
01.08.2026 à 17:32
Majorque se révolte contre un tourisme qui dépossède les habitants de leur territoire
Julio Batle Lorente, Profesor Titular de Universidad, Universitat de les Illes Balears
Texte intégral (2531 mots)

L’ESSENTIEL
À Majorque, les habitants dénoncent un modèle touristique qui aggrave la crise du logement et les pousse à quitter l’île.
Le surtourisme menace l’équilibre des territoires bien au-delà de la seule affluence des visiteurs.
Le concept de « touriste conscient de son impact » invite à repenser ses choix de destination, d’hébergement et d’activités.
Le dimanche 26 juillet 2026, la ville de Palma, capitale des îles Baléares, a été le théâtre d’une manifestation dirigée non pas contre les touristes, mais contre un modèle économique qui commence à considérer ses habitants comme un obstacle.
La manifestation, organisée par la plate-forme Menys Turisme, Més Vida (« Moins de tourisme, plus de vie » en majorquin), a rassemblé environ 25 000 personnes selon la police, et 70 000 selon les organisateurs. Les chiffres peuvent prêter à débat, mais pas la scène elle-même : des dizaines de milliers de personnes sont descendues dans la rue pour revendiquer le droit de continuer à vivre dans l’une des destinations touristiques les plus prisées au monde. Elles ne demandaient pas que Majorque cesse d’accueillir des visiteurs, mais que sa population n’ait pas à être chassée pour les loger.
Parmi les manifestants figuraient des habitants, des écologistes, des agriculteurs, mais aussi de nombreux salariés du secteur touristique. Leurs revendications ne laissent guère de place à l’interprétation : limiter les locations touristiques, réduire le nombre de places aériennes et de vols à destination des îles, et sortir d’une forme de monoculture économique qui consume le territoire, le logement et la vie quotidienne.
Il y a eu des affrontements avec les forces de l’ordre et des blessés, comme l’a rapporté The Times, mais réduire la manifestation à ces incidents reviendrait à passer à côté de son véritable message. Le conflit de fond n’oppose pas des habitants mécontents à des touristes innocents. Il met en tension deux droits qui n’ont plus le même poids : le droit, temporaire, de profiter d’un lieu, et le droit, permanent, d’y vivre.
Une destination touristique peut prospérer… et disparaître
Pendant des décennies, le succès des destinations touristiques a été mesuré à l’aune du nombre d’arrivées, de nuitées, du taux d’occupation ou encore des dépenses des visiteurs. Lorsque ces indicateurs progressent, on parle d’une bonne saison. Pourtant, une économie peut croître tout en détruisant les conditions qui permettent d’y vivre.
La rentabilité de chaque mètre carré peut augmenter, tandis que son utilité sociale diminue. La richesse produite peut s’accroître, tout en empêchant une infirmière, un policier, un enseignant ou un serveur de se loger. Une destination peut offrir aux visiteurs une liberté de circulation extraordinaire, tout en contraignant ses habitants à partir. C’est cette réalité qui n’apparaît presque jamais dans les statistiques : une destination peut prospérer comme produit touristique tout en échouant comme société.
Les locations touristiques n’expliquent pas, à elles seules, la crise du logement. Celle-ci est aussi alimentée par les investissements internationaux, la rareté du foncier, les achats spéculatifs, le manque de logements publics et des politiques publiques insuffisantes depuis des années. Mais minimiser leur rôle serait intellectuellement malhonnête.
Le chercheur Agustín Cócola-Gant décrit les locations touristiques comme un nouveau front de la gentrification. Ses travaux montrent que la prétendue économie collaborative dissimule souvent une opportunité d’accumulation de richesse pour les investisseurs et les propriétaires. Dans ce processus, l’habitant de longue durée cesse d’être le destinataire du logement pour devenir un obstacle à une rentabilité toujours plus élevée.
L’éviction, de surcroît, ne prend pas toujours la forme d’une expulsion. Elle peut se produire logement après logement. Un appartement se libère sans jamais revenir sur le marché résidentiel. Un commerce de proximité disparaît au profit d’une boutique tournée vers une consommation de passage. Les habitants s’en vont, l’économie du quartier change de visage, et ceux qui restent découvrent qu’ils ont toujours une adresse, mais qu’ils n’ont plus vraiment de lieu où vivre.
Parler de « tourismophobie » n’aide pas le débat
Majorque s’inscrit dans un mouvement de contestation territoriale plus large. À Venise, la mobilisation contre les grands navires de croisière a fait de ces immenses paquebots traversant la lagune le symbole d’une industrie dont l’ampleur n’était plus en adéquation avec la ville. Aux Canaries, des dizaines de milliers de personnes ont manifesté derrière un slogan difficile à surpasser : « Ici, des gens vivent. » À Barcelone, les pistolets à eau braqués sur quelques terrasses fréquentées par des touristes ont suscité bien davantage d’attention médiatique que la crise du logement à l’origine de la mobilisation.
Le terme « tourismophobie » parachève cette opération. Il transforme un conflit portant sur le logement, les salaires, les transports, l’eau, le foncier et les choix démocratiques en une simple réaction émotionnelle contre les étrangers. Il dépolitise le problème et, au passage, infantilise ceux qui protestent.
Les spécialistes du surtourisme Claudio Milano, Marina Novelli et Joseph Cheer montrent que le surtourisme ne se résume pas à un excès de visiteurs. Il apparaît lorsque la croissance touristique transforme durablement la vie des habitants, restreint leur accès aux services et aux espaces, et dégrade leur qualité de vie. Leurs travaux établissent également un lien entre ces mobilisations sociales et la contestation de modèles économiques fondés sur une forme de monoculture touristique, ainsi que sur l’idée, rarement remise en question, qu’il faudrait poursuivre la croissance à tout prix.
La vraie question n’est donc pas de savoir combien de personnes une île peut accueillir physiquement. Elle est de déterminer ce que ses habitants doivent sacrifier pour continuer à les accueillir.
Du tourisme responsable au touriste conscient de son impact
La recherche universitaire a forgé plusieurs concepts utiles pour comprendre cette évolution. La décroissance touristique, défendue par les chercheurs Robert Fletcher, Ivan Murray, Asunción Blanco-Romero et Macià Blázquez-Salom, considère que certains territoires n’ont pas besoin de mieux gérer leur croissance, mais de réduire concrètement la pression touristique : moins de capacités d’accueil, moins de vols, moins d’artificialisation des sols et une moindre dépendance économique au tourisme.
Il ne faut pas confondre cette approche avec le slogan « moins de touristes, mais des touristes qui dépensent davantage ». Cette proposition peut certes réduire certaines situations de surfréquentation, mais elle transforme aussi le territoire en un espace réservé aux plus aisés. Même discret, le tourisme de luxe occupe de l’espace, consomme des ressources et contribue à faire monter les prix.
La chercheuse Freya Higgins-Desbiolles déplace le débat de la quantité de richesse produite vers sa répartition : qui bénéficie des retombées économiques, qui en supporte les coûts, et quels droits doivent primer lorsque les intérêts du tourisme entrent en conflit avec la vie des communautés locales.
Le concept de justice de la mobilité, développé par Mimi Sheller, met en lumière une autre forme d’inégalité : toutes les mobilités n’ont pas le même pouvoir. Un visiteur peut traverser l’Europe pour un week-end, tandis qu’une femme de chambre est contrainte de parcourir chaque jour des dizaines de kilomètres parce qu’elle ne peut plus se loger près de son lieu de travail. La mobilité aisée des uns peut ainsi engendrer la mobilité forcée des autres.
Enfin, le concept de souveraineté touristique, que Carter Hunt, María José Barragán-Paladines, Juan Carlos Izurieta et Andrés Ordóñez relient aux luttes des communautés pour reprendre le contrôle de leurs moyens de subsistance, pose la question essentielle : qui est légitime pour décider de l’avenir d’une destination touristique ?
À partir de ces travaux, je propose une notion supplémentaire : celle du touriste conscient de son impact.
Le touriste conscient de son impact sait qu’il n’arrive pas dans un décor mis à sa disposition, mais sur un territoire déjà habité, traversé par des rapports de pouvoir et des conflits bien réels. Il comprend que sa liberté de circuler s’inscrit dans le quotidien de personnes dont la mobilité est, elle, beaucoup plus contrainte. Et il accepte une idée que le tourisme responsable tend souvent à éluder : à savoir que certains hébergements, certaines activités, voire certaines destinations, peuvent ne plus être moralement acceptables.
Il ne cherche pas seulement à réduire son empreinte. Il est prêt à renoncer.
La prise de conscience commence par un « non »
Un touriste conscient de son impact renoncerait à choisir Majorque pour un séjour de cyclotourisme. Non pas parce que le vélo serait immoral, ni parce que chaque cycliste poserait problème. Mais parce qu’une activité cesse d’être anodine lorsque sa concentration dégrade les conditions de déplacement de celles et ceux qui empruntent ces routes pour aller travailler, étudier, s’occuper de leurs proches ou simplement rentrer chez eux. Il choisirait un territoire moins saturé. Une autre période. Une autre activité.
De même, il n’utiliserait pas Airbnb – ni aucune autre plate-forme équivalente – dans les quartiers touchés par la gentrification, où les locations touristiques contribuent à chasser les jeunes qui y sont nés en rendant le logement inaccessible.
Nous pouvons débattre de l’ampleur exacte de chacun de ces effets, de la réglementation la plus efficace ou du poids respectif des différents facteurs. Mais lorsqu’un processus d’éviction des habitants est clairement à l’œuvre, utiliser un logement comme hébergement touristique n’est plus un choix privé sans conséquences.
La conscience touristique consiste à voyager en sachant reconnaître le moment où il vaut mieux choisir une autre destination. Le touriste conscient de son impact se pose une question qui précède toutes les recommandations, les certifications et les listes de bonnes pratiques :
« Est-ce que je devrais vraiment être ici, à faire cela ? »
Parfois, la réponse sera oui. D’autres fois, elle impliquera de changer de saison, d’hébergement ou d’activité. Et, dans certains lieux et à certains moments, la réponse sera tout simplement non.
Le droit de soustraire un territoire au marché
La souveraineté touristique signifie qu’une communauté peut décider de la quantité de tourisme qu’elle souhaite accueillir, des lieux où il est acceptable, des périodes où il peut avoir lieu et des conditions dans lesquelles il se développe.
Elle peut décider que certains logements doivent avant tout servir à loger des habitants. Elle peut limiter le nombre de navires de croisière, de véhicules, de capacités d’accueil touristiques ou de vols. Elle peut fermer un site saturé, retirer des licences et faire primer la pérennité d’une communauté sur la rentabilité maximale de ses actifs.
Cela ne revient pas à fermer les frontières. La souveraineté touristique n’est pas une quête de pureté identitaire, mais une expression de la capacité démocratique d’une communauté. Venise appartient d’abord à ses habitants, et non aux compagnies de croisière. Barcelone à celles et ceux qui y vivent, et non aux plates-formes touristiques. Majorque à ceux qui y construisent leur existence, et non à une industrie qui commercialise sa disponibilité.
Les visiteurs ont droit à l’hospitalité, pas à la souveraineté. Une population doit pouvoir conserver le droit de soustraire une partie de son territoire au marché touristique, même lorsque la demande est forte et que des visiteurs sont prêts à payer.
Le tourisme, un pouvoir sans élection
Le tourisme n’est plus seulement une activité économique. Il a acquis le pouvoir de façonner le territoire, l’emploi, le logement, les infrastructures et jusqu’au calendrier politique. Il agit désormais comme un pouvoir constituant, sans jamais avoir été élu.
La question n’est donc plus de savoir si le tourisme crée de la richesse. Il en crée. La vraie question est de savoir quelle forme de pauvreté il peut produire en retour : pauvreté en matière de logement, de temps, d’espace public, de perspectives et d’avenir.
Les graffitis et les messages apposés sur les voitures des habitants se multiplient. J’en ai moi-même affiché un – une seule fois –, rédigé en allemand, excédé de voir les routes secondaires constamment encombrées par les cyclotouristes :
C’est pathétique, oui. C’est un peu dérisoire, aussi. Et c’est un sujet délicat. Mais les touristes, tout comme les résidents étrangers installés dans des territoires touchés par la gentrification, ont besoin d’entendre certains messages, formulés avec respect, mais sans ambiguïté.
Julio Batle Lorente ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
01.08.2026 à 17:00
À l’heure d’Airbnb, qui sont les gagnants de la location de courte durée à La Rochelle ?
Raphaël Suire, Professeur des Universités en management de l’innovation, Nantes Université
Sylvain Dejean, Maitre de conférences en économie, La Rochelle Université
Texte intégral (1424 mots)
L'ESSENTIEL
Une étude analyse les revenus Airbnb réels et le revenu global des ménages qui louent leurs maisons à La Rochelle.
606 maisons louées sur Airbnb sont comparées à plus de 20 000 maisons non louées.
Les revenus associés à la location sont très inégalement répartis entre les ménages les plus modestes et les plus riches.
L’économie du partage, ou sharing economy, est venue avec ses promesses. Pêle-mêle, il s’est agi de faciliter grandement la rencontre entre une offre excédentaire et une demande, d’offrir une grande souplesse dans l’usage et puis le plus important, de générer un revenu dont on a souvent dit qu’il complète utilement l’existant.
L’objectif : produire du pouvoir d’achat pour les propriétaires et augmenter grandement la variété de ce qui est disponible, comme les logements. Regardons plus précisément qui gagne vraiment de l’argent avec Airbnb.
Au sein d’un projet de recherche, nous avons mené une étude sur l’agglomération de La Rochelle pour mieux identifier et analyser qui bénéficient le plus d’Airbnb.
Les ménages riches ? Modestes ? Les biens en front de mer ?
Un état des lieux
Concrètement, nous avons comparé 606 maisons louées sur Airbnb à plus de 20 000 maisons non louées. C’est une première en France, car jusqu’ici aucune étude n’observait à la fois les revenus Airbnb réels et le revenu global des ménages qui louent.
Pour ce faire, nous avons croisé trois jeux de données :
Les recettes réelles de taxe de séjour de la ville de La Rochelle. Il s’agit ici du prix payé, le nombre de nuits et le nombre de voyageurs pour chaque location réalisée en 2022 ;
Le cadastre qui décrit chaque logement ;
Les données fiscales de l’ensemble des ménages, consultées à partir d’un accès sécurisé aux données ministérielles (CASD).
Nos premiers résultats sont sans équivoque : les ménages aisés et propriétaires ne louent pas plus souvent que les autres, mais ils louent plus cher, jusqu’à 50 euros de plus par nuit.
Logements plus grands et mieux situés
Notre premier constat : les ménages qui louent sur Airbnb sont plus aisés que la moyenne. Leur revenu disponible annuel atteint 52 015 euros, contre 47 129 euros pour les autres. Ils possèdent aussi des maisons plus grandes, 111 mètres carrés en moyenne, contre 99 pour les ménages non loueurs.
Le second constat est plus inattendu. Une fois sur la plateforme, les ménages les 10 % les plus riches et les 10 % les plus modestes louent leur logement à peu près à la même fréquence. Le nombre de nuits louées dans l’année ne varie presque pas selon le revenu.
Ce qui varie, c’est le prix. À La Rochelle, une nuit se loue en moyenne 114 euros. Derrière cette moyenne, l’écart est conséquent. Les maisons des 10 % de ménages les plus modestes se louent près de 50 euros de moins par nuit que celles des 10 % les plus aisés. Et la raison est simple. Les ménages aisés possèdent des logements plus grands, mieux situés, plus proches du littoral ou du centre historique. Ce sont les caractéristiques du logement qui font le prix et pas l’effort du propriétaire.
Écarts de patrimoine
Autrement dit, Airbnb ne crée pas de nouvelles inégalités. La plateforme rend rentables des écarts de patrimoine qui existaient déjà. Il est évident qu’un logement bien placé rapportait déjà plus à la revente ou à la location classique ; Airbnb permet désormais d’en tirer un revenu quelques semaines par an, sans quitter son domicile.
Ce mécanisme rejoint le constat de l’économiste Thomas Piketty. Les revenus du patrimoine progressent plus vite que les revenus du travail alors les écarts de richesse se creusent. Nos résultats montrent que les plateformes numériques accélèrent cette dynamique en accentuant le rendement du capital foncier.
Filet de sécurité
Une autre dynamique apparaît. Chez les rares ménages modestes qui louent, les sommes gagnées comptent énormément. L’hôte médian de notre échantillon gagne 3 623 euros par an sur Airbnb. Pour un ménage aisé, c’est un appoint marginal, quelques pour cent du revenu ; pour les 10 % les plus modestes, cela représente jusqu’à 30 % du revenu disponible.
Qui sont ces ménages à la fois aux revenus modestes et propriétaires d’un bien attractif ?
Nos données ne permettent pas de trancher définitivement. Il peut s’agir de retraités dont la maison est payée, de ménages ayant hérité ou encore de foyers traversant une baisse temporaire de revenus. Pour ces derniers, la location de courte durée fonctionne comme un amortisseur. Elle permet de faire face à une contrainte budgétaire en activant un actif disponible, le logement.
Des enquêtes qualitatives menées aux États-Unis décrivent le même usage d’appoint.
À lire aussi : Comment Airbnb a changé le secteur du tourisme
Que dire alors ? Les revenus Airbnb se concentrent autour des ménages les plus riches. Pour autant, ils pèsent surtout en bas de la distribution. La plateforme amplifie les inégalités tout en dépannant une minorité de ménages fragiles.
Réglementer la location courte durée
Ce double effet interroge la régulation actuelle. En France, dans le cadre de loi ELAN, il existe une limite de la location d’une résidence principale à 120 jours par an. Cette règle unique traite de la même façon deux profils opposés. D’un côté, le propriétaire qui loue sa maison trois semaines en août. De l’autre, l’investisseur qui peut exploiter plusieurs biens à l’année et qui retire des logements du marché. Un véritable moteur de la crise du logement dans les zones touristiques.
Notre recherche suggère qu’une régulation plus fine est possible, voire doit s’imposer pour :
Protéger les hôtes occasionnels, dont l’activité ne retire aucun logement du marché résidentiel ;
Concentrer les contraintes sur les loueurs professionnels ;
Adapter la fiscalité. Puisque les plateformes rendent ces revenus visibles et mesurables, rien n’empêche de les taxer de façon progressive, en préservant l’appoint des ménages modestes.
Reste une question ouverte. La Rochelle est une ville moyenne où la location occasionnelle de résidences principales est présente. Qu’en est-il à Paris, Saint-Malo ou Barcelone, où la location de courte durée est largement professionnalisée ?
Les inégalités que nous mesurons entre ménages pourraient y prendre une tout autre ampleur, entre simples habitants et détenteurs de portefeuilles immobiliers. Mesurer et évaluer ceux qui capturent cette rente reste un impératif pour définir un régime fiscal moins aveugle et réducteur des inégalités de revenus.
Raphaël Suire a reçu des financements de l'Agence Nationale de la Recherche.
Sylvain Dejean a reçu des financements de l'ANR.
01.08.2026 à 12:02
Les plans de travail en quartz, à l’origine d’une crise de santé publique aux États-Unis et dans le monde
David Michaels, Professor of Public Health, George Washington University
Robert Harrison, Senior Attending Physician in Occupational Health, University of California, San Francisco
Texte intégral (2951 mots)

Dans l’imaginaire collectif, la silicose, grave maladie incurable qui détruit la fonction pulmonaire, est associée au travail des mineurs. Mais d’autres ouvriers y sont exposés. C’est notamment le cas de ceux qui travaillent la pierre synthétique, ou quartz aggloméré, qui voient également leur risque de cancer du poumon augmenter.
Si vous vous rendez chez Costco, Home Depot ou Lowe’s (des enseignes proposant notamment des matériaux de rénovation, NdT) pour acheter un plan de travail dans le cadre de la rénovation de votre cuisine, l’objet de votre commande sera vraisemblablement produit dans un atelier de fabrication travaillant un matériau appelé pierre reconstituée.
Souvent commercialisée sous le nom de « quartz », la pierre reconstituée est un produit synthétique contenant jusqu’à 95 % de quartz finement broyé, mélangé à des résines polyester ainsi qu’à des pigments. Derrière l’apparente facilité avec laquelle on peut se procurer ce matériau se cache un fait ignoré des consommateurs : les ouvriers qui découpent, meulent et polissent ces plans de travail s’exposent au risque de développer une maladie redoutable qui détruit leurs poumons, la silicose. Cette maladie évitable, pour laquelle il n’existe aucun remède, est mortelle, et il n’existe aucun remède.
Rien qu’en Californie, plus de 550 travailleurs ont reçu un diagnostic de silicose causée par cette pierre reconstituée depuis 2019. Parmi eux, au moins 100 ont subi une greffe pulmonaire ou sont en attente d’en recevoir une. Cette intervention, complexe, ne fait cependant que prolonger leur vie, sans pouvoir offrir de guérison durable. Entre 2019 et 2026, au moins 30 sont morts de silicose.
Respectivement épidémiologiste et médecin, nous sommes tous deux spécialisés dans les maladies professionnelles. Nous avons étudié les dangers liés au fait de travailler la pierre reconstituée. Selon nous, cette recrudescence des cas de silicose constitue une urgence de santé publique. Toutefois, cette tendance reste presque invisible en dehors de la Californie, car, à l’heure actuelle, dans la plupart des États américains, l’incidence de cette maladie ne fait l’objet d’aucun suivi.
Un matériau à la mode, mais dangereux
Introduite il y a seulement quelques décennies, la pierre reconstituée est devenue le matériau le plus prisé pour les plans de travail de cuisine. Elle est en effet plus résistante et souvent moins coûteuse que le marbre.
Or, lorsque les ouvriers découpent, meulent et polissent ces plans de travail en pierre reconstituée, des milliards de particules très fines de silice cristalline, enrobées de résines synthétiques et de pigments, sont libérées dans l’air. Les travailleurs les inhalent, et nombre d’entre eux développent une forme de silicose sévère et d’évolution rapide.
Comme l’amiante, la silice provoque à la fois des maladies respiratoires et le cancer du poumon. Dans ces ateliers, les ouvriers touchés sont jeunes – l’âge médian des travailleurs californiens atteints est de 46 ans, et l’âge médian au décès de 52 ans.
S’ils cessent de travailler la silice et vivent encore quelques décennies, leur risque de cancer du poumon, de maladie rénale et de diverses maladies auto-immunes demeure accru par rapport à celui de personnes non exposées.

On estime que 100 000 travailleurs sont employés dans les ateliers de fabrication de ce type de plan de travail aux États-Unis. Or, certaines études suggèrent que 20 % ou plus des travailleurs exposés développent une silicose. La prise en charge de ces malades peut coûter des millions de dollars par personne. La majeure partie des frais médicaux est prise en charge par Medicaid et d’autres programmes d’aide publique financés par les contribuables américains.
Malheureusement, de nombreux ouvriers de ces ateliers n’ont pas accès aux soins de santé – et encore moins à des spécialistes formés pour diagnostiquer et traiter la silicose.
Dans de nombreuses grandes surfaces de bricolage, la pierre reconstituée est préférée au verre broyé, alors que les plans de travail fabriqués à partir de ce matériau sont similaires, mais bien plus sûrs pour les ouvriers. En effet, les plans en verre broyés contiennent de la silice amorphe, beaucoup moins toxique que la silice cristalline de la pierre reconstituée. Problème : les consommateurs ignorent généralement l’existence de cette alternative.
Aux États-Unis, Ikea a cessé de vendre des plans de travail en pierre reconstituée en 2025 (en France et dans d’autres pays européens, en juillet 2026, Ikea continuait à vendre des comptoirs de cuisine sur mesure « fabriqués à partir de quartz broyé », NdT). Home Depot, Lowe’s et Costco vendaient quant à eux toujours des produits contenant de la silice cristalline en juin 2026.
Une hausse des cas et des procès en cascade
En 2016, à l’époque où l’un d’entre nous, David Michaels, occupait le poste de secrétaire adjoint au Travail à la tête de l’Occupational Safety and Health Administration (OSHA, l’agence américaine chargée de la sécurité et de la santé au travail), le seuil réglementaire d’exposition professionnelle à la poussière de silice en suspension dans l’air a été abaissé.
Cependant, se conformer à la norme fédérale de l’OSHA ne suffit pas à protéger les travailleurs des effets toxiques extrêmes de la pierre reconstituée.
En 2019, après que les Centers for Disease Control and Prevention (CDC) ont signalé 18 cas de silicose liés au travail de la pierre reconstituée en Californie, au Colorado, au Texas et dans l’État de Washington, des épidémiologistes californiens ont commencé à recenser la maladie chez les ouvriers de ces ateliers.
Depuis cette date, le nombre de cas annuels s’est révélé en constante augmentation. Il est désormais évident que tant que la pierre reconstituée contenant de la silice cristalline sera utilisée pour fabriquer des plans de travail de cuisine, des centaines de jeunes travailleurs courront chaque année le risque de recevoir un diagnostic de silicose.
Aux États-Unis, des cas de silicose ont été signalés dans plusieurs autres États, dont le Massachusetts, l’Illinois, New York, la Floride, l’Utah, l’État de Washington, le Nouveau-Mexique et le Colorado. Cependant, étant donné que la plupart des ouvriers de ces ateliers ne sont pas soumis à un dépistage de la silicose, il est légitime de supposer que des milliers d’autres travailleurs non diagnostiqués souffrent aussi de la maladie.
Aujourd’hui, partout aux États-Unis, des centaines de travailleurs tombés malades poursuivent en justice les fabricants et distributeurs de ces plans de travail mortels, ainsi que les grandes surfaces qui les commercialisent. Certains des premiers cas traités ont fait l’objet d’un règlement à l’amiable. En 2024, lors du premier procès à être allé jusqu’au jugement, un ouvrier de 36 ans atteint de silicose, ayant subi une double greffe pulmonaire alors qu’il était maintenu en vie artificiellement, s’est vu accorder 52 millions de dollars de dommages et intérêts.
Une épidémie mondiale en expansion
Des flambées de silicose ont accompagné, partout dans le monde, l’essor de la production de plans de travail en pierre reconstituée.
Caesarstone, une entreprise israélienne, a été l’une des premières à commercialiser ce matériau. Entre 1997 et 2010, 25 travailleurs israéliens ayant été en contact avec ses produits ont dû recevoir une greffe pulmonaire.
En Espagne, entre 2007 et 2024, 5 900 cas de silicose liée à la pierre reconstituée ont été recensés. En 2023, les médias ont révélé que le propriétaire d’une entreprise espagnole nommée Cosentino a reconnu avoir dissimulé les dangers liés au travail de ce matériau. Il a été condamné à une peine de six mois de prison avec sursis pour cinq chefs de blessures graves par négligence.
À mesure que les ventes de ce nouveau matériau progressaient à l’échelle mondiale, des cas de silicose chez les ouvriers de plans de travail se sont développés aux États-Unis (dès 2014), en Australie (2015), puis plus récemment en Grande-Bretagne, en Chine et à Taïwan (en France, où environ 358 000 salariés seraient exposés à la silice sous toutes ses formes, l’Agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail émettait une alerte en 2019, dans le cadre de son rapport sur le sujet ; Les travaux exposant à la poussière de silice cristalline alvéolaire issue de procédés de travail figurant sur la liste des procédés cancérogènes établie par l’arrêté du 26 octobre 2020)
En mai 2026, en réponse aux décès de jeunes travailleurs atteints de silicose, le Royaume-Uni a publié de nouvelles directives interdisant la découpe à sec des produits en pierre reconstituée, et a annoncé son intention d’inspecter 1 000 ateliers de fabrication.
En Australie, les autorités de santé publique ont commencé à renforcer les exigences de protection sur les lieux de travail dès 2021. Lorsque ces mesures se sont révélées insuffisantes pour maîtriser l’exposition à cette poussière mortelle, le gouvernement fédéral a interdit l’importation et l’utilisation de produits en pierre reconstituée contenant plus de 1 % de silice cristalline.
Pour continuer à vendre leurs produits en Australie, de nombreux fabricants, dont Caesarstone et Cosentino, commercialisent désormais des plaques fabriquées à partir de verre broyé plutôt que de quartz.
Mettre fin à la silicose liée à la pierre reconstituée aux États-Unis
En 2024, l’agence californienne de sécurité et de santé au travail (Cal/OSHA) a adopté une norme de sécurité au travail plus stricte que la réglementation fédérale existante. Toutefois, les moyens de contrôle – tant à l’échelle de cet État qu’à l’échelle nationale – restent désastreusement insuffisants. Avec les effectifs d’inspecteurs dont dispose actuellement l’OSHA au niveau fédéral, chaque lieu de travail où des ouvriers sont susceptibles d’être exposés ne peut être inspecté qu’une fois tous les 191 ans…
De plus, les employeurs font valoir que bon nombre de ces ouvriers sont des travailleurs indépendants, et que, de ce fait, leurs lieux de travail échappent à la compétence de l’OSHA.
Suivant l’exemple de l’Australie, l’agence californienne de sécurité et de santé au travail a entamé une procédure réglementaire d’urgence visant à interdire la fabrication et l’installation de produits en pierre reconstituée contenant plus de 1 % de silice cristalline. Les fabricants de plans de travail ripostent en promouvant une législation fédérale qui interdirait toute action en justice à leur encontre, leur permettant de commercialiser la pierre reconstituée sans jamais engager leur responsabilité.
Tant que les fabricants ne cesseront pas de produire ce matériau et que les distributeurs ne suivront pas l’exemple d’Ikea, qui a renoncé – aux États-Unis – à vendre des plans de travail en pierre reconstituée contenant de la silice cristalline, des milliers de travailleurs continueront d’être exposés à cette poussière mortelle, et un nombre bien trop important d’entre eux développeront une silicose ou un cancer qui auraient pu être évités.
David Michaels a reçu des financements de la Fondation McElhattan.
Robert Harrison ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
01.08.2026 à 12:01
Bavure scientifique : quand un grand physicien se penche sur les « pouvoirs » des sourciers
Denis Machon, Professeur, INSA Lyon – Université de Lyon
Texte intégral (2383 mots)
L’ESSENTIEL
Certaines personnes prétendent détecter la présence d’eau souterraine : les sourciers.
Yves Rocard a proposé une expérience pour tester leur prétendu « pouvoir ».
Lorsque l’on étudie sa méthode et l’analyse qu’il fait de ses résultats, on note de sérieux biais, ce qui permet de conclure à une bavure scientifique (et non une fraude).
Yves Rocard appartient à la classe des « grands scientifiques » français. Il a participé au développement de nouvelles disciplines comme les semi-conducteurs, la RMN et la radioastronomie, programmes de recherche majeurs qu’il a menés dans de prestigieuses institutions. Il a notamment été professeur à l’École Normale Supérieure, directeur du laboratoire de physique de cet établissement et conseiller scientifique du CEA.
À partir de 1957, le Pr Rocard se lance dans une étude scientifique insolite : comprendre l’origine de la sensibilité des sourciers, c’est-à-dire leur prétendue capacité à détecter la présence d’eau souterraine. Cette initiative peut paraître surprenante mais elle fait preuve d’ouverture d’esprit et s’attaque à un problème concret que le magnétisme pourrait expliquer. L’ensemble de sa démarche, de ses expériences, de ses résultats et interprétations est détaillé dans le livre « La science et les sourciers ». En lisant avec un œil critique, on découvre que cette étude est source de surprises.
Une expérience séduisante pour tester une hypothèse audacieuse
Yves Rocard propose une hypothèse pour expliquer le « signal du sourcier » : des variations locales du champ magnétique terrestre seraient induites par la circulation d’eau et certains humains y seraient sensibles.
Il propose alors une expérience pour tester cette hypothèse. Un protocole est mis en place pour générer un champ magnétique contrôlé. L’expérience consiste alors à placer le sujet (une personne affirmant avoir des capacités de sourcellerie) à proximité du fil électrique, en tenant un pendule dans sa main. Si le sujet est sensible aux champs magnétiques, cela devrait induire des mouvements musculaires et donc conduire aux mouvements de rotation du pendule. En changeant le sens du courant, le pendule devrait tourner dans le sens inverse.
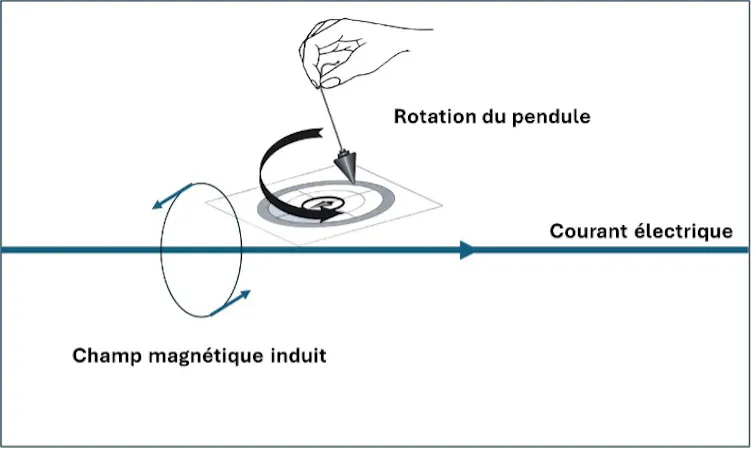
L’expérience se déroule à la campagne, dans une maison isolée afin de minimiser toute pollution « magnétique ». Dans un premier temps, on pratique une calibration. Le sujet à tester est placé à proximité du fil électrique et un opérateur impose le sens du courant électrique. Pour chaque sujet, on observe dans quel sens tourne le pendule quand le courant est dans un sens, puis dans l’autre. Ainsi, pour chacun de ces tests, le sens du courant est annoncé, on attend la stabilisation du pendule et on observe le sens de rotation. L’expérimentateur annonce ensuite qu’il inverse le sens du courant et constate si le sens de rotation s’inverse.
Sur cinq sujets initialement sélectionnés, seuls trois sujets présentent une réponse aux champs magnétiques, c’est-à-dire une mise en rotation du pendule lors du passage du courant et un changement du sens de rotation lors de l’inversion du courant. On pourra dès lors noter que le faible effectif de l’échantillon limite la portée statistique des résultats.
Les biais s’empilent
L’expérimentation peut alors démarrer. Or, dans le rapport qu’en fait le Pr Rocard, elle commence mal : « On envisage des expériences en aveugle. Elles n’étaient pas demandées par mes cinq sujets mais par un jeune homme, physicien de bonne formation expérimentale, venu là pour m’aider. Or, je n’avais rien préparé dans ce sens, ne connaissant pas à l’avance la sensibilité magnétique de mes sujets. Nous étions pressés par le temps, tous voulant bientôt rentrer à Paris ».
Être pressé par le temps ne crée pas les bonnes conditions de travail. Une expérience menée dans la précipitation a peu de chance d’être significative.
L’importance des expériences en aveugle en physique expérimentale était connue au moins depuis 1904 après le cas malheureux des rayons N. Les expérimentations en aveugle sont primordiales lorsque l’expérience est dépendante de la supposée objectivité humaine. Elles consistent à ne pas indiquer l’état du système et donc la réponse attendue à la personne testée lors de l’expérience. Peut-on imaginer ne pas trouver une balle sous une série de gobelets opaques si cette balle a été placée sous nos yeux ?
Dans le cas de l’expérience du professeur Rocard, les sujets doivent ignorer le sens du courant pour espérer une expérience discriminante permettant de valider ou non l’hypothèse. Même de bonne foi, les sourciers peuvent modifier le sens de rotation pour qu’il corresponde à celui observé lors de la calibration et valider ainsi l’essai.
Heureusement, suite à l’insistance de son assistant, le professeur Rocard met en place la possibilité « … de renverser le courant à l’insu du sujet ».
L’étape suivante consiste à prendre des précautions dans le « choix » du sens du courant que doit imposer l’opérateur. Le Pr Rocard rapporte : « le choix au hasard est à la discrétion de l’opérateur, celui-ci, fort honnête, est bien convaincu de jouer au hasard, et nous sommes disposés à admettre ce point sans discussion ».
C’est oublier que l’homme est en fait un très mauvais générateur de hasard et sujet au biais. Dans le protocole, il faut penser à utiliser un véritable hasard « objectif » afin de le rendre totalement imprévisible à l’aide, par exemple, des côtés pile ou face d’une pièce de monnaie. L’effet de biais peut conduire l’expérimentateur à produire une répétition prévisible de l’alternance du courant influant ainsi sur l’analyse statistique des résultats.
De petits arrangements avec les données
Au terme des différents essais sur les trois sujets, voici les résultats :

On observe que les résultats des sujets sont respectivement de 5/10, 4/10 et 4/10. Cela est très proche de la valeur attendue si le sens de rotation du pendule est pris au hasard (le sujet a alors une chance sur deux d’être en accord avec le sens du courant).
On peut conclure, comme le fait le professeur Rocard : « Cette expérience conduit à un échec assez visible ». On pourrait cependant s’interroger sur cette formulation. En quoi cela est un échec si aucun résultat préconçu n’était espéré ? C’est plutôt un succès si cette expérience permet de répondre clairement à la question « Le champ magnétique a-t-il une influence sur le sens de rotation du pendule ? »
Le professeur poursuit : « […], on observe sans peine que les résultats auraient été meilleurs si les séries avaient été plus courtes. Si on convient par exemple de réduire les séries aux quatre premiers coups seulement, les trois sujets s’améliorent beaucoup : les réponses deviennent exactes dans la proportion de ¾, ¾ et 2/4, évidemment meilleures ».
Or, en réduisant le nombre d’expériences pris en compte, la signification statistique se réduit. On pourrait pousser la démarche à son paroxysme : ne considérons que la première expérience. Dans ce cas, les sujets 1 et 3 ont un taux de réussite de 100 %. Reste le cas du sujet 2, peut-être mal disposé ce jour-là…
Dans son analyse des données qui s’ensuit, le Pr Rocard s’engage sur une voie qui n’est plus scientifique : « Il faut encore remarquer que chaque série a été immédiatement précédée de deux coups d’essai renforçant aussi l’imprégnation magnétique. A chaque série de quatre essais, on peut donc en rajouter deux qui sont toujours une réussite, ce qui donne pour des séries de 4+2 des proportions de réussite de 5/6, 5/6 et 4/6 ».
Les deux coups d’essai mentionnés sont les deux mesures de calibration qui sont en effet toujours réussies… sachant qu’elles ne pouvaient pas ne pas l’être. C’est un peu comme si, au mondial de football, l’arbitre de la rencontre entre l’équipe A et l’équipe B demandait à cette dernière, avant le début de la rencontre, de tirer deux fois dans le but adverse, sans gardien, afin de valider que l’arbitrage vidéo fonctionne bien et permet de détecter un but. Ensuite, à la fin de la rencontre qui se terminerait par un score nul, l’arbitre déciderait de rajouter ces deux premiers buts à l’équipe B.
Lors de cette relecture des données, on assiste à une dérive destinée à valider le scénario décidé dès le départ, cette expérimentation se voulant une démonstration de l’effet annoncé. Néanmoins, contrairement au cas des fraudes, tout cela est affiché, présenté et non-dissimulé, ce qui caractérise une bavure scientifique.
En guise de conclusion, M. Rocard termine par : « pourquoi pas ? Si cette procédure avait été convenue avant les expériences, tout le monde l’aurait acceptée ». Cela n’a pas été le cas…
La rigueur scientifique ne tient pas seulement aux compétences des chercheurs, mais aux méthodes qu’ils appliquent. En particulier, la méthodologie compte plus que le nom de l’auteur. Ainsi, la science est avant tout un processus : une expérience mal conçue ne prouve rien… sauf qu’elle est mal conçue.
Denis Machon ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
01.08.2026 à 11:57
What is Genocost? Understanding Congo’s new language of remembrance and justice
Catherine Maia, Professeure de droit international à l’Université Lusófona (Portugal) et professeure invitée à Sciences Po Paris (France), Sciences Po
Rui Garrido, Ph.D Candidate in Political Theory, International Relations and Human Rights, University of Évora
Texte intégral (1782 mots)

On August 2, the Democratic Republic of the Congo (DRC) commemorates Genocost Day, a national day of remembrance dedicated to the millions of victims of the violence that has affected the country since the outbreak of the First Congo War in 1996. First promoted by Congolese civil society in 2013, the commemoration was officially established under Congolese law in December 2022.
The term Genocost may be unfamiliar to many people outside Central Africa. Yet in the DRC, it has become an increasingly powerful symbol of collective memory and a rallying cry for justice. Combining the words “genocide” and “cost”, it seeks to draw attention to the human suffering associated with decades of armed conflicts, while highlighting the role played by the exploitation of natural resources in sustaining violence.
The concept emerged at a time when eastern DRC was — and remains — trapped in cycles of insecurity. Armed groups continue to operate, including in mineral-rich regions, while civilians bear the brunt of the violence and millions have been displaced. Against this backdrop, Genocost has become both a powerful vehicle for remembrance and a political demand for recognition.
But what exactly does it mean, and can it be understood as a legal category under international law?
Why August 2 matters
The choice of August 2 is not accidental. It marks the day the Second Congo War broke out in 1998.
Often described as “Africa’s world war”, it transformed a regional crisis into one of the deadliest conflicts of modern times.
Although estimates vary, millions of people are believed to have died as a direct or indirect consequence of the conflicts that have affected the DRC since the mid-1990s. These deaths resulted not only from direct violence, but also from disease, hunger and the collapse of essential services, often following displacement.
In recent years, Congolese authorities, building on civil society initiatives, have turned the anniversary into a broader day of remembrance for victims of conflict-related violence. The commemoration reflects a growing determination to preserve collective memory and secure greater recognition of the suffering endured by Congolese communities.
Why did the concept of Genocost emerge?
The origins of the concept lie in the long and devastating armed conflicts that the DRC has experienced for nearly three decades. Although their causes are complex, the control and exploitation of natural resources have played an important role in financing and prolonging violence. Eastern DRC contains significant deposits of coltan, cobalt, gold, tin and other strategic minerals that are essential to global industries, including electronics and renewable energy technologies.
For decades, United Nations reports, academic studies and investigations by civil society organisations have documented how armed groups, criminal networks and regional actors have benefited from the extraction and illicit trade of these resources. In many cases, competition for control of mining areas has fuelled violence and contributed to wider regional instability.
It was against this background that Genocost took shape. Its supporters argue that the suffering endured by Congolese communities cannot be understood solely through the conventional lenses of ethnic tensions, political rivalries and military confrontation. They contend that economic predation — and particularly competition over natural resources — has also been a major driver of violence. Genocost thus foregrounds the immense human cost of resource-linked conflicts.
When minerals fuel violence
One of the most distinctive aspects of the Genocost concept is the attention it draws to the destruction of livelihoods and the conditions necessary for survival, rather than to direct killing alone.
Violence in conflict zones is not limited to massacres. Entire communities can be progressively weakened through forced displacement, loss of access to land, destruction of local economies and disruption of essential services. Together, these processes can undermine their ability to survive and rebuild their lives.
This perspective is particularly relevant to the situation in eastern DRC. In conflict-affected areas, access to agricultural land, water, healthcare and economic opportunities is often severely restricted. Repeated displacement and persistent insecurity further weaken communities and hinder recovery and reconstruction efforts.
Supporters of the Genocost concept argue that these realities should be viewed not simply as consequences of war, but as integral components of systems of exploitation and domination. In their view, the pursuit of economic gain can create conditions in which large-scale human suffering is tolerated and, in some cases, becomes profitable.
Whether or not one accepts this interpretation in its entirety, it highlights an important dimension of contemporary conflicts: economic interests and violence are frequently interconnected.
Is Genocost a legal concept?
The growing prominence of Genocost raises an important legal question: can Genocost fall within the legal definition of genocide under international law?
Genocide is one of the most serious crimes recognised under international law. Under the 1948 Genocide Convention and the 1998 Rome Statute of the International Criminal Court, it comprises certain prohibited acts — including killing, causing serious bodily or mental harm, and deliberately inflicting conditions of life calculated to bring about a group’s physical destruction — committed with the specific intent to destroy, in whole or in part, a national, ethnical, racial or religious group.
This requirement is crucial. International tribunals have consistently emphasised that genocide is distinguished from other international crimes by this specific intent. The fact that atrocities produce catastrophic consequences is not enough: it must be demonstrated that the perpetrators intended to destroy a protected group as such. This is where attempts to bring Genocost within the legal definition of genocide encounter significant limitations.
Economic exploitation, however harmful, does not automatically amount to genocide. Individuals or groups may commit grave crimes in pursuit of profit without possessing the specific intent required by international law. Conversely, an economic motive does not exclude genocidal intent: the two may coexist.
This does not mean that acts associated with resource predation escape international law. Depending on the circumstances, they may constitute war crimes, crimes against humanity or genocide, provided that the relevant legal requirements — including, for genocide, the specific intent to destroy a protected group — are established.
Interpreting the definition of genocide too broadly could undermine the precision of international criminal law and blur the distinctions between different international crimes. The particular legal significance of genocide lies in its precisely defined elements, especially the requirement of specific intent.
Genocost therefore remains, at least for now, a political, memorial and analytical concept rather than an autonomous category of crime recognised under international law.
A powerful tool for memory and recognition
Yet these legal limitations do not diminish the broader significance of the Genocost concept.
One of its principal functions is to provide a framework for remembrance. For many Congolese citizens, the term offers a language through which decades of suffering can be acknowledged and remembered. It reflects a desire to ensure that victims are not forgotten and that the scale of the tragedy receives international attention.
The concept also challenges narratives that reduce the conflicts in the DRC to ethnic tensions alone. By emphasising their economic dimensions, it encourages a broader reflection on the structural factors that contribute to violence.
In this sense, Genocost can be situated within a broader global trend towards recognising historical and contemporary forms of collective suffering. Around the world, many societies have developed concepts and commemorative practices to preserve the memory of atrocities and honour victims.
Memory, after all, is not only about the past. It is also about the values societies choose to uphold in the present.
Beyond remembrance: a warning for the future
The significance of Genocost extends beyond commemoration.
The concept also serves as a warning about the risks associated with resource-fuelled conflicts in an increasingly interconnected world. As global demand for strategic minerals continues to grow, questions surrounding responsible sourcing, corporate accountability and conflict prevention are becoming ever more important.
International organisations, including the United Nations, recognise that mass atrocities rarely emerge suddenly. They are often preceded by patterns of exclusion, dispossession, exploitation and structural violence that gradually weaken communities and increase their vulnerability.
By drawing attention to these dynamics, Genocost promotes a preventive approach. It reminds policymakers, international institutions and civil society actors that peace cannot be achieved by military means alone. Addressing the economic interests and structures that sustain violence is equally essential.
For many Congolese citizens, the commemoration is not only about remembering the dead. It is also about demanding recognition, accountability and greater international attention to the violence that has too often been overlooked.
On August 2, as the DRC marks Genocost Day, the debate surrounding the concept is likely to continue. Whether or not it eventually influences legal thinking, its broader message remains clear: behind abstract terms such as “conflict minerals” and “displacement” are human lives and communities whose suffering deserves recognition.
Remembering those lives is not only a matter of justice for the past. It is also a necessary step towards preventing similar tragedies in the future.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
01.08.2026 à 11:57
Inde : la crise de la classe moyenne nourrit la colère étudiante
Christophe Jaffrelot, Directeur de recherche au CERI, Sciences Po
Texte intégral (2005 mots)
La mobilisation des étudiants à laquelle on assiste aujourd’hui en Inde s’explique en grande partie par la crise que traverse la classe moyenne indienne, marquée, notamment, par le chômage des diplômés et la baisse du pouvoir d’achat moyen. C’est que la classe moyenne supérieure s’est enrichie tandis que la classe moyenne inférieure s’est appauvrie.
Jusqu’au milieu des années 2010, l’idée suivant laquelle la classe moyenne de l’Inde avait vocation à s’élargir continûment paraissait une évidence. L’Inde avait flirté avec une croissance à deux chiffres au cours de la décennie 2004-2014 sous l’égide du premier ministre Manmohan Singh, le père de la libéralisation économique des années 1990, portée par les services informatiques et les investissements étrangers. La classe moyenne s’étoffait à ce moment-là grâce à l’essor de nouveaux emplois qualifiés.
Cette dynamique a permis l’émergence d’un groupe social composé de cadres d’entreprise, d’ingénieurs, d’informaticiens, de professions libérales et d’entrepreneurs. Cette classe moyenne s’est définie à la fois par ses revenus, par sa capacité de consommation et par un éthos social souvent associé aux hautes castes, notamment visible dans son opposition aux politiques de discrimination positive.
Mais cette catégorie est restée difficile à mesurer, car les critères utilisés varient fortement selon les organismes : revenus, consommation, patrimoine, niveau d’éducation, type de logement, emploi de col blanc ou auto-identification subjective. Dans les années 2010, plusieurs estimations ont nourri l’idée d’un essor spectaculaire de la classe moyenne indienne. Le think tank indien National Council of Applied Economic Research (NCAER) estimait en 2012 qu’elle représentait environ 142 millions de personnes, soit près de 12 % de la population. D’autres chercheurs, en utilisant des critères plus larges, l’évaluaient à 20 % de la population.
Sur cette base, des cabinets comme Ernst & Young, McKinsey ou Goldman Sachs prévoyaient une croissance rapide de cette catégorie, certains allant jusqu’à anticiper plusieurs centaines de millions de membres à l’horizon 2025-2040. Narendra Modi, lorsqu’il dirigeait le Gujarat, puis son gouvernement après 2014, avaient même mobilisé la notion de « neo-middle class » pour désigner les populations issues du monde rural et entrant dans une forme de modernité urbaine grâce à la croissance. Pourtant, cette notion a rapidement disparu du vocabulaire politique, car la dynamique d’expansion s’est essoufflée.
La classe moyenne indienne a atteint un plateau au milieu des années 2010. Selon le Pew Research Center, en 2017, seuls 108 millions d’Indiens appartenaient à la classe moyenne, définie par un revenu de 10 à 50 dollars par jour en parité de pouvoir d’achat, soit environ 8 % de la population. En ajoutant les plus aisés, la proportion reste proche des estimations antérieures, ce qui confirme l’absence de progression significative.
C’est que les revenus réels des catégories intermédiaires ont stagné entre 2013-2014 et 2023-2024. Les salaires réels ont même reculé dans plusieurs secteurs : industrie manufacturière, mines, énergie, services. Cette situation s’explique par la persistance de l’inflation, notamment alimentaire, et par la faiblesse de la croissance des revenus. Entre 2017-2018 et 2022-2023, le revenu réel urbain n’a quasiment pas progressé. Dans certains secteurs comme l’informatique, la distribution ou la logistique, les hausses des salaires nominaux ont été inférieures à l’inflation.
Les implications sociales d’une reprise en K
Ces moyennes masquent une différenciation interne croissante de la classe moyenne. Une partie des ménages autrefois classés dans cette catégorie a rejoint l’élite économique, tandis que la majorité des segments intermédiaires a stagné ou régressé. Les données du World Inequality Lab montrent en effet une concentration spectaculaire des revenus au sommet de la société : les 10 % les plus riches détenaient 57,7 % du revenu national en 2022-2023, contre 33,5 % en 1990. Le 1 % le plus riche détenait 22,6 % du revenu national, et le 0,1 % environ 10 %.
L’Inde compte désormais plus de 300 milliardaires. À l’inverse, les 40 % situés sous les 10 % les plus riches ont vu leur part du revenu national passer de 44,1 % en 1990 à 27,3 % en 2022-2023, tandis que les 50 % les plus pauvres ont chuté à 15 %. Cette situation conduit certains chercheurs, comme Lucas Chancel et Thomas Piketty, à parler d’une « missing middle class ».
Cette bifurcation « en K » se retrouve dans les modes de consommation. La moitié la plus pauvre des urbains consomme moins de 5 000 roupies par mois, tandis que les 5 % les plus riches consomment plus de quatre fois plus. Les ménages ont puisé massivement dans leur épargne après la pandémie, et cela n’a pas suffi : leur endettement atteint un niveau record, tandis que la demande de biens de consommation ralentit.
Les ventes d’automobiles sont révélatrices : malgré un faible taux d’équipement, le marché stagne, et seuls 12 % des Indiens seraient en mesure d’acheter une voiture. Les petites voitures, auparavant associées à la classe moyenne, reculent, tandis que les SUV et les véhicules haut de gamme progressent fortement, à l’instar des logements de luxe, des services hôteliers haut de gamme, et des billets d’avion en business class.
Cette polarisation paraît paradoxale au regard des taux de croissance officiellement affichés par l’Inde, souvent autour de 7 à 8 % depuis 2014, hors années Covid. Comment expliquer ce paradoxe ?
Premièrement, ces chiffres ont été contestés, notamment en raison de problèmes de comptabilité nationale et de surévaluation du secteur informel. Le FMI a lui-même critiqué la qualité des données indiennes. En réalité, la croissance aurait été surestimée de 1,5 à 2 points. C’est que plusieurs chocs ont frappé l’économie de plein fouet : la démonétisation de 2016, qui a retiré brutalement 85 % de la monnaie en circulation et affecté durablement l’économie informelle ; l’introduction mal gérée de la Goods and Services Taxes en 2017, qui a perturbé les PME ; puis la pandémie de Covid, qui a provoqué un effondrement de l’activité, un exode massif de travailleurs précaires et une crise sociale majeure.
Deuxièmement, depuis la pandémie, la reprise indienne est décrite, nous l’avons dit, comme une croissance « en K ». Les plus riches profitent de la croissance, tandis que les catégories populaires et intermédiaires stagnent ou déclinent. En 2024, les trois quarts des Indiens gagnaient moins de 15 000 roupies par mois, soit environ 140 euros. Cette reprise inégalitaire explique pourquoi la croissance macroéconomique ne se traduit pas par un élargissement de la classe moyenne. Elle profite surtout à une élite capable d’investir, de consommer des biens haut de gamme et de capter les opportunités de la mondialisation, tandis que les diplômés subissent un marché du travail dégradé.
Chômage des diplômés et turbulences dans l’IT
Les jeunes Indiens ayant fait des études supérieures connaissent des taux de chômage très élevés. En 2024, selon l’Organisation internationale du travail, le taux de chômage des diplômés atteignait 29,1 %, soit neuf fois plus que celui des personnes illettrées.
Ce nouveau paradoxe s’explique notamment par un décalage entre les attentes des diplômés et les besoins, tant qualitatifs que quantitatifs des employeurs. Les familles investissent lourdement dans l’éducation privée, souvent au prix d’un endettement important, ce qui pousse les jeunes à refuser des emplois peu rémunérés. Mais les employeurs estiment que beaucoup de diplômés ne disposent pas des compétences nécessaires. Les formations d’excellence, comme les Indian Institutes of Technology, restent très sélectives et ne forment qu’une petite minorité des ingénieurs. Et même ces institutions rencontrent des difficultés de placement, avec une chute importante des offres d’emploi en 2023-2024.
Le secteur informatique, longtemps moteur de l’essor de la classe moyenne, illustre cette crise. Le développement du IT indien a été favorisé par la sous-traitance occidentale, notamment autour du bug de l’an 2000, par la formation d’ingénieurs qualifiés et par des politiques publiques favorables, comme la création de zones économiques spéciales. Des entreprises comme Tata Consultancy Services, Infosys, Wipro ou Satyam ont fait de l’Inde une puissance mondiale des services informatiques. Le secteur représentait 7,4 % du PIB en 2022, contre 1,2 % en 1998, et ses exportations dépassaient 200 milliards de dollars au milieu des années 2020, les États-Unis absorbant une part dominante de ces exportations.
Mais le IT indien ralentit. La croissance du chiffre d’affaires s’est tassée, les investissements ont reculé et les effectifs cessent d’augmenter. L’automatisation et l’intelligence artificielle menacent une part importante des emplois. Les grandes entreprises du secteur ont commencé à réduire leurs effectifs : Infosys, Wipro, TCS ont licencié ou diminué leurs recrutements.
Le IT indien pourrait profiter de l’essor des Global Capability Centers, ou GCC. Ces centres sont créés directement en Inde par des multinationales étrangères pour internaliser certaines fonctions informatiques, financières, RH ou d’innovation. En 2025, l’Inde comptait environ 1 700 GCC employant 1,9 million de personnes, avec une croissance annuelle de 19 %. Ils pourraient se développer davantage en raison du coût de la main-d’œuvre qualifiée et des restrictions de visas aux États-Unis. Toutefois, ces centres ne recrutent pas massivement des jeunes diplômés généralistes : ils recherchent surtout des profils spécialisés, expérimentés, dotés de compétences avancées en IA, cybersécurité ou technologies de pointe. Cette évolution risque donc de renforcer la polarisation du marché du travail plutôt que de contribuer à élargir la classe moyenne indienne.
Au total, la classe moyenne connaît non pas une expansion linéaire, comme on l’imaginait dans les années 2000 mais une forte polarisation : si l’élite prospère, la classe moyenne inférieure est fragilisée. L’ascenseur social qui reposait sur le triptyque éducation/emplois dans les services (informatiques notamment)/urbanisation fonctionne moins bien qu’auparavant. Cette situation est particulièrement problématique dans un pays où, tous les ans, plus de dix millions de jeunes arrivent sur le marché du travail : c’est parmi eux, et dans la Gen Z, que se recrutent les manifestants aujourd’hui dans la rue.
Le prochain livre de Christophe Jaffrelot, L’ambition indienne : les paradoxes d’une nouvelle puissance, va paraître aux éditions Tallandier en octobre 2026.
Christophe Jaffrelot a reçu des financements de l'ANR. Il est membre de l'Association française de science politique.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- Dans les algorithmes
- Framablog
- Goodtech.info
- Libre à lire (April)
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview