. Là, maintenant, en lisant ces lignes : des bruits vous parviennent, une lumière vous éclaire, un tissu touche votre peau. Vous êtes ancré dans le monde. Dormir, c’est un peu l’opposé. Vous êtes immobile, coupé de l’extérieur et habité par des expériences construites de l’intérieur : les rêves.
Entre les deux, il y a un laps de temps. On ne bascule pas d’un état à l’autre comme on éteint une lumière. C’est une transition graduelle où l’activité cérébrale ralentit, les muscles se relâchent, la respiration s’approfondit. Et l’esprit, lui, ne disparaît pas, il prend d’autres formes : des pensées liées à la journée écoulée ou à celle de demain, des images fugaces, quelques bribes de musique, des fragments de rêves… Les chercheurs appellent ça les « hypnagogies ».
Le problème, c’est que ces expériences sont fugaces et changeantes, difficiles à rapporter, encore plus à classifier. Comment passe-t-on de « Qu’est-ce que je mange demain » à « Je suis assis dans un train qui roule sous l’eau » ? Jusqu’ici, les chercheurs tentaient de les ranger dans des cases en fonction de ce qu’elles sont (« Celle-ci semble bizarre, donc c’est un rêve ») ou selon le moment où elles apparaissent (« J’exclus tout ce qui arrive à l’éveil »). Résultat : on savait qu’une multitude d’expériences traversent l’esprit pendant l’endormissement, mais sans être sûrs desquelles ni de quand ou comment le cerveau les fabrique. C’est exactement ce qu’on a voulu comprendre.
Laisser les données parler
Pour y voir plus clair, il fallait abandonner les catégories toutes faites et laisser les données parler. Nous avons enregistré l’activité cérébrale de 103 participants pendant qu’ils faisaient la sieste au laboratoire, par électroencéphalographie ou EEG : des électrodes sont placées sur la tête pour capter les signaux neuronaux et permettent de distinguer l’éveil (ondes rapides alpha) du sommeil léger (ondes plus lentes, thêta et sigma, avec de soudaines ondes très lentes et de brèves bouffées d’activité intense).
À plusieurs reprises, nous les avons interrompus avec un son pour leur poser une question toute simple : « Qu’est-ce qui vous traversait l’esprit juste avant l’alarme ? » Puis on leur a demandé de noter leur expérience sur quatre dimensions : à quel point elle était bizarre (et non ordinaire), fluide et continue (ou, au contraire, fragmentée), spontanée (sans contrôle volontaire), ainsi que leur impression d’être éveillés ou endormis.
Au total, nous avons récolté 375 expériences à l’endormissement. Plutôt que de décider nous-mêmes ce qui relevait du rêve ou de la pensée d’éveil, nous avons confié les expériences à un algorithme de Machine Learning. Sa tâche était de regrouper ces expériences en « états mentaux » sans qu’on lui dise à l’avance ce qu’ils devaient être.
En prenant en compte les notes des participants sur les quatre dimensions simultanément, l’algorithme cherchait des groupes d’expériences qui se ressemblent – un peu comme s’il cherchait des « familles » sur une carte à quatre coordonnées. Grossièrement : des fragments de souvenirs (« Une image de mon père m’est venue à l’esprit »), des pensées liées à l’environnement (« J’écoutais les bruits de la rue »), des imageries oniriques (« Je voyais des petits extraterrestres »), et des réflexions volontaires (« Je pensais à ce que j’allais faire demain »).
La question suivante s’imposait d’elle-même : à quel moment chacun de ces états surgit-il, entre l’éveil et le sommeil ?
Rêver éveillé, réfléchir en dormant
C’est là que les résultats deviennent surprenants. On s’attendait à un scénario simple : les pensées rationnelles à l’éveil, les imageries bizarres dans le sommeil. Et certains schémas allaient dans ce sens : en s’enfonçant dans le sommeil, l’état mental lié à l’environnement et celui lié aux réflexions volontaires se raréfiaient.
Mais voilà le cœur de notre découverte : les quatre états apparaissaient partout – à l’éveil, aux premiers instants de l’endormissement (stade N1) et dans un sommeil plus installé (stade N2). Ce qui nous traverse l’esprit n’est pas dicté par le fait d’être éveillé ou endormi.
En pratique, certains cas se sont révélés franchement paradoxaux. Une participante, parfaitement éveillée (ondes alpha sur l’EEG, signature de l’éveil) rapportait : « Des fourmis grimpaient sur moi avec des mots croisés en arrière-plan. » Un participant endormi en stade N2 (soudaines ondes amples sur le tracé, marqueur classique du sommeil) disait simplement : « Je pensais au travail. » On rêve avant de dormir, on réfléchit en dormant.
Il restait un point à élucider : le cerveau ne fonctionne pas de la même façon à l’éveil et dans le sommeil ; pendant le sommeil, il ralentit, il se synchronise. Alors comment une expérience onirique peut-elle survenir à la fois à l’éveil et au sommeil ? Pour le comprendre, nous avons zoomé : des fenêtres de temps plus courtes pour capter les changements rapides des ondes cérébrales, 64 électrodes pour couvrir le cortex de façon précise, des métriques de signal plus fines que celles utilisées traditionnellement.
Nous avons trouvé des signatures cérébrales des états mentaux. L’imagerie onirique, par exemple, s’accompagnait d’une communication plus faible entre régions cérébrales, comme si ces zones du cerveau parvenaient moins à dialoguer. Le point clé : ces signatures étaient les mêmes, que la personne soit techniquement éveillée ou endormie. Autrement dit, le cerveau peut produire le même type d’expérience mentale indépendamment de l’état de vigilance.
Et vous, qu’est-ce qu’il vous passe par la tête en vous endormant ?
Ces résultats ouvrent une question tout aussi intéressante. Ces expériences mentales, est-ce que tout le monde les traverse ? Dans le même ordre ? Et est-ce que cela dit quelque chose de qui nous sommes ?
Pour le savoir, nous avons conçu Drifting Minds, un questionnaire en ligne d’une vingtaine de minutes qui explore vos expériences mentales à l’endormissement. Plus de 4 500 personnes sur les cinq continents y ont déjà participé. L’objectif est d’identifier des profils d’endormissement dans la population et de voir si s’ils dépendent de l’âge, du sexe, de la culture, mais aussi s’ils sont liés à des traits comme la créativité, l’anxiété, la capacité d’imagerie mentale ou la qualité du sommeil.
À la fin du questionnaire, vous découvrez votre propre profil d’endormissement et pouvez vous comparer aux autres. Participez ici !
Ce que nous cherchons, au fond, c’est à comprendre ce que le cerveau génère dans cet entre-deux. Et ce que cela raconte de nous. Ce soir, en fermant les yeux, vous traverserez une fois de plus ce couloir étrange. Prêtez-y attention : qu’est-ce qui vous passe par la tête juste avant de sombrer ?
Delphine Oudiette a reçu des financements du programme Horizon Europe de l'Union Européenne (ERC consolidator grant).
Nicolas Decat ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
04.06.2026 à 16:09
La fusée de Blue Origin a explosé sur son pas de tir. Quelles conséquences pour le programme lunaire Artemis ?
Wendy Whitman Cobb, Professor of Strategy and Security Studies, Air University
Texte intégral (1978 mots)
Le 28 mai, lors d’un test de mise à feu statique, la fusée New Glenn de Blue Origin, une entreprise du New Space fondée en 2000 par Jeff Bezos, le créateur d’Amazon, a explosé dans le crépuscule, enveloppant sa rampe de lancement d’une énorme boule de feu. L’incendie spectaculaire a détruit le lanceur, causé des dégâts importants à la seule rampe de lancement de Blue Origin, à Cap Canaveral, en Floride, mais n’a blessé personne.
S’il est encore trop tôt pour connaître la cause exacte de l’explosion, cet incident représente déjà un revers important pour Blue Origin, pour son programme de lanceurs New Glenn et leurs missions prévues de mises en orbite. En effet, l’entreprise dispose d’un seul type de lanceurs capables d’atteindre l’orbite terrestre.
Et, compte tenu de mon expérience d’experte en politique spatiale, je prévois des conséquences importantes des suites de cet échec, non seulement pour Blue Origin, mais aussi pour les ambitions lunaires de la Nasa.
Ce que nous savons pour l’instant
L’explosion s’est produite alors que Blue Origin effectuait un essai statique de son tout nouveau lanceur lourd New Glenn. Ce type de test consiste à maintenir la fusée reliée à l’équipement au sol tout en allumant ses sept moteurs afin de s’assurer qu’ils fonctionnent correctement avant un lancement.
Des explosions comme celle-ci sont assez rares mais elles arrivent. En septembre 2016, par exemple, un lanceur Falcon 9 de SpaceX a explosé juste avant son propre essai statique de mise à feu, détruisant le satellite de communication israélien qu’elle devait mettre en orbite. Il a fallu quatre mois pour déterminer la cause de l’accident, et plus d’un an pour reconstruire la rampe de lancement. À cette époque, SpaceX disposait déjà de deux rampes de lancement, ce qui a permis à l’entreprise de reprendre ses vols dès janvier 2017.
Si ce test de mise à feu de New Glenn avait été concluant, le quatrième lancement effectif de ce puissant lanceur aurait pu avoir lieu. Le programme New Glenn n’a pas été sans embûches jusqu’ici : sur les trois lancements réalisés à ce jour, un seul a été un franc succès. Lors de son précédent lancement le 19 avril, un dysfonctionnement du deuxième étage du lanceur a empêché New Glenn de déployer le satellite qu’il transportait sur la bonne orbite.
Le lanceur qui a explosé fin mai aurait dû transporter, lors de son véritable lancement, une charge utile de satellites Amazon Leo (concurrents de la mégaconstellation Starlink, qui appartient à SpaceX). Ces satellites n’étaient pas à bord lors de l’essai de mise à feu.
Les premiers rapports indiquent qu’outre la fusée détruite, le complexe de lancement a subi des dommages importants. Une installation voisine semble également avoir été endommagée.
Des problèmes pour Blue Origin

Dans l’immédiat, cette explosion va considérablement entraver les ambitieux projets de Blue Origin. Alors que Blue Origin a suspendu son programme de fusées suborbitales New Shepard l’an dernier pour se concentrer sur New Glenn et ses différents projets lunaires, celui-ci va être cloué au sol pendant un moment.
Ce revers survient alors que l’entreprise cherchait à augmenter sa cadence de lancement, avec des projets visant à lancer non seulement des satellites commerciaux, mais aussi les atterrisseurs lunaires développés par Blue Origin.
En effet, cette semaine encore, la Nasa a annoncé qu’elle avait attribué des contrats à Blue Origin pour plusieurs lancements lunaires, dont un prévu cet automne qui devait transporter l’atterrisseur lunaire Blue Moon Mark 1 vers la Lune. La Nasa a également passé un contrat avec New Glenn pour le lancement de deux véhicules lunaires habités dans les années à venir.
Or, à l’heure actuelle, la rampe de lancement endommagée est le seul site de lancement opérationnel de Blue Origin. Une deuxième rampe de lancement est en cours de construction à Cap Canaveral, mais celle-ci ne sera pas prête à temps pour éviter de sérieux retards. Se rabattre temporairement sur d’autres rampes de lancement de la Nasa ou de la Space Force n’est pas non plus une option, car les installations de lancement doivent être adaptées spécifiquement à chaque lanceur.
Des problèmes pour Artemis, le grand programme lunaire de la Nasa et ses partenaires
Si l’explosion va sans aucun doute affecter considérablement Blue Origin, ce sont peut-être la Nasa et son programme Artemis qui en subiront les conséquences les plus importantes. En effet, la mission d’alunissage Blue Moon devait être lancée cet automne et aurait transporté plusieurs charges utiles de la Nasa afin de préparer le terrain pour de futures missions habitées et non habitées vers la surface lunaire.
Un impact encore plus direct pourrait toucher la mission Artemis-3 de la Nasa. En effet, le lancement d’Artemis-3 est dorénavant prévu au plus tôt fin 2027 : la mission doit rester dans l’orbite terrestre et y tester les systèmes d’atterrissage lunaire ainsi que le véhicule Orion, destiné à l’équipage.
La Nasa a attribué des contrats pour ces systèmes d’atterrissage à la fois à SpaceX et à Blue Origin. Alors que l’agence avait initialement prévu d’utiliser une version modifiée du Starship de SpaceX pour ces premières missions lunaires, les retards pris par ce programme offraient à Blue Origin une opportunité de rattraper son retard grâce à son atterrisseur Blue Moon. Mais l’incapacité de Blue Origin à lancer Blue Moon dans un avenir proche risque de mettre l’entreprise hors course pour Artemis-3.

Ce revers signifie qu’Artemis-3, et l’ensemble du programme d’exploration lunaire de la Nasa, dépendront probablement de SpaceX pour le moment.
Alors que SpaceX a réalisé un test relativement réussi de sa nouvelle version de Starship, le 22 mai 2026, il lui faut encore faire de nombreux progrès en seulement un an, avant que le système d’atterrissage de Starship ne soit opérationnel. Si SpaceX ne parvient pas à mettre Starship au point à temps, la Nasa devra sans doute reporter Artemis-3 à 2028.
Les accidents arrivent – le lanceur New Glenn n’est pas le premier à exploser, et ne sera pas le dernier. À une époque où les lancements spatiaux sont presque devenus quotidiens, cet incident nous rappelle à quel point l’exploration spatiale est difficile et que le succès des missions ne va pas de soi.
Wendy Whitman Cobb est affiliée à la `Air University’. Les opinions et conclusions sont celles de l'autrice et ne reflètent pas les politiques officielles ni celles de United States Air Force, du Department of War (Defense), ni de tout autre agence gouvernementale états-unienne. Les mentions de noms de marques ou organisations n'impliquent pas un soutien du gouvernement états-unien.
03.06.2026 à 17:01
Passage de la vie terrestre à la vie aquatique : un nouveau fossile éclaire l’évolution des dents des premiers cétacés
Romain Weppe, Paléontologue, Royal Belgian Institute of Natural Sciences
Texte intégral (1359 mots)

Les premiers ancêtres des cétacés – le groupe de mammifères auquel appartiennent les orques et les dauphins – étaient déjà connus pour posséder des dents adaptées à un régime carnivore. Notre découverte récente, publiée dans la revue Nature Ecology & Evolution, permet désormais d’entrevoir ce à quoi pouvait ressembler l’étape intermédiaire entre les dents broyeuses de leurs ancêtres terrestres et les dents tranchantes de ces prédateurs aquatiques.
Dans la région de Kalakot, au Cachemire indien, un nouveau fossile âgé d’environ 48 millions d’années vient d’être découvert : Kalakocetus aurorae.
Les molaires de cet animal de la corpulence d’un petit loup présentent une morphologie inédite, intermédiaire entre celles de ses plus proches parents terrestres et celles des premiers cétacés déjà connus dans le registre fossile. Il apparaît comme le représentant le plus primitif identifié à ce jour parmi les cétacés.
Cette découverte apporte ainsi un nouvel éclairage sur l’une des transitions les plus spectaculaires de l’histoire évolutive des mammifères : le passage progressif d’animaux terrestres herbivores à des prédateurs adaptés à la vie aquatique.
Comment cette découverte a-t-elle été réalisée ?
Le fossile de Kalakocetus aurorae a été découvert dans des roches sédimentaires âgées d’environ 48 millions d’années, dans la région de Kalakot, au nord de l’Inde. Cette région est considérée depuis longtemps par les paléontologues comme le véritable berceau des cétacés, car elle a livré les plus anciens fossiles connus témoignant de l’évolution des mammifères terrestres vers les baleines et dauphins actuels.
L’élément le plus remarquable concerne ses molaires inférieures. Chez les proches parents terrestres des cétacés, les molaires possèdent généralement quatre cuspides principales (les pointes présentes sur les dents), adaptées au broyage des aliments. Chez les premiers cétacés connus jusqu’à présent, ces molaires étaient déjà simplifiées et dominées par deux cuspides tranchantes spécialisées dans le cisaillement. Or, Kalakocetus aurorae présente une configuration intermédiaire originale à trois cuspides.

Pour comprendre sa place dans l’évolution des cétacés, nous avons réalisé une analyse phylogénétique comparant son anatomie dentaire à celle d’autres mammifères ongulés fossiles et des premiers cétacés déjà connus. Cette analyse montre qu’il occupe la position la plus basale dans l’arbre évolutif du groupe.
Nous avons également étudié ses dents grâce à des analyses 3D de surface ainsi qu’à l’étude des traces d’usure dentaires, à différentes échelles. Ces approches permettent de reconstituer le fonctionnement des mâchoires et le régime alimentaire des animaux fossiles.
Les résultats indiquent que Kalakocetus aurorae avait déjà adopté un régime carnivore impliquant principalement des mouvements de cisaillement de la mâchoire tandis que la fonction de broyage des molaires était déjà fortement réduite.
Pourquoi cette découverte est-elle importante ?
L’adaptation des cétacés à la vie aquatique s’est accompagnée de transformations profondes de leur anatomie, notamment au niveau de leur dentition.
Les cétacés modernes présentent aujourd’hui des dents extrêmement spécialisées. Les dauphins et autres cétacés à dents possèdent des dents coniques presque toutes identiques, tandis que les baleines ont perdu leurs dents au profit de fanons.
Les premiers cétacés connus montraient déjà une simplification importante des molaires, avec la disparition des surfaces de broyage au profit de dents plus tranchantes adaptées à la carnivorie. Mais cette transition apparaissait jusqu’ici de manière très brutale dans les archives fossiles, sans qu’aucun stade intermédiaire ne soit clairement documenté.
La morphologie de Kalakocetus aurorae fournit précisément cet élément manquant. Elle montre que l’évolution des dents des cétacés s’est probablement produite de manière plus progressive qu’on ne le pensait. Cette découverte suggère également que les changements alimentaires vers la carnivorie ont commencé très tôt dans l’histoire évolutive des cétacés, probablement en parallèle de leur adaptation croissante aux environnements aquatiques.
Quelles perspectives pour la suite ?
Cette étude ouvre de nouvelles perspectives pour comprendre les premières étapes de l’évolution des cétacés et les mécanismes ayant accompagné leur transition vers la vie aquatique.
La découverte de nouveaux fossiles ainsi que de futures recherches, combinant anatomie fonctionnelle, imagerie 3D et analyses isotopiques, devraient aider à mieux comprendre comment les premiers cétacés capturaient et consommaient leurs proies.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Romain Weppe ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
02.06.2026 à 16:40
Non, nos ancêtres ne se sont pas simplement « redressés » : repenser l’évolution vers notre bipédie
Jérémy Duveau, Chercheur associé, Muséum national d’histoire naturelle (MNHN)
Quentin Cosnefroy, Associate research scientist, Université de Bordeaux
Texte intégral (3698 mots)

Loin de l’image populaire mais fausse d’un grand singe se redressant peu à peu pour devenir bipède, les recherches menées par les paléoanthropologues depuis plus de cinquante ans dévoilent une réalité bien plus complexe. L’histoire des modes de locomotion des membres de la lignée humaine reflète notre évolution : elle n’est pas linéaire, elle est buissonnante et, surtout, d’une incroyable diversité.
Comme toutes les espèces, la nôtre, Homo sapiens, possède des caractéristiques propres au sein du vivant. Mais qu’est-ce qui nous différencie de nos plus proches parents, les autres primates ? La première réponse porte généralement sur notre façon de nous tenir et de nous mouvoir sur deux jambes, la bipédie. En effet, bien que les autres primates soient capables d’une posture (statique) et ponctuellement d’une locomotion (mouvement) bipèdes, nous sommes la seule espèce de primates à l’être de façon permanente. L’acquisition et le développement de ce mode locomoteur sont des éléments clés de notre évolution.
Des fossiles à la locomotion
Tout d’abord, comment reconstruire la locomotion, donc le mouvement, à partir de fossiles inertes ?
Pour y parvenir, l’approche classique consiste à comparer les caractéristiques anatomiques du fossile à celles de primates bien vivants en utilisant l’anatomie comparée et fonctionnelle. Il s’agit d’établir des liens entre anatomie et locomotion chez les espèces actuelles pour les appliquer à des spécimens fossiles afin de reconstruire leur comportement. Cette approche est possible parce que chaque individu de chaque espèce présente des adaptations, des caractères qui ont été sélectionnés et conservés sur le temps long de l’évolution, et certaines de ces adaptations concernent la locomotion.
La comparaison entre l’humain actuel et le chimpanzé permet de comprendre ce concept d’adaptations locomotrices. Ces deux espèces présentent des comportements locomoteurs différents : les humains sont bipèdes de façon permanente alors que les chimpanzés pratiquent une quadrupédie au sol (appelée knuckle-walking), mais peuvent aussi moins fréquemment grimper et se suspendre aux arbres et être ponctuellement bipèdes.
On dit que les chimpanzés, à l’image d’autres primates, ont un répertoire locomoteur, une combinaison entre plusieurs modes dont la fréquence d’utilisation peut varier. Ces différences de locomotion s’illustrent dans un grand nombre de caractéristiques anatomiques, par exemple :
à la tête, le foramen magnum, zone d’insertion de la colonne vertébrale située à la base du crâne chez l’humain se trouve à l’arrière du crâne chez les chimpanzés, indiquant une posture érigée chez les premiers, une posture quadrupède chez les seconds ;
aux jambes, les fémurs humains sont éloignés au niveau de nos larges hanches et se rapprochent en allant vers les genoux, permettant un bon équilibre debout. À l’inverse, chez les chimpanzés, les fémurs sont parallèles ;
les bras des chimpanzés sont plus longs que leurs jambes, permettant une meilleure capacité à la fois à grimper et à marcher à quatre pattes ;
nos pieds présentent un système d’arches anatomiques formant une voûte plantaire. Cette voûte, absente chez les chimpanzés, est une adaptation à la marche bipède : elle agit comme absorbeur de chocs et comme levier lors de la propulsion vers l’avant.
En plus de ces analyses du squelette visibles à l’œil nu, les paléoanthropologues ont recours à des techniques virtuelles, en particulier aux analyses d’imagerie à très haute résolution afin d’étudier l’intérieur même des ossements. La structure interne des os, en particulier celle des membres (le fémur et le tibia pour la jambe et la cuisse, l’humérus pour le bras), permet par exemple d’estimer la robustesse d’un os et, par conséquent, son niveau d’adaptation pour un type de locomotion. En quelques mots, avoir son fémur (cuisse) plus robuste que son humérus (bras) témoigne par exemple d’une préférence pour un déplacement sur les jambes.

Enfin, d’autres vestiges plus rares que les ossements témoignent des comportements locomoteurs du passé : les empreintes de pieds fossiles qui capturent des moments figés dans le temps. L’observation d’empreintes permet aisément de savoir si l’individu qui les a laissées était bipède ou quadrupède. Mais les empreintes offrent également des informations sur la démarche elle-même : la distance entre les pas ou l’angle formé par le pied permettent de mettre les fossiles en mouvement.
Bipèdes mais pas que
C’est donc à partir des restes osseux et d’empreintes de pieds qu’il est possible d’étudier la locomotion des fossiles. Maintenant que la méthode est connue, nous pouvons nous intéresser à l’évolution de la locomotion des hominines, regroupant Homo sapiens et les espèces fossiles plus proches de nous que des chimpanzés, c’est-à-dire les représentants de ce qui est couramment appelé la « lignée humaine ».

Les hominines les plus anciens sont connus grâce à trois groupes : Sahelanthropus dont le célèbre Toumaï (Tchad, 7 millions d’années), Orrorin (Kenya, 6 millions d’années) et Ardipithecus (Éthiopie et Kenya, entre 6,3 et 4,4 millions d’années). L’inclusion de ces trois groupes aux hominines à la base de l’évolution humaine repose en partie sur la présence de caractères adaptés à la bipédie.
Cependant, la présence d’une bipédie fait largement débat au sein de la communauté des paléoanthropologues. En effet, notre connaissance de leur anatomie est limitée par une faible quantité de fossiles pour la plupart fragmentés et par le fait que ces fossiles montrent une « anatomie en mosaïque ». Ce terme désigne le fait qu’un individu fossile peut présenter à la fois des adaptations à la bipédie au sol et à une locomotion arboricole, une anatomie originale et inconnue chez les primates actuels et donc difficilement interprétable. Autre problème : ces adaptations semblent varier d’un groupe à l’autre, témoignant d’une diversité de comportements locomoteurs incluant une forme de bipédie chez ces premiers représentants de la lignée humaine.
Pour les espèces d’hominines plus récentes, du moins à l’échelle des temps géologiques, l’image est plus claire. Les australopithèques, connus entre 4,2 millions et 2 millions d’années en Afrique, sont un groupe bien documenté grâce à la découverte de plusieurs centaines de restes osseux.
Certaines découvertes exceptionnelles – comme le squelette de la célèbre Lucy (Éthiopie, 3,2 millions d’années), complet à 40 %, ou le squelette de Little Foot (Afrique du Sud, 3,7 millions d’années), moins connu du grand public mais complet à près de 90 %, ou encore les empreintes de pieds de Laetoli (Tanzanie, 3,7 millions d’années) – nous livrent des informations sur l’évolution de la locomotion de nos ancêtres. La morphologie de la colonne vertébrale, du bassin, de la hanche, du genou et de la cheville de Lucy et de Little Foot ainsi que les empreintes de Laetoli montrent clairement que les australopithèques étaient bipèdes, au moins en partie. Toutefois, les phalanges de mains courbées et l’orientation de l’épaule suggèrent une locomotion arboricole.
La présence de ces derniers caractères interroge les paléoanthropologues depuis plus de cinquante ans : ces hominines pratiquaient-ils plusieurs modes de locomotion (à l’image des autres primates) ou bien ces caractères anatomiques sont-ils le résidu de l’anatomie de leurs ancêtres sans utilisation réelle ? Cette question ouvre sur une nouvelle problématique qui n’a pas encore trouvé de réponse claire : la distinction entre la capacité à effectuer un comportement et sa pratique réelle.

À côté des célèbres australopithèques, d’autres hominines comme les paranthropes ou les premiers représentants du genre Homo, comme Homo habilis, sont moins bien documentés, bien qu’ils leur soient contemporains. Plusieurs recherches ont cependant souligné que ces espèces, parfois contemporaines, différaient les unes des autres. L’image est donc complexe : des hominines différents coexistent et sont adaptés à des comportements variés. L’évolution n’est pas linéaire, elle témoigne d’une grande diversité passée.
Les derniers représentants du genre Homo ont, pendant longtemps, été considérés comme des bipèdes permanents. C’est le cas pour les Homo erectus ou les néandertaliens qui partagent la majorité des adaptations à la bipédie retrouvées chez Homo sapiens.
Toutefois, les découvertes de nouvelles espèces du genre Homo lors des deux dernières décennies montrent une diversité locomotrice y compris pour des périodes relativement récentes du point de vue de notre longue histoire évolutive.
Homo naledi, connu par près de 1 500 restes osseux représentant au minimum une vingtaine d’individus et découvert en 2013 dans la grotte de Rising Star (Johannesburg, Afrique du Sud), daté entre 330 000 et 230 000 ans, en est l’exemple parfait. Des phalanges de main courbées, une voûte plantaire du pied peu marquée… sont des caractères se rapprochant des australopithèques, alors que ces individus étaient contemporains des premiers représentants de notre espèce Homo sapiens en Afrique.
Ces caractéristiques sont surprenantes pour une date aussi récente. Elles soulèvent des doutes sur la capacité de cette espèce à se déplacer sur de longues distances, un comportement adopté par les Homo erectus, les néandertaliens et les Homo sapiens. Le constat est clair : la diversité des locomotions est restée présente jusque récemment.

L’origine de la bipédie en vue
La locomotion bipède est un élément déterminant de notre évolution, expliquant en grande partie le succès évolutif des hominines par rapport aux autres grands singes. Toutefois, la question de l’origine de la bipédie demeure.
À quoi ressemblait l’ancêtre commun aux humains et aux chimpanzés ? Était-il plus bipède que quadrupède ? Le débat reste ouvert et de nouvelles découvertes de fossiles en Europe soulèvent la question de l’apparition d’une forme de bipédie avant même l’apparition des premiers hominines. Si la question des origines reste ouverte, la diversité comportementale des hominines est désormais un fait.
Jérémy Duveau est enseignant-chercheur à l'Université de Tübingen (Allemagne) et chercheur associé au Muséum national d'Histoire naturelle. Il est membre depuis 2017 de l'International Research Network "Bipedal Equilibrium" (CNRS Ecologie & Environnement). Une partie de ses recherches ont été financées suite à l'obtention du prix de thèse de la Chancellerie des Universités de Paris en 2021. Il a également reçu des financements de la fondation Fyssen pour ses recherches en 2022 et 2023 ainsi que de l'Agence National de la Recherche pour le projet ANR-18-CE27-0010 HoBiS entre 2019 et 2024.
Quentin Cosnefroy est chercheur associé au laboratoire PACEA de Bordeaux et membre de l'International Research Network "Bipedal Equilibrium" (CNRS Ecologie & Environnement). Il a reçu des financements de l'Agence Nationale de la Recherche pour le projet ANR-18-CE27-0010 HoBiS entre 2020 et 2024 et le projet ANR-22-CE27-0016 NeHos entre 2024 et 2026 ; ainsi que du Grand Programme de Recherche "Human Past" de l'Université de Bordeaux.
01.06.2026 à 17:26
Rendre le numérique accessible aux personnes déficientes visuelles : un enjeu à la croisée de la psychologie et de la cybersécurité
Nicolas Louveton, Enseignant-chercheur en psychologie et ergonomie cognitive, Université de Poitiers
Cassandre Simon, Ingénieure de Recherche en Interaction Humain-Machine, Université de Poitiers
Texte intégral (2025 mots)
Entrer un mot de passe puis un code reçu par SMS pour se connecter sur le site de sa banque constitue, pour la plupart des utilisateurs, une démarche contraignante mais réalisable. En revanche, pour les personnes porteuses de déficiences visuelles, cela peut représenter un obstacle majeur, voire insurmontable. Face à ces difficultés, il existe plusieurs solutions, certaines déjà mises en œuvre et d’autres, conçues en partenariat avec les utilisateurs, qui sont en cours de développement.
Les services numériques sont omniprésents dans notre quotidien. Qu’il s’agisse de réserver un billet de train, de déclarer ses impôts ou de prendre un rendez-vous médical, se connecter à des plateformes numériques en ligne est devenu un passage obligé pour de nombreux gestes du quotidien. Pour cela, une étape incontournable : l’authentification, un processus qui permet de contrôler notre identité et de protéger nos données.
Parce que la sécurité sur nos téléphones et autres écrans est bien souvent centrée sur notre capacité à voir lesdits écrans, nombre de personnes aveugles ou malvoyantes renoncent à sécuriser leurs appareils.
L’accessibilité des systèmes d’authentification est pourtant cruciale dans une société qui se veut inclusive et qui promeut l’usage du numérique dans une large gamme de services, et notamment les services publics.
Comment la perception du risque, le design technologique et le handicap interagissent-ils pour conduire à des comportements non sécurisés et à l’exclusion numérique ? C’est ce que nous cherchons à mieux comprendre en mobilisant l’ergonomie cognitive, une discipline scientifique visant à concevoir des systèmes adaptés aux capacités et limites des utilisateurs finaux.
Notre but est de créer un cadre intégrant la recherche scientifique, l’innovation technologique et les considérations éthiques, vers une sécurité numérique véritablement inclusive.
L’authentification : passage obligé de la vie numérique
Bien que nécessaire, cette étape de sécurité soulève certaines difficultés.
De fait, les méthodes d’authentification n’ont pas été conçues avec un objectif de facilité d’utilisation : leurs concepteurs ont plutôt cherché une forme de barrière contre les accès non autorisés. Si ces méthodes posent des difficultés à une grande partie des utilisateurs, les personnes en situation de handicap, et notamment les personnes aveugles et non voyantes, sont particulièrement impactées.
En France, en 2005, 1 700 000 personnes étaient touchées par un handicap visuel, soit près de 2,9 % de la population. Ces utilisateurs sont souvent contraints de limiter leur usage du numérique, de compromettre leur sécurité (absence de code PIN ou de mots de passe) voire de renoncer à leur autonomie vis-à-vis du numérique en demandant systématiquement l’aide d’un tiers de confiance.
Ergonomie de l’authentification
La méthode d’authentification la plus répandue reste le couple nom d’utilisateur-mot de passe, avec des exigences de plus en plus complexes pour les mots de passe. Selon le niveau d’expertise, de sensibilité et de confiance en soi de l’utilisateur, on observe des stratégies très différentes de gestion des mots de passe. Certaines de ces stratégies affaiblissent la sécurité (utiliser des mots familiers, personnaliser une base de mots de passe, conserver une liste papier ou électronique). D’autres sont plus avancées, comme l’utilisation d’un gestionnaire de mots de passe.
Plus récemment, les solutions biométriques se distinguent par leur utilisabilité et leur sécurité, comme la reconnaissance faciale ou le lecteur d’empreintes digitales notamment. Elles ont l’avantage d’être « transparentes », elles peuvent néanmoins soulever des questions quant à la gestion des données personnelles, et elles ne sont pas infaillibles – l’invisibilité elle-même peut devenir un problème d’ergonomie (déverrouillage involontaire du smartphone, par exemple).
Enfin, l’authentification à facteurs multiples (MFA) est désormais largement répandue. Cette méthode est plus sûre, mais aussi plus complexe pour l’utilisateur, car elle ajoute des étapes avant d’accéder au service. Cependant, certaines méthodes posent des défis considérables aux personnes déficientes visuelles. Les captchas, qui impliquent la résolution de défis souvent fondés sur la perception visuelle ou auditive, en sont l’exemple le plus évident.
Handicap visuel et authentification
Pourtant le numérique, et le Web en particulier, sont supposés être accessibles à tous : dans cet esprit, la Web Accessibility Initiative (WAI, Initiative pour l’accessibilité du Web) promeut des standards tels que les Web Content Accessibility Guidelines (WCAG), qui sont des recommandations internationales définissant les critères qu’un site doit respecter pour être utilisable par tous, y compris les personnes en situation de handicap.
En France, leur équivalent réglementaire s’appelle le Référentiel général d’amélioration de l’accessibilité (RGAA), dont le respect est obligatoire pour les services publics en ligne. Par exemple, ces normes définissent des seuils acceptables de contrastes entre les couleurs de pages Web pour en assurer la lisibilité aux malvoyants, ou encore établissent les bonnes pratiques de balisage d’une page pour la rendre accessible aux lecteurs d’écran.
Les interfaces numériques reposent majoritairement sur des modalités visuelles pour transmettre l’information, en particulier lors des procédures d’authentification. Si des outils d’assistance tels que les lecteurs d’écran, les logiciels de grossissement, les commandes vocales ou les terminaux Braille permettent aux personnes aveugles ou malvoyantes d’interagir avec ces interfaces, leur utilisation ne garantit pas toujours la confidentialité des données, selon le contexte.
Ce problème est particulièrement marqué sur mobile, où les écrans tactiles sont omniprésents. Utiliser une interface tactile avec un lecteur d’écran, c’est s’exposer à ce qu’un observateur proche entende ou voie ce que l’on fait. La saisie d’un mot de passe sur smartphone est ainsi considérée comme l’une des tâches les plus difficiles pour un utilisateur aveugle ou malvoyant : elle engendre un inconfort en public et une vulnérabilité particulière aux regards indiscrets (shoulder surfing).
C’est pourquoi la plupart des utilisateurs aveugles ou malvoyants ne protègent pas leur appareil mobile par un mot de passe – et ce, malgré le fait que 96 % d’entre eux considèrent l’authentification comme essentielle ou très importante (enquête menée auprès de 325 personnes).
Par ailleurs, les utilisateurs déficients visuels tendent à abaisser leur vigilance quant à leur sécurité et à la confidentialité de leurs données lorsqu’ils se trouvent entourés de proches, adoptant une attitude plus transparente vis-à-vis de leurs informations personnelles.
Des recherches ont montré que, parmi les méthodes d’authentification, les scans d’iris et les schémas de déverrouillage sont les moins accessibles, tandis que la reconnaissance d’empreintes digitales est la plus accessible et la plus sûre pour les personnes aveugles ou malvoyantes. Les codes PIN, bien qu’omniprésents sur mobile, sont perçus comme inconfortables – ils ralentissent considérablement l’activité.
Enfin, des appareils complémentaires peuvent renforcer la sécurité et la confidentialité, tels que les claviers Braille ou les lunettes numériques grossissantes. Ils nécessitent toutefois d’être correctement intégrés aux outils du quotidien des personnes aveugles ou malvoyantes.
Le projet ALIAS
Nous avons démarré le projet de recherche ALIAS, collaboration entre chercheurs en psychologie et en ergonomie cognitives et un partenaire industriel spécialisé dans les systèmes d’authentification. Notre démarche de conception participative, centrée sur l’utilisateur, place au cœur de la conception, les besoins et les pratiques réels des utilisateurs, y compris ceux en situation de handicap.
Concrètement, le projet se divise en trois étapes majeures. La première – qui est en cours de réalisation – consiste à analyser les besoins, à travers un état de l’art scientifique et des études de terrain menées auprès des utilisateurs. Une première enquête en ligne auprès des personnes atteintes de déficience visuelle (300 participants), complétée par des groupes de discussion, a permis d’identifier les principaux points de friction ainsi que les besoins réels en matière d’interaction et d’accessibilité.
Ces résultats serviront de base à la deuxième étape, dédiée au développement de prototypes élaborés à partir des données recueillies.
Enfin, la troisième étape visera à améliorer ces prototypes de manière itérative, grâce à des tests utilisateurs menés avec les utilisateurs cibles, afin d’aboutir à des recommandations pour la conception d’une solution véritablement adaptée à leurs besoins.
Les auteurs remercient Zoé Ferfaille, ingénieure d’étude sur le projet ALIAS, pour sa contribution aux recherches qui sous-tendent l’article. Le projet ALIAS fait partie du Programme de transfert de compétences et de technologies de la recherche dans le domaine de la cybersécurité et implique l’entreprise OpenSezam, l’Université de Poitiers et le CNRS.
Le Programme de transfert de compétences et de technologies de la recherche dans le domaine de la cybersécurité — P1 (ANR-22-PTCC-0001) est géré par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Nicolas Louveton est membre de l'université de Poitiers. Il a reçu des financements de l’Agence Nationale de la Recherche au titre de France 2030 portant la référence ANR-22-PTCC-0001.
Cassandre Simon est membre du CNRS et de l'université de Poitiers. Elle a reçu des financements de l'Agence Nationale de la Recherche au titre de France 2030 portant la référence ANR-22-PTCC-0001.
30.05.2026 à 08:47
Néandertal utilisait-il les dents de rhinocéros comme outils ?
Camille Daujeard, Archéozoologue, chargée de Recherche, Muséum national d’histoire naturelle (MNHN)
Texte intégral (3553 mots)

Le projet RINO est né de la découverte de traces singulières observées sur des dents de rhinocéros d’un site préhistorique de la vallée du Rhône. L’étude des restes dentaires de rhinocéros du site paléolithique moyen de Payre (vers 250 000-130 000 ans avant le présent) a en effet permis de mettre en évidence des marques qui pourraient indiquer leur utilisation comme outils par Néandertal – un comportement inédit.
À l’inverse de la figure emblématique du mammouth, la place du rhinocéros dans les comportements de subsistance des humains préhistoriques et les relations qu’ils ont entretenues tout au long du paléolithique sont peu connues. Pourtant, bien avant les représentations pariétales de la grotte Chauvet (Ardèche), il y a plus de 30 000 ans, cet animal a été consommé et utilisé à d’autres fins qu’alimentaires. La découverte de marques inhabituelles sur des dents de rhinocéros dans plusieurs sites du paléolithique du sud de la France soulève une question : ces marques pourraient-elles être le résultat d’une activité humaine intentionnelle ?
L’utilisation d’ossements de grands herbivores, y compris de rhinocéros, comme outils pour retoucher et raviver les tranchants de pierres taillées (« retouchoirs ») est un comportement bien connu, dès les périodes anciennes du paléolithique. Les dents de rhinocéros sont nombreuses dans les sites du paléolithique d’Europe et d’Asie et seules quelques rares études font l’hypothèse d’une récupération intentionnelle de celles-ci par les groupes humains.
Des fractures et des marques singulières
Il y a plus de 200 000 ans, à Payre, dans le sud-est de la France, ou encore sur le site de Panxian Dadong, en Chine, qui a livré une centaine de dents isolées de rhinocéros asiatique (Rhinoceros sinensis), des dents de rhinocéros présentant des fractures et des marques récurrentes ont été retrouvées. Ces observations ont conduit à s’interroger sur leur utilisation comme outils, et à explorer d’autres assemblages à rhinocéros de cette période du paléolithique en Europe. Serait-on là face à un comportement encore inconnu chez Néandertal ?
Cette question est à l’origine du projet RINO et de la publication qui vient de paraître dans la revue Journal of Human Evolution : « Elucidating the use of rhinoceros teeth by Neanderthals: Between experiments and the fossil record » (« Élucider l’utilisation des dents de rhinocéros par Néandertal : entre registres expérimental et fossile »), issue d’une collaboration scientifique internationale.
Il s’agit de la première étude approfondie et interdisciplinaire sur l’utilisation des dents de rhinocéros par Néandertal. Cette étude combine des analyses de restes fossiles et des expérimentations archéologiques sur des dents de rhinocéros actuels.
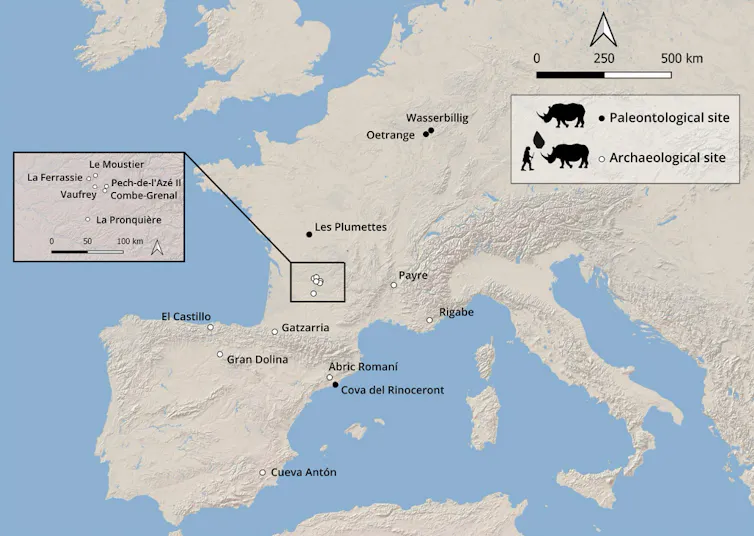
Les dents de rhinocéros possèdent en effet des caractéristiques morphologiques (taille, poids, caractère préhensible, surface occlusale plane et résistance à la fracturation) qui ont pu motiver leur usage à des fins techniques.
Méthode de recherche
Dans le cadre du projet RINO, 12 sites archéologiques ont été sélectionnés pour leurs traces d’activité humaine et leur abondance en dents de rhinocéros.
Afin d’avoir un référentiel de comparaison permettant de distinguer des traces naturelles de traces d’origine anthropique, comme suspectées, nous avons également inclus dans cette étude des séries dentaires provenant de sites paléontologiques d’Europe de l’Ouest et de collections ostéologiques de rhinocéros actuels. Ces séries comprennent au total 168 dents de rhinocéros provenant de quatre sites paléontologiques du Pléistocène en Europe occidentale : Wasserbillig (Luxembourg), Oetrange (Luxembourg), Cova del Rinoceront (Espagne) et Les Plumettes (Saône-et-Loire).
Nous avons également analysé 236 dents provenant de la collection comparative de la salle d’anatomie comparée du Muséum national d’histoire naturelle (MNHN) à Paris, avec l’objectif de reconnaître les altérations susceptibles d’avoir affecté les dents de rhinocéros tout au long de leur vie.
Une analyse des microtraces d’usure dentaire liées aux processus de mastication a été menée sur les dents de rhinocéros fossiles, afin de pouvoir écarter l’hypothèse d’une origine liée à l’alimentation du vivant de l'animal.
Par ailleurs, une part importante du projet concernait la démarche expérimentale. L’utilisation de molaires et de prémolaires de rhinocéros comme percuteurs par des tailleurs experts devaient permettre d’établir un référentiel complet des marques obtenues, et d’identifier la fonction de ces outils.
La principale difficulté rencontrée a été celle de l’acquisition de dents actuelles de rhinocéros pour effectuer ces expérimentations. Après de nombreuses recherches, avec l’aide d’Alexis Lécu, vétérinaire au Muséum national d’histoire naturelle, trois parcs zoologiques nous ont prêté du matériel dentaire, les zoos de Peaugres (Ardèche), de Sigean (Audes) et Montpellier (Hérault). Les extractions ont été effectuées par Benjamin Drouet à Peaugres et par Antoine Joris à Sigean.
Les expérimentations de percussion (retouche, taille, utilisation comme enclume) ont pu ainsi être menées sur 18 dents de rhinocéros, à l’aide d’outils lithiques en quartz et en silex. L’objectif était de reconnaître et d’identifier les traces laissées par l’action humaine.

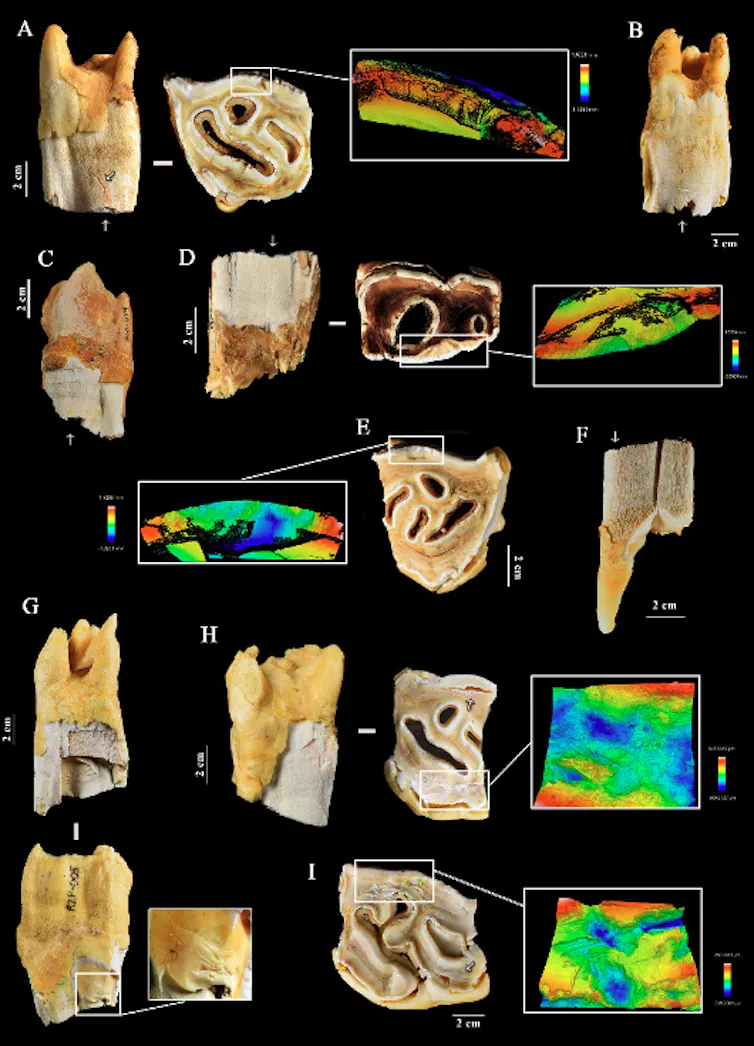
Un dernier volet de référentiel expérimental visait à reproduire des phénomènes naturels d’abrasion (sédiments) et de compaction que peuvent subir des dents durant leur fossilisation. Ces expérimentations ont été menées au sein du laboratoire de taphonomie de Madrid (LeaT laboratory).

Les résultats obtenus révèlent la présence de marques similaires à celles de Payre ainsi qu’à celles produites lors des expérimentations archéologiques, dans deux autres sites néandertaliens : El Castillo (Espagne) et Pech-de-l’Azé II (Dordogne). Dans ces deux sites, qui comptent au total 281 dents analysées, les espèces de rhinocéros concernées sont le rhinocéros de prairie (Stephanorhinus hemitoechus) et le rhinocéros de Merck (Stephanorhinus kirchbergensis). Ce dernier représente la plus grosse forme de rhinocéros fossile européen connue pour cette période.
Les traces observées sur le matériel dentaire diffèrent en revanche clairement des altérations de surface observées dans les collections de référence paléontologiques et modernes ainsi que de celles générées lors des expérimentations d’abrasion et de compaction sédimentaire. Par ailleurs, l’analyse des microtraces d’usure confirme qu’elles ont été produites après la mort de l’animal.
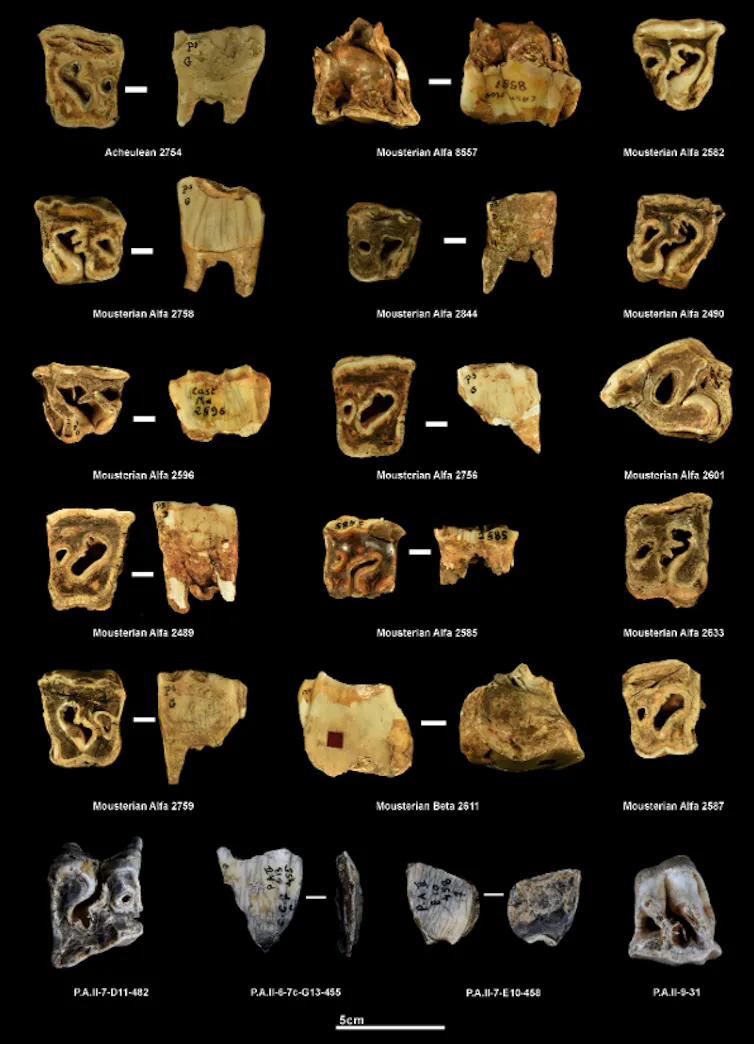
Des dents qui ont probablement servi d’outils percuteurs
Nous pouvons donc conclure que les traces identifiées sur les dents de rhinocéros de ces deux sites du paléolithique moyen – El Castillo (Espagne) et Pech‑de‑l’Azé II (France) – sont d’origine humaine. Ces dents ont probablement servi comme percuteurs dans la confection d’outils lithiques (silex, quartz), jouant un rôle dans la chaîne opératoire au paléolithique moyen. Au vu de l’état d’usure des dents utilisées, les Néandertaliennes et Néandertaliens semblent avoir eu une préférence pour des dents de rhinocéros âgés. Il est possible qu’ils se soient concentrés sur de vieux animaux, parce qu’ils représentaient potentiellement des proies plus faciles, ou des charognes. Leur morphologie dentaire, plus aplatie, était sans doute aussi plus adaptée à leur utilisation.
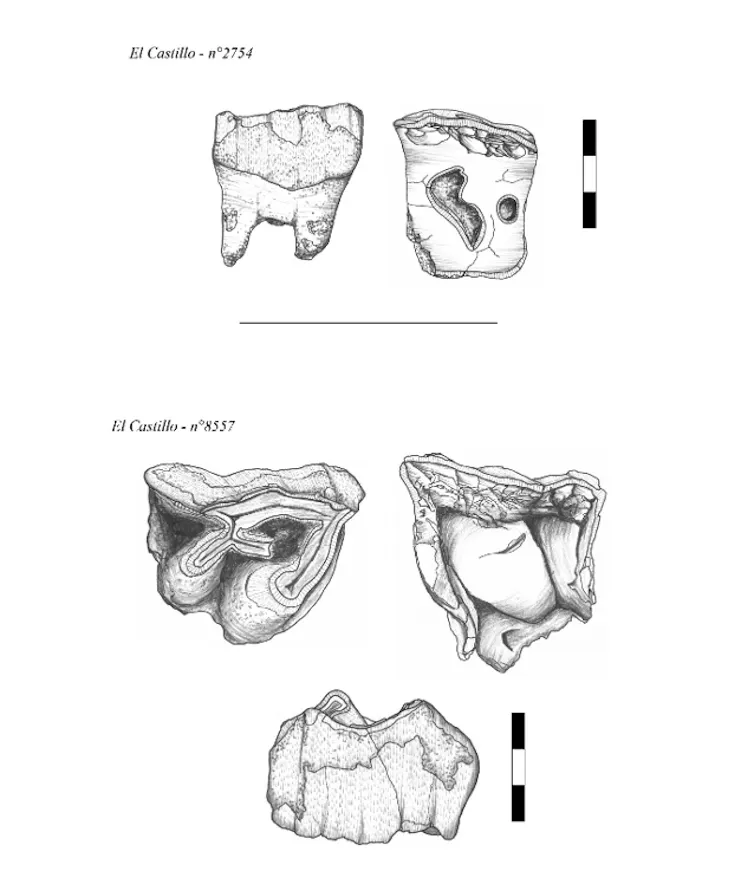
Cette étude permet d’élargir nos connaissances sur les comportements néandertaliens, leurs choix techniques et la diversité des matières premières collectées et utilisées, tout en apportant un nouvel éclairage sur leur utilisation des ressources animales. Malgré cette nette avancée dans le champ de nos connaissances, cette découverte ouvre également de nouvelles et nombreuses questions, qui restent pour le moment encore en suspens :
Qu’est-ce que cette découverte apporte à nos connaissances de Néandertal et de ses relations à son environnement ?
Quelles étaient les stratégies d’acquisition (chasse, charognage, piégeage) et d’utilisation des rhinocéros par Néandertal ? Étaient-elles les mêmes pour tous les types de rhinocéros rencontrés à ces périodes en Europe ? Leurs particularités morphologiques, éthologiques et écologiques et leur disponibilité au sein des biotopes ont-elles influé sur ces comportements ?
Le caractère inédit des marques mises en évidence montre tout l’intérêt de ces recherches, qui ouvrent comme on l’a vu beaucoup de questions qui restent encore à explorer. Il est par ailleurs peu probable qu’une utilisation de dents de rhinocéros comme matière première ait été un comportement limité dans le temps et dans l'espace. C’est pourquoi une révision majeure des séries dentaires de rhinocéros issues des nombreuses collections de sites paléolithiques doit être engagée à la lumière de ces nouvelles observations.
Actuellement, nous ne savons pas si c’est un comportement général ou spécifique aux groupes néandertaliens d’Europe de l’Ouest. Mais que l’on mette en évidence le caractère « universel » ou original de l’utilisation de ces dents, cette découverte ouvre des perspectives en lien avec la connaissance de l’étendue, de la fonction et de la portée symbolique de ce comportement.
Nous remercions le projet RINO (Sorbonne Université et Muséum national d’histoire naturelle) et l’IRN TaphEN (CNRS) pour leur soutien financier. Nous tenons également à exprimer notre gratitude envers toutes les personnes qui nous ont autorisés à accéder aux collections archéologiques et paléontologiques et aux laboratoires qui nous ont accueillis. Enfin, nous adressons nos sincères remerciements aux parcs zoologiques de Peaugres, Sigean et Montpellier (France) pour nous avoir fourni les dents de rhinocéros utilisées lors des expérimentations, avec une mention spéciale à Alexis Lécu, vétérinaire au MNHN, pour son aide précieuse dans cette recherche.
Camille Daujeard a reçu des financements de Sorbonne Université, du Muséum national d'Histoire naturelle, et de l'IRN Taphen (CNRS).
29.05.2026 à 09:00
À force d’utiliser l’IA, les journalistes risquent-ils d’appauvrir la langue ?
Xosé López-García, Periodismo digital, comunicación digital, Universidade de Santiago de Compostela
Cristian Augusto Gonzalez Arias, Investigador, Pontificia Universidad Catolica de Valparaiso; Universidade de Santiago de Compostela
Texte intégral (1673 mots)

Historiquement, le journalisme a contribué à diffuser de nouveaux mots et à nommer les transformations du monde. Si les textes générés par l’IA deviennent dominants, cette dynamique d’innovation linguistique pourrait s'affaiblir.
Que devient le langage public lorsqu’une part croissante des textes qui circulent dans la presse, sur Internet et sur les réseaux sociaux commence à être rédigée par des machines ? La question ne concerne pas seulement le journalisme en tant qu’activité professionnelle. Elle peut aussi affecter la richesse de la langue que nous utilisons pour comprendre, décrire et débattre du réel.
Historiquement, la presse a été l’un des espaces où la langue commune s’est développée et enrichie. Elle n’est évidemment pas le seul moteur du changement linguistique, mais elle constitue l’un des lieux où les sociétés mettent en circulation de nouveaux mots, de nouvelles tournures et de nouvelles façons de nommer des phénomènes émergents. Plusieurs travaux sur le langage journalistique et les néologismes montrent d’ailleurs que les journaux ont longtemps joué un rôle essentiel dans la création et la diffusion de vocabulaire nouveau, en particulier lorsqu’il s’agissait de rendre compte d’événements, de technologies ou de transformations sociales auprès d’un large public.
Ce rôle pourrait s’affaiblir si une part importante de l’écriture journalistique était déléguée à des systèmes d’IA générative. Les grands modèles de langage reposent, de manière générale, sur la prédiction du mot – ou plus précisément du « token » – le plus probable au sein d’une séquence. Ils produisent ainsi des textes fluides et plausibles, mais tendent également à privilégier les régularités statistiques, les formulations les plus fréquentes et les tournures déjà stabilisées.
Cela ne signifie pas, en soi, que le langage se dégrade automatiquement. Le problème apparaît lorsque cette logique devient dominante dans la production des textes qui alimentent l’espace public.
Quand les IA s’entraînent sur des textes produits par d’autres IA
Le risque devient plus sérieux lorsque ces systèmes commencent à être entraînés à partir de textes produits par d’autres IA. C’est ce que plusieurs travaux récents décrivent sous le nom de model collapse, ou « effondrement du modèle » : un processus de dégénérescence dans lequel les données générées par un modèle finissent par contaminer l’entraînement des générations suivantes.
Appliqué au langage, cela signifie que si les systèmes apprennent de plus en plus à partir de textes synthétiques, et si ces textes en viennent à saturer le Web et l’espace public, le réservoir linguistique disponible pour les futurs entraînements se rétrécit. Plus il y a de textes artificiels, moins les modèles sont exposés à la diversité réelle des usages humains de la langue. À terme, cela peut entraîner un appauvrissement du langage dans différents domaines.
Reproduction et amplification des biais
Tout d’abord, lorsque la diversité des données diminue et que les modèles s’appuient principalement sur des schémas déjà établis, les biais présents dans les données d’entraînement risquent d’être renforcés plutôt que corrigés. La littérature récente sur l’évolution des modèles de langage met précisément en garde contre le fait que les processus récursifs peuvent amplifier des préjugés existants au lieu de diversifier les points de vue.
Par ailleurs, l’écriture tend à se ressembler de plus en plus à elle-même : les mêmes structures syntaxiques, les mêmes tonalités intermédiaires, les mêmes formulations et les mêmes façons d’organiser les paragraphes reviennent sans cesse. Cette évolution est particulièrement importante pour le journalisme, car la presse ne se contente pas de transmettre des informations : elle fait le lien entre des savoirs spécialisés et un large public, hiérarchise les enjeux, traduit des vocabulaires techniques et expérimente de nouvelles formulations. Lorsque la langue de l’espace public devient trop uniforme, sa capacité à s’adapter finement à la nouveauté s’affaiblit.
Une érosion de l’innovation linguistique
Dans ce contexte, les mots rares ou spécialisés, les constructions moins fréquentes ainsi que certains nuances pragmatiques — comme l’ironie, l’ambiguïté ou certaines variations du point de vue — tendent à reculer. L’augmentation de la proportion de textes synthétiques dans les données d’entraînement est associée à une dégradation des performances et à une représentation plus pauvre de la diversité du langage humain. En termes simples, le système préserve mieux le centre que les marges.
Or, nombre d’innovations linguistiques naissent précisément dans ces marges : sous la forme d’usages instables, de détournements ponctuels ou de solutions locales inventées pour nommer une réalité nouvelle. Si le système privilégie systématiquement les formulations les plus probables, ces formes émergentes disposent de moins d’espace pour circuler et s’imposer.
Il ne faut pas comprendre cet enjeu comme une opposition abstraite entre « l’humain » et « la machine », mais plutôt comme la différence entre une langue nourrie par les contingences de la vie sociale et une prose produite à partir de régularités déjà apprises.
Un appauvrissement de l’écosystème linguistique
L’enjeu ne se limite pas à une diminution du nombre de mots différents. Il concerne aussi la capacité à établir des distinctions fines. Lorsque le langage devient plus vague, plus répétitif ou plus prévisible, les outils dont dispose une société pour décrire les problèmes, nuancer les positions et débattre dans l’espace public s’appauvrissent eux aussi.
À une échelle plus large, la question n’est donc plus seulement de savoir ce qui arrive à un modèle d’IA, mais ce qui arrive à l’écosystème linguistique public dans son ensemble. Si le Web se remplit de textes synthétiques, lecteurs, journalistes et institutions seront progressivement exposés à une langue publique moins diverse. Certains travaux récents vont jusqu’à évoquer une forme de « contamination » de l’écosystème numérique par les données synthétiques et montrent que la manière dont se combinent données réelles et artificielles est déterminante pour éviter des dégradations plus importantes.
Un scénario inéluctable ?
Il convient toutefois de ne pas exagérer le risque. Les travaux de recherche ne concluent pas que tout usage de l’IA entraîne inévitablement un effondrement ou une dégradation. Certaines études montrent que lorsque les données synthétiques sont mélangées à des données réelles, plutôt que de les remplacer entièrement, les mécanismes de dégradation ne se manifestent pas de la même manière et les erreurs peuvent rester limitées. Autrement dit, le problème ne réside pas dans un usage ponctuel de l’IA ni dans une combinaison prudente de données synthétiques et humaines, mais dans le remplacement massif de l’écriture humaine suivi du recyclage de cette production artificielle comme s’il s’agissait d’un langage vivant.
Avec l’intégration de l’IA dans les routines de production journalistique, le journalisme gagne en efficacité. Mais que perd une société lorsque la langue qui circule dans l’espace public devient plus uniforme, plus prévisible et moins ouverte à la nouveauté ? Si la presse renonce, même partiellement, à sa fonction d’écriture, de traduction, de nomination et d’expérimentation linguistique, ce ne sont pas seulement les pratiques professionnelles qui se transforment. C’est aussi l’un des principaux espaces où la langue commune a historiquement pu s’enrichir, se renouveler et élargir son champ des possibles qui s’en trouve affaibli.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
27.05.2026 à 10:09
Centres de données : pourquoi leur refroidissement consomme autant d’eau (et pourquoi cela pose problème)
Thomas Le Goff, Maître de conférences en droit et régulation du numérique, Télécom Paris – Institut Mines-Télécom
Texte intégral (1838 mots)
La course à l’IA engagée à l’échelle internationale ne doit pas se traduire par un détricotage des règles préservant nos ressources naturelles.
Qui n’a pas déjà expérimenté la désagréable sensation de surchauffe de son téléphone portable ou de son ordinateur lors d’une utilisation prolongée ou lorsque vous avez ouvert trop d’onglets sur votre navigateur ?
Imaginez maintenant la chaleur dégagée par 100 000 puces de calcul de dernière génération, entassées les unes sur les autres et tournant à plein régime, et ce, dans un complexe de plus de 26 kilomètres carrés soit environ 3 714 terrains de football. Placez ce grille-pain géant dans une région où la température est de 35 degrés en moyenne et peut atteindre les 50 °C l’été, et vous voilà devant le projet « Stargate UAE » visant à construire jusqu’à 5 gigawatts de puissance de calcul installée dans un immense centre de données à Abu Dhabi.
Ces projets de centres de données dits « hyperscale » visant à alimenter l’essor de l’intelligence artificielle (IA) se multiplient dans le monde, que ce soit aux États-Unis avec le projet Prometheus de Meta prévoyant la construction d’un centre de données de la taille de Manhattan, et même en France avec le « Campus IA ».
Au-delà de leur importante consommation énergétique, ces mastodontes soulèvent d’autres problèmes. Pour fonctionner correctement, ils ne peuvent pas atteindre des températures trop élevées, et contiennent donc des systèmes de refroidissement qui permettent aux composants électroniques de fonctionner à plein régime tout en évitant qu’ils ne se détériorent sous la chaleur qu’ils dégagent.
Comment ces centres de données sont-ils refroidis ? Quel est l’impact de leur refroidissement sur l’environnement, et comment les rendre plus sobres ?
Centres de données, refroidissement et consommation en eau
Il existe plusieurs techniques pour refroidir un centre de données. Pour le résumer simplement, les systèmes de refroidissement reposaient auparavant exclusivement sur des systèmes de ventilation (comme dans votre ordinateur) ou de climatisation (comme dans votre voiture) qui utilisent la circulation de l’air comme source de fraîcheur et rejettent l’air chaud à l’extérieur.
Une deuxième solution de refroidissement utilise l’eau, beaucoup plus efficace que l’air pour transférer la chaleur. Celle-ci permet de rafraîchir des plaques placées proches des composants électroniques, et/ou de rafraîchir l’air ventilé dans l’entrepôt de données.
Dans le premier cas (la climatisation), l’opérateur a besoin de beaucoup d’énergie pour faire tourner les pompes et systèmes de ventilation. Dans le deuxième (le refroidissement liquide), l’entreprise a besoin de moins d’énergie mais nécessitera l’accès à une source d’eau douce (l’eau salée endommagerait les tuyaux et composants) afin d’alimenter son système en eau fraîche.
Les opérateurs de centres de données sont donc face à un arbitrage complexe : doivent-ils utiliser des systèmes de climatisation énergivores ou bien du refroidissement liquide qui, cette fois, nécessite la consommation d’importantes ressources en eau ?
En effet, la consommation en eau des data centers est estimée à 560 milliards de litres chaque année dans le monde, soit l’équivalent de la consommation annuelle en eau potable de 10 millions de Français.
Cette soif insatiable se retrouve également dans les chiffres publiés par les Gafam. Ainsi, Google a vu sa consommation nette d’eau augmenter de 28 % entre 2023 et 2024, atteignant 30 milliards de litres dont environ un tiers provient de régions en stress hydrique. Microsoft, pour sa part, estime que 46 % de ses prélèvements d’eau ont lieu dans de telles zones en 2024.
Toutefois, il faut avoir à l’esprit que les besoins en eau des data centers ne sont pas uniquement liés aux systèmes de refroidissement. Pour obtenir une vision globale de l’impact du développement de ces infrastructures sur les ressources en eau, il convient de prendre également en compte l’eau utilisée par les centrales électriques qui les alimentent, ainsi que l’eau consommée lors du processus de fabrication des composants électroniques. Des chercheurs estiment ainsi que les mégacentres de données construits spécifiquement pour les besoins de calcul de l’IA utilisent, en moyenne, jusqu’à 20 millions de litres d’eau par jour, soit autant qu’une ville de 10 000 à 50 000 habitants.
Peut-on rendre les centres de données moins gourmands en eau ?
Il existe des solutions innovantes pour limiter cette consommation et rendre les systèmes de refroidissement plus efficients. Des entreprises, comme OVH Cloud, Nvidia ou Nebius, développent et déploient de nouvelles architectures de systèmes de refroidissement liquide au plus proche des puces de calcul. Ces nouvelles techniques permettent de réduire, selon les chiffres annoncés, jusqu’à 50 % de la consommation en eau. Toutefois, elles restent encore onéreuses à mettre en œuvre et assez peu développées sur le parc existant.
De manière plus générale, la principale source de perte en eau lors du fonctionnement des centres de données vient du fait qu’ils reposent aujourd’hui pour la plupart sur des circuits ouverts, conduisant à l’évaporation d’une grande partie de l’eau utilisée. C’est pourquoi les nouveaux centres de données devraient idéalement reposer, autant que possible, sur des systèmes de refroidissement en circuit fermé, évitant ce phénomène d’évaporation. Néanmoins, ce type de refroidissement peut s’avérer plus cher, conduit souvent à une hausse du besoin en électricité, et n’est pas évident à mettre en œuvre dans tous les centres de données « historiques » qui n’ont pas été conçus pour le mettre en œuvre.
Des propositions plus farfelues sont aussi avancées, telles que l’envoi de data centers dans l’espace ou bien en immersion dans les océans. Néanmoins, l’apport réel de ces propositions reste encore largement débattu, que ce soit pour des questions de faisabilité technique (bon courage pour réaliser la maintenance de votre centre de données sous-marin !) ou de bénéfices en termes d’émission de CO₂ par rapport à un centre construit sur terre – le cabinet de conseil en décarbonation, Carbone 4, fondé par Alain Grandjean et Jean-Marc Jancovici a, à cet égard, montré que les data centers spatiaux risquaient d’avoir un impact carbone plus important que sur terre en raison des émissions liées au lancement.
À lire aussi : Pourrait-on faire fonctionner des data centers dans l’espace ?
Pour un développement raisonné des centres de données, conscient du caractère fini des ressources naturelles
Au-delà de la faisabilité technique, ces discours risquent de nous détourner du vrai problème : le développement massif de centres de données hyperscale très gourmands en eau, dont une bonne partie dans des territoires où cette ressource se fait rare et conduit à des conflits d’usage.
Ce développement ne se fait pas dans un vide juridique. Les règles du droit de l’environnement, de l’aménagement du territoire et de l’urbanisme prévoient un certain nombre de régimes d’autorisation et d’évaluation environnementale en amont de la construction de ces projets, notamment en France avec le régime des installations classées pour la protection de l’environnement (ICPE).
Néanmoins, la course à l’IA engagée à l’échelle internationale conduit les pays à rivaliser d’ingéniosité pour attirer les investisseurs quitte, parfois, à assouplir les contraintes réglementaires comme c’est le cas actuellement en France avec la loi dite de simplification de la vie économique récemment adoptée. Il est urgent de prêter attention à l’ode à la « simplification », qui provient des discours politiques au sein de l’Union européenne et transcrite dans la politique menée par la Commission européenne, mais qui ne doivent pas se traduire par un détricotage des règles préservant nos ressources naturelles.
Plus généralement, ces débats soulèvent la question de l’usage : alors que certaines économistes parlent de « bulle de l’IA », qui peut réellement prédire quels seront les véritables usages futurs de ces infrastructures ?
Dans les années 1960, il fallait un bâtiment entier pour faire tenir un ordinateur, ils tiennent aujourd’hui dans notre smartphone. Si les IA de demain tiennent aussi sur nos terminaux, doit-on réellement sacrifier nos ressources naturelles pour créer ces mastodontes ?
À lire aussi : Charles Ponzi nous permet-il de comprendre la bulle de l’IA ?
Thomas Le Goff est Research Fellow au sein du think thank Centre on Regulation in Europe (CERRE).
27.05.2026 à 10:09
L’oubli catastrophique, ou pourquoi les IA ne savent pas encore apprendre en continu
Eric Moulines, Professeur en apprentissage statistique et traitement du signal, EPITA; Académie des sciences
Texte intégral (2961 mots)
Un modèle d’IA peut être très performant dans un cadre contrôlé, mais se dégrader lorsque les données qu’il reçoit en conditions réelles ne ressemblent plus exactement aux données sur lesquelles il a été conçu, validé ou récemment mis à jour.
Ainsi, lorsque la mise à jour du modèle est faite naïvement, on peut être confronté au problème de l’« oubli catastrophique » : le modèle a progressé sur les données récentes, mais perd brutalement en performance sur les données plus anciennes. Ce sont précisément ces difficultés qui motivent le développement de l’« apprentissage continu ».
Dans l’apprentissage automatique « classique », on entraîne un réseau de neurones sur un très grand ensemble de données, puis on l’utilise tel quel. Mais ce cadre devient insuffisant lorsque les données arrivent au fil du temps, par exemple dans le cas de données météo, à l’arrivée de nouveaux patients dont la démographie ou la génération évolue, ou encore avec de nouvelles pratiques professionnelles.
Un système de Google Health destiné à automatiser le dépistage de la rétinopathie diabétique (l’ensemble des maladies de la rétine dues à la détérioration des vaisseaux rétiniens par le diabète) était prometteur lors d’évaluations contrôlées. En clinique, en revanche, il a rencontré des difficultés : sur 1 838 images traitées pendant les six premiers mois d’usage dans onze cliniques en Thaïlande, 393 (21 %) n’atteignaient pas le seuil de qualité requis.
Cet exemple ne signifie pas que la rétinopathie diabétique aurait changé en quelques mois. Il montre plutôt que les données vues par le système en clinique peuvent différer fortement de celles utilisées lors de son développement : qualité variable des images, différences de caméras, luminosité, reflets, patients plus difficiles à photographier, contraintes de temps et organisation du dépistage.
Autrement dit, la distribution des données change lorsque l’on passe d’un cadre contrôlé à un environnement réel. C’est précisément ce type de décalage qui rend insuffisant un modèle figé et qui pose la question suivante : comment adapter le modèle à ces nouvelles conditions sans perdre ce qu’il savait déjà faire ?
Les méthodes les plus simples conceptuellement, par exemple un réentraînement complet sur toutes les données, incluant les nouvelles, exigent beaucoup de calculs et sont donc peu réalistes.
Le continual learning, ou apprentissage continu, vise justement à faire évoluer le modèle au rythme du flux de données : s’adapter, intégrer de l’information nouvelle et apprendre des tâches successives, sans repartir systématiquement de zéro. Il se distingue d’un simple réentraînement périodique par une contrainte essentielle : apprendre le nouveau sans détruire l’ancien.
Au fond, l’apprentissage continu cherche un compromis entre deux exigences opposées] : la plasticité, nécessaire pour apprendre du nouveau, et la stabilité, indispensable pour ne pas effacer l’ancien.
Pourquoi les modèles d’IA oublient-ils ?
La difficulté vient du fait qu’un réseau de neurones n’a pas une mémoire rangée en dossiers indépendants. Les mêmes paramètres – les mêmes neurones et les mêmes connexions – servent souvent à plusieurs tâches.
Si les tâches se ressemblent, cette mutualisation est utile : le modèle peut réutiliser des représentations déjà apprises. Mais si les tâches diffèrent, les mises à jour nécessaires à la nouvelle tâche entrent en concurrence avec ce qui faisait la réussite des anciennes.
Prenons un exemple simple. Un modèle industriel a appris à détecter des défauts sur des pièces métalliques à partir d’images prises avec une première caméra. Plus tard, l’usine remplace la caméra : la résolution, la luminosité et les reflets changent. Si l’on réentraîne le modèle uniquement avec les nouvelles images, il peut s’adapter au nouveau capteur, mais perdre en performance sur les images produites par l’ancien système. Ce n’est pas parce que les anciens défauts ont disparu ; c’est parce que les paramètres qui les reconnaissaient ont été modifiés pour résoudre le nouveau problème.
En production, les incidents publiés sont plus souvent décrits comme des « décalages de données » que comme de l’oubli catastrophique. Les deux problèmes restent liés : dès qu’un modèle est mis à jour avec des données récentes, il faut éviter d’effacer des compétences antérieures.
Une étude récente menée sur des modèles d’IA utilisés à l’hôpital illustre bien cette difficulté. Les chercheurs ont supervisé un système chargé d’estimer le risque de décès de patients hospitalisés. Avec le temps, les dossiers reçus par ce système ont changé : les patients n’étaient plus exactement les mêmes, certaines mesures médicales variaient, et les pratiques hospitalières ont été bouleversées, en particulier pendant le Covid-19.
Le problème n’est donc pas qu’un dossier isolé serait anormal. C’est l’ensemble des données qui se transforme peu à peu. Pour rester utile, le modèle doit alors être mis à jour avec des exemples plus récents. Dans l’étude, cette mise à jour permettait effectivement de meilleurs résultats qu’un modèle laissé tel quel. Mais il y a un risque : si on laisse le système « apprendre » trop sur les données récentes, le modèle peut se spécialiser et devenir très bon sur les cas nouveaux, tout en perdant une partie de ses capacités sur les cas plus anciens. Il s’adapte au présent, mais au prix d’un oubli du passé. C’est ce qu’on appelle l’« oubli catastrophique ».
Pour intégrer des informations nouvelles sans sacrifier ce qui a déjà été appris, plusieurs grandes familles de méthodes existent : rejouer une partie du passé, protéger certains paramètres, modifier l’architecture du modèle ou apprendre des représentations plus stables.
Garder en mémoire des exemples représentatifs
La première, assez intuitive, consiste à rejouer le passé. C’est le « replay » : on conserve une petite mémoire d’exemples représentatifs des tâches antérieures et l’on entraîne le modèle sur un mélange « nouvelles données + mémoire ». C’est une forme de révision : le modèle ne relit pas tout le manuel, mais revoit quelques pages bien choisies.
Dans un système de reconnaissance d’images qui apprend progressivement de nouvelles catégories, on peut garder quelques images typiques de chaque ancienne classe, mais aussi des cas ambigus proches des frontières entre classes. Des méthodes comme iCaRL ont popularisé cette idée : apprendre de nouvelles classes tout en gardant un petit ensemble d’exemples représentatifs des anciennes.
Lorsque stocker des données réelles est difficile – pour des raisons de confidentialité, de coût ou de stockage – on peut recourir à un modèle génératif. Entraîné sur le passé, ce modèle produit des exemples artificiels des anciennes tâches, qui jouent le rôle de « souvenirs » synthétiques. Cette stratégie, appelée generative replay, peut réduire le besoin de conserver les données originales.
Mais ces données synthétiques ne sont pas automatiquement équivalentes aux données initiales. Elles peuvent manquer de diversité, négliger les cas rares, amplifier certains biais ou produire des exemples plausibles mais trompeurs. Il faut donc les valider : vérifier qu’elles couvrent les anciennes classes, préservent les cas difficiles et maintiennent les performances sur des jeux de test indépendants.
Les travaux récents sur l’entraînement répété à partir de données synthétiques montrent aussi un risque d’« effondrement » du modèle : à force d’apprendre sur des données synthétiques, il peut perdre des informations sur la vraie distribution, surtout sur ses parties « rares ».
Toute la question est donc de décider quoi conserver (ou générer) lorsque l’on a un budget restreint : des exemples typiques, rares, difficiles, ou un mélange des trois.
À lire aussi : Apprendre à oublier : le nouveau défi de l’intelligence artificielle
Protéger certains paramètres du modèle
Une deuxième famille de méthodes vise non pas à conserver des exemples, mais à protéger certaines parties du modèle. L’idée est d’identifier les poids déterminants pour les tâches passées, puis d’ajouter une pénalité lorsqu’ils changent trop pendant l’apprentissage d’une nouvelle tâche. Le modèle peut continuer à apprendre, mais il paie un « coût » plus élevé lorsqu’il modifie des paramètres jugés importants pour ses compétences anciennes.
C’est le principe de méthodes comme Elastic Weight Consolidation : ralentir l’apprentissage sur les poids importants pour les tâches déjà vues, afin de réduire l’oubli.
Une approche voisine, mais différente, consiste à préserver le comportement de l’ancien modèle plutôt que ses poids. On ajoute alors un terme de coût qui encourage le modèle mis à jour à produire des sorties proches de celles de l’ancien modèle sur des données de référence. C’est le principe de la « distillation » : l’ancien modèle joue le rôle de professeur, et le nouveau apprend la nouvelle tâche sans trop s’éloigner des réponses du professeur. La méthode Learning without Forgetting repose sur cette logique, même lorsque les données initiales ne sont plus disponibles.
La différence est donc la suivante : la régularisation des poids demande de « ne pas trop déplacer ces réglages internes », tandis que la distillation demande de « garder un comportement proche de l’ancien modèle ». Dans les deux cas, on peut parfois limiter l’oubli sans stocker toutes les données passées.
Leur limite est le compromis imposé : si l’on protège trop le modèle, il devient moins plastique et apprend moins bien la nouvelle tâche. Dans l’exemple du changement de caméra, protéger les anciens paramètres peut aider à reconnaître les défauts déjà connus, mais une protection trop forte empêchera le modèle de s’adapter à la nouvelle luminosité ou à la nouvelle résolution.
Superposer à l’ancien modèle de nouvelles couches de neurones qui apprennent des nouvelles données
Une troisième stratégie consiste à éviter de faire tenir tous les apprentissages dans les mêmes paramètres. Plutôt que de modifier sans cesse le même réseau, on peut réserver des « espaces » distincts à différentes tâches.
Certaines approches figent les parties du réseau déjà apprises et ajoutent, pour chaque nouvelle tâche, de nouveaux modules reliés aux précédents. Les réseaux progressifs, par exemple, ajoutent de nouvelles colonnes de neurones tout en réutilisant les connaissances acquises par des connexions latérales. Le modèle bénéficie ainsi de l’expérience accumulée sans risquer de la dégrader.
D’autres méthodes apprennent à n’activer qu’une partie des paramètres selon la tâche ou le contexte. On peut imaginer le modèle comme un réseau routier : au lieu de faire passer toutes les tâches par la même route, il apprend quels chemins internes utiliser pour chaque situation. Les approches par masques d’attention ou par sélection de sous-réseaux suivent cette logique.
Enfin, lorsque la nouvelle tâche est trop éloignée des précédentes, on peut agrandir le modèle en lui ajoutant des neurones ou des modules. Des méthodes comme PackNet exploitent par exemple les redondances d’un grand réseau pour libérer puis réserver des paramètres à de nouvelles tâches.
Ces stratégies réduisent sensiblement l’oubli, mais elles ont un coût : le modèle peut grossir au fil du temps, et il faut parfois savoir, au moment de l’usage, quelle partie du réseau mobiliser. Dans certains cas, cette information est disponible — par exemple si l’on sait quelle tâche est demandée. Dans d’autres, le modèle doit aussi apprendre à reconnaître le contexte.
Apprendre des représentations plus stables
Une piste complémentaire consiste à agir plus en amont : il ne s’agit pas seulement de protéger le modèle ou de lui ajouter des modules, mais de lui apprendre des représentations internes plus stables.
Une représentation interne, ou embedding, est la description numérique qu’une couche intermédiaire fabrique à partir d’une donnée. Une image, un texte ou un signal de capteur est transformé en un vecteur de nombres qui résume certaines caractéristiques utiles : formes, textures, mots, régularités, anomalies. Si deux données se ressemblent, on aimerait que leurs représentations soient proches ; si elles correspondent à des classes différentes, on aimerait qu’elles soient bien séparées.
L’objectif est alors d’organiser cet espace de représentation de façon à ce qu’il change le moins possible lorsque de nouvelles tâches arrivent. On peut conserver quelques prototypes — des représentants typiques d’une classe — qui servent d’ancrages. On peut aussi utiliser des méthodes contrastives, qui rapprochent les exemples semblables et éloignent les exemples différents dans l’espace des représentations. Ces méthodes sont utiles parce qu’elles tendent à extraire des caractéristiques plus générales, donc moins dépendantes d’un contexte particulier.
On peut également pratiquer un replay en espace latent : au lieu de stocker les données brutes, on mémorise les activations produites par une couche intermédiaire du réseau. Cette stratégie peut réduire fortement le coût en mémoire et en calcul. Elle ne résout toutefois pas automatiquement toutes les questions de confidentialité : une représentation interne peut encore contenir des informations sensibles !
Combiner plusieurs mécanismes pour éviter les oublis catastrophiques
Dans les systèmes les plus efficaces, ces idées ne sont pas utilisées isolément. On combine fréquemment plusieurs mécanismes : un petit tampon de replay avec une régularisation des poids, du replay avec de la distillation, ou encore des représentations stables avec une architecture modulaire.
Le choix dépend des contraintes concrètes : budget mémoire, exigences de confidentialité, coût de calcul, vitesse d’adaptation attendue, criticité de l’application. Dans les domaines sensibles, comme la santé, l’apprentissage continu ne doit pas signifier qu’un modèle se modifie sans contrôle. Il doit s’accompagner d’une surveillance de la dérive des données, d’évaluations régulières, de garde-fous et d’une possibilité de revenir à une version antérieure du modèle.
L’apprentissage continu ne promet donc pas une IA qui apprendrait indéfiniment sans risque. Il propose plutôt une manière plus réaliste de maintenir des modèles utiles dans un monde qui change : apprendre du présent, sans effacer trop vite le passé.
Eric Moulines ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
27.05.2026 à 10:09
Tests de féminité aux JO : un seul gène peut-il déterminer le sexe d’une personne ?
Jean-François Bodart, Professeur des Universités, en Biologie Cellulaire et Biologie du Développement, Université de Lille
Texte intégral (1940 mots)
Pour les Jeux olympiques 2028, le Comité international olympique souhaite réserver la catégorie féminine aux athlètes « de sexe biologique féminin » ne portant pas le gène SRY, présenté comme le déclencheur génétique du développement testiculaire. SRY est certes un acteur clé de la différenciation sexuelle chez les mammifères et a longtemps été enseigné comme le « gène du sexe ». Mais la recherche en biologie du développement montre, aujourd’hui, que le sexe ne se résume ni à ce gène, ni même aux seuls chromosomes XX et XY. En effet, chromosomes non sexuels (autosomes), hormones, récepteurs et environnement s’entrecroisent pour produire une grande diversité de situations.
Depuis 2026, l’admissibilité à toute épreuve féminine des Jeux olympiques est, selon les nouvelles règles annoncées par le Comité international olympique (CIO) pour les JO 2028, réservée aux « personnes de sexe biologique féminin », non porteuses du gène SRY. Ce dernier est pris par le CIO comme critère d’exclusion, y compris pour des athlètes qui s’identifient comme femmes et répondent par ailleurs aux critères hormonaux (seuil de testostérone). Ce critère de port du gène SRY est critiqué par de nombreux spécialistes, perçu comme un indicateur de performance anachronique, reposant sur des bases scientifiques limitées et exposant les athlètes à des effets stigmatisants.
Historiquement, les règlements sportifs se sont d’abord appuyés sur des seuils de testostérone pour définir l’éligibilité à la catégorie féminine, en supposant qu’un taux plus élevé se traduisait mécaniquement par un avantage de performance.
Dans ce schéma, le rôle du SRY est implicite : ce gène influence les gonades, c’est-à-dire les organes responsables de la production des cellules sexuelles et de la sécrétion des hormones sexuelles, jouant de fait un rôle essentiel dans le développement sexuel. SRY oriente les gonades vers la différenciation en testicule, et favorise la production d’androgènes, hormones sexuelles stéroïdiennes (comme la testostérone) qui stimulent le développement et le maintien des caractères sexuels masculins. Ces hormones contribuent notamment à la masse musculaire, à la taille ou au pourcentage du volume sanguin occupé par les globules rouges (hématocrite), autant de facteurs susceptibles d’influencer certains résultats sportifs.
Mais même sur ce point, les données sont discutées : quelques études observent en moyenne un léger avantage pour les sportives avec les taux de testostérone les plus élevés, tandis que d’autres ne retrouvent pas de corrélation simple entre testostérone détectée dans le sang et performance, y compris chez les athlètes intersexes (athlètes nés avec des caractéristiques sexuelles, chromosomes, hormones, organes génitaux, qui ne correspondent pas exactement aux définitions « typiques » du masculin ou du féminin). La biologie du développement et la génétique montrent en effet une réalité beaucoup plus complexe et nuancée, qui déborde largement du cadre des seuls chromosomes sexuels. Le gène SRY ne contrôle pas à lui seul la différenciation des gonades en testicules.
XX, XY et SRY, « gène du sexe »
De manière classique, la détermination du sexe chez les mammifères est souvent présentée comme un mécanisme binaire : les individus XX deviendraient des femmes, les individus XY des hommes, grâce à l’action d’un « gène du sexe », SRY, localisé sur le chromosome Y. On parle de chromosomes sexuels pour désigner cette paire particulière (XX ou XY) qui, contrairement aux autosomes ou chromosomes non sexuels, diffère généralement entre femelles et mâles et porte une partie des gènes impliqués dans la détermination du sexe, comme SRY sur le Y.
Au cours du développement, les gonades du fœtus sont d’abord indifférenciées. Sous l’effet de SRY, elles s’orientent habituellement vers un développement testiculaire, tandis qu’en l’absence de SRY fonctionnel elles évoluent plutôt vers un développement ovarien.
Au début des années 1990, plusieurs équipes ont montré que le gène SRY, situé sur le chromosome Y pouvait être : impliqué dans la mise en place des testicules, présent chez des personnes XX avec un corps « masculin », altéré chez certaines personnes XY au corps « féminin », ce qui le rend nécessaire au développement testiculaire. Des expériences chez la souris ont ensuite prouvé qu’exprimer le gène SRY dans un embryon XX suffit pour qu’il développe des testicules. Ces résultats ont bouleversé les modèles précédents en instaurant l’idée qu’un seul gène peut déclencher toute la cascade de différenciation sexuelle vers le masculin. Cette vision reste cependant très simplificatrice.
Par exemple, l’étude des « variations du développement sexuel » (VDS, ou Disorders/Differences of Sex Development en anglais, DSD) remet en question la stricte équivalence XX = femme et XY = homme. Les variations du développement sexuel sont rares : en France et dans les pays aux profils similaires, les estimations cliniques situent leur fréquence autour d’une naissance sur 2 500 – 4 500, soit de l’ordre de 0,02 - 0,04 % des naissances, selon les définitions retenues. Ces troubles/variations du développement sexuel incluent, par exemple, des individus XY qui présentent des gonades mal développées, souvent réduites à des bandelettes fibreuses non fonctionnelles et un phénotype féminin, ou, inversement, des individus XX présentant des caractères typiquement masculins. Ces variations du développement sexuel, régulièrement rencontrées en clinique pédiatrique et endocrinologique, soulignent que ce que l’on appelle « sexe biologique » recouvre en réalité plusieurs dimensions (chromosomique, gonadique, phénotypique, hormonale) qui ne sont pas toujours alignées.
Un réseau de gènes pour déterminer le sexe
L’analyse moléculaire de la différenciation en testicule ou en ovaire chez les mammifères montre que cette différenciation ne résulte pas de l’action isolée de SRY. Plusieurs gènes s’activent ou se répriment de manière coordonnée dans le temps et dans l’espace. SRY constitue un signal d’initiation majeur dans la gonade XY, mais la mise en place puis la conversion durable de la gonade indifférenciée en testicule fonctionnel avec production d’hormones (androgènes) reposent ensuite sur des facteurs situés sur les chromosomes non sexuels (autosomes). On peut citer parmi eux les gènes SOX9 ou CBX2. Les gènes comme RSPO1 et WNT4 sont, quant à eux, impliqués dans le maintien d’un destin ovarien.
Les phénotypes observés lors de mutations de ces gènes illustrent leur rôle déterminant. Chez l’humain, des anomalies d’expression du gène SOX9 (par exemple des délétions régulatrices en amont du gène) chez des sujets XY peuvent entraîner un développement incomplet ou anormal des gonades et un phénotype féminin malgré un gène SRY fonctionnel.
À l’inverse, des mutations de RSPO1 ou de WNT4 peuvent, chez des individus XX humains, favoriser la formation de tissu testiculaire et une virilisation marquée des organes génitaux externes, en l’absence de chromosome Y.
Il existe donc des femmes XY et des hommes XX, parce que des gènes autosomiques ont fait basculer la cascade du développement sexuel dans un sens ou dans l’autre.
Autrement dit, SRY déclenche une trajectoire, mais ne la détermine pas à lui seul.
Au‑delà du génome : hormones, récepteurs et environnement
Les caractères sexuels secondaires (musculature, pilosité, voix, répartition des graisses, cycles menstruels, etc.) dépendent fortement des hormones sexuelles et de la sensibilité des tissus à ces hormones via leurs récepteurs. Ces hormones, comme les œstrogènes et les androgènes, agissent sur des milliers de gènes répartis sur l’ensemble du génome, et non pas seulement sur les chromosomes sexuels, avec des réponses qui varient selon les organes, l’âge, la nutrition, l’activité physique ou l’exposition à des perturbateurs endocriniens.
Des études récentes d’expression des gènes à l’échelle du génome montrent d’ailleurs de nombreuses différences d’expression génique entre femmes et hommes, qui concernent surtout des gènes sur les chromosomes non sexuels, dont l’activité est modulée par le contexte hormonal et le type de tissu. Même si le caryotype (composition en chromosomes, par exemple XX ou XY) joue un rôle important, la biologie du sexe chez les mammifères résulte ainsi d’interactions continues entre gènes, hormones et environnement au cours du développement et de la vie entière.
Un gène à lui seul ne suffit pas à « dire » le sexe
Les débats récents sur le sport de haut niveau reposent ainsi sur des dispositifs qui supposent que le sexe se laisse réduire à un simple marqueur génétique binaire. Or, la biologie contemporaine du développement décrit une réalité beaucoup plus riche : détermination chromosomique, différenciation gonadique, phénotype des organes génitaux (ensemble des caractères observables), profil hormonal et, au-delà, action de nombreux gènes autosomiques capables d’orienter ou d’inverser la trajectoire sexuelle.
Se pose une question plus large : que se passe-t-il lorsqu’on transforme un « fragment » de génome en critère de classement social ou sportif, alors qu’il ne reflète qu’une partie de la réalité biologique ? Comprendre cette complexité rappelle que le génome n’est pas un arbitre neutre, et que faire de la génétique un outil de tri mérite bien plus de prudence qu’un simple résultat de test ne le suggère.
Jean-François Bodart ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
25.05.2026 à 18:20
Comme l’humain, le chimpanzé a son propre style de dessin et le garde pendant des années
Cédric Sueur, Professeur des Universités en éthologie, primatologie et éthique animale, Université de Strasbourg
Marie Pelé, Directrice de recherche en éthologie, Institut catholique de Lille (ICL)
Texte intégral (1515 mots)
De même que chaque être humain possède une écriture reconnaissable ou que les peintres ont leur style artistique, les chimpanzés (Pan troglodytes) développent une manière de dessiner qui leur est propre et qui reste constante pendant des années. C’est ce que nous montrons dans notre récente étude parue dans la revue Primates.
Ainsi, le mâle Zamba remplit sa feuille de petits points compacts, disposés en grappes denses. Loi, lui, trace des courbes et des triangles répartis sur toute la feuille. La femelle Misaki, quant à elle, produit de grands motifs en éventail.
Ces différences ne relèvent pas du hasard : elles persistent de façon cohérente sur huit années d’observation, suggérant que le comportement graphique des chimpanzés reflète des traits individuels stables, et donc une forme de personnalité esthétique.
Comment cette découverte a-t-elle été réalisée ?
L’étude repose sur l’analyse systématique de 494 dessins produits entre 1999 et 2012 par six chimpanzés, hébergés au Great Ape Research Institute, au Japon. Ces animaux participaient librement à des séances de dessin proposées comme activité d’enrichissement cognitif, sans récompense conditionnelle : ils pouvaient entrer dans la salle, dessiner ou bien partir. Notons que, lors de leur première séance de dessin, les chercheurs leur montrent comment utiliser crayons, pinceaux et peinture et que tous les chimpanzés n’apprécient pas forcément cette pratique.
Quand un chimpanzé se désintéresse de son dessin et le laisse, il est récupéré, numérisé puis examiné, à l’aide d’une grille de 96 cellules permettant de quantifier dix variables dont le taux de remplissage de la feuille, le nombre de couleurs utilisées et leur chevauchement, la distance du dessin par rapport au centre de la feuille ou encore la présence de formes géométriques, telles que des boucles, des triangles ou des motifs en éventail.
Une analyse statistique a ensuite condensé ces mesures en trois grandes dimensions graphiques : le remplissage (densité et couverture), la forme (géométrie des tracés) et la couleur (diversité et superposition). Ces trois dimensions ont été comparées entre les individus, entre les saisons et au fil du temps pour chaque chimpanzé.
En quoi cette découverte est-elle importante ?
C’est la première fois qu’on démontre quantitativement, et durant plusieurs années, la stabilité d’un style graphique individuel chez un primate non humain. Nos études antérieures sur les orangs-outans ou d’autres chimpanzés avaient mis en évidence des différences entre individus, mais à des instants ponctuels ou sur de courtes périodes. Ici, les signatures individuelles persistent au cours d’une période de huit ans, indiquant que le dessin reflète des traits stables et récurrents, tels que les stratégies motrices, les préférences cognitives et les tendances exploratives, plutôt que des fluctuations d’humeur occasionnelles de la part des animaux.
Cette étude révèle par ailleurs que les dessins évoluent avec le temps : chaque chimpanzé remplit davantage la feuille, diversifie son utilisation des couleurs et ses formes au fil des mois et des années, un développement analogue à ce qu’on observe chez les enfants humains qui apprennent à dessiner. On note également un effet saisonnier marqué : en hiver, les productions sont plus légères et plus pauvres en formes, possiblement en lien avec une baisse générale d’activité liée au froid et à la luminosité réduite.
Enfin, si les chimpanzés utilisent préférentiellement leur main droite, ils peuvent aussi mobiliser les deux mains au sein d’un même dessin. Quand ils utilisent les deux mains, les chimpanzés couvrent une plus grande partie de la feuille et superposent davantage de couleurs.

Quelles sont les suites ?
Pour les chimpanzés, nous cherchons à agrandir la taille de la cohorte et à affiner nos résultats en déterminant s’ils sont capables de reconnaître leurs propres dessins.
Étendre cette approche à d’autres espèces de grands singes (gorilles, bonobos, gibbons – espèces encore jamais étudiées sous cet angle) permettrait de savoir si cette personnalité graphique est partagée par l’ensemble de ces espèces et d’en retracer l’histoire évolutive. L’utilisation de tablettes tactiles offrirait en outre accès à la dimension temporelle du dessin : l’ordre des couleurs ou la vitesse des tracés par exemple.
Sur le plan évolutif, la variabilité interindividuelle observée chez les chimpanzés pourrait refléter des comportements protographiques qui existaient chez les hominines (les gestes exploratoires de marquage de surfaces – tracer, gratter, pointer – qui précèdent et préfigurent le dessin intentionnel, sans en avoir encore la dimension symbolique ou représentative) bien avant l’émergence de l’art figuratif dont les premières traces datent de plus de 45 000 ans. Comprendre comment le geste exploratoire devient intentionnel, puis symbolique, passe sans doute par l’étude approfondie de nos plus proches cousins, comme nous l’avons suggéré chez les macaques.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Cédric Sueur a reçu des financements de l'université de Strasbourg (IDEX) et du CNRS MITI pour ces recherches. Il est membre de l'Institut Universitaire de France (IUF) et directeur de la Chaire Conservation et Culture des Grands Singes
Marie Pelé a reçu des financements de l'Université de Strasbourg (IDEX) et du CNRS MITI pour effecteur ces recherches.
24.05.2026 à 12:30
ChatGPT Santé se veut une aide pour les médecins et les patients. Est-ce fiable ? Quels risques pour la confidentialité et le secret médical ?
Nesrine Kaaniche, Associate professor, Télécom SudParis – Institut Mines-Télécom
Texte intégral (2040 mots)
En janvier 2026, OpenAI a lancé, aux États-Unis, ChatGPT Santé. Ce logiciel est principalement destiné aux patients pour les aider à mieux comprendre et à gérer leurs informations de santé. Il peut aussi être utilisé par les médecins afin de faciliter l’accès aux données médicales et d’améliorer le suivi des patients.
Avec une telle utilisation par les médecins et les patients, la protection des patients – que ce soit leur santé ou leurs données – et la préservation du secret médical dépendent des barrières techniques mises en place.
En pratique, ChatGPT Santé permet d’interpréter des résultats d’analyses, de suivre l’évolution de certains indicateurs, de préparer des rendez-vous médicaux ou encore d’obtenir des explications personnalisées à partir de données de santé.
Pour les patients, c’est un outil d’assistance informationnelle visant à les accompagner dans leur parcours de soins, sans se substituer aux professionnels de santé. Pour ces professionnels, ChatGPT peut servir d’aide au diagnostic.
Dans les deux cas, sa légitimité dépend d’un équilibre délicat : il s’agit de transformer des dossiers médicaux éparpillés en une aide au diagnostic fiable, tout en protégeant la vie privée des patients.
En effet, les données de santé, considérées comme sensibles, sont soumises à des réglementations bien précises. Leur confidentialité est essentielle pour garantir le respect du secret médical et limiter les risques d’utilisation abusive. En effet, un accès non consenti par des assureurs ou des banques pourrait entraîner des refus de couverture, des hausses de primes ou des refus de crédit fondés sur l’état de santé d’un individu.
Pour pouvoir garantir la confidentialité des données de santé transmises et traitées par ChatGPT Santé (ou d’autres systèmes équivalents), il faut résoudre des défis techniques majeurs : sécuriser les flux de données, garantir l’anonymisation dans un environnement massivement interconnecté, à la fois lors de la collecte de données, de l’entraînement du modèle et de son utilisation.
Fiabilité algorithmique et risque d’hallucination clinique
En tout premier lieu, la protection du patient repose sur la justesse des informations fournies par l’IA aux utilisateurs, patients comme médecins.
Le phénomène d’hallucination, inhérent aux architectures de type Large Language Model (LLM), prend une dimension critique en milieu clinique : une erreur de conversion d’unité ou une confusion posologique (par exemple, 5 milligrammes contre 50 milligrammes) peut engager le pronostic vital.
Pour neutraliser ce biais, OpenAI déploie des « mécanismes d’ancrage » (grounding) par l’intermédiaire de référentiels tels que HealthBench, un benchmark de 150 000 ressources validées par des pairs. Ce processus transforme l’IA en un moteur de synthèse documentaire où chaque affirmation est corrélée à une source vérifiable (DOI d’études, portails hospitaliers), ce qui permet aux patients de mieux comprendre les résultats de leurs analyses avec un jargon moins technique.
Pour les professionnels de santé, cet ancrage rend l’outil plus fiable, car il repose dès lors sur le concept de garantie humaine : l’interface ne se substitue jamais au décideur final (le médecin, quand il s’agit de poser un diagnostic), mais agit comme un médiateur d’informations dont la traçabilité permet au praticien de valider systématiquement la suggestion du modèle.
Sécuriser les flux de communication
L’architecture de ChatGPT Santé repose sur une organisation claire des différents éléments : les phases de calcul (à distance ou en local) afin de permettre la collecte des données, l’entraînement du modèle et son utilisation ; mais aussi les flux d’information entre différents terminaux (smartphones, laboratoires d’analyses, hôpitaux, data centers, etc.).
La circulation des données est gérée par la plateforme B.Well Connected Health. Cette infrastructure agit comme une interface consacrée au domaine médical, permettant de faire communiquer entre elles différentes sources de données même si elles sont très différentes.
Elle permet ainsi d’harmoniser des données variées, comme celles issues d’applications personnelles (Apple Health, MyFitnessPal) ou celles provenant des dossiers médicaux hospitaliers. En vérifiant que chaque donnée correspond bien au bon patient, et en garantissant que les données respectent les normes et règles en vigueur, la plateforme assure un flux de données déterministe ou associé à un seul utilisateur pour la phase d’inférence du LLM (c’est-à-dire son utilisation grâce à des prompts). L’ensemble de cette chaîne de traitement s’opère dans un environnement maintenu en isolation totale vis-à-vis du réseau public.
Contrairement à l’interface standard de ChatGPT, les informations cliniques des patients sont exclues du processus d’entraînement global du modèle de langage : elles ne modifient jamais les poids synaptiques du réseau de neurones global de ChatGPT. Ces données personnelles sont stockées uniquement dans un espace de recherche spécifique à chaque utilisateur, ce qui garantit que les informations sensibles restent séparées du modèle et de son évolution ultérieure.
De plus, l’architecture de ChatGPT Santé s’appuie sur la méthode RAG (Retrieval-Augmented Generation) : au lieu de mémoriser l’historique médical, le modèle consulte, lors de chaque requête, une base de données privée et isolée. Contrairement à une mémorisation classique, où un modèle pourrait intégrer et retenir directement des informations sensibles dans ses paramètres, ce mécanisme limite le risque que ces données soient apprises ou réutilisées involontairement par le modèle.
Cependant, ces vecteurs restent temporairement stockés sur les serveurs d’OpenAI, notamment pour des raisons de modération, jusqu’à trente jours. Cette conservation, même limitée, représente un point de vulnérabilité potentiel, car elle expose les données à un risque résiduel d’accès non autorisé.
Anonymiser les données pour éviter l’identification des patients
La protection des données dans ChatGPT Santé doit garantir que la nature des informations traitées ne permette pas l’identification du patient.
La première technique de « dés-identification » mise en place par OpenAI est bien sûr de retirer les identifiants directs, par exemple les noms de patients. Mais ceci n’élimine pas le risque de réidentification par corrélation de métadonnées, rendant l’anonymat vulnérable. En effet, une récente étude a démontré que le croisement de seulement trois points de données (une pathologie rare, une géolocalisation précise et un historique de fréquence cardiaque issu d’un wearable) permet une réidentification dans plus de 80 % des cas. Par sa capacité de corrélation, l’IA peut en effet lier des informations anonymes pour isoler un profil unique.
Pour neutraliser ce risque, ChatGPT Santé pourrait se reposer sur la « confidentialité différentielle », qui consiste à ajouter une petite perturbation aléatoire aux données afin qu’aucune analyse ne puisse être rattachée avec certitude à un individu.
L’efficacité du système dépend de la gestion de ce compromis entre bruit et confidentialité : un niveau de confidentialité trop élevé sacrifie l’utilité clinique des informations (qui sont trop bruitées pour être utiles), alors qu’un bruit insuffisant fragilise le secret médical face à la puissance d’analyse croisée des systèmes d’IA.
Garder les données confidentielles lors de la phase d’utilisation du LLM
Si ChatGPT Santé s’appuie sur un chiffrement de bout en bout pour sécuriser les flux de communication, le véritable défi réside dans la protection des données en cours d’utilisation, lors de la phase dite d’« inférence ».
En effet, l’architecture des modèles de type transformer impose à ce jour au système de déchiffrer l’information pour opérer ses calculs d’inférence. Cela implique que, même de manière fugitive, les données de santé résident en clair dans la mémoire vive (RAM) des serveurs de calcul, constituant un point de vulnérabilité face à des vecteurs d’attaque de type « extraction de mémoire ».
L’avenir de la confidentialité des données de santé repose sur des techniques de chiffrement avancées, notamment le chiffrement homomorphe. Cette approche permet d’effectuer des calculs directement sur des données chiffrées, sans avoir besoin de les déchiffrer au préalable. Autrement dit, il est possible de traiter les données tout en les gardant protégées, ce qui garantit que leur contenu reste inaccessible, même pendant leur utilisation.
Pour l’instant, OpenAI adopte une approche hybride : l’utilisation de serveurs spécifiques sur Microsoft Azure doit permettre de garder les données séparées des données des autres utilisateurs (ou celles d’autres applications que ChatGPT Santé). Cette organisation crée un environnement proche d’un système interne (également appelé « sur site »), même s’il repose sur le cloud. Elle permet de mieux protéger les échanges de données, mais n’élimine pas totalement les risques d’exposition temporaire lors de leur traitement.
Le conflit de souveraineté : les données françaises face aux lois états-uniennes
Enfin, le déploiement de ChatGPT Santé en Europe poserait un défi de souveraineté majeur.
En effet, en France, la législation impose l’hébergement des données cliniques chez des prestataires certifiés « Hébergeurs de données de santé ». Bien que Microsoft Azure dispose de centres de données certifiés en France (France Central), le calcul intensif requis par l’IA nécessite des processeurs ultrapuissants qui consomment énormément d’énergie. Pour des raisons de disponibilité électrique, ces moteurs de calcul sont souvent situés dans des fermes de serveurs hors de l’Union européenne.
Or, ce déport de la donnée vers des serveurs états-uniens déclenche l’application du Cloud Act, une loi qui permet aux autorités des États-Unis d’exiger l’accès aux informations gérées par une entreprise états-unienne, indépendamment de leur lieu de stockage physique.
Ce cadre entre en collision directe avec le règlement général sur la protection des données (RGPD) européen, créant un conflit de lois où la protection européenne s’effacerait devant les prérogatives de sécurité américaines.
Nesrine Kaaniche ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
22.05.2026 à 12:53
Comment fonctionnent les climatiseurs et les pompes à chaleur ? L’éclairage de la thermodynamique
Alexandre Malley-Ernewein, Maître de Conférence au CETHIL (Centre d'Energétique et de Thermique de Lyon - UMR5008), Université Claude Bernard Lyon 1
Eric Peyrol, chercheur, Université Claude Bernard Lyon 1
Jocelyn Bonjour, Professeur des universités au CETHIL (UMR5008), INSA Lyon – Université de Lyon
Texte intégral (3165 mots)
De fortes chaleurs sont attendues sur la France dans le courant des prochains jours. Face à des étés toujours plus chauds, la climatisation est de plus en plus incontournable dans les commerces et les logis. Dans le même temps, les pompes à chaleur s’imposent pour chauffer de façon plus performante pendant la saison froide. Comment fonctionnent ces appareils ? Ils s’appuient en réalité sur les mêmes bases thermodynamiques. Mais attention : le changement climatique pourrait bien leur faire atteindre leurs limites physiques.
Après ceux de 2002 et de 2022, l’été 2025 a été le troisème été le plus chaud en France : deux vagues de chaleur l’ont marqué de par leur précocité, leur intensité et leur durée. Ainsi, l’été dernier a enregistré une anomalie thermique de + 1,9 °C (+ 3,3 °C pour juin).
En raison du changement climatique, et même lorsque nos sociétés auront atteint la neutralité carbone, la fréquence et l’intensité de ces épisodes de fortes chaleurs vont continuer à augmenter pendant plusieurs décennies. En conséquence, un sujet s’est imposé dans les discussions : la climatisation, en tant que moyen d’adaptation au changement climatique.
À lire aussi : La climatisation, une solution pour mieux vivre le réchauffement climatique ?
Avant même de débattre de la pertinence d’installer des climatiseurs et de mesurer leurs impacts (énergétique, sonore, thermique), il faut comprendre comment fonctionnent ces équipements. Les climatiseurs (et plus généralement, les systèmes de refroidissement) sont la directe application des principes d’une branche des sciences physiques, la thermodynamique, dont l’objet est l’étude des transferts d’énergie – en particulier de chaleur.
Spontanément, un transfert de chaleur survient du milieu présentant la température la plus élevée (la source chaude) vers celui de la plus faible température (la source froide). Par exemple, quand la température extérieure est supérieure à celle d’un local, le transfert de chaleur se produit de l’extérieur vers l’intérieur par l’intermédiaire des parois du bâtiment.
Un système de climatisation permet d’effectuer l’opération inverse, grâce à un apport d’énergie externe : prélever de l’énergie de la source froide (l’intérieur) pour la transférer vers la source chaude (l’extérieur). Il est alors possible de refroidir l’intérieur en rejetant l’énergie à l’extérieur, même s’il y fait plus chaud. Le principe de fonctionnement d’une pompe à chaleur (PAC) est le même : un local peut-être chauffé en récupérant de l’énergie à l’extérieur, alors même qu’il y fait plus froid.
Pour comprendre comment tout cela est possible, il faut mobiliser les savoirs issus de la thermodynamique.
Le cycle frigorifique, au cœur des climatiseurs et pompes à chaleur
Pour opérer ce transfert d’énergie, on tire parti des propriétés d’un fluide dit « frigorigène ». Ces derniers ont la particularité de pouvoir changer d’état, c’est-à-dire de passer d’une phase liquide à gazeuse et inversement. C’est souvent cette caractéristique qui sera utilisée pour extraire la chaleur.
On parle de « cycle frigorifique » pour décrire les quatre transformations successives qui sont permises par l’utilisation d’un climatiseur ou d’une pompe à chaleur.
Ces transformations peuvent être représentées sur un diagramme enthalpique, aussi appelé « diagramme de Mollier ». L’enthalpie est une grandeur physique souvent utilisée en thermodynamique. Elle peut être envisagée comme un potentiel énergétique qui inclut à la fois les énergies thermique (chaleur) et mécanique, en lien avec des variations de pression et de volume du système.

Cette représentation peut sembler complexe à première vue, mais elle permet de visualiser rapidement l’évolution du fluide frigorigène et, en particulier, ses changements d’état. Elle présente la pression du fluide en ordonnée et son enthalpie en abscisse.
Ce diagramme est divisé en trois parties par la « cloche » qui est en son centre, nommée « courbe de saturation ». Celle-ci indique la limite entre différents états du fluide : à droite, le fluide à l’état de vapeur et, à gauche, le fluide sous forme de liquide. La zone située sous la courbe correspond à l’état de mélange liquide-vapeur du fluide.
Ce diagramme sert à représenter les transformations du cycle frigorifique, comme le montre le schéma ci-dessous.

Les étapes sont les suivantes :
1 à 2 : le fluide frigorigène est à l’état de vapeur ; il est comprimé, ce qui fait augmenter sa pression et sa température ainsi que son enthalpie. C’est le seul apport d’énergie du cycle. Celle-ci est sous forme d’énergie mécanique, produite par un compresseur, qui lui-même consomme de l’électricité.
2 à 3 : le fluide, toujours à l’état de vapeur, mais à haute pression et haute température, traverse alors un échangeur de chaleur, dans lequel il va céder de l’énergie thermique à la source chaude (pour un climatiseur, l’air extérieur, pour une PAC en hiver, l’air intérieur), celle-ci étant nécessairement à une température plus basse que celle du fluide. Cet échangeur est appelé « condenseur », car ce refroidissement provoque la condensation de la vapeur qui devient liquide. L’enthalpie du fluide diminue alors.
3 à 4 : le fluide traverse un détendeur, où un changement de section de la conduite fait baisser la pression.
4 à 1 : le fluide, désormais majoritairement liquide, à basse pression et basse température, traverse un échangeur où il reçoit de la chaleur de la source froide (pour un climatiseur, l’air intérieur, pour une PAC en hiver, l’air extérieur), son enthalpie augmente. Cet échangeur est appelé « évaporateur », car le fluide frigorigène y passe de l’état liquide à celui de vapeur.

{kind=link}
Ces transformations peuvent sembler contre-intuitives, car le fluide frigorigène cède de la chaleur majoritairement sans changer de température, mais en changeant d’état. C’est la différence entre chaleur sensible – liée à un changement de température – et chaleur latente – liée à un changement d’état de la matière.
Le cycle est entretenu tant qu’il y a un besoin de transférer de la chaleur de la source froide à la source chaude, grâce au fonctionnement du compresseur qui met le fluide en mouvement.

Lorsqu’un climatiseur est utilisé pour rafraîchir un local, le condenseur est placé à l’extérieur (le « split » extérieur) et l’évaporateur à l’intérieur (la « cassette »).
Dans le cas d’un système réversible, capable de chauffer en hiver et de refroidir en été, les échangeurs changent de rôle en fonction des saisons, à l’aide d’une vanne 4 voies.
Des systèmes poussés à leurs limites physiques par le changement climatique
Une des principales limites des climatiseurs réside dans leur principe même : leurs performances dépendent des caractéristiques du fluide frigorigène, mais aussi fortement des températures des sources froide et chaude.
Par exemple, l’énergie nécessaire à la compression augmente avec l’écart entre les températures des sources. Le coefficient de performance (COP), c’est-à-dire le rapport entre la chaleur extraite à l’évaporateur et l’électricité consommée, va alors baisser en proportion. C’est d’ailleurs pour cela que la consommation des pompes à chaleur, en hiver, augmente lorsque les températures extérieures diminues. Elles sont parfois munies, pour compenser la baisse du COP lors de températures extérieures très basses, de résistances électriques pour fournir un chauffage d’appoint.
En outre, un fluide frigorigène a des caractéristiques fixes, notamment l’enthalpie de changement d’état (et, en particulier, celle pour passer de l’état liquide à gazeux, que l’on appelle souvent « chaleur latente de vaporisation »), qui dépend de la pression et de la température. Si la température de la source chaude augmente, il ne sera peut-être pas possible de comprimer indéfiniment le fluide pour pouvoir lui céder de la chaleur. Autrement dit, on peut atteindre les limites physiques du cycle frigorifique pour le fluide utilisé.
Or, en France, avec le changement climatique, la température extérieure – la source chaude – va continuer à augmenter en été. Ainsi, un climatiseur installé en 2000 ou en 2020 ne sera pas nécessairement toujours capable de refroidir en 2035.
Par ailleurs, ces fluides ont un pouvoir de réchauffement bien supérieur à celui du CO₂, ce qui questionne leur usage en raison du risque de fuites. C’est pourquoi une réglementation de plus en plus contraignante s’applique à ces produits.
Des risques de « maladaptation » pour les villes
Dans ce contexte, deux problématiques vont se poser pour les villes : l’augmentation de la consommation électrique lors des périodes estivales et celle, locale, de la température dans les zones urbaines due au rejet de chaleur des climatiseurs.
Une étude de 2024 fondée sur des simulations numériques a ainsi montré, pour la ville de Toulouse (Haute-Garonne), que la généralisation de l’usage de la climatisation entraînerait une augmentation de la consommation énergétique en période estivale de 54 %. Si ces climatiseurs sont réversibles et peuvent assurer le chauffage en hiver, en fonctionnant comme une PAC, l’économie d’énergie sur l’année serait de l’ordre de 32 %, car ils ont un meilleur rendement que les chaudières et radiateurs qu’ils remplaceraient.
En 2012 déjà, d’autres simulations numériques montraient que, à Paris, l’augmentation locale de température due au rejet de chaleur pouvait atteindre 2 °C pendant une période de canicule similaire à celle de 2003. Ce résultat est toutefois à nuancer, car le modèle utilisé comporte des simplifications dans la représentation des phénomènes physiques. Ceci appelle à des études complémentaires.
Si les climatiseurs permettent d’évacuer la chaleur de nos lieux de vie, le changement climatique va exacerber leurs limites. Leur généralisation dans nos sociétés nous demande d’étudier leurs impacts sur nos environnements.
Dans tous les cas, elles ne sauraient être l’unique solution qui permettra d’assurer des conditions vivables, en particulier pour les publics les plus vulnérables (par exemple, personnes âgées, jeunes enfants, personnes malades).
À lire aussi : Climatisation : quelles alternatives au quotidien, quelles recherches pour le futur ?
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
21.05.2026 à 17:03
Face aux entreprises privées qui se ruent vers les étoiles, une gouvernance internationale de l’espace devient indispensable
Peter Brown, Professor in Physics and Astronomy, Western University
Texte intégral (2253 mots)

Il y a dix ans, l’orbite basse comptait 2 000 satellites actifs. Aujourd’hui, ils sont près de 20 000 et jusqu’à un million pourraient suivre. Une explosion du trafic spatial qui pousse les chercheurs à réclamer des règles internationales plus strictes.
Les académies des sciences des pays membres du G7 ont fait de la gouvernance internationale de l’espace un enjeu majeur en vue du sommet des dirigeants du G7, qui se tiendra en France du 15 au 17 juin à Évian (Haute-Savoie).
L’essor fulgurant des grandes constellations de satellites au cours de la dernière décennie ouvre la perspective d’un accès quasi universel à l’Internet haut débit. Mais cette croissance s’accompagne de risques encore mal compris.
Parmi ces risques figurent la pollution du ciel nocturne, les perturbations de la recherche astronomique, l’augmentation du risque de collisions entre satellites ainsi que les dangers liés au retour sur Terre d’un grand nombre de satellites.
Notre compréhension de l’impact humain sur l’environnement spatial proche de la Terre en est aujourd’hui à un stade comparable à celui des connaissances sur le changement climatique dans les années 1990. Nous savons que l’intensification des activités humaines provoque d’importantes perturbations dans l’environnement spatial, mais nous ignorons encore si un point de bascule est sur le point d’être atteint.
Dans ce contexte, l’une des recommandations les plus importantes adressées aux États membres du G7 consiste à créer un groupe intergouvernemental sur la durabilité spatiale (IPSS).
Des impacts sur la chimie de l’atmosphère
La recherche et les connaissances sur les impacts des activités humaines dans l’espace en sont encore à un stade très précoce. Ainsi, nous ne savons pas vraiment à partir de quel moment certaines altitudes orbitales deviendront tellement encombrées de débris spatiaux qu’elles atteindront leur capacité opérationnelle maximale.
Les scientifiques ont également récemment constaté que l’augmentation du nombre de lancements de fusées à l’échelle mondiale – avec plus d’une fusée lancée chaque jour désormais – pourrait entraîner une remise en cause de la reconstitution de la couche d’ozone.
De la même manière, nous savons que les satellites qui se consument lors de leur rentrée dans l’atmosphère terrestre auront des effets importants sur la chimie de la haute atmosphère. Nous savons également que plusieurs de ces retours de satellites se produisent désormais chaque jour, mais les conséquences exactes de ce phénomène restent encore mal comprises.
Une gouvernance spatiale fragmentée
Plusieurs organismes scientifiques conseillent aujourd’hui les pouvoirs publics sur les différents enjeux liés à la durabilité de l’espace. Parmi eux figure le Comité de coordination interagences sur les débris spatiaux, chargé des questions liées à la pollution de l’environnement spatial par les débris.
Autre acteur important : le Centre pour la protection d’un ciel sombre et silencieux de l’Union astronomique internationale, qui coordonne les initiatives destinées à limiter l’impact des satellites sur l’astronomie optique et radio.

Mais il n’existe aujourd’hui aucun organisme unique capable de fournir aux gouvernements une expertise globale pour éclairer les décisions politiques et réglementaires. La situation rappelle celle de la recherche sur le changement climatique, lorsque le Groupe consultatif sur les gaz à effet de serre (AGGG), créé dans les années 1980, a progressivement laissé place au Groupe d’experts intergouvernemental sur l’évolution du climat (GIEC).
Nous avons aujourd’hui un besoin urgent d’un groupe intergouvernemental sur la durabilité spatiale (IPSS).
Il y a dix ans, l’orbite basse terrestre comptait près de 2 000 satellites actifs ; aujourd’hui, leur nombre approche les 20 000. Ces dernières années, des gouvernements et des entreprises ont annoncé des projets pouvant conduire au lancement de jusqu’à un million de satellites supplémentaires.
Définir des seuils mondiaux
Comment cet IPSS pourrait-il être structuré pour aborder la gouvernance spatiale d’une manière comparable à celle dont le Giec a abordé le problème du changement climatique ?
L’un de ses premiers objectifs devrait être de définir des seuils mondiaux de durabilité. À l’image de la limite de 1,5 °C dans les sciences du climat, ce groupe devrait identifier les seuils au-delà desquels certaines altitudes orbitales atteignent leur capacité de charge.
Comme le Giec, un IPSS devrait s’appuyer sur plusieurs groupes de travail chargés de fournir aux décideurs des synthèses scientifiques transparentes et accessibles. L’un d’eux devrait se consacrer aux sciences physiques de l’environnement orbital. Il s’agirait notamment d’étudier l’état de l’orbite basse terrestre en tant que ressource limitée : évolution des débris spatiaux et des risques de collision, effets de la météorologie spatiale, ou encore modélisation d’un trafic spatial soutenable à l’avenir.

Un autre groupe de travail devrait se concentrer sur les impacts environnementaux et sociétaux des grandes constellations de satellites. Il pourrait évaluer l’appauvrissement de la couche d’ozone stratosphérique causé par les émissions des lancements de fusées, les effets de l’augmentation des retours de satellites dans l’atmosphère, les modifications de la chimie atmosphérique ainsi que les risques accrus d’accidents pour les populations. Il aurait également pour mission de mesurer l’impact de ces constellations sur l’astronomie au sol.
Enfin, un groupe de travail consacré aux politiques publiques et aux mesures d’atténuation pourrait jeter les bases de normes internationales claires concernant la désorbitation des satellites en fin de mission, le retrait actif des débris spatiaux et de nouvelles exigences en matière de licences prenant en compte le risque « systémique » d’une constellation, plutôt que le risque posé par chaque satellite pris individuellement.
L’empreinte du trafic spatial
L’IPSS pourrait aussi être complété par un groupe de travail consacré à l’empreinte du trafic spatial. Inspiré de la Task Force du Groupe d’experts intergouvernemental sur l’évolution du climat (Giec) sur les inventaires nationaux de gaz à effet de serre, cet organisme aurait pour mission de développer des méthodologies standardisées permettant aux États de mesurer et déclarer leur « empreinte de trafic spatial » – c’est-à-dire la pression exercée par leurs objets spatiaux sur la sécurité et la durabilité de l’orbite basse terrestre.
À l’instar du rôle joué par le Giec dans l’évaluation des modèles climatiques, l’IPSS devrait également fournir une expertise indépendante sur les affirmations concernant la désintégration contrôlée des satellites – autrement dit la manière dont les satellites sont retirés du service puis désorbités en toute sécurité. Cela impliquerait d’évaluer l’efficacité réelle des technologies de désorbitation, mais aussi notre capacité à suivre les satellites et à estimer précisément leur position.
En mettant en place dès aujourd’hui une approche internationale coordonnée, l’IPSS contribuerait à concilier les immenses promesses des activités commerciales spatiales avec les risques environnementaux qu’elles engendrent – de la même manière que le Giec pour le climat terrestre face aux activités humaines.
Peter Brown a reçu des financements du Conseil de recherches en sciences naturelles et en génie du Canada, de la National Aeronautics and Space Administration (NASA) des États-Unis, de l’Agence spatiale européenne, de Ressources naturelles Canada et de Recherche et développement pour la défense Canada.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview