16.06.2026 à 07:00
« C’est de l’IA, je ne l’ai pas lu ! »
Hubert Guillaud
Texte intégral (5084 mots)
À DLA, on connaît bien l’acronyme TL;DR (too long, didn’t read, « trop long ; pas lu ») que de bien peu aimables personnes nous envoient parfois après avoir pris connaissance de notre lettre d’information. Il est peu probable pourtant que l’on passe à l’étape suivante : TL;DW (too long, didn’t write : « c’est trop long à écrire, alors je ne l’ai pas écrit moi-même »), qui consiste à faire écrire ses contenus par une IA générative… Quoique, les articles seraient peut-être plus clairs, les circonvolutions moins alambiquées ? Allez savoir !
Mais c’est d’un autre mème dont je voulais parler. Un mème qui devrait lui aussi beaucoup moins nous être adressé, mais qu’on utilise souvent : AI;DR (AI, didn’t read) : « c’est de l’IA, je ne l’ai pas lu » ! Un jugement qu’on énonce couramment et qui décrit la transformation de notre rapport aux textes, à l’heure où tout doit aller si vite, qu’on n’a plus le temps d’écrire ni de lire. Un refus face au déferlement : « c’est de l’IA, je ne veux même pas le lire » !
A qui profite le verbiage ?
AI;DR donc. L’acronyme exprime quelque chose entre la lassitude et l’hostilité à voir des textes génératifs envahir le web. Qu’ils soient très formatés, énergiques ou lénifiants, l’expression nous dit que nous serions capables de repérer la prose des LLM à leur tiédeur, à leur style, à leurs effets (qu’importe si en vérité, nous nous trompons souvent, comme c’est le cas des enseignants qui peinent à identifier les productions génératives de leurs étudiants). Un peu comme si nous étions dotés d’un système de repérage, une boussole infaillible, alors que les textes génératifs sont souvent corrigés, amendés, modifiés par leurs auteurs, et qu’ils tiennent bien plus d’une forme de coproduction qu’autre chose. Non seulement l’acronyme nous dit que ces productions n’ont finalement pas grande importance, mais il nous dit aussi que nos erreurs d’attribution peuvent être aussi péremptoires que les réponses des chatbots à la confiance survitaminée. Il nous dit que ces productions n’ont finalement pas grande importance au risque de renvoyer avec elles des propos bien humains, un peu comme ceux qui étaient trop longs finalement, trop humains. AI;DR nous dit que ce qui est écrit n’a pas grand intérêt, qu’il soit le fait de robots ou d’humains. Ce que ça fait est bien plus important : même si ce que ça fait (écrire) devient en même temps qu’on l’énonce bien peu important puisqu’on ne lui prête plus aucune attention.
Rapidement, on est saisi d’un vertige : à quoi peuvent bien servir des outils pour produire du texte que les gens ne souhaitent pas lire ? AI;DR semble mettre en abîme le grand vide des machines à verbiage, comme pour rendre béant le vortex qui s’ouvre sous nos mots. Un peu comme vient de le proposer le moteur de traduction Kagi en permettant de traduire (après le Dothraki, le Haut Valyrien ou le Klingon quand même !) n’importe quel texte en « Linked-in speak », c’est-à-dire dans le jargon de Linked-in. En permettant de transformer n’importe quel texte en post de motivation entrepreneuriale, truffé d’emojis, de hashtags et de déconvenues transformées en leçons de vie. « Le traducteur de Kagi ne fabrique pas cette langue, il la révèle. Il en expose la mécanique, la pauvreté, le vide soigneusement emballé dans du vocabulaire managérial », s’amusait la chroniqueuse de Radio France, Constance Vilanova. Elle pointait d’ailleurs vers une étude d’un chercheur en linguistique qui a mis au point une échelle pour mesurer la réceptivité au jargon d’entreprise. Une étude qui montrait que plus on est sensible aux formules creuses, moins on performe soi-même aux tests de pensée analytique et aux tests de prise de décision. « Les grands amateurs de Linked-in speak seraient donc aussi les moins capables de repérer le vide. Ce qui crée un cercle vicieux parfait : les patrons sont récompensés pour leur langue de bois, et les équipes se peuplent progressivement de gens qui n’y voient que du feu. » Mais surtout, les personnes les plus réceptives au jargonnage ont aussi plus tendance à percevoir leurs leaders comme visionnaires, à être plus inspirées par les homélies d’entreprises et à faire plus confiance à leurs managers. « Pour certaines personnes, un discours abstrait et vaporeux peut donner l’impression de profondeur, de vision et de compétence et parfois suffit à produire de la crédibilité. Il peut aussi fonctionner comme un signal de leadership », s’amuse David Gateau… Pire, « plus la réceptivité au bullshit corporate est élevée, plus la qualité des décisions diminue ». « Les personnes les plus sensibles aux discours creux en entreprise ont tendance à choisir systématiquement les pires solutions aux problèmes », explique l’auteur de l’étude, Shane Littrell. Pourtant, l’étude montre aussi finalement que le jargon persuade et impressionne certains publics, explique The Guardian, tout comme le verbiage des LLM finalement. « N’importe qui peut se laisser berner, et nous sommes tous, selon les circonstances, susceptibles d’être influencés par des discours creux présentés de manière à flatter nos préjugés. »
Les contenus produits par l’IA sont-ils faits pour être lus ?
Le hashtag #AI;DR entérine la dépréciation des contenus génératifs, dénigrés depuis leur apparition. Comme le disait John Hermann dans le New York Mag dès 2024 : alors que l’IA est associée au summum des réalisations humaines, pour tout à chacun, elle désigne d’abord des choses assez pauvres, assez communes. Dans le langage courant, dire d’un texte qu’il a été réalisé par ChatGPT qualifie toujours un document sans grand intérêt. Aujourd’hui encore. « Pourquoi devrais-je me donner la peine de lire quelque chose que personne d’autre n’a daigné écrire ? », remarque pertinemment un développeur, relayé par Futurism. Quand on lit le propos de quelqu’un, c’est pour comprendre ce qu’il pense, perçoit et appréhende du monde. Ecrire, c’est penser. Et penser, c’est exister. Mais que signifie lire la prose d’un LLM ? QUI sommes-nous censés comprendre ? Et donc QUE sommes-nous censés comprendre ? Quelque part, les gens qui dénoncent ces contenus, disent que ce qui est écrit par l’IA ne nous est pas adressé. Que ces contenus ne sont pas vraiment pour les humains puisqu’ils ne sont pas humains.
Dans le New York Mag, John Hermann (encore lui), dénonçait récemment le cauchemar de l’e-mail piloté à l’IA : « Êtes-vous impatient de voir vos collègues devenir beaucoup plus bavards, transformant chaque simple « Ça me va » en une lettre de trois paragraphes ? Êtes-vous ravi que le genre d’e-mails de masse semi-personnalisés que vous avez l’habitude de recevoir des grandes marques dotées de services marketing (ou des spammeurs et des auteurs de phishing) soit désormais accessible à toute personne possédant un compte Google ? Avez-vous hâte de vous demander si cette charmante lettre de condoléances d’un ami perdu de vue depuis longtemps a été entièrement générée par un logiciel ou s’il a simplement cliqué sur le bouton pour rendre le contenu « plus sincère » avant de l’envoyer ? » Ce dernier exemple n’est même pas une blague, le mois dernier, l’administration de l’université Vanderbilt a dû présenter ses excuses après avoir envoyé un e-mail de condoléances aux étudiants suite à la fusillade de l’université d’État du Michigan. En bas du message il était indiqué qu’il avait été rédigé par ChatGPT !
Le Financial Times rapporte que le volume des plaintes aux services juridiques et RH des entreprises est en augmentation et que celles-ci sont plus documentées et complexes qu’avant. Ce ne sont plus de simple e-mail à traiter, mais des pièces jointes volumineuses, qui évoquent parfois des législations qui n’existent pas. La raison ? Le recours à l’IA. De plus en plus de plaintes leur arrivent « incompétentes mais sûres d’elles », « superficiellement persuasives », « excessivement juridiques sans être pertinentes »… de gens pouvant avoir des attentes irréalistes, désorientés par les réponses des IA à leurs problèmes. Le volume de récriminations augmente et le temps pour les vérifier également, au risque de ralentir les réponses des employeurs.
Reste que le besoin de formalisation que traduit le passage à un argumentaire structuré par l’IA dit peut-être autre chose du rapport employés-employeurs, où les discussions ne suffisent pas pour être écoutés…
Le New York Times, récemment, expliquait que la romance générative était en pleine explosion et que l’IA était l’avenir du genre. Pas si sûr, contestait Gita Jackson pour Aftermath, les défenseur(e)s de l’IA dans la littérature n’ont pas d’autre but que de gagner de l’argent, en produisant beaucoup de contenus et en vendant des formations pour apprendre à d’autres comment faire. L’une des autrices interviewées par le NYT prétend que ses 200 livres publiés par IA ont totalisé 50 000 ventes… soit en moyenne 250 exemplaires par livre. Ce modèle économique n’est viable que si l’on se fiche de la qualité des livres et de leur popularité, assassine Jackson. Bref, il n’est pas sûr que les romances dopées à l’IA soient l’avenir du genre, comme le défendent les autrices qui le proposent parce qu’elles y ont doublement intérêt. Pas sûr que les contenus dopés à l’IA soient finalement meilleurs que les romances incarnées par leurs autrices.
Deux exemples qui montrent que les contenus génératifs viennent s’intercaler dans les situations de blocages et viennent toujours avec les intérêts de ceux qui les portent, même s’ils ne sont pas toujours faciles à percevoir.
Pour qui écrivons-nous ?
Le mot-clé AI;DR rejoint également celui de sloppers, désignant les producteurs de slop, les producteurs de contenus qui ne produisent plus qu’avec les robots conversationnels (à l’image de la proposition parodique de sloppers.ai, qui se présente comme un service d’IA pour produire… des contenus parfaitement inutiles). Entre résistance et lassitude, le point-virgule, qui à l’origine séparait la cause de l’effet – plus vous écrivez, moins je lis – sépare désormais la production de la machine du refus de lui accorder la moindre attention.
Comme le souligne Alberto Romero, nous passons d’un monde où la longueur d’un texte constitue un obstacle à la lecture, à un monde où le manque d’implication humaine devient un obstacle supplémentaire. Nous sommes passés de « je ne finirai pas ça » à « personne n’a commencé ça ». « La première attitude suppose que l’on est responsable de ses propres limites, tandis que la seconde incite à externaliser sa responsabilité », comme si ce n’était pas à nous de lire, de vérifier, d’agréer aux productions générées. La perspective de notre submersion par les contenus génératifs, par l’intensification des productions, risque de nous laisser plus épuisé que jamais, disions-nous la semaine dernière. Non seulement nous sommes cernés par plus de contenus que jamais, mais nous sommes en même temps confrontés à une forme de post-alphabétisation où l’écrit lui-même semble de plus en plus décrédibilisé par son automatisation.
Pour Romero, l’IA;DR fait écho à son exact inverse : WF;AI (What the fuck; AI, « bordel, écrire pour l’IA ») où nous sommes confrontés au vide de sens qu’exige d’écrire pour l’IA plutôt que pour d’autres humains. Nous sommes en train de passer du pourquoi écrivons-nous à pourquoi lisons-nous, comme si le cœur même de la connaissance n’avait plus de sens, ni pour les autres ni pour nous. « Doit-on consacrer vingt minutes de son attention déjà si sollicitée à un texte qui n’a coûté à son auteur fantôme que quarante-cinq secondes et une consigne maladroite ? »
Perdus au milieu de contenus de plus en plus fantomatiques, comment s’orienter ? « La lecture, comme tout ce que nous faisons, repose sur un contrat social implicite : je vous offre ma réflexion, vous me donnez votre temps. Or, lorsque l’une des parties automatise sa part du marché, l’autre se sent légitimement flouée. Et comme déléguer la lecture n’a aucun sens pour la plupart des gens, ils ne le font tout simplement pas », constate pertinemment Romero. Le contrat de lecture exige une intention et une relation que l’IA ne peut pas produire. Le contrat de lecture est donc profondément rompu, quelles que soient ses conséquences. D’autant que dans la roue du hamster de la lecture/écriture, l’IA a tendance à exclure de plus en plus l’humain. Dans le biais anti-humain de l’IA, l’IA se nourrit de l’IA et récompense plus facilement les contenus IA faisant gonfler plus encore les contenus génératifs qu’on ne veut pas lire. Et pourtant, se moque Romero en conclusion, son texte a été écrit avec une IA. Nous même avons été pris au piège. Le contrat de lecture n’est donc pas totalement rompu, il est flouté au risque de nous abuser en continue.
C’est toute l’aporie où nous sommes réduits, comme l’illustre le dessinateur Tom Fishburne avec un de ses délicieux dessins : l’IA permet de transformer une liste à puce en un long mail qu’on peut prétendre avoir écrit et où son récepteur peut le transformer en liste à puce qu’il peut prétendre avoir lu. Tom Fishburne rappelle qu’il va falloir du temps pour apprendre quand et comment bien utiliser ces outils et surtout quand ne pas les utiliser. L’acronyme AI;DR nous rappelle que nous sommes face à des contenus dont le statut n’est pas clair, des contenus que nous ne savons pas vraiment utiliser. Peut-on vraiment en vouloir à des gens de refuser de lire des contenus qui sont produits par personne et destinés à personne, de refuser de lire des propos d’une machine, aussi séduisants ou creux puissent-ils être ?
Le risque d’une parole sans conséquence
IA;DR nous dit autre chose pourtant. Que ces mots produits sont produits. Que ce qui devait être fait est fait et que la réception est finalement un autre enjeu, comme s’il dépendait d’autres métriques.
« Pour la première fois, la parole est dissociée de ses conséquences. Nous vivons désormais aux côtés de systèmes d’IA qui conversent avec assurance et persuasion – débitant des affirmations sur le monde, des explications, des conseils, des encouragements, des excuses et des promesses – sans jamais assumer la responsabilité de leurs propos. Des millions de personnes utilisent déjà des chatbots, alimentés par de vastes modèles de langage, et ont intégré ces interlocuteurs synthétiques à leur vie personnelle et professionnelle. Les mots d’un chatbot façonnent nos croyances, nos décisions et nos actions, sans qu’aucun locuteur ne les cautionne », explique Deb Roy dans The Atlantic.
Deb Roy est professeur d’arts et de sciences des médias au MIT, où il dirige le Centre pour la communication constructive au Media Lab. Il est également cofondateur et président de Cortico, une organisation à but non lucratif qui se consacre à la construction de réseaux civiques plus forts, notamment en analysant les échanges vocaux de groupes de discussions pour en dégager liens et tendances.
Dans nos échanges avec les chatbots, ceux-ci s’excusent, corrigent, mais débitent une chose puis son contraire, vide de sens, rappelle le professeur. Pour Roy, « il ne s’agit pas d’une simple nouveauté technique, mais d’un bouleversement de la structure morale du langage ». Lorsque nous parlons, nos mots nous engagent dans un contrat social implicite. Ils nous exposent au jugement, aux représailles, à la honte et à la responsabilité. Dire ce que l’on pense, c’est prendre un risque. Le chercheur en intelligence artificielle Andrej Karpathy a comparé les LLM à des fantômes humains : ils ne sont pas des créatures, leur parole est sans conséquence, tout en étant capable de nous hanter. Pour Deb Roy, spécialiste de l’apprentissage du langage, les mots acquièrent du sens en relation avec le monde. Reste que le sens ne découle pas seulement de la fluidité ou de l’incarnation, mais aussi des enjeux sociaux et moraux que nous prenons lorsque nous parlons. Le langage a une dimension morale et sociale. Il nous engage. Il nous rend digne ou indigne, responsable. « Parler, c’est simultanément s’exposer à un jugement moral, encourir des conséquences sociales et parfois juridiques, assumer la responsabilité de la vérité et contracter des obligations qui perdurent au sein des relations. » Avec les chatbots, la parole n’est plus que procédurale. « Les chaînes causales s’obscurcissent. La responsabilité se dilue. L’autorité épistémique s’exerce sans obligation. Les engagements relationnels sont simulés sans persistance. » Cela produit non seulement un obscurcissement des responsabilités, mais plus encore un affaiblissement progressif des attentes. Le risque est de ne plus rien attendre des textes, quels qu’ils soient.
Norbert Wiener l’avait bien compris, dans ses mises en garde à l’encontre de l’automatisation : l’accroissement des capacités des machines entraînerait une perte de responsabilité humaine. Et l’efficacité elle-même éroderait la dignité humaine, nous poussant à devenir des intrants, des opérateurs ou des superviseurs de processus dont les humains ne contrôleraient plus la logique. « Ce qui rend ces systèmes moralement déstabilisants, ce n’est pas leur dysfonctionnement, mais leur capacité à fonctionner exactement comme prévu tout en se soustrayant à toute responsabilité », explique Roy.
L’histoire moderne regorge de technologies médiatiques qui ont transformé la circulation de la parole : l’imprimerie, la radio, la télévision, les réseaux sociaux. Mais aucune de ces technologies ne possédait les propriétés que les systèmes d’IA actuels réunissent simultanément. Aucune ne permettait de dialoguer et donc d’activer une vulnérabilité psychologique inédite. Avec Eliza, Joseph Weizenbaum a compris que les humains projetaient sur la machine du sens, des intentions et une responsabilité qu’elle n’avait pas. Le philosophe J.L Austin affirmait qu’utiliser le langage, c’est agir. « Tout énoncé significatif accomplit une action : il affirme une croyance, formule une revendication, formule une demande, fait une promesse, etc. Dire « oui » lors d’une cérémonie de mariage donne naissance à l’acte de mariage. Dans ce cas, l’acte n’est pas accompli par des mots puis décrit ; il est réalisé dans l’acte même de prononcer ces mots, dans les conditions appropriées. » Pour Roy, pour combattre l’effet Eliza, il ne suffit pas de savoir que ces systèmes sont des machines, car leur efficacité est amplifiée par leur fluidité. Et c’est leur fluidité qui nous conduit à déléguer nos responsabilités, à la faire glisser de l’utilisateur vers l’outil. Nous demandons désormais aux autres de prêter attention à des mots que nous n’avons pas écrits, pas pensés. Ce que nous perdons, c’est notre dignité même. « Dans le cadre d’un usage privé (comme le proposent les chatbots compagnons), l’érosion est plus subtile, mais non moins lourde de conséquences. Les jeunes décrivent leur utilisation de chatbots pour rédiger des messages qu’ils hésitent à envoyer, pour déléguer des réflexions qu’ils estiment devoir mener eux-mêmes, pour obtenir des assurances sans s’exposer, pour répéter des excuses sans rien débourser. Un chatbot dit « Je suis désolé » sans faute, mais est incapable de regret, de réparation ou de changement. Il admet ses erreurs sans conséquence. Il exprime de l’attention sans rien perdre. Il utilise le langage de la bienveillance sans rien risquer. Ces affirmations sont fluides. Et elles habituent les utilisateurs à accepter un langage moral déconnecté des conséquences. Il en résulte un réajustement discret des normes. Les excuses deviennent gratuites. La responsabilité devient théâtrale. La bienveillance devient simulée. »
Les mots eux-mêmes n’ont plus de portée. Ceux des chatbots, bien sûr, mais derrière, les mots de tous ceux qui en portent, et d’abord ceux que les autres humains nous adressent.
« Certains affirment que la responsabilité des propos de ces machines peut être externalisée : vers les entreprises, les réglementations, les marchés. Mais la responsabilité se dilue entre développeurs, déployeurs et utilisateurs, et les boucles d’interaction restent privées et inobservables. L’utilisateur en subit les conséquences ; la machine, non. »
Ceci n’est pas sans rappeler le problème éthique posé par les armes autonomes, estime Roy. En 2007, le philosophe Robert Sparrow soutenait que de telles armes violent le principe de la guerre juste, selon lequel lorsqu’un dommage est infligé, quelqu’un doit répondre de la décision de l’infliger. Le programmeur est protégé par conception, ayant délibérément construit un système dont le comportement est censé se dérouler sans contrôle direct. Le commandant qui déploie l’arme est lui aussi protégé, incapable de contrôler les actions spécifiques de l’arme une fois en mouvement, et cantonné aux rôles prévus pour son utilisation. Quant à l’arme elle-même, elle ne peut être tenue responsable, car elle est dépourvue de toute qualité morale d’agent. Les armes autonomes modernes produisent ainsi des résultats mortels pour lesquels aucun responsable ne peut être identifié de manière pertinente. Les chatbots compagnons, ces « systèmes de gestion de la vie humaine » fonctionnent différemment, mais la logique morale est la même : ils agissent là où les humains ne peuvent pas pleinement superviser, et la responsabilité se dissout dans ce vide.
« La parole sans conséquence contraignante sape le contrat social. La confiance, la coopération et la délibération démocratique reposent toutes sur le principe que les locuteurs sont tenus par leurs propos. » Notre immersion dans un monde de contenus génératifs, de propos sans conséquences, risque de nous habituer à prendre toute parole comme étant sans conséquence, même celle de nos contemporains.
« Nous avons besoin de structures qui réancrent la responsabilité : des contraintes limitant l’utilisation de l’IA dans divers contextes, tels que les écoles et les lieux de travail, et préservant la paternité des travaux, la traçabilité et une responsabilité clairement définie. L’efficacité doit être encadrée lorsqu’elle porte atteinte à la dignité », défend Roy.
Avant de pointer un autre enjeu encore : « Alors que l’idée d’« avatars » IA s’impose dans l’imaginaire collectif, elle est souvent présentée comme un progrès démocratique : elle repose sur des systèmes qui nous connaissent suffisamment bien pour parler en notre nom, délibérer à notre place et nous épargner le fardeau d’une participation constante. Il est facile d’imaginer que cela puisse se transformer en ce que l’on pourrait appeler un « État-avatar » – un système politique où des représentants artificiels débattent, négocient et décident pour nous, efficacement et à grande échelle. Mais cette vision oublie que la démocratie non plus n’est pas simplement l’agrégation de préférences. C’est la pratique de la parole ouverte. S’exprimer politiquement, c’est prendre le risque de se tromper, d’être responsable, d’assumer les conséquences de ses paroles. Un État avatar – fluide, infatigable et parfaitement malléable – simulerait la délibération, mais sans conséquence. De loin, il ressemblerait à un gouvernement autonome. De près, ce serait tout autre chose : la responsabilité rendue facultative, et avec elle, la dignité de devoir assumer ses paroles devenues obsolètes. Wiener avait compris que le tourbillon ne viendrait pas de machines malveillantes, mais de l’abdication humaine. » C’est au bord de ce précipice que nous conduit l’IA.
Ce que traduit AI;DR, c’est qu’à mesure que nous sommes cernés par ces contenus génératifs, la résistance se fait jour, estime Fast Company. Qui souligne que le terme rencontre du succès à un moment où le sentiment anti-IA se développe. Les inquiétudes concernant l’IA chez les adultes américains se sont accrues depuis 2021, selon le Pew Research Center. Plus de la moitié (51 %) se disent plus inquiets qu’enthousiastes face à l’essor de cette technologie. « C’est de l’IA, je ne l’ai pas lu ! », ne traduit-il pas d’abord que tout cela n’est pas de notre responsabilité. Que cet avenir n’est peut-être pas celui que nous avons voulu. « C’est de l’IA, je ne l’ai pas lu ! » est peut-être notre dernier semblant de résistance face à un nouveau web qui va nous submerger.
Même constat pour la journaliste Eve Fairbanks dans The Atlantic. « Travailler sur un texte généré par l’IA, en tant que correcteur, revient à opérer un corps dont la peau, les muscles, les veines, les os et les organes sont tous endommagés. Il n’y a rien à préserver, aucun point de départ », explique-t-elle confrontée à la prose des machines. « L’infltration du non sens est partout, inéluctable. Même ceux qui n’utilisent pas l’IA finiront par lui ressembler. »
Hubert Guillaud
La version originelle de ce texte est paru pour la lettre Café IA le 3 avril 2026.
15.06.2026 à 07:00
Tension de la productivité : le goulot de la diffusion
Hubert Guillaud
Texte intégral (1400 mots)
A l’heure où les outils pour produire du code automatiquement se déploient partout, la question de la productivité devient de plus en plus polarisée, rappelle le journaliste du Financial Times, John Burn-Murdoch. « Un point de tension majeur entre les partisans et les détracteurs de l’IA réside dans le décalage entre l’augmentation constatée de la productivité des développeurs et l’absence apparente d’une croissance correspondante sur la création de produits ou de valeur ». Or, une nouvelle étude permet peut-être de comprendre le hiatus.
Mert Demirer du MIT et ses co-auteurs a analysé le travail des développeurs de logiciels avant et après l’adoption d’outils d’IA. Ils ont mesuré cet impact à différents niveaux : la quantité de code écrit, le nombre de fichiers modifiés, le nombre de projets ou de fonctionnalités développés et les mises en production de nouveaux logiciels. L’étude a révélé que l’IA avait un impact considérable en amont : les développeurs ont créé ou modifié près de 300 % de fichiers supplémentaires. Cependant, cette augmentation a été réduite de moitié (à 150 %) lorsqu’ils ont examiné le nombre de fichiers soumis à l’évaluation, et ce dernier a lui-même été divisé par cinq, pour atteindre une hausse d’environ 30 % du nombre de mises en production complètes.
Une augmentation de 30 % de la production du produit phare d’une entreprise est significative, mais les résultats montrent néanmoins à quel point la perception, voire certaines mesures directes, de l’impact de l’IA sur la productivité peuvent être déconnectées de la valeur ajoutée réelle. L’accélération spectaculaire de la productivité se traduit par des gains bien plus modestes une fois que ce travail a franchi tous les obstacles liés à la validation et à la mise en production. L’enjeu de la vérification reste bien en partie le goulot d’étranglement de la productivité sous IA. Mais ce n’est pas le seul… « Lorsque les chercheurs ont examiné si l’augmentation de la production de logiciels grâce à l’IA avait entraîné une hausse de la consommation, ils n’ont trouvé que peu d’éléments probants. La forte augmentation du nombre de lancements d’applications mobiles au cours de l’année écoulée ne s’est pas accompagnée d’une hausse des téléchargements ; la plupart des nouvelles applications peinent à conquérir un public, même modeste. »
Ce que le Financial Times résume d’un graphique parlant, montrant l’envolée des mises à jour d’applications, alors que l’usage ne progresse pas :
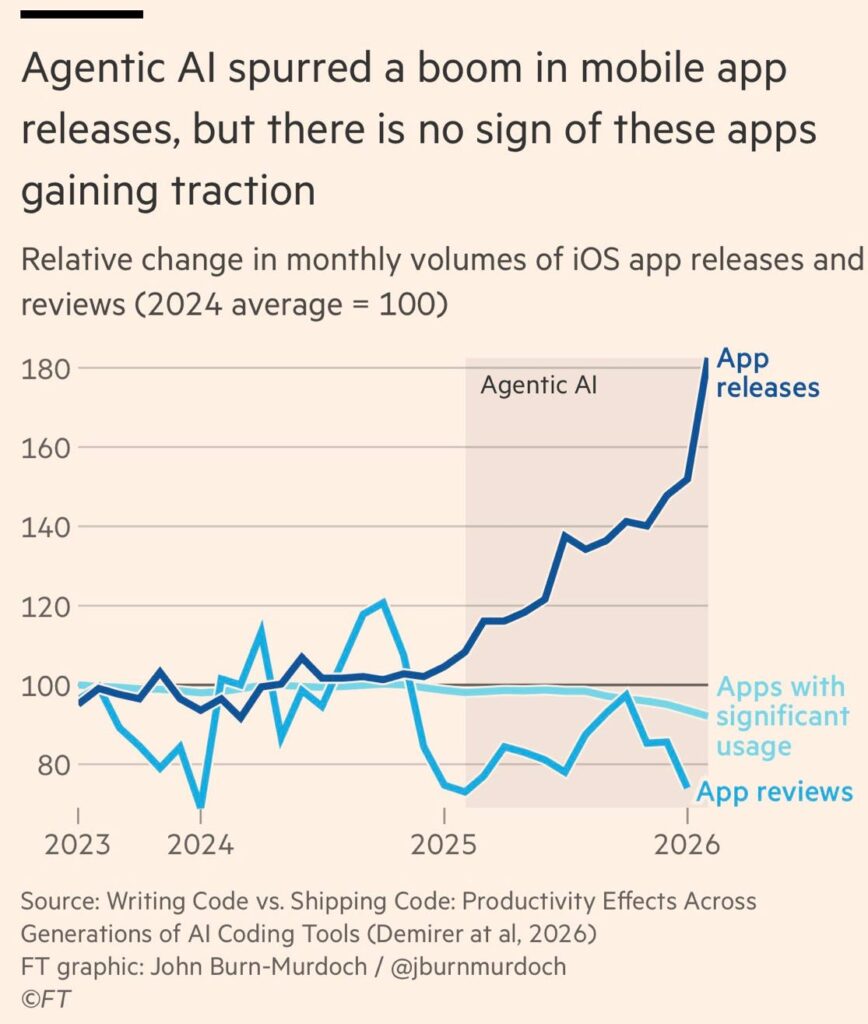
Ce que pointe Burn-Murdoch, c’est qu’entre l’augmentation de la production des systèmes et leur diffusion, il y a également un goulot d’étranglement. Comme le dit Gary Marcus, l’IA appliquée au code permet certainement une productivité importante, mais a un impact concret limité, car produire ne suffit pas. Par exemple, l’IA permet peut-être d’augmenter la production de livres, mais cela ne signifie qu’ils soient de meilleure qualité ni qu’ils se vendent davantage, comme tentait de l’esquisser un graphique du Washington Post montrant la corrélation entre l’essor de l’IA et l’augmentation de la production de livres. Même chose dans le domaine de la musique ou de la production académique. La production augmente, mais les débouchés stagnent. En partie parce que certains marchés sont saturés et de l’autre parce que cette accélération volumétrique n’améliore pas la qualité pour autant. Comme le résume un développeur avec ironie : « avant l’IA, je passais un week-end à développer une seule application inutile. Maintenant, je peux en développer 67 en un week-end, chacune avec un logo, une page web sophistiquée et… zéro utilisateur. » C’est ce que constate également Paul Kedrosky : nous sommes en train de privilégier la production à la valeur, à l’image de la récente démonstration d’Anthropic valorisant l’explosion de la productivité des développeurs grâce à ses modèles. Or, nous ne mesurons ici que le Sloc (software lines of code, le nombre de lignes de code des logiciels), une sorte de Slop interne aux entreprises. Or, rappelle Kedrosky : « Les meilleurs ingénieurs créent de la valeur en écrivant moins de code, pas plus.» Le nombre de lignes de code valorise la quantité, non l’utilité. L’IA gonfle systématiquement cette métrique. Et une multiplication par huit du nombre de lignes de code correspond généralement à une augmentation bien moindre du rendement réel d’ingénierie. Le volume de code engendre des risques. Plus de code signifie plus de maintenance, de complexité, de surface d’attaque et de charge de déboggage.
Les entreprises cherchent désormais à optimiser leurs dépenses de production d’IA afin d’en réduire le coût, estime encore John Burn-Murdoch. Demirer et ses co-auteurs estiment que l’explication la plus probable de l’invisibilisation des gains de productivité réside dans le fait que les structures organisationnelles et les marchés actuels ne sont pas conçus pour tirer pleinement parti des gains sous-jacents. Le fait que les entreprises établies du secteur des logiciels et du travail intellectuel ne constatent que de modestes gains de productivité en intégrant l’IA à leurs méthodes de travail et structures organisationnelles existantes, tandis que l’utilisation, le chiffre d’affaires et la productivité explosent chez Anthropic et OpenAI – des entreprises construites autour de l’IA, dont les produits sont conçus et évalués par elle – est peut-être un premier signe de la même dynamique à l’œuvre ici, mais à un rythme beaucoup plus rapide.
« Je pense que les deux camps ont raison. Une grande partie de l’utilisation et des dépenses des entreprises en matière d’IA sont aujourd’hui inefficaces. Mais les gains de productivité constatés reflètent l’interaction entre de puissants outils et des structures et processus mal adaptés. A terme, ces frictions et ces goulots d’étranglement ne feront que s’atténuer », estime Burn-Murdoch, mais ce n’est peut-être pas si sûr. L’IA sature également le marché et sa prolifération empêche de saisir où des gains sont encore possibles. En rendant tout possible, elle génère une confusion qui n’aide certainement pas à voir là où elle devrait être utile et là où elle ne l’est pas.
11.06.2026 à 07:00
Face à l’IA : armer la vie civique
Hubert Guillaud
Texte intégral (4071 mots)
Le toujours très inspirant institut de recherche indépendant Data & Society lance une nouvelle initiative visant à renforcer la citoyenneté à l’ère de l’IA. L’ambition est forte : faire passer le public du statut d’utilisateur à celui d’acteur, expliquent ses responsables. La culture de l’IA ne suffit pas. « Et le public mérite bien mieux qu’une simple formation à l’utilisation de l’IA. Et il l’exige de plus en plus. » « Les Américains constatent comment les systèmes d’IA façonnent leur accès aux opportunités, à leurs droits et à leur dignité, et ils s’interrogent sérieusement sur l’impact de cette technologie sur tous les aspects de la vie, du travail à l’éducation en passant par l’environnement. Comment les systèmes automatisés évaluent-ils les candidatures et les candidats eux-mêmes ? Les tuteurs IA contribuent-ils à la réussite des élèves ou, au contraire, limitent-ils leurs connaissances ? Les immenses centres de données construits pour alimenter l’IA font-ils exploser les factures d’énergie des collectivités ? Une simple « connaissance » de l’IA ne suffit pas à répondre à ces questions, ni à toutes celles qu’elles soulèvent. Chacune d’elles nous oblige à appréhender clairement la technologie, à examiner de manière critique ses applications et à mobiliser les outils de la participation citoyenne pour en orienter le développement. »
Face à l’IA, renforcer la citoyenneté plutôt qu’acculturer
De même que l’éducation civique aux États-Unis permet aux citoyens de comprendre leurs droits, leurs devoirs et le fonctionnement du gouvernement, ce travail requiert un programme d’enseignement. D’où cette initiative d’éducation civique à l’IA : « une approche de l’éducation publique qui considère l’IA non pas comme un outil à maîtriser, mais comme un domaine de la vie civique où les citoyens ont des droits, des responsabilités et des moyens d’action collective. En mettant en lumière les outils civiques permettant au public d’exercer un pouvoir politique sur les systèmes d’IA et les plateformes technologiques – notamment au niveau local –, l’initiative d’éducation civique à l’IA renforcera la capacité des citoyens à participer à la conception et au déploiement de ces technologies, et contribuera à asseoir un pouvoir démocratique sur les institutions qui les créent et les promeuvent.»
Pour mobiliser la négociation collective pour peser sur l’utilisation de l’IA au travail, pour demander des changements dans les procédures d’achat des systèmes d’IA dans les écoles, pour exiger la transparence des outils de tri et de sélection automatisés, les gens doivent comprendre les processus civiques disponibles pour les utiliser. Tel est l’ambition du programme AI Civics : faciliter et approfondir l’apprentissage des modalités d’action en proposant des modèles et des ressources sur lesquels les communautés de tout le pays pourraient s’appuyer.
Partout dans le monde, les travailleurs utilisent la négociation collective pour influencer l’utilisation de l’IA sur leur lieu de travail. Des militants font pression sur les autorités locales chargées d’autoriser les permis de construire afin d’exercer un pouvoir sur la construction des centres de données. Des élèves et des parents réclament des changements dans les politiques et les procédures d’achat des écoles. C’est la participation citoyenne en action : les communautés utilisent les leviers à leur disposition pour déterminer si et comment l’IA et ses infrastructures sont déployées. Mais avant cela, elles ont dû comprendre ces processus civiques et apprendre à les utiliser à leur avantage. Le programme AI Civics facilitera et approfondira cet apprentissage, en proposant des modèles et des ressources sur lesquels les communautés de tout le pays pourront s’appuyer.
En 2025, D&S a organisé un cycle de conférences sur le thème “Comprendre l’IA”. L’initiative que l’Institut lance est le résultat des commentaires qu’ont adressé le public aux chercheurs. Dans ces commentaires, expliquent les chercheurs et chercheuses de D&S, trois points sont ressortis :
– Comme nous le disions nous même, les gens sont inquiets de l’IA. « Les gens se sentent pris au dépourvu par la rapidité et l’ampleur de ce changement, et frustrés par l’impression qu’il se produit sans leur participation ».
– « Même les utilisateurs de l’IA s’inquiètent de ses impacts. Les participants nous ont confié utiliser des outils d’IA au quotidien, mais être mal à l’aise face aux compromis et aux coûts cachés. Ils souhaitent dépasser le vernis séduisant du battage médiatique autour de l’IA et comprendre les véritables implications de l’utilisation de ces outils, leurs coûts et avantages réels, ainsi que les moyens d’en atténuer les effets néfastes. »
– « Lassés d’être des consommateurs passifs, les citoyens cherchent des moyens de s’engager davantage. Nombreux étaient ceux qui souhaitaient découvrir des pistes concrètes pour une action collective, d’autant plus que la réglementation gouvernementale et les efforts pour responsabiliser les entreprises technologiques sont insuffisants. Nous avons constaté une volonté d’appréhender la complexité et un désir de s’opposer aux discours sur l’inévitabilité technologique. »
La culture de l’IA, la littératie, c’est-à-dire la maîtrise de savoirs, de capacités et d’aptitudes liées à l’IA, telle qu’elle est actuellement conçue, ne répond pas à ces besoins, estime l’Institut. Bien souvent, cette culture se limite à offrir la possibilité d’acquérir les compétences et les connaissances nécessaires pour utiliser l’IA et en tirer profit. Mais c’est un discours qui répète souvent que l’IA est inévitable et que ceux qui ne possèdent pas de connaissances dans ce domaine seront laissés pour compte. Dans un contexte économique déjà particulièrement difficile, pour beaucoup de gens, cette approche sonne comme une menace.
« Dans son nouveau rapport, (404) Job Not Found : What Workforce Training Can’t Fix for Black Atlantans in the Age of AI, Anuli Akanegbu, chercheuse chez Data & Society, analyse la manière dont l’IA est abordée dans les milieux universitaires, promue par l’industrie, mise en œuvre par les pouvoirs publics et perçue au sein de la société civile. Basée à Atlanta, ville qui aspire à devenir l’épicentre de la main-d’œuvre de demain préparée à l’IA, Akanegbu décrit l’incapacité des pouvoirs publics et de l’industrie à définir clairement la culture de l’IA ou à préciser les compétences nécessaires aux travailleurs sur un marché du travail de plus en plus dominé par l’IA comme une abstraction stratégique, une forme de flou intentionnel qui transforme l’avancement professionnel en un objectif en constante évolution » (voir également toutes les limites des annonces qui exigent une « maîtrise de l’IA exigée »). « Ce flou sert un dessein : il reporte la responsabilité du chômage sur une main-d’œuvre majoritairement noire plutôt que de s’attaquer aux conditions structurelles qui rendent l’accès aux emplois de qualité de plus en plus difficile. En présentant l’adoption de l’IA comme une question d’effort individuel plutôt que de limitations systémiques, le concept de littératie de l’IA a été instrumentalisé pour promouvoir une solution simpliste au problème très complexe du déplacement d’emplois. De même que l’éducation aux médias imputait la désinformation, la manipulation médiatique et l’effondrement du système d’information aux utilisateurs individuels des réseaux sociaux, l’éducation à l’IA reproche aux travailleurs de ne pas trouver d’emploi rémunérateur plutôt qu’à un contexte socio-économique plus large qui normalise la précarité. »
D&S souhaite que son initiative parte des travailleurs, des étudiants, des citoyens… et qu’elle s’appuie sur les connaissances militantes pour aider les citoyens à exercer davantage leur pouvoir collectif à l’ère de l’IA. L’enjeu n’est pas seulement de se former à l’IA ou de s’y préparer, mais d’y ajouter la participation et l’intervention citoyenne. D&S est à la recherche d’organisations souhaitant rejoindre ce programme pour construire les ressources permettant de renforcer les capacités d’actions des citoyens. Que ce soit par exemple en créant des ressources pour les usagers des bibliothèques, ou en travaillant avec les associations de parents d’élèves pour documenter leurs méthodes pour mieux inspecter les marchés publics des districts scolaires lorsqu’ils achètent des outils technologiques… (voir notre article sur la montée de la contestation de l’IA à l’école).
« Les risques et les préjudices liés à l’IA sont bien documentés, mais ils ne sont pas inévitables. Notre mission essentielle aujourd’hui est de renforcer le pouvoir démocratique sur les institutions qui conçoivent et déploient les systèmes d’IA. Il est temps que la responsabilité publique et l’intérêt général soient de nouveau au cœur de l’innovation technologique à grande échelle. Il est temps que le grand public exerce un contrôle démocratique plus important sur l’IA. Il est temps d’instaurer une éducation civique sur l’IA. »
En tout cas, cette approche par l’éducation publique qui considère l’IA non pas comme un outil à maîtriser, mais comme un domaine de la vie civique où les citoyens ont des droits, des responsabilités et des moyens d’action collective est stimulante et inspirante. Bien loin par exemple des orientations britanniques prises en janvier de formation à l’IA pour tous, contestées par les acteurs de la médiation du Royaume-Uni (voir « Royaume-Uni : l’IA pour tous ! Laquelle ? »).
Résistances organisées
Ce travail ne part pas de nulle part. En fait, il a déjà largement commencé. A l’heure où les contestations contre la tech sont en passe d’être qualifiées d’extrémistes aux Etats-Unis, plusieurs autres collectifs de recherche et d’action documentent des modalités et des méthodes pour demander des comptes. L’AI Now Institute a ainsi lancé un kit d’action pour aider les citoyens à comprendre les réglementations mobilisables pour développer des recours contre le déploiement de centres de données.
La journaliste Karen Hao, autrice du remarqué L’empire de l’IA (qui vient d’être traduit aux éditions L’écran fantastique) a lancé la liste de résistance à l’IA avec le Laboratoire de droit des réfugiés, le Distributed AI Research Institute (DAIR, fondé par la chercheuse Timnit Gebru) et l’association de justice sociale We and AI. Remettre en question le caractère inéluctable de l’IA est l’enjeu de cette liste qui recense et documente très succinctement et très partiellement les actes de résistance et d’opposition à l’industrie de l’IA à travers le monde. Comme le raconte l’anthropologue et l’avocate du numérique Petra Molnar (auteure de The Walls have Eyes, The New Press, 2024) dans Tech Policy Press, cette liste à été initiée par le travail du collectif Migration Tech Monitor, et notamment de celui du journaliste syrien Wael Qarssifi qui à documenté l’impact de la surveillance dans son pays et de Verónica Martínez qui a travaillé sur les effets de la surveillance et de la militarisation le long de la frontière américano-mexicaine. Comme l’explique Molnar, la liste a été intentionnellement documentée avec les initiatives évoquées et en se concentrant intentionnellement sur les pays en développement où les systèmes d’IA sont fréquemment déployés avec « moins de garanties réglementaires et un potentiel de préjudice plus élevé, et où les formes de résistance sont contraintes à être plus inventives ».
La liste est articulée autour de quatre modes de résistances, afin d’élargir sa définition : résister, refuser, se réapproprier et réinventer. Au Nouveau-Mexique, le site documente les actions en justice menées par le New Mexico Environmental Law Center contre le développement du « Projet Jupiter », un énorme centre de données. En Uruguay, le Mouvement pour un Uruguay soutenable a lancé une campagne pour exiger une plus grande transparence concernant un projet de centre de données de Google. Au Japon, le Syndicat japonais des travailleurs de la métallurgie, de la fabrication, de l’information et des télécommunications a saisi la commission du travail du gouvernement de Tokyo afin de contraindre IBM à divulguer les données d’IA utilisées pour le calcul des salaires. « Au Chili, des habitants de Quilicura, une commune ouvrière de la banlieue de Santiago, se sont transformés en chatbot humain le temps d’une journée. Quili.ai, un site web conçu pour ressembler à une interface d’IA, redirigeait les requêtes des utilisateurs vers des membres de la communauté qui répondaient en temps réel. Pendant plus de 12 heures, en collaboration avec des artistes locaux, ils ont répondu à 25 000 questions d’utilisateurs de 68 pays. L’objectif n’était pas de prouver que les humains pouvaient surpasser l’IA, mais d’amener les gens à s’interroger sur ce qu’ils abandonnaient réellement, et au profit de qui, en externalisant leurs requêtes vers un système bâti sur l’exploitation du bassin du fleuve Maipo et de communautés comme la leur. »
Nombre de résistances sont liées aux transformations du travail, bien sûr. En Californie, les professionnels de la santé mentale de Kaiser Permanente ont mené une grève pour dénoncer le remplacement du jugement clinique par un triage algorithmique. Au Royaume-Uni, les personnels de santé se mobilisent pour refuser l’intégration de Palantir dans le système de santé publique.
Aux Philippines, plusieurs organisations de travailleurs du numérique ont formé une coalition pour promouvoir la représentation des travailleurs dans l’élaboration des politiques relatives à l’IA et documenter les préjudices causés par l’adoption de l’IA. A Nairobi, l’Association des étiqueteurs de données (comptant aujourd’hui près de 900 membres), milite pour des conditions de travail équitables, des contrats transparents et la reconnaissance du travail cognitif et émotionnel lié à l’entraînement des systèmes d’IA. Lorsque Microsoft a commencé à intégrer massivement des fonctionnalités d’IA dans ses produits, des utilisateurs ont lancé un site web dédié, Microslop, pour recenser la dégradation de l’expérience utilisateur. L’artiste Sam Lavigne, lui, a proposé un plug-in pour navigateur, qui manipule les chatbots afin de ralentir leur temps de réponse pour inviter les utilisateurs à s’interroger sur ce qu’ils attendent exactement et pourquoi. Decolonize Digital est une collection de ressources, une « boîte à outils de libération » qui propose des alternatives, comme par exemple des solutions pour Dé-Googliser nos existences. Ou encore O Panóptico, un projet qui recense les initiatives de reconnaissance faciale au sein du système de sécurité publique brésilien.
Transparence, participation, élargissement et contrôle distribué
« Les initiatives recensées sur la liste AI Resist mettent également en lumière un ensemble de revendications auxquelles aucun cadre réglementaire existant ne répond pleinement, et auxquelles toute politique sérieuse de gouvernance de l’IA devrait s’attaquer », souligne Petra Molnar.
La première revendication transversale est bien sûr la transparence. Nombre de mouvements de résistance réclament bien souvent seulement de savoir ce qui est construit, par qui, avec quelles ressources et à quel prix. « Même des exigences de divulgation minimales, si elles étaient appliquées de manière cohérente, bouleverseraient fondamentalement le modèle opérationnel actuel du secteur, qui repose sur l’opacité à chaque étape de la chaîne d’approvisionnement », rappelle Molnar.
La deuxième revendication est la participation. Des employés d’Amazon qui ont exigé d’être consultés avant le déploiement de l’IA au sein de leur entreprise, à la coalition philippine qui milite pour la prise en compte des travailleurs dans l’élaboration des politiques relatives à l’IA… « nombres d’exemples pointent vers le même constat : les décisions concernant l’IA sont prises trop rapidement, en secret, par un petit nombre d’acteurs puissants cherchant à s’enrichir davantage, sans aucun mécanisme efficace permettant aux personnes les plus touchées d’intervenir ». Améliorer les contraintes de participation des publics serait seule à même d’entraver les décisions.
La troisième implication transversale vise à étendre la perception de la chaîne d’approvisionnement de l’IA. Des exactions sur les ressources minières au Congo en passant par celles des étiqueteurs du Kenya, « les coûts de l’IA sont systématiquement répercutés sur les communautés les moins à même de les supporter et les moins représentées dans les instances décisionnelles. Tout cadre de gouvernance qui n’étend pas son champ d’application aux communautés minières de la République démocratique du Congo, aux modérateurs de contenu d’Afrique de l’Est et aux annotateurs d’Asie du Sud-Est ne gouverne pas l’IA. Il gouverne un complexe industriel lucratif et soigneusement orchestré. »
Le quatrième point, et peut-être le plus important sur le plan structurel, qui unifie divers exemples, concerne la question du contrôle de l’infrastructure de l’IA. « Les campagnes contre les centres de données au Nouveau-Mexique et en Uruguay ne sont pas de simples conflits environnementaux locaux. Elles constituent les prémices d’une lutte plus vaste : l’infrastructure physique de l’IA, incluant les terres, l’eau et l’énergie nécessaires à son fonctionnement, sera-t-elle considérée comme une ressource publique ou un actif privé ? Les communautés qui s’y opposent soulèvent des questions auxquelles aucune stratégie nationale en matière d’IA n’a encore apporté de réponse satisfaisante : qui autorise cette infrastructure ? Dans quelles conditions environnementales et démocratiques ? Et quels recours disposent les communautés affectées lorsque ces conditions ne sont pas remplies ? »
La liste des résistances à l’IA ne dit pas que la résistance triomphe toujours, bien au contraire, ni qu’elle suffira à corriger les inégalités de pouvoir que le développement de l’IA renforce. Elle recense seulement des actions juridiques, l’organisation des travailleurs, les campagnes citoyennes, les provocations artistiques, les outils techniques, la création de coalitions et le travail de documentation patient que ceux qui subissent ces préjudices mettent place. Ses exemples proviennent d’Allemagne, du Japon, du Kenya, du Chili, des Philippines, du Royaume-Uni, d’Uruguay, de la République démocratique du Congo et des États-Unis. Mis bout à bout, « ces éléments constituent une réalité que l’industrie de l’IA préférerait ne pas reconnaître : l’IA n’est ni une force irrésistible ni au-dessus de toute contestation démocratique, et des personnes sur tous les continents sont prêtes à remettre en question son caractère prétendument inévitable. »
Mais la liste ne se contente pas de suggestions critiques. Elle recense également des projets plus stimulants et constructifs. Par exemple : Hire a coop, une plateforme argentine et brésilienne doublée d’une campagne de communication pour encourager le recours à des entreprises coopératives, détenues par leurs travailleurs (voir également notre article sur le sujet). Ou encore, le réseau Huniki, un réseau d’entreprises technologiques spécialisées dans les langues africaines pour construire des systèmes sur mesures développées par et pour leurs locuteurs. De même, Lesan AI est un outil de traduction automatique pour deux langues éthiopiennes développés avec les traducteurs et les communautés qu’ils servent. Slow AI, de l’association AIxDesign met en lumière des approches à petites échelles… Enfin, le wiki du réseau Permacomputing défend des initiatives inspirées de la permaculture appliquées à l’informatique.
L’initiative AI Civics de Data & Society ou la liste des résistances à l’IA lancée par Karen Hao nous invitent à amplifier les mobilisations en rendant visibles celles qui se déploient déjà, en documentant leurs réussites et leurs échecs pour permettre à chacun de s’en inspirer… de les prolonger, de les reproduire.
Hubert Guillaud
10.06.2026 à 07:00
Marketing : le boom de l’automatisation
Hubert Guillaud
Texte intégral (771 mots)
« Pendant des années, DribbleUp, une entreprise d’équipements sportifs américaine, a consacré son temps et ses ressources à identifier les cibles publicitaires pour ses ballons de basket et de football sur Facebook. Mais depuis deux ans, elle diffuse ses publicités exclusivement via les outils d’intelligence artificielle de Facebook. Depuis, les ventes de DribbleUp ont dépassé ses dépenses marketing. L’entreprise a également augmenté son budget publicitaire sur Facebook. L’expérience de DribbleUp illustre comment l’IA remodèle le secteur de la publicité numérique.»
Les systèmes d’IA aident les entreprises à automatiser leur marketing. « Petites et grandes entreprises peuvent désormais créer des publicités, cibler des audiences, enchérir sur des espaces publicitaires et mesurer leurs résultats. Ce processus a simplifié la tâche des entreprises locales, qui peuvent ainsi développer des campagnes aussi sophistiquées que celles des géants du secteur. Selon les entreprises technologiques et les marques, cette technologie rend également les publicités plus efficaces. Par conséquent, les investissements publicitaires affluent vers les géants de la tech », notamment Meta et Google. En 2022, année de lancement de ChatGPT, les ventes liées à l’IA totalisaient 1 milliard de dollars, un chiffre qui a atteint 35 milliards de dollars l’année dernière, selon Madison & Wall, un cabinet de conseil spécialisé dans le suivi du secteur. Cette année, les ventes devraient exploser de 60 %, pour atteindre 56 milliards de dollars. « Google et Meta étaient déjà en tête, et maintenant, grâce à ces outils d’IA, ils creusent l’écart », a déclaré Luke Stillman, directeur général chez Madison & Wall. A l’ère de l’IA, « être plus grand n’est pas seulement un avantage proportionnel pour Google et Meta », a-t-il déclaré. « C’est un avantage exponentiel. »
« L’IA a alimenté un boom de la publicité numérique car cette technologie peut analyser instantanément d’énormes quantités d’informations. Elle aide Google et Meta à proposer aux utilisateurs un contenu plus pertinent, ce qui augmente le nombre de publicités que ces entreprises peuvent diffuser. Elle permet de mieux comprendre les centres d’intérêt des utilisateurs, ce qui améliore la capacité des entreprises à cibler les publicités. Enfin, elle réduit les coûts publicitaires, libérant ainsi des fonds pour des campagnes plus ambitieuses. »
« La technologie est prête à remplacer significativement le travail manuel dans notre secteur », conclut un directeur marketing. Avec l’IA, le système est plus facile à utiliser pour les entreprises, même si la technologie sous-jacente est devenue plus complexe et que les annonceurs ont moins de contrôle sur l’apparence, l’emplacement et les performances de leurs publicités. « Les véritables avancées commerciales proviennent du ciblage. Auparavant, un annonceur disait par exemple : « Je souhaite cibler les femmes new-yorkaises âgées de 24 à 35 ans.» Désormais, c’est l’inverse : Meta et Google utilisent l’IA pour recommander aux marques les clients qu’elles devraient cibler. » « Les publicités non pertinentes ont diminué de 40 %, ce qui représente une amélioration significative pour une entreprise rémunérée uniquement lorsqu’un internaute clique sur une annonce. »
« Les outils d’intelligence artificielle (IA) prennent également en charge certains aspects du processus créatif et marketing. Google permet désormais de modifier le message des publicités en temps réel afin de mieux répondre aux attentes des internautes. Ce système, que Google appelle « Recherche réactive », crée et teste les textes publicitaires avant de diffuser automatiquement une campagne correspondant au mieux aux centres d’intérêt de l’utilisateur », et permet de réaliser des économies sur la conception de leurs publicités. « Chris Wilhelmi, responsable mondial des données et des médias chez Monks, agence de marketing, a déclaré que les clients économisaient 30 % sur le coût de leurs campagnes. Sur le contenu, les économies peuvent atteindre 65 %. Nombre d’entre eux réinvestissent ces économies dans le test et l’expérimentation de nouvelles stratégies publicitaires. »
« Aujourd’hui, tout le monde aborde le marketing comme un problème technologique ».
- Persos A à L
- Carmine
- Mona CHOLLET
- Anna COLIN-LEBEDEV
- Julien DEVAUREIX
- Cory DOCTOROW
- Lionel DRICOT (PLOUM)
- EDUC.POP.FR
- Marc ENDEWELD
- Michel GOYA
- Hubert GUILLAUD
- Gérard FILOCHE
- Alain GRANDJEAN
- Hacking-Social
- Samuel HAYAT
- Dana HILLIOT
- François HOUSTE
- Tagrawla INEQQIQI
- Infiltrés (les)
- Clément JEANNEAU
- Paul JORION
- Christophe LEBOUCHER
- Michel LEPESANT
- Persos M à Z
- Henri MALER
- Christophe MASUTTI
- Jean-Luc MÉLENCHON
- MONDE DIPLO (Blogs persos)
- Richard MONVOISIN
- Corinne MOREL-DARLEUX
- Timothée PARRIQUE
- Thomas PIKETTY
- VisionsCarto
- Yannis YOULOUNTAS
- Michaël ZEMMOUR
- LePartisan.info
- Numérique
- Thomas BEAUFILS
- Blog Binaire
- Christophe DESCHAMPS
- Dans les Algorithmes
- Louis DERRAC
- Olivier ERTZSCHEID
- Olivier EZRATY
- Framablog
- Fake Tech (C. LEBOUCHER)
- Romain LECLAIRE
- Tristan NITOT
- Francis PISANI
- Irénée RÉGNAULD
- Nicolas VIVANT
- Collectifs
- Arguments
- Scientifiques en Rebellion
- Bondy Blog
- Dérivation
- Économistes Atterrés
- Dissidences
- Mr Mondialisation
- Palim Psao
- Paris-Luttes.info
- Rojava Info
- X-Alternative
- Créatifs / Art / Fiction
- Nicole ESTEROLLE
- Julien HERVIEUX
- Alessandro PIGNOCCHI
- Laura VAZQUEZ
- XKCD