
12.12.2025 à 13:09
Le sort de Warner Bros suspendu au duel Netflix–Paramount
Julien Jourdan, Professeur, HEC Paris Business School
Texte intégral (1496 mots)
Ce pourrait être un épisode d’une série américaine sur le monde des affaires. Qui, de Paramount ou de Netflix, mettra la main sur la Warner Bros ? Les deux projets n’ont pas les mêmes motivations. Surtout, l’un et l’autre devront faire avec le droit de la concurrence aux États-Unis, mais aussi en Europe, mondialisation oblige. Résumé des premiers épisodes, si vous avez manqué le début…
La nouvelle a frappé Hollywood de stupeur. Le 4 décembre dernier, Netflix annonçait l’acquisition des studios Warner Bros. (WB) pour 83 milliards de dollars, coiffant au poteau le favori Paramount. La situation s’est depuis compliquée : le patron de Paramount, David Ellison, a surenchéri avec une offre hostile à 108 milliards de dollars pour l’ensemble du groupe WB Discovery, incluant les studios ainsi qu’un bouquet – en déclin – de chaînes de télévision, dont la célèbre chaîne d’information CNN.
L’issue de cette bataille est incertaine à l’heure actuelle. Les deux opérations sont de nature différente. Un achat par Paramount impliquerait une triple fusion entre deux studios, deux plates-formes de streaming – Paramount+ (79 millions d’abonnés) et HBO+ (128 millions d’abonnés) – et deux bouquets de chaînes de télévision (dont CNN et CBS). Ce serait une fusion horizontale entre des acteurs en concurrence directe sur leurs marchés. L’impact social pourrait être très lourd : l’opération prévoit 6 milliards de dollars de synergies, en grande partie via la suppression de postes en doublon.
À lire aussi : Netflix, une machine à standardiser les histoires ?
Si Netflix mettait la main sur WB, ce serait principalement pour acquérir le vaste catalogue de WB et de HBO, les chaînes du câble étant exclues de l’offre du géant du streaming. Les synergies anticipées, de l’ordre de 3 milliards, concerneraient les dépenses technologiques pour les deux tiers et seraient constituées, pour le reste, d’économies sur les achats de droits de diffusion. Netflix pourrait ainsi librement diffuser Game of Thrones ou Harry Potter auprès de ses 302 millions d’abonnés dans le monde. Ce serait une fusion verticale combinant un producteur de contenus, WB, et un diffuseur, Netflix, qui éliminerait au passage un concurrent notable, HBO+.
Des précédents coûteux
Ce type d’opération pourrait rendre nerveux quiconque se rappelle l’histoire des fusions de Warner Bros. Déjà en 2001, le mariage de WB et d’AOL célébrait l’alliance du contenu et des « tuyaux » – pour utiliser les termes alors en vogue. L’affaire s’était terminée de piteuse manière par le spin-off d’AOL et l’une des plus grosses dépréciations d’actifs de l’histoire – de l’ordre de 100 milliards de dollars. Quinze ans plus tard, AT&T retentait l’aventure. L’union fut de courte durée. En 2021, le géant des télécoms se séparait de WB, qui se voyait désormais associé au groupe de télévision Discovery, sous la direction de David Zaslav, aujourd’hui à la manœuvre.
Pourquoi ce qui a échoué dans le passé marcherait-il aujourd’hui ? À dire vrai, la position stratégique de Netflix n’a rien à voir avec celle d’AOL et d’AT&T. Les fusions verticales précédentes n’ont jamais produit les synergies annoncées pour une simple raison : disposer de contenu en propre n’a jamais permis de vendre plus d’abonnements au téléphone ou à Internet. Dans les deux cas, le château de cartes, vendu par les dirigeants, et leurs banquiers, s’est rapidement effondré.
Un catalogue sans pareil
Une fusion de Netflix avec WB délivrerait en revanche des bénéfices très concrets : le géant du streaming ajouterait à son catalogue des produits premium – films WB et séries HBO – dont il est à ce jour largement dépourvu. L’opération permettrait de combiner l’une des bibliothèques de contenus les plus riches et les plus prestigieuses avec le média de diffusion mondiale le plus puissant qui ait jamais existé. L’ensemble pourrait en outre attirer les meilleurs talents, qui restent à ce jour largement inaccessibles à Netflix.
En pratique, certains contenus, comme la série Friends, pourraient être inclus dans l’offre de base pour la rendre plus attractive et recruter de nouveaux abonnés. D’autres films et séries pourraient être accessibles via une ou plusieurs options payantes, sur le modèle de ce que fait déjà Amazon Prime, augmentant ainsi le panier moyen de l’abonné.
Le rapprochement de deux stars du divertissement ferait à coup sûr pâlir l’offre de leurs concurrents, dont Disney mais aussi… Paramount. Et c’est là que le bât blesse. Les autorités de la concurrence, aux États-Unis et en Europe, approuveront-elles la formation d’un tel champion mondial ? Si la fusion est confirmée, les procédures en recours ne tarderont pas à arriver.
CNN dans le viseur
C’est l’argument avancé par David Ellison, le patron de Paramount, qui agite le chiffon rouge de l’antitrust pour convaincre les actionnaires de WBD : que restera-t-il du studio si la fusion avec Netflix est rejetée après deux ans de procédures ? Ted Sarandos, le co-PDG de Netflix, pourrait lui retourner la pareille, car une fusion horizontale avec Paramount ne manquerait pas d’éveiller, elle aussi, des inquiétudes – d’autant plus qu’elle serait largement financée par des capitaux étrangers venant du Golfe.
Le fils de Larry Ellison, deuxième fortune mondiale, réputé proche du président américain, s’est assuré le soutien financier du gendre de ce dernier, Jared Kushner. Si Donald Trump se soucie probablement assez peu du marché du streaming, il pourrait être sensible au sort réservé à la chaîne CNN, une de ses bêtes noires. En cas de victoire de Paramount, CNN pourrait être combinée avec CBS et sa ligne éditoriale revue pour apaiser le locataire de la Maison-Blanche. Du côté du vendeur, David Zaslav laisse les enchères monter. Il pourrait empocher une fortune – on parle de plus de 425 millions de dollars.
À cette heure, le sort de WB est entre les mains de cette poignée d’hommes. Des milliers d’emplois à Los Angeles, et ailleurs, sont en jeu. Une fusion WB/Netflix pourrait par ailleurs accélérer la chute de l’exploitation des films en salles, dans un contexte d’extrême fragilité : le nombre de tickets vendus dans les cinémas en Amérique du Nord a chuté de 40 % depuis 2019. Netflix pourrait choisir de diffuser directement sur sa plateforme certains films de WB, qui représente environ un quart du marché domestique du cinéma. Pour les films qui conserveraient une sortie en salle, la fenêtre d’exclusivité réservée aux exploitants pourrait se réduire à quelques semaines, fragilisant un peu plus leur économie. Hollywood retient son souffle.
Julien Jourdan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.12.2025 à 13:08
Le smic protège-t-il encore de la pauvreté ?
Hugo Spring-Ragain, Doctorant en économie / économie mathématique, Centre d'études diplomatiques et stratégiques (CEDS)
Texte intégral (1866 mots)
Vendredi 12 décembre 2025, le Groupe d’experts sur le smic publie un rapport sur l’impact du salaire minimum sur l’économie française. Son impact sur la pauvreté n’est cependant pas univoque. Le smic ne suffit pas à expliquer les trajectoires personnelles de plus en plus diverses. Le revenu disponible qui prend en compte les aides perçues et les dépenses contraintes est un critère plus juste.
La question revient cette année encore avec le rapport du Groupe d’experts du smic publié ce vendredi 12 décembre : le salaire minimum protège-t-il encore réellement de la pauvreté ? Pourtant, comme l’ont rappelé l’Insee et l’Institut des politiques publiques (IPP) dans plusieurs travaux plus ou moins récents, le salaire brut, seul, ne détermine pas la pauvreté. Ce qui importe, c’est le niveau de vie, c’est-à-dire le revenu disponible après transferts sociaux de toutes sortes (qui s’ajoutent), impôts et charges contraintes (qui se soustraient). Dans un contexte de renchérissement du logement (13 % d’augmentation de l’indice de référence des loyers, IRL) et d’hétérogénéité croissante des situations familiales, la question ne doit plus être posée en termes uniquement macroéconomiques.
La littérature académique reprend ce constat. Antony B. Atkinson souligne que la pauvreté ne renvoie pas simplement à un « manque de salaire », mais à un insuffisant accès aux ressources globales ; Patrick Moyes rappelle que la structure familiale modifie profondément le niveau de vie relatif. Quant à France Stratégie et l’Insee, après sa publication faisant l’état des lieux de la pauvreté en France, ils documentent la montée de ce qu’on appelle la pauvreté laborieuse, c’est-à-dire le fait de travailler sans pour autant dépasser les seuils de pauvreté et sans possibilité de profiter de l’ascenseur social.
À lire aussi : La pauvreté de masse : symptôme d’une crise de la cohésion sociale
Un amortisseur d’inflation ?
Notre premier graphique compare l’évolution du smic, des salaires et des prix depuis 2013. On y observe très nettement que le salaire minimum a servi d’amortisseur pendant la séquence inflationniste récente : ses revalorisations automatiques l’ont fait progresser aussi vite, souvent plus vite, que l’indice des prix à la consommation.
Figure 1 – Évolution du smic, du salaire mensuel de base (SMB), du salaire horaire de base des ouvriers et des employés (SHBOE) et de l’indice des prix à la consommation (IPC) hors Tabac – Sources : Dares, Insee, Rapport GES 2025 – Graphique de l’auteur.
Ce mouvement contraste avec celui des salaires moyens, dont la progression a été plus lente. Comme le soulignent plusieurs analyses de France Stratégie et de l’Organisation de coopération et de développement économiques (OCDE), cela a eu pour effet de resserrer la hiérarchie salariale, une situation déjà documentée lors de précédentes périodes de rattrapage du smic.
L’influence du temps de travail
Mais ce constat ne dit rien d’une dimension pourtant déterminante : l’accès au temps plein car une partie des salariés au smic n’y est pas à temps complet. Comme l’ont montré plusieurs travaux de l’Insee et de la direction de l’animation de la recherche, des études et des statistiques (Dares, ministère du travail), une proportion importante de travailleurs rémunérés au salaire minimum occupe des emplois à temps partiel, et souvent non par choix mais parce qu’aucun temps plein n’est disponible. C’est ce que les économistes appellent le temps partiel contraint.
Ce temps partiel modifie radicalement l’interprétation du smic : on parle d’un salaire minimum horaire, mais, concrètement, les ressources mensuelles ne reflètent pas ce taux. Un salaire minimum versé sur 80 % d’un temps plein ou sur des horaires discontinus conduit mécaniquement à un revenu inférieur et donc à une exposition accrue à la pauvreté.
Mais si l’on s’en tenait à cette comparaison, on pourrait conclure que le smic protège pleinement les salariés les plus modestes. Or, c’est précisément ici que la question se complexifie. Car la pauvreté ne dépend pas du seul salaire : elle dépend du revenu disponible et donc de l’ensemble des ressources du ménage. C’est ce que montrent les travaux sur la pauvreté laborieuse, un phénomène en hausse en France selon l’Observatoire des inégalités, environ une personne en situation de pauvreté sur trois occupe un emploi mais les charges familiales, le coût du logement ou l’absence de second revenu maintiennent le ménage sous les seuils de pauvreté.
Du smic au revenu disponible
Pour comprendre la capacité réelle du smic à protéger de la pauvreté, il faut observer ce qu’il devient une fois transformé en revenu disponible grâce aux données de l’Insee et de la Dares, c’est-à-dire le revenu après impôts, aides et charges incompressibles.
Le graphique suivant juxtapose trois situations familiales : une personne seule, un parent isolé avec un enfant et un couple avec un enfant dont les deux adultes perçoivent le smic.
Figure 2 – Revenu disponible et seuils de pauvreté selon trois profils de ménages rémunérés au smic Sources : Dares, Insee, Rapport GES 2025 – Graphique de l’auteur.
Dans le premier panneau, on observe qu’une personne seule rémunérée au smic dispose d’un revenu disponible supérieur au seuil de pauvreté à 60 % du revenu médian. La prime d’activité joue un rôle important, mais c’est surtout l’absence de charge familiale et de coûts fixes élevés qui explique ce résultat.
Ce profil correspond à la représentation classique du smic comme filet de sécurité individuel. Comme le confirment les données de l’Insee et les travaux de France Stratégie, la pauvreté laborieuse y est encore relativement limitée. Cependant, même seul, un actif au smic pourrait avoir des dépenses contraintes extrêmement élevées dans des zones à forte demande locative.
La pauvreté laborieuse
Le deuxième panneau raconte une histoire totalement différente. Le parent isolé, même à temps plein au smic se situe clairement en dessous du seuil de pauvreté, plus grave encore, son revenu disponible ne compense plus le salaire net via les transferts. C’est ici que la notion de pauvreté laborieuse prend tout son sens. Malgré un emploi et malgré les compléments de revenu, le ménage reste dans une situation de fragilité structurelle.
Selon l’Insee, les familles monoparentales sont aujourd’hui le groupe le plus exposé à la pauvreté et notamment à la privation matérielle et sociale, non parce qu’elles travaillent moins, mais parce qu’elles cumulent un revenu unique, des charges plus élevées et une moindre capacité d’ajustement.
Dans le troisième panneau, un couple avec un enfant et deux smic vit lui aussi en dessous de la ligne de pauvreté. Ce résultat laisse penser que la composition familiale, même accompagnée de deux smic crée une pauvreté structurelle sur les bas revenus ; aussi le graphique montre-t-il que la marge est finalement assez limitée. Une partie du gain salarial disparaît en raison de la baisse des aides et de l’entrée dans l’impôt, un phénomène bien documenté par l’IPP et par le rapport Bozio-Wasmer dans leurs travaux sur les « taux marginaux implicites ». Dans les zones de loyers élevés, un choc de dépense ou une hausse de charges peut faire basculer ces ménages vers une situation beaucoup plus précaire.
Situations contrastées
Une conclusion s’impose : le smic protège encore une partie des salariés contre la pauvreté, mais ce résultat est loin d’être uniforme. Il protège l’individu à plein temps et sans enfant, mais ne suffit plus à assurer un niveau de vie décent lorsque le salaire doit couvrir seul les charges d’un foyer, notamment dans les configurations monoparentales. Cette asymétrie est au cœur de la montée de la pauvreté laborieuse observée par l’Insee et documentée par l’Institut des politiques publiques.
Ces résultats rappellent que la pauvreté n’est plus seulement un phénomène d’exclusion du marché du travail. Elle touche des travailleurs insérés, qualifiés et en contrat stable, mais dont le salaire minimum, appliqué sur un volume horaire insuffisant ou absorbé par des dépenses contraintes, ne permet plus un niveau de vie supérieur aux seuils de pauvreté. Le smic se révèle alors davantage un plancher salarial individuel qu’un instrument de garantie sociale familiale.
À l’heure où la question du pouvoir d’achat occupe une place centrale et où la revalorisation du smic reste l’un des outils majeurs d’ajustement, ces conclusions invitent à réorienter le débat. Ce n’est pas seulement le niveau du smic qu’il faut interroger, mais sa capacité à constituer un revenu de référence pour des configurations familiales et territoriales très hétérogènes. Autrement dit, le smic joue encore sa fonction de stabilisateur individuel, mais il n’est plus suffisant seul pour protéger durablement certains ménages.
La question devient alors moins « De combien augmenter le smic ? » que « Comment garantir que le revenu disponible issu d’un emploi au smic permette effectivement d’éviter la pauvreté ? ».
Hugo Spring-Ragain ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.12.2025 à 16:16
L’internationale trumpiste : la Stratégie de sécurité nationale 2025 comme manifeste idéologique
Jérôme Viala-Gaudefroy, Spécialiste de la politique américaine, Sciences Po
Texte intégral (2420 mots)
L’administration Trump vient de rendre publique sa Stratégie de sécurité nationale. Charge virulente contre l’Europe, affirmation de l’exceptionnalisme des États-Unis, présentation du président actuel en héros affrontant au nom de son pays des périls mortels pour la civilisation occidentale : bien plus qu’un simple ensemble de grandes lignes, il s’agit d’une véritable proclamation idéologique.
La Stratégie de sécurité nationale (National Security Strategy, NSS) est normalement un document technocratique, non contraignant juridiquement, que chaque président des États-Unis doit, durant son mandat, adresser au Congrès pour guider la politique étrangère du pays.
La version publiée par l’administration Trump en 2025 (ici en français) ressemble pourtant moins à un texte d’État qu’à un manifeste idéologique MAGA (Make America Great Again) qui s’adresse tout autant à sa base qu’au reste du monde, à commencer par les alliés européens de Washington, accusés de trahir la « vraie » démocratie. Pour la première fois, et contrairement à la NSS du premier mandat Trump publiée en 2017, la sécurité nationale y est définie presque exclusivement à partir des obsessions trumpistes : immigration, guerre culturelle, nationalisme.
Les trois principales articulations du texte
La NSS 2025 rompt complètement avec la tradition libérale de la démocratie constitutionnelle (respect des droits fondamentaux, primauté de l’État de droit, pluralisme) et avec sa traduction internationale — la promotion de la démocratie dans le cadre d’un ordre multilatéral fondé sur des règles. Elle réécrit l’histoire depuis la fin de la guerre froide, construit un ennemi composite (immigration, élites « globalistes », Europe) et détourne le vocabulaire de la liberté et de la démocratie au service d’un exceptionnalisme ethno-populiste.
Ce document présente une grande narration en trois actes.
Acte I : La trahison des élites.
C’est le récit de l’échec des politiques menées par les États-Unis depuis 1991, imputées à l’hubris d’élites qui auraient voulu l’hégémonie globale. Elles auraient mené des « guerres sans fin », mis en place un « prétendu libre-échange » et soumis le pays à des institutions supranationales, au prix de l’industrie américaine, de la classe moyenne, de la souveraineté nationale et de la cohésion culturelle. Ce premier acte souligne enfin l’incapacité à renouveler un récit national crédible après la fin de la guerre froide : c’est sur ce vide narratif que Trump construit son propre récit.
Acte II : Le déclin.
Le déclin des États-Unis tel que vu par l’administration Trump est à la fois économique, moral, géopolitique et démographique. Il se manifeste par la désindustrialisation, les guerres ratées, ou encore par la crise des frontières avec le Mexique. Il fait écho au « carnage américain » que l’actuel président avait dénoncé lors de son premier discours d’investiture, en 2017. L’ennemi est ici décrit comme à la fois intérieur et extérieur : l’immigration, présentée comme une « invasion » liée aux cartels, mais aussi les institutions internationales et les élites de politique étrangère, américaines comme européennes. Tous sont intégrés dans un même schéma conflictuel, celui d’une guerre globale que l’administration Trump serait prête à mener contre ceux qui menaceraient souveraineté, culture et prospérité américaines.
Acte III : Le sauveur.
La NSS présente le locataire de la Maison Blanche comme un leader providentiel, comme le « président de la Paix » qui corrige la trahison des élites. Trump y apparaît comme un « redresseur », héros (ou anti-héros) qui aurait, en moins d’un an, « réglé huit conflits violents ». Il incarnerait une nation retrouvée, prête à connaître un « nouvel âge d’or ». On retrouve ici un schéma narratif typiquement américain, issu de la tradition religieuse de la jérémiade : un prêche qui commence par dénoncer les fautes et la décadence, puis propose un retour aux sources pour « sauver » la communauté. L’historien Sacvan Bercovitch a montré que ce type de récit est au cœur du mythe national américain. Un texte qui devrait être techno-bureaucratique se transforme ainsi en récit de chute et de rédemption.
L’exceptionnalisme américain à la sauce Trump
À y regarder de près, la NSS 2025 foisonne de tropes propres aux grands mythes américains. Il s’agit de « mythifier » la rupture avec des décennies de politique étrangère en présentant la politique conduite par l’administration Trump comme un retour aux origines.
Le texte invoque Dieu et les « droits naturels » comme fondement de la souveraineté, de la liberté, de la famille traditionnelle, voire de la fermeture des frontières. Il convoque la Déclaration d’indépendance et les « pères fondateurs des États-Unis » pour justifier un non-interventionnisme sélectif. Il se réclame aussi de « l’esprit pionnier de l’Amérique » pour expliquer la « domination économique constante » et la « supériorité militaire » de Washington.
Si le mot exceptionalism n’apparaît pas (pas plus que la formule « indispensable nation »), la NSS 2025 est saturée de formulations reprenant l’idée d’une nation unique dans le monde : hyper-superlatifs sur la puissance économique et militaire, rôle central de l’Amérique comme pilier de l’ordre monétaire, technologique et stratégique. Il s’agit d’abord d’un exceptionnalisme de puissance : le texte détaille longuement la domination économique, énergétique, militaire et financière des États-Unis, puis en déduit leur supériorité morale. Si l’Amérique est « la plus grande nation de l’histoire » et « le berceau de la liberté », c’est d’abord parce qu’elle est la plus forte. La vertu n’est plus une exigence qui pourrait limiter l’usage de la puissance ; elle est au contraire validée par cette puissance.
Dans ce schéma, les élites — y compris européennes — qui affaiblissent la capacité américaine en matière d’énergie, d’industrie ou de frontières ne commettent pas seulement une erreur stratégique, mais une faute morale. Ce n’est plus l’exceptionnalisme libéral classique de la diffusion de la démocratie, mais une forme d’exceptionnalisme moral souverainiste : l’Amérique se pense comme principale gardienne de la « vraie » liberté, contre ses adversaires mais aussi contre certains de ses alliés.
Là où les stratégies précédentes mettaient en avant la défense d’un « ordre international libéral », la NSS 2025 décrit surtout un pays victime, exploité par ses alliés, corseté par des institutions hostiles : l’exceptionnalisme devient le récit d’une surpuissance assiégée plutôt que d’une démocratie exemplaire. Derrière cette exaltation de la « grandeur » américaine, la NSS 2025 ressemble davantage à un plan d’affaires, conçu pour servir les intérêts des grandes industries — et, au passage, ceux de Trump lui-même. Ici, ce n’est pas le profit qui se conforme à la morale, c’est la morale qui se met au service du profit.
Une vision très particulière de la doctrine Monroe
De même, le texte propose une version mythifiée de la doctrine Monroe (1823) en se présentant comme un « retour » à la vocation historique des États-Unis : protéger l’hémisphère occidental des ingérences extérieures. Mais ce recours au passé sert à construire une nouvelle doctrine, celui d’un « corollaire Trump » — en écho au « corollaire Roosevelt » : l’Amérique n’y défend plus seulement l’indépendance politique de ses voisins, elle transforme la région en chasse gardée géo-économique et migratoire, prolongement direct de sa frontière sud et vitrine de sa puissance industrielle.
À lire aussi : États-Unis/Venezuela : la guerre ou le deal ?
Sous couvert de renouer avec Monroe, le texte légitime une version trumpiste du leadership régional, où le contrôle des flux (capitaux, infrastructures, populations) devient le cœur de la mission américaine. Là encore, le projet quasi impérialiste de Trump est présenté comme l’extension logique d’une tradition américaine, plutôt que comme une rupture.
La NSS 2025 assume au contraire une ingérence politique explicite en Europe, promettant de s’opposer aux « restrictions antidémocratiques » imposées par les élites européennes (qu’il s’agisse, selon Washington, de régulations visant les plates-formes américaines de réseaux sociaux, de limitations de la liberté d’expression ou de contraintes pesant sur les partis souverainistes) et de peser sur leurs choix énergétiques, migratoires ou sécuritaires. Autrement dit, Washington invoque Monroe pour sanctuariser son hémisphère, tout en s’arrogeant le droit d’intervenir dans la vie politique et normative européenne — ce qui revient à revendiquer pour soi ce que la doctrine refuse aux autres.
Dans la NSS 2025, l’Europe est omniprésente — citée une cinquantaine de fois, soit deux fois plus que la Chine et cinq fois plus que la Russie —, décrite comme le théâtre central d’une crise à la fois politique, démographique et civilisationnelle. Le texte oppose systématiquement les « élites » européennes à leurs peuples, accusant les premières d’imposer, par la régulation, l’intégration européenne et l’ouverture migratoire, une forme d’« effacement civilisationnel » qui reprend, sans le dire, la logique du « grand remplacement » de Renaud Camus, théorie complotiste d’extrême droite largement documentée.
À lire aussi : L’Europe vue par J. D. Vance : un continent à la dérive que seul un virage vers l’extrême droite pourrait sauver
L’administration Trump s’y arroge un droit d’ingérence idéologique inédit : elle promet de défendre les « vraies » libertés des citoyens européens contre Bruxelles, les cours et les gouvernements, tout en soutenant implicitement les partis d’extrême droite ethno-nationalistes qui se posent en porte-voix de peuples trahis. L’Union européenne est dépeinte comme une machine normative étouffante, dont les règles climatiques, économiques ou sociétales affaibliraient la souveraineté des nations et leur vitalité démographique. Ce faisant, le sens même des mots « démocratie » et « liberté » est inversé : ce ne sont plus les institutions libérales et les traités qui garantissent ces valeurs, mais leur contestation au nom d’un peuple soi-disant homogène et menacé, que Washington prétend désormais protéger jusque sur le sol européen.
La Russie, quant à elle, apparaît moins comme ennemi existentiel que comme puissance perturbatrice dont la guerre en Ukraine accélère surtout le déclin européen. La NSS 2025 insiste sur la nécessité d’une cessation rapide des hostilités et de la mise en place d’un nouvel équilibre stratégique, afin de favoriser les affaires. La Chine est le seul véritable rival systémique, surtout économique et technologique. La rivalité militaire (Taïwan, mer de Chine) est bien présente, mais toujours pensée à partir de l’enjeu clé : empêcher Pékin de transformer sa puissance industrielle en hégémonie régionale et globale.
Le Moyen-Orient n’est plus central : grâce à l’indépendance énergétique, Washington cherche à transférer la charge de la sécurité à ses alliés régionaux, en se réservant un rôle de faiseur de deals face à un Iran affaibli. L’Afrique, enfin, est envisagée comme un terrain de reconquête géo-économique face à la Chine, où l’on privilégie les partenariats commerciaux et énergétiques avec quelques États jugés « fiables », plutôt qu’une politique d’aide ou d’interventions lourdes.
Un texte qui ne fait pas consensus
Malgré la cohérence apparente et le ton très péremptoire de cette doctrine, le camp MAGA reste traversé de fortes divisions sur la politique étrangère, entre isolationnistes « America First » hostiles à toute projection de puissance coûteuse et faucons qui veulent continuer à utiliser la supériorité militaire américaine pour imposer des rapports de force favorables.
Surtout, les sondages (ici, ici, ou ici) montrent que, si une partie de l’électorat républicain adhère à la rhétorique de fermeté (frontières, Chine, rejet des élites), l’opinion américaine dans son ensemble demeure majoritairement attachée à la démocratie libérale, aux contre-pouvoirs et aux alliances traditionnelles. Les Américains souhaitent moins de guerres sans fin, mais ils ne plébiscitent ni un repli illibéral ni une remise en cause frontale des institutions qui structurent l’ordre international depuis 1945.
Jérôme Viala-Gaudefroy ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.12.2025 à 15:57
Le cash recule, mais reste solidement ancré dans les portefeuilles des Français
Timothée Waxin, Responsable du département Finance, Data & Performance, Pôle Léonard de Vinci
Texte intégral (1491 mots)
Le cash recule mais ne disparaît pas. Face à l’essor fulgurant des paiements numériques et aux ambitions européennes d’un euro digital, les espèces résistent, portées par la recherche de confidentialité, de contrôle et de résilience. À l’heure du tout dématérialisé, les Français n’ont pas encore remisé pièces et billets.
Le cash, c’est-à-dire l’argent liquide, tangible et immédiatement disponible, est très ancien, bien antérieur au mot lui-même. Les premières pièces de monnaie remontent à 600 avant notre ère environ en Lydie (actuelle Turquie). Les billets de banque remplacent progressivement les pièces à partir du XVIIe siècle.
Plus de 2 600 ans après son apparition, la monnaie fiduciaire (pièces et billets), par opposition à la monnaie scripturale (virements, cartes, paiements mobiles…), est-elle condamnée à disparaître ?
Un moindre usage des espèces au profit des paiements dématérialisés
L’usage des espèces recule progressivement en France au profit de la carte bancaire et des paiements mobiles. La quatrième enquête de la Banque centrale européenne (BCE) sur les habitudes de paiement des consommateurs en zone euro, publiée en décembre 2024, montre en effet que les paiements par carte représentent désormais 48 % des transactions, contre 43 % pour les paiements en espèces.
Pour la première fois, la carte dépasse donc le cash dans l’Hexagone – une situation qui contraste avec celle de l’ensemble de la zone euro, où les espèces demeurent le moyen de paiement le plus utilisé aux points de vente.
Répartition des moyens de paiement aux points de vente, en France et en zone euro (en % du nombre de transactions)
Cette évolution s’inscrit dans une tendance de long terme, nourrie par un environnement propice à l’innovation et à la numérisation des services financiers.
L’écosystème français des paiements, porté par un tissu dynamique de fintech, propose une offre diversifiée de solutions scripturales qui séduit un nombre croissant de consommateurs. L’essor du paiement sans contact accompagne ce mouvement. Apparue en 2012 avec un plafond initial de 20 euros, relevé successivement à 30 puis 50 euros, cette fonctionnalité concerne aujourd’hui près de sept paiements sur dix réalisés au point de vente. Le développement de la technologie dite « PIN online », permettant de dépasser ce seuil après saisie d’un code sur le terminal de paiement, devrait encore accélérer cette adoption. Parallèlement, la croissance du commerce en ligne a profondément transformé les usages.
Un quart des paiements en France s’effectue désormais sur Internet, une évolution largement stimulée par la crise sanitaire, qui a ancré durablement les réflexes numériques des consommateurs. Les paiements mobiles et les virements instantanés connaissent eux aussi une progression rapide, soutenue par l’émergence de solutions innovantes comme Wero, service européen de paiement instantané proposé par les banques de cinq pays européens.
Cette transition vers le numérique soulève des enjeux majeurs
Cette dynamique devrait se poursuivre à mesure que l’écosystème des paiements continue d’évoluer. De nouveaux acteurs – prestataires techniques, grandes entreprises technologiques, fintech spécialisées – renforcent leur présence dans la chaîne de valeur des paiements.
Dans ce contexte d’initiatives privées et de dématérialisation accrue, les banques centrales cherchent à préserver leur rôle dans les paiements. L’Eurosystème prépare ainsi l’émission d’un euro numérique, destiné à compléter les espèces et les moyens de paiement existants. Son déploiement pourrait intervenir à l’horizon 2027 ou 2028, malgré des interrogations persistantes sur sa complexité d’usage et sa valeur ajoutée perçue par le grand public.
De leur côté, les paiements en stablecoins progressent également, portés par des cas d’usage concrets dans le commerce numérique, les transferts de fonds et les paiements internationaux : ils s’intègrent de plus en plus à l’économie réelle et ne relèvent plus uniquement de la spéculation.
Toutefois, cette transition vers le numérique soulève des enjeux majeurs de souveraineté. Comme le souligne François Villeroy de Galhau, gouverneur de la Banque de France, dans sa Lettre au président de la République, d’avril 2025, 72 % des paiements par carte en zone euro au second semestre 2023 reposaient sur des réseaux internationaux. Christine Lagarde, présidente de la BCE, alerte également sur la dépendance de l’Europe à des infrastructures non européennes – Visa, Mastercard, PayPal, Alipay – issues pour la plupart des États-Unis ou de Chine.
Les infrastructures de cartes nationales, comme Carte bleue (CB) en France, s’érodent en Europe : seuls neuf demeurent actives dans l’Union européenne, tandis que treize pays de la zone euro dépendent entièrement d’acteurs internationaux. Cette dépendance accroît la vulnérabilité de l’Europe face à d’éventuelles restrictions d’accès aux systèmes de paiement. Dans un récent rapport de la Fondation Concorde, nous préconisons le développement de solutions européennes et le co-badging sur les cartes pour renforcer l’autonomie financière du continent.
Le numérique séduit, le cash rassure
Malgré cette dématérialisation rapide des paiements, les Français restent profondément attachés aux espèces. L’enquête de la BCE souligne en effet que 60 % d’entre eux jugent important de conserver la possibilité de payer en liquide. L’anonymat et la protection de la vie privée (d’ailleurs, crainte souvent émise à l’égard du projet d’euro numérique de la BCE), le règlement immédiat et la maîtrise des dépenses figurent parmi les avantages les plus fréquemment cités.
L’accès au cash demeure par ailleurs très satisfaisant : 94 % des commerçants acceptent encore les espèces, et la quasi-totalité de la population (99,9 %) vit à moins de quinze minutes de trajet par la route d’un site équipé d’au moins un distributeur automatique de billets (DAB) ou d’un point d’accès privatif chez un commerçant. Bien que le nombre de DAB ait reculé (42 578 DAB fin 2024, contre 52 697 en 2018), 91 % des Français estiment que l’accès au liquide reste « facile » ou « très facile » – l’un des meilleurs scores de la zone euro.
Assez paradoxalement, la Banque centrale européenne elle-même invite dans une note « Gardez votre calme et conservez de l’argent liquide : leçons sur le rôle unique de la monnaie physique à travers quatre crises », parue en septembre dernier, à ne pas tourner totalement le dos au cash. En cas de crise majeure – panne électrique, cyberattaque ou pandémie –, elle recommande de garder entre 70 et 100 euros en liquide par personne pour les dépenses essentielles. Un conseil révélateur : si le cash décline dans nos portefeuilles, il reste une valeur refuge, un symbole de sécurité et d’autonomie. Autrement dit, la France avance vers les paiements du futur… sans tout à fait lâcher ses pièces et ses billets.
Entre la carte et les espèces, les Français se montrent ainsi ambivalents. Ils adoptent avec enthousiasme les technologies sans contact, les paiements mobiles et les virements instantanés, tout en conservant dans leurs portefeuilles un peu de cash « au cas où ». Le futur du paiement s’écrira sans doute à deux vitesses : numérique par choix, mais liquide par prudence.
Timothée Waxin est administrateur et vice-président du conseil scientifique de la Fondation Concorde.
11.12.2025 à 15:57
Comment Paris est passé de capitale de la vie brève à championne de la longévité
Florian Bonnet, Démographe et économiste, spécialiste des inégalités territoriales, Ined (Institut national d'études démographiques)
Catalina Torres, Maîtresse de conférence, Universidad de la República, Montevideo, Uruguay - chercheure associée, unité « Mortalité, santé, épidémiologie », Ined (Institut national d'études démographiques)
France Meslé, Démographe, Ined (Institut national d'études démographiques)
Texte intégral (4249 mots)

Longtemps marquée par une mortalité élevée, la population de Paris accusait à la fin du XIXᵉ siècle un lourd retard d’espérance de vie par rapport à celles des autres régions de France. Un siècle plus tard, la ville est devenue l’un des territoires où l’on vit le plus longtemps au monde. Comment expliquer ce renversement spectaculaire ? Une plongée dans les archives de la capitale permet de retracer les causes de cette transformation, entre recul des maladies infectieuses, progrès de l’hygiène publique et forte baisse des inégalités sociales face à la mort.
Combien de temps peut-on espérer vivre ? Derrière cette question d’apparence simple se cache un des indicateurs les plus brûlants pour appréhender le développement socio-économique d’un pays. Car l’espérance de vie à la naissance ne mesure pas seulement la durée moyenne de la vie ; elle résume à elle seule l’état sanitaire, les conditions de vie ainsi que les inégalités sociales au sein d’une population.
En 2024, la France figurait parmi les pays les plus longévifs au monde (autrement dit, l’un des pays où l’on vit le plus longtemps). L’espérance de vie y était de 80 ans pour les hommes et de 85 ans et 7 mois pour les femmes, selon l’Insee. Derrière ces moyennes nationales se cachent toutefois des disparités territoriales notables.
À Paris, par exemple, l’espérance de vie atteignait 82 ans pour les hommes et 86 ans et 8 mois pour les femmes – soit un avantage de 1 à 2 ans par rapport à la moyenne nationale selon le sexe. Mais cela n’a pas toujours été le cas. Retour sur cent cinquante ans d’évolutions.
Une espérance de vie longtemps inférieure à la moyenne française
Paris n’a pas toujours été un havre de longévité. Il y a cent cinquante ans, la vie moyenne des habitants de la capitale était nettement plus courte. Un petit Parisien ayant soufflé sa première bougie en 1872 pouvait espérer vivre encore 43 ans et 6 mois. Une petite Parisienne, 44 ans et dix mois.
C’est ce que révèle la figure ci-dessous, qui retrace l’évolution de l’espérance de vie à un an entre 1872 et 2019 pour la France entière (en noir) et pour la capitale (en rouge). Cet indicateur, qui exclut la mortalité infantile (très élevée et mal mesurée à Paris à l’époque), permet de mieux suivre les changements structurels de la longévité en France sur le long terme.

On constate que, dans la capitale, l’espérance de vie est longtemps restée inférieure à celle du reste du pays. Ce n’est qu’au début des années 1990 (pour les femmes) et des années 2000 (pour les hommes) qu’elle a dépassé celle de l’ensemble des Français.
À la fin du XIXe siècle, l’écart en défaveur des habitants de la capitale atteignait dix ans pour les hommes et huit ans pour les femmes. Cette situation, commune de par le monde, est connue dans la littérature sous le nom de pénalité urbaine. On l’explique entre autres par une densité de population élevée favorisant la propagation des maladies infectieuses et un accès difficile à une eau potable de qualité.
Dans une étude récemment publiée dans la revue Population and Development Review, nous avons cherché à mieux comprendre comment Paris est passé de la capitale de la vie brève à l’un des territoires dans le monde où les habitants peuvent espérer vivre le plus longtemps.
Une base de données inédite pour remonter le fil de la longévité parisienne
Pour cela, nous avons collecté un ensemble inédit de données sur les causes de décès entre 1890 et 1949 à Paris, seule ville de France pour laquelle ces données ont été produites à cette époque, grâce aux travaux fondateurs des statisticiens Louis-Adolphe et (son fils) Jacques Bertillon.
Cette tâche est pendant très longtemps restée impossible, car, même si les données requises existaient, elles restaient dispersées dans les archives de la Ville et leurs coûts de numérisation étaient élevés. De plus, les statistiques de mortalité par cause étaient difficiles à exploiter, en raison de changements répétés de classification médicale. Nous avons pu récemment lever ces écueils grâce à des innovations de collecte et de méthode statistique.
En pratique, nous sommes allés photographier de nombreux livres renseignant le nombre de décès par âge, sexe et cause pour l’ensemble de la ville de Paris sur près de 60 ans. Puis nous avons extrait cette information (bien souvent à la main) afin qu’elle soit utilisable par nos logiciels statistiques. Pour approfondir nos analyses, nous avons également collecté ces données par quartier – les 80 actuels – pour certaines maladies infectieuses, afin de mieux saisir la transformation des inégalités sociales et spatiales face à la mort durant cette période.
Cette collecte minutieuse de dizaines de milliers de données a permis de constituer une nouvelle base désormais librement accessible à la communauté scientifique. Elle offre la possibilité d’analyser de manière inédite les mécanismes à l’origine de l’amélioration spectaculaire de la longévité à Paris durant la première moitié du XXᵉ siècle, une période où la population de la capitale a fortement augmenté pour atteindre près de trois millions d’habitants, notamment en raison de l’arrivée massive de jeunes migrants venus des campagnes françaises lors de l’exode rural.
Un gain important dû au recul des maladies infectieuses
Entre 1890 et 1950, l’espérance de vie à 1 an a bondi de près de vingt-cinq ans à Paris. À quoi un tel progrès est-il dû ? Si l’on décompose cette formidable hausse par grandes causes de décès, pour les hommes comme pour les femmes, on constate que les maladies infectieuses dominaient largement la mortalité parisienne à la Belle Époque. C’était en particulier le cas de la tuberculose, la diphtérie, la rougeole, la bronchite et la pneumonie. Nous avons également isolé les cancers, les maladies cardio-vasculaires et, pour les femmes, les causes liées à la grossesse.
Le résultat est sans appel : la disparition progressive des maladies infectieuses explique à elle seule près de 80 % des gains de longévité observés dans la capitale. Sur les 25 années d’espérance de vie gagnées, 20 sont dues au recul de ces infections.

La lutte contre la tuberculose, maladie infectieuse provoquée par la bactérie Mycobacterium tuberculosis, a été le principal moteur de ce progrès. Longtemps première cause de décès à Paris, le déclin rapide de cette maladie après la Première Guerre mondiale représente près de huit ans d’espérance de vie gagnés pour les hommes et six ans pour les femmes. Les infections respiratoires (bronchites et pneumonies), très répandues à l’époque, ont quant à elles permis un gain supplémentaire de cinq ans. Des avancées sur plusieurs fronts (transformations économiques et sociales, progrès en santé publique, efforts collectifs de lutte contre la tuberculose et améliorations nutritionnelles) ont pu contribuer à la baisse de la mortalité liée à ces maladies.
La diphtérie, particulièrement meurtrière chez les enfants au XIXᵉ siècle, a également reculé spectaculairement durant les années 1890, ce qui a permis un gain d’espérance de vie d’environ deux ans et six mois. La baisse de la mortalité due à cette cause aurait été impulsée par l’introduction réussie du sérum antidiphtérique – l’un des premiers traitements efficaces contre les maladies infectieuses.
En revanche, les maladies cardio-vasculaires et les cancers n’ont joué qu’un rôle mineur avant 1950. Leurs effets apparaissent plus tardivement, et s’opposent même parfois à la progression générale : les cancers, notamment chez les hommes, ont légèrement freiné la hausse de l’espérance de vie. Quant aux causes liées à la grossesse, leur impact est resté limité.
Cette formidable hausse de l’espérance de vie s’est poursuivie au-delà de notre période d’étude, mais à un rythme moins soutenu. L’augmentation a été d’un peu moins de vingt ans entre 1950 et 2019.
Au début du XXᵉ siècle, de féroces inégalités sociales face à la mort
Nous l’avons vu, la lutte contre la tuberculose a été l’un des principaux moteurs des progrès spectaculaires de l’espérance de vie à Paris entre 1890 et 1950. Grâce aux séries des statistiques de décès par cause que nous avons reconstituées pour les 80 quartiers de la capitale, nous avons cherché à mieux comprendre les ressorts de cette maladie en dressant une véritable géographie sociale.
Pour chaque quartier, nous avons calculé un taux de mortalité « brut »
– c’est-à-dire le rapport entre le nombre de décès dus à la tuberculose et la population totale du quartier, pour 100 000 habitants. Nous avons ainsi pu produire une carte afin de visualiser cette mortalité spécifique, aux alentours de l’année 1900.

On constate que les écarts de mortalité étaient considérables au sein de la capitale en 1900. Les valeurs les plus élevées, souvent supérieures à 400 décès pour 100 000 habitants, se concentraient dans l’est et le sud de Paris. Les trois quartiers où les valeurs étaient les plus élevées sont Saint-Merri (près de 900), Plaisance (850) et Belleville (un peu moins de 800). À l’inverse, les quartiers de l’Ouest parisien affichaient des taux bien plus faibles, et des valeurs minimales proches de 100 dans les quartiers des Champs-Élysées, de l’Europe et de la Chaussée-d’Antin.
Ces différences spatiales reflètent directement les inégalités sociales de l’époque. En nous fondant sur les statistiques de loyers du début du XXᵉ siècle, nous avons estimé quels étaient les dix quartiers les plus riches (matérialisés sur la figure par des triangles noirs) ainsi que les dix plus pauvres (cercles noirs). On constate que la nette fracture sociale entre le Paris aisé du centre-ouest et le Paris populaire des marges orientales se superpose clairement à la carte de la mortalité par tuberculose.
Une situation qui s’équilibre seulement après la Seconde Guerre mondiale
Si l’on se penche sur l’évolution de ces écarts entre la fin du XIXᵉ siècle et 1950, on constate que les quartiers les plus pauvres affichaient à la fin du XIXᵉ siècle des taux de mortalité par tuberculose supérieurs à 600, trois fois et demie supérieurs à ceux des quartiers les plus riches.
L’écart s’est encore creusé jusqu’à la veille de la Première Guerre mondiale, sous l’effet d’une baisse de la mortalité plus forte dans les quartiers riches que dans les quartiers pauvres. Ainsi en 1910, les taux de mortalité par tuberculose étaient encore quatre fois et demie plus élevés dans les quartiers populaires que dans les quartiers riches.

Durant l’entre-deux-guerres, les écarts se sont resserrés. L’éradication progressive des maladies infectieuses a permis les progrès considérables d’espérance de vie observés de la Belle Époque à la fin de la Seconde Guerre mondiale. La mortalité a chuté très rapidement dans les quartiers les plus défavorisés. À la fin des années 1930, elle n’y était plus que deux fois supérieure à celle des quartiers riches.
Après la Seconde Guerre mondiale, les taux sont enfin passés sous les 100 décès pour 100 000 habitants dans les quartiers pauvres. Un seuil que le quartier des Champs-Élysées avait déjà atteint cinquante ans plus tôt…
Quelles leçons pour l’histoire ?
Le rythme de cette transformation – dont la lutte contre la tuberculose a été l’un des moteurs – fut exceptionnel. Ce sont près de six mois d’espérance de vie qui ont été gagnés chaque année sur la période allant des débuts de la Belle Époque à la fin de la Seconde Guerre mondiale. Les déterminants de cette forte baisse de la mortalité sont encore débattus, toutefois on peut les regrouper en trois catégories.
La première concerne les investissements dans les infrastructures sanitaires. La connexion progressive des logements aux réseaux d’assainissement aurait contribué à la réduction de la mortalité causée par les maladies infectieuses transmises par l’eau.
Par ailleurs, la mise en place au tournant du XXᵉ siècle du « casier sanitaire » aurait contribué à la baisse de la mortalité des maladies infectieuses transmises par l’air – notamment la tuberculose –, en permettant l’enregistrement des informations liées à la salubrité des logements : présence d’égouts, d’alimentation en eau, recensement du nombre de pièces sur courette, du nombre de cabinets d’aisances communs ou privatifs, du nombre d’habitants et de logements par étage, liste des interventions effectuées sur la maison (désinfections, rapport de la commission des logements insalubres, maladies contagieuses enregistrées), compte-rendu d’enquête sanitaire (relevant la nature du sol, le système de vidange, l’état des chutes, les ventilations), etc.
La seconde catégorie de déterminants qui ont pu faire augmenter l’espérance de vie tient aux innovations médicales : le vaccin BCG contre la tuberculose (mis au point en 1921) ou le vaccin antidiphtérique (mis au point en 1923) ont, entre autres, modifié le paysage sanitaire.
Enfin, la troisième et dernière catégorie relève des transformations économiques et sociales. La première moitié du XXᵉ siècle a connu une croissance économique soutenue, une amélioration des conditions de vie et une diminution marquée des inégalités de revenus.
L’amélioration du réseau de transport a par ailleurs facilité l’approvisionnement alimentaire depuis les campagnes, contribuant à une meilleure nutrition. Notre étude semble montrer, enfin, que les antibiotiques, découverts plus tardivement, n’ont joué qu’un rôle marginal avant 1950.
Comprendre les dynamiques sanitaires contemporaines
Nos recherches sur le sujet ne sont pas terminées. Nous continuons à accumuler de nouvelles données pour analyser l’évolution de l’espérance de vie et de la mortalité par cause dans chacun des 20 arrondissements et des 80 quartiers de la capitale afin d’analyser plus en détail cette période de cent cinquante ans. Nous pourrons ainsi progressivement lever le voile sur l’ensemble des raisons qui font de Paris cette championne de la longévité que l’on connaît aujourd’hui.
Ces recherches, bien que centrées sur des phénomènes historiques, conservent une importance majeure pour l’analyse des dynamiques sanitaires contemporaines. Elles documentent la manière dont les maladies chroniques ont progressivement commencé à façonner l’évolution de l’espérance de vie, rôle qui structure aujourd’hui les transformations de la longévité.
Elles démontrent également que les disparités de mortalité selon les conditions socio-économiques, désormais bien établies dans la littérature actuelle, étaient déjà présentes dans le Paris de la fin du XIXᵉ siècle.
Surtout, nos analyses examinent un cas concret montrant que, malgré l’ampleur initiale des inégalités socio-économiques de mortalité, celles-ci se sont fortement réduites lorsque les groupes les plus défavorisés ont pu bénéficier d’un accès élargi aux améliorations sanitaires, sociales et environnementales.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
11.12.2025 à 15:56
Entretenir le mythe du Père Noël, une affaire de milieu social ?
Géraldine Bois, Maitresse de conférences en sociologie, Université de Lorraine
Charlotte Moquet, Post-doctorante au CRESPPA-CSU, Ingénieure de recherche au CNRS - Docteure en sociologie de l'Université de Poitiers, Université de Poitiers
Texte intégral (2199 mots)
Dès la grande section de maternelle, des inégalités s’immiscent au sein du quotidien des enfants. Publié sous la direction des chercheuses Frédérique Giraud et Gaële Henri-Panabière, l’ouvrage Premières classes. Comment la reproduction sociale joue avant six ans met en lumière les mécanismes précoces qui sous-tendent leur transmission d’une génération à l’autre, à partir d’une enquête de terrain menée à la fois en famille et en classe.
Dans le premier chapitre, les sociologues Géraldine Bois et Charlotte Moquet s’arrêtent sur les conceptions de l’enfance qui animent les parents. Comment celles-ci orientent-elles leurs pratiques éducatives ? Dans l’extrait ci-dessous, elles nous montrent comment leur attitude vis-à-vis des croyances enfantines, comme le Père Noël et la petite souris, varient selon les milieux sociaux.
On se représente souvent l’enfance comme l’âge de l’innocence, un âge où les enfants doivent pouvoir rêver et s’émerveiller à l’abri des soucis des adultes. De fait, tous les parents que nous avons rencontrés adhèrent à cette conception de l’enfance, à des degrés divers. Ils s’efforcent de tenir leur enfant à distance de certaines de leurs discussions (soucis professionnels, conflits familiaux, etc.) et regrettent de ne pas toujours y parvenir : « On essaye de pas le faire, mais bon quelquefois ça arrive […]. On oublie qu’il y a les petites oreilles des enfants à côté. » (Mme Moreau, pharmacienne en couple avec un ingénieur, classes supérieures)
Ils tentent tout particulièrement de le protéger des événements violents de l’actualité (attentats, guerres, etc.), en contrôlant son accès à ces informations et en évitant d’en parler devant lui. « Je me dis qu’elle a bien le temps de voir l’horreur de la société dans laquelle on vit », « Ils sont encore jeunes, ils ont encore le temps de voir beaucoup de misère », déclarent par exemple les parents interrogés.
Cette tendance à la préservation du monde de l’enfance est cependant plus ou moins marquée selon leurs appartenances sociales : certains parents, plus souvent de classes populaires, s’efforcent de maintenir leur enfant dans ce monde, quand d’autres, plus souvent de classes moyennes et supérieures, l’encouragent plutôt à le questionner.
Sur ce point, les attitudes parentales vis-à-vis des croyances enfantines que sont le Père Noël et la petite souris sont révélatrices. Certains parents entretiennent ces croyances afin de sauvegarder une « magie », un « imaginaire » et une « innocence » qu’ils estiment propres à l’enfance. Mme Chanteau (assistante sociale, classes moyennes), qui « essaye de trouver des réponses qui [lui] semblent les moins farfelues » pour limiter les doutes de sa fille Annabelle, explique : « Je trouve qu’elle est petite et j’ai envie de la conforter encore dans cet imaginaire. » Dans ces familles, la prise de conscience de la réalité à propos de ces croyances est donc remise à plus tard, comme l’exprime le père de Bastien Perret (ouvrier en couple avec une infirmière, classes populaires) : « De toute façon, après, il le saura par l’école, parce que plus il va grandir [moins il y croira]. »
Les récits des pratiques familiales témoignent de stratégies pour retarder le plus possible leur disparition. Ainsi, les parents de Bastien ont demandé à ses cousins plus âgés de ne pas lui révéler la vérité sur l’existence du Père Noël. D’autres parents échafaudent de véritables mises en scène qu’ils racontent avec beaucoup d’enthousiasme : faire disparaître dans la nuit des gâteaux destinés au Père Noël, créer une diversion pour disposer à l’insu des enfants les cadeaux sous le sapin, faire croire que le Père Noël passe en diffusant le son de son traîneau, etc.
Si ces attitudes de préservation des croyances enfantines se rencontrent dans des familles de milieux sociaux variés, elles sont nettement plus présentes dans les classes populaires et concernent la quasi-totalité des familles de ce milieu social. En outre, les quelques familles de classes moyennes et supérieures également concernées se caractérisent souvent par des origines populaires du côté des parents. Cette particularité permet de souligner que, si la façon dont les parents pensent l’enfance et agissent à l’égard de leur enfant a des effets sur son éducation, ces représentations et pratiques des parents sont elles-mêmes le fruit d’une socialisation antérieure, notamment familiale. Autrement dit, les représentations et pratiques des parents sont les produits de ce qu’ils ont appris dans leur propre environnement familial.
D’autres parents, au contraire, ne tiennent pas spécialement à ce que leur enfant continue de croire au Père Noël ou la petite souris. On rencontre cette distance vis-à-vis des croyances enfantines uniquement dans les familles de classes moyennes et supérieures, et dans la très grande majorité des familles de ces milieux sociaux. S’avouant parfois mal à l’aise avec « les mensonges » qu’implique l’entretien de ces croyances, les parents adoptent ici une attitude qui consiste à laisser leur enfant croire si celui-ci en a envie, sans l’y encourager pour autant. Sans dire explicitement la vérité à leur enfant, ces parents se montrent intéressés par les doutes qu’il exprime et voient positivement le fait qu’il ne soit pas totalement dupe ou naïf. En effet, dans ces familles, les croyances enfantines sont avant tout traitées comme un terrain d’exercice du raisonnement logique.
Comme l’explique Mme Tardieu (responsable de communication dans une grande entreprise en couple avec un ingénieur d’affaires, classes supérieures), « on est sur des sujets où justement on veut que [nos enfants] réfléchissent un petit peu ». Les parents évitent donc d’apporter à leur enfant des réponses définitives. Ils encouragent plutôt ses questionnements en lui demandant ce qu’il en pense ou ce qu’il souhaite lui-même croire : « Je lui dis : “Mais qu’est-ce que tu as envie de croire ? Est-ce que tu as envie de croire que le [Père Noël] existe ?” Et dans ces cas-là, elle réfléchit. […] On lui dit : “C’est comme tu veux. Il y en a qui croient, il y en a qui ne croient pas. C’est comme croire en Dieu. Il y en a qui croient, il y en a qui ne croient pas. Après si tu as des questions on répond, mais on ne va pas te faire ton idée.” […] On reste un peu évasifs. » (mère de Lisa Chapuis, au foyer, en couple avec un architecte, classes moyennes)
À lire aussi : Pourquoi les enfants croient-ils (ou pas) au Père Noël ?
Les enfants de classes moyennes et supérieures sont ici familiarisés à des manières de raisonner (questionner, réfléchir par soi-même) qui sont de nos jours particulièrement valorisées à l’École et peuvent de ce fait contribuer à leur procurer certains bénéfices scolaires. L’extrait d’entretien précédent montre bien que les rapports parentaux aux croyances enfantines peuvent s’inscrire dans une tendance plus générale à l’encouragement de l’esprit critique sur différents sujets.
De la même manière, les plaisanteries sur le Père Noël sont l’un des biais par lesquels les mères de Rebecca Santoli (l’une est professeure de français ; l’autre est en situation de reconversion professionnelle et exerce des petits boulots en intérim) habituent leur fille à un regard critique sur les stratégies commerciales et les inégalités de genre : « Moi je lui ai dit que le Père Noël il a le beau rôle et que c’était la Mère Noël qui faisait tout le taf [rires]. Et puis qu’il est habillé en Coca-Cola là… »
Ces mères font partie des rares parents de l’enquête – appartenant essentiellement aux fractions cultivées des classes moyennes et supérieures – à tenir régulièrement des discussions politiques entre adultes devant leur enfant. Elles amènent aussi Rebecca à des réunions militantes mêlant adultes et enfants. À propos de ce qui pourrait inquiéter leur fille, elles ont par ailleurs une attitude ambivalente qui manifeste leur tendance à vouloir solliciter son questionnement. Concernant les événements de l’actualité, elles disent avoir le souci de « l’épargner » mais aussi l’« envie de répondre à ses questions ». Elles doutent également de la pertinence de sa prise de conscience des difficultés financières de l’une d’entre elles, partagées entre le sentiment qu’elle est « un peu jeune » pour « se faire du souci » à ce sujet et la volonté de la « confronter à la réalité ».
À lire aussi : Ce que les enfants pensent vraiment du père Noël
À côté de certains parents de classes moyennes ou supérieures comme ceux de Rebecca, qui ont les moyens de décider ce à quoi ils exposent leur enfant, les parents les plus précarisés des classes populaires habituent eux aussi, mais par la force des choses, leur enfant à certaines réalités. Si Ashan accompagne sa mère, Mme Kumari (sans emploi, antérieurement infirmière au Sri Lanka) qui l’élève seule, aux réunions du comité de soutien des familles sans logement, c’est ainsi par nécessité (faute de moyen de garde aux horaires de ces réunions et parce que la famille est contrainte de vivre dans un foyer de sans-abri), contrairement aux mères de Rebecca lorsqu’elles vont avec leur fille à des réunions militantes.

D’ailleurs, Ashan tend à jouer à l’écart durant ces réunions sans visiblement écouter ce que disent les adultes, quand Rebecca est encouragée à y participer, à y prendre la parole. Contrairement à Rebecca, Ashan retire donc vraisemblablement peu de bénéfices scolaires de sa présence à ces réunions. Plus généralement, Ashan, mais aussi Libertad Anaradu (dont le père enchaîne des contrats précaires en tant qu’employé municipal et la mère est sans emploi), Balkis Bouzid (dont les parents sont sans activité professionnelle) et Flavia Kombate (dont la mère, qui l’élève seule, est auxiliaire de vie à mi-temps) sont, de fait, confrontés aux problèmes de leurs parents, ceux-ci n’ayant pas la possibilité de leur épargner certaines expériences (manque d’argent, expulsions, absence de logement stable, etc.). Ils n’ont pas non plus toujours les moyens d’entretenir les croyances de leur enfant. Par exemple, Mme Kombate dit à Flavia que le Père Noël n’existe pas et, l’année de l’enquête, elle lui explique qu’elle ne lui achètera pas de cadeaux à Noël puisqu’elle lui en a déjà offerts plus tôt dans l’année.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
11.12.2025 à 15:55
« Stranger Things » ou le triomphe de la nostalgie
Sophie Renault, Professeur des Universités en Sciences de Gestion et du Management, Université d’Orléans
Texte intégral (2300 mots)

Miser sur les objets cultes des années 1980, envahir l’espace public et s’inscrire dans la postérité : tel est le programme marketing très bien orchestré de la série « Stranger Things » pour sa cinquième et dernière saison qui surfe plus que jamais sur la nostalgie.
À l’occasion de la sortie de la cinquième et ultime saison de Stranger Things, Netflix déploie un plan d’envergure mondiale : événements publics, collaborations avec des marques internationales, pop-up stores… Derrière l’ampleur promotionnelle, un ressort fondamental unifie la narration, l’esthétique et la stratégie marketing de la série. Il s’agit de la nostalgie.
Objets cultes et nostalgie restauratrice
Depuis 2016, Stranger Things met en scène un imaginaire matérialisé par la présence d’objets emblématiques des années 1980. C’est par l’activation de ces repères culturels que la série prépare et invite le public à l’expérience nostalgique.
Comme l’indiquent les acteurs eux-mêmes dans un teaser promotionnel de la saison 5 :
« Vous allez ressentir des sentiments de nostalgie, ressortez vos chouchous et vos walkmans. »
Parmi les objets emblématiques des années 1980 figurent des téléviseurs à tube cathodique, des cassettes audio, des talkies-walkies, des flippers ou bien encore des bornes d’arcade.
Toutefois, l’efficacité de la nostalgie dans la série va au-delà de ces seules catégories d’objets. Si elle fonctionne si bien à l’écran, c’est parce qu’elle est immédiatement identifiable par l’association à des marques faisant partie intégrante du langage visuel de la culture pop. Les placements de produits y sont nombreux et parfaitement assumés. Il s’agit notamment de la mise en perspective dans cette cinquième saison de produits agroalimentaires parmi lesquels des boissons, comme Sunny Delight ou Coca-Cola. On identifie également plusieurs produits « technologiques », comme une radio Sanyo, un radio-cassette Sidestep, un casque stéréo KOSS, etc. On repère également des marques associées à l’enfance : une parure de lit, une affiche, un puzzle ou bien encore une poupée de l’univers Rainbow Brite, une boîte à goûter G.I. Joe, un bisounours, de la pâte à modeler Play Doh, des crayons de cire Crayola…
Ils sont les véhicules d’une époque que certains ont connue et que d’autres, en écho aux travaux de Svetlana Boym, fantasment ou romancent. Comme le souligne la recherche de Dan Hassler-Forest, Stranger Things illustre une forme de nostalgie « restauratrice », en quelque sorte idéalisée. Les années 1980 apparaissent comme un refuge séduisant face à un présent jugé moins désirable.
Les références empreintes de nostalgie donnent à l’univers de la série sa cohérence esthétique et temporelle. Hawkins, ville fictive dans laquelle se déroule l’action, rappelle selon les recherches de la spécialiste britannique des médias et de la pop culture Antonia Mackay, une forme de « perfectionnisme de la guerre froide », où la tranquillité de la banlieue est interrompue par l’irruption de la menace surnaturelle. En effet, selon la chercheuse, « l’idéologie dominante de l’après-guerre promeut la vie en banlieue, une existence centrée sur l’enfant, Hollywood, la convivialité, le Tupperware et la télévision ». Les frères Duffer, réalisateurs de la série, exploitent ce contraste depuis la première saison. Plus le monde à l’envers gagne du terrain, plus l’univers nostalgique se densifie via les objets, les décors, mais aussi grâce à une bande-son rythmée de tubes des années 1980.
La nostalgie est ainsi l’un des moteurs centraux de la série. Elle s’érige en rempart symbolique contre la terreur associée au monde à l’envers. Passant d’adolescents à jeunes adultes au fil des saisons, les héros évoluent dans un environnement anxiogène figé par l’esthétique rassurante des années 1980. Par effet miroir, en qualité de spectateur, notre propre trajectoire se mêle à celle des personnages de la série. C’est ici aussi que réside l’intuition fondatrice des frères Duffer. Il s’agit de transformer la nostalgie en un espace émotionnel fédérateur, un passé commun recomposé capable de fédérer plusieurs générations.
Licences, « co-branding » et invasion de l’espace public
L’alignement entre l’univers narratif de la série et ses opportunités commerciales ouvre la voie à de multiples partenariats de marque. Le secteur de la restauration rapide, dont la mondialisation s’est accélérée durant les années 1980, est un terrain de jeu idéal pour la mise en place d’opérations commerciales autour de la série. Les exemples sont éloquents : McDonald’s a lancé un Happy Meal accompagné de figurines collector. De son côté, KFC a créé une campagne immersive en se rebaptisant temporairement « Hawkins Fried Chicken », du nom de la ville fictive dans laquelle se déroule la série. Sont mis en scène dans un spot emblématique des employés prêts à affronter tous les dangers du monde à l’envers pour assurer leur livraison. Quant à Burger King, l’enseigne a lancé les menus Hellfire Club d’une part et Upside Down d’autre part, respectivement en référence au club de jeu de rôles Donjons & Dragons de la série et au monde à l’envers qu’elle met en scène.
Cette logique d’extension de la marque Stranger Things se concrétise par des collaborations événementielles qui investissent de nombreux domaines. Par exemple à Paris, l’univers de Stranger Things s’est invité aux Galeries Lafayette. Le grand magasin des Champs-Élysées propose en effet une immersion dans l’atmosphère du monde à l’envers. Des animations interactives y permettent notamment de personnaliser une enceinte Bluetooth en forme de radio. Quant à la chaîne de boulangerie « créative » Bo&Mie, elle décline des pâtisseries aux formes inspirées de la série.
Les exploitations sous licence, depuis Lego aux figurines Pop en passant par Primark, Nike ou Casio, s’emparent de l’esthétique de la série. Stranger Things déborde ainsi de l’écran pour investir les univers marchands mais également l’espace public des grandes villes au travers d’opérations événementielles spectaculaires. C’est notamment le cas lorsque des installations lumineuses immersives sont déployées à l’image de celles de la fête des Lumières de la ville de Lyon.
La postérité en construction
Pour son dernier chapitre, Stranger Things met la nostalgie en scène comme un véritable rituel. La diffusion fractionnée en trois temps n’est pas anodine. Plutôt qu’un lancement d’un seul bloc, Netflix étale la sortie sur trois moments clefs : Thanksgiving, Noël et le Nouvel An. En s’inscrivant dans ce calendrier affectif, la série devient elle‑même un rendez‑vous mémoriel, associé à des fêtes déjà chargées de souvenirs et de traditions.
Ce dispositif permet à Netflix de maintenir l’engouement pendant plusieurs semaines, mais aussi de donner à la série une tonalité plus intime. En effet, la nostalgie du passé se mêle à celle du présent. Les spectateurs vivent les derniers épisodes avec, en filigrane, le souvenir de la découverte de la série près de dix ans plus tôt. La conclusion de Stranger Things active ainsi une double nostalgie : celle, d’une part, des années 1980 reconstituées et celle, d’autre part, de notre propre trajectoire de spectateur.
Alors qu’une page se tourne, Netflix choisit de célébrer la cinquième saison sur l’ensemble des continents à travers le mot d’ordre « One last adventure ». Par exemple, l’événement intitulé « One Last Ride », organisé à Los Angeles le 23 novembre dernier invitait les fans à parcourir Melrose Avenue à vélo, en skate ou à pied. Plus largement, la plateforme déploie une série d’animations, physiques et virtuelles, pour convier les fans du monde entier à accompagner la fin du récit.
Stranger Things est in fine un événement culturel qui va au-delà de l’écran pour occuper l’espace public, les centres‑villes, les grands magasins ou bien encore les réseaux sociaux. La nostalgie y fonctionne comme un vecteur de rassemblement. Cette dynamique s’inscrit dans une stratégie plus large de prolongement de l’univers sériel. On pense notamment aux projets dérivés comme la pièce de théâtre The First Shadow ou bien encore à la série animée Chroniques de 1985. Alors que Stranger Things s’achève, son imaginaire s’installe dans une forme de postérité.
Sophie Renault ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.12.2025 à 15:54
La Syrie d’Al-Charaa : opération séduction à l’international, répression des minorités à l’intérieur
Pierre Firode, Professeur agrégé de géographie, membre du Laboratoire interdisciplinaire sur les mutations des espaces économiques et politiques Paris-Saclay (LIMEEP-PS) et du laboratoire Médiations (Sorbonne Université), Sorbonne Université
Texte intégral (3161 mots)
Le nouvel homme fort de Damas montre patte blanche sur la scène internationale, que ce soit quand il intervient à la tribune de l’ONU ou quand il s’entretient avec Donald Trump, Vladimir Poutine, Recep Tayyip Erdogan, Mohammad ben Salmane ou encore Emmanuel Macron. À l’en croire, l’ancien chef djihadiste souhaite installer un pouvoir – relativement – démocratique et inclusif envers les minorités ethniques de la Syrie. Or le sort des alaouites, des druzes et des Kurdes invite à considérer ces engagements avec la plus grande méfiance.
Les médias occidentaux ont souligné à raison la métamorphose spectaculaire du président syrien Ahmed Al-Charaa et de son image auprès des chancelleries internationales. L’ancien chef du front Al-Nosra (la branche syrienne d’Al-Qaida) s’est lancé depuis cet été dans une véritable offensive diplomatique internationale tous azimuts.
En octobre 2025, Al-Charaa a repris les relations avec la Russie, ancien soutien du régime d’Assad, en réglant la délicate question des bases russes de Tartous et Hmeimim, dont Moscou devrait conserver l’usage. Mais ce qui étonne le plus les journalistes tient à « l’opération séduction » que le président a engagée auprès des puissances occidentales avec des voyages très remarqués en France en mai 2025 et surtout à Washington en novembre 2025. En amont de cette dernière visite, il a obtenu la levée des sanctions onusiennes qui frappaient son groupe Hayat Tahrir al-Cham (HTC), ainsi que son retrait de la liste des organisations reconnues comme terroristes. Il a également pu s’exprimer à la tribune de l’assemblée générale de l’ONU.
Pour autant, si la presse a souligné, à raison, le rapprochement des intérêts de Damas et de Washington, notamment leur projet commun de lutter contre l’État islamique, qui demeure présent en Syrie, la plupart des analystes semblent négliger un paramètre essentiel : la diplomatie syrienne reflète davantage les contraintes géopolitiques qui s’imposent au nouveau régime qu’une véritable volonté de s’ouvrir à l’Occident.
Prisonnier d’une situation domestique très précaire, le pouvoir syrien se doit, s’il veut survivre à court terme, de ménager les intérêts des puissances qui pourraient facilement l’abattre. Il ne peut tenir qu’avec l’assentiment des alliés de Washington, comme Israël ou l’Arabie saoudite, ou des puissances régionales comme la Turquie, qui s’ingèrent dans le jeu politique syrien. Il donne donc des gages à ses partenaires extérieurs mais, dans les faits, le respect des minorités voire l’inclusion tant vantée par les observateurs occidentaux semblent avoir fait long feu, comme le montrent les violences ayant visé diverses communautés et la sous-représentation des minorités parmi les députés élus aux élections législatives d’octobre 2025.
Conserver le soutien de la Turquie dans un contexte domestique fragile
Avant de se rendre dans les chancelleries occidentales, Al-Charaa s’est d’abord assuré du soutien des puissances régionales capables de s’ingérer dans le jeu politique syrien, à commencer par la Turquie, où il s’est rendu dès février 2025. Rappelons que c’est l’alliance entre HTC et les milices de l’ANS, l’armée nationale syrienne, composées de supplétifs de l’armée turque, qui avait permis la rapide chute d’Assad en 2024.
À lire aussi : Syrie : retour sur la chute de la maison Assad
Aujourd’hui, la Turquie continue de dominer le nord de la Syrie, malgré l’intégration de l’ANS dans l’armée syrienne. La région d’Alep reste contrôlée par les ex-chefs du Jabah al-Shamia, ancienne faction de l’ANS, à l’image de tout le reste du nord du pays où les unités de l’ANS, bien qu’ayant officiellement rejoint l’armée syrienne, sont restées cantonnées dans leurs positions, ce qui indique que leur allégeance va plus à Ankara qu’à Damas.
Malgré les appels d’Al-Charaa à l’unité nationale, l’ANS s’est emparée en décembre 2024 et en janvier 2025 des villes de Tall Rifaat et de Manbij, jusqu’alors tenues par les forces kurdes, ennemies traditionnelles de la Turquie. L’ANS a également affronté les Kurdes entre fin 2024 et avril 2025 autour du barrage de Tishrin, qu’elle a finalement reconquis, ce qui lui donne un contrôle sur le débit en aval et une tête de pont sur la rive orientale de l’Euphrate.
Al-Charaa pourrait profiter de sa proximité avec Ankara pour soumettre définitivement le Rojava, c’est-à-dire les régions autonomes du Kurdistan syrien contrôlées par les milices kurdes (les FDS) et dirigées par l’administration autonome du nord et de l’est de la Syrie (AANES). Le contexte est d’autant plus favorable que de l’autre côté de la frontière turco-syrienne, le PKK abandonne progressivement la lutte armée depuis l’appel de son chef, Abdallah Öcalan, à renoncer au conflit avec l’État turc.
Sans l’appui du puissant parrain turc, la soumission du Rojava paraît une entreprise bien périlleuse pour Damas, qui sait pertinemment que les Kurdes n’abandonneront le Rojava que sous la contrainte, puisqu’ils se méfient du nouveau régime, comme le montrent les réticences des FDS à intégrer l’armée syrienne, malgré quelques vagues déclarations en ce sens.
À lire aussi : La Turquie et la Syrie post-Assad : une nouvelle ère ?
Donald Trump, qui lors de son premier mandat avait déjà abandonné son allié kurde lors des opérations turques Rameau d’Olivier en 2018 et Source de Paix en 2019, pourrait chercher à contraindre les milices kurdes à intégrer les forces du régime syrien et à renoncer ainsi à leur assurance-vie. Dans l’optique de Trump, le Rojava, principale réserve pétrolière du pays, doit être pacifié et intégré à l’espace national en vue de son exploitation par les majors pétrolières américaines. Washington, Ankara et Damas pourraient s’accorder sur la question kurde et œuvrer ensemble à la disparition politique du Rojava.
Permettre l’extension des accords d’Abraham sous la supervision américaine
L’intermédiaire américain joue aussi un rôle fondamental dans la normalisation des relations entre Damas et Israël.
Trump et son administration rêvent d’étendre les accords d’Abraham à la Syrie et de pérenniser ainsi la sécurité de leur allié israélien. De ce point de vue, le nouveau pouvoir de Damas fait preuve de Realpolitik puisqu’il refuse, pour l’instant en tout cas, de se confronter à l’État hébreu malgré l’extension par ce dernier de ses marges frontalières sur le Golan lequel, selon Benyamin Nétanyahou, a été annexé « pour l’éternité ». Al-Charaa sait son régime fragile et a conscience du fait que le rapport de force est infiniment favorable à Israël.
À lire aussi : Dans le sud de la Syrie, les affrontements entre les Druzes et les Bédouins ravivent le spectre des divisions communautaires
En plus de s’attirer les faveurs de Washington, Damas souhaite empêcher par tous les moyens l’ingérence israélienne dans ses affaires intérieures. Soucieux de préserver sa sécurité et de créer une zone tampon en Syrie, Israël s’appuie, en effet, sur ses alliés druzes et utilise leur défense comme casus belli afin d’étendre sa profondeur stratégique dans la région.
L’extension des accords d’Abraham et du système d’alliance américain suppose aussi une normalisation des relations avec les puissances du Golfe, à commencer par l’Arabie saoudite qu’Al-Charaa a visitée dès février 2025. De ce point de vue, il est intéressant d’observer que le nouveau régime se garde bien de prendre des mesures qui pourraient provoquer la colère de Riyad ou de ses alliés arabes comme l’Égypte. La déclaration constitutionnelle de mars 2025 ne tombe pas dans les thématiques chères aux Frères musulmans, lesquels s’opposent frontalement aussi bien à la monarchie saoudienne qu’au régime d’Al-Sissi en Égypte.
En effet, cette Constitution provisoire place le régime dans la droite filiation du nationalisme arabe, comme le montre l’article 1 qui qualifie la Syrie de « République arabe ». Cette orientation rassure Le Caire et confirme l’éloignement par rapport à la mouvance frériste : régime autoritaire, le nouveau pouvoir syrien n’aspire pas à devenir la référence ou l’étendard des populations rejetant le joug des tyrannies miliaires (Égypte) ou monarchiques (Riyad).
Le processus démocratique cher aux fréristes est particulièrement freiné par la Constitution de 2025 puisqu’elle ne débouche que sur une participation très superficielle des électeurs syriens : elle ne prévoit qu’un scrutin indirect où seuls 6 000 électeurs, au préalable soumis au contrôle du régime, élisent 140 députés choisis parmi environ 1 500 candidats désignés parmi les notables locaux.
Ce mode de scrutin ne reconnaît par ailleurs que des candidats apolitiques, ce qui limite considérablement sa portée démocratique et l’enracinement des Frères musulmans, et valorise les Cheikhs c’est-à-dire les chefs de tribus. Ce système permet à Al-Charaa de contrôler la vie politique syrienne et place aussi la Syrie dans la continuité de ses voisins arabes, qui sont soit des régimes autoritaires assumés, soit des régimes hybrides semi-autoritaires comme la Jordanie. Al-Charaa n’entend pas faire de Damas l’épicentre d’un nouveau Printemps arabe placé sous le signe de l’islamisme ; une posture qui lui permet notamment d’apaiser les craintes de ses partenaires régionaux.
Damas veut donc, par sa diplomatie très active, ménager les puissances régionales que sont la Turquie, Israël ou les pays arabes. Dans les trois cas, le régime entend profiter de la médiation des Américains, qui espèrent construire un nouveau système diplomatique où la sécurité d’Israël soit garantie. On observe ici tous les paradoxes de la diplomatie syrienne, qui entend se rapprocher d’Israël tout en ménageant son parrain turc, deux projets a priori difficilement conciliables à long terme si on considère l’hostilité croissante d’Ankara envers Israël.
La Turquie émerge en effet de plus en plus comme le leader de l’opposition à Israël dans la région et pourrait occuper le vide laissé par l’effondrement iranien pour construire son propre « axe de la résistance antisioniste », étendant ainsi son emprise sur les sociétés arabes. On comprend dès lors que la diplomatie syrienne révèle les paradoxes, pour ne pas dire les hypocrisies du régime qui entend multiplier les efforts diplomatiques à court terme pour pérenniser son pouvoir, sans souci de cohérence à long terme.
Les minorités dans le viseur du régime
La réalité des projets de long terme d’Al-Charaa transparaît moins dans son activité diplomatique que dans sa gestion réelle des minorités, ainsi que dans sa position plus qu’ambiguë à l’égard du droit. Derrière la rhétorique inclusive, les premiers mois du nouveau régime permettent d’anticiper une dérive répressive envers les minorités dans les mois et les années à venir.
À lire aussi : Dans le sud de la Syrie, les affrontements entre les Druzes et les Bédouins ravivent le spectre des divisions communautaires
Les Kurdes restent menacés, comme le montre la Constitution provisoire de 2025 qui rappelle dans son article 7.1 que l’État « s’engage à préserver l’unité du territoire syrien et criminalise les appels à la division, à la sécession ainsi que les demandes d’intervention extérieure ». Difficile de ne pas voir ici un message hostile envoyé aux Kurdes et à leur projet d’un Rojava autonome, ainsi qu’aux Druzes.
En optant non pas pour un régime de type fédéral mais pour un pouvoir centralisé ultra présidentiel, Al-Charaa nie les aspirations politiques des minorités du pays. Le système électoral confirme cette orientation puisque, nous l’avons dit, les candidats aux élections sont choisis par le président via une commission de sélection qu’il contrôle totalement. Comment s’étonner, dès lors, que les minorités ne représentent qu’une infime partie des élus lors des dernières législatives – 4 députés kurdes, 6 alaouites et 2 chrétiens sur 140, alors que chacune de ces communautés représente environ 10 % de la population totale ?
Surtout, le cycle de violence engagé par les massacres des populations alaouites en mars 2025 ne s’est jamais complètement arrêté, même si ces attaques ont constitué un pic. Les minorités sont quotidiennement victimes d’attaques qui, bien que limitées, instaurent un climat de terreur, ce qui pousse les populations à fuir le pays, comme en témoigne la migration de 50 000 à 100 000 alaouites vers le Liban.
La Syrie semble donc engagée dans la voie d’un long et progressif processus de nettoyage ethnique de facto. La nouvelle Constitution nous le rappelle puisque, comme le stipule l’article 3.1, « la jurisprudence, le Fiqh, est la principale source du droit ». On voit mal comment un État régi par l’orthodoxie sunnite pourrait tolérer les minorités alaouite ou druze dont l’approche syncrétique de l’islam, voire sécularisée dans le cas des alaouites, n’est pas compatible avec la charia.
En outre, la Constitution inscrit dans son article 49 le rejet de toute forme d’héritage de l’ère Assad :
« L’État criminalise la glorification de l’ancien régime d’Assad et de ses symboles, la négation ou l’apologie de ses crimes, leur justification ou leur minimisation, autant de crimes punissables par la loi. »
Étant donné que de nombreux anciens rebelles syriens assimilent les minorités au régime d’Assad, ce passage pourrait servir de base à une répression qui les viserait pour les punir de leur prétendue fidélité au régime déchu. La base militante de HTC n’a pas renoncé à se venger de communautés perçues, de façon simpliste et souvent injuste, comme des soutiens indéfectibles de l’ancien régime : les massacres visant les alaouites dans la région de Banias en mars 2025 l’ont tragiquement illustré. L’inclusivité affichée par le nouveau régime reste une apparence et permet d’anticiper un refroidissement des relations entre Damas et les Américains, une fois que sera revenue à la Maison Blanche une administration davantage soucieuse du respect du droit humanitaire international.
Pour résumer, Al-Charaa a inscrit son pays dans un spectaculaire processus d’ouverture diplomatique, l’amenant à normaliser ses relations tant avec les puissances régionales qu’avec les puissances internationales comme les États-Unis, dont le régime syrien reste pour l’instant à la merci. Il faut bien garder à l’esprit que cette offensive diplomatique, plus qu’une volonté de rapprocher durablement la Syrie de l’Occident ou de ses valeurs, traduit surtout la nécessité de limiter les ingérences étrangères dans un contexte intérieur fragile où la Syrie s’apparente encore à un État quasi failli.
Une fois que son emprise sur la société syrienne se sera durablement pérennisée, le nouvel homme fort de la Syrie, fort d’un pouvoir ultra présidentiel $et du soutien de ses parrains régionaux, pourrait, sur le long terme, sacrifier le sort des minorités et ses bonnes relations avec l’Ouest pour poursuivre une politique hostile autant aux intérêts de l’Occident qu’à ses valeurs.
Pierre Firode ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.12.2025 à 15:54
Faut-il labelliser les médias pour promouvoir une information de qualité ?
Alexandre Joux, Professeur en Sciences de l’information et de la communication, Aix-Marseille Université (AMU)
Texte intégral (2999 mots)
En évoquant un « label » pour l’information, le président Macron a déclenché une polémique alimentée par les médias de Vincent Bolloré, qui dénoncent une volonté de museler la presse. Les labels existants sont-ils efficaces pour promouvoir des médias de qualité ? Quels sont les critères de labellisation, et plus largement, comment définir le « bon » journalisme ?
[Note de la rédaction : The Conversation France a reçu le label Journalism Trust Initiative (JTI) en novembre 2025.]
Le vendredi 28 novembre 2025, dans un échange avec les lecteurs du groupe EBRA, Emmanuel Macron, président de la République, évoquait un « label » pour l’information. Il citait celui de la Journalism Trust Initiative (JTI), créé par Reporters sans frontières (RSF), sans en faire la norme par ailleurs, rappelant que l’engagement des rédactions sur la vérification des faits et de la déontologie est essentiel.
Cette déclaration, qui n’avait pas vocation à faire parler d’elle, sera largement débattue dans les médias du groupe Bolloré, qui vont dénoncer une mise sous tutelle de l’information. L’Élysée réagira dès le lundi 1er décembre et dénoncera une « fausse information ». Ainsi, en trois jours à peine, le trio JDD-Europe 1-CNews sera parvenu à mettre la question du « label » à l’agenda, et le président Macron en porte-à-faux. L’opération est réussie puisque la confusion s’est très vite installée entre, d’une part, un label qui garantit l’information produite par des journalistes selon un certain nombre de critères professionnels – que l’on pourrait appeler « vraie information » et, d’autre part, les velléités prétendues de certains politiques sur la sélection de la « bonne » information.
La Journalism Trust Initiative, une réponse aux logiques des plateformes
Le débat est légitime mais il ne porte pas, en fait, sur les médias entre eux, mais sur les réseaux sociaux et les algorithmes de recommandation. Il porte sur la signalisation de la « vraie » information, celle faite par des journalistes, dans des environnements où prolifèrent les contenus en ligne qui n’ont pas pour objectif la véracité des faits.
La Journalism Trust Initiative a été lancée en 2018 « comme dispositif innovant contre la désinformation », deux ans après la première élection de Donald Trump et le vote des Britanniques en faveur du Brexit, deux élections où les « fake news » ont émaillé les campagnes précédant le vote. La JTI n’avait donc pas pour objectif de discriminer entre « bon » et « mauvais » médias dans un contexte de polarisation des opinions, mais à demander « une distribution et un traitement privilégiés des [médias labellisés] par les algorithmes des moteurs de recherche et des réseaux sociaux ». Elle pointait les premiers responsables de l’actuelle foire d’empoigne médiatique : le relativisme informationnel, le grand gloubi-boulga des contenus sur les réseaux sociaux, où tout et n’importe quoi est mis sur le même plan pourvu que cela satisfasse les attentes des « profils ».
Quand les médias du groupe Bolloré envisagent les labels comme un moyen d’identifier les « bonnes » rédactions, et non pas comme un moyen de distinguer la « vraie » information du reste des contenus, ils déplacent le problème. Et dans ce cas, effectivement, les labels soulèvent des questions, avec trois difficultés au moins : celle de la définition du bon journalisme et de l’information vraie ; celle du thermomètre pour le mesurer ; celle des effets possibles du « label » auprès de ceux qui cherchent à s’informer. Avec, en fin de compte, un risque élevé pour la liberté d’expression.
Comment définir la valeur de l’information ?
Première difficulté : le bon journalisme n’existe pas, il n’y a que des bons articles ou de bons reportages, parce que la valeur de l’information est décidée avec les publics, au cas par cas. Cette valeur ne relève pas des règles que la profession se donne, même si ces règles sont essentielles.
Le journalisme a toujours été une profession « floue », qui s’adapte aux évolutions des techniques, des usages, plus largement des sociétés. D’ailleurs, rien ne définit le journalisme en France dans le Code du travail, sauf le fait d’être payé en tant que journaliste (article L7111-3). Ce flou est utile. Il permet parfois de dire que des journalistes payés n’en sont pas, trahissent les règles qu’ils disent respecter, quand d’autres font du journalisme sans véritablement s’en revendiquer.
Aujourd’hui, la chaîne YouTube HugoDécrypte contribue plus à l’information, notamment auprès des jeunes, que de nombreux médias « reconnus » qui font de l’information avec des bouts de ficelle, quand ils ne volent pas le travail de leurs concurrents, comme le soulignent les débats actuels sur le renouvellement de l’agrément de Var Actu par la CPPAP, la commission qui permet de bénéficier des aides de l’État à la presse. Voici un bel exemple des limites de tout processus de labellisation à partir de règles données.
Parce qu’il n’est pas seulement une profession avec ses règles et ses codes, mais parce qu’il a une utilité sociale, le journalisme se doit donc d’être en permanence discuté, critiqué, repensé pour qu’il serve d’idéal régulateur à tous les producteurs d’information. Le journalisme, ses exigences et la valeur qu’on lui accorde se définissent en effet dans le dialogue qui s’instaure entre les professionnels de l’information, leurs publics et la société. Certes, les journalistes doivent s’engager sur la véracité des faits, sur une exigence de rationalité dans le compte-rendu qu’ils en font, ce qui suppose aussi une intelligence a minima des sujets qu’ils doivent traiter mais, une fois ces règles minimales posées, les modalités de leur mise en œuvre vont varier fortement.
C’est la différence entre la « vraie » information, celle qui respecte des normes, des règles, ce que proposent les labels, et l’information « vraie », celle qui est perçue comme solide par les publics, quand ils reconnaissent, par leurs choix de consommation, la qualité du travail journalistique en tant que tel. Ici, l’information « vraie » recouvre finalement le périmètre de la « bonne » information.
C’est pour insister sur cet autre aspect plus communicationnel du journalisme que j’ai introduit la notion de « presque-vérité » journalistique. Elle permet de souligner que la réalité du métier, avec ses contraintes de temps, de moyens, de compétences rend la réalisation de cet idéal d’information « vraie » toujours difficile. Le terme permet également de souligner que l’information des journalistes entretient quand même un rapport avec la vérité, quand d’autres discours dans l’espace public se libèrent des contraintes de la factualité, de l’épreuve du réel. Elle permet enfin de souligner que l’information journalistique est toujours négociée.
Le journalisme et la vérité
Quel est, alors, ce rapport du journalisme à la vérité, quel serait, de ce point de vue, une « bonne » information ? En premier lieu, l’exercice du métier renvoie à des normes collectives d’établissement des faits – ce sur quoi toutes les rédactions peuvent s’accorder en définissant les critères pour un label. C’est ce qui permet de dire que les faits sont vrais, que leur existence doit être reconnue de tous.
En second lieu, toute information est construite à partir des faits, par le journaliste, en fonction d’une ligne éditoriale, d’un angle qu’il choisit, et en fonction des publics auxquels il s’adresse. Il ne s’agit plus des faits mais de leur interprétation. En la matière, on peut attendre d’un journaliste qu’il propose une interprétation la plus cohérente possible des faits, qu’il fasse un vrai effort de rationalisation, mais il n’y a pas de lecture des faits qui soit plus légitime qu’une autre, si l’exigence de rationalité est respectée.
Ici se joue la négociation de l’information avec son public, la définition de sa portée sociale. Ainsi, une lecture hayekienne ou marxiste d’un même fait seront toutes les deux cohérentes et légitimes, même si elles sont en concurrence. Dans les deux cas, l’information est « vraie », appuyée sur des faits établis, inscrite dans une grille de lecture assumée, expliquée de la manière la plus rationnelle possible, pensée aussi pour répondre aux attentes de certains publics. Il s’agit d’une vérité tout humaine, sans cesse renégociée, qui repose sur la reconnaissance de la pertinence du travail fourni par le journaliste. Et cette possibilité se joue sur chaque article, sur chaque reportage, parce que le journaliste remet en jeu, à chaque fois, sa crédibilité, quand il choisit de traiter l’actualité à partir d’un angle, d’une vision, d’une conception du monde.
De ce point de vue, un label ne permettra jamais de mesurer si le journaliste a fait les bons choix pour interpréter le plus correctement possible les faits, parce qu’il n’y a pas d’interprétation qui soit plus correcte qu’une autre dès qu’elle est rationnelle. La valeur sociale de l’information dépend de la relation entre les journalistes et leurs publics, elle n’est pas liée aux conditions professionnelles de son élaboration.
Qui mesure la qualité de l’information et comment ?
Deuxième difficulté, le thermomètre, c’est-à-dire qui mesure la qualité de l’information et comment ? La plupart des tentatives soulèvent la question de la légitimité de ceux qui définissent les critères, et surtout des fins que ces critères viennent servir. C’est toute la différence qui sépare deux autres projets d’évaluation nés après 2016 et le surgissement massif des « fake news », le Décodex d’une part, les avis du Conseil de déontologie journalistique et de médiation (CDJM) d’autre part.
Lancé en 2017, le Décodex est une initiative des Décodeurs, le service de fact-checking du Monde. Afin de lutter contre la prolifération des fausses informations, signalées jusqu’alors une à une, l’idée fut de catégoriser les sources émettrices, donc de dire quel site est fiable et quel site ne l’est pas. Cette entreprise de labellisation des sources d’information a été finalement très critiquée avant d’être abandonnée, car son résultat le plus évident fut de mettre en avant l’ensemble des médias institués face à des offres qui n’avaient jamais pour elles le journalisme comme étendard.
Au départ, trois pastilles de couleur verte, orange et rouge étaient proposées : tous les médias ont eu leur pastille verte, à de rares exceptions (Fakir, Valeurs actuelles). La confusion s’est donc immédiatement installée entre « vrais » médias et « bons » médias, avec Le Monde en distributeur de bons points, ce qui a conduit les Décodeurs à retirer très vite leurs pastilles. À vouloir qualifier les sources elles-mêmes et pas le travail concret des journalistes, sujet par sujet, le Décodex n’est pas parvenu à discriminer entre « bons » et « mauvais » médias. Il a rappelé que les médias font en général de la « vraie » information, mais il n’a pas pu statuer sur la pertinence de l’information qu’ils produisent. Comme pour le label évoqué par le président Macron, le déplacement du débat de la « vraie » information à la « bonne » information a provoqué une remise en question du « label » imaginé par les Décodeurs.
À l’inverse, le CDJM, lancé en 2019, se prononce bien sur les ratés déontologiques des médias d’information quand il publie ses décisions sur des cas concrets. Il permet de faire le tri entre le bon grain et l’ivraie parmi les informations produites par les rédactions, mais il ne permet pas de statuer sur la qualité des médias et sur les choix des rédactions, considérant que cet aspect de l’information relève de la liberté éditoriale, du jugement aussi des lecteurs (le CDJM inclut d’ailleurs des représentants des lecteurs au côté des professionnels de l’information). Ainsi, le thermomètre fonctionne quand il permet de signaler les manquements de certains journalistes et de leurs rédactions sur des cas concrets, parce que la décision est argumentée, adaptée à chaque cas, et le périmètre bien circonscrit au seul respect des règles qui permettent de garantir la véracité des faits. Mais c’est statuer sur la « vraie » information, et sur ses ratés, jamais sur sa qualité. Or l’idée de « label » véhicule avec elle, de manière latente, un jugement de valeur sur la qualité des médias.
Les risques de l’effet « label »
Le troisième problème d’un label est le label lui-même, comme indication communiquée aux internautes. Quand Facebook a souhaité lutter contre les « fake news », il les a signalées à ses utilisateurs avec un drapeau rouge, ce qui a produit deux résultats très problématiques. Le premier est celui de l’effet de vérité par défaut, un contenu non signalé étant considéré comme vrai par défaut. Dans le cadre d’un label, son absence pourrait signifier « non crédible », ce qui est absurde et confère au journaliste un monopole sur l’information, quand des sources différentes peuvent être très pertinentes. Le second effet est encore plus problématique car les contenus signalés ont été considérés par certains utilisateurs de Facebook comme plus vrais, justement parce qu’ils sont signalés comme problématiques pour et par « le système dominant ». Le non label pourrait dans ce cas devenir l’étendard de tous ceux qui dénoncent le conformisme ou l’alignement des médias sur une idéologie dominante. Et l’on sait combien ce discours est porteur…
En conclusion, le risque est grand de statuer sur les bons et les mauvais médias en transformant le label « info » évoqué par le président de la République en gage de sérieux journalistique. Il a été évoqué dans un contexte de dénonciation de la désinformation sur les réseaux sociaux, pas pour définir un « bon » journalisme réservé aux seules rédactions déclarées vertueuses.
Ce sont la liberté d’expression et la liberté de la presse qui permettent à des voix différentes de rappeler que certains cadrages sont peut-être trop convenus, que certaines sources sont peut-être trop souvent ignorées, soulignant ainsi que le pluralisme, s’il est bien défendu, est une meilleure garantie de qualité pour le journalisme dans son ensemble qu’un label attribué à certains et pas à d’autres. Les publics décideront à la fin car l’information est faite d’abord pour eux.
Il ne faut pas minimiser aussi le risque d’une suspicion accrue face au label, qui produira l’effet inverse de celui souhaité, à savoir mettre sur la touche les médias plutôt que de les replacer au cœur de l’organisation du débat public. C’est ce rôle-là des médias qu’il faut préserver à tout prix, en défendant le pluralisme et l’indépendance des rédactions, quand les plates-formes nous enferment à l’inverse dans des bulles où nos goûts font office de label pour la « bonne » information.
Alexandre Joux ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.12.2025 à 12:13
Célèbres et captifs : comment les réseaux sociaux profitent du mal-être des animaux sauvages
Margot Michaud, Enseignante-chercheuse en biologie évolutive et anatomie , UniLaSalle
Sara Hoummady, DMV, PhD, Associate professor in ethology and animal nutrition, UniLaSalle
Texte intégral (3024 mots)

Sur les réseaux sociaux, la popularité des animaux exotiques va de pair avec la banalisation de leur mauvais traitement. Ces plateformes monétisent la possession d’espèces sauvages tout en invisibilisant leur souffrance. Cette tendance nourrit une méprise courante selon laquelle l’apprivoisement serait comparable à la domestication. Il n’en est rien, comme le montre l’exemple des loutres de compagnie au Japon.
Singes nourris au biberon, perroquets dressés pour les selfies, félins obèses exhibés devant les caméras… Sur TikTok, Instagram ou YouTube, ces mises en scène présentent des espèces sauvages comme des animaux de compagnie, notamment via des hashtags tels que #exoticpetsoftiktok.
Cette tendance virale, favorisée par le fonctionnement même de ces plateformes, normalise l’idée selon laquelle un animal non domestiqué pourrait vivre comme un chat ou un chien, à nos côtés. Dans certains pays, posséder un animal exotique est même devenu un symbole ostentatoire de statut social pour une élite fortunée qui les met en scène lors de séances photo « glamour ».
Or, derrière les images attrayantes qui recueillent des milliers de « likes » se dissimule une réalité bien moins séduisante. Ces stars des réseaux sociaux sont des espèces avec des besoins écologiques, sociaux et comportementaux impossibles à satisfaire dans un foyer humain. En banalisant leur possession, ces contenus, d’une part, entretiennent des croyances erronées et, d’autre part, stimulent aussi le trafic illégal. En cela, ils participent à la souffrance de ces animaux et fragilisent la conservation d’espèces sauvages.
À lire aussi : Qui est le capybara, cet étonnant rongeur qui a gagné le cœur des internautes ?
Ne pas confondre domestique et apprivoisé
Pour comprendre les enjeux liés à la possession d’un animal exotique, il faut d’abord définir les termes : qu’est-ce qu’un animal domestique et qu'est-ce qu'un animal exotique ?

Force est de constater que le terme « animal exotique » est particulièrement ambigu. Même si en France l’arrêté du 11 août 2006 fixe une liste claire des espèces considérées comme domestiques, sa version britannique dresse une liste d’animaux exotiques pour lesquels une licence est requise, à l’exclusion de tous les autres.
Une licence est ainsi requise pour posséder, par exemple, un serval (Leptailurus serval), mais pas pour un hybride de serval et de chat de deuxième génération au moins, ou encore pour détenir un manul, aussi appelé chat de Pallas (Otocolobus manul).
Ce flou sémantique entretient la confusion entre apprivoisement et domestication :
le premier consiste à habituer un animal sauvage à la présence humaine (comme des daims nourris en parc) ;
la seconde correspond à un long processus de sélection prenant place sur des générations et qui entraîne des changements génétiques, comportementaux et morphologiques.

Ce processus s’accompagne de ce que les scientifiques appellent le « syndrome de domestication », un ensemble de traits communs (oreilles tombantes, queue recourbée, etc.) déjà décrits par Darwin dès 1869, même si ce concept est désormais remis en question par la communauté scientifique.
Pour le dire plus simplement : un loup élevé par des humains reste un loup apprivoisé et ne devient pas un chien. Ses besoins et ses capacités physiologiques, son comportement et ses aptitudes cognitives restent fondamentalement les mêmes que celles de ces congénères sauvages. Il en va de même pour toutes les autres espèces non domestiques qui envahissent nos écrans.
À lire aussi : Le chien descend-il vraiment du loup ?
Des animaux stars au destin captif : le cas des loutres d’Asie
Les félins et les primates ont longtemps été les animaux préférés des réseaux sociaux, mais une nouvelle tendance a récemment émergé en Asie : la loutre dite de compagnie.
Parmi les différentes espèces concernées, la loutre cendrée (Aonyx cinereus), particulièrement prisée pour son apparence juvénile, représente la quasi-totalité des annonces de vente en ligne dans cette région. Cela en fait la première victime du commerce clandestin de cette partie du monde, malgré son inscription à l’Annexe I de la Convention sur le commerce international des espèces menacées depuis 2019.
Les cafés à loutres, particulièrement en vogue au Japon, ont largement participé à normaliser cette tendance en les exposant sur les réseaux sociaux comme animaux de compagnie, un phénomène documenté dans un rapport complet de l’ONG World Animal Protection publié en 2019. De même, le cas de Splash, loutre employée par la police pour rechercher des corps en Floride (États-Unis), montre que l’exploitation de ces animaux s’étend désormais au-delà du divertissement.
En milieu naturel, ces animaux passent la majorité de leurs journées à nager et à explorer un territoire qui mesure plus d’une dizaine de kilomètres au sein d’un groupe familial regroupant jusqu’à 12 individus. Recréer ces conditions à domicile est bien entendu impossible. En outre, leur régime, principalement composé de poissons frais, de crustacés et d’amphibiens, est à la fois extrêmement contraignant et coûteux pour leurs propriétaires. Leur métabolisme élevé les oblige en plus à consommer jusqu’à un quart de leur poids corporel chaque jour.
Privés de prédation et souvent nourris avec des aliments pour chats, de nombreux animaux exhibés sur les réseaux développent malnutrition et surpoids. Leur mal-être s’exprime aussi par des vocalisations et des troubles graves du comportement, allant jusqu’à de l’agressivité ou de l’automutilation, et des gestes répétitifs dénués de fonction, appelés « stéréotypies ». Ces comportements sont la conséquence d’un environnement inadapté, sans stimulations cognitives et sociales, quand elles ne sont pas tout simplement privées de lumière naturelle et d’espace aquatique.
Une existence déconnectée des besoins des animaux
Cette proximité n’est pas non plus sans risques pour les êtres humains. Les loutres, tout comme les autres animaux exotiques, peuvent être porteurs de maladies transmissibles à l’humain : salmonellose, parasites ou virus figurent parmi les pathogénies les plus fréquemment signalées. De plus, les soins vétérinaires spécialisés nécessaires pour ces espèces sont rarement accessibles et de ce fait extrêmement coûteux. Rappelons notamment qu’aucun vaccin antirabique n’est homologué pour la majorité des espèces exotiques.
Dans le débat public, on oppose souvent les risques pour l’humain au droit de posséder ces animaux. Mais on oublie l’essentiel : qu’est-ce qui est réellement bon pour l’animal ? La légitimité des zoos reste débattue malgré leur rôle de conservation et de recherche, mais alors comment justifier des lieux comme les cafés à loutres, où l’on paie pour caresser une espèce sauvage ?
Depuis 2018, le bien-être animal est défini par l’Union européenne et l’Anses comme :
« Le bien-être d’un animal est l’état mental et physique positif lié à la satisfaction de ses besoins physiologiques et comportementaux, ainsi que de ses attentes. Cet état varie en fonction de la perception de la situation par l’animal. ».
Dès lors, comment parler de bien-être pour un animal en surpoids, filmé dans des situations anxiogènes pour le plaisir de quelques clients ou pour quelques milliers de likes ?
Braconnés pour être exposés en ligne
Bien que la détention d’animaux exotiques soit soumise à une réglementation stricte en France, la fascination suscitée par ces espèces sur les réseaux ne connaît aucune limite géographique. Malgré les messages d’alerte mis en place par TikTok et Instagram sur certains hashtags, l’engagement du public, y compris en Europe, alimente encore la demande mondiale et favorise les captures illégales.
Une étude de 2025 révèle ainsi que la majorité des loutres captives au Japon proviennent de deux zones de braconnage en Thaïlande, mettant au jour un trafic important malgré la législation. En Thaïlande et au Vietnam, de jeunes loutres sont encore capturées et séparées de leurs mères souvent tuées lors du braconnage, en violation des conventions internationales.
Les réseaux sociaux facilitent la mise en relation entre vendeurs et acheteurs mal informés, conduisant fréquemment à l’abandon d’animaux ingérables, voire des évasions involontaires.

Ce phénomène peut également avoir de graves impacts écologiques, comme la perturbation des écosystèmes locaux, la transmission de maladies infectieuses aux populations sauvages et la compétition avec les espèces autochtones pour les ressources.
Récemment en France, le cas d’un serval ayant erré plusieurs mois dans la région lyonnaise illustre cette réalité : l’animal, dont la détention est interdite, aurait probablement été relâché par un particulier.
Quand l’attention profite à la cause
Mais cette visibilité n’a pas que des effets délétères. Les réseaux sociaux offrent ainsi un nouveau levier pour analyser les tendances d’un marché illégal. D’autres initiatives produites par des centres de soins et de réhabilitation ont une vocation pédagogique : elles sensibilisent le public et permettent de financer des actions de protection et de lutte contre le trafic.
Il ne s’agit donc pas de rejeter en bloc la médiatisation autour de la question de ces animaux, mais d’apprendre à en décoder les intentions et les impacts. En définitive, le meilleur moyen d’aider ces espèces reste de soutenir les associations, les chercheurs et les programmes de réintroduction. Et gardons à l’esprit qu’un simple like peut avoir des conséquences, positives ou négatives, selon le contenu que l’on choisit d’encourager.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
11.12.2025 à 11:49
Mascottes sportives : les clubs peuvent-ils devenir les nouveaux champions de la biodiversité ?
Ugo Arbieu, Chercheur postdoctoral, Université Paris-Saclay
Franck Courchamp, Directeur de recherche CNRS, Université Paris-Saclay
Texte intégral (4257 mots)
Du lion de l’Olympique lyonnais aux ours, tigres et autres aiglons qui ornent les logos des clubs sportifs de toutes disciplines du monde entier, les animaux sauvages sont au cœur de l’imaginaire sportif. Pourtant, dans la nature, beaucoup de ces espèces déclinent. Et si cet engouement se transformait en levier pour mieux défendre la biodiversité ? La littérature scientifique récente propose plusieurs pistes pour faire des clubs de véritables champions de la biodiversité.
Quand on se promène aux abords du Groupama Stadium à Lyon (Rhône), on ne peut les ignorer. Quatre lions majestueux aux couleurs de l’Olympique lyonnais trônent devant le stade, symboles du rayonnement d’un club qui dominait le championnat de France de football au début des années 2000.
Le lion est présent partout dans l’image de marque du club : sur le logo, sur les réseaux, et même sur les pectoraux de quelques supporters qui vivent et respirent pour leur équipe. Ce sont ceux qui se lèvent comme un seul homme quand Lyou, la mascotte, parcourt les travées du stade à chaque but marqué par l’équipe. Pourtant, s’il rugit dans le stade lyonnais, dans la savane, le lion s’éteint.
Lors de la neuvième journée de Ligue 1 (dont les matchs se sont déroulés du 24 au 26 octobre 2025), il y avait deux fois plus de monde dans le stade pour le match Lyon-Strasbourg (soit un peu plus de 49 000 spectateurs) que de lions à l’état sauvage sur la planète (environ 25 000). Les populations de lions en Afrique et en Inde ont chuté de 25 % entre 2006 et 2018, comme bien d’autres espèces sur la planète, selon l’Union internationale pour la conservation de la nature (UICN).

C’est un curieux paradoxe : alors que le secteur du sport est en plein essor, capitalisant souvent sur la symbolique animale pour développer marques et logos et pour fédérer les foules autour de valeurs partagées, ces mêmes espèces animales font face à de nombreuses menaces dans la nature, sans que les fans ou les clubs ne le sachent vraiment.
Ce paradoxe entre l’omniprésence des représentations animales dans le sport et la crise globale de la biodiversité a été le point de départ d’une étude publiée dans la revue BioScience. Celle-ci a quantifié la diversité des espèces représentées dans les plus grands clubs de sport collectif dans chaque région du monde, d’une part, et évalué leur statut de conservation, d’autre part. De quoi dégager au passage des tendances entre régions du globe et sports collectifs (féminins et masculins).
L’enjeu ? Explorer les passerelles possibles entre sport professionnel et protection de la biodiversité. En effet, le sport réunit des millions de passionnés, tandis que l’identité des clubs s’appuie sur des espèces à la fois charismatiques et le plus souvent menacées. À la clé, une opportunité unique de promouvoir la conservation de la biodiversité dans un cadre positif, fédérateur et valorisant.
Le secteur du sport a récemment pris conscience des enjeux climatiques, de par ce qu’ils représentent comme risque pour la pratique sportive, mais aussi par l’impact que les événements sportifs ont sur le climat, mais la biodiversité n’a pas encore reçu la même attention.
La diversité des espèces représentées dans le sport collectif
Ces travaux ont porté sur une sélection de 43 pays sur les cinq grands continents. Ils mettent en lumière de nombreux enseignements, au premier rang desquels l’importance et la grande quantité d’animaux sauvages dans les emblèmes sportifs. Ainsi, 25 % des organisations sportives professionnelles utilisent un animal sauvage soit dans leur nom ou surnom, soit dans leur logo.

Cela représente plus de 700 équipes masculines et féminines, dans chacun des dix sports collectifs pris en compte dans l'étude : football, basketball, football américain, baseball, rugby à XV et à XIII, volleyball, handball, cricket et hockey sur glace. Sans surprise, les espèces les plus représentées sont, dans cet ordre, les lions (Panthera leo), les tigres (Panthera tigris), les loups (Canis lupus), les léopards (Panthera pardus) et les ours bruns (Ursus arctos).
Si les grands mammifères prennent la part du lion sur ce podium, il existe en réalité une formidable diversité taxonomique représentée, avec plus de 160 types d’animaux différents. Ainsi, les calamars, les crabes, les grenouilles ou les frelons côtoient les crocodiles, les cobras et les pélicans, dans un bestiaire sportif riche et révélateur de contextes socio-écologiques très spécifiques. Nous les avons recensés dans une carte interactive accessible en ligne.
On associe plus facilement cette imagerie animale aux grandes franchises états-uniennes de football (NFL), de basket-ball (NBA) ou de hockey sur glace (NHL), avec des clubs comme les Miami Dolphins (NFL), les Memphis Grizzlies (NBA) ou les Pittsburgh Penguins (NHL).

Or, la France aussi possède une faune diverse, avec plus de 20 espèces représentées dans plus de 45 clubs professionnels : les aiglons de l’OGC Nice (football), le loup du LOU Rugby (rugby), ou les lionnes du Paris 92 (handball) en sont de beaux exemples. C’est également le cas pour le volley-ball, comme le montre l’illustration ci-dessus.
À lire aussi : Pas de ski (alpin) cette année… c’est l’occasion de s’intéresser à la biodiversité montagnarde !
Des symboles culturels, esthétiques ou encore identitaires
Les emblèmes des clubs font souvent écho à l’héritage culturel de leur région. L’hermine, emblème des ducs de Bretagne, est ainsi utilisée depuis le XIVe siècle pour véhiculer l’identité culturelle bretonne. On la retrouve dans plusieurs clubs sportifs de la région, dont le Stade rennais FC, le Rugby club Vannes ou le Nantes Basket Hermine.

Les symboles animaliers permettent aussi de communiquer sur les valeurs et spécificités du club, telles que la cohésion et la solidarité, à l’instar du groupe de supporters du LOU Rugby, qui se surnomme « la meute ».
Ces surnoms permettent également de créer un narratif autour de l’esthétique des couleurs de l’équipe, comme le font les « zèbres », surnom donné à l’équipe de la Juventus FC de Turin (Italie) qui joue traditionnellement en blanc rayé de noir.
Enfin, les emblèmes faisant directement référence à l’environnement local sont fréquents, tels les Parramatta Eels (qui doit son nom à celui du quartier de Sydney où joue l’équipe et qui signifie « lieu où vivent les anguilles », en dharug, langue aborigène), ou les « Brûleurs de loups » de Grenoble (du nom d’une pratique en Dauphiné qui consistait à faire de grands feux pour éloigner les prédateurs et gagner des terres agricoles sur les forêts).
À lire aussi : Comprendre la diversité des émotions suscitées par le loup en France
Des clubs au service de la vie sauvage ?
Le secteur du sport a récemment pris conscience des enjeux climatiques, tant ceux liés à la pratique sportive qu’aux événéments sportifs. La biodiversité n’a pas encore reçu la même attention. Or, notre étude montre que 27 % des espèces animales utilisées dans ces identités sportives font face à des risques d’extinction à plus ou moins court terme. Cela concerne 59 % des équipes professionnelles, soit une vaste majorité.
Six espèces, en particulier, sont en danger critique d’extinction selon l’UICN : le rhinocéros noir (Diceros bicornis), la baleine bleue (Balænoptera musculus), l’éléphant d’Afrique (Loxodonta africana), l’éléphant d’Asie (Elephas maximus), le tigre et le carouge (Agelaius xanthomus) de Porto Rico. Lions et léopards, deux des espèces les plus souvent représentées par les clubs sportifs, ont un statut d’espèces vulnérables.
Au total, 64 % des équipes ont un emblème animal dont la population est en déclin dans la nature. Et 18 équipes ont même pour emblème une espèce… dont on ne connaît tout simplement pas la dynamique d’évolution des populations. Si vous pensiez que cela concerne des espèces inconnues, détrompez-vous : l’ours polaire (Ursus maritimus), l’orque (Orcinus orca) ou encore le chat forestier (Felis silvestris) font partie de ces espèces populaires, mais très mal connues au plan démographique.
Dans ces conditions, le sport peut-il aider à promouvoir la conservation de la biodiversité dans un cadre fédérateur et valorisant ? De fait, les clubs et les athlètes emblématiques, dont les identités s’appuient sur des espèces souvent charismatiques mais menacées, rassemblent des millions de passionnés.

Une autre étude publiée récemment présente un modèle qui alignerait les intérêts des clubs, de leurs partenaires commerciaux, de leurs communautés de supporters et des protecteurs de la biodiversité autour de la figure centrale des emblèmes sportifs animaliers.
À lire aussi : Comment limiter l’empreinte carbone des Coupes du monde de football ?
Jouer collectif pour protéger la biodiversité
Le projet The Wild League, dans lequel s’inscrit la nouvelle publication scientifique, vise à mettre ce modèle en application avec l’appui des clubs (professionnels ou non) et de leurs communautés, afin d’impliquer le plus grand nombre d’acteurs (équipes, partenaires, supporters) pour soutenir la recherche en écologie et la préservation de la biodiversité.
Ces engagements sont gagnant-gagnant : pour les clubs, c’est l’occasion de toucher de nouveaux publics et de mobiliser les supporters autour de valeurs fortes. Les sponsors, eux, peuvent associer leurs marques à une cause universelle. En passant à l’échelle, une ligue professionnelle, si elle se mobilisait à travers toutes ses équipes, pourrait ainsi jouer un rôle clé pour sensibiliser à la biodiversité.

Par exemple, la première division de hockey sur glace allemand (Deutsche Eishockey Liga) comprend 15 équipes, dont 13 présentent des emblèmes très charismatiques. Chaque semaine, les panthères affrontent les ours polaires, les pingouins ferraillent contre les tigres et les requins défient les grizzlis. Autant d’occasions pour mieux faire connaître la richesse du vivant sur la Terre.
La diversité des emblèmes animaliers des clubs sportifs permettrait d’attirer l’attention sur la diversité d’espèces pour un animal donné. Par exemple, certains termes comme les « crabes », les « chauve-souris » ou les « abeilles » cachent en réalité une diversité taxonomique immense. Il existe plus de 1 400 espèces de crabes d’eau douce, autant d’espèces de chauve-souris (et qui représentent une espèce sur cinq parmi les mammifères) et plus de 20 000 espèces d’abeilles dans le monde.
Ces mascottes peuvent également mettre en lumière des espèces locales. L’équipe de basket-ball des Auckland Tuatara, par exemple, est la seule équipe à présenter comme emblème le tuatara (Sphenodon punctatus), ce reptile endémique à la Nouvelle-Zélande (qui n'existe que dans ce pays). Ces associations uniques entre une équipe et une espèce sont une occasion rêvée de développer un sens de responsabilité de l’un envers l’autre.
Le sport est avant tout une industrie du divertissement qui propose des expériences émotionnelles fondées sur des valeurs fortes. Les emblèmes animaliers des clubs doivent permettre de mettre ces émotions au service de la nature et d’engager les communautés sportives pour leur protection et pour la préservation de la biodiversité au sens large. C’est à cette condition qu’on évitera que le rugissement du lion, comme cri de ralliement sportif, ne devienne qu’un lointain souvenir et qu’on redonnera un vrai sens symbolique à ces statues si fièrement érigées devant nos stades.
À lire aussi : Sport, nature et empreinte carbone : les leçons du trail pour l’organisation des compétitions sportives
Ugo Arbieu est fondateur de The Wild League, un projet international visant à promouvoir l'intégration des enjeux de la protection de la biodiversité dans les organisations sportives professionnelles
Franck Courchamp ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 16:54
L’Australie interdit les réseaux sociaux aux moins de 16 ans : un modèle bientôt suivi par d’autres pays ?
Lisa M. Given, Professor of Information Sciences & Director, Social Change Enabling Impact Platform, RMIT University
Texte intégral (2339 mots)

C’est le résultat de plusieurs années de campagne du gouvernement australien et de parents d’enfants victimes de harcèlement en ligne : l’entrée en vigueur d’une loi interdisant les réseaux sociaux aux moins de 16 ans. Des applications telles qu’Instagram, Snapchat, X, Facebook ou encore Reddit sont désormais soumises à l’obligation de bannir tous les utilisateurs de moins de 16 ans sous peine d’amendes. Si cette loi soulève de nombreuses questions sur son efficacité réelle et ses modalités de mise en œuvre, et si d’autres pays privilégient des mesures moins contraignantes, le texte n’en constitue pas moins une première mondiale et suscite un intérêt à l’international. Affaire à suivre…
Après des mois d’attente et de débats, la loi sur les réseaux sociaux en Australie est désormais en vigueur. Les Australiens de moins de 16 ans doivent désormais composer avec cette nouvelle réalité qui leur interdit d’avoir un compte sur certaines plates-formes de réseaux sociaux, notamment Instagram, TikTok et Facebook.
Seul le temps dira si cette expérience audacieuse, une première mondiale, sera couronnée de succès. En attendant, de nombreux pays envisagent déjà de suivre l’exemple de l’Australie, tandis que d’autres adoptent une approche différente pour tenter d’assurer la sécurité des jeunes en ligne.
Un mouvement global
En novembre, le Parlement européen a appelé à l’adoption d’une interdiction similaire des réseaux sociaux pour les moins de 16 ans.
La présidente de la Commission européenne, Ursula von der Leyen, a déclaré qu’elle avait étudié les restrictions australiennes et la manière dont elles traitent ce qu’elle a qualifié d’« algorithmes qui exploitent la vulnérabilité des enfants », laissant les parents impuissants face au « tsunami des big tech qui envahit leurs foyers ».
En octobre, la Nouvelle-Zélande a annoncé qu’elle allait introduire une législation similaire à celle de l’Australie, à la suite des travaux d’une commission parlementaire chargée d’examiner la meilleure façon de lutter contre les dommages causés par les réseaux sociaux. Le rapport de la commission sera publié début 2026.
Le Pakistan et l’Inde visent à réduire l’exposition des enfants à des contenus susceptibles de leur porter préjudice, en introduisant des règles exigeant l’accord parental et la vérification de l’âge pour accéder aux réseaux sociaux, ainsi que des exigences en matière de modération adressées aux plates-formes.
La Malaisie a annoncé qu’elle interdirait l’accès aux réseaux sociaux aux enfants de moins de 16 ans à partir de 2026. Cette mesure s’inscrit dans la continuité de l’obligation imposée à partir de janvier 2025 aux réseaux sociaux et aux plates-formes de messagerie comptant au moins huit millions d’utilisateurs d’obtenir une licence d’exploitation et de mettre en place des mesures de vérification de l’âge et de sécurité des contenus.
De son côté, la France envisage d’interdire les réseaux sociaux aux moins de 15 ans et d’imposer un couvre-feu de 22 h à 8 h pour l’utilisation des plates-formes aux 15-18 ans. Ces mesures font partie des recommandations formulées par une commission d’enquête française en septembre 2025, qui a également prescrit d’interdire les smartphones à l’école et d’instaurer un délit de « négligence numérique pour les parents qui ne protègent pas leurs enfants ».
En 2023, la France a promulgué une loi contraignant les plates-formes à obtenir l’accord des parents des enfants de moins de 15 ans pour que ces derniers puissent créer un compte sur les réseaux sociaux. Pour autant, cette mesure n’a pas encore été mise en application. C’est également le cas en Allemagne : dans ce pays, les enfants âgés de 13 à 16 ans ne peuvent accéder aux plates-formes qu’avec l’accord de leurs parents, mais dans les faits, aucun contrôle réel n’est exercé.
En Espagne, l’âge minimum pour créer un compte sur les réseaux sociaux passera de 14 ans actuellement à 16 ans. Les moins de 16 ans pourront tout de même créer un compte à la condition expresse d’avoir l’accord de leurs parents.
La Norvège a annoncé en juillet son intention de restreindre l’accès aux réseaux sociaux pour les moins de 15 ans. Le gouvernement a expliqué que la loi serait « conçue dans le respect des droits fondamentaux des enfants, notamment la liberté d’expression, l’accès à l’information et le droit d’association ».
En novembre, le Danemark a annoncé souhaiter « l’interdiction de l’accès aux réseaux sociaux à toute personne âgée de moins de 15 ans ». Cependant, contrairement à la législation australienne, les parents peuvent passer outre ces règles afin de permettre aux enfants âgés de 13 et 14 ans de conserver leur accès à ces plates-formes. Toutefois, aucune date de mise en œuvre n’a été fixée et l’adoption du texte par les législateurs devrait prendre plusieurs mois. On ignore la façon dont l’interdiction danoise sera appliquée. Mais le pays dispose d’un programme national d’identification numérique qui pourrait être utilisé à cette fin.
En juillet, le Danemark a été sélectionné pour participer à un programme pilote (avec la Grèce, la France, l’Espagne et l’Italie) visant à tester une application de vérification de l’âge qui pourrait être lancée dans toute l’Union européenne à l’intention des sites pour adultes et d’autres fournisseurs de services numériques.

{kind=link}
Des résistances
Pour autant, ce type de restrictions n’est pas appliqué partout dans le monde.
Par exemple, la Corée du Sud a décidé de ne pas adopter une interdiction des réseaux sociaux pour les enfants. Mais elle interdira l’utilisation des téléphones portables et autres appareils dans les salles de classe à partir de mars 2026.
Dans la ville de Toyoake (au sud-ouest de Tokyo, au Japon), une solution très différente a été proposée. Le maire de la ville, Masafumi Koki, a publié en octobre une ordonnance limitant l’utilisation des smartphones, tablettes et ordinateurs à deux heures par jour pour les personnes de tous âges.
Koki est informé des restrictions imposées par l’Australie en matière de réseaux sociaux. Mais comme il l’a expliqué :
« Si les adultes ne sont pas tenus de respecter les mêmes normes, les enfants n’accepteront pas les règles. »
Bien que l’ordonnance ait suscité des réactions négatives et ne soit pas pas contraignante, elle a incité 40 % des habitants à réfléchir à leur comportement, et 10 % d’entre eux ont réduit le temps passé sur leur smartphone.
Aux États-Unis, l’opposition aux restrictions imposées par l’Australie sur les réseaux sociaux a été extrêmement virulente et significative.
Les médias et les plateformes états-uniens ont exhorté le président Donald Trump à « réprimander » l’Australie au sujet de sa législation. Ils affirment que les entreprises états-uniennes sont injustement visées et ont déposé des plaintes officielles auprès du Bureau américain du commerce.
Le président Trump a déclaré qu’il s’opposerait à tout pays qui « attaquerait » les plates-formes états-uniennes. Les États-Unis ont récemment convoqué la commissaire australienne à la sécurité électronique Julie Inman-Grant pour témoigner devant le Congrès. Le représentant républicain Jim Jordan a affirmé que l’application de la loi australienne sur la sécurité en ligne « impose des obligations aux entreprises américaines et menace la liberté d’expression des citoyens américains », ce que Mme Inman-Grant a fermement nié.
Maintien de la vigilance mondiale
Alors que la plupart des pays semblent s’accorder sur les préoccupations liées au fonctionnement des algorithmes et aux contenus néfastes auxquels les enfants sont exposés sur les réseaux sociaux, une seule chose est claire : il n’existe pas de solution miracle pour remédier à ces problèmes.
Il n’existe pas de restrictions faisant consensus ni d’âge spécifique à partir duquel les législateurs s’accorderaient à dire que les enfants devraient avoir un accès illimité à ces plates-formes.
De nombreux pays en dehors de l’Australie donnent aux parents la possibilité d’autoriser l’accès à Internet s’ils estiment que cela est dans l’intérêt de leurs enfants. Et de nombreux pays réfléchissent à la meilleure façon d’appliquer les restrictions, s’ils mettent en place des règles similaires.
Alors que les experts soulignent les difficultés techniques liées à l’application des restrictions australiennes, et que les jeunes Australiens envisagent des solutions de contournement pour conserver leurs comptes ou trouver de nouvelles plates-formes à utiliser, d’autres pays continueront à observer et à planifier leurs prochaines actions.
Lisa M. Given a reçu des financements de l'Australian Research Council et de l'eSafety Commission australienne. Elle est membre de l'Académie des sciences sociales d'Australie et de l'Association for Information Science and Technology.
10.12.2025 à 16:18
Aliments ultratransformés : quels effets sur notre santé et comment réduire notre exposition ?
Mathilde Touvier, Directrice de l'Equipe de Recherche en Epidémiologie Nutritionnelle, U1153 Inserm,Inrae, Cnam, Université Sorbonne Paris Nord, Université Paris Cité, Université Paris Cité
Bernard Srour, Chercheur en épidémiologie au CRESS-EREN (INRAE, Inserm, Université Sorbonne Paris Nord, Université Paris Cité), titulaire de la chaire de Professeur Junior INRAE sur les rythmes alimentaires, et coordonnateur du Réseau NACRe (Nutrition Activité physique Cancer Recherche)., Inrae; Inserm
Texte intégral (4259 mots)
Souvent trop sucrés, trop salés et trop caloriques, les aliments ultratransformés contiennent en outre de nombreux additifs, arômes et autres substances résultant de leurs modes de fabrication industriels. Or, les preuves des liens entre leur consommation et divers troubles de santé s’accumulent. Le point sur l’état des connaissances.
The Kraft Heinz Company, Mondelez International, Post Holdings, The Coca-Cola Company, PepsiCo, General Mills, Nestlé USA, Kellogg’s, Mars Incorporated et Conagra Brands… au-delà de leur secteur d’activité – l’agroalimentaire – et de leur importance économique, ces dix entreprises partagent désormais un autre point commun : elles sont toutes visées par une procédure judiciaire engagée par la Ville de San Francisco, aux États-Unis. Selon le communiqué de presse publié par les services du procureur de la ville David Chiu, cette plainte est déposée, car
ces sociétés « savai[en]t que [leurs] produits rendaient les gens malades, mais [ont] continué à concevoir et à commercialiser des produits de plus en plus addictifs et nocifs afin de maximiser [leurs] profits ».
Cette procédure survient quelques jours après la publication, dans la revue médicale The Lancet, d’un long dossier consacré aux effets des aliments ultratransformés sur la santé. Parmi les travaux présentés figure l’analyse approfondie de la littérature scientifique disponible sur ce sujet que nous avons réalisée.
Voici ce qu’il faut savoir des conséquences de la consommation de tels aliments, en tenant compte des connaissances les plus récentes sur le sujet.
Qu’appelle-t-on « aliments ultratransformés » ?
À l’heure actuelle, en France, on estime qu’en moyenne de 30 à 35 % des calories consommées quotidiennement par les adultes proviennent d’aliments ultratransformés. Cette proportion peut atteindre 60 % au Royaume-Uni et aux États-Unis. Si dans les pays occidentaux, les ventes de ces produits se sont stabilisées (quoiqu’à des niveaux élevés), elles sont en pleine explosion dans les pays à revenu faible et intermédiaire.
Comme leur nom l’indique, les aliments ultratransformés sont des aliments, ou des formulations issues d’aliments, qui ont subi des transformations importantes lors de leur élaboration. Ils sont fabriqués de façon industrielle, selon une grande diversité de procédés (chauffage à haute température, hydrogénation, prétraitement par friture, hydrolyse, extrusion, etc.) qui modifient radicalement la matrice alimentaire de départ.
Par ailleurs, les aliments ultratransformés sont caractérisés dans leur formulation par la présence de « marqueurs d’ultra-transformation », parmi lesquels les additifs alimentaires destinés à en améliorer l’apparence, le goût ou la texture afin de les rendre plus appétissants et plus attrayants : colorants, émulsifiants, édulcorants, exhausteurs de goût, etc. À l’heure actuelle, 330 additifs alimentaires sont autorisés en France et dans l’Union européenne.
En outre, des ingrédients qui ne sont pas concernés par la réglementation sur les additifs alimentaires entrent aussi dans la composition des aliments ultratransformés. Il s’agit par exemple des arômes, des sirops de glucose ou de fructose, des isolats de protéines, etc.
En raison des processus de transformation qu’ils subissent, ces aliments peuvent également contenir des composés dits « néoformés », qui n’étaient pas présents au départ, et dont certains peuvent avoir des effets sur la santé.
Dernier point, les aliments ultratransformés sont généralement vendus dans des emballages sophistiqués, dans lesquels ils demeurent souvent conservés des jours voire des semaines ou mois. Ils sont aussi parfois réchauffés au four à micro-ondes directement dans leurs barquettes en plastique. De ce fait, ils sont plus susceptibles de contenir des substances provenant desdits emballages.
Les procédés possibles et les additifs autorisés pour modifier les aliments sont nombreux. Face à la profusion d’aliments présents dans les rayons de nos magasins, comment savoir si un aliment appartient à la catégorie des « ultratransformés » ?
Une classification pour indiquer le niveau de transformation
Un bon point de départ pour savoir, en pratique, si un produit entre dans la catégorie des aliments ultratransformés est de se demander s’il contient uniquement des ingrédients que l’on peut trouver traditionnellement dans sa cuisine. Si ce n’est pas le cas (s’il contient par exemple des émulsifiants, ou des huiles hydrogénées, etc.), il y a de fortes chances qu’il s’agisse d’un aliment ultratransformé.
La classification NOVA
Dans les années 2010, le chercheur brésilien Carlos Monteiro et son équipe ont proposé une classification des aliments fondée sur leur degré de transformation. Celle-ci comporte quatre groupes :- les aliments pas ou peu transformés ;
- les ingrédients culinaires (sel, sucre, matières grasses animales et végétales, épices, poivre…) ;
- les aliments transformés combinant les deux premiers groupes ;
- les aliments ultratransformés.
Dans le groupe des aliments ultratransformés figurent par exemple les sodas, qu’ils soient sucrés ou édulcorés, les légumes assaisonnés de sauces contenant des additifs alimentaires, les steaks végétaux reconstitués ou les pâtisseries, les confiseries et barres chocolatées avec ajout d’additifs, les nouilles déshydratées instantanées, les yaourts édulcorés…
Saucisses et jambons, qui contiennent des nitrites, sont classés comme « aliments ultratransformés », tandis qu’une viande simplement conservée en salaison est considérée comme des « transformée ». De la même façon, les soupes liquides en brique préparées uniquement avec des légumes, des herbes et des épices sont considérées comme des « aliments transformés », alors que les soupes déshydratées, avec ajout d’émulsifiants ou d’arômes sont classées comme « aliments ultratransformés ».
Des aliments qui contiennent plus de sucre, plus de sel, plus de gras
Les aliments ultratransformés sont en moyenne plus pauvres en fibres et en vitamines que les autres aliments, tout en étant plus denses en énergie et plus riches en sel, en sucre et en acides gras saturés. En outre, ils pousseraient à manger davantage.
De nombreuses études ont également montré que les régimes riches en aliments ultratransformés étaient par ailleurs associés à une plus faible consommation d’aliments nutritionnellement sains et favorables à la santé.
Or, on sait depuis longtemps maintenant que les aliments trop sucrés, trop salés, trop riches en graisses saturées ont des impacts délétères sur la santé s’ils sont consommés en trop grande quantité et fréquence. C’est sur cette dimension fondamentale que renseigne le Nutri-Score.
Il faut toutefois souligner que le fait d’appartenir à la catégorie « aliments ultratransformés » n’est pas systématiquement synonyme de produits riches en sucres, en acides gras saturés et en sel. En effet, la qualité nutritionnelle et l’ultra-transformation/formulation sont deux dimensions complémentaires, et pas colinéaires.
Cependant, depuis quelques années, un nombre croissant de travaux de recherche ont révélé que les aliments ultratransformés ont des effets délétères sur la santé qui ne sont pas uniquement liés à leur qualité nutritionnelle.
Des effets sur la santé avérés, d’autres soupçonnés
Afin de faire le point sur l’état des connaissances, nous avons procédé à une revue systématique de la littérature scientifique sur le sujet. Celle-ci nous a permis d’identifier 104 études épidémiologiques prospectives.
Ce type d’étude consiste à constituer une cohorte de volontaires dont les consommations alimentaires et le mode de vie sont minutieusement renseignés, puis dont l’état de santé est suivi sur le long terme. Certains des membres de la cohorte développent des maladies, et pas d’autres. Les données collectées permettent d’établir les liens entre leurs expositions alimentaires et le risque de développer telle ou telle pathologie, après prise en compte de facteurs qui peuvent « brouiller » ces associations (ce que les épidémiologistes appellent « facteurs de confusion » : tabagisme, activité physique, consommation d’alcool, etc.).
Au total, 92 des 104 études publiées ont observé une association significative entre exposition aux aliments ultratransformés et problèmes de santé.
Les 104 études prospectives ont dans un second temps été incluses dans une méta-analyse (autrement dit, une analyse statistique de ces données déjà publiées), afin d’effectuer un résumé chiffré de ces associations.
Les résultats obtenus indiquent que la mortalité prématurée toutes causes confondues était l’événement de santé associé à la consommation d’aliments transformés pour lequel la densité de preuve était la plus forte (une vingtaine d’études incluses dans la méta-analyse).
Pour le formuler simplement : les gens qui consommaient le plus d’aliments ultratransformés vivaient en général moins longtemps que les autres, toutes choses étant égales par ailleurs en matière d’autres facteurs de risques.
Les preuves sont également solides en ce qui concerne l’augmentation de l’incidence de plusieurs pathologies : maladies cardiovasculaires, obésité, diabète de type 2 et dépression ou symptômes dépressifs.
La méta-analyse suggérait également une association positive entre la consommation d’aliments ultratransformés et le risque de développer une maladie inflammatoire chronique de l’intestin (quatre études incluses).
En ce qui concerne les cancers, notamment le cancer colorectal, les signaux indiquant une corrélation potentielle sont plus faibles. Il faudra donc mener d’autres études pour confirmer ou infirmer le lien.
Des résultats cohérents avec les travaux expérimentaux
Au-delà de ces études de cohorte, ces dernières années, diverses études dites « interventionnelles » ont été menées. Elles consistent à exposer des volontaires à des aliments ultratransformés et un groupe témoin à des aliments pas ou peu transformés, afin de suivre l’évolution de différents marqueurs biologiques (sur une période courte de deux ou trois semaines, afin de ne pas mettre leur santé en danger).
C’est par exemple le cas des travaux menés par Jessica Preston et Romain Barrès, qui ont montré avec leurs collaborateurs que la consommation d’aliments ultratransformés entraînait non seulement une prise de poids plus importante que les aliments non ultratransformés, à calories égales, mais qu’elle perturbait aussi certaines hormones, et était liée à une baisse de la qualité du sperme.
Ces résultats suggèrent que ce type de nourriture serait délétère à la fois pour la santé cardiométabolique et pour la santé reproductive. Les résultats de plusieurs essais randomisés contrôlés menés ces dernières années vont dans le même sens. Cinq ont été répertoriés et décrits dans notre article de revue, et d’autres sont en cours.
Les aliments ultratransformés impactent donc la santé, et ce, très en amont du développement de maladies chroniques comme le diabète.
D’autres travaux expérimentaux, comme ceux de l’équipe de Benoît Chassaing, révèlent que la consommation de certains émulsifiants qui sont aussi des marqueurs d’ultra-transformation perturbe le microbiote. Elle s’accompagne d’une inflammation chronique, et a été associée au développement de cancers colorectaux dans des modèles animaux.
À lire aussi : Comment le plastique est devenu incontournable dans l’industrie agroalimentaire
Rappelons que la majorité des additifs contenus dans les aliments ultratransformés n’ont pas d’intérêt en matière de sécurité sanitaire des aliments. On parle parfois d’additifs « cosmétiques », ce terme n’ayant pas de valeur réglementaire.
Ils servent uniquement à rendre les produits plus appétissants, améliorant leur apparence ou leurs qualités organoleptiques (goût, texture) pour faire en sorte que les consommateurs aient davantage envie de les consommer. Ils permettent aussi de produire à plus bas coût, et d’augmenter les durées de conservation.
Au-delà du principe de précaution
En 2019, à la suite de l’avis du Haut Conseil de la santé publique, le quatrième programme national nutrition santé (PNNS) introduisait pour la première fois la recommandation officielle de favoriser les aliments pas ou peu transformés et limiter les aliments ultratransformés, tels que définis par la classification NOVA.
À l’époque, cette recommandation se fondait sur un nombre relativement restreint de publications, notamment les premières au monde ayant révélé des liens entre aliments ultratransformés et incidence de cancers, maladies cardiovasculaires et diabète de type 2, dans la cohorte française NutriNet-Santé. Il s’agissait donc avant tout d’appliquer le principe de précaution.
Aujourd’hui, les choses sont différentes. Les connaissances accumulées grâce aux nombreuses recherches menées ces cinq dernières années dans le monde ont apporté suffisamment de preuves pour confirmer que la consommation d’aliments ultratransformés pose un réel problème de santé publique.
Dans le cadre de la cohorte NutriNet-Santé, nous avons, par exemple, désormais publié une douzaine d’articles montrant des liens entre la consommation d’émulsifiants, de nitrites, d’édulcorants ainsi que celle de certains mélanges d’additifs et une incidence plus élevée de certains cancers, maladies cardiovasculaires, d’hypertension et de diabète de type 2.
De potentiels « effets cocktails » ont également été suggérés grâce à un design expérimental mis en place par des collègues toxicologues. Des indices collectés lors de travaux toujours en cours suggèrent également que certains colorants et conservateurs pourraient eux aussi s’avérer problématiques. Rappelons en outre qu’en 2023, le Centre international de recherche sur le cancer (CIRC) a classé l’aspartame comme « possiblement cancérigène » pour l’être humain (groupe 2B).
Le problème est que nous sommes exposés à de très nombreuses substances. Or, les données scientifiques concernant leurs effets, notamment sur le long terme ou lorsqu’elles sont en mélange, manquent. Par ailleurs, tout le monde ne réagit pas de la même façon, des facteurs individuels entrant en ligne de compte.
Il est donc urgent que les pouvoirs publics, sur la base des connaissances scientifiques les plus récentes, s’emparent de la question des aliments ultratransformés. Mais par où commencer ?
Quelles mesures prendre ?
Comme souvent en nutrition de santé publique, il est nécessaire d’agir à deux niveaux. Au niveau du consommateur, le cinquième programme national nutrition santé, en cours d’élaboration, devrait pousser encore davantage la recommandation de limiter la consommation d’aliments ultratransformés.
Il s’agira également de renforcer l’éducation à l’alimentation dès le plus jeune âge (et la formation des enseignants et des professionnels de santé) pour sensibiliser les publics à cette question.
En matière d’information des consommateurs, l’étiquetage des denrées alimentaires joue un rôle clé. La première urgence reste de rendre obligatoire le Nutri-Score sur l’ensemble des produits, comme cela est plébiscité par plus de 90 % de la population française, d’après Santé publique France. Les citoyennes et citoyens ont leur rôle à jouer en ce sens, en signant la pétition sur le site de l’Assemblée nationale.
À ce sujet, soulignons que des évolutions du logo Nutri-Score sont envisagées pour mieux renseigner les consommateurs, par exemple en entourant de noir le logo lorsqu’il figure sur des aliments appartenant à la catégorie NOVA « ultratransformé ». Un premier essai randomisé mené sur deux groupes de 10 000 personnes a démontré que les utilisateurs confrontés à un tel logo nutritionnel sont nettement plus à même d’identifier si un produit est ultratransformé, mais également que le Nutri-Score est très performant lorsqu’il s’agit de classer les aliments selon leur profil nutritionnel plus ou moins favorable à la santé.
Il est également fondamental de ne pas faire porter tout le poids de la prévention sur le choix des consommateurs. Des modifications structurelles de l’offre de nos systèmes alimentaires sont nécessaires.
Par exemple, la question de l’interdiction de certains additifs (ou d’une réduction des seuils autorisés), lorsque des signaux épidémiologiques et/ou expérimentaux d’effets délétères s’accumulent, doit être posée dans le cadre de la réévaluation de ces substances par les agences sanitaires. C’est en particulier le cas pour les additifs « cosmétiques » sans bénéfice santé.
Les leviers économiques
Au-delà de la réglementation liée à la composition des aliments ultratransformés, les législateurs disposent d’autres leviers pour en limiter la consommation. Il est par exemple possible de réguler leur marketing et de limiter leur publicité, que ce soit à la télévision, dans l’espace public ou lors des événements sportifs, notamment.
Ce point est d’autant plus important en ce qui concerne les campagnes qui ciblent les enfants et les adolescents, particulièrement vulnérables au marketing. Des tests d’emballage neutre – bien que menés sur de petits effectifs – l’ont notamment mis en évidence.
Autre puissant levier : le prix. À l’instar de ce qui s’est fait dans le domaine de la lutte contre le tabagisme, il pourrait être envisageable de taxer les aliments ultratransformés et ceux avec un Nutri-Score D ou E et, au contraire, de prévoir des systèmes d’incitations économiques pour faire en sorte que les aliments les plus favorables nutritionnellement, pas ou peu ultratransformés, et si possible bio, soient les plus accessibles financièrement et deviennent les choix par défaut.
Il s’agit aussi de protéger les espaces d’éducation et de soin en interdisant la vente ou la distribution d’aliments ultratransformés, et en y améliorant l’offre.
Il est également fondamental de donner les moyens à la recherche académique publique, indemne de conflits d’intérêt économiques, de conduire des études pour évaluer les effets sur la santé des aliments industriels. Ce qui passe par une amélioration de la transparence en matière de composition de ces produits.
Un manque de transparence préjudiciable aux consommateurs
À l’heure actuelle, les doses auxquelles les additifs autorisés sont employés par les industriels ne sont pas publiques. Lorsque les scientifiques souhaitent accéder à ces informations, ils n’ont généralement pas d’autre choix que de faire des dosages dans les matrices alimentaires qu’ils étudient.
C’est un travail long et coûteux : lors de nos travaux sur la cohorte NutriNet-Santé, nous avons dû réaliser des milliers de dosages. Nous avons aussi bénéficié de l’appui d’associations de consommateurs, comme UFC-Que Choisir. Or, il s’agit d’informations essentielles pour qui étudie les impacts de ces produits sur la santé.
Les pouvoirs publics devraient également travailler à améliorer la transparence en matière de composition des aliments ultratransformés, en incitant (ou en contraignant si besoin) les industriels à transmettre les informations sur les doses d’additifs et d’arômes employées, sur les auxiliaires technologiques utilisés, sur la composition des matériaux d’emballages, etc. afin de permettre l’évaluation de leurs impacts sur la santé par la recherche académique.
Cette question de la transparence concerne aussi l’emploi d’auxiliaires technologiques. Ces substances, utilisées durant les étapes de transformation industrielle, ne sont pas censées se retrouver dans les produits finis. Elles ne font donc pas l’objet d’une obligation d’étiquetage. Or, un nombre croissant de travaux de recherche révèle qu’en réalité, une fraction de ces auxiliaires technologiques peut se retrouver dans les aliments.
C’est par exemple le cas de l’hexane, un solvant neurotoxique utilisé dans l’agro-industrie pour améliorer les rendements d’extraction des graines utilisées pour produire les huiles végétales alimentaires.
Le poids des enjeux économiques
Le manque de transparence ne se limite pas aux étiquettes des aliments ultratransformés. Il est également important de vérifier que les experts qui travaillent sur ces sujets n’ont pas de liens d’intérêts avec l’industrie. L’expérience nous a appris que lorsque les enjeux économiques sont élevés, le lobbying – voire la fabrique du doute – sont intenses. Ces pratiques ont été bien documentées dans la lutte contre le tabagisme. Or, les aliments ultratransformés génèrent des sommes considérables.
Enjeux économiques
- Entre 2009 et 2023, les ventes mondiales sur le marché des aliments ultratransformés sont passées de 1 500 milliards de dollars à 1 900 milliards de dollars (en dollars américains constants de 2023, à prix constants ; soit environ de 1 290 milliards à 1 630 milliards d’euros), principalement tirés par la croissance rapide des ventes dans les pays à faible et moyen revenu ;
- Entre 1962 et 2021, plus de la moitié des 2 900 milliards de dollars (environ 2 494 milliards d’euros aujourd’hui) versés aux actionnaires par les entreprises opérant dans les secteurs de la production alimentaire, de la transformation, de la fabrication, de la restauration rapide et de la vente au détail, l’ont été par les fabricants de produits ultratransformés.
Cependant, si élevés que soient ces chiffres, les découvertes scientifiques récentes doivent inciter la puissance publique à prendre des mesures qui feront passer la santé des consommateurs avant les intérêts économiques.
Il s’agit là d’une impérieuse nécessité, alors que l’épidémie de maladies chroniques liées à la nutrition s’aggrave, détruit des vies et pèse de plus en plus sur les systèmes de santé.
Mathilde Touvier a reçu des financements publics ou associatifs à but non lucratif de l'European Research Council, l'INCa, l'ANR, la DGS...
Bernard Srour a reçu des financements de l'Agence nationale de la recherche (ANR), de INRAE et de l'Institut national du cancer (INCa) dans le cadre de ses recherches. Il a reçu des honoraria dans le cadre d'expertises ou de présentations scientifiques de la part de l'American Heart Association, l'European School of Oncology, et de la Danish Diabetes and Endocrine Academy.
10.12.2025 à 16:17
La « littérature rectificative » : quand les personnages littéraires sortent de leur silenciation
Hécate Vergopoulos, Maîtresse de conférences en sciences de l'information et de la communication, Sorbonne Université
Texte intégral (2160 mots)
Fin octobre 2025 sortait sur nos écrans une nouvelle adaptation d’une œuvre littéraire : « l’Étranger », d’Albert Camus, revisité par François Ozon. Cet événement cinématographique nous rappelait, une fois encore, que les personnages de fiction peuvent avoir une vie qui échappe à leur créateur ou créatrice, au point parfois d’avoir envie de les croire « autonomes ».
L’autonomie des personnages de fiction, c’est ce que le professeur de littérature française Pierre Bayard défend dans son ouvrage la Vérité sur « Ils étaient dix » (2020). Il s’autoproclame d’ailleurs « radical » parmi les « intégrationnistes », soit parmi celles et ceux qui, commentant et pensant la fiction, affirment que nous pouvons parler des personnages littéraires comme s’il s’agissait d’êtres vivants.
Donner une voix aux personnages silenciés
Avant le film d’Ozon (L’Étranger, 2025), l’écrivain Kamel Daoud, en publiant Meursault, contre-enquête (2013), entendait donner la parole au frère de celui qui, dans le récit de Camus, ne porte même pas de nom : il est désigné comme « l’Arabe ». Son projet était de rendre compte de cette vie silenciée
– et partant, du caractère colonial de ce monument de la culture francophone – en lui donnant une consistance littéraire. Il s’agissait en somme de « rectifier » non pas une œuvre, l’Étranger (1942), mais la réalité de ce personnage de fiction qui, nous parvenant à travers les mots seuls de Meursault, ne disait rien en propre et dont la trajectoire de vie ne tenait en rien d’autre qu’à l’accomplissement de son propre meurtre.
Plus récemment, l’écrivain américain Percival Everett, lauréat du Pulitzer 2025 pour James (2024), a quant à lui donné la parole au personnage secondaire homonyme de l’esclave apparaissant dans le roman les Aventures de Huckleberry Finn (1848), de Mark Twain. Son projet, selon les propres mots d’Everett était de créer pour James une « capacité d’agir ».
De telles entreprises sont plus fréquentes qu’il n’y paraît. Dans le Journal de L. (1947-1952), Christophe Tison proposait en 2019 de donner la plume à la Lolita de Nabokov dont le grand public ne connaissait jusqu’alors que ce qu’Humbert-Humbert – le pédophile du roman – avait bien voulu en dire. Celle qui nous parvenait comme l’archétype de la « nymphette » aguicheuse et dont la figuration était devenue iconique – alors même que Nabokov avait expressément demandé à ce que les couvertures de ses livres ne montrent ni photos ni représentations de jeune fille –, manifeste, à travers Tison, le désir de reprendre la main sur son propre récit.
À lire aussi : « Lolita » de Nabokov en 2024 : un contresens généralisé enfin levé ?
Il en est allé de même pour Antoinette Cosway, alias Bertha Mason, qui apparaît pour la première fois sous les traits de « la folle dans le grenier » dans le Jane Eyre (1847), de Charlotte Brontë. Quand l’écrivaine britannique née aux Antilles, Jean Rhys décide de raconter l’histoire de cette femme blanche créole originaire de Jamaïque dans la Prisonnière des Sargasses (1966), elle entend montrer que cette folie tient au système patriarcal et colonial qui l’a brisée en la privant de son identité.
Margaret Atwood, quant à elle, avec son Odyssée de Pénélope (2005) s’attache à raconter le périple finalement très masculin de « l’homme aux mille ruses » notamment à travers le regard de Pénélope. Celle qui jusqu’alors n’était que « l’épouse d’Ulysse » se révèle plus complexe et plus ambivalente que ce que l’assignation homérique à la fidélité avait laissé entendre.
Ces œuvres singulières fonctionnent toutes selon les mêmes présupposés : 1. La littérature est faite d’existences ; 2. Or, celles de certains personnages issus d’œuvres « premières » y sont mal représentées ; 3. une nouvelle œuvre va pouvoir leur permettre de dire « leur vérité ».
Ces textes, je propose de les rassembler, sans aucune considération de genres, sous l’intitulé « littérature rectificative ». Leur ambition n’est pas celle de la « réponse », de la « riposte » ou même du « démenti ». Ils n’établissent pas à proprement parler de « dialogue » entre les auteurs et autrices concernées. Ils ont seulement pour ambition de donner à voir un point de vue autre – le point de vue d’un ou d’une autre – sur des choses (trop peu ? trop mal ?) déjà dites par la littérature.
Ce n’est probablement pas un hasard si les textes de cette littérature rectificative donnent ainsi la parole à des sujets littéraires victimes d’injustices et de violences, qu’elles soient raciales, sexistes et sexuelles ou autres, car, au fond, ils cherchent tous à savoir qui détient la parole littéraire sur qui.
Le cas du « Consentement », de Vanessa Springora
Parmi eux, un texte qui aura considérablement marqué notre époque : le Consentement de Vanessa Springora (2020). Dans ce livre, elle raconte, sous forme autobiographique, sa relation avec l’écrivain Gabriel Matzneff, qu’elle rencontre en 1986 à Paris, alors qu’elle a 14 ans et lui environ 50. Elle s’attache à décrire les mécanismes d’emprise mis en place par l’auteur ainsi que l’acceptation tacite de cette relation au sein d’un milieu où sa réputation d’écrivain primé lui offrait une protection sociale.
Si l’on accepte qu’il est autre chose qu’un témoignage à seule valeur référentielle et qu’il dispose de qualités littéraires (ou si l’on entend le « témoignage » dans un sens littéraire), alors il semble clair que le « je » de Vanessa Springora est un personnage. Il ne s’agit en aucun cas ici de disqualifier ce « je » en prétendant qu’il est affabulation, mais bien de le penser comme une construction littéraire, au même titre d’ailleurs qu’on peut parler de personnages dans les documentaires.
À lire aussi : « L’Étranger » : pourquoi le roman de Camus déchaîne toujours les passions
La spécificité de Vanessa Springora est que son texte ne vient pas « rectifier » la réalité instituée par un autre texte, mais par une somme d’écrits de Gabriel Matzneff. Elle détaille (p. 171-172) :
« Entre mes seize et vingt-cinq ans paraissent successivement en librairie, à un rythme qui ne me laisse aucun répit, un roman de G. dont je suis censée être l’héroïne ; puis le tome de son journal qui couvre la période de notre rencontre, comportant certaines de mes lettres écrites à l’âge de quatorze ans ; avec deux ans d’écart, la version poche de ce même livre ; un recueil de lettres de rupture, dont la mienne […] Plus tard suivra encore un autre tome de ses carnets noirs revenant de façon obsessionnelle sur notre séparation. »
À travers tous ces textes, écrit-elle, elle découvre que « les livres peuvent être un piège » :
« La réaction de panique des peuples primitifs devant toute capture de leur image peut prêter à sourire. Ce sentiment d’être piégé dans une représentation trompeuse, une version réductrice de soi, un cliché grotesque et grimaçant, je le comprends pourtant mieux que personne. S’emparer avec une telle brutalité de l’image de l’autre, c’est bien lui voler son âme. » (p. 171).
Ce qu’elle décrit ici, cet enfermement dans un personnage qui n’est pas elle, n’est pas sans rappeler le gaslighting, soit ce procédé manipulatoire à l’issue duquel les victimes, souvent des femmes, finissent par se croire folles. Il doit son nom au film de George Cukor, Gaslight (1944), Hantise dans la version française, qui raconte l’histoire d’un couple au sein duquel l’époux tente de faire croire à sa femme qu’elle perd la raison en modifiant des éléments a priori anodins de son quotidien et en lui répondant, quand elle remarque ces changements, qu’il en a toujours été ainsi (parmi eux, l’intensité de l’éclairage au gaz de leur maison, le « gas light »).
Springora montre en effet que la « réalité littéraire » construite par M. l’a précisément conduite à douter de sa propre réalité (p. 178) :
« Je marchais le long d’une rue déserte avec une question dérangeante qui tournait en boucle dans ma tête, une question qui s’était immiscée plusieurs jours auparavant dans mon esprit, sans que je puisse la chasser : quelle preuve tangible avais-je de mon existence, étais-je bien réelle ? […] Mon corps était fait de papier, dans mes veines ne coulait que de l’encre. »
Le Consentement est certes le récit d’une dépossession de soi – d’une emprise. Il est cependant aussi une forme d’acte performatif puisque Springora y (re)devient le plein sujet de sa propre énonciation après en avoir été privée. Ne serait-ce pas là la portée pleinement politique de cette littérature rectificative, à savoir donner aux sujets littéraires les moyens de conquête leur permettant de redevenir des pleins sujets d’énonciation, soit cette « capacité d’agir » dont parlait justement Percival Everett ?
Si la littérature est un formidable exercice de liberté (liberté de créer, d’imaginer, de choisir un langage, un style, une narration), elle peut être aussi un incroyable exercice de pouvoir. Les auteurs australiens Bill Aschroft, Gareth Griffiths et Helen Tiffin l’avaient déjà montré dans l’Empire vous répond. Théorie et pratique des littératures post-coloniales (The Empire Writes Back, 1989, traduction française 2012). À partir du cas de l’empire colonial britannique, l’ouvrage mettait ainsi au jour les façons dont la littérature du centre s’est imposée (par ses formats, ses styles, ses langages, mais encore par ses visions de l’ordre du monde) aux auteurs de l’empire et la façon dont ceux-ci ont appris à s’en défaire.
À l’ère des « re » (de la « réparation des vivants » ou de la justice dite « restaurative »), la littérature rectificative a sans aucun doute un rôle politique à jouer. D’abord, elle peut nous aider à poursuivre notre chemin dans le travail de reconnaissance de nos aveuglements littéraires et collectifs. Ensuite, elle peut faire la preuve que nos sociétés sont assez solides pour ne pas avoir à faire disparaître de l’espace commun des œuvres que nous jugeons dérangeantes. La littérature rectificative ne soustrait pas les textes comme pourrait le faire la cancel culture. Au contraire, elle en ajoute, nous permettant ainsi de mesurer la distance qui nous a un jour séparés de cet ordre du monde dans lequel nous n’avons pas questionné ces existences littéraires subalternes et silenciées.
Hécate Vergopoulos ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 16:16
À qui appartiennent les poissons ? L’épineuse question de la répartition des quotas de pêche européens
Sigrid Lehuta, Chercheure en halieutique, Ifremer
Verena Trenkel, Chercheuse en écologie marine quantitative, Ifremer
Texte intégral (2285 mots)
Les poissons de la Manche n’ont pas pu voter au moment du Brexit, ceux de l’Atlantique n’ont pas de visa de l’espace Schengen et pourtant, leur sort a été fixé au sein de l’Union européenne dans les années 1970. Actualiser ces statu quo anciens dans une Europe à 27 où les océans se réchauffent et où bon nombre de poissons tendent à migrer vers le nord à cause de la hausse des températures devient plus que nécessaire. Voici pourquoi.
Les populations marines ne connaissent pas de frontières. Tous les océans et toutes les mers du monde sont connectées, permettant la libre circulation des animaux marins. Les seules limitations sont intrinsèques à chaque espèce, dépendantes de sa capacité de déplacement, de ses besoins et tolérances vis-à-vis des températures, des profondeurs et d’autres facteurs.
Les poissons ne connaissent ainsi pas de barrières linéaires ou immuables, mais les États ont, eux, quadrillé les mers en fonction de leurs zones économiques exclusives (ZEE). Des institutions onusiennes, comme l’Organisation des Nations unies pour l’alimentation et l’agriculture (Food and Agriculture Organization, FAO), la Commission générale des pêches pour la Méditerranée (CGPM) ou le Conseil international de l’exploitation de la mer, définissent des zones d’évaluation des stocks ou de gestion des pêches dans lesquelles sont régulées les captures ou les activités de pêche.
Dans l’UE : une règle peu révisée depuis plus de quarante ans
Mais à qui sont donc les poissons qui franchissent allégrement les limites des ZEE et des zones de gestion de pêche ? Pour répondre à cette question et éviter la surpêche, des mécanismes de gestion commune et de partage des captures ont été mis en place au sein de l’Union européenne (UE) et avec les pays voisins.
Le tonnage de poisson que l’on peut pêcher est d’abord défini pour chaque espèce et chaque zone de gestion (un stock) afin d’éviter la surpêche. Puis ce tonnage est divisé entre pays, comme les tantièmes dans une copropriété ou les parts dans un héritage. C’est cette répartition entre pays, appelée la « clé de répartition », qui est ici discutée.
Pour la plupart des stocks, la clé de répartition est encore définie sur la base des captures réalisées dans les années 1973-1978 par chacun des neuf États alors membres de l’UE. Cette référence historique a mené à la dénomination de « stabilité relative » qui désigne la méthode de partage des captures annuelles admissibles : la clé est stable, mais la quantité obtenue chaque année varie en fonction de l’état du stock.
Chaque État membre est ensuite libre de distribuer son quota à ses pêcheurs selon des modalités qu’il choisit. En France, chaque navire possède des antériorités de captures propres mais qui ne lui donnent pas automatiquement accès au quota correspondant. Elles déterminent en revanche les sous-quotas attribués à l’organisation de producteurs (OP) à laquelle le navire choisit d’adhérer. L’OP définit en interne les modalités de répartition de ses sous-quotas entre ses adhérents, qui sont différentes entre OP, stocks, flottilles, années…
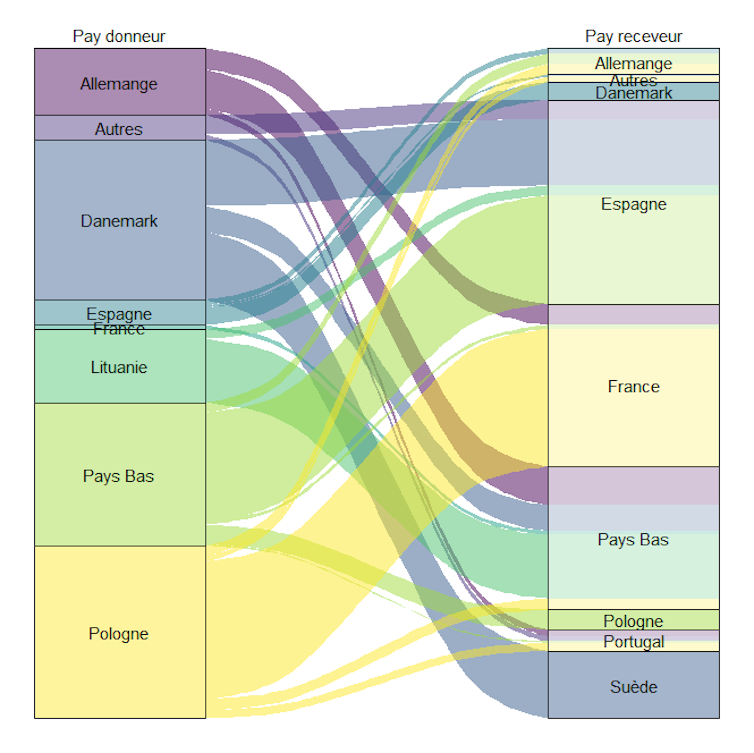
Un partage satisfaisant pour la France mais qui atteint ses limites
La France fait partie des gagnants de ce partage ancien. Le cadre juridique bien établi et la prévisibilité du système facilitent la programmation et évitent d’interminables négociations. Un système assez fluide, avec des échanges parfois systématiques entre États ou entre OP, permet d’éviter d’atteindre les quotas trop tôt dans l’année. Les OP jouent un rôle essentiel pour optimiser l’utilisation et la valorisation des quotas sur l’année, limiter la concurrence entre pêcheurs, ou éviter des crises économiques.
Mais à l’heure du changement climatique, et dans une Europe post-Brexit, ce modèle ancien se frotte à des questionnements nouveaux, qu’ils soient sociétaux ou environnementaux.
Le cas du maquereau est emblématique de cela. Depuis 2010, ce poisson migre de plus en plus vers le nord et atteint les eaux de l’Islande, pays qui n’avait pratiquement pas de quotas pour cette espèce. Faute d’accord avec les pays voisins, la capture annuelle du maquereau dépasse la recommandation scientifique depuis de nombreuses années, menant à la surpêche.
Le Brexit a, quant à lui, provoqué une réduction de la part de l’UE pour les stocks partagés avec le Royaume-Uni, car pêchées dans leur ZEE, avec de lourdes conséquences économiques et sociales : mise à la casse de 90 bateaux français et baisse d’approvisionnement et donc d’activité dans les criées et pour toute la chaîne de transport et de transformation du poisson.
Autre question épineuse : que faire pour les espèces qui sont capturées simultanément par l’engin de pêche alors que leurs niveaux de quota sont très différents ?
C’est le cas par exemple du cabillaud en mer Celtique. Cette espèce est généralement capturée en même temps que le merlu et la baudroie, mais elle fait l’objet d’un quota très faible en raison de l’effondrement du stock. Les pêcheurs qui disposent de quotas pour le merlu ou la baudroie sont donc contraints de cesser leur activité pour éviter de capturer sans le vouloir du cabillaud.
Chaque année, de difficiles négociations sont nécessaires entre l’UE et des pays non membres avec qui des stocks sont partagés, comme la Norvège et le Royaume-Uni, soit des pays qui échappent aux objectifs et critères de répartition définis par la politique commune des pêches.
En France, ce statu quo freine aussi l’installation des jeunes et la transition vers des méthodes de pêche plus vertueuses. En effet, pour s’installer, il ne s’agit pas simplement de pouvoir payer un navire. Le prix de vente d’un navire d’occasion tient en réalité compte des antériorités de pêche qui y restent attachées, ce qui augmente la facture.
Et si l’on veut transitionner vers d’autres techniques ou zones de pêche à des fins de préservation de la biodiversité, d’amélioration du confort ou de la sécurité en mer, ou encore de conciliation des usages avec, par exemple, l’éolien en mer, ce sera nécessairement conditionné à la redistribution des quotas correspondants aux nouvelles espèces pêchées et forcément au détriment d’autres navires qui les exploitent historiquement.
Quelles alternatives au système en place ?
Les atouts et limites du système en place sont bien connus des acteurs de la pêche, mais la réouverture des négociations autour d’une autre clé de répartition promet des débats difficiles entre l'UE et les pays voisins.
L’UE, depuis 2022, incite les États à élargir les critères de répartition du quota national à des considérations environnementales, sociales et économiques. En France, cela s’est traduit en 2024 par de nouveaux critères d’allocation de la réserve nationale de quota. La réserve nationale correspond à une part de quota qui est reprise par l’État à chaque vente et sortie de flotte des navires. Sa répartition favorise désormais les jeunes et la décarbonation des navires.
Cette avancée, même timide, prouve que le choix et l’application de nouveaux critères sont possibles, mais elle reste difficile dans un contexte de faible rentabilité des flottes et de demandes en investissements conséquents pour l’adaptation des bateaux aux transitions écologiques et énergétiques.
En juin 2024, avec un groupe d’une trentaine de scientifiques des pêches, réunis sous l’égide de l’Association française d’halieutique, nous avons mené une réflexion sur les alternatives possibles à la clé actuelle. Parmi les propositions, quatre points ont été saillants pour une pêche durable, équitable et rentable :
la nécessaire prise en compte d’une multitude de critères écologiques et halieutiques pour l’attribution de part de quota. Par exemple, l’utilisation d’engins sélectifs, et moins impactants pour la biodiversité ou la proximité des zones de pêche, traduisant un souci de limitation d’empreinte carbone, et d’adaptabilité aux changements de distribution ;
la nécessaire prise en compte de critères socio-économiques, comme l’équité entre navires, entre générations, entre sexes… ;
la création de récompenses en quota pour la participation à la collecte de données nécessaires pour informer une gestion écosystémique et permettre la mise en place d’un système de répartition fondé sur des critères biologiques (mise en place de caméras à bord, campagnes exploratoires, auto-échantillonnage) ;
la nécessaire transparence concernant la répartition nationale et ses critères.
Conscients de la charge réglementaire qui pèse sur les patrons pêcheurs et des difficultés financières, parfois insurmontables, associées aux adaptations (changement d’engins, de pratiques…), certaines propositions reposent davantage sur des incitations que sur des obligations, c’est-à-dire des quotas supplémentaires venant récompenser des adaptations volontaires.
Pour permettre une transition douce vers les nouvelles règles, nous conseillons le maintien temporaire ou partiel des antériorités afin de donner le temps et la visibilité nécessaires aux pêcheurs pour effectuer les adaptations adéquates.
Nous nous accordons sur une mise à jour à intervalle régulier de la clé de répartition entre pays et navires selon un calendrier prédéfini et en application des critères retenus pour améliorer l’adaptabilité des pêcheries aux changements. Les critères pourraient être aussi révisés, tout en évitant une réouverture des négociations trop régulièrement. Nous insistons sur le nécessaire maintien de la flexibilité indispensable aux adaptations dans un contexte environnemental très fluctuant lié au changement global.
Cet article a été écrit sur la base d’un travail collaboratif mené par Arthur Le Bigot, encadré par les autrices (Ifremer), pour lequel une trentaine de scientifiques a été consultée au cours d’un atelier organisé par l’Association française d’halieutique et des acteurs du système pêche interviewés. Le contenu de cet article reflète l’interprétation des autrices sur la base de leurs connaissances et des propos recueillis au cours des entretiens et de l’atelier. Il n’engage pas les participants à l’atelier, les personnes interviewées ni les membres de l’AFH.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
10.12.2025 à 16:15
Les jeunes veulent-ils encore la démocratie ?
Anne Muxel, Directrice de recherches (CNRS) au Cevipof, Sciences Po
Texte intégral (1893 mots)
Droitisation de la jeunesse, désamour de la démocratie des moins de 35 ans, distanciation de la politique des seniors : « Fractures françaises », dix ans d’enquête menée par le Cevipof, nous apprennent les évolutions du rapport au politique de différentes générations.
Contrairement à ce qui est souvent asséné, les jeunes ne sont ni en voie de dépolitisation, ni désintéressés de la politique. Ils expriment des choix politiques et adoptent des comportements dans un cadre renouvelé du rapport à la citoyenneté.
Les données de l’enquête annuelle Fractures françaises, depuis 2013, permettent de saisir les évolutions les plus repérables du rapport à la politique dans la chaîne des générations, en en mesurant les écarts ou les similitudes entre les plus jeunes et les plus vieux, à l’échelle d’une dizaine d’années.
Évolution de l’intérêt pour la politique en fonction de l’âge (%)
Comparés à leurs aînés, les jeunes font preuve d’un niveau d’intérêt pour la politique certes moindre mais assez stable. Les fluctuations enregistrées, obéissant aux effets de la conjoncture politique et aux périodes électorales, suivent globalement celles qui sont enregistrées dans l’ensemble de la population.
Et si l’on compare le niveau de l’intérêt politique des classes d’âge les plus jeunes à celui qui est enregistré dans les classes d’âge plus âgées, au fil du temps, ils ont plutôt tendance à se rapprocher. L’intérêt pour la politique des plus jeunes augmente plutôt tandis que celui des autres classes d’âge a tendance au mieux à rester stable, voire à régresser. En l’espace de dix ans, l’écart de niveau d’intérêt pour la politique entre les moins de 35 ans et les plus de 60 ans est passé de - 25 points à - 7 points.
S’il y a dépolitisation, distanciation envers la politique, cette évolution est donc loin de ne concerner que les jeunes, elle est aussi visible, et peut être encore plus significative, dans les segments de la population plus âgés. C’est un résultat qui va à l’encontre de bien des idées reçues.
Une demande pressante de démocratie directe
La distanciation envers les partis politiques et, plus largement, la défiance à l’encontre du personnel et des institutions politiques sont bien repérés dans les analyses de sociologie politique et électorale récentes en France. Celles-ci montrent une montée d’une citoyenneté plus critique, plus expressive, plus individualisée, et de fait moins normative et moins institutionnalisée.
L’attachement à la démocratie domine toujours dans les jeunes générations et reste au cœur de leur répertoire politique. Néanmoins, les demandes de démocratie directe et de participation accrue des citoyens, sans la médiation des organisations ou des institutions politiques se font de plus en plus pressantes, et de façon encore plus marquée au sein de la jeunesse que dans l’ensemble de la population.
Les rouages de la démocratie représentative sont mis en cause et les jeunes ont endossé encore plus que leurs aînés les habits d’une citoyenneté critique, où la protestation est devenue un mode d’expression familier.
Le triptyque défiance-intermittence du vote-protestation définit le cadre d’un modèle de participation politique où les formes non conventionnelles sont assez largement investies, au risque même de la radicalité. Ainsi, parmi les moins de 35 ans, la justification de la violence pour défendre ses intérêts entraîne l’adhésion d’environ 30 % d’entre eux ces cinq dernières années.
Parmi les seniors de plus de 60 ans, celle-ci reste très en retrait sur l’ensemble de la période (15 points de moins que les moins de 35 ans en 2025).
Un cadre renouvelé du rapport à la citoyenneté
On observe dans les nouvelles générations des signes palpables d’une « déconsolidation démocratique », à savoir un affaiblissement de la croyance dans l’efficacité de la démocratie pour gouverner et répondre aux attentes des citoyens.
Le politologue Yasha Mounk utilise cette notion pour rendre compte de l’érosion de la confiance accordée aux institutions politiques représentatives dans nombre de démocraties contemporaines.
Dans la dynamique générationnelle, cette déconsolidation peut ouvrir la voie à de nouvelles formes de radicalités marquées par une polarisation aux deux extrêmes de l’échiquier politique et partisan à l’issue démocratique incertaine. La montée des populismes et des leaderships autoritaires en Europe et bien au-delà en est l’un des symptômes les plus patents.
Des seniors plus attachés à la démocratie que les moins de 35 ans
Parmi les moins de 35 ans, plus de quatre jeunes sur dix (42 %) sont d’accord avec l’idée que d’autres systèmes politiques sont aussi bons que la démocratie. Si l’on remonte dix ans en arrière, en 2014, ils étaient 29 % à partager le même avis.
Dans l’ensemble de la population, cette opinion a aussi progressé mais à un niveau plus faible, passant de 19 % à 34 %.
En revanche, et c’est une évolution notable, elle a nettement régressé parmi les seniors de plus de 60 ans, passant de 36 % à 23 %, soit une évolution en sens inverse par rapport aux plus jeunes.
Si la démocratie doit tenir, c’est donc davantage du côté des seniors qu’elle trouvera ses défenseurs que parmi les plus jeunes. Un constat qui peut dans l’avenir être lourd de conséquences politiques.
« Des jeunesses » plutôt qu’« une jeunesse »
S’ajoutent à ce tableau, des fractures intragénérationnelles qui rappellent les fractures sociales, culturelles, et politiques qui traversent la jeunesse. Celle-ci n’est pas une entité homogène. Elle est plurielle et divisée.
Ces fractures peuvent prendre le pas sur celles qui s’expriment au niveau intergénérationnel. Certains segments de la jeunesse, touchés par la précarité du travail et plus faiblement diplômés, ne sont pas exempts d’un repli identitaire favorable aux leaderships autoritaires d’extrême droite.
A contrario, dans la population étudiante et diplômée, à l’autre bout du spectre politique, plus active dans les mobilisations collectives, la tentation de la radicalité à gauche s’exprime.
Par ailleurs, au sein de la jeunesse issue de l’immigration, l’adhésion à certains communautarismes, non dénués de sectarisme et de séparatisme, peut remettre en cause l’universalisme républicain.
Une droitisation qui touche les jeunes générations
Les positionnements politiques des jeunes témoignent d’une certaine désaffiliation idéologique et partisane : 30 % des moins de 35 ans ne se sentent proches d’aucun parti, davantage les jeunes femmes que les jeunes hommes (respectivement 35 % et 27 %, soit un écart similaire à celui que l’on observe dans l’ensemble de la population).
Parmi ceux qui se reconnaissent dans un camp politique, comparés à leurs aînés, la gauche reste mieux placée : 34 % (contre 25 % des 60 ans et plus, et 31 % dans l’ensemble de la population). Le tropisme de gauche de la jeunesse résiste encore dans le renouvellement générationnel mais il a perdu de son acuité. En effet, les positionnements de droite (38 %), certes toujours inférieurs en nombre par rapport à ce que l’on constate chez leurs aînés (44 % des plus de 60 ans et 41 % dans l’ensemble de la population), y sont désormais plus nombreux. Le reste, se déclare au centre (28 %), qui est une position la plupart du temps utilisée comme refuge et expression d’un non-positionnement.
En l’espace de cinq ans (2020-2025), parmi les moins de 35 ans, les positionnements de droite sont passés de 28 % à 38 % (soit + 10 points), tandis que dans le même intervalle de temps les affiliations à la gauche n’ont quasiment pas progressé (33 % en 2020, 34 % en 2024). Un mouvement de droitisation est donc bien visible dans la jeunesse.
Évolution des positionnements à gauche et à droite selon l’âge, 2020-2024 (%)
La proximité déclarée envers le Rassemblement national a nettement progressé. En l’espace de quatre ans, elle est passée de 10 % à 22 % (+ 12 points) dans l’ensemble de la population, de 10 % à 19 % (+ 9 points) parmi les moins de 35 ans, et de 7 % à 20 % parmi les 60 ans et plus (+ 13 points). La progression de l’attractivité du Rassemblement national concerne donc tous les âges.
La gauche mélenchoniste, portée par La France insoumise, pénètre davantage les jeunes générations que les plus anciennes. Entre 2017 et 2025, on enregistre un faible surcroît (+ 3 points) de la proximité déclarée à La France insoumise qui passe de 11 % à 14 %, avec un pic en 2021 à 21 %. Parmi les 60 ans et plus, cette proximité a plutôt diminué, restant à un niveau bas, sans fluctuation, passant de 7 % à 3 % (soit - 4 points).
Évolution de la proximité envers le Rassemblement national selon l’âge (%)
La proximité ressentie pour le Rassemblement national supplante celle que suscite La France insoumise, y compris dans les jeunes générations. Certes à un niveau légèrement moindre que parmi les 60 ans et plus, mais le parti lepéniste apparaît plus ancré en termes de dynamique.
Les évolutions les plus repérables des positionnements politiques dans la chaîne des générations mettent donc en évidence l’équivoque de nombre d’idées reçues.
Plutôt que de s’affaisser, l’intérêt des jeunes pour la politique s’est tendanciellement rapproché du niveau de celui de leurs aînés. Par ailleurs, nos résultats ne révèlent pas de ruptures ou de discontinuités majeures entre les générations.
Les écarts observés sont dus à des phénomènes d’amplifications des effets de conjoncture et de période touchant l’ensemble de la population et qui sont plus visibles au sein des populations juvéniles. Néanmoins, les signes de déconsolidation démocratique sont plus marqués dans ces dernières, ce qui fragilise les conditions de viabilité et de renouvellement des régimes démocratiques dans l’avenir.
Anne Muxel ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 16:12
Économie circulaire : un levier géopolitique pour la résilience et la durabilité de l’Union européenne ?
Pietro Beltramello, PhD candidate at HuManiS (UR7308: Université de Strasbourg and EM Strasbourg Business School), Université de Strasbourg
Ksenija Djuricic, PhD | ScD Stratégie, prospective, entrepreneuriat, Université de Strasbourg
Texte intégral (1904 mots)
Pauvre en terres rares, l’Union européenne doit s’adapter au nouveau contexte géopolitique. Le développement de l’économie circulaire peut l’aider à retrouver des marges de souveraineté. Mais un long chemin reste à parcourir.
Face aux tensions géopolitiques qui perturbent les chaînes d’approvisionnement et fragilisent la souveraineté économique du continent, l’Union européenne (UE) doit composer avec une dépendance accrue aux matières premières importées et un besoin impératif de renforcer son autonomie industrielle. Cette nécessité est d’autant plus pressante que Donald Trump ignore la souveraineté de l’UE, la laissant livrée à elle-même.
Cela constitue un signal d’alarme incitant l’UE à rechercher des solutions durables et résilientes pour son système socio-économique. Dans une telle situation géopolitique, l’économie circulaire pourrait-elle constituer un levier stratégique majeur pour l’Union européenne lui permettant de réduire sa dépendance aux importations de matières premières, de renforcer sa résilience économique et de stimuler l’innovation industrielle réinventant ainsi sa position sur l’échiquier mondial ?
Une dépendance aux matières premières
L’Union européenne importe la majorité des matières premières nécessaires à son industrie. Par exemple, 98 % des terres rares et du borate utilisées en Europe proviennent respectivement de Chine et de Turquie, tandis que 71 % des platinoïdes sont importés d’Afrique du Sud. Une telle dépendance expose le tissu industriel de l’UE aux fluctuations des marchés mondiaux et aux tensions géopolitiques, qui perturbent les chaînes d’approvisionnement.
À lire aussi : Russie : la logistique de l’ombre contre les sanctions occidentales
La guerre en Ukraine et la fermeture aux importations de ressources en provenance de Russie, notamment du gaz, ont révélé la fragilité industrielle de l’Europe, démontrant ainsi l’urgence d’une transition vers un modèle plus résilient. Pour répondre à cette crise, l’UE a mis en place des stratégies de « friendshoring », favorisant des échanges avec des pays partenaires de confiance.
Des accords ont été conclus avec le Canada et l’Australie en 2021 et 2024 pour sécuriser l’approvisionnement en terres rares et métaux critiques nécessaires à l’industrie des batteries et des technologies propres.
De plus, le traité de libre-échange entre l’Union européenne et le Mercosur, conclu récemment après plus de vingt ans de complexes négociations, vise à ouvrir les marchés et faciliter les échanges, notamment en matière de matières premières stratégiques.
Développer ses propres capacités
Malheureusement, le « friendshoring » ne garantit pas une autonomie durable dans un monde de plus en plus protectionniste. Les récents conflits commerciaux et les restrictions à l’exportation montrent que l’Europe doit développer ses propres capacités pour éviter d’être soumise aux fluctuations des alliances internationales.
Les tensions commerciales croissantes et les restrictions sur les exportations imposées par certains alliés afin de renforcer leur suprématie économique et stratégique, révèlent les vulnérabilités de l’UE. Cela souligne la nécessité de l’Union de développer des alternatives durables en interne garantissant ainsi son indépendance et sa résilience industrielle.
Développer l’économie circulaire
Pour répondre aux défis stratégiques et renforcer son autonomie industrielle, L’UE mise sur un développement accru de l’économie circulaire. Le Critical Raw Materials Act et le plan d’action pour l’économie circulaire visent à renforcer les capacités de recyclage et à encourager l’innovation dans la récupération des matériaux stratégiques. En premier lieu, l’UE investit dans la récupération du lithium et du cobalt issus des batteries usées, réduisant ainsi la nécessité d’extraire de nouvelles ressources.
Ensuite, l’Union travaille sur la relocalisation des installations de traitement en Europe afin de limiter l’exportation des déchets industriels vers des pays tiers garantissant un meilleur contrôle sur le recyclage des ressources stratégiques. Enfin, de nouvelles réglementations européennes incitent à l’écoconception et à la durabilité des produits. Toutefois, afin d’atteindre ces objectifs, il est important de résoudre un certain nombre de défis propres à l’Union européenne.
Indispensables investissements massifs
La transition vers une économie circulaire nécessite des investissements massifs, estimés à environ 3 % du PIB européen, un niveau comparable aux efforts de reconstruction économique après la Seconde Guerre mondiale. Or, le financement de telles initiatives est incertain, bien que l’Union européenne ait alloué plus de 10 milliards d’euros entre 2014 et 2020 pour soutenir cette transition, principalement dirigés vers la gestion des déchets. Pourtant, une meilleure allocation des resources – misant par example sur la réduction à la source, l’écoconception et l’efficacité matérielle – pourrait multiplier l’impact des investissements.
Le programme NextGenerationEU, qui a marqué un tournant avec l’émission de dette commune, semble aujourd’hui plus difficile à répliquer en raison des réticences de certains États membres. Par ailleurs, la montée des partis nationalistes en Europe rend plus complexe la mise en place de stratégies d’investissement communes.
Barrières industrielles
Bien que le recyclage puisse réduire la dépendance aux importations, il demeure aujourd’hui plus coûteux que l’extraction de nouvelles ressources. Cependant, des innovations récentes, telles que l’automatisation du tri des déchets par intelligence artificielle et l’optimisation des procédés chimiques, permettent de réduire progressivement ces coûts.
En outre, des incitations financières mises en place par l’UE, comme le Fonds pour l’innovation, ainsi que l’engagement de la Banque européenne d’investissement (BEI) pour orienter les capitaux vers des modèles économiques circulaires visent à industrialiser ces technologies et à les rendre plus compétitives.
Une harmonisation réglementaire nécessaire
L’efficacité de l’économie circulaire repose également sur une coordination entre les États membres. Aujourd’hui, les réglementations divergent d’un pays à l’autre, ce qui ralentit la mise en place de standards communs et d’incitations globales adaptées.
Un exemple particulièrement révélateur concerne le statut de la « fin du déchet ». Dans l’UE, un même flux peut être reconnu comme ressource secondaire dans un pays, tandis qu’il demeure juridiquement un déchet dans un autre : cette divergence bloque son transit transfrontalier et limite sa valorisation industrielle. Des travaux récents montrent comment les hétérogénéités limitent la création de marchés circulaires à l’échelle européenne.
On observe des asymétries similaires dans des secteurs clés pour la transition à l’économie circulaire. Dans le domaine des batteries, les obligations en matière de traçabilité, de recyclage et de contenu recyclé varient encore sensiblement entre les États membres, ce qui complique la mise en place de chaînes de valeur cohérentes. Le secteur du bâtiment illustre également ces désalignements : critères de performance, méthodes de diagnostic des matériaux, ou encore exigences de réemploi diffèrent selon les pays, ce qui freine l’essor d’un marché européen du réemploi ou du recyclage de matériaux de construction.
Ces divergences réglementaires, loin d’être anecdotiques, empêchent l’émergence d’un véritable marché circulaire européen capable de soutenir les investissements, de sécuriser les flux de matériaux et d'accélérer la transition industrielle.
L’UE pourrait mettre en place plusieurs mesures pour harmoniser ces réglementations, à savoir :
la création d’un marché unique des matériaux recyclés pour faciliter leur commercialisation ;
l’harmonisation des normes environnementales qui pourraient inciter les investissements transnationaux ;
le développement de crédits d’impôt et des subventions pour les entreprises adoptant des pratiques circulaires.
Face à une situation géopolitique où l’Union européenne compte de moins en moins d’alliés, l’économie circulaire apparaît comme un levier stratégique pour renforcer son autonomie industrielle et sa résilience économique. En capitalisant sur les forces de chaque État membre, l’UE pourrait construire un modèle commun, conciliant diversité et cohésion. Trouver un langage commun devient ainsi essentiel pour surmonter les défis liés aux contraintes budgétaires, à l’harmonisation réglementaire et aux investissements nécessaires, garantissant une transition efficace et durable vers l’autonomie.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
10.12.2025 à 16:12
Face aux défaillances des marques, les groupes de « haters » organisent leur riposte en ligne
Virginie Uger Rodriguez, Maître de Conférences en marketing, Université d’Orléans
Pierre Buffaz, Professeur assistant en Sciences de Gestion, EDC Paris Business School
Texte intégral (1122 mots)
Que disent les détracteurs d’une marque sur les réseaux ? Une nouvelle étude s’est penchée sur la dynamique des groupes de « haters » sur Facebook. En se fédérant, ces internautes engagés pallient certains manquements des marques qui les ont déçus.
D’ordinaire, les marques ont pour habitude de faire rêver ou d’être idéalisées par les consommateurs. Cependant, depuis quelques années, on note une aversion grandissante pour certaines d’entre elles. Aversion pouvant conduire jusqu’à la haine.
Avec 50,4 millions d’utilisateurs en France, les réseaux sociaux sont un terrain favorable à la propagation de cette haine.
Les consommateurs, fans de marques désireux de partager leurs créations, leur passion voire leur amour, n’hésitent pas à se regrouper au sein de communautés en ligne (groupes publics ou privés) hébergées sur ces réseaux.
Mais il est important de noter que les consommateurs ayant vécu une expérience négative avec une marque auront tendance à en parler plus ou à poster plus de commentaires négatifs que les consommateurs ayant vécu une expérience positive. Car il existe des communautés dont le point de convergence s’avère être la haine pour une marque donnée, notamment pour celles qui ne respectent pas le contrat de confiance établi avec les consommateurs : manquements ou défaillances dans les produits ou les prestations de services, retards de livraisons, vols annulés, pièces manquantes, airbags défectueux… Les marques concernées peuvent être issues de tous les secteurs d’activité. Les membres de ces communautés sont couramment appelés des haters, c’est-à-dire des détracteurs d’une marque.
Dans le cadre de nos travaux publiés dans Journal of Marketing Trends et présentés lors de conférences en France et à l’international, nous avons effectué une netnographie (analyse de données issues des médias sociaux, inspirée des techniques de l’ethnographie) au sein de deux communautés en ligne anti-marques (groupes Facebook). À noter que ces communautés étaient indépendantes des marques, ce qui signifie que celles-ci n’avaient aucune prise directe sur elles. Au total, ce sont plus de 1000 publications qui ont été collectées et analysées.
Une haine bien présente dans les discours des consommateurs
Plusieurs marqueurs permettent d’affirmer que les consommateurs au sein de ces groupes expriment leur haine de façon plus ou moins nuancée, allant d’une haine froide (peu vindicative) à une haine chaude (très virulente), par le vocabulaire utilisé, une ponctuation excessive, les émoticônes choisis…
La nature même des échanges peut être catégorisée selon quatre dimensions :
une dimension normative se référant aux comportements altruistes et d’entraide des membres pour pallier les défaillances des marques ;
une dimension cognitive exprimée à travers la sollicitation du groupe pour répondre à un besoin (question, problème rencontré, démarche à engager…) ;
une dimension affective comprenant l’expression des sentiments et des émotions des membres (déception, mécontentement, colère, dégoût, rage, haine) ;
et une dimension mixte relative aux discours mêlant des tons normatifs et affectifs.
La mise en place d’une structure organisationnelle et sociale
Les membres des groupes anti-marques s’organisent et se sentent investis de missions au travers des rôles qu’ils s’attribuent :
S’ils ont intégré ces groupes anti-marques, c’est que les consommateurs ont eu une expérience négative avec elles dans le passé ou bien, même s’ils ne sont pas consommateurs, qu’ils rejettent les valeurs qu’elles défendent ou représentent. En fonction de la marque et du caractère du fondateur de la communauté anti-marque, celle-ci est plus ou moins démocratique et tolère plus ou moins les discours antagonistes à la haine anti-marque.
À chaque niveau de haine sa réponse
Les manifestations de la haine au sein des communautés étudiées peuvent être catégorisées ainsi :
Pour pallier les défaillances de la marque, les consommateurs ont tendance à s’entraider au sein de la communauté en ligne anti-marque. Ils se partagent des informations et des bons plans. Ils s’apportent mutuellement du soutien tout en se servant de la communauté comme d’un exutoire. Globalement, les consommateurs réparent ou « bouchent les trous » que la marque aurait dû prendre en charge dans son contrat de confiance.
Quelles réponses apporter aux « haters » ?
Les communautés anti-marques peuvent avoir un potentiel de nuisance important se traduisant, entre autres, par une perte de clients et de fait une diminution du chiffre d’affaires.
Voici quelques pistes pour contenir la haine exprimée par certains consommateurs voire tenter de l’enrayer au sein de ces communautés :
une stratégie offensive avec une réponse directe à la communauté et à ses membres lorsque la marque est attaquée directement sur ses réseaux, en apportant des réponses oscillant entre le mea culpa, à travers une « publicité reconnaissant la haine », l’humour et l’entrée en dialogue avec les détracteurs ;
ou une stratégie défensive visant à identifier les communautés en ligne anti-marques, à surveiller leur activité, à comprendre leurs critiques et à mettre en œuvre des mesures correctives et/ou instaurer un dialogue.
Que les revendications des haters à l’égard des marques soient légitimes ou non, elles permettent de révéler des défaillances de marques parfois dramatiques voire illégales pouvant faire intervenir, en réaction, les pouvoirs publics.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
10.12.2025 à 16:12
Pour promouvoir la parité dans les cursus d’ingénieurs, la piste d’un concours spécifique
Diana Griffoulieres, Responsable d'ingénierie pédagogique numérique, EPF
Emmanuel Duflos, Professeur des universités et directeur de l'EPF École d'ingénieur-e-s, EPF
Liliane Dorveaux, PhD Mathématiques Appliquées,Chargée de Projet, EPF
Texte intégral (2071 mots)
Les concours d’accès aux écoles d’ingénieurs sont-ils pensés pour encourager la parité ? Une école tente depuis la rentrée 2025 de repenser ses voies de recrutement pour obtenir davantage de filles dans ses effectifs. Un dispositif trop récent pour en tirer des conclusions définitives mais qui apporte déjà des enseignements intéressants.
La sous-représentation des femmes en ingénierie s’explique en partie par des biais implicites de genre présents dans les processus de sélection académiques et professionnels dont la part de femmes plafonne juste en dessous du tiers des effectifs en cycle ingénieur où le taux reste autour de 29,6 %. Dans un contexte compétitif, les candidates tendent à être désavantagées, non pas en raison de compétences moindres, mais en raison de dynamiques compétitives et de stéréotypes de genre, influençant à la baisse leurs résultats.
L’un des phénomènes en jeu est le « risque du stéréotype » : la peur de confirmer un stéréotype négatif peut affecter les performances cognitives, notamment la mémoire de travail, réduisant ainsi les résultats des femmes lors d’épreuves exigeantes, même si elles réussissent mieux en dehors de ce contexte. Les différences de performances observées entre hommes et femmes dans les environnements compétitifs ne sont pas liées à des différences biologiques, mais à des attentes genrées et à des stéréotypes.
De nombreuses références bibliographiques décrivent comment les structures patriarcales favorisent les parcours masculins en valorisant les normes de compétition, notamment l’affirmation de soi et l’assurance, traits socialement encouragés chez les hommes mais souvent perçus comme inappropriés chez les femmes. Schmader, en 2022, a précisé l’impact des biais culturels et l’influence de l’environnement dans la limitation du choix des jeunes femmes pour les carrières scientifiques et techniques, malgré leur intérêt potentiel.
Dans une vision d’impact sociétal, l’EPF École d’ingénieurs (ex-École polytechnique féminine), l’une des premières grandes écoles en France à avoir formé des femmes au métier d’ingénieure, a créé le dispositif « ParityLab », un concept pensé pour attirer via des actions à court et moyen termes davantage de jeunes femmes vers les écoles d’ingénieurs.
Cette initiative s’appuie notamment sur les résultats de la grande enquête nationale « Stéréotypes et inégalités de genre dans les filières scientifiques », menée par l’association Elles bougent, en 2024, auprès de 6 125 femmes. Elle met en lumière les freins rencontrés par les filles dans les parcours scientifiques et techniques : 82 % déclarent avoir été confrontées à des stéréotypes de genre, et plus de la moitié disent souffrir du syndrome de l’imposteur – un obstacle à leur progression dans des environnements compétitifs. L’enquête Genderscan confirme ces constats, en se focalisant sur les étudiantes.
Une voie d’accès alternative
Le dispositif ParityLab a été conçu en réponse à ces enquêtes et aux biais de genre dans l’accessibilité des filles aux filières scientifiques et techniques, afin de minimiser ces biais et de valoriser leurs compétences tout au long de leur formation. Il se compose de deux parties : un concours d’accès alternatif via Parcoursup, réservé exclusivement aux femmes (validé par la direction des affaires juridiques de l’enseignement supérieur) et un parcours de formation spécifique d’insertion professionnelle consacré aux femmes, qui est proposé depuis cette rentrée aux candidates retenues.
Un panel diversifié de 40 jurés a été constitué pour assurer le processus de sélection. Parmi eux, 26 provenaient du monde de l’entreprise et 14 du corps enseignant et des collaborateurs de l’école. Pour sensibiliser tous les membres du jury sur l’importance de faire une évaluation plus inclusive, un atelier de sensibilisation aux stéréotypes de genre leur a été dispensé.
Afin de faire une évaluation plus enrichie et équilibrée des candidates, les jurés ont travaillé en binôme pendant les sessions de sélection reposant sur une étude de dossier scolaire, une mise en situation collective et un échange individuel. Le binôme était constitué d’un représentant de l’industrie et d’un représentant de l’école afin d’enrichir l’analyse des candidatures par leurs regards croisés multidimensionnels et réduire les biais.
L’épreuve collective a permis via une problématique liée à l’ingénierie fondée sur des documents, d’évaluer la créativité, le leadership ou la capacité d’exécution sans toutefois aborder les connaissances disciplinaires. L’entretien individuel, quant à lui, repose sur un échange librement choisi par la candidate (engagement associatif, sport, intérêt sur un sujet scientifique ou non), visant à révéler sa personnalité et ses aptitudes à communiquer.
Premier bilan du concours
Afin d’évaluer le dispositif mis en place, une enquête a été conçue pour collecter les retours des membres du jury et des candidates sélectionnées à travers deux questionnaires différents. De plus, un retour d’expérience a été demandé à certains membres du jury afin de collecter des données qualitatives sur leur expérience.
Les réponses des candidates ont été recueillies par un questionnaire rempli par 23 candidates sélectionnées sur 35 possibles (65,7 %). Il était composé de 14 questions fermées, utilisant une échelle de Likert à cinq niveaux, et neuf questions ouvertes. Il avait pour objectif de comprendre les motivations des candidates à passer le concours, d’identifier les obstacles ou les découragements qui ont pu freiner leur intérêt pour les sciences et les actions qui pourront encourager davantage de jeunes filles à s’orienter vers les filières scientifiques et technologiques.
L’analyse des réponses montre que 56 % des répondantes doutaient de leurs capacités et 22 % se déclaraient neutres sur ce point. La peur d’être isolée dans la classe est moins marquée, seules 30 % des candidates se sentant concernées. Les réponses sur les préjugés sexistes sont mitigées, 30 % des candidates ont déclaré avoir entendu des commentaires décourageants, 26 % se sont déclarées neutres et 43 % ont affirmé ne pas avoir été confrontées à ce type de remarques.
Quand il leur a ensuite été demandé d’imaginer ce qui pouvait encourager d’autres filles à s’orienter vers les filières scientifiques, les répondantes placent en tête de leurs réponses l’existence de modèles féminins inspirants, une meilleure promotion des métiers liés à l’ingénierie et la déconstruction des stéréotypes de genre dès l’enfance.
Une dynamique encourageante
Le concours a permis de renforcer significativement la présence des femmes dans la formation scientifique généraliste de l’EPF École d’ingénieurs en 2025. Sur les 50 places ouvertes cette année, 35 ont été pourvues, avec un taux de sélection de 32 % parmi les 108 candidates. Une critique fréquente à l’égard de ce type de dispositif est la peur d’une réduction des places pour les hommes, relevant d’une vision « à somme nulle ». Ici, les places créées pour cette nouvelle voie s’ajoutent à l’existant et aucun quota n’est prélevé sur les admissions classiques.
Ces chiffres s’inscrivent dans une dynamique positive et encourageante. Une progression remarquable des néo-bachelières recrutées de + 11,5 % de jeunes femmes en première année du cycle ingénieur.
Il est à noter que la voie d’accès classique affiche elle aussi des résultats en progrès en matière de parité avec une augmentation du nombre de jeunes femmes de + 5 %, probablement en lien avec différentes stratégies internes et externes de lutte contre les biais de genre.
Les étudiantes du ParityLab suivent le même programme académique que les autres élèves de la formation généraliste de première année. En revanche, elles bénéficient (en plus) de modules ciblés sur les questions de stéréotypes et soft skills. Cette première cohorte devient un terrain d’étude pertinent pour mieux comprendre les freins à l’orientation vers ces filières encore majoritairement masculines.
Obtenir un échantillon plus large
La mise en place du concours a été l’objet d’une réflexion approfondie sur la mise en œuvre d’un processus de sélection équitable. Des actions de sensibilisation destinées aux membres des jurys, afin de réduire les biais liés aux stéréotypes de genre et d’évaluer les compétences transversales sans mettre en avant les compétences disciplinaires des candidates, ont été mises en place. Les retours sur l’atelier collectif ont été perçus positivement par les jurys et par les candidates. Cependant des pistes d’améliorations (logistique, gestion de temps) sont envisagées pour la prochaine session.
ParityLab constitue un dispositif qui pourra être transférable à d’autres écoles d’ingénieurs qui souhaitent renforcer la représentation des femmes dans leurs programmes. Les recherches futures pourraient aborder les mêmes problématiques avec un échantillon plus large pour confirmer les résultats obtenus dans cette étude, et mesurer son impact sociétal.
Diana Griffoulières es docteure en Sciences de l’éducation et elearning. Elle mène des travaux de recherche appliquée en éducation et est responsable de l’ingénierie pédagogique numérique à l'EPF Ecole d'Ingénieurs. Diana Griffoulières ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article.
Emmanuel Duflos est membre de la Conférence des directeurs des écoles françaises d'ingénieurs. Il en est le Président actuel. La CDEFI est une conférence inscrite dans le code de l'éducation qui a vocation à représenter les écoles d'ingénieurs auprès de l'Etat. La CDEFI est engagée depuis de nombreuses années dans des actions dont l'objectif est de promouvoir les formations d'ingénieurs auprès des femmes. Emmanuel Duflos est aussi le directeur général de la Fondation EPF, reconnue d'utilité publique (FRUP), qui a pour mission de concourir à la formation des femmes en sciences et technologies. La Fondation EPF porte l'école d'ingénieurs EPF dont il est également le directeur général. La Fondation EPF et l'EPF sont à l'origine de l'expérimentation à l'origine de cet publication. En tant que FRUP, la Fondation EPF partage son savoir et son savoir-faire sur le projet ParityLab qui concoure à sa mission.
Liliane Dorveaux est co-fondatrice et Vice Présidente de WOMENVAI , ONG ayant le statut ECOSOC à l'ONU. Liliane DORVEAUX ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article.
10.12.2025 à 16:11
Les liens de la pensée de Nick Land avec le (néo)nazisme
Arnaud Borremans, Chercheur associé à l'Institut de recherche Montesquieu (IRM), Université Bordeaux Montaigne
Texte intégral (3254 mots)

Cette seconde analyse de l’œuvre de Nick Land, philosophe contemporain dont l’impact est réel sur une partie au moins du mouvement MAGA aux États-Unis et sur de nombreux groupuscules d’ultradroite dans le monde, met en évidence le rapport complexe que l’idéologue des « Lumières sombres » entretient avec le nazisme himmlérien et avec les organisations qui, aujourd’hui encore, s’y réfèrent.
Comme souligné par Philosophie Magazine et évoqué dans notre article précédent sur Nick Land, des connexions existent entre la pensée de ce philosophe britannique – père du concept de « Lumières sombres » en vogue dans une partie du mouvement MAGA autour de Donald Trump – et certains éléments du néonazisme.
Au-delà des liens les plus apparents des Lumières sombres avec le racisme et l’autoritarisme, d’autres éléments troublants semblent attester d’une certaine proximité entre la pensée landienne et l’idéologie nazie ou ses différentes évolutions post-1945.
À quel point le fond de la pensée de Land – et donc de celle de ses fidèles qui murmurent à l’oreille de Donald Trump – s’enracine-t-il dans l’idéologie du IIIe Reich ?
Des loups-garous et du Soleil noir
Dans son essai Spirit and Teeth (1993), Land emploie le terme de « loups-garous » pour qualifier la filiation philosophique dont il se réclame lui-même. Il décrit cet héritage comme celui des penseurs qui ont rejeté à la fois la logique platonicienne et la morale judéo-chrétienne, leur préférant une approche immanentiste, reconnaissant une valeur aux instincts animaux et admettant l’absurdité de rechercher une quelconque vérité objective. Parmi lesdits penseurs, il inclut Friedrich Nietzsche et Emil Cioran, c’est-à-dire un philosophe largement récupéré par les nazis et un intellectuel affilié au mouvement fasciste dans son pays, la Roumanie.
De plus, ce terme de « loups-garous » fait écho à la tentative des nazis, alors que les armées alliées et soviétiques rentraient en Allemagne, de constituer des unités de partisans dits « loups-garous » (Werwolf), censés repousser les envahisseurs et exécuter les traîtres.
Les renvois implicites vers le souvenir du IIIe Reich par ce choix de mot est déjà intrigant de la part de Land. Cependant, il ne s’en est pas tenu là. Il a aussi mobilisé la notion de « Soleil noir » pour un article en ligne censément dédié à l’œuvre du philosophe français Georges Bataille. Or, une recherche amène à retrouver les termes précis de Bataille : il n’a jamais traité d’un « Soleil noir » mais d’un « Soleil pourri ». Cette substitution d’expressions par Land pose question : s’agit-il d’une erreur grossière de sa part ou d’un « dog whistle » (« sifflet à chien », c’est-à-dire un message discret destiné à mobiliser les franges les plus radicales de ses sympathisants) ?
En effet, il est troublant de relever que le Soleil noir est un symbole retrouvé dans le château de Wewelsburg où siégeait Heinrich Himmler, chef de la Schutzstaffel (SS), principale milice du régime nazi. Le Soleil noir fut nommé ainsi après guerre par l’ex-officier SS Wilhelm Landig, comme démontré par l’historien Nicholas Goodrick-Clarke.

.jpg){kind=link}
Ledit Landig a constitué dans les années 1950 un groupe occultiste à Vienne et a propagé avec ses affiliés un narratif autour du Soleil noir, présentant les nazis en perpétuateurs d’une tradition initiatique plurimillénaire et réaffirmant la justesse de leurs thèses racistes et eugénistes. De plus, ils affirmaient que des colonies nazies survivaient en Antarctique et allaient un jour reprendre le contrôle du monde à l’aide d’armes miracles, notamment de soucoupes volantes.
Aussi surprenantes ces correspondances soient-elles, elles ne prouvent rien en soi ; il peut s’agit uniquement de bévues de Land qui aurait mal anticipé les associations d’idées induites par ses mots. Cependant, ce ne sont pas les seuls éléments qui étayent que Land aurait le (néo)nazisme comme référence implicite.
Des liens de Land avec l’Ordre des neuf angles
L’Ordre des neuf angles (O9A) est une mouvance néonazie, occultiste et sataniste théiste, apparue en Angleterre à la fin des années 1960. Au-delà de son magma idéologique, elle est connue pour comprendre en son sein plusieurs organisations effectives, notamment la Division Atomwaffen et Tempel ov Blood aux États-Unis, Sonnenkrieg au Royaume-Uni, ou encore le groupe 764 au niveau mondial. Ces organisations sont traquées par plusieurs services de police, dont le FBI, pour des faits criminels de droit commun et même quelques attentats terroristes.
Or, Land a exprimé sa solidarité à leur égard sur un blog nommé Occult Xenosystems, maintenant fermé, et dont il est acquis par des indiscrétions d’utilisateurs sur une autre page qu’il en était bien l’administrateur.
Land y louait l’O9A pour la qualité de sa production intellectuelle, notamment celle de David Myatt (réputé comme le fondateur de l’O9A, derrière le pseudonyme d’Anton Long). Tout en faisant mine de s’en distinguer – il écrit notamment « le peu que j’ai appris sur David Myatt ne m’a pas attiré vers lui en tant que penseur ou activiste politique, malgré certaines caractéristiques impressionnantes (notamment son intelligence et son classicisme polyglotte) » –, il garde le silence sur le caractère antisocial et criminel du mouvement.
Une autre anecdote relance les spéculations sur l’investissement réel de Land auprès de l’O9A. Le journaliste britannique Tony Gosling a révélé à la radio, en 2022, qu’il avait connu Land au lycée. Selon lui, outre que Land serait le fils d’un cadre de la société pétrolière Shell ayant travaillé en Afrique du Sud (ce qui pourrait expliquer sa sympathie pour le capitalisme et le ségrégationnisme réaffirmée dans Les Lumières sombres), il aurait eu comme surnom, sans que Gosling ne fournisse de raisons objectives pour pareil sobriquet, « Nick the Nazi ».
Gosling sous-entend que ce surnom renvoyait bien à la sensibilité politique que ses camarades de classe imputaient à Land. Selon lui, Land avait surpris tout le monde lorsqu’il déclara, en 1978, qu’il avait pris la décision de devenir « communiste ». Sans présupposer de sa véracité, cette histoire intrigue parce qu’elle rappelle une stratégie assumée de l’O9A : l’infiltration et le noyautage d’autres organisations pour leur voler des ressources (idées, matériels, argent, recrues) et aussi pour leur nuire de l’intérieur, notamment en leur faisant commettre des erreurs.
Dès lors, une question se pose : Land aurait-il toujours été un militant de l’O9A qui aurait infiltré le CCRU, milieu de gauche, pour lui faire promouvoir l’accélérationnisme avec l’arrière-pensée que ce concept servait les intérêts de sa cause véritable, le néonazisme satanique ?
La piste de Miguel Serrano et du Black Order comme précurseurs de l’hyperstition
Parmi les organisations affiliées à l’O9A, une retient particulièrement l’attention : le Black Order qui couvre la zone Pacifique, notamment les Amériques du Nord et du Sud, l’Australie et la Nouvelle-Zélande. Outre son emploi assumé de la violence qui a déjà entraîné la commission d’attentats comme l’attentat de Christchurch en mars 2019 et son nom qui rend hommage explicitement au premier cercle d’Himmler, il apparaît que le fondateur du Black Order est un personnage clé reliant plusieurs protagonistes de ce sujet.
En effet, selon les historiens Nicholas Goodrick-Clarke et Jacob C. Senholt, Kerry Bolton est le distributeur international des ouvrages d’Anton Long, le chef de l’O9A dont Bolton serait par ailleurs un adepte. De plus, Bolton est aussi un associé de l’idéologue russe Alexandre Douguine qui échange directement et même publiquement avec Land. Il apparaît donc évident que si Land a un lien structurel avec l’O9A, celui-ci passe par le Black Order de manière privilégiée.
Une autre corrélation laisse songeur et laisse accroire à une causalité. L’un des fondateurs du Black Order fut Miguel Serrano (1917-2009), ancien diplomate chilien et sympathisant des nazis. Après la Seconde Guerre mondiale, Serrano sera connu comme auteur relayant dans ses ouvrages un narratif similaire à celui du groupe de Landig. Il ajoutait qu’Hitler ne serait pas mort à la fin de la guerre et qu’il reviendrait victorieux de sa base secrète en Antarctique, aidé de troupes de surhommes aryens armés d’artefacts magiques pour conquérir le monde.
Cette dimension eschatologique joue sur une figure du héros en sommeil, comme le roi Arthur ou le roi Sébastien au Portugal. Cette considération amène à se demander si Serrano a propagé ce narratif parce qu’il y croyait sincèrement ou parce que, fasciné par les travaux de Carl Jung sur l’inconscient collectif, il aurait essayé par ce biais d’influencer les esprits et de préparer le terrain mental à un retour du nazisme.
Cette démarche consistant à répandre avec force une idée, en la rendant séduisante autant que possible et en espérant qu’elle altère la réalité dans une certaine mesure, rappelle l’hyperstition de Land. Que Land ait eu l’entreprise de Serrano comme modèle inavoué (et inavouable) ne serait pas absurde, Jung étant une référence assumée par Land également depuis le CCRU.
Plus troublant, Land partage avec Serrano son attachement à une forme d’immanentisme et donc de néopaganisme, si bien qu’ils ont tous les deux refusé l’étiquette de sataniste. Land a ainsi déclaré, en réaction à une vidéo du polémiste états-unien Tucker Carlson, qu’il ne se considérait pas comme sataniste, du moins au sens théiste du terme. De son côté, Serrano a employé l’adjectif « sataniste » pour dénigrer les Juifs.
De la place de Land et de ses fidèles au sein de la mouvance néonazie
Néanmoins, aussi convaincants soient ces éléments, est-ce suffisant pour considérer la pensée politique de Land comme une sous-composante du (néo)nazisme, ou comme une branche distincte mais apparentée parmi les mouvements illibéraux ?
Tout le problème est que Land a lui-même entretenu l’ambiguïté sur des aspects cruciaux de son positionnement idéologique qui pourraient le rapprocher du nazisme. Ainsi, il s’est revendiqué « hyperraciste ». Or des divergences persistent sur le sens du terme : certains le comprennent comme un constat transhumaniste sur le fossé que les améliorations technologiques de l’humain vont creuser entre les élites, qui y auront accès, et le reste de la population ; d’autres y entendent une accentuation des « traits raciaux » par choix politique, ou du moins une accentuation de la ségrégation raciale via la technologie. À la lecture de l’article d’origine par Land, il semble concilier les trois interprétations en même temps.
Pareillement, sa complicité avec Alexandre Douguine pose question : si Land est vraiment un sympathisant inavoué du néonazisme, comment expliquer son dialogue continu jusqu’à cette fin d’année 2025 avec Douguine ? Il y fait mention durant son intervention dans l’émission The Dangerous Maybe d’octobre 2025. En effet, Douguine se définit comme un eurasiste et s’oppose donc à la fois à l’atlantisme anglo-américain et à la figure mythifiée de l’ennemi nazi. Une hypothèse est que leur perspective occultiste partagée les amène à considérer leurs camps comme deux forces antagonistes mais complémentaires, en termes métaphysiques. Cette hypothèse semble étayée par Land lui-même qui l’a mentionnée brièvement, en disant que Douguine voyait en lui un sataniste mais aussi un gnostique comme lui-même, contribuant à la même œuvre mais depuis l’autre bord.
En tout cas, l’influence en retour de Land sur les dernières générations de néonazis est dorénavant indéniable. Comme décrit par l’éditorialiste Rachel Adjogah, il existe une frange du mouvement néonazi qui se réclame fièrement de l’accélérationnisme landien, notamment en recourant à – ou même en créant – des cryptomonnaies et, surtout, en développant des chatbots romantiques tels que « Naifu », clairement biaisés pour relayer des théories du complot antigouvernementales : l’IA et la relation parasociale sont ainsi mises au service de la propagande néonazie.
Qui plus est, lesdits néonazis sont ostensiblement d’inspiration himmlérienne : ils ont repris le Soleil noir à leur compte et s’intéressent à l’occultisme, quitte à se revendiquer, en plus, du thélémisme, la religion créée par l’occultiste anglais Aleister Crowley, lui-même référence pour Land.
Arnaud Borremans ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 16:07
Dans les torrents, des insectes tissent de minuscules filets de pêche qui inspirent de nouveaux matériaux
Christophe Mori, Maitre de conférences, Université de Corse Pascal-Paoli
Texte intégral (1519 mots)
Au fond des torrents et des ruisseaux, de petites larves d’insecte construisent des filets pour attraper leur nourriture et font preuve d’une intelligence remarquable pour s’adapter au courant. Des comportements qui inspirent nos propres innovations techniques.
Imaginez-vous au bord d’un torrent, où l’eau surgit avec une force capable d’emporter des pierres. Au fond de ce tumulte, des larves de quelques millimètres, non seulement survivent, mais prospèrent en bâtissant des pièges ingénieux pour capturer leur nourriture. Sur leurs filets de soie de 2 à 3 cm de diamètre, on les voit s’affairer, le nettoyant régulièrement des petits morceaux de feuilles, de bois, des algues et des petits organismes qui s’y piègent.
Ces larves sont des hydropsychés, des insectes de l’ordre des trichoptères. Après avoir vécu sous la forme de larve dans une rivière pendant un à deux ans, ils s’envolent une fois leur forme adulte atteinte, durant laquelle il ressemble à un petit papillon de nuit. La fin de leur vie sera alors très courte, de 10 à 20 jours seulement.
Les hydropsychés, petits ingénieurs des ruisseaux
Les hydropsychés sont des insectes aquatiques ingénieux qui construisent ces tamis de soie pour filtrer passivement leur nourriture dans les eaux courantes. Cette capacité démontre une réelle intelligence comportementale, d’autant qu’ils savent s’ajuster aux flux de nutriments et qu’elles défendent leur territoire. Les larves tricotent des mailles fines (entre 1/50 e et 1/10 e de mm) adaptées à la vitesse du courant : plus il est fort, plus elles fabriquent un filet aux mailles serrées pour résister au courant ! Et lorsqu’il est obstrué ou endommagé, par exemple par des sédiments ou un courant trop fort, elles sont capables de le reconstruire ou le modifier. Il reste à comprendre le déclencheur précis de cette adaptation – est-ce purement génétique ou influencé par l’apprentissage individuel ?
Un si petit organisme, de seulement 1 à 2 cm de long, et qui possède un cerveau de 0,3 mm3 est non seulement capable de concevoir son filet avec une maille variable, de l’ancrer au substrat et de l’orienter face au courant. Mais il est sait aussi repousser ses congénères qui pourraient s’installer trop près et lui voler sa pêche ! Pour cela, les hydropsychés utilisent des ultrasons (d’une fréquence de 64 à 100 kHz, bien au-delà de ce que l’oreille humaine peut percevoir) pour indiquer leur présence à leurs voisins.
À la manière des cigales, les larves génèrent ces sons par stridulation, en frottant certaines parties de leur corps entre elles. Cette technique acoustique facilite leur navigation dans le tumulte sonore des eaux agitées, et est associée à des signaux chimiques tels que des phéromones qui facilitent l’identification et l’interaction sociale dans des milieux agités.
Des petites larves témoin de la qualité des eaux
Dans les communautés aquatiques, les hydropsychés coexistent avec d’autres espèces filtreuses, comme des larves de diptères, pour optimiser les ressources. Elles influencent la stabilité des cours d’eau en modulant les sédiments organiques et les différents flux nutritifs. Les organismes filtreurs sont de véritables nettoyeurs des rivières et des torrents, de petits ingénieurs qui améliorent la qualité des eaux. Ils sont déterminants dans l’architecture des écosystèmes d’eaux courantes, puisqu’ils constituent des proies pour les autres organismes, et sont donc à la base des chaînes alimentaires.
D’un point de vue morphologique, les branchies spécialisées des hydropsychés leur permettent d’extraire l’oxygène même dans des conditions tumultueuses ou déficientes. Cependant, ce sont aussi des organismes fragiles. Cela en fait de bons indicateurs biologiques qui servent aux scientifiques à évaluer la qualité de l’eau et les impacts de la pollution ou du changement climatique.
De plus, les hydropsyché inspirent le biomimétisme pour des technologies filtrantes durables, des colles aquatiques et la recherche médicale. Contrairement à la soie de ver à soie ou d’araignée, celle des hydropsychés est synthétisée sous l’eau, ce qui lui confère une résistance exceptionnelle à l’humidité, une haute élasticité et une biodégradabilité contrôlée. Ces caractéristiques en font un modèle idéal pour développer des biomatériaux innovants en médecine.
Quand l’hydropsyché inspire nos propres innovations
Dans ce monde aquatique en perpétuel mouvement, ces organismes démontrent que la survie dépend d’une vigilance constante et de l’adaptation face à l’instabilité. L’humanité peut s’inspirer de cette résilience et, plus spécifiquement, des stratégies de ces petits insectes aquatiques. La soie des larves d’hydropsychés intéresse la recherche, car elle adhère facilement aux surfaces immergées tout en restant flexible. Elle présente également une résistance mécanique jusqu’à plusieurs fois celle de l’acier à poids égal, n’induit pas de réactions immunitaires fortes et est biodégradable sans laisser de résidus toxiques.
En imitant la composition de la soie des larves d’hydropsyché, les scientifiques développent des colles synthétiques qui fonctionnent en milieu humide, comme dans le corps humain. Ces adhésifs pourraient révolutionner la chirurgie en permettant de refermer des tissus mous (comme le foie ou le cœur) sans points de suture, réduisant les risques d’infection et accélérant la guérison. Des prototypes sont déjà testés pour sceller des vaisseaux sanguins ou réparer des organes internes.
Le filet adaptable des hydropsychés inspire aussi des filtres intelligents qui ajustent leur porosité selon le débit d’eau et la taille des particules, et qui seraient utiles dans les usines de traitement des eaux et les stations d’épuration. Ce composé intéresse aussi les industries marines, pour créer des matériaux qui absorberaient l’énergie des vagues sans se briser, prolongeant la durée de vie des structures. Cela pourrait notamment être exploité par le secteur de l’énergie, pour les éoliennes marines ou les hydroliennes.
Les habitants des cours d’eau : un exemple à suivre
En nous inspirant de ce petit ingénieur, nous ouvrons des voies pour des avancées concrètes. Les solutions les plus élégantes et durables ne viennent pas toujours de laboratoires, mais souvent de la nature elle-même, où l’ingénieuse simplicité du vivant surpasse notre créativité. Et à l’instar des communautés d’organismes fluviaux qui se soutiennent mutuellement, les sociétés humaines doivent établir des réseaux solidaires pour affronter l’incertitude. La remarquable résilience de ces larves nous exhorte à repenser nos modes de vie, en mettant l’accent sur une adaptation préventive plutôt que sur une réaction tardive.
En fin de compte, les hydropsychés et les organismes aquatiques en général nous offrent un exemple à suivre : dans un environnement instable, la survie réside dans la diversité des adaptations et une réelle persévérance. Dans un monde en mutation, elle n’est pas innée, mais elle peut être cultivée. Ces organismes nous montrent que même dans l’agitation structurelle permanente, la vie persiste. En protégeant les écosystèmes fluviaux, nous préservons non seulement la biodiversité, mais aussi un trésor d’inspirations pour un avenir plus résilient et innovant.
Cet article est publié dans le cadre de la Fête de la science (qui a lieu du 3 au 13 octobre 2025), dont The Conversation France est partenaire. Cette nouvelle édition porte sur la thématique « Intelligence(s) ». Retrouvez tous les événements de votre région sur le site Fetedelascience.fr.
Christophe Mori ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 14:12
Sur Pornhub, un simple message suffit à dissuader les utilisateurs cherchant des vidéos pédopornographiques
Joel Scanlan, Senior Lecturer in Cybersecurity and Privacy, University of Tasmania
Texte intégral (1573 mots)
La sécurité des utilisateurs doit être intégrée à la conception des plateformes numériques. Elle n’est pas forcément complexe ou coûteuse, contrairement à ce que prétendent les entreprises numériques. Une expérience, menée sur la plateforme pornographique Pornhub, montre qu’un simple message adressé aux internautes cherchant des images pédopornographiques est fort dissuasif.
Le mot d’ordre officieux de l’industrie tech pendant deux décennies était « Move fast and break things », qu’on pourrait traduire par « aller vite quitte à tout casser ». Une philosophie qui a brisé bien plus que les seuls monopoles des taxis ou le modèle d’affaires des chaînes hôtelières. Elle a aussi façonné un monde numérique rempli de risques pour les plus vulnérables.
Pour la seule année fiscale 2024-2025, l’Australian Centre to Counter Child Exploitation a reçu près de 83 000 signalements de contenus d’exploitation sexuelle d’enfants en ligne (CSAM), principalement sur des plateformes grand public – une hausse de 41 % par rapport à l’année précédente.
En Australie, avec l’entrée en vigueur cette semaine de l’interdiction d’utiliser les réseaux sociaux pour les moins de 16 ans, ainsi que la mise en place de la vérification de l’âge pour les utilisateurs connectés aux moteurs de recherche le 27 décembre et pour les contenus réservés aux adultes le 9 mars 2026, nous atteignons un moment charnière – mais il faut bien comprendre ce que cette régulation permet et ce qu’elle laisse de côté. (Note du traducteur : En France, la loi du 7 juillet 2023 fixe à 15 ans l’âge minimal pour l’inscription et l’utilisation des réseaux sociaux).
L’interdiction empêchera une partie des enfants d’accéder aux plateformes (s’ils ne la contournent pas), mais elle ne corrige en rien l’architecture toxique qui les attend lorsqu’ils y reviendront. Elle ne s’attaque pas non plus aux comportements nocifs de certains adultes. Nous avons besoin d’un changement réel vers un devoir de vigilance numérique, qui obligerait légalement les plateformes à anticiper les risques et à les atténuer.
Le besoin de penser la sécurité dès la conception
Aujourd’hui, la sécurité en ligne repose souvent sur une approche dite « whack-a-mole », une référence à ce jeu d’arcade qui consiste à donner des coups de maillet sur la tête de taupes émergeant aléatoirement de quelques trous. De fait, les plateformes attendent que les utilisateurs signalent des contenus nocifs, puis les modérateurs les retirent. C’est une méthode réactive, lente, et souvent traumatisante pour les modérateurs humains qui y participent.
Pour remédier réellement au problème, il faut intégrer la sécurité dès la conception. Ce principe impose que les dispositifs de protection soient inscrits au cœur même de l’architecture de la plateforme. Il dépasse la simple restriction d’accès pour interroger les raisons pour lesquelles la plateforme permet, à l’origine, l’existence de mécanismes menant à des usages nocifs.
On en voit déjà les prémices lorsque des plateformes marquées par des précédents problématiques ajoutent de nouvelles fonctions – comme les « connexions de confiance » sur Roblox, qui limitent les interactions dans le jeu aux personnes que l’enfant connaît aussi dans la vie réelle. Cette fonction aurait dû être intégrée dès le départ.
Au CSAM Deterrence Centre, dirigé par Jesuit Social Service en partenariat avec l’Université de Tasmanie, nos travaux contredisent le discours récurrent de l’industrie selon lequel assurer la sécurité serait « trop difficile » ou « trop coûteux ».
En réalité, nous avons constaté que des interventions simples et bien conçues peuvent perturber des comportements nocifs sans nuire à l’expérience des autres utilisateurs.
Perturber les comportements dangereux
L’une de nos découvertes les plus marquantes provient d’un partenariat avec l’un des plus grands sites pour adultes au monde, Pornhub. Lors de la première intervention de dissuasion évaluée publiquement, lorsqu’un utilisateur cherchait des mots-clés liés aux abus sur mineurs, il ne se retrouvait pas face à un écran vide. Un message d’avertissement s’affichait et un chatbot l’orientait vers une aide thérapeutique.
Nous avons observé une baisse des recherches de contenus illégaux, et plus de 80 % des utilisateurs confrontés à cette intervention n’ont pas tenté de rechercher ces contenus à nouveau sur Pornhub durant la même session.
Ces données, cohérentes avec les résultats de trois essais contrôlés randomisés que nous avons menés auprès d’hommes australiens âgés de 18 à 40 ans, démontrent l’efficacité des messages d’avertissement.
Elles confirment également un autre constat : le programme Stop It Now (Australie) de Jesuit Social Service, qui propose des services thérapeutiques aux personnes préoccupées par leurs sentiments envers les enfants, a enregistré une forte augmentation des recommandations web après que le message d’avertissement affiché par Google dans les résultats de recherche liés aux contenus d’abus sur mineurs ait été amélioré plus tôt cette année.
En interrompant le parcours de l’utilisateur par un message clair de dissuasion, on peut empêcher qu’une pensée nocive se transforme en acte dangereux. C’est de la « safety by design » (« sécurité dès la conception »), utilisant l’interface même de la plateforme pour protéger la communauté.
Rendre les plateformes responsables
C’est pourquoi il est crucial d’inclure un devoir de vigilance numérique dans la législation australienne sur la sécurité en ligne, engagement pris par le gouvernement plus tôt cette année.
Plutôt que de laisser les utilisateurs naviguer à leurs risques et périls, les plateformes en ligne seraient légalement tenues de repérer et de réduire les risques qu’ils créent, qu’il s’agisse d’algorithmes suggérant des contenus nocifs ou de fonctions de recherche permettant d’accéder à du matériel illégal.
Parmi les mesures possibles, figurent la détection automatique de comportements de grooming (repérer les personnes cherchant à exploiter des enfants), le blocage du partage d’images et de vidéos d’abus déjà connus ainsi que des liens vers les sites qui les hébergent, et la suppression proactive des voies permettant d’atteindre les personnes vulnérables – par exemple empêcher que des enfants en ligne puissent interagir avec des adultes qu’ils ne connaissent pas.
Comme le montre notre recherche, les messages de dissuasion jouent également un rôle : afficher des avertissements clairs lorsque les utilisateurs recherchent des termes dangereux est très efficace. Les entreprises technologiques devraient collaborer avec des chercheurs et des organisations à but non lucratif pour tester ce qui fonctionne, en partageant les données plutôt qu’en les dissimulant.
L’ère du « aller vite quitte à tout casser » est révolue. Il faut un changement culturel qui fasse de la sécurité en ligne une caractéristique essentielle, et non un simple ajout optionnel. La technologie pour rendre ces plateformes plus sûres existe déjà, et les données montrent qu’intégrer la sécurité dès la conception peut porter ses fruits. Il ne manque plus qu’une réelle volonté de le faire.
Joel Scanlan est le co-responsable académique du CSAM Deterrence Centre, un partenariat entre l’Université de Tasmanie et Jesuit Social Services, qui gèrent Stop It Now (Australie), un service thérapeutique offrant un soutien aux personnes préoccupées par leurs propres sentiments, ou ceux de quelqu’un d’autre, envers les enfants. Joel Scanlan a reçu des financements de l’Australian Research Council, de l’Australian Institute of Criminology, du eSafety Commissioner, de la Lucy Faithfull Foundation et de l’Internet Watch Foundation.
10.12.2025 à 14:04
‘Is my boss a narcissist?’ How researchers look and listen for clues
Ivana Vitanova, Associate professor, EM Lyon Business School
Texte intégral (1615 mots)
Between the public extravagances of today’s business icons and the recent trials of prominent CEOs, narcissistic managers have firmly taken the spotlight. In academia, the fascination with the potent mix of charisma and ego that defines narcissistic leaders has fuelled nearly two decades of extensive research and analysis. Yet one of the central challenges of this work is measurement: how can we identify and assess narcissism in managers outside a clinical setting? Since it’s rarely possible to administer traditional psychometric tests to top executives, management scholars have developed a range of clever, unobtrusive ways to identify narcissistic tendencies by observing behavior, language, and public presence.
Narcissism: its traditional measurement
According to the Diagnostic and Statistical Manual of Mental Disorders (DSM) of the American Psychiatric Association, “narcissistic personality disorder is defined as a pervasive pattern of grandiosity (sense of superiority in fantasy or behavior), need for admiration, and lack of empathy, beginning by early adulthood and occurring in a variety of contexts.” In their 2020 article in the Journal of Management, authors Ormonde Rhees Cragun, Kari Joseph Olsen and Patrick Michael Wright write that “despite its origin in clinical psychology, the DSM’s definition is also widely accepted for defining narcissism in its nonclinical form”.
Research in psychology traditionally assesses narcissism through self-report tests or third-party psychometric tests. As first outlined by R. A. Emmons in 1984, the basic principle of these tests is to link simple statements to the components of narcissism. The most widely used and empirically validated are the 40-item Narcissistic Personality Inventory (NPI) and its shorter version, the NPI-16. The NPI asks respondents to choose between paired statements such as “I really like to be the center of attention” versus “it makes me uncomfortable to be the center of attention”, and “I am much like everybody else” versus “I am an extraordinary person”.
While a few studies have administered the NPI directly to top managers – or adapted it for third-party evaluations, asking employees or stakeholders to rate managers based on daily interactions – such approaches remain extremely rare due to limited access to suitable participants. Faced with these limitations, researchers in management and organizational studies have sought alternative ways to detect narcissism in leaders. They began by identifying behavioral and linguistic cues in CEOs’ official communications that could reflect one or more dimensions of narcissism. More recently, however, the rise of social media has provided researchers with new, more direct opportunities to observe and measure narcissistic behavior in real time.
Spotting narcissistic traits in interviews and official communications
One of the first studies to measure managerial narcissism was developed by Arijit Chatterjee and Donald C. Hambrick in 2007. After consulting with corporate communication experts, they followed Emmons’ principle and identified four potential signs of narcissism in CEOs’ public behavior. These were the prominence of the CEO’s photograph in a company’s annual report; the CEO’s prominence in a company’s press releases; the CEO’s use of first-person singular pronouns (eg I, me and my) in interviews; and the CEO’s compensation divided by that of the second-highest paid executive in the firm.
Later research expanded this approach with new indicators, such as the number of lines in a CEO’s official biography or the number of awards listed in their self-description. Other studies zoomed in on more specific linguistic cues – such as the ratio of singular pronouns to plural pronouns (eg we, us and ours) in CEOs’ press releases.
Inspired by findings in psychology, some researchers have even used the size of a CEO’s signature as a proxy for narcissism – a larger, more flamboyant signature being linked to a higher level of narcissism.
À lire aussi : Signature size and narcissism − a psychologist explains a long-ago discovery that helped establish the link
Importantly, many of these studies have validated their unobtrusive measures against traditional personality tests, finding strong correlations with established tools like the NPI. This evidence suggests that we can reliably spot narcissistic tendencies in leaders by observing their behavior and communication.
How social media reveals narcissistic traits in managers
In recent years, the rise of social media has given researchers unprecedented opportunities to observe how managers present themselves to the public – opening a new window into their narcissistic behavior. For instance, a recent study by Sebastian Junge, Lorenz Graf-Vlachy, Moritz Hagen and Franziska Schlichte analysed managers’ LinkedIn profiles to develop a multidimensional index of narcissism. Building on the DSM’s components of narcissism, the authors identified five features of a profile that may signal narcissistic tendencies: the number of pictures of the executive; the length of the “About” section; the number of listed professional experiences; the number of listed skills; and the number of listed credentials. They then combined these indicators to create an overall index of managerial narcissism.
Admittedly, research that only uses social media profiles may focus on the most narcissistic managers, since less narcissistic executives may not maintain, for example, a LinkedIn presence. Moreover, social psychology research suggests that social media itself encourages exaggeratedly narcissistic communication by encouraging self-promotion. To help address these concerns, Junge et al. assigned managers without LinkedIn profiles the lowest possible narcissism score and included them in their overall analysis. Their study found strong correlations between the LinkedIn-based measure and earlier, unobtrusive measures of narcissistic CEO behavior, as well as traditional psychometric tests such as the NPI.
The takeaway is encouraging: we don’t always need a personality test to spot narcissistic leaders – their words, images and online profiles can reveal a great deal. These tools offer employees, investors and board members a way to better recognize narcissistic tendencies in managers and adjust their decisions and interactions accordingly. And there’s still huge potential for being creative: building on psychologists’ insights into narcissistic behaviors, we could explore psycholinguistic dictionaries of narcissistic rhetoric and even, more eccentrically, analyse facial features such as eyebrow distinctiveness.

A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Ivana Vitanova ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 12:22
Ces pointes de flèches prouvent-elles la présence d’Homo Sapiens en Eurasie il y a 80 000 ans ?
Hugues Plisson, archéologue spécialisé en tracéologie (reconstitution de la fonction des outils préhistoriques par l'analyse de leurs usures), Université de Bordeaux
Andrey I. Krivoshapkin, Acting director, Russian Academy of Sciences
Texte intégral (3861 mots)

De minuscules pointes de projectile triangulaires ont été identifiées à partir de leurs fractures d’impact dans les plus anciennes couches d’occupation du site d’Obi-Rakhmat en Ouzbékistan, vieilles de 80 000 ans. Elles ont la dimension de pointes de flèches et sont identiques à celles découvertes dans une couche beaucoup plus récente d’un site de la vallée du Rhône, en France, à la toute fin du Paléolithique moyen, correspondant à une incursion d’Homo Sapiens en territoire néanderthalien il y a 54 000 ans. Cette nouvelle étude, publiée dans la revue « PLOS One », apporte un argument décisif pour la réécriture du scénario de l’arrivée d’Homo Sapiens en Europe.
Développés en Europe occidentale et plus particulièrement en France à partir de la seconde moitié du XIXe siècle, les cadres chrono-culturels et anthropologiques de la Préhistoire et les modèles évolutifs qu’ils inspirèrent furent d’abord linéaires et européocentrés : Cro-Magnon descendant de Néanderthal posait les fondements d’une supériorité civilisationnelle dont se prévalait alors cette partie du monde. Ce n’est qu’un siècle plus tard que sera mise en évidence l’origine africaine d’Homo Sapiens et des traits technologiques et sociaux structurants du Paléolithique supérieur occidental, de ~ 45 000 à 12 000 ans avant le présent (productions symboliques, réseaux à grande distance, outillages et armements lithiques et osseux diversifiés).
Les plus anciennes évidences de présence d’Homo Sapiens en Australie vers 65 000 ans précèdent de 10 millénaires celles de l’Europe dont les modalités du peuplement demeurent sujet de discussion. À ce jour, le calage chronologique des toutes premières occupations européennes du Paléolithique supérieur par rapport à celles de l’est du bassin méditerranéen, pourtant regardées comme les plus proches, demeure insatisfaisant. Soit les données sont issues de fouilles trop anciennes pour avoir été suffisamment précises, soit elles ne s’inscrivent pas dans la filiation directe supposée entre le Levant et l’Europe. Les racines mêmes du Paléolithique supérieur initial levantin, malgré la proximité africaine, sont incertaines. Une origine centre asiatique, a été suggérée par l’archéologue Ludovic Slimak en 2023.
Un site en Asie centrale

Corridor entre l’ouest et l’est du continent ou zone refuge, selon les phases climatiques, l’Asie centrale n’est encore documentée que par quelques sites paléolithiques, mais qui sont autant de références de l’histoire de la Préhistoire.
Parmi ceux-ci figure l’abri sous roche d’Obi-Rakhmat en Ouzbékistan découvert en 1962. Ce gisement livre sur 10 mètres de stratigraphie, entre 80 000 et 40 000 ans, une industrie lithique qui par certains traits s’inscrit clairement dans la continuité du Paléolithique moyen ancien du Levant mais par d’autres fut rapprochée du Paléolithique supérieur initial. Ce Paléolithique moyen ancien du Levant, associé dans le site de Misliya à de l’Homo Sapiens archaïque, disparut du Proche-Orient vers 100 000 ans. À Obi-Rakhmat, les restes crâniens d’un enfant trouvés dans une couche à ~ 70 000 ans, présentent des caractères regardés comme néanderthaliens et d’autres comme anatomiquement modernes, combinaison pouvant résulter d’une hybridation.
Lames massives mais pointes microlithiques

C’est dans ce contexte que notre équipe internationale, dirigée par Andrei I. Krivoshapkin, a identifié dans les couches les plus anciennes de minuscules pointes de projectiles triangulaires. Mesurant moins de 2 cm de large et ne pesant que quelques grammes, elles sont impropres par leurs dimensions et leur fragilité à avoir été montées sur des hampes de lances. Leur étroitesse correspond au diamètre (inférieur ou égal à 8 mm) des hampes documentées ethnographiquement sur tous les continents pour les flèches tirées à l’arc droit.

Question de balistique
Les armes perforantes projetées constituent des systèmes complexes dont les éléments ne sont pas interchangeables d’un type d’arme à l’autre, car répondant à des contraintes différentes en intensité et en nature.
L’importante force d’impact des lances tenues ou lancées à la main fait de la robustesse de l’arme un paramètre essentiel, aussi bien en termes d’efficacité que de survie du chasseur, la masse assurant à la fois cette robustesse, la force d’impact et la pénétration. À l’opposé, la pénétration des traits légers tirés à grande distance repose sur leur acuité, car l’énergie cinétique, beaucoup plus faible, procède là essentiellement de leur vitesse, laquelle, à la différence de la masse, décroit très rapidement sur la trajectoire et dans la cible. Cette vitesse ne pouvant être atteinte par la seule extension du bras humain, elle est obligatoirement tributaire de l’emploi d’un instrument de lancer. Les pointes de flèche et celles de lances ou de javelines ne sont donc pas conçues selon les mêmes critères et ne se montent pas sur les même hampes, les dimensions et le degré d’élasticité desquelles sont par ailleurs essentiels en terme balistique. Ainsi, comme en paléontologie où la forme d’une dent révèle le type d’alimentation et suggère le mode de locomotion, les caractéristiques d’une armature fournissent des indices sur le type d’arme dont elle est l’élément vulnérant.
Un armement propre à Sapiens ?
Le minuscule gabarit des pointes d’Obi-Rakhmat ne peut être regardé comme un choix par défaut, car non seulement la matière première lithique de bonne qualité dont on a tiré de grandes lames ne manque pas à proximité du site, mais l’inventaire des traces d’usage relevées à la loupe binoculaire et au microscope met en évidence au sein du même assemblage des pointes retouchées beaucoup plus robustes (15 à 20 fois plus lourdes et 3 à 4 fois plus épaisses) et du gabarit des têtes de lance ou de javeline.
En retournant à la bibliographie et à nos propres travaux sur des outillages du Paléolithique moyen, nous avons constaté que la présence dans un même ensemble d’armatures de divers types, pour partie microlithiques et produites à cette fin, n’était à ce jour connue que dans les sites à Homo Sapiens. Les plus anciennes occurrences documentées sont en Afrique du Sud dans les couches culturelles Pre-Still Bay (plus de 77 000 ans) et postérieures du gisement de Sibudu. Dans l’univers néanderthalien, les pointes lithiques endommagées par un usage en armature de projectile sont rares, elles sont de fort gabarit et ne se distinguent ni par leurs dimensions, leur facture ou leur type de celles employées à d’autres activités que la chasse, telles que la collecte de végétaux ou la boucherie. Cette distinction dans la conception des outillages et des armements prend valeur de marqueur anthropologique.

En raison de leurs dates respectives, de la distance entre l’Afrique du sud et l’Asie centrale (14 000 km) et de la différence de facture des armatures d’Obi-Rakhmat et de Sibudu (lithique brut de débitage vs lithique façonné ou retouché, osseux façonné), l’hypothèse de foyers d’invention indépendants est la plus vraisemblable.
Des piémonts du Tien Shan à la vallée du Rhône 25 000 plus tard
La seule forme d’armature miniature de projectile identique actuellement connue est beaucoup plus récente. Elle fut découverte par Laure Metz, sur le site de Mandrin, en vallée du Rhône en France, qui livra aussi une dent de lait d’Homo Sapiens déterminée par Clément Zanolli. L’ensemble est daté d’environ 54 000 ans, soit une dizaine de milliers d’années avant la disparition des Néanderthaliens locaux. La similitude des micro-pointes d’Obi-Rakhmat et de Mandrin, pourtant séparées par plus de 6 000 km et 25 millénaires, est telle que les unes et les autres pourraient être interchangées sans qu’aucun autre détail que la roche ne trahisse la substitution.

Des travaux récents publiés par Leonardo Vallini et Stéphane Mazières définissent le Plateau perse, à la périphérie nord-est duquel est situé Obi-Rakhmat, comme un concentrateur de population où les ancêtres de tous les non-Africains actuels vécurent entre les premières phases de l’expansion hors d’Afrique – donc bien avant le Paléolithique supérieur – et la colonisation plus large de l’Eurasie. Cet environnement riche en ressources pourrait avoir constitué une zone de refuge propice à une régénération démographique après le goulet d’étranglement génétique de la sortie d’Afrique, à l’interaction entre les groupes et par conséquent aux innovations techniques.
Mandrin et Obi-Rakhmat représentent probablement deux extrémités géographiques et temporelles d’une phase pionnière de peuplement telle qu’entrevue par Ludovic Slimak, marquée par ce que les typologues qualifiaient jadis de fossile directeur et qui ici recouvrirait la propagation d’une invention fondamentale propre à Homo Sapiens. Jusqu’à présent passées inaperçues parce que brutes de débitage, minuscules et fragmentaires, il est à parier que les micro-pointes de projectile dont les critères de reconnaissance sont maintenant posés commenceront à apparaître dans des sites intermédiaires entre l’Asie centrale et la Méditerranée occidentale.
Prémisses d’un nouveau scénario du peuplement occidental d’Homo Sapiens
Cette découverte est stimulante à plusieurs titres. Elle valide la cohérence de l’étude du site de Mandrin qui concluait à une brève incursion en territoire néanderthalien de Sapiens armés d’arcs, mais dont plusieurs éléments avaient été critiqués – ce qui est cependant le jeu scientifique habituel lorsqu’une proposition nouvelle s’écarte par trop des connaissances admises – et dont la dimension prédictive n’avait alors pas été considérée.
La similitude des micro-pointes de Mandrin et d’Obi-Rakhmat ne peut être une simple coïncidence. Elle ne porte pas seulement sur leur forme, mais aussi sur leur mode de fabrication, qui requière un réel savoir-faire comme en témoigne la préparation minutieuse de leur plan de frappe avant débitage, et sur leur fonctionnement. On pourra débattre de l’instrument approprié au tir de flèche armées de si minuscules armatures, l’arc étant en filigrane, ou si l’on préfère garder une certaine réserve ne parler que de tir instrumenté, mais cela contraste déjà avec ce que l’on connait des armes de chasse de Néanderthal et de leur conception.
L’autre aspect remarquable, encore peu habituel, est la convergence et la complémentarité de données provenant de la culture matérielle et de la mémoire de nos gènes, qui ne purent s’influencer au regard des dates d’étude et de publication respectives. Les deux conjuguées esquissent la réécriture du scénario de l’arrivée d’Homo Sapiens en Europe : on le pensait venu directement d’Afrique par le chemin le plus court, il y a 45 000 ans, et on le découvre implanté depuis fort longtemps au cœur du continent eurasiatique, bien avant qu’il n’en sorte en quête de nouveaux territoires.
Plisson Hugues a reçu des financements du CNRS et de l'université de Bordeaux
Andrey I. Krivoshapkin ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.12.2025 à 11:45
Au Louvre, la radiologue qui révèle les mystères des chefs-d’œuvre
Elisabeth Ravaud, Ingénieur de recherche, Ministère de la Culture
Texte intégral (3481 mots)

Vous l’ignorez peut-être, mais sous le Louvre, se cache un laboratoire un peu particulier, le Centre de recherche et de restauration des musées de France. Il a pour mission d’étudier, de documenter et d’aider à la restauration des œuvres des 1 200 musées de France. Benoît Tonson, chef de rubrique Science et Technologie, y a rencontré Elisabeth Ravaud. Elle est l’autrice d’un ouvrage de référence sur l’utilisation de la radiographie appliquée à l’étude des peintures « Radiography and Painting » et l’une des plus grandes spécialistes mondiales de cette discipline.
The Conversation : Vous êtes entrée au laboratoire du Louvre en 1993, pourtant à cette époque vous n’étiez ni historienne de l’art ni restauratrice…
Elisabeth Ravaud : À l’époque, je suis médecin, spécialisée en radiodiagnostic et imagerie médicale. J’ai fait mes études de médecine à Paris, à la Pitié-Salpêtrière, puis passé l’internat des hôpitaux de Paris. En parallèle de cette activité hospitalière, j’ai toujours cultivé un goût pour l’histoire de l’art. J’avais d’ailleurs entamé un cursus dans cette discipline, bénéficiant d’une équivalence en deuxième année grâce à ma thèse de doctorat : après sept ans de médecine, on y avait droit. Un jour, on m’a annoncé qu’il me fallait faire un stage. Et c’est comme ça, presque par hasard, que j’ai atterri ici.
Naturellement, je me suis intéressée à la radiographie, le seul point commun évident entre mes études médicales et l’examen des œuvres d’art. Dans le monde hospitalier, je pratiquais la radio conventionnelle, mais aussi l’échographie, l’écho-Doppler, la radiologie interventionnelle, le scanner, l’IRM… Tout un arsenal qui n’existe évidemment pas pour les œuvres. La radio, elle, constituait un vrai pont.
Quelles sont les grandes différences que vous avez pu remarquer entre l’hôpital et le laboratoire ?
E. R. : Très vite, un point m’a frappée : en lisant les rapports ou les articles produits à l’époque, j’ai eu l’impression que l’interprétation des radiographies d’œuvres se limitait aux signes les plus évidents. Par exemple, vous voyez trois personnages sur la radio, mais seulement deux sur le tableau, on en déduit qu’un personnage a été recouvert. Mais tout ce qui relevait d’une information plus subtile semblait laissé de côté. Or, je venais d’un milieu où l’image est examinée en long, en large et en travers. On n’aborde jamais l’examen d’un foie sans jeter un œil aux reins, aux poumons : l’interprétation est systématique, structurée. Cette différence méthodologique m’a immédiatement sauté aux yeux.
Autre surprise : dans les rapports, rien sur les supports, les essences de bois, la toile, les petits signes discrets… On se contentait des évidences. Et quand j’ai voulu me documenter, là où la médecine offre des bibliothèques entières, j’ai découvert qu’en imagerie d’œuvres d’art, il n’existait pratiquement aucun ouvrage. L’information était éparpillée : un peu ici, un peu là, un article isolé… rien de systématisé.
À la fin de mon stage, on m’a proposé de rester. Et si je n’avais pas perçu cette sous-exploitation de l’image, et cette absence d’outils méthodologiques, je ne suis pas sûre que j’aurais accepté : j’avais déjà un poste hospitalier. Mais je me suis dit que je pouvais peut-être apporter quelque chose, une forme d’expertise méthodologique, en faisant passer mes compétences de l’univers médical au monde du patrimoine. C’est ce sentiment qui m’a finalement convaincue.
Sur quels types d’œuvres avez-vous travaillé ?
E. R. : Avec mon parcours, tout portait à croire que je travaillerais sur des objets en volume, comme on travaille en imagerie 3D à l’hôpital, je travaillais sur des corps, donc ce qui aurait pu s’en rapprocher le plus étaient les statues. Mais non : on m’a mise sur… la peinture. Ça m’a surprise. Et en même temps, cela a eu un effet décisif : j’ai réalisé que les tableaux, que beaucoup considèrent comme des objets en deux dimensions (une hauteur et une largeur), possèdent en réalité une profondeur, essentielle à prendre en compte en radiographie. L’épaisseur de la couche picturale, les structures internes du support, l’accumulation des matériaux… tout cela forme une troisième dimension qui conditionne l’interprétation. Et c’est précisément cette profondeur, parfois réduite à quelques millimètres, qui rend l’analyse complexe. Chaque signe radiographique doit être rapporté à sa structure d’origine.

Finalement, ce retour à la radio conventionnelle, alors que je travaillais surtout en scanner et IRM, des techniques plus avancées, s’est révélé cohérent. Comme en médecine, la radiographie conventionnelle conserve son importance. Elle offre une première vision globale, oriente le diagnostic, et guide vers d’autres examens. Dans le domaine du patrimoine, elle joue ce même rôle fondamental.
Pouvez-vous nous rappeler le principe de la radiographie ?
E. R. : La radiographie est une technique d’imagerie fondée sur les rayons X, découverts en 1895 par Wilhelm Röntgen, physicien allemand travaillant à l’Université de Würzburg (Bavière). Elle consiste à produire, à partir d’un tube, un faisceau de rayons X qui traverse la matière en subissant une atténuation. Cette atténuation est décrite par la loi de Beer-Lambert. Il s’agit d’une décroissance exponentielle dépendant de l’épaisseur traversée, plus elle est grande, plus l’atténuation est forte, cette décroissance dépend également de la nature du matériau. Par exemple, un métal a un coefficient d’atténuation très élevé : en quelques dizaines de microns, il arrête presque totalement les rayons X. À l’inverse, l’air laisse passer les rayons X très facilement.
Voici le principe : un faisceau homogène traverse successivement le support, la préparation et la couche picturale. Chaque photon est atténué différemment selon les matériaux rencontrés, transformant le faisceau initialement homogène en un faisceau hétérogène. Cette hétérogénéité est ensuite enregistrée par les émulsions radiographiques ou les capteurs numériques.
Historiquement, sur film, plus l’énergie résiduelle est importante, plus l’émulsion devient noire ; à l’inverse, un matériau très absorbant, comme un clou, laisse très peu d’énergie au film, qui reste blanc. L’air apparaît donc noir, le métal blanc. La radio permet ainsi d’observer simultanément le support, la préparation et la couche picturale.
J’ai illustré cela avec la Belle Ferronnière, de Léonard de Vinci. On y voit les stries du bois de noyer, caractéristiques du support ; les stries transversales correspondant aux coups de pinceau de la préparation, destinée à régulariser la surface du support ; puis la couche picturale, reconnaissable par la forme du portrait et fortement influencée par la nature des pigments. Les carnations, en particulier, apparaissent très marquées en radiographie car elles contiennent un pigment utilisé depuis l’Antiquité jusqu’à la fin du XIXe ou le début XXe siècle : le blanc de plomb. Le plomb arrête fortement les rayons X, ce qui rend ces zones très lisibles.
C’est d’ailleurs parce que les peintres anciens utilisaient du blanc de plomb que la radiographie est si informative sur leurs œuvres. À l’inverse, les peintures acryliques contemporaines sont composées d’éléments organiques : elles se laissent traverser, ce qui rend la radiographie beaucoup moins performante.
Vous disiez qu’au moment de votre arrivée au laboratoire, on n’exploitait pas le plein potentiel de la radiographie, c’est-à-dire ?
E. R. : Ce qui m’a surprise, c’est que personne ne s’était réellement intéressé au bois. Pourtant, l’essence du panneau est essentielle, car elle constitue un véritable témoin de provenance. En Italie, les peintres utilisent généralement le peuplier ou le noyer (en Lombardie, notamment) tandis que les panneaux flamands sont réalisés en chêne. Ainsi, si on vous présente un tableau prétendument italien et que la radiographie révèle un support en chêne, on peut avoir de sérieux doutes quant à l’authenticité. Ces indices concernant les supports (bois, toile, papier) ne sont pas aussi spectaculaires que les repentirs.
Dans les années 1920–1930, la radiographie était perçue comme une « lanterne magique » : on faisait une radio et l’on découvrait trois personnages au lieu de deux, ou un bras levé au lieu d’un bras baissé. Ce caractère spectaculaire a beaucoup impressionné, et il continue d’impressionner : chaque fois que je vois une radio riche en informations cachées, il y a toujours ce « Waouh ! » Mais paradoxalement, cette fascination pour l’effet spectaculaire a plutôt freiné l’intérêt pour des signes plus modestes.
Par exemple, je peux identifier qu’un panneau a été confectionné à partir de noyer. Je peux aussi déterminer le type de préparation utilisé pour préparer les panneaux avant de les peindre : à l’époque de Léonard de Vinci, par exemple, on utilisait surtout des préparations à base de calcium alors que Léonard, lui, utilisait des préparations au blanc de plomb. Ce sont ce type de signes, plus discrets, sur lesquels j’ai passé du temps.
L’examen lui-même est simple à réaliser : l’équipement nécessaire est accessible, et on pourrait même faire une radiographie en ville, chez un radiologue. Mais ce que j’ai surtout transféré de la médecine vers le patrimoine, c’est une méthodologie, une manière d’aborder l’image de façon systématique. Les techniques, elles, sont différentes. J’ai dû réapprendre l’anatomie du tableau : ses couches, comment il est fabriqué, avec quels pigments, quelles compositions. Et ensuite, comme en médecine, voir des cas, accumuler de l’expérience. Cela a été une aventure passionnante.
Au-delà de la radiographie, utilisez-vous d’autres techniques d’imagerie ?
E. R. : La radiographie ne se suffit pas à elle-même. On la croise avec de nombreuses autres techniques d’imagerie, que j’ai dû apprendre en arrivant ici, car elles diffèrent totalement de celles du milieu médical. On ne fait pas d’IRM ni de scanner, mais on utilise des infrarouges qui permettent de pénétrer la couche picturale et de révéler le dessin préparatoire. L’ultraviolet, lui, renseigne surtout sur les matériaux en surface, comme le vernis, ou sur les retouches qui apparaissent comme des taches noires sur la fluorescence du vernis ancien.
La micro-fluorescence X consiste à exciter la matière picturale avec un rayonnement X faible. La matière réémet alors un rayonnement qui est enregistré sous forme de spectre, révélant les éléments présents : calcium, plomb, fer, cuivre, étain, strontium, argent, or, etc. Chaque point fournit la composition de tous les éléments présents. Depuis les années 2010, grâce à l’informatique, on peut faire ces mesures en déplacement continu, générant une « image cube », c’est-à-dire une cartographie complète du tableau où, en chaque point, on peut lire le spectre et isoler la présence d’un élément particulier, par exemple le mercure du vermillon.
Cette technique permet de cartographier différents pigments, comme le plomb, le cuivre ou l’étain, de manière très précise sur la couche picturale.
L’usage combiné de ces techniques a profondément amélioré l’étude fine des couches picturales, permettant d’exploiter au maximum les informations disponibles, tout en gardant la radiographie pour ses informations complémentaires.
Et toutes ces techniques, vous les avez appliquées pour étudier des tableaux de Léonard de Vinci ?
E. R. : Il faut savoir que les collections françaises possèdent cinq œuvres de Léonard de Vinci sur une quinzaine existantes dans le monde. Avoir accès à ce corpus a été une occasion exceptionnelle pour comparer sa manière de travailler au fil du temps. En radiographie, je le rappelle, l’opacité de l’image est proportionnelle à la quantité de matière présente : beaucoup de matière rend l’image opaque, peu de matière la rend transparente.
En comparant la Belle Ferronnière, la Joconde et Saint Jean-Baptiste, on observe une transparence croissante dans les radios : au fil du temps, Léonard utilise la préparation comme réflecteur de lumière, plaçant la matière avec une économie croissante mais précise pour créer des modulations subtiles. Cette information sur la quantité de matière est spécifique à la radio.
Concernant les liants (les matières qui servent à donner de la cohésion et une tenue dans le temps au dépôt de pigments sur un support), il faut savoir que jusqu’au XVe siècle, la peinture se faisait principalement à la tempera à l’œuf (on se servait de jaune d’œuf en guise de liant), liant rapide à sécher, qui obligeait à poser des coups de pinceau courts et qui produisait des couleurs opaques.
L’apparition de la peinture à l’huile a permis de poser des touches plus longues, de moduler la couleur et de créer des transparences impossibles avec la tempera. Elle est documentée dès le XIIIe siècle dans le nord de l’Europe, car dans ces régions la tempera avait tendance à moisir à cause de l’humidité.
En Italie, où le climat était plus clément, l’huile s’est imposée plus tardivement, offrant aux artistes de nouvelles possibilités expressives. Léonard de Vinci, autour de 1472-1473, figure parmi les premiers peintres florentins à utiliser l’huile, marquant ainsi un tournant dans la peinture italienne et la manière de travailler les couches et les effets de lumière.
À l’époque de Léonard, les peintres ne maîtrisaient pas encore très bien le liant et les siccatifs (substances qui jouent un rôle de catalyseur en accélérant le séchage). Ils risquaient soit d’en mettre trop, soit pas assez, et le séchage pouvait devenir problématique : trop rapide, cela provoquait des craquelures prématurées et trop lent, il fallait attendre longtemps avant de poser la couche suivante.
Les écrits de Léonard témoignent de cette inventivité constante : ses recettes de peinture montrent un véritable inventaire de techniques et d’astuces, qu’il mélangeait à des notes sur d’autres domaines. En consultant ses manuscrits pour le travail sur Léonard que nous avons effectué en 2019, on découvre à quel point ces documents sont dispersés : certaines pages contiennent beaucoup d’informations sur la peinture, d’autres seulement trois lignes sur une recette, mêlées à des calculs mathématiques, des études d’hydraulique ou des croquis divers.
Sur une même feuille, il pouvait noter une ébauche pour une Vierge à l’Enfant, un calcul algébrique, un projet hydraulique, et bien d’autres idées, ce qui donne l’impression qu’il avait cent idées à la minute qu’il couchait toutes en vrac.
Grâce à toutes ces lectures, vous êtes capable de reproduire la peinture utilisée par Léonard ?
E. R. : Je me suis particulièrement intéressée à un aspect très spécifique des peintures de Léonard, les grains de verre. On savait déjà que certains peintres, notamment au XVIe siècle, en ajoutaient dans leurs peintures, mais les publications existantes se contentaient de constater leur présence sans vraiment l’expliquer.
Cela m’a amené à me poser la question : à quoi servaient réellement ces grains de verre ? Pour y répondre, j’ai monté un projet de recherche visant à comprendre leur rôle, en testant trois hypothèses principales. La première était que les grains de verre pouvaient modifier la rhéologie de la peinture, c’est-à-dire la manière dont elle se comporte sous le pinceau. La deuxième supposait qu’ils favorisaient le séchage, ce qui était une problématique importante avec le nouveau liant à l’huile utilisé à l’époque. La troisième portait sur la transparence, car le verre est un matériau naturellement transparent et pourrait influencer l’effet visuel.
Les résultats ont montré que les grains de verre n’altèrent pas la texture de la peinture, ce qui est un avantage. Le peintre peut les incorporer sans modifier son geste ou son « écriture ». En revanche, ils favorisent un séchage doux, moins rapide et moins problématique que celui produit par d’autres siccatifs. Sur le plan de la transparence, les analyses optiques ont confirmé que l’ajout de verre fonctionne comme l’ajout d’huile, mais sans entraîner les complications de séchage : l’indice de réfraction du verre et de l’huile étant similaire, la peinture gagne en transparence tout en restant stable. Étant donné l’intérêt constant de Léonard pour la lumière et les effets optiques, je suis convaincue que cette transparence jouait un rôle central et constituait un argument important dans ses choix techniques.
Elisabeth Ravaud ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:27
Des œufs de papillon à l’hybridation des ours polaires : conversation avec la réfugiée scientifique Camille Parmesan
Camille Parmesan, Director, Theoretical and Experimental Ecology Station (SETE), Centre national de la recherche scientifique (CNRS); University of Plymouth; The University of Texas at Austin
Texte intégral (7449 mots)
C’est une écologue texane mondialement connue pour avoir été la première à démontrer l’impact certain du changement climatique sur une espèce sauvage : le papillon damier d’Édith. Ces dernières années, cependant, Camille Parmesan n’est plus seulement célèbre pour son expertise sur l’avenir de la biodiversité dans un monde en surchauffe ou bien pour le prix Nobel de la paix qu’elle a reçu avec ses collègues du Giec, mais aussi en raison de son statut de réfugiée scientifique en Europe.
À deux reprises dans sa vie, elle a choisi de déménager dans un autre pays afin de pouvoir continuer à travailler dans un contexte politique favorable à la recherche sur le changement climatique. Elle a ainsi quitté l’Amérique de Trump en 2016, puis la Grande-Bretagne post-Brexit. Elle vit aujourd’hui à Moulis, en Ariège, où elle dirige la station d’écologie théorique et expérimentale du CNRS.
S’entretenir avec elle permet de mieux comprendre comment protéger une biodiversité pleine de surprises, comment faire face à l’hybridation croissante des espèces ou encore que répondre au climatoscepticisme ambiant.
The Conversation : Vos premiers travaux sur les habitats du papillon damier d’Édith vous ont rapidement valu une reconnaissance internationale. Concrètement, comment avez-vous démontré qu’un papillon pouvait être affecté par le changement climatique ? Quels outils avez-vous utilisés ?
Camille Parmesan : Un pick-up, une tente, un filet à papillons, de bonnes lunettes de lecture pour repérer les œufs minuscules et les dégâts causés par les chenilles sur les feuilles, un cahier et un crayon pour prendre des notes ! Sur le terrain, vous n’avez besoin de rien d’autre.
Mais avant de me lancer dans mon travail de terrain, j’ai passé un an à parcourir les musées des États-Unis, quelques autres au Canada, et même à Londres et à Paris, afin de rassembler toutes les données disponibles sur le damier d’Édith. Je recherchais des informations très précises sur sa localisation, par exemple « Il se trouvait à cet endroit, à un mile [1,6 km] de Parsons Road, le 19 juin 1952 ». Car cette espèce vit en petites populations et est sédentaire. Ce processus m’a pris environ un an, car, à l’époque, il n’existait pas d’archives numérisées. Je devais donc examiner des spécimens épinglés et noter à la main les informations relatives à leur collecte.


Une fois sur le terrain, mon travail consistait à visiter chacun de ces sites pendant la saison de vol des papillons. Comme cette saison ne dure qu’environ un mois, il faut estimer quand ils voleront à chaque endroit afin de pouvoir effectuer un recensement correct. Pour cela, on commence par rechercher les adultes. Si on n’en voit pas, on ne s’arrête pas là. On recherche des œufs, des traces de toile de soie des jeunes chenilles, des marques de dégâts causés par les larves qui commencent à se nourrir après avoir hiberné…
On examine aussi l’habitat : dispose-t-il d’une quantité suffisante de plantes hôtes saines ou de plantes nectarifères pour nourrir les adultes ? Si l’habitat n’était pas satisfaisant, je n’incluais pas le site en question dans mon étude. Car je souhaitais isoler l’impact du changement climatique d’autres facteurs, tels que la dégradation de l’habitat, la pollution… Sur les sites plus vastes, j’ai souvent examiné plus de 900 plantes avant d’estimer avoir effectué un recensement suffisant.
Aujourd’hui, lorsque vous retournez sur les sites que vous avez examinés ainsi il y a plusieurs décennies, voyez-vous des choses que vous ne pouviez pas voir au début de votre travail ?
C. P. : Disons que je regarde des choses que je ne regardais pas vraiment lorsque j’ai commencé, il y a quarante ans, ou que mon mari Michael, [le biologiste Michael C. Singer] ne regardait pas lorsqu’il a commencé il y a cinquante ans. Nous avons découvert, par exemple, que la hauteur à laquelle les œufs sont pondus est désormais légèrement plus élevée, ce qui s’avère être une adaptation très importante au changement climatique.

Les œufs sont en fait pondus plus haut parce que le sol devient beaucoup trop chaud. L’été dernier, nous avons mesuré des températures de 78 °C au sol. Ainsi, si une chenille tombe, elle meurt. On peut également voir des papillons se poser et partir immédiatement, car il fait beaucoup trop chaud pour leurs pattes, alors ils s’envolent vers la végétation ou se posent sur vous.
À mes débuts, je n’aurais jamais pensé que la hauteur à laquelle les œufs sont pondus pouvait être importante. C’est pourquoi il est si important pour les biologistes de tout simplement observer l’organisme qu’ils étudient, son habitat, et d’y prêter vraiment attention. Je vois aujourd’hui beaucoup de jeunes biologistes qui veulent se précipiter, attraper le plus possible de spécimen de l’espèce qu’ils étudient, les examiner en laboratoire ou bien les broyer et faire de la génétique. C’est très bien, mais si vous ne passez pas de temps à observer votre espèce et son habitat, vous ne pouvez pas relier tous vos résultats de laboratoire à ce qui se passe réellement dans la nature.

Grâce à votre travail et à celui de vos collègues, nous savons désormais que les organismes vivants sont fortement affectés par le changement climatique et que de nombreuses espèces doivent modifier leur aire de répartition pour survivre. Mais nous savons également qu’il peut être difficile de prédire où elles pourront persister à l’avenir. Que faire donc pour les protéger ? Quelles terres préserver pour leur permettre de survivre ?
C. P. : C’est la grande question qui tourmente les biologistes spécialisés dans la conservation. Si vous allez à des réunions sur la biologie de la conservation, vous constaterez que beaucoup de gens tombent en dépression parce qu’ils ne savent pas quoi faire.

Nous devons en fait changer notre façon de concevoir la conservation et passer d’une protection stricte à quelque chose qui s’apparente davantage à un bon portefeuille d’assurance. Nous ne connaissons pas l’avenir, nous devons donc élaborer un plan très flexible, que nous pourrons adapter au fur et à mesure que nous observerons ce qui se passe sur le terrain.
En d’autres termes, on ne doit pas s’enfermer dans un seul plan, plutôt partir d’une série d’approches, car vous ne savez pas laquelle fonctionnera.
Nous venons de publier un article scientifique préconisant d’adapter pour la conservation des écosystèmes certaines approches décisionnelles qui existent depuis les années 1960 dans des domaines connus pour leur imprévisibilité, comme l’économie ou la politique urbaine de l’eau. C’est un domaine où l’on ne sait pas à l’avance si l’année suivante sera humide ou sèche. Les urbanistes ont donc mis au point des approches pour faire face à cette incertitude.
Avec les ordinateurs modernes, vous pouvez simuler 1 000 scénarios futurs et vous demander : si nous prenons cette mesure, que se passera-t-il ? Vous constatez alors que certains scénarios sont favorables, d’autres défavorables, et d’autres encore mitigés. À partir de là, il faut chercher un ensemble de mesures dites « robustes », c’est-à-dire qui donnent de bons résultats dans le plus grand nombre de scénarios futurs.
Pour la conservation des écosystèmes, nous avons commencé par utiliser des modèles bioclimatiques standards. Nous avions environ 700 scénarios pour 22 espèces. Il s’avère que si nous nous contentons de protéger les endroits où ces espèces sont présentes aujourd’hui, la plupart des organismes ne survivront pas. Seuls 1 % ou 2 % des scénarios prévoient la présence d’une espèce au même endroit qu’aujourd’hui.
Mais que se passerait-il si on protège l’endroit où elle se trouve actuellement, mais aussi les zones où elle devrait se trouver 30 % du temps, 50 % du temps, 70 % du temps… ? Vous avez comme cela divers seuils. Et, à partir de ces différentes possibilités futures, nous pouvons déterminer, par exemple, que si nous protégeons cet endroit et celui-là, nous pouvons couvrir 50 % des zones où les modèles prédisent que l’espèce persistera à l’avenir. En procédant ainsi, vous pouvez constater que certaines actions sont en fait assez solides, et qu’elles comprennent des combinaisons de conservation traditionnelle et de protection de nouvelles zones en dehors de celles où elles se trouvent actuellement. Protéger les zones actuelles est généralement une bonne chose, mais cela n’est souvent pas suffisant.
Il faut également garder à l’esprit que plus c’est grand, mieux c’est. Nous devons bien sûr continuer à protéger les écosystèmes, et plus les territoires protégés seront grands, mieux ce sera, en particulier dans les zones à forte biodiversité. Il faut continuer à protéger ces endroits, car des espèces vont les quitter, mais aussi d’autres s’y installer. Une zone à forte biodiversité pourrait comme cela finir par abriter un ensemble d’espèces complètement différent de celui qu’on connaît aujourd’hui, tout en restant un haut lieu de biodiversité, parce qu’elle compte par exemple de nombreuses montagnes et vallées et bénéficie d’une grande diversité de microclimats.
À l’échelle mondiale, nous devons disposer de 30 % à 50 % des terres et des océans comme habitat relativement naturel, sans nécessairement exiger une protection stricte.
Entre ces zones, nous avons également besoin de corridors pour permettre aux organismes de se déplacer sans être immédiatement tués. Prenez un ensemble de terres agricoles, des champs de blé par exemple, tout ce qui tente de les traverser risque de mourir. Il faut donc développer des habitats semi-naturels qui serpentent à travers ces zones. Si vous avez une rivière qui traverse ces champs, un très bon moyen d’y parvenir est simplement de créer une grande zone tampon de chaque côté de la rivière afin que les organismes puissent se déplacer. Il n’est pas nécessaire que ce soit un habitat parfait pour une espèce en particulier, il suffit simplement qu’il ne les tue pas.
Un autre point à souligner, et que le grand public ignore souvent, c’est que les jardins de particuliers peuvent aussi servir de corridors. Si vous avez un terrain de taille raisonnable, laissez une partie non tondue, avec des mauvaises herbes. Les orties et les ronces sont des corridors importants pour de nombreux animaux. Cela peut également être fait sur le bord des routes.
Certaines mesures incitatives pourraient encourager cela. Par exemple, accorder des allégements fiscaux aux personnes qui laissent certaines zones privées non développées. Il existe toutes sortes de façons d’aborder la question une fois que l’on a changé d’état d’esprit. Mais pour les scientifiques, donc, le changement important consiste à ne pas mettre tous ses œufs dans le même panier. On ne peut pas se contenter de protéger les sites actuels ni choisir un seul endroit où l’on pense qu’un organisme va se trouver parce que c’est ce que dit votre modèle préféré ou parce que votre collègue au bout du couloir utilise ce modèle.
On ne peut pas non plus sauver tous les sites où une espèce pourrait se trouver à l’avenir, car cela serait trop coûteux et irréalisable. Il faut plutôt constituer un portefeuille de sites à protéger aussi solide que possible, compte tenu des contraintes financières et des partenariats disponibles, afin de s’assurer que nous ne perdrons pas complètement cette espèce. Ainsi, lorsque nous aurons stabilisé le climat, elle disposera d’un habitat à recoloniser et sera saine et sauve.
Une autre question qui préoccupe beaucoup les acteurs de la protection de la biodiversité aujourd’hui est celle de l’hybridation. Comment appréhendez-vous ce phénomène, qui devient de plus en plus courant ?
C. P. : Aujourd’hui, les espèces se déplacent comme elles ne l’ont jamais fait depuis des milliers d’années. Au cours de leurs déplacements, elles se rencontrent désormais régulièrement. Les ours polaires, par exemple, sont contraints de quitter leur habitat en raison de la fonte de la banquise. Cela les oblige à côtoyer des ours bruns et des grizzlis, avec lesquels ils s’accouplent. Il arrive parfois que ces accouplements soient fertiles et donnent naissance à des hybrides.
Historiquement, les biologistes spécialisés dans la conservation ne voulaient pas d’hybridation, ils voulaient protéger les différences entre les espèces, leur comportement, leur apparence, leur régime alimentaire, leur génétique… Ils voulaient préserver cette diversité. De plus, les hybrides ne sont généralement pas aussi performants que les deux espèces d’origine, leur aptitude à survivre est plus réduite. Les gens ont donc essayé de séparer les espèces, et ont parfois été amenés à tuer les hybrides pour y parvenir.
Mais le changement climatique remet tout cela en question. Les espèces se rencontrent sans cesse, c’est donc une bataille perdue d’avance. Nous devons donc repenser notre approche de la biodiversité. Historiquement, préserver la biodiversité signifiait protéger toutes les espèces et toutes les variétés. Mais je pense que nous devons élargir notre réflexion : l’objectif devrait être à présent de préserver une grande variété de gènes.
Car lorsqu’une population présente une forte variation génétique, elle peut évoluer et s’adapter à un environnement qui change à une vitesse incroyable. Si nous luttons contre l’hybridation, nous risquons en fait de réduire cette capacité des espèces à évoluer avec le changement climatique. Pour maintenir une grande diversité post-changement climatique, si jamais ce jour arrive, nous devons conserver autant de gènes que possible, quelle que soit leur forme. Cela peut signifier la perte de ce que nous considérons comme une espèce unique, mais si ces gènes sont toujours présents, ils pourront évoluer assez rapidement, comme nous l’avons vu avec les ours polaires et les grizzlis.
Car au cours des périodes chaudes passées, ces espèces sont entrées en contact et se sont hybridées. Et si l’on regarde tous les fossiles que nous avons, nous perdons la trace des ours polaires pendant certaines périodes, ce qui suggère qu’ils étaient alors très peu nombreux. Mais lorsque le climat s’est refroidi, les ours polaires réapparaissent beaucoup plus rapidement que si leur espèce avait évolué à partir de rien. Ils ont probablement évolué à partir de gènes qui ont persisté chez les grizzlis. Nous avons des preuves que cela fonctionne et que c’est extrêmement important.
Il y a quelque chose qui reste difficile à appréhender pour les non-scientifiques. Nous avons quantité d’exemples remarquables d’adaptation et d’évolution dans la nature, avec, par exemple, des arbres qui modifient la composition chimique de leurs feuilles en réponse à la prédation de certains herbivores, ou bien des papillons qui changent de couleur en fonction de l’altitude et de la température… Mais en même temps, nous assistons à une perte massive de biodiversité à l’échelle mondiale. La biodiversité semble, d’un côté, pouvoir incroyablement bien s’adapter, de l’autre s’effondrer. Ces deux réalités peuvent sembler difficiles à concilier. Comment l’expliqueriez-vous à des profanes ?
C. P. : Cela s’explique en partie par le fait que le changement climatique actuel se produit très rapidement. Il faut également avoir en tête que chaque espèce a une niche physiologique assez fixe dans laquelle elle peut vivre. C’est ce que nous appelons un « espace climatique » [climate space, en anglais], un mélange particulier de précipitations, d’humidité et de sécheresse. Il peut exister certaines variations au sein de cet espace, mais lorsque l’on atteint ses limites, l’organisme meurt. Nous ne savons pas vraiment pourquoi cette limite est si stricte.
Lorsque les espèces sont confrontées à d’autres types de changements, tels que la pollution par le cuivre, la pollution lumineuse et sonore, beaucoup d’entre elles présentent certaines variations génétiques qui leur permettent de s’adapter. Cela ne signifie pas que ces changements ne les affectent pas, mais certaines espèces sont capables de s’adapter. Dans les environnements urbains actuels, par exemple, on observe des moineaux domestiques et des pigeons qui ont réussi à s’adapter.
Il y a donc certaines choses que font les humains face auxquelles certaines espèces peuvent s’adapter. Mais face au changement climatique, la plupart des organismes ne disposent pas des variations génétiques nécessaires pour survivre. La seule chose qui peut apporter de nouvelles variations pour s’adapter à un nouveau climat est soit l’hybridation, qui apporte de nouveaux gènes, soit la mutation, mais c’est un processus très lent. Il faudrait d’un à deux millions d’années pour que les espèces actuelles finissent par évoluer pour s’adapter au climat dans lequel nous entrons.
Si l’on remonte plusieurs centaines de milliers d’années en arrière, à l’époque des glaciations du Pléistocène, lorsque les températures mondiales variaient de 10 °C à 12 °C, on constate que les espèces se sont déplacées. Elles ne sont pas restées sur place pour évoluer.
Mais si l’on remonte encore plus loin, à l’Éocène, les changements étaient encore plus importants, avec des niveaux de CO2 extrêmement élevés, des températures extrêmement chaudes, et des espèces ont disparu. Comme elles ne pouvaient pas se déplacer suffisamment loin, elles se sont éteintes. Cela montre donc que l’évolution face au changement climatique n’est pas quelque chose que l’on peut attendre à l’échelle de quelques centaines d’années. Elle se situe plutôt à l’échelle de centaines de milliers, voire de quelques millions d’années.
Dans l’une de vos publications, vous écrivez : « Les populations qui semblent être très exposées au changement climatique peuvent néanmoins résister à l’extinction, ce qui justifie de continuer à les protéger, à réduire les autres facteurs de stress et à surveiller leurs capacités d’adaptation. » Pouvez-vous donner un exemple de cette réalité ?
C. P. : Bien sûr, je peux vous parler du damier d’Édith, car c’est ce que je connais le mieux. Le damier d’Édith compte plusieurs sous-espèces très distinctes qui sont génétiquement très différentes les unes des autres, avec des comportements et des plantes hôtes distinctes. Une sous-espèce du sud de la Californie a été isolée suffisamment longtemps des autres pour devenir un cas génétique assez particulier. C’est le damier de Quino.

Il s’agit d’une sous-espèce présente dans la partie sud de l’aire de répartition du damier, qui est très durement touchée par le changement climatique. Elle a déjà perdu une grande partie de ses populations en raison du réchauffement climatique et de la sécheresse. Sa minuscule plante hôte se dessèche trop rapidement. Elle a également beaucoup souffert de l’urbanisation : les étalements de San Diego et de Los Angeles ont détruit la majeure partie de son habitat. On pourrait donc se dire qu’il faut abandonner tout espoir, n’est-ce pas ?
Mon mari et moi étions impliqués dans la planification de l’habitat du damier de Quino au début des années 2000. À cette époque, environ 70 % de sa population avait disparu.
Nous avons alors fait valoir que le changement climatique allait les détruire si nous ne protégions que les zones où ils existaient actuellement, car il s’agissait de sites de faible altitude. Mais nous nous sommes dit : pourquoi ne pas protéger des sites, par exemple à plus haute altitude, où ils n’existent pas encore ?
Il existait des plantes hôtes potentielles à plus haute altitude. Il s’agissait d’espèces différentes qui avaient une apparence bien distincte des plantes habituelles, mais dans d’autres régions, des damiers d’Édith utilisaient des espèces similaires. Nous avons donc amené des papillons de basse altitude vers cette nouvelle plante hôte, et les papillons l’ont appréciée. Cela nous a montré qu’aucune évolution n’était nécessaire. Il suffisait que les damiers de Quino montent à cette altitude, et ils pourraient se nourrir de cette plante et survivre.
Il fallait donc protéger la zone où ils se trouvaient à ce moment-là, afin qu’ils puissent migrer, ainsi que ce nouvel habitat plus élevé.
C’est ce qui a été fait. Par chance, la zone la plus élevée appartenait au service forestier américain et à des communautés autochtones, et ces tribus étaient très heureuses de participer à ce plan de conservation.
Dans la zone d’origine, une mare vernale a également été restaurée. Les mares vernales sont de petites dépressions dans le sol dont le fond est argileux. Elles se remplissent d’eau en hiver et tout un écosystème s’y développe. Les plantes poussent à partir de graines qui se trouvaient dans la terre sèche et brûlée. On y trouve également des crevettes féeriques et toutes sortes de petits animaux aquatiques. La plante hôte du damier de Quino pousse au bord des mares vernales. Il s’agit d’un habitat très particulier qui s’assèche vers le mois d’avril. À cette période, le damier de Quino a terminé son cycle de vie et est désormais en dormance. Toutes les graines sont tombées et sont elles aussi en dormance. Le cycle recommence ensuite au mois de novembre suivant.

Malheureusement, San Diego a rasé toutes les mares printanières pour construire des maisons et des immeubles. Afin de protéger le damier de Quino, le service chargé de la protection des espèces menacées a donc restauré une mare vernale sur un petit terrain qui était jonché de déchets et de quads. Ils ont soigneusement creusé une dépression peu profonde, l’ont recouverte d’argile et ont planté de la végétation pour la rendre viable. Ils ont planté entre autres du Plantago erecta, dont se nourrit le damier de Quino.
En trois ans, cette zone restaurée abritait presque toutes les espèces menacées pour lesquelles elle avait été conçue. La plupart d’entre elles n’avaient même pas été introduites. Elles ont simplement colonisé cette nouvelle mare, y compris le damier de Quino.
Par la suite, certains damiers de Quino ont également été trouvés dans des habitats situés à plus haute altitude. Pour être honnête, j’ai été époustouflée. Nous ne savions pas que ce papillon serait capable d’aller en montagne. Je pensais que nous devrions ramasser les œufs et les déplacer. Les distances ne sont pas grandes, quelques kilomètres ou 200 mètres de dénivelé, mais n’oubliez pas que ce papillon ne se déplace généralement pas beaucoup : il reste principalement là où il est né.
Y avait-il un corridor biologique entre ces deux zones ?
C. P. : Il y avait quelques maisons, mais elles étaient très clairsemées, avec beaucoup de broussailles naturelles entre elles. Il n’y avait pas vraiment de plantes hôtes pour les damiers de Quino. Mais cela leur a quand même permis de voler, de trouver en chemin des plantes sauvages à nectar et de ne pas être tués. C’est le plus important. Un corridor n’a pas besoin de soutenir une population. Il suffit qu’il ne la tue pas.
Vous aussi vous avez dû déménager au cours de votre carrière afin de poursuivre vos recherches en écologie sans être affectée par le climat politique. Au cours de l’année écoulée, en France, vous avez été invitée à vous exprimer à plusieurs reprises sur ce sujet et avez fait l’objet de nombreux articles vous décrivant comme une réfugiée scientifique. Aux États-Unis, ce parcours suscite-t-il également la curiosité et l’intérêt des médias ?
C. P. : Beaucoup de collègues, mais aussi des personnes que je connais mais avec lesquelles je n’ai pas nécessairement collaboré, m’ont demandé : « Comment as-tu fait cela ? Est-ce difficile d’obtenir un visa ? Les gens parlent-ils anglais en France ? »
Mais ce qui est intéressant, c’est que les médias américains ne s’y sont pas intéressés. L’attention médiatique est entièrement provenue de l’extérieur des États-Unis – du Canada et d’Europe.
Je ne pense pas que les Américains comprennent l’ampleur des dégâts actuels causés au monde universitaire, à l’éducation et à la recherche. Même ma propre famille ne réalise pas trop cela. C’est difficile de leur expliquer, car plusieurs d’entre eux sont des partisans de Trump, mais on pourrait penser qu’au moins les médias en parleraient.
La plupart des médias ont publié des articles sur les dommages causés à la structure universitaire et à l’éducation, par exemple l’interdiction de certains livres ou la tentative de mettre en place un système éducatif qui n’enseigne que ce que J. D. Vance [le vice-président des États-Unis] veut que les gens apprennent. Mais ces articles ne parlent pas beaucoup des personnes qui partent. Je pense que les Américains peuvent parfois être très arrogants. Ils partent du principe que les États-Unis sont le meilleur pays au monde et que personne ne quitterait les États-Unis pour aller travailler ailleurs.
Et c’est vrai que les [chercheurs aux] États-Unis ont traditionnellement bénéficié d’opportunités incroyables, avec des financements très importants provenant de toutes sortes de sources : des nombreuses agences gouvernementales, finançant divers projets, mais aussi des donateurs privés, des ONG… Tout cela s’est littéralement arrêté net.
Afin d’intéresser les gens à la conservation de la biodiversité et de sortir certains de leur déni, il peut être tentant de mettre en avant certains sujets, tels que l’impact du changement climatique sur la santé humaine. C’est un sujet sur lequel vous avez déjà travaillé. Est-ce qu’il trouve davantage d’écho ?
C. P. : J’ai toujours été intéressée par la santé humaine. Au départ, je voulais faire de la recherche médicale puis j’ai changé d’avis. Mais dès que j’ai commencé à publier les résultats que nous obtenions sur l’ampleur des mouvements des espèces, la première chose qui m’est venue à l’esprit a été : « Les maladies vont, elles aussi, se déplacer. » Le travail de mon laboratoire sur la santé humaine se concentre donc sur la façon dont le changement climatique affecte la propagation des maladies, de leurs vecteurs et de leurs réservoirs. L’une de mes étudiantes a ainsi documenté la propagation de la leishmaniose au Texas, qui s’est déplacée vers le nord en raison du changement climatique.
Au sein du Giec, nous avons également mis en avant que le paludisme, la dengue et trois autres maladies tropicales ont fait leur apparition au Népal, où elles n’avaient jamais été observées auparavant, du moins d’après les archives historiques. Cela est lié au changement climatique, et non aux changements agricoles.
De nouvelles maladies apparaissent également dans le Grand Nord. Mais peu de gens vivent dans cette région. Ce sont surtout des communautés inuites qui sont touchées, ce qui explique pourquoi les politiciens minimisent le problème. En Europe, le moustique tigre se propage en France et apporte avec lui ses maladies.
La leishmaniose est également déjà présente en France. Il n’y a qu’une seule espèce à ce jour, mais les prévisions suggèrent que quatre ou cinq autres espèces pourraient arriver très prochainement. Les maladies transmises par les tiques sont également en augmentation et se propagent vers le nord de l’Europe. Nous constatons donc déjà les effets du changement climatique sur la santé humaine en Europe. Les gens n’en ont tout simplement pas conscience.
Vous avez mentionné votre famille, qui compte des partisans de Trump. Pouvez-vous parler de votre travail avec eux ?
C. P. : Dans ma famille, la seule option envisageable est de ne pas en parler, et sur ça, tout le monde s’accorde. C’est comme ça depuis longtemps pour la politique, et même pour la religion. Nous nous aimons tous, nous voulons nous entendre. Nous ne voulons pas de divisions. Nous avons donc grandi en sachant qu’il y a certains sujets dont on ne parle pas. Parfois, le changement climatique est abordé, cela devient tout de suite difficile, et cela nous rappelle alors pourquoi nous n’en parlons pas. Il n’a donc pas été possible d’avoir une conversation ouverte à ce sujet. J’en suis désolée, mais je ne veux pas perdre ma famille. Je ne vais donc pas non plus essayer de les convaincre. Si un jour cependant, ils veulent un jour en savoir plus, ils savent où me trouver.
Mais j’ai également travaillé avec des personnes qui ont des convictions très différentes des miennes. Lorsque j’étais encore au Texas, j’ai travaillé avec l’Association évangélique nationale. Nous nous accordions sur la nécessité de préserver la biodiversité. Ils la considèrent comme la création de Dieu, je pense simplement que l’humain n’a pas à détruire la Terre et je suis athée, mais cela n’a pas posé de problème. Nous avons donc réalisé ensemble une série de vidéos dans lesquelles j’expliquais les effets du réchauffement climatique. Le résultat était formidable.
Propos recueillis par Gabrielle Maréchaux.
Cet article est publié dans le cadre des 20 ans de l’Agence nationale de la recherche(ANR). Camille Parmesan est lauréate du programme prioritaire de recherche (PPR) « Make Our Planet Great Again » opéré par l'ANR pour le compte de l’État au titre de France 2030. L'ANR, qui a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, est aussi le principal opérateur du plan France 2030 dans le domaine de l’enseignement supérieur et de la recherche.
Camille Parmesan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:27
Une motion de « censure constructive » aiderait-elle à sortir de l’impasse politique ?
Pierre Bréchon, Professeur émérite de science politique, Sciences Po Grenoble, Auteurs historiques The Conversation France
Texte intégral (1952 mots)
En Allemagne et en Espagne, les oppositions souhaitant censurer un gouvernement doivent se mettre d’accord sur une majorité de rechange : on parle de « censure constructive ». Cette option pourrait-elle aider la France à dépasser la situation de paralysie politique actuelle ?
En France, sous la Ve République, la procédure de la motion de censure a été utilisée plus de 150 fois pour essayer de renverser un gouvernement (article 49.2) ou pour faire adopter une loi sans vote (article 49.3). Mais très peu ont été couronnées de succès. Avant 2024, une seule motion avait été adoptée en 1962 sous le gouvernement de Georges Pompidou. Ce caractère unique de motion victorieuse de 1962 à 2024 est largement dû à l’existence de majorités confortables. Mais depuis 2022 et surtout 2024, avec l’absence de majorité absolue ou même relative, dans le contexte d’une tripartition du système partisan, les chances de réussite sont beaucoup plus grandes.
Michel Barnier en a fait les frais fin 2024 et François Bayrou est aussi tombé en septembre 2025, en demandant la confiance de l’Assemblée nationale (art. 49.1), alors que celle-ci se préparait à le censurer. Dans les deux derniers cas, la censure a été adoptée grâce aux voix des groupes parlementaires de gauche et de droite radicale qui sont trop différents pour pouvoir constituer un gouvernement alternatif.
À défaut de majorité de remplacement, le président peut certes dissoudre en espérant que de nouvelles élections permettent de retrouver une majorité, mais cela semble très peu probable dans notre contexte de forte division des forces politiques et de tripartition du système partisan, à moins que l’élection ne permette de porter au pouvoir une majorité issue du Rassemblement national et de ses alliés. Les situations de blocage et de gouvernements minoritaires risquent donc de devenir plus fréquents.
Comment éviter les blocages à répétition ?
D’autres pays limitent les possibilités de censure en imposant aux partisans de cette dernière de s’être mis d’accord au préalable sur une majorité de rechange, ce qu’on appelle souvent une « censure constructive », formule censée être plus responsable, pour qu’on ne puisse pas renverser le gouvernement sans solution alternative. Seuls quelques pays ont adopté ce type de mesure dans l’Union européenne : l’Allemagne, l’Espagne, la Belgique, la Pologne, la Slovénie, la Hongrie. Il existe aussi parfois au niveau régional ou local. Il existe aussi dans quelques pays hors d’Europe (Arménie, Népal, Tunisie, Lesotho, Fidji, Israël).
En France, cette censure dite constructive existe pour certains territoires ultra-marins (Martinique, Saint-Barthélemy, Saint-Martin, Saint-Pierre-et-Miquelon, Polynésie française) et pour l’Assemblée de Corse. Sur l’Île de beauté, la censure dite constructive existe depuis 2018 (elle a été introduite avec le nouveau statut d’autonomie de la collectivité). Sur le modèle qui fonctionne ailleurs, elle prévoit la possibilité de voter une motion de défiance à l’égard de l’exécutif à la condition qu’une liste du nouvel exécutif soit présentée. Le législateur semble avoir craint une instabilité institutionnelle conduisant à davantage encadrer son fonctionnement que celui de l’Assemblée nationale.
Mais c’est en Allemagne et en Espagne que des motions de censure constructive ont été adoptées depuis le plus longtemps. Que nous enseignent ces pratiques ?
En Allemagne, une culture de responsabilité politique
L’Allemagne avait connu une forte instabilité gouvernementale sous la République de Weimar (1918-1933). Des gouvernements étaient renversés facilement par l’alliance entre les communistes et les nazis. Pour éviter ces renversements par des partis incapables de gouverner ensemble, la loi fondamentale de 1949 stipule que :
« Le Bundestag ne peut exprimer sa défiance envers le chancelier fédéral qu’en élisant un successeur à la majorité de ses membres. » (Article 67)
La défiance doit être proposée par un quart des députés et adoptée à la majorité absolue. La défiance n’est entérinée qu’après un vote à la majorité absolue sur un nouveau chancelier. Il n’y a donc pas de période où le gouvernement sortant ne peut qu’« expédier les affaires courantes », c’est-à-dire assurer le suivi de décisions déjà prises, sans pouvoir innover.
Au plan fédéral, cette procédure de censure constructive n’a été utilisée que deux fois dans l’histoire en Allemagne. La première fut en 1972, lorsque le groupe CDU-CSU a proposé qu’un de ses membres (Rainer Barzel) remplace le chancelier Willy Brandt (SPD). Les chrétiens-démocrates critiquaient particulièrement la politique du gouvernement à l’est de l’Europe. Il a manqué seulement deux voix pour que la censure soit acceptée et que la CDU vienne au pouvoir. Mais le chancelier maintenu, ayant perdu sa majorité absolue, demande la convocation d’élections législatives anticipées qui vont confirmer la légitimité des socialistes alliés aux libéro-centristes du FDP.
Une motion de censure constructive a été mise en œuvre une deuxième et dernière fois en 1982. Helmut Schmitt (SPD) est censuré et remplacé par Helmut Kohl (CDU) au terme d’un débat tendu au Bundestag. Le SPD a fait les frais d’un abandon de la coalition par une large partie des libéraux du FDP qui rejoignent le nouveau gouvernement.
Cette procédure parlementaire a suscité du mécontentement, beaucoup estimant que le chancelier devait être désigné par le peuple au terme d’une élection législative. Celui-ci va d’ailleurs demander au Bundestag de voter sa dissolution pour être confirmé dans les urnes. Il le sera largement en mars 1983.
En Espagne, une culture politique conflictuelle
Depuis la Constitution de 1978, après la mort du général Franco, une procédure de censure constructive a été actée sur le même modèle qu’en Allemagne. Deux tentatives d’utilisation ont échoué en 1980 et en 1987, mais celle de 2018 a été couronnée de succès, permettant de remplacer le gouvernement Rajoy (Parti populaire, PP, droite espagnole) par Pedro Sanchez, leader de la gauche socialiste (PSOE).
En 2017, une motion de censure avait déjà été déposée par Podemos (gauche radicale) contre Mariano Raroy, conservateur au pouvoir depuis 2011, et en 2023 cette procédure a aussi été utilisée par le mouvement d’extrême droite Vox. Dans les deux cas, les motions n’avaient aucune chance de passer, car elles n’étaient quasiment soutenues que par leurs initiateurs (82 voix pour la motion de Podemos et 53 pour celle de Vox). Elles visaient surtout à médiatiser leur opposition au gouvernement en place.
L’exemple espagnol montre que la censure constructive ne permet pas toujours de trouver un gouvernement disposant d’une majorité solide. Le gouvernement de Pedro Sanchez n’a pas été renversé, mais il a aujourd’hui beaucoup de difficultés à faire adopter les lois de sa coalition, tout particulièrement les budgets. Le pays fonctionne toujours avec le budget de 2023, ce qui empêche les ajustements, notamment pour des investissements novateurs.
La Belgique partage avec l’Espagne une tradition politique conflictuelle et l’existence d’une motion constructive, appelée « motion de méfiance ». Celle-ci n’a jamais été mise en œuvre au niveau fédéral et n’a pas empêché la vacance du pouvoir pour des périodes extrêmement longues (541 jours entre 2010 et 2011, 652 jours entre fin 2018 et octobre 2020), car aucune coalition suffisamment large n’arrivait à émerger.
Faut-il adopter une procédure de censure constructive en France ?
La procédure de censure constructive présente des avantages :
Elle limite le succès des motions de censure en empêchant le renversement d’un gouvernement sans qu’existe une solution de rechange. Elle favorise donc la stabilité du pouvoir, même s’il doit fonctionner en « mode dégradé », du fait d’une absence de majorité parlementaire.
Elle devrait inciter les députés des oppositions à négocier des compromis pour trouver des formules de gouvernement larges et novatrices.
Elle évite les périodes de vacance du pouvoir, puisqu’un gouvernement ne peut être démissionné que lorsqu’un autre est choisi.
Mais elle n’évite pas toujours les situations de blocage. Car il n’y a pas toujours une situation de rechange possible, même après de nouvelles élections.
Cette procédure est moins adaptée à la culture politique française qu’à celle de l’Allemagne. Notre crainte des compromissions avec des acteurs politiques qui ont pourtant des orientations assez proches rendrait sa mise en œuvre difficile mais pas indépassable à l’avenir.
De plus, sa constitutionnalité pourrait être problématique dans un système semi-présidentiel comme le nôtre, où le choix du premier ministre est une prérogative du président. On a d’ailleurs vu, depuis 2024, la grande détermination d’Emmanuel Macron à ne pas abandonner ce pouvoir régalien, alors que le macronisme est minoritaire à l’Assemblée nationale et de plus en plus divisé en son sein.
La motion constructive n’est donc pas une solution miracle : si elle est instaurée, elle devrait l’être dans le cadre d’une modification substantielle de la Constitution pour rendre notre régime semi-présidentiel plus parlementaire, et donc réduire la domination présidentielle sur l’ensemble de notre système politique.
Pierre Bréchon ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:26
Trains de nuit : une relance peut cacher une pause
Guillaume Carrouet, Maître de conférences en Géographie, Université de Perpignan Via Domitia
Texte intégral (1396 mots)
Alors que le train connaît un engouement depuis la fin du Covid-19, les difficultés pèsent sur certains segments du secteur ferroviaire, comme le train de nuit. Le (re)déploiement de ce service populaire et bas carbone est contraint par une pluralité de facteurs.
Que ce soit à l’international ou à l’échelle de la France, la relance du train de nuit se fait attendre au regard de ce qu’annonçait le gouvernement au sortir de la crise du Covid-19. Si le contexte semble favorable avec près de 114 milliards de voyageurs-kilomètre, une hausse de 6 % par rapport à 2023 et de 14 % par rapport à 2019, l’un des parents pauvres du secteur ferroviaire de voyageurs semble être le train de nuit.
Alors que le rapport additionnel à la loi d’orientation des mobilités (LOM) prévoyait une colonne vertébrale, avec un réseau structurant composé d’une dizaine de lignes, la situation à la fin de 2025 n’est pourtant pas flamboyante. En France hexagonale, la ligne Paris-Aurillac, ouverte en 2023, est la dernière en date d’un plan de relance ligne par ligne (Paris-Tarbes-Lourdes, Paris-Nice), lancé il y a quelques années par l’État.
À lire aussi : Le retour des trains de nuit se fait-il sur de bons rails ?
Le bilan de la relance des dessertes de nuit en Europe est plus négatif, du moins vu depuis la France. Si l’Autriche, par l’intermédiaire de son champion ÖBB, est le fer de lance des lignes européennes depuis quelques années déjà, les liaisons internationales au départ ou à destination de la France peinent à être relancées. Quand elles ne disparaissent pas purement et simplement.
Un exemple du renouveau des lignes internationales
Le cas récent des lignes Paris-Berlin et Paris-Vienne, mises en place en décembre 2023 et qui seront arrêtées le 14 décembre prochain, est particulièrement éclairant sur les contraintes fortes qui viennent contrarier la relance du train de nuit à l’échelle européenne. Cette réouverture était pourtant présentée comme l’exemple du renouveau des lignes internationales de nuit, notamment à la suite de l’arrêt en 2021 d’une autre ligne, Paris-Milan-Venise, opérée par Thello, une entreprise née de l’entente entre Veolia et Trenitalia.
La ligne s’insèrerait pourtant très bien dans les objectifs européens de réduction des émissions de gaz à effet de serre, en sachant que le secteur des transports est le premier émetteur de CO2 en France. Le déploiement de l’usage du train, et du train de nuit en particulier, répond aux objectifs du Green Deal européen annoncé en 2019 avec l’objectif d’une neutralité carbone pour toute l’économie à l’horizon 2050. Pourtant, seulement deux années plus tard, l’ensemble des partenaires du projet (ÖBB, Deutsche Bahn et SNCF) ont annoncé la fin du service, avec pour principale raison, l’arrêt en France de la subvention de l’État.
Pas de compensation au retrait français
À l’origine, la participation de l’État était conditionnée à la mise en place d’une desserte quotidienne entre l’ensemble des villes avec un train comptant 12 wagons, avec séparation en deux : six voitures pour Berlin et six pour Vienne. Face au constat de la mise en service de seulement trois allers-retours par semaine, la France a décidé de suspendre sa participation, ce qui a mécaniquement condamné la ligne, dans un contexte où les autres partenaires ne souhaitent pas compenser ce retrait.
Tout n’est pourtant pas perdu pour les lignes internationales de nuit puisque, devant cet échec, l’entreprise belgo-néerlandaise European sleeper constituée sous forme de coopérative a souhaité reprendre la ligne pour une ouverture prévue le 26 mars 2026. Détail non négligeable, l’opérateur, déjà présent sur le segment Bruxelles-Prague, ne bénéficierait pas de subventions publiques pour le fonctionnement de la desserte.
Les difficultés d’une relance
À l’image du cas des lignes intérieures en France, cet exemple international souligne toutes les difficultés de relance d’un mode de transport alors qu’il répond à des enjeux de décarbonation du secteur. Cette expérience met en évidence le faisceau de contraintes qui pèsent sur le train de nuit. Elles ne se réduisent pas uniquement au caractère internationale de ce type de ligne, comme les changements de locomotives ou encore la planification des horaires pour plusieurs pays.
En effet, si le taux de remplissage de la ligne était jugé correct (près de 70 %), ce service et, plus généralement, l’ensemble des trains de nuit sont contraints par un déficit d’investissement dans le matériel roulant.
En France, l’État a financé dans le cadre du plan national de relance, une rénovation du matériel, en particulier pour les trains de nuit, qui aujourd’hui a plus de 45 ans. Certaines compagnies, n’ayant pas le matériel en propre, se tournent vers la location notamment dans le cas des Rosco (Rolling Stock Company). Dans ce schéma, des entreprises achètent le matériel roulant et le louent aux compagnies. L’intérêt est de ne pas supporter des coûts d’investissement très importants avec une maintenance intégrée. Néanmoins, le bilan financier est moins intéressant sur l’ensemble de la durée de location.
À ces contraintes matérielles s’ajoutent le pan financier inhérent au fonctionnement des lignes de nuit (équipage, contrôleur) et l’impossibilité de faire plusieurs rotations compte tenu de la longueur des parcours, comparativement à des TER, TGV et même par rapport à l'aérien. Ajoutons le coût du péage et l’utilisation du réseau la nuit qui coïncide avec les phases de travaux. Ces derniers ont eu un impact non négligeable sur les problèmes de ponctualité du Paris-Berlin et du Paris-Vienne.
Concurrence interne
Last but not least, le train de nuit souffre de la concurrence, y compris dans son propre segment. À titre d’exemple, on peut rappeler l’ouverture d’une liaison à grande vitesse en ICE (InterCity Express) Paris-Berlin direct, depuis décembre 2024, portée par un partenariat entre les opérateurs SNCF et Deutsche Bahn. Le trajet en ICE, c’est-à-dire à grande vitesse, s’effectue en huit heures avec la desserte de quelques villes intermédiaires comme Strasbourg ou Karlsruhe.
Le train de nuit s’inscrit depuis plusieurs années dans un contexte de fortes incertitudes sur la pérennité de l’offre, du moins dans le cas de la France. Il semble en effet que la SNCF, par ses réticences, souffle le chaud et le froid. Simultanément, aucun opérateur ne semble être à l’heure actuelle en mesure de développer une offre propre, comme en témoigne l’expérience ratée de Midnight Trains pour des questions principalement financières.
Guillaume Carrouet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:26
Face à la guerre économique, l’urgence d’une « Pax Europaea »
Dominique Steiler, Fondateur de la Chaire UNESCO pour une Culture de Paix Economique, Auteurs historiques The Conversation France
Texte intégral (2785 mots)

Alors que le modèle économique libéral montre ses limites et que les crises géopolitiques se multiplient, la « culture de paix économique », dont l’Union européenne pourrait être un vecteur clé, apparaît comme un concept susceptible d’offrir une vraie voie d’avenir.
Au cours des dernières décennies, le modèle économique libéral – qui promeut la libre concurrence, la mondialisation des échanges et la recherche de la croissance à tout prix – a dominé la scène internationale. Cependant, cette dynamique s’essouffle aujourd’hui, face à une montée sans précédent des inégalités, des conflits, des défis climatiques et sociaux.
En 2025, les tensions géopolitiques et économiques s’aggravent, sur fond de fragmentation de l’économie planétaire et d’une guerre économique qui avance à visage découvert.
Repenser les fondements de l’économie apparaît maintenant incontournable, pour inscrire la culture de paix économique au cœur des stratégies, des institutions politiques, économiques et éducatives. La survie de l’Europe est en jeu.
Les limites du modèle économique libéral
Le libéralisme économique repose sur l’idée que la libre concurrence et l’interaction des marchés conduisent naturellement à une allocation optimale des ressources, favorisant la croissance et le bien-être général.
Adam Smith, David Ricardo, puis les marginalistes ont alimenté le mythe d’une « main invisible » permettant à la somme des intérêts privés de produire harmonie sociale et progrès collectif. Cette croyance guide la majeure partie des politiques internationales depuis la fin du XXe siècle.
Cependant, cette théorie, souvent idéalisée, montre de nombreuses limites concrètes, largement illustrées par les crises économiques, écologiques et sociales récentes.
En premier lieu, la mondialisation libérale a creusé les écarts entre pays riches et pays pauvres, mais aussi entre les classes sociales à l’intérieur des États.
La précarisation et la fragmentation du marché du travail, l’accroissement de la concentration des richesses et de la puissance économique aux mains d’une minorité ainsi que les failles dans la protection sociale fragilisent la cohésion collective.
L’ignorance persistante des rapports de pouvoir et des dynamiques de domination a façonné le paysage économique en un terrain de conflit, où la violence structurelle (concurrence exacerbée, exploitation, division sociale) est devenue la norme qui nous a menés au bord du chaos.
Parallèlement, la constante recherche de croissance matérielle inflige des dommages sévères à l’environnement. Le modèle fondé sur la consommation exponentielle des ressources naturelles entre en contradiction flagrante avec les limites écologiques planétaires. La dégradation climatique accélérée entraîne insécurité alimentaire, déplacements massifs de populations et intensification des conflits autour des ressources, comme au Sahel, au Moyen-Orient, mais aussi en Ukraine, dont les ressources en lithium sont fortement convoitées.
Par ailleurs, la fragmentation croissante des politiques économiques des États, entre nationalismes économiques et protectionnisme, mine les fondations de la coopération internationale. La multiplicité des sanctions, des représailles commerciales et des guerres tarifaires accentue les risques d’instabilité politique et économique, posant la question d’un épuisement du modèle libéral mondialisé. Il en est ainsi des jeux politiques sur les droits de douane imposés par Donald Trump ou encore des restrictions à la circulation de la main-d’œuvre demandées dans certains pays d’Europe.
Loin d’une simple réfutation idéologique, ces critiques s’appuient sur des données empiriques rigoureuses et une analyse fine des mécanismes de pouvoir économique. Elles soulignent que le libéralisme, dans sa version actuelle, ne parvient plus à incarner un modèle de progrès partagé et durable. Le modèle se trouve en crise, face à une complexité mondiale croissante, ponctuée par la pandémie de Covid-19, les tensions en Ukraine, les crises sociales internes dans de nombreux pays et les urgences climatiques.
Les travaux précurseurs d’Henri Lambert (1921) et d’Henri Hauser (1935), et plus récemment notre ouvrage Osons la paix économique (2017) avaient prédit cette impasse : les racines économiques des conflits dépassent les motifs politiques superficiels, et une organisation sociale centrée sur le financier ne peut mener qu’à la catastrophe, que ce soit sous la forme d’une guerre ou d’une révolution.
C’est la loi du plus fort, et le mimétisme des grandes puissances ne laisse à l’Europe, fracturée et passive, que le risque d’être dépecée ou marginalisée.
Quelle paix à l’heure de la remilitarisation en Europe ?
Le contexte géopolitique rend la question plus brûlante encore.
L’actuel président des États-Unis Donald Trump navigue de crise en crise, tout en accentuant l’imprévisibilité et la polarisation. Sur le continent, la guerre en Ukraine, la montée des populismes, l’explosion des dépenses militaires et le discours des chefs d’état-major font de l’engagement armé une perspective quasiment banalisée.
Andrius Kubilius, le commissaire européen à la défense, appelle à réinventer la Pax Europaea, tout en affirmant la nécessité pour l’Union européenne de se préparer à la guerre sous toutes ses formes. Son ambition : refonder la souveraineté stratégique par une capacité industrielle et une résilience, alors que le spectre du retrait américain plane sur l’Europe.
De la culture de paix économique
Dans ce contexte, depuis presque deux décennies, la culture de paix économique s’impose comme une réponse globale et innovante, visant à réconcilier économie, société et environnement.
Forgée depuis 2008 par les chercheurs de la chaire Unesco pour une Culture de paix économique, cette notion s’est développée à partir de la contribution d’entreprises et d’expériences de terrain.
La culture de paix économique propose de sortir du cadre guerrier et compétitif du libéralisme, pour repenser l’économie comme espace de coopération, d’émancipation et d’inclusion. La paix économique ne se limite pas à l’absence de guerre ; elle englobe un ensemble de conditions permettant de construire un ordre économique apaisé, juste, démocratique et soutenable. Elle repose sur une anthropologie de l’interdépendance, un rejet de la violence structurelle (compétition, exploitation, exclusion) et une valorisation des liens et du bien commun. Elle exige une transformation des entreprises, mais aussi des institutions – pour développer des pratiques qui réduisent la violence, favorisent l’épanouissement et intègrent la responsabilité écologique, sociale et humaine.
Cette approche prend en compte les dommages induits par la guerre économique larvée, la violence structurelle, la corruption et les inégalités, en mettant l’accent sur la transformation des comportements, la prévention des conflits et la promotion de valeurs communes de responsabilité et de solidarité. Son ontologie se veut simple : la vie est interconnexion et l’économie a pour but de faire vivre ces relations, non pas de les détruire.
Les initiatives internationales récentes, comme le Pacte mondial des Nations unies, l’Agenda 2030 qui inclut l’Objectif de développement durable 16 sur la paix, la justice et des institutions solides, reconnaissent le rôle crucial des entreprises privées dans cet effort.
Les entreprises sont ainsi invitées à dépasser une simple logique de maximisation du profit pour devenir des actrices de cohésion sociale, de respect des droits humains, d’innovation sociale et de protection de l’environnement.
La culture de la paix économique exige une transformation profonde des mentalités et des pratiques managériales, qui doivent intégrer le souci du bien commun, la promotion de la diversité et de l’inclusion, la santé, le bonheur ainsi qu’une gouvernance éthique renforcée. Mais, pour ce faire, nous devrons accepter une mutation globale de l’éducation des plus jeunes aux futurs leaders, donc sur un temps long… que nous n’avons peut-être pas !
« Pax Economica » et « Pax Europaea »
Si ce changement de paradigme porte une utopie, c’est au sens énoncé par André Gorz :
« À ceux qui rejettent cela comme une utopie, je dis que l’utopie […] a pour fonction de nous donner, par rapport à l’état des choses existant, le recul qui nous permet de juger ce que nous faisons à la lumière de ce que nous pourrions ou devrions faire. »
Ce qui semblait utopique hier est devenu l’évidence historique : la démocratie, l’abolition de l’esclavage, la protection sociale. Toutes furent d’abord jugées irréalistes, avant de transformer durablement nos sociétés. La paix économique s’inscrit dans cette même dynamique : une évolution concrète, progressive et pragmatique de nos pratiques – pas un rêve, mais une trajectoire à décider.
Pour cette évolution, l’Union européenne (UE) dispose d’atouts et de responsabilités majeures. En tant que zone économique intégrée, pionnière dans les politiques de régulation sociale et environnementale, l’UE peut incarner une alternative crédible au système libéral mondial fragmenté et conflictuel.
Consciente des fragilités socio-économiques internes et des tensions géopolitiques environnantes, l’Europe doit renforcer son modèle économique en y intégrant les principes de la culture de paix économique. Cela passe par des politiques publiques favorisant l’équité, la transition écologique, la formation orientée vers la paix et la coopération, mais aussi par une diplomatie économique tournée vers la coopération durable et la prévention des conflits.
La construction de la Pax Europaea s’appuie aussi sur le développement des territoires de paix économique. Dans ces endroits, on expérimentera des pratiques économiques inclusives, durables, et des modèles d’entreprise responsables, à l’image des appels de la chaire Unesco pour une culture de paix économique.
Cinq étapes
Ce changement de paradigme devient une nécessité, si ce n’est une urgence, si l’Europe veut éviter le chaos et échapper à la prédation des grandes puissances. Les dirigeants économiques et politiques ont un rôle d’avant-garde courageux à jouer pour impulser ces transformations. Cinq étapes leur sont proposées comme feuille de route pragmatique.
1. Reconstruire la confiance entre économie et société. Redéfinir la mission de l’entreprise ou de l’institution s’avère nécessaire, en inscrivant son activité dans la contribution au bien commun, en dépassant la recherche exclusive du profit. Ce dernier ne constitue plus l’objectif, mais devient la contrainte nécessaire à la pérennité et aux investissements vers la vie commune heureuse. Cela implique la valorisation de la responsabilité sociale et environnementale (RSE), le respect et la contribution à l’épanouissement de toutes les parties prenantes et la mise en place d’indicateurs intégrant la performance globale.
2. Éduquer les enfants à la culture de paix pour qu’ils puissent pleinement vivre comme des enfants et avoir la possibilité de devenir des adultes et des acteurs responsables, peu importe leur lieu d’implication future dans le tissu économique.
3. Former des managers et leaders d’aujourd’hui et de demain capables d’intégrer les valeurs de la paix économique, au sein d’une éducation globale et d’une transformation culturelle profonde. Leur transmettre toutes les compétences personnelles, sociales et techniques facilitant la confrontation à un monde économique en tension pour avancer de manière pacifiée et productive. Qui veut la paix prépare la paix !
4. Instaurer une culture de paix économique dans les organisations, réinventer des modèles de gouvernance et des modèles d’affaires capables de promouvoir la collaboration et la paix entre l’ensemble des parties prenantes. Développer un climat organisationnel fondé sur le dialogue, la reconnaissance, la coopération et le respect de la diversité est un levier puissant. Cela favorise l’engagement des collaborateurs, la gestion pacifique des conflits, et le développement durable des organisations.
5. Piloter une transition des institutions, non seulement vers plus d’efficacité et de transparence (ODD 16), mais surtout vers une architecture qui empêche la répétition des crises et la violence endémique. Agir activement contre les violences et les corruptions internes et externes. Les entreprises doivent veiller à ne pas financer indirectement des conflits, à lutter contre la corruption dans l’ensemble de la chaîne de valeur, et à soutenir les institutions publiques dans les pays où elles sont implantées. Cette posture exige transparence, formation et adoption de pratiques responsables exemplaires.
Transformation par l’engagement collectif
L’heure est à la responsabilité collective et à la volonté politique. Le modèle libéral, fragilisé par ses contradictions internes et les crises mondiales, ne peut plus répondre seul à la complexité contemporaine. La culture de paix économique offre un projet de transformation systémique, allant de la réinvention du rôle de l’entreprise à la construction d’un ordre international apaisé.
Les dirigeants éclairés, les entreprises responsables, les citoyens engagés, les institutions publiques doivent relever un défi historique : construire un monde économique humain, durable et pacifique pour dessiner le socle d’une Pax Europaea. C’est un défi à la mesure des enjeux du XXIe siècle, un choix de civilisation tournée vers le dialogue, l’éducation et la coexistence
– contre la domination, la compétition aveugle et la fragmentation européenne.
Dominique Steiler ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:25
Roger Caillois, ses pierres et son écriture : de nouvelles découvertes mises en scène
Francois Farges, professeur en minéralogie, gemmologie, histoire des sciences minéralogiques et objets d'arts, Muséum national d’histoire naturelle (MNHN)
Texte intégral (2836 mots)

Le grammairien, essayiste, critique, sociologue et poète français Roger Caillois (1913-1978) est l’écrivain contemporain qui a le plus magnifiquement écrit sur les pierres, mais il demeure méconnu. L’exposition « Rêveries de pierres » à l’École des arts joailliers (Paris) permet de revenir sur sa passion, qui donna naissance à une écriture d’une poésie rare.
Entre 2017 et 2023, deux grands événements ont bouleversé la perception de l’univers géopoétique de Roger Caillois : l’acquisition du noyau de sa collection de pierres en 2017 et la découverte de manuscrits inédits en 2023. Ces découvertes font l’objet d’une exposition « Rêveries de pierres », d’une publication inédite (Pierres anagogiques) et d’une anthologie (Chuchotements & Enchantements).

Caillois, le rêveur de pierres
Selon sa biographe Odile Felgine, cet ancien adepte du surréalisme (dans les années 1930) devint sociologue dès les années 1950. Il écrivit des essais sur le sport, les jeux, les masques, la fête, le fantastique, etc. Ses essais, d’une lecture exigeante, résument une large érudition.
Caillois a été élu à l’Académie française en 1971 quand les pierres sont devenues essentielles pour l’essor de sa prose (1952-1978). Ses pierres nourrissent ses écrits, jamais minéralogiques mais plutôt d’histoire de l’art, avec une écriture singulière qui transcende notre vision de ces précieux témoins géologiques : « L’agate de Pyrrhus » des Grecs, les « pierres de rêve » des chinois et les paésines de la Renaissance. Pierres (1966) et l’Écriture des pierres (1970) sont ses ouvrages les plus connus et les plus traduits sur le sujet.
L’héritage au Muséum national d’histoire naturelle
Devenue veuve, son épouse Aléna Caillois destinait au Muséum national d’histoire naturelle en 1983 une sélection de 217 pièces (sur les 1 300), incluant deux manuscrits. Le premier, intitulé Pierres anagogiques, avait été décrit par Aléna en 1983 comme « le dernier manuscrit de Roger Caillois ». Ce texte est annoncé comme étant associé à une agate, dite « n° 2.193 », sans aucune autre précision. Ni le texte ni l’agate n’ont pu être retrouvés à mon arrivée au MNHN en 2006 (j’y reviendrai).
En 2017, l’autre partie de la collection de pierres de Caillois, qui était restée dans les mains de ses héritiers, a été acquise par mécénat pour le MNHN par la Maison Van Cleef & Arpels via l’École des arts joailliers. Ce corpus contient de nombreux spécimens illustrés dans l’Écriture des pierres, mais jamais exposés auparavant, comme le calcaire à dendrites « Le Château », peut-être la pierre de Caillois la plus connue au monde. Cette donation inclut le catalogue manuscrit de sa collection, dont l’agate « n° 2.193 » dont la description permet enfin de l’identifier.
Les (re)découvertes d’inédits en 2023
En 2023, lors d’une nouvelle inspection des archives de l’écrivain qu’il avait léguées à la médiathèque Valery-Larbaud de Vichy (Allier), j’ai étudié neuf caisses d’archives peu explorées, provenant également des héritiers d’Aléna. L’une d’elles, nommée « Pierres », contient le manuscrit mentionné dans la dation et intitulé « Pierres anagogiques ». Comment est-il passé du Muséum à Vichy ? Mystère ! Ce dossier contient deux textes : « Un miroir sans tain » et sa suite, « Agate anarchique (disparate) », le dernier étant, de par le style et son incomplétude relative, le dernier texte de Caillois, écrit quelques jours seulement avant de disparaître. La pensée ultime de Caillois s’éteint sur cette phrase d’une froide lucidité :

L’anagogie par les pierres
La mention de l’anagogie peut sembler déroutante de la part d’un tel matérialiste et athée revendiqué. Mais dans des notes inédites, Caillois nous explique sa logique : il passe sous silence la définition originelle de l’anagogie (une extase spirituelle envers les dieux célestes) puisée dans la mythologie grecque, pour se focaliser sur celle du moine Bernard de Clairvaux (1090-1153), soit une extase spirituelle envers ce Dieu céleste. En vérité, Caillois ne se convertit à aucune doctrine, y compris cistercienne, mais adapte le concept d’anagogie à sa manière, certes personnelle voire scandaleuse, en reprenant une philosophie bernardine médiévale que je résume ainsi : « Tu écouteras davantage les pierres que tes professeurs ».

L’influence des écrits chinois
Mais Caillois s’inspire également de Mi Fu (1051-1107), ce lettré chinois de la dynastie Song du Nord, qui se livrait à des rêveries sur les pierres. Cet érudit se prosternait devant la pierre la plus importante de sa collection, appelée 寶晉齋研山 ce qui signifie « pierre à encre de l’atelier de Baojin », et qui est devenue cultissime en Chine, encore de nos jours. Elle a été perdue de vue au XIXe siècle mais quelques gravures médiévales subsistent, dont la plus ancienne trouve son origine en 1366. Ce dessin, pourtant imprécis, inclut toutefois de précieuses annotations attribuées à Mi Fu qui expliquent les rêveries que cette pierre lui inspire et qu’il sacralise en retour, un concept typiquement taoïste. L’une d’elles est 嘗神游於其間 : littéralement « J’ai déjà rêvé de me promener ici ». Mais je montre que, dans Pierres (1966, pp. 72-74), le français reprend le texte de la [sinologue Vandier-Nicolas] publiée en 1963 dans Art et sagesse en Chine/Mi Fou (1051-1107), qui proposait alors « randonnée mystique ». Cette traduction, assez interprétée, correspond cependant à l’approche de Caillois des pierres, entre rêverie et mystique.
{kind=link}
Plus tard, au crépuscule de sa vie, dans le Fleuve Alphée (1978, pp. 187-188), il mentionne un second récit taoïste décrivant l’ascension des Huit Immortels qui survolent la mer pour se rendre à un banquet sur l’île-montagne paradisiaque de Penglai. Ces extases en forme d’élévations induites par une pierre, me semblent constituer une sorte d’« anagogie taoïsante » dans laquelle Caillois a pu trouver, à travers cette ontologie non-théiste et synchrétique entre Orient et Occident, une ultime inspiration.
Des preuves d’un projet de livre ultime aux accents « environnementalistes » prémonitoires ?
Une note manuscrite retient l’attention dans ces archives : il s’agit d’une liste de titres de textes dans un ordre bien précis : ses descriptions d’agates « naturalisantes » sont suivies d’exposés de plus en plus philosophiques, empreints d’une anagogie ultime. Avec plus de 200 000 signes, cette liste est celle d’un grand ouvrage sur les pierres, inédit, le dernier de Caillois dont le titre semble être celui annoncé par Aléna en 1983 soit « Pierres anagogiques ».
Surtout, Caillois nous questionne, avec les textes « La baignoire », « Interrègne » et « La Toile d’Araignée », avec une cinquantaine d’années d’avance, sur notre rapport à cette Terre que nous exploitons trop avidement, sans penser aux lendemains qui déchanteront. Si Caillois n’est pas le premier à prédire notre perte inéluctable, il a été parmi les premiers. Et surtout, il l’exprime mieux que quiconque, avec la force de ses mots, pour nous induire un choc de conscience et de respect envers cette Terre qui nous a légué tant de choses sans rien attendre en retour.

« Chuchotements & Enchantements »
Pendant cinquante ans, et plus particulièrement depuis mon arrivée au MNHN en 2006, je m’attelle à comprendre cet « écrivain des pierres ». Cette anthologie résume toutes ces découvertes. À mi-chemin entre un beau livre et un essai scientifique en grande partie français-anglais, il raconte comment les minéraux y ont été esthétiquement valorisés avant, pendant et après Caillois. Un regard croisé avec l’exposition « Rêveries de pierres » permettra au lecteur de voir, pendant un temps limité (novembre 2025-mars 2026), une partie significative de ces accords pierres-mots à travers une sélection de 200 spécimens à contempler, de textes à lire et écouter pour s’y fondre, un peu à la manière de Caillois.
Francois Farges ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:23
Favoriser l’investissement dans les études en apprenant aux jeunes à mieux gérer leur rapport au temps
Zara-Anna Mathieu, Doctorante en psychologie - Psychologue clinicienne spécialisée en santé, Université de Poitiers
Texte intégral (1436 mots)
Comment la manière dont les étudiantes et les étudiants lisent leur passé et envisagent leur avenir influence-t-elle leur investissement dans leur formation ? Une étude fait le point sur le sujet, ouvrant des pistes pour comprendre les mécanismes du décrochage académique.
Pour poursuivre des études, il faut s’appuyer sur des expériences passées positives (par exemple, la réussite à un examen), réaliser sur le moment présent des tâches parfois perçues comme fastidieuses tout en gardant à l’esprit ses objectifs futurs, en l’occurrence, l’obtention d’un diplôme.
Cette prise en compte globale du passé, du présent et de l’avenir correspond au concept de perspective temporelle, qui fait référence à la relation que les individus entretiennent avec le temps. C’est un filtre omniprésent, qui nous sert à trier et nous rappeler des événements, à former nos attentes.
Comment la perspective temporelle que l’on adopte influence-t-elle la manière dont on s’investit dans un parcours académique ? Une étude fait le point sur le sujet.
Se projeter vers le futur, une dynamique positive
La perspective temporelle impacte nos pensées et nos comportements. Elle se compose de cinq orientations temporelles, regroupées en trois dimensions :
Le passé peut être envisagé de façon positive ou négative. Le passé positif renvoie à une vision enthousiaste, parfois nostalgique, à l’égard des événements de vie passés. À l’inverse, le passé négatif est marqué par des souvenirs désagréables et une focalisation sur les expériences négatives.
Le présent peut être orienté vers l’hédonisme ou le fatalisme. Le présent hédoniste se définit comme la recherche de plaisir immédiat. Le présent fataliste, quant à lui, se caractérise par une vision plus pessimiste du monde et une impression de manque de contrôle.
L’orientation future correspond à la capacité à se projeter dans l’avenir et à se fixer des objectifs.
Les chercheurs ont tenté d’identifier l’orientation temporelle la plus en lien avec l’engagement académique, facteur de bien-être psychologique et de performance universitaire. Les étudiants dont l’attention est fortement focalisée vers le futur seraient les plus engagés.
Néanmoins, la perspective temporelle est un processus dynamique. Les étudiants peuvent être simultanément reliés à toutes les orientations à des degrés divers et jongler de l’une à l’autre, en fonction de leurs ressources personnelles et de la situation dans laquelle ils se trouvent.
Zimbardo et Boyd émettent l’hypothèse que la dynamique donnant lieu au fonctionnement le plus bénéfique pour l’individu serait une forte focalisation de l’attention sur le passé positif et le futur, associée à une focalisation modérée sur le présent hédoniste, ainsi qu’une faible focalisation sur le passé négatif et le présent fataliste. Selon eux, cette combinaison serait la plus adaptative pour les individus.
Nous avons souhaité tester cette hypothèse avec l’engagement académique chez les étudiants.
Les orientations temporelles des étudiants
L’objectif de notre étude était double :
mettre à jour les différentes combinaisons d’orientations temporelles ;
mettre en relation ces combinaisons avec l’engagement afin d’identifier la combinaison la plus pertinente dans le domaine académique.
Âgés en moyenne de 19,2 ans, 451 étudiants français inscrits en sciences humaines et sociales ont répondu à un questionnaire en ligne permettant de mesurer leur niveau d’engagement académique ainsi que leur perspective temporelle. Le traitement statistique des données fait apparaître cinq combinaisons d’orientations temporelles :
La combinaison 1 (4,6 % des étudiants) se caractérise par un passé négatif très élevé. Les étudiants de ce groupe ont tendance à accorder une place importante aux expériences désagréables du passé.
La combinaison 2 « Combinaison adaptative » (33 % des étudiants) correspond au résultat attendu : une prédominance du passé positif et du futur, un présent hédoniste moyen et un passé négatif et un présent fataliste faible. Ces étudiants semblent capables d’entretenir des souvenirs agréables tout en se projetant vers leurs objectifs.
La combinaison 3 (18 % des étudiants) est marquée par un passé négatif élevé (moins prononcé que dans la combinaison 1) et un présent fataliste fort. Ces étudiants perçoivent leurs expériences passées et leurs efforts présents de manière pessimiste.
La combinaison 4 (17,5 % des étudiants) se distingue par des scores faibles sur l’ensemble des orientations temporelles ; passé, présent et futur, quel que soit leur type. Ces étudiants semblent avoir une relation au temps peu investie voire désengagée.
La combinaison 5 (26,6 % des étudiants) présente des scores moyens pour chacune des orientations temporelles. Il s’agit d’une combinaison sans dimension prédominante.
Des combinaisons « à risque » pour l’engagement universitaire
Conformément à notre hypothèse, ladite combinaison adaptative est la mieux associée à l’engagement dans les études. Bonne nouvelle, cette combinaison est la plus représentée parmi les étudiants. En effet, elle concerne environ un tiers d’entre eux. Par ailleurs, notre étude a permis d’identifier certaines combinaisons « à risque », notamment la 1 et la 3, marquées par une forte orientation vers le passé négatif et une faible orientation vers le futur.
Ces tendances peuvent s’avérer problématiques et pourraient être un indicateur d’un risque de décrochage académique. Effectivement, pour les étudiants, la capacité à se projeter vers un objectif est essentielle pour persévérer dans une formation.
Les recherches à venir devraient s’intéresser aux facteurs qui favorisent le maintien et le développement de ladite combinaison adaptative, comme la flexibilité psychologique, qui permet de gérer des états de stress de manière constructive.
Zara-Anna Mathieu ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:22
La société civile syrienne un an après la chute du régime Assad
Léo Fourn, Docteur en sociologie, Institut de recherche pour le développement (IRD)
Texte intégral (2291 mots)
Le 8 décembre 2024 a refermé un demi-siècle de pouvoir autoritaire du clan Assad en Syrie, renversé par le groupe islamiste rebelle Hayat Tahrir al-Cham. Le pays émerge enfin d’une guerre civile qui l’a ravagé pendant quatorze ans. Une année s’est écoulée depuis ce basculement historique : assez pour esquisser les contours d’une transition politique encore fragile, mais déjà révélatrice de profondes recompositions au sein de la société civile. Entre cooptation, coopération et vigilance critique, les acteurs de la société civile syrienne jouent un rôle déterminant dans la reconstruction politique du pays.
En cette fin d’année 2025, de très nombreux rassemblements sont organisés en Syrie pour célébrer le premier anniversaire de la chute du régime dirigé par Bachar al-Assad le 8 décembre 2024.
La foule agite le nouveau drapeau officiel en scandant des chants révolutionnaires, tandis que les représentants du nouveau pouvoir paradent en héros libérateurs. Ces nouvelles autorités, dominées par Hayat Tahrir al-Cham (HTC) et son leader désigné président, Ahmad al-Charaa, tentent de mettre en œuvre un processus de transition politique et d’entamer la reconstruction d’un pays dévasté par plus d’une décennie de guerre. Les défis qu’elles affrontent sont énormes et leurs capacités très limitées. Le territoire national demeure divisé, le pouvoir central étant contesté par l’administration kurde autonome du Nord-Est, des groupes armés druzes et l’incursion de l’armée israélienne dans le Sud.
Dans ce contexte, quelle est la situation de ce que l’on appelle communément la « société civile syrienne », c’est-à-dire l’ensemble hétéroclite de groupes ni étatiques, ni partisans, ni militaires, mais engagés dans la défense de causes publiques ?
Cet article propose de dresser le bilan des changements vécus par cette société civile lors de la première année de la transition. La chute de l’ancien régime a bouleversé en profondeur les relations qui liaient l’État à la société. En l’absence d’opposition partisane solide, les organisations composant la société civile tiennent un rôle de premier plan, entre coopération et vigilance. Leur situation est donc révélatrice de l’orientation que prend la transition politique.
L’épanouissement de la société civile syrienne, de la révolution à la chute du régime
Avant 2011, le régime limitait drastiquement toute activité politique et toute action de la société civile hors de marges très restreintes, autorisant par exemple le travail des organisations caritatives et autres ONG parrainées par lui.
Le soulèvement qui démarre en 2011 va donner lieu à un épanouissement sans précédent de la société civile syrienne.
On l’observe d’abord dans la rue, lors des nombreuses manifestations demandant la chute du régime, davantage de liberté et de dignité. Puis par la multiplication des médias indépendants et la création de milliers d’organisations dédiées à la défense des droits humains ou à l’action humanitaire.
L’exil vécu par plus de 7 millions de Syriens produit une transnationalisation de cette société civile, dispersée entre la Syrie de l’intérieur et les pays de la diaspora. Des espaces comme la ville turque de Gaziantep et plus tard Berlin deviennent des centres majeurs de la mobilisation en exil. Ces organisations connaissent une professionnalisation de leurs activités, qui contribue à leur pérennité mais accroît également leur dépendance à l’égard des bailleurs internationaux. Elles tentent de s’unir en formant des coalitions afin d’augmenter leur influence, à l’exemple de la coalition la plus récente et la plus importante, Madaniya, qui regroupe plus de 200 organisations.
Lors des dernières années du conflit, ces organisations ont vu l’intérêt des bailleurs internationaux à leur endroit se réduire, ce qui a entraîné une baisse des financements. Ces financements ne vont pas s’accroître de sitôt, à la suite de la suspension de l’USAID par Donald Trump.
Mais la chute du régime va leur donner un nouveau souffle : elles peuvent enfin travailler dans l’ensemble du pays sans être réprimées. Les organisations agissant auparavant depuis les zones sous contrôle des rebelles et celles qui étaient installées en exil reviennent très rapidement ouvrir des bureaux à Damas. Après des années de fragmentation et de dispersion, on assiste alors à une relocalisation et une centralisation de la société civile dans la capitale syrienne.
Plusieurs réunions et événements publics sont organisés chaque semaine, par exemple au siège de la coalition Madaniya. Le 15 novembre, pour la première fois, une « Journée du Dialogue » est organisée par l’Union européenne à Damas, avec la participation d’ONG et du gouvernement syrien.
Les multiples facettes de la mobilisation de la société civile
Les domaines d’activité de ces organisations n’ont pas fondamentalement changé depuis la chute du régime, si ce n’est qu’elles ne luttent désormais plus dans ce but. Derrière le terme générique de « société civile » se cache en réalité une très grande diversité d’acteurs aux positionnements politiques multiples. L’usage de ce terme en Syrie fait toutefois principalement référence à des organisations pouvant être qualifiées de « libérales », c’est-à-dire favorables à une démocratie libérale. Leurs activités – qu’elles soient de nature humanitaire ou plus contestataire – sont pour la plupart des réponses aux exactions commises par l’ancien régime.
Elles comprennent un ensemble de mobilisations pour la justice dite transitionnelle, désormais mises en œuvre depuis le territoire syrien et plus seulement depuis les pays d’exil.
De la même façon, la cause du sort des victimes et plus particulièrement des personnes victimes de disparitions forcées fait l’objet d’une mobilisation constante. Elle a pris la forme des tentes de la vérité dressées temporairement dans plusieurs localités ou de soutien psychologique apporté aux proches et survivants.
Les besoins en matière d’aide humanitaire et de développement demeurent également massifs, la situation du pays restant fortement affectée par les conséquences de la guerre. Auparavant fragmentée entre les différentes zones d’influence au sein du territoire syrien et depuis les pays frontaliers, ce type d’aide peut désormais s’étendre à l’ensemble du territoire national. Mais elle souffre, comme les autres domaines, de la diminution des fonds internationaux, ce qui incite les organisations humanitaires à tenter de réduire la dépendance à l’aide en favorisant des programmes d’empowerment économique, particulièrement à destination de la jeunesse, en partenariat avec le secteur privé, comme le programme Dollani mis en œuvre par le Syrian Forum.
D’autres domaines ont gagné en importance lors de la dernière année. C’est le cas des groupes spécialisés dans le dialogue intercommunautaire et la « paix civile », à l’exemple de la plate-forme The Syrian Family.
Cette question du dialogue intercommunautaire, déjà centrale avant 2025, est effectivement au cœur des préoccupations actuelles du fait des massacres perpétrés sur la côte à l’égard de la communauté alaouite en mars et de la communauté druze dans le sud en juillet, sans oublier les tensions persistantes dans des espaces multiconfessionnels comme la ville de Homs.
De la même façon, le retour des réfugiés est devenu une question essentielle pour les organisations syriennes et internationales.
Enfin, il existe désormais à Damas un nouveau type d’organisation de la société civile qui était inexistant avant 2011, à savoir les centres de recherche indépendants et think tanks, qui fournissent des conseils au pouvoir et assurent des formations para-universitaires, comme le centre Jusoor.
La société civile face au nouveau pouvoir : entre coopération et méfiance
Le changement de régime a des conséquences majeures sur l’évolution des relations entre le pouvoir politique et la société civile.
Issus d’un mouvement militaire islamiste, les nouveaux dirigeants étaient a priori peu enclins à collaborer avec la société civile. Cependant, avant d’accéder au pouvoir en renversant Bachar Al-Assad, ce mouvement avait connu un processus de déradicalisation et d’ouverture relative vers d’autres composantes de la société syrienne.
La formation du nouveau gouvernement, le renouvellement et la création d’institutions étatiques ou encore les élections/nominations législatives partielles ont ainsi représenté des étapes permettant d’évaluer la position des dirigeants à l’égard des acteurs de la société civile. Nous pouvons observer trois modes de relations entre ces deux ensembles d’acteurs.
Le premier est la cooptation, qui a vu un certain nombre d’acteurs jusqu’alors engagés dans des organisations de la société civile intégrer des ministères ou des commissions formées par les nouvelles autorités. C’est le cas par exemple de la ministre des affaires sociales et du travail Hind Kabawat qui était à la fois active dans une ONG et dans l’opposition politique à Bachar.
C’est également le cas du ministre des situations d’urgence et de la gestion des catastrophes, Raed Saleh, auparavant responsable de la Défense civile syrienne, surnommée les Casques blancs. Cet exemple est particulièrement emblématique, puisque c’est presque l’ensemble de cette organisation qui a intégré le ministère.
Pour la plupart des individus et organisations de la société civile, la relation avec les autorités prend la forme d’une coopération dans le cadre de laquelle leur indépendance est maintenue. Les très faibles ressources dont dispose l’État ne lui permettent pas de mettre en œuvre une action publique répondant aux besoins de la population. Il n’a donc d’autre choix que de la déléguer aux organisations, qui tenaient déjà ce rôle avant la chute de l’ancien régime dans de multiples domaines, comme l’éducation et la santé. Elles collaborent également avec les ONG internationales et les organisations onusiennes et se rendent ainsi indispensables pour la reconstruction du pays.
Malgré cette coopération, de nombreux acteurs de la société civile restent méfiants à l’égard du nouveau pouvoir et exercent une forme de vigilance. Leurs craintes concernent les pratiques à dimension autoritaire qui demeurent très présentes. À titre d’exemple, plusieurs organisations se sont exprimées début octobre pour critiquer une circulaire du ministère des affaires sociales et du travail concernant la déclaration de l’origine des financements des ONG. Elles doivent effectivement désormais composer avec les exigences d’un État en restructuration.
Leurs responsables affirment disposer pour le moment de marges de liberté relativement larges, mais craignent que celles-ci se réduisent rapidement lorsque le pouvoir des dirigeants de l’État sera plus assuré. En ce sens, on peut considérer que les organisations de la société civile représentent toujours un contre-pouvoir, comme c’était dans le cas face à l’ancien régime.
Léo Fourn est chercheur postdoctorant à l'Institut de Recherche pour le Développement (IRD), membre du Centre Population & Développement (Ceped) et du projet LIVE-AR, financé par le Conseil Européen de la Recherche (ERC). Il a reçu pour cette recherche des financements de la Fondation Croix-Rouge française.
09.12.2025 à 15:21
Atteindre les objectifs climatiques améliorera aussi la santé publique
Kévin Jean, Professeur junior en Santé et Changements Globaux, Université Paris Dauphine – PSL
Laura Temime, Professor, Conservatoire national des arts et métiers (CNAM)
Léo Moutet, Doctorant en sécurité sanitaire, Conservatoire national des arts et métiers (CNAM)
Texte intégral (2049 mots)
Le 12 décembre 2015, 196 gouvernements adoptaient l’accord de Paris, qui ambitionnait de réduire les émissions de gaz à effet de serre pour lutter contre le changement climatique. Dix ans plus tard, les mesures prises par les États restent insuffisantes pour atteindre les objectifs fixés. Un retard d’autant plus dommageable que les mesures permettant d’améliorer le climat ont aussi des bénéfices conséquents en matière de santé publique. Explications.
L’urgence climatique impose une transformation profonde de nos systèmes énergétiques, de notre économie et de nos modes de vie. Or, ces transformations sont largement présentées dans le débat public sous l’angle des coûts à payer : investissements publics et privés, possibles pertes d’emplois dans certains secteurs, ou tout simplement coût du changement. Or, la transition écologique en vue de l’atteinte de la neutralité carbone (qui, rappelons-le, constitue la condition physique à la stabilisation du climat) peut également représenter des bénéfices, et en particulier dans le domaine de la santé.
C’est pour documenter l’ampleur de ces bénéfices que nous avons effectué une revue systématique de la littérature scientifique récente, et synthétisé 58 études ayant modélisé l’impact sur la santé humaine de 125 scénarios atteignant la neutralité carbone en 2050.
Les résultats de nos travaux, parus dans la revue The Lancet Planetary Health, sont sans appel : en plus d’être indispensables pour limiter les changements climatiques, les mesures prises dans ces scénarios ont le potentiel d’offrir des gains importants et immédiats pour la santé des populations.
Un enjeu non seulement climatique, mais également de santé publique
Alors que 3,6 milliards de personnes vivent déjà dans des zones très sensibles au changement climatique, celui-ci pourrait causer environ 250 000 décès supplémentaires par an d’ici 2030 et engendrer entre 2 et 4 milliards de dollars de dommages sanitaires directs chaque année, selon les projections de l’Organisation mondiale de la santé (OMS).
Il y a dix ans, le 12 décembre 2015, 196 gouvernements ont adopté l’accord de Paris, qui visait à réduire les émissions anthropiques de gaz à effet de serre (GES) afin de contenir l’élévation de la température moyenne de la planète en dessous de 2 °C par rapport aux niveaux préindustriels.
Malheureusement, les engagements nationaux actuels restent insuffisants pour atteindre ces objectifs. Ils placent actuellement nos sociétés sur une trajectoire de réchauffement de + 2 à + 3 °C d’ici la fin du siècle.
Or, les conséquences du changement climatique ont des effets sur la santé humaine. Ces derniers peuvent être directs, lorsqu’ils résultent de modifications des schémas climatiques, ou indirects, quand ils découlent de perturbations des écosystèmes, des systèmes alimentaires, des infrastructures ou des conditions sociales.
Les canicules relèvent par exemple de la première catégorie : à l’échelle européenne, on estime que sur les 2 300 décès dus à la chaleur survenus lors de la canicule de juin 2025, 1 500 sont directement attribuables au changement climatique.
En ce qui concerne les conséquences indirectes, on peut citer l’expansion des insectes vecteurs de certaines maladies, comme le moustique tigre (Aedes albopictus). Cet insecte propage notamment le virus chikungunya, à l’origine d’un nombre de cas autochtones sans précédent dans l’Hexagone en 2025.
Pourtant, si ces risques pour la santé sont de mieux en mieux décrits, leur connaissance ne suffit à l’évidence pas à impulser des mesures d’atténuation suffisantes.
Étant donné que la menace climatique, pourtant étayée scientifiquement, ne semble pas constituer un levier suffisant pour entraîner l’action, nous proposons d’adopter une autre approche, plus positive : expliquer les impacts, très souvent bénéfiques, que les politiques de réduction des gaz à effet de serre peuvent avoir sur la santé publique.
Les résultats de notre revue de la littérature scientifique sur ce sujet sont éloquents.
Des bénéfices sanitaires d’ampleur
Parmi 96 scénarios visant à atteindre la neutralité carbone comparés dans notre revue de littérature, 94 ont prédit que les politiques préconisées pour améliorer le climat auront aussi des impacts sanitaires favorables. Et ce, avant même que les effets des mesures d’atténuation prises ne modifient l’évolution du climat (laquelle devrait avoir elle aussi, à terme, des effets bénéfiques sur la santé).
Les études disponibles se concentrent principalement sur l’amélioration de trois déterminants de santé : l’alimentation, la qualité de l’air et l’activité physique.
La moitié des scénarios anticipent une réduction de la mortalité de plus de 1,5 %, soit environ 10 000 décès par an en France. Pour donner un ordre d’idée, ce chiffre représente le nombre de décès annuels par suicide ou à cause du cancer du foie. Les accidents dus aux transports représentent quant à eux environ 2 500 décès par an. De plus, cette valeur de 1,5 % de réduction de la mortalité prématurée est très vraisemblablement à interpréter comme une sous-estimation des bénéfices sanitaires de politiques de neutralité carbone, car une grande partie des scénarios ne se sont intéressés qu’à la qualité de l’air, en négligeant l’alimentation et l’activité physique.
Ces résultats sont cohérents avec ceux d’autres études établissant que l’adoption de régimes alimentaires plus sains, l’arrêt de la combustion d’énergie fossile et la pratique régulière d’une activité physique pourraient éviter respectivement 10, 5 et 4 millions de décès annuel dans le monde.
Ces co-bénéfices mèneraient à des améliorations de l’ordre de celles attendues à la suite de la mise en place de politiques de santé publique ambitieuses. Et ce, alors qu’ils ne font que découler de la mise en place de mesures visant à améliorer le climat, rappelons-le…
Trois caractéristiques intéressantes
Les co-bénéfices sanitaires auraient également trois caractéristiques particulièrement intéressantes :
1. Ils s’accompagnent de co-bénéfices économiques : onze des treize études ayant comparé les coûts de mise en œuvre des politiques climatiques avec leurs bénéfices sanitaires concluent que les gains économiques issus de la réduction de la mortalité dépassent les investissements initiaux. La diminution des maladies cardiovasculaires et respiratoires réduirait les pressions sur les systèmes de santé, entraînerait des gains de productivité et une baisse des arrêts maladie. Par ailleurs, d’autres bénéfices économiques apparaissent également, tels que la création d’emplois, l’amélioration de la résilience énergétique et l’augmentation des rendements agricoles.
2. Ils permettent une amélioration à court terme de la santé publique : comme mentionné précédemment, ces co-bénéfices permettent d’améliorer rapidement la santé humaine, car ils sont consécutifs à la mise en place des stratégies d’atténuation destinées à atteindre la neutralité carbone. Diminuer la pollution de l’air et promouvoir les modes de transport actifs ainsi qu’une alimentation de meilleure qualité se traduit par une amélioration immédiate des capacités cardiovasculaires, respiratoires et de la santé mentale, tout en diminuant l’incidence de certains cancers à plus long terme.
Nul besoin d’attendre d’avoir atteint la neutralité carbone, laquelle pourrait n’être atteinte qu’à moyen terme, voire à long terme (2030 à 2035 dans le meilleur des cas pour l’agriculture, 2050 pour l’industrie), étant donné la durée pendant laquelle persistent les gaz à effet de serre dans l’atmosphère (en particulier le CO2).
3. Ils ne nécessitent pas d’action coordonnée à l’échelle mondiale : les co-bénéfices sanitaires des politiques d’atténuation se manifestent indépendamment des efforts d’autres pays. Autrement dit, un pays qui adopte des mesures de réduction des émissions profite directement d’une amélioration de la santé de sa population, même si d’autres nations tardent à agir. Ce n’est pas le cas des bénéfices climatiques, puisque leur obtention nécessite que tous les pays participent. Cet aspect est crucial pour l’adhésion politique et citoyenne aux politiques climatiques.
Un appel à l’action pour une politique climatique et sanitaire conjointe
Prendre du retard dans la transition vers la neutralité carbone, ce n’est donc pas seulement payer un coût environnemental plus élevé : c’est aussi manquer l’opportunité d’améliorer la santé humaine.
Les politiques d’atténuation devraient être considérées non seulement comme une nécessité climatique, mais aussi comme un levier efficace de transformation de la santé publique. Plutôt que de voir la transition écologique comme un coût, les décideurs politiques et les acteurs économiques doivent la considérer comme un investissement dans la santé et le bien-être présent et futur des populations.
Cette perspective pourrait accélérer l’adoption de mesures ambitieuses et renforcer l’acceptabilité sociale et la mise en place de politiques climatiques cohérentes avec l’accord de Paris.
Kévin Jean est membre du conseil d'administration de l'association Science Citoyennes.
Laura Temime et Léo Moutet ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
09.12.2025 à 15:17
‘We need to rethink how we approach biodiversity’: an interview with IPCC ecologist and ‘refugee scientist’ Camille Parmesan
Camille Parmesan, Director, Theoretical and Experimental Ecology Station (SETE), Centre national de la recherche scientifique (CNRS); University of Plymouth; The University of Texas at Austin
Texte intégral (6220 mots)

She is an ecologist recognized worldwide for being the first to unequivocally demonstrate the impact of climate change on a wild species: the Edith’s checkerspot butterfly. In recent years, however, Camille Parmesan has been interviewed not only for her expertise on the future of biodiversity in a warming world or for her share in the Nobel Prize awarded to the IPCC, but for her status as a refugee scientist.
Twice in her life, she has chosen to move to another country in order to continue working under political conditions that support research on climate change. She left Trump’s America in 2016, and later post-Brexit Britain. She now lives in Moulis in the Ariège region of southwestern France, where she heads the CNRS’s Theoretical and Experimental Ecology Station.
Speaking with her offers deeper insight into how to protect biodiversity – whose responses to climate change continue to surprise scientists – what to do about species that are increasingly hybridizing, and how to pursue research on a planet that is becoming ever more climate-skeptical.
The Conversation: Your early work on the habitats of the Edith’s checkerspot butterfly quickly brought you international recognition. In practical terms, how did you demonstrate that a butterfly can be affected by climate change? What tools did you use?
Camille Parmesan: A pickup truck, a tent, and a butterfly net, good strong reading glasses to search for very tiny eggs and caterpillar damage to leaves, a notebook and a pencil to write notes in! In the field, you don’t need more than that. But before doing my fieldwork, I had spent a year going around museums all across the USA, a couple in Canada, and even in London and Paris collecting all the records for Edith’s checkerspot. I was looking for really precise location information like ‘it was at this spot, one mile down Parsons Road, on June the 19th, 1952’, because this species lives in tiny populations and is sedentary. That process alone took about a year, since at the time there were no digitized records and I had to look at pinned specimens and write their collecting information down by hand.


Once in the field, my work consisted of visiting each of these sites during the butterfly’s flight season. Since the season lasts only about a month, you have to estimate when they will be flying in each location in order to run a proper census. For this, you start by looking for adults. If you do not see adults, you do not stop there. You look for eggs, evidence of web, like bits of silks, damage from the overwintering larvae starting to feed…
You also look at the habitat: does it have a good quantity of healthy host plants? A good quantity of healthy nectar plants for adult food? If the habitat was not good, that location did not go into my study. Because I wanted to isolate the impact of climate change, from other factors like habitat degradation, pollution… At the larger sites, I often searched more than 900 plants before I felt like I had censused enough.
Today, when you go back to the fields you started monitoring decades ago, do you see things you were not able to see at the beginning of your work?
C. P.: I know to look for things I didn’t really look for when I started 40 years ago, or that my husband Michael [the biologist Michael Singer] didn’t look for when he started 50 years ago. For instance, we discovered that the height at which the eggs are laid is a bit higher now, and that turns out to be a really significant adaptation to climate change.
The eggs are being laid higher because the ground is getting far too hot. Last summer, we measured temperatures of 78°C (172.4°F) on the ground. So if a caterpillar falls, it dies. You can also see butterflies landing and immediately flying up, as it is way too hot for their feet and they’ll then fly onto vegetation or land on you.
In my early days, it wouldn’t have occurred to me that the height of where the eggs are laid could be important. That is why it is so important for biologists to simply watch their study organism, their habitat, to really pay attention. I see a lot of young biologists today who want to run in, grab a bunch of whatever their organism is, take it back to the lab, grind it up and do genetics or look at it in the lab. That’s fine, but if you don’t spend time watching your organism and its habitat, you can’t relate all your lab results back to what is actually happening in the wild.

Thanks to your work and that of your colleagues, we now know that living organisms are greatly affected by climate change and that many species must shift their range in order to survive. But we also know that it can be difficult to predict where they will be able to persist in the future. So what can be done to protect them? Where should we be protecting lands for them?
C. P.: That is the big question plaguing conservation biologists. If you go to the conservation biology meetings, a lot of people are getting depression because they don’t know what to do. We actually need to change the way we think of conservation, away from strict protection toward something more like a good insurance portfolio. We don’t know the future, therefore we need to develop a very flexible plan, one that we can adjust as we observe what’s happening on the ground. In other words, don’t lock yourself into one plan, Start instead with an array of approaches, because you don’t know which one will work.
We just published a paper on adapting, for land conservation, some decision-making approaches that have been around since the 1960s in fields known to be unpredictable, like economics, for instance, or urban water policy, where you don’t know in advance if it is going to be a wet year or a dry year. So urban planners came up with these approaches for dealing with uncertainty.
With modern computers, you can simulate 1000 futures and ask: if we take this action, what is happening? And you see it is good in these futures, but bad in those, and not too bad in others. What you’re looking for is a set of actions that is what they call robust – that performs well across the largest number of futures. For conservation, we did so by starting with standard bioclimatic models. We had about 700 futures for 22 species. It turns out that if we just protect where these species occur today, most organisms don’t survive. Only 1 or 2% of the futures actually contain those species in the same place. But what if you protect where it is now, but also where it’s expected to be 30% of the time, 50% of the time, 70% and so on? You have these different thresholds. And from these different future possibilities, we can determine, for instance, that if we protect this location and that one, we can cover 50% of areas where the models predict the organism persists in the future. By doing that, you can see that some actions are actually pretty robust, and they include combinations of traditional conservation, plus protecting new areas outside of where the species are now. Protecting where it is now is usually a good thing, but it is often not enough.
Another thing to bear in mind is that bigger is better. We do still need to protect lands for sure, and the bigger the better, especially in high biodiversity areas. You still want to protect those places, because species will be moving out, but also moving in. The area might end up with a completely different set of species than it has today, yet still remain a biodiversity hotspot, perhaps because it has a lot of mountains and valleys, and a diversity of microclimates.
On a global scale, we need to have 30 to 50 percent of land and ocean as relatively natural habitat, without necessarily requiring strict protection.
Between these areas we also need corridors to allow organisms to move without being killed immediately. If you have a bunch of crop land, wheat fields for example, anything trying to move through them is likely to die. So you need to develop seminatural habitats winding through these areas. If you have a river going through, a really good way to do this is just have a big buffer zone on either side of the river so that organisms can move though. It doesn’t have to be a perfect habitat for any particular organism, it just has to not kill them. Another point to highlight is that the public often doesn’t realize their own backyards can serve as corridors. If you have a reasonably sized garden, leave part of it unmown, with weeds. The nettles and the bramble are actually important corridors for a lot of animals. This can be done also on the side of roads.
Some incentives could encourage this. For example, giving people tax breaks for leaving certain private areas undeveloped. There are just all kinds of ways of thinking about it once you shift your mindset. But for scientists, the important shift is to not put all your eggs in one basket. You cannot just protect where it is now, or just pick one spot where you think an organism is going because your favorite model says so, or the guy down the corridor from you uses this model. At the same time, you cannot save everywhere a species might be in the future, it would be too expensive and impractical. Instead, you need to develop a portfolio of sites that is as robust as possible, given financial constraints and available partnerships, to make sure we won’t completely lose this organism. Then, when we stabilize the climate and eventually bring it back down, it’s got the habitat to recolonize and become happy and healthy and whole again.
Another issue that is very much on the minds of those involved in biodiversity protection today is hybridization. How do you view this phenomenon, which is becoming increasingly common?
C. P.: Species are moving around in ways they haven’t done in many thousands of years. As they are moving around, they keep bumping into each other. For example, polar bears are forced out of their habitat because the sea ice is melting. It forces them to be in contact with brown bears, grizzly bears, and so they mate. Once in a while, it’s a fertile mating, and you get a hybrid.
Historically, conservation biologists did not want hybridization, they wanted to protect the differences between species, the distinct behavior, look, diet, genetics… They wanted to preserve that diversity. Also, hybrids usually don’t do as well as the original two species, you get this depression of their fitness. So people tried to keep species separate, and were sometimes motivated to kill the hybrids to do so.
But climate change is challenging all of that. The species are running into each other all the time, so it is a losing battle. Also, we need to rethink how we approach biodiversity. Historically, conserving biodiversity meant protecting every species, and variety. But I believe we need to think more broadly: the goal should be to conserve a wide variety of genes.
Because when a population has strong genetic variation, it can evolve and adapt to an incredibly rapidly changing environment. If we fight hybridization, we may actually reduce the ability of species to evolve with climate change. To maintain high diversity after climate change – if that day ever comes – we need to retain as many genes as possible, in whatever form they exist. That may mean losing what we perceive as being a unique species, but if those genes are still there, it can revolve fairly rapidly, and that’s what we’ve seen with polar bears and grizzly bears.
In past warm periods, these species came into contact and hybridized. In the fossil record, polar bears disappear during certain periods, which suggests there were very few of them at the time. But then, when it got cold again, polar bears reappeared much faster than you’d expect if they were evolving from nothing. They likely evolved from genes that persisted in grizzly bears. We have evidence that this works and it is incredibly important.
Something that can be hard for non-scientists to understand is that, on the one hand we see remarkable examples of adaptation and evolution in nature (for instance trees changing the chemistry of their leaves in response to herbivores, or butterflies changing colors with altitude… ) while, on the other hand, we are experiencing massive biodiversity loss worldwide. Biodiversity seems incredibly adaptable, but is still collapsing. These two realities are sometimes hard to connect. How would you explain this to a non-specialist?
C. P.: Part of the reason is that ongoing climate change is happening very quickly. Another reason is that species have a pretty fixed physiological niche that they can live in. It is what we call a climate space, a particular mix of rainfall, humidity and dryness. There is some variation, but when you get to the edge of that space, the organism dies. We don’t really know why that is such a hard boundary.

When species face other types of changes like copper pollution, light and noise pollution, many of them have some genetic variation to adapt. That doesn’t mean these changes won’t harm them, but some species are able to adjust. For example, in urban environments today, we see house sparrows and pigeons that have managed to adapt.
So there are some things that humans are doing that species can adapt to, but not all. Facing climate change, most organisms don’t have existing genetic variation that would allow them to survive. The only thing that can bring in new variation to adapt to a new climate is either hybridizing – which will bring in new genes – or mutations, which is a very slow process. In 1-2 million years, today’s species would eventually evolve to deal with whatever climate we’re going into.
If you look back hundreds of thousands of years when you had the Pleistocene glaciations, when global temperatures changed by 10 to 12°C, what we saw is species moving. You didn’t see them staying in place and evolving.
Going back even further to the Eocene, the shifts were even bigger, with enormously higher CO2 and enormously warmer temperatures, species went extinct. As they can’t shift far enough, they die off. So that tells you that evolution to climate change is not something you expect on the time scale of a few 100 years. It’s on the time scale of hundreds of thousands to a couple of million years.
In one of your publications, you write: “Populations that appear to be at high risk from climate change may nonetheless resist extinction, making it worthwhile to continue to protect them, reduce other stressors and monitor for adaptive responses.” Can you give an example of this?
C. P.: Sure, let me talk about the Edith’s checkerspot, as that’s what I know the best. Edith’s checkerspot has several really distinctive subspecies that are genetically quite different from each other, with distinct behaviors, and host plants. One subspecies in southern California has been isolated long enough from the others that it is quite a genetic outlier. It’s called the Quino checkerspot.
It is a subspecies at the southern part of the range, and it’s being really slammed by climate change. It already has lost a lot of populations due to warming and drying. Its tiny host plant just dries up too fast. It’s lost a lot due to urbanization too: San Diego and Los Angeles have just wiped out most of its habitat. So you might say, well, give up on it, right?
My husband and I were on the conservation habitat planning for the Quino Checkerspot in the early 2000s. By that time, about 70% of its population had gone extinct.
My husband and I argued that climate change is going to slam them if we only protected the areas where they currently existed, because they were low elevation sites. But we thought, what about protecting sites, such as at higher elevations, where they don’t exist now?
There were potential host plants at higher elevation. They were different species that looked completely different, but in other areas Edith’s checkerspot used similar species. We brought some low elevation butterflies to this new host plant, and the butterflies liked it. That showed us that no evolution was needed. It just needed the Quino checkerspot to get up that high, and it would eat this, it could survive.
Therefore, we needed to protect the area where they were at the time, for them to be able to migrate, as well as this novel, higher habitat.
That’s what was done. Luckily, the higher area was owned by US Forest Service and Native American tribal lands. These tribes were really happy to be part of a conservation plan.
In the original area, a vernal pool was also restored. Vernal pools are little depressions in the grounds that are clay at the bottom. They fill up with water in the winter and entire ecosystems develop. Plants come up from seeds that were in the dry, baked dirt. You also get fairy shrimp and all kinds of little aquatic animals. The host plant of the Quino checkerspot pops out at the edge of the vernal pool. It is a very special habitat that dries up around April. By that time, the Quino checkerspot has gone through its whole life cycle, and it’s now asleep. All the seeds have dropped and are also dormant. The cycle then starts again the next November.
Sadly, San Diego’s been bulldozing all the vernal pools to create houses and condos. So in order to protect the Quino checkerspot, the Endangered fish and wildlife service restored a vernal pool on a small piece of land that had been full of trash and all-terrain vehicles. They carefully dug out a shallow depression, lined it with clay and planted vegetation to get it going. Among other things, they planted Plantago erecta, which Quino checkerspot lives off.
Within three years, this restored land had almost all of the endangered species it was designed for. Most of them had not been brought in. They just colonized this new pool, including Quino checkerspot.
After that, some Quino checkerspot were also found in the higher-environment habitat. I was blown away to be honest. We didn’t know this butterfly would be able to get up the mountain. I thought we’d have to pick up eggs and move them. The distances aren’t large (a few kilometers over, or 200 m upward), but remember that this butterfly doesn’t normally move much – it mostly stays where it was born.
Was there a wildlife corridor between these two areas?
C. P.: There were some houses, but they were very sparse, with lots of natural scrubby stuff in between. There weren’t really host plants for the Quino checkerspots. But it would allow them to fly through, have wild nectar plants on the way and not be killed. That’s the big point. A corridor doesn’t have to support a population. It just has to not kill it.
You too have had to relocate during your career in order to continue your research in ecology without being affected by the political climate. Over the past year in France, you have been asked to speak about this on numerous occasions and have been the subject of many articles describing you as a scientific refugee. In the United States, does this background also generate curiosity and media interest?
C. P.: A lot of colleagues, but also just people I know and have not necessarily collaborated with have asked me: How did you do that? How hard is it to get a visa? Do people speak English in France? But what’s interesting is the media in the USA has taken no interest. The media attention has been entirely outside of the USA, in Canada and Europe.
I don’t think Americans understand how much damage is being done to academia, education and research. I mean, even my own family doesn’t understand how much harm is being done. It’s difficult to explain to them because several of them are Trump supporters, but you would think the media would talk about that.
Most of the media have articles about damage to the university structure and damage to education, banning of books for instance, or the attempt to have an education system that only teaches what JD Vance wants people to learn. But you don’t really have a lot in those articles about people leaving. I think Americans can sometimes be very arrogant. They just presume America is the best and that no one would leave America to work somewhere else.
And it’s true that the USA traditionally has had such amazing opportunities, with so much funding from all kinds: many governmental agencies, funding many different projects, but also private donors, NGOs… All of this really literally stopped just cold.
In order to get people interested in biodiversity conservation and move them out of denial, it can be tempting to highlight certain topics, such as the impact on human health. This is a topic you have already worked on. Does it resonate more?
C. P.: I’ve always been interested in human health. I was going to be a medical researcher early on and I switched. But as soon as I started publishing the results that we were getting on the extent of species movements, the first thing I thought of was, ‘well diseases are going to be moving too’. So my lab’s work on human health focuses on how climate change is affecting where diseases, their vectors, and their reservoirs are spreading. One of my grad students documented the movement of leishmaniasis into Texas, going northward into Texas related to climate change.
In the IPCC we documented malaria, dengue and three other tropical diseases that have moved into Nepal, where they’ve never been before, at least in historical record, and that’s related to climate change, not to agricultural changes.
We also have new diseases emerging in the high Arctic. But not many people live in the high Arctic. It’s the Inuit communities that are being affected, so it gets downplayed by politicians. In Europe,the tiger mosquito is spreading into France, carrying its diseases with it.
Leishmaniasis is also already present in France, one species so far, but predictions suggest that four or five more species could arrive very soon. Tick-borne diseases are also increasing and moving north across Europe. So we are seeing the effect of climate change on human disease risk in Europe right now. People just aren’t aware of it.
You mentioned your family, some of whom are Trump supporters. Are you able to talk about your work with them?
C. P.: In my family, the only option is to not talk about it, and it’s agreed upon by everyone. It’s been that way for a long time about politics, even religion. We all love each other. We want to get along. We don’t want any divisions. So we kind of grow up knowing there are just certain topics you don’t talk about. Occasionally, climate change does come up and it gets difficult and it’s like, that’s why we don’t talk about it. So it’s not been possible to have an open conversation about it. I’m sorry about that, but I’m not going to lose my family. Nor, obviously, just push to convince them. I mean, if they want to know about it, they know where to come.
But I’ve also experienced working with people who have very different beliefs from mine. When I was still in Texas I worked with the National Evangelical Association. We both wanted to preserve biodiversity. They see it as God’s creation, I just think it’s just none of man’s business to destroy the Earth and I am an atheist, but that is fine. We did a series of videos together where I explained the effect of global warming. The result was wonderful.
This article is published as part of the 20th anniversary celebrations of the French Agence Nationale de la Recherche (ANR). Camille Parmesan is a winner of the “Make Our Planet Great Again” (MOPGA) program managed by the ANR on behalf of the French government. The ANR’s mission is to support and promote the development of fundamental and applied research in all disciplines, and to strengthen the dialogue between science and society.
Camille Parmesan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 15:17
Radiographie du soft power russe au Sénégal
Ibrahima Dabo, Docteur en science politique (relations internationales, Russie), Université Paris-Panthéon-Assas
Texte intégral (2188 mots)
C’est avant tout via son soft power – médias, langue, culture, bourses pour les étudiants… – que la Russie renforce son implantation au Sénégal, même si les dimensions géopolitique, militaire, énergétique et économique des relations bilatérales sont également en progression.
Dans un contexte mondial marqué par une recomposition des alliances, le Sénégal cherche – tout spécialement depuis l’arrivée à la présidence en mars 2024 de Bassirou Diomaye Faye – à diversifier ses partenariats tout en préservant sa souveraineté. L’évolution des relations entre Dakar et Moscou reflète les mutations plus larges du rôle de la Russie en Afrique de l’Ouest.
Au niveau économique, la présence russe reste faible en Afrique en général, y compris au Sénégal. Et même si un accord de coopération militaire a été signé fin 2023 avec Dakar, c’est surtout à travers l’expansion de son soft power que Moscou s’impose, s’appuyant notamment sur ses instruments culturels et éducatifs tels que l’agence fédérale Rossotroudnitchestvo (« Coopération russe »), la Fondation Russkiy Mir (« Monde russe ») et sur ses médias internationaux Sputnik et RT.
Une présence économique très marginale
La Chambre de commerce et d’investissement d’Afrique, de Russie et d’Eurasie a été ouverte à Dakar en 2024, ce qui témoigne d’une volonté d’explorer de nouvelles opportunités de coopération. Mais malgré l’existence de perspectives de collaboration dans des secteurs stratégiques tels que l’énergie, les ressources naturelles, les infrastructures et l’agriculture, les échanges économiques entre les deux pays restent à ce stade limités.
Dans une interview accordée début 2025 à Dakartimes, l’ambassadeur de la Fédération de Russie à Dakar, Dimitri Kourakov, a indiqué que les échanges entre le Sénégal et la Russie étaient estimés à 850 milliards de FCFA (1,3 milliard d’euros) pour cette année, contre environ 700 milliards de FCFA pour l’année 2024 (1,07 milliard d’euros). Les exportations de la Russie vers le Sénégal sont principalement constituées de produits pétroliers, d’engrais et de blé.
Dans le transport urbain, la filiale du géant technologique russe Yandex, Yango est devenue indispensable pour de nombreux déplacements quotidiens à Dakar. L’arrivée de Yango a créé de nombreuses opportunités d’emploi pour les chauffeurs locaux. Il n’empêche : la Russie est un partenaire économique secondaire et ses relations économiques avec le Sénégal restent modestes.
La coopération militaire entre Dakar et Moscou
À ce jour, la coopération militaire entre le Sénégal et la Russie demeure quasiment inexistante comparée à celle que Dakar entretient avec la Turquie, la Chine ou avec ses partenaires traditionnels, notamment les États-Unis ou la France malgré le départ des troupes françaises. Un accord bilatéral relatif à la coopération militaro-technique a été signé le 14 septembre 2007 qui prévoit la fourniture d’armes et de matériel militaire, ainsi que le détachement de spécialistes pour aider à la mise en œuvre de programmes conjoints dans le domaine de la coopération militaro-technique.
Un pas significatif a été franchi lorsque le gouvernement russe a approuvé un projet d’accord de coopération militaire avec le Sénégal le 3 novembre 2023, conformément à un décret du gouvernement de la Fédération de Russie. Cet accord porte sur la formation militaire et la lutte contre le terrorisme. Force est de constater qu’il existe un intérêt mutuel en ce qui concerne la coopération militaro-technique.
Une coopération éducative et culturelle en pleine expansion
Durant l’époque soviétique, l’URSS offrait des bourses d’étude aux étudiants sénégalais. Plusieurs cadres sénégalais ont été formés dans les universités soviétiques. La chute de l’Union soviétique a mis un coup d’arrêt à la présence culturelle de Moscou au Sénégal.
À partir de 2012, la coopération éducative s’est imposée comme un pilier de la relation sénégalo-russe. Le nombre de bourses d’études offertes par la Russie au Sénégal a alors fortement augmenté. Moins de 20 bourses étaient offertes par an au début des années 2000. Ce chiffre n’a cessé de monter, s’élevant à 130 au titre de l’année académique 2026-2027. En Russie, les jeunes Sénégalais étudient dans des domaines variés tels que l’ingénierie, la médecine, les relations internationales ou encore l’agriculture.
L’éducation et la culture sont au cœur de la politique africaine de la Russie. À l’instar de modèles tels que l’Alliance française, le British Council, les Instituts Confucius ou les Maisons russes dans d’autres pays, la Russie mise pour le moment au Sénégal sur l’implantation d’une médiathèque. À Dakar, la fondation Innopraktika offre une médiathèque à l’Université Cheikh Anta Diop pour faire la promotion de la langue et de la culture russe au Sénégal. L’apprentissage de la langue russe et la formation pour les enseignants du russe avec des méthodes innovantes sont au cœur des actions de la Fondation Russkiy Mir au Sénégal.
Rossotroudnitchestvo soutient ces initiatives en fournissant des manuels et des ressources pédagogiques, facilitant ainsi l’enseignement du russe. Dans le cadre de la coopération éducative, l’Agence fédérale, en collaboration avec l’Université électronique d’État de Saint-Pétersbourg (LETI), a lancé au Sénégal la semaine russe des mathématiques, de la physique et de l’informatique.
S’y ajoute la coopération entre la Bibliothèque d’État russe et l’Université Cheikh Anta Diop de Dakar. Dans le domaine culturel, chaque année, une célébration de l’anniversaire du poète russe Alexandre Pouchkine est organisée à Dakar. Dans le cadre de la promotion de la culture russe, une association privée, non gouvernementale et apolitique, CCR Kalinka a été lancée en 2009. Ce Centre culturel russe a pour objectif de familiariser la société sénégalaise avec la culture russe et les « valeurs traditionnelles slaves ». La coopération cinématographique Sénégal-Russie s’impose aussi aujourd’hui comme un pilier du dialogue culturel entre Dakar et Moscou.
L’évolution de l’influence médiatique russe au Sénégal depuis le changement de régime
Les relations tendues entre Dakar et Paris, qui se sont récemment manifestées par la fin de plus de 60 ans de présence militaire française au Sénégal, constituent une aubaine pour la Russie, qui cherche à étendre sa zone d’influence en Afrique de l’Ouest, plus particulièrement au Sahel.
De plus en plus, les médias deviennent des acteurs incontournables de la diplomatie des États. Dans ce contexte, les organes russes d’information, tels que RT et Sputnik, jouent un rôle central dans la diffusion de narratifs souvent critiques à l’égard de l’Occident et séduisants pour une partie des opinions publiques africaines francophones.
À lire aussi : RT et Sputnik : comment les médias internationaux russes se restructurent après leur interdiction dans les pays occidentaux
L’Afrique de l’Ouest est devenue un terrain stratégique pour Moscou dans sa guerre d’influence contre l’Occident. Depuis l’interdiction de RT et Sputnik dans l’espace européen, la Russie a recentré ses efforts médiatiques sur les pays africains où le rejet du néocolonialisme et la contestation de l’ordre occidental rencontrent un fort écho.
Au Sénégal, cette stratégie trouve un écho favorable avec l’arrivée au pouvoir de Bassirou Diomaye Faye, président de la « rupture », issu d’un parti souverainiste porté par un discours hostile au système néocolonial et à la Françafrique. Même si le régime n’a pas rompu avec les partenaires traditionnels, il affiche une réelle volonté de diversification de ses partenariats, notamment avec les pays arabes du Golfe et les BRICS.
RT dispose désormais d’un correspondant établi à Dakar, ce qui témoigne d’une stratégie de maillage territorial plus affirmée en Afrique de l’Ouest. Cette présence permet une meilleure couverture de l’actualité locale, et implique une meilleure compréhension des dynamiques politiques et sociales sénégalaises, ce qui laisse penser que RT est sur une trajectoire propice à l’accroissement de son influence.
Sputnik et RT veulent s’imposer comme des sources alternatives de narratifs favorables à la Russie en Afrique. Les contenus de RT dénonçant les bases militaires françaises en Afrique, le franc CFA, le néocolonialisme ou la Françafrique sont partagés par une partie de la jeunesse sénégalaise sur les réseaux sociaux pour légitimer son rejet de la présence française. Le discours souverainiste des nouvelles autorités du Sénégal et leur décision d’ordonner le retrait des troupes françaises sont salués par RT sur ses différentes plates-formes.
Il reste que l’influence directe des médias internationaux russes au Sénégal est très modeste en comparaison avec celle d’autres médias internationaux. Néanmoins, toutes les conditions semblent réunies pour une progression significative de la présence médiatique de la Russie au Sénégal.
Poursuivant la ligne déjà établie, les nouvelles autorités sénégalaises maintiennent une posture de neutralité au sujet de la guerre entre la Russie et l’Ukraine et encouragent les deux camps à parvenir à une issue pacifique. Le récent incident autour du navire Mersin à Dakar, présumé avoir un lien avec Moscou, remet au premier plan la question des conséquences pour le Sénégal du conflit russo-ukrainien.
Ibrahima Dabo ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.12.2025 à 11:59
Plantes médicinales : valider la tradition, prévenir les risques
François Chassagne, Chargé de recherche en ethnopharmacologie, Institut de recherche pour le développement (IRD)
Texte intégral (3772 mots)

En France, dans les territoires d’outre-mer en particulier, mais aussi ailleurs dans le monde, l’ethnopharmacologie doit faire face à plusieurs enjeux. Les laboratoires spécialisés dans cette discipline sont sollicités pour confirmer, ou non, l’intérêt thérapeutique de remèdes, à base de plantes notamment, utilisés dans les traditions. Mais ils doivent mener ce travail en préservant ces savoirs dans leurs contextes culturels.
Saviez-vous que près d’une plante sur dix dans le monde était utilisée à des fins médicinales ? Certaines ont même donné naissance à des médicaments que nous connaissons tous : l’aspirine, dérivé du saule (Salix alba L.), ou la morphine, isolée du pavot à opium (Papaver somniferum L.).
Au fil des siècles, les remèdes traditionnels, consignés dans des textes comme ceux de la médecine traditionnelle chinoise ou ayurvédique, ou transmis oralement, ont permis de soulager une multitude de maux. Ainsi, en Chine, les tiges de l’éphédra (Ephedra sinica Stapf), contenant de l’éphédrine (un puissant décongestionnant), étaient employées contre le rhume, la toux et l’asthme il y a déjà 5 000 ans. En Europe, les feuilles de digitale (Digitalis purpurea L.), d’où est extraite la digoxine (un cardiotonique), servaient dès le Moyen Âge à traiter les œdèmes.
En Amérique du Sud, l’écorce du quinquina (Cinchona pubescens Vahl.), contenant de la quinine (antipaludique), étaient utilisées par des communautés indigènes pour combattre les fièvres. En Inde, les racines de rauvolfia (Rauvolfia serpentina (L.) Benth. ex Kurz) contenant de la réserpine (antihypertenseur), furent même employées par Mahatma Gandhi pour traiter son hypertension.
Aujourd’hui encore, les plantes médicinales restent très utilisées, notamment dans les régions où l’accès aux médicaments conventionnels est limité. Mais une question demeure : sont-elles toutes réellement efficaces ? Leur action va-t-elle au-delà d’un simple effet placebo ? Et peuvent-elles être dangereuses ?
C’est à ces interrogations que répond l’ethnopharmacologie : une science à la croisée de l’ethnobotanique et de la pharmacologie. Elle vise à étudier les remèdes traditionnels pour en comprendre leurs effets, valider leur usage et prévenir les risques. Elle contribue aussi à préserver et valoriser les savoirs médicinaux issus des cultures du monde.
Un patrimoine mondial… encore peu étudié
Ces études sont d’autant plus cruciales que les plantes occupent encore une place centrale dans la vie quotidienne de nombreuses sociétés. En Afrique subsaharienne, environ 60 % de la population a recours à la médecine traditionnelle. En Asie, ce chiffre avoisine les 50 %. Et en Europe, 35 % de la population française déclare avoir utilisé des plantes médicinales ou d’autres types de médecines non conventionnelles dans les douze derniers mois – l’un des taux les plus élevés du continent !
Cette spécificité française s’explique par un faisceau de facteurs : une culture de résistance à l’autorité (face à la rigidité bureaucratique ou au monopole médical), un héritage rural (valorisation des « simples » de nos campagnes et méfiance envers une médecine jugée trop technologique), mais aussi une ouverture au religieux, au spirituel et au « paranormal » (pèlerinages de Lourdes, magnétisme, voyance…).
Ces chiffres ne reflètent pourtant pas toute la richesse de la phytothérapie française (la phytothérapie correspondant littéralement à l’usage thérapeutique des plantes). Dans les territoires d’outre-mer, les savoirs traditionnels sont particulièrement vivants.
Que ce soit en Nouvelle-Calédonie, où se côtoient traditions kanak, polynésienne, wallisienne, chinoise et vietnamienne, ou en Guyane française, avec les médecines créole, amérindienne, hmong ou noir-marron. Au total, les 13 territoires ultramarins apportent une richesse indéniable à la pharmacopée française. Preuve en est : 75 plantes ultramarines utilisées en Guadeloupe, en Guyane française, à la Martinique et à La Réunion ont récemment été intégrées à la pharmacopée nationale, un document officiel recensant les matières premières autorisées pour la fabrication des médicaments. Parmi elles, le gros thym (Coleus amboinicus Lour.) dont les feuilles sont utilisées pour traiter les rhumatismes, les fièvres ou encore l’asthme dans ces quatre territoires.

Mais cela reste l’arbre qui cache la forêt : sur les quelques 610 plantes inscrites à la pharmacopée française, seules quelques-unes proviennent des territoires ultramarins, alors même que les Antilles, la Guyane française et la Nouvelle-Calédonie comptent chacune environ 600 espèces médicinales recensées par la recherche. Plus largement encore, à l’échelle mondiale, seules 16 % des 28 187 plantes médicinales connues figurent aujourd’hui dans une pharmacopée officielle ou un ouvrage réglementaire. Autrement dit, l’immense majorité de ce patrimoine reste à explorer, comprendre et valoriser.
Étudier, valider, protéger
Dans les pharmacopées officielles, chaque plante fait l’objet d’une monographie : un document scientifique qui rassemble son identité botanique, ses composés bioactifs connus, ses données pharmacologiques et toxicologiques ainsi que les usages traditionnels et établis scientifiquement (indications thérapeutiques, posologies, modes d’administration, précautions d’emploi). En somme, une monographie joue à la fois le rôle de carte d’identité et de notice d’emploi de la plante. Validée par des comités d’experts, elle constitue une référence solide pour les professionnels de santé comme pour les autorités sanitaires.
Lorsqu’une plante n’est pas intégrée dans une pharmacopée, son usage reste donc empirique : on peut l’utiliser depuis des siècles, mais sans données claires sur son efficacité, la sécurité ou les risques d’interactions avec d’autres traitements.
Pour avancer vers la création de monographies et mieux intégrer ces plantes aux systèmes de santé, plusieurs outils sont à notre disposition :
des enquêtes ethnobotaniques, pour recenser les savoirs traditionnels et décrire les remèdes utilisés ;
des tests pharmacologiques, pour comprendre l’effet biologique des plantes et le lien avec leur usage (ex. : une plante utilisée contre les furoncles peut être testée contre le staphylocoque doré) ;
des analyses toxicologiques, pour évaluer l’innocuité des plantes, sur cellules humaines ou organismes vivants ;
des analyses phytochimiques, pour identifier les molécules actives, grâce à des techniques comme la chromatographie ou la spectrométrie de masse.

Au sein de nos laboratoires PharmaDev à Toulouse (Haute-Garonne) et à Nouméa (Nouvelle-Calédonie), nous combinons ces approches pour mieux comprendre les plantes et les intégrer, à terme, dans les systèmes de soins. Nous étudions des pharmacopées issues de Mayotte, de Nouvelle-Calédonie, de Polynésie française, mais aussi du Bénin, du Pérou, du Cambodge ou du Vanuatu.
Par exemple, nous avons analysé des remèdes du Pacifique utilisés chez les enfants pour en comprendre les bénéfices thérapeutiques et les risques toxiques. En Nouvelle-Calédonie, les feuilles de niaouli (Melaleuca quinquenervia (Cav.) S.T.Blake) sont couramment utilisées contre les rhumes en automédication. Or, elles contiennent de l’eucalyptol, susceptible de provoquer des convulsions chez les enfants de moins de 36 mois. Il est donc recommandé de ne pas employer ce remède chez les enfants de cet âge et/ou ayant eu des antécédents d’épilepsie ou de convulsions fébriles et, en cas de doute, de se référer à un professionnel de santé (médecin, pharmacien…). D’ailleurs, certains médicaments à base d’huile essentielle de niaouli peuvent, en fonction du dosage, être réservés à l’adulte. C’est précisément pour cela que nous diffusons nos résultats à travers des articles scientifiques, des séminaires et des livrets de vulgarisation, afin que chacun puisse faire un usage éclairé de ces remèdes.

Médecine traditionnelle et enjeux de développement durable
En Polynésie française, nous étudions la médecine traditionnelle à travers le développement durable. Plusieurs menaces pèsent aujourd’hui sur ces pratiques : la migration des jeunes, qui fragilise la transmission intergénérationnelle des savoirs ; le changement climatique, qui modifie la répartition des plantes ; ou encore les espèces invasives, qui concurrencent et parfois supplantent les espèces locales.
Or, ces savoirs sont essentiels pour assurer un usage sûr et efficace des plantes médicinales. Sortis de leur contexte ou mal interprétés, ils peuvent conduire à une perte d’efficacité, voire à des intoxications.
Un exemple concret est celui du faux-tabac (Heliotropium arboreum), ou tahinu en tahitien, dont les feuilles sont traditionnellement utilisées dans le traitement de la ciguatera, une intoxication alimentaire liée à la consommation de poissons, en Polynésie et ailleurs dans le Pacifique. Des études scientifiques ont confirmé son activité neuroprotectrice et identifié la molécule responsable : l’acide rosmarinique. Mais une réinterprétation erronée de ces résultats a conduit certaines personnes à utiliser l’huile essentielle de romarin. Or, malgré son nom, cette huile ne contient pas d’acide rosmarinique. Résultat : non seulement le traitement est inefficace, mais il peut même devenir toxique, car les huiles essentielles doivent être manipulées avec une grande précaution.
Cet exemple illustre un double enjeu : la nécessité de préserver les savoirs traditionnels dans leur contexte culturel et celle de les valider scientifiquement pour éviter les dérives.
En ce sens, la médecine traditionnelle est indissociable des objectifs de développement durable : elle offre une approche biologique, sociale, psychologique et spirituelle de la santé, elle permet de maintenir les savoirs intergénérationnels, de valoriser la biodiversité locale et de réduire la dépendance aux médicaments importés.
C’est dans cette perspective que notre programme de recherche s’attache à identifier les menaces, proposer des solutions, par exemple en renforçant les liens intergénérationnels ou en intégrant les connaissances sur les plantes dans le système scolaire, et à valider scientifiquement les plantes les plus utilisées.

François Chassagne a reçu des financements de l'ANR (Agence Nationale de la Recherche)
09.12.2025 à 11:59
Et si la masturbation pouvait réduire les effets indésirables de la ménopause ?
Jennifer Power, Principal Research Fellow, Australian Research Centre in Sex, Health and Society, La Trobe University
Texte intégral (1520 mots)

Une étude récente relayée dans le monde entier suggère que la masturbation pourrait atténuer certains symptômes désagréables chez les femmes en périménopause ou ménopause. Si cette attention médiatique peut surprendre, c’est sans doute parce que la masturbation reste peu évoquée, surtout chez les femmes plus âgées, et apparaît ici comme une stratégie inédite – voire audacieuse – de soulagement. Mais cette pratique peut-elle réellement améliorer les troubles liés à la ménopause ?
Selon une étude qui a suscité l’intérêt des médias dans le monde entier, une femme périménopausée et ménopausée sur dix se masturbe pour adoucir (soulager) les symptômes de la ménopause.
Cette attention s’explique sans doute par le fait que la masturbation est une méthode nouvelle – et peut-être un peu audacieuse – pour soulager les symptômes désagréables de la ménopause, tandis que les femmes, à partir d’un certain âge, sont souvent perçues comme asexuées.
La masturbation soulage-t-elle vraiment les effets indésirables, comme le suggère l’étude publiée dans la revue scientifique américaine Menopause ? Examinons la solidité des preuves.
Les bienfaits de la masturbation pour la santé
L’étude, menée aux États-Unis par des chercheurs du Kinsey Institute de l’Université de l’Indiana – l’un des instituts de recherche les plus reconnus dans le domaine du sexe et des relations –, a été financée par la société de sex-toys Womanizer.
Les chercheurs ont interrogé un échantillon représentatif de 1 178 femmes âgées de 40 à 65 ans, en périménopause et ménopause.
Celles ayant constaté des changements dans leurs règles tout en ayant eu au moins une menstruation durant l’année précédente ont été classées comme périménopausées, tandis que celles n’ayant plus eu de règles depuis un an ou plus ont été classées comme ménopausées.
Environ quatre femmes sur cinq ont déjà pratiqué la masturbation. Parmi elles, environ 20 % ont déclaré qu’elle soulageait leurs symptômes dans une certaine mesure. Chez les femmes en périménopause, les symptômes les plus atténués concernaient les troubles du sommeil et l’irritabilité. Chez un petit nombre de femmes ménopausées, la masturbation semblait surtout aider à réduire les inconforts sexuels, les ballonnements et les mictions douloureuses.
Ces résultats rejoignent ceux d’études antérieures montrant que la masturbation jusqu’à l’orgasme peut aider à réduire l’anxiété et la détresse psychologique, améliorer le sommeil et réduire les inconforts sexuels.
Toutefois, les recherches portant sur les bienfaits de la masturbation – sur la santé, la vie sociale, les relations ou le soulagement des symptômes de la ménopause – restent rares.
Nous ne savons donc pas précisément par quels mécanismes la masturbation pourrait améliorer ces symptômes. Les chercheurs avancent néanmoins que les effets relaxants de l’orgasme et la libération d’endorphines peuvent améliorer l’humeur, favoriser le sommeil et réduire les irritations et les douleurs lors des rapports sexuels. L’afflux sanguin induit par la masturbation au niveau de la zone génitale serait en effet de nature à améliorer les symptômes, à redonner de l'élasticité aux tissus et à réduire la sécheresse vaginale.
Un petit nombre de femmes ont toutefois indiqué que la masturbation avait aggravé leurs symptômes, sans que les raisons ne soient claires.
La masturbation reste stigmatisée
La masturbation n’est généralement plus considérée comme un péché ou un acte dangereux. Mais elle demeure stigmatisée. Les femmes, en particulier, l’associent souvent à quelque chose de honteux et ont tendance à en parler peu. La stigmatisation et l’invisibilité qui l’entourent expliquent qu’elle soit rarement étudiée dans des recherches cliniques.
Il en découle un manque de preuves concernant son efficacité pour soulager les symptômes de la ménopause, surtout en comparaison avec d’autres interventions non médicales, telles que l’activité physique ou la réduction du stress.
L’étude états-unienne montre d’ailleurs que les femmes s’appuient beaucoup plus volontiers sur des stratégies validées scientifiquement – activité physique, alimentation, gestion du stress, que sur la masturbation, même si beaucoup n’avaient probablement jamais envisagé cette dernière comme une option.
La masturbation ne convient pas à tout le monde
La masturbation est gratuite, relativement simple et, pour la plupart des femmes, agréable. Il n’y a donc aucune raison de ne pas la promouvoir comme une stratégie accessible pouvant soulager les symptômes chez certaines femmes. Mais la réalité est plus complexe : certaines rencontrent des obstacles.
Toutes les femmes ne se masturbent pas et ne trouvent pas forcément la pratique plaisante. Près d’une femme sur cinq interrogée dans l’étude américaine n’avait jamais pratiqué la masturbation. Ce chiffre, plus élevé chez les femmes plus âgées et ménopausées, reflète peut-être un changement générationnel dans les attitudes. Certaines participantes évoquaient des réticences morales ou religieuses.
D’autres études ont également montré qu’un nombre significatif de femmes ne se masturbent pas. Il peut y avoir de nombreuses raisons à cela, allant du manque de désir à un manque d’intimité ou de « temps pour soi ». Les femmes plus âgées peuvent rencontrer des obstacles physiques complexes : baisse de libido, mobilité réduite, douleur, etc.
Le silence et la stigmatisation entourant la masturbation rendent également difficile pour les professionnels de santé d’aborder ce sujet. L’étude américaine révèle ainsi que presque toutes les participantes n’avaient jamais parlé de masturbation avec un médecin.
Pourtant, beaucoup se sont montrées ouvertes à l’idée : environ 56 % des femmes en périménopause seraient prêtes à inclure la masturbation à leur routine bien-être si le médecin le leur conseillait.
La masturbation comme nouvelle stratégie
Même s’il n’existe aucune garantie que la masturbation soulagera les symptômes de la ménopause chez toutes les femmes, la proposer comme piste ne présente pas de risque : il s’agit de la pratique sexuelle la plus sûre qui soit.
Nous parlons peu de la masturbation, surtout chez les femmes d’un certain âge. En montrant que la majorité d’entre elles s’y adonnent et que cela peut offrir des effets bénéfiques sur la santé, cette étude représente une contribution. Importante et novatrice.
Jennifer Power a reçu des financements de l'Australian Research Council et du ministère australien de la Santé, du Handicap et du Vieillissement, et a précédemment reçu des financements de ViiV Healthcare et Gilead Sciences pour des projets sans rapport avec ce sujet.
08.12.2025 à 16:22
Apprentissage, service civique, stages… Les politiques d’insertion des jeunes, entre promesses d’embauche et faux espoirs
Florence Ihaddadene, Maîtresse de conférences en sciences de l'éducation et sociologie, Université de Picardie Jules Verne (UPJV)
Texte intégral (2155 mots)
Du stage au service civique, en passant par l’apprentissage, les dispositifs visant à favoriser l’insertion des jeunes se sont multipliés ces dernières décennies. Au-delà de leur diversité, tous reposent sur une politique de l’espoir qui cache des dérogations au droit du travail et d’importantes inégalités.
Revenu au cœur de l’actualité pendant les débats sur le budget à l’Assemblée nationale, le soutien aux entreprises qui recrutent en apprentissage est remis en cause par le gouvernement. Largement financé par le plan « Un jeune, une solution » qui faisait suite à la crise sanitaire, l’apprentissage a vécu un âge d’or depuis 2020, avec un objectif affiché de 1 million d’apprenties et apprentis en 2027 (en 2017, ils étaient 295 000).
Cette voie de formation est alors décrite comme la voie royale vers l’insertion professionnelle et ses bénéfices pour les jeunes sont rarement discutés. Comme d’autres programmes à destination de ce public, il repose surtout sur un espoir, celui de se rendre « employable », c’est-à-dire conforme aux exigences des employeurs, et de se distinguer dans la course à l’emploi.
Exposée dans l’ouvrage Promesse d’embauche. Comment l’État met l’espoir des jeunes au travail (éditions La Dispute, 2025), l’étude de ces programmes montre qu’ils génèrent, à partir d’une injonction à l’activité et souvent au travail (quasi) gratuit, d’importantes dérogations au droit du travail et aux droits sociaux, dont le service civique est emblématique. L’apprentissage n’échappe pas à ces logiques en générant des effets d’aubaine et de sélection.
Des politiques d’insertion aux politiques d’activation
Dans les années 1980 surgit le problème social du chômage, notamment celui des jeunes, et avec lui, les politiques d’insertion. À partir du Pacte national pour l’emploi de jeunes, de Raymond Barre, en 1977, des dispositifs sont créés pour faciliter l’embauche des jeunes de moins de 25 ans.
Globalement, ils mènent à une subvention des emplois par l’État, souvent dans le public ou l’associatif, comme dans le cas des emplois aidés, ou à une prise en charge des cotisations patronales (et sociales) par l’État (notamment dans le secteur privé lucratif). Par exemple, les 1,7 million de jeunes qui s’engagent dans les travaux d’utilité collective (TUC), entre 1984 et 1990, ne verront pas cette période reconnue pour leur retraite.
En parallèle, le rapport de Bertrand Schwartz au premier ministre mène à la création des missions locales en 1982, qui vont être spécifiquement chargées de l’insertion professionnelle et sociale des moins de 25 ans. Ce traitement particulier, différent de celui du reste de la population active, justifiera ensuite que les jeunes n’aient pas accès au RSA de droit commun. Aujourd’hui encore, les missions locales, qui sont des associations, assument le rôle de service public de l’emploi pour les jeunes.
Depuis la fin des années 2000, sous la double influence de l’Union européenne et des discours du président Nicolas Sarkozy sur l’« assistanat », les politiques d’insertion vont peu à peu être remplacées par des politiques dites d’activation. Celles-ci ont comme spécificité, pour « activer » les dépenses sociales, de demander aux publics concernés de prouver leur activité. Traquant l’oisiveté supposée des bénéficiaires des allocations sociales, particulièrement lorsqu’ils sont jeunes, ces programmes font reposer la responsabilité de l’insertion sur les individus qui doivent faire preuve de leur bonne volonté et même parfois de leur citoyenneté.
Ces politiques visent également de plus en plus l’individualisation des parcours d’insertion. Le plan « Un jeune, une solution », par exemple, propose une palette de dispositifs, dans laquelle chaque jeune doit piocher pour trouver sa solution et créer son propre parcours, à la manière du nouveau baccalauréat par combinaison d’options.
Une dérogation au droit du travail au nom de l’insertion
Avec ces politiques d’activation, il s’agit désormais de travailler à son « employabilité ». Il s’agit de prouver que l’on peut et veut travailler, quitte à le faire gratuitement. C’est le hope labor décrit aux États-Unis par la chercheuse Kathleen Kuehn et le chercheur Thomas F. Corrigan, travail gratuit réalisé dans l’espoir d’une embauche.
C’est sur cet espoir que vont reposer un grand nombre de dispositifs d’insertion promus par les gouvernements successifs depuis les années 2010, énonçant à demi-mot une promesse non d’emploi mais d’« employabilité ». Le public jeune est alors poussé à s’inscrire dans un certain nombre de dispositifs de courte durée, pour construire des parcours d’insertion. Ce qui paradoxalement tend à rallonger la durée d’attente avant le premier emploi.
Déployé à partir de 2010 pour les jeunes de 16 à 25 ans, le service civique est emblématique de ces logiques. Ce programme de volontariat (site officiel du service civique suppose un engagement pour une période qui varie de six à douze mois dans une mission dite d’intérêt général en association ou dans le public, dans le cadre d’une durée hebdomadaire de 24 à 48 heures en contrepartie d’une indemnité de 620 euros (en 2025) et d’un accompagnement au « projet d’avenir ». Ce contrat, inscrit au Code du service national ne permet pas d’accéder à l’assurance chômage pourtant cruciale pour des jeunes qui, rappelons-le, n’ont pas droit au RSA.
À lire aussi : « Une jeunesse, des jeunesses » : des diplômes pour imaginer l’avenir ?
Ce programme illustre bien les mutations des politiques d’insertion : il n’est pas présenté comme tel, mais plutôt comme un engagement, un don de soi, au nom de l’utilité sociale. Pourtant, les enquêtes montrent qu’il est utilisé par des associations en manque de moyens comme une main-d’œuvre peu coûteuse et souvent déjà formée. En toute logique, les jeunes l’utilisent donc également comme une expérience au service de leur insertion, une ligne en plus sur leur CV, une façon de se faire du réseau, et de prouver leur bonne volonté.
Le service civique produit et reproduit les assignations sociales, genrées et raciales qui attendent les jeunes sur le marché de l’emploi. « Super bénévolat » pour les jeunes de milieu favorisé, il est un « sous-salariat » pour les autres. Selon la structure qui accueille le ou la volontaire, selon la complexité de la mission, sa durée et même le lieu où elle prend place, l’expérience ne sera pas également valorisable.
On trouve ainsi plutôt de jeunes hommes non diplômés dans des missions sportives, dont ils attendent surtout un revenu de subsistance ou une suspension du temps (dans l’attente de repasser le baccalauréat, de trouver un employeur pour une alternance, etc.) Des programmes voués à de jeunes réfugiés tendent même à les assigner aux secteurs qui pourront les employer ensuite (mécanique, aide à la personne, entretien).
À l’inverse, les missions proposées par des associations culturelles attirent plutôt de jeunes femmes diplômées, pour qui elles sont une période de stage, de sas avant l’emploi, voire de préembauche quand un emploi peut potentiellement ouvrir dans la structure. Sorte de marché de l’emploi avant le marché de l’emploi, le service civique peut alors devenir sélectif et faire l’objet d’une vraie concurrence.
L’apprentissage est-il une solution ?
L’apprentissage est l’un des axes centraux du plan « Un jeune, une solution », prévoyant, en 2020, une aide de 5 000 euros ou 8 000 euros pour le recrutement d’un alternant ou d’une alternante. Entre 2019 et 2022, le nombre de contrats d’apprentissage a ainsi plus que doublé selon la Dares au détriment des contrats de professionnalisation.
De fait, l’incitation à l’apprentissage va aussi avec sa promotion dans de nouveaux domaines (dont le secteur des services, notamment celui du sanitaire et social). Mais c’est surtout sa diffusion à d’autres niveaux de formation que ceux initialement visés (à la sortie du collège, pour une insertion rapide sur le marché de l’emploi) qui explique sa hausse : ainsi, les 576 300 apprentis, hommes et femmes, de l’enseignement supérieur représentaient 60 % des effectifs de l’alternance en 2022, contre 20 % en 2009 (ce qui était déjà une forte hausse depuis 1995).
Depuis les années 1980, l’injonction à l’apprentissage reposait plutôt sur les classes populaires, en parallèle d’une incitation à l’amélioration du niveau de qualification. Pourtant, il reste sélectif, par manque de places, et contribue bientôt à la dévalorisation du lycée professionnel, qui reste associé à une forme d’enseignement scolaire.
La promotion de l’alternance dans le plan « Un jeune, une solution » s’inscrit dans une individualisation de la relation salariale, qui pousse les jeunes à chercher un employeur pour signer ce contrat, trouver leur place dans une entreprise, mais aussi à retourner ensuite vers la recherche d’emploi, l’apprentissage ne débouchant que rarement sur un contrat de travail.
Avant 2018, les centres de formation d’apprentis recevaient une subvention forfaitaire de la région mais, depuis leur réforme en 2018, le soutien de l’État aux entreprises recrutant des alternantes et alternants se fait en « coût-contrat », fixé par les partenaires sociaux de chaque branche professionnelle. Il lui est aussi reproché d’engendrer des effets d’aubaine, en faveur des jeunes diplômés de l’enseignement supérieur suffisamment armés pour s’insérer professionnellement, effet d’aubaine largement exploité par les universités. De fait, les entreprises prêtes à assumer leur rôle formateur sont rares. Elles préfèrent recruter des jeunes déjà qualifiés, tout en bénéficiant du principal budget des politiques d’emploi en faveur des jeunes.
Dans un contexte de concurrence pour l’emploi, chaque programme, même de courte durée, peut servir à se distinguer. Service civique, stages, apprentissage, bénévolat, etc. sont autant de cartes à ajouter à son CV pour prouver sa bonne volonté et ses compétences.
Pourtant, ces programmes mènent rarement directement à un emploi et ils génèrent de fait deux effets pervers. D’abord, ils concentrent les financements consacrés à l’insertion des jeunes dans des dispositifs de courte durée plutôt que dans la création d’emplois durables, entraînant aussi une tentation pour les employeurs de les renouveler plutôt que d’embaucher. Mais surtout, ils ont en commun de rallonger la période d’insertion, en maintenant les jeunes dans la précarité de cette période mais aussi en augmentant les exigences des employeurs à l’entrée dans un premier emploi.
Florence Ihaddadene ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
08.12.2025 à 16:21
Émancipation des Juifs sous la Révolution et l’Empire, intégration des musulmans aujourd’hui : des controverses qui se ressemblent
Danièle Lochak, Porfesseure émérite de droit public, Université Paris Nanterre
Texte intégral (2646 mots)

{kind=link}
Il y a cent vingt ans, le 9 décembre 1905, la loi de séparation des Églises et de l’État était promulguée en France. Mais dès la Révolution, la question de la place concédée aux minorités religieuses – en l’occurrence au sujet des juifs, dans le cadre républicain fait débat. Ces discussions, qui portent notamment sur l’abandon de certaines pratiques cultuelles, font écho aux controverses actuelles portant sur l’islam et les musulmans.
Dans son ouvrage Libres et égaux… L’émancipation des Juifs sous la Révolution française (1789-1791), Robert Badinter souligne qu’en proclamant « la pleine citoyenneté des juifs en France, le 27 septembre 1791, les [révolutionnaires] faisaient triompher leur idéal, celui des Droits de l’Homme, sur les préjugés et la prudence politique ».
À la veille de la Révolution, en effet, les Juifs sont encore soumis, à des degrés variables selon leur origine et leur implantation géographique, à un statut diminué et précaire, dépendant du bon vouloir du roi. La question de savoir s’ils seraient inclus et à quelles conditions dans la communauté des citoyens se pose donc avec acuité dès la convocation des États généraux.
Finalement, en dépit des préjugés à l’égard des Juifs qui s’expriment jusque dans la bouche ou sous la plume des révolutionnaires les plus acquis à leur cause, le décret d’émancipation leur confère l’égalité des droits et l’accès à la citoyenneté sans autre condition que de prêter le serment civique. Pour l’abbé Grégoire, c’est l’émancipation des Juifs qui doit ouvrir la voie à leur « régénération », autrement dit leur assimilation ; aux yeux de Stanislas de Clermont-Tonnerre, de même, dès lors qu’on leur donnera l’égalité de droits, les Juifs s’affranchiront, grâce aux Lumières, « de leurs pratiques fanatiques ou détestables ».
Mais ce qui est frappant, lorsqu’on se replonge dans les débats de l’époque, c’est à quel point on en retrouve l’écho dans les controverses actuelles autour de l’intégration des immigrés, de la laïcité ou du communautarisme. Les solutions aujourd’hui préconisées sont-elles pour autant fidèles aux principes qui ont inspiré « cette mesure véritablement révolutionnaire », pour reprendre l’expression de Robert Badinter, qu’a été le décret d’émancipation des Juifs ? On peut légitimement en douter.
Assimilation, intégration : la constance d’une préoccupation
La question de l’assimilation n’est plus posée désormais – officiellement s’entend – s’agissant des juifs. Mais elle a été érigée en condition d’accès à la nationalité française : « Nul ne peut être naturalisé s’il ne justifie de son assimilation à la communauté française », énonce le Code civil, une assimilation qui s’apprécie notamment au regard d’une connaissance suffisante « de la langue, de l’histoire, de la culture et de la société françaises » et de « l’adhésion aux principes et aux valeurs essentiels de la République ». La laïcité compte au nom de ces « principes et valeurs essentiels » – le « défaut d’assimilation » est en pratique souvent invoqué pour rejeter une demande de naturalisation au vu de comportements ou d’attitudes (le port du foulard, la conception des rapports sociaux de sexe) liés ou imputés à la pratique de l’islam.
En ce qui concerne les étrangers de façon générale, le concept qui a émergé est celui d’intégration. Théoriquement moins impliquante en termes de renonciation à son appartenance d’origine et à ses particularismes, l’intégration est devenue, à partir du milieu des années 1970, un objectif officiel de la politique d’immigration.
L’intégration comme injonction : le syndrome napoléonien
Mais l’effort d’intégration, dont la responsabilité incombait aux pouvoirs publics, a été progressivement reporté sur les immigrés et converti en injonction de s’intégrer, sous peine de conserver à jamais un statut précaire, voire de perdre tout droit au séjour.
Le premier pas en ce sens est intervenu avec la loi Sarkozy de 2003 qui a subordonné l’obtention d’un titre de séjour pérenne à des preuves d’intégration. Aujourd’hui, à l’issue d’une série de réformes législatives allant dans le sens d’un renforcement croissant des exigences – et dernièrement encore avec la loi Darmanin de 2024 –, tout étranger qui sollicite la délivrance d’un titre de séjour doit signer un « contrat d’engagement au respect des principes de la République » et tout manquement aux obligations souscrites entraîne le retrait ou le non-renouvellement du titre.
Comment ne pas penser au retournement imposé par Napoléon lorsque, inversant la problématique du décret d’émancipation de 1791, il décide de conditionner la possession des droits civiques à des preuves préalables de « régénération » et impose aux Juifs d’Alsace une période probatoire ?
Le parallèle avec l’époque napoléonienne va même plus loin. Lisons quelques-unes des questions posées par Napoléon aux représentants de la communauté juive, destinées à « tester » la capacité d’assimilation des Juifs, avec le présupposé implicite que les contraintes de leur religion y font obstacle : 1. Est-il licite aux Juifs d’épouser plusieurs femmes ? 2. Le divorce est-il permis par la religion juive ? 4. Aux yeux des Juifs, les Français sont-ils leurs frères, ou sont-ils des étrangers ? 6. […] Sont-ils obligés d’obéir aux lois et de suivre toutes les dispositions du Code civil ? Le reste à l’avenant. Autant de questions auxquelles le Grand Sanhédrin, réuni en 1807, va répondre point par point, afin de démontrer que les obligations religieuses des juifs ne s’opposent en aucune manière au respect des lois civiles.
Les ressemblances avec la philosophie qui sous-tend les gages d’intégration exigés aujourd’hui des étrangers sont frappantes. Le « contrat d’engagement au respect des principes de la République » comporte sept engagements parmi lesquels le respect de l’égalité entre les femmes et les hommes et le respect du principe de laïcité – qui visent implicitement mais évidemment les étrangers de religion ou de culture musulmane.
On repense aussi aux prises de position de Gérald Darmanin, ministre de l’intérieur, se targuant de prendre modèle sur Napoléon pour endiguer le séparatisme, suggérant que l’État impose aujourd’hui aux musulmans ce que Napoléon avait imposé aux Juifs et n’hésitant pas à affirmer :
« Le bon modèle, pour moi, c’est le Grand Sanhédrin convoqué en 1807 par Napoléon pour vérifier qu’il n’y avait pas d’incompatibilité entre son Code civil et la religion juive. »
Les religions minoritaires prises au piège de la « laïcité républicaine »
La question de savoir si et jusqu’à quel point l’émancipation suppose l’abandon des pratiques religieuses a été débattue dès avant la Révolution, sans être finalement clairement tranchée. Certes, les conflits de normes entre le droit étatique et les préceptes de la religion ne sont pas propres aux religions minoritaires comme le montrent les relations tumultueuses entre la République et l’Église catholique tout au long du XIXᵉ et une partie du XXᵉ siècle. Mais ils sont nécessairement plus fréquents pour les premières.
Et de fait, les juifs, comme les musulmans, subissent aujourd’hui encore
- quoiqu’à un degré inégal - leur statut de minorité religieuse dans un pays où tout est calé en fonction d’un catholicisme culturellement dominant et où le point de savoir jusqu’où doivent aller les « accommodements raisonnables » fait plus que jamais débat.
Les dérogations à la loi commune ne vont jamais de soi, même si certaines sont plus facilement acceptées que d’autres. Un modus vivendi paraît avoir été trouvé dans certains domaines : les autorisations d’absence les jours de fêtes religieuses, dans un contexte où le calendrier légal des jours chômés est calqué sur celui des fêtes chrétiennes ; les carrés confessionnels dans les cimetières, théoriquement interdits en droit mais autorisés en fait sur la base de circulaires ministérielles ; l’abattage rituel, reconnu par le Conseil d’État au nom du libre exercice du culte dès 1936 et autorisé par le Code rural – une dérogation dont la pérennité n’est toutefois pas assurée.
Mais il y a aussi des points de fixation. La loi de 2004 interdisant le port de tout signe d’appartenance religieuse dans les établissements scolaires attestait déjà du raidissement des pouvoirs publics face aux manifestations extérieures de la religion. On sait à quel point cette loi et son application extensive – comme l’attestent les polémiques sur les mamans accompagnatrices ou celle, plus récente, sur l’abaya – ont fait et font encore débat. Elle aura aussi contribué – on ne le relève pas assez – à la communautarisation tant décriée, en incitant à la fuite des élèves vers les écoles privées juives et musulmanes.
Plus curieusement, la question de la nourriture est apparue récemment comme un autre point de fixation. Dans la République et le Cochon (2013), Pierre Birnbaum rappelle que, dès la Révolution, la question a été posée dans les débats sur l’assimilation des Juifs. Clermont-Tonnerre énonce, en 1789, les reproches adressés aux Juifs à cet égard pour immédiatement les écarter :
« Nos mets leur sont défendus, nos tables leur sont interdites. Ces reproches sont soit injustes, soit spécieux. Y a-t-il une loi qui m’oblige à manger du lièvre et à le manger avec vous ? »
Si les polémiques actuelles visant le cochon, la nourriture casher ou halal, répercutées parfois au plus haut niveau de l’État, n’épargnent pas les juifs, elles sont principalement dirigées contre les musulmans. On rappellera ici, parmi une multitude d’exemples, les accusations de « tomber dans le communautarisme » formulées, en 2010, à l’encontre de la chaîne Quick dont quelques établissements avaient décidé de ne plus servir de viande de porc, les éternelles controverses sur la composition des menus des cantines scolaires ou encore les déclarations du ministre de l’intérieur Gérald Darmanin, en 2020, se disant choqué par la présence de rayons halal dans les supermarchés et concluant : « C’est comme ça que ça commence, le communautarisme. »
Le spectre du communautarisme : deux poids, deux mesures ?
Qui n’a en mémoire la fameuse phrase de Clermont-Tonnerre : « Il faut refuser tout aux Juifs comme nation […] Il faut qu’ils ne fassent dans l’État ni un corps politique ni un ordre […] Qu’on leur refuse toute institution communautaire et toute loi particulière » ?
À première vue, on pourrait penser que la dénonciation actuelle du « communautarisme », stigmatisé comme incompatible avec le « modèle républicain », s’inscrit dans le prolongement des principes ainsi énoncés. Ce qui frappe, pourtant, c’est l’attitude ambivalente à cet égard des pouvoirs publics qui se reflète notamment dans le contraste entre ce qu’on concède aux juifs et ce qu’on refuse aux musulmans.
Est caractéristique à cet égard la place officielle reconnue au Conseil représentatif des institutions juives de France (Crif) et le dialogue égalitaire qu’il entretient avec les autorités de l’État, dont la reconnaissance tranche assurément avec la dénonciation virulente et constamment réitérée du communautarisme musulman.
D’autant que le soupçon de dérive « communautariste » commence très tôt, lorsqu’il s’agit des musulmans, puisque de simples coutumes vestimentaires – ou le port de la barbe – seront le cas échéant interprétés, non comme une expression légitime de la liberté religieuse, mais comme la porte ouverte à l’ethnicisation de la société française, sapant les bases du « modèle républicain ». Un « modèle républicain », largement fantasmé, mais qu’on brandit comme arme rhétorique pour justifier le resserrement sur une laïcité de combat présentée comme le seul antidote aux risques de dérive communautariste.
Cet article est tiré d’une intervention de Danièle Lochak à l’occasion d’un colloque en hommage à Robert Badinter, le 8 octobre 2025 à l’Université Paris 1 Panthéon-Sorbonne.
Danièle Lochak est membre de la Ligue des droits de l'Homme et du Groupe d'information et de soutien des immigré·es (Gisti)
08.12.2025 à 16:21
De « Mafiosa » à « Plaine orientale », l’imaginaire de la mafia corse à l’écran
Isabelle-Rachel Casta, Professeur émérite, culture sérielle, poicière et fantastique, Université d'Artois
Texte intégral (2227 mots)

En Corse, dit le dicton, tout se fait, tout se sait, tout se tait (« Tuttu si face, tuttu si sà, tuttu si tace »)… Alors, Corse « terre d’omerta » selon le mot du criminologue Jean-François Gayraud ? En tout cas, terre d’imaginaire et de séries criminelles. Faut-il pour autant déduire de l’abondante production (télé)filmique récente une flambée de fascination pour les « banditi » insulaires ?
Si la conflictualité réelle de la société corse est bien documentée, tous les homicides commis sur l’île ne relèvent pas forcément de la « mafiacraft », selon le titre de l’anthropologue Deborah Puccio-Den. Or, les séries et les films sortis en France ces dernières années tendent à tout confondre, abusant parfois des clichés associés à la mafia dans l’imaginaire collectif.
Les défilés des comités antimafia font souvent la une de la presse régionale corse, en parallèle avec les récits de règlements de compte, de racket et de crimes crapuleux. De Mafiosa, le clan (2006-2014) à Plaine orientale (2025), de À son image (2024) au Royaume (2024), on peut avoir l’impression que les exactions réelles infusent la fiction criminelle, dans une porosité quasi incestueuse où le fait divers d’hier nourrit le scénario de demain, comme si l’imaginaire du voyou se régénérait sans cesse au contact d’une société à la fois clanique et violente, traversée par toutes les manifestations du crime contemporain (drogue, extorsion, chantage…).
Pourtant, aucun auteur français n’est menacé à la hauteur de ce que subit l’écrivain et journaliste italien Roberto Saviano, sous protection judiciaire depuis la publication de son très réaliste roman Gomorra en 2006, sans doute parce que parler des « mafieux corses » relève à la fois d’un mythe, d’un fantasme, d’un abus de langage et, à tout le moins, d’une réalité partielle.
Un folklore ancien, une actualisation récente
Le « milieu » et ses « beaux mecs » ont toujours séduit et fasciné les « caves » (autrement dit, le bon peuple !), par l’atmosphère d’interdit et d’ambiance sulfureuse que véhiculent les grands récits qui fondent cet imaginaire : Ange Bastiani, Albert Simonin, Auguste Le Breton corroborent le mythe viriliste du mauvais garçon dur à cuire, charmeur et violent, riche d’argent facile et prompt à jouer du couteau.
Mais ce folklore du premier XXe siècle englobe un sous-folklore corso-marseillais, dont la famille Guérini représente le « totem » le plus célèbre. Or, peu à peu le monde change, et les protagonistes sont désormais immergés dans des affaires de spéculation immobilière qui, comme dans le film le Mohican (Frédéric Farrucci, 2025), spéculation qui amène à s’entretuer, très littéralement. Ainsi, romanciers et cinéastes actuels font rarement l’économie d’une scène de mort violente, comme en témoigne ici l’extrait de Ceux que la nuit choisit (Joris Giovanetti, Denoël, 2025, p. 412-413) :
« On avait ramassé, à côté du corps criblé de plomb du jeune homme, un croissant ainsi qu’un Coca […] ; dans sa sacoche, une arme de poing de type Glock avait été retrouvée avec deux balles dans le chargeur. »
Mais c’est la drogue, la French Connection (1971), qui est surtout une « Corsican connection », qui a bouleversé le narratif traditionnel du « bandit d’honneur ». Les années 1970 voient en effet la drogue conquérir la Corse, en fabriquant nombre de « consommateurs-revendeurs ».
Mais tout explose vraiment entre 2000 et 2025, détruisant les anciennes solidarités et recomposant (dans la réalité comme dans les fictions) les hiérarchies délinquantes. Les saisies font d’ailleurs l’objet de nombreuses allusions :
« Ils limitent la morphine… Paraît que ça coûte trop cher… Tu parles, on est quand même bien placé pour connaître tous les stocks saisis sur les trafiquants, non ? » (Jean-Pierre Larminier, les Bergers, Nera Albiana, 2006, p. 98).
Peu à peu les bandes, comme (Petit Bar et Brise de mer…), ont remplacé les clans, et s’est formé un banditisme de l’extorsion, de la terreur et de l’assassinat – même si, pour la couleur locale nombre de titres d’œuvres de fiction utilisent toujours « le clan », terme plus connoté « corse » et plus mystérieux.
Plus récemment, à la disparition des « parrains » historiques puis à l’émiettement des bandes en groupes déstructurés, ultraviolents mais éphémères, s’est ajoutée l’arrivée des « petites mains » maghrébines qui à leur tour veulent s’emparer des marchés – c’est tout l’objet du film Un prophète (2009) et de la série Plaine orientale, tandis que s’accentue au gré des fictions un rapprochement purement « sensationnaliste » entre nationalisme et grand banditisme, par l’allusion à « l’impôt révolutionnaire » qui occupe bien des fantasmes, comme on le voit dans le film le Royaume, ou le roman À son image. Pourquoi cette appétence, sinon cette complaisance, pour le malheur ?
Omerta, vindetta : une vie… violente !
N’oublions pas qu’un féminicide, celui de Vanina d’Ornano par son époux Sampiero Corso, en 1563, reste un événement marquant de l’histoire de la violence en Corse. Il est difficile, après cela, de ne pas idéaliser une forme de romantisme du mauvais garçon, de l’« outlaw », alors que la plupart des faits divers sont objectivement épouvantables (pour les victimes) et dégradants (pour les tueurs).
Cette fascination pour le mal gagne du terrain un peu partout, dans la fiction comme les séries « de true crimes ».
Certes, ici la vignette pittoresque n’est jamais loin (violence, clanisme, fierté virile…) et Borgo (2023), film de Stéphane Demoustier, donne l’exemple même d’une porosité troublante entre fiction, fait divers et actualité brûlante. Quand le film, qui s’inspire d’un double assassinat qui a eu lieu à l’aéroport de Bastia en 2017, affaire dans laquelle une surveillante de prison est suspectée d’avoir eu un rôle décisif, est sorti en salle, le procès de la « vraie » gardienne de prison, complice d’un double assassinat, commençait. Et l’article du Monde de mentionner que cette femme aurait été fière d’être surnommée « Sandra Paoli », nom de la terrible cheffe de bande de la série Mafiosa…
De fait, le grand banditisme comme la lutte identitaire sont d’inépuisables filons de fictions sanglantes, et les petits caïds de Plaine orientale rejoignent dans cette parade macabre les clandestins d’Une vie violente (2017). La figure romanesque et télévisuelle du bandit se porte ainsi fort bien, et irrigue nombre d’œuvres qui déconstruisent puis redessinent un nouveau visage du délinquant, ce que ne manque pas de souligner ironiquement le journaliste Sampiero Sanguinetti : « Comme le dit en substance Jacques Follorou : c’est la mafia, sans être la mafia, tout en étant la mafia. » (Jacques Follorou est un journaliste d’investigation du Monde, ndlr.) Tout annonce dès lors la trajectoire de Sandra Paoli, héroïne de la série Mafiosa.
Meurtres et forfaitures : à son image ?
En effet, « l’image » emblématique de la mafia dans la fiction reste celle de la série Mafiosa. C’est qu’il ne faut pas nier le goût du grand public pour le fantasme toujours renaissant d’une supposée cosa nostra, si présente dans le discours, si proche géographiquement (l’Italie), même s’il s’agit davantage d’un objet de pensée, avec lequel on aime jouer à se faire peur, voire à se sentir important !
Évacuons tout de suite la question du « réalisme » : Mafiosa est complètement imaginée et recréée, et non l’habillage maladroit de faits divers éparpillés. Le slogan de la série est, lui, immédiatement parlant : « L’homme le plus dangereux de Corse est une femme. »
En cinq saisons, nous suivons la chute et la rédemption d’une jeune avocate, devenue capo di tutti capi, la mafiosa Sandra Paoli : trente meurtres sont commis. Enfin, la dernière scène laisse supposer qu’elle-même est tuée par sa nièce Carmen – cette même Sandra qui confiait à la femme qu’elle aime :
« C’est ça ma vie. Des gens qui se tuent et des gens qui meurent. Même si je fais tout pour que ça s’arrête, ça ne marche pas. »
La trame de référence ici, ce n’est pas le réel, mais la tragédie grecque ; d’ailleurs le réalisateur Pierre Leccia a souvent comparé les Paoli aux Atrides, car dans la mythologie grecque, le destin des Atrides est marqué par le meurtre, le parricide, l’infanticide et l’inceste.
En résumé, la Corse présente deux faces, l’une solaire, rieuse, vacancière et festive, bref touristique. Mais un autre aspect, venu de croyances archaïques, révèle un fond tragique : celui des mazzeri, chasseurs de nuit qui, en rêve, viennent avertir les gens de leur mort prochaine. On peut y voir une sorte de préfiguration des « loups solitaires » du crime, ces berserkers de tradition nordique qui, importés sur les terres corses, ensanglantent eux aussi l’univers romanesque, car certains écrivains, comme François-Xavier Dianoux-Stefani, n’hésitent pas à installer une figure encore plus sinistre, celle du tueur en série, qui par haine du tourisme assassine d’innocents voyageurs :
« Choc terrifiant […]. Son crâne explose contre l’inox brillant des pare-buffles […]. Le monstre d’acier écrase littéralement la voiturette, la coupant en deux et broyant la passagère restée à l’intérieur. »
On peut au moins avoir une certitude : l’horrible et le sordide écrivent une fresque pleine de douleur, où extorsions, assassinats et vengeances défraient interminablement la chronique romanesque des vies sans destin. Après Mafiosa viendra une nouvelle série nommée Vendetta dont le réalisateur, Ange Basterga, dit qu’elle tordra le cou aux clichés. Soit ! mais le titre, lui, appartient bien aux stéréotypes du récit corse. Tant qu’à faire, les voyous de l’autrice Anna de Tavera étaient plus explicites, en ciblant le fléau majeur des sociétés contemporaines, corses et non-corses et ce, quel que soit le nom qu’on donne aux trafiquants qui en font métier :
« De toute façon […] il va falloir vous mettre dans vos têtes de politiciens que la drogue, c’est le monde entier ! »
Isabelle-Rachel Casta ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
08.12.2025 à 16:18
La gouvernance par les nombres ne façonne-t-elle pas trop les politiques publiques ?
Benjamin Benoit, Enseignant-chercheur en sciences de gestion (MRM-UPVD), Université de Perpignan Via Domitia
Hien Do Benoit, Enseignante-chercheure, Conservatoire national des arts et métiers (CNAM)
Stéphane Trébucq, RSE, développement durable, capital humain, pilotage de la performance, IAE Bordeaux
Texte intégral (1709 mots)
Les chiffres sont omniprésents dans les débats publics et apparaissent souvent comme une vérité objective. Or, ils ne sont pas produits ex nihilo. Pour ne pas être gouvernés par eux, il est essentiel d’apprendre à gouverner les chiffres.
Statistiques, classements, indices, tableaux de bord, indicateurs, jamais les chiffres n’ont occupé une place aussi centrale, à l’heure où une part croissante des activités est de nature digitale. Centraux dans les échanges et les argumentaires, leur pouvoir persuasif semble universel. Ils s’adressent tout autant aux experts, qu’aux citoyens ou journalistes, qui en font grand usage dans les médias.
Pourtant, derrière cette apparente neutralité, la quantification est une activité pouvant être biaisée par l’idéologie de ceux qui en opèrent la production et l’interprétation. Elle est devenue un langage de légitimation des réformes et un outil au service de pratiques rhétoriques, voire un instrument de discipline et de coercition.
C’est à ce titre que nos recherches s’inscrivent dans le débat plus large de la « gouvernance par les nombres », dont nous avons pu voir récemment les manifestations diverses à l’occasion de la pandémie de la COVID 19. Ces pratiques de management public et de communication politique amènent à soulever un ensemble de questions sur la rationalité des systèmes démocratiques.
Le tournant des années 2000
L’usage des chiffres pour gouverner n’est certes pas nouveau dans la mesure où l’État moderne s’est construit autour des statistiques, qu’elles soient démographiques, militaires, fiscales ou économiques. Mais depuis le tournant des années 2000, on observe une multiplication des indicateurs, indices et classements destinés à comparer, hiérarchiser et piloter les politiques publiques. Le baromètre des résultats de l’action publique française représente un bon exemple de cette tendance.
À lire aussi : Philosophie : penser la crise avec Bentham
Cette logique de pilotage reposant sur des indicateurs est supposée renforcer la transparence et la redevabilité – l’obligation de rendre des comptes – des décideurs envers ceux qui leur ont confié un mandat. On retrouve cette même logique à l’échelle internationale, dans le domaine éducatif, avec les classements PISA réalisés par l’Organisation de coopération et de développement économiques (OCDE), ou bien encore dans les domaines financiers ou de santé avec le Worldwide Governance Indicators et le Global Health Security Index.
Cette approche favorise l’usage d’indicateurs économiques – visibles, mesurables et rapidement évaluables – au détriment d’autres dimensions plus qualitatives (bien-être, justice, environnement) moins directement saisissables. Les données quantifiées guident alors les approches comparatives et créent un effet d’autorité. Un score faible peut attester d’une mauvaise performance, justifier une réforme et montrer l’évidence de l’utilité de débloquer des fonds.
Du panoptique au « panoptisme numérocratique »
La référence au dispositif du panoptique, décrit par Jeremy Bentham puis Michel Foucault, aide à mieux saisir un état de « visibilité permanente ». Dans ce modèle, un gardien placé au centre d’une prison voit sans être vu, incitant chacun à l’autodiscipline.
Avec les chiffres, les conditions de réalisation d’un « panoptisme numérocratique » sont réunies. Le contrôle devient multicentré puisque les chiffres viennent de multiples institutions telles qu’États, ONG, médias ou entreprises. Le contrôle n’est plus spatialisé dans le sens où il ne se limite pas à un lieu précis (une prison, une école, un espace territorial) mais se déploie dans tout l’espace public, sur des réseaux sociaux, dans les médias d’information.
Sa finalité est enfin diversifiée car les mêmes indicateurs peuvent aussi bien servir à informer, comparer, sanctionner ou encore à motiver des réformes. On voit ainsi poindre une nouvelle capacité de surveillance au travers des nombres, qui repose sur un maillage en réseau qui façonne l’acceptabilité des décisions publiques et l’adhésion des citoyens.
L’empire des chiffres
C’est ainsi que l’empire des chiffres transforme peu à peu notre rapport au pouvoir, dans la mesure où nous nous savons « évalués » et « guidés » en permanence par les nombres que nous côtoyons au quotidien. On en vient alors à s’interroger sur le fondement et la pertinence de tels chiffres présentés comme scientifiques et incontestables, alors qu’ils sont le produit d’une construction sociale et de choix méthodologiques.
Outre leur caractère discutable, ces dispositifs de quantification et d’optimisation peuvent apparaître oppressants et contreproductifs, en créant des effets de surcharge mentale. L’obsession des chiffres peut même se traduire par une perte de plaisir de sorte que l’activité cesse d’être vécue pour elle-même. Elle devient dominée par la performance numérique.
La crise Covid-19
La pandémie de Covid-19 a fourni une nouvelle illustration de la puissance des chiffres afin de conforter la légitimité de l’action publique. Chaque jour, la diffusion des courbes d’infections, des taux de vaccination ou des tableaux de bord publiés par les bureaux de l’Organisation mondiale de la santé (OMS) a permis de justifier les décisions des gouvernements. Ces indicateurs avaient vocation à comparer les situations respectives des pays mais aussi à servir d’appui à des décisions de confinement, avec des citoyens invités à intérioriser la logique des décisions prises à partir des indicateurs.
Certes, la quantification présente des avantages évidents. Elle favorise la transparence et renforce la redevabilité des gouvernants, si bien que les citoyens disposent de repères apparemment objectifs pour apprécier les décisions publiques. Mais ces avantages présentent un revers. Les indicateurs simplifient des réalités complexes et avantagent certains acteurs, à la suite de choix méthodologiques qui ont été opérés.
Quel impact sur la perception ?
Le cas du Vietnam apparaît intéressant à étudier, au regard de ses particularités culturelles, historiques et politiques. Les valeurs culturelles vietnamiennes reposent historiquement sur la recherche de l’harmonie sociale et de la solidarité. Les politiques publiques peuvent s’appuyer sur ce socle.
Dans la perspective d’une étude de la gestion publique et du rôle attribué à la quantification à l’occasion de la crise du Covid-19, nous avons collecté 24 000 réponses de professeurs et étudiants universitaires à propos de l’efficacité de la « gouvernance par les nombres ». La question centrale était la suivante : comment la transparence et l’utilisation intensive de données quantitatives ont-elles influencé la perception publique et l’adhésion des citoyens vietnamiens aux décisions prises pour gérer la pandémie ?
L’analyse de la perception des chiffres, de la confiance dans les décisions publiques et du rôle des données dans la stratégie de gestion de la crise montre, dans ce contexte institutionnel, une forte adhésion aux décisions prises sur la base des chiffres publiés.
La contribution de cette recherche met ainsi en lumière la performativité élevée des chiffres qui, non seulement apparaissent refléter la réalité, mais participent aussi de sa construction. Elle souligne également les limites d’une gouvernance par les nombres en termes de sursimplification et au risque d’une altération de la participation citoyenne à l’élaboration des décisions publiques.
Gouverner les chiffres
Ainsi, qu’il s’agisse d’Asie, d’Europe ou d’ailleurs, nous vivons désormais dans un monde où les chiffres sont devenus un langage universel de l’action publique. La « gouvernance par les nombres » n’est pas seulement la résultante d’une évolution technique mais participe d’une transformation sociale, en organisant la comparaison, en redistribuant l’autorité entre experts, gouvernants et organisations internationales, et en façonnant la perception des citoyens.
Toutefois, si un chiffre peut éclairer une décision, il ne peut pas en tenir lieu, d’où la nécessité de « gouverner les chiffres » en débattant de leur pertinence et de leurs limites. En effet, la question n’est pas tant celle des chiffres eux-mêmes que de la relation que nous entretenons avec eux, entre outils de légitimation et instruments de dialogue.
La gouvernance par les nombres peut constituer un levier de confiance ou de manipulation selon la transparence du processus et la capacité des citoyens à s’approprier les données. L’enjeu démocratique réside alors dans la manière dont les chiffres sont mobilisés, partagés et débattus.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
08.12.2025 à 16:17
Ce que révèle l’enquête sur le rôle des réseaux sociaux dans la crise de Madagascar 2025
Fabrice Lollia, Docteur en sciences de l'information et de la communication, chercheur associé laboratoire DICEN Ile de France, Université Gustave Eiffel
Texte intégral (1688 mots)
Antananarivo, 12 octobre 2025, le président Rajoelina a pris la fuite et l’armée s’est emparée du pouvoir, à l’issue d’une vaste mobilisation de la jeunesse, largement alimentée par la circulation d’images et d’informations sur les réseaux sociaux. Une enquête conduite peu après les événements montre la façon dont les Malgaches construisent leur vision de la vie politique dans l’espace numérique.
En septembre 2025, alors que la crise socio-politique s’intensifie à Madagascar, une réalité s’impose discrètement mais puissamment : l’essentiel du débat public ne se joue plus sur les ondes ni dans les colonnes des journaux, mais dans les flux rapides et émotionnels de Facebook et WhatsApp. En quelques minutes, une rumeur peut mobiliser, inquiéter, rassurer ou diviser. En quelques heures, elle peut redessiner la perception collective d’un événement.
Les résultats de notre récente enquête menée auprès de 253 répondants, complétés par 42 contributions qualitatives, révèlent que la crise est autant une crise politique qu’une crise de médiation où les réseaux sociaux deviennent les principaux architectes du réel. Derrière la simple perception de réseaux sociaux dédiés à la transmission d’informations, ils façonnent les émotions, orientent les interprétations et reconfigurent la confiance.
Ce basculement, largement anticipé par les sciences de l’information et de la communication (SIC), s’observe ici avec une netteté particulière. Les médiations traditionnelles (radio, télévision, presse) cèdent du terrain à des dispositifs socio-techniques qui redéfinissent la manière dont les citoyens perçoivent, réagissent… et croient.
Derrière la crise malgache, c’est donc une transformation plus profonde qui apparaît. C’est celle d’un espace public recomposé où l’attention, l’émotion et la vitesse deviennent les nouveaux moteurs de l’opinion malgache.
La fin des médiations traditionnelles : vers un nouvel environnement cognitif
Le déplacement observé dans l’enquête – de la radio et de la presse vers Facebook et WhatsApp – illustre ce que Louise Merzeau appelait une médiation environnementale. C’est-à-dire que l’information ne circule plus dans des canaux distincts mais s’inscrit dans un environnement continu, ubiquitaire, où chacun est simultanément récepteur et relais.
Dominique Cardon rappelait que les plateformes numériques transforment la visibilité publique selon des logiques de hiérarchisation algorithmique qui ne reposent plus sur l’autorité éditoriale mais sur la dynamique attentionnelle.
L’enquête confirme ce point : les Malgaches ne s’informent pas sur les réseaux, ils s’informent dans les réseaux, c’est-à-dire dans un écosystème où la temporalité, la viralité et l’émotion structurent la réception de l’information.
Conformément à un phénomène analysé dans les travaux de Manuel Castells, nous passons d’un modèle de communication de masse vertical à un modèle de « mass self communication », intensément horizontal, instantané et émotionnel.
Les plateformes comme infrastructures du réel : une crise des médiations
Yves Jeanneret indiquait que la communication n’est pas un simple transfert d’informations mais un processus qui transforme les êtres et les formes. Les résultats de l’enquête malgache confirment cette thèse.
L’enquête montre que 48 % des répondants déclarent avoir modifié leur opinion après avoir consulté des contenus numériques. Ce chiffre illustre ce que Jeanneret appelle « la performativité des dispositifs » : les messages ne se contentent pas de signifier ; ils organisent des parcours d’interprétations, orientent des sensibilités et éprouvent des affects.
La crise malgache est ainsi moins une crise de l’information qu’une crise des médiations, où l’autorité symbolique se déplace vers des acteurs hybrides (groupes WhatsApp, influenceurs locaux, communautés émotionnelles, micro-réseaux sociaux affinitaires).
L’espace public affectif : l’émotion comme norme d’intelligibilité
Les données de l’enquête – les répondants disent éprouver colère, peur, tristesse mais aussi espoir – confirment le constat formulé par Yves Citton selon lequel nous vivons dans un régime d’attention émotionnelle où les affects structurent la réception bien plus que les faits.
La viralité observée relève de ce que Morin nommait la logique dialogique. C’est-à-dire que le numérique agrège simultanément les forces de rationalisation (recherches d’informations, vérification) et les forces d’irrationalité (panique, rumeurs, indignation…). Ce qui circule, ce ne sont pas seulement des informations, ce sont des structures affectives, des dispositifs d’émotion qui modulent les perceptions collectives. Danah Boyd évoquait à ce propos le « context collapse », à savoir l’effondrement des cadres sociaux distincts qui expose les individus à des flux ininterrompus d’émotions hétérogènes sans médiation contextuelle.
Dans ce paysage, l’émotion devient un raccourci cognitif, un critère de vérité, voire un mode d’appartenance.
Une crise de confiance plus qu’une crise d’information
Dominique Wolton insistait sur le fait que la communication politique repose d’abord sur un contrat de confiance et non sur la quantité d’information disponible. L’enquête malgache montre que ce contrat est rompu : il en ressort que les réseaux sociaux sont jugés peu fiables (2,4/5) mais sont massivement utilisés ; que les médias traditionnels sont perçus comme prudents ou silencieux ; que la parole institutionnelle est jugée trop lente ; et que les algorithmes sont accusés de censure.
En résulte une fragmentation du récit national, chaque groupe social reconstruisant son propre réel, comme l’ont montré Alloing et Pierre dans leurs travaux sur les émotions et la réputation numérique. La crise révèle ainsi une dissociation entre l’autorité de l’information (affaiblie) et l’autorité des narratifs (renforcée).
De la désinformation à la fragilité cognitive : une lecture écosystémique
Réduire la situation à un phénomène de « fake news » serait, pour reprendre Morin, une « erreur de réduction ». La désinformation n’est ici que la surface visible d’un phénomène bien plus profond, qui est celui de la vulnérabilité cognitive structurelle. Elle repose sur : la saturation attentionnelle, la rapidité des cycles émotionnels, la fragmentation des médiations, le déficit de littératie médiatique et l’architecture algorithmique des plates-formes.
L’ensemble de ces éléments forment un écosystème au sens de Miège, dans lequel l’information et la communication ne peuvent être séparées des logiques techniques, économiques et sociales qui les produisent. C’est dans ce cadre que la souveraineté cognitive devient une question stratégique comparable à ce que Proulx appelait la nécessité de « réapprendre à habiter en réseaux ».
La nécessité d’une transition cognitive révélée par la crise
L’enquête révèle l’urgence, à Madagascar, d’opérer une transition cognitive. Cela implique une veille capable de détecter rapidement les signaux faibles, une communication publique adaptée au rythme émotionnel des plateformes, une éducation critique aux biais de réception et une coopération structurée entre État, régulateurs, société civile et plateformes pour encadrer la circulation des contenus.
Ces pistes s’inscrivent dans la perspective d’un « État élargi », c’est-à-dire un État qui reconnaît que la stabilité collective dépend désormais de nouveaux acteurs : infrastructures numériques, entreprises technologiques, médias sociaux, communautés connectées. Dans ce modèle, la confiance devient une infrastructure qui est le socle indispensable au fonctionnement de la vie publique, à l’image de l’électricité ou des réseaux de communication.
La crise malgache de 2025 n’est pas un accident. C’est un révélateur des transformations profondes de nos sociétés numériques. Elle montre un espace public recomposé où s’entremêlent architectures techniques globales, émotions collectives locales et médiations affaiblies. Elle a aussi entraîné une prise de conscience au sein des médias malgaches, qui développent désormais une approche plus réflexive sur ces enjeux. Comme l’écrivait Merzeau, « la mémoire est un milieu » ; en 2025, à Madagascar, le réel l’est devenu aussi.
Le défi dépasse largement la lutte contre la désinformation. Il s’agit désormais de reconstruire des médiations fiables, capables d’articuler faits, émotions et légitimité dans une écologie informationnelle où le vrai ne circule plus seul, mais au milieu de récits concurrents, d’affects partagés et d’algorithmes invisibles.
Fabrice Lollia ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
08.12.2025 à 16:16
L’intelligence artificielle au service de la médecine régénérative pour concevoir de nouvelles protéines
Jad Eid, Professeur de biophysique et bio-informatique, École de Biologie Industrielle (EBI)
Texte intégral (2057 mots)
Comment aider notre corps à se réparer après une blessure ? Trouver et produire les bonnes molécules qui stimulent la régénération cellulaire reste un défi pour la médecine régénérative. Mais l’intelligence artificielle assiste maintenant les chercheurs pour réussir à concevoir le composé chimique idéal.
La médecine pourra-t-elle un jour réparer durablement des tissus ou des organes gravement blessés ? Derrière cette question se cache un enjeu central de la médecine régénérative : contrôler finement le comportement des cellules. C’est ce qui permettra de maîtriser des processus déterminants tels que la cicatrisation, la croissance de nouveaux tissus ou encore la capacité des cellules à bien s’accrocher à leur environnement.
Lorsqu’un tissu est endommagé, les cellules ne savent pas, à elles seules, comment s’organiser pour le réparer. Elles s’appuient pour cela sur les signaux présents dans leur environnement immédiat, la matrice extracellulaire. Cette matrice est formée d’un réseau dense de protéines et de sucres qui non seulement soutient physiquement les cellules, mais leur fournit aussi des informations essentielles pour s’orienter, s’agréger ou migrer. À cette échelle, elle joue un rôle comparable à une cartographie biologique : elle indique aux cellules où aller, comment se fixer et quelles fonctions activer pour que la réparation tissulaire puisse se dérouler correctement. Mais parfois, ces mécanismes échouent à régénérer complètement les tissus.
Et si l’intelligence artificielle (IA) pouvait nous aider à franchir un cap dans ce domaine ? Aujourd’hui, les chercheurs explorent une voie émergente : concevoir, avec l’aide de l’IA, de nouvelles protéines capables de guider et de stimuler la régénération des tissus abîmés, là où les cellules ne réagissent plus spontanément. L’objectif est d’imaginer des molécules qui envoient aux cellules les bons signaux, au bon endroit et au bon moment, pour relancer un processus de réparation insuffisant ou défaillant.
Imaginer de nouvelles protéines pour guider les cellules
À terme, cette nouvelle façon de concevoir des protéines, appuyée par l’IA, pourrait contribuer au développement d’implants dits intelligents, de pansements bioactifs ou de thérapies personnalisées capables de dialoguer avec les cellules du patient. On peut imaginer, par exemple, un implant conçu pour interagir finement avec la matrice et les récepteurs cellulaires, afin d’accélérer la régénération d’un tissu après une chirurgie ou une blessure, de manière rapide, contrôlée et durable.
Au sein du laboratoire EBInnov de l’École de biologie industrielle, nous concevons des protéines simplifiées. Plutôt que d’utiliser une protéine naturelle dans son intégralité – qui sera fragile, longue et complexe à produire – nous en découpons les parties utiles qui permettent aux cellules de s’accrocher, de se déplacer vers une zone à réparer ou de recevoir un signal pour activer la cicatrisation. Cette stratégie repose sur le génie génétique : nous modifions et réassemblons l’ADN codant la protéine, puis nous l’exprimons biologiquement en laboratoire grâce à des bactéries modifiées.
Le recours à cette approche est motivé par deux impératifs scientifiques et industriels. D’un côté, nous obtenons une molécule plus simple, plus stable et plus facile à fabriquer que la protéine complète. De l’autre, nous pouvons tester plus précisément les fonctions que nous visons sans être perturbés par des régions de la protéine d’origine qui ne sont pas nécessaires, voire parfois gênantes.
La migration cellulaire se joue à petite échelle : il s’agit d’un déplacement local sur quelques micromètres, réalisé par des cellules de la peau ou du tissu conjonctif qui se dirigent vers une zone lésée pour déclencher la réparation du tissu. Ce guidage repose sur la signalisation cellulaire, un langage biochimique basé sur la reconnaissance et l’échange de motifs moléculaires, permettant aux cellules d’activer les bonnes réponses au bon moment. C’est ce langage que nous essayons d’apprendre et de maîtriser.
Un avantage majeur : tester virtuellement les molécules
Observer expérimentalement la structure 3D et les interactions entre protéines reste aujourd’hui lent et coûteux, car ces approches nécessitent des infrastructures lourdes et de l’expertise. À l’inverse, les méthodes récentes d’IA permettent d’inférer des formes tridimensionnelles très réalistes et très précises à partir de larges jeux de données.
Ces modèles apprennent les règles statistiques et physiques du repliement moléculaire, en s’entraînant sur des milliers de structures biologiques déjà élucidées. Cela fournit un avantage stratégique : évaluer virtuellement si une molécule conçue conservera ses zones d’interaction correctement exposées et atteignables par les récepteurs cellulaires, avant de la produire au laboratoire, réduisant ainsi le nombre d’essais exploratoires nécessaires in vitro.
Cette synergie entre design génétique simplifié, modélisation 3D par IA et simulations d’interactions moléculaires nous permet de rationaliser nos choix expérimentaux et d’anticiper la compatibilité biologique des protéines. Cela accélère aussi la conception de nouvelles biomolécules pour des matériaux thérapeutiques et cosmétiques bioactifs, tout en renforçant une ingénierie moléculaire guidée par les données et la simulation.
Prédire le repliement des protéines grâce à l’IA
Comprendre l’efficacité d’une protéine conçue en laboratoire impose de relier deux échelles : celle du corps humain et celle des interactions moléculaires, où tout se joue à la taille de quelques atomes et de quelques nanomètres. Une protéine est une chaîne d’éléments minuscules, des acides aminés, qui s’assemblent puis se plient spontanément pour former une architecture 3D. C’est cette forme qui lui permet ensuite d’agir comme un point d’ancrage, un message chimique ou un guide pour les cellules qui doivent réparer un tissu.
Un point essentiel est donc la prédiction de la structure tridimensionnelle de la protéine, c’est-à-dire la façon dont elle va se replier dans l’espace en fonction de la séquence d’acides aminés qui la composent. Cette tâche, historiquement difficile, a connu une transformation radicale avec l’émergence des modèles d’intelligence artificielle. Ces modèles sont entraînés sur de vastes bases de données combinant des séquences d’acides aminés et des structures déjà connues expérimentalement. Ils apprennent ainsi à établir un lien statistique entre la séquence et la forme finale de la protéine.
Concrètement, ils sont capables de prédire comment une protéine va se replier, un peu comme si l’on devinait la forme finale d’un origami complexe en ne connaissant que les plis de départ. Ils fournissent une forme 3D plausible en estimant, avec une grande précision, les distances entre acides aminés, les angles de repliement locaux et l’organisation spatiale des différentes régions de la protéine.
Dans notre projet, ces prédictions constituent une première évaluation critique de la cohérence structurale de la molécule que nous concevons expérimentalement. Elles nous permettent d’identifier les zones où les différentes parties de la molécule s’articulent entre elles et de repérer d’éventuels conflits de forme où une zone en gênerait une autre. Nous pouvons aussi localiser des régions potentiellement désordonnées ou trop flexibles et anticiper l’impact de ces caractéristiques sur la stabilité globale de la protéine et sur l’accessibilité de ses zones d’interaction.
Simuler les interactions dans un contexte biologique réaliste
Une molécule n’agit jamais seule : son efficacité dépend de sa capacité à interagir avec d’autres partenaires biologiques, au sein d’un environnement dense comme la matrice extracellulaire, où de nombreuses protéines, récepteurs et signaux coexistent en permanence.
C’est pourquoi, au-delà de la structure isolée, nous avons utilisé des approches de modélisation pour étudier comment notre molécule se comporte au contact de différents partenaires clés de la matrice. Cette phase d’analyse des interactions est essentielle : l’efficacité biologique d’une molécule dépend non seulement de sa capacité à se lier à ses cibles, mais aussi de la stabilité de ces liaisons dans le temps et de leur bonne compatibilité avec les récepteurs concernés.
Pour nous rapprocher des conditions biologiques réelles, nous avons simulé des systèmes complexes proches des tissus réels où des dizaines ou centaines de protéines identiques interagissent en même temps avec leurs cibles. Cela permet d’explorer des phénomènes de coopération entre molécules, de tester la robustesse des contacts lorsqu’elles sont nombreuses et d’analyser comment les domaines actifs se répartissent dans un espace tridimensionnel dense. Cette simulation nous permet de déterminer si les multiples copies de la protéine restent capables d’interagir ensemble sans perdre leur lisibilité biologique et sans se gêner physiquement.
Ces simulations fournissent des indices précieux sur la capacité de la molécule à maintenir des interactions efficaces malgré les contraintes physiques et géométriques de son environnement. Elles nous permettent de rationaliser la conception expérimentale, d’écarter certains scénarios peu prometteurs avant de passer à la paillasse, et ainsi de mieux cibler les expériences in vitro qui seront réellement informatives.
Vers une ingénierie moléculaire augmentée par l’IA
Ces approches ne remplacent pas l’expérience : elles nous permettent surtout de comprendre à l’avance si une molécule produite par génie génétique a la bonne forme, si elle garde ses zones d’action accessibles, et si elle peut maintenir des interactions solides dans un environnement aussi encombré que la matrice extracellulaire du corps humain. En bref, l’IA nous aide à mieux concevoir et à éviter de tester à l’aveugle, pour que les expériences menées ensuite sur de vraies cellules soient plus ciblées, pertinentes et rapides.
Si l’IA ouvre aujourd’hui un champ immense pour concevoir des protéines bioactives et des matériaux capables d’orienter la réparation des tissus, plusieurs verrous persistent encore dans la recherche académique. En premier lieu, il reste difficile de prédire la dynamique de la conformation des protéines sur de très longues échelles de temps. Un autre obstacle réside dans notre capacité à modéliser fidèlement tous les composants d’un tissu réel. Les prochaines étapes consistent donc à renforcer encore cette boucle vertueuse entre IA et biologie expérimentale, en intégrant davantage de données biologiques, en évaluant plus finement la tenue des interactions multiples et en préparant les validations in vitro les plus informatives possible.
Jad Eid ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- Dans les algorithmes
- Framablog
- Gigawatts.fr
- Goodtech.info
- Quadrature du Net
- INTERNATIONAL
- Alencontre
- Alterinfos
- CETRI
- ESSF
- Inprecor
- Journal des Alternatives
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview