
30.05.2026 à 08:47
Néandertal utilisait-il les dents de rhinocéros comme outils ?
Camille Daujeard, Archéozoologue, chargée de Recherche, Muséum national d’histoire naturelle (MNHN)
Texte intégral (3553 mots)

Le projet RINO est né de la découverte de traces singulières observées sur des dents de rhinocéros d’un site préhistorique de la vallée du Rhône. L’étude des restes dentaires de rhinocéros du site paléolithique moyen de Payre (vers 250 000-130 000 ans avant le présent) a en effet permis de mettre en évidence des marques qui pourraient indiquer leur utilisation comme outils par Néandertal – un comportement inédit.
À l’inverse de la figure emblématique du mammouth, la place du rhinocéros dans les comportements de subsistance des humains préhistoriques et les relations qu’ils ont entretenues tout au long du paléolithique sont peu connues. Pourtant, bien avant les représentations pariétales de la grotte Chauvet (Ardèche), il y a plus de 30 000 ans, cet animal a été consommé et utilisé à d’autres fins qu’alimentaires. La découverte de marques inhabituelles sur des dents de rhinocéros dans plusieurs sites du paléolithique du sud de la France soulève une question : ces marques pourraient-elles être le résultat d’une activité humaine intentionnelle ?
L’utilisation d’ossements de grands herbivores, y compris de rhinocéros, comme outils pour retoucher et raviver les tranchants de pierres taillées (« retouchoirs ») est un comportement bien connu, dès les périodes anciennes du paléolithique. Les dents de rhinocéros sont nombreuses dans les sites du paléolithique d’Europe et d’Asie et seules quelques rares études font l’hypothèse d’une récupération intentionnelle de celles-ci par les groupes humains.
Des fractures et des marques singulières
Il y a plus de 200 000 ans, à Payre, dans le sud-est de la France, ou encore sur le site de Panxian Dadong, en Chine, qui a livré une centaine de dents isolées de rhinocéros asiatique (Rhinoceros sinensis), des dents de rhinocéros présentant des fractures et des marques récurrentes ont été retrouvées. Ces observations ont conduit à s’interroger sur leur utilisation comme outils, et à explorer d’autres assemblages à rhinocéros de cette période du paléolithique en Europe. Serait-on là face à un comportement encore inconnu chez Néandertal ?
Cette question est à l’origine du projet RINO et de la publication qui vient de paraître dans la revue Journal of Human Evolution : « Elucidating the use of rhinoceros teeth by Neanderthals: Between experiments and the fossil record » (« Élucider l’utilisation des dents de rhinocéros par Néandertal : entre registres expérimental et fossile »), issue d’une collaboration scientifique internationale.
Il s’agit de la première étude approfondie et interdisciplinaire sur l’utilisation des dents de rhinocéros par Néandertal. Cette étude combine des analyses de restes fossiles et des expérimentations archéologiques sur des dents de rhinocéros actuels.
Les dents de rhinocéros possèdent en effet des caractéristiques morphologiques (taille, poids, caractère préhensible, surface occlusale plane et résistance à la fracturation) qui ont pu motiver leur usage à des fins techniques.
Méthode de recherche
Dans le cadre du projet RINO, 12 sites archéologiques ont été sélectionnés pour leurs traces d’activité humaine et leur abondance en dents de rhinocéros.
Afin d’avoir un référentiel de comparaison permettant de distinguer des traces naturelles de traces d’origine anthropique, comme suspectées, nous avons également inclus dans cette étude des séries dentaires provenant de sites paléontologiques d’Europe de l’Ouest et de collections ostéologiques de rhinocéros actuels. Ces séries comprennent au total 168 dents de rhinocéros provenant de quatre sites paléontologiques du Pléistocène en Europe occidentale : Wasserbillig (Luxembourg), Oetrange (Luxembourg), Cova del Rinoceront (Espagne) et Les Plumettes (Saône-et-Loire).
Nous avons également analysé 236 dents provenant de la collection comparative de la salle d’anatomie comparée du Muséum national d’histoire naturelle (MNHN) à Paris, avec l’objectif de reconnaître les altérations susceptibles d’avoir affecté les dents de rhinocéros tout au long de leur vie.
Une analyse des microtraces d’usure dentaire liées aux processus de mastication a été menée sur les dents de rhinocéros fossiles, afin de pouvoir écarter l’hypothèse d’une origine liée à l’alimentation du vivant de l'animal.
Par ailleurs, une part importante du projet concernait la démarche expérimentale. L’utilisation de molaires et de prémolaires de rhinocéros comme percuteurs par des tailleurs experts devaient permettre d’établir un référentiel complet des marques obtenues, et d’identifier la fonction de ces outils.
La principale difficulté rencontrée a été celle de l’acquisition de dents actuelles de rhinocéros pour effectuer ces expérimentations. Après de nombreuses recherches, avec l’aide d’Alexis Lécu, vétérinaire au Muséum national d’histoire naturelle, trois parcs zoologiques nous ont prêté du matériel dentaire, les zoos de Peaugres (Ardèche), de Sigean (Audes) et Montpellier (Hérault). Les extractions ont été effectuées par Benjamin Drouet à Peaugres et par Antoine Joris à Sigean.
Les expérimentations de percussion (retouche, taille, utilisation comme enclume) ont pu ainsi être menées sur 18 dents de rhinocéros, à l’aide d’outils lithiques en quartz et en silex. L’objectif était de reconnaître et d’identifier les traces laissées par l’action humaine.

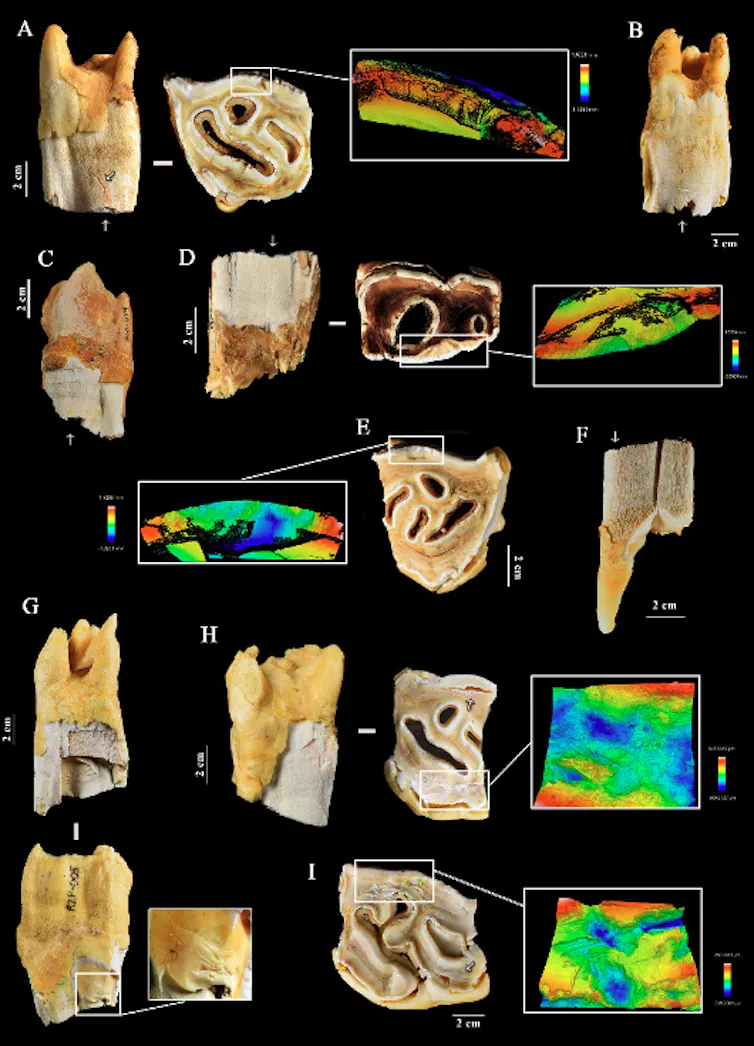
Un dernier volet de référentiel expérimental visait à reproduire des phénomènes naturels d’abrasion (sédiments) et de compaction que peuvent subir des dents durant leur fossilisation. Ces expérimentations ont été menées au sein du laboratoire de taphonomie de Madrid (LeaT laboratory).

Les résultats obtenus révèlent la présence de marques similaires à celles de Payre ainsi qu’à celles produites lors des expérimentations archéologiques, dans deux autres sites néandertaliens : El Castillo (Espagne) et Pech-de-l’Azé II (Dordogne). Dans ces deux sites, qui comptent au total 281 dents analysées, les espèces de rhinocéros concernées sont le rhinocéros de prairie (Stephanorhinus hemitoechus) et le rhinocéros de Merck (Stephanorhinus kirchbergensis). Ce dernier représente la plus grosse forme de rhinocéros fossile européen connue pour cette période.
Les traces observées sur le matériel dentaire diffèrent en revanche clairement des altérations de surface observées dans les collections de référence paléontologiques et modernes ainsi que de celles générées lors des expérimentations d’abrasion et de compaction sédimentaire. Par ailleurs, l’analyse des microtraces d’usure confirme qu’elles ont été produites après la mort de l’animal.
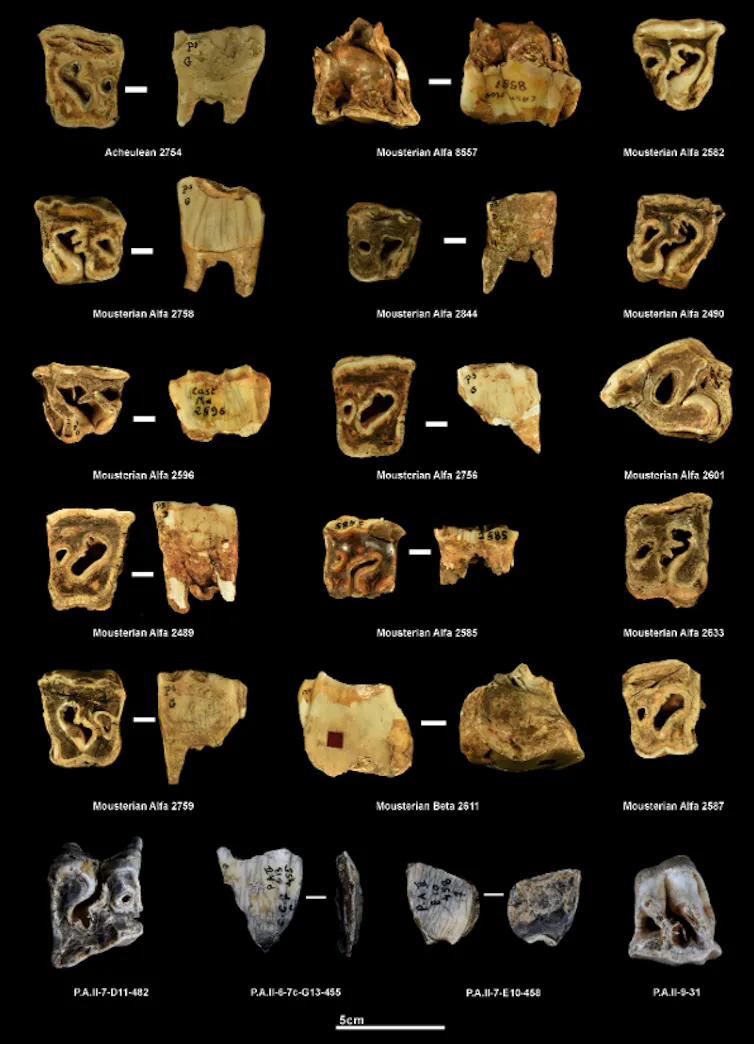
Des dents qui ont probablement servi d’outils percuteurs
Nous pouvons donc conclure que les traces identifiées sur les dents de rhinocéros de ces deux sites du paléolithique moyen – El Castillo (Espagne) et Pech‑de‑l’Azé II (France) – sont d’origine humaine. Ces dents ont probablement servi comme percuteurs dans la confection d’outils lithiques (silex, quartz), jouant un rôle dans la chaîne opératoire au paléolithique moyen. Au vu de l’état d’usure des dents utilisées, les Néandertaliennes et Néandertaliens semblent avoir eu une préférence pour des dents de rhinocéros âgés. Il est possible qu’ils se soient concentrés sur de vieux animaux, parce qu’ils représentaient potentiellement des proies plus faciles, ou des charognes. Leur morphologie dentaire, plus aplatie, était sans doute aussi plus adaptée à leur utilisation.
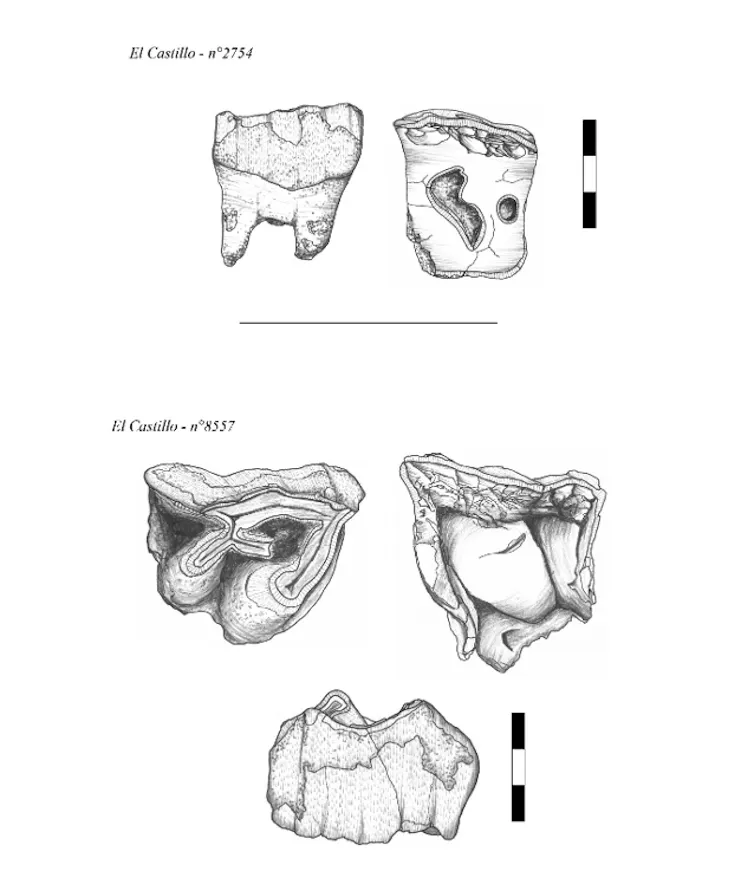
Cette étude permet d’élargir nos connaissances sur les comportements néandertaliens, leurs choix techniques et la diversité des matières premières collectées et utilisées, tout en apportant un nouvel éclairage sur leur utilisation des ressources animales. Malgré cette nette avancée dans le champ de nos connaissances, cette découverte ouvre également de nouvelles et nombreuses questions, qui restent pour le moment encore en suspens :
Qu’est-ce que cette découverte apporte à nos connaissances de Néandertal et de ses relations à son environnement ?
Quelles étaient les stratégies d’acquisition (chasse, charognage, piégeage) et d’utilisation des rhinocéros par Néandertal ? Étaient-elles les mêmes pour tous les types de rhinocéros rencontrés à ces périodes en Europe ? Leurs particularités morphologiques, éthologiques et écologiques et leur disponibilité au sein des biotopes ont-elles influé sur ces comportements ?
Le caractère inédit des marques mises en évidence montre tout l’intérêt de ces recherches, qui ouvrent comme on l’a vu beaucoup de questions qui restent encore à explorer. Il est par ailleurs peu probable qu’une utilisation de dents de rhinocéros comme matière première ait été un comportement limité dans le temps et dans l'espace. C’est pourquoi une révision majeure des séries dentaires de rhinocéros issues des nombreuses collections de sites paléolithiques doit être engagée à la lumière de ces nouvelles observations.
Actuellement, nous ne savons pas si c’est un comportement général ou spécifique aux groupes néandertaliens d’Europe de l’Ouest. Mais que l’on mette en évidence le caractère « universel » ou original de l’utilisation de ces dents, cette découverte ouvre des perspectives en lien avec la connaissance de l’étendue, de la fonction et de la portée symbolique de ce comportement.
Nous remercions le projet RINO (Sorbonne Université et Muséum national d’histoire naturelle) et l’IRN TaphEN (CNRS) pour leur soutien financier. Nous tenons également à exprimer notre gratitude envers toutes les personnes qui nous ont autorisés à accéder aux collections archéologiques et paléontologiques et aux laboratoires qui nous ont accueillis. Enfin, nous adressons nos sincères remerciements aux parcs zoologiques de Peaugres, Sigean et Montpellier (France) pour nous avoir fourni les dents de rhinocéros utilisées lors des expérimentations, avec une mention spéciale à Alexis Lécu, vétérinaire au MNHN, pour son aide précieuse dans cette recherche.
Camille Daujeard a reçu des financements de Sorbonne Université, du Muséum national d'Histoire naturelle, et de l'IRN Taphen (CNRS).
29.05.2026 à 09:00
À force d’utiliser l’IA, les journalistes risquent-ils d’appauvrir la langue ?
Xosé López-García, Periodismo digital, comunicación digital, Universidade de Santiago de Compostela
Cristian Augusto Gonzalez Arias, Investigador, Pontificia Universidad Catolica de Valparaiso; Universidade de Santiago de Compostela
Texte intégral (1673 mots)

Historiquement, le journalisme a contribué à diffuser de nouveaux mots et à nommer les transformations du monde. Si les textes générés par l’IA deviennent dominants, cette dynamique d’innovation linguistique pourrait s'affaiblir.
Que devient le langage public lorsqu’une part croissante des textes qui circulent dans la presse, sur Internet et sur les réseaux sociaux commence à être rédigée par des machines ? La question ne concerne pas seulement le journalisme en tant qu’activité professionnelle. Elle peut aussi affecter la richesse de la langue que nous utilisons pour comprendre, décrire et débattre du réel.
Historiquement, la presse a été l’un des espaces où la langue commune s’est développée et enrichie. Elle n’est évidemment pas le seul moteur du changement linguistique, mais elle constitue l’un des lieux où les sociétés mettent en circulation de nouveaux mots, de nouvelles tournures et de nouvelles façons de nommer des phénomènes émergents. Plusieurs travaux sur le langage journalistique et les néologismes montrent d’ailleurs que les journaux ont longtemps joué un rôle essentiel dans la création et la diffusion de vocabulaire nouveau, en particulier lorsqu’il s’agissait de rendre compte d’événements, de technologies ou de transformations sociales auprès d’un large public.
Ce rôle pourrait s’affaiblir si une part importante de l’écriture journalistique était déléguée à des systèmes d’IA générative. Les grands modèles de langage reposent, de manière générale, sur la prédiction du mot – ou plus précisément du « token » – le plus probable au sein d’une séquence. Ils produisent ainsi des textes fluides et plausibles, mais tendent également à privilégier les régularités statistiques, les formulations les plus fréquentes et les tournures déjà stabilisées.
Cela ne signifie pas, en soi, que le langage se dégrade automatiquement. Le problème apparaît lorsque cette logique devient dominante dans la production des textes qui alimentent l’espace public.
Quand les IA s’entraînent sur des textes produits par d’autres IA
Le risque devient plus sérieux lorsque ces systèmes commencent à être entraînés à partir de textes produits par d’autres IA. C’est ce que plusieurs travaux récents décrivent sous le nom de model collapse, ou « effondrement du modèle » : un processus de dégénérescence dans lequel les données générées par un modèle finissent par contaminer l’entraînement des générations suivantes.
Appliqué au langage, cela signifie que si les systèmes apprennent de plus en plus à partir de textes synthétiques, et si ces textes en viennent à saturer le Web et l’espace public, le réservoir linguistique disponible pour les futurs entraînements se rétrécit. Plus il y a de textes artificiels, moins les modèles sont exposés à la diversité réelle des usages humains de la langue. À terme, cela peut entraîner un appauvrissement du langage dans différents domaines.
Reproduction et amplification des biais
Tout d’abord, lorsque la diversité des données diminue et que les modèles s’appuient principalement sur des schémas déjà établis, les biais présents dans les données d’entraînement risquent d’être renforcés plutôt que corrigés. La littérature récente sur l’évolution des modèles de langage met précisément en garde contre le fait que les processus récursifs peuvent amplifier des préjugés existants au lieu de diversifier les points de vue.
Par ailleurs, l’écriture tend à se ressembler de plus en plus à elle-même : les mêmes structures syntaxiques, les mêmes tonalités intermédiaires, les mêmes formulations et les mêmes façons d’organiser les paragraphes reviennent sans cesse. Cette évolution est particulièrement importante pour le journalisme, car la presse ne se contente pas de transmettre des informations : elle fait le lien entre des savoirs spécialisés et un large public, hiérarchise les enjeux, traduit des vocabulaires techniques et expérimente de nouvelles formulations. Lorsque la langue de l’espace public devient trop uniforme, sa capacité à s’adapter finement à la nouveauté s’affaiblit.
Une érosion de l’innovation linguistique
Dans ce contexte, les mots rares ou spécialisés, les constructions moins fréquentes ainsi que certains nuances pragmatiques — comme l’ironie, l’ambiguïté ou certaines variations du point de vue — tendent à reculer. L’augmentation de la proportion de textes synthétiques dans les données d’entraînement est associée à une dégradation des performances et à une représentation plus pauvre de la diversité du langage humain. En termes simples, le système préserve mieux le centre que les marges.
Or, nombre d’innovations linguistiques naissent précisément dans ces marges : sous la forme d’usages instables, de détournements ponctuels ou de solutions locales inventées pour nommer une réalité nouvelle. Si le système privilégie systématiquement les formulations les plus probables, ces formes émergentes disposent de moins d’espace pour circuler et s’imposer.
Il ne faut pas comprendre cet enjeu comme une opposition abstraite entre « l’humain » et « la machine », mais plutôt comme la différence entre une langue nourrie par les contingences de la vie sociale et une prose produite à partir de régularités déjà apprises.
Un appauvrissement de l’écosystème linguistique
L’enjeu ne se limite pas à une diminution du nombre de mots différents. Il concerne aussi la capacité à établir des distinctions fines. Lorsque le langage devient plus vague, plus répétitif ou plus prévisible, les outils dont dispose une société pour décrire les problèmes, nuancer les positions et débattre dans l’espace public s’appauvrissent eux aussi.
À une échelle plus large, la question n’est donc plus seulement de savoir ce qui arrive à un modèle d’IA, mais ce qui arrive à l’écosystème linguistique public dans son ensemble. Si le Web se remplit de textes synthétiques, lecteurs, journalistes et institutions seront progressivement exposés à une langue publique moins diverse. Certains travaux récents vont jusqu’à évoquer une forme de « contamination » de l’écosystème numérique par les données synthétiques et montrent que la manière dont se combinent données réelles et artificielles est déterminante pour éviter des dégradations plus importantes.
Un scénario inéluctable ?
Il convient toutefois de ne pas exagérer le risque. Les travaux de recherche ne concluent pas que tout usage de l’IA entraîne inévitablement un effondrement ou une dégradation. Certaines études montrent que lorsque les données synthétiques sont mélangées à des données réelles, plutôt que de les remplacer entièrement, les mécanismes de dégradation ne se manifestent pas de la même manière et les erreurs peuvent rester limitées. Autrement dit, le problème ne réside pas dans un usage ponctuel de l’IA ni dans une combinaison prudente de données synthétiques et humaines, mais dans le remplacement massif de l’écriture humaine suivi du recyclage de cette production artificielle comme s’il s’agissait d’un langage vivant.
Avec l’intégration de l’IA dans les routines de production journalistique, le journalisme gagne en efficacité. Mais que perd une société lorsque la langue qui circule dans l’espace public devient plus uniforme, plus prévisible et moins ouverte à la nouveauté ? Si la presse renonce, même partiellement, à sa fonction d’écriture, de traduction, de nomination et d’expérimentation linguistique, ce ne sont pas seulement les pratiques professionnelles qui se transforment. C’est aussi l’un des principaux espaces où la langue commune a historiquement pu s’enrichir, se renouveler et élargir son champ des possibles qui s’en trouve affaibli.
Les auteurs ne travaillent pas, ne conseillent pas, ne possèdent pas de parts, ne reçoivent pas de fonds d'une organisation qui pourrait tirer profit de cet article, et n'ont déclaré aucune autre affiliation que leur organisme de recherche.
27.05.2026 à 10:09
Centres de données : pourquoi leur refroidissement consomme autant d’eau (et pourquoi cela pose problème)
Thomas Le Goff, Maître de conférences en droit et régulation du numérique, Télécom Paris – Institut Mines-Télécom
Texte intégral (1838 mots)
La course à l’IA engagée à l’échelle internationale ne doit pas se traduire par un détricotage des règles préservant nos ressources naturelles.
Qui n’a pas déjà expérimenté la désagréable sensation de surchauffe de son téléphone portable ou de son ordinateur lors d’une utilisation prolongée ou lorsque vous avez ouvert trop d’onglets sur votre navigateur ?
Imaginez maintenant la chaleur dégagée par 100 000 puces de calcul de dernière génération, entassées les unes sur les autres et tournant à plein régime, et ce, dans un complexe de plus de 26 kilomètres carrés soit environ 3 714 terrains de football. Placez ce grille-pain géant dans une région où la température est de 35 degrés en moyenne et peut atteindre les 50 °C l’été, et vous voilà devant le projet « Stargate UAE » visant à construire jusqu’à 5 gigawatts de puissance de calcul installée dans un immense centre de données à Abu Dhabi.
Ces projets de centres de données dits « hyperscale » visant à alimenter l’essor de l’intelligence artificielle (IA) se multiplient dans le monde, que ce soit aux États-Unis avec le projet Prometheus de Meta prévoyant la construction d’un centre de données de la taille de Manhattan, et même en France avec le « Campus IA ».
Au-delà de leur importante consommation énergétique, ces mastodontes soulèvent d’autres problèmes. Pour fonctionner correctement, ils ne peuvent pas atteindre des températures trop élevées, et contiennent donc des systèmes de refroidissement qui permettent aux composants électroniques de fonctionner à plein régime tout en évitant qu’ils ne se détériorent sous la chaleur qu’ils dégagent.
Comment ces centres de données sont-ils refroidis ? Quel est l’impact de leur refroidissement sur l’environnement, et comment les rendre plus sobres ?
Centres de données, refroidissement et consommation en eau
Il existe plusieurs techniques pour refroidir un centre de données. Pour le résumer simplement, les systèmes de refroidissement reposaient auparavant exclusivement sur des systèmes de ventilation (comme dans votre ordinateur) ou de climatisation (comme dans votre voiture) qui utilisent la circulation de l’air comme source de fraîcheur et rejettent l’air chaud à l’extérieur.
Une deuxième solution de refroidissement utilise l’eau, beaucoup plus efficace que l’air pour transférer la chaleur. Celle-ci permet de rafraîchir des plaques placées proches des composants électroniques, et/ou de rafraîchir l’air ventilé dans l’entrepôt de données.
Dans le premier cas (la climatisation), l’opérateur a besoin de beaucoup d’énergie pour faire tourner les pompes et systèmes de ventilation. Dans le deuxième (le refroidissement liquide), l’entreprise a besoin de moins d’énergie mais nécessitera l’accès à une source d’eau douce (l’eau salée endommagerait les tuyaux et composants) afin d’alimenter son système en eau fraîche.
Les opérateurs de centres de données sont donc face à un arbitrage complexe : doivent-ils utiliser des systèmes de climatisation énergivores ou bien du refroidissement liquide qui, cette fois, nécessite la consommation d’importantes ressources en eau ?
En effet, la consommation en eau des data centers est estimée à 560 milliards de litres chaque année dans le monde, soit l’équivalent de la consommation annuelle en eau potable de 10 millions de Français.
Cette soif insatiable se retrouve également dans les chiffres publiés par les Gafam. Ainsi, Google a vu sa consommation nette d’eau augmenter de 28 % entre 2023 et 2024, atteignant 30 milliards de litres dont environ un tiers provient de régions en stress hydrique. Microsoft, pour sa part, estime que 46 % de ses prélèvements d’eau ont lieu dans de telles zones en 2024.
Toutefois, il faut avoir à l’esprit que les besoins en eau des data centers ne sont pas uniquement liés aux systèmes de refroidissement. Pour obtenir une vision globale de l’impact du développement de ces infrastructures sur les ressources en eau, il convient de prendre également en compte l’eau utilisée par les centrales électriques qui les alimentent, ainsi que l’eau consommée lors du processus de fabrication des composants électroniques. Des chercheurs estiment ainsi que les mégacentres de données construits spécifiquement pour les besoins de calcul de l’IA utilisent, en moyenne, jusqu’à 20 millions de litres d’eau par jour, soit autant qu’une ville de 10 000 à 50 000 habitants.
Peut-on rendre les centres de données moins gourmands en eau ?
Il existe des solutions innovantes pour limiter cette consommation et rendre les systèmes de refroidissement plus efficients. Des entreprises, comme OVH Cloud, Nvidia ou Nebius, développent et déploient de nouvelles architectures de systèmes de refroidissement liquide au plus proche des puces de calcul. Ces nouvelles techniques permettent de réduire, selon les chiffres annoncés, jusqu’à 50 % de la consommation en eau. Toutefois, elles restent encore onéreuses à mettre en œuvre et assez peu développées sur le parc existant.
De manière plus générale, la principale source de perte en eau lors du fonctionnement des centres de données vient du fait qu’ils reposent aujourd’hui pour la plupart sur des circuits ouverts, conduisant à l’évaporation d’une grande partie de l’eau utilisée. C’est pourquoi les nouveaux centres de données devraient idéalement reposer, autant que possible, sur des systèmes de refroidissement en circuit fermé, évitant ce phénomène d’évaporation. Néanmoins, ce type de refroidissement peut s’avérer plus cher, conduit souvent à une hausse du besoin en électricité, et n’est pas évident à mettre en œuvre dans tous les centres de données « historiques » qui n’ont pas été conçus pour le mettre en œuvre.
Des propositions plus farfelues sont aussi avancées, telles que l’envoi de data centers dans l’espace ou bien en immersion dans les océans. Néanmoins, l’apport réel de ces propositions reste encore largement débattu, que ce soit pour des questions de faisabilité technique (bon courage pour réaliser la maintenance de votre centre de données sous-marin !) ou de bénéfices en termes d’émission de CO₂ par rapport à un centre construit sur terre – le cabinet de conseil en décarbonation, Carbone 4, fondé par Alain Grandjean et Jean-Marc Jancovici a, à cet égard, montré que les data centers spatiaux risquaient d’avoir un impact carbone plus important que sur terre en raison des émissions liées au lancement.
À lire aussi : Pourrait-on faire fonctionner des data centers dans l’espace ?
Pour un développement raisonné des centres de données, conscient du caractère fini des ressources naturelles
Au-delà de la faisabilité technique, ces discours risquent de nous détourner du vrai problème : le développement massif de centres de données hyperscale très gourmands en eau, dont une bonne partie dans des territoires où cette ressource se fait rare et conduit à des conflits d’usage.
Ce développement ne se fait pas dans un vide juridique. Les règles du droit de l’environnement, de l’aménagement du territoire et de l’urbanisme prévoient un certain nombre de régimes d’autorisation et d’évaluation environnementale en amont de la construction de ces projets, notamment en France avec le régime des installations classées pour la protection de l’environnement (ICPE).
Néanmoins, la course à l’IA engagée à l’échelle internationale conduit les pays à rivaliser d’ingéniosité pour attirer les investisseurs quitte, parfois, à assouplir les contraintes réglementaires comme c’est le cas actuellement en France avec la loi dite de simplification de la vie économique récemment adoptée. Il est urgent de prêter attention à l’ode à la « simplification », qui provient des discours politiques au sein de l’Union européenne et transcrite dans la politique menée par la Commission européenne, mais qui ne doivent pas se traduire par un détricotage des règles préservant nos ressources naturelles.
Plus généralement, ces débats soulèvent la question de l’usage : alors que certaines économistes parlent de « bulle de l’IA », qui peut réellement prédire quels seront les véritables usages futurs de ces infrastructures ?
Dans les années 1960, il fallait un bâtiment entier pour faire tenir un ordinateur, ils tiennent aujourd’hui dans notre smartphone. Si les IA de demain tiennent aussi sur nos terminaux, doit-on réellement sacrifier nos ressources naturelles pour créer ces mastodontes ?
À lire aussi : Charles Ponzi nous permet-il de comprendre la bulle de l’IA ?
Thomas Le Goff est Research Fellow au sein du think thank Centre on Regulation in Europe (CERRE).
- GÉNÉRALISTES
- Ballast
- Fakir
- Interstices
- Issues
- Korii
- Lava
- La revue des médias
- Time France
- Mouais
- Multitudes
- Positivr
- Regards
- Slate
- Smolny
- Socialter
- UPMagazine
- Le Zéphyr
- Idées ‧ Politique ‧ A à F
- Accattone
- À Contretemps
- Alter-éditions
- Contre-Attaque
- Contretemps
- CQFD
- Comptoir (Le)
- Déferlante (La)
- Esprit
- Frustration
- Idées ‧ Politique ‧ i à z
- L'Intimiste
- Jef Klak
- Lignes de Crêtes
- NonFiction
- Nouveaux Cahiers du Socialisme
- Période
- ARTS
- L'Autre Quotidien
- Villa Albertine
- THINK-TANKS
- Fondation Copernic
- Institut La Boétie
- Institut Rousseau
- TECH
- April - Libre à lire
- Dans les algorithmes
- Framablog
- Goodtech.info
- Quadrature du Net
- Revue Eur. Médias et Numérique
- INTERNATIONAL
- Alencontre
- Alterinfos
- Gauche.Media
- CETRI
- ESSF
- Inprecor
- Guitinews
- MULTILINGUES
- Kedistan
- Quatrième Internationale
- Viewpoint Magazine
- +972 mag
- PODCASTS
- Arrêt sur Images
- Le Diplo
- LSD
- Thinkerview