
14.07.2026 à 18:50
Face aux marchés, Andy Burnham aura-t-il les moyens de ses ambitions ?
Patrick Le Galès, Directeur de recherche CNRS, Centre d'études européennes et de politique comparée (CEE), Sciences Po
Texte intégral (1833 mots)
Keir Starmer ayant démissionné le 22 juin dernier, Andy Burnham s’apprête à s’installer au 10, Downing Street. Dix ans après le référendum de 2016, les promesses du Brexit n’ont été que partiellement tenues, tant le Royaume-Uni et l’Union européenne restent étroitement imbriqués. Dans ce contexte, les exigences des marchés financiers continuent de peser lourdement sur l’action des gouvernements britanniques successifs, qui peinent à répondre aux besoins du pays. État des lieux, à l’aube de l’arrivée du septième premier ministre de la décennie.
Andy Burnham se prépare à succéder à Keir Starmer au poste de premier ministre, sans doute le 20 juillet. À rebours aussi bien du thatchérisme que du New Labour en place de 1997 à 2010 (il fut l’un des ministres de Gordon Brown), l’ancien maire de Manchester esquisse un projet réformiste « soft left » qui vise à la fois à mobiliser et à reconfigurer l’État britannique.
Il promeut un État activiste qui contrôle les infrastructures, protège le niveau de vie de la population et doit engager une décentralisation — en dehors des périphéries celtiques, l’État est hyper-centralisé — ainsi qu’un rapprochement avec l’Union européenne… mais pas trop.
Un État européanisé lost in transition
Tik Tok the Brexit clock. Dix ans après le vote en faveur du Brexit les négociations entre l’Union européenne et le Royaume-Uni s’étirent, sans fin, au gré d’accords partiels, d’échecs, d’incompréhensions et de défiance. Dé-européaniser l’État, ou l’européaniser autrement, s’avère particulièrement complexe. Les Britanniques se heurtent au mirage de la souveraineté dans un monde où les pays sont plus interdépendants que jamais.
L’Europe avait contribué à transformer l’État britannique. Elle avait favorisé la constitutionnalisation de certaines lois, renforcé le rôle des juges dans l’arbitrage des conflits et, à travers la juridiction européenne et son interprétation, accru l’autonomie du pouvoir judiciaire vis-à-vis du pouvoir législatif. Ces contraintes juridiques et institutionnelles ont profondément affecté le « modèle de Westminster », caractérisé par la souveraineté du Parlement, une Constitution non écrite, une centralisation du pouvoir autour du premier ministre et un exécutif dont les membres sont collectivement et individuellement responsables devant le Parlement.
Le Brexit était présenté comme le retour à la souveraineté pleine et entière de l’État, loin d’une Union européenne décrite dans le programme du Parti conservateur comme « too big, bossy, bureaucratic and undemocratic »(« trop volumineuse, trop dirigiste, trop bureaucratique et non démocratique »). Il promettait un nouvel élan porté par un gouvernement et un Parlement libérés des contraintes bruxelloises.
Les fantasmes de grandeur impériale de Global Britain apparaissent aujourd’hui englués dans les difficultés économiques, la crise sociale, les inégalités territoriales, les velléités d’autonomie et d’indépendance du Pays de Galles, de l’Écosse et de l’Irlande du Nord, la fragmentation des partis et les difficultés de l’État.
Le Brexit a engagé un processus de longue haleine de dé-européanisation du droit, des organisations, des régulations… mais a surtout imposé une adaptation permanente aux évolutions des règles européennes. En matière de normes, de standards et de réglementations, les autorités britanniques sont partagées entre d’une part le souhait de renforcer la compétitivité et l’attractivité de l’économie par le développement de la concurrence et l’abaissement des normes, et d’autre part celui de limiter les divergences avec les Européens afin de préserver les échanges commerciaux et d’éviter d’éventuelles sanctions.
Dans la majorité des secteurs, le gouvernement a choisi la continuité. Certes, les lois relatives au retrait de l’Union ont mis fin à l’application directe de la législation européenne ; cependant, dans les faits, une partie des modifications s’est limitée à remplacer dans la loi les termes « Union européenne » par « Royaume-Uni ». Dans la plupart des cas, on a observé un simple transfert ou une adoption des règles européennes, ou encore la reconnaissance mutuelle des standards.
Dans d’autres domaines, en revanche, les tensions persistent. C’est notamment le cas de l’alimentation, de l’environnement, de la pêche et surtout de la finance, dont profite la City de Londres. De même, en matière d’intelligence artificielle, une régulation plus faible est privilégiée outre-Manche afin d’attirer les investisseurs.
Un État plus dépendant de la City
Comme ailleurs en Europe, et peut-être davantage, l’État britannique peine à gérer les crises, à améliorer le niveau de vie, à protéger les citoyens contre les chocs extérieurs, à maintenir la qualité des services de l’État-providence ou des grands réseaux d’infrastructure, et à anticiper la transition écologique. Autant d’éléments au cœur du programme d’Andy Burnham. L’impopularité de Keir Starmer s’explique en partie par l’impuissance de son gouvernement en la matière.
Les élites des pays européens ne rendent pas seulement des comptes à leurs électeurs et à l’UE. Elles sont aussi dépendantes des marchés financiers et des grandes entreprises, si bien que Wolfgang Streeck qualifie ces États d’« États de consolidation budgétaire », c’est-à-dire d’États dont la priorité est de préserver la confiance des créanciers et des marchés financiers avant même de répondre aux demandes sociales.
Le bref épisode du gouvernement Liz Truss, en septembre-octobre 2022, en a fourni un exemple notable. Les projets économiques de Truss, radicalement néolibéraux, ont provoqué l’ire des marchés et une fuite des capitaux, contraignant le gouvernement à démissionner.
Côté travailliste, Keir Starmer et sa ministre des finances Rachel Reeves ont pris bien soin de s’engager sur des trajectoires budgétaires incrémentales et prévisibles. Andy Burnham se veut plus interventionniste et plus à gauche, mais cherche à rassurer les marchés financiers sur ses intentions, car ils frémissent déjà et multiplient les avertissements.
L’UE protège partiellement ses pays membres d’une influence plus directe des marchés et des contraintes qu’ils exercent sur leurs choix politiques et budgétaires. Le Royaume-Uni dispose certes d’une plus grande souveraineté politique mais, avec une dette s’élevant à 93,5 % du PIB (selon l’OCDE) et du fait du poids considérable de la finance dans son économie, ses choix politiques sont devenus encore plus sensibles aux réactions des marchés financiers. La capture d’une partie de l’État par les intérêts économiques, notamment ceux de la City, apparaît de plus en plus nettement.

Les ménages britanniques ont le sentiment de perdre sur tous les tableaux, l’État s’avérant par ailleurs incapable de réduire des inégalités de richesse plus marquées qu’en Europe, tant en termes de revenu que de patrimoine. Hormis les groupes les plus favorisés, le pouvoir d’achat des ménages a stagné, voire reculé. En outre, les privatisations initiées par Margaret Thatcher, les partenariats public-privés (PPP) et les restrictions budgétaires drastiques mises en œuvre par les gouvernements Cameron dans les années 2010 ont souvent donné lieu à un manque d’investissement, à une captation des profits par les actionnaires, les dirigeants et les consultants — notamment dans les secteurs de l’eau, de l’énergie, du ferroviaire et du logement —, ainsi qu’à une dégradation des infrastructures, comme en témoigne l’état des routes et des écoles. Pourtant, les impôts et la dette ont continué d’augmenter.
Au bout du compte, les Britanniques payent plus cher que les autres Européens le « privilège » d’avoir des services et des infrastructures de qualité moindre. Le pays cherche son cap. Entre le Bregret des écologistes et des libéraux-démocrates, la montée en puissance de l’extrême droite de Reform_UK, et des accords partiels laborieusement négociés, compliqués et incertains, l’État britannique est lost in Brexit. Good luck to Andy Burnham.
Patrick Le Galès a reçu des financements de l'ANR mais pas pour cet article
14.07.2026 à 18:49
Cosmétiques, médicaments, gels douches… Pourquoi l’omniprésence du polyéthylène glycol pose question, et que sont les POx, qui pourraient le remplacer ?
Oksana Krupka, Professor, Université d’Angers
Texte intégral (2003 mots)
Les polyéthylène glycols (PEGs) figurent parmi les ingrédients que l’on retrouve fréquemment dans les notices de cosmétiques, de médicaments ou encore de vaccins. Cependant, leur usage est aujourd’hui de plus en plus questionné, notamment en raison de leurs effets avérés ou supposés sur la santé et l’environnement. Ces interrogations s’inscrivent dans un contexte plus large : celui de la recherche de polymères plus sûrs, mieux contrôlés et plus durables.
Gels douche, shampoings, lubrifiants, gels hydroalcooliques, vaccins et médicaments, crèmes hydratantes ou peintures… Les polyéthylènes glycols (PEGs) sont présents dans de nombreux produits du quotidien.
Appréciés pour leur capacité à améliorer la solubilité de nombreuses substances actives, ainsi que pour leur coût modéré et la simplicité de leur production, cette famille de composés s’est imposée dans de nombreux secteurs industriels, de la pharmacie à la chimie, ou encore dans la fabrication de détergents, de peintures et d’encres.
Longtemps considérés comme des substances inertes, les PEGs font aujourd’hui l’objet de débats en raison de leur origine pétrochimique, de leur faible biodégradabilité, et de certaines interrogations concernant leurs effets à long terme sur la santé ou l’environnement.
Dans ce contexte, la recherche de solutions alternatives s’intensifie. Parmi les familles de polymères explorées, les poly(2-oxazolines) (POx) font aujourd’hui l’objet d’une attention croissante, car leurs propriétés en font de prometteurs candidats au remplacement des PEGs.
Qu’est-ce que le polyéthylène glycol ?
Issus de la pétrochimie, les PEGs forment une large famille de composés utilisés à grande échelle en cosmétique et pharmacie. Concrètement, le polyéthylène glycol (PEG) est un polymère constitué par la répétition d’une même unité de base, l’oxyde d’éthylène.
Les différentes sortes de PEGs se distinguent principalement par leur poids moléculaire, qui dépend du nombre d’unités répétées dans la chaîne. C’est ce poids (exprimé en g/mol) qui figure dans leur nom : PEG-40, PEG-400, etc. Certains laxatifs, comme le macrogol, correspondent à des PEGs de masse moléculaire élevée (PEG-3350 ou 4000).
Ce poids moléculaire influence directement les propriétés physiques des PEGs. En dessous d’environ 500 g/mol, ils sont généralement liquides et plutôt utilisés dans les formulations cosmétiques. À mesure que leur poids moléculaire augmente, ils deviennent plus visqueux, puis huileux ou cireux, ce qui est recherché dans certaines formulations pharmaceutiques ou pour certains additifs industriels.
Des polymères polyvalents
Les PEGs sont souvent qualifiés de « couteaux suisses » de la cosmétique moderne. Peu coûteux et polyvalents, ils remplissent plusieurs fonctions dans les formulations.
Hydrophiles, ils retiennent l’eau et participent à l’hydratation de la peau en formant un film limitant l’évaporation. Ils agissent également comme émulsifiants, stabilisant les mélanges eau/huile dans les crèmes et lotions. Enfin, ils facilitent l’élimination des impuretés grasses dans les produits lavants.
Ces propriétés expliquent leur large utilisation dans les cosmétiques, mais aussi leur rôle d’excipients dans les médicaments, où ils améliorent la solubilité ou la stabilité des principes actifs.
Dans l’alimentation et les produits d’entretien, certains dérivés sont également autorisés comme agents technologiques, mais dans un cadre réglementaire plus strict.
Vaccins à ARNm : le PEG, un ingrédient clé
Les PEGs ont également joué un rôle important dans le développement des vaccins à ARN messager (ARNm), comme ceux destinés à lutter contre le SARS-CoV-2, responsable de la pandémie de Covid-19.
L’ARNm étant fragile, il doit être protégé pour atteindre les cellules sans être dégradé. Cette fonction est assurée par de minuscules vésicules,appelées « nanoparticules lipidiques », capables d’encapsuler l’ARNm et de faciliter son entrée dans les cellules.
Ces nanoparticules sont constituées de différents lipides et surfactants (substances ayant un composant hydrophobe – qui exclue l’eau – et un composant hydrophile – qui présente une affinité pour l’eau). Parmi ceux-ci figure un lipide « PEGylé », c’est-à-dire portant une chaîne de PEG.
Celui-ci joue un rôle clé dans la stabilisation des nanoparticules lipidiques qui transportent l’ARNm, en limitant leur agrégation et en contrôlant leurs interactions avec le milieu biologique.
Il forme également une couche hydrophile à leur surface, qui les rend moins visibles pour le système immunitaire. Cet effet furtif prolonge leur circulation dans l’organisme et contribue ainsi à améliorer l’efficacité de la délivrance de l’ARNm.
Les limites des PEGs
Malgré leur succès industriel, les PEGs ne sont pas exempts de limites. Leur fabrication peut laisser des traces de sous-produits, notamment l’oxyde d’éthylène ou le 1,4-dioxane. Tous deux toxiques et cancérigènes, ils sont strictement encadrés et sont normalement absents des produits finis.
Sur le plan biologique, des réponses immunitaires ont été observées chez certaines personnes exposées aux PEGs, se traduisant par la production d’anticorps anti-PEG. Dans de rares cas, ces réactions peuvent être associées à des réactions allergiques, voire à des épisodes d’anaphylaxie, notamment après l’administration de certains médicaments ou vaccins. Il faut cependant souligner que ces événements restent très rares au regard des millions de doses administrées.
Enfin, la biodégradabilité des PEGs soulève des questions environnementales. S’ils sont majoritairement éliminés par voie rénale lorsqu’ils sont de faible masse molaire, certains PEGs peuvent persister dans les milieux aquatiques, sans que leurs effets écotoxicologiques à long terme soient pleinement établis.
Face à ces limites, d’autres polymères, les poly(2-oxazolines) (POx), suscitent un intérêt croissant.
La redécouverte de polymères anciens : les POx
Connus depuis les années 1960, les POx ont longtemps été peu exploités, notamment en raison de procédés de synthèse moins standardisés et moins industrialisés que ceux des PEGs.
Les progrès récents en chimie des polymères ont toutefois permis de mieux contrôler leur fabrication et de relancer l’intérêt pour ces matériaux.
Contrairement aux PEGs, les POx sont plus facilement « fonctionnalisables ». Ce terme désigne la possibilité de modifier chimiquement leurs extrémités ou leur chaîne pour y greffer d’autres unités moléculaires, tels que des sondes fluorescentes ou ligands biologiques (des molécules ayant la capacité d’interagir avec d’autres molécules). Ce contrôle fin de leur architecture et cette modularité offre une plus grande flexibilité dans la conception de systèmes thérapeutiques.
De ce fait, les POx présentent plusieurs propriétés qui intéressent les chercheurs en nanomédecine.
Des propriétés intéressantes pour la nanomédecine
Selon les études disponibles, les POx présentent une faible immunogénicité (la capacité à déclencher une réaction du système immunitaire). Cela signifie qu’ils sont mieux tolérés par le corps humain.
Il s’agit là d’un avantage majeur, notamment dans les domaines de la vaccination ou de la lutte contre le cancer. En effet, le faible pouvoir immunogène des POx en fait des candidats intéressants pour un usage répété, y compris chez des patients déjà sensibilisés à d’autres polymères, comme les PEGs.
Par ailleurs, la biodégradabilité des POx peut être modulée chimiquement. Il est de ce fait possible de concevoir des structures qui restent stables pendant le temps nécessaire à leur action thérapeutique, puis se dégradent ensuite dans l’organisme de manière contrôlée.
Cette dégradation peut être influencée par des stimuli biologiques, tels qu’un changement de pH, la présence de certaines enzymes ou un environnement chimique spécifique. Cette capacité ouvre la voie à une médecine ajustée aux besoins thérapeutiques, notamment pour les traitements de longue durée ou à fortes doses.
Enfin, le comportement des POx peut-être modifié par la température. Cette propriété, appelée thermosensibilité, est particulièrement utile en formulation galénique (l’art de transformer un principe actif en médicament administrable). Elle permet, par exemple, de créer des gels injectables qui sont liquides à température ambiante, mais se solidifient dans le corps, ou inversement.
Cette capacité à « s’adapter » ouvre des perspectives intéressantes pour des applications en libération contrôlée de médicaments ou en administration ciblée.
Applications et limites des POx
Ces propriétés font des POx des candidats prometteurs pour la vectorisation de médicaments, notamment dans le domaine de la lutte contre le cancer.
Des systèmes sont actuellement explorés pour améliorer la délivrance de chimiothérapies, comme les taxanes (des médicaments dérivés de l’if, parmi lesquels figure, par exemple, le paclitaxel). Ces expérimentations en sont actuellement principalement au stade préclinique ou des premiers essais.
Des applications sont également à l’étude dans le domaine des vaccins et de la cosmétique, mais elles restent encore expérimentales.
Une alternative en développement, pas un remplacement immédiat
Pour conclure, soulignons que pour l’instant, les POx ne constituent pas encore une alternative établie. Leur industrialisation est en cours, mais leur production peut s’avérer plus complexe et moins standardisée que celle des PEGs.
Par ailleurs, les données toxicologiques à long terme et leur devenir dans l’environnement restent encore limités, ce qui impose une certaine prudence.
À l’heure actuelle, les POx ne remplacent donc pas les PEGs, mais ils constituent une piste complémentaire, explorée pour des applications spécifiques où la modularité chimique et la tolérance immunologique sont déterminantes.
Leur développement à plus grande échelle dépendra autant des avancées scientifiques que de leur capacité à être produits de manière reproductible, sûre et économiquement viable.
Oksana Krupka a reçu des financements de l'Agence nationale de la recherche (ANR-22-CPJ1-0026-01).
14.07.2026 à 18:48
Quel est le point commun entre les muons cosmiques et l’astronaute Sophie Adenot ?
Fabrizio Bucella, Full Professor, Université Libre de Bruxelles (ULB)
Texte intégral (2712 mots)

Alors que vous lisez ces lignes, vous êtes bombardé en permanence par une dizaine de milliers de muons cosmiques. On a beau ne pas s’en rendre compte, cela reste vertigineux. Ce qui est très curieux, c’est que ces muons sont des particules particulièrement instables, qui ne vivent en moyenne que 2,2 microsecondes avant de se désintégrer en électrons.
Mais alors, d’où viennent-ils et comment nous atteignent-ils ? Curieusement, la réponse a à voir avec l’âge du capitaine, ou plutôt celui de Sophie Adenot quand elle reviendra de la station spatiale internationale.
Les rayons cosmiques primaires arrivent de l’espace. Ce sont essentiellement des protons. Quand des rayons cosmiques atteignent la haute atmosphère terrestre (entre quinze et vingt kilomètres d’altitude), ils frappent des atomes d’azote et d’oxygène. Ces collisions produisent des « pions chargés », des particules instables qui se désintègrent quasi instantanément en muons.
En 2,2 microsecondes, même à la vitesse ultra-proche de celle de la lumière à laquelle il se déplace, un muon ne parcourt pas plus de 660 mètres. S’il est créé à quinze kilomètres d’altitude, jamais il ne peut arriver sur Terre. Mais alors, comment se fait-il que nous soyons bombardés de muons à chaque instant ?
Pour le comprendre, je vous propose un voyage dans le temps, à la découverte de Galilée et Einstein, et dans l’espace, en compagnie de l’astronaute Sophie Adenot.
Le principe de la relativité, de Galilée à Einstein
Galilée avait posé le principe de la relativité. Il avait pris l’exemple de la cale d’un bateau. Avec mes étudiants je prends l’exemple d’un train, qui est plus stable qu’un bateau qui tangue. Imaginez que vous placez un laboratoire de physique dans un train, laboratoire fermé et sans accès au monde extérieur. Vous pouvez faire toutes les expériences de physique que vous voulez, vous ne pourrez pas détecter si le train est en mouvement ou bien s’il est au repos — attention, il ne faut pas que le train accélère, sinon des forces fictives apparaissent dans le laboratoire et vous pouvez en déduire le mouvement du train !
Ce principe de relativité a deux conséquences incroyables : la première est que le mouvement est relatif (on se déplace toujours par rapport à quelque chose) ; la seconde est que le repos absolu n’existe pas.

.jpg){kind=link}
Toute cette discussion part d’un présupposé implicite, tellement implicite qu’on ne l’avait pas évoqué : le temps est absolu. C’est le même temps, la même horloge pour l’observateur dans le train et pour un observateur à la gare. Le temps s’écoule de manière uniforme, c’est une sorte de grille rigide qui séquence l’espace.
Pour sauver le principe de relativité, Albert Einstein avait englobé le temps dans le référentiel lui-même. Le temps n’est plus absolu, il devient relatif. Chaque observateur mesure son temps à lui, qu’on appelle « temps propre ». Il n’y a pas de temps qui est meilleur qu’un autre, le tout est de bien distinguer de quel temps on parle. Le cadre de référence n’est plus l’espace relatif auquel on ajoute un temps absolu, mais un espace-temps relatif. D’où le terme de théorie de la relativité bien sûr.
Le paradoxe des jumeaux
En 1911, Paul Langevin popularise une conséquence troublante de la relativité d’Einstein. C’est le paradoxe des jumeaux.

Imaginez deux jumeaux Alice et Bob. Alice part dans un voyage vers Proxima du Centaure, l’étoile la plus proche de la Terre (après le Soleil bien sûr). Cette étoile se trouve à quatre années-lumière de la Terre. Mettons qu’Alice file dans un vaisseau spatial à 99 % de la vitesse de la lumière. Elle part de la Terre, arrive à Proxima du Centaure et puis fait demi-tour et revient, sans même s’arrêter pour boire un café.
Bob voit Alice faire ce déplacement quasiment à la vitesse de la lumière pendant qu’il reste sur la Terre. Vu que Proxima du Centaure se trouve à quatre années-lumière, Bob mesure huit ans entre le départ et le retour d’Alice. Huit vraies années. Bob aura fêté huit fois son anniversaire, il aura mangé huit fois du gâteau et soufflé huit fois les bougies.
Comme Alice se déplace à des vitesses incroyables (99 % de la vitesse de la lumière), Bob voit l’horloge d’Alice se dilater par rapport à la sienne. Les physiciens peuvent vous calculer cette chose précisément, c’est le facteur de dilatation. Dans notre cas, c’est un facteur sept : dans son vaisseau, Alice voit 1,143 an s’écouler (huit divisé par sept), soit 13 mois et 22 jours. Alice aura fêté un seul anniversaire dans son vaisseau, elle aura mangé une seule fois du gâteau et soufflé une seule fois les bougies. Quand elle rejoint Bob sur Terre, elle trouve un Bob plus vieux de huit ans alors qu’elle-même est plus vieille d’un peu plus d’un an. C’est la première partie du paradoxe des jumeaux, que j’appelle version faible du paradoxe des jumeaux.

L’autre partie du paradoxe des jumeaux est un petit jeu mental, que Richard Feynman a développé de la manière la plus claire possible dans ses cours de physique. Pour Alice dans sa fusée, c’est Bob qui s’éloigne, Alice ne bouge pas par rapport à la fusée. Donc Alice imagine que Bob devrait être plus jeune car c’est Bob qui a bougé par rapport à Alice. La situation semble symétrique entre Alice et Bob et on ne sait pas savoir quel jumeau doit être plus jeune que l’autre. Assurément, ils ne peuvent pas être tous deux plus jeunes en même temps. C’est exactement la version forte du paradoxe des jumeaux.
En vérité, on a l’impression que la situation est symétrique mais elle ne l’est pas vraiment. Tant qu’Alice s’éloigne de Bob, il est impossible de dire qui est en mouvement dans l’absolu, car comme on l’a vu le mouvement est relatif. Sauf qu’Alice doit faire demi-tour à Proxima du Centaure pour revenir sur Terre. En faisant son demi-tour, elle voit bien que c’est elle qui bouge alors que Bob reste à la maison tranquille comme Baptiste. Donc, Alice fait un demi-tour, Bob ne fait pas de demi-tour, c’est bien Alice qui bouge, la situation n’est pas symétrique, Alice sera plus jeune.
Le cas Sophie Adenot
Dans la Station spatiale internationale, l’astronaute Sophie Adenot ne se déplace pas à des vitesses proches de la lumière, néanmoins la vitesse reste conséquente par rapport à celles que nous avons l’habitude de traiter sur Terre. La Station se déplace à 27 600 kilomètres par heure, le facteur de dilatation est faible mais non négligeable. Ceci étant, Sophie Adenot restera neuf mois dans la station. À la fin du voyage, elle bénéficiera quand même de l’effet relativiste : elle sera plus jeune de six millisecondes par rapport à nous, qui sommes restés sur le plancher des vaches. Si Sophie Adenot avait eu une sœur ou un frère jumeau, elle serait à jamais plus jeune que son jumeau.
Six millisecondes, ça vous paraît imperceptible à l’échelle humaine ? Pourtant, la finale du cent mètres homme des Jeux olympiques de Paris 2024 s’est gagnée sur moins que ça, c’étaient cinq millisecondes !
Boucler la boucle cosmique
Pour revenir à nos muons : comme ils se déplacent dans l’espace à des vitesses approchant celle de la lumière, leur horloge à eux est très dilatée par rapport à la nôtre. Dans leurs référentiels à eux, 2,2 microsecondes sont amplement suffisantes pour parcourir les quelque quinze ou vingt kilomètres qui les séparent de la surface de la Terre.
À lire aussi : Une chambre à étincelles pour voir les muons cosmiques
La mesure directe a été affinée en 1963 en comparant le flux de muons au sommet du mont Washington et au niveau de la mer. L’exemple des muons est d’ailleurs l’exemple canonique qu’avait pris Feynman pour illustrer la dilatation du temps dans son fameux cours de physique.
C’est ainsi que Sophie Adenot et les muons cosmiques ont un point commun. Tous les deux voyagent avec une horloge ralentie depuis la Terre et Sophie Adenot exploite en plus le paradoxe des jumeaux.
Pour les lecteurs intéressés, l’auteur renvoie à une de ses conférences grand public à l’Université de Mons, et à un simulateur de voyages paradoxaux qu’il a fabriqué pour ses étudiants de l’Université libre de Bruxelles.
Fabrizio Bucella ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.07.2026 à 18:47
Du Mississippi à l’intelligence artificielle : la Louisiane, laboratoire inattendu de la nouvelle économie américaine
Fabien Nadou, Professeur d'Economie territoriale, Directeur de l'Institut sur les Mutations Economiques et Territoriales, EM Normandie,Laboratoire Métis, EM Normandie
Texte intégral (1863 mots)
La géographie des États-Unis est en pleine recomposition. Un nouveau pôle d’attractivité émerge en Louisiane. De quels atouts dispose cet État, qui devrait accueillir prochainement un mégacentre de données de Meta ?
Dans une Amérique en recomposition, la Louisiane apparaît comme un cas particulièrement intrigant dans la mesure où peu d’observateurs l’auraient spontanément désignée comme une candidate crédible à l’économie de la connaissance.
Longtemps associée au pétrole, au Mississippi et aux ouragans dévastateurs comme Katrina, la Louisiane est en train de s’imposer comme l’un des territoires les plus convoités de l’économie numérique américaine. Portée par l’intelligence artificielle, les centres de données et les infrastructures énergétiques, elle illustre l’émergence d’un nouveau modèle de développement qui pourrait redessiner la géographie de l’innovation aux États-Unis.
Entre champs et rives du Mississippi
La Silicon Valley, ses campus historiques et ultramodernes, ses start-up devenues multinationales et ses investisseurs visionnaires ont façonné l’imaginaire mondial de l’innovation. Elle a imposé un modèle de développement fondé sur la concentration des talents, du capital-risque et de la recherche universitaire
C’est désormais à 3 000 kilomètres de là que des géants de la Tech ont jeté leur dévolu. Dans les plaines du nord-est de la Louisiane, entre champs agricoles, infrastructures énergétiques et rives du Mississippi, Meta construit un complexe de Data Center à plus de 10 milliards de dollars. Présenté comme le plus important de son histoire, mobilisant plus de 5 000 travailleurs durant sa phase de construction, il générera plus de 500 emplois permanents une fois opérationnel.
À lire aussi : « Boz Angeles » et « Nash-Vegas », ces nouveaux pôles de croissance aux États-Unis, nouvel eldorado de l’économie américaine
Cette évolution révèle une transformation profonde où l’IA est en train de redessiner la carte économique des États-Unis.
Une terre autrefois française
Pour un lecteur français, la Louisiane demeure un territoire à part. Vendue aux États-Unis par Napoléon Bonaparte en 1803, lors du célèbre « Louisiana Purchase », elle conserve encore aujourd’hui de nombreuses traces de cet héritage. Les noms de Bâton Rouge, Lafayette ou La Nouvelle-Orléans, la présence des communautés cajun, la gastronomie locale… rappellent l’ex-ancrage français de ce vaste territoire situé à l’embouchure du Mississippi.
Derrière ce passé franco-américain se cache une autre histoire, celle d’un État qui cherche à réinventer son modèle de développement. Au XXe siècle, la prospérité louisianaise a reposé sur l’exploitation des hydrocarbures (pétrolières et pétrochimiques) qui ont profondément structuré l’économie régionale. Les immenses complexes industriels installés le long du fleuve couru par Tom Sawyer ont fait de la Louisiane l’un des principaux centres énergétiques du pays.
Cette spécialisation a longtemps constitué une force, créant aussi une dépendance aux marchés énergétiques fluctuants, à la concurrence internationale, aux transformations industrielles et les enjeux environnementaux ont progressivement mis en évidence la nécessité de diversification.
Dans ce contexte, les responsables politiques et économiques locaux poursuivent un objectif ambitieux : faire de la Louisiane un territoire d’innovation, appuyé par la création de multiples dispositifs d’accompagnement des entreprises innovantes, par le développement de partenariats entre universités et entreprises et par une politique volontariste d’attractivité portée par Louisiana Economic Development et l’initiative Louisiana Innovation.
Quand l’IA change les règles du jeu
Pour comprendre l’intérêt soudain des géants technologiques pour la Louisiane, il faut d’abord comprendre ce que l’IA change dans les logiques de localisation des activités économiques.
Depuis les années 1980, les entreprises technologiques recherchaient principalement trois ressources :
des universités d’excellence,
une main-d’œuvre hautement qualifiée
et un accès privilégié au financement.
L’IA modifie progressivement cette équation, et les modèles les plus avancés nécessitent désormais des capacités de calcul gigantesques. Leur développement repose sur de vastes Data Centers, consommant d’importantes quantités d’électricité aux infrastructures de refroidissement sophistiquées.
L’accès à une énergie abondante, à un foncier disponible et à des infrastructures performantes devient aussi stratégique que la proximité d’une université prestigieuse ou d’un fonds de capital-risque. Autrement dit, l’IA réinterroge la valeur des ressources territoriales, que l’économie numérique semblait avoir reléguées au second plan.
Le pari de Meta
Le choix de la Louisiane par Meta traduit cette évolution des besoins de cette industrie numérique. La Louisiane offre une combinaison rare d’avantages compétitifs : capacités énergétiques considérables, coûts fonciers relativement faibles, infrastructures logistiques de premier plan, une position stratégique sur le réseau de fibre optique national, une tradition industrielle permettant de gérer des projets de grande ampleur.
Son gouverneur, Jeff Landry, a qualifié l’investissement de Meta de « nouveau chapitre dans l’histoire économique de l’État » ajoutant que « cet investissement allait permettre de faire de la région un point d’ancrage de l’économie technologique US créant des emplois qualifiés pour les générations futures »
Au-delà, les autorités locales espèrent surtout générer des effets d’entraînement : nouvelles formations universitaires, attractivité accrue pour les entreprises technologiques, développement de start-up spécialisées dans l’IA et renforcement des capacités de recherche. L’objectif n’est pas seulement d’accueillir des infrastructures, mais de construire un véritable écosystème.
Cette stratégie s’appuie sur plusieurs établissements d’enseignement supérieur qui cherchent à renforcer leur positionnement dans les technologies numériques. Ainsi, la Louisiana State University (LSU), à Bâton Rouge, développe des programmes dédiés à la science des données, à la cybersécurité et à l’IA. À La Nouvelle-Orléans, Tulane University participe à la structuration d’un environnement favorable à l’innovation et à l’entrepreneuriat technologique.
De la Silicon Valley au golfe du Mexique
Si la comparaison entre la Louisiane et la Silicon Valley peut sembler provocatrice, car les deux territoires restent profondément différents, cela devient intéressant, lorsque cette comparaison permet d’identifier l’émergence d’un nouveau modèle de développement.
Les ports, les réseaux électriques, les centres de production énergétique et les infrastructures industrielles retrouvent une importance stratégique. La Louisiane semble être un laboratoire particulièrement révélateur, avec un avantage logistique qui est loin d’être anecdotique. Le Port of South Louisiana (entre La Nouvelle-Orléans et Bâton Rouge) demeure l’un des plus importants du continent américain et figure régulièrement parmi les deux premiers ports américains en tonnage, après Houston
L’innovation ne se concentre plus uniquement là où se trouvent les programmeurs, mais là où se trouvent les mégawatts qui deviennent aussi stratégiques que les lignes de code.
Une nouvelle géographie de l’Amérique
Partout aux États-Unis, de nouveaux pôles de croissance émergent. Austin attire massivement les investissements technologiques au Texas, le Tennessee renforce son attractivité autour de Nashville, Salt Lake City s’impose progressivement comme un pôle des technologies numériques et Raleigh-Durham bénéficie du dynamisme du « Research Triangle ». Cette recomposition rappelle que les centres de gravité économiques américains n’ont jamais été figés. L’histoire économique des États-Unis est celle d’une succession de déplacements régionaux, souvenons-nous de Detroit devenue la capitale mondiale de l’automobile avant de connaître son déclin au profit d’autres régions.
Feldman, Boschma, ou encore Cooke et al, ont montré que l’innovation ne repose pas uniquement sur la concentration géographique des entreprises technologiques, mais sur la capacité des territoires à mobiliser leurs ressources spécifiques, à construire des institutions adaptées favorisant les interactions entre acteurs divers. La Louisiane ne veut pas ressembler à la Silicon Valley, elle cherche à construire une trajectoire originale à partir de ses propres atouts : l’énergie, les infrastructures, la position géographique et l’héritage industriel.
Les défis d’une ambition nouvelle
Cette trajectoire reste néanmoins incertaine. L’arrivée massive des géants technologiques soulève plusieurs interrogations sur la consommation d’importantes quantités d’énergie et d’eau. Les aides publiques accordées aux grandes entreprises font l’objet de débats récurrents. La dépendance à quelques acteurs dominants peut fragiliser les économies locales. L’érosion côtière et la vulnérabilité aux événements météorologiques extrêmes constituent déjà des enjeux majeurs pour la Louisiane.
Le défi n’est pas seulement d’attirer Meta ou quelques autres mastodontes, il est de transformer ces investissements en un véritable processus de développement territorial. À quelques jours du 250e anniversaire de la naissance des États-Unis, la Louisiane rappelle une constante de l’histoire des États-Unis, cette capacité à réinventer sans cesse ses géographies économiques.
Elle est aujourd’hui projetée au cœur de l’une des plus grandes révolutions technologiques, non pas comme une seconde Silicon Valley, mais en incarnant une autre trajectoire possible, loin du modèle californien et de San Francisco.
Fabien Nadou ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.07.2026 à 18:47
En voulant figurer sur un billet de 250 dollars, Donald Trump impose sa méthode à l’opposé de la BCE et de la Suisse
Mathieu Bidaux, chercheur associé au laboratoire GRHIS, Université de Rouen Normandie
Texte intégral (1603 mots)
Alors que Donald Trump souhaite imprimer sa signature et son visage sur un billet de 250 dollars états-uniens, la Banque nationale suisse présente sa nouvelle gamme de billets tandis que la Banque centrale européenne (BCE) a sélectionné deux thèmes pour ses nouveaux billets : « La culture européenne : un héritage commun » et « Fleuves et oiseaux : force et diversité ». Alors, quel objectif poursuivent les banques centrales ?
Le 27 mars 2026, le département du Trésor des États-Unis annonce que la signature du président Donald Trump allait figurer sur le billet vert. Si, jusqu’à présent, seuls le ministre des Finances et le trésorier signaient, c’était pour de bonnes raisons. Le modèle standard des banques centrales suppose qu’elles doivent mener leur action de manière indépendante, car ce qui est en jeu, c’est la confiance du public dans la monnaie fiduciaire.
Le dollar est un instrument clé de la puissance économique états-unienne mondiale. Toucher aux symboles qui y sont imprimés comporte un risque. La raison ? D’autres projets de monnaies fiduciaires ayant l’ambition de devenir ou de rester une devise concurrente existent comme le projet UNIT des BRICS – Brésil, Russie, Inde, Chine, Afrique du Sud – ou bien l’euro de l’Union européenne.
Quoi que l’on pense de la politique de Donald Trump et de sa personnalité, tout le monde peut convenir que sa figure est très loin d’être consensuelle. Or, les symboles imprimés sur les billets cherchent à susciter un minimum d’adhésion ou, du moins, à ne pas créer du rejet de la part des consommateurs. C’est pourquoi les banques centrales se méfient des symboles politiques contemporains. Si le billet n’est plus accepté comme moyen de paiement alors, in fine, il n’a plus de valeur.
Ma recherche sur la fabrication des billets montre que la confiance dans la monnaie s’incarne dans une double matérialité : le billet et les usines le fabriquant. C’est pour cette raison que les banques d’émission investissent autant dans l’appareil industriel comme dans le cas de la nouvelle imprimerie de la Banque de France à Vic-le-Comte (Puy-de-Dôme).
Objet de détournement
Le billet de banque porte des images, des messages et circule beaucoup. Par conséquent, le graphisme du billet est scruté. C’est un mass média comme le montre le chercheur Gilles Caire. L’industrie fiduciaire entoure la fabrication de ses billets de prudence ; elle s’est toujours montrée attentive aux représentations qu’elle imprimait. La décrédibilisation de la monnaie est vite arrivée.
La monnaie fiduciaire a souvent été l’objet de détournements. C’est le cas du billet de 20 francs en circulation dans les années 1940 sur lequel un citoyen s’était servi de la corde du pêcheur pour donner l’impression qu’il étranglait Adolf Hitler ; le visage du dictateur avait été récupéré via des timbres allemands et collé dans un des angles de la coupure.

En 1950, à l’aide d’une presse personnelle, l’écrivain et artiste normand Pierre Bettencourt avait imprimé sur des billets de la Banque de France des citations irrévérencieuses d’auteurs tels qu’André Gide ou Charles Baudelaire. « Familles, je vous hais ! » peut-on lire sur ses 20 francs. L’institut d’émission l’avait alors prié de cesser son entreprise afin de ne pas susciter le rejet de la monnaie.
Même si le président états-unien a été réélu le 5 novembre 2024, il est évident que la personnalité de Donald Trump suscite un rejet profond de la part d’une partie de la population états-unienne et d’une partie de la planète.
Le dollar prend le risque d’éroder la confiance dont il bénéficiait jusqu’alors. L’autorité avec laquelle Donald Trump impose son projet – comme en témoigne le limogeage de la directrice du Bureau of Engraving and Printing – contraste avec les précautions et les sondages publics mobilisés par les banques d’émission européennes pour choisir leurs vignettes.
Nouvelle gamme de billet en Suisse
Après un processus original de sélection impliquant la population suisse, la Banque nationale du pays a présenté publiquement sa nouvelle gamme de billets le 4 mars 2026.
Pour les professionnels de l’industrie fiduciaire, la présentation d’une nouvelle gamme de billets de banque est toujours un événement. La banque centrale helvète a lancé un concours de graphistes en octobre 2024 afin de remplacer l’autre série en circulation actuellement en Suisse. Plus de trois cents candidats ont proposé leur projet. Douze ont passé la première sélection.
À l’issue d’une nouvelle phase comprenant un sondage d’opinion et l’expertise de spécialistes du fiduciaire, six maquettes ont été choisies. Dans le processus de fabrication du billet, ce protocole, à cette échelle du moins, est inédit. En 2031, la gamme « La Suisse, tout en relief » sera mise en circulation.
Derrière des choix esthétiques se cache un enjeu majeur : sécuriser les billets et gagner la confiance des porteurs. Un billet reste une promesse de valeur émise par les banques centrales.
Le billet de banque de la BCE
Depuis 2002, les billets de banque en circulation en Europe ne comptent que la signature du président de la Banque centrale européenne (BCE). Le graphisme de la première gamme de l’euro « Époques et styles », représentant des ponts, portails et fenêtres caractéristiques de l’architecture européenne, n’avait pas suscité l’enthousiasme sans aller jusqu’à la décrédibilisation du billet.
La nouvelle gamme de l’euro appelée « Europa », émise depuis 2013, avait rehaussé le niveau de sécurité tout en s’inscrivant graphiquement dans la continuité de la gamme précédente.
Pour sa troisième série, la BCE a lancé des groupes de discussion entre décembre 2021 et mars 2022 puis organisé des enquêtes publiques mobilisant jusqu’à 365 000 Européens. De ces consultations sont sorties deux gammes « La culture européenne : un héritage commun » et « Fleuves et oiseaux : force et diversité », dont l’une d’elles propose le retour des portraits de personnalités, permettant de donner de la chair au billet, permettant de s’identifier.
Banque nationale Suisse et BCE mettent à profit les progrès techniques permettant de consulter les populations avant l’émission des billets afin de s’assurer l’adhésion des peuples à leurs monnaies. La démarche de Donald Trump prend ainsi le contre-pied des banques d’émission attachées à leur indépendance dans le processus de fabrication des billets. Deux modèles coexistent. L’avenir dira si le dollar états-unien gagnera ou perdra en crédibilité.
Mathieu Bidaux ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
14.07.2026 à 18:46
L’Odyssée : voyage d’un mythe au cinéma
Anne Gangloff, Professeure d'histoire ancienne, Université Rennes 2
Texte intégral (1785 mots)

En 2024 est sorti Le Retour d’Ulysse, coproduction internationale du réalisateur italien Uberto Pasolini ; en 2026, c’est le britannico-américain Christopher Nolan qui réalise L’Odyssée. Comment expliquer le succès actuel d’une épopée écrite dans la seconde moitié du VIIIᵉ siècle avant notre ère ?
Le retour d’Ulysse a été beaucoup moins porté à l’écran que la guerre de Troie : l’encyclopédie des films sur l’Antiquité de l’historien du cinéma Hervé Dumont consacre 24 pages aux adaptations du « cycle de Troie », contre neuf aux « errances d’Ulysse ». Ces dernières sont surtout présentes à l’écran à partir des années 1970. Il est certes plus difficile d’adapter l’Odyssée, poème découpé en 24 chants qui met en scène la virtuosité de la parole : les aèdes, poètes itinérants qui célèbrent les exploits des héros, y ont une place significative et Ulysse qui raconte ses aventures à la cour de Phéacie (chants 9-12) peut être considéré comme l’un d’eux.
Les thèmes y sont nombreux et la narration n’est pas linéaire, puisqu’elle est interrompue par le long flashback dû au récit d’Ulysse. Une place particulière était reconnue à l’Odyssée dès l’Antiquité. Si elle fait partie du cycle des retours des guerriers après la guerre de Troie, elle rapporte un voyage exceptionnel, hors du monde connu et habité par les hommes. Ulysse y est confronté à des divinités ou à des créatures sauvages qui ne respectent pas les règles humaines. Dans l’Antiquité déjà, l’Odyssée était plutôt le livre des philosophes, d’où l’on tirait des leçons de vie.
L’intérêt actuel pose ainsi la question de l’adaptabilité et de la modernité de l’Odyssée. Les adaptations les plus abouties ont en exploré deux grands aspects, complémentaires mais divergents.
Ulysse aux mille tours et détours
La capacité du héros à surmonter les épreuves est au cœur des films Ulysse de Mario Camerini (1953) et O’Brother du réalisateur américain Joel Coen (2000).
La genèse du premier est très intéressante. Il est commencé entre 1950 et 1953 par le réalisateur autrichien Georg Whilhelm Pabst. Dans le contexte de l’après-guerre, celui-ci veut faire d’Ulysse un soldat traumatisé, pacifiste, illustrant la supériorité de l’intelligence sur la force. Les coproducteurs américains, jugeant le scénario trop noir, imposent alors M. Camerini, spécialiste italien des péplums qui rapportent les exploits de héros ou héroïnes antiques.
Le rôle d’Ulysse est confié à la star américaine Kirk Douglas, dont la personnalité déteint sur le héros, comme on le voit dans l’épisode des concours en Phéacie. Chez Homère, Ulysse se distingue au lancer de disque (chant 8), alors que dans le film, il triomphe à la lutte, sport dans lequel l’acteur excellait. Celui-ci incarne un Ulysse enjoué, optimiste et sûr de lui jusqu’à la témérité, partagé entre son goût pour l’aventure et son aspiration à rentrer chez lui, ce qui est une vision anachronique car le héros d’Homère désire surtout retrouver sa patrie. Une autre particularité est que la star italienne Silvana Mangano interprète à la fois Circé et Pénélope, afin de montrer, dans une vision très datée, deux visages de « la femme » – femme fatale et épouse fidèle.
Soulignant l’adaptabilité et l’universalité de l’Odyssée, la comédie de J. Coen déplace les aventures d’Ulysses Everett McGill (George Clooney) et de ses compagnons Delmar et Pete dans le Sud des États-Unis, pendant la Grande Dépression des années 1930. La sauvagerie est réintégrée dans le monde des hommes, représentée par exemple par la trahison d’un homme ruiné par la crise ou par le Klu Klux Klan. Le merveilleux et les dieux sont néanmoins très présents : Ulysse dénonce l’exploitation de la crédulité religieuse, mais ses compagnons et lui-même sont finalement sauvés par un déluge miraculeux. Surmonter les épreuves est possible grâce à la débrouillardise, l’amitié (alors que chez Homère Ulysse perd tous ses compagnons), l’éloquence et la musique. Ulysses est un faux avocat, un menteur, qui parvient à rebondir grâce au succès de son interprétation de Man of Constant Sorrow (« L’homme au chagrin constant »), une chanson folk bien adaptée au héros homérique.
Errances et souffrances
Le héros persécuté par le dieu Poséidon, luttant pour retrouver sa place dans son foyer et son royaume, a inspiré des interprétations plus sombres, comme celle de L’Odyssée du réalisateur italien Franco Rossi (1968). Cette minisérie est très riche et fidèle au poème d’Homère dont elle respecte la trame narrative. Elle creuse une thématique essentielle, le rapport du héros aux dieux qui se manifeste en particulier dans le refus de l’immortalité que lui offre la nymphe Calypso (chant 5).
Elle amplifie le goût d’Ulysse pour l’exploration et fait ressortir, dans le contexte de la guerre du Vietnam, l’image de l’ancien combattant, en développant les difficultés du chef à se faire obéir de ses hommes épuisés (par exemple au chant 12), et en transformant le concours de lancer de disque chez les Phéaciens en combat à l’épée.
Elle montre aussi la diversité et l’importance des femmes dans l’Odyssée d’Homère. Pénélope est interprétée par l’actrice grecque Irène Papas, spécialiste des rôles d’héroïnes tragiques au cinéma. Ce choix semble entraîner naturellement dans la tragédie le dernier épisode où Pénélope affirme l’impuissance des hommes, dont la destinée est entre les mains des dieux. Décor et costumes font osciller le film entre un passé antique, rappelé par les références archéologiques, et les années 1960. L’histoire apparaît hors du temps, ce qui est le propre du temps mythique.
Le retour d’Ulysse d’U. Pasolini (2024) se focalise sur la difficulté d’Ulysse, figure d’ancien combattant traumatisé, à réintégrer son foyer, et sur sa vengeance sanglante envers les prétendants de Pénélope. Écartant toute référence au merveilleux et aux dieux, le film prend le parti du réalisme pour dénoncer les conséquences familiales, sociales et politiques de la guerre, à un point tel qu’on peut se demander pourquoi les prétendants restent à Ithaque, étant donné la misère dans laquelle est plongé le royaume.
Le cinéaste revendique une adaptation intime pour faire redécouvrir « l’universalité intemporelle de la vision grecque de la condition humaine ». L’interprétation est cependant beaucoup plus moderne qu’antique. Uberto Pasolini dit s’être inspiré de travaux de philologues féministes, aussi bien que de lettres d’épouses de combattants du Vietnam, pour concevoir la psychologie de Pénélope et comprendre pourquoi celle-ci, contrairement aux serviteurs ou à son fils Télémaque, peine à reconnaître Ulysse au chant 16 de l’Odyssée.
Modernité de l’Odyssée
Ces adaptations montrent donc le caractère universel de l’Odyssée et son ambivalence, car elle peut être interprétée dans un sens positif ou plus sombre. Son caractère adaptable et moderne repose beaucoup sur Ulysse, qui est un héros complexe. S’il a beaucoup de qualités, il est aussi orgueilleux, impitoyable et individualiste, et ce dernier trait est considéré comme caractéristique de nos sociétés contemporaines.
C’est un héros guerrier qui excelle à l’arc, mais c’est surtout un héros culturel, qui explore des mondes inconnus, tiraillé entre sa curiosité, bien visible dans l’épisode fameux où il s’attache au mât de son navire pour écouter les sirènes (chant 12), et son attachement au foyer. Bien qu’il soit le favori d’Athéna avec qui il a en partage l’intelligence rusée, la mètis, il est du côté des hommes car il refuse l’immortalité. Comme tous les héros épiques, il pleure, mais il est le héros endurant par excellence, capable de surmonter toutes les épreuves.
On peut donc l’associer à l’idée, rebattue depuis l’épidémie de Covid-19, de résilience. Ulysse enfin permet de s’interroger sur la notion de masculinité : c’est un grand séducteur qui ne maltraite pas les femmes, contrairement à Héraclès qui tue son épouse Mégara ou à Énée qui cause le suicide de Didon, la reine de Carthage, en l’abandonnant. Autant d’aspects qui expliquent les retours de l’Odyssée à l’écran.
Anne Gangloff a reçu des financements d'Erasmus + (Chaire Jean Monnet FABER 2021-2024 sur la Fabrique des héros/héroïnes)
14.07.2026 à 08:56
Le trouble développemental du langage, un enjeu de santé publique
Marcela Perrone-Bertolotti, Enseignante-Chercheuse au Laboratoire de Psychologie et NeuroCognition (UMR 5105, CNRS), Université Grenoble Alpes (UGA)
Estelle Gillet-Perret, Orthophoniste, centre de référence des troubles du langage et des apprentissages (CRTLA) - CHU Grenoble-Alpes
Louise Faure, Doctorante, Université Grenoble Alpes (UGA)
Rachel Zoubrinetzky, Neuropsychologue au CRTLA du CHU Grenoble-Alpes et Enseignante-chercheuse, Laboratoire de Psychologie et NeuroCognition, Université Grenoble Alpes (UGA)
Texte intégral (2897 mots)
Peu connu, le trouble développemental du langage affecterait 7,5 % de la population française. Souvent confondu avec de la timidité, un problème d’attention, ou des difficultés intellectuelles, ce handicap invisible, dont les causes sont encore mal comprises, gâche la vie de nombreux enfants, et a aussi des répercussions sur leur vie d’adulte.
La consigne donnée était simple : « Prenez vos cahiers et écrivez la date du jour ». Pourtant, dans la classe, un élève reste immobile, les yeux fixés sur la page blanche. L’enseignant se dit qu’une fois de plus, l’enfant ne l’a pas écouté, qu’il a encore « la tête dans les nuages ».
Il ne voit pas l’effort considérable que déploie cet élève : dès le début de sa journée, l’enfant a dû mobiliser toute son énergie pour décoder les sons, assembler les mots et en extraire le sens. Pendant que les autres ont déjà commencé à écrire, lui essaie encore simplement de comprendre ce qu’on lui demande. Cet enfant vit avec un trouble invisible : le trouble développemental du langage (TDL).
Anciennement désigné sous les termes de « dysphasie » ou de « trouble spécifique du langage oral », le TDL fait partie des troubles neurodéveloppementaux. Ces troubles débutent précocement au cours du développement et altèrent durablement le fonctionnement personnel, social, scolaire et professionnel tout au long de la vie (DSM-5). Voici ce qu’il faut savoir sur le TDL.
Des difficultés de langage
L’acquisition et le développement du langage oral sont très rapides : vers l’âge de cinq ans, un enfant est capable d’établir et de maintenir une conversation similaire à celle d’un adulte, alors qu’il ne sait pas encore faire ses lacets. Derrière cet apprentissage qui semble aller de soi se cache l’une des fonctions les plus complexes du cerveau humain. Une complexité qui devient particulièrement tangible lorsque des dysfonctionnements surviennent durant le développement, comme c’est le cas dans le TDL.
Le TDL est généralement diagnostiqué lorsqu’un enfant présente des difficultés significatives et persistantes dans la compréhension ou la production du langage, avec une répercussion fonctionnelle dans la vie quotidienne. De plus, les enfants concernés ont bénéficié d’une exposition linguistique adéquate, et ne présentent aucune condition biomédicale (c’est-à-dire aucun déficit sensoriel, neurologique ou intellectuel) qui permettrait d’expliquer ces difficultés.
Les difficultés langagières rencontrées par les enfants présentant un TDL peuvent être très diverses. Elles peuvent concerner la production des sons de la langue, l’utilisation du vocabulaire, la structuration des phrases, l’application des règles grammaticales, la capacité à raconter une histoire, le respect des règles de communication et de conversation, la mémorisation d’informations verbales ou encore la compréhension des mots et des consignes.
Il est important de souligner que ces manifestations sont très hétérogènes d’un individu à l’autre. De plus, le langage évoluant avec l’âge, les difficultés se transforment au cours du développement. Ainsi, les manifestations du TDL diffèrent non seulement d’une personne à l’autre, mais elles peuvent également évoluer chez une même personne au fil du temps.
Dans tous les cas, ces difficultés langagières ont un impact significatif sur la vie quotidienne de l’enfant, que ce soit en famille, dans ses apprentissages, dans ses relations avec ses pairs, ou encore concernant son estime de lui-même.
Des causes mal comprises
Le TDL affecterait 7,5 % de la population, soit environ 2 enfants par classe, ce qui représente environ 50 000 naissances par an et près de 5 millions de personnes en France. À titre de comparaison, le trouble du spectre de l’autisme, davantage connu du grand public, concerne environ 1 à 2 % de la population, soit environ 15 000 nouvelles naissances concernées chaque année en France.
Les causes du TDL ne sont pas entièrement comprises. Il s’agit d’un trouble multifactoriel, résultant de l’interaction de facteurs génétiques, biologiques et environnementaux. À ce jour, aucun gène unique n’a été identifié comme responsable du TDL. Toutefois, une composante héréditaire est bien établie : le risque de présenter ce trouble est plus élevé lorsque d’autres membres de la famille sont concernés.
Certains facteurs biologiques ou environnementaux précoces ont aussi été associés à un risque accru de difficultés langagières, sans pour autant être considérés comme des causes directes du TDL. C’est par exemple le cas de la prématurité, d’un faible poids à la naissance ou d’autres complications périnatales.
Les recherches montrent également qu’un faible niveau socio-économique ou un manque de stimulation (dans le cas de parents qui parleraient peu à leur enfant, par exemple) représentent des facteurs de risque de présenter un trouble du langage et, à l’inverse, le fait de vivre dans un environnement langagier riche (lire des livres aux enfants, faire des activités stimulant le langage, bénéficier de situations sociales de qualité et variées) constitue un facteur de protection, favorisant le développement du langage chez tous les enfants, mais il n’empêche pas à lui seul l’apparition d’un TDL.
Il est important de souligner que le bilinguisme, ou plus largement l’exposition à plusieurs langues, ne provoque pas de TDL. Les enfants sont capables d’apprendre plusieurs langues dès la petite enfance.
À l’heure actuelle, aucun marqueur biologique, neurologique ou environnemental spécifique ne permet d’expliquer à lui seul ou de déterminer la présence du trouble, ni d’en prédire l’apparition avec certitude.
Des difficultés qui débutent très tôt et persistent
Il est souvent difficile de poser un diagnostic de TDL avant l’âge de 3 à 4 ans, car les difficultés langagières transitoires peuvent ressembler à celles associées au TDL. Toutefois, des difficultés persistantes de compréhension ou de production du langage entre 18 mois et 5 ans sont associées à un risque accru de TDL.
Les efforts de clarification et de diffusion d’informations autour du TDL se sont nettement structurés ces dernières années. Un tournant majeur a été l’établissement du consensus international CATALISE, issu d’un panel pluridisciplinaire de 59 experts internationaux et coordonnées par plusieurs chercheurs et cliniciens, dont la psychologue britannique Dorothy Bishop.
Parmi les recommandations, l’appellation « trouble développemental du langage » est préconisée lorsque les difficultés langagières persistent au-delà de l’école maternelle (après six ans) et entraînent un retentissement fonctionnel notable dans la vie quotidienne, sans qu’aucune condition environnementale ou biomédicale puisse venir expliquer ce développement atypique.
En harmonisant la terminologie et les critères d’identification, ce consensus fournit un cadre commun aux travaux scientifiques, ce qui facilite l’acquisition progressive de données scientifiques et leur comparaison. Des repères concernant le développement de la communication, du langage et de la parole ont également été discutés dans le cadre de ce consensus.
En effet, des signes d’un développement atypique du langage chez l’enfant peuvent alerter. Ils varient en fonction de l’âge de l’enfant (pour en savoir plus sur ces signes d’alertes, vous pouvez consulter le site allo-ortho).
À partir de cinq ans, lorsque des difficultés sont toujours présentes, il est probable qu’elles persistent. Il est donc important, si des questionnements existent quant au développement du langage d’un enfant, de les prendre en considération sans attendre.
Au cours de l’enfance, ce sont souvent les difficultés d’apprentissage qui alertent. Les enfants avec un TDL ont six fois plus de risques de rencontrer des difficultés d’apprentissage du langage écrit, quatre fois plus de risques de présenter des difficultés en mathématiques, et jusqu’à douze fois plus de risques de cumuler l’ensemble de ces difficultés.
Au-delà des enjeux scolaires, les conséquences du TDL s’étendent à la sphère psychosociale. Ces enfants sont davantage sujets à l’anxiété et à la dépression et aux troubles du comportement.
Des difficultés qui persistent à l’âge adulte
Les vulnérabilités qui touchent les enfants atteints de TDL tendent aussi à persister à l’âge adulte. Elles se traduisent par des difficultés en matière d’insertion professionnelle, de bien-être psychologique et de vie sociale.
Jusqu’à présent, les expériences vécues par les adultes avec un TDL ont fait l’objet d’un nombre limité de recherches. En 2024, des travaux ont été menés pour comprendre comment le TDL impacte la vie quotidienne des adultes tout au long de leur parcours. Leurs auteurs ont recueilli les points de vue d’adultes vivant avec ce trouble au Royaume-Uni. Les résultats ont révélé que ce trouble a un impact durable sur la vie des adultes qui en sont atteints.
Ils ressentent notamment un sentiment d’exclusion, et rencontrent des difficultés à suivre les conversations, ce qui peut entraîner un sentiment de solitude, d’isolement et d’anxiété. Sur le plan professionnel, ils ont souvent du mal à trouver ou à conserver un emploi, en raison de malentendus, de discrimination ou de la crainte de devoir révéler leur trouble.
Si plusieurs études internationales soulignent une persistance des vulnérabilités sur le plan académique, professionnel et psychosocial, aucun travail de grande ampleur n’a, à ce jour, documenté ces trajectoires en France. Cette absence de données empiriques constitue un frein important à l’élaboration de dispositifs d’accompagnement ciblés et fondés sur des preuves.
Un enjeu de santé publique invisibilisé
Le TDL présente toutes les caractéristiques d’un enjeu de santé publique (prévalence, impacts fonctionnels significatifs au quotidien). Pourtant, il demeure relativement méconnu du grand public et bénéficie d’une visibilité plus limitée que d’autres troubles neurodéveloppementaux dans la recherche, les médias et les politiques publiques.
Ce manque de visibilité du TDL est directement observable dans les travaux de recherche. En effet, en 2020, on ne dénombrait que 0,03 publication scientifique pour 100 enfants atteints de TDL aux États-Unis. Pour les troubles du spectre autistique, par exemple, ce ratio s’élève à 7,94. Cette disproportion n’est pas anodine et est au centre d’enjeux majeurs concernant non seulement la production de connaissances fondamentales sur le TDL, mais aussi la mise au point d’outils de diagnostic, ou encore les recommandations de prise en charge et la disponibilité des financements pour la recherche et la clinique.
L’une des raisons principales de cette invisibilité est, entre autres, la grande hétérogénéité des termes diagnostiques utilisés dans le passé. Le TDL a porté plus de 30 appellations différentes : dysphasie, trouble spécifique du langage, aphasie développementale, etc. En France, le terme « dysphasie » lui est encore souvent préféré pour l’évoquer au sein des troubles “DYS”. Cette grande variabilité terminologique entrave encore nettement la caractérisation et à la prise en charge de ce trouble.
Elle reflète aussi la complexité inhérente au langage. En effet, une autre raison importante expliquant l’invisibilisation du TDL est sa nature « cachée » : les difficultés langagières peuvent être subtiles (par exemple, chercher ses mots, utiliser des mots-valises comme « truc » ou « machin », formuler des phrases simples), mal interprétées (confondu avec de la timidité, ou avec un problème d’intelligence) ou masquées par des stratégies de compensation, ce qui complique l’identification précise des difficultés.
Parler davantage du TDL
Donner de la visibilité au TDL permettra aux recherches sur le sujet de progresser.
Les connaissances acquises favoriseront la mise en place de méthodes de repérage plus précoce et d’interventions plus ciblées. Elles amélioreront l’identification des compétences préservées chez les enfants concernés (leurs points forts), ainsi que celle des facteurs de protection à renforcer, susceptibles d’améliorer leur situation, pendant l’enfance et à l’âge adulte (interactions sociales de qualité, activités épanouissantes permettant de renforcer l’estime de soi, etc.).
Car il faut le répéter : le TDL peut nécessiter des interventions adaptées tout au long de la vie, notamment dans les moments de transition (à l’adolescence, passages aux études supérieures, vie active…). Le premier pas vers une meilleure prise en charge est des plus simples : il faut parler davantage du trouble développemental du langage !
Pour aller plus loin :
Rendre visible le TDL dépasse le champ académique : c’est aussi une démarche portée par des personnes concernées, des familles et des professionnels. Le mouvement international Raising Awareness of Developmental Language Disorder, fondé en 2012, en est l’illustration. Coordonné par un comité bénévole international et actif dans plus de 40 pays, dont la France, ce mouvement organise chaque année en octobre une Journée internationale de sensibilisation au TDL, pour rendre visible ce trouble invisible.
D’autres ressources sont aussi disponibles :
_ – Des vidéos explicatives réalisées par Estelle Gillet-Perret, orthophoniste au Centre de référence des troubles du langage et des apprentissages du CHU Grenoble Alpes ;_
_ – Le site de l’association Avenir Dysphasie TDL France ;_
_ – Du matériel visuel explicatif, tel que des cartes postales et posters ; _
_ – L’actualité du regroupement EVEIL TDL France peut être consultée sur Instagram (@radldfrance) et LinkedIn (RADLDFRANCE)._
_ – Des informations sur le langage et le TDL se trouvent également sur les sites Internet Allo-ortho, Fédération française de dys et Regroupement TDL Quebec. _
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
14.07.2026 à 08:53
Si l’IA est capable de tout traduire, pourquoi encore apprendre des langues étrangères ?
Dr Olivia Maurice, PhD, Cognitive Neuroscience, Western Sydney University; University of Sydney
Mark Antoniou, Associate Professor, The MARCS Institute for Brain, Behaviour and Development, Western Sydney University
Texte intégral (1851 mots)
Même à l’heure de la traduction instantanée par intelligence artificielle, l’apprentissage d’une nouvelle langue demeure bénéfique. En effet, de nombreux indices suggèrent qu’elle améliore la résilience cognitive du cerveau à mesure que l’on avance en âge. Par ailleurs, elle permet de saisir des nuances culturelles que les traducteurs automatiques sont encore incapables de rendre correctement.
Traduction audio en temps réel durant les visioconférences, doublage automatique des vidéos sur TikTok… L’abolition des barrières linguistiques grâce à la technologie semble aujourd’hui s’être concrétisée. La traduction en temps réel par intelligence artificielle (IA) fait désormais partie de notre quotidien.
Les outils mis au point par OpenAI, Meta, Google et bien d’autres sociétés proposent désormais une traduction quasi instantanée dans des dizaines de langues, et ne cessent de s’améliorer.
Cette situation pose une question cruciale : si des machines peuvent traduire plus vite et plus précisément que les humains, cela vaut-il encore la peine de s’investir, des années durant, dans l’apprentissage d’une langue étrangère ?
D’un point de vue purement logique, la situation a quelque chose de séduisant. En effet, au fil de leur histoire, les humains n’ont jamais hésité à déléguer une part de leur travail cognitif à des outils. Grâce à l’écriture, nous avons pu alléger les contraintes pesant sur notre mémoire. Les calculatrices nous ont libérés du fardeau du calcul mental. L’IA s’inscrit elle aussi dans cette longue tradition : bien utilisée, elle peut constituer une aide à l’apprentissage, et l’améliorer de diverses façons.
Cependant, il existe une différence de taille entre le fait d’utiliser un outil pour étendre ses capacités et celui de s’en servir pour, purement et simplement, éviter de produire tout effort.
Cette distinction s’avère essentielle dès lors que l’emploi d’un nouvel outil ne se résume pas au remplacement d’une capacité donnée, mais aboutit aussi à l’effacement de l’engagement cognitif et culturel qui lui est associé.
Ce qui compte, c’est l’effort
L’effort joue un rôle central dans la manière dont nous acquérons des connaissances.
Les psychologues emploient l’expression « difficultés désirables » pour désigner des défis qui peuvent sembler inutiles sur le moment, mais qui, sur le long terme, aboutissent à une rétention et à une compréhension renforcées.
Se débattre avec la grammaire, chercher le mot juste ou chercher à construire du sens dans différentes langues mobilise des réseaux cérébraux qui renforcent non seulement la mémoire, mais aussi l’attention et la flexibilité cognitive. Au fil du temps, ces activités consolident bien plus les connaissances que dans le cas d’une simple exposition passive aux langues.
Le fait de s’investir dans un engagement mental soutenu contribue à ce que les chercheurs appellent la résilience cognitive (une expression désignant la capacité de notre cerveau à préserver ses fonctions à mesure que nous vieillissons et que celles-ci déclinent). Passer d’une langue à l’autre requiert un tel engagement : le cerveau doit en effet arbitrer entre plusieurs langues concurrentes, tout en surveillant le contexte et en s’y adaptant de façon dynamique.
Se plier à de telles exigences n’a rien d’anodin. Or, lorsque nous nous contentons de recourir passivement à des outils de traduction pour comprendre, d’un simple clic, le sens d’une phrase rédigée ou prononcée dans une langue étrangère, le niveau d’effort demandé est loin d’être le même…
Ce que révèlent les recherches sur le multilinguisme
Les données sur le multilinguisme sont souvent résumées par une formule simpliste : « l’avantage bilingue ».
Ce raccourci masque une réalité bien plus complexe que cette expression ne le laisse supposer. En effet, si certaines études sur le multilinguisme rapportent que celui-ci pourrait être lié à l’existence de bénéfices en matière d’attention ou de mémoire de travail, d’autres ne relèvent aucune différence. La réalité semble plus sélective.
Au cours de nos récents travaux, nous avons examiné les performances cognitives de 94 adultes âgés de 18 à 83 ans, à l’aide de tâches à la fois visuospatiales et auditives impliquant la mémoire de travail, l’attention et l’inhibition. Concrètement, nous avons observé comment les participants traitent les informations qu’ils voient ou se représentent mentalement dans l’espace (dimension visuospatiale) ainsi que les informations qu’ils entendent (dimension auditive), et comment ils y réagissent. Il pouvait s’agir, par exemple, de mémoriser des sons, de se concentrer sur des motifs visuels ou d’ignorer des distractions.
Ces travaux indiquent que le multilinguisme est plutôt un continuum qu’une catégorie aux contours bien définis. Cette approche nous a en particulier permis de mieux saisir la diversité des parcours et des expériences linguistiques. Les participants multilingues parlaient en effet tout un éventail de langues, avec des niveaux de maîtrise variables. D’un participant à l’autre, l’usage quotidien de chaque langue variait également. Autant de différences reflétant la diversité linguistique propre aux communautés multiculturelles.
Nos résultats ont révélé que, concernant la plupart des tâches, les performances des personnes multilingues et monolingues étaient similaires. Un résultat s’est toutefois démarqué des autres : les personnes ayant une expérience multilingue plus riche et plus diversifiée ont affiché des performances nettement meilleures dans les tâches mobilisant la mémoire de travail visuospatiale. Ces effets étaient en outre plus marqués chez les personnes âgées.
Ces données suggèrent que le multilinguisme n’améliore pas la cognition de manière générale, comme certains le prétendent. Le fait de parler plusieurs langues contribuerait plutôt à préserver certaines fonctions spécifiques au fil du temps.
Des recherches distinctes, menées à l’échelle des populations, ont également établi un lien entre le multilinguisme et le fait de déclencher plus tardivement la maladie d’Alzheimer, ainsi qu’avec le fait de globalement mieux vieillir. Toutefois, les mécanismes en jeu font encore l’objet de débats.
L’ensemble de ces travaux suggèrent cependant que pratiquer plusieurs langues de façon soutenue constitue une forme d’activité mentale dont les effets se cumulent tout au long de l’existence.
Ce que la traduction par IA ne fait pas
Certes, la traduction par IA est rapide, et facile d’accès. D’un point de vue purement pratique, elle fonctionne remarquablement bien. Mais elle procède par reconnaissance de motifs, et non par une compréhension découlant d’un vécu. En conséquence, elle se heurte parfois à des difficultés dans certains contextes culturels, ou face à l’humour, à certains registres de langage ou lorsque le sens est chargé d’émotion. C’est d’autant plus le cas pour les langues les moins bien représentées dans les données d’entraînement.
Au mieux, l’IA saisit les dimensions littérales du langage, mais passe à côté de ses dimensions sociales. Pour le comprendre, il suffit de voir ou revoir la scène du film Love Actually (2003), où Jamie, interprété par Colin Firth, formule une demande en mariage maladroite, mais sincère, à Aurelia, dans un portugais hésitant.
Cette scène fonctionne précisément parce que ses mots imparfaits traduisent à la fois son effort, sa vulnérabilité et son intention. S’il avait utilisé un logiciel de traduction en temps réel, sa phrase n’aurait transmis qu’une simple information.
C’est là une distinction fondamentale à garder en mémoire : traduction ne rime pas toujours avec participation. Apprendre une langue implique de comprendre la manière dont les gens pensent, leurs valeurs, et la façon dont le sens se construit à travers un contexte, une histoire. Acquérir cette culture se fait par des interactions et des expériences. Elle ne peut pas être entièrement déléguée à des systèmes qui traduisent à la demande.
Les participants multilingues de notre étude en témoignent directement :
« Je pense assurément en télougou, mais je me souviens des nombres et je compte en anglais. »
« L’afrikaans est la langue de mon cœur, celle qui exprime le mieux les émotions intenses. L’anglais est la langue des affaires, utilisée surtout dans la vie quotidienne. »
Il ne s’agit pas là des descriptions de simples basculements entre divers modes de traduction. Ces témoignages décrivent des façons différentes d’habiter sa propre identité.
L’IA continuera de transformer notre rapport à l’apprentissage des langues. Elle pourra être utilisée pour personnaliser l’enseignement, franchir certains obstacles et offrir un accompagnement à grande échelle. En revanche, elle ne pourra pas se substituer au travail cognitif et culturel qu’implique l’apprentissage d’une langue. Cet investissement nous connecte plus fortement avec la manière dont les autres perçoivent le monde, et avec la façon nous nous exprimons nous-mêmes. Et aujourd’hui encore, cette différence importe.
Olivia Maurice a obtenu son doctorat à l'Institut MARCS de l'Université de Western Sydney.
Mark Antoniou bénéficie d'un financement du Conseil australien de la recherche.
13.07.2026 à 17:35
Les raisons du revers judiciaire du prince Harry face au « Daily Mail »
John Jewell, Director of Undergraduate Studies, School of Journalism, Media and Cultural Studies, Cardiff University
Texte intégral (1904 mots)
La justice britannique vient de donner raison à l’éditeur du Daily Mail face au prince Harry et à plusieurs autres personnalités qui l’accusaient d’avoir obtenu illégalement des informations privées. Ce revers judiciaire fragilise le combat de Harry contre les tabloïds, malgré ses précédentes victoires contre d’autres groupes de presse, et pourrait marquer la fin d’une longue saga judiciaire sur les pratiques de la presse britannique.
La Haute Cour de justice de Londres a statué en faveur de l’éditeur du Daily Mail, Associated Newspapers, dans le cadre de l’action en justice intentée par le prince Harry et d’autres personnalités publiques.
Cette décision devrait mettre fin au long combat judiciaire engagé par le duc de Sussex, qui cherchait à prouver que certains médias avaient obtenu des informations sur sa vie privée par des moyens illégaux.
Un manque de preuves
Selon le juge Matthew Nicklin, les plaignants n’ont pas réussi à démontrer que les informations publiées avaient été recueillies illégalement. Les 97 allégations de pratiques illicites ont ainsi toutes été rejetées.
Nicklin a également souligné qu’« en appréciant l’ensemble du témoignage du prince Harry, il apparaissait clairement que celui-ci souhaitait souligner les répercussions personnelles des faits en cause. Il lui est arrivé, ce faisant, de s’éloigner d’un témoignage factuel pour avancer ses propres arguments. »
Cette décision constitue un revers majeur pour tous les plaignants concernés, notamment Elton John et son mari David Furnish, l’actrice Liz Hurley et la baronne Doreen Lawrence. Si Associated Newspapers décidait de tenter de se faire rembourser ses frais de justice, ce qui est probable, la facture pourrait s’élever à 50 millions de livres sterling (plus de 58 millions d’euros) pour les plaignants.
La plainte, déposée en 2022, affirmait que le quotidien s’était livré à une collecte illégale d’informations, en particulier à l’interception de messages vocaux, à la mise sur écoute de lignes fixes et au « blagging » — c’est-à-dire l’obtention d’informations par la tromperie.
Harry n’en était pas à son premier bras de fer judiciaire contre la presse. En décembre 2023, il avait gagné son procès civil contre Mirror Group Newspapers. Le juge avait estimé que, selon le principe de prépondérance de la preuve, 15 des 33 articles examinés avaient été rédigés à la suite de mises sur écoute téléphonique et d’autres actions illégales. Il avait ainsi conclu à l’existence de preuves d’un recours « généralisé et habituel » à des pratiques illicites au sein des journaux du groupe.
Dans cette affaire, le duc a obtenu 140 600 livres sterling (près de 165 000 euros) de dommages-intérêts. Dans un communiqué publié par la suite, il a salué « un grand jour pour la vérité et la responsabilité ». « Cette affaire ne concerne pas uniquement le piratage de téléphones. Elle met au jour un système de pratiques illégales et répréhensibles », a-t-il ajouté.
Plus tard, en janvier 2025, Harry a accepté les excuses du journal The Sun, ainsi qu’un accord financier estimé à 10 millions de livres sterling (plus de 11 millions d’euros) pour « atteinte grave » à sa vie privée. Selon son avocat David Sherborne, ce règlement constituait une forme de réparation pour les « centaines d’autres plaignants qui ont été contraints de conclure un accord à l’amiable, sans pouvoir faire toute la lumière sur ce qui leur avait été infligé ».
À lire aussi : The Sun settles with Prince Harry: here’s what we still don’t know
Cette dernière affaire s’est distinguée à plusieurs égards, notamment par le témoignage émouvant livré par Harry, qui n’a jamais caché son aversion pour la presse. En 2021, il a même explicitement déclaré que les médias avaient contribué à la mort de sa mère, la princesse Diana, estimant que « la culture de l’exploitation médiatique et les « pratiques contraires à l’éthique » avaient « fini par lui coûter la vie ».
Dans son témoignage contre le Daily Mail, le duc a déclaré que la couverture médiatique de sa vie par le journal avait été « terrifiante » et l’avait laissé « profondément inquiet à l’idée que quelque chose de grave allait se produire. » Il a ajouté que cette situation avait fait de sa vie « un véritable calvaire ».
Parmi les autres plaignants figurait la baronne Doreen Lawrence, mère de Stephen Lawrence, un adolescent assassiné en 1993. Lors de l’audience en janvier dernier, elle a affirmé que le journal avait mis sa ligne fixe sur écoute. Il aurait également piraté sa messagerie vocale, surveillé son compte bancaire et ses factures de téléphone. Elle a en outre soutenu que le Daily Mail avait rémunéré des policiers en échange d’informations.
Questions de crédibilité
Associated Newspapers s’est vigoureusement défendu devant la Cour. L’éditeur a expliqué que les journalistes du Mail on Sunday et du Daily Mail disposaient d’une justification convaincante et étaient en mesure de retracer précisément l’origine de leurs informations. Selon lui, ils ont légitimement eu recours à des attachés de presse, des porte-parole, des journalistes indépendants et à des informations déjà publiées.
Le groupe a accusé certains représentants de l’équipe juridique du duc de Sussex de malhonnêteté, de fraude et de manquements professionnels, ainsi que d’avoir versé de l’argent à des témoins potentiels.
Dans une déposition de 2021, l’un des principaux témoins, le détective privé Gavin Burrows, aurait affirmé avoir mené des activités illégales pour le compte d’Associated, visant « peut-être des milliers » de personnes. Mais il s’est défendu devant le tribunal d’avoir signé une telle déclaration : « On voit bien que ce n’est même pas une signature en bonne et due forme. Je peux dire qu’elle a été falsifiée et calquée. Dans son jugement, Nicklin a estimé que la crédibilité de Burrows avait été « complètement ébranlée ».
La baronne Lawrence a, quant à elle, déclaré à la BBC en 2025 qu’elle avait longtemps fait confiance au Daily Mail et qu’elle n’avait découvert les pratiques qui lui étaient reprochées qu’après avoir été contactée de façon inattendue par le prince Harry.

Le tribunal a finalement été convaincu par la défense.
Un porte-parole d’Associated Newspapers a qualifié ce jugement de « victoire écrasante pour le Daily Mail, ses journalistes, et, plus largement, pour la liberté de la presse ».
La fin d’une saga ?
Cette décision marque-t-elle la fin de la saga des écoutes téléphoniques ? Le collectif Hacked off, créé en 2011 pour défendre « une presse libre et responsable », a laissé entendre qu’un appel contre cette décision était peu probable. « Les tribunaux ne sont pas un cadre approprié pour examiner de manière exhaustive les allégations d’actes répréhensibles visant le Daily Mail ».
Bien que le prince Harry ait qualifié ce jugement d’opération de « blanchiment », rien n’indique qu’il poursuivra son combat. Quant aux autres plaignants, cette défaite extrêmement coûteuse aura très certainement un effet dissuasif.
John Jewell ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 17:19
Analyses stratégiques, timing et feintes : comment les gardiens réussissent l'exploit d'arrêter un penalty
Clément Libreau, ATER, Université de Toulouse
Nicolas Benguigui, Professeur en sciences cognitives, sciences du sport et de la motricité - Laboratoire GREYC - UMR 6072 UNICAEN CNRS - UFR STAPS, Université de Caen Normandie
Texte intégral (2354 mots)
Le penalty au football est sans doute une des situations les plus marquantes de ce sport qui concentre toute la dramaturgie du jeu et le stress extrême que peuvent ressentir les joueurs ou joueuses impliquées. Un ballon placé à 11 mètres, un tireur face à un gardien de but, quelques dixièmes de seconde pour décider et agir… et parfois tout un match et même un titre prestigieux qui se jouent sur ce duel. Quelles stratégies les gardiens mettent-ils en place pour réussir à stopper ces frappes ?
La Coupe du Monde qui se déroule actuellement est le théâtre de dénouements marquants dans l’épreuve des tirs au but d’autant plus que l’augmentation du nombre de participants a doublé le nombre de matchs à élimination directe. Et on se souvient si bien de l’issue défavorable pour l’équipe de France lors de la dernière finale de cette compétition. Il y a seulement quelques semaines, le Paris Saint-Germain en remportant la Ligue des Champions 2026, a confirmé une tendance remarquable qui a permis au club parisien de remporter ses six dernières séances de tirs au but. Derrière ces succès se cache un travail considérable de préparation, tant sur le plan technique que psychologique, devenu aujourd’hui incontournable au plus haut niveau.
Dans ce duel, l’attention est souvent portée aux tireurs qui font face à une pression psychologique très importante dans la mesure où le droit à l’erreur n’est pas autorisé, sachant l’énorme avantage pour le tireur dans cet exercice qui se traduit par un taux de conversion des penaltys en buts qui peut monter jusqu’à plus de 90 % pour les meilleurs tireurs. Mais l’histoire du football regorge d’exemples où un gardien a fait basculer le destin d’une équipe. L’un des cas les plus célèbres reste celui de Petr Čech lors de la finale de la Ligue des Champions 2012 entre son club de Chelsea et le Bayern Munich. Ce soir-là, le gardien tchèque arrête trois penaltys au cours de la rencontre et de la séance de tirs au but. Plus impressionnant encore, il plonge du bon côté sur l’ensemble des six penaltys auxquels il est confronté. Cette performance exceptionnelle n’était pas le fruit du hasard. Elle reposait sur un travail d’analyse minutieux réalisé en amont avec l’entraîneur des gardiens et les autres gardiens du club, visant à identifier les habitudes et préférences des tireurs adverses.
Aujourd’hui, cette préparation spécifique constitue l’un des principaux axes de travail des gardiens professionnels et de leurs entraîneurs. Les séances vidéo, l’analyse statistique des habitudes des tireurs, l’étude des courses d’élan ou des zones de frappe privilégiées font désormais partie intégrante de la préparation des grandes compétitions. Concernant les études scientifiques, une large majorité des travaux s’est intéressée aux tireurs dont les échecs dans cet exercice sont souvent décrits comme une défaillance psychologique. Le cas du gardien a été moins étudié.
Pourquoi est-il si difficile d’arrêter un penalty ?
La première constatation qui peut être faite est que le duel entre le tireur de penalty et le gardien de but est très défavorable à ce dernier. Une étude de la Société d’analyse de données sportive a établi à partir d’une base de 100 000 penaltys tirés dans des matchs de haut niveau que le taux de conversion se situait autour de 75 % aussi bien pour les hommes que pour les femmes.
Cette supériorité du tireur s’explique par les contraintes spatiales et temporelles auxquelles le gardien doit faire face. Une frappe peut dépasser 100 km/h et atteindre le but en moins d’une demi-seconde (500 ms) alors que le gardien doit défendre un but de 7,32 m de large et 2,44 m de hauteur. Or il faut environ 200 ms pour identifier une information et initier une réponse motrice dans une situation aussi complexe même pour des athlètes super-entraînés, puis encore 500 à 600 ms pour produire un plongeon couvrant efficacement le but. Attendre le départ du ballon conduit donc presque toujours à une action trop tardive. Les gardiens doivent ainsi anticiper, c’est-à-dire engager une action avant la frappe adverse sur la base d’informations prédictives mais partielles.
Le sujet de l’anticipation a été très largement étudié en sport et certaines études ont porté précisément sur celles des gardiens de but au football. Pour prédire la direction du tir avant la frappe, il a été montré que les gardiens de but sont capables d’utiliser des connaissances préalables sur les tireurs en termes de probabilités de choix ainsi que des indices biomécaniques relatifs à la course d’élan et la préparation de la frappe des tireurs – orientation des hanches, du pied d’appui, des épaules ou posture générale. Cela a été montré avec des dispositifs permettant d’occulter certaines parties du corps de tireurs ou d’analyser les stratégies visuelles mises en œuvre par les gardiens pour extraire des informations significatives.
Pour autant, les stratégies d’anticipation présentent des limites. Les informations extraites avant la frappe sont nécessairement imprécises d’autant plus qu’elles sont prélevées tôt et se répercutent par des erreurs de décision. De plus, les meilleurs tireurs retardent parfois leur décision ou modifient leur geste afin de masquer leurs intentions ou de tromper le gardien en choisissant le côté du tir après avoir vu le gardien partir d’un côté, comme le fait avec beaucoup d’habileté le joueur brésilien Neymar.
Les gardiens font ainsi face à de nombreuses feintes possibles des tireurs. Cela a été étudié notamment dans une étude menée en 2012 qui a reproduit expérimentalement sur la base de vidéos les effets des feintes pour des gardiens de haut niveau. Par exemple, pendant son élan, le tireur pouvait délibérément fixer du regard la direction opposée à son tir. L’angle de la course d’élan vers le ballon était aussi manipulé et rendu opposé à la relation qui pourrait être attendue entre la direction de la course d’élan et la direction du tir. Ces deux feintes se traduisaient par une diminution du taux de bonne décision des gardiens de but passant d’environ 65 % pour les tirs sans feinte à seulement 45 % pour les tirs avec feintes et même 25 % quand deux feintes étaient additionnées.
Si les gardiens subissent les feintes de tireurs, ils peuvent aussi en produire pour perturber le tireur. Une analyse rétrospective réalisée en 2016 sur un total de 322 penaltys frappés lors des Coupes du monde de la FIFA (1986-2010) et des Championnats d’Europe de l’UEFA (1984-2012), a permis de montrer que les scores de réussite de tireurs diminuaient lorsque les gardiens de but réalisaient des actions de distraction avant le tir comme de se déplacer sur leur ligne ou faire des mouvements de bras. Cela était aussi le cas quand les joueurs portaient une attention plus importante au gardien de but montrant que cette dernière met en difficulté les tireurs.
Une étude réalisée en 2024 s’est intéressée à l’efficacité des feintes que pouvaient produire les gardiens pour gêner les tireurs où les conduire à tirer du côté où le gardien avait décidé de plonger. Pour cela, les chercheurs ont analysé 714 penaltys tirés lors de matchs de la Premier League anglaise et de la Bundesliga allemande, couvrant les saisons 2016-2017 à 2019-2020. Les résultats ont montré que les gardiens de but recouraient à des feintes dans la moitié des tirs au but, ce qui se traduisait par un nombre de buts nettement inférieur par rapport aux tirs au but sans feinte. Cet avantage était similaire pour les différents types de feintes, mais plus marqué lorsque les tireurs prêtaient attention aux gardiens.
Le dilemme du gardien : partir tôt… ou attendre ?
Une des questions qui reste en suspens concerne le timing du plongeon du gardien de but. En effet, le gardien fait face à un dilemme : partir tôt au risque d’être pris à contre-pied, ou attendre davantage pour disposer d’informations plus fiables, tout en réduisant le temps disponible pour atteindre le ballon. Ce compromis est d’autant plus contraignant que les règles du jeu imposent au gardien de conserver au moins un pied en contact avec la ligne de but au moment où le tireur frappe le ballon. Cette obligation limite sa capacité à avancer significativement avant la frappe et réduit la marge temporelle disponible pour réagir, accentuant ainsi l’importance du choix du moment optimal pour initier le plongeon.
Une étude de 2018 a montré que les gardiens professionnels déclenchent majoritairement leur plongeon environ 200 ms avant la frappe. Une autre plus ancienne avait distingué des stratégies précoces et tardives, suggérant un avantage pour ces dernières, mais sur un échantillon limité de 108 penaltys étudiés.
Une nouvelle étude sur près de 1000 penaltys
Pour répondre à cette question du timing du gardien, nous pouvons présenter les premiers résultats issus d’une étude que nous menons à l’heure actuelle et qui a porté sur une analyse de 938 penaltys professionnels à l’aide d’un logiciel d’analyse vidéo image par image. Chaque plongeon du gardien a été mesuré avec une précision de 10 millisecondes afin de déterminer exactement à quel moment le mouvement débutait par rapport à la frappe du ballon. En général il s’agissait de l’apparition d’un décalage des appuis pour permettre une poussée latérale ou bien une inclinaison du buste. En complément de ce timing, nous avons ensuite analysé la pertinence du choix du gardien dans la direction de son plongeon et le taux d’arrêt.
Notre principal résultat est l’identification d’une véritable « fenêtre optimale » de déclenchement. Les gardiens les plus performants initient leur plongeon autour de 240 ms avant la frappe, avec une efficacité élevée entre -200 et -300 ms. Dans cette fenêtre, ils plongent plus souvent du bon côté et obtiennent les meilleurs taux d’arrêt. À l’inverse, les plongeons très précoces (avant -360 ms) sont associés à de faibles performances, tandis que les plongeons tardifs permettent parfois de mieux lire la direction du tir sans améliorer le taux d’arrêt.
On le voit clairement, ce duel entre tireur et gardien illustre parfaitement les enjeux cognitifs, perceptifs et moteurs du sport de haut niveau, cristallisés autour de l’anticipation. Nos résultats ouvrent plusieurs perspectives pour l’entraînement des gardiens. La préparation doit d’abord s’appuyer sur l’analyse des préférences des tireurs, de leurs probabilités de choix et des indices perceptifs révélant leurs intentions durant la course d’élan et la préparation de la frappe.
Le comportement préparatoire du gardien mérite également une attention particulière : attirer l’attention du tireur par des comportements de distraction autorisés ou des feintes de départ peut réduire son avantage et améliorer les chances d’arrêt, dans le respect des règles et du fair-play. Les résultats soulignent aussi l’intérêt de développer les routines de préparation et l’analyse vidéo des indices corporels utiles à la prise de décision.
Enfin, la maîtrise du timing décisionnel apparaît déterminante. Nos données montrent qu’un déclenchement entre -200 et -300 ms avant l’impact constitue le meilleur compromis entre anticipation et temps d’intervention. Les gardiens doivent donc apprendre à synchroniser leur plongeon avec la frappe, y compris lorsque le tireur ralentit ou interrompt brièvement sa course. Ces pistes constituent des leviers prometteurs pour optimiser la performance des gardiens et, espérons-le, permettre à celui de l’équipe de France de devenir un véritable héros.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
13.07.2026 à 17:18
Écrire au président de la République : le service courrier de l’Élysée, baromètre de l’opinion publique ?
Michel Offerlé, Sociologie du politique, École normale supérieure (ENS) – PSL
Texte intégral (2793 mots)
Cartes postales, lettres de revendication ou requêtes, fleurs, dessins d’enfants… Chaque jour, ce sont des centaines, voire des milliers de courriers qui sont envoyés au président de la République. Qu’est-ce qui incite des citoyennes et citoyens à s’adresser de manière aussi directe au chef de l’État ? Comment leurs demandes sont-elles traitées ? Et dans quelle mesure sont-elles des capteurs d’opinion ? Plongée dans les coulisses du service de la correspondance présidentielle.
Il suffit d’un clic pour remplir le formulaire. Ou d’une enveloppe et d’une feuille de papier que l’on adresse sans timbrer (jusqu’à 20 grammes) à Monsieur le président de la République, Palais de l’Élysée, 55 rue du Faubourg-Saint-Honoré 75008 Paris France.
Le courrier ne sera pas reçu toutefois à cette adresse, mais de l’autre côté de la Seine, au Palais de l’Alma, 11 Quai Branly dans le VIIe arrondissement de Paris, anciennement Service du Courrier de la Présidence de la République devenu service du Dialogue citoyen, et service de la Correspondance. Une soixantaine de salariés y travaillent.
Le service du courrier existe depuis longtemps. René Coty, dernier président de la IVe République et sa femme Germaine en recevaient déjà. De Gaulle le faisait traiter par son secrétariat particulier. C’est sous Valéry Giscard d’Estaing président de 1974 à 1981 que le service s’est constitué, a émigré quai Branly, a commencé à appliquer systématiquement la règle : « répondre à tous ». Seuls les lettres d’insulte et les courriers dits incohérents restent sans réponse. Hervé Le Tellier s’est livré à un exercice de style oulipien autour d’échanges fictifs de correspondance entre lui et François Mitterrand.
Il est très difficile de travailler sur cette masse documentaire car il s’agit de correspondances contenant des renseignements parfois très personnels (conflits familiaux souvent violents, dossiers médicaux, affaires pénales, désarrois sociaux..). Nous avons pu, Julien Fretel et moi, toutefois obtenir, sous régime strict de confidentialité, l’autorisation du président Hollande de travailler pendant plusieurs mois sur ses courriers au sein même du service. Nous avons pu aussi avoir un accès (limité du fait du Covid) aux archives des courriers de Nicolas Sarkozy ; et l’ancien chef du service durant près de 10 ans, Michel Hénocq, a pu nous fournir aussi des documents sur cette période.
Le service, rénové, est toujours à l’Alma mais son organisation spatiale a complètement changé, ainsi que les modalités de traitement des envois et des réponses. (entretien avec des responsables des services 26/06/2026).
Une forme ancienne d’adresse au pouvoir politique
Le courrier présidentiel offre une plongée dans le quotidien de(s) Français qui se décrivent, invectivent, interpellent, scrutent, conseillent, le président et la « première dame », en direct, sans filtre, et sans dispositif préalable comme dans les mécaniques sophistiquées et opaques des sondages d’opinion.
Travailler sur le courrier présidentiel, c’est se poser trois séries de questions.
D’abord, qui écrit, pourquoi ? Puis, du côté du service, qui sont les premiers lecteurs-récepteurs et comment « traitent-ils » tous ces envois ? Du côté des divers présidents, quelle importance accordent-ils à cette « communication directe » ? La comparaison est ici intéressante avec l’attention particulière accordée par Barack Obama à ce mode de contact, puisque le président états-unien disait lire chaque soir, comme une piqure de rappel démocratique, une dizaine de lettres avant de s’endormir.
Étudier le courrier c’est donc réfléchir sur un des moyens par lesquels les citoyens peuvent faire entendre leur(s) voix, à côté du vote, des manifestations, des pétitions, des conférences citoyennes ou des sondages. Écrire aux autorités est une forme à la fois toujours renouvelée, et très ancienne, d’adresse au Prince sous forme de placet, de requête, de supplique, de réclamation et d’interpellation.
C’est un moyen d’accéder à la façon dont les citoyens se représentent les institutions et particulièrement l’institution présidentielle. Du côté de la présidence, l’attention prêtée aux courriers est un moyen d’objectiver la hiérarchie des « capteurs d’opinion » à la disposition des autorités. Le « contacting » (le fait de s’adresser aux autorités personnellement) est un axe de recherche important aux États-Unis beaucoup plus qu’en France.
De la déférence à l’indignation, des styles variés
On envoie de tout au 55 Faubourg Saint Honoré, des cartes postales, des fleurs, des tricots, des poèmes, des prières, des dessins d’enfants, des cadeaux désintéressés ou promotionnels (du vin ou du foie gras en espérant qu’ils pourront un jour être servis sur la table présidentielle, des livres, des tableaux…). Plus rarement des balles de revolver ou des miettes de pain rassis (pour se plaindre de la mise à la diète), ou de la farine et du sucre.

Il est donc difficile de dire combien de « lettres » sont reçues par jour. Il était question d’un millier, parfois de plusieurs milliers lors d’évènements particulièrement graves (les attentats de 2015), ou lors de l’entrée en fonction ou des vœux de nouvelle année. Sur un septennat on pouvait arriver à plus d’un million, sous François Hollande, on en était plutôt à 400000/500 000 pour le quinquennat.
Actuellement il y a eu un affaissement significatif. 400 envois arrivent chaque jour, dont une quarantaine pour « le courrier Madame », plus une trentaine d’appels au standard de l’Élysée. On écrit beaucoup moins à un président en fin de double mandat et affaibli par une dissolution.
Il est aussi difficile de préciser quelle est la représentativité des Français-es qui écrivent. Le droit d’entrée en contact est peu coûteux financièrement mais symboliquement fort (parler en son nom, donner son nom, se sentir le droit d’interpeller).
On peut tout dire au président, parler de soi, de sa vie quotidienne, « parler au nom de » (un groupe social, des habitants de..), on peut réagir sur tout, sur les grandes questions abordées par les médias, sur la manière d’exercer la fonction (sa coiffure, son maintien, ses phrases jugées blessantes, mais aussi sa politique, parfois scrutée dans les moindres détails). D’aucuns peuvent aussi entretenir une correspondance régulière avec l’Élysée. Et les styles d’écriture peuvent aller de la déférence, à l’indignation, et à l’insulte.
Classer/Qualifier/Répondre
Ce flux permanent arrivant à l’Alma était d’abord classé manuellement en 5 grandes catégories. Les courriers manuscrits représentent encore un tiers des envois car les courriels n’admettent pas de pièces jointes (dossiers médicaux, pénaux, administratifs..) et certaines et certains correspondants veulent préserver les formes épistolaires.
Les courriers indiquant explicitement ou implicitement une menace de suicide, sont mis à part et une intervention urgente peut être mise en œuvre. Les courriers auxquels on ne répond pas (anonymes, délirants, insultants) sont mis de côté.
Ensuite, les 3 catégories organisant les taxinomies ordinaires du service répartissent les courriers en « requêtes », « opinions » et « courrier réservé ». Relève de ce dernier les courriers des personnalités (parlementaires, maires, chefs d’État, grands patrons, entreprises…). En principe tout passe par le service du courrier mais certains solliciteurs bien introduits auprès de la Présidence, peuvent faire passer leurs demandes en remettant un dossier directement au 55 Rue du Faubourg Saint Honoré.
Quant aux deux autres, la frontière est poreuse entre un scripteur-e qui expose son cas personnel et un autre qui en parlant de lui, parle aussi « politique ». Toujours est-il que les « requêtes » ont droit à une réponse de principe et sont orientés vers les services sociaux compétents et que les « opinions » ont une « carrière » plus notoire puisqu’il y est répondu de manière détaillée, puisqu’elles vont se transformer en tableaux de chiffres, voire en baromètres, et figurer dans des revues hebdomadaires ou mensuelles, voire remonter dans leur intégralité (notamment les « belles lettres »), vers le cabinet ou sur le bureau présidentiel qui en signe quelques-unes.
Les requêtes sont toujours majoritaires (environ 70 % des flux). Elles sont désormais plus valorisées car elles entrent dans la base de données générale et sont appréhendées comme des symptômes « d’errance administrative ». Une volonté affichée de « débureaucratisation » du style administratif des réponses et de suivi des dossiers (Retour de service) est en cours.
Les réponses sont bien souvent décevantes pour les scripteur-es, mais le fait de recevoir une enveloppe à en-tête de la Présidence, ou d’avoir poussé son « coup de gueule » (« ça m’a fait du bien) peuvent être des premières rétributions à l’acte d’écriture aux autorités.
Une nouvelle catégorie a récemment été créée : les « sollicitations », qui obtiennent une réponse immédiate (visiter le Palais, obtenir un autographe, demande d’enfants, soumission d’un projet mémoriel) et parfois signée par le président lui-même.
Les procédures d’enregistrement ont considérablement évolué. Les courriers scannés viennent rejoindre les courriels sur une base numérique, auxquels sont adjointes des données provenant de la presse quotidienne régionale et de certains réseaux sociaux, particulièrement X. Les rédacteurs enregistrent et qualifient cet ensemble avec l’aide d’une IA, qui les accompagne dans leur travail « d’objectivation ».
Les présidents et leurs courriers
Les présidents successifs ont diversement utilisé cette source documentaire comme capteur « d’opinions » voire de « l’opinion ». Valéry Giscard d’Estaing avait une conception très fonctionnelle du courrier alors que François Mitterrand avait engagé les Français à lui écrire. Sous Sarkozy, il fallait que le travail soit fait, que chacun ait sa réponse mais l’opinion au travers des sondages lui importait plus.
François Hollande sans nul doute s’est plus intéressé au service. Le contact local lui manquait. Il a d’ailleurs reçu des scripteur-es quelques samedis après-midi à l’Élysée et c’est en fin de mandat que s’amorce la transformation du service : on investit alors dans des moyens plus sophistiqués de traitement des envois, les lettres types s’enrichissent et les verbatim citoyens remontent plus souvent et sous une forme plus détaillée au cabinet.
Emmanuel Macron utilise quant à lui beaucoup plus le service pour notamment préparer des voyages présidentiels. Sous ses quinquennats, le courrier devient une pièce importante de la connaissance « des » Français par un président qui n’avait pas eu le cursus partisan et/ou local de ses prédécesseurs. Le travail du service est dès lors un des éléments d’objectivation de « ce que pensent les Français » et de la manière dont ils perçoivent et reçoivent les politiques présidentielles. Le service de veille et d’analyse fait donc remonter par notes, tableaux de bord, baromètres et verbatim tout ce qui arrive dans la base de données (« tout ce qui rentre, ça nous intéresse »). Et cherche à repérer les « signaux faibles », et à comparer les agendas des diverses sources (presse, réseaux sociaux, correspondance).
Les multiples correspondances sont désormais mixées avec d’autres indicateurs du « pouls » des Français mais, dans le même temps, le nombre des interpellateurs de tous ordres ne cesse de baisser. Est-ce une baisse temporaire ? ou un effondrement définitif : le président et la Présidence indiffèrent-ils et n’intéressent-ils plus que de plus petites cohortes de scripteur-es ? La concurrence avec la croissance des recours auprès du Défenseur des Droits peut être aussi une explication.
De plus l’usage de l’IA dans l’enregistrement et la qualification des correspondances (un logiciel a « avalé » et « digéré » la mémoire des réponses antérieures) et dans l’aide à la rédaction des réponses est bel et bien un pari présenté dans l’actuel service comme un moyen d’améliorer la rapidité de la perception de « l’opinion » et d’approfondir la qualité des réponses de « mettre de l’humain » dans les relations verticales entre une institution et ses usagers. À suivre donc.
Reste une question sensible. La politique d’archivage. Ce flux constant est une mine documentaire, une ouverture extraordinaire sur la vie quotidienne ressentie par des Français. Il ne reste dans les archives (qui ne seront désormais consultables quasiment qu’à la fin du siècle, eu égard aux renseignements personnels qu’ils contiennent) que quelques milliers de lettres afférant aux quinquennats de Nicolas Sarkozy et de François Hollande.
Une politique de destruction de 9 dossiers sur 10 a été remplacée par une politique de « conservation » encore bien plus restrictive, qui, sans considération pour les évènements les plus importants, a détruit une partie de la mémoire des Français. Si cet article peut avoir un intérêt, aussi scientifique, il devrait permettre d’alerter le président de la République sur cet état de fait. En principe, la numérisation intégrale devrait permettre de préserver la mémoire de toutes ces « vies minuscules » C’est une lettre que je lui adresse.
Michel Offerlé ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 17:18
Bouilloires et passoires thermiques, les deux faces d’une même précarité énergétique
Dorothée Charlier, Professeur des universités en économie de l’énergie et de l’environnement, IREGE, IAE Savoie Mont Blanc
Texte intégral (1440 mots)
Alors que la France a déjà connu trois vagues de chaleur à la mi-juillet 2026 se pose la question du manque d’adaptation des logements aux températures extrêmes. Or, les logements les plus exposés à la chaleur sont souvent aussi ceux qui sont le plus exposés au froid en hiver. La précarité énergétique n’est plus seulement un problème hivernal, mais désormais aussi estival.
Depuis le 5 juillet 2026, la France connaît sa troisième vague de chaleur de l’année, le tout en l’espace de quelques semaines. Et pourtant, nous continuons de penser la précarité énergétique comme un problème hivernal.
Pourtant, à chaque nouvel épisode caniculaire, le même scénario se répète : records de température battus, services d’urgence sous tension, travailleurs exposés en plein air, mais également personnes vulnérables isolées dont le logement surchauffe et qui se retrouvent encore plus à risque. Par analogie avec les passoires thermiques hivernales, on parle désormais de plus en plus de bouilloires thermiques. Puis les températures redescendent, l’inquiétude s’estompe et le débat public se déplace vers d’autres urgences.
Pourtant, ces épisodes ne sont plus exceptionnels. Ils dessinent une nouvelle normalité climatique. La véritable question n’est plus de savoir si les vagues de chaleur vont se multiplier, mais si notre société est prête à protéger celles et ceux qui y sont les plus exposés. Car face à la chaleur, nous ne sommes pas tous égaux.
Une précarité énergétique devenue permanente
Pour les ménages les plus aisés, l’adaptation est souvent une possibilité. Ils peuvent rénover leur logement, installer des protections solaires, acquérir une pompe à chaleur réversible ou une climatisation performante (sous réserve d’obtenir l’accord de leur copropriété s’ils vivent en collectif), télétravailler ou simplement quitter temporairement les zones les plus exposées.
Pour les plus modestes, la chaleur s’ajoute à des difficultés déjà anciennes : logements mal isolés, faibles revenus, état de santé plus fragile, impossibilité de financer des travaux ou même d’avoir le droit d’installer une climatisation, lorsqu’il ne s’agit pas de l’absence pure et simple de certains équipements comme des volets.
Cette fracture sociale prolonge une autre inégalité, bien connue celle-là : la précarité énergétique hivernale. Depuis plus de vingt ans, les politiques publiques l’ont essentiellement abordée sous l’angle du froid. Cette approche était légitime. Mais le changement climatique nous oblige aujourd’hui à changer de regard.
À lire aussi : Vivre dans un logement trop froid : la réalité sociale de la précarité énergétique
Au-delà de la facture, l’enjeu de santé publique
Plus d’un Français sur deux déclare désormais avoir souffert de la chaleur dans son logement pendant au moins vingt-quatre heures au cours de l’été, selon les données de l’Observatoire national de la précarité énergétique.
Or, les logements les plus difficiles à chauffer sont souvent les mêmes que ceux qui deviennent inhabitables lors des canicules, même si des logements neufs dotés d’un bon DPE peuvent également être problématiques. Les « passoires thermiques » de l’hiver deviennent les « bouilloires » de l’été. La précarité énergétique n’est plus seulement saisonnière : elle est devenue permanente.
À lire aussi : Climatisation : quelles alternatives au quotidien, quelles recherches pour le futur ?
Nos recherches menées avec Anna Risch, maître de conférences en sciences économiques à l’Université Grenoble Alpes (UGA), montrent que cette accumulation de vulnérabilités dépasse largement la seule question de la facture énergétique. La rénovation énergétique améliore non seulement le confort thermique, mais aussi la santé mentale, le bien-être et le sentiment de sécurité.
Les logements rénovés restent généralement plus frais en été, avec une température ressentie inférieure d’environ 0,6 °C lors des fortes chaleurs. À mesure que les canicules se multiplient, ces bénéfices deviennent des enjeux de santé publique.
Disposer (ou non) de marges d’adaptation
Nos recherches montrent toutefois que cette vulnérabilité ne s’explique pas uniquement par la qualité du logement ou le niveau de revenu.
En effet, face aux contraintes énergétiques, tous les ménages ne disposent pas des mêmes marges de manœuvre pour adapter leurs comportements. Réduire sa consommation, décaler certains usages, protéger son logement de la chaleur ou investir dans des équipements adaptés suppose des ressources matérielles, mais aussi des capacités d’action qui sont très inégalement réparties.
Cette capacité de sobriété et d’adaptation constitue aujourd’hui une dimension essentielle de la précarité énergétique. Certains ménages disposent de nombreuses possibilités pour arbitrer leurs consommations sans dégrader leur confort. D’autres, au contraire, vivent déjà dans des logements peu performants et disposent de très peu de leviers pour faire face à la hausse des prix de l’énergie et aux épisodes de chaleur.
C’est ce que confirment des travaux que nous avons menés avec Elisabeth Bourgeois de l’Université Savoie Mont Blanc et David Grover de Grenoble École de Management. Chez les personnes âgées, par exemple, les émotions, la perception du risque ou encore certaines capacités cognitives vont influencer fortement l’adoption des comportements de protection. Une personne qui sous-estime le danger modifiera moins facilement ses habitudes, même lorsqu’elle est objectivement exposée.
La nouvelle fracture climatique n’oppose donc plus seulement les ménages riches et pauvres. Elle oppose aussi ceux qui disposent d’un logement protecteur et/ou de marges de manœuvre pour adapter leurs comportements, à ceux qui cumulent logements peu performants, faibles ressources et faibles capacités d’adaptation.
À lire aussi : Lors des canicules, notre cerveau ne s’aligne pas toujours avec le thermomètre et peut nous mettre en danger
Des vulnérabilités qui se cumulent
Ces vulnérabilités ne s’additionnent pas : elles se renforcent mutuellement. C’est cette réalité que les politiques publiques doivent désormais prendre en compte.
Rénover un logement ne consiste plus seulement à réduire les consommations d’énergie ou les émissions de gaz à effet de serre. C’est aussi protéger la santé des occupants en toute saison, renforcer la résilience face aux extrêmes climatiques et permettre aux ménages de retrouver des marges de manœuvre dans leurs usages quotidiens de l’énergie.
Pendant longtemps, la précarité énergétique désignait l’incapacité à chauffer correctement son logement. Aujourd’hui, elle doit désigner plus largement l’incapacité à vivre dans un logement protecteur et à s’adapter aux contraintes énergétiques et climatiques, qu’elles soient liées au froid, à la chaleur ou à la hausse durable des prix de l’énergie.
Le changement climatique ne crée pas les inégalités. Il révèle celles qui existaient déjà et les amplifie. À nous de décider si la transition écologique contribuera à les réduire, ou à les rendre encore plus profondes.
Dorothée Charlier ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 17:17
Échecs budgétaires et optimisation bi-niveau : pourquoi les politiques publiques dérapent
Stefano Nasini, Professeur de Méthodes Quantitatives, IÉSEG School of Management
Texte intégral (2437 mots)
La réussite d’une politique publique dépend pour partie de la réaction des agents économiques. Pour cela, la définition des moyens et des objectifs doit intégrer les réactions des ménages ou des entreprises. Or, cela s’avère souvent très complexe. Des avancées dans la puissance de calcul apportent des pistes intéressantes. Illustration avec la politique du logement.
À l’horizon 2027, la France devra trouver des dizaines de milliards d’euros d’ajustements budgétaires pour respecter ses engagements, selon les estimations de l’observatoire français des conjonctures économiques. Le défi n’est pas seulement de décider où couper, taxer ou plafonner. Il est surtout d’anticiper les stratégies d’adaptation des ménages et des entreprises, car chaque réforme modifie leurs choix économiques : ils réagissent en ajustant leurs achats, leurs investissements, leurs demandes d’aide ou de logement.
Une économie annoncée peut alors avoir un effet boomerang : contournements, reports vers d’autres guichets publics, blocages administratifs ou coûts indirects. Dans un tel contexte, une politique efficace doit être pensée comme une décision stratégique, dont le résultat dépend aussi des réponses qu’elle déclenche.
Un laboratoire de l’effet boomerang
Le logement constitue un terrain particulièrement parlant pour comprendre ces effets boomerang. C’est un secteur où les règles publiques ne se contentent pas de distribuer des aides ou de fixer des plafonds : elles modifient directement les arbitrages des ménages. Lorsqu’une allocation, un barème ou un plafond rend le logement social nettement plus avantageux que d’autres solutions, et que l’offre de petits logements reste rare, les ménages déjà logés peuvent avoir intérêt à conserver leur logement plutôt qu’à prendre le risque d’un déménagement coûteux, incertain ou moins favorable.
À lire aussi : Derrière le sans-abrisme, la face cachée du mal-logement
Cette logique individuelle, parfaitement rationnelle à l’échelle d’un ménage, produit alors un blocage collectif. Deux phénomènes se superposent. D’un côté, la pression de la demande atteint des niveaux records : plus de 2,6 millions de ménages étaient en attente au premier semestre 2024, selon l’Union sociale pour l’habitat. De l’autre, l’offre effectivement disponible se renouvelle lentement : la Cour des comptes observe une rotation annuelle inférieure à 8 % en 2020, contre plus de 10 % en 2011. La tension naît précisément de cet écart entre une demande élevée et un flux de logements qui se libèrent trop lentement. En Île-de-France, cette tension est particulièrement visible dans le parc social : la demande de T1 est 20 fois supérieure à la capacité d’attribution.
Trop d’interventions inefficaces ?
Ce constat conduit au cœur du problème. Si la tension persiste malgré l’intervention ancienne et massive de l’État sur le marché du logement, ce n’est pas seulement parce que les objectifs seraient mal choisis ou les moyens insuffisants. C’est aussi parce que chaque règle publique crée des incitations, donc des réponses. Un plafond de ressources, une aide, une exemption, une priorité d’attribution ou une pénalité ne produisent pas seulement un effet comptable immédiat : ils modifient les stratégies des ménages. Certains restent, d’autres demandent un relogement, d’autres se tournent vers le parc privé, d’autres encore attendent, ou cherchent à entrer dans une catégorie plus favorable.
L’État poursuit alors une cible mobile : le résultat final d’une politique dépend des comportements qu’elle déclenche. Or ces stratégies d’adaptation sont difficiles à anticiper, à quantifier et à intégrer au moment même où la décision publique est prise.
Une cible mouvante
Comment décider, alors, lorsque l’effet réel d’une politique dépend des réactions qu’elle provoque ? Le problème n’est pas seulement de savoir que les ménages et les entreprises s’adaptent. Les économistes le savent depuis longtemps, et la théorie économique dispose déjà de cadres pour représenter ces interactions, comme les jeux de Stackelberg ou les fonctions de réaction des banques centrales. La difficulté est plus opérationnelle : comment intégrer la complexité computationnelle de ces réactions dans la conception même d’une politique publique, avant que la réforme ne soit appliquée ?
C’est ici que l’optimisation bi-niveau devient utile. Elle permet de représenter une décision publique comme une interaction stratégique entre un décideur et des agents qui réagissent à ses choix. Le décideur public, que l’on appelle le leader, choisit d’abord une politique, notée « x » : un barème, une taxe, une subvention, une exemption ou une règle d’attribution. Les ménages, les entreprises ou les citoyens, que l’on appelle les suiveurs, répondent ensuite par leurs propres décisions. Ces décisions ne sont pas indépendantes de la règle adoptée : elles dépendent de x. On les note donc « y(x) », c’est-à-dire les réponses des agents à la politique choisie.
La nouveauté n’est donc pas de constater que les agents réagissent, mais de pouvoir intégrer ces réactions dans des politiques beaucoup plus complexes qu’un simple taux ou un prix unique. Dans la réalité, une réforme combine souvent des barèmes, des seuils, des quotas, des zonages, des exemptions et des contraintes de capacité. L’enjeu est alors de choisir une règle publique en tenant compte, dès sa conception, des comportements qu’elle risque de déclencher.
Dans ce cadre, l’État ne mesure pas seulement l’effet direct de sa décision x. Il cherche à évaluer son effet réel, que l’on peut noter F(x, y(x)) : le résultat obtenu une fois que les ménages et les entreprises ont adapté leurs choix à la règle adoptée. Selon le cas, cette fonction peut représenter une économie budgétaire nette, le nombre de logements effectivement libérés, le coût total pour les finances publiques, ou un compromis entre efficacité, équité et faisabilité politique. Le problème consiste donc à choisir la politique x qui produit le meilleur résultat, en anticipant les réponses y(x). Lorsque ces réponses sont nombreuses, hétérogènes et contraintes par des ressources limitées, la difficulté devient aussi computationnelle.
Un vrai casse-tête computationnel
Prenons un exemple volontairement simplifié. Supposons qu’une collectivité souhaite libérer de grands logements sociaux occupés par des ménages devenus plus petits, afin de les attribuer à des familles en attente. Elle envisage une mesure combinant trois leviers : une contribution mensuelle en cas de sous-occupation, une aide au déménagement et des exemptions pour les ménages fragiles. Sur le papier, le calcul semble immédiat : si 1 000 ménages sont concernés et que la contribution est fixée à 50 euros par mois, la recette attendue atteint 600 000 euros par an. Mais ce raisonnement suppose implicitement que tous les ménages restent en place et paient. Or c’est précisément ce qui risque de ne pas se produire.
Certains ménages resteront et paieront. D’autres demanderont un logement plus petit dans le parc social. D’autres encore chercheront une solution dans le parc privé, ce qui peut accroître le coût des aides au logement. Imaginons que, parmi les 1 000 ménages concernés, 450 demandent un logement plus petit, alors que seuls 150 T1 ou T2 sont disponibles dans l’année. Les 300 autres restent bloqués dans la file d’attente. Si 200 ménages basculent vers le parc privé avec une aide publique supplémentaire de 120 euros par mois, cela représente déjà 288 000 euros de dépense annuelle supplémentaire, sans compter l’effet possible sur les loyers du parc privé. Si, en outre, 250 ménages sont exemptés ou différés, et que seuls 100 paient effectivement la contribution, la recette réelle n’est plus de 600 000 euros, mais de 60 000 euros. Dans ce scénario, la mesure ne libère que 150 grands logements et déplace une partie de la dépense publique vers d’autres guichets.
À propos de l'explosion combinatoire
La difficulté ne tient donc pas seulement au calcul d’une taxe ou d’une aide, mais à l’enchaînement des réactions qu’elles provoquent. Supposons, par exemple, que l’administration teste cinq niveaux de contribution, quatre montants d’aide au déménagement, trois durées de période transitoire, trois règles d’exemption et quatre critères de priorité géographique, comme le montre la Figure 1. On obtient déjà 5 × 4 × 3 × 3 × 4 = 720 configurations de politique publique. Pour chacune d’elles, il faut encore anticiper les réponses de ménages hétérogènes. Même avec seulement vingt types de ménages et quatre réactions possibles par type, cela représente 420 =1 099 511 627 776 profils de réaction. Au total, l’espace à explorer atteint donc 720 × 420 = 791 648 371 998 720 combinaisons politique-réactions. C’est cette explosion combinatoire qui rend ces problèmes impraticables par simple énumération.
Figure 1 : L’Optimisation bi-niveau dans les politiques du logement.
L’explosion combinatoire ne signifie pas que ces problèmes sont insolubles. Elle signifie surtout qu’ils ne peuvent pas être abordés par une simple énumération de toutes les politiques et de toutes les réactions possibles. Pour les rendre analysables, il faut les formuler comme des problèmes structurés sur le plan mathématique et numérique. Les progrès récents en optimisation numérique, en simulation et en calcul parallèle permettent déjà d’explorer ce type de scénarios de manière beaucoup plus organisée. À plus long terme, le calcul quantique pourrait encore élargir cet horizon, même s’il ne constitue pas aujourd’hui une solution immédiatement mobilisable pour la décision publique.
Importer la perspective bi-niveau dans l’analyse des échecs budgétaires
Cet effort de structuration mathématique et numérique a déjà été mené dans d’autres domaines où l’optimisation bi-niveau s’applique. La logique leader-suiveurs n’est donc pas propre au logement, ni même aux politiques publiques. Elle apparaît chaque fois qu’une autorité centrale fixe des règles, tandis que des acteurs autonomes prennent ensuite leurs propres décisions à l’intérieur de ce cadre. Dans mes travaux, cette architecture a par exemple été mobilisée en finance, lorsqu’une banque définit des règles générales d’allocation ou de gestion du risque, tandis que des entités décentralisées et des intermédiaires prennent des décisions plus fines, parfois en tension avec l’objectif initial (articles 1, 2, et 3) ; dans les transports urbains, lorsqu’un opérateur choisit des investissements, des tarifs ou des péages tout en anticipant les choix d’itinéraires des usagers ; ou encore dans l’organisation des entreprises, lorsqu’une maison mère fixe des incitations à la production, comme des prix de transfert ou des investissements technologiques, puis observe comment les filiales ajustent leur comportement.
Plusieurs situations, une seule logique : réduire le risque d’effet boomerang
De la finance aux transports, en passant par l’organisation des entreprises, le même schéma revient : une règle fixée en amont déclenche des réponses en aval. Le logement montre que ce schéma n’a rien d’abstrait. Un barème, un plafond, une subvention, une exonération ou une priorité d’attribution représentent des signaux qui modifient les décisions des ménages : rester, déménager, demander un relogement, différer un choix ou arbitrer entre parc social et parc privé.
C’est pourquoi une réforme ne peut pas être évaluée uniquement à partir de son effet attendu sur le papier. Elle doit aussi être testée à travers les réactions qu’elle est susceptible de provoquer. Les outils d’optimisation numérique, de simulation et de calcul parallèle permettent désormais d’explorer ces scénarios de façon plus structurée que par simple intuition ou par énumération exhaustive. Ils ne remplacent pas le choix politique, mais rendent plus visibles les arbitrages entre économies budgétaires, justice sociale et faisabilité.
Dans un contexte où chaque milliard compte, l’enjeu n’est donc pas seulement d’être « plus strict » ou « plus généreux ». Il est de concevoir des politiques suffisamment robustes pour rester efficaces une fois les comportements ajustés. C’est précisément ce que permet la perspective bi-niveau : transformer une réforme en laboratoire de scénarios, afin de réduire le risque qu’une économie annoncée se retourne en effet boomerang.
Stefano Nasini ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 17:16
Se déconnecter en montagne : pourquoi les refuges nous font tant de bien
Isabelle Frochot, Maître de Conférences HDR - Comportement du Consommateur, Université Bourgogne Europe
Alain Decrop, Professeur de marketing , Université de Namur
Texte intégral (1751 mots)
Surcharge mentale, fatigue chronique, frustrations diverses, mais que cherchons-nous vraiment quand nous fuyons nos écrans et nos agendas surchargés ? Une étude menée auprès de randonneurs séjournant dans les refuges alpins apporte des éléments de réponse. Ce qui les motive, c’est surtout la capacité retrouvée à nous reconnecter à nous-mêmes, aux autres et au monde.
La vie contemporaine est gouvernée par ce que le sociologue Hartmut Rosa appelle l’accélération sociale : toujours plus de tâches, de messages, de décisions, dans toujours moins de temps. L’individu hypermoderne est libre, mais épuisé, malade du temps et tiraillé entre différentes injonctions et responsabilités, incapable de ralentir. Le burn-out n’est plus une pathologie marginale, il est devenu un horizon malheureusement familier.
Face à cela, la demande explose pour tout ce qui promet une déconnexion radicale avec le quotidien, comme les retraites de méditation, les séjours de digital detox, mais aussi les pèlerinages… Même si cette tendance ne remettra pas en cause le tourisme de masse, elle démontre une volonté claire et croissante pour des vacances où l’on vient volontairement se perdre et couper clairement avec un quotidien très (trop ?) chargé. Cette évolution s’observe également dans la demande grandissante pour les vacances en van, ou à vélo.
À lire aussi : Détox digitale : se déconnecter, entre le luxe et le droit fondamental
Par ailleurs, la randonnée est désormais le sport le plus pratiqué en France, avec 27 millions de pratiquants. Les hébergements ne sont pas en reste, avec un foisonnement d’offres facilitant la déconnexion. Les hôtels du silence en sont un bel exemple mais des formules plus anciennes connaissent également un engouement certain. Ainsi, la fréquentation des refuges alpins a bondi de 40 % en 2022 par rapport à l’avant-Covid. Toutes ces évolutions démontrent qu’un changement de fond s’opère et qu’il mérite d’être étudié.
Les refuges alpins comme échappatoire
Pour mieux comprendre le mécanisme de déconnexion, nous avons mené 45 entretiens individuels approfondis avec des randonneurs séjournant dans 12 refuges différents des Alpes françaises, complétés par 18 journées d’observation participante. Les refuges offrent une prestation relativement frugale avec un confort minimal : pas de wifi, dortoirs collectifs, menu unique servi à heures fixes, toilettes sèches, pas toujours d’eau chaude dans les douches, etc. Les refuges que nous avons étudiés ne sont accessibles qu’à pied. À leur arrivée, les randonneurs posent leurs sacs, laissent leurs chaussures de randonnée à l’entrée et socialisent avec des inconnus autour de grandes tablées.
Ce qu’ils sont nombreux à valoriser, c’est la coupure nette que cet univers de vacances leur offre spontanément. La combinaison de l’effort (la marche), l’univers montagnard naturel et grandiose, et la frugalité des refuges offrent un univers de vacances « ultra-déconnectant ». Tous identifient un lâcher-prise rapide, spontané, tant physique que psychologique. Ainsi, Noé déclare « Je suis surchargé de responsabilités. Ici, il suffit de penser à la météo du lendemain et à l’heure du lever. C’est une parenthèse enchantée. »
À lire aussi : Refuges de montagne : entre regain de fréquentation et menaces climatiques
Ces refuges sont limités en connexion digitale (pas de wifi, pas ou peu de réseau), c’est donc une coupure qui s’impose et que les usagers apprécient : « Rien que le fait de ne pas pouvoir avoir accès à Internet, ça fait vraiment du bien. Je pense à rien, je discute avec les gens. Ça nous humanise. » (Florence). Si, pour ces vacanciers, la déconnexion est la première étape des vacances, c’est aussi une condition pour qu’ils se rendent enfin disponibles pour leurs vacances et pour y vivre des moments intenses.
Une disponibilité résonante
Notre analyse de données a progressivement fait émerger un concept que nous n’avions pas anticipé, celui de disponibilité résonante. Ce dernier traduit un état spontané d’ouverture et de réceptivité qui s’installe une fois la déconnexion opérée. Cet état rend les individus capables de se reconnecter différemment à leur expérience et, plus largement, au monde environnant.
Plus précisément, l’état de disponibilité résonante est caractérisé par cinq dimensions :
l’instantanéité : vivre pleinement le moment présent, sans l’emprise des horaires ni des obligations ;
la sérénité : un apaisement mental profond, le sentiment de se vider de ses fardeaux ;
l’humilité : face à la montagne, à son échelle et à sa puissance, on retrouve sa juste place, comme en témoigne Baptiste : « J’aime me sentir tout petit, redevenir une petite chose qui galope sur la terre » ;
l’oisiveté : la permission (rare dans nos sociétés) de ne rien faire et de l’apprécier : « Je crois que c’est le seul endroit où je suis capable de ne rien faire » (Fabrice) ;
l’acceptation : les contraintes du refuge ne sont pas vécues comme des privations mais comme des conditions favorables au retour à l’essentiel.
Contrairement à la pleine conscience (en anglais mindfulness) qui nécessite un apprentissage et une intention, la disponibilité résonante survient spontanément. Ce n’est pas une technique. C’est un état que l’environnement et l’activité étudiés provoque.
Il est important de comprendre cet état car il est une clé d’entrée à une transformation importante chez nos « informants », qui va venir donner du sens à leurs vacances et à leurs vies.
Des décisions prises en altitude
Une fois en disponibilité résonante, les randonneurs ne se reconnectent pas à ce qu’ils ont quitté, mais bien à autre chose. La première reconnexion est à eux-mêmes. La marche ouvre un espace de réflexion que la vie ordinaire ne permet plus ; on vagabonde dans sa tête, on repense et réévalue des événements/situations personnels…
Ainsi, plusieurs participants évoquent des décisions prises en altitude, des priorités retrouvées, un rapport à soi plus lucide. Le quotidien est donc toujours présent, mais très différemment. La personne se recentre sur l’essentiel avec une distanciation qui ouvre un espace de réflexion dans un état d’esprit bienveillant.
Deuxièmement, les vacanciers se reconnectent aux autres. Le refuge est un lieu de socialisation spontanée, le tutoiement prend vite le dessus, on partage des tablées, on échange des conseils… Les familles retrouvent une disponibilité mutuelle que le quotidien a érodée. Dans cette dynamique, le gardien joue un rôle central : au-delà de la gestion de son refuge, il veille, guide, conseille, fédère…
Un sentiment d’émerveillement
Enfin, les usagers se reconnectent à l’univers. La confrontation à la montagne, à sa beauté et sa démesure provoque ce que certains chercheurs appellent le sentiment d’émerveillement qui convoque une révision de leur compréhension du monde et de leur manière de l’habiter.
Si notre étude porte sur un environnement très spécifique de vacances, nos résultats dépassent largement le cadre des refuges alpins. Ils viennent nous rappeler que nous avons à disposition des environnements naturels, authentiques et immersifs qui permettent spontanément de retrouver un rapport à soi et au monde, apaisé et plus riche. Ils viennent également questionner d’autres formules de vacances, certes appréciables, comme les hôtels-clubs ou les croisières. Ceux-ci tendent davantage à la reproduction en partie du quotidien plutôt que de permettre de rompre avec lui.
Une source d’iniquité ?
La pratique de la randonnée en montagne soulève cependant une question d’équité car elle est socialement connotée. En effet, les adeptes de la montagne et des refuges les fréquentent souvent depuis leur enfance. Même si l’on rencontre différents types de randonneurs, les niveaux d’éducation ont tendance à rester élevés – enseignants, ingénieurs, étudiants…
Ouvrir cet univers à des clientèles non-expertes est un enjeu de taille et qui nécessite des accompagnements aussi bien pour le matériel que la transmission de compétences et de réassurance.
Les Grecs avaient la skhole, ce temps libre, fécond et non planifié, consacré à la sagesse plutôt qu’à la productivité. Les Romains avaient l’otium, un temps de loisirs productif dédié à la lecture, l’écriture, la culture. Ces temps se sont étiolés par nos rythmes de vie effrénés. La montagne, elle, les distribue encore avec une certaine générosité, à condition qu’on en accepte ses conditions.
Ce travail a bénéficié d'une aide de l'Etat gérée par l'Agence Nationale de la Recherche au titre du programme « France 2030 » portant la référence ANR-15-IDEX-0002 via le Labex ITTEM
Alain Decrop ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 14:10
Les volcans du Cantal sont des montagnes…de verre!
Patrick De Wever, Professeur, géologie, micropaléontologie, Muséum national d’histoire naturelle (MNHN)
Texte intégral (1556 mots)

{kind=link}
Au-delà du sport, le Tour de France donne aussi l’occasion de (re)découvrir nos paysages et parfois leurs bizarreries géologiques. Ce mardi 14 juillet, les coureurs du Tour de France vont traverser les volcans du Cantal sans craindre les crevaisons… et pourtant, ils traversent des montagnes de verre ! En effet, la plupart des laves volcaniques sont essentiellement constituées de verre.
Pour un géologue, parler de « verre en cristal » est une aberration : dans la nature, le verre est un matériau solide amorphe – c’est-à-dire désordonné à l’échelle atomique, contrairement au cristal. C’est une sorte de liquide figé.
Lorsqu’on parle de verre, il faut se méfier de la polysémie du terme : il y a le verre que l’homme fabrique depuis des millénaires pour concevoir par exemple des vitres ou des récipients, mais il existe aussi toute une série de verres naturels.
À lire aussi : Fées, lutins et extraterrestres, comment le pic de Bugarach a donné vie aux mythes les plus fous
Comme l’explique Daniel R. Neuville, chargé de recherche à l’Institut de Physique du Globe de Paris, un « verre » est un silicate fondu fabriqué par l’homme, tandis qu’une lave volcanique ou un magma est un silicate issu des profondeurs de la terre – ou d’autres planètes.
Quand une coulée de lave refroidit rapidement, sa matière ne peut cristalliser, elle se fige alors sous forme de verre. On observe une « bordure figée » autour de certaines coulées, filons, ou bombes volcaniques.
Certaines roches sont particulièrement riches en verre, tels les magmas riches en silice, comme le sont les magmas acides.
À lire aussi : Les tours Saint-Jacques, un prodige d’équilibre au cœur des Alpes
Avec une telle composition chimique, les molécules ont tendance à polymériser, ce qui explique leur forte viscosité. Cette consistance limite la diffusion des éléments, qui ne réussissent alors pas à se mettre aux endroits ad hoc pour former des cristaux. La polymérisation conduit à une roche non organisée (à l’inverse des cristaux) qui, en refroidissant donne un verre : l’obsidienne.
Il existe aussi le verre des impactites ou celui des tectites. Les impactites sont des verres naturels formés au moment de l’impact d’un astéroïde. A l’inverse des tectites, elles n’ont pas été projetées dans l’atmosphère. On retrouve dans la composition chimique des impactites des traces de la météorite incidente.

Le verre industriel
Le verre industriel, lui, est obtenu par fusion d’une roche siliceuse, généralement du sable. Des éléments sont souvent ajoutés pour en modifier les propriétés : le pyrex, par exemple, plus résistant aux chocs thermiques qu’un verre ordinaire, est enrichi en bore.
Les puissants de ce monde ont longtemps possédé des objets d’une grande rareté et donc précieux. Parmi ces objets, on trouvait des coupes, ou des verres, en « cristal de roche », c’est-à-dire en quartz (un oxyde de silicium cristallisé). Ces objets avaient un magnifique éclat lumineux et un son caractéristique. Pour imiter ces objets précieux et fabriquer des verres en « cristal », on a ajouté à la composition siliceuse un oxyde de plomb qui apporte l’éclat et permet d’obtenir un son caractéristique.

Plus il y a de plomb, plus le son est cristallin : la vitesse de la lumière est fonction du milieu dans lequel elle se propage. Plus le milieu est dense, plus la lumière est fortement déviée, elle peut aller jusqu’à la réflexion complète si le cristal est taillé en facettes, qui jouent alors le rôle de miroirs. Pour la même raison, le son qu’un tel verre produit lorsqu’on le fait vibrer est plus aigu, plus… cristallin.
Une version plus longue de ce texte a été publiée le 29 juin 2026 sur le site Planet Terre de l’ENS Lyon.
Patrick De Wever ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
13.07.2026 à 11:16
Le vrai mystère de « Vaiana » : qu’est-ce qui a bien pu pousser les Polynésiens à repartir vers l’est après 1 700 ans de pause ?
David Sear, Professor in Physical Geography, University of Southampton
Manoj Joshi, Professor of Climate Dynamics, University of East Anglia
Mark Peaple, Research Fellow, Palaeoclimate, University of Southampton
Texte intégral (2305 mots)

Le mystère de la « longue pause » fascine les archéologues depuis des décennies : pourquoi les Polynésiens ont-ils cessé d’explorer le Pacifique pendant près de 1 700 ans avant de reprendre soudain leurs voyages ? De nouvelles archives climatiques offrent une explication convaincante.
La même question est au cœur de l’intrigue de Vaiana, la légende du bout du monde et de plusieurs décennies de recherches archéologiques : pourquoi, après des siècles de relative stabilité, les navigateurs polynésiens se sont-ils soudainement mis à coloniser des îles situées à des milliers de kilomètres les unes des autres à travers le Pacifique ?
Le dernier film Vaiana est une adaptation en prises de vues réelles du long métrage d’animation de Disney du même nom. Bien que fictifs, ces films s’inspirent du remarquable héritage maritime des peuples polynésiens, dont les ancêtres ont accompli l’un des plus extraordinaires épisodes d’exploration océanique de l’histoire de l’humanité.
De nouvelles données climatiques pourraient aider à comprendre ce qui les a poussés à entreprendre ces voyages.
En toile de fond de Vaiana se trouve le mystère de la « longue pause ». Les ancêtres des Polynésiens, les Lapita, ont atteint les archipels des Samoa et des Tonga il y a environ 3 000 ans. Ils y ont apporté un style de poterie caractéristique ainsi qu’une culture insulaire qui leur était propre.
Les migrations humaines dans le Pacifique

Pourtant, durant les 1 700 années qui ont suivi, les expéditions plus à l’est sont restées très rares. Les données archéologiques indiquent que les populations des Tonga et des Samoa ont augmenté et développé une culture propre, distincte de celle des Lapita.
Puis, entre 900 et 1100 de notre ère, les ancêtres des Polynésiens ont soudainement entrepris une vaste phase de migration vers l’est. Au cours du siècle suivant, des navigateurs embarqués sur d’immenses pirogues à double coque et à voile ont atteint Hawaï, Aotearoa (la Nouvelle-Zélande) et Rapa Nui (l’île de Pâques). La présence de patates douces sur de nombreuses îles du Pacifique suggère qu’ils ont probablement également été en contact avec les côtes du continent américain.
Lorsque les navigateurs européens arrivèrent enfin, plusieurs siècles plus tard, ils furent stupéfaits de découvrir que même les plus petits atolls étaient habités par des communautés partageant de profondes parentés culturelles et linguistiques.
Le mystère de la « longue pause »
Depuis des générations, anthropologues et historiens cherchent à comprendre ce qui a mis fin à la longue pause. Les Polynésiens ont-ils mis au point de nouvelles techniques de navigation leur permettant de remonter les alizés d’est ? Ont-ils été poussés par la croissance démographique et des pressions sociales ? Ou leur décision a-t-elle été déclenchée par un facteur physique, lié à l’environnement ?
Pour répondre à cette question, il faut s’intéresser aux conditions matérielles qui rendent la vie possible sur une île du Pacifique : l’eau douce et la nourriture. À mesure que la population augmente, la pression sur ces ressources s’intensifie.
Les ancêtres des Polynésiens étaient très adaptables et habitués aux sécheresses saisonnières. Mais des épisodes de sécheresse prolongés et sévères, survenant alors que la densité de population était élevée, pouvaient faire qu’une île ne soit plus en mesure de faire vivre ses habitants. En définitive, la survie sur une île dépend d’une ressource essentielle : les précipitations.
Décrypter les archives du climat

Jusqu’à récemment, les scientifiques ne disposaient d’aucune donnée permettant de reconstituer le climat qui régnait dans la région des Tonga et des Samoa à cette période cruciale des migrations. Nous avons toutefois pu retracer ces évolutions en analysant les isotopes de l’hydrogène – des variantes légèrement différentes d’un même élément chimique – conservés dans d’anciens sédiments prélevés dans des marais et des lacs.
Sous les tropiques, la composition isotopique de l’eau de pluie reflète la quantité de précipitations. En se développant, les algues et les plantes absorbent cette eau et en enregistrent la signature chimique dans des molécules capables de se conserver pendant des milliers d’années dans les sédiments, constituant ainsi une archive naturelle des précipitations passées.
Grâce à cette technique, nous avons mis en évidence une période de sécheresse durable et particulièrement sévère dans le sud-ouest du Pacifique tropical entre 850 et 1200 de notre ère. Nos résultats, récemment publiés dans le Journal of Pacific Archaeology, montrent qu’il s’agit de la période la plus sèche qu’ait connue la région au cours des 2 000 dernières années. Surtout, cette sécheresse est survenue à une époque où les populations insulaires étaient devenues plus nombreuses.
La grande migration vers l’est du Pacifique a coïncidé avec une période de sécheresse dans l’ouest du Pacifique :

Pourquoi certaines îles connaissent-elles des sécheresses qui durent plusieurs décennies, voire plusieurs siècles ? Les précipitations dans le sud du Pacifique tropical dépendent de la position de la zone de convergence du Pacifique Sud (SPCZ), une vaste bande de nuages et de pluies qui se déplace d’est en ouest au fil du temps sous l’effet des variations de la température de surface des océans. À court terme, ces déplacements sont liés aux phénomènes El Niño et La Niña. Mais la SPCZ peut aussi se déplacer sur des périodes beaucoup plus longues, entraînant des décennies de conditions exceptionnellement sèches ou humides dans différentes régions du Pacifique.
L’ensemble concorde avec les données génétiques, qui indiquent que la population des Samoa a connu une forte croissance autour de l’an 1000, peut-être grâce à l’arrivée de nouveaux groupes de population. Tout porte donc à croire que plusieurs facteurs se sont conjugués – un stress climatique intense, une population en expansion et des progrès dans la technologie des pirogues – pour déclencher cette audacieuse exploration vers l’est.
L’expansion polynésienne constitue, à elle seule, un épisode remarquable de l’histoire humaine. Tandis que Vaiana fait découvrir à un nouveau public les traditions de navigation des peuples du Pacifique, les scientifiques continuent d’affiner notre compréhension des défis environnementaux auxquels ces navigateurs hors du commun ont été confrontés – et de la manière dont ils y ont répondu avec ingéniosité, résilience et un extraordinaire esprit d’exploration à l’échelle de l’océan Pacifique.
David Sear a reçu des financements de UKRI-NERC et de la National Geographic Society.
Manoj Joshi a reçu des financements de UKRI-NERC.
Mark Peaple a reçu des financements de UKRI-NERC.
12.07.2026 à 17:46
World Cup 2026: how are posts on diversity and inclusion being received on social media?
Willem Standaert, Associate Professor, Université de Liège
Arno De Caigny, Full Professor of Marketing Analytics, IÉSEG School of Management
Kristof Coussement, Professor of Business Analytics, IÉSEG School of Management
Matthijs Meire, Associate professor, IÉSEG School of Management
Texte intégral (1515 mots)
Football has embraced the issue of diversity, though not without controversy. But how do online communities respond to these efforts? An analysis of several thousand social media posts reveals a more nuanced reality: in the eyes of the public, not all forms of diversity are received in the same way.
Nelson Mandela famously said that “sport has the power to unite people in a way that little else does.” This ideal lies at the heart of Fifa’s message for the 2026 World Cup, presented as a celebration of unity, diversity, and inclusion.
The tournament itself reflects this ambition: a significant share of players now represent a country other than the one in which they were born, illustrating the impact of migration and the rise of multiple identities in modern football. A case in point is provided by the French team.
Polarised social issues
But this symbolism comes with tensions. Against a global backdrop of debates over immigration, national identity, and LGBTQ+ rights, the World Cup continues to generate controversy, whether over the visa of a Somali referee, fans’ travel, or Iran’s participation. As with the debate surrounding the “OneLove” armband at the 2022 World Cup, football remains a central arena where broader, and often polarised, societal issues come into sharp focus.
These discussions do not stop at the stadium. They continue across social media, where every post, campaign, or public statement is instantly amplified, commented on, and debated at great speed. In this environment, football associations, sponsors, and brands benefit from unprecedented visibility but also face increased exposure to public reactions. This raises a fundamental question: how can organisations communicate effectively about diversity and inclusion in such a fragmented and polarised space?
Is diversity a disadvantage on social media?
To answer this question, we analysed more than 6,000 Facebook and Instagram posts published by nine European football associations. Drawing on interviews with industry experts, we identified seven dimensions of diversity and inclusion: gender, race and ethnicity, age, disability, religion and culture, sexual orientation, and social class.
Taken as a whole, posts related to diversity appear to generate fewer interactions, on average, than other types of content. This finding, consistent with some earlier studies, could easily lead to the simplistic conclusion that diversity is somehow ‘penalised’ on social media. Such an interpretation, however, would be misleading.
A closer look at the individual dimensions reveals a much more nuanced pattern of audience responses. Posts highlighting gender or age diversity tend to generate lower engagement on average. By contrast, posts depicting racial diversity receive more positive engagement on both Facebook and Instagram. These important differences help explain why previous research has often reached conflicting conclusions: some studies focus on a single dimension of diversity, while others combine them into a single measure.
Our findings show that diversity and inclusion are not a homogeneous concept but rather a set of distinct dimensions that can trigger very different social, emotional, and cultural responses, depending on the audience.
A communication challenge
These findings shift the central question. It is no longer whether organisations should communicate about diversity and inclusion, but how they can do so in ways that are both relevant and sensitive to context.
First, organisations need to move beyond generic messages about inclusion and identify precisely which dimensions of diversity they are highlighting in their communications.
Audience responses depend heavily on cultural context, industry, and the implicit norms of each online community. A consumer brand, a technology company, or a university may, therefore, observe very different or even opposite patterns of audience response. The challenge is not to follow a universal formula, but to understand the expectations and sensitivities of one’s own audience.
Second, it is essential to distinguish between communication and impact. Content in which diversity is integrated naturally into everyday communication tends to perform better than content that relies primarily on explicit campaigns, slogans, or dedicated hashtags. This does question the legitimacy of taking a public stand. Rather, it suggests that its effectiveness depends largely on its consistency with the brand’s broader narrative and on its integration into content that audiences perceive as authentic.
Subtle effects that should not be overlooked
Third, organisations should move beyond a purely quantitative view of social media engagement. Although some diversity-related content may generate fewer likes or comments, it can still produce a more subtle, but strategically important, effect: changing the composition of the engaged audience. Our exploratory analyses suggest that certain types of content attract more diverse audiences across different identity dimensions. In other words, the value of these communications lies not only in the volume of interactions they generate, but also in their ability to broaden and diversify the audience that engages with them, an increasingly important objective for organisations.
With the World Cup in full swing, football continues to spark debates about identity, belonging, and representation that extend far beyond the pitch. These discussions will take place as much on social media as in stadiums, with every public statement immediately interpreted and debated in environments that are often highly polarised.
For sports associations and brands alike, the challenge is no longer to decide whether diversity belongs in their communications. Rather, it is to recognise that diversity is multidimensional, audiences are heterogeneous, and the success of a communication strategy cannot be reduced to short-term engagement metrics alone.

A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Willem Standaert received a subsidy from UEFA, the Union of European Football Associations.
Arno De Caigny received a subsidy from UEFA, the Union of European Football Associations.
Kristof Coussement received a subsidy from UEFA, the Union of European Football Associations.
Matthijs Meire received a subsidy from UEFA, the Union of European Football Associations.
12.07.2026 à 17:45
Peut-on mieux recycler les métaux précieux contenus dans nos ordinateurs ?
Solène Touze, Cheffe de projet, génie des procédés, BRGM
Texte intégral (1559 mots)
L’ESSENTIELCliquez pour lire les trois points à retenir La carte-mère d’un ordinateur est pleine de métaux précieux : du cuivre, de l’or, de l’argent, du palladium, du platine, de l’europium… il y en a une cinquantaine sur une seule carte. Aujourd’hui, seuls cinq de ces métaux précieux peuvent être récupérés (au mieux), pour des raisons économiques et technologiques. Un des obstacles est que l’on sait très mal quantifier les métaux présents dans la benne à ordures électroniques. Cette quantification est indispensable pour évaluer le potentiel de valorisation, et, quand c’est possible, récupérer davantage de matière. Replier
Tout commence dans nos maisons. Lors d’un ménage de printemps, l’ordinateur portable hors service qui traîne est enfin emmené à la déchèterie et est déposé dans le bac déchets d’équipements électriques et électroniques (DEEE). S’il ne peut pas être réutilisé ou réemployé, il part vers une filière de recyclage. Que sait-on réellement, aujourd’hui, recycler de ce déchet ?
La première étape se fait à la main : on trie les déchets électriques et électroniques, et l’ordinateur va dans un bac dédié aux ordinateurs. Ensuite, toujours manuellement, on enlève la batterie qui est envoyée vers une filière spécialisée — c’est une obligation réglementaire.
À cette étape, plusieurs chemins sont possibles : nous allons ici considérer que l’opérateur qui extrait la batterie isole aussi la carte mère ; et que le reste, l’écran et le boîtier partent vers des procédés de tri automatisés qui vont recycler les métaux présents en grande quantité (fer, cuivre, aluminium), et parfois les plastiques.
Maintenant, suivons la carte mère. Elle est considérée comme une carte électronique riche car elle contient du cuivre et des métaux précieux en quantité intéressante : plus de 20 % de cuivre, plus de 150 milligrammes d’or par kilogramme de carte-mère, et plus de 600 milligrammes d’argent par kilogramme. Ainsi, le déchet carte-mère se vend entre 3 et 8 € le kilogramme. Plus la carte est avancée (avec davantage de RAM ou des processeurs plus puissants, par exemple), plus elle a des chances d’avoir des quantités de métaux précieux importantes.
Les cartes sont triées en différentes catégories, du plus riche au moins riche — une nouvelle fois manuellement, à l’œil. C’est l’étape de massification : le but consiste à regrouper les cartes de même catégorie en un seul lot. Cela va faciliter le transport, le stockage et la revente.
Lorsque le lot atteint une certaine quantité (environ la vingtaine de tonnes), il est vendu aux métallurgistes du cuivre. Ce sont les industriels qui produisent et vendent du cuivre pur, on les appelle les « smelters » de cuivre. Il y a aujourd’hui sur Terre moins d’une dizaine de smelters qui récupèrent le cuivre en même temps que les métaux précieux. Aucun n’est en France, mais une majorité est en Europe (Belgique, Suede Autriche et Allemagne). Face à ces « géants de la métallurgie » (Umicore, Aurubis, Boliden par exemple), il existe aussi quelques PME du monde du recyclage (dont, en France, WeeeCycling).
La plupart des smelters ont été conçus, à la base, pour traiter du minerai de cuivre (roche extraite d’une mine de cuivre). Ils ont progressivement intégré des déchets dans leur alimentation mais cette alimentation reste souvent minoritaire. Les métaux qui y sont valorisés sont le cuivre, l’or, l’argent, le palladium et le platine s’il y en a (soit seulement cinq métaux, alors que la carte en contient presque une cinquantaine).
Les cartes qui ne sont pas assez « riches » vont, elles, vers des « smelters » qui ne récupèrent que le cuivre.
Pourquoi ne pas recycler davantage ?
La réponse n’est pas triviale. Il y a des raisons économiques, technologiques, géopolitiques et de marché et à cela s’ajoute une dynamique temporelle complexe.
Sur la partie économique, l’évidence est que la filière doit être rentable : les coûts de traitement de cette matière secondaire (les cartes-mères) doivent donc être inférieurs à celui du traitement de la matière primaire (le minerai de cuivre).
Le deuxième point économique, moins connu, est les risques liés à la volatilité des cours des métaux : il peut être difficile d’investir sur la récupération d’un métal quand son prix peut fluctuer du simple au double en très peu de temps.
Dans cette même logique, nos objets (comme ceux du numérique) évoluent très vite et certains métaux utilisés aujourd’hui risquent de ne plus l’être demain. Faut-il mettre en place des chaînes de traitement éphémères ? Quid, par exemple, de la filière de recyclage des lampes à économie d’énergie qui ont été remplacées par les LED en une décennie ?
Côté technologique, les technologies de récupération de cette cinquantaine de métaux existent déjà dans le domaine minier, et beaucoup peuvent être adaptées au domaine du recyclage.
Peut-on valoriser de très faibles quantités ?
Mais ce catalogue de technologies de recyclage ne peut pas se déployer raisonnablement sur la cinquantaine de métaux présents.
Dans le minerai comme dans les déchets, la production des métaux suit de grandes familles de métaux : la sidérurgie pour l’acier, la métallurgie du cuivre, du nickel, de l’aluminium, le groupe des terres rares… Par exemple, dans la nature, le gallium est associé aux minerais de bauxite (aluminium), il est donc produit par la filière métallurgie de l’aluminium.
La carte électronique, elle, fait fi de ces associations. Une carte-mère d’ordinateur est traitée uniquement par la métallurgie du cuivre, et aucune de ces installations ne valorise le gallium. Les 3 milligrammes de gallium présents dans une carte sont donc perdus.
Au-delà de ces questions de filières, se pose aussi la question d’aller valoriser un métal en très faible quantité. Quel est le coût énergétique d’aller chercher les 0,075 milligramme d’Europium dans une carte mère ?
Connaître la matière
Enfin, une troisième raison du recyclage partiel des cartes est le manque de donnée sur leur contenu. En effet, aujourd’hui, les ordinateurs et leurs cartes-mères ne sont pas fournis avec un « passeport matière » qui donne leur composition précise ; alors même que celle-ci varie aussi bien avec le producteur et le temps.
Si nous voulons bâtir de nouvelles filières de recyclage, il est nécessaire de connaître ce gisement pour affirmer la faisabilité économique et technique du recyclage : quelle quantité de tel métal est accessible et à quelle concentration se trouve-t-il ? Accéder à ces données est difficile et demande une recherche approfondie.
Repartons des 20 tonnes de cartes électroniques vendues au smelter : il est clairement impossible de caractériser et d’analyser la totalité du lot. En effet, les outils d’analyse fonctionnent sur des échantillons de quelques grammes seulement, voire quelques milligrammes. Par construction, l’échantillon analysé n’est jamais tout à fait représentatif du lot d’origine. Il s’accompagne d’une « valeur d’incertitude » : a-t-on analysé 30 milligrammes de germanium par kilo, plus ou moins 5 ou 20 milligrammes par kilo ? Cette marge d’erreur change totalement le potentiel de valorisation du lot.
Avec mes collègues, nous travaillons dans le cadre du projet ReviWEEE, pour développer une méthodologie d’échantillonnage et d’évaluation des incertitudes.
Le projet ReviWEEE est soutenu par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Solène Touze a reçu des financements de l'ANR - 22-PERE-0009.
12.07.2026 à 11:35
Peut-on cartographier l’Odyssée ? Comment géographes antiques et chercheurs d’aujourd’hui ont retracé le voyage d’Ulysse
Pragya Agarwal, Visiting Professor of Social Inequities and Injustice, Loughborough University
Texte intégral (2401 mots)
L’Odyssée, le très attendu film de Christopher Nolan, sort en salles le 15 juillet. L’occasion de revenir sur une question qui fascine historiens et archéologues depuis des siècles : les lieux traversés par Ulysse ont-ils réellement existé ?
L’Odyssée d’Homère est une quête, celle du roi Ulysse, qui met dix ans à regagner son royaume d’Ithaque après la guerre de Troie. C’est un récit aux dimensions géographiques, spatiales et temporelles très marquées. Il n’est donc pas surprenant que, depuis des siècles, les lieux évoqués dans ce récit fascinent les lecteurs, qui se demandent combien d’entre eux ont réellement existé.
Quelques historiens et spécialistes de l’Antiquité estiment toutefois que l’Odyssée n’est qu’une œuvre poétique. Selon eux, en tant que création littéraire et récit mythologique, il est vain de chercher à situer ces lieux sur une carte.
Le savant grec de l’Antiquité Ératosthène, premier à avoir mesuré la circonférence de la Terre, contestait tout lien entre l’Odyssée et la géographie. Il affirmait : « Vous trouverez le théâtre des errances d’Ulysse lorsque vous aurez trouvé le cordonnier qui a cousu le sac des vents. »
J’étudie l’histoire de la cartographie et des représentations mentales de l’espace depuis plus de vingt ans. À mes yeux, ce sont précisément les dimensions géographiques du récit qui lui donnent tout son ancrage. Le désir d’Ulysse de retrouver le chemin de son foyer est au cœur même du poème. Et c’est au fil de sa traversée de ces différents lieux et espaces que le héros se transforme.
Cartographier le mythe
L’historien grec de l’Antiquité Polybe, qui vécut environ six siècles après Homère, estimait que l’Odyssée relatait un récit réel agrémenté de quelques éléments mythologiques, et non l’inverse. Il soulignait par exemple que certaines techniques de pêche décrites près de Scylla étaient semblables à celles pratiquées autour de la Sicile. Selon lui, Scylla devait donc se trouver au large des côtes siciliennes.
Strabon était un philosophe et géographe grec qui écrivait près de sept siècles après Homère. Sa Géographie, vaste œuvre en 17 livres, constitue à la fois un atlas et une encyclopédie du monde grec à l’époque de l’empereur Auguste. On y trouve également le récit d’îles peuplées uniquement d’hommes ou de femmes dans l’océan Indien, un motif qui rappelle ceux décrits par Homère dans l’Odyssée :
« Dans l’océan se trouve une petite île, située non loin du large, en face de l’embouchure du fleuve Liger ; elle est habitée par des femmes du peuple des Samnites, possédées par Dionysos, qu’elles cherchent à rendre favorable en l’apaisant par leurs rites. »
Les légendes et les mythes de l’époque regorgent de récits de femmes séduisant les hommes pour les entraîner à leur perte. C’est le cas de Circé, que Homère décrit comme « une redoutable déesse aux beaux cheveux ». Elle vit seule sur l’île d’Aiaié, entourée de loups et de lions apprivoisés, et attire Ulysse et ses compagnons dans son domaine pour les transformer en porcs.
Homère évoque également Calypso, qui retient Ulysse sur son île d’Ogygie pendant sept ans dans ce que certains traduisent comme une « captivité sexuelle ». D’autres traductions suggèrent toutefois qu’Ulysse y demeure de son plein gré, jusqu’au moment où il décide qu’il est temps de repartir.
Sur les cartes et les globes de l’Antiquité, le monde réel et les mythes se superposent et s’entremêlent. Le mathématicien et astronome romain Ptolémée, qui a cartographié le monde connu au IIe siècle après J.-C., fait figurer sur ses cartes plusieurs lieux issus de l’univers homérique, comme la Lotophagitis (le pays des Lotophages), le Circaeum Promontorium (Aiaié, le royaume de Circé) ou encore les Sirenusae Insulae (les îles des Sirènes).

{kind=link}
Les tentatives visant à reporter précisément ces lieux sur des cartes modernes se sont révélées difficiles. Les calculs de latitude et de longitude de Ptolémée reposaient sur une projection très différente de la nôtre ainsi que sur une estimation erronée de la circonférence de la Terre. Une correspondance approximative entre ces lieux et les cartes actuelles laisse penser que la Lotophagitis se situerait en Afrique.
À la fin du XVIe siècle, le cartographe néerlandais Abraham Ortelius fut le premier à représenter l’intégralité du voyage d’Ulysse dans son Theatrum Orbis Terrarum. Cette carte, intitulée Map of the Wanderings of Ulysses (« Carte des errances d’Ulysse »), utilise le nom latin Ulysses et non le grec Odysseus pour désigner le héros.
Ortelius représente à la fois les mondes mythique et fictif d’Ulysse comme s’il s’agissait de réalités scientifiques, et affirme qu’Ithaque correspond à l’actuelle Corfou. Homère situait l’île de Calypso au large de Schérie, un havre mythique constituant la dernière étape du voyage d’Ulysse avant son retour à Ithaque.
Or, aucune île ne se trouve à l’ouest de Corfou. Ortelius en a donc inventé une sur sa carte. Cette île fictive est ensuite devenue une référence pour les cartographes, au point de continuer à figurer sur les cartes jusque dans les XIXe et XXe siècles.

{kind=link}
En 1912, le politicien et voyageur français Victor Bérard entreprit de reconstituer l’itinéraire d’Ulysse en parcourant lui-même la Méditerranée. Il situait l’île de Calypso près de Gibraltar, le pays des Lotophages sur l’île de Djerba, au large du sud de la Tunisie, et le pays des Cyclopes à Posillipo, près de Naples.
Selon la théorie de Bérard, l’Odyssée d’Homère aurait été influencée par les voyages et les cartes des Phéniciens, notamment par leurs instructions de navigation côtière, qui s’appuyaient sur les étoiles pour s’orienter. Mais nombre de ces « cartes » relevaient davantage de l’imaginaire et de la tradition orale que d’objets cartographiques réels.
À la recherche d’Ithaque
L’un des grands débats autour de la géographie de l’Odyssée consiste à déterminer où se trouvait réellement Ithaque. Pendant longtemps, les spécialistes ont soutenu qu’il s’agissait de l’actuelle île d’Ithaki, dans la mer Ionienne. Le problème est qu’Ithaki est une île montagneuse, alors que l’Ithaque décrite par Homère est « basse ».
Des chercheurs des universités de Cambridge et d’Aberdeen ont récemment avancé qu’Homère ne décrit en réalité jamais Ithaque comme une île. Selon eux, il la présente plutôt comme une terre ou un territoire appartenant à une île plus vaste.
Cette interprétation ferait de Paliki, située sur la côte ouest de Céphalonie, une candidate plus crédible. Des études géoscientifiques et des fouilles archéologiques ont en effet montré que Paliki constituait un important site de l’âge du bronze, ce qui renforce l’hypothèse qu’elle puisse correspondre à l’Ithaque d’Homère.
Les étapes du voyage d’Ulysse correspondent peut-être à des lieux bien réels, ou relèvent peut-être entièrement du mythe. Dans les deux cas, les liens qu’elles entretiennent les unes avec les autres racontent une même histoire : celle du désir profond de retrouver son foyer et de la quête d’appartenance. Ils éclairent aussi la manière dont les Anciens percevaient le monde, comme un espace peuplé de mystères et de dangers.
La géographie de l’Odyssée offre ainsi une clé de lecture des vulnérabilités et des peurs des hommes de la Grèce antique. Les cartes retraçant le voyage d’Ulysse ne sont peut-être pas fidèles à la réalité, mais après tout, aucune carte ne l’est totalement. Les cartes ne sont au fond que des récits que nous nous racontons : des voyages vers l’inconnu, bien au-delà des frontières de notre imagination. Dans l’Odyssée, Homère ne se contente pas de cartographier le monde ; il en crée un.
Pragya Agarwal ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.07.2026 à 10:39
Opération de la cataracte, prothèse de hanche… quand les dépassements d’honoraires des médecins se généralisent pour des actes fréquents
Renaud Legal, Directeur de recherche, Institut de recherche et documentation en économie de la santé (Irdes)
Véronique Lucas-Gabrielli, Directrice de recherche, Institut de recherche et documentation en économie de la santé (Irdes)
Texte intégral (2953 mots)
L’ESSENTIEL Les dépassements d’honoraires des médecins spécialistes se généralisent, voire deviennent majoritaires pour certains soins et dans certains territoires. Des études récentes de l’Institut de recherche et documentation en économie de la santé (Irdes) montrent que certains actes sont particulièrement concernés, comme l’opération de la cataracte, la reconstruction du ligament croisé, la « sleeve gastrectomy » ou encore la pose de prothèse de hanche. Ce constat pose question quant à l’accès aux soins pour tous, notamment pour les ménages dont les ressources se situent juste au-dessus des seuils pour bénéficier des dispositifs de prise en charge destinés aux foyers les plus modestes.
Les dépassements d’honoraires sont devenus une réalité pour un nombre croissant de Français. Ce terme un peu technique renvoie au supplément de prix facturé par certains médecins libéraux au-delà du tarif conventionnel de la Sécurité sociale – et donc souvent à la charge du patient. Car la règle est simple : la Sécurité sociale ne rembourse pas ces dépassements.
Ils restent donc à la charge des patients… sauf si leur complémentaire santé (souvent appelée « mutuelle », même quand elle ne relève pas du Code de la mutualité) prend le relais. Or, ce relais est fortement inégal et souvent incomplet, quand il n’est pas inexistant : au total, seuls 40 % de ces frais sont effectivement pris en charge par les complémentaires santé en moyenne.
Une part importante des dépenses reste donc directement supportée par les ménages. À travers cette réalité, c’est l’accessibilité financière aux soins qui se trouve directement interrogée.
Un phénomène qui ne date pas d’hier
Ce constat n’est pas récent. Au début des années 1980, lors de la négociation d’un nouvel accord entre l’Assurance-maladie et les médecins, ces derniers demandent une hausse de leurs tarifs. Mais cette requête se heurte aux difficultés financières de l’Assurance-maladie.
Pour faire face à cette situation, le gouvernement décide de créer deux secteurs conventionnels :
dans le secteur 1, les médecins s’engagent à respecter les tarifs fixés par l’Assurance-maladie…
dans le secteur 2, les médecins peuvent fixer des tarifs plus élevés en demandant des compléments d’honoraires aux patients.
Dans les années 1990, la forte augmentation des médecins optant pour le secteur 2 fait craindre un basculement massif vers ce mode d’exercice. Pour freiner ce mouvement, l’accès au secteur 2 est restreint aux seuls médecins disposant de certains titres hospitaliers – notamment anciens chefs de clinique et assistants des hôpitaux. Ces parcours étant propres aux médecins spécialistes, les médecins généralistes ont, de fait, été exclus en pratique du dispositif. Ceux qui exercent encore aujourd’hui en secteur 2 y ont donc accédé avant ce « gel », ce qui explique leur très faible proportion.
Dans les années 2010, dans un contexte d’augmentation préoccupante des niveaux de dépassements, la régulation s’oriente vers des mécanismes d’incitation à la modération des dépassements : d’abord le contrat d’accès aux soins (CAS) en 2012, remplacé en 2016 par l’option de pratique tarifaire maîtrisée (Optam). Les médecins qui y souscrivent s’engagent pour trois ans à ne pas augmenter leurs tarifs, à stabiliser leur taux de dépassement d’honoraires et la part des actes qu’ils réalisent sans dépassement.
Dans les faits, ces mécanismes de régulation des tarifs et les modalités de prise en charge des dépassements d’honoraires par les complémentaires santé sont complexes. S’y ajoute bien souvent un manque de visibilité pour le patient sur le niveau du dépassement qui va lui être appliqué. Dans ces conditions, difficile pour lui d’estimer le montant qui va rester à sa charge.
Aujourd’hui, des pratiques largement répandues chez les médecins
En 2024, selon le Haut Conseil pour l’avenir de l’Assurance-maladie (Hcaam), 56 % des spécialistes libéraux (qui consultent en médecine libérale) exercent en secteur 2, contre 37 % en 2000. Sur les vingt dernières années, la proportion de médecins libéraux en secteur 2 a fortement progressé dans l’ensemble des spécialités.
Elle atteint, par exemple, 86 % chez les chirurgiens et 72 % chez les ophtalmologues. Chez les dermatologues, la proportion est d’environ 50 %. Au contraire, pour certaines spécialités comme la cardiologie ou la radiologie, elle est plus proche d’un tiers (31 % en cardiologie, 35 % en radiologie en 2024).
En 2024, le taux moyen de dépassement des médecins de secteur 2 s’élève à 50 %. Cela signifie que, en moyenne, un acte dont le tarif de l’assurance-maladie est de 100 euros est facturé 150 euros (toutefois, en se limitant uniquement aux actes qui ont fait l’objet d’un dépassement, ce montant s’élève en réalité à 189 euros.
Mais ce taux moyen de 50 % varie largement selon les spécialités et selon les praticiens : par exemple, il était, en 2024, de 60 % chez les chirurgiens, mais de 20 % environ chez les cardiologues ou les pneumologues.
À lire aussi : Médecins spécialistes et déserts médicaux : leur présence sur un territoire ne suffit pas à garantir l’accès aux soins
Même à l’intérieur d’une même spécialité, les pratiques de dépassements d’honoraires sont très variables d’un praticien à l’autre et peuvent atteindre des niveaux élevés : ainsi, chez les chirurgiens libéraux de secteur 2 par exemple, le taux de dépassement excédait 184 % pour les 10 % de chirurgiens ayant les plus forts dépassements, en 2023.
Exemples à l’appui : des dépassements loin d’être marginaux pour les patients
L’Institut de recherche et documentation en économie de la santé (Irdes) a réalisé plusieurs études afin d’alimenter les travaux du Haut Conseil pour l’avenir de l’Assurance-maladie (Hcaam). Certaines visent à objectiver la fréquence et les montants que les dépassements d’honoraires représentent concrètement pour les patients dans l’accès à certaines spécialités, certains actes ou épisodes de soins et selon les territoires.
L’Irdes a ainsi analysé les tarifs pratiqués pour une sélection de 14 actes techniques fréquents, à partir des données du Système national des données de santé (SNDS). Les résultats montrent que, pour certains actes, la proportion de patients s’étant vu facturer un dépassement est élevée.
Par exemple, en 2021, sept reconstructions du ligament croisé antérieur du genou par autogreffe sur dix ont donné lieu à un dépassement d’un montant de 535 euros en moyenne.
Pour la gastrectomie longitudinale (sleeve gastrectomy) pour obésité morbide par coelioscopie, 58 % des patients ont dû acquitter un dépassement d’honoraires d’un montant de 880 euros en moyenne, mais supérieur à 1 500 euros dans 10 % des cas.
Mais un acte de soins est rarement isolé : à une intervention chirurgicale sont le plus souvent associés une consultation et un acte d’anesthésie, des actes d’imagerie pré et/ou postopératoire… Dans ce cas, les dépassements d’honoraires peuvent relever de différents médecins et se cumuler tout le long de l’épisode de soins.
Dans une deuxième étude, l’Irdes a analysé ces phénomènes de cumul pour quatre épisodes de soins fréquents, liés à quatre actes hospitaliers : l’accouchement, la chirurgie du cristallin, la prothèse totale de hanche et la coloscopie.
En 2021, un peu plus d’une patiente sur deux ayant eu un accouchement par voie basse sans complication a été exposée à des dépassements au cours de son épisode de soins, pour un montant de 300 euros en moyenne.
Mais pour une prothèse de hanche, 79 % des patients (soit près de huit sur dix) ont été exposés à des dépassements, pour un montant de 700 euros en moyenne, la facture dépassant les 1 400 euros dans 10 % des cas.
Ainsi, pour bon nombre de soins ou épisodes de soins, avoir à régler un dépassement est aujourd’hui devenu la situation la plus courante pour le patient.
Quasiment pas de dépassements en cardiologie de ville ou pour un accouchement par voie basse
Pour certains soins, l’offre dite à tarif opposable (notamment celle assurée par les hôpitaux publics ou les médecins libéraux de secteur 1) demeure majoritaire et globalement accessible dans la plupart des territoires.
C’est, par exemple, le cas des actes d’accouchements par voie naturelle qui, dans 59 départements, ne donnent quasiment jamais lieu (dans plus de 95 % des cas) à un dépassement d’honoraires de la part du gynécologue-obstétricien qui l’a réalisé.
Il en va de même pour les cardiologues de ville qui exercent aux trois quarts en secteur 1, ce qui permet aux patients d’accéder à une offre sans dépassement dans la plupart des territoires, sauf dans certains départements ou régions très urbanisés, comme l’Île-de-France ou la Gironde.
Niveaux d’accessibilité (APL) aux cardiologues selon le périmètre de l’offre
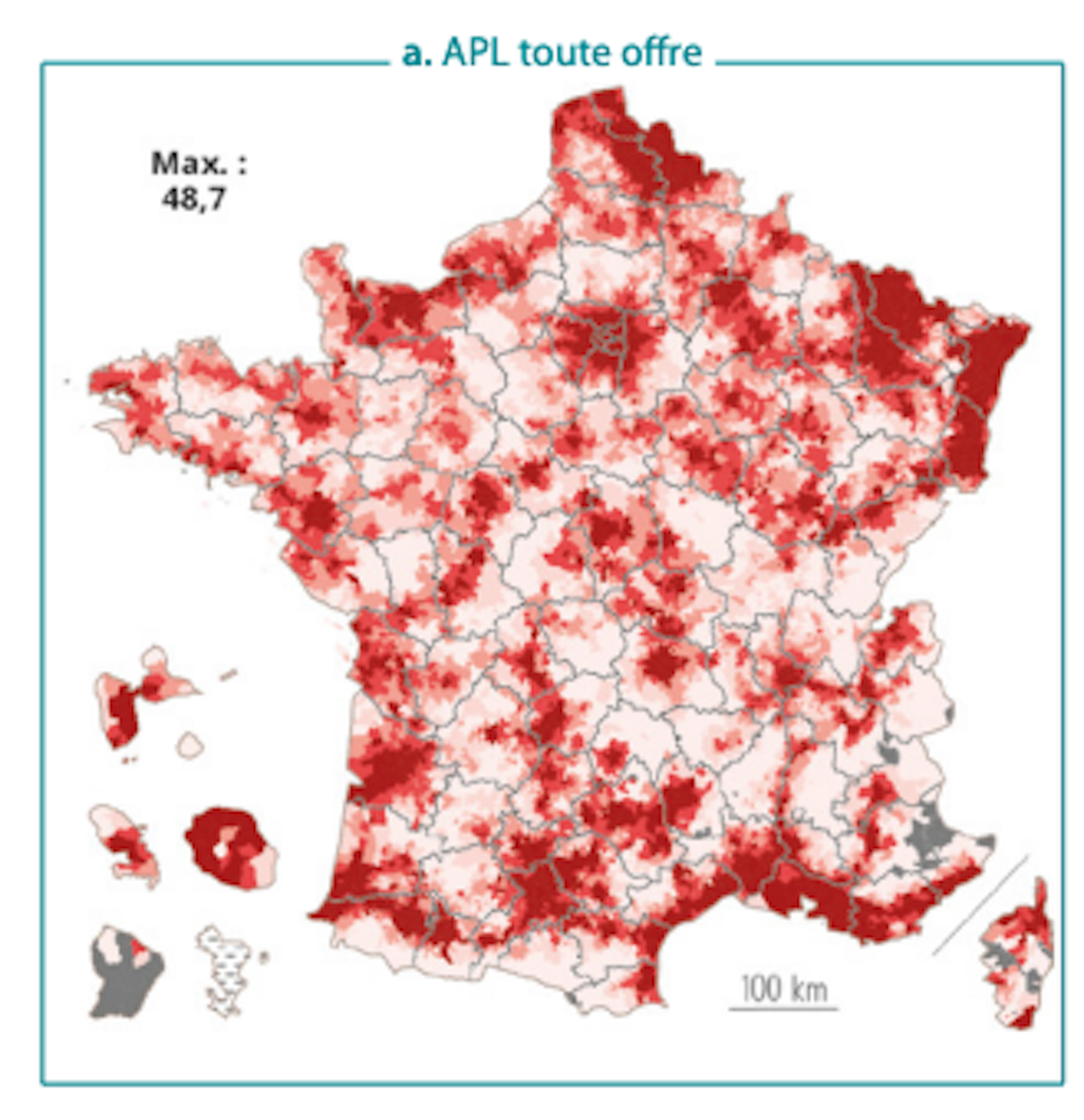
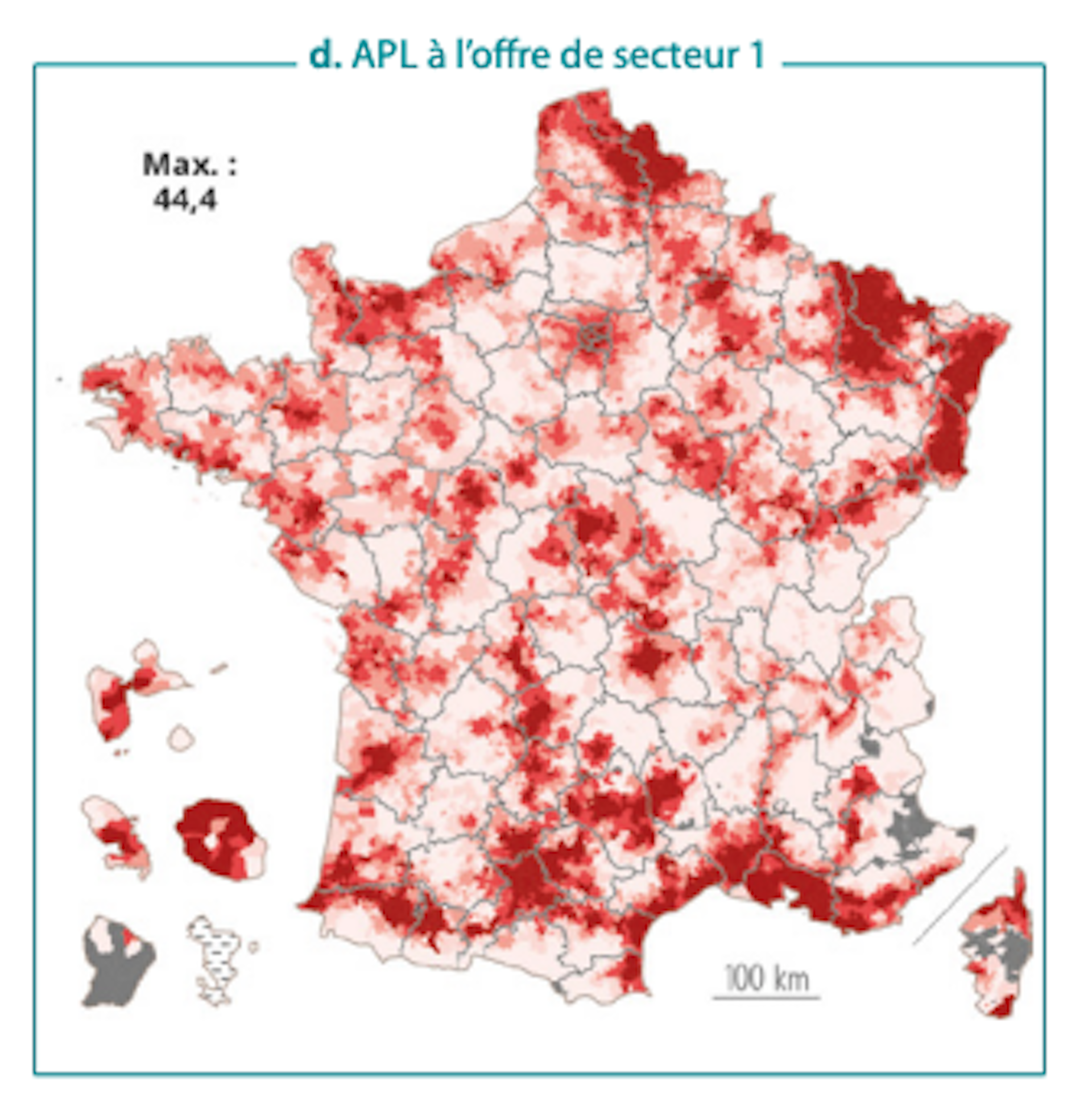
Ces territoires où l’offre de soins sans dépassement a disparu
À l’inverse, pour d’autres soins, le secteur 2 s’est fortement diffusé. Dans la plupart des territoires, l’accessibilité géographique repose alors largement sur ces praticiens, rendant parfois les dépassements difficiles à éviter.
C’est notamment le cas en ophtalmologie et en dermatologie de ville.
Niveaux d’accessibilité (APL) aux ophtalmologistes selon le périmètre de l’offre
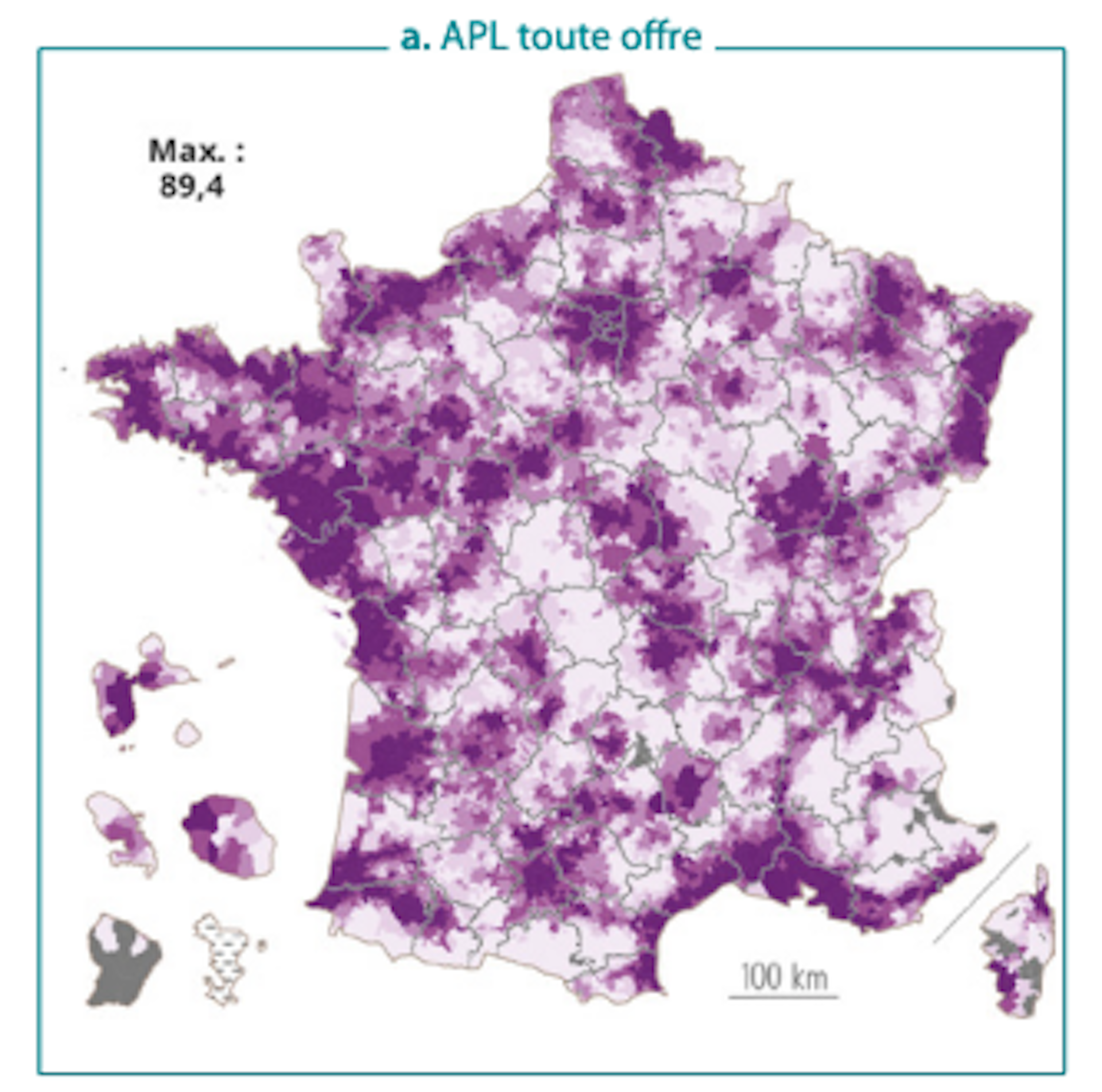
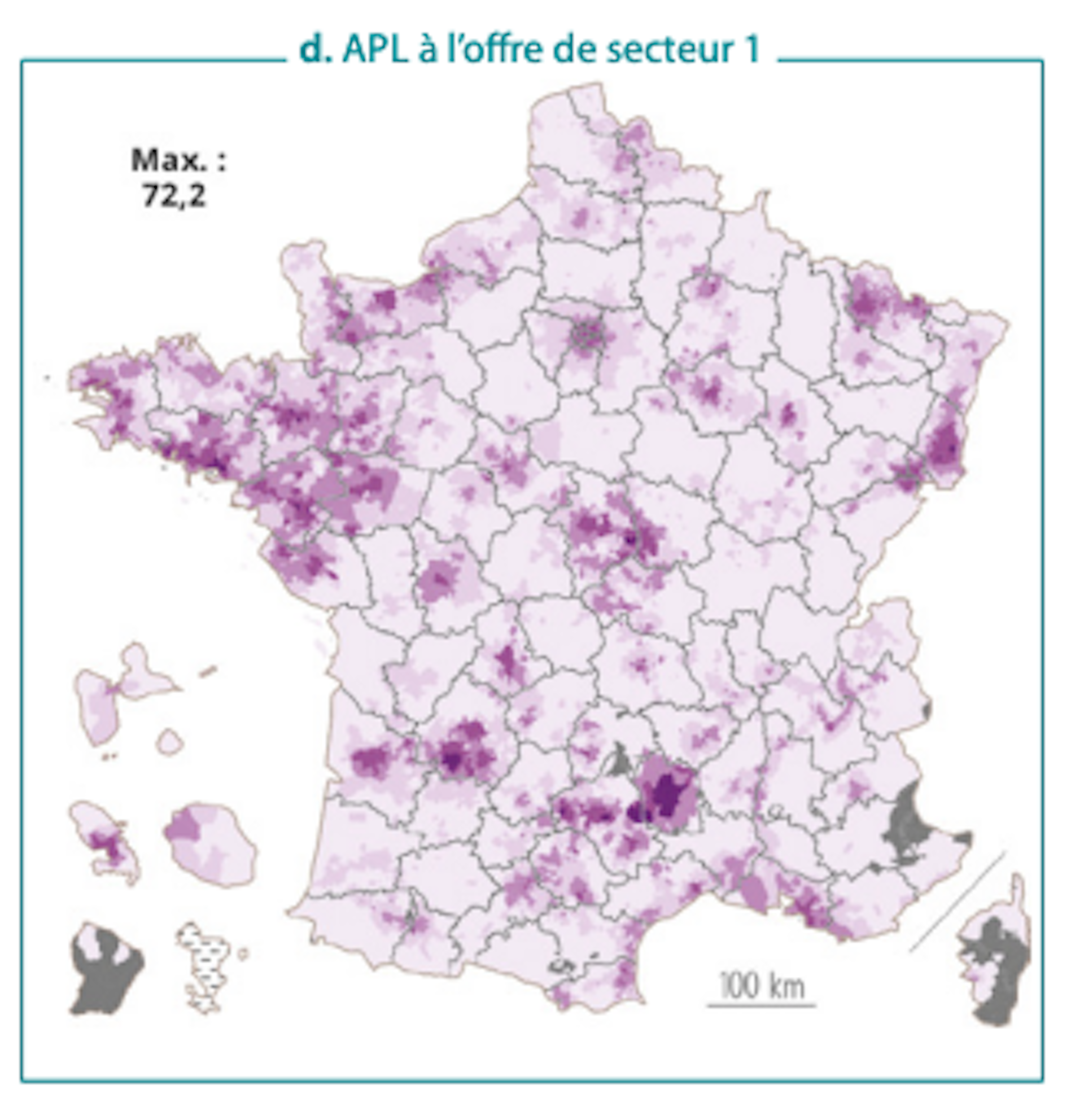
On observe également ce phénomène pour la sleeve gastrectomy : dans 61 départements, plus d’un acte sur deux donne lieu à un dépassement et, dans 16 départements, plus de trois sur quatre.
Or, le profil des patients qui acquittent ces dépassements dépend directement de l’accessibilité à une offre sans dépassement, laquelle varie fortement selon les soins. Les travaux de l’Irdes montrent ainsi que lorsque l’offre à tarif opposable (hôpitaux publics, établissements privés à but non lucratif et libéraux de secteur 1) est majoritaire et bien répartie sur le territoire – comme pour les accouchements – les dépassements concernent principalement les patients issus des communes les plus favorisées.
À l’inverse, lorsque le secteur 2 est prédominant, comme pour la reconstruction du ligament croisé, les dépassements tendent à se répartir entre tous les profils de patients, y compris ceux des communes les plus défavorisées.
L’accès universel aux soins est-il menacé ?
Loin de constituer des situations marginales, ces configurations tendent à devenir la norme dans un nombre croissant de territoires et de spécialités. À mesure que l’offre à tarif opposable recule, l’accès à des soins sans dépassement cesse d’être garanti et dépend du lieu de résidence, du type de soins, et in fine des ressources des patients.
Cette question ne se pose pas, en droit, pour les assurés les plus précaires : près de 8 millions de personnes bénéficient aujourd’hui de la complémentaire santé solidaire (C2S), un dispositif destiné aux personnes à faibles ressources, pour lesquelles la facturation de dépassements d’honoraires est interdite par la loi.
En revanche, pour l’ensemble des autres assurés, aucune protection équivalente n’existe. Dans les territoires et spécialités où l’offre à tarif opposable (sans dépassement) s’est amenuisée, les dépassements deviennent de fait difficilement évitables, y compris pour des patients aux ressources modestes mais situées au‑dessus des seuils d’éligibilité à la complémentaire santé solidaire.
Au rythme actuel des installations en secteur 2 (qui autorise les dépassements d’honoraires), la dynamique apparaît difficilement soutenable. À l’horizon 2040, le secteur 2 pourrait représenter près de 89 % des médecins spécialistes exerçant en libéral, tandis que le montant total des dépassements d’honoraires dépasserait 10 milliards d’euros, contre 4,7 milliards en 2025.
Une telle trajectoire pose de manière aiguë la question de l’accès équitable aux soins, comme l’illustrent les travaux récents du Haut Conseil pour l’avenir de l’Assurance-maladie, qui explorent plusieurs scénarios de réforme des dépassements d’honoraires des médecins.
La question devient centrale : le système de santé français restera-t-il fondé sur un accès universel aux soins, indépendant des ressources des patients et de leur lieu de résidence, ou évoluera-t-il vers un modèle où le niveau de couverture par la complémentaire santé et la capacité à payer conditionneront de plus en plus l’accès effectif aux médecins spécialistes ?
Ces travaux ont bénéficié du soutien financier du Haut conseil pour l’avenir de l’assurance maladie (Hcaam).
12.07.2026 à 10:39
Quand la Légion d’honneur fait monter les cours de Bourse : les décorations d’État, signaux de proximité politique ?
Stéphane Benveniste, Maître de conférences en sciences économiques, Université Paris 1 Panthéon-Sorbonne
Marc Sangnier, Enseignant-chercheur en sciences économiques, Aix-Marseille Université (AMU)
Renaud Coulomb, Professor of Economics, Mines Paris - PSL
Texte intégral (2136 mots)
Instituée en 1802, la Légion d’honneur est la plus haute distinction nationale décernée à des citoyens français ou à des personnes étrangères pour leurs mérites au service de la nation, à titre civil ou sous les armes. Symbolique, serait-elle dénuée de toute valeur économique ? Une étude montre que, au contraire, son attribution peut agir comme un signal positif sur les marchés financiers. Explications à l’occasion de la promotion du 14-Juillet.
De la Légion d’honneur française à la Presidential Medal of Freedom américaine et à l’Ordre de la République chinois, les décorations civiles d’État existent dans plus de neuf pays sur dix. Sans récompense matérielle directe, elles sont souvent perçues essentiellement comme une reconnaissance symbolique, des « hochets avec lesquels on mène les hommes », selon une formule attribuée à Napoléon Bonaparte. Sont-elles pour autant dénuées de valeur économique ?
Nous avons étudié la réaction des marchés lorsqu’un administrateur d’entreprise cotée reçoit la Légion d’honneur (Journal of Law, Economics, and Organization, à paraître). La valeur boursière de son entreprise augmente alors significativement.
Cette réaction financière est concentrée sur les administrateurs pour lesquels la distinction semble révéler une proximité politique auparavant invisible aux investisseurs. Une décoration d’État peut ainsi agir comme le signal public d’un accès privilégié aux décideurs publics.
Une distinction prestigieuse mais discrétionnaire
Créée en 1802 par Napoléon Bonaparte, la Légion d’honneur demeure très prestigieuse. Elle est attribuée chaque année à plusieurs centaines de civils, issus de la fonction publique, du monde associatif, des arts, de la recherche ou des entreprises. Les personnes proposées doivent justifier de « mérites éminents », mais sans critère précis et directement observable. Les ministres constituent et transmettent des dossiers de proposition de décoration.
Après instruction et examen, les nominations et promotions sont officialisées par décret signé par le président de la République. Le processus comporte ainsi une dimension largement discrétionnaire.
Pour en mesurer la valeur économique, nous avons relié l’ensemble des décorations civiles attribuées entre 1995 et 2019 aux membres des conseils d’administration d’entreprises françaises cotées. Notre base ainsi constituée rassemble 1 240 décorations reçues par 1 074 administrateurs alors qu’ils siégeaient dans ces entreprises. À partir d’un corpus de vingt-cinq ans d’articles de presse tirés des cinq principaux quotidiens nationaux, nous montrons que les noms des récipiendaires ne sont pas publics avant la publication des décrets. Ceux-ci apportent donc aux investisseurs une information publique nouvelle.
Un « hochet » à 7 millions d’euros
Nous comparons, autour du décret, le rendement de chaque titre à celui attendu d’après l’évolution du marché. L’écart entre les deux, appelé « rendement anormal », mesure la réaction propre à l’annonce. Cette réaction est positive : en moyenne, le cours des entreprises concernées enregistre une surperformance de 0,21 % dans les deux jours suivant l’annonce, puis de 0,43 % après cinq jours, sans que cette surperformance ne soit ensuite effacée. Si ces chiffres peuvent sembler modestes, pour l’entreprise médiane de notre échantillon, dont la capitalisation boursière s’élève à environ 3,5 milliards d’euros, cela représente, deux jours après l’annonce, 7 millions d’euros de valeur supplémentaire (euros constants de 2000).
Cet effet reste inférieur à ceux mis en évidence pour d’autres formes de connexions politiques des dirigeants d’entreprise : les liens avec un président nouvellement élu, observés en France lors de l’élection de Nicolas Sarkozy, ou les passages entre les sphères des affaires et de la politique (« pantouflage »), étudiés dans 47 pays.
Mais les décorations d’État sont bien plus fréquentes et sont peu coûteuses à attribuer : leur portée est ainsi substantielle. Selon l’hypothèse d’efficience des marchés, une telle réaction traduit une information nouvelle et jugée pertinente par les investisseurs. Mais elle ne dit pas, à elle seule, ce qu’ils apprennent.
Les décorations d’État comme un signal de connexions politiques
Une première explication est celle du mérite : la reconnaissance publique pourrait conduire les investisseurs à réviser leur jugement sur les compétences, la réputation ou l’effort futur d’un administrateur. Une seconde est celle de la proximité politique. L’accès aux décideurs est précieux pour les entreprises, notamment celles pour lesquelles la réglementation, les licences, les subventions ou les marchés publics jouent un rôle déterminant dans les perspectives économiques. La dimension discrétionnaire de la Légion d’honneur ouvre la voie à cette seconde interprétation.
Pour les départager, nous exploitons une caractéristique des élites françaises : une part importante des responsables économiques et politiques est issue d’un nombre restreint de grandes écoles. Leurs promotions, de taille réduite, favorisent des réseaux d’anciens élèves identifiables et durables. Ainsi, nous avons apparié les dirigeants d’entreprises et les membres des gouvernements successifs à des registres historiques d’anciens élèves d’une quinzaine de grandes écoles.
À lire aussi : Grandes écoles : 80 fois plus de chances d’admission quand on est enfant d’ancien diplômé
Un administrateur est considéré comme ayant, avant sa décoration, un lien identifiable avec le gouvernement lorsqu’il a fréquenté le même établissement, dans la même promotion (ou dans la promotion voisine) qu’un membre du gouvernement impliqué dans le processus d’attribution. Cette mesure saisit une proximité institutionnelle qu’un investisseur peut plausiblement identifier à partir des biographies publiques ou des interactions qu’elle a pu engendrer.

{kind=link}
Lorsqu’un tel lien est déjà identifiable, la décoration devrait apporter peu d’information supplémentaire et générer peu ou pas de réaction boursière. Dans le cas contraire, les investisseurs peuvent y voir la révélation d’un accès aux décideurs publics jusque-là inobservable. C’est précisément ce que montrent nos résultats. Aucune réaction boursière n’est observée lorsqu’un administrateur décoré apparaît déjà connecté à un responsable politique impliqué dans le processus d’attribution. À l’inverse, la réaction est positive et significative lorsque l’on n’observe pas de lien préalable. La Légion d’honneur semble alors révéler des liens nouveaux, ou jusque-là inconnus, avec les décideurs publics.
D’autres résultats vont dans le même sens. Les réactions boursières sont plus fortes lorsque la décoration est attribuée tôt dans le cycle politique, tandis qu’on ne mesure plus de réaction en fin de mandat. Ce calendrier semble indiquer que les investisseurs valorisent la durée anticipée de l’accès politique que la distinction peut révéler. Elles sont aussi plus marquées pour les entreprises les plus exposées aux décisions de l’État (commandes publiques, réglementation ou présence de l’État au capital).
Enfin, elles ne se propagent pas aux autres entreprises du même secteur : les investisseurs y voient une information propre à l’entreprise, et non l’annonce d’un changement plus général de politique publique.
Que nous disent les décorations d’État ?
Nos résultats ne montrent pas que certaines décorations auraient été attribuées de manière indue ni que des récipiendaires auraient bénéficié d’un traitement préférentiel. Ils mettent plutôt en évidence un mécanisme souvent négligé dans les interactions entre les États et les marchés : en distribuant du prestige public, un État peut aussi diffuser une information ayant une valeur économique, notamment sur l’accès potentiel aux décideurs publics.
Cette conclusion dépasse le seul cas français, puisque les systèmes de décorations civiles existent dans la plupart des pays et types de régimes politiques. Ces distinctions peuvent légitimement récompenser le service rendu, entretenir des normes civiques et reconnaître des contributions que les marchés valorisent imparfaitement. Il ne s’ensuit donc pas nécessairement qu’il faudrait en attribuer moins.
Mais lorsque leur attribution implique des procédures discrétionnaires et des acteurs politiques, elles peuvent aussi modifier les anticipations sur l’influence future de leurs récipiendaires.
Des critères plus explicites, un examen indépendant des dossiers et une plus grande transparence sur les voies institutionnelles de nomination pourraient réduire le risque qu’elles soient d’abord interprétées comme des signaux de proximité politique. De telles évolutions auraient toutefois un coût : elles réduiraient la souplesse qui peut favoriser la reconnaissance de formes diverses de mérite et, surtout, qui contribue à préserver les fonctions symboliques et d’influence des distinctions d’État.
Le projet ayant conduit à cette publication a bénéficié d’un financement de l’État français dans le cadre du plan d’investissement « France 2030 », géré par l’Agence nationale de la recherche (référence : ANR-17-EURE-0020), de l’Initiative d’excellence de l’université d’Aix-Marseille — A*MIDEX, du Fonds Wetenschappelijk Onderzoek—Vlaanderen (FWO) et du Fonds de la recherche scientifique — FNRS, dans le cadre du projet EOS O020918F (EOS ID 30784531).
Le projet ayant conduit à cette publication a bénéficié d’un financement de l’État français dans le cadre du plan d’investissement « France 2030 », géré par l’Agence nationale de la recherche (référence : ANR-17-EURE-0020), de l’Initiative d’excellence de l’université d’Aix-Marseille — A*MIDEX, du Fonds Wetenschappelijk Onderzoek—Vlaanderen (FWO) et du Fonds de la recherche scientifique — FNRS, dans le cadre du projet EOS O020918F (EOS ID 30784531).
12.07.2026 à 10:38
Marianne : pourquoi la République a-t-elle choisi une femme désincarnée comme symbole d’unité nationale ?
Yann Rigolet, Doctorant en Histoire Contemporaine, Université d’Orléans
Texte intégral (2290 mots)
Tous les camps politiques se réclament d’elle, de la Manif pour tous aux féministes, en passant par les gilets jaunes, ou des militants pro Gaza. Une proposition de loi Les Républicains veut même rendre son buste obligatoire dans toutes les mairies. Pourtant, chaque tentative de donner un vrai visage à Marianne finit en polémique. Que représente Marianne et comment la représenter ?
De toutes les figures symboliques qui jalonnent l’histoire de France, Marianne est un cas singulier, car elle pose la question complexe de l’incarnation de la République. Peut-on la personnifier et selon quels critères ?
Dès son apparition, la représentation de Marianne est un sujet parce qu’elle repose sur une construction en deux temps, associant tout d’abord un corps puis, plus tard, le célèbre prénom que l’on connaît.
Après l’abolition de la monarchie, le 21 septembre 1792, il devient nécessaire de remplacer le sceau du roi (qui incarnait jusque-là l’État) par un symbole visuel de la Première République naissante. Le 25 septembre, la nouvelle Assemblée nationale, la Convention, décrète ainsi que le sceau de l’État représentera désormais la France « sous les traits d’une femme vêtue à l’Antique, debout, tenant de la main droite une pique surmontée du bonnet phrygien ou bonnet de la liberté, la gauche appuyée sur un faisceau d’armes ; à ses pieds un gouvernail ».
Ce choix d’une allégorie (la représentation concrète d’une idée abstraite) permet notamment aux révolutionnaires de cultiver une certaine ambiguïté. En effet, symboliser la France républicaine sous les traits d’une figure féminine leur permet d’y associer divers modèles interchangeables popularisés dès 1789. L’allégorie de la « République » fusionne ou se confond alors avec celle de « La Révolution », de « la Liberté » ou bien de la « Patrie ».

C’est visiblement dans les semaines qui suivent, entre l’automne 1792 et le début 1793 que débute la seconde phase. Le prénom « Marianne » va alors être progressivement associé à l’allégorie mise en place. Dans une chanson occitane probablement écrite au mois d’octobre, la Guérison de Marianne, le cordonnier poète Guillaume Lavabre l’utilise pour la première fois afin de représenter une France malade de la guerre et de la monarchie, que sa transformation toute récente en République s’apprête à soigner.
Si Marianne signe ici son acte de naissance comme emblème national, il faudra attendre la Troisième République et les années 1880 pour que la fusion du corps et du prénom soit officialisée durablement. Son buste trône alors dans chaque mairie française comme le veut l’usage républicain conseillé, mais non obligatoire.
Entre 1940 et 1944, avec l’abolition de la République et l’avènement de la révolution nationale, le régime de Vichy va multiplier les tentatives de proscrire l’image de Marianne au profit de celle de Jeanne d’Arc, considérée comme sa rivale, ou celle du maréchal Pétain. Si le succès de cette entreprise est limité par manque de temps et de moyens, c’est la IVᵉ et surtout la Vᵉ République depuis 1958 qui permettent enfin à Marianne de s’imposer comme emblème définitif d’un régime stabilisé.
À la recherche d’un modèle introuvable
Reste la difficulté à représenter Marianne, figure consensuelle et rassembleuse censée s’adresser à tous. Contrairement à d’autres symboles nationaux tels le drapeau tricolore, aucun modèle officiel réglementaire n’a jamais été proposé pour l’encadrer. Sujet de création libre et mouvant, Marianne, jusqu’au milieu du XXᵉ siècle, est assez généralement désignée par un modèle féminin parfois vivant et souvent anonyme, portant ses attributs distinctifs : drapeau tricolore, sein nu et bonnet phrygien.
Par la suite, la pratique consistant à régulièrement sélectionner une célébrité pour la personnifier va cristalliser les passions. La transition de l’allégorie à la personnalité identifiée va dès lors métamorphoser Marianne en figure dissensuelle tranchant avec les valeurs de stabilité et d’apaisement supposées l’accompagner.
De Brigitte Bardot à Laetitia Casta, en passant par la Femen Inna Schevchenko, la mannequin Zahia Dehar ou l’actrice Sophie Marceau, chaque nouvelle Marianne choisie déclenche son lot de polémiques sur son apparence et ses formes, son processus de sélection ou la pertinence à privilégier le physique ou la personnalité d’un modèle au détriment d’un visage perçu comme neutre et toléré par le plus grand nombre. Après l’ultime controverse autour de la nomination d’Évelyne Thomas en 2003, la pratique a été abandonnée. Aucune autre Marianne-star n’a depuis été officiellement promue.
Ces débats prouvent que penser le corps de Marianne est un sujet incandescent. Ces célébrités ne lui prêtaient finalement que temporairement une enveloppe, mais l’allégorie peut-elle se risquer à devenir une incarnation ? Marianne serait-elle forte et acceptable uniquement lorsqu’elle reste désincarnée, fictive et sans identité ?
Peut-être une part de cette tension réside-t-elle dans le fait d’avoir choisi de représenter la République par une femme dans un pays historiquement gouverné par des hommes ? C’est ce qu’avance l’historienne Michelle Perrot en insistant sur cette tradition héritée de la loi salique qui « exclut vigoureusement les femmes de la vie politique » dans la France où « l’État est spécialement mâle ».
Quand les femmes politiques veulent devenir Marianne
Lorsque des femmes engagées dans la conquête du pouvoir reprennent les codes de Marianne ou tentent de l’incarner, le symbole républicain cesse d’être une simple représentation décorative : le corps féminin de Marianne devient alors un objet politique et donc conflictuel. C’est ce que soulignait le grand spécialiste de Marianne, Maurice Agulhon :
« La féminité de la représentation allégorique est un handicap pour la République. »
Ce basculement s’opère en 2007 avec la présence de Ségolène Royal à l’élection présidentielle. Une femme représentant la République cesse alors d’être une seule projection allégorique. Marianne pourrait-elle être directement incarnée par une femme politique toute proche de l’investiture suprême ? Plus ou moins consciemment, l’analogie est mobilisée par Ségolène Royal, par les médias et d’autres personnalités politiques. Notamment surnommée « Marianne d’Arc » par Jean-Marie Le Pen et croquée dans le Monde en « Liberté » de Delacroix (que la culture populaire associe – à tort – à Marianne), elle renvoie l’image d’une république féminisée proche et protectrice, cette image d’une « mère de la Nation » que Ségolène Royal défendait encore récemment.
En 2011, Marine Le Pen, fraîchement élue présidente du Front national, tente également de capter Marianne comme figure de résistance idéale d’un peuple souverain menacé. Si l’identification reste suggérée, tout un travail de communication est entrepris, dans et hors du parti, jusqu’à fondre l’image de Marine Le Pen dans celle de célèbres visuels de Marianne.
Dans un registre encore plus ouvertement marketing, l’ancienne ministre déléguée aux droits des femmes Marlène Schiappa use du symbole et multiplie les expositions et les projets tels l’« Initiative Marianne », le collectif Toutes Marianne proposant de créer le visage de la future Marianne par intelligence artificielle, ou le fiasco du Fonds Marianne, ce « véritable fardeau, ce boulet attaché à l’allégorie de la République » comme le mentionne Jean-François Husson, président de la commission d’enquête sur les potentielles malversations liées à ce fonds. De l’appropriation à l’analogie, le pas est franchi en juin 2023, quand Marlène Schiappa accepte une interview dans le magazine Playboy et un shooting photos jouant sur les codes visuels de Marianne, sans s’y identifier ouvertement. Une opération de communication décriée mais assumée sur fond d’émancipation féminine et de pop-trangression, forme de culture populaire cherchant à choquer et à provoquer les normes sociales et morales.
Si le corps de Marianne est devenu un enjeu de concurrence symbolique dans l’ascension des femmes politiques, son incarnation semble toutefois autant relever de la tentation que du fantasme. En effet, comment réussir à concilier la fonction unificatrice et l’unanimité autour d’un seul et unique modèle par essence clivant ?
Même la tentative légitime et saluée de la sénatrice Fabienne Keller de faire de Simone Veil, archétype de l’icône consensuelle panthéonisée, le nouveau visage de Marianne en 2019 a finalement été abandonnée.
Le choix de représenter la République s’est rarement porté sur une figure masculine, même allégorique, car l’image de la femme – considérée comme dépolitisée par essence – s’est imposée pour promouvoir l’unité nationale. Mais si la République accepte qu’une femme la représente, la légitimité du pouvoir féminin demeure cantonné à une image abstraite, sans parole, sans projet et sans corps.
Yann Rigolet ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
12.07.2026 à 10:37
Allons-nous vers une « corridorisation » du monde ?
Eric Guiochon, Doctorant en sciences politiques, Institut catholique de Paris (ICP); Université Paul Valéry – Montpellier III
Texte intégral (1866 mots)
Les grandes puissances déploient des initiatives de connectivité qui redessinent la carte du monde. La Chine avec ses Nouvelles Routes de la soie, l’Union européenne et son Global Gateway, les États-Unis et le G7 à travers le Build Back Better World ou B3W/PGII… Tous ces projets traduisent une même ambition : organiser, sécuriser et contrôler l’internationalisation de l’économie, plutôt que la subir.
Depuis plusieurs années, il semblerait que l’ère de la « mondialisation heureuse » soit dépassée, ou, a minima, que cet inexorable mouvement d’interconnexion croissante ait cessé d’apparaître comme une réalité universelle.
Nourrie par des chocs exogènes – rivalité commerciale sino-américaine, pandémie de Covid-19, guerre en Ukraine ou encore tensions autour du détroit d’Ormuz –, cette perception découle surtout d’un phénomène plus discret de réorganisation, voire de transformation, des flux.
Plusieurs initiatives sont attendues : les Nouvelles Routes de la soie chinoise (Belt and Road Initiative, ou BRI) ; le Global Gateway (GG), un projet de connectivité global européen, lancé par la Commission européenne en 2021 ; l’Indian Middle East Corridor (IMEC), un projet de corridor reliant le sous-continent indien à l’Europe ; l’International North-South Transport Corridor (INSTC), projet de corridor reliant la Russie à l’Inde ; et enfin le Build Back Better World (B3W/PGII), projet de connectivité globale états-unien, porté par l’administration Biden et le G7, partiellement repris à travers le Partnership for Global Infrastructure and Investment (PGII).
Ces projets ne relèvent pas de la même logique. Certains correspondent à des initiatives commerciales géographiquement bornées, articulant parfois l’ensemble des outils de la projection économique – infrastructures, financements, normes, dispositifs logistiques ou encore architectures numériques. D’autres poursuivent une ambition plus vaste : structurer un cadre politique et financier de connectivité globale, intégrant plusieurs corridors physiques au sein d’une stratégie bien plus large.
Dès lors, le corridor n’est plus un simple vecteur qui représenterait une route commerciale ou une infrastructure de transport ; il devient un espace. Regroupant des fonctions de circulation, de dépendance, et de sécurisation des flux, il intègre des logiques économiques, financières, technologiques et géopolitiques.
Cette évolution traduit une transformation bien plus profonde de la mondialisation : depuis la création de l’Organisation mondiale du commerce (OMC) en 1995, le volume et la valeur des échanges mondiaux ont progressé, en moyenne, de respectivement 4 % et 6 % par an. Ces flux, qui n’ont jamais été aussi importants, doivent maintenant s’inscrire dans des logiques et architectures régionales, hiérarchisées et stratégiquement orientées.
En un mot, nous assistons à la « corridorisation » du monde.
La fin de la mondialisation « neutre »
À partir de 1945, et de façon plus nette depuis les années 1990, la mondialisation a été pensée puis installée comme un processus de fluidification croissante des échanges. L’abaissement des barrières douanières et la réorganisation des chaînes de valeur ont entraîné une réduction drastique des coûts logistiques et une fragmentation de la production, ce qui a donné naissance à un espace économique mondial de plus en plus intégré.
L’efficacité a primé : produire à moindre coût, transporter sur des routes rentables et rapides, intégrer des marchés utiles, et développer l’interconnexion à tout prix… afin de faire baisser les coûts. Des infrastructures physiques et intangibles – commerciales, financières, réglementaires – ont naturellement émergé en tant que supports techniques de la mondialisation, dans un esprit d’accélération des échanges plutôt que de réponse à des impératifs stratégiques ou de sécurité.
Les crises récentes ont remis en cause cette représentation plutôt prosaïque de la puissance, chacune à sa façon. La pandémie a mis en évidence la vulnérabilité des chaînes d’approvisionnement mondiales ainsi que la dépendance occidentale à l’égard des puissances industrielles asiatiques et des Suds. L’agression russe visant l’Ukraine, avec les sanctions qui s’en sont suivies, a rappelé l’importance de la souveraineté énergétique et du contrôle des infrastructures critiques, tout en accélérant le développement de systèmes de paiements internationaux alternatifs. Les tensions dans le détroit d’Ormuz ou, de façon plus diffuse, autour de Taïwan, rappellent enfin qu’une part déterminante des flux essentiels dépend de goulots d’étranglement difficilement sécurisables.
Depuis le 28 février 2026, la quasi-interruption des circulations dans le détroit d’Ormuz a donné une dimension concrète à cette vulnérabilité. Avant la crise, près de 20 millions de barils de brut et de produits pétroliers y transitaient chaque jour, soit environ un quart du commerce maritime mondial de pétrole. En quelques jours, ces flux ont été réduits à presque rien, immobilisant une partie considérable des exportations d’hydrocarbures du Golfe, renchérissant le transport et l’assurance maritimes, et contraignant les États à mobiliser leurs stocks stratégiques, leurs oléoducs de contournement et leurs capacités diplomatiques ou militaires.
Le 11 mars, les membres de l’Agence internationale de l’énergie (AIE) ont ainsi décidé de rendre disponibles 400 millions de barils provenant de leurs réserves d’urgence – une situation inédite dans l’histoire de l’AIE.
En cela, cette crise ne révèle donc pas seulement la fragilité d’une route, mais démontre que la puissance réside désormais dans la capacité à maintenir une continuité de circulation, à déterminer les flux qui pourront passer et à disposer d’une solution lorsque le passage se ferme. Or, les infrastructures alternatives se sont révélées incapables d’absorber rapidement les volumes transitant jusqu’alors par le détroit. L’enjeu n’est donc plus seulement de posséder des ressources ou d’accéder à des marchés, mais de maîtriser l’architecture qui les relie. Face à cela, ces infrastructures imaginées dans l’esprit d’une mondialisation qui se voulait naturelle révèlent leurs limites. À la suite d’une parenthèse d’optimisation économique constante s’installe un monde de rivalité systémique durable.
La fragmentation géopolitique contemporaine balaie l’hypothèse d’une stabilité politique des flux engendrée par la mondialisation. Désormais, la sécurisation des actifs essentiels à la souveraineté – énergie, minéraux et minerais, alimentation – devient un impératif des politiques économiques nationales. Cette sécurisation implique notamment la protection des routes commerciales, tout comme le contournement d’infrastructures rivales.
Ces contournements ont cependant un coût : en 2024, la distance totale parcourue par les marchandises transportées par mer a augmenté de 6 %, soit près de trois fois plus rapidement que les volumes échangés.
Il ne s’agit donc plus uniquement d’accélérer les échanges, mais aussi de reprendre le contrôle.
Le corridor, nouvelle unité stratégique de la mondialisation
Le corridor – sous toutes ses formes, incluant donc les initiatives de connectivité globale – répond précisément à ce besoin de contrôle. L’objectif du corridor est d’organiser des espaces cohérents et résilients face aux chocs exogènes, et de sécuriser les besoins essentiels de ses bénéficiaires. La logique traditionnelle de transport s’accompagne de dimensions complémentaires, allant du développement d’infrastructures portuaires ou ferroviaires – notamment de stockage –, à la confection d’outils de financements, la construction de normes et d’accords commerciaux, voire à l’établissement de mécanismes politico-militaires.
L’intérêt économique de ces dispositifs demeure considérable. Dans le cas des Nouvelles Routes de la soie, la Banque mondiale estimait que la mise en œuvre complète des infrastructures de transport projetées pourrait réduire jusqu’à 12 % les temps de trajet, le long des corridors concernés, et augmenter les échanges de 2,8 % à 9,7 % pour les économies traversées.
Plus qu’un simple axe de passage, le corridor devient un espace économique structuré, au sein duquel les flux restent accélérés tout en étant orientés, hiérarchisés et protégés.
Cette évolution des pratiques du commerce international modifie également la nature des interdépendances, tant le choix d’une route, d’un port ou d’un système de paiement ne relève plus uniquement de considérations pécuniaires ou logistiques. Une forme d’engagement des entreprises et des États à l’égard d’une architecture donnée se forme, au sein de laquelle ils ne maîtrisent pas nécessairement ni les financements, ni les technologies, ni les conditions d’accès.
Le corridor, loin de supprimer les dépendances, les organise et les déplace. Il renforce la centralité ou l’essentialité des États traversés, mais surtout des puissances qui financent les infrastructures, en déterminent les normes et en assurent la continuité. À l’inverse, les territoires contournés ou sous-connectés perdent progressivement leur attractivité et leur influence.
Ensuite, et surtout, la construction de nouvelles routes masque une compétition plus large : il s’agit de maîtriser les conditions et les déterminants de l’économie mondiale. Financer, normaliser et sécuriser les flux constitue une manière d’exercer la puissance qui est loin d’être nouvelle, mais dont plusieurs décennies de mondialisation avaient pu faire oublier l’importance.
Eric Guiochon ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.07.2026 à 15:58
Plages et baignades : dix conseils pour profiter pleinement de l’océan cet été
Jeoffrey Dehez, Chargé de recherche en économie des loisirs et environnement, Inrae
Bruno Castelle, Directeur de Recherche CNRS, Université de Bordeaux
Texte intégral (2698 mots)
Que signifie un drapeau jaune sur une plage ? À quel moment les courants de baïnes sont-ils les plus intenses ? Que faire si un courant nous emporte au large ? Le point sur les choses à savoir pour se baigner en toute sécurité.
La plage est un environnement exceptionnel, et notre territoire possède une façade maritime extrêmement étendue. Cet été, il est fort probable que le littoral reste la première destination touristique des Français.
Se baigner en mer ou dans l’océan est un plaisir simple qui présente d’indéniables bienfaits pour la santé. Cependant, ce qui en fait l’attrait peut aussi se révéler dangereux, si l’on n’y prête pas un minimum attention.
Voici quelques conseils de sécurité élémentaires, fondés sur la recherche scientifique et l’expertise des nageurs sauveteurs.
1. Se renseigner avant de partir
Avant d’aller planter son parasol dans le sable ou d’étendre sa serviette sur les galets, on pense généralement à consulter la météo et les conditions de circulation pour accéder aux plages.
Un autre bon réflexe est de se renseigner sur la taille des vagues et l’état de la marée, en particulier sur les plages exposées aux houles océaniques et sur celles sur lesquelles le marnage (c’est-à-dire la différence entre la hauteur d’eau à marée basse et la hauteur d’eau à marée haute) est potentiellement important (Atlantique, mer du Nord, Manche). En effets, dans bon nombre d’endroits, ces deux paramètres conditionnent les aléas (c’est-à-dire les dangers), notamment les courants ou les vagues de shore break, aussi appelées vagues de bord.
En plus de leur hauteur, la « période » des vagues (autrement dit la durée qui sépare deux vagues successives) est une autre information potentiellement importante. Des houles dites « longues » (c’est-à-dire avec une longue période entre deux vagues), formées par des dépressions lointaines plusieurs jours avant, peuvent générer des vagues plus puissantes et des courants plus forts que les vagues dites « courtes ».
Particulièrement recherchées par les surfeurs, les houles longues sont plus rares en été, mais elles peuvent tout de même arriver.
2. Lire les panneaux d’information
En arrivant à la plage, il vaut mieux prendre quelques minutes pour lire les panneaux d’informations. Ces derniers indiquent la façon dont la surveillance s’organise, la signification des drapeaux et les horaires de présence des nageurs sauveteurs.
Y figurent aussi les conditions du jour (température de l’air et de l’eau, taille des vagues, horaires de marée) et les éléments de vigilance locaux (alerte canicule, alerte orage, présence de méduses, etc.). Parfois même, les courants spécifiques à la plage y sont schématisés, avec la localisation de la zone de bain.
Ces panneaux sont généralement situés à côté du poste de secours ou dans l’accès à la plage. Non loin du poste de secours se trouve également le drapeau indiquant la dangerosité de la baignade. Ce dernier suit un code à trois couleurs :
il est vert si la baignade est surveillée et sans danger apparent ;
il est jaune si la baignade est surveillée, avec un danger limité ou marqué ;
il est rouge si la baignade est interdite ; dans ce dernier cas, les nageurs sauveteurs seront présents sur site.
Si le drapeau est baissé ou absent, alors la baignade n’est pas surveillée : dans ce cas, les usagers se baignent à leurs risques et périls. Se baigner seul constitue naturellement un facteur de risque supplémentaire à éviter.
3. Savoir identifier les zones de bain, et les respecter
En ce qui concerne la matérialisation des zones de bain, la France se conforme depuis 2022 aux standards internationaux. En théorie, la signalétique utilisée sur les plages françaises va donc être retrouvée dans la plupart des pays où l’on est susceptible de voyager.
Les zones de bain sécurisées et surveillées sont délimitées entre deux drapeaux rectangulaires bicolores jaune et rouge (ceux-ci remplacent les flammes triangulaires bleues utilisées jusqu’en 2022).
En France, ces zones sont exclusivement réservées à la baignade : elles sont donc interdites aux activités nautiques telles que le surf. À l’inverse, des zones consacrées au surf sont parfois signalées par un drapeau rectangulaire à damier noir et blanc, sur la plage.
L’établissement de telles zones de bain sécurisées, implantées dans les secteurs les plus favorables à la baignade, permet une surveillance optimale et permanente par les nageurs sauveteurs, favorise une intervention rapide en cas de besoin et participe à la réduction du risque d’accident et de noyade.
4. Ne pas se précipiter, prendre le temps d’observer
Même si l’envie est forte, à l’arrivée sur la plage il faut toujours prendre le temps d’évaluer les conditions.
Il faut faire attention à l’entrée dans l’eau après une exposition prolongée au soleil (c’est d’ailleurs encore mieux d’éviter une telle exposition…). En effet, un brusque changement de température lors de l’entrée dans l’eau peut entraîner différentes réactions physiologiques, notamment une stimulation vagale, pouvant provoquer un malaise, une perte de connaissance voire, dans de rares cas, un arrêt cardiaque. Ces réactions, maladroitement rassemblées dans le langage courant sous le terme « hydrocution », augmentent le risque de noyade.
Autre recommandation importante : ne jamais plonger la tête la première, a fortiori quand on ne connaît pas le fond. Le risque de se blesser, en particulier aux vertèbres cervicales, est en effet bien réel.
Ce risque est également très élevé avec les vagues de bord, ou vagues de shore break. Ces vagues déferlent brutalement au bord de la plage dans très peu d’eau. Elles ne sont pas nécessairement très grosses, mais peuvent faire chuter violemment les baigneurs et les plaquer au sol. Il ne faut pas essayer de sauter au-dessus de la vague : il est recommandé de passer sous elle et de ne jamais lui tourner le dos afin d’éviter d’être projeté violemment contre le sable.
5. Ne pas surestimer ses capacités
Pour se baigner en toute sécurité, savoir nager est évidemment un prérequis indispensable. Mais les piscines où se dispense cet apprentissage n’ont rien à voir avec le milieu naturel, en particulier l’océan. Les vagues, les courants ou l’absence de repères changent complètement la donne.
De plus, nous avons forcément une vision subjective de nos aptitudes, parfois soumise à des biais cognitifs documentés dans la littérature scientifique. Lesdits biais nous incitent à retenir uniquement les informations qui nous confortent dans notre sentiment (de compétence, par exemple) et à oublier les autres.
À lire aussi : Prévention des noyades : face à l’océan, aiguisons notre perception du risque
Les études montrent que ces biais sont plus souvent présents chez les hommes que chez les femmes, lesquelles se comportent généralement de façon plus prudente. Selon les données des enquêtes NOYADES 2018 et 2021 analysées par Santé publique France, les noyades graves concernaient davantage les hommes. Il importe donc de rester humble vis-à-vis de ses capacités.
6. Surveiller les enfants, à tous âges
Si les jeunes enfants se noient surtout en piscine, les adolescents et les adultes ont plus d’accidents en milieu naturel.
Les plus petits requièrent une attention de tous les instants. La bouée, le gilet flottant ou les brassards ne remplaceront jamais la surveillance d’un adulte.
Et si l’on préfère rester sur la plage, il vaut mieux faire des châteaux de sable que de creuser des trous avec eux. En effet, les trous creusés dans le sable peuvent s’effondrer brutalement, ensevelissant partiellement ou totalement une personne, en particulier les enfants.
Lorsque les enfants seront devenus adolescents, la prévention ne devra pas se limiter à l’apprentissage de la natation. Même à cette période de la vie, le rôle des parents reste essentiel, notamment en matière d’exemplarité.
7. Face au courant, ne pas lutter
Les courants d’arrachement sont des courants intenses et étroits dirigés vers le large qui prennent naissance dans la zone de déferlement, parfois très près de la plage, et qui peuvent s’étendre bien au-delà des déferlantes. Ils se forment lorsque leur eau trouve un passage pour retourner vers le large, souvent par des chenaux sous-marins incisant les bancs de sable.
Il existe plusieurs types de courants d’arrachement que l’on peut retrouver sur diverses façades maritimes en France, ou dans le monde.
Dans le sud-ouest de la France, les courants dits de « baine » appartiennent à cette famille de courants. Ils sont généralement plus intenses entre la mi-marée et la marée basse et peuvent être violents, de l’ordre d’un mètre par seconde, même par houle de taille moyenne.
Des courants d’arrachement peuvent également se former en Méditerranée. En outre, des courants d’arrachement spécifiques peuvent se former aux abords des épis et des digues rocheuses.
Si l’on est emporté, il ne faut pas lutter mais flotter et se laisser dériver, pour économiser ses forces, garder son calme, signaler sa présence par de grands mouvements de bras afin d’être repéré pour être ensuite pris en charge par les secours. La panique est souvent la principale cause de l’accident.
Si on peut difficilement l’empêcher, des stratégies peuvent aider à la limiter, par exemple se concentrer sur sa respiration, que l’on essaie de maintenir lente et régulière. Cela permet d’adopter plus facilement des comportements adaptés.
À lire aussi : Baïnes et courants d’arrachement : ce qu’il faut savoir avant d’aller se baigner
8. Garder à l’esprit que porter secours ne s’improvise pas
Chaque année, de nombreuses personnes se noient en tentant de porter assistance à quelqu’un.
Sur la plage, il ne faut absolument pas se précipiter dans l’eau si l’on est témoin d’un accident, au risque de se mettre en danger soi-même. S’il n’y a pas de sauveteurs à proximité immédiate, il faut appeler le 112 ou le 196 (pour les secours en mer) qui basculeront l’appel vers le poste de secours le plus proche.
Si l’on est en train de surfer ou de pratiquer une activité nautique impliquant l’emploi d’une planche, cette dernière peut constituer un précieux support pour se reposer ou aider une autre personne.
9. Ne pas consommer d’alcool
Sur les plages, la consommation d’alcool est très souvent interdite par arrêté municipal. Il s’agit en effet d’un facteur de risque très aggravant en matière d’accidents, comme l’ont démontré de nombreuses études scientifiques.
Les vagues de chaleur estivales incitent nombre d’entre nous à adapter nos horaires de visite en arrivant plus tard, par exemple pour profiter d’un pique-nique en soirée. Ces moments festifs constituent une tentation supplémentaire pour consommer de d’alcool, à une période où, qui plus est, la baignade ne sera plus surveillée.
Raison de plus pour ne pas relâcher sa vigilance durant de tels moments : on reste sur la plage et on profite du coucher de soleil…
10. Expérimenter, apprendre
À la plage, une large part de l’activité des nageurs sauveteurs consiste à faire de la prévention et à communiquer. Il ne faut donc pas hésiter à aller à leur rencontre. Et, pourquoi pas, s’immerger dans leur quotidien.
Dans les Landes, le syndicat mixte de gestion des baignades landaises (SMGBL) a développé le dispositif « NSXL Tour », qui propose de passer quelques heures dans la peau d’un nageur sauveteur, afin d’appréhender les diverses facettes du métier.
Depuis peu, le SMGBL a également mis en place la « NSXL Académie » qui offre des sessions gratuites d’initiation au sauvetage professionnel.
Pour les plus jeunes, un autre programme, « Junior Lifeguard », porté par une association basée en Charente-Maritime, initie gratuitement aux gestes de secours, aux règles de sécurité et à l’environnement côtier.
Qui sait ? Ces premières expériences créeront peut-être des vocations qui pourraient amener certaines personnes à s’inscrire dans des club de sauvetage aquatique à la rentrée ? Et pourquoi pas, viser de participer aux Jeux olympiques de Brisbane, en Australie, en 2032 : le sauvetage aquatique pourrait y faire partie des sports des démonstrations !
Cet article a été co-écrit avec Guillaume Blancart, chef de poste sur la commune de Seignosse (Landes) et coordinateur du dispositif NSXL.
Jeoffrey Dehez est membre du groupe de recherche sur la sécurité de la baignade de l'université de New South Wales (University of New South Wales Beach Safety Research Group) Jeoffrey Dehez a reçu des fonds du Conseil Régional de Nouvelle Aquitaine
Bruno Castelle est membre du groupe de recherche sur la sécurité de la baignade de l'université de New South Wales (University of New South Wales Beach Safety Research Group).
11.07.2026 à 11:05
Et si les fan-zones étaient plutôt des « fun zones » ?
Nico Didry, Maître de conférences en ethnomarketing, Stratégies Economiques du Sport et du Tourisme, CREG, Université Grenoble Alpes (UGA)
Texte intégral (1841 mots)
Au-delà des supporters d’une équipe sportive, les fan-zones attirent un public bien plus large à la recherche d’un moment fun. Plongeons dans cette expérience collective pour comprendre les raisons de cet engouement.
Assister à une rencontre sportive au sein d’un large public permet de vivre ce que Durkheim a appelé les effervescences collectives qui sont la conséquence d’une sacralisation du sentiment d’appartenance collective. Ce besoin de se retrouver physiquement, de vivre ensemble et partager des émotions dans notre société de plus en plus digitalisée.
Dans ce contexte, les événements sportifs et musicaux (concerts, festivals, free party) tendent à remplacer les grands rassemblements (notamment religieux ou politiques) qui constituaient autrefois des espaces privilégiés de communion émotionnelle collective.
Mes précédentes études ont montré que les dimensions sociales et émotionnelles de l’expérience jouent un rôle central pour le spectateur ou le festivalier ; confirmant dans le secteur de l’événementiel, le résultat des études en psychologie sociale de P. Rimé : les individus cherchent plus à vivre une émotion pour la partager que pour la ressentir eux-mêmes. Ce phénomène explique en grande partie le succès des fan-zones, quelle que soit leur forme
À lire aussi : Les fan-zones, fan ou pas fan ?
La fan-zone, un espace de communion émotionnelle avant tout
Notre étude met en avant le fait que la fan-zone est perçue comme un espace de lien social et de vécu collectif aussi bien avant de s’y rendre qu’après avoir vécu l’expérience. Certains s’y rendent pour « vibrer ensemble », notamment quand il n’est pas possible d’accéder au stade :
« Tu vas dans la fan-zone, car tu n’as pas envie de regarder le match tout seul ou à deux chez toi, c’est plus grand qu’un pub, c’est pas mal, car tu n’as pas forcément les moyens [d’aller sur l’événement], ça remplace avantageusement, tu sors de chez toi, tu es avec d’autres supporters. » (Vincent)
Elle développe donc le sentiment de communion émotionnelle, de vivre ensemble un moment mémorable :
« On a senti la bonne humeur de tout le monde, c’était agréable de voir la foule réunie derrière les équipes françaises. » (Emmanuelle, JOP 2024, Club France à Nantes.)
La circulation des émotions via le phénomène de contagion émotionnelle – qui fait que l’on est saisi et touché par les émotions exprimées par les autres et que l’on va partager à son tour – est renforcée par la configuration spatiale des fan-zones, qui implique une grande proximité entre les spectateurs. Cette forte densité sociale ne se retrouve d’ailleurs pas systématiquement lors d’événements sportifs lorsque les espaces dédiés au public sont peu concentrés (spectateurs le long de la route du Tour de France, ou du parcours d’un biathlon) ou que le stade est parsemé.
Dans les fan-zones, ce partage d’émotions recherché par les spectateurs d’événement sportifs y est omniprésent :
« L’intérêt de la fan-zone, c’est de partager à l’instant T, partager cette ferveur à distance avec des gens, c’est la puissance de regarder du sport à plusieurs, après l’émotion est décuplée. » (Marie)
Les valeurs sociales associées au vécu de l’événement sportif (interactions sociales, communion, patriotisme) sont importantes et sont systématiquement présentes dans ces espaces.
Ainsi, la fan-zone répond à l’attente des spectateurs sur le plan social et émotionnel, c’est son point fort. Néanmoins, au regard des autres dimensions de l’expérience, les représentations demeurent largement négatives.
Un espace ludique, malgré une mauvaise image
Les représentations des fan-zones sont assez mauvaises, l’expérience n’apparaissant pas forcément agréable a priori (confort, qualité de la vision, possibilité de choisir sa place et sa position (assis ou debout par exemple). Elles sont souvent perçues comme des espaces très basiques :
« Sur une place en plein air avec plein de gens serrés. » (Karine)
Pourtant, dans certaines fan-zones, par exemple celles des JOP 2024 à Paris et dans les grandes villes, de nombreuses animations étaient mises en place. L’expérience ne se réduisait pas à la projection des épreuves sportives sur écran géant mais incluait de nombreux services pour les visiteurs (restauration, jeux, spectacles, présentations, DJ ou concerts…). Dans ce cadre-là, l’expérience peut être très ludique et interactive, ce qui ne sera pas le cas dans la fan-zone organisée par un bar.
D’ailleurs, les fan-zones institutionnelles (gérées par les organisateurs de l’événement) sont ouvertes bien en amont et en aval de la rencontre sportive à l’instar de la fan-zone mise en place par le PSG au Parc des Princes pour les finales de la ligue des champions 2025 et 2026 ne se déroulant pas à Paris. Ce type de fan-zones sont par ailleurs considérées par certains spectateurs d’événements sportifs comme « un piège à touristes ou piège à consommation » (Pierre).
La fan-zone de New Jersey lors de la Coupe du monde de football 2026 est d’ailleurs la première fan zone payante. Cette image marchande tend à occulter, dans les représentations, la dimension ludique que peut revêtir une fan-zone.
Un substitut à l’expérience télévisée ou à l’expérience du stade ?
Au premier abord, la fan-zone est d’abord perçue comme un remplacement de l’expérience télévisée :
« Ça ne remplace pas le stade, c’est un ersatz, la fan-zone va plutôt remplacer l’expérience TV chez toi, c’est l’intermédiaire, tu vas dans la fan-zone, car tu n’as pas envie de regarder le match tout seul chez toi. » (Vincent)
L’expérience fan-zone est souvent associée à l’expérience TV chez soi par les répondants, qui comparent (ou opposent) l’expérience in situ à l’expérience « écran » :
« Ce que tu vis, tu ne peux pas le comparer à ce que tu regardes à la télé. » (Clément)
Cependant, il est à noter que l’expérience spectateur sur site se rapproche parfois de l’expérience fan-zone en fonction des sports. C’est le cas notamment pour les sports de plein air :
« Quand tu vas voir une course de ski alpin, c’est un peu une fan-zone, tu regardes le coureur sur l’écran, puis tu vois le coureur deux secondes passer la ligne d’arrivée. » (Thierry)
ou encore :
« Au biathlon, on est au bord de la piste et donc on essaie d’avoir un écran en face de nous. » (Karine)
Une fois l’expérience fan-zone vécue, elle peut apparaître comme un substitut à l’expérience stade, notamment au niveau émotionnel :
« Pour aller en fan-zone, faut être droguée, être shootée aux sensations, sur les JO, j’allais en fan-zone si je n’avais pas de billet. » (Patricia)
De plus, l’expérience fan-zone, même à distance, procure un sentiment d’appartenance à l’événement, le sentiment de pouvoir participer à la fête : « Y être sans y être » (Valérie, fan-zone JOP 2024, à Angers). Ce qui participe aussi à une forme d’inclusion pour ceux qui n’ont pu acheter des billets :
« Ici, on a l’impression d’assister aux compétitions comme si on était dans les gradins. » (Jérémy, JOP 2024, Club France Paris.)
ou bien :
« On a vécu l’esprit JO, je me dis que moi aussi je suis allé aux Jeux, alors que je ne suis pas allé voir une épreuve en direct. » (Marie, JOP 2024, Club France Paris.)
Ainsi, vivre l’événement sportif en fan-zone locale ou distale peut être, du point de vue de la valeur affective, une solution de remplacement à l’expérience sur site pour certains spectateurs.
Et enfin, cela peut aussi être ni l’un ni l’autre pour les personnes qui n’auraient pas regardé le match à la télé et encore moins acheté des places pour le stade mais qui vont quand même aller dans une fan-zone. Car comme nous l’avons vu, on ne va pas dans une fan-zone uniquement pour supporter son équipe ou regarder le spectacle sportif mais pour vivre un moment partagé. Nos observations montrent que c’est particulièrement le cas dans les fan-zones opportunistes (les bars, par exemple), ou intimes (organisées dans une sphère privée) même si on retrouve ce type de profil aussi dans les fan-zones institutionnelles.
Fan-zone ou « fun zone » ?
On y vient pour jouer, que cela soit jouer à faire la Ola, à chanter ensemble, s’amuser et interagir avec les autres tout en regardant l’écran de manière plus ou moins intense en fonction du profil du spectateur. En ce sens la fan zone est aussi un espace ludique qui n’est pas exclusivement plébiscité par les fans, définis comme « admirateur enthousiaste, passionné de quelqu’un, de quelque chose ». On y vient pour avoir du fun (au sens de plaisir, amusement.
La fan zone est alors plus qu’un « espace réservé aux supporteurs » (selon la traduction de fan zone proposée par l’académie française). Nous pouvons aussi nous demander de quoi sommes-nous fans ? : Ce sera de l’équipe qui joue pour certains, de l’événement pour d’autres, ou tout simplement des célébrations collectives pour les « passionnés de la fête », et dans ce cas, la fan zone devient fun zone.
Nico Didry a reçu le soutien du Centre d’Études Olympiques Français pour cette recherche.
11.07.2026 à 11:04
Pays pauvres : comment les institutions financières internationales leur permettent de se financer à moindre coût ?
Tidiani Sidibe, Doctorant en Banque & Finance, Université de Perpignan Via Domitia
Éric Paget Blanc, Professeur en sciences de gestion, Université d’Evry – Université Paris-Saclay
Texte intégral (2252 mots)
Alors que les pays les plus pauvres connaissent des situations économiques fragiles, les banques multilatérales de développement, ou BMD, comme la Banque mondiale, leur octroient des prêts à des conditions avantageuses par rapport à des banques commerciales et aux marchés financiers. Quel est leur secret pour éviter des pertes sur ces opérations ? La réponse se trouve du côté du statut de créancier privilégié ou preferred creditor status.
Les pays à faible revenu se caractérisent par un accès très limité, voire inexistant, aux marchés internationaux de capitaux en devises comme le dollar, l’euro, la livre sterling ou le yen – ces marchés permettent aux États d’emprunter auprès d’investisseurs internationaux. Cette quasi-exclusion s’explique par la fragilité de leurs finances publiques, mais aussi par leur forte exposition à des chocs politiques, climatiques ou sécuritaires.
En conséquence, le risque de non-remboursements des prêteurs (ou risque de défaut souverain) est structurellement plus élevé pour ces pays que pour les économies avancées ou émergentes. Résultat ? Les prêteurs privés tels que les banques commerciales et les marchés sont dissuadés de leur accorder des financements. A contrario, ils n’hésitent pas à prêter aux pays riches endettés, car ils ont confiance – à tort ou à raison – dans le fait d’être remboursés.
Dans ce contexte, les institutions financières internationales, notamment les banques multilatérales de développement – Banque mondiale, Banque africaine de développement, Banque asiatique de développement, etc. – jouent un rôle central dans le financement des pays pauvres. Elles ont reçu de la part de leurs États membres un mandat de prêteur contracyclique, à savoir leur accorder des financements alors que les acteurs privés s’y refusent.
Pour autant, elles subissent peu de pertes et leur qualité de crédit, mesurée par la note de crédit, ou rating, est généralement très élevée.
Pour expliciter ce paradoxe, notre article met en évidence un mécanisme institutionnel propre aux banques multilatérales de développement (BMD) : le statut de créancier privilégié, ou preferred creditor status (PCS). Concrètement, lorsqu’un État éprouve des difficultés à rembourser sa dette, il accorde la priorité au service des prêts des banques multilatérales de développement par rapport à ses autres créanciers – banques commerciales, détenteurs d’obligations ou prêteurs bilatéraux.
Dépendance aux notations de S&P, Moody’s et Fitch
La question du financement en devises des pays pauvres, comme le dollar ou l’euro, se pose avec une acuité particulière lorsque l’accès aux marchés internationaux dépend fortement des notes souveraines.
L’obtention d’une « note en catégorie d’investissement » attribué par les grandes agences de notation financière – Standard & Poor’s, Moody’s, Fitch – constitue une condition clé pour mobiliser des ressources financières à des conditions soutenables. Or, la majorité des pays pauvres ne remplissent pas ces critères. Pour nombre d’entre eux, les banques multilatérales de développement sont leurs principaux bailleurs de fonds.
À lire aussi : African Credit Rating Agency : l’Afrique cherche à s’émanciper des agences de notation occidentales
Certes, des initiatives émergent pour développer une grande agence de notation africaine, afin de mieux tenir compte des réalités économiques et institutionnelles du continent. À ce jour, les trois grandes agences internationales continuent de jouer un rôle central dans l’appréciation du risque souverain de ces pays par les marchés financiers.
Les banques multilatérales de développement
Contrairement aux banques commerciales et aux investisseurs obligataires, les banques multilatérales de développement (BMD) sont des créanciers officiels. Ces dernières sont guidées par des objectifs d’intérêt public, et non de rendement. Elles se distinguent par plusieurs autres caractéristiques :
elles ont un mandat de financement du développement à long terme ;
leur actionnariat est composé d’États membres, dont certains ne sont pas emprunteurs, mais accordent leur soutien à l’institution. C’est le cas des États-Unis, principal actionnaire de la Banque africaine de développement, de la Banque asiatique de développement ou de la Banque inter-américaine de développement ; un pays qui ne recourt pas à des emprunts auprès de ces institutions.
elles ont un accès privilégié aux marchés internationaux de capitaux grâce à un rating généralement élevé – la Banque mondiale, la Banque africaine de développement ou la Banque asiatique de développement sont notées AAA ;
elles bénéficient d’une protection contre le risque de crédit émanant du statut de créancier privilégié.
Un statut de créancier privilégié
Le statut de créancier privilégié est informel – ou de facto –, car il n’est pas inscrit dans le droit international. Il repose sur une pratique solidement ancrée en s’appuyant sur des incitations fortes pour les États emprunteurs.
Par exemple, un pays pauvre peut obtenir un prêt en devises auprès de la Banque mondiale à long terme et à taux d’intérêt très faible – 3 ou 4 % –, alors qu’il paierait beaucoup plus cher – voire ne pourrait pas – sur les marchés internationaux.

Grâce aux dons qu’elles mobilisent, les banques multilatérales de développement accordent aux pays les plus pauvres des prêts à des taux bonifiés et à des maturités très longues – dits « concessionnels ». En conséquence, un défaut vis‑à‑vis d’une banque multilatérale de développement entraîne non seulement un coût réputationnel élevé, mais a pour effet de compromettre durablement l’accès aux financements les moins chers pour un État.
Risque de défaut extrêmement faible
Les données que nous avons relevées à partir des comptes des banques multilatérales de développement confirment la solidité de ce modèle.
Sur la période 1992‑2022, la probabilité annuelle de défaut d’un État vis‑à‑vis des banques multilatérales de développement s’élève à 0,4 %. À titre de comparaison, elle se situe entre 6 % et 12 % pour les autres créanciers publics et privés, selon la base de données compilées par la Banque du Canada et de la Banque d’Angleterre.
Même en cas de défaut du pays emprunteur, les pertes subies par les banques multilatérales de développement après recouvrement restent très limitées, de l’ordre de 3 à 4 %, grâce au effet bénéfique de leur statut de créancier privilégié, contre près de 50 % pour les créanciers privés sur les obligations souveraines.
Cette différence s’explique précisément par le statut de créancier privilégié. Celui-ci réduit significativement le risque de crédit et permet aux banques multilatérales de développement de préserver la qualité de leur actif.
Le contrat implicite entre les États et les banques multilatérales de développement
Le modèle économique des banques multilatérales de développement est unique. Afin d’accorder des prêts à des conditions favorables, elles doivent elles-mêmes se financer à faible coût sur les marchés obligataires internationaux. Ceci suppose de maintenir des notations élevées, rendues possibles, outre le statut de créancier privilégié, par :
d’importantes dotations en capital (ressources financières apportées par les actionnaires) ;
un soutien total des États membres, prenant la forme de capital souscrit mais non versé, réclamé en cas de difficultés ;
une gestion prudente des risques de crédit et des risques financiers ;
Il en résulte une forme de contrat implicite entre les banques multilatérales de développement et leurs États membres. Les premières fournissent des financements en devises à faible coût sur de longues maturités. En échange, les États leur accordent un traitement privilégié.
En moyenne, les taux de provisionnement des banques multilatérales de développement s’élèvent à seulement 1,5 %, contre 2,5 % pour les banques commerciales comparables. Sans les protections dont elles bénéficient, dont le statut de créancier privilégié, ce ratio serait plus élevé ; elles augmenteraient leur taux afin de maintenir leur marge et éviter des pertes.
Complémentarité avec les acteurs privés
Les banques commerciales et les investisseurs obligataires, de leur côté, interviennent peu dans le financement souverain des pays pauvres. Ils ne bénéficient ni du statut de créancier privilégié ni du soutien des États membres ; ils sont fortement exposés au risque de défaut des emprunteurs si ceux-ci rencontrent des difficultés financières. En conséquence, ils accordent très peu de financements aux pays pauvres et exigent des taux d’intérêt élevés.
Les banques multilatérales de développement n’ont pas vocation à se substituer au secteur privé, mais à le compléter. Leur rôle est d’intervenir là où le marché est défaillant, tout en contribuant à stabiliser les économies et à créer les conditions d’un retour progressif des investisseurs privés.
Dans un contexte marqué par la multiplication des crises de la dette souveraine et l’augmentation des besoins de financement, le statut de créancier privilégié est parfois remis en question. Le supprimer serait toutefois contre-productif. Il renchérirait le coût des ressources des pays à faible revenu et réduirait les financements disponibles au moment où ils sont le plus nécessaires. Préserver ce mécanisme revient à garantir un accès durable des pays les plus pauvres aux financements en devises, et, au-delà, à renforcer l’efficacité du système financier international au service du développement durable.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
11.07.2026 à 11:04
En devenant des icônes portées même par Barbie, les Birkenstock sont aussi devenues une proie de choix pour les dupes
François Lévêque, Professeur d’économie, Mines Paris - PSL
Texte intégral (2505 mots)
En quelques années, les Birkenstock sont devenues des chaussures à la mode, présentant même des caractéristiques des produits de luxe. À commencer par la possibilité d’augmenter les prix sans affecter la demande. Le résultat est le développement d’imitations, mais aussi de dupes. Pour les contrer, la marque d’origine allemande a intenté plusieurs procès. Mais à qui appartient in fine la « Birk » préférée de Barbie ou de Leonardo DiCaprio ?
À qui appartient cette sandale à brides montée sur une semelle en liège ? À Birkenstock, étoile désormais dans l’orbite de LVMH ? À tous ceux qui la chaussent comme Leonardo DiCaprio à Malibu ou Barbie dans son film à l’eau de rose ? Pour certains juges, ce modèle iconique de sandales est protégé par le droit d’auteur au même titre qu’une œuvre d’art ; d’autres sont d’avis contraire.
Une réponse claire serait décisive pour les consommateurs qui boudent les originaux et préfèrent s’acheter des imitations sans pour autant se sentir coupables et passer pour des hors-la-loi. Les duplications de Birkenstock ont explosé, sur Internet comme en ville. Un phénomène qui en dit long sur l’économie des « dupes », mot forgé, tout comme les « Birks », par raccourci. Si ces mots tronqués ne vous parlent pas, vous avez sans doute connu l’époque où ces mêmes sandales étaient alors réservées aux hippies et aux professionnels de la santé.
Nous verrons aussi que la divergence entre les juges révèle aussi un paradoxe économique : en cherchant à faire de ses sandales un objet de désir, Birkenstock n’a-t-elle pas favorisé le succès même des dupes ?
À lire aussi : Les « dupes », ces copies légales de produit best-seller que vous avez déjà dû acheter
Du quasi orthopédique au quasi-luxe
Rien ne vaut le cinéma pour percevoir l’incroyable transformation de l’image des Birkenstock. Rapprochons deux scènes de Barbie. Dans l’une, l’héroïne doit choisir entre une paire d’escarpins rose – 10 centimètres de talon au moins – et une paire de sandales marron à double lanière sans aucun glamour. Un dilemme se pose alors : si elle opte pour les stilettos, elle reste définitivement à BarbieLand ; en se décidant pour les sandalettes, elle rejoint la vraie vie. Dupée, Barbie est forcée de prendre le modèle moche. On la retrouve dans la scène finale sortant d’une voiture en tenue urbaine décontractée chic avec, au pied des Birkenstock rose pâle à grandes boucles. Exit l’image de la contre-culture et de la chaussure pour infirmière. Vive la mode du design rustique, authentique et confortable ! Le ringard est devenu tendance.Une chance pour moi qui ai pu ressortir sans honte mes vieilles « Birks-sabot », dont la forme rappelle une pomme de terre.
L’entreprise pluricentenaire a su accompagner les nouveaux traits de la mode. Citons en néophyte de la chose : le culte du moche (pensez aux crocs) ; la soif de coolitude et de bien-être ; la valorisation du confort ; et même la recherche du non-look parfait (le style normcore disent les Anglo-saxons).
Birkenstock a surtout mené une stratégie typique du monde du luxe :
collaboration avec la haute couture (par exemple, Dior, Valentino) pour l’image ;
fabrication maintenue dans le pays d’origine (l’Allemagne) pour l’authenticité ;
contrôle de la distribution avec des magasins en propre pour garantir la qualité de service et empêcher les remises.
Enfin, les prix ont sans cesse été poussés vers le haut. En augmentant celui des modèles ordinaires au-delà de l’inflation, mais avant tout en développant des versions nouvelles beaucoup plus chères, à l’instar des sandales de Barbie à grandes boucles ou en jouant sur les coloris (mauve, argent, taupe, etc.), les qualités de cuir et les éditions limitées.
La famille Arnault au capital
Cette stratégie s’est vue renforcée avec la prise de contrôle de Birkenstock en 2021 par des investisseurs privés, dont la société financière de la famille Arnault. Puis la marque est entrée en fanfare à la bourse à New York, grâce à des perspectives alléchantes tant sur l’accélération de la transformation des sandales en produit premium, voire de luxe, mais aussi grâce à la capacité anticipée de l’entreprise d’en fixer le prix sans trop se préoccuper de la concurrence. Les résultats financiers espérés ne seront cependant pas au rendez-vous : le cours de l’action n’a toujours pas décollé de son niveau d’introduction.
L’imitation d’un produit renommé et cher n’est pas un phénomène nouveau. Mais elle s’est longtemps cantonnée à de la pure contrefaçon avec nom de la marque et copie plus ou moins réussie des autres signes distinctifs de l’original. À l’inverse, les dupes ne cherchent pas à passer pour vrais, ni à tromper le consommateur et son entourage sur la marchandise.
Les dupes se contentent d’épouser le style et de s’inspirer de la forme des produits à succès. Pas d’inscription du logo, du monogramme ou de la marque permettant à l’acheteur de faire valoir qu’il possède le vrai produit. Le consommateur de dupes cherche plutôt à montrer qu’il n’a justement pas acheté un original. Il adresse un pied de nez aux marques premium et de luxe. Il cherche bien sûr aussi à réaliser des économies. Bref, il dupe.
Et le dupe fut
TikTok devient l’accélérateur de la culture et du marché des dupes au début des années 2020, au moment même où Birkenstock réalise son rapprochement avec le monde du luxe. Le réseau social devient la plate-forme centrale de recommandation de dupes, qu’il s’agisse de rouge à lèvres, de meubles ou de chaussures. Ses vidéos avec le mot-clic #dupes comptent plusieurs milliards de vues. Les magazines de mode et les journaux économiques s’intéressent aussi de près au phénomène des dupes.
Dès lors, les efforts de l’entreprise pour rendre les Birkenstock désirables afin de renforcer son pouvoir sur les prix contribuent paradoxalement à favoriser la prolifération des dupes. Ils accentuent les incitations culturelles et économiques à y recourir.
Birkenstock contre-attaque
Pour tenter de contenir la concurrence des dupes, Birkenstock va multiplier les procès contre les imitateurs de ses sandales pour infraction au droit d’auteur. Une stratégie juridique maligne, car ce droit de propriété intellectuelle confère une très longue protection. La plupart des modèles historiques de Birks ont bénéficié d’une exclusivité pour leur forme générale mais elle a expiré. Comme pour le brevet d’invention, la durée conférée par le droit des modèles et dessins ne peut en effet dépasser vingt-cinq ans. Rien à voir avec le droit d’auteur qui ne s’éteint que soixante-dix ans après le décès du créateur de l’œuvre. En l’occurrence, ici, Karl Birkenstock lui-même (né en 1936) .
En Allemagne, l’entreprise a perdu la contre-attaque contre ses imitateurs. La Cour fédérale de justice a jugé en effet qu’aucun de ses modèles de sandale pouvaient être considéré comme des œuvres d’art. Attention : si cela vous paraît sans doute évident, cela ne l’est pas ! De premières instances avaient rendu des décisions contraires (l’une favorable et l’autre défavorable pour Birkenstock). En outre, le droit d’auteur couvre bien les œuvres de l’art appliqué comme des meubles et des vêtements et non seulement la littérature ou la peinture.
Le rejet de la Cour fédérale est motivé par l’absence d’éléments artistiques. Résumons en une phrase sa décision de 25 pages en disant qu’elle juge que le design des sandales provient de considérations fonctionnelles et ergonomiques et non d’un choix créatif et d’une conception artistique.
Original ou pas ?
Moins d’un an après, dans un autre litige contre les dupes, un tribunal hollandais va reconnaître que Birkenstock dispose bien d’un droit d’auteur pour ses sandales. Plus précisément, pour certains modèles comme l’Arizona porté par Barbie, mais pas pour d’autres à l’instar de mes sabots en forme de pomme de terre. Comment s’y retrouver ? Pas facile mais essayons.
Les juges néerlandais considèrent que le modèle Arizona est une création originale qui reflète la personnalité de son auteur, le fameux Karl Birkenstock déjà évoqué plus haut. Cette sandale n’est pas seulement le résultat de contraintes techniques que l’ergonomie et l’orthopédie imposeraient. L’Arizona est une combinaison de choix originaux en particulier pour le lit du pied (très parlante expression à ne pas confondre avec le pied du lit !), le liège laissé apparent et les brides d’une seule pièce de cuir.
Pas de droit d’auteur en revanche pour le sabot car les juges pointent l’existence d’un modèle similaire à quelques différences près, modèle d’un autre fabricant mis sur le marché antérieurement. Ironie du sort, le sabot de Birkenstock, un de ses modèles les plus vendus, serait donc un dupe !
Un droit d’auteur trop protecteur ?
L’économiste apporte en revanche une position nette et tranchée : pas de droit d’auteur pour les Birks ! En analyse économique, le droit de la propriété intellectuelle est vu comme un équilibre entre innovation et diffusion. Il incite l’innovation en accordant une exclusivité à l’inventeur et au créateur mais cette rente de monopole est temporaire afin de faciliter la diffusion. L’accès devient libre et gratuit au bout d’un certain laps de temps, (vingt-cinq ans donc) pour le brevet et les modèles et dessins mais plus d’un siècle pour le droit d’auteur car ses héritiers en bénéficient aussi. Une durée vraiment excessive. Les efforts du créateur ne sont pas motivés uniquement, ni même principalement sans doute, par l’argent qu’il pourrait gagner ; encore moins par le souci d’enrichir ses descendants. La célébrité et la reconnaissance jouent. Dans mon cas par exemple, je n’ai pas rédigé un ouvrage sur l’économie de la propriété intellectuelle pour l’argent. Sa version anglaise est même en accès libre et gratuit pour qu’il soit plus lu.
Il est désormais bien connu que l’allongement historique de la durée de protection offerte par le droit d’auteur est avant tout le résultat de lobbying des ayants droit, en particulier de Walt Disney Company peu désireuse de voir Mickey et Donald tomber dans le domaine public. Par ailleurs, le monopole temporaire bloque également les innovations de seconde génération alors qu’elles pourraient apporter des améliorations bienvenues. Imaginons Birkenstock empêché par son concurrent initial de commercialiser son modèle de sabot jusqu’au milieu du siècle prochain. L’entreprise subirait un manque à gagner mais les consommateurs seraient aussi perdants avec un choix de couleur et de matériau sans doute restreint sans parler du prestige de la marque pour ses sabots préférés.
Bref, oui à la protection des Birks par le droit des modèles et des dessins qui offre un monopole temporaire de courte durée. Mais non à celle défavorablement trop longue du point de vue du bien-être social, soit le nom donné à l’intérêt général en économie.
Finalement, la question est moins de savoir si les dupes copient les Birks que si Birkenstock n’a pas créé les conditions de leur succès. À force de transformer une sandale quasi orthopédique en objet de désir, la marque a rendu les dupes désirables eux-aussi. Qui dupe qui ?
En attendant que les juristes tranchent, chacun reste libre cet été de voter avec ses pieds : chausser des « Birks », des imitations… ou, tout simplement, des tongs ou des crocs (j’ai d’ailleurs vanté dans ces colonnes la vertu des premières et dénoncé les secondes comme la pire des inventions).
François Lévêque ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
11.07.2026 à 11:04
Interdiction des PFAS en France et en Europe : ce qui change en 2026
Stéphane Jomini, Chercheur et expert des évaluations REACH, Agence nationale de sécurité sanitaire de l’alimentation, de l’environnement et du travail (Anses)
Texte intégral (1906 mots)
Début 2026, la France a interdit certains produits à l’origine de pollution aux perfluoroalkylées et polyfluoroalkylées, ou PFAS. Cette évolution de la législation anticipe la réglementation européenne qui pourrait changer fin 2026, à la suite d’un projet de restriction déposé par plusieurs États européens et soutenu par la France. Deux comités consultatifs de l’Agence européenne des produits chimiques ont déjà livré des avis favorables au projet. Mais la transcription finale dans le droit européen devrait se jouer courant 2027.
Les substances perfluoroalkylées et polyfluoroalkylées (PFAS) sont un groupe de plusieurs milliers de substances chimiques (polymériques ou non) et d’origine synthétique ou liée à la dégradation d’autres PFAS. On les utilise dans de nombreuses applications du quotidien. On en retrouve dans les textiles, les emballages (alimentaires), les lubrifiants, les réfrigérants, l’électronique, la construction et bien d’autres encore.
Les propriétés physico-chimiques de ces substances conduisent à leur très grande persistance dans l’environnement du fait de la stabilité de la liaison chimique carbone-fluor, qui confère aux PFAS une résistance à la dégradation thermique, chimique et biologique. Cette persistance est associée à d’autres propriétés de dangers tels qu’une grande mobilité, de la bioaccumulation, de la toxicité pour l’humain et pour l’environnement.
À la suite de la médiatisation des problématiques liées au PFAS, la France a introduit une réglementation prévoyant l’interdiction progressive de certains produits contenant des PFAS, certains étant déjà interdits depuis le 1er janvier 2026. Ces interdictions devraient ensuite être étendues en 2030. Ceci fait suite à l’anticipation de dispositions européennes qui devraient être actées dans le courant de l’année, dans le sillage d’un projet de restriction déposé par l’Allemagne, le Danemark, les Pays-Bas, la Suède et la Norvège, et soutenu par la France.
À lire aussi : Les PFAS, « polluants éternels » : quels enjeux et nécessités réglementaires ?
Le comité d’évaluation des risques (CER) et le comité d’analyse socioéconomique (CASE) de l’Agence européenne des produits chimiques (ECHA) ont déjà rendu, en mars 2026, des avis favorables à la restriction.
L’opinion finale, compilation de l’opinion du CER déjà finalisée et de celle du CASE à la suite de la consultation publique sur celle-ci (obligation réglementaire dans le processus de restriction, 3 511 commentaires reçus, de 3 200 organisations et 250 individus, originaire de 44 pays), prélude à l’adoption finale du projet, devrait être déposée auprès des services de la Commission européenne en décembre 2026.
Mais la transcription de ce projet dans le droit européen n’est pas encore garantie à ce stade et tout va se jouer en 2027 au sortir des discussions qui vont avoir lieu entre les États membres et les services de la Commission européenne.
Les produits interdits, aujourd’hui demain
La législation européenne encadre déjà certaines substances de la famille des PFAS avec le règlement REACH (enregistrement, évaluation, autorisation et restriction des substances chimiques). Plusieurs composés sont déjà restreints ou interdits dans certains usages. C’est par exemple le cas de l’acide perfluorooctanoïque (PFOA), de l’acide perfluorooctanesulfonique (PFOS) et de l’acide perfluorohexane sulfonique (PFHxS).

Depuis le 1er janvier 2026, la fabrication, l’importation, l’exportation et la mise sur le marché de cosmétiques, produits de fartage (pour les skis), vêtements, chaussures et leurs imperméabilisants contenant des PFAS sont désormais interdits. Une exception est toutefois prévue pour les textiles d’habillement et chaussures de protection pour les professionnels, notamment ceux ayant des missions de défense nationale ou de sécurité civile, comme les militaires ou les pompiers, qui seront listés par décret.
Cette action s’inscrit dans le plan d’action interministériel sur les PFAS publié en avril 2024. Ce plan s’articule autour de cinq axes de travail qui impliquent différents ministères (santé, écologie, industrie, consommation, recherche, agriculture, intérieur, armées…), opérateurs de l’État (Ineris, BRGM, Ifremer…) et agences (Anses, Santé publique France, Ademe, OFB, agences de l’eau…).
Le projet de restriction en cours d’examen par l’Union européenne
Concrètement, le dossier de restriction déposé par plusieurs États européens auprès de l’ECHA présente deux scénarios de restriction, à savoir :
une interdiction totale des PFAS, assortie d’une période de transition de dix-huit mois ;
et une interdiction partielle, c’est-à-dire assortie de dérogations spécifiques (de cinq à douze ans) pour certaines utilisations, en plus d’une période de transition de dix-huit mois.
Dans son avis rendu en mars 2026, le comité d’évaluation des risques (CER) de l’ECHA estime les rejets dans l’environnement liés à l’ensemble des utilisations des PFAS à environ 70 000 tonnes par an. En fonction des secteurs d’utilisation, les émissions de PFAS peuvent survenir dans l’atmosphère, les systèmes aquatiques (eaux de surface ou souterraines, eau douce ou marine), les sols ou les sédiments. Ils surviennent lors de la fabrication de ces substances, de leur utilisation ou de leur élimination.
Les gaz fluorés constituent la principale source de ces émissions environnementales (environ 60 000 tonnes par an), suivis par l’utilisation de polymères fluorés notamment dans les textiles, les tissus d’ameublement, le cuir, les vêtements et les moquettes. Le CER a conclu que le premier scénario (l’interdiction totale des PFAS) constitue la mesure la plus efficace pour réduire au maximum ces rejets. Cela pourrait entraîner leur réduction de 96 % sur une période de trente ans (soit 3,3 millions de tonnes en moins).
Tout comme le CER, le comité d’analyse socioéconomique (CASE) de l’ECHA conclut qu’une restriction visant les PFAS constitue l’option de gestion des risques la plus appropriée. Comme dans l’avis du CER, il est préconisé une restriction de groupe (c’est-à-dire, de l’ensemble des substances couvertes par la définition des PFAS, explicitée dans le dossier) fondée sur la similitude structurelle et le danger des molécules. Ceci permettra à la fois d’éviter une substitution regrettable où des PFAS non réglementés remplaceraient ceux visés par cette restriction ou ceux déjà réglementés par ailleurs et de limiter l’exposition future à des PFAS qui ne sont pas actuellement utilisés.
Cependant, à l’inverse du CER, le CASE estime que le scénario d’un bannissement total des PFAS est disproportionné au vu de son impact sur la société, que ce soit en matière de coûts, de bénéfices et de services rendus. Le CASE préconise donc l’application du deuxième scénario, avec des dérogations ciblées et limitées dans le temps.
L’avis du CASE a été soumis à une consultation publique, qui devrait s’achever fin juin. À la suite de quoi, le CASE adoptera son avis final d’ici fin 2026, puis les avis du CER et du CASE seront officiellement transmis à la Commission européenne, qui aura un délai de trois mois pour se prononcer. La Commission européenne pourra alors proposer une restriction qui sera soumise à l’examen et au vote du comité REACH, composé des États membres de l’UE.
Réguler les usages actuels ne sera toutefois qu’une première étape : il faudra gérer ensuite les conséquences de l’utilisation qui a été faite des PFAS au cours des dernières décennies. La dépollution des stocks environnementaux, du fait de la très forte persistance de ces composés et de l’utilisation continue de ces substances, sera un réel défi pour le monde de la recherche et les autorités publiques. Ce sera pourtant nécessaire pour garantir un environnement sain pour l’ensemble des citoyens, comme acté au sein du Green Deal européen.
À lire aussi : Ces PFAS qui échappent à la surveillance environnementale
Stéphane Jomini a reçu des financements du Ministère de l'enseignement supérieur et de la recherche (Doctorat). Financement de projet Européen (Commission Européenne, projet RiskGone).
10.07.2026 à 14:24
Présomption de légitime défense pour les policiers : une proposition de loi qui pose problème ?
Olivier Cahn, Professeur de droit, Université Paris Nanterre
Texte intégral (2255 mots)
Déposée en décembre 2024 au Parlement, rejetée en commission une première fois début 2026, la « proposition de loi visant à reconnaître une présomption de légitime défense pour les forces de l’ordre dans l’exercice de leurs fonctions » a été adoptée à l’Assemblée nationale, le 7 juillet. Revendiquée de longue date par les syndicats de police, elle fait polémique et a réuni contre elle en deux jours plus de 500 000 signatures dans une pétition déposée sur le site de l’Assemblée. Pour le professeur de droit Olivier Cahn, ce texte fragilise l’exercice du contrôle judiciaire sur l’activité des gendarmes et policiers. Entretien.
The Conversation : Il y a eu des modifications entre la version initiale de la proposition de loi sur la présomption de légitime défense des forces de l’ordre, portée par Les Républicains, et le texte voté par l’Assemblée nationale. Que dit finalement le texte adopté le 7 juillet ?
Olivier Cahn : La « petite loi », c’est-à-dire le texte adopté par l’Assemblée nationale et désormais transmis au Sénat, prévoit que les policiers et les gendarmes, lorsqu’ils font usage de leur arme, sont présumés avoir agi dans l’un des cas autorisés par l’article L435-1 du Code de la sécurité intérieure, et conformément aux conditions d’absolue nécessité et de stricte proportionnalité.
Les policiers ne sont donc plus présumés – comme le souhaitait le député qui avait fait la proposition de loi – agir en état de légitime défense. Néanmoins, il y a une petite ambiguïté puisque le législateur, s’il a changé le contenu du texte, a omis de changer son titre, qui reste celui d’une proposition de loi « créant une présomption de légitime défense pour les forces de l’ordre ».
Quel était jusque-là le cadre légal concernant le recours aux armes des forces de l’ordre ?
O. C. : En 2017, le législateur a clarifié les règles d’usage des armes par les agents de la force publique. L’article L435-1 du Code de la sécurité intérieure, applicable à l’ensemble des agents de la force publique, prévoit deux choses. La première, c’est que les agents de la force publique revêtus des marques de leur autorité, soit le brassard, soit l’uniforme, peuvent faire usage de leur arme de manière absolument nécessaire et avec une stricte proportionnalité.
Deuxième chose, ils doivent être dans l’un des cas suivants : la légitime défense, la conservation d’une position, le fait d’arrêter un fuyard, la situation de refus d’obtempérer créatrice d’un danger et ce qu’on appelle le périple meurtrier, c’est-à-dire l’individu en train de commettre un massacre et qui va pouvoir être neutralisé sans attendre qu’il soit directement menaçant pour les agents.
Avec la proposition de loi adoptée par l’Assemblée nationale le 7 juillet, les agents seront présumés avoir agi dans ce cadre-là quand ils feront usage de leur arme. Ainsi, il appartiendra soit au ministère public, soit aux victimes ou à leurs ayants droit de montrer que les policiers ou les gendarmes n’ont pas respecté les dispositions de l’article L435-1.
Que change ce texte ?
O. C. : On a entendu beaucoup de discours autour de la création d’un « permis de tuer ». C’est faux : le texte de l’article L435-1 n’est pas modifié, et les agents restent bien soumis à un cadre légal contraignant pour faire usage de leur arme, d’autant qu’ils sont aussi soumis à la jurisprudence de la Cour européenne des droits de l’homme, très exigeante en la matière.
De sorte que ce qui change fondamentalement est principalement la manière dont l’enquête consécutive à l’usage de son arme par un agent de la force publique pourra être menée. En effet, selon l’article 62-2 du Code de procédure pénale, la garde à vue est « une mesure de contrainte décidée par un officier de police judiciaire, sous le contrôle de l’autorité judiciaire, par laquelle une personne, à l’encontre de laquelle il existe une ou plusieurs raisons plausibles de soupçonner qu’elle a commis ou tenté de commettre un crime ou un délit puni d’emprisonnement, est maintenue à la disposition des enquêteurs ».
Or, si les policiers sont présumés avoir agi légalement, ils ne peuvent plus être soupçonnés d’avoir commis une infraction et être placés en garde à vue. Et c’est là que réside le problème.
Pouvez-vous nous en dire plus sur les problèmes que cela soulève ?
O. C. : Régulièrement, les rapports de l’inspection générale de la police nationale, l’IGPN, indiquent que l’un des problèmes que posent les policiers dans le cadre des procédures judiciaires est qu’ils n’hésitent pas à mentir, c’est-à-dire à faire de faux procès-verbaux, à falsifier les circonstances de faits pour essayer de leur donner l’apparence de la légalité. Aujourd’hui, lorsqu’un policier ou un gendarme fait un usage suspect de son arme, il peut être immédiatement placé en garde à vue, ce qui permet de l’entendre avant qu’il ait pu se coordonner avec les autres policiers présents au moment des faits.
Par la réforme envisagée, on supprime cette possibilité. Les agents vont ainsi disposer d’un temps pour visionner leurs images, discuter entre eux et se mettre d’accord sur une version « légale » des faits. Le contrôle judiciaire susceptible d’être exercé sur le tir litigieux en sera compliqué d’autant.
Y avait-il une forte demande au sein de la police en faveur de l’instauration de cette présomption de légitime défense ?
O. C. : C’est une proposition ancienne, partagée par de nombreux syndicats, et qui a connu un regain depuis quelques années, en réaction au développement de la diffusion de vidéos des interventions policières. Politiquement, jusqu’à une période récente, elle n’était soutenue que par l’extrême droite. Mais l’actuel ministre de l’intérieur Laurent Nuñez, ancien préfet de police, s’est déclaré, à titre personnel, favorable à ce texte.
La proposition de loi, déposée en décembre 2024, inscrite à l’ordre du jour de l’Assemblée nationale seulement en janvier 2026, retoquée par la commission des lois et enlisée au Parlement est, par l’intermédiaire d’un amendement gouvernemental, revenue à l’Assemblée. Et pour s’épargner un débat parlementaire houleux et incertain, le ministre de l’intérieur a eu recours au vote bloqué, prévu par l’article 44 de la Constitution qui dit que le texte est mis au vote selon la rédaction voulue par le gouvernement (seuls sont intégrés les amendements qu’il a acceptés).
Le texte est désormais transmis au Sénat où la forte majorité de Républicains devrait permettre son adoption.
La défenseure des droits Claire Hédon s’est alarmée des risques que comporte le texte. Elle dit aussi que cela va complexifier un cadre juridique déjà dérogatoire et protecteur. Que dire à ce sujet ?
O. C. : En effet, l’article L435-1 du Code de la sécurité intérieure est un texte compliqué, qui laisse une importante marge d’appréciation, parce que les définitions des situations dans lesquelles l’agent peut faire usage de son arme ne sont pas nécessairement très claires.
Or, outre les difficultés que pose l’appréciation des circonstances, il faudra, si la réforme est adoptée, se demander s’il existe des éléments qui permettent de renverser la présomption de légalité de l’acte accompli par le policier, ce qui va évidemment complexifier la procédure.
La réforme est justifiée par une prétendue « insécurité juridique », à laquelle seraient confrontés les agents. Il existe un moyen de la résoudre, qui consiste, d’une part, à ramener l’article L435-1 à son premier alinéa : quelles que soient les circonstances, un tir n’est légal que s’il est effectué en état d’absolue nécessité et qu’il est strictement proportionné ; et, d’autre part, à conserver l’exception de la neutralisation de l’auteur d’un périple meurtrier – ce que prévoit au demeurant la réforme en ajoutant un II à l’article L435-1.
Mais le ministre et les soutiens du texte ont choisi une autre voie, plus politique. En premier lieu, dans le rapport Boucard remis à la commission des lois, il est à nouveau argué que ces règles, en créant une sorte d’« insécurité juridique », inhibent les policiers, qui peuvent se trouver dans une situation où ils n’osent pas faire usage de leur arme. Cet argument avait déjà été invoqué, en 2017, devant la commission des lois, par le sénateur Grosdidier. Et, après l’entrée en vigueur de l’article L435-1, les tirs policiers ont fortement augmenté, jusqu’à obliger la direction générale de la police à rappeler à l’ordre les agents. Les tirs ont alors subitement diminué.
En deuxième lieu, le texte adopté le 7 juillet tend à satisfaire la revendication des syndicats de police majoritaires de limiter la judiciarisation de l’activité des agents et le contrôle exercé par les magistrats.
La réglementation du recours aux armes par les forces de police est-elle très différente dans d’autres pays d’Europe ? La France est-elle une exception ?
O. C. : Dans les pays voisins, par exemple le Royaume-Uni, la Belgique ou l’Allemagne, les règles qui s’appliquent sont simplement celles qui découlent de la jurisprudence de la Cour européenne des droits de l’homme. L’usage des armes par la police ne fait pas débat et la volonté d’assouplir les règles reste un marqueur de l’extrême droite. En Angleterre et en Allemagne, les policiers ont refusé d’être dotés de certaines armes et de voir les autorisations de tirer élargies. Il y a une pression des syndicats de policiers français dont on ne trouve pas nécessairement l’écho dans d’autres États.
Le seul pays qui connaisse une évolution comparable à celle voulue par le législateur français est l’Italie, à la suite des réformes élargissant le champ de la légitime défense, adoptées en 2019 et en 2024, à l’initiative de M. Salvini, ministre d’extrême droite et chef de la Ligue du Nord, et de la création d’un « bouclier pénal » au profit des policiers. Il en a principalement résulté l’accroissement des condamnations de l’Italie par la Cour européenne des droits de l’homme pour des faits de violence de la part des policiers.
Propos recueillis par Aurélie Djavadi.
Olivier Cahn ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.07.2026 à 12:46
Les Vikings étaient bien plus que des pillards barbus : pourquoi les musées scandinaves entretiennent encore cette image ?
Julia Håkansson, Postdoctoral fellow in Museology, Lund University
Texte intégral (2066 mots)

{kind=link}
Des salles d’exposition de Copenhague à Oslo, les Vikings occupent une place centrale dans le récit national. Mais derrière les objets archéologiques se joue aussi une bataille contemporaine autour de l’identité, de la mémoire et de la politique.
Si vous voyagez en Scandinavie, il y a de fortes chances que vous visitiez une exposition consacrée aux Vikings. Et vous n’aurez que l’embarras du choix. À Copenhague, le Musée national d’histoire du Danemark propose une importante exposition permanente sur les Vikings. À Stockholm, le Musée historique suédois abrite la plus grande exposition au monde consacrée à cette époque. Quant au nouveau Musée de l’âge viking d’Oslo, dont l’ouverture est prévue en 2027, il ambitionne de devenir la référence mondiale sur le sujet. En attendant, une exposition temporaire au Musée d’histoire culturelle de la ville présente quelques-unes des plus remarquables découvertes archéologiques de l’époque viking.
Il va de soi que les musées nationaux scandinaves s’attendent à ce que les visiteurs, qu’ils soient locaux ou étrangers, viennent y découvrir des objets et des récits liés aux Vikings. Mais cette omniprésence des Vikings dans les musées nationaux ne répond pas seulement à une demande du public. Les musées utilisent aussi l’histoire pour façonner les représentations de l’identité nationale, et les Vikings servent souvent de miroir aux valeurs et aux besoins de chaque époque.
Au XIXe siècle, alors que les projets de construction nationale se multipliaient, l’époque viking est devenue un élément central de la construction des identités nationales en Scandinavie. Depuis, les Vikings sont devenus des symboles si puissants qu’ils sont aujourd’hui reconnus dans le monde entier. Dans l’imaginaire collectif, le Viking est un homme grand, robuste, l’épée à la main, arborant parfois une coupe de cheveux très contemporaine, comme un dégradé (« skin fade »), ou couvert de tatouages. Une image pourtant largement fabriquée de toutes pièces.
Les équipes scientifiques des musées nationaux scandinaves savent pourtant que les Vikings formaient un groupe très divers, bien loin du mythe du guerrier exclusivement masculin. Malgré cela, la figure du guerrier continue de s’imposer. Elle attire les visiteurs tout en revenant sans cesse hanter les galeries des musées.
Dans les trois expositions, l’homme viking apparaît tour à tour comme guerrier, navigateur et marchand. Il est aussi régulièrement présenté comme agriculteur, travaillant la terre au quotidien. Cette dimension apporte davantage de nuance, mais la scénographie continue de privilégier l’image la plus spectaculaire et la plus populaire, au détriment d’une réalité plus complexe.
L’exposition suédoise en offre un bon exemple : elle rappelle que de nombreux hommes et femmes libres possédaient des armes, mais que seuls quelques-uns se considéraient véritablement comme des guerriers. Malgré cette mise au point, les navires, les épées et les objets liés au commerce et aux voyages restent les pièces maîtresses du parcours, occupant le devant de la scène.

.jpg){kind=link}
À Copenhague, le Musée national invite les visiteurs à découvrir « notre exposition sur les Vikings, où nous explorerons un monde vieux de plus de mille ans, façonné par une culture guerrière et par les dieux Odin, Thor et Freyja ». On voit ici comment l’histoire documentée se heurte aux attentes nourries par les légendes nordiques, les guerriers et les dieux.
Les conservateurs semblent ainsi tiraillés entre la volonté d’offrir au public ce qu’il est venu chercher et celle de présenter une histoire fidèle aux connaissances historiques. Cette tension apparaît également dans la manière dont les femmes vikings sont représentées. Si ces institutions cherchent à réintégrer les femmes dans une vision de l’époque viking longtemps dominée par les figures masculines, les descriptions de leur vie quotidienne ou de leur influence sociale et culturelle restent souvent limitées.
Il existe par ailleurs une longue tradition consistant à ne mettre en avant que des femmes vikings hors du commun, comme les nobles dames ou les shieldmaidens (guerrières), reléguant les femmes ordinaires à l’arrière-plan. Ailleurs, les représentations restent marquées par des stéréotypes de genre, insistant surtout sur leur rôle au sein du foyer ou sur leur apparence vestimentaire. Ainsi, dans l’exposition danoise, on peut lire que « les invités étaient accueillis par la maîtresse de maison, qui veillait à ce que tout soit réuni pour assurer le succès de la réception. Les femmes jouaient un rôle actif dans la gestion de la ferme et voyageaient également beaucoup. » Une autre légende précise : « Les bijoux et les objets découverts dans les tombes de nombreuses femmes riches et aristocrates témoignent de la complexité des rôles qu’elles occupaient. »

{kind=link}
La scénographie est également façonnée par les grands récits fondateurs des nations scandinaves. Dans les trois expositions, sous des formes diverses, revient l’idée que l’époque viking a constitué un moment décisif dans la naissance des nations et des cultures scandinaves. Le récit est le suivant : c’est durant cette période que la Scandinavie serait passée d’un ensemble de tribus païennes dispersées et décentralisées à des royaumes chrétiens unifiés et distincts. Aujourd’hui, les Scandinaves n’adhèrent pas tous avec le même enthousiasme à cette lecture de leur histoire. Elle continue néanmoins de structurer, en toile de fond, le récit proposé par les expositions sur cette période.
Au Danemark, l’histoire se confond presque avec l’identité nationale. Cette vision est renforcée par la légende fondatrice de Harald à la Dent bleue. Père de Sven à la Barbe fourchue et grand-père de Knut le Grand, Harald se serait converti au christianisme après avoir assisté au miracle du moine Poppo, qui aurait porté un morceau de fer chauffé à blanc sans se brûler les mains.
Plusieurs chercheurs ont montré que, depuis les années 1980, l’époque viking est mobilisée pour construire des récits contemporains répondant à des enjeux actuels. C’est le cas, par exemple, des récits qui mettent en avant les échanges fructueux entre Scandinaves et musulmans, en s’appuyant sur des découvertes archéologiques attestant de ces contacts. Cette relecture du passé reflète la volonté, en Suède et en Norvège, de proposer un contre-récit face aux usages nationalistes de l’époque viking, souvent mobilisés dans des discours hostiles aux musulmans.
Comme le montrent ces exemples, concevoir une exposition muséale relève d’un exercice d’équilibriste : il faut composer avec des récits profondément ancrés dans l’imaginaire collectif tout en proposant une représentation fidèle des connaissances historiques. L’omniprésence des Vikings dans les musées nationaux scandinaves s’explique peut-être, au fond, par leur volonté de raconter un passé qui en dit davantage sur les préoccupations de la société contemporaine que sur ce que l’on sait réellement du monde viking.
Julia Håkansson a reçu un financement de la fondation Gunvor och Josef Anérs Stiftelse (subvention n° FB23-0180).
10.07.2026 à 11:01
3I/Atlas, une comète venue d’une autre étoile qui ne ressemble à rien de connu dans le Système solaire
Matthew Hopkins, Postdoctoral Fellow, University of Canterbury
Texte intégral (1827 mots)

Troisième objet interstellaire jamais détecté, 3I/Atlas ne ressemble à aucune comète du Système solaire. Sa composition et son âge exceptionnel en font un précieux témoin de la jeunesse de notre galaxie.
Des astronomes viennent de révéler de nouveaux détails sur la composition et l’âge d’une comète de passage, née autour d’une étoile lointaine. Ils concluent de leurs travaux que la composition de 3I/Atlas est radicalement différente de celle de tous les objets connus de notre Système solaire.
Trois études, publiées récemment et ici, apportent ainsi un nouvel éclairage sur les origines de cette comète hors du commun. 3I/Atlas semble s’être formée dans un environnement très froid, il y a environ 12 milliards d’années.
La comète est un objet interstellaire (interstellar object, ou ISO), c’est-à-dire un astéroïde ou une comète provenant de l’extérieur du Système solaire. Il s’agit du troisième objet de ce type jamais identifié, après 1I/ʻOumuamua et 2I/Borisov. Elle a été découverte il y a presque exactement un an, alors qu’elle arrivait de l’espace interstellaire sur une trajectoire traversant le Système solaire interne avant de s’en éloigner de nouveau.
Ces origines lointaines rendent les objets interstellaires particulièrement fascinants pour les astronomes, car ils constituent des fragments matériels d’autres systèmes planétaires, apportés jusqu’à nous par les courants gravitationnels de la galaxie et que nous pouvons étudier sans quitter le confort de notre propre Système solaire.
En tant que comète, 3I/Atlas contenait des glaces qui se sont sublimées, c’est-à-dire qu’elles sont passées directement de l’état solide à l’état gazeux. En se réchauffant sous l’effet du Soleil, ces gaz se sont échappés de la comète, donnant naissance à une spectaculaire chevelure (ou coma), l’enveloppe lumineuse qui entoure son noyau, ainsi qu’à une longue queue.
Une comète ne possède pas de source de lumière propre. La poussière présente dans sa chevelure réfléchit la lumière du Soleil, tandis que ses composés volatils (des substances qui se vaporisent ou se subliment facilement) émettent une fluorescence.
Mais il ne s’agit pas d’un simple spectacle lumineux : chaque molécule fluorescente laisse une empreinte spectrale dans la lumière qui parvient jusqu’à nos télescopes. Ces signatures permettent d’identifier les composés chimiques présents dans la comète.
Pour les révéler, les astronomes décomposent la lumière en ses différentes longueurs d’onde grâce à une technique appelée spectroscopie. Ils peuvent ainsi déterminer la composition chimique de la comète.
Un cocktail chimique inédit
Les observations ont révélé que 3I/Atlas renferme un mélange d’eau, de dioxyde et de monoxyde de carbone, de méthane, de cyanures, de sulfures, ainsi que d’atomes de fer et de nickel à l’état libre. Pris séparément, ces composés n’ont rien d’inhabituel : ils sont régulièrement détectés dans les comètes de notre propre Système solaire. En revanche, leurs proportions diffèrent nettement dans 3I/Atlas. Sa forte teneur en dioxyde de carbone (CO2) et sa faible abondance en ammoniac (NH3) trahissent son origine extérieure au Système solaire.
Les molécules constituées d’atomes appartenant à différents isotopes (des variantes d’un même élément chimique) présentent également des signatures spectrales légèrement différentes. Grâce à l’éclat de 3I/Atlas et à la puissance des plus grands télescopes, les astronomes ont pu distinguer ces signatures et mesurer les rapports isotopiques de la comète.
L’une des nouvelles études, publiée dans Nature, s’appuie sur les signatures spectrales de l’eau et du dioxyde de carbone mesurées par le télescope spatial James Webb pour déterminer le rapport entre les deux principaux isotopes du carbone, le 12C et le 13C, présents dans 3I/Atlas, ainsi que son rapport deutérium/hydrogène (D/H), le deutérium étant une forme lourde de l’hydrogène.
Ces résultats sont particulièrement enthousiasmants, car les rapports isotopiques d’un objet interstellaire comme 3I/Atlas sont censés refléter ceux du disque protoplanétaire dans lequel il s’est formé. Ils permettent donc de reconstituer avec une grande précision les conditions de sa formation, ainsi que les caractéristiques de l’étoile autour de laquelle il est né.
L’eau de 3I/Atlas présente un rapport deutérium/hydrogène (D/H) d’environ 1 %, soit une valeur nettement supérieure à celle mesurée dans toutes les comètes connues du Système solaire.
De telles concentrations en deutérium ne se rencontrent que dans des environnements extrêmement froids, où la température est inférieure à 30 kelvins (-243 °C). Dans ces conditions, les atomes d’hydrogène « ordinaires » sont progressivement remplacés par des atomes de deutérium, plus lourds, dans la glace d’eau qui recouvre de minuscules grains de poussière. Avec le temps, ces grains glacés s’agglomèrent pour former des comètes.
Une voyageuse venue des premiers âges de la galaxie
Le rapport 12C/13C de 3I/Atlas est lui aussi exceptionnel, bien supérieur à toutes les valeurs mesurées dans le Système solaire. Ce rapport isotopique fonctionne comme une véritable horloge cosmique. Au début de l’histoire de l’Univers, la première génération d’étoiles produisait un carbone très riche en 12C par rapport au 13C. Puis, au fil des cycles de naissance et de mort des étoiles, ce rapport a progressivement diminué. Si 3I/Atlas présente une valeur aussi élevée, c’est qu’elle s’est formée très tôt dans l’histoire de la Voie lactée, il y a environ 12 milliards d’années.
Des études menées peu après sa découverte avaient déjà suggéré que 3I/Atlas était probablement âgée d’au moins 7 milliards d’années, d’après sa vitesse. Son ancienneté est donc désormais étayée par plusieurs indices indépendants.
Si le ciel nocturne, au-delà des confins du Système solaire, peut sembler immuable, l’Univers comme notre galaxie évoluent bel et bien, à l’échelle de milliards d’années.

Lorsque 3I/Atlas s’est formée, l’Univers était encore dans sa prime jeunesse et la Voie lactée était encore en train de se construire, au gré de violentes collisions et fusions avec d’autres galaxies.
Si l’étoile autour de laquelle 3I/Atlas s’est formée avait une masse comparable à celle du Soleil, elle a probablement déjà achevé son existence. Les objets interstellaires qu’elle a éjectés peu après sa naissance, comme 3I/Atlas, lui ont ainsi survécu.
Au cours des dix prochaines années, de nouveaux télescopes de pointe dédiés à la découverte d’objets célestes, comme le NEO Surveyor de la NASA et l’observatoire Vera C. Rubin, au Chili, devraient multiplier par dix le nombre d’objets interstellaires connus. Cette moisson offrira aux astronomes une véritable archive fossile de l’évolution des systèmes planétaires tout au long de l’histoire de la Voie lactée.
Matthew Hopkins a reçu une bourse Elaine P. Snowden Fellow à l'université de Canterbury, en Nouvelle-Zélande.
10.07.2026 à 11:00
Les algues ne sont pas des plantes… et six autres faits surprenants sur la flore aquatique
Alexander Bowles, Glasstone Research Fellow, Plant Science, University of Oxford
Texte intégral (2748 mots)

Des plantes sans racines, d’autres carnivores, certaines capables de fleurir sous l’eau… Les plantes aquatiques ont développé des adaptations spectaculaires qui défient notre vision du monde végétal.
À l’abri des regards, sous la surface des eaux, se déploie un monde végétal d’une étonnante inventivité et parmi les plus importants sur le plan écologique.
Comme je le souligne dans une publication récente, les plantes aquatiques ont développé une extraordinaire diversité d’adaptations pour vivre sous l’eau. Certaines fleurissent sous la surface, d’autres capturent des animaux grâce à d’ingénieux pièges. Voici sept faits qui montrent à quel point ces organismes remarquables bousculent nos idées reçues sur ce qu’est une plante et sur les stratégies qu’elle déploie pour survivre.
1. Les plantes n’en finissent pas de retourner à l’eau
Quand on pense aux plantes, on imagine spontanément les forêts, les prairies ou les champs. Pourtant, au cours de leur histoire évolutive, les plantes sont retournées à de nombreuses reprises dans le milieu aquatique, là même où elles sont apparues. Il y a environ 500 millions d’années, elles ont conquis les terres émergées. Depuis, nombre d’entre elles ont fait le chemin inverse. Les scientifiques estiment que le mode de vie aquatique est apparu indépendamment plus de 100 fois au sein de différents groupes de plantes.
Les nénuphars font flotter leurs feuilles à la surface, les lentilles d’eau dérivent librement et les herbiers marins vivent entièrement immergés dans l’océan. Certains de ces groupes sont retournés à l’eau il y a plus de 100 millions d’années. Cette réapparition répétée des plantes aquatiques constitue l’un des exemples les plus spectaculaires de l’évolution convergente dans la nature.
2. Les plantes qui n’en sont pas
Parmi les organismes les plus visibles sous la surface de l’eau figurent les algues. Elles réalisent la photosynthèse et ressemblent souvent à des plantes sous-marines. Pourtant, malgré les apparences, les algues ne sont pas de véritables plantes.

Les algues marines appartiennent en réalité à plusieurs lignées d’algues distinctes dans l’arbre du vivant. Les laminaires géantes, qui forment de véritables forêts sous-marines, sont des algues brunes. Le nori et la dulse sont des algues rouges, tandis que la laitue de mer appartient aux algues vertes.
Contrairement aux plantes, elles ne possèdent ni véritables racines, ni tiges, ni feuilles, et ne produisent ni fleurs ni graines. Leur ressemblance avec les plantes rappelle toutefois que l’évolution peut conduire à des formes très similaires chez des organismes pourtant très éloignés, lorsqu’ils sont confrontés aux mêmes contraintes environnementales.
3. Des plantes qui vivent dans les profondeurs
Les plantes ont besoin de lumière pour réaliser la photosynthèse, ce qui les cantonne généralement aux milieux terrestres ou aux eaux peu profondes. Pourtant, certaines mousses aquatiques survivent à des profondeurs étonnantes. La faucillette courbée (Drepanocladus aduncus) a ainsi été observée à 140 mètres sous la surface dans les eaux exceptionnellement limpides de Crater Lake, dans l’État américain de l’Oregon. Il s’agit de la plante aquatique connue poussant aussi sur terre qui vit à la plus grande profondeur, environ la hauteur de la cathédrale de Strasbourg.
Des mousses de grande profondeur ont également été recensées dans des lacs de Nouvelle-Zélande, d’Antarctique et d’autres régions. Elles prospèrent dans des environnements si profonds qu’ils sont presque totalement privés de lumière et où très peu d’animaux peuvent survivre.
4. Des plantes sans racines
Les racines sont l’une des caractéristiques emblématiques des plantes. Elles les ancrent dans le sol et y puisent l’eau ainsi que les nutriments. Pourtant, de nombreuses plantes aquatiques ont considérablement réduit leur système racinaire, et certaines semblent même avoir complètement perdu leurs racines.

La vie sous l’eau change les règles du jeu. L’eau et les nutriments dissous entourent directement la plante, rendant les vastes systèmes racinaires beaucoup moins utiles que sur terre. De nombreuses espèces aquatiques absorbent ainsi les nutriments directement par leurs feuilles et leurs tiges.
Les lentilles d’eau en offrent l’un des exemples les plus extrêmes. Certaines espèces ne possèdent qu’une seule racine, contrairement à des parentes comme la grande lentille d’eau, qui en développe plusieurs. Quant aux espèces du genre Wolffia – les plus petites plantes à fleurs du monde –, elles n’ont plus aucune racine et flottent librement à la surface de l’eau. Un individu mesure à peine un millimètre de long et ses fleurs ne dépassent pas 0,3 millimètre.
5. Des plantes carnivores sous l’eau
Toutes les plantes aquatiques ne se contentent pas de la lumière du Soleil et des nutriments dissous dans l’eau. Certaines complètent leur alimentation en capturant et en digérant de petits animaux.
Les exemples les plus spectaculaires sont les utriculaires (Utricularia), un groupe de plantes aquatiques dépourvues de racines que l’on trouve dans les eaux douces du monde entier. Leurs feuilles se sont transformées en minuscules pièges en forme de vessie qui créent un vide en expulsant l’eau contenue dans leur cavité.

Lorsqu’un minuscule animal effleure les poils sensitifs situés à l’entrée du piège, une trappe s’ouvre brusquement et la proie est aspirée en moins d’une milliseconde. Les pièges des utriculaires figurent ainsi parmi les mouvements les plus rapides du règne végétal. S’ils capturent le plus souvent de petits invertébrés aquatiques, il leur arrive aussi de piéger des larves de poissons et des têtards.
Ce mode de vie carnivore permet aux utriculaires de prospérer dans des eaux pauvres en nutriments, où la plupart des autres plantes peinent à survivre.
6. Une pollinisation portée par les courants
Quand on pense à la pollinisation des plantes, on imagine volontiers des abeilles butinant de fleur en fleur par une belle journée ensoleillée. Mais sous l’eau, la pollinisation devient beaucoup plus compliquée. Au lieu de compter sur les insectes ou le vent, de nombreuses plantes aquatiques, comme les herbiers marins, utilisent directement les courants pour transporter leur pollen jusqu’à sa destination.
Sur terre, les plantes attirent leurs pollinisateurs en diffusant des parfums dans l’air. Sous l’eau, en revanche, ces signaux volatils sont inefficaces. Cette contrainte a conduit à un changement évolutif : les plantes entièrement aquatiques, comme les herbiers marins, ont perdu les gènes responsables de la production de ces composés odorants. Ne procurant plus d’avantage, ils ont progressivement disparu au cours de l’évolution.
7. Les herbiers marins et les mangroves, de puissants puits de carbone
Les herbiers marins et les mangroves capturent et stockent le carbone dans leurs tissus ainsi que dans les sédiments qui les entourent, ce qui les classe parmi les puits de carbone naturels les plus efficaces de la planète. Ensemble, ils emmagasinent ce que les scientifiques appellent le « carbone bleu » : le carbone piégé dans les écosystèmes côtiers, où il peut rester stocké pendant des siècles, voire des millénaires.

À l’échelle mondiale, ces écosystèmes – herbiers marins et mangroves – stockent 11,5 milliards de tonnes de carbone. Les mangroves représentent à elles seules le plus grand réservoir de carbone bleu, avec 6,5 milliards de tonnes.
Qu’elles capturent leurs proies en quelques fractions de milliseconde, poussent dans une quasi-obscurité ou stockent du carbone pendant des siècles, les plantes aquatiques témoignent de l’extraordinaire capacité du vivant à s’adapter.
Alexander Bowles a reçu une bourse « Glasstone Fellowship » à l'Université d'Oxford.
10.07.2026 à 10:59
La « malédiction » du « Titanic » et la vie oubliée de la fille du capitaine
Caroline Cauchi, Reader in Creative Writing, University of Hull
Texte intégral (1530 mots)
Réduite pendant des décennies au rôle de « fille du capitaine du Titanic », Helen Melville Smith fut aussi une pionnière de l’aviation, une passionnée d’automobile et une femme qui refusa de se laisser définir par le deuil. Son histoire révèle les angles morts de notre mémoire collective.
Un paquebot réputé insubmersible, un iceberg et une catastrophe entrée dans la culture populaire : le naufrage du Titanic est l’un des événements les plus souvent racontés de l’histoire moderne. Mais cette familiarité a un prix. À force d’être répétés, les récits simplifient ce qui s’est réellement passé et réduisent les personnes qui l’ont vécu à une histoire trop schématique.
Les récits du naufrage du Titanic se concentrent souvent sur le drame lui-même, en oubliant ce qui s’est passé ensuite. Bien après la catastrophe, celle-ci a continué de marquer profondément de nombreuses vies, y compris celles de personnes qui n’étaient même pas à bord du navire.
L’une d’elles est Helen Melville Smith, la fille du capitaine Edward Smith, qui commandait le paquebot lors de son voyage inaugural. En menant les recherches pour mon nouveau roman, Daughter of the Titanic (non traduit), j’ai été de plus en plus frappée non par l’ampleur de la catastrophe elle-même, mais par les vies silencieusement façonnées par ses conséquences. Melville avait 14 ans lorsque son père disparut avec le navire, en avril 1912. Du jour au lendemain, elle hérita non seulement d’un deuil intime, mais aussi d’une identité publique qu’elle n’avait pas choisie : celle de « la fille du capitaine », à jamais associée à une tragédie dont elle n’avait pas été témoin, mais à laquelle elle ne pouvait échapper.
La suite de son existence est souvent racontée sous l’angle de la fatalité. Au cours des décennies suivantes, son mari mourut dans un accident, sa mère fut tuée dans un accident de la route, son fils trouva la mort pendant la Seconde Guerre mondiale et sa fille succomba à la poliomyélite.
Pris ensemble, ces événements peuvent facilement être interprétés comme une prétendue « malédiction du Titanic ». Aussi récemment qu’en juillet 2025, un article du Daily Mail revenait sur la vie de Melville en suivant cette logique, présentant des drames sans lien entre eux comme les chapitres d’un destin inexorable.
Les travaux en psychologie et les recherches sur la construction narrative du sens montrent depuis longtemps que les êtres humains sont naturellement enclins à rechercher des motifs et des liens, en particulier après des événements traumatiques. Comme l’a montré le psychologue Jerome Bruner, nous donnons du sens à notre expérience en la transformant en récit, en organisant les événements dans une histoire qui leur confère une cohérence. Lorsque plusieurs tragédies surviennent, nous avons tendance à les relier pour en faire une suite porteuse de sens.
Le Titanic renforce encore cette tendance. Parce que la catastrophe occupe une place si importante dans la mémoire collective, elle exerce une sorte de gravité narrative. Les vies qui lui sont liées sont happées dans son orbite, interprétées à travers son prisme et réduites à de simples prolongements de son histoire. Le naufrage est ainsi devenu, à bien des égards, un mythe moderne : un événement historique transformé en récit symbolique, à travers lequel on interprète des existences bien postérieures.
Pourtant, Melville ne se résume pas à la catastrophe. Elle apprit à piloter des avions à une époque où l’aviation en était encore à ses débuts et demeurait particulièrement dangereuse. Elle conduisait des voitures de sport, fréquentait les milieux mondains et artistiques, et conserva une certaine notoriété qui nuance l’image d’une vie entièrement écrasée par le drame. Les photographies prises plus tard la montrent élégante, sûre d’elle et pleinement engagée dans la vie publique, malgré les épreuves qu’elle avait traversées.
À l’époque, l’aviation et l’automobile étaient associées à la modernité, au glamour et au goût du risque. L’enthousiasme de Melville pour ces deux passions laisse entrevoir une femme attirée par l’expérience plutôt que par le repli sur soi. Il se dessine ainsi le portrait non seulement d’une fille, d’une épouse et d’une mère endeuillée, mais aussi d’une femme restée curieuse, socialement active et déterminée à vivre pleinement.
Les récits publics cherchent souvent à figer les individus dans un rôle, en particulier lorsqu’ils sont liés à un grand événement historique. Pourtant, les personnes concernées continuent de façonner leur existence d’une manière qui déborde ces récits. L’histoire de Melville n’est donc pas seulement celle d’une succession de pertes. C’est aussi celle d’une négociation permanente entre l’expérience intime et les attentes du public, entre une identité héritée et la volonté de tracer sa propre voie.
La vie après la catastrophe
La vie de Melville met aussi en lumière un problème plus général dans notre manière de raconter l’histoire. Les catastrophes ne s’achèvent pas lorsque la crise immédiate prend fin. Elles continuent longtemps à façonner les représentations, les réputations, les identités et les interprétations, parfois sur plusieurs générations. Pourtant, les récits populaires privilégient presque toujours le moment de l’impact plutôt que ses conséquences. Le Titanic est sans cesse reconstruit comme un spectacle (le naufrage, l’héroïsme, les défaillances) tandis que les effets plus discrets et durables passent au second plan.
En privilégiant l’événement plutôt que ce qui lui succède, nous réduisons l’histoire à une succession de moments spectaculaires, au lieu de la considérer comme un processus qui se prolonge dans le temps. La vie de Melville offre un contrepoint à cette vision en déplaçant le regard de la catastrophe elle-même vers ses effets persistants. Pourquoi sommes-nous si enclins à voir, dans une succession de drames, les signes du destin, d’une malédiction ou d’une fatalité ? Et que se passe-t-il lorsque ces schémas narratifs sont plaqués sur des vies bien réelles ?
Dans le cas de Melville Smith, l’idée d’une « malédiction du Titanic » impose une cohérence là où il n’y en a peut-être aucune, condensant des décennies d’existence en un récit unique, simple à comprendre. Ce faisant, elle en vient à présenter le simple fait d’avoir survécu comme une forme de malheur.
Ce processus n’a rien de neutre. Les historiens, les journalistes et les romanciers – dont je fais partie – contribuent à façonner la manière dont les vies sont retenues par la mémoire collective et, parfois, réduites à un récit simplificateur. Cela nous confère une responsabilité éthique : résister à la tentation d’imposer des schémas narratifs qui rendent les existences plus cohérentes ou plus satisfaisantes qu’elles ne l’ont réellement été, et rester attentifs à leurs contradictions, à leur complexité et à leur réalité.
La vie de Melville résiste à ce type de conclusion toute faite. Elle est marquée par l’indépendance, la persévérance et les contradictions, autant de dimensions qui s’accordent mal avec le récit qu’on a voulu lui imposer. Prendre cette réalité au sérieux, ce n’est pas seulement redonner sa place à une figure oubliée, c’est aussi reconnaître les limites des grilles de lecture à travers lesquelles nous cherchons à la comprendre.
L’histoire du naufrage du Titanic se poursuit dans les existences qu’il a façonnées – des vies qui ne peuvent être réduites à cette seule tragédie sans perdre ce qui faisait leur profonde humanité.
Caroline Cauchi ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
10.07.2026 à 10:59
Avant Epstein, le scandale sexuel qui a forcé la Grande-Bretagne à changer sa loi
Claire Cunnington, Research associate, University of Sheffield
Caroline Derry, Professor of Feminism, Law and History, The Open University
Texte intégral (2609 mots)

Loin d'être une spécificité de notre époque, les scandales mettant en cause des hommes puissants pour des abus sexuels existaient déjà au XIXe siècle. Retour sur une affaire qui a transformé le droit britannique tout en laissant la plupart des responsables impunis.
Des médias mettent au jour un scandale : un réseau d'hommes riches et puissants abuse de jeunes adolescentes. L'indignation se propage rapidement et l'opinion publique exige des autorités qu'elles rendent les preuves publiques et traduisent les responsables en justice. Pourtant, le système protège nombre d'entre eux et rares sont ceux qui subissent de véritables conséquences. Il ne s'agit pas de Jeffrey Epstein, mais d'un scandale qui a éclaté dans le Londres victorien.
Nos recherches s'intéressent aux femmes et aux jeunes filles au cœur de cette affaire. En juillet 1885, le Pall Mall Gazette publie une série d'articles sous le titre « The Maiden Tribute of Modern Babylon » (« Le sacrifice des jeunes filles de la Babylone moderne »). Ils révèlent l'existence d'un système d'abus et de traite de jeunes filles. Dès leur publication, le scandale éclate. Le Parlement est submergé de pétitions et une immense manifestation est organisée à Hyde Park.
Les députés sont contraints de réagir en adoptant une loi qui relève de 13 à 16 ans l'âge légal du consentement des jeunes filles aux relations sexuelles. Les archives de ces événements sont conservées à la Women’s Library de la London School of Economics, dont une partie est présentée dans l'exposition actuelle, The Women’s Library at 100.

{kind=link}
Le scandale marquait l'aboutissement de plusieurs années de campagne en faveur d'un relèvement de l'âge du consentement. Jusque-là, les projets de loi allant dans ce sens étaient restés lettre morte au Parlement. Selon les rumeurs qui circulaient parmi les militants et les responsables politiques, certains députés étaient eux-mêmes coupables d'abus sur de jeunes filles. Certains opposants soutenaient même ouvertement qu'une telle réforme risquerait d'exposer leurs propres fils à des poursuites judiciaires.
Face à l'inaction des pouvoirs publics, les militants se tournèrent vers W.T. Stead, rédacteur en chef du Pall Mall Gazette. La militante féministe Josephine Butler, des responsables de l'Armée du Salut et Stead menèrent une enquête sur l'exploitation sexuelle des enfants, se rendant aussi bien dans des maisons closes que dans des foyers d'accueil. Pour démontrer que le recrutement et la traite de très jeunes filles étaient bien une réalité, Stead alla jusqu'à « acheter » une adolescente de 13 ans, Eliza Armstrong, avant de l'envoyer en France, où elle fut prise en charge par l'Armée du Salut.
Josephine Butler le résume ainsi dans une lettre à une amie : « Oh ! Quelles horreurs nous avons vues ! »
Le scandale londonien
Les articles entraînaient les lecteurs au cœur du mécanisme de recrutement et d'exploitation de jeunes filles. Ils décrivaient toute une industrie organisée autour de leur exploitation : des recruteurs et tenanciers de maisons closes, des médecins qui « certifiaient » leur virginité, ainsi que des sages-femmes chargées de soigner leurs blessures après les abus.
La série fut rapidement reprise par des journaux du monde entier sous le nom de « scandale de Londres », suscitant toutes les spéculations sur l'identité des hommes mis en cause. À New York, on racontait que de nombreuses personnalités américaines fréquentaient les établissements de la célèbre tenancière de maisons closes Mrs Jeffries. Le journal militant The Sentinel alla jusqu'à désigner certains de ses clients : des députés, des lords, des ducs, le prince de Galles et le roi Léopold II de Belgique.

Sous la pression de l'indignation populaire, les députés adoptèrent dès le mois d'août le Criminal Law Amendment Act. Outre le relèvement de l'âge du consentement des jeunes filles, cette loi créa dans l'urgence de nouvelles infractions liées au recrutement de jeunes filles à des fins d'exploitation sexuelle et à la tenue de maisons closes.
Certaines de ces dispositions eurent toutefois pour effet d'accroître la répression contre les femmes plutôt que contre ceux qui les exploitaient. Ainsi, lorsque deux travailleuses du sexe ou plus partageaient un même logement pour assurer leur sécurité, elles pouvaient être poursuivies pour tenue de maison close — une disposition toujours en vigueur aujourd'hui. Un amendement de dernière minute présenté par le député Henry Labouchere criminalisa également toute relation sexuelle consentie entre hommes. C'est sur le fondement de cette nouvelle infraction que le écrivain Oscar Wilde fut condamné une dizaine d'années plus tard.
Ironie de l'histoire, seuls Stead et plusieurs de ses collaborateurs furent finalement condamnés à l'issue de cette affaire. Ils furent emprisonnés pour l'enlèvement d'Eliza Armstrong. Pendant ce temps, les hommes accusés par les militants d'avoir exploité sexuellement des mineures ne furent ni poursuivis ni sanctionnés.
Les leçons pour aujourd'hui
Cette histoire offre plusieurs enseignements. Le premier est que certaines personnes très puissantes n'ont aucun intérêt à voir disparaître l'exploitation sexuelle des enfants, ce qui rend les réformes réellement efficaces particulièrement difficiles à mettre en œuvre. Ce n'est que sous la pression de l'opinion publique que de nouvelles lois furent finalement adoptées en 1885. Mais élaborée dans l'urgence, marquée par le conservatisme de l'époque et la volonté de préserver les intérêts des élites masculines, cette législation demeurait profondément imparfaite et empreinte de moralisme.
Le deuxième enseignement est que les victimes et les survivantes de violences sont trop souvent accusées, ignorées ou instrumentalisées à des fins politiques. La couverture médiatique du scandale du « Maiden Tribute » servit ainsi différents objectifs. En France comme aux États-Unis, elle fut présentée comme la preuve de la décadence de l'aristocratie. Quant aux jeunes filles exploitées, la bonne société les considérait comme des « filles perdues ». Comme l'affirmait le député Charles Hopwood à la Chambre des communes, les jeunes filles des classes populaires « qui se retrouvaient dans la rue […] étaient familiarisées avec ces choses dès leur plus jeune âge et étaient tout à fait capables de se débrouiller seules ».

{kind=link}
En rejetant la faute sur les victimes, l'attention se détournait des recruteurs, comme Mrs Jeffries, qui offraient aux jeunes filles une échappatoire à l'extrême pauvreté ou les attiraient avec de fausses promesses d'emplois légitimes. Les méthodes de recrutement et de contrainte décrites dans les années 1880 ressemblent fortement à celles utilisées aujourd'hui dans les réseaux de traite. Même les jeunes filles qui tiraient un bénéfice financier de leur exploitation en subissaient de lourdes conséquences sur leur santé physique et mentale.
Troisième enseignement : les institutions déploient souvent des efforts considérables pour dissimuler ce type d'abus. Dans le Londres victorien, des policiers étaient achetés, et l'un de ceux qui refusa de se laisser corrompre fut poussé vers la sortie. Plus tôt en 1885, des militants avaient engagé des poursuites privées contre Mrs Jeffries après que la police eut refusé d'aller plus loin dans l'enquête. Pendant le procès, le juge rappela à plusieurs reprises aux témoins de ne pas citer le nom des clients, et Mrs Jeffries plaida coupable avant la fin des débats, évitant ainsi que sa clientèle prestigieuse ne soit révélée. Elle s'en tira avec une simple amende au lieu d'une peine de prison. En 1887, elle fut de nouveau poursuivie en vertu de la nouvelle loi ; ses clients, eux, ne le furent jamais.
Il n'est jamais facile d'amener les puissants à rendre des comptes. Parmi les principales figures mises en cause dans le scandale du Maiden Tribute, une seule personne finit en prison : Mary Jeffries. Les hommes, eux, n'eurent jamais à répondre de leurs actes, si ce n'est à travers les rumeurs qui circulaient sur leur implication.
Cette histoire livre ainsi plusieurs enseignements pour aujourd'hui : exercer une pression constante sur les responsables politiques afin qu'ils agissent rapidement et efficacement, se méfier des dirigeants qui instrumentalisent les affaires d'abus pour conquérir le pouvoir, enquêter sans relâche sur les mécanismes de corruption institutionnelle et veiller à ce que l'argent et l'influence ne permettent pas aux auteurs de violences d'échapper aux conséquences de leurs actes. Plus que tout, il faut écouter les victimes et les survivantes, et placer leur parole au cœur de toute réponse.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
09.07.2026 à 17:27
Damanhur : pourquoi cette utopie italienne survit depuis cinquante ans. Et que peut-elle nous apprendre ?
Xavier Pavie, Philosophe, Professeur à l'ESSEC, Directeur de programme au Collège International de Philosophie, ESSEC
Texte intégral (3383 mots)
Connaissez-vous Damnhur, dans le Piémont, une communauté italienne qui développe un mode de vie alternatif ? Que vous y souscriviez ou non, il est intéressant de se pencher sur le fonctionnement de cette microsociété. Son étude livre un éclairage, par contraste, des sociétés capitalistes.
Malgré leur longévité remarquable et leur capacité à maintenir des formes originales d’organisation collective, des communautés comme Auroville en Inde, Findhorn en Écosse, Christiania au Danemark, Tamera au Portugal ou encore Damanhur en Italie, demeurent rarement des destinations privilégiées pour les voyages d’études, les learning expeditions et autres séminaires.
Pourtant, leur résilience dans le temps invite à dépasser les jugements rapides pour comprendre les mécanismes qui assurent leur pérennité. Ces expériences ont souvent en commun une dimension spirituelle. Une spiritualité généralement détachée des religions instituées, mais qui interroge néanmoins les représentations dominantes de la rationalité moderne. Cette caractéristique peut expliquer une partie des réticences qu’elles suscitent jusqu’à parfois être accusée de dérives sectaires. D’où l’importance de se rendre sur place pour y étudier les enseignements qu’elles offrent ne se réduisent pas à cette dimension. Ils concernent autant l’innovation que la gouvernance, l’organisation du travail, les modes de décision collective, la gestion des ressources ou encore la construction du lien social.
Un industriel visionnaire
La fédération de Damanhur constitue un cas particulièrement éclairant parmi les communautés intentionnelles contemporaines. Fondée à la fin des années 1970 dans la vallée de Valchiusella, au nord de l’Italie, entre Turin et Ivrée, elle a progressivement transformé une vision philosophique et spirituelle en une communauté durable dotée d’institutions, d’activités économiques et d’infrastructures propres.
À lire aussi : Penser le monde d’après : l’utopie de la « République de l’Économie sociale et solidaire »
Son implantation dans ce territoire n’est pas anodine. La région porte l’héritage d’Adriano Olivetti, industriel visionnaire qui défendait une conception profondément humaniste de l’entreprise, articulant développement économique, culture, éducation et bien commun. Sans s’inscrire directement à sa suite, Damanhur prolonge à sa manière cette intuition selon laquelle une communauté humaine ne peut être réduite à sa seule fonction productive et doit penser conjointement l’économie, le territoire, la culture et la qualité de la vie collective.

Dans un contexte marqué par les crises écologiques, sociales et politiques, Damanhur apparaît ainsi comme un laboratoire vivant de résilience collective. Son expérience offre un terrain d’observation précieux pour comprendre comment une organisation parvient à maintenir dans le temps un projet commun, à renouveler ses institutions et à concilier vision, gouvernance et pérennité.
Naissance d’une utopie
L’histoire commence avec la création du Centre Horus à Turin en 1975. Quelques années plus tard, les premiers membres s’installent dans la vallée sous l’impulsion d’Oberto Airaudi, connu sous le nom de Falco Tarassaco. Celui-ci développe progressivement une vision mêlant spiritualité, écologie et organisation communautaire, avec l’ambition de construire une société capable d’articuler développement humain, créativité et vie collective.
Dès l’origine, Damanhur constitue une expérimentation sociale à grande échelle. La communauté entend explorer de nouvelles façons d’habiter un territoire, de produire, d’apprendre et de vivre ensemble. Elle s’inscrit ainsi dans une tradition humaniste qui considère que l’économie, la culture, l’éducation et la vie collective ne peuvent être pensées séparément.
L’une des questions les plus intéressantes que soulève Damanhur est celle de sa gouvernance. Comment une communauté fondée sur un projet spirituel peut-elle préserver sa cohésion sur plusieurs décennies sans dépendre uniquement de l’autorité de son fondateur ?
La circulation des expériences
La vie collective s’organise autour de petites unités d’habitation appelées Nuclei, regroupant généralement une dizaine à une vingtaine de personnes. Les membres changent régulièrement de noyau afin de favoriser la circulation des expériences et d’éviter la formation de groupes fermés.
Au fil du temps, Damanhur a progressivement transformé l’autorité initialement incarnée par Falco Tarassaco en institutions capables de lui survivre. Sa constitution a été révisée à de nombreuses reprises et le pouvoir est aujourd’hui réparti entre plusieurs organes chargés de l’administration, de la vie spirituelle et de la résolution des conflits. Les responsables sont élus pour une durée limitée et leur action fait l’objet d’évaluations régulières.
Cette évolution illustre ce que le sociologue Max Weber appelait la « routinisation du charisme », soit le passage d’une organisation fondée sur une personnalité exceptionnelle à un système institutionnel capable d’assurer sa continuité dans le temps.
Un acteur majeur de la région
L’une des singularités de Damanhur est d’avoir construit sa pérennité en s’intégrant à l’économie locale plutôt qu’en s’en isolant. En créant des emplois, en réhabilitant des bâtiments industriels et en participant au développement du territoire, la communauté est progressivement passée du statut d’expérience marginale à celui d’acteur reconnu de la région.
Cette orientation se matérialise notamment à travers Damanhur Crea, installé dans une ancienne usine Olivetti à Vidracco. Le choix du lieu fait écho à l’héritage de l’industriel. Le site accueille aujourd’hui diverses activités liées à l’architecture écologique, à l’artisanat, au bien-être et aux services.
La communauté cherche également à renforcer son autonomie à travers l’agriculture, l’écoconstruction, la production énergétique locale et une monnaie complémentaire, le Crédito, utilisée parallèlement à l’euro. Pour les Damanhuriens, cette autonomie n’est pas une fin en soi mais une condition permettant de préserver la liberté d’expérimentation sociale et culturelle qui constitue le cœur du projet.
Des temples clandestins devenus attractions
Aucune analyse de Damanhur ne peut faire l’impasse sur les Temples de l’humanité. Creusé clandestinement dans la montagne pendant plus de quinze ans, cet ensemble souterrain constitue aujourd’hui l’emblème de la communauté. Répartis sur plusieurs niveaux et composés de différentes salles thématiques – consacrées notamment à l’eau, à la terre, aux métaux ou aux miroirs –, les temples matérialisent la vision spirituelle développée par les fondateurs.
Pour les Damanhuriens, ces espaces participent à une démarche de transformation personnelle et collective fondée sur l’idée d’une connexion entre l’être humain, la nature et les différentes dimensions du vivant. Quelles que soient les croyances que l’on accorde à cette vision, les temples jouent un rôle central dans la construction de l’identité collective de la fédération.

Paradoxalement, c’est leur découverte par les autorités italiennes en 1992 qui va contribuer à la reconnaissance publique de Damanhur. Ce qui aurait pu conduire à la disparition du projet s’est progressivement transformé en un processus de patrimonialisation. Aujourd’hui, les temples attirent des milliers de visiteurs chaque année et constituent l’un des principaux vecteurs de visibilité de la communauté.
L’image de Damanhur n’est pas sans ombre. D’anciens membres, rassemblent témoignages critiques et enquêtes dénonçant conditionnement psychologique, irrégularités fiscales et manœuvres d’influence politique locale. Sur le plan judiciaire, le fondateur a fait l’objet d’accusations de fraude fiscale réglées par accord amiable avec le fisc, sans condamnation pénale. Une procédure relative au statut des travailleurs a quant à elle donné lieu à une décision de la Cour suprême italienne en 2018, imposant que les membres soient rémunérés conformément au droit du travail.
À ce jour, aucune condamnation pénale pour dérive sectaire n’a été prononcée. Ces tensions ne sont d’ailleurs pas propres à Damanhur : la plupart des communautés intentionnelles connaissent, à un moment ou un autre, leur lot de dissidences et de départs, dont les motivations mêlent souvent désillusion sincère, conflits personnels et réinterprétation rétrospective de l’expérience vécue.
Recherche, éducation et expérimentation
L’originalité de Damanhur ne réside pas uniquement dans son organisation sociale ou sa dimension spirituelle. La communauté se présente également comme un espace permanent d’expérimentation. Parmi les domaines les plus singuliers, figure le travail consacré aux relations entre l’être humain et le monde végétal. Les recherches menées autour de la « Musique des plantes » ou des dispositifs PlantTunes reposent sur l’idée que les végétaux peuvent être intégrés à de nouvelles formes d’interaction et de communication avec les humains.
Au-delà de la validité scientifique de ces travaux, leur intérêt réside dans la place qu’ils occupent dans l’imaginaire collectif de la communauté : ils traduisent une volonté constante d’explorer des voies alternatives de connaissance et de remettre en question les frontières traditionnelles entre nature et culture.
Cette ambition se prolonge à travers l’Olami Damanhur University, structure chargée de transmettre les savoirs développés au sein de la fédération. L’université propose des séminaires, des formations et des programmes consacrés notamment à la gouvernance communautaire, au développement personnel, à l’écologie ou encore à la création de communautés intentionnelles. Damanhur ne cherche donc pas seulement à expérimenter pour elle-même ; elle entend également diffuser ses apprentissages au-delà de ses frontières.
L’avenir d’une utopie
Si Damanhur est née dans une vallée du Piémont, son influence dépasse aujourd’hui largement les frontières italiennes. La communauté a développé un réseau international de groupes affiliés et de sympathisants présents en Europe, en Amérique du Nord, au Japon ou encore en Australie. Cette ouverture s’appuie notamment sur le projet Vajne, destiné à maintenir les liens entre la fédération et ses membres vivant à l’extérieur, ainsi que sur sa participation à des réseaux internationaux tels que le Global Ecovillage Network.
Cette capacité d’ouverture constitue sans doute l’une des clés de sa longévité. Comme de nombreuses communautés intentionnelles, Damanhur a dû faire face aux défis du renouvellement générationnel, de l’institutionnalisation et de la disparition de son fondateur. Jusqu’à présent, elle semble avoir répondu à ces enjeux par une adaptation continue de ses institutions, de sa gouvernance et de ses modes d’engagement.
L’ambition affichée aujourd’hui dépasse la seule pérennité de la communauté elle-même. Damanhur entend contribuer, à travers ses activités éducatives, culturelles et internationales, à la réflexion sur de nouvelles formes de vie collective dans un contexte marqué par les crises écologiques et sociales contemporaines.
Que peut-on apprendre de Damanhur ?
Que l’on adhère ou non à ses croyances, Damanhur constitue un terrain d’observation exceptionnel. Alors que de nombreuses initiatives alternatives disparaissent après quelques années, cette communauté a réussi à traverser un demi-siècle d’histoire en combinant vision collective, institutions durables, activités économiques et capacité d’adaptation.
Son principal enseignement réside peut-être moins dans sa spiritualité que dans sa faculté à articuler des dimensions souvent séparées dans les organisations contemporaines : la quête de sens, la gouvernance, l’économie, l’éducation et le rapport au territoire. À ce titre, Damanhur apparaît moins comme une utopie réalisée que comme un laboratoire vivant qui interroge nos manières de faire société et d’imaginer des formes alternatives de vie collective.
Au-delà du cas de Damanhur, les communautés intentionnelles, les expériences utopiques et plus largement les formes d’organisation situées à la marge des modèles dominants constituent des sources d’apprentissage souvent sous-estimées. Qu’il s’agisse de communautés écologiques, de lieux autogérés, de mouvements contre-culturels ou d’autres formes de vie collective, ces expériences explorent des questions qui traversent aujourd’hui nos sociétés : comment renforcer la solidarité ? Comment concilier autonomie et coopération ? Comment produire et consommer autrement ? Comment redonner du sens à l’action collective ?
Expérimenter des formes inédites
Aucune de ces expériences n’est parfaite. Elles connaissent leurs tensions, leurs contradictions et parfois leurs échecs, tout comme les organisations conventionnelles. Leur intérêt réside ailleurs : dans leur capacité à expérimenter des solutions inédites et à ouvrir des espaces de réflexion que les institutions établies peinent parfois à explorer.

Dans un monde largement structuré par les impératifs de performance, de rentabilité et d’efficacité, ces communautés offrent la possibilité d’un véritable réveil humaniste. Non parce qu’elles détiendraient les réponses aux défis contemporains, mais parce qu’elles nous invitent à réinterroger des questions fondamentales : qu’est-ce qu’une vie collective réussie ? Comment articuler liberté individuelle et responsabilité commune ? Quelle place accorder à la coopération, au sens ou encore au rapport au vivant ?
L’enjeu n’est sans doute pas de reproduire ces modèles à l’identique. Il est plutôt d’accepter de les considérer comme des laboratoires à ciel ouvert, dont les réussites comme les limites peuvent nourrir notre réflexion. Les explorer permet moins de trouver des solutions toutes faites que d’élargir le champ des possibles et de remettre en question certaines de nos certitudes sur les manières d’organiser le travail, l’économie et la vie en société.
Xavier Pavie ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.07.2026 à 17:26
Avec « The Mandalorian », comprendre les enjeux derrière les métaux rares
Olivier Pourret, Enseignant-chercheur en géochimie et responsable intégrité scientifique et science ouverte, UniLaSalle
Elodie Pourret-Saillet, Enseignante-chercheuse en géologie structurale, UniLaSalle
Texte intégral (2849 mots)

Armures étincelantes, forges ancestrales et batailles galactiques : dans l’univers de Star Wars, le « beskar » occupe une place à part. Ce métal légendaire, au cœur de l’identité mandalorienne, est réputé presque indestructible. Il résiste aux tirs de blaster et autres pistolasers, supporte des températures extrêmes et constitue un héritage transmis de génération en génération.
Avec la sortie en salle, le 20 mai dernier, de The Mandalorian and Grogu, premier film Star Wars à retrouver les écrans de cinéma depuis l’Ascension de Skywalker en 2019, le « beskar », matériau légendaire, revient au centre du récit. Présenté comme quasiment indestructible, capable de résister aux tirs de blaster et même aux sabres laser, le beskar appartient évidemment au domaine de la fiction.
Pourtant, derrière cette invention scénaristique se cache une réalité étonnamment familière : notre monde dépend lui aussi de matériaux rares, concentrés dans quelques régions du monde, convoités par les grandes puissances et devenus indispensables au fonctionnement des technologies modernes. La galaxie de Star Wars n’est peut-être pas aussi éloignée de nos préoccupations géologiques qu’elle en a l’air.
Un métal fictif qui ressemble à nos ressources stratégiques
Dans The Mandalorian, le beskar est bien davantage qu’un simple matériau. Il est rare, convoité, difficile à extraire et étroitement associé à une région unique de la galaxie : la planète Mandalore. Sa possession confère un avantage décisif, qu’il soit militaire, politique ou symbolique.
Cette situation n’est pas sans rappeler celle de certaines matières premières que géologues et économistes qualifient aujourd’hui de « critiques » ou de « stratégiques ». Ces ressources sont indispensables au fonctionnement de technologies essentielles, mais leur production demeure concentrée dans un nombre limité de pays, créant des dépendances parfois importantes.
Les terres rares en constituent sans doute l’exemple le plus connu. Derrière ce nom se cache un groupe de 17 éléments chimiques utilisés dans les aimants permanents des éoliennes, les moteurs de véhicules électriques, les smartphones ou encore certains équipements militaires. D’autres métaux, comme le cobalt, le gallium, le germanium ou l’indium, jouent également un rôle central dans les batteries, les semi-conducteurs ou les écrans tactiles.
Comme le beskar, ces ressources se distinguent moins par leur valeur marchande que par leur importance stratégique.
Leur répartition géographique est également très inégale. En 2025, la Chine assure près de 69 % de la production mondiale de terres rares et domine largement leur transformation industrielle. La République démocratique du Congo fournit quant à elle près des trois quarts du cobalt extrait dans le monde. Cette concentration crée une dépendance structurelle pour les grandes puissances industrielles, à l’image de celle que connaît la galaxie fictive de Star Wars vis-à-vis du beskar de Mandalore.
Quand la géologie rejoint la science-fiction
Les créateurs de Star Wars n’ont évidemment pas conçu le beskar comme un objet géologique. Pourtant, les propriétés qu’ils lui attribuent présentent une certaine cohérence avec ce que nous connaissons des matériaux les plus performants développés par l’industrie moderne.
Le beskar est présenté comme un alliage plutôt que comme un élément pur. Ce choix est particulièrement crédible. Dans le monde réel, les matériaux aux propriétés mécaniques exceptionnelles résultent presque toujours d’associations complexes entre plusieurs éléments chimiques.
L’acier inoxydable combine ainsi fer, chrome et nickel. Les alliages de titane utilisés dans l’aéronautique incorporent de l’aluminium et du vanadium. Les superalliages employés dans les turbines aéronautiques peuvent contenir une dizaine d’éléments différents afin de résister simultanément aux contraintes mécaniques, à l’oxydation et aux températures extrêmes.
La résistance thermique du beskar évoque également certains métaux réfractaires bien connus des géologues et des métallurgistes. Le tungstène, par exemple, possède la température de fusion la plus élevée parmi les métaux connus, atteignant 3 422 °C. Le rhénium, plus rare encore, est utilisé dans les composants soumis à des températures particulièrement élevées, notamment dans l’industrie aéronautique.

){kind=link}
Quant à sa capacité à absorber des impacts sans se rompre, elle rappelle les recherches menées depuis une vingtaine d’années sur les alliages à haute entropie. Ces matériaux de nouvelle génération associent plusieurs éléments en proportions voisines, produisant des combinaisons inédites de dureté, de résistance mécanique et de résistance à la corrosion.
Bien sûr, aucun de ces matériaux ne pourrait réellement arrêter un sabre laser. Mais la logique scientifique qui sous-tend le beskar apparaît moins fantaisiste qu’il n’y paraît au premier abord.
Des ressources au cœur des rapports de puissance
La comparaison devient encore plus frappante lorsqu’on s’intéresse à la géopolitique des ressources.
Dans l’univers du Mandalorian, le contrôle du beskar constitue un enjeu de pouvoir majeur. Les conflits qui entourent son extraction, sa circulation et sa réappropriation participent directement à l’équilibre politique de la galaxie. L’histoire récente fournit plusieurs exemples comparables.
En 2010, dans un contexte de tensions territoriales avec le Japon, la Chine a temporairement restreint ses exportations de terres rares. L’événement a provoqué une forte inquiétude parmi les industriels dépendants de ces matériaux et a accéléré les réflexions sur la diversification des approvisionnements.
Plus récemment, Pékin a instauré des restrictions à l’exportation concernant le gallium, le germanium, puis d’autres matériaux stratégiques utilisés dans les semi-conducteurs et les technologies de défense.
Ces épisodes rappellent que les matières premières critiques ne constituent pas seulement des ressources économiques. Elles représentent également des instruments d’influence et de souveraineté.
Face à ces enjeux, l’Union européenne a adopté en 2024 le Critical Raw Materials Act, destiné à renforcer la sécurité d’approvisionnement en matières premières critiques, à développer les capacités de recyclage et à diversifier les sources d’importation. Les États-Unis poursuivent des objectifs similaires à travers différents programmes de soutien à l’industrie minière et métallurgique.
Face à cette dépendance, deux grandes stratégies s’offrent aux pays importateurs : diversifier les sources d’extraction ou apprendre à récupérer ce que l’on a déjà consommé. C’est cette deuxième voie, celle du recyclage, que la série illustre, sans le savoir, avec une grande précision.
Le recyclage, ou l’art mandalorien appliqué à nos déchets
L’un des aspects les plus intéressants de la série réside peut-être dans la place accordée au recyclage du beskar. À plusieurs reprises, le personnage de l’armurière récupère d’anciens fragments de métal pour les fondre et leur donner une nouvelle forme. Dans la fiction, ce geste possède une dimension culturelle et spirituelle forte : il permet de préserver un héritage tout en l’adaptant aux besoins du présent.
Cette pratique fait écho à un défi bien réel. Aujourd’hui, moins de 1 % des terres rares contenues dans les produits en fin de vie sont effectivement recyclées. Les obstacles sont nombreux : faibles concentrations dans les objets, difficultés de démontage, coûts élevés des procédés de récupération ou encore insuffisance des filières de collecte.
Pourtant, les millions de véhicules électriques, d’éoliennes et d’équipements électroniques actuellement en circulation constituent déjà un immense gisement urbain de métaux stratégiques.
De nombreux programmes de recherche européens et asiatiques cherchent ainsi à développer de nouvelles méthodes permettant de récupérer le néodyme des aimants permanents ou le cobalt contenu dans les batteries. À leur manière, ces chercheurs pratiquent eux aussi une forme de forge moderne : ils transforment les déchets technologiques d’aujourd’hui en ressources stratégiques de demain.
Ce que le beskar révèle de notre monde
Au fond, The Mandalorian ne raconte pas une histoire de métallurgie. La série parle avant tout d’identité, de transmission, de mémoire collective et de résilience culturelle.
Mais si le beskar occupe une place aussi centrale dans cet univers, c’est précisément parce qu’il matérialise ces enjeux sous une forme immédiatement compréhensible. La rareté de la ressource, la dépendance qu’elle crée et les conflits qu’elle suscite donnent une profondeur supplémentaire aux thèmes explorés par la fiction.
Comme souvent, la science-fiction agit ici comme un miroir. Elle déplace les questions dans une galaxie imaginaire pour mieux éclairer celles qui traversent notre propre société.
Les terres rares, le cobalt ou le gallium ne bénéficient pas de l’aura mythique du beskar. Leurs noms sont moins évocateurs et leurs propriétés moins spectaculaires. Pourtant, ils jouent un rôle tout aussi déterminant dans les transformations technologiques, énergétiques et géopolitiques du XXIᵉ siècle.
La fiction n’invente donc pas tant qu’elle ne révèle. En imaginant un métal rare dont le contrôle influence le destin d’une galaxie entière, Star Wars nous invite à porter un regard nouveau sur les ressources dont dépend notre propre avenir.
Ignorer cette réalité, c’est avancer dans la galaxie sans armure : vulnérable, exposé, dépendant des autres.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
09.07.2026 à 17:25
GPA à l’étranger et reconnaissance de filiation en France : la Cour de cassation acte un profond changement de logique
Valérie Depadt, Maître de conférences en droit, Université Sorbonne Paris Nord
Texte intégral (2885 mots)
Le 3 juillet 2026, la Cour de cassation a rendu deux arrêts très attendus concernant la filiation des enfants nés grâce à une gestation pour autrui effectuée à l’étranger. Bien que cette pratique soit interdite en France, la Cour considère que « compte tenu de l’intérêt supérieur de l’enfant », cet interdit ne permet pas, à lui seul, de refuser la reconnaissance de la filiation. Une décision qui acte un changement profond de logique.
La gestation pour autrui (GPA) – autrement dit, le fait, pour une femme, de porter un enfant pour le compte d’un couple de « parents d’intention » à qui il sera remis après sa naissance – demeure interdite en France. Néanmoins, les questions qu’elle soulève continuent d’alimenter les débats juridiques.
Il en est ainsi notamment de la transcription, sur les registres de l’état civil français, des actes de naissance des enfants nés à l’étranger grâce à ce processus. Ce sujet, depuis près d’une vingtaine d’années, n’a jamais longtemps quitté la scène juridique, nourrissant une jurisprudence particulièrement médiatique.
Il est revenu sous le feu des projecteurs via le cas d’un couple d’hommes français, installé au Canada (où la gestation pour autrui est légalement autorisée) : ayant eu recours à deux GPA, dont sont nés trois enfants, ils ont demandé que la filiation déjà obtenue au Canada soit aussi reconnue en France.
La Cour de cassation (la plus haute juridiction française), en cette matière, se trouve confrontée à deux exigences apparemment contradictoires : d’un côté, le respect de la prohibition de la gestation pour autrui, inscrite à l’article 16-7 du Code civil ; de l’autre, la nécessité de protéger les droits des enfants nés à l’étranger.
Afin de mesurer toute la portée des deux arrêts rendus le 3 juillet 2026 par l’Assemblée plénière de cette instance, il est utile de revenir sur les principales étapes de ce parcours jurisprudentiel.
D’un refus absolu à une ouverture progressive
Dans un premier temps, la Cour de cassation s’est opposée à toute transcription des actes de naissance d’enfants nés d’une gestation pour autrui à l’étranger. Cette position a notamment été illustrée par l’arrêt Mennesson du 17 décembre 2008.
Elle fut remise en cause quelques années plus tard, à la suite des condamnations de la France par la Cour européenne des droits de l’homme, fondées sur l’atteinte portée au droit des enfants au respect de la vie privée.
En 2015, l’Assemblée plénière de la Cour de cassation admet la transcription des actes étrangers dès lors qu’ils sont « conformes à la réalité » au sens de l’article 47 du Code civil, selon lequel un acte d’état civil étranger fait foi dès lors que les faits qu’il relate correspondent à la réalité.
Cependant, cette réalité demeure alors entendue comme celle de l’accouchement : ainsi, seuls pouvaient être transcrits les actes désignant comme parents le père biologique et la femme ayant accouché, autrement dit les personnes génétiquement liées à l’enfant.
Deux ans plus tard, en 2017, la Première chambre civile admet explicitement la possibilité pour le parent d’intention (non génétiquement lié à l’enfant) de l’adopter.
Mais le véritable tournant allait survenir durant l’année 2019.
La transcription totale de l’acte de naissance
Saisie pour avis par la Cour de cassation française, la Cour européenne des droits de l’homme indique, dans un avis consultatif publié le 10 avril 2019, que les États doivent permettre l’établissement de la filiation avec le parent d’intention. Elle n’impose pas pour pour autant la transcription de l’acte de naissance. L’adoption peut donc être le moyen de remplir cette obligation.
Pourtant, à l’étonnement d’une large partie de la doctrine, le 4 octobre de la même année, l’Assemblée plénière de la Cour de cassation française se prononce pour la transcription complète de l’acte de naissance, en soulignant toutefois la spécificité de cette solution au cas d’espèce, en raison de la longueur de la procédure : les fillettes, dont la situation avait donné lieu à l’arrêt de 2008, étaient à cette époque âgées de 19 ans…
Deux mois plus tard, la Cour de cassation réaffirma néanmoins sa position, et l’étendit, en ordonnant la transcription totale d’un acte de naissance qui désignait le père biologique et son compagnon ou son époux en tant que parents, dès lors que l’acte en question s’avérait probant au sens de l’article 47 du Code civil.
La notion de « réalité » visée par l’article 47 cesse dès lors d’être exclusivement biologique : elle s’apprécie désormais au regard de la filiation légalement établie dans le pays d’origine.
En ordonnant la transcription totale de l’acte de naissance, alors que la Cour européenne laissait à la France le choix de l’adoption, la Cour de cassation a fait preuve d’une certaine audace au regard du droit français.
Le coup d’arrêt de la jurisprudence de 2019 par la loi de 2021
On a pu voir dans cette décision de la Cour de cassation un appel au législateur, afin qu’une solution légale soit donnée. Si cette hypothèse est correcte, on peut considérer que l’appel a été entendu.
En effet, la loi du 2 août 2021 est venue porter un coup d’arrêt à ce mouvement jurisprudentiel.
En précisant que la réalité des faits déclarés dans l’acte étranger doit être appréciée « au regard de la loi française », le législateur a entendu « acter le fait que l’acte de naissance d’un enfant né d’une GPA à l’étranger, qui désigne la mère d’intention comme mère, n’est pas conforme à la réalité, puisque, en droit français, la mère est celle qui accouche, hors hypothèse de l’adoption ».
Le simple ajout, dans l’article 47 du Code civil, de la courte mention « au regard de la loi française » a donc transformé l’interprétation de ce texte.
La réforme laisse cependant intacte une autre voie de reconnaissance des filiations établies hors de nos frontières : l’exequatur des décisions étrangères.
La voie de l’exequatur
L’exequatur est un terme juridique désignant la décision par laquelle une autorité judiciaire d’un État reconnaît et autorise l’exécution sur son territoire d’une décision rendue par une juridiction étrangère, ou parfois d’une sentence arbitrale internationale.
L’exequatur n’est pas une simple formalité. Il permet au juge français de contrôler qu’une décision étrangère remplit les conditions requises pour produire ses effets en France, notamment qu’elle ne méconnaît pas les principes essentiels de l’ordre juridique français.
L’intérêt de l’exequatur tient à ce qu’il obéit à une logique différente de celle de la transcription.
La transcription suppose un contrôle de l’acte de naissance étranger au regard de l’article 47 du Code civil et conduit le juge à apprécier la « réalité » des faits déclarés selon les exigences du droit français. L’exequatur, au contraire, n’a pas pour objet le contrôle d’un acte d’état civil, mais celui d’une décision juridictionnelle étrangère.
Autrement dit, dans le contentieux de la transcription, le juge français confronte l’acte de naissance étranger à la conception française de la filiation.
En revanche, dans le contentieux de l’exequatur, il n’appartient plus au juge de rediscuter cette filiation : il vérifie seulement que la décision étrangère a été rendue dans des conditions compatibles avec l’ordre public international français.
Le contrôle se déplace donc de la filiation elle-même vers le jugement qui l’établit.
L’avantage de l’exequatur sur la transcription
Il faut souligner ici que la transcription est une formalité « de publicité » : elle ne fait que constater la filiation établie à l’étranger, sans la créer.
À la différence d’un jugement qui établit la filiation et bénéficie de l’autorité de la chose jugée, la transcription n’empêche donc pas une contestation ultérieure de l’acte.
En revanche, à l’instar de l’adoption, l’exequatur présente un avantage sur la transcription : une fois prononcé, il confère en principe un caractère incontestable à la filiation établie.
Dans ce contexte, on comprend que la majorité des parents d’intention se tournent aujourd’hui vers cette procédure.
Les arrêts du 3 juillet déplacent donc le centre de gravité du débat, jusque-là fixé sur la notion de « réalité » au sens de l’article 47 du Code civil. Ce n’est plus principalement la conformité de l’acte de naissance étranger au regard de l’article 47 qui est contrôlée, mais les conditions dans lesquelles une juridiction étrangère a établi la filiation.
La motivation de la décision de la Cour de cassation
Le cas à l’origine de ce changement de logique était celui d’un couple d’hommes français, installé au Canada (où la gestation pour autrui est légalement autorisée), ayant eu recours à deux GPA, dont sont nés trois enfants.
Les juridictions canadiennes ont établi la filiation des enfants à l’égard des deux hommes, en les désignant comme leurs parents légaux. De retour en France, ces derniers ont demandé l’exequatur de ces décisions afin qu’elles produisent leurs effets sur le territoire français.
Par deux arrêts du 4 juin 2024, la Cour d’appel de Paris a accueilli les demandes d’exequatur des jugements canadiens désignant le couple comme parents (jugeant que lesdites décisions produiraient les effets d’une adoption plénière en France).
Cependant, la procureure générale auprès de la Cour d’appel de Paris a formé deux pourvois en cassation contre ces arrêts, qui ont donc été renvoyés devant l’Assemblée plénière de la Cour de cassation.
La formation la plus solennelle de la Cour de cassation était questionnée sur deux points :
la régularité des décisions canadiennes au regard de l’ordre public international ;
les effets de l’exequatur en droit français.
Régularité des décisions étrangères : le rôle central du juge français
À la question de la régularité des décisions au regard de l’ordre public international, l’Assemblée plénière de la Cour de cassation affirme que, si la prohibition de la gestation pour autrui constitue un principe d’ordre public international français, elle ne peut, à elle seule, justifier le refus de reconnaître une décision étrangère établissant la filiation d’un enfant né d’une GPA.
Le juge doit concilier cette interdiction avec le droit de l’enfant au respect de sa vie privée et familiale, garanti par l’article 8 de la CEDH et son intérêt supérieur protégé par l’article 3 de la Convention de New York du 20 novembre 1989 relative aux droits de l’enfant, l’un et l’autre participant de l’ordre public international français.
La Cour confirme ainsi que le contrôle du juge français ne porte plus sur la réalité de la filiation elle-même, mais sur la décision étrangère qui l’a établie. Le lien génétique n’est plus un paramètre de ce contrôle.
Le juge de l’exequatur doit en revanche procéder à un certain nombre de vérifications. À partir de la décision étrangère ou de documents équivalents, il doit notamment s’assurer que la mère porteuse a donné un consentement libre et éclairé, que les droits des personnes impliquées ont été respectés et que l’intérêt de l’enfant a été préservé. Si ces conditions ne sont pas réunies, l’exequatur est refusé.
La motivation de la décision étrangère doit donc permettre au juge français d’une part d’identifier la qualité des personnes ayant participé au projet parental d’autrui, d’autre part de s’assurer que les parties au contrat de gestation pour autrui (principalement la mère porteuse), ont consenti aux modalités et effets prévus par le contrat de gestation.
Effets de l’exequatur en droit français
Concernant le second questionnement, à savoir les effets de l’exequatur en droit français, la Cour de cassation rappelle que :
« Le juge de l’exequatur, lorsqu’il se prononce sur la régularité internationale de la décision étrangère, ne peut procéder à la révision au fond de celle-ci, et, d’autre part, qu’une fois revêtue de l’exequatur, une décision étrangère ne peut davantage être modifiée. »
Les juges de la Cour d’appel de Paris ont donc été censurés pour avoir jugé que la décision d’exequatur produirait en France les effets d’une adoption plénière des enfants, bien que la décision revêtue de l’exequatur ne fût pas un jugement d’adoption.
En définitive, les arrêts du 3 juillet 2026 ne consacrent pas la gestation pour autrui en droit français. Ils rappellent en revanche que son interdiction ne saurait, à elle seule, faire obstacle à la reconnaissance d’une filiation régulièrement établie à l’étranger.
Lorsqu’en 2021, le législateur s’est abstenu de remettre en cause le recours à l’exequatur, l’a-t-il fait délibérément, afin de préserver cette possibilité ?
Si tel n’est pas le cas, il lui appartient désormais d’intervenir expressément.
À défaut, l’exequatur pourrait bien s’imposer comme la principale voie de reconnaissance en France des filiations établies à l’étranger à la suite d’une GPA.
Valérie Depadt ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.07.2026 à 17:25
Affaire Lyhanna : « Les défaillances de la gendarmerie et de la police sont d’abord liées à un manque de moyens humains »
Olivier Cahn, Professeur de droit, Université Paris Nanterre
Texte intégral (2763 mots)
Comment expliquer les défaillances des services d’enquête dans l’affaire Lyhanna ? Les gendarmes et les policiers, chargés des missions de police judiciaire, sont en sous-effectif, à l’instar des magistrats. Submergés de dossiers, ils peinent à hiérarchiser les priorités, alors que les directives ministérielles multiplient les criminalités prioritaires. Entretien avec le professeur de droit Olivier Cahn.
The Conversation : Après le meurtre de la petite Lyhanna, on a beaucoup parlé des dysfonctionnements de la justice, un peu moins des défaillances de la gendarmerie nationale. En l’occurrence, on reproche aux gendarmes de Lectoure (Gers) de ne pas avoir auditionné le suspect, pourtant accusé d’une cinquantaine de viols sur une autre enfant. Que s’est-il passé ?
Olivier Cahn : Dans leur pré-rapport, l’inspection générale de la gendarmerie nationale et l’inspection générale de la justice considèrent que la plainte déposée par la mère de Rosa en août 2025 a été bien prise en charge par le parquet et la gendarmerie de Toulouse. Puis la procédure a été transmise au parquet d’Auch en raison de la domiciliation de la victime, mais par courrier postal, générant un premier retard.
La première observation, c’est donc que les outils informatiques du ministère de la justice et de l’intérieur sont largement obsolètes et que les informations circulent mal. Il n’existe pas de circulation fluide de l’information – ni entre les tribunaux ni entre les tribunaux et les services de sécurité intérieure.
Le second problème réside dans le pilotage de l’enquête par les gendarmes de Lectoure. Le pré-rapport reconnaît la charge de travail extraordinaire de la substitut du procureur d’Auch. Cette juridiction est confrontée à un nombre d’affaires d’infractions à caractère sexuel sur mineur « nettement supérieur à celui de la moyenne » des tribunaux judiciaires équivalents (en 2025, 167 affaires). Au 1er juin 2026, 154 enquêtes pour de tels faits étaient enregistrées, dont 62 depuis moins de six mois, 30 dans une période allant de six mois à un an, 44 depuis un à deux ans et 18 depuis deux à trois ans, pour une ancienneté moyenne de 11,3 mois.
Ces procédures sont traitées par le substitut du procureur de la République en charge des mineurs qui, en cette qualité, traite les signalements, représente le ministère public devant le tribunal pour enfants, assure le suivi des structures d’accueil de mineurs et les relations avec la protection judiciaire de la jeunesse, l’aide sociale à l’enfance et l’éducation nationale et gère la boîte à lettres spécifique destinée aux signalements prioritaires adressés par les institutions (éducation nationale, hôpitaux, etc.). En outre, il est compétent en matière d’atteintes aux personnes, de violences intrafamiliales, d’infractions à la législation sur les étrangers et il participe à la permanence générale du parquet, à la représentation du ministère public aux audiences correctionnelles et à la rédaction des règlements définitifs.
Sans que cela puisse surprendre, le parquet a délégué l’enquête à la gendarmerie, ce qui est la norme : les procureurs, n’ayant pas le temps de traiter toutes les procédures, délèguent, hors cas exceptionnel, les enquêtes aux officiers de police judiciaire.
Le pré-rapport suggère que le gendarme, directeur d’enquête, n’a peut-être pas perçu le caractère prioritaire de ce dossier, sur lequel son attention n’avait pas été attirée par le procureur. Je resterais néanmoins prudent, car il semblerait aussi que le parquet et la gendarmerie aient voulu « bétonner » la procédure, en procédant à une série d’actes d’enquête avant de convoquer l’individu suspecté. En effet, ce dernier avait déjà bénéficié d’un classement sans suite dans une affaire précédente et les enquêteurs ont peut-être voulu « sécuriser » son placement en garde à vue. On pourrait alors difficilement considérer que cela constitue une faute dans la conduite de l’enquête.
Quelle est la dimension structurelle de ces défaillances ?
O. C. : Les tribunaux sont confrontés à un nombre assez considérable d’affaires d’agressions sexuelles sur mineurs. Ainsi, par exemple, selon le pré-rapport, la région de gendarmerie Occitanie a connu, entre 2021 et 2025, une augmentation de 45 % des affaires d’infractions sexuelles sur mineurs et, s’agissant particulièrement du groupement de gendarmerie départementale du Gers, de 27 % de ces affaires, quand les effectifs ont été accrus de moins de 5 % et que le « trou à l’emploi » (mutations, détachements et arrêts de travail) dans la gendarmerie principalement concernée est de 5 à 7 militaires sur un effectif de 26.
S’il faut se féliciter de l’augmentation du nombre de plaintes pour des infractions sexuelles sur mineurs, qui témoigne de la libération de la parole des victimes et du changement d’attitude des parents, qui n’hésitent plus à dénoncer les faits, il n’en demeure pas moins que cet afflux de procédures pèse sur les services de police judiciaire. Ainsi, en l’espèce, le pré-rapport montre la grande implication de la mère de la petite Rosa, qui avait déposé plainte à Toulouse et qui a appelé à de très nombreuses reprises les services de police et de justice, pour leur mettre un peu la pression.
Mais, dès lors que, comme c’était le cas dans le Gers, les services judiciaires et de police croulent sous les dossiers en attente ou en cours de traitement, ils ont inévitablement du mal à prioriser et ne disposent pas d’un temps suffisant à consacrer à chaque affaire pour pouvoir finement distinguer l’urgent de l’impérieux.
Gérald Darmanin avait pourtant donné des directives pour prioriser les affaires de violences sexuelles sur mineurs…
O. C. : Quand tout est prioritaire, plus rien n’est prioritaire. Gérald Darmanin, au ministère de l’intérieur comme à celui de la justice, pratique la fait-diversification de la politique pénale. Les services reçoivent constamment des notes qui créent de nouvelles priorités, en fonction des émotions de l’opinion ou de l’électorat qu’il souhaite satisfaire. Ces notes exigent systématiquement des parquets et des services de police judiciaire un traitement « ferme, rapide et prioritaire » – c’est, à peu près, les termes employés.
On peut citer les Jeux olympiques et les opérations « Place nette » contre le narcotrafic, qui ont beaucoup mobilisé les services. Certaines directives sont plus démagogiques : par exemple, Gérald Darmanin a fait une priorité de la lutte contre les rodéos motorisés. La note précisait le nombre de rodéos qu’il fallait traiter chaque semaine et elle était renouvelée tous les printemps, obligeant alors les services de police à délaisser leurs dossiers en cours pour faire le chiffre réclamé.
En quoi a consisté la réforme de la police voulue par Gérald Darmanin, en 2023, qui visait, déjà, à résorber les procédures en souffrance ?
O. C. : En 2023, la loi a profondément modifié l’organisation de la police nationale en supprimant l’échelon régional. La gendarmerie n’était pas concernée. L’objectif initialement affiché était, entre autres, de contribuer à résorber le stock de procédures d’enquête en souffrance, alors évalué à 3 millions.
Le pré-rapport permet de constater que deux ans après la réforme, rien n’a été résolu, qu’il reste des stocks considérables d’affaires en souffrance au niveau territorial, en zone police ou en zone gendarmerie. En mars 2026, le ministère de l’intérieur continue d’admettre le chiffre d’environ 3 millions de procédures en souffrance, confirmant l’effet modeste de la réforme de 2023.
Avant 2023, l’organisation du traitement des procédures judiciaires au sein de la police distinguait les affaires locales ou d’une gravité mineure, qui étaient traitées par la sécurité publique, et les affaires plus graves ou complexes, qui étaient confiées, au niveau régional, aux services régionaux de police judiciaire (SRPJ) ou aux sections de recherches de la gendarmerie et, lorsqu’elles impliquaient une dimension (inter)nationale, aux offices centraux.
La loi a supprimé l’échelon régional de la police nationale et, désormais, l’échelon (inter)départemental est censé traiter tous les dossiers, de la délinquance du quotidien (cambriolages ou petites violences) jusqu’aux actes graves, comme les violences sexuelles sur mineurs. Seuls les dossiers de dimension (inter)nationale continuent d’être traités par les offices centraux.
Le niveau régional était celui de l’efficacité, abaissant les entraves à l’enquête induites par la compétence territoriale plus limitée des juridictions, alors que la police judiciaire voit aujourd’hui sa compétence circonscrite au département. Il n’est pas extravagant d’imaginer que, s’agissant en l’espèce de départements limitrophes, l’intervention d’un service doté d’une compétence régionale aurait été appropriée.
Mais les SRPJ ont été supprimés et les sections de recherches de la gendarmerie – encore une fois pour préserver des ressources humaines limitées – ne prennent pas en charge des affaires considérées comme dénuées de complexité en matière d’investigations, telles les affaires d’infractions sexuelles sur mineur, lorsque l’auteur est identifié.
Y a-t-il aussi un problème d’effectifs dans la police judiciaire ?
O. C. : La police judiciaire, qui était autrefois la mission la plus prestigieuse, est désormais délaissée, malgré des plans de recrutement. Travailler dans un service spécifique de la police judiciaire – contrairement à l’activité judiciaire de la sécurité publique – est un sacerdoce : c’est être sur le pont en fonction des opérations, sans emploi du temps fixe, avec une vie personnelle qui est largement dépendante de l’activité du service. Cela ne correspond plus aux mentalités des générations qui rejoignent les forces de sécurité intérieure.
Il y a des propositions gouvernementales pour améliorer les conditions de travail et la rémunération, mais les syndicats ne considèrent pas qu’elles sont suffisamment attractives pour remédier aux difficultés constatées.
Par ailleurs, les plans de recrutement ne prévoient l’embauche que de 700 enquêteurs de police. Or, l’Association nationale de la police judiciaire estime que c’est très insuffisant : les besoins seraient de l’ordre de 12 000 fonctionnaires.
Que contient la proposition de loi intégrale contre les violences sexistes et sexuelles promise par le premier ministre et réclamée par les associations et quelle analyse en faites-vous ?
O. C. : Selon son exposé des motifs, la proposition de loi visant à lutter de manière intégrale contre les violences sexistes et sexuelles commises à l’encontre des femmes et des enfants, du 2 décembre 2025, « embrasse l’ensemble des sphères dans lesquelles les violences s’exercent : justice, police, santé, éducation, travail, enfance, enseignement supérieur, numérique, etc., (…) s’attaque à toutes les formes de violences sexistes ou sexuelles envers les femmes et les enfants, qu’elles se produisent au sein de la famille ou en dehors, en ligne ou hors ligne, dans les commissariats ou les tribunaux, dans la sphère médicale ou professionnelle et dans le cadre du système prostitutionnel (…) [et] vise à supprimer les angles morts du droit, à mieux protéger les publics les plus exposés (femmes et enfants en situation de handicap, femmes migrantes, mineurs) et à garantir un accompagnement digne, une prise en charge adaptée, une justice accessible et une prévention des violences enfin efficace ».
Son inscription à l’agenda du Parlement a été annoncée par le premier ministre et elle devrait être examinée en septembre. Mais, elle ne réglera pas le problème du manque d’effectifs des services de police judiciaire. Il faut reconstruire des services dotés d’une compétence territoriale plus large et qui coopèrent entre eux, mais aussi prévoir des moyens importants – humains, matériels, de communication entre les services –, qui – n’en déplaise au président de la République – ont clairement manqué dans le traitement de l’affaire Lyhanna.
La justice pénale française dispose de quatre fois moins de procureurs que les pays comparables et, si le nombre d’agents de la force publique par habitant est satisfaisant, soit 37 pour 10 000 habitants en France, au regard de 32,5 pour 10 000 habitants en moyenne au sein de l’Union européenne, le nombre d’agents exerçant en police judiciaire demeure inférieur à 10 % des effectifs et diminue régulièrement.
Le fait d’avoir un parquet spécialisé et peut-être des services d’enquête spécialisés n’aurait-il pas du sens ?
O. C. : Un parquet national se justifie quand des individus ou des groupes criminels opèrent sur différents points du territoire, voire de manière transnationale. C’est le cas pour le parquet national financier, le parquet national antiterroriste et pour le parquet anti-criminalité organisée. Cette dimension n’existe pas lorsque l’on considère la criminalité sexuelle contre les enfants ou intrafamiliale.
Aussi, la création de juridictions spécialisées ne me semble pas justifiée. D’autant moins que la spécialisation de certains procureurs et policiers entraîne la surcharge de travail de leurs collègues qui travaillent dans les services « ordinaires » et que nous ne disposons pas d’un nombre suffisant de magistrats et d’enquêteurs pour nous le permettre.
En revanche, le résultat recherché par la création de juridictions spécialisées pourrait amplement être obtenu en continuant, et en renforçant, la spécialisation des acteurs à l’intérieur des parquets et à l’intérieur des services de police judiciaire. À Toulouse, la prise en charge de la plainte de Rosa par des professionnels formés a permis que soit menée une enquête efficace et de qualité. Il y a déjà des progrès en la matière dans certains services, il faut continuer en ce sens.
Propos recueillis par David Bornstein.
Olivier Cahn ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.07.2026 à 17:24
Les États-Unis à l’heure des christianismes concurrents
Blandine Chelini-Pont, Professeur des Universités en histoire contemporaine et relations internationales, Aix-Marseille Université (AMU)
Texte intégral (2223 mots)
Aux États-Unis, la religion demeure un facteur majeur de la vie politique et des comportements électoraux. Depuis le retour de Donald Trump à la Maison-Blanche, elle est également mobilisée pour légitimer des politiques intérieures et une vision particulière de l’ordre international. Cette évolution alimente une confrontation entre des interprétations concurrentes du christianisme, qui reflètent la profonde polarisation de la société américaine.
Dans la plupart des démocraties occidentales, le fait religieux a été significativement marginalisé dans l’espace politique. En la matière, les États-Unis font exception. Les débats collectifs y demeurent en effet empreints d’un haut niveau élevé de religiosité et les références confessionnelles y sont très visibles.
Cette permanence a conduit de nombreux chercheurs, comme Kenneth D. Wald ou Michael O. Emerson à s’intéresser prioritairement à la relation entre appartenance religieuse et comportement électoral. Les enquêtes menées depuis plusieurs décennies montrent en effet que les affiliations confessionnelles constituent l’un des meilleurs prédicteurs des préférences partisanes.
Toutefois, les évolutions observées depuis le retour de Donald Trump à la Maison-Blanche en 2025 invitent à élargir l’analyse. La religion n’est pas seulement une variable permettant d’expliquer les comportements politiques ; elle est aussi une ressource explicitement mobilisée par des acteurs concurrents afin de légitimer des projets de société, des orientations gouvernementales et des visions de l’ordre international.
La religion comme variable structurante du comportement électoral
L’élection présidentielle de 2024 a confirmé la persistance du facteur religieux dans la compétition électorale américaine. Malgré les transformations démographiques et l’augmentation de la proportion de citoyens se disant dénués d’affiliation religieuse, les appartenances confessionnelles demeurent fortement corrélées aux préférences partisanes.
Le principal soutien électoral de Donald Trump continue d’être constitué par les chrétiens blancs conservateurs. Les évangéliques blancs représentent à cet égard le groupe le plus solidement ancré dans la coalition républicaine. Leur soutien repose à la fois sur des positionnements classiques en matière de principes moraux — opposition à l’avortement, défense des libertés religieuses ou nominations judiciaires conservatrices – et sur le fait qu’ils ont davantage tendance à se représenter l’identité nationale américaine comme étant l’héritière d’un passé chrétien particulier. Cette orientation s’inscrit dans le développement du nationalisme chrétien, entendu comme la conviction selon laquelle les États-Unis seraient fondamentalement une nation chrétienne dont les institutions devraient refléter davantage les valeurs religieuses traditionnelles.
Si cette sensibilité demeure particulièrement forte parmi les évangéliques blancs, elle dépasse aujourd’hui largement ce seul groupe. À la présidentielle de 2024, Donald Trump a enregistré une progression auprès des électeurs hispaniques ainsi que, dans une moindre mesure, parmi certains segments de l’électorat afro-américain.
Face à cette coalition conservatrice, le Parti démocrate continue de s’appuyer sur un ensemble plus hétérogène associant protestants afro-américains, catholiques hispaniques, musulmans, juifs américains et individus sans affiliation religieuse. Les « nones », qui représentent désormais près d’un tiers de la population adulte, constituent l’un des segments les plus fidèles à la coalition démocrate. La religion conserve ainsi sa fonction classique de structuration des comportements électoraux.
La religion comme ressource de légitimation des politiques intérieures
Depuis 2025, la religion intervient bien au-delà de la seule sphère électorale. Elle constitue désormais un registre explicite de justification de l’action publique.
L’administration Trump s’appuie sur une coalition associant évangéliques conservateurs, nationalistes chrétiens, certains courants catholiques post-libéraux et diverses composantes du conservatisme culturel américain. Ces acteurs partagent le diagnostic d’un déclin moral de la société américaine provoqué par la sécularisation, le multiculturalisme et les politiques de diversité. Dans cette perspective, la lutte contre le wokeism occupe une place centrale, qui dépasse la critique culturelle ou la reformulation des débats publics.
Depuis 2025, elle se traduit par une série de mesures visant à supprimer ou à restreindre des politiques publiques considérées comme inspirées par les principes de diversité, d’équité et d’inclusion (DEI). Plusieurs programmes fédéraux ont été interrompus ou réorganisés, tandis que les administrations ont reçu pour instruction de mettre fin à certaines formations relatives aux discriminations systémiques, aux biais implicites ou aux politiques de diversité.
Cette approche s’étend également au secteur universitaire. L’administration fédérale a cherché à conditionner les financements fédéraux à l’abandon de dispositifs d’inclusion jugés discriminatoires, tout en soutenant les initiatives visant à limiter ou à supprimer certaines politiques de discrimination positive.
À lire aussi : Harvard face à l’administration Trump : une lecture éthique d’un combat pour la liberté académique
Tout cela participe d’un projet plus large visant à restaurer ce que ses promoteurs considèrent comme les fondements culturels, moraux et civiques traditionnels de la société américaine. Autrement dit, le christianisme conservateur ne sert plus seulement à interpréter le monde ; il contribue à légitimer une reconfiguration concrète de l’État fédéral, de l’université, de l’administration et des politiques publiques. Le nationalisme chrétien fournit ici un cadre idéologique particulièrement important. Il permet de présenter certaines politiques publiques comme des instruments de réaffirmation d’une identité nationale supposément menacée. Les politiques migratoires restrictives sont ainsi souvent justifiées au nom de la protection de la civilisation américaine et de ses fondements culturels.
Parallèlement, certains courants plus radicaux développent une réflexion critique à l’égard du libéralisme politique lui-même. Les milieux dominionistes – croyance que les chrétiens doivent prendre le contrôle de toutes les sphères de la société (gouvernement, éducation, médias, etc.) pour établir un ordre biblique, inspiré de la Genèse – au sein du protestantisme pentecôtiste ou certains auteurs catholiques post-libéraux contestent les principes traditionnels de séparation entre sphère religieuse et sphère politique et envisagent des formes plus étroites d’articulation entre pouvoir et christianisme.
Cette dynamique a suscité une contre-mobilisation religieuse inattendue. À partir de 2025, de nombreuses Églises protestantes historiques, des organisations œcuméniques et, surtout, plusieurs institutions catholiques se sont engagées dans une critique croissante des politiques migratoires de l’administration Trump, et leurs universités ont résisté à la suppression des politiques de diversité. Leurs prises de position s’appuient sur des références religieuses relatives à l’accueil de l’étranger, à la protection des plus vulnérables et à la dignité humaine.
Le rôle du catholicisme apparaît particulièrement significatif. Alors que les catholiques blancs avaient largement soutenu Donald Trump en 2024, une partie importante des institutions catholiques a progressivement pris ses distances avec nombre d’orientations gouvernementales, dont la suppression de l’agence USAid. La doctrine sociale de l’Église offre à cet égard un cadre normatif alternatif fondé sur le bien commun, la solidarité et la protection des migrants.
Parallèlement, plusieurs mouvements chrétiens progressistes ont gagné en visibilité. Ils cherchent à démontrer que les références religieuses peuvent également servir à défendre la justice sociale, la lutte contre les inégalités ou la protection des minorités. La religion devient ainsi un terrain de confrontation politique directe entre des interprétations concurrentes du christianisme.
La religion comme matrice de visions concurrentes de l’ordre international
Cette concurrence religieuse se prolonge aujourd’hui dans le domaine des relations internationales.
Le premier terrain de confrontation concerne le rapport à l’Europe et à la Russie. Une partie de l’entourage trumpiste développe une lecture civilisationnelle des relations internationales dans laquelle le principal clivage n’oppose plus démocraties et régimes autoritaires mais défenseurs et adversaires de l’héritage chrétien occidental. Les critiques adressées à l’Union européenne portent ainsi moins sur des désaccords stratégiques que sur la dénonciation de son supposé abandon des valeurs chrétiennes traditionnelles.
Le deuxième dossier concerne Israël. Pour une partie importante du protestantisme évangélique conservateur, le soutien à l’État hébreu ne relève pas uniquement de considérations géopolitiques. Il possède également une dimension théologique héritée du sionisme chrétien. Israël est alors conçu comme un acteur central du plan divin et comme un élément constitutif de la civilisation judéo-chrétienne.
Le troisième débat porte sur la guerre et sur les conditions légitimes du recours à la force. Certains milieux évangéliques développent une lecture providentialiste de l’histoire dans laquelle les États-Unis seraient investis d’une mission particulière. La figure de Donald Trump est parfois présentée comme celle d’un dirigeant choisi pour restaurer la grandeur nationale face aux menaces contemporaines.
Face à ces lectures, les Églises protestantes historiques, de nombreuses institutions catholiques et le Vatican défendent une vision davantage centrée sur le droit international, la coopération entre les peuples et les principes de la guerre juste.
Trump contre Léon XIV : une bataille pour l’autorité morale
Cette opposition traverse désormais le christianisme américain lui-même. Une partie importante des catholiques demeure proche du camp républicain. Une autre se reconnaît davantage dans les positions du nouveau pape. Les protestants historiques, les organisations œcuméniques et de nombreux mouvements de justice sociale se situent également dans cette seconde perspective. L’affrontement entre Donald Trump et Léon XIV constitue aujourd’hui l’expression la plus visible de cette polarisation religieuse.
À lire aussi : « Magnifica Humanitas » : le manifeste politique de Léon XIV
Les désaccords relatifs aux migrations, aux conflits armés ou au rôle des institutions internationales renvoient en réalité à deux conceptions distinctes de l’ordre mondial. L’une privilégie la souveraineté nationale, les rapports de puissance et la défense des civilisations ; l’autre insiste sur l’universalité de la dignité humaine, la coopération internationale et le multilatéralisme.
Au fond, le débat dépasse largement la seule question religieuse. Il porte sur la définition même de l’ordre politique contemporain. Faut-il privilégier la puissance ou le droit ? La nation ou l’humanité ? La civilisation ou l’universalité ? À travers ces interrogations, ce sont deux visions concurrentes du christianisme qui structurent aujourd’hui une part croissante de la vie politique américaine. C’est dans cette concurrence entre usages rivaux du christianisme que réside aujourd’hui l’une des clés d’interprétation de la polarisation politique américaine.
Blandine Chelini-Pont ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.07.2026 à 17:23
Écoles en surchauffe : un problème qui se joue avant tout à l’échelle des salles de classe
Mona Noroozi, Doctorante, Génie Civil et Sciences de l'Habitat, Université Savoie Mont Blanc
Monika Woloszyn, Professeure en physique du bâtiment, Université Savoie Mont Blanc
Nolwenn Hurel, Chercheuse en physique du bâtiment, Cerema
Texte intégral (2454 mots)
La canicule qui a frappé la France fin mai et en juin 2026 a illustré le manque d’adaptation du bâti scolaire face aux vagues de chaleur. L’éducation nationale entend y remédier à travers un plan spécifique, qui doit passer par le diagnostic des établissements scolaires les plus exposés à la chaleur. Une approche qui ignore que, au sein d’une même école, l’exposition aux températures peut varier en fonction de toutes sortes de facteurs. C’est notamment le cas de l’étage et de l’exposition des salles de classe, qui ont été examinées ici.
Les vagues de chaleur sont de plus en plus intenses, fréquentes, et surtout précoces. Elles arrivent de plus en plus tôt dans la saison, désormais dès les mois de mai ou de juin, pendant les dernières semaines de l’année scolaire. Les vagues de chaleur récemment connues par la France, fin mai puis de mi à fin juin 2026, l’ont illustré : elles ont affecté le déroulement des cours et des examens de fin d’année, comme le brevet ou le baccalauréat
À la clé, des canicules souvent éprouvantes, qui ont parfois forcé la fermeture de nombreuses écoles. Or, les enfants sont particulièrement vulnérables à la chaleur, car leur corps régule moins bien sa température que celui des adultes. Dans une salle surchauffée, leur concentration et leur capacité d’apprentissage chutent fortement.
Face à ces épisodes, on cherche naturellement des solutions pour rafraîchir les écoles. La circulaire du 27 mai 2026 relative au plan ministériel de gestion des vagues de chaleur prévoit ainsi d’établir une cartographie des bâtiments scolaires les plus exposés à la chaleur. Mais, avant cela, il conviendrait déjà de se demander si toutes les salles de classe chauffent de la même manière au sein d’un même bâtiment scolaire.
À lire aussi : Protéger les écoles des prochaines canicules : des solutions low-tech à expérimenter dès maintenant
La réponse est loin d’être évidente. Au sein d’un même bâtiment, deux classes peuvent connaître des températures très différentes. Il faut alors regarder ce qui se passe à l’échelle de la classe, et pas seulement à celle du bâtiment.
Ceci implique de ne plus considérer les écoles comme des blocs de salles de classe équivalentes où les écoles récemment rénovées ou construites seraient nécessairement davantage à l’abri que les autres : il convient d’examiner chaque situation dans les détails.
Quatre bâtiments scolaires pour illustrer la diversité du bâti scolaire français
Pour y voir plus clair, nous avons mené, dans le cadre d'un projet de recherche en cours, des mesures pendant la canicule de juin 2026 dans quatre écoles d’une même agglomération en Savoie.
Ces écoles n’ont pas été choisies au hasard : chacune est bâtie différemment, ce qui affecte la façon dont elle encaisse et restitue la chaleur. Pour chacune, des capteurs ont relevé la température de plusieurs salles, heure par heure, pendant toute la durée de la vague de chaleur.
Le bâtiment de l’école 1, dont la construction est très récente, est en béton isolé par l’extérieur, c’est aussi la seule école où une partie des fenêtres s’ouvre automatiquement la nuit.
Le bâtiment de l’école 2 est en parpaing non isolé.
le bâtiment de l’école 3 est en parpaing isolé par l’extérieur, ayant fait l’objet d’une rénovation énergétique récente.
Et enfin, le bâtiment de l’école 4 est en pierre.
D’un étage à l’autre, les salles de classe ne chauffent pas pareil
L’étage est le premier facteur que l’on peut examiner. Dans les quatre écoles étudiées, le rez-de-chaussée était presque toujours réservé aux espaces administratifs et communs, comme le bureau du directeur, la cantine, la bibliothèque ou la salle polyvalente, et comptait peu de salles de classe. Les classes se trouvaient surtout dans les étages supérieurs.
Or, ce simple déplacement des salles en hauteur peut suffire à changer du tout au tout l’expérience thermique des enfants. En effet, il existe des différences notables de température entre les classes du rez-de-chaussée et celles des étages élevés, comme le montrent nos mesures dans des classes situées dans le même bâtiment, soit en rez-de-chaussée, soit au dernier étage, pour une exposition équivalente des fenêtres.

Le résultat a été le même dans tous les cas : la classe à l’étage est restée plus chaude, sans jamais que l’inverse ne se produise. Ce qui frappe, c’est que cette tendance s’est vérifiée dans les quatre écoles, quelles que soient les caractéristiques du bâtiment.
Qu’il s’agisse de l’école de construction récente où les fenêtres s’ouvraient automatiquement la nuit pour laisser entrer l’air frais, de celle qui a été rénovée avec une isolation extérieure ou de celle qui ne l’était pas, dans tous les cas, les salles de classe à l’étage sont restées plus chaudes que celles du rez-de-chaussée. Aucune de ces caractéristiques n’a suffi à compenser l’effet de l’étage ou à l’effacer.
À quelques mètres près, l’orientation change tout
Sans surprise, l’orientation des fenêtres de la classe joue également un rôle crucial dans l’exposition à la chaleur. Entre deux classes du même bâtiment situées au même étage, l’orientation des ouvrants pouvait, à elle seule, entraîner des températures très différentes. C’est ce que montrent les résultats ci-dessous.

L’hétérogénéité du bâti scolaire explique en partie ces contrastes : les orientations des fenêtres diffèrent en fonction des salles et des bâtiments scolaires. Certaines donnent sur le soleil du matin, d’autres sur le soleil de l’après-midi, d’autres encore sur une cour brûlante ou ombragée.
Pourtant, lorsqu’il s’agit de déterminer le plan de l’école et de décider de l’affectation des pièces, le risque de canicule entre trop rarement en ligne de compte. Quelle pièce deviendra une salle de classe ? Laquelle servira de bureau, de réserve ou de salle commune ?
Le confort thermique des enfants, en toutes saisons, devrait être un critère déterminant. En cas de force majeure, le plan d’occupation des bâtiments doit pouvoir être adapté. On se souvient par exemple qu’il y a quelques semaines, certains élèves de Rueil-Malmaison (Hauts-de-Seine) ont dû passer les épreuves orales du bac de français dans un parking souterrain.
À lire aussi : Lors des canicules, notre cerveau ne s’aligne pas toujours avec le thermomètre et peut nous mettre en danger
Les écoles ne sont pas des espaces homogènes
Pour autant, les différences observées ici entre les classes ne sauraient être exclusivement attribuées à leur étage ou à leur orientation. Le comportement des occupants pendant les jours de classe, le moment où les fenêtres sont ouvertes et fermées, celui où les protections solaires sont abaissées ainsi que l’état des fenêtres et des protections pendant les jours de fermeture, qui conditionne leur efficacité pour limiter la surchauffe lorsque l’école est vide, sont autant de paramètres pouvant jouer sur les écarts de températures entre deux classes qui seraient, par ailleurs, dans des situations comparables en matière d’étage, d’exposition et de type de construction.
L’étage et l’orientation des fenêtres ne sont ainsi que deux facteurs parmi de nombreux autres : taille, nombre et type de fenêtres, matériaux, couleur des murs extérieurs, état des protections solaires, nombre d’enfants accueillis… on pourrait encore en dénombrer une dizaine d’autres.
Mais lorsqu’on voit à quel point ces deux facteurs simples suffisent à rendre deux classes d’un même bâtiment aussi différentes, on mesure à quel point il peut être trompeur de considérer une école entière comme un ensemble homogène.
C’est pourquoi il convient de se méfier des solutions toutes faites et de ramener le questionnement au bon niveau. Avant de se demander « comment rafraîchir les écoles », ne pas oublier : « Dans cette école en particulier, quelles pièces conviennent le mieux pour être utilisées comme salles de classe ? » Et, bien sûr, pour les écoles dont les murs ne sont pas encore sortis de terre : « Comment les classes pourraient-elles être plus fraîches dès le départ ? »
Mona Noroozi a reçu des financements de l'État, gérés par l'ANR au titre du PIA (réf. ANR-18-EURE-0016 – Solar Academy), et un cofinancement de l'ADEME (contrat n° TEZ24-039).
Monika Woloszyn a reçu des financements de l'ADEME et de l'ANR au titre du PIA (ref. ANR-18-EURE-0016 – Solar Academy).
Nolwenn Hurel a reçu des financements publics de l'ADEME et de l'ANR.
09.07.2026 à 17:19
Making scientific knowledge free for all
Frédéric Schmidt, Professeur, Planétologie, Université Paris-Saclay
Camille Thomas, Chercheur en géologie, University of Bern
Romain Vaucher, Senior Lecturer in Sedimentology, James Cook University
Texte intégral (2331 mots)

Scientific research publishing is a particularly lucrative industry. The most recent estimates suggest that it generates around 19 billion US dollars (or 16.67 billion euros) in annual turnover, with margins of around 40 per cent. These staggering figures largely reflect the fact that the “Big Five” commercial publishers, such as Elsevier, Springer Nature, Wiley, Taylor & Francis and SAGE, are capitalising on work that is largely funded by public money.
This monetisation takes place either by making a scientific article fee-paying, accessible via paid subscription, or by charging authors to publish in open access for readers. Yet most of the work required for publication – notably writing, peer review and a large part of the editorial work – is carried out free of charge by researchers. The direct consequence is that an institution or a country’s wealth still partly dictates access to scientific knowledge.
Paywalls
For decades, the vast majority of research has been published behind paywalls. This means that scientists, their institutions and the general public have to pay to gain access to scientific findings. An individual can purchase access to a specific article for a few tens or sometimes a hundred euros. Research institutes, for their part, pay for subscriptions that often run into millions of euros to thousands of scientific journals so that their researchers can access these articles.
Looking back, before the advent of the internet and the widespread publishing of journals in electronic format, it was understandable that the production of scientific articles incurred very high costs, particularly due to the print process and delivering journals to university libraries. Today, this justification no longer holds water.
Production costs may have fallen sharply thanks to the digital distribution of articles, but publication costs have risen dramatically. In response to this privatisation of knowledge, Aaron Swartz published the Guerrilla Open Access Manifesto in 2008, which aimed to raise awareness and highlight the lack of access for countries in the Global South.
Against this backdrop, Alexandra Elbakyan set up Sci-Hub in 2011, a platform providing access to a vast number of scientific publications, which has become one of the largest leaks of scientific knowledge of our time. Although this initiative is based on an ethical argument for universal access to knowledge, it remains illegal and is condemned in many countries, and cannot be a sustainable solution to the problem of access to scientific knowledge.
Is Open Access the answer?
In the face of growing frustration at research results being locked behind paywalls, and the resulting significant inequalities in access to science, Open Access (OA), is increasingly being demanded by research funding agencies, and sometimes by governments themselves. The aim is simple: to ensure that research, particularly when funded by public money, is accessible as a common good.
Today, while Open Access has become the norm, several models coexist and do not all address the issue in the same way.
The three main approaches are Green OA, Gold OA and Diamond OA:
Green OA involves publishing in a traditional, often commercial, journal and then depositing an accepted but unformatted version of the manuscript in an Open Access archive or an institutional repository
Gold OA makes the final article immediately accessible to everyone, but involves publication fees amounting (i.e. Article Processing Charge, APC) to several thousand euros, paid by the authors or their institutions
Diamond OA, finally, allows authors to publish content for free and gives readers free access, thanks to journals that are backed by scientific communities, university libraries or non-profit organisations.
Green and Gold Open Access models remain dependent on commercial publishers and often entail hidden costs for researchers, institutions or funding bodies. In contrast, Diamond Open Access is community-driven, free for both authors and readers, and maintains research as a “public good” rather than a source of private profit. While Green Open Access improves access in the short term, it can also delay more profound structural changes by preserving the existing system.
Examples of diamond open access
Thanks to recent advances in technology, it is easy to share computer code, and the scientific community, supported by public funding bodies, has come together to create Open Journal System, a ready-to-use software package for managing the entire editorial process of a scientific journal (from manuscript submission through peer review, editing, publication and dissemination).
Today, the system is used in 148 countries worldwide and enables scientists themselves to manage the editorial side of journals free of charge. Among these journals are Sedimentologika, founded in November 2022, which will soon publish its fiftieth article in the field of sedimentology, and Planetary Research, which is set to publish its first article in the field of planetary science this month, are two journals that we helped to found.
Other initiatives, organised as platforms, such as Sci|Post, which has historically been rooted in the field of physics, or Episciences, now offer models that extend to all fields of science, including the humanities and social sciences. At the more local level of institutions and universities, new academic publishing projects are emerging, such as POPS at Paris-Saclay University.
Scientists have also proposed alternative ways of publishing, breaking free from the most common codes of conduct. For example, publishing on Cornell University’s arXiv, a vast, free repository containing 2.4 million articles, or on its French equivalent, HAL, allows manuscripts to be shared without peer review (so-called ‘preprint’ articles). The only criterion for access is that the contributor must have an institutional email address or be endorsed by their peers (a recent requirement, necessary to filter out fake articles generated by artificial intelligence). Scientific quality assurance therefore remains relatively limited, but the advantage lies in the immediacy of dissemination to everyone.
Many highly influential and widely cited works, for example, in the field of artificial intelligence, such papers are thus accessible without ever having undergone peer review. However, most papers submitted to arXiv are subsequently published in scientific journals following a peer-review process. In such cases, arXiv serves primarily as a platform for rapid dissemination and scientific exchange, complementing rather than replacing the traditional editorial process.
Some learned societies have long offered journals with Diamond Open Access, such as the Comptes Rendus de l’Académie des sciences or certain papers from the American Mathematical Society. Unfortunately, the Diamond Open Access business model can sometimes be difficult to establish, but innovative solutions are being proposed. For example, the Bulletin de la Société mathématique de France offers a Subscribe-to-Open (S2O) model. Under this model, readers pay an annual subscription fee, but once the break-even point is reached, all articles published in the journal become freely accessible ad vitam aeternam. The counter is reset to zero every year.
Another way of publishing is to open up a free discussion about the article after it has been published. This type of approach has the advantage of allowing the article to be evaluated, but, as yet, no sustainable, large-scale solution has emerged. There are, however, some interesting options. For example, Peer Community In currently comprises 21 peer-reviewed thematic journals, publishes articles free of charge once the peer review process is complete, and leaves it up to authors to decide whether to resubmit to a traditional journal or not.
Future dangers, but also opportunities
Scientific publishing is currently under threat from the capitalist logic of major commercial publishers, who profit from an aura of prestige and respectability that is, in fact, created by the scientists themselves. Breaking this system remains difficult, as the most renowned scientists are sought after by the most prominent journals, thereby helping to perpetuate this model. Furthermore, the big publishing groups control a significant proportion of the tools used for searching, indexing and linking scientific articles, thereby further enhancing the visibility of their own journals.
Furthermore, these actors play an active role in producing scientometric pseudoscience by proposing quantitative metrics, such as citation counts, impact factors, etc. Although the limitations and pitfalls of these metrics have been extensively documented, and despite the existence of initiatives such as DORA, which calls for a reform of research evaluation, many public policies continue to rely solely on these indicators to assess science (prioritising the quantity of articles over their quality). Researchers’ careers are thus still largely assessed on the basis of the supposed prestige of the journals in which they publish.
In the face of authoritarian tendencies and the promotion of ‘alternative’ facts, science must preserve its independence and maintain the public’s trust now more than ever. Against a backdrop of budgetary constraints, collectively regaining control of scientific publishing infrastructure in a more efficient, less costly and more sustainable manner appears to be a major challenge for the scientific community.
Beyond the academic world, open access to knowledge also benefits the general public, teachers, organisations, decision-makers and the private sector by facilitating access to the latest scientific advances. Finally, making science more accessible does not simply mean disseminating more knowledge: it also helps to strengthen transparency, critical thinking and the collective ability to debate and respond to current challenges in an informed and reasoned manner.
A weekly e-mail in English featuring expertise from scholars and researchers. It provides an introduction to the diversity of research coming out of the continent and considers some of the key issues facing European countries. Get the newsletter!
Frédéric Schmidt is a lecturer at Université Paris-Saclay, member of the Institut Universitaire de France (IUF). He was awarded public (Université Paris-Saclay, CNRS, CNES, ANR, UE, ESA, France 2030) and private (Airbus) research funding. He is the Editor of the scientific journal Planetary Research and founding member of Planetary Research Cooperative, a non-profit organisation which owns the review.
Camille Thomas is co-founder and board member of Sedimentologika. He received funding to fund for Swiss scientific research. He works voluntarily as Editorial Manager for Sedimentologika and co-chairs the non profit organisation that owns the journal.
Romain Vaucher is co-founder and board member of Sedimentologika. He works voluntarily as Editorial Manager for Sedimentologika and is vice-president of the non profit organisation which owns the journal.
09.07.2026 à 14:32
Mbappé ne défend pas ? Et si, au football comme dans l’entreprise, le débat était mal posé ?
Laurent Modolo, Maître de Conférences en Sciences de Gestion, Université Bourgogne Europe
Texte intégral (1265 mots)
Le footballeur Kylian Mbappé est parfois critiqué pour son jeu insuffisamment défensif. Or, ces propos se fondent sur ce qui se voit en ignorant les consignes données au capitaine de l’équipe de France. Au-delà du football, cette attitude se retrouve souvent dans le monde professionnel. Elle révèle surtout un dysfonctionnement de l’entreprise.
Kylian Mbappé ne revient pas toujours défendre. Tout le monde l’a vu. Tout le monde a un avis. Mais avant de conclure qu’il ne fait pas son travail, une question mérite d’être posée : savons-nous réellement ce que Didier Deschamps lui demande de faire ?
Il ne revient pas. Il marche parfois. Il laisse ses coéquipiers défendre sans lui. À l’approche du Mondial 2026, les critiques s’étaient accumulées. Des statistiques sur le faible volume d’actions défensives de Kylian Mbappé ont circulé. Le verdict est rapidement tombé ! « Il ne fait pas assez d’efforts », « Il joue pour lui », « Il n’est pas assez collectif ». Pourtant, peu d’observateurs connaissent précisément la consigne.
Déviation par rapport au comportement attendu
On entend régulièrement dans le football actuel que « tout le monde doit défendre ». À force d’être répétée, cette affirmation finit par devenir une norme implicite : celui qui ne défend pas semble dévier du comportement attendu. Or cette norme suppose que le même comportement est attendu de tous les joueurs, indépendamment du rôle que leur attribue leur sélectionneur. C’est précisément cette hypothèse que le débat sur Mbappé invite à interroger.
À lire aussi : Mon salaire est-il vraiment le fruit de mon travail ?
Didier Deschamps l’a placé dans l’axe et lui a confié le brassard de capitaine. Mbappé lui-même rappelle que l’efficacité de l’attaque dépend de la coordination, des mouvements, du positionnement et des rotations entre les joueurs. Autrement dit, son rôle ne peut pas être compris isolément. On juge donc un comportement visible sans connaître ce qui était demandé.
Une erreur de raisonnement courante
C’est une erreur de raisonnement très courante. Nous observons ce qu’un individu fait ou ne fait pas et nous en déduisons ce qu’il vaut. Mais un comportement ne dit rien par lui-même. Il ne prend son sens qu’au regard de ce qu’on attendait de la personne. Sans cette information, le jugement est aveugle.
Nous commettons exactement la même erreur au travail, tous les jours. C’est peut-être même l’une des sources fréquentes du sentiment d’injustice au travail. Nous avons parfois l’impression d’être évalués sur ce qui se voit, plutôt que sur ce qui nous était réellement demandé.
Un commercial passe ses journées au téléphone, en rendez-vous ou à déjeuner avec des clients. Pour ses collègues qui ne voient pas directement son activité, il peut donner l’impression d’être peu présent, voire peu impliqué. Derrière ce jugement, une norme implicite : un bon salarié serait d’abord un salarié visible à son poste. Mais prospecter, négocier et entretenir des relations font précisément partie de son métier.
Des exemples dans la vie professionnelle
Un salarié quitte systématiquement le bureau à 17 heures. Certains collègues y voient un manque d’investissement. Là encore, une norme culturelle implicite agit. La personne qui reste tard serait plus engagée que celle qui part à l’heure. Pourtant, il a peut-être simplement terminé ce qu’on lui demandait, tandis que celui qui reste jusqu’à 20 heures compense une mauvaise organisation.
Un manager passe ses journées en réunion. On peut avoir l’impression qu’il ne produit rien. La norme implicite : travailler, c’est produire quelque chose de directement observable. Pourtant, si son rôle consiste à coordonner des équipes, ces réunions sont précisément son travail.
L’activité visible ou l’objectif ?
Dans chaque cas, l’erreur est la même ; on juge l’activité visible sans connaître l’objectif assigné. Cette erreur est d’autant plus tentante que l’effort visible rassure. Quelqu’un qui court, qui reste tard, qui répond vite ou qui enchaîne les réunions, donne des signes immédiatement lisibles d’engagement. À l’inverse, celui qui marche, part à l’heure ou travaille loin du regard collectif, paraît plus suspect. Mais ces signes disent parfois peu de la contribution réelle. Ils disent surtout ce qui est facile à observer.
Pourquoi cette erreur est-elle si fréquente ? Parce que, contrairement aux objectifs, les comportements sont toujours visibles. On voit Mbappé marcher, mais on ne voit pas les consignes de Deschamps. On voit le salarié partir à 17 heures, mais on ne voit pas ce qu’il avait à accomplir dans sa journée.
Quelle définition du « bon » travail ?
Le problème n’est donc pas seulement individuel. Quand une organisation laisse ses attentes implicites, elle pousse chacun à interpréter les comportements à partir de ses propres critères. Certains valorisent la présence, d’autres la réactivité, d’autres encore la disponibilité permanente. Faute de cadre partagé, chacun fabrique sa propre définition du « bon travail ».
C’est cette asymétrie qui explique un sentiment que beaucoup connaissent. Celui d’être jugé sur de mauvais critères. D’être évalué sur ce qu’on voit de nous plutôt que sur ce qu’on nous a demandé d’accomplir. Ce sentiment n’est pas toujours une illusion. Il reflète souvent une réalité. Les attentes n’ont pas été rendues suffisamment lisibles, ni pour la personne évaluée ni pour ceux qui l’observent. Quand les rôles restent flous, chacun finit par juger à l’aune des critères qu’il voit.
Alors, Mbappé doit-il défendre ? Peut-être. Peut-être pas. La réponse dépend du rôle que Didier Deschamps lui a confié, et c’est précisément ce que nous ignorons. Pour que le débat soit bien posé, avant de juger un collaborateur, un collègue… ou un joueur de foot et avant de dire que son comportement est acceptable ou non, interrogeons-nous d’abord sur les objectifs qui lui ont été réellement assignés.
Laurent Modolo ne travaille pas, ne conseille pas, ne possède pas de parts, ne reçoit pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'a déclaré aucune autre affiliation que son organisme de recherche.
09.07.2026 à 14:31
Ce que la Coupe du monde 2026 nous apprend sur la diversité et l’inclusion sur les réseaux sociaux
Matthijs Meire, Associate professor, IÉSEG School of Management
Arno De Caigny, Full Professor of Marketing Analytics, IÉSEG School of Management
Kristof Coussement, Professor of Business Analytics, IÉSEG School of Management
Willem Standaert, Associate Professor, Université de Liège
Texte intégral (1464 mots)
Le monde du football s’est emparé de la question de la diversité, non sans que quelques tensions soient observées. Mais comment est accueillie cette démarche ? Une analyse de plusieurs milliers de publications en ligne révèle une réalité subtile. Où l’on constate que, pour le public, toutes les formes de diversité ne se valent pas !
Nelson Mandela affirmait que « le sport a le pouvoir d’unir les gens comme peu d’autres choses le font ». Cet idéal est au cœur du message de la FIFA pour la Coupe du monde 2026, présentée comme une célébration de l’unité, de la diversité et de l’inclusion.
Le tournoi illustre cette ambition : une part importante des joueurs représente aujourd’hui un pays différent de celui de leur naissance, reflétant l’impact des migrations et la montée des identités multiples dans le football moderne.
Des enjeux sociétaux polarisés
Mais cette symbolique s’accompagne de tensions. Dans un contexte mondial marqué par les débats sur l’immigration, l’identité nationale et les droits des personnes LGBTQIA+, la Coupe du monde continue de susciter des controverses autour du visa d’un arbitre somalien, des déplacements des supporters et de la participation de l’Iran. Comme lors du débat autour du brassard « OneLove » en 2022, le football reste un espace central où se cristallisent des enjeux sociétaux plus larges et souvent polarisés.
À lire aussi : Coupe du monde de football 2026 : faut-il craindre une hausse des violences envers les femmes ?
Ces discussions ne s’arrêtent pas aux stades. Elles se prolongent sur les réseaux sociaux, où, chaque publication, campagne ou prise de position est immédiatement amplifiée, commentée et débattue à grande vitesse. Dans cet environnement, les fédérations, sponsors et marques doivent composer avec une forte visibilité mais aussi une exposition accrue aux réactions publiques. Une question centrale émerge alors : comment communiquer efficacement sur la diversité et l’inclusion dans un espace aussi fragmenté et polarisé ?
Une diversité pénalisante ?
Pour répondre à cette question, nous avons analysé plus de 6 000 publications Facebook et Instagram issues de neuf fédérations européennes de football. En nous appuyant sur des entretiens avec des experts du secteur, nous avons distingué sept dimensions de la diversité : le genre, la race et l’origine ethnique, l’âge, le handicap, la religion et la culture, l’orientation sexuelle et la classe sociale.
Pris dans leur ensemble, les contenus liés à la diversité semblent générer en moyenne moins d’engagements que les autres publications. Ce résultat, cohérent avec certaines études antérieures, peut facilement conduire à une lecture simpliste selon laquelle la diversité serait « pénalisante » sur les réseaux sociaux. Une telle interprétation serait toutefois trompeuse.
En réalité, l’analyse par dimension révèle une structure beaucoup plus fine des réactions du public. Les publications mettant en avant la diversité de genre ou d’âge suscitent en moyenne moins d’engagements. À l’inverse, celles illustrant la diversité raciale génèrent davantage de réactions positives sur Facebook comme sur Instagram. Ces différences importantes expliquent en partie pourquoi la littérature scientifique est souvent contradictoire : certaines recherches isolent une seule dimension de la diversité, tandis que d’autres les agrègent en un indicateur unique. Nos résultats montrent que la diversité et l’inclusion ne forment pas un concept homogène, mais un ensemble de dimensions distinctes, susceptibles de déclencher des réponses sociales, émotionnelles et culturelles très différentes selon les publics.
Un enjeu de communication
Ces résultats déplacent la question centrale, puisqu’il ne s’agit pas de savoir si les organisations doivent communiquer sur la diversité et l’inclusion, mais comment elles doivent le faire de manière pertinente et contextualisée.
Premièrement, les organisations doivent aller au-delà des messages génériques sur l’inclusion et identifier précisément quelles dimensions de la diversité elles mettent en avant dans leur communication. Les réactions des publics dépendent fortement du contexte culturel, du secteur d’activité, mais aussi des normes implicites propres à chaque communauté en ligne. Une marque de grande consommation, une entreprise technologique ou une université peuvent ainsi observer des dynamiques très différentes, voire opposées. L’enjeu n’est donc pas de suivre une recette universelle, mais de comprendre les attentes et sensibilités de sa propre audience.
Deuxièmement, il est essentiel de distinguer communication et impact. Les contenus où la diversité est intégrée de manière naturelle dans la communication quotidienne tendent à générer des performances plus solides que ceux reposant principalement sur des campagnes explicites, des slogans ou des hashtags dédiés. Cela ne remet pas en cause la légitimité des prises de position publiques, mais suggère que leur efficacité dépend fortement de leur cohérence avec l’ensemble du discours de marque et de leur intégration dans des contenus perçus comme authentiques.
Des effets discrets à ne pas ignorer
Troisièmement, il faut dépasser une lecture strictement quantitative de l’engagement. Si certains contenus liés à la diversité génèrent moins de « j’aime » ou de commentaires, ils peuvent néanmoins avoir un effet plus discret mais stratégique : celui de modifier la composition de l’audience engagée. Nos analyses exploratoires suggèrent en effet que certains types de contenus attirent des publics plus diversifiés selon différentes dimensions identitaires. Autrement dit, la valeur de ces communications ne réside pas uniquement dans le volume d’interactions, mais également dans la capacité à élargir et diversifier la base sociale de l’engagement, ce qui constitue un enjeu croissant pour les organisations.
À mesure que la Coupe du monde 2026 se déroule, le football continuera de générer des débats sur l’identité, l’appartenance et la représentation, bien au-delà des terrains. Ces discussions se joueront autant sur les réseaux sociaux que dans les stades, et chaque prise de position y sera immédiatement interprétée et discutée dans des environnements souvent polarisés.
Pour les organisations sportives comme pour les marques, l’enjeu n’est plus de déterminer si la diversité a sa place dans la communication. Il s’agit désormais de reconnaître qu’elle est multidimensionnelle, que les publics sont hétérogènes, et que la performance d’une stratégie de communication ne peut être réduite aux seuls indicateurs d’engagement à court terme.
Les auteurs ont reçu une subvention de l’Union des associations européennes de football (UEFA).
Arno De Caigny et Kristof Coussement ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
09.07.2026 à 11:07
Pourquoi les alertes environnementales sont-elles si difficiles à entendre ?
Guy Richard, Directeur de l'expertise scientifique collective, de la prospective et des études à l'Institut national de la recherche pour l'agriculture, l'alimentation et l'environnement (INRAE), Inrae
Jean-Michel Salles, Directeur de recherche, Centre national de la recherche scientifique (CNRS)
Michel Colombier, Directeur scientifique, Iddri
Texte intégral (2996 mots)

Les dernières canicules en Europe ont pris de court les populations et les pouvoirs publics, mais pas les scientifiques qui alertent depuis des décennies sur le réchauffement climatique. Pourquoi, dès lors, n’ont-ils pas été plus écoutés ?
L’histoire contemporaine des alertes environnementales trouve l’un de ses moments fondateurs dans la publication, en 1962, de Silent Spring (Printemps silencieux) par Rachel Carson (1907-1964). En révélant les effets délétères des pesticides sur la santé humaine et les écosystèmes, la biologiste américaine inaugure une forme moderne d’alerte fondée sur l’expertise scientifique. Son ouvrage a contribué à transformer les politiques environnementales, mais a également suscité de vives réactions de la part des industriels concernés. Ceux-ci ont contesté à la fois ses conclusions et sa crédibilité.
Depuis lors, les alertes se sont multipliées : pluies acides, destruction de la couche d’ozone, changement climatique, désertification, érosion de la biodiversité ou pollutions chimiques. Pourtant, malgré l’accumulation des connaissances scientifiques, elles demeurent souvent remises en cause, ignorées ou accueillies avec scepticisme.
Les alertes ne restent pas nécessairement lettre morte. Printemps silencieux, par exemple, a débouché sur une large interdiction du DDT. Les travaux des chimistes Mario Molina et Frank Rowland ont conduit à une interdiction progressive des CFC, principales substances appauvrissant la couche d’ozone. Dans ces deux cas, des solutions de substitution assez simples à mettre en œuvre ont rapidement émergé ; ce qui a pu limiter le coût du changement tout en faisant émerger des acteurs économiques favorables à cette transition.
Mais même ces changements ne se sont pas faits sans résistances. Dans la plupart des cas, on doit s’interroger sur les raisons qui rendent si difficile de faire entendre ces alertes.
Des risques que nous percevons de moins en moins
Les premières alertes environnementales portaient souvent sur des nuisances locales : fumées industrielles, rivières polluées, déchets toxiques ou intoxications chimiques. Elles étaient fréquemment relayées par les populations directement concernées – riverains, pêcheurs, agriculteurs ou associations de victimes. Les populations éloignées des zones concernées percevaient rarement le problème, comme nous sous-estimons souvent les pollutions engendrées dans les pays en développement par notre consommation.
Aujourd’hui, les principaux enjeux environnementaux présentent une difficulté supplémentaire. Le changement climatique, l’érosion de la biodiversité ou la perturbation des grands cycles biogéochimiques résultent de l’accumulation de millions de décisions individuelles et collectives. Leurs effets apparaissent parfois à l’autre bout du monde et souvent plusieurs décennies après leurs causes.
Plus les problèmes deviennent globaux, moins ils sont directement perceptibles. La plupart d’entre nous ne voient ni l’augmentation de la concentration atmosphérique en CO₂, ni l’érosion de la diversité génétique des espèces, ni l’acidification progressive des océans.
La disparition des insectes pollinisateurs ou le déclin des populations d’oiseaux communs passent largement inaperçus pour les non-spécialistes, a fortiori avec une population massivement urbanisée. Ce n’est qu’à travers des suivis scientifiques réalisés sur plusieurs décennies que ces tendances deviennent visibles.
Une amnésie générationnelle
Prenons l’exemple des oiseaux communs. Beaucoup ont le sentiment d’en voir encore dans leur jardin. C’est ce qu’on appelle l’« amnésie écologique ».
En France, la mesure du déclin des populations d’oiseaux n’apparaît clairement qu’en réunissant les observations recueillies depuis plus de trente ans par des milliers d’observateurs bénévoles. Ces derniers ont suivi un protocole identique dans toute la France, à travers le Suivi temporel des oiseaux communs (STOC), coordonné par la Ligue de protection des oiseaux et le Muséum national d’histoire naturelle.
Sans cet effort de long terme, cette érosion resterait largement invisible. Nous savons, grâce à ce travail minutieux, que les populations d’oiseaux ont décliné de 57 % depuis 1980 dans les plaines agricoles.
Les alertes environnementales contemporaines reposent ainsi de moins en moins sur l’observation d’événements intelligibles et de plus en plus sur l’interprétation de séries de données accumulées au cours de plusieurs décennies.
À lire aussi : Quand et comment décide-t-on qu’une espèce est éteinte ?
De même, personne ne perçoit directement une hausse moyenne de la température mondiale d’environ 1,3 °C. Celle-ci n’apparaît qu’à travers l’accumulation de millions de mesures réalisées sur l’ensemble de la planète. Inversement, les épisodes de 1976 ou de 2003 sont toujours dans les mémoires et alimentent l’idée que « [la canicule,] ce n’est pas nouveau ».
Le « paradoxe de l’environnementaliste »
Un paradoxe supplémentaire complique la situation. Malgré la multiplication des alertes, une grande partie de l’humanité a connu au cours des dernières décennies une amélioration de ses conditions de vie : allongement de l’espérance de vie, recul de certaines formes de pauvreté, accès accru à l’éducation, à l’énergie ou aux soins. Cette situation correspond à ce que certains chercheurs ont appelé le « paradoxe de l’environnementaliste ».
Les alertes décrivent ainsi des dégradations peu ou pas perceptibles par la population. À l'inverse, les bénéfices des activités qui les provoquent demeurent largement visibles dans l’expérience quotidienne.
À lire aussi : La catastrophe qui tarde : pourquoi les humains semblent-ils vivre mieux sur une planète qui se dégrade ?
Croire ceux qui voient ce que nous ne voyons pas
Face à ces phénomènes, l’expérience personnelle ne suffit donc plus. Les alertes environnementales reposent de plus en plus sur la médiation de la science.
De fait, les scientifiques ont appris à détecter des dégradations invisibles à l’échelle individuelle, à identifier les causes, à anticiper les conséquences futures et à explorer les réponses possibles. Sans les mesures atmosphériques, les suivis de biodiversité, les modèles climatiques ou les études épidémiologiques, une grande partie des atteintes environnementales contemporaines resterait encore imperceptible.
Cette situation crée cependant une difficulté. La science parle un langage qui n’est pas celui du débat public. Elle raisonne en probabilités, en scénarios, en marge d’erreur et en niveaux de confiance. Elle expose ses controverses et ses incertitudes. Cette prudence constitue une force, du point de vue de la connaissance. Mais elle peut devenir une faiblesse dans l’espace médiatique ou politique, où les messages simples et catégoriques circulent souvent plus facilement.
Par exemple, les travaux du Groupe d’experts intergouvernemental sur l’évolution du climat (Giec) n’annoncent pas un futur unique, mais explorent plusieurs trajectoires possibles en fonction de différents scénarios d’émissions. Les conclusions sont exprimées sous forme de probabilités ou de niveaux de confiance. Cette manière de raisonner est indispensable à la démarche scientifique, mais contraste avec l’attente fréquente de réponses simples et définitives.
Pour la plupart des citoyens, il est impossible de vérifier personnellement ces résultats. L’adhésion repose donc largement sur la confiance accordée aux institutions scientifiques et à leur méthode. Or, cette confiance n’est plus aussi évidente qu’elle a pu l’être.
À lire aussi : Pourquoi le climatoscepticisme séduit-il encore ?
Des récits concurrents plus simples et rassurants
Cette dépendance à l’expertise scientifique rend également les individus plus sensibles à certains mécanismes psychologiques bien identifiés. De nombreux travaux en sciences comportementales, notamment ceux du psychologue et économiste Daniel Kahneman ou de la psychologue Elke Weber, montrent que nous avons tendance à privilégier les bénéfices immédiats, les situations familières et les informations compatibles avec nos valeurs ou nos intérêts.
Or, les alertes environnementales demandent souvent l’inverse. Elles invitent à prendre au sérieux des risques futurs, à envisager des transformations profondes et à accepter des messages complexes ou anxiogènes.
Dans le même temps, les environnements numériques facilitent la circulation de récits concurrents qui proposent des explications plus simples du monde. Ces récits offrent souvent davantage de certitudes, désignent clairement des responsables et procurent un sentiment d’appartenance à une communauté partageant les mêmes convictions.
La recherche (par exemple, les travaux du chercheur en sciences cognitives Stephan Lewandowsky) montre que leur attractivité ne dépend pas seulement du niveau d’éducation ou d’information. Elle répond également à des besoins psychologiques et sociaux : réduire l’incertitude, préserver une identité collective ou maintenir un sentiment de contrôle sur les événements. La difficulté des alertes environnementales tient donc aussi à la concurrence entre différents récits du réel.
Quand les alertes semblent remettre en cause la prospérité
Une autre singularité des alertes environnementales est qu’elles concernent souvent des activités qui ont largement contribué à l’amélioration du bien-être humain. L’industrialisation, l’exploitation des énergies fossiles, l’intensification agricole ou le développement des transports ont permis des progrès considérables en matière de santé, d’alimentation, de mobilité ou de richesse matérielle.
Cette situation distingue les alertes environnementales de nombreuses autres alertes sanitaires ou techniques. Ces dernières portent souvent sur des produits ou des pratiques dont les bénéfices apparaissent limités au regard des dommages qu’ils provoquent. Ainsi, l’interdiction des chlorofluorocarbures (CFC), responsables de la destruction de la couche d’ozone et utilisés notamment dans le fonctionnement de réfrigérateurs et de climatiseurs, a été facilitée par l’existence de substituts techniques rapidement disponibles.
Cette situation distingue les grands enjeux environnementaux contemporains d’alertes sanitaires plus anciennes qui ont pu être résolues sans remettre en cause l’organisation générale de l’économie. Ainsi, l’interdiction progressive de l’amiante ou la suppression de l’essence plombée ont porté sur des produits clairement identifiés, pour lesquels des solutions de remplacement ont progressivement été développées.
À l’inverse, réduire la dépendance aux combustibles fossiles suppose de transformer simultanément les systèmes énergétiques, les transports, une partie de l’industrie, l’agriculture ou encore l’aménagement des territoires. Les alertes environnementales contemporaines mettent ainsi en question des activités qui restent associées, dans l’expérience collective, au progrès matériel et à l’amélioration des conditions de vie.
Les scientifiques qui identifient les causes des dégradations environnementales sont ainsi conduits à interroger des technologies, des secteurs économiques et des modes de vie qui demeurent étroitement liés à notre prospérité.
Le biais de « statu quo »
Cette difficulté est renforcée par ce que les psychologues et les économistes comportementaux appellent le biais de « statu quo » : face à l’incertitude, nous avons spontanément tendance à préférer les situations existantes, même lorsqu’elles comportent des risques à plus long terme.
Même lorsque des alternatives existent, elles apparaissent souvent comme des promesses futures, alors que les coûts du changement semblent immédiats : investissements, transformations industrielles, modifications des habitudes de consommation ou craintes pour l’emploi.
L’alerte environnementale ne demande donc pas seulement de reconnaître un risque. Elle invite aussi à réévaluer certains fondements matériels du développement contemporain.
À lire aussi : Inaction climatique : et si on était victime du biais de « statu quo » ?
Intérêts économiques et fabrication du doute
Depuis plusieurs décennies, enfin, de nombreux travaux ont documenté les stratégies mises en œuvre par certains secteurs économiques pour retarder ou affaiblir les régulations. Par exemple : financement de recherches destinées à entretenir la controverse, campagnes de communication, lobbying politique ou mise en avant systématique des incertitudes résiduelles.
Les historiens des sciences Naomi Oreskes et Erik M. Conway ont montré comment certains acteurs industriels ont développé des stratégies visant moins à réfuter les résultats scientifiques qu’à maintenir l’impression d’une controverse permanente. Ceci notamment en finançant des recherches ou des expertises mettant en avant des explications alternatives susceptibles de détourner l’attention des causes les mieux établies. Ces pratiques ont été documentées dans les domaines du tabac, des pluies acides, des pesticides – où de multiples facteurs alternatifs ont été invoqués pour relativiser la responsabilité des néonicotinoïdes dans le déclin des pollinisateurs – et, surtout, du changement climatique.
Les stratégies ont cependant évolué. Pendant longtemps, il s’agissait principalement de contester certains résultats scientifiques. Aujourd’hui, les attaques visent plus largement la crédibilité des scientifiques, des institutions de recherche ou de la démarche scientifique elle-même, comme le montrent Olivier Berné, Emmanuelle Perez Tisserant et Tamara Ben Ari.
Cette évolution intervient dans un contexte où la confiance envers les institutions est fragilisée et où la diffusion de récits concurrents est devenue plus rapide et plus massive.
Faire reconnaître des connaissances dérangeantes
Les alertes environnementales ne sont pas les seules à rencontrer des résistances. L’histoire des lanceurs d’alerte, des controverses sanitaires ou des révélations politiques montre que les sociétés n’accueillent pas sans résistance les informations qui remettent en cause des intérêts établis ou des représentations dominantes. Depuis le mythe de Cassandre, condamnée à annoncer des catastrophes sans jamais être crue, jusqu’aux débats contemporains sur le climat ou la biodiversité, le problème n’est donc pas seulement de produire des connaissances, mais de faire accepter des informations dérangeantes.
Les alertes environnementales ne posent donc pas seulement la question des connaissances scientifiques. Elles révèlent une transformation plus profonde : à mesure que les risques deviennent globaux, diffus et différés, l’expérience individuelle ne suffit plus à les appréhender. Les alertes environnementales reposent désormais largement sur des connaissances auxquelles le public doit faire confiance, sans pouvoir les vérifier directement.
Cette situation ouvre aussi un espace particulièrement favorable aux stratégies de manipulation : lorsque les faits ne peuvent plus être directement éprouvés, la confiance accordée à ceux qui les établissent devient elle-même un enjeu du débat public, voire un objet de confrontation politique ou économique. L’enjeu n’est donc pas seulement de produire des savoirs, mais de préserver les conditions qui permettent à une expertise indépendante d’être reconnue comme suffisamment crédible pour éclairer les choix collectifs.
Jean-Michel Salles a reçu des financements de l"ANR au cours de sa carrière, mais pas directement sur cette thématique..
Guy Richard et Michel Colombier ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur poste universitaire.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview