
20.07.2026 à 17:15
La théorie de l’évolution est mal comprise : est-ce un problème de langue, de vocabulaire ou de psychologie ?
Nicolas Gergaud, Docteur en sciences du langage, Université Bordeaux Montaigne
Texte intégral (2387 mots)
Notre langue « ordinaire » peut-elle décrire correctement un savoir scientifique et des concepts très précis ? La difficulté s’accroît lorsque l’on utilise des mots qui n’ont pas le même sens dans l’usage courant que dans le champ des sciences. L’exemple de la théorie de l’évolution est particulièrement parlant.
La théorie de l’évolution semble souffrir d’un malentendu : si la biologie dispose d’un vocabulaire spécifique dont la fonction est l’univocité, la langue commune, elle, reste polysémique. C’est précisément dans cet écart, entre unicité et variété, que se logent les représentations qui accompagnent encore notre manière de penser l’évolution.
Mes recherches se situent dans le champ des sciences du langage. C’est en analysant une centaine de productions écrites d’étudiants en sciences de la vie qu’un constat s’est progressivement imposé à moi. Alors que je cherchais à décrire les caractéristiques du discours disciplinaire en anatomie comparée, j’ai rencontré une difficulté qui ne relevait pas uniquement de la maîtrise d’un lexique spécialisé ou d’une méthodologie discursive particulière : elle engageait plus largement la capacité de la langue ordinaire à exprimer des concepts issus de la biologie évolutive.
Les termes spécialisés – acide désoxyribonucléique, tétrapode, xylème, ostéichtyen et autres syncrétismes gréco-latins – remplissent une fonction spécifique. Ils permettent de désigner des objets et des phénomènes de façon univoque. Cependant, lorsque les biologistes mettent le savoir en discours, ils mobilisent nécessairement des mots du quotidien dont le sens déborde forcément du cadre scientifique. La difficulté n’est donc pas seulement de vulgariser un savoir complexe, elle est d’abord de traduire un système conceptuel à travers une langue qui par nature est culturellement marquée. Comprendre ce que disent les groupes de mots « théorie de l’évolution » et « les mammifères se sont adaptés » nécessite une posture particulière.
Le mot « théorie » ne signifie pas toujours la même chose
Le mot « théorie » par exemple, dans l’usage courant, renvoie à une opinion personnelle, parfois à une simple conjecture : on peut entendre des énoncés contenant « ma théorie, c’est… » en lieu et place « à mon avis, c’est… » (de cela devraient se méfier d’ailleurs les complotistes). En sciences expérimentales, le terme « théorie » désigne un cadre explicatif robuste, construit à partir d’observations et de résultats expérimentaux, éprouvés par les faits et toujours susceptible d’être révisé. Une théorie n’est jamais absolument vraie ; pour qu’elle le soit, il faudrait admettre qu’elle englobe tous les faits passés, présents et futurs, « la science serait terminée » enseigne le père de la méthode expérimentale, Claude Bernard.
Quant au verbe « s’adapter », avec son pronom réfléchi, il évoque une action volontaire, une capacité à modifier consciemment son comportement face aux circonstances. Pourtant, le discours de la biologie évolutive exclut toute intentionnalité. En effet, le vivant n’a pas décidé d’être ce qu’il est, et encore moins dans une optique d’adaptation. Dans une même population, les individus montrant certaines caractéristiques avantageuses dans un écosystème donné laisseront davantage de descendants. D’un point de vue évolutif, le vivant ne s’adapte pas : il est adapté.
Ces glissements de sens ne relèvent pas d’un simple malentendu lexical. Ils révèlent une manière spontanée de penser le vivant. Comme le montre la psychologie cognitive, nous sommes enclins à attribuer des intentions à des phénomènes naturels qui n’en possèdent aucune. Nous voyons des projets là où n’opèrent que des mécanismes physiques. Nous prêtons des stratégies à ce qui résulte de processus aveugles. Nous avons des intuitions et nous les prêtons aux choses.
L’anthropomorphisme naît de ce phénomène. Thierry Ripoll, professeur de psychologie cognitive à l’université d’Aix-Marseille, écrit dans son ouvrage Pourquoi croit-on ? (2020) que le système intuitif répond à un besoin de sens immédiat et à l’espoir de ne pas être le produit contingent de phénomènes dépourvus de finalité. Bref, nous aimons nous raconter des histoires pour mieux rêver. L’une des conséquences les plus persistantes de cette disposition cognitive consiste à interpréter l’évolution comme une marche vers le progrès.
Progrès ? Quel progrès ?
Le mythe du progrès sous-tend largement notre manière de penser l’évolution du vivant. Il constitue l’un des cadres interprétatifs à travers lesquels nous donnons intuitivement un sens positif à l’évolution. Pourtant, le progrès est une notion historique, sociale ou technique, il n’est pas une catégorie biologique. On peut parler de progrès scientifique, économique ou politique ; on ne saurait parler d’un progrès de la nature. Si une structure organique (comme l’œil par exemple) demeure dans les populations, c’est parce que l’efficacité fonctionnelle contribue à sa persistance, et non pas parce qu’elle représenterait une amélioration inscrite dans un projet d’ensemble. Nos yeux, nos poumons ou notre cerveau ne sont pas l’aboutissement d’un dessein, ils sont les produits contingents de l’histoire évolutive.
Pourtant, en dépit de la liste de mots à éviter en sciences de l’évolution, notre langage continue d’introduire partout des hiérarchies implicites. Nous parlons encore volontiers d’espèces « primitives », de « fossiles vivants », ce qui revient à parler d’organismes qui seraient « moins » ou « plus » évolués que d’autres (ce qui est erroné, convenons-en). Nous évoquons encore souvent une nature « bien faite », voire qui serait « inventive ».
La métaphore de la « sortie des eaux » fonctionne elle-même comme un récit de promotion où quitter le milieu aquatique reviendrait à franchir un degré supérieur de l’évolution. Mais que dire alors des méduses et des baleines ? Des bactéries ou des champignons ? Des plantes ? À quelle aune mesurerions-nous leur prétendue infériorité ? Ces questions n’ont, du point de vue de la biologie, aucun sens. Elles témoignent seulement de la persistance d’un imaginaire finaliste.
Une question socialement vive
Le savoir lié à l’évolution se heurte toujours à de multiples représentations sociales où se rencontrent croyances et biais épistémologiques. Si le débat scientifique catalysé par Darwin semble réglé, la théorie est loin de faire consensus dans la sphère sociétale : la théorie de l’évolution demeure une question socialement vive. Les difficultés de compréhension de la théorie de l’évolution ne relèvent pas d’une simple confusion terminologique.
Elles traversent l’école, l’université et, plus largement, la société. Récemment, une étude de l’IFOP révèle que 27 % des 18-24 ans sondés adhèrent à une représentation créationniste du monde (« les êtres humains ne sont pas le fruit d’une longue évolution d’autres espèces comme les singes mais ont été créés par une force spirituelle »), tandis qu’un quart des étudiants inscrits en licence ou en master conservent une représentation erronée de l’évolution. Dès lors, l’enjeu dépasse largement le cadre de la biologie : il touche à la manière dont la société s’approprie les connaissances scientifiques. C’est pourquoi la vulgarisation occupe une place décisive. Il ne s’agit pas seulement de rendre le savoir accessible, mais aussi d’éviter que le langage ordinaire ne réintroduise dans la narration des schémas de pensée que la théorie de l’évolution permet pourtant de dépasser.
Un storytelling contre-productif
L’une des images les plus ancrées de l’évolution reste celle d’un continuum linéaire, au travers duquel l’idée du primate « moins évolué » se redresse progressivement jusqu’à devenir un être humain assurément « plus évolué ».
Les documentaires sur la nature sont souvent des invitations au voyage. Mais, là où tout est supposé n’être qu’ordre et beauté, les récits consacrés au vivant sont largement imprégnés d’anthropomorphisme. La nature « invente », les animaux deviennent « ingénieux », les plantes « décident » et possèdent des « superpouvoirs » tandis que l’évolution déploie ses « ruses ». Pris isolément, ces procédés relèvent de nécessités narratives. Accumulés, ils composent cependant une véritable commedia dell’arte du vivant, où les personnages – le progrès, l’intention, le génie de la nature – avancent masqués. Dans ce « storytelling mental » : nous construisons des narrations qui nous procurent le sentiment de comprendre le monde. Ce qui facilite le récit brouille la compréhension de la théorie : il y a du bruit dans la transmission.
Tout cela indique que la vulgarisation peine encore à dépasser l’obstacle à la bonne transmission du savoir. Cela suppose peut-être de soumettre notre langue commune à l’analyse. À la lumière de La Psychanalyse du feu, nous sommes invités à nous interroger sur les images, les intuitions et les valeurs que nous projetons sur le monde. Il nous appartient sans doute d’exercer cette même vigilance à l’égard des mots par lesquels nous racontons le vivant. Pour la connaissance objective, rectifier le discours n’est pas seulement mieux dire la science ; c’est aussi apprendre à mieux la penser.

À partir de séquences d’ARN ribosomal, des chercheurs de l’université du Texas fournissent une représentation graphique de la parenté d’environ 3000 espèces actuelles. Cela prend la forme d’un cercle, dont chacun des points se trouve équidistant de l’ancêtre commun universel. Notre position n’y occupe aucun sommet. Homo sapiens partage le même temps évolutif que Gallus gallus(coq doré), qu’un chêne, un champignon ou une bactérie. Les degrés de complexité diffèrent ; le temps évolutif, lui, est identique. Aucune espèce contemporaine n’est plus évoluée qu’une autre.
Cette idée, de se situer au même rang évolutif que tous les êtres vivants, est peut-être l’une des plus difficiles à accepter, tant elle heurte nos intuitions. Elle exige que nous renoncions au récit du progrès pour penser l’histoire du vivant sans direction, sans intention et sans hiérarchie. Il nous faudra sans doute décoloniser notre imaginaire, non pour renoncer à raconter des histoires, mais pour apprendre enfin à raconter celle de l’évolution.
Nicolas Gergaud ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
19.07.2026 à 11:21
Les centres de données spatiaux posent aussi des risques écologiques. Qu’en dit le droit ?
Anna Hurova, Post-doctorante, Chaire Espace, École normale supérieure (ENS) – PSL
Texte intégral (2032 mots)

{kind=link}
Différents acteurs du spatial prévoient d’envoyer des centres de données en orbite, souvent sous la forme de constellations de nombreux satellites. Souvent, l’argument est de délocaliser les nuisances contre lesquelles des voix s’élèvent sur Terre. Mais les centres de données spatiaux ne règlent pas tous les problèmes, et en génèrent des nouveaux. Un regard juridique.
Le 30 janvier, l’entreprise SpaceX a sollicité l’autorisation de lancer un million de satellites dotés d’une capacité de calcul destinée à alimenter des modèles avancés d’intelligence artificielle (IA). À la fin du mois de mars, un premier modèle de satellite, l’AI Sat Mini, a été présenté : l’appareil mesurerait environ 170 mètres de long, dont près de 100 mètres de panneaux solaires, soit une dimension proche de celle de la Station spatiale internationale. Pour l’instant, le projet est encore en cours de développement et les caractéristiques précises de la configuration des satellites qui seront déployés au sein d’une constellation d’un million d’unités ne sont pas encore connues. Néanmoins, il permet d’illustrer les perspectives de ce futur déploiement.
Parallèlement, la Chine prévoit le lancement de la constellation Three-Body Computing Constellation, composée de 2 800 satellites. De plus en plus d’États et d’acteurs privés envisagent également le déploiement de satellites destinés à soutenir ce type de technologie.
L’émergence simultanée de ces projets témoigne d’une concurrence technologique particulièrement intense et met en lumière la nécessité de repenser, de manière qualitative, les cadres actuels de la gouvernance spatiale. Cette réflexion pourrait notamment s’inscrire dans le cadre des consultations relatives aux aspects juridiques et politiques de la gestion du trafic spatial au sein du Sous-comité juridique du Comité des utilisations pacifiques de l’espace extra-atmosphérique, ou encore prendre la forme d’un nouveau cadre normatif, tel qu’évoqué dans le Pacte pour l’avenir de l’ONU.
L’argument écologique contestable
L’objectif consiste à fournir une puissance de calcul inédite afin de faire tourner des modèles avancés d’IA de manière plus viable économiquement, directement dans l’espace. Cela concerne notamment le traitement des images satellitaires sans les dupliquer, par exemple pour la gestion des catastrophées, le suivi des ressourcés agricoles ou encore d’étude du climat, etc.
En effet, ces derniers consomment des quantités considérables d’électricité, et certains scénarios estimant qu’ils pourraient représenter jusqu’à 30 % de la consommation électrique européenne, ainsi que d’importants volumes d’eau nécessaires au refroidissement des infrastructures. Véolia rapporte par exemple que la consommation d’eau des centres de données de Virginie, aux États-Unis, est passée de 1,13 à 1,85 milliard de gallons entre 2019 et 2023.
Le projet de recherche ASCEND, mené par l’Union européenne, souligne également que le déploiement futur de capacités de traitement de données en orbite pourrait contribuer à la stratégie de réduction de l’empreinte carbone du secteur numérique, conformément aux objectifs du Pacte vert pour l’Europe.
À première vue, le transfert des centres de données vers l’espace apparaît comme une solution écologiquement prometteuse.
Plan d’encombrement des orbites et conséquences environnementales
L’espace peut sembler infini et détaché des contraintes environnementales terrestres. Pourtant, une approche systémique des interactions entre l’espace et la Terre permet de mettre en évidence de profondes interdépendances.
Il convient notamment de souligner que les projets visant à déployer des centres de données en orbite concernent principalement l’orbite basse, qui constitue déjà la région orbitale la plus encombrée. Dans le projet de SpaceX, par exemple, la constellation serait déployée à des altitudes comprises entre 500 et 2 000 kilomètres. Les satellites seraient répartis dans des « coquilles orbitales » étroites, d’une épaisseur maximale de 50 kilomètres chacune.
Or, le nombre d’objets en orbite autour de la Terre connaît une croissance extrêmement rapide. Aujourd’hui, on estime qu’environ 26 000 objets de plus de 10 centimètres se trouvent en orbite terrestre basse, dont près de 9 300 satellites actifs. À cela s’ajoutent environ 1,2 million d’objets mesurant entre 1 et 10 centimètres, ainsi qu’environ 130 millions de fragments compris entre 1 millimètre et 1 centimètre.
La combinaison du nombre actuel d’objets spatiaux et des futurs déploiements alimente les craintes liées à ce que l’on appelle le « syndrome de Kessler » : une réaction en chaîne de collisions générant toujours plus de débris et pouvant rendre certaines orbites inutilisables durant des décennies. L’augmentation du nombre et de la taille des satellites accentue ce risque et impose de repenser la gestion du trafic spatial.
À lire aussi : Pollution dans l’espace : et si on taxait ?
D’autres conséquences environnementales liées à ce type de projets méritent également d’être soulignées.
Tout d’abord, la dissipation thermique produite par les infrastructures orbitales dans le vide spatial pourrait créer des interférences nuisibles pour les satellites évoluant sur la même trajectoire et ainsi soulever des interrogations au regard de l’obligation de ne pas créer d’entraves injustifiées aux activités spatiales d’autres États, telle qu’énoncée à l’article IX du Traité de l’espace de 1967.
Ensuite, les impacts sur l’environnement terrestre associés aux lancements et aux rentrées atmosphériques des satellites suscitent des préoccupations croissantes. Les panaches d’émissions des lanceurs ainsi que les processus de désintégration atmosphérique pourraient notamment affecter la couche d’ozone.
Afin de mieux appréhender ces contraintes, il est possible de mobiliser la théorie des « limites de la croissance », initialement développée pour analyser les limites écologiques de l’expansion économique humaine.
Face à ces défis, le droit reste relativement limité
Plusieurs documents juridiques existent, mais ils sont insuffisamment coordonnés.
Les lignes directrices relatives à l’atténuation des débris spatiaux élaborées par les Nations unies, l’Agence spatiale européenne et l’Inter Agency Space Debris Coordination Committee abordent par exemple peu les impacts des débris spatiaux sur l’environnement terrestre. Par ailleurs, certaines mesures destinées à réduire les débris en orbite, comme la désorbitation des satellites, peuvent paradoxalement accentuer les effets sur l’atmosphère ou sur les écosystèmes marins.
D’autres instruments juridiques présentent également des limites. En particulier, le Protocole de Montréal relatif aux substances qui appauvrissent la couche d’ozone, même modifié par l’amendement de Kigali, ne prend pas en compte certaines substances issues de la rentrée des satellites, comme l’alumine.
Similairement, la Convention sur la pollution atmosphérique transfrontière à longue distance (c’est-à-dire qui exerce des effets dommageables dans une zone soumise à la juridiction d’un autre État, et à une distance telle qu’il n’est généralement pas possible de distinguer les apports des sources individuelles ou groupes de sources d’émission) ne s’applique pas à ce type de phénomènes.
Dépasser les limitations du droit actuel en s’appuyant sur les obligations des États en matière de changement climatique
En l’absence de règles internationales précises, les juridictions internationales pourraient jouer un rôle important. Dans son avis consultatif sur les « obligations des États en matière de changement climatique », la Cour internationale de justice a rappelé plusieurs principes importants :
Les activités menées au-delà de la juridiction nationale mais sous le contrôle d’un État peuvent engager sa responsabilité si elles causent un préjudice.
Les effets à prendre en compte ne se limitent pas aux impacts directs : les effets cumulatifs ou indirects doivent également être considérés.
La responsabilité d’un État ne consiste pas seulement à mettre en place des mécanismes institutionnels de contrôle, mais aussi à garantir l’effectivité et la qualité de leur mise en œuvre.
Ces principes pourraient servir de base juridique pour interpréter l’article IX du Traité de l’espace. Celui-ci prévoit notamment la tenue de consultations internationales lorsque les activités d’un État causeraient une gêne potentiellement nuisible aux activités d’autres États parties au Traité en matière d’exploration et d’utilisation pacifiques de l’espace extra-atmosphérique.
Dans un contexte de multiplication rapide des satellites, cette approche pourrait contribuer à développer progressivement un cadre juridique.
Anna Hurova ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
17.07.2026 à 10:58
À quoi servent les grosses boules orange suspendues aux lignes électriques ?
Rui Bo, Associate Professor of Electrical and Computer Engineering, Missouri University of Science and Technology
Texte intégral (1787 mots)

{kind=link}
Ces sphères orange que l’on aperçoit au-dessus des lignes à haute tension ne transportent pas l’électricité. Elles constituent en réalité un dispositif de sécurité aérienne aussi simple qu’efficace, conçu pour protéger les pilotes, leurs passagers et les personnes au sol.
Vous est-il déjà arrivé, sur l’autoroute, de lever les yeux et d’apercevoir ces grosses boules orange suspendues aux lignes électriques ? On dirait d’immenses perles enfilées sur les câbles à haute tension. Mais que font donc ces ballons de basket géants perchés là-haut ?
Je suis professeur et mes recherches portent sur les réseaux électriques, ces vastes infrastructures qui acheminent l’électricité des centrales jusqu’à nos maisons, nos écoles et nos entreprises.
Ces grosses boules orange ne servent ni à transporter l’électricité ni à améliorer le fonctionnement des lignes à haute tension. En revanche, elles remplissent une mission essentielle. Officiellement appelées « balises aéronautiques sphériques » ou « sphères de balisage », elles permettent aux pilotes de repérer les lignes électriques afin d’éviter que des avions ou des hélicoptères ne les percutent.
En quelque sorte, ce sont de grands panneaux d’avertissement suspendus dans le ciel, destinés à protéger les pilotes, leurs passagers et les personnes au sol.
De grands panneaux d’avertissement dans le ciel
Depuis un avion ou un hélicoptère, les lignes électriques peuvent être très difficiles à distinguer, en particulier lorsque les pilotes volent à basse altitude. Les câbles métalliques, très fins, se fondent facilement dans le paysage. Les boules orange rendent ces lignes beaucoup plus visibles. On peut les comparer aux bandes réfléchissantes d’un vélo : un dispositif simple, mais qui permet de repérer un danger avant qu’il ne soit trop tard.
Le choix de la couleur orange n’a rien d’un hasard. Cette teinte très vive est particulièrement visible pour l’œil humain et se détache nettement des couleurs plus discrètes de l’environnement, qu’il s’agisse du bleu du ciel, du vert des arbres ou du gris des nuages.
Il arrive que ces sphères soient rouges, blanches ou même rayées, mais l’orange reste la couleur la plus répandue, car elle offre une excellente visibilité dans la plupart des conditions d’éclairage.
Les règles de sécurité aérienne de nombreux pays précisent les couleurs à utiliser afin que les pilotes puissent identifier rapidement les obstacles. Aux États-Unis, par exemple, la Federal Aviation Administration publie des recommandations détaillant le balisage des obstacles situés à proximité des trajectoires aériennes.

Depuis le sol, ces sphères peuvent sembler à peine plus grosses que des balles de ping-pong. En réalité, la plupart sont beaucoup plus imposantes : elles mesurent environ 60 centimètres à 1 mètre de diamètre, soit la taille d’un gros ballon de plage.
Chacune pèse entre 4,5 et 11 kilogrammes, l’équivalent d’un grand sac à dos rempli de livres. Elles sont généralement fabriquées en plastique très résistant ou en fibre de verre, des matériaux également utilisés pour les bateaux ou les équipements d’aires de jeux. Elles peuvent ainsi résister pendant des années au soleil, à la pluie, à la neige, au vent… et même aux oiseaux qui viennent s’y poser de temps à autre.
Même si elles sont fixées sur des lignes transportant d’énormes quantités d’électricité, ces sphères ne sont pas elles-mêmes sous tension. Elles sont fabriquées à partir de matériaux isolants, qui ne laissent pas passer le courant électrique.
Pourquoi y a-t-il autant de câbles dans notre ciel ?
Les lignes à haute tension sont les autoroutes de l’électricité : elles acheminent le courant depuis les centrales où il est produit jusqu’aux lieux où il est consommé.
Les câbles sont suspendus entre de solides pylônes métalliques ou des poteaux en bois de grande hauteur. L’objectif est de maintenir ces lignes à haute tension suffisamment éloignées du sol pour garantir la sécurité des personnes qui circulent ou vivent à proximité. Certains pylônes de transport d’électricité, notamment ceux qui supportent les lignes à très haute tension, peuvent atteindre la hauteur d’un immeuble de 15 étages.
Si vous observez attentivement une ligne à très haute tension, vous verrez souvent trois gros câbles, parfois surmontés d’un quatrième, plus fin, appelé câble de garde. Placée au point le plus élevé, cette ligne est la plus susceptible d’être frappée par la foudre. Elle protège ainsi les autres câbles contre les surtensions susceptibles d’endommager les équipements ou de provoquer des coupures d’électricité. Relié à la terre, le câble de garde permet au courant de la foudre de s’écouler en toute sécurité le long du pylône jusqu’au sol.
Les trois principaux câbles fonctionnent ensemble pour transporter l’électricité selon un système triphasé. En répartissant le courant sur trois conducteurs plutôt qu’un seul, le réseau peut acheminer davantage d’énergie tout en limitant les pertes, ce qui améliore son efficacité.
Comment les boules sont-elles fixées aux câbles ?
L’installation des sphères de balisage aéronautique est réalisée par des équipes spécialement formées, qui interviennent souvent depuis un hélicoptère. Dans la plupart des cas, la ligne électrique reste sous tension pendant les travaux, ce qui exige des procédures de sécurité très strictes et une préparation minutieuse.
La sphère est constituée de deux demi-coques qui se referment autour du câble avant d’être solidement boulonnées l’une à l’autre.
Une fois en place, ces balises peuvent rester en service de 10 à 15 ans, selon les conditions météorologiques et leur environnement. Elles nécessitent peu d’entretien, mais les gestionnaires des réseaux les inspectent régulièrement afin de vérifier qu’elles ne sont ni fissurées ni trop décolorées.
Toutes les lignes électriques n’ont pas besoin de ces balises. Elles sont principalement installées dans les zones où les aéronefs sont susceptibles de voler à basse altitude, par exemple à proximité des rivières, des vallées, des aéroports ou des couloirs empruntés par les hélicoptères. Les lignes de distribution qui alimentent les quartiers sont généralement trop basses pour nécessiter un tel balisage.
La prochaine fois que vous apercevrez ces points orange dans le ciel, vous saurez donc qu’il ne s’agit pas d’un équipement destiné au transport de l’électricité, et que leur couleur n’a rien d’un hasard. Ces sphères sont des dispositifs simples mais ingénieux, conçus pour rendre le ciel un peu plus sûr.
Rui Bo ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
16.07.2026 à 17:18
L’affaire des rayons N : l’une des plus grandes bavures scientifiques de l’histoire
Denis Machon, Professeur, INSA Lyon – Université de Lyon
Texte intégral (2336 mots)
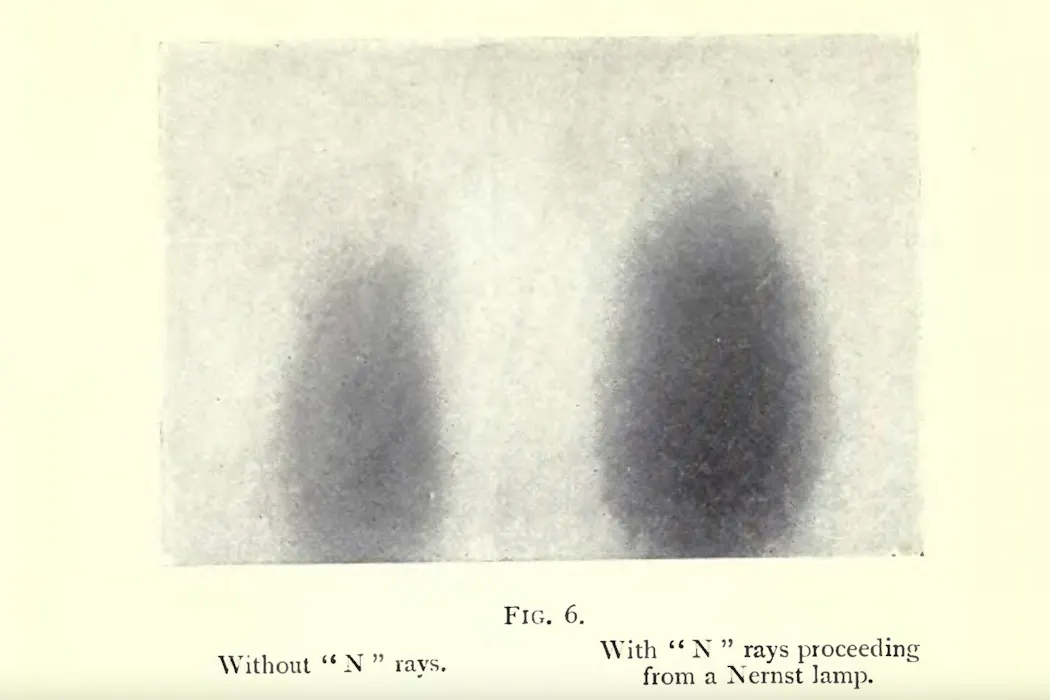
Il faut le croire pour le voir : voilà ce qui a conduit des scientifiques renommés à percevoir des rayons émis qui finalement n’existaient pas. L’affaire des rayons N illustre l’un des plus grands égarements collectifs de l’histoire de la physique, et rappelle pourquoi la science reste la meilleure protection contre ses propres illusions. Cette affaire constitue un exemple marquant de bavure scientifique.
En 1903, le professeur Blondlot, scientifique de premier plan, professeur à l’université de Nancy, membre de l’Académie des sciences reconnu pour son travail expérimental, publie une série d’articles dans les Comptes rendus de l’Académie des sciences sur la mise en évidence des rayons N (pour Nancy). Cette annonce s’inscrit dans une course à la découverte de nouveaux types de rayonnement. En 1895, les rayons X ont été mis en évidence par le physicien allemand Whilelm Röntgen (qui sera récompensé par le prix Nobel de physique) et en 1896, Becquerel découvre la radioactivité qui sera étudiée et comprise par Pierre et Marie Curie. Ces trois découvreurs se verront attribuer le prix Nobel de physique en 1903.

{kind=link}
Ces fameux Rayons N seraient émis lors d’une décharge d’une lampe électrique utilisant un bâtonnet céramique incandescent au lieu d’un filament métallique. Cette lampe développée par Walther Nernst est un dispositif innovant à cette époque. Blondlot affirmait que, lorsque les rayons N issus de la lampe atteignaient un écran faiblement éclairé, celui-ci devenait légèrement plus brillant. Cette variation était extrêmement subtile, proche du seuil de perception visuelle, et nécessitait un observateur expérimenté. Blondlot pensait ainsi pouvoir suivre la propagation, la réfraction et la diffraction de ces rayons, en s’inspirant des méthodes de l’optique classique.
En optique, lorsque l’on veut étudier un rayonnement complexe, on le décompose à l’aide d’un prisme. Par exemple, quand la lumière blanche passe au travers d’un prisme en verre, elle se décompose en une multitude de couleurs (longueurs d’onde) visibles. C’est la superposition de cet ensemble qui donne la lumière blanche.
Un problème de détecteur
Dans le cas des rayonnements observés par le Pr. Blondlot, l’étude des rayons N nécessite un prisme en aluminium que l’on place sur le trajet entre la lampe et l’observateur. Au début du XXe siècle, les scientifiques n’avaient pas encore à leur disposition des capteurs perfectionnés. Leur meilleur détecteur était… leur œil et cela nécessitait de travailler dans une quasi-obscurité. À cette époque, il s’agissait d’une pratique tout à fait acceptable. Néanmoins, pour répondre aux critiques de ce protocole à la suite de la publication des premiers résultats, des plaques photographiques ont ensuite été utilisées pour capter les Rayons N.

Malgré la fébrilité entourant cette découverte, une polémique entre les scientifiques français et anglais enfle (exacerbée par une rivalité scientifique nationale) puisque de nombreuses équipes de recherche anglo-saxonnes et allemandes ne parviennent pas à reproduire les observations des rayons N alors que des expériences de confirmation sont rapportées dans plus de 300 publications impliquant 100 coauteurs.
Une expérience à l’aveugle
En février 1904, la revue Nature consacre un éditorial discutant des expériences de Blondlot. Si la découverte est présentée avec sérieux, le texte souligne déjà le caractère inhabituel et délicat des observations, reposant sur de faibles variations de luminosité perçues à l’œil relayant ainsi certaines critiques issues de la communauté scientifique internationale.
Sans rejeter les résultats, la revue insiste sur la nécessité de confirmations indépendantes. Ainsi, Nature soutient la démarche indépendante du physicien américain Robert W. Wood, spécialiste de l’optique, curieux du phénomène qui se rend au laboratoire du professeur Blondlot pour étudier le protocole expérimental.
Il étudie sur place le protocole expérimental et comprend rapidement que l’observation à l’œil nu est très subjective et l’utilisation des plaques photographiques par l’équipe nancéienne pour apporter des preuves objectives de l’existence des rayons N n’est pas convaincante. En effet, Wood pressent que, la durée d’exposition étant critique, l’expérimentateur peut être tenté de surexposer la plaque, même inconsciemment. Il décide alors de mettre en place une variation dans l’expérience : lors des expériences dans la quasi-obscurité, il retire de temps à autre le prisme, élément majeur de l’expérience, à l’insu du Pr. Blondlot et de ses assistants. Ces derniers continuent pourtant d’observer les Rayons N.
En proposant cette méthodologie, Wood est précurseur dans l’utilisation de l’expérience « en aveugle » en physique expérimentale. Cette méthode consiste à mener une expérience dans deux configurations : une qui est censée donner un résultat positif et une autre un résultat négatif. Un observateur met en place une des deux configurations tandis que l’expérimentateur ignore le résultat qui doit être attendu. Ce protocole élimine les biais liés à la personne menant l’expérience, en particulier quand celle-ci souhaite voir des résultats positifs.
Wood conclut qu’il s’agit d’un phénomène d’autopersuasion que de simples expériences en aveugle auraient permis de mettre en évidence. L e rapport d’expérience qu’il produit dans la revue Nature à la suite de sa visite signe la fin de l’aventure des rayons N. Ainsi, pendant trois ans, un ensemble de scientifiques (de domaines différents : physiciens, biologistes, médecins) reconnus pour leurs qualités d’expérimentateurs ont perçu, à tort, les effets des rayons N. Environ 300 publications produites par une centaine de scientifiques ont documenté les propriétés de ces rayons inexistants. Il s’agit d’un cas d’hallucination, d’autoconfirmation collective, chacun alimentant la croyance portée par un enthousiasme scientifique débordant.
Des leçons toujours d’actualité
De cet épisode, nous pouvons retirer au moins deux leçons pour mener objectivement ou analyser des investigations scientifiques. Tout d’abord, la nécessité de prendre conscience du contexte ; une découverte, publiée dans la précipitation, surtout si elle se place dans le développement d’un nouveau champ scientifique, doit être reçue avec circonspection. En particulier, des affirmations extraordinaires nécessitent des preuves plus qu’ordinaires (au-delà de l’affirmation « je les vois » dans le cas traité ici). Deuxièmement, une adaptation simple du protocole expérimental telle qu’une expérience en aveugle permet souvent de conclure à l’existence ou non d’un phénomène.
Cet exemple du début du XXe siècle peut toujours nous éclairer sur notre présent. En effet, les attaques contre la science et ses institutions sont de plus en plus nombreuses, présentant les résultats issus de la démarche scientifique comme une opinion. Or, cette démarche est la plus sûre pour comprendre les mécanismes naturels. Elle permet de s’affranchir des a priori, des observations évidentes et même des scientifiques qui s’égarent.
Gardons tout de même en tête que la science, bien que construite sur la rationalité et la démonstration rigoureuse, est menée par des personnes influencées par leurs émotions. Oublier un temps la démarche scientifique peut conduire à des bavures scientifiques. Néanmoins, le processus de la démarche scientifique permet de corriger ces dérives inconscientes. Il faut bien distinguer ces égarements méthodologiques passagers des erreurs classiques de l’investigation scientifique. Ainsi, l’hypothèse largement acceptée de l’existence de l’éther comme support de propagation de la lumière s’est avérée inexacte. Cela fait partie intégrante de la démarche scientifique et est bénéfique dans la construction de la science. À l’autre bout du spectre, on trouve les fraudes scientifiques, de plus en plus nombreuses (par exemple Jan Hendrik Schön a délibérément fabriqué des données dans le cadre de ses recherches en nanoélectronique constituant ainsi un cas de fraude scientifique). Une bavure scientifique n’est pas une fraude, mais peut advenir lorsque les émotions prennent temporairement le pas sur la méthode.
Denis Machon ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
15.07.2026 à 16:23
Lutter contre les incendies avec des produits qui aggravent le changement climatique et nuisent à la santé : les pompiers au piège des PFAS
Gilles Mailhot, Directeur de Recherche, Centre national de la recherche scientifique (CNRS); Université Clermont Auvergne (UCA)
Texte intégral (2923 mots)
Les PFAS (substances per — et polyfluoroalkylées) ont d’abord été célébrés comme une innovation industrielle, permettant notamment de lutter plus efficacement contre les incendies. Aujourd’hui, ils sont pourtant au cœur d’une crise sanitaire et environnementale mondiale. Les pompiers sont pris au piège d’un cycle infernal, entre le besoin de PFAS pour protéger les populations (et eux-mêmes !), l’exposition à ces composés dangereux, et la contribution au réchauffement climatique des gaz fluorés libérés lors des feux… qui aggrave en retour les risques d’incendie.
Découverts à la fin des années 1930, les PFAS sont des composés synthétiques qui ont séduit l’industrie grâce à des propriétés uniques : une stabilité thermique exceptionnelle, une résistance chimique remarquable, ainsi qu’une capacité à réduire fortement la tension superficielle des liquides, les rendant à la fois hydrophobes et lipophobes.
Ces caractéristiques en ont fait des ingrédients incontournables dans de nombreux secteurs : des revêtements antiadhésifs (comme le PTFE, plus connu sous le nom de Téflon) aux textiles imperméables… en passant par les mousses extinctrices utilisées par les sapeurs-pompiers.
Pourtant, leur persistance extrême dans l’environnement, on les surnomme d’ailleurs les « polluants éternels », et leur bioaccumulation dans les chaînes alimentaires ont progressivement révélé un envers du décor : ces substances, conçues pour protéger, sont devenues une menace insidieuse pour la santé humaine et les écosystèmes.
Aujourd’hui, cette contradiction entre innovation et risques est particulièrement poignante dans la lutte contre les incendies, et l’exposition des pompiers qui sont en première ligne.

Les PFAS, alliés historiques de la lutte contre l’incendie
Dans le domaine de la sécurité incendie, les PFAS jouent un rôle décisif depuis les années 1960. Leur incorporation dans les mousses a permis une avancée majeure dans l’extinction des feux de liquides inflammables (hydrocarbures, solvants, etc.). En effet, en formant un film aqueux à la surface du combustible, ces mousses isolent l’oxygène et étouffent les flammes avec une efficacité inégalée.
Les PFAS ont également été intégrés dans les équipements de protection individuelle des sapeurs-pompiers (tenues, gants, bottes) pour améliorer leur résistance thermique, leur imperméabilité et leur résistance aux hydrocarbures.
Ces innovations ont transformé les conditions de travail des pompiers : ils permettent de réduire les temps d’intervention grâce à une extinction plus rapide des feux ; de mieux protéger les pompiers eux-mêmes contre les brûlures et les projections de produits chimiques ; et de diminuer leur exposition aux fumées toxiques en limitant la durée des opérations en milieu hostile.
Sur le papier, les PFAS semblaient donc parfaits : ils sauvaient des vies et protégeaient l’environnement en réduisant la durée des émissions polluantes liées aux incendies. C’était sans compter les conséquences imprévues.
L’exposition multiple des sapeurs-pompiers : un risque sous-estimé
L’omniprésence des PFAS dans l’univers des pompiers en fait aussi une source majeure d’exposition professionnelle.
Celle-ci ne se limite pas à l’utilisation directe des mousses extinctrices. Elle est multiforme et diffuse, car les équipements de protection individuels, l’environnement des casernes, les fumées, l’eau et les sols sont tous contaminés.
En effet, sous l’effet de l’usure, des lavages répétés, de la chaleur ou du contact prolongé, les PFAS peuvent migrer depuis les tissus ou les revêtements des équipements de protection et pénétrer l’organisme par contact cutané ou inhalation.
De plus, les poussières, les véhicules d’intervention, les casiers ou les sols des centres de secours sont souvent imprégnés de PFAS, créant une exposition chronique pour les pompiers — même en dehors des opérations.
Les PFAS présents dans les matériaux touchés par le feu (moquettes, isolants, plastiques) se dégradent partiellement lors des combustions et libèrent des composés toxiques inhalés par les pompiers.

Enfin, les exercices d’extinction ou les interventions sur des sites industriels peuvent laisser des résidus de mousses d’extinctions qui polluent durablement les nappes phréatiques, exposant les pompiers par ingestion ou contact lors de futures interventions.
Cette exposition cumulée est d’autant plus préoccupante que les PFAS sont associés à des risques sanitaires graves : cancers (rein, testicules, pancréas), troubles thyroïdiens, immunodépression, complications pendant la grossesse, ou encore maladies hépatiques.
Des études épidémiologiques ont mis en évidence des taux élevés de pathologies chez les professionnels exposés.
Le cycle infernal : PFAS, réchauffement climatique et multiplication des feux
Mais le paradoxe ne s’arrête pas là. Les PFAS contribuent à aggraver la crise climatique, créant un cercle vicieux. En effet, lors des feux, les PFAS se volatilisent : c’est-à-dire que, loin de disparaître, ils passent dans l’atmosphère.

D’une part, les PFAS à chaîne carbonée courte (entre 1 et 4 atomes de carbone) possèdent une tension de vapeur élevée à température ambiante, ce qui leur permet de passer en phase gazeuse naturellement.
D’autre part, les PFAS à chaîne longue soumis à de hautes températures (comme lors d’un incendie) se décomposent et libèrent des gaz fluorés. Ceux-ci ont des pouvoirs de réchauffement global colossaux, jusqu’à 23 000 fois supérieur à celui du CO₂ pour certains composés comme le tétrafluorométhane (CF4) ; et leur durée de vie atmosphérique se mesure en centaines voire en dizaines de milliers d’années, bien au-delà de celle du CO2.
Le problème est donc autoentretenu : les PFAS favorisent l’extinction des feux mais leur contribution au réchauffement climatique est de nature à augmenter la fréquence et l’intensité des incendies, notamment dans les régions tempérées comme l’Europe du Sud.
Résultat : les sapeurs-pompiers sont contraints d’intervenir plus souvent, s’exposant davantage aux PFAS… qui aggravent le problème. Un cercle vicieux dont il est difficile de sortir.
Vers une réglementation équilibrée : comment protéger sans sacrifier la sécurité ?
Face à ces constats, les autorités sanitaires et environnementales ont réagi. En Europe, la réglementation REACH et la directive de 2020 sur l’eau potable ont déjà restreint l’usage de certains PFAS, et une interdiction totale est en discussion pour 2025-2030.

Aux États-Unis, l’Agence de protection de l’environnement (dite « EPA ») a fixé des seuils maximaux pour les PFAS dans l’eau potable, tandis que plusieurs États ont banni les mousses contenant ces substances.
Pourtant, dans le domaine de la lutte contre l’incendie, une approche progressive s’impose. Une interdiction brutale des PFAS dans les mousses et les équipements de protection en l’absence d’alternatives aussi performantes pourrait compromettre la sécurité des pompiers.
C’est pourquoi les experts scientifiques plaident pour un phasage réaliste, permettant aux industriels de développer des solutions de remplacement (mousses sans PFAS, équipements innovants) ; un accompagnement des professionnels, avec des campagnes de dépistage pour les pompiers exposés et des protocoles de décontamination des casernes ; une recherche active sur les alternatives durables, comme les mousses à base de tensioactifs biodégradables ou les revêtements sans fluor (le fluor se lie très solidement aux atomes de carbone et rend les PFAS extrêmement résistants à la dégradation).
Le projet ALERT-PFAS : éclairer pour agir
C’est dans ce contexte complexe que le projet européen ALERT-PFAS Interreg Sudoe a été lancé en 2024. Un de ses objectifs est de comprendre le cycle de vie des PFAS dans l’univers des sapeurs-pompiers, depuis leur utilisation jusqu’à leur dispersion dans l’environnement, en passant par leur impact sur la santé des professionnels.
Nous avons mené une campagne de mesures des PFAS inédite au niveau du Service Départemental d’Incendie et de Secours de l’Hérault (SDIS34) mais aussi en Espagne et au Portugal, des pays partenaires du projet.
Nous analysons des sources d’exposition des pompiers aux PFAS (mousses, équipements de protection, fumées, eaux usées) et modélisons les risques pour identifier les scénarios les plus critiques et proposer des mesures de prévention ciblées.
Enfin, nous sensibilisons les acteurs (pompiers, élus, industriels) aux enjeux des PFAS et aux bonnes pratiques pour limiter leur impact.
L’auteur remercie pour leurs contributions : le Lieutenant-Colonel Raphaël DU BOULLAY et Fanny CHOULET du SDIS 34 (sapeurs-pompiers de l’Hérault) ; Mona SEMSARILAR, directrice de recherche CNRS à l’Institut européen des membranes ainsi que Georginan BOUTAOUAKOU et Florence CHARNAY-POUGET de l’Institut de Chimie de Clermont-Ferrand.
Gilles Mailhot a reçu des financements du programme Interreg Sudoe pour le projet ALERT-PFAS.
14.07.2026 à 18:48
Quel est le point commun entre les muons cosmiques et l’astronaute Sophie Adenot ?
Fabrizio Bucella, Full Professor, Université Libre de Bruxelles (ULB)
Texte intégral (2712 mots)

Alors que vous lisez ces lignes, vous êtes bombardé en permanence par une dizaine de milliers de muons cosmiques. On a beau ne pas s’en rendre compte, cela reste vertigineux. Ce qui est très curieux, c’est que ces muons sont des particules particulièrement instables, qui ne vivent en moyenne que 2,2 microsecondes avant de se désintégrer en électrons.
Mais alors, d’où viennent-ils et comment nous atteignent-ils ? Curieusement, la réponse a à voir avec l’âge du capitaine, ou plutôt celui de Sophie Adenot quand elle reviendra de la station spatiale internationale.
Les rayons cosmiques primaires arrivent de l’espace. Ce sont essentiellement des protons. Quand des rayons cosmiques atteignent la haute atmosphère terrestre (entre quinze et vingt kilomètres d’altitude), ils frappent des atomes d’azote et d’oxygène. Ces collisions produisent des « pions chargés », des particules instables qui se désintègrent quasi instantanément en muons.
En 2,2 microsecondes, même à la vitesse ultra-proche de celle de la lumière à laquelle il se déplace, un muon ne parcourt pas plus de 660 mètres. S’il est créé à quinze kilomètres d’altitude, jamais il ne peut arriver sur Terre. Mais alors, comment se fait-il que nous soyons bombardés de muons à chaque instant ?
Pour le comprendre, je vous propose un voyage dans le temps, à la découverte de Galilée et Einstein, et dans l’espace, en compagnie de l’astronaute Sophie Adenot.
Le principe de la relativité, de Galilée à Einstein
Galilée avait posé le principe de la relativité. Il avait pris l’exemple de la cale d’un bateau. Avec mes étudiants je prends l’exemple d’un train, qui est plus stable qu’un bateau qui tangue. Imaginez que vous placez un laboratoire de physique dans un train, laboratoire fermé et sans accès au monde extérieur. Vous pouvez faire toutes les expériences de physique que vous voulez, vous ne pourrez pas détecter si le train est en mouvement ou bien s’il est au repos — attention, il ne faut pas que le train accélère, sinon des forces fictives apparaissent dans le laboratoire et vous pouvez en déduire le mouvement du train !
Ce principe de relativité a deux conséquences incroyables : la première est que le mouvement est relatif (on se déplace toujours par rapport à quelque chose) ; la seconde est que le repos absolu n’existe pas.

.jpg){kind=link}
Toute cette discussion part d’un présupposé implicite, tellement implicite qu’on ne l’avait pas évoqué : le temps est absolu. C’est le même temps, la même horloge pour l’observateur dans le train et pour un observateur à la gare. Le temps s’écoule de manière uniforme, c’est une sorte de grille rigide qui séquence l’espace.
Pour sauver le principe de relativité, Albert Einstein avait englobé le temps dans le référentiel lui-même. Le temps n’est plus absolu, il devient relatif. Chaque observateur mesure son temps à lui, qu’on appelle « temps propre ». Il n’y a pas de temps qui est meilleur qu’un autre, le tout est de bien distinguer de quel temps on parle. Le cadre de référence n’est plus l’espace relatif auquel on ajoute un temps absolu, mais un espace-temps relatif. D’où le terme de théorie de la relativité bien sûr.
Le paradoxe des jumeaux
En 1911, Paul Langevin popularise une conséquence troublante de la relativité d’Einstein. C’est le paradoxe des jumeaux.

Imaginez deux jumeaux Alice et Bob. Alice part dans un voyage vers Proxima du Centaure, l’étoile la plus proche de la Terre (après le Soleil bien sûr). Cette étoile se trouve à quatre années-lumière de la Terre. Mettons qu’Alice file dans un vaisseau spatial à 99 % de la vitesse de la lumière. Elle part de la Terre, arrive à Proxima du Centaure et puis fait demi-tour et revient, sans même s’arrêter pour boire un café.
Bob voit Alice faire ce déplacement quasiment à la vitesse de la lumière pendant qu’il reste sur la Terre. Vu que Proxima du Centaure se trouve à quatre années-lumière, Bob mesure huit ans entre le départ et le retour d’Alice. Huit vraies années. Bob aura fêté huit fois son anniversaire, il aura mangé huit fois du gâteau et soufflé huit fois les bougies.
Comme Alice se déplace à des vitesses incroyables (99 % de la vitesse de la lumière), Bob voit l’horloge d’Alice se dilater par rapport à la sienne. Les physiciens peuvent vous calculer cette chose précisément, c’est le facteur de dilatation. Dans notre cas, c’est un facteur sept : dans son vaisseau, Alice voit 1,143 an s’écouler (huit divisé par sept), soit 13 mois et 22 jours. Alice aura fêté un seul anniversaire dans son vaisseau, elle aura mangé une seule fois du gâteau et soufflé une seule fois les bougies. Quand elle rejoint Bob sur Terre, elle trouve un Bob plus vieux de huit ans alors qu’elle-même est plus vieille d’un peu plus d’un an. C’est la première partie du paradoxe des jumeaux, que j’appelle version faible du paradoxe des jumeaux.

L’autre partie du paradoxe des jumeaux est un petit jeu mental, que Richard Feynman a développé de la manière la plus claire possible dans ses cours de physique. Pour Alice dans sa fusée, c’est Bob qui s’éloigne, Alice ne bouge pas par rapport à la fusée. Donc Alice imagine que Bob devrait être plus jeune car c’est Bob qui a bougé par rapport à Alice. La situation semble symétrique entre Alice et Bob et on ne sait pas savoir quel jumeau doit être plus jeune que l’autre. Assurément, ils ne peuvent pas être tous deux plus jeunes en même temps. C’est exactement la version forte du paradoxe des jumeaux.
En vérité, on a l’impression que la situation est symétrique mais elle ne l’est pas vraiment. Tant qu’Alice s’éloigne de Bob, il est impossible de dire qui est en mouvement dans l’absolu, car comme on l’a vu le mouvement est relatif. Sauf qu’Alice doit faire demi-tour à Proxima du Centaure pour revenir sur Terre. En faisant son demi-tour, elle voit bien que c’est elle qui bouge alors que Bob reste à la maison tranquille comme Baptiste. Donc, Alice fait un demi-tour, Bob ne fait pas de demi-tour, c’est bien Alice qui bouge, la situation n’est pas symétrique, Alice sera plus jeune.
Le cas Sophie Adenot
Dans la Station spatiale internationale, l’astronaute Sophie Adenot ne se déplace pas à des vitesses proches de la lumière, néanmoins la vitesse reste conséquente par rapport à celles que nous avons l’habitude de traiter sur Terre. La Station se déplace à 27 600 kilomètres par heure, le facteur de dilatation est faible mais non négligeable. Ceci étant, Sophie Adenot restera neuf mois dans la station. À la fin du voyage, elle bénéficiera quand même de l’effet relativiste : elle sera plus jeune de six millisecondes par rapport à nous, qui sommes restés sur le plancher des vaches. Si Sophie Adenot avait eu une sœur ou un frère jumeau, elle serait à jamais plus jeune que son jumeau.
Six millisecondes, ça vous paraît imperceptible à l’échelle humaine ? Pourtant, la finale du cent mètres homme des Jeux olympiques de Paris 2024 s’est gagnée sur moins que ça, c’étaient cinq millisecondes !
Boucler la boucle cosmique
Pour revenir à nos muons : comme ils se déplacent dans l’espace à des vitesses approchant celle de la lumière, leur horloge à eux est très dilatée par rapport à la nôtre. Dans leurs référentiels à eux, 2,2 microsecondes sont amplement suffisantes pour parcourir les quelque quinze ou vingt kilomètres qui les séparent de la surface de la Terre.
À lire aussi : Une chambre à étincelles pour voir les muons cosmiques
La mesure directe a été affinée en 1963 en comparant le flux de muons au sommet du mont Washington et au niveau de la mer. L’exemple des muons est d’ailleurs l’exemple canonique qu’avait pris Feynman pour illustrer la dilatation du temps dans son fameux cours de physique.
C’est ainsi que Sophie Adenot et les muons cosmiques ont un point commun. Tous les deux voyagent avec une horloge ralentie depuis la Terre et Sophie Adenot exploite en plus le paradoxe des jumeaux.
Pour les lecteurs intéressés, l’auteur renvoie à une de ses conférences grand public à l’Université de Mons, et à un simulateur de voyages paradoxaux qu’il a fabriqué pour ses étudiants de l’Université libre de Bruxelles.
Fabrizio Bucella ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 17:19
Analyses stratégiques, timing et feintes : comment les gardiens réussissent l'exploit d'arrêter un penalty
Clément Libreau, ATER, Université de Toulouse
Nicolas Benguigui, Professeur en sciences cognitives, sciences du sport et de la motricité - Laboratoire GREYC - UMR 6072 UNICAEN CNRS - UFR STAPS, Université de Caen Normandie
Texte intégral (2354 mots)
Le penalty au football est sans doute une des situations les plus marquantes de ce sport qui concentre toute la dramaturgie du jeu et le stress extrême que peuvent ressentir les joueurs ou joueuses impliquées. Un ballon placé à 11 mètres, un tireur face à un gardien de but, quelques dixièmes de seconde pour décider et agir… et parfois tout un match et même un titre prestigieux qui se jouent sur ce duel. Quelles stratégies les gardiens mettent-ils en place pour réussir à stopper ces frappes ?
La Coupe du Monde qui se déroule actuellement est le théâtre de dénouements marquants dans l’épreuve des tirs au but d’autant plus que l’augmentation du nombre de participants a doublé le nombre de matchs à élimination directe. Et on se souvient si bien de l’issue défavorable pour l’équipe de France lors de la dernière finale de cette compétition. Il y a seulement quelques semaines, le Paris Saint-Germain en remportant la Ligue des Champions 2026, a confirmé une tendance remarquable qui a permis au club parisien de remporter ses six dernières séances de tirs au but. Derrière ces succès se cache un travail considérable de préparation, tant sur le plan technique que psychologique, devenu aujourd’hui incontournable au plus haut niveau.
Dans ce duel, l’attention est souvent portée aux tireurs qui font face à une pression psychologique très importante dans la mesure où le droit à l’erreur n’est pas autorisé, sachant l’énorme avantage pour le tireur dans cet exercice qui se traduit par un taux de conversion des penaltys en buts qui peut monter jusqu’à plus de 90 % pour les meilleurs tireurs. Mais l’histoire du football regorge d’exemples où un gardien a fait basculer le destin d’une équipe. L’un des cas les plus célèbres reste celui de Petr Čech lors de la finale de la Ligue des Champions 2012 entre son club de Chelsea et le Bayern Munich. Ce soir-là, le gardien tchèque arrête trois penaltys au cours de la rencontre et de la séance de tirs au but. Plus impressionnant encore, il plonge du bon côté sur l’ensemble des six penaltys auxquels il est confronté. Cette performance exceptionnelle n’était pas le fruit du hasard. Elle reposait sur un travail d’analyse minutieux réalisé en amont avec l’entraîneur des gardiens et les autres gardiens du club, visant à identifier les habitudes et préférences des tireurs adverses.
Aujourd’hui, cette préparation spécifique constitue l’un des principaux axes de travail des gardiens professionnels et de leurs entraîneurs. Les séances vidéo, l’analyse statistique des habitudes des tireurs, l’étude des courses d’élan ou des zones de frappe privilégiées font désormais partie intégrante de la préparation des grandes compétitions. Concernant les études scientifiques, une large majorité des travaux s’est intéressée aux tireurs dont les échecs dans cet exercice sont souvent décrits comme une défaillance psychologique. Le cas du gardien a été moins étudié.
Pourquoi est-il si difficile d’arrêter un penalty ?
La première constatation qui peut être faite est que le duel entre le tireur de penalty et le gardien de but est très défavorable à ce dernier. Une étude de la Société d’analyse de données sportive a établi à partir d’une base de 100 000 penaltys tirés dans des matchs de haut niveau que le taux de conversion se situait autour de 75 % aussi bien pour les hommes que pour les femmes.
Cette supériorité du tireur s’explique par les contraintes spatiales et temporelles auxquelles le gardien doit faire face. Une frappe peut dépasser 100 km/h et atteindre le but en moins d’une demi-seconde (500 ms) alors que le gardien doit défendre un but de 7,32 m de large et 2,44 m de hauteur. Or il faut environ 200 ms pour identifier une information et initier une réponse motrice dans une situation aussi complexe même pour des athlètes super-entraînés, puis encore 500 à 600 ms pour produire un plongeon couvrant efficacement le but. Attendre le départ du ballon conduit donc presque toujours à une action trop tardive. Les gardiens doivent ainsi anticiper, c’est-à-dire engager une action avant la frappe adverse sur la base d’informations prédictives mais partielles.
Le sujet de l’anticipation a été très largement étudié en sport et certaines études ont porté précisément sur celles des gardiens de but au football. Pour prédire la direction du tir avant la frappe, il a été montré que les gardiens de but sont capables d’utiliser des connaissances préalables sur les tireurs en termes de probabilités de choix ainsi que des indices biomécaniques relatifs à la course d’élan et la préparation de la frappe des tireurs – orientation des hanches, du pied d’appui, des épaules ou posture générale. Cela a été montré avec des dispositifs permettant d’occulter certaines parties du corps de tireurs ou d’analyser les stratégies visuelles mises en œuvre par les gardiens pour extraire des informations significatives.
Pour autant, les stratégies d’anticipation présentent des limites. Les informations extraites avant la frappe sont nécessairement imprécises d’autant plus qu’elles sont prélevées tôt et se répercutent par des erreurs de décision. De plus, les meilleurs tireurs retardent parfois leur décision ou modifient leur geste afin de masquer leurs intentions ou de tromper le gardien en choisissant le côté du tir après avoir vu le gardien partir d’un côté, comme le fait avec beaucoup d’habileté le joueur brésilien Neymar.
Les gardiens font ainsi face à de nombreuses feintes possibles des tireurs. Cela a été étudié notamment dans une étude menée en 2012 qui a reproduit expérimentalement sur la base de vidéos les effets des feintes pour des gardiens de haut niveau. Par exemple, pendant son élan, le tireur pouvait délibérément fixer du regard la direction opposée à son tir. L’angle de la course d’élan vers le ballon était aussi manipulé et rendu opposé à la relation qui pourrait être attendue entre la direction de la course d’élan et la direction du tir. Ces deux feintes se traduisaient par une diminution du taux de bonne décision des gardiens de but passant d’environ 65 % pour les tirs sans feinte à seulement 45 % pour les tirs avec feintes et même 25 % quand deux feintes étaient additionnées.
Si les gardiens subissent les feintes de tireurs, ils peuvent aussi en produire pour perturber le tireur. Une analyse rétrospective réalisée en 2016 sur un total de 322 penaltys frappés lors des Coupes du monde de la FIFA (1986-2010) et des Championnats d’Europe de l’UEFA (1984-2012), a permis de montrer que les scores de réussite de tireurs diminuaient lorsque les gardiens de but réalisaient des actions de distraction avant le tir comme de se déplacer sur leur ligne ou faire des mouvements de bras. Cela était aussi le cas quand les joueurs portaient une attention plus importante au gardien de but montrant que cette dernière met en difficulté les tireurs.
Une étude réalisée en 2024 s’est intéressée à l’efficacité des feintes que pouvaient produire les gardiens pour gêner les tireurs où les conduire à tirer du côté où le gardien avait décidé de plonger. Pour cela, les chercheurs ont analysé 714 penaltys tirés lors de matchs de la Premier League anglaise et de la Bundesliga allemande, couvrant les saisons 2016-2017 à 2019-2020. Les résultats ont montré que les gardiens de but recouraient à des feintes dans la moitié des tirs au but, ce qui se traduisait par un nombre de buts nettement inférieur par rapport aux tirs au but sans feinte. Cet avantage était similaire pour les différents types de feintes, mais plus marqué lorsque les tireurs prêtaient attention aux gardiens.
Le dilemme du gardien : partir tôt… ou attendre ?
Une des questions qui reste en suspens concerne le timing du plongeon du gardien de but. En effet, le gardien fait face à un dilemme : partir tôt au risque d’être pris à contre-pied, ou attendre davantage pour disposer d’informations plus fiables, tout en réduisant le temps disponible pour atteindre le ballon. Ce compromis est d’autant plus contraignant que les règles du jeu imposent au gardien de conserver au moins un pied en contact avec la ligne de but au moment où le tireur frappe le ballon. Cette obligation limite sa capacité à avancer significativement avant la frappe et réduit la marge temporelle disponible pour réagir, accentuant ainsi l’importance du choix du moment optimal pour initier le plongeon.
Une étude de 2018 a montré que les gardiens professionnels déclenchent majoritairement leur plongeon environ 200 ms avant la frappe. Une autre plus ancienne avait distingué des stratégies précoces et tardives, suggérant un avantage pour ces dernières, mais sur un échantillon limité de 108 penaltys étudiés.
Une nouvelle étude sur près de 1000 penaltys
Pour répondre à cette question du timing du gardien, nous pouvons présenter les premiers résultats issus d’une étude que nous menons à l’heure actuelle et qui a porté sur une analyse de 938 penaltys professionnels à l’aide d’un logiciel d’analyse vidéo image par image. Chaque plongeon du gardien a été mesuré avec une précision de 10 millisecondes afin de déterminer exactement à quel moment le mouvement débutait par rapport à la frappe du ballon. En général il s’agissait de l’apparition d’un décalage des appuis pour permettre une poussée latérale ou bien une inclinaison du buste. En complément de ce timing, nous avons ensuite analysé la pertinence du choix du gardien dans la direction de son plongeon et le taux d’arrêt.
Notre principal résultat est l’identification d’une véritable « fenêtre optimale » de déclenchement. Les gardiens les plus performants initient leur plongeon autour de 240 ms avant la frappe, avec une efficacité élevée entre -200 et -300 ms. Dans cette fenêtre, ils plongent plus souvent du bon côté et obtiennent les meilleurs taux d’arrêt. À l’inverse, les plongeons très précoces (avant -360 ms) sont associés à de faibles performances, tandis que les plongeons tardifs permettent parfois de mieux lire la direction du tir sans améliorer le taux d’arrêt.
On le voit clairement, ce duel entre tireur et gardien illustre parfaitement les enjeux cognitifs, perceptifs et moteurs du sport de haut niveau, cristallisés autour de l’anticipation. Nos résultats ouvrent plusieurs perspectives pour l’entraînement des gardiens. La préparation doit d’abord s’appuyer sur l’analyse des préférences des tireurs, de leurs probabilités de choix et des indices perceptifs révélant leurs intentions durant la course d’élan et la préparation de la frappe.
Le comportement préparatoire du gardien mérite également une attention particulière : attirer l’attention du tireur par des comportements de distraction autorisés ou des feintes de départ peut réduire son avantage et améliorer les chances d’arrêt, dans le respect des règles et du fair-play. Les résultats soulignent aussi l’intérêt de développer les routines de préparation et l’analyse vidéo des indices corporels utiles à la prise de décision.
Enfin, la maîtrise du timing décisionnel apparaît déterminante. Nos données montrent qu’un déclenchement entre -200 et -300 ms avant l’impact constitue le meilleur compromis entre anticipation et temps d’intervention. Les gardiens doivent donc apprendre à synchroniser leur plongeon avec la frappe, y compris lorsque le tireur ralentit ou interrompt brièvement sa course. Ces pistes constituent des leviers prometteurs pour optimiser la performance des gardiens et, espérons-le, permettre à celui de l’équipe de France de devenir un véritable héros.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
13.07.2026 à 14:10
Les volcans du Cantal sont des montagnes… de verre!
Patrick De Wever, Professeur, géologie, micropaléontologie, Muséum national d’histoire naturelle (MNHN)
Texte intégral (1556 mots)

{kind=link}
Au-delà du sport, le Tour de France donne aussi l’occasion de (re)découvrir nos paysages et parfois leurs bizarreries géologiques. Ce mardi 14 juillet, les coureurs du Tour de France vont traverser les volcans du Cantal sans craindre les crevaisons… et pourtant, ils traversent des montagnes de verre ! En effet, la plupart des laves volcaniques sont essentiellement constituées de verre.
Pour un géologue, parler de « verre en cristal » est une aberration : dans la nature, le verre est un matériau solide amorphe – c’est-à-dire désordonné à l’échelle atomique, contrairement au cristal. C’est une sorte de liquide figé.
Lorsqu’on parle de verre, il faut se méfier de la polysémie du terme : il y a le verre que l’homme fabrique depuis des millénaires pour concevoir par exemple des vitres ou des récipients, mais il existe aussi toute une série de verres naturels.
À lire aussi : Fées, lutins et extraterrestres, comment le pic de Bugarach a donné vie aux mythes les plus fous
Comme l’explique Daniel R. Neuville, chargé de recherche à l’Institut de Physique du Globe de Paris, un « verre » est un silicate fondu fabriqué par l’homme, tandis qu’une lave volcanique ou un magma est un silicate issu des profondeurs de la terre – ou d’autres planètes.
Quand une coulée de lave refroidit rapidement, sa matière ne peut cristalliser, elle se fige alors sous forme de verre. On observe une « bordure figée » autour de certaines coulées, filons, ou bombes volcaniques.
Certaines roches sont particulièrement riches en verre, tels les magmas riches en silice, comme le sont les magmas acides.
À lire aussi : Les tours Saint-Jacques, un prodige d’équilibre au cœur des Alpes
Avec une telle composition chimique, les molécules ont tendance à polymériser, ce qui explique leur forte viscosité. Cette consistance limite la diffusion des éléments, qui ne réussissent alors pas à se mettre aux endroits ad hoc pour former des cristaux. La polymérisation conduit à une roche non organisée (à l’inverse des cristaux) qui, en refroidissant donne un verre : l’obsidienne.
Il existe aussi le verre des impactites ou celui des tectites. Les impactites sont des verres naturels formés au moment de l’impact d’un astéroïde. A l’inverse des tectites, elles n’ont pas été projetées dans l’atmosphère. On retrouve dans la composition chimique des impactites des traces de la météorite incidente.

Le verre industriel
Le verre industriel, lui, est obtenu par fusion d’une roche siliceuse, généralement du sable. Des éléments sont souvent ajoutés pour en modifier les propriétés : le pyrex, par exemple, plus résistant aux chocs thermiques qu’un verre ordinaire, est enrichi en bore.
Les puissants de ce monde ont longtemps possédé des objets d’une grande rareté et donc précieux. Parmi ces objets, on trouvait des coupes, ou des verres, en « cristal de roche », c’est-à-dire en quartz (un oxyde de silicium cristallisé). Ces objets avaient un magnifique éclat lumineux et un son caractéristique. Pour imiter ces objets précieux et fabriquer des verres en « cristal », on a ajouté à la composition siliceuse un oxyde de plomb qui apporte l’éclat et permet d’obtenir un son caractéristique.

Plus il y a de plomb, plus le son est cristallin : la vitesse de la lumière est fonction du milieu dans lequel elle se propage. Plus le milieu est dense, plus la lumière est fortement déviée, elle peut aller jusqu’à la réflexion complète si le cristal est taillé en facettes, qui jouent alors le rôle de miroirs. Pour la même raison, le son qu’un tel verre produit lorsqu’on le fait vibrer est plus aigu, plus… cristallin.
Une version plus longue de ce texte a été publiée le 29 juin 2026 sur le site Planet Terre de l’ENS Lyon.
Patrick De Wever ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.07.2026 à 17:45
Peut-on mieux recycler les métaux précieux contenus dans nos ordinateurs ?
Solène Touze, Cheffe de projet, génie des procédés, BRGM
Texte intégral (1559 mots)
L’ESSENTIELCliquez pour lire les trois points à retenir La carte-mère d’un ordinateur est pleine de métaux précieux : du cuivre, de l’or, de l’argent, du palladium, du platine, de l’europium… il y en a une cinquantaine sur une seule carte. Aujourd’hui, seuls cinq de ces métaux précieux peuvent être récupérés (au mieux), pour des raisons économiques et technologiques. Un des obstacles est que l’on sait très mal quantifier les métaux présents dans la benne à ordures électroniques. Cette quantification est indispensable pour évaluer le potentiel de valorisation, et, quand c’est possible, récupérer davantage de matière. Replier
Tout commence dans nos maisons. Lors d’un ménage de printemps, l’ordinateur portable hors service qui traîne est enfin emmené à la déchèterie et est déposé dans le bac déchets d’équipements électriques et électroniques (DEEE). S’il ne peut pas être réutilisé ou réemployé, il part vers une filière de recyclage. Que sait-on réellement, aujourd’hui, recycler de ce déchet ?
La première étape se fait à la main : on trie les déchets électriques et électroniques, et l’ordinateur va dans un bac dédié aux ordinateurs. Ensuite, toujours manuellement, on enlève la batterie qui est envoyée vers une filière spécialisée — c’est une obligation réglementaire.
À cette étape, plusieurs chemins sont possibles : nous allons ici considérer que l’opérateur qui extrait la batterie isole aussi la carte mère ; et que le reste, l’écran et le boîtier partent vers des procédés de tri automatisés qui vont recycler les métaux présents en grande quantité (fer, cuivre, aluminium), et parfois les plastiques.
Maintenant, suivons la carte mère. Elle est considérée comme une carte électronique riche car elle contient du cuivre et des métaux précieux en quantité intéressante : plus de 20 % de cuivre, plus de 150 milligrammes d’or par kilogramme de carte-mère, et plus de 600 milligrammes d’argent par kilogramme. Ainsi, le déchet carte-mère se vend entre 3 et 8 € le kilogramme. Plus la carte est avancée (avec davantage de RAM ou des processeurs plus puissants, par exemple), plus elle a des chances d’avoir des quantités de métaux précieux importantes.
Les cartes sont triées en différentes catégories, du plus riche au moins riche — une nouvelle fois manuellement, à l’œil. C’est l’étape de massification : le but consiste à regrouper les cartes de même catégorie en un seul lot. Cela va faciliter le transport, le stockage et la revente.
Lorsque le lot atteint une certaine quantité (environ la vingtaine de tonnes), il est vendu aux métallurgistes du cuivre. Ce sont les industriels qui produisent et vendent du cuivre pur, on les appelle les « smelters » de cuivre. Il y a aujourd’hui sur Terre moins d’une dizaine de smelters qui récupèrent le cuivre en même temps que les métaux précieux. Aucun n’est en France, mais une majorité est en Europe (Belgique, Suede Autriche et Allemagne). Face à ces « géants de la métallurgie » (Umicore, Aurubis, Boliden par exemple), il existe aussi quelques PME du monde du recyclage (dont, en France, WeeeCycling).
La plupart des smelters ont été conçus, à la base, pour traiter du minerai de cuivre (roche extraite d’une mine de cuivre). Ils ont progressivement intégré des déchets dans leur alimentation mais cette alimentation reste souvent minoritaire. Les métaux qui y sont valorisés sont le cuivre, l’or, l’argent, le palladium et le platine s’il y en a (soit seulement cinq métaux, alors que la carte en contient presque une cinquantaine).
Les cartes qui ne sont pas assez « riches » vont, elles, vers des « smelters » qui ne récupèrent que le cuivre.
Pourquoi ne pas recycler davantage ?
La réponse n’est pas triviale. Il y a des raisons économiques, technologiques, géopolitiques et de marché et à cela s’ajoute une dynamique temporelle complexe.
Sur la partie économique, l’évidence est que la filière doit être rentable : les coûts de traitement de cette matière secondaire (les cartes-mères) doivent donc être inférieurs à celui du traitement de la matière primaire (le minerai de cuivre).
Le deuxième point économique, moins connu, est les risques liés à la volatilité des cours des métaux : il peut être difficile d’investir sur la récupération d’un métal quand son prix peut fluctuer du simple au double en très peu de temps.
Dans cette même logique, nos objets (comme ceux du numérique) évoluent très vite et certains métaux utilisés aujourd’hui risquent de ne plus l’être demain. Faut-il mettre en place des chaînes de traitement éphémères ? Quid, par exemple, de la filière de recyclage des lampes à économie d’énergie qui ont été remplacées par les LED en une décennie ?
Côté technologique, les technologies de récupération de cette cinquantaine de métaux existent déjà dans le domaine minier, et beaucoup peuvent être adaptées au domaine du recyclage.
Peut-on valoriser de très faibles quantités ?
Mais ce catalogue de technologies de recyclage ne peut pas se déployer raisonnablement sur la cinquantaine de métaux présents.
Dans le minerai comme dans les déchets, la production des métaux suit de grandes familles de métaux : la sidérurgie pour l’acier, la métallurgie du cuivre, du nickel, de l’aluminium, le groupe des terres rares… Par exemple, dans la nature, le gallium est associé aux minerais de bauxite (aluminium), il est donc produit par la filière métallurgie de l’aluminium.
La carte électronique, elle, fait fi de ces associations. Une carte-mère d’ordinateur est traitée uniquement par la métallurgie du cuivre, et aucune de ces installations ne valorise le gallium. Les 3 milligrammes de gallium présents dans une carte sont donc perdus.
Au-delà de ces questions de filières, se pose aussi la question d’aller valoriser un métal en très faible quantité. Quel est le coût énergétique d’aller chercher les 0,075 milligramme d’Europium dans une carte mère ?
Connaître la matière
Enfin, une troisième raison du recyclage partiel des cartes est le manque de donnée sur leur contenu. En effet, aujourd’hui, les ordinateurs et leurs cartes-mères ne sont pas fournis avec un « passeport matière » qui donne leur composition précise ; alors même que celle-ci varie aussi bien avec le producteur et le temps.
Si nous voulons bâtir de nouvelles filières de recyclage, il est nécessaire de connaître ce gisement pour affirmer la faisabilité économique et technique du recyclage : quelle quantité de tel métal est accessible et à quelle concentration se trouve-t-il ? Accéder à ces données est difficile et demande une recherche approfondie.
Repartons des 20 tonnes de cartes électroniques vendues au smelter : il est clairement impossible de caractériser et d’analyser la totalité du lot. En effet, les outils d’analyse fonctionnent sur des échantillons de quelques grammes seulement, voire quelques milligrammes. Par construction, l’échantillon analysé n’est jamais tout à fait représentatif du lot d’origine. Il s’accompagne d’une « valeur d’incertitude » : a-t-on analysé 30 milligrammes de germanium par kilo, plus ou moins 5 ou 20 milligrammes par kilo ? Cette marge d’erreur change totalement le potentiel de valorisation du lot.
Avec mes collègues, nous travaillons dans le cadre du projet ReviWEEE, pour développer une méthodologie d’échantillonnage et d’évaluation des incertitudes.
Le projet ReviWEEE est soutenu par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Solène Touze a reçu des financements de l'ANR - 22-PERE-0009.
10.07.2026 à 11:01
3I/Atlas, une comète venue d’une autre étoile qui ne ressemble à rien de connu dans le Système solaire
Matthew Hopkins, Postdoctoral Fellow, University of Canterbury
Texte intégral (1827 mots)

Troisième objet interstellaire jamais détecté, 3I/Atlas ne ressemble à aucune comète du Système solaire. Sa composition et son âge exceptionnel en font un précieux témoin de la jeunesse de notre galaxie.
Des astronomes viennent de révéler de nouveaux détails sur la composition et l’âge d’une comète de passage, née autour d’une étoile lointaine. Ils concluent de leurs travaux que la composition de 3I/Atlas est radicalement différente de celle de tous les objets connus de notre Système solaire.
Trois études, publiées récemment et ici, apportent ainsi un nouvel éclairage sur les origines de cette comète hors du commun. 3I/Atlas semble s’être formée dans un environnement très froid, il y a environ 12 milliards d’années.
La comète est un objet interstellaire (interstellar object, ou ISO), c’est-à-dire un astéroïde ou une comète provenant de l’extérieur du Système solaire. Il s’agit du troisième objet de ce type jamais identifié, après 1I/ʻOumuamua et 2I/Borisov. Elle a été découverte il y a presque exactement un an, alors qu’elle arrivait de l’espace interstellaire sur une trajectoire traversant le Système solaire interne avant de s’en éloigner de nouveau.
Ces origines lointaines rendent les objets interstellaires particulièrement fascinants pour les astronomes, car ils constituent des fragments matériels d’autres systèmes planétaires, apportés jusqu’à nous par les courants gravitationnels de la galaxie et que nous pouvons étudier sans quitter le confort de notre propre Système solaire.
En tant que comète, 3I/Atlas contenait des glaces qui se sont sublimées, c’est-à-dire qu’elles sont passées directement de l’état solide à l’état gazeux. En se réchauffant sous l’effet du Soleil, ces gaz se sont échappés de la comète, donnant naissance à une spectaculaire chevelure (ou coma), l’enveloppe lumineuse qui entoure son noyau, ainsi qu’à une longue queue.
Une comète ne possède pas de source de lumière propre. La poussière présente dans sa chevelure réfléchit la lumière du Soleil, tandis que ses composés volatils (des substances qui se vaporisent ou se subliment facilement) émettent une fluorescence.
Mais il ne s’agit pas d’un simple spectacle lumineux : chaque molécule fluorescente laisse une empreinte spectrale dans la lumière qui parvient jusqu’à nos télescopes. Ces signatures permettent d’identifier les composés chimiques présents dans la comète.
Pour les révéler, les astronomes décomposent la lumière en ses différentes longueurs d’onde grâce à une technique appelée spectroscopie. Ils peuvent ainsi déterminer la composition chimique de la comète.
Un cocktail chimique inédit
Les observations ont révélé que 3I/Atlas renferme un mélange d’eau, de dioxyde et de monoxyde de carbone, de méthane, de cyanures, de sulfures, ainsi que d’atomes de fer et de nickel à l’état libre. Pris séparément, ces composés n’ont rien d’inhabituel : ils sont régulièrement détectés dans les comètes de notre propre Système solaire. En revanche, leurs proportions diffèrent nettement dans 3I/Atlas. Sa forte teneur en dioxyde de carbone (CO2) et sa faible abondance en ammoniac (NH3) trahissent son origine extérieure au Système solaire.
Les molécules constituées d’atomes appartenant à différents isotopes (des variantes d’un même élément chimique) présentent également des signatures spectrales légèrement différentes. Grâce à l’éclat de 3I/Atlas et à la puissance des plus grands télescopes, les astronomes ont pu distinguer ces signatures et mesurer les rapports isotopiques de la comète.
L’une des nouvelles études, publiée dans Nature, s’appuie sur les signatures spectrales de l’eau et du dioxyde de carbone mesurées par le télescope spatial James Webb pour déterminer le rapport entre les deux principaux isotopes du carbone, le 12C et le 13C, présents dans 3I/Atlas, ainsi que son rapport deutérium/hydrogène (D/H), le deutérium étant une forme lourde de l’hydrogène.
Ces résultats sont particulièrement enthousiasmants, car les rapports isotopiques d’un objet interstellaire comme 3I/Atlas sont censés refléter ceux du disque protoplanétaire dans lequel il s’est formé. Ils permettent donc de reconstituer avec une grande précision les conditions de sa formation, ainsi que les caractéristiques de l’étoile autour de laquelle il est né.
L’eau de 3I/Atlas présente un rapport deutérium/hydrogène (D/H) d’environ 1 %, soit une valeur nettement supérieure à celle mesurée dans toutes les comètes connues du Système solaire.
De telles concentrations en deutérium ne se rencontrent que dans des environnements extrêmement froids, où la température est inférieure à 30 kelvins (-243 °C). Dans ces conditions, les atomes d’hydrogène « ordinaires » sont progressivement remplacés par des atomes de deutérium, plus lourds, dans la glace d’eau qui recouvre de minuscules grains de poussière. Avec le temps, ces grains glacés s’agglomèrent pour former des comètes.
Une voyageuse venue des premiers âges de la galaxie
Le rapport 12C/13C de 3I/Atlas est lui aussi exceptionnel, bien supérieur à toutes les valeurs mesurées dans le Système solaire. Ce rapport isotopique fonctionne comme une véritable horloge cosmique. Au début de l’histoire de l’Univers, la première génération d’étoiles produisait un carbone très riche en 12C par rapport au 13C. Puis, au fil des cycles de naissance et de mort des étoiles, ce rapport a progressivement diminué. Si 3I/Atlas présente une valeur aussi élevée, c’est qu’elle s’est formée très tôt dans l’histoire de la Voie lactée, il y a environ 12 milliards d’années.
Des études menées peu après sa découverte avaient déjà suggéré que 3I/Atlas était probablement âgée d’au moins 7 milliards d’années, d’après sa vitesse. Son ancienneté est donc désormais étayée par plusieurs indices indépendants.
Si le ciel nocturne, au-delà des confins du Système solaire, peut sembler immuable, l’Univers comme notre galaxie évoluent bel et bien, à l’échelle de milliards d’années.

Lorsque 3I/Atlas s’est formée, l’Univers était encore dans sa prime jeunesse et la Voie lactée était encore en train de se construire, au gré de violentes collisions et fusions avec d’autres galaxies.
Si l’étoile autour de laquelle 3I/Atlas s’est formée avait une masse comparable à celle du Soleil, elle a probablement déjà achevé son existence. Les objets interstellaires qu’elle a éjectés peu après sa naissance, comme 3I/Atlas, lui ont ainsi survécu.
Au cours des dix prochaines années, de nouveaux télescopes de pointe dédiés à la découverte d’objets célestes, comme le NEO Surveyor de la NASA et l’observatoire Vera C. Rubin, au Chili, devraient multiplier par dix le nombre d’objets interstellaires connus. Cette moisson offrira aux astronomes une véritable archive fossile de l’évolution des systèmes planétaires tout au long de l’histoire de la Voie lactée.
Matthew Hopkins a reçu une bourse Elaine P. Snowden Fellow à l'université de Canterbury, en Nouvelle-Zélande.
10.07.2026 à 11:00
Ces algues qui ne sont pas des plantes… Six faits surprenants sur la flore aquatique
Alexander Bowles, Glasstone Research Fellow, Plant Science, University of Oxford
Texte intégral (2748 mots)

Des plantes sans racines, d’autres carnivores, certaines capables de fleurir sous l’eau… Les plantes aquatiques ont développé des adaptations spectaculaires qui défient notre vision du monde végétal.
À l’abri des regards, sous la surface des eaux, se déploie un monde végétal d’une étonnante inventivité et parmi les plus importants sur le plan écologique.
Comme je le souligne dans une publication récente, les plantes aquatiques ont développé une extraordinaire diversité d’adaptations pour vivre sous l’eau. Certaines fleurissent sous la surface, d’autres capturent des animaux grâce à d’ingénieux pièges. Voici sept faits qui montrent à quel point ces organismes remarquables bousculent nos idées reçues sur ce qu’est une plante et sur les stratégies qu’elle déploie pour survivre.
1. Les plantes n’en finissent pas de retourner à l’eau
Quand on pense aux plantes, on imagine spontanément les forêts, les prairies ou les champs. Pourtant, au cours de leur histoire évolutive, les plantes sont retournées à de nombreuses reprises dans le milieu aquatique, là même où elles sont apparues. Il y a environ 500 millions d’années, elles ont conquis les terres émergées. Depuis, nombre d’entre elles ont fait le chemin inverse. Les scientifiques estiment que le mode de vie aquatique est apparu indépendamment plus de 100 fois au sein de différents groupes de plantes.
Les nénuphars font flotter leurs feuilles à la surface, les lentilles d’eau dérivent librement et les herbiers marins vivent entièrement immergés dans l’océan. Certains de ces groupes sont retournés à l’eau il y a plus de 100 millions d’années. Cette réapparition répétée des plantes aquatiques constitue l’un des exemples les plus spectaculaires de l’évolution convergente dans la nature.
2. Les plantes qui n’en sont pas
Parmi les organismes les plus visibles sous la surface de l’eau figurent les algues. Elles réalisent la photosynthèse et ressemblent souvent à des plantes sous-marines. Pourtant, malgré les apparences, certaines algues ne sont pas de véritables plantes.

Les algues marines appartiennent en réalité à plusieurs lignées d’algues distinctes dans l’arbre du vivant. Les laminaires géantes, qui forment de véritables forêts sous-marines, sont des algues brunes. Le nori et la dulse sont des algues rouges, tandis que la laitue de mer appartient aux algues vertes.
Contrairement aux plantes, elles ne possèdent ni véritables racines, ni tiges, ni feuilles, et ne produisent ni fleurs ni graines. Leur ressemblance avec les plantes rappelle toutefois que l’évolution peut conduire à des formes très similaires chez des organismes pourtant très éloignés, lorsqu’ils sont confrontés aux mêmes contraintes environnementales.
3. Des plantes qui vivent dans les profondeurs
Les plantes ont besoin de lumière pour réaliser la photosynthèse, ce qui les cantonne généralement aux milieux terrestres ou aux eaux peu profondes. Pourtant, certaines mousses aquatiques survivent à des profondeurs étonnantes. La faucillette courbée (Drepanocladus aduncus) a ainsi été observée à 140 mètres sous la surface dans les eaux exceptionnellement limpides de Crater Lake, dans l’État américain de l’Oregon. Il s’agit de la plante aquatique connue poussant aussi sur terre qui vit à la plus grande profondeur, environ la hauteur de la cathédrale de Strasbourg.
Des mousses de grande profondeur ont également été recensées dans des lacs de Nouvelle-Zélande, d’Antarctique et d’autres régions. Elles prospèrent dans des environnements si profonds qu’ils sont presque totalement privés de lumière et où très peu d’animaux peuvent survivre.
4. Des plantes sans racines
Les racines sont l’une des caractéristiques emblématiques des plantes. Elles les ancrent dans le sol et y puisent l’eau ainsi que les nutriments. Pourtant, de nombreuses plantes aquatiques ont considérablement réduit leur système racinaire, et certaines semblent même avoir complètement perdu leurs racines.

La vie sous l’eau change les règles du jeu. L’eau et les nutriments dissous entourent directement la plante, rendant les vastes systèmes racinaires beaucoup moins utiles que sur terre. De nombreuses espèces aquatiques absorbent ainsi les nutriments directement par leurs feuilles et leurs tiges.
Les lentilles d’eau en offrent l’un des exemples les plus extrêmes. Certaines espèces ne possèdent qu’une seule racine, contrairement à des parentes comme la grande lentille d’eau, qui en développe plusieurs. Quant aux espèces du genre Wolffia – les plus petites plantes à fleurs du monde –, elles n’ont plus aucune racine et flottent librement à la surface de l’eau. Un individu mesure à peine un millimètre de long et ses fleurs ne dépassent pas 0,3 millimètre.
5. Des plantes carnivores sous l’eau
Toutes les plantes aquatiques ne se contentent pas de la lumière du Soleil et des nutriments dissous dans l’eau. Certaines complètent leur alimentation en capturant et en digérant de petits animaux.
Les exemples les plus spectaculaires sont les utriculaires (Utricularia), un groupe de plantes aquatiques dépourvues de racines que l’on trouve dans les eaux douces du monde entier. Leurs feuilles se sont transformées en minuscules pièges en forme de vessie qui créent un vide en expulsant l’eau contenue dans leur cavité.

Lorsqu’un minuscule animal effleure les poils sensitifs situés à l’entrée du piège, une trappe s’ouvre brusquement et la proie est aspirée en moins d’une milliseconde. Les pièges des utriculaires figurent ainsi parmi les mouvements les plus rapides du règne végétal. S’ils capturent le plus souvent de petits invertébrés aquatiques, il leur arrive aussi de piéger des larves de poissons et des têtards.
Ce mode de vie carnivore permet aux utriculaires de prospérer dans des eaux pauvres en nutriments, où la plupart des autres plantes peinent à survivre.
6. Une pollinisation portée par les courants
Quand on pense à la pollinisation des plantes, on imagine volontiers des abeilles butinant de fleur en fleur par une belle journée ensoleillée. Mais sous l’eau, la pollinisation devient beaucoup plus compliquée. Au lieu de compter sur les insectes ou le vent, de nombreuses plantes aquatiques, comme les herbiers marins, utilisent directement les courants pour transporter leur pollen jusqu’à sa destination.
Sur terre, les plantes attirent leurs pollinisateurs en diffusant des parfums dans l’air. Sous l’eau, en revanche, ces signaux volatils sont inefficaces. Cette contrainte a conduit à un changement évolutif : les plantes entièrement aquatiques, comme les herbiers marins, ont perdu les gènes responsables de la production de ces composés odorants. Ne procurant plus d’avantage, ils ont progressivement disparu au cours de l’évolution.
7. Les herbiers marins et les mangroves, de puissants puits de carbone
Les herbiers marins et les mangroves capturent et stockent le carbone dans leurs tissus ainsi que dans les sédiments qui les entourent, ce qui les classe parmi les puits de carbone naturels les plus efficaces de la planète. Ensemble, ils emmagasinent ce que les scientifiques appellent le « carbone bleu » : le carbone piégé dans les écosystèmes côtiers, où il peut rester stocké pendant des siècles, voire des millénaires.

À l’échelle mondiale, ces écosystèmes – herbiers marins et mangroves – stockent 11,5 milliards de tonnes de carbone. Les mangroves représentent à elles seules le plus grand réservoir de carbone bleu, avec 6,5 milliards de tonnes.
Qu’elles capturent leurs proies en quelques fractions de milliseconde, poussent dans une quasi-obscurité ou stockent du carbone pendant des siècles, les plantes aquatiques témoignent de l’extraordinaire capacité du vivant à s’adapter.
Alexander Bowles a reçu une bourse « Glasstone Fellowship » à l'Université d'Oxford.
09.07.2026 à 17:26
Avec « The Mandalorian », comprendre les enjeux derrière les métaux rares
Olivier Pourret, Enseignant-chercheur en géochimie et responsable intégrité scientifique et science ouverte, UniLaSalle
Elodie Pourret-Saillet, Enseignante-chercheuse en géologie structurale, UniLaSalle
Texte intégral (2849 mots)

Armures étincelantes, forges ancestrales et batailles galactiques : dans l’univers de Star Wars, le « beskar » occupe une place à part. Ce métal légendaire, au cœur de l’identité mandalorienne, est réputé presque indestructible. Il résiste aux tirs de blaster et autres pistolasers, supporte des températures extrêmes et constitue un héritage transmis de génération en génération.
Avec la sortie en salle, le 20 mai dernier, de The Mandalorian and Grogu, premier film Star Wars à retrouver les écrans de cinéma depuis l’Ascension de Skywalker en 2019, le « beskar », matériau légendaire, revient au centre du récit. Présenté comme quasiment indestructible, capable de résister aux tirs de blaster et même aux sabres laser, le beskar appartient évidemment au domaine de la fiction.
Pourtant, derrière cette invention scénaristique se cache une réalité étonnamment familière : notre monde dépend lui aussi de matériaux rares, concentrés dans quelques régions du monde, convoités par les grandes puissances et devenus indispensables au fonctionnement des technologies modernes. La galaxie de Star Wars n’est peut-être pas aussi éloignée de nos préoccupations géologiques qu’elle en a l’air.
Un métal fictif qui ressemble à nos ressources stratégiques
Dans The Mandalorian, le beskar est bien davantage qu’un simple matériau. Il est rare, convoité, difficile à extraire et étroitement associé à une région unique de la galaxie : la planète Mandalore. Sa possession confère un avantage décisif, qu’il soit militaire, politique ou symbolique.
Cette situation n’est pas sans rappeler celle de certaines matières premières que géologues et économistes qualifient aujourd’hui de « critiques » ou de « stratégiques ». Ces ressources sont indispensables au fonctionnement de technologies essentielles, mais leur production demeure concentrée dans un nombre limité de pays, créant des dépendances parfois importantes.
Les terres rares en constituent sans doute l’exemple le plus connu. Derrière ce nom se cache un groupe de 17 éléments chimiques utilisés dans les aimants permanents des éoliennes, les moteurs de véhicules électriques, les smartphones ou encore certains équipements militaires. D’autres métaux, comme le cobalt, le gallium, le germanium ou l’indium, jouent également un rôle central dans les batteries, les semi-conducteurs ou les écrans tactiles.
Comme le beskar, ces ressources se distinguent moins par leur valeur marchande que par leur importance stratégique.


Leur répartition géographique est également très inégale. En 2025, la Chine assure près de 69 % de la production mondiale de terres rares et domine largement leur transformation industrielle. La République démocratique du Congo fournit quant à elle près des trois quarts du cobalt extrait dans le monde. Cette concentration crée une dépendance structurelle pour les grandes puissances industrielles, à l’image de celle que connaît la galaxie fictive de Star Wars vis-à-vis du beskar de Mandalore.
Quand la géologie rejoint la science-fiction
Les créateurs de Star Wars n’ont évidemment pas conçu le beskar comme un objet géologique. Pourtant, les propriétés qu’ils lui attribuent présentent une certaine cohérence avec ce que nous connaissons des matériaux les plus performants développés par l’industrie moderne.
Le beskar est présenté comme un alliage plutôt que comme un élément pur. Ce choix est particulièrement crédible. Dans le monde réel, les matériaux aux propriétés mécaniques exceptionnelles résultent presque toujours d’associations complexes entre plusieurs éléments chimiques.
L’acier inoxydable combine ainsi fer, chrome et nickel. Les alliages de titane utilisés dans l’aéronautique incorporent de l’aluminium et du vanadium. Les superalliages employés dans les turbines aéronautiques peuvent contenir une dizaine d’éléments différents afin de résister simultanément aux contraintes mécaniques, à l’oxydation et aux températures extrêmes.
La résistance thermique du beskar évoque également certains métaux réfractaires bien connus des géologues et des métallurgistes. Le tungstène, par exemple, possède la température de fusion la plus élevée parmi les métaux connus, atteignant 3 422 °C. Le rhénium, plus rare encore, est utilisé dans les composants soumis à des températures particulièrement élevées, notamment dans l’industrie aéronautique.

){kind=link}
Quant à sa capacité à absorber des impacts sans se rompre, elle rappelle les recherches menées depuis une vingtaine d’années sur les alliages à haute entropie. Ces matériaux de nouvelle génération associent plusieurs éléments en proportions voisines, produisant des combinaisons inédites de dureté, de résistance mécanique et de résistance à la corrosion.
Bien sûr, aucun de ces matériaux ne pourrait réellement arrêter un sabre laser. Mais la logique scientifique qui sous-tend le beskar apparaît moins fantaisiste qu’il n’y paraît au premier abord.
Des ressources au cœur des rapports de puissance
La comparaison devient encore plus frappante lorsqu’on s’intéresse à la géopolitique des ressources.
Dans l’univers du Mandalorian, le contrôle du beskar constitue un enjeu de pouvoir majeur. Les conflits qui entourent son extraction, sa circulation et sa réappropriation participent directement à l’équilibre politique de la galaxie. L’histoire récente fournit plusieurs exemples comparables.
En 2010, dans un contexte de tensions territoriales avec le Japon, la Chine a temporairement restreint ses exportations de terres rares. L’événement a provoqué une forte inquiétude parmi les industriels dépendants de ces matériaux et a accéléré les réflexions sur la diversification des approvisionnements.
Plus récemment, Pékin a instauré des restrictions à l’exportation concernant le gallium, le germanium, puis d’autres matériaux stratégiques utilisés dans les semi-conducteurs et les technologies de défense.
Ces épisodes rappellent que les matières premières critiques ne constituent pas seulement des ressources économiques. Elles représentent également des instruments d’influence et de souveraineté.
Face à ces enjeux, l’Union européenne a adopté en 2024 le Critical Raw Materials Act, destiné à renforcer la sécurité d’approvisionnement en matières premières critiques, à développer les capacités de recyclage et à diversifier les sources d’importation. Les États-Unis poursuivent des objectifs similaires à travers différents programmes de soutien à l’industrie minière et métallurgique.
Face à cette dépendance, deux grandes stratégies s’offrent aux pays importateurs : diversifier les sources d’extraction ou apprendre à récupérer ce que l’on a déjà consommé. C’est cette deuxième voie, celle du recyclage, que la série illustre, sans le savoir, avec une grande précision.
Le recyclage, ou l’art mandalorien appliqué à nos déchets
L’un des aspects les plus intéressants de la série réside peut-être dans la place accordée au recyclage du beskar. À plusieurs reprises, le personnage de l’armurière récupère d’anciens fragments de métal pour les fondre et leur donner une nouvelle forme. Dans la fiction, ce geste possède une dimension culturelle et spirituelle forte : il permet de préserver un héritage tout en l’adaptant aux besoins du présent.
Cette pratique fait écho à un défi bien réel. Aujourd’hui, moins de 1 % des terres rares contenues dans les produits en fin de vie sont effectivement recyclées. Les obstacles sont nombreux : faibles concentrations dans les objets, difficultés de démontage, coûts élevés des procédés de récupération ou encore insuffisance des filières de collecte.
Pourtant, les millions de véhicules électriques, d’éoliennes et d’équipements électroniques actuellement en circulation constituent déjà un immense gisement urbain de métaux stratégiques.
De nombreux programmes de recherche européens et asiatiques cherchent ainsi à développer de nouvelles méthodes permettant de récupérer le néodyme des aimants permanents ou le cobalt contenu dans les batteries. À leur manière, ces chercheurs pratiquent eux aussi une forme de forge moderne : ils transforment les déchets technologiques d’aujourd’hui en ressources stratégiques de demain.
Ce que le beskar révèle de notre monde
Au fond, The Mandalorian ne raconte pas une histoire de métallurgie. La série parle avant tout d’identité, de transmission, de mémoire collective et de résilience culturelle.
Mais si le beskar occupe une place aussi centrale dans cet univers, c’est précisément parce qu’il matérialise ces enjeux sous une forme immédiatement compréhensible. La rareté de la ressource, la dépendance qu’elle crée et les conflits qu’elle suscite donnent une profondeur supplémentaire aux thèmes explorés par la fiction.
Comme souvent, la science-fiction agit ici comme un miroir. Elle déplace les questions dans une galaxie imaginaire pour mieux éclairer celles qui traversent notre propre société.
Les terres rares, le cobalt ou le gallium ne bénéficient pas de l’aura mythique du beskar. Leurs noms sont moins évocateurs et leurs propriétés moins spectaculaires. Pourtant, ils jouent un rôle tout aussi déterminant dans les transformations technologiques, énergétiques et géopolitiques du XXIᵉ siècle.
La fiction n’invente donc pas tant qu’elle ne révèle. En imaginant un métal rare dont le contrôle influence le destin d’une galaxie entière, Star Wars nous invite à porter un regard nouveau sur les ressources dont dépend notre propre avenir.
Ignorer cette réalité, c’est avancer dans la galaxie sans armure : vulnérable, exposé, dépendant des autres.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
08.07.2026 à 10:00
Une découverte inattendue : des traces de séismes anciens dans le Bassin parisien
Stéphane Baize, Géologue des tremblements de terre, Directeur de Recherches, ASNR; Académie des sciences
Pierre Louis Antoine, Directeur de Recherche CNRS, géoloque et géomorphologue spécialiste des paléoenvironnements du Quaternaire, Centre national de la recherche scientifique (CNRS)
Texte intégral (1776 mots)
En 1993, lors de fouilles archéologiques préventives pour la construction d’une route à Beauvais, dans l’Oise, des géologues et des archéologues ont mis au jour un site paléolithique exceptionnel. Occupé par des néandertaliens il y a environ 60 000 ans, il révèle bien plus que des outils en silex ou des ossements d’animaux, de mammouths, de rennes et de rhinocéros laineux.
En effet, nous avons identifié un réseau de failles traversant les dépôts sédimentaires récents et les restes archéologiques associés ainsi que le substrat rocheux (ici, la craie). Dans notre étude publiée ce mois-ci dans les Comptes Rendus Géoscience, nous proposons une nouvelle interprétation à ces déformations : elles seraient d’origine sismique.
Les failles que nous observons présentent des décalages verticaux cumulés jusqu’à 25 centimètres (pour comparaison, c’est significativement plus grand que celles mesurées après le séisme de magnitude proche de 5 qui a secoué et endommagé les communes du Teil, de Viviers et Saint-Thomé en Ardèche, le 11 novembre 2019).
Ces failles ne peuvent pas être expliquées par des phénomènes comme l’effondrement liés à la dissolution de la craie (le « karst »), ni par le gel et le dégel de sols riches en glace (appelé « pergélisol », ni enfin par l’activité humaine…
C’est pourquoi l’hypothèse la plus plausible est une origine tectonique, c’est-à-dire que le déplacement soit lié aux mouvements de la croûte terrestre pendant un ou plusieurs séismes. Cette origine devra être confirmée par des études complémentaires, notamment par des explorations du sous-sol, ou la recherche d’autres indices similaires par d’autres fouilles dans la même zone.

Les structures que nous avons observées sont cohérentes avec l’expression superficielle de ruptures sismiques profondes, qui seraient liées au grand pli et à la faille du Pays de Bray, une des structures géologiques majeures du Bassin parisien, qui s’enracine à plusieurs kilomètres dans la croûte terrestre.
Si les failles observées à Beauvais sur le site du lieu-dit « La Justice » sont bien liées à un séisme ancien, leur taille et leur décalage suggèrent un événement d’une magnitude d’au moins 5,5.
Pourquoi cette découverte est-elle importante ?
Le Bassin parisien est traditionnellement considéré comme une région peu sismique, avec une activité tectonique quasi nulle depuis des millénaires. On n’y connaît guère que quelques séismes historiques, comme celui de Veules-les-Roses, dans l’actuelle Seine-Maritime, en 1769 (magnitude estimée proche de 5), qui a causé des dégâts localement.
La découverte de Beauvais modifie notre perception du « danger » sismique dans la zone. Elle suggère, par l’ampleur des déformations observées, qu’il n’est pas négligeable et que des séismes forts ont pu se produire sur des failles il y a seulement 50 000 à 60 000 ans, une période géologiquement récente.
Une autre conséquence est qu’on peut maintenant considérer la faille du Pays de Bray comme potentiellement active. Ce changement d’appréciation du degré d’activité de cette faille rejoint celui qui avait suivi l’occurrence du séisme du Teil en 2019, en Ardèche, sur une faille alors inconnue pour être active.
Ces deux exemples supportent le même constat : les failles « intraplaques » (situées à l’intérieur des continents, loin des limites de plaques tectoniques) peuvent produire des séismes forts avec ruptures en surface, même dans des régions réputées stables. C’est ce qu’ont connu, par exemple, le centre du continent australien en avril dernier et le nord-est des États-Unis en 2020.
Quelles suites pour ces recherches ?
Cette découverte soulève des questions cruciales : la faille du Pays de Bray, longue de près de 100 kilomètres, est-elle toujours active et capable de causer des séismes importants dans un futur proche ? Quelle est la probabilité de séismes futurs dans cette zone densément peuplée et industrialisée, et avec quelle magnitude peuvent-ils survenir ? Comment affiner les modèles d’aléa sismique en conséquence, pour cette région comme pour les zones intraplaques comparables ?
Pour répondre à ces interrogations, il faut poursuivre les investigations sur le terrain autour du site fouillé, notamment utiliser des méthodes géophysiques de haute résolution et non invasives, pour sonder et cartographier précisément les failles enterrées, à des profondeurs allant de quelques dizaines à plusieurs centaines de mètres. Il faudrait ensuite étendre les fouilles pour dater d’éventuelles traces de séismes passés et estimer leur fréquence (ce qu’on appelle l’analyse paléosismologique).
Un autre enjeu est de renforcer la collaboration interdisciplinaire : les traces de séismes passés dans les sols sont, dans le contexte français de tectonique lente, souvent masquées ou abîmées par l’érosion ou les activités humaines. Il est donc nécessaire de combiner les approches des archéologues, des géologues et des géophysiciens.
Au-delà des recherches proprement dites, l’objectif est de mettre à jour et de compléter la base de données des failles actives et des séismes préhistoriques connus, publiée il y a bientôt dix ans.
Enfin, ces résultats seront pris en compte dans l’évaluation des risques, qui est, par exemple, périodiquement mise à jour à l’échelle de l’Europe. Cette étude souligne que, même dans des zones réputées stables, le risque sismique ne doit pas être sous-estimé, même si les causes des séismes y restent encore débattues.
Tout savoir en trois minutes sur des résultats récents de recherches, commentés et contextualisés par les chercheuses et les chercheurs qui ont menées ces dernières, c’est le principe de nos « Research Briefs ». Un format à retrouver ici.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
08.07.2026 à 10:00
Avec ou sans synapses ? Le singulier système nerveux des cténophores, ou comment un débat scientifique vieux de 100 ans refait surface
David Stroebel, Ingénieur de recherche hors classe CNRS dans l'équipe Récepteurs du glutamate et synapses excitatrices, Institut de biologie, École normale supérieure (ENS) – PSL
Texte intégral (2359 mots)

Dans les livres de biologie, on apprend que le système nerveux se compose de neurones connectés par des synapses, indispensables à nos capacités de cognition. Jusqu’à très récemment, les synapses étaient un élément incontournable de tous les systèmes nerveux connus. Mais voilà que des chercheurs ont observé un système différent, sans synapses, chez d’intrigants animaux marins, les cténophores. Cette avancée suscite les débats chez les scientifiques.
Aux prémices de la neurobiologie moderne, au début du XXᵉ siècle, une rivalité d’anthologie opposa Camillo Golgi, médecin italien, pionnier et figure tutélaire de la microscopie cellulaire, et l’Espagnol Santiago Ramón y Cajal, génie de la neuroanatomie. L’Italien avançait que le système nerveux formait un réseau unique et continu : un syncytium. L’Espagnol y voyait plutôt un réseau discontinu, fait de cellules indépendantes se contactant par des synapses.

Cent vingt ans après l’attribution du même prix Nobel de physiologie aux deux scientifiques, le succès de Cajal apparaît total : les synapses constituent une pièce maîtresse de notre compréhension actuelle du fonctionnement du système nerveux. De fait, ces structures submicrométriques innombrables dans le cerveau (près d’un demi-million de milliards de synapses chez l’humain) forment le support des capacités de computation, d’apprentissage et de mémorisation.
Mais si, envers et contre l’histoire de la neurobiologie moderne, Golgi avait pu aussi avoir raison ? Et si le système nerveux d’un organisme pouvait également fonctionner en syncytium ?
C’est précisément ce que des chercheurs ont découvert en 2023, en imageant un cténophore par tomographie électronique. Les cténophores sont des créatures marines translucides, familières de presque tous les environnements marins, qui se distinguent par de délicates ondulations irisées à leur surface. Certains cténophores peuvent sembler, à première vue, être de proches cousins des méduses. Cependant, l’étude publiée en 2023, dans la revue Science, révèle que la partie centrale du réseau neural de cténophore est continu, un cas sans équivalent dans le monde vivant.
Le syncytium neural de Golgi se trouvait en fait… dans les mers.

Les cténophores n’en sont pas à leur première originalité
Contredisant leur apparente ressemblance, l’étude du génome des cténophores indiquait déjà en 2013 qu’ils sont plus éloignés des cnidaires (méduses) que ces dernières ne le sont de nous. Plusieurs études scientifiques placent désormais le groupe des cténophores comme ancêtres des animaux (on appelle le groupe des animaux les « Métazoaires »), avant même les éponges ! Mais ce classement reste encore aujourd’hui très débattu.
Pourquoi une telle querelle entre spécialistes ? Parce que l’ancestralité des cténophores chez les animaux (Métazoaires) complexifie le scénario d’émergence du système nerveux.
En effet, les classifications du vivant considéraient jusque-là que notre ancêtre commun, Eumétazaoire, a acquis un système nerveux après la séparation du groupe des éponges, qui, elles, seraient demeurées dépourvues de système nerveux. Le repositionnement des cténophores dans l’arbre du vivant bouscule complètement ce scénario : il impliquerait l’émergence multiple et séparée de systèmes nerveux potentiellement différents, couplée ou non à la disparition du système nerveux chez certaines espèces (par exemple, chez les éponges).
L’état actuel des recherches ne permet d’exclure aucun des deux scénarios. Le scénario initial a pour lui une grande simplicité (on parle de scénario « parcimonieux »), permettant aisément d’envisager un assemblage progressif de la complexité du système nerveux. Le scénario nouvellement remanié est porté par l’évolution exceptionnelle des données de séquençage de génome et des outils d’analyse bio-informatique. Ce nouveau scénario a le bénéfice et l’attrait de la nouveauté. Mais, pour convaincre, il lui reste encore à élaborer un mécanisme évolutif convaincant de formation du système nerveux.
C’est là qu’intervient la découverte de la singularité du système nerveux des cténophores, appuyant l’originalité biologique de ces discrets organismes marins parmi les animaux (Métazoaires). Si, à ce stade, elle ne permet pas formellement de trancher entre les deux théories, cette découverte offre un aperçu des possibilités insoupçonnées d’organisation du système nerveux dans le vivant. Par là même, elle ouvre les chemins des possibles évolutifs, ceux qui faisaient défaut aux scénarios complexes de co-émergence de systèmes nerveux.
Les cténophores déterrent le débat entre Golgi et Cajal
Mais revenons à l’autre débat, celui d’il y a plus de cent ans, entre Cajal et Golgi – ou, désormais transposé à la biologie marine, la distinction d’organisation neurobiologique entre cténophores et cnidaires. Que peut bien apporter une organisation neurale en syncytium par rapport à celle bien connue basée sur des synapses (et vice versa) ?
Pour l’instant, on ne sait encore presque rien du fonctionnement de ce syncytium neural des cténophores, seulement qu’il connecte les cellules excitables sensorielles et motrices de l’animal. En attendant les résultats de futures investigations, nous en sommes aujourd’hui juste réduits à spéculer sur ce qu’un tel réseau pourrait procurer : une économie d’énergie ? Un gain de rapidité de réponse ?
Le rôle des synapses, des méduses aux humains
Dans les organismes neuraux, les synapses constituent la base des capacités d’encodage complexe du signal au sein du réseau. L’importance de leur capacité d’adaptation (appelée aussi plasticité) et l’étendue de leur diversité constituent des champs d’investigation actifs de la neurobiologie actuelle. Plusieurs décennies de recherche intensive nous ont appris que, selon leur type et leur environnement cellulaire, les synapses modulent la force, la dynamique et même la nature des signaux transmis au neurone qu’elle contacte.
Ces propriétés sont vraisemblablement à l’origine des possibilités d’expansion et de complexification des réseaux neuronaux des organismes à synapses, comme chez nous autres Vertébrés. In fine, ce sont cette expansion et cette complexification qui ont permis de supporter le développement de comportements et d’apprentissages élaborés, jusqu’aux prouesses des transmissions culturelles humaines.
Embrasser la complexité du vivant
Alors, système à syncytium ou à synapses ?
Si juger (neurobiologiquement) de l’efficacité relative d’organisations si différentes n’a guère de sens, un regard sur les chiffres de population des espèces concernées révèle une profonde asymétrie. Seule une centaine d’espèces de cténophores est référencée alors qu’il existerait plus d’un million d’espèces d’animaux neuraux. Le succès évolutif des organismes à synapses – à la fois en termes de diversité que de biotopes occupés – est aussi incontestable que la postérité de Cajal.
Pourtant, après 600 millions d’années marquées par plusieurs extinctions massives, les cténophores continuent de cohabiter avec les autres espèces peuplant nos océans. La sélection naturelle n’a pas tranché entre système à syncytium et à synapses.
Et les cténophores, tels des clins d’yeux facétieux aux modèles de Golgi, persistent à tourner en dérision nos schémas simplistes, du fonctionnement neural au scénario de nos origines.
David Stroebel est un agent du CNRS, France. Il a reçu des financements de l'ANR (Agence Nationale pour la Recherche, France) ainsi que de la FRM (Fondation pour la recherche médicale).
08.07.2026 à 09:59
La respiration nous permet de communiquer avec nous-mêmes, avec les autres et avec les robots
Thomas Similowski, Professeur de pneumologie, directeur de l'unité de recherche UMRS1158 (Neurophysiologie Respiratoire Expérimentale et Clinique), spécialiste des interactions entre système respiratoire, système nerveux, et société, Sorbonne Université
Texte intégral (1852 mots)

La respiration n’a pas comme unique fonction de nous apporter de l’oxygène et d’éliminer du dioxyde de carbone. Loin de là. Elle sert aussi à communiquer de multiples manières : avec les autres explicitement ou implicitement ; avec soi-même ; et même avec des robots ou des œuvres d’art. Cette faculté est propre à la respiration : on ne communique avec son cœur ou ses tripes qu’au figuré.
Parmi les fonctions vitales, la respiration possède deux grandes particularités. La première est que nous pouvons en prendre temporairement le contrôle. Comment est-ce possible ? Parce que l’automatisme respiratoire ne vient pas des poumons eux-mêmes, comme c’est le cas pour les automatismes du cœur et de l’intestin, mais d’ailleurs : du système nerveux central. Pour respirer, il faut contracter des muscles « squelettiques » (qui font bouger des os), dont le plus connu est le diaphragme, la coupole musculaire qui sépare thorax et abdomen. Ces muscles respiratoires sont commandés par des neurones de la moelle épinière. Notre cortex cérébral y a accès pour en faire ce que nous voulons, en court-circuitant temporairement les structures automatiques qui assurent le rythme respiratoire (des oscillateurs neuronaux du tronc cérébral). Ce phénomène n’existe pour aucune autre fonction vitale.
Pour parler (ou chanter, ou siffler, ou jouer d’un instrument à vent), il faut pouvoir arrêter la respiration automatique, prendre une grande inspiration pour une voix forte ou une phrase longue, segmenter son souffle pour moduler sa prosodie. Une fois dit, cela paraît évident. Mais aviez-vous vraiment conscience que sans contrôle de la respiration, c’est le silence ?
Respirer, c’est communiquer
Deuxième particularité de la respiration : elle se voit et elle s’entend. Nous pouvons communiquer impatience, lassitude, colère, fatigue, soulagement, surprise, ou peur par des soupirs expressifs. Mais il y a plus subtil.
La respiration est branchée sur notre état physiologique (le sommeil ou l’effort), notre santé, nos émotions. Tous ces sentiments caricaturés explicitement par les soupirs appuyés, la respiration les traduit implicitement par des modifications de son amplitude et de sa fréquence, et des sons de notre « soufflet ».
Respiration lente, régulière et profonde de l’apaisé qui somnole. Respiration superficielle, rapide, monotone de la crise d’anxiété. Respiration saccadée, irrégulière de la joie et de l’excitation. Que nous en ayons conscience ou pas (plus souvent « pas », d’ailleurs), nous envoyons aux autres un flux continu d’information sur nous-mêmes par le simple fait de respirer. C’est d’ailleurs une source d’alliance : la synchronisation respiratoire, implicite ou explicite, peut créer un lien, favoriser la coopération. Nous avons même chacun notre signature motrice respiratoire : en effet, la façon dont notre poitrine se gonfle et se dégonfle nous est propre, comme l’est notre démarche.
Par ailleurs, notre cerveau est bombardé en permanence de milliers de messages qui proviennent de notre appareil respiratoire. Il se sert de ces messages comme d’un échafaudage pour coordonner des aires cérébrales impliquées dans de multiples fonctions cognitives : mémoriser ou décider, par exemple. Des recherches ont montré que nous enregistrons mieux une image si elle nous est présentée pendant l’inspiration que pendant l’expiration.
Ainsi, par la respiration, nous communiquons avec nous-mêmes. Et nous pouvons agir sur notre cerveau, en particulier l’apaiser, en changeant notre façon de respirer, une propriété largement mise à profit par la plupart des approches psychocorporelles.
Faire respirer les robots
Mais revenons à cette respiration qui se voit et qui s’entend, qui renseigne sur vous, qui dit en fait « Regarde, écoute, je suis vivant », et ce, dès notre tout premier cri, jusqu’à notre dernier souffle.
Pour savoir si quelque chose est vivant, les enfants utilisent trois indices : ça bouge ; ça respire ; ça grandit (mais celui-ci demande du temps). Donc pour savoir tout de suite si c’est vivant, même si cela ne bouge pas : est-ce que cela respire ?
Au laboratoire de physiopathologie respiratoire de l’unité de recherche UMRS 1158 Inserm-Sorbonne Université, et en collaboration avec l’Institut des systèmes intelligents et de robotique de Sorbonne Université, nous avons mobilisé ce concept pour l’appliquer à une problématique très spécifique, celle des interactions humains-robots.
Est-ce qu’un robot qui « respire » est plus « engageant » qu’un robot « normal » ? Ceci avait déjà été observé par d’autres chercheurs qui avaient animé un bras mécanique de mouvements cadencés ressemblant à une respiration. Les humains, qui travaillaient avec le robot sur une chaîne de coproduction humains-machines, avaient trouvé le « bras respirant » plus « vivant », plus « humain », plus « intelligent », plus « aimable » et plus « rassurant », selon un outil d’évaluation très utilisé en robotique (le questionnaire « Godspeed »). Mais notre question s’adressait davantage à ces robots humanoïdes qui seront peut-être nos compagnons, nos interlocuteurs de demain. Faire respirer un robot déjà très attractif par sa morphologie, est-ce mieux ? Ou au contraire, est-ce dérangeant ?
Pour tester cela, nous avons programmé deux robots « Pepper » (un petit humanoïde bourré de capteurs qui ressemble à un enfant d’une dizaine d’années) pour qu’ils puissent converser avec des humains. Nous en avons animé un de petits bruits et mouvements aléatoires que l’on injecte souvent dans le comportement des robots pour les rendre plus « vivants ». Nous avons animé l’autre d’un mouvement associant redressement du torse et rotation des épaules (comme ce qui se passe lorsque nous inspirons) ainsi que d’un discret souffle. Le résultat a été probant. Alors que la plupart des participants ne réalisaient pas consciemment que l’un des deux robots respirait, ils trouvaient celui-ci « plus vivant » et « plus intelligent ».
Surtout, l’interaction changeait : les participants passaient davantage de temps à regarder la tête et le visage du robot (« temps de regard ») et l’échange durait plus longtemps. Statistiquement, deux facteurs seulement étaient significativement associés au temps de regard : la respiration du robot d’une part et le niveau de sollicitude empathique de son interlocuteur de l’autre.
Un humain s’implique plus dans une interaction avec un robot si le robot « respire ». Donc, la respiration est un vecteur de communication même avec le « non-vivant ». Une piste si l’on souhaite humaniser toujours plus robots, intelligences artificielles et autres agents virtuels ?
Quand l’art respire

C’est selon ce principe d’animéité respiratoire que notre unité de recherche s’est intégrée à une équipe multidisciplinaire, réunie par Samuel Bianchini, artiste et enseignant-chercheur à l’École nationale supérieure des arts décoratifs, équipe dont les efforts ont convergé vers la création d’une œuvre d’art respirante.
Réespiration combine création artistique, robotique souple, ingénierie mécanique, intelligence artificielle, physiologie, design textile, design sonore, et bien d’autres choses encore, en une entité qui respire comme un humain (grâce à l’entraînement d’un algorithme spécialisé et qui peut synchroniser son rythme respiratoire à celui de son spectateur, voire l’influencer. Les réactions du public et les premières données de recherche montrent qu’en présence de Réespiration, les corps se détendent, les cerveaux s’apaisent. Ils vagabondent même, en chemin vers un état modifié de conscience.
Les robots respirants en général, et Réespiration en particulier, auront-ils des applications médicales ? Apaiseront-ils l’anxiété, aideront-ils à soulager la souffrance des patients atteints de maladies respiratoires chroniques ? C’est la prochaine question…
L’UMRS 1158 et le projet Réespiration sont soutenus par la Fondation du Souffle, www.lesouffle.org
08.07.2026 à 09:59
Les astronomes cherchent-ils vraiment des extraterrestres ? Oui, mais pas comme dans les films
Quentin Kral, Astrophysicien à l'observatoire de Paris-PSL, CNRS, Sorbonne Université, Université Paris Cité
Texte intégral (1999 mots)
La recherche de vie ailleurs que sur Terre n’est pas de la science-fiction, mais un domaine très sérieux de recherche : l’exobiologie. Découvrez les techniques qui pourraient permettre, un jour, une rencontre du troisième type.
Sommes-nous seuls dans l’Univers ? Pendant longtemps, cette question relevait surtout de la philosophie. Chacun pouvait avoir son intuition. Kant disait même qu’il parierait toute sa fortune sur l’existence d’une vie ailleurs dans l’Univers. Il ne prenait pourtant pas un très grand risque : à son époque, il était impossible de tester cette hypothèse.
Aujourd’hui, la situation a profondément changé. Grâce aux progrès de l’astronomie, de la biologie, de la chimie et de la géologie, la recherche de la vie extraterrestre est devenue une véritable discipline scientifique : l’exobiologie. Des milliers de chercheurs tentent désormais de répondre expérimentalement à une question qui semblait encore hors de portée il y a quelques décennies.
Plusieurs approches sont explorées. L’idée est d’apprendre ce que l’on peut du cas terrestre avant d’extrapoler à d’autres mondes. Ainsi, certaines équipes cherchent à comprendre comment la vie est apparue sur Terre afin d’identifier les ingrédients indispensables à son émergence. D’autres étudient son évolution vers des organismes plus complexes.
Les astronomes, eux, s’intéressent à une autre question : si la vie existe ailleurs, comment pourrions-nous la détecter ?
Deux grandes stratégies se dessinent. La première consiste à rechercher des biosignatures, c’est-à-dire des traces laissées par des organismes vivants. La seconde vise les technosignatures, des indices qui pourraient révéler l’existence d’une civilisation suffisamment avancée pour développer une technologie détectable.
Chercher la vie dans le système solaire
La façon de rechercher la vie dépend avant tout de la distance. Dans notre système solaire, nous pouvons envoyer des sondes pour analyser directement des roches, des glaces ou des océans cachés sous la surface. Autour d’autres étoiles, en revanche, nous sommes condamnés à observer les planètes à distance et à interpréter la faible lumière qui nous parvient.
Mars reste l’une des cibles les plus étudiées. Le rover Perseverance ne cherche pas à photographier d’éventuels organismes vivants, mais à identifier des biosignatures fossiles : des traces chimiques ou géologiques qui indiqueraient qu’une vie microbienne a existé lorsque Mars possédait des lacs et des rivières il y a plusieurs milliards d’années. Les échantillons qu’il collecte devraient être rapportés sur Terre dans les prochaines décennies – sûrement avec beaucoup de retard à cause de coupes budgétaires sévères de l’administration Trump – afin d’être analysés avec les instruments les plus performants.
D’autres mondes suscitent également beaucoup d’espoir. Les lunes glacées Europe, autour de Jupiter, et Encelade, autour de Saturne, abritent un océan d’eau liquide sous leur croûte de glace. Encelade projette même dans l’espace des panaches d’eau provenant de son océan, offrant une occasion unique d’en analyser directement la composition. Les missions Europa Clipper et Juice, actuellement en route, permettront de mieux comprendre si ces océans réunissent les conditions favorables à l’apparition de la vie.
Au-delà du système solaire, cette approche directe devient impossible. Les astronomes doivent alors rechercher les traces que la vie pourrait laisser dans l’atmosphère ou à la surface des exoplanètes.
Les biosignatures : rechercher les empreintes laissées par la vie
Sur Terre, les êtres vivants modifient profondément leur environnement. Certaines bactéries produisent de l’oxygène, d’autres du méthane. Les plantes absorbent certaines longueurs d’onde de la lumière pour réaliser la photosynthèse. Toutes ces activités laissent des signatures qui pourraient, en principe, être détectées à des dizaines d’années-lumière.
On pourrait croire qu’il suffit de détecter de l’oxygène dans l’atmosphère d’une exoplanète pour conclure à la présence de vie. Malheureusement, la nature sait produire de l’oxygène sans intervention biologique. Il existe de nombreux mécanismes dits abiotiques capables d’imiter certaines signatures du vivant.
On recherche donc des indices plus subtils : des déséquilibres chimiques. Sur Terre, par exemple, l’oxygène et le méthane coexistent alors qu’ils devraient rapidement réagir entre eux pour former du dioxyde de carbone. S’ils restent présents simultanément, c’est parce que les organismes vivants les renouvellent en permanence. Une telle combinaison constitue une biosignature beaucoup plus convaincante qu’une seule molécule prise isolément.
L’actualité récente illustre parfaitement cette difficulté. En 2025, des observations réalisées avec le télescope spatial James-Webb sur l’exoplanète K2-18 b ont révélé la présence possible de molécules comme le sulfure de diméthyle (DMS), un composé qui, sur Terre, est principalement produit par le phytoplancton marin. L’annonce a suscité un immense enthousiasme, mais aussi de nombreuses réserves : les données restent limitées et les conclusions ont sans doute été tirées un peu trop rapidement. De plus, il est possible que ces molécules puissent être produites par des processus non biologiques. Cette étude rappelle qu’aucune molécule, à elle seule, ne peut aujourd’hui être considérée comme une preuve de l’existence de la vie. Il faudra réunir plusieurs indices indépendants et convergents avant de pouvoir revendiquer une détection crédible.
Une autre approche consiste à observer directement la lumière réfléchie par une planète. Sur Terre, les végétaux absorbent fortement la lumière rouge pour alimenter la photosynthèse, puis réfléchissent très efficacement le proche infrarouge. Cette transition brutale, appelée le « bord rouge » de la végétation (vegetation red edge), est visible lorsqu’on observe notre planète depuis l’espace. Si une biosphère extraterrestre exploitait elle aussi l’énergie de son étoile grâce à un processus analogue, elle pourrait laisser une signature similaire, même si ses organismes étaient très différents des plantes terrestres.
Aucune de ces observations ne suffira, à elle seule, à démontrer l’existence de la vie. Les astronomes devront croiser plusieurs indices : la composition de l’atmosphère, la présence éventuelle d’eau liquide, la nature rocheuse de la planète, son champ magnétique ou encore les propriétés de son étoile. Comme dans une enquête policière, c’est l’accumulation de preuves indépendantes qui permettra de construire un scénario crédible.
Les technosignatures : rechercher des civilisations plutôt que des microbes
On pourrait penser que les astronomes devraient concentrer tous leurs efforts sur la recherche de vie microbienne, probablement beaucoup plus abondante que les civilisations technologiques. Pourtant, les deux approches sont complémentaires.
Les biosignatures sont sans doute plus fréquentes, mais souvent ambiguës. Les technosignatures, elles, seraient probablement beaucoup plus rares, mais aussi beaucoup plus difficiles à expliquer autrement. Si nous recevions un signal radio contenant les décimales du nombre π ou une suite de nombres premiers, le doute serait permis bien moins longtemps.
Depuis les années 1960, les recherches regroupées sous le nom de SETI (Search for Extraterrestrial Intelligence) scrutent le ciel à la recherche de signaux radio artificiels. L’idée est qu’une civilisation pourrait chercher à communiquer avec d’autres ou laisser s’échapper involontairement des émissions, comme nos propres transmissions radio et télévisées fuient dans l’espace depuis près d’un siècle.
À ce jour, aucune détection n’a été confirmée. Le célèbre « signal Wow ! », enregistré en 1977 par un radiotélescope de l’Ohio State University, est une émission radio de 72 secondes très intense et de bande étroite provenant de la constellation du Sagittaire. Son caractère inhabituel a suscité de nombreuses spéculations, mais son origine demeure inconnue. Surtout, l’absence de toute nouvelle détection similaire empêche d’y voir une preuve convaincante d’une civilisation extraterrestre.
Aujourd’hui, des chercheurs explorent un éventail beaucoup plus large de technosignatures. Une planète couverte d’éclairages artificiels pourrait produire une émission lumineuse inhabituelle. Une civilisation très avancée pourrait construire d’immenses infrastructures destinées à exploiter l’énergie de son étoile, comme les sphères de Dyson, un hypothétique immense ensemble de satellites collecteurs répartis autour de l’étoile pour en récupérer une grande partie de l’énergie. Il est également envisageable de rechercher des polluants industriels impossibles à produire naturellement, des faisceaux laser utilisés pour communiquer, voire des constellations de satellites semblables au réseau Starlink.
Une quête qui ne fait que commencer
Le télescope spatial James-Webb inaugure une nouvelle ère en permettant de sonder les atmosphères d’exoplanètes avec une précision jamais atteinte. Mais les instruments actuels restent encore limités.
La prochaine révolution viendra probablement de l’Extremely Large Telescope (ELT), actuellement en construction au Chili. Avec son miroir de 39 mètres de diamètre, il pourra analyser en détail l’atmosphère de petites planètes rocheuses situées autour d’étoiles proches. Les futurs observatoires spatiaux iront encore plus loin. Ensemble, ils permettront de tester des biosignatures toujours plus subtiles et d’éliminer progressivement les explications alternatives.
La découverte d’une vie extraterrestre ne prendra probablement pas la forme d’une photographie spectaculaire ou d’un unique signal mystérieux. Elle résultera plutôt d’une accumulation patiente d’indices, confrontés pendant des années à toutes les explications possibles.
Pour la première fois de l’histoire, la question « Sommes-nous seuls dans l’Univers ? » n’appartient plus seulement à la philosophie. Elle est devenue une question scientifique. Et les prochaines décennies pourraient enfin nous apporter les premiers éléments de réponse.
Pour en savoir plus sur cette quête de la vie extraterrestre, vous pouvez consulter le livre de Quentin Kral, Les Astronomes à la recherche de la vie extraterrestre, aux éditions Ellipses, 2025.
Quentin Kral est l'auteur de l'ouvrage : « Les astronomes à la recherche de la vie extraterrestre » aux éditions ellipses.
07.07.2026 à 15:53
Comment les constellations de satellites pourraient transformer la surveillance climatique
Mustapha Meftah, Chercheur au LATMOS/CNRS/UVSQ/SU et professeur à l'UVSQ, spécialisé en physique solaire, sciences de l'atmosphère, instrumentation spatiale et missions satellitaires, Sorbonne Université
Alain Sarkissian, 11 Boulevard d'Alembert, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Philippe Keckhut, vice-président innovation, Université de Versailles Saint-Quentin-en-Yvelines (UVSQ) – Université Paris-Saclay
Texte intégral (2875 mots)
Pour détecter et réguler les émissions responsables du changement climatique, certains phénomènes doivent désormais être suivis en temps réel, ou presque. Une solution consiste à démultiplier les instruments d’observation grâce à des constellations de satellites. Mais comment faire en sorte que ces constellations à but scientifique ne provoquent pas plus de problèmes qu’elles ne contribuent à en résoudre ?
Les satellites sont devenus indispensables pour observer le changement climatique. Ils mesurent les gaz à effet de serre, surveillent les incendies, observent les nuages et suivent l’évolution des océans.
Mais certains phénomènes évoluent plus vite que le rythme des observations spatiales, ce qui rend leur observation plus difficile. Ainsi, un incendie, un épisode de pollution ou une fuite de méthane d’origine anthropique (provenant par exemple d’infrastructures pétrolières et gazières, de mines de charbon ou de centres d’enfouissement) peuvent évoluer plus rapidement que le temps nécessaire à un satellite pour observer à nouveau une même région. Des étapes clés de leur évolution peuvent alors être manquées, retardant leur détection, leur localisation et les interventions visant à en limiter les impacts.
C’est pour cela que la fréquence des observations satellitaires devient désormais presque aussi importante que leur précision. Une des pistes explorées consiste à déployer des constellations de satellites afin d’augmenter fortement la fréquence des mesures depuis l’espace. Dans cette approche, l’objectif n’est plus seulement d’utiliser quelques satellites très performants, mais également d’observer la Terre beaucoup plus fréquemment grâce à des constellations composées de dizaines, voire de centaines de satellites.
Être précis ou être rapide : le compromis des observations satellitaires actuelles
Ces nouvelles approches s’inscrivent dans la continuité des grandes missions spatiales d’observation du climat, telles que OCO-2, GOSAT ou la famille des satellites Sentinel du programme Copernicus, qui fournissent déjà des données essentielles pour suivre l’évolution de l’atmosphère et du cycle du carbone. La plupart de ces missions reposent sur un nombre limité de satellites.


{kind=link}
La mesure des gaz à effet de serre depuis l’espace est aujourd’hui considérée comme un enjeu majeur par les grandes organisations internationales de surveillance de la Terre, comme le Groupe d’observations de la Terre (en anglais, Group on Earth Observations, GEO) ou le Comité d’observation satellite de la Terre (Committee on Earth Observation Satellites, CEOS).
Pour répondre à ce besoin, plusieurs missions spatiales sont aujourd’hui en opération, telles que OCO-2, GOSAT ou Sentinel-5P, tandis que d’autres, comme CO2M, sont en préparation. Elles visent à mesurer les concentrations de gaz à effet de serre avec une précision toujours plus élevée. Certaines missions atteignent une précision de l’ordre de 1 partie par million (1 ppm) sur la concentration atmosphérique de CO₂, une performance nécessaire pour estimer les sources et les puits de carbone et mieux quantifier les échanges de CO₂ entre l’atmosphère, les océans et les continents.
Mais cette précision s’accompagne d’un compromis : pour obtenir des mesures très précises et une résolution spatiale élevée, les satellites observent généralement une bande de terrain de largeur limitée, ce qui augmente le temps nécessaire pour observer à nouveau une même région. C’est précisément cette limite que les constellations cherchent à dépasser en multipliant le nombre de satellites en orbite.
Le méthane réchauffe l’atmosphère bien plus rapidement que le CO₂, mais ses émissions évoluent trop vite pour les observations actuelles
Le méthane illustre particulièrement cette difficulté. Selon le Groupe d’experts intergouvernemental sur l’évolution du climat (Giec), le méthane réchauffe l’atmosphère environ 80 fois plus que le CO₂ sur une période de vingt ans. Réduire rapidement les émissions de méthane constitue donc un levier important pour limiter le réchauffement climatique à court terme. Le suivi du méthane repose sur la combinaison des observations satellitaires et des modèles de transport atmosphérique, qui permettent d’estimer la dispersion du méthane et l’évolution de ses émissions à l’échelle globale.

Les satellites permettent déjà de détecter certaines émissions depuis l’espace. Sentinel-5P/TROPOMI fournit par exemple une couverture quotidienne globale permettant d’identifier de grands « super-émetteurs » régionaux. D’autres instruments, comme Sentinel-2 ou certains imageurs hyperspectraux, permettent d’observer des émissions beaucoup plus localisées.
Mais certaines émissions restent intermittentes. Une fuite de méthane peut apparaître puis disparaître entre deux observations. Pour les agences environnementales comme pour les industriels, disposer de mesures plus fréquentes devient essentiel afin de localiser rapidement ces émissions et de répondre aux nouvelles exigences de surveillance et de déclaration des émissions de gaz à effet de serre (GES), dans le cadre notamment du CBAM européen.
La fréquence d’observation, grand intérêt scientifique des constellations de satellites
C’est précisément l’intérêt des constellations de satellites. Contrairement aux missions spatiales traditionnelles, qui reposent sur quelques plates-formes complexes, ces architectures utilisent plusieurs dizaines de satellites plus petits répartis sur plusieurs plans orbitaux, généralement à des altitudes comparables. L’objectif est moins de maximiser la performance de chaque satellite que de multiplier les observations au cours d’une même journée. Selon les caractéristiques des instruments embarqués, une constellation d’une vingtaine à quelques dizaines de satellites peut ainsi réduire le temps de revisite de plusieurs jours à quelques heures.
Les avancées dans la miniaturisation des satellites et des instruments rendent désormais possibles des capteurs scientifiques plus petits, plus légers et moins coûteux. Cette miniaturisation permet de développer des capteurs adaptés à des besoins d’observation ciblés, sans chercher systématiquement à maximiser les performances ni la complexité des instruments.
S’intégrer dans des constellations de télécommunications
Une autre évolution pourrait également transformer l’observation du climat : l’intégration de capteurs scientifiques miniaturisés à bord des satellites appartenant à des constellations de télécommunications. Cette approche est notamment étudiée dans le cadre des futures générations de satellites d’Eutelsat-OneWeb, qui pourraient accueillir des charges utiles auxiliaires.
Plutôt que de lancer une constellation scientifique entièrement dédiée, avec les enjeux associés en termes de débris spatiaux, d’occupation des orbites et de pollution lumineuse, il deviendrait possible d’embarquer de tels instruments à bord de ces satellites.
Ces infrastructures pourraient ainsi servir à la fois aux télécommunications et à l’observation du climat, en mutualisant les plates-formes et les lancements, ce qui pourrait réduire significativement les coûts par rapport à une constellation scientifique entièrement dédiée, tout en augmentant la fréquence des observations.
Ces nouvelles approches ne remplaceraient pas les grandes missions climatiques institutionnelles, indispensables pour garantir la stabilité et la qualité scientifique des mesures de référence. Elles pourraient en revanche compléter les infrastructures existantes grâce à des observations beaucoup plus fréquentes de la Terre.

La mission française UVSQ-SAT NG, développée par le laboratoire Atmosphères, observations spatiales (LATMOS), s’inscrit dans la continuité des missions UVSQ-SAT et INSPIRE-SAT 7, deux nanosatellites démonstrateurs dédiés à l’observation du bilan radiatif de la Terre.
UVSQ-SAT NG teste de nouvelles approches de miniaturisation pour l’observation du bilan radiatif terrestre et de certains gaz à effet de serre depuis une plateforme nanosatellite. Cette mission n’est pas intégrée à une constellation de télécommunications ; elle constitue un démonstrateur technologique destiné à préparer de futures architectures de constellations scientifiques. Les données de ces missions sont accessibles librement à la communauté scientifique et au public sur la plateforme NAHLA.
Mustapha Meftah a reçu des financements de l'Agence nationale de la recherche (ANR).
Alain Sarkissian a reçu des financements de l'Agence nationale de la recherche (ANR).
Philippe Keckhut a reçu des financements de l'ANR pour le projet Compétences et Métiers d'Avenir France2030; Académie Spatiale
06.07.2026 à 15:47
La sécurité des drones militaires, ou comment protéger ce qui compte (et ce n’est pas toujours le drone lui-même)
Serge Chaumette, Professeur des Universités en Informatique, chercheur au LaBRI (Laboratoire Bordelais de Recherche en Informatique) et responsable des activités drones de ce laboratoire, Université de Bordeaux
Damien Sauveron, Professeur des Universités en Informatique à la Faculté des Sciences et Techniques, Université de Limoges
Texte intégral (2420 mots)
Sur les théâtres d’opération militaire, les drones évoluent dans un environnement hostile où ils doivent avant tout protéger les troupes qu’ils accompagnent. Pour mener à bien cette mission, ils déploient des stratégies qui leur offrent une certaine résilience, le but n’étant finalement pas de les protéger pour eux-mêmes, mais de leur permettre d’accomplir leur tâche coûte que coûte. Leur propre protection n’est qu’un enjeu secondaire : on les dit sacrifiables.
Face aux vulnérabilités de ces nouveaux acteurs des conflits militaires, on se trouve devant un jeu du gendarme et du voleur où le gendarme court après de nouvelles solutions pour se protéger du voleur alors que le voleur cherche de nouvelles failles lui permettant de mettre à mal les stratégies développées par le gendarme.
La guerre en Ukraine a suscité un regain d’intérêt des forces armées pour les drones, en particulier de taille petite et moyenne, qu’ils soient unitaires ou en essaim. On le constate quotidiennement, ils sont partout sur le champ de bataille et constituent un atout majeur pour les forces : ils portent le feu pour elles vers les lignes ennemies, mais surtout ils les renseignent, leur évitent une exposition inutile, les protègent.
Mais comment assurer leur propre protection afin de garantir leur disponibilité face aux attaques de l’ennemi et à la « guerre électronique », qui sert parfois de prélude aux opérations cyber (opérations visant à mettre à mal, voire à pirater, leurs composants matériels ou logiciels) ? Des technologies et des stratégies existent, qui se construisent dans les laboratoires de recherche académiques, dans les start-up et les entreprises spécialisées et, pour certaines, au jour le jour sur le front (ukrainien, en particulier).
Mais tout d’abord, précisons qu’un drone est rarement isolé. Les drones sont la plupart du temps pilotés par un opérateur distant, généralement au sol. Le pilote et les équipements informatiques nécessaires à l’analyse des données collectées et au suivi de la mission sont hébergés, selon la terminologie militaire, dans un C2 (Command and Control), souvent un camion ou un bâtiment où se trouvent les équipements et les personnels nécessaires.
Pour en assurer la sécurité, il faut donc envisager les drones comme des systèmes à plusieurs composantes, au-delà de l’aéronef lui-même.
La résilience, un enjeu civil et militaire
Quand on parle de protection du drone, on parle avant tout de sa résilience, c’est-à-dire de la capacité du système à conserver un fonctionnement aussi nominal que possible face à un environnement ou à des événements hostiles. Cette hostilité peut être le fait de l’action volontaire d’un ennemi, qui va tout faire pour perturber leur fonctionnement en intervention ; mais elle peut également être liée à la nature même de certaines missions, par exemple la surveillance de zones forestières pour la lutte contre les incendies de forêt, qui peuvent conduire le drone à s’approcher ou à survoler des « zones interdites de fréquences » (terrains militaires, aéroports, centrales nucléaires, etc.). Dans ces zones, il est impossible ou interdit de communiquer en utilisant des ondes radio. Il faut être capable de s’adapter à cette contrainte, d’être résilient face à elle.
Il est toutefois plus ou moins critique qu’un système de drone soit résilient, selon les cas : un appareil suffisamment petit, peu coûteux, et que l’on sait produire en masse, peut être perdu sans grande conséquence.
Le premier objectif de la résilience est d’assurer à un drone la capacité à mener à bien sa mission. Certains drones, par exemple, jouent le rôle d’éclaireurs : le succès de leur mission conditionne le bon déroulement des opérations qui s’ensuivent. C’est le cas également dans un cadre civil, par exemple pour le transport de matières biologiques ou d’organes nécessaires à des greffes.
Il faut parfois également respecter certaines contraintes, par exemple conserver la confidentialité des données transportées, qu’elles soient collectées pendant la mission ou nécessaires à la mission elle-même. Par exemple, le plan de vol (c’est-à-dire les différents points GPS que le drone doit atteindre successivement) peut être une information sensible, dont il est nécessaire d’assurer la confidentialité, la disponibilité et/ou le retour en fin de mission, même en cas de perte ou de dégradation de certains composants matériels ou logiciels du système.
Comme nous l’avons vu, les drones et leur environnement constituent un système complexe et donc fragile par définition. Ces fragilités se situent à tous les niveaux : interne, externe et au niveau des interconnexions entre les éléments du système (drone, opérateur, C2, etc.).
Les fragilités internes
Les fragilités internes concernent aussi bien l’électronique que le logiciel embarqué. Par exemple, l’électronique peut être victime d’attaques par des « fusils électromagnétiques », qui utilisent des micro-ondes pour détruire certains circuits. Des approches à base de laser se développent aussi. Ces attaques peuvent conduire à la perte totale d’un appareil et peuvent aussi provoquer des failles propices à une attaque cyber (qui peut être effectuée en vol, mais plus aisément au sol après capture de l’appareil) : modifier des données en mémoire grâce à un rayonnement peut aider à faire apparaître une faille logicielle qui sera exploitée par la suite.
Les drones, comme tout autre système, ne sont pas exempts de bugs logiciels ou de sécurités défaillantes par construction. Une conséquence qui peut s’avérer fatale est, par exemple, la survenue d’un flyaway : le drone part vers une destination non prévue. Ce type de bug peut aussi avoir une composante matérielle. De manière plus globale, la perte de contrôle d’un appareil représente 36 % des accidents, toutes causes confondues.
Les attaques externes, un enjeu majeur
Les attaques externes consistent pour un ennemi à cibler les interactions entre le système et le monde extérieur, par exemple le système de navigation par satellite (souvent dénommé abusivement GPS – Global Positioning System, qui est le système américain – au lieu de GNSS pour Global Navigation Satellite System) ou la radio (que le drone utilise pour communiquer avec une station au sol).
Le GPS peut être brouillé – auquel cas le signal reçu n’est plus exploitable : le drone n’est alors plus en mesure de connaître sa position effective. Il devient inutilisable : on parle d’environnement « GNSS denied », c’est-à-dire d’environnement dans lequel le GNSS ne peut pas être utilisé. Cela peut par exemple conduire à sa capture : les forces armées iraniennes, en 2011, ont capturé un drone américain RQ-170 Sentinel de cette façon. En Ukraine, nombreuses sont les zones dans lesquelles le signal GPS est soit inexistant, soit brouillé et devient donc inutilisable pour naviguer.
Ce phénomène a également été observé sur des événements de type show lumineux, à Shanghai par exemple, où des dizaines de drones sont allés se poser de manière inopinée sur des bateaux situés à proximité.
Les attaques d’interconnexion
Les attaques d’interconnexion portent sur l’interface du drone avec les autres éléments du système, typiquement sur ses échanges avec la station sol, et donc sur le lien radio.
Elles peuvent par exemple consister à envoyer des ordres contrefaits ou à transmettre des données erronées vers la station au sol. Le composant cible croit échanger avec un autre composant légitime alors qu’il échange avec un attaquant. Il devient ainsi possible d’exploiter les captations vidéo d’un drone pour déterminer la localisation de sa base de lancement, puis de la prendre pour cible.
Les solutions : un puzzle de stratégies
Tout d’abord, pour ce qui concerne les problématiques clés, il existe de nombreux travaux de recherche fondamentale.
Aujourd’hui, les spécialistes travaillent en particulier sur la capacité à poursuivre la navigation en environnement GNSS denied et sur la sécurisation des liens de communication drone sol-sol drone. En effet il est indispensable que les appareils disposent de solutions de repli en environnement GNSS denied. Des approches algorithmiques reposant sur une analyse fine et un filtrage des signaux reçus, des antennes spécifiques et même des approches de type IA permettent de traiter certaines attaques.
En cas d’échec de ces stratégies de remédiation, l’utilisation d’amers (terme de navigation faisant référence à des points de repère fixes) permet de se repérer en s’accrochant visuellement à des points au sol. C’est souvent une combinaison de plusieurs de ces techniques qui permet en cas de perte de la disponibilité de l’une d’entre elles d’assurer la résilience du système.
Pour ce qui est de la radio, qui en plus d’être inutilisable (neutralisée ou interdite), peut être exploitée pour localiser un C2, des stratégies sont étudiées ou déjà mises en œuvre. Par exemple, des fibres optiques reliant un télépilote à son appareil pour communiquer en lieu et place de la radio ont été expérimentées en Ukraine. À plus long terme, des approches quantiques permettront de sécuriser ces communications de manière efficace.
Pour d’autres problématiques, des stratégies existent déjà, et peuvent être exploitées. Leur coût en revanche peut ne pas être négligeable. Un compromis coût/capacité de résilience est donc à trouver.
De manière plus méthodologique, il existe des processus de certification permettant de valider la conformité à la réglementation en vigueur, laquelle intègre par nature une notion de résilience. Les enjeux sont différents dans le domaine militaire : ceux-ci n’échappent évidemment pas à toute réglementation, mais la résilience est plus focalisée sur le succès de la mission que sur la sécurité de l’environnement dans lequel elle se déroule, comme discuté dans cet article.
Il s’agit dans ce cas de développer des solutions au plus vite, de les tester, de les valider et de les déployer.
La première étape consiste à valider chaque sous-système et à mesurer son TRL (Technology Readiness Level – niveau de maturité de la technologie). On évalue ensuite la capacité de chaque sous-système à s’intégrer avec d’autres, son IRL (Intégration Readiness Level – niveau de maturité d’intégration) ; puis on intègre le système et on évalue son SRL (System Readiness Level – niveau de maturité du système global). Ces mesures sont loin d’apporter des garanties universelles, mais elles permettent déjà d’assurer une qualité significative du produit final.
Rappelons, enfin, que les drones de petite et moyenne taille, objets technologiques pourtant anciens, n’ont révélé tout leur potentiel militaire que récemment. Il faut donc garder en tête qu’il ne faudra pas ralentir les efforts de recherche et les expérimentations quand les conflits actuels seront derrière nous.
Il en va de la capacité de ces systèmes à réaliser leurs missions, qui visent, redisons-le, à nous protéger lors d’éventuels futurs conflits.
Serge Chaumette a reçu des financements de l'ANR, de BPI, de l'AID, de l'EDA, des ARL (Army Research Labs), de l'ORNL (Office of Naval Research). Il est Professeur et Chercheur à l'Université de Bordeaux et conseille et détient des parts dans la société IcarusSwamrs.ai dont il est Directeur Scientifique. Il est membre du Comité Stratégique Drones et Nouveaux Usages du Pôle de Compétitivité Mondial Aerospace Valley et co-animateur du groupe Drones et Systèmes Autonomes du GIS Albatros (Groupement d'Intérêt Scientifique entre Thales et l'Université de Bordeaux). Enfin, il collabore ou pilote de nombreux projets avec des partenaires académiques, industriels et institutionnels dans le monde du drone.
Damien Sauveron a reçu des financements de l'ANR (notamment pour le projet PANDRONE dédié à la sécurité des flottes de drones), du CNRS (PEPS TRUSTED), de la Région Nouvelle-Aquitaine et de la fédération de recherche MIRES. Dans le cadre de ses collaborations industrielles passées, ses travaux sur les flottes de drones ont également été soutenus par Thales (projet NetCod). Il est Professeur des Universités en Informatique à l'Université de Limoges et chercheur au laboratoire XLIM (UMR CNRS 7252), dont il est Doyen Honoraire de la Faculté des Sciences et Techniques. Ses recherches portent sur la cybersécurité, les systèmes embarqués et la souveraineté des architectures autonomes. Enfin, il intervient comme expert auprès de la Commission Européenne.
05.07.2026 à 11:35
Sommes-nous prêts à faire confiance à l’IA pour organiser nos vacances ?
VO-THANH Tan, Full Professor, EMLV Business School, Pôle Léonard de Vinci, Pôle Léonard de Vinci
Texte intégral (1550 mots)
« Je vais passer une semaine à Rome en amoureux, trouve-moi cinq hôtels romantiques en centre-ville. » Faites-vous confiance aux IA génératives pour vous aider à organiser vos vacances ? Une nouvelle étude montre les points de résistance à l’utilisation de ces nouvelles technologies.
Les outils d’intelligence artificielle (IA) générative comme ChatGPT peuvent être considérés comme des compagnons de voyage et aident désormais les voyageurs à concevoir leurs itinéraires, à rechercher des destinations, à réserver des prestations touristiques et à résoudre leurs problèmes en temps réel.
Pourtant, malgré l’engouement, un nombre important de voyageurs reste profondément hésitants à les utiliser. Concrètement, une récente enquête de Longwoods International a révélé que seulement 33 % des voyageurs américains étaient disposés à utiliser ChatGPT pour planifier leurs voyages. Des hésitations similaires ont été constatées sur d’autres marchés comme la Corée du Sud, notamment là où la confiance numérique, les attentes culturelles et les pratiques de planification divergent des normes occidentales.
Alors que les défenseurs de la technologie se concentrent sur « l’adoption », notre étude récente explore l’envers du décor : pourquoi tant d’entre nous résistent-ils aux conseils de voyage générés par l’IA ? Cette étude utilise une approche qualitative pour explorer comment les voyageurs résistent aux conseils de voyage générés par l’IA. Elle permet de montrer comment les gens appréhendent, jugent et réagissent aux outils d’IA dans leurs contextes sociaux et culturels.
Une nouvelle étude menée en Iran
Elle a été menée en Iran, un pays en développement dont le tourisme représente une source de revenu important. Un échantillonnage raisonné (une méthode de sélection des participants dans laquelle le chercheur choisit délibérément les personnes les plus pertinentes pour répondre à la question de recherche, plutôt que de les sélectionner au hasard) a été utilisé pour recruter des voyageurs ayant effectué au moins quatre voyages internationaux au cours des trois dernières années. Ce critère garantissait que les participants étaient activement impliqués dans la planification de leurs voyages et avaient probablement déjà rencontré des recommandations générées par l’IA.
Les participants ont été recrutés via deux canaux : trois agences de voyages spécialisées dans les voyages à l’étranger permettant d’accéder à des clients réguliers, et des comptes Instagram publics présentant du contenu de voyage généré par les utilisateurs. Pour élargir l’échantillon, l’échantillonnage en boule de neige (une méthode de sélection des participants dans laquelle les premiers participants recrutés recommandent d’autres personnes qui répondent aux critères de l’étude) a également été utilisé.
Le guide d’entretien semi-structuré (une méthode de collecte de données, principalement utilisée dans les recherches qualitatives, où le chercheur suit un guide d’entretien composé de questions préparées à l’avance, tout en restant libre d’adapter l’ordre des questions et d’en poser de nouvelles selon les réponses du participant) a été élaboré à partir d’une analyse des recherches antérieures sur la résistance à la technologie, l’adoption de l’IA et le comportement des consommateurs dans le tourisme et d’autres domaines connexes. La collecte de données s’est poursuivie jusqu’à l’obtention de la saturation théorique (atteinte lorsque les nouvelles données ne permettent plus d’enrichir la théorie ou les catégories d’analyse que le chercheur développe) après 22 entretiens. Ce nombre est conforme aux normes de la recherche qualitative, qui privilégient le sens et la profondeur thématique plutôt que la couverture statistique.
Une résistance complexe
La résistance à l’utilisation de l’IA pour la planification de voyages n’est pas seulement une question d’être « en retard sur son temps ». Il s’agit plutôt d’une réaction complexe façonnée par des frustrations pratiques, des valeurs culturelles et même notre sentiment d’identité.
Plus qu’un simple problème technique, pour beaucoup, la résistance commence par des barrières fonctionnelles. Bien que l’IA puisse agréger des données rapidement, elle échoue souvent au « dernier kilomètre » de la planification de voyage.
On note différentes barrières :
la barrière d’usage : Les utilisateurs trouvent souvent les interfaces d’IA encombrantes ou déconnectées. Par exemple, si ChatGPT peut suggérer un vol, il ne peut pas le réserver, forçant les utilisateurs à basculer entre plusieurs plates-formes ;
la barrière de valeur : De nombreux voyageurs trouvent les suggestions de l’IA redondantes ou se limitant à des listes génériques de type « top 10 » qui n’offrent pas plus de valeur qu’une simple recherche Google ;
la barrière de risque : L’obstacle le plus important est sans doute celui des « hallucinations de l’IA » – où les systèmes fournissent avec assurance de fausses informations, comme fournir des informations imprécises sur les sites de visite ou suggérer des hôtels inexistants ou des règles de visa obsolètes. Un participant a partagé : « … Je l’ai testé en demandant les sites classés par l’Unesco à proximité, et il s’est trompé… Il a donné plusieurs mauvaises réponses, alors que ce sont des informations de base qu’on trouve facilement en ligne… S’il n’arrive pas à trouver ça, comment puis-je faire confiance à tout le reste qu’il suggère ? » Un autre participant a expliqué : « … Ses informations ne sont pas à jour, donc je ne m’y fie pas pour des informations importantes concernant les voyages, comme les règles relatives aux frontières ou aux visas. Ces règles changent souvent, et une erreur à ce sujet peut gâcher un voyage. »
Dans le monde à enjeux élevés des voyages internationaux, ces erreurs pourraient transformer des vacances de rêve en cauchemar.
La menace pour notre identité de voyageur
Au-delà des défauts techniques, il existe des barrières psychologiques plus profondes. Pour beaucoup, planifier un voyage n’est pas seulement une corvée à automatiser ; c’est un rituel précieux et une source de fierté personnelle. Certains voyageurs voient l’IA comme une menace pour leur autonomie. Utiliser une machine pour planifier un voyage donne l’impression de « déléguer » un processus créatif, rendant le voyage final moins personnel.
De plus, la tradition joue un rôle majeur. Dans la culture iranienne, les conseils de voyage reposent sur une confiance relationnelle – demander à un proche qui y est « réellement allé ». L’IA, en revanche, semble froide et impersonnelle, manquant de l’authenticité émotionnelle d’une recommandation humaine.
Notre recherche identifie finalement trois types distincts de « résistants » :
les opposants : ils considèrent la planification de voyage comme un acte personnel et relationnel et voient l’IA comme une menace pour leur autonomie ;
les temporisateurs : ce groupe n’est pas « anti-IA » mais attend que la technologie fasse ses preuves et nécessite des témoignages de réussite avant de s’engager ;
les leaders d’opinion : les résistants les plus actifs. Ils s’engagent de manière critique avec l’IA et expriment souvent leur opposition, considérant ces outils comme des systèmes « biaisés par l’Occident » ou culturellement déphasés qui ne comprennent pas les réalités locales.
Les développeurs devraient se concentrer sur des modèles hybrides qui soutiennent, plutôt que de supplanter, l’agence humaine. Le voyage est une expérience profondément humaine, ancrée dans l’interaction sociale. Tant que l’IA ne respectera pas ces nuances culturelles et émotionnelles, beaucoup préféreront encore discuter avec un ami plutôt que de rédiger une commande pour un robot.
VO-THANH Tan ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- Dans les algorithmes
- Framablog
- Goodtech.info
- Libre à lire (April)
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview