
01.06.2026 à 17:26
Rendre le numérique accessible aux personnes déficientes visuelles : un enjeu à la croisée de la psychologie et de la cybersécurité
Nicolas Louveton, Enseignant-chercheur en psychologie et ergonomie cognitive, Université de Poitiers
Cassandre Simon, Ingénieure de Recherche en Interaction Humain-Machine, Université de Poitiers
Texte intégral (2025 mots)
Entrer un mot de passe puis un code reçu par SMS pour se connecter sur le site de sa banque constitue, pour la plupart des utilisateurs, une démarche contraignante mais réalisable. En revanche, pour les personnes porteuses de déficiences visuelles, cela peut représenter un obstacle majeur, voire insurmontable. Face à ces difficultés, il existe plusieurs solutions, certaines déjà mises en œuvre et d’autres, conçues en partenariat avec les utilisateurs, qui sont en cours de développement.
Les services numériques sont omniprésents dans notre quotidien. Qu’il s’agisse de réserver un billet de train, de déclarer ses impôts ou de prendre un rendez-vous médical, se connecter à des plateformes numériques en ligne est devenu un passage obligé pour de nombreux gestes du quotidien. Pour cela, une étape incontournable : l’authentification, un processus qui permet de contrôler notre identité et de protéger nos données.
Parce que la sécurité sur nos téléphones et autres écrans est bien souvent centrée sur notre capacité à voir lesdits écrans, nombre de personnes aveugles ou malvoyantes renoncent à sécuriser leurs appareils.
L’accessibilité des systèmes d’authentification est pourtant cruciale dans une société qui se veut inclusive et qui promeut l’usage du numérique dans une large gamme de services, et notamment les services publics.
Comment la perception du risque, le design technologique et le handicap interagissent-ils pour conduire à des comportements non sécurisés et à l’exclusion numérique ? C’est ce que nous cherchons à mieux comprendre en mobilisant l’ergonomie cognitive, une discipline scientifique visant à concevoir des systèmes adaptés aux capacités et limites des utilisateurs finaux.
Notre but est de créer un cadre intégrant la recherche scientifique, l’innovation technologique et les considérations éthiques, vers une sécurité numérique véritablement inclusive.
L’authentification : passage obligé de la vie numérique
Bien que nécessaire, cette étape de sécurité soulève certaines difficultés.
De fait, les méthodes d’authentification n’ont pas été conçues avec un objectif de facilité d’utilisation : leurs concepteurs ont plutôt cherché une forme de barrière contre les accès non autorisés. Si ces méthodes posent des difficultés à une grande partie des utilisateurs, les personnes en situation de handicap, et notamment les personnes aveugles et non voyantes, sont particulièrement impactées.
En France, en 2005, 1 700 000 personnes étaient touchées par un handicap visuel, soit près de 2,9 % de la population. Ces utilisateurs sont souvent contraints de limiter leur usage du numérique, de compromettre leur sécurité (absence de code PIN ou de mots de passe) voire de renoncer à leur autonomie vis-à-vis du numérique en demandant systématiquement l’aide d’un tiers de confiance.
Ergonomie de l’authentification
La méthode d’authentification la plus répandue reste le couple nom d’utilisateur-mot de passe, avec des exigences de plus en plus complexes pour les mots de passe. Selon le niveau d’expertise, de sensibilité et de confiance en soi de l’utilisateur, on observe des stratégies très différentes de gestion des mots de passe. Certaines de ces stratégies affaiblissent la sécurité (utiliser des mots familiers, personnaliser une base de mots de passe, conserver une liste papier ou électronique). D’autres sont plus avancées, comme l’utilisation d’un gestionnaire de mots de passe.
Plus récemment, les solutions biométriques se distinguent par leur utilisabilité et leur sécurité, comme la reconnaissance faciale ou le lecteur d’empreintes digitales notamment. Elles ont l’avantage d’être « transparentes », elles peuvent néanmoins soulever des questions quant à la gestion des données personnelles, et elles ne sont pas infaillibles – l’invisibilité elle-même peut devenir un problème d’ergonomie (déverrouillage involontaire du smartphone, par exemple).
Enfin, l’authentification à facteurs multiples (MFA) est désormais largement répandue. Cette méthode est plus sûre, mais aussi plus complexe pour l’utilisateur, car elle ajoute des étapes avant d’accéder au service. Cependant, certaines méthodes posent des défis considérables aux personnes déficientes visuelles. Les captchas, qui impliquent la résolution de défis souvent fondés sur la perception visuelle ou auditive, en sont l’exemple le plus évident.
Handicap visuel et authentification
Pourtant le numérique, et le Web en particulier, sont supposés être accessibles à tous : dans cet esprit, la Web Accessibility Initiative (WAI, Initiative pour l’accessibilité du Web) promeut des standards tels que les Web Content Accessibility Guidelines (WCAG), qui sont des recommandations internationales définissant les critères qu’un site doit respecter pour être utilisable par tous, y compris les personnes en situation de handicap.
En France, leur équivalent réglementaire s’appelle le Référentiel général d’amélioration de l’accessibilité (RGAA), dont le respect est obligatoire pour les services publics en ligne. Par exemple, ces normes définissent des seuils acceptables de contrastes entre les couleurs de pages Web pour en assurer la lisibilité aux malvoyants, ou encore établissent les bonnes pratiques de balisage d’une page pour la rendre accessible aux lecteurs d’écran.
Les interfaces numériques reposent majoritairement sur des modalités visuelles pour transmettre l’information, en particulier lors des procédures d’authentification. Si des outils d’assistance tels que les lecteurs d’écran, les logiciels de grossissement, les commandes vocales ou les terminaux Braille permettent aux personnes aveugles ou malvoyantes d’interagir avec ces interfaces, leur utilisation ne garantit pas toujours la confidentialité des données, selon le contexte.
Ce problème est particulièrement marqué sur mobile, où les écrans tactiles sont omniprésents. Utiliser une interface tactile avec un lecteur d’écran, c’est s’exposer à ce qu’un observateur proche entende ou voie ce que l’on fait. La saisie d’un mot de passe sur smartphone est ainsi considérée comme l’une des tâches les plus difficiles pour un utilisateur aveugle ou malvoyant : elle engendre un inconfort en public et une vulnérabilité particulière aux regards indiscrets (shoulder surfing).
C’est pourquoi la plupart des utilisateurs aveugles ou malvoyants ne protègent pas leur appareil mobile par un mot de passe – et ce, malgré le fait que 96 % d’entre eux considèrent l’authentification comme essentielle ou très importante (enquête menée auprès de 325 personnes).
Par ailleurs, les utilisateurs déficients visuels tendent à abaisser leur vigilance quant à leur sécurité et à la confidentialité de leurs données lorsqu’ils se trouvent entourés de proches, adoptant une attitude plus transparente vis-à-vis de leurs informations personnelles.
Des recherches ont montré que, parmi les méthodes d’authentification, les scans d’iris et les schémas de déverrouillage sont les moins accessibles, tandis que la reconnaissance d’empreintes digitales est la plus accessible et la plus sûre pour les personnes aveugles ou malvoyantes. Les codes PIN, bien qu’omniprésents sur mobile, sont perçus comme inconfortables – ils ralentissent considérablement l’activité.
Enfin, des appareils complémentaires peuvent renforcer la sécurité et la confidentialité, tels que les claviers Braille ou les lunettes numériques grossissantes. Ils nécessitent toutefois d’être correctement intégrés aux outils du quotidien des personnes aveugles ou malvoyantes.
Le projet ALIAS
Nous avons démarré le projet de recherche ALIAS, collaboration entre chercheurs en psychologie et en ergonomie cognitives et un partenaire industriel spécialisé dans les systèmes d’authentification. Notre démarche de conception participative, centrée sur l’utilisateur, place au cœur de la conception, les besoins et les pratiques réels des utilisateurs, y compris ceux en situation de handicap.
Concrètement, le projet se divise en trois étapes majeures. La première – qui est en cours de réalisation – consiste à analyser les besoins, à travers un état de l’art scientifique et des études de terrain menées auprès des utilisateurs. Une première enquête en ligne auprès des personnes atteintes de déficience visuelle (300 participants), complétée par des groupes de discussion, a permis d’identifier les principaux points de friction ainsi que les besoins réels en matière d’interaction et d’accessibilité.
Ces résultats serviront de base à la deuxième étape, dédiée au développement de prototypes élaborés à partir des données recueillies.
Enfin, la troisième étape visera à améliorer ces prototypes de manière itérative, grâce à des tests utilisateurs menés avec les utilisateurs cibles, afin d’aboutir à des recommandations pour la conception d’une solution véritablement adaptée à leurs besoins.
Les auteurs remercient Zoé Ferfaille, ingénieure d’étude sur le projet ALIAS, pour sa contribution aux recherches qui sous-tendent l’article. Le projet ALIAS fait partie du Programme de transfert de compétences et de technologies de la recherche dans le domaine de la cybersécurité et implique l’entreprise OpenSezam, l’Université de Poitiers et le CNRS.
Le Programme de transfert de compétences et de technologies de la recherche dans le domaine de la cybersécurité — P1 (ANR-22-PTCC-0001) est géré par l’Agence nationale de la recherche (ANR), qui finance en France la recherche sur projets. L’ANR a pour mission de soutenir et de promouvoir le développement de recherches fondamentales et finalisées dans toutes les disciplines, et de renforcer le dialogue entre science et société. Pour en savoir plus, consultez le site de l’ANR.
Nicolas Louveton est membre de l'université de Poitiers. Il a reçu des financements de l’Agence Nationale de la Recherche au titre de France 2030 portant la référence ANR-22-PTCC-0001.
Cassandre Simon est membre du CNRS et de l'université de Poitiers. Elle a reçu des financements de l'Agence Nationale de la Recherche au titre de France 2030 portant la référence ANR-22-PTCC-0001.
30.05.2026 à 08:47
Néandertal utilisait-il les dents de rhinocéros comme outils ?
Camille Daujeard, Archéozoologue, chargée de Recherche, Muséum national d’histoire naturelle (MNHN)
Texte intégral (3553 mots)

Le projet RINO est né de la découverte de traces singulières observées sur des dents de rhinocéros d’un site préhistorique de la vallée du Rhône. L’étude des restes dentaires de rhinocéros du site paléolithique moyen de Payre (vers 250 000-130 000 ans avant le présent) a en effet permis de mettre en évidence des marques qui pourraient indiquer leur utilisation comme outils par Néandertal – un comportement inédit.
À l’inverse de la figure emblématique du mammouth, la place du rhinocéros dans les comportements de subsistance des humains préhistoriques et les relations qu’ils ont entretenues tout au long du paléolithique sont peu connues. Pourtant, bien avant les représentations pariétales de la grotte Chauvet (Ardèche), il y a plus de 30 000 ans, cet animal a été consommé et utilisé à d’autres fins qu’alimentaires. La découverte de marques inhabituelles sur des dents de rhinocéros dans plusieurs sites du paléolithique du sud de la France soulève une question : ces marques pourraient-elles être le résultat d’une activité humaine intentionnelle ?
L’utilisation d’ossements de grands herbivores, y compris de rhinocéros, comme outils pour retoucher et raviver les tranchants de pierres taillées (« retouchoirs ») est un comportement bien connu, dès les périodes anciennes du paléolithique. Les dents de rhinocéros sont nombreuses dans les sites du paléolithique d’Europe et d’Asie et seules quelques rares études font l’hypothèse d’une récupération intentionnelle de celles-ci par les groupes humains.
Des fractures et des marques singulières
Il y a plus de 200 000 ans, à Payre, dans le sud-est de la France, ou encore sur le site de Panxian Dadong, en Chine, qui a livré une centaine de dents isolées de rhinocéros asiatique (Rhinoceros sinensis), des dents de rhinocéros présentant des fractures et des marques récurrentes ont été retrouvées. Ces observations ont conduit à s’interroger sur leur utilisation comme outils, et à explorer d’autres assemblages à rhinocéros de cette période du paléolithique en Europe. Serait-on là face à un comportement encore inconnu chez Néandertal ?
Cette question est à l’origine du projet RINO et de la publication qui vient de paraître dans la revue Journal of Human Evolution : « Elucidating the use of rhinoceros teeth by Neanderthals: Between experiments and the fossil record » (« Élucider l’utilisation des dents de rhinocéros par Néandertal : entre registres expérimental et fossile »), issue d’une collaboration scientifique internationale.
Il s’agit de la première étude approfondie et interdisciplinaire sur l’utilisation des dents de rhinocéros par Néandertal. Cette étude combine des analyses de restes fossiles et des expérimentations archéologiques sur des dents de rhinocéros actuels.
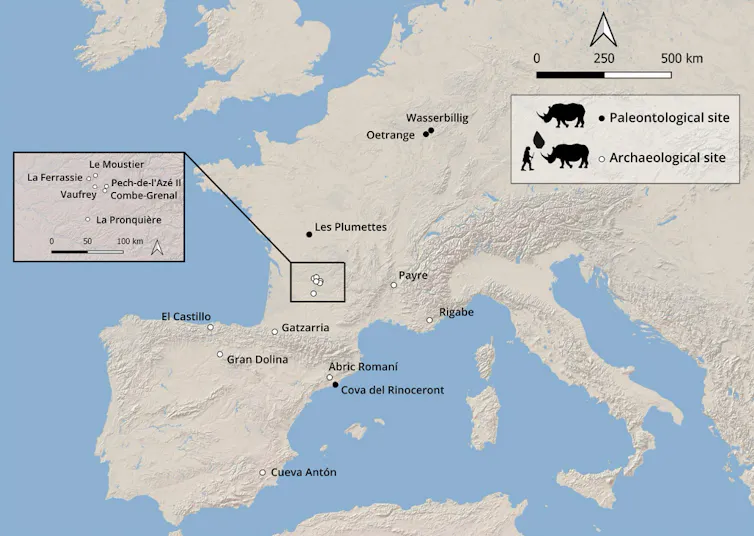
Les dents de rhinocéros possèdent en effet des caractéristiques morphologiques (taille, poids, caractère préhensible, surface occlusale plane et résistance à la fracturation) qui ont pu motiver leur usage à des fins techniques.
Méthode de recherche
Dans le cadre du projet RINO, 12 sites archéologiques ont été sélectionnés pour leurs traces d’activité humaine et leur abondance en dents de rhinocéros.
Afin d’avoir un référentiel de comparaison permettant de distinguer des traces naturelles de traces d’origine anthropique, comme suspectées, nous avons également inclus dans cette étude des séries dentaires provenant de sites paléontologiques d’Europe de l’Ouest et de collections ostéologiques de rhinocéros actuels. Ces séries comprennent au total 168 dents de rhinocéros provenant de quatre sites paléontologiques du Pléistocène en Europe occidentale : Wasserbillig (Luxembourg), Oetrange (Luxembourg), Cova del Rinoceront (Espagne) et Les Plumettes (Saône-et-Loire).
Nous avons également analysé 236 dents provenant de la collection comparative de la salle d’anatomie comparée du Muséum national d’histoire naturelle (MNHN) à Paris, avec l’objectif de reconnaître les altérations susceptibles d’avoir affecté les dents de rhinocéros tout au long de leur vie.
Une analyse des microtraces d’usure dentaire liées aux processus de mastication a été menée sur les dents de rhinocéros fossiles, afin de pouvoir écarter l’hypothèse d’une origine liée à l’alimentation du vivant de l'animal.
Par ailleurs, une part importante du projet concernait la démarche expérimentale. L’utilisation de molaires et de prémolaires de rhinocéros comme percuteurs par des tailleurs experts devaient permettre d’établir un référentiel complet des marques obtenues, et d’identifier la fonction de ces outils.
La principale difficulté rencontrée a été celle de l’acquisition de dents actuelles de rhinocéros pour effectuer ces expérimentations. Après de nombreuses recherches, avec l’aide d’Alexis Lécu, vétérinaire au Muséum national d’histoire naturelle, trois parcs zoologiques nous ont prêté du matériel dentaire, les zoos de Peaugres (Ardèche), de Sigean (Audes) et Montpellier (Hérault). Les extractions ont été effectuées par Benjamin Drouet à Peaugres et par Antoine Joris à Sigean.
Les expérimentations de percussion (retouche, taille, utilisation comme enclume) ont pu ainsi être menées sur 18 dents de rhinocéros, à l’aide d’outils lithiques en quartz et en silex. L’objectif était de reconnaître et d’identifier les traces laissées par l’action humaine.

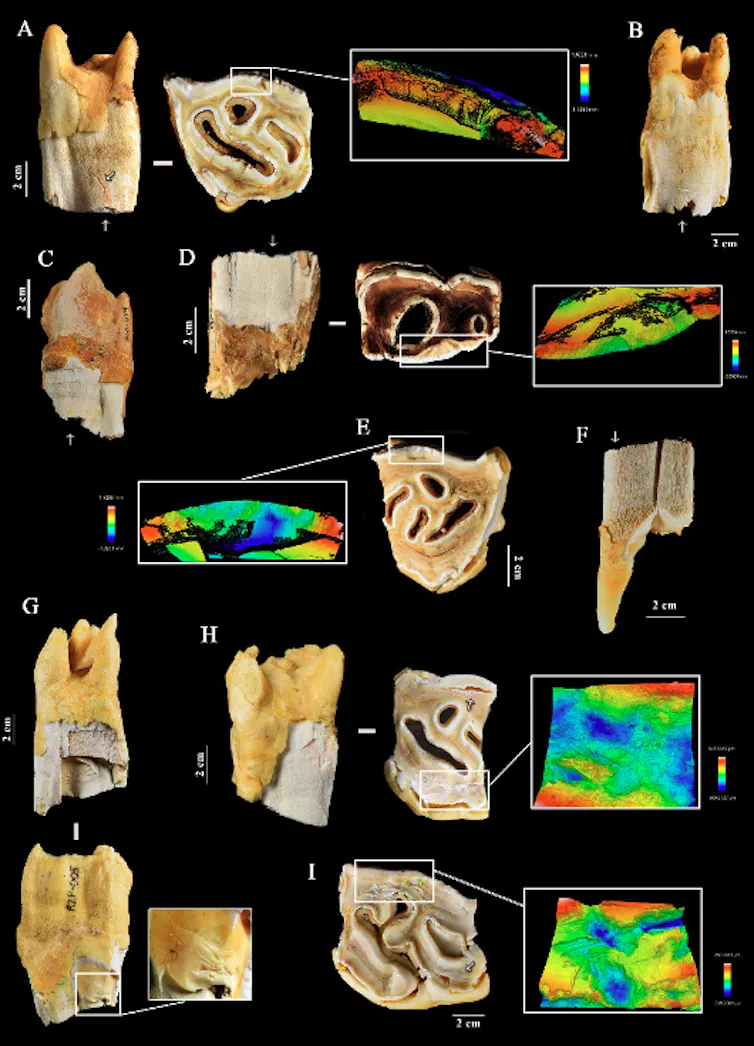
Un dernier volet de référentiel expérimental visait à reproduire des phénomènes naturels d’abrasion (sédiments) et de compaction que peuvent subir des dents durant leur fossilisation. Ces expérimentations ont été menées au sein du laboratoire de taphonomie de Madrid (LeaT laboratory).

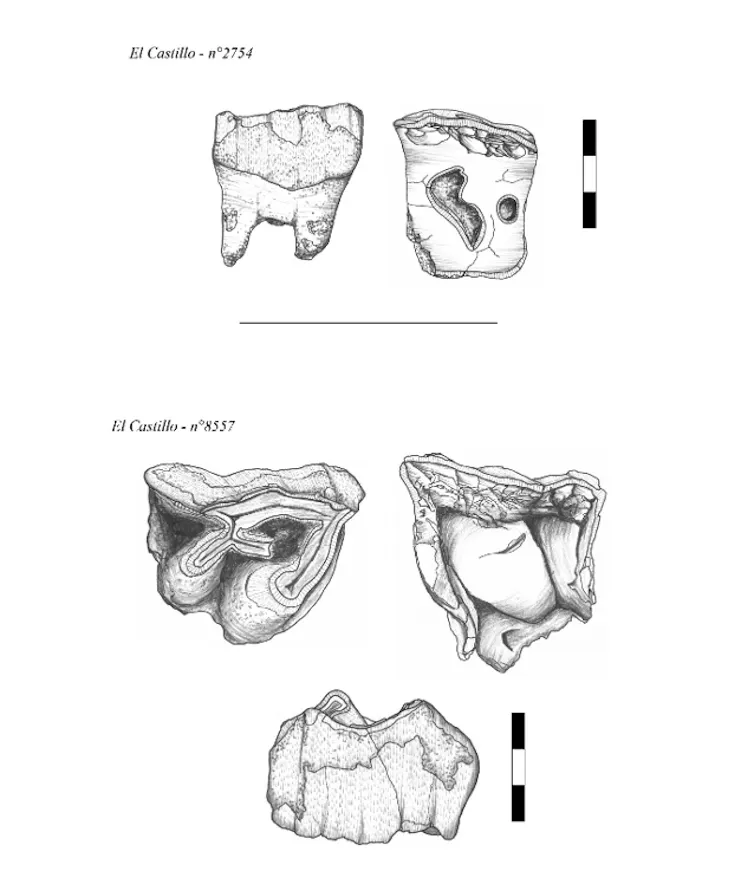
Les résultats obtenus révèlent la présence de marques similaires à celles de Payre ainsi qu’à celles produites lors des expérimentations archéologiques, dans deux autres sites néandertaliens : El Castillo (Espagne) et Pech-de-l’Azé II (Dordogne). Dans ces deux sites, qui comptent au total 281 dents analysées, les espèces de rhinocéros concernées sont le rhinocéros de prairie (Stephanorhinus hemitoechus) et le rhinocéros de Merck (Stephanorhinus kirchbergensis). Ce dernier représente la plus grosse forme de rhinocéros fossile européen connue pour cette période.
Les traces observées sur le matériel dentaire diffèrent en revanche clairement des altérations de surface observées dans les collections de référence paléontologiques et modernes ainsi que de celles générées lors des expérimentations d’abrasion et de compaction sédimentaire. Par ailleurs, l’analyse des microtraces d’usure confirme qu’elles ont été produites après la mort de l’animal.
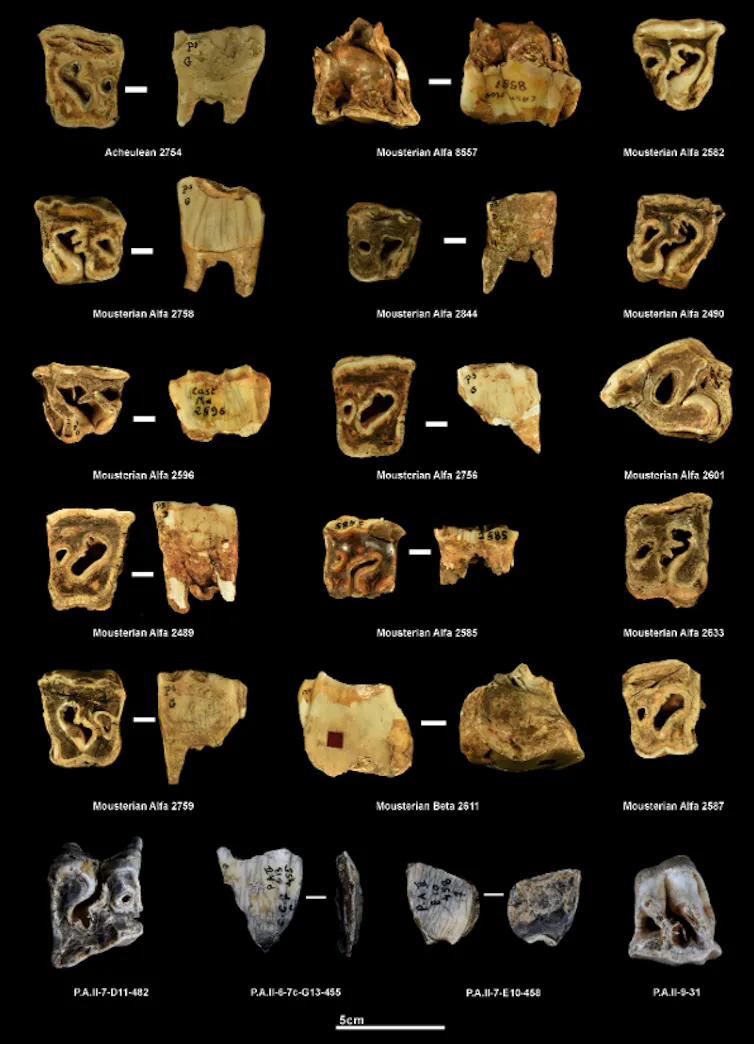
Des dents qui ont probablement servi d’outils percuteurs
Nous pouvons donc conclure que les traces identifiées sur les dents de rhinocéros de ces deux sites du paléolithique moyen – El Castillo (Espagne) et Pech‑de‑l’Azé II (France) – sont d’origine humaine. Ces dents ont probablement servi comme percuteurs dans la confection d’outils lithiques (silex, quartz), jouant un rôle dans la chaîne opératoire au paléolithique moyen. Au vu de l’état d’usure des dents utilisées, les Néandertaliennes et Néandertaliens semblent avoir eu une préférence pour des dents de rhinocéros âgés. Il est possible qu’ils se soient concentrés sur de vieux animaux, parce qu’ils représentaient potentiellement des proies plus faciles, ou des charognes. Leur morphologie dentaire, plus aplatie, était sans doute aussi plus adaptée à leur utilisation.
Cette étude permet d’élargir nos connaissances sur les comportements néandertaliens, leurs choix techniques et la diversité des matières premières collectées et utilisées, tout en apportant un nouvel éclairage sur leur utilisation des ressources animales. Malgré cette nette avancée dans le champ de nos connaissances, cette découverte ouvre également de nouvelles et nombreuses questions, qui restent pour le moment encore en suspens :
Qu’est-ce que cette découverte apporte à nos connaissances de Néandertal et de ses relations à son environnement ?
Quelles étaient les stratégies d’acquisition (chasse, charognage, piégeage) et d’utilisation des rhinocéros par Néandertal ? Étaient-elles les mêmes pour tous les types de rhinocéros rencontrés à ces périodes en Europe ? Leurs particularités morphologiques, éthologiques et écologiques et leur disponibilité au sein des biotopes ont-elles influé sur ces comportements ?
Le caractère inédit des marques mises en évidence montre tout l’intérêt de ces recherches, qui ouvrent comme on l’a vu beaucoup de questions qui restent encore à explorer. Il est par ailleurs peu probable qu’une utilisation de dents de rhinocéros comme matière première ait été un comportement limité dans le temps et dans l'espace. C’est pourquoi une révision majeure des séries dentaires de rhinocéros issues des nombreuses collections de sites paléolithiques doit être engagée à la lumière de ces nouvelles observations.
Actuellement, nous ne savons pas si c’est un comportement général ou spécifique aux groupes néandertaliens d’Europe de l’Ouest. Mais que l’on mette en évidence le caractère « universel » ou original de l’utilisation de ces dents, cette découverte ouvre des perspectives en lien avec la connaissance de l’étendue, de la fonction et de la portée symbolique de ce comportement.
Nous remercions le projet RINO (Sorbonne Université et Muséum national d’histoire naturelle) et l’IRN TaphEN (CNRS) pour leur soutien financier. Nous tenons également à exprimer notre gratitude envers toutes les personnes qui nous ont autorisés à accéder aux collections archéologiques et paléontologiques et aux laboratoires qui nous ont accueillis. Enfin, nous adressons nos sincères remerciements aux parcs zoologiques de Peaugres, Sigean et Montpellier (France) pour nous avoir fourni les dents de rhinocéros utilisées lors des expérimentations, avec une mention spéciale à Alexis Lécu, vétérinaire au MNHN, pour son aide précieuse dans cette recherche.
Camille Daujeard a reçu des financements de Sorbonne Université, du Muséum national d'Histoire naturelle, et de l'IRN Taphen (CNRS).
29.05.2026 à 09:00
À force d’utiliser l’IA, les journalistes risquent-ils d’appauvrir la langue ?
Xosé López-García, Periodismo digital, comunicación digital, Universidade de Santiago de Compostela
Cristian Augusto Gonzalez Arias, Investigador, Pontificia Universidad Catolica de Valparaiso; Universidade de Santiago de Compostela
Texte intégral (1673 mots)

Historiquement, le journalisme a contribué à diffuser de nouveaux mots et à nommer les transformations du monde. Si les textes générés par l’IA deviennent dominants, cette dynamique d’innovation linguistique pourrait s'affaiblir.
Que devient le langage public lorsqu’une part croissante des textes qui circulent dans la presse, sur Internet et sur les réseaux sociaux commence à être rédigée par des machines ? La question ne concerne pas seulement le journalisme en tant qu’activité professionnelle. Elle peut aussi affecter la richesse de la langue que nous utilisons pour comprendre, décrire et débattre du réel.
Historiquement, la presse a été l’un des espaces où la langue commune s’est développée et enrichie. Elle n’est évidemment pas le seul moteur du changement linguistique, mais elle constitue l’un des lieux où les sociétés mettent en circulation de nouveaux mots, de nouvelles tournures et de nouvelles façons de nommer des phénomènes émergents. Plusieurs travaux sur le langage journalistique et les néologismes montrent d’ailleurs que les journaux ont longtemps joué un rôle essentiel dans la création et la diffusion de vocabulaire nouveau, en particulier lorsqu’il s’agissait de rendre compte d’événements, de technologies ou de transformations sociales auprès d’un large public.
Ce rôle pourrait s’affaiblir si une part importante de l’écriture journalistique était déléguée à des systèmes d’IA générative. Les grands modèles de langage reposent, de manière générale, sur la prédiction du mot – ou plus précisément du « token » – le plus probable au sein d’une séquence. Ils produisent ainsi des textes fluides et plausibles, mais tendent également à privilégier les régularités statistiques, les formulations les plus fréquentes et les tournures déjà stabilisées.
Cela ne signifie pas, en soi, que le langage se dégrade automatiquement. Le problème apparaît lorsque cette logique devient dominante dans la production des textes qui alimentent l’espace public.
Quand les IA s’entraînent sur des textes produits par d’autres IA
Le risque devient plus sérieux lorsque ces systèmes commencent à être entraînés à partir de textes produits par d’autres IA. C’est ce que plusieurs travaux récents décrivent sous le nom de model collapse, ou « effondrement du modèle » : un processus de dégénérescence dans lequel les données générées par un modèle finissent par contaminer l’entraînement des générations suivantes.
Appliqué au langage, cela signifie que si les systèmes apprennent de plus en plus à partir de textes synthétiques, et si ces textes en viennent à saturer le Web et l’espace public, le réservoir linguistique disponible pour les futurs entraînements se rétrécit. Plus il y a de textes artificiels, moins les modèles sont exposés à la diversité réelle des usages humains de la langue. À terme, cela peut entraîner un appauvrissement du langage dans différents domaines.
Reproduction et amplification des biais
Tout d’abord, lorsque la diversité des données diminue et que les modèles s’appuient principalement sur des schémas déjà établis, les biais présents dans les données d’entraînement risquent d’être renforcés plutôt que corrigés. La littérature récente sur l’évolution des modèles de langage met précisément en garde contre le fait que les processus récursifs peuvent amplifier des préjugés existants au lieu de diversifier les points de vue.
Par ailleurs, l’écriture tend à se ressembler de plus en plus à elle-même : les mêmes structures syntaxiques, les mêmes tonalités intermédiaires, les mêmes formulations et les mêmes façons d’organiser les paragraphes reviennent sans cesse. Cette évolution est particulièrement importante pour le journalisme, car la presse ne se contente pas de transmettre des informations : elle fait le lien entre des savoirs spécialisés et un large public, hiérarchise les enjeux, traduit des vocabulaires techniques et expérimente de nouvelles formulations. Lorsque la langue de l’espace public devient trop uniforme, sa capacité à s’adapter finement à la nouveauté s’affaiblit.
Une érosion de l’innovation linguistique
Dans ce contexte, les mots rares ou spécialisés, les constructions moins fréquentes ainsi que certains nuances pragmatiques — comme l’ironie, l’ambiguïté ou certaines variations du point de vue — tendent à reculer. L’augmentation de la proportion de textes synthétiques dans les données d’entraînement est associée à une dégradation des performances et à une représentation plus pauvre de la diversité du langage humain. En termes simples, le système préserve mieux le centre que les marges.
Or, nombre d’innovations linguistiques naissent précisément dans ces marges : sous la forme d’usages instables, de détournements ponctuels ou de solutions locales inventées pour nommer une réalité nouvelle. Si le système privilégie systématiquement les formulations les plus probables, ces formes émergentes disposent de moins d’espace pour circuler et s’imposer.
Il ne faut pas comprendre cet enjeu comme une opposition abstraite entre « l’humain » et « la machine », mais plutôt comme la différence entre une langue nourrie par les contingences de la vie sociale et une prose produite à partir de régularités déjà apprises.
Un appauvrissement de l’écosystème linguistique
L’enjeu ne se limite pas à une diminution du nombre de mots différents. Il concerne aussi la capacité à établir des distinctions fines. Lorsque le langage devient plus vague, plus répétitif ou plus prévisible, les outils dont dispose une société pour décrire les problèmes, nuancer les positions et débattre dans l’espace public s’appauvrissent eux aussi.
À une échelle plus large, la question n’est donc plus seulement de savoir ce qui arrive à un modèle d’IA, mais ce qui arrive à l’écosystème linguistique public dans son ensemble. Si le Web se remplit de textes synthétiques, lecteurs, journalistes et institutions seront progressivement exposés à une langue publique moins diverse. Certains travaux récents vont jusqu’à évoquer une forme de « contamination » de l’écosystème numérique par les données synthétiques et montrent que la manière dont se combinent données réelles et artificielles est déterminante pour éviter des dégradations plus importantes.
Un scénario inéluctable ?
Il convient toutefois de ne pas exagérer le risque. Les travaux de recherche ne concluent pas que tout usage de l’IA entraîne inévitablement un effondrement ou une dégradation. Certaines études montrent que lorsque les données synthétiques sont mélangées à des données réelles, plutôt que de les remplacer entièrement, les mécanismes de dégradation ne se manifestent pas de la même manière et les erreurs peuvent rester limitées. Autrement dit, le problème ne réside pas dans un usage ponctuel de l’IA ni dans une combinaison prudente de données synthétiques et humaines, mais dans le remplacement massif de l’écriture humaine suivi du recyclage de cette production artificielle comme s’il s’agissait d’un langage vivant.
Avec l’intégration de l’IA dans les routines de production journalistique, le journalisme gagne en efficacité. Mais que perd une société lorsque la langue qui circule dans l’espace public devient plus uniforme, plus prévisible et moins ouverte à la nouveauté ? Si la presse renonce, même partiellement, à sa fonction d’écriture, de traduction, de nomination et d’expérimentation linguistique, ce ne sont pas seulement les pratiques professionnelles qui se transforment. C’est aussi l’un des principaux espaces où la langue commune a historiquement pu s’enrichir, se renouveler et élargir son champ des possibles qui s’en trouve affaibli.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview