
13.03.2024 à 16:58
#BoycottIsrael : Ce que la campagne BDS révèle des nouvelles formes de lobbying en ligne
Le déclenchement de la guerre Israël-Hamas après l'attaque terroriste du 7 octobre s'est accompagné d'une vague d'appels au boycott sur les réseaux sociaux. Cette étude explore le rôle central de la campagne BDS, l’impact des médias d’influence étrangers, le rôle de TikTok et des néo-medias sur X, et analyse la circulation de narratifs confusionnistes.
L’article #BoycottIsrael : Ce que la campagne BDS révèle des nouvelles formes de lobbying en ligne est apparu en premier sur Observatoire stratégique de l'information.
Texte intégral (16077 mots)
La guerre Israël-Hamas, déclenchée après l’attaque terroriste du 7 octobre 2023, s’est très vite accompagnée d’appels au boycott visant des produits d’origine israélienne, ou des marques accusées de prétendue collusion avec l’État d’Israël. Ce mode d’action, qui a trouvé sur le web et les réseaux sociaux son principal terrain d’expression, s’inscrit dans le cadre de la stratégie de la campagne BDS, acronyme de boycott – désinvestissement – sanction. Lancée en 2005 en Palestine, BDS n’est pas à proprement parler une association, mais plutôt une coalition mondiale d’associations, d’ONG, de syndicats et de partis politiques pro-palestiniens, organisée par sections nationales. Elle demeure, près de vingt ans après son lancement, l’un des principaux vecteurs utilisés par les militants pro-palestiniens pour peser dans l’opinion et essayer de faire pression sur les marques avec des méthodes radicales et faisant régulièrement l’objet de critiques. Depuis octobre dernier, cette dernière connaît une nouvelle dynamique et entend exploiter au maximum les réseaux sociaux pour faire avancer son agenda, que ce soit sur X (ex-Twitter) ou sur TikTok. Quitte à s’autoriser quelques petits arrangements avec la vérité.

Le boycott, un mode d’action historique de la cause palestinienne
Le boycott est un mode d’action ancien de la cause palestinienne, qui s’inspire de prescriptions religieuses et, à partir du XXe siècle, des actions mises en œuvre par d’autres militants anticoloniaux dans l’Empire britannique. Dès 1894, le grand Mufti de Jérusalem donne l’ordre aux musulmans de la ville de boycotter les bouchers juifs[1]. A partir des années 1920, le boycott devient un registre d’action de plus en plus utilisé par les nationalistes arabes qui luttent contre la présence britannique en Palestine et pour l’indépendance du pays. L’idée de boycotter les entreprises juives afin de contraindre les Juifs au départ est ainsi formulée lors du Ve Congrès arabe en 1922. Les actions se multiplient comme en 1921 à Jaffa, en 1929 à Jérusalem ou encore en 1930 à Naplouse. Dans les années 1930, les nationalistes Palestiniens s’inspirent de la campagne de boycott des produits anglais en Inde initiée par Gandhi[2]. L’arme du boycott est encore mobilisée par le leadership arabe de la Palestine mandataire contre la communauté juive de Palestine pendant la révolte arabe de 1936-1939. Le boycott ne donne pas les résultats escomptés, et accélère au contraire l’autonomisation économique de la communauté juive[3].
En dépit de ses effets limités en Israël, le boycott devient un pilier de l’action politique en faveur d’un État palestinien arabe au niveau international. Dès sa formation le 2 décembre 1945, la Ligue arabe adopte une résolution instituant un embargo de tous les produits et biens fabriqués ou commercialisés par la communauté juive de Palestine, sans exception d’aucune sorte.
La création de l’État d’Israël en 1948 conduit la Ligue arabe à étendre l’application du boycott. En 1951, celle-ci se dote d’un Bureau central du boycott officiellement basé à Damas et va définir trois catégories de boycott :
- Le boycott “primaire” qui interdit aux citoyens des États de la Ligue d’acheter ou de vendre des produits “made in Israël” et d’établir une relation contractuelle avec une entreprise israélienne.
- Le boycott “secondaire” qui cible tous les opérateurs économiques à travers le monde “qui maintiennent certains types de contact avec Israël au-delà de simples relations d’import export” ou entretiennent des “sympathies pour le sionisme”[4].
- Le boycott “tertiaire” cible les ressortissants des États de la Ligue arabe faisant affaires avec une entreprise ciblée par le “boycott secondaire”.
Après avoir atteint le pic de son efficacité dans les années 70, après la guerre du Kippour et les chocs pétroliers de 1973 et 1979, le boycott de la Ligue arabe s’essouffle progressivement sous la pression des États-Unis, du fait du retournement de la conjoncture pétrolière et à mesure que les États arabes normalisent leurs relations diplomatiques avec Israël, à commencer par l’Égypte dès 1979, l’Autorité palestinienne en 1993 ou encore la Jordanie en 1994.
À partir des années 1990, les États qui continuent officiellement de participer au boycott se montrent de moins en moins stricts dans son application ; certains d’entre eux, comme l’Arabie saoudite, entretiennent notoirement des liens avec des acteurs économiques visés par le boycott[5].
Un renouvellement du boycott par la société civile
Le boycott des produits israéliens connaît cependant un second souffle avec le lancement de la campagne BDS (Boycott, désinvestissement, sanctions) par 171 ONG palestiniennes, après la seconde intifada en juillet 2005, en revendiquant de s’inspirer du boycott de l’Afrique du Sud dans les années 1980[6]. Sa création s’inscrit à la suite de la conférence de Durban contre le racisme de 2001 et dans un contexte de revalorisation du boycott comme « djihad des consommateurs » par les universitaires islamiques après le déclenchement de la «Guerre contre la terreur » et l’occupation israélienne de la Cisjordanie lors de l’opération « Rempart » en avril 2002[7].
Omar Barghouti, cofondateur de BDS, a énoncé les trois objectifs officiels du mouvement :
- « La fin de l’occupation israélienne de 1967, ce qui inclut le démantèlement des colonies de Cisjordanie et la destruction du mur [de séparation entre Israël et la Palestine] » ;
- « La fin du système israélien de discrimination juridique à l’égard des citoyens palestiniens d’Israël, système qui correspond aux critères de l’apartheid tels que définis par l’ONU » ;
- « L’autorisation pour les réfugiés palestiniens, chassés de force en 1948 et en 1967, de regagner leur domicile ou leur région d’origine, dans le cadre des résolutions de l’ONU sur ce point. »
Dès son origine, la campagne BDS s’inscrit en faux contre la réponse diplomatique des États arabes, jugée inefficace et insuffisante[8].
Le mouvement coalise progressivement des centaines d’organisations (associations, syndicats, ONG, partis politiques) engagées dans la cause palestinienne, qui s’organisent par pays. Le caractère décentralisé et la diversité des membres de la plateforme BDS lui permet de « s’enraciner dans des réalités locales », c’est-à-dire de cibler dans chaque État des acteurs économiques spécifiques. Dans le même temps, ce caractère éclaté nuit à la cohérence globale de la campagne, notamment en termes d’intensité dans le temps, de discours et de moyens employés selon les pays[9]. Les pics d’intérêt (y compris médiatiques) sont essentiellement liés à des épisodes du conflit israélo-palestinien et retombent rapidement par la suite.
Ce phénomène peut être illustré avec l’analyse des données de Google Trends, qui montrent l’évolution du nombre de recherches sur Google des utilisateurs français concernant le boycott des produits israéliens et le mouvement BDS.

Dans le graphique ci-dessus, trois pics sont particulièrement visibles :
- Décembre 2008 – janvier 2009 : guerre de Gaza de 2008-2009 (ou « opération Plomb durci »), pour le boycott mais pas pour BDS dont la notoriété reste encore très faible en France à l’époque.
- Juillet-août 2014 : guerre de Gaza de 2014.
- Octobre 2023 : guerre Israël-Hamas de 2023-2024. La séquence ouverte après l’attaque terroriste du 7 octobre est de loin celle qui a vu le plus grand nombre de recherches sur le boycott des produits israéliens.
L’intérêt pour le boycott reste ainsi fortement corrélé à une réaction spontanée et émotionnelle liée aux développements du conflit israélo-palestinien.
Depuis 2015, le BDS accentue sa stratégie visant à abîmer les marques
En parallèle d’autres mouvements militants ciblant les modes de consommation pour faire avancer leur agenda politique (par exemple le mouvement animaliste), et en suivant l’évolution impulsée par le mouvement au niveau monde, BDS France a, au cours des dernières années, fait évoluer sa stratégie. Alors que la coalition s’était surtout spécialisée dans l’établissement de listes de produits à boycotter (au point d’envisager la réalisation d’une application pour scanner les codes barre des produits en supermarché), les campagnes BDS ont évolué pour cibler plus précisément la réputation des entreprises, et se faire remarquer au plan médiatique en ciblant des marques et des événements.
En 2015, l’association apparaît en pointe de la protestation contre le projet de la Mairie de Paris baptisé « Tel-Aviv sur Seine » – l’une des opérations qui fera le plus parler du boycott des produits israéliens hors période de conflit ouvert. À cette occasion, BDS fait parvenir un « argumentaire coup-de-poing » contre l’événement aux rédactions françaises. L’association se mobilise au même titre que divers mouvements pro-palestiniens (dont certains très radicaux), au risque de brouiller son image modérée auprès des milieux de gauche.
La même année, le mouvement de boycott revendique une série de victoires, notamment sur de grands groupes :
- En juin, lors d’un déplacement au Caire, Stéphane Richard, PDG d’Orange, affirme que « s’il le pouvait, il déciderait “dès demain” le retrait du groupe d’Israël » après la publication d’un rapport intitulé « Les liaisons dangereuses d’Orange dans le territoire palestinien occupé ».
- En août, BDS se félicite du retrait de Veolia d’Israël, et revendique d’avoir fait perdre « 20 milliards de dollars à l’entreprise ».
- En novembre, l’Union européenne approuve l’étiquetage des produits en provenance des colonies israéliennes.
À l’instar de pratiques également éprouvées par L214, des associations composant BDS (CCFD Terre solidaire, la FIDH, l’AFPS, Al Haq, la LDH, la CGT et l’Union syndicale Solidaires) publient trois rapports ciblant de grandes entreprises françaises, destinés à nourrir le débat public en arguments de fond :
- « Les liaisons dangereuses d’Orange dans le Territoire palestinien occupé » (juin 2015)
- « Les liaisons dangereuses de banques françaises avec la colonisation israélienne » (septembre 2017)
- « Les liaisons dangereuses du groupe Carrefour avec la colonisation israélienne » (novembre 2022)
À partir de 2022, la campagne BDS France relaiera des appels à réaliser des Twitter storm à des dates et heures précises, sur le modèle d’une manifestation numérique, pour faire plier des marques.
Avec le déclenchement de la guerre entre Israël et le Hamas, conséquence directe de l’attaque terroriste perpétrée sur le territoire israélien par le groupe terroriste islamiste, l’opinion publique internationale a pu observer la nouvelle itération des campagnes de type BDS.
Cette itération se caractérise par deux caractéristiques :
- Une utilisation tous azimuts des réseaux sociaux et tout particulièrement de TikTok et X ;
- Une approche agressive à l’égard des marques, qui n’hésite pas à distordre les faits de manière opportuniste et à adopter une rhétorique radicale afin de faire avancer son agenda militant.
Ces pratiques reflètent du reste les pratiques déjà adoptées par ses sympathisants. Ces derniers, selon BDS, sont des jeunes, maîtrisant les réseaux sociaux et les codes de la mobilisation en ligne, en rupture de ban avec le monde politique traditionnel, qui seraient séduits par le boycott en raison de son caractère « concret, citoyen et efficace ». Ces utilisateurs disposent désormais d’un registre d’action très vaste ressortant du slacktivism (publication et relais de contenu sur les réseaux sociaux, signature de pétition en ligne, boycott…).
La construction d’une mobilisation numérique
L’analyse de la conversation sur X de la discussion relative au boycott en langue française, soit plus de 157 000 posts publiés entre le 10 octobre 2023 et le 9 mars 2024, nous montre la dynamique du phénomène.
En moyenne, et sur la période couverte par notre étude, ce sont plus de 1000 tweets par jour qui sont publiés concernant des appels au boycott. Comme le montre le graphique volumétrique ci-dessus, force est de constater que la campagne tous azimuts de boycott de l’État hébreu et de ses soutiens, réels ou supposés, a débuté quasiment dans l’immédiat de l’après attentat du 7 octobre 2023.
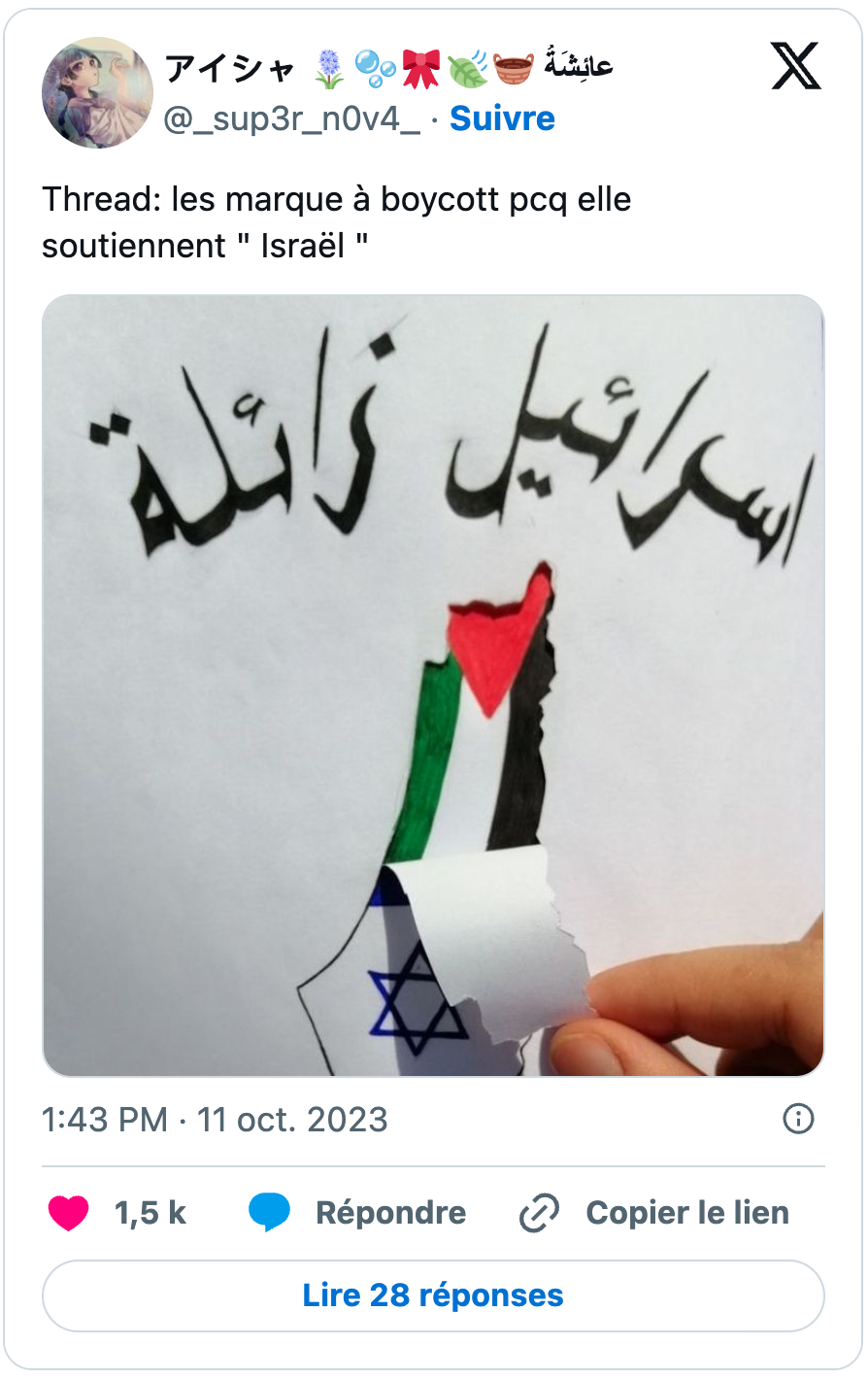
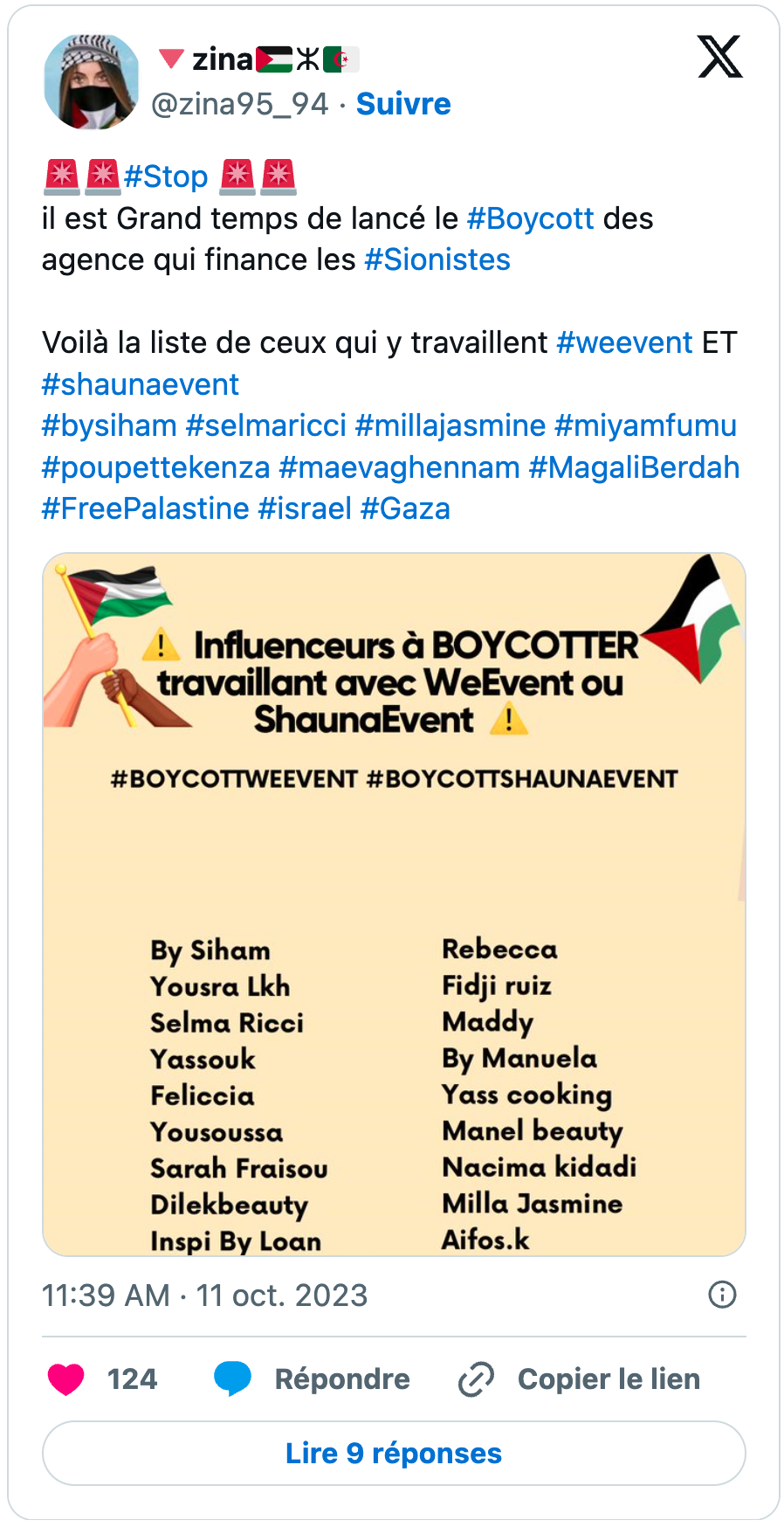
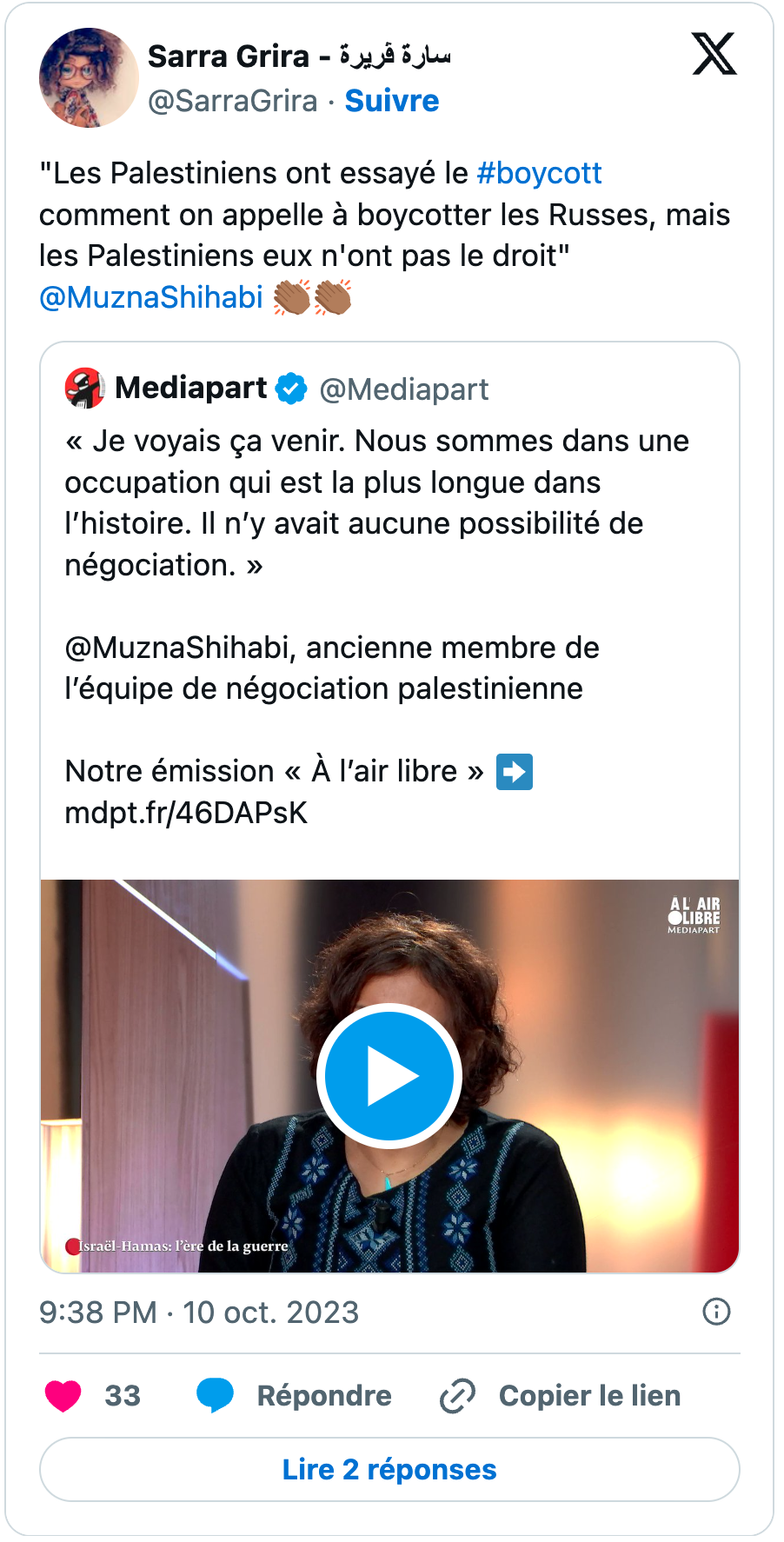

Sélection des premiers posts viraux publiés sur X appelant au boycott
Ces premiers tweets sur le boycott, partagés pour certains des milliers de fois, se caractérisent par une certaine dimension hétéroclite qui, depuis, ne cessera de caractériser l’expression de ce phénomène militant sur les réseaux sociaux. Elle correspond du reste au caractère décentralisé et éclaté du mouvement.
Appels au boycott, règlements de comptes et antisionisme militant
Au niveau des codes des réseaux sociaux, on constate notamment que le format du thread est celui auquel ont fréquemment recours les auteurs des publications parmi les plus virales. Les premiers threads sont relativement artisanaux, avec des utilisateurs pro-palestiniens qui proposent pêle-mêle des marques et autres enseignes à boycotter, en piochant dans du contenu sédimenté et fabriqué à l’occasion de campagnes précédentes, pour l’essentiel au sein de l’écosystème gravitant autour de la plateforme BDS.
Outre cet aspect, on retrouve également une dimension assez marquée de culture populaire et digitale dans ces appels au boycott. Des tweets circulent ainsi appelant à boycotter des influenceurs, sur Instagram ou Youtube pour l’essentiel, accusés de travailler avec des « agence (sic) qui finance (sic) les sionistes ». Tout semble ainsi très vite se mélanger dans un fourre-tout assez étrange, entre règlements de comptes et un discours antisioniste duquel perce un antisémitisme à peine dissimulé. De manière archétypique, l’un des premiers grands déclencheurs des vagues de boycott va concerner l’une des émissions françaises avec le plus fort audimat dans le pays, à savoir TPMP animé par Cyril Hanouna. Dans les jours qui suivent la survenue des attentats du 7 octobre, des utilisateurs de X, majoritairement pro-palestiniens, vont ainsi prendre à partie l’animateur, et dénoncer ce qu’ils considèrent être comme une ligne éditoriale « pro-sioniste ». Ces narratifs confusionnistes qui mêlent antisionisme, antisémitisme et complotisme sont un peu le creuset duquel se forment maints posts d’appels au boycott. Seule la part allouée à l’un des trois composants constitue en définitive une variable.
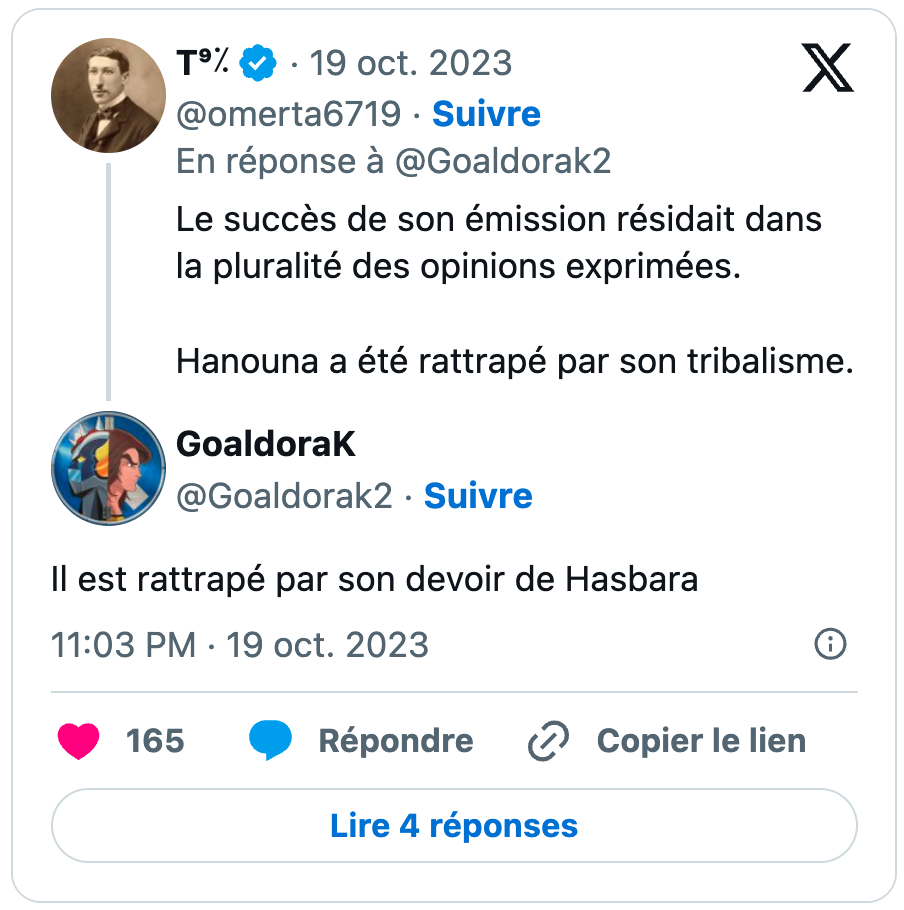
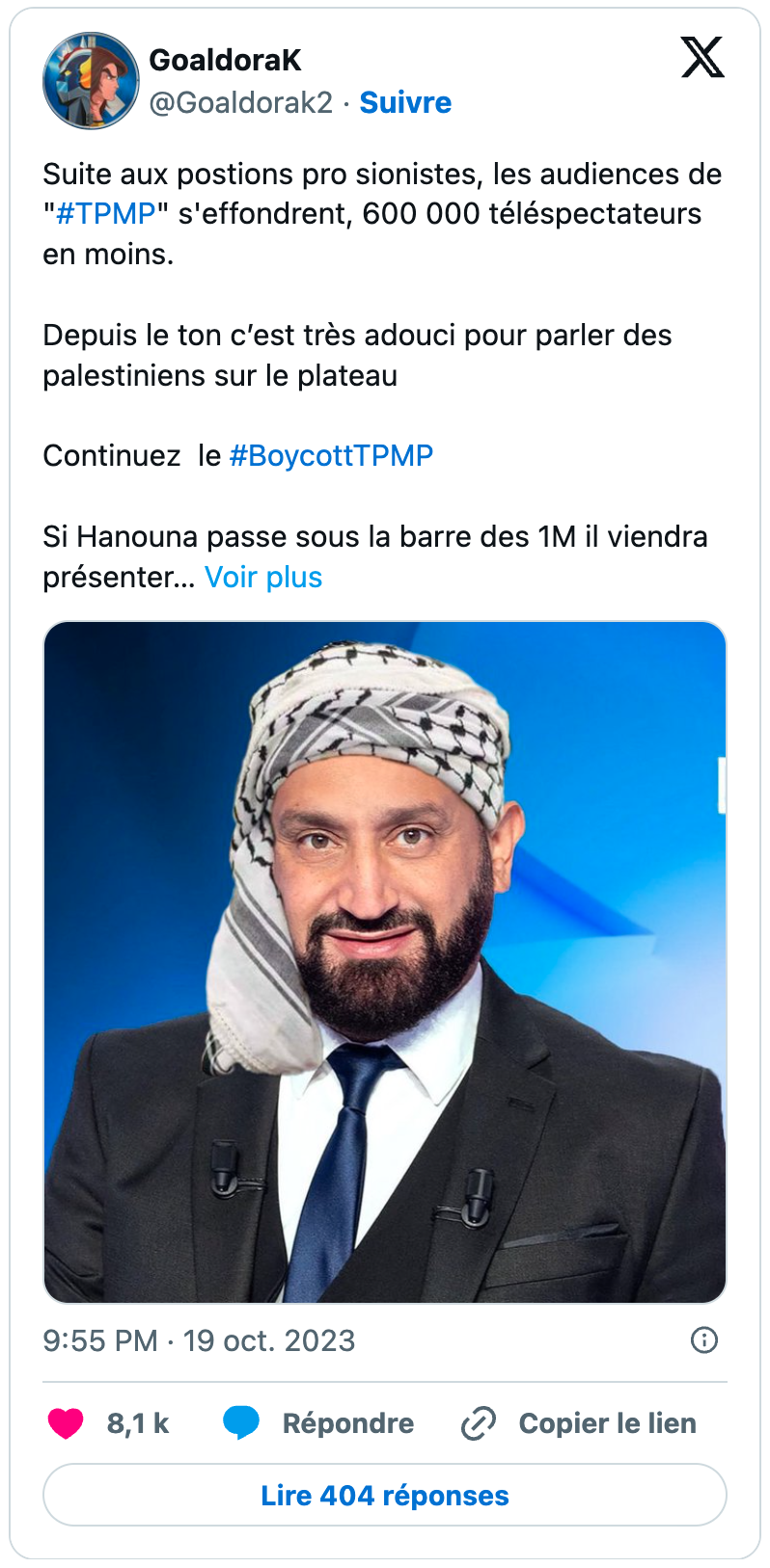
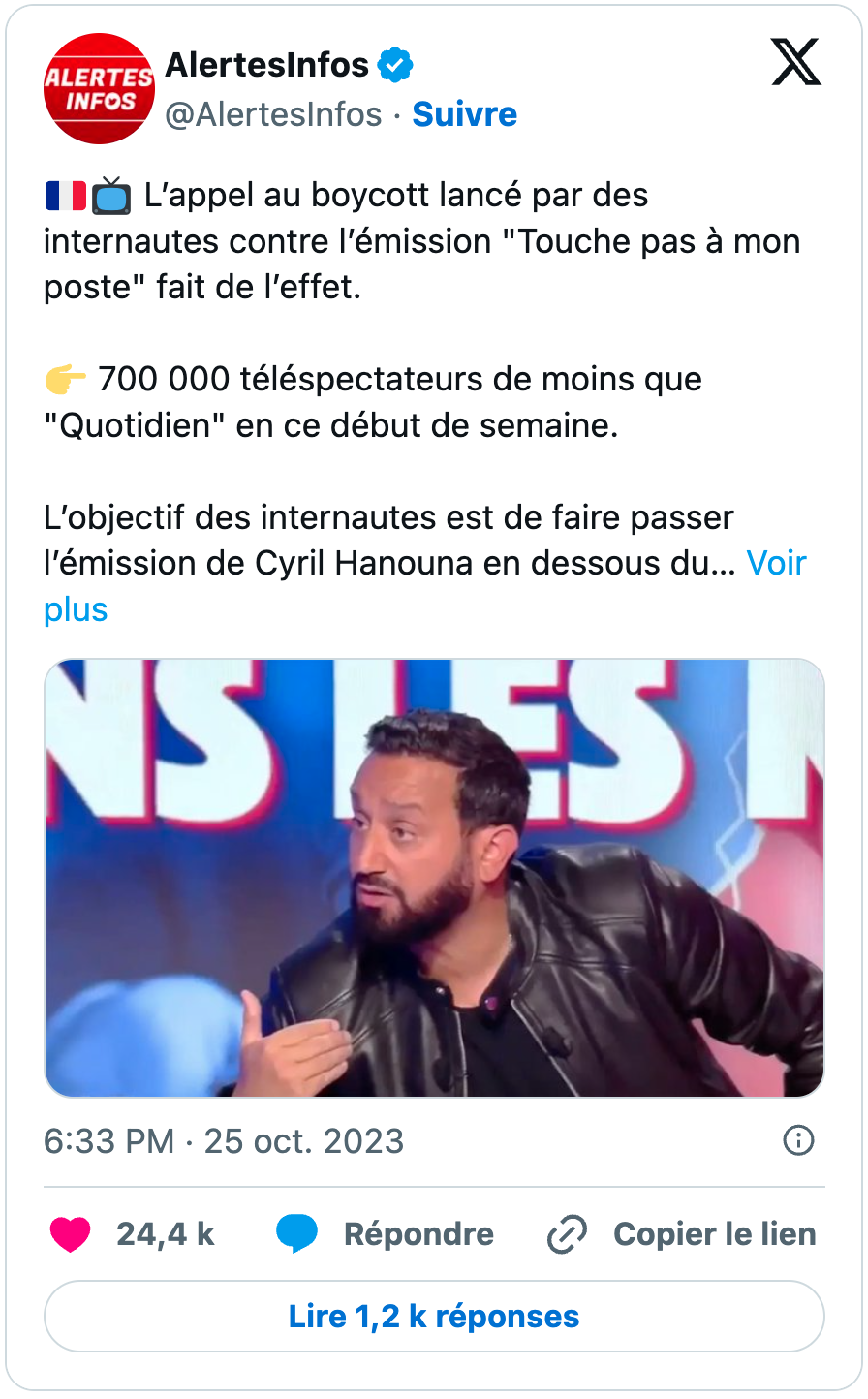
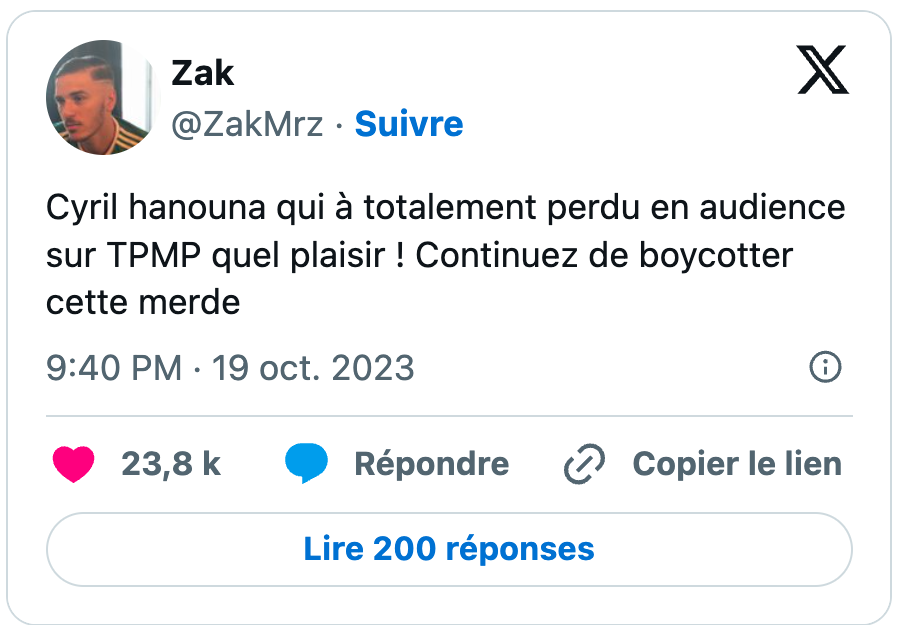
Sélection de tweets en lien avec l’appel au boycott de TPMP et de Cyril Hanouna publiés en octobre 2023
Les principales thématiques qui structurent la discussion associée au boycott
Afin de mieux cerner la structuration de la conversation francophone relative au boycott nous avons utilisé une approche par text-embedding qui permet, au bout du processus, de visualiser en deux dimensions la manière dont se structure en thématiques un corpus documentaire. Il s’agit d’une approche, dans notre cas recourant à OpenAI, qui permet d’avoir une vision synthétique d’un corpus de posts et de mettre au jour les principaux sujets qui le composent.

Il ressort de cette analyse que la conversation sur X autour du boycott peut-être segmentée en quatre grandes catégories :
- Les posts qui se limitent à des appels boycott contre des marques et enseignes accusées de collusion avec l’État hébreu, voire d’encouragement au génocide ;
- Les posts centrés sur des enseignes de fast food (à noter que les chaînes de fast food sont les marques qui font le plus l’objet d’appels au boycott « spontané ») ;
- Les posts ressortant de la « discussion communautaire » ;
- Enfin, une quatrième catégorie a trait aux critiques dirigées contre les médias, que ce soit contre Cyril Hanouna, BFM TV/RMC ou encore Patrick Drahi. Les posts au sein de cette catégorie sont également les plus suspsects de céder au tropisme complotiste, voire ouvertement antisémite. C’est, en effet, dans cette quatrième catégorie que l’on relève notamment des posts critiquant les médias « mainstream », qui seraient trop favorables à Israël ou cacheraient l’ampleur réelle du boycott, car ceux-ci seraient “aux ordres” de l’État hébreu.
Structuration communautaire

Comme l’illustre cette cartographie, la discussion sur X autour du boycott est, en grande partie, cadrée par des néo-médias ainsi que des influenceurs, de différentes natures et qualités.
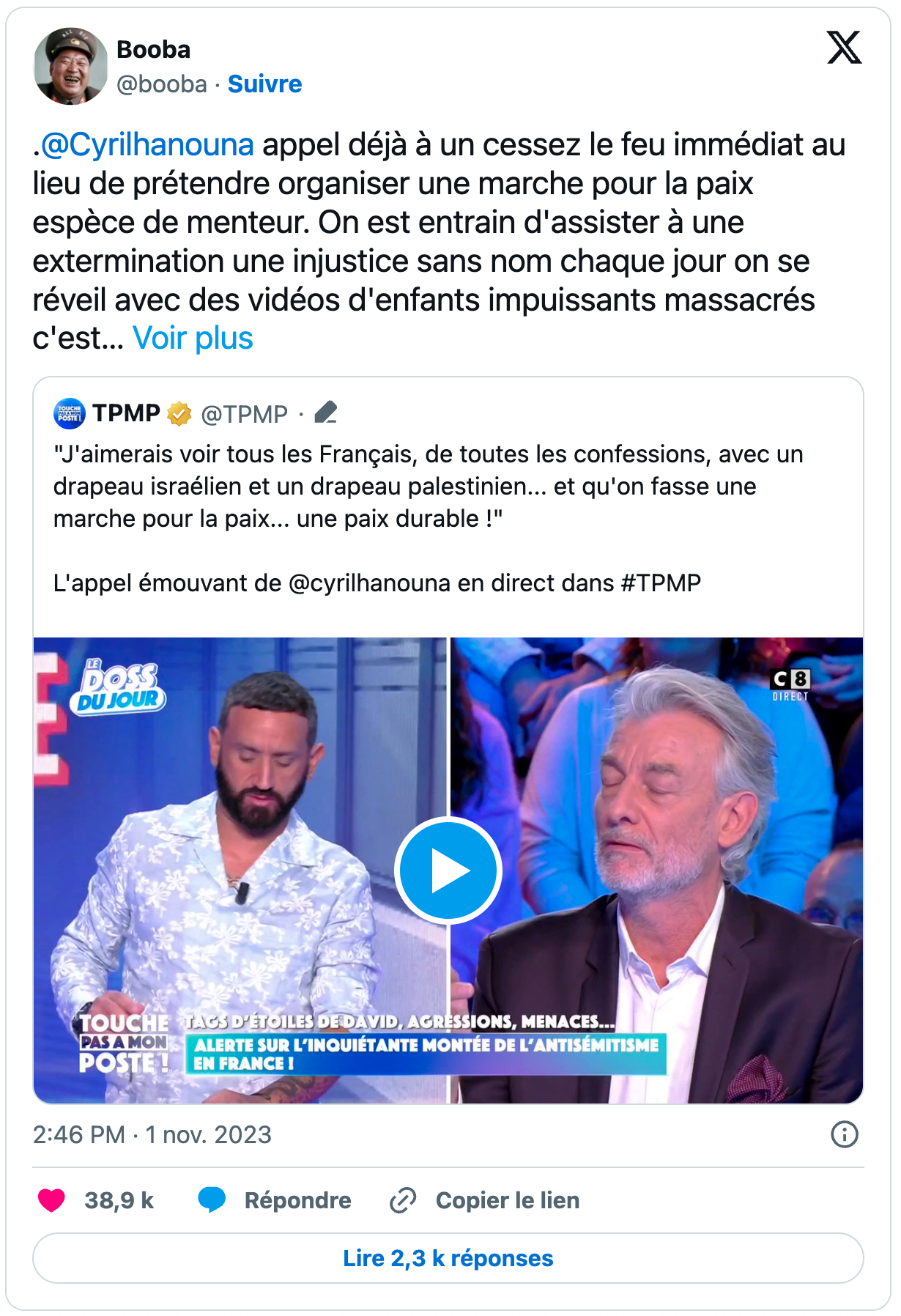
Le tweet du rappeur Booba, suivi par plus de 6M d’abonnés sur X, a été vu plus de 7 millions de fois
Du côté des influenceurs de la société civile, le rappeur Booba avec son tweet à charge contre Cyril Hanouna a contribué à cristalliser les critiques sur la ligne éditoriale supposément pro-israélienne de TPMP.
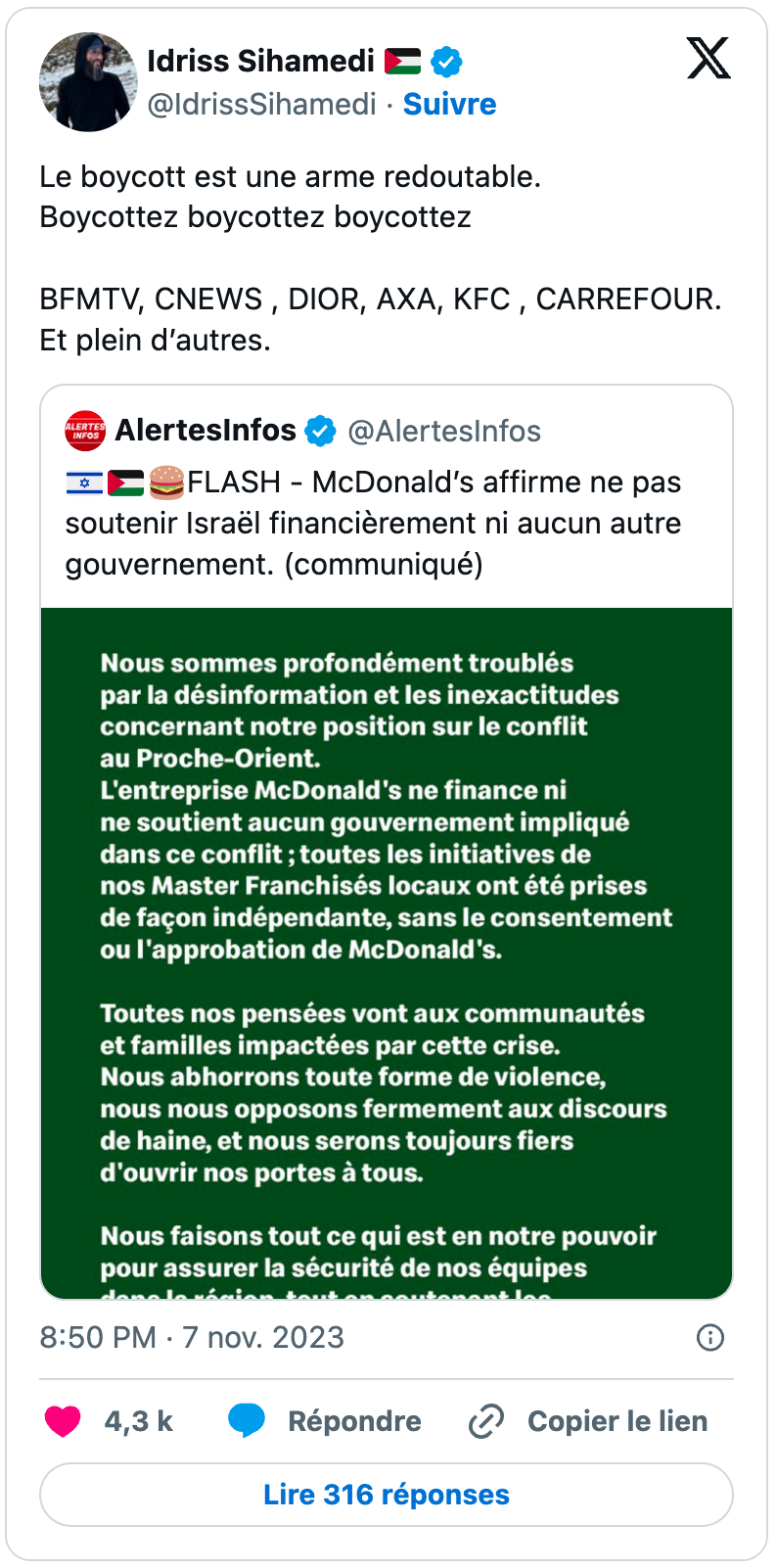
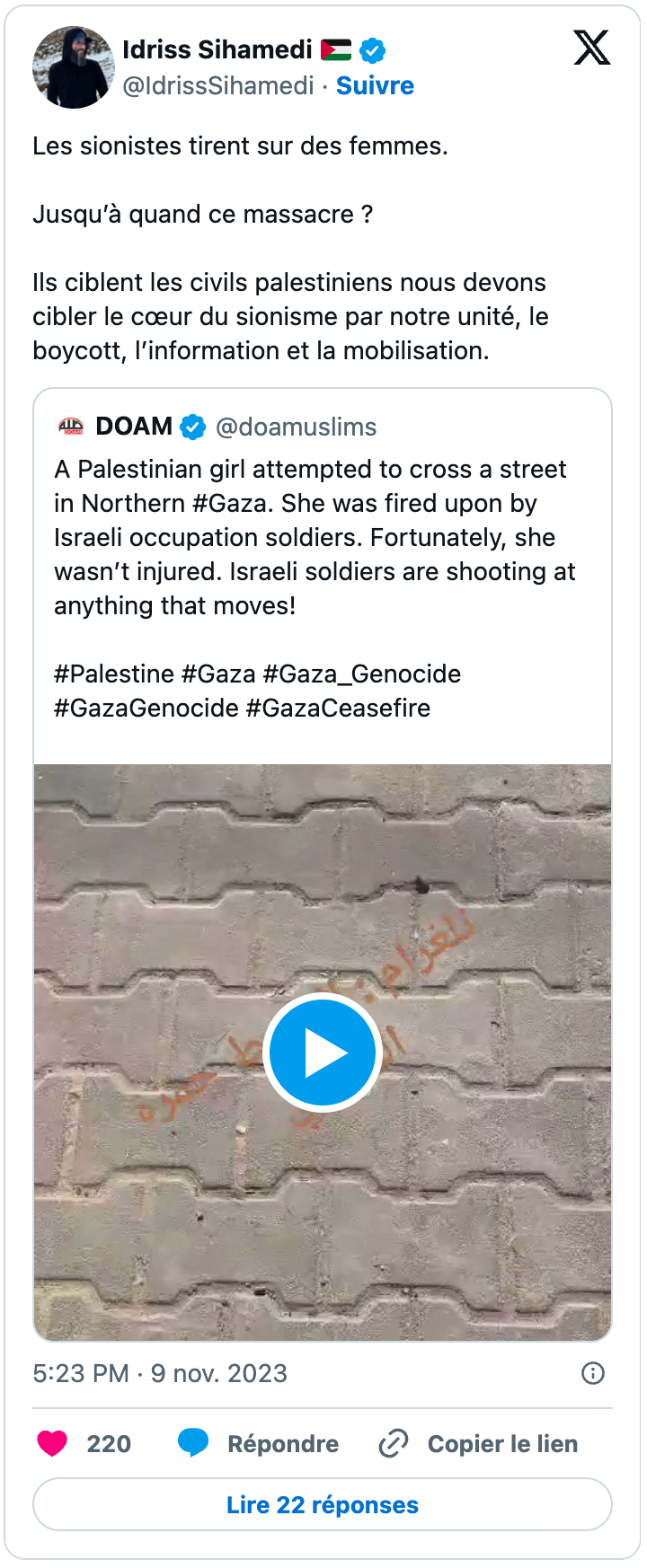
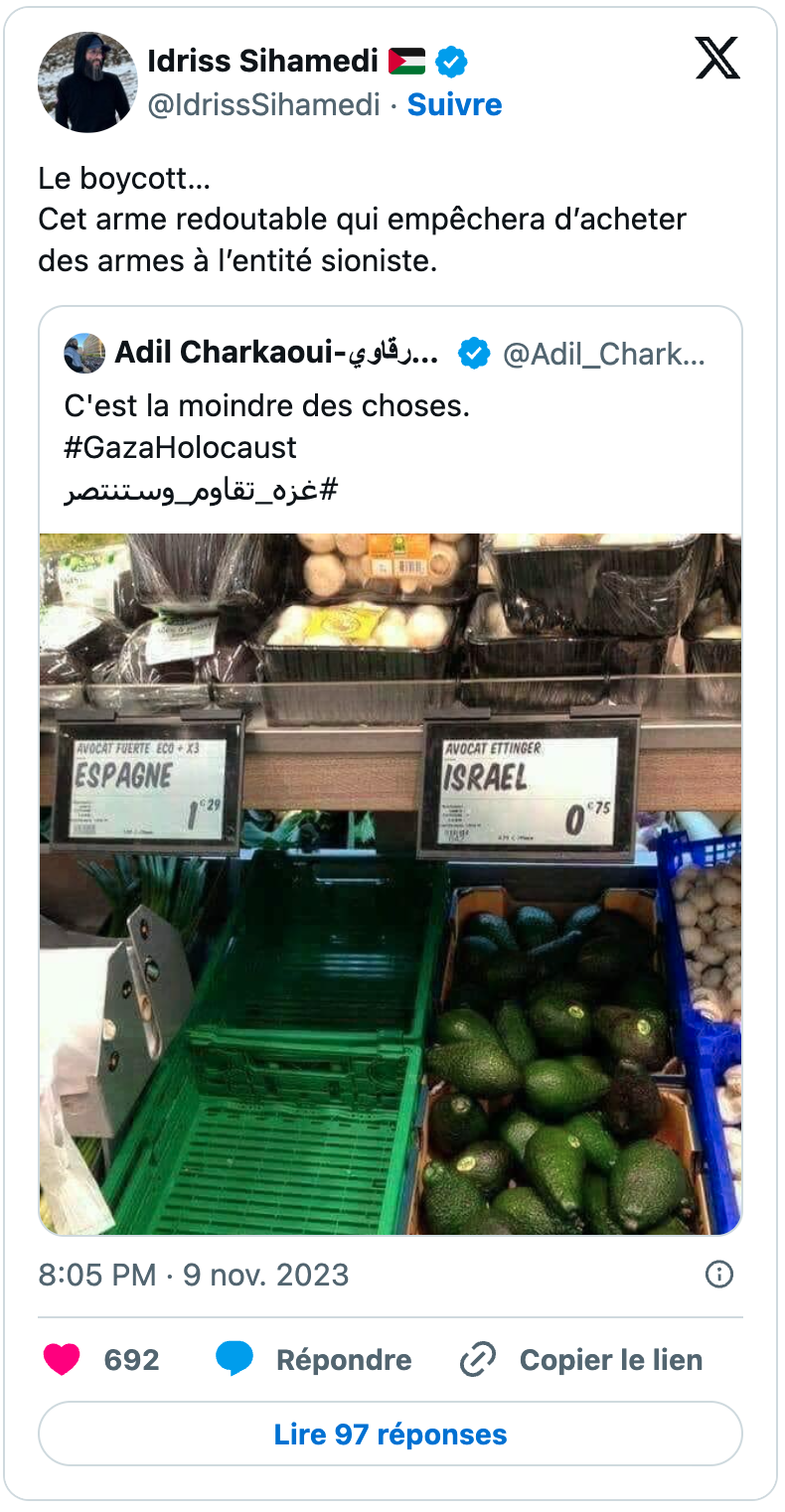
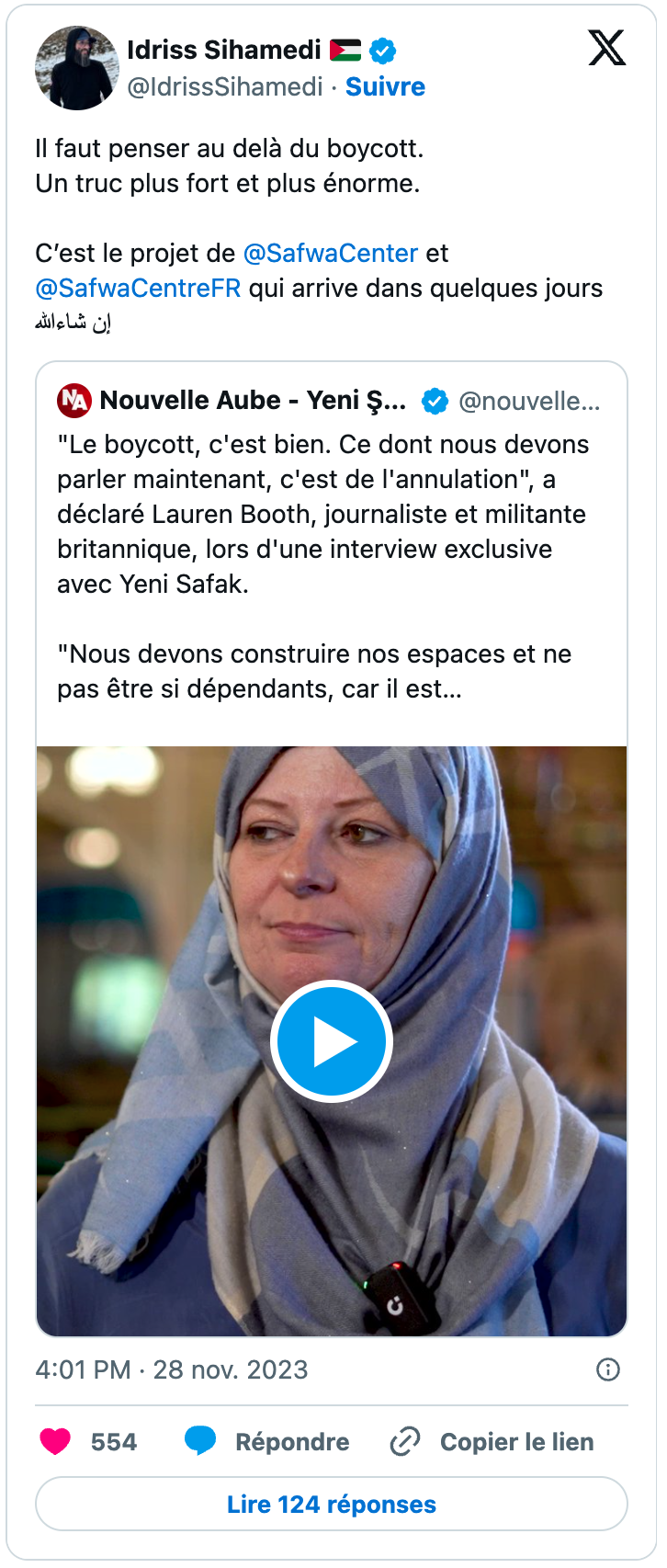
Les influenceurs communautaires ont également joué un rôle significatif dans le cadrage du boycott au service de leur agenda politique, idéologique et religieux, à l’image notamment d’Idriss Sihamedi, ancien animateur de BarakaCity, une structure dissoute en 2022 par le ministère de l’Intérieur. On notera que parmi ses tweets, certains sont des quotes soit de néo-médias, en l’espèce Alertes Infos, soit d’édition francophone de médias étrangers, comme ici avec Nouvelle Aube (Yeni Şafak), un média turc à ligne éditoriale généralement considérée comme islamiste.
Le rôle des néo-médias
Depuis la fin des années 2010, plusieurs comptes X spécialisés dans le relais d’information tirés des médias comme Mediavenir, Cerfia et Alertes Infos se sont imposés comme des moyens très populaires pour suivre l’actualité – ce en dépit des nombreuses mises en garde quant à leur déontologie et à leur fiabilité, puisque à plusieurs reprises certains de ces néo-médias ont été épinglés par des observateurs et chercheurs spécialisés en raison de leurs errements, voire de leur tropisme les conduisant à céder à la désinformation pour accroître les vues et les clics sur leurs contenus.
À l’instar de précédentes grandes séquences médiatiques comme la crise sanitaire de 2020 ou les émeutes de 2023, ces « néo-médias » ont profité du conflit Israël-Hamas pour gagner en visibilité. Cerfia et Alertes Infos ressortent ainsi parmi les utilisateurs les plus influents dans la conversation autour du boycott.
Les marques les plus ciblées par le mouvement BDS
Pour analyser les marques ciblées par le mouvement BDS, en France et à l’international, nous avons dans un premier temps procédé à une analyse quantitative. Pour ce faire, nous avons extrait l’ensemble des articles et contenus publiés sur le site internet du mouvement international (bdsmovement.net) et nous avons réalisé une analyse par reconnaissance d’entités nommés (NER) ciblant tout particulièrement les organisations. Le tableau ci-dessous présente les marques qui sont le plus souvent citées par le BDSmovement. Cette approche automatisée n’est pas parfaite, et présente quelques limites, en partie liées à la manière dont le site en question est structuré, mais permet néanmoins d’avoir une vision assez globale des entités ciblées comme l’indique le graphique ci-dessous.
Outre les organisations, marques et entreprises mentionnées, notons également que la campagne de boycott au niveau international s’inscrit dans une stratégie de communication opportuniste de newsjacking.
L’extraction de l’ensemble des événements mentionnés dans les articles du BDS movement fait ainsi ressortir que l’organisation communique de manière fréquente ces derniers temps sur les Jeux Olympiques ou encore l’Eurovision. Pour ces deux événements internationaux le BDS demande à ce que les athlètes et chanteurs israéliens soient interdits de participation. Dans les deux cas, la dénonciation d’un supposé deux poids deux mesures est mise en avant, notamment pour dénoncer le fait que le CIO (Comité international olympique) aurait été davantage prompt à sanctionner les athlètes russes dans l’immédiat du déclenchement de la guerre en Ukraine, plutôt que de se positionner sur les athlètes israéliens.
Le BDS se positionne également sur des événements internationaux à fort impact commercial comme le black friday ou encore le cyber monday en appelant d’une part les soutiens du mouvement à boycotter pour leurs achats les marques listées par le BDS, ainsi qu’à interpeller ces dernières sur les réseaux sociaux. Pour ce faire, la plateforme propose par exemple à ses utilisateurs de publier des posts sur X pré-rédigés, avec le #BoycottGenocideEnablers, afin de faciliter les prises de position et autres logiques d’interpellation des marques sur les réseaux sociaux.


Par ailleurs, le mouvement BDS France a publié le 5 novembre un guide réalisé par le Comité national BDS indiquant les marques à boycotter. Le guide distingue :
- Les « Cibles du boycott des consommateurs » : des marques sélectionnées par BDS en fonction de leur “complicité avérée dans l’apartheid israélien”, de leur notoriété et du “réel potentiel de victoire” (par exemple Carrefour) ;
- Les « Objectifs de désinvestissement » : des fonds d’investissements, banques et assurances dont BDS souhaite qu’ils désinvestissement d’entreprises “complices” (par exemple Axa) ;
- Les « Objectifs de pression » : des marques contre lesquelles BDS appellent “activement à des campagnes de pression” sans appeler au boycott (par exemple Google, Amazon ou Disney) – peut-être par manque de potentialité de succès ;
- Les « Cibles du boycott spontané » : des marques qui n’étaient pas ciblés par BDS, faisant l’objet d’appels spontanés au boycott désormais soutenus par BDS, et parmi lesquels on retrouve essentiellement des chaînes de fast food (par exemple McDonald’s ou Burger King).
Selon les pays, les marques diffèrent. Aux États-Unis, le Washington Post mentionne parmi les marques les plus ciblées :
- Puma, en raison de son contrat de sponsoring avec la Fédération israélienne de football “qui régit les équipes des colonies illégales israéliennes situées sur les terres palestiniennes occupées” ;
- Ahava, une marque de cosmétique qui dispose d’une usine dans une colonie israélienne en Cisjordanie ;
- McDonald’s, dont un franchisé local a promis des repas gratuits aux soldats de Tsahal ;
- Starbucks, qui a poursuivi en justice certains de ses syndicalistes ayant manifesté leur soutien envers la cause palestinienne ;
- Disney en raison d’un scénario à venir d’un film Marvel qui mettrait en valeur un superhéros issu d’une agence d’espionnage inspirée du Mossad.
La conversation francophone se distingue avec une primauté accordée à plusieurs marques emblématiques de la grande consommation dans l’Hexagone : McDonald’s, Carrefour, Starbucks, Zara. On note également la présence dans la liste de SFR, dont la maison mère, Altice, est dirigée par Patrick Drahi, cible de nombreuses attaques antisémites. Les acteurs des secteurs de la finance ou de l’assurance sont également ciblés, à l’image notamment d’Axa.
Plusieurs marques apparaissent visées par le boycott pour des raisons relativement ténues. A contrario, certaines d’entre elles ayant fait l’objet de rapports détaillés semblent échapper à la vindicte. Les marques les plus exposées ressortent en fait du même univers : celui de la grande consommation liée au modèle du centre commercial et de l’hypermarché. Au-delà de la dénonciation des pratiques de certains groupes, se dessine un imaginaire politique qui associe le capitalisme au soutien à la politique de l’État d’Israël.
Carrefour, une des principales cibles du boycott en France
Carrefour se distingue nettement dans la liste des marques les plus mentionnées sur X en France. Le cas de l’enseigne illustre la stratégie de BDS et son opportunisme tactique.
De 2010 à 2012, les seules mentions de Carrefour sur le compte X de BDS concernent les supermarchés où ses militants organisent des actions de distribution de tracts ; actions parfois relayées par la PQR. Cette période correspond à une époque où le mouvement se focalise sur l’élaboration de listes et la sensibilisation des consommateurs sur l’origine des produits qu’ils achètent.
En 2014, on note de la part de BDS des critiques contre l’étiquetage de certains produits mis en vente par l’enseigne, et l’organisation de voyages en Israël par la filiale du groupe Carrefour Voyages. Mais Carrefour ne devient une cible de la campagne BDS qu’à partir de novembre 2022 et la publication du rapport « Les liaisons dangereuses du groupe Carrefour avec la colonisation israélienne » – corédigé par plusieurs associations membres de la coalition. Ce rapport accuse le groupe d’avoir signé un accord de franchise en mars 2022 avec deux sociétés israéliennes, Electra Consumer Products et Yenot Bitan, indirectement liées à la colonisation israélienne selon BDS. La société mère d’Electra Consumer Products, Elco Ltd, dispose d’une autre filiale dont le nom est inscrit sur la liste des 112 entreprises liées à la colonisation établie par l’ONU. Notons d’ailleurs que Carrefour ne figure pas sur cette même liste, et que la multinationale française se défend de tout lien (capitalistique notamment) avec les sociétés de son prestataire liées à la colonisation.
Le rapport est notamment relayé par le compte global du mouvement BDS en décembre 2022 – au même titre que le rapport contre l’assureur Axa publié en juin 2017. Le mouvement manifeste sa volonté de faire pression sur l’enseigne en usant du levier de la réputation.
- Le 14 décembre 2022, BDS organise une “Twitterstorm” pour dénoncer l’enseigne. En janvier, la campagne se fait le relais d’un article paru sur le média en ligne The Electronic Intifada accusant Carrefour de « profiter des crimes de guerre d’Israël ».
- De janvier à mars 2023, BDS publie plusieurs contenus (dont une courte vidéo) pour revenir sur le sujet.
- Le 28 février, BDS publie une lettre ouverte au groupe Carrefour.
- Le 10 mai, BDS accuse Carrefour d’avoir publié une publicité dans un magazine israélien montrant la carte du pays incluant la Palestine et le plateau du Golan.
- Du 21 au 26 mai, BDS organise une « semaine d’action mondiale » pour appeler au boycott de Carrefour « jusqu’à ce qu’il mette fin à sa complicité avec l’apartheid israélien et le colonialisme de peuplement ». Cette semaine comprend entre autres une “tweet storm”.
Cette campagne qui prend appui sur les éléments du rapport reste cependant limitée, et ne prend véritablement de l’ampleur qu’après l’attaque terroriste du 7 octobre.
Le 10 octobre, la branche israélienne du groupe annonce dans un post Instagram avoir « fait don de milliers de livraisons personnelles aux soldats ». Cette publication est largement relayée notamment sur Twitter et sur TikTok. Entre-temps, le groupe Carrefour modifie son post en remplaçant la mention des soldats par celle « des habitants d’Israël », avant de le supprimer.
Ces publications suscitent l’indignation parmi des utilisateurs affichant leur soutien à la cause palestinienne – mais cette indignation se concentre sur le soutien logistique que la franchise de Carrefour en Israël offrirait à l’armée israélienne et à sa prise de position, que les utilisateurs prêtent également au groupe au niveau global. Le 21 octobre, BDS France réagit à son tour et accuse le groupe Carrefour d’être « un facilitateur de génocide » (une traduction du terme “genocide enabler” fréquemment utilisé par le mouvement BDS dans ses campagnes internationales) en recadrant la polémique sur la base des accusations contenues dans son rapport de 2022.

Le service de fact checking de Libération, Check News, consacre un article aux accusations visant le groupe Carrefour le 30 octobre, qui mentionne les origines de la polémique, puis les critiques de BDS France.
Carrefour devient officiellement une cible prioritaire du mouvement avec la publication début novembre d’un guide de campagne du Comité national palestinien qui appelle à concentrer l’effort sur quelques cibles symboliques plutôt qu’à établir de “vastes listes de boycott” pour maximiser l’impact de la mobilisation. Carrefour figure parmi les “Cibles du boycott des consommateurs”, “des marques soigneusement sélectionnées en raison de leur complicité avérée dans l’apartheid israélien”, et pour lesquelles, il existe “un réel potentiel de victoire”.
Dans le courant du mois de novembre, BDS publie des contenus de campaigning sur son site en vue de faire pression sur l’enseigne lors de manifestations physiques ou sur les réseaux sociaux : visuels, tracts, modèles de pancartes, slogans, lettres et emails pré-rédigés menaçant Carrefour de perdre sa « bonne image ». BDS appelle notamment à interpeller directement Alice Vachet, manager digitale du groupe Carrefour, et à mentionner le compte X d’Alexandre Bompard, PDG de l’enseigne, dans chaque publication.
Le 2 décembre, BDS France mène une journée d’action devant des supermarchés Carrefour à Lyon, Marseille, Paris, Saint-Denis et Aubervilliers afin d’inciter les clients à les boycotter. En parallèle, BDS France adresse une « lettre ouverte » à Alexandre Bompard, l’invitant à cesser la « présence problématique du groupe Carrefour en Israël » et à rompre ses contrats de franchise. Le 24 janvier, BDS France organise une journée d’action sur les réseaux sociaux : une “Tweet storm” destinée à « inonder les réseaux de Carrefour avec nos messages de soutien au peuple palestinien ». BDS France réitère cette action le 17 février. Le 26 février, BDS France publie un communiqué de presse annonçant que le boycott de Carrefour France “prend une ampleur historique”.
En exploitant la dissonance de communication entre un franchisé en Israël et le groupe en France autour de la réponse immédiate à l’attaque terroriste du 7 octobre, le mouvement BDS France a réussi à remettre sur le devant de la scène ses précédentes accusations et à s’approprier un élan de mobilisation né spontanément sur les réseaux sociaux. Le mouvement BDS a ainsi su mettre à profit l’émoi lié à la situation au Proche-Orient pour donner un second souffle à sa campagne en érigeant Carrefour en bouc émissaire, alors même que ses liens effectifs avec la colonisation sont, si ce n’est inexistants, ténus et très indirects.
En comparaison, le groupe Axa, qui avait aussi fait l’objet d’un rapport très critique et de précédentes mises en cause par BDS France, mais n’a pas donné les mêmes prises à la polémique, apparaît beaucoup moins mentionné et central dans la polémique – quoique lui aussi ciblé par la campagne depuis octobre.
Une campagne qui bénéficie d’un important écho dans les sphères de l’extrême gauche radicale
Outre les marques les plus mentionnées par la branche francophone du BDS, nous avons également analysé les sites qui renvoient vers la campagne et contribuent ainsi à renforcer sa viralité, ainsi que son autorité en termes de SEO.
Pour ce faire, nous avons extrait l’ensemble des backlinks pointant, depuis les six derniers mois, vers le site bdsfrance.org et avons analysé ceux qui reviennent le plus fréquemment.
Il ressort de cette analyse que la plateforme BDS française peut compter sur le soutien de sites relativement influents de la galaxie de médias d’extrême gauche comme Révolution Permanente, Info Libertaire, Le Média, Paris Luttes, Attac ou encore Centre Attaque.
Par ailleurs, le mouvement BDS francophone bénéficie également de relais significatifs de la part de médias généralement considérés comme d’influence, si ce n’est de states-backed medias, à l’image des deux articles publiés en novembre 2023 par Middle East Eye (MEE) ou encore par l’édition francophone de TRT, acronyme de la Radio et Télévision de Turquie, donc ici clairement un média dit d’État.

Middle East Eye, un média généralement considéré comme proche du Qatar, à publier deux articles en novembre 2023 renvoyant en backlink vers le site de la plateforme bdsfrance.org
Un article de TRT Français publié le 6 décembre 2023
Et sur TikTok ?
Dans la séquence ouverte par l’attaque terroriste du 7 octobre, TikTok occupe une place particulière, du fait notamment de son audience très importante chez les jeunes aux États-Unis et en Europe. Le 10 octobre 2023, les hashtags #Israel et #Palestine avaient déjà cumulé plus de 50 milliards de vues. Les images du conflit (bombardements, civils blessés) et les prises de position ultra-polarisées se révèlent particulièrement efficaces auprès de leur audience. Certains influenceurs très suivi ont changé de ligne éditoriale à l’occasion du conflit, parfois par conviction, parfois pour de simples fins économiques. TikTok fait aussi l’objet du débat habituel concernant le rôle des réseaux sociaux dans la formation de l’opinion : entre vecteur d’influence, capable de faire changer ses utilisateurs d’avis, ou simple reflet de l’opinion existante dans la jeune génération. De fait, TikTok s’est imposé comme un nouveau “champ de bataille” qui révélerait la faillite des médias traditionnels dans leur couverture du conflit, selon le quotidien israélien Haaretz.
C’est donc logiquement que TikTok s’est imposé comme l’un des principaux canaux par lesquels circulent les appels au boycott. Deux mois après le 7 octobre, le hashtag #BoycottIsrael avait cumulé plus de 340 millions de vues sur TikTok, et plus de 3 milliards pour le hashtag #BDS. En janvier, le Washington Post recensait plus de 500 000 publications portant le hashtag #BoycottIsrael.
Parmi les raisons de ce succès, on peut citer l’audience de TikTok, qui correspond aux cibles du mouvement BDS (des jeunes, bien informés mais en rupture de ban avec la politique traditionnelle et en recherche d’actions ponctuelles et concrètes à réaliser), tout comme la typologie de contenu valorisée par la plateforme (contenus à forte charge émotionnelle ou fortement polarisée).
Pour analyser plus avant et plus précisément le sujet, nous avons constitué un corpus de plus de 2400 vidéos mentionnant des hashtags en lien avec la campagne de boycott. Ces contenus proviennent de différentes zones géographiques. En procédant de la sorte, nous avons ainsi extrait plus de 1300 vidéos publiées, selon les données fournies par TikTok, depuis les États-Unis, 277 depuis la France ou encore 233 depuis la Grande-Bretagne.
Le graphique ci-dessous présente l’évolution dans le temps des vidéos TiKTok qui font mention des marques boycottées dans le cadre de la campagne internationale du BDS.
Le boycott marche : un leitmotiv des vidéos sur TikTok
@socratepls♬ son original - Socrate tfou
Avec 2.6M vues, 46K likes et 4K commentaires cette vidéo est la plus vue, en France, concernant le boycott et concerne TPMP/Cyril Hanouna
Vue et partagée plus de 2.6M de fois, c’est une vidéo relative au boycott de TPMP qui, en France, a été la plus vue. Cela confirme, en un certain sens, les enseignements issus de l’analyse précédente réalisée sur X. De TPMP aux enseignes, en passant par les marques grand public ainsi que les chaînes de fast food, les marques avec la surface d’opinion la plus large sont celles qui font le plus parler.
L’un des axes narratifs les plus utilisés sur TikTok afin de soutenir le boycott est celui consistant à essayer d’objectiver l’impact, notamment d’un point de vue économique de ce dernier. Ils sont nombreux à publier des courtes vidéos dans des enseignes de distribution (Carrefour, Action, Auchan…) ou encore des fast-foods (McDonald’s, Burger King…) pour montrer des rayons vides, conséquence directe, selon ces derniers, de la dimension massive du boycott. Leurs auteurs et les personnes qui réagissent à leurs vidéos opposent ces images à la dissimulation supposément orchestrée par les médias “mainstream” ; l’ampleur du boycott constituerait selon eux une sorte de plébiscite silencieux en faveur de la cause palestinienne et une incitation à poursuivre le boycott puisque celui-ci serait efficace.
Les captures d’écran ci-dessus proviennent d’une chaîne TikTok, relativement modeste, suivie par plus de 7.5K abonnés, et qui publie de manière récurrente des vidéos de ce type. Dans notre corpus nous avons ainsi 6 vidéos de cet utilisateur, qui totalise plus de 100K engagements, et qui consistent toutes à déambuler dans des Carrefour ou des McDonald’s pour illustrer l’impact supposé du boycott les visant.
Pour étayer leur discours certains influenceurs TikTok n’hésitent pas à détourner certains faits pour souligner la supposée efficacité du boycott sur les grandes marques. Dans une vidéo qui totalise plus de 250K engagements, un influenceur communautaire, suivie par plus de 72K abonnés, explique ainsi que le boycott aurait mis à genou Coca-Cola qui, faute de clients, en serait aujourd’hui réduit à devoir faire des promotions sur ces canettes et autres bouteilles afin de pouvoir écouler ses stocks.
La consultation du cours de bourse de The Coca Cola Company au cours des cinq dernières années ne montre pas d’impact très marqué consécutif au déclenchement de la guerre Israël-Hamas.

Évolution du cours de bourse de The Coca-Cola Company au cours des 5 dernières années
Une campagne soutenue et amplifiée par des médias d’État, notamment turcs
Parmi les vidéos virales en lien avec le boycott circulant sur TikTok, nous avons pu mettre au jour une série de vidéos publiées par TRT.
Sur TikTok, TRT, via ses différentes déclinaisons régionales, est particulièrement active pour mettre en avant le boycott contre Israël, ainsi que l’impact économique de ce dernier
Ces quatre vidéos ont donné lieu à plus de 2.1M engagements en additionnant les vues, les likes, les partages ainsi que les téléchargements suscités par celle-ci.
L’édition anglaise de Yeni Şafak, un média turc pro-islamiste, publie une vidéo sur TikTok le 11 février 2024 d’une action de boycott dans un magasin Carrefour en Espagne
Toujours du côté des médias turcs, nous pouvons également notamment la présence parmi les vidéos en lien avec le boycott de notre corpus d’un contenu publié mi février par l’édition en anglais de Yeni Şafak, un média proche de l’AKP et généralement considéré comme pro-islamiste, qui partage une action de militants BDS en Espagnol contre un magasin de l’enseigne Carrefour.
AJ+ en français dénonce des étiquetages de produits supposément trompeurs dans les enseignes français
Sur le même axe que TRT, AJ+ en français a également relayé, début mars 2024, les appels au boycott lancés par le BDS. Dans une vidéo, dans laquelle est interrogée une avocate et membre de la campagne BDS France, la déclinaison GenZ et français d’Al Jazeera, dénonce une supposée astuce utilisée par les enseignes afin de dissimuler l’origine israélienne de certains produits vendus dans les rayons. Les produits sont des dattes et des avocats prétendument produits en Israël et qui seraient ainsi distribuées sous étiquettes maquillées par les principales enseignes françaises comme l’indiquent les hashtags utilisés :
#ajplusfrançais #dattes #avocats #israel #palestine #bds #lidl #carrefour #auchan #intermarche #aldi #leclerc #bonplan #boycott #gaza
On notera l’utilisation du #BonPlan qui témoigne d’une volonté de viraliser la vidéo auprès d’un public non nécessairement intéressé en premier lieu par la thématique de la vidéo. Cette dernière a cependant eu un impact relativement modéré pour la plateforme, avec un peu moins de 4K vues pour près de 1K likes.
Notes
[1] Delmaire, Jean-Marie. De Jaffa jusqu’en Galilée : Les premiers pionniers juifs (1882/1904). Villeneuve d’Ascq : Presses universitaires du Septentrion, 1999, p. 114.
[2] Sur l’historique des boycotts, voir Weinstock, Nathan. Terre promise, trop promise. Genèse du conflit israélo-palestinien (1882-1948). Odile Jacob, 2011
[3] Schirman, Chalom. « Le boycott arabe d’Israël : les limites de l’arme économique », Monde Arabe, vol. 108, no. 2, 1985, pp. 66-71.
[4] Weiss, Martin A.. Arab League boycott of Israel. Congressional Research Service, 2017.
[5] Weiss, Martin A.. Arab League boycott of Israel. Congressional Research Service, 2017.
[6] Bargouti, Omar. Boycott, Désinvestissement, Sanctions. BDS contre l’apartheid et l’occupation de la Palestine. La Fabrique éditions, 2010.
[7] Carter Hallward, Maia. Transnational Activism and the Israeli-Palestinian Conflict, Palgrave Macmillan, 2013, p. 18.
[8] Ibid, pp. 19-20
[9] Carter Hallward, Maia. Transnational Activism and the Israeli-Palestinian Conflict, Palgrave Macmillan, 2013, p. 34.
L’article #BoycottIsrael : Ce que la campagne BDS révèle des nouvelles formes de lobbying en ligne est apparu en premier sur Observatoire stratégique de l'information.
25.01.2024 à 16:45
Faut-il brûler les riches ? Plongée au coeur des nouveaux narratifs anticapitalistes
Depuis la crise sanitaire et les élections de 2022, les mentions des ultra-riches augmentent en ligne, critiquant leur impact environnemental et politique. Influencées par des théories complotistes, des communautés amplifient ces discours, créant un mélange de militantisme et de conspirationnisme.
L’article Faut-il brûler les riches ? Plongée au coeur des nouveaux narratifs anticapitalistes est apparu en premier sur Observatoire stratégique de l'information.
Lire plus (490 mots)
Les mentions des ultra-riches à des fins de dénonciation des grandes fortunes augmentent significativement dans le débat public en ligne, en particulier depuis la crise sanitaire (fin-2021) et la séquence électorale de 2022 (présidentielle puis législatives), sur les réseaux sociaux et le web.
Parmi les publications mentionnant ce terme, celles critiquant l’impact du mode de vie des grandes fortunes sur l’environnement et leur poids politique (33%) arrivent devant celles ayant trait aux profits qu’ils tireraient des soubresauts de l’actualité mondiale, comme la crise sanitaire ou la guerre en Ukraine (32%).
Première cause de ce basculement : la stratégie de conflictualité de LFI et la mobilisation des activistes écologistes à l’occasion de la polémique sur les jets privés et de la réforme des retraites. En dernier ressort, leur mobilisation vise Emmanuel Macron et le Gouvernement, accusés de collusion avec les grandes fortunes. D’après les tenants les plus extrêmes du narratif, l’exécutif actuel serait aux mains des ultra-riches, selon une logique de pouvoir occulte habituelle dans les sphères conspirationnistes.
Cette mobilisation est la résultante d’un travail théorique mené de longue date à gauche, porté par des intellectuels et des associations militantes, mais elle est aussi le fruit d’une mobilisation des communautés « conspirationnistes » agrégées durant la crise sanitaire, influencées notamment par la théorie du « great reset », et jouant le rôle d’alliés de circonstance.
Ces communautés alternatives sont notamment enclines à amplifier la diffusion des discours sur les ultra-riches, ainsi qu’à leur ajouter, lorsque celle-ci n’est pas originellement présente, une dimension complotiste.
Ces communautés, qui sont aussi aujourd’hui les plus actives sur certains réseaux sociaux comme X, démultiplient l’audience des narratifs contre les ultra-riches, qui participent dès lors à diffuser un certain imaginaire conspirationniste.
Certains acteurs, médias et leaders d’opinion, jouent un rôle de passerelle entre les écosystèmes militants à gauche et des écosystèmes complotistes. Ce « confusionnisme » peut être le fruit d’une bascule idéologique de certains d’entre eux, ou d’une opération tactique à des fins de gains d’audience.
L’article Faut-il brûler les riches ? Plongée au coeur des nouveaux narratifs anticapitalistes est apparu en premier sur Observatoire stratégique de l'information.
09.01.2023 à 09:39
La propagande russe à l’épreuve de la déplateformisation
Après l'invasion de l'Ukraine en 2022, la Russie utilise des blogueurs nationalistes pour propager sa propagande. Malgré la restriction des médias officiels comme RT et Sputnik, ces blogueurs sur Telegram influencent les opinions globales. Des "passeurs de contenus" aident à internationaliser ces narratifs, déjouant la modération des plateformes.
L’article La propagande russe à l’épreuve de la déplateformisation est apparu en premier sur Observatoire stratégique de l'information.
Texte intégral (729 mots)
En envahissant l’Ukraine en février 2022, la Russie s’est également lancée dans une campagne à l’échelle globale pour rallier les opinions mondiales à sa cause. Avec la “déplateformisation” de ses médias officiels RT et Sputnik, le dispositif de propagande officiel de l’État russe a accusé une perte importante en termes de visibilité et d’influence à l’international. Pour autant, la circulation des contenus pro-guerre reste assurée sur le web et les réseaux sociaux par une nébuleuse de blogueurs nationalistes russes dont les contenus, visant en premier lieu les opinions russes et ukrainiennes, sont traduits et relayés dans le reste du monde par l’entremise de “passeurs de contenus”. Une étude, réalisée par l’agence IDS, s’intéresse aux stratégies déployées par ces différents acteurs pour contourner la modération des plateformes, aux narratifs qu’ils diffusent et au processus d’internationalisation de ces contenus.
Une propagande sur Telegram menée par des blogueurs sans lien officiels avec le Kremlin
L’étude s’appuie sur une cartographie de 1 800 chaînes russophones publiant sur la guerre en Ukraine sur Telegram, à l’origine de plus de 8 millions de posts depuis janvier 2022. Certaines d’entre elles, comme Rybar, Colonel Cassad ou Golos Mordora, sont suivies par plusieurs centaines de milliers de personnes et jouent le rôle de véritables médias sur la guerre en Ukraine. Leur grande liberté de ton vis-à-vis du commandement militaire russe (notamment lors du retrait de l’armée russe de Kherson), leur idéologie nationaliste jusqu’au-boutiste et leur influence croissante interrogent sur le rôle que ces blogueurs pourraient jouer dans la suite du conflit – notamment en cas de défaite et de désaveu de l’actuel pouvoir russe.

Bien que ces blogueurs ne sont pas officiellement liés à l’État russe (mais entretiennent pour certains des liens avec des oligarques proches du Kremlin comme Evgueni Prigojine), leur contenus s’inscrivent pleinement dans l’entreprise globale de propagande autour de la guerre en Ukraine. Ceux-ci sont notamment repris et relayés par un écosystème de 23 faux médias locaux en Ukraine, qui cherchent à légitimer l’invasion auprès des minorités russes dans le pays. De même, l’étude met en lumière un écosystème de chaînes Telegram “officielles” créés en mars et avril 2022 cherche à normaliser la présence russe dans les territoires occupés.
Une diffusion des contenus pro-russe à l’international via l’entremise de “passeurs de contenus”
Si les contenus diffusés par l’écosystème nationaliste sur Telegram visent en premier lieu les opinions russes et ukrainiennes, leur influence s’étend cependant à l’international. L’étude montre le rôle joué par certains « passeurs de contenus » qui continuent de relayer les contenus des médias russes (notamment ceux de Sputnik Afrique) en promouvant l’usage de VPN pour y accéder, en traduisant des posts de blogueurs nationalistes pour assurer leur diffusion ou en exploitant les failles de la modération des grandes plateformes.

Ainsi, l’analyse de la diffusion du terme “ukronazis” sur Twitter, popularisé depuis le début de l’invasion par des blogueurs nationalistes russes, montre que ce terme a acquis une grande popularité dans le monde entier, touchant selon les pays des segments différents. Si une partie de l’extrême-droite française s’est appropriée le terme, celui-ci connaît surtout un grand succès auprès de sphères d’extrême-gauche situées en Amérique du Sud. Des bots et comptes de spam semblent utilisés pour amplifier la visibilité de ces contenus.
L’article La propagande russe à l’épreuve de la déplateformisation est apparu en premier sur Observatoire stratégique de l'information.
- GÉNÉRALISTES
- Le Canard Enchaîné
- La Croix
- Le Figaro
- France 24
- France-Culture
- FTVI
- HuffPost
- L'Humanité
- LCP / Senat
- Le Media
- La Tribune
- Time France
- EUROPE ‧ RUSSIE
- Courrier Europe Ctrale
- Desk-Russie
- Euractiv
- Euronews
- Toute l'Europe
- Afrique du Nord ‧ Proche-Orient
- Haaretz
- Info Asie
- Inkyfada
- Jeune Afrique
- Kurdistan au féminin
- L'Orient - Le Jour
- Orient XXI
- Rojava I.C
- INTERNATIONAL
- Courrier International
- Equaltimes
- Global Voices
- Infomigrants
- I.R.I.S
- The New-York Times
- OSINT ‧ INVESTIGATION
- OFF Investigation
- OpenFacto°
- Bellingcat
- Disclose
- G.I.J
- I.C.I.J
- OPINION
- Au Poste
- Cause Commune
- CrimethInc.
- Hors-Serie
- L'Insoumission
- Là-bas si j'y suis
- Les Jours
- LVSL
- Politis
- Quartier Général
- Rapports de force
- Reflets
- Reseau Bastille
- StreetPress
- OBSERVATOIRES
- Armements
- Acrimed
- Catastrophes naturelles
- Conspis
- Culture
- Curation IA
- Extrême-droite
- Human Rights Watch
- Inégalités
- Information
- Justice fiscale
- Liberté de création
- Multinationales
- Situationnisme
- Sondages
- Street-Médics
- Routes de la Soie