BINAIRE
Société Informatique de FranceBlogs Le Monde - L'informatique : science et technique au coeur du numérique
17.05.2024 à 07:10
Grandes Constellations de Satellites, deuxième partie
binaire
Continuer la lecture de « Grandes Constellations de Satellites, deuxième partie »
Texte intégral (2116 mots)
Nous assistons au déploiement de constellations de satellites avec des
dizaines de milliers de satellites en orbite basse. Les fonctionnalités
de ces constellations sont essentiellement les télécommunications haut-débit,
la géolocalisation et l’observation de la Terre. Quelles sont les avancées
scientifiques et technologiques qui permettent ces développements ?
Quels sont les enjeux économiques et géostratégiques associés ?
Ces constellations conduisent à une densification de l’espace et à
une multiplication des lancements et des débris. Elles ont un impact
négatif sur sur l’observation astronomique dans le domaine optique et dans
celui de la radioastronomie. Quels sont les dangers encourus avec la
multiplication des débris en orbite basse ? Quel est l’impact des lancements
sur la stratosphère et celui des rentrées de satellites dans l’atmosphère ?
Un groupe de travail de l’Académie des sciences s’est penché sur le sujet,
a auditionné de nombreux spécialistes, et publié un rapport en mars 2024,
rédigé par François Baccelli, Sébastien Candel, Guy Perrin et Jean-Loup
Puget.
Les deux premiers auteurs nous éclairent sur le sujet. Serge Abiteboul (qui a
participé au groupe de travail), voici la deuxième partie de ce partage, après la première.

Impact sur l’astronomie
Le lancement de milliers de satellites en orbite basse change fondamentalement l’accès de l’être humain au ciel nocturne. Ses effets se font déjà ressentir pour l’astronomie au sol dans un ensemble de domaines.
Pour l’astronomie optique (incluant l’infrarouge proche et moyen), le problème principal est celui de la réflexion du flux solaire par les satellites défilant dans le champ de vision des télescopes avec des effets marqués au lever et au coucher du Soleil avec des effets marqués sur la prise d’images par les instruments à grand champ de vue. S’il y a une bonne coopération avec Starlink pour la réduction de la lumière solaire réfléchie par les satellites, le futur est loin d’être sous contrôle avec la multiplication des interlocuteurs et des constellations stratégiques et commerciales.
Pour la radioastronomie, la perspective d’une perturbation permanente venant par le haut est préoccupante. La politique de sanctuaire radio local (qui consiste à ne pas émettre dans les régions qui hébergent les grands observatoires radio) acceptée par Starlink atténue les problèmes pour les fréquences adjacentes à celles des émissions des satellites. Mais les électroniques des satellites rayonnent aussi à basse fréquence et constituent une source de bruit pour les observations radio dans une autre gamme de fréquences même si les émissions de signaux de télécommunication des satellites sont momentanément interrompues. À cela s’ajoute des besoins de protection des observations en mode interférométrique qui impliquent des installations réparties sur plusieurs continents et nécessitent des actions coordonnées spécifiques.
Les conséquences négatives pour l’astronomie d’une multiplication incontrôlée de ces constellations doivent impérativement être prises en compte et des mesures pour pallier ces problèmes doivent être mises en œuvre par leurs promoteurs.

Impact sur l’environnement
Dans un contexte de multiplication des lancements, il est important d’examiner la question de l’impact des émissions sur la haute atmosphère. Ces émissions dépendent du type de motorisation, de la masse au décollage et du nombre de lancements. C’est le lanceur Falcon de SpaceX qui réalise actuellement le plus grand nombre de lancements, plus d’une centaine en 2023.
Les émissions correspondantes de 140 kilotonnes de carbone, de vapeur d’eau, d’hydrocarbures imbrûlés et de particules de suies sont en valeur absolue relativement faibles si on les compare à celles issues des transports mais elles sont cependant non-négligeables car ces émissions vont s’accumuler dans la haute atmosphère. C’est le cas notamment des particules de carbone, désignées sous le nom de “black carbon » (BC), qui sont nettement plus nombreuses par unité de masse de kérosène, dans les gaz éjectés par les moteurs du lanceur, et nettement plus importante que celles qui existent dans les jets des moteurs d’avion (le rapport serait de l’ordre de 104). Comme une partie de ces émissions est faite au-dessus de la tropopause, les aérosols formés par les particules BC peuvent s’accumuler pendant plusieurs années, interagir avec la couche d’ozone, modifier le bilan radiatif et changer la distribution de température. Il y a des incertitudes sur ces effets, car les niveaux d’émissions sont faibles, mais la question de l’impact sur la haute atmosphère mérite d’être approfondie. L’impact sur l’environnement des fins de vie opérationnelle des satellites est lui aussi à prendre en compte même si la masse associée au retour sur Terre de 2400 objets, d’une masse totale de 340 tonnes, reste finalement modérée par rapport aux 15 à 20000 tonnes de météorites qui pénètrent chaque année dans l’atmosphère terrestre.
Un problème majeur est celui des débris spatiaux. Il y aurait déjà en orbite un demi-million à un million de débris de 1 à 10 cm et cent à cent trente millions de taille entre 1 mm et 1 cm selon l’ESA et la NASA. Sur les 14 000 satellites en orbite, environ 35% ont été lancés au cours de ces trois dernières années et 100 000 autres sont prévus dans la décennie à venir, toujours selon l’ONU. Ces données communiquées – récemment par l’AFP montrent la nécessité de la mise en place d’une régulation contraignante sur le contrôle des fins de vie opérationnelle des satellites.

Nécessité d’un renforcement de la régulation internationale
L’analyse des impacts négatifs fait apparaître un besoin de régulation internationale d’un domaine qui pour le moment se développe en l’absence de toute contrainte (si ce n’est celle du coût des lancements) et elle souligne la nécessité d’initiatives et d’actions engagées par les parties prenantes pour identifier des principes et des codes de bonnes pratiques qui puissent être adoptés par un nombre croissant de pays. Une autre question importante est celle des solutions techniques permettant de prendre en compte ces impacts négatifs et de se prémunir des scénarios les plus inquiétants. Les règles internationales se construisent par l’identification de principes et de codes de bonne pratique adoptés par un nombre croissant de pays. Plusieurs exemples d’efforts de ce type sont décrits dans le rapport. Il est essentiel que les États et les communautés scientifiques concernées contribuent à la formalisation de ces principes et codes dans le but d’obtenir rapidement une régulation internationale du secteur.
Constat d’ensemble et perspectives
Les constellations de satellites ouvrent des perspectives intéressantes, elles offrent des possibilités nouvelles pour les communications, l’observation de la Terre, la géolocalisation et la connectivité et cela, avec des capacités de résilience supérieures à celles des infrastructures terrestres. Sans pouvoir remplacer les réseaux actuels pour l’accès à internet, elles peuvent compléter ces réseaux et assurer une couverture des zones blanches dans lesquelles cet accès n’est pas disponible ou encore permettre des connexions lorsque ces infrastructures sont détruites à la suite de catastrophes naturelles ou de conflits armés. Les constellations de satellites font aussi apparaître des enjeux de souveraineté résultant de la dépendance et de la perte de contrôle induite par la prééminence de certains acteurs privés. L’expansion du nombre et de la taille des constellations pose aussi des questions majeures en matière d’impact sur l’environnement spatial par la densification en satellites et en débris, sur l’environnement atmosphérique par l’augmentation du nombre de lancements et par les retours sur Terre des satellites en fin de vie opérationnelle. Dans un contexte de croissance incontrôlée qui prévaut actuellement, l’augmentation du nombre d’objets en orbite fait que les manœuvres d’évitement deviennent de plus en plus fréquentes et elle conduit à une multiplication du nombre de collisions. L’impact des constellations sur l’astronomie est également préoccupant car il touche à la fois les observations optiques et infrarouges et celles qui sont réalisées dans le domaine radioélectrique. L’analyse des impacts négatifs fait apparaître un besoin de régulation internationale d’un domaine qui pour le moment évolue en l’absence de toute contrainte (si ce n’est celle du coût des lancements) et elle souligne la nécessité d’initiatives et d’actions engagées par les parties prenantes pour identifier des principes et des codes de bonnes pratiques qui puissent être adoptés par un nombre croissant de pays.
François Baccelli, Inria et Télécom-Paris, membre de l’Académie des sciences et Sébastien Candel, Centrale Supélec, membre de l’Académie des sciences
10.05.2024 à 07:05
Grandes Constellations de Satellites, première partie
binaire
Continuer la lecture de « Grandes Constellations de Satellites, première partie »
Texte intégral (2129 mots)
dizaines de milliers de satellites en orbite basse. Les fonctionnalités
de ces constellations sont essentiellement les télécommunications haut-débit,
la géolocalisation et l’observation de la Terre. Quelles sont les avancées
scientifiques et technologiques qui permettent ces développements ?
Quels sont les enjeux économiques et géostratégiques associés ?
Ces constellations conduisent à une densification de l’espace et à
une multiplication des lancements et des débris. Elles ont un impact
négatif sur sur l’observation astronomique dans le domaine optique et dans
celui de la radioastronomie. Quels sont les dangers encourus avec la
multiplication des débris en orbite basse ? Quel est l’impact des lancements
sur la stratosphère et celui des rentrées de satellites dans l’atmosphère ?
Un groupe de travail de l’Académie des sciences s’est penché sur le sujet,
a auditionné de nombreux spécialistes, et publié un rapport en mars 2024,
rédigé par François Baccelli, Sébastien Candel, Guy Perrin et Jean-Loup
Puget.
Les deux premiers auteurs nous éclairent sur le sujet. Serge Abiteboul (qui a
participé au groupe de travail) : voici la première partie de ce partage en deux parties.
Introduction
Cet article rassemble quelques points clés d’un rapport de l’Académie de sciences. Il traite d’abord des nouvelles fonctionnalités des constellations de satellites dans l’accès à l’Internet, l’observation de la Terre, la géolocalisation, l’interaction avec des objets connectés. Les principaux enjeux et l’évolution du domaine sont analysés dans un premier temps. Comme toute nouvelle avancée technologique, ces constellations soulèvent aussi, de nombreuses questions, et notamment celles relatives à l’encombrement de l’espace, avec l’augmentation du nombre d’objets satellisés et de débris issus de ces objets et de leur lancement, la croissance des collisions qui peut en résulter et d’autre part de l’impact sur les observations astronomiques dans les domaines optiques et radio. Ce rapport met ainsi en évidence un défi majeur, celui de la cohabitation d’une ceinture satellitaire sécurisée et durable évitant la pollution par ses débris et de l’accès au ciel de l’astronomie, la plus ancienne des sciences, celle qui a été à la source des connaissances et qui a encore beaucoup à nous apprendre. Avec la montée en puissance d’acteurs et investisseurs privés dans un domaine qui était initialement réservé aux États, ce rapport fait apparaître des enjeux géostratégiques et des enjeux de souveraineté. Il soutient la mise en place d’une régulation internationale du secteur mais souligne également la nécessité d’une participation de la France et de l’Europe à ces développements.

Les fonctionnalités des constellations
Les nouvelles constellations de satellites en orbite basse ou moyenne ouvrent des perspectives dans trois grands domaines qui sont les communications haut-débit, l’observation de la Terre et la géolocalisation. Les constellations offrant le haut-débit sont encore peu nombreuses mais elles impliquent, pour certaines, un très grand nombre de satellites. Les constellations destinées à l’observation de la Terre ou à la géolocalisation comportent un nombre plus réduit de satellites mais sont bien plus nombreuses. Il est à remarquer, cependant, qu’en ce qui concerne l’accès haut-débit à l’Internet, les réseaux à base de constellations ne pourront remplacer les réseaux terrestres mais qu’ils devraient plutôt offrir un complément notamment pour la couverture des zones blanches et des territoires enclavés ou encore pour la couverture haut-débit des navires et des avions.
Des protocoles pour les communications entre satellites en orbites basses sont en cours de normalisation. Ceci pourrait conduire à terme à un cœur de réseau Internet spatial avec des fonctionnalités et des mécanismes de routage propres à la dynamique des constellations. Certaines fonctions qui sont actuellement celles des routeurs Internet et des stations de base de la 5G pourraient à terme devenir des fonctions embarquées dans les satellites de cet Internet spatial, comme par exemple le traitement du signal, le routage ou même le calcul en périphérie de réseaux (edge computing). Cet Internet spatial a cependant des limites associées à la puissance électrique disponible à bord des satellites, qui est elle-même fonction de la surface des panneaux solaires qui peuvent être embarqués sur lanceurs et déployés dans l’espace.
Enjeux
Une question clé, dans le domaine des télécommunications, est celle du contrôle de ces nouvelles classes de réseaux. On note par exemple que les réseaux de communications fondés sur des flottes de satellites, s’affranchissent de fait, sinon de droit, de toutes les règles qui sont imposées par les États aux opérateurs des réseaux terrestres offrant des services sur leur sol. Cette perte de contrôle concerne tous les aspects les plus fondamentaux : les mécanismes d’attribution des fréquences, les règles de confidentialité sur les conversations ou les données transmises, les règles de localisation des cœurs de réseaux, etc. Dès aujourd’hui, ces réseaux peuvent se passer complètement de stations d’ancrage dans les pays qu’ils couvrent. Le déploiement de ces réseaux dans leurs formes actuelles (typiquement celle de la constellation Starlink) induit une perte de souveraineté directe des États sur ce secteur.
Une seconde question a trait au modèle économique des grandes constellations destinées à la couverture internet haut-débit. On sait, en effet, que les entreprises qui se sont engagées dans la mise en place des premières constellations de ce type ont toutes fait faillite et il n’est pas certain que les constellations déployées aujourd’hui puissent atteindre l’équilibre économique et devenir viables à long terme. La réponse à cette seconde question dépendra sans doute des résultats de la course actuelle à l’occupation de l’espace ainsi que de la nature des interactions et accords entre ces réseaux satellitaires et les réseaux terrestres de type 5G. Elle dépendra aussi de l’évolution de la taille et du prix des antennes permettant à un utilisateur final muni d’un téléphone portable de communiquer efficacement avec un satellite.
Les enjeux en termes de souveraineté apparaissent ainsi comme les raisons les plus fortes pour le développement de ces constellations car ces dernières procurent à ceux qui les contrôlent un moyen de communication haut-débit sécurisé à faible latence qui est aussi caractérisé par sa résilience. Cette résilience vient du fait que les flottes de satellites restent en grande partie fonctionnelles en cas de catastrophe naturelle et de destruction des réseaux terrestres. Elles sont par ailleurs difficiles à détruire puisque constituées de nombreuses plateformes en mouvement rapide dans des flottes organisées de façon fortement redondante. La latence faible des constellations en orbite basse joue un rôle central dans le contexte du temps réel critique car leur couverture universelle permet l’observation instantanée d’événements survenant en tout point de la planète et elle offre de nouveaux moyens d’interaction.

Évolution du domaine
Le domaine dans son ensemble est dans une phase très dynamique avec beaucoup d’innovations dans le domaine industriel, une expansion rapide du NewSpace aux États-Unis, une volonté au niveau de la Commission Européenne de lancer une constellation, l’émergence de nouveaux États spatiaux et d’acteurs privés, de nouveaux formats de lanceurs (petits lanceurs, lanceurs réutilisables), une réduction des coûts de lancement associée notamment à la réutilisation. Il en résulte une multiplication des projets de constellations et une explosion du nombre des satellites en orbite basse ou moyenne.
Cette dynamique repose sur des progrès scientifiques et des innovations technologiques dans le domaine des télécommunications, de l’informatique du traitement de l’information, de la focalisation dynamique, de l’électromagnétisme et des communications radio, des systèmes de communication optiques inter-satellites, de la miniaturisation de l’électronique embarquée, des systèmes de propulsion à bord des satellites (propulsion plasmique) ainsi que sur des avancées dans l’accès à l’espace, les télécommunications et l’informatique. Cette dynamique exploite les résultats des recherches dans le domaine des communications portant notamment sur (i) la théorie de l’information multi-utilisateurs, sur le codage pour la maîtrise de liens radio avec les satellites, avec des questions nouvelles comme par exemple celle de la focalisation adaptative des antennes (MIMO massif et dynamique) ou encore celle du contrôle des interférences ; (ii) la définition de nouveaux protocoles de routage adaptés à la dynamique très rapide du graphe des satellites et des stations d’ancrages ; (iii) l’identification d’architectures optimales pour les fonctionnalités de haut débit ou d’observation dans un ensemble de régions donné de la Terre.
François Baccelli, Inria et Télécom-Paris, membre de l’Académie des sciences et Sébastien Candel, Centrale Supélec, membre de l’Académie des sciences
03.05.2024 à 07:39
Qui a voulu effacer Alice Recoque ? Sur les traces d’une pionnière oubliée de l’IA
binaire
Texte intégral (1485 mots)
Un billet à propos d’un livre. Nous avons demandé à Isabelle Astic, Responsable des collections Informatique au Musée des arts et métiers, de nous faire partager son avis du livre de Marion Carré à propos de Alice Recoque. Pierre Paradinas
 Le titre de l’ouvrage de Marion Carré, un brin provocateur : « Qui a voulu effacer Alice Recoque ?», pourrait laisser penser qu’Alice Recoque est un de ces avatars informatiques issu des jeux vidéo. Mais c’est bien une femme en chair et en os qu’elle nous présente.
Le titre de l’ouvrage de Marion Carré, un brin provocateur : « Qui a voulu effacer Alice Recoque ?», pourrait laisser penser qu’Alice Recoque est un de ces avatars informatiques issu des jeux vidéo. Mais c’est bien une femme en chair et en os qu’elle nous présente.
Ce titre est celui du premier chapitre, introductif, durant lequel l’autrice nous décrit les complications rencontrées pour que Alice Recoque puisse avoir sa page dans Wikipédia. Ou la double peine de l’effet Matilda : la minimalisation du rôle des femmes dans la recherche a pour conséquence qu’elles sont autrices de peu d’articles scientifiques, c’est pourquoi elles ne sont donc pas jugées dignes d’un article dans Wikipédia.
Les chapitres suivants décrivent la vie et la carrière d’Alice Recoque, contextualisées dans l’histoire quotidienne ou professionnelle de son époque. Ils s’appuient sur un témoignage de première main : les mémoires de Mme Recoque. Son enfance en Algérie, ses études à l’ENSPCI, à Paris, sont l’occasion de parler du contexte international et de la guerre qui ont imprégné l’enfance et l’adolescence de la jeune Alice, de l’ambiance familiale qui a forgé certains traits de son caractère, de sa capacité à sortir des chemins convenus grâce à certaines figures inspirantes de son entourage.
Ces premiers chapitres expliquent les suivants, consacrés plutôt à son expérience professionnelle. La SEA (Société d’Électronique et d’Automatisme) d’abord, jeune pousse créée par un ingénieur clairvoyant, François-Henri Raymond, qui a très tôt compris l’avenir de l’informatique. Elle s’y épanouit et développe ses connaissances en conception d’ordinateur, en hardware. Puis la CII, dans laquelle doit se fondre la SEA sous l’injonction du Plan Calcul, qui devient CII-Honeywell Bull, puis Bull. Elle prend peu à peu des galons pour gérer finalement une équipe qui va construire le mini-ordinateur qu’elle a en tête, le Mitra 15. Enfin, c’est la découverte de l’Intelligence Artificielle, lors d’un voyage au Japon, domaine dans lequel Bull acceptera de s’engager, opportunité pour Alice Recoque de passer du matériel au logiciel.
En parallèle de la vie d’Alice Recoque, nous suivons le développement de l’industrie informatique en France. Nous assistons à ses débuts où il y avait tout à faire : le processeur à concevoir, les techniques de mémorisation à imaginer. L’ouvrage décrit l’effervescence d’une jeune entreprise, poussée par cette nouveauté, par l’exaltation de la découverte, par les visions de son fondateur mais aussi par les risques et les difficultés qu’elle rencontre pour survivre. Avec l’évolution de la carrière d’Alice Recoque, nous suivons les hauts et les bas de cette industrie, à travers l’entreprise Bull. Mais l’ouvrage dresse également, et surtout, le portrait d’une femme de sciences et de techniques, qui s’engage dans un univers d’homme. Il nous décrit ses questionnements, ses choix, les heurs et malheurs d’une vie. Cet angle du livre créé une empathie avec Mme Recoque, ouvrant un dialogue entre son époque et la nôtre. C’est donc un voyage dans le contexte social, économique, technique et informatique de l’époque qu’il nous propose.
Certains diront que ce n’est pas un ouvrage d’historien. Et il est vrai qu’en suivant la vie d’Alice Recoque, nous manquons parfois un peu de recul. Certains points pourraient demander des approfondissements, comme le rôle de la politique sociale et l’organisation d’une entreprise dans les possibilités de carrière des femmes. De même, on peut s’interroger sur la part et le rôle de l’état dans le succès du Mitra 15, sans remettre en question la qualité du travail d’Alice Recoque. Mais Marion Carré ne revendique pas un rôle d’historienne. Elle préfère parler d’ « investigations » et son ouvrage est effectivement le résultat d’un long travail d’enquête, de la recherche de ses sources à l’analyse qu’elle en fait, qui offre de nombreuses perspectives à des travaux scientifiques.

Photo Aconit
Marion Carré a su faire un beau portrait de femme dans un ouvrage facile à lire, qui ne s’aventure pas dans les descriptions techniques ardues pouvant rebuter certains ou certaines et qui ne se perd pas non plus dans les méandres d’une vie familiale et personnelle. Il est l’un des rares livres consacré à une femme informaticienne française, à une femme de science contemporaine qui a su se donner un rôle dans l’émergence de l’industrie de l’informatique en France. Grâce aux rencontres provoquées, aux sources retrouvées, Alice Recoque est enfin sortie de l’ombre. Espérons que d’autres portraits d’informaticiennes verront bientôt le jour, comme celui de Marion Créhange, première femme à soutenir une thèse en informatique en France (1961), qui nous avait régalé, sur le site d’Interstices, d’une randonnée informatique quelques mois avant son décès. Ces portraits contribueraient sans aucun doute à ce que de jeunes femmes puissent se rêver, à leurs tours, informaticiennes.
Isabelle Astic, Musée des Arts et Métiers (Paris)
26.04.2024 à 07:46
Faire écran à l’usage des écrans : un écran de fumée ?
binaire
Continuer la lecture de « Faire écran à l’usage des écrans : un écran de fumée ? »
Texte intégral (1798 mots)
Les enfants et les écrans : attention ! Oui mais à quoi ? Et comment ? Gérard Giraudon et Thierry Viéville nous rassemblent des références et des éléments pour nous montrer que [dé]laisser les enfants devant les écrans est bien négatif et qu’il est préférable d’y aller avec elles et eux. Dans cet article, après par exemple [10], on questionne non seulement la pratique des enfants mais aussi « notre ´´ pratique de parents face à nos enfants. Marie-Agnès Enard et Pascal Guitton.

Il existe des effets négatifs du numérique sur notre vie et notre santé ainsi que celles de nos enfants [0], tout particulièrement lors d’un mésusage . Les scientifiques en informatique en sont conscient·e·s et font partie de celles et ceux qui alertent sur le sujet [0], et relaient les travaux scientifiques d’autres disciplines qui permettent de comprendre le caractère négatif potentiel de ces effets et de les dépasser [9]. On parle ici de résultats scientifiques [9,11] au delà de l’emballement des médias alimenté par les promoteurs des “paniques morales” ([9], pp 4).
L’angle d’attaque de telles paniques est souvent résumé par le seul terme “écran”, la plupart du temps associé au mot “enfant”, faisant ainsi un amalgame entre contenant et contenu, entre adultes et société. Il en ressort généralement des questions mal posées qui ne peuvent conduire qu’à des polémiques faisant peu avancer le débat. Par ailleurs, la question des impacts de la technologie sur le développement de l’enfant est fondamentale et le numérique n’y échappe pas.

Abordons ici la question des contenus. Les études scientifiques sur l’impact des “contenus numériques disponibles à travers différentes interfaces matérielles” qu’on réduit souvent au seul “écran” alors qu’on pourrait par exemple y inclure aussi des systèmes robotisés. Mais concentrons nous ici sur les interfaces que l’on nommera par abus de langage, pour la facilité d’écriture, encore “écran”. Les résultats sont difficiles à interpréter car il manque un cadre de comparaison formel par exemple pour établir et mesurer la dépendance [1]. On note par ailleurs que les effets négatifs des écrans sont plus importants dans les populations moins favorisées [4]. À l’inverse, les effets cognitifs des écrans peuvent être positifs [4,5,6] mais pas en cas d’usage avant le sommeil, qu’ils perturbent [3].

On doit donc avant tout considérer les usages qui en sont faits et arrêter de considérer le paramètre de durée (temps devant les écrans) qui occulte d’autres éléments au moins aussi importants [1,3] comme illustrés ci-après.
Les études les plus fines distinguent les usages, en particulier passif (comme la télévision) versus actif, autrement dit isolé (on « colle » l’enfant devant les écrans) opposé à coopératif.
C’est l’usage de ces écrans pour « occuper » les enfants pendant que les adultes vaquent à leurs autres tâches qui présente un effet délétère [2].
Au delà, une plus grande quantité d’utilisation de l’écran (c’est-à-dire des heures par jour/semaine) est associée négativement au développement du langage de l’enfant, tandis qu’une meilleure qualité d’utilisation de l’écran (c’est-à-dire des programmes éducatifs et un visionnage conjoint avec les adultes éduquant) est positivement associée aux compétences linguistiques de l’enfant [3].

Comparons « screen-time » versus « green-time » [4], c’est à dire le temps passé dans l’environnement extérieur (ex: forêt, parc public). On observe là encore qu’il faut distinguer l’usage modéré avec des contenus choisis et un accompagnement éducatif qui a des effets positifs, de l’inverse qui peut avoir un effet négatif, voire très négatif. Le « green-time » limite les effets cognitifs négatifs des écrans, au delà de l’effet bien connu de l’hyper sédentarité qui conduit à des troubles physiologiques dérivés [6].
C’est donc, au niveau cognitif et éducatif essentiellement un enjeu de contenu numérique. Ainsi, la lecture sur écran est moins efficace que sur un livre papier, sauf si le contenu est « augmenté » (accès à un lexique, récit interactif, …) [5], en notant que la lecture en interaction avec une personne éducative référente augmente les performances dans les deux cas.
 On insistera finalement sur ce que la communauté de l’éducation à l’informatique sait depuis longtemps :
On insistera finalement sur ce que la communauté de l’éducation à l’informatique sait depuis longtemps :
–comprendre comment fonctionnent les ordinateurs conduit à un bien meilleur usage récréatif et éducatif, et aussi souvent moins dépendant [7] ;
– pour apprendre les concepts informatiques, les « activités débranchées » où on « éteint son écran pour aller jouer au robot dans la cour » sont les plus efficaces au niveau didactique et pédagogique [8].
Pour moins utiliser les écrans, le plus important est de commencer à les utiliser mieux.
Gérard Giraudon et Thierry Viéville.
Références :
[0] https://www.lemonde.fr/blog/binaire/2023/10/06/ntic-etat-des-lieux-en-france-et-consequences-sur-la-sante-physique-partie-1/
[1] https://www.sciencedirect.com/science/article/pii/S0190740922000093
[2] https://www.pafmj.org/index.php/PAFMJ/article/view/6648
[3] https://jamanetwork.com/journals/jamapediatrics/article-abstract/2762864
[4] https ://journals.plos.org/plosone/article?id=10.1371/journal.pone.0237725
[5] https://journals.sagepub.com/doi/full/10.3102/0034654321998074
[6] https://www.sciencedirect.com/science/article/pii/S0765159711001043
[7] https://inria.hal.science/hal-03051329
[8] https://inria.hal.science/hal-02281037
[9] https://www.cairn.info/les-enfants-et-les-ecrans–9782725643816-page-150.htm
[10] https://naitreetgrandir.com/fr/etape/1_3_ans/jeux/usage-ecrans-parents-equilibre
[11] https://www.u-bordeaux.fr/actualites/Addiction-aux-écrans-mythe-ou-réalité
19.04.2024 à 07:00
Fact checking : l’intelligence artificielle au service des journalistes
binaire
Continuer la lecture de « Fact checking : l’intelligence artificielle au service des journalistes »
Texte intégral (2212 mots)
Les progrès récents de l’intelligence artificielle générative , outils qui permettent de produire du texte, du son, des images ou des vidéos de manière complètement automatique, font craindre une diffusion massive de fausses informations qui risquent de devenir de plus en plus « authentique ». Comment font les journalistes pour adresser ce sujet ?
Merci à inria.fr qui nous offre ce texte en partage, originalement publié le 06/02/2024. Ikram Chraibi Kaadoud

À vos yeux, quels sont les défis à relever par les journalistes en matière de fact checking aujourd’hui ?
Estelle Cognacq : Franceinfo s’est engagé dans la lutte contre la désinformation et pour la restauration de la confiance dans les médias depuis plus de 10 ans : la première chronique « Vrai ou faux » date par exemple de 2012 et un service spécial, dédié au fact checking, a été créé en 2019. Les journalistes qui y travaillent se sont fixé deux objectifs. D’une part, puisqu’il est impossible d’éradiquer les fausses informations, nous cherchons à donner au grand public les outils qui lui permettent de développer un esprit critique, de remettre en question ce qu’il voit, ce qu’il lit, ce qu’il entend. Nous allons donc expliquer notre façon de travailler, donner des astuces sur la façon de détecter des images truquées par exemple.
D’autre part, nous allons nous saisir directement des fausses informations qui circulent, lorsque celles-ci entrent en résonance avec la démocratie, la citoyenneté ou les questions d’actualité importantes, pour établir les faits. Mais plus il y a de monde sur les réseaux sociaux, plus des informations y circulent et plus les journalistes ont besoin d’aide : l’humain a ses limites lorsqu’il s’agit de trier des quantités phénoménales de données.
Iona Manolescu : Et c’est justement là tout l’intérêt des recherches que nous menons au sein de l’équipe-projet Cedar, (équipe commune au centre Inria de Saclay et à l’Institut Polytechnique de Paris, au sein du laboratoire LIX), qui est spécialisée en sciences des données et en intelligence artificielle (IA). Sur la question du fact checking, il nous faut d’un côté vérifier automatiquement une masse d’informations, mais de l’autre, nous disposons de quantités de données de qualité disponibles en open source, sur les bases statistiques officielles par exemple. La comparaison des unes aux autres constitue un procédé éminemment automatisable pour vérifier davantage et plus vite.
Et c’est pourquoi un partenariat s’est noué entre Radio France et Cedar… Comment a-t-il vu jour ?
I.M. : De 2016 à 2019, l’un de mes doctorants avait travaillé sur un premier logiciel de fact checking automatique, baptisé StatCheck, dans le cadre du projet ANR ContentCheck que j’avais coordonné, en collaboration avec Le Monde. Ce projet est arrivé jusqu’aux oreilles d’Eric Labaye, président de l’Institut polytechnique de Paris, qui en a lui-même parlé à Sybile Veil, directrice de Radio France. De là est née l’idée d’une collaboration entre chercheurs d’Inria et journalistes de Radio France. Du fait de la pandémie de Covid, il a fallu attendre l’automne 2021 pour que celle-ci se concrétise.
E.C. : Notre objectif était vraiment de partir des besoins de nos journalistes, de disposer d’un outil qui les aide efficacement au quotidien. Antoine Krempf, qui dirigeait la cellule « Vrai ou faux » à l’époque, a par exemple dressé la liste des bases de données qu’il souhaitait voir prises en compte par l’outil.
Toutes les semaines, nous avions également un point qui réunissait les deux ingénieurs en charge du projet chez Inria et les journalistes : l’occasion pour les premiers de présenter l’évolution de l’outil et pour les seconds de préciser ce qui manquait encore ou ce qui leur convenait. Et ces échanges se poursuivent aujourd’hui. Croiser les disciplines entre chercheurs et journalistes dans une optique de partage est très intéressant.
I.M. : Au cours de ce processus, nous avons réécrit tout le code de StatCheck, travaillé sur la compréhension du langage naturel pour permettre à l’outil d’apprendre à analyser un tweet par exemple, avec la contribution essentielle de Oana Balalau, chercheuse (Inria Starting Faculty Position) au sein de l’équipe Cedar. Deux jeunes ingénieurs de l’équipe, Simon Ebel et Théo Galizzi, ont échangé régulièrement avec les journalistes pour imaginer et mettre au point une nouvelle interface, plus agréable et plus adaptée à leur utilisation.
Ce logiciel est-il maintenant capable de faire le travail du « fact checker » ?
I.M. : Aujourd’hui, StatCheck est à la disposition de la dizaine de journalistes de la cellule « Le vrai du faux »… mais il ne les remplace pas ! D’abord parce que nous ne pouvons pas atteindre une précision de 100% dans l’analyse des informations. Donc le logiciel affiche ses sources pour le journaliste, qui va pouvoir vérifier que l’outil n’a pas fait d’erreur. Ensuite, parce que l’humain reste maître de l’analyse qu’il produit à partir du recoupement de données réalisé par StatCheck.
E.C. : Ainsi, chaque journaliste l’utilise à sa manière. Mais cet outil s’avère particulièrement précieux pour les plus jeunes, qui n’ont pas forcément encore l’habitude de savoir où regarder parmi les sources.
Quels sont les développements en cours ou à venir pour StatCheck ?
E.C. : Nous profitons déjà de fonctionnalités ajoutées récemment, comme la détection de données quantitatives. Nous avons entré dans StatCheck des dizaines de comptes Twitter (devenu X) de personnalités politiques et le logiciel nous signale les tweets qui contiennent des données chiffrées. Ce sont des alertes très utiles qui nous permettent de rapidement repérer les informations à vérifier.
L’outil a également été amélioré pour détecter la propagande et les éléments de persuasion dans les tweets. Nous utilisons cette fonctionnalité sur du plus long terme que le fact checking : elle nous permet d’identifier les sujets qu’il pourrait être pertinent de traiter sur le fond.
I.M. : Pour l’instant, StatCheck va puiser dans les bases de données de l’Insee (Institut national de la statistique et des études économiques) et d’EuroStat, la direction générale de la Commission européenne chargée de l’information statistique. Mais dans la liste établie par Antoine Krempf, il y a aussi une kyrielle de sites très spécialisés comme les directions statistiques des ministères. Le problème est que leurs formats de données ne sont pas homogènes. Il faut donc une chaîne d’analyse et d’acquisition des informations à partir de ces sites, pour les extraire et les exploiter de manière automatique. Les deux ingénieurs du projet sont sur une piste intéressante sur ce point.
Et votre partenariat lui-même, est-il amené à évoluer ?
E.C. : Nous sommes en train de réfléchir à son inscription dans une collaboration plus large avec Inria, en incluant par exemple la cellule investigation et la rédaction internationale de Radio France, pourquoi pas au sein d’un laboratoire IA commun.
I.M. : Nous avons d’autres outils qui pourraient être utiles aux journalistes de Radio France, comme ConnectionLens. Celui-ci permet de croiser des sources de données de tous formats et de toutes origines grâce à l’IA… Pratique par exemple pour repérer qu’une personne mentionnée dans un appel d’offres est la belle-sœur d’un membre du comité de sélection de l’appel d’offres ! Là encore, le journaliste restera indispensable pour identifier le type d’information à rechercher, ainsi que pour vérifier et analyser ces connexions, mais l’outil lui fournira des pièces du puzzle. En fait, toutes les évolutions sont envisageables… elles demandent simplement parfois du temps !
12.04.2024 à 08:26
Ce qu’on sait et ce qu’on ne sait pas sur les effets environnementaux de la numérisation
binaire
Texte intégral (3856 mots)

Gauthier Roussilhe est doctorant au RMIT. Il étudie la façon dont nos pratiques numériques se modifient dans le cadre de la crise environnementale planétaire en proposant une vision systémique, de l’extraction des matières à la fin de vie, et des infrastructures à l’usage des services numériques. Antoine Rousseau & Ikram Chraibi Kaadoud
On pourrait penser que les conséquences environnementales de la numérisation est un sujet récent , or cela fait bientôt 30 ans qu’on se demande quel est son poids environnemental et si numériser aide à la transition écologique. En 1996, l’Information Society Forum fait le constat suivant : « La plupart des experts ne pensent pas que le développement durable soit réalisable sans les technologies de l’information, mais ils ne sont pas non plus sûrs qu’il soit garanti avec elles. […] Il existe un risque d’effet « rebond » par lequel ils pourraient stimuler de nouvelles demandes de consommation matérielle » (ISF, 1996, 30). 26 ans plus tard, en 2022, le 3e groupe de GIEC proposait une synthèse peu encourageante : « Pour le moment, la compréhension des impacts directs et indirects de la numérisation sur la consommation d’énergie, les émissions de carbone et le potentiel d’atténuation est limité » (IPCC, 2022, 132). Est-ce que cela veut dire pour autant que nous n’avons pas progressé sur le sujet depuis 30 ans ? Loin de là, revenons ensemble sur l’état de l’art de la recherche scientifique sur les deux questions principales de ce champ : l’empreinte environnementale du secteur et les effets environnementaux de la numérisation dans les autres secteurs.
L’empreinte carbone du secteur numérique
La production des savoirs scientifiques dans ce domaine s’est concentrée principalement sur l’empreinte environnementale du secteur numérique, c’est-à-dire le poids écologique lié à la fabrication, l’usage et la fin de vie de tous les équipements et services qui composent ce secteur. Il y a assez peu d’articles de recherche qui se sont aventurés dans l’estimation mondiale du secteur. Ces dernières il y a trois estimations concurrentes (Andrae & Edler, 2015 (remplacé par Andrae 2020) ; Malmodin & Lundén, 2018 ; Belkhir & Elmeligi, 2018). Freitag et al ont proposé une analyse de ces travaux proposant que les émissions du secteur numérique représentaient en 2020 entre 2,1 et 3,9% des émissions mondiales (1,2-2,2 Gt eq-CO2). Le plus important ici n’est pas forcément cette estimation mais la tendance de ces émissions, or, depuis juin 2023, la communauté scientifique sur ce sujet est plus ou moins arrivé à un consensus : les émissions du secteur augmentent. Ce n’est pas une croissance exponentielle mais l’arrivée massive de nouveaux types d’équipements comme les objets connectés donne à voir plutôt une augmentation annuelle constante. Et nous n’avons pas mis à jour nos projections avec le nouveau marché de l’IA, d’autant plus que les premiers travaux d’estimation semblent inquiétants. Concernant les autres facteurs environnementaux, épuisement de ressources minérales, utilisation d’eau, pollutions des sols et des eaux, etc nous ne disposons aujourd’hui d’aucune estimation d’envergure ni de vision claire même si de nombreux projets de recherche avancent sur ces questions.
Les centres de données
Dans le travail de modélisation, nous privilégions pour l’instant la découpe du secteur en trois tiers : les centres de données, les réseaux et les équipements utilisateurs. Chacun de ces tiers poursuit sa propre trajectoire qu’il est nécessaire d’aborder. En premier lieu, les centres de données ont fait l’objet de travaux de fond sur leur consommation électrique pour ensuite obtenir des émissions carbone. Deux estimations font référence, celle de Masanet et al (2018) à 205 TWh de consommation électrique mondiale et celle de l’Institut Borderstep à 400 TWh. L’Agence Internationale de l’Énergie (IEA) a utilisé la première estimation pendant quelques années mais a revu ses travaux récemment et propose plutôt une fourchette entre 220 et 320 TWh (cela exclut la consommation électrique des cryptomonnaies qui est comptée à part par l’IEA). Il existe bien aussi un consensus sur l’augmentation croissante de la consommation électrique des centres de données mais les opérateurs misent sur l’achat ou la production d’énergie bas carbone pour décorreler consommation d’électricité et émissions de carbone avec plus ou moins de succès. Encore une fois ces chiffres ne prennent en compte que l’usage des centres de données et n’intégrent pas les impacts environnementaux liés à la fabrication des serveurs et autres équipements. Au-delà de la consommation électrique c’est plutôt le poids local de ces infrastructures qui devient de plus en plus problématique autant pour la disponibilité électrique que pour l’accès à l’eau. De nombreux conflits locaux se développent : Irlande, Espagne, Chili, Amsterdam, Francfort, Londres, États-Unis. À l’échelle française, L’Île-de-France héberge la plupart des centres de données français et fait face à de nombreuses problématiques qui invite à une réflexion et une planification profonde comme très bien démontré par l’étude récente de l’Institut Paris Région.
Les réseaux de télécommunication
Les réseaux de télécommunications comprennent tous les réseaux d’accès fixes (ADSL, Fibre), les réseaux d’accès mobile (2G/3G/4G/5G) et les réseaux coeurs. En 2015, Malmodin & Lundén (2018) estimaient la consommation électrique mondiale des réseaux à 242 TWh et l’empreinte carbone à 169 Mt eq-CO2. Depuis peu de travaux se sont réessayés à l’exercice. Coroama (2021) a proposé une estimation à 340 TWh pour les réseaux en 2020 et aujourd’hui l’IEA estime la consommation électrique en 260 et 340 TWh (IEA). L’empreinte carbone des réseaux, autant au niveau de la fabrication du matériel que de l’usage reste à mieux définir mais implique aussi de redoubler d’efforts sur de nombreux angles morts : le déploiement (génie civil, etc.) et la maintenance sont des parts significatives de l’empreinte des réseaux qui n’ont quasiment pas été comptées jusque là. De même, les satellites de télécommunication devraient faire partie du périmètre des réseaux mais leur impact avait été considéré comme minime. Toutefois, le déploiement massif de constellation avec des satellites d’une durée de vie de 5 ans implique une attention renouvelée.
Les équipements utilisateurs
Finalement, le dernier tiers, celui des équipements utilisateurs, inclut à la fois les équipements personnels (smartphone, portable, tablette, ordinateurs, écrans, etc) et professionnels. Certains segments connaissent une contraction depuis quelques années : le vente d’ordinateurs fixes chute (sauf pour le gaming), de même que les livraisons de smartphones. De l’autre, de nouveaux segments apparaissent comme les objets connectés grand public (enceinte, caméra, etc.). C’est l’arrivée de ces derniers qui est profondément inquiétante si les projections de marché se maintiennent car elle suggère le déploiement massif d’objets de qualité variable, à faible durée de vie et donc à fort taux de renouvellement (Pirson et Bol, 2021). En descendant d’un niveau, à l’échelle des composants clés, nous voyons une augmentation de l’empreinte de fabrication des circuits intégrés les plus avancés (<10nm) (Pirson et al, 2022), c’est-à-dire les nouveaux processeurs (Apple série M) ou dans les puces de calcul graphique (produits Nvidia par exemple) aujourd’hui très recherchées pour l’entrainement d’IA génératives.
Les services numériques
À cela s’ajoute une inconnue évidente : l’évolution des services numériques. Les équipes de recherche ne peuvent pas prévoir l’apparition de nouveaux usages dans leur estimation, or les usages se sont plutôt stabilisés depuis quelques années. Le passage en force du Métaverse consistant à créer de nouveaux usages, de nouveaux services et de nouveaux équipements dédiés à échouer. Le dernier grand changement date d’un alignement des planètes entre 2010 et 2012 avec le déploiement massif de smartphones, la mise en route des réseaux 4G et la massification de l’offre vidéo en ligne. Aujourd’hui, les services grand public supportés par l’IA proposent une nouvelle évolution des usages mais, au-delà des discours mercantiles et/ou prophétiques, la tendance est encore loin d’être claire.
Malgré les immenses zones d’ombre qui restent encore à éclairer la connaissance de l’empreinte carbone du secteur numérique commence à se stabiliser. Les tendances futures montrent plutôt une augmentation globale de l’impact et une tension locale de plus en plus accrue. Face à cela, une question demeure, est-ce que l’augmentation de cette empreinte permet de réduire celles des autres secteurs ? En somme, est-ce que la numérisation est un « investissement environnemental » cohérent. Voyons cela ensemble dans la deuxième partie.
Les effets sur les émissions de carbone dans les autres secteurs
Comme vu au début de cet article, la question des effets environnementaux de la numérisation dans les autres secteurs, que ces effets soient positifs ou/et négatifs, s’est posée d’emblée, toutefois, elle a été bien moins traitée que la question de l’empreinte du secteur. Au même titre que les économistes ont de nombreuses difficultés à isoler la contribution de la numérisation au PIB ou à la productivité, les chercheurs en sciences environnementales font face au même défi. Dans un premier temps, les effets environnementaux liés à des services numériques ont dû faire l’objet d’une classification qui commence doucement à se stabiliser aujourd’hui : les effets de second ordre (gain d’efficacité, substitution, effet rebond direct) et de plus grande ordre (effets rebonds indirects, rebond macro-économique, induction, etc.) (Hilty et al, 2006 ; Hilty et Aebischer, 2015 ; Horner et al, 2016). Si un gain d’efficacité est simple à comprendre la question des effets rebonds poursuit le secteur numérique depuis 30 ans. Un effet rebond peut être simplement défini comme un gain d’efficacité ou une optimisation qui conduit à une augmentation de la production ou de la demande, contrecarrant ainsi une partie, voire tous les gains obtenus. C’est un principe économique qui est
théorisé depuis un siècle et demi, historiquement associé avec la question énergétique, qui est particulièrement pertinent dans le phénomène de numérisation à cause des effets macro et microéconomiques de ce dernier.
Les études industrielles
On distingue trois types de littérature sur ce sujet : la production industrielle (rapport, livre blanc, etc), la production scientifique (articles de recherche, etc), et la littérature institutionnelle qui pioche dans les deux. La littérature industrielle a une tendance farouche à se concentrer que sur la modélisation des effets positifs (efficacité, optimisation) en mettant systématiquement de côté les effets négatifs (effets rebonds, induction, etc.). Deux rapports industriels ont été particulièrement diffusés et cités : le rapport SMARTer2030 de GeSI (un groupe de réflexion des entreprises de la tech sur la question environnementale) qui estime que la numérisation peut réduire les émissions mondiales de 20% d’ici 2030, et le rapport ‘Enablement Effect’ de GSMA (l’organisation mondiale des opérateurs télécom) qui estime que les technologies mobiles ont permis d’éviter 2,1 Gt eq-CO2 en 2018. Ces rapports visent à promouvoir l’idée d’un effet d’abattement (enablement effect), c’est-à-dire, un 1g d’eqCO2 émis par le secteur numérique pourrait permettre d’éviter 10g d’eqCO2 dans les autres secteurs. Ces affirmations ont eu une grande popularité au sein des entreprises du secteur et dans le monde institutionnel. Dans la communauté scientifique, aucune équipe s’est aventurée dans de tels travaux tant les difficultés méthodologiques sont nombreuses. Il est en fait bien connu parmi les scientifiques spécialisés que ces affirmations sont notoirement douteuses et les défauts méthodologiques de ces rapports trop nombreux pour qu’ils soient utilisés pour orienter la prise de décision publique ou privée (Malmodin et al, 2014 ; Malmodin et Coroama, 2016 ; Bieser et Hilty, 2018 ; Coroama et al, 2020 ; Bergmark et al, 2020 ; Rasoldier et al, 2022 ; Bieser et al, 2023). Leurs principaux défauts sont des extrapolations globales à partir d’études de cas ou d’échantillons très réduits, la représentativité de ces mêmes échantillons, l’omission des effets directs des solutions étudiées (l’empreinte environnementale) et des effets rebonds, et de tous les effets structuraux dont dépendent le succès ou l’échec d’une solution numérique.
La complexité du problème
Les chercheurs qui travaillent sur ces sujets savent que les effets environnementaux d’une solution numérique dépendent bien plus de facteurs contextuels que de ses capacités propres : politiques publiques, prix, culture, infrastructures disponibles, contexte commerciale, etc. Par exemple, une application de partage de vélo a bien moins de chances de produire des effets positifs dans une ville sans infrastructure vélo développée, ou un système intelligent de gestion du chauffage sera bien mieux efficace dans une maison isolée. Cela ne veut pas dire pour autant que la numérisation de certaines activités permet effectivement d’éviter des émissions mais ce qui est observable à petite échelle peine à se réaliser à plus grande échelle. Par exemple, il est évident aujourd’hui que le télétravail permet d’éviter à court terme des trajets en voitures individuelles. Toutefois, pris sur une période de temps plus longue et à une échelle nationale, les choses se compliquent. Caldarola et Sorrell (2022) ont publié un article pour répondre à une question fondamentale : est-ce que les télétravailleurs voyagent moins ? Pour ce faire ils se sont appuyés sur des données longitudinales d’un échantillon randomisé de 13 000 foyers anglais de 2005 à 2019. Ils ont observé que le groupe de télétravailleurs faisaient moins de trajets que le groupe de non-télétravailleurs mais que les deux groupes parcouraient un nombre similaire de kilomètres à l’année. Cela est du à plusieurs effets adverses : l’éloignement croissant entre foyer et lieu de travail, voyages plus loin le week-end, modes de transport, trajets non évitables, etc. Néanmoins, les auteurs notent qu’à partir de trois jours et plus de télétravail, les télétravailleurs commencent à parcourir moins de kilomètres que l’autre groupe. Cet exemple donne à voir à quel point il est complexe d’inférer qu’un effet positif observé à petite échelle se maintienne en toutes conditions à l’échelle d’un pays car de nombreux autres effets, notamment différents types d’effets rebonds et d’induction, peuvent compenser les gains bruts.
Savoir où chercher
Savoir si la numérisation a un potentiel pour aider à la décarbonation d’une économie n’est pas la question, tout le monde reconnaît ce potentiel. Par contre, ce potentiel ne semble pas s’être manifesté structurellement au sein des économies les plus numérisées de la planète. Nous disposons de nombreuses études de cas qui montrent des solutions numériques avec des effets encourageants dans certains contextes, mais le problème est que même si nous pouvons déployer massivement ces solutions nous ne pouvons pas répliquer les contextes d’application et surtout les répliquer à plus grande échelle. Cela implique que certaines voies de numérisation ne sont pas
compatibles avec la décarbonation. Premièrement, les solutions numériques qui rendent plus efficaces l’extraction d’énergies fossiles : en 2019, Microsoft mettait en avant que leurs solutions numériques pour Exxon permettraient d’augmenter la production journalière de barils de 50 000 d’ici 2025 (pour l’instant personne ne s’est donné la peine d’estimer toutes les émissions ajoutées de la numérisation dans le secteur des énergies fossiles). Deuxièmement, certaines solutions numériques proposent plutôt un statu quo qu’un réel gain, ici les solutions de smart home démontre une grande ambivalence entre gain de confort supposé (automatisation et programmation des fonctions d’une maison), ajout de nouvelles options de divertissement (enceintes, etc.) et économies d’énergie (Sovacool et al, 2020). Prises ensemble, toutes ces promesses tendent à se contrecarrer et à maintenir un statu quo. De façon générale, les solutions numériques qui misent la plupart de leurs gains potentiels sur des changements de comportement individuel constants et stables dans le temps présentent un plus grand risque. Les solutions numériques pouvant avoir le plus d’effets positifs sont généralement celles qui s’appuient sur un financement stable et pérenne, qui évoluent dans des univers assez contrôlés où le comportement humain est moins central et qui sont appliqués sur des infrastructures déjà établies à grande échelle (ou en passe de l’être). Toutefois, il faudra encore de nombreuses années de recherche pour comprendre ces dynamiques et arriver à une vue stratégique plus fine et surtout moins biaisée par les intérêts industriels.
Ce que permet et ne permettra pas la numérisation
Se poser sérieusement la question de la contribution de la numérisation à la transition écologique d’un pays implique de se décentrer d’une vue mono-solution où on infère des effets à partir d’une étude de cas mené à un instant t, qui est généralement celle des entreprises ou des industries numériques. La planification écologique d’un pays comme la France requiert d’identifier les leviers les plus importants au niveau de leur effet à grande échelle, et de la stabilité de leur effet dans le temps, dans les secteurs les plus urgents à décarboner. Ces leviers sont rarement les solutions les plus faciles et les moins chères, ce sont généralement des politiques publiques qui essayent de modifier en profondeur des modes de vie. Les solutions numériques ont encore une place indéterminée dans cette réflexion. Un problème central pour les solutions numériques est la persistance des effets. Pour reprendre le cas du télétravail, si aujourd’hui cela évite un trajet en voiture individuelle essence ou diesel, les trajectoires de décarbonation de la France laissent imaginer que le télétravail évitera en 2030 un trajet à pied ou à vélo, ou un trajet en voiture ou en transport en commun électrique. Cela implique que l’effet positif sera forcément à rendement décroissant et constitue plutôt un levier à court-terme, moins structurant pour une planification écologique. La logique peut aussi s’inverser : on observe généralement que des économies d’énergie liées à un système de chauffage plus intelligent sont généralement réinvesties par une augmentation de la température de chauffe du logement et donc un gain de confort (Belaïd et al, 2020), ce qui est un effet rebond direct classique. Toutefois, en pleine crise du coût de la vie et avec un prix du kWh plus élevé, il y a de fortes chances que cet effet rebond disparaisse à cause de budgets bien plus serrés dans les foyers. C’est cette grande ambivalence et cette grande exposition aux facteurs « contextuels » qui maintient en partie la numérisation comme un impensé de la transition écologique et explique la prudence du GIEC dans l’extrait cité en introduction. Ces grands chantiers de recherche ne font encore que commencer.
Gauthier Roussilhe, doctorant RMIT / page web perso
Bibliographie complète à télécharger ici
05.04.2024 à 07:13
Vive les communs numériques !
binaire
Texte intégral (950 mots)
Un des éditeurs de Binaire, Pierre Paradinas a lu le livre de Serge Abiteboul & François Bancilhon, Vive les communs numérique ! Il nous en dit quelques mots gentils. Binaire.

