
16.05.2026 à 08:38

Vendredi, Volodymyr Zelensky a promis des frappes contre des sites pétroliers et militaires russes après l’attaque meurtrière sur Kiev, qui a fait au moins 24 morts.
Vendredi, Volodymyr Zelensky a promis des frappes contre des sites pétroliers et militaires russes après l’attaque meurtrière sur Kiev, qui a fait au moins 24 morts.
16.05.2026 à 08:35
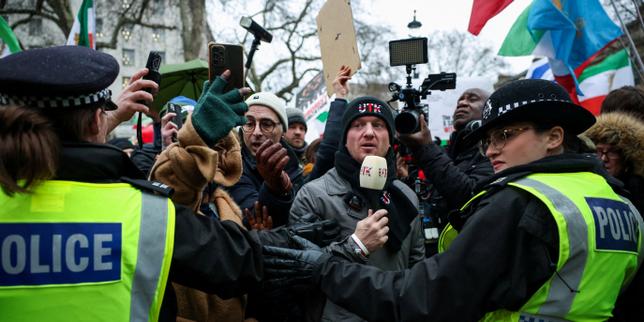
La capitale britannique s’apprête à déployer quelque 4 000 policiers alors que Tommy Robinson, activiste anti-islam et anti-immigration, organise une nouvelle marche après celle de septembre qui a mobilisé 150 000 personnes. Plus de 50 000 manifestants sont attendus ce samedi, alors que Londres accueille aussi la finale de la Coupe d’Angleterre et une manifestation propalestinienne.
La capitale britannique s’apprête à déployer quelque 4 000 policiers alors que Tommy Robinson, activiste anti-islam et anti-immigration, organise une nouvelle marche après celle de septembre qui a mobilisé 150 000 personnes. Plus de 50 000 manifestants sont attendus ce samedi, alors que Londres accueille aussi la finale de la Coupe d’Angleterre et une manifestation propalestinienne.
16.05.2026 à 08:07

La diplomatie américaine a annoncé une prolongation du cessez-le-feu – déjà largement violé – de quarante-cinq jours entre Israël et le Liban. Le premier ministre libanais, Nawaf Salam, a fustigé le Hezbollah pour avoir entraîné le Liban dans une nouvelle guerre « irresponsable », ajoutant que seules les forces armées devraient détenir des armes dans le pays.
La diplomatie américaine a annoncé une prolongation du cessez-le-feu – déjà largement violé – de quarante-cinq jours entre Israël et le Liban. Le premier ministre libanais, Nawaf Salam, a fustigé le Hezbollah pour avoir entraîné le Liban dans une nouvelle guerre « irresponsable », ajoutant que seules les forces armées devraient détenir des armes dans le pays.
- GÉNÉRALISTES
- Le Canard Enchaîné
- La Croix
- Le Figaro
- France 24
- France-Culture
- FTVI
- HuffPost
- L'Humanité
- LCP / Senat
- Le Media
- La Tribune
- Time France
- EUROPE ‧ RUSSIE
- Courrier Europe Ctrale
- Desk-Russie
- Euractiv
- Euronews
- Toute l'Europe
- Afrique ‧ Asie ‧ Proche-Orient
- Haaretz
- Info Asie
- Inkyfada
- Jeune Afrique
- Kurdistan au féminin
- L'Orient - Le Jour
- Orient XXI
- Rojava I.C
- INTERNATIONAL
- Courrier International
- Equaltimes
- Global Voices
- Infomigrants
- I.R.I.S
- The New-York Times
- OSINT ‧ INVESTIGATION
- OFF Investigation
- OpenFacto°
- Bellingcat
- Disclose
- G.I.J
- I.C.I.J
- OPINION
- Au Poste
- Cause Commune
- CrimethInc.
- Hors-Serie
- L'Insoumission
- Là-bas si j'y suis
- Les Jours
- LVSL
- Politis
- Quartier Général
- Rapports de force
- Reflets
- Reseau Bastille
- StreetPress
- OBSERVATOIRES
- Armements
- Acrimed
- Catastrophes naturelles
- Conspis
- Culture
- Curation IA
- Extrême-droite
- Human Rights Watch
- Inégalités
- Information
- Justice fiscale
- Liberté de création
- Multinationales
- Situationnisme
- Sondages
- Street-Médics
- Routes de la Soie