Le livre de Serge et François, Vive les communs numériques ! est un excellent livre -oui, je suis en conflit d’intérêts car les auteurs sont de bons copains.
C’est un livre facile et agréable à lire, mais sérieux et extrêmement bien documenté sur la question des communs numériques. En effet, nos deux collègues universitaires, scientifiques et entrepreneurs expliquent, explicitent et démontent les rouages des communs numériques.
Partant de l’exemple d’un champ partagé par les habitants d’un village, ils définissent les communs numériques et nous expliquent ce qu’ils sont, et pourquoi certains objets numériques (gratuits ou pas) ne peuvent pas être considérés comme des communs numériques. L’ensemble des communs numériques sont décrits, allant des données, au réseau en passant par l’information, les logiciels et la connaissance.
Une partie est consacré au « comment ça marche », qui nous donne des éléments sur les communautés au cœur du réacteur des communs numériques, sans oublier les licences qui doivent accompagner systématiquement un élément mis à disposition sous forme de commun numérique. Enfin, comme le diable est dans le détail, les auteurs nous expliquent la gouvernance des communs numériques et les vraies questions de gestion des communs numériques.
Le livre explore aussi les liens avec les entreprises des technologies informatiques -parfois très largement contributrices au logiciel libre-, comme Linux, les suites bureautiques ou les bases de données dont nos deux auteurs sont des spécialistes reconnus.
Le livre est enclin à un certain optimisme qui reposes sur les nombreuses opportunités offertes par les communs numériques. De même, on apprécie le point évoqué par les auteurs de la souveraineté numérique où les communs numériques sont analysés pour l’établir, la développer et la maintenir. Par de nombreux exemples, les communs numériques permettent une plus grande prise en compte des utilisateurs, ce qui devrait conduire à des solutions technologiques mieux adaptées.
Si vous voulez comprendre les communs numériques, courez vite l’acheter ! Si vous voulez compléter vos cours sur les données ouvertes et/ou le logiciel libre, c’est l’ouvrage de référence.
Le livre est très riche, il compte de nombreux encadrés, consacrés à des communs numériques ou à des personnalités ; il contient aussi un lexique, une bibliographie et une chronologie qui complètent l’ouvrage. Écrit avec passion, c’est un plaidoyer richement documenté. Vive les communs numériques !
Pierre Paradinas
PS : Le livre sera en accès ouvert à partir de décembre 2024 
01.04.2024 à 08:35
JO de Paris 2024 : une IA désignée pour chanter à l’inauguration
binaire
Continuer la lecture de « JO de Paris 2024 : une IA désignée pour chanter à l’inauguration »
Texte intégral (1201 mots)
Le comité français olympique a tranché cédant à des pressions intenses et parfois contradictoires de l’Élysée. La chanson inaugurale des JO 2024 sera chantée par AÏcha (prononcer É-aille-cha) Chantouvère.
Mais qui est cette AÏcha apparue récemment dans les radars de la chanson française ? Une bot conçue et réalisée par le collectif d’enseignants-chercheurs parisiens, Chantouvère. L’entreprise française Mistral aurait procuré les moyens de calculs pour la génération de la chanson. Des équipes bordelaises d’Inria et du CNRS lui aurait donné un visage et un corps. Le visage de la bot a été généré artificiellement à partir des visages de plusieurs chercheuses issues de la diversité pour être « le plus inclusif » selon une source proche. Leur représentante nous a déclaré : « Nous ne comptons pas garder un centime. L’essentiel des royalties pour l’usage de cette nouvelle image ira au blog Binaire ! »
Nous avons demandé à Olive Commun-Nhume, porte-parole de Chantouvère, quelles difficultés particulières ils avaient rencontrées. Elle nous a expliqué que, d’abord, il a été compliqué de convaincre l’IA de ne pas mélanger la musique de La Marseillaise et les paroles de Kostís Palamás de l’hymne olympique. Elle a ajouté : « Ensuite, pour choisir entre plusieurs propositions de notre IA, nous avons voulu utiliser un panel d’ados sur TikTok. Ils n’ont cessé de nous proposer des alternatives qu’ils inventaient en argumentant sur le fait qu’ils les trouvaient bien meilleures que les chansons de notre IA. Finalement, nous avons utilisé un panel d’IA (plusieurs copies de notre logiciel) qui a plébiscité la chanson d’AÏcha Chantouvère que nous avons sélectionnée. »
Polémique de Palais
L’Élysée a beaucoup hésité sur le choix de cette chanson. Une partie des conseillers, que l’on pourrait qualifier d’ « aile gauche » penchait pour celle d’Aya Nakamura. L’aile droite poussait pour AÏcha Chantouvère. (Les mots « gauche » et « droite » ont ici un sens bien relatif.) Alors qu’on pensait qu’AÏcha avait été choisie, l’ « aile madame » (l’aile du palais réservée à la première dame) s’est mise à pousser pour Michel Sardou. Ce débat existentiel a été tranché au plus haut niveau.
Polémique politique
Les partis politiques se sont positionnés, la gauche pour Aya, les macroniens pour AÏcha, et la droite pour Michel. L’extrême droite s’est élevée violemment contre le choix d’AÏcha. Selon un représentant du Rassemblement national : « Son prénom est clairement à consonance pas vraiment française, voire limite maghrébine ». « La France est plurielle », s’est contentée de répondre la porte-parole de Chantouvère. Pour Reconquête, « Les chansons d’AÏcha Chantouvère ne sont pas plus en français que celles d’Aya Nakamura ». Selon Olive Commun-Nhume, « le panel d’ado a déclaré la chanson sélectionnée 100% française. Un d’entre eux a précisé que la bot parlait plutôt comme son daron ».
Polémique paillarde
Une polémique a enfin été soulevée par des internautes. En prenant les premières lettres de chaque mot, on obtient comme texte « De Profundis Morpionibus », le titre d’une chanson paillarde (*). Nous avons pu vérifier. Est-ce une facétie des chercheurs du collectif ou de l’IA ? Olive Commun-Nhume a refusé de commenter.
Pour conclure, nous devons avouer qu’à titre personnel nous ne sommes fans musicalement d’aucun des trois. Pourquoi pas Zaz ?
Serge Abiteboul, Ikram Chraibi Kaadoud, Marie-Agnès Enard
|
Le comité éditorial de Binaire s’oppose à la publication de cet article qui soutient clairement le choix d’AÏcha Chantouvère. Au sein du comité, certains ont déjà tranché, ils veulent entendre IA Nakamura et personne d’autre. Le seul point de consensus est qu’ils sont tous d’accord, et c’est assez rare pour le souligner, sur le fait qu’on souhaite entendre une femme. |
(*) Cette chanson du XIXe siècle aurait été écrite par Théophile Gautier. Il en aurait refusé la paternité pour se présenter à l’Académie Française. Il est resté bien plus populaire pour cette chanson que pour son passage à l’académie.
27.03.2024 à 06:23
Sarah et le virus de bioinformatique
binaire
Continuer la lecture de « Sarah et le virus de bioinformatique »
Texte intégral (3080 mots)
Un nouvel entretien autour de l’informatique.
Sarah Cohen-Boulakia est bioinformaticienne, professeure à l’Université Paris Saclay et chercheuse au Laboratoire Interdisciplinaire des Sciences du Numérique. Elle est spécialiste en science des données, notamment de l’analyse et l’intégration de données biologiques et biomédicales. Pendant la crise du covid, elle a participé à l’intégration les résultats de milliers d’essais cliniques. Elle a obtenu en 2024 la médaille d’argent du CNRS. Elle est directrice adjointe sur les aspects formation de l’institut DATAIA. Elle participe également au montage du réseau français de reproductibilité.

Binaire : Comment es-tu devenue informaticienne ?
SCB : Quand je suis entrée à l’Université, j’ai commencé par faire des maths. Et puis j’ai rencontré des informaticiennes, des enseignantes formidables comme Marie-Christine Rousset, Christine Froidevaux, ou Claire Mathieu, qui commençait ses cours en poussant les tables dans toute la salle, parce qu’elle disait que c’était comme ça qu’on pouvait mieux “travailler l’algo”. Elles étaient brillantes, passionnées ; certaines avaient même un côté un peu dingue qui me plaisait énormément. Je me suis mise à l’informatique.
J’avais de bons résultats, mais je n’aurais jamais osé penser que je pouvais faire une thèse. C’est encore une enseignante, Christine Paulin, qui m’a littéralement fait passer de la salle de réunion d’information sur les Masters Pro (DESS à l’époque) à celle pour les Master Recherche (DEA). Je l’ai écoutée, j’ai fait de belles rencontres, fini major de promo de mon DEA et j’ai décidé avec grand plaisir de faire une thèse.
Binaire : Tu cites des enseignantes. C’était important que ce soit des femmes ?
SCB : Oh oui ! Parce que c’était impressionnant en licence d’être seulement sept filles dans un amphi de 180 personnes. Elles m’ont montré qu’il y avait aussi une place pour nous. Mais j’ai eu aussi d’excellents enseignants masculins ! Grâce à elles et eux, j’ai mordu à la recherche. Pour moi, la science est un virus qui fait du bien. Les enseignants se doivent de transmettre ce virus. Maintenant, j’essaie à mon tour de le partager au maximum.
Binaire : Tu travailles sur l’intégration de données biologiques. Qu’est-ce que ça veut dire ?
SCB : En biologie, on dispose de beaucoup de données, de points de vue différents, de formats très différents : des mesures, des diagrammes, des images, des textes, etc. L’intégration de données biologiques consiste à combiner ces données provenant de différentes sources pour en extraire des connaissances : l’évolution d’une maladie, la santé d’un patient ou d’une population…
Binaire : Où sont stockées ces données ?
SCB : Des données de santé sont collectées dans de grandes bases de données gérées par l’État, le Ministère de la Santé, la CNAM. Elles sont pseudonymisées : le nom du patient est remplacé par un pseudonyme qui permet de relier les données concernant le même patient mais en protégeant son identité. D’autres données sont obtenues par les hôpitaux pour tracer le parcours de soin. En plus de tout cela, il y a toutes les données de la recherche, comme les études sur une cohorte pour une pathologie donnée. Toutes ces données sont essentielles mais également sensibles. On ne peut pas faire n’importe quoi avec.
Binaire : Pourrais-tu nous donner un exemple de ton travail, un exemple de recherche en informatique sur ce qu’on peut faire avec ces données ?
SCB : Un médecin peut rechercher, par exemple, les gènes associés à une maladie. Avec un moteur de recherche médical, il tape le nom de la maladie qu’il étudie et il obtient une liste de gènes, triés dans l’ordre de pertinence. Le problème, c’est que la maladie peut être référencée sous plusieurs noms. Si le médecin tape un synonyme du nom de la maladie dans le moteur de recherche, la liste de gènes obtenus est sensiblement modifiée, de nouveaux gènes peuvent apparaître et leur ordre d’importance être différent. L’enjeu ici c’est à partir d’un ensemble de listes de gènes de construire une liste de gènes consensuelle : classant au début les gènes très bien classés dans un grand nombre de listes tout en minimisant les désaccords. Ce classement est bien plus riche en information pour les médecins que celui obtenu avec une simple recherche avec le nom commun de la maladie. Derrière cela, il y a un objet mathématique beaucoup étudié, les permutations.
Travailler sur les classements de résultats, c’est loin d’être simple algorithmiquement. Et ce problème est proche d’un autre problème dans une autre communauté : la théorie du vote. La situation est similaire, pour le vote, on a un grand nombre de votants (de milliers) qui votent pour un relativement petit nombre de candidats (une dizaine). Dans notre contexte biomédical, nous avons un grand nombre de gènes potentiellement associés à une maladie (des centaines) et un petit nombre de synonymes pour la maladie (une dizaine). Cela change un peu les choses, on reste dans un problème difficile et on peut s’inspirer de certaines solutions. Nous avons développé un outil basé sur ces recherches dans lequel les médecins mettent simplement le nom de la maladie à étudier, l’outil cherche automatiquement les synonymes dans les bases de synonymes, récupère les listes de gènes et fournit un classement consensuel. Avec notre outil, les médecins accèdent à une liste de gènes qui leur donne des informations plus complètes et plus fiables.
Binaire : Les données de santé sont évidemment essentielles. On parle beaucoup en ce moment du Health Data Hub. Pourrais-tu nous en dire quelques mots ?
SCB : Le Health Data Hub (HDH) propose un guichet d’entrée aux données de santé pour améliorer les soins, l’accompagnement des patients, et la recherche sur ces données. Le HDH a soulevé une polémique en choisissant un stockage dans Microsoft Azure, un service de cloud américain. Même si le stockage est conforme au RGPD, il pose un problème de souveraineté. Ce n’est pas une question d’impossibilité : d’autres données, de volume et complexité comparables sont sur des serveurs français. On espère que ce sera corrigé mais cela va sûrement durer au moins quelques années.
Binaire : Tu travailles sur les workflows scientifiques. Pourrais-tu expliquer cela aux lecteurs de binaire ?
SCB : Pour intégrer de gros volumes de données et les analyser, on est amené à combiner un assez grand nombre d’opérations avec différents logiciels, souvent des logiciels libres. On crée des chaînes de traitements parfois très complexes, en séquençant ou en menant en parallèle certains de ces traitements. Un workflow est une description d’un tel processus (souvent un code) pour s’en souvenir, le transmettre, peut-être le réaliser automatiquement. Pour les chercheurs, il tient un peu la place des cahiers de laboratoires d’antan.
Un workflow favorise la transparence, ce qui est fondamental en recherche. Définir du code informatique qui peut être réalisé par une machine mais également lu et compris par un humain permet de partager son travail, de travailler avec des collègues experts de différents domaines.
Binaire : Les workflows nous amènent à la reproductibilité, un sujet qui te tient particulièrement à cœur.
SCB : La reproductibilité d’une expérience permet à quelqu’un d’autre de réaliser la même expérience de nouveau, et d’obtenir, on l’espère, le même résultat. Compte tenu de la complexité d’une expérience et des variations de ses conditions de réalisation, c’est loin d’être évident. Nous avons toutes et tous vécu de grands moments de solitude en travaux pratiques de chimie quand on fait tout comme le prof a dit : on mélange, on secoue, c’est censé devenir bleu, et … ça ne se passe pas comme ça. Cela peut être pour de nombreuses raisons : parce qu’on n’est pas à la bonne température, que le mélange est mal fait, que le tube n’est pas propre, etc. Pour permettre la reproductibilité il faut préciser les conditions exactes qui font que l’expérience marche.
Le problème se pose aussi en informatique. Par exemple, on peut penser que si on fait tourner deux fois le même programme sur la même machine, on obtient le même résultat. La réponse courte c’est pas toujours ! Il suffit de presque rien, une mise à jour du compilateur du langage, du contexte d’exécution, d’un paramétrage un peu différent, et, par exemple, on obtient des arbres phylogénétiques complètement différents sur les mêmes données génétiques !
Binaire : Pourquoi est-il important d’être capable de reproduire les expériences ?
SCB : La science est cumulative. Le scientifique est un nain sur des épaules de géants. Il s’appuie sur les résultats des scientifiques avant lui pour ne pas tout refaire, ne pas tout réinventer. S’il utilise des résultats erronés, il peut partir sur une mauvaise piste, la science se fourvoie, le géant chancelle.
Des résultats peuvent être faux à cause de la fraude, parce que le scientifique a trafiqué ses résultats pour que son article soit publié. Ils peuvent être faux parce que le travail a été bâclé. Une étude de 2009 publiée par le New York Times a montré que la proportion de fraude varie peu, par contre le nombre de résultats faux a beaucoup augmenté. Les erreurs viennent d’erreurs de calcul statistiques, de mauvaises utilisations de modèles, parfois de calculs de logiciels mal utilisés. Cela arrive beaucoup en ce moment à cause d’une règle qui s’est imposée aux chercheurs : “publish or perish” (publie ou péris, en français) ; cette loi pousse les scientifiques à publier de façon massive au détriment de la qualité et de la vérification de leurs résultats.
La reproductibilité s’attache à combattre cette tendance. Il ne s’agit pas de rajouter des couches de processus lourds mais de les amener à une prise de conscience collective. Il faudrait aller vers moins de publications mais des publications beaucoup plus solides. Publier moins peut avoir des effets très positifs. Par exemple, en vérifiant un résultat, en cherchant les effets des variations de paramètres, on peut être conduit à bien mieux comprendre son résultat, ce qui fait progresser la science.
Binaire : Tu es directrice adjointe de l’institut DATAIA. Qu’est-ce que c’est ?
SCB : L’Université Paris-Saclay est prestigieuse, mais elle est aussi très grande. On y trouve de l’IA et des données dans de nombreux établissements et l’IA est utilisée dans de nombreuses disciplines. Dans l’institut DATAIA, nous essayons de coordonner la recherche, la formation et l’innovation à UPS dans ces domaines. Il s’agit en particulier de fédérer les expertises pluridisciplinaires des scientifiques de UPS pour développer une recherche de pointe en science des données en lien avec d’autres disciplines telles que la médecine, la physique ou les sciences humaines et sociales. En ce qui me concerne, je coordonne le volet formation à l’IA dans toutes les disciplines de l’université. Un de mes objectifs est d’attirer des talents plus variés dans l’IA, plus mixtes et paritaires.
Binaire : Tu travailles dans un domaine interdisciplinaire. Est-ce que, par exemple, les différences entre informaticiens et biologistes ne posent pas de problèmes particuliers ?
SCB : Je dis souvent pour provoquer que l’interdisciplinarité, “ça fait mal”… parce que les résultats sont longs à émerger. Il faut au départ se mettre d’accord sur le vocabulaire, les enjeux, les partages du travail et des résultats (qui profite de ce travail). Chaque discipline a sa conférence ou revue phare et ce qui est un objectif de résultat pour les uns ne l’est pas pour les autres. L’interdisciplinarité doit se construire comme un échange : en tant qu’informaticienne je dois parfois coder, implémenter des solutions assez classiques sur les données de mes collaborateurs mais en retour ces médecins et biologistes passent un temps long et précieux à annoter, interpréter les résultats que j’ai pu obtenir et ils me font avancer.
Depuis le début de ma carrière, j’ai toujours adoré les interactions interdisciplinaires avec les biologistes et les médecins. Grâce à ces échanges, on développe un algorithme nouveau qui répond à leur besoin, cet algorithme n’est pas juste un résultat dans un article, il est utilisé par eux. Parfois plus tard on se rend aussi compte que cet algorithme répond aux besoins d’autres disciplines.
Pendant la crise du covid, le CNRS m’a demandé de monter une équipe – collègues enseignants-chercheurs et ingénieurs – et ensemble nous sommes partis au feu pour aider des médecins à rapidement extraire les traitements prometteurs pour la Covid-19 à partir des données de l’OMS… Ces médecins travaillaient jours et nuits depuis plusieurs semaines… Nous les avons rejoints dans leurs nuits blanches pour les aider à automatiser leurs actions, pour intégrer ces données et proposer un cadre représentant tous les essais de façon uniforme. J’étais très heureuse de pouvoir les aider. Ils m’ont fait découvrir comment étaient gérés les essais cliniques au niveau international. A l’époque, je ne savais pas ce qu’était un essai clinique mais cela ressemblait fort à des données que je connaissais bien et j’avais l’habitude d’interagir avec des non informaticiens; maintenant je peux t’en parler pendant des heures. J’ai fait des rencontres incroyables avec des chercheurs passionnants.
Serge Abiteboul, Inria et ENS, Paris, Charlotte Truchet, Université de Nantes.
Les entretiens autour de l’informatique
22.03.2024 à 06:11
Une « glaise électronique » re-modelable a volonté !
binaire
Continuer la lecture de « Une « glaise électronique » re-modelable a volonté ! »
Texte intégral (2632 mots)
Concevoir les puces de demain grâce aux FPGA*s, une « glaise électronique » re-modelable a volonté, nous explique Bruno Levy. Bruno est Directeur de Recherche Inria au sein du projet ParMA de l’Inria Saclay et du Laboratoires de Mathématiques d’Orsay. Il conduit des recherches en physique numérique et en cosmologie. Il joue également le rôle d’ambassadeur pour Risc-V. Pierre Paradinas.
(*) FPGA : Pour « Field Programmable Gate Array », à savoir, ensemble de portes logiques programmable « sur le terrain » …

« S’il te plait, dessine moi la super-puce du futur pour l’IA de demain ? »
« Ça, c’est la caisse, la super-puce que tu veux est dedans ! » (D’après St Exupéry et Igor Carron)
La micro-electronique : des milliards de connexions sans s’emmêler les fils ! Les circuits intégrés, ou « puces », sont d’incroyables réalisations technologiques. Ils ont été inventés en 1958 par Jack Kilby dans l’objectif de simplifier la fabrication des circuits électroniques. Cette industrie était alors confrontée au problème d’arriver à fabriquer de manière fiable un grand nombre d’éléments. Le plus gros problème était posé par le nombre considérables de fils censés connecter les composants entre eux ! En gravant directement par un procédé photographique les composants et leurs connexions dans un morceau de semi-conducteur de quelques millimètres carrés, son invention révolutionne ce domaine, car elle a permis non-seulement d’automatiser le processus de fabrication, mais également de miniaturiser la taille des circuits et leur consommation énergétique de manière spectaculaire. Grâce à son invention, il propose une dizaine d’années plus tard, en 1972, la première calculatrice de poche. Dans la même période (en 1971), la firme Intel, à présent bien connue, sort une puce révolutionnaire, le Intel 4004, qui contient un ordinateur quasi complet (le tout premier microprocesseur), également dans l’objectif de fabriquer des calculatrices de poches. En quelques décennies, cette technologie progresse plus rapidement que n’importe quelle autre. Les premières puces des années 70 comportaient quelques milliers d’éléments (des transistors), connectés par des fils de quelques micromètres d’épaisseur (dans un millimètre on casait 1000 fils, ce qui était déjà considérable, mais attendez la suite…). Les puces d’aujourd’hui les plus performances comportent des centaines de milliards de transistors, et les fils font quelques nanomètres de large (dans un millimètre, on case maintenant un million de fils).
Comment fabrique-t-on une puce ? Il y a un petit problème : arriver à structurer la matière à l’échelle atomique ne peut pas se faire dans un garage ! Pour donner une idée de la finesse de gravure (quelques nanomètres), on peut garder à l’esprit que la lumière visible a une longueur d’onde entre 300 et 500 nanomètres. Autrement dit, dans l’intervalle minuscule correspondant à une seule longueur d’onde électromagnétique de lumière visible, on sait graver une centaine de fils !!! Alors avec quoi peut-on réaliser ce tour de force ? Toujours avec des ondes électromagnétiques, mais de très très petite longueur d’onde, émises par un laser, à savoir des ultra-violets très énergétiques (qui sont une forme de « lumière » invisible), appelés EUV pour Extreme Ultra Violets. La firme néerlandaise ASML maîtrise cette technologie et équipe les principaux fabricants de puces (appelés des « fondeurs »), dont le Taïwanais TSMC, Samsung et Intel, avec sa machine (à plusieurs centaines de millions d’Euros, grosse comme un autobus, bourrée de technologie) qui permet de graver la matière à l’échelle atomique . La machine, et surtout l’usine autour de celle-ci, coûtent ensemble plusieurs dizaines de milliards d’Euros ! A moins d’être elle-même un fondeur (comme Intel), une entreprise conceptrice de puces va donc en général dépendre de l’une de ces entreprises, qui a déjà réalisé les investissements colossaux, et qui va fabriquer les puces à partir de son design. Cela a été le cas par exemple de Nvidia (qui fabrique à présent la plupart des puces pour l’IA), qui a fait fabriquer ses trois premières générations de puces graphiques dans la fin des années 1990 par le fondeur Franco-Italien ST-Microelectronics (qui gravait alors en 500 nanomètres, puis 350 nanomètres), pour passer ensuite au Taïwanais TSMC, qui avait déjà à l’époque un processus plus performant.

Représentation de l’intérieur d’un FPGA, constitué d’un grand nombre de portes logiques, de cellules de mémoire et d’aiguillages permettant de les connecter. Ici, le circuit correspond à FemtoRV, un petit processeur Risc-V conçu par l’auteur.
Et les petits acteurs ? Comment un petit acteur concepteur de puces peut-il accéder à cette technologie ? Le coût en faisant appel à un fondeur reste important, car pour chaque puce plusieurs étapes de développement sont à réaliser, comme la création des masques, sortes de « négatifs photo » permettant de créer par projection les circuits sur la puce. Afin de réaliser des prototypes, ou encore quand les exigences de performances sont moins importantes, il serait bien d’avoir une sorte de « boite » remplie de portes logiques, de fils et de cellules mémoires (comme sur l’illustration sous le titre), et de pouvoir rebrancher à volonté tous ces éléments au gré de l’imagination du concepteur. C’est exactement ce que permet de réaliser un FPGA. Un tel FPGA se présente sous la forme d’un circuit intégré, avec à l’intérieur tous ces éléments génériques, et un très grand nombre d’ « aiguillages » reconfigurables par logiciel (voir la figure). On peut le considérer comme une « glaise électronique », modelable à façon, permettant de réaliser n’importe quel circuit logique, à l’aide de langages de description spécialisés.
Il existe une grande variété de FPGA, des plus petits, à quelques dizaines d’Euros, comportant quelques milliers d’éléments logiques, jusqu’au plus gros, à plusieurs milliers d’Euros, comportant des millions d’éléments. Ceci rend le « ticket d’entrée » bien moins onéreux. Combinées avec la disponibilité de FPGAs à faible coût, deux autres nouveautés favorisent considérablement l’émergence de petits acteurs dans ce domaine :
- tout d’abord, l’apparition d’outils Open-Source, tels que Yosys et NextPNR, qui remplacent de grosses suites logicielles monolithiques par un ensemble d’outils simples, faciles à utiliser et réactifs. Ceci rend cette technologie accessible non-seulement aux petits acteurs, mais également à toute une communauté de hobbyistes, de manière similaire à ce qui s’est passé pour l’impression 3D.
- d’autre part, le standard ouvert RiscV fournit à tous ces projets une norme libre de droit, facilitant l’émergence d’un écosystème de composants compatibles entre eux (c.f. cet article sur binaire ). Il est assez facile de réaliser un processeur Risc-V à partir d’un FPGA (tutoriel réalisé par l’auteur ici ).
- et enfin, des initiatives comme TinyTapeOut, qui permettent à tout un chacun de s’initier à la fabrication de circuit intégrés, en intégrant les projets de plusieurs personnes sur une seule puce afin de réduire les coûts de production.
Pourquoi est-ce intéressant et qu’est-ce que ça change ? Au-delà d’introduire plus de « bio-diversité » dans un domaine jusqu’à présent dominé par quelques acteurs, certains domaines peuvent grandement bénéficier de la possibilité de créer facilement des circuits électroniques : par exemple, les expériences réalisées à l’aide de l’accélérateur à particules LHC (Large Hadron Collider) du CERN génèrent un très grand volume de données, qui nécessite une électronique spécialisée pour leur traitement. D’autres domaines d’application nécessitent de contrôler très exactement le temps, d’une manière telle que seule un circuit spécialisé peut le faire. Enfin, un grand nombre de gadgets de type « Internet des Objets » possède à l’intérieur un système informatique complet, tournant sous Linux, ce qui représente un ensemble de problèmes en termes de sécurité informatique. Ceci est résumé dans cet article qui décrit un scénario fictif, où des brosses à dents connectés sont utilisées pour organiser une attaque par déni de service. Même si ce scénario était fictif, il reste malheureusement très réaliste ! Grâce aux FPGAs, il sera possible de remplacer tous ces petits ordinateurs génériques de l’Internet des objets par des versions spécialisées, à la fois plus économes en énergie et moins sensibles aux attaques informatiques.
Et demain, une convergence entre le soft et le hard ? Avec les FPGAs, on assiste à une évolution où la frontière entre le soft (le logiciel) et le hard (le matériel) est de plus en plus ténue. Si on imagine qu’elle devienne totalement poreuse, on voit alors des ordinateurs qui reconfigurent automatiquement leurs circuits en fonction du programme à exécuter, afin d’être plus efficace et/ou de consommer moins d’énergie. Intel et AMD explorent déjà cette voie, en intégrant un FPGA dans un microprocesseur, ce qui permet de définir pour ce dernier de nouvelles instructions à volonté. En extrapolant encore plus loin cette vision, on pourra imaginer dans un futur proche une grande variété de schémas de conceptions et de modèles d’exécution, permettant de remplacer la puissance brute de calcul par plus de créativité et d’intelligence, réelle ou artificielle !

Alors, de quoi rêvent les FPGAs … ?
… de moutons électriques, bien évidement !
Bruno Lévy, Inria
15.03.2024 à 08:06
Quand le responsable de la sécurité informatique doit (vraiment) aller en prison
binaire
Texte intégral (2686 mots)
Les cyberattaques nous sont – malheureusement – devenues familières ; pas un jour où une nouvelle annonce d’une fuite de données ou du blocage d’un service numérique ne fasse la une de l’actualité. Si des spécialistes cherchent en permanence à concevoir des solutions visant à diminuer leur nombre et leur portée, il convient ensuite de les mettre en œuvre dans les systèmes numériques pour les contrer. L’histoire que nous racontent Charles Cuveliez et Jean-Charles Quisquater est édifiante : elle nous explique exactement tout ce qu’il ne faut pas faire ! Pascal Guitton
C’est une plainte en bonne et due forme qu’a déposée la Commission américaine de réglementation et de contrôle des marchés financiers (SEC) contre la société SolarWinds et son Chief Information Security Officer dans le cadre de l’attaque qu’elle a subie. Elle avait fait du bruit car elle a permis à des hackers de diffuser, depuis l’intérieur des systèmes de la société, une version modifiée du logiciel de gestion des réseaux que la compagnie propose à ses clients (Orion). Il faut dire que les dégâts furent considérables puisque les entreprises qui avaient installé la version modifiée permettaient aux hackers d’entrer librement dans leur réseau.
L’enquête de la SEC relatée dans le dépôt de plainte montre l’inimaginable en termes de manque de culture de sûreté, de déficience et de négligence, le tout mâtiné de mauvaise foi.
![]()
Absence de cadre de référence de sûreté
SolarWinds a d’abord prétendu et publié qu’il avait implémenté la méthodologie de l’agence chargée du développement de l’économie notamment en développant des normes (NIST, National Institute of Standards and Technology) pour évaluer les pratiques de cybersécurité et pour atténuer les risques organisationnels mais ce n’était pas vrai. Des audits internes ont montré qu’une petite fraction seulement des contrôles de ce cadre de référence était en place (40 %). Les 60% restants n’étaient tout simplement pas implémentés. SolarWinds, dans le cadre de ses évaluations internes, avait identifié trois domaines à la sécurité déficiente : la manière de gérer cette sécurité dans les logiciels tout au long de leur vie commerciale, les mots de passe et les contrôles d’accès aux ressources informatiques.
Un développement sans sécurité
Le logiciel de base qui sert à son produit Orion, faisait partie des développements qui ne suivaient absolument aucun cadre de sécurité. L’enquête a montré en 2018 qu’il y avait eu un début d‘intention pour introduire du développement sûr de logiciel mais qu’il fallait commencer par le début… une formation destinée aux développeurs pour savoir ce qu’est un développement sûr, suivi par des expériences pilotes pour déployer graduellement cette méthodologie, par équipe, sans se presser, sur une base trimestrielle. Entretemps, SolarWinds continuait à prétendre qu’elle pratiquait ses développements en suivant les méthodes de sécurité adéquates.
Mot de passe
La qualité de la politique des mots de passe était elle aussi défaillante : à nouveau, entre ce que SolarWinds prétendait et ce qui était en place, il y avait un fossé. La politique des mots de passe de SolarWinds obligeait à les changer tous les 90 jours, avec une longueur minimum et, comme toujours, imposait des caractères spéciaux, lettres et chiffres. Malheureusement, cette politique n’était pas déployée sur tous les systèmes d’information, applications ou bases de données. La compagnie en était consciente mais les déficiences ont persisté des années durant. Un employé de SolarWinds écrivit même un courriel au nouveau patron de l’informatique que des mots de passe par défaut subsistaient toujours pour certaines applications. Le mot de passe ‘password’ fut même découvert ! Un audit a mis en évidence plusieurs systèmes critiques sur lesquels la politique des mots de passe n’était pas appliquée. Des mots de passe partagés ont été découverts pour accéder à des serveurs SQL. Encore pire : on a trouvé des mots de passe non chiffrés sur un serveur public web, des identifiants sauvés dans des fichiers en clair. C’est via la société Akamai qui possède des serveurs un peu partout dans le monde et qui duplique le contenu d’internet notamment (les CDN, Content Distribution Networks) que SolarWinds distribuait ses mises à jour. Un chercheur fit remarquer à SolarWinds que le mot de passe pour accéder au compte de l’entreprise sur Akamai se trouvait sur Internet. Ce n’est pourtant pas via Akamai que la modification et la diffusion du logiciel eut lieu. Les hackers l’ont fait depuis l’intérieur même des systèmes de SolarWinds.
Gestion des accès
La gestion des accès c’est-à-dire la gestion des identités des utilisateurs, les autorisations d’accès aux systèmes informatique et la définition des rôles et fonctions pour savoir qui peut avoir accès à quoi dans l’entreprise étaient eux aussi déficients. La direction de SolarWinds savait entre 2017 et 2020 qu’on donnait de manière routinière et à grande échelle aux employés des autorisations qui leur permettaient d’avoir accès à plus de systèmes informatiques que nécessaires pour leur travail. Dès 2017, cette pratique était bien connue du directeur IT et du CIO. Pourquoi diable a-t-on donné des accès administrateurs à des employés qui n’avaient que des tâches routinières à faire ? Cela a aussi compté dans l’attaque.
Les VPN furent un autre souci bien connu et non pris en compte. A travers le VPN pour accéder au réseau de SolarWinds, une machine qui n’appartient pas à SolarWinds pouvait contourner le système qui détecte les fuites de données (data loss prevention). L’accès VPN contournait donc cette protection. Comme d’habitude, serait-on tenté de dire à ce stade, c’était su et connu de la direction. Toute personne avec n’importe quelle machine, grâce au VPN de SolarWinds et un simple identifiant (volé), pouvait donc capter des données, de manière massive sans se faire remarquer. En 2018, un ingénieur leva l’alerte en expliquant que le VPN tel qu’il avait été configuré et installé pouvait permettre à un attaquant d’accéder au réseau, d’y charger du code informatique corrompu et de le stocker dans le réseau de SolarWinds. Rien n’y fit, aucune action correctrice ne fut menée. En octobre 2018, SolarWinds, une vraie passoire de sécurité, faisait son entrée en bourse sans rien dévoiler de tous ces manquements. C’est d’ailleurs la base de la plainte de la SEC, le régulateur américain des marchés. Toutes ces informations non divulguées n’ont pas permis aux investisseurs de se faire une bonne idée de la valeur de la société. Solarwinds ne se contenta pas de mentir sur son site web : dans des communiqués de presse, dans des podcasts and des blogs, SolarWinds faisait, la main sur le cœur, des déclarations relatives à ses bonnes pratiques cyber.
Avec toutes ces déficiences dont la direction était au courant, il est clair pour la SEC que la direction de SolarWinds aurait dû anticiper qu’il allait faire l’objet d’une cyberattaque.
Alerté mais silencieux
Encore plus grave : SolarWinds avait été averti de l’attaque par des clients et n’a rien fait pour la gérer. C’est bien via le VPN que les attaquants ont pénétré le réseau de SolarWinds via des mots de passe volés et via des machines qui n’appartenaient pas à SolarWinds (cette simple précaution de n’autoriser que des machines répertoriées par la société aurait évité l’attaque). Les accès via le VPN ont eu lieu entre janvier 2019 et novembre 2020. Les criminels eurent tout le temps de circuler dans le réseau à la recherche de mots de passe, d’accès à d’autres machines pour bien planifier l’attaque. Celle-ci a donc finalement consisté à ajouter des lignes de code malicieuses dans Orion, le programme phare de SolarWinds, utilisé pour gérer les réseaux d’entreprise. Ils n’ont eu aucun problème pour aller et venir entre les espaces de l’entreprise et les espaces de développement du logiciel, autre erreur de base (ségrégation et segmentation). A cause des problèmes relevés ci-dessus avec les accès administrateurs, donnés à tout bout de champ, notamment, les antivirus ont pu être éteints. Les criminels ont ainsi pu obtenir des privilèges supplémentaires, accéder et exfiltrer des lignes de codes sans générer d’alerte. Ils ont aussi pu récupérer 7 millions de courriels du personnel clé de Solarwind.
Jusqu’en février 2020, ils ont testé l’inclusion de lignes de code inoffensives dans le logiciel sans être repérés. Ils ont donc ensuite inséré des lignes de code malicieuses dans trois produits phares de la suite Orion. La suite, on connait : ce sont près de 18 000 clients qui ont reçu ces versions contaminées. Il y avait dans ces clients des agences gouvernementales américaines.
On s’est bien retranché, chez SolarWinds, derrière une soi-disant attaque d’un État pour justifier la gravité de ce qui s’est passé et sous-entendre qu’il n’y avait rien à faire pour la contrer mais le niveau de négligence, analyse la SEC, est si immense qu’il ne fallait pas être un État pour mettre en œuvre Sunburst, le surnom donné à l’attaque. Il y a aussi eu des fournisseurs de service (MSP) attaqués : ceux-ci utilisent les produits de SolarWinds pour proposer des services de gestion de leur réseau aux clients, ce qui donc démultipliait les effets.
Alors que des clients ont averti que non seulement le produit Orion était attaqué mais que les systèmes même de SolarWinds étaient affectés, la société a tu ces alertes. Elle fut aussi incapable de trouver la cause de ces attaques et d’y remédier. SolarWinds a même osé prétendre que les hackers se trouvaient déjà dans le réseau des clients (rien à avoir avec SolarWinds) ou que l’attaque était contre le produit Orion seul (sur laquelle une vulnérabilité aurait été découverte par exemple) alors que cette attaque avait eu lieu parce que les hackers avaient réussi à infester le réseau de SolarWinds
Pour la SEC, le manque de sécurité mise en place justifie déjà à lui seul la plainte et l’attaque elle-même donne des circonstances aggravantes.
L’audit interne a montré que de nombreuses vulnérabilités étaient restées non traitées depuis des années. De toute façon le personnel était largement insuffisant, a pu constater la SEC dans les documents internes, pour pouvoir traiter toutes ces vulnérabilités en un temps raisonnable. On parlait d’années. Lors de l’attaque, SolarWinds a menti sur ce qui se passait. Au lieu de dire qu’une attaque avait lieu, SolarWinds avait écrit que du code dans le produit Orion avait été modifié et pourrait éventuellement permettre à un attaquant de compromettre les serveurs sur lesquels le produit Orion avait été installé et tournait !
Que retenir de tout ceci ? Il ne faut pas se contenter des déclarations des fournisseurs sur leurs pratiques de sécurité. En voilà un qui a menti tout en sachant que son produit était une passoire. Ce qui frappe est la quantité d’ingénieurs et d’employés qui ont voulu être lanceurs d’alerte au sein de SolarWinds. Ils ne furent pas écoutés. Faut-il légiférer et prévoir une procédure de lanceur d’alerte sur ces matières-là aussi vers des autorités ? On se demande aussi si dans tous les clients d’Orion, il n’y en a eu aucun pour faire une due diligence avec des interviews sur site. Il est quasiment certain que des langues se seraient déliées.
Jean-Jacques Quisquater (Ecole Polytechnique de Louvain, Université de Louvain et MIT) & Charles Cuvelliez (Ecole Polytechnique de Bruxelles, Université de Bruxelles)
Pour en savoir plus : Christopher BRUCKMANN, (SDNY Bar No. CB-7317), SECURITIES AND EXCHANGE COMMISSION, Plaintiff, Civil Action No. 23-cv-9518, against SOLARWINDS CORP. and TIMOTHY G. BROWN
11.03.2024 à 11:22
Femmes et numérique inclusif par la pratique
binaire
Continuer la lecture de « Femmes et numérique inclusif par la pratique »
Texte intégral (3258 mots)
Concrètement, quelles actions pour plus d’égalité entre les sexes dans le domaine du numérique ont démontré leur efficacité avec, parfois, des retombées étonnamment rapides ?
Comment penser notre société de demain, un monde où le numérique nourrit tous les secteurs – la santé, les transports, l’éducation, la communication, l’art, pour n’en citer que certains –, un thème mis en avant par l’ONU : « Pour un monde digital inclusif : innovation et technologies pour l’égalité des sexes ».
Pour répondre à ces questions, nous poursuivons notre lecture croisée d’ouvrages et de points de vue de la sociologue et politologue Véra Nikolski [Nikolski, 2023], de l’anthropologue Emmanuelle Joseph-Dailly [Joseph-Dailly, 2021], de l’informaticienne Anne-Marie Kermarrec [Kermarrec, 2021], de la philosophe Michèle Le Dœuff [Le Dœuff, 2020], et de l’informaticienne et docteure en sciences de l’éducation Isabelle Collet [Collet, 2019].

Féminisme et numérique
Bien avant le numérique et l’informatique née au milieu du XXe siècle, l’égalité entre les sexes a été une question dont plusieurs mouvements féministes se sont emparés dès la fin du XIXe siècle, avec des textes majeurs et des luttes de fond à travers le monde : Dona Haraway, pionnière du cyberféminisme aux États-Unis, Gisèle Halimi en France, Nawal El Saadaoui en Égypte, Prem Chowdhry en Inde, Wassyla Tamzali en Algérie, et bien d’autres.
Dans son ouvrage Féminicène, Véra Nikolski questionne la corrélation directe entre les progrès de l’émancipation féminine et les efforts pour y parvenir :
« Il y a bien, d’un côté, l’histoire des féminismes, retraçant les actions et les tentatives d’action des individus, puis des mouvements ayant pour but l’amélioration de la condition des femmes et, de l’autre, l’histoire des avancées législatives et pratiques dont les femmes bénéficient, ces deux histoires suivant chacune son rythme, sans qu’on puisse établir entre elles un quelconque rapport de cause à effet. » [Nikolski, 2023]
Véra Nikolski fait le constat que des avancées législatives pour les droits des femmes ont parfois été obtenues sans mobilisation, au sens de soulèvements et luttes féministes. Par exemple, si le droit de vote des femmes proposé en 1919 aux États-Unis fait suite aux manifestations et luttes pour le suffrage féminin, dans de nombreux autres pays y compris les premiers à avoir accordé le droit de vote aux femmes (la Nouvelle-Zélande en 1893, l’Australie en 1901, puis les pays scandinaves à partir de 1906), il n’y a pas eu de soulèvement spectaculaire. Un constat similaire est fait concernant l’ouverture des lycées publics aux jeunes filles en 1880 en France, l’exercice des professions médicales ou du métier d’avocate entre 1881 et 1899. Quel a donc été le facteur majeur de ces avancées ? Le point de bascule, selon Véra Nikolski, est la révolution industrielle et la période de l’anthropocène. Le progrès économique et technologique décolle à partir de cette révolution, et apporte progrès technologique et progrès médical, les deux, et en particulier, ce dernier étant particulièrement favorables à la condition des femmes. À cela s’ajoute le capitalisme qui ne rend pas uniquement le travail des femmes possible, mais indispensable : « il faut faire des femmes des travailleurs comme les autres ».
Après la révolution industrielle, suit la révolution numérique que nous vivons actuellement, et qui voit la transformation d’un monde où les technologies numériques se généralisent à de nombreux secteurs et les affectent profondément, tels que la santé, les transports, l’éducation, la communication, ou l’art, pour n’en citer que certains [Harari, 2015]. Le secteur du numérique est devenu source de richesse, et sa part dans l’économie de plus en plus importante. Selon l’OCDE, en 2019, la part du numérique dans le PIB était de 6% en France, 8% aux États-Unis, 9,2% en Chine, 10% au Royaume-Uni, et 10,1% en Corée du Sud. Plus récemment, une étude en 2020 montre que les STIM représentent 39% du PIB des États-Unis. Cette étude est plus inclusive et considère non seulement les ingénieurs et docteurs du domaine, mais également des spécialistes de domaines d’application des STIM qui ne détiennent pas forcément un diplôme de bachelor mais d’autres formations plus courtes et spécifiques pour la montée en compétence en STIM. Les chiffres globaux inclusifs montrent alors que les employés en STIM représentent deux travailleurs États-Uniens sur trois, avec un impact global de 69% du PIB des États-Unis.
Ainsi, le besoin de main d’œuvre croissant pousse les entreprises à rechercher des talents dans les rangs féminins, et à mettre en place des actions pour plus de diversité et de parité. Ce besoin croissant de main d’œuvre dans le numérique fait également prendre conscience aux gouvernements de la nécessité d’une politique de formation en STIM plus inclusive pour les femmes. Aujourd’hui, tous types d’acteurs arrivent à la même conclusion, à savoir la nécessité de mettre en place une action volontariste pour une égalité entre les sexes dans les STIM, en termes de nombre de femmes formées, d’égalité des salaires à postes équivalents, d’évolution de carrière et d’accès aux postes de direction.
Elles et ils l’ont fait, et ça a marché
Quelles actions pour plus d’inclusion de femmes dans le domaine des STIM ont démontré leur efficacité ? Un exemple concret est celui de l’école d’ingénieur.es l’INSA Lyon qui a réussi, à travers plusieurs actions proactives, à avoir 45% de jeunes femmes en entrée de l’école. L’INSA Lyon compte un institut – l’Institut Gaston Berger (IGB) – qui a pour objectif, entre autres, de promouvoir l’égalité de genre. Pour ce faire, l’IGB a mis en place des actions auprès des plus jeunes, en faisant intervenir des étudiantes et des étudiants de l’INSA Lyon auprès d’élèves de collèges et de lycées. L’INSA Lyon a par ailleurs mis en place, et ce depuis plusieurs années, un processus de sélection après le baccalauréat qui prend en compte les résultats scolaires à la fois en classe de terminale et en classe de première au lycée, ce qui a eu pour effet d’augmenter les effectifs féminins admis à l’INSA Lyon ; les jeunes filles au lycée feraient preuve de plus de régularité dans leurs études et résultats scolaires.
Cela dit, malgré ce contexte favorable, après les deux premières années de formation initiale généraliste à l’INSA Lyon, lorsque les étudiant.es choisissaient une spécialité d’études pour intégrer l’un ou l’autre des départements de formation spécialisée de l’INSA Lyon, les étudiant.es optant pour le département Informatique comptaient seulement entre 10% et 15% de femmes. Le département Informatique a alors mis en place une commission Femmes & Informatique dès 2018, avec pour objectif là encore de mener des actions proactives pour augmenter la participation féminine en informatique. En effet, le vivier de femmes était juste là, avec 45% de femmes à l’entrée de l’INSA Lyon. Des rencontres des étudiant.es en formation initiale à l’INSA Lyon (avant leur choix de spécialité) avec des étudiantes et des étudiants du département Informatique, ainsi que des enseignantes et des enseignants de ce département, ont été organisées. Ces rencontres ont été l’occasion de présenter la formation en informatique et les métiers dans le secteur du numérique, de briser les idées reçues et les stéréotypes de genre, et de permettre aux étudiantes et étudiants en informatique de faire part de leur parcours et choix d’études, et de partager leur expérience. Par ailleurs, l’Institut Gaston Berger conjointement avec le département Informatique ont mis en place pour les élèves de première année à l’INSA Lyon des aménagements pédagogiques et des séances de tutorat pour l’algorithmique et la programmation. Deux ans plus tard, les étudiant.es de l’INSA Lyon rejoignant le département d’Informatique comptent 30% de femmes. Preuve, s’il en faut, que des actions proactives ciblées peuvent avoir des retombées rapides. Des actions spécifiques pour l’augmentation des effectifs féminins ont également été menées avec succès dans d’autres universités, à Carnegie Mellon University aux États-Unis, et à la Norwegian University of Science and Technology en Norvège.
Hormis les actions proactives de ce type, Isabelle Collet mentionne dans son ouvrage Les oubliées du numérique un certain nombre de bonnes pratiques pour l’inclusion des femmes, dont la lutte contre les stéréotypes avec, toutefois, un regard circonstancié [Collet, 2019] :
« La lutte contre les stéréotypes est un travail indispensable, mais dont il faut connaître les limites. En particulier, il est illusoire de penser qu’il suffit de déconstruire les stéréotypes (c’est-à-dire de comprendre comment ils ont été fabriqués) pour qu’ils cessent d’être opérants.
[..]
Un discours exclusivement centré sur les stéréotypes a tendance à rendre ceux-ci déconnectés du système de genre qui les produit. [..] L’entrée unique « lutte contre les stéréotypes » fait peser la responsabilité de la discrimination sur les individus et évite d’attaquer la source du problème (le système de genre) en ne s’occupant que de ses sous-produits (les stéréotypes), présentés comme premiers, obsolètes, désincarnés. »
Sur la question des stéréotypes, dans son ouvrage Le sexe du savoir, Michèle Le Dœuff rappelle que durant la Grèce antique, l’intuition était une qualité intellectuelle très valorisée, la plus élevée [Le Dœuff, 2020]. Elle était alors jugée comme une qualité masculine, dont les hommes étaient principalement dotés. Aujourd’hui, la qualité intellectuelle jugée la plus élevée est le raisonnement logique – une qualité là encore perçue comme masculine –, alors que les femmes sont à présent jugées plus intuitives. Et Isabelle Collet de conclure à ce propos :
« Si l’on se met à croire que les disciplines scientifiques, telles que les mathématiques et l’informatique, nécessitent avant tout de l’intuition, et de manière moindre, de la logique et du raisonnement, cette compétence jugée aujourd’hui féminine redeviendra l’apanage des hommes. »
Un autre type d’action d’inclusion féminine est l’action affirmative[2], avec l’application de quotas et de places réservées. Dans son ouvrage Numérique, compter avec les femmes, Anne-Marie Kermarrec dresse le pour et le contre d’une telle mesure [Kermarrec, 2021]. Ce type d’action, appliqué dans différentes universités dans le monde, mais également dans des conseils d’administration et des instances politiques, a le mérite de démontrer des résultats rapides et efficaces. Ainsi, en France, de nouvelles lois ont été instaurées pour garantir la parité politique. En 2000, une loi est promulguée pour une égalité obligatoire des candidatures femmes et hommes pour les scrutins de liste. En 2013, une autre loi est mise en place obligeant les scrutins départementaux et les scrutins municipaux pour les communes de plus de 1000 habitants à présenter un binôme constitué obligatoirement d’une femme et d’un homme. Une nouvelle législation s’applique également aux entreprises. En 2011, une loi est adoptée pour imposer 40% de femmes dans les conseils d’administration et de surveillance des grandes entreprises cotées. En 2021, une autre loi est promulguée pour imposer des quotas de 40 % de femmes dans les postes de direction des grandes entreprises à horizon 2030, sous peine de pénalités financières pour les entreprises. Et en 2023, une loi visant à renforcer l’accès des femmes aux responsabilités dans la fonction publique porte à 50% le quota obligatoire de primo-nominations féminines aux emplois supérieurs et de direction. En résumé, alors que ces pratiques se généralisent au monde politique et aux entreprises, verra-t-on des pratiques similaires pour la formation des jeunes femmes aux sciences et aux STIM, pour le recrutement des enseignant.es de ces domaines, pour une inclusion effective des femmes dans l’innovation et l’économie de ces secteurs ?
La promulgation de lois sur des quotas a montré des effets rapides et a aidé à briser le plafond de verre. Cela dit, le principe de quota peut soulever des interrogations et causer une appréhension de la part de certaines personnes qui bénéficieraient de ces mesures, et qui ne pourraient s’empêcher de se demander si elles ont été choisies pour leurs compétences ou uniquement pour leur genre. À propos de ce dilemme, Isabelle Collet, invitée aux assises de féminisation des métiers du numérique en 2023, répond ceci :
« Soyons clair.es. Je préfère être recrutée parce que je suis une femme, plutôt que ne pas être recrutée parce que je suis une femme. »
Même si l’on peut reprocher à la mesure d’être imparfaite – à vrai dire, l’imperfection vient de la cause et non de la mesure –, le choix à faire aujourd’hui est clair.
Et (en cette veille de) demain ?
Nous vivons actuellement des transformations de notre monde, certes, des transformations et des évolutions technologiques qui ont amélioré notre qualité de vie, mais également des transformations dues à l’impact de l’activité humaine sur la planète, la raréfaction des ressources naturelles, et l’altération de l’environnement et de sa stabilité. Dans ce contexte, nous devons être conscients que l’émancipation féminine reste fragile. En effet, par temps de crise, les acquis d’égalité entre les sexes peuvent malheureusement être réversibles. Comment sauvegarder et développer les droits des femmes ? Véra Nikolski conclut dans Féminicène par l’importance de « comprendre les lois naturelles et historiques, et à travailler au maintien des conditions matérielles de l’émancipation [..] Ce travail passe, entre autres, par la sauvegarde de l’infrastructure technologique qui, si étonnant que cela puisse paraître, a favorisé l’émancipation des femmes ».
Alors, mesdames, investissons massivement tous les secteurs d’un numérique qui s’inscrit dans les limites planétaires. Et mesdames et messieurs, travaillons à permettre l’inclusion massive des jeunes filles dans les formations scientifiques, et ce dès le plus jeune âge.
Sara Bouchenak, Professeure d’informatique à l’INSA Lyon, Directrice de la Fédération Informatique de Lyon.
[2] Ou sa variante anglophone positive discrimination.
Pour aller plus loin
- Isabelle Collet. Les oubliées du numérique. Le Passeur, 2019.
- Catherine Dufour. Ada ou la beauté des nombres. Fayard, 2019.
- David Alan Grier. When Computers Were Human. Princeton University Press, 2007.
- Yuval Noah Harari. Sapiens : Une brève histoire de l’humanité. Albin Michel, 2015.
- Emmanuelle Joseph-Dailly. La stratégie du poulpe. Eyrolles, 2021.
- Emmanuelle Joseph-Dailly, Bernard Anselm. Les talents cachés de votre cerveau au travail. Eyrolles, 2019.
- Anne-Marie Kermarrec. Numérique, compter avec les femmes. Odile Jacob, 2021.
- Michèle Le Dœuff. Le Sexe du savoir. Flammarion, 2000.
- Véra Nikolski. Féminicène. Fayard, 2023.
08.03.2024 à 08:56
Non, les femmes n’ont pas déserté le numérique
binaire
Continuer la lecture de « Non, les femmes n’ont pas déserté le numérique »
Texte intégral (3008 mots)

Où en est-on en 2024 de la place des femmes et de l’égalité entre les sexes dans le domaine du numérique ?
C’est une question aux histoires et aux géographies variables. La situation a certes évolué au cours du temps, au cours de l’histoire de la science informatique et avec l’avènement du numérique, mais pas forcément dans le bon sens : pourquoi ?
L’égalité entre les sexes dans le secteur du numérique est bien présente dans certains pays du monde, mais pas dans les pays les plus égalitaires entre les sexes et auxquels on penserait de prime abord : pourquoi ?
Quelles actions pour plus d’égalité entre les sexes dans le domaine du numérique ont démontré leur efficacité avec, parfois, des retombées étonnamment rapides ?
Comment penser notre société de demain, un monde où le numérique nourrit tous les secteurs – la santé, les transports, l’éducation, la communication, l’art, pour n’en citer que certains –, un thème mis en avant par l’ONU : « Pour un monde digital inclusif : innovation et technologies pour l’égalité des sexes ».
Pour répondre à ces questions, nous proposons une lecture croisée d’ouvrages et de points de vue de la sociologue et politologue Véra Nikolski [Nikolski, 2023], de l’anthropologue Emmanuelle Joseph-Dailly [Joseph-Dailly, 2021], de l’informaticienne Anne-Marie Kermarrec [Kermarrec, 2021], de la philosophe Michèle Le Dœuff [Le Dœuff, 2020], et de l’informaticienne et docteure en sciences de l’éducation Isabelle Collet [Collet, 2019].

Aujourd’hui, le constat est le même dans plusieurs pays, la proportion de femmes dans le numérique est faible. En France, les écoles d’ingénieur.es ne comptent en 2020 qu’entre 17% et 20% de femmes parmi leurs étudiant.es en numérique de niveau Licence ou Master. Des proportions similaires (entre 21% et 24%) sont observées dans les pays de l’Union Européenne. Comment se fait-il que la proportion de femmes dans le numérique soit aujourd’hui si faible, alors que les premiers programmeurs des ordinateurs étaient des programmeuses ? Est-ce que les femmes sont moins nombreuses à s’orienter dans le numérique ?
La réponse est non, bien au contraire. Par exemple, aux États-Unis (où les statistiques par genre sont collectées depuis plusieurs décennies), les femmes n’ont pas cessé d’être de plus en plus nombreuses à effectuer des études supérieures en général, et à s’orienter en informatique et dans le numérique en particulier. Ainsi, le nombre d’étudiantes femmes en informatique a été multiplié par x1495 entre 1964-1965 et 1984-1985, et ce nombre a plus que doublé entre 1984-1985 et 2020-2021. Alors, pourquoi cette faible proportion aujourd’hui, alors que les femmes représentaient jusqu’à 36% des personnes formées en informatique aux États-Unis jusque dans les années 1980 ?
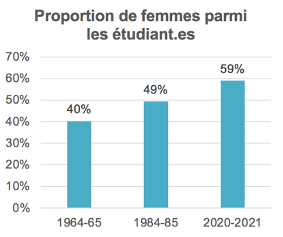
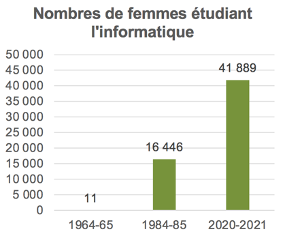
Statistiques aux États-Unis
Le paradoxe de l’égalité des sexes est-il vraiment un paradoxe ?
Il existe aujourd’hui des pays présentant plus d’égalité entre les femmes et les hommes dans le domaine du numérique. C’est le cas par exemple de l’Indonésie, de la Turquie, des Émirats arabes unis, et des pays du Maghreb. Une étude a été menée sur plusieurs pays dans le monde, et arrive à la conclusion suivante : dans les pays moins égalitaires entre les sexes, la proportion de femmes parmi les personnes diplômées en STIM (sciences, technologie, ingénierie et mathématiques) est plus importante, en comparaison avec les pays les plus égalitaires entre les sexes. Ceci soulève deux questions. D’une part, pourquoi les pays les plus égalitaires entre les sexes ont-ils une proportion faible de femmes dans les STIM ? D’autre part, comment se fait-il que des pays les moins égalitaires entre les sexes arrivent à avoir une proportion élevée de femmes dans les STIM ?
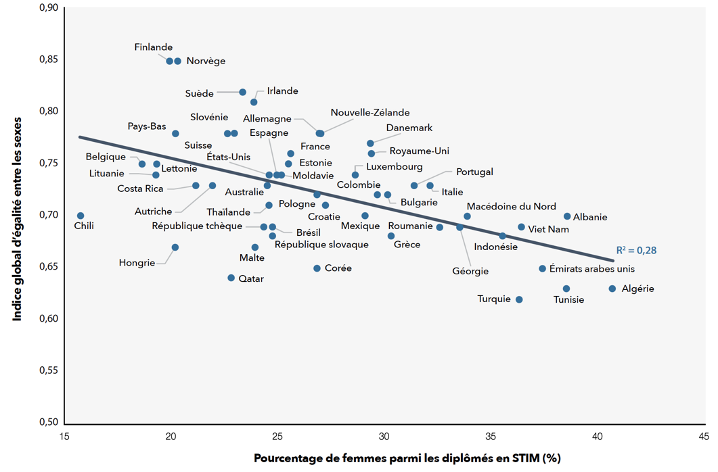
Pourquoi dans les pays les plus égalitaires entre les sexes, la proportion des femmes dans les STIM et le numérique est-elle faible ?
Si l’on remonte dans le temps, il y a environ 150 ans, le groupe des « Harvard Computers » venait de voir le jour. Il était constitué de femmes engagées par l’observatoire de l’université de Harvard comme calculatrices, pour effectuer des traitements mathématiques sur d’importantes quantités de données astronomiques. Un travail répétitif, méticuleux et fastidieux, auquel les femmes étaient supposées naturellement prédisposées [Collet, 2019]. Des scientifiques ont alors utilisé une nouvelle unité de mesure du temps de calcul, appelée girl-year [Grier, 2007]. Comme d’autres avaient défini auparavant le cheval-vapeur, unité de mesure de puissance. Deux unités pour deux usages différents, mais faisant chacune référence en définitive, avec plus ou moins de subtilité, à une bête de somme.
Dans les années 1940, lorsque les ordinateurs sont finalement devenus une réalité, les femmes ont été pionnières dans l’écriture de programmes pour les ordinateurs. Un travail là encore dévolu uniquement aux femmes, qui sont passées de calculatrices à programmeuses ; le travail de programmation était alors considéré comme déqualifié et sans importance. Dans les années 1950 et 1960, à mesure que les ordinateurs sont devenus indispensables dans de nombreux secteurs du gouvernement et de l’industrie, le nombre d’emplois dans la programmation a explosé. Ces emplois sont encore en grande partie féminins, et plébiscités par le magazine féminin Cosmopolitan dans son édition d’avril 1967. Ceci a duré jusqu’au milieu des années 1980, où les femmes représentaient 36% des personnes formées en informatique.

L’analyse de l’évolution au cours du temps montre qu’il y a eu deux périodes dans l’histoire récente de l’informatique où le nombre de femmes s’orientant vers l’informatique a baissé : en 1984-1985, puis en 2002-2003, et ce pendant environ sept ans. Deux dates qui peuvent être corrélées à deux crises : la récession et la crise du chômage au début des années 1980, et le krach boursier dû à l’éclatement de la bulle internet au début des années 2000. Ces crises ont certes impacté femmes et hommes, mais les femmes ont été plus lourdement touchées : moins 43%-44% de femmes formées dans le domaine vs. moins 23%-24% d’hommes.
Simone de Beauvoir l’a bien dit : « Il suffira d’une crise politique, économique ou religieuse pour que les droits des femmes soient remis en question. »
À cela s’ajoute la transformation survenue à la fin des années 1970 et au début des années 1980, avec l’entrée des ordinateurs personnels dans les foyers familiaux. Cette nouvelle technologie a subi les stéréotypes en vigueur : les garçons étaient encouragés à jouer avec les objets électroniques, tandis que les filles étaient orientées vers les poupées et les dînettes. Depuis lors, l’informatique a pâti de ce stéréotype faisant d’elle un domaine masculin, elle qui a d’abord été féminine [Dufour, 2019].
L’anthropologue Emmanuelle Joseph-Dailly aborde la question des biais cognitifs. Dans son ouvrage Les talents cachés de votre cerveau au travail, elle rappelle le rôle majeur que tiennent les émotions dans nos décisions et nos actions, leur aide précieuse, mais également leur effet néfaste lorsque nos biais cognitifs prennent le dessus [Joseph-Dailly, 2019]. Aujourd’hui, les biais cognitifs sont bien à l’œuvre dans les pays plus égalitaires entre les sexes. Ainsi, lorsqu’il y a eu reprise économique suite aux crises dans les années 1980 et 2000, les hommes ont bénéficié de la reprise bien plus avantageusement que les femmes, avec une multiplication du nombre de personnes formées en informatique par x4 pour les hommes vs. x2,5 pour les femmes, entre 1984 et 2020.
Pourquoi les pays les moins égalitaires entre les sexes ont-ils une proportion élevée de femmes dans les STIM et le numérique ?
Alors que les baby-boomers et la génération X dans les pays occidentaux ont initialement vu l’arrivée de l’ordinateur personnel à la fin des années 1970 et au début des années 1980 comme un objet électronique rare, et plutôt dédié aux garçons, la population dans les pays en voie de développement n’avait à ce moment-là, quant à elle, pas accès à cet objet, du fait d’une politique économique moins ouverte et d’un pouvoir d’achat plus faible. Ces derniers pays ont ainsi été épargnés des stéréotypes et biais de genre liés aux ordinateurs et à l’informatique. Les générations Y et Z dans ces pays ont ensuite coïncidé avec une ouverture économique des pays, et un accès aux ordinateurs et aux smartphones dont a bénéficié la population plus largement sans inégalité de genre.
Aujourd’hui, la proportion de femmes diplômées en STIM dans ces pays est bien au-delà de celle des pays égalitaires entre les sexes. Mais il est à noter que contrairement à ces derniers où le numérique joue un rôle important dans l’économie du pays (10% du PIB du Royaume-Uni, 8% du PIB des États-Unis en 2019 selon l’OCDE), dans les pays les moins égalitaires entre les sexes, les principales sources de richesse économique proviennent d’autres secteurs que le numérique, comme par exemple les hydrocarbures (Émirats arabes unis, Algérie), l’agriculture (Turquie, Indonésie), ou les industries de main d’œuvre (Tunisie). Lorsque les STIM prendront une part plus importante dans l’économie de ces pays, il faudra alors veiller à maintenir une proportion féminine suffisante, et ne pas la voir réduite drastiquement suite à une participation massive des hommes au détriment des femmes comme cela a pu être le cas dans d’autres pays.
Éloge de la dissemblance
Aujourd’hui, bon nombre d’entreprises et de grands groupes du numérique cherchent à augmenter leurs effectifs féminins. C’est un moyen d’augmenter le vivier de candidat.es à recruter, étant donné les estimations de nouveaux postes qui seront créés dans le domaine dans les années à venir, et la pénurie de talents. Mais il se trouve également que la mixité et la diversité sont reconnues comme sources d’innovation et de créativité, permettant, d’une part, le développement de l’entreprise, et d’autre part, une meilleure stimulation et inclusion des salariés.
À ce propos, dans son ouvrage La stratégie du poulpe, Emmanuelle Joseph-Dailly pose un regard riche et lucide sur la dissemblance :
« L’entreprise projette souvent intellectuellement la diversité comme une opportunité, tout en refusant le risque de s’y aventurer en pratique. [..] Si l’hétérogénéité est promesse d’innovation et de performance, elle introduit une forme de non-alignement, de possibilité de divergence qui peut au départ ralentir le système.
[..]
Mais dans l’environnement changeant qui est le nôtre, l’agilité ne peut passer que par une diversité d’expériences et de perceptions du monde, de la réalité, de la vérité, créatrices de valeur. Les réponses au renouvellement et à la réinvention viendront avec le « dissensus », qui sera une occasion d’expérimentation pour tester d’autres réponses aux besoins émergents. Plutôt que de systématiquement chercher le consensus, nous devrions chercher le débat, aussi vif soit-il, en prenant la précaution de toujours préserver la relation. »
Sara Bouchenak, Professeure d’informatique à l’INSA Lyon, Directrice de la Fédération Informatique de Lyon.
Pour aller plus loin
- Isabelle Collet. Les oubliées du numérique. Le Passeur, 2019.
- Catherine Dufour. Ada ou la beauté des nombres. Fayard, 2019.
- David Alan Grier. When Computers Were Human. Princeton University Press, 2007.
- Yuval Noah Harari. Sapiens : Une brève histoire de l’humanité. Albin Michel, 2015.
- Emmanuelle Joseph-Dailly. La stratégie du poulpe. Eyrolles, 2021.
- Emmanuelle Joseph-Dailly, Bernard Anselm. Les talents cachés de votre cerveau au travail. Eyrolles, 2019.
- Anne-Marie Kermarrec. Numérique, compter avec les femmes. Odile Jacob, 2021.
- Michèle Le Dœuff. Le Sexe du savoir. Flammarion, 2000.
- Véra Nikolski. Féminicène. Fayard, 2023.
[1] Illustration schématique, non basée sur un fondement formel.
06.03.2024 à 06:51
ASDN #52 – Vive les communs numériques !
binaire
Continuer la lecture de « ASDN #52 – Vive les communs numériques ! »
Texte intégral (1052 mots)
ASDN, Aux sources du numérique
Mercredi 13 mars, à 8h30
Pour la 52ème édition d’ASDN, nous recevrons Serge Abiteboul et François Bancilhon pour échanger autour de leur livre Vive les communs numériques ! Logiciels libres, wikipedia, le web, la science ouverte, etc (Odile Jacob 2024).
- Serge Abiteboul est un informaticien, membre du laboratoire d’informatique de l’ENS et directeur de recherche Inria.
- François Bancilhon a été chercheur à Inria et à l’université Paris XI, créateur et dirigeant de plusieurs entreprises dans le domaine du logiciel libre et du big data.
 Venez en parler avec les auteurs, le Conseil national du numérique et Renaissance numérique !
Venez en parler avec les auteurs, le Conseil national du numérique et Renaissance numérique !
Intervenants
 |
Serge Abiteboul, Informaticien et directeur de recherche, Inria et ENS |
 |
François Bancilhon, Dirigeant d’entreprises et ancien chercheur |
Animation
 |
Margot Godefroi, Rapporteure, Conseil national du numérique |
 |
Nicolas Vanbremeersch, Président, Renaissance Numérique |
21.02.2024 à 18:24
Vision croisée de l’IA Explicable entre philosophie et informatique
binaire
Continuer la lecture de « Vision croisée de l’IA Explicable entre philosophie et informatique »
Texte intégral (5518 mots)
Philosophie de l’IA
La philosophie s’est très tôt intéressée à l’IA comme discipline et comme projet théorique.
D’abord parce qu’une partie de l’IA et de la philosophie de l’esprit posent des questions proches, avec des outils différents. Par exemple, John Haugeland, feu professeur émérite de philosophie à l’université de Chicago, a discuté en 1980 dans son livre “Artificial Intelligence, the Very Idea” (image ci dessous) de l’idée que la pensée humaine et le traitement formel de l’’information dans une machine sont « radicalement les mêmes ». Le contexte de l’époque opposait alors les humanistes qui soulignaient que “Les machines qui pensent – c’est tout à fait absurde » et les techno-visionnaires qui soutenaient que “L’intelligence artificielle est là et sur le point de surpasser la nôtre ».
43 ans après, force est de constater que ces questions, posées probablement différemment, sont toujours d’actualité.

L’une des questions centrales mais souvent évitées est celle de la nature de l’intelligence : qu’est-ce que l’intelligence ? L’intelligence humaine peut-elle être reproduite, voire dépassée, par des outils computationnels ? La conscience (ou au moins la connaissance réflexive) d’un agent intelligent humain peut-elle être simulée, reproduite, voire réalisée par des machines ?
Hilary Putnam, philosophe américain co-fondateur du computationnalisme* et figure centrale de la philosophie contemporaine américaine, a tenté d’apporter des éléments de réponses à ces questions dans son article “Minds and Machines” (Les esprits et les machines) de 1960. Selon lui, les différentes questions et énigmes qui constituent le problème traditionnel du corps et de l’esprit peuvent entièrement être approchées par leur nature linguistique et logique. Cette approche l’a ainsi conduit à conclure que la cognition humaine n’est pas fondamentalement de nature différente d’un traitement formel de symboles par un ordinateur.

|
Moment Glossaire: *Un système computationnel est un modèle qui fait des calculs à partir d’informations données en entrée, et qui donne en sortie un résultat numérique. Source: Collins, A., & Khamassi, M. (2021). Initiation à la modélisation computationnelle
* Le computationnalisme est une théorie fonctionnaliste en philosophie de l’esprit qui conçoit l’esprit comme un système de traitement de l’information et compare la pensée à un calcul (en anglais, computation) et, plus précisément, à l’application d’un système de règles. Cette théorie est différente du cognitivisme. Source: https://fr.wikipedia.org/wiki/Computationnalisme * Le cognitivisme est le courant de recherche scientifique endossant l’hypothèse selon laquelle la pensée est analogue à un processus de traitement de l’information, cadre théorique qui s’est opposé, dans les années 1950, au béhaviorisme. La notion de cognition y est centrale. Elle est définie en lien avec l’intelligence artificielle comme une manipulation de symboles ou de représentations symboliques effectuée selon un ensemble de règles. Elle peut être réalisée par n’importe quel dispositif capable d’opérer ces manipulations. Source: https://fr.wikipedia.org/wiki/Cognitivisme |
Plus récemment, la philosophie de l’IA s’est davantage tournée vers des questions techniques relatives aux différentes architectures et méthodes computationnelles et leurs enjeux épistémologiques, éthiques et politiques du fait de la pénétration et du développement de l’IA dans la pratique scientifique et dans la société.
Daniel Andler dans son livre Intelligence artificielle, intelligence humaine : la double énigme en 2023 (image ci dessous), a introduit l’idée qu’il existait un écart entre la représentation de la philosophie de l’IA chez les non spécialistes et l’actualité de la recherche en philosophie de l’IA. Cela est d’autant plus vrai pour lui lorsqu’il s’agit des sujets éthiques et des problèmes fondationnels sur la possibilité d’une Intelligence Générale Artificielle (IGA) ou d’une IA forte, sujets très présents dans la philosophie du transhumanisme*.

Une bonne partie de la philosophie de l’IA concerne des enjeux éthiques et politiques de l’IA tels que par exemple les biais, l’équité, la confiance, la transparence, mais reste toujours liée à des enjeux épistémologiques* selon les outils techniques mobilisés en IA, à savoir apprentissage machine supervisé ou non, Réseaux de neurones profonds convolutifs ou encore systèmes symboliques classiques.
|
Moment Glossaire: * La philosophie du transhumanisme ou transhumanisme est une doctrine philosophique prétendant qu’il est possible d’améliorer l’humanité par la science et la technologie en libérant l’humanité de ses limites biologiques notamment en surmontant l’évolution naturelle. Le changement apporté à l’humain serait positif, car cela pourrait signifier la libération des contraintes de la nature, comme la maladie ou la mort. L’idée centrale est celle d’un dépassement de l’humain (et non de son élimination) par l’intermédiaire des techniques qui évoluent de manière très rapide. Source: Le transhumanisme selon https://philosciences.com/ Pour en savoir plus: https://encyclo-philo.fr/transhumanisme-a * L’épistémologie désigne de manière générale l’étude de la connaissance et de ses conditions de possibilité. En un sens plus spécifique, c’est un domaine de la philosophie qui étudie les disciplines scientifiques et les conditions logiques, méthodologiques et conceptuelles de production des connaissances scientifiques. Pour un domaine scientifique particulier (l’IA par exemple), l’épistémologie désignera l’étude critique des savoirs qu’il produit à partir de l’analyse de ses méthodes, pratiques et concepts. |
Opacité et transparence des Systèmes Computationnels Complexes (SCC)
L’opacité d’un Système Computationnel Complexe (SCC) est dérivée du concept d’opacité épistémique. Au sens le plus fort, l’opacité épistémique désigne la complexité (voir l’impossibilité) de suivre et comprendre les processus computationnels impliqués dans un système: les étapes, les justifications et les implications de chaque étape du processus deviennent hors de porté pour des agents cognitifs humains.
Autrement dit, nous ne pouvons expliquer ni pourquoi, ni comment le système produit, en sortie, les résultats (classifications, décisions) qu’il produit selon les données fournies (ou collectées) en entrées du système. On parle alors de boîte-noire, puisque les processus internes en sont inscrutables.
Cette opacité s’étend aussi à la nature exacte des données pertinentes au fonctionnement du système dans le cas de l’apprentissage profond.
Rappelez-vous les réactions aux premiers résultats de Parcoursup en mai 2023, faites une recherche “#PARCOURSUP + opacité” sur X (anciennement Twitter), pour voir. Nous retrouvons alors des opinions comme celle-ci :
En résumé, l’opacité survient lorsque nous ne savons pas exactement comment le comportement du système est produit ni sur quelles données (ou propriétés de ces données) il s’appuie pour produire ce comportement.
Dans un article de 2016 intitulé “How the machine ‘thinks’: Understanding opacity in machine learning algorithms” (Comment les machines pensent: comprendre l’opacité dans les algorithmes d’apprentissage autonome), Jenna Burrell @jennaburrell , alors professeure à l’UC Berkeley, a examiné la question de l’opacité en tant que problème pour les mécanismes de classification et de classement ayant des conséquences sociales, tels que les filtres anti-spam, la détection des fraudes à la carte de crédit, les moteurs de recherche, les tendances de l’actualité, la segmentation du marché et la publicité, l’assurance ou la qualification des prêts, et l’évaluation de la solvabilité. Ces mécanismes de classification s’appuyent tous fréquemment sur des algorithmes et, dans de nombreux cas, sur des algorithmes d’apprentissage automatique.
La chercheuse distingue ainsi 3 types d’opacité :
- (1) Intentionnel : l’opacité en tant que secret d’entreprise ou d’État intentionnel,
- (2) Educationnelle : l’opacité en tant qu’analphabétisme technique (technical illiteracy)
- (3) Opératoire : l’opacité qui découle des caractéristiques des algorithmes d’apprentissage automatique et de l’échelle requise pour les appliquer de manière utile.
Les deux premiers types ne sont pas spécifiques à l’apprentissage machine/profond. On les retrouve dans tous les domaines techniques et scientifiques : essayez de démonter et réparer un écran OLED de dernière génération, pour voir ; ou de dépanner vous-mêmes votre voiture hybride. Ne serait-ce que comprendre les processus engagés entre l’action réalisée par votre votre index sur la télécommande et le résultat sur l’écran ( par exemple le changement de chaîne) représente un défi si vous n’avez pas de connaissances poussées en physique et en électronique. Votre téléviseur est une boîte-noire, autrement dit une « lucarne MAGIQUE ».
La spécificité des SCC, en tout cas de certains, c’est que même si vous avez accès au code et que vous avez toutes les connaissances nécessaires pour concevoir ce système, son caractère récursif, l’échelle à laquelle il fonctionne et l’organisation dynamique de ses données produisent une opacité opératoire qui vous affecte quasiment au même titre que le béotien1 !

Quid de la communauté scientifique IA ?
Les chercheur.e.s en IA, les scientifiques qui utilisent des outils complexes de traitement computationnel des données massives et les philosophes de l’IA ont fait valoir que réduire l’opacité, et amener de la transparence exigeait : (i) un effort en direction de plus de transparence, d’interprétabilité ou d’explicabilité (tous ces concepts doivent être soigneusement distingués, mais cela nous engagerait dans un long développement technique). Cela s’est parfois traduit dans des règlements internationaux (RGPD par exemple en Europe), (ii) des programmes de recherche (privés et publics) et (iii) un grand nombre de publications en IA, en SHS, en droit, en sciences politiques, autrement dit, de la pluridisciplinarité!
Cette exigence de transparence repose sur l’espoir d’une plus grande confiance des utilisateurs proximaux ou finaux. L’argument étant le suivant: la confiance dans une personne provient de la capacité à exhiber les raisons de ses décisions. Si ces raisons sont impénétrables, inaccessibles ou opaques, alors il n’y aura pas de pleine confiance. Certains auteurs ont cependant déjà prévenu (il y a déjà un certain temps) que cette opacité des SCC était inhérente, insurmontable et inéliminable et qu’il fallait faire avec.
– Deal with it! –
Paul Humphreys, Professeur britannique de philosophie à l’université de Virginie, spécialisé dans la philosophie des sciences, la métaphysique et l’épistémologie, s’est intéressé à la métaphysique et à l’épistémologie de l’émergence, à la science informatique, à l’empirisme et au réalisme. En 2009, il explique dans son article “The philosophical novelty of computer simulation methods” (La nouveauté philosophique des méthodes de simulation informatique) que les simulations informatiques et la science computationnelle sont un ensemble de méthodes scientifiques distinctement nouvelles qui introduisent de nouvelles questions à la fois épistémologiques et méthodologiques dans la philosophie des sciences.
Ces outils numériques, utilisés à grande échelle, modifient profondément la pratique scientifique, mais surtout les buts de la recherche scientifique: La modélisation et la simulation computationnelles nous conduiraient à envisager la recherche scientifique comme visant la prédiction de phénomènes ou processus modélisés, plutôt que leur compréhension ou explication.

Certains chercheurs considèrent que si l’on ne parvient pas à réduire cette opacité fondamentale en choisissant des architectures et méthodes plus transparentes que l’apprentissage machine non supervisé ou l’apprentissage profond, il faudrait alors exclure l’utilisation des SCC de certains cas.
Par exemple, en médecine, dans le domaine judiciaire ou l’éducation, les SCC devraient être suffisamment transparents du point de vue opératoire car sans cela, leur utilisation ne devrait pas être autorisée.
C’est autour de cette idée que se sont construits les travaux de Cynthia Rudin @CynthiaRudin qui ont annoncé un changement de cap dans le domaine de l’explicabilité en IA notamment centrée-humain.
Informaticienne et statisticienne américaine spécialisée dans l’apprentissage automatique, elle est notamment connue pour ses travaux sur l’interprétabilité des algorithmes d’apprentissage automatique. Directrice de l‘Interpretable Machine Learning Lab à l’université Duke, où elle est professeur d’informatique, d’ingénierie électrique et informatique, de science statistique, de biostatistique et de bio-informatique, elle a remporté en 2022 le Squirrel AI Award for Artificial Intelligence for the Benefit of Humanity de l’Association for the Advancement of Artificial Intelligence (AAAI) pour ses travaux sur l’importance de la transparence des systèmes d’IA dans les domaines à haut risque.
Dans son article de 2019 intitulé “Stop explaining black-box machine learning models for high-stakes decisions and use interpretable models instead.” (Cessez d’expliquer des modèles d’apprentissage automatique à boîte noire pour des décisions à fort enjeu et utilisez plutôt des modèles interprétables.), Cynthia Rudin se penche sur l’idée que la création de méthodes permettant d’expliquer ces modèles boîtes noires atténuera certains des problèmes éthiques recensés dans la littérature. Elle y discute notamment l’idée que s’échiner à expliquer les modèles boîte noire, plutôt que de créer des modèles interprétables en premier lieu, risque de perpétuer les mauvaises pratiques et peut potentiellement causer un grand préjudice à la société.
La voie à suivre, selon elle, consiste à concevoir des modèles intrinsèquement interprétables notamment pour les décisions à fort enjeu comme dans la justice pénale, les soins de santé et la vision par ordinateur.

En parallèle à ce mouvement lancé par Cyntia Rudin, d’autres chercheurs et industriels, pensent qu’en distinguant des types de transparence on pourra limiter l’opacité opératoire et gagner en confiance, ainsi qu’en maîtrise (recherche de bugs par les modélisateurs) et en capacité explicative (pour les scientifiques utilisant ces outils). C’est notamment ce que propose Kathleen Creel @KathleenACreel dans un article de 2020 extrêmement éclairant, “Transparency in Complex Computational Systems” (“Transparence des systèmes computationnels complexes”).
Professeur assistante à la Northeastern University, Kathleen Creel mène des travaux sur les implications morales, politiques et épistémiques de l’apprentissage automatique tel qu’il est utilisé dans la prise de décision automatisée non étatique et dans la science. Elle a notamment contribué à intégrer les enseignements d’éthique aux programmes informatiques de Stanford afin de permettre l’acquisition de compétences aux étudiants qui leur permettraient de discuter et de réfléchir aux dilemmes éthiques qu’ils pourraient rencontrer dans leur carrière professionnelle.
Dans cet article de 2020, Kathleen Creel propose une analyse de la transparence sous trois formes : (i) la transparence de l’algorithme, (ii) la réalisation de l’algorithme dans le code et (iii)la manière dont le code est exécuté sur un matériel et des données particuliers. En visant la transparence sous ces trois formes, cela permettrait de cibler la transparence la plus utile pour une tâche donnée en fournissant une transparence partielle lorsque la transparence totale est impossible, tout en évitant un usage instrumentaliste des systèmes opaques.

Enfin, d’autres considèrent qu’en exigeant une telle transparence des SCC, nous faisons deux poids-deux mesures puisque cette opacité opératoire n’est qu’une sous-catégorie de l’opacité épistémique dans laquelle nous nous trouvons face à nos congénères :
Au fond, nous serions face à l’aide à la décision apportée par un.e docteur.e en médecine avant de donner notre consentement éclairé pour une opération comme nous sommes face à un SCC d’aide à la décision en apprentissage profond. Seul le contexte d’interaction permettrait de fonder notre confiance, sans compter que des travaux menés en explicabilité centrée humain, montrent que dans certains contextes, l’accès à des explications est plus source de stress (et donc de rejets de l’information) que de confiance et d’acceptabilité des SCC.
Dr Juliette @FerryDanini, enseignante chercheuse en philosophie à l’université de Namur, a fait une communication sur ce débat en 2021 au Congress of the Quebec Philosophy Society, nous vous conseillons de la voir si ça vous intéresse, la vidéo étant ci dessous:
Vidéo youtube: https://www.youtube.com/watch?v=xNWe3PsfNng
TAKE HOME MESSAGE
Alors que retenir de cette vision croisée de l’IA Explicable, entre philosophie et informatiques ? des réflexions et probablement des questionnements aussi !
‘Take home message #1 : Comme toujours en philosophie des sciences et techniques, les problèmes éthiques sont liés à des problèmes épistémologiques qui supposent une compréhension des questions pratiques et théoriques centrales soulevées par l’usage de ces méthodes : pas d’indépendance des deux.
Take-home message #2 : La philosophie de l’IA suppose une certaine familiarité avec des questions techniques. Idéalement, savoir coder est potentiellement une exigence à viser.
Take-home message #3 : Un gros travail interdisciplinaire de définition des concepts centraux (transparence, explicabilité, interprétabilité, opacité) doit être fait pour stabiliser le champ et les stratégies théoriques et pratiques, voire industrielles.
Take-Home message #4 : La confiance comme vertu cardinale du rapport aux SCC nous semble à questionner. Il y a du boulot à faire 
Cédric Brun, chercheur en philosophie des sciences en Neuroscience, Humanities & Society (NeHuS) et Ikram Chraibi Kaadoud, chercheuse en IA explicable et IA digne de confiance.
1 L’adjectif béotien : de la région de Béotie. Les habitants de la Béotie, province de l’ancienne Grèce, avaient, à Athènes, la réputation d’être un peuple inculte, lourdaud et peu raffiné. De nos jours, l’adjectif béotien, béotienne qualifie un individu peu ouvert aux lettres et aux arts, aux goûts grossiers. Source: https://www.projet-voltaire.fr/culture-generale/beotien-marathon-sybarite-ces-mots-francais_toponymes-grecs-antiques-noms-lieux-grecs/
Pour en savoir plus/Références
- “How a new program at Stanford is embedding ethics into computer science?” Juin 2022, Site : stanford.edu/ , URL article: https://urlz.fr/mf3z
- L’intelligence artificielle explicable (XAI) :
- Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., … & Herrera, F. (2020). Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information fusion, 58, 82-115. URL: https://www.sciencedirect.com/science/article/abs/pii/S1566253519308103
- Comment saisir ce que font les réseaux de neurones ? Série de trois articles du blog binaire sur les concepts d’intéprétabilité et d’explicabilité: https://www.lemonde.fr/blog/binaire/2020/09/04/comment-saisir-ce-que-font-les-reseaux-de-neurones/
16.02.2024 à 08:54
La Bible nous parle de l’informatique
binaire
Continuer la lecture de « La Bible nous parle de l’informatique »
Texte intégral (3679 mots)
Un nouvel « Entretien autour de l’informatique » avec Haïm Korsia, grand-rabbin de France depuis 2014 et membre de l’académie des sciences morales et politique. Haïm Korsia est rabbin, ancien aumônier en chef du culte israélite des armées, aumônier de l’École polytechnique depuis 2005, administrateur du Souvenir français et ancien membre du Comité consultatif national d’éthique.

« Quand personne ne me pose la question, je le sais ; mais si quelqu’un me la pose et que je veuille y répondre, je ne sais plus ». (Saint Augustin, Confessions XI). Pour moi, l’informatique est un peu comme cela. Haïm Korsia.
Binaire : Vous êtes rabbin. Comment en êtes-vous arrivé à vous intéresser à l’informatique et à l’intelligence artificielle ?
HK : Je fais partie de la première génération à utiliser des ordinateurs de façon quotidienne. A l’école rabbinique, mon professeur d’histoire, le Professeur Gérard Nahon, nous disait deux choses : « Vous devrez apprendre à parler anglais », et : « Un jour, vous n’aurez plus de secrétaire et il faudra taper vous-mêmes vos lettres. » Pour nous, cela tenait de l’impossible. D’abord, la langue à apprendre était l’hébreu. Et puis, le rabbin faisait le sermon et allait voir les gens. Taper des lettres à la machine, ne faisait pas partie de son travail.

J’ai écouté ce prof et j’ai appris l’anglais. Et puis, rue Gay-Lussac, dans un magasin d’antiquités, j’ai vu une machine Rheinmetall. J’en ai rêvé et je l’ai achetée dès que j’ai eu un peu d’argent. Plus tard, quand j’ai vu mon collègue de Besançon qui avait une machine de traitement de texte, j’ai fait en sorte d’avoir un ordinateur portable. J’ai continué et depuis j’utilise des ordinateurs. Sans être un geek, j’ai appris à utiliser ces machines.
Pour moi, l’informatique est d’abord utilitaire et émancipatrice. L’informatique libère en évitant, par exemple, d’avoir à retaper plusieurs de fois un même texte, parce qu’on peut le corriger. Et puis, il est devenu impensable aujourd’hui de vivre sans les connexions que l’informatique nous apporte ! Mais il faut savoir doser cette utilisation.
Binaire : L’informatique et le numérique permettent de tisser des liens. Est-ce que vous pensez que le développement de tels liens a transformé la notion de communauté ?
HK : Bien sûr ! On voit bien, par exemple, avec des gens qui ont 5 000 amis sur Facebook mais aucun n’est capable d’aller leur chercher un médicament quand ils sont malades. Pour moi, c’est une dévalorisation de la notion d’ami. Cela m’évoque la fable d’Ésope, « la langue est la meilleure et la pire des choses ». Les réseaux sociaux peuvent enfermer les gens dans un même mode de pensée et en même temps ils ouvrent des potentiels incroyables. Cela dépend de la façon dont on les utilise.
Dans le judaïsme, nous avons un avantage sur les autres religions : quoi que vous me donniez comme moyen de communication, le samedi, je vais uniquement « là où mes pieds me portent ». Je retrouve en cela mon humanité sans tout ce qui me donne habituellement le sentiment d’avoir une humanité augmentée. Ni voiture, ni vélo, ni avion, ni téléphone. Rien. Au moins un jour par semaine, le samedi, je retrouve ma communauté telle qu’elle est vraiment. Tous les appendices qui augmentent ma capacité de lien sont supprimés le jour du shabbat, et je me désintoxique aussi de l’addiction aux moyens numérique de communication. Le samedi je n’ai pas de téléphone.
En quoi est-ce un avantage ? Cela me permet de ne pas perdre l’idée que ces outils sont juste des extensions de moi, qu’ils ne font pas partie de moi.
Binaire : Est-ce que la Bible peut nous aider à comprendre l’informatique ?
HK : La Bible nous parle de la vie des hommes, des femmes, et des invariants humains : la toute-puissance, la peur, la confiance, le rejet, la haine, la jalousie, l’amour, etc. Tout est là et chacun s’y retrouve. Mon maitre le grand rabbin Chouchena disait : Si tu lis un verset de la Bible et que tu ne vois pas ce qu’il t’apporte, c’est que tu l’as mal lu, relis-le !
Prenons un exemple. Considérez ce que dit la Bible [1] sur la neuvième plaie d’Égypte, la plaie de l’obscurité :
« Moïse dirigea sa main vers le ciel et d’épaisses ténèbres couvrirent tout le pays d’Égypte, durant trois jours. On ne se voyait pas l’un l’autre et nul ne se leva de sa place, durant trois jours mais tous les enfants d’Israël jouissaient de la lumière dans leurs demeures. Exode, 10-22,23.
Une interprétation possible, c’est d’imaginer qu’un volcan a explosé quelque part, ou qu’il y a eu une éclipse du soleil, comme dans Tintin et le temple du soleil. Une autre interprétation, c’est de lire, littéralement : « Un homme ne voyait pas son prochain comme un frère. » L’obscurité, alors, ce n’est pas un moment où il fait nuit, mais un moment où on devient indifférent à la fraternité qui devrait nous lier l’un à l’autre. Ainsi, l’indifférence dans la société, c’est la nuit du monde. Ce n’est pas inscrit comme cela dans le verset. Tout est question de l’interprétation du texte.
Autre exemple. J’ai connu le confinement au début de la pandémie, et cela m’a donné une capacité à interpréter autrement la Bible. Par exemple, dans Bible, il est dit :
« et ton existence flottera incertaine devant toi, et tu trembleras nuit et jour, et tu ne croiras pas à ta propre vie ! ». Deutéronome, 28-66.
Il s’agit du grand discours du dernier jour de la vie de Moïse, dans la partie sur les malédictions. Dans ce contexte, Rachi [2], un des plus grands commentateurs de Bible, parle de celui qui achète son blé au marché. Pendant le Covid, j’ai vu un avion atterrir avec une cargaison de masques et un acheteur étranger acheter toute la cargaison. Cela met en évidence le problème d’une dépendance au marché pour les choses stratégiques, les masques, les médicaments… Tant que tout va bien, tu te fournis au marché, quitte à payer plus cher ; mais s’il n’y a pas ces choses, même milliardaire, ta vie se retrouve en suspens. Si on dépend du marché pour des approvisionnements stratégiques, c’est une vie d’angoisse. Cela conduit à un commentaire que je propose suite à cet épisode. Les rabbins avant moi ne pouvaient pas proposer cette interprétation parce qu’ils n’avaient pas connu le covid.
Ces exemples illustrent la méthode. Confronter des questions d’actualité aux textes bibliques amène un entrechoquement fécond de la pensée. Posez-moi une question sur l’informatique. Je ne dis pas que la réponse est dans la Bible. Mais la Bible et ses commentaires proposent des façons de réfléchir, des pistes de réflexion.
Binaire : Alors sur l’informatique, que peut-on trouver dans la Bible selon vous ?
HK : L’informatique, c’est une volonté de maitrise, de l’ultra-rapidité, l’agglomération de tous les savoirs. Les questions d’augmentation, d’orgueil, de sentiment de puissance ou de toute-puissance, la Bible en parle. À nous d’y trouver un sens actuel, contemporain.
L’intelligence, ce n’est pas d’avoir des savoirs, mais de savoir où chercher, à qui demander. Individuellement je suis limité par mes capacités d’analyse, mais celui qui sait où chercher, lui est intelligent. Des machines toujours plus rapides, avec des capacités de mémorisation toujours plus importantes, ce n’est pas forcément ce qui va marcher le mieux. Pour prendre une métaphore sportive, ce n’est pas en prenant les onze meilleurs joueurs de foot du monde qu’on a la meilleure équipe du monde. Il faut onze joueurs qui jouent ensemble. Il faut savoir s’appuyer les uns sur les autres.
Binaire : Que pensez-vous de l’intelligence artificielle ?
HK : Prenons par exemple un dermatologue. Combien d’image de maladie de la peau arrive-t-il à mémoriser ? Quelques milliers. Le logiciel Watson d’IBM en mémorise 40 000. Il a acquis plus de points de comparaisons. Autre exemple : la justice. Prenez toutes les jurisprudences, c’est formidable de précision. L’intelligence artificielle peut nous aider à analyser les jurisprudences. Mais est-ce qu’elle permet de juger ? Est-ce qu’elle prend en compte la réalité humaine des gens qui viennent devant le juge ?

Dans la Bible, le roi David, quand un pauvre volait un riche, condamnait le pauvre parce que c’est la loi. Mais de sa cassette personnelle, il lui donnait de quoi payer l’amende. Une machine ne peut pas faire ça. On ne peut pas demander à une machine d’avoir de l’humanité. Dans l’histoire « Les aventures de Rabbi Harvey », Monsieur Katz est chez lui. Un pauvre gars lui rapporte son portefeuille. Katz se dit : « Quel idiot ! Il m’a rendu le portefeuille avec 200 dollars dedans ! » Il lui dit : « Enfin, il y avait 300 dollars, tu es un voleur ! » On soumet le cas au rabbin Harvey. Le rabbin comprend que Katz se moque du pauvre. Réponse du rabbin : « Ce n’est pas compliqué. Puisque ce n’est pas la bonne somme, ce n’est pas ton portefeuille. » ; et il le rend au pauvre ! Est-ce qu’un ordinateur aurait trouvé cela ? Est-ce qu’il aurait cet humour ? Je ne sais pas.
L’humanité ne peut pas être transformée en pensée informatique, en se laissant confiner dans la précision. La vie n’est pas seulement dans la précision. La machine crée une cohérence mais, en réalité, sans pouvoir comprendre.
Ne juge pas ton prochain avant de te trouver à sa place, dit le Talmud. Une machine ne peut pas être à la place de l’accusé.
Binaire : Qu’attendez-vous de l’intelligence artificielle ?
HK : Elle pourrait nous permettre de faire mieux certaines choses. En médecine par exemple, on s’est rendu compte que 25% des ordonnances contiennent des contre-indications connues entre médicaments ! Jamais une machine ne ferait de telles erreurs. Le médecin ne sait pas forcement certaines choses sur les antécédents mais l’ordinateur, le système informatique peut le savoir, donc peut en tenir compte dans les prescriptions. D’où l’intérêt d’utiliser l’informatique dans les prescriptions.
Mais il ne faut pas que cela ait pour conséquence que le médecin se contente de regarder l’écran, et oublie de regarder son patient. Et puis, imaginez une panne informatique dans un système médical ; tout le système s’écroule, plus rien ne marche. De mon point de vue, il faut toujours faire en sorte qu’on ait le maximum d’aide mais avec le minimum de dépendance. Donc oui, il faut utiliser l’intelligence artificielle. Mais il faut éviter la dépendance.
L’informatique et l’intelligence artificielle nous permettent d’aller plus loin. Deep Blue a battu Kasparov. Mais pourquoi voir cela comme une compétition ? Nous ne sommes pas sur un même plan. Il n’y a aucune raison de comparer, d’opposer l’humain et l’informatique. L’informatique n’est ni bonne ni mauvaise, elle est ce que nous en faisons. Nous devons utiliser cette force extraordinaire mais ne pas être utilisées par elles. En particulier, nous ne devons pas laisser l’informatique s’interposer entre les humains. Nous avons cette force d’imagination, sortir de ce qui a été pensé avant. Il nous faut trouver une autre façon d’être humain.
Binaire : Est-ce que l’intelligence artificielle soulève des problèmes nouveaux pour un juif pratiquant ?
HK : L’informatique en soulève déjà. Il y avait par exemple déjà la question de l’accès aux maisons avec digicodes pendant le shabbat. Le shabbat, je n’ai plus de téléphone portable, donc je n’existe plus ? Comment vivre le shabbat quand le monde est devenu numérique ? On m’a dit que ce sont les juifs qui sauveront les livres en papier parce que, pendant le shabbat, les livres numériques, c’est impossible.
Le shabbat, l’utilisation de l’électricité est interdite. En Israël, certains rabbins ont autorisé les visioconférences pour la fête de Pessah, pendant la pandémie. Le but était de faciliter des rassemblements familiaux virtuels, pour permettre de vivre les fêtes en famille. La question m’a été posée. J’ai dit non aux visios, car si on accepte une fois, les gens vont se dire que ce n’est pas grave de faire ça tout le temps. J’ai préféré refuser.
Et puis, vivre une journée sans technologie, je trouve ça formidable. Le shabbat est une très grande liberté.
Binaire : Vous parlez de « golémisation des humains ». Que voulez-vous dire par ça ?
HK : C’est le sujet de ma conférence dans le cycle des Conférences de l’Institut. Golem, GLM, les mêmes initiales que Generalized Language Model, ce ne peut être par hasard. Il s’agit de la mise en place de processus qui nient l’unicité de chaque personne. Le processus admet ce qui sort du lot, mais considère que si on arrive à gérer 95% des cas, on est tranquille. Mais nous, on est tous dans les 5% ! C’est ça, la golémisation : fonctionner avec des cases, des réponses préremplies, et si ça dépasse, si ça sort des cases, ce n’est pas bon. On ne doit jamais oublier que l’informatique est une aide. Quand l’aide de l’informatique devient un poids, un problème, j’appelle cela la golémisation.
L’informatique devient un poids symbolique inacceptable si ça m’empêche de pouvoir faire par moi-même. Dans ces problèmes idiots de nos rapports avec l’informatique, il faut remettre de l’intelligence plus fine et plus l’humanité. C’est une grande crainte, que la machine prenne le dessus sur les hommes. On irait vers un monde où les machines imposent leur mode de fonctionnement aux hommes qui, en adoptant le fonctionnement des machines, abdiquent leur humanité.
Binaire : Pour certains penseurs de la silicone vallée, l’IA pourrait nous permettre de devenir immortels.
HK : Selon eux, on pourrait arriver à concevoir comment les neurones conservent, gardent la mémoire, les espérances, à externaliser la mémoire de quelqu’un et à la transmettre. Si on y arrivait, le rêve d’immortalité se réaliserait. On est dans la science-fiction. Chaque époque a produit sa façon d’être immortel, par l’habit vert à l’académie par exemple. Léonard de Vinci est immortel d’une certaine manière ; Moïse en transmettant la Torah aux hébreux acquiert aussi une forme d’immortalité. On peut chercher l’immortalité à travers sa descendance.
La véritable obligation du judaïsme, ce n’est pas le shabbat, la nourriture cacher, etc., mais la phrase : « tu le raconteras à tes enfants et aux enfants de tes enfants. Et comme c’est dit dans la Bible :
Souviens-toi des jours antiques, médite les annales de chaque siècle ; interroge ton père, il te l’apprendra, tes vieillards, ils te le diront ! Deuteronome 32, 7.
On s’assure qu’il y ait deux générations qui puissent porter une mémoire une expérience de vie. Les rescapés de la Shoah ont voulu protéger leurs enfants en ne parlant pas. Mais quand ils sont devenus grands-parents, leurs petits-enfants leur ont demandé de raconter.
Binaire : Pour conclure, peut-être voulez-vous revenir sur la question de l’hyper-puissance de l’informatique.
HK : Cette technologie donne un sentiment de tout maitriser, et moi j’aime des fragilités. Quand je me suis marié, la personne qui m’a vendu mon alliance m’a dit : « il y a 12 000 personnes par an qui ont le doigt arraché par une anneau. Mais chez nous, il y a une fragilité dans l’or de l’anneau qui fait que l’anneau cède s’il y a une traction sur votre doigt. » La force de mon anneau, c’est sa fragilité ! Cela m’a impressionné. L’ordinateur ne sait pas intégrer la faiblesse dans sa réflexion, la fragilité, alors que c’est l’une des forces de l’humain. Cette toute puissance, conduit précisément à la faiblesse des systèmes informatiques. La super machine dans sa surpuissance devient fragile, alors que nous, notre fragilité fait notre force.
Serge Abiteboul, Inria et ENS Paris, Claire Mathieu, CNRS
[1] Les traductions de la Bible sont prises de Torah-Box, https://www.torah-box.com/
[2] Rabbi Salomon fils d’Isaac le Français, aussi connu sous le nom de Salomon de Troyes, est un rabbin, exégète, talmudiste, poète, légiste et décisionnaire français, né vers 1040 à Troyes en France et mort le 13 juillet 1105 dans la même ville. [Wikipédia]
Les entretiens autour de l’informatique
09.02.2024 à 09:56
Un nouveau RISC-V
binaire
Texte intégral (2447 mots)
 Binaire a demandé à Bruno Levy, de nous parler d’un processeur spécifique le RISC-V. Ce processeur ouvert/libre pourrait rebattre les cartes des coeurs de processeurs. Bruno Levy est chercheur Inria, spécialiste des optimisations mathématiques, il a rejoint la nouvelle équipe projet PARMA (une machine mathématique à remonter le temps pour explorer l’univers). Bruno est aussi l’un des ambassadeurs du RISC-V, nous lui avons ouvert nos colonnes. Pierre Paradinas
Binaire a demandé à Bruno Levy, de nous parler d’un processeur spécifique le RISC-V. Ce processeur ouvert/libre pourrait rebattre les cartes des coeurs de processeurs. Bruno Levy est chercheur Inria, spécialiste des optimisations mathématiques, il a rejoint la nouvelle équipe projet PARMA (une machine mathématique à remonter le temps pour explorer l’univers). Bruno est aussi l’un des ambassadeurs du RISC-V, nous lui avons ouvert nos colonnes. Pierre ParadinasRisc-V, une nouvelle donne dans le monde des micro-processeurs
Les micro-processeurs, au coeur du numérique… Véritable concentrés de technologie, objets les plus complexes jamais conçu par l’être humain, constitués de milliards d’éléments, mais guère plus grands qu’une tête d’épingle, les microprocesseurs sont omniprésents dans notre quotidien. Que ça soit pour envoyer la photographie du petit dernier à la famille, pour réserver un billet de train, pour nous assister dans la conduite de nos véhicules, et même pour optimiser la consommation d’eau du lave vaisselle, de plus en plus rares sont les gestes du quotidien qui n’impliquent pas de près ou de loin des microprocesseurs. Une évolution majeure, nommée RISC-V, est susceptible de changer en profondeur la donne pour ces objets de haute technologie au coeur de notre quotidien.
Le jeu d’instructions, l’« alphabet » du microprocesseur. En quelque sorte, pour nos appareils numériques, le microprocesseur joue le rôle du « chef d’orchestre », jocoeuruant la « partition » – un programme – qui décrit le fonctionnement de l’appareil. Ce programme est écrit dans un langage, qui a son propre « alphabet », constitué d’instructions élémentaires, très simples, encodées sous forme de nombres dans la mémoire de l’ordinateur. De la même manière qu’il existe plusieurs alphabets (mandarin, cantonais, japonais, latin, grec, cyrillique …), il existe plusieurs jeux d’instructions différents : x86 pour les processeurs Intel, ARM très utilisé pour les téléphones portables et les Macs, AVR utilisé par des microcontroleurs dans les systèmes embarqués … Et parmi ces jeux d’instruction, il existe deux grandes classes, les jeux d’instructions dits CISC (pour Complex Instruction Set), qui comportent un grand nombre d’instructions élémentaires, ou encore un grand nombre de lettres différentes dans leur « alphabet » (comme dans les alphabets chinois qui comportent des milliers d’idéogrammes). C’est le cas des processeurs x86 Intel, dont les dernières évolutions supportent plusieurs milliers d’instructions différentes, la documentation comportant plus de 5000 pages, réparties dans 10 volumes (!). L’autre grande famille de jeux d’instruction, appelée RISC (pour Reduced Instruction Set) se fonde sur un « alphabet » plus restreint, avec tout au plus une petite centaine d’instructions différentes, qui ressemble plus à l’alphabet latin ou grec. D’une certaine manière, les instructions CISC correspondent plus à des syllables qu’à des lettres, et il faudra plusieurs instructions RISC pour faire la même chose.
Ecosystème et normalisation : tout seul, le microprocesseur ne peut rien faire ! Il ne peut vivre qu’au sein d’un réseau d’acteurs différents, fournissant à la fois l’environnement matériel (les ordinateurs ou gadgets électroniques autour du microprocesseur, les périphériques, …) et l’environnement logiciel (les logiciels, le système d’exploitation, les langages de programmation…). Ce qui permet à toute cette chaîne d’acteurs de travailler ensemble, c’est la normalisation du jeu d’instruction (Instruction Set Architecture), un document qui décrit dans le détail chaque instruction élémentaire et ce qu’elle est censée faire. C’est en quelque sorte le « contrat » que passe le micro-processeur (et son fabriquant) avec les autres acteurs, garant du fait que tout ce petit monde saura « se parler » et travailler ensemble. Par exemple, le jeu d’instruction ARM de l’entreprise britannique du même nom est utilisé par beaucoup d’acteur, notamment Apple, Samsung, Qualcomm, MediaTek, Nvidia. Pour obtenir le droit d’utiliser le jeu d’instruction ARM, ces acteurs doivent payer un « ticket d’entrée », à savoir une licence, 1 ou 2 % du prix de vente de la puce, reversé à ARM. Mais ARM a été rachetée par l’entreprise Japonaise SoftBank (pour 32 milliards de dollars), qui prévoit d’augmenter significativement le prix de la licence. Nvidia prévoyait à son tour de racheter ARM à Softbank (pour 40 milliards de dollars), projet finalement abandonné après que la FTC américaine ait saisi la justice. Les rachats sont monnaie courante dans le monde des microprocesseurs, comme le rachat d’Atmel par Microchip en 2016 (fabriquant de micro-controlleurs pour les systèmes embarqués). Ces rachats font peser à chaque fois des grandes incertitudes sur les clients utilisant ces microprocesseurs dans leur produit. C’est particulièrement le cas de produits de type « internet des objets », utilisant des microcontrôleurs à quelques centimes d’Euros pièce, pour lesquels le prix d’une licence peut représenter une part significative du coût de revient.

RISC-V, un jeu d’instruction et une organisation qui pourraient changer la donne : RISC-V est à la fois une architecture de jeu d’instruction et une organisation visant à développer l’écosystème d’acteurs autour de ce jeu d’instructions. Issue de travaux de recherche académiques, la première mouture du jeu d’instruction a été conçue en 2010. Le jeu d’instruction en lui-même est issu des travaux d’Asanovic, Lee et Waterman au Parallel Computing Lab de l’Université de Berkeley, dirigé par Patterson. Il a été soutenu par différentes sources de financement, par des industriels (dont Intel et Microsoft), par l’état de Californie et par un projet DARPA. En 2015 est créée la fondation RISCV-International, une association à but non lucratif ayant pour objectif de développer le standard et de stimuler l’émergence d’un écosystèmes d’acteurs pour créer du matériel et du logiciel autour du standard. Afin de mieux garantir son indépendance, l’association a déménagé en Suisse à Zurich en 2020.

Des petits et des grands microprocesseurs : Du plus petit microcontrôleur intégré au lave-vaisselle jusqu’au grands centres de calculs qui brassent des péta-octets de données, les microprocesseurs peuvent avoir des fonctionnalités et des puissances de calcul très différentes. Malgré cela, tous ces secteurs sont susceptibles d’être impactés par RISC-V. Le jeu d’instruction est conçu en « oignon », avec un « alphabet » pour les tâches les plus simples, et des « lettres en plus » pour certaines tâches spécialisées. Par exemple, un mathématicien va utiliser en plus des 26 lettres de l’alphabet des symboles spéciaux. Il en va de même dans la norme RISC-V, qui introduit des instructions spéciales pour le calcul. Et pour que tout le monde continue à se comprendre, il est possible pour un processeur de base de comprendre ces instructions supplémentaires en les traduisant à la volée, grâce à un logiciel spécial. Cela prend un peu plus de temps, mais cela fonctionne, et tout le monde reste compatible. D’autre part, la norme RISC-V prévoit la possibilité d’ajouter des instructions. Par exemple, il sera possible de créer des instructions spécifiques pour accélérer les calculs en IA, ou encore pour assurer des propriétés renforcées de sécurité informatique.
Et après, quels enjeux pour le futur ?
En ouvrant la conception de micro-processeurs qui était jusqu’à maintenant contrôlée par quelques gros acteurs, et en offrant des garanties sur la libre utilisation du jeu d’instruction, la norme RISC-V va favoriser l’émergence de petits acteurs dans le monde des micro-processeurs. Une plus grande « bio-diversité » est susceptible de conduire vers plus d’innovation, tant dans les usages que dans l’architecture de ces micro-processeurs : le microprocesseur est une véritable petite « ville », à l’échelle microscopique (et même nano-scopique!), avec ses routes, qui acheminent les données, son réseau électrique qui distribue le courant, ses usines qui traitent les données. Ces « villes » sont conçues par des architectes (c’est le même nom qui leur est donné), à l’aide d’outils logiciels d’aide à la conception (la chaîne EDA, pour Electronic Design and Automation). Cette chaîne d’outil est également en train de s’ouvrir, avec l’émergence de logiciels open-source et d’approches nouvelles, comme l’introduction de l’intelligence artificielle pour optimiser le plan global de la « ville », utilisé par Google pour sa prochaine génération de processeurs. Dans un futur proche, la frontière entre le matériel et le logiciel va devenir de plus en plus floue, avec des nouvelles générations de micro-processeurs plus efficaces, plus économes en énergie, mieux adaptés aux différents usages. Dans cette nouvelle donne, les deux principaux enjeux seront la création et l’accès aux nouveaux outils EDA d’aide à la conception de microprocesseur, et surtout la formation de la nouvelle génération d’architectes, à savoir des ingénieurs « parlant couramment » ces nouveaux paradigmes, outils et langages de description du matériel, qui vont devenir rapidement assez différents des langages de programmation pratiqués par les ingénieurs du numérique actuel.
Bruno Levy, DR-Inria, https://bsky.app/profile/brunolevy01.bsky.social ou https://www.linkedin.com/in/blevy/
Pour aller plus loin
- Jeu d’instruction Intel x86-32 et 64: https://www.intel.fr/content/www/fr/fr/content-details/782158/intel-64-and-ia-32-architectures-software-developer-s-manual-combined-volumes-1-2a-2b-2c-2d-3a-3b-3c-3d-and-4.html
- Historique de la fondation RISCV: https://riscv.org/about/history/
- Utilisation de l’IA pour concevoir des puces: https://www.nature.com/articles/s41586-021-03544-w
02.02.2024 à 13:53
Des IA conseillères assurément, une IA présidente jamais de la vie
binaire
Continuer la lecture de « Des IA conseillères assurément, une IA présidente jamais de la vie »
Texte intégral (3658 mots)
Des IA conseillères assurément, une IA présidente jamais de la vie
Jason Richard s’interrogeait dans ce blog sur la possibilité et l’opportunité qu’un pays soit gouverné par une IA1. Recensant le pour et le contre, il laissait la question ouverte.
La réponse se précise si l’on considère que l’intelligence obéit à des lois universelles de l’information et qu’elle n’a rien de spécifiquement humain, au même titre que la force obéit aux lois universelles de la physique. L’IA apparaît alors comme un outil parmi les autres, aux côtés de la machine à vapeur. Parce que c’est un outil, il ne faut pas se priver de son aide, parce que ce n’est qu’un outil, l’idée qu’elle préside à notre destinée est vide de sens.
Cependant l’IA n’est pas n’importe quel outil. Elle est de ces instruments qui révolutionnent les civilisations, comme la lunette astronomique mena à l’héliocentrisme, l’imprimerie à la démocratie libérale. En étendant sans limites notre intelligence, et en la libérant de ses biais cognitifs, l’IA « peut conduire à une renaissance de l’humanité, un nouveau siècle des Lumières2 ».
Les politiques répètent à l’envie qu’il faut « changer de logiciel ». Changeons donc de logiciel.
Une seconde révolution copernicienne
En se penchant sur ses morts, le Sapiens s’interrogea sur son sort. Il imagina son salut par l’obéissance à des lois divines. Quand la révolution copernicienne discrédita l’idée d’une création dont il était le centre, vinrent les Lumières où l’homme se reporta sur sa raison pour comprendre et organiser le monde à son avantage. Cette arrogance de l’esprit nous a conduits au pied d’un mur environnemental qui va selon certains jusqu’à menacer notre espèce. Une nouvelle révolution voit le jour, celle de l’intelligence partagée, instrumentée par l’Intelligence dite Artificielle pour éclairer nos choix. Se priver d’IA dans les débats parlementaires serait désormais aussi stupide que jadis partir en exploration sans boussole, ou maintenant délibérer en COP sans l’expertise du GIEC.
Si nous répugnons encore à cette perspective, c’est que nous demeurons dans l’idée toute cartésienne que l’intelligence est l’apanage de l’humain. C’est pourquoi nous sommes troublés de voir l’intelligence machine pulvériser nos capacités, alors que nous nous félicitons que nos engins soient bien plus forts que nous pour nous aider dans les chantiers. Quand nous avons inventé la machine à vapeur, nous ne l’avons pas nommée Puissance Artificielle, parce que nous savions que la force et la puissance obéissent à des lois universelles de la mécanique et que nos prédateurs ancestraux nous surpassaient dans ce registre. C’est dans l’intelligence que nous avons placé ces derniers siècles la fierté de notre espèce, comme en témoignent nos contes et récits, où c’est toujours le petit futé qui l’emporte sur le grand crétin. Nous devons désormais nous faire à l’idée que l’intelligence n’est pas non plus notre apanage, qu’elle est partagée avec la nature et nos machines
La révolution des réseaux de neurones
La révolution informatique repose sur l’universalité des ordinateurs, leur capacité à « calculer tout ce qui est calculable », pourvu qu’ils aient assez de mémoire et de temps. La difficulté est que pour tout problème, il faut trouver un algorithme qui le résout. La révolution de l’IA repose sur une double universalité : d’une part un réseau de neurones artificiels peut « souvent apprendre approximativement ce qui est apprenable », pourvu qu’il soit assez grand, et d’autre part il peut le faire avec un même et seul algorithme, l’algorithme de rétro-propagation du gradient. En cela l’IA connexionnisme, celle des réseaux de neurones, ne fait que mimer la formidable trouvaille de l’évolution darwinienne qu’est le cortex et ses circonvolutions, avec l’avantage pour la machine de ne pas devoir se tasser dans une boîte crânienne.
Que des théorèmes expliquent pourquoi l’IA semble faire « tout mieux que nous »3 est de nature à nous rassurer et à tordre le cou aux obscurantismes. Cependant cette affirmation met à l’état de l’art « ses habits du dimanche » comme aurait joliment dit Marcel Pagnol, car il est bon de garder en tête qu’elle cache de nombreux bémols, qui sont autant de pistes pour les recherches futures4.
Cette révolution ne pouvait avoir lieu que maintenant, car le connexionnisme ne fonctionne que dans la gigantisme, quand tout se compte en milliards, milliards de données, milliards de neurones, milliardièmes de seconde, ce qui n’était pas technologiquement abordable avant ces dernières années.
Des intelligences non biaisées par la condition humaine
Un autre avantage de la machine est qu’elle est exempte de nos biais cognitifs5. Des biais sont souvent imputés aux machines, des déboires historiques de Siri aux dérapages récents de la reconnaissance faciale6. Ce faisant on oublie que ces biais ne sont pas liés au fonctionnement des machines mais aux comportements humains, en l’occurrence sexistes ou racistes, reflétés dans les échantillons d’apprentissage. Il faut donc distinguer les biais dans les données et les biais de traitement : là où notre raisonnement est biaisé, le traitement machine des mêmes données ne l’est pas.
Le Monde a consacré à nos biais cognitifs une série d’articles l’été dernier, « Les intox du cortex », et la chaîne YouTube « La Tronche en Biais », 300k abonnés, dédiée à l’esprit critique, accorde comme son nom l’indique une large place au sujet.
Un biais cognitif qualifie la différence d’analyse entre celle faite par un humain et celle réalisée de façon purement logique et rationnelle. Il est vraisemblable que nos biais trouvent leurs origines dans des avantages compétitifs qu’ils procuraient à notre espèce et ses individus au cours de la sélection darwinienne, avantages qui peuvent se retourner en handicaps quand l’environnement change. Sébastien Bohler va très loin en la matière7. Selon ce neuro-scientifique vulgarisateur, notre espèce doit sa survie à sa propension à dévorer, copuler, en imposer à la première occasion, tant la condition de nos ancêtre ne tenait qu’à un fil, avec la nourriture rare, la mortalité précoce et la trahison quotidienne. Avec l’abondance de l’ère industrielle, cette tendance – que Bohler nomme bug – qui nous a conduit à la surconsommation, à l explosion démographique, à la profusion de bagnoles, de fringues, et autres biens statutaires, jusqu’au pied du mur écologique.
Des intelligences machines novatrices
Le conformisme des IA est souvent évoqué pour les moteurs de recommandations, qui en se basant sur les statistiques de nos goûts nous proposent ce que l’on aime déjà. Mais cela ne vaut pas dans des applications avancées. Ainsi lors du match historique de 2016 AlphaGo réussit contre Lee Sedol un « coup de Dieu », comme le qualifient les spécialistes du jeu de Go. Des recherches récentes expliquent qu’au cours de son apprentissage un réseau connexionniste peut détecter entre des situations des similitudes qui nous échappent tant les sens que nous leur attribuons sont éloignés8. C’est ce que nous appelons parfois la créativité. Là où nos raisonnement seront prisonniers de nos biais, la machine privilégiera des principes mathématiques qui conduiront à des scénarios inédits, qu’elle alimentera de sa capacité à articuler des milliards de données hétérogènes, humaines, économiques, culturelles, scientifiques.
Quand l’IA éclairera le politique…
La voiture. Capter le regard envieux du voisin ou celui conquis de l’être convoité est selon les publicités le rêve de tout possesseur d’une voiture. Quitte à frustrer notre goût pour les biens statutaires, l’IA proposera la suppression de la voiture individuelle au profit de flottes collectives semi-autonomes appelées et congédiées d’un clic, elle élaborera des scénarios chiffrés de transition, dont la difficulté est actuellement prétexte à écarter l’idée.
Les retraites. Par principe de parcimonie, qui privilégie les hypothèses les plus simples, l’IA favorisera l’assertion « tous les humains ont une égale dignité, ils doivent être traités à égalité dès lors qu’ils cessent d’être des agents sociaux-économiques », et elle détaillera là aussi les difficiles scénarios de transition.
Les migrations. L’humanité s’est fondée sur les migrations, cela n’échappera pas aux machines.
La fin de vie. La machine ne produira rien qui fasse sens pour nous, car il s’agit de notre mort.
… dans une génération
Bien entendu nous serons libres de critiquer et réfuter les scénarios des machines. Cependant nos décisions face à ces scénarios devront être solidement argumentées et débattues, car nous aurons à en rendre compte aux générations futures. Les décisions des COP face aux expertises du GIEC donnent un avant goût de cette situation.
Il faudra une génération pour que le recours institutionnel à l’IA se mette en place. Le temps que celle-ci conquière progressivement notre confiance dans ce rôle. Il faudra en codifier l’usage au fil des expérimentations, comme on codifie le fonctionnement démocratique. Tout comme les experts sont corruptibles, les IA sont manipulables, aussi faudra-t-il également codifier les protocoles de traitement et confronter les IA comme on confronte les experts.
En revanche l’IA possède un énorme avantage en matière de transparence9. On ne peut pas sonder les crânes pour estimer la sincérité d’un argument, en revanche on peut expertiser les processus de façon reproductible, contradictoire et opposable.
Le spectre souvent évoqué de la dictature des algorithmes ou des IA n’est pas à craindre : la machine proposera, nous éclairant en surplomb de notre condition, nous seuls disposerons de notre destin. L’intelligence machine pèsera certes sur nos décisions, mais il n’y a là rien de nouveau, nous co-évoluons avec les outils dont nous nous dotons depuis l’époque où nos ancêtres taillaient les silex.
Max Dauchet, Professeur à l’Université de Lille
1 Une intelligence artificielle à la tête d’un pays : science fiction ou réalité future ? 27 octobre 2023
2Propos de Yann le Cun, prix Turing et un des pères de l’IA actuelle, dans une interview au Monde, le 28 avril 2023
3On a l’embarras du choix d’articles de tous niveaux sur le net. Pour un scientifique francophone non spécialiste, les cours du Collège de France, disponibles en vidéo, sont une entrée attrayante : ceux de Stanislas Dehaene, titulaire de la chaire «Psychologie cognitive expérimentale » pour les aspects biologiques, et pour les aspects sciences du numérique le cours de Yann Le Cun invité en 2015-2016 sur la chaire « Informatique et sciences numériques », ainsi que les cours de Stéphane Mallat, titulaire de la chaire « Sciences des données », axés autour du triangle « régularité, approximation, parcimonie », où l’extraction d’informations de masses de données s’apparente à une réduction de dimension des problèmes à milliards de paramètres.
On peut aussi aborder la comparaison entre biologie et numérique par le petit bout de la lorgnette, sans aucune connaissance préalable, à travers trois courts articles de mon blog https://la-data-au-secours-des-lumieres.blogspot.com/: « L’affaire du Perceptron » raconte par l’anecdote l’émoi suscité par le Perceptron dans les années 70, imposante machine qui s’avéra avec le recul n’être qu’un séparateur linéaire, comme l’est un neurone muni de la loi formulée par Hebb d’évolution des connexions, dont la vérification expérimentale valut à Eric Kandel le prix Nobel de médecine 2000, séparation linéaire qui est l’opération la plus élémentaire de classification, celle que les enfants apprennent en maternelle (« Le petit neurone et la règle d’écolier »). Dans « Le théorème de convergence du Perceptron », un cadre mathématique élémentaire élucide complètement le comportement du Perceptron, que d’aucuns voyaient un demi siècle auparavant supplanter l’homme.
4– La notion de ce qui est apprenable est cernée mathématiquement mais floue dans la pratique. Intuitivement, est apprenable ce qui est structuré, d’où la boutade des chercheurs « Soit le monde est structuré, soit Dieu existe » (rapportée d’Outre Atlantique par Yann le Cun), face aux succès dépassant mystérieusement leurs attentes. Il s’avère que le connexionnisme permet d’ exploiter les structures (d’un problème souvent riche de milliards de paramètres) sans avoir à les décrire. C’est ce que fait un enfant quand il apprend à faire des phrases sans rien connaître de la grammaire, ou qu’il apprend à se repérer sans rien connaître de la géométrie.
– Dans la pratique l’apprentissage ou la génération sont améliorés par des intervenants humains, qui peuvent être une foultitude de petites mains pour les grandes applications.
– L’universalité est théorique, pour être efficace dans la pratique, l’architecture d’un réseau est adaptée à tâtons à un problème, et tous les problèmes ne sont pas traitables en temps réaliste.
– De part son principe, l’algorithme de rétro-propagation peut converger vers divers comportements du réseau, sans que l’on puisse préciser à quel point ils sont bons. Des résultats théoriques montrent que de telles limitations sont inévitables.
– Dans l’intelligence humaine comme dans celle de la machine bien d’autres fonctions entrent en jeu, souvent encore mal connues en neurosciences, et souvent relevant de techniques dites symboliques en IA, techniques objets de controverses face au connexionnisme au cours de la jeune histoire de l’IA.
5Comme le relève Jason Richard dans sa liste des avantages de l’IA.
6Siri, un des premiers assistants personnels sur smartphone, fut accusé de tenir des propos inappropriés. Plus récemment des systèmes de reconnaissance faciale, entraînés principalement sur des blancs, commettaient des confusions sur les personnes de couleur.
7 Le Bug humain, Robert Laffont, 2020
8 Jean-Paul Delahaye, « Derrière les modèles massifs de langage », Pour la science, janvier 2024
9On reproche couramment à l’IA son manque d’explicabilité, parce que dans les applications de masse, les conditions d’exploitation ne permettent pas l’analyse des traces de calcul. Ce ne sera pas le cas ici.
26.01.2024 à 06:24
L’universalité de la vérification des démonstrations mathématiques
binaire
Continuer la lecture de « L’universalité de la vérification des démonstrations mathématiques »
Texte intégral (3335 mots)
Un nouvel « Entretien autour de l’informatique ». Gilles Dowek est chercheur en informatique chez Inria et enseignant à l’ENS de Paris-Saclay. Il est lauréat du Grand prix de philosophie 2007 de l’Académie française pour son ouvrage Les métamorphoses du calcul, une étonnante histoire de mathématiques (éditions Le Pommier) et du Grand prix Inria – Académie des sciences 2023 pour ses travaux sur les systèmes de vérification automatique de démonstrations mathématiques. Il a brièvement travaillé sur le système Coq au début de sa carrière. Il est à l’origine de Dedukti, un cadre logique permettant d’exprimer les théories utilisées dans différents systèmes de vérification de démonstrations. C’est l’une des personnes qui a le plus contribué à l’introduction en France de l’enseignement de l’informatique au collège et au lycée.

Binaire : Comment doit-on te présenter ? Mathématicien, logicien, informaticien ou philosophe ?
GD : Le seul métier que j’aie jamais exercé, c’est informaticien. La séparation des connaissances en disciplines est bien sûr toujours un peu arbitraire. Il y a des frontières qu’on passe facilement. Mes travaux empiètent donc sur les mathématiques, la logique et la philosophie. Mais je suis informaticien.
Binaire : Peux-tu nous raconter brièvement ta vie professionnelle ?
GD : Enfant, je voulais déjà être chercheur, mais je ne savais pas dans quelle discipline. Les chercheurs que je connaissais étaient surtout des physiciens : Einstein, Marie Curie… Je voyais dans la recherche une construction collective qui durait toute l’histoire de l’humanité. J’étais attiré par l’idée d’apporter une contribution, peut-être modeste, à cette grande aventure. Mes fréquentes visites au Palais de la Découverte m’ont encouragé dans cette voie.
J’ai commencé ma carrière de chercheur assez jeune grâce à l’entreprise Philips, qui organisait, à l’époque, chaque année un concours pour les chercheurs de moins de 21 ans, des amateurs donc. J’ai proposé un programme pour jouer au Master Mind et j’ai obtenu le 3ème prix. Jacques-Louis Lions qui participait au jury a fait lire mon mémoire à Gérard Huet, qui l’a fait lire à François Fages. J’avais chez moi en 1982 un ordinateur avec 1 k-octet de mémoire et mon algorithme avait besoin de plus. Je ne pouvais l’utiliser qu’en fin de partie et je devais utiliser un autre algorithme, moins bon, pour le début et le milieu de la partie.
Gérard et François m’ont invité à faire un stage pendant les vacances de Noël 1982. Ils ont tenté de m’intéresser à leurs recherches sur la réécriture, mais sans succès. La seule chose que je voulais était utiliser leurs ordinateurs pour implémenter mon algorithme pour jouer au Master Mind. Et ils m’ont laissé faire. Cela m’a permis d’avoir de bien meilleurs résultats et de finir avec le 3ème prix, cette fois au niveau européen.
Durant ce stage, Gérard m’avait quand même expliqué qu’il n’y avait pas d’algorithme pour décider si un programme terminait ou non ; il m’a juste dit que c’était un théorème, sans m’en donner la démonstration. Mais cela me semblait incroyable. À l’époque, pour moi, l’informatique se résumait à écrire des programmes ; je voyais cela comme une forme d’artisanat. Ce théorème m’ouvrait de nouveaux horizons : l’informatique devenait une vraie science, avec des résultats, et même des résultats négatifs. C’est ce qui m’a fait changer de projet professionnel.
Gérard m’avait aussi dit que, pour si je voulais vraiment être chercheur et avoir un poste, je devais faire des études. Alors j’ai fait des études, prépa puis école d’ingénieur. Je suis retourné chez Gérard Huet, pour mon stage de recherche de fin d’étude, puis pour ma thèse. Ensuite, je suis devenu professionnel de la recherche ; j’ai eu un poste et j’ai obtenu le grand plaisir de gagner ma vie en faisant ce qui m’intéressait et qui, le plus souvent, qui me procure toujours une très grande joie.
Binaire : Peux-tu nous parler de ta recherche ?
GD : En thèse, je cherchais des algorithmes de démonstration automatique pour produire des démonstrations dans un système qui est devenu aujourd’hui le système Coq. Mais dans les conférences, je découvrais que d’autres gens développaient d’autres systèmes de vérification de démonstrations, un peu différents. Cela me semblait une organisation curieuse du travail. Chacun de son côté développait son propre système, alors que les mathématiques sont, par nature, universelles.
Qu’est-ce qu’un système de vérification de démonstrations mathématiques ? Prouver un théorème n’est pas facile. En fait, comme l’ont montré Church et Turing, il n’existe pas d’algorithme qui puisse nous dire, quand on lui donne un énoncé, si cet énoncé a une démonstration ou non. En revanche, si, en plus de l’énoncé du théorème, on donne une démonstration potentielle de cet énoncé, il est possible de vérifier avec un algorithme que la démonstration est correcte. Trouver des méthodes pour vérifier automatiquement les démonstrations mathématiques était le programme de recherche de Robin Milner (Prix Turing) et également de Nicolaas De Bruijn. Mais en faisant cela, ils se sont rendu compte que si on voulait faire vérifier des démonstrations par des machines, il fallait les écrire très différemment, et beaucoup plus rigoureusement, que la manière dont on les écrit habituellement pour les communiquer à d’autres mathématiciens.
Les travaux de Milner et de De Bruijn ouvraient donc une nouvelle étape dans l’histoire de la rigueur mathématique, comme avant eux, ceux d’Euclide, de Russell et Whitehead et de Bourbaki. Le langage dans lequel on exprime les démonstrations devient plus précis, plus rigoureux. L’utilisation de logiciels change la nature même des mathématiques en créant, par exemple, la possibilité de construire des démonstrations qui font des millions de pages.
Notre travail était passionnant mais je restais insatisfait par le côté tour de Babel : chaque groupe arrivait avec son langage et son système de vérification. Est-ce que cela impliquait à un relativisme de la notion de vérité ? Il me semblait que cela conduisait à une crise de l’universalité de la vérité mathématique. Ce n’était certes pas la première de l’histoire, mais les crises précédentes avaient été résolues. J’ai donc cherché à construire des outils pour résoudre cette crise-là.
Binaire : Est-ce qu’on ne rencontre pas un problème assez semblable avec les langages de programmation ? On a de nombreuses propositions de langages.
GD : Tout à fait. Cela tient à la nature même des langages formels. Il faut faire des choix dans la manière de s’exprimer. Pour implémenter l’algorithme de l’addition dans un langage de programmation (ajouter les unités avec les unités, puis les dizaines avec les dizaines, etc. en propageant la retenue), on doit décider comment représenter les nombres, si le symbole « etc. » traduit une boucle, une définition par récurrence, une définition récursive, etc. Mais pour les langages de programmation, il y a des traducteurs (les compilateurs) pour passer d’un langage à un autre. Et on a un avantage énorme : tous les langages de programmation permettent d’exprimer les mêmes fonctions : les fonctions calculables.
Avec les démonstrations mathématiques, c’est plus compliqué. Tous les langages ne sont pas équivalents. Une démonstration particulière peut être exprimable dans un langage mais pas dans un autre. Pire, il n’y a pas de langage qui permette d’exprimer toutes les démonstrations : c’est une conséquence assez simple du théorème de Gödel. Peut-on traduire des démonstrations d’un langage vers un autre ? Oui, mais seulement partiellement.
Pour résoudre une précédente crise de l’universalité de la vérité mathématique, la crise des géométries non euclidiennes (*), Hilbert et Ackermann avaient introduit une méthode : ils avaient mis en évidence que Euclide, Lobatchevski et Riemann n’utilisaient pas les mêmes axiomes, mais surtout ils avaient proposé un langage universel, la logique des prédicats, dans lequel ces différents axiomes pouvaient s’exprimer. Cette logique des prédicats a été un grand succès des mathématiques des années 1920 et 1930 puisque, non seulement les différentes géométries, mais aussi l’arithmétique et la théorie des ensembles s’exprimaient dans ce cadre. Mais, rétrospectivement, on voit bien qu’il y avait un problème avec la logique des prédicats, puisque personne n’avait exprimé, dans ce cadre logique, la théorie des types de Russell, une autre théorie importante à cette époque. Et pour le faire, il aurait fallu étendre la logique des prédicats. Par la suite, de nombreuses autres théories ont été proposées, en particulier le Calcul des Constructions, qui est le langage du système Coq, et n’ont pas été exprimée dans ce cadre.
Au début de ma carrière, je pensais qu’il suffisait d’exprimer le Calcul des Constructions dans la logique des prédicats pour sortir de la tour de Babel et retrouver l’universalité de la vérité mathématique. C’était long, pénible, frustrant, et en fait, cette piste m’a conduit à une impasse. Mais cela m’a surtout permis de comprendre que nous avions besoin d’autres cadres que la logique des prédicats. Et, depuis les années 1980, plusieurs nouveaux cadres logiques étaient apparus dans les travaux de Dale Miller, Larry Paulson, Tobias Nipkow, Bob Harper, Furio Honsel, Gordon Plotkin, et d’autres. Nous avons emprunté de nombreuses idées à ces travaux pour aboutir à un nouveau cadre logique que nous avons appelé Dedukti (“déduire” en espéranto). C’est un cadre général, c’est-à-dire un langage pour définir des langages pour exprimer des démonstrations. En Dedukti, on peut définir par exemple la théorie des types de Russell ou le Calcul des Constructions et on peut mettre en évidence les axiomes utilisés dans chaque théorie, et surtout dans chaque démonstration.
Binaire : Pourquoi l’appeler Dedukti ? Ce n’est pas anodin ?
GD : Qu’est-ce qui guidait ces travaux ? L’idée que certaines choses, comme la vérité mathématique, sont communes à toute l’humanité, par-delà les différences culturelles. Nous étions attachés à cette universalité des démonstrations mathématiques, les voir comme des “communs”. Dans l’esprit, les liens avec des communs numériques comme les logiciels libres sont d’ailleurs étroits. On retrouve les valeurs d’universalité et de partage. Il se trouve d’ailleurs que la plupart des systèmes de vérification de démonstrations sont des logiciels libres. Coq et Dedukti le sont. Vérifier une démonstration avec un système qu’on ne peut pas lui-même vérifier, parce que son code n’est pas ouvert, ce serait bizarre.
Revenons sur cette universalité. Si quelqu’un arrivait avec une théorie et qu’on n’arrivait pas à exprimer cette théorie dans Dedukti, il faudrait changer Dedukti, le faire évoluer. Il n’est pas question d’imposer un seul système, ce serait brider la créativité. Ce qu’on vise, c’est un cadre général qui englobe tous les systèmes de vérification de démonstrations utilisés.
Longtemps, nous étions des gourous sans disciples : nous avions un langage universel, mais les seuls utilisateurs de Dedukti étaient l’équipe de ses concepteurs. Mais depuis peu, Dedukti commence à avoir des utilisateurs extérieurs à notre équipe, un peu partout dans le monde. C’est bien entendu une expansion modeste, mais cela montre que nos idées commencent à être comprises et partagées.
Binaire : Tu es très intéressé par les langages formels. Tu as même écrit un livre sur ce sujet. Pourrais-tu nous en parler ?
GD : Les débutants en informatique découvrent d’abord les langages de programmation. L’apprentissage d’un langage de programmation n’est pas facile. Mais la principale difficulté de cet apprentissage vient du fait que les langages de programmation sont des langages. Quand on s’exprime dans un langage, il faut tout dire, mais avec un vocabulaire et une syntaxe très pauvre. Les langages de démonstrations sont proches des langages de programmation. Mais de nombreux autres langages formels sont utilisés en informatique, par exemple des langages de requêtes comme SQL, des langages de description de pages web comme HTML, et d’autres. Le concept de langage formel est un concept central de l’informatique.
Mais ce concept a une histoire bien plus ancienne que l’informatique elle-même. Les humains ont depuis longtemps inventé des langages dans des domaines particuliers, comme les ophtalmologistes pour prescrire des lunettes. On peut multiplier les exemples : en mathématiques, les langages des nombres, de l’arithmétique, de l’algèbre, où apparaît pour la première fois la notion de variable, les cylindres à picots des automates, le langage des réactions chimiques, inventé au XIXe siècle, la notation musicale.
C’est le sujet de mon livre, Ce dont on ne peut parler, il faut l’écrire (Le Pommier, 2019). La création de langage est un énorme champ de notre culture. Les langages sont créés de toute pièce dans des buts spécifiques. Ils sont bien plus simples que les langues naturelles utilisées à l’oral. Ils expriment moins de choses mais ils sont souvent au centre des progrès scientifiques. L’écriture a probablement été inventée d’abord pour fixer des textes exprimés dans des langages formels et non dans des langues.
Binaire : Tu fais une très belle recherche, plutôt fondamentale. Est-ce que faire de la recherche fondamentale sert à quelque chose ?
GD : Je ne sais pas si je fais de la recherche fondamentale. En un certain sens, toute l’informatique est appliquée.
Maintenant, est-ce que la recherche fondamentale sert à quelque chose ? Cela me rappelle une anecdote. À l’École polytechnique, le poly d’informatique disait que la moitié de l’industrie mondiale était due aux découvertes de l’informatique et celui de physique que deux tiers de l’industrie mondiale étaient dus aux découvertes de la physique quantique. Les élèves nous faisaient remarquer que 1/2 + 2/3, cela faisait plus que 1. Bien entendu, les physiciens avaient compté toute l’informatique dans la partie de l’industrie que nous devions à la physique quantique, car sans physique quantique, pas de transistors, et sans transistors, pas d’informatique. Mais le message commun que nous voulions faire passer était que des pans entiers de l’économie existent du fait de découvertes scientifiques au départ perçues comme fondamentales. L’existence d’un algorithme pour décider de la correction d’une démonstration mathématique, question qui semble très détachée de l’économie, nous a conduit à concevoir des logiciels plus sûrs. La recherche la plus désintéressée, éloignée a priori de toute application, peut conduire à des transformations majeures de l’économie.
Cependant, ce n’est pas parce que la recherche a une forte influence sur le développement économique que nous pouvons en conclure que c’est sa seule motivation. La recherche nous sert aussi à mieux comprendre le monde, à développer notre agilité intellectuelle, notre esprit critique, notre curiosité. Cette quête participe de notre humanité. Et si cela conduit à des progrès industriels, tant mieux.
Serge Abiteboul, Inria, & Claire Mathieu, CNRS
(*) Des géomètres comme Euclide ont démontré que la somme des angles d’un triangle est toujours égale à 180 degrés. Mais des mathématiciens comme Lobatchevski ont démontré que cette somme était inférieure à 180 degrés. Crise ! Cette crise a été résolue au début du XXe siècle par l’observation, finalement banale, que Euclide et Lobatchevski n’utilisaient pas les mêmes axiomes, les mêmes présupposés sur l’espace géométrique.
https://www.lemonde.fr/blog/binaire/les-entretiens-de-la-sif/
19.01.2024 à 06:49
DAO : la gouvernance des communs par du code
binaire
Continuer la lecture de « DAO : la gouvernance des communs par du code »
Texte intégral (1692 mots)

F&S : qu’est-ce qui t’a conduite à étudier des sujets comme la blockchain ou les DAO ?
Primavera : je m’intéresse depuis longtemps aux communs, les Creative Commons, et aux formes décentralisées de production, de création. Je me suis intéressée aux blockchains et aux DAO parce ce que ces technologies permettent, facilitent et nécessitent des formes nouvelles de gouvernance des communs.
F&S : on va supposer que les lecteurs de binaire sont déjà familiers des blockchains. Pourrais-tu leur expliquer rapidement ce que sont les DAO et la place que tiennent les smart contracts dans ces organisations ?
Primavera : commençons par le smart contract. C’est un programme informatique qui sert à contrôler ou documenter automatiquement des actions entre des personnes (physiques ou morales) suivant les termes d’un accord ou d’un contrat entre elles. Une DAO (decentralized autonomous organization), en français organisation autonome décentralisée, est une organisation qui fonctionne grâce à des smart contracts. Le code qui définit les règles transparentes de gouvernance de son organisation est inscrit dans une blockchain.
F&S : nous nous intéressons aux communs. Que peuvent apporter les DAO aux communs ?
Primavera : les communs visent à gérer le partage de ressources par une communauté. Cette communauté a besoin de suivre des règles, et d’une gouvernance. Une DAO peut procurer cette gouvernance.
F&S : mais un commun n’est pas figé. Il évolue naturellement. Comment la DAO peut-elle s’adapter à de telles évolutions ?
Primavera : le smart contract doit évoluer et ce n’est pas simple une fois que la DAO fonctionne. Il faut avoir prévu des mécanismes pour de telles évolutions avant même son lancement. Cela peut-être des paramètres que la communauté modifie. Parfois, les fondateurs peuvent prévoir aussi des procédures pour faire évoluer le code. Enfin, l’ensemble de règles qui définissent le smart contract (son code) peut être lui-même une ressource d’une autre DAO. Cette seconde DAO est utilisée pour faire évoluer le code.
F&S : quelle est la valeur légale d’un smart contract ? Peut-on le voir comme un contrat ?
Primavera : non, un smart contract n’est pas un contrat au sens juridique du terme. Mais dans son esprit, cela peut être vu comme un accord entre deux parties. Si les deux parties agissent de manière éclairée, cela peut être vu comme un contrat juridique implicite. De fait, on dispose d’assez peu de jurisprudence sur ce sujet et la loi n’apporte pas de vraie reconnaissance aux smart contracts.
F&S : que se passe-t-il à la friction avec le monde physique, le monde légal. Quelle est, par exemple, la valeur légale d’un achat passé par un individu sur une blockchain, ou par une DAO ?
Primavera : on voit se multiplier ce genre de questions qui parlent de transferts d’un monde à l’autre. En fait, ce qui est passionnant dans la rencontre entre ces deux mondes, c’est que, dans le monde classique, le droit détermine la loi, alors, que dans ces mondes numériques, le code définit la loi. Il faut donc établir une reconnaissance juridique du code.
F&S : mais concrètement, comment fait une DAO pour payer des employés ou louer des locaux ?
Primavera : C’est compliqué parce que la DAO n’a pas de personnalité juridique. Une solution aujourd’hui qui ne marche pas parfaitement consiste à placer la DAO à l’intérieur d’une entité juridique ; on parle d’« enveloppe légale » (legal wrapper). Cela conduit à des entités qui sont semi technologiques et semi juridiques. Mais même si on prétend que ces deux entités forment un seul corps, ce n’est en réalité pas le cas.
F&S : est-ce que cela ne pose pas des questions de gouvernance et de responsabilité ?
Primavera : c’est bien le problème. L’entité juridique a des acteurs qui sont supposés être responsables. Mais les actions de la DAO ne sont pas nécessairement alignées avec celles de l’entité juridique, parce que la gouvernance n’est pas la même.
F&S : est-ce qu’on ne rencontre pas une situation semblable en cas de désaccords entre un commun, et la fondation qui le représente ? On pourrait penser, par exemple, à un désaccord entre le commun Wikipédia et la fondation Wikimédia.
Primavera : ce n’est pas vraiment pareil. Dans le cas du commun et de sa fondation, on peut imaginer que la fondation contrôle le commun parce qu’elle en est une émanation. Si elle entre en conflit avec la communauté, la communauté va faire évoluer la fondation ou faire sécession. Pour ce qui est de la DAO, ce n’est pas possible.
F&S : tu t’intéresses aussi au métavers. Pourquoi ?
Primavera : le web est un monde décentralisé de contenus numériques. Toute la beauté d’internet et du web tient à l’interopérabilité qui est à leur base qui est source de partage. Cette interopérabilité est déjà mise à mal par des silos dans lesquels on veut vous confiner : les réseaux sociaux, les App… Dans cette lignée, les métavers sont des mondes virtuels a priori très centralisés. Comment peut-on les faire interopérer ?
Par exemple, dans ces mondes, on possède des objets numériques que l’on peut acheter et vendre. Comment retrouver dans un de ces mondes un objet que j’aurais acheté dans un autre. C’est là que la blockchain et les non-fungible-tokens (NFT) deviennent intéressants. Avec un NFT, j’ai une preuve de propriété de mon achat d’un objet numérique. C’est une possibilité d’interopérabilité d’un monde à l’autre.
Dans tous ces sujets qui m’intéressent, on retrouve ce même souhait de faire du monde numérique un commun, de refuser de se laisser enfermer dans des silos.
Serge Abiteboul, Inria, et François Bancilhon, entrepreneur en série
- Persos A à L
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- EDUC.POP.FR
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Frédéric LORDON
- LePartisan.info
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Romain MIELCAREK
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Emmanuel PONT
- Nicos SMYRNAIOS
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- Numérique
- Binaire [Blogs Le Monde]
- Christophe DESCHAMPS
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Francis PISANI
- Pixel de Tracking
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Bondy Blog
- Dérivation
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- ROJAVA Info
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- XKCD